diff --git a/docs/.vuepress/config.ts b/docs/.vuepress/config.ts
index 8fa92a8..63869db 100644
--- a/docs/.vuepress/config.ts
+++ b/docs/.vuepress/config.ts
@@ -8,7 +8,7 @@ import { gitPlugin } from '@vuepress/plugin-git'
export default defineUserConfig({
lang: "zh-CN",
- title: "Java学习&面试指南-程序员大彬",
+ title: "大彬",
description: "Java学习、面试指南,涵盖大部分 Java 程序员所需要掌握的核心知识",
base: "/",
dest: './public',
diff --git a/docs/.vuepress/navbar.ts b/docs/.vuepress/navbar.ts
index 6713299..d2fcdc3 100644
--- a/docs/.vuepress/navbar.ts
+++ b/docs/.vuepress/navbar.ts
@@ -215,6 +215,54 @@ export default navbar([
},
]
},
+
+ {
+ text: "源码解读",
+ icon: "source",
+ children: [
+ {
+ text: "Spring",
+ children: [
+ {text: "整体架构", link: "/source/spring/1-architect.md", icon: "book"},
+ {text: "IOC 容器基本实现", link: "/source/spring/2-ioc-overview", icon: "book"},
+ {text: "IOC默认标签解析(上)", link: "/source/spring/3-ioc-tag-parse-1", icon: "book"},
+ {text: "IOC默认标签解析(下)", link: "/source/spring/4-ioc-tag-parse-2", icon: "book"},
+ {text: "IOC之自定义标签解析", link: "/source/spring/5-ioc-tag-custom.md", icon: "book"},
+ {text: "IOC-开启 bean 的加载", link: "/source/spring/6-bean-load", icon: "book"},
+ {text: "IOC之bean创建", link: "/source/spring/7-bean-build", icon: "book"},
+ {text: "IOC属性填充", link: "/source/spring/8-ioc-attribute-fill", icon: "book"},
+ {text: "IOC之循环依赖处理", link: "/source/spring/9-ioc-circular-dependency", icon: "book"},
+ {text: "IOC之bean 的初始化", link: "/source/spring/10-bean-initial", icon: "book"},
+ {text: "ApplicationContext容器refresh过程", link: "/source/spring/11-application-refresh", icon: "book"},
+ {text: "AOP的使用及AOP自定义标签", link: "/source/spring/12-aop-custom-tag", icon: "book"},
+ {text: "创建AOP代理之获取增强器", link: "/source/spring/13-aop-proxy-advisor", icon: "book"},
+ {text: "AOP代理的生成", link: "/source/spring/14-aop-proxy-create", icon: "book"},
+ {text: "AOP目标方法和增强方法的执行", link: "/source/spring/15-aop-advice-create", icon: "book"},
+ {text: "@Transactional注解的声明式事物介绍", link: "/source/spring/16-transactional", icon: "book"},
+ {text: "Spring事务是怎么通过AOP实现的?", link: "/source/spring/17-spring-transaction-aop", icon: "book"},
+ {text: "事务增强器", link: "/source/spring/18-transaction-advice", icon: "book"},
+ {text: "事务的回滚和提交", link: "/source/spring/19-transaction-rollback-commit", icon: "book"},
+ ]
+ },
+ {
+ text: "SpringMVC",
+ children: [
+ {text: "文件上传和拦截器", link: "/source/spring-mvc/1-overview", icon: "book"},
+ {text: "导读篇", link: "/source/spring-mvc/2-guide", icon: "book"},
+ {text: "场景分析", link: "/source/spring-mvc/3-scene", icon: "book"},
+ {text: "事务的回滚和提交", link: "/source/spring-mvc/4-fileupload-interceptor", icon: "book"},
+ ]
+ },
+ {
+ text: "MyBatis(更新中)",
+ children: [
+ {text: "整体架构", link: "/source/mybatis/1-overview", icon: "book"},
+ {text: "反射模块", link: "/source/mybatis/2-reflect", icon: "book"},
+ ]
+ },
+
+ ]
+ },
//{
// text: "场景题",
// icon: "design",
diff --git a/docs/README.md b/docs/README.md
index f38c835..9f8ba39 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -47,10 +47,6 @@ projects:
[ ](https://www.zhihu.com/people/dai-shu-bin-13)
[
](https://www.zhihu.com/people/dai-shu-bin-13)
[ ](https://github.com/Tyson0314/java-books)
-## 秋招提前批信息汇总
-
-[秋招提前批及正式批信息汇总(含内推)](https://docs.qq.com/sheet/DYW9ObnpobXNRTXpq?tab=BB08J2)
-
## 面试手册电子版
本网站所有内容已经汇总成**PDF电子版**,**PDF电子版**在我的[**学习圈**](zsxq/introduce.md)可以获取~
diff --git a/docs/advance/distributed/2-distributed-lock.md b/docs/advance/distributed/2-distributed-lock.md
index a269865..1016022 100644
--- a/docs/advance/distributed/2-distributed-lock.md
+++ b/docs/advance/distributed/2-distributed-lock.md
@@ -181,6 +181,8 @@ public class RedisTest {
前面的方案是基于**Redis单机版**的分布式锁讨论,还不是很完美。因为Redis一般都是集群部署的。
+
+
如果线程一在`Redis`的`master`节点上拿到了锁,但是加锁的`key`还没同步到`slave`节点。恰好这时,`master`节点发生故障,一个`slave`节点就会升级为`master`节点。线程二就可以顺理成章获取同个`key`的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者antirez提出一种高级的分布式锁算法:**Redlock**。它的核心思想是这样的:
@@ -189,6 +191,8 @@ public class RedisTest {
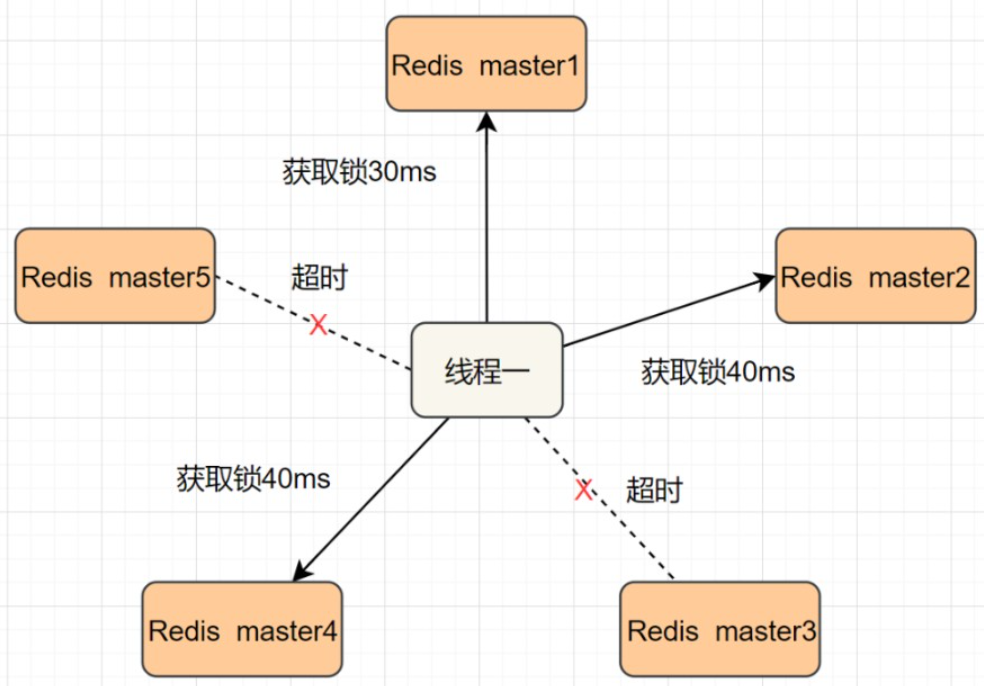
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
+
+
RedLock的实现步骤:
1. 获取当前时间,以毫秒为单位。
@@ -204,6 +208,8 @@ RedLock的实现步骤:
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
+Redisson 实现了 redLock 版本的锁,有兴趣的小伙伴,可以去了解一下。
+
### 基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
diff --git a/docs/advance/distributed/4-micro-service.md b/docs/advance/distributed/4-micro-service.md
index 286e61b..aec218d 100644
--- a/docs/advance/distributed/4-micro-service.md
+++ b/docs/advance/distributed/4-micro-service.md
@@ -47,9 +47,15 @@ head:
## 分布式和微服务的区别
-从概念理解,分布式服务架构强调的是服务化以及服务的**分散化**,微服务则更强调服务的**专业化和精细分工**;
+微服务解决的是系统复杂度问题,一般来说是业务问题,即在一个系统中承担职责太多了,需要打散,便于理解和维护,进而提升系统的开发效率和运行效率,微服务一般来说是针对应用层面的。
-从实践的角度来看,**微服务架构通常是分布式服务架构**,反之则未必成立。
+分布式解决的是系统性能问题,即解决系统部署上单点的问题,尽量让组成系统的子系统分散在不同的机器上进而提高系统的吞吐能力。
+
+两者概念层面也是不一样的,微服务是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分;
+
+而分布式是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机上。
+
+微服务可以是分布式的,即可以将不同服务部署在不同计算机上,当然如果量小也可以部署在单机上。
一句话概括:分布式:分散部署;微服务:分散能力。
diff --git a/docs/advance/excellent-article/10-file-upload.md b/docs/advance/excellent-article/10-file-upload.md
index f483d02..0064765 100644
--- a/docs/advance/excellent-article/10-file-upload.md
+++ b/docs/advance/excellent-article/10-file-upload.md
@@ -345,9 +345,7 @@ public abstract class SliceUploadTemplate implements SliceUploadStrategy {
本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的**md5**值计算,后端写入的速度还是比较快。
-如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:
-
-> https://help.aliyun.com/product/31815.html
+如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器。
阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
diff --git a/docs/advance/excellent-article/29-idempotent-design.md b/docs/advance/excellent-article/29-idempotent-design.md
index 3ab7b34..6cf7d5b 100644
--- a/docs/advance/excellent-article/29-idempotent-design.md
+++ b/docs/advance/excellent-article/29-idempotent-design.md
@@ -12,6 +12,7 @@ head:
- name: description
content: 努力打造最优质的Java学习网站
---
+
## 接口的幂等性如何设计?
分布式系统中的某个接口,该如何保证幂等性?
diff --git a/docs/advance/excellent-article/30-yi-di-duo-huo.md b/docs/advance/excellent-article/30-yi-di-duo-huo.md
new file mode 100644
index 0000000..75657f1
--- /dev/null
+++ b/docs/advance/excellent-article/30-yi-di-duo-huo.md
@@ -0,0 +1,563 @@
+---
+sidebar: heading
+title: 异地多活
+category: 优质文章
+tag:
+ - 架构
+head:
+ - - meta
+ - name: keywords
+ content: 异地多活,同城灾备,同城双活,两地三中心,异地双活,异地多活
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+在软件开发领域,「异地多活」是分布式系统架构设计的一座高峰,很多人经常听过它,但很少人理解其中的原理。
+
+**异地多活到底是什么?为什么需要异地多活?它到底解决了什么问题?究竟是怎么解决的?**
+
+这些疑问,想必是每个程序看到异地多活这个名词时,都想要搞明白的问题。
+
+有幸,我曾经深度参与过一个中等互联网公司,建设异地多活系统的设计与实施过程。所以今天,我就来和你聊一聊异地多活背后的的实现原理。
+
+认真读完这篇文章,我相信你会对异地多活架构,有更加深刻的理解。
+
+**这篇文章干货很多,希望你可以耐心读完。**
+
+
+
+
+
+# 01 系统可用性
+
+要想理解异地多活,我们需要从架构设计的原则说起。
+
+现如今,我们开发一个软件系统,对其要求越来越高,如果你了解一些「架构设计」的要求,就知道一个好的软件架构应该遵循以下 3 个原则:
+
+1. 高性能
+2. 高可用
+3. 易扩展
+
+其中,高性能意味着系统拥有更大流量的处理能力,更低的响应延迟。例如 1 秒可处理 10W 并发请求,接口响应时间 5 ms 等等。
+
+易扩展表示系统在迭代新功能时,能以最小的代价去扩展,系统遇到流量压力时,可以在不改动代码的前提下,去扩容系统。
+
+而「高可用」这个概念,看起来很抽象,怎么理解它呢?通常用 2 个指标来衡量:
+
+- **平均故障间隔 MTBF**(Mean Time Between Failure):表示两次故障的间隔时间,也就是系统「正常运行」的平均时间,这个时间越长,说明系统稳定性越高
+- **故障恢复时间 MTTR**(Mean Time To Repair):表示系统发生故障后「恢复的时间」,这个值越小,故障对用户的影响越小
+
+可用性与这两者的关系:
+
+> 可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
+
+这个公式得出的结果是一个「比例」,通常我们会用「N 个 9」来描述一个系统的可用性。
+
+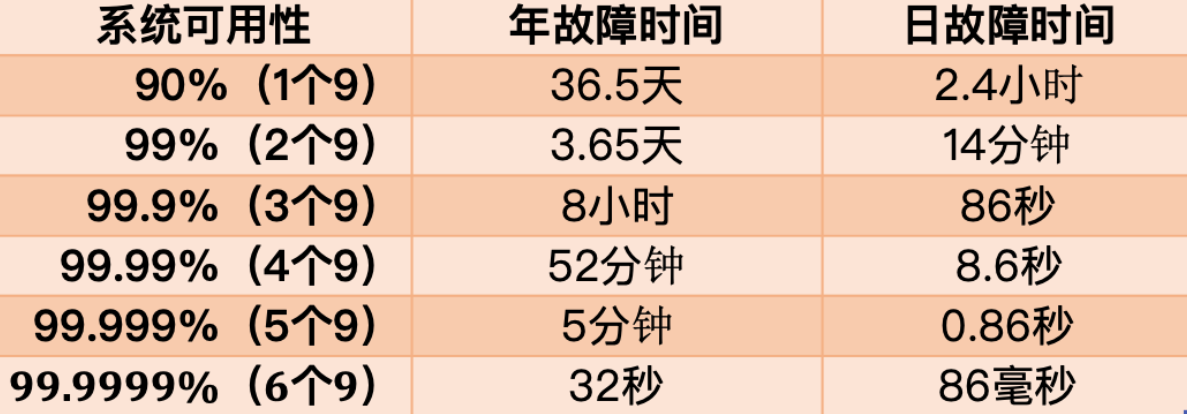
+
+从这张图你可以看到,要想达到 4 个 9 以上的可用性,平均每天故障时间必须控制在 10 秒以内。
+
+也就是说,只有故障的时间「越短」,整个系统的可用性才会越高,每提升 1 个 9,都会对系统提出更高的要求。
+
+我们都知道,系统发生故障其实是不可避免的,尤其是规模越大的系统,发生问题的概率也越大。这些故障一般体现在 3 个方面:
+
+1. **硬件故障**:CPU、内存、磁盘、网卡、交换机、路由器
+2. **软件问题**:代码 Bug、版本迭代
+3. **不可抗力**:地震、水灾、火灾、战争
+
+这些风险随时都有可能发生。所以,在面对故障时,我们的系统能否以「最快」的速度恢复,就成为了可用性的关键。
+
+可如何做到快速恢复呢?
