+
+ by
+
+ Chaoyang He, Shen Li, Mahdi Soltanolkotabi, and Salman Avestimehr
+
+
+ In this blog post, we describe the first peer-reviewed research paper that explores accelerating the hybrid of PyTorch DDP (torch.nn.parallel.DistributedDataParallel) [1] and Pipeline (torch.distributed.pipeline) - PipeTransformer: Automated Elastic Pipelining for Distributed Training of Large-scale Models (Transformers such as BERT [2] and ViT [3]), published at ICML 2021.
+
+PipeTransformer leverages automated elastic pipelining for efficient distributed training of Transformer models. In PipeTransformer, we designed an adaptive on-the-fly freeze algorithm that can identify and freeze some layers gradually during training and an elastic pipelining system that can dynamically allocate resources to train the remaining active layers. More specifically, PipeTransformer automatically excludes frozen layers from the pipeline, packs active layers into fewer GPUs, and forks more replicas to increase data-parallel width. We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on SQuAD and GLUE datasets. Our results show that compared to the state-of-the-art baseline, PipeTransformer attains up to 2.83-fold speedup without losing accuracy. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design.
+
+Next, we will introduce the background, motivation, our idea, design, and how we implement the algorithm and system with PyTorch Distributed APIs.
+
+
+
+Introduction
+
+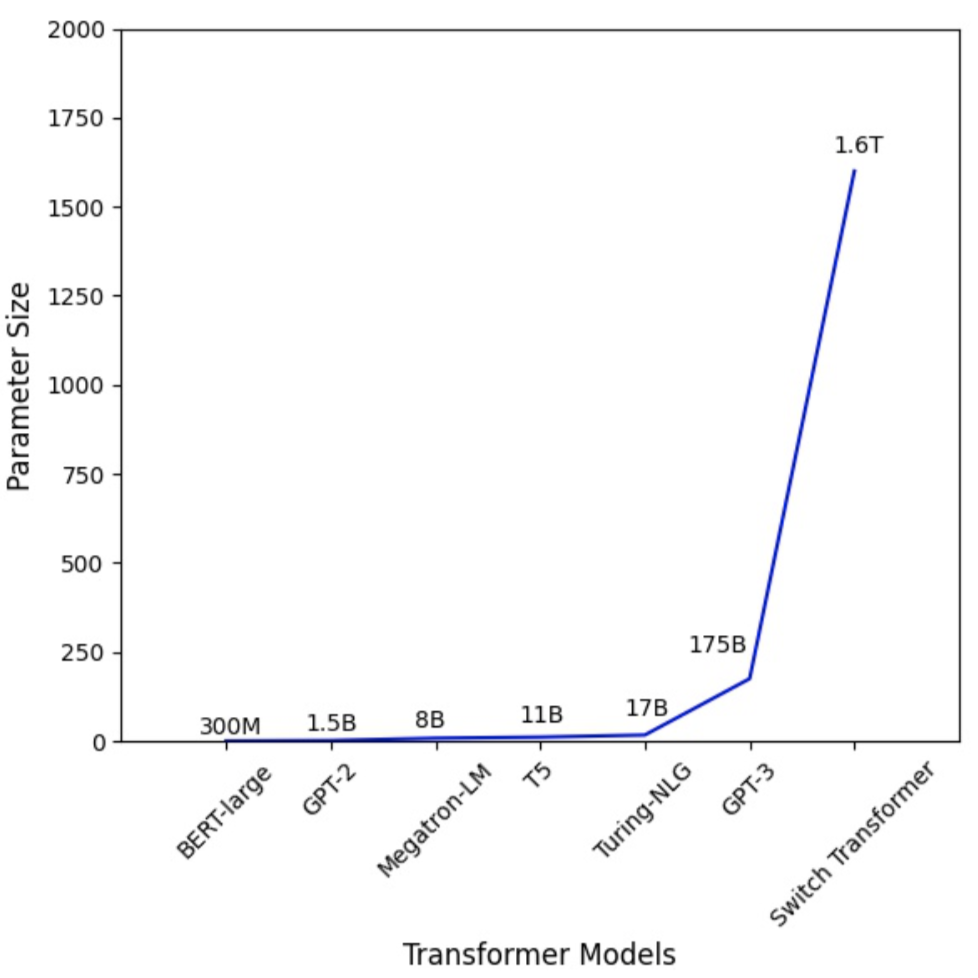 +
+
+Figure 1: the Parameter Number of Transformer Models Increases Dramatically.
+
+
+Large Transformer models [4][5] have powered accuracy breakthroughs in both natural language processing and computer vision. GPT-3 [4] hit a new record high accuracy for nearly all NLP tasks. Vision Transformer (ViT) [3] also achieved 89\% top-1 accuracy in ImageNet, outperforming state-of-the-art convolutional networks ResNet-152 and EfficientNet. To tackle the growth in model sizes, researchers have proposed various distributed training techniques, including parameter servers [6][7][8], pipeline parallelism [9][10][11][12], intra-layer parallelism [13][14][15], and zero redundancy data-parallel [16].
+
+Existing distributed training solutions, however, only study scenarios where all model weights are required to be optimized throughout the training (i.e., computation and communication overhead remains relatively static over different iterations). Recent works on progressive training suggest that parameters in neural networks can be trained dynamically:
+
+
+ - Freeze Training: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability. NeurIPS 2017
+ - Efficient Training of BERT by Progressively Stacking. ICML 2019
+ - Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping. NeurIPS 2020.
+ - On the Transformer Growth for Progressive BERT Training. NACCL 2021
+
+
+
+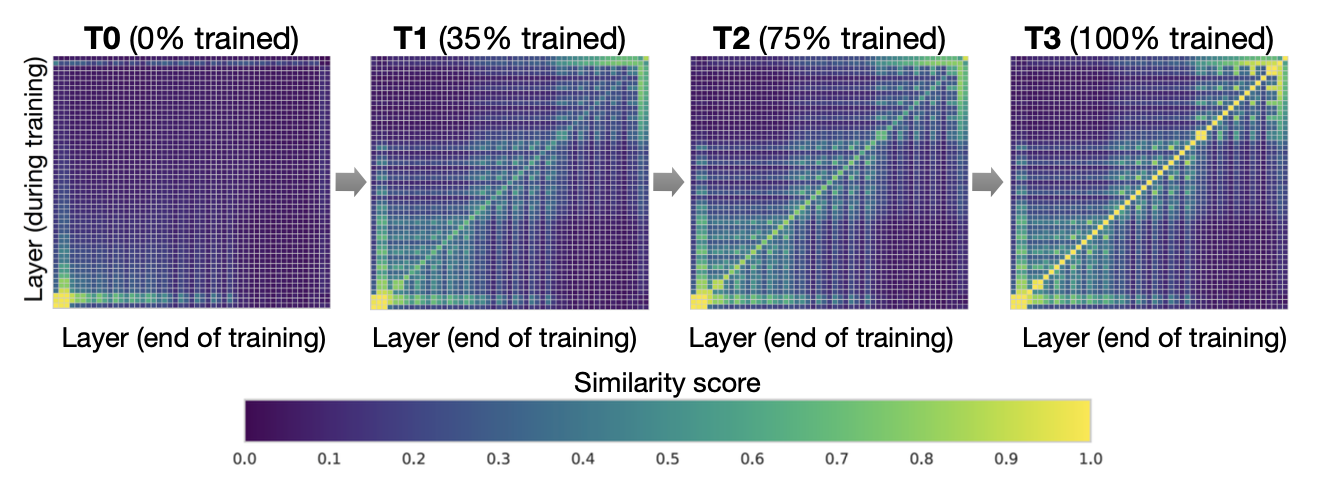 +
+
+
+Figure 2. Interpretable Freeze Training: DNNs converge bottom-up (Results on CIFAR10 using ResNet). Each pane shows layer-by-layer similarity using SVCCA [17][18]
+
+For example, in freeze training [17][18], neural networks usually converge from the bottom-up (i.e., not all layers need to be trained all the way through training). Figure 2 shows an example of how weights gradually stabilize during training in this approach. This observation motivates us to utilize freeze training for distributed training of Transformer models to accelerate training by dynamically allocating resources to focus on a shrinking set of active layers. Such a layer freezing strategy is especially pertinent to pipeline parallelism, as excluding consecutive bottom layers from the pipeline can reduce computation, memory, and communication overhead.
+
+
+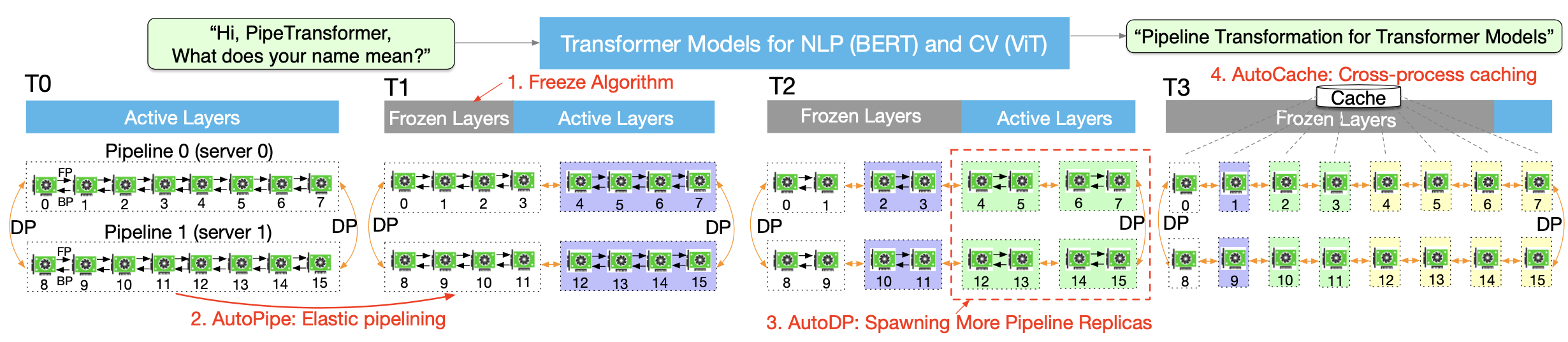 +
+
+Figure 3. The process of PipeTransformer’s automated and elastic pipelining to accelerate distributed training of Transformer models
+
+
+We propose PipeTransformer, an elastic pipelining training acceleration framework that automatically reacts to frozen layers by dynamically transforming the scope of the pipelined model and the number of pipeline replicas. To the best of our knowledge, this is the first paper that studies layer freezing in the context of both pipeline and data-parallel training. Figure 3 demonstrates the benefits of such a combination. First, by excluding frozen layers from the pipeline, the same model can be packed into fewer GPUs, leading to both fewer cross-GPU communications and smaller pipeline bubbles. Second, after packing the model into fewer GPUs, the same cluster can accommodate more pipeline replicas, increasing the width of data parallelism. More importantly, the speedups acquired from these two benefits are multiplicative rather than additive, further accelerating the training.
+
+The design of PipeTransformer faces four major challenges. First, the freeze algorithm must make on-the-fly and adaptive freezing decisions; however, existing work [17][18] only provides a posterior analysis tool. Second, the efficiency of pipeline re-partitioning results is influenced by multiple factors, including partition granularity, cross-partition activation size, and the chunking (the number of micro-batches) in mini-batches, which require reasoning and searching in a large solution space. Third, to dynamically introduce additional pipeline replicas, PipeTransformer must overcome the static nature of collective communications and avoid potentially complex cross-process messaging protocols when onboarding new processes (one pipeline is handled by one process). Finally, caching can save time for repeated forward propagation of frozen layers, but it must be shared between existing pipelines and newly added ones, as the system cannot afford to create and warm up a dedicated cache for each replica.
+
+
+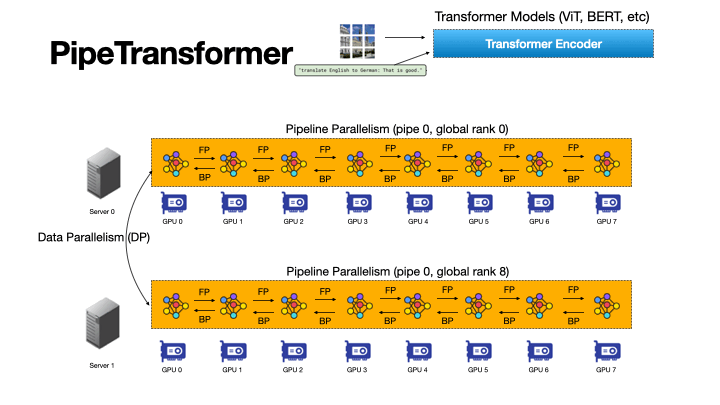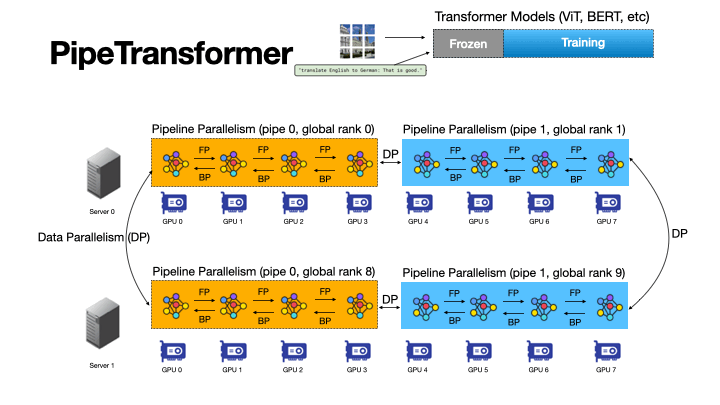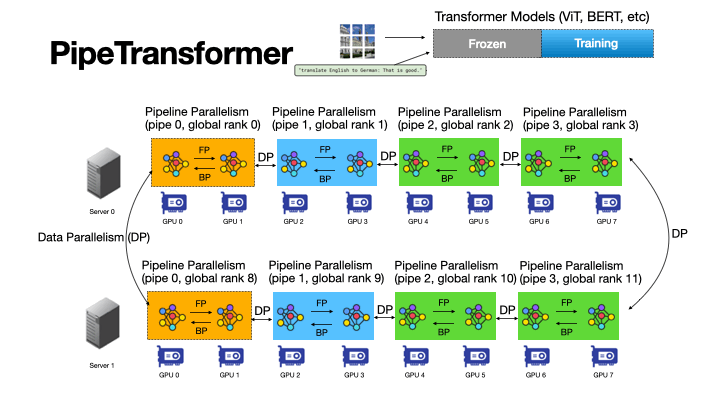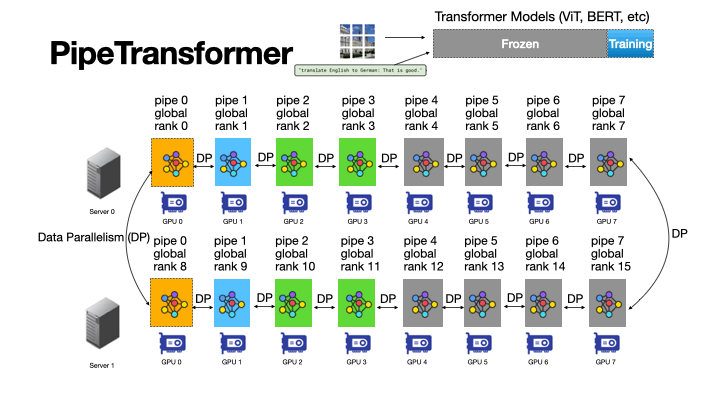 +
+
+Figure 4: An Animation to Show the Dynamics of PipeTransformer
+
+
+As shown in the animation (Figure 4), PipeTransformer is designed with four core building blocks to address the aforementioned challenges. First, we design a tunable and adaptive algorithm to generate signals that guide the selection of layers to freeze over different iterations (Freeze Algorithm). Once triggered by these signals, our elastic pipelining module (AutoPipe), then packs the remaining active layers into fewer GPUs by taking both activation sizes and variances of workloads across heterogeneous partitions (frozen layers and active layers) into account. It then splits a mini-batch into an optimal number of micro-batches based on prior profiling results for different pipeline lengths. Our next module, AutoDP, spawns additional pipeline replicas to occupy freed-up GPUs and maintains hierarchical communication process groups to attain dynamic membership for collective communications. Our final module, AutoCache, efficiently shares activations across existing and new data-parallel processes and automatically replaces stale caches during transitions.
+
+Overall, PipeTransformer combines the Freeze Algorithm, AutoPipe, AutoDP, and AutoCache modules to provide a significant training speedup.
+We evaluate PipeTransformer using Vision Transformer (ViT) on ImageNet and BERT on GLUE and SQuAD datasets. Our results show that PipeTransformer attains up to 2.83-fold speedup without losing accuracy. We also provide various performance analyses for a more comprehensive understanding of our algorithmic and system-wise design.
+Finally, we have also developed open-source flexible APIs for PipeTransformer, which offer a clean separation among the freeze algorithm, model definitions, and training accelerations, allowing for transferability to other algorithms that require similar freezing strategies.
+
+Overall Design
+
+Suppose we aim to train a massive model in a distributed training system where the hybrid of pipelined model parallelism and data parallelism is used to target scenarios where either the memory of a single GPU device cannot hold the model, or if loaded, the batch size is small enough to avoid running out of memory. More specifically, we define our settings as follows:
+
+Training task and model definition. We train Transformer models (e.g., Vision Transformer, BERT on large-scale image or text datasets. The Transformer model mathcal{F} has L layers, in which the i th layer is composed of a forward computation function f_i and a corresponding set of parameters.
+
+Training infrastructure. Assume the training infrastructure contains a GPU cluster that has N GPU servers (i.e. nodes). Each node has I GPUs. Our cluster is homogeneous, meaning that each GPU and server have the same hardware configuration. Each GPU’s memory capacity is M_\text{GPU}. Servers are connected by a high bandwidth network interface such as InfiniBand interconnect.
+
+Pipeline parallelism. In each machine, we load a model \mathcal{F} into a pipeline \mathcal{P} which has Kpartitions (K also represents the pipeline length). The kth partition p_k consists of consecutive layers. We assume each partition is handled by a single GPU device. 1 \leq K \leq I, meaning that we can build multiple pipelines for multiple model replicas in a single machine. We assume all GPU devices in a pipeline belonging to the same machine. Our pipeline is a synchronous pipeline, which does not involve stale gradients, and the number of micro-batches is M. In the Linux OS, each pipeline is handled by a single process. We refer the reader to GPipe [10] for more details.
+
+Data parallelism. DDP is a cross-machine distributed data-parallel process group within R parallel workers. Each worker is a pipeline replica (a single process). The rth worker’s index (ID) is rank r. For any two pipelines in DDP, they can belong to either the same GPU server or different GPU servers, and they can exchange gradients with the AllReduce algorithm.
+
+Under these settings, our goal is to accelerate training by leveraging freeze training, which does not require all layers to be trained throughout the duration of the training. Additionally, it may help save computation, communication, memory cost, and potentially prevent overfitting by consecutively freezing layers. However, these benefits can only be achieved by overcoming the four challenges of designing an adaptive freezing algorithm, dynamical pipeline re-partitioning, efficient resource reallocation, and cross-process caching, as discussed in the introduction.
+
+
+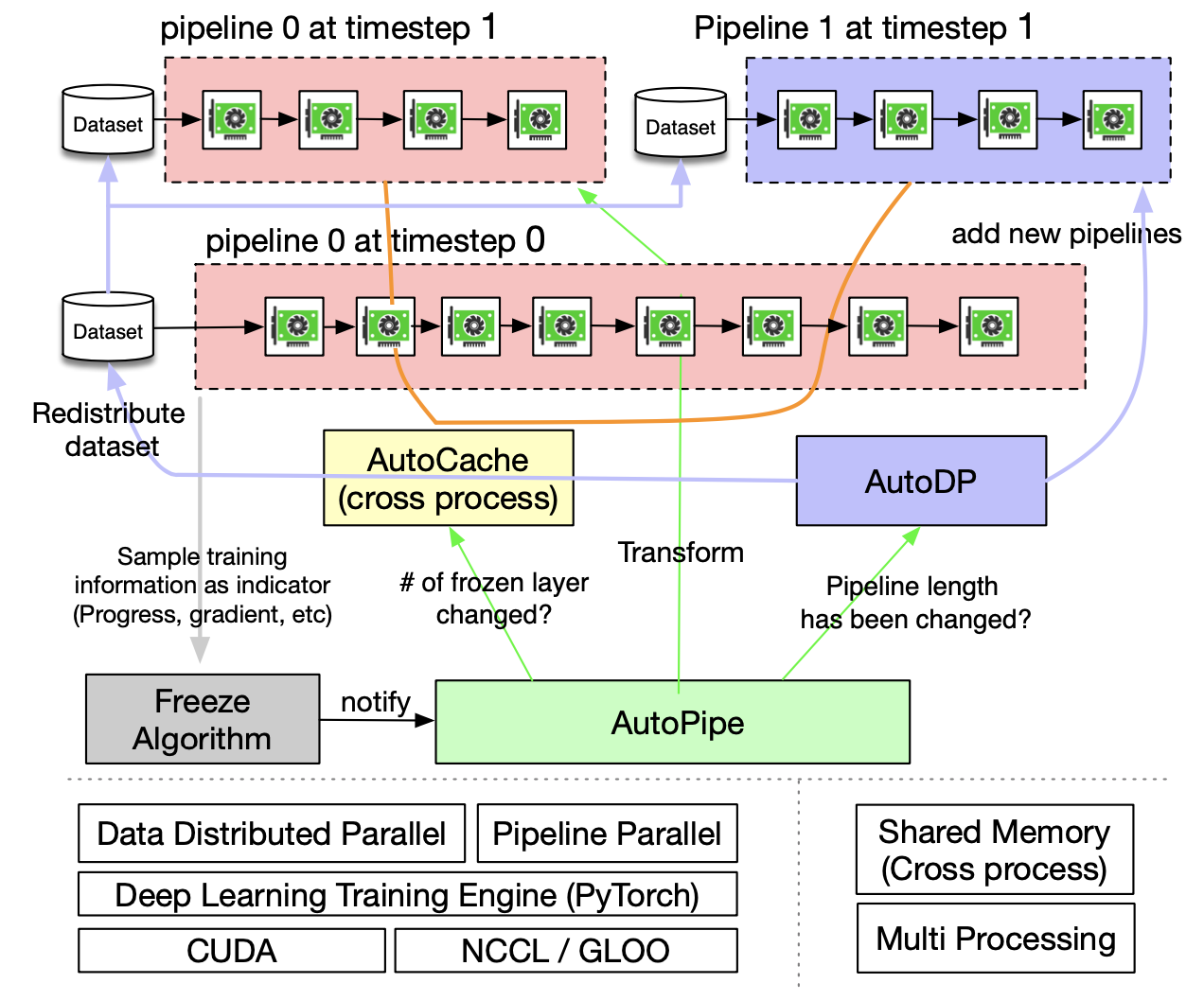 +
+
+Figure 5. Overview of PipeTransformer Training System
+
+
+PipeTransformer co-designs an on-the-fly freeze algorithm and an automated elastic pipelining training system that can dynamically transform the scope of the pipelined model and the number of pipeline replicas. The overall system architecture is illustrated in Figure 5. To support PipeTransformer’s elastic pipelining, we maintain a customized version of PyTorch Pipeline. For data parallelism, we use PyTorch DDP as a baseline. Other libraries are standard mechanisms of an operating system (e.g.,multi-processing) and thus avoid specialized software or hardware customization requirements. To ensure the generality of our framework, we have decoupled the training system into four core components: freeze algorithm, AutoPipe, AutoDP, and AutoCache. The freeze algorithm (grey) samples indicators from the training loop and makes layer-wise freezing decisions, which will be shared with AutoPipe (green). AutoPipe is an elastic pipeline module that speeds up training by excluding frozen layers from the pipeline and packing the active layers into fewer GPUs (pink), leading to both fewer cross-GPU communications and smaller pipeline bubbles. Subsequently, AutoPipe passes pipeline length information to AutoDP (purple), which then spawns more pipeline replicas to increase data-parallel width, if possible. The illustration also includes an example in which AutoDP introduces a new replica (purple). AutoCache (orange edges) is a cross-pipeline caching module, as illustrated by connections between pipelines. The source code architecture is aligned with Figure 5 for readability and generality.
+
+Implementation Using PyTorch APIs
+
+As can be seen from Figure 5, PipeTransformers contain four components: Freeze Algorithm, AutoPipe, AutoDP, and AutoCache. Among them, AutoPipe and AutoDP relies on PyTorch DDP (torch.nn.parallel.DistributedDataParallel) [1] and Pipeline (torch.distributed.pipeline), respectively. In this blog, we only highlight the key implementation details of AutoPipe and AutoDP. For details of Freeze Algorithm and AutoCache, please refer to our paper.
+
+AutoPipe: Elastic Pipelining
+
+AutoPipe can accelerate training by excluding frozen layers from the pipeline and packing the active layers into fewer GPUs. This section elaborates on the key components of AutoPipe that dynamically 1) partition pipelines, 2) minimize the number of pipeline devices, and 3) optimize mini-batch chunk size accordingly.
+
+Basic Usage of PyTorch Pipeline
+
+Before diving into details of AutoPipe, let us warm up the basic usage of PyTorch Pipeline (torch.distributed.pipeline.sync.Pipe, see this tutorial). More specially, we present a simple example to understand the design of Pipeline in practice:
+
+# Step 1: build a model including two linear layers
+fc1 = nn.Linear(16, 8).cuda(0)
+fc2 = nn.Linear(8, 4).cuda(1)
+
+# Step 2: wrap the two layers with nn.Sequential
+model = nn.Sequential(fc1, fc2)
+
+# Step 3: build Pipe (torch.distributed.pipeline.sync.Pipe)
+model = Pipe(model, chunks=8)
+
+# do training/inference
+input = torch.rand(16, 16).cuda(0)
+output_rref = model(input)
+
In this basic example, we can see that before initializing Pipe, we need to partition the model nn.Sequential into multiple GPU devices and set optimal chunk number (chunks). Balancing computation time across partitions is critical to pipeline training speed, as skewed workload distributions across stages can lead to stragglers and forcing devices with lighter workloads to wait. The chunk number may also have a non-trivial influence on the throughput of the pipeline.
+
+Balanced Pipeline Partitioning
+
+In dynamic training system such as PipeTransformer, maintaining optimally balanced partitions in terms of parameter numbers does not guarantee the fastest training speed because other factors also play a crucial role:
+
+
+ +
+
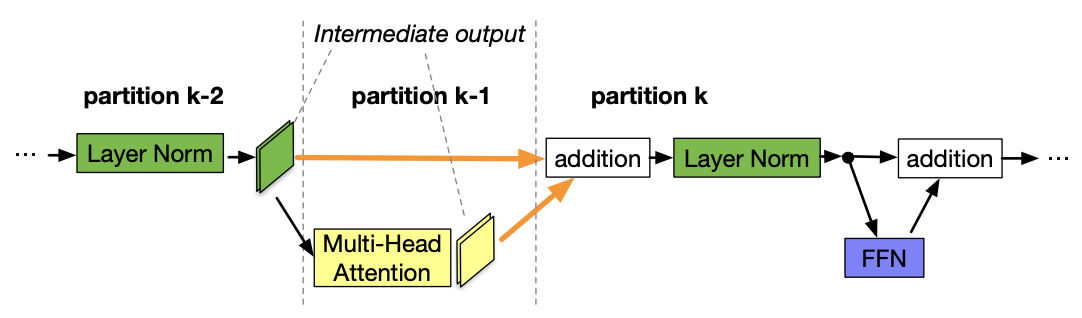
+Figure 6. The partition boundary is in the middle of a skip connection
+
+
+
+ -
+
Cross-partition communication overhead. Placing a partition boundary in the middle of a skip connection leads to additional communications since tensors in the skip connection must now be copied to a different GPU. For example, with BERT partitions in Figure 6, partition k must take intermediate outputs from both partition k-2 and partition k-1. In contrast, if the boundary is placed after the addition layer, the communication overhead between partition k-1 and k is visibly smaller. Our measurements show that having cross-device communication is more expensive than having slightly imbalanced partitions (see the Appendix in our paper). Therefore, we do not consider breaking skip connections (highlighted separately as an entire attention layer and MLP layer in green color at line 7 in Algorithm 1.
+
+ -
+
Frozen layer memory footprint. During training, AutoPipe must recompute partition boundaries several times to balance two distinct types of layers: frozen layers and active layers. The frozen layer’s memory cost is a fraction of that inactive layer, given that the frozen layer does not need backward activation maps, optimizer states, and gradients. Instead of launching intrusive profilers to obtain thorough metrics on memory and computational cost, we define a tunable cost factor lambda_{\text{frozen}} to estimate the memory footprint ratio of a frozen layer over the same active layer. Based on empirical measurements in our experimental hardware, we set it to \frac{1}{6}.
+
+
+
+
+ +
+
+
+
+Based on the above two considerations, AutoPipe balances pipeline partitions based on parameter sizes. More specifically, AutoPipe uses a greedy algorithm to allocate all frozen and active layers to evenly distribute partitioned sublayers into K GPU devices. Pseudocode is described as the load\_balance() function in Algorithm 1. The frozen layers are extracted from the original model and kept in a separate model instance \mathcal{F}_{\text{frozen}} in the first device of a pipeline.
+
+Note that the partition algorithm employed in this paper is not the only option; PipeTransformer is modularized to work with any alternatives.
+
+Pipeline Compression
+
+Pipeline compression helps to free up GPUs to accommodate more pipeline replicas and reduce the number of cross-device communications between partitions. To determine the timing of compression, we can estimate the memory cost of the largest partition after compression, and then compare it with that of the largest partition of a pipeline at timestep T=0. To avoid extensive memory profiling, the compression algorithm uses the parameter size as a proxy for the training memory footprint. Based on this simplification, the criterion of pipeline compression is as follows:
+
+
+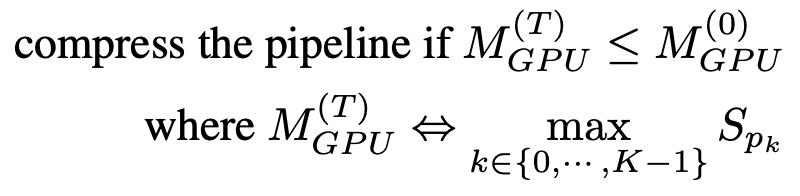 +
+
+
+
+Once the freeze notification is received, AutoPipe will always attempt to divide the pipeline length K by 2 (e.g., from 8 to 4, then 2). By using \frac{K}{2} as the input, the compression algorithm can verify if the result satisfies the criterion in Equation (1). Pseudocode is shown in lines 25-33 in Algorithm 1. Note that this compression makes the acceleration ratio exponentially increase during training, meaning that if a GPU server has a larger number of GPUs (e.g., more than 8), the acceleration ratio will be further amplified.
+
+
+ +
+
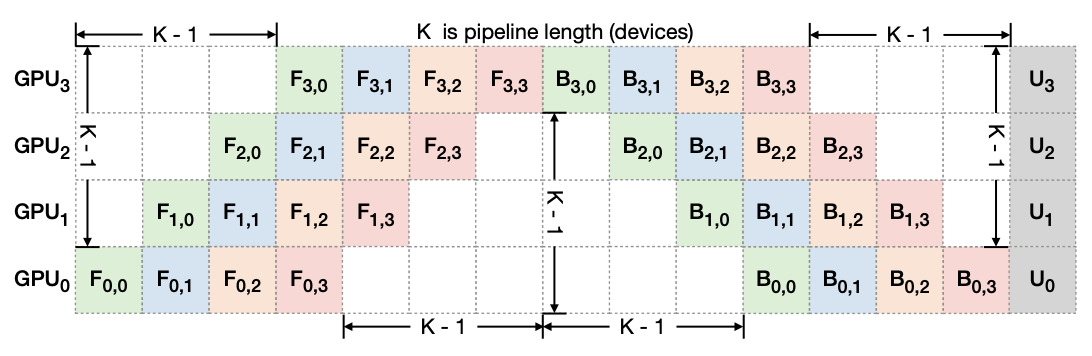
+Figure 7. Pipeline Bubble: F_{d,b}, and U_d" denote forward, backward, and the optimizer update of micro-batch b on device d, respectively. The total bubble size in each iteration is K-1 times per micro-batch forward and backward cost.
+
+
+Additionally, such a technique can also speed up training by shrinking the size of pipeline bubbles. To explain bubble sizes in a pipeline, Figure 7 depicts how 4 micro-batches run through a 4-device pipeline K = 4. In general, the total bubble size is (K-1) times per micro-batch forward and backward cost. Therefore, it is clear that shorter pipelines have smaller bubble sizes.
+
+Dynamic Number of Micro-Batches
+
+Prior pipeline parallel systems use a fixed number of micro-batches per mini-batch (M ). GPipe suggests M \geq 4 \times K, where K is the number of partitions (pipeline length). However, given that PipeTransformer dynamically configures K, we find it to be sub-optimal to maintain a static M during training. Moreover, when integrated with DDP, the value of M also has an impact on the efficiency of DDP gradient synchronizations. Since DDP must wait for the last micro-batch to finish its backward computation on a parameter before launching its gradient synchronization, finer micro-batches lead to a smaller overlap between computation and communication. Hence, instead of using a static value, PipeTransformer searches for optimal M on the fly in the hybrid of DDP environment by enumerating M values ranging from K to 6K. For a specific training environment, the profiling needs only to be done once (see Algorithm 1 line 35).
+
+For the complete source code, please refer to https://github.com/Distributed-AI/PipeTransformer/blob/master/pipe_transformer/pipe/auto_pipe.py.
+
+AutoDP: Spawning More Pipeline Replicas
+As AutoPipe compresses the same pipeline into fewer GPUs, AutoDP can automatically spawn new pipeline replicas to increase data-parallel width.
+
+Despite the conceptual simplicity, subtle dependencies on communications and states require careful design. The challenges are threefold:
+
+
+ -
+
DDP Communication: Collective communications in PyTorch DDP requires static membership, which prevents new pipelines from connecting with existing ones;
+
+ -
+
State Synchronization: newly activated processes must be consistent with existing pipelines in the training progress (e.g., epoch number and learning rate), weights and optimizer states, the boundary of frozen layers, and pipeline GPU range;
+
+ -
+
Dataset Redistribution: the dataset should be re-balanced to match a dynamic number of pipelines. This not only avoids stragglers but also ensures that gradients from all DDP processes are equally weighted.
+
+
+
+
+ +
+
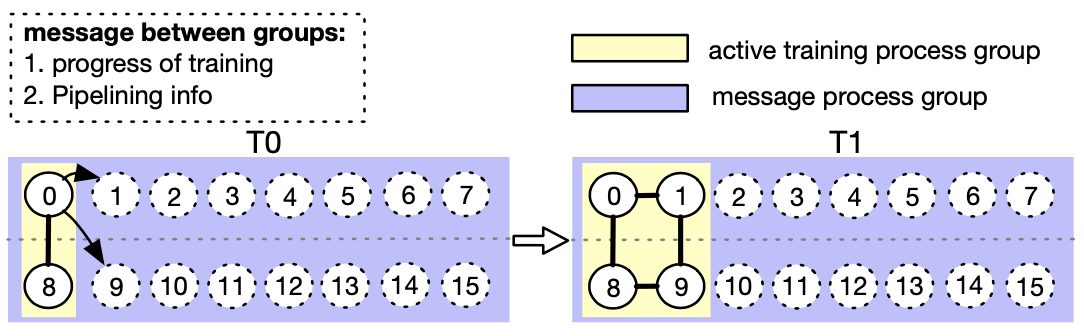
+Figure 8. AutoDP: handling dynamical data-parallel with messaging between double process groups (Process 0-7 belong to machine 0, while process 8-15 belong to machine 1)
+
+
+To tackle these challenges, we create double communication process groups for DDP. As in the example shown in Figure 8, the message process group (purple) is responsible for light-weight control messages and covers all processes, while the active training process group (yellow) only contains active processes and serves as a vehicle for heavy-weight tensor communications during training. The message group remains static, whereas the training group is dismantled and reconstructed to match active processes.
+In T0, only processes 0 and 8 are active. During the transition to T1, process 0 activates processes 1 and 9 (newly added pipeline replicas) and synchronizes necessary information mentioned above using the message group. The four active processes then form a new training group, allowing static collective communications adaptive to dynamic memberships.
+To redistribute the dataset, we implement a variant of DistributedSampler that can seamlessly adjust data samples to match the number of active pipeline replicas.
+
+The above design also naturally helps to reduce DDP communication overhead. More specifically, when transitioning from T0 to T1, processes 0 and 1 destroy the existing DDP instances, and active processes construct a new DDP training group using a cached pipelined model (AutoPipe stores frozen model and cached model separately).
+
+We use the following APIs to implement the design above.
+
+import torch.distributed as dist
+from torch.nn.parallel import DistributedDataParallel as DDP
+
+# initialize the process group (this must be called in the initialization of PyTorch DDP)
+dist.init_process_group(init_method='tcp://' + str(self.config.master_addr) + ':' +
+str(self.config.master_port), backend=Backend.GLOO, rank=self.global_rank, world_size=self.world_size)
+...
+
+# create active process group (yellow color)
+self.active_process_group = dist.new_group(ranks=self.active_ranks, backend=Backend.NCCL, timeout=timedelta(days=365))
+...
+
+# create message process group (yellow color)
+self.comm_broadcast_group = dist.new_group(ranks=[i for i in range(self.world_size)], backend=Backend.GLOO, timeout=timedelta(days=365))
+...
+
+# create DDP-enabled model when the number of data-parallel workers is changed. Note:
+# 1. The process group to be used for distributed data all-reduction.
+If None, the default process group, which is created by torch.distributed.init_process_group, will be used.
+In our case, we set it as self.active_process_group
+# 2. device_ids should be set when the pipeline length = 1 (the model resides on a single CUDA device).
+
+self.pipe_len = gpu_num_per_process
+if gpu_num_per_process > 1:
+ model = DDP(model, process_group=self.active_process_group, find_unused_parameters=True)
+else:
+ model = DDP(model, device_ids=[self.local_rank], process_group=self.active_process_group, find_unused_parameters=True)
+
+# to broadcast message among processes, we use dist.broadcast_object_list
+def dist_broadcast(object_list, src, group):
+ """Broadcasts a given object to all parties."""
+ dist.broadcast_object_list(object_list, src, group=group)
+ return object_list
+
For the complete source code, please refer to https://github.com/Distributed-AI/PipeTransformer/blob/master/pipe_transformer/dp/auto_dp.py.
+
+Experiments
+
+This section first summarizes experiment setups and then evaluates PipeTransformer using computer vision and natural language processing tasks.
+
+Hardware. Experiments were conducted on 2 identical machines connected by InfiniBand CX353A (5GB/s), where each machine is equipped with 8 NVIDIA Quadro RTX 5000 (16GB GPU memory). GPU-to-GPU bandwidth within a machine (PCI 3.0, 16 lanes) is 15.754GB/s.
+
+Implementation. We used PyTorch Pipe as a building block. The BERT model definition, configuration, and related tokenizer are from HuggingFace 3.5.0. We implemented Vision Transformer using PyTorch by following its TensorFlow implementation. More details can be found in our source code.
+
+Models and Datasets. Experiments employ two representative Transformers in CV and NLP: Vision Transformer (ViT) and BERT. ViT was run on an image classification task, initialized with pre-trained weights on ImageNet21K and fine-tuned on ImageNet and CIFAR-100. BERT was run on two tasks, text classification on the SST-2 dataset from the General Language Understanding Evaluation (GLUE) benchmark, and question answering on the SQuAD v1.1 Dataset (Stanford Question Answering), which is a collection of 100k crowdsourced question/answer pairs.
+
+Training Schemes. Given that large models normally would require thousands of GPU-days {\emph{e.g.}, GPT-3) if trained from scratch, fine-tuning downstream tasks using pre-trained models has become a trend in CV and NLP communities. Moreover, PipeTransformer is a complex training system that involves multiple core components. Thus, for the first version of PipeTransformer system development and algorithmic research, it is not cost-efficient to develop and evaluate from scratch using large-scale pre-training. Therefore, the experiments presented in this section focuses on pre-trained models. Note that since the model architectures in pre-training and fine-tuning are the same, PipeTransformer can serve both. We discussed pre-training results in the Appendix.
+
+Baseline. Experiments in this section compare PipeTransformer to the state-of-the-art framework, a hybrid scheme of PyTorch Pipeline (PyTorch’s implementation of GPipe) and PyTorch DDP. Since this is the first paper that studies accelerating distributed training by freezing layers, there are no perfectly aligned counterpart solutions yet.
+
+Hyper-parameters. Experiments use ViT-B/16 (12 transformer layers, 16 \times 16 input patch size) for ImageNet and CIFAR-100, BERT-large-uncased (24 layers) for SQuAD 1.1, and BERT-base-uncased (12 layers) for SST-2. With PipeTransformer, ViT and BERT training can set the per-pipeline batch size to around 400 and 64, respectively. Other hyperparameters (e.g., epoch, learning rate) for all experiments are presented in Appendix.
+
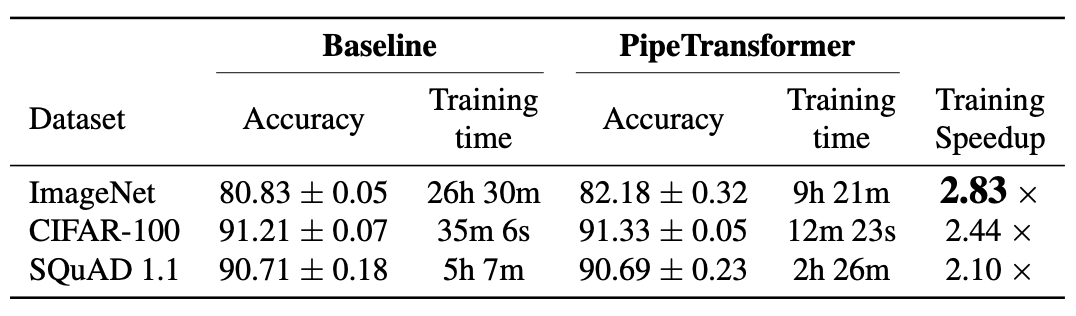
+Overall Training Acceleration
+
+ +
+
+
+
+We summarize the overall experimental results in the table above. Note that the speedup we report is based on a conservative \alpha \frac{1}{3} value that can obtain comparable or even higher accuracy. A more aggressive \alpha (\frac{2}{5}, \frac{1}{2}) can obtain a higher speedup but may lead to a slight loss in accuracy. Note that the model size of BERT (24 layers) is larger than ViT-B/16 (12 layers), thus it takes more time for communication.
+
+
+
+Speedup Breakdown
+
+This section presents evaluation results and analyzes the performance of different components in \autopipe. More experimental results can be found in the Appendix.
+
+
+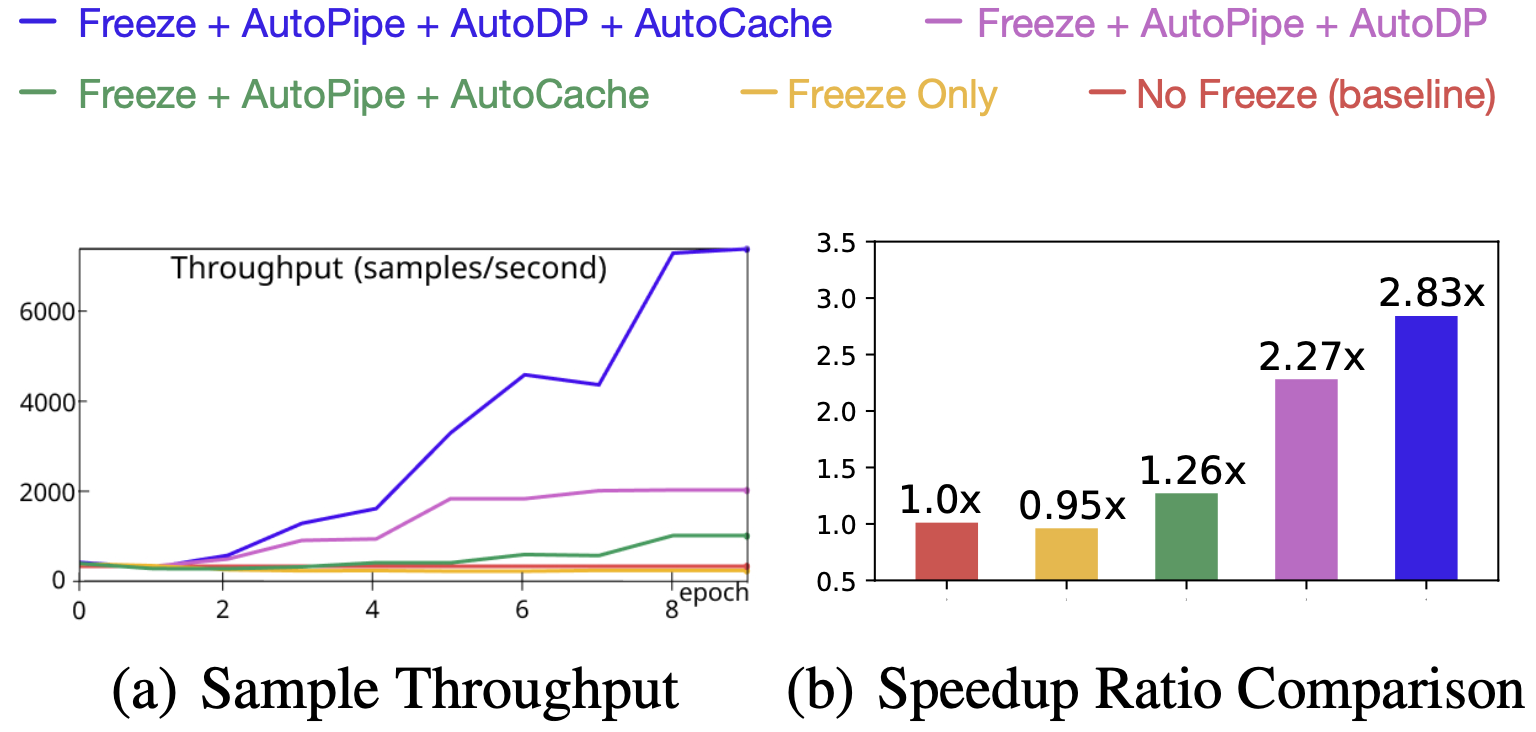 +
+
+Figure 9. Speedup Breakdown (ViT on ImageNet)
+
+
+To understand the efficacy of all four components and their impacts on training speed, we experimented with different combinations and used their training sample throughput (samples/second) and speedup ratio as metrics. Results are illustrated in Figure 9. Key takeaways from these experimental results are:
+
+
+ - the main speedup is the result of elastic pipelining which is achieved through the joint use of AutoPipe and AutoDP;
+ - AutoCache’s contribution is amplified by AutoDP;
+ - freeze training alone without system-wise adjustment even downgrades the training speed.
+
+
+Tuning \alpha in Freezing Algorithm
+
+
+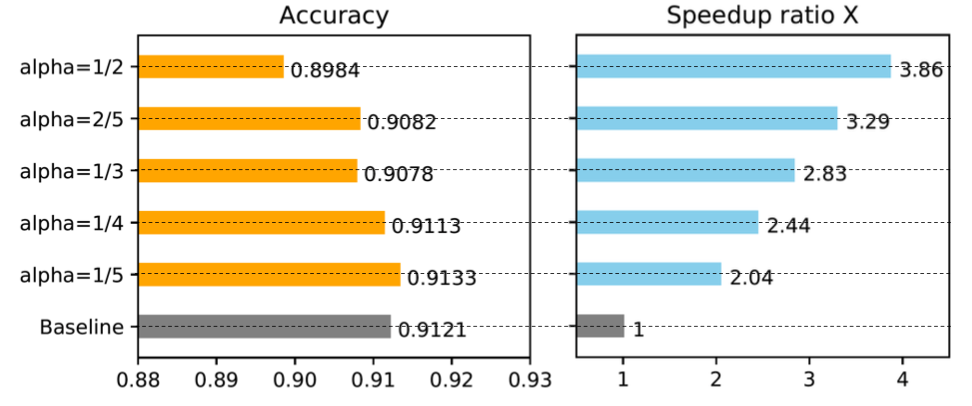 +
+
+Figure 10. Tuning \alpha in Freezing Algorithm
+
+
+We ran experiments to show how the \alpha in the freeze algorithms influences training speed. The result clearly demonstrates that a larger \alpha (excessive freeze) leads to a greater speedup but suffers from a slight performance degradation. In the case shown in Figure 10, where \alpha=1/5, freeze training outperforms normal training and obtains a 2.04-fold speedup. We provide more results in the Appendix.
+
+Optimal Chunks in the elastic pipeline
+
+
+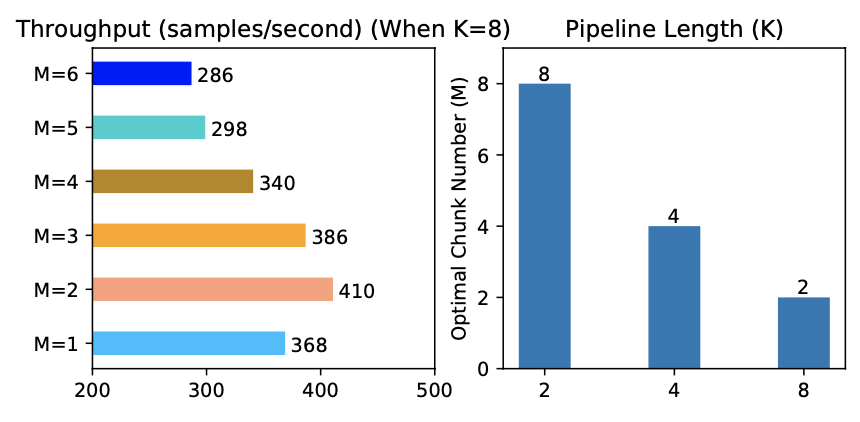 +
+
+Figure 11. Optimal chunk number in the elastic pipeline
+
+
+We profiled the optimal number of micro-batches M for different pipeline lengths K. Results are summarized in Figure 11. As we can see, different K values lead to different optimal M, and the throughput gaps across different M values are large (as shown when K=8), which confirms the necessity of an anterior profiler in elastic pipelining.
+
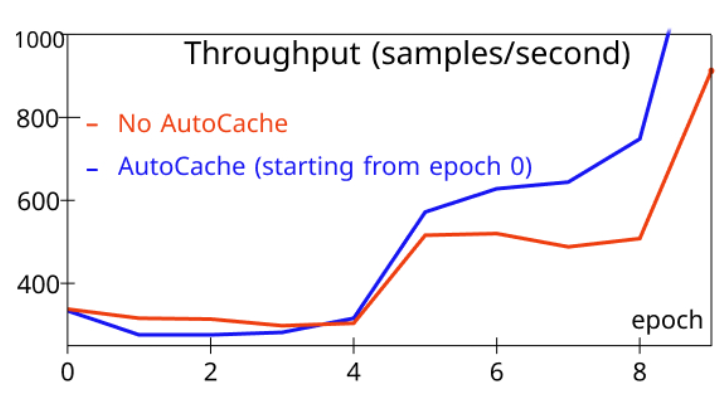
+Understanding the Timing of Caching
+
+
+ +
+
+Figure 12. the timing of caching
+
+
+To evaluate AutoCache, we compared the sample throughput of training that activates AutoCache from epoch 0 (blue) with the training job without AutoCache (red). Figure 12 shows that enabling caching too early can slow down training, as caching can be more expensive than the forward propagation on a small number of frozen layers. After more layers are frozen, caching activations clearly outperform the corresponding forward propagation. As a result, AutoCache uses a profiler to determine the proper timing to enable caching. In our system, for ViT (12 layers), caching starts from 3 frozen layers, while for BERT (24 layers), caching starts from 5 frozen layers.
+
+For more detailed experimental analysis, please refer to our paper.
+
+Summarization
+This blog introduces PipeTransformer, a holistic solution that combines elastic pipeline-parallel and data-parallel for distributed training using PyTorch Distributed APIs. More specifically, PipeTransformer incrementally freezes layers in the pipeline, packs remaining active layers into fewer GPUs, and forks more pipeline replicas to increase the data-parallel width. Evaluations on ViT and BERT models show that compared to the state-of-the-art baseline, PipeTransformer attains up to 2.83× speedups without accuracy loss.
+
+Reference
+
+[1] Li, S., Zhao, Y., Varma, R., Salpekar, O., Noordhuis, P., Li,T., Paszke, A., Smith, J., Vaughan, B., Damania, P., et al. Pytorch Distributed: Experiences on Accelerating Dataparallel Training. Proceedings of the VLDB Endowment,13(12), 2020
+
+[2] Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT, 2019
+
+[3] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is Worth 16x16 words: Transformers for Image Recognition at Scale.
+
+[4] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language Models are Few-shot Learners.
+
+[5] Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. Gshard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
+
+[6] Li, M., Andersen, D. G., Park, J. W., Smola, A. J., Ahmed, A., Josifovski, V., Long, J., Shekita, E. J., and Su, B. Y. Scaling Distributed Machine Learning with the Parameter Server. In 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14), pp. 583–598, 2014.
+
+[7] Jiang, Y., Zhu, Y., Lan, C., Yi, B., Cui, Y., and Guo, C. A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters. In 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pp. 463–479. USENIX Association, November 2020. ISBN 978-1-939133-19- 9.
+
+[8] Kim, S., Yu, G. I., Park, H., Cho, S., Jeong, E., Ha, H., Lee, S., Jeong, J. S., and Chun, B. G. Parallax: Sparsity-aware Data Parallel Training of Deep Neural Networks. In Proceedings of the Fourteenth EuroSys Conference 2019, pp. 1–15, 2019.
+
+[9] Kim, C., Lee, H., Jeong, M., Baek, W., Yoon, B., Kim, I., Lim, S., and Kim, S. TorchGPipe: On-the-fly Pipeline Parallelism for Training Giant Models.
+
+[10] Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, M. X., Chen, D., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., et al. Gpipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism.
+
+[11] Park, J. H., Yun, G., Yi, C. M., Nguyen, N. T., Lee, S., Choi, J., Noh, S. H., and ri Choi, Y. Hetpipe: Enabling Large DNN Training on (whimpy) Heterogeneous GPU Clusters through Integration of Pipelined Model Parallelism and Data Parallelism. In 2020 USENIX Annual Technical Conference (USENIX ATC 20), pp. 307–321. USENIX Association, July 2020. ISBN 978-1-939133- 14-4.
+
+[12] Narayanan, D., Harlap, A., Phanishayee, A., Seshadri, V., Devanur, N. R., Ganger, G. R., Gibbons, P. B., and Zaharia, M. Pipedream: Generalized Pipeline Parallelism for DNN Training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, SOSP ’19, pp. 1–15, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450368735. doi: 10.1145/3341301.3359646.
+
+[13] Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., Krikun, M., Shazeer, N., and Chen, Z. Gshard: Scaling Giant Models with Conditional Computation and Automatic Sharding.
+
+[14] Shazeer, N., Cheng, Y., Parmar, N., Tran, D., Vaswani, A., Koanantakool, P., Hawkins, P., Lee, H., Hong, M., Young, C., Sepassi, R., and Hechtman, B. Mesh-Tensorflow: Deep Learning for Supercomputers. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 31, pp. 10414–10423. Curran Associates, Inc., 2018.
+
+[15] Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-LM: Training Multi-billion Parameter Language Models using Model Parallelism.
+
+[16] Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y. ZERO: Memory Optimization towards Training a Trillion Parameter Models.
+
+[17] Raghu, M., Gilmer, J., Yosinski, J., and Sohl Dickstein, J. Svcca: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability. In NIPS, 2017.
+
+[18] Morcos, A., Raghu, M., and Bengio, S. Insights on Representational Similarity in Neural Networks with Canonical Correlation. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31, pp. 5732–5741. Curran Associates, Inc., 2018.
+
+  +
+
+
+  +
+  +
+  \n",
+ "\n",
+ "HybridNets is an end2end perception network for multi-tasks. Our work focused on traffic object detection, drivable area segmentation and lane detection. HybridNets can run real-time on embedded systems, and obtains SOTA Object Detection, Lane Detection on BDD100K Dataset.\n",
+ "\n",
+ "### Results\n",
+ "\n",
+ "### Traffic Object Detection\n",
+ "\n",
+ "| Model | Recall (%) | mAP@0.5 (%) |\n",
+ "|:------------------:|:------------:|:---------------:|\n",
+ "| `MultiNet` | 81.3 | 60.2 |\n",
+ "| `DLT-Net` | 89.4 | 68.4 |\n",
+ "| `Faster R-CNN` | 77.2 | 55.6 |\n",
+ "| `YOLOv5s` | 86.8 | 77.2 |\n",
+ "| `YOLOP` | 89.2 | 76.5 |\n",
+ "| **`HybridNets`** | **92.8** | **77.3** |\n",
+ "\n",
+ "
\n",
+ "\n",
+ "HybridNets is an end2end perception network for multi-tasks. Our work focused on traffic object detection, drivable area segmentation and lane detection. HybridNets can run real-time on embedded systems, and obtains SOTA Object Detection, Lane Detection on BDD100K Dataset.\n",
+ "\n",
+ "### Results\n",
+ "\n",
+ "### Traffic Object Detection\n",
+ "\n",
+ "| Model | Recall (%) | mAP@0.5 (%) |\n",
+ "|:------------------:|:------------:|:---------------:|\n",
+ "| `MultiNet` | 81.3 | 60.2 |\n",
+ "| `DLT-Net` | 89.4 | 68.4 |\n",
+ "| `Faster R-CNN` | 77.2 | 55.6 |\n",
+ "| `YOLOv5s` | 86.8 | 77.2 |\n",
+ "| `YOLOP` | 89.2 | 76.5 |\n",
+ "| **`HybridNets`** | **92.8** | **77.3** |\n",
+ "\n",
+ "
 \n",
+ " \n",
+ "### Drivable Area Segmentation\n",
+ "\n",
+ "| Model | Drivable mIoU (%) |\n",
+ "|:----------------:|:-----------------:|\n",
+ "| `MultiNet` | 71.6 |\n",
+ "| `DLT-Net` | 71.3 |\n",
+ "| `PSPNet` | 89.6 |\n",
+ "| `YOLOP` | 91.5 |\n",
+ "| **`HybridNets`** | **90.5** |\n",
+ "\n",
+ "
\n",
+ " \n",
+ "### Drivable Area Segmentation\n",
+ "\n",
+ "| Model | Drivable mIoU (%) |\n",
+ "|:----------------:|:-----------------:|\n",
+ "| `MultiNet` | 71.6 |\n",
+ "| `DLT-Net` | 71.3 |\n",
+ "| `PSPNet` | 89.6 |\n",
+ "| `YOLOP` | 91.5 |\n",
+ "| **`HybridNets`** | **90.5** |\n",
+ "\n",
+ "
 \n",
+ " \n",
+ "### Lane Line Detection\n",
+ "\n",
+ "| Model | Accuracy (%) | Lane Line IoU (%) |\n",
+ "|:----------------:|:------------:|:-----------------:|\n",
+ "| `Enet` | 34.12 | 14.64 |\n",
+ "| `SCNN` | 35.79 | 15.84 |\n",
+ "| `Enet-SAD` | 36.56 | 16.02 |\n",
+ "| `YOLOP` | 70.5 | 26.2 |\n",
+ "| **`HybridNets`** | **85.4** | **31.6** |\n",
+ "\n",
+ "
\n",
+ " \n",
+ "### Lane Line Detection\n",
+ "\n",
+ "| Model | Accuracy (%) | Lane Line IoU (%) |\n",
+ "|:----------------:|:------------:|:-----------------:|\n",
+ "| `Enet` | 34.12 | 14.64 |\n",
+ "| `SCNN` | 35.79 | 15.84 |\n",
+ "| `Enet-SAD` | 36.56 | 16.02 |\n",
+ "| `YOLOP` | 70.5 | 26.2 |\n",
+ "| **`HybridNets`** | **85.4** | **31.6** |\n",
+ "\n",
+ "
 \n",
+ " \n",
+ "
\n",
+ " \n",
+ " \n",
+ " \n",
+ " \n",
+ "### Load From PyTorch Hub\n",
+ "\n",
+ "This example loads the pretrained **HybridNets** model and passes an image for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4b94d3f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# load model\n",
+ "model = torch.hub.load('datvuthanh/hybridnets', 'hybridnets', pretrained=True)\n",
+ "\n",
+ "#inference\n",
+ "img = torch.randn(1,3,640,384)\n",
+ "features, regression, classification, anchors, segmentation = model(img)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fdb0bae",
+ "metadata": {},
+ "source": [
+ "### Citation\n",
+ "\n",
+ "If you find our [paper](https://arxiv.org/abs/2203.09035) and [code](https://github.com/datvuthanh/HybridNets) useful for your research, please consider giving a star and citation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76552e35",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "BibTeX"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@misc{vu2022hybridnets,\n",
+ " title={HybridNets: End-to-End Perception Network}, \n",
+ " author={Dat Vu and Bao Ngo and Hung Phan},\n",
+ " year={2022},\n",
+ " eprint={2203.09035},\n",
+ " archivePrefix={arXiv},\n",
+ " primaryClass={cs.CV}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_WSL-Images_resnext.ipynb b/assets/hub/facebookresearch_WSL-Images_resnext.ipynb
new file mode 100644
index 000000000000..874d8fe2b6c3
--- /dev/null
+++ b/assets/hub/facebookresearch_WSL-Images_resnext.ipynb
@@ -0,0 +1,128 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8ef1d490",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNext WSL\n",
+ "\n",
+ "*Author: Facebook AI*\n",
+ "\n",
+ "**ResNext models trained with billion scale weakly-supervised data.**\n",
+ "\n",
+ "
\n",
+ " \n",
+ " \n",
+ "### Load From PyTorch Hub\n",
+ "\n",
+ "This example loads the pretrained **HybridNets** model and passes an image for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4b94d3f8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# load model\n",
+ "model = torch.hub.load('datvuthanh/hybridnets', 'hybridnets', pretrained=True)\n",
+ "\n",
+ "#inference\n",
+ "img = torch.randn(1,3,640,384)\n",
+ "features, regression, classification, anchors, segmentation = model(img)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fdb0bae",
+ "metadata": {},
+ "source": [
+ "### Citation\n",
+ "\n",
+ "If you find our [paper](https://arxiv.org/abs/2203.09035) and [code](https://github.com/datvuthanh/HybridNets) useful for your research, please consider giving a star and citation:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76552e35",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "BibTeX"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@misc{vu2022hybridnets,\n",
+ " title={HybridNets: End-to-End Perception Network}, \n",
+ " author={Dat Vu and Bao Ngo and Hung Phan},\n",
+ " year={2022},\n",
+ " eprint={2203.09035},\n",
+ " archivePrefix={arXiv},\n",
+ " primaryClass={cs.CV}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_WSL-Images_resnext.ipynb b/assets/hub/facebookresearch_WSL-Images_resnext.ipynb
new file mode 100644
index 000000000000..874d8fe2b6c3
--- /dev/null
+++ b/assets/hub/facebookresearch_WSL-Images_resnext.ipynb
@@ -0,0 +1,128 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8ef1d490",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNext WSL\n",
+ "\n",
+ "*Author: Facebook AI*\n",
+ "\n",
+ "**ResNext models trained with billion scale weakly-supervised data.**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4cd8dad2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')\n",
+ "# or\n",
+ "# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x16d_wsl')\n",
+ "# or\n",
+ "# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x32d_wsl')\n",
+ "# or\n",
+ "#model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x48d_wsl')\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a74a046",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96400b56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a5a0f9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab881a6",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "The provided ResNeXt models are pre-trained in weakly-supervised fashion on **940 million** public images with 1.5K hashtags matching with 1000 ImageNet1K synsets, followed by fine-tuning on ImageNet1K dataset. Please refer to \"Exploring the Limits of Weakly Supervised Pretraining\" (https://arxiv.org/abs/1805.00932) presented at ECCV 2018 for the details of model training.\n",
+ "\n",
+ "We are providing 4 models with different capacities.\n",
+ "\n",
+ "| Model | #Parameters | FLOPS | Top-1 Acc. | Top-5 Acc. |\n",
+ "| ------------------ | :---------: | :---: | :--------: | :--------: |\n",
+ "| ResNeXt-101 32x8d | 88M | 16B | 82.2 | 96.4 |\n",
+ "| ResNeXt-101 32x16d | 193M | 36B | 84.2 | 97.2 |\n",
+ "| ResNeXt-101 32x32d | 466M | 87B | 85.1 | 97.5 |\n",
+ "| ResNeXt-101 32x48d | 829M | 153B | 85.4 | 97.6 |\n",
+ "\n",
+ "Our models significantly improve the training accuracy on ImageNet compared to training from scratch. **We achieve state-of-the-art accuracy of 85.4% on ImageNet with our ResNext-101 32x48d model.**\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Exploring the Limits of Weakly Supervised Pretraining](https://arxiv.org/abs/1805.00932)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb b/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb
new file mode 100644
index 000000000000..85ac76ff49f2
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb
@@ -0,0 +1,94 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1b258978",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# DCGAN on FashionGen\n",
+ "\n",
+ "*Author: FAIR HDGAN*\n",
+ "\n",
+ "**A simple generative image model for 64x64 images**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4cd8dad2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x8d_wsl')\n",
+ "# or\n",
+ "# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x16d_wsl')\n",
+ "# or\n",
+ "# model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x32d_wsl')\n",
+ "# or\n",
+ "#model = torch.hub.load('facebookresearch/WSL-Images', 'resnext101_32x48d_wsl')\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5a74a046",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96400b56",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a5a0f9c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1ab881a6",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "The provided ResNeXt models are pre-trained in weakly-supervised fashion on **940 million** public images with 1.5K hashtags matching with 1000 ImageNet1K synsets, followed by fine-tuning on ImageNet1K dataset. Please refer to \"Exploring the Limits of Weakly Supervised Pretraining\" (https://arxiv.org/abs/1805.00932) presented at ECCV 2018 for the details of model training.\n",
+ "\n",
+ "We are providing 4 models with different capacities.\n",
+ "\n",
+ "| Model | #Parameters | FLOPS | Top-1 Acc. | Top-5 Acc. |\n",
+ "| ------------------ | :---------: | :---: | :--------: | :--------: |\n",
+ "| ResNeXt-101 32x8d | 88M | 16B | 82.2 | 96.4 |\n",
+ "| ResNeXt-101 32x16d | 193M | 36B | 84.2 | 97.2 |\n",
+ "| ResNeXt-101 32x32d | 466M | 87B | 85.1 | 97.5 |\n",
+ "| ResNeXt-101 32x48d | 829M | 153B | 85.4 | 97.6 |\n",
+ "\n",
+ "Our models significantly improve the training accuracy on ImageNet compared to training from scratch. **We achieve state-of-the-art accuracy of 85.4% on ImageNet with our ResNext-101 32x48d model.**\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Exploring the Limits of Weakly Supervised Pretraining](https://arxiv.org/abs/1805.00932)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb b/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb
new file mode 100644
index 000000000000..85ac76ff49f2
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorch-gan-zoo_dcgan.ipynb
@@ -0,0 +1,94 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1b258978",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# DCGAN on FashionGen\n",
+ "\n",
+ "*Author: FAIR HDGAN*\n",
+ "\n",
+ "**A simple generative image model for 64x64 images**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c32ce03d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "use_gpu = True if torch.cuda.is_available() else False\n",
+ "\n",
+ "model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True, useGPU=use_gpu)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "262b4ccb",
+ "metadata": {},
+ "source": [
+ "The input to the model is a noise vector of shape `(N, 120)` where `N` is the number of images to be generated.\n",
+ "It can be constructed using the function `.buildNoiseData`.\n",
+ "The model has a `.test` function that takes in the noise vector and generates images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6c00225",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_images = 64\n",
+ "noise, _ = model.buildNoiseData(num_images)\n",
+ "with torch.no_grad():\n",
+ " generated_images = model.test(noise)\n",
+ "\n",
+ "# let's plot these images using torchvision and matplotlib\n",
+ "import matplotlib.pyplot as plt\n",
+ "import torchvision\n",
+ "plt.imshow(torchvision.utils.make_grid(generated_images).permute(1, 2, 0).cpu().numpy())\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "12cb57e2",
+ "metadata": {},
+ "source": [
+ "You should see an image similar to the one on the left.\n",
+ "\n",
+ "If you want to train your own DCGAN and other GANs from scratch, have a look at [PyTorch GAN Zoo](https://github.com/facebookresearch/pytorch_GAN_zoo).\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "In computer vision, generative models are networks trained to create images from a given input. In our case, we consider a specific kind of generative networks: GANs (Generative Adversarial Networks) which learn to map a random vector with a realistic image generation.\n",
+ "\n",
+ "DCGAN is a model designed in 2015 by Radford et. al. in the paper [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434). It is a GAN architecture both very simple and efficient for low resolution image generation (up to 64x64).\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "- Currently only supports Python 3\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb b/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb
new file mode 100644
index 000000000000..26c0c359e205
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb
@@ -0,0 +1,103 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "101b74b4",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Progressive Growing of GANs (PGAN)\n",
+ "\n",
+ "*Author: FAIR HDGAN*\n",
+ "\n",
+ "**High-quality image generation of fashion, celebrity faces**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e69f3757",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "use_gpu = True if torch.cuda.is_available() else False\n",
+ "\n",
+ "# trained on high-quality celebrity faces \"celebA\" dataset\n",
+ "# this model outputs 512 x 512 pixel images\n",
+ "model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub',\n",
+ " 'PGAN', model_name='celebAHQ-512',\n",
+ " pretrained=True, useGPU=use_gpu)\n",
+ "# this model outputs 256 x 256 pixel images\n",
+ "# model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub',\n",
+ "# 'PGAN', model_name='celebAHQ-256',\n",
+ "# pretrained=True, useGPU=use_gpu)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d21bcb3",
+ "metadata": {},
+ "source": [
+ "The input to the model is a noise vector of shape `(N, 512)` where `N` is the number of images to be generated.\n",
+ "It can be constructed using the function `.buildNoiseData`.\n",
+ "The model has a `.test` function that takes in the noise vector and generates images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cd6247e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_images = 4\n",
+ "noise, _ = model.buildNoiseData(num_images)\n",
+ "with torch.no_grad():\n",
+ " generated_images = model.test(noise)\n",
+ "\n",
+ "# let's plot these images using torchvision and matplotlib\n",
+ "import matplotlib.pyplot as plt\n",
+ "import torchvision\n",
+ "grid = torchvision.utils.make_grid(generated_images.clamp(min=-1, max=1), scale_each=True, normalize=True)\n",
+ "plt.imshow(grid.permute(1, 2, 0).cpu().numpy())\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d38bb5f5",
+ "metadata": {},
+ "source": [
+ "You should see an image similar to the one on the left.\n",
+ "\n",
+ "If you want to train your own Progressive GAN and other GANs from scratch, have a look at [PyTorch GAN Zoo](https://github.com/facebookresearch/pytorch_GAN_zoo).\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "In computer vision, generative models are networks trained to create images from a given input. In our case, we consider a specific kind of generative networks: GANs (Generative Adversarial Networks) which learn to map a random vector with a realistic image generation.\n",
+ "\n",
+ "Progressive Growing of GANs is a method developed by Karras et. al. [1] in 2017 allowing generation of high resolution images. To do so, the generative network is trained slice by slice. At first the model is trained to build very low resolution images, once it converges, new layers are added and the output resolution doubles. The process continues until the desired resolution is reached.\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "- Currently only supports Python 3\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "[1] Tero Karras et al, \"Progressive Growing of GANs for Improved Quality, Stability, and Variation\" https://arxiv.org/abs/1710.10196"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb b/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb
new file mode 100644
index 000000000000..4b4641722270
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb
@@ -0,0 +1,283 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e4f99e2c",
+ "metadata": {},
+ "source": [
+ "# 3D ResNet\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**Resnet Style Video classification networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96affaa2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `slow_r50` model \n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', 'slow_r50', pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d0359d9",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ab84506f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import urllib\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06976792",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "680df0e7",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "python "
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68096afb",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c1eaa3c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "134f9719",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b53cb1e8",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7f317a15",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "side_size = 256\n",
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "crop_size = 256\n",
+ "num_frames = 8\n",
+ "sampling_rate = 8\n",
+ "frames_per_second = 30\n",
+ "\n",
+ "# Note that this transform is specific to the slow_R50 model.\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(num_frames),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(\n",
+ " size=side_size\n",
+ " ),\n",
+ " CenterCropVideo(crop_size=(crop_size, crop_size))\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (num_frames * sampling_rate)/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2126afcc",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d22db1ed",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a51f110a",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29a3ea72",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = inputs.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d6b6e2c",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4190298",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs[None, ...])\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "15cd8cf7",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "The model architecture is based on [1] with pretrained weights using the 8x8 setting\n",
+ "on the Kinetics dataset. \n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| Slow | R50 | 8x8 | 74.58 | 91.63 | 54.52 | 32.45 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer et al, \"SlowFast Networks for Video Recognition\"\n",
+ "https://arxiv.org/pdf/1812.03982.pdf"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb b/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb
new file mode 100644
index 000000000000..a95866528fae
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb
@@ -0,0 +1,308 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "43b62276",
+ "metadata": {},
+ "source": [
+ "# SlowFast\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**SlowFast networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cad7ce41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `slowfast_r50` model \n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', 'slowfast_r50', pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0105e28f",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "21ec21fc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import Dict\n",
+ "import json\n",
+ "import urllib\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample,\n",
+ " UniformCropVideo\n",
+ ") "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "88fe7c95",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8e439a0f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "python "
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c9126ed1",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a9f96e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "de3e0e3f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6866da20",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8beb0a98",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "side_size = 256\n",
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "crop_size = 256\n",
+ "num_frames = 32\n",
+ "sampling_rate = 2\n",
+ "frames_per_second = 30\n",
+ "slowfast_alpha = 4\n",
+ "num_clips = 10\n",
+ "num_crops = 3\n",
+ "\n",
+ "class PackPathway(torch.nn.Module):\n",
+ " \"\"\"\n",
+ " Transform for converting video frames as a list of tensors. \n",
+ " \"\"\"\n",
+ " def __init__(self):\n",
+ " super().__init__()\n",
+ " \n",
+ " def forward(self, frames: torch.Tensor):\n",
+ " fast_pathway = frames\n",
+ " # Perform temporal sampling from the fast pathway.\n",
+ " slow_pathway = torch.index_select(\n",
+ " frames,\n",
+ " 1,\n",
+ " torch.linspace(\n",
+ " 0, frames.shape[1] - 1, frames.shape[1] // slowfast_alpha\n",
+ " ).long(),\n",
+ " )\n",
+ " frame_list = [slow_pathway, fast_pathway]\n",
+ " return frame_list\n",
+ "\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(num_frames),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(\n",
+ " size=side_size\n",
+ " ),\n",
+ " CenterCropVideo(crop_size),\n",
+ " PackPathway()\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (num_frames * sampling_rate)/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7db0efb",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9d215227",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fafecfaa",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a2d91dfe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = [i.to(device)[None, ...] for i in inputs]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f2387d0e",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55825ac2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs)\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5f95a42d",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "SlowFast model architectures are based on [1] with pretrained weights using the 8x8 setting\n",
+ "on the Kinetics dataset. \n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| SlowFast | R50 | 8x8 | 76.94 | 92.69 | 65.71 | 34.57 |\n",
+ "| SlowFast | R101 | 8x8 | 77.90 | 93.27 | 127.20 | 62.83 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer et al, \"SlowFast Networks for Video Recognition\"\n",
+ "https://arxiv.org/pdf/1812.03982.pdf"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb b/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb
new file mode 100644
index 000000000000..6f75fcbc1524
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb
@@ -0,0 +1,297 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "89d5af57",
+ "metadata": {},
+ "source": [
+ "# X3D\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**X3D networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "daf69981",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `x3d_s` model\n",
+ "model_name = 'x3d_s'\n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', model_name, pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f4f316f",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42dbe99f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import urllib\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ab48f59a",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18d25fa0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bfed8b6b",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dbf220ef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9ccab195",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f2ffd57e",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b387fdb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "frames_per_second = 30\n",
+ "model_transform_params = {\n",
+ " \"x3d_xs\": {\n",
+ " \"side_size\": 182,\n",
+ " \"crop_size\": 182,\n",
+ " \"num_frames\": 4,\n",
+ " \"sampling_rate\": 12,\n",
+ " },\n",
+ " \"x3d_s\": {\n",
+ " \"side_size\": 182,\n",
+ " \"crop_size\": 182,\n",
+ " \"num_frames\": 13,\n",
+ " \"sampling_rate\": 6,\n",
+ " },\n",
+ " \"x3d_m\": {\n",
+ " \"side_size\": 256,\n",
+ " \"crop_size\": 256,\n",
+ " \"num_frames\": 16,\n",
+ " \"sampling_rate\": 5,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "# Get transform parameters based on model\n",
+ "transform_params = model_transform_params[model_name]\n",
+ "\n",
+ "# Note that this transform is specific to the slow_R50 model.\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(transform_params[\"num_frames\"]),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(size=transform_params[\"side_size\"]),\n",
+ " CenterCropVideo(\n",
+ " crop_size=(transform_params[\"crop_size\"], transform_params[\"crop_size\"])\n",
+ " )\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (transform_params[\"num_frames\"] * transform_params[\"sampling_rate\"])/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a5de0111",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd125847",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ceb379eb",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5147a11a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = inputs.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb9be637",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6079fb75",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs[None, ...])\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a6e53a9a",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "X3D model architectures are based on [1] pretrained on the Kinetics dataset.\n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| X3D | XS | 4x12 | 69.12 | 88.63 | 0.91 | 3.79 |\n",
+ "| X3D | S | 13x6 | 73.33 | 91.27 | 2.96 | 3.79 |\n",
+ "| X3D | M | 16x5 | 75.94 | 92.72 | 6.72 | 3.79 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer, \"X3D: Expanding Architectures for\n",
+ " Efficient Video Recognition.\" https://arxiv.org/abs/2004.04730"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb b/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb
new file mode 100644
index 000000000000..64a285b7b6ff
--- /dev/null
+++ b/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "6c28f06b",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Semi-supervised and semi-weakly supervised ImageNet Models\n",
+ "\n",
+ "*Author: Facebook AI*\n",
+ "\n",
+ "**ResNet and ResNext models introduced in the \"Billion scale semi-supervised learning for image classification\" paper**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c32ce03d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "use_gpu = True if torch.cuda.is_available() else False\n",
+ "\n",
+ "model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True, useGPU=use_gpu)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "262b4ccb",
+ "metadata": {},
+ "source": [
+ "The input to the model is a noise vector of shape `(N, 120)` where `N` is the number of images to be generated.\n",
+ "It can be constructed using the function `.buildNoiseData`.\n",
+ "The model has a `.test` function that takes in the noise vector and generates images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6c00225",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_images = 64\n",
+ "noise, _ = model.buildNoiseData(num_images)\n",
+ "with torch.no_grad():\n",
+ " generated_images = model.test(noise)\n",
+ "\n",
+ "# let's plot these images using torchvision and matplotlib\n",
+ "import matplotlib.pyplot as plt\n",
+ "import torchvision\n",
+ "plt.imshow(torchvision.utils.make_grid(generated_images).permute(1, 2, 0).cpu().numpy())\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "12cb57e2",
+ "metadata": {},
+ "source": [
+ "You should see an image similar to the one on the left.\n",
+ "\n",
+ "If you want to train your own DCGAN and other GANs from scratch, have a look at [PyTorch GAN Zoo](https://github.com/facebookresearch/pytorch_GAN_zoo).\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "In computer vision, generative models are networks trained to create images from a given input. In our case, we consider a specific kind of generative networks: GANs (Generative Adversarial Networks) which learn to map a random vector with a realistic image generation.\n",
+ "\n",
+ "DCGAN is a model designed in 2015 by Radford et. al. in the paper [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434). It is a GAN architecture both very simple and efficient for low resolution image generation (up to 64x64).\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "- Currently only supports Python 3\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks](https://arxiv.org/abs/1511.06434)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb b/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb
new file mode 100644
index 000000000000..26c0c359e205
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorch-gan-zoo_pgan.ipynb
@@ -0,0 +1,103 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "101b74b4",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Progressive Growing of GANs (PGAN)\n",
+ "\n",
+ "*Author: FAIR HDGAN*\n",
+ "\n",
+ "**High-quality image generation of fashion, celebrity faces**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e69f3757",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "use_gpu = True if torch.cuda.is_available() else False\n",
+ "\n",
+ "# trained on high-quality celebrity faces \"celebA\" dataset\n",
+ "# this model outputs 512 x 512 pixel images\n",
+ "model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub',\n",
+ " 'PGAN', model_name='celebAHQ-512',\n",
+ " pretrained=True, useGPU=use_gpu)\n",
+ "# this model outputs 256 x 256 pixel images\n",
+ "# model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub',\n",
+ "# 'PGAN', model_name='celebAHQ-256',\n",
+ "# pretrained=True, useGPU=use_gpu)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d21bcb3",
+ "metadata": {},
+ "source": [
+ "The input to the model is a noise vector of shape `(N, 512)` where `N` is the number of images to be generated.\n",
+ "It can be constructed using the function `.buildNoiseData`.\n",
+ "The model has a `.test` function that takes in the noise vector and generates images."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cd6247e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "num_images = 4\n",
+ "noise, _ = model.buildNoiseData(num_images)\n",
+ "with torch.no_grad():\n",
+ " generated_images = model.test(noise)\n",
+ "\n",
+ "# let's plot these images using torchvision and matplotlib\n",
+ "import matplotlib.pyplot as plt\n",
+ "import torchvision\n",
+ "grid = torchvision.utils.make_grid(generated_images.clamp(min=-1, max=1), scale_each=True, normalize=True)\n",
+ "plt.imshow(grid.permute(1, 2, 0).cpu().numpy())\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d38bb5f5",
+ "metadata": {},
+ "source": [
+ "You should see an image similar to the one on the left.\n",
+ "\n",
+ "If you want to train your own Progressive GAN and other GANs from scratch, have a look at [PyTorch GAN Zoo](https://github.com/facebookresearch/pytorch_GAN_zoo).\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "In computer vision, generative models are networks trained to create images from a given input. In our case, we consider a specific kind of generative networks: GANs (Generative Adversarial Networks) which learn to map a random vector with a realistic image generation.\n",
+ "\n",
+ "Progressive Growing of GANs is a method developed by Karras et. al. [1] in 2017 allowing generation of high resolution images. To do so, the generative network is trained slice by slice. At first the model is trained to build very low resolution images, once it converges, new layers are added and the output resolution doubles. The process continues until the desired resolution is reached.\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "- Currently only supports Python 3\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "[1] Tero Karras et al, \"Progressive Growing of GANs for Improved Quality, Stability, and Variation\" https://arxiv.org/abs/1710.10196"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb b/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb
new file mode 100644
index 000000000000..4b4641722270
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_resnet.ipynb
@@ -0,0 +1,283 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e4f99e2c",
+ "metadata": {},
+ "source": [
+ "# 3D ResNet\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**Resnet Style Video classification networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96affaa2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `slow_r50` model \n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', 'slow_r50', pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d0359d9",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ab84506f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import urllib\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "06976792",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "680df0e7",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "python "
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68096afb",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9c1eaa3c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "134f9719",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b53cb1e8",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7f317a15",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "side_size = 256\n",
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "crop_size = 256\n",
+ "num_frames = 8\n",
+ "sampling_rate = 8\n",
+ "frames_per_second = 30\n",
+ "\n",
+ "# Note that this transform is specific to the slow_R50 model.\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(num_frames),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(\n",
+ " size=side_size\n",
+ " ),\n",
+ " CenterCropVideo(crop_size=(crop_size, crop_size))\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (num_frames * sampling_rate)/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2126afcc",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d22db1ed",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a51f110a",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "29a3ea72",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = inputs.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5d6b6e2c",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4190298",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs[None, ...])\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "15cd8cf7",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "The model architecture is based on [1] with pretrained weights using the 8x8 setting\n",
+ "on the Kinetics dataset. \n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| Slow | R50 | 8x8 | 74.58 | 91.63 | 54.52 | 32.45 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer et al, \"SlowFast Networks for Video Recognition\"\n",
+ "https://arxiv.org/pdf/1812.03982.pdf"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb b/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb
new file mode 100644
index 000000000000..a95866528fae
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_slowfast.ipynb
@@ -0,0 +1,308 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "43b62276",
+ "metadata": {},
+ "source": [
+ "# SlowFast\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**SlowFast networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cad7ce41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `slowfast_r50` model \n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', 'slowfast_r50', pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0105e28f",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "21ec21fc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from typing import Dict\n",
+ "import json\n",
+ "import urllib\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample,\n",
+ " UniformCropVideo\n",
+ ") "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "88fe7c95",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8e439a0f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "python "
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c9126ed1",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a9f96e8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "de3e0e3f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6866da20",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8beb0a98",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "side_size = 256\n",
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "crop_size = 256\n",
+ "num_frames = 32\n",
+ "sampling_rate = 2\n",
+ "frames_per_second = 30\n",
+ "slowfast_alpha = 4\n",
+ "num_clips = 10\n",
+ "num_crops = 3\n",
+ "\n",
+ "class PackPathway(torch.nn.Module):\n",
+ " \"\"\"\n",
+ " Transform for converting video frames as a list of tensors. \n",
+ " \"\"\"\n",
+ " def __init__(self):\n",
+ " super().__init__()\n",
+ " \n",
+ " def forward(self, frames: torch.Tensor):\n",
+ " fast_pathway = frames\n",
+ " # Perform temporal sampling from the fast pathway.\n",
+ " slow_pathway = torch.index_select(\n",
+ " frames,\n",
+ " 1,\n",
+ " torch.linspace(\n",
+ " 0, frames.shape[1] - 1, frames.shape[1] // slowfast_alpha\n",
+ " ).long(),\n",
+ " )\n",
+ " frame_list = [slow_pathway, fast_pathway]\n",
+ " return frame_list\n",
+ "\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(num_frames),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(\n",
+ " size=side_size\n",
+ " ),\n",
+ " CenterCropVideo(crop_size),\n",
+ " PackPathway()\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (num_frames * sampling_rate)/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d7db0efb",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9d215227",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fafecfaa",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a2d91dfe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = [i.to(device)[None, ...] for i in inputs]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f2387d0e",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55825ac2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs)\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5f95a42d",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "SlowFast model architectures are based on [1] with pretrained weights using the 8x8 setting\n",
+ "on the Kinetics dataset. \n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| SlowFast | R50 | 8x8 | 76.94 | 92.69 | 65.71 | 34.57 |\n",
+ "| SlowFast | R101 | 8x8 | 77.90 | 93.27 | 127.20 | 62.83 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer et al, \"SlowFast Networks for Video Recognition\"\n",
+ "https://arxiv.org/pdf/1812.03982.pdf"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb b/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb
new file mode 100644
index 000000000000..6f75fcbc1524
--- /dev/null
+++ b/assets/hub/facebookresearch_pytorchvideo_x3d.ipynb
@@ -0,0 +1,297 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "89d5af57",
+ "metadata": {},
+ "source": [
+ "# X3D\n",
+ "\n",
+ "*Author: FAIR PyTorchVideo*\n",
+ "\n",
+ "**X3D networks pretrained on the Kinetics 400 dataset**\n",
+ "\n",
+ "\n",
+ "### Example Usage\n",
+ "\n",
+ "#### Imports\n",
+ "\n",
+ "Load the model:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "daf69981",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# Choose the `x3d_s` model\n",
+ "model_name = 'x3d_s'\n",
+ "model = torch.hub.load('facebookresearch/pytorchvideo', model_name, pretrained=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f4f316f",
+ "metadata": {},
+ "source": [
+ "Import remaining functions:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "42dbe99f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import json\n",
+ "import urllib\n",
+ "from pytorchvideo.data.encoded_video import EncodedVideo\n",
+ "\n",
+ "from torchvision.transforms import Compose, Lambda\n",
+ "from torchvision.transforms._transforms_video import (\n",
+ " CenterCropVideo,\n",
+ " NormalizeVideo,\n",
+ ")\n",
+ "from pytorchvideo.transforms import (\n",
+ " ApplyTransformToKey,\n",
+ " ShortSideScale,\n",
+ " UniformTemporalSubsample\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ab48f59a",
+ "metadata": {},
+ "source": [
+ "#### Setup\n",
+ "\n",
+ "Set the model to eval mode and move to desired device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "18d25fa0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Set to GPU or CPU\n",
+ "device = \"cpu\"\n",
+ "model = model.eval()\n",
+ "model = model.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bfed8b6b",
+ "metadata": {},
+ "source": [
+ "Download the id to label mapping for the Kinetics 400 dataset on which the torch hub models were trained. This will be used to get the category label names from the predicted class ids."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dbf220ef",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "json_url = \"https://dl.fbaipublicfiles.com/pyslowfast/dataset/class_names/kinetics_classnames.json\"\n",
+ "json_filename = \"kinetics_classnames.json\"\n",
+ "try: urllib.URLopener().retrieve(json_url, json_filename)\n",
+ "except: urllib.request.urlretrieve(json_url, json_filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9ccab195",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with open(json_filename, \"r\") as f:\n",
+ " kinetics_classnames = json.load(f)\n",
+ "\n",
+ "# Create an id to label name mapping\n",
+ "kinetics_id_to_classname = {}\n",
+ "for k, v in kinetics_classnames.items():\n",
+ " kinetics_id_to_classname[v] = str(k).replace('\"', \"\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f2ffd57e",
+ "metadata": {},
+ "source": [
+ "#### Define input transform"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b387fdb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "mean = [0.45, 0.45, 0.45]\n",
+ "std = [0.225, 0.225, 0.225]\n",
+ "frames_per_second = 30\n",
+ "model_transform_params = {\n",
+ " \"x3d_xs\": {\n",
+ " \"side_size\": 182,\n",
+ " \"crop_size\": 182,\n",
+ " \"num_frames\": 4,\n",
+ " \"sampling_rate\": 12,\n",
+ " },\n",
+ " \"x3d_s\": {\n",
+ " \"side_size\": 182,\n",
+ " \"crop_size\": 182,\n",
+ " \"num_frames\": 13,\n",
+ " \"sampling_rate\": 6,\n",
+ " },\n",
+ " \"x3d_m\": {\n",
+ " \"side_size\": 256,\n",
+ " \"crop_size\": 256,\n",
+ " \"num_frames\": 16,\n",
+ " \"sampling_rate\": 5,\n",
+ " }\n",
+ "}\n",
+ "\n",
+ "# Get transform parameters based on model\n",
+ "transform_params = model_transform_params[model_name]\n",
+ "\n",
+ "# Note that this transform is specific to the slow_R50 model.\n",
+ "transform = ApplyTransformToKey(\n",
+ " key=\"video\",\n",
+ " transform=Compose(\n",
+ " [\n",
+ " UniformTemporalSubsample(transform_params[\"num_frames\"]),\n",
+ " Lambda(lambda x: x/255.0),\n",
+ " NormalizeVideo(mean, std),\n",
+ " ShortSideScale(size=transform_params[\"side_size\"]),\n",
+ " CenterCropVideo(\n",
+ " crop_size=(transform_params[\"crop_size\"], transform_params[\"crop_size\"])\n",
+ " )\n",
+ " ]\n",
+ " ),\n",
+ ")\n",
+ "\n",
+ "# The duration of the input clip is also specific to the model.\n",
+ "clip_duration = (transform_params[\"num_frames\"] * transform_params[\"sampling_rate\"])/frames_per_second"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a5de0111",
+ "metadata": {},
+ "source": [
+ "#### Run Inference\n",
+ "\n",
+ "Download an example video."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd125847",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "url_link = \"https://dl.fbaipublicfiles.com/pytorchvideo/projects/archery.mp4\"\n",
+ "video_path = 'archery.mp4'\n",
+ "try: urllib.URLopener().retrieve(url_link, video_path)\n",
+ "except: urllib.request.urlretrieve(url_link, video_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ceb379eb",
+ "metadata": {},
+ "source": [
+ "Load the video and transform it to the input format required by the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5147a11a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Select the duration of the clip to load by specifying the start and end duration\n",
+ "# The start_sec should correspond to where the action occurs in the video\n",
+ "start_sec = 0\n",
+ "end_sec = start_sec + clip_duration\n",
+ "\n",
+ "# Initialize an EncodedVideo helper class and load the video\n",
+ "video = EncodedVideo.from_path(video_path)\n",
+ "\n",
+ "# Load the desired clip\n",
+ "video_data = video.get_clip(start_sec=start_sec, end_sec=end_sec)\n",
+ "\n",
+ "# Apply a transform to normalize the video input\n",
+ "video_data = transform(video_data)\n",
+ "\n",
+ "# Move the inputs to the desired device\n",
+ "inputs = video_data[\"video\"]\n",
+ "inputs = inputs.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fb9be637",
+ "metadata": {},
+ "source": [
+ "#### Get Predictions"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6079fb75",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Pass the input clip through the model\n",
+ "preds = model(inputs[None, ...])\n",
+ "\n",
+ "# Get the predicted classes\n",
+ "post_act = torch.nn.Softmax(dim=1)\n",
+ "preds = post_act(preds)\n",
+ "pred_classes = preds.topk(k=5).indices[0]\n",
+ "\n",
+ "# Map the predicted classes to the label names\n",
+ "pred_class_names = [kinetics_id_to_classname[int(i)] for i in pred_classes]\n",
+ "print(\"Top 5 predicted labels: %s\" % \", \".join(pred_class_names))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a6e53a9a",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "X3D model architectures are based on [1] pretrained on the Kinetics dataset.\n",
+ "\n",
+ "| arch | depth | frame length x sample rate | top 1 | top 5 | Flops (G) | Params (M) |\n",
+ "| --------------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- | ----------- |\n",
+ "| X3D | XS | 4x12 | 69.12 | 88.63 | 0.91 | 3.79 |\n",
+ "| X3D | S | 13x6 | 73.33 | 91.27 | 2.96 | 3.79 |\n",
+ "| X3D | M | 16x5 | 75.94 | 92.72 | 6.72 | 3.79 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "[1] Christoph Feichtenhofer, \"X3D: Expanding Architectures for\n",
+ " Efficient Video Recognition.\" https://arxiv.org/abs/2004.04730"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb b/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb
new file mode 100644
index 000000000000..64a285b7b6ff
--- /dev/null
+++ b/assets/hub/facebookresearch_semi-supervised-ImageNet1K-models_resnext.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "6c28f06b",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Semi-supervised and semi-weakly supervised ImageNet Models\n",
+ "\n",
+ "*Author: Facebook AI*\n",
+ "\n",
+ "**ResNet and ResNext models introduced in the \"Billion scale semi-supervised learning for image classification\" paper**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "73f3e3f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# === SEMI-WEAKLY SUPERVISED MODELS PRETRAINED WITH 940 HASHTAGGED PUBLIC CONTENT ===\n",
+ "model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_swsl')\n",
+ "# ================= SEMI-SUPERVISED MODELS PRETRAINED WITH YFCC100M ==================\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_ssl')\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a25ad51a",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3eec8b87",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "08b15593",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "77e2a4e3",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "This project includes the semi-supervised and semi-weakly supervised ImageNet models introduced in \"Billion-scale Semi-Supervised Learning for Image Classification\"
