|
| 1 | +## 为什么要做优化 |
| 2 | + |
| 3 | +这是一个速度决定一切的年代,只要我们的生活还在继续数字化,线下的流程与系统就在持续向线上转移,在这个转移过程中,我们会碰到持续的性能问题。 |
| 4 | + |
| 5 | +互联网公司本质是将用户共通的行为流程进行了集中化管理,通过中心化的信息交换达到效率提升的目的,同时用规模效应降低了数据交换的成本。 |
| 6 | + |
| 7 | +用人话来讲,公司希望的是用尽量少的机器成本来赚取尽量多的利润。利润的提升与业务逻辑本身相关,与技术关系不大。而降低成本则是与业务无关,纯粹的技术话题。这里面最重要的主题就是“性能优化”。 |
| 8 | + |
| 9 | +如果业务的后端服务规模足够大,那么一个程序员通过优化帮公司节省的成本,或许就可以负担他十年的工资了。 |
| 10 | + |
| 11 | +## 优化的前置知识 |
| 12 | + |
| 13 | +从资源视角出发来对一台服务器进行审视的话,CPU、内存、磁盘与网络是后端服务最需要关注的四种资源类型。 |
| 14 | + |
| 15 | +对于计算密集型的程序来说,优化的主要精力会放在 CPU 上,要知道 CPU 基本的流水线概念,知道怎么样在使用少的 CPU 资源的情况下,达到相同的计算目标。 |
| 16 | + |
| 17 | +对于 IO 密集型的程序(后端服务一般都是 IO 密集型)来说,优化可以是降低程序的服务延迟,也可以是提升系统整体的吞吐量。 |
| 18 | + |
| 19 | +IO 密集型应用主要与磁盘、内存、网络打交道。因此我们需要知道一些基本的与磁盘、内存、网络相关的基本数据与常见概念: |
| 20 | + |
| 21 | +- 要了解内存的多级存储结构:L1,L2,L3,主存。还要知道这些不同层级的存储操作时的大致延迟:[latency numbers every programmer should know](https://colin-scott.github.io/personal_website/research/interactive_latency.html)。 |
| 22 | +- 要知道基本的文件系统读写 syscall,批量 syscall,数据同步 syscall。 |
| 23 | +- 要熟悉项目中使用的网络协议,至少要对 TCP, HTTP 有所了解。 |
| 24 | + |
| 25 | +## 优化越靠近应用层效果越好 |
| 26 | + |
| 27 | +> Performance tuning is most effective when done closest to where the work is performed. For workloads driven by applications, this means within the application itself. |
| 28 | +
|
| 29 | +我们在应用层的逻辑优化能够帮助应用提升几十倍的性能,而最底层的优化可能也就只能提升几个百分点了。 |
| 30 | + |
| 31 | +这个很好理解,我们可以看到一个 GTA Online 的新闻:[rockstar thanks gta online player who fixed poor load times](https://www.pcgamer.com/rockstar-thanks-gta-online-player-who-fixed-poor-load-times-official-update-coming/)。 |
| 32 | + |
| 33 | +简单来说,GTA online 的游戏启动过程让玩家等待时间过于漫长,经过各种工具分析,发现一个 10M 的文件加载就需要几十秒,用户 diy 进行优化之后,将加载时间减少 70%,并分享出来:[how I cut GTA Online loading times by 70%](https://nee.lv/2021/02/28/How-I-cut-GTA-Online-loading-times-by-70/)。 |
