diff --git a/springboot-dubbo/dubbo-interface/target/maven-status/maven-compiler-plugin/testCompile/default-testCompile/inputFiles.lst b/.nojekyll
similarity index 100%
rename from springboot-dubbo/dubbo-interface/target/maven-status/maven-compiler-plugin/testCompile/default-testCompile/inputFiles.lst
rename to .nojekyll
diff --git a/404.md b/404.md
new file mode 100644
index 0000000..f79b657
--- /dev/null
+++ b/404.md
@@ -0,0 +1,15 @@
+### 联系我
+
+添加我的微信备注“Github”,回复关键字 **“加群”** 即可入群。
+
+
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
\ No newline at end of file
diff --git a/README.md b/README.md
index e2cc5bb..e98b843 100644
--- a/README.md
+++ b/README.md
@@ -1,20 +1,83 @@
-> 工作一年以上的小伙伴可以加这个交流群,群内有免费公开课,现在加入就送Java架构师进阶系列电子书籍:[](https://jq.qq.com/?_wv=1027&k=5tjF8vk)
+👍推荐[2021最新实战项目源码下载](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100018862&idx=1&sn=858e00b60c6097e3ba061e79be472280&chksm=4ea1856579d60c73224e4d852af6b0188c3ab905069fc28f4b293963fd1ee55d2069fb229848#rd)
-# springboot-integration-examples
+👍[《JavaGuide 面试突击版》PDF 版本](#公众号) 。[图解计算机基础 PDF 版](#优质原创PDF资源)
-SpringBoot和其他常用技术的整合,可能是你遇到的讲解最详细的学习案例,力争新手也能看懂并且能够在看完之后独立实践。基于最新的 SpringBoot2.0+,是你学习SpringBoot 的最佳指南。
+书单已经被移动到[awesome-cs](https://github.com/CodingDocs/awesome-cs) 这个仓库。
-## springboot-mybatis(SpringBoot+Mybatis 的最佳实践)
-[优雅整合 SpringBoot+Mybatis,可能是你见过把 SpringBoot 整合 Mybatis 写的最详细的一篇文章](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-mybatis.md)
-[新手也能看懂,基于SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-mybatis-mutipledatasource.md)
-## springboot-oss(SpringBoot 整合 阿里云OSS 存储服务)
+
+
+  +
+
+
+
-[SpringBoot 整合 阿里云OSS 存储服务,快来免费搭建一个自己的图床](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-oss.md)
+
+  +
+  +
+  +
+  +
+
+**在线阅读** : https://snailclimb.gitee.io/springboot-guide (上面的地址访问速度缓慢的建议使用这个路径访问)
-## springboot-dubbo(使用SpringBoot+Dubbo 搭建一个分布式服务)
+**开源的目的是为了大家能一起完善,如果你觉得内容有任何需要完善/补充的地方,欢迎提交 issue/pr。**
-[超详细,新手都能看懂 !使用SpringBoot+Dubbo 搭建一个分布式服务](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-dubbo.md)
+- Github地址:https://github.com/CodingDocs/springboot-guide
+- 码云地址:https://gitee.com/SnailClimb/springboot-guide(Github无法访问或者访问速度比较慢的小伙伴可以看码云上的对应内容)
+## 重要知识点
+
+### 基础
+
+1. [Spring Boot 介绍](./docs/start/springboot-introduction.md)
+2. [第一个 Hello World](./docs/start/springboot-hello-world.md)
+3. [第一个 RestFul Web 服务](./docs/basis/sringboot-restful-web-service.md)
+4. [Spring 如何优雅读取配置文件?](./docs/basis/read-config-properties.md)
+5. **异常处理** :[Spring Boot 异常处理的几种方式](./docs/advanced/springboot-handle-exception.md)、[Spring Boot 异常处理在实际项目中的应用](./docs/advanced/springboot-handle-exception-plus.md)
+6. **JPA** : [ Spring Boot JPA 基础:常见操作解析](./docs/basis/springboot-jpa.md) 、 [JPA 中非常重要的连表查询就是这么简单](./docs/basis/springboot-jpa-lianbiao.md)
+7. **拦截器和过滤器** :[SpringBoot 实现过滤器](./docs/basis/springboot-filter.md) 、[SpringBoot 实现拦截器](./docs/basis/springboot-interceptor.md)
+8. **MyBatis** :[整合 SpringBoot+Mybatis](./docs/basis/springboot-mybatis.md) 、[SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](./docs/basis/springboot-mybatis-mutipledatasource.md) (TODO:早期文章,不建议阅读,待重构~)
+9. [MyBatis-Plus 从入门到上手干事!](./docs/MyBatisPlus.md)
+10. [SpringBoot 2.0+ 集成 Swagger 官方 Starter + knife4j 增强方案](./docs/basis/swagger.md)
+
+### 进阶
+
+1. Bean映射工具 :[Bean映射工具之Apache BeanUtils VS Spring BeanUtils](./docs/advanced/Apache-BeanUtils-VS-SpringBean-Utils.md) 、[5种常见Bean映射工具的性能比对](./docs/advanced/Performance-of-Java-Mapping-Frameworks.md)
+3. [如何在 Spring/Spring Boot 中优雅地做参数校验?](./docs/spring-bean-validation.md)
+3. [使用 PowerMockRunner 和 Mockito 编写单元测试用例](./docs/PowerMockRunnerAndMockito.md)
+4. [5分钟搞懂如何在Spring Boot中Schedule Tasks](./docs/advanced/SpringBoot-ScheduleTasks.md)
+5. [新手也能看懂的 Spring Boot 异步编程指南](./docs/advanced/springboot-async.md)
+6. [Kafka 入门+SpringBoot整合Kafka系列](https://github.com/Snailclimb/springboot-kafka)
+7. [超详细,新手都能看懂 !使用Spring Boot+Dubbo 搭建一个分布式服务](./docs/advanced/springboot-dubbo.md)
+8. [从零入门 !Spring Security With JWT(含权限验证)](https://github.com/Snailclimb/spring-security-jwt-guide)
+
+### 补充
+
+1. [`@PostConstruct`和`@PreDestroy` 简单使用以及Java9+中的替代方案](./docs/basis/@PostConstruct与@PreDestroy.md)
+
+## 实战项目
+
+1. [使用 Spring Boot搭建一个在线文件预览系统!支持ppt、doc等多种类型文件预览](./docs/projects/kkFileView-SpringBoot在线文件预览系统.md)
+2. [ SpringBoot 前后端分离后台管理系统分析!分模块开发、RBAC权限控制...](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247495011&idx=1&sn=f574f5d75c3720d8b2a665d1d5234d28&chksm=cea1a2a8f9d62bbe9f13f5a030893fe3da6956c4be41471513e6247f74cba5a8df9941798b6e&token=212861022&lang=zh_CN#rd)
+3. [一个基于Spring Cloud 的面试刷题系统。](./docs/projects/SpringCloud刷题系统.md)
+4. [一个基于 Spring Boot 的在线考试系统](./docs/projects/一个基于SpringBoot的在线考试系统.md)
+
+## 说明
+
+1. 项目 logo 由 [logoly](https://logoly.pro/#/) 生成。
+2. 利用 docsify 生成文档部署在 Github Pages 和 Gitee Pages: [docsify 官网介绍](https://docsify.js.org/#/)
+
+### 优质原创PDF资源
+
+
+
+### 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+
+**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git a/_coverpage.md b/_coverpage.md
new file mode 100644
index 0000000..2b1858d
--- /dev/null
+++ b/_coverpage.md
@@ -0,0 +1,13 @@
+
+
+
+
+
+
+Spring Boot 学习/面试指南
+
+[常用资源](https://shimo.im/docs/MuiACIg1HlYfVxrj/)
+[GitHub](https://github.com/Snailclimb/springboot-guide)
+[开始阅读](#重要知识点)
+
+
\ No newline at end of file
diff --git a/docs/MyBatisPlus.md b/docs/MyBatisPlus.md
new file mode 100644
index 0000000..afd4043
--- /dev/null
+++ b/docs/MyBatisPlus.md
@@ -0,0 +1,975 @@
+`MyBatis` 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射,而实际开发中,我们都会选择使用 `MyBatisPlus`,它是对 `MyBatis` 框架的进一步增强,能够极大地简化我们的持久层代码,下面就一起来看看 `MyBatisPlus` 中的一些奇淫巧技吧。
+
+> 说明:本篇文章需要一定的 `MyBatis` 与 `MyBatisPlus` 基础
+
+MyBatis-Plus 官网地址 : https://baomidou.com/ 。
+
+## CRUD
+
+使用 `MyBatisPlus` 实现业务的增删改查非常地简单,一起来看看吧。
+
+**1.首先新建一个 SpringBoot 工程,然后引入依赖:**
+
+```xml
+
+ com.baomidou
+ mybatis-plus-boot-starter
+ 3.4.2
+
+
+ mysql
+ mysql-connector-java
+ runtime
+
+
+ org.projectlombok
+ lombok
+
+```
+
+**2.配置一下数据源:**
+
+```yaml
+spring:
+ datasource:
+ driver-class-name: com.mysql.cj.jdbc.Driver
+ username: root
+ url: jdbc:mysql:///mybatisplus?serverTimezone=UTC
+ password: 123456
+```
+
+**3.创建一下数据表:**
+
+```sql
+CREATE DATABASE `mybatisplus`;
+
+USE `mybatisplus`;
+
+DROP TABLE IF EXISTS `tbl_employee`;
+
+CREATE TABLE `tbl_employee` (
+ `id` bigint(20) NOT NULL,
+ `last_name` varchar(255) DEFAULT NULL,
+ `email` varchar(255) DEFAULT NULL,
+ `gender` char(1) DEFAULT NULL,
+ `age` int(11) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=gbk;
+
+insert into `tbl_employee`(`id`,`last_name`,`email`,`gender`,`age`) values (1,'jack','jack@qq.com','1',35),(2,'tom','tom@qq.com','1',30),(3,'jerry','jerry@qq.com','1',40);
+```
+
+**4.创建对应的实体类:**
+
+```java
+@Data
+public class Employee {
+
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+}
+```
+
+**4.编写 `Mapper` 接口:**
+
+```java
+public interface EmployeeMapper extends BaseMapper {
+}
+```
+
+我们只需继承 `MyBatisPlus` 提供的 `BaseMapper` 接口即可,现在我们就拥有了对 `Employee` 进行增删改查的 API,比如:
+
+```java
+@SpringBootTest
+@MapperScan("com.wwj.mybatisplusdemo.mapper")
+class MybatisplusDemoApplicationTests {
+
+ @Autowired
+ private EmployeeMapper employeeMapper;
+
+ @Test
+ void contextLoads() {
+ List employees = employeeMapper.selectList(null);
+ employees.forEach(System.out::println);
+ }
+}
+```
+
+运行结果:
+
+```java
+org.springframework.jdbc.BadSqlGrammarException:
+### Error querying database. Cause: java.sql.SQLSyntaxErrorException: Table 'mybatisplus.employee' doesn't exist
+```
+
+程序报错了,原因是不存在 `employee` 表,这是因为我们的实体类名为 `Employee`,`MyBatisPlus` 默认是以类名作为表名进行操作的,可如果类名和表名不相同(实际开发中也确实可能不同),就需要在实体类中使用 `@TableName` 注解来声明表的名称:
+
+```java
+@Data
+@TableName("tbl_employee") // 声明表名称
+public class Employee {
+
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+}
+```
+
+重新执行测试代码,结果如下:
+
+```java
+Employee(id=1, lastName=jack, email=jack@qq.com, age=35)
+Employee(id=2, lastName=tom, email=tom@qq.com, age=30)
+Employee(id=3, lastName=jerry, email=jerry@qq.com, age=40)
+```
+
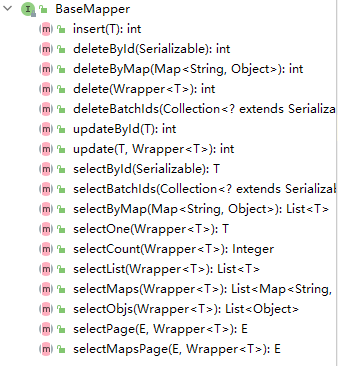
+`BaseMapper` 提供了常用的一些增删改查方法:
+
+
+
+具体细节可以查阅其源码自行体会,注释都是中文的,非常容易理解。
+
+在开发过程中,我们通常会使用 `Service` 层来调用 `Mapper` 层的方法,而 `MyBatisPlus` 也为我们提供了通用的 `Service`:
+
+```java
+public interface EmployeeService extends IService {
+}
+
+@Service
+public class EmployeeServiceImpl extends ServiceImpl implements EmployeeService {
+}
+```
+
+事实上,我们只需让 `EmployeeServiceImpl` 继承 `ServiceImpl` 即可获得 `Service` 层的方法,**那么为什么还需要实现 `EmployeeService` 接口呢?**
+
+这是因为实现 `EmployeeService` 接口能够更方便地对业务进行扩展,一些复杂场景下的数据处理,`MyBatisPlus` 提供的 `Service` 方法可能无法处理,此时我们就需要自己编写代码,这时候只需在 `EmployeeService` 中定义自己的方法,并在 `EmployeeServiceImpl` 中实现即可。
+
+先来测试一下 `MyBatisPlus` 提供的 `Service` 方法:
+
+```java
+@SpringBootTest
+@MapperScan("com.wwj.mybatisplusdemo.mapper")
+class MybatisplusDemoApplicationTests {
+
+ @Autowired
+ private EmployeeService employeeService;
+
+ @Test
+ void contextLoads() {
+ List list = employeeService.list();
+ list.forEach(System.out::println);
+ }
+}
+```
+
+运行结果:
+
+```java
+Employee(id=1, lastName=jack, email=jack@qq.com, age=35)
+Employee(id=2, lastName=tom, email=tom@qq.com, age=30)
+Employee(id=3, lastName=jerry, email=jerry@qq.com, age=40)
+```
+
+接下来模拟一个自定义的场景,我们来编写自定义的操作方法,首先在 `EmployeeMapper` 中进行声明:
+
+```java
+public interface EmployeeMapper extends BaseMapper {
+
+ List selectAllByLastName(@Param("lastName") String lastName);
+}
+```
+
+此时我们需要自己编写配置文件实现该方法,在 `resource` 目录下新建一个 `mapper` 文件夹,然后在该文件夹下创建 `EmployeeMapper.xml` 文件:
+
+```xml
+
+
+
+
+
+ id, last_name, email, gender, age
+
+
+
+
+```
+
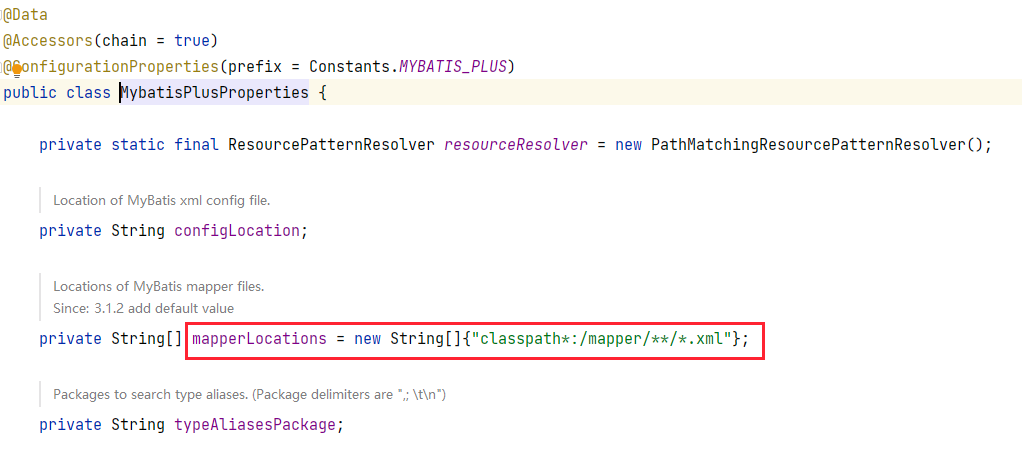
+`MyBatisPlus` 默认扫描的是类路径下的 `mapper` 目录,这可以从源码中得到体现:
+
+
+
+所以我们直接将 `Mapper` 配置文件放在该目录下就没有任何问题,可如果不是这个目录,我们就需要进行配置,比如:
+
+```yaml
+mybatis-plus:
+ mapper-locations: classpath:xml/*.xml
+```
+
+编写好 `Mapper` 接口后,我们就需要定义 `Service` 方法了:
+
+```java
+public interface EmployeeService extends IService {
+
+ List listAllByLastName(String lastName);
+}
+
+@Service
+public class EmployeeServiceImpl extends ServiceImpl implements EmployeeService {
+
+ @Override
+ public List listAllByLastName(String lastName) {
+ return baseMapper.selectAllByLastName(lastName);
+ }
+}
+```
+
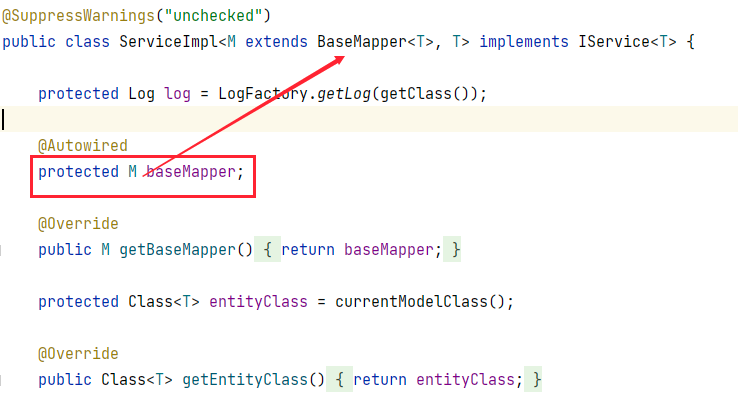
+在 `EmployeeServiceImpl` 中我们无需将 `EmployeeMapper` 注入进来,而是使用 `BaseMapper`,查看 `ServiceImpl` 的源码:
+
+
+
+可以看到它为我们注入了一个 `BaseMapper` 对象,而它是第一个泛型类型,也就是 `EmployeeMapper` 类型,所以我们可以直接使用这个 `baseMapper` 来调用 `Mapper` 中的方法,此时编写测试代码:
+
+```java
+@SpringBootTest
+@MapperScan("com.wwj.mybatisplusdemo.mapper")
+class MybatisplusDemoApplicationTests {
+
+ @Autowired
+ private EmployeeService employeeService;
+
+ @Test
+ void contextLoads() {
+ List list = employeeService.listAllByLastName("tom");
+ list.forEach(System.out::println);
+ }
+}
+```
+
+运行结果:
+
+```java
+Employee(id=2, lastName=tom, email=tom@qq.com, age=30)
+```
+
+## ID 策略
+
+在创建表的时候我故意没有设置主键的增长策略,现在我们来插入一条数据,看看主键是如何增长的:
+
+```java
+@Test
+void contextLoads() {
+ Employee employee = new Employee();
+ employee.setLastName("lisa");
+ employee.setEmail("lisa@qq.com");
+ employee.setAge(20);
+ employeeService.save(employee);
+}
+```
+
+插入成功后查询一下数据表:
+
+```sql
+mysql> select * from tbl_employee;
++---------------------+-----------+--------------+--------+------+
+| id | last_name | email | gender | age |
++---------------------+-----------+--------------+--------+------+
+| 1 | jack | jack@qq.com | 1 | 35 |
+| 2 | tom | tom@qq.com | 1 | 30 |
+| 3 | jerry | jerry@qq.com | 1 | 40 |
+| 1385934720849584129 | lisa | lisa@qq.com | NULL | 20 |
++---------------------+-----------+--------------+--------+------+
+4 rows in set (0.00 sec)
+```
+
+可以看到 id 是一串相当长的数字,这是什么意思呢?提前剧透一下,这其实是分布式 id,那又何为分布式 id 呢?
+
+我们知道,对于一个大型应用,其访问量是非常巨大的,就比如说一个网站每天都有人进行注册,注册的用户信息就需要存入数据表,随着日子一天天过去,数据表中的用户越来越多,此时数据库的查询速度就会受到影响,所以一般情况下,当数据量足够庞大时,数据都会做分库分表的处理。
+
+然而,一旦分表,问题就产生了,很显然这些分表的数据都是属于同一张表的数据,只是因为数据量过大而分成若干张表,那么这几张表的主键 id 该怎么管理呢?每张表维护自己的 id?那数据将会有很多的 id 重复,这当然是不被允许的,其实,我们可以使用算法来生成一个绝对不会重复的 id,这样问题就迎刃而解了,事实上,分布式 id 的解决方案有很多:
+
+1. UUID
+1. SnowFlake
+1. TinyID
+1. Uidgenerator
+1. Leaf
+6. Tinyid
+7. ......
+
+以 UUID 为例,它生成的是一串由数字和字母组成的字符串,显然并不适合作为数据表的 id,而且 id 保持递增有序会加快表的查询效率,基于此,`MyBatisPlus` 使用的就是 `SnowFlake`(雪花算法)。
+
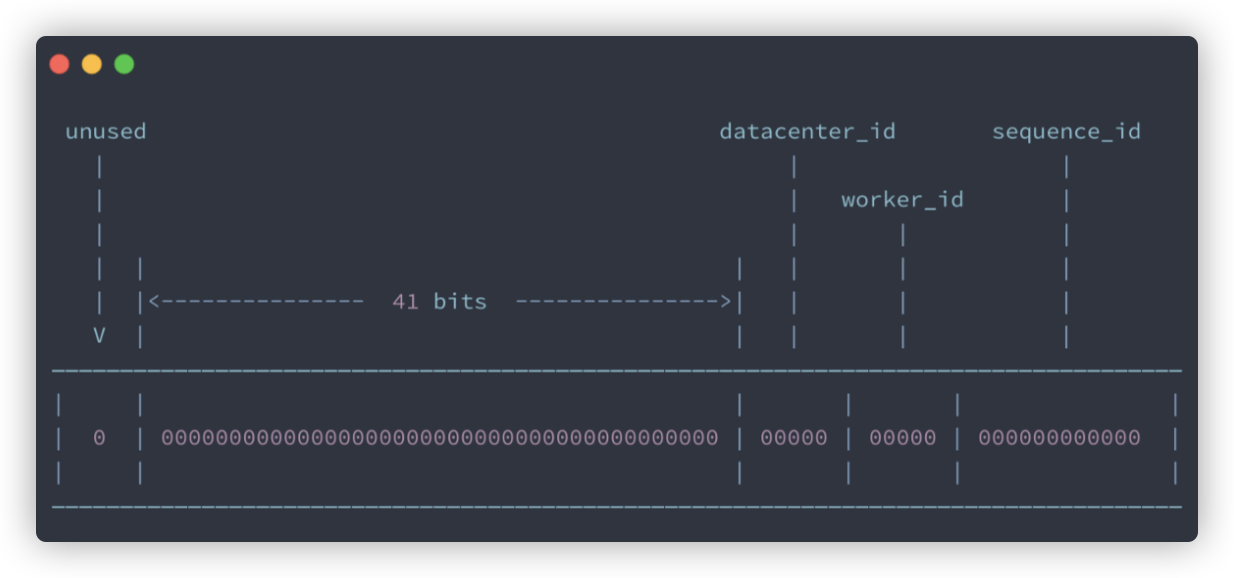
+`Snowflake` 是 Twitter 开源的分布式 ID 生成算法。`Snowflake` 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
+
+- **第 0 位**: 符号位(标识正负),始终为 0,没有用,不用管。
+- **第 1~41 位** :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
+- **第 42~52 位** :一共 10 位,一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **第 53~64 位** :一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+
+
+这也就是为什么插入数据后新的数据 id 是一长串数字的原因了,我们可以在实体类中使用 `@TableId` 来设置主键的策略:
+
+```java
+@Data
+@TableName("tbl_employee")
+public class Employee {
+
+ @TableId(type = IdType.AUTO) // 设置主键策略
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+}
+```
+
+`MyBatisPlus` 提供了几种主键的策略:
+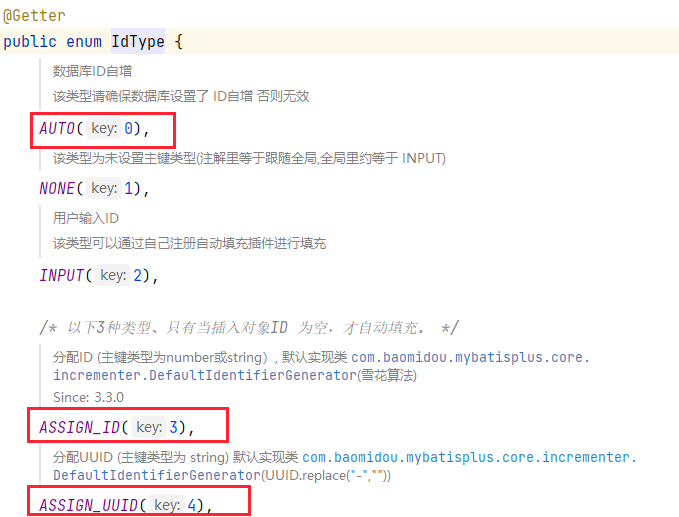
+其中 `AUTO` 表示数据库自增策略,该策略下需要数据库实现主键的自增(auto_increment),`ASSIGN_ID` 是雪花算法,默认使用的是该策略,`ASSIGN_UUID` 是 UUID 策略,一般不会使用该策略。
+
+这里多说一点, 当实体类的主键名为 id,并且数据表的主键名也为 id 时,此时 `MyBatisPlus` 会自动判定该属性为主键 id,倘若名字不是 id 时,就需要标注 `@TableId` 注解,若是实体类中主键名与数据表的主键名不一致,则可以进行声明:
+
+```java
+@TableId(value = "uid",type = IdType.AUTO) // 设置主键策略
+private Long id;
+```
+
+还可以在配置文件中配置全局的主键策略:
+
+```yaml
+mybatis-plus:
+ global-config:
+ db-config:
+ id-type: auto
+```
+
+这样能够避免在每个实体类中重复设置主键策略。
+
+## 属性自动填充
+
+翻阅《阿里巴巴Java开发手册》,在第 5 章 MySQL 数据库可以看到这样一条规范:
+
+对于一张数据表,它必须具备三个字段:
+
+- `id` : 唯一ID
+- `gmt_create` : 保存的是当前数据创建的时间
+- `gmt_modified` : 保存的是更新时间
+
+我们改造一下数据表:
+
+```sql
+alter table tbl_employee add column gmt_create datetime not null;
+alter table tbl_employee add column gmt_modified datetime not null;
+```
+
+然后改造一下实体类:
+
+```java
+@Data
+@TableName("tbl_employee")
+public class Employee {
+
+ @TableId(type = IdType.AUTO) // 设置主键策略
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+ private LocalDateTime gmtCreate;
+ private LocalDateTime gmtModified;
+}
+```
+
+此时我们在插入数据和更新数据的时候就需要手动去维护这两个属性:
+
+```java
+@Test
+void contextLoads() {
+ Employee employee = new Employee();
+ employee.setLastName("lisa");
+ employee.setEmail("lisa@qq.com");
+ employee.setAge(20);
+ // 设置创建时间
+ employee.setGmtCreate(LocalDateTime.now());
+ employee.setGmtModified(LocalDateTime.now());
+ employeeService.save(employee);
+}
+
+@Test
+void contextLoads() {
+ Employee employee = new Employee();
+ employee.setId(1385934720849584130L);
+ employee.setAge(50);
+ // 设置创建时间
+ employee.setGmtModified(LocalDateTime.now());
+ employeeService.updateById(employee);
+}
+```
+
+每次都需要维护这两个属性未免过于麻烦,好在 `MyBatisPlus` 提供了字段自动填充功能来帮助我们进行管理,需要使用到的是 `@TableField` 注解:
+
+```java
+@Data
+@TableName("tbl_employee")
+public class Employee {
+
+ @TableId(type = IdType.AUTO)
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+ @TableField(fill = FieldFill.INSERT) // 插入的时候自动填充
+ private LocalDateTime gmtCreate;
+ @TableField(fill = FieldFill.INSERT_UPDATE) // 插入和更新的时候自动填充
+ private LocalDateTime gmtModified;
+}
+```
+
+然后编写一个类实现 MetaObjectHandler 接口:
+
+```java
+@Component
+@Slf4j
+public class MyMetaObjectHandler implements MetaObjectHandler {
+
+ /**
+ * 实现插入时的自动填充
+ * @param metaObject
+ */
+ @Override
+ public void insertFill(MetaObject metaObject) {
+ log.info("insert开始属性填充");
+ this.strictInsertFill(metaObject,"gmtCreate", LocalDateTime.class,LocalDateTime.now());
+ this.strictInsertFill(metaObject,"gmtModified", LocalDateTime.class,LocalDateTime.now());
+ }
+
+ /**
+ * 实现更新时的自动填充
+ * @param metaObject
+ */
+ @Override
+ public void updateFill(MetaObject metaObject) {
+ log.info("update开始属性填充");
+ this.strictInsertFill(metaObject,"gmtModified", LocalDateTime.class,LocalDateTime.now());
+ }
+}
+```
+
+该接口中有两个未实现的方法,分别为插入和更新时的填充方法,在方法中调用 `strictInsertFill()` 方法 即可实现属性的填充,它需要四个参数:
+
+1. `metaObject`:元对象,就是方法的入参
+1. `fieldName`:为哪个属性进行自动填充
+1. `fieldType`:属性的类型
+1. `fieldVal`:需要填充的属性值
+
+此时在插入和更新数据之前,这两个方法会先被执行,以实现属性的自动填充,通过日志我们可以进行验证:
+
+```java
+@Test
+void contextLoads() {
+ Employee employee = new Employee();
+ employee.setId(1385934720849584130L);
+ employee.setAge(15);