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "73f3e3f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# === SEMI-WEAKLY SUPERVISED MODELS PRETRAINED WITH 940 HASHTAGGED PUBLIC CONTENT ===\n",
+ "model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_swsl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_swsl')\n",
+ "# ================= SEMI-SUPERVISED MODELS PRETRAINED WITH YFCC100M ==================\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet18_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnet50_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext50_32x4d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x4d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x8d_ssl')\n",
+ "# model = torch.hub.load('facebookresearch/semi-supervised-ImageNet1K-models', 'resnext101_32x16d_ssl')\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a25ad51a",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3eec8b87",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "08b15593",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "77e2a4e3",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "This project includes the semi-supervised and semi-weakly supervised ImageNet models introduced in \"Billion-scale Semi-Supervised Learning for Image Classification\"  \n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "GPT was released together with the paper [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) by Alec Radford et al at OpenAI. It's a combination of two ideas: Transformer model and large scale unsupervised pre-training.\n",
+ "\n",
+ "Here are three models based on [OpenAI's pre-trained weights](https://github.com/openai/finetune-transformer-lm) along with the associated Tokenizer.\n",
+ "It includes:\n",
+ "- `openAIGPTModel`: raw OpenAI GPT Transformer model (fully pre-trained)\n",
+ "- `openAIGPTLMHeadModel`: OpenAI GPT Transformer with the tied language modeling head on top (fully pre-trained)\n",
+ "- `openAIGPTDoubleHeadsModel`: OpenAI GPT Transformer with the tied language modeling head and a multiple choice classification head on top (OpenAI GPT Transformer is pre-trained, the multiple choice classification head is only initialized and has to be trained)\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "Unlike most other PyTorch Hub models, BERT requires a few additional Python packages to be installed."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install tqdm boto3 requests regex"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example\n",
+ "\n",
+ "Here is an example on how to tokenize the text with `openAIGPTTokenizer`, and then get the hidden states computed by `openAIGPTModel` or predict the next token using `openAIGPTLMHeadModel`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "### First, tokenize the input\n",
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTTokenizer', 'openai-gpt')\n",
+ "\n",
+ "# Prepare tokenized input\n",
+ "text = \"Who was Jim Henson ? Jim Henson was a puppeteer\"\n",
+ "tokenized_text = tokenizer.tokenize(text)\n",
+ "indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "### Get the hidden states computed by `openAIGPTModel`\n",
+ "model = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTModel', 'openai-gpt')\n",
+ "model.eval()\n",
+ "\n",
+ "# Compute hidden states features for each layer\n",
+ "with torch.no_grad():\n",
+ "\thidden_states = model(tokens_tensor)\n",
+ "\n",
+ "### Predict the next token using `openAIGPTLMHeadModel`\n",
+ "lm_model = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTLMHeadModel', 'openai-gpt')\n",
+ "lm_model.eval()\n",
+ "\n",
+ "# Predict all tokens\n",
+ "with torch.no_grad():\n",
+ "\tpredictions = lm_model(tokens_tensor)\n",
+ "\n",
+ "# Get the last predicted token\n",
+ "predicted_index = torch.argmax(predictions[0, -1, :]).item()\n",
+ "predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]\n",
+ "assert predicted_token == '.'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Requirement\n",
+ "The model only support python3.\n",
+ "\n",
+ "### Resources\n",
+ "\n",
+ " - Paper: [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)\n",
+ " - [Blogpost from OpenAI](https://openai.com/blog/language-unsupervised/)\n",
+ " - Initial repository (with detailed examples and documentation): [pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/assets/hub/huggingface_pytorch-transformers.ipynb b/assets/hub/huggingface_pytorch-transformers.ipynb
new file mode 100644
index 000000000000..fc6856f7f5ba
--- /dev/null
+++ b/assets/hub/huggingface_pytorch-transformers.ipynb
@@ -0,0 +1,452 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "aebf87f7",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# PyTorch-Transformers\n",
+ "\n",
+ "*Author: HuggingFace Team*\n",
+ "\n",
+ "**PyTorch implementations of popular NLP Transformers**\n",
+ "\n",
+ "\n",
+ "# Model Description\n",
+ "\n",
+ "\n",
+ "PyTorch-Transformers (formerly known as `pytorch-pretrained-bert`) is a library of state-of-the-art pre-trained models for Natural Language Processing (NLP).\n",
+ "\n",
+ "The library currently contains PyTorch implementations, pre-trained model weights, usage scripts and conversion utilities for the following models:\n",
+ "\n",
+ "1. **[BERT](https://github.com/google-research/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.\n",
+ "2. **[GPT](https://github.com/openai/finetune-transformer-lm)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.\n",
+ "3. **[GPT-2](https://blog.openai.com/better-language-models/)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.\n",
+ "4. **[Transformer-XL](https://github.com/kimiyoung/transformer-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.\n",
+ "5. **[XLNet](https://github.com/zihangdai/xlnet/)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.\n",
+ "6. **[XLM](https://github.com/facebookresearch/XLM/)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.\n",
+ "7. **[RoBERTa](https://github.com/pytorch/fairseq/tree/master/examples/roberta)** (from Facebook), released together with the paper a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.\n",
+ "8. **[DistilBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)** (from HuggingFace), released together with the blogpost [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5) by Victor Sanh, Lysandre Debut and Thomas Wolf.\n",
+ "\n",
+ "The components available here are based on the `AutoModel` and `AutoTokenizer` classes of the `pytorch-transformers` library.\n",
+ "\n",
+ "# Requirements\n",
+ "\n",
+ "Unlike most other PyTorch Hub models, BERT requires a few additional Python packages to be installed."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "569404ad",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install tqdm boto3 requests regex sentencepiece sacremoses"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfccbc22",
+ "metadata": {},
+ "source": [
+ "# Usage\n",
+ "\n",
+ "The available methods are the following:\n",
+ "- `config`: returns a configuration item corresponding to the specified model or pth.\n",
+ "- `tokenizer`: returns a tokenizer corresponding to the specified model or path\n",
+ "- `model`: returns a model corresponding to the specified model or path\n",
+ "- `modelForCausalLM`: returns a model with a language modeling head corresponding to the specified model or path\n",
+ "- `modelForSequenceClassification`: returns a model with a sequence classifier corresponding to the specified model or path\n",
+ "- `modelForQuestionAnswering`: returns a model with a question answering head corresponding to the specified model or path\n",
+ "\n",
+ "All these methods share the following argument: `pretrained_model_or_path`, which is a string identifying a pre-trained model or path from which an instance will be returned. There are several checkpoints available for each model, which are detailed below:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "The available models are listed on the [transformers documentation, models page](https://huggingface.co/models).\n",
+ "\n",
+ "# Documentation\n",
+ "\n",
+ "Here are a few examples detailing the usage of each available method.\n",
+ "\n",
+ "\n",
+ "## Tokenizer\n",
+ "\n",
+ "The tokenizer object allows the conversion from character strings to tokens understood by the different models. Each model has its own tokenizer, and some tokenizing methods are different across tokenizers. The complete documentation can be found [here](https://huggingface.co/docs/transformers/main_classes/tokenizer)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a52f187f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-uncased') # Download vocabulary from S3 and cache.\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', './test/bert_saved_model/') # E.g. tokenizer was saved using `save_pretrained('./test/saved_model/')`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2765418b",
+ "metadata": {},
+ "source": [
+ "## Models\n",
+ "\n",
+ "The model object is a model instance inheriting from a `nn.Module`. Each model is accompanied by their saving/loading methods, either from a local file or directory, or from a pre-trained configuration (see previously described `config`). Each model works differently, a complete overview of the different models can be found in the [documentation](https://huggingface.co/docs/transformers/main_classes/model)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b170367e",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased', output_attentions=True) # Update configuration during loading\n",
+ "assert model.config.output_attentions == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d9e3b45",
+ "metadata": {},
+ "source": [
+ "## Models with a language modeling head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional language modeling head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d2e64b72",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', 'gpt2') # Download model and configuration from huggingface.co and cache.\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', './test/saved_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', 'gpt2', output_attentions=True) # Update configuration during loading\n",
+ "assert model.config.output_attentions == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_pretrained('./tf_model/gpt_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', './tf_model/gpt_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "56838e82",
+ "metadata": {},
+ "source": [
+ "## Models with a sequence classification head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional sequence classification head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0fede52f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-uncased', output_attention=True) # Update configuration during loading\n",
+ "assert model.config.output_attention == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a17e2167",
+ "metadata": {},
+ "source": [
+ "## Models with a question answering head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional question answering head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2a340191",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-base-uncased', output_attention=True) # Update configuration during loading\n",
+ "assert model.config.output_attention == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a347055f",
+ "metadata": {},
+ "source": [
+ "## Configuration\n",
+ "\n",
+ "The configuration is optional. The configuration object holds information concerning the model, such as the number of heads/layers, if the model should output attentions or hidden states, or if it should be adapted for TorchScript. Many parameters are available, some specific to each model. The complete documentation can be found [here](https://huggingface.co/docs/transformers/main_classes/configuration)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "83bdbd7d",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased') # Download configuration from S3 and cache.\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', './test/bert_saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', './test/bert_saved_model/my_configuration.json')\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased', output_attention=True, foo=False)\n",
+ "assert config.output_attention == True\n",
+ "config, unused_kwargs = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased', output_attention=True, foo=False, return_unused_kwargs=True)\n",
+ "assert config.output_attention == True\n",
+ "assert unused_kwargs == {'foo': False}\n",
+ "\n",
+ "# Using the configuration with a model\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased')\n",
+ "config.output_attentions = True\n",
+ "config.output_hidden_states = True\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased', config=config)\n",
+ "# Model will now output attentions and hidden states as well\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4afcf83b",
+ "metadata": {},
+ "source": [
+ "# Example Usage\n",
+ "\n",
+ "Here is an example on how to tokenize the input text to be fed as input to a BERT model, and then get the hidden states computed by such a model or predict masked tokens using language modeling BERT model.\n",
+ "\n",
+ "## First, tokenize the input"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "91ab7b53",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-cased')\n",
+ "\n",
+ "text_1 = \"Who was Jim Henson ?\"\n",
+ "text_2 = \"Jim Henson was a puppeteer\"\n",
+ "\n",
+ "# Tokenized input with special tokens around it (for BERT: [CLS] at the beginning and [SEP] at the end)\n",
+ "indexed_tokens = tokenizer.encode(text_1, text_2, add_special_tokens=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c057c229",
+ "metadata": {},
+ "source": [
+ "## Using `BertModel` to encode the input sentence in a sequence of last layer hidden-states"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "95ac4662",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define sentence A and B indices associated to 1st and 2nd sentences (see paper)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]\n",
+ "\n",
+ "# Convert inputs to PyTorch tensors\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-cased')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " encoded_layers, _ = model(tokens_tensor, token_type_ids=segments_tensors)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70f4fefd",
+ "metadata": {},
+ "source": [
+ "## Using `modelForMaskedLM` to predict a masked token with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48bde1ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Mask a token that we will try to predict back with `BertForMaskedLM`\n",
+ "masked_index = 8\n",
+ "indexed_tokens[masked_index] = tokenizer.mask_token_id\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "masked_lm_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForMaskedLM', 'bert-base-cased')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " predictions = masked_lm_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "# Get the predicted token\n",
+ "predicted_index = torch.argmax(predictions[0][0], dim=1)[masked_index].item()\n",
+ "predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]\n",
+ "assert predicted_token == 'Jim'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b4a6bef",
+ "metadata": {},
+ "source": [
+ "## Using `modelForQuestionAnswering` to do question answering with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f37585",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "question_answering_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-large-uncased-whole-word-masking-finetuned-squad')\n",
+ "question_answering_tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-large-uncased-whole-word-masking-finetuned-squad')\n",
+ "\n",
+ "# The format is paragraph first and then question\n",
+ "text_1 = \"Jim Henson was a puppeteer\"\n",
+ "text_2 = \"Who was Jim Henson ?\"\n",
+ "indexed_tokens = question_answering_tokenizer.encode(text_1, text_2, add_special_tokens=True)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "# Predict the start and end positions logits\n",
+ "with torch.no_grad():\n",
+ " out = question_answering_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "# get the highest prediction\n",
+ "answer = question_answering_tokenizer.decode(indexed_tokens[torch.argmax(out.start_logits):torch.argmax(out.end_logits)+1])\n",
+ "assert answer == \"puppeteer\"\n",
+ "\n",
+ "# Or get the total loss which is the sum of the CrossEntropy loss for the start and end token positions (set model to train mode before if used for training)\n",
+ "start_positions, end_positions = torch.tensor([12]), torch.tensor([14])\n",
+ "multiple_choice_loss = question_answering_model(tokens_tensor, token_type_ids=segments_tensors, start_positions=start_positions, end_positions=end_positions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6ee33213",
+ "metadata": {},
+ "source": [
+ "## Using `modelForSequenceClassification` to do paraphrase classification with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9384a8b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sequence_classification_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-cased-finetuned-mrpc')\n",
+ "sequence_classification_tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-cased-finetuned-mrpc')\n",
+ "\n",
+ "text_1 = \"Jim Henson was a puppeteer\"\n",
+ "text_2 = \"Who was Jim Henson ?\"\n",
+ "indexed_tokens = sequence_classification_tokenizer.encode(text_1, text_2, add_special_tokens=True)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "# Predict the sequence classification logits\n",
+ "with torch.no_grad():\n",
+ " seq_classif_logits = sequence_classification_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "predicted_labels = torch.argmax(seq_classif_logits[0]).item()\n",
+ "\n",
+ "assert predicted_labels == 0 # In MRPC dataset this means the two sentences are not paraphrasing each other\n",
+ "\n",
+ "# Or get the sequence classification loss (set model to train mode before if used for training)\n",
+ "labels = torch.tensor([1])\n",
+ "seq_classif_loss = sequence_classification_model(tokens_tensor, token_type_ids=segments_tensors, labels=labels)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/hustvl_yolop.ipynb b/assets/hub/hustvl_yolop.ipynb
new file mode 100644
index 000000000000..2c3496f534fc
--- /dev/null
+++ b/assets/hub/hustvl_yolop.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8ac5a855",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# YOLOP\n",
+ "\n",
+ "*Author: Hust Visual Learning Team*\n",
+ "\n",
+ "**YOLOP pretrained on the BDD100K dataset**\n",
+ "\n",
+ "## Before You Start\n",
+ "To install YOLOP dependencies:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16ed4d6d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install -qr https://github.com/hustvl/YOLOP/blob/main/requirements.txt # install dependencies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "484a5e2b",
+ "metadata": {},
+ "source": [
+ "## YOLOP: You Only Look Once for Panoptic driving Perception\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "GPT was released together with the paper [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) by Alec Radford et al at OpenAI. It's a combination of two ideas: Transformer model and large scale unsupervised pre-training.\n",
+ "\n",
+ "Here are three models based on [OpenAI's pre-trained weights](https://github.com/openai/finetune-transformer-lm) along with the associated Tokenizer.\n",
+ "It includes:\n",
+ "- `openAIGPTModel`: raw OpenAI GPT Transformer model (fully pre-trained)\n",
+ "- `openAIGPTLMHeadModel`: OpenAI GPT Transformer with the tied language modeling head on top (fully pre-trained)\n",
+ "- `openAIGPTDoubleHeadsModel`: OpenAI GPT Transformer with the tied language modeling head and a multiple choice classification head on top (OpenAI GPT Transformer is pre-trained, the multiple choice classification head is only initialized and has to be trained)\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "Unlike most other PyTorch Hub models, BERT requires a few additional Python packages to be installed."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install tqdm boto3 requests regex"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Example\n",
+ "\n",
+ "Here is an example on how to tokenize the text with `openAIGPTTokenizer`, and then get the hidden states computed by `openAIGPTModel` or predict the next token using `openAIGPTLMHeadModel`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "### First, tokenize the input\n",
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTTokenizer', 'openai-gpt')\n",
+ "\n",
+ "# Prepare tokenized input\n",
+ "text = \"Who was Jim Henson ? Jim Henson was a puppeteer\"\n",
+ "tokenized_text = tokenizer.tokenize(text)\n",
+ "indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "### Get the hidden states computed by `openAIGPTModel`\n",
+ "model = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTModel', 'openai-gpt')\n",
+ "model.eval()\n",
+ "\n",
+ "# Compute hidden states features for each layer\n",
+ "with torch.no_grad():\n",
+ "\thidden_states = model(tokens_tensor)\n",
+ "\n",
+ "### Predict the next token using `openAIGPTLMHeadModel`\n",
+ "lm_model = torch.hub.load('huggingface/pytorch-pretrained-BERT', 'openAIGPTLMHeadModel', 'openai-gpt')\n",
+ "lm_model.eval()\n",
+ "\n",
+ "# Predict all tokens\n",
+ "with torch.no_grad():\n",
+ "\tpredictions = lm_model(tokens_tensor)\n",
+ "\n",
+ "# Get the last predicted token\n",
+ "predicted_index = torch.argmax(predictions[0, -1, :]).item()\n",
+ "predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]\n",
+ "assert predicted_token == '.'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Requirement\n",
+ "The model only support python3.\n",
+ "\n",
+ "### Resources\n",
+ "\n",
+ " - Paper: [Improving Language Understanding by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)\n",
+ " - [Blogpost from OpenAI](https://openai.com/blog/language-unsupervised/)\n",
+ " - Initial repository (with detailed examples and documentation): [pytorch-pretrained-BERT](https://github.com/huggingface/pytorch-pretrained-BERT)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/assets/hub/huggingface_pytorch-transformers.ipynb b/assets/hub/huggingface_pytorch-transformers.ipynb
new file mode 100644
index 000000000000..fc6856f7f5ba
--- /dev/null
+++ b/assets/hub/huggingface_pytorch-transformers.ipynb
@@ -0,0 +1,452 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "aebf87f7",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# PyTorch-Transformers\n",
+ "\n",
+ "*Author: HuggingFace Team*\n",
+ "\n",
+ "**PyTorch implementations of popular NLP Transformers**\n",
+ "\n",
+ "\n",
+ "# Model Description\n",
+ "\n",
+ "\n",
+ "PyTorch-Transformers (formerly known as `pytorch-pretrained-bert`) is a library of state-of-the-art pre-trained models for Natural Language Processing (NLP).\n",
+ "\n",
+ "The library currently contains PyTorch implementations, pre-trained model weights, usage scripts and conversion utilities for the following models:\n",
+ "\n",
+ "1. **[BERT](https://github.com/google-research/bert)** (from Google) released with the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.\n",
+ "2. **[GPT](https://github.com/openai/finetune-transformer-lm)** (from OpenAI) released with the paper [Improving Language Understanding by Generative Pre-Training](https://blog.openai.com/language-unsupervised/) by Alec Radford, Karthik Narasimhan, Tim Salimans and Ilya Sutskever.\n",
+ "3. **[GPT-2](https://blog.openai.com/better-language-models/)** (from OpenAI) released with the paper [Language Models are Unsupervised Multitask Learners](https://blog.openai.com/better-language-models/) by Alec Radford*, Jeffrey Wu*, Rewon Child, David Luan, Dario Amodei** and Ilya Sutskever**.\n",
+ "4. **[Transformer-XL](https://github.com/kimiyoung/transformer-xl)** (from Google/CMU) released with the paper [Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context](https://arxiv.org/abs/1901.02860) by Zihang Dai*, Zhilin Yang*, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.\n",
+ "5. **[XLNet](https://github.com/zihangdai/xlnet/)** (from Google/CMU) released with the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Zhilin Yang*, Zihang Dai*, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le.\n",
+ "6. **[XLM](https://github.com/facebookresearch/XLM/)** (from Facebook) released together with the paper [Cross-lingual Language Model Pretraining](https://arxiv.org/abs/1901.07291) by Guillaume Lample and Alexis Conneau.\n",
+ "7. **[RoBERTa](https://github.com/pytorch/fairseq/tree/master/examples/roberta)** (from Facebook), released together with the paper a [Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692) by Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov.\n",
+ "8. **[DistilBERT](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation)** (from HuggingFace), released together with the blogpost [Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT](https://medium.com/huggingface/distilbert-8cf3380435b5) by Victor Sanh, Lysandre Debut and Thomas Wolf.\n",
+ "\n",
+ "The components available here are based on the `AutoModel` and `AutoTokenizer` classes of the `pytorch-transformers` library.\n",
+ "\n",
+ "# Requirements\n",
+ "\n",
+ "Unlike most other PyTorch Hub models, BERT requires a few additional Python packages to be installed."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "569404ad",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install tqdm boto3 requests regex sentencepiece sacremoses"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dfccbc22",
+ "metadata": {},
+ "source": [
+ "# Usage\n",
+ "\n",
+ "The available methods are the following:\n",
+ "- `config`: returns a configuration item corresponding to the specified model or pth.\n",
+ "- `tokenizer`: returns a tokenizer corresponding to the specified model or path\n",
+ "- `model`: returns a model corresponding to the specified model or path\n",
+ "- `modelForCausalLM`: returns a model with a language modeling head corresponding to the specified model or path\n",
+ "- `modelForSequenceClassification`: returns a model with a sequence classifier corresponding to the specified model or path\n",
+ "- `modelForQuestionAnswering`: returns a model with a question answering head corresponding to the specified model or path\n",
+ "\n",
+ "All these methods share the following argument: `pretrained_model_or_path`, which is a string identifying a pre-trained model or path from which an instance will be returned. There are several checkpoints available for each model, which are detailed below:\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "The available models are listed on the [transformers documentation, models page](https://huggingface.co/models).\n",
+ "\n",
+ "# Documentation\n",
+ "\n",
+ "Here are a few examples detailing the usage of each available method.\n",
+ "\n",
+ "\n",
+ "## Tokenizer\n",
+ "\n",
+ "The tokenizer object allows the conversion from character strings to tokens understood by the different models. Each model has its own tokenizer, and some tokenizing methods are different across tokenizers. The complete documentation can be found [here](https://huggingface.co/docs/transformers/main_classes/tokenizer)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a52f187f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-uncased') # Download vocabulary from S3 and cache.\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', './test/bert_saved_model/') # E.g. tokenizer was saved using `save_pretrained('./test/saved_model/')`"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2765418b",
+ "metadata": {},
+ "source": [
+ "## Models\n",
+ "\n",
+ "The model object is a model instance inheriting from a `nn.Module`. Each model is accompanied by their saving/loading methods, either from a local file or directory, or from a pre-trained configuration (see previously described `config`). Each model works differently, a complete overview of the different models can be found in the [documentation](https://huggingface.co/docs/transformers/main_classes/model)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b170367e",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased', output_attentions=True) # Update configuration during loading\n",
+ "assert model.config.output_attentions == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d9e3b45",
+ "metadata": {},
+ "source": [
+ "## Models with a language modeling head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional language modeling head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d2e64b72",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', 'gpt2') # Download model and configuration from huggingface.co and cache.\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', './test/saved_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', 'gpt2', output_attentions=True) # Update configuration during loading\n",
+ "assert model.config.output_attentions == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_pretrained('./tf_model/gpt_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/transformers', 'modelForCausalLM', './tf_model/gpt_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "56838e82",
+ "metadata": {},
+ "source": [
+ "## Models with a sequence classification head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional sequence classification head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0fede52f",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-uncased', output_attention=True) # Update configuration during loading\n",
+ "assert model.config.output_attention == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a17e2167",
+ "metadata": {},
+ "source": [
+ "## Models with a question answering head\n",
+ "\n",
+ "Previously mentioned `model` instance with an additional question answering head."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2a340191",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-base-uncased') # Download model and configuration from S3 and cache.\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', './test/bert_model/') # E.g. model was saved using `save_pretrained('./test/saved_model/')`\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-base-uncased', output_attention=True) # Update configuration during loading\n",
+ "assert model.config.output_attention == True\n",
+ "# Loading from a TF checkpoint file instead of a PyTorch model (slower)\n",
+ "config = AutoConfig.from_json_file('./tf_model/bert_tf_model_config.json')\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', './tf_model/bert_tf_checkpoint.ckpt.index', from_tf=True, config=config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a347055f",
+ "metadata": {},
+ "source": [
+ "## Configuration\n",
+ "\n",
+ "The configuration is optional. The configuration object holds information concerning the model, such as the number of heads/layers, if the model should output attentions or hidden states, or if it should be adapted for TorchScript. Many parameters are available, some specific to each model. The complete documentation can be found [here](https://huggingface.co/docs/transformers/main_classes/configuration)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "83bdbd7d",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "py"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased') # Download configuration from S3 and cache.\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', './test/bert_saved_model/') # E.g. config (or model) was saved using `save_pretrained('./test/saved_model/')`\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', './test/bert_saved_model/my_configuration.json')\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased', output_attention=True, foo=False)\n",
+ "assert config.output_attention == True\n",
+ "config, unused_kwargs = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased', output_attention=True, foo=False, return_unused_kwargs=True)\n",
+ "assert config.output_attention == True\n",
+ "assert unused_kwargs == {'foo': False}\n",
+ "\n",
+ "# Using the configuration with a model\n",
+ "config = torch.hub.load('huggingface/pytorch-transformers', 'config', 'bert-base-uncased')\n",
+ "config.output_attentions = True\n",
+ "config.output_hidden_states = True\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-uncased', config=config)\n",
+ "# Model will now output attentions and hidden states as well\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4afcf83b",
+ "metadata": {},
+ "source": [
+ "# Example Usage\n",
+ "\n",
+ "Here is an example on how to tokenize the input text to be fed as input to a BERT model, and then get the hidden states computed by such a model or predict masked tokens using language modeling BERT model.\n",
+ "\n",
+ "## First, tokenize the input"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "91ab7b53",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-cased')\n",
+ "\n",
+ "text_1 = \"Who was Jim Henson ?\"\n",
+ "text_2 = \"Jim Henson was a puppeteer\"\n",
+ "\n",
+ "# Tokenized input with special tokens around it (for BERT: [CLS] at the beginning and [SEP] at the end)\n",
+ "indexed_tokens = tokenizer.encode(text_1, text_2, add_special_tokens=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c057c229",
+ "metadata": {},
+ "source": [
+ "## Using `BertModel` to encode the input sentence in a sequence of last layer hidden-states"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "95ac4662",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Define sentence A and B indices associated to 1st and 2nd sentences (see paper)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]\n",
+ "\n",
+ "# Convert inputs to PyTorch tensors\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "model = torch.hub.load('huggingface/pytorch-transformers', 'model', 'bert-base-cased')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " encoded_layers, _ = model(tokens_tensor, token_type_ids=segments_tensors)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70f4fefd",
+ "metadata": {},
+ "source": [
+ "## Using `modelForMaskedLM` to predict a masked token with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48bde1ca",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Mask a token that we will try to predict back with `BertForMaskedLM`\n",
+ "masked_index = 8\n",
+ "indexed_tokens[masked_index] = tokenizer.mask_token_id\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "masked_lm_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForMaskedLM', 'bert-base-cased')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " predictions = masked_lm_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "# Get the predicted token\n",
+ "predicted_index = torch.argmax(predictions[0][0], dim=1)[masked_index].item()\n",
+ "predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]\n",
+ "assert predicted_token == 'Jim'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b4a6bef",
+ "metadata": {},
+ "source": [
+ "## Using `modelForQuestionAnswering` to do question answering with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f37585",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "question_answering_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForQuestionAnswering', 'bert-large-uncased-whole-word-masking-finetuned-squad')\n",
+ "question_answering_tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-large-uncased-whole-word-masking-finetuned-squad')\n",
+ "\n",
+ "# The format is paragraph first and then question\n",
+ "text_1 = \"Jim Henson was a puppeteer\"\n",
+ "text_2 = \"Who was Jim Henson ?\"\n",
+ "indexed_tokens = question_answering_tokenizer.encode(text_1, text_2, add_special_tokens=True)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "# Predict the start and end positions logits\n",
+ "with torch.no_grad():\n",
+ " out = question_answering_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "# get the highest prediction\n",
+ "answer = question_answering_tokenizer.decode(indexed_tokens[torch.argmax(out.start_logits):torch.argmax(out.end_logits)+1])\n",
+ "assert answer == \"puppeteer\"\n",
+ "\n",
+ "# Or get the total loss which is the sum of the CrossEntropy loss for the start and end token positions (set model to train mode before if used for training)\n",
+ "start_positions, end_positions = torch.tensor([12]), torch.tensor([14])\n",
+ "multiple_choice_loss = question_answering_model(tokens_tensor, token_type_ids=segments_tensors, start_positions=start_positions, end_positions=end_positions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6ee33213",
+ "metadata": {},
+ "source": [
+ "## Using `modelForSequenceClassification` to do paraphrase classification with BERT"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9384a8b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sequence_classification_model = torch.hub.load('huggingface/pytorch-transformers', 'modelForSequenceClassification', 'bert-base-cased-finetuned-mrpc')\n",
+ "sequence_classification_tokenizer = torch.hub.load('huggingface/pytorch-transformers', 'tokenizer', 'bert-base-cased-finetuned-mrpc')\n",
+ "\n",
+ "text_1 = \"Jim Henson was a puppeteer\"\n",
+ "text_2 = \"Who was Jim Henson ?\"\n",
+ "indexed_tokens = sequence_classification_tokenizer.encode(text_1, text_2, add_special_tokens=True)\n",
+ "segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1]\n",
+ "segments_tensors = torch.tensor([segments_ids])\n",
+ "tokens_tensor = torch.tensor([indexed_tokens])\n",
+ "\n",
+ "# Predict the sequence classification logits\n",
+ "with torch.no_grad():\n",
+ " seq_classif_logits = sequence_classification_model(tokens_tensor, token_type_ids=segments_tensors)\n",
+ "\n",
+ "predicted_labels = torch.argmax(seq_classif_logits[0]).item()\n",
+ "\n",
+ "assert predicted_labels == 0 # In MRPC dataset this means the two sentences are not paraphrasing each other\n",
+ "\n",
+ "# Or get the sequence classification loss (set model to train mode before if used for training)\n",
+ "labels = torch.tensor([1])\n",
+ "seq_classif_loss = sequence_classification_model(tokens_tensor, token_type_ids=segments_tensors, labels=labels)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/hustvl_yolop.ipynb b/assets/hub/hustvl_yolop.ipynb
new file mode 100644
index 000000000000..2c3496f534fc
--- /dev/null
+++ b/assets/hub/hustvl_yolop.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8ac5a855",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# YOLOP\n",
+ "\n",
+ "*Author: Hust Visual Learning Team*\n",
+ "\n",
+ "**YOLOP pretrained on the BDD100K dataset**\n",
+ "\n",
+ "## Before You Start\n",
+ "To install YOLOP dependencies:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16ed4d6d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install -qr https://github.com/hustvl/YOLOP/blob/main/requirements.txt # install dependencies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "484a5e2b",
+ "metadata": {},
+ "source": [
+ "## YOLOP: You Only Look Once for Panoptic driving Perception\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n",
+ "- YOLOP is an efficient multi-task network that can jointly handle three crucial tasks in autonomous driving: object detection, drivable area segmentation and lane detection. And it is also the first to reach real-time on embedded devices while maintaining state-of-the-art level performance on the **BDD100K** dataset.\n",
+ "\n",
+ "\n",
+ "### Results\n",
+ "\n",
+ "#### Traffic Object Detection Result\n",
+ "\n",
+ "| Model | Recall(%) | mAP50(%) | Speed(fps) |\n",
+ "| -------------- | --------- | -------- | ---------- |\n",
+ "| `Multinet` | 81.3 | 60.2 | 8.6 |\n",
+ "| `DLT-Net` | 89.4 | 68.4 | 9.3 |\n",
+ "| `Faster R-CNN` | 77.2 | 55.6 | 5.3 |\n",
+ "| `YOLOv5s` | 86.8 | 77.2 | 82 |\n",
+ "| `YOLOP(ours)` | 89.2 | 76.5 | 41 |\n",
+ "\n",
+ "#### Drivable Area Segmentation Result\n",
+ "\n",
+ "| Model | mIOU(%) | Speed(fps) |\n",
+ "| ------------- | ------- | ---------- |\n",
+ "| `Multinet` | 71.6 | 8.6 |\n",
+ "| `DLT-Net` | 71.3 | 9.3 |\n",
+ "| `PSPNet` | 89.6 | 11.1 |\n",
+ "| `YOLOP(ours)` | 91.5 | 41 |\n",
+ "\n",
+ "#### Lane Detection Result\n",
+ "\n",
+ "| Model | mIOU(%) | IOU(%) |\n",
+ "| ------------- | ------- | ------ |\n",
+ "| `ENet` | 34.12 | 14.64 |\n",
+ "| `SCNN` | 35.79 | 15.84 |\n",
+ "| `ENet-SAD` | 36.56 | 16.02 |\n",
+ "| `YOLOP(ours)` | 70.50 | 26.20 |\n",
+ "\n",
+ "#### Ablation Studies 1: End-to-end v.s. Step-by-step\n",
+ "\n",
+ "| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) |\n",
+ "| --------------- | --------- | ----- | ------- | ----------- | ------ |\n",
+ "| `ES-W` | 87.0 | 75.3 | 90.4 | 66.8 | 26.2 |\n",
+ "| `ED-W` | 87.3 | 76.0 | 91.6 | 71.2 | 26.1 |\n",
+ "| `ES-D-W` | 87.0 | 75.1 | 91.7 | 68.6 | 27.0 |\n",
+ "| `ED-S-W` | 87.5 | 76.1 | 91.6 | 68.0 | 26.8 |\n",
+ "| `End-to-end` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 |\n",
+ "\n",
+ "#### Ablation Studies 2: Multi-task v.s. Single task\n",
+ "\n",
+ "| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) | Speed(ms/frame) |\n",
+ "| --------------- | --------- | ----- | ------- | ----------- | ------ | --------------- |\n",
+ "| `Det(only)` | 88.2 | 76.9 | - | - | - | 15.7 |\n",
+ "| `Da-Seg(only)` | - | - | 92.0 | - | - | 14.8 |\n",
+ "| `Ll-Seg(only)` | - | - | - | 79.6 | 27.9 | 14.8 |\n",
+ "| `Multitask` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 | 24.4 |\n",
+ "\n",
+ "**Notes**:\n",
+ "\n",
+ "- In table 4, E, D, S and W refer to Encoder, Detect head, two Segment heads and whole network. So the Algorithm (First, we only train Encoder and Detect head. Then we freeze the Encoder and Detect head as well as train two Segmentation heads. Finally, the entire network is trained jointly for all three tasks.) can be marked as ED-S-W, and the same for others.\n",
+ "\n",
+ "### Visualization\n",
+ "\n",
+ "#### Traffic Object Detection Result\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "- YOLOP is an efficient multi-task network that can jointly handle three crucial tasks in autonomous driving: object detection, drivable area segmentation and lane detection. And it is also the first to reach real-time on embedded devices while maintaining state-of-the-art level performance on the **BDD100K** dataset.\n",
+ "\n",
+ "\n",
+ "### Results\n",
+ "\n",
+ "#### Traffic Object Detection Result\n",
+ "\n",
+ "| Model | Recall(%) | mAP50(%) | Speed(fps) |\n",
+ "| -------------- | --------- | -------- | ---------- |\n",
+ "| `Multinet` | 81.3 | 60.2 | 8.6 |\n",
+ "| `DLT-Net` | 89.4 | 68.4 | 9.3 |\n",
+ "| `Faster R-CNN` | 77.2 | 55.6 | 5.3 |\n",
+ "| `YOLOv5s` | 86.8 | 77.2 | 82 |\n",
+ "| `YOLOP(ours)` | 89.2 | 76.5 | 41 |\n",
+ "\n",
+ "#### Drivable Area Segmentation Result\n",
+ "\n",
+ "| Model | mIOU(%) | Speed(fps) |\n",
+ "| ------------- | ------- | ---------- |\n",
+ "| `Multinet` | 71.6 | 8.6 |\n",
+ "| `DLT-Net` | 71.3 | 9.3 |\n",
+ "| `PSPNet` | 89.6 | 11.1 |\n",
+ "| `YOLOP(ours)` | 91.5 | 41 |\n",
+ "\n",
+ "#### Lane Detection Result\n",
+ "\n",
+ "| Model | mIOU(%) | IOU(%) |\n",
+ "| ------------- | ------- | ------ |\n",
+ "| `ENet` | 34.12 | 14.64 |\n",
+ "| `SCNN` | 35.79 | 15.84 |\n",
+ "| `ENet-SAD` | 36.56 | 16.02 |\n",
+ "| `YOLOP(ours)` | 70.50 | 26.20 |\n",
+ "\n",
+ "#### Ablation Studies 1: End-to-end v.s. Step-by-step\n",
+ "\n",
+ "| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) |\n",
+ "| --------------- | --------- | ----- | ------- | ----------- | ------ |\n",
+ "| `ES-W` | 87.0 | 75.3 | 90.4 | 66.8 | 26.2 |\n",
+ "| `ED-W` | 87.3 | 76.0 | 91.6 | 71.2 | 26.1 |\n",
+ "| `ES-D-W` | 87.0 | 75.1 | 91.7 | 68.6 | 27.0 |\n",
+ "| `ED-S-W` | 87.5 | 76.1 | 91.6 | 68.0 | 26.8 |\n",
+ "| `End-to-end` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 |\n",
+ "\n",
+ "#### Ablation Studies 2: Multi-task v.s. Single task\n",
+ "\n",
+ "| Training_method | Recall(%) | AP(%) | mIoU(%) | Accuracy(%) | IoU(%) | Speed(ms/frame) |\n",
+ "| --------------- | --------- | ----- | ------- | ----------- | ------ | --------------- |\n",
+ "| `Det(only)` | 88.2 | 76.9 | - | - | - | 15.7 |\n",
+ "| `Da-Seg(only)` | - | - | 92.0 | - | - | 14.8 |\n",
+ "| `Ll-Seg(only)` | - | - | - | 79.6 | 27.9 | 14.8 |\n",
+ "| `Multitask` | 89.2 | 76.5 | 91.5 | 70.5 | 26.2 | 24.4 |\n",
+ "\n",
+ "**Notes**:\n",
+ "\n",
+ "- In table 4, E, D, S and W refer to Encoder, Detect head, two Segment heads and whole network. So the Algorithm (First, we only train Encoder and Detect head. Then we freeze the Encoder and Detect head as well as train two Segmentation heads. Finally, the entire network is trained jointly for all three tasks.) can be marked as ED-S-W, and the same for others.\n",
+ "\n",
+ "### Visualization\n",
+ "\n",
+ "#### Traffic Object Detection Result\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n",
+ "#### Drivable Area Segmentation Result\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "#### Drivable Area Segmentation Result\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n",
+ "#### Lane Detection Result\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "#### Lane Detection Result\n",
+ "\n",
+ " \n",
+ " \n",
+ "\n",
+ "**Notes**:\n",
+ "\n",
+ "- The visualization of lane detection result has been post processed by quadratic fitting.\n",
+ "\n",
+ "### Deployment\n",
+ "\n",
+ "Our model can reason in real-time on **Jetson Tx2**, with **Zed Camera** to capture image. We use **TensorRT** tool for speeding up. We provide code for deployment and reasoning of model in [github code](https://github.com/hustvl/YOLOP/tree/main/toolkits/deploy).\n",
+ "\n",
+ "\n",
+ "### Load From PyTorch Hub\n",
+ "This example loads the pretrained **YOLOP** model and passes an image for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a50d292a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# load model\n",
+ "model = torch.hub.load('hustvl/yolop', 'yolop', pretrained=True)\n",
+ "\n",
+ "#inference\n",
+ "img = torch.randn(1,3,640,640)\n",
+ "det_out, da_seg_out,ll_seg_out = model(img)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f07a9063",
+ "metadata": {},
+ "source": [
+ "### Citation\n",
+ "\n",
+ "See for more detail in [github code](https://github.com/hustvl/YOLOP) and [arxiv paper](https://arxiv.org/abs/2108.11250).\n",
+ "\n",
+ "If you find our paper and code useful for your research, please consider giving a star and citation:"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/intelisl_midas_v2.ipynb b/assets/hub/intelisl_midas_v2.ipynb
new file mode 100644
index 000000000000..9c7a4480f581
--- /dev/null
+++ b/assets/hub/intelisl_midas_v2.ipynb
@@ -0,0 +1,270 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "0595d980",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MiDaS\n",
+ "\n",
+ "*Author: Intel ISL*\n",
+ "\n",
+ "**MiDaS models for computing relative depth from a single image.**\n",
+ "\n",
+ "
\n",
+ " \n",
+ "\n",
+ "**Notes**:\n",
+ "\n",
+ "- The visualization of lane detection result has been post processed by quadratic fitting.\n",
+ "\n",
+ "### Deployment\n",
+ "\n",
+ "Our model can reason in real-time on **Jetson Tx2**, with **Zed Camera** to capture image. We use **TensorRT** tool for speeding up. We provide code for deployment and reasoning of model in [github code](https://github.com/hustvl/YOLOP/tree/main/toolkits/deploy).\n",
+ "\n",
+ "\n",
+ "### Load From PyTorch Hub\n",
+ "This example loads the pretrained **YOLOP** model and passes an image for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a50d292a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# load model\n",
+ "model = torch.hub.load('hustvl/yolop', 'yolop', pretrained=True)\n",
+ "\n",
+ "#inference\n",
+ "img = torch.randn(1,3,640,640)\n",
+ "det_out, da_seg_out,ll_seg_out = model(img)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f07a9063",
+ "metadata": {},
+ "source": [
+ "### Citation\n",
+ "\n",
+ "See for more detail in [github code](https://github.com/hustvl/YOLOP) and [arxiv paper](https://arxiv.org/abs/2108.11250).\n",
+ "\n",
+ "If you find our paper and code useful for your research, please consider giving a star and citation:"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/intelisl_midas_v2.ipynb b/assets/hub/intelisl_midas_v2.ipynb
new file mode 100644
index 000000000000..9c7a4480f581
--- /dev/null
+++ b/assets/hub/intelisl_midas_v2.ipynb
@@ -0,0 +1,270 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "0595d980",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MiDaS\n",
+ "\n",
+ "*Author: Intel ISL*\n",
+ "\n",
+ "**MiDaS models for computing relative depth from a single image.**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "[MiDaS](https://arxiv.org/abs/1907.01341) computes relative inverse depth from a single image. The repository provides multiple models that cover different use cases ranging from a small, high-speed model to a very large model that provide the highest accuracy. The models have been trained on 10 distinct datasets using\n",
+ "multi-objective optimization to ensure high quality on a wide range of inputs.\n",
+ "\n",
+ "### Dependencies\n",
+ "\n",
+ "MiDaS depends on [timm](https://github.com/rwightman/pytorch-image-models). Install with"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db3fd908",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "shell"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "pip install timm"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8892d100",
+ "metadata": {},
+ "source": [
+ "### Example Usage\n",
+ "\n",
+ "Download an image from the PyTorch homepage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "758e089f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import cv2\n",
+ "import torch\n",
+ "import urllib.request\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d5fb41f",
+ "metadata": {},
+ "source": [
+ "Load a model (see [https://github.com/intel-isl/MiDaS/#Accuracy](https://github.com/intel-isl/MiDaS/#Accuracy) for an overview)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49acb469",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_type = \"DPT_Large\" # MiDaS v3 - Large (highest accuracy, slowest inference speed)\n",
+ "#model_type = \"DPT_Hybrid\" # MiDaS v3 - Hybrid (medium accuracy, medium inference speed)\n",
+ "#model_type = \"MiDaS_small\" # MiDaS v2.1 - Small (lowest accuracy, highest inference speed)\n",
+ "\n",
+ "midas = torch.hub.load(\"intel-isl/MiDaS\", model_type)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d785d8c2",
+ "metadata": {},
+ "source": [
+ "Move model to GPU if available"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2aa0b2d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "midas.to(device)\n",
+ "midas.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d0a6f5b",
+ "metadata": {},
+ "source": [
+ "Load transforms to resize and normalize the image for large or small model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "763b447a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "midas_transforms = torch.hub.load(\"intel-isl/MiDaS\", \"transforms\")\n",
+ "\n",
+ "if model_type == \"DPT_Large\" or model_type == \"DPT_Hybrid\":\n",
+ " transform = midas_transforms.dpt_transform\n",
+ "else:\n",
+ " transform = midas_transforms.small_transform"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ce837f1c",
+ "metadata": {},
+ "source": [
+ "Load image and apply transforms"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "412901d6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "img = cv2.imread(filename)\n",
+ "img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n",
+ "\n",
+ "input_batch = transform(img).to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d621088",
+ "metadata": {},
+ "source": [
+ "Predict and resize to original resolution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d0d2db5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " prediction = midas(input_batch)\n",
+ "\n",
+ " prediction = torch.nn.functional.interpolate(\n",
+ " prediction.unsqueeze(1),\n",
+ " size=img.shape[:2],\n",
+ " mode=\"bicubic\",\n",
+ " align_corners=False,\n",
+ " ).squeeze()\n",
+ "\n",
+ "output = prediction.cpu().numpy()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "991ee991",
+ "metadata": {},
+ "source": [
+ "Show result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c630ed12",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.imshow(output)\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f4c23d91",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "[Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer](https://arxiv.org/abs/1907.01341)\n",
+ "\n",
+ "[Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413)\n",
+ "\n",
+ "Please cite our papers if you use our models:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8248831c",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@article{Ranftl2020,\n",
+ "\tauthor = {Ren\\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun},\n",
+ "\ttitle = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer},\n",
+ "\tjournal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},\n",
+ "\tyear = {2020},\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e2a1bd81",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@article{Ranftl2021,\n",
+ "\tauthor = {Ren\\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},\n",
+ "\ttitle = {Vision Transformers for Dense Prediction},\n",
+ "\tjournal = {ArXiv preprint},\n",
+ "\tyear = {2021},\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb b/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb
new file mode 100644
index 000000000000..f91614481594
--- /dev/null
+++ b/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb
@@ -0,0 +1,117 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e3af3710",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# U-Net for brain MRI\n",
+ "\n",
+ "*Author: mateuszbuda*\n",
+ "\n",
+ "**U-Net with batch normalization for biomedical image segmentation with pretrained weights for abnormality segmentation in brain MRI**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "[MiDaS](https://arxiv.org/abs/1907.01341) computes relative inverse depth from a single image. The repository provides multiple models that cover different use cases ranging from a small, high-speed model to a very large model that provide the highest accuracy. The models have been trained on 10 distinct datasets using\n",
+ "multi-objective optimization to ensure high quality on a wide range of inputs.\n",
+ "\n",
+ "### Dependencies\n",
+ "\n",
+ "MiDaS depends on [timm](https://github.com/rwightman/pytorch-image-models). Install with"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "db3fd908",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "shell"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "pip install timm"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8892d100",
+ "metadata": {},
+ "source": [
+ "### Example Usage\n",
+ "\n",
+ "Download an image from the PyTorch homepage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "758e089f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import cv2\n",
+ "import torch\n",
+ "import urllib.request\n",
+ "\n",
+ "import matplotlib.pyplot as plt\n",
+ "\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d5fb41f",
+ "metadata": {},
+ "source": [
+ "Load a model (see [https://github.com/intel-isl/MiDaS/#Accuracy](https://github.com/intel-isl/MiDaS/#Accuracy) for an overview)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49acb469",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_type = \"DPT_Large\" # MiDaS v3 - Large (highest accuracy, slowest inference speed)\n",
+ "#model_type = \"DPT_Hybrid\" # MiDaS v3 - Hybrid (medium accuracy, medium inference speed)\n",
+ "#model_type = \"MiDaS_small\" # MiDaS v2.1 - Small (lowest accuracy, highest inference speed)\n",
+ "\n",
+ "midas = torch.hub.load(\"intel-isl/MiDaS\", model_type)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d785d8c2",
+ "metadata": {},
+ "source": [
+ "Move model to GPU if available"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2aa0b2d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "midas.to(device)\n",
+ "midas.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d0a6f5b",
+ "metadata": {},
+ "source": [
+ "Load transforms to resize and normalize the image for large or small model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "763b447a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "midas_transforms = torch.hub.load(\"intel-isl/MiDaS\", \"transforms\")\n",
+ "\n",
+ "if model_type == \"DPT_Large\" or model_type == \"DPT_Hybrid\":\n",
+ " transform = midas_transforms.dpt_transform\n",
+ "else:\n",
+ " transform = midas_transforms.small_transform"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ce837f1c",
+ "metadata": {},
+ "source": [
+ "Load image and apply transforms"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "412901d6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "img = cv2.imread(filename)\n",
+ "img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n",
+ "\n",
+ "input_batch = transform(img).to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9d621088",
+ "metadata": {},
+ "source": [
+ "Predict and resize to original resolution"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d0d2db5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " prediction = midas(input_batch)\n",
+ "\n",
+ " prediction = torch.nn.functional.interpolate(\n",
+ " prediction.unsqueeze(1),\n",
+ " size=img.shape[:2],\n",
+ " mode=\"bicubic\",\n",
+ " align_corners=False,\n",
+ " ).squeeze()\n",
+ "\n",
+ "output = prediction.cpu().numpy()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "991ee991",
+ "metadata": {},
+ "source": [
+ "Show result"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c630ed12",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.imshow(output)\n",
+ "# plt.show()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f4c23d91",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "[Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer](https://arxiv.org/abs/1907.01341)\n",
+ "\n",
+ "[Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413)\n",
+ "\n",
+ "Please cite our papers if you use our models:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8248831c",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@article{Ranftl2020,\n",
+ "\tauthor = {Ren\\'{e} Ranftl and Katrin Lasinger and David Hafner and Konrad Schindler and Vladlen Koltun},\n",
+ "\ttitle = {Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer},\n",
+ "\tjournal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)},\n",
+ "\tyear = {2020},\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e2a1bd81",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@article{Ranftl2021,\n",
+ "\tauthor = {Ren\\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},\n",
+ "\ttitle = {Vision Transformers for Dense Prediction},\n",
+ "\tjournal = {ArXiv preprint},\n",
+ "\tyear = {2021},\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb b/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb
new file mode 100644
index 000000000000..f91614481594
--- /dev/null
+++ b/assets/hub/mateuszbuda_brain-segmentation-pytorch_unet.ipynb
@@ -0,0 +1,117 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e3af3710",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# U-Net for brain MRI\n",
+ "\n",
+ "*Author: mateuszbuda*\n",
+ "\n",
+ "**U-Net with batch normalization for biomedical image segmentation with pretrained weights for abnormality segmentation in brain MRI**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76536d46",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',\n",
+ " in_channels=3, out_channels=1, init_features=32, pretrained=True)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a28792eb",
+ "metadata": {},
+ "source": [
+ "Loads a U-Net model pre-trained for abnormality segmentation on a dataset of brain MRI volumes [kaggle.com/mateuszbuda/lgg-mri-segmentation](https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation)\n",
+ "The pre-trained model requires 3 input channels, 1 output channel, and 32 features in the first layer.\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "This U-Net model comprises four levels of blocks containing two convolutional layers with batch normalization and ReLU activation function, and one max pooling layer in the encoding part and up-convolutional layers instead in the decoding part.\n",
+ "The number of convolutional filters in each block is 32, 64, 128, and 256.\n",
+ "The bottleneck layer has 512 convolutional filters.\n",
+ "From the encoding layers, skip connections are used to the corresponding layers in the decoding part.\n",
+ "Input image is a 3-channel brain MRI slice from pre-contrast, FLAIR, and post-contrast sequences, respectively.\n",
+ "Output is a one-channel probability map of abnormality regions with the same size as the input image.\n",
+ "It can be transformed to a binary segmentation mask by thresholding as shown in the example below.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "Input images for pre-trained model should have 3 channels and be resized to 256x256 pixels and z-score normalized per volume."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "edae5a92",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/mateuszbuda/brain-segmentation-pytorch/raw/master/assets/TCGA_CS_4944.png\", \"TCGA_CS_4944.png\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2900236",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "\n",
+ "input_image = Image.open(filename)\n",
+ "m, s = np.mean(input_image, axis=(0, 1)), np.std(input_image, axis=(0, 1))\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=m, std=s),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0)\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model = model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "\n",
+ "print(torch.round(output[0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b5cdbd4e",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ "- [Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm](http://arxiv.org/abs/1906.03720)\n",
+ "- [U-Net: Convolutional Networks for Biomedical Image Segmentation](https://arxiv.org/abs/1505.04597)\n",
+ "- [Brain MRI segmentation dataset](https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb b/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb
new file mode 100644
index 000000000000..53fc1a9826b6
--- /dev/null
+++ b/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb
@@ -0,0 +1,118 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "20f62891",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ntsnet\n",
+ "\n",
+ "*Author: Moreno Caraffini and Nicola Landro*\n",
+ "\n",
+ "**classify birds using this fine-grained image classifier**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "76536d46",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',\n",
+ " in_channels=3, out_channels=1, init_features=32, pretrained=True)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a28792eb",
+ "metadata": {},
+ "source": [
+ "Loads a U-Net model pre-trained for abnormality segmentation on a dataset of brain MRI volumes [kaggle.com/mateuszbuda/lgg-mri-segmentation](https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation)\n",
+ "The pre-trained model requires 3 input channels, 1 output channel, and 32 features in the first layer.\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "This U-Net model comprises four levels of blocks containing two convolutional layers with batch normalization and ReLU activation function, and one max pooling layer in the encoding part and up-convolutional layers instead in the decoding part.\n",
+ "The number of convolutional filters in each block is 32, 64, 128, and 256.\n",
+ "The bottleneck layer has 512 convolutional filters.\n",
+ "From the encoding layers, skip connections are used to the corresponding layers in the decoding part.\n",
+ "Input image is a 3-channel brain MRI slice from pre-contrast, FLAIR, and post-contrast sequences, respectively.\n",
+ "Output is a one-channel probability map of abnormality regions with the same size as the input image.\n",
+ "It can be transformed to a binary segmentation mask by thresholding as shown in the example below.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "Input images for pre-trained model should have 3 channels and be resized to 256x256 pixels and z-score normalized per volume."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "edae5a92",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/mateuszbuda/brain-segmentation-pytorch/raw/master/assets/TCGA_CS_4944.png\", \"TCGA_CS_4944.png\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b2900236",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "\n",
+ "input_image = Image.open(filename)\n",
+ "m, s = np.mean(input_image, axis=(0, 1)), np.std(input_image, axis=(0, 1))\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=m, std=s),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0)\n",
+ "\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model = model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "\n",
+ "print(torch.round(output[0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b5cdbd4e",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ "- [Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm](http://arxiv.org/abs/1906.03720)\n",
+ "- [U-Net: Convolutional Networks for Biomedical Image Segmentation](https://arxiv.org/abs/1505.04597)\n",
+ "- [Brain MRI segmentation dataset](https://www.kaggle.com/mateuszbuda/lgg-mri-segmentation)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb b/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb
new file mode 100644
index 000000000000..53fc1a9826b6
--- /dev/null
+++ b/assets/hub/nicolalandro_ntsnet-cub200_ntsnet.ipynb
@@ -0,0 +1,118 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "20f62891",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ntsnet\n",
+ "\n",
+ "*Author: Moreno Caraffini and Nicola Landro*\n",
+ "\n",
+ "**classify birds using this fine-grained image classifier**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6d78a29",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True,\n",
+ " **{'topN': 6, 'device':'cpu', 'num_classes': 200})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfa847dd",
+ "metadata": {},
+ "source": [
+ "### Example Usage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bdde7974",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from torchvision import transforms\n",
+ "import torch\n",
+ "import urllib\n",
+ "from PIL import Image\n",
+ "\n",
+ "transform_test = transforms.Compose([\n",
+ " transforms.Resize((600, 600), Image.BILINEAR),\n",
+ " transforms.CenterCrop((448, 448)),\n",
+ " # transforms.RandomHorizontalFlip(), # only if train\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),\n",
+ "])\n",
+ "\n",
+ "\n",
+ "model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True, **{'topN': 6, 'device':'cpu', 'num_classes': 200})\n",
+ "model.eval()\n",
+ "\n",
+ "url = 'https://raw.githubusercontent.com/nicolalandro/ntsnet-cub200/master/images/nts-net.png'\n",
+ "img = Image.open(urllib.request.urlopen(url))\n",
+ "scaled_img = transform_test(img)\n",
+ "torch_images = scaled_img.unsqueeze(0)\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " top_n_coordinates, concat_out, raw_logits, concat_logits, part_logits, top_n_index, top_n_prob = model(torch_images)\n",
+ "\n",
+ " _, predict = torch.max(concat_logits, 1)\n",
+ " pred_id = predict.item()\n",
+ " print('bird class:', model.bird_classes[pred_id])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "20fe5d0c",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "This is an nts-net pretrained with CUB200 2011 dataset, which is a fine grained dataset of birds species.\n",
+ "\n",
+ "### References\n",
+ "You can read the full paper at this [link](http://artelab.dista.uninsubria.it/res/research/papers/2019/2019-IVCNZ-Nawaz-Birds.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "74ed0a07",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@INPROCEEDINGS{Gallo:2019:IVCNZ,\n",
+ " author={Nawaz, Shah and Calefati, Alessandro and Caraffini, Moreno and Landro, Nicola and Gallo, Ignazio},\n",
+ " booktitle={2019 International Conference on Image and Vision Computing New Zealand (IVCNZ 2019)},\n",
+ " title={Are These Birds Similar: Learning Branched Networks for Fine-grained Representations},\n",
+ " year={2019},\n",
+ " month={Dec},\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb b/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb
new file mode 100644
index 000000000000..04ec17f4104f
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb
@@ -0,0 +1,204 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b913a656",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# EfficientNet\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, being an order-of-magnitude smaller and faster. Trained with mixed precision using Tensor Cores.**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6d78a29",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True,\n",
+ " **{'topN': 6, 'device':'cpu', 'num_classes': 200})"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cfa847dd",
+ "metadata": {},
+ "source": [
+ "### Example Usage"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bdde7974",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from torchvision import transforms\n",
+ "import torch\n",
+ "import urllib\n",
+ "from PIL import Image\n",
+ "\n",
+ "transform_test = transforms.Compose([\n",
+ " transforms.Resize((600, 600), Image.BILINEAR),\n",
+ " transforms.CenterCrop((448, 448)),\n",
+ " # transforms.RandomHorizontalFlip(), # only if train\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),\n",
+ "])\n",
+ "\n",
+ "\n",
+ "model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True, **{'topN': 6, 'device':'cpu', 'num_classes': 200})\n",
+ "model.eval()\n",
+ "\n",
+ "url = 'https://raw.githubusercontent.com/nicolalandro/ntsnet-cub200/master/images/nts-net.png'\n",
+ "img = Image.open(urllib.request.urlopen(url))\n",
+ "scaled_img = transform_test(img)\n",
+ "torch_images = scaled_img.unsqueeze(0)\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " top_n_coordinates, concat_out, raw_logits, concat_logits, part_logits, top_n_index, top_n_prob = model(torch_images)\n",
+ "\n",
+ " _, predict = torch.max(concat_logits, 1)\n",
+ " pred_id = predict.item()\n",
+ " print('bird class:', model.bird_classes[pred_id])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "20fe5d0c",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "This is an nts-net pretrained with CUB200 2011 dataset, which is a fine grained dataset of birds species.\n",
+ "\n",
+ "### References\n",
+ "You can read the full paper at this [link](http://artelab.dista.uninsubria.it/res/research/papers/2019/2019-IVCNZ-Nawaz-Birds.pdf)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "74ed0a07",
+ "metadata": {
+ "attributes": {
+ "classes": [
+ "bibtex"
+ ],
+ "id": ""
+ }
+ },
+ "outputs": [],
+ "source": [
+ "@INPROCEEDINGS{Gallo:2019:IVCNZ,\n",
+ " author={Nawaz, Shah and Calefati, Alessandro and Caraffini, Moreno and Landro, Nicola and Gallo, Ignazio},\n",
+ " booktitle={2019 International Conference on Image and Vision Computing New Zealand (IVCNZ 2019)},\n",
+ " title={Are These Birds Similar: Learning Branched Networks for Fine-grained Representations},\n",
+ " year={2019},\n",
+ " month={Dec},\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb b/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb
new file mode 100644
index 000000000000..04ec17f4104f
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_efficientnet.ipynb
@@ -0,0 +1,204 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b913a656",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# EfficientNet\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, being an order-of-magnitude smaller and faster. Trained with mixed precision using Tensor Cores.**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "EfficientNet is an image classification model family. It was first described in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946). This notebook allows you to load and test the EfficientNet-B0, EfficientNet-B4, EfficientNet-WideSE-B0 and, EfficientNet-WideSE-B4 models.\n",
+ "\n",
+ "EfficientNet-WideSE models use Squeeze-and-Excitation layers wider than original EfficientNet models, the width of SE module is proportional to the width of Depthwise Separable Convolutions instead of block width.\n",
+ "\n",
+ "WideSE models are slightly more accurate than original models.\n",
+ "\n",
+ "This model is trained with mixed precision using Tensor Cores on Volta and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results over 2x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.\n",
+ "\n",
+ "We use [NHWC data layout](https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html) when training using Mixed Precision.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below we will use the pretrained ***EfficientNet*** model to perform inference on image and present the result.\n",
+ "\n",
+ "To run the example you need some extra python packages installed. These are needed for preprocessing images and visualization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49342854",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install validators matplotlib"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17a365de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from PIL import Image\n",
+ "import torchvision.transforms as transforms\n",
+ "import numpy as np\n",
+ "import json\n",
+ "import requests\n",
+ "import matplotlib.pyplot as plt\n",
+ "import warnings\n",
+ "warnings.filterwarnings('ignore')\n",
+ "%matplotlib inline\n",
+ "\n",
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "print(f'Using {device} for inference')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc63c523",
+ "metadata": {},
+ "source": [
+ "Load the model pretrained on ImageNet dataset.\n",
+ "\n",
+ "You can choose among the following models:\n",
+ "\n",
+ "| TorchHub entrypoint | Description |\n",
+ "| :----- | :----- |\n",
+ "| `nvidia_efficientnet_b0` | baseline EfficientNet |\n",
+ "| `nvidia_efficientnet_b4` | scaled EfficientNet|\n",
+ "| `nvidia_efficientnet_widese_b0` | model with Squeeze-and-Excitation layers wider than baseline EfficientNet model |\n",
+ "| `nvidia_efficientnet_widese_b4` | model with Squeeze-and-Excitation layers wider than scaled EfficientNet model |\n",
+ "\n",
+ "There are also quantized version of the models, but they require nvidia container. See [quantized models](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet#quantization)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9434f5c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "efficientnet = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_efficientnet_b0', pretrained=True)\n",
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_convnets_processing_utils')\n",
+ "\n",
+ "efficientnet.eval().to(device)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7303edb8",
+ "metadata": {},
+ "source": [
+ "Prepare sample input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "489f6768",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "uris = [\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000024309.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000028117.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000006149.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000004954.jpg',\n",
+ "]\n",
+ "\n",
+ "batch = torch.cat(\n",
+ " [utils.prepare_input_from_uri(uri) for uri in uris]\n",
+ ").to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "21f12d5e",
+ "metadata": {},
+ "source": [
+ "Run inference. Use `pick_n_best(predictions=output, n=topN)` helper function to pick N most probable hypotheses according to the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d997b6f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " output = torch.nn.functional.softmax(efficientnet(batch), dim=1)\n",
+ " \n",
+ "results = utils.pick_n_best(predictions=output, n=5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b7a0638",
+ "metadata": {},
+ "source": [
+ "Display the result."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "401003b6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for uri, result in zip(uris, results):\n",
+ " img = Image.open(requests.get(uri, stream=True).raw)\n",
+ " img.thumbnail((256,256), Image.ANTIALIAS)\n",
+ " plt.imshow(img)\n",
+ " plt.show()\n",
+ " print(result)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4780b64",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit:\n",
+ "[github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet)\n",
+ "and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:efficientnet_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)\n",
+ " - [model on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:efficientnet_for_pytorch)\n",
+ " - [model on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet)\n",
+ " - [pretrained model on NGC (efficientnet-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_b0_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_b4_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-widese-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b0_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-widese-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b4_pyt_amp)\n",
+ " - [pretrained, quantized model on NGC (efficientnet-widese-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b0_pyt_amp)\n",
+ " - [pretrained, quantized model on NGC (efficientnet-widese-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b4_pyt_amp)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb b/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb
new file mode 100644
index 000000000000..09ca3a568f57
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb
@@ -0,0 +1,324 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b844056c",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# FastPitch 2\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**The FastPitch model for generating mel spectrograms from text**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "EfficientNet is an image classification model family. It was first described in [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946). This notebook allows you to load and test the EfficientNet-B0, EfficientNet-B4, EfficientNet-WideSE-B0 and, EfficientNet-WideSE-B4 models.\n",
+ "\n",
+ "EfficientNet-WideSE models use Squeeze-and-Excitation layers wider than original EfficientNet models, the width of SE module is proportional to the width of Depthwise Separable Convolutions instead of block width.\n",
+ "\n",
+ "WideSE models are slightly more accurate than original models.\n",
+ "\n",
+ "This model is trained with mixed precision using Tensor Cores on Volta and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results over 2x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.\n",
+ "\n",
+ "We use [NHWC data layout](https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html) when training using Mixed Precision.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below we will use the pretrained ***EfficientNet*** model to perform inference on image and present the result.\n",
+ "\n",
+ "To run the example you need some extra python packages installed. These are needed for preprocessing images and visualization."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "49342854",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install validators matplotlib"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "17a365de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "from PIL import Image\n",
+ "import torchvision.transforms as transforms\n",
+ "import numpy as np\n",
+ "import json\n",
+ "import requests\n",
+ "import matplotlib.pyplot as plt\n",
+ "import warnings\n",
+ "warnings.filterwarnings('ignore')\n",
+ "%matplotlib inline\n",
+ "\n",
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "print(f'Using {device} for inference')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc63c523",
+ "metadata": {},
+ "source": [
+ "Load the model pretrained on ImageNet dataset.\n",
+ "\n",
+ "You can choose among the following models:\n",
+ "\n",
+ "| TorchHub entrypoint | Description |\n",
+ "| :----- | :----- |\n",
+ "| `nvidia_efficientnet_b0` | baseline EfficientNet |\n",
+ "| `nvidia_efficientnet_b4` | scaled EfficientNet|\n",
+ "| `nvidia_efficientnet_widese_b0` | model with Squeeze-and-Excitation layers wider than baseline EfficientNet model |\n",
+ "| `nvidia_efficientnet_widese_b4` | model with Squeeze-and-Excitation layers wider than scaled EfficientNet model |\n",
+ "\n",
+ "There are also quantized version of the models, but they require nvidia container. See [quantized models](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet#quantization)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9434f5c7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "efficientnet = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_efficientnet_b0', pretrained=True)\n",
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_convnets_processing_utils')\n",
+ "\n",
+ "efficientnet.eval().to(device)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7303edb8",
+ "metadata": {},
+ "source": [
+ "Prepare sample input data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "489f6768",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "uris = [\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000024309.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000028117.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000006149.jpg',\n",
+ " 'http://images.cocodataset.org/test-stuff2017/000000004954.jpg',\n",
+ "]\n",
+ "\n",
+ "batch = torch.cat(\n",
+ " [utils.prepare_input_from_uri(uri) for uri in uris]\n",
+ ").to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "21f12d5e",