+
+这篇文章要讲的「异地多活」架构,就是为了解决这个问题,而提出的高效解决方案。
+
+下面,我会从一个最简单的系统出发,带你一步步演化出一个支持「异地多活」的系统架构。
+
+在这个过程中,你会看到一个系统会遇到哪些可用性问题,以及为什么架构要这样演进,从而理解异地多活架构的意义。
+
+# 02 单机架构
+
+我们从最简单的开始讲起。
+
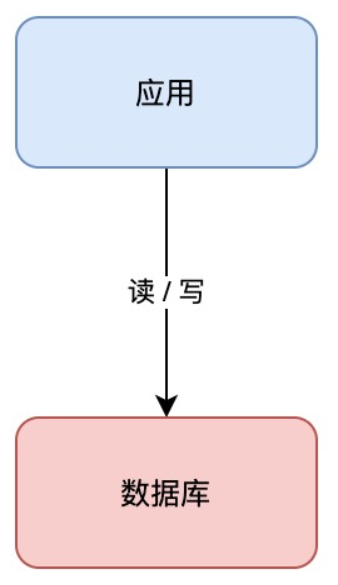
+假设你的业务处于起步阶段,体量非常小,那你的架构是这样的:
+
+
+
+这个架构模型非常简单,客户端请求进来,业务应用读写数据库,返回结果,非常好理解。
+
+但需要注意的是,这里的数据库是「单机」部署的,所以它有一个致命的缺点:一旦遭遇意外,例如磁盘损坏、操作系统异常、误删数据,那这意味着所有数据就全部「丢失」了,这个损失是巨大的。
+
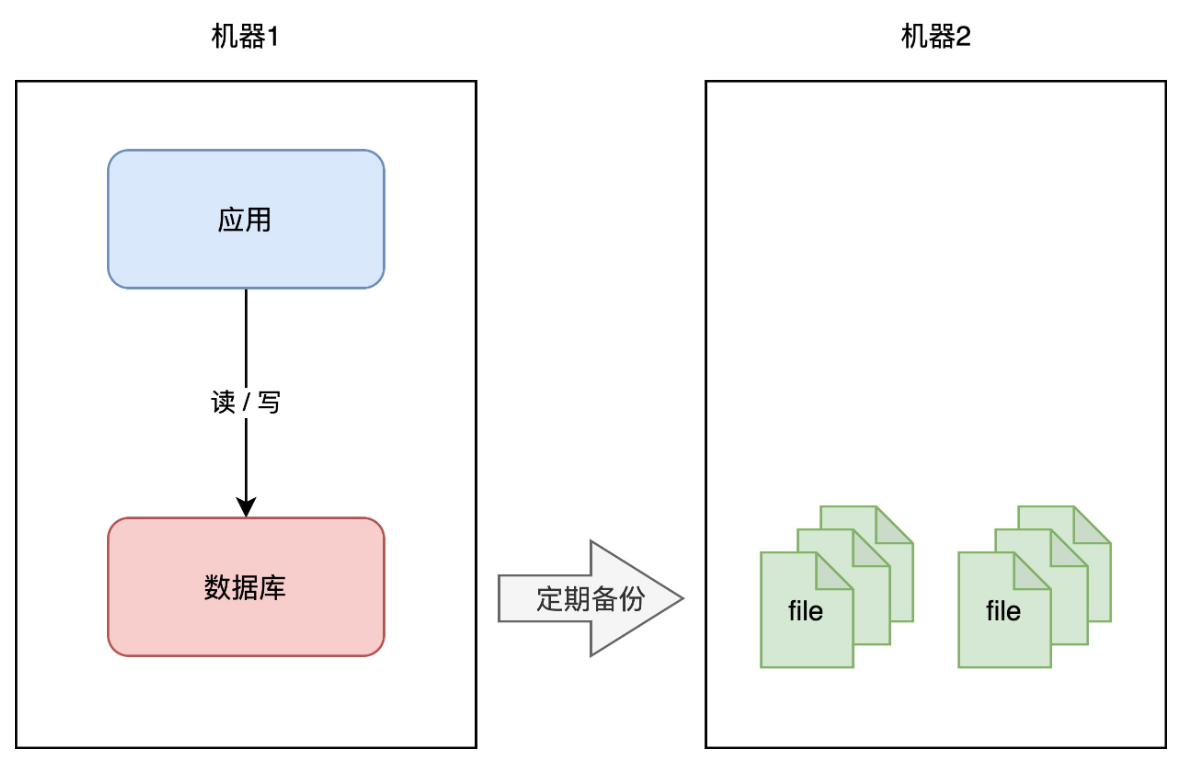
+如何避免这个问题呢?我们很容易想到一个方案:**备份**。
+
+
+
+你可以对数据做备份,把数据库文件「定期」cp 到另一台机器上,这样,即使原机器丢失数据,你依旧可以通过备份把数据「恢复」回来,以此保证数据安全。
+
+这个方案实施起来虽然比较简单,但存在 2 个问题:
+
+1. **恢复需要时间**:业务需先停机,再恢复数据,停机时间取决于恢复的速度,恢复期间服务「不可用」
+2. **数据不完整**:因为是定期备份,数据肯定不是「最新」的,数据完整程度取决于备份的周期
+
+很明显,你的数据库越大,意味故障恢复时间越久。那按照前面我们提到的「高可用」标准,这个方案可能连 1 个 9 都达不到,远远无法满足我们对可用性的要求。
+
+那有什么更好的方案,既可以快速恢复业务?还能尽可能保证数据完整性呢?
+
+这时你可以采用这个方案:**主从副本**。
+
+# 03 主从副本
+
+你可以在另一台机器上,再部署一个数据库实例,让这个新实例成为原实例的「副本」,让两者保持「实时同步」,就像这样:
+
+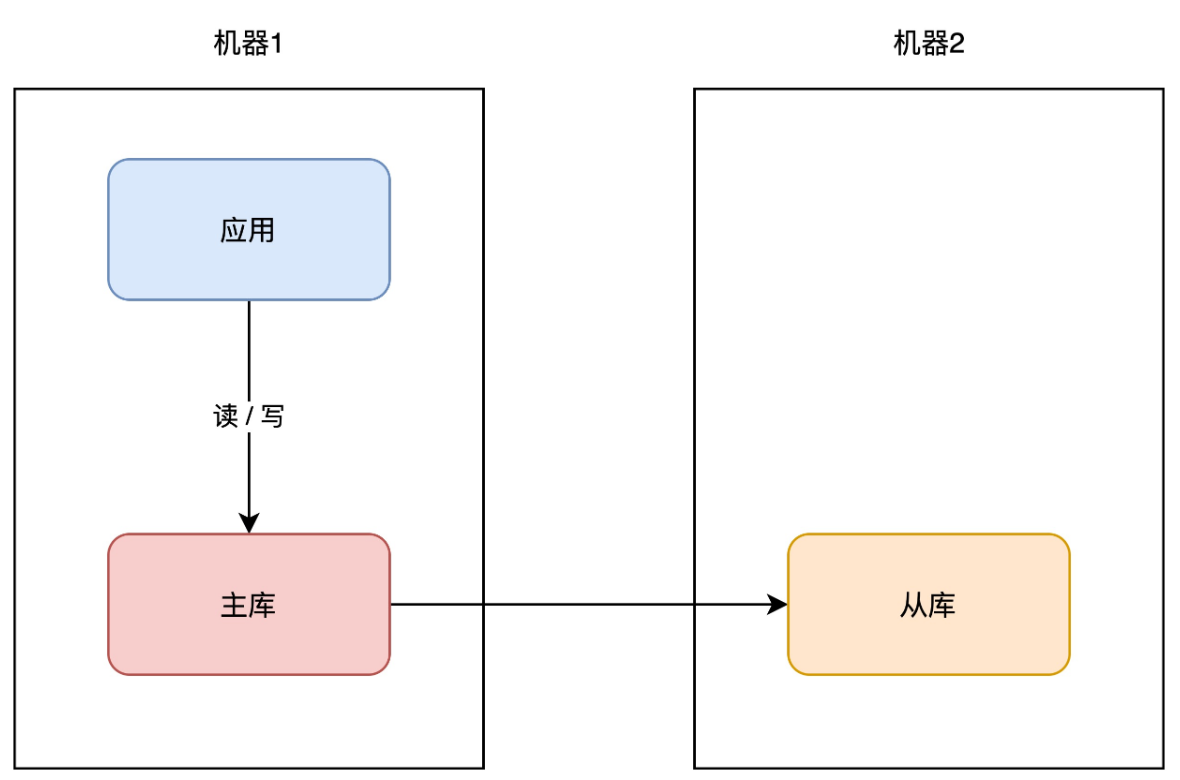
+
+我们一般把原实例叫作主库(master),新实例叫作从库(slave)。这个方案的优点在于:
+
+- **数据完整性高**:主从副本实时同步,数据「差异」很小
+- **抗故障能力提升**:主库有任何异常,从库可随时「切换」为主库,继续提供服务
+- **读性能提升**:业务应用可直接读从库,分担主库「压力」读压力
+
+这个方案不错,不仅大大提高了数据库的可用性,还提升了系统的读性能。
+
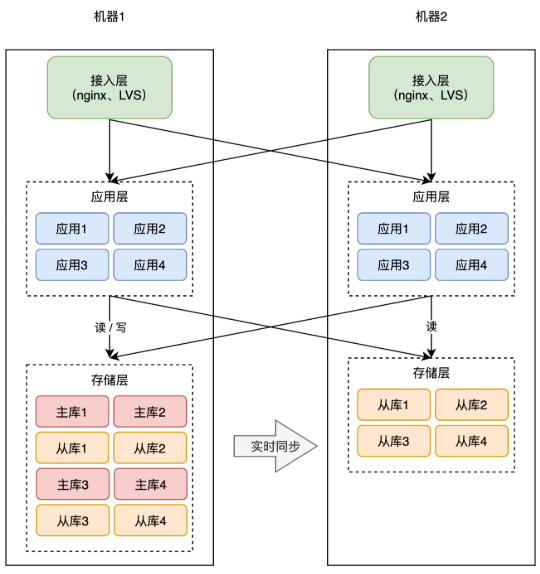
+同样的思路,你的「业务应用」也可以在其它机器部署一份,避免单点。因为业务应用通常是「无状态」的(不像数据库那样存储数据),所以直接部署即可,非常简单。
+
+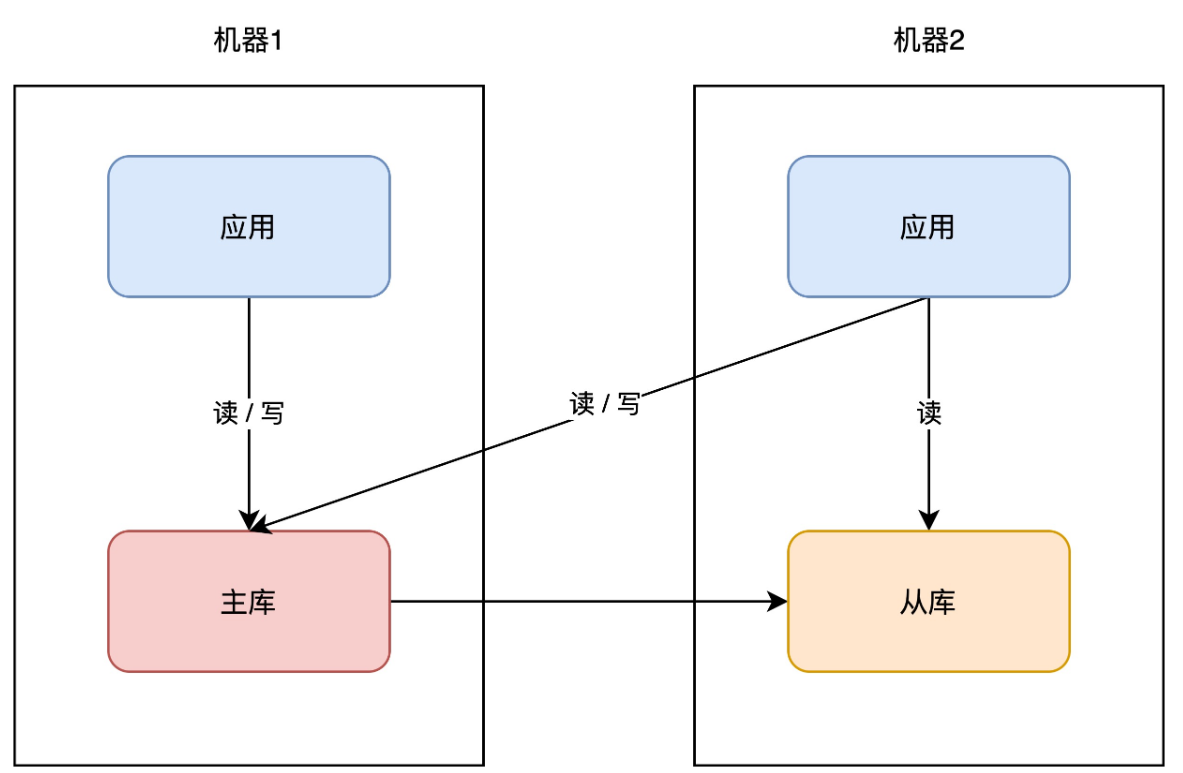
+
+因为业务应用部署了多个,所以你现在还需要部署一个「接入层」,来做请求的「负载均衡」(一般会使用 nginx 或 LVS),这样当一台机器宕机后,另一台机器也可以「接管」所有流量,持续提供服务。
+
+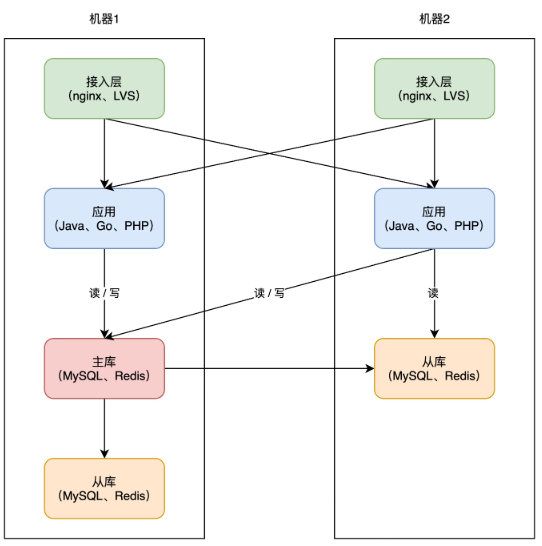
+
+从这个方案你可以看出,提升可用性的关键思路就是:**冗余**。
+
+没错,担心一个实例故障,那就部署多个实例,担心一个机器宕机,那就部署多台机器。
+
+到这里,你的架构基本已演变成主流方案了,之后开发新的业务应用,都可以按照这种模式去部署。
+
+
+
+但这种方案还有什么风险吗?
+
+# 04 风险不可控
+
+现在让我们把视角下放,把焦点放到具体的「部署细节」上来。
+
+按照前面的分析,为了避免单点故障,你的应用虽然部署了多台机器,但这些机器的分布情况,我们并没有去深究。
+
+而一个机房有很多服务器,这些服务器通常会分布在一个个「机柜」上,如果你使用的这些机器,刚好在一个机柜,还是存在风险。
+
+如果恰好连接这个机柜的交换机 / 路由器发生故障,那么你的应用依旧有「不可用」的风险。
+
+> 虽然交换机 / 路由器也做了路线冗余,但不能保证一定不出问题。
+
+部署在一个机柜有风险,那把这些机器打散,分散到不同机柜上,是不是就没问题了?
+
+这样确实会大大降低出问题的概率。但我们依旧不能掉以轻心,因为无论怎么分散,它们总归还是在一个相同的环境下:**机房**。
+
+那继续追问,机房会不会发生故障呢?
+
+一般来讲,建设一个机房的要求其实是很高的,地理位置、温湿度控制、备用电源等等,机房厂商会在各方面做好防护。但即使这样,我们每隔一段时间还会看到这样的新闻:
+
+- 2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法访问支付宝
+- 2021 年 7 月 13 日,B 站部分服务器机房发生故障,造成整站持续 3 个小时无法访问
+- 2021 年 10 月 9 日,富途证券服务器机房发生电力闪断故障,造成用户 2 个小时无法登陆、交易
+- …
+
+可见,即使机房级别的防护已经做得足够好,但只要有「概率」出问题,那现实情况就有可能发生。虽然概率很小,但一旦真的发生,影响之大可见一斑。
+
+看到这里你可能会想,机房出现问题的概率也太小了吧,工作了这么多年,也没让我碰上一次,有必要考虑得这么复杂吗?
+
+但你有没有思考这样一个问题:**不同体量的系统,它们各自关注的重点是什么?**
+
+体量很小的系统,它会重点关注「用户」规模、增长,这个阶段获取用户是一切。等用户体量上来了,这个阶段会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。
+
+等体量再大到一定规模后你会发现,「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用,如果机房发生一次故障,那整个影响范围可以说是非常巨大的。
+
+所以,再小概率的风险,我们在提高系统可用性时,也不能忽视。
+
+分析了风险,再说回我们的架构。那到底该怎么应对机房级别的故障呢?