+ employeeService.updateById(employee);
+}
+```
+
+运行结果:
+
+```java
+INFO 15584 --- [ main] c.w.m.handler.MyMetaObjectHandler : update开始属性填充
+2021-04-24 21:32:19.788 INFO 15584 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
+2021-04-24 21:32:21.244 INFO 15584 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
+```
+
+属性填充其实可以进行一些优化,考虑一些特殊情况,对于一些不存在的属性,就不需要进行属性填充,对于一些设置了值的属性,也不需要进行属性填充,这样可以提高程序的整体运行效率:
+
+```java
+@Component
+@Slf4j
+public class MyMetaObjectHandler implements MetaObjectHandler {
+
+ @Override
+ public void insertFill(MetaObject metaObject) {
+ boolean hasGmtCreate = metaObject.hasSetter("gmtCreate");
+ boolean hasGmtModified = metaObject.hasSetter("gmtModified");
+ if (hasGmtCreate) {
+ Object gmtCreate = this.getFieldValByName("gmtCreate", metaObject);
+ if (gmtCreate == null) {
+ this.strictInsertFill(metaObject, "gmtCreate", LocalDateTime.class, LocalDateTime.now());
+ }
+ }
+ if (hasGmtModified) {
+ Object gmtModified = this.getFieldValByName("gmtModified", metaObject);
+ if (gmtModified == null) {
+ this.strictInsertFill(metaObject, "gmtModified", LocalDateTime.class, LocalDateTime.now());
+ }
+ }
+ }
+
+ @Override
+ public void updateFill(MetaObject metaObject) {
+ boolean hasGmtModified = metaObject.hasSetter("gmtModified");
+ if (hasGmtModified) {
+ Object gmtModified = this.getFieldValByName("gmtModified", metaObject);
+ if (gmtModified == null) {
+ this.strictInsertFill(metaObject, "gmtModified", LocalDateTime.class, LocalDateTime.now());
+ }
+ }
+ }
+}
+```
+
+## 逻辑删除
+
+逻辑删除对应的是物理删除,分别介绍一下这两个概念:
+
+1. **物理删除** :指的是真正的删除,即:当执行删除操作时,将数据表中的数据进行删除,之后将无法再查询到该数据
+1. **逻辑删除** :并不是真正意义上的删除,只是对于用户不可见了,它仍然存在与数据表中
+
+在这个数据为王的时代,数据就是财富,所以一般并不会有哪个系统在删除某些重要数据时真正删掉了数据,通常都是在数据库中建立一个状态列,让其默认为 0,当为 0 时,用户可见;当执行了删除操作,就将状态列改为 1,此时用户不可见,但数据还是在表中的。
+
+
+
+按照《阿里巴巴Java开发手册》第 5 章 MySQL 数据库相关的建议,我们来为数据表新增一个`is_deleted` 字段:
+
+```sql
+alter table tbl_employee add column is_deleted tinyint not null;
+```
+
+在实体类中也要添加这一属性:
+
+```java
+@Data
+@TableName("tbl_employee")
+public class Employee {
+
+ @TableId(type = IdType.AUTO)
+ private Long id;
+ private String lastName;
+ private String email;
+ private Integer age;
+ @TableField(fill = FieldFill.INSERT)
+ private LocalDateTime gmtCreate;
+ @TableField(fill = FieldFill.INSERT_UPDATE)
+ private LocalDateTime gmtModified;
+ /**
+ * 逻辑删除属性
+ */
+ @TableLogic
+ @TableField("is_deleted")
+ private Boolean deleted;
+}
+```
+
+
+
+还是参照《阿里巴巴Java开发手册》第 5 章 MySQL 数据库相关的建议,对于布尔类型变量,不能加 is 前缀,所以我们的属性被命名为 `deleted`,但此时就无法与数据表的字段进行对应了,所以我们需要使用 `@TableField` 注解来声明一下数据表的字段名,而 `@TableLogin` 注解用于设置逻辑删除属性;此时我们执行删除操作:
+
+```java
+@Test
+void contextLoads() {
+ employeeService.removeById(3);
+}
+```
+
+查询数据表:
+
+```sql
+mysql> select * from tbl_employee;
++---------------------+-----------+--------------+--------+------+---------------------+---------------------+------------+
+| id | last_name | email | gender | age | gmt_create | gmt_modified | is_deleted |
++---------------------+-----------+--------------+--------+------+---------------------+---------------------+------------+
+| 1 | jack | jack@qq.com | 1 | 35 | 0000-00-00 00:00:00 | 0000-00-00 00:00:00 | 0 |
+| 2 | tom | tom@qq.com | 1 | 30 | 0000-00-00 00:00:00 | 0000-00-00 00:00:00 | 0 |
+| 3 | jerry | jerry@qq.com | 1 | 40 | 0000-00-00 00:00:00 | 0000-00-00 00:00:00 | 1 |
+| 1385934720849584129 | lisa | lisa@qq.com | NULL | 20 | 0000-00-00 00:00:00 | 0000-00-00 00:00:00 | 0 |
+| 1385934720849584130 | lisa | lisa@qq.com | NULL | 15 | 2021-04-24 21:14:18 | 2021-04-24 21:32:19 | 0 |
++---------------------+-----------+--------------+--------+------+---------------------+---------------------+------------+
+5 rows in set (0.00 sec)
+```
+
+可以看到数据并没有被删除,只是 `is_deleted` 字段的属性值被更新成了 1,此时我们再来执行查询操作:
+
+```java
+@Test
+void contextLoads() {
+ List list = employeeService.list();
+ list.forEach(System.out::println);
+}
+```
+
+执行结果:
+
+```java
+Employee(id=1, lastName=jack, email=jack@qq.com, age=35, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=false)
+Employee(id=2, lastName=tom, email=tom@qq.com, age=30, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=false)
+Employee(id=1385934720849584129, lastName=lisa, email=lisa@qq.com, age=20, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=false)
+Employee(id=1385934720849584130, lastName=lisa, email=lisa@qq.com, age=15, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:32:19, deleted=false)
+```
+
+会发现第三条数据并没有被查询出来,它是如何实现的呢?我们可以输出 `MyBatisPlus` 生成的 SQL 来分析一下,在配置文件中进行配置:
+
+```yaml
+mybatis-plus:
+ configuration:
+ log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 输出SQL日志
+```
+
+运行结果:
+
+```java
+==> Preparing: SELECT id,last_name,email,age,gmt_create,gmt_modified,is_deleted AS deleted FROM tbl_employee WHERE is_deleted=0
+==> Parameters:
+<== Columns: id, last_name, email, age, gmt_create, gmt_modified, deleted
+<== Row: 1, jack, jack@qq.com, 35, 2021-04-24 21:14:18, 2021-04-24 21:14:18, 0
+<== Row: 2, tom, tom@qq.com, 30, 2021-04-24 21:14:18, 2021-04-24 21:14:18, 0
+<== Row: 1385934720849584129, lisa, lisa@qq.com, 20, 2021-04-24 21:14:18, 2021-04-24 21:14:18, 0
+<== Row: 1385934720849584130, lisa, lisa@qq.com, 15, 2021-04-24 21:14:18, 2021-04-24 21:32:19, 0
+<== Total: 4
+```
+
+原来它在查询时携带了一个条件: `is_deleted=0` ,这也说明了 `MyBatisPlus` 默认 0 为不删除,1 为删除。
+若是你想修改这个规定,比如设置-1 为删除,1 为不删除,也可以进行配置:
+
+```yaml
+mybatis-plus:
+ global-config:
+ db-config:
+ id-type: auto
+ logic-delete-field: deleted # 逻辑删除属性名
+ logic-delete-value: -1 # 删除值
+ logic-not-delete-value: 1 # 不删除值
+```
+
+但建议使用默认的配置,阿里巴巴开发手册也规定 1 表示删除,0 表示未删除。
+
+## 分页插件
+
+对于分页功能,`MyBatisPlus` 提供了分页插件,只需要进行简单的配置即可实现:
+
+```java
+@Configuration
+public class MyBatisConfig {
+
+ /**
+ * 注册分页插件
+ * @return
+ */
+ @Bean
+ public MybatisPlusInterceptor mybatisPlusInterceptor() {
+ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
+ interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
+ return interceptor;
+ }
+}
+```
+
+接下来我们就可以使用分页插件提供的功能了:
+
+```java
+@Test
+void contextLoads() {
+ Page page = new Page<>(1,2);
+ employeeService.page(page, null);
+ List employeeList = page.getRecords();
+ employeeList.forEach(System.out::println);
+ System.out.println("获取总条数:" + page.getTotal());
+ System.out.println("获取当前页码:" + page.getCurrent());
+ System.out.println("获取总页码:" + page.getPages());
+ System.out.println("获取每页显示的数据条数:" + page.getSize());
+ System.out.println("是否有上一页:" + page.hasPrevious());
+ System.out.println("是否有下一页:" + page.hasNext());
+}
+```
+
+其中的 `Page` 对象用于指定分页查询的规则,这里表示按每页两条数据进行分页,并查询第一页的内容,运行结果:
+
+```java
+Employee(id=1, lastName=jack, email=jack@qq.com, age=35, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=0)
+Employee(id=2, lastName=tom, email=tom@qq.com, age=30, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=0)
+获取总条数:4
+获取当前页码:1
+获取总页码:2
+获取每页显示的数据条数:2
+是否有上一页:false
+是否有下一页:true
+```
+
+倘若在分页过程中需要限定一些条件,我们就需要构建 QueryWrapper 来实现:
+
+```java
+@Test
+void contextLoads() {
+ Page page = new Page<>(1, 2);
+ employeeService.page(page, new QueryWrapper()
+ .between("age", 20, 50)
+ .eq("gender", 1));
+ List employeeList = page.getRecords();
+ employeeList.forEach(System.out::println);
+}
+```
+
+此时分页的数据就应该是年龄在 20~50 岁之间,且 gender 值为 1 的员工信息,然后再对这些数据进行分页。
+
+## 乐观锁
+
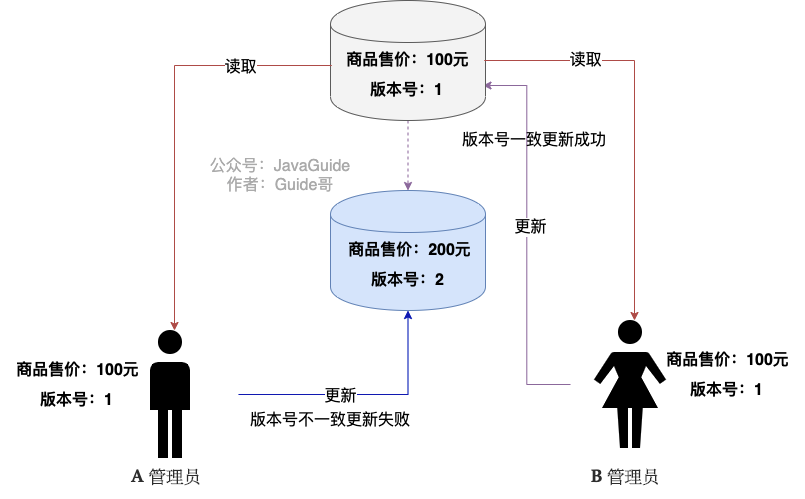
+当程序中出现并发访问时,就需要保证数据的一致性。以商品系统为例,现在有两个管理员均想对同一件售价为 100 元的商品进行修改,A 管理员正准备将商品售价改为 150 元,但此时出现了网络问题,导致 A 管理员的操作陷入了等待状态;此时 B 管理员也进行修改,将商品售价改为了 200 元,修改完成后 B 管理员退出了系统,此时 A 管理员的操作也生效了,这样便使得 A 管理员的操作直接覆盖了 B 管理员的操作,B 管理员后续再进行查询时会发现商品售价变为了 150 元,这样的情况是绝对不允许发生的。
+
+要想解决这一问题,可以给数据表加锁,常见的方式有两种:
+
+1. 乐观锁
+1. 悲观锁
+
+悲观锁认为并发情况一定会发生,所以在某条数据被修改时,为了避免其它人修改,会直接对数据表进行加锁,它依靠的是数据库本身提供的锁机制(表锁、行锁、读锁、写锁)。
+
+而乐观锁则相反,它认为数据产生冲突的情况一般不会发生,所以在修改数据的时候并不会对数据表进行加锁的操作,而是在提交数据时进行校验,判断提交上来的数据是否会发生冲突,如果发生冲突,则提示用户重新进行操作,一般的实现方式为 `设置版本号字段` 。
+
+就以商品售价为例,在该表中设置一个版本号字段,让其初始为 1,此时 A 管理员和 B 管理员同时需要修改售价,它们会先读取到数据表中的内容,此时两个管理员读取到的版本号都为 1,此时 B 管理员的操作先生效了,它就会将当前数据表中对应数据的版本号与最开始读取到的版本号作一个比对,发现没有变化,于是修改就生效了,此时版本号加 1。
+
+而 A 管理员马上也提交了修改操作,但是此时的版本号为 2,与最开始读取到的版本号并不对应,这就说明数据发生了冲突,此时应该提示 A 管理员操作失败,并让 A 管理员重新查询一次数据。
+
+
+
+乐观锁的优势在于采取了更加宽松的加锁机制,能够提高程序的吞吐量,适用于读操作多的场景。
+
+那么接下来我们就来模拟这一过程。
+
+**1.创建一张新的数据表:**
+
+```sql
+create table shop(
+ id bigint(20) not null auto_increment,
+ name varchar(30) not null,
+ price int(11) default 0,
+ version int(11) default 1,
+ primary key(id)
+);
+
+insert into shop(id,name,price) values(1,'笔记本电脑',8000);
+```
+
+**2.创建实体类:**
+
+```java
+@Data
+public class Shop {
+
+ private Long id;
+ private String name;
+ private Integer price;
+ private Integer version;
+}
+```
+
+**3.创建对应的 `Mapper` 接口:**
+
+```java
+public interface ShopMapper extends BaseMapper {
+}
+```
+
+**4.编写测试代码:**
+
+```java
+@SpringBootTest
+@MapperScan("com.wwj.mybatisplusdemo.mapper")
+class MybatisplusDemoApplicationTests {
+
+ @Autowired
+ private ShopMapper shopMapper;
+
+ /**
+ * 模拟并发场景
+ */
+ @Test
+ void contextLoads() {
+ // A、B管理员读取数据
+ Shop A = shopMapper.selectById(1L);
+ Shop B = shopMapper.selectById(1L);
+ // B管理员先修改
+ B.setPrice(9000);
+ int result = shopMapper.updateById(B);
+ if (result == 1) {
+ System.out.println("B管理员修改成功!");
+ } else {
+ System.out.println("B管理员修改失败!");
+ }
+ // A管理员后修改
+ A.setPrice(8500);
+ int result2 = shopMapper.updateById(A);
+ if (result2 == 1) {
+ System.out.println("A管理员修改成功!");
+ } else {
+ System.out.println("A管理员修改失败!");
+ }
+ // 最后查询
+ System.out.println(shopMapper.selectById(1L));
+ }
+}
+```
+
+执行结果:
+
+```java
+B管理员修改成功!
+A管理员修改成功!
+Shop(id=1, name=笔记本电脑, price=8500, version=1)
+```
+
+**问题出现了,B 管理员的操作被 A 管理员覆盖,那么该如何解决这一问题呢?**
+
+其实 `MyBatisPlus` 已经提供了乐观锁机制,只需要在实体类中使用 `@Version` 声明版本号属性:
+
+```java
+@Data
+public class Shop {
+
+ private Long id;
+ private String name;
+ private Integer price;
+ @Version // 声明版本号属性
+ private Integer version;
+}
+```
+
+然后注册乐观锁插件:
+
+```java
+@Configuration
+public class MyBatisConfig {
+
+ /**
+ * 注册插件
+ * @return
+ */
+ @Bean
+ public MybatisPlusInterceptor mybatisPlusInterceptor() {
+ MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
+ // 分页插件
+ interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
+ // 乐观锁插件
+ interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
+ return interceptor;
+ }
+}
+```
+
+重新执行测试代码,结果如下:
+
+```java
+B管理员修改成功!
+A管理员修改失败!
+Shop(id=1, name=笔记本电脑, price=9000, version=2)
+```
+
+此时 A 管理员的修改就失败了,它需要重新读取最新的数据才能再次进行修改。
+
+## 条件构造器
+
+在分页插件中我们简单地使用了一下条件构造器(`Wrapper`),下面我们来详细了解一下。
+先来看看 `Wrapper` 的继承体系:
+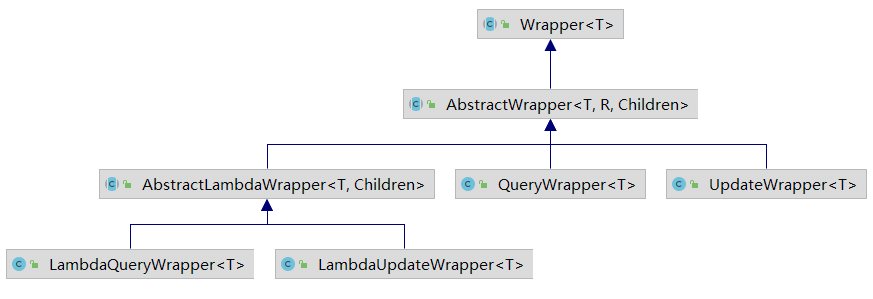
+分别介绍一下它们的作用:
+
+- `Wrapper`:条件构造器抽象类,最顶端的父类
+ - `AbstractWrapper`:查询条件封装抽象类,生成 SQL 的 where 条件
+ - `QueryWrapper`:用于对象封装
+ - `UpdateWrapper`:用于条件封装
+ - `AbstractLambdaWrapper`:Lambda 语法使用 Wrapper
+ - `LambdaQueryWrapper`:用于对象封装,使用 Lambda 语法
+ - `LambdaUpdateWrapper`:用于条件封装,使用 Lambda 语法
+
+通常我们使用的都是 `QueryWrapper` 和 `UpdateWrapper`,若是想使用 Lambda 语法来编写,也可以使用 `LambdaQueryWrapper` 和 `LambdaUpdateWrapper`,通过这些条件构造器,我们能够很方便地来实现一些复杂的筛选操作,比如:
+
+```java
+@SpringBootTest
+@MapperScan("com.wwj.mybatisplusdemo.mapper")
+class MybatisplusDemoApplicationTests {
+
+ @Autowired
+ private EmployeeMapper employeeMapper;
+
+ @Test
+ void contextLoads() {
+ // 查询名字中包含'j',年龄大于20岁,邮箱不为空的员工信息
+ QueryWrapper wrapper = new QueryWrapper<>();
+ wrapper.like("last_name", "j");
+ wrapper.gt("age", 20);
+ wrapper.isNotNull("email");
+ List list = employeeMapper.selectList(wrapper);
+ list.forEach(System.out::println);
+ }
+}
+```
+
+运行结果:
+
+```java
+Employee(id=1, lastName=jack, email=jack@qq.com, age=35, gmtCreate=2021-04-24T21:14:18, gmtModified=2021-04-24T21:14:18, deleted=0)
+```
+
+条件构造器提供了丰富的条件方法帮助我们进行条件的构造,比如 `like` 方法会为我们建立模糊查询,查看一下控制台输出的 SQL:
+
+```sql
+==> Preparing: SELECT id,last_name,email,age,gmt_create,gmt_modified,is_deleted AS deleted FROM tbl_employee WHERE is_deleted=0 AND (last_name LIKE ? AND age > ? AND email IS NOT NULL)
+==> Parameters: %j%(String), 20(Integer)
+```
+
+可以看到它是对 `j` 的前后都加上了 `%` ,若是只想查询以 `j` 开头的名字,则可以使用 `likeRight` 方法,若是想查询以 `j` 结尾的名字,,则使用 `likeLeft` 方法。
+
+年龄的比较也是如此, `gt` 是大于指定值,若是小于则调用 `lt` ,大于等于调用 `ge` ,小于等于调用 `le` ,不等于调用 `ne` ,还可以使用 `between` 方法实现这一过程,相关的其它方法都可以查阅源码进行学习。
+
+因为这些方法返回的其实都是自身实例,所以可使用链式编程:
+
+```java
+@Test
+void contextLoads() {
+ // 查询名字中包含'j',年龄大于20岁,邮箱不为空的员工信息
+ QueryWrapper wrapper = new QueryWrapper()
+ .likeLeft("last_name", "j")
+ .gt("age", 20)
+ .isNotNull("email");
+ List list = employeeMapper.selectList(wrapper);
+ list.forEach(System.out::println);
+}
+```
+
+也可以使用 `LambdaQueryWrapper` 实现:
+
+```java
+@Test
+void contextLoads() {
+ // 查询名字中包含'j',年龄大于20岁,邮箱不为空的员工信息
+ LambdaQueryWrapper wrapper = new LambdaQueryWrapper()
+ .like(Employee::getLastName,"j")
+ .gt(Employee::getAge,20)
+ .isNotNull(Employee::getEmail);
+ List list = employeeMapper.selectList(wrapper);
+ list.forEach(System.out::println);
+}
+```
+
+这种方式的好处在于对字段的设置不是硬编码,而是采用方法引用的形式,效果与 `QueryWrapper` 是一样的。
+
+`UpdateWrapper` 与 `QueryWrapper` 不同,它的作用是封装更新内容的,比如:
+
+```java
+@Test
+void contextLoads() {
+ UpdateWrapper wrapper = new UpdateWrapper()
+ .set("age", 50)
+ .set("email", "emp@163.com")
+ .like("last_name", "j")
+ .gt("age", 20);
+ employeeMapper.update(null, wrapper);
+}
+```
+
+将名字中包含 `j` 且年龄大于 20 岁的员工年龄改为 50,邮箱改为 emp@163.com,`UpdateWrapper` 不仅能够封装更新内容,也能作为查询条件,所以在更新数据时可以直接构造一个 `UpdateWrapper` 来设置更新内容和条件。
\ No newline at end of file
diff --git a/docs/PowerMockRunnerAndMockito.md b/docs/PowerMockRunnerAndMockito.md
new file mode 100644
index 0000000..469e075
--- /dev/null
+++ b/docs/PowerMockRunnerAndMockito.md
@@ -0,0 +1,161 @@
+单元测试可以提高测试开发的效率,减少代码错误率,提高代码健壮性,提高代码质量。在 Spring 框架中常用的两种测试框架:`PowerMockRunner` 和 `SpringRunner` 两个单元测试,鉴于 `SpringRunner` 启动的一系列依赖和数据连接的问题,推荐使用 `PowerMockRunner`,这样能有效的提高测试的效率,并且其提供的 API 能覆盖的场景广泛,使用方便,可谓是 Java 单元测试之模拟利器。
+
+## 1. PowerMock 是什么?
+
+`PowerMock` 是一个 Java 模拟框架,可用于解决通常认为很难甚至无法测试的测试问题。使用 `PowerMock`,可以模拟静态方法,删除静态初始化程序,允许模拟而不依赖于注入,等等。`PowerMock` 通过在执行测试时在运行时修改字节码来完成这些技巧。`PowerMock` 还包含一些实用程序,可让您更轻松地访问对象的内部状态。
+
+举个例子,你在使用 `Junit` 进行单元测试时,并不想让测试数据进入数据库,怎么办?这个时候就可以使用 `PowerMock`,拦截数据库操作,并模拟返回参数。
+
+## 2. PowerMock 包引入
+
+```xml
+
+
+ org.powermock
+ powermock-core
+ 2.0.2
+ test
+
+
+ org.mockito
+ mockito-core
+ 2.23.0
+
+
+ org.powermock
+ powermock-module-junit4
+ 2.0.4
+ test
+
+
+ org.powermock
+ powermock-api-mockito2
+ 2.0.2
+ test
+
+
+ com.github.jsonzou
+ jmockdata
+ 4.3.0
+
+```
+
+## 3. 重要注解说明
+
+```java
+@RunWith(PowerMockRunner.class) // 告诉JUnit使用PowerMockRunner进行测试
+@PrepareForTest({RandomUtil.class}) // 所有需要测试的类列在此处,适用于模拟final类或有final, private, static, native方法的类
+@PowerMockIgnore("javax.management.*") //为了解决使用powermock后,提示classloader错误
+```
+
+## 4. 使用示例
+
+### 4.1 模拟接口返回
+
+首先对接口进行 mock,然后录制相关行为
+
+```java
+InterfaceToMock mock = Powermockito.mock(InterfaceToMock.class)
+Powermockito.when(mock.method(Params…)).thenReturn(value)
+Powermockito.when(mock.method(Params..)).thenThrow(Exception)
+```
+
+### 4.2 设置对象的 private 属性
+
+需要使用 `Whitebox` 向 class 或者对象中赋值。
+
+如我们已经对接口尽心了 mock,现在需要将此 mock 加入到对象中,可以采用如下方法:
+
+```java
+Whitebox.setInternalState(Object object, String fieldname, Object… value);
+```
+
+其中 object 为需要设置属性的静态类或对象。
+
+### 4.3 模拟构造函数
+
+对于模拟构造函数,也即当出现 `new InstanceClass()` 时可以将此构造函数拦截并替换结果为我们需要的 mock 对象。
+
+注意:使用时需要加入标记:
+
+```java
+@RunWith(PowerMockRunner.class)
+@PrepareForTest({ InstanceClass.class })
+@PowerMockIgnore("javax.management.\*")
+
+Powermockito.whenNew(InstanceClass.class).thenReturn(Object value)
+```
+
+##### 4.4 模拟静态方法
+
+模拟静态方法类似于模拟构造函数,也需要加入注释标记。
+
+```java
+@RunWith(PowerMockRunner.class)
+@PrepareForTest({ StaticClassToMock.class })
+@PowerMockIgnore("javax.management.\*")
+
+Powermockito.mockStatic(StaticClassToMock.class);
+Powermockito.when(StaticClassToMock.method(Object.. params)).thenReturn(Object value)
+```
+
+##### 4.5 模拟 final 方法
+
+Final 方法的模拟类似于模拟静态方法。
+
+```java
+@RunWith(PowerMockRunner.class)
+@PrepareForTest({ FinalClassToMock.class })
+@PowerMockIgnore("javax.management.\*")
+
+Powermockito.mockStatic(FinalClassToMock.class);
+Powermockito.when(StaticClassToMock.method(Object.. params)).thenReturn(Object value)
+```
+
+### 4.6 模拟静态类
+
+模拟静态类类似于模拟静态方法。
+
+### 4.7 使用 spy 方法避免执行被测类中的成员函数
+
+如被测试类为:TargetClass,想要屏蔽的方法为 targetMethod.