+ "metadata": {},
+ "source": [
+ "Run inference. Use `pick_n_best(predictions=output, n=topN)` helper function to pick N most probable hypotheses according to the model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d997b6f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " output = torch.nn.functional.softmax(efficientnet(batch), dim=1)\n",
+ " \n",
+ "results = utils.pick_n_best(predictions=output, n=5)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b7a0638",
+ "metadata": {},
+ "source": [
+ "Display the result."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "401003b6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for uri, result in zip(uris, results):\n",
+ " img = Image.open(requests.get(uri, stream=True).raw)\n",
+ " img.thumbnail((256,256), Image.ANTIALIAS)\n",
+ " plt.imshow(img)\n",
+ " plt.show()\n",
+ " print(result)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4780b64",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit:\n",
+ "[github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet)\n",
+ "and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:efficientnet_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)\n",
+ " - [model on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:efficientnet_for_pytorch)\n",
+ " - [model on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/Classification/ConvNets/efficientnet)\n",
+ " - [pretrained model on NGC (efficientnet-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_b0_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_b4_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-widese-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b0_pyt_amp)\n",
+ " - [pretrained model on NGC (efficientnet-widese-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b4_pyt_amp)\n",
+ " - [pretrained, quantized model on NGC (efficientnet-widese-b0)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b0_pyt_amp)\n",
+ " - [pretrained, quantized model on NGC (efficientnet-widese-b4)](https://ngc.nvidia.com/catalog/models/nvidia:efficientnet_widese_b4_pyt_amp)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb b/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb
new file mode 100644
index 000000000000..09ca3a568f57
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_fastpitch.ipynb
@@ -0,0 +1,324 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b844056c",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# FastPitch 2\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**The FastPitch model for generating mel spectrograms from text**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "This notebook demonstrates a PyTorch implementation of the FastPitch model described in the [FastPitch](https://arxiv.org/abs/2006.06873) paper.\n",
+ "The FastPitch model generates mel-spectrograms and predicts a pitch contour from raw input text. In version 1.1, it does not need any pre-trained aligning model to bootstrap from. To get the audio waveform we need a second model that will produce it from the generated mel-spectrogram. In this notebook we use HiFi-GAN model for that second step.\n",
+ "\n",
+ "The FastPitch model is based on the [FastSpeech](https://arxiv.org/abs/1905.09263) model. The main differences between FastPitch vs FastSpeech are as follows:\n",
+ "* no dependence on external aligner (Transformer TTS, Tacotron 2); in version 1.1, FastPitch aligns audio to transcriptions by itself as in [One TTS Alignment To Rule Them All](https://arxiv.org/abs/2108.10447),\n",
+ "* FastPitch explicitly learns to predict the pitch contour,\n",
+ "* pitch conditioning removes harsh sounding artifacts and provides faster convergence,\n",
+ "* no need for distilling mel-spectrograms with a teacher model,\n",
+ "* capabilities to train a multi-speaker model.\n",
+ "\n",
+ "\n",
+ "#### Model architecture\n",
+ "\n",
+ "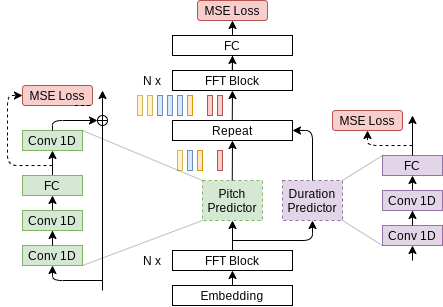\n",
+ "\n",
+ "### Example\n",
+ "In the example below:\n",
+ "\n",
+ "- pretrained FastPitch and HiFiGAN models are loaded from torch.hub\n",
+ "- given tensor representation of an input text (\"Say this smoothly to prove you are not a robot.\"), FastPitch generates mel spectrogram\n",
+ "- HiFiGAN generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed. These are needed for preprocessing of text and audio, as well as for display and input/output handling. Finally, for better performance of FastPitch model, we download the CMU pronounciation dictionary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "05ac615a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1 wget\n",
+ "pip install numpy scipy librosa unidecode inflect librosa matplotlib==3.6.3\n",
+ "wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/heteronyms-052722 -qO heteronyms\n",
+ "wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/cmudict-0.7b_nv22.08 -qO cmudict-0.7b"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "848828d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import matplotlib.pyplot as plt\n",
+ "from IPython.display import Audio\n",
+ "import warnings\n",
+ "warnings.filterwarnings('ignore')\n",
+ "\n",
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "print(f'Using {device} for inference')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8a93fec",
+ "metadata": {},
+ "source": [
+ "Download and setup FastPitch generator model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0de224eb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fastpitch, generator_train_setup = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_fastpitch')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4f160e82",
+ "metadata": {},
+ "source": [
+ "Download and setup vocoder and denoiser models."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0655df7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "hifigan, vocoder_train_setup, denoiser = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_hifigan')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c8575d3",
+ "metadata": {},
+ "source": [
+ "Verify that generator and vocoder models agree on input parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d2140a54",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "CHECKPOINT_SPECIFIC_ARGS = [\n",
+ " 'sampling_rate', 'hop_length', 'win_length', 'p_arpabet', 'text_cleaners',\n",
+ " 'symbol_set', 'max_wav_value', 'prepend_space_to_text',\n",
+ " 'append_space_to_text']\n",
+ "\n",
+ "for k in CHECKPOINT_SPECIFIC_ARGS:\n",
+ "\n",
+ " v1 = generator_train_setup.get(k, None)\n",
+ " v2 = vocoder_train_setup.get(k, None)\n",
+ "\n",
+ " assert v1 is None or v2 is None or v1 == v2, \\\n",
+ " f'{k} mismatch in spectrogram generator and vocoder'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e24e3c5d",
+ "metadata": {},
+ "source": [
+ "Put all models on available device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7383ab5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fastpitch.to(device)\n",
+ "hifigan.to(device)\n",
+ "denoiser.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd803d24",
+ "metadata": {},
+ "source": [
+ "Load text processor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3f512618",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tp = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_textprocessing_utils', cmudict_path=\"cmudict-0.7b\", heteronyms_path=\"heteronyms\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3ee8163",
+ "metadata": {},
+ "source": [
+ "Set the text to be synthetized, prepare input and set additional generation parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fad7df55",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"Say this smoothly, to prove you are not a robot.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3bca9235",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batches = tp.prepare_input_sequence([text], batch_size=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3993c431",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gen_kw = {'pace': 1.0,\n",
+ " 'speaker': 0,\n",
+ " 'pitch_tgt': None,\n",
+ " 'pitch_transform': None}\n",
+ "denoising_strength = 0.005"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8d4b3ecd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for batch in batches:\n",
+ " with torch.no_grad():\n",
+ " mel, mel_lens, *_ = fastpitch(batch['text'].to(device), **gen_kw)\n",
+ " audios = hifigan(mel).float()\n",
+ " audios = denoiser(audios.squeeze(1), denoising_strength)\n",
+ " audios = audios.squeeze(1) * vocoder_train_setup['max_wav_value']\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c48a0f58",
+ "metadata": {},
+ "source": [
+ "Plot the intermediate spectorgram."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "006163af",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.figure(figsize=(10,12))\n",
+ "res_mel = mel[0].detach().cpu().numpy()\n",
+ "plt.imshow(res_mel, origin='lower')\n",
+ "plt.xlabel('time')\n",
+ "plt.ylabel('frequency')\n",
+ "_=plt.title('Spectrogram')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6629975b",
+ "metadata": {},
+ "source": [
+ "Syntesize audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "251ea5b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "audio_numpy = audios[0].cpu().numpy()\n",
+ "Audio(audio_numpy, rate=22050)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "98a6104e",
+ "metadata": {},
+ "source": [
+ "Write audio to wav file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c246eca4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", vocoder_train_setup['sampling_rate'], audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6a978c6c",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/HiFiGAN) and/or [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/fastpitch_pyt)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [FastPitch paper](https://arxiv.org/abs/2006.06873)\n",
+ " - [FastPitch on NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/fastpitch_pyt)\n",
+ " - [HiFi-GAN on NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/hifigan_pyt)\n",
+ " - [FastPitch and HiFi-GAN on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/HiFiGAN)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb b/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb
new file mode 100644
index 000000000000..248a21648804
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb
@@ -0,0 +1,218 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "f003828f",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# GPUNet\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**GPUNet is a new family of Convolutional Neural Networks designed to max out the performance of NVIDIA GPU and TensorRT.**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "This notebook demonstrates a PyTorch implementation of the FastPitch model described in the [FastPitch](https://arxiv.org/abs/2006.06873) paper.\n",
+ "The FastPitch model generates mel-spectrograms and predicts a pitch contour from raw input text. In version 1.1, it does not need any pre-trained aligning model to bootstrap from. To get the audio waveform we need a second model that will produce it from the generated mel-spectrogram. In this notebook we use HiFi-GAN model for that second step.\n",
+ "\n",
+ "The FastPitch model is based on the [FastSpeech](https://arxiv.org/abs/1905.09263) model. The main differences between FastPitch vs FastSpeech are as follows:\n",
+ "* no dependence on external aligner (Transformer TTS, Tacotron 2); in version 1.1, FastPitch aligns audio to transcriptions by itself as in [One TTS Alignment To Rule Them All](https://arxiv.org/abs/2108.10447),\n",
+ "* FastPitch explicitly learns to predict the pitch contour,\n",
+ "* pitch conditioning removes harsh sounding artifacts and provides faster convergence,\n",
+ "* no need for distilling mel-spectrograms with a teacher model,\n",
+ "* capabilities to train a multi-speaker model.\n",
+ "\n",
+ "\n",
+ "#### Model architecture\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Example\n",
+ "In the example below:\n",
+ "\n",
+ "- pretrained FastPitch and HiFiGAN models are loaded from torch.hub\n",
+ "- given tensor representation of an input text (\"Say this smoothly to prove you are not a robot.\"), FastPitch generates mel spectrogram\n",
+ "- HiFiGAN generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed. These are needed for preprocessing of text and audio, as well as for display and input/output handling. Finally, for better performance of FastPitch model, we download the CMU pronounciation dictionary."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "05ac615a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1 wget\n",
+ "pip install numpy scipy librosa unidecode inflect librosa matplotlib==3.6.3\n",
+ "wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/heteronyms-052722 -qO heteronyms\n",
+ "wget https://raw.githubusercontent.com/NVIDIA/NeMo/263a30be71e859cee330e5925332009da3e5efbc/scripts/tts_dataset_files/cmudict-0.7b_nv22.08 -qO cmudict-0.7b"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "848828d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import matplotlib.pyplot as plt\n",
+ "from IPython.display import Audio\n",
+ "import warnings\n",
+ "warnings.filterwarnings('ignore')\n",
+ "\n",
+ "device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n",
+ "print(f'Using {device} for inference')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8a93fec",
+ "metadata": {},
+ "source": [
+ "Download and setup FastPitch generator model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0de224eb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fastpitch, generator_train_setup = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_fastpitch')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4f160e82",
+ "metadata": {},
+ "source": [
+ "Download and setup vocoder and denoiser models."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b0655df7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "hifigan, vocoder_train_setup, denoiser = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_hifigan')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c8575d3",
+ "metadata": {},
+ "source": [
+ "Verify that generator and vocoder models agree on input parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d2140a54",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "CHECKPOINT_SPECIFIC_ARGS = [\n",
+ " 'sampling_rate', 'hop_length', 'win_length', 'p_arpabet', 'text_cleaners',\n",
+ " 'symbol_set', 'max_wav_value', 'prepend_space_to_text',\n",
+ " 'append_space_to_text']\n",
+ "\n",
+ "for k in CHECKPOINT_SPECIFIC_ARGS:\n",
+ "\n",
+ " v1 = generator_train_setup.get(k, None)\n",
+ " v2 = vocoder_train_setup.get(k, None)\n",
+ "\n",
+ " assert v1 is None or v2 is None or v1 == v2, \\\n",
+ " f'{k} mismatch in spectrogram generator and vocoder'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e24e3c5d",
+ "metadata": {},
+ "source": [
+ "Put all models on available device."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c7383ab5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "fastpitch.to(device)\n",
+ "hifigan.to(device)\n",
+ "denoiser.to(device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd803d24",
+ "metadata": {},
+ "source": [
+ "Load text processor."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3f512618",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tp = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_textprocessing_utils', cmudict_path=\"cmudict-0.7b\", heteronyms_path=\"heteronyms\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c3ee8163",
+ "metadata": {},
+ "source": [
+ "Set the text to be synthetized, prepare input and set additional generation parameters."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fad7df55",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"Say this smoothly, to prove you are not a robot.\""
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3bca9235",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "batches = tp.prepare_input_sequence([text], batch_size=1)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3993c431",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "gen_kw = {'pace': 1.0,\n",
+ " 'speaker': 0,\n",
+ " 'pitch_tgt': None,\n",
+ " 'pitch_transform': None}\n",
+ "denoising_strength = 0.005"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8d4b3ecd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "for batch in batches:\n",
+ " with torch.no_grad():\n",
+ " mel, mel_lens, *_ = fastpitch(batch['text'].to(device), **gen_kw)\n",
+ " audios = hifigan(mel).float()\n",
+ " audios = denoiser(audios.squeeze(1), denoising_strength)\n",
+ " audios = audios.squeeze(1) * vocoder_train_setup['max_wav_value']\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c48a0f58",
+ "metadata": {},
+ "source": [
+ "Plot the intermediate spectorgram."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "006163af",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "plt.figure(figsize=(10,12))\n",
+ "res_mel = mel[0].detach().cpu().numpy()\n",
+ "plt.imshow(res_mel, origin='lower')\n",
+ "plt.xlabel('time')\n",
+ "plt.ylabel('frequency')\n",
+ "_=plt.title('Spectrogram')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6629975b",
+ "metadata": {},
+ "source": [
+ "Syntesize audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "251ea5b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "audio_numpy = audios[0].cpu().numpy()\n",
+ "Audio(audio_numpy, rate=22050)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "98a6104e",
+ "metadata": {},
+ "source": [
+ "Write audio to wav file."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c246eca4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", vocoder_train_setup['sampling_rate'], audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6a978c6c",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/HiFiGAN) and/or [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/fastpitch_pyt)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [FastPitch paper](https://arxiv.org/abs/2006.06873)\n",
+ " - [FastPitch on NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/fastpitch_pyt)\n",
+ " - [HiFi-GAN on NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/hifigan_pyt)\n",
+ " - [FastPitch and HiFi-GAN on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/HiFiGAN)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb b/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb
new file mode 100644
index 000000000000..248a21648804
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_gpunet.ipynb
@@ -0,0 +1,218 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "f003828f",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# GPUNet\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**GPUNet is a new family of Convolutional Neural Networks designed to max out the performance of NVIDIA GPU and TensorRT.**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "This notebook demonstrates a PyTorch implementation of the HiFi-GAN model described in the paper: [HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/abs/2010.05646).\n",
+ "The HiFi-GAN model implements a spectrogram inversion model that allows to synthesize speech waveforms from mel-spectrograms. It follows the generative adversarial network (GAN) paradigm, and is composed of a generator and a discriminator. After training, the generator is used for synthesis, and the discriminator is discarded.\n",
+ "\n",
+ "Our implementation is based on the one [published by the authors of the paper](https://github.com/jik876/hifi-gan). We modify the original hyperparameters and provide an alternative training recipe, which enables training on larger batches and faster convergence. HiFi-GAN is trained on a publicly available [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/). The
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "This notebook demonstrates a PyTorch implementation of the HiFi-GAN model described in the paper: [HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/abs/2010.05646).\n",
+ "The HiFi-GAN model implements a spectrogram inversion model that allows to synthesize speech waveforms from mel-spectrograms. It follows the generative adversarial network (GAN) paradigm, and is composed of a generator and a discriminator. After training, the generator is used for synthesis, and the discriminator is discarded.\n",
+ "\n",
+ "Our implementation is based on the one [published by the authors of the paper](https://github.com/jik876/hifi-gan). We modify the original hyperparameters and provide an alternative training recipe, which enables training on larger batches and faster convergence. HiFi-GAN is trained on a publicly available [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/). The  \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "The Tacotron 2 and WaveGlow model form a text-to-speech system that enables user to synthesise a natural sounding speech from raw transcripts without any additional prosody information. The Tacotron 2 model produces mel spectrograms from input text using encoder-decoder architecture. WaveGlow (also available via torch.hub) is a flow-based model that consumes the mel spectrograms to generate speech.\n",
+ "\n",
+ "This implementation of Tacotron 2 model differs from the model described in the paper. Our implementation uses Dropout instead of Zoneout to regularize the LSTM layers.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below:\n",
+ "- pretrained Tacotron2 and Waveglow models are loaded from torch.hub\n",
+ "- Given a tensor representation of the input text (\"Hello world, I missed you so much\"), Tacotron2 generates a Mel spectrogram as shown on the illustration\n",
+ "- Waveglow generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed.\n",
+ "These are needed for preprocessing the text and audio, as well as for display and input / output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a384b737",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install numpy scipy librosa unidecode inflect librosa\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2578bea8",
+ "metadata": {},
+ "source": [
+ "Load the Tacotron2 model pre-trained on [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/) and prepare it for inference:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d735c9f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')\n",
+ "tacotron2 = tacotron2.to('cuda')\n",
+ "tacotron2.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "96353646",
+ "metadata": {},
+ "source": [
+ "Load pretrained WaveGlow model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "726773b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp16')\n",
+ "waveglow = waveglow.remove_weightnorm(waveglow)\n",
+ "waveglow = waveglow.to('cuda')\n",
+ "waveglow.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0055a4a6",
+ "metadata": {},
+ "source": [
+ "Now, let's make the model say:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c432a2a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"Hello world, I missed you so much.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09f3df08",
+ "metadata": {},
+ "source": [
+ "Format the input using utility methods"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1186aca4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')\n",
+ "sequences, lengths = utils.prepare_input_sequence([text])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52b62d50",
+ "metadata": {},
+ "source": [
+ "Run the chained models:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe9a3235",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " mel, _, _ = tacotron2.infer(sequences, lengths)\n",
+ " audio = waveglow.infer(mel)\n",
+ "audio_numpy = audio[0].data.cpu().numpy()\n",
+ "rate = 22050"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4f981ac4",
+ "metadata": {},
+ "source": [
+ "You can write it to a file and listen to it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4811ba40",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", rate, audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8484e97",
+ "metadata": {},
+ "source": [
+ "Alternatively, play it right away in a notebook with IPython widgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4aea3333",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import Audio\n",
+ "Audio(audio_numpy, rate=rate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d9b03f",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2) and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions](https://arxiv.org/abs/1712.05884)\n",
+ " - [WaveGlow: A Flow-based Generative Network for Speech Synthesis](https://arxiv.org/abs/1811.00002)\n",
+ " - [Tacotron2 and WaveGlow on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ " - [Tacotron2 and Waveglow on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb b/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb
new file mode 100644
index 000000000000..be4c1c4b8b72
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb
@@ -0,0 +1,228 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1d26fab5",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# WaveGlow\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**WaveGlow model for generating speech from mel spectrograms (generated by Tacotron2)**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "The Tacotron 2 and WaveGlow model form a text-to-speech system that enables user to synthesise a natural sounding speech from raw transcripts without any additional prosody information. The Tacotron 2 model produces mel spectrograms from input text using encoder-decoder architecture. WaveGlow (also available via torch.hub) is a flow-based model that consumes the mel spectrograms to generate speech.\n",
+ "\n",
+ "This implementation of Tacotron 2 model differs from the model described in the paper. Our implementation uses Dropout instead of Zoneout to regularize the LSTM layers.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below:\n",
+ "- pretrained Tacotron2 and Waveglow models are loaded from torch.hub\n",
+ "- Given a tensor representation of the input text (\"Hello world, I missed you so much\"), Tacotron2 generates a Mel spectrogram as shown on the illustration\n",
+ "- Waveglow generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed.\n",
+ "These are needed for preprocessing the text and audio, as well as for display and input / output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a384b737",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install numpy scipy librosa unidecode inflect librosa\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2578bea8",
+ "metadata": {},
+ "source": [
+ "Load the Tacotron2 model pre-trained on [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/) and prepare it for inference:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6d735c9f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp16')\n",
+ "tacotron2 = tacotron2.to('cuda')\n",
+ "tacotron2.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "96353646",
+ "metadata": {},
+ "source": [
+ "Load pretrained WaveGlow model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "726773b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp16')\n",
+ "waveglow = waveglow.remove_weightnorm(waveglow)\n",
+ "waveglow = waveglow.to('cuda')\n",
+ "waveglow.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0055a4a6",
+ "metadata": {},
+ "source": [
+ "Now, let's make the model say:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c432a2a5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"Hello world, I missed you so much.\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "09f3df08",
+ "metadata": {},
+ "source": [
+ "Format the input using utility methods"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1186aca4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')\n",
+ "sequences, lengths = utils.prepare_input_sequence([text])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "52b62d50",
+ "metadata": {},
+ "source": [
+ "Run the chained models:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe9a3235",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " mel, _, _ = tacotron2.infer(sequences, lengths)\n",
+ " audio = waveglow.infer(mel)\n",
+ "audio_numpy = audio[0].data.cpu().numpy()\n",
+ "rate = 22050"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4f981ac4",
+ "metadata": {},
+ "source": [
+ "You can write it to a file and listen to it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4811ba40",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", rate, audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a8484e97",
+ "metadata": {},
+ "source": [
+ "Alternatively, play it right away in a notebook with IPython widgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4aea3333",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import Audio\n",
+ "Audio(audio_numpy, rate=rate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d9b03f",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2) and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions](https://arxiv.org/abs/1712.05884)\n",
+ " - [WaveGlow: A Flow-based Generative Network for Speech Synthesis](https://arxiv.org/abs/1811.00002)\n",
+ " - [Tacotron2 and WaveGlow on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ " - [Tacotron2 and Waveglow on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb b/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb
new file mode 100644
index 000000000000..be4c1c4b8b72
--- /dev/null
+++ b/assets/hub/nvidia_deeplearningexamples_waveglow.ipynb
@@ -0,0 +1,228 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1d26fab5",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# WaveGlow\n",
+ "\n",
+ "*Author: NVIDIA*\n",
+ "\n",
+ "**WaveGlow model for generating speech from mel spectrograms (generated by Tacotron2)**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "The Tacotron 2 and WaveGlow model form a text-to-speech system that enables user to synthesise a natural sounding speech from raw transcripts without any additional prosody information. The Tacotron 2 model (also available via torch.hub) produces mel spectrograms from input text using encoder-decoder architecture. WaveGlow is a flow-based model that consumes the mel spectrograms to generate speech.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below:\n",
+ "- pretrained Tacotron2 and Waveglow models are loaded from torch.hub\n",
+ "- Given a tensor representation of the input text (\"Hello world, I missed you so much\"), Tacotron2 generates a Mel spectrogram as shown on the illustration\n",
+ "- Waveglow generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed.\n",
+ "These are needed for preprocessing the text and audio, as well as for display and input / output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "406508db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install numpy scipy librosa unidecode inflect librosa\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "942e77d1",
+ "metadata": {},
+ "source": [
+ "Load the WaveGlow model pre-trained on [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "537f1a63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp32')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7a47b767",
+ "metadata": {},
+ "source": [
+ "Prepare the WaveGlow model for inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1fbed70c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waveglow = waveglow.remove_weightnorm(waveglow)\n",
+ "waveglow = waveglow.to('cuda')\n",
+ "waveglow.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b0dcbce",
+ "metadata": {},
+ "source": [
+ "Load a pretrained Tacotron2 model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1e1c62ea",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp32')\n",
+ "tacotron2 = tacotron2.to('cuda')\n",
+ "tacotron2.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df4cc284",
+ "metadata": {},
+ "source": [
+ "Now, let's make the model say:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa1ca779",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"hello world, I missed you so much\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ad6ebad",
+ "metadata": {},
+ "source": [
+ "Format the input using utility methods"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b6dc4d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')\n",
+ "sequences, lengths = utils.prepare_input_sequence([text])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2de62c22",
+ "metadata": {},
+ "source": [
+ "Run the chained models"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "881b70b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " mel, _, _ = tacotron2.infer(sequences, lengths)\n",
+ " audio = waveglow.infer(mel)\n",
+ "audio_numpy = audio[0].data.cpu().numpy()\n",
+ "rate = 22050"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9471a982",
+ "metadata": {},
+ "source": [
+ "You can write it to a file and listen to it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "87449085",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", rate, audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8555270",
+ "metadata": {},
+ "source": [
+ "Alternatively, play it right away in a notebook with IPython widgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1a54e376",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import Audio\n",
+ "Audio(audio_numpy, rate=rate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "461a1cf1",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2) and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions](https://arxiv.org/abs/1712.05884)\n",
+ " - [WaveGlow: A Flow-based Generative Network for Speech Synthesis](https://arxiv.org/abs/1811.00002)\n",
+ " - [Tacotron2 and WaveGlow on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ " - [Tacotron2 and Waveglow on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_fairseq_roberta.ipynb b/assets/hub/pytorch_fairseq_roberta.ipynb
new file mode 100644
index 000000000000..a0b9e24a2743
--- /dev/null
+++ b/assets/hub/pytorch_fairseq_roberta.ipynb
@@ -0,0 +1,190 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a22ee80f",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# RoBERTa\n",
+ "\n",
+ "*Author: Facebook AI (fairseq Team)*\n",
+ "\n",
+ "**A Robustly Optimized BERT Pretraining Approach**\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "Bidirectional Encoder Representations from Transformers, or [BERT][1], is a\n",
+ "revolutionary self-supervised pretraining technique that learns to predict\n",
+ "intentionally hidden (masked) sections of text. Crucially, the representations\n",
+ "learned by BERT have been shown to generalize well to downstream tasks, and when\n",
+ "BERT was first released in 2018 it achieved state-of-the-art results on many NLP\n",
+ "benchmark datasets.\n",
+ "\n",
+ "[RoBERTa][2] builds on BERT's language masking strategy and modifies key\n",
+ "hyperparameters in BERT, including removing BERT's next-sentence pretraining\n",
+ "objective, and training with much larger mini-batches and learning rates.\n",
+ "RoBERTa was also trained on an order of magnitude more data than BERT, for a\n",
+ "longer amount of time. This allows RoBERTa representations to generalize even\n",
+ "better to downstream tasks compared to BERT.\n",
+ "\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "We require a few additional Python dependencies for preprocessing:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31bf82e3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install regex requests hydra-core omegaconf"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c661359f",
+ "metadata": {},
+ "source": [
+ "### Example\n",
+ "\n",
+ "##### Load RoBERTa"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ea6f6c39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "roberta = torch.hub.load('pytorch/fairseq', 'roberta.large')\n",
+ "roberta.eval() # disable dropout (or leave in train mode to finetune)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec181a50",
+ "metadata": {},
+ "source": [
+ "##### Apply Byte-Pair Encoding (BPE) to input text"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb01609c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokens = roberta.encode('Hello world!')\n",
+ "assert tokens.tolist() == [0, 31414, 232, 328, 2]\n",
+ "assert roberta.decode(tokens) == 'Hello world!'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6903db0b",
+ "metadata": {},
+ "source": [
+ "##### Extract features from RoBERTa"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "637c35e5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract the last layer's features\n",
+ "last_layer_features = roberta.extract_features(tokens)\n",
+ "assert last_layer_features.size() == torch.Size([1, 5, 1024])\n",
+ "\n",
+ "# Extract all layer's features (layer 0 is the embedding layer)\n",
+ "all_layers = roberta.extract_features(tokens, return_all_hiddens=True)\n",
+ "assert len(all_layers) == 25\n",
+ "assert torch.all(all_layers[-1] == last_layer_features)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db346d27",
+ "metadata": {},
+ "source": [
+ "##### Use RoBERTa for sentence-pair classification tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "898b46e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download RoBERTa already finetuned for MNLI\n",
+ "roberta = torch.hub.load('pytorch/fairseq', 'roberta.large.mnli')\n",
+ "roberta.eval() # disable dropout for evaluation\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " # Encode a pair of sentences and make a prediction\n",
+ " tokens = roberta.encode('Roberta is a heavily optimized version of BERT.', 'Roberta is not very optimized.')\n",
+ " prediction = roberta.predict('mnli', tokens).argmax().item()\n",
+ " assert prediction == 0 # contradiction\n",
+ "\n",
+ " # Encode another pair of sentences\n",
+ " tokens = roberta.encode('Roberta is a heavily optimized version of BERT.', 'Roberta is based on BERT.')\n",
+ " prediction = roberta.predict('mnli', tokens).argmax().item()\n",
+ " assert prediction == 2 # entailment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c234073",
+ "metadata": {},
+ "source": [
+ "##### Register a new (randomly initialized) classification head"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1a89094b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "roberta.register_classification_head('new_task', num_classes=3)\n",
+ "logprobs = roberta.predict('new_task', tokens) # tensor([[-1.1050, -1.0672, -1.1245]], grad_fn=
\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "The Tacotron 2 and WaveGlow model form a text-to-speech system that enables user to synthesise a natural sounding speech from raw transcripts without any additional prosody information. The Tacotron 2 model (also available via torch.hub) produces mel spectrograms from input text using encoder-decoder architecture. WaveGlow is a flow-based model that consumes the mel spectrograms to generate speech.\n",
+ "\n",
+ "### Example\n",
+ "\n",
+ "In the example below:\n",
+ "- pretrained Tacotron2 and Waveglow models are loaded from torch.hub\n",
+ "- Given a tensor representation of the input text (\"Hello world, I missed you so much\"), Tacotron2 generates a Mel spectrogram as shown on the illustration\n",
+ "- Waveglow generates sound given the mel spectrogram\n",
+ "- the output sound is saved in an 'audio.wav' file\n",
+ "\n",
+ "To run the example you need some extra python packages installed.\n",
+ "These are needed for preprocessing the text and audio, as well as for display and input / output."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "406508db",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install numpy scipy librosa unidecode inflect librosa\n",
+ "apt-get update\n",
+ "apt-get install -y libsndfile1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "942e77d1",
+ "metadata": {},
+ "source": [
+ "Load the WaveGlow model pre-trained on [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "537f1a63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "waveglow = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_waveglow', model_math='fp32')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7a47b767",
+ "metadata": {},
+ "source": [
+ "Prepare the WaveGlow model for inference"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1fbed70c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waveglow = waveglow.remove_weightnorm(waveglow)\n",
+ "waveglow = waveglow.to('cuda')\n",
+ "waveglow.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8b0dcbce",
+ "metadata": {},
+ "source": [
+ "Load a pretrained Tacotron2 model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1e1c62ea",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tacotron2 = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tacotron2', model_math='fp32')\n",
+ "tacotron2 = tacotron2.to('cuda')\n",
+ "tacotron2.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "df4cc284",
+ "metadata": {},
+ "source": [
+ "Now, let's make the model say:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aa1ca779",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "text = \"hello world, I missed you so much\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ad6ebad",
+ "metadata": {},
+ "source": [
+ "Format the input using utility methods"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1b6dc4d1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "utils = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_tts_utils')\n",
+ "sequences, lengths = utils.prepare_input_sequence([text])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2de62c22",
+ "metadata": {},
+ "source": [
+ "Run the chained models"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "881b70b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "with torch.no_grad():\n",
+ " mel, _, _ = tacotron2.infer(sequences, lengths)\n",
+ " audio = waveglow.infer(mel)\n",
+ "audio_numpy = audio[0].data.cpu().numpy()\n",
+ "rate = 22050"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9471a982",
+ "metadata": {},
+ "source": [
+ "You can write it to a file and listen to it"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "87449085",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from scipy.io.wavfile import write\n",
+ "write(\"audio.wav\", rate, audio_numpy)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b8555270",
+ "metadata": {},
+ "source": [
+ "Alternatively, play it right away in a notebook with IPython widgets"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1a54e376",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from IPython.display import Audio\n",
+ "Audio(audio_numpy, rate=rate)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "461a1cf1",
+ "metadata": {},
+ "source": [
+ "### Details\n",
+ "For detailed information on model input and output, training recipies, inference and performance visit: [github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2) and/or [NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions](https://arxiv.org/abs/1712.05884)\n",
+ " - [WaveGlow: A Flow-based Generative Network for Speech Synthesis](https://arxiv.org/abs/1811.00002)\n",
+ " - [Tacotron2 and WaveGlow on NGC](https://ngc.nvidia.com/catalog/resources/nvidia:tacotron_2_and_waveglow_for_pytorch)\n",
+ " - [Tacotron2 and Waveglow on github](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_fairseq_roberta.ipynb b/assets/hub/pytorch_fairseq_roberta.ipynb
new file mode 100644
index 000000000000..a0b9e24a2743
--- /dev/null
+++ b/assets/hub/pytorch_fairseq_roberta.ipynb
@@ -0,0 +1,190 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a22ee80f",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# RoBERTa\n",
+ "\n",
+ "*Author: Facebook AI (fairseq Team)*\n",
+ "\n",
+ "**A Robustly Optimized BERT Pretraining Approach**\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Model Description\n",
+ "\n",
+ "Bidirectional Encoder Representations from Transformers, or [BERT][1], is a\n",
+ "revolutionary self-supervised pretraining technique that learns to predict\n",
+ "intentionally hidden (masked) sections of text. Crucially, the representations\n",
+ "learned by BERT have been shown to generalize well to downstream tasks, and when\n",
+ "BERT was first released in 2018 it achieved state-of-the-art results on many NLP\n",
+ "benchmark datasets.\n",
+ "\n",
+ "[RoBERTa][2] builds on BERT's language masking strategy and modifies key\n",
+ "hyperparameters in BERT, including removing BERT's next-sentence pretraining\n",
+ "objective, and training with much larger mini-batches and learning rates.\n",
+ "RoBERTa was also trained on an order of magnitude more data than BERT, for a\n",
+ "longer amount of time. This allows RoBERTa representations to generalize even\n",
+ "better to downstream tasks compared to BERT.\n",
+ "\n",
+ "\n",
+ "### Requirements\n",
+ "\n",
+ "We require a few additional Python dependencies for preprocessing:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31bf82e3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install regex requests hydra-core omegaconf"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c661359f",
+ "metadata": {},
+ "source": [
+ "### Example\n",
+ "\n",
+ "##### Load RoBERTa"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ea6f6c39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "roberta = torch.hub.load('pytorch/fairseq', 'roberta.large')\n",
+ "roberta.eval() # disable dropout (or leave in train mode to finetune)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec181a50",
+ "metadata": {},
+ "source": [
+ "##### Apply Byte-Pair Encoding (BPE) to input text"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb01609c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "tokens = roberta.encode('Hello world!')\n",
+ "assert tokens.tolist() == [0, 31414, 232, 328, 2]\n",
+ "assert roberta.decode(tokens) == 'Hello world!'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6903db0b",
+ "metadata": {},
+ "source": [
+ "##### Extract features from RoBERTa"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "637c35e5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Extract the last layer's features\n",
+ "last_layer_features = roberta.extract_features(tokens)\n",
+ "assert last_layer_features.size() == torch.Size([1, 5, 1024])\n",
+ "\n",
+ "# Extract all layer's features (layer 0 is the embedding layer)\n",
+ "all_layers = roberta.extract_features(tokens, return_all_hiddens=True)\n",
+ "assert len(all_layers) == 25\n",
+ "assert torch.all(all_layers[-1] == last_layer_features)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db346d27",
+ "metadata": {},
+ "source": [
+ "##### Use RoBERTa for sentence-pair classification tasks"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "898b46e2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download RoBERTa already finetuned for MNLI\n",
+ "roberta = torch.hub.load('pytorch/fairseq', 'roberta.large.mnli')\n",
+ "roberta.eval() # disable dropout for evaluation\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " # Encode a pair of sentences and make a prediction\n",
+ " tokens = roberta.encode('Roberta is a heavily optimized version of BERT.', 'Roberta is not very optimized.')\n",
+ " prediction = roberta.predict('mnli', tokens).argmax().item()\n",
+ " assert prediction == 0 # contradiction\n",
+ "\n",
+ " # Encode another pair of sentences\n",
+ " tokens = roberta.encode('Roberta is a heavily optimized version of BERT.', 'Roberta is based on BERT.')\n",
+ " prediction = roberta.predict('mnli', tokens).argmax().item()\n",
+ " assert prediction == 2 # entailment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6c234073",
+ "metadata": {},
+ "source": [
+ "##### Register a new (randomly initialized) classification head"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1a89094b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "roberta.register_classification_head('new_task', num_classes=3)\n",
+ "logprobs = roberta.predict('new_task', tokens) # tensor([[-1.1050, -1.0672, -1.1245]], grad_fn= "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4d3c51de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huawei-noah/ghostnet', 'ghostnet_1x', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f950f2af",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58fbf55e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ab2d59bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2979ac25",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b59152d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d889cf0",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "The GhostNet architecture is based on an Ghost module structure which generate more features from cheap operations. Based on a set of intrinsic feature maps, a series of cheap operations are applied to generate many ghost feature maps that could fully reveal information underlying intrinsic features. Experiments conducted on benchmarks demonstrate that the superiority of GhostNet in terms of speed and accuracy tradeoff.\n",
+ "\n",
+ "The corresponding accuracy on ImageNet dataset with pretrained model is listed below.\n",
+ "\n",
+ "| Model structure | FLOPs | Top-1 acc | Top-5 acc |\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| GhostNet 1.0x | 142M | 73.98 | 91.46 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "You can read the full paper at this [link](https://arxiv.org/abs/1911.11907).\n",
+ "\n",
+ ">@inproceedings{han2019ghostnet,\n",
+ "> title={GhostNet: More Features from Cheap Operations},\n",
+ "> author={Kai Han and Yunhe Wang and Qi Tian and Jianyuan Guo and Chunjing Xu and Chang Xu},\n",
+ "> booktitle={CVPR},\n",
+ "> year={2020},\n",
+ ">}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_googlenet.ipynb b/assets/hub/pytorch_vision_googlenet.ipynb
new file mode 100644
index 000000000000..a17e3e2097ae
--- /dev/null
+++ b/assets/hub/pytorch_vision_googlenet.ipynb
@@ -0,0 +1,148 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "3de6cad3",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# GoogLeNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**GoogLeNet was based on a deep convolutional neural network architecture codenamed \"Inception\" which won ImageNet 2014.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9f47a584",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'googlenet', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "535bcc73",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb150def",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b6cbf35",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59b9161f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "19a93651",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84c98908",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "GoogLeNet was based on a deep convolutional neural network architecture codenamed \"Inception\", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The 1-crop error rates on the ImageNet dataset with a pretrained model are list below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| googlenet | 30.22 | 10.47 |\n",
+ "\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_hardnet.ipynb b/assets/hub/pytorch_vision_hardnet.ipynb
new file mode 100644
index 000000000000..f362326c17e2
--- /dev/null
+++ b/assets/hub/pytorch_vision_hardnet.ipynb
@@ -0,0 +1,161 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7b71e157",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# HarDNet\n",
+ "\n",
+ "*Author: PingoLH*\n",
+ "\n",
+ "**Harmonic DenseNet pre-trained on ImageNet**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ "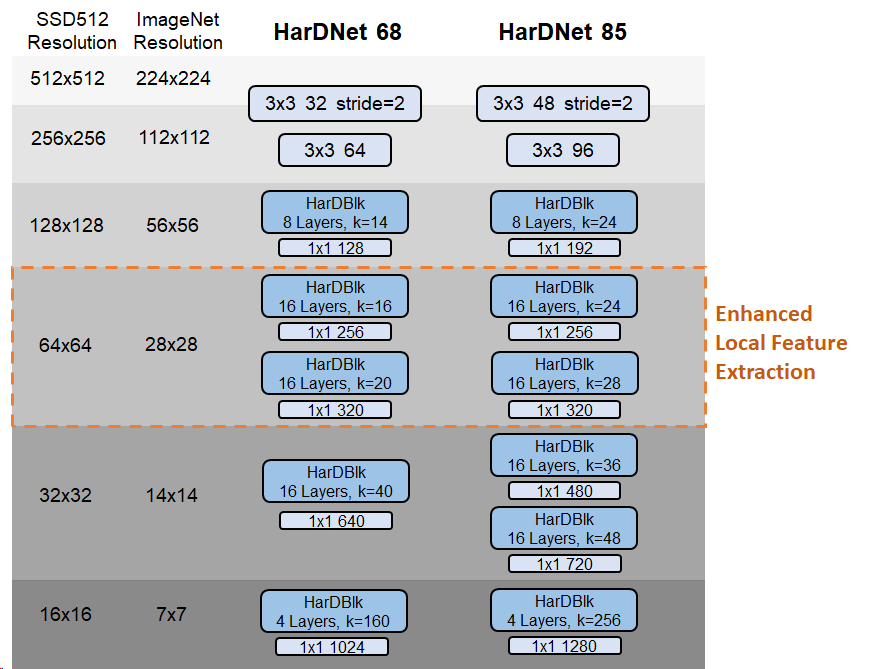 | 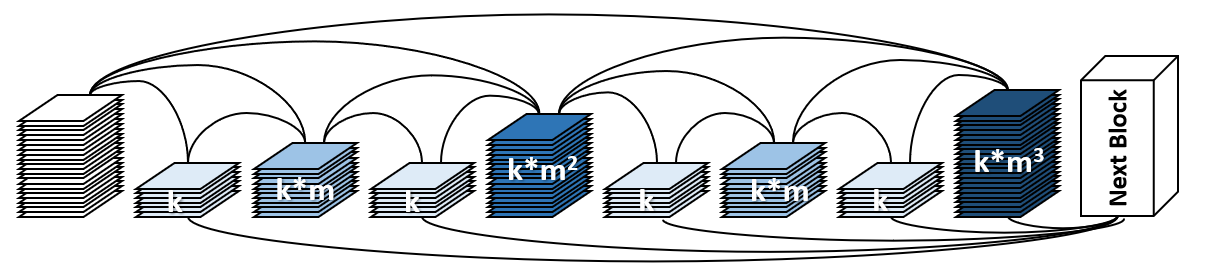"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3be2b63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet85', pretrained=True)\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68ds', pretrained=True)\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet39ds', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "781d2cd7",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e95526f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1e7c2c3e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a40b533b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cfeff952",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b85e734e",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Harmonic DenseNet (HarDNet) is a low memory traffic CNN model, which is fast and efficient.\n",
+ "The basic concept is to minimize both computational cost and memory access cost at the same\n",
+ "time, such that the HarDNet models are 35% faster than ResNet running on GPU\n",
+ "comparing to models with the same accuracy (except the two DS models that\n",
+ "were designed for comparing with MobileNet).\n",
+ "\n",
+ "Here we have the 4 versions of hardnet models, which contains 39, 68, 85 layers\n",
+ "w/ or w/o Depthwise Separable Conv respectively.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| hardnet39ds | 27.92 | 9.57 |\n",
+ "| hardnet68ds | 25.71 | 8.13 |\n",
+ "| hardnet68 | 23.52 | 6.99 |\n",
+ "| hardnet85 | 21.96 | 6.11 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [HarDNet: A Low Memory Traffic Network](https://arxiv.org/abs/1909.00948)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_ibnnet.ipynb b/assets/hub/pytorch_vision_ibnnet.ipynb
new file mode 100644
index 000000000000..d5e9bbcc434e
--- /dev/null
+++ b/assets/hub/pytorch_vision_ibnnet.ipynb
@@ -0,0 +1,164 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "981d849a",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# IBN-Net\n",
+ "\n",
+ "*Author: Xingang Pan*\n",
+ "\n",
+ "**Networks with domain/appearance invariance**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4d3c51de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huawei-noah/ghostnet', 'ghostnet_1x', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f950f2af",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58fbf55e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ab2d59bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2979ac25",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b59152d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1d889cf0",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "The GhostNet architecture is based on an Ghost module structure which generate more features from cheap operations. Based on a set of intrinsic feature maps, a series of cheap operations are applied to generate many ghost feature maps that could fully reveal information underlying intrinsic features. Experiments conducted on benchmarks demonstrate that the superiority of GhostNet in terms of speed and accuracy tradeoff.\n",
+ "\n",
+ "The corresponding accuracy on ImageNet dataset with pretrained model is listed below.\n",
+ "\n",
+ "| Model structure | FLOPs | Top-1 acc | Top-5 acc |\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| GhostNet 1.0x | 142M | 73.98 | 91.46 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "You can read the full paper at this [link](https://arxiv.org/abs/1911.11907).\n",
+ "\n",
+ ">@inproceedings{han2019ghostnet,\n",
+ "> title={GhostNet: More Features from Cheap Operations},\n",
+ "> author={Kai Han and Yunhe Wang and Qi Tian and Jianyuan Guo and Chunjing Xu and Chang Xu},\n",
+ "> booktitle={CVPR},\n",
+ "> year={2020},\n",
+ ">}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_googlenet.ipynb b/assets/hub/pytorch_vision_googlenet.ipynb
new file mode 100644
index 000000000000..a17e3e2097ae
--- /dev/null
+++ b/assets/hub/pytorch_vision_googlenet.ipynb
@@ -0,0 +1,148 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "3de6cad3",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# GoogLeNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**GoogLeNet was based on a deep convolutional neural network architecture codenamed \"Inception\" which won ImageNet 2014.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9f47a584",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'googlenet', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "535bcc73",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb150def",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b6cbf35",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "59b9161f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "19a93651",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84c98908",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "GoogLeNet was based on a deep convolutional neural network architecture codenamed \"Inception\", which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC 2014). The 1-crop error rates on the ImageNet dataset with a pretrained model are list below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| googlenet | 30.22 | 10.47 |\n",
+ "\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Going Deeper with Convolutions](https://arxiv.org/abs/1409.4842)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_hardnet.ipynb b/assets/hub/pytorch_vision_hardnet.ipynb
new file mode 100644
index 000000000000..f362326c17e2
--- /dev/null
+++ b/assets/hub/pytorch_vision_hardnet.ipynb
@@ -0,0 +1,161 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7b71e157",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# HarDNet\n",
+ "\n",
+ "*Author: PingoLH*\n",
+ "\n",
+ "**Harmonic DenseNet pre-trained on ImageNet**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c3be2b63",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet85', pretrained=True)\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet68ds', pretrained=True)\n",
+ "# model = torch.hub.load('PingoLH/Pytorch-HarDNet', 'hardnet39ds', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "781d2cd7",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7e95526f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1e7c2c3e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a40b533b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "cfeff952",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b85e734e",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Harmonic DenseNet (HarDNet) is a low memory traffic CNN model, which is fast and efficient.\n",
+ "The basic concept is to minimize both computational cost and memory access cost at the same\n",
+ "time, such that the HarDNet models are 35% faster than ResNet running on GPU\n",
+ "comparing to models with the same accuracy (except the two DS models that\n",
+ "were designed for comparing with MobileNet).\n",
+ "\n",
+ "Here we have the 4 versions of hardnet models, which contains 39, 68, 85 layers\n",
+ "w/ or w/o Depthwise Separable Conv respectively.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| hardnet39ds | 27.92 | 9.57 |\n",
+ "| hardnet68ds | 25.71 | 8.13 |\n",
+ "| hardnet68 | 23.52 | 6.99 |\n",
+ "| hardnet85 | 21.96 | 6.11 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [HarDNet: A Low Memory Traffic Network](https://arxiv.org/abs/1909.00948)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_ibnnet.ipynb b/assets/hub/pytorch_vision_ibnnet.ipynb
new file mode 100644
index 000000000000..d5e9bbcc434e
--- /dev/null
+++ b/assets/hub/pytorch_vision_ibnnet.ipynb
@@ -0,0 +1,164 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "981d849a",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# IBN-Net\n",
+ "\n",
+ "*Author: Xingang Pan*\n",
+ "\n",
+ "**Networks with domain/appearance invariance**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "638d2324",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('XingangPan/IBN-Net', 'resnet50_ibn_a', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd36e6ab",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50499219",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81296a41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8f1a0cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "805ecb76",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85dcd9b3",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "IBN-Net is a CNN model with domain/appearance invariance.\n",
+ "Motivated by style transfer works, IBN-Net carefully unifies instance normalization and batch normalization in a single deep network.\n",
+ "It provides a simple way to increase both modeling and generalization capacities without adding model complexity.\n",
+ "IBN-Net is especially suitable for cross domain or person/vehicle re-identification tasks.\n",
+ "\n",
+ "The corresponding accuracies on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model name | Top-1 acc | Top-5 acc |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| resnet50_ibn_a | 77.46 | 93.68 |\n",
+ "| resnet101_ibn_a | 78.61 | 94.41 |\n",
+ "| resnext101_ibn_a | 79.12 | 94.58 |\n",
+ "| se_resnet101_ibn_a | 78.75 | 94.49 |\n",
+ "\n",
+ "The rank1/mAP on two Re-ID benchmarks Market1501 and DukeMTMC-reID are listed below (from [michuanhaohao/reid-strong-baseline](https://github.com/michuanhaohao/reid-strong-baseline)).\n",
+ "\n",
+ "| Backbone | Market1501 | DukeMTMC-reID |\n",
+ "| --- | -- | -- |\n",
+ "| ResNet50 | 94.5 (85.9) | 86.4 (76.4) |\n",
+ "| ResNet101 | 94.5 (87.1) | 87.6 (77.6) |\n",
+ "| SeResNet50 | 94.4 (86.3) | 86.4 (76.5) |\n",
+ "| SeResNet101 | 94.6 (87.3) | 87.5 (78.0) |\n",
+ "| SeResNeXt50 | 94.9 (87.6) | 88.0 (78.3) |\n",
+ "| SeResNeXt101 | 95.0 (88.0) | 88.4 (79.0) |\n",
+ "| ResNet50-IBN-a | 95.0 (88.2) | 90.1 (79.1) |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net](https://arxiv.org/abs/1807.09441)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_inception_v3.ipynb b/assets/hub/pytorch_vision_inception_v3.ipynb
new file mode 100644
index 000000000000..087a6201fe8f
--- /dev/null
+++ b/assets/hub/pytorch_vision_inception_v3.ipynb
@@ -0,0 +1,146 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "6a0633dd",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Inception_v3\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Also called GoogleNetv3, a famous ConvNet trained on ImageNet from 2015**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "638d2324",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('XingangPan/IBN-Net', 'resnet50_ibn_a', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd36e6ab",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "50499219",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81296a41",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8f1a0cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "805ecb76",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "85dcd9b3",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "IBN-Net is a CNN model with domain/appearance invariance.\n",
+ "Motivated by style transfer works, IBN-Net carefully unifies instance normalization and batch normalization in a single deep network.\n",
+ "It provides a simple way to increase both modeling and generalization capacities without adding model complexity.\n",
+ "IBN-Net is especially suitable for cross domain or person/vehicle re-identification tasks.\n",
+ "\n",
+ "The corresponding accuracies on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model name | Top-1 acc | Top-5 acc |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| resnet50_ibn_a | 77.46 | 93.68 |\n",
+ "| resnet101_ibn_a | 78.61 | 94.41 |\n",
+ "| resnext101_ibn_a | 79.12 | 94.58 |\n",
+ "| se_resnet101_ibn_a | 78.75 | 94.49 |\n",
+ "\n",
+ "The rank1/mAP on two Re-ID benchmarks Market1501 and DukeMTMC-reID are listed below (from [michuanhaohao/reid-strong-baseline](https://github.com/michuanhaohao/reid-strong-baseline)).\n",
+ "\n",
+ "| Backbone | Market1501 | DukeMTMC-reID |\n",
+ "| --- | -- | -- |\n",
+ "| ResNet50 | 94.5 (85.9) | 86.4 (76.4) |\n",
+ "| ResNet101 | 94.5 (87.1) | 87.6 (77.6) |\n",
+ "| SeResNet50 | 94.4 (86.3) | 86.4 (76.5) |\n",
+ "| SeResNet101 | 94.6 (87.3) | 87.5 (78.0) |\n",
+ "| SeResNeXt50 | 94.9 (87.6) | 88.0 (78.3) |\n",
+ "| SeResNeXt101 | 95.0 (88.0) | 88.4 (79.0) |\n",
+ "| ResNet50-IBN-a | 95.0 (88.2) | 90.1 (79.1) |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net](https://arxiv.org/abs/1807.09441)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_inception_v3.ipynb b/assets/hub/pytorch_vision_inception_v3.ipynb
new file mode 100644
index 000000000000..087a6201fe8f
--- /dev/null
+++ b/assets/hub/pytorch_vision_inception_v3.ipynb
@@ -0,0 +1,146 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "6a0633dd",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Inception_v3\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Also called GoogleNetv3, a famous ConvNet trained on ImageNet from 2015**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b593a71f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'inception_v3', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "24d6e73e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `299`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1228762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c187630",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(299),\n",
+ " transforms.CenterCrop(299),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4d1c366",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "adc090b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e0199fa7",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Inception v3: Based on the exploration of ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.\n",
+ "\n",
+ "The 1-crop error rates on the ImageNet dataset with the pretrained model are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| inception_v3 | 22.55 | 6.44 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/abs/1512.00567)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_meal_v2.ipynb b/assets/hub/pytorch_vision_meal_v2.ipynb
new file mode 100644
index 000000000000..bea099f0d0cb
--- /dev/null
+++ b/assets/hub/pytorch_vision_meal_v2.ipynb
@@ -0,0 +1,199 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "87b6d7ba",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MEAL_V2\n",
+ "\n",
+ "*Author: Carnegie Mellon University*\n",
+ "\n",
+ "**Boosting Tiny and Efficient Models using Knowledge Distillation.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ "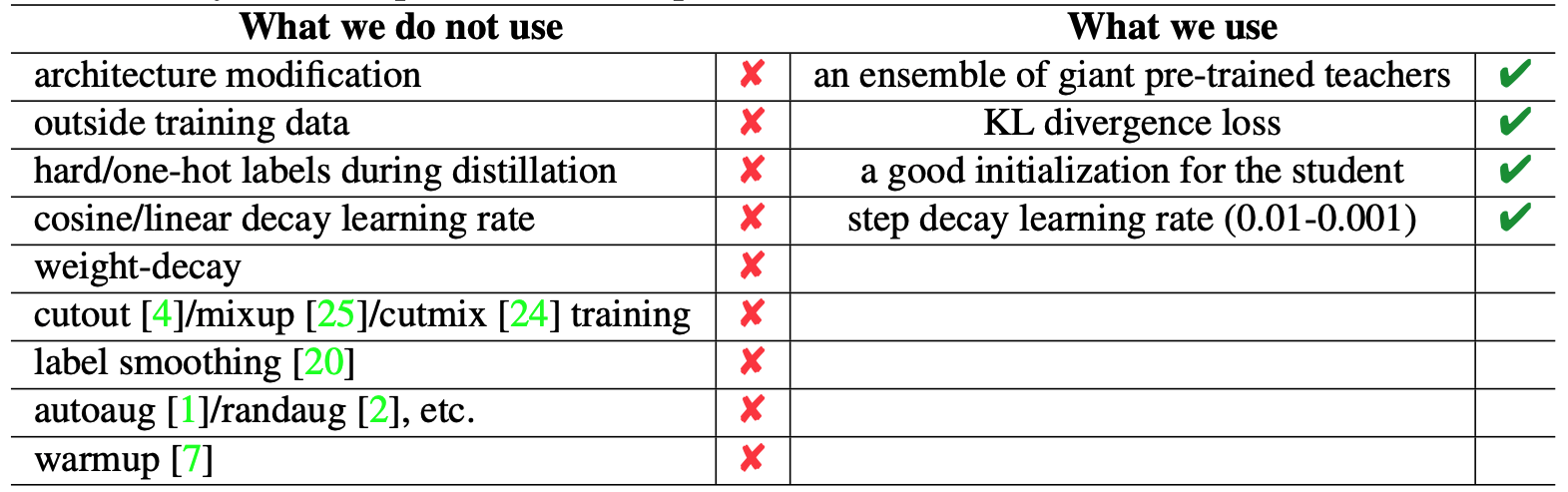 | 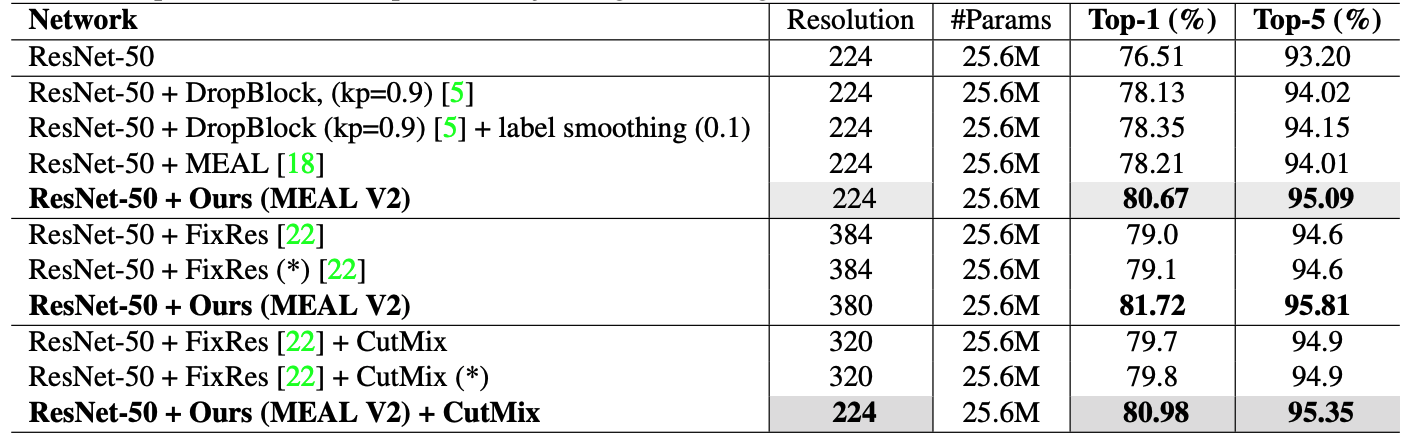\n",
+ "\n",
+ "\n",
+ "We require one additional Python dependency"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "041ba368",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "!pip install timm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d29f16dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# list of models: 'mealv1_resnest50', 'mealv2_resnest50', 'mealv2_resnest50_cutmix', 'mealv2_resnest50_380x380', 'mealv2_mobilenetv3_small_075', 'mealv2_mobilenetv3_small_100', 'mealv2_mobilenet_v3_large_100', 'mealv2_efficientnet_b0'\n",
+ "# load pretrained models, using \"mealv2_resnest50_cutmix\" as an example\n",
+ "model = torch.hub.load('szq0214/MEAL-V2','meal_v2', 'mealv2_resnest50_cutmix', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "99c27a3e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5aa4fa53",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9f18274",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2ce4b3fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c392ed05",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2de17ed5",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "MEAL V2 models are from the [MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks](https://arxiv.org/pdf/2009.08453.pdf) paper.\n",
+ "\n",
+ "In this paper, we introduce a simple yet effective approach that can boost the vanilla ResNet-50 to 80%+ Top-1 accuracy on ImageNet without any tricks. Generally, our method is based on the recently proposed [MEAL](https://arxiv.org/abs/1812.02425), i.e., ensemble knowledge distillation via discriminators. We further simplify it through 1) adopting the similarity loss and discriminator only on the final outputs and 2) using the average of softmax probabilities from all teacher ensembles as the stronger supervision for distillation. One crucial perspective of our method is that the one-hot/hard label should not be used in the distillation process. We show that such a simple framework can achieve state-of-the-art results without involving any commonly-used tricks, such as 1) architecture modification; 2) outside training data beyond ImageNet; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix training; 6) label smoothing; etc.\n",
+ "\n",
+ "| Models | Resolution| #Parameters | Top-1/Top-5 |\n",
+ "| :---: | :-: | :-: | :------:| :------: | \n",
+ "| [MEAL-V1 w/ ResNet50](https://arxiv.org/abs/1812.02425) | 224 | 25.6M |**78.21/94.01** | [GitHub](https://github.com/AaronHeee/MEAL#imagenet-model) |\n",
+ "| MEAL-V2 w/ ResNet50 | 224 | 25.6M | **80.67/95.09** | \n",
+ "| MEAL-V2 w/ ResNet50| 380 | 25.6M | **81.72/95.81** | \n",
+ "| MEAL-V2 + CutMix w/ ResNet50| 224 | 25.6M | **80.98/95.35** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Small 0.75| 224 | 2.04M | **67.60/87.23** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Small 1.0| 224 | 2.54M | **69.65/88.71** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | **76.92/93.32** | \n",
+ "| MEAL-V2 w/ EfficientNet-B0| 224 | 5.29M | **78.29/93.95** | \n",
+ "\n",
+ "### References\n",
+ "\n",
+ "Please refer to our papers [MEAL V2](https://arxiv.org/pdf/2009.08453.pdf), [MEAL](https://arxiv.org/pdf/1812.02425.pdf) for more details."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1966f9f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@article{shen2020mealv2,\n",
+ " title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},\n",
+ " author={Shen, Zhiqiang and Savvides, Marios},\n",
+ " journal={arXiv preprint arXiv:2009.08453},\n",
+ " year={2020}\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4fed91a2",
+ "metadata": {},
+ "source": [
+ "@inproceedings{shen2019MEAL,\n",
+ "\t\ttitle = {MEAL: Multi-Model Ensemble via Adversarial Learning},\n",
+ "\t\tauthor = {Shen, Zhiqiang and He, Zhankui and Xue, Xiangyang},\n",
+ "\t\tbooktitle = {AAAI},\n",
+ "\t\tyear = {2019}\n",
+ "\t}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_mobilenet_v2.ipynb b/assets/hub/pytorch_vision_mobilenet_v2.ipynb
new file mode 100644
index 000000000000..b33561619ff5
--- /dev/null
+++ b/assets/hub/pytorch_vision_mobilenet_v2.ipynb
@@ -0,0 +1,147 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "eb5333f8",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MobileNet v2\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Efficient networks optimized for speed and memory, with residual blocks**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ "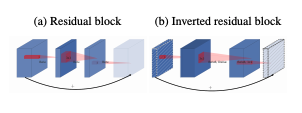 | 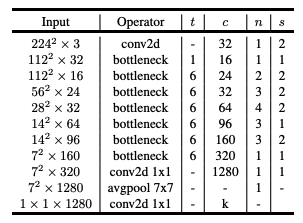"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9ec286f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'mobilenet_v2', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "efb840d6",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "82571048",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28f02763",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6380a714",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92b2e982",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "805611f2",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "The MobileNet v2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input. MobileNet v2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, non-linearities in the narrow layers were removed in order to maintain representational power.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| mobilenet_v2 | 28.12 | 9.71 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_once_for_all.ipynb b/assets/hub/pytorch_vision_once_for_all.ipynb
new file mode 100644
index 000000000000..0183543a65a3
--- /dev/null
+++ b/assets/hub/pytorch_vision_once_for_all.ipynb
@@ -0,0 +1,210 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a1a4b7f5",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Once-for-All\n",
+ "\n",
+ "*Author: MIT Han Lab*\n",
+ "\n",
+ "**Once-for-all (OFA) decouples training and search, and achieves efficient inference across various edge devices and resource constraints.**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b593a71f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'inception_v3', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "24d6e73e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `299`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f1228762",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4c187630",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(299),\n",
+ " transforms.CenterCrop(299),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f4d1c366",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "adc090b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e0199fa7",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Inception v3: Based on the exploration of ways to scale up networks in ways that aim at utilizing the added computation as efficiently as possible by suitably factorized convolutions and aggressive regularization. We benchmark our methods on the ILSVRC 2012 classification challenge validation set demonstrate substantial gains over the state of the art: 21.2% top-1 and 5.6% top-5 error for single frame evaluation using a network with a computational cost of 5 billion multiply-adds per inference and with using less than 25 million parameters. With an ensemble of 4 models and multi-crop evaluation, we report 3.5% top-5 error on the validation set (3.6% error on the test set) and 17.3% top-1 error on the validation set.\n",
+ "\n",
+ "The 1-crop error rates on the ImageNet dataset with the pretrained model are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| inception_v3 | 22.55 | 6.44 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/abs/1512.00567)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_meal_v2.ipynb b/assets/hub/pytorch_vision_meal_v2.ipynb
new file mode 100644
index 000000000000..bea099f0d0cb
--- /dev/null
+++ b/assets/hub/pytorch_vision_meal_v2.ipynb
@@ -0,0 +1,199 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "87b6d7ba",
+ "metadata": {},
+ "source": [
+ "### This notebook requires a GPU runtime to run.\n",
+ "### Please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MEAL_V2\n",
+ "\n",
+ "*Author: Carnegie Mellon University*\n",
+ "\n",
+ "**Boosting Tiny and Efficient Models using Knowledge Distillation.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | \n",
+ "\n",
+ "\n",
+ "We require one additional Python dependency"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "041ba368",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "!pip install timm"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d29f16dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# list of models: 'mealv1_resnest50', 'mealv2_resnest50', 'mealv2_resnest50_cutmix', 'mealv2_resnest50_380x380', 'mealv2_mobilenetv3_small_075', 'mealv2_mobilenetv3_small_100', 'mealv2_mobilenet_v3_large_100', 'mealv2_efficientnet_b0'\n",
+ "# load pretrained models, using \"mealv2_resnest50_cutmix\" as an example\n",
+ "model = torch.hub.load('szq0214/MEAL-V2','meal_v2', 'mealv2_resnest50_cutmix', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "99c27a3e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5aa4fa53",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c9f18274",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2ce4b3fd",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c392ed05",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2de17ed5",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "MEAL V2 models are from the [MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks](https://arxiv.org/pdf/2009.08453.pdf) paper.\n",
+ "\n",
+ "In this paper, we introduce a simple yet effective approach that can boost the vanilla ResNet-50 to 80%+ Top-1 accuracy on ImageNet without any tricks. Generally, our method is based on the recently proposed [MEAL](https://arxiv.org/abs/1812.02425), i.e., ensemble knowledge distillation via discriminators. We further simplify it through 1) adopting the similarity loss and discriminator only on the final outputs and 2) using the average of softmax probabilities from all teacher ensembles as the stronger supervision for distillation. One crucial perspective of our method is that the one-hot/hard label should not be used in the distillation process. We show that such a simple framework can achieve state-of-the-art results without involving any commonly-used tricks, such as 1) architecture modification; 2) outside training data beyond ImageNet; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix training; 6) label smoothing; etc.\n",
+ "\n",
+ "| Models | Resolution| #Parameters | Top-1/Top-5 |\n",
+ "| :---: | :-: | :-: | :------:| :------: | \n",
+ "| [MEAL-V1 w/ ResNet50](https://arxiv.org/abs/1812.02425) | 224 | 25.6M |**78.21/94.01** | [GitHub](https://github.com/AaronHeee/MEAL#imagenet-model) |\n",
+ "| MEAL-V2 w/ ResNet50 | 224 | 25.6M | **80.67/95.09** | \n",
+ "| MEAL-V2 w/ ResNet50| 380 | 25.6M | **81.72/95.81** | \n",
+ "| MEAL-V2 + CutMix w/ ResNet50| 224 | 25.6M | **80.98/95.35** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Small 0.75| 224 | 2.04M | **67.60/87.23** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Small 1.0| 224 | 2.54M | **69.65/88.71** | \n",
+ "| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | **76.92/93.32** | \n",
+ "| MEAL-V2 w/ EfficientNet-B0| 224 | 5.29M | **78.29/93.95** | \n",
+ "\n",
+ "### References\n",
+ "\n",
+ "Please refer to our papers [MEAL V2](https://arxiv.org/pdf/2009.08453.pdf), [MEAL](https://arxiv.org/pdf/1812.02425.pdf) for more details."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1966f9f3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@article{shen2020mealv2,\n",
+ " title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},\n",
+ " author={Shen, Zhiqiang and Savvides, Marios},\n",
+ " journal={arXiv preprint arXiv:2009.08453},\n",
+ " year={2020}\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4fed91a2",
+ "metadata": {},
+ "source": [
+ "@inproceedings{shen2019MEAL,\n",
+ "\t\ttitle = {MEAL: Multi-Model Ensemble via Adversarial Learning},\n",
+ "\t\tauthor = {Shen, Zhiqiang and He, Zhankui and Xue, Xiangyang},\n",
+ "\t\tbooktitle = {AAAI},\n",
+ "\t\tyear = {2019}\n",
+ "\t}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_mobilenet_v2.ipynb b/assets/hub/pytorch_vision_mobilenet_v2.ipynb
new file mode 100644
index 000000000000..b33561619ff5
--- /dev/null
+++ b/assets/hub/pytorch_vision_mobilenet_v2.ipynb
@@ -0,0 +1,147 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "eb5333f8",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# MobileNet v2\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Efficient networks optimized for speed and memory, with residual blocks**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a9ec286f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'mobilenet_v2', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "efb840d6",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "82571048",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28f02763",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6380a714",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "92b2e982",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "805611f2",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "The MobileNet v2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input. MobileNet v2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, non-linearities in the narrow layers were removed in order to maintain representational power.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| mobilenet_v2 | 28.12 | 9.71 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_once_for_all.ipynb b/assets/hub/pytorch_vision_once_for_all.ipynb
new file mode 100644
index 000000000000..0183543a65a3
--- /dev/null
+++ b/assets/hub/pytorch_vision_once_for_all.ipynb
@@ -0,0 +1,210 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a1a4b7f5",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Once-for-All\n",
+ "\n",
+ "*Author: MIT Han Lab*\n",
+ "\n",
+ "**Once-for-all (OFA) decouples training and search, and achieves efficient inference across various edge devices and resource constraints.**\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Get supernet\n",
+ "\n",
+ "You can quickly load a supernet as following"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53f8de30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "super_net_name = \"ofa_supernet_mbv3_w10\" \n",
+ "# other options: \n",
+ "# ofa_supernet_resnet50 / \n",
+ "# ofa_supernet_mbv3_w12 / \n",
+ "# ofa_supernet_proxyless\n",
+ "\n",
+ "super_net = torch.hub.load('mit-han-lab/once-for-all', super_net_name, pretrained=True).eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fd4088d",
+ "metadata": {},
+ "source": [
+ "| OFA Network | Design Space | Resolution | Width Multiplier | Depth | Expand Ratio | kernel Size | \n",
+ "|----------------------|----------|----------|---------|------------|---------|------------|\n",
+ "| ofa_resnet50 | ResNet50D | 128 - 224 | 0.65, 0.8, 1.0 | 0, 1, 2 | 0.2, 0.25, 0.35 | 3 |\n",
+ "| ofa_mbv3_d234_e346_k357_w1.0 | MobileNetV3 | 128 - 224 | 1.0 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "| ofa_mbv3_d234_e346_k357_w1.2 | MobileNetV3 | 160 - 224 | 1.2 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "| ofa_proxyless_d234_e346_k357_w1.3 | ProxylessNAS | 128 - 224 | 1.3 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "\n",
+ "\n",
+ "Below are the usage of sampling / selecting a subnet from the supernet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b33c44d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Randomly sample sub-networks from OFA network\n",
+ "super_net.sample_active_subnet()\n",
+ "random_subnet = super_net.get_active_subnet(preserve_weight=True)\n",
+ " \n",
+ "# Manually set the sub-network\n",
+ "super_net.set_active_subnet(ks=7, e=6, d=4)\n",
+ "manual_subnet = super_net.get_active_subnet(preserve_weight=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd512c03",
+ "metadata": {},
+ "source": [
+ "### Get Specialized Architecture"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e1d56c24",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# or load a architecture specialized for certain platform\n",