| 34 | + |
| 35 | +这就是一个非常典型的案例,GTA 在商业上取得了巨大的成功,但不妨碍它局部的代码是一坨屎。我们只要把这里的重复逻辑干掉,就可以完成三倍的优化效果。同样的案例,如果我们去优化磁盘的读写速度,则可能收效甚微。 |
| 36 | + |
| 37 | +## 优化是与业务场景相关的 |
| 38 | + |
| 39 | +不同的业务场景优化的侧重也是不同的。 |
| 40 | + |
| 41 | +对于大多数无状态业务模块来说,内存一般不是瓶颈,所以业务 API 的优化主要聚焦于延迟和吞吐。对于网关类的应用,因为有海量的连接,除了延迟和吞吐,内存占用可能就会成为一个关注的重点。对于存储类应用,内存是个逃不掉的瓶颈点。 |
| 42 | + |
| 43 | +在关注一些性能优化文章时,我们也应特别留意作者的业务场景。场景的侧重可能会让某些人去选择使用更为 hack 的手段进行优化,而 hack 往往也就意味着 bug。如果你选择了少有人走过的路,那你未来要面临的也是少有人会碰到的 bug。解决起来令人头疼。 |
| 44 | + |
| 45 | +## 优化的工作流程 |
| 46 | + |
| 47 | +对于一个典型的 API 应用来说,优化工作基本遵从下面的工作流: |
| 48 | + |
| 49 | +1. 建立评估指标,例如固定 QPS 压力下的延迟或内存占用,或模块在满足 SLA 前提下的极限 QPS |
| 50 | +2. 通过自研、开源压测工具进行压测,直到模块无法满足预设性能要求:如大量超时,QPS 不达预期,OOM |
| 51 | +3. 通过内置 profile 工具寻找性能瓶颈 |
| 52 | +4. 本地 benchmark 证明优化效果 |
| 53 | +5. 集成 patch 到业务模块,回到 2 |
| 54 | + |
| 55 | +## 可以使用的工具 |
| 56 | + |
| 57 | +### pprof |
| 58 | + |
| 59 | +#### memory profiler |
| 60 | + |
| 61 | +Go 内置的内存 profiler 可以让我们对线上系统进行内存使用采样,有四个相应的指标: |
| 62 | + |
| 63 | +- inuse\_objects:当我们认为内存中的驻留对象过多时,就会关注该指标 |
| 64 | +- inuse\_space:当我们认为应用程序占据的 RSS 过大时,会关注该指标 |
| 65 | +- alloc\_objects:当应用曾经发生过历史上的大量内存分配行为导致 CPU 或内存使用大幅上升时,可能关注该指标 |
| 66 | +- alloc\_space:当应用历史上发生过内存使用大量上升时,会关注该指标 |
| 67 | + |
| 68 | +网关类应用因为海量连接的关系,会导致进程消耗大量内存,所以我们经常看到相关的优化文章,主要就是降低应用的 inuse\_space。 |
| 69 | + |
| 70 | +而两个对象数指标主要是为 GC 优化提供依据,当我们进行 GC 调优时,会同时关注应用分配的对象数、正在使用的对象数,以及 GC 的 CPU 占用的指标。 |
| 71 | + |
| 72 | +GC 的 CPU 占用情况可以由内置的 CPU profiler 得到。 |
| 73 | + |
| 74 | +#### cpu profiler |
| 75 | + |