+
+```java
+1) PowerMockito.spy(TargetClass.class);
+
+2) Powemockito.when(TargetClass.targetMethod()).doReturn()
+
+3) 注意加入
+
+@RunWith(PowerMockRunner.class)
+@PrepareForTest(DisplayMoRelationBuilder.class)
+@PowerMockIgnore("javax.management.*")
+```
+
+### 4.8 参数匹配器
+
+有时我们在处理 `doMethod(Param param)` 时,不想进行精确匹配,这时可以使用 `Mockito` 提供的模糊匹配方式。
+
+如:`Mockito.anyInt()`,`Mockito.anyString()`
+
+### 4.9 处理 public void 型的静态方法
+
+```java
+Powermockito.doNothing.when(T class2mock, String method, … params>
+```
+
+## 5. 单元测试用例可选清单
+
+输入数据验证:这些检查通常可以对输入到应用程序系统中的数据采用。
+
+- 必传项测试
+- 唯一字段值测试
+- 空值测试
+- 字段只接受允许的字符
+- 负值测试
+- 字段限于字段长度规范
+- 不可能的值
+- 垃圾值测试
+- 检查字段之间的依赖性
+- 等效类划分和边界条件测试
+- 错误和异常处理测试单元测试可以提高测试开发的效率,减少代码错误率,提高代码健壮性,提高代码质量。在 Spring 框架中常用的两种测试框架:PowerMockRunner 和 SpringRunner 两个单元测试,鉴于 SpringRunner 启动的一系列依赖和数据连接的问题,推荐使用 PowerMockRunner,这样能有效的提高测试的效率,并且其提供的 API 能覆盖的场景广泛,使用方便,可谓是 Java 单元测试之模拟利器。
\ No newline at end of file
diff --git a/docs/advanced/Apache-BeanUtils-VS-SpringBean-Utils.md b/docs/advanced/Apache-BeanUtils-VS-SpringBean-Utils.md
new file mode 100644
index 0000000..9a87bda
--- /dev/null
+++ b/docs/advanced/Apache-BeanUtils-VS-SpringBean-Utils.md
@@ -0,0 +1,218 @@
+>本文转载自:[https://pjmike.github.io/2018/11/03/Bean映射工具之Apache-BeanUtils-VS-Spring-BeanUtils/](https://pjmike.github.io/2018/11/03/Bean映射工具之Apache-BeanUtils-VS-Spring-BeanUtils/),作者 pjmike 。
+
+## 前言
+
+在我们实际项目开发过程中,我们经常需要将不同的两个对象实例进行属性复制,从而基于源对象的属性信息进行后续操作,而不改变源对象的属性信息,比如DTO数据传输对象和数据对象DO,我们需要将DO对象进行属性复制到DTO,但是对象格式又不一样,所以我们需要编写映射代码将对象中的属性值从一种类型转换成另一种类型。
+
+## 对象拷贝
+
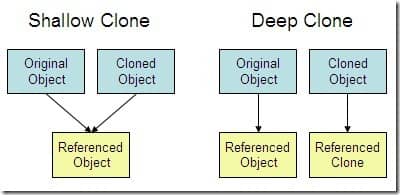
+在具体介绍两种 BeanUtils 之前,先来补充一些基础知识。它们两种工具本质上就是对象拷贝工具,而对象拷贝又分为深拷贝和浅拷贝,下面进行详细解释。
+
+### 什么是浅拷贝和深拷贝
+
+在Java中,除了 **基本数据类型**之外,还存在 **类的实例对象**这个引用数据类型,而一般使用 “=”号做赋值操作的时候,对于基本数据类型,实际上是拷贝的它的值,但是对于对象而言,其实赋值的只是这个对象的引用,将原对象的引用传递过去,他们实际还是指向的同一个对象。
+
+而浅拷贝和深拷贝就是在这个基础上做的区分,如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对引用数据类型只是进行引用的传递,而没有真实的创建一个新的对象,则认为是**浅拷贝**。反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量,则认为是**深拷贝**。
+
+简单来说:
+
+- **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝
+- **深拷贝**: 对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
+
+
+
+## BeanUtils
+
+前面简单讲了一下对象拷贝的一些知识,下面就来具体看下两种 BeanUtils 工具
+
+### Apache 的 BeanUtils
+
+首先来看一个非常简单的BeanUtils的例子
+
+```java
+public class PersonSource {
+ private Integer id;
+ private String username;
+ private String password;
+ private Integer age;
+ // getters/setters omiited
+}
+public class PersonDest {
+ private Integer id;
+ private String username;
+ private Integer age;
+ // getters/setters omiited
+}
+public class TestApacheBeanUtils {
+ public static void main(String[] args) throws InvocationTargetException, IllegalAccessException {
+ //下面只是用于单独测试
+ PersonSource personSource = new PersonSource(1, "pjmike", "12345", 21);
+ PersonDest personDest = new PersonDest();
+ BeanUtils.copyProperties(personDest,personSource);
+ System.out.println("persondest: "+personDest);
+ }
+}
+persondest: PersonDest{id=1, username='pjmike', age=21}
+```
+
+从上面的例子可以看出,对象拷贝非常简单,BeanUtils最常用的方法就是:
+
+```java
+//将源对象中的值拷贝到目标对象
+public static void copyProperties(Object dest, Object orig) throws IllegalAccessException, InvocationTargetException {
+ BeanUtilsBean.getInstance().copyProperties(dest, orig);
+}
+```
+
+默认情况下,使用`org.apache.commons.beanutils.BeanUtils`对复杂对象的复制是引用,这是一种**浅拷贝**
+
+但是由于 Apache下的BeanUtils对象拷贝性能太差,不建议使用,而且在**阿里巴巴Java开发规约插件**上也明确指出:
+
+> Ali-Check | 避免用Apache Beanutils进行属性的copy。
+
+commons-beantutils 对于对象拷贝加了很多的检验,包括类型的转换,甚至还会检验对象所属的类的可访问性,可谓相当复杂,这也造就了它的差劲的性能,具体实现代码如下:
+
+```java
+public void copyProperties(final Object dest, final Object orig)
+ throws IllegalAccessException, InvocationTargetException {
+
+ // Validate existence of the specified beans
+ if (dest == null) {
+ throw new IllegalArgumentException
+ ("No destination bean specified");
+ }
+ if (orig == null) {
+ throw new IllegalArgumentException("No origin bean specified");
+ }
+ if (log.isDebugEnabled()) {
+ log.debug("BeanUtils.copyProperties(" + dest + ", " +
+ orig + ")");
+ }
+
+ // Copy the properties, converting as necessary
+ if (orig instanceof DynaBean) {
+ final DynaProperty[] origDescriptors =
+ ((DynaBean) orig).getDynaClass().getDynaProperties();
+ for (DynaProperty origDescriptor : origDescriptors) {
+ final String name = origDescriptor.getName();
+ // Need to check isReadable() for WrapDynaBean
+ // (see Jira issue# BEANUTILS-61)
+ if (getPropertyUtils().isReadable(orig, name) &&
+ getPropertyUtils().isWriteable(dest, name)) {
+ final Object value = ((DynaBean) orig).get(name);
+ copyProperty(dest, name, value);
+ }
+ }
+ } else if (orig instanceof Map) {
+ @SuppressWarnings("unchecked")
+ final
+ // Map properties are always of type
+ Map propMap = (Map) orig;
+ for (final Map.Entry entry : propMap.entrySet()) {
+ final String name = entry.getKey();
+ if (getPropertyUtils().isWriteable(dest, name)) {
+ copyProperty(dest, name, entry.getValue());
+ }
+ }
+ } else /* if (orig is a standard JavaBean) */ {
+ final PropertyDescriptor[] origDescriptors =
+ getPropertyUtils().getPropertyDescriptors(orig);
+ for (PropertyDescriptor origDescriptor : origDescriptors) {
+ final String name = origDescriptor.getName();
+ if ("class".equals(name)) {
+ continue; // No point in trying to set an object's class
+ }
+ if (getPropertyUtils().isReadable(orig, name) &&
+ getPropertyUtils().isWriteable(dest, name)) {
+ try {
+ final Object value =
+ getPropertyUtils().getSimpleProperty(orig, name);
+ copyProperty(dest, name, value);
+ } catch (final NoSuchMethodException e) {
+ // Should not happen
+ }
+ }
+ }
+ }
+
+ }
+```
+
+### Spring 的 BeanUtils
+
+使用spring的BeanUtils进行对象拷贝:
+
+```java
+public class TestSpringBeanUtils {
+ public static void main(String[] args) throws InvocationTargetException, IllegalAccessException {
+
+ //下面只是用于单独测试
+ PersonSource personSource = new PersonSource(1, "pjmike", "12345", 21);
+ PersonDest personDest = new PersonDest();
+ BeanUtils.copyProperties(personSource,personDest);
+ System.out.println("persondest: "+personDest);
+ }
+}
+```
+
+spring下的BeanUtils也是使用 `copyProperties`方法进行拷贝,只不过它的实现方式非常简单,就是对两个对象中相同名字的属性进行简单的get/set,仅检查属性的可访问性。具体实现如下:
+
+```Java
+private static void copyProperties(Object source, Object target, @Nullable Class editable,
+ @Nullable String... ignoreProperties) throws BeansException {
+
+ Assert.notNull(source, "Source must not be null");
+ Assert.notNull(target, "Target must not be null");
+
+ Class actualEditable = target.getClass();
+ if (editable != null) {
+ if (!editable.isInstance(target)) {
+ throw new IllegalArgumentException("Target class [" + target.getClass().getName() +
+ "] not assignable to Editable class [" + editable.getName() + "]");
+ }
+ actualEditable = editable;
+ }
+ PropertyDescriptor[] targetPds = getPropertyDescriptors(actualEditable);
+ List ignoreList = (ignoreProperties != null ? Arrays.asList(ignoreProperties) : null);
+
+ for (PropertyDescriptor targetPd : targetPds) {
+ Method writeMethod = targetPd.getWriteMethod();
+ if (writeMethod != null && (ignoreList == null || !ignoreList.contains(targetPd.getName()))) {
+ PropertyDescriptor sourcePd = getPropertyDescriptor(source.getClass(), targetPd.getName());
+ if (sourcePd != null) {
+ Method readMethod = sourcePd.getReadMethod();
+ if (readMethod != null &&
+ ClassUtils.isAssignable(writeMethod.getParameterTypes()[0], readMethod.getReturnType())) {
+ try {
+ if (!Modifier.isPublic(readMethod.getDeclaringClass().getModifiers())) {
+ readMethod.setAccessible(true);
+ }
+ Object value = readMethod.invoke(source);
+ if (!Modifier.isPublic(writeMethod.getDeclaringClass().getModifiers())) {
+ writeMethod.setAccessible(true);
+ }
+ writeMethod.invoke(target, value);
+ }
+ catch (Throwable ex) {
+ throw new FatalBeanException(
+ "Could not copy property '" + targetPd.getName() + "' from source to target", ex);
+ }
+ }
+ }
+ }
+ }
+ }
+```
+
+
+
+可以看到,成员变量赋值是基于目标对象的成员列表,并且会跳过ignore的以及在源对象中不存在,所以这个方法是安全的,不会因为两个对象之间的结构差异导致错误,但是**必须保证同名的两个成员变量类型相同**
+
+## 小结
+
+以上简要的分析两种BeanUtils,因为Apache下的BeanUtils性能较差,不建议使用,可以使用 Spring的BeanUtils ,或者使用其他拷贝框架,比如:**[Dozer](http://dozer.sourceforge.net/documentation/gettingstarted.html)**、**[ModelMapper](http://modelmapper.org/)**等等,在后面的文章中我会对这些拷贝框架进行介绍。
+
+## 参考资料 & 鸣谢
+
+- [谈谈 Java 开发中的对象拷贝](http://www.importnew.com/26306.html)
+- [细说 Java 的深拷贝和浅拷贝](https://segmentfault.com/a/1190000010648514)
\ No newline at end of file
diff --git a/docs/advanced/Performance-of-Java-Mapping-Frameworks.md b/docs/advanced/Performance-of-Java-Mapping-Frameworks.md
new file mode 100644
index 0000000..f5ee0be
--- /dev/null
+++ b/docs/advanced/Performance-of-Java-Mapping-Frameworks.md
@@ -0,0 +1,438 @@
+> 本文由 JavaGuide 翻译自 https://www.baeldung.com/java-performance-mapping-frameworks 。转载请注明原文地址以及翻译作者。
+
+## 1. 介绍
+
+创建由多个层组成的大型 Java 应用程序需要使用多种领域模型,如持久化模型、领域模型或者所谓的 DTO。为不同的应用程序层使用多个模型将要求我们提供 bean 之间的映射方法。手动执行此操作可以快速创建大量样板代码并消耗大量时间。幸运的是,Java 有多个对象映射框架。在本教程中,我们将比较最流行的 Java 映射框架的性能。
+
+> 综合日常使用情况和相关测试数据,个人感觉 MapStruct、ModelMapper 这两个 Bean 映射框架是最佳选择。
+
+## 2. 常见 Bean 映射框架概览
+
+### 2.1. Dozer
+
+Dozer 是一个映射框架,它使用递归将数据从一个对象复制到另一个对象。框架不仅能够在 bean 之间复制属性,还能够在不同类型之间自动转换。
+
+要使用 Dozer 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ net.sf.dozer
+ dozer
+ 5.5.1
+
+```
+
+更多关于 Dozer 的内容可以在官方文档中找到: http://dozer.sourceforge.net/documentation/gettingstarted.html ,或者你也可以阅读这篇文章:https://www.baeldung.com/dozer 。
+
+### 2.2. Orika
+
+Orika 是一个 bean 到 bean 的映射框架,它递归地将数据从一个对象复制到另一个对象。
+
+Orika 的工作原理与 Dozer 相似。两者之间的主要区别是 Orika 使用字节码生成。这允许以最小的开销生成更快的映射器。
+
+要使用 Orika 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ ma.glasnost.orika
+ orika-core
+ 1.5.2
+
+```
+
+更多关于 Orika 的内容可以在官方文档中找到:https://orika-mapper.github.io/orika-docs/,或者你也可以阅读这篇文章:https://www.baeldung.com/orika-mapping。
+
+### 2.3. MapStruct
+
+MapStruct 是一个自动生成 bean mapper 类的代码生成器。MapStruct 还能够在不同的数据类型之间进行转换。Github 地址:https://github.com/mapstruct/mapstruct。
+
+要使用 MapStruct 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ org.mapstruct
+ mapstruct-processor
+ 1.2.0.Final
+
+```
+
+更多关于 MapStruct 的内容可以在官方文档中找到:https://mapstruct.org/,或者你也可以阅读这篇文章:https://www.baeldung.com/mapstruct。
+
+要使用 MapStruct 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ org.mapstruct
+ mapstruct-processor
+ 1.2.0.Final
+
+```
+
+### 2.4. ModelMapper
+
+ModelMapper 是一个旨在简化对象映射的框架,它根据约定确定对象之间的映射方式。它提供了类型安全的和重构安全的 API。
+
+更多关于 ModelMapper 的内容可以在官方文档中找到:http://modelmapper.org/ 。
+
+要使用 ModelMapper 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ org.modelmapper
+ modelmapper
+ 1.1.0
+
+```
+
+### 2.5. JMapper
+
+JMapper 是一个映射框架,旨在提供易于使用的、高性能的 Java bean 之间的映射。该框架旨在使用注释和关系映射应用 DRY 原则。该框架允许不同的配置方式:基于注释、XML 或基于 api。
+
+更多关于 JMapper 的内容可以在官方文档中找到:https://github.com/jmapper-framework/jmapper-core/wiki。
+
+要使用 JMapper 框架,我们需要添加这样的依赖到我们的项目:
+
+```xml
+
+ com.googlecode.jmapper-framework
+ jmapper-core
+ 1.6.0.1
+
+
+```
+
+## 3.测试模型
+
+为了能够正确地测试映射,我们需要有一个源和目标模型。我们已经创建了两个测试模型。
+
+第一个是一个只有一个字符串字段的简单 POJO,它允许我们在更简单的情况下比较框架,并检查如果我们使用更复杂的 bean 是否会发生任何变化。
+
+简单的源模型如下:
+
+```java
+public class SourceCode {
+ String code;
+ // getter and setter
+}
+
+```
+
+它的目标也很相似:
+
+```java
+public class DestinationCode {
+ String code;
+ // getter and setter
+}
+```
+
+源 bean 的实际示例如下:
+
+```java
+public class SourceOrder {
+ private String orderFinishDate;
+ private PaymentType paymentType;
+ private Discount discount;
+ private DeliveryData deliveryData;
+ private User orderingUser;
+ private List orderedProducts;
+ private Shop offeringShop;
+ private int orderId;
+ private OrderStatus status;
+ private LocalDate orderDate;
+ // standard getters and setters
+}
+```
+
+目标类如下图所示:
+
+```java
+public class Order {
+ private User orderingUser;
+ private List orderedProducts;
+ private OrderStatus orderStatus;
+ private LocalDate orderDate;
+ private LocalDate orderFinishDate;
+ private PaymentType paymentType;
+ private Discount discount;
+ private int shopId;
+ private DeliveryData deliveryData;
+ private Shop offeringShop;
+ // standard getters and setters
+}
+```
+
+整个模型结构可以在这里找到:https://github.com/eugenp/tutorials/tree/master/performance-tests/src/main/java/com/baeldung/performancetests/model/source。
+
+## 4. 转换器
+
+为了简化测试设置的设计,我们创建了如下所示的转换器接口:
+
+```java
+public interface Converter {
+ Order convert(SourceOrder sourceOrder);
+ DestinationCode convert(SourceCode sourceCode);
+}
+```
+
+我们所有的自定义映射器都将实现这个接口。
+
+### 4.1. OrikaConverter
+
+Orika 支持完整的 API 实现,这大大简化了 mapper 的创建:
+
+```java
+public class OrikaConverter implements Converter{
+ private MapperFacade mapperFacade;
+
+ public OrikaConverter() {
+ MapperFactory mapperFactory = new DefaultMapperFactory
+ .Builder().build();
+
+ mapperFactory.classMap(Order.class, SourceOrder.class)
+ .field("orderStatus", "status").byDefault().register();
+ mapperFacade = mapperFactory.getMapperFacade();
+ }
+
+ @Override
+ public Order convert(SourceOrder sourceOrder) {
+ return mapperFacade.map(sourceOrder, Order.class);
+ }
+
+ @Override
+ public DestinationCode convert(SourceCode sourceCode) {
+ return mapperFacade.map(sourceCode, DestinationCode.class);
+ }
+}
+```
+
+### 4.2. **DozerConverter**
+
+Dozer 需要 XML 映射文件,有以下几个部分:
+
+```xml
+
+
+
+ com.baeldung.performancetests.model.source.SourceOrder
+ com.baeldung.performancetests.model.destination.Order
+
+ status
+ orderStatus
+
+
+
+ com.baeldung.performancetests.model.source.SourceCode
+ com.baeldung.performancetests.model.destination.DestinationCode
+
+
+```
+
+定义了 XML 映射后,我们可以从代码中使用它:
+
+```java
+public class DozerConverter implements Converter {
+ private final Mapper mapper;
+
+ public DozerConverter() {
+ DozerBeanMapper mapper = new DozerBeanMapper();
+ mapper.addMapping(
+ DozerConverter.class.getResourceAsStream("/dozer-mapping.xml"));
+ this.mapper = mapper;
+ }
+
+ @Override
+ public Order convert(SourceOrder sourceOrder) {
+ return mapper.map(sourceOrder,Order.class);
+ }
+
+ @Override
+ public DestinationCode convert(SourceCode sourceCode) {
+ return mapper.map(sourceCode, DestinationCode.class);
+ }
+}
+```
+
+### 4.3. MapStructConverter
+
+Map 结构的定义非常简单,因为它完全基于代码生成:
+
+```java
+@Mapper
+public interface MapStructConverter extends Converter {
+ MapStructConverter MAPPER = Mappers.getMapper(MapStructConverter.class);
+
+ @Mapping(source = "status", target = "orderStatus")
+ @Override
+ Order convert(SourceOrder sourceOrder);
+
+ @Override
+ DestinationCode convert(SourceCode sourceCode);
+}
+```
+
+### 4.4. **JMapperConverter**
+
+JMapperConverter 需要做更多的工作。接口实现后:
+
+```java
+public class JMapperConverter implements Converter {
+ JMapper realLifeMapper;
+ JMapper simpleMapper;
+
+ public JMapperConverter() {
+ JMapperAPI api = new JMapperAPI()
+ .add(JMapperAPI.mappedClass(Order.class));
+ realLifeMapper = new JMapper(Order.class, SourceOrder.class, api);
+ JMapperAPI simpleApi = new JMapperAPI()
+ .add(JMapperAPI.mappedClass(DestinationCode.class));
+ simpleMapper = new JMapper(
+ DestinationCode.class, SourceCode.class, simpleApi);
+ }
+
+ @Override
+ public Order convert(SourceOrder sourceOrder) {
+ return (Order) realLifeMapper.getDestination(sourceOrder);
+ }
+
+ @Override
+ public DestinationCode convert(SourceCode sourceCode) {
+ return (DestinationCode) simpleMapper.getDestination(sourceCode);
+ }
+}
+```
+
+我们还需要向目标类的每个字段添加`@JMap`注释。此外,JMapper 不能在 enum 类型之间转换,它需要我们创建自定义映射函数:
+
+```java
+@JMapConversion(from = "paymentType", to = "paymentType")
+public PaymentType conversion(com.baeldung.performancetests.model.source.PaymentType type) {
+ PaymentType paymentType = null;
+ switch(type) {
+ case CARD:
+ paymentType = PaymentType.CARD;
+ break;
+
+ case CASH:
+ paymentType = PaymentType.CASH;
+ break;
+
+ case TRANSFER:
+ paymentType = PaymentType.TRANSFER;
+ break;
+ }
+ return paymentType;
+}
+```
+
+### 4.5. **ModelMapperConverter**
+
+ModelMapperConverter 只需要提供我们想要映射的类:
+
+```java
+public class ModelMapperConverter implements Converter {
+ private ModelMapper modelMapper;
+
+ public ModelMapperConverter() {
+ modelMapper = new ModelMapper();
+ }
+
+ @Override
+ public Order convert(SourceOrder sourceOrder) {
+ return modelMapper.map(sourceOrder, Order.class);
+ }
+
+ @Override
+ public DestinationCode convert(SourceCode sourceCode) {
+ return modelMapper.map(sourceCode, DestinationCode.class);
+ }
+}
+
+```
+
+## 5. 简单的模型测试
+
+对于性能测试,我们可以使用 Java Microbenchmark Harness,关于如何使用它的更多信息可以在 这篇文章:https://www.baeldung.com/java-microbenchmark-harness 中找到。
+
+我们为每个转换器创建了一个单独的基准测试,并将基准测试模式指定为 Mode.All。
+
+### 5.1. 平均时间
+
+对于平均运行时间,JMH 返回以下结果(越少越好):
+
+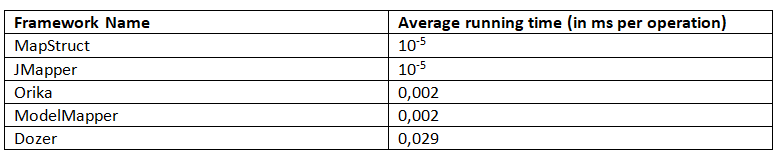
+
+这个基准测试清楚地表明,MapStruct 和 JMapper 都有最佳的平均工作时间。
+
+### 5.2. 吞吐量
+
+在这种模式下,基准测试返回每秒的操作数。我们收到以下结果(越多越好):
+
+
+
+在吞吐量模式中,MapStruct 是测试框架中最快的,JMapper 紧随其后。
+
+### 5.3. **SingleShotTime**
+
+这种模式允许测量单个操作从开始到结束的时间。基准给出了以下结果(越少越好):
+
+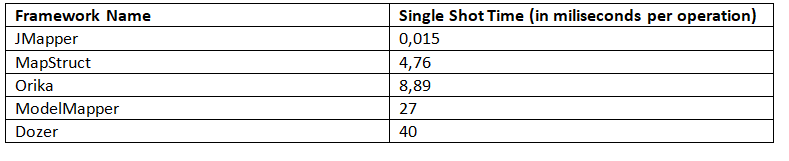
+
+这里,我们看到 JMapper 返回的结果比 MapStruct 好得多。
+
+### 5.4. **采样时间**
+
+这种模式允许对每个操作的时间进行采样。三个不同百分位数的结果如下:
+
+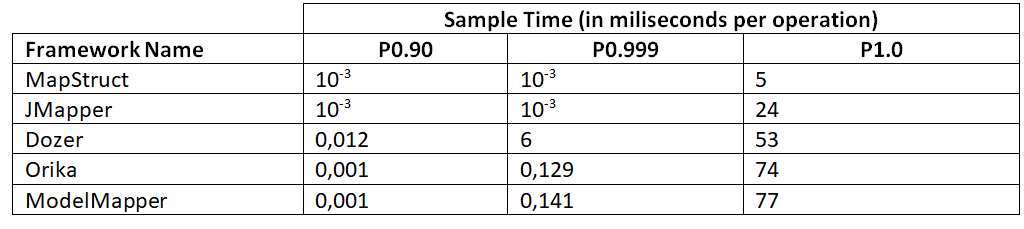
+
+所有的基准测试都表明,根据场景的不同,MapStruct 和 JMapper 都是不错的选择,尽管 MapStruct 对 SingleShotTime 给出的结果要差得多。
+
+## 6. 真实模型测试
+
+对于性能测试,我们可以使用 Java Microbenchmark Harness,关于如何使用它的更多信息可以在 这篇文章:https://www.baeldung.com/java-microbenchmark-harness 中找到。
+
+我们为每个转换器创建了一个单独的基准测试,并将基准测试模式指定为 Mode.All。
+
+### 6.1. 平均时间
+
+JMH 返回以下平均运行时间结果(越少越好):
+
+
+
+该基准清楚地表明,MapStruct 和 JMapper 均具有最佳的平均工作时间。
+
+### 6.2. 吞吐量
+
+在这种模式下,基准测试返回每秒的操作数。我们收到以下结果(越多越好):
+
+
+
+在吞吐量模式中,MapStruct 是测试框架中最快的,JMapper 紧随其后。
+
+### 6.3. **SingleShotTime**
+
+这种模式允许测量单个操作从开始到结束的时间。基准给出了以下结果(越少越好):
+
+
+
+### 6.4. **采样时间**
+
+这种模式允许对每个操作的时间进行采样。三个不同百分位数的结果如下:
+
+
+
+尽管简单示例和实际示例的确切结果明显不同,但是它们的趋势相同。在哪种算法最快和哪种算法最慢方面,两个示例都给出了相似的结果。
+
+### 6.5. 结论
+
+根据我们在本节中执行的真实模型测试,我们可以看出,最佳性能显然属于 MapStruct。在相同的测试中,我们看到 Dozer 始终位于结果表的底部。
+
+## 7. **总结**
+
+在这篇文章中,我们已经进行了五个流行的 Java Bean 映射框架性能测试:ModelMapper **,** MapStruct **,** Orika ,Dozer, JMapper。
+
+示例代码地址:https://github.com/eugenp/tutorials/tree/master/performance-tests。
diff --git a/docs/advanced/SpringBoot-ScheduleTasks.md b/docs/advanced/SpringBoot-ScheduleTasks.md
new file mode 100644
index 0000000..a443545
--- /dev/null
+++ b/docs/advanced/SpringBoot-ScheduleTasks.md
@@ -0,0 +1,220 @@
+很多时候我们都需要为系统建立一个定时任务来帮我们做一些事情,SpringBoot 已经帮我们实现好了一个,我们只需要直接使用即可,当然你也可以不用 SpringBoot 自带的定时任务,整合 Quartz 很多时候也是一个不错的选择。
+
+本文不涉及 SpringBoot 整合 Quartz 的内容,只演示了如何使用 SpringBoot 自带的实现定时任务的方式。相关代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/springboot-schedule-tast
+
+## Spring Schedule 实现定时任务
+
+我们只需要 SpringBoot 项目最基本的依赖即可,所以这里就不贴配置文件了。
+
+### 1. 创建一个 scheduled task
+
+我们使用 `@Scheduled` 注解就能很方便地创建一个定时任务,下面的代码中涵盖了 `@Scheduled `的常见用法,包括:固定速率执行、固定延迟执行、初始延迟执行、使用 Cron 表达式执行定时任务。
+
+> Cron 表达式: 主要用于定时作业(定时任务)系统定义执行时间或执行频率的表达式,非常厉害,你可以通过 Cron 表达式进行设置定时任务每天或者每个月什么时候执行等等操作。
+>
+> 推荐一个在线Cron表达式生成器: [https://crontab.guru/](https://crontab.guru/)
+
+```java
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+import org.springframework.scheduling.annotation.Scheduled;
+import org.springframework.stereotype.Component;
+
+import java.text.SimpleDateFormat;
+import java.util.Date;
+import java.util.concurrent.TimeUnit;
+
+/**
+ * @author shuang.kou
+ */
+@Component
+public class ScheduledTasks {
+ private static final Logger log = LoggerFactory.getLogger(ScheduledTasks.class);
+ private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss");
+
+ /**
+ * fixedRate:固定速率执行。每5秒执行一次。
+ */
+ @Scheduled(fixedRate = 5000)
+ public void reportCurrentTimeWithFixedRate() {
+ log.info("Current Thread : {}", Thread.currentThread().getName());
+ log.info("Fixed Rate Task : The time is now {}", dateFormat.format(new Date()));
+ }
+
+ /**
+ * fixedDelay:固定延迟执行。距离上一次调用成功后2秒才执。
+ */
+ @Scheduled(fixedDelay = 2000)
+ public void reportCurrentTimeWithFixedDelay() {
+ try {
+ TimeUnit.SECONDS.sleep(3);
+ log.info("Fixed Delay Task : The time is now {}", dateFormat.format(new Date()));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+
+ /**
+ * initialDelay:初始延迟。任务的第一次执行将延迟5秒,然后将以5秒的固定间隔执行。
+ */
+ @Scheduled(initialDelay = 5000, fixedRate = 5000)
+ public void reportCurrentTimeWithInitialDelay() {
+ log.info("Fixed Rate Task with Initial Delay : The time is now {}", dateFormat.format(new Date()));
+ }
+
+ /**
+ * cron:使用Cron表达式。 每分钟的1,2秒运行
+ */
+ @Scheduled(cron = "1-2 * * * * ? ")
+ public void reportCurrentTimeWithCronExpression() {
+ log.info("Cron Expression: The time is now {}", dateFormat.format(new Date()));
+ }
+}
+
+```
+
+关于 fixedRate 这里其实有个坑,假如我们有这样一种情况:我们某个方法的定时器设定的固定速率是每5秒执行一次。这个方法现在要执行下面四个任务,四个任务的耗时是:6 s、6s、 2s、 3s,请问这些任务默认情况下(单线程)将如何被执行?
+
+我们写一段简单的程序验证:
+
+```java
+ private static final Logger log = LoggerFactory.getLogger(AsyncScheduledTasks.class);
+ private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss");
+ private List index = Arrays.asList(6, 6, 2, 3);
+ int i = 0;
+ @Scheduled(fixedRate = 5000)
+ public void reportCurrentTimeWithFixedRate() {
+ if (i == 0) {
+ log.info("Start time is {}", dateFormat.format(new Date()));
+ }
+ if (i < 5) {
+ try {
+ TimeUnit.SECONDS.sleep(index.get(i));
+ log.info("Fixed Rate Task : The time is now {}", dateFormat.format(new Date()));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ i++;
+ }
+ }
+```
+
+运行程序输出如下:
+
+```java
+Start time is 20:58:33
+Fixed Rate Task : The time is now 20:58:39
+Fixed Rate Task : The time is now 20:58:45
+Fixed Rate Task : The time is now 20:58:47
+Fixed Rate Task : The time is now 20:58:51
+```
+
+ 看下面的运行任务示意图应该很好理解了。
+
+
+
+如果我们将这个方法改为并行运行,运行结果就截然不同了。
+
+### 2. 启动类上加上`@EnableScheduling`注解
+
+在 SpringBoot 中我们只需要在启动类上加上`@EnableScheduling`便可以启动定时任务了。
+
+```java
+@SpringBootApplication
+@EnableScheduling
+public class DemoApplication {
+
+ public static void main(String[] args) {
+ SpringApplication.run(DemoApplication.class, args);
+ }
+}
+```
+
+### 3. 自定义线程池执行 scheduled task
+
+默认情况下,`@Scheduled`任务都在Spring创建的大小为1的默认线程池中执行,你可以通过在加了`@Scheduled`注解的方法里加上下面这段代码来验证。
+
+```java
+logger.info("Current Thread : {}", Thread.currentThread().getName());
+```
+
+你会发现加上上面这段代码的定时任务,每次运行都会输出:
+
+```
+Current Thread : scheduling-1
+```
+
+如果我们需要自定义线程池执行话只需要新加一个实现`SchedulingConfigurer`接口的 `configureTasks` 的类即可,这个类需要加上 `@Configuration` 注解。
+
+```java
+@Configuration
+public class SchedulerConfig implements SchedulingConfigurer {
+ private final int POOL_SIZE = 10;
+
+ @Override
+ public void configureTasks(ScheduledTaskRegistrar scheduledTaskRegistrar) {
+ ThreadPoolTaskScheduler threadPoolTaskScheduler = new ThreadPoolTaskScheduler();
+
+ threadPoolTaskScheduler.setPoolSize(POOL_SIZE);
+ threadPoolTaskScheduler.setThreadNamePrefix("my-scheduled-task-pool-");
+ threadPoolTaskScheduler.initialize();
+
+ scheduledTaskRegistrar.setTaskScheduler(threadPoolTaskScheduler);
+ }
+}
+```
+
+通过上面的验证的方式输出当前线程的名字会改变。
+
+### 4. @EnableAsync 和 @Async 使定时任务并行执行
+
+如果你想要你的代码并行执行的话,还可以通过`@EnableAsync` 和 @`Async `这两个注解实现
+
+```java
+@Component
+@EnableAsync
+public class AsyncScheduledTasks {
+ private static final Logger log = LoggerFactory.getLogger(AsyncScheduledTasks.class);
+ private static final SimpleDateFormat dateFormat = new SimpleDateFormat("HH:mm:ss");
+
+ /**
+ * fixedDelay:固定延迟执行。距离上一次调用成功后2秒才执。
+ */
+ //@Async
+ @Scheduled(fixedDelay = 2000)
+ public void reportCurrentTimeWithFixedDelay() {
+ try {
+ TimeUnit.SECONDS.sleep(3);
+ log.info("Fixed Delay Task : The time is now {}", dateFormat.format(new Date()));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+运行程序输出如下,`reportCurrentTimeWithFixedDelay()` 方法会每5秒执行一次,因为我们说过了`@Scheduled`任务都在Spring创建的大小为1的默认线程池中执行。
+
+```
+Current Thread : scheduling-1
+Fixed Delay Task : The time is now 14:24:23
+Current Thread : scheduling-1
+Fixed Delay Task : The time is now 14:24:28
+Current Thread : scheduling-1
+Fixed Delay Task : The time is now 14:24:33
+```
+
+`reportCurrentTimeWithFixedDelay()` 方法上加上 `@Async` 注解后输出如下,`reportCurrentTimeWithFixedDelay()` 方法会每 2 秒执行一次。
+
+```
+Current Thread : task-1
+Fixed Delay Task : The time is now 14:27:32
+Current Thread : task-2
+Fixed Delay Task : The time is now 14:27:34
+Current Thread : task-3
+Fixed Delay Task : The time is now 14:27:36
+```
+
+
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/advanced/springboot-schedule-tast
\ No newline at end of file
diff --git a/docs/advanced/springboot-async.md b/docs/advanced/springboot-async.md
new file mode 100644
index 0000000..57b7a51
--- /dev/null
+++ b/docs/advanced/springboot-async.md
@@ -0,0 +1,270 @@
+> 本文已经收录自 springboot-guide : [https://github.com/Snailclimb/springboot-guide](https://github.com/Snailclimb/springboot-guide) (Spring Boot 核心知识点整理。 基于 Spring Boot 2.19+。)
+
+# 新手也能看懂的 SpringBoot 异步编程指南
+
+通过本文你可以了解到下面这些知识点:
+
+1. Future 模式介绍以及核心思想
+2. 核心线程数、最大线程数的区别,队列容量代表什么;
+3. `ThreadPoolTaskExecutor` 饱和策略;
+4. SpringBoot 异步编程实战,搞懂代码的执行逻辑。
+
+## Future 模式
+
+异步编程在处理耗时操作以及多任务处理的场景下非常有用,我们可以更好的让我们的系统利用好机器的 CPU 和 内存,提高它们的利用率。多线程设计模式有很多种,Future模式是多线程开发中非常常见的一种设计模式,本文也是基于这种模式来说明 SpringBoot 对于异步编程的知识。
+
+实战之前我先简单介绍一下 **Future 模式的核心思想** 吧!。
+
+Future 模式的核心思想是 **异步调用** 。当我们执行一个方法时,假如这个方法中有多个耗时的任务需要同时去做,而且又不着急等待这个结果时可以让客户端立即返回然后,后台慢慢去计算任务。当然你也可以选择等这些任务都执行完了,再返回给客户端。这个在 Java 中都有很好的支持,我在后面的示例程序中会详细对比这两种方式的区别。
+
+## SpringBoot 异步编程实战
+
+如果我们需要在 SpringBoot 实现异步编程的话,通过 Spring 提供的两个注解会让这件事情变的非常简单。
+
+1. `@EnableAsync`:通过在配置类或者Main类上加@EnableAsync开启对异步方法的支持。
+2. `@Async` 可以作用在类上或者方法上,作用在类上代表这个类的所有方法都是异步方法。
+
+### 1. 自定义 TaskExecutor
+
+很多人对于 TaskExecutor 不是太了解,所以我们花一点篇幅先介绍一下这个东西。从名字就能看出它是任务的执行者,它领导执行着线程来处理任务,就像司令官一样,而我们的线程就好比一只只军队一样,这些军队可以异步对敌人进行打击👊。
+
+Spring 提供了`TaskExecutor`接口作为任务执行者的抽象,它和`java.util.concurrent`包下的`Executor`接口很像。稍微不同的 `TaskExecutor`接口用到了 Java 8 的语法`@FunctionalInterface`声明这个接口是一个函数式接口。
+
+`org.springframework.core.task.TaskExecutor`
+
+```java
+@FunctionalInterface
+public interface TaskExecutor extends Executor {
+ void execute(Runnable var1);
+}
+```
+
+
+
+如果没有自定义Executor, Spring 将创建一个 `SimpleAsyncTaskExecutor` 并使用它。
+
+```java
+import org.springframework.context.annotation.Bean;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.scheduling.annotation.AsyncConfigurer;
+import org.springframework.scheduling.annotation.EnableAsync;
+import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
+
+import java.util.concurrent.Executor;
+
+/** @author shuang.kou */
+@Configuration
+@EnableAsync
+public class AsyncConfig implements AsyncConfigurer {
+
+ private static final int CORE_POOL_SIZE = 6;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+
+ @Bean
+ public Executor taskExecutor() {
+ // Spring 默认配置是核心线程数大小为1,最大线程容量大小不受限制,队列容量也不受限制。
+ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
+ // 核心线程数
+ executor.setCorePoolSize(CORE_POOL_SIZE);
+ // 最大线程数
+ executor.setMaxPoolSize(MAX_POOL_SIZE);
+ // 队列大小
+ executor.setQueueCapacity(QUEUE_CAPACITY);
+ // 当最大池已满时,此策略保证不会丢失任务请求,但是可能会影响应用程序整体性能。
+ executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
+ executor.setThreadNamePrefix("My ThreadPoolTaskExecutor-");
+ executor.initialize();
+ return executor;
+ }
+}
+
+```
+
+**`ThreadPoolTaskExecutor` 常见概念:**
+
+- **Core Pool Size :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **Queue Capacity :** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,信任就会被存放在队列中。
+- **Maximum Pool Size :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+
+一般情况下不会将队列大小设为:`Integer.MAX_VALUE`,也不会将核心线程数和最大线程数设为同样的大小,这样的话最大线程数的设置都没什么意义了,你也无法确定当前 CPU 和内存利用率具体情况如何。
+
+**如果队列已满并且当前同时运行的线程数达到最大线程数的时候,如果再有新任务过来会发生什么呢?**
+
+ Spring 默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在Spring的默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。
+
+**`ThreadPoolTaskExecutor` 饱和策略定义:**
+
+如果当前同时运行的线程数量达到最大线程数量时,`ThreadPoolTaskExecutor` 定义一些策略:
+
+- **ThreadPoolExecutor.AbortPolicy**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
+- **ThreadPoolExecutor.CallerRunsPolicy**:调用执行自己的线程运行任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
+- **ThreadPoolExecutor.DiscardPolicy:** 不处理新任务,直接丢弃掉。
+- **ThreadPoolExecutor.DiscardOldestPolicy:** 此策略将丢弃最早的未处理的任务请求。
+
+### 2. 编写一个异步的方法
+
+下面模拟一个查找对应字符开头电影的方法,我们给这个方法加上了` @Async`注解来告诉 Spring 它是一个异步的方法。另外,这个方法的返回值 `CompletableFuture.completedFuture(results)`这代表我们需要返回结果,也就是说程序必须把任务执行完成之后再返回给用户。
+
+**请留意`completableFutureTask`方法中的第一行打印日志这句代码,后面分析程序中会用到,很重要!**
+
+```java
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+import org.springframework.scheduling.annotation.Async;
+import org.springframework.stereotype.Service;
+
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.List;
+import java.util.concurrent.CompletableFuture;
+import java.util.stream.Collectors;
+
+/** @author shuang.kou */
+@Service
+public class AsyncService {
+
+ private static final Logger logger = LoggerFactory.getLogger(AsyncService.class);
+
+ private List movies =
+ new ArrayList<>(
+ Arrays.asList(
+ "Forrest Gump",
+ "Titanic",
+ "Spirited Away",
+ "The Shawshank Redemption",
+ "Zootopia",
+ "Farewell ",
+ "Joker",
+ "Crawl"));
+
+ /** 示范使用:找到特定字符/字符串开头的电影 */
+ @Async
+ public CompletableFuture> completableFutureTask(String start) {
+ // 打印日志
+ logger.warn(Thread.currentThread().getName() + "start this task!");
+ // 找到特定字符/字符串开头的电影
+ List results =
+ movies.stream().filter(movie -> movie.startsWith(start)).collect(Collectors.toList());
+ // 模拟这是一个耗时的任务
+ try {
+ Thread.sleep(1000L);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ //返回一个已经用给定值完成的新的CompletableFuture。
+ return CompletableFuture.completedFuture(results);
+ }
+}
+
+```
+
+### 3. 测试编写的异步方法
+
+```java
+/** @author shuang.kou */
+@RestController
+@RequestMapping("/async")
+public class AsyncController {
+ @Autowired
+ AsyncService asyncService;
+
+ @GetMapping("/movies")
+ public String completableFutureTask() throws ExecutionException, InterruptedException {
+ //开始时间
+ long start = System.currentTimeMillis();
+ // 开始执行大量的异步任务
+ List words = Arrays.asList("F", "T", "S", "Z", "J", "C");
+ List>> completableFutureList =
+ words.stream()
+ .map(word -> asyncService.completableFutureTask(word))
+ .collect(Collectors.toList());
+ // CompletableFuture.join()方法可以获取他们的结果并将结果连接起来
+ List> results = completableFutureList.stream().map(CompletableFuture::join).collect(Collectors.toList());
+ // 打印结果以及运行程序运行花费时间
+ System.out.println("Elapsed time: " + (System.currentTimeMillis() - start));
+ return results.toString();
+ }
+}
+```
+
+请求这个接口,控制台打印出下面的内容:
+
+```
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-1] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-1start this task!