+ "net_config = \"resnet50D_MAC_4_1B\"\n",
+ "\n",
+ "specialized_net, image_size = torch.hub.load('mit-han-lab/once-for-all', net_config, pretrained=True)\n",
+ "specialized_net.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "157a77cd",
+ "metadata": {},
+ "source": [
+ "More models and configurations can be found in [once-for-all/model-zoo](https://github.com/mit-han-lab/once-for-all#evaluate-1)\n",
+ "and obtained through the following scripts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9985bdd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ofa_specialized_get = torch.hub.load('mit-han-lab/once-for-all', \"ofa_specialized_get\")\n",
+ "model, image_size = ofa_specialized_get(\"flops@595M_top1@80.0_finetune@75\", pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b98bdea4",
+ "metadata": {},
+ "source": [
+ "The model's prediction can be evalutaed by"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d86ac1d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: \n",
+ " urllib.URLopener().retrieve(url, filename)\n",
+ "except: \n",
+ " urllib.request.urlretrieve(url, filename)\n",
+ "\n",
+ "\n",
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db6dd8fb",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "Once-for-all models are from [Once for All: Train One Network and Specialize it for Efficient Deployment](https://arxiv.org/abs/1908.09791). Conventional approaches either manually design or use neural architecture search (NAS) to find a specialized neural network and train it from scratch for each case, which is computationally prohibitive (causing CO2 emission as much as 5 cars' lifetime) thus unscalable. In this work, we propose to train a once-for-all (OFA) network that supports diverse architectural settings by decoupling training and search. Across diverse edge devices, OFA consistently outperforms state-of-the-art (SOTA) NAS methods (up to 4.0% ImageNet top1 accuracy improvement over MobileNetV3, or same accuracy but 1.5x faster than MobileNetV3, 2.6x faster than EfficientNet w.r.t measured latency) while reducing many orders of magnitude GPU hours and CO2 emission. In particular, OFA achieves a new SOTA 80.0% ImageNet top-1 accuracy under the mobile setting (<600M MACs).\n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Get supernet\n",
+ "\n",
+ "You can quickly load a supernet as following"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "53f8de30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "super_net_name = \"ofa_supernet_mbv3_w10\" \n",
+ "# other options: \n",
+ "# ofa_supernet_resnet50 / \n",
+ "# ofa_supernet_mbv3_w12 / \n",
+ "# ofa_supernet_proxyless\n",
+ "\n",
+ "super_net = torch.hub.load('mit-han-lab/once-for-all', super_net_name, pretrained=True).eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1fd4088d",
+ "metadata": {},
+ "source": [
+ "| OFA Network | Design Space | Resolution | Width Multiplier | Depth | Expand Ratio | kernel Size | \n",
+ "|----------------------|----------|----------|---------|------------|---------|------------|\n",
+ "| ofa_resnet50 | ResNet50D | 128 - 224 | 0.65, 0.8, 1.0 | 0, 1, 2 | 0.2, 0.25, 0.35 | 3 |\n",
+ "| ofa_mbv3_d234_e346_k357_w1.0 | MobileNetV3 | 128 - 224 | 1.0 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "| ofa_mbv3_d234_e346_k357_w1.2 | MobileNetV3 | 160 - 224 | 1.2 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "| ofa_proxyless_d234_e346_k357_w1.3 | ProxylessNAS | 128 - 224 | 1.3 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |\n",
+ "\n",
+ "\n",
+ "Below are the usage of sampling / selecting a subnet from the supernet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6b33c44d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Randomly sample sub-networks from OFA network\n",
+ "super_net.sample_active_subnet()\n",
+ "random_subnet = super_net.get_active_subnet(preserve_weight=True)\n",
+ " \n",
+ "# Manually set the sub-network\n",
+ "super_net.set_active_subnet(ks=7, e=6, d=4)\n",
+ "manual_subnet = super_net.get_active_subnet(preserve_weight=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dd512c03",
+ "metadata": {},
+ "source": [
+ "### Get Specialized Architecture"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e1d56c24",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# or load a architecture specialized for certain platform\n",
+ "net_config = \"resnet50D_MAC_4_1B\"\n",
+ "\n",
+ "specialized_net, image_size = torch.hub.load('mit-han-lab/once-for-all', net_config, pretrained=True)\n",
+ "specialized_net.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "157a77cd",
+ "metadata": {},
+ "source": [
+ "More models and configurations can be found in [once-for-all/model-zoo](https://github.com/mit-han-lab/once-for-all#evaluate-1)\n",
+ "and obtained through the following scripts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9985bdd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "ofa_specialized_get = torch.hub.load('mit-han-lab/once-for-all', \"ofa_specialized_get\")\n",
+ "model, image_size = ofa_specialized_get(\"flops@595M_top1@80.0_finetune@75\", pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b98bdea4",
+ "metadata": {},
+ "source": [
+ "The model's prediction can be evalutaed by"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2d86ac1d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: \n",
+ " urllib.URLopener().retrieve(url, filename)\n",
+ "except: \n",
+ " urllib.request.urlretrieve(url, filename)\n",
+ "\n",
+ "\n",
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "db6dd8fb",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "Once-for-all models are from [Once for All: Train One Network and Specialize it for Efficient Deployment](https://arxiv.org/abs/1908.09791). Conventional approaches either manually design or use neural architecture search (NAS) to find a specialized neural network and train it from scratch for each case, which is computationally prohibitive (causing CO2 emission as much as 5 cars' lifetime) thus unscalable. In this work, we propose to train a once-for-all (OFA) network that supports diverse architectural settings by decoupling training and search. Across diverse edge devices, OFA consistently outperforms state-of-the-art (SOTA) NAS methods (up to 4.0% ImageNet top1 accuracy improvement over MobileNetV3, or same accuracy but 1.5x faster than MobileNetV3, 2.6x faster than EfficientNet w.r.t measured latency) while reducing many orders of magnitude GPU hours and CO2 emission. In particular, OFA achieves a new SOTA 80.0% ImageNet top-1 accuracy under the mobile setting (<600M MACs).\n",
+ "\n",
+ "\n",
+ " \n",
+ "\n",
+ "\n",
+ "### References"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6fa6a8b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@inproceedings{\n",
+ " cai2020once,\n",
+ " title={Once for All: Train One Network and Specialize it for Efficient Deployment},\n",
+ " author={Han Cai and Chuang Gan and Tianzhe Wang and Zhekai Zhang and Song Han},\n",
+ " booktitle={International Conference on Learning Representations},\n",
+ " year={2020},\n",
+ " url={https://arxiv.org/pdf/1908.09791.pdf}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_proxylessnas.ipynb b/assets/hub/pytorch_vision_proxylessnas.ipynb
new file mode 100644
index 000000000000..0bf04652b2a2
--- /dev/null
+++ b/assets/hub/pytorch_vision_proxylessnas.ipynb
@@ -0,0 +1,159 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "68fb6d6f",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ProxylessNAS\n",
+ "\n",
+ "*Author: MIT Han Lab*\n",
+ "\n",
+ "**Proxylessly specialize CNN architectures for different hardware platforms.**\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ "### References"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6fa6a8b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@inproceedings{\n",
+ " cai2020once,\n",
+ " title={Once for All: Train One Network and Specialize it for Efficient Deployment},\n",
+ " author={Han Cai and Chuang Gan and Tianzhe Wang and Zhekai Zhang and Song Han},\n",
+ " booktitle={International Conference on Learning Representations},\n",
+ " year={2020},\n",
+ " url={https://arxiv.org/pdf/1908.09791.pdf}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_proxylessnas.ipynb b/assets/hub/pytorch_vision_proxylessnas.ipynb
new file mode 100644
index 000000000000..0bf04652b2a2
--- /dev/null
+++ b/assets/hub/pytorch_vision_proxylessnas.ipynb
@@ -0,0 +1,159 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "68fb6d6f",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ProxylessNAS\n",
+ "\n",
+ "*Author: MIT Han Lab*\n",
+ "\n",
+ "**Proxylessly specialize CNN architectures for different hardware platforms.**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2515655",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "target_platform = \"proxyless_cpu\"\n",
+ "# proxyless_gpu, proxyless_mobile, proxyless_mobile14 are also avaliable.\n",
+ "model = torch.hub.load('mit-han-lab/ProxylessNAS', target_platform, pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57e3d1a0",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1366edb4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55b37d3a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8503aa7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bec59ca2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be80f865",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "ProxylessNAS models are from the [ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware](https://arxiv.org/abs/1812.00332) paper.\n",
+ "\n",
+ "Conventionally, people tend to design *one efficient model* for *all hardware platforms*. But different hardware has different properties, for example, CPU has higher frequency and GPU is better at parallization. Therefore, instead of generalizing, we need to **specialize** CNN architectures for different hardware platforms. As shown in below, with similar accuracy, specialization offers free yet significant performance boost on all three platforms.\n",
+ "\n",
+ "| Model structure | GPU Latency | CPU Latency | Mobile Latency\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| proxylessnas_gpu | **5.1ms** | 204.9ms | 124ms |\n",
+ "| proxylessnas_cpu | 7.4ms | **138.7ms** | 116ms |\n",
+ "| proxylessnas_mobile | 7.2ms | 164.1ms | **78ms** |\n",
+ "\n",
+ "The corresponding top-1 accuracy with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error |\n",
+ "| --------------- | ----------- |\n",
+ "| proxylessnas_cpu | 24.7 |\n",
+ "| proxylessnas_gpu | 24.9 |\n",
+ "| proxylessnas_mobile | 25.4 |\n",
+ "| proxylessnas_mobile_14 | 23.3 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware](https://arxiv.org/abs/1812.00332)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnest.ipynb b/assets/hub/pytorch_vision_resnest.ipynb
new file mode 100644
index 000000000000..d7641840d1f9
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnest.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8521b666",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNeSt\n",
+ "\n",
+ "*Author: Hang Zhang*\n",
+ "\n",
+ "**A new ResNet variant.**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c2515655",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "target_platform = \"proxyless_cpu\"\n",
+ "# proxyless_gpu, proxyless_mobile, proxyless_mobile14 are also avaliable.\n",
+ "model = torch.hub.load('mit-han-lab/ProxylessNAS', target_platform, pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "57e3d1a0",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1366edb4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "55b37d3a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a8503aa7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "bec59ca2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "be80f865",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "ProxylessNAS models are from the [ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware](https://arxiv.org/abs/1812.00332) paper.\n",
+ "\n",
+ "Conventionally, people tend to design *one efficient model* for *all hardware platforms*. But different hardware has different properties, for example, CPU has higher frequency and GPU is better at parallization. Therefore, instead of generalizing, we need to **specialize** CNN architectures for different hardware platforms. As shown in below, with similar accuracy, specialization offers free yet significant performance boost on all three platforms.\n",
+ "\n",
+ "| Model structure | GPU Latency | CPU Latency | Mobile Latency\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| proxylessnas_gpu | **5.1ms** | 204.9ms | 124ms |\n",
+ "| proxylessnas_cpu | 7.4ms | **138.7ms** | 116ms |\n",
+ "| proxylessnas_mobile | 7.2ms | 164.1ms | **78ms** |\n",
+ "\n",
+ "The corresponding top-1 accuracy with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error |\n",
+ "| --------------- | ----------- |\n",
+ "| proxylessnas_cpu | 24.7 |\n",
+ "| proxylessnas_gpu | 24.9 |\n",
+ "| proxylessnas_mobile | 25.4 |\n",
+ "| proxylessnas_mobile_14 | 23.3 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware](https://arxiv.org/abs/1812.00332)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnest.ipynb b/assets/hub/pytorch_vision_resnest.ipynb
new file mode 100644
index 000000000000..d7641840d1f9
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnest.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "8521b666",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNeSt\n",
+ "\n",
+ "*Author: Hang Zhang*\n",
+ "\n",
+ "**A new ResNet variant.**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68bf59b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# get list of models\n",
+ "torch.hub.list('zhanghang1989/ResNeSt', force_reload=True)\n",
+ "# load pretrained models, using ResNeSt-50 as an example\n",
+ "model = torch.hub.load('zhanghang1989/ResNeSt', 'resnest50', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d356c0",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "196e3c9a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96819a60",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "57aa5766",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3189a592",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cbaa3b10",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "ResNeSt models are from the [ResNeSt: Split-Attention Networks](https://arxiv.org/pdf/2004.08955.pdf) paper.\n",
+ "\n",
+ "While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities, and also help downstream tasks including object detection, instance segmentation and semantic segmentation.\n",
+ "\n",
+ "| | crop size | PyTorch |\n",
+ "|-------------|-----------|---------|\n",
+ "| ResNeSt-50 | 224 | 81.03 |\n",
+ "| ResNeSt-101 | 256 | 82.83 |\n",
+ "| ResNeSt-200 | 320 | 83.84 |\n",
+ "| ResNeSt-269 | 416 | 84.54 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ResNeSt: Split-Attention Networks](https://arxiv.org/abs/2004.08955)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnet.ipynb b/assets/hub/pytorch_vision_resnet.ipynb
new file mode 100644
index 000000000000..2fda8ca3e66e
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnet.ipynb
@@ -0,0 +1,156 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b74d19a0",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Deep residual networks pre-trained on ImageNet**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "68bf59b7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# get list of models\n",
+ "torch.hub.list('zhanghang1989/ResNeSt', force_reload=True)\n",
+ "# load pretrained models, using ResNeSt-50 as an example\n",
+ "model = torch.hub.load('zhanghang1989/ResNeSt', 'resnest50', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d8d356c0",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "196e3c9a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96819a60",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "57aa5766",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3189a592",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cbaa3b10",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "ResNeSt models are from the [ResNeSt: Split-Attention Networks](https://arxiv.org/pdf/2004.08955.pdf) paper.\n",
+ "\n",
+ "While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities, and also help downstream tasks including object detection, instance segmentation and semantic segmentation.\n",
+ "\n",
+ "| | crop size | PyTorch |\n",
+ "|-------------|-----------|---------|\n",
+ "| ResNeSt-50 | 224 | 81.03 |\n",
+ "| ResNeSt-101 | 256 | 82.83 |\n",
+ "| ResNeSt-200 | 320 | 83.84 |\n",
+ "| ResNeSt-269 | 416 | 84.54 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ResNeSt: Split-Attention Networks](https://arxiv.org/abs/2004.08955)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnet.ipynb b/assets/hub/pytorch_vision_resnet.ipynb
new file mode 100644
index 000000000000..2fda8ca3e66e
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnet.ipynb
@@ -0,0 +1,156 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "b74d19a0",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Deep residual networks pre-trained on ImageNet**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7de1aa61",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet18', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet34', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet101', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet152', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ddf328e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94991788",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86dcba1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ace2a087",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8448d407",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70b4e1b9",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Resnet models were proposed in \"Deep Residual Learning for Image Recognition\".\n",
+ "Here we have the 5 versions of resnet models, which contains 18, 34, 50, 101, 152 layers respectively.\n",
+ "Detailed model architectures can be found in Table 1.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| resnet18 | 30.24 | 10.92 |\n",
+ "| resnet34 | 26.70 | 8.58 |\n",
+ "| resnet50 | 23.85 | 7.13 |\n",
+ "| resnet101 | 22.63 | 6.44 |\n",
+ "| resnet152 | 21.69 | 5.94 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnext.ipynb b/assets/hub/pytorch_vision_resnext.ipynb
new file mode 100644
index 000000000000..eb0f20bea282
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnext.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "f2256586",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNext\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Next generation ResNets, more efficient and accurate**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7de1aa61",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet18', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet34', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet101', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet152', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ddf328e",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94991788",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "86dcba1c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ace2a087",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8448d407",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "70b4e1b9",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Resnet models were proposed in \"Deep Residual Learning for Image Recognition\".\n",
+ "Here we have the 5 versions of resnet models, which contains 18, 34, 50, 101, 152 layers respectively.\n",
+ "Detailed model architectures can be found in Table 1.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| resnet18 | 30.24 | 10.92 |\n",
+ "| resnet34 | 26.70 | 8.58 |\n",
+ "| resnet50 | 23.85 | 7.13 |\n",
+ "| resnet101 | 22.63 | 6.44 |\n",
+ "| resnet152 | 21.69 | 5.94 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_resnext.ipynb b/assets/hub/pytorch_vision_resnext.ipynb
new file mode 100644
index 000000000000..eb0f20bea282
--- /dev/null
+++ b/assets/hub/pytorch_vision_resnext.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "f2256586",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ResNext\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Next generation ResNets, more efficient and accurate**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6ee13ed9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'resnext50_32x4d', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnext101_32x8d', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d73fa36",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd200719",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7753e3c1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d81ccdf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a71ac5d9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f7ddaedf",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Resnext models were proposed in [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431).\n",
+ "Here we have the 2 versions of resnet models, which contains 50, 101 layers repspectively.\n",
+ "A comparison in model archetechure between resnet50 and resnext50 can be found in Table 1.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| ----------------- | ----------- | ----------- |\n",
+ "| resnext50_32x4d | 22.38 | 6.30 |\n",
+ "| resnext101_32x8d | 20.69 | 5.47 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_shufflenet_v2.ipynb b/assets/hub/pytorch_vision_shufflenet_v2.ipynb
new file mode 100644
index 000000000000..6af2a18507be
--- /dev/null
+++ b/assets/hub/pytorch_vision_shufflenet_v2.ipynb
@@ -0,0 +1,147 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ceddae15",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ShuffleNet v2\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**An efficient ConvNet optimized for speed and memory, pre-trained on ImageNet**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ "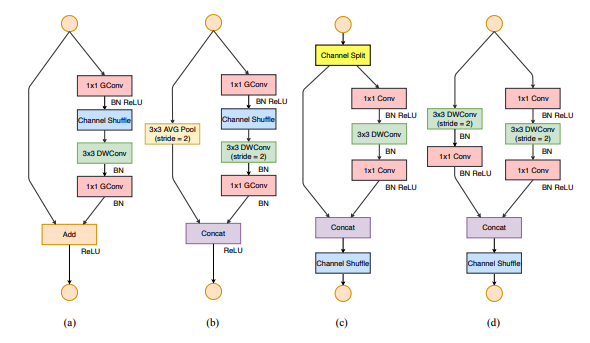 | 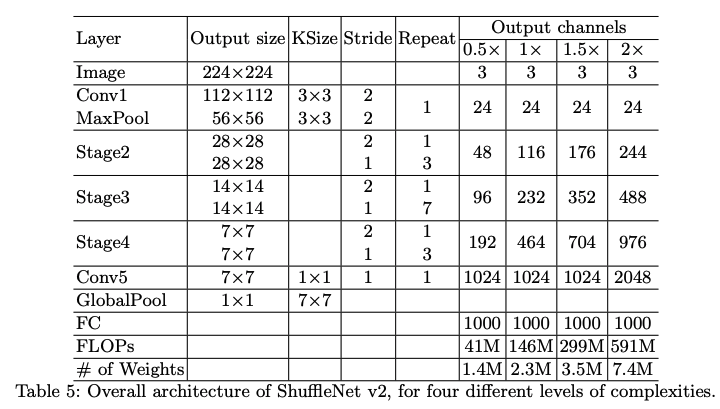"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f5e75733",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'shufflenet_v2_x1_0', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68f3912c",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b128da6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "70d5a956",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "416164dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a9adec0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d969a239",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Previously, neural network architecture design was mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, e.g., speed, also depends on the other factors such as memory access cost and platform characteristics. Based on a series of controlled experiments, this work derives several practical guidelines for efficient network design. Accordingly, a new architecture is presented, called ShuffleNet V2. Comprehensive ablation experiments verify that our model is the state of-the-art in terms of speed and accuracy tradeoff.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| shufflenet_v2 | 30.64 | 11.68 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_snnmlp.ipynb b/assets/hub/pytorch_vision_snnmlp.ipynb
new file mode 100644
index 000000000000..0b2d3ec2d3bf
--- /dev/null
+++ b/assets/hub/pytorch_vision_snnmlp.ipynb
@@ -0,0 +1,141 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "679d03cf",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SNNMLP\n",
+ "\n",
+ "*Author: Huawei Noah's Ark Lab*\n",
+ "\n",
+ "**Brain-inspired Multilayer Perceptron with Spiking Neurons**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6ee13ed9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'resnext50_32x4d', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'resnext101_32x8d', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d73fa36",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fd200719",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7753e3c1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d81ccdf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a71ac5d9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f7ddaedf",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Resnext models were proposed in [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431).\n",
+ "Here we have the 2 versions of resnet models, which contains 50, 101 layers repspectively.\n",
+ "A comparison in model archetechure between resnet50 and resnext50 can be found in Table 1.\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| ----------------- | ----------- | ----------- |\n",
+ "| resnext50_32x4d | 22.38 | 6.30 |\n",
+ "| resnext101_32x8d | 20.69 | 5.47 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_shufflenet_v2.ipynb b/assets/hub/pytorch_vision_shufflenet_v2.ipynb
new file mode 100644
index 000000000000..6af2a18507be
--- /dev/null
+++ b/assets/hub/pytorch_vision_shufflenet_v2.ipynb
@@ -0,0 +1,147 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ceddae15",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# ShuffleNet v2\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**An efficient ConvNet optimized for speed and memory, pre-trained on ImageNet**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f5e75733",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'shufflenet_v2_x1_0', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "68f3912c",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9b128da6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "70d5a956",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "416164dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6a9adec0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d969a239",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Previously, neural network architecture design was mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, e.g., speed, also depends on the other factors such as memory access cost and platform characteristics. Based on a series of controlled experiments, this work derives several practical guidelines for efficient network design. Accordingly, a new architecture is presented, called ShuffleNet V2. Comprehensive ablation experiments verify that our model is the state of-the-art in terms of speed and accuracy tradeoff.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| shufflenet_v2 | 30.64 | 11.68 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_snnmlp.ipynb b/assets/hub/pytorch_vision_snnmlp.ipynb
new file mode 100644
index 000000000000..0b2d3ec2d3bf
--- /dev/null
+++ b/assets/hub/pytorch_vision_snnmlp.ipynb
@@ -0,0 +1,141 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "679d03cf",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SNNMLP\n",
+ "\n",
+ "*Author: Huawei Noah's Ark Lab*\n",
+ "\n",
+ "**Brain-inspired Multilayer Perceptron with Spiking Neurons**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e4eb3d83",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_t', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_s', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_b', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2ac61fc",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32db137b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15f2f96a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "391bc7b8",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "SNNMLP incorporates the mechanism of LIF neurons into the MLP models, to achieve better accuracy without extra FLOPs. We propose a full-precision LIF operation to communicate between patches, including horizontal LIF and vertical LIF in different directions. We also propose to use group LIF to extract better local features. With LIF modules, our SNNMLP model achieves 81.9%, 83.3% and 83.6% top-1 accuracy on ImageNet dataset with only 4.4G, 8.5G and 15.2G FLOPs, respectively.\n",
+ "\n",
+ "The corresponding accuracy on ImageNet dataset with pretrained model is listed below.\n",
+ "\n",
+ "| Model structure | #Parameters | FLOPs | Top-1 acc |\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| SNNMLP Tiny | 28M | 4.4G | 81.88 |\n",
+ "| SNNMLP Small | 50M | 8.5G | 83.30 |\n",
+ "| SNNMLP Base | 88M | 15.2G | 85.59 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "You can read the full paper [here](https://arxiv.org/abs/2203.14679)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a3bee9bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@inproceedings{li2022brain,\n",
+ " title={Brain-inspired multilayer perceptron with spiking neurons},\n",
+ " author={Li, Wenshuo and Chen, Hanting and Guo, Jianyuan and Zhang, Ziyang and Wang, Yunhe},\n",
+ " booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},\n",
+ " pages={783--793},\n",
+ " year={2022}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_squeezenet.ipynb b/assets/hub/pytorch_vision_squeezenet.ipynb
new file mode 100644
index 000000000000..71af8b401bf9
--- /dev/null
+++ b/assets/hub/pytorch_vision_squeezenet.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cd4df47c",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SqueezeNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Alexnet-level accuracy with 50x fewer parameters.**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e4eb3d83",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_t', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_s', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('huawei-noah/Efficient-AI-Backbones', 'snnmlp_b', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d2ac61fc",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "32db137b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "15f2f96a",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "print(torch.nn.functional.softmax(output[0], dim=0))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "391bc7b8",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "SNNMLP incorporates the mechanism of LIF neurons into the MLP models, to achieve better accuracy without extra FLOPs. We propose a full-precision LIF operation to communicate between patches, including horizontal LIF and vertical LIF in different directions. We also propose to use group LIF to extract better local features. With LIF modules, our SNNMLP model achieves 81.9%, 83.3% and 83.6% top-1 accuracy on ImageNet dataset with only 4.4G, 8.5G and 15.2G FLOPs, respectively.\n",
+ "\n",
+ "The corresponding accuracy on ImageNet dataset with pretrained model is listed below.\n",
+ "\n",
+ "| Model structure | #Parameters | FLOPs | Top-1 acc |\n",
+ "| --------------- | ----------- | ----------- | ----------- |\n",
+ "| SNNMLP Tiny | 28M | 4.4G | 81.88 |\n",
+ "| SNNMLP Small | 50M | 8.5G | 83.30 |\n",
+ "| SNNMLP Base | 88M | 15.2G | 85.59 |\n",
+ "\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "You can read the full paper [here](https://arxiv.org/abs/2203.14679)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a3bee9bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "@inproceedings{li2022brain,\n",
+ " title={Brain-inspired multilayer perceptron with spiking neurons},\n",
+ " author={Li, Wenshuo and Chen, Hanting and Guo, Jianyuan and Zhang, Ziyang and Wang, Yunhe},\n",
+ " booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},\n",
+ " pages={783--793},\n",
+ " year={2022}\n",
+ "}"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_squeezenet.ipynb b/assets/hub/pytorch_vision_squeezenet.ipynb
new file mode 100644
index 000000000000..71af8b401bf9
--- /dev/null
+++ b/assets/hub/pytorch_vision_squeezenet.ipynb
@@ -0,0 +1,152 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cd4df47c",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SqueezeNet\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Alexnet-level accuracy with 50x fewer parameters.**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b58effa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_0', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_1', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fc0fbc27",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8740dd7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "978191be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e475d7e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f18701",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "066555b8",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Model `squeezenet1_0` is from the [SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size](https://arxiv.org/pdf/1602.07360.pdf) paper\n",
+ "\n",
+ "Model `squeezenet1_1` is from the [official squeezenet repo](https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1).\n",
+ "It has 2.4x less computation and slightly fewer parameters than `squeezenet1_0`, without sacrificing accuracy.\n",
+ "\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| squeezenet1_0 | 41.90 | 19.58 |\n",
+ "| squeezenet1_1 | 41.81 | 19.38 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5MB model size](https://arxiv.org/pdf/1602.07360.pdf)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_vgg.ipynb b/assets/hub/pytorch_vision_vgg.ipynb
new file mode 100644
index 000000000000..689966eb07c5
--- /dev/null
+++ b/assets/hub/pytorch_vision_vgg.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "48c981c1",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# vgg-nets\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Award winning ConvNets from 2014 ImageNet ILSVRC challenge**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b58effa",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_0', pretrained=True)\n",
+ "# or\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'squeezenet1_1', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fc0fbc27",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b8740dd7",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "978191be",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2e475d7e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f18701",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "066555b8",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Model `squeezenet1_0` is from the [SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size](https://arxiv.org/pdf/1602.07360.pdf) paper\n",
+ "\n",
+ "Model `squeezenet1_1` is from the [official squeezenet repo](https://github.com/DeepScale/SqueezeNet/tree/master/SqueezeNet_v1.1).\n",
+ "It has 2.4x less computation and slightly fewer parameters than `squeezenet1_0`, without sacrificing accuracy.\n",
+ "\n",
+ "Their 1-crop error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| squeezenet1_0 | 41.90 | 19.58 |\n",
+ "| squeezenet1_1 | 41.81 | 19.38 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5MB model size](https://arxiv.org/pdf/1602.07360.pdf)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_vgg.ipynb b/assets/hub/pytorch_vision_vgg.ipynb
new file mode 100644
index 000000000000..689966eb07c5
--- /dev/null
+++ b/assets/hub/pytorch_vision_vgg.ipynb
@@ -0,0 +1,165 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "48c981c1",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# vgg-nets\n",
+ "\n",
+ "*Author: Pytorch Team*\n",
+ "\n",
+ "**Award winning ConvNets from 2014 ImageNet ILSVRC challenge**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "353975ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19_bn', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "49b59512",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "30b08430",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8e70afe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c29c5f9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f0a2573",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f02f5387",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Here we have implementations for the models proposed in [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556),\n",
+ "for each configurations and their with batchnorm version.\n",
+ "\n",
+ "For example, configuration `A` presented in the paper is `vgg11`, configuration `B` is `vgg13`, configuration `D` is `vgg16`\n",
+ "and configuration `E` is `vgg19`. Their batchnorm version are suffixed with `_bn`.\n",
+ "\n",
+ "Their Top-1 error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| vgg11 | 30.98 | 11.37 |\n",
+ "| vgg11_bn | 26.70 | 8.58 |\n",
+ "| vgg13 | 30.07 | 10.75 |\n",
+ "| vgg13_bn | 28.45 | 9.63 |\n",
+ "| vgg16 | 28.41 | 9.62 |\n",
+ "| vgg16_bn | 26.63 | 8.50 |\n",
+ "| vgg19 | 27.62 | 9.12 |\n",
+ "| vgg19_bn | 25.76 | 8.15 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_wide_resnet.ipynb b/assets/hub/pytorch_vision_wide_resnet.ipynb
new file mode 100644
index 000000000000..4d81cad7d879
--- /dev/null
+++ b/assets/hub/pytorch_vision_wide_resnet.ipynb
@@ -0,0 +1,157 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a42a2c48",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Wide ResNet\n",
+ "\n",
+ "*Author: Sergey Zagoruyko*\n",
+ "\n",
+ "**Wide Residual Networks**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "353975ab",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11', pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg11_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg13_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg16_bn', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19', pretrained=True)\n",
+ "# model = torch.hub.load('pytorch/vision:v0.10.0', 'vgg19_bn', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "49b59512",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "30b08430",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f8e70afe",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c29c5f9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5f0a2573",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f02f5387",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Here we have implementations for the models proposed in [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556),\n",
+ "for each configurations and their with batchnorm version.\n",
+ "\n",
+ "For example, configuration `A` presented in the paper is `vgg11`, configuration `B` is `vgg13`, configuration `D` is `vgg16`\n",
+ "and configuration `E` is `vgg19`. Their batchnorm version are suffixed with `_bn`.\n",
+ "\n",
+ "Their Top-1 error rates on ImageNet dataset with pretrained models are listed below.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error |\n",
+ "| --------------- | ----------- | ----------- |\n",
+ "| vgg11 | 30.98 | 11.37 |\n",
+ "| vgg11_bn | 26.70 | 8.58 |\n",
+ "| vgg13 | 30.07 | 10.75 |\n",
+ "| vgg13_bn | 28.45 | 9.63 |\n",
+ "| vgg16 | 28.41 | 9.62 |\n",
+ "| vgg16_bn | 26.63 | 8.50 |\n",
+ "| vgg19 | 27.62 | 9.12 |\n",
+ "| vgg19_bn | 25.76 | 8.15 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)."
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/pytorch_vision_wide_resnet.ipynb b/assets/hub/pytorch_vision_wide_resnet.ipynb
new file mode 100644
index 000000000000..4d81cad7d879
--- /dev/null
+++ b/assets/hub/pytorch_vision_wide_resnet.ipynb
@@ -0,0 +1,157 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "a42a2c48",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Wide ResNet\n",
+ "\n",
+ "*Author: Sergey Zagoruyko*\n",
+ "\n",
+ "**Wide Residual Networks**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6367742",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# load WRN-50-2:\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'wide_resnet50_2', pretrained=True)\n",
+ "# or WRN-101-2\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'wide_resnet101_2', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "758f9e23",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "faf3a0f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc6a9980",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28122f5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3d2f6fcb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9b740da",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Wide Residual networks simply have increased number of channels compared to ResNet.\n",
+ "Otherwise the architecture is the same. Deeper ImageNet models with bottleneck\n",
+ "block have increased number of channels in the inner 3x3 convolution.\n",
+ "\n",
+ "The `wide_resnet50_2` and `wide_resnet101_2` models were trained in FP16 with\n",
+ "mixed precision training using SGD with warm restarts. Checkpoints have weights in\n",
+ "half precision (except batch norm) for smaller size, and can be used in FP32 models too.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error | # parameters |\n",
+ "| ----------------- | :---------: | :---------: | :----------: |\n",
+ "| wide_resnet50_2 | 21.49 | 5.91 | 68.9M |\n",
+ "| wide_resnet101_2 | 21.16 | 5.72 | 126.9M |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Wide Residual Networks](https://arxiv.org/abs/1605.07146)\n",
+ " - [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)\n",
+ " - [Mixed Precision Training](https://arxiv.org/abs/1710.03740)\n",
+ " - [SGDR: Stochastic Gradient Descent with Warm Restarts](https://arxiv.org/abs/1608.03983)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb b/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb
new file mode 100644
index 000000000000..de8bc7d3b942
--- /dev/null
+++ b/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb
@@ -0,0 +1,120 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "99fde666",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Open-Unmix\n",
+ "\n",
+ "*Author: Inria*\n",
+ "\n",
+ "**Reference implementation for music source separation**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b6367742",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "# load WRN-50-2:\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'wide_resnet50_2', pretrained=True)\n",
+ "# or WRN-101-2\n",
+ "model = torch.hub.load('pytorch/vision:v0.10.0', 'wide_resnet101_2', pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "758f9e23",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "faf3a0f5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dc6a9980",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "28122f5d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3d2f6fcb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9b740da",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Wide Residual networks simply have increased number of channels compared to ResNet.\n",
+ "Otherwise the architecture is the same. Deeper ImageNet models with bottleneck\n",
+ "block have increased number of channels in the inner 3x3 convolution.\n",
+ "\n",
+ "The `wide_resnet50_2` and `wide_resnet101_2` models were trained in FP16 with\n",
+ "mixed precision training using SGD with warm restarts. Checkpoints have weights in\n",
+ "half precision (except batch norm) for smaller size, and can be used in FP32 models too.\n",
+ "\n",
+ "| Model structure | Top-1 error | Top-5 error | # parameters |\n",
+ "| ----------------- | :---------: | :---------: | :----------: |\n",
+ "| wide_resnet50_2 | 21.49 | 5.91 | 68.9M |\n",
+ "| wide_resnet101_2 | 21.16 | 5.72 | 126.9M |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Wide Residual Networks](https://arxiv.org/abs/1605.07146)\n",
+ " - [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385)\n",
+ " - [Mixed Precision Training](https://arxiv.org/abs/1710.03740)\n",
+ " - [SGDR: Stochastic Gradient Descent with Warm Restarts](https://arxiv.org/abs/1608.03983)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb b/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb
new file mode 100644
index 000000000000..de8bc7d3b942
--- /dev/null
+++ b/assets/hub/sigsep_open-unmix-pytorch_umx.ipynb
@@ -0,0 +1,120 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "99fde666",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Open-Unmix\n",
+ "\n",
+ "*Author: Inria*\n",
+ "\n",
+ "**Reference implementation for music source separation**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c1b6c35b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# assuming you have a PyTorch >=1.6.0 installed\n",
+ "pip install -q torchaudio"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "869d0784",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# loading umxhq four target separator\n",
+ "separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq')\n",
+ "\n",
+ "# generate random audio\n",
+ "# ... with shape (nb_samples, nb_channels, nb_timesteps)\n",
+ "# ... and with the same sample rate as that of the separator\n",
+ "audio = torch.rand((1, 2, 100000))\n",
+ "original_sample_rate = separator.sample_rate\n",
+ "\n",
+ "# make sure to resample the audio to models' sample rate, separator.sample_rate, if the two are different\n",
+ "# resampler = torchaudio.transforms.Resample(original_sample_rate, separator.sample_rate)\n",
+ "# audio = resampler(audio)\n",
+ "\n",
+ "estimates = separator(audio)\n",
+ "# estimates.shape = (1, 4, 2, 100000)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7e8fcf3c",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "__Open-Unmix__ provides ready-to-use models that allow users to separate pop music into four stems: __vocals__, __drums__, __bass__ and the remaining __other__ instruments. The models were pre-trained on the freely available [MUSDB18](https://sigsep.github.io/datasets/musdb.html) dataset.\n",
+ "\n",
+ "Each target model is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target source, like vocals, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error.\n",
+ "\n",
+ "A `Separator` meta-model (as shown in the code example above) puts together multiple _Open-unmix_ spectrogram models for each desired target, and combines their output through a multichannel generalized Wiener filter, before application of inverse STFTs using `torchaudio`.\n",
+ "The filtering is differentiable (but parameter-free) version of [norbert](https://github.com/sigsep/norbert).\n",
+ "\n",
+ "### Pre-trained `Separator` models\n",
+ "\n",
+ "* __`umxhq` (default)__ trained on [MUSDB18-HQ](https://sigsep.github.io/datasets/musdb.html#uncompressed-wav) which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz.\n",
+ "\n",
+ "* __`umx`__ is trained on the regular [MUSDB18](https://sigsep.github.io/datasets/musdb.html#compressed-stems) which is bandwidth limited to 16 kHz due to AAC compression. This model should be used for comparison with other (older) methods for evaluation in [SiSEC18](sisec18.unmix.app).\n",
+ "\n",
+ "Furthermore, we provide a model for speech enhancement trained by [Sony Corporation](link)\n",
+ "\n",
+ "* __`umxse`__ speech enhancement model is trained on the 28-speaker version of the [Voicebank+DEMAND corpus](https://datashare.is.ed.ac.uk/handle/10283/1942?show=full).\n",
+ "\n",
+ "All three models are also available as spectrogram (core) models, which take magnitude spectrogram inputs and ouput separated spectrograms.\n",
+ "These models can be loaded using `umxhq_spec`, `umx_spec` and `umxse_spec`.\n",
+ "\n",
+ "### Details\n",
+ "\n",
+ "For additional examples, documentation and usage examples, please visit this [the github repo](https://github.com/sigsep/open-unmix-pytorch).\n",
+ "\n",
+ "Furthermore, the models and all utility function to preprocess, read and save audio stems, are available in a python package that can be installed via"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ad88076",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install openunmix"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f026e5d",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ "- [Open-Unmix - A Reference Implementation for Music Source Separation](https://doi.org/10.21105/joss.01667)\n",
+ "- [SigSep - Open Ressources for Music Separation](https://sigsep.github.io/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/simplenet.ipynb b/assets/hub/simplenet.ipynb
new file mode 100644
index 000000000000..b9e57af0ee25
--- /dev/null
+++ b/assets/hub/simplenet.ipynb
@@ -0,0 +1,169 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "72d50304",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SimpleNet\n",
+ "\n",
+ "*Author: Seyyed Hossein Hasanpour*\n",
+ "\n",
+ "**Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c1b6c35b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# assuming you have a PyTorch >=1.6.0 installed\n",
+ "pip install -q torchaudio"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "869d0784",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "# loading umxhq four target separator\n",
+ "separator = torch.hub.load('sigsep/open-unmix-pytorch', 'umxhq')\n",
+ "\n",
+ "# generate random audio\n",
+ "# ... with shape (nb_samples, nb_channels, nb_timesteps)\n",
+ "# ... and with the same sample rate as that of the separator\n",
+ "audio = torch.rand((1, 2, 100000))\n",
+ "original_sample_rate = separator.sample_rate\n",
+ "\n",
+ "# make sure to resample the audio to models' sample rate, separator.sample_rate, if the two are different\n",
+ "# resampler = torchaudio.transforms.Resample(original_sample_rate, separator.sample_rate)\n",
+ "# audio = resampler(audio)\n",
+ "\n",
+ "estimates = separator(audio)\n",
+ "# estimates.shape = (1, 4, 2, 100000)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7e8fcf3c",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "__Open-Unmix__ provides ready-to-use models that allow users to separate pop music into four stems: __vocals__, __drums__, __bass__ and the remaining __other__ instruments. The models were pre-trained on the freely available [MUSDB18](https://sigsep.github.io/datasets/musdb.html) dataset.\n",
+ "\n",
+ "Each target model is based on a three-layer bidirectional deep LSTM. The model learns to predict the magnitude spectrogram of a target source, like vocals, from the magnitude spectrogram of a mixture input. Internally, the prediction is obtained by applying a mask on the input. The model is optimized in the magnitude domain using mean squared error.\n",
+ "\n",
+ "A `Separator` meta-model (as shown in the code example above) puts together multiple _Open-unmix_ spectrogram models for each desired target, and combines their output through a multichannel generalized Wiener filter, before application of inverse STFTs using `torchaudio`.\n",
+ "The filtering is differentiable (but parameter-free) version of [norbert](https://github.com/sigsep/norbert).\n",
+ "\n",
+ "### Pre-trained `Separator` models\n",
+ "\n",
+ "* __`umxhq` (default)__ trained on [MUSDB18-HQ](https://sigsep.github.io/datasets/musdb.html#uncompressed-wav) which comprises the same tracks as in MUSDB18 but un-compressed which yield in a full bandwidth of 22050 Hz.\n",
+ "\n",
+ "* __`umx`__ is trained on the regular [MUSDB18](https://sigsep.github.io/datasets/musdb.html#compressed-stems) which is bandwidth limited to 16 kHz due to AAC compression. This model should be used for comparison with other (older) methods for evaluation in [SiSEC18](sisec18.unmix.app).\n",
+ "\n",
+ "Furthermore, we provide a model for speech enhancement trained by [Sony Corporation](link)\n",
+ "\n",
+ "* __`umxse`__ speech enhancement model is trained on the 28-speaker version of the [Voicebank+DEMAND corpus](https://datashare.is.ed.ac.uk/handle/10283/1942?show=full).\n",
+ "\n",
+ "All three models are also available as spectrogram (core) models, which take magnitude spectrogram inputs and ouput separated spectrograms.\n",
+ "These models can be loaded using `umxhq_spec`, `umx_spec` and `umxse_spec`.\n",
+ "\n",
+ "### Details\n",
+ "\n",
+ "For additional examples, documentation and usage examples, please visit this [the github repo](https://github.com/sigsep/open-unmix-pytorch).\n",
+ "\n",
+ "Furthermore, the models and all utility function to preprocess, read and save audio stems, are available in a python package that can be installed via"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8ad88076",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install openunmix"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2f026e5d",
+ "metadata": {},
+ "source": [
+ "### References\n",
+ "\n",
+ "- [Open-Unmix - A Reference Implementation for Music Source Separation](https://doi.org/10.21105/joss.01667)\n",
+ "- [SigSep - Open Ressources for Music Separation](https://sigsep.github.io/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/simplenet.ipynb b/assets/hub/simplenet.ipynb
new file mode 100644
index 000000000000..b9e57af0ee25
--- /dev/null
+++ b/assets/hub/simplenet.ipynb
@@ -0,0 +1,169 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "72d50304",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# SimpleNet\n",
+ "\n",
+ "*Author: Seyyed Hossein Hasanpour*\n",
+ "\n",
+ "**Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d02ef84",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_5m_m1\", pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_5m_m2\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_9m_m1\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_9m_m2\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m1_05\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m2_05\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m1_075\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m2_075\", pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec4ddcb6",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0c655a2d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "43bb8ba8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d89b13ff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff946e58",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dbd43f60",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "SimpleNet models were proposed in \"Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures\". \n",
+ "Here we have the 8 versions of simplenet models, which contains 1.5m, 3.2m, 5.7m and 9.5m parameters respectively. \n",
+ "Detailed model architectures can be found in Table 1 and Table 2. \n",
+ "Their 1-crop errors on ImageNet dataset with pretrained models are listed below. \n",
+ "\n",
+ "The m2 variants \n",
+ "\n",
+ "| Model structure | Top-1 errors | Top-5 errors |\n",
+ "| :------------------------- | :-----------: | :-----------:|\n",
+ "| simplenetv1_small_m2_05 | 38.33 | 16.512 |\n",
+ "| simplenetv1_small_m2_075 | 31.494 | 11.85 |\n",
+ "| simplenetv1_5m_m2 | 27.97 | 9.676 |\n",
+ "| simplenetv1_9m_m2 | 25.77 | 8.252 |\n",
+ "\n",
+ "The m1 variants \n",
+ "\n",
+ "| Model structure | Top-1 errors | Top-5 errors |\n",
+ "| :------------------------- | :-----------: | :-----------:|\n",
+ "| simplenetv1_small_m1_05 | 38.878 | 17.012 |\n",
+ "| simplenetv1_small_m1_075 | 32.216 | 12.282 |\n",
+ "| simplenetv1_5m_m1 | 28.452 | 10.06 |\n",
+ "| simplenetv1_9m_m1 | 26.208 | 8.514 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures](https://arxiv.org/abs/1608.06037)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-models_stt.ipynb b/assets/hub/snakers4_silero-models_stt.ipynb
new file mode 100644
index 000000000000..df2cd221f606
--- /dev/null
+++ b/assets/hub/snakers4_silero-models_stt.ipynb
@@ -0,0 +1,106 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cadeb1df",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Speech-To-Text Models\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**A set of compact enterprise-grade pre-trained STT Models for multiple languages.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df36f984",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio omegaconf soundfile"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1ab515b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import zipfile\n",
+ "import torchaudio\n",
+ "from glob import glob\n",
+ "\n",
+ "device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU\n",
+ "\n",
+ "model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',\n",
+ " model='silero_stt',\n",
+ " language='en', # also available 'de', 'es'\n",
+ " device=device)\n",
+ "(read_batch, split_into_batches,\n",
+ " read_audio, prepare_model_input) = utils # see function signature for details\n",
+ "\n",
+ "# download a single file, any format compatible with TorchAudio (soundfile backend)\n",
+ "torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',\n",
+ " dst ='speech_orig.wav', progress=True)\n",
+ "test_files = glob('speech_orig.wav')\n",
+ "batches = split_into_batches(test_files, batch_size=10)\n",
+ "input = prepare_model_input(read_batch(batches[0]),\n",
+ " device=device)\n",
+ "\n",
+ "output = model(input)\n",
+ "for example in output:\n",
+ " print(decoder(example.cpu()))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84bebade",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero Speech-To-Text models provide enterprise grade STT in a compact form-factor for several commonly spoken languages. Unlike conventional ASR models our models are robust to a variety of dialects, codecs, domains, noises, lower sampling rates (for simplicity audio should be resampled to 16 kHz). The models consume a normalized audio in the form of samples (i.e. without any pre-processing except for normalization to -1 ... 1) and output frames with token probabilities. We provide a decoder utility for simplicity (we could include it into our model itself, but scripted modules had problems with storing model artifacts i.e. labels during certain export scenarios).\n",
+ "\n",
+ "We hope that our efforts with Open-STT and Silero Models will bring the ImageNet moment in speech closer.\n",
+ "\n",
+ "### Supported Languages and Formats\n",
+ "\n",
+ "As of this page update, the following languages are supported:\n",
+ "\n",
+ "- English\n",
+ "- German\n",
+ "- Spanish\n",
+ "\n",
+ "To see the always up-to-date language list, please visit our [repo](https://github.com/snakers4/silero-models) and see the `yml` [file](https://github.com/snakers4/silero-models/blob/master/models.yml) for all available checkpoints.\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-models). For quality and performance benchmarks please see the [wiki](https://github.com/snakers4/silero-models/wiki). These resources will be updated from time to time.\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Silero Models](https://github.com/snakers4/silero-models)\n",
+ "- [Alexander Veysov, \"Toward's an ImageNet Moment for Speech-to-Text\", The Gradient, 2020](https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/)\n",
+ "- [Alexander Veysov, \"A Speech-To-Text Practitioner’s Criticisms of Industry and Academia\", The Gradient, 2020](https://thegradient.pub/a-speech-to-text-practitioners-criticisms-of-industry-and-academia/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-models_tts.ipynb b/assets/hub/snakers4_silero-models_tts.ipynb
new file mode 100644
index 000000000000..5a674397cd29
--- /dev/null
+++ b/assets/hub/snakers4_silero-models_tts.ipynb
@@ -0,0 +1,99 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ff883b45",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Text-To-Speech Models\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**A set of compact enterprise-grade pre-trained TTS Models for multiple languages**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1ce245de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio omegaconf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39b1ae7f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "language = 'en'\n",
+ "speaker = 'lj_16khz'\n",
+ "device = torch.device('cpu')\n",
+ "model, symbols, sample_rate, example_text, apply_tts = torch.hub.load(repo_or_dir='snakers4/silero-models',\n",
+ " model='silero_tts',\n",
+ " language=language,\n",
+ " speaker=speaker)\n",
+ "model = model.to(device) # gpu or cpu\n",
+ "audio = apply_tts(texts=[example_text],\n",
+ " model=model,\n",
+ " sample_rate=sample_rate,\n",
+ " symbols=symbols,\n",
+ " device=device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "352c834f",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero Text-To-Speech models provide enterprise grade TTS in a compact form-factor for several commonly spoken languages:\n",
+ "\n",
+ "- One-line usage\n",
+ "- Naturally sounding speech\n",
+ "- No GPU or training required\n",
+ "- Minimalism and lack of dependencies\n",
+ "- A library of voices in many languages\n",
+ "- Support for `16kHz` and `8kHz` out of the box\n",
+ "- High throughput on slow hardware. Decent performance on one CPU thread\n",
+ "\n",
+ "### Supported Languages and Formats\n",
+ "\n",
+ "As of this page update, the speakers of the following languages are supported both in 8 kHz and 16 kHz:\n",
+ "\n",
+ "- Russian (6 speakers)\n",
+ "- English (1 speaker)\n",
+ "- German (1 speaker)\n",
+ "- Spanish (1 speaker)\n",
+ "- French (1 speaker)\n",
+ "\n",
+ "To see the always up-to-date language list, please visit our [repo](https://github.com/snakers4/silero-models) and see the `yml` [file](https://github.com/snakers4/silero-models/blob/master/models.yml) for all available checkpoints.\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-models). For quality and performance benchmarks please see the [wiki](https://github.com/snakers4/silero-models/wiki). These resources will be updated from time to time.\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Silero Models](https://github.com/snakers4/silero-models)\n",
+ "- [High-Quality Speech-to-Text Made Accessible, Simple and Fast](https://habr.com/ru/post/549482/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-vad_vad.ipynb b/assets/hub/snakers4_silero-vad_vad.ipynb
new file mode 100644
index 000000000000..9cdf0c02f217
--- /dev/null
+++ b/assets/hub/snakers4_silero-vad_vad.ipynb
@@ -0,0 +1,95 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4e119581",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Voice Activity Detector\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**Pre-trained Voice Activity Detector**\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0d02ef84",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_5m_m1\", pretrained=True)\n",
+ "# or any of these variants\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_5m_m2\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_9m_m1\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_9m_m2\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m1_05\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m2_05\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m1_075\", pretrained=True)\n",
+ "# model = torch.hub.load(\"coderx7/simplenet_pytorch:v1.0.0\", \"simplenetv1_small_m2_075\", pretrained=True)\n",
+ "model.eval()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ec4ddcb6",
+ "metadata": {},
+ "source": [
+ "All pre-trained models expect input images normalized in the same way,\n",
+ "i.e. mini-batches of 3-channel RGB images of shape `(3 x H x W)`, where `H` and `W` are expected to be at least `224`.\n",
+ "The images have to be loaded in to a range of `[0, 1]` and then normalized using `mean = [0.485, 0.456, 0.406]`\n",
+ "and `std = [0.229, 0.224, 0.225]`.\n",
+ "\n",
+ "Here's a sample execution."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0c655a2d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download an example image from the pytorch website\n",
+ "import urllib\n",
+ "url, filename = (\"https://github.com/pytorch/hub/raw/master/images/dog.jpg\", \"dog.jpg\")\n",
+ "try: urllib.URLopener().retrieve(url, filename)\n",
+ "except: urllib.request.urlretrieve(url, filename)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "43bb8ba8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# sample execution (requires torchvision)\n",
+ "from PIL import Image\n",
+ "from torchvision import transforms\n",
+ "input_image = Image.open(filename)\n",
+ "preprocess = transforms.Compose([\n",
+ " transforms.Resize(256),\n",
+ " transforms.CenterCrop(224),\n",
+ " transforms.ToTensor(),\n",
+ " transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),\n",
+ "])\n",
+ "input_tensor = preprocess(input_image)\n",
+ "input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model\n",
+ "\n",
+ "# move the input and model to GPU for speed if available\n",
+ "if torch.cuda.is_available():\n",
+ " input_batch = input_batch.to('cuda')\n",
+ " model.to('cuda')\n",
+ "\n",
+ "with torch.no_grad():\n",
+ " output = model(input_batch)\n",
+ "# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes\n",
+ "print(output[0])\n",
+ "# The output has unnormalized scores. To get probabilities, you can run a softmax on it.\n",
+ "probabilities = torch.nn.functional.softmax(output[0], dim=0)\n",
+ "print(probabilities)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d89b13ff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Download ImageNet labels\n",
+ "!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "ff946e58",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Read the categories\n",
+ "with open(\"imagenet_classes.txt\", \"r\") as f:\n",
+ " categories = [s.strip() for s in f.readlines()]\n",
+ "# Show top categories per image\n",
+ "top5_prob, top5_catid = torch.topk(probabilities, 5)\n",
+ "for i in range(top5_prob.size(0)):\n",
+ " print(categories[top5_catid[i]], top5_prob[i].item())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dbd43f60",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "SimpleNet models were proposed in \"Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures\". \n",
+ "Here we have the 8 versions of simplenet models, which contains 1.5m, 3.2m, 5.7m and 9.5m parameters respectively. \n",
+ "Detailed model architectures can be found in Table 1 and Table 2. \n",
+ "Their 1-crop errors on ImageNet dataset with pretrained models are listed below. \n",
+ "\n",
+ "The m2 variants \n",
+ "\n",
+ "| Model structure | Top-1 errors | Top-5 errors |\n",
+ "| :------------------------- | :-----------: | :-----------:|\n",
+ "| simplenetv1_small_m2_05 | 38.33 | 16.512 |\n",
+ "| simplenetv1_small_m2_075 | 31.494 | 11.85 |\n",
+ "| simplenetv1_5m_m2 | 27.97 | 9.676 |\n",
+ "| simplenetv1_9m_m2 | 25.77 | 8.252 |\n",
+ "\n",
+ "The m1 variants \n",
+ "\n",
+ "| Model structure | Top-1 errors | Top-5 errors |\n",
+ "| :------------------------- | :-----------: | :-----------:|\n",
+ "| simplenetv1_small_m1_05 | 38.878 | 17.012 |\n",
+ "| simplenetv1_small_m1_075 | 32.216 | 12.282 |\n",
+ "| simplenetv1_5m_m1 | 28.452 | 10.06 |\n",
+ "| simplenetv1_9m_m1 | 26.208 | 8.514 |\n",
+ "\n",
+ "### References\n",
+ "\n",
+ " - [Lets Keep it simple, Using simple architectures to outperform deeper and more complex architectures](https://arxiv.org/abs/1608.06037)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-models_stt.ipynb b/assets/hub/snakers4_silero-models_stt.ipynb
new file mode 100644
index 000000000000..df2cd221f606
--- /dev/null
+++ b/assets/hub/snakers4_silero-models_stt.ipynb
@@ -0,0 +1,106 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "cadeb1df",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Speech-To-Text Models\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**A set of compact enterprise-grade pre-trained STT Models for multiple languages.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "df36f984",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio omegaconf soundfile"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1ab515b9",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "import zipfile\n",
+ "import torchaudio\n",
+ "from glob import glob\n",
+ "\n",
+ "device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU\n",
+ "\n",
+ "model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',\n",
+ " model='silero_stt',\n",
+ " language='en', # also available 'de', 'es'\n",
+ " device=device)\n",
+ "(read_batch, split_into_batches,\n",
+ " read_audio, prepare_model_input) = utils # see function signature for details\n",
+ "\n",
+ "# download a single file, any format compatible with TorchAudio (soundfile backend)\n",
+ "torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',\n",
+ " dst ='speech_orig.wav', progress=True)\n",
+ "test_files = glob('speech_orig.wav')\n",
+ "batches = split_into_batches(test_files, batch_size=10)\n",
+ "input = prepare_model_input(read_batch(batches[0]),\n",
+ " device=device)\n",
+ "\n",
+ "output = model(input)\n",
+ "for example in output:\n",
+ " print(decoder(example.cpu()))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "84bebade",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero Speech-To-Text models provide enterprise grade STT in a compact form-factor for several commonly spoken languages. Unlike conventional ASR models our models are robust to a variety of dialects, codecs, domains, noises, lower sampling rates (for simplicity audio should be resampled to 16 kHz). The models consume a normalized audio in the form of samples (i.e. without any pre-processing except for normalization to -1 ... 1) and output frames with token probabilities. We provide a decoder utility for simplicity (we could include it into our model itself, but scripted modules had problems with storing model artifacts i.e. labels during certain export scenarios).\n",
+ "\n",
+ "We hope that our efforts with Open-STT and Silero Models will bring the ImageNet moment in speech closer.\n",
+ "\n",
+ "### Supported Languages and Formats\n",
+ "\n",
+ "As of this page update, the following languages are supported:\n",
+ "\n",
+ "- English\n",
+ "- German\n",
+ "- Spanish\n",
+ "\n",
+ "To see the always up-to-date language list, please visit our [repo](https://github.com/snakers4/silero-models) and see the `yml` [file](https://github.com/snakers4/silero-models/blob/master/models.yml) for all available checkpoints.\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-models). For quality and performance benchmarks please see the [wiki](https://github.com/snakers4/silero-models/wiki). These resources will be updated from time to time.\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Silero Models](https://github.com/snakers4/silero-models)\n",
+ "- [Alexander Veysov, \"Toward's an ImageNet Moment for Speech-to-Text\", The Gradient, 2020](https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/)\n",
+ "- [Alexander Veysov, \"A Speech-To-Text Practitioner’s Criticisms of Industry and Academia\", The Gradient, 2020](https://thegradient.pub/a-speech-to-text-practitioners-criticisms-of-industry-and-academia/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-models_tts.ipynb b/assets/hub/snakers4_silero-models_tts.ipynb
new file mode 100644
index 000000000000..5a674397cd29
--- /dev/null
+++ b/assets/hub/snakers4_silero-models_tts.ipynb
@@ -0,0 +1,99 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ff883b45",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Text-To-Speech Models\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**A set of compact enterprise-grade pre-trained TTS Models for multiple languages**"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1ce245de",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio omegaconf"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "39b1ae7f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "\n",
+ "language = 'en'\n",
+ "speaker = 'lj_16khz'\n",
+ "device = torch.device('cpu')\n",
+ "model, symbols, sample_rate, example_text, apply_tts = torch.hub.load(repo_or_dir='snakers4/silero-models',\n",
+ " model='silero_tts',\n",
+ " language=language,\n",
+ " speaker=speaker)\n",
+ "model = model.to(device) # gpu or cpu\n",
+ "audio = apply_tts(texts=[example_text],\n",
+ " model=model,\n",
+ " sample_rate=sample_rate,\n",
+ " symbols=symbols,\n",
+ " device=device)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "352c834f",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero Text-To-Speech models provide enterprise grade TTS in a compact form-factor for several commonly spoken languages:\n",
+ "\n",
+ "- One-line usage\n",
+ "- Naturally sounding speech\n",
+ "- No GPU or training required\n",
+ "- Minimalism and lack of dependencies\n",
+ "- A library of voices in many languages\n",
+ "- Support for `16kHz` and `8kHz` out of the box\n",
+ "- High throughput on slow hardware. Decent performance on one CPU thread\n",
+ "\n",
+ "### Supported Languages and Formats\n",
+ "\n",
+ "As of this page update, the speakers of the following languages are supported both in 8 kHz and 16 kHz:\n",
+ "\n",
+ "- Russian (6 speakers)\n",
+ "- English (1 speaker)\n",
+ "- German (1 speaker)\n",
+ "- Spanish (1 speaker)\n",
+ "- French (1 speaker)\n",
+ "\n",
+ "To see the always up-to-date language list, please visit our [repo](https://github.com/snakers4/silero-models) and see the `yml` [file](https://github.com/snakers4/silero-models/blob/master/models.yml) for all available checkpoints.\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-models). For quality and performance benchmarks please see the [wiki](https://github.com/snakers4/silero-models/wiki). These resources will be updated from time to time.\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "- [Silero Models](https://github.com/snakers4/silero-models)\n",
+ "- [High-Quality Speech-to-Text Made Accessible, Simple and Fast](https://habr.com/ru/post/549482/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/snakers4_silero-vad_vad.ipynb b/assets/hub/snakers4_silero-vad_vad.ipynb
new file mode 100644
index 000000000000..9cdf0c02f217
--- /dev/null
+++ b/assets/hub/snakers4_silero-vad_vad.ipynb
@@ -0,0 +1,95 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "4e119581",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# Silero Voice Activity Detector\n",
+ "\n",
+ "*Author: Silero AI Team*\n",
+ "\n",
+ "**Pre-trained Voice Activity Detector**\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a9a1b01",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a638e514",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "torch.set_num_threads(1)\n",
+ "\n",
+ "from IPython.display import Audio\n",
+ "from pprint import pprint\n",
+ "# download example\n",
+ "torch.hub.download_url_to_file('https://models.silero.ai/vad_models/en.wav', 'en_example.wav')\n",
+ "\n",
+ "model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',\n",
+ " model='silero_vad',\n",
+ " force_reload=True)\n",
+ "\n",
+ "(get_speech_timestamps,\n",
+ " _, read_audio,\n",
+ " *_) = utils\n",
+ "\n",
+ "sampling_rate = 16000 # also accepts 8000\n",
+ "wav = read_audio('en_example.wav', sampling_rate=sampling_rate)\n",
+ "# get speech timestamps from full audio file\n",
+ "speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=sampling_rate)\n",
+ "pprint(speech_timestamps)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c5dc9e9",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD). Enterprise-grade Speech Products made refreshingly simple (see our STT models). **Each model is published separately**.\n",
+ "\n",
+ "Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link). WebRTC though starts to show its age and it suffers from many false positives.\n",
+ "\n",
+ "**(!!!) Important Notice (!!!)** - the models are intended to run on CPU only and were optimized for performance on 1 CPU thread. Note that the model is quantized.\n",
+ "\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-vad) and please refer to the extensive examples in the Colab format (including the streaming examples).\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "VAD model architectures are based on similar STT architectures.\n",
+ "\n",
+ "- [Silero VAD](https://github.com/snakers4/silero-vad)\n",
+ "- [Alexander Veysov, \"Toward's an ImageNet Moment for Speech-to-Text\", The Gradient, 2020](https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/)\n",
+ "- [Alexander Veysov, \"A Speech-To-Text Practitioner’s Criticisms of Industry and Academia\", The Gradient, 2020](https://thegradient.pub/a-speech-to-text-practitioners-criticisms-of-industry-and-academia/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/ultralytics_yolov5.ipynb b/assets/hub/ultralytics_yolov5.ipynb
new file mode 100644
index 000000000000..1dacc0f1dc8d
--- /dev/null
+++ b/assets/hub/ultralytics_yolov5.ipynb
@@ -0,0 +1,167 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5c265ba5",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# YOLOv5\n",
+ "\n",
+ "*Author: Ultralytics*\n",
+ "\n",
+ "**Ultralytics YOLOv5 🚀 for object detection, instance segmentation and image classification.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | 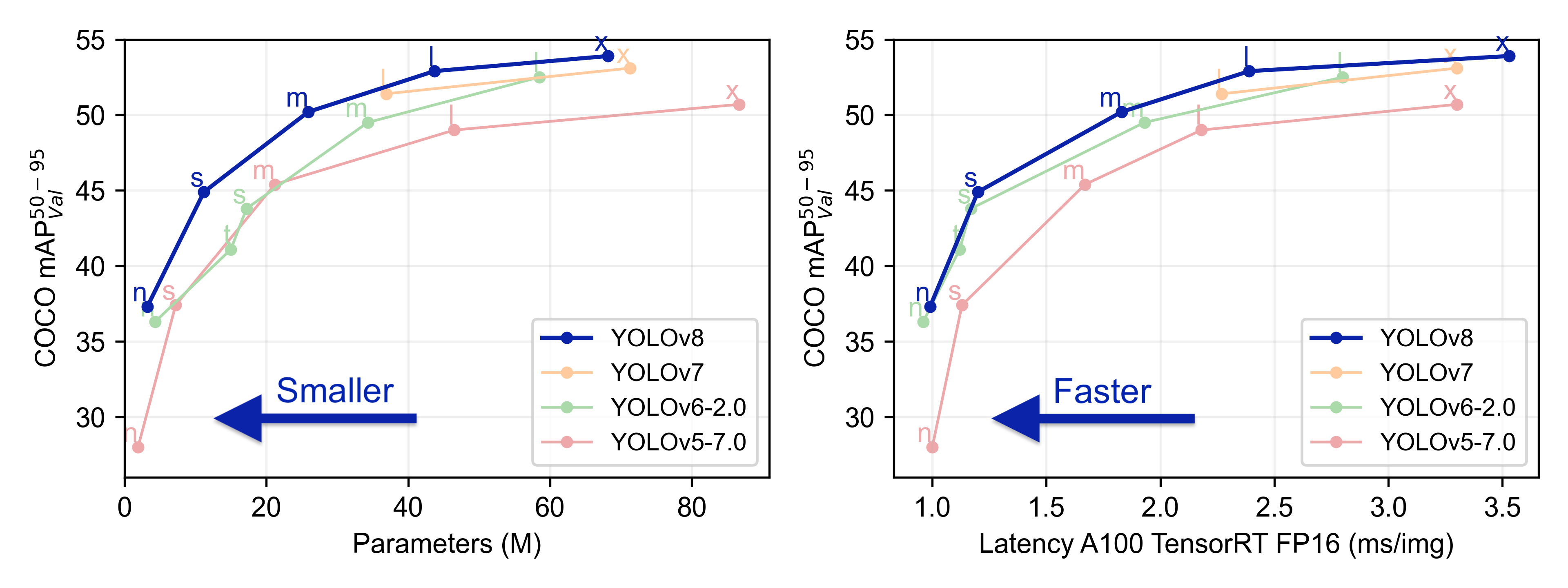\n",
+ "\n",
+ "\n",
+ "## Before You Start\n",
+ "\n",
+ "Start from a **Python>=3.8** environment with **PyTorch>=1.7** installed. To install PyTorch see [https://pytorch.org/get-started/locally/](https://pytorch.org/get-started/locally/). To install YOLOv5 dependencies:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f3bfa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install -U ultralytics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f248585",
+ "metadata": {},
+ "source": [
+ "## Model Description\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0a9a1b01",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "# this assumes that you have a proper version of PyTorch already installed\n",
+ "pip install -q torchaudio"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a638e514",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import torch\n",
+ "torch.set_num_threads(1)\n",
+ "\n",
+ "from IPython.display import Audio\n",
+ "from pprint import pprint\n",
+ "# download example\n",
+ "torch.hub.download_url_to_file('https://models.silero.ai/vad_models/en.wav', 'en_example.wav')\n",
+ "\n",
+ "model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',\n",
+ " model='silero_vad',\n",
+ " force_reload=True)\n",
+ "\n",
+ "(get_speech_timestamps,\n",
+ " _, read_audio,\n",
+ " *_) = utils\n",
+ "\n",
+ "sampling_rate = 16000 # also accepts 8000\n",
+ "wav = read_audio('en_example.wav', sampling_rate=sampling_rate)\n",
+ "# get speech timestamps from full audio file\n",
+ "speech_timestamps = get_speech_timestamps(wav, model, sampling_rate=sampling_rate)\n",
+ "pprint(speech_timestamps)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c5dc9e9",
+ "metadata": {},
+ "source": [
+ "### Model Description\n",
+ "\n",
+ "Silero VAD: pre-trained enterprise-grade Voice Activity Detector (VAD). Enterprise-grade Speech Products made refreshingly simple (see our STT models). **Each model is published separately**.\n",
+ "\n",
+ "Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link). WebRTC though starts to show its age and it suffers from many false positives.\n",
+ "\n",
+ "**(!!!) Important Notice (!!!)** - the models are intended to run on CPU only and were optimized for performance on 1 CPU thread. Note that the model is quantized.\n",
+ "\n",
+ "\n",
+ "### Additional Examples and Benchmarks\n",
+ "\n",
+ "For additional examples and other model formats please visit this [link](https://github.com/snakers4/silero-vad) and please refer to the extensive examples in the Colab format (including the streaming examples).\n",
+ "\n",
+ "### References\n",
+ "\n",
+ "VAD model architectures are based on similar STT architectures.\n",
+ "\n",
+ "- [Silero VAD](https://github.com/snakers4/silero-vad)\n",
+ "- [Alexander Veysov, \"Toward's an ImageNet Moment for Speech-to-Text\", The Gradient, 2020](https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/)\n",
+ "- [Alexander Veysov, \"A Speech-To-Text Practitioner’s Criticisms of Industry and Academia\", The Gradient, 2020](https://thegradient.pub/a-speech-to-text-practitioners-criticisms-of-industry-and-academia/)"
+ ]
+ }
+ ],
+ "metadata": {},
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/assets/hub/ultralytics_yolov5.ipynb b/assets/hub/ultralytics_yolov5.ipynb
new file mode 100644
index 000000000000..1dacc0f1dc8d
--- /dev/null
+++ b/assets/hub/ultralytics_yolov5.ipynb
@@ -0,0 +1,167 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "5c265ba5",
+ "metadata": {},
+ "source": [
+ "### This notebook is optionally accelerated with a GPU runtime.\n",
+ "### If you would like to use this acceleration, please select the menu option \"Runtime\" -> \"Change runtime type\", select \"Hardware Accelerator\" -> \"GPU\" and click \"SAVE\"\n",
+ "\n",
+ "----------------------------------------------------------------------\n",
+ "\n",
+ "# YOLOv5\n",
+ "\n",
+ "*Author: Ultralytics*\n",
+ "\n",
+ "**Ultralytics YOLOv5 🚀 for object detection, instance segmentation and image classification.**\n",
+ "\n",
+ "_ | _\n",
+ "- | -\n",
+ " | \n",
+ "\n",
+ "\n",
+ "## Before You Start\n",
+ "\n",
+ "Start from a **Python>=3.8** environment with **PyTorch>=1.7** installed. To install PyTorch see [https://pytorch.org/get-started/locally/](https://pytorch.org/get-started/locally/). To install YOLOv5 dependencies:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6f3bfa8",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "pip install -U ultralytics"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6f248585",
+ "metadata": {},
+ "source": [
+ "## Model Description\n",
+ "\n",
+ " \n",
+ "\n",
+ "Ultralytics YOLOv5 🚀 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv5 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, instance segmentation and image classification tasks.\n",
+ "\n",
+ "We hope that the resources here will help you get the most out of YOLOv5. Please browse the YOLOv5 [Docs](https://docs.ultralytics.com/yolov5) for details, raise an issue on [GitHub](https://github.com/ultralytics/yolov5/issues/new/choose) for support, and join our [Discord](https://discord.gg/n6cFeSPZdD) community for questions and discussions!\n",
+ "\n",
+ "| Model | size
\n",
+ "\n",
+ "Ultralytics YOLOv5 🚀 is a cutting-edge, state-of-the-art (SOTA) model that builds upon the success of previous YOLO versions and introduces new features and improvements to further boost performance and flexibility. YOLOv5 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, instance segmentation and image classification tasks.\n",
+ "\n",
+ "We hope that the resources here will help you get the most out of YOLOv5. Please browse the YOLOv5 [Docs](https://docs.ultralytics.com/yolov5) for details, raise an issue on [GitHub](https://github.com/ultralytics/yolov5/issues/new/choose) for support, and join our [Discord](https://discord.gg/n6cFeSPZdD) community for questions and discussions!\n",
+ "\n",
+ "| Model | size +
+ 