| 76 | +> The builtin Go CPU profiler uses the setitimer(2) system call to ask the operating system to be sent a SIGPROF signal 100 times a second. Each signal stops the Go process and gets delivered to a random thread’s sigtrampgo() function. This function then proceeds to call sigprof() or sigprofNonGo() to record the thread’s current stack. |
| 77 | +
|
| 78 | +Go 语言内置的 CPU profiler 使用 setitimer 系统调用,操作系统会每秒 100 次向程序发送 SIGPROF 信号。在 Go 进程中会选择随机的信号执行 sigtrampgo 函数。该函数使用 sigprof 或 sigprofNonGo 来记录线程当前的栈。 |
| 79 | + |
| 80 | +> Since Go uses non-blocking I/O, Goroutines that wait on I/O are parked and not running on any threads. Therefore they end up being largely invisible to Go’s builtin CPU profiler. |
| 81 | +
|
| 82 | +Go 语言内置的 cpu profiler 是在性能领域比较常见的 On-CPU profiler,对于瓶颈主要在 CPU 消耗的应用,我们使用内置的 profiler 也就足够了。 |
| 83 | + |
| 84 | +如果我们碰到的问题是应用的 CPU 使用不高,但接口的延迟却很大,那么就需要用上 Off-CPU profiler,遗憾的是官方的 profiler 并未提供该功能,我们需要借助社区的 fgprof。 |
| 85 | + |
| 86 | +### fgprof |
| 87 | + |
| 88 | +> fgprof is implemented as a background goroutine that wakes up 99 times per second and calls runtime.GoroutineProfile. This returns a list of all goroutines regardless of their current On/Off CPU scheduling status and their call stacks. |
| 89 | +
|
| 90 | +fgprof 是启动了一个后台的 goroutine,每秒启动 99 次,调用 runtime.GoroutineProfile 来采集所有 gorooutine 的栈。 |
| 91 | + |
| 92 | +虽然看起来很美好: |
| 93 | + |
| 94 | +``` |
| 95 | +func GoroutineProfile(p []StackRecord) (n int, ok bool) { |
| 96 | + ..... |
| 97 | +stopTheWorld("profile") |
| 98 | +
|
| 99 | +for _, gp1 := range allgs { |
| 100 | +...... |
| 101 | +} |
| 102 | +
|
| 103 | +if n <= len(p) { |
| 104 | +// Save current goroutine. |
| 105 | +........ |
| 106 | +systemstack(func() { |
| 107 | +saveg(pc, sp, gp, &r[0]) |
| 108 | +}) |
| 109 | +
|
| 110 | +// Save other goroutines. |
| 111 | +for _, gp1 := range allgs { |
| 112 | +if isOK(gp1) { |
| 113 | +....... |
