From 5dda3425451094f416a6486b9d128e1f619a514c Mon Sep 17 00:00:00 2001
From: dabin <1713476357@qq.com>
Date: Sat, 12 Aug 2023 11:14:21 +0800
Subject: [PATCH 1/8] update
---
.../excellent-article/29-idempotent-design.md | 1 +
.../excellent-article/30-yi-di-duo-huo.md | 563 ++++++++++++++++++
.../31-mysql-data-sync-es.md | 503 ++++++++++++++++
docs/learn/ghelper.md | 29 +-
docs/note/docker-note.md | 15 +
docs/note/write-sql.md | 93 +++
docs/zsxq/article/select-max-rows.md | 225 +++++++
docs/zsxq/article/sql-optimize.md | 196 ++++++
docs/zsxq/introduce.md | 2 +-
docs/zsxq/question/qa-or-java.md | 29 +
docs/zsxq/share/completable-future-bug.md | 250 ++++++++
docs/zsxq/share/oom.md | 13 +
docs/zsxq/share/slow-query.md | 62 ++
.../zsxq/share/spring-upgrade-copy-problem.md | 146 +++++
package-lock.json | 159 +++++
15 files changed, 2280 insertions(+), 6 deletions(-)
create mode 100644 docs/advance/excellent-article/30-yi-di-duo-huo.md
create mode 100644 docs/advance/excellent-article/31-mysql-data-sync-es.md
create mode 100644 docs/note/docker-note.md
create mode 100644 docs/note/write-sql.md
create mode 100644 docs/zsxq/article/select-max-rows.md
create mode 100644 docs/zsxq/article/sql-optimize.md
create mode 100644 docs/zsxq/question/qa-or-java.md
create mode 100644 docs/zsxq/share/completable-future-bug.md
create mode 100644 docs/zsxq/share/oom.md
create mode 100644 docs/zsxq/share/slow-query.md
create mode 100644 docs/zsxq/share/spring-upgrade-copy-problem.md
diff --git a/docs/advance/excellent-article/29-idempotent-design.md b/docs/advance/excellent-article/29-idempotent-design.md
index 3ab7b34..6cf7d5b 100644
--- a/docs/advance/excellent-article/29-idempotent-design.md
+++ b/docs/advance/excellent-article/29-idempotent-design.md
@@ -12,6 +12,7 @@ head:
- name: description
content: 努力打造最优质的Java学习网站
---
+
## 接口的幂等性如何设计?
分布式系统中的某个接口,该如何保证幂等性?
diff --git a/docs/advance/excellent-article/30-yi-di-duo-huo.md b/docs/advance/excellent-article/30-yi-di-duo-huo.md
new file mode 100644
index 0000000..75657f1
--- /dev/null
+++ b/docs/advance/excellent-article/30-yi-di-duo-huo.md
@@ -0,0 +1,563 @@
+---
+sidebar: heading
+title: 异地多活
+category: 优质文章
+tag:
+ - 架构
+head:
+ - - meta
+ - name: keywords
+ content: 异地多活,同城灾备,同城双活,两地三中心,异地双活,异地多活
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+在软件开发领域,「异地多活」是分布式系统架构设计的一座高峰,很多人经常听过它,但很少人理解其中的原理。
+
+**异地多活到底是什么?为什么需要异地多活?它到底解决了什么问题?究竟是怎么解决的?**
+
+这些疑问,想必是每个程序看到异地多活这个名词时,都想要搞明白的问题。
+
+有幸,我曾经深度参与过一个中等互联网公司,建设异地多活系统的设计与实施过程。所以今天,我就来和你聊一聊异地多活背后的的实现原理。
+
+认真读完这篇文章,我相信你会对异地多活架构,有更加深刻的理解。
+
+**这篇文章干货很多,希望你可以耐心读完。**
+
+
+
+
+
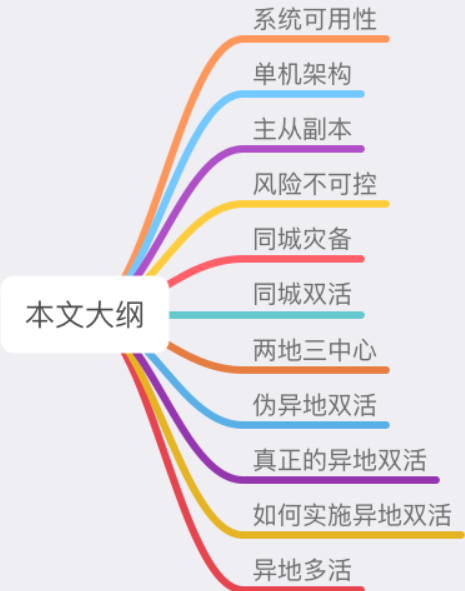
+# 01 系统可用性
+
+要想理解异地多活,我们需要从架构设计的原则说起。
+
+现如今,我们开发一个软件系统,对其要求越来越高,如果你了解一些「架构设计」的要求,就知道一个好的软件架构应该遵循以下 3 个原则:
+
+1. 高性能
+2. 高可用
+3. 易扩展
+
+其中,高性能意味着系统拥有更大流量的处理能力,更低的响应延迟。例如 1 秒可处理 10W 并发请求,接口响应时间 5 ms 等等。
+
+易扩展表示系统在迭代新功能时,能以最小的代价去扩展,系统遇到流量压力时,可以在不改动代码的前提下,去扩容系统。
+
+而「高可用」这个概念,看起来很抽象,怎么理解它呢?通常用 2 个指标来衡量:
+
+- **平均故障间隔 MTBF**(Mean Time Between Failure):表示两次故障的间隔时间,也就是系统「正常运行」的平均时间,这个时间越长,说明系统稳定性越高
+- **故障恢复时间 MTTR**(Mean Time To Repair):表示系统发生故障后「恢复的时间」,这个值越小,故障对用户的影响越小
+
+可用性与这两者的关系:
+
+> 可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
+
+这个公式得出的结果是一个「比例」,通常我们会用「N 个 9」来描述一个系统的可用性。
+
+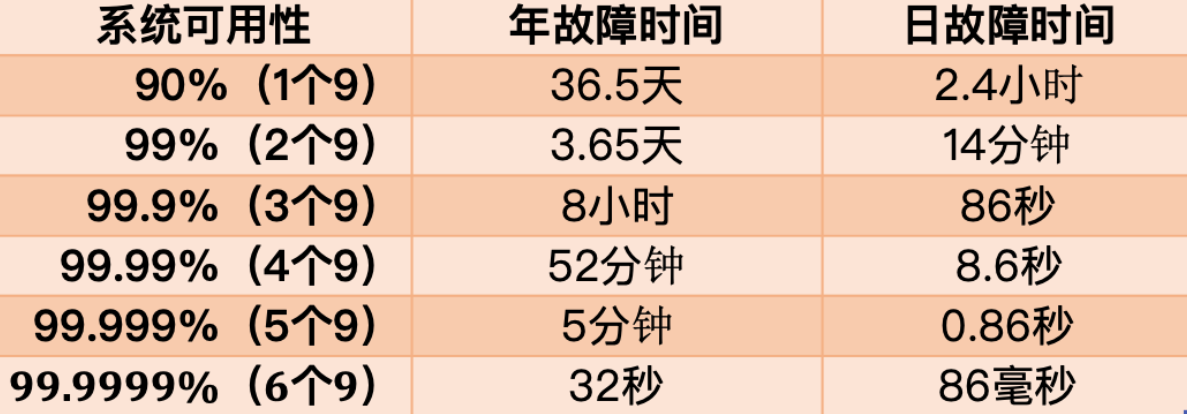
+
+从这张图你可以看到,要想达到 4 个 9 以上的可用性,平均每天故障时间必须控制在 10 秒以内。
+
+也就是说,只有故障的时间「越短」,整个系统的可用性才会越高,每提升 1 个 9,都会对系统提出更高的要求。
+
+我们都知道,系统发生故障其实是不可避免的,尤其是规模越大的系统,发生问题的概率也越大。这些故障一般体现在 3 个方面:
+
+1. **硬件故障**:CPU、内存、磁盘、网卡、交换机、路由器
+2. **软件问题**:代码 Bug、版本迭代
+3. **不可抗力**:地震、水灾、火灾、战争
+
+这些风险随时都有可能发生。所以,在面对故障时,我们的系统能否以「最快」的速度恢复,就成为了可用性的关键。
+
+可如何做到快速恢复呢?
+
+这篇文章要讲的「异地多活」架构,就是为了解决这个问题,而提出的高效解决方案。
+
+下面,我会从一个最简单的系统出发,带你一步步演化出一个支持「异地多活」的系统架构。
+
+在这个过程中,你会看到一个系统会遇到哪些可用性问题,以及为什么架构要这样演进,从而理解异地多活架构的意义。
+
+# 02 单机架构
+
+我们从最简单的开始讲起。
+
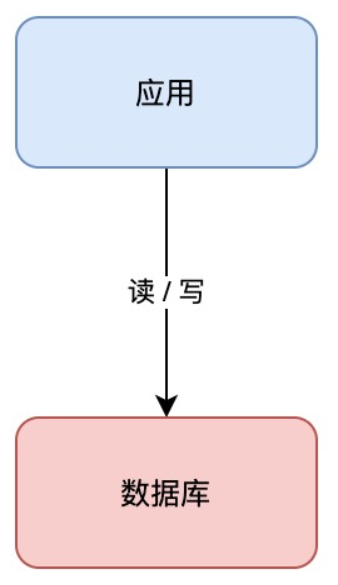
+假设你的业务处于起步阶段,体量非常小,那你的架构是这样的:
+
+
+
+这个架构模型非常简单,客户端请求进来,业务应用读写数据库,返回结果,非常好理解。
+
+但需要注意的是,这里的数据库是「单机」部署的,所以它有一个致命的缺点:一旦遭遇意外,例如磁盘损坏、操作系统异常、误删数据,那这意味着所有数据就全部「丢失」了,这个损失是巨大的。
+
+如何避免这个问题呢?我们很容易想到一个方案:**备份**。
+
+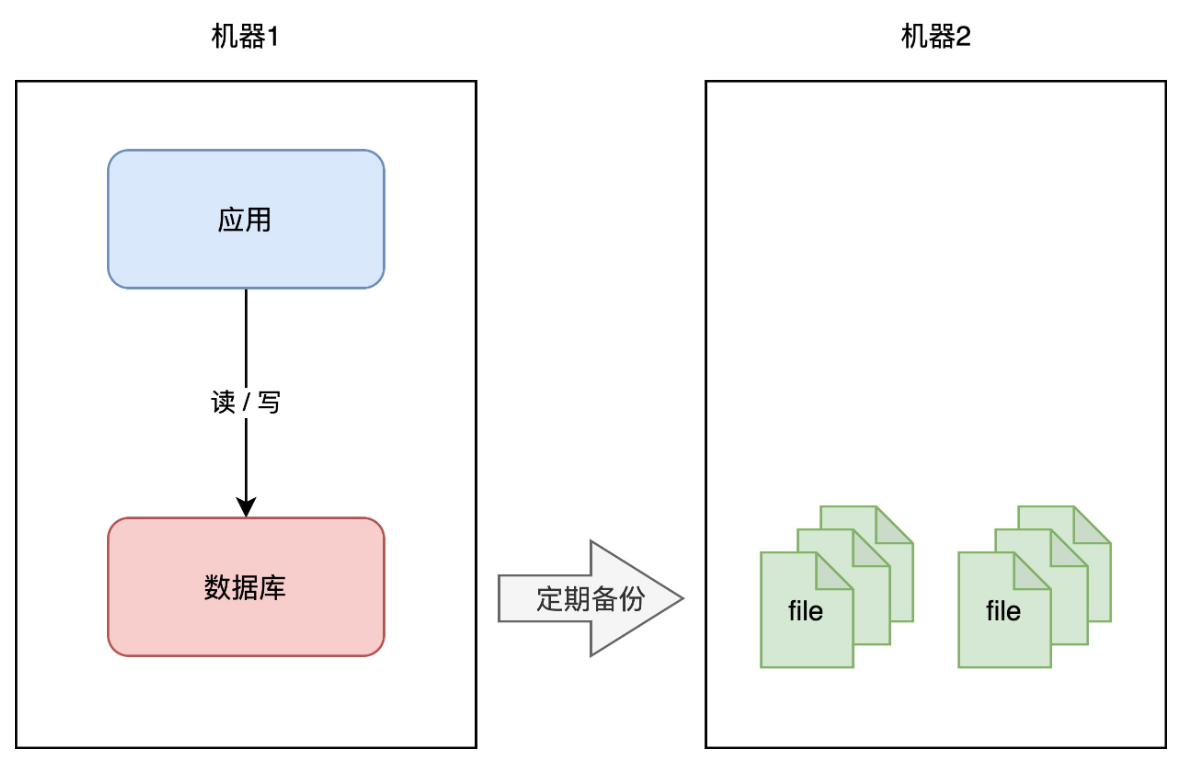
+
+你可以对数据做备份,把数据库文件「定期」cp 到另一台机器上,这样,即使原机器丢失数据,你依旧可以通过备份把数据「恢复」回来,以此保证数据安全。
+
+这个方案实施起来虽然比较简单,但存在 2 个问题:
+
+1. **恢复需要时间**:业务需先停机,再恢复数据,停机时间取决于恢复的速度,恢复期间服务「不可用」
+2. **数据不完整**:因为是定期备份,数据肯定不是「最新」的,数据完整程度取决于备份的周期
+
+很明显,你的数据库越大,意味故障恢复时间越久。那按照前面我们提到的「高可用」标准,这个方案可能连 1 个 9 都达不到,远远无法满足我们对可用性的要求。
+
+那有什么更好的方案,既可以快速恢复业务?还能尽可能保证数据完整性呢?
+
+这时你可以采用这个方案:**主从副本**。
+
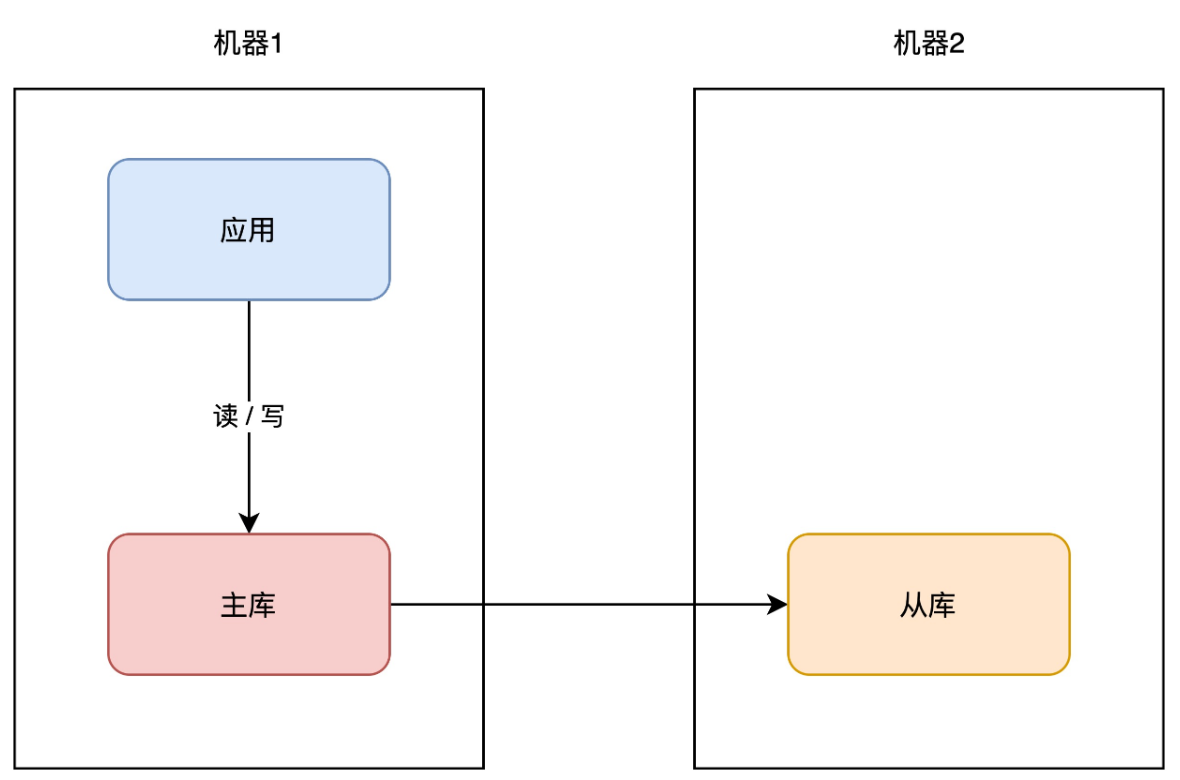
+# 03 主从副本
+
+你可以在另一台机器上,再部署一个数据库实例,让这个新实例成为原实例的「副本」,让两者保持「实时同步」,就像这样:
+
+
+
+我们一般把原实例叫作主库(master),新实例叫作从库(slave)。这个方案的优点在于:
+
+- **数据完整性高**:主从副本实时同步,数据「差异」很小
+- **抗故障能力提升**:主库有任何异常,从库可随时「切换」为主库,继续提供服务
+- **读性能提升**:业务应用可直接读从库,分担主库「压力」读压力
+
+这个方案不错,不仅大大提高了数据库的可用性,还提升了系统的读性能。
+
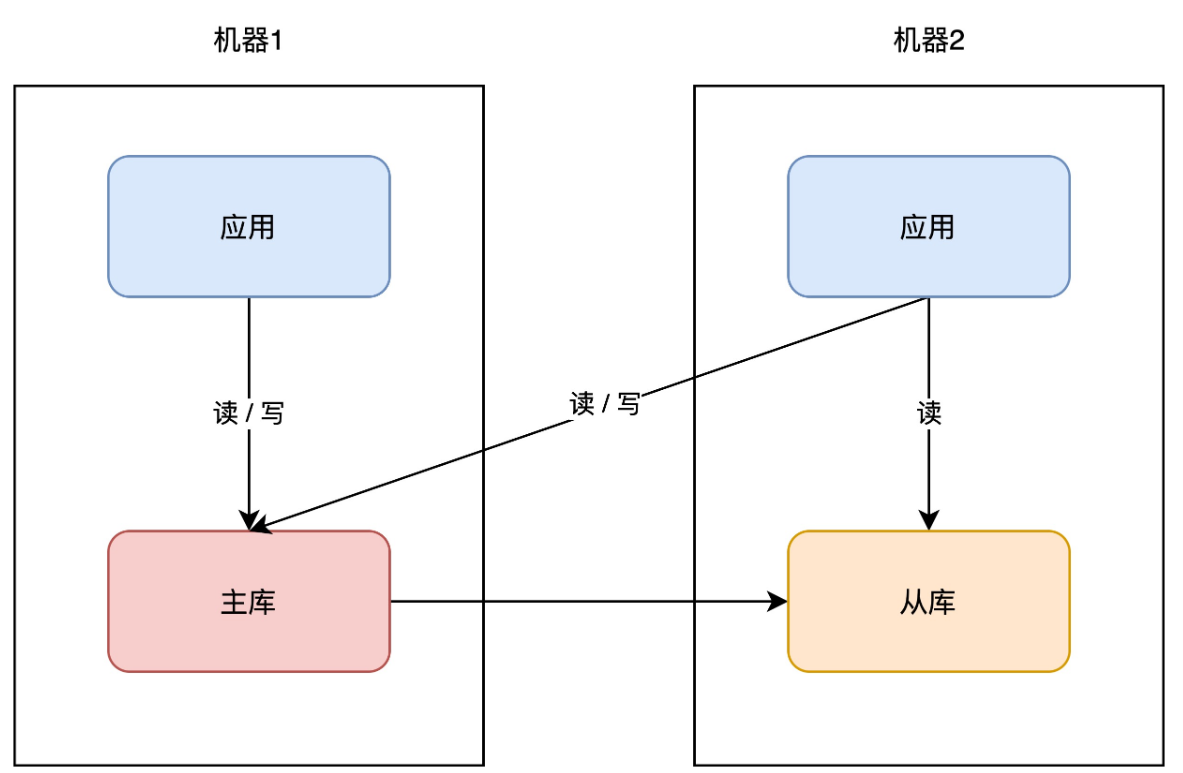
+同样的思路,你的「业务应用」也可以在其它机器部署一份,避免单点。因为业务应用通常是「无状态」的(不像数据库那样存储数据),所以直接部署即可,非常简单。
+
+
+
+因为业务应用部署了多个,所以你现在还需要部署一个「接入层」,来做请求的「负载均衡」(一般会使用 nginx 或 LVS),这样当一台机器宕机后,另一台机器也可以「接管」所有流量,持续提供服务。
+
+
+
+从这个方案你可以看出,提升可用性的关键思路就是:**冗余**。
+
+没错,担心一个实例故障,那就部署多个实例,担心一个机器宕机,那就部署多台机器。
+
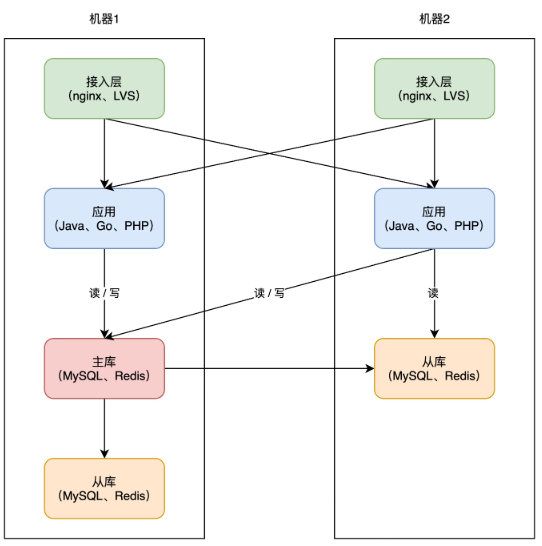
+到这里,你的架构基本已演变成主流方案了,之后开发新的业务应用,都可以按照这种模式去部署。
+
+
+
+但这种方案还有什么风险吗?
+
+# 04 风险不可控
+
+现在让我们把视角下放,把焦点放到具体的「部署细节」上来。
+
+按照前面的分析,为了避免单点故障,你的应用虽然部署了多台机器,但这些机器的分布情况,我们并没有去深究。
+
+而一个机房有很多服务器,这些服务器通常会分布在一个个「机柜」上,如果你使用的这些机器,刚好在一个机柜,还是存在风险。
+
+如果恰好连接这个机柜的交换机 / 路由器发生故障,那么你的应用依旧有「不可用」的风险。
+
+> 虽然交换机 / 路由器也做了路线冗余,但不能保证一定不出问题。
+
+部署在一个机柜有风险,那把这些机器打散,分散到不同机柜上,是不是就没问题了?
+
+这样确实会大大降低出问题的概率。但我们依旧不能掉以轻心,因为无论怎么分散,它们总归还是在一个相同的环境下:**机房**。
+
+那继续追问,机房会不会发生故障呢?
+
+一般来讲,建设一个机房的要求其实是很高的,地理位置、温湿度控制、备用电源等等,机房厂商会在各方面做好防护。但即使这样,我们每隔一段时间还会看到这样的新闻:
+
+- 2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法访问支付宝
+- 2021 年 7 月 13 日,B 站部分服务器机房发生故障,造成整站持续 3 个小时无法访问
+- 2021 年 10 月 9 日,富途证券服务器机房发生电力闪断故障,造成用户 2 个小时无法登陆、交易
+- …
+
+可见,即使机房级别的防护已经做得足够好,但只要有「概率」出问题,那现实情况就有可能发生。虽然概率很小,但一旦真的发生,影响之大可见一斑。
+
+看到这里你可能会想,机房出现问题的概率也太小了吧,工作了这么多年,也没让我碰上一次,有必要考虑得这么复杂吗?
+
+但你有没有思考这样一个问题:**不同体量的系统,它们各自关注的重点是什么?**
+
+体量很小的系统,它会重点关注「用户」规模、增长,这个阶段获取用户是一切。等用户体量上来了,这个阶段会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。
+
+等体量再大到一定规模后你会发现,「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用,如果机房发生一次故障,那整个影响范围可以说是非常巨大的。
+
+所以,再小概率的风险,我们在提高系统可用性时,也不能忽视。
+
+分析了风险,再说回我们的架构。那到底该怎么应对机房级别的故障呢?
+
+没错,还是**冗余**。
+
+# 05 同城灾备
+
+想要抵御「机房」级别的风险,那应对方案就不能局限在一个机房内了。
+
+现在,你需要做机房级别的冗余方案,也就是说,你需要再搭建一个机房,来部署你的服务。
+
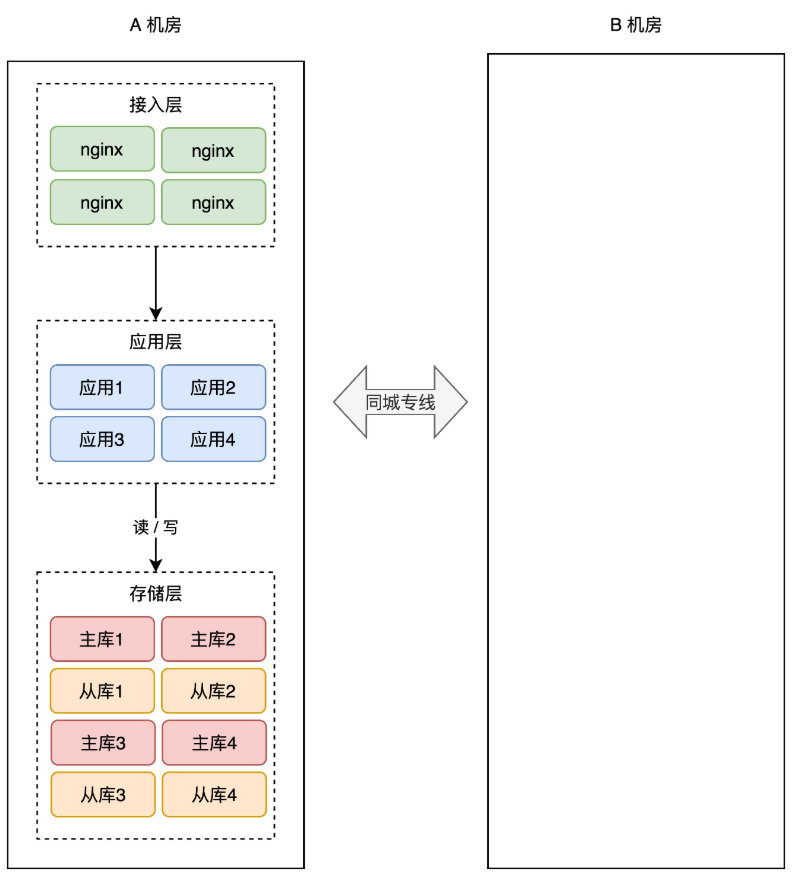
+简单起见,你可以在「同一个城市」再搭建一个机房,原机房我们叫作 A 机房,新机房叫 B 机房,这两个机房的网络用一条「专线」连通。
+
+
+
+有了新机房,怎么把它用起来呢?这里还是要优先考虑「数据」风险。
+
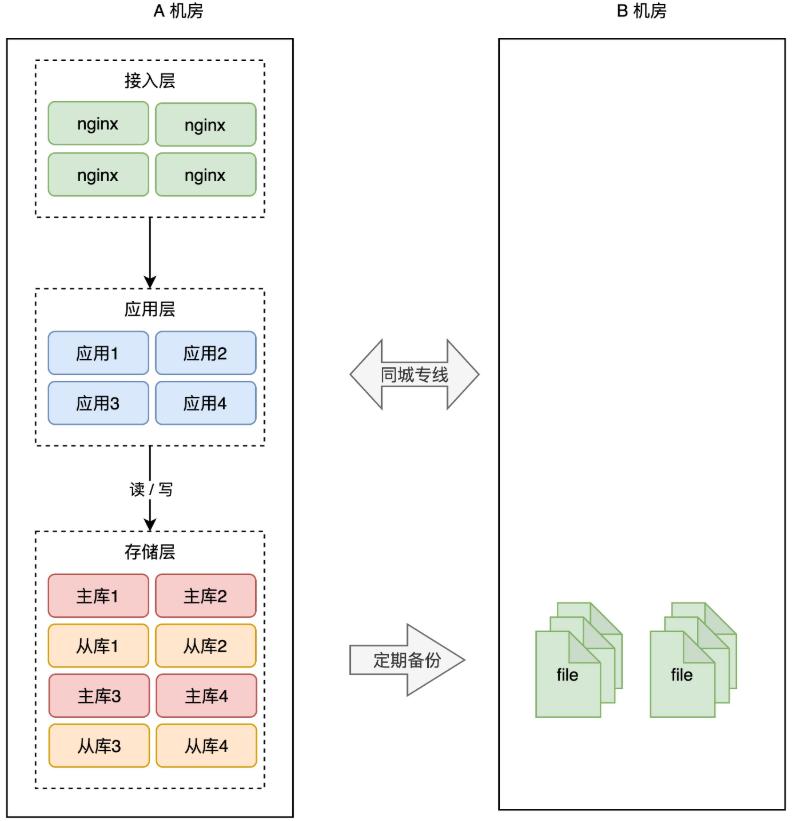
+为了避免 A 机房故障导致数据丢失,所以我们需要把数据在 B 机房也存一份。最简单的方案还是和前面提到的一样:**备份**。
+
+A 机房的数据,定时在 B 机房做备份(拷贝数据文件),这样即使整个 A 机房遭到严重的损坏,B 机房的数据不会丢,通过备份可以把数据「恢复」回来,重启服务。
+
+
+
+这种方案,我们称之为「**冷备**」。为什么叫冷备呢?因为 B 机房只做备份,不提供实时服务,它是冷的,只会在 A 机房故障时才会启用。
+
+但备份的问题依旧和之前描述的一样:数据不完整、恢复数据期间业务不可用,整个系统的可用性还是无法得到保证。
+
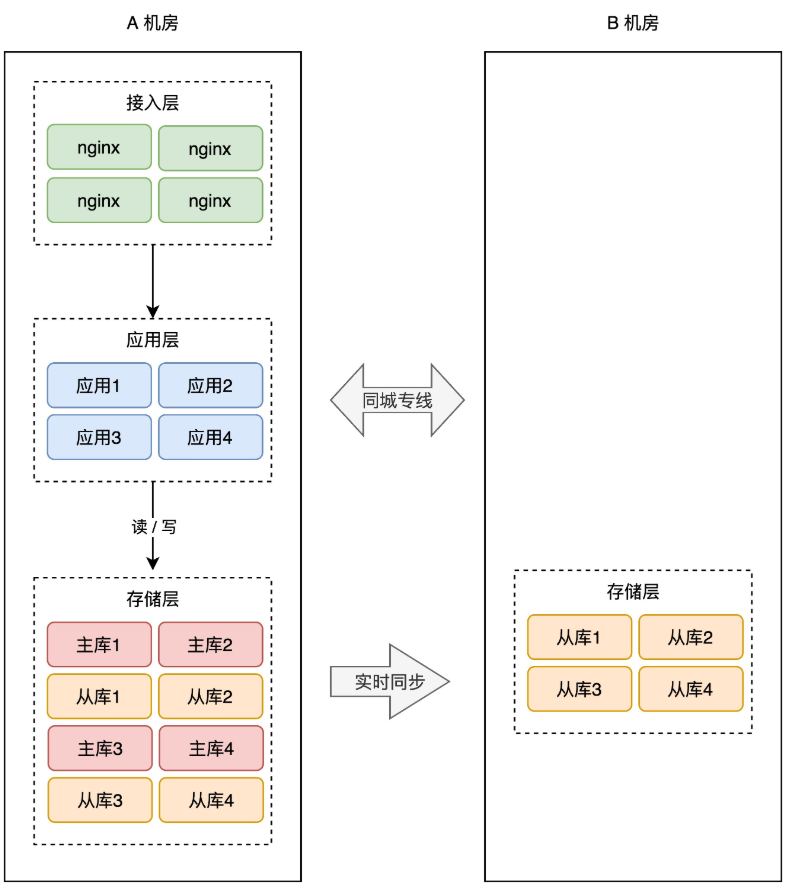
+所以,我们还是需要用「主从副本」的方式,在 B 机房部署 A 机房的数据副本,架构就变成了这样:
+
+
+
+这样,就算整个 A 机房挂掉,我们在 B 机房也有比较「完整」的数据。
+
+数据是保住了,但这时你需要考虑另外一个问题:**如果 A 机房真挂掉了,要想保证服务不中断,你还需要在 B 机房「紧急」做这些事情**:
+
+1. B 机房所有从库提升为主库
+2. 在 B 机房部署应用,启动服务
+3. 部署接入层,配置转发规则
+4. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+看到了么?A 机房故障后,B 机房需要做这么多工作,你的业务才能完全「恢复」过来。
+
+你看,整个过程需要人为介入,且需花费大量时间来操作,恢复之前整个服务还是不可用的,这个方案还是不太爽,如果能做到故障后立即「切换」,那就好了。
+
+因此,要想缩短业务恢复的时间,你必须把这些工作在 B 机房「提前」做好,也就是说,你需要在 B 机房提前部署好接入层、业务应用,等待随时切换。架构就变成了这样:
+
+
+
+这样的话,A 机房整个挂掉,我们只需要做 2 件事即可:
+
+1. B 机房所有从库提升为主库
+2. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+这样一来,恢复速度快了很多。
+
+到这里你会发现,B 机房从最开始的「空空如也」,演变到现在,几乎是「镜像」了一份 A 机房的所有东西,从最上层的接入层,到中间的业务应用,到最下层的存储。两个机房唯一的区别是,**A 机房的存储都是主库,而 B 机房都是从库**。
+
+这种方案,我们把它叫做「**热备**」。
+
+热的意思是指,B 机房处于「待命」状态,A 故障后 B 可以随时「接管」流量,继续提供服务。热备相比于冷备最大的优点是:**随时可切换**。
+
+无论是冷备还是热备,因为它们都处于「备用」状态,所以我们把这两个方案统称为:**同城灾备**。
+
+同城灾备的最大优势在于,我们再也不用担心「机房」级别的故障了,一个机房发生风险,我们只需把流量切换到另一个机房即可,可用性再次提高,是不是很爽?(后面还有更爽的)
+
+# 06 同城双活
+
+我们继续来看这个架构。
+
+虽然我们有了应对机房故障的解决方案,但这里有个问题是我们不能忽视的:**A 机房挂掉,全部流量切到 B 机房,B 机房能否真的如我们所愿,正常提供服务?**
+
+这是个值得思考的问题。
+
+这就好比有两支军队 A 和 B,A 军队历经沙场,作战经验丰富,而 B 军队只是后备军,除了有军人的基本素养之外,并没有实战经验,战斗经验基本为 0。
+
+如果 A 军队丧失战斗能力,需要 B 军队立即顶上时,作为指挥官的你,肯定也会担心 B 军队能否真的担此重任吧?
+
+我们的架构也是如此,此时的 B 机房虽然是随时「待命」状态,但 A 机房真的发生故障,我们要把全部流量切到 B 机房,其实是不敢百分百保证它可以「如期」工作的。
+
+你想,我们在一个机房内部署服务,还总是发生各种各样的问题,例如:发布应用的版本不一致、系统资源不足、操作系统参数不一样等等。现在多部署一个机房,这些问题只会增多,不会减少。
+
+另外,从「成本」的角度来看,我们新部署一个机房,需要购买服务器、内存、硬盘、带宽资源,花费成本也是非常高昂的,只让它当一个后备军,未免也太「大材小用」了!
+
+因此,我们需要让 B 机房也接入流量,实时提供服务,这样做的好处,**一是可以实时训练这支后备军,让它达到与 A 机房相同的作战水平,随时可切换,二是 B 机房接入流量后,可以分担 A 机房的流量压力**。这才是把 B 机房资源优势,发挥最大化的最好方案!
+
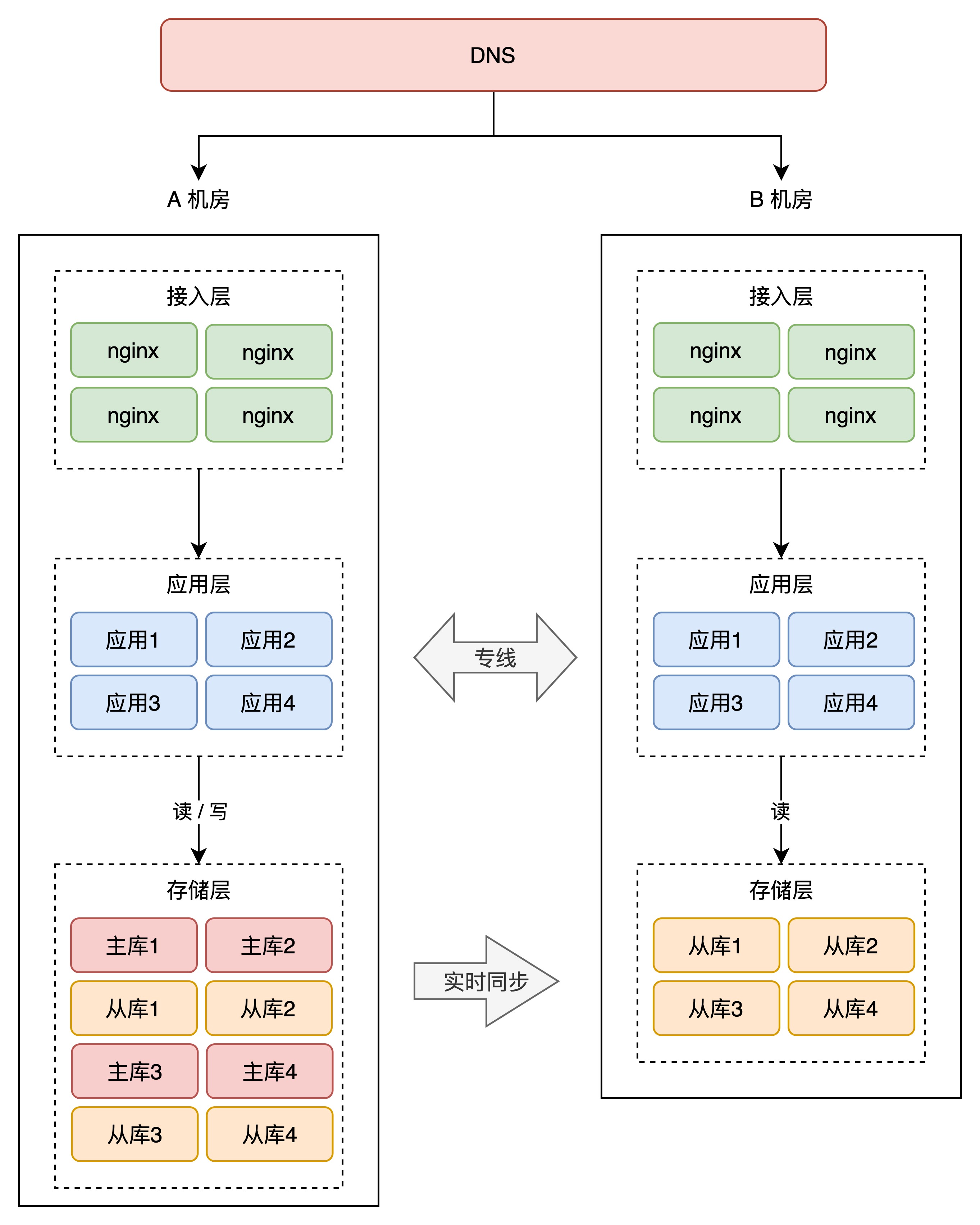
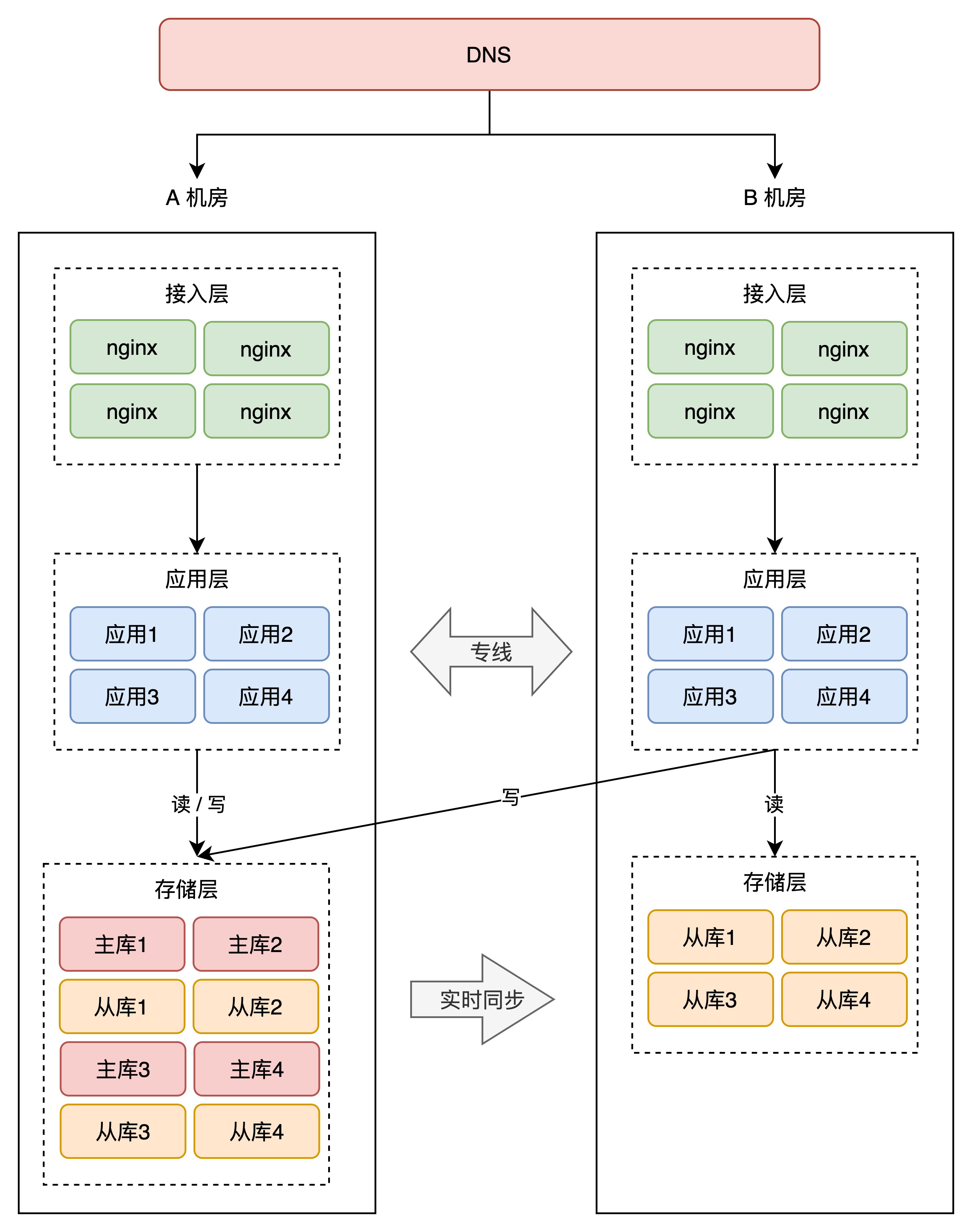
+那怎么让 B 机房也接入流量呢?很简单,就是把 B 机房的接入层 IP 地址,加入到 DNS 中,这样,B 机房从上层就可以有流量进来了。
+
+
+
+但这里有一个问题:别忘了,B 机房的存储,现在可都是 A 机房的「从库」,从库默认可都是「不可写」的,B 机房的写请求打到本机房存储上,肯定会报错,这还是不符合我们预期。怎么办?