 +
+ 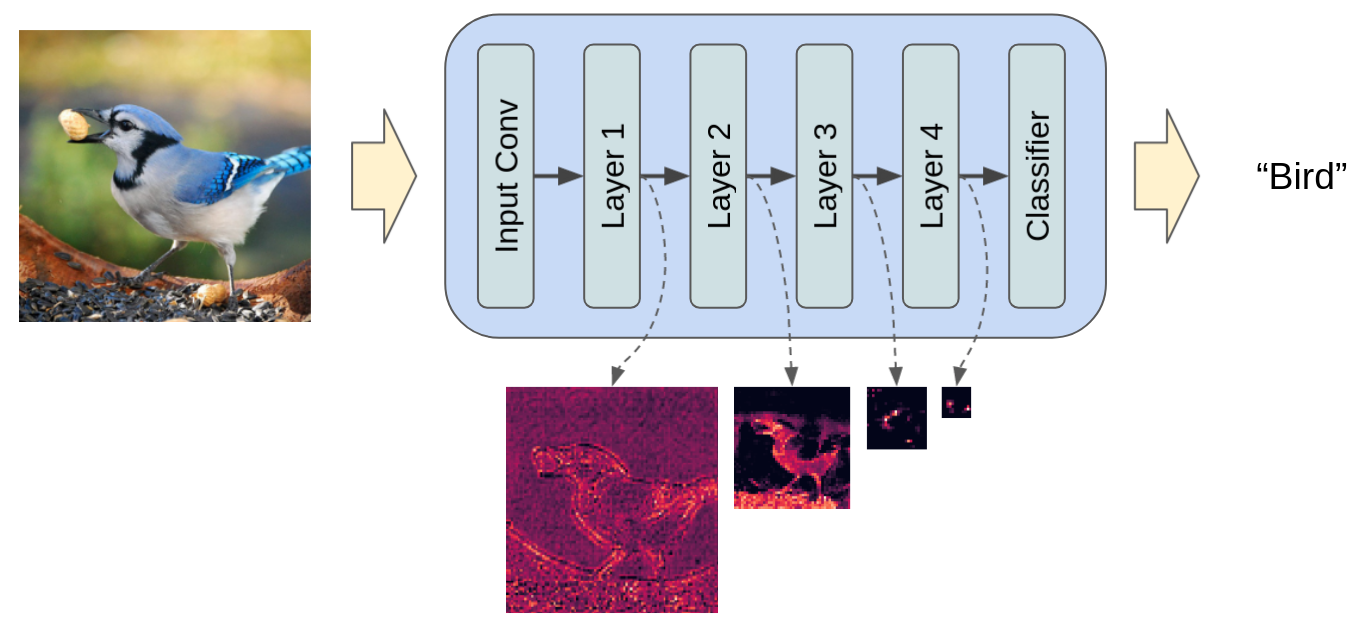 +
+ 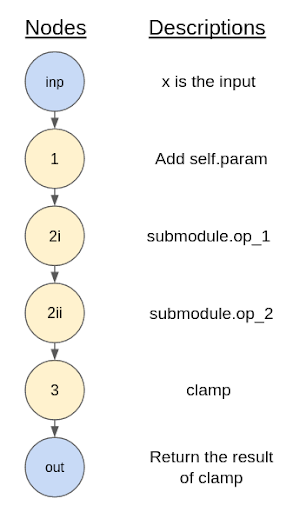 +
+  +
+ 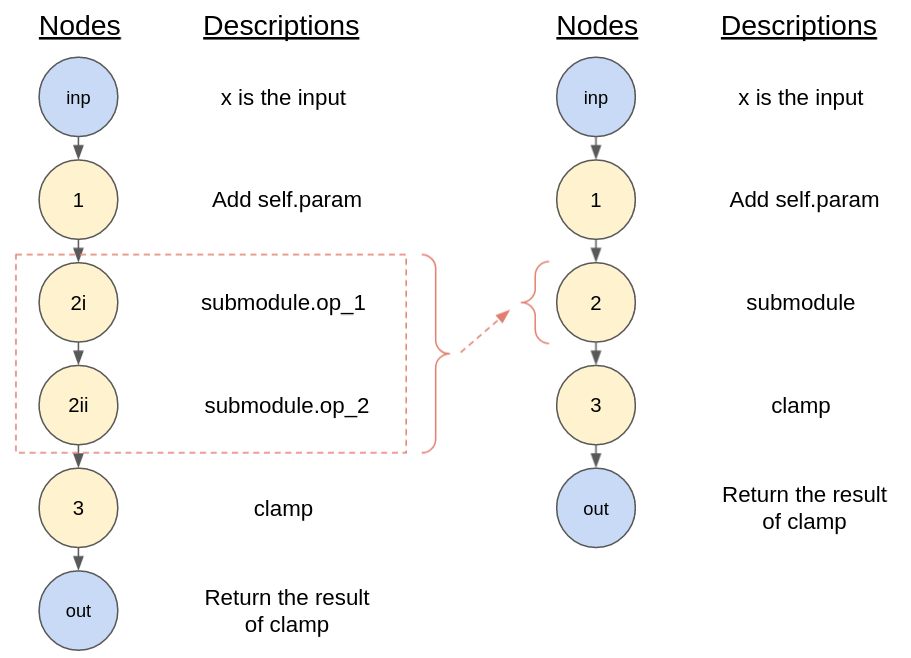 +
+  +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+  +
+ +
+
