| 114 | +saveg(^uintptr(0), ^uintptr(0), gp1, &r[0]) |
| 115 | + ....... |
| 116 | +} |
| 117 | +} |
| 118 | +} |
| 119 | +
|
| 120 | +startTheWorld() |
| 121 | +
|
| 122 | +return n, ok |
| 123 | +} |
| 124 | +``` |
| 125 | + |
| 126 | +但调用 GoroutineProfile 函数的开销并不低,如果线上系统的 goroutine 上万,每次采集 profile 都遍历上万个 goroutine 的成本实在是太高了。所以 fgprof 只适合在测试环境中使用。 |
| 127 | + |
| 128 | +### trace |
| 129 | + |
| 130 | +一般情况下我们是不需要使用 trace 来定位性能问题的,通过压测 + profile 就可以解决大部分问题,除非我们的问题与 runtime 本身的问题相关。 |
| 131 | + |
| 132 | +比如 STW 时间比预想中长,超过百毫秒,向官方反馈问题时,才需要出具相关的 trace 文件。比如类似 [long stw](https://github.com/golang/go/issues/19378) 这样的 issue。 |
| 133 | + |
| 134 | +采集 trace 对系统的性能影响还是比较大的,即使我们只是开启 gctrace,把 gctrace 日志重定向到文件,对系统延迟也会有一定影响,因为 gctrace 的 print 是在 stw 期间来做的:[gc trace 阻塞调度](http://xiaorui.cc/archives/6232)。 |
| 135 | + |
| 136 | +### perf |
| 137 | + |
| 138 | +如果应用没有开启 pprof,在线上应急时,我们也可以临时使用 perf: |
| 139 | + |
| 140 | +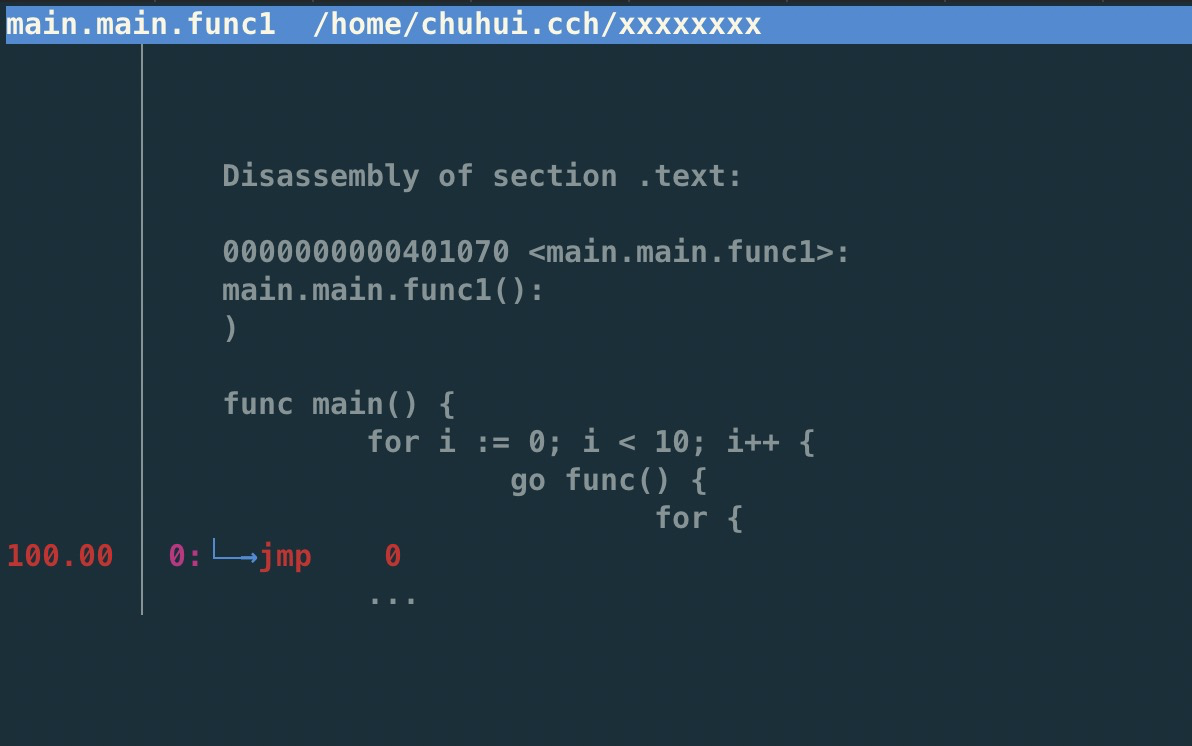 |
| 141 | + |
| 142 | +## 微观性能优化 |
| 143 | + |
| 144 | +在编写 library 时,我们会关注关键的函数性能,这时可以脱离系统去探讨性能优化,Go 语言的 test 子命令集成了相关的功能,只要我们按照约定来写 Benchmark 前缀的测试函数,就可以实现函数级的基准测试。我们以常见的二维数组遍历为例: |
| 145 | + |
| 146 | +``` |
| 147 | +package main |
| 148 | +
|
| 149 | +import "testing" |
| 150 | +
|
| 151 | +var x = make([][]int, 100) |
| 152 | +
|
| 153 | +func init() { |
| 154 | +for i := 0; i < 100; i++ { |
| 155 | +x[i] = make([]int, 100) |
| 156 | +} |
| 157 | +} |
| 158 | +
|
| 159 | +func traverseVertical() { |
| 160 | +for i := 0; i < 100; i++ { |
| 161 | +for j := 0; j < 100; j++ { |
| 162 | +x[j][i] = 1 |
| 163 | +} |
| 164 | +} |
| 165 | +} |
| 166 | +
|
| 167 | +func traverseHorizontal() { |
| 168 | +for i := 0; i < 100; i++ { |
| 169 | +for j := 0; j < 100; j++ { |
