 diff --git a/defer.md b/defer.md
index ae0d8bf..ada7c2b 100644
--- a/defer.md
+++ b/defer.md
@@ -76,7 +76,7 @@ func newdefer(siz int32) *_defer {
```go
type _defer struct {
siz int32 // 函数的参数总大小
- started bool // TODO defer 是否已开始执行?
+ started bool // defer 是否已开始执行
sp uintptr // 存储调用 defer 函数的函数的 sp 寄存器值
pc uintptr // 存储 call deferproc 的下一条汇编指令的指令地址
fn *funcval // 描述函数的变长结构体,包括函数地址及参数
@@ -160,3 +160,6 @@ A: deferproc 和 deferreturn 是成对出现的,对于编译器的实现来说
https://ieevee.com/tech/2017/11/23/go-panic.html
+
+
+
diff --git a/futex.md b/futex.md
index 812d091..9d51161 100644
--- a/futex.md
+++ b/futex.md
@@ -235,3 +235,6 @@ http://blog.sina.com.cn/s/blog_e59371cc0102v29b.html
https://www.jianshu.com/p/570a61f08e27
https://eli.thegreenplace.net/2018/basics-of-futexes/
+
+
+
diff --git a/gc.md b/gc.md
index ff0ec21..b7973ed 100644
--- a/gc.md
+++ b/gc.md
@@ -742,3 +742,5 @@ gc时间,stw时间和响应延迟之间是什么关系
宏观来看gc划分为多少个阶段
+
+
diff --git a/gc_write_barrier.md b/gc_write_barrier.md
new file mode 100644
index 0000000..d606aff
--- /dev/null
+++ b/gc_write_barrier.md
@@ -0,0 +1,37 @@
+# GC write barrier 详解
+
+在垃圾回收领域所讲的 barrier 包括 read barrier 与 write barrier,无论是哪一种,都与并发编程领域的 memory barrier 不是一回事。
+
+在 GC 中的 barrier 其本质是 : snippet of code insert before pointer modify。
+
+所以在阅读相关材料时,请注意不要将两者混淆。
+
+在当前 Go 语言的实现中,GC 只有 write barrier,没有 read barrier。
+
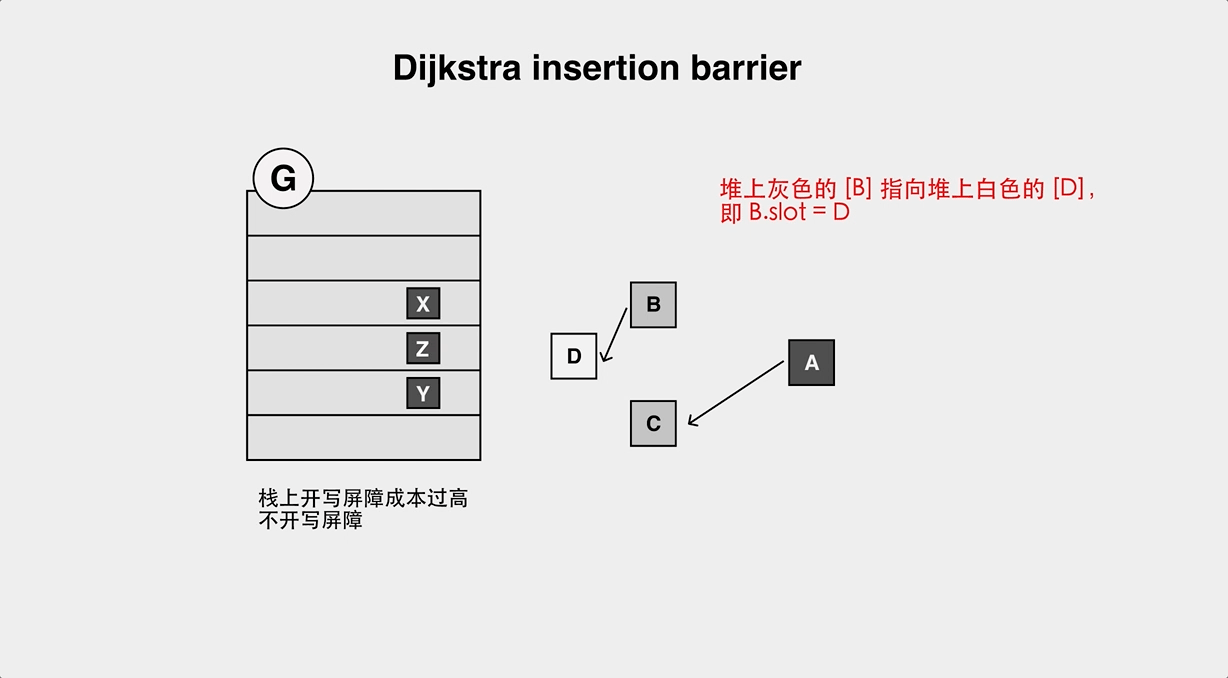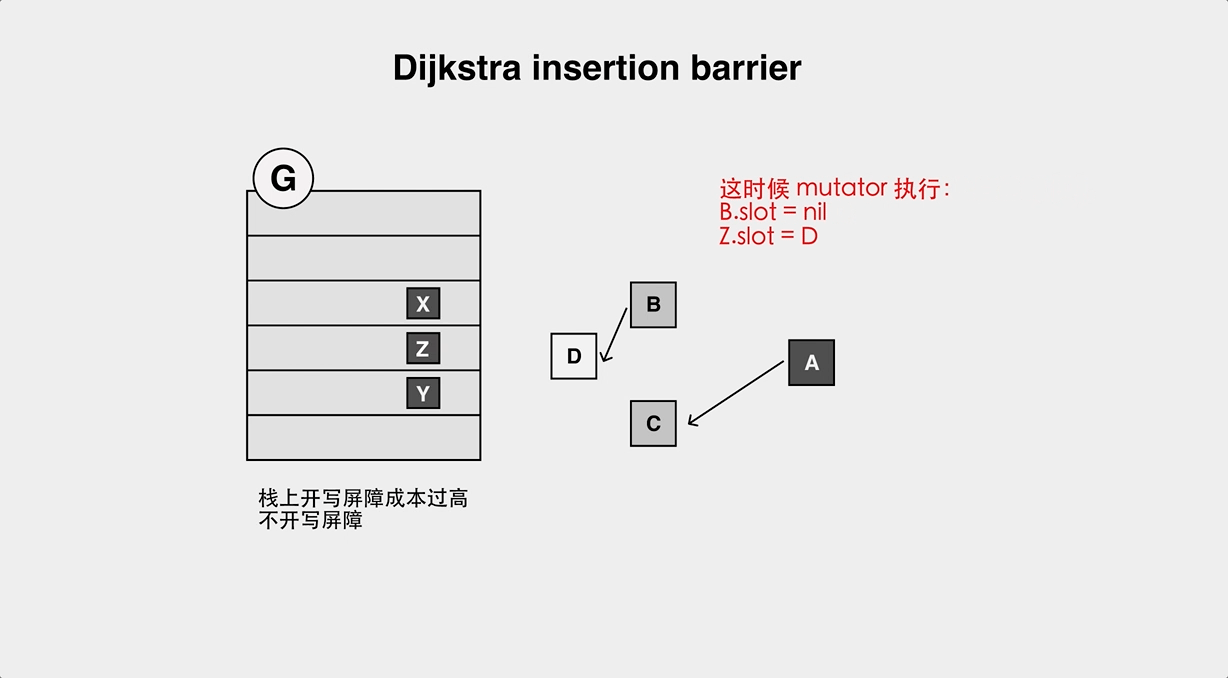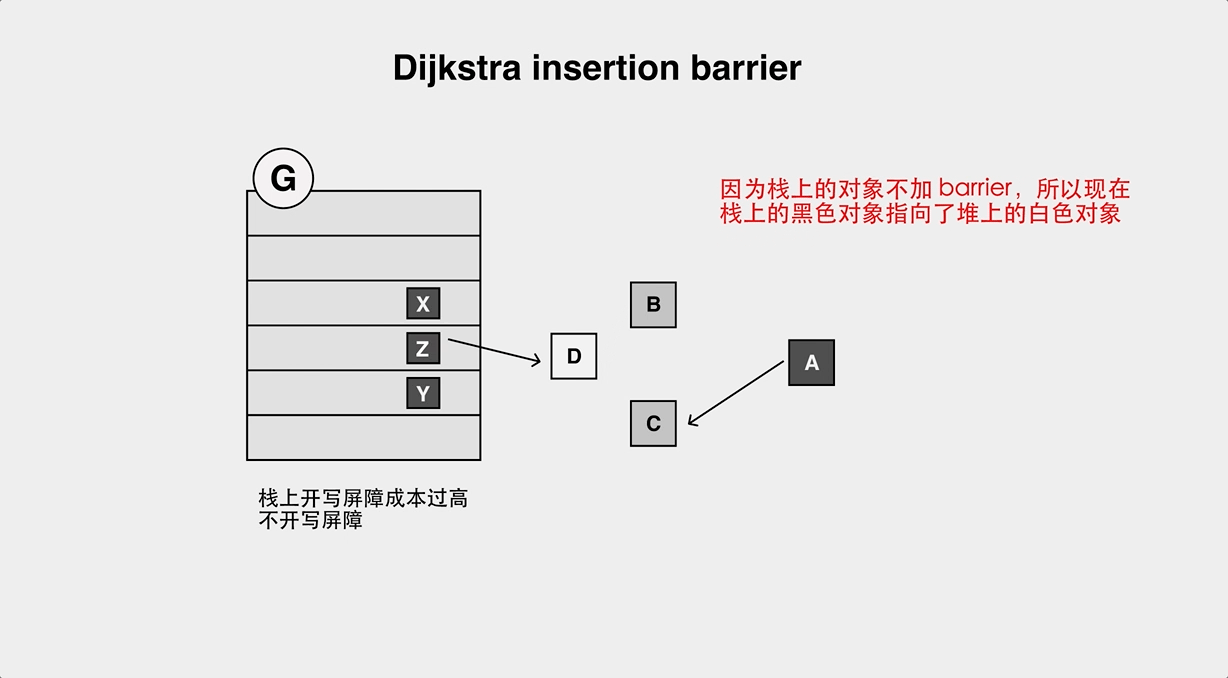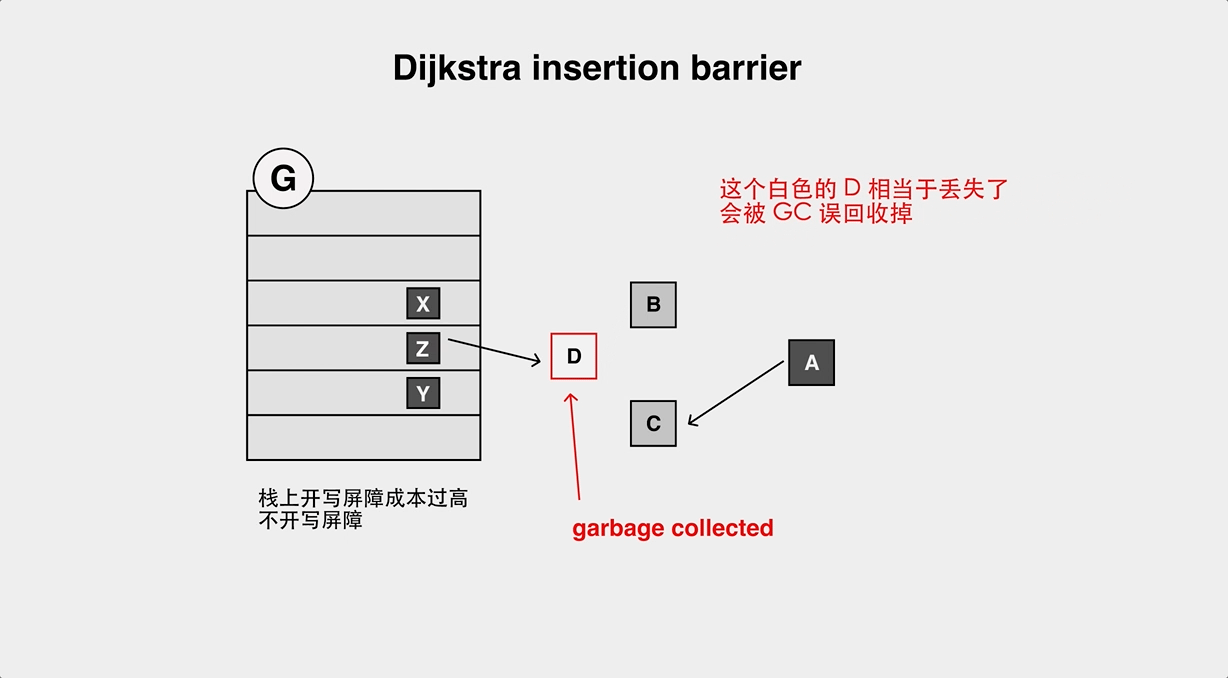
+在应用进入 GC 标记阶段前的 stw 阶段,会将全局变量 runtime.writeBarrier.enabled 修改为 true,当应用从 STW 中恢复,重新开始执行,垃圾回收的标记阶段便与应用逻辑开始并发执行,这时所有的堆上指针修改操作在修改之前会额外调用 runtime.gcWriteBarrier:
+
+
+
+我们随便找找这些反汇编结果在代码中对应的行:
+
+
+
+Go 语言当前使用了混合 barrier 来实现 gc 标记期间的被修改对象动态跟踪,早期只使用了 Dijistra 插入 barrier,但 Dijistra barrier 需要在标记完成之后进行栈重扫,因此在 1.8 时修改为混合 barrier。
+
+Dijistra 插入屏障伪代码如下:
+
+
+
+堆上指针修改时,新指向的对象要标灰。
+
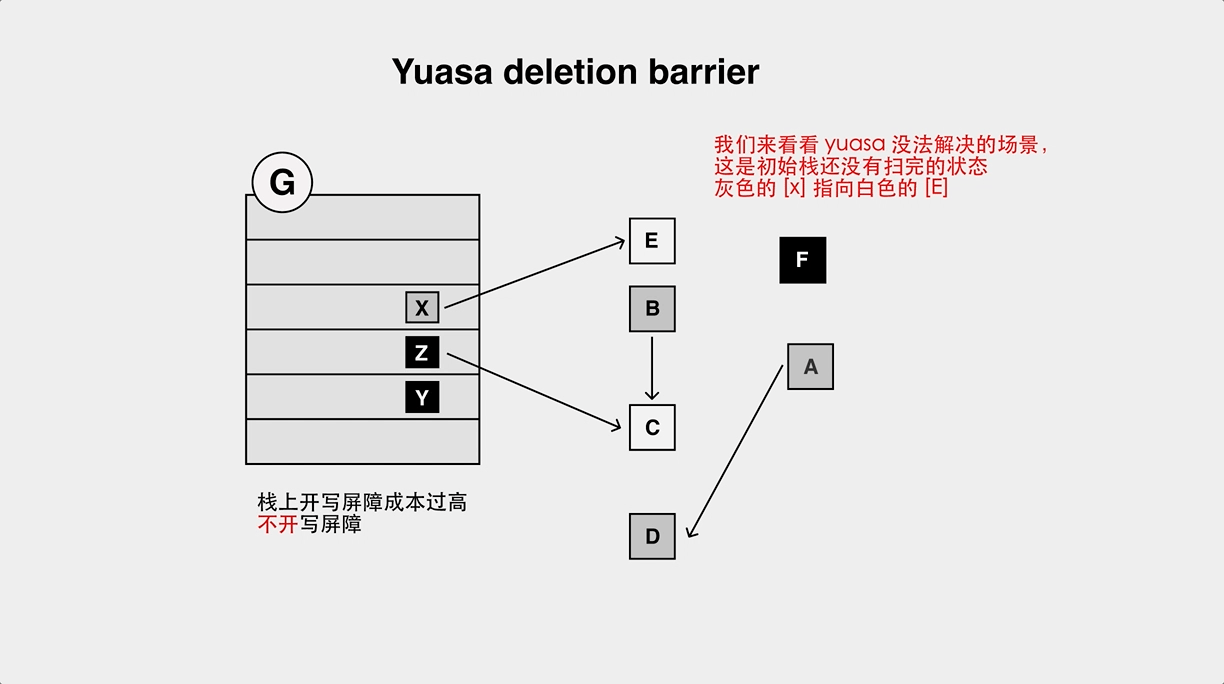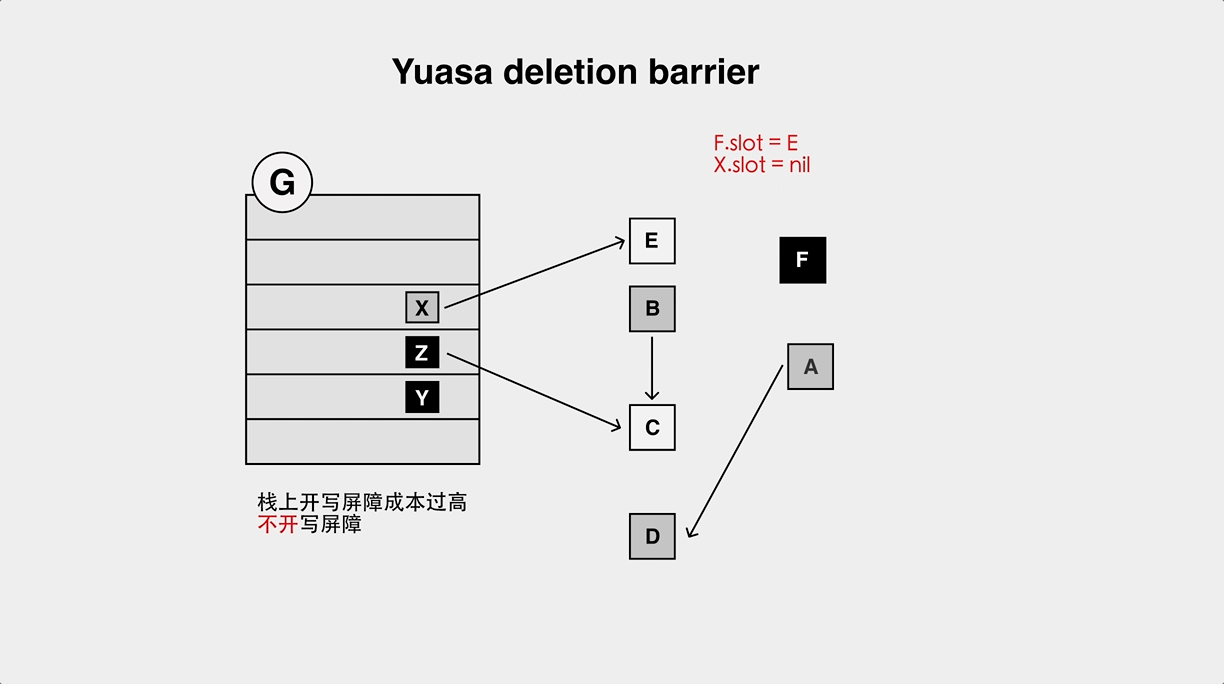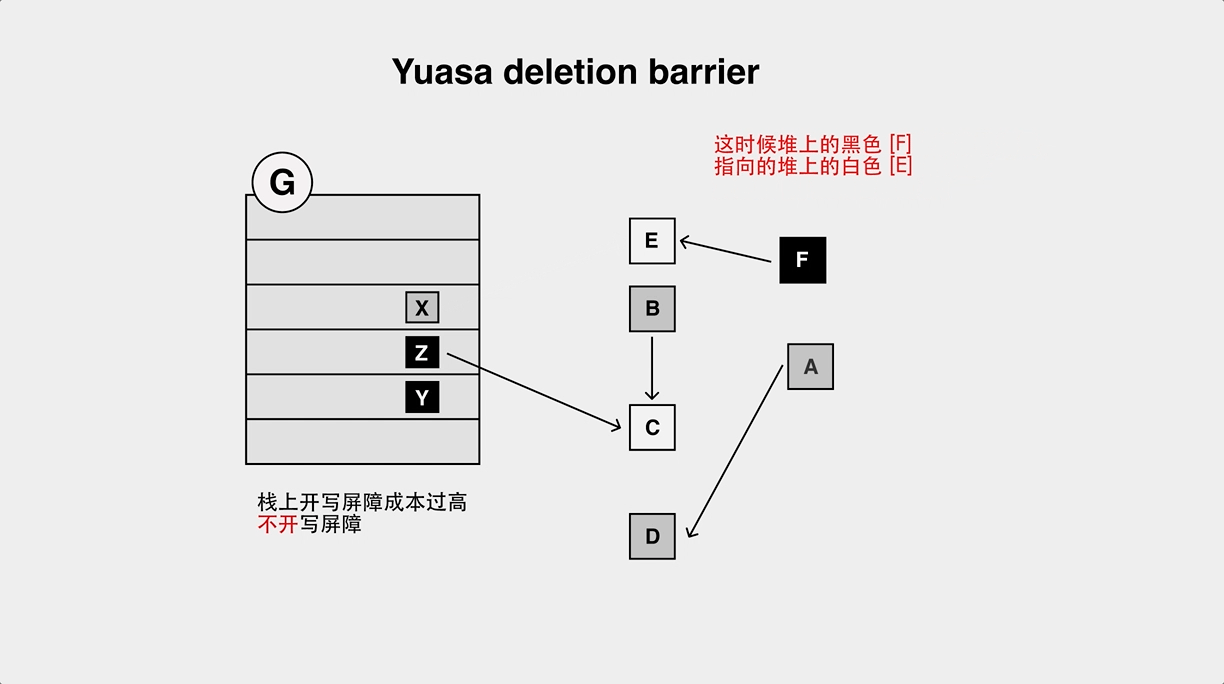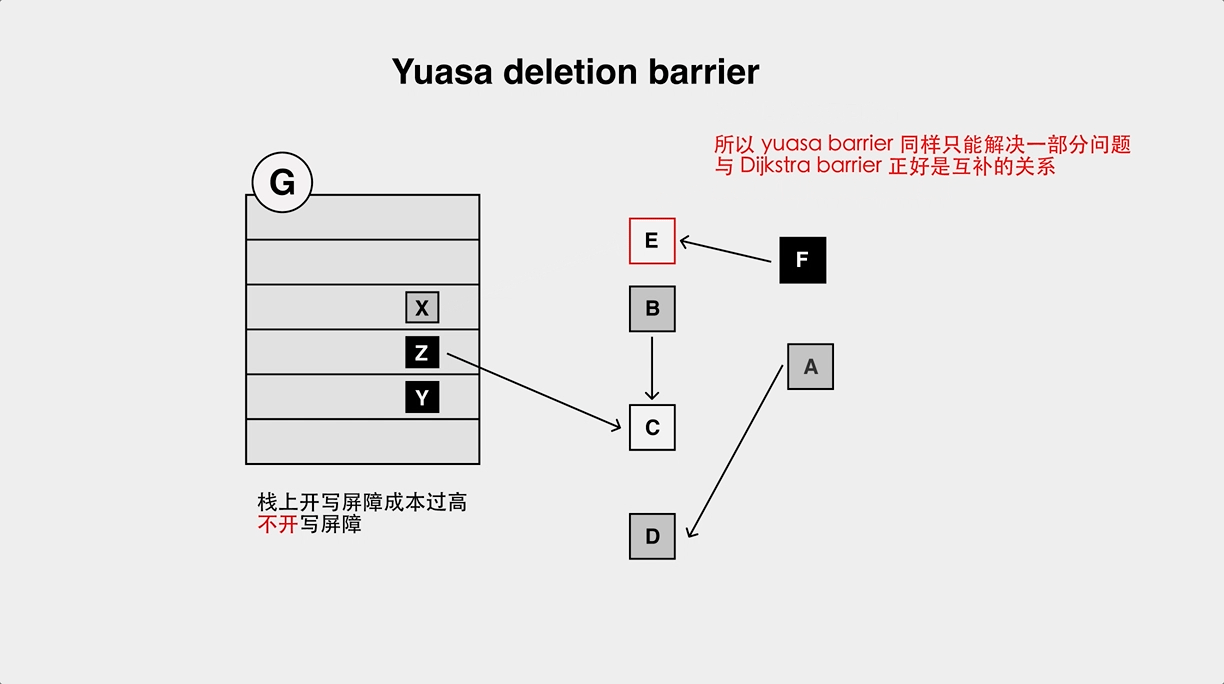
+但是因为 Go 的栈上对象不加 barrier,所以会存在对象丢失的问题:
+
+
+
+还有一种非常有名的 barrier,Yuasa 删除屏障,与 Dijistra 屏障相反,它是在堆指针指向的对象发生变化时,将之前指向的对象标灰:
+
+
+
+和 Dijistra 类似,也存在对象漏标问题:
+
+
diff --git a/generics.md b/generics.md
index caf2ba5..4a36142 100644
--- a/generics.md
+++ b/generics.md
@@ -40,3 +40,5 @@ cat source.go | genny gen "Something=string"
没有官方的泛型支持,社区怎么搞都是邪道。2021 年 1 月,官方的方案已经基本上成型,并释出了 [draft design](https://go.googlesource.com/proposal/+/refs/heads/master/design/go2draft-type-parameters.md)。
+
+
diff --git a/goroutine.md b/goroutine.md
index 0de6ace..38b020b 100644
--- a/goroutine.md
+++ b/goroutine.md
@@ -7,4 +7,6 @@
> Written with [StackEdit](https://stackedit.io/).