+
+这时,你就需要在「业务应用」层做改造了。
+
+你的业务应用在操作数据库时,需要区分「读写分离」(一般用中间件实现),即两个机房的「读」流量,可以读任意机房的存储,但「写」流量,只允许写 A 机房,因为主库在 A 机房。
+
+
+
+这会涉及到你用的所有存储,例如项目中用到了 MySQL、Redis、MongoDB 等等,操作这些数据库,都需要区分读写请求,所以这块需要一定的业务「改造」成本。
+
+因为 A 机房的存储都是主库,所以我们把 A 机房叫做「主机房」,B 机房叫「从机房」。
+
+两个机房部署在「同城」,物理距离比较近,而且两个机房用「专线」网络连接,虽然跨机房访问的延迟,比单个机房内要大一些,但整体的延迟还是可以接受的。
+
+业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%,你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。
+
+现在,因为 B 机房实时接入了流量,此时如果 A 机房挂了,那我们就可以「大胆」地把 A 的流量,全部切换到 B 机房,完成快速切换!
+
+到这里你可以看到,我们部署的 B 机房,在物理上虽然与 A 有一定距离,但整个系统从「逻辑」上来看,我们是把这两个机房看做一个「整体」来规划的,也就是说,相当于把 2 个机房当作 1 个机房来用。
+
+这种架构方案,比前面的同城灾备更「进了一步」,B 机房实时接入了流量,还能应对随时的故障切换,这种方案我们把它叫做「**同城双活**」。
+
+因为两个机房都能处理业务请求,这对我们系统的内部维护、改造、升级提供了更多的可实施空间(流量随时切换),现在,整个系统的弹性也变大了,是不是更爽了?
+
+那这种架构有什么问题呢?
+
+# 07 两地三中心
+
+还是回到风险上来说。
+
+虽然我们把 2 个机房当做一个整体来规划,但这 2 个机房在物理层面上,还是处于「一个城市」内,如果是整个城市发生自然灾害,例如地震、水灾(河南水灾刚过去不久),那 2 个机房依旧存在「全局覆没」的风险。
+
+真是防不胜防啊?怎么办?没办法,继续冗余。
+
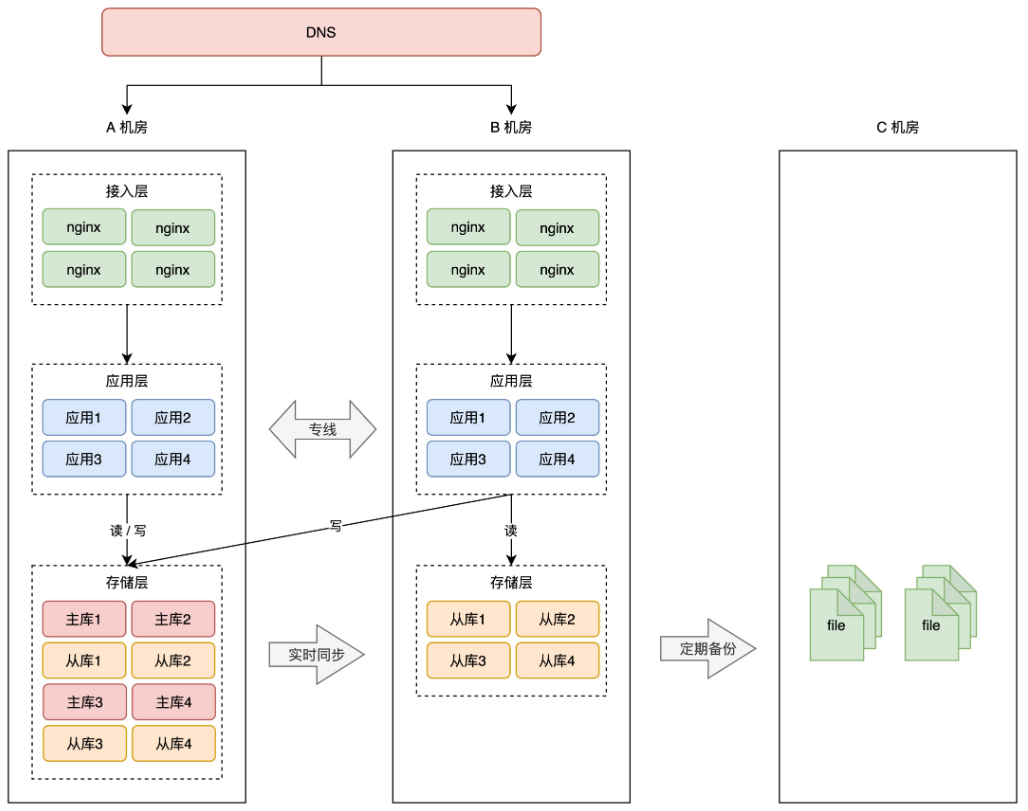
+但这次冗余机房,就不能部署在同一个城市了,你需要把它放到距离更远的地方,部署在「异地」。
+
+> 通常建议两个机房的距离要在 1000 公里以上,这样才能应对城市级别的灾难。
+
+假设之前的 A、B 机房在北京,那这次新部署的 C 机房可以放在上海。
+
+按照前面的思路,把 C 机房用起来,最简单粗暴的方案还就是做「冷备」,即定时把 A、B 机房的数据,在 C 机房做备份,防止数据丢失。
+
+
+
+这种方案,就是我们经常听到的「**两地三中心**」。
+
+**两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市,并且同时提供服务,第 3 个机房部署在异地,只做数据灾备。**
+
+这种架构方案,通常用在银行、金融、政企相关的项目中。它的问题还是前面所说的,启用灾备机房需要时间,而且启用后的服务,不确定能否如期工作。
+
+所以,要想真正的抵御城市级别的故障,越来越多的互联网公司,开始实施「**异地双活**」。
+
+# 08 伪异地双活
+
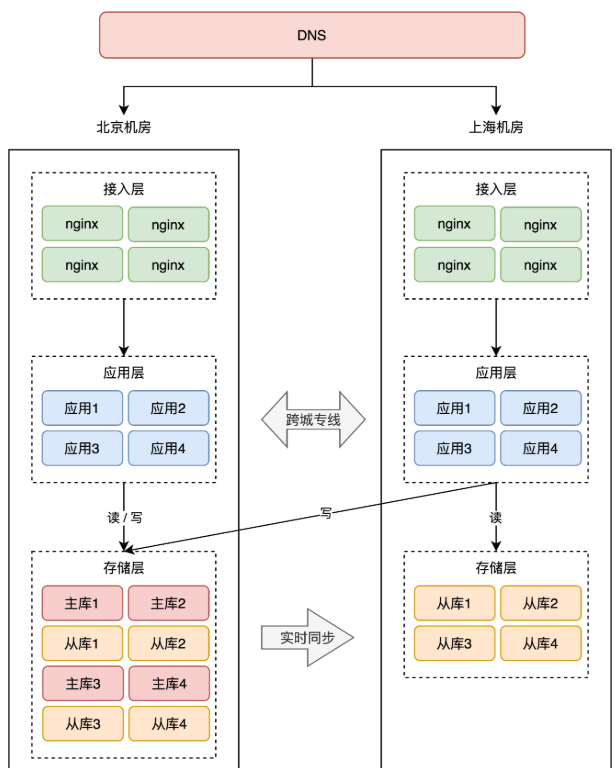
+这里,我们还是分析 2 个机房的架构情况。我们不再把 A、B 机房部署在同一个城市,而是分开部署,例如 A 机房放在北京,B 机房放在上海。
+
+前面我们讲了同城双活,那异地双活是不是直接「照搬」同城双活的模式去部署就可以了呢?
+
+事情没你想的那么简单。
+
+如果还是按照同城双活的架构来部署,那异地双活的架构就是这样的:
+
+
+
+注意看,两个机房的网络是通过「跨城专线」连通的。
+
+此时两个机房都接入流量,那上海机房的请求,可能要去读写北京机房的存储,这里存在一个很大的问题:**网络延迟**。
+
+因为两个机房距离较远,受到物理距离的限制,现在,两地之间的网络延迟就变成了「**不可忽视**」的因素了。
+
+北京到上海的距离大约 1300 公里,即使架设一条高速的「网络专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。
+
+况且,网络线路之间还会经历各种路由器、交换机等网络设备,实际延迟可能会达到 30ms ~ 100ms,如果网络发生抖动,延迟甚至会达到 1 秒。
+
+> 不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的,专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
+
+你可能会问,这点延迟对业务影响很大吗?影响非常大!
+
+试想,一个客户端请求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房访问延迟就达到了 30ms,这大致是机房内网网络(0.5 ms)访问速度的 60 倍(30ms / 0.5ms),一次请求慢 60 倍,来回往返就要慢 100 倍以上。
+
+而我们在 App 打开一个页面,可能会访问后端几十个 API,每次都跨机房访问,整个页面的响应延迟有可能就达到了**秒级**,这个性能简直惨不忍睹,难以接受。
+
+看到了么,虽然我们只是简单的把机房部署在了「异地」,但「同城双活」的架构模型,在这里就不适用了,还是按照这种方式部署,这是「伪异地双活」!
+
+那如何做到真正的异地双活呢?
+
+# 09 真正的异地双活
+
+既然「跨机房」调用延迟是不容忽视的因素,那我们只能尽量避免跨机房「调用」,规避这个延迟问题。
+
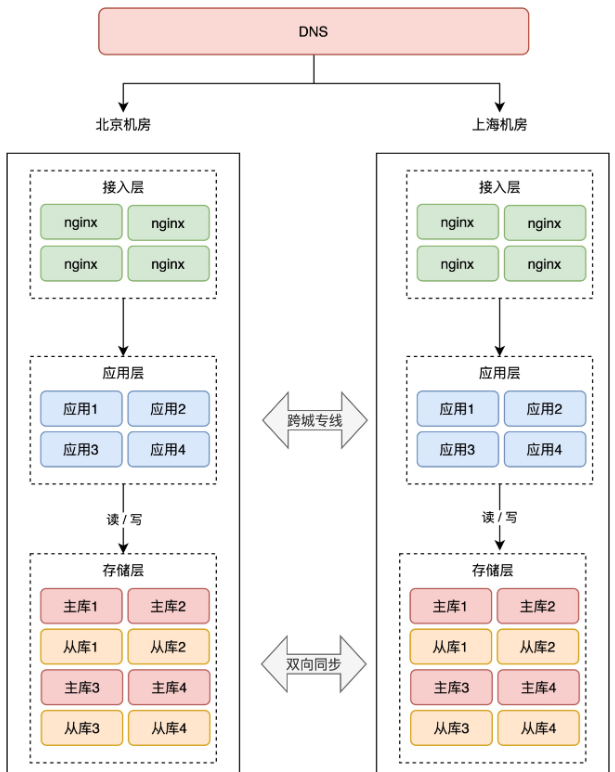
+也就是说,上海机房的应用,不能再「跨机房」去读写北京机房的存储,只允许读写上海本地的存储,实现「就近访问」,这样才能避免延迟问题。
+
+还是之前提到的问题:上海机房存储都是从库,不允许写入啊,除非我们只允许上海机房接入「读流量」,不接收「写流量」,否则无法满足不再跨机房的要求。
+
+很显然,只让上海机房接收读流量的方案不现实,因为很少有项目是只有读流量,没有写流量的。所以这种方案还是不行,这怎么办?
+
+此时,你就必须在「**存储层**」做改造了。
+
+要想上海机房读写本机房的存储,那上海机房的存储不能再是北京机房的从库,而是也要变为「主库」。
+
+你没看错,两个机房的存储必须都是「**主库**」,而且两个机房的数据还要「**互相同步**」数据,即客户端无论写哪一个机房,都能把这条数据同步到另一个机房。
+
+因为只有两个机房都拥有「全量数据」,才能支持任意切换机房,持续提供服务。
+
+怎么实现这种「双主」架构呢?它们之间如何互相同步数据?
+
+如果你对 MySQL 有所了解,MySQL 本身就提供了双主架构,它支持双向复制数据,但平时用的并不多。而且 Redis、MongoDB 等数据库并没有提供这个功能,所以,你必须开发对应的「数据同步中间件」来实现双向同步的功能。
+
+此外,除了数据库这种有状态的软件之外,你的项目通常还会使用到消息队列,例如 RabbitMQ、Kafka,这些也是有状态的服务,所以它们也需要开发双向同步的中间件,支持任意机房写入数据,同步至另一个机房。
+
+看到了么,这一下子复杂度就上来了,单单针对每个数据库、队列开发同步中间件,就需要投入很大精力了。
+
+> 业界也开源出了很多数据同步中间件,例如阿里的 Canal、RedisShake、MongoShake,可分别在两个机房同步 MySQL、Redis、MongoDB 数据。
+>
+> 很多有能力的公司,也会采用自研同步中间件的方式来做,例如饿了么、携程、美团都开发了自己的同步中间件。
+>
+> 我也有幸参与设计开发了 MySQL、Redis/Codis、MongoDB 的同步中间件,有时间写一篇文章详细聊聊实现细节,欢迎持续关注。:)
+
+现在,整个架构就变成了这样:
+
+
+
+注意看,两个机房的存储层都互相同步数据的。有了数据同步中间件,就可以达到这样的效果:
+
+- 北京机房写入 X = 1
+- 上海机房写入 Y = 2
+- 数据通过中间件双向同步
+- 北京、上海机房都有 X = 1、Y = 2 的数据
+
+这里我们用中间件双向同步数据,就不用再担心专线问题,专线出问题,我们的中间件可以自动重试,直到成功,达到数据最终一致。
+
+但这里还会遇到一个问题,两个机房都可以写,操作的不是同一条数据那还好,如果修改的是同一条的数据,发生冲突怎么办?
+
+- 用户短时间内发了 2 个修改请求,都是修改同一条数据
+- 一个请求落在北京机房,修改 X = 1(还未同步到上海机房)
+- 另一个请求落在上海机房,修改 X = 2(还未同步到北京机房)
+- 两个机房以哪个为准?
+
+也就是说,在很短的时间内,同一个用户修改同一条数据,两个机房无法确认谁先谁后,数据发生「冲突」。
+
+这是一个很严重的问题,系统发生故障并不可怕,可怕的是数据发生「错误」,因为修正数据的成本太高了。我们一定要避免这种情况的发生。解决这个问题,有 2 个方案。
+
+**第一个方案**,数据同步中间件要有自动「合并」数据、解决「冲突」的能力。
+
+这个方案实现起来比较复杂,要想合并数据,就必须要区分出「先后」顺序。我们很容易想到的方案,就是以「时间」为标尺,以「后到达」的请求为准。
+
+但这种方案需要两个机房的「时钟」严格保持一致才行,否则很容易出现问题。例如:
+
+- 第 1 个请求落到北京机房,北京机房时钟是 10:01,修改 X = 1
+- 第 2 个请求落到上海机房,上海机房时钟是 10:00,修改 X = 2
+
+因为北京机房的时间「更晚」,那最终结果就会是 X = 1。但这里其实应该以第 2 个请求为准,X = 2 才对。
+
+可见,完全「依赖」时钟的冲突解决方案,不太严谨。
+
+所以,通常会采用第二种方案,从「源头」就避免数据冲突的发生。
+
+# 10 如何实施异地双活
+
+既然自动合并数据的方案实现成本高,那我们就要想,能否从源头就「避免」数据冲突呢?
+
+这个思路非常棒!
+
+从源头避免数据冲突的思路是:**在最上层接入流量时,就不要让冲突的情况发生**。
+
+具体来讲就是,要在最上层就把用户「区分」开,部分用户请求固定打到北京机房,其它用户请求固定打到上海 机房,进入某个机房的用户请求,之后的所有业务操作,都在这一个机房内完成,从根源上避免「跨机房」。
+
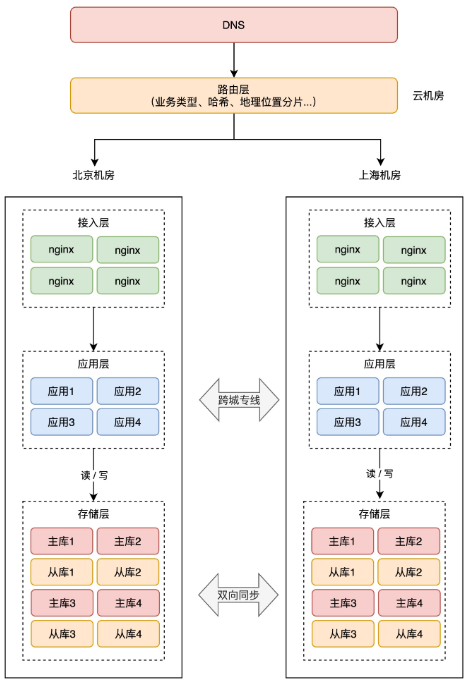
+所以这时,你需要在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内。
+
+
+
+但这个路由规则,具体怎么定呢?有很多种实现方式,最常见的我总结了 3 类:
+
+1. 按业务类型分片
+2. 直接哈希分片
+3. 按地理位置分片
+
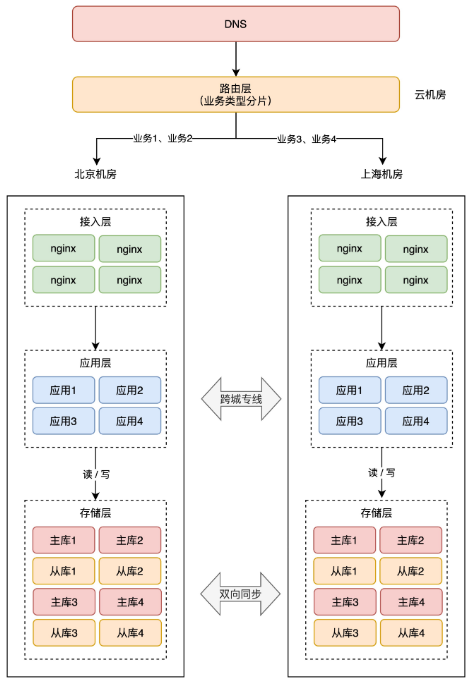
+**1、按业务类型分片**
+
+这种方案是指,按应用的「业务类型」来划分。
+
+举例:假设我们一共有 4 个应用,北京和上海机房都部署这些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
+
+这样一来,应用 1、2 的所有业务请求,只读写北京机房存储,应用 3、4 的所有请求,只会读写上海机房存储。
+
+
+
+这样按业务类型分片,也可以避免同一个用户修改同一条数据。
+
+> 这里按业务类型在不同机房接入流量,还需要考虑多个应用之间的依赖关系,要尽可能的把完成「相关」业务的应用部署在同一个机房,避免跨机房调用。
+>
+> 例如,订单、支付服务有依赖关系,会产生互相调用,那这 2 个服务在 A 机房接入流量。社区、发帖服务有依赖关系,那这 2 个服务在 B 机房接入流量。
+
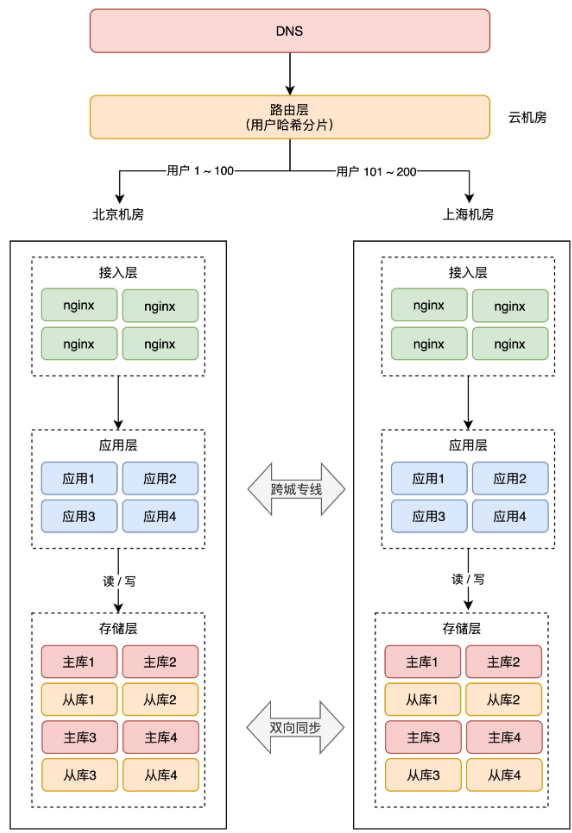
+**2、直接哈希分片**
+
+这种方案就是,最上层的路由层,会根据用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把请求转发到指定机房内。
+
+举例:一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,这样,就避免了同一个用户修改同一条数据的情况发生。
+
+
+
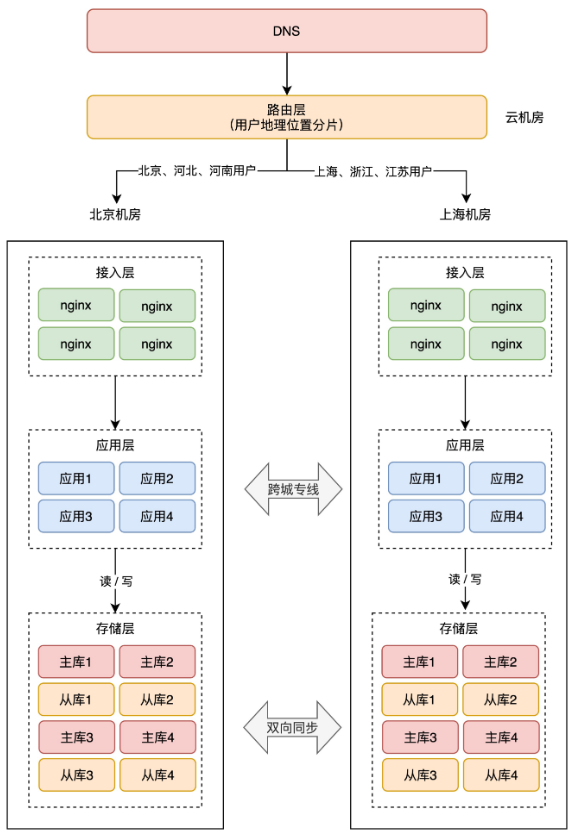
+**3、按地理位置分片**
+
+这种方案,非常适合与地理位置密切相关的业务,例如打车、外卖服务就非常适合这种方案。
+
+拿外卖服务举例,你要点外卖肯定是「就近」点餐,整个业务范围相关的有商家、用户、骑手,它们都是在相同的地理位置内的。
+
+针对这种特征,就可以在最上层,按用户的「地理位置」来做分片,分散到不同的机房。
+
+举例:北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。这样的分片规则,也能避免数据冲突。
+
+
+
+> 提醒:这 3 种常见的分片规则,第一次看不太好理解,建议配合图多理解几遍。搞懂这 3 个分片规则,你才能真正明白怎么做异地多活。
+
+总之,分片的核心思路在于,**让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问**。
+
+阿里在实施这种方案时,给它起了个名字,叫做「**单元化**」。
+
+> 当然,最上层的路由层把用户分片后,理论来说同一个用户只会落在同一个机房内,但不排除程序 Bug 导致用户会在两个机房「漂移」。
+>
+> 安全起见,每个机房在写存储时,还需要有一套机制,能够检测「数据归属」,应用层操作存储时,需要通过中间件来做「兜底」,避免不该写本机房的情况发生。(篇幅限制,这里不展开讲,理解思路即可)
+
+现在,两个机房就可以都接收「读写」流量(做好分片的请求),底层存储保持「双向」同步,两个机房都拥有全量数据,当任意机房故障时,另一个机房就可以「接管」全部流量,实现快速切换,简直不要太爽。
+
+不仅如此,因为机房部署在异地,我们还可以更细化地「优化」路由规则,让用户访问就近的机房,这样整个系统的性能也会大大提升。
+
+> 这里还有一种情况,是无法做数据分片的:**全局数据**。例如系统配置、商品库存这类需要强一致的数据,这类服务依旧只能采用写主机房,读从机房的方案,不做双活。
+>
+> 双活的重点,是要优先保证「核心」业务先实现双活,并不是「全部」业务实现双活。
+
+至此,我们才算实现了真正的「**异地双活**」!
+
+> 到这里你可以看出,完成这样一套架构,需要投入的成本是巨大的。
+>
+> 路由规则、路由转发、数据同步中间件、数据校验兜底策略,不仅需要开发强大的中间件,同时还要业务配合改造(业务边界划分、依赖拆分)等一些列工作,没有足够的人力物力,这套架构很难实施。
+
+# 11 异地多活
+
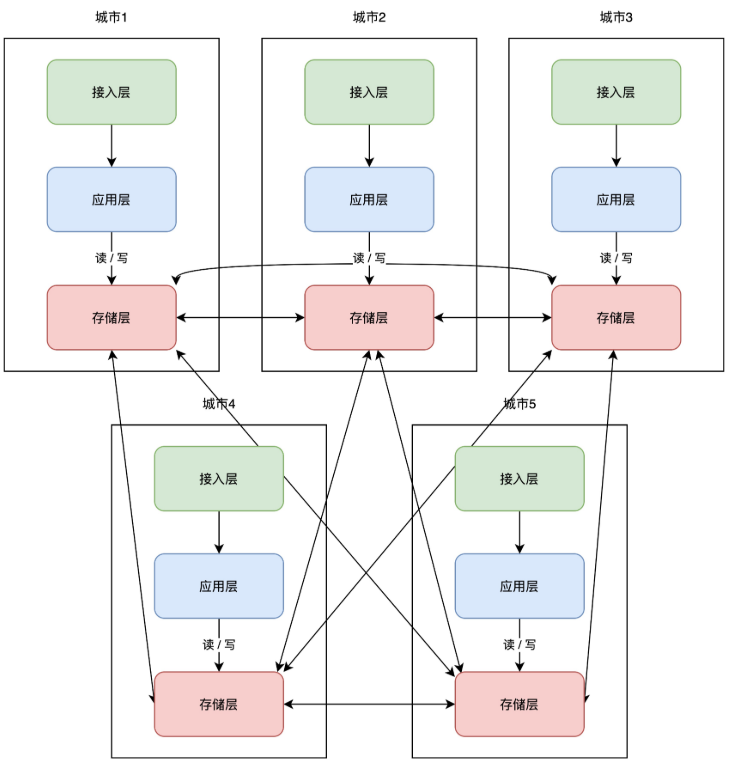
+理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。架构变成了这样:
+
+
+
+这些服务按照「单元化」的部署方式,可以让每个机房部署在任意地区,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
+
+但这里还有一个小问题,随着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,这个实现复杂度会比较高。
+
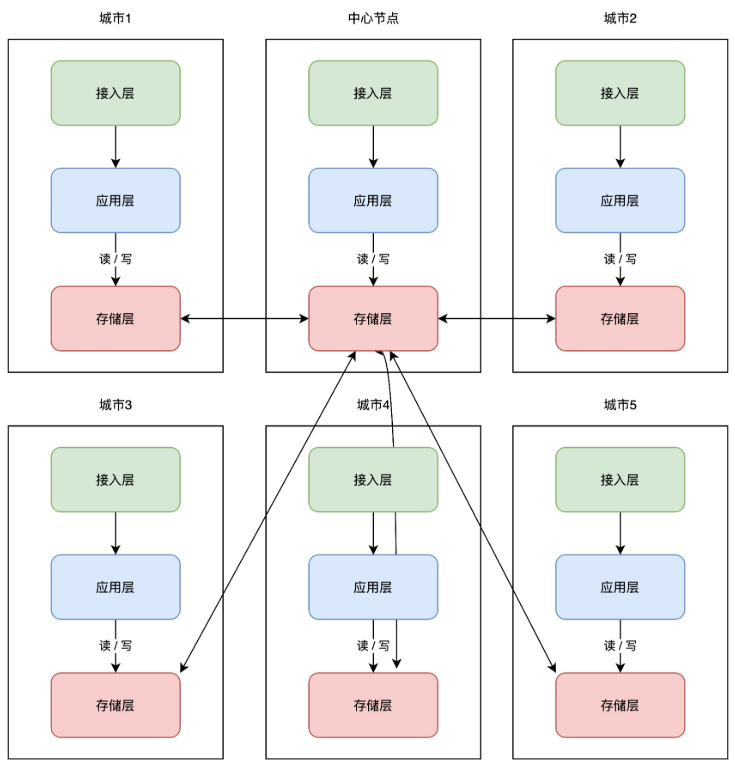
+所以业界又把这一架构又做了进一步优化,把「网状」架构升级为「星状」:
+
+
+
+这种方案必须设立一个「中心机房」,任意机房写入数据后,都只同步到中心机房,再由中心机房同步至其它机房。
+
+这样做的好处是,一个机房写入数据,只需要同步数据到中心机房即可,不需要再关心一共部署了多少个机房,实现复杂度大大「简化」。
+
+但与此同时,这个中心机房的「稳定性」要求会比较高。不过也还好,即使中心机房发生故障,我们也可以把任意一个机房,提升为中心机房,继续按照之前的架构提供服务。
+
+至此,我们的系统彻底实现了「**异地多活**」!
+
+多活的优势在于,**可以任意扩展机房「就近」部署。任意机房发生故障,可以完成快速「切换」**,大大提高了系统的可用性。
+
+同时,我们也再也不用担心系统规模的增长,因为这套架构具有极强的「**扩展能力**」。
+
+怎么样?我们从一个最简单的应用,一路优化下来,到最终的架构方案,有没有帮你彻底理解异地多活呢?