+
+没错,还是**冗余**。
+
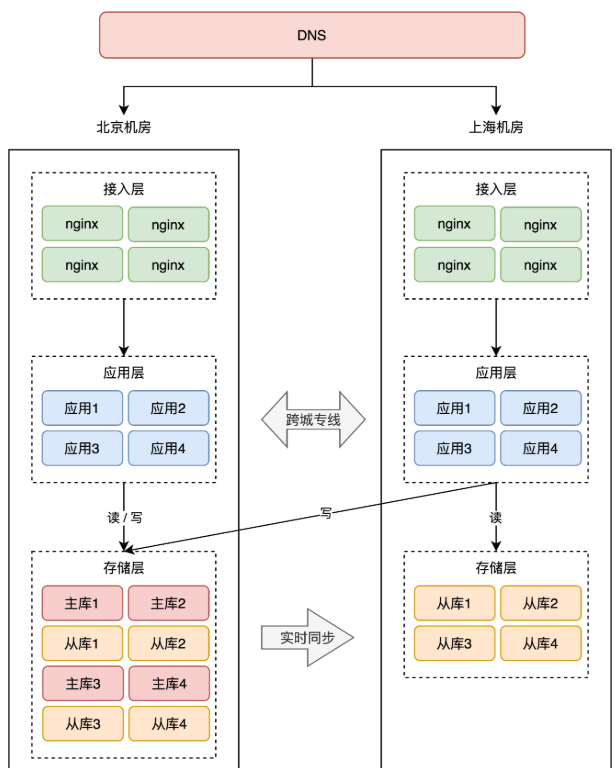
+# 05 同城灾备
+
+想要抵御「机房」级别的风险,那应对方案就不能局限在一个机房内了。
+
+现在,你需要做机房级别的冗余方案,也就是说,你需要再搭建一个机房,来部署你的服务。
+
+简单起见,你可以在「同一个城市」再搭建一个机房,原机房我们叫作 A 机房,新机房叫 B 机房,这两个机房的网络用一条「专线」连通。
+
+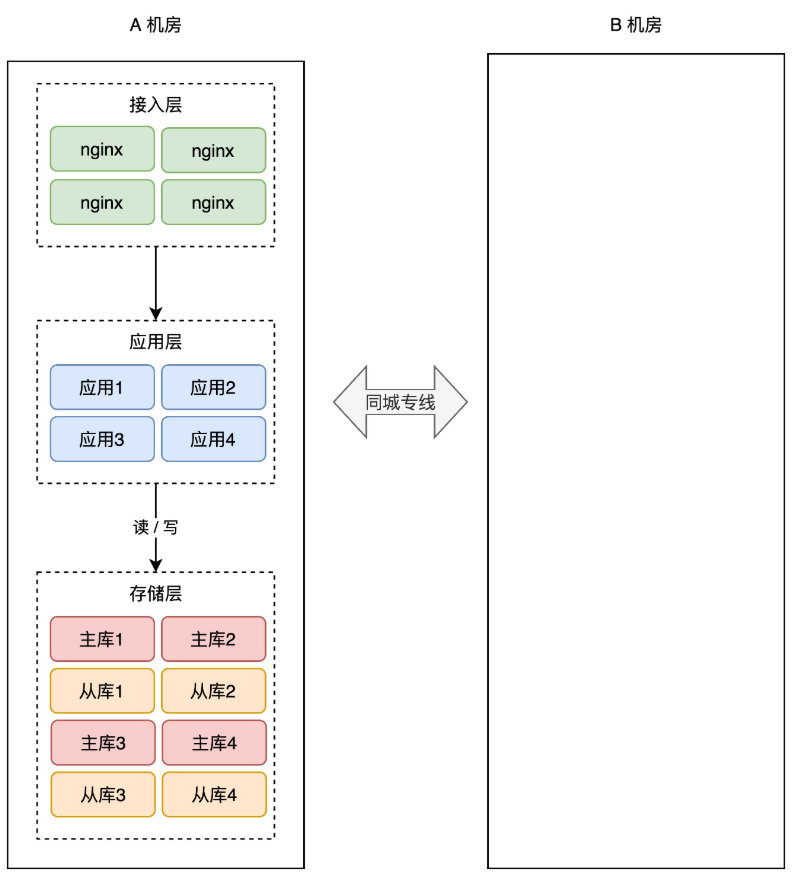
+
+有了新机房,怎么把它用起来呢?这里还是要优先考虑「数据」风险。
+
+为了避免 A 机房故障导致数据丢失,所以我们需要把数据在 B 机房也存一份。最简单的方案还是和前面提到的一样:**备份**。
+
+A 机房的数据,定时在 B 机房做备份(拷贝数据文件),这样即使整个 A 机房遭到严重的损坏,B 机房的数据不会丢,通过备份可以把数据「恢复」回来,重启服务。
+
+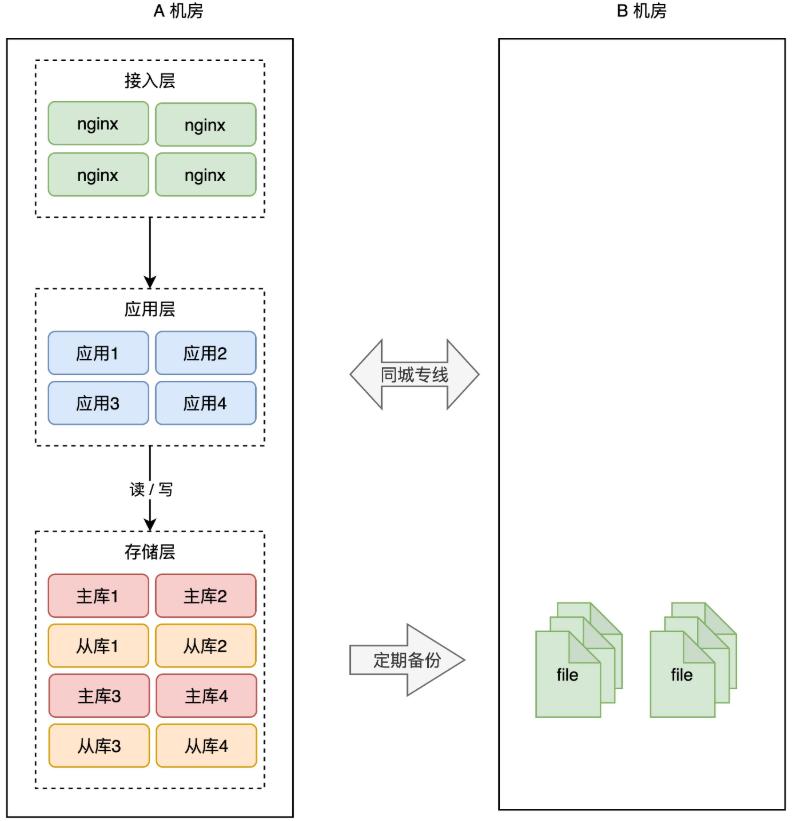
+
+这种方案,我们称之为「**冷备**」。为什么叫冷备呢?因为 B 机房只做备份,不提供实时服务,它是冷的,只会在 A 机房故障时才会启用。
+
+但备份的问题依旧和之前描述的一样:数据不完整、恢复数据期间业务不可用,整个系统的可用性还是无法得到保证。
+
+所以,我们还是需要用「主从副本」的方式,在 B 机房部署 A 机房的数据副本,架构就变成了这样:
+
+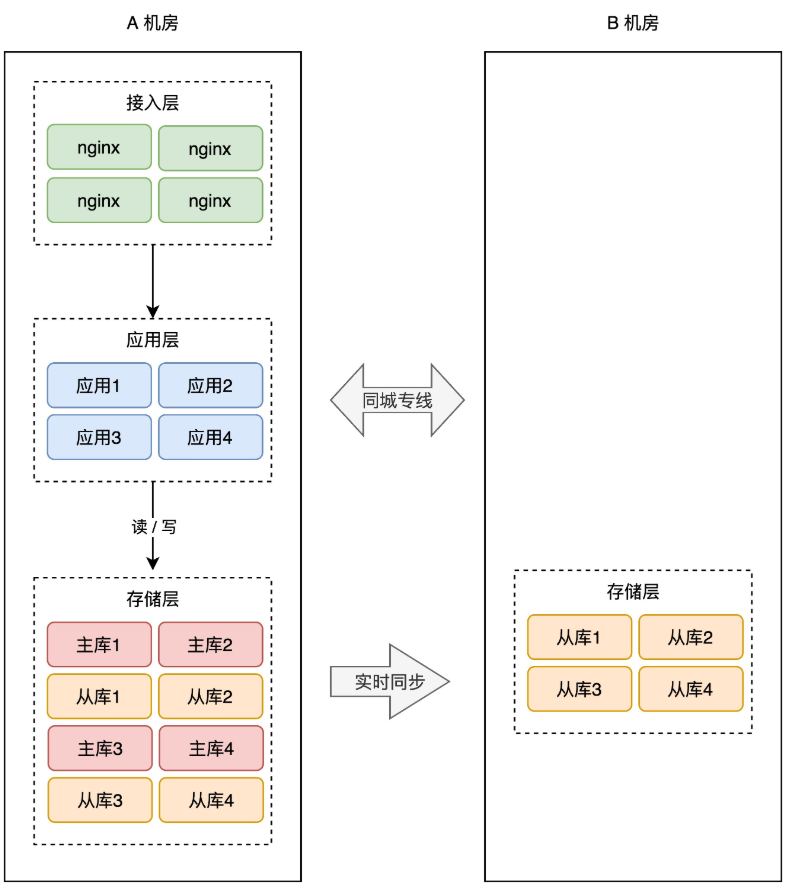
+
+这样,就算整个 A 机房挂掉,我们在 B 机房也有比较「完整」的数据。
+
+数据是保住了,但这时你需要考虑另外一个问题:**如果 A 机房真挂掉了,要想保证服务不中断,你还需要在 B 机房「紧急」做这些事情**:
+
+1. B 机房所有从库提升为主库
+2. 在 B 机房部署应用,启动服务
+3. 部署接入层,配置转发规则
+4. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+看到了么?A 机房故障后,B 机房需要做这么多工作,你的业务才能完全「恢复」过来。
+
+你看,整个过程需要人为介入,且需花费大量时间来操作,恢复之前整个服务还是不可用的,这个方案还是不太爽,如果能做到故障后立即「切换」,那就好了。
+
+因此,要想缩短业务恢复的时间,你必须把这些工作在 B 机房「提前」做好,也就是说,你需要在 B 机房提前部署好接入层、业务应用,等待随时切换。架构就变成了这样:
+
+
+
+这样的话,A 机房整个挂掉,我们只需要做 2 件事即可:
+
+1. B 机房所有从库提升为主库
+2. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+这样一来,恢复速度快了很多。
+
+到这里你会发现,B 机房从最开始的「空空如也」,演变到现在,几乎是「镜像」了一份 A 机房的所有东西,从最上层的接入层,到中间的业务应用,到最下层的存储。两个机房唯一的区别是,**A 机房的存储都是主库,而 B 机房都是从库**。
+
+这种方案,我们把它叫做「**热备**」。
+
+热的意思是指,B 机房处于「待命」状态,A 故障后 B 可以随时「接管」流量,继续提供服务。热备相比于冷备最大的优点是:**随时可切换**。
+
+无论是冷备还是热备,因为它们都处于「备用」状态,所以我们把这两个方案统称为:**同城灾备**。
+
+同城灾备的最大优势在于,我们再也不用担心「机房」级别的故障了,一个机房发生风险,我们只需把流量切换到另一个机房即可,可用性再次提高,是不是很爽?(后面还有更爽的)
+
+# 06 同城双活
+
+我们继续来看这个架构。
+
+虽然我们有了应对机房故障的解决方案,但这里有个问题是我们不能忽视的:**A 机房挂掉,全部流量切到 B 机房,B 机房能否真的如我们所愿,正常提供服务?**
+
+这是个值得思考的问题。
+
+这就好比有两支军队 A 和 B,A 军队历经沙场,作战经验丰富,而 B 军队只是后备军,除了有军人的基本素养之外,并没有实战经验,战斗经验基本为 0。
+
+如果 A 军队丧失战斗能力,需要 B 军队立即顶上时,作为指挥官的你,肯定也会担心 B 军队能否真的担此重任吧?
+
+我们的架构也是如此,此时的 B 机房虽然是随时「待命」状态,但 A 机房真的发生故障,我们要把全部流量切到 B 机房,其实是不敢百分百保证它可以「如期」工作的。
+
+你想,我们在一个机房内部署服务,还总是发生各种各样的问题,例如:发布应用的版本不一致、系统资源不足、操作系统参数不一样等等。现在多部署一个机房,这些问题只会增多,不会减少。
+
+另外,从「成本」的角度来看,我们新部署一个机房,需要购买服务器、内存、硬盘、带宽资源,花费成本也是非常高昂的,只让它当一个后备军,未免也太「大材小用」了!
+
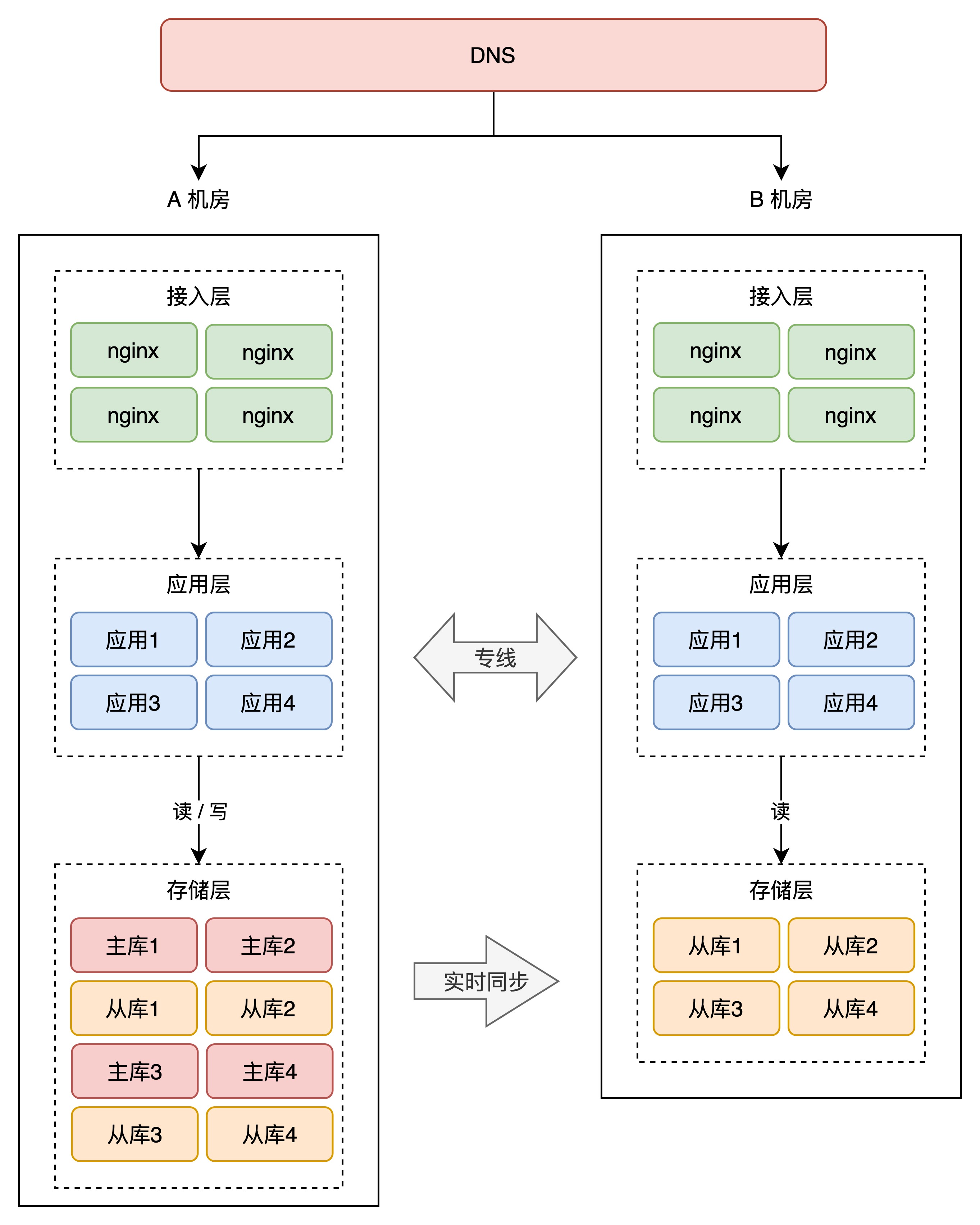
+因此,我们需要让 B 机房也接入流量,实时提供服务,这样做的好处,**一是可以实时训练这支后备军,让它达到与 A 机房相同的作战水平,随时可切换,二是 B 机房接入流量后,可以分担 A 机房的流量压力**。这才是把 B 机房资源优势,发挥最大化的最好方案!
+
+那怎么让 B 机房也接入流量呢?很简单,就是把 B 机房的接入层 IP 地址,加入到 DNS 中,这样,B 机房从上层就可以有流量进来了。
+
+
+
+但这里有一个问题:别忘了,B 机房的存储,现在可都是 A 机房的「从库」,从库默认可都是「不可写」的,B 机房的写请求打到本机房存储上,肯定会报错,这还是不符合我们预期。怎么办?
+
+这时,你就需要在「业务应用」层做改造了。
+
+你的业务应用在操作数据库时,需要区分「读写分离」(一般用中间件实现),即两个机房的「读」流量,可以读任意机房的存储,但「写」流量,只允许写 A 机房,因为主库在 A 机房。
+
+
+
+这会涉及到你用的所有存储,例如项目中用到了 MySQL、Redis、MongoDB 等等,操作这些数据库,都需要区分读写请求,所以这块需要一定的业务「改造」成本。
+
+因为 A 机房的存储都是主库,所以我们把 A 机房叫做「主机房」,B 机房叫「从机房」。
+
+两个机房部署在「同城」,物理距离比较近,而且两个机房用「专线」网络连接,虽然跨机房访问的延迟,比单个机房内要大一些,但整体的延迟还是可以接受的。
+
+业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%,你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。
+
+现在,因为 B 机房实时接入了流量,此时如果 A 机房挂了,那我们就可以「大胆」地把 A 的流量,全部切换到 B 机房,完成快速切换!
+
+到这里你可以看到,我们部署的 B 机房,在物理上虽然与 A 有一定距离,但整个系统从「逻辑」上来看,我们是把这两个机房看做一个「整体」来规划的,也就是说,相当于把 2 个机房当作 1 个机房来用。
+
+这种架构方案,比前面的同城灾备更「进了一步」,B 机房实时接入了流量,还能应对随时的故障切换,这种方案我们把它叫做「**同城双活**」。
+
+因为两个机房都能处理业务请求,这对我们系统的内部维护、改造、升级提供了更多的可实施空间(流量随时切换),现在,整个系统的弹性也变大了,是不是更爽了?