\ No newline at end of file
+-->
+
+
diff --git a/images/garbage_collection/barrier_asm.png b/images/garbage_collection/barrier_asm.png
new file mode 100644
index 0000000..5012031
Binary files /dev/null and b/images/garbage_collection/barrier_asm.png differ
diff --git a/images/garbage_collection/barrier_code.png b/images/garbage_collection/barrier_code.png
new file mode 100644
index 0000000..5f971b0
Binary files /dev/null and b/images/garbage_collection/barrier_code.png differ
diff --git a/interface.md b/interface.md
index 703507d..a365ff4 100644
--- a/interface.md
+++ b/interface.md
@@ -543,3 +543,5 @@ go.itab.*os.File,io.Writer SRODATA dupok size=32
// 下面就是正常流程了
```
+
+
diff --git a/io.md b/io.md
index 2bbac62..c15b884 100644
--- a/io.md
+++ b/io.md
@@ -193,4 +193,534 @@ vmtouch /disk/data/tmp/test
- https://tech.meituan.com/2017/05/19/about-desk-io.html
- https://github.com/ncw/directio
# DMA
-# Zero-Copy
\ No newline at end of file
+# Zero-Copy
+
+## splice
+在介绍 splice 及其在 golang 中的应用之前, 先从一段简单的网络代理代码开始入手
+#### read & write
+```go
+var (
+ p sync.Pool
+)
+
+func init() {
+ p.New = func() interface{} {
+ return make([]byte, DEFAULTSIZE)
+ }
+}
+// src 客户端 tcp 链接
+// dst mock server tcp 链接
+func normal(src, dst net.Conn) {
+ var bts []byte = p.Get().([]byte)
+ var bts2 []byte = p.Get().([]byte)
+ defer p.Put(bts)
+ defer p.Put(bts2)
+ // mock server to client
+ go func() {
+ for {
+ num, err := dst.Read(bts2[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = src.Write(bts2[num_write:num])
+ if err != nil {
+ return
+ }
+ num -= num_write
+ }
+ }
+ }()
+ // client to mock server
+ for {
+ num, err := src.Read(bts[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = dst.Write(bts[num_write:num])
+ if err != nil {
+ return
+ }
+ num -= num_write
+ }
+ }
+}
+```
+以上片段实现了一个简单的功能: 将客户端请求的 tcp 数据通过`read`系统调用读出放入本地用户空间 缓存, 而后再调用`write`发送给目标服务器,反之亦然
+
+整个过程如下图所示(暂不考虑 IO 模型调度以及 DMA 等细节部分)
+
+```shell
+[ user space ]
+
+ --------------------------------------------
+ | application |
+ --------------------------------------------
+ ····················|·································|··················
+ | read() | write()
+[ kernel space ] | |
+ ----------------- -----------------
+ | socket buffer | | socket buffer |
+ ----------------- -----------------
+ | copy |
+ ····················|·································|··················
+[ hardware sapce ] | |
+ ------------------------------------------------------
+ | network interface |
+ ------------------------------------------------------
+
+```
+对于透传或者部分透传(例如七层头部解析后透明代理请求体)之类的需求场景来说, 这种流程的成本无疑是很高的, 可以总结下涉及的几个浪费点
+
+- 数据需要从内核态拷贝到用户态
+- 应用层在 read 及 write 的过程中对这部分 byte 的操作开销(申请、释放、对象池维护等)
+
+#### splice 介绍
+```c
+/*
+ splice() moves data between two file descriptors without copying
+ between kernel address space and user address space. It
+ transfers up to len bytes of data from the file descriptor fd_in
+ to the file descriptor fd_out, where one of the file descriptors
+ must refer to a pipe.
+*/
+ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
+ off64_t *off_out, size_t len, unsigned int flags);
+```
+一句话概括就是, `splice` 不需要从内核空间复制这部分数据到用户空间就可以支持将数据从两个文件描述符之间进行转移, 不过两个描述符至少得有一个是 `pipe`, 以下列举如何利用`splice`完成 `socket->socket` 的数据代理
+
+example:
+```go
+func example(src, dst net.Conn) {
+ // 由于 src 及 dst 都是 socket, 没法直接使用 splice, 因此先创建临时 pipe
+ const flags = syscall.O_CLOEXEC | syscall.O_NONBLOCK
+ var fds [2]int // readfd, writefd
+ if err := syscall.Pipe2(fds[:], flags); err != nil {
+ panic(err)
+ }
+ // 使用完后关闭 pipe
+ defer syscall.Close(fds[0])
+ defer syscall.Close(fds[1])
+ // 获取 src fd
+ srcfile, err := src.(*net.TCPConn).File()
+ if err != nil {
+ panic(err)
+ }
+ srcfd := int(srcfile.Fd())
+ syscall.SetNonblock(srcfd, true)
+ ...
+ // 从 srcfd 读出, 写入 fds[1] (pipe write fd)
+ num, err := syscall.Splice(srcfd, nil, fds[1], nil, DEFAULTSIZE/* size to splice */, SPLICE_F_NONBLOCK)
+ ...
+}
+```
+此时的调用过程变为:
+
+```shell
+[ user space ]
+
+ -----------------------------------------------------------------------------------------------
+ | application |
+ -----------------------------------------------------------------------------------------------
+ ········································|····················|·····················|··································
+ | splice() | pipe() | splice()
+[ kernel space ] | | |
+ ----------------- ”copy“ ----------------------- ”copy“ -----------------
+ | socket buffer |· · · · · · · · · >| pipe writefd & readfd |· · · · · · · · >| socket buffer |
+ ----------------- ----------------------- -----------------
+ | copy |
+ ····················|··············································································|
+[ hardware sapce ] | |
+ -----------------------------------------------------------------------------------------------
+ | network interface |
+ -----------------------------------------------------------------------------------------------
+```
+此时产生的系统调用为
+- 首先 `pipe()` 调用, 创建临时管道
+- 调用 `splice()` 将 `srcfd` 数据 ”拷贝“ 到 `pipe`
+- 调用 `splice()` 将 `pipe` 中的数据 ”拷贝“ 到 `dstfd`
+
+可以注意到图中以及总结部分的”拷贝“给加了引号, 具体了解过`pipe`底层实现的小伙伴应该理解, 在这边简单表述下, `splice` 是基于 `pipe buffer` 实现的, 本质上在数据传输的时候并没有进行数据的拷贝, 而是仅仅将数据的内存地址等信息塞进了`pipe_buffer`中对应的字段
+
+至此, 完成了 kernel-user space 的拷贝优化, 不过可能细心的人会发现, 这种方式虽然减少了数据的拷贝, 但是同样额外增加了系统调用(create pipe & close pipe), 接下来就关于这部分的取舍与具体场景进行具体讨论
+
+#### splice 还是 read & write?
+如何取舍使用哪种方式?
+
+两种方法各有各的好处, 往往选择层面的考虑在于应用层的具体策略, 如是否进行透传(/部分), 饥饿问题, 对象池策略等等
+
+下面提供几种场景下的测试以供参考
+benchmark 代码:
+```go
+/*
+ * 测试环境: go 1.14.3 centos7
+ */
+package main
+
+import (
+ "bytes"
+ "io"
+ "net"
+ "net/http"
+ "sync"
+ "sync/atomic"
+ "testing"
+ "time"
+)
+
+var (
+ p sync.Pool
+)
+
+func init() {
+ p.New = func() interface{} {
+ return make([]byte, DEFAULTSIZE)
+ }
+}
+
+const (
+ // mock http 请求体大小
+ REQUESTBYTESIZE = 0
+ // 应用层对象池 byte 大小
+ DEFAULTSIZE = 1 << 10
+
+ SPLICE_F_MOVE = 0x1
+ SPLICE_F_NONBLOCK = 0x2
+ SPLICE_F_MORE = 0x4
+ SPLICE_F_GIFT = 0x8
+)
+// io.Copy 该场景下内部调用 splice syscall, 感兴趣的自行查看源码
+func gosplice(src, dst net.Conn) {
+ defer src.Close()
+ defer dst.Close()
+ go func() {
+ io.Copy(src, dst)
+ }()
+ io.Copy(dst, src)
+}
+
+func normal(src, dst net.Conn) {
+ defer src.Close()
+ defer dst.Close()
+ var bts []byte = p.Get().([]byte)
+ var bts2 []byte = p.Get().([]byte)
+ defer p.Put(bts)
+ defer p.Put(bts2)
+ go func() {
+ for {
+ num, err := dst.Read(bts2[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = src.Write(bts2[num_write:num])
+ num -= num_write
+ if err != nil {
+ return
+ }
+ }
+ }
+ }()
+ // local to mock serve
+ for {
+ num, err := src.Read(bts[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = dst.Write(bts[num_write:num])
+ num -= num_write
+ if err != nil {
+ return
+ }
+ }
+ }
+}
+
+// Server http server
+var Server *http.Server
+
+type s struct{}
+
+func (ss s) ServeHTTP(res http.ResponseWriter, req *http.Request) {
+ res.WriteHeader(200)
+ return
+}
+func TestMain(m *testing.M) {
+ // mock tcp server
+ var ss s
+ go func() {
+ Server = &http.Server{
+ Addr: "0.0.0.0:9610",
+ Handler: ss,
+ WriteTimeout: 60 * time.Second,
+ ReadTimeout: 60 * time.Second,
+ }
+ err := Server.ListenAndServe()
+ if err != nil {
+ panic(err)
+ }
+ }()
+ go func() { // normal 9611
+ l, err := net.ListenTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"),
+ Port: 9611,
+ })
+ if err != nil {
+ panic(err)
+ }
+ for {
+ n, err := l.Accept()
+ if err != nil {
+ continue
+ }
+ remote, err := net.DialTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 0,
+ }, &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 9610,
+ })
+ if err != nil {
+ continue
+ }
+ go normal(n, remote)
+ }
+ }()
+ go func() { // gosplice 9612
+ l, err := net.ListenTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"),
+ Port: 9612,
+ })
+ if err != nil {
+ panic(err)
+ }
+ for {
+ n, err := l.Accept()
+ if err != nil {
+ continue
+ }
+ remote, err := net.DialTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 0,
+ }, &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 9610,
+ })
+ if err != nil {
+ continue
+ }
+ go gosplice(n, remote)
+ }
+ }()
+ m.Run()
+}
+func BenchmarkNormalReadWrite(b *testing.B) {
+ // normal 9611
+ c := http.Client{
+ Timeout: time.Minute,
+ }
+ var total, success uint32
+ b.ResetTimer()
+ for i := 0; i < b.N; i++ {
+ atomic.AddUint32(&total, 1)
+ req, err := http.NewRequest("POST", "http://0.0.0.0:9611", bytes.NewReader(make([]byte, REQUESTBYTESIZE)))
+ if err != nil {
+ b.Fatalf("%s", err.Error())
+ }
+ res, err := c.Do(req)
+ if err == nil && res.StatusCode == 200 {
+ atomic.AddUint32(&success, 1)
+ }
+ c.CloseIdleConnections()
+ }
+ b.Logf("test:%s,total: %d,rate: %.2f%%\n", b.Name(), total, float64(success*100/total))
+}
+
+func BenchmarkGoSplice(b *testing.B) {
+ // normal 9612
+ c := http.Client{
+ Timeout: time.Minute,
+ }
+ var total, success uint32
+ b.ResetTimer()
+ for i := 0; i < b.N; i++ {
+ atomic.AddUint32(&total, 1)
+ req, err := http.NewRequest("POST", "http://0.0.0.0:9612", bytes.NewReader(make([]byte, REQUESTBYTESIZE)))
+ if err != nil {
+ b.Fatalf("%s", err.Error())
+ }
+ res, err := c.Do(req)
+ if err == nil && res.StatusCode == 200 {
+ atomic.AddUint32(&success, 1)
+ }
+ c.CloseIdleConnections()
+ }
+ b.Logf("test:%s, total: %d, success rate: %.2f%%\n", b.Name(), total, float64(success*100/total))
+}
+```
+- 场景一: 单次请求数据量较少, 应用维护单个 buffer 较小
+```go
+REQUESTBYTESIZE = 0 // http request body
+DEFAULTSIZE = 1 << 10 // buffer size 1kb
+```
+```shell
+RRunning tool: /usr/local/bin/go test -benchmem -run=^$ -bench ^(BenchmarkNormalReadWrite|BenchmarkGoSplice)$ barrier/t
+
+goos: linux
+goarch: amd64
+pkg: barrier/t
+BenchmarkNormalReadWrite-4 6348 179699 ns/op 4847 B/op 62 allocs/op
+--- BENCH: BenchmarkNormalReadWrite-4
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 1,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 100,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 6348,rate: 100.00%
+BenchmarkGoSplice-4 6652 179622 ns/op 4852 B/op 62 allocs/op
+--- BENCH: BenchmarkGoSplice-4
+ test_test.go:194: test:BenchmarkGoSplice, total: 1, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 100, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 6652, success rate: 100.00%
+PASS
+ok barrier/t 2.391s
+```
+两种方式无明显性能差异
+- 场景二: 单次请求数据量多, 应用维护单个 buffer 较小
+```go
+REQUESTBYTESIZE = 1 << 20 // 1 MB
+DEFAULTSIZE = 1 << 10 // buffer size 1kb
+```
+```shell
+Running tool: /usr/local/bin/go test -benchmem -run=^$ -bench ^(BenchmarkNormalReadWrite|BenchmarkGoSplice)$ barrier/t
+
+goos: linux
+goarch: amd64
+pkg: barrier/t
+BenchmarkNormalReadWrite-4 465 2329209 ns/op 1073956 B/op 163 allocs/op
+--- BENCH: BenchmarkNormalReadWrite-4
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 1,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 100,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 376,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 465,rate: 100.00%
+BenchmarkGoSplice-4 963 1555386 ns/op 1070506 B/op 157 allocs/op
+--- BENCH: BenchmarkGoSplice-4
+ test_test.go:194: test:BenchmarkGoSplice, total: 1, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 100, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 963, success rate: 100.00%
+PASS
+ok barrier/t 4.056s
+```
+当链接需要处理的数据量较多而应用层每次处理的 buffer 相比起来较小, 以至于需要 read & write 的次数更多的时候, 差异就会比较明显
+
+#### go 中的 splice
+在上面的介绍过程中简单说了下 `io.Copy` 在 `socket` 之间操作的时候, 当机器架构支持的时候会采取 `splice`, 接下来就此进行详细分析来介绍下 `runtime` 在 `splice` 上的一些决策以及当前`runtime`在 `splice` 上的一些不足
+```go
+/*
+ * src/net/spice_linux.go
+ */
+// splice transfers data from r to c using the splice system call to minimize
+// copies from and to userspace. c must be a TCP connection. Currently, splice
+// is only enabled if r is a TCP or a stream-oriented Unix connection.
+//
+// If splice returns handled == false, it has performed no work.
+func splice(c *netFD, r io.Reader) (written int64, err error, handled bool) {
+ /*
+ * 因为前面介绍过 splice 是通过 pipe buffer 实现的
+ * 在调用的时候 kernel无需进行数据拷贝, 仅操作数据原信息(基础字段的指针等)
+ * 所以这边默认 splice 的 len 开得比较大, 读到 EOF 为止
+ */
+ var remain int64 = 1 << 62 // by default, copy until EOF
+ lr, ok := r.(*io.LimitedReader)
+ if ok {
+ remain, r = lr.N, lr.R
+ if remain <= 0 {
+ return 0, nil, true
+ }
+ }
+
+ var s *netFD
+ if tc, ok := r.(*TCPConn); ok {
+ s = tc.fd
+ } else if uc, ok := r.(*UnixConn); ok {
+ if uc.fd.net != "unix" {
+ return 0, nil, false
+ }
+ s = uc.fd
+ } else {
+ return 0, nil, false
+ }
+
+ written, handled, sc, err := poll.Splice(&c.pfd, &s.pfd, remain)
+ if lr != nil {
+ lr.N -= written
+ }
+ return written, wrapSyscallError(sc, err), handled
+}
+```
+```go
+/*
+ * go 1.14.3
+ * src/internal/poll/splice_linux.go
+ */
+// Splice transfers at most remain bytes of data from src to dst, using the
+// splice system call to minimize copies of data from and to userspace.
+//
+// Splice creates a temporary pipe, to serve as a buffer for the data transfer.
+// src and dst must both be stream-oriented sockets.
+//
+// If err != nil, sc is the system call which caused the error.
+func Splice(dst, src *FD, remain int64) (written int64, handled bool, sc string, err error) {
+ // dst 以及 src 均为 socket.fd, 因此若想使用 splice 则需要借助 pipe
+ // 创建临时 pipe
+ prfd, pwfd, sc, err := newTempPipe()
+ if err != nil {
+ return 0, false, sc, err
+ }
+ defer destroyTempPipe(prfd, pwfd)
+ var inPipe, n int
+ for err == nil && remain > 0 {
+ max := maxSpliceSize
+ if int64(max) > remain {
+ max = int(remain)
+ }
+ // spliceDrain 调用 splice syscall
+ inPipe, err = spliceDrain(pwfd, src, max)
+ // The operation is considered handled if splice returns no
+ // error, or an error other than EINVAL. An EINVAL means the
+ // kernel does not support splice for the socket type of src.
+ // The failed syscall does not consume any data so it is safe
+ // to fall back to a generic copy.
+ //
+ // spliceDrain should never return EAGAIN, so if err != nil,
+ // Splice cannot continue.
+ //
+ // If inPipe == 0 && err == nil, src is at EOF, and the
+ // transfer is complete.
+ handled = handled || (err != syscall.EINVAL)
+ if err != nil || (inPipe == 0 && err == nil) {
+ break
+ }
+ // splicePump 调用 splice syscall
+ n, err = splicePump(dst, prfd, inPipe)
+ if n > 0 {
+ written += int64(n)
+ remain -= int64(n)
+ }
+ }
+ if err != nil {
+ return written, handled, "splice", err
+ }
+ return written, true, "", nil
+}
+```
+
+相信上面简短的分析大家也可以看到, 每次在进行 `splice` 的时候都会利用临时 `pipe`, 频繁的创建、销毁, 用户态-内核态的切换会带来非常多不必要的开销, 当前社区内也有关于 `splice temp-pipe` 生命周期的[讨论](https://go-review.googlesource.com/c/go/+/271537/)。
+
+再者, 因为当前关联到 `socket` 的 `splice` 实现在 `runtime` 层面和内置 `io 模型(epoll 等)`高度耦合, 基本无法解耦单独应用, 而如果想自己来实现 `splice(syscall.Splice)` 的话则不得不顺带在用户层面实现自己的`io 模型`再来使用, 会比较繁琐(上面测试用例使用内置 `splice api` 也是因为这个原因)
+
+## 参考资料
+
+- https://go-review.googlesource.com/c/go/+/271537/
+- https://zhuanlan.zhihu.com/p/308054212
+
+
diff --git a/lockfree.md b/lockfree.md
index f9c19d1..261e9cb 100644
--- a/lockfree.md
+++ b/lockfree.md
@@ -1,4 +1,6 @@
# lock free programming in Go
# 参考资料
-https://docs.google.com/presentation/d/1wuNNW-g6v8qizIc_IxAGZTj-49TODKF0TYddTA1VDUo/mobilepresent?slide=id.p
\ No newline at end of file
+https://docs.google.com/presentation/d/1wuNNW-g6v8qizIc_IxAGZTj-49TODKF0TYddTA1VDUo/mobilepresent?slide=id.p
+
+
diff --git a/map.md b/map.md
index 123cfd8..351146d 100644
--- a/map.md
+++ b/map.md
@@ -1267,3 +1267,5 @@ func (h *hmap) incrnoverflow() {
}
}
```
+
+
diff --git a/memory.md b/memory.md
index d71141a..b937fcf 100644
--- a/memory.md
+++ b/memory.md
@@ -1396,3 +1396,6 @@ func (p *notInHeap) add(bytes uintptr) *notInHeap {
### 堆外内存用法
嗯,堆外内存只是 runtime 自己玩的东西,用户态是使用不了的,属于 runtime 专用的 directive。
+
+
+
diff --git a/memory_barrier.md b/memory_barrier.md
index 94383c0..cc1a7ce 100644
--- a/memory_barrier.md
+++ b/memory_barrier.md
@@ -126,7 +126,7 @@ mesi 协议解决了多核环境下,内存多层级带来的问题。使得 ca
## CPU 导致乱序
-使用 litmus 进行形式化验证:
+使用 litmus 进行验证:
```
cat sb.litmus
@@ -181,6 +181,56 @@ Time SB 0.11
在两个核心上运行汇编指令,意料之外的情况 100w 次中出现了 96 次。虽然很少,但确实是客观存在的情况。
+有文档提到,x86 体系的内存序本身比较严格,除了 store-load 以外不存在其它类型的重排,也可以用下列脚本验证:
+
+```
+X86 RW
+{ x=0; y=0; }
+ P0 | P1 ;
+ MOV EAX,[y] | MOV EAX,[x] ;
+ MOV [x],$1 | MOV [y],$1 ;
+locations [x;y;]
+exists (0:EAX=1 /\ 1:EAX=1)
+```
+
+```
+%%%%%%%%%%%%%%%%%%%%%%%%%
+% Results for sb.litmus %
+%%%%%%%%%%%%%%%%%%%%%%%%%
+X86 OOO
+
+{x=0; y=0;}
+
+ P0 | P1 ;
+ MOV EAX,[y] | MOV EAX,[x] ;
+ MOV [x],$1 | MOV [y],$1 ;
+
+locations [x; y;]
+exists (0:EAX=1 /\ 1:EAX=1)
+Generated assembler
+ ##START _litmus_P0
+ movl -4(%rsi,%rcx,4), %eax
+ movl $1, -4(%rbx,%rcx,4)
+ ##START _litmus_P1
+ movl -4(%rbx,%rcx,4), %eax
+ movl $1, -4(%rsi,%rcx,4)
+
+Test OOO Allowed
+Histogram (2 states)
+500000:>0:EAX=1; 1:EAX=0; x=1; y=1;
+500000:>0:EAX=0; 1:EAX=1; x=1; y=1;
+No
+
+Witnesses
+Positive: 0, Negative: 1000000
+Condition exists (0:EAX=1 /\ 1:EAX=1) is NOT validated
+Hash=7cdd62e8647b817c1615cf8eb9d2117b
+Observation OOO Never 0 1000000
+Time OOO 0.14
+```
+
+无论运行多少次,Positive 应该都是 0。
+
## barrier
从功能上来讲,barrier 有四种:
@@ -519,3 +569,5 @@ https://stackoverflow.com/questions/29880015/lock-prefix-vs-mesi-protocol
https://github.com/torvalds/linux/blob/master/Documentation/memory-barriers.txt
http://www.overbyte.com.au/misc/Lesson3/CacheFun.html
+
+
diff --git a/netpoll.md b/netpoll.md
index 942adad..7ab59f9 100644
--- a/netpoll.md
+++ b/netpoll.md
@@ -1355,3 +1355,5 @@ func poll_runtime_pollUnblock(pd *pollDesc) {
}
}
```
+
+
diff --git a/panic.md b/panic.md
index 7765ec1..e34b3ad 100644
--- a/panic.md
+++ b/panic.md
@@ -295,4 +295,6 @@ func main() {
defer panic(2)
panic(1)
}
-```
\ No newline at end of file
+```
+
+
diff --git a/pprof.md b/pprof.md
new file mode 100644
index 0000000..f825a1a
--- /dev/null
+++ b/pprof.md
@@ -0,0 +1,778 @@
+# pprof
+> 本章节没有介绍具体 pprof 以及周边工具的使用, 而是进行了 runtime pprof 实现原理的分析, 旨在提供给读者一个使用方面的参考
+在进行深入本章节之前, 让我们来看三个问题, 相信下面这几个问题也是大部分人在使用 pprof 的时候对它最大的困惑, 那么可以带着这三个问题来进行接下去的分析
+- 开启 pprof 会对 runtime 产生多大的压力?
+- 能否选择性在合适阶段对生产环境的应用进行 pprof 的开启 / 关闭操作?
+- pprof 的原理是什么?
+
+go 内置的 `pprof API` 在 `runtime/pprof` 包内, 它提供给了用户与 `runtime` 交互的能力, 让我们能够在应用运行的过程中分析当前应用的各项指标来辅助进行性能优化以及问题排查, 当然也可以直接加载 `_ "net/http/pprof"` 包使用内置的 `http 接口` 来进行使用, `net` 模块内的 pprof 即为 go 替我们封装好的一系列调用 `runtime/pprof` 的方法, 当然也可以自己直接使用
+```go
+// src/runtime/pprof/pprof.go
+// 可观察类目
+profiles.m = map[string]*Profile{
+ "goroutine": goroutineProfile,
+ "threadcreate": threadcreateProfile,
+ "heap": heapProfile,
+ "allocs": allocsProfile,
+ "block": blockProfile,
+ "mutex": mutexProfile,
+ }
+```
+
+## allocs
+```go
+
+var allocsProfile = &Profile{
+ name: "allocs",
+ count: countHeap, // identical to heap profile
+ write: writeAlloc,
+}
+```
+- writeAlloc (主要涉及以下几个 api)
+ - ReadMemStats(m *MemStats)
+ - MemProfile(p []MemProfileRecord, inuseZero bool)
+
+```go
+// ReadMemStats populates m with memory allocator statistics.
+//
+// The returned memory allocator statistics are up to date as of the
+// call to ReadMemStats. This is in contrast with a heap profile,
+// which is a snapshot as of the most recently completed garbage
+// collection cycle.
+func ReadMemStats(m *MemStats) {
+ // STW 操作
+ stopTheWorld("read mem stats")
+ // systemstack 切换
+ systemstack(func() {
+ // 将 memstats 通过 copy 操作复制给 m
+ readmemstats_m(m)
+ })
+
+ startTheWorld()
+}
+```
+
+```go
+// MemProfile returns a profile of memory allocated and freed per allocation
+// site.
+//
+// MemProfile returns n, the number of records in the current memory profile.
+// If len(p) >= n, MemProfile copies the profile into p and returns n, true.
+// If len(p) < n, MemProfile does not change p and returns n, false.
+//
+// If inuseZero is true, the profile includes allocation records
+// where r.AllocBytes > 0 but r.AllocBytes == r.FreeBytes.
+// These are sites where memory was allocated, but it has all
+// been released back to the runtime.
+//
+// The returned profile may be up to two garbage collection cycles old.
+// This is to avoid skewing the profile toward allocations; because
+// allocations happen in real time but frees are delayed until the garbage
+// collector performs sweeping, the profile only accounts for allocations
+// that have had a chance to be freed by the garbage collector.
+//
+// Most clients should use the runtime/pprof package or
+// the testing package's -test.memprofile flag instead
+// of calling MemProfile directly.
+func MemProfile(p []MemProfileRecord, inuseZero bool) (n int, ok bool) {
+ lock(&proflock)
+ // If we're between mProf_NextCycle and mProf_Flush, take care
+ // of flushing to the active profile so we only have to look
+ // at the active profile below.
+ mProf_FlushLocked()
+ clear := true
+ /*
+ * 记住这个 mbuckets -- memory profile buckets
+ * allocs 的采样都是记录在这个全局变量内, 下面会进行详细分析
+ * -------------------------------------------------
+ * (gdb) info variables mbuckets
+ * All variables matching regular expression "mbuckets":
+
+ * File runtime:
+ * runtime.bucket *runtime.mbuckets;
+ * (gdb)
+ */
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ n++
+ }
+ if mp.active.allocs != 0 || mp.active.frees != 0 {
+ clear = false
+ }
+ }
+ if clear {
+ // Absolutely no data, suggesting that a garbage collection
+ // has not yet happened. In order to allow profiling when
+ // garbage collection is disabled from the beginning of execution,
+ // accumulate all of the cycles, and recount buckets.