| 170 | +x[i][j] = 1 |
| 171 | +} |
| 172 | +} |
| 173 | +} |
| 174 | +
|
| 175 | +func BenchmarkHorizontal(b *testing.B) { |
| 176 | +for i := 0; i < b.N; i++ { |
| 177 | +traverseHorizontal() |
| 178 | +} |
| 179 | +} |
| 180 | +
|
| 181 | +func BenchmarkVertical(b *testing.B) { |
| 182 | +for i := 0; i < b.N; i++ { |
| 183 | +traverseVertical() |
| 184 | +} |
| 185 | +} |
| 186 | +
|
| 187 | +``` |
| 188 | + |
| 189 | +执行 `go test -bench=.` |
| 190 | + |
| 191 | +``` |
| 192 | +BenchmarkHorizontal-12 102368 10916 ns/op |
| 193 | +BenchmarkVertical-12 66612 18197 ns/op |
| 194 | +``` |
| 195 | + |
| 196 | +可见横向遍历数组要快得多,这提醒我们在写代码时要考虑 CPU 的 cache 设计及局部性原理,以使程序能够在相同的逻辑下获得更好的性能。 |
| 197 | + |
| 198 | +除了 CPU 优化,我们还经常会碰到要优化内存分配的场景。只要带上 -benchmem 的 flag 就可以实现了。 |
| 199 | + |
| 200 | +举个例子,形如下面这样的代码: |
| 201 | + |
| 202 | +``` |
| 203 | +logStr := "userid :" + userID + "; orderid:" + orderID |
| 204 | +``` |
| 205 | + |
| 206 | +你觉得代码写的很难看,想要优化一下可读性,就改成了下列代码: |
| 207 | + |
| 208 | +``` |
| 209 | +logStr := fmt.Sprintf("userid: %v; orderid: %v", userID, orderID) |
| 210 | +``` |
| 211 | + |
| 212 | +这样的修改方式在某公司的系统中曾经导致了 p2 事故,上线后接口的超时俱增至 SLA 承诺以上。 |
| 213 | + |
| 214 | +我们简单验证就可以发现: |
| 215 | + |
| 216 | +``` |
| 217 | +BenchmarkPrint-12 7168467 157 ns/op 64 B/op 3 allocs/op |
| 218 | +BenchmarkPlus-12 43278558 26.7 ns/op 0 B/op 0 allocs/op |
| 219 | +``` |
| 220 | + |
| 221 | +使用 + 进行字符串拼接,不会在堆上产生额外对象。而使用 fmt 系列函数,则会造成局部对象逃逸到堆上,这里是高频路径上有大量逃逸,所以导致线上服务的 GC 压力加重,大量接口超时。 |
| 222 | + |
| 223 | +出于谨慎考虑,修改高并发接口时,拿不准的尽量都应进行简单的线下 benchmark 测试。 |
| 224 | + |
| 225 | +当然,我们不能指望靠写一大堆 benchmark 帮我们发现系统的瓶颈。 |
| 226 | + |
| 227 | +实际工作中还是要使用前文提到的优化工作流来进行系统性能优化。也就是尽量从接口整体而非函数局部考虑去发现与解决瓶颈。 |
| 228 | + |
| 229 | +## 宏观性能优化 |
| 230 | + |