+
+# 总结
+
+好了,总结一下这篇文章的重点。
+
+1、一个好的软件架构,应该遵循高性能、高可用、易扩展 3 大原则,其中「高可用」在系统规模变得越来越大时,变得尤为重要
+
+2、系统发生故障并不可怕,能以「最快」的速度恢复,才是高可用追求的目标,异地多活是实现高可用的有效手段
+
+3、提升高可用的核心是「冗余」,备份、主从副本、同城灾备、同城双活、两地三中心、异地双活,异地多活都是在做冗余
+
+4、同城灾备分为「冷备」和「热备」,冷备只备份数据,不提供服务,热备实时同步数据,并做好随时切换的准备
+
+5、同城双活比灾备的优势在于,两个机房都可以接入「读写」流量,提高可用性的同时,还提升了系统性能。虽然物理上是两个机房,但「逻辑」上还是当做一个机房来用
+
+6、两地三中心是在同城双活的基础上,额外部署一个异地机房做「灾备」,用来抵御「城市」级别的灾害,但启用灾备机房需要时间
+
+7、异地双活才是抵御「城市」级别灾害的更好方案,两个机房同时提供服务,故障随时可切换,可用性高。但实现也最复杂,理解了异地双活,才能彻底理解异地多活
+
+8、异地多活是在异地双活的基础上,任意扩展多个机房,不仅又提高了可用性,还能应对更大规模的流量的压力,扩展性最强,是实现高可用的最终方案
+
+# 后记
+
+这篇文章我从「宏观」层面,向你介绍了异地多活架构的「核心」思路,整篇文章的信息量还是很大的,如果不太好理解,我建议你多读几遍。
+
+因为篇幅限制,很多细节我并没有展开来讲。这篇文章更像是讲异地多活的架构之「道」,而真正实施的「术」,要考虑的点其实也非常繁多,因为它需要开发强大的「基础设施」才可以完成实施。
+
+不仅如此,要想真正实现异地多活,还需要遵循一些原则,例如业务梳理、业务分级、数据分类、数据最终一致性保障、机房切换一致性保障、异常处理等等。同时,相关的运维设施、监控体系也要能跟得上才行。
+
+宏观上需要考虑业务(微服务部署、依赖、拆分、SDK、Web 框架)、基础设施(服务发现、流量调度、持续集成、同步中间件、自研存储),微观上要开发各种中间件,还要关注中间件的高性能、高可用、容错能力,其复杂度之高,只有亲身参与过之后才知道。
+
+我曾经有幸参与过,存储层同步中间件的设计与开发,实现过「跨机房」同步 MySQL、Redis、MongoDB 的中间件,踩过的坑也非常多。当然,这些中间件的设计思路也非常有意思,有时间单独分享一下这些中间件的设计思路。
+
+值得提醒你的是,只有真正理解了「异地双活」,才能彻底理解「异地多活」。在我看来,从同城双活演变为异地双活的过程,是最为复杂的,最核心的东西包括,**业务单元化划分、存储层数据双向同步、最上层的分片逻辑**,这些是实现异地多活的重中之重。
+
diff --git a/docs/advance/excellent-article/31-mysql-data-sync-es.md b/docs/advance/excellent-article/31-mysql-data-sync-es.md
new file mode 100644
index 0000000..8d43d94
--- /dev/null
+++ b/docs/advance/excellent-article/31-mysql-data-sync-es.md
@@ -0,0 +1,503 @@
+---
+sidebar: heading
+title: MySQL数据如何实时同步到ES
+category: 优质文章
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL,ES,elasticsearch,数据同步
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+
+## 前言
+
+我们一般会使用MySQL用来存储数据,用Es来做全文检索和特殊查询,那么如何将数据优雅的从MySQL同步到Es呢?我们一般有以下几种方式:
+
+1.**双写**。在代码中先向MySQL中写入数据,然后紧接着向Es中写入数据。这个方法的缺点是代码严重耦合,需要手动维护MySQL和Es数据关系,非常不便于维护。
+
+2.**发MQ,异步执行**。在执行完向Mysql中写入数据的逻辑后,发送MQ,告诉消费端这个数据需要写入Es,消费端收到消息后执行向Es写入数据的逻辑。这个方式的优点是Mysql和Es数据维护分离,开发Mysql和Es的人员只需要关心各自的业务。缺点是依然需要维护发送、接收MQ的逻辑,并且引入了MQ组件,增加了系统的复杂度。
+
+3.**使用Datax进行全量数据同步**。这个方式优点是可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。缺点是Datax是一种全量同步数据的方式,不使用实时同步。如果系统对数据时效性不强,可以考虑此方式。
+
+4.**使用Canal进行实时数据同步**。这个方式具有跟Datax一样的优点,可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。与Datax不同的是Canal是一种实时同步数据的方式,对数据时效性较强的系统,我们会采用Canal来进行实时数据同步。
+
+那么就让我们来看看Canal是如何使用的。
+
+## 官网
+
+https://github.com/alibaba/canal
+
+## 1.Canal简介
+
+
+
+**canal [kə'næl]** ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
+
+早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
+
+基于日志增量订阅和消费的业务包括
+
+- 数据库镜像
+- 数据库实时备份
+- 索引构建和实时维护(拆分异构索引、倒排索引等)
+- 业务 cache 刷新
+- 带业务逻辑的增量数据处理
+
+当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
+
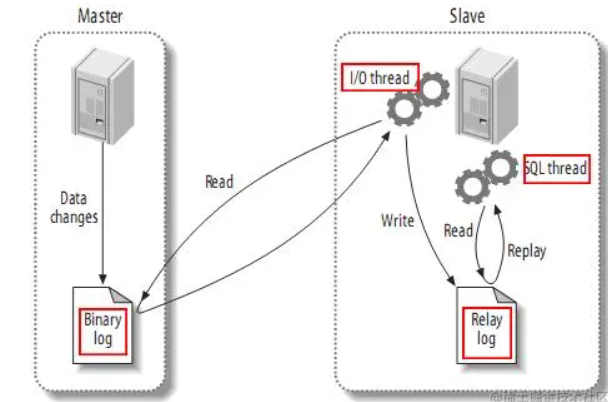
+### **MySQL主备复制原理**
+
+
+
+- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
+- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
+- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
+
+### **canal工作原理**
+
+- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
+- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
+- canal 解析 binary log 对象(原始为 byte 流)
+
+## 2.开启MySQL Binlog
+
+- 对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
+
+```ini
+[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
+lua
+## 复制代码注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
+```
+
+- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
+
+```sql
+CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;
+```
+
+注意:Mysql版本为8.x时启动canal可能会出现“caching_sha2_password Auth failed”错误,这是因为8.x创建用户时默认的密码加密方式为**caching_sha2_password**,与canal的方式不一致,所以需要将canal用户的密码加密方式修改为**mysql_native_password**
+
+```sql
+ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; #更新一下用户密码
+FLUSH PRIVILEGES; #刷新权限
+```
+
+## 3.安装Canal
+
+### 3.1 下载Canal
+
+**点击下载地址,选择版本后点击canal.deployer文件下载**
+
+
+
+### 3.2 修改配置文件
+
+打开目录下conf/example/instance.properties文件,主要修改以下内容
+
+```ini
+## mysql serverId,不要和 mysql 的 server_id 重复
+canal.instance.mysql.slaveId = 10
+#position info,需要改成自己的数据库信息
+canal.instance.master.address = 127.0.0.1:3306
+#username/password,需要改成自己的数据库信息,与刚才添加的用户保持一致
+canal.instance.dbUsername = canal
+canal.instance.dbPassword = canal
+```
+
+### 3.3 启动和关闭
+
+```bash
+#进入文件目录下的bin文件夹
+#启动
+sh startup.sh
+#关闭
+sh stop.sh
+```
+
+## 4.Springboot集成Canal
+
+### 4.1 Canal数据结构
+
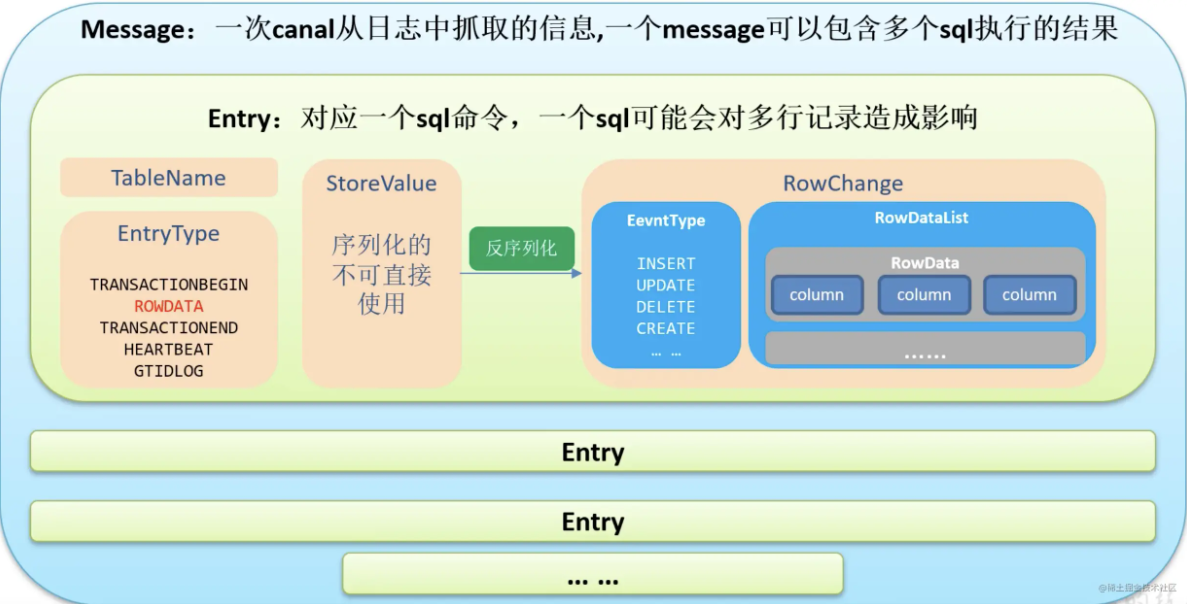
+
+
+### 4.2 引入依赖
+
+```xml
+
+
+ com.alibaba.otter
+ canal.client
+ 1.1.6
+
+
+
+
+
+ com.alibaba.otter
+ canal.protocol
+ 1.1.6
+
+
+
+
+ co.elastic.clients
+ elasticsearch-java
+ 8.4.3
+
+
+
+
+ jakarta.json
+ jakarta.json-api
+ 2.0.1
+
+```
+
+### 4.3 application.yaml
+
+```yaml
+custom:
+ elasticsearch:
+ host: localhost #主机
+ port: 9200 #端口
+ username: elastic #用户名
+ password: 3bf24a76 #密码
+```
+
+### 4.4 EsClient
+
+```java
+@Setter
+@ConfigurationProperties(prefix = "custom.elasticsearch")
+@Configuration
+public class EsClient {
+
+ /**
+ * 主机
+ */
+ private String host;
+
+ /**
+ * 端口
+ */
+ private Integer port;
+
+ /**
+ * 用户名
+ */
+ private String username;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+
+ @Bean
+ public ElasticsearchClient elasticsearchClient() {
+ CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
+ credentialsProvider.setCredentials(
+ AuthScope.ANY, new UsernamePasswordCredentials(username, password));
+
+ // Create the low-level client
+ RestClient restClient = RestClient.builder(new HttpHost(host, port))
+ .setHttpClientConfigCallback(httpAsyncClientBuilder ->
+ httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider))
+ .build();
+ // Create the transport with a Jackson mapper
+ RestClientTransport transport = new RestClientTransport(
+ restClient, new JacksonJsonpMapper());
+ // Create the transport with a Jackson mapper
+ return new ElasticsearchClient(transport);
+ }
+}
+```
+
+### 4.5 Music实体类
+
+```java
+@Data
+@Builder
+@NoArgsConstructor
+@AllArgsConstructor
+public class Music {
+
+ /**
+ * id
+ */
+ private String id;
+
+ /**
+ * 歌名
+ */
+ private String name;
+
+ /**
+ * 歌手名
+ */
+ private String singer;
+
+ /**
+ * 封面图地址
+ */
+ private String imageUrl;
+
+ /**
+ * 歌曲地址
+ */
+ private String musicUrl;
+
+ /**
+ * 歌词地址
+ */
+ private String lrcUrl;
+
+ /**
+ * 歌曲类型id
+ */
+ private String typeId;
+
+ /**
+ * 是否被逻辑删除,1 是,0 否
+ */
+ private Integer isDeleted;
+
+ /**
+ * 创建时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date createTime;
+
+ /**
+ * 更新时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date updateTime;
+
+}
+```
+
+### 4.6 CanalClient
+
+```java
+@Slf4j
+@Component
+public class CanalClient {
+
+ @Resource
+ private ElasticsearchClient client;
+
+
+ /**
+ * 实时数据同步程序
+ *
+ * @throws InterruptedException
+ * @throws InvalidProtocolBufferException
+ */
+ public void run() throws InterruptedException, IOException {
+ CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(
+ "localhost", 11111), "example", "", "");
+
+ while (true) {
+ //连接
+ connector.connect();
+ //订阅数据库
+ connector.subscribe("cloudmusic_music.music");
+ //获取数据
+ Message message = connector.get(100);
+
+ List entryList = message.getEntries();
+ if (CollectionUtils.isEmpty(entryList)) {
+ //没有数据,休息一会
+ TimeUnit.SECONDS.sleep(2);
+ } else {
+ for (CanalEntry.Entry entry : entryList) {
+ //获取类型
+ CanalEntry.EntryType entryType = entry.getEntryType();
+
+ //判断类型是否为ROWDATA
+ if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
+ //获取序列化后的数据
+ ByteString storeValue = entry.getStoreValue();
+ //反序列化数据
+ CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
+ //获取当前事件操作类型
+ CanalEntry.EventType eventType = rowChange.getEventType();
+ //获取数据集
+ List rowDataList = rowChange.getRowDatasList();
+
+ if (eventType == CanalEntry.EventType.INSERT) {
+ log.info("------新增操作------");
+
+ List musicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ musicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量新增文档
+ index(musicList);
+ //打印新增集合
+ log.info(Arrays.toString(musicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.UPDATE) {
+ log.info("------更新操作------");
+
+ List beforeMusicList = new ArrayList<>();
+ List afterMusicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ //更新前
+ beforeMusicList.add(createMusic(rowData.getBeforeColumnsList()));
+ //更新后
+ afterMusicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量更新文档
+ index(afterMusicList);
+ //打印更新前集合
+ log.info("更新前:{}", Arrays.toString(beforeMusicList.toArray()));
+ //打印更新后集合
+ log.info("更新后:{}", Arrays.toString(afterMusicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.DELETE) {
+ //删除操作
+ log.info("------删除操作------");
+
+ List idList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ for (CanalEntry.Column column : rowData.getBeforeColumnsList()) {
+ if("id".equals(column.getName())) {
+ idList.add(column.getValue());
+ break;
+ }
+ }
+ }
+ //es批量删除文档
+ delete(idList);
+ //打印删除id集合
+ log.info(Arrays.toString(idList.toArray()));
+ }
+ }
+ }
+ }
+ }
+ }
+
+ /**
+ * 根据canal获取的数据创建Music对象
+ *
+ * @param columnList
+ * @return
+ */
+ private Music createMusic(List columnList) {
+ Music music = new Music();
+ DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
+
+ for (CanalEntry.Column column : columnList) {
+ switch (column.getName()) {
+ case "id" -> music.setId(column.getValue());
+ case "name" -> music.setName(column.getValue());
+ case "singer" -> music.setSinger(column.getValue());
+ case "image_url" -> music.setImageUrl(column.getValue());
+ case "music_url" -> music.setMusicUrl(column.getValue());
+ case "lrc_url" -> music.setLrcUrl(column.getValue());
+ case "type_id" -> music.setTypeId(column.getValue());
+ case "is_deleted" -> music.setIsDeleted(Integer.valueOf(column.getValue()));
+ case "create_time" ->
+ music.setCreateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ case "update_time" ->
+ music.setUpdateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ default -> {
+ }
+ }
+ }
+
+ return music;
+ }
+
+ /**
+ * es批量新增、更新文档(不存在:新增, 存在:更新)
+ *
+ * @param musicList 音乐集合
+ * @throws IOException
+ */
+ private void index(List musicList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ musicList.forEach(music -> br
+ .operations(op -> op
+ .index(idx -> idx
+ .index("music")
+ .id(music.getId())
+ .document(music))));
+
+ client.bulk(br.build());
+ }
+
+ /**
+ * es批量删除文档
+ *
+ * @param idList 音乐id集合
+ * @throws IOException
+ */
+ private void delete(List idList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ idList.forEach(id -> br
+ .operations(op -> op
+ .delete(idx -> idx
+ .index("music")
+ .id(id))));
+
+ client.bulk(br.build());
+ }
+
+}
+```
+
+### 4.7 ApplicationContextAware
+
+```java
+@Component
+public class ApplicationContextUtil implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ ApplicationContextUtil.applicationContext = applicationContext;
+ }
+
+ public static T getBean (Class classType) {
+ return applicationContext.getBean(classType);
+ }
+
+}
+```
+
+### 4.8 main
+
+```java
+@Slf4j
+@SpringBootApplication
+public class CanalApplication {
+ public static void main(String[] args) throws InterruptedException, IOException {
+ SpringApplication.run(CanalApplication.class, args);
+ log.info("数据同步程序启动");
+
+ CanalClient client = ApplicationContextUtil.getBean(CanalClient.class);
+ client.run();
+ }
+}
+```
+
+## 5.总结
+
+那么以上就是Canal组件的介绍啦,希望大家都能有所收获~
+
diff --git a/docs/learn/ghelper.md b/docs/learn/ghelper.md
index a640f63..f5de885 100644
--- a/docs/learn/ghelper.md
+++ b/docs/learn/ghelper.md
@@ -1,4 +1,17 @@
-# 科学上网教程
+---
+sidebar: heading
+title: 科学上网教程
+category: 工具
+tag:
+ - 工具
+head:
+ - - meta
+ - name: keywords
+ content: ghelper
+ - - meta
+ - name: description
+ content: 提高工作效率的工具
+---
@@ -64,10 +77,16 @@ Ghelper可以在google play商店进行下载,需要访问google商店,无
-> 最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、架构、分布式、微服务、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-
-
+最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-**Github地址**:https://github.com/Tyson0314/java-books
\ No newline at end of file
+
+
+
+
+[**Github地址**](https://github.com/Tyson0314/java-books)
+
+如果访问不了Github,可以访问码云地址。
+
+[码云地址](https://gitee.com/tysondai/java-books)
\ No newline at end of file
diff --git a/docs/note/docker-note.md b/docs/note/docker-note.md
new file mode 100644
index 0000000..68a8f62
--- /dev/null
+++ b/docs/note/docker-note.md
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+
+
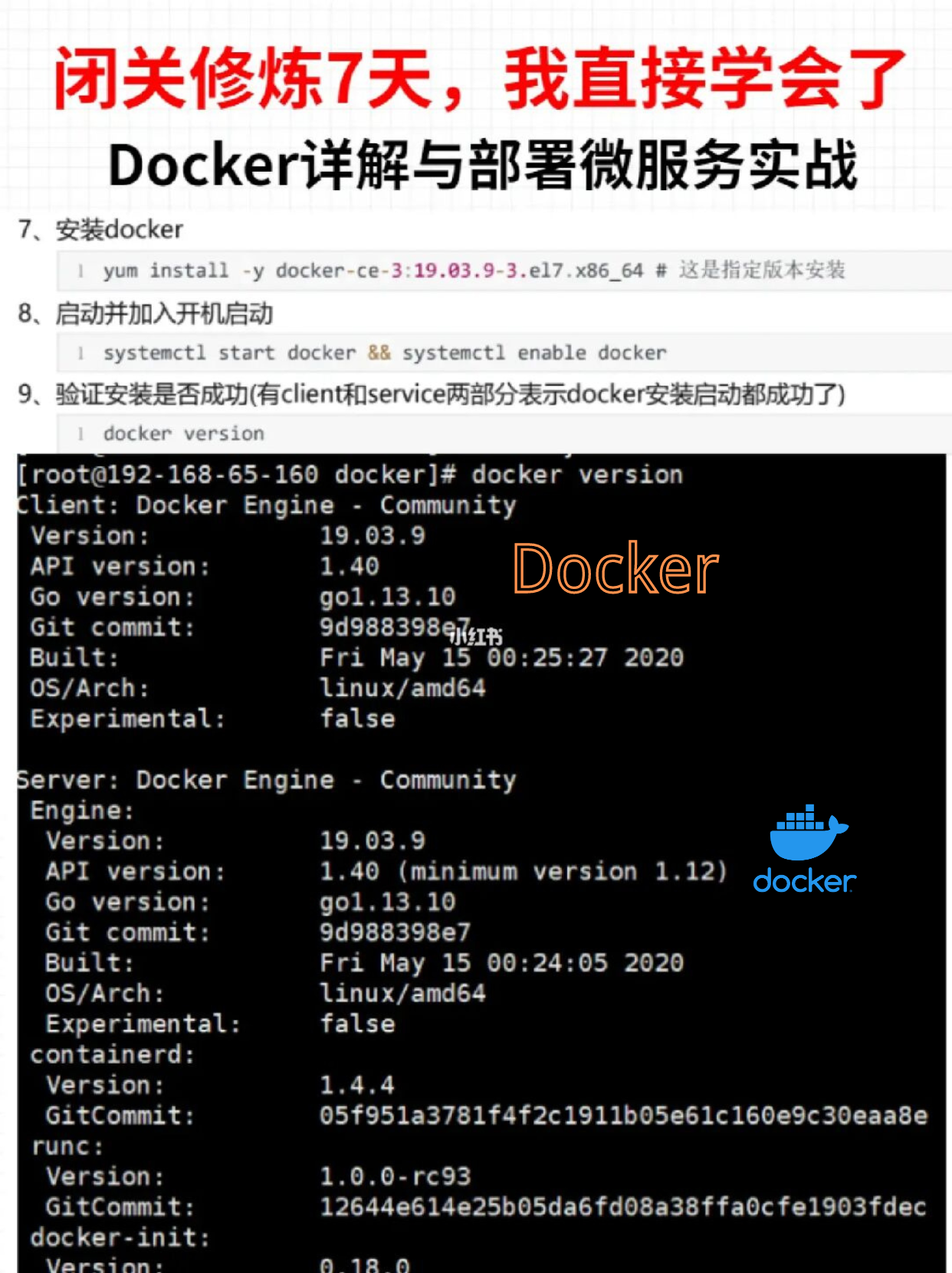
+
+
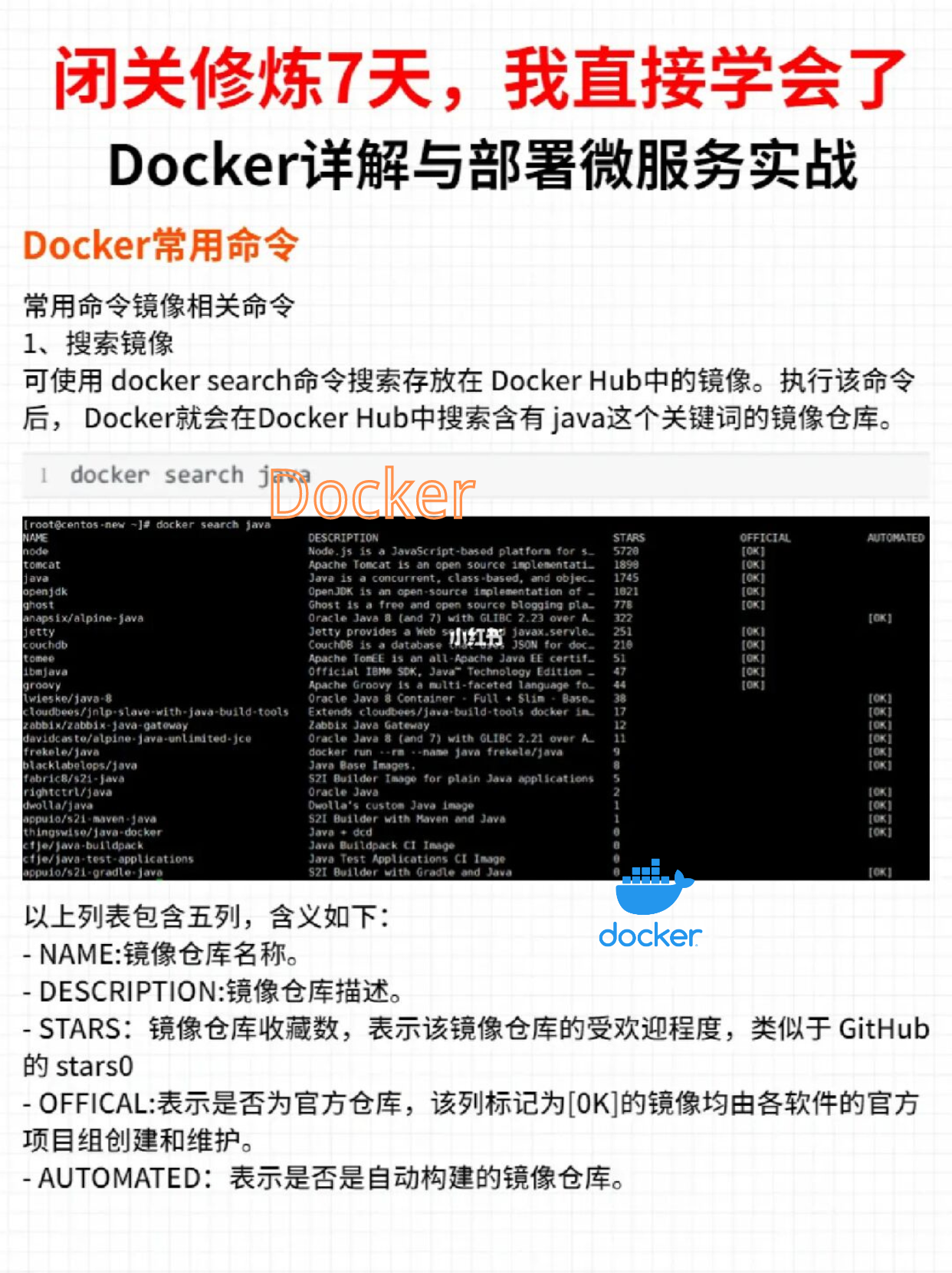
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/note/write-sql.md b/docs/note/write-sql.md
new file mode 100644
index 0000000..14faa3a
--- /dev/null
+++ b/docs/note/write-sql.md
@@ -0,0 +1,93 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 21个写SQL的好习惯
+
+
+
+
+
+
+
+
+
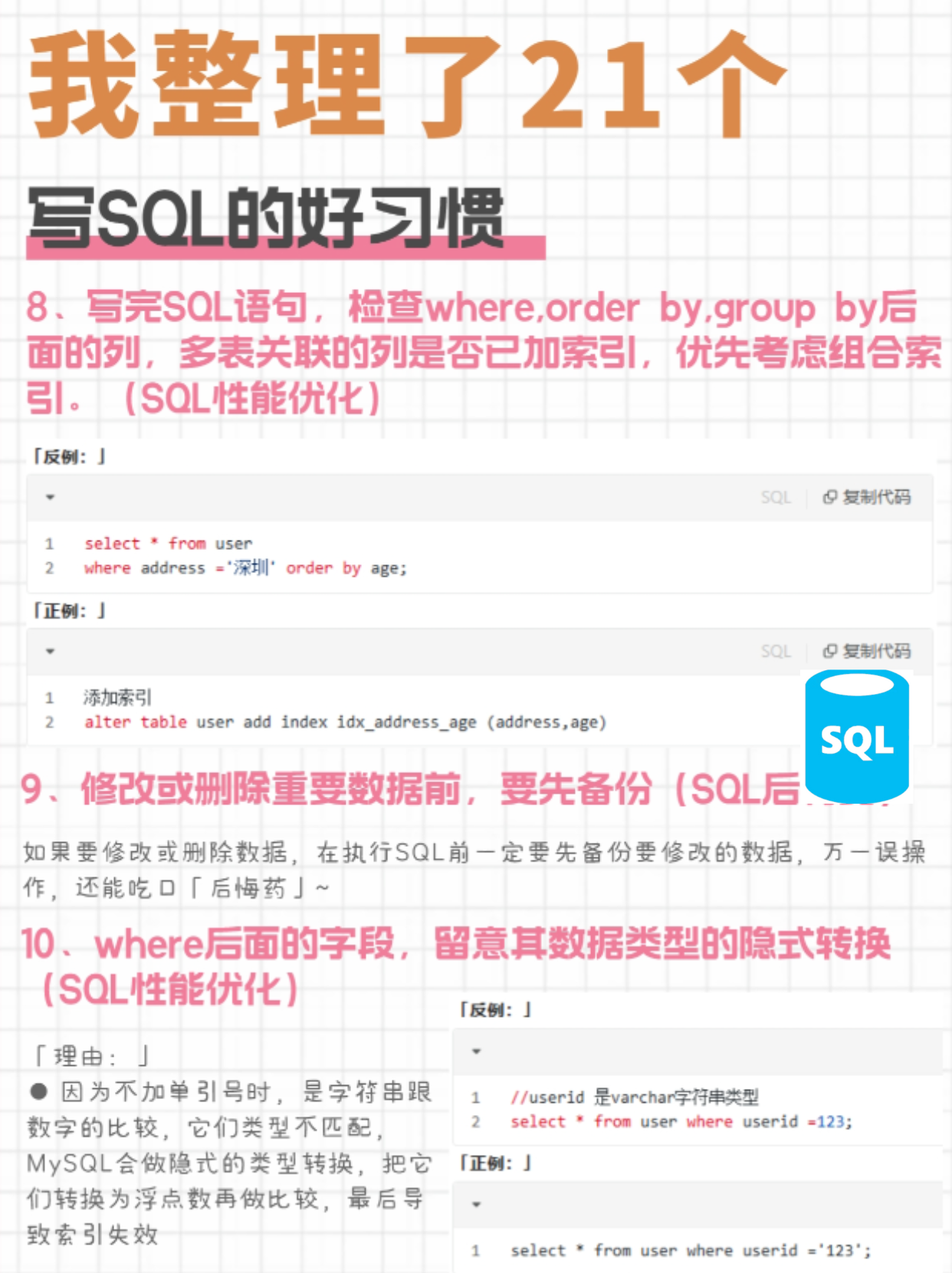
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## MySQL面试题
+
+下面分享MySQL常考的**面试题目**。
+
+- [事务的四大特性?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E7%9A%84%E5%9B%9B%E5%A4%A7%E7%89%B9%E6%80%A7)
+- [数据库的三大范式](https://topjavaer.cn/database/mysql.html#%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E4%B8%89%E5%A4%A7%E8%8C%83%E5%BC%8F)
+- [事务隔离级别有哪些?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [生产环境数据库一般用的什么隔离级别呢?](https://topjavaer.cn/database/mysql.html#%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%80%E8%88%AC%E7%94%A8%E7%9A%84%E4%BB%80%E4%B9%88%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E5%91%A2)
+- [编码和字符集的关系](https://topjavaer.cn/database/mysql.html#%E7%BC%96%E7%A0%81%E5%92%8C%E5%AD%97%E7%AC%A6%E9%9B%86%E7%9A%84%E5%85%B3%E7%B3%BB)
+- [utf8和utf8mb4的区别](https://topjavaer.cn/database/mysql.html#utf8%E5%92%8Cutf8mb4%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [什么是索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95)
+- [索引的优缺点?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9)
+- [索引的作用?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BD%9C%E7%94%A8)
+- [什么情况下需要建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E9%9C%80%E8%A6%81%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [什么情况下不建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E4%B8%8D%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [索引的数据结构](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
+- [Hash索引和B+树索引的区别?](https://topjavaer.cn/database/mysql.html#hash%E7%B4%A2%E5%BC%95%E5%92%8Cb%E6%A0%91%E7%B4%A2%E5%BC%95%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [为什么B+树比B树更适合实现数据库索引?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88b%E6%A0%91%E6%AF%94b%E6%A0%91%E6%9B%B4%E9%80%82%E5%90%88%E5%AE%9E%E7%8E%B0%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95)
+- [索引有什么分类?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E6%9C%89%E4%BB%80%E4%B9%88%E5%88%86%E7%B1%BB)
+- [什么是最左匹配原则?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E6%9C%80%E5%B7%A6%E5%8C%B9%E9%85%8D%E5%8E%9F%E5%88%99)
+- [什么是聚集索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%81%9A%E9%9B%86%E7%B4%A2%E5%BC%95)
+- [什么是覆盖索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%A6%86%E7%9B%96%E7%B4%A2%E5%BC%95)
+- [索引的设计原则?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99)
+- [索引什么时候会失效?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%BB%80%E4%B9%88%E6%97%B6%E5%80%99%E4%BC%9A%E5%A4%B1%E6%95%88)
+- [什么是前缀索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%89%8D%E7%BC%80%E7%B4%A2%E5%BC%95)
+- [索引下推](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%B8%8B%E6%8E%A8)
+- [常见的存储引擎有哪些?](https://topjavaer.cn/database/mysql.html#%E5%B8%B8%E8%A7%81%E7%9A%84%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [MyISAM和InnoDB的区别?](https://topjavaer.cn/database/mysql.html#myisam%E5%92%8Cinnodb%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL有哪些锁?](https://topjavaer.cn/database/mysql.html#mysql%E6%9C%89%E5%93%AA%E4%BA%9B%E9%94%81)
+- [MVCC 实现原理?](https://topjavaer.cn/database/mysql.html#mvcc-%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86)
+- [快照读和当前读](https://topjavaer.cn/database/mysql.html#%E5%BF%AB%E7%85%A7%E8%AF%BB%E5%92%8C%E5%BD%93%E5%89%8D%E8%AF%BB)
+- [共享锁和排他锁](https://topjavaer.cn/database/mysql.html#%E5%85%B1%E4%BA%AB%E9%94%81%E5%92%8C%E6%8E%92%E4%BB%96%E9%94%81)
+- [bin log/redo log/undo log](https://topjavaer.cn/database/mysql.html#bin-logredo-logundo-log)
+- [bin log和redo log有什么区别?](https://topjavaer.cn/database/mysql.html#bin-log%E5%92%8Credo-log%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [讲一下MySQL架构?](https://topjavaer.cn/database/mysql.html#%E8%AE%B2%E4%B8%80%E4%B8%8Bmysql%E6%9E%B6%E6%9E%84)
+- [分库分表](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [什么是分区表?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%88%86%E5%8C%BA%E8%A1%A8)
+- [分区表类型](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E8%A1%A8%E7%B1%BB%E5%9E%8B)
+- [分区的问题?](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E7%9A%84%E9%97%AE%E9%A2%98)
+- [查询语句执行流程?](https://topjavaer.cn/database/mysql.html#%E6%9F%A5%E8%AF%A2%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B)
+- [更新语句执行过程?](https://topjavaer.cn/database/mysql.html#%E6%9B%B4%E6%96%B0%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E8%BF%87%E7%A8%8B)
+- [exist和in的区别?](https://topjavaer.cn/database/mysql.html#exist%E5%92%8Cin%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中int()和char()的区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADint10%E5%92%8Cchar10%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [truncate、delete与drop区别?](https://topjavaer.cn/database/mysql.html#truncatedelete%E4%B8%8Edrop%E5%8C%BA%E5%88%AB)
+- [having和where区别?](https://topjavaer.cn/database/mysql.html#having%E5%92%8Cwhere%E5%8C%BA%E5%88%AB)
+- [什么是MySQL主从同步?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AFmysql%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [为什么要做主从同步?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E5%81%9A%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [乐观锁和悲观锁是什么?](https://topjavaer.cn/database/mysql.html#%E4%B9%90%E8%A7%82%E9%94%81%E5%92%8C%E6%82%B2%E8%A7%82%E9%94%81%E6%98%AF%E4%BB%80%E4%B9%88)
+- [用过processlist吗?](https://topjavaer.cn/database/mysql.html#%E7%94%A8%E8%BF%87processlist%E5%90%97)
+- [MySQL查询 limit 1000,10 和limit 10 速度一样快吗?](https://topjavaer.cn/database/mysql.html#mysql%E6%9F%A5%E8%AF%A2-limit-100010-%E5%92%8Climit-10-%E9%80%9F%E5%BA%A6%E4%B8%80%E6%A0%B7%E5%BF%AB%E5%90%97)
+- [深分页怎么优化?](https://topjavaer.cn/database/mysql.html#%E6%B7%B1%E5%88%86%E9%A1%B5%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [高度为3的B+树,可以存放多少数据?](https://topjavaer.cn/database/mysql.html#%E9%AB%98%E5%BA%A6%E4%B8%BA3%E7%9A%84b%E6%A0%91%E5%8F%AF%E4%BB%A5%E5%AD%98%E6%94%BE%E5%A4%9A%E5%B0%91%E6%95%B0%E6%8D%AE)
+- [MySQL单表多大进行分库分表?](https://topjavaer.cn/database/mysql.html#mysql%E5%8D%95%E8%A1%A8%E5%A4%9A%E5%A4%A7%E8%BF%9B%E8%A1%8C%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [大表查询慢怎么优化?](https://topjavaer.cn/database/mysql.html#%E5%A4%A7%E8%A1%A8%E6%9F%A5%E8%AF%A2%E6%85%A2%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [说说count()、count()和count()的区别](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4count1count%E5%92%8Ccount%E5%AD%97%E6%AE%B5%E5%90%8D%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中DATETIME 和 TIMESTAMP有什么区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADdatetime-%E5%92%8C-timestamp%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [说说为什么不建议用外键?](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E5%BB%BA%E8%AE%AE%E7%94%A8%E5%A4%96%E9%94%AE)
+- [使用自增主键有什么好处?](https://topjavaer.cn/database/mysql.html#%E4%BD%BF%E7%94%A8%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E6%9C%89%E4%BB%80%E4%B9%88%E5%A5%BD%E5%A4%84)
+- [自增主键保存在什么地方?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%BF%9D%E5%AD%98%E5%9C%A8%E4%BB%80%E4%B9%88%E5%9C%B0%E6%96%B9)
+- [自增主键一定是连续的吗?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%B8%80%E5%AE%9A%E6%98%AF%E8%BF%9E%E7%BB%AD%E7%9A%84%E5%90%97)
+- [InnoDB的自增值为什么不能回收利用?](https://topjavaer.cn/database/mysql.html#innodb%E7%9A%84%E8%87%AA%E5%A2%9E%E5%80%BC%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E8%83%BD%E5%9B%9E%E6%94%B6%E5%88%A9%E7%94%A8)
+- [MySQL数据如何同步到Redis缓存?](https://topjavaer.cn/database/mysql.html#mysql%E6%95%B0%E6%8D%AE%E5%A6%82%E4%BD%95%E5%90%8C%E6%AD%A5%E5%88%B0redis%E7%BC%93%E5%AD%98)
\ No newline at end of file
diff --git a/docs/zsxq/article/select-max-rows.md b/docs/zsxq/article/select-max-rows.md
new file mode 100644
index 0000000..9ffabc2
--- /dev/null
+++ b/docs/zsxq/article/select-max-rows.md
@@ -0,0 +1,225 @@
+## 问题
+
+一条这样的 SQL 语句能查询出多少条记录?
+
+```SQL
+select * from user
+```
+
+表中有 100 条记录的时候能全部查询出来返回给客户端吗?
+
+如果记录数是 1w 呢? 10w 呢? 100w 、1000w 呢?
+
+虽然在实际业务操作中我们不会这么干,尤其对于数据量大的表不会这样干,但这是个值得想一想的问题。
+
+## 寻找答案
+
+前提:以下所涉及资料全部基于 MySQL 8
+
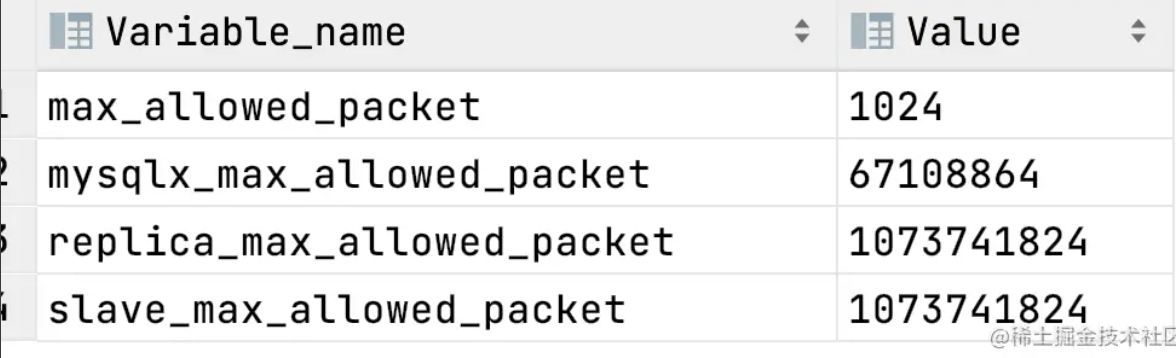
+### max_allowed_packet
+
+在查询资料的过程中发现了这个参数 `max_allowed_packet`
+
+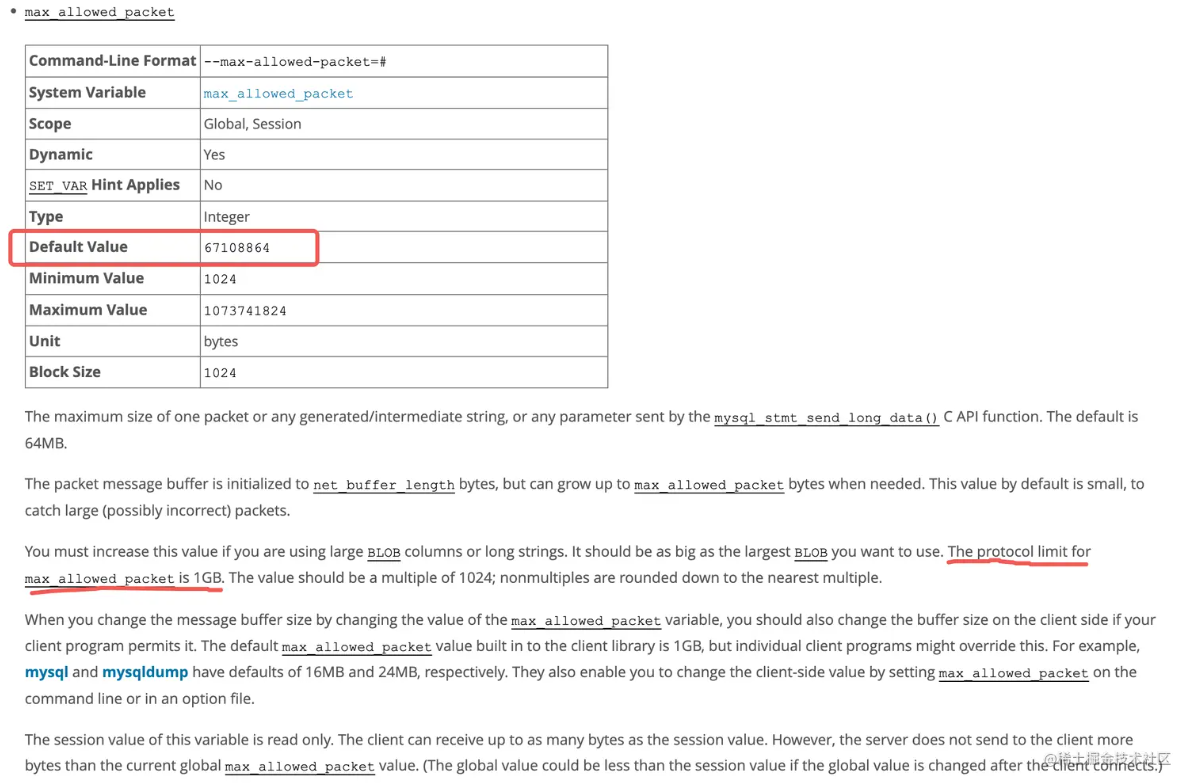
+
+上图参考了 MySQL 的官方文档,根据文档我们知道:
+
+- MySQL 客户端 `max_allowed_packet` 值的默认大小为 16M(不同的客户端可能有不同的默认值,但最大不能超过 1G)
+- MySQL 服务端 `max_allowed_packet` 值的默认大小为 64M
+- `max_allowed_packet` 值最大可以设置为 1G(1024 的倍数)
+
+然而 根据上图的文档中所述
+
+> The maximum size of one packet or any generated/intermediate string,or any parameter sent by the mysql_smt_send_long_data() C API function
+
+- one packet
+- generated/intermediate string
+- any parameter sent by the mysql_smt_send_long_data() C API function
+
+这三个东东具体都是什么呢? `packet` 到底是结果集大小,还是网络包大小还是什么? 于是 google 了一下,搜索排名第一的是这个:
+
+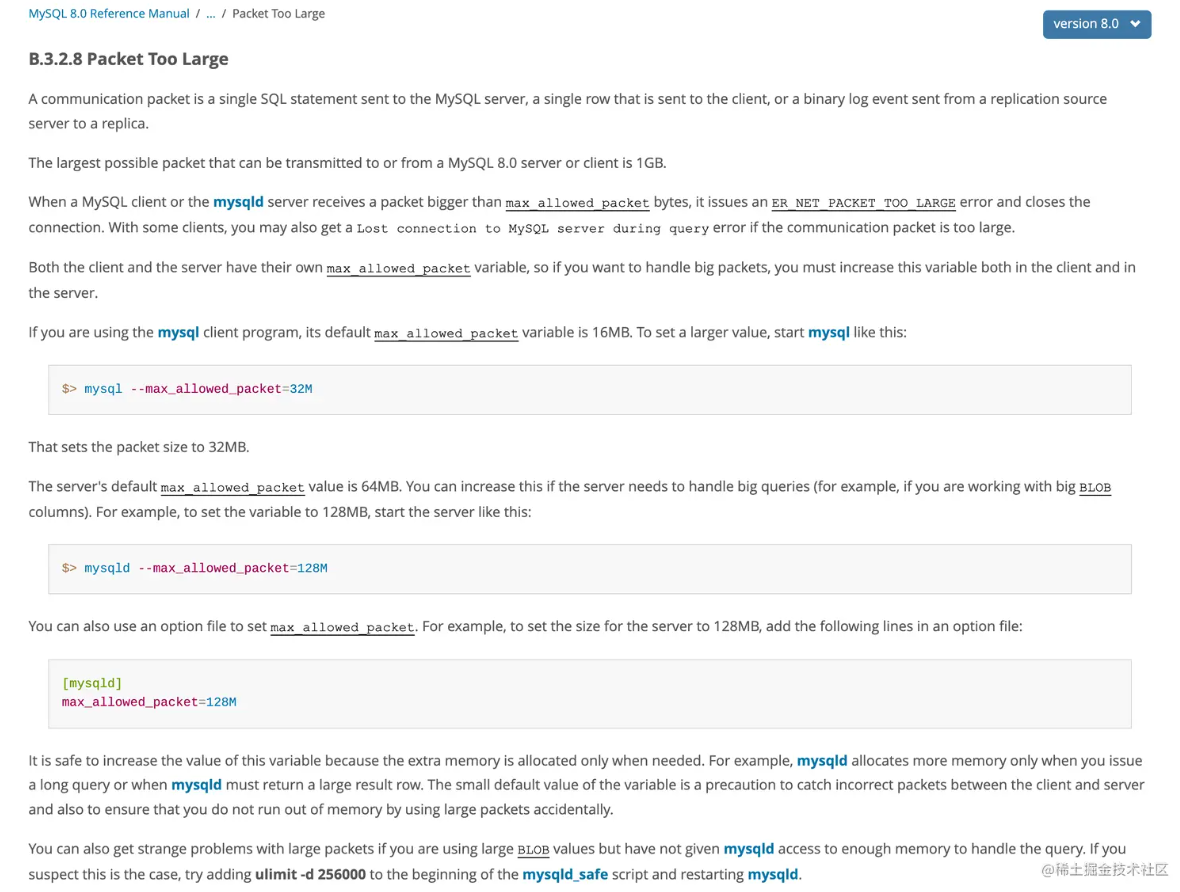
+
+根据 “Packet Too Large” 的说明, 通信包 (communication packet) 是
+
+- 一个被发送到 MySQL 服务器的单个 SQL 语句
+- 或者是一个被发送到客户端的**单行记录**
+- 或者是一个从主服务器 (replication source server) 被发送到从属服务器 (replica) 的二进制日志事件。
+
+1、3 点好理解,这也同时解释了,如果你发送的一条 SQL 语句特别大可能会执行不成功的原因,尤其是`insert` `update` 这种,单个 SQL 语句不是没有上限的,不过这种情况一般不是因为 SQL 语句写的太长,主要是由于某个字段的值过大,比如有 BLOB 字段。
+
+那么第 2 点呢,单行记录,默认值是 64M,会不会太大了啊,一行记录有可能这么大的吗? 有必要设置这么大吗? 单行最大存储空间限制又是多少呢?