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-6] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-6start this task!
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-5] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-5start this task!
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-4] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-4start this task!
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-3] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-3start this task!
+2019-10-01 13:50:17.007 WARN 18793 --- [lTaskExecutor-2] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-2start this task!
+Elapsed time: 1010
+```
+
+首先我们可以看到处理所有任务花费的时间大概是 1 s。这与我们自定义的 `ThreadPoolTaskExecutor` 有关,我们配置的核心线程数是 6 ,然后通过通过下面的代码模拟分配了 6 个任务给系统执行。这样每个线程都会被分配到一个任务,每个任务执行花费时间是 1 s ,所以处理 6 个任务的总花费时间是 1 s。
+
+```java
+List words = Arrays.asList("F", "T", "S", "Z", "J", "C");
+List>> completableFutureList =
+ words.stream()
+ .map(word -> asyncService.completableFutureTask(word))
+ .collect(Collectors.toList());
+```
+
+你可以自己验证一下,试着去把核心线程数的数量改为 3 ,再次请求这个接口你会发现处理所有任务花费的时间大概是 2 s。
+
+另外,**从上面的运行结果可以看出,当所有任务执行完成之后才返回结果。这种情况对应于我们需要返回结果给客户端请求的情况下,假如我们不需要返回任务执行结果给客户端的话呢?** 就比如我们上传一个大文件到系统,上传之后只要大文件格式符合要求我们就上传成功。普通情况下我们需要等待文件上传完毕再返回给用户消息,但是这样会很慢。采用异步的话,当用户上传之后就立马返回给用户消息,然后系统再默默去处理上传任务。**这样也会增加一点麻烦,因为文件可能会上传失败,所以系统也需要一点机制来补偿这个问题,比如当上传遇到问题的时候,发消息通知用户。**
+
+下面会演示一下客户端不需要返回结果的情况:
+
+将`completableFutureTask`方法变为 void 类型
+
+```java
+@Async
+public void completableFutureTask(String start) {
+ ......
+ //这里可能是系统对任务执行结果的处理,比如存入到数据库等等......
+ //doSomeThingWithResults(results);
+}
+```
+
+Controller 代码修改如下:
+
+```java
+ @GetMapping("/movies")
+ public String completableFutureTask() throws ExecutionException, InterruptedException {
+ // Start the clock
+ long start = System.currentTimeMillis();
+ // Kick of multiple, asynchronous lookups
+ List words = Arrays.asList("F", "T", "S", "Z", "J", "C");
+ words.stream()
+ .forEach(word -> asyncService.completableFutureTask(word));
+ // Wait until they are all done
+ // Print results, including elapsed time
+ System.out.println("Elapsed time: " + (System.currentTimeMillis() - start));
+ return "Done";
+ }
+```
+
+请求这个接口,控制台打印出下面的内容:
+
+```
+Elapsed time: 0
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-4] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-4start this task!
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-3] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-3start this task!
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-2] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-2start this task!
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-1] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-1start this task!
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-6] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-6start this task!
+2019-10-01 14:02:44.052 WARN 19051 --- [lTaskExecutor-5] g.j.a.service.AsyncService : My ThreadPoolTaskExecutor-5start this task!
+```
+
+可以看到系统会直接返回给用户结果,然后系统才真正开始执行任务。
+
+## 待办
+
+- [ ] [**Future vs. CompletableFuture**](https://blog.knoldus.com/future-vs-completablefuture-1/)
+- [ ] 源代码分析
+
+## Reference
+
+- https://spring.io/guides/gs/async-method/
+- https://medium.com/trendyol-tech/spring-boot-async-executor-management-with-threadpooltaskexecutor-f493903617d
\ No newline at end of file
diff --git a/md/springboot-dubbo.md b/docs/advanced/springboot-dubbo.md
similarity index 98%
rename from md/springboot-dubbo.md
rename to docs/advanced/springboot-dubbo.md
index 938c54d..69b6844 100644
--- a/md/springboot-dubbo.md
+++ b/docs/advanced/springboot-dubbo.md
@@ -53,7 +53,7 @@ Apache Dubbo (incubating) |ˈdʌbəʊ| 是一款高性能、轻量级的开源Ja
Dubbo 目前已经有接近 23k 的 Star ,Dubbo的Github 地址:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo) 。 另外,在开源中国举行的2018年度最受欢迎中国开源软件这个活动的评选中,Dubbo 更是凭借其超高人气仅次于 vue.js 和 ECharts 获得第三名的好成绩。
-Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
**下面我们简单地来看一下 Dubbo 的架构,加深对 Dubbo 的理解。**
@@ -131,7 +131,7 @@ mv zookeeper-3.4.12 zookeeper
```shell
rm -rf zookeeper-3.4.12.tar.gz
-```
+```
### 3. 进入zookeeper目录,创建data文件夹。
@@ -176,8 +176,7 @@ dataDir=/usr/local/zookeeper/data
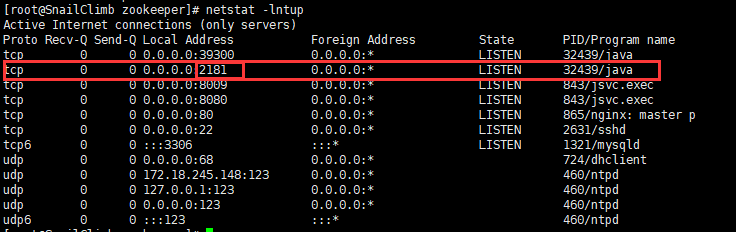
-
-----
+----
注意没有关闭防火墙可能出现的问题!!!
@@ -234,7 +233,7 @@ public interface HelloService {
### 3. 将项目打成 jar 包供其他项目使用
-点击右边的 Maven Projects 然后选择 install ,这样 jar 宝就打好了。
+点击右边的 Maven Projects 然后选择 install ,这样 jar 包就打好了。
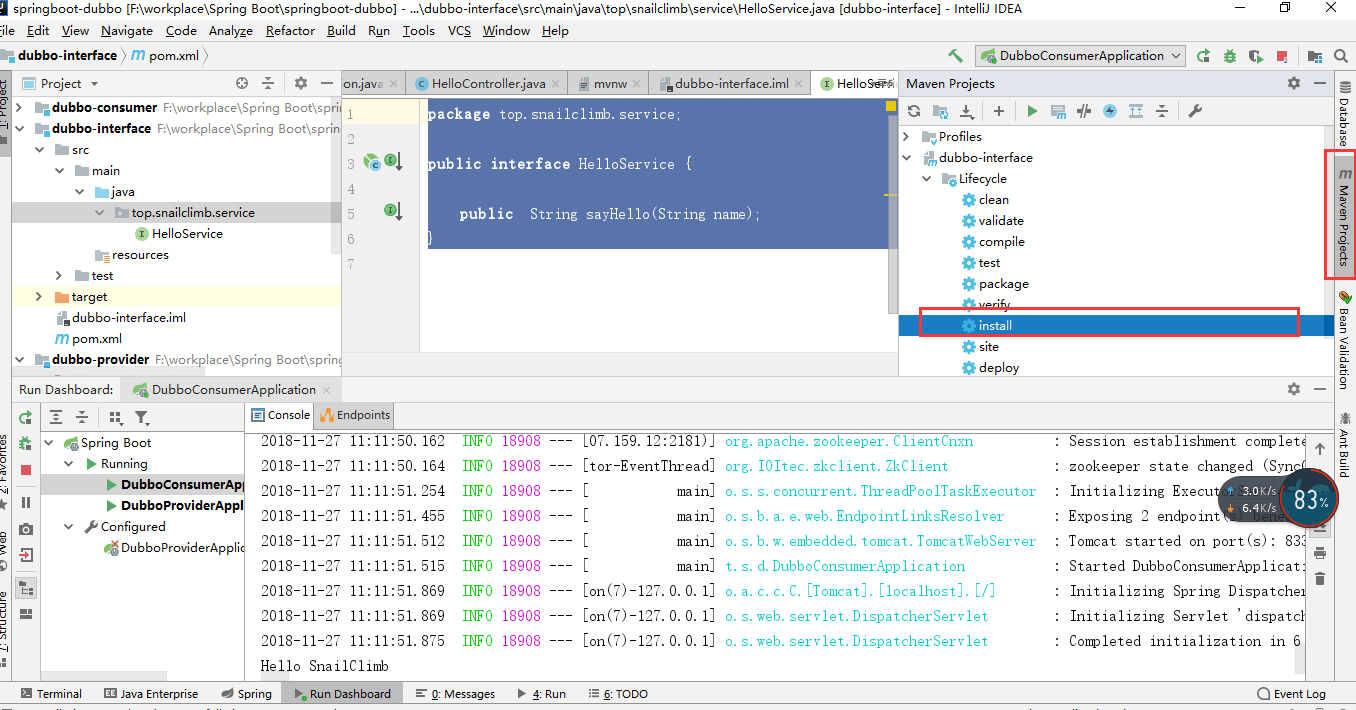
## 开始实战 3 :实现服务提供者 dubbo-provider
@@ -406,4 +405,6 @@ public class DubboConsumerApplication {
### 6. 测试效果
-浏览器访问 [http://localhost:8330/hello](http://localhost:8330/hello) 页面返回 Hello world,控制台输出 Hello SnailClimb,和预期一直,使用SpringBoot+Dubbo 搭建第一个简单的分布式服务实验成功!
+浏览器访问 [http://localhost:8330/hello](http://localhost:8330/hello) 页面返回 Hello world,控制台输出 Hello SnailClimb,和预期一致,使用SpringBoot+Dubbo 搭建第一个简单的分布式服务实验成功!
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/advanced/springboot-dubbo
diff --git a/docs/advanced/springboot-handle-exception-plus.md b/docs/advanced/springboot-handle-exception-plus.md
new file mode 100644
index 0000000..ad8a809
--- /dev/null
+++ b/docs/advanced/springboot-handle-exception-plus.md
@@ -0,0 +1,291 @@
+
+
+> 这篇文章鸽了很久,我在这篇文章 [《用好Java中的枚举,真的没有那么简单!》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486111&idx=2&sn=8299a42edc4733bdf012ebfe9ebf3fbb&chksm=cea24554f9d5cc42eac0e0ecd851c201831f3b149e64fe11f94b548031f10ff2dac1ea9743d3&token=1729829670&lang=zh_CN#rd) 中就提到要分享。还是昨天一个读者提醒我之后,我才发现自己没有将这篇文章发到公众号。说到这里,我发现自己一个很大的问题,就是有时候在文章里面说要更新什么,结果后面就忘记了,很多时候不是自己没写,就因为各种事情混杂导致忘记发了。以后要尽量改正这个问题!
+
+在上一篇文章[《SpringBoot 处理异常的几种常见姿势》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485568&idx=2&sn=c5ba880fd0c5d82e39531fa42cb036ac&chksm=cea2474bf9d5ce5dcbc6a5f6580198fdce4bc92ef577579183a729cb5d1430e4994720d59b34&token=1729829670&lang=zh_CN#rd)中我介绍了:
+
+1. 使用 `@ControllerAdvice` 和 `@ExceptionHandler` 处理全局异常
+2. `@ExceptionHandler` 处理 Controller 级别的异常
+3. `ResponseStatusException`
+
+通过这篇文章,可以搞懂如何在 Spring Boot 中进行异常处理。但是,光是会用了还不行,我们还要思考如何把异常处理这部分的代码写的稍微优雅一点。下面我会以我在工作中学到的一点实际项目中异常处理的方式,来说说我觉得稍微优雅点的异常处理解决方案。
+
+下面仅仅是我作为一个我个人的角度来看的,如果各位读者有更好的解决方案或者觉得本文提出的方案还有优化的余地的话,欢迎在评论区评论。
+
+## 最终效果展示
+
+下面先来展示一下完成后的效果,当我们定义的异常被系统捕捉后返回给客户端的信息是这样的:
+
+
+
+返回的信息包含了异常下面 5 部分内容:
+
+1. 唯一标示异常的 code
+2. HTTP状态码
+3. 错误路径
+4. 发生错误的时间戳
+5. 错误的具体信息
+
+这样返回异常信息,更利于我们前端根据异常信息做出相应的表现。
+
+## 异常处理核心代码
+
+`ErrorCode.java` (此枚举类中包含了异常的唯一标识、HTTP状态码以及错误信息)
+
+这个类的主要作用就是统一管理系统中可能出现的异常,比较清晰明了。但是,可能出现的问题是当系统过于复杂,出现的异常过多之后,这个类会比较庞大。有一种解决办法:将多种相似的异常统一为一个,比如将用户找不到异常和订单信息未找到的异常都统一为“未找到该资源”这一种异常,然后前端再对相应的情况做详细处理(我个人的一种处理方法,不敢保证是比较好的一种做法)。
+
+```java
+import org.springframework.http.HttpStatus;
+
+
+public enum ErrorCode {
+
+ RESOURCE_NOT_FOUND(1001, HttpStatus.NOT_FOUND, "未找到该资源"),
+ REQUEST_VALIDATION_FAILED(1002, HttpStatus.BAD_REQUEST, "请求数据格式验证失败");
+ private final int code;
+
+ private final HttpStatus status;
+
+ private final String message;
+
+ ErrorCode(int code, HttpStatus status, String message) {
+ this.code = code;
+ this.status = status;
+ this.message = message;
+ }
+
+ public int getCode() {
+ return code;
+ }
+
+ public HttpStatus getStatus() {
+ return status;
+ }
+
+ public String getMessage() {
+ return message;
+ }
+
+ @Override
+ public String toString() {
+ return "ErrorCode{" +
+ "code=" + code +
+ ", status=" + status +
+ ", message='" + message + '\'' +
+ '}';
+ }
+}
+```
+
+**`ErrorReponse.java`(返回给客户端具体的异常对象)**
+
+这个类作为异常信息返回给客户端,里面包括了当出现异常时我们想要返回给客户端的所有信息。
+
+```java
+import org.springframework.util.ObjectUtils;
+
+import java.time.Instant;
+import java.util.HashMap;
+import java.util.Map;
+
+public class ErrorReponse {
+ private int code;
+ private int status;
+ private String message;
+ private String path;
+ private Instant timestamp;
+ private HashMap data = new HashMap();
+
+ public ErrorReponse() {
+ }
+
+ public ErrorReponse(BaseException ex, String path) {
+ this(ex.getError().getCode(), ex.getError().getStatus().value(), ex.getError().getMessage(), path, ex.getData());
+ }
+
+ public ErrorReponse(int code, int status, String message, String path, Map data) {
+ this.code = code;
+ this.status = status;
+ this.message = message;
+ this.path = path;
+ this.timestamp = Instant.now();
+ if (!ObjectUtils.isEmpty(data)) {
+ this.data.putAll(data);
+ }
+ }
+
+// 省略 getter/setter 方法
+
+ @Override
+ public String toString() {
+ return "ErrorReponse{" +
+ "code=" + code +
+ ", status=" + status +
+ ", message='" + message + '\'' +
+ ", path='" + path + '\'' +
+ ", timestamp=" + timestamp +
+ ", data=" + data +
+ '}';
+ }
+}
+
+```
+
+**`BaseException.java`(继承自 `RuntimeException` 的抽象类,可以看做系统中其他异常类的父类)**
+
+系统中的异常类都要继承自这个类。
+
+```java
+
+public abstract class BaseException extends RuntimeException {
+ private final ErrorCode error;
+ private final HashMap data = new HashMap<>();
+
+ public BaseException(ErrorCode error, Map data) {
+ super(error.getMessage());
+ this.error = error;
+ if (!ObjectUtils.isEmpty(data)) {
+ this.data.putAll(data);
+ }
+ }
+
+ protected BaseException(ErrorCode error, Map data, Throwable cause) {
+ super(error.getMessage(), cause);
+ this.error = error;
+ if (!ObjectUtils.isEmpty(data)) {
+ this.data.putAll(data);
+ }
+ }
+
+ public ErrorCode getError() {
+ return error;
+ }
+
+ public Map getData() {
+ return data;
+ }
+
+}
+```
+
+**`ResourceNotFoundException.java` (自定义异常)**
+
+可以看出通过继承 `BaseException` 类我们自定义异常会变的非常简单!
+
+```java
+import java.util.Map;
+
+public class ResourceNotFoundException extends BaseException {
+
+ public ResourceNotFoundException(Map data) {
+ super(ErrorCode.RESOURCE_NOT_FOUND, data);
+ }
+}
+```
+
+**`GlobalExceptionHandler.java`(全局异常捕获)**
+
+我们定义了两个异常捕获方法。
+
+这里再说明一下,实际上这个类只需要 `handleAppException()` 这一个方法就够了,因为它是本系统所有异常的父类。只要是抛出了继承 `BaseException` 类的异常后都会在这里被处理。
+
+```java
+import com.twuc.webApp.web.ExceptionController;
+import org.springframework.http.HttpHeaders;
+import org.springframework.http.HttpStatus;
+import org.springframework.http.ResponseEntity;
+import org.springframework.web.bind.annotation.ControllerAdvice;
+import org.springframework.web.bind.annotation.ExceptionHandler;
+import org.springframework.web.bind.annotation.ResponseBody;
+import javax.servlet.http.HttpServletRequest;
+
+@ControllerAdvice(assignableTypes = {ExceptionController.class})
+@ResponseBody
+public class GlobalExceptionHandler {
+
+ // 也可以将 BaseException 换为 RuntimeException
+ // 因为 RuntimeException 是 BaseException 的父类
+ @ExceptionHandler(BaseException.class)
+ public ResponseEntity handleAppException(BaseException ex, HttpServletRequest request) {
+ ErrorReponse representation = new ErrorReponse(ex, request.getRequestURI());
+ return new ResponseEntity<>(representation, new HttpHeaders(), ex.getError().getStatus());
+ }
+
+ @ExceptionHandler(value = ResourceNotFoundException.class)
+ public ResponseEntity handleResourceNotFoundException(ResourceNotFoundException ex, HttpServletRequest request) {
+ ErrorReponse errorReponse = new ErrorReponse(ex, request.getRequestURI());
+ return ResponseEntity.status(HttpStatus.BAD_REQUEST).body(errorReponse);
+ }
+}
+
+```
+
+**(重要)一点扩展:**
+
+哈哈!实际上我多加了一个算是多余的异常捕获方法`handleResourceNotFoundException()` 主要是为了考考大家当我们抛出了 `ResourceNotFoundException`异常会被下面哪一个方法捕获呢?
+
+答案:
+
+会被`handleResourceNotFoundException()`方法捕获。因为 `@ExceptionHandler` 捕获异常的过程中,会优先找到最匹配的。
+
+下面通过源码简单分析一下:
+
+`ExceptionHandlerMethodResolver.java`中`getMappedMethod`决定了具体被哪个方法处理。
+
+```java
+
+@Nullable
+ private Method getMappedMethod(Class exceptionType) {
+ List> matches = new ArrayList<>();
+ //找到可以处理的所有异常信息。mappedMethods 中存放了异常和处理异常的方法的对应关系
+ for (Class mappedException : this.mappedMethods.keySet()) {
+ if (mappedException.isAssignableFrom(exceptionType)) {
+ matches.add(mappedException);
+ }
+ }
+ // 不为空说明有方法处理异常
+ if (!matches.isEmpty()) {
+ // 按照匹配程度从小到大排序
+ matches.sort(new ExceptionDepthComparator(exceptionType));
+ // 返回处理异常的方法
+ return this.mappedMethods.get(matches.get(0));
+ }
+ else {
+ return null;
+ }
+ }
+```
+
+从源代码看出:**`getMappedMethod()`会首先找到可以匹配处理异常的所有方法信息,然后对其进行从小到大的排序,最后取最小的那一个匹配的方法(即匹配度最高的那个)。**
+
+## 写一个抛出异常的类测试
+
+**`Person.java`**
+
+```java
+public class Person {
+ private Long id;
+ private String name;
+
+ // 省略 getter/setter 方法
+}
+```
+
+**`ExceptionController.java`(抛出异常的类)**
+
+```java
+@RestController
+@RequestMapping("/api")
+public class ExceptionController {
+
+ @GetMapping("/resourceNotFound")
+ public void throwException() {
+ Person p=new Person(1L,"SnailClimb");
+ throw new ResourceNotFoundException(ImmutableMap.of("person id:", p.getId()));
+ }
+
+}
+```
+
+源码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-handle-exception-improved
+
diff --git a/docs/advanced/springboot-handle-exception.md b/docs/advanced/springboot-handle-exception.md
new file mode 100644
index 0000000..bad4a7c
--- /dev/null
+++ b/docs/advanced/springboot-handle-exception.md
@@ -0,0 +1,277 @@
+### 1. 使用 **@ControllerAdvice和**@ExceptionHandler处理全局异常
+
+这是目前很常用的一种方式,非常推荐。测试代码中用到了 Junit 5,如果你新建项目验证下面的代码的话,记得添加上相关依赖。
+
+**1. 新建异常信息实体类**
+
+非必要的类,主要用于包装异常信息。
+
+`src/main/java/com/twuc/webApp/exception/ErrorResponse.java`
+
+```java
+/**
+ * @author shuang.kou
+ */
+public class ErrorResponse {
+
+ private String message;
+ private String errorTypeName;
+
+ public ErrorResponse(Exception e) {
+ this(e.getClass().getName(), e.getMessage());
+ }
+
+ public ErrorResponse(String errorTypeName, String message) {
+ this.errorTypeName = errorTypeName;
+ this.message = message;
+ }
+ ......省略getter/setter方法
+}
+```
+
+**2. 自定义异常类型**
+
+`src/main/java/com/twuc/webApp/exception/ResourceNotFoundException.java`
+
+一般我们处理的都是 `RuntimeException` ,所以如果你需要自定义异常类型的话直接集成这个类就可以了。
+
+```java
+/**
+ * @author shuang.kou
+ * 自定义异常类型
+ */
+public class ResourceNotFoundException extends RuntimeException {
+ private String message;
+
+ public ResourceNotFoundException() {
+ super();
+ }
+
+ public ResourceNotFoundException(String message) {
+ super(message);
+ this.message = message;
+ }
+
+ @Override
+ public String getMessage() {
+ return message;
+ }
+
+ public void setMessage(String message) {
+ this.message = message;
+ }
+}
+```
+
+**3. 新建异常处理类**
+
+我们只需要在类上加上`@ControllerAdvice`注解这个类就成为了全局异常处理类,当然你也可以通过 `assignableTypes `指定特定的 `Controller `类,让异常处理类只处理特定类抛出的异常。
+
+`src/main/java/com/twuc/webApp/exception/GlobalExceptionHandler.java`
+
+```java
+/**
+ * @author shuang.kou
+ */
+@ControllerAdvice(assignableTypes = {ExceptionController.class})
+@ResponseBody
+public class GlobalExceptionHandler {
+
+ ErrorResponse illegalArgumentResponse = new ErrorResponse(new IllegalArgumentException("参数错误!"));
+ ErrorResponse resourseNotFoundResponse = new ErrorResponse(new ResourceNotFoundException("Sorry, the resourse not found!"));
+
+ @ExceptionHandler(value = Exception.class)// 拦截所有异常, 这里只是为了演示,一般情况下一个方法特定处理一种异常
+ public ResponseEntity exceptionHandler(Exception e) {
+
+ if (e instanceof IllegalArgumentException) {
+ return ResponseEntity.status(400).body(illegalArgumentResponse);
+ } else if (e instanceof ResourceNotFoundException) {
+ return ResponseEntity.status(404).body(resourseNotFoundResponse);
+ }
+ return null;
+ }
+}
+```
+
+**4. controller模拟抛出异常**
+
+`src/main/java/com/twuc/webApp/web/ExceptionController.java`
+
+```java
+/**
+ * @author shuang.kou
+ */
+@RestController
+@RequestMapping("/api")
+public class ExceptionController {
+
+ @GetMapping("/illegalArgumentException")
+ public void throwException() {
+ throw new IllegalArgumentException();
+ }
+
+ @GetMapping("/resourceNotFoundException")
+ public void throwException2() {
+ throw new ResourceNotFoundException();
+ }
+}
+```
+
+使用 Get 请求 [localhost:8080/api/resourceNotFoundException](localhost:8333/api/resourceNotFoundException) (curl -i -s -X GET url),服务端返回的 JSON 数据如下:
+
+```json
+{
+ "message": "Sorry, the resourse not found!",
+ "errorTypeName": "com.twuc.webApp.exception.ResourceNotFoundException"
+}
+```
+
+**5. 编写测试类**
+
+MockMvc 由`org.springframework.boot.test`包提供,实现了对Http请求的模拟,一般用于我们测试 controller 层。
+
+```java
+/**
+ * @author shuang.kou
+ */
+@AutoConfigureMockMvc
+@SpringBootTest
+public class ExceptionTest {
+ @Autowired
+ MockMvc mockMvc;
+
+ @Test
+ void should_return_400_if_param_not_valid() throws Exception {
+ mockMvc.perform(get("/api/illegalArgumentException"))
+ .andExpect(status().is(400))
+ .andExpect(jsonPath("$.message").value("参数错误!"));
+ }
+
+ @Test
+ void should_return_404_if_resourse_not_found() throws Exception {
+ mockMvc.perform(get("/api/resourceNotFoundException"))
+ .andExpect(status().is(404))
+ .andExpect(jsonPath("$.message").value("Sorry, the resourse not found!"));
+ }
+}
+```
+
+### 2. @ExceptionHandler 处理 Controller 级别的异常
+
+我们刚刚也说了使用`@ControllerAdvice`注解 可以通过 `assignableTypes `指定特定的类,让异常处理类只处理特定类抛出的异常。所以这种处理异常的方式,实际上现在使用的比较少了。
+
+ 我们把下面这段代码移到 `src/main/java/com/twuc/webApp/exception/GlobalExceptionHandler.java` 中就可以了。
+
+```java
+ @ExceptionHandler(value = Exception.class)// 拦截所有异常
+ public ResponseEntity exceptionHandler(Exception e) {
+
+ if (e instanceof IllegalArgumentException) {
+ return ResponseEntity.status(400).body(illegalArgumentResponse);
+ } else if (e instanceof ResourceNotFoundException) {
+ return ResponseEntity.status(404).body(resourseNotFoundResponse);
+ }
+ return null;
+ }
+```
+
+### 3. ResponseStatusException
+
+研究 ResponseStatusException 我们先来看看,通过 `ResponseStatus`注解简单处理异常的方法(将异常映射为状态码)。
+
+`src/main/java/com/twuc/webApp/exception/ResourceNotFoundException.java`
+
+ ```java
+@ResponseStatus(code = HttpStatus.NOT_FOUND)
+public class ResourseNotFoundException2 extends RuntimeException {
+
+ public ResourseNotFoundException2() {
+ }
+
+ public ResourseNotFoundException2(String message) {
+ super(message);
+ }
+}
+ ```
+
+ `src/main/java/com/twuc/webApp/web/ResponseStatusExceptionController.java`
+
+```java
+@RestController
+@RequestMapping("/api")
+public class ResponseStatusExceptionController {
+ @GetMapping("/resourceNotFoundException2")
+ public void throwException3() {
+ throw new ResourseNotFoundException2("Sorry, the resourse not found!");
+ }
+}
+```
+
+ 使用 Get 请求 [localhost:8080/api/resourceNotFoundException2](localhost:8333/api/resourceNotFoundException2) ,服务端返回的 JSON 数据如下:
+
+```json
+{
+ "timestamp": "2019-08-21T07:11:43.744+0000",
+ "status": 404,
+ "error": "Not Found",
+ "message": "Sorry, the resourse not found!",
+ "path": "/api/resourceNotFoundException2"
+}
+```
+
+这种通过 `ResponseStatus`注解简单处理异常的方法是的好处是比较简单,但是一般我们不会这样做,通过`ResponseStatusException`会更加方便,可以避免我们额外的异常类。
+
+```java
+ @GetMapping("/resourceNotFoundException2")
+ public void throwException3() {
+ throw new ResponseStatusException(HttpStatus.NOT_FOUND, "Sorry, the resourse not found!", new ResourceNotFoundException());
+ }
+```
+
+ 使用 Get 请求 [localhost:8080/api/resourceNotFoundException2](localhost:8333/api/resourceNotFoundException2) ,服务端返回的 JSON 数据如下,和使用 `ResponseStatus` 实现的效果一样:
+
+ ```json
+{
+ "timestamp": "2019-08-21T07:28:12.017+0000",
+ "status": 404,
+ "error": "Not Found",
+ "message": "Sorry, the resourse not found!",
+ "path": "/api/resourceNotFoundException3"
+}
+ ```
+
+`ResponseStatusException` 提供了三个构造方法:
+
+```java
+ public ResponseStatusException(HttpStatus status) {
+ this(status, null, null);
+ }
+
+ public ResponseStatusException(HttpStatus status, @Nullable String reason) {
+ this(status, reason, null);
+ }
+
+ public ResponseStatusException(HttpStatus status, @Nullable String reason, @Nullable Throwable cause) {
+ super(null, cause);
+ Assert.notNull(status, "HttpStatus is required");
+ this.status = status;
+ this.reason = reason;
+ }
+
+```
+
+构造函数中的参数解释如下:
+
+- status : http status
+- reason :response 的消息内容
+- cause : 抛出的异常
+
+### 总结
+
+本文主要讲了 3 种捕获处理异常的方式:
+
+1. 使用 `@ControllerAdvice` 和 `@ExceptionHandler` 处理全局异常
+2. `@ExceptionHandler` 处理 Controller 级别的异常
+3. `ResponseStatusException`
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-handle-exception
\ No newline at end of file
diff --git a/md/springboot-oss.md b/docs/advanced/springboot-oss.md
similarity index 98%
rename from md/springboot-oss.md
rename to docs/advanced/springboot-oss.md
index aa2a98d..ed7843d 100644
--- a/md/springboot-oss.md
+++ b/docs/advanced/springboot-oss.md
@@ -2,7 +2,7 @@
[https://help.aliyun.com/product/31815.html?spm=a2c4g.11186623.6.540.4e401c62EyJK5T](https://help.aliyun.com/product/31815.html?spm=a2c4g.11186623.6.540.4e401c62EyJK5T)
-本篇文章会介绍到 SpringBoot 整合阿里云OSS 存储服务实现文件上传下载以及简单的查看。其实今天将的应该算的上是一个简单的小案例了,涉及到的知识点还算是比较多。
+本篇文章会介绍到 SpringBoot 整合阿里云OSS 存储服务实现文件上传下载以及简单的查看。其实今天讲的应该算的上是一个简单的小案例了,涉及到的知识点还算是比较多。相关代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/springboot-oss 。
@@ -32,7 +32,7 @@
具有 Java 基础以及SpringBoot 简单基础知识即可。
### 1.2 环境参数
-
+
- 开发工具:IDEA
- 基础工具:Maven+JDK8
- 所用技术:SpringBoot+阿里云OSS 存储服务 Java 相关API
@@ -510,3 +510,6 @@ JS 的内容主要是让我们上传的图片可以预览,就像我们在网
我们终于能够独立利用阿里云 OSS 完成一个自己的图床服务,但是其实如果你想用阿里云OSS当做图床可以直接使用极简图床:[http://jiantuku.com](http://jiantuku.com) 上传图片,比较方便!大家可能心里在想那你特么让我实现个图床干嘛?我觉得通过学习,大家以后可以做很多事情,比如 利用阿里云OSS 存储服务存放自己网站的相关图片。
+
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/advanced/springboot-oss
diff --git "a/docs/basis/@PostConstruct\344\270\216@PreDestroy.md" "b/docs/basis/@PostConstruct\344\270\216@PreDestroy.md"
new file mode 100644
index 0000000..1e0fafb
--- /dev/null
+++ "b/docs/basis/@PostConstruct\344\270\216@PreDestroy.md"
@@ -0,0 +1,110 @@
+`@PostConstruct`和`@PreDestroy` 是两个作用于 Servlet 生命周期的注解,相信从 Servlet 开始学 Java 后台开发的同学对他应该不陌生。
+
+**被这两个注解修饰的方法可以保证在整个 Servlet 生命周期只被执行一次,即使 Web 容器在其内部中多次实例化该方法所在的 bean。**
+
+**这两个注解分别有什么作用呢**?