| 231 | +接口类的服务,我们可以使用两种方式对其进行压测: |
| 232 | + |
| 233 | +- 固定 QPS 压测:在每次系统有大的特性发布时,都应进行固定 QPS 压测,与历史版本进行对比,需要关注的指标包括,相同 QPS 下的系统的 CPU 使用情况,内存占用情况(监控中的 RSS 值),goroutine 数,GC 触发频率和相关指标(是否有较长的 stw,mark 阶段是否时间较长等),平均延迟,p99 延迟。 |
| 234 | +- 极限 QPS 压测:极限 QPS 压测一般只是为了 benchmark show,没有太大意义。系统满负荷时,基本 p99 已经超出正常用户的忍受范围了。 |
| 235 | + |
| 236 | +压测过程中需要采集不同 QPS 下的 CPU profile,内存 profile,记录 goroutine 数。与历史情况进行 AB 对比。 |
| 237 | + |
| 238 | +Go 的 pprof 还提供了 --base 的 flag,能够很直观地帮我们发现不同版本之间的指标差异:[用 pprof 比较内存使用差异](https://colobu.com/2019/08/20/use-pprof-to-compare-go-memory-usage/)。 |
| 239 | + |
| 240 | +总之记住一点,接口的性能一定是通过压测来进行优化的,而不是通过硬啃代码找瓶颈点。关键路径的简单修改往往可以带来巨大收益。如果只是啃代码,很有可能将 1% 优化到 0%,优化了 100% 的局部性能,对接口整体影响微乎其微。 |
| 241 | + |
| 242 | +## 寻找性能瓶颈 |
| 243 | + |
| 244 | +在压测时,我们通过以下步骤来逐渐提升接口的整体性能: |
| 245 | + |
| 246 | +1. 使用固定 QPS 压测,以阶梯形式逐渐增加压测 QPS,如 1000 -> 每分钟增加 1000 QPS |
| 247 | +2. 压测过程中观察系统的延迟是否异常 |
| 248 | +3. 观察系统的 CPU 使用情况 |
| 249 | +4. 如果 CPU 使用率在达到一定值之后不再上升,反而引起了延迟的剧烈波动,这时大概率是发生了阻塞,进入 pprof 的 web 页面,点击 goroutine,查看 top 的 goroutine 数,这时应该有大量的 goroutine 阻塞在某处,比如 Semacquire |
| 250 | +5. 如果 CPU 上升较快,未达到预期吞吐就已经过了高水位,则可以重点考察 CPU 使用是否合理,在 CPU 高水位进行 profile 采样,重点关注火焰图中较宽的“平顶山” |
| 251 | + |
| 252 | +## 一些优化案例 |
| 253 | + |
| 254 | +### gc mark 占用过多 CPU |
| 255 | + |
| 256 | +在 Go 语言中 gc mark 占用的 CPU 主要和运行时的对象数相关,也就是我们需要看 inuse\_objects。 |
| 257 | + |
| 258 | +定时任务,或访问流量不规律的应用,需要关注 alloc\_objects。 |
| 259 | + |
| 260 | +优化主要是下面几方面: |
| 261 | + |
| 262 | +#### 减少变量逃逸 |
| 263 | + |
| 264 | +尽量在栈上分配对象,关于逃逸的规则,可以查看 Go 编译器代码中的逃逸测试部分: |
| 265 | + |
| 266 | + |
| 267 | + |
| 268 | +查看某个 package 内的逃逸情况,可以使用 build + 全路径的方式,如: |
| 269 | + |
| 270 | +`go build -gcflags="-m -m" github.com/cch123/elasticsql` |
| 271 | + |