+
+### 单行最大存储空间
+
+MySQL 单行最大宽度是 65535 个字节,也就是 64KB 。无论是 InnoDB 引擎还是 MyISAM 引擎。
+
+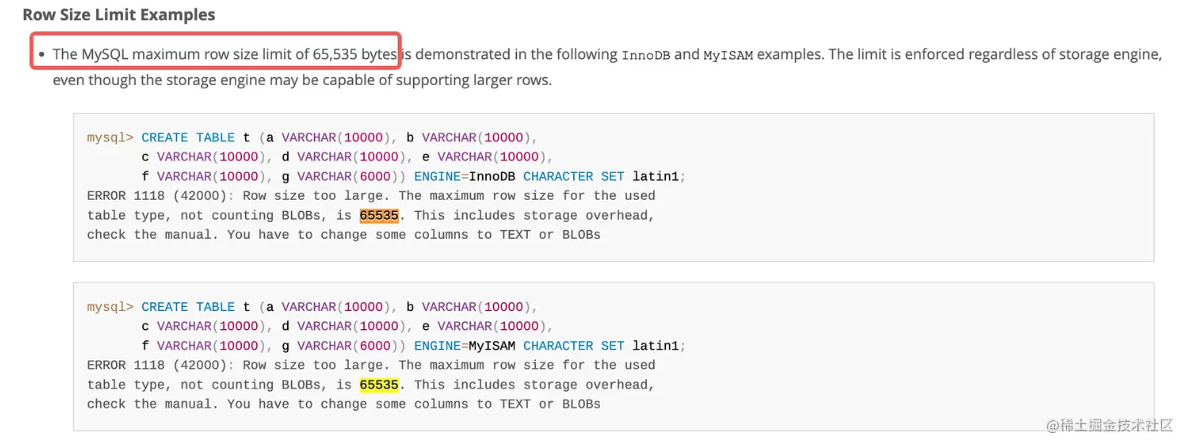
+
+通过上图可以看到 超过 65535 不行,不过请注意其中的错误提示:“Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535” ,如果字段是变长类型的如 BLOB 和 TEXT 就不包括了,那么我们试一下用和上图一样的字段长度,只把最后一个字段的类型改成 BLOB 和 TEXT
+
+```SQL
+mysql> CREATE TABLE t (a VARCHAR(10000), b VARCHAR(10000),
+ c VARCHAR(10000), d VARCHAR(10000), e VARCHAR(10000),
+ f VARCHAR(10000), g TEXT(6000)) ENGINE=InnoDB CHARACTER SET latin1;
+Query OK, 0 rows affected (0.02 sec)
+```
+
+可见无论 是改成 BLOB 还是 TEXT 都可以成功。但这里请注意,字符集是 `latin1` 可以成功,如果换成 `utf8mb4` 或者 `utf8mb3` 就不行了,会报错,仍然是 :“Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535.” 为什么呢?
+
+**因为虽然不包括 TEXT 和 BLOB, 但总长度还是超了!**
+
+我们先看一下这个熟悉的 VARCHAR(255) , 你有没有想过为什么用 255,不用 256?
+
+> 在 4.0 版本以下,varchar(255) 指的是 255 个字节,使用 1 个字节存储长度即可。当大于等于 256 时,要使用 2 个字节存储长度。所以定义 varchar(255) 比 varchar(256) 更好。
+>
+> 但是在 5.0 版本以上,varchar(255) 指的是 255 个字符,每个字符可能占用多个字节,例如使用 UTF8 编码时每个汉字占用 3 字节,使用 GBK 编码时每个汉字占 2 字节。
+
+例子中我们用的是 MySQL8 ,由于字符集是 utf8mb3 ,存储一个字要用三个字节, 长度为 255 的话(列宽),总长度要 765 字节 ,再加上用 2 个字节存储长度,那么这个列的总长度就是 767 字节。所以用 latin1 可以成功,是因为一个字符对应一个字节,而 utf8mb3 或 utf8mb4 一个字符对应三个或四个字节,VARCHAR(10000) 就可能等于要占用 30000 多 40000 多字节,比原来大了 3、4 倍,肯定放不下了。
+
+**另外,还有一个要求**,列的宽度不要超过 MySQL 页大小 (默认 16K)的一半,要比一半小一点儿。 例如,对于默认的 16KB `InnoDB` 页面大小,最大行大小略小于 8KB。
+
+下面这个例子就是超过了一半,所以报错,当然解决办法也在提示中给出了。
+
+```SQL
+mysql> CREATE TABLE t4 (
+ c1 CHAR(255),c2 CHAR(255),c3 CHAR(255),
+ c4 CHAR(255),c5 CHAR(255),c6 CHAR(255),
+ c7 CHAR(255),c8 CHAR(255),c9 CHAR(255),
+ c10 CHAR(255),c11 CHAR(255),c12 CHAR(255),
+ c13 CHAR(255),c14 CHAR(255),c15 CHAR(255),
+ c16 CHAR(255),c17 CHAR(255),c18 CHAR(255),
+ c19 CHAR(255),c20 CHAR(255),c21 CHAR(255),
+ c22 CHAR(255),c23 CHAR(255),c24 CHAR(255),
+ c25 CHAR(255),c26 CHAR(255),c27 CHAR(255),
+ c28 CHAR(255),c29 CHAR(255),c30 CHAR(255),
+ c31 CHAR(255),c32 CHAR(255),c33 CHAR(255)
+ ) ENGINE=InnoDB ROW_FORMAT=DYNAMIC DEFAULT CHARSET latin1;
+ERROR 1118 (42000): Row size too large (> 8126). Changing some columns to TEXT or BLOB may help.
+In current row format, BLOB prefix of 0 bytes is stored inline.
+```
+
+**那么为什么是 8K,不是 7K,也不是 9K 呢?** 这么设计的原因可能是:MySQL 想让一个数据页中能存放更多的数据行,至少也得要存放两行数据(16K)。否则就失去了 B+Tree 的意义。B+Tree 会退化成一个低效的链表。
+
+**你可能还会奇怪,不超过 8K ?你前面的例子明明都快 64K 也能存下,那 8K 到 64K 中间这部分怎么解释?**
+
+答:如果包含可变长度列的行超过 `InnoDB` 最大行大小, `InnoDB` 会选择可变长度列进行页外存储,直到该行适合 `InnoDB` ,这也就是为什么前面有超过 8K 的也能成功,那是因为用的是`VARCHAR`这种可变长度类型。
+
+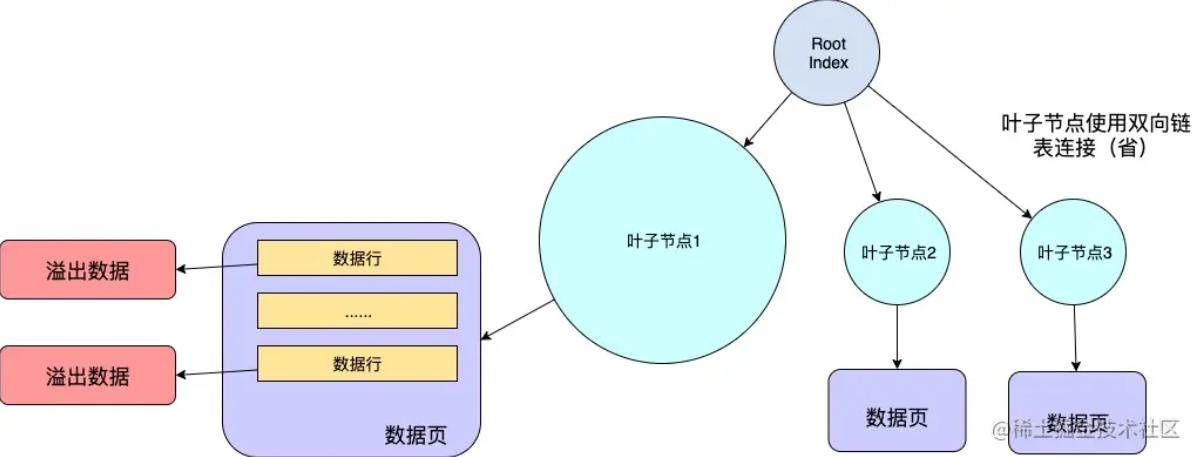
+
+当你往这个数据页中写入一行数据时,即使它很大将达到了数据页的极限,但是通过行溢出机制。依然能保证你的下一条数据还能写入到这个数据页中。
+
+**我们通过 Compact 格式,简单了解一下什么是 `页外存储` 和 `行溢出`**
+
+MySQL8 InnoDB 引擎目前有 4 种 行记录格式:
+
+- REDUNDANT
+- COMPACT
+- DYNAMIC(默认 default 是这个)
+- COMPRESSED
+
+`行记录格式` 决定了其行的物理存储方式,这反过来又会影响查询和 DML 操作的性能。
+
+
+
+Compact 格式的实现思路是:当列的类型为 VARCHAR、 VARBINARY、 BLOB、TEXT 时,该列超过 768byte 的数据放到其他数据页中去。
+
+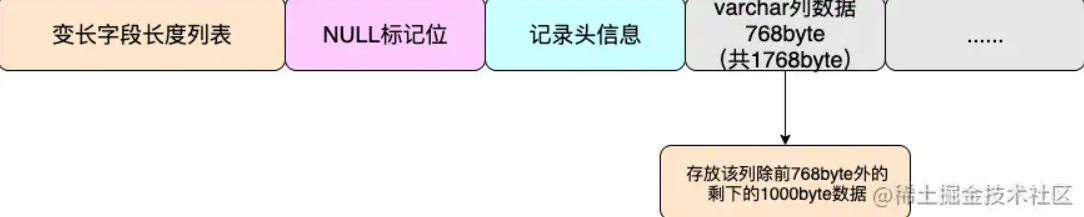
+
+在 MySQL 设定中,当 varchar 列长度达到 768byte 后,会将该列的前 768byte 当作当作 prefix 存放在行中,多出来的数据溢出存放到溢出页中,然后通过一个偏移量指针将两者关联起来,这就是 `行溢出`机制
+
+> **假如你要存储的数据行很大超过了 65532byte 那么你是写入不进去的。假如你要存储的单行数据小于 65535byte 但是大于 16384byte,这时你可以成功 insert,但是一个数据页又存储不了你插入的数据。这时肯定会行溢出!**
+
+MySQL 这样做,有效的防止了单个 varchar 列或者 Text 列太大导致单个数据页中存放的行记录过少的情况,避免了 IO 飙升的窘境。
+
+### 单行最大列数限制
+
+**mysql 单表最大列数也是有限制的,是 4096 ,但 InnoDB 是 1017**
+
+
+
+### 实验
+
+前文中我们疑惑 `max_allowed_packet` 在 MySQL8 的默认值是 64M,又说这是限制单行数据的,单行数据有这么大吗? 在前文我们介绍了行溢出, 由于有了 `行溢出` ,单行数据确实有可能比较大。
+
+那么还剩下一个问题,`max_allowed_packet` 限制的确定是单行数据吗,难道不是查询结果集的大小吗 ? 下面我们做个实验,验证一下。
+
+建表
+
+```SQL
+CREATE TABLE t1 (
+ c1 CHAR(255),c2 CHAR(255),c3 CHAR(255),
+ c4 CHAR(255),c5 CHAR(255),c6 CHAR(255),
+ c7 CHAR(255),c8 CHAR(255),c9 CHAR(255),
+ c10 CHAR(255),c11 CHAR(255),c12 CHAR(255),
+ c13 CHAR(255),c14 CHAR(255),c15 CHAR(255),
+ c16 CHAR(255),c17 CHAR(255),c18 CHAR(255),
+ c19 CHAR(255),c20 CHAR(255),c21 CHAR(255),
+ c22 CHAR(255),c23 CHAR(255),c24 CHAR(255),
+ c25 CHAR(255),c26 CHAR(255),c27 CHAR(255),
+ c28 CHAR(255),c29 CHAR(255),c30 CHAR(255),
+ c31 CHAR(255),c32 CHAR(192)
+ ) ENGINE=InnoDB ROW_FORMAT=DYNAMIC DEFAULT CHARSET latin1;
+```
+
+经过测试虽然提示的是 `Row size too large (> 8126)` 但如果全部长度加起来是 8126 建表不成功,最终我试到 8097 是能建表成功的。为什么不是 8126 呢 ?可能是还需要存储一些其他的东西占了一些字节吧,比如隐藏字段什么的。
+
+用存储过程造一些测试数据,把表中的所有列填满
+
+```SQL
+create
+ definer = root@`%` procedure generate_test_data()
+BEGIN
+ DECLARE i INT DEFAULT 0;
+ DECLARE col_value TEXT DEFAULT REPEAT('a', 255);
+ WHILE i < 5 DO
+ INSERT INTO t1 VALUES
+ (
+ col_value, col_value, col_value,
+ col_value, REPEAT('b', 192)
+ );
+ SET i = i + 1;
+ END WHILE;
+END;
+```
+
+将 `max_allowed_packet` 设置的小一些,先用 `show VARIABLES like '%max_allowed_packet%';` 看一下当前的大小,我的是 `67108864` 这个单位是字节,等于 64M,然后用 `set global max_allowed_packet =1024` 将它设置成允许的最小值 1024 byte。 设置好后,关闭当前查询窗口再新建一个,然后再查看:
+
+
+
+这时我用 `select * from t1;` 查询表数据时就会报错:
+
+
+
+因为我们一条记录的大小就是 8K 多了,所以肯定超过 1024byte。可见文档的说明是对的, `max_allowed_packet` 确实是可以约束单行记录大小的。
+
+## 答案
+
+文章写到这里,我有点儿写不下去了,一是因为懒,另外一个原因是关于这个问题:“一条 SQL 最多能查询出来多少条记录?” 肯定没有标准答案
+
+目前我们可以知道的是:
+
+- 你的单行记录大小不能超过 `max_allowed_packet`
+- 一个表最多可以创建 1017 列 (InnoDB)
+- 建表时定义列的固定长度不能超过 页的一半(8k,16k...)
+- 建表时定义列的总长度不能超过 65535 个字节
+
+如果这些条件我们都满足了,然后发出了一个没有 where 条件的全表查询 `select *` 那么.....
+
+首先,你我都知道,这种情况不会发生在生产环境的,如果真发生了,一定是你写错了,忘了加条件。因为几乎没有这种要查询出所有数据的需求。如果有,也不能开发,因为这不合理。
+
+我考虑的也就是个理论情况,从理论上讲能查询出多少数据不是一个确定的值,除了前文提到的一些条件外,它肯定与以下几项有直接的关系
+
+- 数据库的可用内存
+- 数据库内部的缓存机制,比如缓存区的大小
+- 数据库的查询超时机制
+- 应用的可用物理内存
+- ......
+
+说到这儿,我确实可以再做个实验验证一下,但因为懒就不做了,大家有兴趣可以自己设定一些条件做个实验试一下,比如在特定内存和特定参数的情况下,到底能查询出多少数据,就能看得出来了。
+
+虽然我没能给出文章开头问题的答案,但通过寻找答案也弄清楚了 MySQL 的一些限制条件,并加以了验证,也算是有所收获了。
+
+
+
+**参考**链接:https://juejin.cn/post/7255478273652834360
diff --git a/docs/zsxq/article/sql-optimize.md b/docs/zsxq/article/sql-optimize.md
new file mode 100644
index 0000000..952c970
--- /dev/null
+++ b/docs/zsxq/article/sql-optimize.md
@@ -0,0 +1,196 @@
+在应用开发的早期,数据量少,开发人员开发功能时更重视功能上的实现,随着生产数据的增长,很多SQL语句开始暴露出性能问题,对生产的影响也越来越大,有时可能这些有问题的SQL就是整个系统性能的瓶颈。
+
+## SQL优化一般步骤
+
+#### 1、通过慢查日志等定位那些执行效率较低的SQL语句
+
+#### 2、explain 分析SQL的执行计划
+
+需要重点关注type、rows、filtered、extra。
+
+type由上至下,效率越来越高
+
+- ALL 全表扫描
+- index 索引全扫描
+- range 索引范围扫描,常用语<,<=,>=,between,in等操作
+- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
+- eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
+- const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
+- null MySQL不访问任何表或索引,直接返回结果 虽然上至下,效率越来越高,但是根据cost模型,假设有两个索引idx1(a, b, c),idx2(a, c),SQL为"select * from t where a = 1 and b in (1, 2) order by c";如果走idx1,那么是type为range,如果走idx2,那么type是ref;当需要扫描的行数,使用idx2大约是idx1的5倍以上时,会用idx1,否则会用idx2
+
+Extra
+
+- Using filesort:MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。
+- Using temporary:使用了临时表保存中间结果,性能特别差,需要重点优化
+- Using index:表示相应的 select 操作中使用了覆盖索引(Coveing Index),避免访问了表的数据行,效率不错!如果同时出现 using where,意味着无法直接通过索引查找来查询到符合条件的数据。
+- Using index condition:MySQL5.6之后新增的ICP,using index condtion就是使用了ICP(索引下推),在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
+
+#### 3、show profile 分析
+
+了解SQL执行的线程的状态及消耗的时间。默认是关闭的,开启语句“set profiling = 1;”
+
+```
+SHOW PROFILES ;
+SHOW PROFILE FOR QUERY #{id};
+```
+
+#### 4、trace
+
+trace分析优化器如何选择执行计划,通过trace文件能够进一步了解为什么优惠券选择A执行计划而不选择B执行计划。
+
+```
+set optimizer_trace="enabled=on";
+set optimizer_trace_max_mem_size=1000000;
+select * from information_schema.optimizer_trace;
+```
+
+#### 5、确定问题并采用相应的措施
+
+- 优化索引
+- 优化SQL语句:修改SQL、IN 查询分段、时间查询分段、基于上一次数据过滤
+- 改用其他实现方式:ES、数仓等
+- 数据碎片处理
+
+## 场景分析
+
+#### 案例1、最左匹配
+
+索引
+
+```
+KEY `idx_shopid_orderno` (`shop_id`,`order_no`)
+```
+
+SQL语句
+
+```
+select * from _t where orderno=''
+```
+
+查询匹配从左往右匹配,要使用order_no走索引,必须查询条件携带shop_id或者索引(`shop_id`,`order_no`)调换前后顺序。
+
+#### 案例2、隐式转换
+
+索引
+
+```
+KEY `idx_mobile` (`mobile`)
+```
+
+SQL语句
+
+```
+select * from _user where mobile=12345678901
+```
+
+隐式转换相当于在索引上做运算,会让索引失效。mobile是字符类型,使用了数字,应该使用字符串匹配,否则MySQL会用到隐式替换,导致索引失效。
+
+#### 案例3、大分页
+
+索引
+
+```
+KEY `idx_a_b_c` (`a`, `b`, `c`)
+```
+
+SQL语句
+
+```
+select * from _t where a = 1 and b = 2 order by c desc limit 10000, 10;
+```
+
+对于大分页的场景,可以优先让产品优化需求,如果没有优化的,有如下两种优化方式, 一种是把上一次的最后一条数据,也即上面的c传过来,然后做“c < xxx”处理,但是这种一般需要改接口协议,并不一定可行。
+
+另一种是采用延迟关联的方式进行处理,减少SQL回表,但是要记得索引需要完全覆盖才有效果,SQL改动如下
+
+```
+select t1.* from _t t1, (select id from _t where a = 1 and b = 2 order by c desc limit 10000, 10) t2 where t1.id = t2.id;
+```
+
+#### 案例4、in + order by
+
+索引
+
+```
+KEY `idx_shopid_status_created` (`shop_id`, `order_status`, `created_at`)
+```
+
+SQL语句
+
+```
+select * from _order where shop_id = 1 and order_status in (1, 2, 3) order by created_at desc limit 10
+```
+
+in查询在MySQL底层是通过n*m的方式去搜索,类似union,但是效率比union高。in查询在进行cost代价计算时(代价 = 元组数 * IO平均值),是通过将in包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢,所以MySQL设置了个临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。
+
+因此会导致执行计划选择不准确。默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确。
+
+处理方式,可以(`order_status`, `created_at`)互换前后顺序,并且调整SQL为延迟关联。
+
+#### 案例5、范围查询阻断,后续字段不能走索引
+
+索引
+
+```
+KEY `idx_shopid_created_status` (`shop_id`, `created_at`, `order_status`)
+```
+
+SQL语句
+
+```
+select * from _order where shop_id = 1 and created_at > '2021-01-01 00:00:00' and order_status = 10
+```
+
+范围查询还有“IN、between”
+
+#### 案例6、不等于、不包含不能用到索引的快速搜索。(可以用到ICP)
+
+```
+select * from _order where shop_id=1 and order_status not in (1,2)
+select * from _order where shop_id=1 and order_status != 1
+```
+
+在索引上,避免使用NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE等
+
+#### 案例7、优化器选择不使用索引的情况
+
+如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。
+
+```
+select * from _order where order_status = 1
+```
+
+查询出所有未支付的订单,一般这种订单是很少的,即使建了索引,也没法使用索引。
+
+#### 案例8、复杂查询
+
+```
+select sum(amt) from _t where a = 1 and b in (1, 2, 3) and c > '2020-01-01';
+select * from _t where a = 1 and b in (1, 2, 3) and c > '2020-01-01' limit 10;
+```
+
+如果是统计某些数据,可能改用数仓进行解决;
+
+如果是业务上就有那么复杂的查询,可能就不建议继续走SQL了,而是采用其他的方式进行解决,比如使用ES等进行解决。
+
+#### 案例9、asc和desc混用
+
+```
+select * from _t where a=1 order by b desc, c asc
+```
+
+desc 和asc混用时会导致索引失效
+
+#### 案例10、大数据
+
+对于推送业务的数据存储,可能数据量会很大,如果在方案的选择上,最终选择存储在MySQL上,并且做7天等有效期的保存。
+
+那么需要注意,频繁的清理数据,会照成数据碎片,需要联系DBA进行数据碎片处理。
+
+参考资料:
+
+- 深入浅出MySQL:数据库开发、优化与管理维护(唐汉明 / 翟振兴 / 关宝军 / 王洪权)
+- MySQL技术内幕——InnoDB存储引擎(姜承尧)
+- https://dev.mysql.com/doc/refman/5.7/en/explain-output.html
+- https://dev.mysql.com/doc/refman/5.7/en/cost-model.html
+- https://www.yuque.com/docs/share/3463148b-05e9-40ce-a551-ce93a53a2c66
\ No newline at end of file
diff --git a/docs/zsxq/introduce.md b/docs/zsxq/introduce.md
index e3c4f85..bae53f0 100644
--- a/docs/zsxq/introduce.md
+++ b/docs/zsxq/introduce.md
@@ -181,7 +181,7 @@ APP端页面如下(建议大家**使用APP**,因为APP布局更加美观,
## 怎么进入星球?
-如果你下定决心要加入的话,可以直接扫下面这个二维码。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元(**拒绝割韭菜**)的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务**远超**门票价格了。
+如果你下定决心要加入的话,可以直接扫下面这个二维码。星球定价**178**元,减去**50**元的优惠券,等于说只需要**128**元(**拒绝割韭菜**)的价格就可以加入,服务期一年,**每天只要三毛钱**(0.35元),相比培训班几万块的学费,非常值了,星球提供的服务**远超**门票价格了。
随着星球内容不断积累,星球定价也会不断**上涨**,所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
diff --git a/docs/zsxq/question/qa-or-java.md b/docs/zsxq/question/qa-or-java.md
new file mode 100644
index 0000000..919a3da
--- /dev/null
+++ b/docs/zsxq/question/qa-or-java.md
@@ -0,0 +1,29 @@
+大彬老师您好
+
+我是参加今年24届秋招的研二学生,本科就读于某211信息安全专业,硕士就读于中国科学院大学 网络空间安全专业,最近开始了秋招,但是在职业规划上十分迷茫,想听听您的建议。
+
+我得求职期望是,在北京找一个高薪的岗位,工作几年后回家乡,找一个国企躺平。
+
+目前我已经排除了算法岗,虽然已经发表了两篇论文,但是研究方向小众,不足以支撑我找到一个算法岗的工作。所以我在以下几个岗位中有所纠结:
+
+1. java开发岗:为了准备开发岗,我跟着教程自己做了一个项目,整体的感受是工程能力很薄弱,并且只有一个学习项目,没有真正的工程项目。
+2. 安全岗位:虽然我本硕都是安全专业,但是研究方向都比较小众,目前互联网需要的安全人才都是攻防方向的,我的竞争力不够。
+3. 测试开发岗:这是我比较有把握的一个求职方向,因为之前有过一段在字节的测开实习经历,加上一直准备java开发,很多八股都是通用的。但是我比较担心测开岗位会不会不太好跳槽到国企,对未来比较担忧。
+
+所以我目前采取的策略是:大厂投测开、中小厂投开发、国企/银行投安全
+
+这令我十分地疲惫。很羞愧,已经7月份了,我竟让自己陷入了如此被动的局面,加上这两年互联网寒冬,我对秋招很担心。实际上我从很早之前就在准备找工作了,科研之余每天刷题、学java基础、学框架、写项目,但是时至今日我还是不够,始终比不上那些硕士阶段一直在参加工程的同学。
+
+以上是我的基本情况
+- 想听听老师对我的现状有没有什么建议
+- 您是否了解测试开发岗位的发展前景,它的薪资和开发是差不多的嘛?
+- 测开有没有可能从互联网顺利转国企
+- 现阶段我是继续补充java基础卷java岗,还是把重点放在测开上呢?
+
+原谅我现在处于焦虑状态因此问题比较多,图片是我的简历方便老师了解我的基本情况,期待老师回复🍓
+谢谢老师~
+
+1、建议投测开,你这个简历在测开岗里面算是比较好的,相反在Java开发岗中算是比较一般的,没有很大的竞争力。有了字节的测开实习,在测开岗里面应该领先一大波人了。
+2、测开发展前景个人觉得也是不错的,随着互联网行业的发展,用户对产品的质量要求也越来越高,软件的性能测试、需求测试等方面的需求目前看是只增不减的。薪资方面,同职级测开跟开发基本持平。
+3、测开有没有可能从互联网顺利转国企?完全可以,没问题
+4、把重点放在测开,不建议同时准备两个岗位,可能顾此失彼
\ No newline at end of file
diff --git a/docs/zsxq/share/completable-future-bug.md b/docs/zsxq/share/completable-future-bug.md
new file mode 100644
index 0000000..6ff1be0
--- /dev/null
+++ b/docs/zsxq/share/completable-future-bug.md
@@ -0,0 +1,250 @@
+---
+sidebar: heading
+title: 记一次生产中使用CompletableFuture遇到的坑
+category: 优质文章
+tag:
+ - 生产问题
+head:
+ - - meta
+ - name: keywords
+ content: CompletableFuture,生产问题,bug,异步调用
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+#### 为什么使用CompletableFuture
+
+业务功能描述:有一个功能是需要调用基础平台接口组装我们需要的数据,在这个功能里面我们要调用多次基础平台的接口,我们的入参是一个id,但是这个id是一个集合。我们都是使用RPC调用,一般常规的想法去遍历循环这个idList,但是呢这个id集合里面的数据可能会有500个左右。说多不多,说少也不少,主要是在for循环里面多次去RPC调用是一件特别费时的事情。
+
+我用代码大致描述一下这个需求:
+
+```java
+public List buildBasicInfo(List ids) {
+ List basicInfoList = new ArrayList<>();
+ for (Long id : ids) {
+ getBasicData(basicInfoList, id);
+ }
+ }
+
+ private List getBasicData(List basicInfoList, Long id) {
+ BasicInfo basicInfo = rpcGetBasicInfo(id);
+ return basicInfoList.add(basicInfo);
+ }
+
+ public BasicInfo rpcGetBasicInfo(Long id) {
+ // 第一次RPC 调用
+ rpcInvoking_1()...........
+
+ // 拿到第一次的结果进行第二次RPC 调用
+ rpcInvoking_2()...........
+
+ // 拿到第二次的结果进行第三次RPC 调用、
+ rpcInvoking_3()...........
+
+ // 拿到第三次的结果进行第四次RPC 调用、
+ rpcInvoking_4()...........
+
+ // 组装结果返回
+
+ return BasicInfo;
+ }
+```
+
+是的,这个数据的获取就是这么的扯淡。。。如果使用循环的方式,当ids数据量在500个左右的时候,这个接口返回的时间再8s左右,这是万万不能接受的,那如果ids数据更多呢?所以不能用for循环去遍历ids呀,这样确实是太费时了。
+
+既然远程调用避免不了,那就想办法让这个接口快一点,这时候就想到了多线程去处理,然后就想到使用CompletableFuture异步调用:
+
+#### CompletableFuture多线程异步调用
+
+```java
+List basicInfoList = new ArrayList<>();
+ CompletableFuture> future = CompletableFuture.supplyAsync(() -> {
+ ids.forEach(id -> {
+ getBasicData(basicInfoList, id);
+ });
+ return basicInfoList;
+ });
+ try {
+ List basicInfos = future.get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+```
+
+> 这里补充一点:**CompletableFuture是否使用默认线程池的依据,和机器的CPU核心数有关。当CPU核心数减1大于1时,才会使用默认的线程池(ForkJoinPool),否则将会为每个CompletableFuture的任务创建一个新线程去执行**。即,CompletableFuture的默认线程池,只有在**双核以上的机器**内才会使用。在双核及以下的机器中,会为每个任务创建一个新线程,**等于没有使用线程池,且有资源耗尽的风险**。
+
+默认线程池,**池内的核心线程数,也为机器核心数减1**,这里我们的机器是8核的,也就是会创建7个线程去执行。
+
+上面这种方式虽然实现了多线程异步执行,但是如果ids集合很多话,依然会很慢,因为`future.get();`也是堵塞的,必须等待所有的线程执行完成才能返回结果。
+
+#### 改进CompletableFuture多线程异步调用
+
+想让速度更快一点,就想到了把ids进行分隔:
+
+```ini
+ini复制代码 int pageSize = ids.size() > 8 ? ids.size() >> 3 : 1;
+ List> partitionAssetsIdList = Lists.partition(ids, pageSize);
+```
+
+因为我们CPU核数为8核,所有当ids的大小小于8时,就开启8个线程,每个线程分一个。这里的>>3(右移运算)相当于ids的大小除以2的3次方也就是除以8;右移运算符相比除效率会高。毕竟现在是在优化提升速度。
+
+如果这里的ids的大小是500个,就是开启9个线程,其中8个线程是处理62个数据,另一个线程处理4个数据,因为有余数会另开一个线程处理。具体代码如下:
+
+```java
+int pageSize = ids.size() > 8 ? ids.size() >> 3 : 1;
+ List> partitionIdList = Lists.partition(ids, pageSize);
+ List> futures = new ArrayList<>();
+ //如果ids为500,这里会分隔成9份,也就是partitionIdList.size()=9;遍历9次,也相当于创建了9个CompletableFuture对象,前8个CompletableFuture对象处理62个数据。第9个处理4个数据。
+ partitionIdList.forEach(partitionIds -> {
+ List basicInfoList = new ArrayList<>();
+ CompletableFuture> future = CompletableFuture.supplyAsync(() -> {
+ partitionIds.forEach(id -> {
+ getBasicData(basicInfoList, id);
+ });
+ return basicInfoList;
+ });
+ futures.add(future);
+ });
+ // 把所有线程执行的结果进行汇总
+ List basicInfoResult = new ArrayList<>();
+ for (CompletableFuture future : futures) {
+ try {
+ basicInfoResult.addAll((List)future.get());
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+```
+
+如果ids的大小等于500,就会被分隔成9份,创建9个CompletableFuture对象,前8个CompletableFuture对象处理62个数据(id),第9个处理4个数据(id)。这62个数据又会被分成7个线程去执行(CPU核数减1个线程)。经过分隔之后充分利用了CPU。速度也从8s减到1-2s。得到了总监和同事的夸赞,同时也被写到正向事件中;哈哈哈哈。
+
+#### 在生产环境中遇到的坑
+
+上面说了那么多还没有说到坑在哪里,下面我们就说说坑在哪里?
+
+本地和测试都没有啥问题,那就找个时间上生产呗,升级到生产环境,发现这个接口堵塞了,超时了。。。
+
+
+
+刚被记录到正向事件,可不想在被记录个负向时间。感觉去看日志。
+
+发现日志就执行了将ids进行分隔,后面循环去创建CompletableFuture对象之后的代码都没有在执行了。然后我第一感觉测试是future.get()获取结果的时候堵塞了,所以一直没有结果返回。
+
+#### 排查问题过程
+
+我们要解决这个问题就要看看问题出现在哪里?
+
+当执行到这个接口时候我们第一时间看了看CPU的使用率:
+
+
+
+这是访问接口之前:
+
+
+
+发现执行这个接口时PID为10348的这个进程的CPU突然的高了起来。
+
+紧接着使用`jps -l` :打印出我们服务进程的PID
+
+
+
+PID为10348正式我们现在执行这个服务。
+
+接着我就详细的看一下这个PID为10348的进程下哪里线程占用的高:
+
+发现这几个占用的相对高一点:
+
+
+
+
+
+紧接着使用jstack命令生成java虚拟机当前时刻的线程快照,生成线程快照的主要目的是定位线程出现长时间停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等。 线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做什么事情,或者等待什么资源
+
+`jstack -l 10348 >/tmp/10348.log`,使用此命令将PID为10348的进程下所有线程快照输出到log文件中。
+
+同时我们将线程比较的PID转换成16进制:printf "%x\n" 10411
+
+
+
+我们将转换成16进制的数值28ab,28a9在10348.log中搜索一下:
+
+
+
+
+
+看到线程的快照发现这不是本次修改的接口呀。看到日志4处但是也是用了CompletableFuture。找到对应4处的代码发现这是监听mq消息,然后异步去执行,代码类型这样:
+
+
+
+经过查看日志发现这个mq消息处理很频繁,每秒都会有很多的数据上来。
+
+
+
+我们知道CompletableFuture默认是使用ForkJoinPool作为线程池。难道mq使用ForkJoinPool和我当前接口使用的都是同一个线程池中的线程?难道是共用的吗?
+
+MQ监听使用的线程池:
+
+
+
+我们当前接口使用的线程池:
+
+
+
+
+
+
+
+
+
+它们使用的都是ForkJoinPool.commonPool()公共线程池中的线程!
+
+看到这个结论就很好理解了,我们目前修改的接口使用的线程池中的线程全部都被MQ消息处理占用,我们修改优化的接口得不到资源,所以一直处于等待。
+
+同时我们在线程快照10348.log日志中也看到我们优化的接口对应的线程处于WAITING状态!