 +Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for
+Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for 































































 +
+  +
+ 











































































 +
+ +
+ +
+ +
+ +
+ +
+ +
+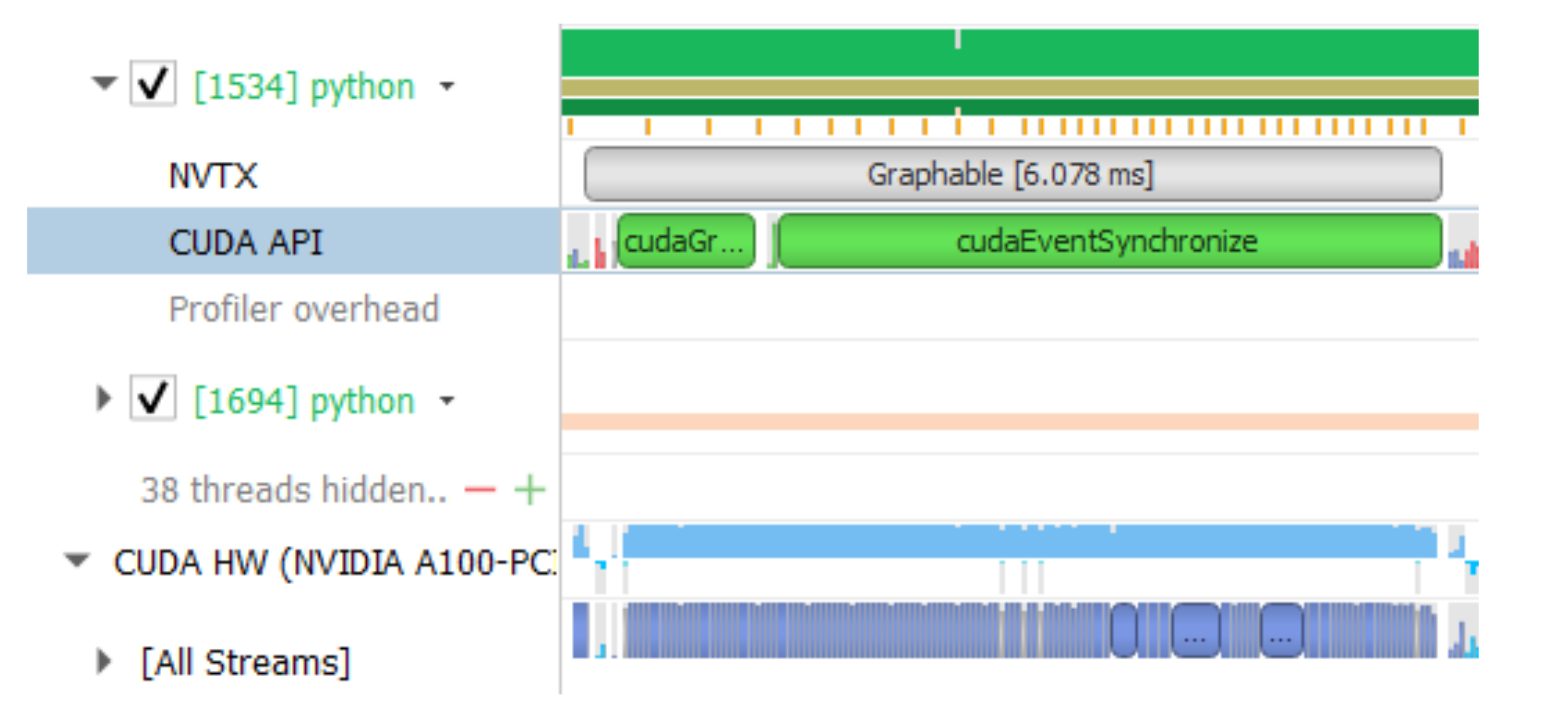 +
+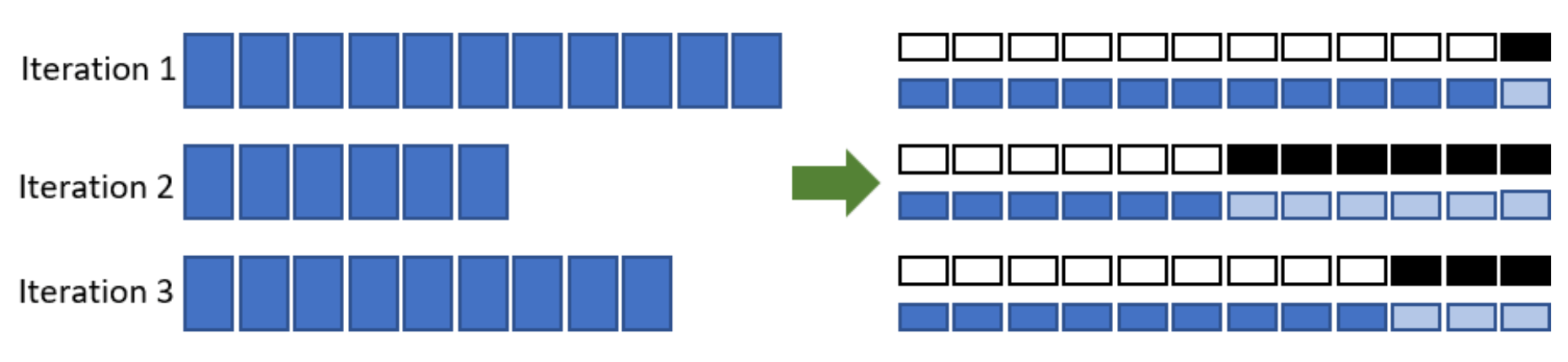 +
+  +
+ +
+






 +
+ +
+

































 +
+ +
+ +
+ +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+ 
 +
+
+
+  +
+
+
+  +
+
+
+  +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+