| 272 | +需要注意的是,逃逸分析的结果是会**随着版本变化**的,所以去背诵网上逃逸相关的文章结论是没有什么意义的。 |
| 273 | + |
| 274 | +#### 使用 sync.Pool 复用堆上对象 |
| 275 | + |
| 276 | +sync.Pool 用出花儿的就是 fasthttp 了,可以看看我之前写的这一篇:[fasthttp 为什么快](http://xargin.com/why-fasthttp-is-fast-and-the-cost-of-it/)。 |
| 277 | + |
| 278 | +最简单的复用就是复用各种 struct,slice,在复用时 put 时,需要 size 是否已经扩容过头,小心因为 sync.Pool 中存了大量的巨型对象导致进程占用了大量内存。 |
| 279 | + |
| 280 | +### 调度占用过多 CPU |
| 281 | + |
| 282 | +goroutine 频繁创建与销毁会给调度造成较大的负担,如果我们发现 CPU 火焰图中 schedule,findrunnable 占用了大量 CPU,那么可以考虑使用开源的 workerpool 来进行改进,比较典型的 [fasthttp worker pool](https://github.com/valyala/fasthttp/blob/master/workerpool.go#L19)。 |
| 283 | + |
| 284 | +如果客户端与服务端之间使用的是短连接,那么我们可以使用长连接。 |
| 285 | + |
| 286 | +### 进程占用大量内存 |
| 287 | + |
| 288 | +当前大多数的业务后端服务是不太需要关注进程消耗的内存的。 |
| 289 | + |
| 290 | +我们经常看到做 Go 内存占用优化的是在网关(包括 mesh)、存储系统这两个场景。 |
| 291 | + |
| 292 | +对于网关类系统来说,Go 的内存占用主要是因为 Go 独特的抽象模型造成的,这个很好理解: |
| 293 | + |
| 294 | +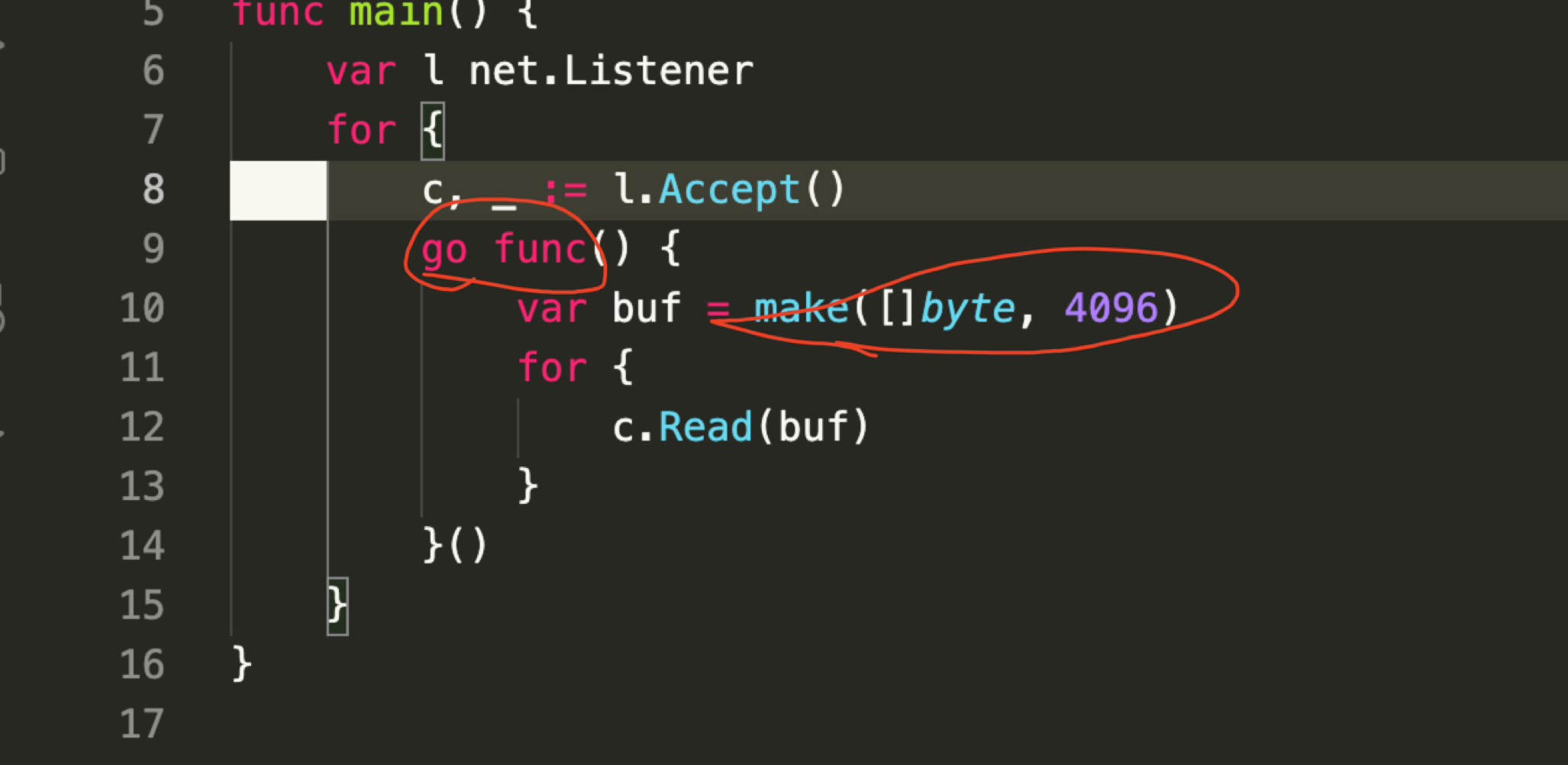 |
| 295 | + |
| 296 | +海量的连接加上海量的 goroutine,使网关和 mesh 成为 Go OOM 的重灾区。所以网关侧的优化一般就是优化: |
| 297 | + |
| 298 | +- goroutine 占用的栈内存 |
| 299 | +- read buffer 和 write buffer 占用的内存 |
| 300 | + |
| 301 | +很多项目都有相关的分享,这里就不再赘述了。 |
| 302 | + |
| 303 | +对于存储类系统来说,内存占用方面的努力也是在优化 buffer,比如 dgraph 使用 cgo + jemalloc 来优化他们的产品[内存占用](https://dgraph.io/blog/post/manual-memory-management-golang-jemalloc/)。 |
| 304 | + |
| 305 | +堆外内存不会在 Go 的 GC 系统里进行管辖,所以也不会影响到 Go 的 GC Heap Goal,所以也不会像 Go 这样内存占用难以控制。 |
| 306 | + |
| 307 | +### 锁冲突严重,导致吞吐量瓶颈 |
| 308 | + |
| 309 | +我在 [几个 Go 系统可能遇到的锁问题](http://xargin.com/lock-contention-in-go/) 中分享过实际的线上 case。 |
| 310 | + |
| 311 | +进行锁优化的思路无非就一个“拆”和一个“缩”字: |
| 312 | + |
| 313 | +- 拆:将锁粒度进行拆分,比如全局锁,我能不能把锁粒度拆分为连接粒度的锁;如果是连接粒度的锁,那我能不能拆分为请求粒度的锁;在 logger fd 或 net fd 上加的锁不太好拆,那么我们增加一些客户端,比如从 1-> 100,降低锁的冲突是不是就可以了。 |