+
+那这种架构有什么问题呢?
+
+# 07 两地三中心
+
+还是回到风险上来说。
+
+虽然我们把 2 个机房当做一个整体来规划,但这 2 个机房在物理层面上,还是处于「一个城市」内,如果是整个城市发生自然灾害,例如地震、水灾(河南水灾刚过去不久),那 2 个机房依旧存在「全局覆没」的风险。
+
+真是防不胜防啊?怎么办?没办法,继续冗余。
+
+但这次冗余机房,就不能部署在同一个城市了,你需要把它放到距离更远的地方,部署在「异地」。
+
+> 通常建议两个机房的距离要在 1000 公里以上,这样才能应对城市级别的灾难。
+
+假设之前的 A、B 机房在北京,那这次新部署的 C 机房可以放在上海。
+
+按照前面的思路,把 C 机房用起来,最简单粗暴的方案还就是做「冷备」,即定时把 A、B 机房的数据,在 C 机房做备份,防止数据丢失。
+
+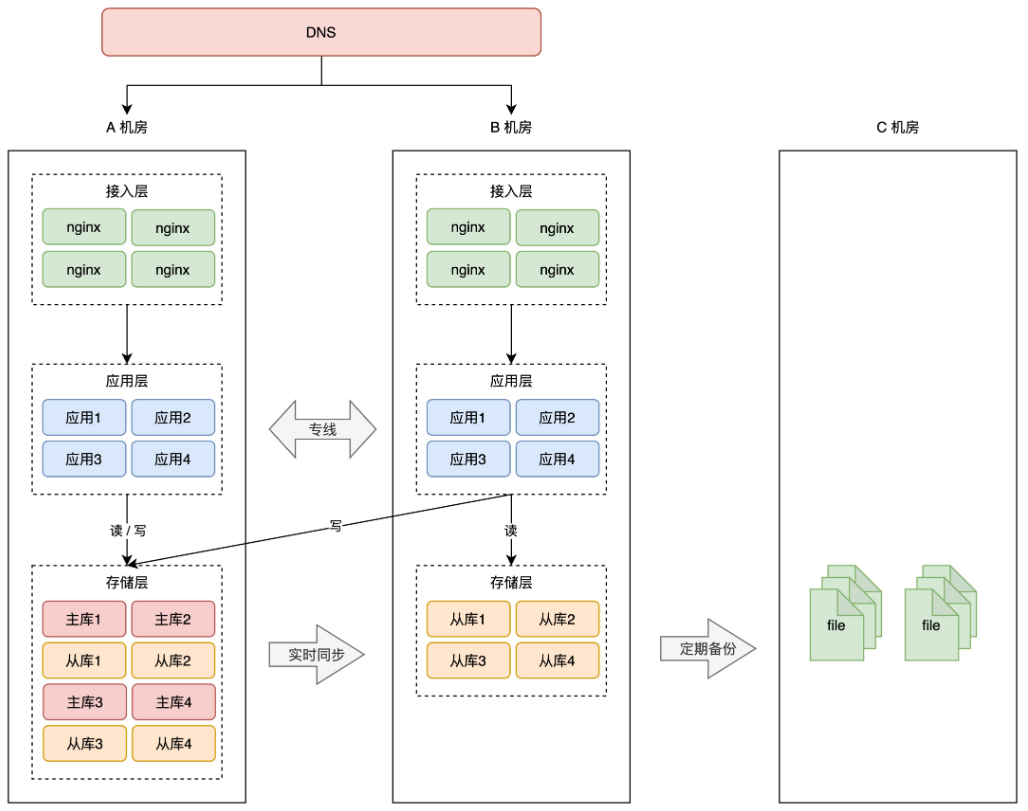
+
+这种方案,就是我们经常听到的「**两地三中心**」。
+
+**两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市,并且同时提供服务,第 3 个机房部署在异地,只做数据灾备。**
+
+这种架构方案,通常用在银行、金融、政企相关的项目中。它的问题还是前面所说的,启用灾备机房需要时间,而且启用后的服务,不确定能否如期工作。
+
+所以,要想真正的抵御城市级别的故障,越来越多的互联网公司,开始实施「**异地双活**」。
+
+# 08 伪异地双活
+
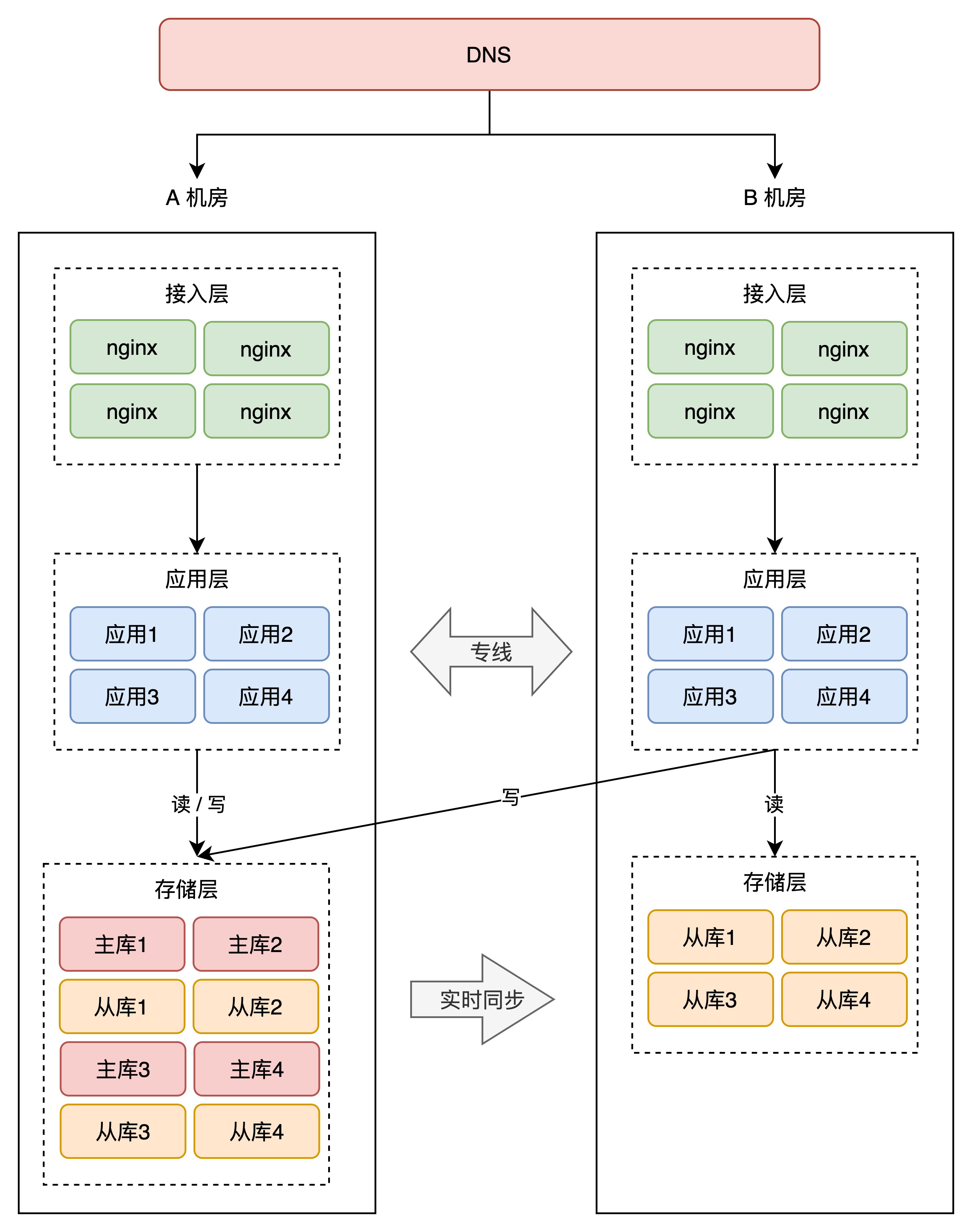
+这里,我们还是分析 2 个机房的架构情况。我们不再把 A、B 机房部署在同一个城市,而是分开部署,例如 A 机房放在北京,B 机房放在上海。
+
+前面我们讲了同城双活,那异地双活是不是直接「照搬」同城双活的模式去部署就可以了呢?
+
+事情没你想的那么简单。
+
+如果还是按照同城双活的架构来部署,那异地双活的架构就是这样的:
+
+
+
+注意看,两个机房的网络是通过「跨城专线」连通的。
+
+此时两个机房都接入流量,那上海机房的请求,可能要去读写北京机房的存储,这里存在一个很大的问题:**网络延迟**。
+
+因为两个机房距离较远,受到物理距离的限制,现在,两地之间的网络延迟就变成了「**不可忽视**」的因素了。
+
+北京到上海的距离大约 1300 公里,即使架设一条高速的「网络专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。
+
+况且,网络线路之间还会经历各种路由器、交换机等网络设备,实际延迟可能会达到 30ms ~ 100ms,如果网络发生抖动,延迟甚至会达到 1 秒。
+
+> 不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的,专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
+
+你可能会问,这点延迟对业务影响很大吗?影响非常大!
+
+试想,一个客户端请求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房访问延迟就达到了 30ms,这大致是机房内网网络(0.5 ms)访问速度的 60 倍(30ms / 0.5ms),一次请求慢 60 倍,来回往返就要慢 100 倍以上。
+
+而我们在 App 打开一个页面,可能会访问后端几十个 API,每次都跨机房访问,整个页面的响应延迟有可能就达到了**秒级**,这个性能简直惨不忍睹,难以接受。
+
+看到了么,虽然我们只是简单的把机房部署在了「异地」,但「同城双活」的架构模型,在这里就不适用了,还是按照这种方式部署,这是「伪异地双活」!
+
+那如何做到真正的异地双活呢?
+
+# 09 真正的异地双活
+
+既然「跨机房」调用延迟是不容忽视的因素,那我们只能尽量避免跨机房「调用」,规避这个延迟问题。
+
+也就是说,上海机房的应用,不能再「跨机房」去读写北京机房的存储,只允许读写上海本地的存储,实现「就近访问」,这样才能避免延迟问题。
+
+还是之前提到的问题:上海机房存储都是从库,不允许写入啊,除非我们只允许上海机房接入「读流量」,不接收「写流量」,否则无法满足不再跨机房的要求。
+
+很显然,只让上海机房接收读流量的方案不现实,因为很少有项目是只有读流量,没有写流量的。所以这种方案还是不行,这怎么办?
+
+此时,你就必须在「**存储层**」做改造了。
+
+要想上海机房读写本机房的存储,那上海机房的存储不能再是北京机房的从库,而是也要变为「主库」。
+
+你没看错,两个机房的存储必须都是「**主库**」,而且两个机房的数据还要「**互相同步**」数据,即客户端无论写哪一个机房,都能把这条数据同步到另一个机房。
+
+因为只有两个机房都拥有「全量数据」,才能支持任意切换机房,持续提供服务。
+
+怎么实现这种「双主」架构呢?它们之间如何互相同步数据?
+
+如果你对 MySQL 有所了解,MySQL 本身就提供了双主架构,它支持双向复制数据,但平时用的并不多。而且 Redis、MongoDB 等数据库并没有提供这个功能,所以,你必须开发对应的「数据同步中间件」来实现双向同步的功能。
+
+此外,除了数据库这种有状态的软件之外,你的项目通常还会使用到消息队列,例如 RabbitMQ、Kafka,这些也是有状态的服务,所以它们也需要开发双向同步的中间件,支持任意机房写入数据,同步至另一个机房。
+
+看到了么,这一下子复杂度就上来了,单单针对每个数据库、队列开发同步中间件,就需要投入很大精力了。
+
+> 业界也开源出了很多数据同步中间件,例如阿里的 Canal、RedisShake、MongoShake,可分别在两个机房同步 MySQL、Redis、MongoDB 数据。
+>
+> 很多有能力的公司,也会采用自研同步中间件的方式来做,例如饿了么、携程、美团都开发了自己的同步中间件。
+>
+> 我也有幸参与设计开发了 MySQL、Redis/Codis、MongoDB 的同步中间件,有时间写一篇文章详细聊聊实现细节,欢迎持续关注。:)
+
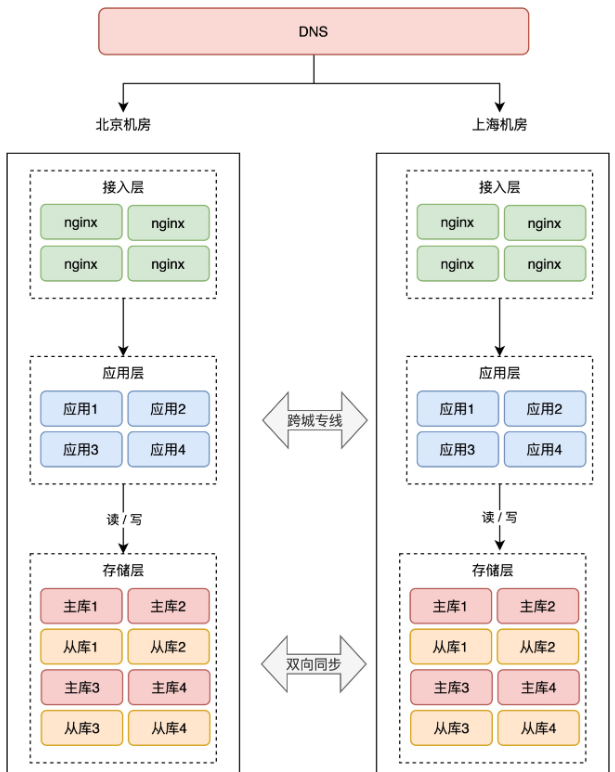
+现在,整个架构就变成了这样:
+
+
+
+注意看,两个机房的存储层都互相同步数据的。有了数据同步中间件,就可以达到这样的效果:
+
+- 北京机房写入 X = 1
+- 上海机房写入 Y = 2
+- 数据通过中间件双向同步
+- 北京、上海机房都有 X = 1、Y = 2 的数据
+
+这里我们用中间件双向同步数据,就不用再担心专线问题,专线出问题,我们的中间件可以自动重试,直到成功,达到数据最终一致。
+
+但这里还会遇到一个问题,两个机房都可以写,操作的不是同一条数据那还好,如果修改的是同一条的数据,发生冲突怎么办?
+
+- 用户短时间内发了 2 个修改请求,都是修改同一条数据
+- 一个请求落在北京机房,修改 X = 1(还未同步到上海机房)
+- 另一个请求落在上海机房,修改 X = 2(还未同步到北京机房)
+- 两个机房以哪个为准?
+
+也就是说,在很短的时间内,同一个用户修改同一条数据,两个机房无法确认谁先谁后,数据发生「冲突」。
+
+这是一个很严重的问题,系统发生故障并不可怕,可怕的是数据发生「错误」,因为修正数据的成本太高了。我们一定要避免这种情况的发生。解决这个问题,有 2 个方案。
+
+**第一个方案**,数据同步中间件要有自动「合并」数据、解决「冲突」的能力。
+
+这个方案实现起来比较复杂,要想合并数据,就必须要区分出「先后」顺序。我们很容易想到的方案,就是以「时间」为标尺,以「后到达」的请求为准。
+
+但这种方案需要两个机房的「时钟」严格保持一致才行,否则很容易出现问题。例如:
+
+- 第 1 个请求落到北京机房,北京机房时钟是 10:01,修改 X = 1
+- 第 2 个请求落到上海机房,上海机房时钟是 10:00,修改 X = 2
+
+因为北京机房的时间「更晚」,那最终结果就会是 X = 1。但这里其实应该以第 2 个请求为准,X = 2 才对。
+
+可见,完全「依赖」时钟的冲突解决方案,不太严谨。
+
+所以,通常会采用第二种方案,从「源头」就避免数据冲突的发生。
+
+# 10 如何实施异地双活
+
+既然自动合并数据的方案实现成本高,那我们就要想,能否从源头就「避免」数据冲突呢?
+
+这个思路非常棒!