 +
+ +
+ +
+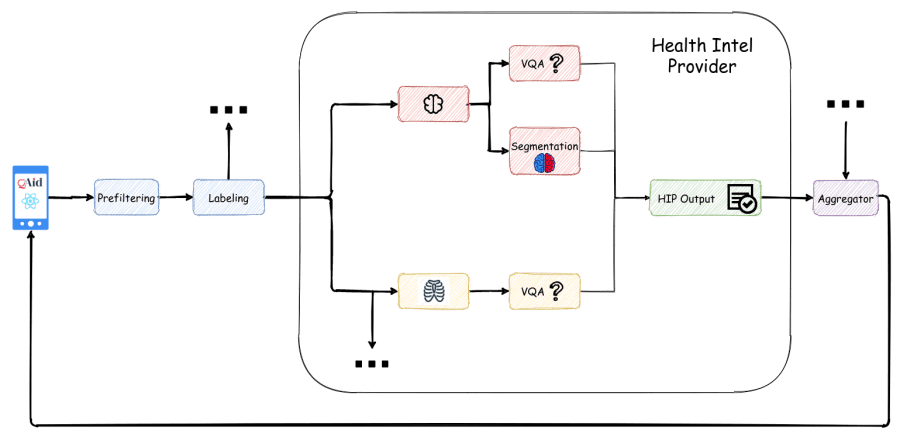 +
+ +
+












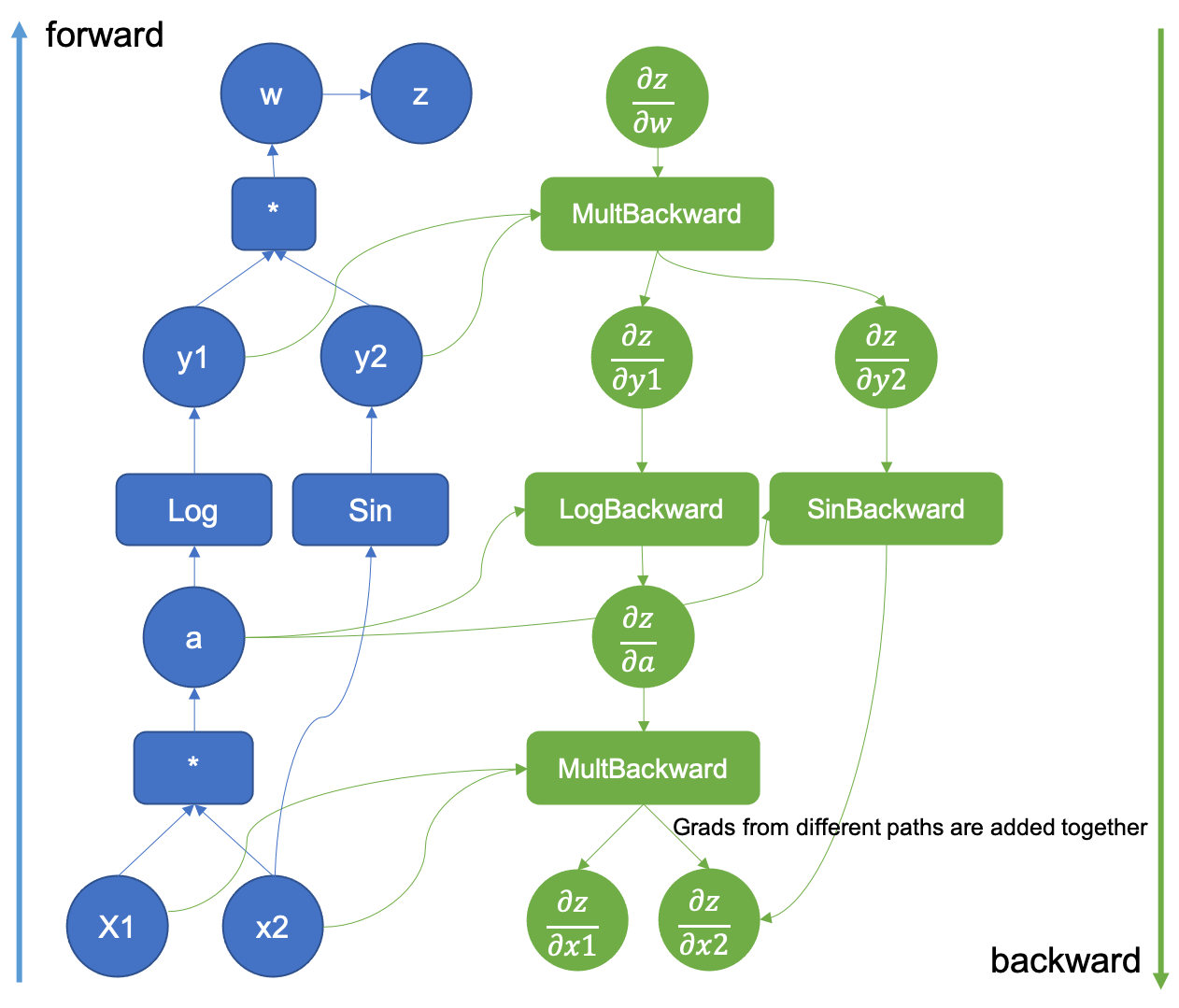 +
+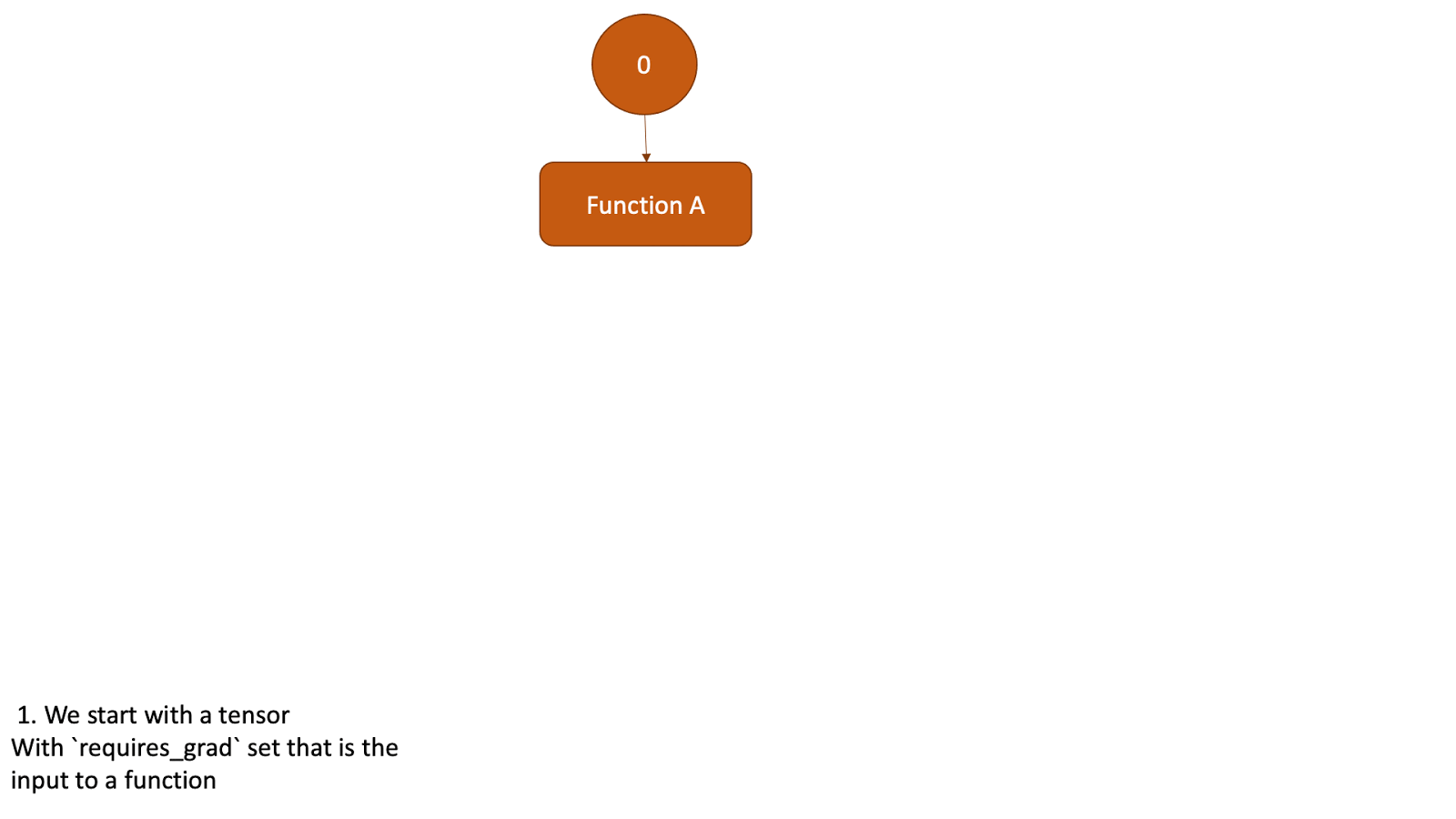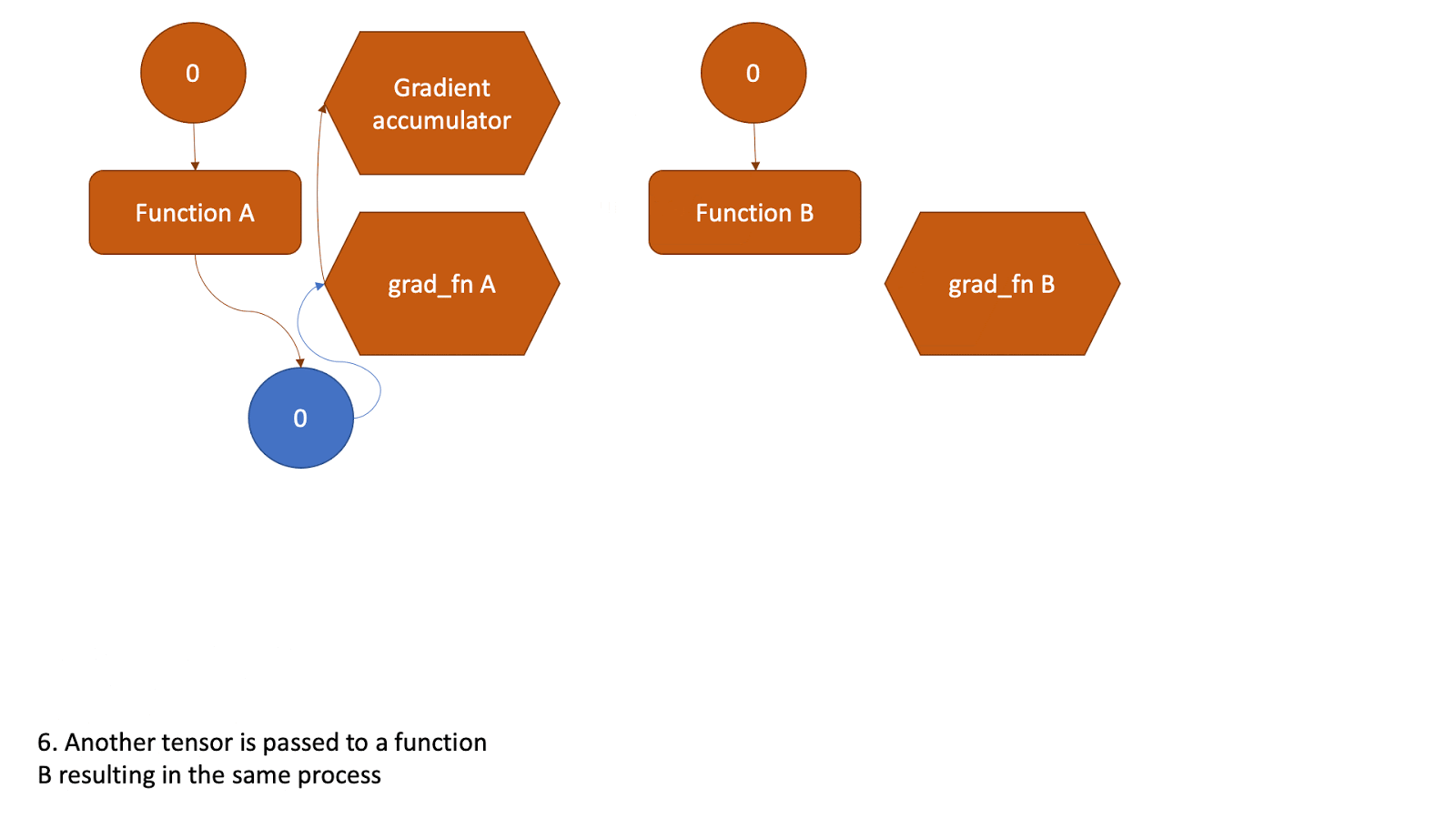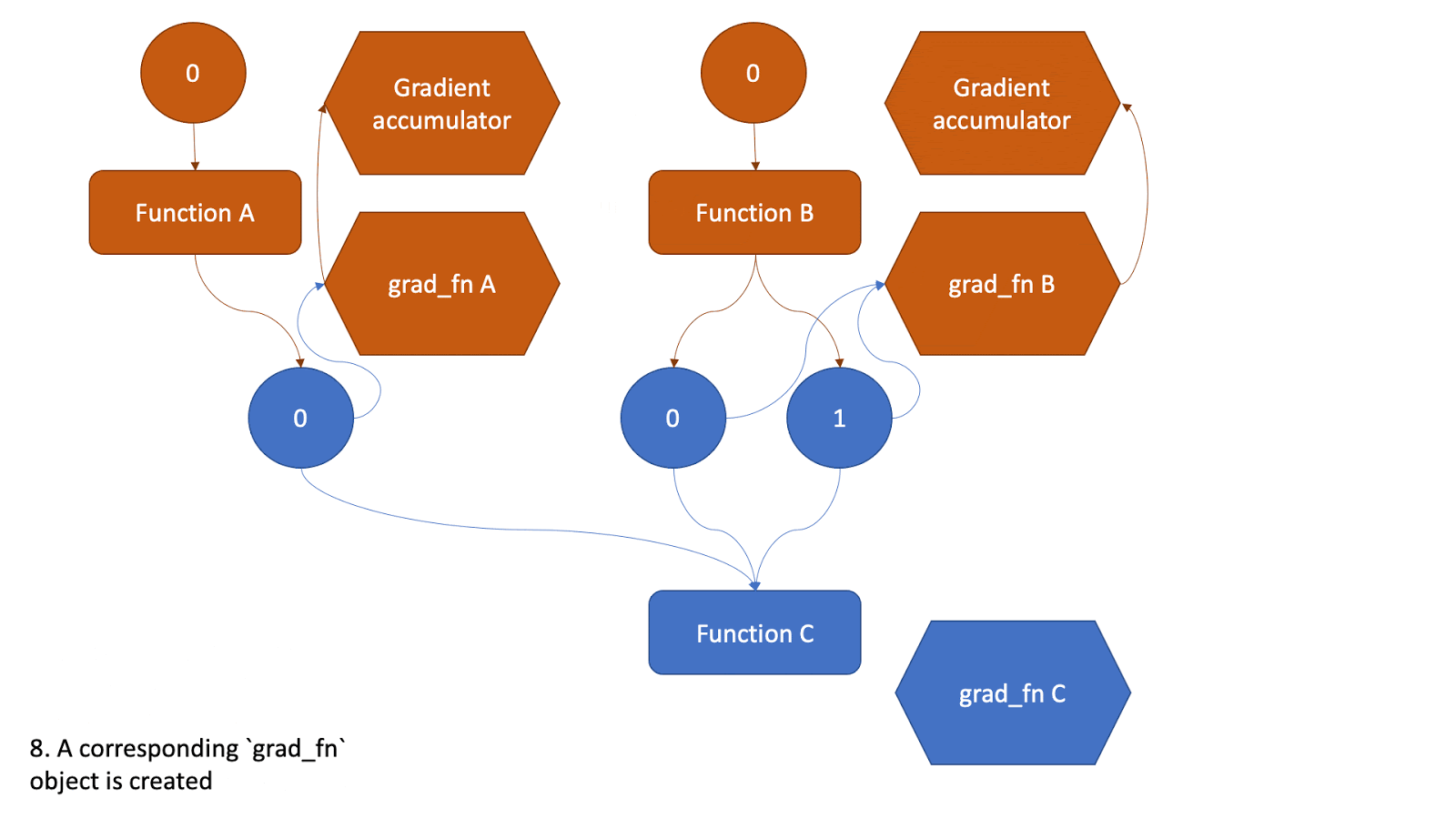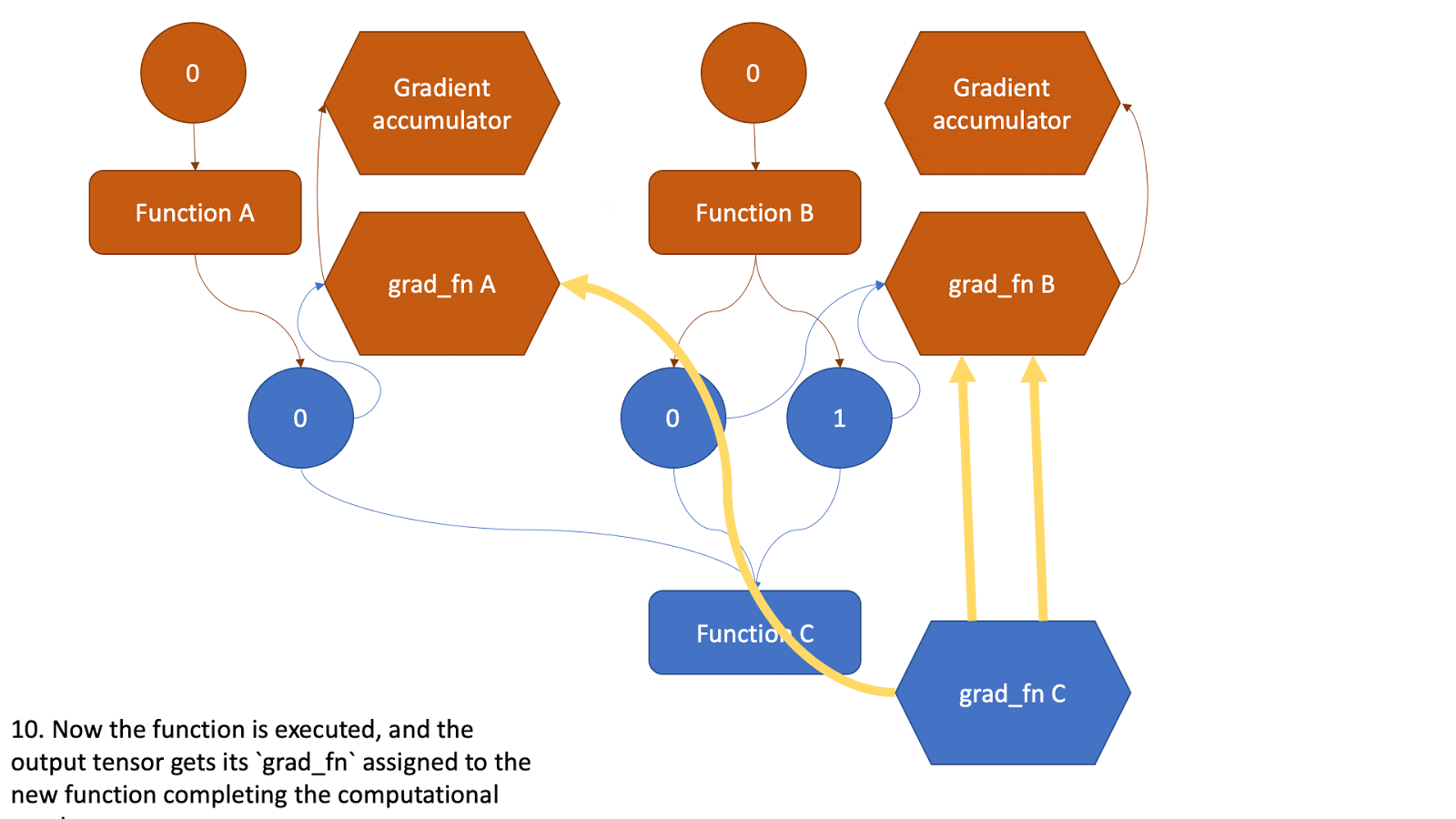 +
+
 +Figure 3. Trace of Llama3-8B with torch.compile, showing CUDA kernels being used for matrix multiplications and flash attention
+Figure 3. Trace of Llama3-8B with torch.compile, showing CUDA kernels being used for matrix multiplications and flash attention

























 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+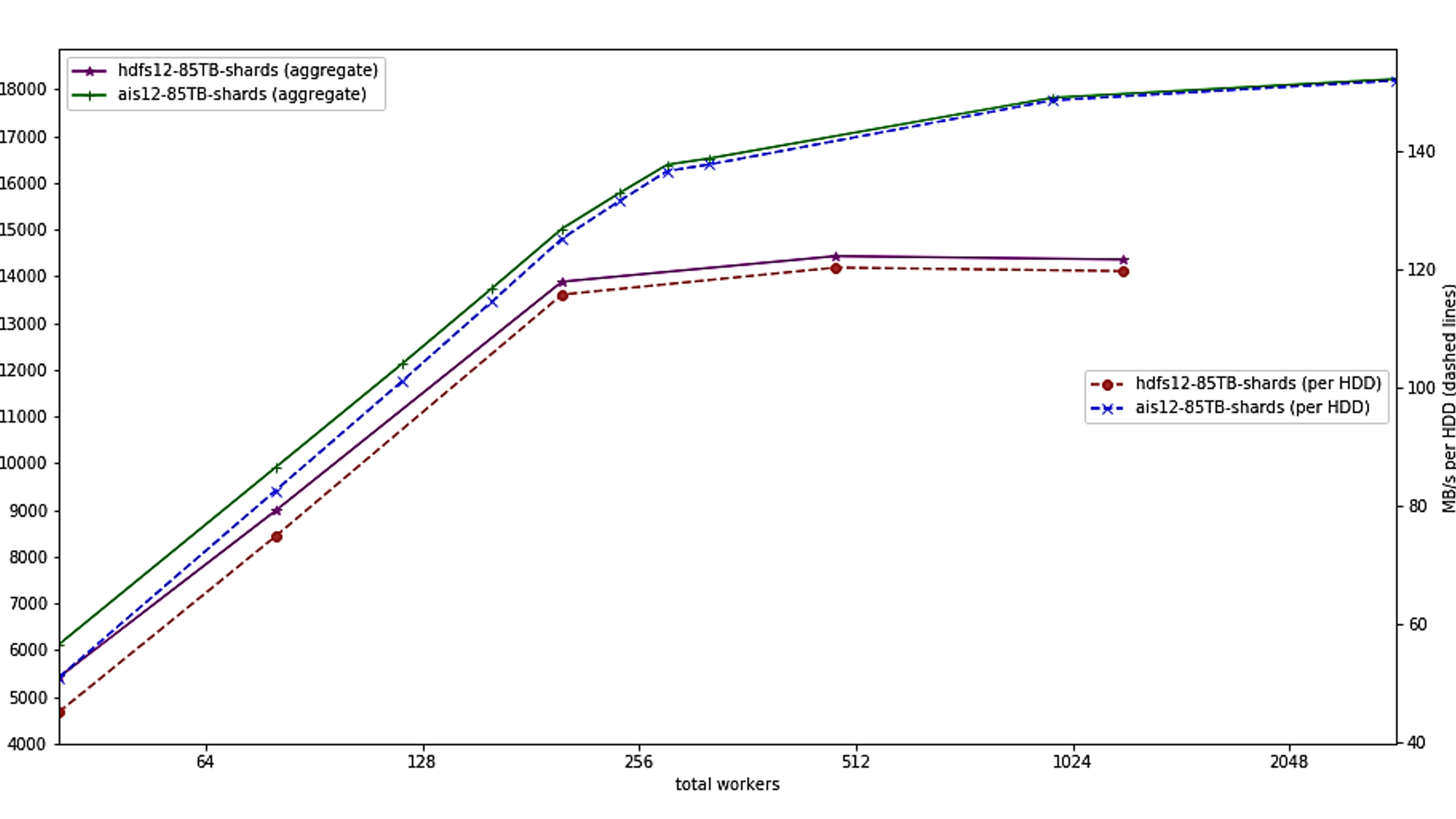 +
+




 +
+
 +
+ +
+ +
+ +
+ +
+





















































 +
+ +
+ +
+ +
+ +
+ +
+ +
+



































 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+










 +
+ +
+ +
+ +
+ +
+ +
+























































 +
+ +
+


 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+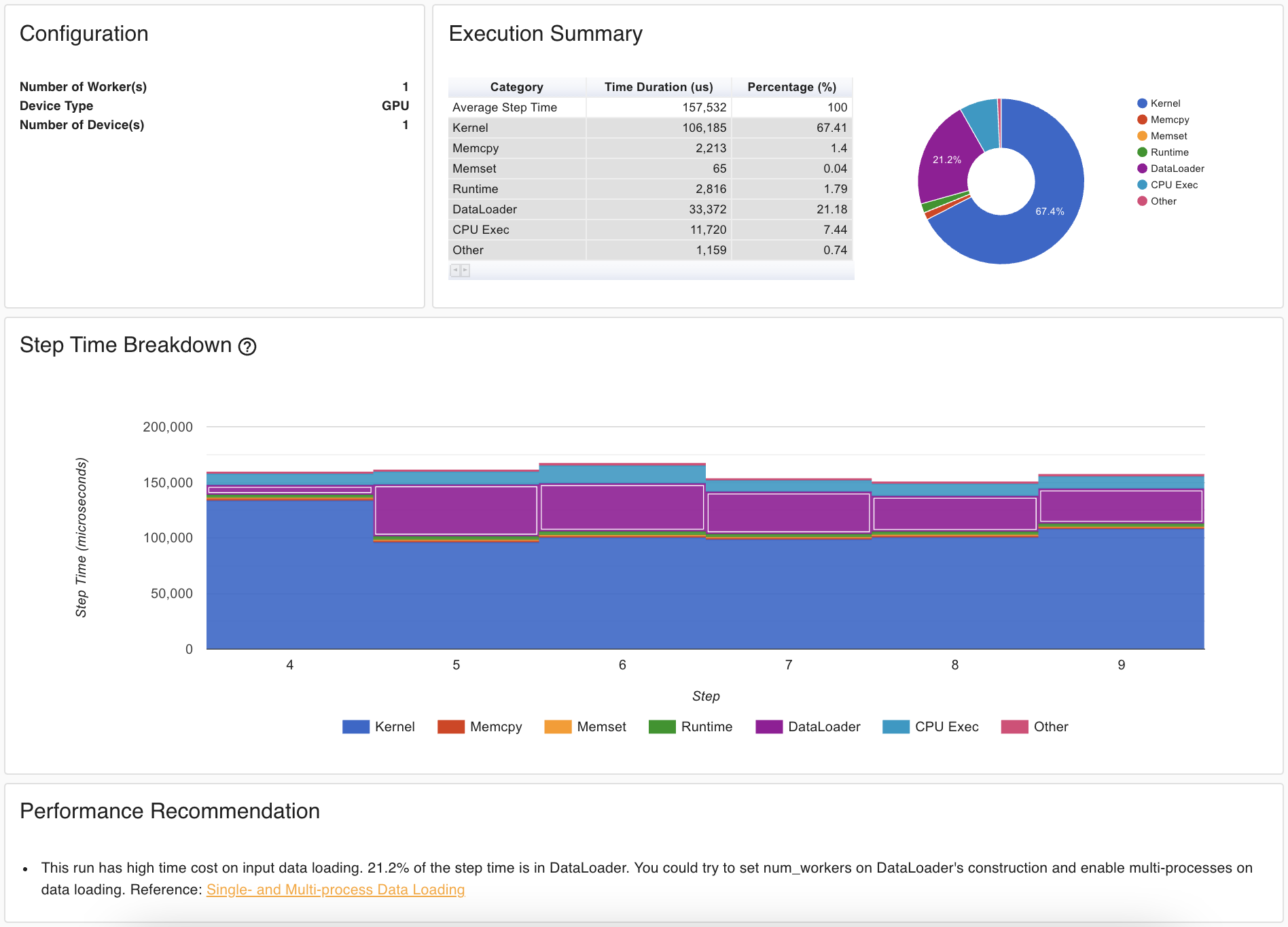 +
+ +
+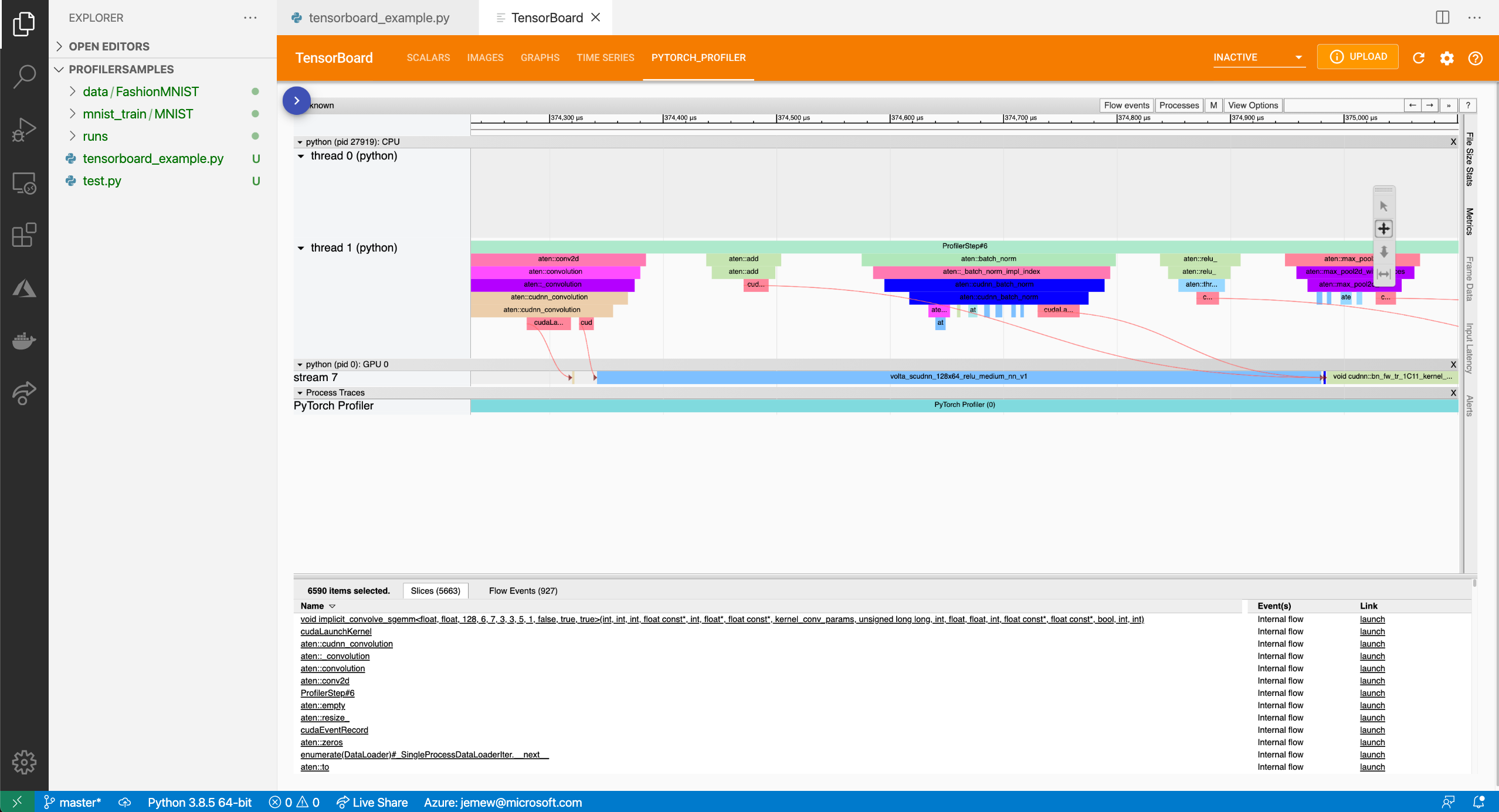 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+






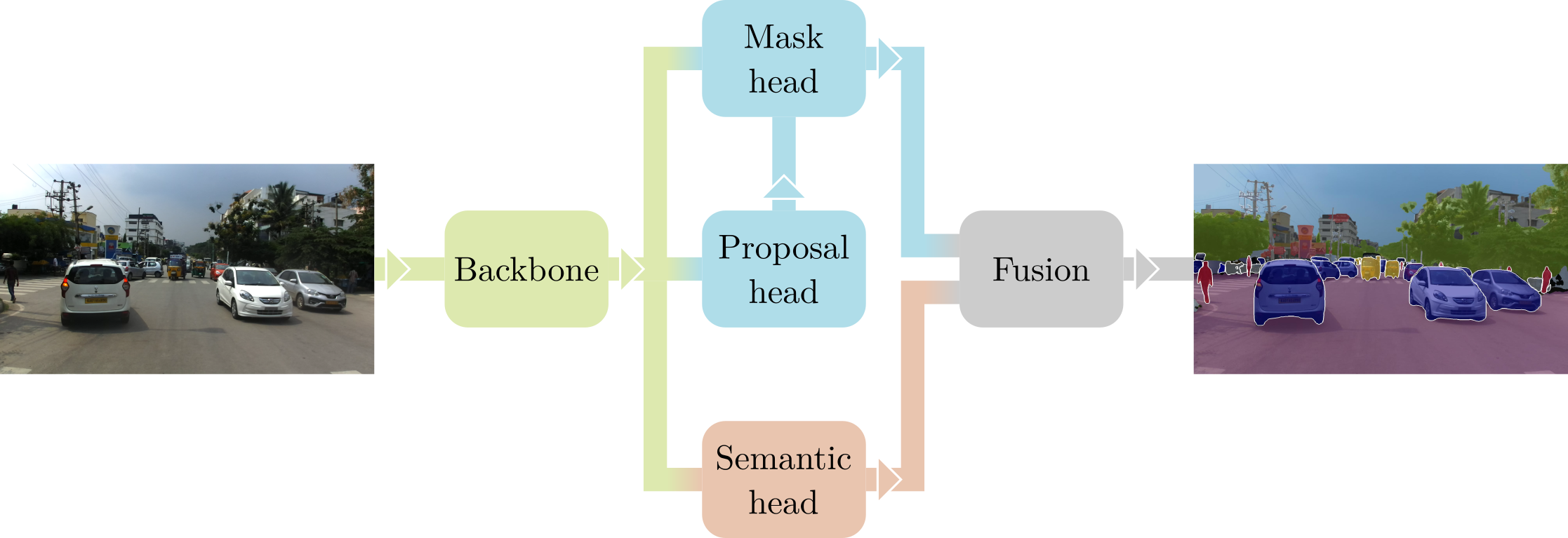 +
+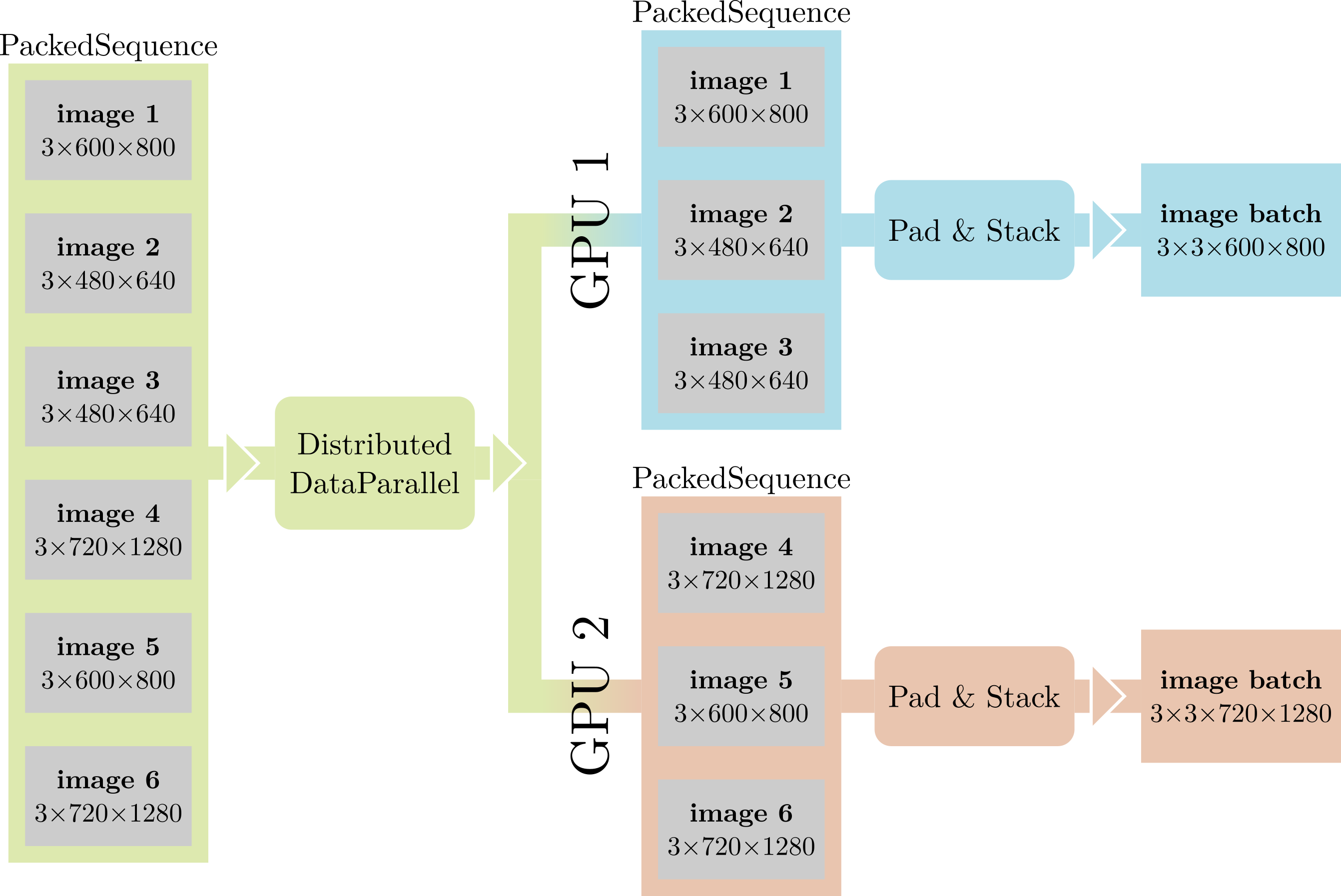 +
+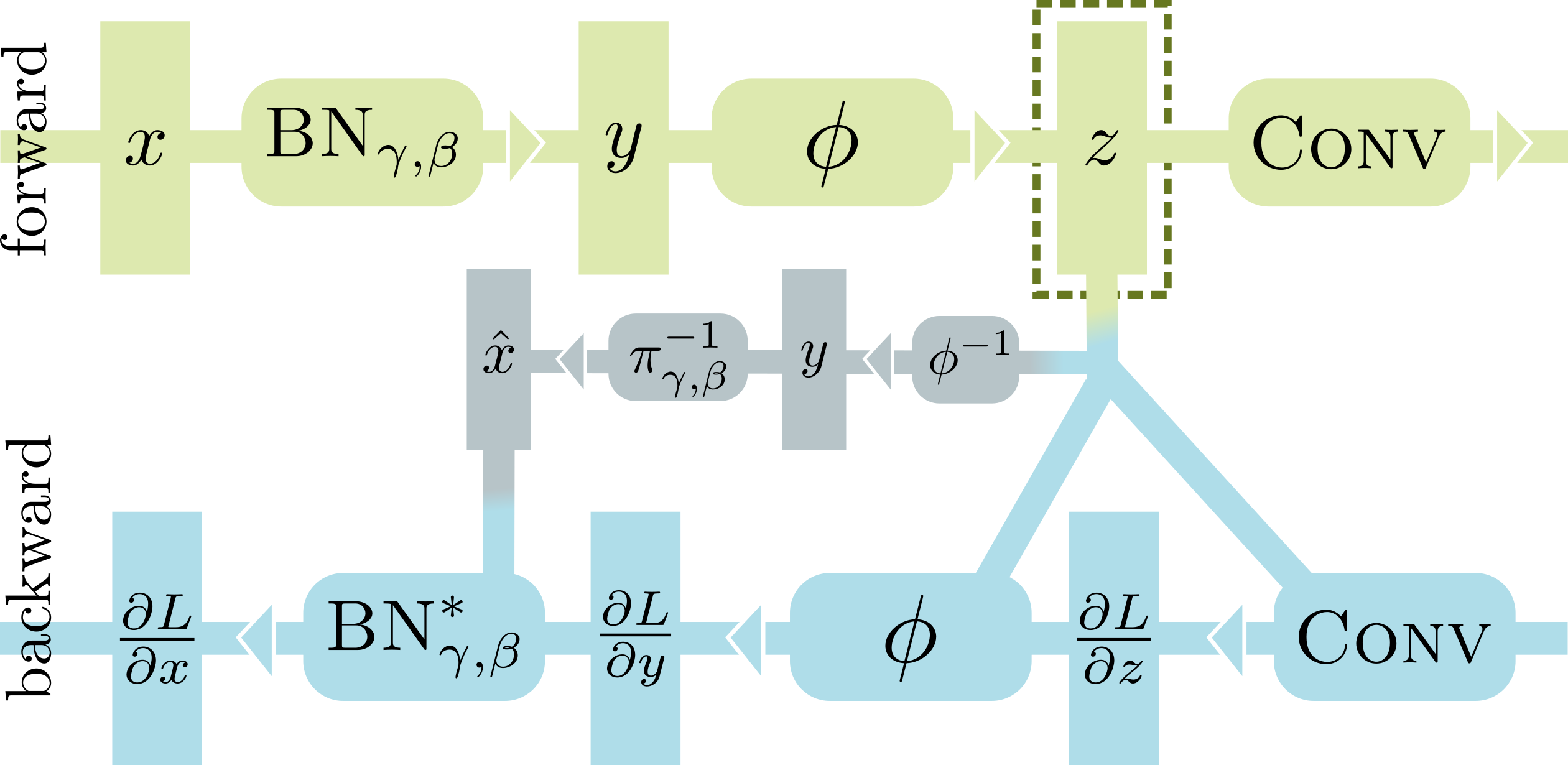 +
+




 +
+












 +
+
 +
+ +
+ +
+

 +
+
 +
+
 +
+
 +
+
 +
+
 +
+
 +
+
 +
+ +The PyTorch Foundation is excited to welcome Matt White, our new executive director. The PyTorch Foundation formed in 2022 with the goal to drive adoption of AI tooling by fostering and sustaining an ecosystem of open source, vendor-neutral projects with PyTorch. Over the past 2 years, we’ve seen excellent growth across the project – with both contributor and member growth.
+The PyTorch Foundation is excited to welcome Matt White, our new executive director. The PyTorch Foundation formed in 2022 with the goal to drive adoption of AI tooling by fostering and sustaining an ecosystem of open source, vendor-neutral projects with PyTorch. Over the past 2 years, we’ve seen excellent growth across the project – with both contributor and member growth.
 +
+







 +
+ +
+




 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +Inference benchmark on a single A10G GPU, AWS g5.4xlarge instance
+Inference benchmark on a single A10G GPU, AWS g5.4xlarge instance +Training benchmark on a single A10G GPU, AWS g5.4xlarge instance
+Training benchmark on a single A10G GPU, AWS g5.4xlarge instance +Training benchmark on a single A100-SXM4-80GB, Nvidia DGX
+Training benchmark on a single A100-SXM4-80GB, Nvidia DGX +Training benchmark on two A100-SXM4-80GB, Nvidia DGX, using 🤗 Accelerate library for distributed training
+Training benchmark on two A100-SXM4-80GB, Nvidia DGX, using 🤗 Accelerate library for distributed training +Using memory-efficient attention SDP kernel (forward-only), A100
+Using memory-efficient attention SDP kernel (forward-only), A100 +Using math (without dropout), A100
+Using math (without dropout), A100 +Using flash attention SDP kernel (without dropout), A100
+Using flash attention SDP kernel (without dropout), A100 +Using memory-efficient attention SDP kernel (without dropout), A100
+Using memory-efficient attention SDP kernel (without dropout), A100

 +
+  +
+  +
+  +
+  +
+  +
+ 















 +
+ +
+ +
+ +
+ +
+























 +
+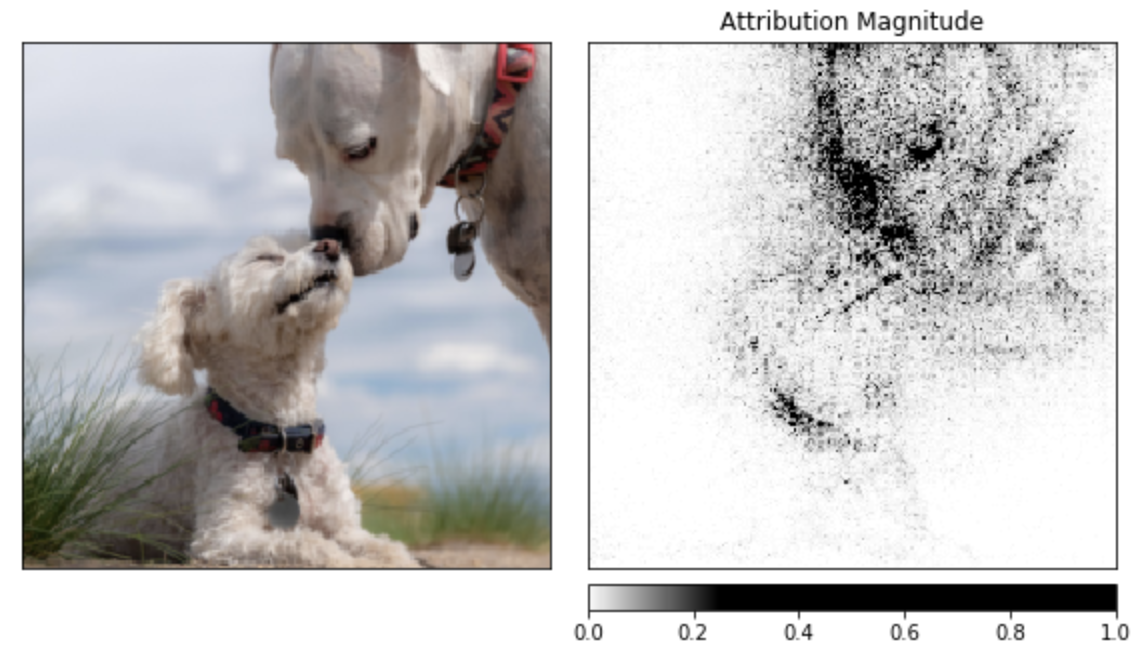 +
+ +
+ +
+
 +
+ +
+ +
+ +
+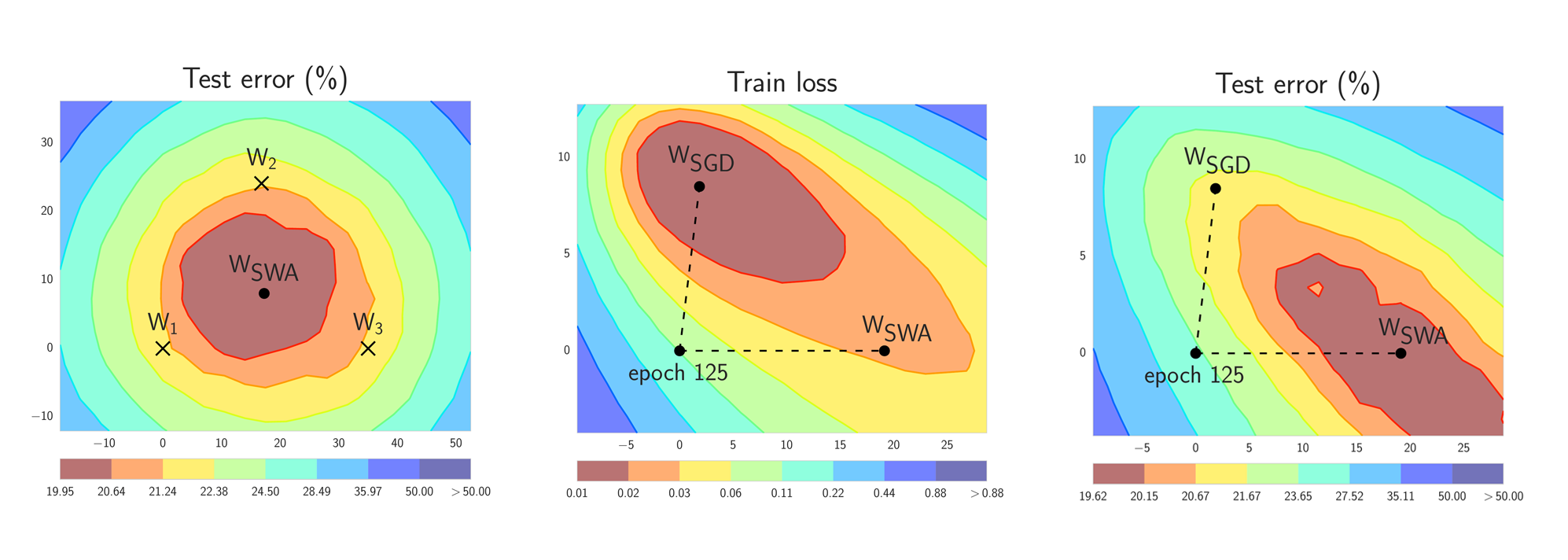 +
+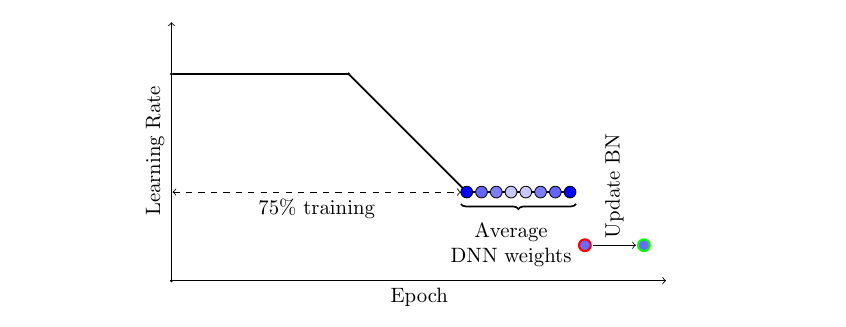 +
+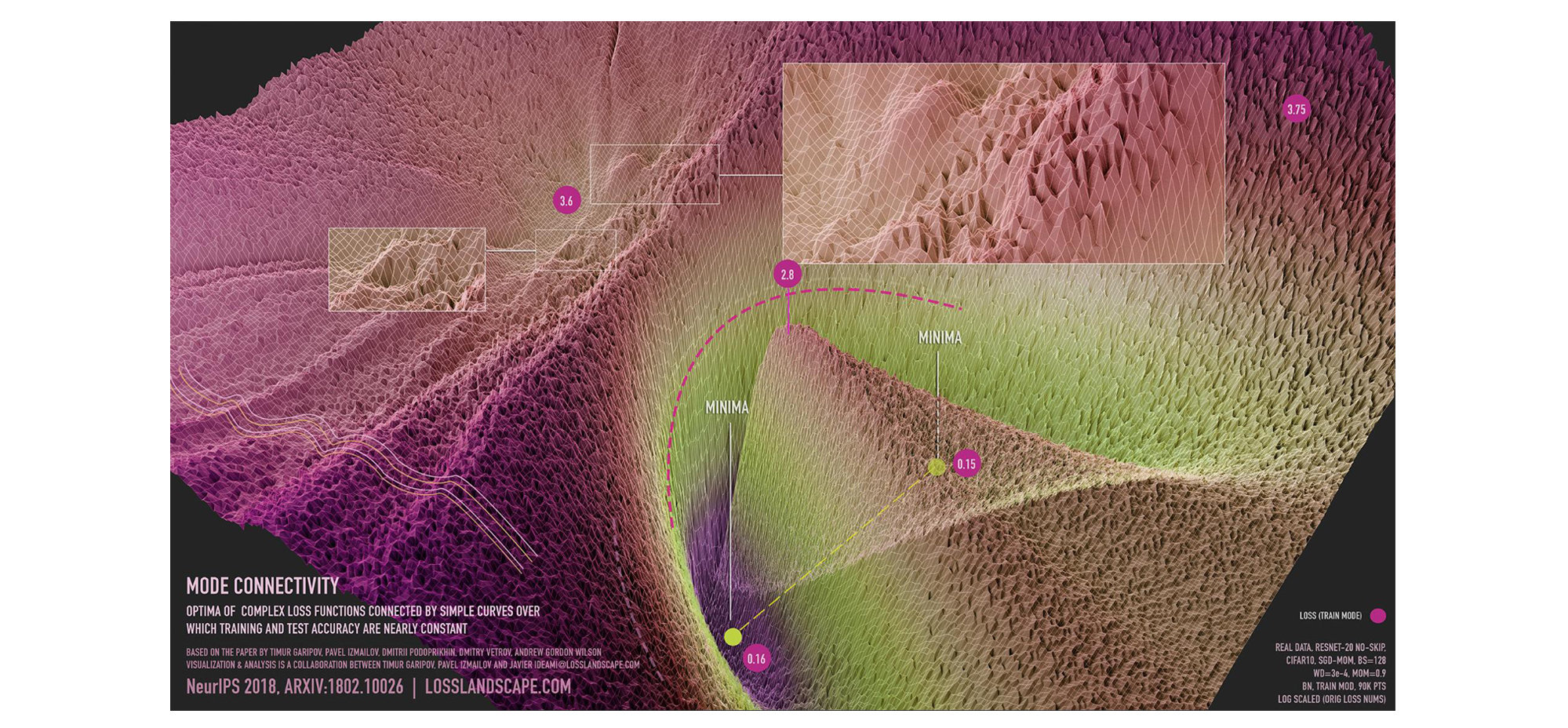 +
+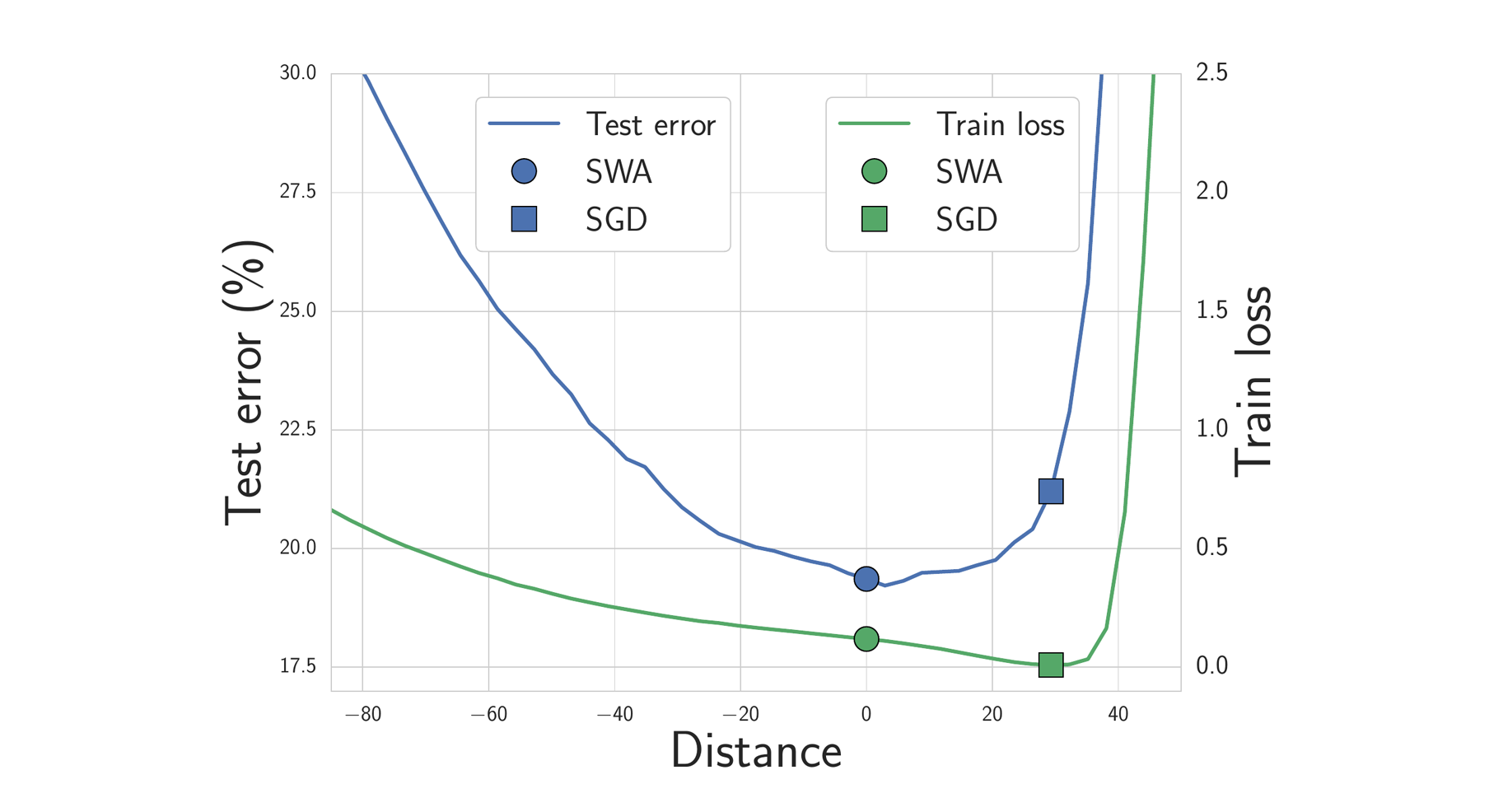 +
+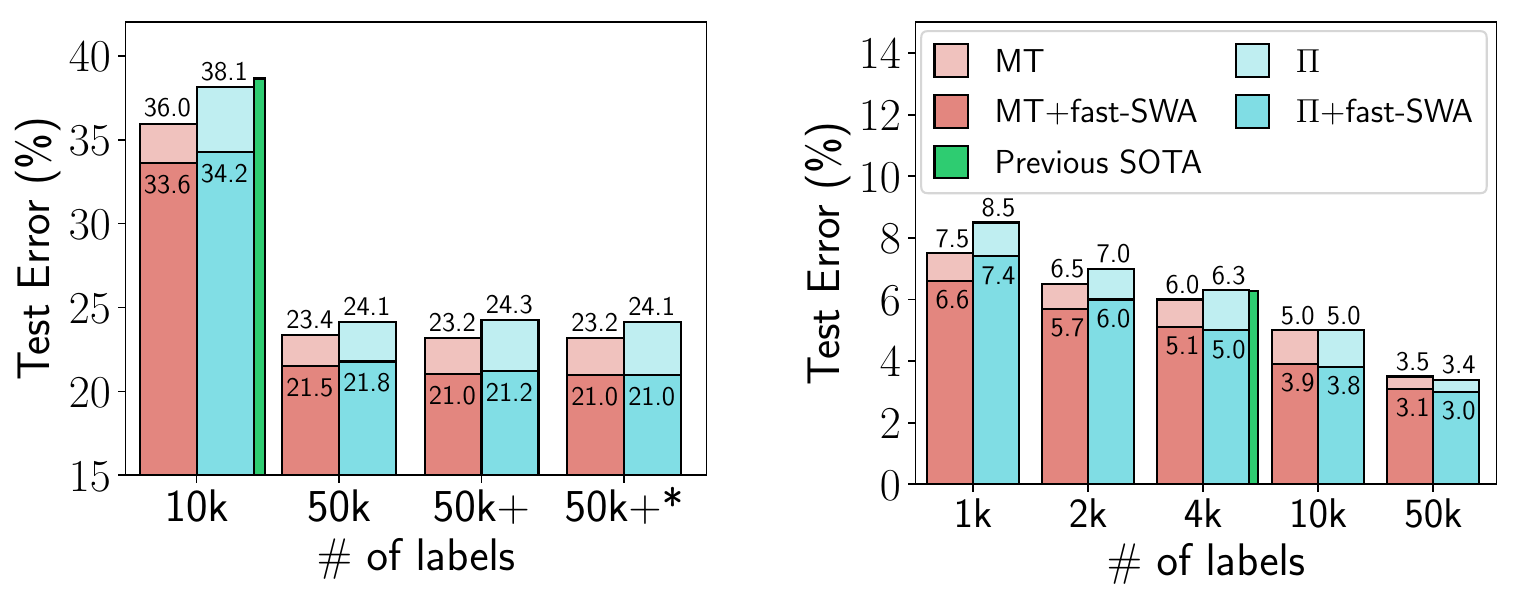 +
+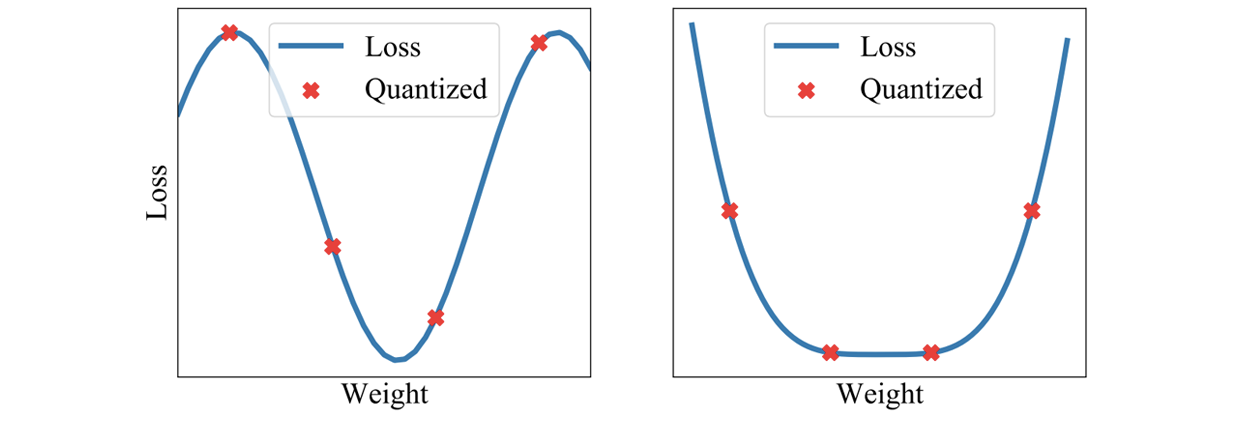 +
+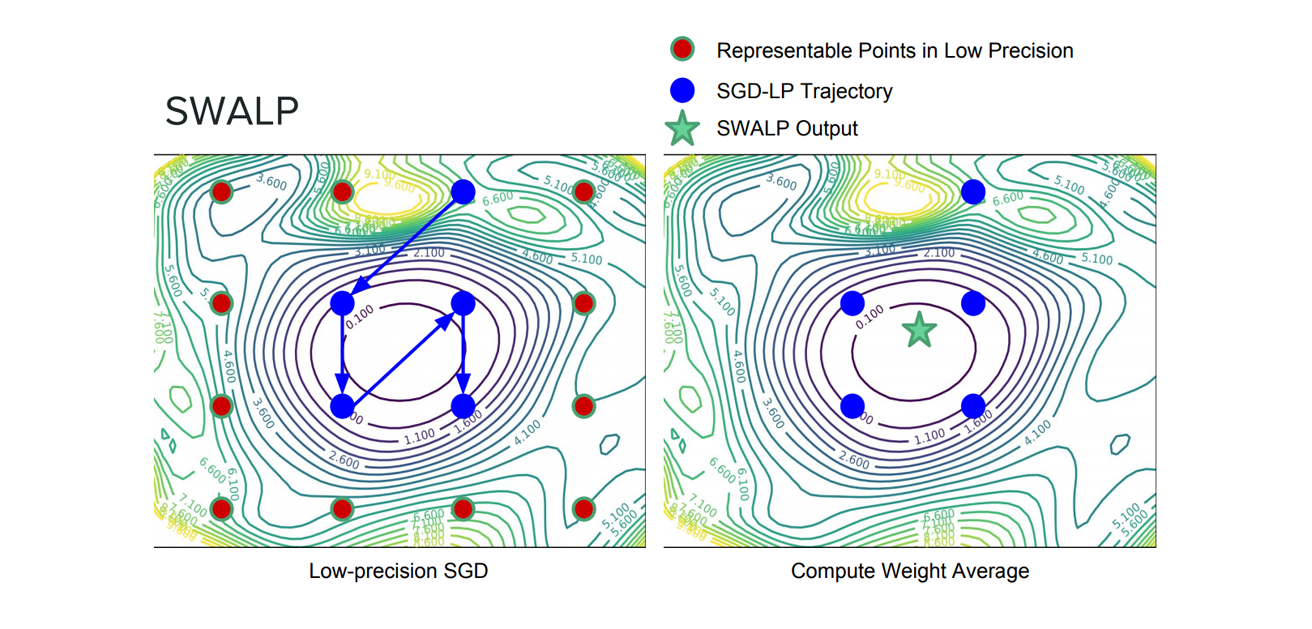 +
+ +
+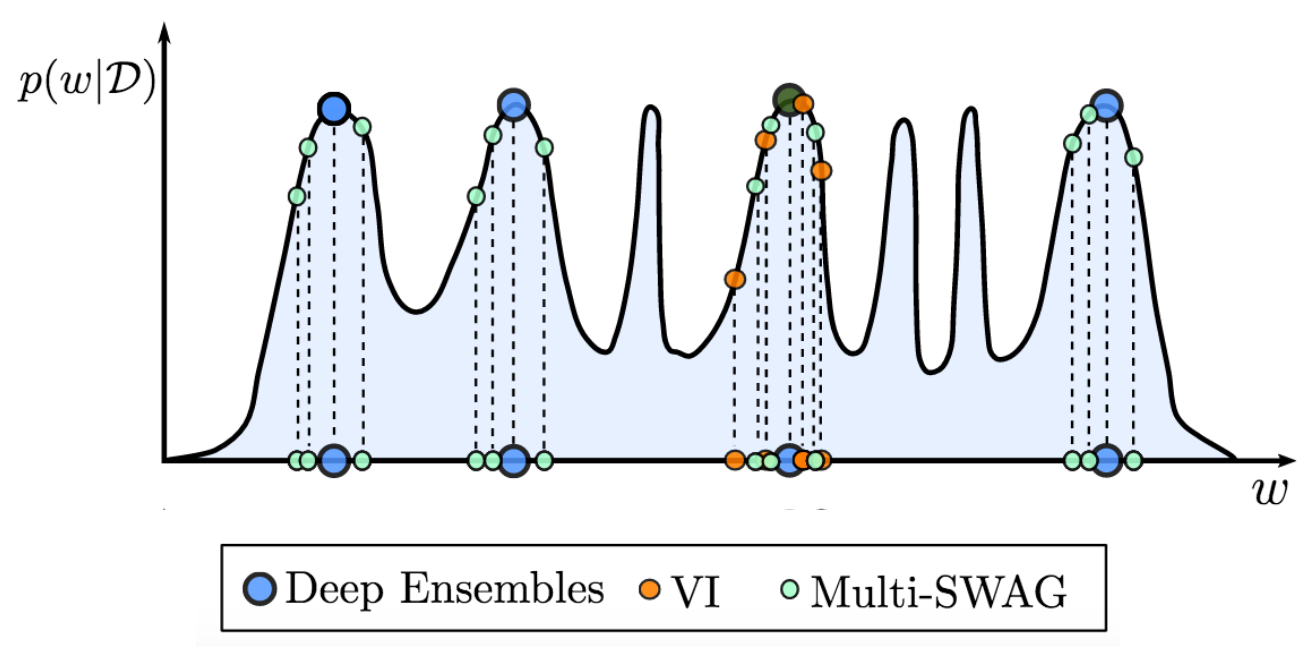 +
+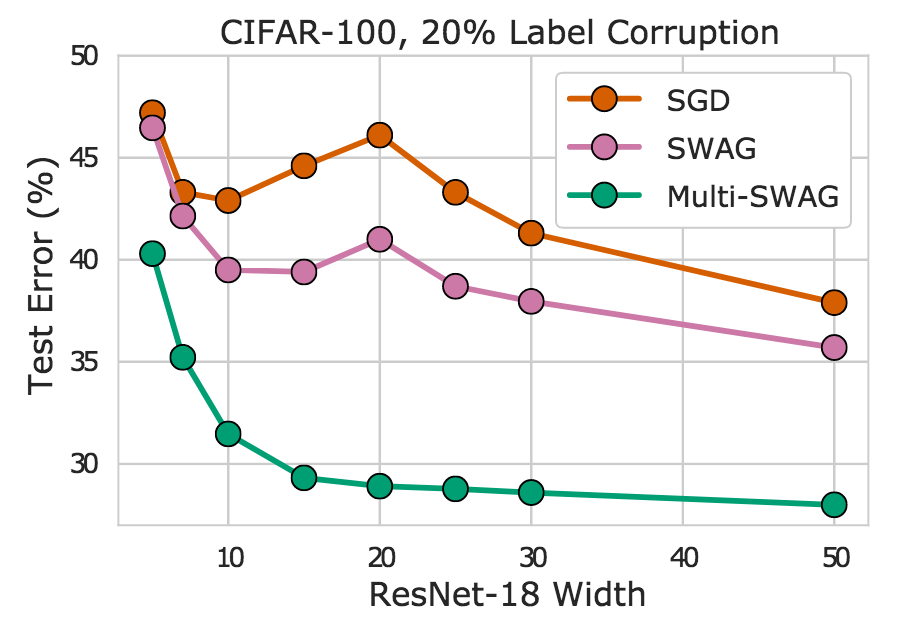 +
+ +
+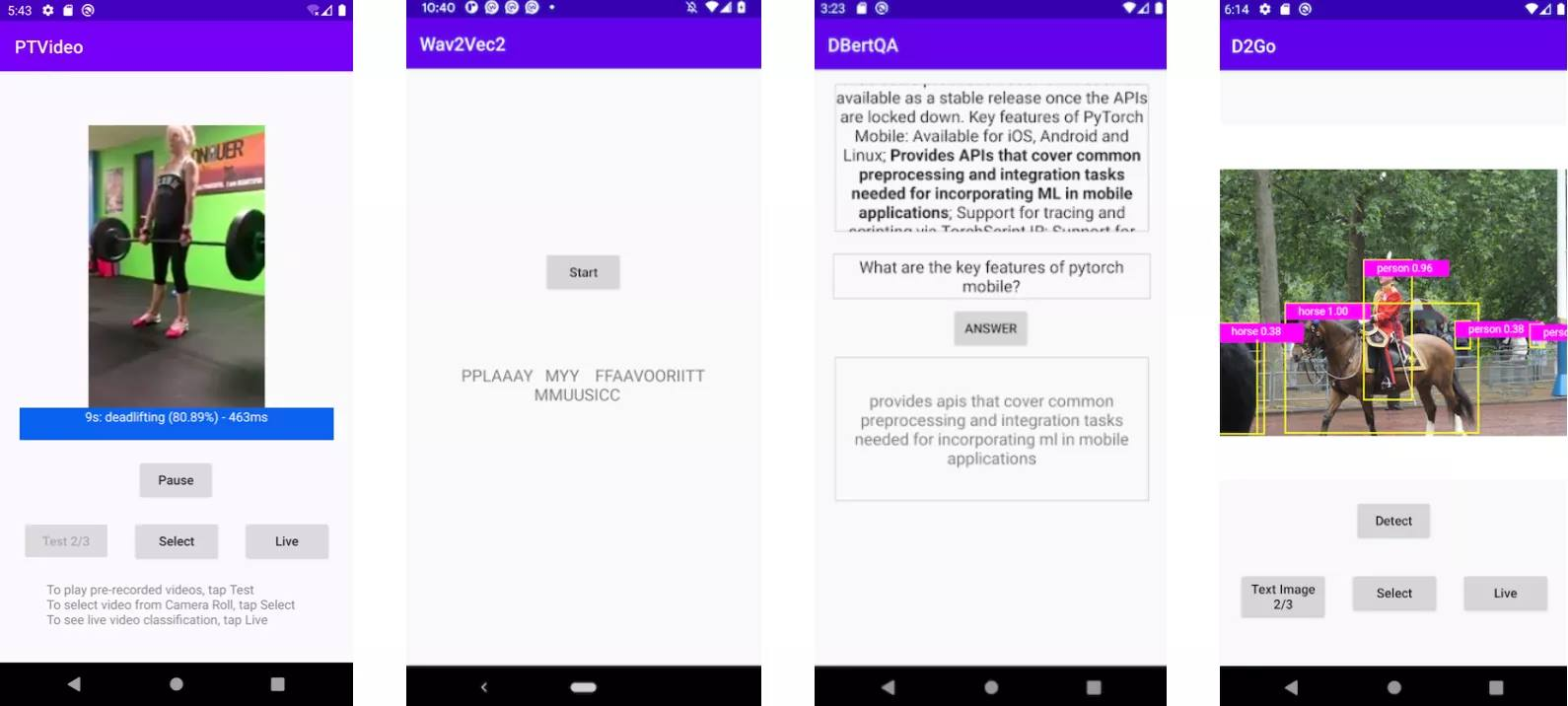 +
+ +
+