| 314 | +- 缩:缩小锁的临界区,比如业务允许的前提下,可以把 syscall 移到锁外面;比如我们只是想要锁 map,但是却不小心锁了连接读写的逻辑,或许简单地用 sync.Map 来代替 map Lock,defer Unlock 就能简单地缩小临界区了。 |
| 315 | + |
| 316 | +### timer 相关函数占用大量 CPU |
| 317 | + |
| 318 | +同样是在某些网关应用中较常见,优化方法手段: |
| 319 | + |
| 320 | +- 使用时间轮/粗粒度的时间管理,精确到 ms 级一般就足够了 |
| 321 | +- 升级到 Go 1.14+,享受官方的升级红利 |
| 322 | + |
| 323 | +## 模拟真实工作负载 |
| 324 | + |
| 325 | +在前面的论述中,我们对问题进行了简化。真实世界中的后端系统往往不只一个接口,压测工具、平台往往只支持单接口压测。 |
| 326 | + |
| 327 | +公司的业务希望知道的是某个后端系统最终能支持多少业务量,例如系统整体能承载多少发单量而不会在重点环节出现崩溃。 |
| 328 | + |
| 329 | +虽然大家都在讲微服务,但单一服务往往也不只有单一功能,如果一个系统有 10 个接口(已经算是很小的服务了),那么这个服务的真实负载是很难靠人肉去模拟的。 |
| 330 | + |
| 331 | +这也就是为什么互联网公司普遍都需要做全链路压测。像样点的公司都会定期进行全链路压测演练,以便知晓随着系统快速迭代变化,系统整体是否出现了严重的性能衰退。 |
| 332 | + |
| 333 | +通过真实的工作负载,我们才能发现真实的线上性能问题。讲全链路压测的文章也很多,本文就不再赘述了。 |
| 334 | + |
| 335 | +## 当前性能问题定位工具的局限性 |
| 336 | + |
| 337 | +本文中几乎所有优化手段都是通过 Benchmark 和压测来进行的,但真实世界的软件会有下列场景: |
| 338 | + |
| 339 | +- 做 ToB 生意,我们的应用是部署在客户侧(比如一些数据库产品),客户说我们的应用会 OOM,但是我们很难拿到 OOM 的现场,不知道到底是哪些对象分配导致了 OOM |
| 340 | +- 做大型平台,平台上有各种不同类型的用户编写代码,升级用户代码后,线上出现各种 CPU 毛刺和 OOM 问题 |
| 341 | + |
| 342 | +这些问题在压测中是发现不了的,需要有更为灵活的工具和更为强大的平台,关于这些问题,我将在 4 月 10 日的武汉 Gopher Meetup 上进行分享,欢迎关注。 |
| 343 | + |
| 344 | +参考资料: |
| 345 | + |
| 346 | +[cache contention](https://web.eecs.umich.edu/~zmao/Papers/xu10mar.pdf) |
| 347 | + |
| 348 | +[every-programmer-should-know](https://github.com/mtdvio/every-programmer-should-know) |
| 349 | + |
| 350 | +[go-perfbook](https://github.com/dgryski/go-perfbook) |
| 351 | + |
| 352 | +[Systems Performance](https://www.amazon.com/Systems-Performance-Brendan-Gregg/dp/0136820158/ref=sr_1_1?dchild=1&keywords=systems+performance&qid=1617092159&sr=8-1) |
0 commit comments