Detoxify is a open source model used to identify prompts as toxic
It contains 3 different models that vary in transformer type and data it was trained on
| Model name | Transformer type | Data from |
|---|---|---|
| original | bert-base-uncased | Toxic Comment Classification Challenge |
| unbiased | roberta-base | Unintended Bias in Toxicity Classification |
| multilingual | xlm-roberta-base | Multilingual Toxic Comment Classification |
Unbiased and original models also have a 'small' version - but since normal models are not memory heavy, and small models perform noticeably worse, they are only described in the notebook
Charts showing detailed memory usages and times for different sentence lengths and batch sizes are inside the notebook Quick overview batch size 16, sentence length 4k for training, batch size 128 sentence length 4k for Inference
| Model name | Training memory | Training speed | Inference Memory | Inference Speed |
|---|---|---|---|---|
| original | 11.8GB | 2.40s | 4.8GB | 16.48s |
| unbiased | 12GB | 1.09s | 4.8GB | 5.59s |
| multilingual | 14GB | 1.00s | 5.5GB | 4.89s |
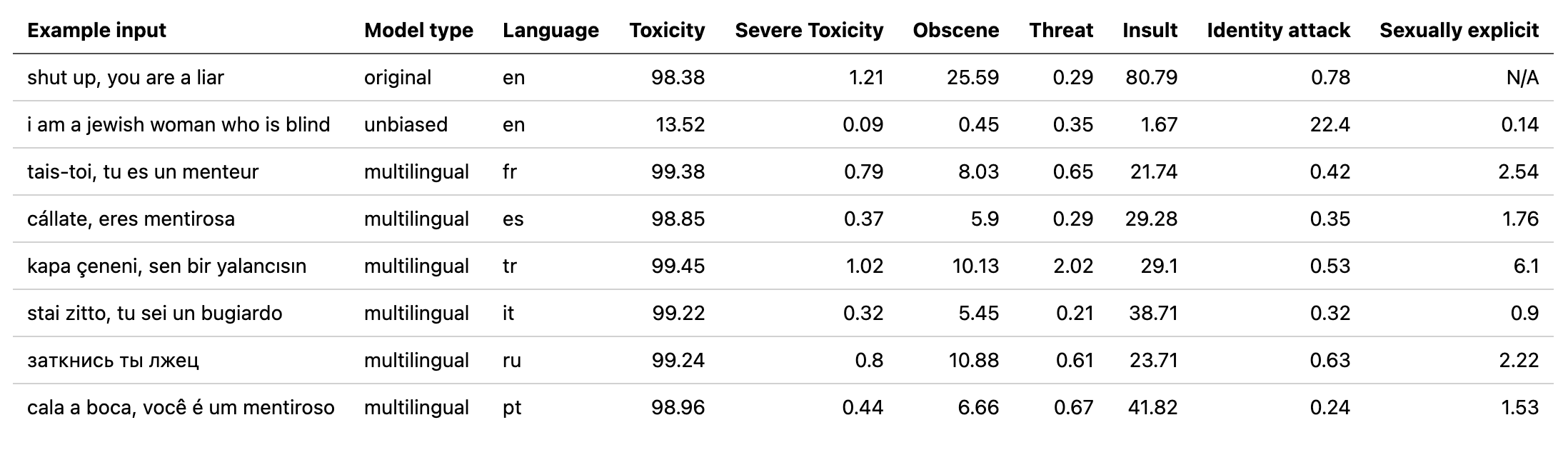
Detoxify was tested on 4 different types of inputs
- Not obviously toxic
- Not obviously non-toxic
- Obviously toxic
- Obviously non-toxic
| Model name | Not obviously toxic | Not obviously non-toxic | Obviously toxic | Obviously non-toxic |
|---|---|---|---|---|
| original | failed at all, easily accepted racist, sexist overally toxic prompts that were well formulated | Very sensitive on swear words, failed to reckognize context | good performance | good performance |
| unbiased | Managed to find some hidden toxicity but not on all sentences | Very sensitive explicit language but shown ability to recognize context | Did well but failed to reckognize some gender stereotype mockery | good performance |
| multilingual | Managed to find some hidden toxicity but not on all sentences | Very sensitive explicit language but shown ability to recognize context | Did well but failed to reckognize some gender stereotype mockery | good performance |
Subjectivly 'unbiased' looks like the best performing model.
I don't think it would do well as a security layer in a live version of open assistant unless we do some finetuning first, because it can be fooled to pass toxicity if it's presented in formal language.
With some caution it can be used to filter prompts but I would suggest also using someone for verification of messages that are marked as toxic but still below 90% confidence
Detoxify is on Apache-2.0 license that means:
-
Commercial use
-
Modification
-
Distribution
-
Patent use
-
Private use
-
Hold the owner liable
-
Use the owner's trademark
-
Include Copyright
-
Include License
-
State changes you made to the product
-
Include notice
This is obviously not legal advice.
The model is currently available on huggingface and torch hub
torch.hub.load('unitaryai/detoxify',model)
where model is one of:
-
toxic_bert
-
unbiased_toxic_roberta
-
multilingual_toxic_xlm_r