+
+从源头避免数据冲突的思路是:**在最上层接入流量时,就不要让冲突的情况发生**。
+
+具体来讲就是,要在最上层就把用户「区分」开,部分用户请求固定打到北京机房,其它用户请求固定打到上海 机房,进入某个机房的用户请求,之后的所有业务操作,都在这一个机房内完成,从根源上避免「跨机房」。
+
+所以这时,你需要在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内。
+
+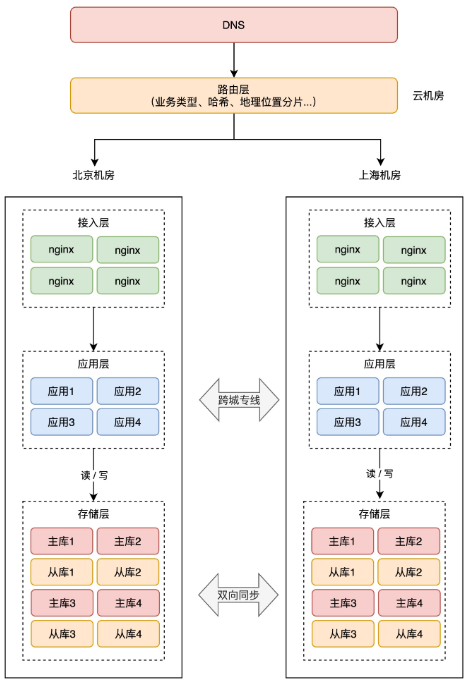
+
+但这个路由规则,具体怎么定呢?有很多种实现方式,最常见的我总结了 3 类:
+
+1. 按业务类型分片
+2. 直接哈希分片
+3. 按地理位置分片
+
+**1、按业务类型分片**
+
+这种方案是指,按应用的「业务类型」来划分。
+
+举例:假设我们一共有 4 个应用,北京和上海机房都部署这些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
+
+这样一来,应用 1、2 的所有业务请求,只读写北京机房存储,应用 3、4 的所有请求,只会读写上海机房存储。
+
+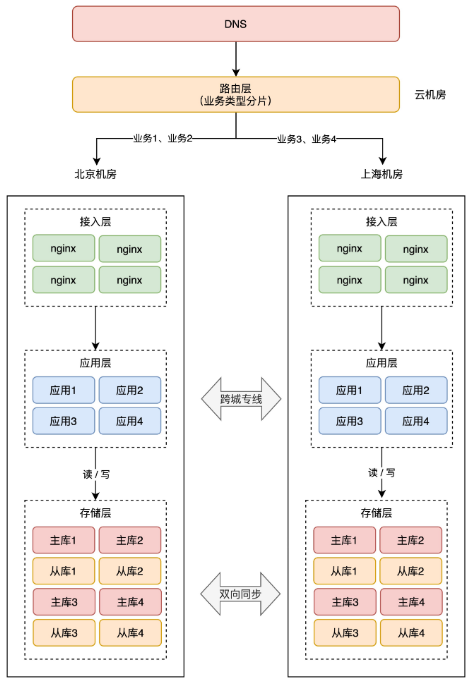
+
+这样按业务类型分片,也可以避免同一个用户修改同一条数据。
+
+> 这里按业务类型在不同机房接入流量,还需要考虑多个应用之间的依赖关系,要尽可能的把完成「相关」业务的应用部署在同一个机房,避免跨机房调用。
+>
+> 例如,订单、支付服务有依赖关系,会产生互相调用,那这 2 个服务在 A 机房接入流量。社区、发帖服务有依赖关系,那这 2 个服务在 B 机房接入流量。
+
+**2、直接哈希分片**
+
+这种方案就是,最上层的路由层,会根据用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把请求转发到指定机房内。
+
+举例:一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,这样,就避免了同一个用户修改同一条数据的情况发生。
+
+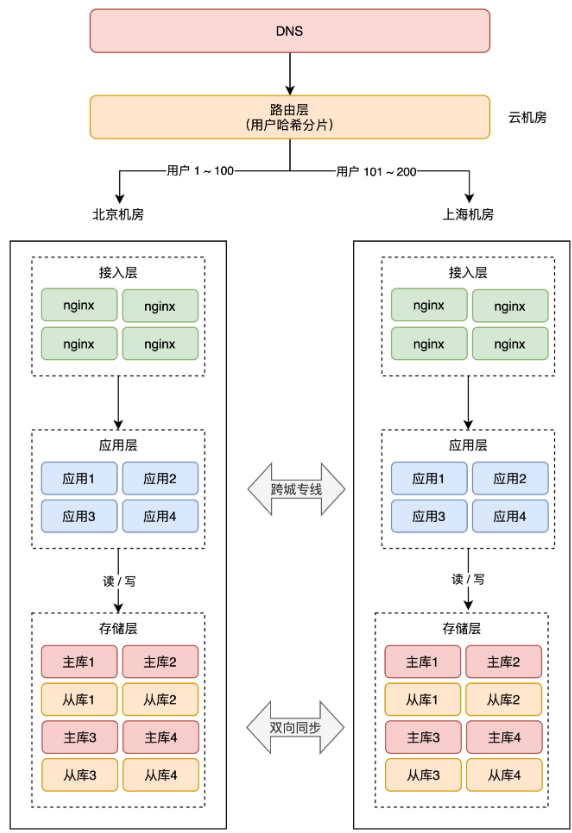
+
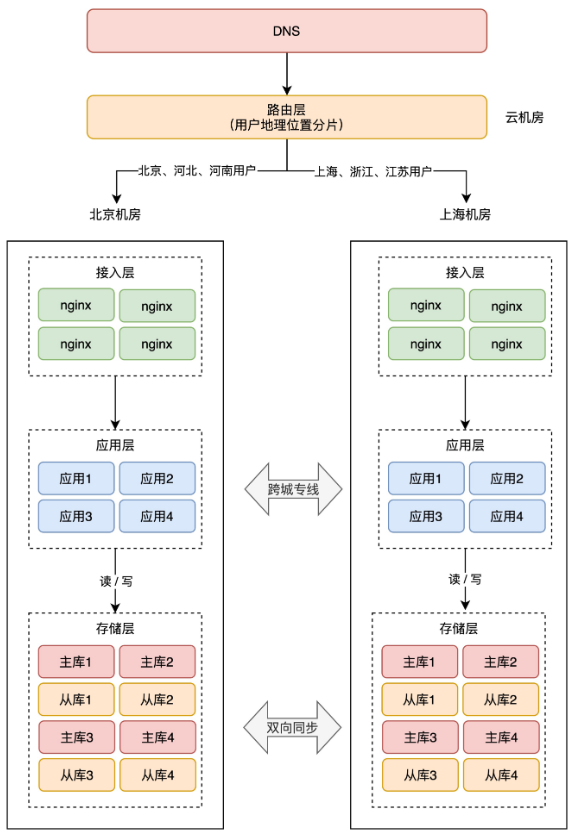
+**3、按地理位置分片**
+
+这种方案,非常适合与地理位置密切相关的业务,例如打车、外卖服务就非常适合这种方案。
+
+拿外卖服务举例,你要点外卖肯定是「就近」点餐,整个业务范围相关的有商家、用户、骑手,它们都是在相同的地理位置内的。
+
+针对这种特征,就可以在最上层,按用户的「地理位置」来做分片,分散到不同的机房。
+
+举例:北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。这样的分片规则,也能避免数据冲突。
+
+
+
+> 提醒:这 3 种常见的分片规则,第一次看不太好理解,建议配合图多理解几遍。搞懂这 3 个分片规则,你才能真正明白怎么做异地多活。
+
+总之,分片的核心思路在于,**让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问**。
+
+阿里在实施这种方案时,给它起了个名字,叫做「**单元化**」。
+
+> 当然,最上层的路由层把用户分片后,理论来说同一个用户只会落在同一个机房内,但不排除程序 Bug 导致用户会在两个机房「漂移」。
+>
+> 安全起见,每个机房在写存储时,还需要有一套机制,能够检测「数据归属」,应用层操作存储时,需要通过中间件来做「兜底」,避免不该写本机房的情况发生。(篇幅限制,这里不展开讲,理解思路即可)
+
+现在,两个机房就可以都接收「读写」流量(做好分片的请求),底层存储保持「双向」同步,两个机房都拥有全量数据,当任意机房故障时,另一个机房就可以「接管」全部流量,实现快速切换,简直不要太爽。
+
+不仅如此,因为机房部署在异地,我们还可以更细化地「优化」路由规则,让用户访问就近的机房,这样整个系统的性能也会大大提升。
+
+> 这里还有一种情况,是无法做数据分片的:**全局数据**。例如系统配置、商品库存这类需要强一致的数据,这类服务依旧只能采用写主机房,读从机房的方案,不做双活。
+>
+> 双活的重点,是要优先保证「核心」业务先实现双活,并不是「全部」业务实现双活。
+
+至此,我们才算实现了真正的「**异地双活**」!
+
+> 到这里你可以看出,完成这样一套架构,需要投入的成本是巨大的。
+>
+> 路由规则、路由转发、数据同步中间件、数据校验兜底策略,不仅需要开发强大的中间件,同时还要业务配合改造(业务边界划分、依赖拆分)等一些列工作,没有足够的人力物力,这套架构很难实施。
+
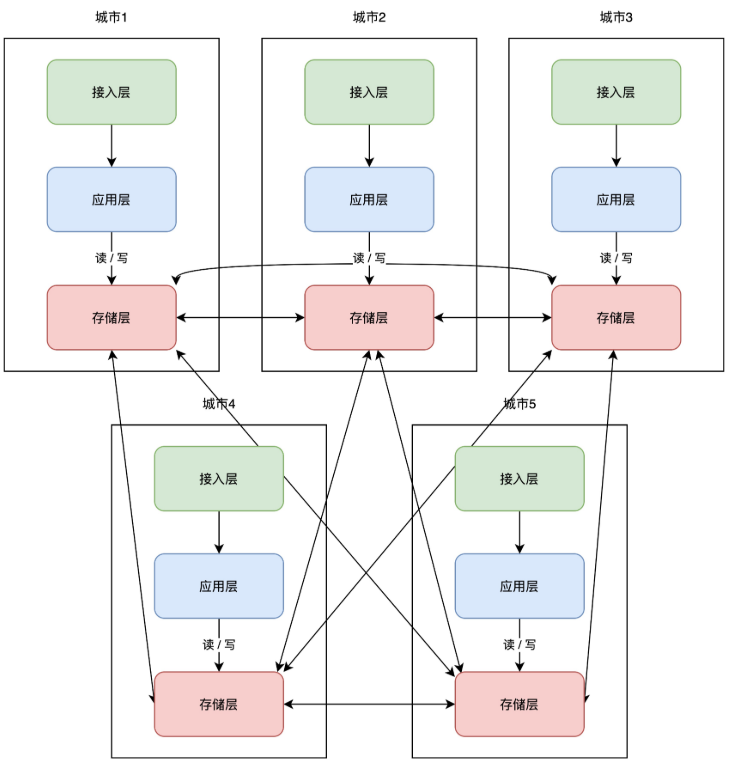
+# 11 异地多活
+
+理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。架构变成了这样:
+
+
+
+这些服务按照「单元化」的部署方式,可以让每个机房部署在任意地区,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
+
+但这里还有一个小问题,随着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,这个实现复杂度会比较高。
+
+所以业界又把这一架构又做了进一步优化,把「网状」架构升级为「星状」:
+
+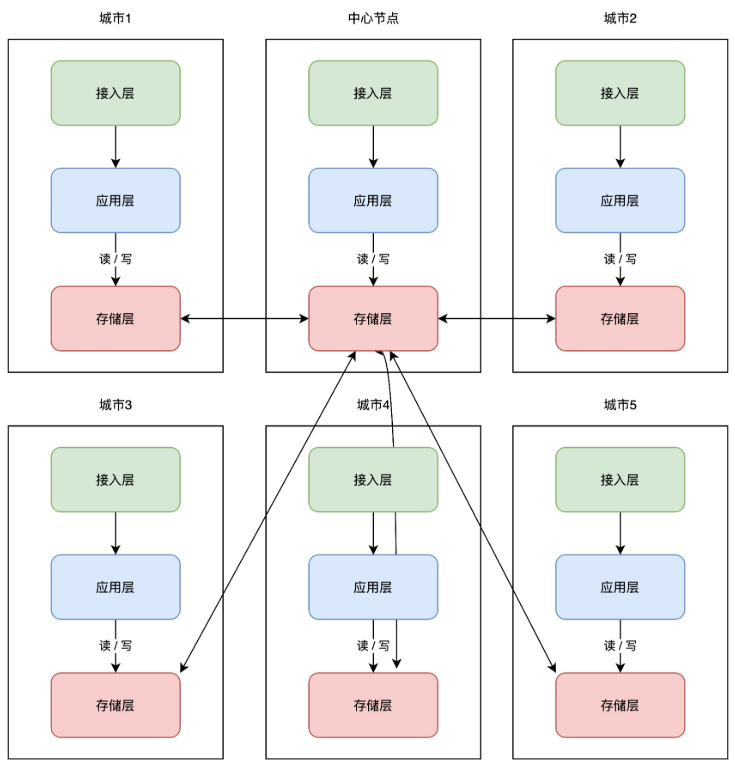
+
+这种方案必须设立一个「中心机房」,任意机房写入数据后,都只同步到中心机房,再由中心机房同步至其它机房。
+
+这样做的好处是,一个机房写入数据,只需要同步数据到中心机房即可,不需要再关心一共部署了多少个机房,实现复杂度大大「简化」。
+
+但与此同时,这个中心机房的「稳定性」要求会比较高。不过也还好,即使中心机房发生故障,我们也可以把任意一个机房,提升为中心机房,继续按照之前的架构提供服务。
+
+至此,我们的系统彻底实现了「**异地多活**」!
+
+多活的优势在于,**可以任意扩展机房「就近」部署。任意机房发生故障,可以完成快速「切换」**,大大提高了系统的可用性。
+
+同时,我们也再也不用担心系统规模的增长,因为这套架构具有极强的「**扩展能力**」。
+
+怎么样?我们从一个最简单的应用,一路优化下来,到最终的架构方案,有没有帮你彻底理解异地多活呢?