+ n = 0
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ for c := range mp.future {
+ mp.active.add(&mp.future[c])
+ mp.future[c] = memRecordCycle{}
+ }
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ n++
+ }
+ }
+ }
+ if n <= len(p) {
+ ok = true
+ idx := 0
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ // mbuckets 数据拷贝
+ record(&p[idx], b)
+ idx++
+ }
+ }
+ }
+ unlock(&proflock)
+ return
+}
+```
+
+总结一下 `pprof/allocs` 所涉及的操作
+- 短暂的 `STW` 以及 `systemstack` 切换来获取 `runtime` 相关信息
+- 拷贝全局对象 `mbuckets` 值返回给用户
+
+### mbuckets
+上文提到, `pprof/allocs` 的核心在于对 `mbuckets` 的操作, 下面用一张图来简单描述下 `mbuckets` 的相关操作
+```go
+var mbuckets *bucket // memory profile buckets
+type bucket struct {
+ next *bucket
+ allnext *bucket
+ typ bucketType // memBucket or blockBucket (includes mutexProfile)
+ hash uintptr
+ size uintptr
+ nstk uintptr
+}
+```
+
+
+```shell
+ ---------------
+ | user access |
+ ---------------
+ |
+ ------------------ |
+| mbuckets list | copy |
+| (global) | -------------------------------------
+ ------------------
+ |
+ |
+ | create_or_get && insert_or_update bucket into mbuckets
+ |
+ |
+ --------------------------------------
+| func stkbucket & typ == memProfile |
+ --------------------------------------
+ |
+ ----------------
+ | mProf_Malloc | // 堆栈等信息记录
+ ----------------
+ |
+ ----------------
+ | profilealloc | // next_sample 计算
+ ----------------
+ |
+ | /*
+ | * if rate := MemProfileRate; rate > 0 {
+ | * if rate != 1 && size < c.next_sample {
+ | * c.next_sample -= size
+ | 采样 * } else {
+ | 记录 * mp := acquirem()
+ | * profilealloc(mp, x, size)
+ | * releasem(mp)
+ | * }
+ | * }
+ | */
+ |
+ ------------ 不采样
+ | mallocgc |-----------...
+ ------------
+```
+
+由上图我们可以清晰的看见, `runtime` 在内存分配的时候会根据一定策略进行采样, 记录到 `mbuckets` 中让用户得以进行分析, 而采样算法有个重要的依赖 `MemProfileRate`
+
+```go
+// MemProfileRate controls the fraction of memory allocations
+// that are recorded and reported in the memory profile.
+// The profiler aims to sample an average of
+// one allocation per MemProfileRate bytes allocated.
+//
+// To include every allocated block in the profile, set MemProfileRate to 1.
+// To turn off profiling entirely, set MemProfileRate to 0.
+//
+// The tools that process the memory profiles assume that the
+// profile rate is constant across the lifetime of the program
+// and equal to the current value. Programs that change the
+// memory profiling rate should do so just once, as early as
+// possible in the execution of the program (for example,
+// at the beginning of main).
+var MemProfileRate int = 512 * 1024
+```
+默认大小是 512 KB, 可以由用户自行配置.
+
+值的注意的是, 由于开启了 pprof 会产生一些采样的额外压力及开销, go 团队已经在较新的编译器中有选择地进行了这个变量的配置以[改变](https://go-review.googlesource.com/c/go/+/299671/8/src/runtime/mprof.go)默认开启的现状
+
+具体方式为代码未进行相关引用则编译器将初始值配置为 0, 否则则为默认(512 KB)
+
+(本文讨论的基于 1.14.3 版本, 如有差异请进行版本确认)
+
+#### pprof/allocs 总结
+- 开启后会对 runtime 产生额外压力, 采样时会在 `runtime malloc` 时记录额外信息以供后续分析
+- 可以人为选择是否开启, 以及采样频率, 通过设置 `runtime.MemProfileRate` 参数, 不同 go 版本存在差异(是否默认开启), 与用户代码内是否引用(linker)相关模块/变量有关, 默认大小为 512 KB
+
+`allocs` 部分还包含了 `heap` 情况的近似计算, 放在下一节分析
+## heap
+>allocs: A sampling of all past memory allocations
+
+>heap: A sampling of memory allocations of live objects. You can specify the gc GET parameter to run GC before taking the heap sample.
+
+对比下 `allocs` 和 `heap` 官方说明上的区别, 一个是分析所有内存分配的情况, 一个是当前 `heap` 上的分配情况. `heap` 还能使用额外参数运行一次 `GC` 后再进行分析
+
+看起来两者差别很大。。。不过实质上在代码层面两者除了一次 `GC` 可以人为调用以及生成的文件类型不同之外 (debug == 0 的时候) 之外没啥区别.
+
+### heap 采样(伪)
+```go
+// p 为上文提到过的 MemProfileRecord 采样记录
+for _, r := range p {
+ hideRuntime := true
+ for tries := 0; tries < 2; tries++ {
+ stk := r.Stack()
+ // For heap profiles, all stack
+ // addresses are return PCs, which is
+ // what appendLocsForStack expects.
+ if hideRuntime {
+ for i, addr := range stk {
+ if f := runtime.FuncForPC(addr); f != nil && strings.HasPrefix(f.Name(), "runtime.") {
+ continue
+ }
+ // Found non-runtime. Show any runtime uses above it.
+ stk = stk[i:]
+ break
+ }
+ }
+ locs = b.appendLocsForStack(locs[:0], stk)
+ if len(locs) > 0 {
+ break
+ }
+ hideRuntime = false // try again, and show all frames next time.
+ }
+ // rate 即为 runtime.MemProfileRate
+ values[0], values[1] = scaleHeapSample(r.AllocObjects, r.AllocBytes, rate)
+ values[2], values[3] = scaleHeapSample(r.InUseObjects(), r.InUseBytes(), rate)
+ var blockSize int64
+ if r.AllocObjects > 0 {
+ blockSize = r.AllocBytes / r.AllocObjects
+ }
+ b.pbSample(values, locs, func() {
+ if blockSize != 0 {
+ b.pbLabel(tagSample_Label, "bytes", "", blockSize)
+ }
+ })
+ }
+```
+```go
+// scaleHeapSample adjusts the data from a heap Sample to
+// account for its probability of appearing in the collected
+// data. heap profiles are a sampling of the memory allocations
+// requests in a program. We estimate the unsampled value by dividing
+// each collected sample by its probability of appearing in the
+// profile. heap profiles rely on a poisson process to determine
+// which samples to collect, based on the desired average collection
+// rate R. The probability of a sample of size S to appear in that
+// profile is 1-exp(-S/R).
+func scaleHeapSample(count, size, rate int64) (int64, int64) {
+ if count == 0 || size == 0 {
+ return 0, 0
+ }
+
+ if rate <= 1 {
+ // if rate==1 all samples were collected so no adjustment is needed.
+ // if rate<1 treat as unknown and skip scaling.
+ return count, size
+ }
+
+ avgSize := float64(size) / float64(count)
+ scale := 1 / (1 - math.Exp(-avgSize/float64(rate)))
+
+ return int64(float64(count) * scale), int64(float64(size) * scale)
+}
+```
+
+为什么要在标题里加个伪? 看上面代码片段也可以注意到, 实质上在 `pprof` 分析的时候并没有扫描所有堆上内存进行分析 (想想也不现实) , 而是通过之前采样出的数据, 进行计算 (现有对象数量, 大小, 采样率等) 来估算出 `heap` 上的情况, 当然给我们参考一般来说是足够了
+
+## goroutine
+- debug >= 2 的情况, 直接进行堆栈输出, 详情可以查看 [stack](runtime_stack.md) 章节
+
+```go
+// fetch == runtime.GoroutineProfile
+func writeRuntimeProfile(w io.Writer, debug int, name string, fetch func([]runtime.StackRecord) (int, bool)) error {
+ // Find out how many records there are (fetch(nil)),
+ // allocate that many records, and get the data.
+ // There's a race—more records might be added between
+ // the two calls—so allocate a few extra records for safety
+ // and also try again if we're very unlucky.
+ // The loop should only execute one iteration in the common case.
+ var p []runtime.StackRecord
+ n, ok := fetch(nil)
+ for {
+ // Allocate room for a slightly bigger profile,
+ // in case a few more entries have been added
+ // since the call to ThreadProfile.
+ p = make([]runtime.StackRecord, n+10)
+ n, ok = fetch(p)
+ if ok {
+ p = p[0:n]
+ break
+ }
+ // Profile grew; try again.
+ }
+
+ return printCountProfile(w, debug, name, runtimeProfile(p))
+}
+```
+
+```go
+// GoroutineProfile returns n, the number of records in the active goroutine stack profile.
+// If len(p) >= n, GoroutineProfile copies the profile into p and returns n, true.
+// If len(p) < n, GoroutineProfile does not change p and returns n, false.
+//
+// Most clients should use the runtime/pprof package instead
+// of calling GoroutineProfile directly.
+func GoroutineProfile(p []StackRecord) (n int, ok bool) {
+ gp := getg()
+
+ isOK := func(gp1 *g) bool {
+ // Checking isSystemGoroutine here makes GoroutineProfile
+ // consistent with both NumGoroutine and Stack.
+ return gp1 != gp && readgstatus(gp1) != _Gdead && !isSystemGoroutine(gp1, false)
+ }
+ // 熟悉的味道, STW 又来了
+ stopTheWorld("profile")
+ // 统计有多少 goroutine
+ n = 1
+ for _, gp1 := range allgs {
+ if isOK(gp1) {
+ n++
+ }
+ }
+ // 当传入的 p 非空的时候, 开始获取各个 goroutine 信息, 整体姿势和 stack api 几乎一模一样
+ if n <= len(p) {
+ ok = true
+ r := p
+
+ // Save current goroutine.
+ sp := getcallersp()
+ pc := getcallerpc()
+ systemstack(func() {
+ saveg(pc, sp, gp, &r[0])
+ })
+ r = r[1:]
+
+ // Save other goroutines.
+ for _, gp1 := range allgs {
+ if isOK(gp1) {
+ if len(r) == 0 {
+ // Should be impossible, but better to return a
+ // truncated profile than to crash the entire process.
+ break
+ }
+ saveg(^uintptr(0), ^uintptr(0), gp1, &r[0])
+ r = r[1:]
+ }
+ }
+ }
+
+ startTheWorld()
+
+ return n, ok
+}
+```
+总结下 `pprof/goroutine`
+- STW 操作, 如果需要观察详情的需要注意这个 API 带来的风险
+- 整体流程基本就是 stackdump 所有协程信息的流程, 差别不大没什么好讲的, 不熟悉的可以去看下 stack 对应章节
+
+## pprof/threadcreate
+可能会有人想问, 我们通常只关注 `goroutine` 就够了, 为什么还需要对线程的一些情况进行追踪? 例如无法被抢占的阻塞性[系统调用](syscall.md), `cgo` 相关的线程等等, 都可以利用它来进行一个简单的分析, 当然大多数情况考虑的线程问题(诸如泄露等), 一般都是上层的使用问题所导致的(线程泄露等)
+```go
+// 还是用之前用过的无法被抢占的阻塞性系统调用来进行一个简单的实验
+package main
+
+import (
+ "fmt"
+ "net/http"
+ _ "net/http/pprof"
+ "os"
+ "syscall"
+ "unsafe"
+)
+
+const (
+ SYS_futex = 202
+ _FUTEX_PRIVATE_FLAG = 128
+ _FUTEX_WAIT = 0
+ _FUTEX_WAKE = 1
+ _FUTEX_WAIT_PRIVATE = _FUTEX_WAIT | _FUTEX_PRIVATE_FLAG
+ _FUTEX_WAKE_PRIVATE = _FUTEX_WAKE | _FUTEX_PRIVATE_FLAG
+)
+
+func main() {
+ fmt.Println(os.Getpid())
+ go func() {
+ b := make([]byte, 1<<20)
+ _ = b
+ }()
+ for i := 1; i < 13; i++ {
+ go func() {
+ var futexVar int = 0
+ for {
+ // Syscall && RawSyscall, 具体差别分析可自行查看 syscall 章节
+ fmt.Println(syscall.Syscall6(
+ SYS_futex, // trap AX 202
+ uintptr(unsafe.Pointer(&futexVar)), // a1 DI 1
+ uintptr(_FUTEX_WAIT), // a2 SI 0
+ 0, // a3 DX
+ 0, //uintptr(unsafe.Pointer(&ts)), // a4 R10
+ 0, // a5 R8
+ 0))
+ }
+ }()
+ }
+ http.ListenAndServe("0.0.0.0:8899", nil)
+}
+```
+```shell
+# GET /debug/pprof/threadcreate?debug=1
+threadcreate profile: total 18
+17 @
+# 0x0
+
+1 @ 0x43b818 0x43bfa3 0x43c272 0x43857d 0x467fb1
+# 0x43b817 runtime.allocm+0x157 /usr/local/go/src/runtime/proc.go:1414
+# 0x43bfa2 runtime.newm+0x42 /usr/local/go/src/runtime/proc.go:1736
+# 0x43c271 runtime.startTemplateThread+0xb1 /usr/local/go/src/runtime/proc.go:1805
+# 0x43857c runtime.main+0x18c /usr/local/go/src/runtime/proc.go:186
+```
+```shell
+# 再结合诸如 pstack 的工具
+ps -efT | grep 22298 # pid = 22298
+root 22298 22298 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22299 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22300 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22301 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22302 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22303 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22304 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22305 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22306 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22307 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22308 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22309 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22310 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22311 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22312 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22316 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22317 13767 0 16:59 pts/4 00:00:00 ./mstest
+
+pstack 22299
+Thread 1 (process 22299):
+#0 runtime.futex () at /usr/local/go/src/runtime/sys_linux_amd64.s:568
+#1 0x00000000004326f4 in runtime.futexsleep (addr=0xb2fd78
diff --git a/readme.md b/readme.md
index cbd4555..d0c7ab2 100644
--- a/readme.md
+++ b/readme.md
@@ -29,6 +29,8 @@
23. [x] [stack dump](runtime_stack.md)
24. [x] [Atomic](atomic.md)
25. [ ] [Generics](generics.md)
+26. [x] [IO](io.md)
+26. [x] [pprof](pprof.md)
# Authors
diff --git a/scheduler.md b/scheduler.md
index ec9ed3e..7d4557b 100644
--- a/scheduler.md
+++ b/scheduler.md
@@ -1,4 +1,4 @@
-> 注: 在抢占式调度的 go 版本下如果需要对 runtime 进行调试,诸如使用 gdb, lldb, [delve](https://github.com/go-delve/delve) 等工具时,需要注意 GODEBUG=asyncpreemptoff=1 环境变量,该变量会导致 runtime 是否进行抢占式调度,由于 https://github.com/golang/go/issues/36494 ,导致部分系统下该变量会被一些(如 delve)工具配置开启,从而导致超出预期的调试情况,需要读者自行关注
+> 注: 在抢占式调度的 go 版本下如果需要对 runtime 进行调试,诸如使用 gdb, lldb, [delve](https://github.com/go-delve/delve) 等工具时,需要注意 GODEBUG=asyncpreemptoff=1 环境变量,该变量会决定 runtime 是否开启抢占式调度,由于 https://github.com/golang/go/issues/36494 ,导致部分系统下该变量会被一些(如 delve)工具配置开启,从而导致超出预期的调试情况,需要读者自行关注
# 调度
## 基本数据结构
@@ -752,6 +752,8 @@ runtime.gcenable --> main.init
main.init --> main.main
```
+**主线程也是需要和 p 绑定来运行的**,绑定过程在 procresize -> acquirep 中。
+
### sysmon 线程
sysmon 是在 `runtime.main` 中启动的,不过需要注意的是 sysmon 并不是在 m0 上执行的。因为:
@@ -2346,3 +2348,4 @@ gcMarkDone --> forEachP
当然,这里 entersyscall 和 entersyscallblock 比较特殊,虽然这俩函数的实现中有设置抢占标记,但实际上这两段逻辑是不会被走到的。因为 syscall 执行时是在 m 的 g0 栈上,如果在执行时被抢占,那么会直接 throw,而无法恢复。
+
diff --git a/select.md b/select.md
index 24d32d0..ed93053 100644
--- a/select.md
+++ b/select.md
@@ -826,3 +826,5 @@ sclose:
Q: 如果select多个channel,有一个channel触发了,其他channel的waitlist需要不要主动去除?还是一直在那等着?
A: waitlist 的出列是由 `func (q *waitq) dequeue() *sudog` 函数控制的,每个 sudog 携带了一个 `selectDone` 标志位,通过 `cas` 操作在每次 `dequeue` 的时候「惰性」去除队列中无效的元素
+
+
diff --git a/semaphore.md b/semaphore.md
index 4fbeddd..51d4640 100644
--- a/semaphore.md
+++ b/semaphore.md
@@ -236,7 +236,7 @@ func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags) {
// 高成本的情况:
// 增加 waiter count 的值
- // 再尝试调用一次 cansemacquire,成本了就直接返回
+ // 再尝试调用一次 cansemacquire,成功了就直接返回
// 没成功就把自己作为一个 waiter 入队
// sleep
// (之后 waiter 的 descriptor 被 signaler 用 dequeue 踢出)
@@ -735,4 +735,6 @@ func notifyListCheck(sz uintptr) {
func sync_nanotime() int64 {
return nanotime()
}
-```
\ No newline at end of file
+```
+
+
diff --git a/signal.md b/signal.md
deleted file mode 100644
index 09c2668..0000000
--- a/signal.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Signal
-
-Go 1.12 的抢占使用 signal 来实现,所以我们来分析一下 Go runtime 中是怎么处理这些 signal 的。
diff --git a/site/README.md b/site/README.md
new file mode 100644
index 0000000..f6a4c5e
--- /dev/null
+++ b/site/README.md
@@ -0,0 +1,3 @@
+# golang
+
+source of go.xargin.com
diff --git a/site/archetypes/default.md b/site/archetypes/default.md
new file mode 100644
index 0000000..00e77bd
--- /dev/null
+++ b/site/archetypes/default.md
@@ -0,0 +1,6 @@
+---
+title: "{{ replace .Name "-" " " | title }}"
+date: {{ .Date }}
+draft: true
+---
+
diff --git a/site/config.toml b/site/config.toml
new file mode 100644
index 0000000..80f33af
--- /dev/null
+++ b/site/config.toml
@@ -0,0 +1,6 @@
+baseURL = "http://go.xargin.com/"
+languageCode = "en-us"
+title = "Go 语言笔记"
+theme = "book"
+googleAnalytics = "G-KLR638LKEQ"
+
diff --git a/site/content/_index.md b/site/content/_index.md
new file mode 100644
index 0000000..e5fb159
--- /dev/null
+++ b/site/content/_index.md
@@ -0,0 +1,13 @@
+---
+title: Go 语言笔记
+type: docs
+---
+
+# Go 语言笔记
+
+## 为什么会有这本书
+
+之前关于 Go 的输出主要散落在 blog 和 github 的 golang-notes 以及公众号中,内容比较分散。不方便阅读,到了这个时间点,本人已经使用 Go 已有超过 6 个年头,可以将之前的输出集合起来,进行系统化的输出了。
+
+
+
diff --git a/site/content/docs/_index.md b/site/content/docs/_index.md
new file mode 100644
index 0000000..e69de29
diff --git a/site/content/docs/api_programming/_index.md b/site/content/docs/api_programming/_index.md
new file mode 100644
index 0000000..7718841
--- /dev/null
+++ b/site/content/docs/api_programming/_index.md
@@ -0,0 +1,6 @@
+---
+title: API 开发
+weight: 5
+bookCollapseSection: true
+draft: true
+---
diff --git a/site/content/docs/api_programming/fasthttp.md b/site/content/docs/api_programming/fasthttp.md
new file mode 100644
index 0000000..a886942
--- /dev/null
+++ b/site/content/docs/api_programming/fasthttp.md
@@ -0,0 +1,2 @@
+# FastHTTP
+
diff --git a/site/content/docs/api_programming/httprouter.md b/site/content/docs/api_programming/httprouter.md
new file mode 100644
index 0000000..bc5ea15
--- /dev/null
+++ b/site/content/docs/api_programming/httprouter.md
@@ -0,0 +1 @@
+# http router 的实现
diff --git a/site/content/docs/api_programming/mysql.md b/site/content/docs/api_programming/mysql.md
new file mode 100644
index 0000000..c64321e
--- /dev/null
+++ b/site/content/docs/api_programming/mysql.md
@@ -0,0 +1 @@
+# mysql
diff --git a/site/content/docs/api_programming/orm.md b/site/content/docs/api_programming/orm.md
new file mode 100644
index 0000000..c69e1ca
--- /dev/null
+++ b/site/content/docs/api_programming/orm.md
@@ -0,0 +1 @@
+# orm && sql builder
diff --git a/site/content/docs/api_programming/validator.md b/site/content/docs/api_programming/validator.md
new file mode 100644
index 0000000..76a423c
--- /dev/null
+++ b/site/content/docs/api_programming/validator.md
@@ -0,0 +1 @@
+# validator
diff --git a/site/content/docs/api_programming/viper.md b/site/content/docs/api_programming/viper.md
new file mode 100644
index 0000000..63d973f
--- /dev/null
+++ b/site/content/docs/api_programming/viper.md
@@ -0,0 +1 @@
+# viper
diff --git a/site/content/docs/assembly/_index.md b/site/content/docs/assembly/_index.md
new file mode 100644
index 0000000..18a2318
--- /dev/null
+++ b/site/content/docs/assembly/_index.md
@@ -0,0 +1,6 @@
+---
+title: 汇编基础
+weight: 1
+bookCollapseSection: true
+---
+
diff --git a/site/content/docs/assembly/assembly.md b/site/content/docs/assembly/assembly.md
new file mode 100644
index 0000000..22fef9c
--- /dev/null
+++ b/site/content/docs/assembly/assembly.md
@@ -0,0 +1,1006 @@
+---
+title: Plan9 汇编解析
+weight: 10
+---
+
+# plan9 assembly 完全解析
+
+众所周知,Go 使用了 Unix 老古董(误 们发明的 plan9 汇编。就算你对 x86 汇编有所了解,在 plan9 里还是有些许区别。说不定你在看代码的时候,偶然发现代码里的 SP 看起来是 SP,但它实际上不是 SP 的时候就抓狂了哈哈哈。
+
+本文将对 plan9 汇编进行全面的介绍,同时解答你在接触 plan9 汇编时可能遇到的大部分问题。
+
+本文所使用的平台是 linux amd64,因为不同的平台指令集和寄存器都不一样,所以没有办法共同探讨。这也是由汇编本身的性质决定的。
+
+## 基本指令
+
+### 栈调整
+
+intel 或 AT&T 汇编提供了 push 和 pop 指令族,~~plan9 中没有 push 和 pop~~,plan9 中虽然有 push 和 pop 指令,但一般生成的代码中是没有的,我们看到的栈的调整大多是通过对硬件 SP 寄存器进行运算来实现的,例如:
+
+```go
+SUBQ $0x18, SP // 对 SP 做减法,为函数分配函数栈帧
+... // 省略无用代码
+ADDQ $0x18, SP // 对 SP 做加法,清除函数栈帧
+```
+
+通用的指令和 X64 平台差不多,下面分节详述。
+
+### 数据搬运
+
+常数在 plan9 汇编用 $num 表示,可以为负数,默认情况下为十进制。可以用 $0x123 的形式来表示十六进制数。
+
+```go
+MOVB $1, DI // 1 byte
+MOVW $0x10, BX // 2 bytes
+MOVD $1, DX // 4 bytes
+MOVQ $-10, AX // 8 bytes
+```
+
+可以看到,搬运的长度是由 MOV 的后缀决定的,这一点与 intel 汇编稍有不同,看看类似的 X64 汇编:
+
+```asm
+mov rax, 0x1 // 8 bytes
+mov eax, 0x100 // 4 bytes
+mov ax, 0x22 // 2 bytes
+mov ah, 0x33 // 1 byte
+mov al, 0x44 // 1 byte
+```
+
+plan9 的汇编的操作数的方向是和 intel 汇编相反的,与 AT&T 类似。
+
+```go
+MOVQ $0x10, AX ===== mov rax, 0x10
+ | |------------| |
+ |------------------------|
+```
+
+不过凡事总有例外,如果想了解这种意外,可以参见参考资料中的 [1]。
+
+### 常见计算指令
+
+```go
+ADDQ AX, BX // BX += AX
+SUBQ AX, BX // BX -= AX
+IMULQ AX, BX // BX *= AX
+```
+
+类似数据搬运指令,同样可以通过修改指令的后缀来对应不同长度的操作数。例如 ADDQ/ADDW/ADDL/ADDB。
+
+### 条件跳转/无条件跳转
+
+```go
+// 无条件跳转
+JMP addr // 跳转到地址,地址可为代码中的地址,不过实际上手写不会出现这种东西
+JMP label // 跳转到标签,可以跳转到同一函数内的标签位置
+JMP 2(PC) // 以当前指令为基础,向前/后跳转 x 行
+JMP -2(PC) // 同上
+
+// 有条件跳转
+JZ target // 如果 zero flag 被 set 过,则跳转
+
+```
+
+
+### 指令集
+
+可以参考源代码的 [arch](https://github.com/golang/arch/blob/master/x86/x86.csv) 部分。
+
+额外提一句,Go 1.10 添加了大量的 SIMD 指令支持,所以在该版本以上的话,不像之前写那样痛苦了,也就是不用人肉填 byte 了。
+
+## 寄存器
+
+### 通用寄存器
+
+amd64 的通用寄存器:
+
+```gdb
+(lldb) reg read
+General Purpose Registers:
+ rax = 0x0000000000000005
+ rbx = 0x000000c420088000
+ rcx = 0x0000000000000000
+ rdx = 0x0000000000000000
+ rdi = 0x000000c420088008
+ rsi = 0x0000000000000000
+ rbp = 0x000000c420047f78
+ rsp = 0x000000c420047ed8
+ r8 = 0x0000000000000004
+ r9 = 0x0000000000000000
+ r10 = 0x000000c420020001
+ r11 = 0x0000000000000202
+ r12 = 0x0000000000000000
+ r13 = 0x00000000000000f1
+ r14 = 0x0000000000000011
+ r15 = 0x0000000000000001
+ rip = 0x000000000108ef85 int`main.main + 213 at int.go:19
+ rflags = 0x0000000000000212
+ cs = 0x000000000000002b
+ fs = 0x0000000000000000
+ gs = 0x0000000000000000
+```
+
+在 plan9 汇编里都是可以使用的,应用代码层面会用到的通用寄存器主要是: rax, rbx, rcx, rdx, rdi, rsi, r8~r15 这 14 个寄存器,虽然 rbp 和 rsp 也可以用,不过 bp 和 sp 会被用来管理栈顶和栈底,最好不要拿来进行运算。
+
+plan9 中使用寄存器不需要带 r 或 e 的前缀,例如 rax,只要写 AX 即可:
+
+```go
+MOVQ $101, AX = mov rax, 101
+```
+
+下面是通用通用寄存器的名字在 X64 和 plan9 中的对应关系:
+
+| X64 | rax | rbx| rcx | rdx | rdi | rsi | rbp | rsp | r8 | r9 | r10 | r11 | r12 | r13 | r14 | rip|
+|--|--|--|--| --| --|--| --|--|--|--|--|--|--|--|--|--|
+| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
+
+### 伪寄存器
+
+Go 的汇编还引入了 4 个伪寄存器,援引官方文档的描述:
+
+>- `FP`: Frame pointer: arguments and locals.
+>- `PC`: Program counter: jumps and branches.
+>- `SB`: Static base pointer: global symbols.
+>- `SP`: Stack pointer: the highest address within the local stack frame.