+
+1. **`@PostConstruct`** : 用来修饰方法,标记在项目启动的时候执行这个方法,一般用来执行某些初始化操作比如全局配置。`PostConstruct` 注解的方法会在构造函数之后执行,Servlet 的`init()`方法之前执行。
+2. **`@PreDestroy`** : 当 bean 被 Web 容器的时候被调用,一般用来释放 bean 所持有的资源。。`@PreDestroy` 注解的方法会在Servlet 的`destroy()`方法之前执行。
+
+被这个注解修饰的方法需要满足下面这些基本条件:
+
+- 非静态
+- 该方法必须没有任何参数,除非在拦截器的情况下,在这种情况下,它接受一个由拦截器规范定义的InvocationContext对象
+- void()也就是没有返回值
+- 该方法抛出未检查的异常
+- ......
+
+我们新建一个 Spring 程序,其中有一段代码是这样的,输出结果会是什么呢?
+
+```java
+
+import org.springframework.context.annotation.Configuration;
+
+import javax.annotation.PostConstruct;
+import javax.annotation.PreDestroy;
+
+@Configuration
+public class MyConfiguration {
+ public MyConfiguration() {
+ System.out.println("构造方法被调用");
+ }
+
+ @PostConstruct
+ private void init() {
+ System.out.println("PostConstruct注解方法被调用");
+ }
+
+ @PreDestroy
+ private void shutdown() {
+ System.out.println("PreDestroy注解方法被调用");
+ }
+}
+
+
+```
+
+输出结果如下:
+
+
+
+但是 J2EE已在Java 9中弃用 `@PostConstruct`和`@PreDestroy`这两个注解 ,并计划在Java 11中将其删除。我们有什么更好的替代方法吗?当然有!
+
+```java
+package cn.javaguide.config;
+
+import org.springframework.beans.factory.DisposableBean;
+import org.springframework.beans.factory.InitializingBean;
+import org.springframework.context.annotation.Configuration;
+
+@Configuration
+public class MyConfiguration2 implements InitializingBean, DisposableBean {
+ public MyConfiguration2() {
+ System.out.println("构造方法被调用");
+ }
+
+ @Override
+ public void afterPropertiesSet() {
+ System.out.println("afterPropertiesSet方法被调用");
+ }
+
+ @Override
+ public void destroy() {
+ System.out.println("destroy方法被调用");
+ }
+
+}
+
+```
+
+输出结果如下,可以看出实现Spring 提供的 `InitializingBean`和 `DisposableBean`接口的效果和使用`@PostConstruct`和`@PreDestroy` 注解的效果一样。
+
+
+
+但是,Spring 官方不推荐使用上面这种方式,[Spring 官方文档](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#beans-factory-lifecycle)是这样说的:
+
+> We recommend that you do not use the `InitializingBean` interface, because it unnecessarily couples the code to Spring. Alternatively, we suggest using the [`@PostConstruct`](https://docs.spring.io/spring/docs/current/spring-framework-reference/core.html#beans-postconstruct-and-predestroy-annotations) annotation or specifying a POJO initialization method. (我们建议您不要使用 `InitializingBean`回调接口,因为它不必要地将代码耦合到 Spring。另外,我们建议使用`@PostConstruct`注解或指定bean定义支持的通用方法。)
+
+如果你还是非要使用 Java 9 及以后的版本使用 `@PostConstruct`和`@PreDestroy` 这两个注解的话,你也可以手动添加相关依赖。
+
+Maven:
+
+```xml
+
+ javax.annotation
+ javax.annotation-api
+ 1.3.2
+
+```
+
+Gradle:
+
+```groovy
+compile group: 'javax.annotation', name: 'javax.annotation-api', version: '1.3.2'
+```
+
+> 源码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/life-cycle-annotation
+
+推荐阅读:
+
+- [Spring Bean Life Cycle](https://netjs.blogspot.com/2016/03/spring-bean-life-cycle.html)
diff --git a/docs/basis/RestControllerVSController.md b/docs/basis/RestControllerVSController.md
new file mode 100644
index 0000000..a3d2fcb
--- /dev/null
+++ b/docs/basis/RestControllerVSController.md
@@ -0,0 +1,145 @@
+周末的时候分享了一个技术session,讲到了`@RestController` 和 `@Controller`,当时没有太讲清楚,因为 team 里很多同事之前不是做 Java的,所以对这两个东西不太熟悉,于是写了篇文章整理了一下。
+
+## @RestController vs @Controller
+
+### Controller 返回一个页面
+
+单独使用 `@Controller` 不加 `@ResponseBody`的话一般使用在要返回一个视图的情况,这种情况属于比较传统的Spring MVC 的应用,对应于前后端不分离的情况。
+
+
+
+### @RestController 返回JSON 或 XML 形式数据
+
+但`@RestController`只返回对象,对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中,这种情况属于 RESTful Web服务,这也是目前日常开发所接触的最常用的情况(前后端分离)。
+
+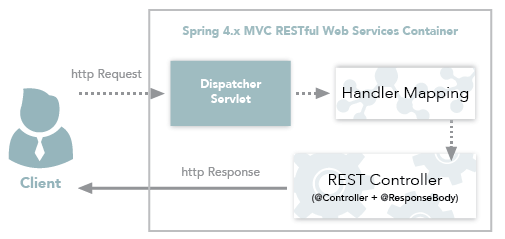
+
+### @Controller +@ResponseBody 返回JSON 或 XML 形式数据
+
+如果你需要在Spring4之前开发 RESTful Web服务的话,你需要使用`@Controller` 并结合`@ResponseBody`注解,也就是说`@Controller` +`@ResponseBody`= `@RestController`(Spring 4 之后新加的注解)。
+
+> `@ResponseBody` 注解的作用是将 `Controller` 的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到HTTP 响应(Response)对象的 body 中,通常用来返回 JSON 或者 XML 数据,返回 JSON 数据的情况比较多。
+
+
+
+Reference:
+
+- https://dzone.com/articles/spring-framework-restcontroller-vs-controller(图片来源)
+- https://javarevisited.blogspot.com/2017/08/difference-between-restcontroller-and-controller-annotations-spring-mvc-rest.html?m=1
+
+### 示例1: @Controller 返回一个页面
+
+当我们需要直接在后端返回一个页面的时候,Spring 推荐使用 Thymeleaf 模板引擎。Spring MVC中`@Controller`中的方法可以直接返回模板名称,接下来 Thymeleaf 模板引擎会自动进行渲染,模板中的表达式支持Spring表达式语言(Spring EL)。**如果需要用到 Thymeleaf 模板引擎,注意添加依赖!不然会报错。**
+
+Gradle:
+
+```groovy
+ compile 'org.springframework.boot:spring-boot-starter-thymeleaf'
+```
+
+Maven:
+
+```xml
+
+ org.springframework.boot
+ spring-boot-starter-thymeleaf
+
+```
+
+`src/main/java/com/example/demo/controller/HelloController.java`
+
+```java
+@Controller
+public class HelloController {
+ @GetMapping("/hello")
+ public String greeting(@RequestParam(name = "name", required = false, defaultValue = "World") String name, Model model) {
+ model.addAttribute("name", name);
+ return "hello";
+ }
+}
+```
+`src/main/resources/templates/hello.html`
+
+Spring 会去 resources 目录下 templates 目录下找,所以建议把页面放在 resources/templates 目录下
+
+```html
+
+
+
+ Getting Started: Serving Web Content
+
+
+
+
+
+
+```
+
+访问:http://localhost:8999/hello?name=team-c ,你将看到下面的内容
+
+```
+Hello, team-c!
+```
+
+如果要对页面在templates目录下的hello文件夹中的话,返回页面的时候像下面这样写就可以了。
+
+`src/main/resources/templates/hello/hello.html`
+
+```java
+ return "hello/hello";
+```
+
+### 示例2: @Controller+@ResponseBody 返回 JSON 格式数据
+
+**SpringBoot 默认集成了 jackson ,对于此需求你不需要添加任何相关依赖。**
+
+`src/main/java/com/example/demo/controller/Person.java`
+
+```java
+public class Person {
+ private String name;
+ private Integer age;
+ ......
+ 省略getter/setter ,有参和无参的construtor方法
+}
+
+```
+
+`src/main/java/com/example/demo/controller/HelloController.java`
+
+```java
+@Controller
+public class HelloController {
+ @PostMapping("/hello")
+ @ResponseBody
+ public Person greeting(@RequestBody Person person) {
+ return person;
+ }
+
+}
+```
+
+使用 post 请求访问 http://localhost:8080/hello ,body 中附带以下参数,后端会以json 格式将 person 对象返回。
+
+```json
+{
+ "name": "teamc",
+ "age": 1
+}
+```
+
+### 示例3: @RestController 返回 JSON 格式数据
+
+只需要将`HelloController`改为如下形式:
+
+```java
+@RestController
+public class HelloController {
+ @PostMapping("/hello")
+ public Person greeting(@RequestBody Person person) {
+ return person;
+ }
+
+}
+```
+
diff --git a/docs/basis/read-config-properties.md b/docs/basis/read-config-properties.md
new file mode 100644
index 0000000..b959952
--- /dev/null
+++ b/docs/basis/read-config-properties.md
@@ -0,0 +1,245 @@
+很多时候我们需要将一些常用的配置信息比如阿里云oss配置、发送短信的相关信息配置等等放到配置文件中。
+
+下面我们来看一下 Spring 为我们提供了哪些方式帮助我们从配置文件中读取这些配置信息。
+
+`application.yml` 内容如下:
+
+```yaml
+wuhan2020: 2020年初武汉爆发了新型冠状病毒,疫情严重,但是,我相信一切都会过去!武汉加油!中国加油!
+
+my-profile:
+ name: Guide哥
+ email: koushuangbwcx@163.com
+
+library:
+ location: 湖北武汉加油中国加油
+ books:
+ - name: 天才基本法
+ description: 二十二岁的林朝夕在父亲确诊阿尔茨海默病这天,得知自己暗恋多年的校园男神裴之即将出国深造的消息——对方考取的学校,恰是父亲当年为她放弃的那所。
+ - name: 时间的秩序
+ description: 为什么我们记得过去,而非未来?时间“流逝”意味着什么?是我们存在于时间之内,还是时间存在于我们之中?卡洛·罗韦利用诗意的文字,邀请我们思考这一亘古难题——时间的本质。
+ - name: 了不起的我
+ description: 如何养成一个新习惯?如何让心智变得更成熟?如何拥有高质量的关系? 如何走出人生的艰难时刻?
+
+```
+
+### 1.通过 `@value` 读取比较简单的配置信息
+
+使用 `@Value("${property}")` 读取比较简单的配置信息:
+
+```java
+@Value("${wuhan2020}")
+String wuhan2020;
+```
+
+> **需要注意的是 `@value`这种方式是不被推荐的,Spring 比较建议的是下面几种读取配置信息的方式。**
+
+### 2.通过`@ConfigurationProperties`读取并与 bean 绑定
+
+> **`LibraryProperties` 类上加了 `@Component` 注解,我们可以像使用普通 bean 一样将其注入到类中使用。**
+
+```java
+
+import lombok.Getter;
+import lombok.Setter;
+import lombok.ToString;
+import org.springframework.boot.context.properties.ConfigurationProperties;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.stereotype.Component;
+
+import java.util.List;
+
+@Component
+@ConfigurationProperties(prefix = "library")
+@Setter
+@Getter
+@ToString
+class LibraryProperties {
+ private String location;
+ private List books;
+
+ @Setter
+ @Getter
+ @ToString
+ static class Book {
+ String name;
+ String description;
+ }
+}
+
+```
+
+这个时候你就可以像使用普通 bean 一样,将其注入到类中使用:
+
+```java
+package cn.javaguide.readconfigproperties;
+
+import org.springframework.beans.factory.InitializingBean;
+import org.springframework.boot.SpringApplication;
+import org.springframework.boot.autoconfigure.SpringBootApplication;
+
+/**
+ * @author shuang.kou
+ */
+@SpringBootApplication
+public class ReadConfigPropertiesApplication implements InitializingBean {
+
+ private final LibraryProperties library;
+
+ public ReadConfigPropertiesApplication(LibraryProperties library) {
+ this.library = library;
+ }
+
+ public static void main(String[] args) {
+ SpringApplication.run(ReadConfigPropertiesApplication.class, args);
+ }
+
+ @Override
+ public void afterPropertiesSet() {
+ System.out.println(library.getLocation());
+ System.out.println(library.getBooks()); }
+}
+```
+
+控制台输出:
+
+```
+湖北武汉加油中国加油
+[LibraryProperties.Book(name=天才基本法, description........]
+```
+
+### 3.通过`@ConfigurationProperties`读取并校验
+
+我们先将`application.yml`修改为如下内容,明显看出这不是一个正确的 email 格式:
+
+```yaml
+my-profile:
+ name: Guide哥
+ email: koushuangbwcx@
+```
+
+>**`ProfileProperties` 类没有加 `@Component` 注解。我们在我们要使用`ProfileProperties` 的地方使用`@EnableConfigurationProperties`注册我们的配置bean:**
+
+ ```java
+import lombok.Getter;
+import lombok.Setter;
+import lombok.ToString;
+import org.springframework.boot.context.properties.ConfigurationProperties;
+import org.springframework.stereotype.Component;
+import org.springframework.validation.annotation.Validated;
+
+import javax.validation.constraints.Email;
+import javax.validation.constraints.NotEmpty;
+
+/**
+ * @author shuang.kou
+ */
+@Getter
+@Setter
+@ToString
+@ConfigurationProperties("my-profile")
+@Validated
+public class ProfileProperties {
+ @NotEmpty
+ private String name;
+
+ @Email
+ @NotEmpty
+ private String email;
+
+ //配置文件中没有读取到的话就用默认值
+ private Boolean handsome = Boolean.TRUE;
+
+}
+ ```
+
+具体使用:
+
+```java
+package cn.javaguide.readconfigproperties;
+
+import org.springframework.beans.factory.InitializingBean;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.boot.SpringApplication;
+import org.springframework.boot.autoconfigure.SpringBootApplication;
+import org.springframework.boot.context.properties.EnableConfigurationProperties;
+
+/**
+ * @author shuang.kou
+ */
+@SpringBootApplication
+@EnableConfigurationProperties(ProfileProperties.class)
+public class ReadConfigPropertiesApplication implements InitializingBean {
+ private final ProfileProperties profileProperties;
+
+ public ReadConfigPropertiesApplication(ProfileProperties profileProperties) {
+ this.profileProperties = profileProperties;
+ }
+
+ public static void main(String[] args) {
+ SpringApplication.run(ReadConfigPropertiesApplication.class, args);
+ }
+
+ @Override
+ public void afterPropertiesSet() {
+ System.out.println(profileProperties.toString());
+ }
+}
+
+```
+
+因为我们的邮箱格式不正确,所以程序运行的时候就报错,根本运行不起来,保证了数据类型的安全性:
+
+```visual basic
+Binding to target org.springframework.boot.context.properties.bind.BindException: Failed to bind properties under 'my-profile' to cn.javaguide.readconfigproperties.ProfileProperties failed:
+
+ Property: my-profile.email
+ Value: koushuangbwcx@
+ Origin: class path resource [application.yml]:5:10
+ Reason: must be a well-formed email address
+```
+
+我们把邮箱测试改为正确的之后再运行,控制台就能成功打印出读取到的信息:
+
+```
+ProfileProperties(name=Guide哥, email=koushuangbwcx@163.com, handsome=true)
+```
+
+### 4.`@PropertySource`读取指定 properties 文件
+
+```java
+import lombok.Getter;
+import lombok.Setter;
+import org.springframework.beans.factory.annotation.Value;
+import org.springframework.context.annotation.PropertySource;
+import org.springframework.stereotype.Component;
+
+@Component
+@PropertySource("classpath:website.properties")
+@Getter
+@Setter
+class WebSite {
+ @Value("${url}")
+ private String url;
+}
+```
+
+使用:
+
+```java
+@Autowired
+private WebSite webSite;
+
+System.out.println(webSite.getUrl());//https://javaguide.cn/
+
+```
+
+### 5.题外话:Spring加载配置文件的优先级
+
+Spring 读取配置文件也是有优先级的,直接上图:
+
+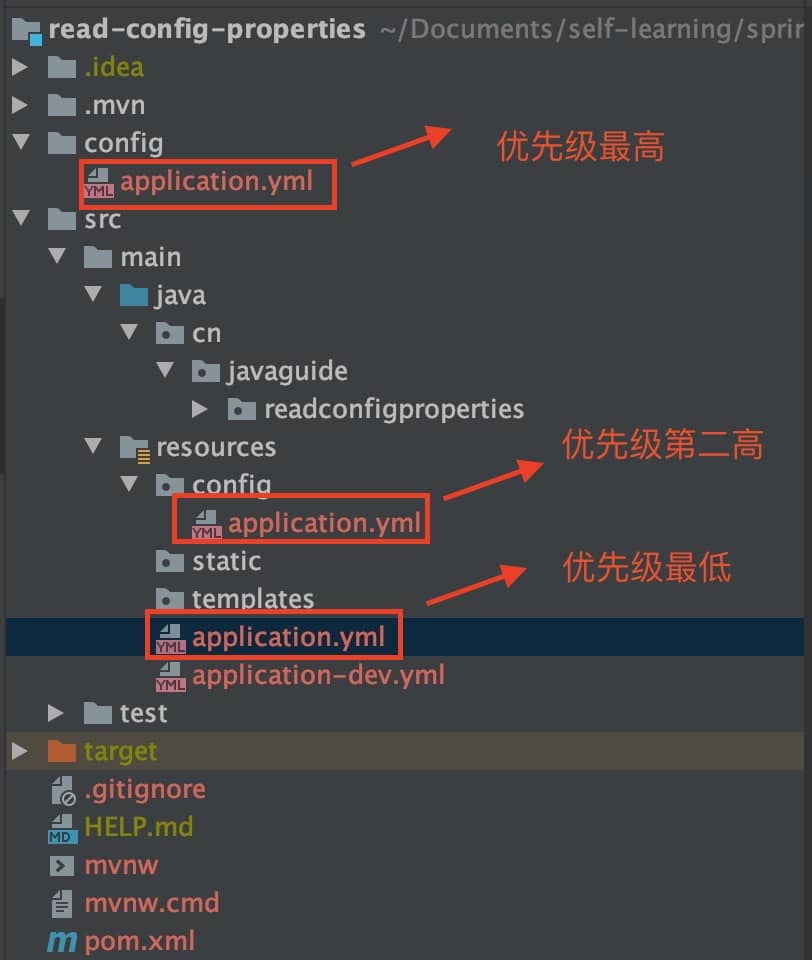 +
+更对内容请查看官方文档:https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config
+
+> 本文源码:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/read-config-properties
\ No newline at end of file
diff --git a/docs/basis/springboot-filter.md b/docs/basis/springboot-filter.md
new file mode 100644
index 0000000..e9903bc
--- /dev/null
+++ b/docs/basis/springboot-filter.md
@@ -0,0 +1,220 @@
+### 1. Filter 介绍
+
+Filter 过滤器这个概念应该大家不会陌生,特别是对与从 Servlet 开始入门学 Java 后台的同学来说。那么这个东西我们能做什么呢?Filter 过滤器主要是用来过滤用户请求的,它允许我们对用户请求进行前置处理和后置处理,比如实现 URL 级别的权限控制、过滤非法请求等等。Filter 过滤器是面向切面编程——AOP 的具体实现(AOP切面编程只是一种编程思想而已)。
+
+另外,Filter 是依赖于 Servlet 容器,`Filter`接口就在 Servlet 包下面,属于 Servlet 规范的一部分。所以,很多时候我们也称其为“增强版 Servlet”。
+
+如果我们需要自定义 Filter 的话非常简单,只需要实现 `javax.Servlet.Filter` 接口,然后重写里面的 3 个方法即可!
+
+`Filter.java`
+
+```java
+public interface Filter {
+
+ //初始化过滤器后执行的操作
+ default void init(FilterConfig filterConfig) throws ServletException {
+ }
+ // 对请求进行过滤
+ void doFilter(ServletRequest var1, ServletResponse var2, FilterChain var3) throws IOException, ServletException;
+ // 销毁过滤器后执行的操作,主要用户对某些资源的回收
+ default void destroy() {
+ }
+}
+```
+
+### 2. Filter是如何实现拦截的?
+
+`Filter`接口中有一个叫做 `doFilter` 的方法,这个方法实现了对用户请求的过滤。具体流程大体是这样的:
+
+1. 用户发送请求到 web 服务器,请求会先到过滤器;
+2. 过滤器会对请求进行一些处理比如过滤请求的参数、修改返回给客户端的 response 的内容、判断是否让用户访问该接口等等。
+3. 用户请求响应完毕。
+4. 进行一些自己想要的其他操作。
+
+
+
+### 3. 如何自定义Filter
+
+下面提供两种方法。
+
+#### 3.1自己手动注册配置实现
+
+**自定义的 Filter 需要实现`javax.Servlet.Filter`接口,并重写接口中定义的3个方法。**
+
+`MyFilter.java`
+
+```java
+/**
+ * @author shuang.kou
+ */
+@Component
+public class MyFilter implements Filter {
+ private static final Logger logger = LoggerFactory.getLogger(MyFilter.class);
+
+ @Override
+ public void init(FilterConfig filterConfig) {
+ logger.info("初始化过滤器:", filterConfig.getFilterName());
+ }
+
+ @Override
+ public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
+ //对请求进行预处理
+ logger.info("过滤器开始对请求进行预处理:");
+ HttpServletRequest request = (HttpServletRequest) servletRequest;
+ String requestUri = request.getRequestURI();
+ System.out.println("请求的接口为:" + requestUri);
+ long startTime = System.currentTimeMillis();
+ //通过 doFilter 方法实现过滤功能
+ filterChain.doFilter(servletRequest, servletResponse);
+ // 上面的 doFilter 方法执行结束后用户的请求已经返回
+ long endTime = System.currentTimeMillis();
+ System.out.println("该用户的请求已经处理完毕,请求花费的时间为:" + (endTime - startTime));
+ }
+
+ @Override
+ public void destroy() {
+ logger.info("销毁过滤器");
+ }
+}
+```
+
+`MyFilterConfig.java`
+
+**在配置中注册自定义的过滤器。**
+
+```java
+@Configuration
+public class MyFilterConfig {
+ @Autowired
+ MyFilter myFilter;
+ @Bean
+ public FilterRegistrationBean thirdFilter() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+
+ filterRegistrationBean.setFilter(myFilter);
+
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+
+ return filterRegistrationBean;
+ }
+}
+```
+
+#### 3.2 通过提供好的一些注解实现
+
+**在自己的过滤器的类上加上`@WebFilter` 然后在这个注解中通过它提供好的一些参数进行配置。**
+
+```java
+@WebFilter(filterName = "MyFilterWithAnnotation", urlPatterns = "/api/*")
+public class MyFilterWithAnnotation implements Filter {
+
+ ......
+}
+```
+
+另外,为了能让 Spring 找到它,你需要在启动类上加上 `@ServletComponentScan` 注解。
+
+### 4.定义多个拦截器,并决定它们的执行顺序
+
+**假如我们现在又加入了一个过滤器怎么办?**
+
+`MyFilter2.java`
+
+```java
+@Component
+public class MyFilter2 implements Filter {
+ private static final Logger logger = LoggerFactory.getLogger(MyFilter2.class);
+
+ @Override
+ public void init(FilterConfig filterConfig) {
+ logger.info("初始化过滤器2");
+ }
+
+ @Override
+ public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
+ //对请求进行预处理
+ logger.info("过滤器开始对请求进行预处理2:");
+ HttpServletRequest request = (HttpServletRequest) servletRequest;
+ String requestUri = request.getRequestURI();
+ System.out.println("请求的接口为2:" + requestUri);
+ long startTime = System.currentTimeMillis();
+ //通过 doFilter 方法实现过滤功能
+ filterChain.doFilter(servletRequest, servletResponse);
+ // 上面的 doFilter 方法执行结束后用户的请求已经返回
+ long endTime = System.currentTimeMillis();
+ System.out.println("该用户的请求已经处理完毕,请求花费的时间为2:" + (endTime - startTime));
+ }
+
+ @Override
+ public void destroy() {
+ logger.info("销毁过滤器2");
+ }
+}
+
+```
+
+**在配置中注册自定义的过滤器,通过`FilterRegistrationBean` 的`setOrder` 方法可以决定 Filter 的执行顺序。**
+
+```java
+@Configuration
+public class MyFilterConfig {
+ @Autowired
+ MyFilter myFilter;
+
+ @Autowired
+ MyFilter2 myFilter2;
+
+ @Bean
+ public FilterRegistrationBean setUpMyFilter() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+ filterRegistrationBean.setOrder(2);
+ filterRegistrationBean.setFilter(myFilter);
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+
+ return filterRegistrationBean;
+ }
+
+ @Bean
+ public FilterRegistrationBean setUpMyFilter2() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+ filterRegistrationBean.setOrder(1);
+ filterRegistrationBean.setFilter(myFilter2);
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+ return filterRegistrationBean;
+ }
+}
+```
+
+**自定义 Controller 验证过滤器**
+
+```java
+import org.springframework.web.bind.annotation.GetMapping;
+import org.springframework.web.bind.annotation.RequestMapping;
+import org.springframework.web.bind.annotation.RestController;
+
+@RestController
+@RequestMapping("/api")
+public class MyController {
+
+ @GetMapping("/hello")
+ public String getHello() throws InterruptedException {
+ Thread.sleep(1000);
+ return "Hello";
+ }
+}
+```
+
+**实际测试效果如下:**
+
+```shell
+2019-10-22 22:32:15.569 INFO 1771 --- [ main] g.j.springbootfilter.filter.MyFilter2 : 初始化过滤器2
+2019-10-22 22:32:15.569 INFO 1771 --- [ main] g.j.springbootfilter.filter.MyFilter : 初始化过滤器
+2019-10-22 22:32:55.199 INFO 1771 --- [nio-8080-exec-1] g.j.springbootfilter.filter.MyFilter2 : 过滤器开始对请求进行预处理2:
+请求的接口为2:/api/hello
+2019-10-22 22:32:55.199 INFO 1771 --- [nio-8080-exec-1] g.j.springbootfilter.filter.MyFilter : 过滤器开始对请求进行预处理:
+请求的接口为:/api/hello
+该用户的请求已经处理完毕,请求花费的时间为:1037
+该用户的请求已经处理完毕,请求花费的时间为2:1037
+```
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-filter-interceptor
\ No newline at end of file
diff --git a/docs/basis/springboot-interceptor.md b/docs/basis/springboot-interceptor.md
new file mode 100644
index 0000000..dc924f3
--- /dev/null
+++ b/docs/basis/springboot-interceptor.md
@@ -0,0 +1,339 @@
+> 本文大部分内容是对国外一个不错的文章 :https://o7planning.org/en/11689/spring-boot-interceptors-tutorial 的翻译,做了适当的修改。
+
+### 1.Interceptor介绍
+
+**拦截器(Interceptor)同** Filter 过滤器一样,它俩都是面向切面编程——AOP 的具体实现(AOP切面编程只是一种编程思想而已)。
+
+你可以使用 Interceptor 来执行某些任务,例如在 **Controller** 处理请求之前编写日志,添加或更新配置......
+
+在 **Spring中**,当请求发送到 **Controller** 时,在被**Controller**处理之前,它必须经过 **Interceptors**(0或更多)。
+
+**Spring Interceptor**是一个非常类似于**Servlet Filter** 的概念 。
+
+### 2.过滤器和拦截器的区别
+
+对于过滤器和拦截器的区别, [知乎@Kangol LI](https://www.zhihu.com/question/35225845/answer/61876681) 的回答很不错。
+
+- 过滤器(Filter):当你有一堆东西的时候,你只希望选择符合你要求的某一些东西。定义这些要求的工具,就是过滤器。
+- 拦截器(Interceptor):在一个流程正在进行的时候,你希望干预它的进展,甚至终止它进行,这是拦截器做的事情。
+
+### 3.自定义 Interceptor
+
+如果你需要自定义 **Interceptor** 的话必须实现 **org.springframework.web.servlet.HandlerInterceptor**接口或继承 **org.springframework.web.servlet.handler.HandlerInterceptorAdapter**类,并且需要重写下面下面3个方法:
+
+```java
+public boolean preHandle(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler)
+
+
+public void postHandle(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler,
+ ModelAndView modelAndView)
+
+
+public void afterCompletion(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler,
+ Exception ex)
+```
+
+注意: ***preHandle***方法返回 **true**或 **false**。如果返回 **true**,则意味着请求将继续到达 **Controller** 被处理。
+
+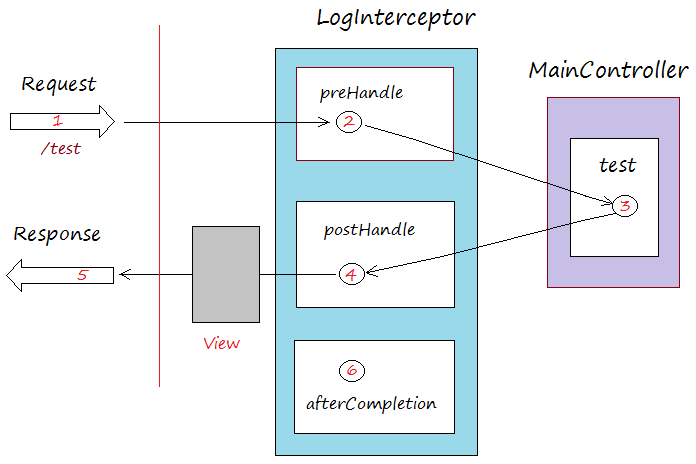
+
+每个请求可能会通过许多拦截器。下图说明了这一点。
+
+
+
+**`LogInterceptor`用于过滤所有请求**
+
+```java
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class LogInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+ long startTime = System.currentTimeMillis();
+ System.out.println("\n-------- LogInterception.preHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("Start Time: " + System.currentTimeMillis());
+
+ request.setAttribute("startTime", startTime);
+
+ return true;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ System.out.println("\n-------- LogInterception.postHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+
+ // You can add attributes in the modelAndView
+ // and use that in the view page
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+ System.out.println("\n-------- LogInterception.afterCompletion --- ");
+
+ long startTime = (Long) request.getAttribute("startTime");
+ long endTime = System.currentTimeMillis();
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("End Time: " + endTime);
+
+ System.out.println("Time Taken: " + (endTime - startTime));
+ }
+
+}
+```
+
+**`OldLoginInterceptor`**是一个拦截器,如果用户输入已经被废弃的链接 **“ / admin / oldLogin”**,它将重定向到新的 **“ / admin / login”。**
+
+```java
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class OldLoginInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+
+ System.out.println("\n-------- OldLoginInterceptor.preHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("Sorry! This URL is no longer used, Redirect to /admin/login");
+
+ response.sendRedirect(request.getContextPath() + "/admin/login");
+ return false;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ // This code will never be run.