+
+
+
+这里`- parking to wait for <0x00000000fe2081d8>`肯定也是MQ消费线程中的某一个。由于MQ消费消息比较多,每秒都会监听到大量的数据,线程的快照日志收集不全。所以在10348.log中没有找到,这不影响我们修改bug。问题的原因已经找到了。
+
+#### 解决问题
+
+上面我们知道两边使用的都是公共静态线程池,我们只要让他们各用各的就行了:自定义一个线程池:`ForkJoinPool pool = new ForkJoinPool();`
+
+```java
+int pageSize = ids.size() > 8 ? ids.size() >> 3 : 1;
+ List> partitionIdList = Lists.partition(ids, pageSize);
+ List> futures = new ArrayList<>();
+ partitionIdList.forEach(partitionIds -> {
+ List basicInfoList = new ArrayList<>();
+ //重新创建一个ForkJoinPool对象就可以了
+ ForkJoinPool pool = new ForkJoinPool();
+ CompletableFuture> future = CompletableFuture.supplyAsync(() -> {
+ partitionIds.forEach(id -> {
+ getMonitoringCoverage(basicInfoList, id);
+ });
+ return basicInfoList;
+ //在这里使用
+ },pool);
+ futures.add(future);
+ });
+ // 把所有线程执行的结果进行汇总
+ List basicInfoResult = new ArrayList<>();
+ for (CompletableFuture future : futures) {
+ try {
+ basicInfoResult.addAll((List)future.get());
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+```
+
+这样他们就各自用各自的线程池中的线程了。不会存在资源的等待现场了。
+
+#### 总结:
+
+之所以测试环境和开发环境没有出现这样的问题是因为这两个环境mq没有监听到消息。大量的消息都在生产环境中才会出现。由于测试环境的数据量达不到生产环境的数据量,所以有些问题在测试环境体验不出来。
+
+
+
+> 原文链接:https://juejin.cn/post/7165704556540755982
\ No newline at end of file
diff --git a/docs/zsxq/share/oom.md b/docs/zsxq/share/oom.md
new file mode 100644
index 0000000..d378bbf
--- /dev/null
+++ b/docs/zsxq/share/oom.md
@@ -0,0 +1,13 @@
+记录一次内存泄露排查的过程。
+
+最近经常告警有空指针异常报出,于是找到运维查日志定位到具体是哪一行代码抛出的空指针异常,发现是在解析cookie的一个方法内,调用`HttpServletRequest.getServerName()`获取不到抛出的NPE,这个获取服务名获取不到,平时都没有出现过的问题,最近也没有发版,那初步怀疑应该前端或者传输过程有问题导致获取不到参数。
+
+后续找了运维查了ng的日志,确实存在状态码为**499**的错误码,查了一下这个是**客户端主动关闭请求或者客户端网络断掉时**报的错误码,那也就是前端断开了请求。
+
+继续排查为啥前端会中断请求的原因,问了前端同学说是超时时间设置了10秒,又看了日志,确实是有处理时间超过10秒的,那问题大概定位到了。
+
+接下来就是分析处理时长为什么会那么长,看了报错的时候请求量并没有很大,后续让运维查了机器有几台cpu用量处于30%左右,明显高于另外几台3%,而且499错误的集中在cpu用量高的几台,怀疑是否是内存问题导致,让运维跑了`jstat -gcutil`看了一下,确实存在full GC问题,又跑了`jmap -dump`下了dump文件,定位到是ip限流的方法,有一个清除Map的方法在多线程并发情况下没有生效,导致内存泄露。
+
+知道问题后反推感觉就一切的疑问有了结果,ng报499是前置超时,超时是服务频繁full gc导致stw,无法处理请求导致耗时增加,ng探活接口在机器stw期间无法响应产生了error.log,而有几台机器cpu不高是因为之前重启过所以释放掉了内存没有触发full gc。
+
+后续处理是改进了ip限流的方法,测试环境复现问题和改动限流方法,通过guaua的LoadingCache监听器的方式过期自动处理,这次问题嵌套问题比较多,由于上报量低,ng侧报了499没有纳入监控范围,而且机器由于重启没有快速发现问题,后续改进是代码侧能复用规范代码最好复用,不要重复造轮子。
\ No newline at end of file
diff --git a/docs/zsxq/share/slow-query.md b/docs/zsxq/share/slow-query.md
new file mode 100644
index 0000000..4d3ab7f
--- /dev/null
+++ b/docs/zsxq/share/slow-query.md
@@ -0,0 +1,62 @@
+**最近的生产慢查询问题分析与总结**
+
+**1.问题描述**
+
+前几天凌晨出现大量慢查询告警,经DBA定位为某个子系统涉及的一条查询语句出现慢查询,引起数据库服务器的cpu使用率突增,触发大量告警,查看生产执行计划发现慢查询为索引跳变引起;具体出现问题的sql语句如下:
+
+```
+select * from ( select t.goods id as cardid,p.validate as validate, p.create timecreateTime
+ p.repay_coupon type as repaycoupontype,p.require anount as requireAmount, p.goods tag as goodsTag,
+ p.deduction anount as deductionAmount, p.repay coupon remark as repay(ouponkemark,
+ p.sale_point as salepoint from user_prizes p join trans_order t
+ on p.user_id = t.user_id and p.order_no = t.order_no
+ where p.user_id = #{user_id} and p.wmkt_type = '6' and t.status = 's' and p.equity_code_status = 'N'
+ and p.create_time >= #{beginDate}
+ order by p.create_time dese limit 1000) as cc group by cc.cardid:
+```
+
+ 该sql为查询三个月内满足条件的还款代金券列表,其中user_prizes表和trans_order表都是大表,数据量达到亿级别,user_prizes表有如下几个索引:
+
+```sql
+PRIMARY KEY ('merchant_order_no ,partition key ) USING BTREE,
+KEY “thirdOrderNo" ("third_order_no","app_id"),
+KEY "createTime" ("create_time"),
+KEY "userId" ("user_id"),
+KEY "time_activity" ("create_time', 'activity_name')
+```
+
+ 正常情况下该语句走的userId索引,当天零点后该sql语句出现索引跳变,走了createTime索引,导致出现慢查询。
+
+**2.问题处理方式**
+
+ 生产定位到问题后,因该sql的查询场景为前端触发,当天为账单日,请求量大,DBA通过kill脚本临时进行处理,同时准备增加强制索引优化的紧急版本,通过加上强制索引force index(userId)处理索引跳变,DBA也同步在备库删除createTime索引观察效果,准备进行主备切换尝试解决,但在备库执行索引删除后查看执行计划发现又走了time_activity索引,最后通过发布增加强制索引优化的紧急版本进行解决。
+
+**3.问题分析**
+
+MySQL优化器选择索引的目的是找到一个最优的执行方案,并用最小的代价去执行语句,扫描行数是影响执行代价的重要因素,扫描行数越少,意味着访问磁盘数据次数越少,消耗的cpu资源越少,除此之外,优化器还会结合是否使用临时表,以及是否排序等因素综合判断。
+
+出现索引跳变的这个sql有order by create_time,且create_time为索引,user_prizes表是按月分区的,数据总量为1亿400多万,通过统计生产数据量分布情况发现,近几个月的分区数据量如下:
+
+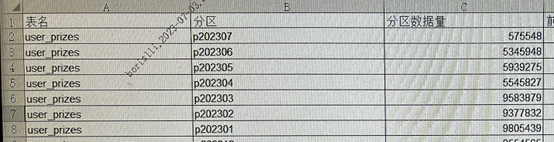
+
+ 该sql7月1日零点后查询的是4月1日之后的数据,3月份分区的数据量为958万多,4月之后分区数量都保持在500多万。4月份之后分区数据减少了,可能是这个原因导致优化器认为走时间索引createTime的区分度更高,同时还可以避免排序,因而选择了时间索引。查看索引跳变后的执行计划如下:
+
+
+
+走createTime索引虽然可以避免排序,但从执行计划的type=range可看出为索引范围的扫描,根据索引createTime扫描记录,通过索引叶子节点的主键值回表查找完整记录,然后判断记录中满足sql过滤条件的数据,再将结果进行返回,而该语句为查找满足条件的1000条数据,正常情况下一个user_id满足条件的数据量不会超过1000条,要找到所有满足条件的记录就是索引范围的扫描加回表查询,加上查询范围内的数据量大,因此走createTime索引就会非常慢。
+
+**4.总结**
+
+由于mysql在真正执行语句的时候,并不能准确的知道满足这个条件的记录有多少,只能通过统计信息来估算记录,而优化器并不是非常智能的,就有可能发生索引跳变的情况,这种情况很难在测试的时候复现出来,生产也可能是突然出现,所以我们只能在使用上尽量的去降低索引发生跳变的可能性,尽量避免出现该问题。我们可以在创建索引和使用sql的时候通过以下几个点进行检视。
+
+(1) 索引的创建
+
+ 创建索引的时候要注意尽量避免创建单列的时间字段(createTime、updateTime)索引,避免留坑,因为很多场景都可能用到时间字段进行排序,有排序的情况若排序字段又是单列索引字段,就可能引起索引跳变,如果需要使用时间字段作为索引时,尽量使用联合索引,且时间字段放在后面;高效的索引应遵循高区分度字段+避免排序的原则。
+
+ 创建索引的时候也要尽量避免索引重复,且一张表的索引个数也要控制好,索引过多也会影响增删改的效率。
+
+(2) sql的检视
+
+ 检视历史和新增的sql是否有order by,且order by的第一个字段是否有单列索引,这种存在索引跳变的风险,需要具体分析后进行优化;
+
+ 写sql语句的时候,尽可能简单化,像union、排序等尽量少在sql中实现,减少sql慢查询的风险。
\ No newline at end of file
diff --git a/docs/zsxq/share/spring-upgrade-copy-problem.md b/docs/zsxq/share/spring-upgrade-copy-problem.md
new file mode 100644
index 0000000..07b2f5c
--- /dev/null
+++ b/docs/zsxq/share/spring-upgrade-copy-problem.md
@@ -0,0 +1,146 @@
+最近内部组件升级到spring5.3.x的时候对象拷贝内容不全,定位分析总结如下(可直接拉到最后看结论和解决办法):
+
+**1.现象:**
+
+源对象的类里有个内部类的成员变量,是List类型,,List的元素类型是自己的内部静态类
+
+目标对象的类里有个内部类的成员变量,也是List类型,List的元素类型是自己的内部静态类
+
+源对象的代码示例如下(省略了get set方法):
+
+```java
+/**
+ * 源对象
+ * @author dabin
+ *
+ */
+public class Rsp_07300240_01 {
+ private int totals;
+ private List contracts;//合同列表
+ static public class Contract{
+ private String constractId;//合同编号
+ private String constractName;//合同名称
+ private String type;//合同类型
+ private String fileId;//fps文件id
+ private String fileHash;//fps文件hash
+ @Override
+ public String toString() {
+ StringBuilder builder = new StringBuilder();
+ builder.append("Rsp_07300240_01.Contract [constractId=");
+ builder.append(constractId);
+ builder.append(", constractName=");
+ builder.append(constractName);
+ builder.append(", type=");
+ builder.append(type);
+ builder.append(", fileId=");
+ builder.append(fileId);
+ builder.append(", fileHash=");
+ builder.append(fileHash);
+ builder.append("]");
+ return builder.toString();
+ }
+ }
+}
+```
+
+目标对象的代码示例如下(省略了get set方法):
+
+```java
+public class Rsp_04301099_01 {
+ @RmbField(seq = 1, title = "总条数")
+ private int totals;
+ @RmbField(seq = 2, title = "合同列表")
+ // 这里是自己的内部类
+ private List contracts;// 合同列表
+ static public class Contract{
+ private String constractId;//合同编号
+ private String constractName;//合同名称
+ private String type;//合同类型
+ private String fileId;//fps文件id
+ private String fileHash;//fps文件hash
+@Override
+ public String toString() {
+ StringBuilder builder = new StringBuilder();
+ builder.append("Rsp_04301099_01.Contract [constractId=");
+ builder.append(constractId);
+ builder.append(", constractName=");
+ builder.append(constractName);
+ builder.append(", type=");
+ builder.append(type);
+ builder.append(", fileId=");
+ builder.append(fileId);
+ builder.append(", fileHash=");
+ builder.append(fileHash);
+ builder.append("]");
+ return builder.toString();
+ }
+ }
+}
+```
+
+单元测试验证代码如下:
+
+```java
+public class SpringBeanCopyUtilTest {
+ @Test
+ public void testBeanCopy() {
+ Rsp_07300240_01 orgResp = new Rsp_07300240_01();
+ orgResp.setTotals(100);
+ List contracts = new ArrayList<>();
+ Rsp_07300240_01.Contract cc = new Rsp_07300240_01.Contract();
+ cc.setConstractId("aaa");
+ contracts.add(cc);
+ orgResp.setContracts(contracts);
+ Rsp_04301099_01 destResp = new Rsp_04301099_01();
+ System.out.println("源对象的值:" + orgResp);
+ System.out.println("复制前的值:" + destResp);
+ BeanUtils.copyProperties(orgResp, destResp);
+ System.out.println("Spring版本" + BeanUtils.class.getPackage().getImplementationVersion());
+ System.out.println("复制后的值:" + destResp);
+// if (destResp.getContracts() != null && destResp.getContracts().size() > 0) {
+// System.out.println("复制后的list成员类型是:" + destResp.getContracts().get(0));
+// }
+ }
+}
+```
+
+分别依赖spring 5.2.4和5.3.9版本,运行结果如下:
+
+```java
+源对象的值:Rsp_07300240_01 [totals=100, contracts=[Rsp_07300240_01.Contract [constractId=aaa, constractName=null, type=null, fileId=null, fileHash=null]]]
+复制前的值:Rsp_04301099_01 [totals=0, contracts=null]
+
+Spring版本5.2.4.RELEASE
+复制后的值:Rsp_04301099_01 [totals=100, contracts=[Rsp_07300240_01.Contract [constractId=aaa, constractName=null, type=null, fileId=null, fileHash=null]]]
+
+Spring版本5.3.9
+复制后的值:Rsp_04301099_01 [totals=100, contracts=null]
+```
+
+**2.分析**
+
+可以看到在依赖spring 5.3.x的时候,contracts的值是没有复制过来的。
+
+但是也可以看到在依赖spring 5.2.x的时候,contracts的值是直接设置的引用,List的成员变量类型是 Rsp_07300240_01.Contract,Rsp_04301099_01.Contract。
+
+这个其实也是有问题的。但是为啥在业务逻辑中没有暴雷呢?
+
+经核实,业务代码中,是在返回应答对象之前执行的 org.springframework.beans.BeanUtils.copyProperties 操作,执行完之后,立即返回了对象,然后内部使用的框架,直接使用jackson进行系列化,此时类型信息已经擦除,不涉及类型转换,所以正常生成了json字符串。
+
+而上面示例中被注释的代码里,如果启用的话,测试的时候就会立即报错,提示类型转换异常。
+
+对比代码可以发现:
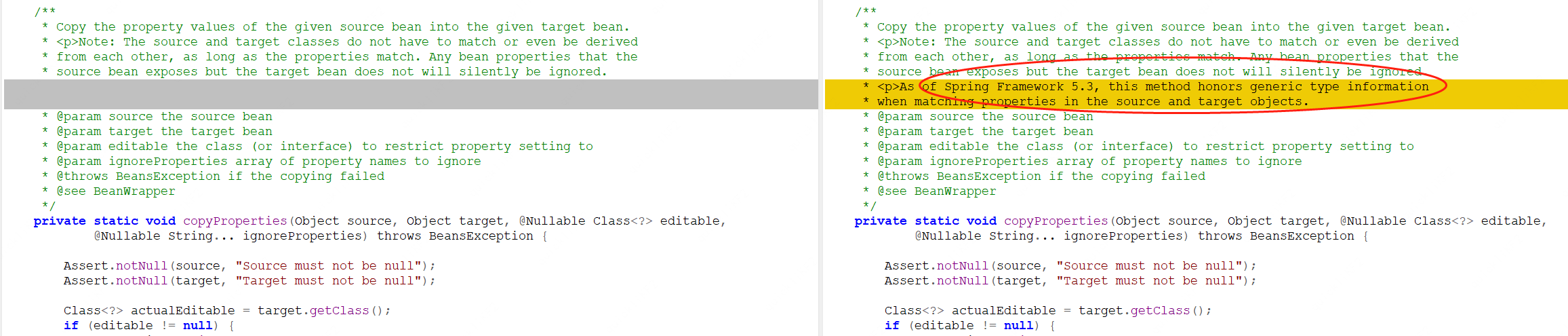
+
+
+
+经过一番搜索,原来是在2019年的时候就有人向Spring社区提了bug,然后spring增加了泛型判断逻辑,杜绝了错误的赋值,在5.3.x中修复了这个bug。
+
+https://github.com/spring-projects/spring-framework/issues/24187
+
+由于平时大部分使用场景都是执行BeanUtils.copyProperties后立即取出里面的对象进行操作,这种情况下,就会提前触发bug,然后调用方自己想办法规避掉spring bug。
+
+恰好内部使用的xx框架在BeanUtils.copyProperties之后没有显式的操作成员对象,因此一直没有触发bug,直到升级到spring 5.3.x时才暴雷。
+
+**3.解决办法:**
+
+先回退版本,然后检视所有调用BeanUtils.copyProperties的地方,针对触发bug的这种场景优化代码,比如把两个内部静态class合并使用一个公共的class。
\ No newline at end of file
diff --git a/package-lock.json b/package-lock.json
index 45fa65f..57fab08 100644
--- a/package-lock.json
+++ b/package-lock.json
@@ -2351,6 +2351,13 @@
"integrity": "sha512-I4BD3L+6AWiUobfxZ49DlU43gtI+FTHSv9pE2Zekg6KjMpre4ByusaljW3vYSLJrvQ1ck1hUaeVu8HVlY3vzHg==",
"dev": true
},
+ "node_modules/@types/prop-types": {
+ "version": "15.7.5",
+ "resolved": "https://registry.npmmirror.com/@types/prop-types/-/prop-types-15.7.5.tgz",
+ "integrity": "sha512-JCB8C6SnDoQf0cNycqd/35A7MjcnK+ZTqE7judS6o7utxUCg6imJg3QK2qzHKszlTjcj2cn+NwMB2i96ubpj7w==",
+ "dev": true,
+ "peer": true
+ },
"node_modules/@types/qs": {
"version": "6.9.7",
"resolved": "https://registry.npmmirror.com/@types/qs/-/qs-6.9.7.tgz",
@@ -2363,6 +2370,25 @@
"integrity": "sha512-EEhsLsD6UsDM1yFhAvy0Cjr6VwmpMWqFBCb9w07wVugF7w9nfajxLuVmngTIpgS6svCnm6Vaw+MZhoDCKnOfsw==",
"dev": true
},
+ "node_modules/@types/react": {
+ "version": "18.2.7",
+ "resolved": "https://registry.npmmirror.com/@types/react/-/react-18.2.7.tgz",
+ "integrity": "sha512-ojrXpSH2XFCmHm7Jy3q44nXDyN54+EYKP2lBhJ2bqfyPj6cIUW/FZW/Csdia34NQgq7KYcAlHi5184m4X88+yw==",
+ "dev": true,
+ "peer": true,
+ "dependencies": {
+ "@types/prop-types": "*",
+ "@types/scheduler": "*",
+ "csstype": "^3.0.2"
+ }
+ },
+ "node_modules/@types/react/node_modules/csstype": {
+ "version": "3.1.2",
+ "resolved": "https://registry.npmmirror.com/csstype/-/csstype-3.1.2.tgz",
+ "integrity": "sha512-I7K1Uu0MBPzaFKg4nI5Q7Vs2t+3gWWW648spaF+Rg7pI9ds18Ugn+lvg4SHczUdKlHI5LWBXyqfS8+DufyBsgQ==",
+ "dev": true,
+ "peer": true
+ },
"node_modules/@types/resolve": {
"version": "1.17.1",
"resolved": "https://registry.npmmirror.com/@types/resolve/-/resolve-1.17.1.tgz",
@@ -2381,6 +2407,13 @@
"@types/node": "*"
}
},
+ "node_modules/@types/scheduler": {
+ "version": "0.16.3",
+ "resolved": "https://registry.npmmirror.com/@types/scheduler/-/scheduler-0.16.3.tgz",
+ "integrity": "sha512-5cJ8CB4yAx7BH1oMvdU0Jh9lrEXyPkar6F9G/ERswkCuvP4KQZfZkSjcMbAICCpQTN4OuZn8tz0HiKv9TGZgrQ==",
+ "dev": true,
+ "peer": true
+ },
"node_modules/@types/serve-static": {
"version": "1.15.0",
"resolved": "https://registry.npmmirror.com/@types/serve-static/-/serve-static-1.15.0.tgz",
@@ -5906,6 +5939,19 @@
"node": ">=10"
}
},
+ "node_modules/loose-envify": {
+ "version": "1.4.0",
+ "resolved": "https://registry.npmmirror.com/loose-envify/-/loose-envify-1.4.0.tgz",
+ "integrity": "sha512-lyuxPGr/Wfhrlem2CL/UcnUc1zcqKAImBDzukY7Y5F/yQiNdko6+fRLevlw1HgMySw7f611UIY408EtxRSoK3Q==",
+ "dev": true,
+ "peer": true,
+ "dependencies": {
+ "js-tokens": "^3.0.0 || ^4.0.0"
+ },
+ "bin": {
+ "loose-envify": "cli.js"
+ }
+ },
"node_modules/magic-string": {
"version": "0.25.9",
"resolved": "https://registry.npmmirror.com/magic-string/-/magic-string-0.25.9.tgz",
@@ -6324,6 +6370,33 @@
"eve-raphael": "0.5.0"
}
},
+ "node_modules/react": {
+ "version": "18.2.0",
+ "resolved": "https://registry.npmmirror.com/react/-/react-18.2.0.tgz",
+ "integrity": "sha512-/3IjMdb2L9QbBdWiW5e3P2/npwMBaU9mHCSCUzNln0ZCYbcfTsGbTJrU/kGemdH2IWmB2ioZ+zkxtmq6g09fGQ==",
+ "dev": true,
+ "peer": true,
+ "dependencies": {
+ "loose-envify": "^1.1.0"
+ },
+ "engines": {
+ "node": ">=0.10.0"
+ }
+ },
+ "node_modules/react-dom": {
+ "version": "18.2.0",
+ "resolved": "https://registry.npmmirror.com/react-dom/-/react-dom-18.2.0.tgz",
+ "integrity": "sha512-6IMTriUmvsjHUjNtEDudZfuDQUoWXVxKHhlEGSk81n4YFS+r/Kl99wXiwlVXtPBtJenozv2P+hxDsw9eA7Xo6g==",
+ "dev": true,
+ "peer": true,
+ "dependencies": {
+ "loose-envify": "^1.1.0",
+ "scheduler": "^0.23.0"
+ },
+ "peerDependencies": {
+ "react": "^18.2.0"
+ }
+ },
"node_modules/readable-stream": {
"version": "3.6.0",
"resolved": "https://registry.npmmirror.com/readable-stream/-/readable-stream-3.6.0.tgz",
@@ -6601,6 +6674,16 @@
"integrity": "sha512-NqVDv9TpANUjFm0N8uM5GxL36UgKi9/atZw+x7YFnQ8ckwFGKrl4xX4yWtrey3UJm5nP1kUbnYgLopqWNSRhWw==",
"dev": true
},
+ "node_modules/scheduler": {
+ "version": "0.23.0",
+ "resolved": "https://registry.npmmirror.com/scheduler/-/scheduler-0.23.0.tgz",
+ "integrity": "sha512-CtuThmgHNg7zIZWAXi3AsyIzA3n4xx7aNyjwC2VJldO2LMVDhFK+63xGqq6CsJH4rTAt6/M+N4GhZiDYPx9eUw==",
+ "dev": true,
+ "peer": true,
+ "dependencies": {
+ "loose-envify": "^1.1.0"
+ }
+ },
"node_modules/section-matter": {
"version": "1.0.0",
"resolved": "https://registry.npmmirror.com/section-matter/-/section-matter-1.0.0.tgz",
@@ -9675,6 +9758,13 @@
"integrity": "sha512-I4BD3L+6AWiUobfxZ49DlU43gtI+FTHSv9pE2Zekg6KjMpre4ByusaljW3vYSLJrvQ1ck1hUaeVu8HVlY3vzHg==",
"dev": true
},
+ "@types/prop-types": {
+ "version": "15.7.5",
+ "resolved": "https://registry.npmmirror.com/@types/prop-types/-/prop-types-15.7.5.tgz",
+ "integrity": "sha512-JCB8C6SnDoQf0cNycqd/35A7MjcnK+ZTqE7judS6o7utxUCg6imJg3QK2qzHKszlTjcj2cn+NwMB2i96ubpj7w==",
+ "dev": true,
+ "peer": true
+ },
"@types/qs": {
"version": "6.9.7",
"resolved": "https://registry.npmmirror.com/@types/qs/-/qs-6.9.7.tgz",
@@ -9687,6 +9777,27 @@
"integrity": "sha512-EEhsLsD6UsDM1yFhAvy0Cjr6VwmpMWqFBCb9w07wVugF7w9nfajxLuVmngTIpgS6svCnm6Vaw+MZhoDCKnOfsw==",
"dev": true
},
+ "@types/react": {
+ "version": "18.2.7",
+ "resolved": "https://registry.npmmirror.com/@types/react/-/react-18.2.7.tgz",
+ "integrity": "sha512-ojrXpSH2XFCmHm7Jy3q44nXDyN54+EYKP2lBhJ2bqfyPj6cIUW/FZW/Csdia34NQgq7KYcAlHi5184m4X88+yw==",
+ "dev": true,
+ "peer": true,
+ "requires": {
+ "@types/prop-types": "*",
+ "@types/scheduler": "*",
+ "csstype": "^3.0.2"
+ },
+ "dependencies": {
+ "csstype": {
+ "version": "3.1.2",
+ "resolved": "https://registry.npmmirror.com/csstype/-/csstype-3.1.2.tgz",
+ "integrity": "sha512-I7K1Uu0MBPzaFKg4nI5Q7Vs2t+3gWWW648spaF+Rg7pI9ds18Ugn+lvg4SHczUdKlHI5LWBXyqfS8+DufyBsgQ==",
+ "dev": true,
+ "peer": true
+ }
+ }
+ },
"@types/resolve": {
"version": "1.17.1",
"resolved": "https://registry.npmmirror.com/@types/resolve/-/resolve-1.17.1.tgz",
@@ -9705,6 +9816,13 @@
"@types/node": "*"
}
},
+ "@types/scheduler": {
+ "version": "0.16.3",
+ "resolved": "https://registry.npmmirror.com/@types/scheduler/-/scheduler-0.16.3.tgz",
+ "integrity": "sha512-5cJ8CB4yAx7BH1oMvdU0Jh9lrEXyPkar6F9G/ERswkCuvP4KQZfZkSjcMbAICCpQTN4OuZn8tz0HiKv9TGZgrQ==",
+ "dev": true,
+ "peer": true
+ },
"@types/serve-static": {
"version": "1.15.0",
"resolved": "https://registry.npmmirror.com/@types/serve-static/-/serve-static-1.15.0.tgz",
@@ -12534,6 +12652,16 @@
"is-unicode-supported": "^0.1.0"
}
},
+ "loose-envify": {
+ "version": "1.4.0",
+ "resolved": "https://registry.npmmirror.com/loose-envify/-/loose-envify-1.4.0.tgz",
+ "integrity": "sha512-lyuxPGr/Wfhrlem2CL/UcnUc1zcqKAImBDzukY7Y5F/yQiNdko6+fRLevlw1HgMySw7f611UIY408EtxRSoK3Q==",
+ "dev": true,
+ "peer": true,
+ "requires": {
+ "js-tokens": "^3.0.0 || ^4.0.0"
+ }
+ },
"magic-string": {
"version": "0.25.9",
"resolved": "https://registry.npmmirror.com/magic-string/-/magic-string-0.25.9.tgz",
@@ -12876,6 +13004,27 @@
"eve-raphael": "0.5.0"
}
},
+ "react": {
+ "version": "18.2.0",
+ "resolved": "https://registry.npmmirror.com/react/-/react-18.2.0.tgz",
+ "integrity": "sha512-/3IjMdb2L9QbBdWiW5e3P2/npwMBaU9mHCSCUzNln0ZCYbcfTsGbTJrU/kGemdH2IWmB2ioZ+zkxtmq6g09fGQ==",
+ "dev": true,
+ "peer": true,
+ "requires": {
+ "loose-envify": "^1.1.0"
+ }
+ },
+ "react-dom": {
+ "version": "18.2.0",
+ "resolved": "https://registry.npmmirror.com/react-dom/-/react-dom-18.2.0.tgz",
+ "integrity": "sha512-6IMTriUmvsjHUjNtEDudZfuDQUoWXVxKHhlEGSk81n4YFS+r/Kl99wXiwlVXtPBtJenozv2P+hxDsw9eA7Xo6g==",
+ "dev": true,
+ "peer": true,
+ "requires": {
+ "loose-envify": "^1.1.0",
+ "scheduler": "^0.23.0"
+ }
+ },
"readable-stream": {
"version": "3.6.0",
"resolved": "https://registry.npmmirror.com/readable-stream/-/readable-stream-3.6.0.tgz",
@@ -13102,6 +13251,16 @@
"integrity": "sha512-NqVDv9TpANUjFm0N8uM5GxL36UgKi9/atZw+x7YFnQ8ckwFGKrl4xX4yWtrey3UJm5nP1kUbnYgLopqWNSRhWw==",
"dev": true
},
+ "scheduler": {
+ "version": "0.23.0",
+ "resolved": "https://registry.npmmirror.com/scheduler/-/scheduler-0.23.0.tgz",
+ "integrity": "sha512-CtuThmgHNg7zIZWAXi3AsyIzA3n4xx7aNyjwC2VJldO2LMVDhFK+63xGqq6CsJH4rTAt6/M+N4GhZiDYPx9eUw==",
+ "dev": true,
+ "peer": true,
+ "requires": {
+ "loose-envify": "^1.1.0"
+ }
+ },
"section-matter": {
"version": "1.0.0",
"resolved": "https://registry.npmmirror.com/section-matter/-/section-matter-1.0.0.tgz",
From 7e7fb51291824c30cb7020a5db3ae4f8f7cdb208 Mon Sep 17 00:00:00 2001
From: dabin <1713476357@qq.com>
Date: Sat, 23 Sep 2023 17:56:46 +0800
Subject: [PATCH 2/8] =?UTF-8?q?spring=E6=BA=90=E7=A0=81?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../advance/distributed/2-distributed-lock.md | 6 +
docs/advance/distributed/4-micro-service.md | 10 +-
docs/advance/system-design/README.md | 4 +-
docs/computer-basic/network.md | 4 +-
docs/database/mysql.md | 34 +
docs/java/java-basic.md | 2 +
docs/java/java-concurrent.md | 119 +++
docs/java/jvm.md | 4 +-
docs/note/README.md | 6 +
docs/note/redis-note.md | 28 +
docs/other/site-diary.md | 3 +
docs/redis/redis.md | 12 +
...64\344\275\223\346\236\266\346\236\204.md" | 73 ++
...20\357\274\210\344\270\212\357\274\211.md" | 864 ++++++++++++++++
...20\357\274\210\344\270\213\357\274\211.md" | 501 +++++++++
...72\346\234\254\345\256\236\347\216\260.md" | 979 ++++++++++++++++++
...35\350\265\226\345\244\204\347\220\206.md" | 178 ++++
...36\346\200\247\345\241\253\345\205\205.md" | 563 ++++++++++
...64\344\275\223\346\236\266\346\236\204.md" | 73 ++
...n \347\232\204\345\212\240\350\275\275.md" | 650 ++++++++++++
...44\271\213bean\345\210\233\345\273\272.md" | 702 +++++++++++++
...07\347\255\276\350\247\243\346\236\220.md" | 602 +++++++++++
docs/zsxq/introduce.md | 4 +-
...\214 PO\357\274\214 DO\357\274\214 DTO.md" | 31 +
docs/zsxq/question/tech/service-expansion.md | 7 +
...00\350\275\254\345\220\216\347\253\257.md" | 61 ++
...57\346\211\276\345\267\245\344\275\234.md" | 22 +
...52\345\260\217\345\273\272\350\256\256.md" | 332 ++++++
...347\272\247SQL\345\206\231\346\263\225.md" | 219 ++++
...345\274\225\345\217\221\347\232\204bug.md" | 49 +
30 files changed, 6135 insertions(+), 7 deletions(-)
create mode 100644 docs/note/README.md
create mode 100644 docs/note/redis-note.md
create mode 100644 "docs/source/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224\346\225\264\344\275\223\346\236\266\346\236\204.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\212\357\274\211.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\213\357\274\211.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC \345\256\271\345\231\250\345\237\272\346\234\254\345\256\236\347\216\260.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213\345\276\252\347\216\257\344\276\235\350\265\226\345\244\204\347\220\206.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\345\261\236\346\200\247\345\241\253\345\205\205.md"
create mode 100644 "docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224\346\225\264\344\275\223\346\236\266\346\236\204.md"
create mode 100644 "docs/source/spring/spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC-\345\274\200\345\220\257 bean \347\232\204\345\212\240\350\275\275.md"
create mode 100644 "docs/source/spring/spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213bean\345\210\233\345\273\272.md"
create mode 100644 "docs/source/spring/spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213\350\207\252\345\256\232\344\271\211\346\240\207\347\255\276\350\247\243\346\236\220.md"
create mode 100644 "docs/zsxq/question/VO\357\274\214 BO\357\274\214 PO\357\274\214 DO\357\274\214 DTO.md"
create mode 100644 docs/zsxq/question/tech/service-expansion.md
create mode 100644 "docs/zsxq/question/\344\270\211\345\271\264\346\265\213\345\274\200\350\275\254\345\220\216\347\253\257.md"
create mode 100644 "docs/zsxq/question/\350\257\273\345\215\232\350\277\230\346\230\257\346\211\276\345\267\245\344\275\234.md"
create mode 100644 "docs/zsxq/share/Java\345\274\200\345\217\221\347\232\20416\344\270\252\345\260\217\345\273\272\350\256\256.md"
create mode 100644 "docs/zsxq/share/\345\210\206\344\272\25310\344\270\252\351\253\230\347\272\247SQL\345\206\231\346\263\225.md"
create mode 100644 "docs/zsxq/share/\347\224\261\342\200\234 YYYY-MM-dd \342\200\235\345\274\225\345\217\221\347\232\204bug.md"
diff --git a/docs/advance/distributed/2-distributed-lock.md b/docs/advance/distributed/2-distributed-lock.md
index a269865..1016022 100644
--- a/docs/advance/distributed/2-distributed-lock.md
+++ b/docs/advance/distributed/2-distributed-lock.md
@@ -181,6 +181,8 @@ public class RedisTest {
前面的方案是基于**Redis单机版**的分布式锁讨论,还不是很完美。因为Redis一般都是集群部署的。
+
+
如果线程一在`Redis`的`master`节点上拿到了锁,但是加锁的`key`还没同步到`slave`节点。恰好这时,`master`节点发生故障,一个`slave`节点就会升级为`master`节点。线程二就可以顺理成章获取同个`key`的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者antirez提出一种高级的分布式锁算法:**Redlock**。它的核心思想是这样的:
@@ -189,6 +191,8 @@ public class RedisTest {
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
+
+
RedLock的实现步骤:
1. 获取当前时间,以毫秒为单位。
@@ -204,6 +208,8 @@ RedLock的实现步骤:
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
+Redisson 实现了 redLock 版本的锁,有兴趣的小伙伴,可以去了解一下。
+
### 基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
diff --git a/docs/advance/distributed/4-micro-service.md b/docs/advance/distributed/4-micro-service.md
index 286e61b..aec218d 100644
--- a/docs/advance/distributed/4-micro-service.md
+++ b/docs/advance/distributed/4-micro-service.md
@@ -47,9 +47,15 @@ head:
## 分布式和微服务的区别
-从概念理解,分布式服务架构强调的是服务化以及服务的**分散化**,微服务则更强调服务的**专业化和精细分工**;
+微服务解决的是系统复杂度问题,一般来说是业务问题,即在一个系统中承担职责太多了,需要打散,便于理解和维护,进而提升系统的开发效率和运行效率,微服务一般来说是针对应用层面的。
-从实践的角度来看,**微服务架构通常是分布式服务架构**,反之则未必成立。
+分布式解决的是系统性能问题,即解决系统部署上单点的问题,尽量让组成系统的子系统分散在不同的机器上进而提高系统的吞吐能力。
+
+两者概念层面也是不一样的,微服务是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分;
+
+而分布式是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机上。
+
+微服务可以是分布式的,即可以将不同服务部署在不同计算机上,当然如果量小也可以部署在单机上。
一句话概括:分布式:分散部署;微服务:分散能力。
diff --git a/docs/advance/system-design/README.md b/docs/advance/system-design/README.md
index 79b8eb1..8f7b4c1 100644
--- a/docs/advance/system-design/README.md
+++ b/docs/advance/system-design/README.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要三毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。

\ No newline at end of file
diff --git a/docs/computer-basic/network.md b/docs/computer-basic/network.md
index 465d1bc..127e6ab 100644
--- a/docs/computer-basic/network.md
+++ b/docs/computer-basic/network.md
@@ -41,6 +41,8 @@ head:
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要三毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。

diff --git a/docs/database/mysql.md b/docs/database/mysql.md
index 9559ede..4edc5fb 100644
--- a/docs/database/mysql.md
+++ b/docs/database/mysql.md
@@ -1180,4 +1180,38 @@ COUNT(`*`)是SQL92定义的标准统计行数的语法,效率高,MySQL对它
所以,建议使用COUNT(\*)查询表的行数!
+## 存储MD5值应该用VARCHAR还是用CHAR?
+
+首先说说CHAR和VARCHAR的区别:
+
+1、存储长度:
+
+CHAR类型的长度是固定的
+
+当我们当定义CHAR(10),输入的值是"abc",但是它占用的空间一样是10个字节,会包含7个空字节。当输入的字符长度超过指定的数时,CHAR会截取超出的字符。而且,当存储为CHAR的时候,MySQL会自动删除输入字符串末尾的空格。
+
+VARCHAR的长度是可变的
+
+比如VARCHAR(10),然后输入abc三个字符,那么实际存储大小为3个字节。
+
+除此之外,VARCHAR还会保留1个或2个额外的字节来记录字符串的实际长度。如果定义的最大长度小于等于255个字节,那么,就会预留1个字节;如果定义的最大长度大于255个字节,那么就会预留2个字节。
+
+2、存储效率
+
+CHAR类型每次修改后的数据长度不变,效率更高。
+
+VARCHAR每次修改的数据要更新数据长度,效率更低。
+
+3、存储空间
+
+CHAR存储空间是初始的预计长度字符串再加上一个记录字符串长度的字节,可能会存在多余的空间。
+
+VARCHAR存储空间的时候是实际字符串再加上一个记录字符串长度的字节,占用空间较小。
+
+
+
+根据以上的分析,由于MD5是一个定长的值,所以MD5值适合使用CHAR存储。对于固定长度的非常短的列,CHAR比VARCHAR效率也更高。
+
+
+

diff --git a/docs/java/java-basic.md b/docs/java/java-basic.md
index 5a4b19a..b3ef235 100644
--- a/docs/java/java-basic.md
+++ b/docs/java/java-basic.md
@@ -274,6 +274,8 @@ Integer x = 1; // 装箱 调⽤ Integer.valueOf(1)
int y = x; // 拆箱 调⽤了 X.intValue()
```
+## 两个Integer 用== 比较不相等的原因
+
下面看一道常见的面试题:
```java
diff --git a/docs/java/java-concurrent.md b/docs/java/java-concurrent.md
index bb62dcc..e1c611a 100644
--- a/docs/java/java-concurrent.md
+++ b/docs/java/java-concurrent.md
@@ -231,6 +231,14 @@ executor提供一个原生函数isTerminated()来判断线程池中的任务是
- 调用new Thread()创建的线程缺乏管理,可以无限制的创建,线程之间的相互竞争会导致过多占用系统资源而导致系统瘫痪
- 直接使用new Thread()启动的线程不利于扩展,比如定时执行、定期执行、定时定期执行、线程中断等都不好实现
+## execute和submit的区别
+
+execute只能提交Runnable类型的任务,无返回值。submit既可以提交Runnable类型的任务,也可以提交Callable类型的任务,会有一个类型为Future的返回值,但当任务类型为Runnable时,返回值为null。
+
+execute在执行任务时,如果遇到异常会直接抛出,而submit不会直接抛出,只有在使用Future的get方法获取返回值时,才会抛出异常
+
+execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
+
## 进程线程
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间。
@@ -1238,4 +1246,115 @@ epoll的时间复杂度O(1)。epoll可以理解为event poll,不同于忙轮
> 参考链接:https://blog.csdn.net/u014209205/article/details/80598209
+## ReadWriteLock 和 StampedLock 的区别
+
+在多线程编程中,对于共享资源的访问控制是一个非常重要的问题。在并发环境下,多个线程同时访问共享资源可能会导致数据不一致的问题,因此需要一种机制来保证数据的一致性和并发性。
+
+Java提供了多种机制来实现并发控制,其中 ReadWriteLock 和 StampedLock 是两个常用的锁类。本文将分别介绍这两个类的特性、使用场景以及示例代码。
+
+**ReadWriteLock**
+
+ReadWriteLock 是Java提供的一个接口,全类名:`java.util.concurrent.locks.ReentrantLock`。它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种机制可以提高读取操作的并发性,但写入操作需要独占资源。
+
+**特性**
+
+- 多个线程可以同时获取读锁,但只有一个线程可以获取写锁。
+- 当一个线程持有写锁时,其他线程无法获取读锁和写锁,读写互斥。
+- 当一个线程持有读锁时,其他线程可以同时获取读锁,读读共享。
+
+**使用场景**
+
+**ReadWriteLock** 适用于读多写少的场景,例如缓存系统、数据库连接池等。在这些场景中,读取操作占据大部分时间,而写入操作较少。
+
+**示例代码**
+
+下面是一个使用 ReadWriteLock 的示例,实现了一个简单的缓存系统:
+
+```java
+public class Cache {
+ private Map data = new HashMap<>();
+ private ReadWriteLock lock = new ReentrantReadWriteLock();
+
+ public Object get(String key) {
+ lock.readLock().lock();
+ try {
+ return data.get(key);
+ } finally {
+ lock.readLock().unlock();
+ }
+ }
+
+ public void put(String key, Object value) {
+ lock.writeLock().lock();
+ try {
+ data.put(key, value);
+ } finally {
+ lock.writeLock().unlock();
+ }
+ }
+}
+```
+
+在上述示例中,Cache 类使用 ReadWriteLock 来实现对 data 的并发访问控制。get 方法获取读锁并读取数据,put 方法获取写锁并写入数据。
+
+**StampedLock**
+
+StampedLock 是Java 8 中引入的一种新的锁机制,全类名:`java.util.concurrent.locks.StampedLock`,它提供了一种乐观读的机制,可以进一步提升读取操作的并发性能。
+
+**特性**
+
+- 与 ReadWriteLock 类似,StampedLock 也支持多个线程同时获取读锁,但只允许一个线程获取写锁。
+- 与 ReadWriteLock 不同的是,StampedLock 还提供了一个乐观读锁(Optimistic Read Lock),即不阻塞其他线程的写操作,但在读取完成后需要验证数据的一致性。
+
+**使用场景**
+
+StampedLock 适用于读远远大于写的场景,并且对数据的一致性要求不高,例如统计数据、监控系统等。
+
+**示例代码**
+
+下面是一个使用 StampedLock 的示例,实现了一个计数器:
+
+```java
+public class Counter {
+ private int count = 0;
+ private StampedLock lock = new StampedLock();
+
+ public int getCount() {
+ long stamp = lock.tryOptimisticRead();
+ int value = count;
+ if (!lock.validate(stamp)) {
+ stamp = lock.readLock();
+ try {
+ value = count;
+ } finally {
+ lock.unlockRead(stamp);
+ }
+ }
+ return value;
+ }
+
+ public void increment() {
+ long stamp = lock.writeLock();
+ try {
+ count++;
+ } finally {
+ lock.unlockWrite(stamp);
+ }
+ }
+}
+```
+
+在上述示例中,Counter 类使用 StampedLock 来实现对计数器的并发访问控制。getCount 方法首先尝试获取乐观读锁,并读取计数器的值,然后通过 validate 方法验证数据的一致性。如果验证失败,则获取悲观读锁,并重新读取计数器的值。increment 方法获取写锁,并对计数器进行递增操作。
+
+**总结**
+
+**ReadWriteLock** 和 **StampedLock** 都是Java中用于并发控制的重要机制。
+
+- **ReadWriteLock** 适用于读多写少的场景;
+- **StampedLock** 则适用于读远远大于写的场景,并且对数据的一致性要求不高;
+
+在实际应用中,我们需要根据具体场景来选择合适的锁机制。通过合理使用这些锁机制,我们可以提高并发程序的性能和可靠性。
+
+
+

diff --git a/docs/java/jvm.md b/docs/java/jvm.md
index 8690bfc..c51ab23 100644
--- a/docs/java/jvm.md
+++ b/docs/java/jvm.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要三毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。

\ No newline at end of file
diff --git a/docs/note/README.md b/docs/note/README.md
new file mode 100644
index 0000000..3a19bc2
--- /dev/null
+++ b/docs/note/README.md
@@ -0,0 +1,6 @@
+- [一小时彻底吃透Redis](https://topjavaer.cn/note/redis-note.html)
+- [21个写SQL的好习惯](https://topjavaer.cn/note/write-sql.html)
+- [Docker详解与部署微服务实战](https://topjavaer.cn/note/docker-note.html)
+- [计算机专业的同学都看看这几点建议](https://topjavaer.cn/note/computor-advice.html)
+- [建议计算机专业同学都看看这门课](https://topjavaer.cn/note/computor-advice.html)
+
diff --git a/docs/note/redis-note.md b/docs/note/redis-note.md
new file mode 100644
index 0000000..02e5569
--- /dev/null
+++ b/docs/note/redis-note.md
@@ -0,0 +1,28 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 一小时彻底吃透Redis
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/other/site-diary.md b/docs/other/site-diary.md
index d9b9ac9..711b790 100644
--- a/docs/other/site-diary.md
+++ b/docs/other/site-diary.md
@@ -8,7 +8,10 @@ sidebar: heading
## 更新记录
+- 2023.08.10,分布式锁实现-[RedLock](http://topjavaer.cn/advance/distributed/2-distributed-lock.html)补充图片
+
- 2023.05.04,导航栏增加图标。
+
- 2023.05.01,新增[Tomcat基础知识总结](/web/tomcat.html)
- 2023.03.25,新增[TCP面试题](/computer-basic/tcp.html)、[MongoDB面试题](/database/mongodb.html)、[ZooKeeper面试题](/zookeeper/zk.html)
diff --git a/docs/redis/redis.md b/docs/redis/redis.md
index 8a6d471..ff4dc4e 100644
--- a/docs/redis/redis.md
+++ b/docs/redis/redis.md
@@ -787,4 +787,16 @@ Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Se
对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
+
+
+## Redis遇到哈希冲突怎么办?