+
+官方的描述稍微有一些问题,我们对这些说明进行一点扩充:
+
+- FP: 使用形如 `symbol+offset(FP)` 的方式,引用函数的输入参数。例如 `arg0+0(FP)`,`arg1+8(FP)`,使用 FP 不加 symbol 时,无法通过编译,在汇编层面来讲,symbol 并没有什么用,加 symbol 主要是为了提升代码可读性。另外,官方文档虽然将伪寄存器 FP 称之为 frame pointer,实际上它根本不是 frame pointer,按照传统的 x86 的习惯来讲,frame pointer 是指向整个 stack frame 底部的 BP 寄存器。假如当前的 callee 函数是 add,在 add 的代码中引用 FP,该 FP 指向的位置不在 callee 的 stack frame 之内,而是在 caller 的 stack frame 上。具体可参见之后的 **栈结构** 一章。
+- PC: 实际上就是在体系结构的知识中常见的 pc 寄存器,在 x86 平台下对应 ip 寄存器,amd64 上则是 rip。除了个别跳转之外,手写 plan9 代码与 PC 寄存器打交道的情况较少。
+- SB: 全局静态基指针,一般用来声明函数或全局变量,在之后的函数知识和示例部分会看到具体用法。
+- SP: plan9 的这个 SP 寄存器指向当前栈帧的局部变量的开始位置,使用形如 `symbol+offset(SP)` 的方式,引用函数的局部变量。offset 的合法取值是 [-framesize, 0),注意是个左闭右开的区间。假如局部变量都是 8 字节,那么第一个局部变量就可以用 `localvar0-8(SP)` 来表示。这也是一个词不表意的寄存器。与硬件寄存器 SP 是两个不同的东西,在栈帧 size 为 0 的情况下,伪寄存器 SP 和硬件寄存器 SP 指向同一位置。手写汇编代码时,如果是 `symbol+offset(SP)` 形式,则表示伪寄存器 SP。如果是 `offset(SP)` 则表示硬件寄存器 SP。务必注意。对于编译输出(go tool compile -S / go tool objdump)的代码来讲,目前所有的 SP 都是硬件寄存器 SP,无论是否带 symbol。
+
+我们这里对容易混淆的几点简单进行说明:
+
+1. 伪 SP 和硬件 SP 不是一回事,在手写代码时,伪 SP 和硬件 SP 的区分方法是看该 SP 前是否有 symbol。如果有 symbol,那么即为伪寄存器,如果没有,那么说明是硬件 SP 寄存器。
+2. SP 和 FP 的相对位置是会变的,所以不应该尝试用伪 SP 寄存器去找那些用 FP + offset 来引用的值,例如函数的入参和返回值。
+3. 官方文档中说的伪 SP 指向 stack 的 top,是有问题的。其指向的局部变量位置实际上是整个栈的栈底(除 caller BP 之外),所以说 bottom 更合适一些。
+4. 在 go tool objdump/go tool compile -S 输出的代码中,是没有伪 SP 和 FP 寄存器的,我们上面说的区分伪 SP 和硬件 SP 寄存器的方法,对于上述两个命令的输出结果是没法使用的。在编译和反汇编的结果中,只有真实的 SP 寄存器。
+5. FP 和 Go 的官方源代码里的 framepointer 不是一回事,源代码里的 framepointer 指的是 caller BP 寄存器的值,在这里和 caller 的伪 SP 是值是相等的。
+
+以上说明看不懂也没关系,在熟悉了函数的栈结构之后再反复回来查看应该就可以明白了。
+
+## 变量声明
+
+在汇编里所谓的变量,一般是存储在 .rodata 或者 .data 段中的只读值。对应到应用层的话,就是已初始化过的全局的 const、var、static 变量/常量。
+
+使用 DATA 结合 GLOBL 来定义一个变量。DATA 的用法为:
+
+```go
+DATA symbol+offset(SB)/width, value
+```
+
+大多数参数都是字面意思,不过这个 offset 需要稍微注意。其含义是该值相对于符号 symbol 的偏移,而不是相对于全局某个地址的偏移。
+
+使用 GLOBL 指令将变量声明为 global,额外接收两个参数,一个是 flag,另一个是变量的总大小。
+
+```go
+GLOBL divtab(SB), RODATA, $64
+```
+
+GLOBL 必须跟在 DATA 指令之后,下面是一个定义了多个 readonly 的全局变量的完整例子:
+
+```go
+DATA age+0x00(SB)/4, $18 // forever 18
+GLOBL age(SB), RODATA, $4
+
+DATA pi+0(SB)/8, $3.1415926
+GLOBL pi(SB), RODATA, $8
+
+DATA birthYear+0(SB)/4, $1988
+GLOBL birthYear(SB), RODATA, $4
+```
+
+正如之前所说,所有符号在声明时,其 offset 一般都是 0。
+
+有时也可能会想在全局变量中定义数组,或字符串,这时候就需要用上非 0 的 offset 了,例如:
+
+```go
+DATA bio<>+0(SB)/8, $"oh yes i"
+DATA bio<>+8(SB)/8, $"am here "
+GLOBL bio<>(SB), RODATA, $16
+```
+
+大部分都比较好理解,不过这里我们又引入了新的标记 `<>`,这个跟在符号名之后,表示该全局变量只在当前文件中生效,类似于 C 语言中的 static。如果在另外文件中引用该变量的话,会报 `relocation target not found` 的错误。
+
+本小节中提到的 flag,还可以有其它的取值:
+>- `NOPROF` = 1
+ (For `TEXT` items.) Don't profile the marked function. This flag is deprecated.
+>- `DUPOK` = 2
+ It is legal to have multiple instances of this symbol in a single binary. The linker will choose one of the duplicates to use.
+>- `NOSPLIT` = 4
+ (For `TEXT` items.) Don't insert the preamble to check if the stack must be split. The frame for the routine, plus anything it calls, must fit in the spare space at the top of the stack segment. Used to protect routines such as the stack splitting code itself.
+>- `RODATA` = 8
+ (For `DATA` and `GLOBL` items.) Put this data in a read-only section.
+>- `NOPTR` = 16
+ (For `DATA` and `GLOBL` items.) This data contains no pointers and therefore does not need to be scanned by the garbage collector.
+>- `WRAPPER` = 32
+ (For `TEXT` items.) This is a wrapper function and should not count as disabling `recover`.
+>- `NEEDCTXT` = 64
+ (For `TEXT` items.) This function is a closure so it uses its incoming context register.
+
+当使用这些 flag 的字面量时,需要在汇编文件中 `#include "textflag.h"`。
+
+## .s 和 .go 文件的全局变量互通
+
+在 `.s` 文件中是可以直接使用 `.go` 中定义的全局变量的,看看下面这个简单的例子:
+
+refer.go:
+
+```go
+package main
+
+var a = 999
+func get() int
+
+func main() {
+ println(get())
+}
+
+```
+
+refer.s:
+
+```go
+#include "textflag.h"
+
+TEXT ·get(SB), NOSPLIT, $0-8
+ MOVQ ·a(SB), AX
+ MOVQ AX, ret+0(FP)
+ RET
+```
+
+·a(SB),表示该符号需要链接器来帮我们进行重定向(relocation),如果找不到该符号,会输出 `relocation target not found` 的错误。
+
+例子比较简单,大家可以自行尝试。
+
+## 函数声明
+
+我们来看看一个典型的 plan9 的汇编函数的定义:
+
+```go
+// func add(a, b int) int
+// => 该声明定义在同一个 package 下的任意 .go 文件中
+// => 只有函数头,没有实现
+TEXT pkgname·add(SB), NOSPLIT, $0-8
+ MOVQ a+0(FP), AX
+ MOVQ a+8(FP), BX
+ ADDQ AX, BX
+ MOVQ BX, ret+16(FP)
+ RET
+```
+
+为什么要叫 TEXT ?如果对程序数据在文件中和内存中的分段稍有了解的同学应该知道,我们的代码在二进制文件中,是存储在 .text 段中的,这里也就是一种约定俗成的起名方式。实际上在 plan9 中 TEXT 是一个指令,用来定义一个函数。除了 TEXT 之外还有前面变量声明说到的 DATA/GLOBL。
+
+定义中的 pkgname 部分是可以省略的,非想写也可以写上。不过写上 pkgname 的话,在重命名 package 之后还需要改代码,所以推荐最好还是不要写。
+
+中点 `·` 比较特殊,是一个 unicode 的中点,该点在 mac 下的输入方法是 `option+shift+9`。在程序被链接之后,所有的中点`·` 都会被替换为句号`.`,比如你的方法是 `runtime·main`,在编译之后的程序里的符号则是 `runtime.main`。嗯,看起来很变态。简单总结一下:
+
+```go
+
+ 参数及返回值大小
+ |
+ TEXT pkgname·add(SB),NOSPLIT,$32-32
+ | | |
+ 包名 函数名 栈帧大小(局部变量+可能需要的额外调用函数的参数空间的总大小,但不包括调用其它函数时的 ret address 的大小)
+
+```
+
+## 栈结构
+
+下面是一个典型的函数的栈结构图:
+
+```
+
+ -----------------
+ current func arg0
+ ----------------- <----------- FP(pseudo FP)
+ caller ret addr
+ +---------------+
+ | caller BP(*) |
+ ----------------- <----------- SP(pseudo SP,实际上是当前栈帧的 BP 位置)
+ | Local Var0 |
+ -----------------
+ | Local Var1 |
+ -----------------
+ | Local Var2 |
+ ----------------- -
+ | ........ |
+ -----------------
+ | Local VarN |
+ -----------------
+ | |
+ | |
+ | temporarily |
+ | unused space |
+ | |
+ | |
+ -----------------
+ | call retn |
+ -----------------
+ | call ret(n-1)|
+ -----------------
+ | .......... |
+ -----------------
+ | call ret1 |
+ -----------------
+ | call argn |
+ -----------------
+ | ..... |
+ -----------------
+ | call arg3 |
+ -----------------
+ | call arg2 |
+ |---------------|
+ | call arg1 |
+ ----------------- <------------ hardware SP 位置
+ return addr
+ +---------------+
+
+
+```
+
+从原理上来讲,如果当前函数调用了其它函数,那么 return addr 也是在 caller 的栈上的,不过往栈上插 return addr 的过程是由 CALL 指令完成的,在 RET 时,SP 又会恢复到图上位置。我们在计算 SP 和参数相对位置时,可以认为硬件 SP 指向的就是图上的位置。
+
+图上的 caller BP,指的是 caller 的 BP 寄存器值,有些人把 caller BP 叫作 caller 的 frame pointer,实际上这个习惯是从 x86 架构沿袭来的。Go 的 asm 文档中把伪寄存器 FP 也称为 frame pointer,但是这两个 frame pointer 根本不是一回事。
+
+此外需要注意的是,caller BP 是在编译期由编译器插入的,用户手写代码时,计算 frame size 时是不包括这个 caller BP 部分的。是否插入 caller BP 的主要判断依据是:
+
+1. 函数的栈帧大小大于 0
+2. 下述函数返回 true
+
+```go
+func Framepointer_enabled(goos, goarch string) bool {
+ return framepointer_enabled != 0 && goarch == "amd64" && goos != "nacl"
+}
+```
+
+如果编译器在最终的汇编结果中没有插入 caller BP(源代码中所称的 frame pointer)的情况下,伪 SP 和伪 FP 之间只有 8 个字节的 caller 的 return address,而插入了 BP 的话,就会多出额外的 8 字节。也就说伪 SP 和伪 FP 的相对位置是不固定的,有可能是间隔 8 个字节,也有可能间隔 16 个字节。并且判断依据会根据平台和 Go 的版本有所不同。
+
+图上可以看到,FP 伪寄存器指向函数的传入参数的开始位置,因为栈是朝低地址方向增长,为了通过寄存器引用参数时方便,所以参数的摆放方向和栈的增长方向是相反的,即:
+
+```shell
+ FP
+high ----------------------> low
+argN, ... arg3, arg2, arg1, arg0
+```
+
+假设所有参数均为 8 字节,这样我们就可以用 symname+0(FP) 访问第一个 参数,symname+8(FP) 访问第二个参数,以此类推。用伪 SP 来引用局部变量,原理上来讲差不多,不过因为伪 SP 指向的是局部变量的底部,所以 symname-8(SP) 表示的是第一个局部变量,symname-16(SP)表示第二个,以此类推。当然,这里假设局部变量都占用 8 个字节。
+
+图的最上部的 caller return address 和 current func arg0 都是由 caller 来分配空间的。不算在当前的栈帧内。
+
+因为官方文档本身较模糊,我们来一个函数调用的全景图,来看一下这些真假 SP/FP/BP 到底是个什么关系:
+
+```
+
+ caller
+ +------------------+
+ | |
+ +----------------------> --------------------
+ | | |
+ | | caller parent BP |
+ | BP(pseudo SP) --------------------
+ | | |
+ | | Local Var0 |
+ | --------------------
+ | | |
+ | | ....... |
+ | --------------------
+ | | |
+ | | Local VarN |
+ --------------------
+ caller stack frame | |
+ | callee arg2 |
+ | |------------------|
+ | | |
+ | | callee arg1 |
+ | |------------------|
+ | | |
+ | | callee arg0 |
+ | ----------------------------------------------+ FP(virtual register)
+ | | | |
+ | | return addr | parent return address |
+ +----------------------> +------------------+--------------------------- <-------------------------------+
+ | caller BP | |
+ | (caller frame pointer) | |
+ BP(pseudo SP) ---------------------------- |
+ | | |
+ | Local Var0 | |
+ ---------------------------- |
+ | |
+ | Local Var1 |
+ ---------------------------- callee stack frame
+ | |
+ | ..... |
+ ---------------------------- |
+ | | |
+ | Local VarN | |
+ SP(Real Register) ---------------------------- |
+ | | |
+ | | |
+ | | |
+ | | |
+ | | |
+ +--------------------------+ <-------------------------------+
+
+ callee
+```
+
+## argsize 和 framesize 计算规则
+
+### argsize
+
+在函数声明中:
+
+```go
+ TEXT pkgname·add(SB),NOSPLIT,$16-32
+```
+
+前面已经说过 $16-32 表示 $framesize-argsize。Go 在函数调用时,参数和返回值都需要由 caller 在其栈帧上备好空间。callee 在声明时仍然需要知道这个 argsize。argsize 的计算方法是,参数大小求和+返回值大小求和,例如入参是 3 个 int64 类型,返回值是 1 个 int64 类型,那么这里的 argsize = sizeof(int64) * 4。
+
+不过真实世界永远没有我们假设的这么美好,函数参数往往混合了多种类型,还需要考虑内存对齐问题。
+
+如果不确定自己的函数签名需要多大的 argsize,可以通过简单实现一个相同签名的空函数,然后 go tool objdump 来逆向查找应该分配多少空间。
+
+### framesize
+
+函数的 framesize 就稍微复杂一些了,手写代码的 framesize 不需要考虑由编译器插入的 caller BP,要考虑:
+
+1. 局部变量,及其每个变量的 size。
+2. 在函数中是否有对其它函数调用时,如果有的话,调用时需要将 callee 的参数、返回值考虑在内。虽然 return address(rip)的值也是存储在 caller 的 stack frame 上的,但是这个过程是由 CALL 指令和 RET 指令完成 PC 寄存器的保存和恢复的,在手写汇编时,同样也是不需要考虑这个 PC 寄存器在栈上所需占用的 8 个字节的。
+3. 原则上来说,调用函数时只要不把局部变量覆盖掉就可以了。稍微多分配几个字节的 framesize 也不会死。
+4. 在确保逻辑没有问题的前提下,你愿意覆盖局部变量也没有问题。只要保证进入和退出汇编函数时的 caller 和 callee 能正确拿到返回值就可以。
+
+## 地址运算
+
+地址运算也是用 lea 指令,英文原意为 `Load Effective Address`,amd64 平台地址都是 8 个字节,所以直接就用 LEAQ 就好:
+
+```go
+LEAQ (BX)(AX*8), CX
+// 上面代码中的 8 代表 scale
+// scale 只能是 0、2、4、8
+// 如果写成其它值:
+// LEAQ (BX)(AX*3), CX
+// ./a.s:6: bad scale: 3
+
+// 用 LEAQ 的话,即使是两个寄存器值直接相加,也必须提供 scale
+// 下面这样是不行的
+// LEAQ (BX)(AX), CX
+// asm: asmidx: bad address 0/2064/2067
+// 正确的写法是
+LEAQ (BX)(AX*1), CX
+
+
+// 在寄存器运算的基础上,可以加上额外的 offset
+LEAQ 16(BX)(AX*1), CX
+
+// 三个寄存器做运算,还是别想了
+// LEAQ DX(BX)(AX*8), CX
+// ./a.s:13: expected end of operand, found (
+```
+
+使用 LEAQ 的好处也比较明显,可以节省指令数。如果用基本算术指令来实现 LEAQ 的功能,需要两~三条以上的计算指令才能实现 LEAQ 的完整功能。
+
+## 示例
+
+### add/sub/mul
+
+math.go:
+
+```go
+package main
+
+import "fmt"
+
+func add(a, b int) int // 汇编函数声明
+
+func sub(a, b int) int // 汇编函数声明
+
+func mul(a, b int) int // 汇编函数声明
+
+func main() {
+ fmt.Println(add(10, 11))
+ fmt.Println(sub(99, 15))
+ fmt.Println(mul(11, 12))
+}
+```
+
+math.s:
+
+```go
+#include "textflag.h" // 因为我们声明函数用到了 NOSPLIT 这样的 flag,所以需要将 textflag.h 包含进来
+
+// func add(a, b int) int
+TEXT ·add(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX // 参数 a
+ MOVQ b+8(FP), BX // 参数 b
+ ADDQ BX, AX // AX += BX
+ MOVQ AX, ret+16(FP) // 返回
+ RET
+
+// func sub(a, b int) int
+TEXT ·sub(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX
+ MOVQ b+8(FP), BX
+ SUBQ BX, AX // AX -= BX
+ MOVQ AX, ret+16(FP)
+ RET
+
+// func mul(a, b int) int
+TEXT ·mul(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX
+ MOVQ b+8(FP), BX
+ IMULQ BX, AX // AX *= BX
+ MOVQ AX, ret+16(FP)
+ RET
+ // 最后一行的空行是必须的,否则可能报 unexpected EOF
+```
+
+把这两个文件放在任意目录下,执行 `go build` 并运行就可以看到效果了。
+
+### 伪寄存器 SP 、伪寄存器 FP 和硬件寄存器 SP
+
+来写一段简单的代码证明伪 SP、伪 FP 和硬件 SP 的位置关系。
+spspfp.s:
+
+```go
+#include "textflag.h"
+
+// func output(int) (int, int, int)
+TEXT ·output(SB), $8-48
+ MOVQ 24(SP), DX // 不带 symbol,这里的 SP 是硬件寄存器 SP
+ MOVQ DX, ret3+24(FP) // 第三个返回值
+ MOVQ perhapsArg1+16(SP), BX // 当前函数栈大小 > 0,所以 FP 在 SP 的上方 16 字节处
+ MOVQ BX, ret2+16(FP) // 第二个返回值
+ MOVQ arg1+0(FP), AX
+ MOVQ AX, ret1+8(FP) // 第一个返回值
+ RET
+
+```
+
+spspfp.go:
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+func output(int) (int, int, int) // 汇编函数声明
+
+func main() {
+ a, b, c := output(987654321)
+ fmt.Println(a, b, c)
+}
+```
+
+执行上面的代码,可以得到输出:
+
+```shell
+987654321 987654321 987654321
+```
+
+和代码结合思考,可以知道我们当前的栈结构是这样的:
+
+```shell
+------
+ret2 (8 bytes)
+------
+ret1 (8 bytes)
+------
+ret0 (8 bytes)
+------
+arg0 (8 bytes)
+------ FP
+ret addr (8 bytes)
+------
+caller BP (8 bytes)
+------ pseudo SP
+frame content (8 bytes)
+------ hardware SP
+```
+
+本小节例子的 framesize 是大于 0 的,读者可以尝试修改 framesize 为 0,然后调整代码中引用伪 SP 和硬件 SP 时的 offset,来研究 framesize 为 0 时,伪 FP,伪 SP 和硬件 SP 三者之间的相对位置。
+
+本小节的例子是为了告诉大家,伪 SP 和伪 FP 的相对位置是会变化的,手写时不应该用伪 SP 和 >0 的 offset 来引用数据,否则结果可能会出乎你的预料。
+
+### 汇编调用非汇编函数
+
+output.s:
+
+```go
+#include "textflag.h"
+
+// func output(a,b int) int
+TEXT ·output(SB), NOSPLIT, $24-24
+ MOVQ a+0(FP), DX // arg a
+ MOVQ DX, 0(SP) // arg x
+ MOVQ b+8(FP), CX // arg b
+ MOVQ CX, 8(SP) // arg y
+ CALL ·add(SB) // 在调用 add 之前,已经把参数都通过物理寄存器 SP 搬到了函数的栈顶
+ MOVQ 16(SP), AX // add 函数会把返回值放在这个位置
+ MOVQ AX, ret+16(FP) // return result
+ RET
+
+```
+
+output.go:
+
+```go
+package main
+
+import "fmt"
+
+func add(x, y int) int {
+ return x + y
+}
+
+func output(a, b int) int
+
+func main() {
+ s := output(10, 13)
+ fmt.Println(s)
+}
+
+```
+
+### 汇编中的循环
+
+通过 DECQ 和 JZ 结合,可以实现高级语言里的循环逻辑:
+
+sum.s:
+
+```go
+#include "textflag.h"
+
+// func sum(sl []int64) int64
+TEXT ·sum(SB), NOSPLIT, $0-32
+ MOVQ $0, SI
+ MOVQ sl+0(FP), BX // &sl[0], addr of the first elem
+ MOVQ sl+8(FP), CX // len(sl)
+ INCQ CX // CX++, 因为要循环 len 次
+
+start:
+ DECQ CX // CX--
+ JZ done
+ ADDQ (BX), SI // SI += *BX
+ ADDQ $8, BX // 指针移动
+ JMP start
+
+done:
+ // 返回地址是 24 是怎么得来的呢?