+ System.out.println("\n-------- OldLoginInterceptor.postHandle --- ");
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+
+ // This code will never be run.
+ System.out.println("\n-------- QueryStringInterceptor.afterCompletion --- ");
+ }
+
+}
+```
+
+
+
+
+
+**`AdminInterceptor`**
+
+```java
+package org.o7planning.sbinterceptor.interceptor;
+
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class AdminInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.preHandle --- ");
+ return true;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.postHandle --- ");
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.afterCompletion --- ");
+ }
+
+}
+```
+
+**配置拦截器**
+
+```java
+import github.javaguide.springbootfilter.interceptor.AdminInterceptor;
+import github.javaguide.springbootfilter.interceptor.LogInterceptor;
+import github.javaguide.springbootfilter.interceptor.OldLoginInterceptor;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
+import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
+
+@Configuration
+public class WebConfig implements WebMvcConfigurer {
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ // LogInterceptor apply to all URLs.
+ registry.addInterceptor(new LogInterceptor());
+
+ // Old Login url, no longer use.
+ // Use OldURLInterceptor to redirect to a new URL.
+ registry.addInterceptor(new OldLoginInterceptor())//
+ .addPathPatterns("/admin/oldLogin");
+
+ // This interceptor apply to URL like /admin/*
+ // Exclude /admin/oldLogin
+ registry.addInterceptor(new AdminInterceptor())//
+ .addPathPatterns("/admin/*")//
+ .excludePathPatterns("/admin/oldLogin");
+ }
+
+}
+
+```
+
+**自定义 Controller 验证拦截器**
+
+```java
+import org.springframework.stereotype.Controller;
+import org.springframework.ui.Model;
+import org.springframework.web.bind.annotation.RequestMapping;
+
+@Controller
+public class InterceptorTestController {
+
+ @RequestMapping(value = { "/", "/test" })
+ public String test(Model model) {
+
+ System.out.println("\n-------- MainController.test --- ");
+
+ System.out.println(" ** You are in Controller ** ");
+
+ return "test";
+ }
+
+ // This path is no longer used.
+ // It will be redirected by OldLoginInterceptor
+ @Deprecated
+ @RequestMapping(value = { "/admin/oldLogin" })
+ public String oldLogin(Model model) {
+
+ // Code here never run.
+ return "oldLogin";
+ }
+
+ @RequestMapping(value = { "/admin/login" })
+ public String login(Model model) {
+
+ System.out.println("\n-------- MainController.login --- ");
+
+ System.out.println(" ** You are in Controller ** ");
+
+ return "login";
+ }
+
+}
+
+```
+
+**thymeleaf 模板引擎**
+
+`test.html`
+
+```html
+
+
+
+
+
+ Spring Boot Mvc Interceptor example
+
+
+
+
+
+
+
+更对内容请查看官方文档:https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config
+
+> 本文源码:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/read-config-properties
\ No newline at end of file
diff --git a/docs/basis/springboot-filter.md b/docs/basis/springboot-filter.md
new file mode 100644
index 0000000..e9903bc
--- /dev/null
+++ b/docs/basis/springboot-filter.md
@@ -0,0 +1,220 @@
+### 1. Filter 介绍
+
+Filter 过滤器这个概念应该大家不会陌生,特别是对与从 Servlet 开始入门学 Java 后台的同学来说。那么这个东西我们能做什么呢?Filter 过滤器主要是用来过滤用户请求的,它允许我们对用户请求进行前置处理和后置处理,比如实现 URL 级别的权限控制、过滤非法请求等等。Filter 过滤器是面向切面编程——AOP 的具体实现(AOP切面编程只是一种编程思想而已)。
+
+另外,Filter 是依赖于 Servlet 容器,`Filter`接口就在 Servlet 包下面,属于 Servlet 规范的一部分。所以,很多时候我们也称其为“增强版 Servlet”。
+
+如果我们需要自定义 Filter 的话非常简单,只需要实现 `javax.Servlet.Filter` 接口,然后重写里面的 3 个方法即可!
+
+`Filter.java`
+
+```java
+public interface Filter {
+
+ //初始化过滤器后执行的操作
+ default void init(FilterConfig filterConfig) throws ServletException {
+ }
+ // 对请求进行过滤
+ void doFilter(ServletRequest var1, ServletResponse var2, FilterChain var3) throws IOException, ServletException;
+ // 销毁过滤器后执行的操作,主要用户对某些资源的回收
+ default void destroy() {
+ }
+}
+```
+
+### 2. Filter是如何实现拦截的?
+
+`Filter`接口中有一个叫做 `doFilter` 的方法,这个方法实现了对用户请求的过滤。具体流程大体是这样的:
+
+1. 用户发送请求到 web 服务器,请求会先到过滤器;
+2. 过滤器会对请求进行一些处理比如过滤请求的参数、修改返回给客户端的 response 的内容、判断是否让用户访问该接口等等。
+3. 用户请求响应完毕。
+4. 进行一些自己想要的其他操作。
+
+
+
+### 3. 如何自定义Filter
+
+下面提供两种方法。
+
+#### 3.1自己手动注册配置实现
+
+**自定义的 Filter 需要实现`javax.Servlet.Filter`接口,并重写接口中定义的3个方法。**
+
+`MyFilter.java`
+
+```java
+/**
+ * @author shuang.kou
+ */
+@Component
+public class MyFilter implements Filter {
+ private static final Logger logger = LoggerFactory.getLogger(MyFilter.class);
+
+ @Override
+ public void init(FilterConfig filterConfig) {
+ logger.info("初始化过滤器:", filterConfig.getFilterName());
+ }
+
+ @Override
+ public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
+ //对请求进行预处理
+ logger.info("过滤器开始对请求进行预处理:");
+ HttpServletRequest request = (HttpServletRequest) servletRequest;
+ String requestUri = request.getRequestURI();
+ System.out.println("请求的接口为:" + requestUri);
+ long startTime = System.currentTimeMillis();
+ //通过 doFilter 方法实现过滤功能
+ filterChain.doFilter(servletRequest, servletResponse);
+ // 上面的 doFilter 方法执行结束后用户的请求已经返回
+ long endTime = System.currentTimeMillis();
+ System.out.println("该用户的请求已经处理完毕,请求花费的时间为:" + (endTime - startTime));
+ }
+
+ @Override
+ public void destroy() {
+ logger.info("销毁过滤器");
+ }
+}
+```
+
+`MyFilterConfig.java`
+
+**在配置中注册自定义的过滤器。**
+
+```java
+@Configuration
+public class MyFilterConfig {
+ @Autowired
+ MyFilter myFilter;
+ @Bean
+ public FilterRegistrationBean thirdFilter() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+
+ filterRegistrationBean.setFilter(myFilter);
+
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+
+ return filterRegistrationBean;
+ }
+}
+```
+
+#### 3.2 通过提供好的一些注解实现
+
+**在自己的过滤器的类上加上`@WebFilter` 然后在这个注解中通过它提供好的一些参数进行配置。**
+
+```java
+@WebFilter(filterName = "MyFilterWithAnnotation", urlPatterns = "/api/*")
+public class MyFilterWithAnnotation implements Filter {
+
+ ......
+}
+```
+
+另外,为了能让 Spring 找到它,你需要在启动类上加上 `@ServletComponentScan` 注解。
+
+### 4.定义多个拦截器,并决定它们的执行顺序
+
+**假如我们现在又加入了一个过滤器怎么办?**
+
+`MyFilter2.java`
+
+```java
+@Component
+public class MyFilter2 implements Filter {
+ private static final Logger logger = LoggerFactory.getLogger(MyFilter2.class);
+
+ @Override
+ public void init(FilterConfig filterConfig) {
+ logger.info("初始化过滤器2");
+ }
+
+ @Override
+ public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
+ //对请求进行预处理
+ logger.info("过滤器开始对请求进行预处理2:");
+ HttpServletRequest request = (HttpServletRequest) servletRequest;
+ String requestUri = request.getRequestURI();
+ System.out.println("请求的接口为2:" + requestUri);
+ long startTime = System.currentTimeMillis();
+ //通过 doFilter 方法实现过滤功能
+ filterChain.doFilter(servletRequest, servletResponse);
+ // 上面的 doFilter 方法执行结束后用户的请求已经返回
+ long endTime = System.currentTimeMillis();
+ System.out.println("该用户的请求已经处理完毕,请求花费的时间为2:" + (endTime - startTime));
+ }
+
+ @Override
+ public void destroy() {
+ logger.info("销毁过滤器2");
+ }
+}
+
+```
+
+**在配置中注册自定义的过滤器,通过`FilterRegistrationBean` 的`setOrder` 方法可以决定 Filter 的执行顺序。**
+
+```java
+@Configuration
+public class MyFilterConfig {
+ @Autowired
+ MyFilter myFilter;
+
+ @Autowired
+ MyFilter2 myFilter2;
+
+ @Bean
+ public FilterRegistrationBean setUpMyFilter() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+ filterRegistrationBean.setOrder(2);
+ filterRegistrationBean.setFilter(myFilter);
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+
+ return filterRegistrationBean;
+ }
+
+ @Bean
+ public FilterRegistrationBean setUpMyFilter2() {
+ FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean<>();
+ filterRegistrationBean.setOrder(1);
+ filterRegistrationBean.setFilter(myFilter2);
+ filterRegistrationBean.setUrlPatterns(new ArrayList<>(Arrays.asList("/api/*")));
+ return filterRegistrationBean;
+ }
+}
+```
+
+**自定义 Controller 验证过滤器**
+
+```java
+import org.springframework.web.bind.annotation.GetMapping;
+import org.springframework.web.bind.annotation.RequestMapping;
+import org.springframework.web.bind.annotation.RestController;
+
+@RestController
+@RequestMapping("/api")
+public class MyController {
+
+ @GetMapping("/hello")
+ public String getHello() throws InterruptedException {
+ Thread.sleep(1000);
+ return "Hello";
+ }
+}
+```
+
+**实际测试效果如下:**
+
+```shell
+2019-10-22 22:32:15.569 INFO 1771 --- [ main] g.j.springbootfilter.filter.MyFilter2 : 初始化过滤器2
+2019-10-22 22:32:15.569 INFO 1771 --- [ main] g.j.springbootfilter.filter.MyFilter : 初始化过滤器
+2019-10-22 22:32:55.199 INFO 1771 --- [nio-8080-exec-1] g.j.springbootfilter.filter.MyFilter2 : 过滤器开始对请求进行预处理2:
+请求的接口为2:/api/hello
+2019-10-22 22:32:55.199 INFO 1771 --- [nio-8080-exec-1] g.j.springbootfilter.filter.MyFilter : 过滤器开始对请求进行预处理:
+请求的接口为:/api/hello
+该用户的请求已经处理完毕,请求花费的时间为:1037
+该用户的请求已经处理完毕,请求花费的时间为2:1037
+```
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-filter-interceptor
\ No newline at end of file
diff --git a/docs/basis/springboot-interceptor.md b/docs/basis/springboot-interceptor.md
new file mode 100644
index 0000000..dc924f3
--- /dev/null
+++ b/docs/basis/springboot-interceptor.md
@@ -0,0 +1,339 @@
+> 本文大部分内容是对国外一个不错的文章 :https://o7planning.org/en/11689/spring-boot-interceptors-tutorial 的翻译,做了适当的修改。
+
+### 1.Interceptor介绍
+
+**拦截器(Interceptor)同** Filter 过滤器一样,它俩都是面向切面编程——AOP 的具体实现(AOP切面编程只是一种编程思想而已)。
+
+你可以使用 Interceptor 来执行某些任务,例如在 **Controller** 处理请求之前编写日志,添加或更新配置......
+
+在 **Spring中**,当请求发送到 **Controller** 时,在被**Controller**处理之前,它必须经过 **Interceptors**(0或更多)。
+
+**Spring Interceptor**是一个非常类似于**Servlet Filter** 的概念 。
+
+### 2.过滤器和拦截器的区别
+
+对于过滤器和拦截器的区别, [知乎@Kangol LI](https://www.zhihu.com/question/35225845/answer/61876681) 的回答很不错。
+
+- 过滤器(Filter):当你有一堆东西的时候,你只希望选择符合你要求的某一些东西。定义这些要求的工具,就是过滤器。
+- 拦截器(Interceptor):在一个流程正在进行的时候,你希望干预它的进展,甚至终止它进行,这是拦截器做的事情。
+
+### 3.自定义 Interceptor
+
+如果你需要自定义 **Interceptor** 的话必须实现 **org.springframework.web.servlet.HandlerInterceptor**接口或继承 **org.springframework.web.servlet.handler.HandlerInterceptorAdapter**类,并且需要重写下面下面3个方法:
+
+```java
+public boolean preHandle(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler)
+
+
+public void postHandle(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler,
+ ModelAndView modelAndView)
+
+
+public void afterCompletion(HttpServletRequest request,
+ HttpServletResponse response,
+ Object handler,
+ Exception ex)
+```
+
+注意: ***preHandle***方法返回 **true**或 **false**。如果返回 **true**,则意味着请求将继续到达 **Controller** 被处理。
+
+
+
+每个请求可能会通过许多拦截器。下图说明了这一点。
+
+
+
+**`LogInterceptor`用于过滤所有请求**
+
+```java
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class LogInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+ long startTime = System.currentTimeMillis();
+ System.out.println("\n-------- LogInterception.preHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("Start Time: " + System.currentTimeMillis());
+
+ request.setAttribute("startTime", startTime);
+
+ return true;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ System.out.println("\n-------- LogInterception.postHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+
+ // You can add attributes in the modelAndView
+ // and use that in the view page
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+ System.out.println("\n-------- LogInterception.afterCompletion --- ");
+
+ long startTime = (Long) request.getAttribute("startTime");
+ long endTime = System.currentTimeMillis();
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("End Time: " + endTime);
+
+ System.out.println("Time Taken: " + (endTime - startTime));
+ }
+
+}
+```
+
+**`OldLoginInterceptor`**是一个拦截器,如果用户输入已经被废弃的链接 **“ / admin / oldLogin”**,它将重定向到新的 **“ / admin / login”。**
+
+```java
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class OldLoginInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+
+ System.out.println("\n-------- OldLoginInterceptor.preHandle --- ");
+ System.out.println("Request URL: " + request.getRequestURL());
+ System.out.println("Sorry! This URL is no longer used, Redirect to /admin/login");
+
+ response.sendRedirect(request.getContextPath() + "/admin/login");
+ return false;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ // This code will never be run.
+ System.out.println("\n-------- OldLoginInterceptor.postHandle --- ");
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+
+ // This code will never be run.
+ System.out.println("\n-------- QueryStringInterceptor.afterCompletion --- ");
+ }
+
+}
+```
+
+
+
+
+
+**`AdminInterceptor`**
+
+```java
+package org.o7planning.sbinterceptor.interceptor;
+
+import javax.servlet.http.HttpServletRequest;
+import javax.servlet.http.HttpServletResponse;
+
+import org.springframework.web.servlet.ModelAndView;
+import org.springframework.web.servlet.handler.HandlerInterceptorAdapter;
+
+public class AdminInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
+ throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.preHandle --- ");
+ return true;
+ }
+
+ @Override
+ public void postHandle(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, ModelAndView modelAndView) throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.postHandle --- ");
+ }
+
+ @Override
+ public void afterCompletion(HttpServletRequest request, HttpServletResponse response, //
+ Object handler, Exception ex) throws Exception {
+
+ System.out.println("\n-------- AdminInterceptor.afterCompletion --- ");
+ }
+
+}
+```
+
+**配置拦截器**
+
+```java
+import github.javaguide.springbootfilter.interceptor.AdminInterceptor;
+import github.javaguide.springbootfilter.interceptor.LogInterceptor;
+import github.javaguide.springbootfilter.interceptor.OldLoginInterceptor;
+import org.springframework.context.annotation.Configuration;
+import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
+import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
+
+@Configuration
+public class WebConfig implements WebMvcConfigurer {
+ @Override
+ public void addInterceptors(InterceptorRegistry registry) {
+ // LogInterceptor apply to all URLs.
+ registry.addInterceptor(new LogInterceptor());
+
+ // Old Login url, no longer use.
+ // Use OldURLInterceptor to redirect to a new URL.
+ registry.addInterceptor(new OldLoginInterceptor())//
+ .addPathPatterns("/admin/oldLogin");
+
+ // This interceptor apply to URL like /admin/*
+ // Exclude /admin/oldLogin
+ registry.addInterceptor(new AdminInterceptor())//
+ .addPathPatterns("/admin/*")//
+ .excludePathPatterns("/admin/oldLogin");
+ }
+
+}
+
+```
+
+**自定义 Controller 验证拦截器**
+
+```java
+import org.springframework.stereotype.Controller;
+import org.springframework.ui.Model;
+import org.springframework.web.bind.annotation.RequestMapping;
+
+@Controller
+public class InterceptorTestController {
+
+ @RequestMapping(value = { "/", "/test" })
+ public String test(Model model) {
+
+ System.out.println("\n-------- MainController.test --- ");
+
+ System.out.println(" ** You are in Controller ** ");
+
+ return "test";
+ }
+
+ // This path is no longer used.
+ // It will be redirected by OldLoginInterceptor
+ @Deprecated
+ @RequestMapping(value = { "/admin/oldLogin" })
+ public String oldLogin(Model model) {
+
+ // Code here never run.
+ return "oldLogin";
+ }
+
+ @RequestMapping(value = { "/admin/login" })
+ public String login(Model model) {
+
+ System.out.println("\n-------- MainController.login --- ");
+
+ System.out.println(" ** You are in Controller ** ");
+
+ return "login";
+ }
+
+}
+
+```
+
+**thymeleaf 模板引擎**
+
+`test.html`
+
+```html
+
+
+
+
+
+ Spring Boot Mvc Interceptor example
+
+
+
+
+
+ Spring Boot Mvc Interceptor
+
+ Testing LogInterceptor
+
+
+ See Log in Console..
+
+
+
+```
+
+`login.html`
+
+```html
+
+
+
+
+ Spring Boot Mvc Interceptor example
+
+
+
+
+
+ This is Login Page
+
+ Testing OldLoginInterceptor & AdminInterceptor
+
+ See more info in the Console.
+
+
+
+
+```
+
+### 4.运行程序并测试效果
+
+测试用户访问 http://localhost:8080/ 的时候, **LogInterceptor**记录相关信息(页面地址,访问时间),并计算 **Web服务器**处理请求的时间。另外,页面会被渲染成 `test.html`。
+
+当用户访问 http://localhost:8080/admin/oldLogin 也就是旧的登录页面(不再使用)时, **OldLoginInterceptor**将请求重定向 http://localhost:8080/admin/login 页面会被渲染成正常的登录页面 `login.html`。
+
+**注意看控制台打印出的信息。**
+
+### 5.总结
+
+首先介绍了 Interceptor 的一些概念,然后通过一个简单的小案例走了一遍自定义实现 Interceptor 的过程。
+
+代办:
+
+1. Filter 和 Interceptor 执行顺序分析;
+2. Spring Boot 实现监听器;
+3. Filter、Interceptor、Listener对比分析;
+
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-filter-interceptor
\ No newline at end of file
diff --git a/docs/basis/springboot-jpa-lianbiao.md b/docs/basis/springboot-jpa-lianbiao.md
new file mode 100644
index 0000000..8e5ac19
--- /dev/null
+++ b/docs/basis/springboot-jpa-lianbiao.md
@@ -0,0 +1,160 @@
+# JPA 连表查询和分页
+
+对于连表查询,在 JPA 中还是非常常见的,由于 JPA 可以在 respository 层自定义 SQL 语句,所以通过自定义 SQL 语句的方式实现连表还是挺简单。这篇文章是在上一篇[入门 JPA](./springboot-jpa.md)的文章的基础上写的,不了解 JPA 的可以先看上一篇文章。
+
+在[上一节](./springboot-jpa.md)的基础上我们新建了两个实体类,如下:
+
+## 相关实体类创建
+
+`Company.java`
+
+```java
+@Entity
+@Data
+@NoArgsConstructor
+public class Company {
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+ @Column(unique = true)
+ private String companyName;
+ private String description;
+
+ public Company(String name, String description) {
+ this.companyName = name;
+ this.description = description;
+ }
+}
+```
+
+`School.java`
+
+```java
+@Entity
+@Data
+@NoArgsConstructor
+@AllArgsConstructor
+public class School {
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+ @Column(unique = true)
+ private String name;
+ private String description;
+}
+```
+
+## 自定义 SQL语句实现连表查询
+
+假如我们当前要通过 person 表的 id 来查询 Person 的话,我们知道 Person 的信息一共分布在`Company`、`School`、`Person`这三张表中,所以,我们如果要把 Person 的信息都查询出来的话是需要进行连表查询的。
+
+首先我们需要创建一个包含我们需要的 Person 信息的 DTO 对象,我们简单第将其命名为 `UserDTO`,用于保存和传输我们想要的信息。
+
+```java
+@Data
+@NoArgsConstructor
+@Builder(toBuilder = true)
+@AllArgsConstructor
+public class UserDTO {
+ private String name;
+ private int age;
+ private String companyName;
+ private String schoolName;
+}
+```
+
+下面我们就来写一个方法查询出 Person 的基本信息。
+
+```java
+ /**
+ * 连表查询
+ */
+ @Query(value = "select new github.snailclimb.jpademo.model.dto.UserDTO(p.name,p.age,c.companyName,s.name) " +
+ "from Person p left join Company c on p.companyId=c.id " +
+ "left join School s on p.schoolId=s.id " +
+ "where p.id=:personId")
+ Optional getUserInformation(@Param("personId") Long personId);
+```
+
+可以看出上面的 sql 语句和我们平时写的没啥区别,差别比较大的就是里面有一个 new 对象的操作。
+
+## 自定义 SQL 语句连表查询并实现分页操作
+
+假如我们要查询当前所有的人员信息并实现分页的话,你可以按照下面这种方式来做。可以看到,为了实现分页,我们在`@Query`注解中还添加了 **countQuery** 属性。
+
+```java
+@Query(value = "select new github.snailclimb.jpademo.model.dto.UserDTO(p.name,p.age,c.companyName,s.name) " +
+ "from Person p left join Company c on p.companyId=c.id " +
+ "left join School s on p.schoolId=s.id ",
+ countQuery = "select count(p.id) " +
+ "from Person p left join Company c on p.companyId=c.id " +
+ "left join School s on p.schoolId=s.id ")
+Page getUserInformationList(Pageable pageable);
+```
+
+实际使用:
+
+```java
+//分页选项
+PageRequest pageRequest = PageRequest.of(0, 3, Sort.Direction.DESC, "age");
+Page userInformationList = personRepository.getUserInformationList(pageRequest);
+//查询结果总数
+System.out.println(userInformationList.getTotalElements());// 6
+//按照当前分页大小,总页数
+System.out.println(userInformationList.getTotalPages());// 2
+System.out.println(userInformationList.getContent());
+```
+
+## 加餐:自定以SQL语句的其他用法
+
+下面我只介绍两种比较常用的:
+
+1. IN 查询
+2. BETWEEN 查询
+
+当然,还有很多用法需要大家自己去实践了。
+
+### IN 查询
+
+ 在 sql 语句中加入我们需要筛选出符合几个条件中的一个的情况下,可以使用 IN 查询,对应到 JPA 中也非常简单。比如下面的方法就实现了,根据名字过滤需要的人员信息。
+
+```java
+@Query(value = "select new github.snailclimb.jpademo.model.dto.UserDTO(p.name,p.age,c.companyName,s.name) " +
+ "from Person p left join Company c on p.companyId=c.id " +
+ "left join School s on p.schoolId=s.id " +
+ "where p.name IN :peopleList")
+List filterUserInfo(List peopleList);
+```
+
+实际使用:
+
+```java
+List personList=new ArrayList<>(Arrays.asList("person1","person2"));
+List userDTOS = personRepository.filterUserInfo(personList);
+```
+
+### BETWEEN 查询
+
+查询满足某个范围的值。比如下面的方法就实现查询满足某个年龄范围的人员的信息。
+
+```java
+ @Query(value = "select new github.snailclimb.jpademo.model.dto.UserDTO(p.name,p.age,c.companyName,s.name) " +
+ "from Person p left join Company c on p.companyId=c.id " +
+ "left join School s on p.schoolId=s.id " +
+ "where p.age between :small and :big")
+ List filterUserInfoByAge(int small,int big);
+```
+
+实际使用:
+
+```java
+List userDTOS = personRepository.filterUserInfoByAge(19,20);
+```
+
+## 总结
+
+本节我们主要学习了下面几个知识点:
+
+1. 自定义 SQL 语句实现连表查询;
+2. 自定义 SQL 语句连表查询并实现分页操作;
+3. 条件查询:IN 查询,BETWEEN查询。
diff --git a/docs/basis/springboot-jpa.md b/docs/basis/springboot-jpa.md
new file mode 100644
index 0000000..de4d8c3
--- /dev/null
+++ b/docs/basis/springboot-jpa.md
@@ -0,0 +1,348 @@
+# 一文搞懂如何在 Spring Boot 中正确使用 JPA
+
+JPA 这部分内容上手很容易,但是涉及到的东西还是挺多的,网上大部分关于 JPA 的资料都不是特别齐全,大部分用的版本也是比较落后的。另外,我下面讲到了的内容也不可能涵盖所有 JPA 相关内容,我只是把自己觉得比较重要的知识点总结在了下面。我自己也是参考着官方文档写的,[官方文档](https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#reference)非常详细了,非常推荐阅读一下。这篇文章可以帮助对 JPA 不了解或者不太熟悉的人来在实际项目中正确使用 JPA。
+
+项目代码基于 Spring Boot 最新的 2.1.9.RELEASE 版本构建(截止到这篇文章写完),另外,新建项目就不多说了,前面的文章已经很详细介绍过。
+
+## 1.相关依赖
+
+我们需要下面这些依赖支持我们完成这部分内容的学习:
+
+```xml
+
+
+ org.springframework.boot
+ spring-boot-starter-web
+
+
+ org.springframework.boot
+ spring-boot-starter-data-jpa
+
+
+ mysql
+ mysql-connector-java
+ runtime
+
+
+ org.projectlombok
+ lombok
+ true
+
+
+ org.springframework.boot
+ spring-boot-starter-test
+ test
+
+
+```
+
+## 2.配置数据库连接信息和JPA配置
+
+由于使用的是 h2 内存数据库,所以你直接运行项目数据库就会自动创建好。
+
+下面的配置中需要单独说一下 `spring.jpa.hibernate.ddl-auto=create`这个配置选项。
+
+这个属性常用的选项有四种:
+
+1. `create`:每次重新启动项目都会重新创新表结构,会导致数据丢失
+2. `create-drop`:每次启动项目创建表结构,关闭项目删除表结构
+3. `update`:每次启动项目会更新表结构
+4. `validate`:验证表结构,不对数据库进行任何更改
+
+但是,**一定要不要在生产环境使用 ddl 自动生成表结构,一般推荐手写 SQL 语句配合 Flyway 来做这些事情。**
+
+```properties
+# 数据库url地址
+spring.datasource.url=jdbc:h2:mem:jpa-demo
+spring.datasource.username=root
+spring.datasource.password=123456
+spring.datasource.platform=h2
+spring.datasource.driverClassName =org.h2.Driver
+
+spring.jpa.properties.hibernate.enable_lazy_load_no_trans=true
+# 打印出 sql 语句
+spring.jpa.show-sql=true
+spring.jpa.hibernate.ddl-auto=update
+spring.jpa.open-in-view=false
+server.port=8080
+#H2控制台
+spring.h2.console.enabled=true
+
+```
+
+## 3.实体类
+
+我们为这个类添加了 `@Entity` 注解代表它是数据库持久化类,还配置了主键 id。
+
+```java
+import lombok.Data;
+import lombok.NoArgsConstructor;
+
+import javax.persistence.Column;
+import javax.persistence.Entity;
+import javax.persistence.GeneratedValue;
+import javax.persistence.GenerationType;
+import javax.persistence.Id;
+
+@Entity
+@Data
+@NoArgsConstructor
+public class Person {
+
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+ @Column(unique = true)
+ private String name;
+ private Integer age;
+
+ public Person(String name, Integer age) {
+ this.name = name;
+ this.age = age;
+ }
+
+}
+```
+
+如何检验你是否正确完成了上面 3 步?很简单,运行项目,查看数据如果发现控制台打印出创建表的 sql 语句,并且数据库中表真的被创建出来的话,说明你成功完成前面 3 步。
+
+控制台打印出来的 sql 语句类似下面这样:
+
+```sql
+drop table if exists person
+CREATE TABLE `person` (
+ `id` bigint(20) NOT NULL AUTO_INCREMENT,
+ `age` int(11) DEFAULT NULL,
+ `name` varchar(255) DEFAULT NULL,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+alter table person add constraint UK_p0wr4vfyr2lyifm8avi67mqw5 unique (name)
+```
+
+## 4.创建操作数据库的 Repository 接口
+
+```java
+@Repository
+public interface PersonRepository extends JpaRepository {
+}
+```
+
+首先这个接口加了 `@Repository` 注解,代表它和数据库操作有关。另外,它继承了 `JpaRepository`接口,而`JpaRepository`长这样:
+
+```java
+
+@NoRepositoryBean
+public interface JpaRepository extends PagingAndSortingRepository, QueryByExampleExecutor {
+ List findAll();
+
+ List findAll(Sort var1);
+
+ List findAllById(Iterable var1);
+
+ List saveAll(Iterable var1);
+
+ void flush();
+
+ S saveAndFlush(S var1);
+
+ void deleteInBatch(Iterable var1);
+
+ void deleteAllInBatch();
+
+ T getOne(ID var1);
+
+ List findAll(Example var1);
+
+ List findAll(Example var1, Sort var2);
+}
+```
+
+这表明我们只要继承了` JpaRepository` 就具有了 JPA 为我们提供好的增删改查、分页查询以及根据条件查询等方法。
+
+### 4.1 JPA 自带方法实战
+
+#### 1) 增删改查
+
+**1.保存用户到数据库**
+
+```java
+ Person person = new Person("SnailClimb", 23);
+ personRepository.save(person);
+```
+
+`save()`方法对应 sql 语句就是:`insert into person (age, name) values (23,"snailclimb")`
+
+**2.根据 id 查找用户**
+
+```java
+ Optional personOptional = personRepository.findById(id);
+```
+
+`findById()`方法对应 sql 语句就是:`select * from person p where p.id = id`
+
+**3.根据 id 删除用户**
+
+```java
+ personRepository.deleteById(id);
+```
+
+`deleteById()`方法对应 sql 语句就是:`delete from person where id=id`
+
+**4.更新用户**
+
+更新操作也要通过 `save()`方法来实现,比如:
+
+```java
+ Person person = new Person("SnailClimb", 23);
+ Person savedPerson = personRepository.save(person);
+ // 更新 person 对象的姓名
+ savedPerson.setName("UpdatedName");
+ personRepository.save(savedPerson);
+```
+
+在这里 `save()`方法相当于 sql 语句:`update person set name="UpdatedName" where id=id`
+
+#### 2) 带条件的查询
+
+下面这些方法是我们根据 JPA 提供的语法自定义的,你需要将下面这些方法写到 `PersonRepository` 中。
+
+假如我们想要根据 Name 来查找 Person ,你可以这样:
+
+```java
+ Optional findByName(String name);
+```
+
+如果你想要找到年龄大于某个值的人,你可以这样:
+
+```java
+ List findByAgeGreaterThan(int age);
+```
+
+### 4.2 自定义 SQL 语句实战
+
+很多时候我们自定义 sql 语句会非常有用。
+
+根据 name 来查找 Person:
+
+```java
+ @Query("select p from Person p where p.name = :name")
+ Optional findByNameCustomeQuery(@Param("name") String name);
+```
+
+Person 部分属性查询,避免 `select *`操作:
+
+```java
+ @Query("select p.name from Person p where p.id = :id")
+ String findPersonNameById(@Param("id") Long id);
+```
+
+根据 id 更新Person name:
+
+```java
+
+ @Modifying
+ @Query("update Person p set p.name = ?1 where p.id = ?2")
+ void updatePersonNameById(String name, Long id);
+```
+
+### 4.3 创建异步方法
+
+如果我们需要创建异步方法的话,也比较方便。
+
+异步方法在调用时立即返回,然后会被提交给`TaskExecutor`执行。当然你也可以选择得出结果后才返回给客户端。如果对 Spring Boot 异步编程感兴趣的话可以看这篇文章:[《新手也能看懂的 SpringBoot 异步编程指南》](https://snailclimb.gitee.io/springboot-guide/#/./docs/advanced/springboot-async) 。
+
+```java
+@Async
+Future findByName(String name);
+
+@Async
+CompletableFuture findByName(String name);
+```
+
+## 5.测试类和源代码地址
+
+测试类:
+
+```java
+
+@SpringBootTest
+@RunWith(SpringRunner.class)
+public class PersonRepositoryTest {
+ @Autowired
+ private PersonRepository personRepository;
+ private Long id;
+
+ /**
+ * 保存person到数据库
+ */
+ @Before
+ public void setUp() {
+ assertNotNull(personRepository);
+ Person person = new Person("SnailClimb", 23);
+ Person savedPerson = personRepository.saveAndFlush(person);// 更新 person 对象的姓名
+ savedPerson.setName("UpdatedName");
+ personRepository.save(savedPerson);
+
+ id = savedPerson.getId();
+ }
+
+ /**
+ * 使用 JPA 自带的方法查找 person
+ */
+ @Test
+ public void should_get_person() {
+ Optional personOptional = personRepository.findById(id);
+ assertTrue(personOptional.isPresent());
+ assertEquals("SnailClimb", personOptional.get().getName());
+ assertEquals(Integer.valueOf(23), personOptional.get().getAge());
+
+ List personList = personRepository.findByAgeGreaterThan(18);
+ assertEquals(1, personList.size());
+ // 清空数据库
+ personRepository.deleteAll();
+ }
+
+ /**
+ * 自定义 query sql 查询语句查找 person
+ */
+
+ @Test
+ public void should_get_person_use_custom_query() {
+ // 查找所有字段
+ Optional personOptional = personRepository.findByNameCustomeQuery("SnailClimb");
+ assertTrue(personOptional.isPresent());
+ assertEquals(Integer.valueOf(23), personOptional.get().getAge());
+ // 查找部分字段
+ String personName = personRepository.findPersonNameById(id);
+ assertEquals("SnailClimb", personName);
+ System.out.println(id);
+ // 更新
+ personRepository.updatePersonNameById("UpdatedName", id);
+ Optional updatedName = personRepository.findByNameCustomeQuery("UpdatedName");
+ assertTrue(updatedName.isPresent());
+ // 清空数据库
+ personRepository.deleteAll();
+ }
+
+}
+```
+
+源代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/jpa-demo
+
+## 6. 总结
+
+本文主要介绍了 JPA 的基本用法:
+
+1. 使用 JPA 自带的方法进行增删改查以及条件查询。
+
+2. 自定义 SQL 语句进行查询或者更新数据库。
+
+3. 创建异步的方法。
+
+
+
+在下一篇关于 JPA 的文章中我会介绍到非常重要的两个知识点:
+
+1. 基本分页功能实现
+2. 多表联合查询以及多表联合查询下的分页功能实现。
+
diff --git a/md/springboot-mybatis-mutipledatasource.md b/docs/basis/springboot-mybatis-mutipledatasource.md
similarity index 100%
rename from md/springboot-mybatis-mutipledatasource.md
rename to docs/basis/springboot-mybatis-mutipledatasource.md
diff --git a/md/springboot-mybatis.md b/docs/basis/springboot-mybatis.md
similarity index 98%
rename from md/springboot-mybatis.md
rename to docs/basis/springboot-mybatis.md
index 6c14ea4..1955c8c 100644
--- a/md/springboot-mybatis.md
+++ b/docs/basis/springboot-mybatis.md
@@ -35,13 +35,9 @@ SpringBoot 整合 Mybatis 有两种常用的方式,一种就是我们常见的
- 数据库:MySQL
- SpringBoot版本:2.1.0
-
-
### 1.2 创建工程
-创建一个基本的 SpringBoot 项目,我这里就不多说这方面问题了,具体可以参考下面这篇文章:
-
-[https://blog.csdn.net/qq_34337272/article/details/79563606](https://blog.csdn.net/qq_34337272/article/details/79563606)
+创建一个基本的 SpringBoot 项目,我这里就不多说这方面问题了,具体可以参考前面的文章。
### 1.3 创建数据库和 user 用户表
@@ -90,7 +86,7 @@ CREATE TABLE `user` (
test
-```
+```
### 1.5 配置 application.properties
@@ -102,7 +98,7 @@ spring.datasource.url=jdbc:mysql://127.0.0.1:3306/erp?useUnicode=true&characterE
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
-```
+```
注意:我们使用的 mysql-connector-java 8+ ,JDBC 连接到mysql-connector-java 6+以上的需要指定时区 `serverTimezone=GMT%2B8`。另外我们之前使用配置 Mysql数据连接是一般是这样指定`driver-class-name=com.mysql.jdbc.Driver`,但是现在不可以必须为 否则控制台下面的异常:
@@ -337,3 +333,4 @@ public interface UserDao {
+代码地址:https://github.com/Snailclimb/springboot-guide/tree/master/source-code/basis/springboot-mybatis
\ No newline at end of file
diff --git a/docs/basis/sringboot-restful-web-service.md b/docs/basis/sringboot-restful-web-service.md
new file mode 100644
index 0000000..b211593
--- /dev/null
+++ b/docs/basis/sringboot-restful-web-service.md
@@ -0,0 +1,124 @@
+### RESTful Web 服务介绍
+
+本节我们将开发一个简单的 RESTful Web 服务。
+
+ RESTful Web 服务与传统的 MVC 开发一个关键区别是返回给客户端的内容的创建方式:**传统的 MVC 模式开发会直接返回给客户端一个视图,但是 RESTful Web 服务一般会将返回的数据以 JSON 的形式返回,这也就是现在所推崇的前后端分离开发。**
+
+为了节省时间,本篇内容的代码是在 **[Spring Boot 版 Hello World & Spring Boot 项目结构分析](https://snailclimb.gitee.io/springboot-guide/#/./start/springboot-hello-world)** 基础上进行开发的。
+
+### 内容概览
+
+通过下面的内容你将学习到下面这些东西:
+
+1. Lombok 优化代码利器
+2. `@RestController`
+3. `@RequestParam`以及`@Pathvairable`
+4. `@RequestMapping`、` @GetMapping`......