+
+# 总结
+
+好了,总结一下这篇文章的重点。
+
+1、一个好的软件架构,应该遵循高性能、高可用、易扩展 3 大原则,其中「高可用」在系统规模变得越来越大时,变得尤为重要
+
+2、系统发生故障并不可怕,能以「最快」的速度恢复,才是高可用追求的目标,异地多活是实现高可用的有效手段
+
+3、提升高可用的核心是「冗余」,备份、主从副本、同城灾备、同城双活、两地三中心、异地双活,异地多活都是在做冗余
+
+4、同城灾备分为「冷备」和「热备」,冷备只备份数据,不提供服务,热备实时同步数据,并做好随时切换的准备
+
+5、同城双活比灾备的优势在于,两个机房都可以接入「读写」流量,提高可用性的同时,还提升了系统性能。虽然物理上是两个机房,但「逻辑」上还是当做一个机房来用
+
+6、两地三中心是在同城双活的基础上,额外部署一个异地机房做「灾备」,用来抵御「城市」级别的灾害,但启用灾备机房需要时间
+
+7、异地双活才是抵御「城市」级别灾害的更好方案,两个机房同时提供服务,故障随时可切换,可用性高。但实现也最复杂,理解了异地双活,才能彻底理解异地多活
+
+8、异地多活是在异地双活的基础上,任意扩展多个机房,不仅又提高了可用性,还能应对更大规模的流量的压力,扩展性最强,是实现高可用的最终方案
+
+# 后记
+
+这篇文章我从「宏观」层面,向你介绍了异地多活架构的「核心」思路,整篇文章的信息量还是很大的,如果不太好理解,我建议你多读几遍。
+
+因为篇幅限制,很多细节我并没有展开来讲。这篇文章更像是讲异地多活的架构之「道」,而真正实施的「术」,要考虑的点其实也非常繁多,因为它需要开发强大的「基础设施」才可以完成实施。
+
+不仅如此,要想真正实现异地多活,还需要遵循一些原则,例如业务梳理、业务分级、数据分类、数据最终一致性保障、机房切换一致性保障、异常处理等等。同时,相关的运维设施、监控体系也要能跟得上才行。
+
+宏观上需要考虑业务(微服务部署、依赖、拆分、SDK、Web 框架)、基础设施(服务发现、流量调度、持续集成、同步中间件、自研存储),微观上要开发各种中间件,还要关注中间件的高性能、高可用、容错能力,其复杂度之高,只有亲身参与过之后才知道。
+
+我曾经有幸参与过,存储层同步中间件的设计与开发,实现过「跨机房」同步 MySQL、Redis、MongoDB 的中间件,踩过的坑也非常多。当然,这些中间件的设计思路也非常有意思,有时间单独分享一下这些中间件的设计思路。
+
+值得提醒你的是,只有真正理解了「异地双活」,才能彻底理解「异地多活」。在我看来,从同城双活演变为异地双活的过程,是最为复杂的,最核心的东西包括,**业务单元化划分、存储层数据双向同步、最上层的分片逻辑**,这些是实现异地多活的重中之重。
+
diff --git a/docs/advance/excellent-article/31-mysql-data-sync-es.md b/docs/advance/excellent-article/31-mysql-data-sync-es.md
new file mode 100644
index 0000000..8d43d94
--- /dev/null
+++ b/docs/advance/excellent-article/31-mysql-data-sync-es.md
@@ -0,0 +1,503 @@
+---
+sidebar: heading
+title: MySQL数据如何实时同步到ES
+category: 优质文章
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL,ES,elasticsearch,数据同步
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+
+## 前言
+
+我们一般会使用MySQL用来存储数据,用Es来做全文检索和特殊查询,那么如何将数据优雅的从MySQL同步到Es呢?我们一般有以下几种方式:
+
+1.**双写**。在代码中先向MySQL中写入数据,然后紧接着向Es中写入数据。这个方法的缺点是代码严重耦合,需要手动维护MySQL和Es数据关系,非常不便于维护。
+
+2.**发MQ,异步执行**。在执行完向Mysql中写入数据的逻辑后,发送MQ,告诉消费端这个数据需要写入Es,消费端收到消息后执行向Es写入数据的逻辑。这个方式的优点是Mysql和Es数据维护分离,开发Mysql和Es的人员只需要关心各自的业务。缺点是依然需要维护发送、接收MQ的逻辑,并且引入了MQ组件,增加了系统的复杂度。
+
+3.**使用Datax进行全量数据同步**。这个方式优点是可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。缺点是Datax是一种全量同步数据的方式,不使用实时同步。如果系统对数据时效性不强,可以考虑此方式。
+
+4.**使用Canal进行实时数据同步**。这个方式具有跟Datax一样的优点,可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。与Datax不同的是Canal是一种实时同步数据的方式,对数据时效性较强的系统,我们会采用Canal来进行实时数据同步。
+
+那么就让我们来看看Canal是如何使用的。
+
+## 官网
+
+https://github.com/alibaba/canal
+
+## 1.Canal简介
+
+
+
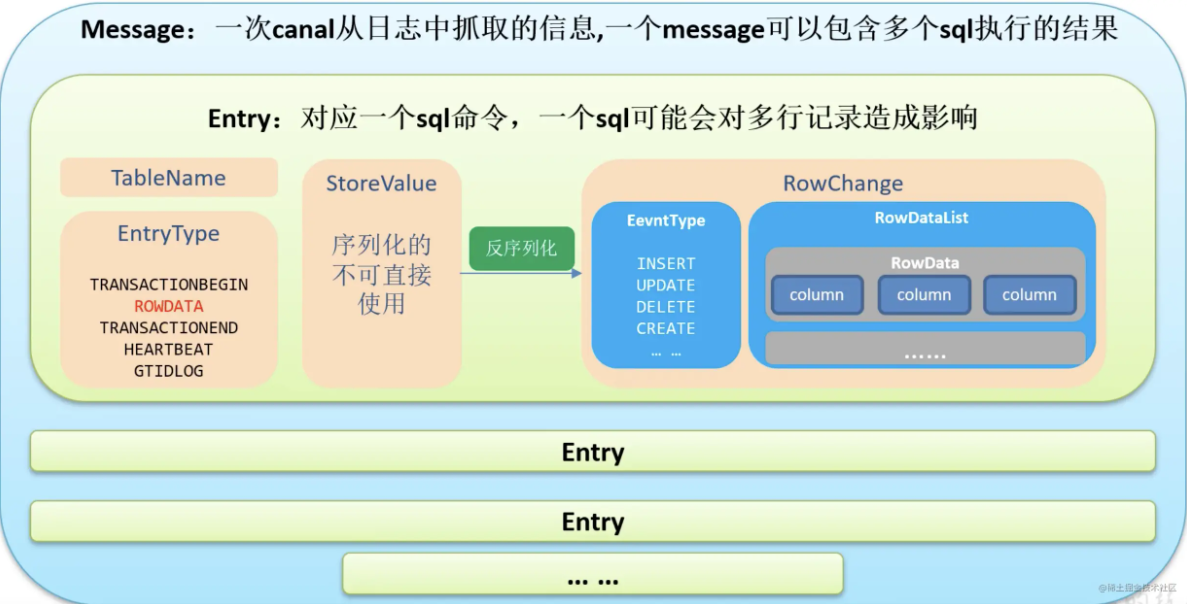
+**canal [kə'næl]** ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
+
+早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
+
+基于日志增量订阅和消费的业务包括
+
+- 数据库镜像
+- 数据库实时备份
+- 索引构建和实时维护(拆分异构索引、倒排索引等)
+- 业务 cache 刷新
+- 带业务逻辑的增量数据处理
+
+当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
+
+### **MySQL主备复制原理**
+
+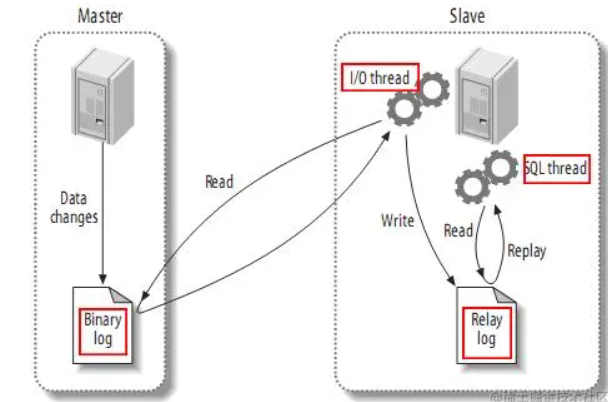
+
+- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
+- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
+- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
+
+### **canal工作原理**
+
+- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
+- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
+- canal 解析 binary log 对象(原始为 byte 流)
+
+## 2.开启MySQL Binlog
+
+- 对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
+
+```ini
+[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
+lua
+## 复制代码注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
+```
+
+- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
+
+```sql
+CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;
+```
+
+注意:Mysql版本为8.x时启动canal可能会出现“caching_sha2_password Auth failed”错误,这是因为8.x创建用户时默认的密码加密方式为**caching_sha2_password**,与canal的方式不一致,所以需要将canal用户的密码加密方式修改为**mysql_native_password**
+
+```sql
+ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; #更新一下用户密码
+FLUSH PRIVILEGES; #刷新权限
+```
+
+## 3.安装Canal
+
+### 3.1 下载Canal
+
+**点击下载地址,选择版本后点击canal.deployer文件下载**
+
+
+
+### 3.2 修改配置文件
+
+打开目录下conf/example/instance.properties文件,主要修改以下内容
+
+```ini
+## mysql serverId,不要和 mysql 的 server_id 重复
+canal.instance.mysql.slaveId = 10
+#position info,需要改成自己的数据库信息
+canal.instance.master.address = 127.0.0.1:3306
+#username/password,需要改成自己的数据库信息,与刚才添加的用户保持一致
+canal.instance.dbUsername = canal
+canal.instance.dbPassword = canal
+```
+
+### 3.3 启动和关闭
+
+```bash
+#进入文件目录下的bin文件夹
+#启动
+sh startup.sh
+#关闭
+sh stop.sh
+```
+
+## 4.Springboot集成Canal
+
+### 4.1 Canal数据结构
+
+
+
+### 4.2 引入依赖
+
+```xml
+
+
+ com.alibaba.otter
+ canal.client
+ 1.1.6
+
+
+
+
+
+ com.alibaba.otter
+ canal.protocol
+ 1.1.6
+
+
+
+
+ co.elastic.clients
+ elasticsearch-java
+ 8.4.3
+
+
+
+
+ jakarta.json
+ jakarta.json-api
+ 2.0.1
+
+```
+
+### 4.3 application.yaml
+
+```yaml
+custom:
+ elasticsearch:
+ host: localhost #主机
+ port: 9200 #端口
+ username: elastic #用户名
+ password: 3bf24a76 #密码
+```
+
+### 4.4 EsClient
+
+```java
+@Setter
+@ConfigurationProperties(prefix = "custom.elasticsearch")
+@Configuration
+public class EsClient {
+
+ /**
+ * 主机
+ */
+ private String host;
+
+ /**
+ * 端口
+ */
+ private Integer port;
+
+ /**
+ * 用户名
+ */
+ private String username;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+
+ @Bean
+ public ElasticsearchClient elasticsearchClient() {
+ CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
+ credentialsProvider.setCredentials(
+ AuthScope.ANY, new UsernamePasswordCredentials(username, password));
+
+ // Create the low-level client
+ RestClient restClient = RestClient.builder(new HttpHost(host, port))
+ .setHttpClientConfigCallback(httpAsyncClientBuilder ->
+ httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider))
+ .build();
+ // Create the transport with a Jackson mapper
+ RestClientTransport transport = new RestClientTransport(
+ restClient, new JacksonJsonpMapper());
+ // Create the transport with a Jackson mapper
+ return new ElasticsearchClient(transport);
+ }
+}
+```
+
+### 4.5 Music实体类
+
+```java
+@Data
+@Builder
+@NoArgsConstructor
+@AllArgsConstructor
+public class Music {
+
+ /**
+ * id
+ */
+ private String id;
+
+ /**
+ * 歌名
+ */
+ private String name;
+
+ /**
+ * 歌手名
+ */
+ private String singer;
+
+ /**
+ * 封面图地址
+ */
+ private String imageUrl;
+
+ /**
+ * 歌曲地址
+ */
+ private String musicUrl;
+
+ /**
+ * 歌词地址
+ */
+ private String lrcUrl;
+
+ /**
+ * 歌曲类型id
+ */
+ private String typeId;
+
+ /**
+ * 是否被逻辑删除,1 是,0 否
+ */
+ private Integer isDeleted;
+
+ /**
+ * 创建时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date createTime;
+
+ /**
+ * 更新时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date updateTime;
+
+}
+```
+
+### 4.6 CanalClient
+
+```java
+@Slf4j
+@Component
+public class CanalClient {
+
+ @Resource
+ private ElasticsearchClient client;
+
+
+ /**
+ * 实时数据同步程序
+ *
+ * @throws InterruptedException
+ * @throws InvalidProtocolBufferException
+ */
+ public void run() throws InterruptedException, IOException {
+ CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(
+ "localhost", 11111), "example", "", "");
+
+ while (true) {
+ //连接
+ connector.connect();
+ //订阅数据库
+ connector.subscribe("cloudmusic_music.music");
+ //获取数据
+ Message message = connector.get(100);
+
+ List entryList = message.getEntries();
+ if (CollectionUtils.isEmpty(entryList)) {
+ //没有数据,休息一会
+ TimeUnit.SECONDS.sleep(2);
+ } else {
+ for (CanalEntry.Entry entry : entryList) {
+ //获取类型
+ CanalEntry.EntryType entryType = entry.getEntryType();
+
+ //判断类型是否为ROWDATA
+ if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
+ //获取序列化后的数据
+ ByteString storeValue = entry.getStoreValue();
+ //反序列化数据
+ CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
+ //获取当前事件操作类型
+ CanalEntry.EventType eventType = rowChange.getEventType();
+ //获取数据集
+ List rowDataList = rowChange.getRowDatasList();
+
+ if (eventType == CanalEntry.EventType.INSERT) {
+ log.info("------新增操作------");
+
+ List musicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ musicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量新增文档
+ index(musicList);
+ //打印新增集合
+ log.info(Arrays.toString(musicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.UPDATE) {
+ log.info("------更新操作------");
+
+ List beforeMusicList = new ArrayList<>();
+ List afterMusicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ //更新前
+ beforeMusicList.add(createMusic(rowData.getBeforeColumnsList()));
+ //更新后
+ afterMusicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量更新文档
+ index(afterMusicList);
+ //打印更新前集合
+ log.info("更新前:{}", Arrays.toString(beforeMusicList.toArray()));
+ //打印更新后集合
+ log.info("更新后:{}", Arrays.toString(afterMusicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.DELETE) {
+ //删除操作
+ log.info("------删除操作------");
+
+ List idList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ for (CanalEntry.Column column : rowData.getBeforeColumnsList()) {
+ if("id".equals(column.getName())) {
+ idList.add(column.getValue());
+ break;
+ }
+ }
+ }
+ //es批量删除文档
+ delete(idList);
+ //打印删除id集合
+ log.info(Arrays.toString(idList.toArray()));
+ }
+ }
+ }
+ }
+ }
+ }
+
+ /**
+ * 根据canal获取的数据创建Music对象
+ *
+ * @param columnList
+ * @return
+ */
+ private Music createMusic(List columnList) {
+ Music music = new Music();
+ DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
+
+ for (CanalEntry.Column column : columnList) {
+ switch (column.getName()) {
+ case "id" -> music.setId(column.getValue());
+ case "name" -> music.setName(column.getValue());
+ case "singer" -> music.setSinger(column.getValue());
+ case "image_url" -> music.setImageUrl(column.getValue());
+ case "music_url" -> music.setMusicUrl(column.getValue());
+ case "lrc_url" -> music.setLrcUrl(column.getValue());
+ case "type_id" -> music.setTypeId(column.getValue());
+ case "is_deleted" -> music.setIsDeleted(Integer.valueOf(column.getValue()));
+ case "create_time" ->
+ music.setCreateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ case "update_time" ->
+ music.setUpdateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ default -> {
+ }
+ }
+ }
+
+ return music;
+ }
+
+ /**
+ * es批量新增、更新文档(不存在:新增, 存在:更新)
+ *
+ * @param musicList 音乐集合
+ * @throws IOException
+ */
+ private void index(List musicList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ musicList.forEach(music -> br
+ .operations(op -> op
+ .index(idx -> idx
+ .index("music")
+ .id(music.getId())
+ .document(music))));
+
+ client.bulk(br.build());
+ }
+
+ /**
+ * es批量删除文档
+ *
+ * @param idList 音乐id集合
+ * @throws IOException
+ */
+ private void delete(List idList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ idList.forEach(id -> br
+ .operations(op -> op
+ .delete(idx -> idx
+ .index("music")
+ .id(id))));
+
+ client.bulk(br.build());
+ }
+
+}
+```
+
+### 4.7 ApplicationContextAware
+
+```java
+@Component
+public class ApplicationContextUtil implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ ApplicationContextUtil.applicationContext = applicationContext;
+ }
+
+ public static T getBean (Class classType) {
+ return applicationContext.getBean(classType);
+ }
+
+}
+```
+
+### 4.8 main
+
+```java
+@Slf4j
+@SpringBootApplication
+public class CanalApplication {
+ public static void main(String[] args) throws InterruptedException, IOException {
+ SpringApplication.run(CanalApplication.class, args);
+ log.info("数据同步程序启动");
+
+ CanalClient client = ApplicationContextUtil.getBean(CanalClient.class);
+ client.run();
+ }
+}
+```
+
+## 5.总结
+
+那么以上就是Canal组件的介绍啦,希望大家都能有所收获~
+
diff --git "a/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md" "b/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md"
new file mode 100644
index 0000000..9a2241a
--- /dev/null
+++ "b/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md"
@@ -0,0 +1,91 @@
+MySQL中编写SQL时,遵循良好的习惯能够提高查询性能、保障数据一致性、提升代码可读性和维护性。以下列举了多个编写SQL的好习惯
+
+#### 1.使用EXPLAIN分析查询计划
+
+在编写或优化复杂查询时,先使用EXPLAIN命令查看查询执行计划,理解MySQL如何执行查询、访问哪些表、使用哪种类型的联接以及索引的使用情况。
+
+好处:有助于识别潜在的性能瓶颈,如全表扫描、错误的索引选择、过多的临时表或文件排序等,从而针对性地优化查询或调整索引结构。
+
+#### 2.避免全表扫描
+
+2. 习惯:尽可能利用索引来避免全表扫描,尤其是在处理大表时。确保在WHERE、JOIN条件和ORDER BY、GROUP BY子句中使用的列有适当的索引。
+
+好处:极大地减少数据访问量,提高查询性能,减轻I/O压力。
+
+#### 3. 为表和字段添加注释
+
+3. 习惯:在创建表时,为表和每个字段添加有意义的注释,描述其用途、数据格式、业务规则等信息。
+
+好处:提高代码可读性和可维护性,帮助其他开发人员快速理解表结构和字段含义,减少沟通成本和误解。
+
+#### 4. 明确指定INSERT语句的列名
+
+习惯:在INSERT语句中显式列出要插入数据的列名,即使插入所有列也应如此。
+
+好处:避免因表结构变化导致的插入错误,增强代码的健壮性,同时也提高了语句的清晰度。
+
+#### 5. 格式化SQL语句
+
+习惯:保持SQL语句的格式整洁,使用一致的大小写(如关键词大写、表名和列名小写),合理缩进,避免过长的单行语句。
+
+好处:提高代码可读性,便于审查、调试和团队协作。
+
+#### 6. 使用LIMIT限制结果集大小
+
+习惯:在执行SELECT、DELETE或UPDATE操作时,若不需要处理全部数据,务必使用LIMIT子句限制结果集大小,特别是在生产环境中。
+
+好处:防止因误操作导致大量数据被修改或删除,降低风险,同时也能提高查询性能。
+
+#### 7.使用JOIN语句代替子查询
+
+习惯:在可能的情况下,优先使用JOIN操作代替嵌套的子查询,特别是在处理多表关联查询时。
+
+好处:许多情况下JOIN的执行效率高于子查询,而且JOIN语句通常更易于理解和优化。
+
+#### 8.避免在WHERE子句中对NULL进行比较
+
+习惯:使用IS NULL和IS NOT NULL来检查字段是否为NULL,而不是直接与NULL进行等值或不等值比较。
+
+好处:正确处理NULL值,避免逻辑错误和未预期的结果。
+
+#### 9.避免在查询中使用SELECT
+
+习惯:明确列出需要的列名,而不是使用SELECT *从表中获取所有列。
+
+好处:减少网络传输的数据量,降低I/O开销,提高查询性能,同时也有利于代码的清晰性和可维护性。
+
+#### 10. 数据库对象命名规范
+
+习惯:遵循一致且有意义的命名约定,如使用小写字母、下划线分隔单词,避免使用MySQL保留字,保持表名、列名、索引名等的简洁性和一致性。
+
+好处:提高代码可读性,减少命名冲突,便于团队协作和维护。
+
+#### 11. 事务管理
+
+习惯:对一系列需要保持原子性的操作使用事务管理,确保数据的一致性。
+
+好处:在发生异常时能够回滚未完成的操作,避免数据处于不一致状态。
+
+#### 12.适时使用索引覆盖
+
+习惯:对于只查询索引列且不需要访问数据行的查询(如计数、统计),创建覆盖索引以避免回表操作。
+
+好处:极大提升查询性能,减少I/O开销。
+
+#### 13.遵循第三范式或适当反范式
+
+习惯:根据业务需求和查询模式,合理设计表结构,遵循第三范式以减少数据冗余和更新异常,或适当反范式以优化查询性能。
+
+好处:保持数据一致性,减少数据维护成本,或提高查询效率。
+
+#### 14.使用预编译语句(PreparedStatement)
+
+习惯:在应用程序中使用预编译语句(如Java中的PreparedStatement)执行SQL,特别是对于动态拼接SQL语句的情况。
+
+好处:避免SQL注入攻击,提高查询性能,减少数据库服务器的解析开销。
+
+#### 15.定期分析与优化表和索引
+
+习惯:定期运行ANALYZE TABLE收集统计信息,以便MySQL优化器做出更准确的查询计划决策。根据查询性能监控结果,适时调整索引或重构表结构。
+
+好处:确保数据库持续高效运行,适应不断变化的业务需求和数据分布。
\ No newline at end of file
diff --git "a/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md" "b/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md"
new file mode 100644
index 0000000..92ca41f
--- /dev/null
+++ "b/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md"
@@ -0,0 +1,430 @@
+# 实现异步编程,我有八种方式!