+
+当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。
+
+Redis 的哈希表使用链地址法(separate chaining)来解决键冲突: 每个哈希表节点都有一个 `next` 指针, 多个哈希表节点可以用 `next` 指针构成一个单向链表, 被分配到同一个索引上的多个节点可以用这个单向链表连接起来, 这就解决了键冲突的问题。
+
+原理跟 Java 的 HashMap 类似,都是数组+链表的结构。当发生 hash 碰撞时将会把元素追加到链表上。
+
+
+

diff --git "a/docs/source/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224\346\225\264\344\275\223\346\236\266\346\236\204.md" "b/docs/source/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224\346\225\264\344\275\223\346\236\266\346\236\204.md"
new file mode 100644
index 0000000..ce9103c
--- /dev/null
+++ "b/docs/source/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224\346\225\264\344\275\223\346\236\266\346\236\204.md"
@@ -0,0 +1,73 @@
+## 概述
+
+Spring是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用。Spring是于2003 年兴起的一个轻量级的Java 开发框架,由Rod Johnson创建。简单来说,Spring是一个分层的JavaSE/EE full-stack(一站式) 轻量级开源框架。
+
+## spring的整体架构
+
+Spring框架是一个分层架构,它包含一系列的功能要素,并被分为大约20个模块,如下图所示:
+
+
+
+从上图spring framework整体架构图可以看到,这些模块被总结为以下几个部分:
+
+### 1. Core Container
+
+Core Container(核心容器)包含有Core、Beans、Context和Expression Language模块
+
+Core和Beans模块是框架的基础部分,提供IoC(转控制)和依赖注入特性。这里的基础概念是BeanFactory,它提供对Factory模式的经典实现来消除对程序性单例模式的需要,并真正地允许你从程序逻辑中分离出依赖关系和配置。
+
+Core模块主要包含Spring框架基本的核心工具类
+
+Beans模块是所有应用都要用到的,它包含访问配置文件、创建和管理bean以及进行Inversion of Control/Dependency Injection(Ioc/DI)操作相关的所有类
+
+Context模块构建于Core和Beans模块基础之上,提供了一种类似于JNDI注册器的框架式的对象访问方法。Context模块继承了Beans的特性,为Spring核心提供了大量扩展,添加了对国际化(如资源绑定)、事件传播、资源加载和对Context的透明创建的支持。
+
+ApplicationContext接口是Context模块的关键
+
+Expression Language模块提供了一个强大的表达式语言用于在运行时查询和操纵对象,该语言支持设置/获取属性的值,属性的分配,方法的调用,访问数组上下文、容器和索引器、逻辑和算术运算符、命名变量以及从Spring的IoC容器中根据名称检索对象
+
+
+
+### 2. Data Access/Integration
+
+JDBC模块提供了一个JDBC抽象层,它可以消除冗长的JDBC编码和解析数据库厂商特有的错误代码,这个模块包含了Spring对JDBC数据访问进行封装的所有类
+
+ORM模块为流行的对象-关系映射API,如JPA、JDO、Hibernate、iBatis等,提供了一个交互层,利用ORM封装包,可以混合使用所有Spring提供的特性进行O/R映射,如前边提到的简单声明性事务管理
+
+OXM模块提供了一个Object/XML映射实现的抽象层,Object/XML映射实现抽象层包括JAXB,Castor,XMLBeans,JiBX和XStream
+JMS(java Message Service)模块主要包含了一些制造和消费消息的特性
+
+Transaction模块支持编程和声明式事物管理,这些事务类必须实现特定的接口,并且对所有POJO都适用
+
+
+
+### 3. Web
+
+Web上下文模块建立在应用程序上下文模块之上,为基于Web的应用程序提供了上下文,所以Spring框架支持与Jakarta Struts的集成。
+
+Web模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。Web层包含了Web、Web-Servlet、Web-Struts和Web、Porlet模块
+
+Web模块:提供了基础的面向Web的集成特性,例如,多文件上传、使用Servlet listeners初始化IoC容器以及一个面向Web的应用上下文,它还包含了Spring远程支持中Web的相关部分
+
+Web-Servlet模块web.servlet.jar:该模块包含Spring的model-view-controller(MVC)实现,Spring的MVC框架使得模型范围内的代码和web forms之间能够清楚地分离开来,并与Spring框架的其他特性基础在一起
+
+Web-Struts模块:该模块提供了对Struts的支持,使得类在Spring应用中能够与一个典型的Struts Web层集成在一起
+
+Web-Porlet模块:提供了用于Portlet环境和Web-Servlet模块的MVC的实现
+
+
+
+### 4. AOP
+
+AOP模块提供了一个符合AOP联盟标准的面向切面编程的实现,它让你可以定义例如方法拦截器和切点,从而将逻辑代码分开,降低它们之间的耦合性,利用source-level的元数据功能,还可以将各种行为信息合并到你的代码中
+
+Spring AOP模块为基于Spring的应用程序中的对象提供了事务管理服务,通过使用Spring AOP,不用依赖EJB组件,就可以将声明性事务管理集成到应用程序中
+
+
+
+### 5. Test
+
+Test模块支持使用Junit和TestNG对Spring组件进行测试
+
+
+
diff --git "a/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\212\357\274\211.md" "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\212\357\274\211.md"
new file mode 100644
index 0000000..45712c4
--- /dev/null
+++ "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\212\357\274\211.md"
@@ -0,0 +1,864 @@
+## 概述
+
+本文主要研究Spring标签的解析,Spring的标签中有默认标签和自定义标签,两者的解析有着很大的不同,这次重点说默认标签的解析过程。
+
+默认标签的解析是在DefaultBeanDefinitionDocumentReader.parseDefaultElement函数中进行的,分别对4种不同的标签(import,alias,bean和beans)做了不同处理。我们先看下此函数的源码:
+
+```java
+private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
+ if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
+ importBeanDefinitionResource(ele);
+ }
+ else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
+ processAliasRegistration(ele);
+ }
+ else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
+ processBeanDefinition(ele, delegate);
+ }
+ else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
+ // recurse
+ doRegisterBeanDefinitions(ele);
+ }
+}
+```
+
+## Bean标签的解析及注册
+
+在4中标签中对bean标签的解析最为复杂也最为重要,所以从此标签开始深入分析,如果能理解这个标签的解析过程,其他标签的解析就迎刃而解了。对于bean标签的解析用的是processBeanDefinition函数,首先看看函数processBeanDefinition(ele,delegate),其代码如下:
+
+```java
+protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
+ BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
+ if (bdHolder != null) {
+ bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
+ try {
+ // Register the final decorated instance.
+ BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
+ }
+ catch (BeanDefinitionStoreException ex) {
+ getReaderContext().error("Failed to register bean definition with name '" +
+ bdHolder.getBeanName() + "'", ele, ex);
+ }
+ // Send registration event.
+ getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
+ }
+}
+```
+
+刚开始看这个函数体时一头雾水,没有以前的函数那样的清晰的逻辑,我们细致的理下逻辑,大致流程如下:
+
+- 首先委托BeanDefinitionDelegate类的parseBeanDefinitionElement方法进行元素的解析,返回BeanDefinitionHolder类型的实例bdHolder,经过这个方法后bdHolder实例已经包含了我们配置文件中的各种属性了,例如class,name,id,alias等。
+
+- 当返回的dbHolder不为空的情况下若存在默认标签的子节点下再有自定义属性,还需要再次对自定义标签进行解析
+- 当解析完成后,需要对解析后的bdHolder进行注册,注册过程委托给了BeanDefinitionReaderUtils的registerBeanDefinition方法。
+- 最后发出响应事件,通知相关的监听器已经加载完这个Bean了。
+
+### 解析BeanDefinition
+
+接下来我们就针对具体的方法进行分析,首先我们从元素解析及信息提取开始,也就是BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele),进入 BeanDefinitionDelegate 类的 parseBeanDefinitionElement 方法。我们看下源码:
+
+```java
+public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
+ // 解析 ID 属性
+ String id = ele.getAttribute(ID_ATTRIBUTE);
+ // 解析 name 属性
+ String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
+
+ // 分割 name 属性
+ List aliases = new ArrayList<>();
+ if (StringUtils.hasLength(nameAttr)) {
+ String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
+ aliases.addAll(Arrays.asList(nameArr));
+ }
+
+ String beanName = id;
+ if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
+ beanName = aliases.remove(0);
+ if (logger.isDebugEnabled()) {
+ logger.debug("No XML 'id' specified - using '" + beanName +
+ "' as bean name and " + aliases + " as aliases");
+ }
+ }
+
+ // 检查 name 的唯一性
+ if (containingBean == null) {
+ checkNameUniqueness(beanName, aliases, ele);
+ }
+
+ // 解析 属性,构造 AbstractBeanDefinition
+ AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
+ if (beanDefinition != null) {
+ // 如果 beanName 不存在,则根据条件构造一个 beanName
+ if (!StringUtils.hasText(beanName)) {
+ try {
+ if (containingBean != null) {
+ beanName = BeanDefinitionReaderUtils.generateBeanName(
+ beanDefinition, this.readerContext.getRegistry(), true);
+ }
+ else {
+ beanName = this.readerContext.generateBeanName(beanDefinition);
+ String beanClassName = beanDefinition.getBeanClassName();
+ if (beanClassName != null &&
+ beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
+ !this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
+ aliases.add(beanClassName);
+ }
+ }
+ if (logger.isDebugEnabled()) {
+ logger.debug("Neither XML 'id' nor 'name' specified - " +
+ "using generated bean name [" + beanName + "]");
+ }
+ }
+ catch (Exception ex) {
+ error(ex.getMessage(), ele);
+ return null;
+ }
+ }
+ String[] aliasesArray = StringUtils.toStringArray(aliases);
+
+ // 封装 BeanDefinitionHolder
+ return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
+ }
+
+ return null;
+}
+```
+
+上述方法就是对默认标签解析的全过程了,我们分析下当前层完成的工作:
+
+(1)提取元素中的id和name属性
+(2)进一步解析其他所有属性并统一封装到GenericBeanDefinition类型的实例中
+(3)如果检测到bean没有指定beanName,那么使用默认规则为此bean生成beanName。
+(4)将获取到的信息封装到BeanDefinitionHolder的实例中。
+
+代码:`AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);`是用来对标签中的其他属性进行解析,我们详细看下源码:
+
+```java
+public AbstractBeanDefinition parseBeanDefinitionElement(
+ Element ele, String beanName, @Nullable BeanDefinition containingBean) {
+
+ this.parseState.push(new BeanEntry(beanName));
+
+ String className = null;
+ //解析class属性
+ if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
+ className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
+ }
+ String parent = null;
+ //解析parent属性
+ if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
+ parent = ele.getAttribute(PARENT_ATTRIBUTE);
+ }
+
+ try {
+ //创建用于承载属性的AbstractBeanDefinition类型的GenericBeanDefinition实例
+ AbstractBeanDefinition bd = createBeanDefinition(className, parent);
+ //硬编码解析bean的各种属性
+ parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
+ //设置description属性
+ bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
+ //解析元素
+ parseMetaElements(ele, bd);
+ //解析lookup-method属性
+ parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
+ //解析replace-method属性
+ parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
+ //解析构造函数的参数
+ parseConstructorArgElements(ele, bd);
+ //解析properties子元素
+ parsePropertyElements(ele, bd);
+ //解析qualifier子元素
+ parseQualifierElements(ele, bd);
+ bd.setResource(this.readerContext.getResource());
+ bd.setSource(extractSource(ele));
+
+ return bd;
+ }
+ catch (ClassNotFoundException ex) {
+ error("Bean class [" + className + "] not found", ele, ex);
+ }
+ catch (NoClassDefFoundError err) {
+ error("Class that bean class [" + className + "] depends on not found", ele, err);
+ }
+ catch (Throwable ex) {
+ error("Unexpected failure during bean definition parsing", ele, ex);
+ }
+ finally {
+ this.parseState.pop();
+ }
+
+ return null;
+}
+```
+
+接下来我们一步步分析解析过程。
+
+## bean详细解析过程
+
+### 创建用于承载属性的BeanDefinition
+
+BeanDefinition是一个接口,在spring中此接口有三种实现:RootBeanDefinition、ChildBeanDefinition已经GenericBeanDefinition。而三种实现都继承了AbstractBeanDefinition,其中BeanDefinition是配置文件元素标签在容器中的内部表示形式。元素标签拥有class、scope、lazy-init等属性,BeanDefinition则提供了相应的beanClass、scope、lazyInit属性,BeanDefinition和中的属性一一对应。其中RootBeanDefinition是最常用的实现类,他对应一般性的元素标签,GenericBeanDefinition是自2.5版本以后新加入的bean文件配置属性定义类,是一站式服务的。
+
+在配置文件中可以定义父和字,父用RootBeanDefinition表示,而子用ChildBeanDefinition表示,而没有父的就使用RootBeanDefinition表示。AbstractBeanDefinition对两者共同的类信息进行抽象。
+
+Spring通过BeanDefinition将配置文件中的配置信息转换为容器的内部表示,并将这些BeanDefinition注册到BeanDefinitionRegistry中。Spring容器的BeanDefinitionRegistry就像是Spring配置信息的内存数据库,主要是以map的形式保存,后续操作直接从BeanDefinitionResistry中读取配置信息。它们之间的关系如下图所示:
+
+
+
+因此,要解析属性首先要创建用于承载属性的实例,也就是创建GenericBeanDefinition类型的实例。而代码createBeanDefinition(className,parent)的作用就是实现此功能。我们详细看下方法体,代码如下:
+
+```java
+protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)
+ throws ClassNotFoundException {
+
+ return BeanDefinitionReaderUtils.createBeanDefinition(
+ parentName, className, this.readerContext.getBeanClassLoader());
+}
+public static AbstractBeanDefinition createBeanDefinition(
+ @Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader) throws ClassNotFoundException {
+
+ GenericBeanDefinition bd = new GenericBeanDefinition();
+ bd.setParentName(parentName);
+ if (className != null) {
+ if (classLoader != null) {
+ bd.setBeanClass(ClassUtils.forName(className, classLoader));
+ }
+ else {
+ bd.setBeanClassName(className);
+ }
+ }
+ return bd;
+}
+```
+
+
+
+### 各种属性的解析
+
+ 当创建好了承载bean信息的实例后,接下来就是解析各种属性了,首先我们看下parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);方法,代码如下:
+
+```java
+public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
+ @Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {
+ //解析singleton属性
+ if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
+ error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
+ }
+ //解析scope属性
+ else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
+ bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
+ }
+ else if (containingBean != null) {
+ // Take default from containing bean in case of an inner bean definition.
+ bd.setScope(containingBean.getScope());
+ }
+ //解析abstract属性
+ if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
+bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
+ }
+ //解析lazy_init属性
+ String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
+ if (DEFAULT_VALUE.equals(lazyInit)) {
+ lazyInit = this.defaults.getLazyInit();
+ }
+ bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
+ //解析autowire属性
+ String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
+ bd.setAutowireMode(getAutowireMode(autowire));
+ //解析dependsOn属性
+ if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
+ String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
+ bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
+ }
+ //解析autowireCandidate属性
+ String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
+ if ("".equals(autowireCandidate) || DEFAULT_VALUE.equals(autowireCandidate)) {
+ String candidatePattern = this.defaults.getAutowireCandidates();
+ if (candidatePattern != null) {
+ String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
+ bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
+ }
+ }
+ else {
+ bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
+ }
+ //解析primary属性
+ if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
+ bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
+ }
+ //解析init_method属性
+ if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
+ String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
+ bd.setInitMethodName(initMethodName);
+ }
+ else if (this.defaults.getInitMethod() != null) {
+ bd.setInitMethodName(this.defaults.getInitMethod());
+ bd.setEnforceInitMethod(false);
+ }
+ //解析destroy_method属性
+ if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
+ String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
+ bd.setDestroyMethodName(destroyMethodName);
+ }
+ else if (this.defaults.getDestroyMethod() != null) {
+ bd.setDestroyMethodName(this.defaults.getDestroyMethod());
+ bd.setEnforceDestroyMethod(false);
+ }
+ //解析factory_method属性
+ if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
+ bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
+ }
+ //解析factory_bean属性
+ if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
+ bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
+ }
+
+ return bd;
+}
+```
+
+
+
+### 解析meta元素
+
+ 在开始对meta元素解析分析前我们先简单回顾下meta属性的使用,简单的示例代码如下:
+
+```xml
+
+
+
+
+```
+
+这段代码并不会提现在demo的属性中,而是一个额外的声明,如果需要用到这里面的信息时可以通过BeanDefinition的getAttribute(key)方法获取,对meta属性的解析用的是:parseMetaElements(ele, bd);具体的方法体如下:
+
+```java
+public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccessor) {
+ NodeList nl = ele.getChildNodes();
+ for (int i = 0; i < nl.getLength(); i++) {
+ Node node = nl.item(i);
+ if (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) {
+ Element metaElement = (Element) node;
+ String key = metaElement.getAttribute(KEY_ATTRIBUTE);
+ String value = metaElement.getAttribute(VALUE_ATTRIBUTE);
+ BeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value);
+ attribute.setSource(extractSource(metaElement));
+ attributeAccessor.addMetadataAttribute(attribute);
+ }
+ }
+}
+```
+
+
+
+### 解析replaced-method属性
+
+ 在分析代码前我们还是先简单的了解下replaced-method的用法,其主要功能是方法替换:即在运行时用新的方法替换旧的方法。与之前的lookup-method不同的是此方法不仅可以替换返回的bean,还可以动态的更改原有方法的运行逻辑,我们看下使用:
+
+```java
+//原有的changeMe方法
+public class TestChangeMethod {
+ public void changeMe()
+ {
+ System.out.println("ChangeMe");
+ }
+}
+//新的实现方法
+public class ReplacerChangeMethod implements MethodReplacer {
+ public Object reimplement(Object o, Method method, Object[] objects) throws Throwable {
+ System.out.println("I Replace Method");
+ return null;
+ }
+}
+//新的配置文件
+
+
+
+
+
+
+
+
+//测试方法
+public class TestDemo {
+ public static void main(String[] args) {
+ ApplicationContext context = new ClassPathXmlApplicationContext("replaced-method.xml");
+
+ TestChangeMethod test =(TestChangeMethod) context.getBean("changeMe");
+
+ test.changeMe();
+ }
+}
+```
+
+接下来我们看下解析replaced-method的方法代码:
+
+```java
+public void parseReplacedMethodSubElements(Element beanEle, MethodOverrides overrides) {
+ NodeList nl = beanEle.getChildNodes();
+ for (int i = 0; i < nl.getLength(); i++) {
+ Node node = nl.item(i);
+ if (isCandidateElement(node) && nodeNameEquals(node, REPLACED_METHOD_ELEMENT)) {
+ Element replacedMethodEle = (Element) node;
+ String name = replacedMethodEle.getAttribute(NAME_ATTRIBUTE);
+ String callback = replacedMethodEle.getAttribute(REPLACER_ATTRIBUTE);
+ ReplaceOverride replaceOverride = new ReplaceOverride(name, callback);
+ // Look for arg-type match elements.
+ List argTypeEles = DomUtils.getChildElementsByTagName(replacedMethodEle, ARG_TYPE_ELEMENT);
+ for (Element argTypeEle : argTypeEles) {
+ String match = argTypeEle.getAttribute(ARG_TYPE_MATCH_ATTRIBUTE);
+ match = (StringUtils.hasText(match) ? match : DomUtils.getTextValue(argTypeEle));
+ if (StringUtils.hasText(match)) {
+ replaceOverride.addTypeIdentifier(match);
+ }
+ }
+ replaceOverride.setSource(extractSource(replacedMethodEle));
+ overrides.addOverride(replaceOverride);
+ }
+ }
+}
+```
+
+我们可以看到无论是 look-up 还是 replaced-method 是构造了 MethodOverride ,并最终记录在了 AbstractBeanDefinition 中的 methodOverrides 属性中
+
+### 解析constructor-arg
+
+对构造函数的解析式非常常用,也是非常复杂的,我们先从一个简单配置构造函数的例子开始分析,代码如下:
+
+```java
+public void parseConstructorArgElement(Element ele, BeanDefinition bd) {
+ //提前index属性
+ String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);
+ //提前type属性
+ String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);
+ //提取name属性
+ String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
+ if (StringUtils.hasLength(indexAttr)) {
+ try {
+ int index = Integer.parseInt(indexAttr);
+ if (index < 0) {
+ error("'index' cannot be lower than 0", ele);
+ }
+ else {
+ try {
+ this.parseState.push(new ConstructorArgumentEntry(index));
+ //解析ele对应的元素属性
+ Object value = parsePropertyValue(ele, bd, null);
+ ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
+ if (StringUtils.hasLength(typeAttr)) {
+ valueHolder.setType(typeAttr);
+ }
+ if (StringUtils.hasLength(nameAttr)) {
+ valueHolder.setName(nameAttr);
+ }
+ valueHolder.setSource(extractSource(ele));
+ if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {
+ error("Ambiguous constructor-arg entries for index " + index, ele);
+ }
+ else {
+ bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);
+ }
+ }
+ finally {
+ this.parseState.pop();
+ }
+ }
+ }
+ catch (NumberFormatException ex) {
+ error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);
+ }
+ }
+ else {
+ try {
+ this.parseState.push(new ConstructorArgumentEntry());
+ Object value = parsePropertyValue(ele, bd, null);
+ ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
+ if (StringUtils.hasLength(typeAttr)) {
+ valueHolder.setType(typeAttr);
+ }
+ if (StringUtils.hasLength(nameAttr)) {
+ valueHolder.setName(nameAttr);
+ }
+ valueHolder.setSource(extractSource(ele));
+ bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);
+ }
+ finally {
+ this.parseState.pop();
+ }
+ }
+}
+```
+
+上述代码的流程可以简单的总结为如下:
+
+(1)首先提取index、type、name等属性
+(2)根据是否配置了index属性解析流程不同
+
+如果配置了index属性,解析流程如下:
+
+(1)使用parsePropertyValue(ele, bd, null)方法读取constructor-arg的子元素
+
+(2)使用ConstructorArgumentValues.ValueHolder封装解析出来的元素
+
+(3)将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的indexedArgumentValues,而indexedArgumentValues是一个map类型
+
+如果没有配置index属性,将index、type、name属性也封装进ValueHolder中,然后将ValueHoder添加到当前beanDefinition的ConstructorArgumentValues的genericArgumentValues中
+
+```java
+public Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {
+ String elementName = (propertyName != null) ?
+ " element for property '" + propertyName + "'" :
+ " element";
+
+ // Should only have one child element: ref, value, list, etc.
+ NodeList nl = ele.getChildNodes();
+ Element subElement = null;
+ for (int i = 0; i < nl.getLength(); i++) {
+ Node node = nl.item(i);
+ //略过description和meta属性
+ if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) &&
+ !nodeNameEquals(node, META_ELEMENT)) {
+ // Child element is what we're looking for.
+ if (subElement != null) {
+ error(elementName + " must not contain more than one sub-element", ele);
+ }
+ else {
+ subElement = (Element) node;
+ }
+ }
+ }
+ //解析ref属性
+ boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);
+ //解析value属性
+ boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);
+ if ((hasRefAttribute && hasValueAttribute) ||
+ ((hasRefAttribute || hasValueAttribute) && subElement != null)) {
+ error(elementName +
+ " is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);
+ }
+
+ if (hasRefAttribute) {
+ String refName = ele.getAttribute(REF_ATTRIBUTE);
+ if (!StringUtils.hasText(refName)) {
+ error(elementName + " contains empty 'ref' attribute", ele);
+ }
+ //使用RuntimeBeanReference来封装ref对应的bean
+ RuntimeBeanReference ref = new RuntimeBeanReference(refName);
+ ref.setSource(extractSource(ele));
+ return ref;
+ }
+ else if (hasValueAttribute) {
+ //使用TypedStringValue 来封装value属性
+ TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));
+ valueHolder.setSource(extractSource(ele));
+ return valueHolder;
+ }
+ else if (subElement != null) {
+ //解析子元素
+ return parsePropertySubElement(subElement, bd);
+ }
+ else {
+ // Neither child element nor "ref" or "value" attribute found.
+ error(elementName + " must specify a ref or value", ele);
+ return null;
+ }
+}
+```
+
+上述代码的执行逻辑简单总结为:
+
+(1)首先略过decription和meta属性
+
+(2)提取constructor-arg上的ref和value属性,并验证是否存在
+
+(3)存在ref属性时,用RuntimeBeanReference来封装ref
+
+(4)存在value属性时,用TypedStringValue来封装
+
+(5)存在子元素时,对于子元素的处理使用了方法parsePropertySubElement(subElement, bd);,其代码如下:
+
+```java
+public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd) {
+ return parsePropertySubElement(ele, bd, null);
+}
+public Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd, @Nullable String defaultValueType) {
+ //判断是否是默认标签处理
+ if (!isDefaultNamespace(ele)) {
+ return parseNestedCustomElement(ele, bd);
+ }
+ //对于bean标签的处理
+ else if (nodeNameEquals(ele, BEAN_ELEMENT)) {
+ BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);
+ if (nestedBd != null) {
+ nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);
+ }
+ return nestedBd;
+ }
+ else if (nodeNameEquals(ele, REF_ELEMENT)) {
+ // A generic reference to any name of any bean.
+ String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);
+ boolean toParent = false;
+ if (!StringUtils.hasLength(refName)) {
+ // A reference to the id of another bean in a parent context.
+ refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);
+ toParent = true;
+ if (!StringUtils.hasLength(refName)) {
+ error("'bean' or 'parent' is required for [ element", ele);
+ return null;
+ }
+ }
+ if (!StringUtils.hasText(refName)) {
+ error("][ element contains empty target attribute", ele);
+ return null;
+ }
+ RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);
+ ref.setSource(extractSource(ele));
+ return ref;
+ }
+ //idref元素处理
+ else if (nodeNameEquals(ele, IDREF_ELEMENT)) {
+ return parseIdRefElement(ele);
+ }
+ //value元素处理
+ else if (nodeNameEquals(ele, VALUE_ELEMENT)) {
+ return parseValueElement(ele, defaultValueType);
+ }
+ //null元素处理
+ else if (nodeNameEquals(ele, NULL_ELEMENT)) {
+ // It's a distinguished null value. Let's wrap it in a TypedStringValue
+ // object in order to preserve the source location.
+ TypedStringValue nullHolder = new TypedStringValue(null);
+ nullHolder.setSource(extractSource(ele));
+ return nullHolder;
+ }
+ //array元素处理
+ else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {
+ return parseArrayElement(ele, bd);
+ }
+ //list元素处理
+ else if (nodeNameEquals(ele, LIST_ELEMENT)) {
+ return parseListElement(ele, bd);
+ }
+ //set元素处理
+ else if (nodeNameEquals(ele, SET_ELEMENT)) {
+ return parseSetElement(ele, bd);
+ }
+ //map元素处理
+ else if (nodeNameEquals(ele, MAP_ELEMENT)) {
+ return parseMapElement(ele, bd);
+ }
+ //props元素处理
+ else if (nodeNameEquals(ele, PROPS_ELEMENT)) {
+ return parsePropsElement(ele);
+ }
+ else {
+ error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);
+ return null;
+ }
+}
+```
+
+
+
+### 解析子元素properties
+
+对于propertie元素的解析是使用的parsePropertyElements(ele, bd);方法,我们看下其源码如下:
+
+```java
+public void parsePropertyElements(Element beanEle, BeanDefinition bd) {
+ NodeList nl = beanEle.getChildNodes();
+ for (int i = 0; i < nl.getLength(); i++) {
+ Node node = nl.item(i);
+ if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {
+ parsePropertyElement((Element) node, bd);
+ }
+ }
+}
+```
+
+里面实际的解析是用的parsePropertyElement((Element) node, bd);方法,继续跟踪代码:
+
+```java
+public void parsePropertyElement(Element ele, BeanDefinition bd) {
+ String propertyName = ele.getAttribute(NAME_ATTRIBUTE);
+ if (!StringUtils.hasLength(propertyName)) {
+ error("Tag 'property' must have a 'name' attribute", ele);
+ return;
+ }
+ this.parseState.push(new PropertyEntry(propertyName));
+ try {
+ //不允许多次对同一属性配置
+ if (bd.getPropertyValues().contains(propertyName)) {
+ error("Multiple 'property' definitions for property '" + propertyName + "'", ele);
+ return;
+ }
+ Object val = parsePropertyValue(ele, bd, propertyName);
+ PropertyValue pv = new PropertyValue(propertyName, val);
+ parseMetaElements(ele, pv);
+ pv.setSource(extractSource(ele));
+ bd.getPropertyValues().addPropertyValue(pv);
+ }
+ finally {
+ this.parseState.pop();
+ }
+}
+```
+
+我们看到代码的逻辑非常简单,在获取了propertie的属性后使用PropertyValue 进行封装,然后将其添加到BeanDefinition的propertyValueList中
+
+### 解析子元素 qualifier
+
+对于 qualifier 元素的获取,我们接触更多的是注解的形式,在使用 Spring 架中进行自动注入时,Spring 器中匹配的候选 Bean 数目必须有且仅有一个,当找不到一个匹配的 Bean 时, Spring容器将抛出 BeanCreationException 异常, 并指出必须至少拥有一个匹配的 Bean。
+
+Spring 允许我们通过Qualifier 指定注入 Bean的名称,这样歧义就消除了,而对于配置方式使用如:
+
+```xml
+
+
+
+```
+
+其解析过程与之前大同小异 这里不再重复叙述
+
+至此我们便完成了对 XML 文档到 GenericBeanDefinition 的转换, 就是说到这里, XML 中所有的配置都可以在 GenericBeanDefinition的实例类中应找到对应的配置。
+
+GenericBeanDefinition 只是子类实现,而大部分的通用属性都保存在了 bstractBeanDefinition 中,那么我们再次通过 AbstractBeanDefinition 的属性来回顾一 下我们都解析了哪些对应的配置。
+
+```java
+public abstract class AbstractBeanDefinition extends BeanMetadataAttributeAccessor
+ implements BeanDefinition, Cloneable {
+
+ // 此处省略静态变量以及final变量
+
+ @Nullable
+ private volatile Object beanClass;
+ /**
+ * bean的作用范围,对应bean属性scope
+ */
+ @Nullable
+ private String scope = SCOPE_DEFAULT;
+ /**
+ * 是否是抽象,对应bean属性abstract
+ */
+ private boolean abstractFlag = false;
+ /**
+ * 是否延迟加载,对应bean属性lazy-init
+ */
+ private boolean lazyInit = false;
+ /**
+ * 自动注入模式,对应bean属性autowire
+ */
+ private int autowireMode = AUTOWIRE_NO;
+ /**
+ * 依赖检查,Spring 3.0后弃用这个属性
+ */
+ private int dependencyCheck = DEPENDENCY_CHECK_NONE;
+ /**
+ * 用来表示一个bean的实例化依靠另一个bean先实例化,对应bean属性depend-on
+ */
+ @Nullable
+ private String[] dependsOn;
+ /**
+ * autowire-candidate属性设置为false,这样容器在查找自动装配对象时,
+ * 将不考虑该bean,即它不会被考虑作为其他bean自动装配的候选者,
+ * 但是该bean本身还是可以使用自动装配来注入其他bean的
+ */
+ private boolean autowireCandidate = true;
+ /**
+ * 自动装配时出现多个bean候选者时,将作为首选者,对应bean属性primary
+ */
+ private boolean primary = false;
+ /**
+ * 用于记录Qualifier,对应子元素qualifier
+ */
+ private final Map qualifiers = new LinkedHashMap<>(0);
+
+ @Nullable
+ private Supplier instanceSupplier;
+ /**
+ * 允许访问非公开的构造器和方法,程序设置
+ */
+ private boolean nonPublicAccessAllowed = true;
+ /**
+ * 是否以一种宽松的模式解析构造函数,默认为true,
+ * 如果为false,则在以下情况
+ * interface ITest{}
+ * class ITestImpl implements ITest{};
+ * class Main {
+ * Main(ITest i) {}
+ * Main(ITestImpl i) {}
+ * }
+ * 抛出异常,因为Spring无法准确定位哪个构造函数程序设置
+ */
+ private boolean lenientConstructorResolution = true;
+ /**
+ * 对应bean属性factory-bean,用法:
+ *
+ *
+ */
+ @Nullable
+ private String factoryBeanName;
+ /**
+ * 对应bean属性factory-method
+ */
+ @Nullable
+ private String factoryMethodName;
+ /**
+ * 记录构造函数注入属性,对应bean属性constructor-arg
+ */
+ @Nullable
+ private ConstructorArgumentValues constructorArgumentValues;
+ /**
+ * 普通属性集合
+ */
+ @Nullable
+ private MutablePropertyValues propertyValues;
+ /**
+ * 方法重写的持有者,记录lookup-method、replaced-method元素
+ */
+ @Nullable
+ private MethodOverrides methodOverrides;
+ /**
+ * 初始化方法,对应bean属性init-method
+ */
+ @Nullable
+ private String initMethodName;
+ /**
+ * 销毁方法,对应bean属性destroy-method
+ */
+ @Nullable
+ private String destroyMethodName;
+ /**
+ * 是否执行init-method,程序设置
+ */
+ private boolean enforceInitMethod = true;
+ /**
+ * 是否执行destroy-method,程序设置
+ */
+ private boolean enforceDestroyMethod = true;
+ /**
+ * 是否是用户定义的而不是应用程序本身定义的,创建AOP时候为true,程序设置
+ */
+ private boolean synthetic = false;
+ /**
+ * 定义这个bean的应用,APPLICATION:用户,INFRASTRUCTURE:完全内部使用,与用户无关,
+ * SUPPORT:某些复杂配置的一部分
+ * 程序设置
+ */
+ private int role = BeanDefinition.ROLE_APPLICATION;
+ /**
+ * bean的描述信息
+ */
+ @Nullable
+ private String description;
+ /**
+ * 这个bean定义的资源
+ */
+ @Nullable
+ private Resource resource;
+}
+```
\ No newline at end of file
diff --git "a/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\213\357\274\211.md" "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\213\357\274\211.md"
new file mode 100644
index 0000000..b92d7e7
--- /dev/null
+++ "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224 IOC\351\273\230\350\256\244\346\240\207\347\255\276\350\247\243\346\236\220\357\274\210\344\270\213\357\274\211.md"
@@ -0,0 +1,501 @@
+**正文**
+
+在上一篇我们已经完成了从xml配置文件到BeanDefinition的转换,转换后的实例是GenericBeanDefinition的实例。本文主要来看看标签解析剩余部分及BeanDefinition的注册。
+
+## 默认标签中的自定义标签解析
+
+在上篇博文中我们已经分析了对于默认标签的解析,我们继续看戏之前的代码,如下图片中有一个方法:delegate.decorateBeanDefinitionIfRequired(ele, bdHolder)
+
+
+
+这个方法的作用是什么呢?首先我们看下这种场景,如下配置文件:
+
+```xml
+
+
+
+
+
+```
+
+这个配置文件中有个自定义的标签,decorateBeanDefinitionIfRequired方法就是用来处理这种情况的,其中的null是用来传递父级BeanDefinition的,我们进入到其方法体:
+
+```java
+public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder) {
+ return decorateBeanDefinitionIfRequired(ele, definitionHolder, null);
+}
+public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
+ Element ele, BeanDefinitionHolder definitionHolder, @Nullable BeanDefinition containingBd) {
+
+ BeanDefinitionHolder finalDefinition = definitionHolder;
+
+ // Decorate based on custom attributes first.
+ NamedNodeMap attributes = ele.getAttributes();
+ for (int i = 0; i < attributes.getLength(); i++) {
+ Node node = attributes.item(i);
+ finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
+ }
+
+ // Decorate based on custom nested elements.
+ NodeList children = ele.getChildNodes();
+ for (int i = 0; i < children.getLength(); i++) {
+ Node node = children.item(i);
+ if (node.getNodeType() == Node.ELEMENT_NODE) {
+ finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
+ }
+ }
+ return finalDefinition;
+}
+```
+
+我们看到上面的代码有两个遍历操作,一个是用于对所有的属性进行遍历处理,另一个是对所有的子节点进行处理,两个遍历操作都用到了decorateIfRequired(node, finalDefinition, containingBd);方法,我们继续跟踪代码,进入方法体:
+
+```java
+public BeanDefinitionHolder decorateIfRequired(
+ Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) {
+ // 获取自定义标签的命名空间
+ String namespaceUri = getNamespaceURI(node);
+ // 过滤掉默认命名标签
+ if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) {
+ // 获取相应的处理器
+ NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
+ if (handler != null) {
+ // 进行装饰处理
+ BeanDefinitionHolder decorated =
+ handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
+ if (decorated != null) {
+ return decorated;
+ }
+ }
+ else if (namespaceUri.startsWith("http://www.springframework.org/")) {
+ error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);
+ }
+ else {
+ if (logger.isDebugEnabled()) {
+ logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]");
+ }
+ }
+ }
+ return originalDef;
+}
+
+public String getNamespaceURI(Node node) {
+ return node.getNamespaceURI();
+}
+
+public boolean isDefaultNamespace(@Nullable String namespaceUri) {
+ //BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans";
+ return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri));
+}
+```
+
+首先获取自定义标签的命名空间,如果不是默认的命名空间则根据该命名空间获取相应的处理器,最后调用处理器的 `decorate()` 进行装饰处理。具体的装饰过程这里不进行讲述,在后面分析自定义标签时会做详细说明。
+
+
+
+## 注册解析的BeanDefinition
+
+对于配置文件,解析和装饰完成之后,对于得到的beanDefinition已经可以满足后续的使用要求了,还剩下注册,也就是processBeanDefinition函数中的BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder,getReaderContext().getRegistry())代码的解析了。进入方法体:
+
+```java
+public static void registerBeanDefinition(
+ BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
+ throws BeanDefinitionStoreException {
+ // Register bean definition under primary name.
+ //使用beanName做唯一标识注册
+ String beanName = definitionHolder.getBeanName();
+ registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
+
+ // Register aliases for bean name, if any.