+5. `Responsity`
+
+### 下载 Lombok 优化代码利器
+
+因为本次开发用到了 Lombok 这个简化 Java 代码的工具,所以我们需要在 pom.xml 中添加相关依赖。如果对 Lombok 不熟悉的话,我强烈建议你去了解一下,可以参考这篇文章:[《十分钟搞懂Java效率工具Lombok使用与原理》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=1381785723&lang=zh_CN#rd)
+
+```xml
+
+ org.projectlombok
+ lombok
+ 1.18.10
+
+```
+
+并且你需要下载 IDEA 中支持 lombok 的插件:
+
+
+
+### RESTful Web 服务开发
+
+假如我们有一个书架,上面放了很多书。为此,我们需要新建一个 `Book` 实体类。
+
+`com.example.helloworld.entity`
+
+```java
+/**
+ * @author shuang.kou
+ */
+@Data
+public class Book {
+ private String name;
+ private String description;
+}
+```
+
+我们还需要一个控制器对书架上进行添加、查找以及查看。为此,我们需要新建一个 `BookController` 。
+
+```java
+import com.example.helloworld.entity.Book;
+import org.springframework.http.ResponseEntity;
+import org.springframework.web.bind.annotation.DeleteMapping;
+import org.springframework.web.bind.annotation.GetMapping;
+import org.springframework.web.bind.annotation.PathVariable;
+import org.springframework.web.bind.annotation.PostMapping;
+import org.springframework.web.bind.annotation.RequestBody;
+import org.springframework.web.bind.annotation.RequestParam;
+import org.springframework.web.bind.annotation.RestController;
+
+import java.util.ArrayList;
+import java.util.List;
+import java.util.stream.Collectors;
+
+@RestController
+@RequestMapping("/api")
+public class BookController {
+
+ private List books = new ArrayList<>();
+
+ @PostMapping("/book")
+ public ResponseEntity> addBook(@RequestBody Book book) {
+ books.add(book);
+ return ResponseEntity.ok(books);
+ }
+
+ @DeleteMapping("/book/{id}")
+ public ResponseEntity deleteBookById(@PathVariable("id") int id) {
+ books.remove(id);
+ return ResponseEntity.ok(books);
+ }
+
+ @GetMapping("/book")
+ public ResponseEntity getBookByName(@RequestParam("name") String name) {
+ List results = books.stream().filter(book -> book.getName().equals(name)).collect(Collectors.toList());
+ return ResponseEntity.ok(results);
+ }
+}
+```
+
+1. `@RestController` **将返回的对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中。**绝大部分情况下都是直接以 JSON 形式返回给客户端,很少的情况下才会以 XML 形式返回。转换成 XML 形式还需要额为的工作,上面代码中演示的直接就是将对象数据直接以 JSON 形式写入 HTTP 响应(Response)中。关于`@Controller`和`@RestController` 的对比,我会在下一篇文章中单独介绍到(`@Controller` +`@ResponseBody`= `@RestController`)。
+2. `@RequestMapping` :上面的示例中没有指定 GET 与 PUT、POST 等,因为**`@RequestMapping`默认映射所有HTTP Action**,你可以使用`@RequestMapping(method=ActionType)`来缩小这个映射。
+3. `@PostMapping`实际上就等价于 `@RequestMapping(method = RequestMethod.POST)`,同样的 ` @DeleteMapping` ,`@GetMapping`也都一样,常用的 HTTP Action 都有一个这种形式的注解所对应。
+4. `@PathVariable` :取url地址中的参数。`@RequestParam ` url的查询参数值。
+5. `@RequestBody`:可以**将 *HttpRequest* body 中的 JSON 类型数据反序列化为合适的 Java 类型。**
+6. `ResponseEntity`: **表示整个HTTP Response:状态码,标头和正文内容**。我们可以使用它来自定义HTTP Response 的内容。
+
+### 运行项目并测试效果
+
+这里我们又用到了开发 Web 服务必备的 **Postman** 来帮助我们发请求测试。
+
+**1.使用 post 请求给书架增加书籍**
+
+这里我模拟添加了 3 本书籍。
+
+
+
+**2.使用 Delete 请求删除书籍**
+
+这个就不截图了,可以参考上面发Post请求的方式来进行,请求的 url: [localhost:8333/api/book/1](localhost:8333/api/book/1)。
+
+**3.使用 Get 请求根据书名获取特定的书籍**
+
+请求的 url:[localhost:8333/api/book?name=book1](localhost:8333/api/book?name=book1)
+
+### 总结
+
+通过本文我们需到了使用 Lombok 来优化 Java 代码,以及一些开发 RestFul Web 服务常用的注解:`@RestController` 、`@RequestMapping`、`@PostMapping`、`@PathVariable`、`@RequestParam`、`@RequestBody`以及和HTTP Response 有关的 `Responsity`类。关于这些知识点的用法,我在上面都有介绍到,更多用法还需要自己去查阅相关文档。
+
+代码地址:(建议自己手敲一遍!!!)
\ No newline at end of file
diff --git a/docs/basis/swagger.md b/docs/basis/swagger.md
new file mode 100644
index 0000000..3b83260
--- /dev/null
+++ b/docs/basis/swagger.md
@@ -0,0 +1,216 @@
+> 若图片无法显示,👉:[Swagger 官方 Starter 配上这个增强方案是真的香!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247496557&idx=1&sn=77100461596999128e5d721e07f7fe3d&chksm=cea1bca6f9d635b01f45a68a6034faf76c2f5a54223b23b2dc5a0bdb15c7b7bfea0a20a76c1a&token=1835542145&lang=zh_CN#rd)
+
+这篇文章,我就简单给大家聊聊项目必备的 Swagger 该怎么玩。
+
+**何为 Swagger ?** 简单来说,Swagger 就是一套基于 OpenAPI 规范构建的开源工具,可以帮助我们设计、构建、记录以及使用 Rest API。
+
+**为何要用 Swagger ?** 前后端分离的情况下,一份 Rest API 文档将会极大的提高我们的工作效率。前端小伙伴只需要对照着 Rest API 文档就可以搞清楚一个接口需要的参数以及返回值。通过 Swagger 我们只需要少量注解即可生成一份自带 UI 界面的 Rest API 文档,不需要我们后端手动编写。并且,通过 UI 界面,我们还可以直接对相应的 API 进行调试,省去了准备复杂的调用参数的过程。
+
+这篇文章的主要内容:
+
+1. SpringBoot 项目中如何使用?
+2. Spring Security 项目中如何使用?
+3. 使用 knife4j 增强 Swagger
+
+以下演示所用代码,你可以在这个仓库找到:[https://github.com/Snailclimb/spring-security-jwt-guide](https://github.com/Snailclimb/spring-security-jwt-guide) (从零入门 !Spring Security With JWT(含权限验证)后端部分代码)
+
+## SpringBoot 项目中如何使用?
+
+Swagger3.0 官方已经有了自己的 Spring Boot Starter,只需要添加一个 jar 包即可(SpringBoot 版本 2.3.6.RELEASE)。。
+
+```xml
+
+
+ io.springfox
+ springfox-boot-starter
+ 3.0.0
+
+```
+
+什么都不用配置!直接在浏览器中访问 :[http://ip:port/swagger-ui/](http://ip:port/swagger-ui/) 即可。
+
+
+
+## Spring Security 项目中如何使用?
+
+如果你的项目使用了 Spring Security 做权限认证的话,你需要为 Swagger 相关 url 添加白名单。
+
+```java
+ String[] SWAGGER_WHITELIST = {
+ "/swagger-ui.html",
+ "/swagger-ui/*",
+ "/swagger-resources/**",
+ "/v2/api-docs",
+ "/v3/api-docs",
+ "/webjars/**"
+ };
+
+ @Override
+ protected void configure(HttpSecurity http) throws Exception {
+ http.cors().and()
+ // 禁用 CSRF
+ .csrf().disable()
+ .authorizeRequests()
+ // swagger
+ .antMatchers(SWAGGER_WHITELIST).permitAll()
+ ......
+ }
+```
+
+另外,某些请求需要认证之后才可以访问,为此,我们需要对 Swagger 做一些简单的配置。
+
+配置的方式非常简单,我提供两种不同的方式给小伙伴们。
+
+1. 登录后自动为请求添加 token。
+2. 为请求的 Header 添加一个认证参数,每次请求的时候,我们需要手动输入 token。
+
+### 登录后自动为请求添加 token
+
+通过这种方式我们只需要授权一次即可使用所有需要授权的接口。
+
+
+
+```java
+/**
+ * @author shuang.kou
+ * @description swagger 相关配置
+ */
+@Configuration
+public class SwaggerConfig {
+
+ @Bean
+ public Docket createRestApi() {
+ return new Docket(DocumentationType.SWAGGER_2)
+ .apiInfo(apiInfo())
+ .select()
+ .apis(RequestHandlerSelectors.basePackage("github.javaguide.springsecurityjwtguide"))
+ .paths(PathSelectors.any())
+ .build()
+ .securityContexts(securityContext())
+ .securitySchemes(securitySchemes());
+ }
+
+ private List securitySchemes() {
+ return Collections.singletonList(new ApiKey("JWT", SecurityConstants.TOKEN_HEADER, "header"));
+ }
+
+ private List securityContext() {
+ SecurityContext securityContext = SecurityContext.builder()
+ .securityReferences(defaultAuth())
+ .build();
+ return Collections.singletonList(securityContext);
+ }
+
+ List defaultAuth() {
+ AuthorizationScope authorizationScope
+ = new AuthorizationScope("global", "accessEverything");
+ AuthorizationScope[] authorizationScopes = new AuthorizationScope[1];
+ authorizationScopes[0] = authorizationScope;
+ return Collections.singletonList(new SecurityReference("JWT", authorizationScopes));
+ }
+
+ private ApiInfo apiInfo() {
+ return new ApiInfoBuilder()
+ .title("Spring Security JWT Guide")
+ .build();
+ }
+}
+```
+
+**未登录前:**
+
+
+
+**登录后:**
+
+
+
+### 为请求的 Header 添加一个认证参数
+
+每次请求的时候,我们需要手动输入 token 到指定位置。
+
+
+
+```java
+@Configuration
+public class SwaggerConfig {
+
+ @Bean
+ public Docket createRestApi() {
+ return new Docket(DocumentationType.SWAGGER_2)
+ .apiInfo(apiInfo())
+ .select()
+ .apis(RequestHandlerSelectors.basePackage("github.javaguide.springsecurityjwtguide"))
+ .paths(PathSelectors.any())
+ .build()
+ .globalRequestParameters(authorizationParameter())
+ .securitySchemes(securitySchemes());
+ }
+
+ private List securitySchemes() {
+ return Collections.singletonList(new ApiKey("JWT", SecurityConstants.TOKEN_HEADER, "header"));
+ }
+
+ private List authorizationParameter() {
+ RequestParameterBuilder tokenBuilder = new RequestParameterBuilder();
+ tokenBuilder
+ .name("Authorization")
+ .description("JWT")
+ .required(false)
+ .in("header")
+ .accepts(Collections.singleton(MediaType.APPLICATION_JSON))
+ .build();
+ return Collections.singletonList(tokenBuilder.build());
+ }
+
+ private ApiInfo apiInfo() {
+ return new ApiInfoBuilder()
+ .title("Spring Security JWT Guide")
+ .build();
+ }
+}
+```
+
+## 使用 knife4j 增强 Swagger
+
+根据官网介绍,knife4j 是为 Java MVC 框架集成 Swagger 生成 Api 文档的增强解决方案。
+
+项目地址:[https://gitee.com/xiaoym/knife4j](https://gitee.com/xiaoym/knife4j) 。
+
+使用方式非常简单,添加到相关依赖即可(SpringBoot 版本 2.3.6.RELEASE)。
+
+```xml
+
+ com.github.xiaoymin
+ knife4j-spring-boot-starter
+ 3.0.2
+
+```
+
+完成之后,访问:[http://ip:port/doc.html](http://ip:port/doc.html) 即可。
+
+效果如下。可以看出,相比于 swagger 原生 ui 确实好看实用了很多。
+
+
+
+除了 UI 上的增强之外,knife4j 还提供了一些开箱即用的功能。
+
+比如:**搜索 API 接口** (`knife4j` 版本>2.0.1 )
+
+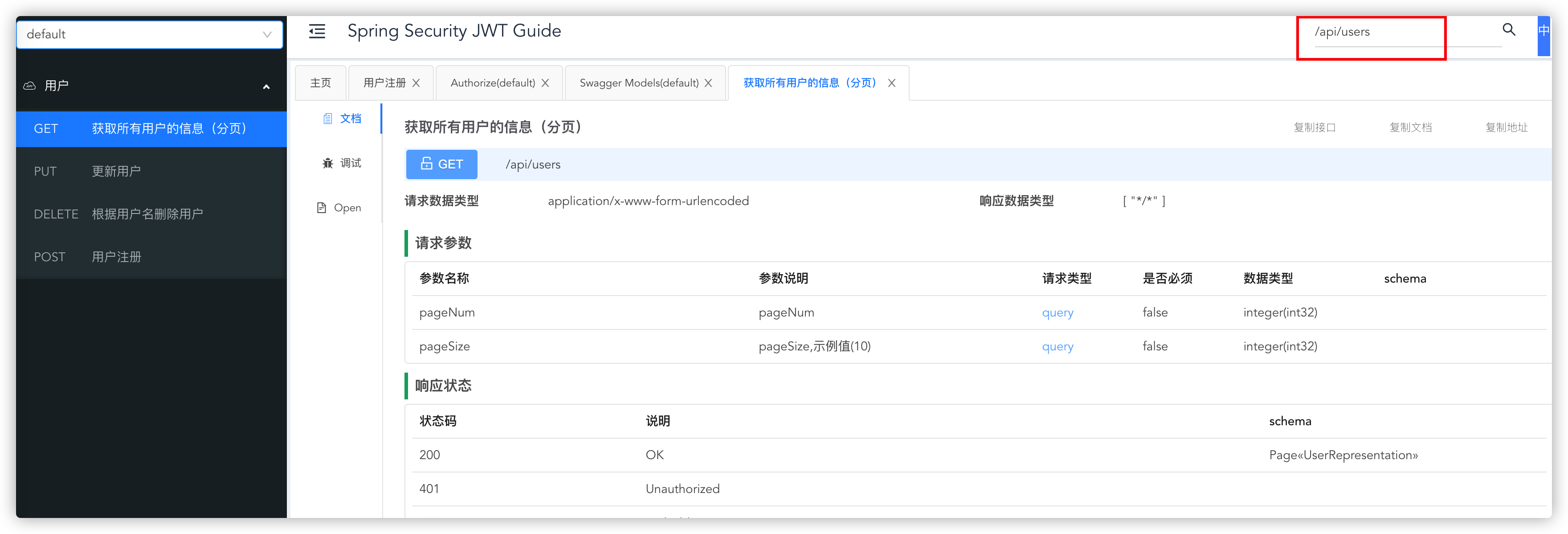
+
+再比如:**导出离线文档**
+
+通过 `Knife4j` 我们可以非常方便地导出 Swagger 文档 ,并且支持多种格式。
+
+> - markdown:导出当前逻辑分组下所有接口的 Markdown 格式的文档
+> - Html:导出当前逻辑分组下所有接口的 Html 格式的文档
+> - Word:导出当前逻辑分组下所有接口的 Word 格式的文档(自 2.0.5 版本开始)
+> - OpenAPI:导出当前逻辑分组下的原始 OpenAPI 的规范 json 结构(自 2.0.6 版本开始)
+> - PDF:未实现
+
+以 HTML 格式导出的效果图如下。
+
+
+
+还等什么?快去试试吧!
\ No newline at end of file
diff --git "a/docs/projects/SpringCloud\345\210\267\351\242\230\347\263\273\347\273\237.md" "b/docs/projects/SpringCloud\345\210\267\351\242\230\347\263\273\347\273\237.md"
new file mode 100644
index 0000000..2309eab
--- /dev/null
+++ "b/docs/projects/SpringCloud\345\210\267\351\242\230\347\263\273\347\273\237.md"
@@ -0,0 +1,121 @@
+> 推荐👍:
+> - [接近100K star 的 Java 学习/面试指南](https://github.com/Snailclimb/JavaGuide)
+> - [Github 95k+点赞的 Java 面试/学习手册.PDF](https://www.yuque.com/docs/share/f0c5ffbc-48b5-45f3-af66-2a5e6f212595)
+
+今天给小伙伴们推荐一个朋友开源的面试刷题系统。
+
+这篇文章我会从系统架构设计层面详解介绍这个开源项目,并且会把微服务常用的一些技术都介绍一下。即使你对这个项目不感兴趣,也能了解到很多微服务相关的知识。美滋滋!
+
+_昨晚肝了很久~原创不易,若有帮助,求赞求转发啊!_
+
+不得不说,这个刷题系统确实是有点东西,你真的值得拥有!首先,这是一个微服务的项目,其次这个系统涵盖了市面上常用的主流技术比如 SpringBoot、Spring Cloud 等等(后面会详细介绍)。
+
+不论是你想要学习分布式的技术,还是想找一个实战项目练手或者作为自己的项目经验,这个项目都非常适合你。
+
+另外,因为项目作者提供了详细的技术文档,所以你不用担心上手太难!
+
+
+
+## 效果图
+
+我们先来看看这个面试刷题系统的效果图。这里我们只展示的是这个系统的前端(微信小程序),后台管理系统这里就不展示了。
+
+
+
+可以看到,除了少部分地方的颜色搭配比较难看之外,页面整体 UI 还是比较美观的。
+
+## 技术栈
+
+再聊聊大家最关心的问题:“**这套系统的技术栈是什么样的呢?**”。
+
+这套系统采用了目前企业都在用的主流技术:SpringBoot(基础框架)、Spring Cloud(微服务)、MyBatis(ORM框架)、Redis(缓存)、MySql(关系型数据库)、MongoDB(NoSQL)、RabbitMQ(消息队列)、Elasticsearch(搜索引擎)。并且,这个系统是以 Docker 容器化的方式进行部署的。非常实用!
+
+## 系统架构设计
+
+了解了技术栈之后,那必然需要简单了解一下整个 **系统的架构设计** ,这是系统的灵魂所在了(图源:[PassJava 官方文档](http://jayh2018.gitee.io/passjava-learning/#/01.项目简介/2.项目微服务架构图 "PassJava官方文档"))。
+
+
+
+### 网关
+
+网关负责认证授权、限流、熔断、降级、请求分发、负载均衡等等操作。一般情况下,网关一般都会提供这些功能。
+
+这里使用的是 **Spring Cloud Gateway** 作为网关。Spring Cloud Gateway 是 Spring Cloud 官方推出的第二代网关框架,目的是取代 netflix 的 Zuul 网关。
+
+### 注册中心和配置中心
+
+注册中心和配置中心这块使用的是阿里巴巴开源的 **Nacos** 。Nacos 目前属于 Spring Cloud Alibaba 中的一员。主要用于发现、配置和管理微服务,类似于 Consul、Eureka。并且,提供了分布式配置管理功能。
+
+Nacos 的基本介绍如下(图源:[官网文档-什么是 Nacos](https://nacos.io/zh-cn/docs/what-is-nacos.html "官网文档-什么是 Nacos")):
+
+
+
+详解介绍一下 Nacos 在这个项目中提供的两个核心功能:
+
+- **注册中心** :API 网关通过注册中心实时获取到服务的路由地址,准确地将请求路由到各个服务。
+- **配置中心** :传统的配置方式需要重新启动服务。如果服务很多,则需要重启所有服务,非常不方便。通过 Nacos,我们可以动态配置服务。并且,Nacos 提供了一个简洁易用的 UI 帮助我们管理所有的服务和应用的配置。
+
+关于配置中心,我们这里再拓展一下,除了 Nacos ,还有 Apollo、SpringCloud Config、K8s ConfigMap 可供选择。
+
+### 分布式链路追踪
+
+> 不同于单体架构,在分布式架构下,请求需要在多个服务之间调用,排查问题会非常麻烦。我们需要分布式链路追踪系统来解决这个痛点。
+
+分布式链路追踪这块使用的是 Twitter 的 **Zipkin** ,并且结合了 **Spring Cloud Sleuth** 。
+
+Spring Cloud Sleuth 只是做一些链路追踪相关的数据记录,我们可以使用 Zipkin Server 来处理这些数据。
+
+相关阅读:[《40 张图看懂分布式追踪系统原理及实践》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247492112&idx=3&sn=4eb100f4ecef98a475d7f7650c993222&chksm=cea1addbf9d624cdc0e868d3b72edf40a7a6880218ecb1a9ddbac50423d20dceceb8dca804f4&token=2007747701&lang=zh_CN#rd) 。
+
+### 监控系统
+
+监控系统可以帮助我们监控应用程序的状态,并且能够在风险发生前告警。
+
+监控系统这块使用的是 **Prometheus + Grafana**。Prometheus 负责收集监控数据,Grafana 用于展示监控数据。我们直接将 Grafana 的数据源选择为 Prometheus 即可。
+
+关于监控系统更详细的技术选型,可以看这篇文章:[《监控系统选型看这一篇够了!选择 Prometheus 还是 Zabbix ?》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247490068&idx=2&sn=3ac42f6891fec8906230cc9e0ec28ba7&chksm=cea255dff9d5dcc9369c9c30eb55925cd16045d914cbfe194ea7d5630c3339630d731d654527&token=2007747701&lang=zh_CN#rd) 。
+
+### 消息队列
+
+我们知道,消息队列主要能为系统带来三点好处:
+
+1. **通过异步处理提高系统性能(减少响应所需时间)。**
+2. **削峰/限流**
+3. **降低系统耦合性。**
+
+常用的消息队列有:RabbitMQ(本系统所采用的方案)、Kafka、RocketMQ。
+
+### 缓存
+
+缓存这里使用的是 Redis ,老生常谈了,这里就不再多做介绍。
+
+另外, 为了保证缓存服务的高可用,我们使用 Redis 官方提供了一种 Redis 集群的解决方案 Redis Sentinel 来管理 Redis 集群。
+
+### 数据库
+
+数据库这里使用的是 MySQL ,并使用主从模式实现读写分离,以提高读性能。
+
+### 对象存储
+
+由于是分布式系统,传统的将文件上传到本机已经没办法满足我们的需求了。
+
+由于自己搭建分布式文件系统也比较麻烦,所以对象存储这里我们使用的是阿里云 OSS,它主要用于存储一些文件比如图片。
+
+### 快速开发脚手架
+
+另外,为了后台的快速搭建这里使用的是 **[renren-fast](https://gitee.com/renrenio/renren-fast "renren-fast")** 快速开发脚手架。使用这个脚手架配合上代码生成器 **[renren-generator](https://gitee.com/renrenio/renren-generator "renren-generator")** ,我们可以快速生成 70%左右的前后端代码。绝对是快速开发项目并交付以及接私活的利器了!
+
+我在之前的也推荐过这个脚手架,详情请看下面这两篇文章:
+
+1. [听说你要接私活?Guide 连夜整理了 5 个开源免费的 Java 项目快速开发脚手架。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247487002&idx=1&sn=e9db79f1bbd561b3ead1c9475f8fd7f5&chksm=cea241d1f9d5c8c72fa33764208a26a26de5d2d3e4ac2a6794e0792ba779bb11414b3fd506e3&token=2007747701&lang=zh_CN#rd)
+2. [解放双手,再来推荐 5 个 Java 项目开发快速开发脚手架!项目经验和私活都不愁了!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247487467&idx=1&sn=c2d2bd28918b58d8646f1441791aeaaf&chksm=cea24020f9d5c9364afc22013fac3266fabffcaa370f708434a6a304274c6b1d8bce235b7a24&token=2007747701&lang=zh_CN#rd)
+
+## 总结
+
+这篇文章我主要从架构设计层面分析了朋友开源的这个基于微服务的刷题系统。
+
+当然了,朋友使用微服务开发这个项目的主要目的也是为了自己实践微服务相关的知识,同时也是为了给需要微服务相关实战项目经验的小伙伴一个可以学习的项目。不然的话,直接用单体就完事了,完全可以支撑这个项目目前的并发量以及可预见的未来的并发量。
+
+- 项目地址:https://github.com/Jackson0714/PassJava-Platform
+- 文档地址:http://jayh2018.gitee.io/passjava-learning/#/
+
diff --git "a/docs/projects/kkFileView-SpringBoot\345\234\250\347\272\277\346\226\207\344\273\266\351\242\204\350\247\210\347\263\273\347\273\237.md" "b/docs/projects/kkFileView-SpringBoot\345\234\250\347\272\277\346\226\207\344\273\266\351\242\204\350\247\210\347\263\273\347\273\237.md"
new file mode 100644
index 0000000..19d09a0
--- /dev/null
+++ "b/docs/projects/kkFileView-SpringBoot\345\234\250\347\272\277\346\226\207\344\273\266\351\242\204\350\247\210\347\263\273\347\273\237.md"
@@ -0,0 +1,239 @@
+> 昨晚搭建环境都花了好一会时间,主要在浪费在了安装 openoffice 这个依赖环境上(_Mac 需要手动安装_)。
+>
+> 然后,又一步一步功能演示,记录,调试项目,并且简单研究了一下核心代码之后才把这篇文章写完。
+>
+> 另外,这篇文章我还会简单分析一下项目核心代码。
+>
+> _如果有帮助,欢迎点赞/再看鼓励,我会开心很久 ღ( ´・ᴗ・` )比心_
+
+## 项目介绍
+
+官方是这样介绍 kkFileView 的:
+
+> kkFileView 是使用 spring boot 打造文件文档在线预览项目解决方案,支持 doc、docx、ppt、pptx、xls、xlsx、zip、rar、mp4、mp3 以及众多类文本如 txt、html、xml、java、properties、sql、js、md、json、conf、ini、vue、php、py、bat、gitignore 等文件在线预览
+
+**简单来说 kkFileView 就是常见的文件类型的在线预览解决方案。**
+
+总的来说我觉得 kkFileView 是一个非常棒的开源项目,在线文件预览这个需求非常常见。感谢开源!