+ // 可以通过 go tool compile -S math.go 得知
+ // 在调用 sum 函数时,会传入三个值,分别为:
+ // slice 的首地址、slice 的 len, slice 的 cap
+ // 不过我们这里的求和只需要 len,但 cap 依然会占用参数的空间
+ // 就是 16(FP)
+ MOVQ SI, ret+24(FP)
+ RET
+```
+
+sum.go:
+
+```go
+package main
+
+func sum([]int64) int64
+
+func main() {
+ println(sum([]int64{1, 2, 3, 4, 5}))
+}
+```
+
+## 扩展话题
+
+### 标准库中的一些数据结构
+
+#### 数值类型
+
+标准库中的数值类型很多:
+
+1. int/int8/int16/int32/int64
+2. uint/uint8/uint16/uint32/uint64
+3. float32/float64
+4. byte/rune
+5. uintptr
+
+这些类型在汇编中就是一段存储着数据的连续内存,只是内存长度不一样,操作的时候看好数据长度就行。
+
+#### slice
+
+前面的例子已经说过了,slice 在传递给函数的时候,实际上会展开成三个参数:
+
+1. 首元素地址
+2. slice 的 len
+3. slice 的 cap
+
+在汇编中处理时,只要知道这个原则那就很好办了,按顺序还是按索引操作随你开心。
+
+#### string
+
+```go
+package main
+
+//go:noinline
+func stringParam(s string) {}
+
+func main() {
+ var x = "abcc"
+ stringParam(x)
+}
+```
+
+用 `go tool compile -S` 输出其汇编:
+
+```go
+0x001d 00029 (stringParam.go:11) LEAQ go.string."abcc"(SB), AX // 获取 RODATA 段中的字符串地址
+0x0024 00036 (stringParam.go:11) MOVQ AX, (SP) // 将获取到的地址放在栈顶,作为第一个参数
+0x0028 00040 (stringParam.go:11) MOVQ $4, 8(SP) // 字符串长度作为第二个参数
+0x0031 00049 (stringParam.go:11) PCDATA $0, $0 // gc 相关
+0x0031 00049 (stringParam.go:11) CALL "".stringParam(SB) // 调用 stringParam 函数
+```
+
+在汇编层面 string 就是地址 + 字符串长度。
+
+#### struct
+
+struct 在汇编层面实际上就是一段连续内存,在作为参数传给函数时,会将其展开在 caller 的栈上传给对应的 callee:
+
+struct.go
+
+```go
+package main
+
+type address struct {
+ lng int
+ lat int
+}
+
+type person struct {
+ age int
+ height int
+ addr address
+}
+
+func readStruct(p person) (int, int, int, int)
+
+func main() {
+ var p = person{
+ age: 99,
+ height: 88,
+ addr: address{
+ lng: 77,
+ lat: 66,
+ },
+ }
+ a, b, c, d := readStruct(p)
+ println(a, b, c, d)
+}
+```
+
+struct.s
+
+```go
+#include "textflag.h"
+
+TEXT ·readStruct(SB), NOSPLIT, $0-64
+ MOVQ arg0+0(FP), AX
+ MOVQ AX, ret0+32(FP)
+ MOVQ arg1+8(FP), AX
+ MOVQ AX, ret1+40(FP)
+ MOVQ arg2+16(FP), AX
+ MOVQ AX, ret2+48(FP)
+ MOVQ arg3+24(FP), AX
+ MOVQ AX, ret3+56(FP)
+ RET
+```
+
+上述的程序会输出 99, 88, 77, 66,这表明即使是内嵌结构体,在内存分布上依然是连续的。
+
+#### map
+
+通过对下述文件进行汇编(go tool compile -S),我们可以得到一个 map 在对某个 key 赋值时所需要做的操作:
+
+m.go:
+
+```go
+package main
+
+func main() {
+ var m = map[int]int{}
+ m[43] = 1
+ var n = map[string]int{}
+ n["abc"] = 1
+ println(m, n)
+}
+```
+
+看一看第七行的输出:
+
+```go
+0x0085 00133 (m.go:7) LEAQ type.map[int]int(SB), AX
+0x008c 00140 (m.go:7) MOVQ AX, (SP)
+0x0090 00144 (m.go:7) LEAQ ""..autotmp_2+232(SP), AX
+0x0098 00152 (m.go:7) MOVQ AX, 8(SP)
+0x009d 00157 (m.go:7) MOVQ $43, 16(SP)
+0x00a6 00166 (m.go:7) PCDATA $0, $1
+0x00a6 00166 (m.go:7) CALL runtime.mapassign_fast64(SB)
+0x00ab 00171 (m.go:7) MOVQ 24(SP), AX
+0x00b0 00176 (m.go:7) MOVQ $1, (AX)
+```
+
+前面我们已经分析过调用函数的过程,这里前几行都是在准备 runtime.mapassign_fast64(SB) 的参数。去 runtime 里看看这个函数的签名:
+
+```go
+func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
+```
+
+不用看函数的实现我们也大概能推测出函数输入参数和输出参数的关系了,把入参和汇编指令对应的话:
+
+```go
+t *maptype
+=>
+LEAQ type.map[int]int(SB), AX
+MOVQ AX, (SP)
+
+h *hmap
+=>
+LEAQ ""..autotmp_2+232(SP), AX
+MOVQ AX, 8(SP)
+
+key uint64
+=>
+MOVQ $43, 16(SP)
+```
+
+返回参数就是 key 对应的可以写值的内存地址,拿到该地址后我们把想要写的值写进去就可以了:
+
+```go
+MOVQ 24(SP), AX
+MOVQ $1, (AX)
+```
+
+整个过程还挺复杂的,我们手抄一遍倒也可以实现。不过还要考虑,不同类型的 map,实际上需要执行的 runtime 中的 assign 函数是不同的,感兴趣的同学可以汇编本节的示例自行尝试。
+
+整体来讲,用汇编来操作 map 并不是一个明智的选择。
+
+#### channel
+
+channel 在 runtime 也是比较复杂的数据结构,如果在汇编层面操作,实际上也是调用 runtime 中 chan.go 中的函数,和 map 比较类似,这里就不展开说了。
+
+### 获取 goroutine id
+
+Go 的 goroutine 是一个叫 g 的结构体,内部有自己的唯一 id,不过 runtime 没有把这个 id 暴露出来,但不知道为什么有很多人就是想把这个 id 得到。于是就有了各种或其 goroutine id 的库。
+
+在 struct 一小节我们已经提到,结构体本身就是一段连续的内存,我们知道起始地址和字段的偏移量的话,很容易就可以把这段数据搬运出来:
+
+go_tls.h:
+
+```go
+#ifdef GOARCH_arm
+#define LR R14
+#endif
+
+#ifdef GOARCH_amd64
+#define get_tls(r) MOVQ TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+
+#ifdef GOARCH_amd64p32
+#define get_tls(r) MOVL TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+
+#ifdef GOARCH_386
+#define get_tls(r) MOVL TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+```
+
+goid.go:
+
+```go
+package goroutineid
+import "runtime"
+var offsetDict = map[string]int64{
+ // ... 省略一些行
+ "go1.7": 192,
+ "go1.7.1": 192,
+ "go1.7.2": 192,
+ "go1.7.3": 192,
+ "go1.7.4": 192,
+ "go1.7.5": 192,
+ "go1.7.6": 192,
+ // ... 省略一些行
+}
+
+var offset = offsetDict[runtime.Version()]
+
+// GetGoID returns the goroutine id
+func GetGoID() int64 {
+ return getGoID(offset)
+}
+
+func getGoID(off int64) int64
+```
+
+goid.s:
+
+```go
+#include "textflag.h"
+#include "go_tls.h"
+
+// func getGoID() int64
+TEXT ·getGoID(SB), NOSPLIT, $0-16
+ get_tls(CX)
+ MOVQ g(CX), AX
+ MOVQ offset(FP), BX
+ LEAQ 0(AX)(BX*1), DX
+ MOVQ (DX), AX
+ MOVQ AX, ret+8(FP)
+ RET
+```
+
+这样就实现了一个简单的获取 struct g 中的 goid 字段的小 library,作为玩具放在这里:
+>https://github.com/cch123/goroutineid
+
+### SIMD
+
+[SIMD](https://cch123.gitbooks.io/duplicate/content/part3/performance/simd-instruction-class.html) 是 Single Instruction, Multiple Data 的缩写,在 Intel 平台上的 SIMD 指令集先后为 SSE,AVX,AVX2,AVX512,这些指令集引入了标准以外的指令,和宽度更大的寄存器,例如:
+
+- 128 位的 XMM0~XMM31 寄存器。
+- 256 位的 YMM0~YMM31 寄存器。
+- 512 位的 ZMM0~ZMM31 寄存器。
+
+这些寄存器的关系,类似 RAX,EAX,AX 之间的关系。指令方面可以同时对多组数据进行移动或者计算,例如:
+
+- movups : 把4个不对准的单精度值传送到xmm寄存器或者内存
+- movaps : 把4个对准的单精度值传送到xmm寄存器或者内存
+
+上述指令,当我们将数组作为函数的入参时有很大概率会看到,例如:
+
+arr_par.go:
+
+```go
+package main
+
+import "fmt"
+
+func pr(input [3]int) {
+ fmt.Println(input)
+}
+
+func main() {
+ pr([3]int{1, 2, 3})
+}
+```
+
+go compile -S:
+
+```go
+0x001d 00029 (arr_par.go:10) MOVQ "".statictmp_0(SB), AX
+0x0024 00036 (arr_par.go:10) MOVQ AX, (SP)
+0x0028 00040 (arr_par.go:10) MOVUPS "".statictmp_0+8(SB), X0
+0x002f 00047 (arr_par.go:10) MOVUPS X0, 8(SP)
+0x0034 00052 (arr_par.go:10) CALL "".pr(SB)
+```
+
+可见,编译器在某些情况下已经考虑到了性能问题,帮助我们使用 SIMD 指令集来对数据搬运进行了优化。
+
+因为 SIMD 这个话题本身比较广,这里就不展开细说了。
+
+## 特别感谢
+
+研究过程基本碰到不太明白的都去骚扰卓巨巨了,就是这位 https://mzh.io/ 大大。特别感谢他,给了不少线索和提示。
+
+## 参考资料
+
+1. https://quasilyte.github.io/blog/post/go-asm-complementary-reference/#external-resources
+2. http://davidwong.fr/goasm
+3. https://www.doxsey.net/blog/go-and-assembly
+4. https://github.com/golang/go/files/447163/GoFunctionsInAssembly.pdf
+5. https://golang.org/doc/asm
+
+参考资料[4]需要特别注意,在该 slide 中给出的 callee stack frame 中把 caller 的 return address 也包含进去了,个人认为不是很合适。
+
+
diff --git a/site/content/docs/assembly/exercises.md b/site/content/docs/assembly/exercises.md
new file mode 100644
index 0000000..3c16b05
--- /dev/null
+++ b/site/content/docs/assembly/exercises.md
@@ -0,0 +1,7 @@
+---
+title: 习题
+weight: 2
+draft: true
+---
+
+# 习题
diff --git a/site/content/docs/bootstrap/_index.md b/site/content/docs/bootstrap/_index.md
new file mode 100644
index 0000000..3832726
--- /dev/null
+++ b/site/content/docs/bootstrap/_index.md
@@ -0,0 +1,7 @@
+---
+title: Go 进程的启动流程
+weight: 2
+bookCollapseSection: true
+draft: true
+---
+
diff --git a/site/content/docs/bootstrap/boot.md b/site/content/docs/bootstrap/boot.md
new file mode 100644
index 0000000..a8fe587
--- /dev/null
+++ b/site/content/docs/bootstrap/boot.md
@@ -0,0 +1,7 @@
+---
+title: 启动流程
+weight: 2
+---
+# 启动流程
+
+
diff --git a/site/content/docs/bootstrap/elf.md b/site/content/docs/bootstrap/elf.md
new file mode 100644
index 0000000..15a78a7
--- /dev/null
+++ b/site/content/docs/bootstrap/elf.md
@@ -0,0 +1 @@
+# elf 文件简介
diff --git a/site/content/docs/bootstrap/exercises.md b/site/content/docs/bootstrap/exercises.md
new file mode 100644
index 0000000..a49ba48
--- /dev/null
+++ b/site/content/docs/bootstrap/exercises.md
@@ -0,0 +1,2 @@
+---
+---
\ No newline at end of file
diff --git a/site/content/docs/compiler_and_linker/_index.md b/site/content/docs/compiler_and_linker/_index.md
new file mode 100644
index 0000000..ce63fe2
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/_index.md
@@ -0,0 +1,6 @@
+---
+title: 编译器与链接器
+weight: 3
+bookCollapseSection: true
+draft: true
+---
diff --git a/site/content/docs/compiler_and_linker/calling_convention.md b/site/content/docs/compiler_and_linker/calling_convention.md
new file mode 100644
index 0000000..e0609f0
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/calling_convention.md
@@ -0,0 +1,25 @@
+---
+title: 调用规约
+weight: 3
+draft: true
+---
+
+# 调用规约
+
+早期版本的 Go 在向函数传递参数时,是使用栈的。
+
+从 1.17 开始,调用函数时会尽量使用寄存器传参。
+
+"".add STEXT size=121 args=0x10 locals=0x18 funcid=0x0
+ 0x0000 00000 (add.go:8) TEXT "".add(SB), ABIInternal, $24-16
+ 0x0000 00000 (add.go:8) CMPQ SP, 16(R14)
+ 0x0004 00004 (add.go:8) JLS 94
+ 0x0006 00006 (add.go:8) SUBQ $24, SP
+ 0x005d 00093 (add.go:11) RET
+ 0x005e 00094 (add.go:11) NOP
+ 0x005e 00094 (add.go:8) MOVQ AX, 8(SP)
+ 0x0063 00099 (add.go:8) MOVQ BX, 16(SP)
+ 0x0068 00104 (add.go:8) CALL runtime.morestack_noctxt(SB)
+ 0x006d 00109 (add.go:8) MOVQ 8(SP), AX
+ 0x0072 00114 (add.go:8) MOVQ 16(SP), BX
+ 0x0077 00119 (add.go:8) JMP 0
diff --git a/site/content/docs/compiler_and_linker/compiler.md b/site/content/docs/compiler_and_linker/compiler.md
new file mode 100644
index 0000000..6592c8e
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/compiler.md
@@ -0,0 +1,6 @@
+---
+title: 编译器
+weight: 3
+draft: true
+---
+# 编译器
diff --git a/site/content/docs/compiler_and_linker/linker.md b/site/content/docs/compiler_and_linker/linker.md
new file mode 100644
index 0000000..ea2d801
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/linker.md
@@ -0,0 +1,6 @@
+---
+title: 链接器
+weight: 3
+draft: true
+---
+# linker
diff --git a/site/content/docs/data_structure/_index.md b/site/content/docs/data_structure/_index.md
new file mode 100644
index 0000000..08b7aa5
--- /dev/null
+++ b/site/content/docs/data_structure/_index.md
@@ -0,0 +1,5 @@
+---
+title: 内置数据结构
+weight: 10
+bookCollapseSection: true
+---
diff --git a/site/content/docs/data_structure/channel.md b/site/content/docs/data_structure/channel.md
new file mode 100644
index 0000000..da9c943
--- /dev/null
+++ b/site/content/docs/data_structure/channel.md
@@ -0,0 +1,10 @@
+---
+title: channel
+weight: 10
+bookCollapseSection: false
+---
+# channel 实现
+
+{{
diff --git a/defer.md b/defer.md
index ae0d8bf..ada7c2b 100644
--- a/defer.md
+++ b/defer.md
@@ -76,7 +76,7 @@ func newdefer(siz int32) *_defer {
```go
type _defer struct {
siz int32 // 函数的参数总大小
- started bool // TODO defer 是否已开始执行?
+ started bool // defer 是否已开始执行
sp uintptr // 存储调用 defer 函数的函数的 sp 寄存器值
pc uintptr // 存储 call deferproc 的下一条汇编指令的指令地址
fn *funcval // 描述函数的变长结构体,包括函数地址及参数
@@ -160,3 +160,6 @@ A: deferproc 和 deferreturn 是成对出现的,对于编译器的实现来说
https://ieevee.com/tech/2017/11/23/go-panic.html
+
+
+
diff --git a/futex.md b/futex.md
index 812d091..9d51161 100644
--- a/futex.md
+++ b/futex.md
@@ -235,3 +235,6 @@ http://blog.sina.com.cn/s/blog_e59371cc0102v29b.html
https://www.jianshu.com/p/570a61f08e27
https://eli.thegreenplace.net/2018/basics-of-futexes/
+
+
+
diff --git a/gc.md b/gc.md
index ff0ec21..b7973ed 100644
--- a/gc.md
+++ b/gc.md
@@ -742,3 +742,5 @@ gc时间,stw时间和响应延迟之间是什么关系
宏观来看gc划分为多少个阶段
+
+
diff --git a/gc_write_barrier.md b/gc_write_barrier.md
new file mode 100644
index 0000000..d606aff
--- /dev/null
+++ b/gc_write_barrier.md
@@ -0,0 +1,37 @@
+# GC write barrier 详解
+
+在垃圾回收领域所讲的 barrier 包括 read barrier 与 write barrier,无论是哪一种,都与并发编程领域的 memory barrier 不是一回事。
+
+在 GC 中的 barrier 其本质是 : snippet of code insert before pointer modify。
+
+所以在阅读相关材料时,请注意不要将两者混淆。
+
+在当前 Go 语言的实现中,GC 只有 write barrier,没有 read barrier。
+
+在应用进入 GC 标记阶段前的 stw 阶段,会将全局变量 runtime.writeBarrier.enabled 修改为 true,当应用从 STW 中恢复,重新开始执行,垃圾回收的标记阶段便与应用逻辑开始并发执行,这时所有的堆上指针修改操作在修改之前会额外调用 runtime.gcWriteBarrier:
+
+
+
+我们随便找找这些反汇编结果在代码中对应的行:
+
+
+
+Go 语言当前使用了混合 barrier 来实现 gc 标记期间的被修改对象动态跟踪,早期只使用了 Dijistra 插入 barrier,但 Dijistra barrier 需要在标记完成之后进行栈重扫,因此在 1.8 时修改为混合 barrier。
+
+Dijistra 插入屏障伪代码如下:
+
+
+
+堆上指针修改时,新指向的对象要标灰。
+
+但是因为 Go 的栈上对象不加 barrier,所以会存在对象丢失的问题:
+
+
+
+还有一种非常有名的 barrier,Yuasa 删除屏障,与 Dijistra 屏障相反,它是在堆指针指向的对象发生变化时,将之前指向的对象标灰:
+
+
+
+和 Dijistra 类似,也存在对象漏标问题:
+
+
diff --git a/generics.md b/generics.md
index caf2ba5..4a36142 100644
--- a/generics.md
+++ b/generics.md
@@ -40,3 +40,5 @@ cat source.go | genny gen "Something=string"
没有官方的泛型支持,社区怎么搞都是邪道。2021 年 1 月,官方的方案已经基本上成型,并释出了 [draft design](https://go.googlesource.com/proposal/+/refs/heads/master/design/go2draft-type-parameters.md)。
+
+
diff --git a/goroutine.md b/goroutine.md
index 0de6ace..38b020b 100644
--- a/goroutine.md
+++ b/goroutine.md
@@ -7,4 +7,6 @@
> Written with [StackEdit](https://stackedit.io/).
\ No newline at end of file
+-->
+
+
diff --git a/images/garbage_collection/barrier_asm.png b/images/garbage_collection/barrier_asm.png
new file mode 100644
index 0000000..5012031
Binary files /dev/null and b/images/garbage_collection/barrier_asm.png differ
diff --git a/images/garbage_collection/barrier_code.png b/images/garbage_collection/barrier_code.png
new file mode 100644
index 0000000..5f971b0
Binary files /dev/null and b/images/garbage_collection/barrier_code.png differ
diff --git a/interface.md b/interface.md
index 703507d..a365ff4 100644
--- a/interface.md
+++ b/interface.md
@@ -543,3 +543,5 @@ go.itab.*os.File,io.Writer SRODATA dupok size=32
// 下面就是正常流程了
```
+
+
diff --git a/io.md b/io.md
index 2bbac62..c15b884 100644
--- a/io.md
+++ b/io.md
@@ -193,4 +193,534 @@ vmtouch /disk/data/tmp/test
- https://tech.meituan.com/2017/05/19/about-desk-io.html
- https://github.com/ncw/directio
# DMA
-# Zero-Copy
\ No newline at end of file
+# Zero-Copy
+
+## splice
+在介绍 splice 及其在 golang 中的应用之前, 先从一段简单的网络代理代码开始入手
+#### read & write
+```go
+var (
+ p sync.Pool
+)
+
+func init() {
+ p.New = func() interface{} {
+ return make([]byte, DEFAULTSIZE)
+ }
+}
+// src 客户端 tcp 链接
+// dst mock server tcp 链接
+func normal(src, dst net.Conn) {
+ var bts []byte = p.Get().([]byte)
+ var bts2 []byte = p.Get().([]byte)
+ defer p.Put(bts)
+ defer p.Put(bts2)
+ // mock server to client
+ go func() {
+ for {
+ num, err := dst.Read(bts2[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = src.Write(bts2[num_write:num])
+ if err != nil {
+ return
+ }
+ num -= num_write
+ }
+ }
+ }()
+ // client to mock server
+ for {
+ num, err := src.Read(bts[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = dst.Write(bts[num_write:num])
+ if err != nil {
+ return
+ }
+ num -= num_write
+ }
+ }
+}
+```
+以上片段实现了一个简单的功能: 将客户端请求的 tcp 数据通过`read`系统调用读出放入本地用户空间 缓存, 而后再调用`write`发送给目标服务器,反之亦然
+
+整个过程如下图所示(暂不考虑 IO 模型调度以及 DMA 等细节部分)
+
+```shell
+[ user space ]
+
+ --------------------------------------------
+ | application |
+ --------------------------------------------
+ ····················|·································|··················
+ | read() | write()
+[ kernel space ] | |
+ ----------------- -----------------
+ | socket buffer | | socket buffer |
+ ----------------- -----------------
+ | copy |
+ ····················|·································|··················
+[ hardware sapce ] | |
+ ------------------------------------------------------
+ | network interface |
+ ------------------------------------------------------
+
+```
+对于透传或者部分透传(例如七层头部解析后透明代理请求体)之类的需求场景来说, 这种流程的成本无疑是很高的, 可以总结下涉及的几个浪费点
+
+- 数据需要从内核态拷贝到用户态
+- 应用层在 read 及 write 的过程中对这部分 byte 的操作开销(申请、释放、对象池维护等)
+
+#### splice 介绍
+```c
+/*
+ splice() moves data between two file descriptors without copying
+ between kernel address space and user address space. It
+ transfers up to len bytes of data from the file descriptor fd_in
+ to the file descriptor fd_out, where one of the file descriptors
+ must refer to a pipe.
+*/
+ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
+ off64_t *off_out, size_t len, unsigned int flags);
+```
+一句话概括就是, `splice` 不需要从内核空间复制这部分数据到用户空间就可以支持将数据从两个文件描述符之间进行转移, 不过两个描述符至少得有一个是 `pipe`, 以下列举如何利用`splice`完成 `socket->socket` 的数据代理
+
+example:
+```go
+func example(src, dst net.Conn) {
+ // 由于 src 及 dst 都是 socket, 没法直接使用 splice, 因此先创建临时 pipe
+ const flags = syscall.O_CLOEXEC | syscall.O_NONBLOCK
+ var fds [2]int // readfd, writefd
+ if err := syscall.Pipe2(fds[:], flags); err != nil {
+ panic(err)
+ }
+ // 使用完后关闭 pipe
+ defer syscall.Close(fds[0])
+ defer syscall.Close(fds[1])
+ // 获取 src fd
+ srcfile, err := src.(*net.TCPConn).File()
+ if err != nil {
+ panic(err)
+ }
+ srcfd := int(srcfile.Fd())
+ syscall.SetNonblock(srcfd, true)
+ ...
+ // 从 srcfd 读出, 写入 fds[1] (pipe write fd)
+ num, err := syscall.Splice(srcfd, nil, fds[1], nil, DEFAULTSIZE/* size to splice */, SPLICE_F_NONBLOCK)
+ ...
+}
+```
+此时的调用过程变为:
+
+```shell
+[ user space ]
+
+ -----------------------------------------------------------------------------------------------
+ | application |
+ -----------------------------------------------------------------------------------------------
+ ········································|····················|·····················|··································
+ | splice() | pipe() | splice()
+[ kernel space ] | | |
+ ----------------- ”copy“ ----------------------- ”copy“ -----------------
+ | socket buffer |· · · · · · · · · >| pipe writefd & readfd |· · · · · · · · >| socket buffer |
+ ----------------- ----------------------- -----------------
+ | copy |
+ ····················|··············································································|
+[ hardware sapce ] | |
+ -----------------------------------------------------------------------------------------------
+ | network interface |
+ -----------------------------------------------------------------------------------------------
+```
+此时产生的系统调用为
+- 首先 `pipe()` 调用, 创建临时管道
+- 调用 `splice()` 将 `srcfd` 数据 ”拷贝“ 到 `pipe`
+- 调用 `splice()` 将 `pipe` 中的数据 ”拷贝“ 到 `dstfd`
+
+可以注意到图中以及总结部分的”拷贝“给加了引号, 具体了解过`pipe`底层实现的小伙伴应该理解, 在这边简单表述下, `splice` 是基于 `pipe buffer` 实现的, 本质上在数据传输的时候并没有进行数据的拷贝, 而是仅仅将数据的内存地址等信息塞进了`pipe_buffer`中对应的字段
+
+至此, 完成了 kernel-user space 的拷贝优化, 不过可能细心的人会发现, 这种方式虽然减少了数据的拷贝, 但是同样额外增加了系统调用(create pipe & close pipe), 接下来就关于这部分的取舍与具体场景进行具体讨论
+
+#### splice 还是 read & write?
+如何取舍使用哪种方式?
+
+两种方法各有各的好处, 往往选择层面的考虑在于应用层的具体策略, 如是否进行透传(/部分), 饥饿问题, 对象池策略等等
+
+下面提供几种场景下的测试以供参考
+benchmark 代码:
+```go
+/*
+ * 测试环境: go 1.14.3 centos7
+ */
+package main
+
+import (
+ "bytes"
+ "io"
+ "net"
+ "net/http"
+ "sync"
+ "sync/atomic"
+ "testing"
+ "time"
+)
+
+var (
+ p sync.Pool
+)
+
+func init() {
+ p.New = func() interface{} {
+ return make([]byte, DEFAULTSIZE)
+ }
+}
+
+const (
+ // mock http 请求体大小
+ REQUESTBYTESIZE = 0
+ // 应用层对象池 byte 大小
+ DEFAULTSIZE = 1 << 10
+
+ SPLICE_F_MOVE = 0x1
+ SPLICE_F_NONBLOCK = 0x2
+ SPLICE_F_MORE = 0x4
+ SPLICE_F_GIFT = 0x8
+)
+// io.Copy 该场景下内部调用 splice syscall, 感兴趣的自行查看源码
+func gosplice(src, dst net.Conn) {
+ defer src.Close()
+ defer dst.Close()
+ go func() {
+ io.Copy(src, dst)
+ }()
+ io.Copy(dst, src)
+}
+
+func normal(src, dst net.Conn) {
+ defer src.Close()
+ defer dst.Close()
+ var bts []byte = p.Get().([]byte)
+ var bts2 []byte = p.Get().([]byte)
+ defer p.Put(bts)
+ defer p.Put(bts2)
+ go func() {
+ for {
+ num, err := dst.Read(bts2[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = src.Write(bts2[num_write:num])
+ num -= num_write
+ if err != nil {
+ return
+ }
+ }
+ }
+ }()
+ // local to mock serve
+ for {
+ num, err := src.Read(bts[:])
+ if err != nil {
+ break
+ }
+ var num_write int
+ for num > 0 {
+ num_write, err = dst.Write(bts[num_write:num])
+ num -= num_write
+ if err != nil {
+ return
+ }
+ }
+ }
+}
+
+// Server http server
+var Server *http.Server
+
+type s struct{}
+
+func (ss s) ServeHTTP(res http.ResponseWriter, req *http.Request) {
+ res.WriteHeader(200)
+ return
+}
+func TestMain(m *testing.M) {
+ // mock tcp server
+ var ss s
+ go func() {
+ Server = &http.Server{
+ Addr: "0.0.0.0:9610",
+ Handler: ss,
+ WriteTimeout: 60 * time.Second,
+ ReadTimeout: 60 * time.Second,
+ }
+ err := Server.ListenAndServe()
+ if err != nil {
+ panic(err)
+ }
+ }()
+ go func() { // normal 9611
+ l, err := net.ListenTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"),
+ Port: 9611,
+ })
+ if err != nil {
+ panic(err)
+ }
+ for {
+ n, err := l.Accept()
+ if err != nil {
+ continue
+ }
+ remote, err := net.DialTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 0,
+ }, &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 9610,
+ })
+ if err != nil {
+ continue
+ }
+ go normal(n, remote)
+ }
+ }()
+ go func() { // gosplice 9612
+ l, err := net.ListenTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"),
+ Port: 9612,
+ })
+ if err != nil {
+ panic(err)
+ }
+ for {
+ n, err := l.Accept()
+ if err != nil {
+ continue
+ }
+ remote, err := net.DialTCP("tcp4", &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 0,
+ }, &net.TCPAddr{
+ IP: net.ParseIP("0.0.0.0"), Port: 9610,
+ })
+ if err != nil {
+ continue
+ }
+ go gosplice(n, remote)
+ }
+ }()
+ m.Run()
+}
+func BenchmarkNormalReadWrite(b *testing.B) {
+ // normal 9611
+ c := http.Client{
+ Timeout: time.Minute,
+ }
+ var total, success uint32
+ b.ResetTimer()
+ for i := 0; i < b.N; i++ {
+ atomic.AddUint32(&total, 1)
+ req, err := http.NewRequest("POST", "http://0.0.0.0:9611", bytes.NewReader(make([]byte, REQUESTBYTESIZE)))
+ if err != nil {
+ b.Fatalf("%s", err.Error())
+ }
+ res, err := c.Do(req)
+ if err == nil && res.StatusCode == 200 {
+ atomic.AddUint32(&success, 1)
+ }
+ c.CloseIdleConnections()
+ }
+ b.Logf("test:%s,total: %d,rate: %.2f%%\n", b.Name(), total, float64(success*100/total))
+}
+
+func BenchmarkGoSplice(b *testing.B) {
+ // normal 9612
+ c := http.Client{
+ Timeout: time.Minute,
+ }
+ var total, success uint32
+ b.ResetTimer()
+ for i := 0; i < b.N; i++ {
+ atomic.AddUint32(&total, 1)
+ req, err := http.NewRequest("POST", "http://0.0.0.0:9612", bytes.NewReader(make([]byte, REQUESTBYTESIZE)))
+ if err != nil {
+ b.Fatalf("%s", err.Error())
+ }
+ res, err := c.Do(req)
+ if err == nil && res.StatusCode == 200 {
+ atomic.AddUint32(&success, 1)
+ }
+ c.CloseIdleConnections()
+ }
+ b.Logf("test:%s, total: %d, success rate: %.2f%%\n", b.Name(), total, float64(success*100/total))
+}
+```
+- 场景一: 单次请求数据量较少, 应用维护单个 buffer 较小
+```go
+REQUESTBYTESIZE = 0 // http request body
+DEFAULTSIZE = 1 << 10 // buffer size 1kb
+```
+```shell
+RRunning tool: /usr/local/bin/go test -benchmem -run=^$ -bench ^(BenchmarkNormalReadWrite|BenchmarkGoSplice)$ barrier/t
+
+goos: linux
+goarch: amd64
+pkg: barrier/t
+BenchmarkNormalReadWrite-4 6348 179699 ns/op 4847 B/op 62 allocs/op
+--- BENCH: BenchmarkNormalReadWrite-4
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 1,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 100,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 6348,rate: 100.00%
+BenchmarkGoSplice-4 6652 179622 ns/op 4852 B/op 62 allocs/op
+--- BENCH: BenchmarkGoSplice-4
+ test_test.go:194: test:BenchmarkGoSplice, total: 1, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 100, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 6652, success rate: 100.00%
+PASS
+ok barrier/t 2.391s
+```
+两种方式无明显性能差异
+- 场景二: 单次请求数据量多, 应用维护单个 buffer 较小
+```go
+REQUESTBYTESIZE = 1 << 20 // 1 MB
+DEFAULTSIZE = 1 << 10 // buffer size 1kb
+```
+```shell
+Running tool: /usr/local/bin/go test -benchmem -run=^$ -bench ^(BenchmarkNormalReadWrite|BenchmarkGoSplice)$ barrier/t
+
+goos: linux
+goarch: amd64
+pkg: barrier/t
+BenchmarkNormalReadWrite-4 465 2329209 ns/op 1073956 B/op 163 allocs/op
+--- BENCH: BenchmarkNormalReadWrite-4
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 1,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 100,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 376,rate: 100.00%
+ test_test.go:173: test:BenchmarkNormalReadWrite,total: 465,rate: 100.00%
+BenchmarkGoSplice-4 963 1555386 ns/op 1070506 B/op 157 allocs/op
+--- BENCH: BenchmarkGoSplice-4
+ test_test.go:194: test:BenchmarkGoSplice, total: 1, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 100, success rate: 100.00%
+ test_test.go:194: test:BenchmarkGoSplice, total: 963, success rate: 100.00%
+PASS
+ok barrier/t 4.056s
+```
+当链接需要处理的数据量较多而应用层每次处理的 buffer 相比起来较小, 以至于需要 read & write 的次数更多的时候, 差异就会比较明显
+
+#### go 中的 splice
+在上面的介绍过程中简单说了下 `io.Copy` 在 `socket` 之间操作的时候, 当机器架构支持的时候会采取 `splice`, 接下来就此进行详细分析来介绍下 `runtime` 在 `splice` 上的一些决策以及当前`runtime`在 `splice` 上的一些不足
+```go
+/*
+ * src/net/spice_linux.go
+ */
+// splice transfers data from r to c using the splice system call to minimize
+// copies from and to userspace. c must be a TCP connection. Currently, splice
+// is only enabled if r is a TCP or a stream-oriented Unix connection.