+
+## **一、前言**
+
+> 异步执行对于开发者来说并不陌生,在实际的开发过程中,很多场景多会使用到异步,相比同步执行,异步可以大大缩短请求链路耗时时间,比如:**发送短信、邮件、异步更新等**,这些都是典型的可以通过异步实现的场景。
+
+## **二、异步的八种实现方式**
+
+1. 线程Thread
+2. Future
+3. 异步框架`CompletableFuture`
+4. Spring注解@Async
+5. Spring `ApplicationEvent`事件
+6. 消息队列
+7. 第三方异步框架,比如Hutool的`ThreadUtil`
+8. Guava异步
+
+## **三、什么是异步?**
+
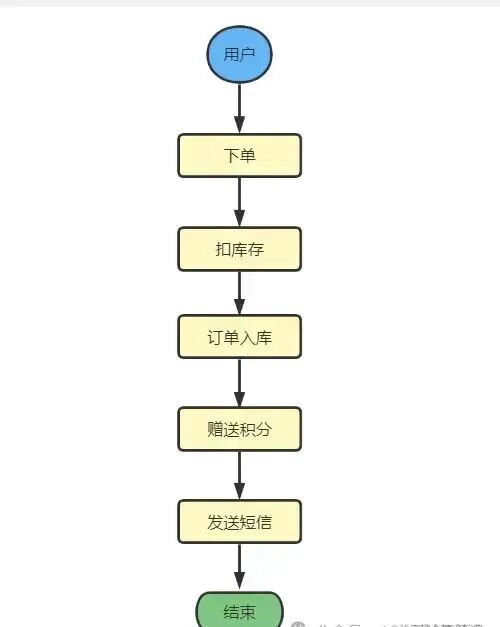
+首先我们先看一个常见的用户下单的场景:
+
+
+
+在同步操作中,我们执行到 **发送短信** 的时候,我们必须等待这个方法彻底执行完才能执行 **赠送积分** 这个操作,如果 **赠送积分** 这个动作执行时间较长,发送短信需要等待,这就是典型的同步场景。
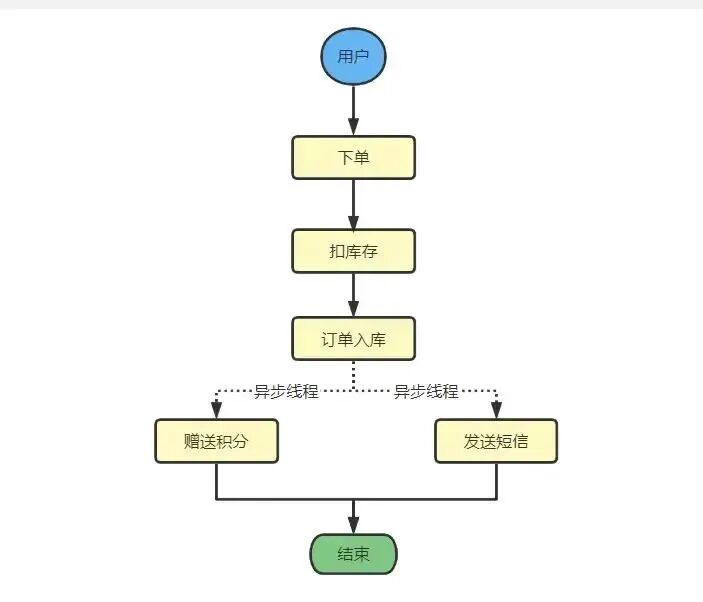
+
+实际上,发送短信和赠送积分没有任何的依赖关系,通过异步,我们可以实现`赠送积分`和`发送短信`这两个操作能够同时进行,比如:
+
+
+
+这就是所谓的异步,是不是非常简单,下面就说说异步的几种实现方式吧。
+
+## **四、异步编程**
+
+#### **4.1 线程异步**
+
+```java
+public class AsyncThread extends Thread {
+
+ @Override
+ public void run() {
+ System.out.println("Current thread name:" + Thread.currentThread().getName() + " Send email success!");
+ }
+
+ public static void main(String[] args) {
+ AsyncThread asyncThread = new AsyncThread();
+ asyncThread.run();
+ }
+}
+```
+
+当然如果每次都创建一个`Thread`线程,频繁的创建、销毁,浪费系统资源,我们可以采用线程池:
+
+```java
+private ExecutorService executorService = Executors.newCachedThreadPool();
+
+public void fun() {
+ executorService.submit(new Runnable() {
+ @Override
+ public void run() {
+ log.info("执行业务逻辑...");
+ }
+ });
+}
+```
+
+可以将业务逻辑封装到`Runnable`或`Callable`中,交由线程池来执行。
+
+#### **4.2 Future异步**
+
+```java
+@Slf4j
+public class FutureManager {
+
+ public String execute() throws Exception {
+
+ ExecutorService executor = Executors.newFixedThreadPool(1);
+ Future future = executor.submit(new Callable() {
+ @Override
+ public String call() throws Exception {
+
+ System.out.println(" --- task start --- ");
+ Thread.sleep(3000);
+ System.out.println(" --- task finish ---");
+ return "this is future execute final result!!!";
+ }
+ });
+
+ //这里需要返回值时会阻塞主线程
+ String result = future.get();
+ log.info("Future get result: {}", result);
+ return result;
+ }
+
+ @SneakyThrows
+ public static void main(String[] args) {
+ FutureManager manager = new FutureManager();
+ manager.execute();
+ }
+}
+```
+
+输出结果:
+
+```
+ --- task start ---
+ --- task finish ---
+ Future get result: this is future execute final result!!!
+```
+
+##### **4.2.1 Future的不足之处**
+
+Future的不足之处的包括以下几点:
+
+1️⃣ 无法被动接收异步任务的计算结果:虽然我们可以主动将异步任务提交给线程池中的线程来执行,但是待异步任务执行结束之后,主线程无法得到任务完成与否的通知,它需要通过get方法主动获取任务执行的结果。
+
+2️⃣ Future件彼此孤立:有时某一个耗时很长的异步任务执行结束之后,你想利用它返回的结果再做进一步的运算,该运算也会是一个异步任务,两者之间的关系需要程序开发人员手动进行绑定赋予,Future并不能将其形成一个任务流(pipeline),每一个Future都是彼此之间都是孤立的,所以才有了后面的`CompletableFuture`,`CompletableFuture`就可以将多个Future串联起来形成任务流。
+
+3️⃣ Futrue没有很好的错误处理机制:截止目前,如果某个异步任务在执行发的过程中发生了异常,调用者无法被动感知,必须通过捕获get方法的异常才知晓异步任务执行是否出现了错误,从而在做进一步的判断处理。
+
+#### **4.3 CompletableFuture实现异步**
+
+```java
+public class CompletableFutureCompose {
+
+ /**
+ * thenAccept子任务和父任务公用同一个线程
+ */
+ @SneakyThrows
+ public static void thenRunAsync() {
+ CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
+ System.out.println(Thread.currentThread() + " cf1 do something....");
+ return 1;
+ });
+ CompletableFuture cf2 = cf1.thenRunAsync(() -> {
+ System.out.println(Thread.currentThread() + " cf2 do something...");
+ });
+ //等待任务1执行完成
+ System.out.println("cf1结果->" + cf1.get());
+ //等待任务2执行完成
+ System.out.println("cf2结果->" + cf2.get());
+ }
+
+ public static void main(String[] args) {
+ thenRunAsync();
+ }
+}
+```
+
+我们不需要显式使用`ExecutorService,CompletableFuture `内部使用了`ForkJoinPool`来处理异步任务,如果在某些业务场景我们想自定义自己的异步线程池也是可以的。
+
+#### **4.4 Spring的@Async异步**
+
+##### **4.4.1 自定义异步线程池**
+
+```
+/**
+ * 线程池参数配置,多个线程池实现线程池隔离,@Async注解,默认使用系统自定义线程池,可在项目中设置多个线程池,在异步调用的时候,指明需要调用的线程池名称,比如:@Async("taskName")
+ *
+ * @author: jacklin
+ * @since: 2021/5/18 11:44
+ **/
+@EnableAsync
+@Configuration
+public class TaskPoolConfig {
+
+ /**
+ * 自定义线程池
+ *
+ * @author: jacklin
+ * @since: 2021/11/16 17:41
+ **/
+ @Bean("taskExecutor")
+ public Executor taskExecutor() {
+ //返回可用处理器的Java虚拟机的数量 12
+ int i = Runtime.getRuntime().availableProcessors();
+ System.out.println("系统最大线程数 : " + i);
+ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
+ //核心线程池大小
+ executor.setCorePoolSize(16);
+ //最大线程数
+ executor.setMaxPoolSize(20);
+ //配置队列容量,默认值为Integer.MAX_VALUE
+ executor.setQueueCapacity(99999);
+ //活跃时间
+ executor.setKeepAliveSeconds(60);
+ //线程名字前缀
+ executor.setThreadNamePrefix("asyncServiceExecutor -");
+ //设置此执行程序应该在关闭时阻止的最大秒数,以便在容器的其余部分继续关闭之前等待剩余的任务完成他们的执行
+ executor.setAwaitTerminationSeconds(60);
+ //等待所有的任务结束后再关闭线程池
+ executor.setWaitForTasksToCompleteOnShutdown(true);
+ return executor;
+ }
+}
+```
+
+##### **4.4.2 AsyncService**
+
+```java
+public interface AsyncService {
+
+ MessageResult sendSms(String callPrefix, String mobile, String actionType, String content);
+
+ MessageResult sendEmail(String email, String subject, String content);
+}
+
+@Slf4j
+@Service
+public class AsyncServiceImpl implements AsyncService {
+
+ @Autowired
+ private IMessageHandler mesageHandler;
+
+ @Override
+ @Async("taskExecutor")
+ public MessageResult sendSms(String callPrefix, String mobile, String actionType, String content) {
+ try {
+
+ Thread.sleep(1000);
+ mesageHandler.sendSms(callPrefix, mobile, actionType, content);
+
+ } catch (Exception e) {
+ log.error("发送短信异常 -> ", e)
+ }
+ }
+
+
+ @Override
+ @Async("taskExecutor")
+ public sendEmail(String email, String subject, String content) {
+ try {
+
+ Thread.sleep(1000);
+ mesageHandler.sendsendEmail(email, subject, content);
+
+ } catch (Exception e) {
+ log.error("发送email异常 -> ", e)
+ }
+ }
+}
+```
+
+在实际项目中, 使用`@Async`调用线程池,推荐等方式是是使用自定义线程池的模式,不推荐直接使用@Async直接实现异步。
+
+#### **4.5 Spring ApplicationEvent事件实现异步**
+
+##### **4.5.1 定义事件**
+
+```java
+public class AsyncSendEmailEvent extends ApplicationEvent {
+
+ /**
+ * 邮箱
+ **/
+ private String email;
+
+ /**
+ * 主题
+ **/
+ private String subject;
+
+ /**
+ * 内容
+ **/
+ private String content;
+
+ /**
+ * 接收者
+ **/
+ private String targetUserId;
+
+}
+```
+
+##### **4.5.2 定义事件处理器**
+
+```java
+@Slf4j
+@Component
+public class AsyncSendEmailEventHandler implements ApplicationListener {
+
+ @Autowired
+ private IMessageHandler mesageHandler;
+
+ @Async("taskExecutor")
+ @Override
+ public void onApplicationEvent(AsyncSendEmailEvent event) {
+ if (event == null) {
+ return;
+ }
+
+ String email = event.getEmail();
+ String subject = event.getSubject();
+ String content = event.getContent();
+ String targetUserId = event.getTargetUserId();
+ mesageHandler.sendsendEmailSms(email, subject, content, targerUserId);
+ }
+}
+```
+
+另外,可能有些时候采用ApplicationEvent实现异步的使用,当程序出现异常错误的时候,需要考虑补偿机制,那么这时候可以结合Spring Retry重试来帮助我们避免这种异常造成数据不一致问题。
+
+#### **4.6 消息队列**
+
+##### **4.6.1 回调事件消息生产者**
+
+```
+@Slf4j
+@Component
+public class CallbackProducer {
+
+ @Autowired
+ AmqpTemplate amqpTemplate;
+
+ public void sendCallbackMessage(CallbackDTO allbackDTO, final long delayTimes) {
+
+ log.info("生产者发送消息,callbackDTO,{}", callbackDTO);
+
+ amqpTemplate.convertAndSend(CallbackQueueEnum.QUEUE_GENSEE_CALLBACK.getExchange(), CallbackQueueEnum.QUEUE_GENSEE_CALLBACK.getRoutingKey(), JsonMapper.getInstance().toJson(genseeCallbackDTO), new MessagePostProcessor() {
+ @Override
+ public Message postProcessMessage(Message message) throws AmqpException {
+ //给消息设置延迟毫秒值,通过给消息设置x-delay头来设置消息从交换机发送到队列的延迟时间
+ message.getMessageProperties().setHeader("x-delay", delayTimes);
+ message.getMessageProperties().setCorrelationId(callbackDTO.getSdkId());
+ return message;
+ }
+ });
+ }
+}
+```
+
+##### **4.6.2 回调事件消息消费者**
+
+```
+@Slf4j
+@Component
+@RabbitListener(queues = "message.callback", containerFactory = "rabbitListenerContainerFactory")
+public class CallbackConsumer {
+
+ @Autowired
+ private IGlobalUserService globalUserService;
+
+ @RabbitHandler
+ public void handle(String json, Channel channel, @Headers Map map) throws Exception {
+
+ if (map.get("error") != null) {
+ //否认消息
+ channel.basicNack((Long) map.get(AmqpHeaders.DELIVERY_TAG), false, true);
+ return;
+ }
+
+ try {
+
+ CallbackDTO callbackDTO = JsonMapper.getInstance().fromJson(json, CallbackDTO.class);
+ //执行业务逻辑
+ globalUserService.execute(callbackDTO);
+ //消息消息成功手动确认,对应消息确认模式acknowledge-mode: manual
+ channel.basicAck((Long) map.get(AmqpHeaders.DELIVERY_TAG), false);
+
+ } catch (Exception e) {
+ log.error("回调失败 -> {}", e);
+ }
+ }
+}
+```
+
+#### **4.7 ThreadUtil异步工具类**
+
+```java
+@Slf4j
+public class ThreadUtils {
+
+ public static void main(String[] args) {
+ for (int i = 0; i < 3; i++) {
+ ThreadUtil.execAsync(() -> {
+ ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
+ int number = threadLocalRandom.nextInt(20) + 1;
+ System.out.println(number);
+ });
+ log.info("当前第:" + i + "个线程");
+ }
+
+ log.info("task finish!");
+ }
+}
+```
+
+#### **4.8 Guava异步**
+
+`Guava`的`ListenableFuture`顾名思义就是可以监听的`Future`,是对java原生Future的扩展增强。我们知道Future表示一个异步计算任务,当任务完成时可以得到计算结果。
+
+如果我们希望一旦计算完成就拿到结果展示给用户或者做另外的计算,就必须使用另一个线程不断的查询计算状态。这样做,代码复杂,而且效率低下。
+
+使用**Guava ListenableFuture**可以帮我们检测Future是否完成了,不需要再通过get()方法苦苦等待异步的计算结果,如果完成就自动调用回调函数,这样可以减少并发程序的复杂度。
+
+`ListenableFuture`是一个接口,它从`jdk`的`Future`接口继承,添加了`void addListener(Runnable listener, Executor executor)`方法。
+
+我们看下如何使用`ListenableFuture`。首先需要定义`ListenableFuture`的实例:
+
+```java
+ListeningExecutorService executorService = MoreExecutors.listeningDecorator(Executors.newCachedThreadPool());
+ final ListenableFuture listenableFuture = executorService.submit(new Callable() {
+ @Override
+ public Integer call() throws Exception {
+ log.info("callable execute...")