+
+下面, 我站在一个“上帝”的角度从多个维度来评价一下 kkFileView:
+
+1. 代码质量一般,有很多可以优化的地方比如:
+ - `Controller` 层代码嵌套太多逻辑
+ - 没有进行全局异常处理(_代码中是直接返回错误信息的 json 数据给前端,我并不推荐这样做_)
+ - 返回值不需要通过`ObjectMapper`转换为 JSON 格式(`ResponseEntity`+`@RestController` 就行了)
+ - ......
+2. 使用的公司比较多,说明项目整体功能还是比较稳定和成熟的!
+3. 代码整体逻辑还是比较清晰的,比较容易看懂,给作者们点个赞!
+
+## 环境搭建
+
+### 克隆项目
+
+通过以下命令即可将项目克隆到本地:
+
+```bash
+git clone https://gitee.com/kekingcn/file-online-preview.git
+```
+
+### 安装 OpenOffice
+
+office 类型的文件的预览依赖了 OpenOffice ,所以我们首先要安装 OpenOffice(Windows 下已内置,Linux 会自动安装,Mac OS 下需要手动安装)。
+
+下面演示一下如何在 Mac 上安装 OpenOffice。
+
+你可以通过以下命令安装最新版的 OpenOffice:
+
+```bash
+brew cask install openoffice
+```
+
+不过,这种方式下载可能会比较慢,你可以直接去官网下载 dmg 安装包。
+
+官方下载地址:[https://www.openoffice.org/download/](https://www.openoffice.org/download/)
+
+
+
+很多小伙伴就要问了:**OpenOffice 是什么呢?**
+
+[OpenOffice](https://www.openoffice.org/) 是 Apache 旗下的一款开源免费的文字处理软件,支持 Windows、Liunx、OS X 等主流操作系统。
+
+OpenOffice 和 Windows 下 office 办公软件有点类似,不过其实开源免费的。
+
+
+
+### 启动项目
+
+运行`FilePreviewApplication`的 main 方法,服务启动后,访问[http://localhost:8012/](http://localhost:8012/) 会看到如下界面,代表服务启动成功。
+
+
+
+## 使用
+
+我们首先上传了 3 个不同的类型的文件来分别演示一下图片、PDF、Word 文档的预览。
+
+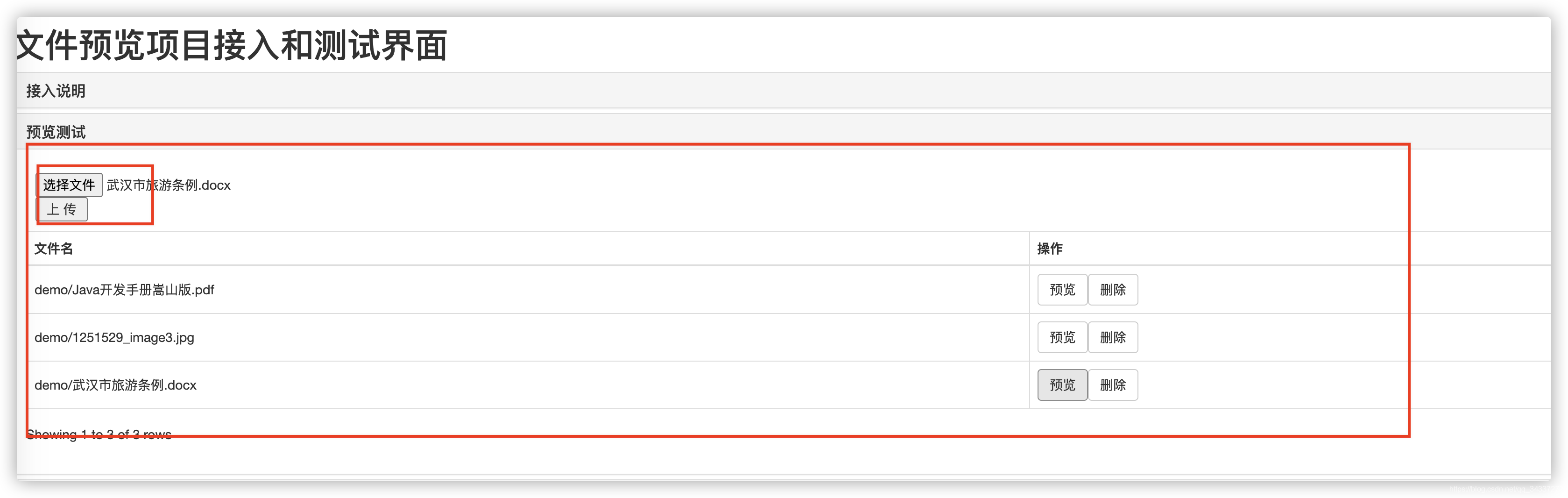
+
+### 图片的预览
+
+**kkFileView 支持 jpg,jpeg,png,gif 等多种格式图片的预览,还包括了翻转,缩放图片等操作。**
+
+图片的预览效果如下。
+
+
+
+### Word 文档的预览
+
+**kkFileView 支持 doc,docx 文档预览。**
+
+另外,根据 Word 大小以及网速问题, Word 预览提供了两种模式:
+
+- 每页 Word 转为图片预览
+- 整个 Word 文档转成 PDF,再预览 PDF。
+
+两种模式的适用场景如下
+
+- **图片预览** :Word 文件大(加载 PDF 速度比较慢)的情况。
+- **PDF 预览** :内网访问(加载 PDF 速度比较快)的情况。
+
+图片预览模式预览效果如下:
+
+
+
+PDF 预览模式预览效果如下:
+
+
+
+### PDF 文档的预览
+
+kkFileView 支持 PDF 文档预览。类似 Word 文档预览, PDF 预览提供了两种模式:
+
+- 每页 Word 转为图片预览
+- 整个 Word 文档转成 PDF,再预览 PDF。
+
+由于和 Word 文档的预览展示效果一致,这里就不放图片了。
+
+## 文件预览核心代码分析
+
+### API 层
+
+文件预览调用的接口是 `/onlinePreview` 。
+
+通过分析 `/onlinePreview` 接口我们发现, 后端接收到预览请求之后,会从 URL 和请求中筛选出自己需要的信息比如文件后缀、文件名。
+
+之后会调用`FilePreview`类 的 `filePreviewHandle()` 方法。`filePreviewHandle()` 方法是实现文件预览的核心方法。
+
+```java
+@RequestMapping(value = "/onlinePreview")
+public String onlinePreview(String url, Model model, HttpServletRequest req) {
+ FileAttribute fileAttribute = fileUtils.getFileAttribute(url);
+ req.setAttribute("fileKey", req.getParameter("fileKey"));
+ model.addAttribute("pdfDownloadDisable", ConfigConstants.getPdfDownloadDisable());
+ model.addAttribute("officePreviewType", req.getParameter("officePreviewType"));
+ FilePreview filePreview = previewFactory.get(fileAttribute);
+ logger.info("预览文件url:{},previewType:{}", url, fileAttribute.getType());
+ return filePreview.filePreviewHandle(url, model, fileAttribute);
+}
+```
+
+`FilePreview` 是文件预览接口,不同的文件类型的预览都实现了 `FilePreview` 接口,并实现了 `filePreviewHandle()` 方法。
+
+### 文件预览接口
+
+```java
+public interface FilePreview {
+ String filePreviewHandle(String url, Model model, FileAttribute fileAttribute);
+}
+```
+
+不同的文件类型的预览都实现了 `FilePreview` 接口,如下图所示。
+
+
+
+不同文件类型的预览都会实现 `FilePreview` 接口,然后重写`filePreviewHandle()`方法。比如: `OfficeFilePreviewImpl` 这个主要负责处理 office 文件的预览、`PdfFilePreviewImpl` 主要负责处理 pdf 文件的预览。
+
+### 文件预览具体实现分析
+
+下面我们以 office 文件的预览为入口来分析。
+
+首先要明确的是 excel 类型的预览是通过将 excel 文件转换为 HTML 实现的,其他类型 office 文件的预览是通过将文件转换为 PDF 或者是 图片的方式来预览的。
+
+举个例子。我们上传了一份名为 `武汉市文化市场管理办法.docx` 的 Word 文件并预览的话,`jodconverter-web/src/main/file` 路径下会生成两个相关文件,这两个文件分别对应了我们提到的 PDF 预览 和 图片预览这两种方式。
+
+- `武汉市文化市场管理办法.pdf`
+- 由 Word 文件所转化得到的一系列图片
+
+
+
+我们以一个名为 `武汉市文化市场管理办法.docx` 的文件来举例说明一下代码中是如何做的。
+
+通过分析代码, 我们定位到了 `OfficeFilePreviewImpl` 这个主要负责处理 office 文件预览的类。
+
+```java
+/**
+ * 处理office文件
+ */
+@Service
+public class OfficeFilePreviewImpl implements FilePreview {
+
+}
+```
+
+我们来简单分析一下 `OfficeFilePreviewImpl` 类中实现预览的核心方法是 `filePreviewHandle` 。
+
+> 说明:这部分代码的逻辑不够清晰,还可以抽方法优化以让人更容易读懂,感兴趣的小伙伴可以自己动手重构一下,然后去给作者提个 PR。
+
+```java
+ @Override
+ public String filePreviewHandle(String url, Model model, FileAttribute fileAttribute) {
+ // 1.获取预览类型(image/pdf/html),用户请求中传了officePreviewType参数就取参数的,没传取系统默认(image)
+ String officePreviewType = model.asMap().get("officePreviewType") == null ? ConfigConstants.getOfficePreviewType() : model.asMap().get("officePreviewType").toString();
+ // 2.获取 URL 地址
+ String baseUrl = BaseUrlFilter.getBaseUrl();// http://localhost:8012/
+ // 3.获取图片相关信息
+ String suffix=fileAttribute.getSuffix();//文件后缀如docx
+ String fileName=fileAttribute.getName();//文件名如:武汉市文化市场管理办法.docx
+ // 4. 判断是否为 html 格式预览也就是判断文件否为 excel
+ boolean isHtml = suffix.equalsIgnoreCase("xls") || suffix.equalsIgnoreCase("xlsx");
+ // 5. 将文件的后缀名更换为 .pdf 或者 .html(excel文件的情况)
+ String pdfName = fileName.substring(0, fileName.lastIndexOf(".") + 1) + (isHtml ? "html" : "pdf");
+ // 6. 转换后的文件输出的文件夹如 file-online-preview/jodconverter-web/src/main/file/武汉市文化市场管理办法.pdf)
+ String outFilePath = FILE_DIR + pdfName;
+ // 7 .判断之前是否已转换过,如果转换过,直接返回,否则执行转换
+ // 文件第一次被预览的时候会首先对文件进行缓存处理
+ if (!fileUtils.listConvertedFiles().containsKey(pdfName) || !ConfigConstants.isCacheEnabled()) {
+ String filePath;
+ // 下载文件
+ ReturnResponse response = downloadUtils.downLoad(fileAttribute, null);
+ if (0 != response.getCode()) {
+ model.addAttribute("fileType", suffix);
+ model.addAttribute("msg", response.getMsg());
+ return "fileNotSupported";
+ }
+ filePath = response.getContent();
+ if (StringUtils.hasText(outFilePath)) {
+ officeToPdf.openOfficeToPDF(filePath, outFilePath);
+ if (isHtml) {
+ // 对转换后的文件进行操作(改变编码方式)
+ fileUtils.doActionConvertedFile(outFilePath);
+ }
+ if (ConfigConstants.isCacheEnabled()) {
+ // 加入缓存
+ fileUtils.addConvertedFile(pdfName, fileUtils.getRelativePath(outFilePath));
+ }
+ }
+ }
+ // 8.根据预览类型officePreviewType,选择不同的预览方式
+ // 比如,如果预览类型officePreviewType为pdf则进行pdf方式预览
+ if (!isHtml && baseUrl != null && (OFFICE_PREVIEW_TYPE_IMAGE.equals(officePreviewType) || OFFICE_PREVIEW_TYPE_ALL_IMAGES.equals(officePreviewType))) {
+ return getPreviewType(model, fileAttribute, officePreviewType, baseUrl, pdfName, outFilePath, pdfUtils, OFFICE_PREVIEW_TYPE_IMAGE);
+ }
+ model.addAttribute("pdfUrl", pdfName);
+ return isHtml ? "html" : "pdf";
+ }
+
+```
+
+项目地址: [https://github.com/kekingcn/kkFileView](https://github.com/kekingcn/kkFileView) 。
+
+
diff --git "a/docs/projects/\344\270\200\344\270\252\345\237\272\344\272\216SpringBoot\347\232\204\345\234\250\347\272\277\350\200\203\350\257\225\347\263\273\347\273\237.md" "b/docs/projects/\344\270\200\344\270\252\345\237\272\344\272\216SpringBoot\347\232\204\345\234\250\347\272\277\350\200\203\350\257\225\347\263\273\347\273\237.md"
new file mode 100644
index 0000000..0c92bf0
--- /dev/null
+++ "b/docs/projects/\344\270\200\344\270\252\345\237\272\344\272\216SpringBoot\347\232\204\345\234\250\347\272\277\350\200\203\350\257\225\347\263\273\347\273\237.md"
@@ -0,0 +1,174 @@
+[大家好!我是 Guide 哥,Java 后端开发。一个会一点前端,喜欢烹饪的自由少年。](https://www.yuque.com/docs/share/71251673-1fef-416e-93d7-489a25a9eda5?#%20%E3%80%8A%E8%B5%B0%E8%BF%91JavaGuide%E3%80%8B)
+
+## 前言
+
+最近看到了一个考试系统,感觉做的挺不错,并且也比较成熟,所以我就简单玩了一下。另外,考试系统应用场景还挺多的,不论是对于在校大学生还是已经工作的小伙伴,并且,类似的私活也有很多。
+
+
+
+下面我就把这个项目分享给小伙伴们,非常值得学习,拿来即用!
+
+_为了一步一步演示,让小伙伴们都能成功部署/运行项目, Guide 哥自己本地搭建了项目环境,并将项目成功跑了起来。照着我的步骤,新手也能成功把项目跑起来!_
+
+_如果你“感动”的话,点个赞/在看,就是对我最大的支持!_
+
+另外,以下内容不涉及代码分析,整体代码结构比较清晰,熟悉了基本功能之后会很容易看明白。
+
+## 介绍
+
+[uexam](https://gitee.com/mindskip/uexam) 是一款前后端分离的在线考试系统。这款在线考试系统,不光支持 web 端,同时还支持微信小程序端。
+
+[uexam](https://gitee.com/mindskip/uexam) 界面设计美观,代码整体结构清晰,表设计比较规范。
+
+[uexam](https://gitee.com/mindskip/uexam) 后端基于 Spring Boot 2.0+MySQL/PostgreSQL+Redis+MyBatis,前端基于 Vue,采用前端后端分离开发!
+
+另外,这个项目提供了 MySQL 和 PostgreSQL 两种不同的数据库版本,下面我以 PostgreSQL 数据库版本的来演示(_建议大家使用和体验 PostgreSQL 版本_)。
+
+项目地址:[https://gitee.com/SnailClimb/uexam](https://gitee.com/SnailClimb/uexam) 。
+
+## 软件架构
+
+
+
+## 使用效果
+
+样式以及操作体验都是非常不错的,这也是我推荐这个项目很重要的一个原因。
+
+### 管理端
+
+#### 添加学科
+
+在创建题目之前,你需要首要创建学科。这里我们创建的学科是编程,年级是三年级。
+
+
+
+#### 添加题目
+
+可以看到这里可以添加多种题型: 单选题、多选题、判断题、填空题、简答题。
+
+
+
+我们以单选题为例,添加题目界面如下。
+
+
+
+添加成功之后,题目列表就会出现我们刚刚添加的题目。
+
+
+
+#### 添加试卷
+
+有了学科和题目之后才能添加试卷。
+
+
+
+添加成功之后,试卷列表就会出现我们刚刚添加的试卷。
+
+
+
+#### 添加学生
+
+**注意:这里的学生要和我们前面创建的学科对应的年级对应上。**
+
+
+
+### 学生端
+
+使用我们刚刚创建的学生账号登录,你会发现主页多了一个试卷。这个试卷就是我们刚刚在管理端创建的。
+
+
+
+试卷答题界面如下。
+
+
+
+## 启动
+
+### 后端
+
+我们这里以 PostgreSQL 数据库版本来演示。
+
+#### 安装 PostgreSQL
+
+**这里我们使用 Docker 下载最近版的 PostgreSQL 镜像 ,默认大家已经安装了 Docker。**
+
+```bash
+$ docker pull postgres
+```
+
+**查看 PostgreSQL 镜像:**
+
+```bash
+$ docker images |grep postgres
+postgres latest 62473370e7ee 2 weeks ago 314MB
+```
+
+**运行 PostgreSQL:**
+
+```bash
+$ docker run -d -p 5432:5432 --name postgresql -e POSTGRES_PASSWORD=123456 postgres
+```
+
+#### 安装 Redis
+
+**这里我们使用 Docker 下载最近版的 Redis 镜像 ,默认大家已经安装了 Docker。**
+
+```bash
+$ docker pull redis
+```
+
+**查看 Redis 镜像:**
+
+```bash
+$ docker images |grep redis
+```
+
+**运行 Redis:**
+
+```bash
+$ docker run -itd --name redis-test -p 6379:6379 redis
+```
+
+#### 创建数据库并执行数据库脚本
+
+首先创建一个名字叫做`xzs` 的数据库,然后执行相应的数据库脚本即可(数据库脚本在 `uexam/source/xzs/sql` 目录下。)。
+
+#### 配置文件修改
+
+使用 IntelliJ IDEA 打开 `uexam/source/xzs` (后台代码),修改 `application-dev.yml` ,将 postgesql/mysql、redis 的服务地址改为自己本地的。
+
+#### 启动项目
+
+直接运行 `XzsApplication` 即可。
+
+
+
+启动成功后,打开下面的链接即可跳转到对应的端:
+
+- 学生系统地址:http://localhost:8000/student
+- 管理端地址:http://localhost:8000/admin
+
+**注意:这种方式,前端虽然也启动了,也能访问,不过是内嵌在后端项目中。如果如果我们需要前后端分离的话,需要单独运行前端项目**
+
+### 前端
+
+小程序端的就不演示了,我这里只演示一下 web 端的。
+
+web 端代码在 `uexam/source/vue` 下,我们需要首先进入这个目录,然后分别对 `xzs-admin` (管理端) 和 `xzs-student` (学生端)执行下面两个命令。
+
+**1.下载相关依赖**
+
+```bash
+$ npm install
+```
+
+**2.启动项目**
+
+```bash
+$ npm run serve
+```
+
+启动完成之后,打开下面的链接即可跳转到对应的端:
+
+- 学生系统地址:http://localhost:8001
+- 管理端地址:http://localhost:8002
\ No newline at end of file
diff --git a/docs/spring-bean-validation.md b/docs/spring-bean-validation.md
new file mode 100644
index 0000000..5839a28
--- /dev/null
+++ b/docs/spring-bean-validation.md
@@ -0,0 +1,584 @@
+数据的校验的重要性就不用说了,即使在前端对数据进行校验的情况下,我们还是要对传入后端的数据再进行一遍校验,避免用户绕过浏览器直接通过一些 HTTP 工具直接向后端请求一些违法数据。
+
+最普通的做法就像下面这样。我们通过 `if/else` 语句对请求的每一个参数一一校验。
+
+```java
+@RestController
+@RequestMapping("/api/person")
+public class PersonController {
+
+ @PostMapping
+ public ResponseEntity save(@RequestBody PersonRequest personRequest) {
+ if (personRequest.getClassId() == null
+ || personRequest.getName() == null
+ || !Pattern.matches("(^Man$|^Woman$|^UGM$)", personRequest.getSex())) {
+
+ }
+ return ResponseEntity.ok().body(personRequest);
+ }
+}
+```
+
+这样的代码,小伙伴们在日常开发中一定不少见,很多开源项目都是这样对请求入参做校验的。
+
+但是,不太建议这样来写,这样的代码明显违背了 **单一职责原则**。大量的非业务代码混杂在业务代码中,非常难以维护,还会导致业务层代码冗杂!
+
+实际上,我们是可以通过一些简单的手段对上面的代码进行改进的!这也是本文主要要介绍的内容!
+
+废话不多说!下面我会结合自己在项目中的实际使用经验,通过实例程序演示如何在 SpringBoot 程序中优雅地的进行参数验证(普通的 Java 程序同样适用)。
+
+不了解的朋友一定要好好看一下,学完马上就可以实践到项目上去。
+
+并且,本文示例项目使用的是目前最新的 Spring Boot 版本 2.4.5!(截止到 2021-04-21)
+
+示例项目源代码地址:[https://github.com/CodingDocs/springboot-guide/tree/master/source-code/bean-validation-demo](https://github.com/CodingDocs/springboot-guide/tree/master/source-code/bean-validation-demo) 。
+
+## 添加相关依赖
+
+如果开发普通 Java 程序的的话,你需要可能需要像下面这样依赖:
+
+```xml
+
+ org.hibernate.validator
+ hibernate-validator
+ 6.0.9.Final
+
+
+ javax.el
+ javax.el-api
+ 3.0.0
+
+
+ org.glassfish.web
+ javax.el
+ 2.2.6
+
+```
+
+不过,相信大家都是使用的 Spring Boot 框架来做开发。
+
+基于 Spring Boot 的话,就比较简单了,只需要给项目添加上 `spring-boot-starter-web` 依赖就够了,它的子依赖包含了我们所需要的东西。另外,我们的示例项目中还使用到了 Lombok。
+
+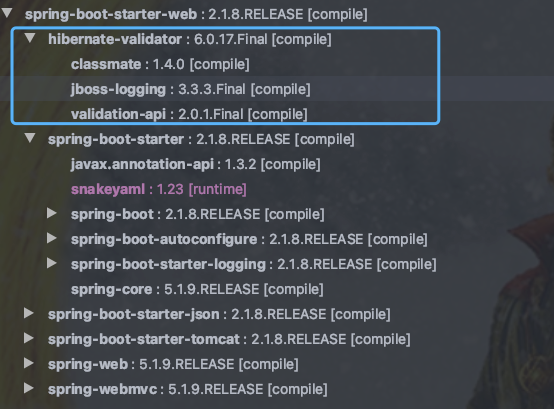
+
+```xml
+
+
+ org.springframework.boot
+ spring-boot-starter-web
+
+
+ org.projectlombok
+ lombok
+ true
+
+
+ junit
+ junit
+ 4.13.1
+ test
+
+
+ org.springframework.boot
+ spring-boot-starter-test
+ test
+
+
+```
+
+但是!!! Spring Boot 2.3 1 之后,`spring-boot-starter-validation` 已经不包括在了 `spring-boot-starter-web` 中,需要我们手动加上!
+
+
+
+```xml
+
+ org.springframework.boot
+ spring-boot-starter-validation
+
+```
+
+## 验证 Controller 的输入
+
+### 验证请求体
+
+验证请求体即使验证被 `@RequestBody` 注解标记的方法参数。
+
+**`PersonController`**
+
+我们在需要验证的参数上加上了`@Valid`注解,如果验证失败,它将抛出`MethodArgumentNotValidException`。默认情况下,Spring 会将此异常转换为 HTTP Status 400(错误请求)。
+
+```java
+@RestController
+@RequestMapping("/api/person")
+@Validated
+public class PersonController {
+
+ @PostMapping
+ public ResponseEntity save(@RequestBody @Valid PersonRequest personRequest) {
+ return ResponseEntity.ok().body(personRequest);
+ }
+}
+```
+
+**`PersonRequest`**
+
+我们使用校验注解对请求的参数进行校验!
+
+```java
+@Data
+@Builder
+@AllArgsConstructor
+@NoArgsConstructor
+public class PersonRequest {
+
+ @NotNull(message = "classId 不能为空")
+ private String classId;
+
+ @Size(max = 33)
+ @NotNull(message = "name 不能为空")
+ private String name;
+
+ @Pattern(regexp = "(^Man$|^Woman$|^UGM$)", message = "sex 值不在可选范围")
+ @NotNull(message = "sex 不能为空")
+ private String sex;
+
+}
+
+```
+
+正则表达式说明:
+
+- `^string` : 匹配以 string 开头的字符串
+- `string$` :匹配以 string 结尾的字符串
+- `^string$` :精确匹配 string 字符串
+- `(^Man$|^Woman$|^UGM$)` : 值只能在 Man,Woman,UGM 这三个值中选择
+
+**`GlobalExceptionHandler`**
+
+自定义异常处理器可以帮助我们捕获异常,并进行一些简单的处理。如果对于下面的处理异常的代码不太理解的话,可以查看这篇文章 [《SpringBoot 处理异常的几种常见姿势》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485568&idx=2&sn=c5ba880fd0c5d82e39531fa42cb036ac&chksm=cea2474bf9d5ce5dcbc6a5f6580198fdce4bc92ef577579183a729cb5d1430e4994720d59b34&token=1924773784&lang=zh_CN#rd)。
+
+```java
+@ControllerAdvice(assignableTypes = {PersonController.class})
+public class GlobalExceptionHandler {
+ @ExceptionHandler(MethodArgumentNotValidException.class)
+ public ResponseEntity> handleValidationExceptions(
+ MethodArgumentNotValidException ex) {
+ Map errors = new HashMap<>();
+ ex.getBindingResult().getAllErrors().forEach((error) -> {
+ String fieldName = ((FieldError) error).getField();
+ String errorMessage = error.getDefaultMessage();
+ errors.put(fieldName, errorMessage);
+ });
+ return ResponseEntity.status(HttpStatus.BAD_REQUEST).body(errors);
+ }
+}
+```
+
+**通过测试验证**
+
+下面我通过 `MockMvc` 模拟请求 `Controller` 的方式来验证是否生效。当然了,你也可以通过 `Postman` 这种工具来验证。
+
+```java
+@SpringBootTest
+@AutoConfigureMockMvc
+public class PersonControllerTest {
+ @Autowired
+ private MockMvc mockMvc;
+
+ @Autowired
+ private ObjectMapper objectMapper;
+ /**
+ * 验证出现参数不合法的情况抛出异常并且可以正确被捕获
+ */
+ @Test
+ public void should_check_person_value() throws Exception {
+ PersonRequest personRequest = PersonRequest.builder().sex("Man22")
+ .classId("82938390").build();
+ mockMvc.perform(post("/api/personRequest")
+ .contentType(MediaType.APPLICATION_JSON)
+ .content(objectMapper.writeValueAsString(personRequest)))
+ .andExpect(MockMvcResultMatchers.jsonPath("sex").value("sex 值不在可选范围"))
+ .andExpect(MockMvcResultMatchers.jsonPath("name").value("name 不能为空"));
+ }
+}
+```
+
+**使用 `Postman` 验证**
+
+
+
+### 验证请求参数
+
+验证请求参数(Path Variables 和 Request Parameters)即是验证被 `@PathVariable` 以及 `@RequestParam` 标记的方法参数。
+
+**`PersonController`**
+
+**一定一定不要忘记在类上加上 `Validated` 注解了,这个参数可以告诉 Spring 去校验方法参数。**
+
+```java
+@RestController
+@RequestMapping("/api/persons")
+@Validated
+public class PersonController {
+
+ @GetMapping("/{id}")
+ public ResponseEntity getPersonByID(@Valid @PathVariable("id") @Max(value = 5, message = "超过 id 的范围了") Integer id) {
+ return ResponseEntity.ok().body(id);
+ }
+
+ @PutMapping
+ public ResponseEntity getPersonByName(@Valid @RequestParam("name") @Size(max = 6, message = "超过 name 的范围了") String name) {
+ return ResponseEntity.ok().body(name);
+ }
+}
+```
+
+**`ExceptionHandler`**
+
+```java
+ @ExceptionHandler(ConstraintViolationException.class)
+ ResponseEntity handleConstraintViolationException(ConstraintViolationException e) {
+ return ResponseEntity.status(HttpStatus.BAD_REQUEST).body(e.getMessage());
+ }
+```
+
+**通过测试验证**
+
+```java
+@Test
+public void should_check_path_variable() throws Exception {
+ mockMvc.perform(get("/api/person/6")
+ .contentType(MediaType.APPLICATION_JSON))
+ .andExpect(status().isBadRequest())
+ .andExpect(content().string("getPersonByID.id: 超过 id 的范围了"));
+}
+
+@Test
+public void should_check_request_param_value2() throws Exception {
+ mockMvc.perform(put("/api/person")
+ .param("name", "snailclimbsnailclimb")
+ .contentType(MediaType.APPLICATION_JSON))
+ .andExpect(status().isBadRequest())
+ .andExpect(content().string("getPersonByName.name: 超过 name 的范围了"));
+}
+```
+
+**使用 `Postman` 验证**
+
+
+
+
+
+## 验证 Service 中的方法
+
+我们还可以验证任何 Spring Bean 的输入,而不仅仅是 `Controller` 级别的输入。通过使用`@Validated`和`@Valid`注释的组合即可实现这一需求!
+
+一般情况下,我们在项目中也更倾向于使用这种方案。
+
+**一定一定不要忘记在类上加上 `Validated` 注解了,这个参数可以告诉 Spring 去校验方法参数。**
+
+```java
+@Service
+@Validated
+public class PersonService {
+
+ public void validatePersonRequest(@Valid PersonRequest personRequest) {
+ // do something
+ }
+
+}
+```
+
+**通过测试验证:**
+
+```java
+@RunWith(SpringRunner.class)
+@SpringBootTest
+public class PersonServiceTest {
+ @Autowired
+ private PersonService service;
+
+ @Test
+ public void should_throw_exception_when_person_request_is_not_valid() {
+ try {
+ PersonRequest personRequest = PersonRequest.builder().sex("Man22")
+ .classId("82938390").build();
+ service.validatePersonRequest(personRequest);
+ } catch (ConstraintViolationException e) {
+ // 输出异常信息
+ e.getConstraintViolations().forEach(constraintViolation -> System.out.println(constraintViolation.getMessage()));
+ }
+ }
+}
+```
+
+输出结果如下:
+
+```
+name 不能为空
+sex 值不在可选范围
+```
+
+## Validator 编程方式手动进行参数验证
+
+某些场景下可能会需要我们手动校验并获得校验结果。
+
+我们通过 `Validator` 工厂类获得的 `Validator` 示例。另外,如果是在 Spring Bean 中的话,还可以通过 `@Autowired` 直接注入的方式。
+
+```java
+@Autowired
+Validator validate
+```
+
+具体使用情况如下:
+
+```java
+/**
+ * 手动校验对象
+ */
+@Test
+public void check_person_manually() {
+ ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
+ Validator validator = factory.getValidator();
+ PersonRequest personRequest = PersonRequest.builder().sex("Man22")
+ .classId("82938390").build();
+ Set> violations = validator.validate(personRequest);
+ violations.forEach(constraintViolation -> System.out.println(constraintViolation.getMessage()));
+}
+```
+
+输出结果如下:
+
+```
+sex 值不在可选范围
+name 不能为空
+```
+
+## 自定义 Validator(实用)
+
+如果自带的校验注解无法满足你的需求的话,你还可以自定义实现注解。
+
+### 案例一:校验特定字段的值是否在可选范围
+
+比如我们现在多了这样一个需求:`PersonRequest` 类多了一个 `Region` 字段,`Region` 字段只能是`China`、`China-Taiwan`、`China-HongKong`这三个中的一个。
+
+**第一步,你需要创建一个注解 `Region`。**
+
+```java
+@Target({FIELD})
+@Retention(RUNTIME)
+@Constraint(validatedBy = RegionValidator.class)
+@Documented
+public @interface Region {
+
+ String message() default "Region 值不在可选范围内";
+
+ Class[] groups() default {};
+
+ Class[] payload() default {};
+}
+```
+
+**第二步,你需要实现 `ConstraintValidator`接口,并重写`isValid` 方法。**
+
+```java
+public class RegionValidator implements ConstraintValidator {
+
+ @Override
+ public boolean isValid(String value, ConstraintValidatorContext context) {
+ HashSet