+//
+// If splice returns handled == false, it has performed no work.
+func splice(c *netFD, r io.Reader) (written int64, err error, handled bool) {
+ /*
+ * 因为前面介绍过 splice 是通过 pipe buffer 实现的
+ * 在调用的时候 kernel无需进行数据拷贝, 仅操作数据原信息(基础字段的指针等)
+ * 所以这边默认 splice 的 len 开得比较大, 读到 EOF 为止
+ */
+ var remain int64 = 1 << 62 // by default, copy until EOF
+ lr, ok := r.(*io.LimitedReader)
+ if ok {
+ remain, r = lr.N, lr.R
+ if remain <= 0 {
+ return 0, nil, true
+ }
+ }
+
+ var s *netFD
+ if tc, ok := r.(*TCPConn); ok {
+ s = tc.fd
+ } else if uc, ok := r.(*UnixConn); ok {
+ if uc.fd.net != "unix" {
+ return 0, nil, false
+ }
+ s = uc.fd
+ } else {
+ return 0, nil, false
+ }
+
+ written, handled, sc, err := poll.Splice(&c.pfd, &s.pfd, remain)
+ if lr != nil {
+ lr.N -= written
+ }
+ return written, wrapSyscallError(sc, err), handled
+}
+```
+```go
+/*
+ * go 1.14.3
+ * src/internal/poll/splice_linux.go
+ */
+// Splice transfers at most remain bytes of data from src to dst, using the
+// splice system call to minimize copies of data from and to userspace.
+//
+// Splice creates a temporary pipe, to serve as a buffer for the data transfer.
+// src and dst must both be stream-oriented sockets.
+//
+// If err != nil, sc is the system call which caused the error.
+func Splice(dst, src *FD, remain int64) (written int64, handled bool, sc string, err error) {
+ // dst 以及 src 均为 socket.fd, 因此若想使用 splice 则需要借助 pipe
+ // 创建临时 pipe
+ prfd, pwfd, sc, err := newTempPipe()
+ if err != nil {
+ return 0, false, sc, err
+ }
+ defer destroyTempPipe(prfd, pwfd)
+ var inPipe, n int
+ for err == nil && remain > 0 {
+ max := maxSpliceSize
+ if int64(max) > remain {
+ max = int(remain)
+ }
+ // spliceDrain 调用 splice syscall
+ inPipe, err = spliceDrain(pwfd, src, max)
+ // The operation is considered handled if splice returns no
+ // error, or an error other than EINVAL. An EINVAL means the
+ // kernel does not support splice for the socket type of src.
+ // The failed syscall does not consume any data so it is safe
+ // to fall back to a generic copy.
+ //
+ // spliceDrain should never return EAGAIN, so if err != nil,
+ // Splice cannot continue.
+ //
+ // If inPipe == 0 && err == nil, src is at EOF, and the
+ // transfer is complete.
+ handled = handled || (err != syscall.EINVAL)
+ if err != nil || (inPipe == 0 && err == nil) {
+ break
+ }
+ // splicePump 调用 splice syscall
+ n, err = splicePump(dst, prfd, inPipe)
+ if n > 0 {
+ written += int64(n)
+ remain -= int64(n)
+ }
+ }
+ if err != nil {
+ return written, handled, "splice", err
+ }
+ return written, true, "", nil
+}
+```
+
+相信上面简短的分析大家也可以看到, 每次在进行 `splice` 的时候都会利用临时 `pipe`, 频繁的创建、销毁, 用户态-内核态的切换会带来非常多不必要的开销, 当前社区内也有关于 `splice temp-pipe` 生命周期的[讨论](https://go-review.googlesource.com/c/go/+/271537/)。
+
+再者, 因为当前关联到 `socket` 的 `splice` 实现在 `runtime` 层面和内置 `io 模型(epoll 等)`高度耦合, 基本无法解耦单独应用, 而如果想自己来实现 `splice(syscall.Splice)` 的话则不得不顺带在用户层面实现自己的`io 模型`再来使用, 会比较繁琐(上面测试用例使用内置 `splice api` 也是因为这个原因)
+
+## 参考资料
+
+- https://go-review.googlesource.com/c/go/+/271537/
+- https://zhuanlan.zhihu.com/p/308054212
+
+
diff --git a/lockfree.md b/lockfree.md
index f9c19d1..261e9cb 100644
--- a/lockfree.md
+++ b/lockfree.md
@@ -1,4 +1,6 @@
# lock free programming in Go
# 参考资料
-https://docs.google.com/presentation/d/1wuNNW-g6v8qizIc_IxAGZTj-49TODKF0TYddTA1VDUo/mobilepresent?slide=id.p
\ No newline at end of file
+https://docs.google.com/presentation/d/1wuNNW-g6v8qizIc_IxAGZTj-49TODKF0TYddTA1VDUo/mobilepresent?slide=id.p
+
+
diff --git a/map.md b/map.md
index 123cfd8..351146d 100644
--- a/map.md
+++ b/map.md
@@ -1267,3 +1267,5 @@ func (h *hmap) incrnoverflow() {
}
}
```
+
+
diff --git a/memory.md b/memory.md
index d71141a..b937fcf 100644
--- a/memory.md
+++ b/memory.md
@@ -1396,3 +1396,6 @@ func (p *notInHeap) add(bytes uintptr) *notInHeap {
### 堆外内存用法
嗯,堆外内存只是 runtime 自己玩的东西,用户态是使用不了的,属于 runtime 专用的 directive。
+
+
+
diff --git a/memory_barrier.md b/memory_barrier.md
index 94383c0..cc1a7ce 100644
--- a/memory_barrier.md
+++ b/memory_barrier.md
@@ -126,7 +126,7 @@ mesi 协议解决了多核环境下,内存多层级带来的问题。使得 ca
## CPU 导致乱序
-使用 litmus 进行形式化验证:
+使用 litmus 进行验证:
```
cat sb.litmus
@@ -181,6 +181,56 @@ Time SB 0.11
在两个核心上运行汇编指令,意料之外的情况 100w 次中出现了 96 次。虽然很少,但确实是客观存在的情况。
+有文档提到,x86 体系的内存序本身比较严格,除了 store-load 以外不存在其它类型的重排,也可以用下列脚本验证:
+
+```
+X86 RW
+{ x=0; y=0; }
+ P0 | P1 ;
+ MOV EAX,[y] | MOV EAX,[x] ;
+ MOV [x],$1 | MOV [y],$1 ;
+locations [x;y;]
+exists (0:EAX=1 /\ 1:EAX=1)
+```
+
+```
+%%%%%%%%%%%%%%%%%%%%%%%%%
+% Results for sb.litmus %
+%%%%%%%%%%%%%%%%%%%%%%%%%
+X86 OOO
+
+{x=0; y=0;}
+
+ P0 | P1 ;
+ MOV EAX,[y] | MOV EAX,[x] ;
+ MOV [x],$1 | MOV [y],$1 ;
+
+locations [x; y;]
+exists (0:EAX=1 /\ 1:EAX=1)
+Generated assembler
+ ##START _litmus_P0
+ movl -4(%rsi,%rcx,4), %eax
+ movl $1, -4(%rbx,%rcx,4)
+ ##START _litmus_P1
+ movl -4(%rbx,%rcx,4), %eax
+ movl $1, -4(%rsi,%rcx,4)
+
+Test OOO Allowed
+Histogram (2 states)
+500000:>0:EAX=1; 1:EAX=0; x=1; y=1;
+500000:>0:EAX=0; 1:EAX=1; x=1; y=1;
+No
+
+Witnesses
+Positive: 0, Negative: 1000000
+Condition exists (0:EAX=1 /\ 1:EAX=1) is NOT validated
+Hash=7cdd62e8647b817c1615cf8eb9d2117b
+Observation OOO Never 0 1000000
+Time OOO 0.14
+```
+
+无论运行多少次,Positive 应该都是 0。
+
## barrier
从功能上来讲,barrier 有四种:
@@ -519,3 +569,5 @@ https://stackoverflow.com/questions/29880015/lock-prefix-vs-mesi-protocol
https://github.com/torvalds/linux/blob/master/Documentation/memory-barriers.txt
http://www.overbyte.com.au/misc/Lesson3/CacheFun.html
+
+
diff --git a/netpoll.md b/netpoll.md
index 942adad..7ab59f9 100644
--- a/netpoll.md
+++ b/netpoll.md
@@ -1355,3 +1355,5 @@ func poll_runtime_pollUnblock(pd *pollDesc) {
}
}
```
+
+
diff --git a/panic.md b/panic.md
index 7765ec1..e34b3ad 100644
--- a/panic.md
+++ b/panic.md
@@ -295,4 +295,6 @@ func main() {
defer panic(2)
panic(1)
}
-```
\ No newline at end of file
+```
+
+
diff --git a/pprof.md b/pprof.md
new file mode 100644
index 0000000..f825a1a
--- /dev/null
+++ b/pprof.md
@@ -0,0 +1,778 @@
+# pprof
+> 本章节没有介绍具体 pprof 以及周边工具的使用, 而是进行了 runtime pprof 实现原理的分析, 旨在提供给读者一个使用方面的参考
+在进行深入本章节之前, 让我们来看三个问题, 相信下面这几个问题也是大部分人在使用 pprof 的时候对它最大的困惑, 那么可以带着这三个问题来进行接下去的分析
+- 开启 pprof 会对 runtime 产生多大的压力?
+- 能否选择性在合适阶段对生产环境的应用进行 pprof 的开启 / 关闭操作?
+- pprof 的原理是什么?
+
+go 内置的 `pprof API` 在 `runtime/pprof` 包内, 它提供给了用户与 `runtime` 交互的能力, 让我们能够在应用运行的过程中分析当前应用的各项指标来辅助进行性能优化以及问题排查, 当然也可以直接加载 `_ "net/http/pprof"` 包使用内置的 `http 接口` 来进行使用, `net` 模块内的 pprof 即为 go 替我们封装好的一系列调用 `runtime/pprof` 的方法, 当然也可以自己直接使用
+```go
+// src/runtime/pprof/pprof.go
+// 可观察类目
+profiles.m = map[string]*Profile{
+ "goroutine": goroutineProfile,
+ "threadcreate": threadcreateProfile,
+ "heap": heapProfile,
+ "allocs": allocsProfile,
+ "block": blockProfile,
+ "mutex": mutexProfile,
+ }
+```
+
+## allocs
+```go
+
+var allocsProfile = &Profile{
+ name: "allocs",
+ count: countHeap, // identical to heap profile
+ write: writeAlloc,
+}
+```
+- writeAlloc (主要涉及以下几个 api)
+ - ReadMemStats(m *MemStats)
+ - MemProfile(p []MemProfileRecord, inuseZero bool)
+
+```go
+// ReadMemStats populates m with memory allocator statistics.
+//
+// The returned memory allocator statistics are up to date as of the
+// call to ReadMemStats. This is in contrast with a heap profile,
+// which is a snapshot as of the most recently completed garbage
+// collection cycle.
+func ReadMemStats(m *MemStats) {
+ // STW 操作
+ stopTheWorld("read mem stats")
+ // systemstack 切换
+ systemstack(func() {
+ // 将 memstats 通过 copy 操作复制给 m
+ readmemstats_m(m)
+ })
+
+ startTheWorld()
+}
+```
+
+```go
+// MemProfile returns a profile of memory allocated and freed per allocation
+// site.
+//
+// MemProfile returns n, the number of records in the current memory profile.
+// If len(p) >= n, MemProfile copies the profile into p and returns n, true.
+// If len(p) < n, MemProfile does not change p and returns n, false.
+//
+// If inuseZero is true, the profile includes allocation records
+// where r.AllocBytes > 0 but r.AllocBytes == r.FreeBytes.
+// These are sites where memory was allocated, but it has all
+// been released back to the runtime.
+//
+// The returned profile may be up to two garbage collection cycles old.
+// This is to avoid skewing the profile toward allocations; because
+// allocations happen in real time but frees are delayed until the garbage
+// collector performs sweeping, the profile only accounts for allocations
+// that have had a chance to be freed by the garbage collector.
+//
+// Most clients should use the runtime/pprof package or
+// the testing package's -test.memprofile flag instead
+// of calling MemProfile directly.
+func MemProfile(p []MemProfileRecord, inuseZero bool) (n int, ok bool) {
+ lock(&proflock)
+ // If we're between mProf_NextCycle and mProf_Flush, take care
+ // of flushing to the active profile so we only have to look
+ // at the active profile below.
+ mProf_FlushLocked()
+ clear := true
+ /*
+ * 记住这个 mbuckets -- memory profile buckets
+ * allocs 的采样都是记录在这个全局变量内, 下面会进行详细分析
+ * -------------------------------------------------
+ * (gdb) info variables mbuckets
+ * All variables matching regular expression "mbuckets":
+
+ * File runtime:
+ * runtime.bucket *runtime.mbuckets;
+ * (gdb)
+ */
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ n++
+ }
+ if mp.active.allocs != 0 || mp.active.frees != 0 {
+ clear = false
+ }
+ }
+ if clear {
+ // Absolutely no data, suggesting that a garbage collection
+ // has not yet happened. In order to allow profiling when
+ // garbage collection is disabled from the beginning of execution,
+ // accumulate all of the cycles, and recount buckets.
+ n = 0
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ for c := range mp.future {
+ mp.active.add(&mp.future[c])
+ mp.future[c] = memRecordCycle{}
+ }
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ n++
+ }
+ }
+ }
+ if n <= len(p) {
+ ok = true
+ idx := 0
+ for b := mbuckets; b != nil; b = b.allnext {
+ mp := b.mp()
+ if inuseZero || mp.active.alloc_bytes != mp.active.free_bytes {
+ // mbuckets 数据拷贝
+ record(&p[idx], b)
+ idx++
+ }
+ }
+ }
+ unlock(&proflock)
+ return
+}
+```
+
+总结一下 `pprof/allocs` 所涉及的操作
+- 短暂的 `STW` 以及 `systemstack` 切换来获取 `runtime` 相关信息
+- 拷贝全局对象 `mbuckets` 值返回给用户
+
+### mbuckets
+上文提到, `pprof/allocs` 的核心在于对 `mbuckets` 的操作, 下面用一张图来简单描述下 `mbuckets` 的相关操作
+```go
+var mbuckets *bucket // memory profile buckets
+type bucket struct {
+ next *bucket
+ allnext *bucket
+ typ bucketType // memBucket or blockBucket (includes mutexProfile)
+ hash uintptr
+ size uintptr
+ nstk uintptr
+}
+```
+
+
+```shell
+ ---------------
+ | user access |
+ ---------------
+ |
+ ------------------ |
+| mbuckets list | copy |
+| (global) | -------------------------------------
+ ------------------
+ |
+ |
+ | create_or_get && insert_or_update bucket into mbuckets
+ |
+ |
+ --------------------------------------
+| func stkbucket & typ == memProfile |
+ --------------------------------------
+ |
+ ----------------
+ | mProf_Malloc | // 堆栈等信息记录
+ ----------------
+ |
+ ----------------
+ | profilealloc | // next_sample 计算
+ ----------------
+ |
+ | /*
+ | * if rate := MemProfileRate; rate > 0 {
+ | * if rate != 1 && size < c.next_sample {
+ | * c.next_sample -= size
+ | 采样 * } else {
+ | 记录 * mp := acquirem()
+ | * profilealloc(mp, x, size)
+ | * releasem(mp)
+ | * }
+ | * }
+ | */
+ |
+ ------------ 不采样
+ | mallocgc |-----------...
+ ------------
+```
+
+由上图我们可以清晰的看见, `runtime` 在内存分配的时候会根据一定策略进行采样, 记录到 `mbuckets` 中让用户得以进行分析, 而采样算法有个重要的依赖 `MemProfileRate`
+
+```go
+// MemProfileRate controls the fraction of memory allocations
+// that are recorded and reported in the memory profile.
+// The profiler aims to sample an average of
+// one allocation per MemProfileRate bytes allocated.
+//
+// To include every allocated block in the profile, set MemProfileRate to 1.
+// To turn off profiling entirely, set MemProfileRate to 0.
+//
+// The tools that process the memory profiles assume that the
+// profile rate is constant across the lifetime of the program
+// and equal to the current value. Programs that change the
+// memory profiling rate should do so just once, as early as
+// possible in the execution of the program (for example,
+// at the beginning of main).
+var MemProfileRate int = 512 * 1024
+```
+默认大小是 512 KB, 可以由用户自行配置.
+
+值的注意的是, 由于开启了 pprof 会产生一些采样的额外压力及开销, go 团队已经在较新的编译器中有选择地进行了这个变量的配置以[改变](https://go-review.googlesource.com/c/go/+/299671/8/src/runtime/mprof.go)默认开启的现状
+
+具体方式为代码未进行相关引用则编译器将初始值配置为 0, 否则则为默认(512 KB)
+
+(本文讨论的基于 1.14.3 版本, 如有差异请进行版本确认)
+
+#### pprof/allocs 总结
+- 开启后会对 runtime 产生额外压力, 采样时会在 `runtime malloc` 时记录额外信息以供后续分析
+- 可以人为选择是否开启, 以及采样频率, 通过设置 `runtime.MemProfileRate` 参数, 不同 go 版本存在差异(是否默认开启), 与用户代码内是否引用(linker)相关模块/变量有关, 默认大小为 512 KB
+
+`allocs` 部分还包含了 `heap` 情况的近似计算, 放在下一节分析
+## heap
+>allocs: A sampling of all past memory allocations
+
+>heap: A sampling of memory allocations of live objects. You can specify the gc GET parameter to run GC before taking the heap sample.
+
+对比下 `allocs` 和 `heap` 官方说明上的区别, 一个是分析所有内存分配的情况, 一个是当前 `heap` 上的分配情况. `heap` 还能使用额外参数运行一次 `GC` 后再进行分析
+
+看起来两者差别很大。。。不过实质上在代码层面两者除了一次 `GC` 可以人为调用以及生成的文件类型不同之外 (debug == 0 的时候) 之外没啥区别.
+
+### heap 采样(伪)
+```go
+// p 为上文提到过的 MemProfileRecord 采样记录
+for _, r := range p {
+ hideRuntime := true
+ for tries := 0; tries < 2; tries++ {
+ stk := r.Stack()
+ // For heap profiles, all stack
+ // addresses are return PCs, which is
+ // what appendLocsForStack expects.
+ if hideRuntime {
+ for i, addr := range stk {
+ if f := runtime.FuncForPC(addr); f != nil && strings.HasPrefix(f.Name(), "runtime.") {
+ continue
+ }
+ // Found non-runtime. Show any runtime uses above it.
+ stk = stk[i:]
+ break
+ }
+ }
+ locs = b.appendLocsForStack(locs[:0], stk)
+ if len(locs) > 0 {
+ break
+ }
+ hideRuntime = false // try again, and show all frames next time.
+ }
+ // rate 即为 runtime.MemProfileRate
+ values[0], values[1] = scaleHeapSample(r.AllocObjects, r.AllocBytes, rate)
+ values[2], values[3] = scaleHeapSample(r.InUseObjects(), r.InUseBytes(), rate)
+ var blockSize int64
+ if r.AllocObjects > 0 {
+ blockSize = r.AllocBytes / r.AllocObjects
+ }
+ b.pbSample(values, locs, func() {
+ if blockSize != 0 {
+ b.pbLabel(tagSample_Label, "bytes", "", blockSize)
+ }
+ })
+ }
+```
+```go
+// scaleHeapSample adjusts the data from a heap Sample to
+// account for its probability of appearing in the collected
+// data. heap profiles are a sampling of the memory allocations
+// requests in a program. We estimate the unsampled value by dividing
+// each collected sample by its probability of appearing in the
+// profile. heap profiles rely on a poisson process to determine
+// which samples to collect, based on the desired average collection
+// rate R. The probability of a sample of size S to appear in that
+// profile is 1-exp(-S/R).
+func scaleHeapSample(count, size, rate int64) (int64, int64) {
+ if count == 0 || size == 0 {
+ return 0, 0
+ }
+
+ if rate <= 1 {
+ // if rate==1 all samples were collected so no adjustment is needed.
+ // if rate<1 treat as unknown and skip scaling.
+ return count, size
+ }
+
+ avgSize := float64(size) / float64(count)
+ scale := 1 / (1 - math.Exp(-avgSize/float64(rate)))
+
+ return int64(float64(count) * scale), int64(float64(size) * scale)
+}
+```
+
+为什么要在标题里加个伪? 看上面代码片段也可以注意到, 实质上在 `pprof` 分析的时候并没有扫描所有堆上内存进行分析 (想想也不现实) , 而是通过之前采样出的数据, 进行计算 (现有对象数量, 大小, 采样率等) 来估算出 `heap` 上的情况, 当然给我们参考一般来说是足够了
+
+## goroutine
+- debug >= 2 的情况, 直接进行堆栈输出, 详情可以查看 [stack](runtime_stack.md) 章节
+
+```go
+// fetch == runtime.GoroutineProfile
+func writeRuntimeProfile(w io.Writer, debug int, name string, fetch func([]runtime.StackRecord) (int, bool)) error {
+ // Find out how many records there are (fetch(nil)),
+ // allocate that many records, and get the data.
+ // There's a race—more records might be added between
+ // the two calls—so allocate a few extra records for safety
+ // and also try again if we're very unlucky.
+ // The loop should only execute one iteration in the common case.
+ var p []runtime.StackRecord
+ n, ok := fetch(nil)
+ for {
+ // Allocate room for a slightly bigger profile,
+ // in case a few more entries have been added
+ // since the call to ThreadProfile.
+ p = make([]runtime.StackRecord, n+10)
+ n, ok = fetch(p)
+ if ok {
+ p = p[0:n]
+ break
+ }
+ // Profile grew; try again.
+ }
+
+ return printCountProfile(w, debug, name, runtimeProfile(p))
+}
+```
+
+```go
+// GoroutineProfile returns n, the number of records in the active goroutine stack profile.
+// If len(p) >= n, GoroutineProfile copies the profile into p and returns n, true.
+// If len(p) < n, GoroutineProfile does not change p and returns n, false.
+//
+// Most clients should use the runtime/pprof package instead
+// of calling GoroutineProfile directly.
+func GoroutineProfile(p []StackRecord) (n int, ok bool) {
+ gp := getg()
+
+ isOK := func(gp1 *g) bool {
+ // Checking isSystemGoroutine here makes GoroutineProfile
+ // consistent with both NumGoroutine and Stack.
+ return gp1 != gp && readgstatus(gp1) != _Gdead && !isSystemGoroutine(gp1, false)
+ }
+ // 熟悉的味道, STW 又来了
+ stopTheWorld("profile")
+ // 统计有多少 goroutine
+ n = 1
+ for _, gp1 := range allgs {
+ if isOK(gp1) {
+ n++
+ }
+ }
+ // 当传入的 p 非空的时候, 开始获取各个 goroutine 信息, 整体姿势和 stack api 几乎一模一样
+ if n <= len(p) {
+ ok = true
+ r := p
+
+ // Save current goroutine.
+ sp := getcallersp()
+ pc := getcallerpc()
+ systemstack(func() {
+ saveg(pc, sp, gp, &r[0])
+ })
+ r = r[1:]
+
+ // Save other goroutines.
+ for _, gp1 := range allgs {
+ if isOK(gp1) {
+ if len(r) == 0 {
+ // Should be impossible, but better to return a
+ // truncated profile than to crash the entire process.