+ //注册所有的别名
+ String[] aliases = definitionHolder.getAliases();
+ if (aliases != null) {
+ for (String alias : aliases) {
+ registry.registerAlias(beanName, alias);
+ }
+ }
+}
+```
+
+从上面的代码我们看到是用了beanName作为唯一标示进行注册的,然后注册了所有的别名aliase。而beanDefinition最终都是注册到BeanDefinitionRegistry中,接下来我们具体看下注册流程。
+
+
+
+## 通过beanName注册BeanDefinition
+
+在spring中除了使用beanName作为key将BeanDefinition放入Map中还做了其他一些事情,我们看下方法registerBeanDefinition代码,BeanDefinitionRegistry是一个接口,他有三个实现类,DefaultListableBeanFactory、SimpleBeanDefinitionRegistry、GenericApplicationContext,其中SimpleBeanDefinitionRegistry非常简单,而GenericApplicationContext最终也是使用的DefaultListableBeanFactory中的实现方法,我们看下代码:
+
+```java
+public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
+ throws BeanDefinitionStoreException {
+
+ // 校验 beanName 与 beanDefinition
+ Assert.hasText(beanName, "Bean name must not be empty");
+ Assert.notNull(beanDefinition, "BeanDefinition must not be null");
+
+ if (beanDefinition instanceof AbstractBeanDefinition) {
+ try {
+ // 校验 BeanDefinition
+ // 这是注册前的最后一次校验了,主要是对属性 methodOverrides 进行校验
+ ((AbstractBeanDefinition) beanDefinition).validate();
+ }
+ catch (BeanDefinitionValidationException ex) {
+ throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
+ "Validation of bean definition failed", ex);
+ }
+ }
+
+ BeanDefinition oldBeanDefinition;
+
+ // 从缓存中获取指定 beanName 的 BeanDefinition
+ oldBeanDefinition = this.beanDefinitionMap.get(beanName);
+ /**
+ * 如果存在
+ */
+ if (oldBeanDefinition != null) {
+ // 如果存在但是不允许覆盖,抛出异常
+ if (!isAllowBeanDefinitionOverriding()) {
+ throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
+ "Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
+ "': There is already [" + oldBeanDefinition + "] bound.");
+ }
+ //
+ else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
+ // e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
+ if (this.logger.isWarnEnabled()) {
+ this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
+ "' with a framework-generated bean definition: replacing [" +
+ oldBeanDefinition + "] with [" + beanDefinition + "]");
+ }
+ }
+ // 覆盖 beanDefinition 与 被覆盖的 beanDefinition 不是同类
+ else if (!beanDefinition.equals(oldBeanDefinition)) {
+ if (this.logger.isInfoEnabled()) {
+ this.logger.info("Overriding bean definition for bean '" + beanName +
+ "' with a different definition: replacing [" + oldBeanDefinition +
+ "] with [" + beanDefinition + "]");
+ }
+ }
+ else {
+ if (this.logger.isDebugEnabled()) {
+ this.logger.debug("Overriding bean definition for bean '" + beanName +
+ "' with an equivalent definition: replacing [" + oldBeanDefinition +
+ "] with [" + beanDefinition + "]");
+ }
+ }
+
+ // 允许覆盖,直接覆盖原有的 BeanDefinition
+ this.beanDefinitionMap.put(beanName, beanDefinition);
+ }
+ /**
+ * 不存在
+ */
+ else {
+ // 检测创建 Bean 阶段是否已经开启,如果开启了则需要对 beanDefinitionMap 进行并发控制
+ if (hasBeanCreationStarted()) {
+ // beanDefinitionMap 为全局变量,避免并发情况
+ synchronized (this.beanDefinitionMap) {
+ //
+ this.beanDefinitionMap.put(beanName, beanDefinition);
+ List updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
+ updatedDefinitions.addAll(this.beanDefinitionNames);
+ updatedDefinitions.add(beanName);
+ this.beanDefinitionNames = updatedDefinitions;
+ if (this.manualSingletonNames.contains(beanName)) {
+ Set updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames);
+ updatedSingletons.remove(beanName);
+ this.manualSingletonNames = updatedSingletons;
+ }
+ }
+ }
+ else {
+ // 不会存在并发情况,直接设置
+ this.beanDefinitionMap.put(beanName, beanDefinition);
+ this.beanDefinitionNames.add(beanName);
+ this.manualSingletonNames.remove(beanName);
+ }
+ this.frozenBeanDefinitionNames = null;
+ }
+
+ if (oldBeanDefinition != null || containsSingleton(beanName)) {
+ // 重新设置 beanName 对应的缓存
+ resetBeanDefinition(beanName);
+ }
+}
+```
+
+处理过程如下:
+
+- 首先 BeanDefinition 进行校验,该校验也是注册过程中的最后一次校验了,主要是对 AbstractBeanDefinition 的 methodOverrides 属性进行校验
+- 根据 beanName 从缓存中获取 BeanDefinition,如果缓存中存在,则根据 allowBeanDefinitionOverriding 标志来判断是否允许覆盖,如果允许则直接覆盖,否则抛出 BeanDefinitionStoreException 异常
+- 若缓存中没有指定 beanName 的 BeanDefinition,则判断当前阶段是否已经开始了 Bean 的创建阶段(),如果是,则需要对 beanDefinitionMap 进行加锁控制并发问题,否则直接设置即可。对于 `hasBeanCreationStarted()` 方法后续做详细介绍,这里不过多阐述。
+- 若缓存中存在该 beanName 或者 单利 bean 集合中存在该 beanName,则调用 `resetBeanDefinition()` 重置 BeanDefinition 缓存。
+
+其实整段代码的核心就在于 `this.beanDefinitionMap.put(beanName, beanDefinition);` 。BeanDefinition 的缓存也不是神奇的东西,就是定义 一个 ConcurrentHashMap,key 为 beanName,value 为 BeanDefinition。
+
+
+
+## 通过别名注册BeanDefinition
+
+通过别名注册BeanDefinition最终是在SimpleBeanDefinitionRegistry中实现的,我们看下代码:
+
+```java
+public void registerAlias(String name, String alias) {
+ Assert.hasText(name, "'name' must not be empty");
+ Assert.hasText(alias, "'alias' must not be empty");
+ synchronized (this.aliasMap) {
+ if (alias.equals(name)) {
+ this.aliasMap.remove(alias);
+ }
+ else {
+ String registeredName = this.aliasMap.get(alias);
+ if (registeredName != null) {
+ if (registeredName.equals(name)) {
+ // An existing alias - no need to re-register
+ return;
+ }
+ if (!allowAliasOverriding()) {
+ throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" +
+ name + "': It is already registered for name '" + registeredName + "'.");
+ }
+ }
+ //当A->B存在时,若再次出现A->C->B时候则会抛出异常。
+ checkForAliasCircle(name, alias);
+ this.aliasMap.put(alias, name);
+ }
+ }
+}
+```
+
+上述代码的流程总结如下:
+
+(1)alias与beanName相同情况处理,若alias与beanName并名称相同则不需要处理并删除原有的alias
+
+(2)alias覆盖处理。若aliasName已经使用并已经指向了另一beanName则需要用户的设置进行处理
+
+(3)alias循环检查,当A->B存在时,若再次出现A->C->B时候则会抛出异常。
+
+
+
+## alias标签的解析
+
+对应bean标签的解析是最核心的功能,对于alias、import、beans标签的解析都是基于bean标签解析的,接下来我就分析下alias标签的解析。我们回到 parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate)方法,继续看下方法体,如下图所示:
+
+
+
+对bean进行定义时,除了用id来 指定名称外,为了提供多个名称,可以使用alias标签来指定。而所有这些名称都指向同一个bean。在XML配置文件中,可用单独的元素来完成bean别名的定义。我们可以直接使用bean标签中的name属性,如下:
+
+```xml
+
+
+
+```
+
+在Spring还有另外一种声明别名的方式:
+
+```xml
+
+
+```
+
+我们具体看下alias标签的解析过程,解析使用的方法processAliasRegistration(ele),方法体如下:
+
+```java
+protected void processAliasRegistration(Element ele) {
+ //获取beanName
+ String name = ele.getAttribute(NAME_ATTRIBUTE);
+ //获取alias
+ String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
+ boolean valid = true;
+ if (!StringUtils.hasText(name)) {
+ getReaderContext().error("Name must not be empty", ele);
+ valid = false;
+ }
+ if (!StringUtils.hasText(alias)) {
+ getReaderContext().error("Alias must not be empty", ele);
+ valid = false;
+ }
+ if (valid) {
+ try {
+ //注册alias
+ getReaderContext().getRegistry().registerAlias(name, alias);
+ }
+ catch (Exception ex) {
+ getReaderContext().error("Failed to register alias '" + alias +
+ "' for bean with name '" + name + "'", ele, ex);
+ }
+ getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
+ }
+}
+```
+
+通过代码可以发现解析流程与bean中的alias解析大同小异,都是讲beanName与别名alias组成一对注册到registry中。跟踪代码最终使用了SimpleAliasRegistry中的registerAlias(String name, String alias)方法
+
+
+
+## import标签的解析
+
+对于Spring配置文件的编写,经历过大型项目的人都知道,里面有太多的配置文件了。基本采用的方式都是分模块,分模块的方式很多,使用import就是其中一种,例如我们可以构造这样的Spring配置文件:
+
+```xml
+
+
+
+
+
+
+
+
+
+```
+
+applicationContext.xml文件中使用import方式导入有模块配置文件,以后若有新模块入加,那就可以简单修改这个文件了。这样大大简化了配置后期维护的复杂度,并使配置模块化,易于管理。我们来看看Spring是如何解析import配置文件的呢。解析import标签使用的是importBeanDefinitionResource(ele),进入方法体:
+
+```java
+protected void importBeanDefinitionResource(Element ele) {
+ // 获取 resource 的属性值
+ String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
+ // 为空,直接退出
+ if (!StringUtils.hasText(location)) {
+ getReaderContext().error("Resource location must not be empty", ele);
+ return;
+ }
+
+ // 解析系统属性,格式如 :"${user.dir}"
+ location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
+
+ Set actualResources = new LinkedHashSet<>(4);
+
+ // 判断 location 是相对路径还是绝对路径
+ boolean absoluteLocation = false;
+ try {
+ absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
+ }
+ catch (URISyntaxException ex) {
+ // cannot convert to an URI, considering the location relative
+ // unless it is the well-known Spring prefix "classpath*:"
+ }
+
+ // 绝对路径
+ if (absoluteLocation) {
+ try {
+ // 直接根据地址加载相应的配置文件
+ int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");
+ }
+ }
+ catch (BeanDefinitionStoreException ex) {
+ getReaderContext().error(
+ "Failed to import bean definitions from URL location [" + location + "]", ele, ex);
+ }
+ }
+ else {
+ // 相对路径则根据相应的地址计算出绝对路径地址
+ try {
+ int importCount;
+ Resource relativeResource = getReaderContext().getResource().createRelative(location);
+ if (relativeResource.exists()) {
+ importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
+ actualResources.add(relativeResource);
+ }
+ else {
+ String baseLocation = getReaderContext().getResource().getURL().toString();
+ importCount = getReaderContext().getReader().loadBeanDefinitions(
+ StringUtils.applyRelativePath(baseLocation, location), actualResources);
+ }
+ if (logger.isDebugEnabled()) {
+ logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");
+ }
+ }
+ catch (IOException ex) {
+ getReaderContext().error("Failed to resolve current resource location", ele, ex);
+ }
+ catch (BeanDefinitionStoreException ex) {
+ getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",
+ ele, ex);
+ }
+ }
+ // 解析成功后,进行监听器激活处理
+ Resource[] actResArray = actualResources.toArray(new Resource[0]);
+ getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
+}
+```
+
+解析 import 过程较为清晰,整个过程如下:
+
+1. 获取 source 属性的值,该值表示资源的路径
+2. 解析路径中的系统属性,如”${user.dir}”
+3. 判断资源路径 location 是绝对路径还是相对路径
+4. 如果是绝对路径,则调递归调用 Bean 的解析过程,进行另一次的解析
+5. 如果是相对路径,则先计算出绝对路径得到 Resource,然后进行解析
+6. 通知监听器,完成解析
+
+**判断路径**
+
+方法通过以下方法来判断 location 是为相对路径还是绝对路径:
+
+```java
+absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
+```
+
+判断绝对路径的规则如下:
+
+- 以 classpath*: 或者 classpath: 开头为绝对路径
+- 能够通过该 location 构建出 `java.net.URL`为绝对路径
+- 根据 location 构造 `java.net.URI` 判断调用 `isAbsolute()` 判断是否为绝对路径
+
+如果 location 为绝对路径则调用 `loadBeanDefinitions()`,该方法在 AbstractBeanDefinitionReader 中定义。
+
+```java
+public int loadBeanDefinitions(String location, @Nullable Set actualResources) throws BeanDefinitionStoreException {
+ ResourceLoader resourceLoader = getResourceLoader();
+ if (resourceLoader == null) {
+ throw new BeanDefinitionStoreException(
+ "Cannot import bean definitions from location [" + location + "]: no ResourceLoader available");
+ }
+
+ if (resourceLoader instanceof ResourcePatternResolver) {
+ // Resource pattern matching available.
+ try {
+ Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
+ int loadCount = loadBeanDefinitions(resources);
+ if (actualResources != null) {
+ for (Resource resource : resources) {
+ actualResources.add(resource);
+ }
+ }
+ if (logger.isDebugEnabled()) {
+ logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]");
+ }
+ return loadCount;
+ }
+ catch (IOException ex) {
+ throw new BeanDefinitionStoreException(
+ "Could not resolve bean definition resource pattern [" + location + "]", ex);
+ }
+ }
+ else {
+ // Can only load single resources by absolute URL.
+ Resource resource = resourceLoader.getResource(location);
+ int loadCount = loadBeanDefinitions(resource);
+ if (actualResources != null) {
+ actualResources.add(resource);
+ }
+ if (logger.isDebugEnabled()) {
+ logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]");
+ }
+ return loadCount;
+ }
+}
+```
+
+
+
+整个逻辑比较简单,首先获取 ResourceLoader,然后根据不同的 ResourceLoader 执行不同的逻辑,主要是可能存在多个 Resource,但是最终都会回归到 `XmlBeanDefinitionReader.loadBeanDefinitions()` ,所以这是一个递归的过程。
+
+至此,import 标签解析完毕,整个过程比较清晰明了:获取 source 属性值,得到正确的资源路径,然后调用 `loadBeanDefinitions()` 方法进行递归的 BeanDefinition 加载。
\ No newline at end of file
diff --git "a/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC \345\256\271\345\231\250\345\237\272\346\234\254\345\256\236\347\216\260.md" "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC \345\256\271\345\231\250\345\237\272\346\234\254\345\256\236\347\216\260.md"
new file mode 100644
index 0000000..e8a89a8
--- /dev/null
+++ "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC \345\256\271\345\231\250\345\237\272\346\234\254\345\256\236\347\216\260.md"
@@ -0,0 +1,979 @@
+## 概述
+
+上一篇我们了解了Spring的整体架构,这篇我们开始真正的阅读Spring源码。在分析spring的源码之前,我们先来简单回顾下spring核心功能的简单使用。
+
+## 容器的基本用法
+
+bean是spring最核心的东西。我们简单看下bean的定义,代码如下:
+
+```java
+public class MyTestBean {
+ private String name = "dabin";
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+```
+
+代码很简单,bean没有特别之处,spring的的目的就是让我们的bean成为一个纯粹的的POJO,这就是spring追求的,接下来就是在配置文件中定义这个bean,配置文件如下:
+
+```xml
+
+
+
+
+
+
+```
+
+在上面的配置中我们可以看到bean的声明方式,在spring中的bean定义有N种属性,但是我们只要像上面这样简单的声明就可以使用了。
+具体测试代码如下:
+
+```
+import com.dabin.spring.MyTestBean;
+import org.junit.Test;
+import org.springframework.beans.factory.BeanFactory;
+import org.springframework.beans.factory.xml.XmlBeanFactory;
+import org.springframework.core.io.ClassPathResource;
+
+public class AppTest {
+ @Test
+ public void MyTestBeanTest() {
+ BeanFactory bf = new XmlBeanFactory( new ClassPathResource("spring-config.xml"));
+ MyTestBean myTestBean = (MyTestBean) bf.getBean("myTestBean");
+ System.out.println(myTestBean.getName());
+ }
+}
+```
+
+运行上述测试代码就可以看到输出结果如下:
+
+```
+dabin
+```
+
+其实直接使用BeanFactory作为容器对于Spring的使用并不多见,因为企业级应用项目中大多会使用的是ApplicationContext(后面我们会讲两者的区别,这里只是测试)
+
+
+
+## 功能分析
+
+接下来我们分析2中代码完成的功能;
+
+- 读取配置文件spring-config.xml。
+
+- 根据spring-config.xml中的配置找到对应的类的配置,并实例化。
+- 调用实例化后的实例
+
+下图是一个最简单spring功能架构,如果想完成我们预想的功能,至少需要3个类:
+
+
+
+**ConfigReader** :用于读取及验证自己直文件 我们妥用配直文件里面的东西,当然首先 要做的就是读取,然后放直在内存中.
+
+**ReflectionUtil** :用于根据配置文件中的自己直进行反射实例化,比如在上例中 spring-config.xml 出现的``,我们就可以根据 com.dabin.spring.MyTestBean 进行实例化。
+
+**App** :用于完成整个逻辑的串联。
+
+
+
+## 工程搭建
+
+spring的源码中用于实现上面功能的是spring-bean这个工程,所以我们接下来看这个工程,当然spring-core是必须的。
+
+### beans包的层级结构
+
+阅读源码最好的方式是跟着示例操作一遍,我们先看看beans工程的源码结构,如下图所示:
+
+
+
+- src/main/java 用于展现Spring的主要逻辑
+- src/main/resources 用于存放系统的配置文件
+- src/test/java 用于对主要逻辑进行单元测试
+- src/test/resources 用于存放测试用的配置文件
+
+
+
+### 核心类介绍
+
+接下来我们先了解下spring-bean最核心的两个类:DefaultListableBeanFactory和XmlBeanDefinitionReader
+
+#### *DefaultListableBeanFactory*
+
+XmlBeanFactory继承自DefaultListableBeanFactory,而DefaultListableBeanFactory是整个bean加载的核心部分,是Spring注册及加载bean的默认实现,而对于XmlBeanFactory与DefaultListableBeanFactory不同的地方其实是在XmlBeanFactory中使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取,DefaultListableBeanFactory继承了AbstractAutowireCapableBeanFactory并实现了ConfigurableListableBeanFactory以及BeanDefinitionRegistry接口。以下是ConfigurableListableBeanFactory的层次结构图以下相关类图:
+
+
+
+上面类图中各个类及接口的作用如下:
+- AliasRegistry:定义对alias的简单增删改等操作
+- SimpleAliasRegistry:主要使用map作为alias的缓存,并对接口AliasRegistry进行实现
+- SingletonBeanRegistry:定义对单例的注册及获取
+- BeanFactory:定义获取bean及bean的各种属性
+- DefaultSingletonBeanRegistry:默认对接口SingletonBeanRegistry各函数的实现
+- HierarchicalBeanFactory:继承BeanFactory,也就是在BeanFactory定义的功能的基础上增加了对parentFactory的支持
+- BeanDefinitionRegistry:定义对BeanDefinition的各种增删改操作
+- FactoryBeanRegistrySupport:在DefaultSingletonBeanRegistry基础上增加了对FactoryBean的特殊处理功能
+- ConfigurableBeanFactory:提供配置Factory的各种方法
+- ListableBeanFactory:根据各种条件获取bean的配置清单
+- AbstractBeanFactory:综合FactoryBeanRegistrySupport和ConfigurationBeanFactory的功能
+- AutowireCapableBeanFactory:提供创建bean、自动注入、初始化以及应用bean的后处理器
+- AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory并对接口AutowireCapableBeanFactory进行实现
+- ConfigurableListableBeanFactory:BeanFactory配置清单,指定忽略类型及接口等
+- DefaultListableBeanFactory:综合上面所有功能,主要是对Bean注册后的处理
+XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用从父类DefaultListableBeanFactory继承的方法去实现,而唯独与父类不同的个性化实现就是增加了XmlBeanDefinitionReader类型的reader属性。在XmlBeanFactory中主要使用reader属性对资源文件进行读取和注册
+
+#### XmlBeanDefinitionReader
+
+XML配置文件的读取是Spring中重要的功能,因为Spring的大部分功能都是以配置作为切入点的,可以从XmlBeanDefinitionReader中梳理一下资源文件读取、解析及注册的大致脉络,首先看看各个类的功能
+
+- ResourceLoader:定义资源加载器,主要应用于根据给定的资源文件地址返回对应的Resource
+- BeanDefinitionReader:主要定义资源文件读取并转换为BeanDefinition的各个功能
+- EnvironmentCapable:定义获取Environment方法
+- DocumentLoader:定义从资源文件加载到转换为Document的功能
+- AbstractBeanDefinitionReader:对EnvironmentCapable、BeanDefinitionReader类定义的功能进行实现
+- BeanDefinitionDocumentReader:定义读取Document并注册BeanDefinition功能
+- BeanDefinitionParserDelegate:定义解析Element的各种方法
+
+整个XML配置文件读取的大致流程,在XmlBeanDefinitionReader中主要包含以下几步处理
+
+
+
+(1)通过继承自AbstractBeanDefinitionReader中的方法,来使用ResourceLoader将资源文件路径转换为对应的Resource文件
+(2)通过DocumentLoader对Resource文件进行转换,将Resource文件转换为Document文件
+(3)通过实现接口BeanDefinitionDocumentReader的DefaultBeanDefinitionDocumentReader类对Document进行解析,并使用BeanDefinitionParserDelegate对Element进行解析
+
+## 容器的基础XmlBeanFactory
+
+ 通过上面的内容我们对spring的容器已经有了大致的了解,接下来我们详细探索每个步骤的详细实现,接下来要分析的功能都是基于如下代码:
+
+```java
+BeanFactory bf = new XmlBeanFactory( new ClassPathResource("spring-config.xml"));
+```
+
+首先调用ClassPathResource的构造函数来构造Resource资源文件的实例对象,这样后续的资源处理就可以用Resource提供的各种服务来操作了。有了Resource后就可以对BeanFactory进行初始化操作,那配置文件是如何封装的呢?
+
+### 配置文件的封装
+
+ Spring的配置文件读取是通过ClassPathResource进行封装的,Spring对其内部使用到的资源实现了自己的抽象结构:Resource接口来封装底层资源,如下源码:
+
+```java
+public interface InputStreamSource {
+ InputStream getInputStream() throws IOException;
+}
+public interface Resource extends InputStreamSource {
+ boolean exists();
+ default boolean isReadable() {
+ return true;
+ }
+ default boolean isOpen() {
+ return false;
+ }
+ default boolean isFile() {
+ return false;
+ }
+ URL getURL() throws IOException;
+ URI getURI() throws IOException;
+ File getFile() throws IOException;
+ default ReadableByteChannel readableChannel() throws IOException {
+ return Channels.newChannel(getInputStream());
+ }
+ long contentLength() throws IOException;
+ long lastModified() throws IOException;
+ Resource createRelative(String relativePath) throws IOException;
+ String getFilename();
+ String getDescription();
+}
+```
+
+ InputStreamSource封装任何能返回InputStream的类,比如File、Classpath下的资源和Byte Array等, 它只有一个方法定义:getInputStream(),该方法返回一个新的InputStream对象 。
+
+Resource接口抽象了所有Spring内部使用到的底层资源:File、URL、Classpath等。首先,它定义了3个判断当前资源状态的方法:存在性(exists)、可读性(isReadable)、是否处于打开状态(isOpen)。另外,Resource接口还提供了不同资源到URL、URI、File类型的转换,以及获取lastModified属性、文件名(不带路径信息的文件名,getFilename())的方法,为了便于操作,Resource还提供了基于当前资源创建一个相对资源的方法:createRelative(),还提供了getDescription()方法用于在错误处理中的打印信息。
+
+对不同来源的资源文件都有相应的Resource实现:文件(FileSystemResource)、Classpath资源(ClassPathResource)、URL资源(UrlResource)、InputStream资源(InputStreamResource)、Byte数组(ByteArrayResource)等。
+
+在日常开发中我们可以直接使用spring提供的类来加载资源文件,比如在希望加载资源文件时可以使用下面的代码:
+
+```
+Resource resource = new ClassPathResource("spring-config.xml");
+InputStream is = resource.getInputStream();
+```
+
+有了 Resource 接口便可以对所有资源文件进行统一处理 至于实现,其实是非常简单的,以 getlnputStream 为例,ClassPathResource 中的实现方式便是通 class 或者 classLoader 提供的底层方法进行调用,而对于 FileSystemResource 其实更简单,直接使用 FileInputStream 对文件进行实例化。
+
+**ClassPathResource.java**
+
+```java
+InputStream is;
+if (this.clazz != null) {
+ is = this.clazz.getResourceAsStream(this.path);
+}
+else if (this.classLoader != null) {
+ is = this.classLoader.getResourceAsStream(this.path);
+}
+else {
+ is = ClassLoader.getSystemResourceAsStream(this.path);
+}
+```
+
+**FileSystemResource.java**
+
+```java
+public InputStream getinputStream () throws IOException {
+ return new FilelnputStream(this file) ;
+}
+```
+
+当通过Resource相关类完成了对配置文件进行封装后,配置文件的读取工作就全权交给XmlBeanDefinitionReader来处理了。
+接下来就进入到XmlBeanFactory的初始化过程了,XmlBeanFactory的初始化有若干办法,Spring提供了很多的构造函数,在这里分析的是使用Resource实例作为构造函数参数的办法,代码如下:
+
+**XmlBeanFactory.java**
+
+```java
+public XmlBeanFactory(Resource resource) throws BeansException {
+ this(resource, null);
+}
+public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
+ super(parentBeanFactory);
+ this.reader.loadBeanDefinitions(resource);
+}
+```
+
+
+
+上面函数中的代码this.reader.loadBeanDefinitions(resource)才是资源加载的真正实现,但是在XmlBeanDefinitionReader加载数据前还有一个调用父类构造函数初始化的过程:super(parentBeanFactory),我们按照代码层级进行跟踪,首先跟踪到如下父类代码:
+
+```java
+public DefaultListableBeanFactory(@Nullable BeanFactory parentBeanFactory) {
+ super(parentBeanFactory);
+}
+```
+
+然后继续跟踪,跟踪代码到父类AbstractAutowireCapableBeanFactory的构造函数中:
+
+```java
+public AbstractAutowireCapableBeanFactory(@Nullable BeanFactory parentBeanFactory) {
+ this();
+ setParentBeanFactory(parentBeanFactory);
+}
+public AbstractAutowireCapableBeanFactory() {
+ super();
+ ignoreDependencyInterface(BeanNameAware.class);
+ ignoreDependencyInterface(BeanFactoryAware.class);
+ ignoreDependencyInterface(BeanClassLoaderAware.class);
+}
+```
+
+这里有必要提及 ignoreDependencylnterface方法,ignoreDependencylnterface 的主要功能是 忽略给定接口的向动装配功能,那么,这样做的目的是什么呢?会产生什么样的效果呢?
+
+举例来说,当 A 中有属性 B ,那么当 Spring 在获取 A的 Bean 的时候如果其属性 B 还没有 初始化,那么 Spring 会自动初始化 B,这也是 Spring 提供的一个重要特性 。但是,某些情况 下, B不会被初始化,其中的一种情况就是B 实现了 BeanNameAware 接口 。Spring 中是这样介绍的:自动装配时忽略给定的依赖接口,典型应用是边过其他方式解析 Application 上下文注册依赖,类似于 BeanFactor 通过 BeanFactoryAware 进行注入或者 ApplicationContext 通过 ApplicationContextAware 进行注入。
+
+调用ignoreDependencyInterface方法后,被忽略的接口会存储在BeanFactory的名为ignoredDependencyInterfaces的Set集合中:
+
+```java
+public abstract class AbstractAutowireCapableBeanFactory extends AbstractBeanFactory
+ implements AutowireCapableBeanFactory {
+
+ private final Set> ignoredDependencyInterfaces = new HashSet<>();
+
+ public void ignoreDependencyInterface(Class ifc) {
+ this.ignoredDependencyInterfaces.add(ifc);
+ }
+...
+}
+```
+
+ignoredDependencyInterfaces集合在同类中被使用仅在一处——isExcludedFromDependencyCheck方法中:
+
+```java
+protected boolean isExcludedFromDependencyCheck(PropertyDescriptor pd) {
+ return (AutowireUtils.isExcludedFromDependencyCheck(pd) || this.ignoredDependencyTypes.contains(pd.getPropertyType()) || AutowireUtils.isSetterDefinedInInterface(pd, this.ignoredDependencyInterfaces));
+}
+```
+
+而ignoredDependencyInterface的真正作用还得看AutowireUtils类的isSetterDfinedInInterface方法。
+
+```java
+public static boolean isSetterDefinedInInterface(PropertyDescriptor pd, Set> interfaces) {
+ //获取bean中某个属性对象在bean类中的setter方法
+ Method setter = pd.getWriteMethod();
+ if (setter != null) {
+ // 获取bean的类型
+ Class targetClass = setter.getDeclaringClass();
+ for (Class ifc : interfaces) {
+ if (ifc.isAssignableFrom(targetClass) && // bean类型是否接口的实现类
+ ClassUtils.hasMethod(ifc, setter.getName(), setter.getParameterTypes())) { // 接口是否有入参和bean类型完全相同的setter方法
+ return true;
+ }
+ }
+ }
+ return false;
+}
+```
+
+ignoredDependencyInterface方法并不是让我们在自动装配时直接忽略实现了该接口的依赖。这个方法的真正意思是忽略该接口的实现类中和接口setter方法入参类型相同的依赖。
+
+举个例子。首先定义一个要被忽略的接口。
+
+```java
+public interface IgnoreInterface {
+
+ void setList(List list);
+
+ void setSet(Set set);
+}
+```
+
+然后需要实现该接口,在实现类中注意要有setter方法入参相同类型的域对象,在例子中就是`List`和`Set`。
+
+```java
+public class IgnoreInterfaceImpl implements IgnoreInterface {
+
+ private List list;
+ private Set set;
+
+ @Override
+ public void setList(List list) {
+ this.list = list;
+ }
+
+ @Override
+ public void setSet(Set set) {
+ this.set = set;
+ }
+
+ public List getList() {
+ return list;
+ }
+
+ public Set getSet() {
+ return set;
+ }
+}
+```
+
+定义xml配置文件:
+
+```xml
+
+
+
+
+
+
+ ]
+ foo
+ bar
+
+
+
+
+
+
+
+ foo
+ bar
+
+
+
+
+
+
+
+```
+
+最后调用ignoreDependencyInterface:
+
+```xml
+beanFactory.ignoreDependencyInterface(IgnoreInterface.class);
+```
+
+运行结果:
+
+```
+null
+null
+```
+
+而如果不调用ignoreDependencyInterface,则是:
+
+```
+[foo, bar]
+[bar, foo]
+```
+
+我们最初理解是在自动装配时忽略该接口的实现,实际上是在自动装配时忽略该接口实现类中和setter方法入参相同的类型,也就是忽略该接口实现类中存在依赖外部的bean属性注入。
+
+典型应用就是BeanFactoryAware和ApplicationContextAware接口。
+
+首先看该两个接口的源码:
+
+```java
+public interface BeanFactoryAware extends Aware {
+ void setBeanFactory(BeanFactory beanFactory) throws BeansException;
+}
+
+public interface ApplicationContextAware extends Aware {
+ void setApplicationContext(ApplicationContext applicationContext) throws BeansException;
+}
+```
+
+在Spring源码中在不同的地方忽略了该两个接口:
+
+```java
+beanFactory.ignoreDependencyInterface(ApplicationContextAware.class);
+ignoreDependencyInterface(BeanFactoryAware.class);
+```
+
+使得我们的BeanFactoryAware接口实现类在自动装配时不能被注入BeanFactory对象的依赖:
+
+```java
+public class MyBeanFactoryAware implements BeanFactoryAware {
+ private BeanFactory beanFactory; // 自动装配时忽略注入
+
+ @Override
+ public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
+ this.beanFactory = beanFactory;
+ }
+
+ public BeanFactory getBeanFactory() {
+ return beanFactory;
+ }
+}
+```
+
+ApplicationContextAware接口实现类中的ApplicationContext对象的依赖同理:
+
+```java
+public class MyApplicationContextAware implements ApplicationContextAware {
+ private ApplicationContext applicationContext; // 自动装配时被忽略注入
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ this.applicationContext = applicationContext;
+ }
+
+ public ApplicationContext getApplicationContext() {
+ return applicationContext;
+ }
+}
+```
+
+这样的做法使得ApplicationContextAware和BeanFactoryAware中的ApplicationContext或BeanFactory依赖在自动装配时被忽略,而统一由框架设置依赖,如ApplicationContextAware接口的设置会在ApplicationContextAwareProcessor类中完成:
+
+```java
+private void invokeAwareInterfaces(Object bean) {
+ if (bean instanceof Aware) {
+ if (bean instanceof EnvironmentAware) {
+ ((EnvironmentAware) bean).setEnvironment(this.applicationContext.getEnvironment());
+ }
+ if (bean instanceof EmbeddedValueResolverAware) {
+ ((EmbeddedValueResolverAware) bean).setEmbeddedValueResolver(this.embeddedValueResolver);
+ }
+ if (bean instanceof ResourceLoaderAware) {
+ ((ResourceLoaderAware) bean).setResourceLoader(this.applicationContext);
+ }
+ if (bean instanceof ApplicationEventPublisherAware) {
+ ((ApplicationEventPublisherAware) bean).setApplicationEventPublisher(this.applicationContext);
+ }
+ if (bean instanceof MessageSourceAware) {
+ ((MessageSourceAware) bean).setMessageSource(this.applicationContext);
+ }
+ if (bean instanceof ApplicationContextAware) {
+ ((ApplicationContextAware) bean).setApplicationContext(this.applicationContext);
+ }
+ }
+}
+```
+
+通过这种方式保证了ApplicationContextAware和BeanFactoryAware中的容器保证是生成该bean的容器。
+
+
+
+### bean加载
+
+在之前XmlBeanFactory构造函数中调用了XmlBeanDefinitionReader类型的reader属性提供的方法
+
+this.reader.loadBeanDefinitions(resource),而这句代码则是整个资源加载的切入点,这个方法的时序图如下:
+
+
+
+我们来梳理下上述时序图的处理过程:
+
+(1)封装资源文件。当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装
+(2)获取输入流。从Resource中获取对应的InputStream并构造InputSource
+(3)通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions,loadBeanDefinitions函数具体的实现过程:
+
+```java
+public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
+ Assert.notNull(encodedResource, "EncodedResource must not be null");
+ if (logger.isTraceEnabled()) {
+ logger.trace("Loading XML bean definitions from " + encodedResource);
+ }
+
+ Set currentResources = this.resourcesCurrentlyBeingLoaded.get();
+ if (currentResources == null) {
+ currentResources = new HashSet<>(4);
+ this.resourcesCurrentlyBeingLoaded.set(currentResources);
+ }
+ if (!currentResources.add(encodedResource)) {
+ throw new BeanDefinitionStoreException(
+ "Detected cyclic loading of " + encodedResource + " - check your import definitions!");
+ }
+ try {
+ InputStream inputStream = encodedResource.getResource().getInputStream();
+ try {
+ InputSource inputSource = new InputSource(inputStream);
+ if (encodedResource.getEncoding() != null) {
+ inputSource.setEncoding(encodedResource.getEncoding());
+ }
+ return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
+ }
+ finally {
+ inputStream.close();
+ }
+ }
+ ...
+}
+```
+
+EncodedResource的作用是对资源文件的编码进行处理的,其中的主要逻辑体现在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码,在构造好了encodeResource对象后,再次转入了可复用方法loadBeanDefinitions(new EncodedResource(resource)),这个方法内部才是真正的数据准备阶段,代码如下:
+
+```java
+protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
+ throws BeanDefinitionStoreException {
+ try {
+ // 获取 Document 实例
+ Document doc = doLoadDocument(inputSource, resource);
+ // 根据 Document 实例****注册 Bean信息
+ return registerBeanDefinitions(doc, resource);
+ }
+ ...
+}
+```
+
+核心部分就是 try 块的两行代码。
+
+1. 调用 `doLoadDocument()` 方法,根据 xml 文件获取 Document 实例。
+2. 根据获取的 Document 实例注册 Bean 信息
+
+其实在`doLoadDocument()`方法内部还获取了 xml 文件的验证模式。如下:
+
+```java
+protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
+ return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
+ getValidationModeForResource(resource), isNamespaceAware());
+}
+```
+
+调用 `getValidationModeForResource()` 获取指定资源(xml)的验证模式。所以 `doLoadBeanDefinitions()`主要就是做了三件事情。
+
+1. 调用 `getValidationModeForResource()` 获取 xml 文件的验证模式
+ 2. 调用 `loadDocument()` 根据 xml 文件获取相应的 Document 实例。
+ 3. 调用 `registerBeanDefinitions()` 注册 Bean 实例。
+
+### 获取XML的验证模式
+
+#### *DTD和XSD区别*
+
+DTD(Document Type Definition)即文档类型定义,是一种XML约束模式语言,是XML文件的验证机制,属于XML文件组成的一部分。DTD是一种保证XML文档格式正确的有效方法,可以通过比较XML文档和DTD文件来看文档是否符合规范,元素和标签使用是否正确。一个DTD文档包含:元素的定义规则,元素间关系的定义规则,元素可使用的属性,可使用的实体或符合规则。
+
+使用DTD验证模式的时候需要在XML文件的头部声明,以下是在Spring中使用DTD声明方式的代码:
+
+```xml
+
+
+```
+
+XML Schema语言就是XSD(XML Schemas Definition)。XML Schema描述了XML文档的结构,可以用一个指定的XML Schema来验证某个XML文档,以检查该XML文档是否符合其要求,文档设计者可以通过XML Schema指定一个XML文档所允许的结构和内容,并可据此检查一个XML文档是否是有效的。
+
+在使用XML Schema文档对XML实例文档进行检验,除了要声明**名称空间**外(**xmlns=http://www.Springframework.org/schema/beans**),还必须指定该名称空间所对应的**XML Schema文档的存储位置**,通过**schemaLocation**属性来指定名称空间所对应的XML Schema文档的存储位置,它包含两个部分,一部分是名称空间的URI,另一部分就该名称空间所标识的XML Schema文件位置或URL地址(xsi:schemaLocation=”http://www.Springframework.org/schema/beans **http://www.Springframework.org/schema/beans/Spring-beans.xsd**“),代码如下:
+
+```xml
+
+
+
+
+
+
+```
+
+#### *验证模式的读取*
+
+在spring中,是通过getValidationModeForResource方法来获取对应资源的验证模式,其源码如下:
+
+```java
+protected int getValidationModeForResource(Resource resource) {
+ int validationModeToUse = getValidationMode();
+ if (validationModeToUse != VALIDATION_AUTO) {
+ return validationModeToUse;
+ }
+ int detectedMode = detectValidationMode(resource);
+ if (detectedMode != VALIDATION_AUTO) {
+ return detectedMode;
+ }
+ // Hmm, we didn't get a clear indication... Let's assume XSD,
+ // since apparently no DTD declaration has been found up until
+ // detection stopped (before finding the document's root tag).
+ return VALIDATION_XSD;
+}
+```
+
+方法的实现还是很简单的,如果设定了验证模式则使用设定的验证模式(可以通过使用XmlBeanDefinitionReader中的setValidationMode方法进行设定),否则使用自动检测的方式。而自动检测验证模式的功能是在函数detectValidationMode方法中,而在此方法中又将自动检测验证模式的工作委托给了专门处理类XmlValidationModeDetector的validationModeDetector方法,具体代码如下:
+
+```java
+public int detectValidationMode(InputStream inputStream) throws IOException {
+ // Peek into the file to look for DOCTYPE.
+ BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream));
+ try {
+ boolean isDtdValidated = false;
+ String content;
+ while ((content = reader.readLine()) != null) {
+ content = consumeCommentTokens(content);
+ if (this.inComment || !StringUtils.hasText(content)) {
+ continue;
+ }
+ if (hasDoctype(content)) {
+ isDtdValidated = true;
+ break;
+ }
+ if (hasOpeningTag(content)) {
+ // End of meaningful data...
+ break;
+ }
+ }
+ return (isDtdValidated ? VALIDATION_DTD : VALIDATION_XSD);
+ }
+ catch (CharConversionException ex) {
+ // Choked on some character encoding...
+ // Leave the decision up to the caller.
+ return VALIDATION_AUTO;
+ }
+ finally {
+ reader.close();
+ }
+}
+```
+
+从代码中看,主要是通过读取 XML 文件的内容,判断内容中是否包含有 DOCTYPE ,如果是 则为 DTD,否则为 XSD,当然只会读取到 第一个 “<” 处,因为 验证模式一定会在第一个 “<” 之前。如果当中出现了 CharConversionException 异常,则为 XSD模式。
+
+
+
+### 获取Document
+
+经过了验证模式准备的步骤就可以进行Document加载了,对于文档的读取委托给了DocumentLoader去执行,这里的DocumentLoader是个接口,而真正调用的是DefaultDocumentLoader,解析代码如下:
+
+```java
+public Document loadDocument(InputSource inputSource, EntityResolver entityResolver,
+ ErrorHandler errorHandler, int validationMode, boolean namespaceAware) throws Exception {
+ DocumentBuilderFactory factory = createDocumentBuilderFactory(validationMode, namespaceAware);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Using JAXP provider [" + factory.getClass().getName() + "]");
+ }
+ DocumentBuilder builder = createDocumentBuilder(factory, entityResolver, errorHandler);
+ return builder.parse(inputSource);
+}
+```
+
+分析代码,首选创建DocumentBuildFactory,再通过DocumentBuilderFactory创建DocumentBuilder,进而解析InputSource来返回Document对象。对于参数entityResolver,传入的是通过getEntityResolver()函数获取的返回值,代码如下:
+
+```java
+protected EntityResolver getEntityResolver() {
+ if (this.entityResolver == null) {
+ // Determine default EntityResolver to use.