 +Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for
+Figure: Using scaled dot product attention with custom kernels and torch.compile delivers significant speedups for training large language models, such as for 




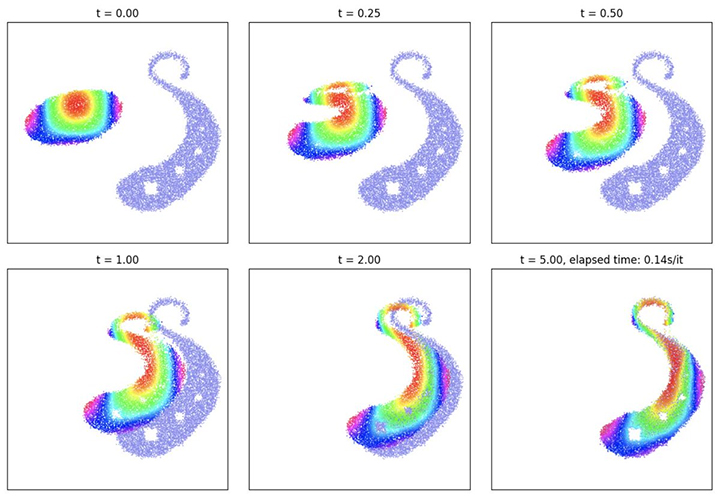 +
+











 +
+ +
+
 +
+ +
+ +
+ +
+



 +(source:
+(source: 
 +
+ +
+  +
+ +
+ +
+ +
+  +
+  +
+ +
+ +
+ +
+ +
+ 









 +
+ +
+ +
+ +
+









 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ 
 +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+ 





 +
+ +
+  +
+ +
+  +
+ +
+ +
+  +
+ +
+  +
+ +
+  +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+

 +
+ +
+ +
+ +
+ +
+








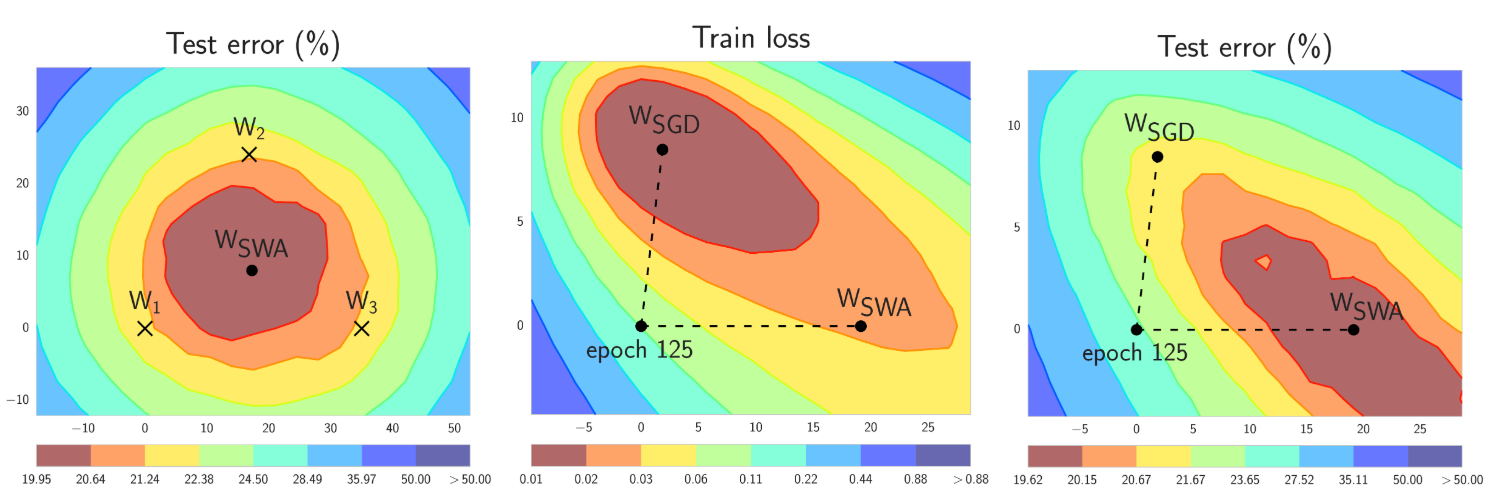 +
+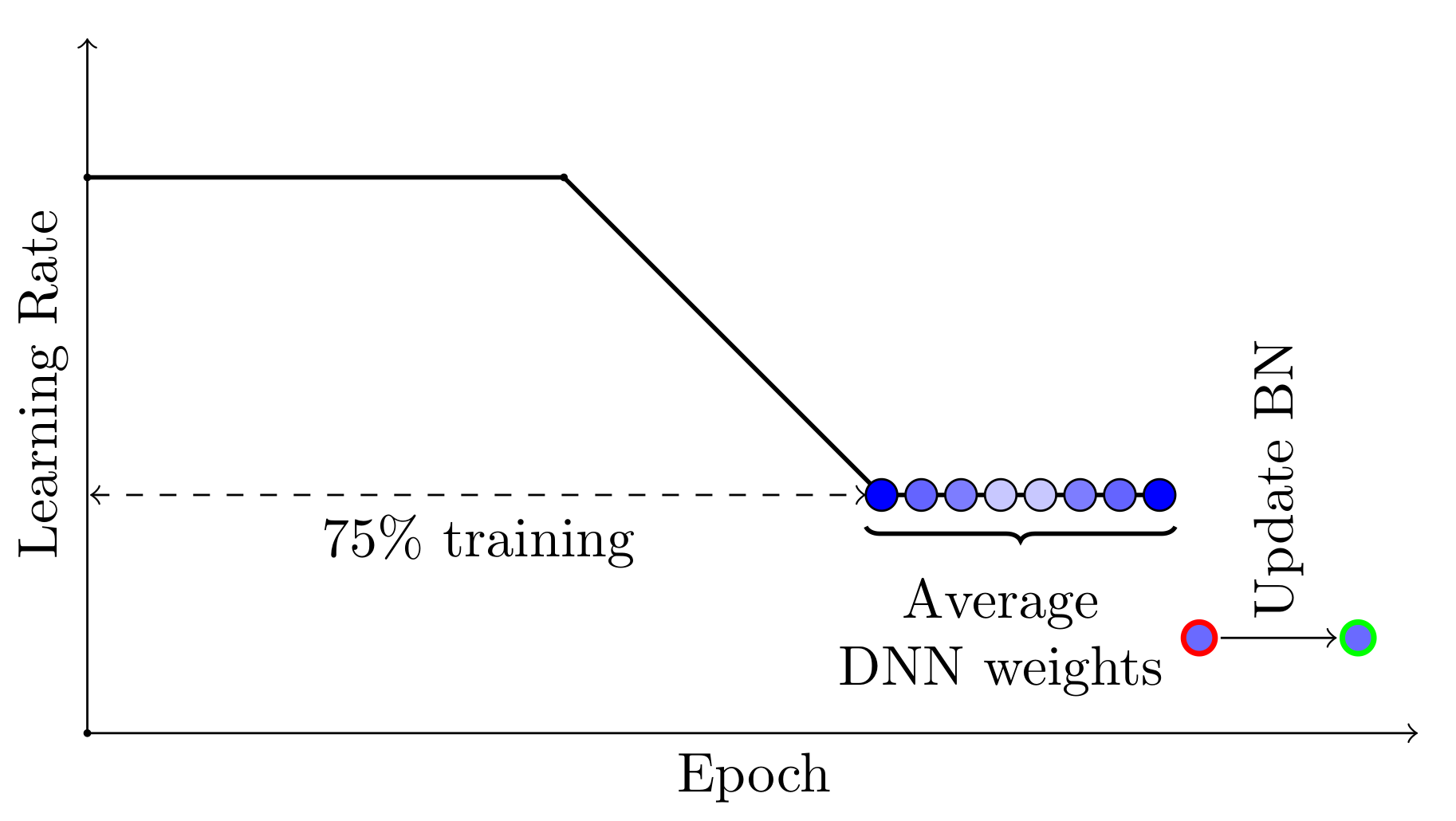 +
+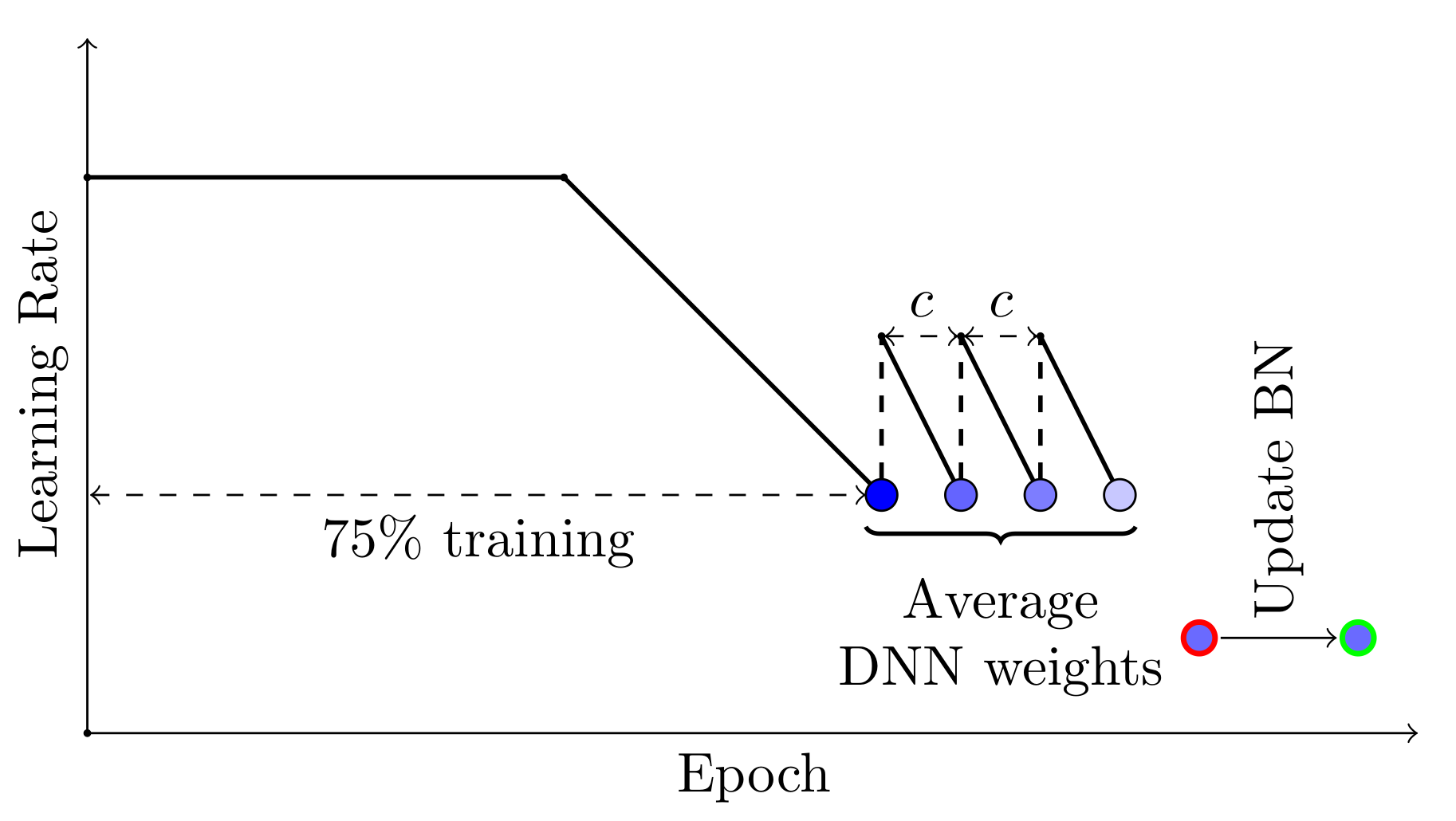 +
+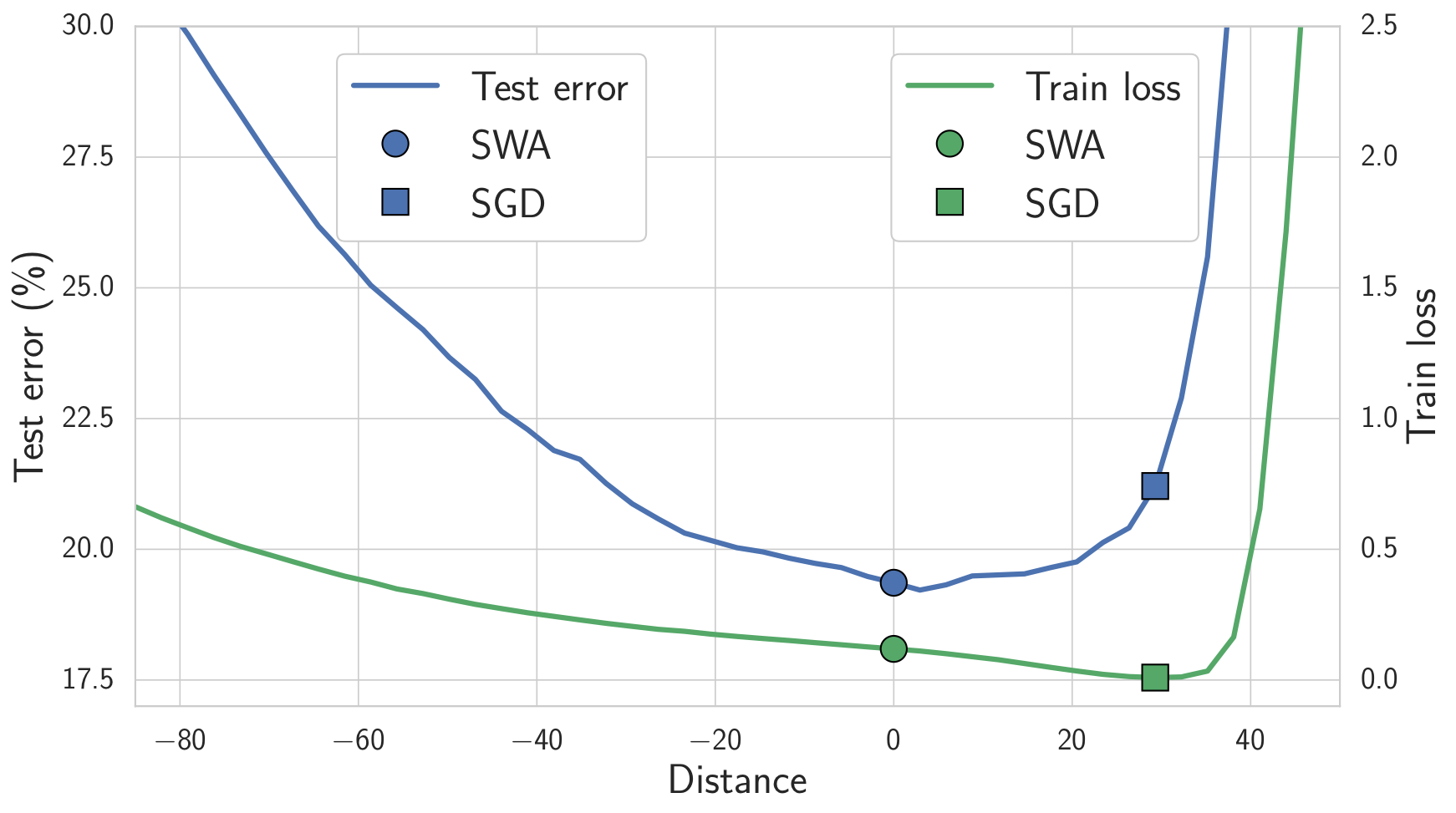 +
+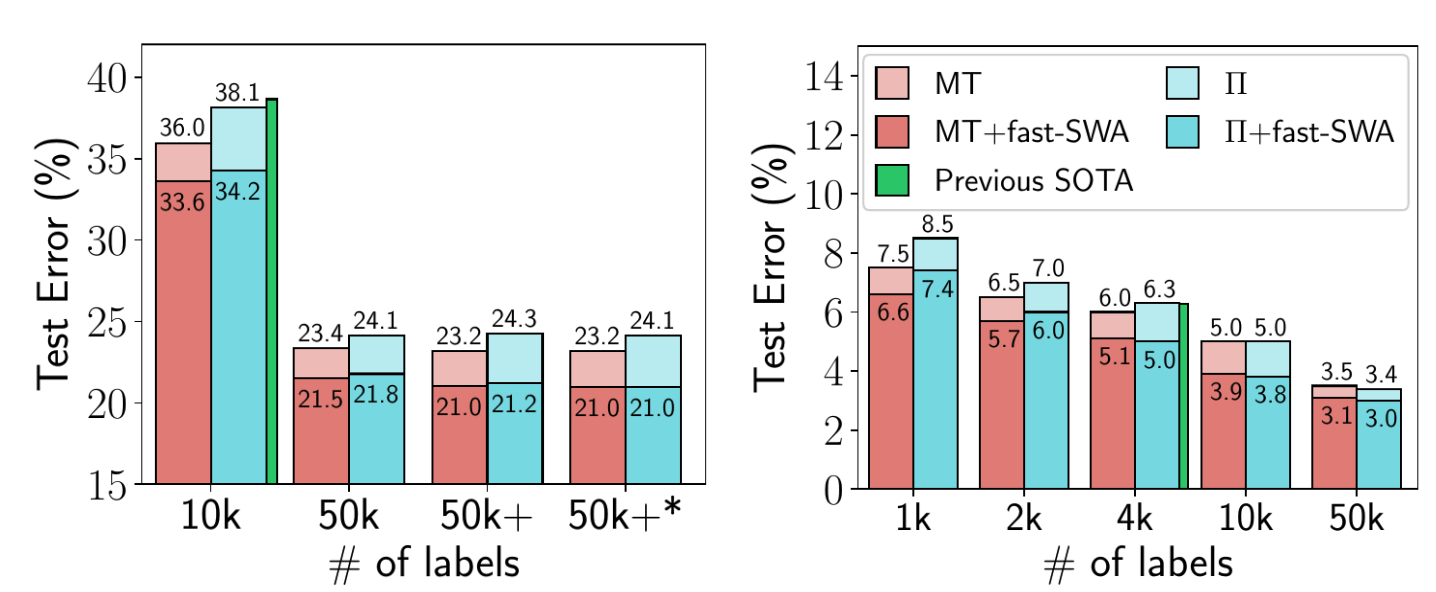 +
+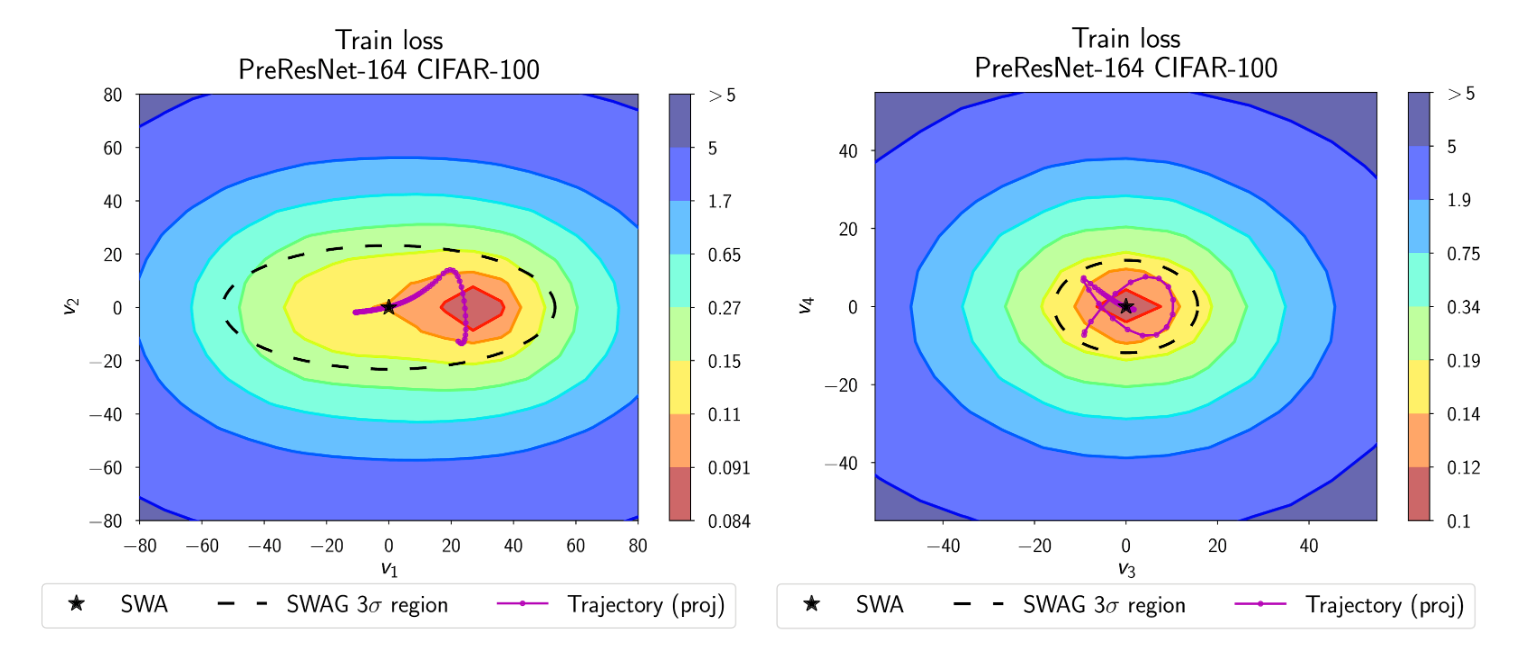 +
+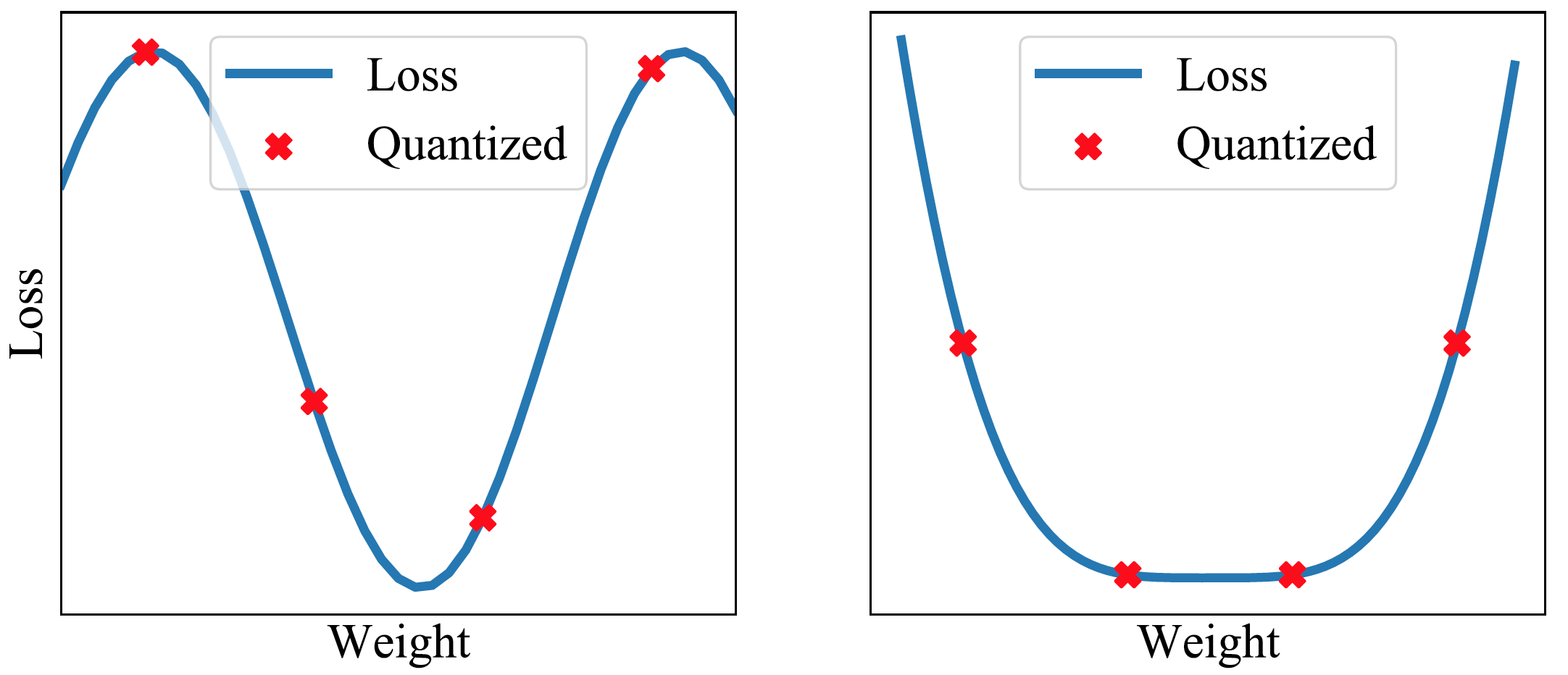 +
+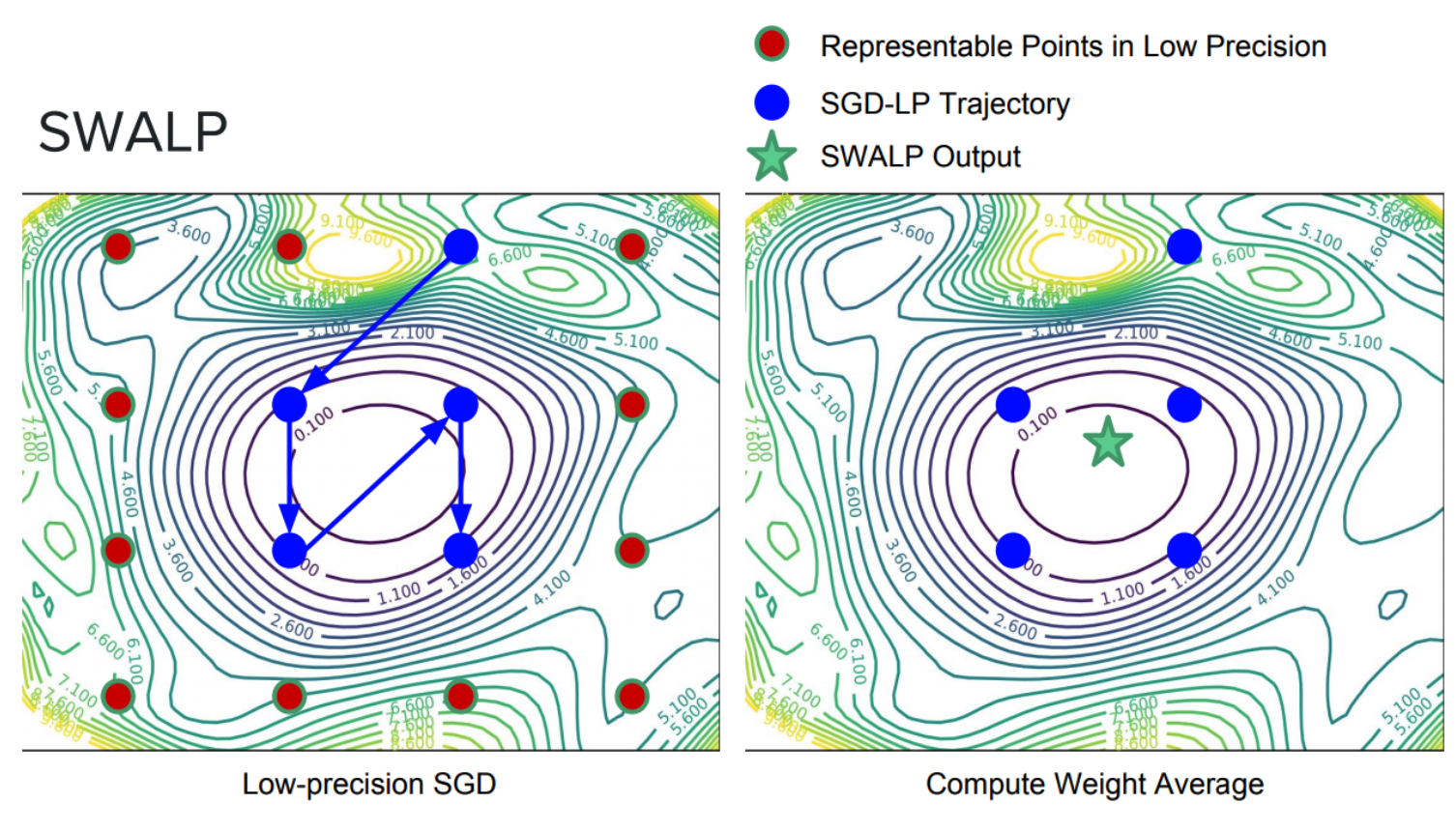 +
+











 +
+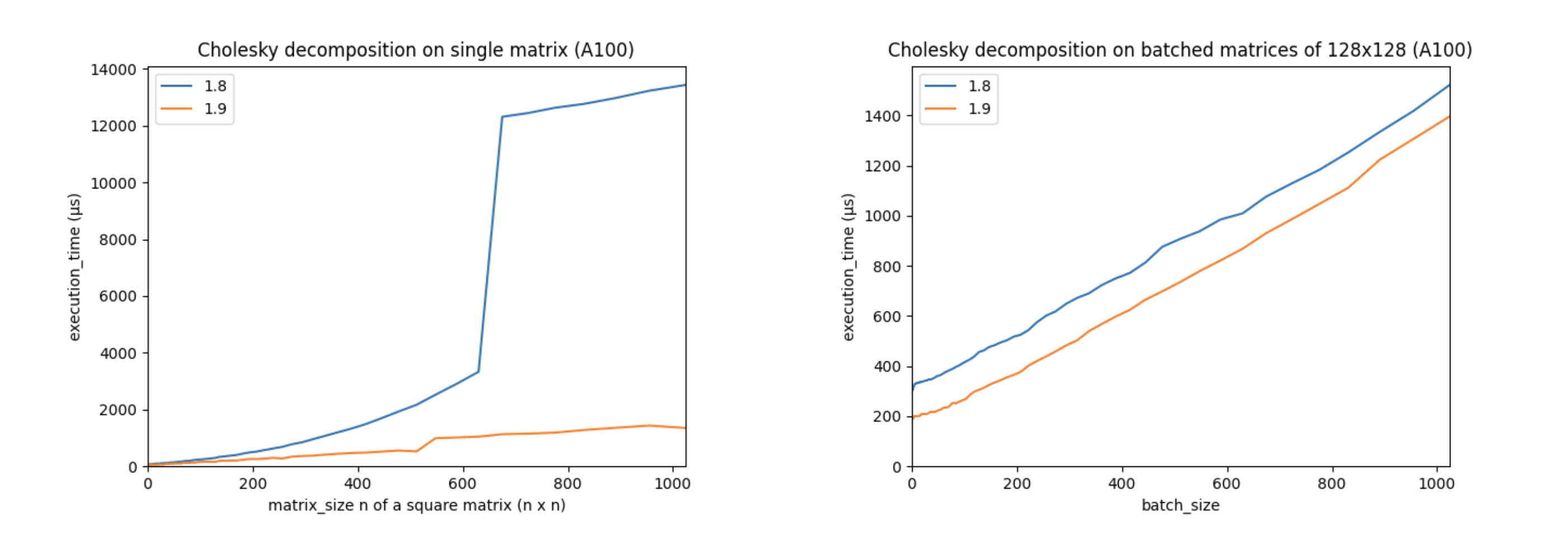 +
+

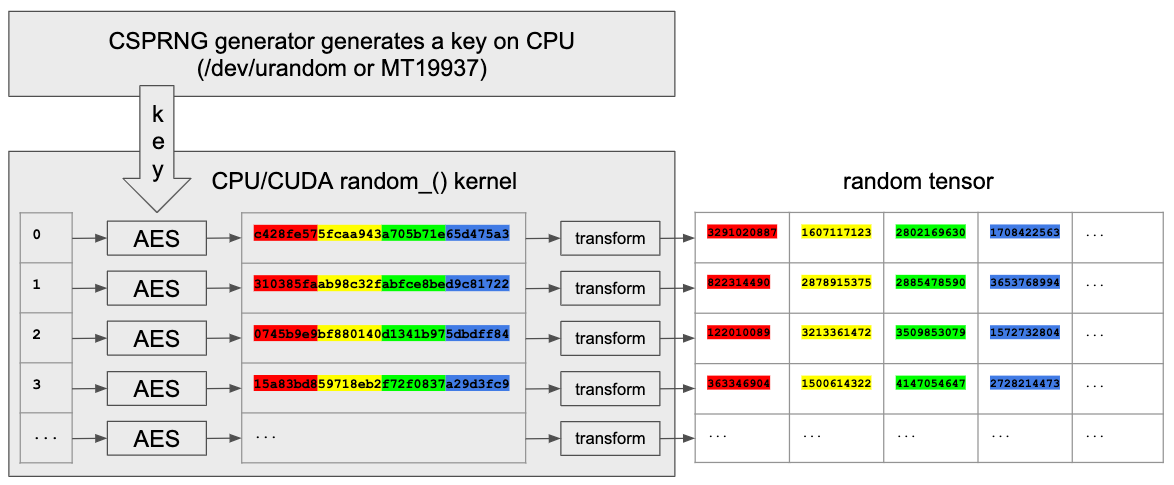 +
+

 +
+ +
+ +
+ +
+ +
+ +
+ +
+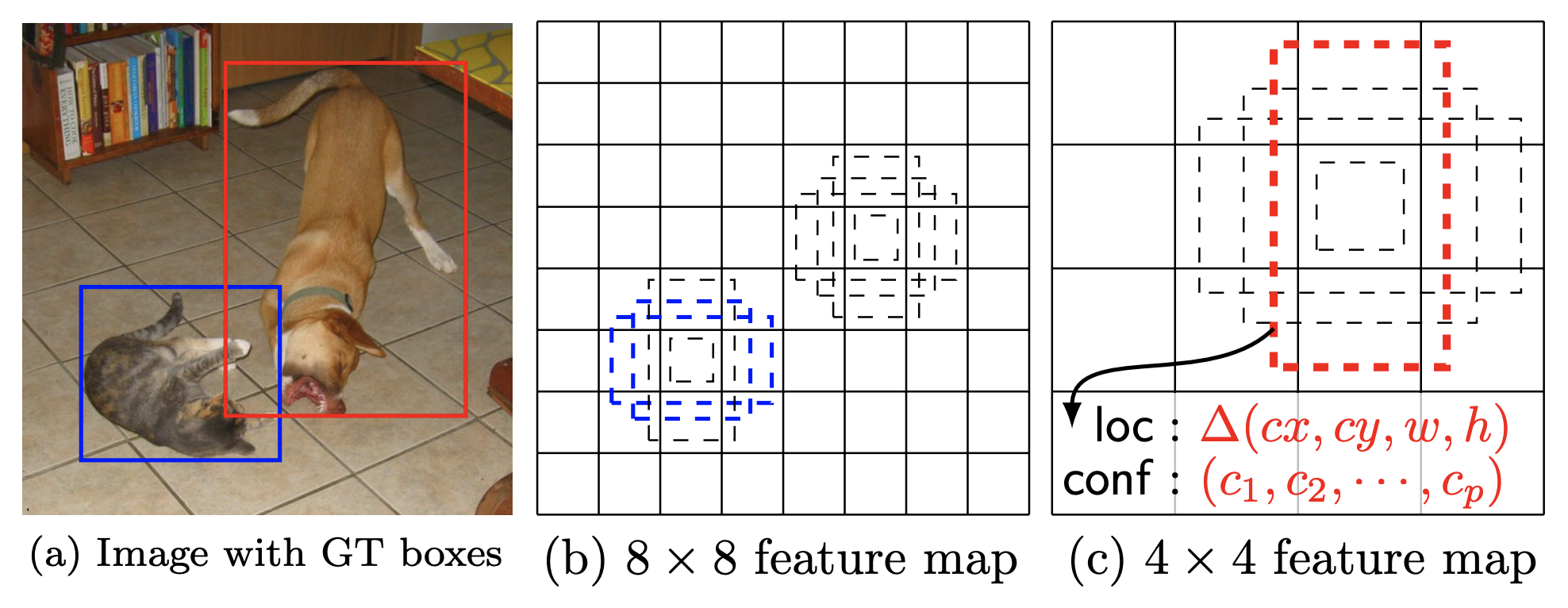 +
+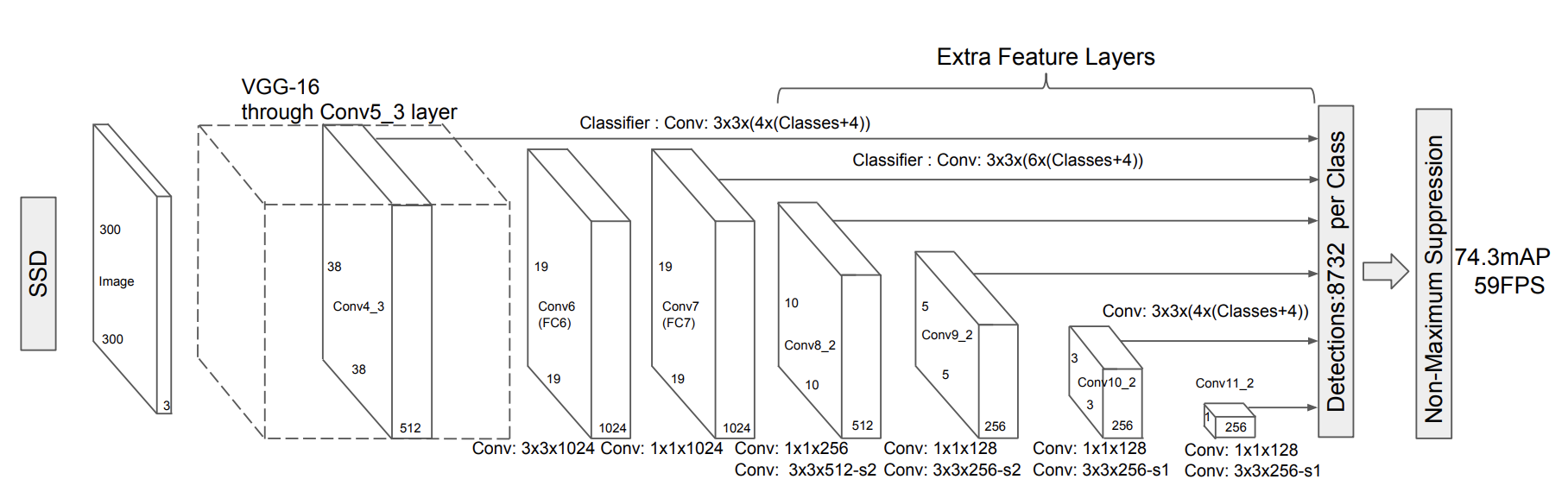 +
+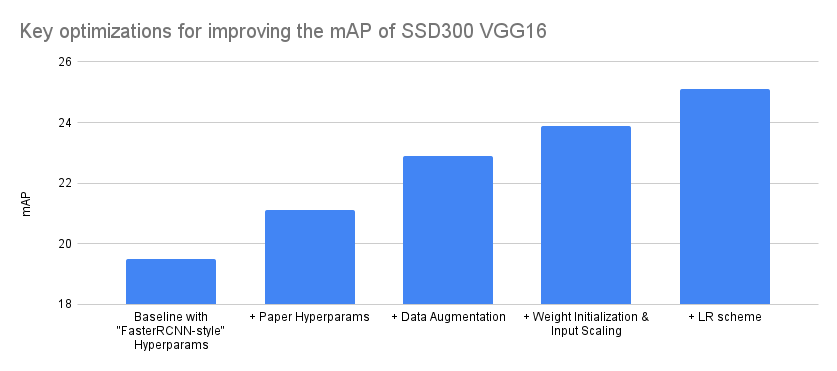 +
+ +
+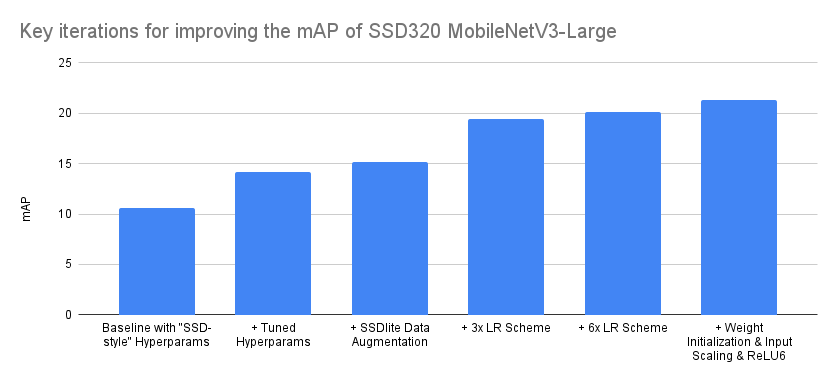 +
+ +
+ +
+ +
+


































 +
+ +
+ +
+






 +
+ +
+




 +
+ +
+ +
+ +
+


 +
+ {kind=link}
{kind=link}
{kind=link}