+ break
+ }
+ saveg(^uintptr(0), ^uintptr(0), gp1, &r[0])
+ r = r[1:]
+ }
+ }
+ }
+
+ startTheWorld()
+
+ return n, ok
+}
+```
+总结下 `pprof/goroutine`
+- STW 操作, 如果需要观察详情的需要注意这个 API 带来的风险
+- 整体流程基本就是 stackdump 所有协程信息的流程, 差别不大没什么好讲的, 不熟悉的可以去看下 stack 对应章节
+
+## pprof/threadcreate
+可能会有人想问, 我们通常只关注 `goroutine` 就够了, 为什么还需要对线程的一些情况进行追踪? 例如无法被抢占的阻塞性[系统调用](syscall.md), `cgo` 相关的线程等等, 都可以利用它来进行一个简单的分析, 当然大多数情况考虑的线程问题(诸如泄露等), 一般都是上层的使用问题所导致的(线程泄露等)
+```go
+// 还是用之前用过的无法被抢占的阻塞性系统调用来进行一个简单的实验
+package main
+
+import (
+ "fmt"
+ "net/http"
+ _ "net/http/pprof"
+ "os"
+ "syscall"
+ "unsafe"
+)
+
+const (
+ SYS_futex = 202
+ _FUTEX_PRIVATE_FLAG = 128
+ _FUTEX_WAIT = 0
+ _FUTEX_WAKE = 1
+ _FUTEX_WAIT_PRIVATE = _FUTEX_WAIT | _FUTEX_PRIVATE_FLAG
+ _FUTEX_WAKE_PRIVATE = _FUTEX_WAKE | _FUTEX_PRIVATE_FLAG
+)
+
+func main() {
+ fmt.Println(os.Getpid())
+ go func() {
+ b := make([]byte, 1<<20)
+ _ = b
+ }()
+ for i := 1; i < 13; i++ {
+ go func() {
+ var futexVar int = 0
+ for {
+ // Syscall && RawSyscall, 具体差别分析可自行查看 syscall 章节
+ fmt.Println(syscall.Syscall6(
+ SYS_futex, // trap AX 202
+ uintptr(unsafe.Pointer(&futexVar)), // a1 DI 1
+ uintptr(_FUTEX_WAIT), // a2 SI 0
+ 0, // a3 DX
+ 0, //uintptr(unsafe.Pointer(&ts)), // a4 R10
+ 0, // a5 R8
+ 0))
+ }
+ }()
+ }
+ http.ListenAndServe("0.0.0.0:8899", nil)
+}
+```
+```shell
+# GET /debug/pprof/threadcreate?debug=1
+threadcreate profile: total 18
+17 @
+# 0x0
+
+1 @ 0x43b818 0x43bfa3 0x43c272 0x43857d 0x467fb1
+# 0x43b817 runtime.allocm+0x157 /usr/local/go/src/runtime/proc.go:1414
+# 0x43bfa2 runtime.newm+0x42 /usr/local/go/src/runtime/proc.go:1736
+# 0x43c271 runtime.startTemplateThread+0xb1 /usr/local/go/src/runtime/proc.go:1805
+# 0x43857c runtime.main+0x18c /usr/local/go/src/runtime/proc.go:186
+```
+```shell
+# 再结合诸如 pstack 的工具
+ps -efT | grep 22298 # pid = 22298
+root 22298 22298 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22299 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22300 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22301 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22302 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22303 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22304 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22305 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22306 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22307 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22308 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22309 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22310 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22311 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22312 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22316 13767 0 16:59 pts/4 00:00:00 ./mstest
+root 22298 22317 13767 0 16:59 pts/4 00:00:00 ./mstest
+
+pstack 22299
+Thread 1 (process 22299):
+#0 runtime.futex () at /usr/local/go/src/runtime/sys_linux_amd64.s:568
+#1 0x00000000004326f4 in runtime.futexsleep (addr=0xb2fd78
diff --git a/readme.md b/readme.md
index cbd4555..d0c7ab2 100644
--- a/readme.md
+++ b/readme.md
@@ -29,6 +29,8 @@
23. [x] [stack dump](runtime_stack.md)
24. [x] [Atomic](atomic.md)
25. [ ] [Generics](generics.md)
+26. [x] [IO](io.md)
+26. [x] [pprof](pprof.md)
# Authors
diff --git a/scheduler.md b/scheduler.md
index ec9ed3e..7d4557b 100644
--- a/scheduler.md
+++ b/scheduler.md
@@ -1,4 +1,4 @@
-> 注: 在抢占式调度的 go 版本下如果需要对 runtime 进行调试,诸如使用 gdb, lldb, [delve](https://github.com/go-delve/delve) 等工具时,需要注意 GODEBUG=asyncpreemptoff=1 环境变量,该变量会导致 runtime 是否进行抢占式调度,由于 https://github.com/golang/go/issues/36494 ,导致部分系统下该变量会被一些(如 delve)工具配置开启,从而导致超出预期的调试情况,需要读者自行关注
+> 注: 在抢占式调度的 go 版本下如果需要对 runtime 进行调试,诸如使用 gdb, lldb, [delve](https://github.com/go-delve/delve) 等工具时,需要注意 GODEBUG=asyncpreemptoff=1 环境变量,该变量会决定 runtime 是否开启抢占式调度,由于 https://github.com/golang/go/issues/36494 ,导致部分系统下该变量会被一些(如 delve)工具配置开启,从而导致超出预期的调试情况,需要读者自行关注
# 调度
## 基本数据结构
@@ -752,6 +752,8 @@ runtime.gcenable --> main.init
main.init --> main.main
```
+**主线程也是需要和 p 绑定来运行的**,绑定过程在 procresize -> acquirep 中。
+
### sysmon 线程
sysmon 是在 `runtime.main` 中启动的,不过需要注意的是 sysmon 并不是在 m0 上执行的。因为:
@@ -2346,3 +2348,4 @@ gcMarkDone --> forEachP
当然,这里 entersyscall 和 entersyscallblock 比较特殊,虽然这俩函数的实现中有设置抢占标记,但实际上这两段逻辑是不会被走到的。因为 syscall 执行时是在 m 的 g0 栈上,如果在执行时被抢占,那么会直接 throw,而无法恢复。
+
diff --git a/select.md b/select.md
index 24d32d0..ed93053 100644
--- a/select.md
+++ b/select.md
@@ -826,3 +826,5 @@ sclose:
Q: 如果select多个channel,有一个channel触发了,其他channel的waitlist需要不要主动去除?还是一直在那等着?
A: waitlist 的出列是由 `func (q *waitq) dequeue() *sudog` 函数控制的,每个 sudog 携带了一个 `selectDone` 标志位,通过 `cas` 操作在每次 `dequeue` 的时候「惰性」去除队列中无效的元素
+
+
diff --git a/semaphore.md b/semaphore.md
index 4fbeddd..51d4640 100644
--- a/semaphore.md
+++ b/semaphore.md
@@ -236,7 +236,7 @@ func semacquire1(addr *uint32, lifo bool, profile semaProfileFlags) {
// 高成本的情况:
// 增加 waiter count 的值
- // 再尝试调用一次 cansemacquire,成本了就直接返回
+ // 再尝试调用一次 cansemacquire,成功了就直接返回
// 没成功就把自己作为一个 waiter 入队
// sleep
// (之后 waiter 的 descriptor 被 signaler 用 dequeue 踢出)
@@ -735,4 +735,6 @@ func notifyListCheck(sz uintptr) {
func sync_nanotime() int64 {
return nanotime()
}
-```
\ No newline at end of file
+```
+
+
diff --git a/signal.md b/signal.md
deleted file mode 100644
index 09c2668..0000000
--- a/signal.md
+++ /dev/null
@@ -1,3 +0,0 @@
-# Signal
-
-Go 1.12 的抢占使用 signal 来实现,所以我们来分析一下 Go runtime 中是怎么处理这些 signal 的。
diff --git a/site/README.md b/site/README.md
new file mode 100644
index 0000000..f6a4c5e
--- /dev/null
+++ b/site/README.md
@@ -0,0 +1,3 @@
+# golang
+
+source of go.xargin.com
diff --git a/site/archetypes/default.md b/site/archetypes/default.md
new file mode 100644
index 0000000..00e77bd
--- /dev/null
+++ b/site/archetypes/default.md
@@ -0,0 +1,6 @@
+---
+title: "{{ replace .Name "-" " " | title }}"
+date: {{ .Date }}
+draft: true
+---
+
diff --git a/site/config.toml b/site/config.toml
new file mode 100644
index 0000000..80f33af
--- /dev/null
+++ b/site/config.toml
@@ -0,0 +1,6 @@
+baseURL = "http://go.xargin.com/"
+languageCode = "en-us"
+title = "Go 语言笔记"
+theme = "book"
+googleAnalytics = "G-KLR638LKEQ"
+
diff --git a/site/content/_index.md b/site/content/_index.md
new file mode 100644
index 0000000..e5fb159
--- /dev/null
+++ b/site/content/_index.md
@@ -0,0 +1,13 @@
+---
+title: Go 语言笔记
+type: docs
+---
+
+# Go 语言笔记
+
+## 为什么会有这本书
+
+之前关于 Go 的输出主要散落在 blog 和 github 的 golang-notes 以及公众号中,内容比较分散。不方便阅读,到了这个时间点,本人已经使用 Go 已有超过 6 个年头,可以将之前的输出集合起来,进行系统化的输出了。
+
+
+
diff --git a/site/content/docs/_index.md b/site/content/docs/_index.md
new file mode 100644
index 0000000..e69de29
diff --git a/site/content/docs/api_programming/_index.md b/site/content/docs/api_programming/_index.md
new file mode 100644
index 0000000..7718841
--- /dev/null
+++ b/site/content/docs/api_programming/_index.md
@@ -0,0 +1,6 @@
+---
+title: API 开发
+weight: 5
+bookCollapseSection: true
+draft: true
+---
diff --git a/site/content/docs/api_programming/fasthttp.md b/site/content/docs/api_programming/fasthttp.md
new file mode 100644
index 0000000..a886942
--- /dev/null
+++ b/site/content/docs/api_programming/fasthttp.md
@@ -0,0 +1,2 @@
+# FastHTTP
+
diff --git a/site/content/docs/api_programming/httprouter.md b/site/content/docs/api_programming/httprouter.md
new file mode 100644
index 0000000..bc5ea15
--- /dev/null
+++ b/site/content/docs/api_programming/httprouter.md
@@ -0,0 +1 @@
+# http router 的实现
diff --git a/site/content/docs/api_programming/mysql.md b/site/content/docs/api_programming/mysql.md
new file mode 100644
index 0000000..c64321e
--- /dev/null
+++ b/site/content/docs/api_programming/mysql.md
@@ -0,0 +1 @@
+# mysql
diff --git a/site/content/docs/api_programming/orm.md b/site/content/docs/api_programming/orm.md
new file mode 100644
index 0000000..c69e1ca
--- /dev/null
+++ b/site/content/docs/api_programming/orm.md
@@ -0,0 +1 @@
+# orm && sql builder
diff --git a/site/content/docs/api_programming/validator.md b/site/content/docs/api_programming/validator.md
new file mode 100644
index 0000000..76a423c
--- /dev/null
+++ b/site/content/docs/api_programming/validator.md
@@ -0,0 +1 @@
+# validator
diff --git a/site/content/docs/api_programming/viper.md b/site/content/docs/api_programming/viper.md
new file mode 100644
index 0000000..63d973f
--- /dev/null
+++ b/site/content/docs/api_programming/viper.md
@@ -0,0 +1 @@
+# viper
diff --git a/site/content/docs/assembly/_index.md b/site/content/docs/assembly/_index.md
new file mode 100644
index 0000000..18a2318
--- /dev/null
+++ b/site/content/docs/assembly/_index.md
@@ -0,0 +1,6 @@
+---
+title: 汇编基础
+weight: 1
+bookCollapseSection: true
+---
+
diff --git a/site/content/docs/assembly/assembly.md b/site/content/docs/assembly/assembly.md
new file mode 100644
index 0000000..22fef9c
--- /dev/null
+++ b/site/content/docs/assembly/assembly.md
@@ -0,0 +1,1006 @@
+---
+title: Plan9 汇编解析
+weight: 10
+---
+
+# plan9 assembly 完全解析
+
+众所周知,Go 使用了 Unix 老古董(误 们发明的 plan9 汇编。就算你对 x86 汇编有所了解,在 plan9 里还是有些许区别。说不定你在看代码的时候,偶然发现代码里的 SP 看起来是 SP,但它实际上不是 SP 的时候就抓狂了哈哈哈。
+
+本文将对 plan9 汇编进行全面的介绍,同时解答你在接触 plan9 汇编时可能遇到的大部分问题。
+
+本文所使用的平台是 linux amd64,因为不同的平台指令集和寄存器都不一样,所以没有办法共同探讨。这也是由汇编本身的性质决定的。
+
+## 基本指令
+
+### 栈调整
+
+intel 或 AT&T 汇编提供了 push 和 pop 指令族,~~plan9 中没有 push 和 pop~~,plan9 中虽然有 push 和 pop 指令,但一般生成的代码中是没有的,我们看到的栈的调整大多是通过对硬件 SP 寄存器进行运算来实现的,例如:
+
+```go
+SUBQ $0x18, SP // 对 SP 做减法,为函数分配函数栈帧
+... // 省略无用代码
+ADDQ $0x18, SP // 对 SP 做加法,清除函数栈帧
+```
+
+通用的指令和 X64 平台差不多,下面分节详述。
+
+### 数据搬运
+
+常数在 plan9 汇编用 $num 表示,可以为负数,默认情况下为十进制。可以用 $0x123 的形式来表示十六进制数。
+
+```go
+MOVB $1, DI // 1 byte
+MOVW $0x10, BX // 2 bytes
+MOVD $1, DX // 4 bytes
+MOVQ $-10, AX // 8 bytes
+```
+
+可以看到,搬运的长度是由 MOV 的后缀决定的,这一点与 intel 汇编稍有不同,看看类似的 X64 汇编:
+
+```asm
+mov rax, 0x1 // 8 bytes
+mov eax, 0x100 // 4 bytes
+mov ax, 0x22 // 2 bytes
+mov ah, 0x33 // 1 byte
+mov al, 0x44 // 1 byte
+```
+
+plan9 的汇编的操作数的方向是和 intel 汇编相反的,与 AT&T 类似。
+
+```go
+MOVQ $0x10, AX ===== mov rax, 0x10
+ | |------------| |
+ |------------------------|
+```
+
+不过凡事总有例外,如果想了解这种意外,可以参见参考资料中的 [1]。
+
+### 常见计算指令
+
+```go
+ADDQ AX, BX // BX += AX
+SUBQ AX, BX // BX -= AX
+IMULQ AX, BX // BX *= AX
+```
+
+类似数据搬运指令,同样可以通过修改指令的后缀来对应不同长度的操作数。例如 ADDQ/ADDW/ADDL/ADDB。
+
+### 条件跳转/无条件跳转
+
+```go
+// 无条件跳转
+JMP addr // 跳转到地址,地址可为代码中的地址,不过实际上手写不会出现这种东西
+JMP label // 跳转到标签,可以跳转到同一函数内的标签位置
+JMP 2(PC) // 以当前指令为基础,向前/后跳转 x 行
+JMP -2(PC) // 同上
+
+// 有条件跳转
+JZ target // 如果 zero flag 被 set 过,则跳转
+
+```
+
+
+### 指令集
+
+可以参考源代码的 [arch](https://github.com/golang/arch/blob/master/x86/x86.csv) 部分。
+
+额外提一句,Go 1.10 添加了大量的 SIMD 指令支持,所以在该版本以上的话,不像之前写那样痛苦了,也就是不用人肉填 byte 了。
+
+## 寄存器
+
+### 通用寄存器
+
+amd64 的通用寄存器:
+
+```gdb
+(lldb) reg read
+General Purpose Registers:
+ rax = 0x0000000000000005
+ rbx = 0x000000c420088000
+ rcx = 0x0000000000000000
+ rdx = 0x0000000000000000
+ rdi = 0x000000c420088008
+ rsi = 0x0000000000000000
+ rbp = 0x000000c420047f78
+ rsp = 0x000000c420047ed8
+ r8 = 0x0000000000000004
+ r9 = 0x0000000000000000
+ r10 = 0x000000c420020001
+ r11 = 0x0000000000000202
+ r12 = 0x0000000000000000
+ r13 = 0x00000000000000f1
+ r14 = 0x0000000000000011
+ r15 = 0x0000000000000001
+ rip = 0x000000000108ef85 int`main.main + 213 at int.go:19
+ rflags = 0x0000000000000212
+ cs = 0x000000000000002b
+ fs = 0x0000000000000000
+ gs = 0x0000000000000000
+```
+
+在 plan9 汇编里都是可以使用的,应用代码层面会用到的通用寄存器主要是: rax, rbx, rcx, rdx, rdi, rsi, r8~r15 这 14 个寄存器,虽然 rbp 和 rsp 也可以用,不过 bp 和 sp 会被用来管理栈顶和栈底,最好不要拿来进行运算。
+
+plan9 中使用寄存器不需要带 r 或 e 的前缀,例如 rax,只要写 AX 即可:
+
+```go
+MOVQ $101, AX = mov rax, 101
+```
+
+下面是通用通用寄存器的名字在 X64 和 plan9 中的对应关系:
+
+| X64 | rax | rbx| rcx | rdx | rdi | rsi | rbp | rsp | r8 | r9 | r10 | r11 | r12 | r13 | r14 | rip|
+|--|--|--|--| --| --|--| --|--|--|--|--|--|--|--|--|--|
+| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
+
+### 伪寄存器
+
+Go 的汇编还引入了 4 个伪寄存器,援引官方文档的描述:
+
+>- `FP`: Frame pointer: arguments and locals.
+>- `PC`: Program counter: jumps and branches.
+>- `SB`: Static base pointer: global symbols.
+>- `SP`: Stack pointer: the highest address within the local stack frame.
+
+官方的描述稍微有一些问题,我们对这些说明进行一点扩充:
+
+- FP: 使用形如 `symbol+offset(FP)` 的方式,引用函数的输入参数。例如 `arg0+0(FP)`,`arg1+8(FP)`,使用 FP 不加 symbol 时,无法通过编译,在汇编层面来讲,symbol 并没有什么用,加 symbol 主要是为了提升代码可读性。另外,官方文档虽然将伪寄存器 FP 称之为 frame pointer,实际上它根本不是 frame pointer,按照传统的 x86 的习惯来讲,frame pointer 是指向整个 stack frame 底部的 BP 寄存器。假如当前的 callee 函数是 add,在 add 的代码中引用 FP,该 FP 指向的位置不在 callee 的 stack frame 之内,而是在 caller 的 stack frame 上。具体可参见之后的 **栈结构** 一章。
+- PC: 实际上就是在体系结构的知识中常见的 pc 寄存器,在 x86 平台下对应 ip 寄存器,amd64 上则是 rip。除了个别跳转之外,手写 plan9 代码与 PC 寄存器打交道的情况较少。
+- SB: 全局静态基指针,一般用来声明函数或全局变量,在之后的函数知识和示例部分会看到具体用法。
+- SP: plan9 的这个 SP 寄存器指向当前栈帧的局部变量的开始位置,使用形如 `symbol+offset(SP)` 的方式,引用函数的局部变量。offset 的合法取值是 [-framesize, 0),注意是个左闭右开的区间。假如局部变量都是 8 字节,那么第一个局部变量就可以用 `localvar0-8(SP)` 来表示。这也是一个词不表意的寄存器。与硬件寄存器 SP 是两个不同的东西,在栈帧 size 为 0 的情况下,伪寄存器 SP 和硬件寄存器 SP 指向同一位置。手写汇编代码时,如果是 `symbol+offset(SP)` 形式,则表示伪寄存器 SP。如果是 `offset(SP)` 则表示硬件寄存器 SP。务必注意。对于编译输出(go tool compile -S / go tool objdump)的代码来讲,目前所有的 SP 都是硬件寄存器 SP,无论是否带 symbol。
+
+我们这里对容易混淆的几点简单进行说明:
+
+1. 伪 SP 和硬件 SP 不是一回事,在手写代码时,伪 SP 和硬件 SP 的区分方法是看该 SP 前是否有 symbol。如果有 symbol,那么即为伪寄存器,如果没有,那么说明是硬件 SP 寄存器。
+2. SP 和 FP 的相对位置是会变的,所以不应该尝试用伪 SP 寄存器去找那些用 FP + offset 来引用的值,例如函数的入参和返回值。
+3. 官方文档中说的伪 SP 指向 stack 的 top,是有问题的。其指向的局部变量位置实际上是整个栈的栈底(除 caller BP 之外),所以说 bottom 更合适一些。
+4. 在 go tool objdump/go tool compile -S 输出的代码中,是没有伪 SP 和 FP 寄存器的,我们上面说的区分伪 SP 和硬件 SP 寄存器的方法,对于上述两个命令的输出结果是没法使用的。在编译和反汇编的结果中,只有真实的 SP 寄存器。
+5. FP 和 Go 的官方源代码里的 framepointer 不是一回事,源代码里的 framepointer 指的是 caller BP 寄存器的值,在这里和 caller 的伪 SP 是值是相等的。
+
+以上说明看不懂也没关系,在熟悉了函数的栈结构之后再反复回来查看应该就可以明白了。
+
+## 变量声明
+
+在汇编里所谓的变量,一般是存储在 .rodata 或者 .data 段中的只读值。对应到应用层的话,就是已初始化过的全局的 const、var、static 变量/常量。
+
+使用 DATA 结合 GLOBL 来定义一个变量。DATA 的用法为:
+
+```go
+DATA symbol+offset(SB)/width, value
+```
+
+大多数参数都是字面意思,不过这个 offset 需要稍微注意。其含义是该值相对于符号 symbol 的偏移,而不是相对于全局某个地址的偏移。
+
+使用 GLOBL 指令将变量声明为 global,额外接收两个参数,一个是 flag,另一个是变量的总大小。
+
+```go
+GLOBL divtab(SB), RODATA, $64
+```
+
+GLOBL 必须跟在 DATA 指令之后,下面是一个定义了多个 readonly 的全局变量的完整例子:
+
+```go
+DATA age+0x00(SB)/4, $18 // forever 18
+GLOBL age(SB), RODATA, $4
+
+DATA pi+0(SB)/8, $3.1415926
+GLOBL pi(SB), RODATA, $8
+
+DATA birthYear+0(SB)/4, $1988
+GLOBL birthYear(SB), RODATA, $4
+```
+
+正如之前所说,所有符号在声明时,其 offset 一般都是 0。
+
+有时也可能会想在全局变量中定义数组,或字符串,这时候就需要用上非 0 的 offset 了,例如:
+
+```go
+DATA bio<>+0(SB)/8, $"oh yes i"
+DATA bio<>+8(SB)/8, $"am here "
+GLOBL bio<>(SB), RODATA, $16
+```
+
+大部分都比较好理解,不过这里我们又引入了新的标记 `<>`,这个跟在符号名之后,表示该全局变量只在当前文件中生效,类似于 C 语言中的 static。如果在另外文件中引用该变量的话,会报 `relocation target not found` 的错误。
+
+本小节中提到的 flag,还可以有其它的取值:
+>- `NOPROF` = 1
+ (For `TEXT` items.) Don't profile the marked function. This flag is deprecated.
+>- `DUPOK` = 2
+ It is legal to have multiple instances of this symbol in a single binary. The linker will choose one of the duplicates to use.
+>- `NOSPLIT` = 4
+ (For `TEXT` items.) Don't insert the preamble to check if the stack must be split. The frame for the routine, plus anything it calls, must fit in the spare space at the top of the stack segment. Used to protect routines such as the stack splitting code itself.
+>- `RODATA` = 8
+ (For `DATA` and `GLOBL` items.) Put this data in a read-only section.
+>- `NOPTR` = 16
+ (For `DATA` and `GLOBL` items.) This data contains no pointers and therefore does not need to be scanned by the garbage collector.
+>- `WRAPPER` = 32
+ (For `TEXT` items.) This is a wrapper function and should not count as disabling `recover`.
+>- `NEEDCTXT` = 64
+ (For `TEXT` items.) This function is a closure so it uses its incoming context register.