+ ResourceLoader resourceLoader = getResourceLoader();
+ if (resourceLoader != null) {
+ this.entityResolver = new ResourceEntityResolver(resourceLoader);
+ }
+ else {
+ this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
+ }
+ }
+ return this.entityResolver;
+}
+```
+
+这个entityResolver是做什么用的呢,接下来我们详细分析下。
+
+#### EntityResolver 的用法
+
+对于解析一个XML,SAX首先读取该XML文档上的声明,根据声明去寻找相应的DTD定义,以便对文档进行一个验证,默认的寻找规则,即通过网络(实现上就是声明DTD的URI地址)来下载相应的DTD声明,并进行认证。下载的过程是一个漫长的过程,而且当网络中断或不可用时,这里会报错,就是因为相应的DTD声明没有被找到的原因.
+
+EntityResolver的作用是项目本身就可以提供一个如何寻找DTD声明的方法,即由程序来实现寻找DTD声明的过程,比如将DTD文件放到项目中某处,在实现时直接将此文档读取并返回给SAX即可,在EntityResolver的接口只有一个方法声明:
+
+```java
+public abstract InputSource resolveEntity (String publicId, String systemId)
+ throws SAXException, IOException;
+```
+
+它接收两个参数publicId和systemId,并返回一个InputSource对象,以特定配置文件来进行讲解
+
+(1)如果在解析验证模式为XSD的配置文件,代码如下:
+
+```xml
+
+
+....
+
+```
+
+则会读取到以下两个参数
+
+- publicId:null
+- systemId:[http://www.Springframework.org/schema/beans/Spring-beans.xsd](http://www.springframework.org/schema/beans/Spring-beans.xsd)
+
+
+
+(2)如果解析验证模式为DTD的配置文件,代码如下:
+
+```xml
+
+
+....
+
+```
+
+读取到以下两个参数
+- publicId:-//Spring//DTD BEAN 2.0//EN
+- systemId:http://www.Springframework.org/dtd/Spring-beans-2.0.dtd
+
+
+
+一般都会把验证文件放置在自己的工程里,如果把URL转换为自己工程里对应的地址文件呢?以加载DTD文件为例来看看Spring是如何实现的。根据之前Spring中通过getEntityResolver()方法对EntityResolver的获取,我们知道,Spring中使用DelegatingEntityResolver类为EntityResolver的实现类,resolveEntity实现方法如下:
+
+```java
+@Override
+@Nullable
+public InputSource resolveEntity(String publicId, @Nullable String systemId) throws SAXException, IOException {
+ if (systemId != null) {
+ if (systemId.endsWith(DTD_SUFFIX)) {
+ return this.dtdResolver.resolveEntity(publicId, systemId);
+ }
+ else if (systemId.endsWith(XSD_SUFFIX)) {
+ return this.schemaResolver.resolveEntity(publicId, systemId);
+ }
+ }
+ return null;
+}
+```
+
+不同的验证模式使用不同的解析器解析,比如加载DTD类型的BeansDtdResolver的resolveEntity是直接截取systemId最后的xx.dtd然后去当前路径下寻找,而加载XSD类型的PluggableSchemaResolver类的resolveEntity是默认到META-INF/Spring.schemas文件中找到systemId所对应的XSD文件并加载。 BeansDtdResolver 的解析过程如下:
+
+```java
+public InputSource resolveEntity(String publicId, @Nullable String systemId) throws IOException {
+ if (logger.isTraceEnabled()) {
+ logger.trace("Trying to resolve XML entity with public ID [" + publicId +
+ "] and system ID [" + systemId + "]");
+ }
+ if (systemId != null && systemId.endsWith(DTD_EXTENSION)) {
+ int lastPathSeparator = systemId.lastIndexOf('/');
+ int dtdNameStart = systemId.indexOf(DTD_NAME, lastPathSeparator);
+ if (dtdNameStart != -1) {
+ String dtdFile = DTD_NAME + DTD_EXTENSION;
+ if (logger.isTraceEnabled()) {
+ logger.trace("Trying to locate [" + dtdFile + "] in Spring jar on classpath");
+ }
+ try {
+ Resource resource = new ClassPathResource(dtdFile, getClass());
+ InputSource source = new InputSource(resource.getInputStream());
+ source.setPublicId(publicId);
+ source.setSystemId(systemId);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Found beans DTD [" + systemId + "] in classpath: " + dtdFile);
+ }
+ return source;
+ }
+ catch (IOException ex) {
+ if (logger.isDebugEnabled()) {
+ logger.debug("Could not resolve beans DTD [" + systemId + "]: not found in classpath", ex);
+ }
+ }
+ }
+ }
+ return null;
+}
+```
+
+从上面的代码中我们可以看到加载 DTD 类型的 `BeansDtdResolver.resolveEntity()` 只是对 systemId 进行了简单的校验(从最后一个 / 开始,内容中是否包含 `spring-beans`),然后构造一个 InputSource 并设置 publicId、systemId,然后返回。 PluggableSchemaResolver 的解析过程如下:
+
+```java
+public InputSource resolveEntity(String publicId, @Nullable String systemId) throws IOException {
+ if (logger.isTraceEnabled()) {
+ logger.trace("Trying to resolve XML entity with public id [" + publicId +
+ "] and system id [" + systemId + "]");
+ }
+
+ if (systemId != null) {
+ String resourceLocation = getSchemaMappings().get(systemId);
+ if (resourceLocation != null) {
+ Resource resource = new ClassPathResource(resourceLocation, this.classLoader);
+ try {
+ InputSource source = new InputSource(resource.getInputStream());
+ source.setPublicId(publicId);
+ source.setSystemId(systemId);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Found XML schema [" + systemId + "] in classpath: " + resourceLocation);
+ }
+ return source;
+ }
+ catch (FileNotFoundException ex) {
+ if (logger.isDebugEnabled()) {
+ logger.debug("Couldn't find XML schema [" + systemId + "]: " + resource, ex);
+ }
+ }
+ }
+ }
+ return null;
+}
+```
+
+首先调用 getSchemaMappings() 获取一个映射表(systemId 与其在本地的对照关系),然后根据传入的 systemId 获取该 systemId 在本地的路径 resourceLocation,最后根据 resourceLocation 构造 InputSource 对象。 映射表如下(部分):
+
+
+
+### 解析及注册BeanDefinitions
+
+当把文件转换成Document后,接下来就是对bean的提取及注册,当程序已经拥有了XML文档文件的Document实例对象时,就会被引入到XmlBeanDefinitionReader.registerBeanDefinitions这个方法:
+
+```java
+public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
+ BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
+ int countBefore = getRegistry().getBeanDefinitionCount();
+ documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
+ return getRegistry().getBeanDefinitionCount() - countBefore;
+}
+```
+
+其中的doc参数即为上节读取的document,而BeanDefinitionDocumentReader是一个接口,而实例化的工作是在createBeanDefinitionDocumentReader()中完成的,而通过此方法,BeanDefinitionDocumentReader真正的类型其实已经是DefaultBeanDefinitionDocumentReader了,进入DefaultBeanDefinitionDocumentReader后,发现这个方法的重要目的之一就是提取root,以便于再次将root作为参数继续BeanDefinition的注册,如下代码:
+
+```java
+public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
+ this.readerContext = readerContext;
+ logger.debug("Loading bean definitions");
+ Element root = doc.getDocumentElement();
+ doRegisterBeanDefinitions(root);
+}
+```
+
+通过这里我们看到终于到了解析逻辑的核心方法doRegisterBeanDefinitions,接着跟踪源码如下:
+
+```java
+protected void doRegisterBeanDefinitions(Element root) {
+ BeanDefinitionParserDelegate parent = this.delegate;
+ this.delegate = createDelegate(getReaderContext(), root, parent);
+ if (this.delegate.isDefaultNamespace(root)) {
+ String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
+ if (StringUtils.hasText(profileSpec)) {
+ String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
+ profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
+ if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
+ if (logger.isInfoEnabled()) {
+ logger.info("Skipped XML bean definition file due to specified profiles [" + profileSpec +
+ "] not matching: " + getReaderContext().getResource());
+ }
+ return;
+ }
+ }
+ }
+ preProcessXml(root);
+ parseBeanDefinitions(root, this.delegate);
+ postProcessXml(root);
+ this.delegate = parent;
+}
+```
+
+我们看到首先要解析profile属性,然后才开始XML的读取,具体的代码如下:
+
+```java
+protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
+ if (delegate.isDefaultNamespace(root)) {
+ NodeList nl = root.getChildNodes();
+ for (int i = 0; i < nl.getLength(); i++) {
+ Node node = nl.item(i);
+ if (node instanceof Element) {
+ Element ele = (Element) node;
+ if (delegate.isDefaultNamespace(ele)) {
+ parseDefaultElement(ele, delegate);
+ }
+ else {
+ delegate.parseCustomElement(ele);
+ }
+ }
+ }
+ }
+ else {
+ delegate.parseCustomElement(root);
+ }
+}
+```
+
+最终解析动作落地在两个方法处:`parseDefaultElement(ele, delegate)` 和 `delegate.parseCustomElement(root)`。我们知道在 Spring 有两种 Bean 声明方式:
+
+- 配置文件式声明:``
+- 自定义注解方式:``
+
+两种方式的读取和解析都存在较大的差异,所以采用不同的解析方法,如果根节点或者子节点采用默认命名空间的话,则调用 `parseDefaultElement()` 进行解析,否则调用 `delegate.parseCustomElement()` 方法进行自定义解析。
+
+而判断是否默认命名空间还是自定义命名空间的办法其实是使用node.getNamespaceURI()获取命名空间,并与Spring中固定的命名空间http://www.springframework.org/schema/beans进行对比,如果一致则认为是默认,否则就认为是自定义。
+
+#### profile的用法
+
+通过profile标记不同的环境,可以通过设置spring.profiles.active和spring.profiles.default激活指定profile环境。如果设置了active,default便失去了作用。如果两个都没有设置,那么带有profiles的bean都不会生成。
+
+配置spring配置文件最下面配置如下beans
+
+```xml
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+```
+
+配置web.xml
+
+```xml
+
+
+ spring.profiles.default
+ production
+
+
+
+
+
+ spring.profiles.active
+ test
+
+```
+
+这样启动的时候就可以按照切换spring.profiles.active的属性值来进行切换了。
\ No newline at end of file
diff --git "a/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213\345\276\252\347\216\257\344\276\235\350\265\226\345\244\204\347\220\206.md" "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213\345\276\252\347\216\257\344\276\235\350\265\226\345\244\204\347\220\206.md"
new file mode 100644
index 0000000..328c93d
--- /dev/null
+++ "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\344\271\213\345\276\252\347\216\257\344\276\235\350\265\226\345\244\204\347\220\206.md"
@@ -0,0 +1,178 @@
+## **什么是循环依赖**
+
+循环依赖其实就是循环引用,也就是两个或则两个以上的bean互相持有对方,最终形成闭环。比如A依赖于B,B依赖于C,C又依赖于A。如下图所示:
+
+
+
+注意,这里不是函数的循环调用,是对象的相互依赖关系。循环调用其实就是一个死循环,除非有终结条件。
+
+Spring中循环依赖场景有:
+
+(1)构造器的循环依赖
+
+(2)field属性的循环依赖。
+
+对于构造器的循环依赖,Spring 是无法解决的,只能抛出 BeanCurrentlyInCreationException 异常表示循环依赖,所以下面我们分析的都是基于 field 属性的循环依赖。
+
+Spring 只解决 scope 为 singleton 的循环依赖,对于scope 为 prototype 的 bean Spring 无法解决,直接抛出 BeanCurrentlyInCreationException 异常。
+
+### **如何检测循环依赖**
+
+检测循环依赖相对比较容易,Bean在创建的时候可以给该Bean打标,如果递归调用回来发现正在创建中的话,即说明了循环依赖了。
+
+### 解决循环依赖
+
+我们先从加载 bean 最初始的方法 `doGetBean()` 开始。
+
+在 `doGetBean()` 中,首先会根据 beanName 从单例 bean 缓存中获取,如果不为空则直接返回。
+
+```java
+protected Object getSingleton(String beanName, boolean allowEarlyReference) {
+ Object singletonObject = this.singletonObjects.get(beanName);
+ if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
+ synchronized (this.singletonObjects) {
+ singletonObject = this.earlySingletonObjects.get(beanName);
+ if (singletonObject == null && allowEarlyReference) {
+ ObjectFactory singletonFactory = this.singletonFactories.get(beanName);
+ if (singletonFactory != null) {
+ singletonObject = singletonFactory.getObject();
+ this.earlySingletonObjects.put(beanName, singletonObject);
+ this.singletonFactories.remove(beanName);
+ }
+ }
+ }
+ }
+ return singletonObject;
+}
+```
+
+这个方法主要是从三个缓存中获取,分别是:singletonObjects、earlySingletonObjects、singletonFactories,三者定义如下:
+
+```java
+private final Map singletonObjects = new ConcurrentHashMap<>(256);
+
+private final Map> singletonFactories = new HashMap<>(16);
+
+private final Map earlySingletonObjects = new HashMap<>(16);
+```
+
+这三级缓存分别指:
+
+(1)singletonFactories : 单例对象工厂的cache
+
+(2)earlySingletonObjects :提前暴光的单例对象的Cache
+
+(3)singletonObjects:单例对象的cache
+
+他们就是 Spring 解决 singleton bean 的关键因素所在,我称他们为三级缓存,第一级为 singletonObjects,第二级为 earlySingletonObjects,第三级为 singletonFactories。这里我们可以通过 `getSingleton()` 看到他们是如何配合的,这分析该方法之前,提下其中的 `isSingletonCurrentlyInCreation()` 和 `allowEarlyReference`。
+
+- `isSingletonCurrentlyInCreation()`:判断当前 singleton bean 是否处于创建中。bean 处于创建中也就是说 bean 在初始化但是没有完成初始化,有一个这样的过程其实和 Spring 解决 bean 循环依赖的理念相辅相成,因为 Spring 解决 singleton bean 的核心就在于提前曝光 bean。
+- allowEarlyReference:从字面意思上面理解就是允许提前拿到引用。其实真正的意思是是否允许从 singletonFactories 缓存中通过 `getObject()` 拿到对象,为什么会有这样一个字段呢?原因就在于 singletonFactories 才是 Spring 解决 singleton bean 的诀窍所在,这个我们后续分析。
+
+`getSingleton()` 整个过程如下:首先从一级缓存 singletonObjects 获取,如果没有且当前指定的 beanName 正在创建,就再从二级缓存中 earlySingletonObjects 获取,如果还是没有获取到且运行 singletonFactories 通过 `getObject()` 获取,则从三级缓存 singletonFactories 获取,如果获取到则,通过其 `getObject()` 获取对象,并将其加入到二级缓存 earlySingletonObjects 中 从三级缓存 singletonFactories 删除,如下:
+
+```java
+singletonObject = singletonFactory.getObject();
+this.earlySingletonObjects.put(beanName, singletonObject);
+this.singletonFactories.remove(beanName);
+```
+
+这样就从三级缓存升级到二级缓存了。
+
+上面是从缓存中获取,但是缓存中的数据从哪里添加进来的呢?一直往下跟会发现在 `doCreateBean()` ( AbstractAutowireCapableBeanFactory ) 中,有这么一段代码:
+
+```java
+boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
+if (earlySingletonExposure) {
+ if (logger.isDebugEnabled()) {
+ logger.debug("Eagerly caching bean '" + beanName +
+ "' to allow for resolving potential circular references");
+ }
+ addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
+}
+```
+
+也就是我们上一篇文章中讲的最后一部分,提前将创建好但还未进行属性赋值的的Bean放入缓存中。
+
+如果 `earlySingletonExposure == true` 的话,则调用 `addSingletonFactory()` 将他们添加到缓存中,但是一个 bean 要具备如下条件才会添加至缓存中:
+
+- 单例
+- 运行提前暴露 bean
+- 当前 bean 正在创建中
+
+`addSingletonFactory()` 代码如下:
+
+```java
+protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) {
+ Assert.notNull(singletonFactory, "Singleton factory must not be null");
+ synchronized (this.singletonObjects) {
+ if (!this.singletonObjects.containsKey(beanName)) {
+ this.singletonFactories.put(beanName, singletonFactory);
+ this.earlySingletonObjects.remove(beanName);
+ this.registeredSingletons.add(beanName);
+ }
+ }
+}
+```
+
+从这段代码我们可以看出 singletonFactories 这个三级缓存才是解决 Spring Bean 循环依赖的诀窍所在。同时这段代码发生在 `createBeanInstance()` 方法之后,也就是说这个 bean 其实已经被创建出来了,但是它还不是很完美(没有进行属性填充和初始化),但是对于其他依赖它的对象而言已经足够了(可以根据对象引用定位到堆中对象),能够被认出来了,所以 Spring 在这个时候选择将该对象提前曝光出来让大家认识认识。
+
+介绍到这里我们发现三级缓存 singletonFactories 和 二级缓存 earlySingletonObjects 中的值都有出处了,那一级缓存在哪里设置的呢?在类 DefaultSingletonBeanRegistry 中可以发现这个 `addSingleton()` 方法,源码如下:
+
+```java
+protected void addSingleton(String beanName, Object singletonObject) {
+ synchronized (this.singletonObjects) {
+ this.singletonObjects.put(beanName, singletonObject);
+ this.singletonFactories.remove(beanName);
+ this.earlySingletonObjects.remove(beanName);
+ this.registeredSingletons.add(beanName);
+ }
+}
+```
+
+添加至一级缓存,同时从二级、三级缓存中删除。这个方法在我们创建 bean 的链路中有哪个地方引用呢?其实在前面博客已经提到过了,在 `doGetBean()` 处理不同 scope 时,如果是 singleton,则调用 `getSingleton()`,如下:
+
+```java
+if (mbd.isSingleton()) {
+ sharedInstance = getSingleton(beanName, () -> {
+ try {
+ return createBean(beanName, mbd, args);
+ }
+ catch (BeansException ex) {
+ // Explicitly remove instance from singleton cache: It might have been put there
+ // eagerly by the creation process, to allow for circular reference resolution.
+ // Also remove any beans that received a temporary reference to the bean.
+ destroySingleton(beanName);
+ throw ex;
+ }
+ });
+ bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
+}
+```
+
+
+
+```java
+public Object getSingleton(String beanName, ObjectFactory singletonFactory) {
+ Assert.notNull(beanName, "Bean name must not be null");
+ synchronized (this.singletonObjects) {
+ Object singletonObject = this.singletonObjects.get(beanName);
+ if (singletonObject == null) {
+ //....
+ try {
+ singletonObject = singletonFactory.getObject();
+ newSingleton = true;
+ }
+ //.....
+ if (newSingleton) {
+ addSingleton(beanName, singletonObject);
+ }
+ }
+ return singletonObject;
+ }
+}
+```
+
+至此,Spring 关于 singleton bean 循环依赖已经分析完毕了。所以我们基本上可以确定 Spring 解决循环依赖的方案了:Spring 在创建 bean 的时候并不是等它完全完成,而是在创建过程中将创建中的 bean 的 ObjectFactory 提前曝光(即加入到 singletonFactories 缓存中),这样一旦下一个 bean 创建的时候需要依赖 bean ,则直接使用 ObjectFactory 的 `getObject()` 获取了,也就是 `getSingleton()`中的代码片段了。
+
+最后来描述下就上面那个循环依赖 Spring 解决的过程:首先 A 完成初始化第一步并将自己提前曝光出来(通过 ObjectFactory 将自己提前曝光),在初始化的时候,发现自己依赖对象 B,此时就会去尝试 get(B),这个时候发现 B 还没有被创建出来,然后 B 就走创建流程,在 B 初始化的时候,同样发现自己依赖 C,C 也没有被创建出来,这个时候 C 又开始初始化进程,但是在初始化的过程中发现自己依赖 A,于是尝试 get(A),这个时候由于 A 已经添加至缓存中(一般都是添加至三级缓存 singletonFactories ),通过 ObjectFactory 提前曝光,所以可以通过 `ObjectFactory.getObject()` 拿到 A 对象,C 拿到 A 对象后顺利完成初始化,然后将自己添加到一级缓存中,回到 B ,B 也可以拿到 C 对象,完成初始化,A 可以顺利拿到 B 完成初始化。到这里整个链路就已经完成了初始化过程了。
\ No newline at end of file
diff --git "a/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\345\261\236\346\200\247\345\241\253\345\205\205.md" "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\345\261\236\346\200\247\345\241\253\345\205\205.md"
new file mode 100644
index 0000000..dc7b99b
--- /dev/null
+++ "b/docs/source/spring/Spring\346\272\220\347\240\201\350\247\243\346\236\220\342\200\224\342\200\224IOC\345\261\236\346\200\247\345\241\253\345\205\205.md"
@@ -0,0 +1,563 @@
+**正文**
+
+`doCreateBean()` 主要用于完成 bean 的创建和初始化工作,我们可以将其分为四个过程:
+
+- `createBeanInstance()` 实例化 bean
+- `populateBean()` 属性填充
+- 循环依赖的处理
+- `initializeBean()` 初始化 bean
+
+第一个过程实例化 bean在前面一篇博客中已经分析完了,这篇博客开始分析 属性填充,也就是 `populateBean()`
+
+```java
+protected void populateBean(String beanName, RootBeanDefinition mbd, BeanWrapper bw) {
+ PropertyValues pvs = mbd.getPropertyValues();
+
+ if (bw == null) {
+ if (!pvs.isEmpty()) {
+ throw new BeanCreationException(
+ mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
+ }
+ else {
+ // Skip property population phase for null instance.
+ return;
+ }
+ }
+
+ // Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
+ // state of the bean before properties are set. This can be used, for example,
+ // to support styles of field injection.
+ boolean continueWithPropertyPopulation = true;
+
+ if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
+ for (BeanPostProcessor bp : getBeanPostProcessors()) {
+ if (bp instanceof InstantiationAwareBeanPostProcessor) {
+ InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
+ //返回值为是否继续填充bean
+ if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
+ continueWithPropertyPopulation = false;
+ break;
+ }
+ }
+ }
+ }
+ //如果后处理器发出停止填充命令则终止后续的执行
+ if (!continueWithPropertyPopulation) {
+ return;
+ }
+
+ if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
+ mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
+ MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
+
+ // Add property values based on autowire by name if applicable.
+ //根据名称自动注入
+ if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
+ autowireByName(beanName, mbd, bw, newPvs);
+ }
+
+ // Add property values based on autowire by type if applicable.
+ //根据类型自动注入
+ if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
+ autowireByType(beanName, mbd, bw, newPvs);
+ }
+
+ pvs = newPvs;
+ }
+ //后处理器已经初始化
+ boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
+ //需要依赖检查
+ boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
+
+ if (hasInstAwareBpps || needsDepCheck) {
+ PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
+ if (hasInstAwareBpps) {
+ for (BeanPostProcessor bp : getBeanPostProcessors()) {
+ if (bp instanceof InstantiationAwareBeanPostProcessor) {
+ InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
+ //对所有需要依赖检查的属性进行后处理
+ pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
+ if (pvs == null) {
+ return;
+ }
+ }
+ }
+ }
+ if (needsDepCheck) {
+ //依赖检查,对应depends-on属性,3.0已经弃用此属性
+ checkDependencies(beanName, mbd, filteredPds, pvs);
+ }
+ }
+ //将属性应用到bean中
+ //将所有ProtertyValues中的属性填充至BeanWrapper中。
+ applyPropertyValues(beanName, mbd, bw, pvs);
+}
+```
+
+我们来分析下populateBean的流程:
+
+(1)首先进行属性是否为空的判断
+
+(2)通过调用InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)方法来控制程序是否继续进行属性填充
+
+(3)根据注入类型(byName/byType)提取依赖的bean,并统一存入PropertyValues中
+
+(4)应用InstantiationAwareBeanPostProcessor的postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName)方法,对属性获取完毕填充前的再次处理,典型的应用是RequiredAnnotationBeanPostProcesser类中对属性的验证
+
+(5)将所有的PropertyValues中的属性填充至BeanWrapper中
+
+上面步骤中有几个地方是我们比较感兴趣的,它们分别是依赖注入(autowireByName/autowireByType)以及属性填充,接下来进一步分析这几个功能的实现细节
+
+
+
+## 自动注入
+
+Spring 会根据注入类型( byName / byType )的不同,调用不同的方法(`autowireByName()` / `autowireByType()`)来注入属性值。
+
+### autowireByName()
+
+```java
+protected void autowireByName(
+ String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
+
+ // 获取 Bean 对象中非简单属性
+ String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
+ for (String propertyName : propertyNames) {
+ // 如果容器中包含指定名称的 bean,则将该 bean 注入到 bean中
+ if (containsBean(propertyName)) {
+ // 递归初始化相关 bean
+ Object bean = getBean(propertyName);
+ // 为指定名称的属性赋予属性值
+ pvs.add(propertyName, bean);
+ // 属性依赖注入
+ registerDependentBean(propertyName, beanName);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Added autowiring by name from bean name '" + beanName +
+ "' via property '" + propertyName + "' to bean named '" + propertyName + "'");
+ }
+ }
+ else {
+ if (logger.isTraceEnabled()) {
+ logger.trace("Not autowiring property '" + propertyName + "' of bean '" + beanName +
+ "' by name: no matching bean found");
+ }
+ }
+ }
+}
+```
+
+该方法逻辑很简单,获取该 bean 的非简单属性,什么叫做非简单属性呢?就是类型为对象类型的属性,但是这里并不是将所有的对象类型都都会找到,比如 8 个原始类型,String 类型 ,Number类型、Date类型、URL类型、URI类型等都会被忽略,如下:
+
+```java
+protected String[] unsatisfiedNonSimpleProperties(AbstractBeanDefinition mbd, BeanWrapper bw) {
+ Set result = new TreeSet<>();
+ PropertyValues pvs = mbd.getPropertyValues();
+ PropertyDescriptor[] pds = bw.getPropertyDescriptors();
+ for (PropertyDescriptor pd : pds) {
+ if (pd.getWriteMethod() != null && !isExcludedFromDependencyCheck(pd) && !pvs.contains(pd.getName()) &&
+ !BeanUtils.isSimpleProperty(pd.getPropertyType())) {
+ result.add(pd.getName());
+ }
+ }
+ return StringUtils.toStringArray(result);
+}
+```
+
+这里获取的就是需要依赖注入的属性。
+
+autowireByName()函数的功能就是根据传入的参数中的pvs中找出已经加载的bean,并递归实例化,然后加入到pvs中
+
+
+
+### autowireByType
+
+autowireByType与autowireByName对于我们理解与使用来说复杂程度相似,但是实现功能的复杂度却不一样,我们看下方法代码:
+
+```java
+protected void autowireByType(
+ String beanName, AbstractBeanDefinition mbd, BeanWrapper bw, MutablePropertyValues pvs) {
+
+ TypeConverter converter = getCustomTypeConverter();
+ if (converter == null) {
+ converter = bw;
+ }
+
+ Set autowiredBeanNames = new LinkedHashSet(4);
+ //寻找bw中需要依赖注入的属性
+ String[] propertyNames = unsatisfiedNonSimpleProperties(mbd, bw);
+ for (String propertyName : propertyNames) {
+ try {
+ PropertyDescriptor pd = bw.getPropertyDescriptor(propertyName);
+ // Don't try autowiring by type for type Object: never makes sense,
+ // even if it technically is a unsatisfied, non-simple property.
+ if (!Object.class.equals(pd.getPropertyType())) {
+ //探测指定属性的set方法
+ MethodParameter methodParam = BeanUtils.getWriteMethodParameter(pd);
+ // Do not allow eager init for type matching in case of a prioritized post-processor.
+ boolean eager = !PriorityOrdered.class.isAssignableFrom(bw.getWrappedClass());
+ DependencyDescriptor desc = new AutowireByTypeDependencyDescriptor(methodParam, eager);
+ //解析指定beanName的属性所匹配的值,并把解析到的属性名称存储在autowiredBeanNames中,
+ Object autowiredArgument = resolveDependency(desc, beanName, autowiredBeanNames, converter);
+ if (autowiredArgument != null) {
+ pvs.add(propertyName, autowiredArgument);
+ }
+ for (String autowiredBeanName : autowiredBeanNames) {
+ //注册依赖
+ registerDependentBean(autowiredBeanName, beanName);
+ if (logger.isDebugEnabled()) {
+ logger.debug("Autowiring by type from bean name '" + beanName + "' via property '" +
+ propertyName + "' to bean named '" + autowiredBeanName + "'");
+ }
+ }
+ autowiredBeanNames.clear();
+ }
+ }
+ catch (BeansException ex) {
+ throw new UnsatisfiedDependencyException(mbd.getResourceDescription(), beanName, propertyName, ex);
+ }
+ }
+}
+```
+
+根据名称第一步与根据属性第一步都是寻找bw中需要依赖注入的属性,然后遍历这些属性并寻找类型匹配的bean,其中最复杂就是寻找类型匹配的bean。spring中提供了对集合的类型注入支持,如使用如下注解方式:
+
+```java
+@Autowired
+private List tests;
+```
+
+这种方式spring会把所有与Test匹配的类型找出来并注入到tests属性中,正是由于这一因素,所以在autowireByType函数,新建了局部遍历autowireBeanNames,用于存储所有依赖的bean,如果只是对非集合类的属性注入来说,此属性并无用处。
+
+对于寻找类型匹配的逻辑实现是封装在了resolveDependency函数中,其实现如下:
+
+```java
+public Object resolveDependency(DependencyDescriptor descriptor, String beanName, Set autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
+ descriptor.initParameterNameDiscovery(getParameterNameDiscoverer());
+ if (descriptor.getDependencyType().equals(ObjectFactory.class)) {
+ //ObjectFactory类注入的特殊处理
+ return new DependencyObjectFactory(descriptor, beanName);
+ }
+ else if (descriptor.getDependencyType().equals(javaxInjectProviderClass)) {
+ //javaxInjectProviderClass类注入的特殊处理
+ return new DependencyProviderFactory().createDependencyProvider(descriptor, beanName);
+ }
+ else {
+ //通用处理逻辑
+ return doResolveDependency(descriptor, descriptor.getDependencyType(), beanName, autowiredBeanNames, typeConverter);
+ }
+}
+
+protected Object doResolveDependency(DependencyDescriptor descriptor, Class type, String beanName,
+ Set autowiredBeanNames, TypeConverter typeConverter) throws BeansException {
+ /*
+ * 用于支持Spring中新增的注解@Value
+ */
+ Object value = getAutowireCandidateResolver().getSuggestedValue(descriptor);
+ if (value != null) {
+ if (value instanceof String) {
+ String strVal = resolveEmbeddedValue((String) value);
+ BeanDefinition bd = (beanName != null && containsBean(beanName) ? getMergedBeanDefinition(beanName) : null);
+ value = evaluateBeanDefinitionString(strVal, bd);
+ }
+ TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
+ return (descriptor.getField() != null ?
+ converter.convertIfNecessary(value, type, descriptor.getField()) :
+ converter.convertIfNecessary(value, type, descriptor.getMethodParameter()));
+ }
+ //如果解析器没有成功解析,则需要考虑各种情况
+ //属性是数组类型
+ if (type.isArray()) {
+ Class componentType = type.getComponentType();
+ //根据属性类型找到beanFactory中所有类型的匹配bean,
+ //返回值的构成为:key=匹配的beanName,value=beanName对应的实例化后的bean(通过getBean(beanName)返回)
+ Map matchingBeans = findAutowireCandidates(beanName, componentType, descriptor);
+ if (matchingBeans.isEmpty()) {
+ //如果autowire的require属性为true而找到的匹配项却为空则只能抛出异常
+ if (descriptor.isRequired()) {
+ raiseNoSuchBeanDefinitionException(componentType, "array of " + componentType.getName(), descriptor);
+ }
+ return null;
+ }
+ if (autowiredBeanNames != null) {
+ autowiredBeanNames.addAll(matchingBeans.keySet());
+ }
+ TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
+ //通过转换器将bean的值转换为对应的type类型
+ return converter.convertIfNecessary(matchingBeans.values(), type);
+ }
+ //属性是Collection类型
+ else if (Collection.class.isAssignableFrom(type) && type.isInterface()) {
+ Class elementType = descriptor.getCollectionType();
+ if (elementType == null) {
+ if (descriptor.isRequired()) {
+ throw new FatalBeanException("No element type declared for collection [" + type.getName() + "]");
+ }
+ return null;
+ }
+ Map matchingBeans = findAutowireCandidates(beanName, elementType, descriptor);
+ if (matchingBeans.isEmpty()) {
+ if (descriptor.isRequired()) {
+ raiseNoSuchBeanDefinitionException(elementType, "collection of " + elementType.getName(), descriptor);
+ }
+ return null;
+ }
+ if (autowiredBeanNames != null) {
+ autowiredBeanNames.addAll(matchingBeans.keySet());
+ }
+ TypeConverter converter = (typeConverter != null ? typeConverter : getTypeConverter());
+ return converter.convertIfNecessary(matchingBeans.values(), type);
+ }
+ //属性是Map类型
+ else if (Map.class.isAssignableFrom(type) && type.isInterface()) {
+ Class keyType = descriptor.getMapKeyType();
+ if (keyType == null || !String.class.isAssignableFrom(keyType)) {
+ if (descriptor.isRequired()) {
+ throw new FatalBeanException("Key type [" + keyType + "] of map [" + type.getName() +
+ "] must be assignable to [java.lang.String]");
+ }
+ return null;
+ }
+ Class valueType = descriptor.getMapValueType();
+ if (valueType == null) {
+ if (descriptor.isRequired()) {
+ throw new FatalBeanException("No value type declared for map [" + type.getName() + "]");
+ }
+ return null;
+ }
+ Map matchingBeans = findAutowireCandidates(beanName, valueType, descriptor);
+ if (matchingBeans.isEmpty()) {
+ if (descriptor.isRequired()) {
+ raiseNoSuchBeanDefinitionException(valueType, "map with value type " + valueType.getName(), descriptor);
+ }
+ return null;
+ }
+ if (autowiredBeanNames != null) {
+ autowiredBeanNames.addAll(matchingBeans.keySet());
+ }
+ return matchingBeans;
+ }
+ else {
+ Map matchingBeans = findAutowireCandidates(beanName, type, descriptor);
+ if (matchingBeans.isEmpty()) {
+ if (descriptor.isRequired()) {
+ raiseNoSuchBeanDefinitionException(type, "", descriptor);
+ }
+ return null;
+ }
+ if (matchingBeans.size() > 1) {
+ String primaryBeanName = determinePrimaryCandidate(matchingBeans, descriptor);
+ if (primaryBeanName == null) {
+ throw new NoUniqueBeanDefinitionException(type, matchingBeans.keySet());
+ }
+ if (autowiredBeanNames != null) {
+ autowiredBeanNames.add(primaryBeanName);
+ }
+ return matchingBeans.get(primaryBeanName);
+ }
+ // We have exactly one match.
+ Map.Entry entry = matchingBeans.entrySet().iterator().next();
+ if (autowiredBeanNames != null) {
+ autowiredBeanNames.add(entry.getKey());
+ }
+ //已经确定只有一个匹配项
+ return entry.getValue();
+ }
+}
+```
+
+主要就是通过Type从BeanFactory中找到对应的benaName,然后通过getBean获取实例
+
+```java
+protected Map findAutowireCandidates(
+ @Nullable String beanName, Class requiredType, DependencyDescriptor descriptor) {
+ //在BeanFactory找到所有Type类型的beanName
+ String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
+ this, requiredType, true, descriptor.isEager());
+ Map result = new LinkedHashMap<>(candidateNames.length);
+
+ //遍历所有的beanName,通过getBean获取
+ for (String candidate : candidateNames) {
+ if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
+ //
+ addCandidateEntry(result, candidate, descriptor, requiredType);
+ }
+ }
+ return result;
+}
+
+private void addCandidateEntry(Map candidates, String candidateName,
+ DependencyDescriptor descriptor, Class requiredType) {
+
+ Object beanInstance = descriptor.resolveCandidate(candidateName, requiredType, this);
+ if (!(beanInstance instanceof NullBean)) {
+ candidates.put(candidateName, beanInstance);
+ }
+}
+
+public Object resolveCandidate(String beanName, Class requiredType, BeanFactory beanFactory)
+ throws BeansException {
+ //通过类型找到beanName,然后再找到其实例
+ return beanFactory.getBean(beanName);
+}
+```
+
+## applyPropertyValues
+
+程序运行到这里,已经完成了对所有注入属性的获取,但是获取的属性是以PropertyValues形式存在的,还并没有应用到已经实例化的bean中,这一工作是在applyPropertyValues中。继续跟踪到方法体中:
+
+```java
+protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
+ if (pvs == null || pvs.isEmpty()) {
+ return;
+ }
+
+ MutablePropertyValues mpvs = null;
+ List original;
+
+ if (System.getSecurityManager() != null) {
+ if (bw instanceof BeanWrapperImpl) {
+ ((BeanWrapperImpl) bw).setSecurityContext(getAccessControlContext());
+ }
+ }
+
+ if (pvs instanceof MutablePropertyValues) {
+ mpvs = (MutablePropertyValues) pvs;
+ //如果mpvs中的值已经被转换为对应的类型那么可以直接设置到beanwapper中
+ if (mpvs.isConverted()) {
+ // Shortcut: use the pre-converted values as-is.
+ try {
+ bw.setPropertyValues(mpvs);
+ return;
+ }
+ catch (BeansException ex) {
+ throw new BeanCreationException(
+ mbd.getResourceDescription(), beanName, "Error setting property values", ex);
+ }
+ }
+ original = mpvs.getPropertyValueList();
+ }
+ else {
+ //如果pvs并不是使用MutablePropertyValues封装的类型,那么直接使用原始的属性获取方法
+ original = Arrays.asList(pvs.getPropertyValues());
+ }
+
+ TypeConverter converter = getCustomTypeConverter();
+ if (converter == null) {
+ converter = bw;
+ }
+ //获取对应的解析器
+ BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
+
+ // Create a deep copy, resolving any references for values.
+ List deepCopy = new ArrayList(original.size());
+ boolean resolveNecessary = false;
+ //遍历属性,将属性转换为对应类的对应属性的类型
+ for (PropertyValue pv : original) {
+ if (pv.isConverted()) {
+ deepCopy.add(pv);
+ }
+ else {
+ String propertyName = pv.getName();
+ Object originalValue = pv.getValue();
+ Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
+ Object convertedValue = resolvedValue;
+ boolean convertible = bw.isWritableProperty(propertyName) &&
+ !PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
+ if (convertible) {
+ convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
+ }
+ // Possibly store converted value in merged bean definition,
+ // in order to avoid re-conversion for every created bean instance.
+ if (resolvedValue == originalValue) {
+ if (convertible) {
+ pv.setConvertedValue(convertedValue);
+ }
+ deepCopy.add(pv);
+ }
+ else if (convertible && originalValue instanceof TypedStringValue &&
+ !((TypedStringValue) originalValue).isDynamic() &&
+ !(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
+ pv.setConvertedValue(convertedValue);
+ deepCopy.add(pv);
+ }
+ else {
+ resolveNecessary = true;
+ deepCopy.add(new PropertyValue(pv, convertedValue));
+ }
+ }
+ }
+ if (mpvs != null && !resolveNecessary) {
+ mpvs.setConverted();
+ }
+
+ // Set our (possibly massaged) deep copy.
+ try {
+ bw.setPropertyValues(new MutablePropertyValues(deepCopy));
+ }
+ catch (BeansException ex) {
+ throw new BeanCreationException(
+ mbd.getResourceDescription(), beanName, "Error setting property values", ex);
+ }
+}
+```
+
+我们来看看具体的属性赋值过程
+
+```java
+public class MyTestBean {
+ private String name ;
+
+ public MyTestBean(String name) {
+ this.name = name;
+ }
+
+ public MyTestBean() {
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+
+
+
+
+```
+
+如上 **bw.setPropertyValues** 最终都会走到如下方法
+
+```java
+@Override
+public void setValue(final @Nullable Object value) throws Exception {
+ //获取writeMethod,也就是我们MyTestBean的setName方法
+ final Method writeMethod = (this.pd instanceof GenericTypeAwarePropertyDescriptor ?
+ ((GenericTypeAwarePropertyDescriptor) this.pd).getWriteMethodForActualAccess() :
+ this.pd.getWriteMethod());
+ if (System.getSecurityManager() != null) {
+ AccessController.doPrivileged((PrivilegedAction