+
+当使用这些 flag 的字面量时,需要在汇编文件中 `#include "textflag.h"`。
+
+## .s 和 .go 文件的全局变量互通
+
+在 `.s` 文件中是可以直接使用 `.go` 中定义的全局变量的,看看下面这个简单的例子:
+
+refer.go:
+
+```go
+package main
+
+var a = 999
+func get() int
+
+func main() {
+ println(get())
+}
+
+```
+
+refer.s:
+
+```go
+#include "textflag.h"
+
+TEXT ·get(SB), NOSPLIT, $0-8
+ MOVQ ·a(SB), AX
+ MOVQ AX, ret+0(FP)
+ RET
+```
+
+·a(SB),表示该符号需要链接器来帮我们进行重定向(relocation),如果找不到该符号,会输出 `relocation target not found` 的错误。
+
+例子比较简单,大家可以自行尝试。
+
+## 函数声明
+
+我们来看看一个典型的 plan9 的汇编函数的定义:
+
+```go
+// func add(a, b int) int
+// => 该声明定义在同一个 package 下的任意 .go 文件中
+// => 只有函数头,没有实现
+TEXT pkgname·add(SB), NOSPLIT, $0-8
+ MOVQ a+0(FP), AX
+ MOVQ a+8(FP), BX
+ ADDQ AX, BX
+ MOVQ BX, ret+16(FP)
+ RET
+```
+
+为什么要叫 TEXT ?如果对程序数据在文件中和内存中的分段稍有了解的同学应该知道,我们的代码在二进制文件中,是存储在 .text 段中的,这里也就是一种约定俗成的起名方式。实际上在 plan9 中 TEXT 是一个指令,用来定义一个函数。除了 TEXT 之外还有前面变量声明说到的 DATA/GLOBL。
+
+定义中的 pkgname 部分是可以省略的,非想写也可以写上。不过写上 pkgname 的话,在重命名 package 之后还需要改代码,所以推荐最好还是不要写。
+
+中点 `·` 比较特殊,是一个 unicode 的中点,该点在 mac 下的输入方法是 `option+shift+9`。在程序被链接之后,所有的中点`·` 都会被替换为句号`.`,比如你的方法是 `runtime·main`,在编译之后的程序里的符号则是 `runtime.main`。嗯,看起来很变态。简单总结一下:
+
+```go
+
+ 参数及返回值大小
+ |
+ TEXT pkgname·add(SB),NOSPLIT,$32-32
+ | | |
+ 包名 函数名 栈帧大小(局部变量+可能需要的额外调用函数的参数空间的总大小,但不包括调用其它函数时的 ret address 的大小)
+
+```
+
+## 栈结构
+
+下面是一个典型的函数的栈结构图:
+
+```
+
+ -----------------
+ current func arg0
+ ----------------- <----------- FP(pseudo FP)
+ caller ret addr
+ +---------------+
+ | caller BP(*) |
+ ----------------- <----------- SP(pseudo SP,实际上是当前栈帧的 BP 位置)
+ | Local Var0 |
+ -----------------
+ | Local Var1 |
+ -----------------
+ | Local Var2 |
+ ----------------- -
+ | ........ |
+ -----------------
+ | Local VarN |
+ -----------------
+ | |
+ | |
+ | temporarily |
+ | unused space |
+ | |
+ | |
+ -----------------
+ | call retn |
+ -----------------
+ | call ret(n-1)|
+ -----------------
+ | .......... |
+ -----------------
+ | call ret1 |
+ -----------------
+ | call argn |
+ -----------------
+ | ..... |
+ -----------------
+ | call arg3 |
+ -----------------
+ | call arg2 |
+ |---------------|
+ | call arg1 |
+ ----------------- <------------ hardware SP 位置
+ return addr
+ +---------------+
+
+
+```
+
+从原理上来讲,如果当前函数调用了其它函数,那么 return addr 也是在 caller 的栈上的,不过往栈上插 return addr 的过程是由 CALL 指令完成的,在 RET 时,SP 又会恢复到图上位置。我们在计算 SP 和参数相对位置时,可以认为硬件 SP 指向的就是图上的位置。
+
+图上的 caller BP,指的是 caller 的 BP 寄存器值,有些人把 caller BP 叫作 caller 的 frame pointer,实际上这个习惯是从 x86 架构沿袭来的。Go 的 asm 文档中把伪寄存器 FP 也称为 frame pointer,但是这两个 frame pointer 根本不是一回事。
+
+此外需要注意的是,caller BP 是在编译期由编译器插入的,用户手写代码时,计算 frame size 时是不包括这个 caller BP 部分的。是否插入 caller BP 的主要判断依据是:
+
+1. 函数的栈帧大小大于 0
+2. 下述函数返回 true
+
+```go
+func Framepointer_enabled(goos, goarch string) bool {
+ return framepointer_enabled != 0 && goarch == "amd64" && goos != "nacl"
+}
+```
+
+如果编译器在最终的汇编结果中没有插入 caller BP(源代码中所称的 frame pointer)的情况下,伪 SP 和伪 FP 之间只有 8 个字节的 caller 的 return address,而插入了 BP 的话,就会多出额外的 8 字节。也就说伪 SP 和伪 FP 的相对位置是不固定的,有可能是间隔 8 个字节,也有可能间隔 16 个字节。并且判断依据会根据平台和 Go 的版本有所不同。
+
+图上可以看到,FP 伪寄存器指向函数的传入参数的开始位置,因为栈是朝低地址方向增长,为了通过寄存器引用参数时方便,所以参数的摆放方向和栈的增长方向是相反的,即:
+
+```shell
+ FP
+high ----------------------> low
+argN, ... arg3, arg2, arg1, arg0
+```
+
+假设所有参数均为 8 字节,这样我们就可以用 symname+0(FP) 访问第一个 参数,symname+8(FP) 访问第二个参数,以此类推。用伪 SP 来引用局部变量,原理上来讲差不多,不过因为伪 SP 指向的是局部变量的底部,所以 symname-8(SP) 表示的是第一个局部变量,symname-16(SP)表示第二个,以此类推。当然,这里假设局部变量都占用 8 个字节。
+
+图的最上部的 caller return address 和 current func arg0 都是由 caller 来分配空间的。不算在当前的栈帧内。
+
+因为官方文档本身较模糊,我们来一个函数调用的全景图,来看一下这些真假 SP/FP/BP 到底是个什么关系:
+
+```
+
+ caller
+ +------------------+
+ | |
+ +----------------------> --------------------
+ | | |
+ | | caller parent BP |
+ | BP(pseudo SP) --------------------
+ | | |
+ | | Local Var0 |
+ | --------------------
+ | | |
+ | | ....... |
+ | --------------------
+ | | |
+ | | Local VarN |
+ --------------------
+ caller stack frame | |
+ | callee arg2 |
+ | |------------------|
+ | | |
+ | | callee arg1 |
+ | |------------------|
+ | | |
+ | | callee arg0 |
+ | ----------------------------------------------+ FP(virtual register)
+ | | | |
+ | | return addr | parent return address |
+ +----------------------> +------------------+--------------------------- <-------------------------------+
+ | caller BP | |
+ | (caller frame pointer) | |
+ BP(pseudo SP) ---------------------------- |
+ | | |
+ | Local Var0 | |
+ ---------------------------- |
+ | |
+ | Local Var1 |
+ ---------------------------- callee stack frame
+ | |
+ | ..... |
+ ---------------------------- |
+ | | |
+ | Local VarN | |
+ SP(Real Register) ---------------------------- |
+ | | |
+ | | |
+ | | |
+ | | |
+ | | |
+ +--------------------------+ <-------------------------------+
+
+ callee
+```
+
+## argsize 和 framesize 计算规则
+
+### argsize
+
+在函数声明中:
+
+```go
+ TEXT pkgname·add(SB),NOSPLIT,$16-32
+```
+
+前面已经说过 $16-32 表示 $framesize-argsize。Go 在函数调用时,参数和返回值都需要由 caller 在其栈帧上备好空间。callee 在声明时仍然需要知道这个 argsize。argsize 的计算方法是,参数大小求和+返回值大小求和,例如入参是 3 个 int64 类型,返回值是 1 个 int64 类型,那么这里的 argsize = sizeof(int64) * 4。
+
+不过真实世界永远没有我们假设的这么美好,函数参数往往混合了多种类型,还需要考虑内存对齐问题。
+
+如果不确定自己的函数签名需要多大的 argsize,可以通过简单实现一个相同签名的空函数,然后 go tool objdump 来逆向查找应该分配多少空间。
+
+### framesize
+
+函数的 framesize 就稍微复杂一些了,手写代码的 framesize 不需要考虑由编译器插入的 caller BP,要考虑:
+
+1. 局部变量,及其每个变量的 size。
+2. 在函数中是否有对其它函数调用时,如果有的话,调用时需要将 callee 的参数、返回值考虑在内。虽然 return address(rip)的值也是存储在 caller 的 stack frame 上的,但是这个过程是由 CALL 指令和 RET 指令完成 PC 寄存器的保存和恢复的,在手写汇编时,同样也是不需要考虑这个 PC 寄存器在栈上所需占用的 8 个字节的。
+3. 原则上来说,调用函数时只要不把局部变量覆盖掉就可以了。稍微多分配几个字节的 framesize 也不会死。
+4. 在确保逻辑没有问题的前提下,你愿意覆盖局部变量也没有问题。只要保证进入和退出汇编函数时的 caller 和 callee 能正确拿到返回值就可以。
+
+## 地址运算
+
+地址运算也是用 lea 指令,英文原意为 `Load Effective Address`,amd64 平台地址都是 8 个字节,所以直接就用 LEAQ 就好:
+
+```go
+LEAQ (BX)(AX*8), CX
+// 上面代码中的 8 代表 scale
+// scale 只能是 0、2、4、8
+// 如果写成其它值:
+// LEAQ (BX)(AX*3), CX
+// ./a.s:6: bad scale: 3
+
+// 用 LEAQ 的话,即使是两个寄存器值直接相加,也必须提供 scale
+// 下面这样是不行的
+// LEAQ (BX)(AX), CX
+// asm: asmidx: bad address 0/2064/2067
+// 正确的写法是
+LEAQ (BX)(AX*1), CX
+
+
+// 在寄存器运算的基础上,可以加上额外的 offset
+LEAQ 16(BX)(AX*1), CX
+
+// 三个寄存器做运算,还是别想了
+// LEAQ DX(BX)(AX*8), CX
+// ./a.s:13: expected end of operand, found (
+```
+
+使用 LEAQ 的好处也比较明显,可以节省指令数。如果用基本算术指令来实现 LEAQ 的功能,需要两~三条以上的计算指令才能实现 LEAQ 的完整功能。
+
+## 示例
+
+### add/sub/mul
+
+math.go:
+
+```go
+package main
+
+import "fmt"
+
+func add(a, b int) int // 汇编函数声明
+
+func sub(a, b int) int // 汇编函数声明
+
+func mul(a, b int) int // 汇编函数声明
+
+func main() {
+ fmt.Println(add(10, 11))
+ fmt.Println(sub(99, 15))
+ fmt.Println(mul(11, 12))
+}
+```
+
+math.s:
+
+```go
+#include "textflag.h" // 因为我们声明函数用到了 NOSPLIT 这样的 flag,所以需要将 textflag.h 包含进来
+
+// func add(a, b int) int
+TEXT ·add(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX // 参数 a
+ MOVQ b+8(FP), BX // 参数 b
+ ADDQ BX, AX // AX += BX
+ MOVQ AX, ret+16(FP) // 返回
+ RET
+
+// func sub(a, b int) int
+TEXT ·sub(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX
+ MOVQ b+8(FP), BX
+ SUBQ BX, AX // AX -= BX
+ MOVQ AX, ret+16(FP)
+ RET
+
+// func mul(a, b int) int
+TEXT ·mul(SB), NOSPLIT, $0-24
+ MOVQ a+0(FP), AX
+ MOVQ b+8(FP), BX
+ IMULQ BX, AX // AX *= BX
+ MOVQ AX, ret+16(FP)
+ RET
+ // 最后一行的空行是必须的,否则可能报 unexpected EOF
+```
+
+把这两个文件放在任意目录下,执行 `go build` 并运行就可以看到效果了。
+
+### 伪寄存器 SP 、伪寄存器 FP 和硬件寄存器 SP
+
+来写一段简单的代码证明伪 SP、伪 FP 和硬件 SP 的位置关系。
+spspfp.s:
+
+```go
+#include "textflag.h"
+
+// func output(int) (int, int, int)
+TEXT ·output(SB), $8-48
+ MOVQ 24(SP), DX // 不带 symbol,这里的 SP 是硬件寄存器 SP
+ MOVQ DX, ret3+24(FP) // 第三个返回值
+ MOVQ perhapsArg1+16(SP), BX // 当前函数栈大小 > 0,所以 FP 在 SP 的上方 16 字节处
+ MOVQ BX, ret2+16(FP) // 第二个返回值
+ MOVQ arg1+0(FP), AX
+ MOVQ AX, ret1+8(FP) // 第一个返回值
+ RET
+
+```
+
+spspfp.go:
+
+```go
+package main
+
+import (
+ "fmt"
+)
+
+func output(int) (int, int, int) // 汇编函数声明
+
+func main() {
+ a, b, c := output(987654321)
+ fmt.Println(a, b, c)
+}
+```
+
+执行上面的代码,可以得到输出:
+
+```shell
+987654321 987654321 987654321
+```
+
+和代码结合思考,可以知道我们当前的栈结构是这样的:
+
+```shell
+------
+ret2 (8 bytes)
+------
+ret1 (8 bytes)
+------
+ret0 (8 bytes)
+------
+arg0 (8 bytes)
+------ FP
+ret addr (8 bytes)
+------
+caller BP (8 bytes)
+------ pseudo SP
+frame content (8 bytes)
+------ hardware SP
+```
+
+本小节例子的 framesize 是大于 0 的,读者可以尝试修改 framesize 为 0,然后调整代码中引用伪 SP 和硬件 SP 时的 offset,来研究 framesize 为 0 时,伪 FP,伪 SP 和硬件 SP 三者之间的相对位置。
+
+本小节的例子是为了告诉大家,伪 SP 和伪 FP 的相对位置是会变化的,手写时不应该用伪 SP 和 >0 的 offset 来引用数据,否则结果可能会出乎你的预料。
+
+### 汇编调用非汇编函数
+
+output.s:
+
+```go
+#include "textflag.h"
+
+// func output(a,b int) int
+TEXT ·output(SB), NOSPLIT, $24-24
+ MOVQ a+0(FP), DX // arg a
+ MOVQ DX, 0(SP) // arg x
+ MOVQ b+8(FP), CX // arg b
+ MOVQ CX, 8(SP) // arg y
+ CALL ·add(SB) // 在调用 add 之前,已经把参数都通过物理寄存器 SP 搬到了函数的栈顶
+ MOVQ 16(SP), AX // add 函数会把返回值放在这个位置
+ MOVQ AX, ret+16(FP) // return result
+ RET
+
+```
+
+output.go:
+
+```go
+package main
+
+import "fmt"
+
+func add(x, y int) int {
+ return x + y
+}
+
+func output(a, b int) int
+
+func main() {
+ s := output(10, 13)
+ fmt.Println(s)
+}
+
+```
+
+### 汇编中的循环
+
+通过 DECQ 和 JZ 结合,可以实现高级语言里的循环逻辑:
+
+sum.s:
+
+```go
+#include "textflag.h"
+
+// func sum(sl []int64) int64
+TEXT ·sum(SB), NOSPLIT, $0-32
+ MOVQ $0, SI
+ MOVQ sl+0(FP), BX // &sl[0], addr of the first elem
+ MOVQ sl+8(FP), CX // len(sl)
+ INCQ CX // CX++, 因为要循环 len 次
+
+start:
+ DECQ CX // CX--
+ JZ done
+ ADDQ (BX), SI // SI += *BX
+ ADDQ $8, BX // 指针移动
+ JMP start
+
+done:
+ // 返回地址是 24 是怎么得来的呢?
+ // 可以通过 go tool compile -S math.go 得知
+ // 在调用 sum 函数时,会传入三个值,分别为:
+ // slice 的首地址、slice 的 len, slice 的 cap
+ // 不过我们这里的求和只需要 len,但 cap 依然会占用参数的空间
+ // 就是 16(FP)
+ MOVQ SI, ret+24(FP)
+ RET
+```
+
+sum.go:
+
+```go
+package main
+
+func sum([]int64) int64
+
+func main() {
+ println(sum([]int64{1, 2, 3, 4, 5}))
+}
+```
+
+## 扩展话题
+
+### 标准库中的一些数据结构
+
+#### 数值类型
+
+标准库中的数值类型很多:
+
+1. int/int8/int16/int32/int64
+2. uint/uint8/uint16/uint32/uint64
+3. float32/float64
+4. byte/rune
+5. uintptr
+
+这些类型在汇编中就是一段存储着数据的连续内存,只是内存长度不一样,操作的时候看好数据长度就行。
+
+#### slice
+
+前面的例子已经说过了,slice 在传递给函数的时候,实际上会展开成三个参数:
+
+1. 首元素地址
+2. slice 的 len
+3. slice 的 cap
+
+在汇编中处理时,只要知道这个原则那就很好办了,按顺序还是按索引操作随你开心。
+
+#### string
+
+```go
+package main
+
+//go:noinline
+func stringParam(s string) {}
+
+func main() {
+ var x = "abcc"
+ stringParam(x)
+}
+```
+
+用 `go tool compile -S` 输出其汇编:
+
+```go
+0x001d 00029 (stringParam.go:11) LEAQ go.string."abcc"(SB), AX // 获取 RODATA 段中的字符串地址
+0x0024 00036 (stringParam.go:11) MOVQ AX, (SP) // 将获取到的地址放在栈顶,作为第一个参数
+0x0028 00040 (stringParam.go:11) MOVQ $4, 8(SP) // 字符串长度作为第二个参数
+0x0031 00049 (stringParam.go:11) PCDATA $0, $0 // gc 相关
+0x0031 00049 (stringParam.go:11) CALL "".stringParam(SB) // 调用 stringParam 函数
+```
+
+在汇编层面 string 就是地址 + 字符串长度。
+
+#### struct
+
+struct 在汇编层面实际上就是一段连续内存,在作为参数传给函数时,会将其展开在 caller 的栈上传给对应的 callee:
+
+struct.go
+
+```go
+package main
+
+type address struct {
+ lng int
+ lat int
+}
+
+type person struct {
+ age int
+ height int
+ addr address
+}
+
+func readStruct(p person) (int, int, int, int)
+
+func main() {
+ var p = person{
+ age: 99,
+ height: 88,
+ addr: address{
+ lng: 77,
+ lat: 66,
+ },
+ }
+ a, b, c, d := readStruct(p)
+ println(a, b, c, d)
+}
+```
+
+struct.s
+
+```go
+#include "textflag.h"
+
+TEXT ·readStruct(SB), NOSPLIT, $0-64
+ MOVQ arg0+0(FP), AX
+ MOVQ AX, ret0+32(FP)
+ MOVQ arg1+8(FP), AX
+ MOVQ AX, ret1+40(FP)
+ MOVQ arg2+16(FP), AX
+ MOVQ AX, ret2+48(FP)
+ MOVQ arg3+24(FP), AX
+ MOVQ AX, ret3+56(FP)
+ RET
+```
+
+上述的程序会输出 99, 88, 77, 66,这表明即使是内嵌结构体,在内存分布上依然是连续的。
+
+#### map
+
+通过对下述文件进行汇编(go tool compile -S),我们可以得到一个 map 在对某个 key 赋值时所需要做的操作:
+
+m.go:
+
+```go
+package main
+
+func main() {
+ var m = map[int]int{}
+ m[43] = 1
+ var n = map[string]int{}
+ n["abc"] = 1
+ println(m, n)
+}
+```
+
+看一看第七行的输出:
+
+```go
+0x0085 00133 (m.go:7) LEAQ type.map[int]int(SB), AX
+0x008c 00140 (m.go:7) MOVQ AX, (SP)
+0x0090 00144 (m.go:7) LEAQ ""..autotmp_2+232(SP), AX
+0x0098 00152 (m.go:7) MOVQ AX, 8(SP)
+0x009d 00157 (m.go:7) MOVQ $43, 16(SP)
+0x00a6 00166 (m.go:7) PCDATA $0, $1
+0x00a6 00166 (m.go:7) CALL runtime.mapassign_fast64(SB)
+0x00ab 00171 (m.go:7) MOVQ 24(SP), AX
+0x00b0 00176 (m.go:7) MOVQ $1, (AX)
+```
+
+前面我们已经分析过调用函数的过程,这里前几行都是在准备 runtime.mapassign_fast64(SB) 的参数。去 runtime 里看看这个函数的签名:
+
+```go
+func mapassign_fast64(t *maptype, h *hmap, key uint64) unsafe.Pointer {
+```
+
+不用看函数的实现我们也大概能推测出函数输入参数和输出参数的关系了,把入参和汇编指令对应的话:
+
+```go
+t *maptype
+=>
+LEAQ type.map[int]int(SB), AX
+MOVQ AX, (SP)
+
+h *hmap
+=>
+LEAQ ""..autotmp_2+232(SP), AX
+MOVQ AX, 8(SP)
+
+key uint64
+=>
+MOVQ $43, 16(SP)
+```
+
+返回参数就是 key 对应的可以写值的内存地址,拿到该地址后我们把想要写的值写进去就可以了:
+
+```go
+MOVQ 24(SP), AX
+MOVQ $1, (AX)
+```
+
+整个过程还挺复杂的,我们手抄一遍倒也可以实现。不过还要考虑,不同类型的 map,实际上需要执行的 runtime 中的 assign 函数是不同的,感兴趣的同学可以汇编本节的示例自行尝试。
+
+整体来讲,用汇编来操作 map 并不是一个明智的选择。
+
+#### channel
+
+channel 在 runtime 也是比较复杂的数据结构,如果在汇编层面操作,实际上也是调用 runtime 中 chan.go 中的函数,和 map 比较类似,这里就不展开说了。
+
+### 获取 goroutine id
+
+Go 的 goroutine 是一个叫 g 的结构体,内部有自己的唯一 id,不过 runtime 没有把这个 id 暴露出来,但不知道为什么有很多人就是想把这个 id 得到。于是就有了各种或其 goroutine id 的库。
+
+在 struct 一小节我们已经提到,结构体本身就是一段连续的内存,我们知道起始地址和字段的偏移量的话,很容易就可以把这段数据搬运出来:
+
+go_tls.h:
+
+```go
+#ifdef GOARCH_arm
+#define LR R14
+#endif
+
+#ifdef GOARCH_amd64
+#define get_tls(r) MOVQ TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+
+#ifdef GOARCH_amd64p32
+#define get_tls(r) MOVL TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+
+#ifdef GOARCH_386
+#define get_tls(r) MOVL TLS, r
+#define g(r) 0(r)(TLS*1)
+#endif
+```
+
+goid.go:
+
+```go
+package goroutineid
+import "runtime"
+var offsetDict = map[string]int64{
+ // ... 省略一些行
+ "go1.7": 192,
+ "go1.7.1": 192,
+ "go1.7.2": 192,
+ "go1.7.3": 192,
+ "go1.7.4": 192,
+ "go1.7.5": 192,
+ "go1.7.6": 192,
+ // ... 省略一些行
+}
+
+var offset = offsetDict[runtime.Version()]
+
+// GetGoID returns the goroutine id
+func GetGoID() int64 {
+ return getGoID(offset)
+}
+
+func getGoID(off int64) int64
+```
+
+goid.s:
+
+```go
+#include "textflag.h"
+#include "go_tls.h"
+
+// func getGoID() int64
+TEXT ·getGoID(SB), NOSPLIT, $0-16
+ get_tls(CX)
+ MOVQ g(CX), AX
+ MOVQ offset(FP), BX
+ LEAQ 0(AX)(BX*1), DX
+ MOVQ (DX), AX
+ MOVQ AX, ret+8(FP)
+ RET
+```
+
+这样就实现了一个简单的获取 struct g 中的 goid 字段的小 library,作为玩具放在这里:
+>https://github.com/cch123/goroutineid
+
+### SIMD
+
+[SIMD](https://cch123.gitbooks.io/duplicate/content/part3/performance/simd-instruction-class.html) 是 Single Instruction, Multiple Data 的缩写,在 Intel 平台上的 SIMD 指令集先后为 SSE,AVX,AVX2,AVX512,这些指令集引入了标准以外的指令,和宽度更大的寄存器,例如:
+
+- 128 位的 XMM0~XMM31 寄存器。
+- 256 位的 YMM0~YMM31 寄存器。
+- 512 位的 ZMM0~ZMM31 寄存器。
+
+这些寄存器的关系,类似 RAX,EAX,AX 之间的关系。指令方面可以同时对多组数据进行移动或者计算,例如:
+
+- movups : 把4个不对准的单精度值传送到xmm寄存器或者内存
+- movaps : 把4个对准的单精度值传送到xmm寄存器或者内存
+
+上述指令,当我们将数组作为函数的入参时有很大概率会看到,例如:
+
+arr_par.go:
+
+```go
+package main
+
+import "fmt"
+
+func pr(input [3]int) {
+ fmt.Println(input)
+}
+
+func main() {
+ pr([3]int{1, 2, 3})
+}
+```
+
+go compile -S:
+
+```go
+0x001d 00029 (arr_par.go:10) MOVQ "".statictmp_0(SB), AX
+0x0024 00036 (arr_par.go:10) MOVQ AX, (SP)
+0x0028 00040 (arr_par.go:10) MOVUPS "".statictmp_0+8(SB), X0
+0x002f 00047 (arr_par.go:10) MOVUPS X0, 8(SP)
+0x0034 00052 (arr_par.go:10) CALL "".pr(SB)
+```
+
+可见,编译器在某些情况下已经考虑到了性能问题,帮助我们使用 SIMD 指令集来对数据搬运进行了优化。
+
+因为 SIMD 这个话题本身比较广,这里就不展开细说了。
+
+## 特别感谢
+
+研究过程基本碰到不太明白的都去骚扰卓巨巨了,就是这位 https://mzh.io/ 大大。特别感谢他,给了不少线索和提示。
+
+## 参考资料
+
+1. https://quasilyte.github.io/blog/post/go-asm-complementary-reference/#external-resources
+2. http://davidwong.fr/goasm
+3. https://www.doxsey.net/blog/go-and-assembly
+4. https://github.com/golang/go/files/447163/GoFunctionsInAssembly.pdf
+5. https://golang.org/doc/asm
+
+参考资料[4]需要特别注意,在该 slide 中给出的 callee stack frame 中把 caller 的 return address 也包含进去了,个人认为不是很合适。
+
+
diff --git a/site/content/docs/assembly/exercises.md b/site/content/docs/assembly/exercises.md
new file mode 100644
index 0000000..3c16b05
--- /dev/null
+++ b/site/content/docs/assembly/exercises.md
@@ -0,0 +1,7 @@
+---
+title: 习题
+weight: 2
+draft: true
+---
+
+# 习题
diff --git a/site/content/docs/bootstrap/_index.md b/site/content/docs/bootstrap/_index.md
new file mode 100644
index 0000000..3832726
--- /dev/null
+++ b/site/content/docs/bootstrap/_index.md
@@ -0,0 +1,7 @@
+---
+title: Go 进程的启动流程
+weight: 2
+bookCollapseSection: true
+draft: true
+---
+
diff --git a/site/content/docs/bootstrap/boot.md b/site/content/docs/bootstrap/boot.md
new file mode 100644
index 0000000..a8fe587
--- /dev/null
+++ b/site/content/docs/bootstrap/boot.md
@@ -0,0 +1,7 @@
+---
+title: 启动流程
+weight: 2
+---
+# 启动流程
+
+
diff --git a/site/content/docs/bootstrap/elf.md b/site/content/docs/bootstrap/elf.md
new file mode 100644
index 0000000..15a78a7
--- /dev/null
+++ b/site/content/docs/bootstrap/elf.md
@@ -0,0 +1 @@
+# elf 文件简介
diff --git a/site/content/docs/bootstrap/exercises.md b/site/content/docs/bootstrap/exercises.md
new file mode 100644
index 0000000..a49ba48
--- /dev/null
+++ b/site/content/docs/bootstrap/exercises.md
@@ -0,0 +1,2 @@
+---
+---
\ No newline at end of file
diff --git a/site/content/docs/compiler_and_linker/_index.md b/site/content/docs/compiler_and_linker/_index.md
new file mode 100644
index 0000000..ce63fe2
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/_index.md
@@ -0,0 +1,6 @@
+---
+title: 编译器与链接器
+weight: 3
+bookCollapseSection: true
+draft: true
+---
diff --git a/site/content/docs/compiler_and_linker/calling_convention.md b/site/content/docs/compiler_and_linker/calling_convention.md
new file mode 100644
index 0000000..e0609f0
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/calling_convention.md
@@ -0,0 +1,25 @@
+---
+title: 调用规约
+weight: 3
+draft: true
+---
+
+# 调用规约
+
+早期版本的 Go 在向函数传递参数时,是使用栈的。
+
+从 1.17 开始,调用函数时会尽量使用寄存器传参。
+
+"".add STEXT size=121 args=0x10 locals=0x18 funcid=0x0
+ 0x0000 00000 (add.go:8) TEXT "".add(SB), ABIInternal, $24-16
+ 0x0000 00000 (add.go:8) CMPQ SP, 16(R14)
+ 0x0004 00004 (add.go:8) JLS 94
+ 0x0006 00006 (add.go:8) SUBQ $24, SP
+ 0x005d 00093 (add.go:11) RET
+ 0x005e 00094 (add.go:11) NOP
+ 0x005e 00094 (add.go:8) MOVQ AX, 8(SP)
+ 0x0063 00099 (add.go:8) MOVQ BX, 16(SP)
+ 0x0068 00104 (add.go:8) CALL runtime.morestack_noctxt(SB)
+ 0x006d 00109 (add.go:8) MOVQ 8(SP), AX
+ 0x0072 00114 (add.go:8) MOVQ 16(SP), BX
+ 0x0077 00119 (add.go:8) JMP 0
diff --git a/site/content/docs/compiler_and_linker/compiler.md b/site/content/docs/compiler_and_linker/compiler.md
new file mode 100644
index 0000000..6592c8e
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/compiler.md
@@ -0,0 +1,6 @@
+---
+title: 编译器
+weight: 3
+draft: true
+---
+# 编译器
diff --git a/site/content/docs/compiler_and_linker/linker.md b/site/content/docs/compiler_and_linker/linker.md
new file mode 100644
index 0000000..ea2d801
--- /dev/null
+++ b/site/content/docs/compiler_and_linker/linker.md
@@ -0,0 +1,6 @@
+---
+title: 链接器
+weight: 3
+draft: true
+---
+# linker
diff --git a/site/content/docs/data_structure/_index.md b/site/content/docs/data_structure/_index.md
new file mode 100644
index 0000000..08b7aa5
--- /dev/null
+++ b/site/content/docs/data_structure/_index.md
@@ -0,0 +1,5 @@
+---
+title: 内置数据结构
+weight: 10
+bookCollapseSection: true
+---
diff --git a/site/content/docs/data_structure/channel.md b/site/content/docs/data_structure/channel.md
new file mode 100644
index 0000000..da9c943
--- /dev/null
+++ b/site/content/docs/data_structure/channel.md
@@ -0,0 +1,10 @@
+---
+title: channel
+weight: 10
+bookCollapseSection: false
+---
+# channel 实现
+
+{{