+ TimeUnit.SECONDS.sleep(1);
+ return 1;
+ }
+ });
+```
+
+首先通过`MoreExecutors`类的静态方法`listeningDecorator`方法初始化一个`ListeningExecutorService`的方法,然后使用此实例的`submit`方法即可初始化`ListenableFuture`对象。
+
+`ListenableFuture`要做的工作,在Callable接口的实现类中定义,这里只是休眠了1秒钟然后返回一个数字1,有了`ListenableFuture`实例,可以执行此Future并执行Future完成之后的回调函数。
+
+```java
+ Futures.addCallback(listenableFuture, new FutureCallback() {
+ @Override
+ public void onSuccess(Integer result) {
+ //成功执行...
+ System.out.println("Get listenable future's result with callback " + result);
+ }
+
+ @Override
+ public void onFailure(Throwable t) {
+ //异常情况处理...
+ t.printStackTrace();
+ }
+});
+```
\ No newline at end of file
diff --git a/docs/advance/system-design/2-order-timeout-auto-cancel.md b/docs/advance/system-design/2-order-timeout-auto-cancel.md
index 5ffaf4e..b100f91 100644
--- a/docs/advance/system-design/2-order-timeout-auto-cancel.md
+++ b/docs/advance/system-design/2-order-timeout-auto-cancel.md
@@ -42,11 +42,11 @@ head:
对上述的任务,我们给一个专业的名字来形容,那就是延时任务。那么这里就会产生一个问题,这个延时任务和定时任务的区别究竟在哪里呢?一共有如下几点区别
-定时任务有明确的触发时间,延时任务没有
+1、定时任务有明确的触发时间,延时任务没有
-定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
+2、定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
-定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
+3、定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
下面,我们以判断订单是否超时为例,进行方案分析
@@ -340,13 +340,13 @@ public class HashedWheelTimerTest {
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
-## 方案 4:redis 缓存
+## 方案 4:Redis 缓存
### 思路一
利用 redis 的 zset,zset 是一个有序集合,每一个元素(member)都关联了一个 score,通过 score 排序来取集合中的值
-添加元素:ZADD key score member [[score member][score member] …]
+添加元素:ZADD key score member [score member …]
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
@@ -619,11 +619,11 @@ ps:redis 的 pub/sub 机制存在一个硬伤,官网内容如下
### 思路
-我们可以采用 rabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
+我们可以采用 RabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
RabbitMQ 可以针对 Queue 和 Message 设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为 dead letter
-lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。
+lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能。
### 优点
diff --git a/docs/advance/system-design/README.md b/docs/advance/system-design/README.md
index 79b8eb1..15ef840 100644
--- a/docs/advance/system-design/README.md
+++ b/docs/advance/system-design/README.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
\ No newline at end of file
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/3-baidu.md b/docs/campus-recruit/interview/3-baidu.md
index d5918e5..3cd2f26 100644
--- a/docs/campus-recruit/interview/3-baidu.md
+++ b/docs/campus-recruit/interview/3-baidu.md
@@ -36,6 +36,18 @@
- 刷脏页的流程
- 算法题:平方根
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经3
- 自我介绍
@@ -104,6 +116,12 @@
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/4-ali.md b/docs/campus-recruit/interview/4-ali.md
index 2c99b2e..00b2a7a 100644
--- a/docs/campus-recruit/interview/4-ali.md
+++ b/docs/campus-recruit/interview/4-ali.md
@@ -48,6 +48,18 @@
24. 操作系统的内存管理的页面淘汰 算法 ,介绍下LRU(最近最少使用算法 )
25. B+树的特点与优势
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经3
- 自我介绍,说简历里没有的东西
@@ -74,6 +86,14 @@
- 服务注册的时候发现没有注册成功会是什么原因。
- 讲讲你认为的rpc和service mesh之间的关系。
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/5-kuaishou.md b/docs/campus-recruit/interview/5-kuaishou.md
index 1b24e6d..539a84a 100644
--- a/docs/campus-recruit/interview/5-kuaishou.md
+++ b/docs/campus-recruit/interview/5-kuaishou.md
@@ -67,6 +67,18 @@
1. 对于部门的业务、技术栈
2. 对我的建议、和整个面试的感觉
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经1-二面
> **Java基础**
@@ -307,6 +319,14 @@ while (true) {
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/6-meituan.md b/docs/campus-recruit/interview/6-meituan.md
index 43a1b71..32cb5bf 100644
--- a/docs/campus-recruit/interview/6-meituan.md
+++ b/docs/campus-recruit/interview/6-meituan.md
@@ -68,3 +68,12 @@
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/share/2-years-tech-upgrade.md b/docs/campus-recruit/share/2-years-tech-upgrade.md
index b2aa471..5322d98 100644
--- a/docs/campus-recruit/share/2-years-tech-upgrade.md
+++ b/docs/campus-recruit/share/2-years-tech-upgrade.md
@@ -58,4 +58,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券即可加入~
-
+
diff --git a/docs/career-plan/3-years-reflect.md b/docs/career-plan/3-years-reflect.md
index 8c4c12c..21e4cfc 100644
--- a/docs/career-plan/3-years-reflect.md
+++ b/docs/career-plan/3-years-reflect.md
@@ -95,5 +95,5 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/career-plan/how-to-prepare-job-hopping.md b/docs/career-plan/how-to-prepare-job-hopping.md
index 0dea290..59aee75 100644
--- a/docs/career-plan/how-to-prepare-job-hopping.md
+++ b/docs/career-plan/how-to-prepare-job-hopping.md
@@ -85,4 +85,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/career-plan/java-or-bigdata.md b/docs/career-plan/java-or-bigdata.md
index d3bbf32..cf98ec1 100644
--- a/docs/career-plan/java-or-bigdata.md
+++ b/docs/career-plan/java-or-bigdata.md
@@ -59,4 +59,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/computer-basic/network.md b/docs/computer-basic/network.md
index 465d1bc..831488a 100644
--- a/docs/computer-basic/network.md
+++ b/docs/computer-basic/network.md
@@ -41,6 +41,8 @@ head:
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
diff --git a/docs/database/mysql.md b/docs/database/mysql.md
index 9559ede..c8b0032 100644
--- a/docs/database/mysql.md
+++ b/docs/database/mysql.md
@@ -20,6 +20,12 @@ head:
:::
+## 更新记录
+
+- 2024.06.05,更新[MySQL查询 limit 1000,10 和limit 10 速度一样快吗?](###MySQL查询 limit 1000,10 和limit 10 速度一样快吗?)
+
+- 2024.5.15,新增[B树和B+树的区别?](###B树和B+树的区别?)
+
## 什么是MySQL
MySQL是一个关系型数据库,它采用表的形式来存储数据。你可以理解成是Excel表格,既然是表的形式存储数据,就有表结构(行和列)。行代表每一行数据,列代表该行中的每个值。列上的值是有数据类型的,比如:整数、字符串、日期等等。
@@ -262,6 +268,18 @@ Index_comment:
- 哈希索引**不支持模糊查询**及多列索引的最左前缀匹配。
- 因为哈希表中会**存在哈希冲突**,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。
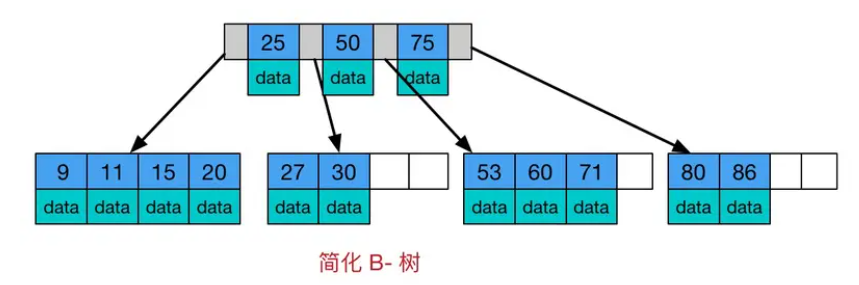
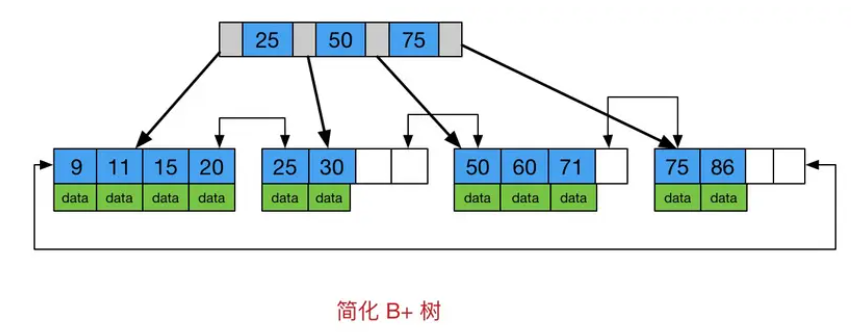
+### B树和B+树的区别?
+
+
+
+
+
+1. **数据存储方式**:在B树中,每个节点都包含键和对应的值,叶子节点存储了实际的数据记录;而B+树中,仅仅只有叶子节点存储了实际的数据记录,非叶子节点只包含键信息和指向子节点的指针。
+2. **数据检索方式**:在B树中,由于非叶子节点也存储了数据,所以查询时可以直接在非叶子节点找到对应的数据,具有更短的查询路径;
+ 而B+树的所有数据都存储在叶子节点上,只有通过子节点才能获取到完整的数据。
+3. **范围查询效率**:由于B+树的所有数据都存储在叶子节点上,并且叶子节点之间使用链表连接,所以范围查询的效率比较高。而在B树中,范围查询需要通过遍历多个层级的节点,效率相对较低。
+4. **适用场景**:B树适合进行随机读写操作,因为每个节点都包含了数据。而B+树适合进行范围查询和顺序访问,因为数据都存储在叶子节点上,并且叶子节点之间使用链表连接,便于进行顺序遍历。
+
### 为什么B+树比B树更适合实现数据库索引?
- 由于B+树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以通常B+树用于数据库索引。
@@ -1180,4 +1198,38 @@ COUNT(`*`)是SQL92定义的标准统计行数的语法,效率高,MySQL对它
所以,建议使用COUNT(\*)查询表的行数!
+## 存储MD5值应该用VARCHAR还是用CHAR?
+
+首先说说CHAR和VARCHAR的区别:
+
+1、存储长度:
+
+CHAR类型的长度是固定的
+
+当我们当定义CHAR(10),输入的值是"abc",但是它占用的空间一样是10个字节,会包含7个空字节。当输入的字符长度超过指定的数时,CHAR会截取超出的字符。而且,当存储为CHAR的时候,MySQL会自动删除输入字符串末尾的空格。
+
+VARCHAR的长度是可变的
+
+比如VARCHAR(10),然后输入abc三个字符,那么实际存储大小为3个字节。
+
+除此之外,VARCHAR还会保留1个或2个额外的字节来记录字符串的实际长度。如果定义的最大长度小于等于255个字节,那么,就会预留1个字节;如果定义的最大长度大于255个字节,那么就会预留2个字节。
+
+2、存储效率
+
+CHAR类型每次修改后的数据长度不变,效率更高。
+
+VARCHAR每次修改的数据要更新数据长度,效率更低。
+
+3、存储空间
+
+CHAR存储空间是初始的预计长度字符串再加上一个记录字符串长度的字节,可能会存在多余的空间。
+
+VARCHAR存储空间的时候是实际字符串再加上一个记录字符串长度的字节,占用空间较小。
+
+
+
+根据以上的分析,由于MD5是一个定长的值,所以MD5值适合使用CHAR存储。对于固定长度的非常短的列,CHAR比VARCHAR效率也更高。
+
+
+

diff --git "a/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md" "b/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md"
new file mode 100644
index 0000000..94d82b5
--- /dev/null
+++ "b/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md"
@@ -0,0 +1,67 @@
+一条 SQL 查询语句如何执行的
+
+在平常的开发中,可能很多人都是 CRUD,对 SQL 语句的语法很熟练,但是说起一条 SQL 语句在 MySQL 中是怎么执行的却浑然不知,今天大彬就由浅入深,带大家一点点剖析一条 SQL 语句在 MySQL 中是怎么执行的。
+
+比如你执行下面这个 SQL 语句时,我们看到的只是输入一条语句,返回一个结果,却不知道 MySQL 内部的执行过程:
+
+```mysql
+mysql> select * from T where ID=10;
+```
+
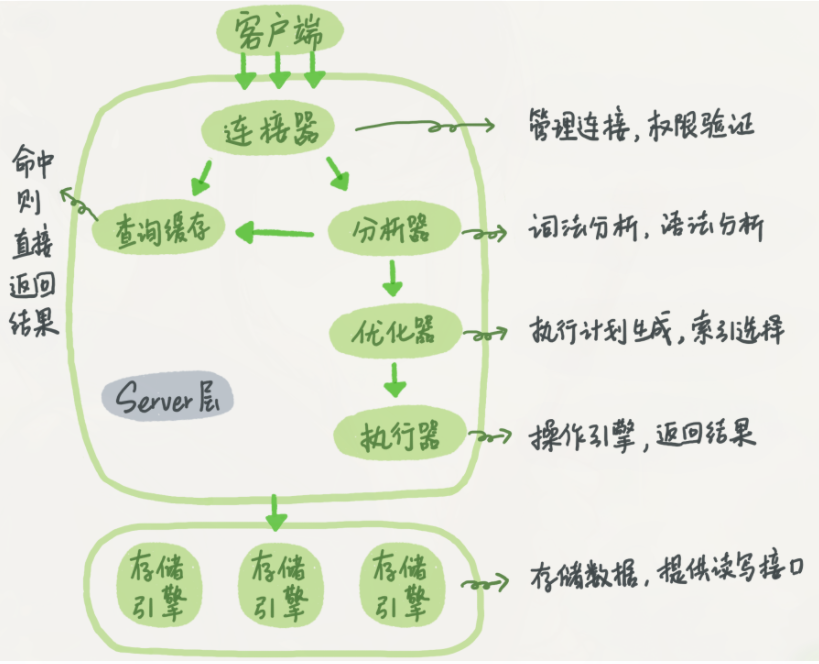
+在剖析这个语句怎么执行之前,我们先看一下 MySQL 的基本架构示意图,能更清楚的看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
+
+
+
+整体来说,MySQL 可以分为 Server 层和存储引擎两部分。
+
+Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
+
+### 连接器
+
+如果要操作 MySQL 数据库,我们必须使用 MySQL 客户端来连接 MySQL 服务器,这时候就是服务器中的连接器来负责根客户端建立连接、获取权限、维持和管理连接。
+
+在和服务端完成 TCP 连接后,连接器就要认证身份,需要用到用户名和密码,确保用户有足够的权限执行该SQL语句。
+
+### 查询缓存
+
+建立完连接后,就可以执行查询语句了,来到第二步:查询缓存。
+
+MySQL 拿到第一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中,如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
+
+如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
+
+### 分析器
+
+如果没有命中缓存,就要开始真正执行语句了,MySQL 首先会对 SQL 语句做解析。
+
+分析器会先做 “词法分析”,MySQL 需要识别出 SQL 里面的字符串分别是什么,代表什么。
+
+做完之后就要做“语法分析”,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。若果语句不对,就会收到错误提醒。
+
+### 优化器
+
+经过了分析器,MySQL 就知道要做什么了,但是在开始执行之前,要先经过优化器的处理。
+
+比如:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
+
+MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据**成本最小原则**来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本。
+
+### 执行器
+
+执行优化之后的执行计划,在开始执行之前,先判断一下用户对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
+
+### 存储引擎
+
+执行器将查询请求发送给存储引擎组件。
+
+存储引擎组件负责具体的数据存储、检索和修改操作。
+
+存储引擎根据执行器的请求,从磁盘或内存中读取或写入相关数据。
+
+### 返回结果
+
+存储引擎将查询结果返回给执行器。
+
+执行器将结果返回给连接器。
+
+最后,连接器将结果发送回客户端,完成整个执行过程。
\ No newline at end of file
diff --git a/docs/framework/mybatis.md b/docs/framework/mybatis.md
index 0337815..b21cb9d 100644
--- a/docs/framework/mybatis.md
+++ b/docs/framework/mybatis.md
@@ -27,6 +27,17 @@ head:
- MyBatis作为持久层框架,其主要思想是将程序中的大量SQL语句剥离出来,配置在配置文件当中,实现SQL的灵活配置。
- 这样做的好处是将SQL与程序代码分离,可以在不修改代码的情况下,直接在配置文件当中修改SQL。
+## 为什么使用Mybatis代替JDBC?
+
+MyBatis 是一种优秀的 ORM(Object-Relational Mapping)框架,与 JDBC 相比,有以下几点优势:
+
+1. 简化了 JDBC 的繁琐操作:使用 JDBC 进行数据库操作需要编写大量的样板代码,如获取连接、创建 Statement/PreparedStatement,设置参数,处理结果集等。而使用 MyBatis 可以将这些操作封装起来,通过简单的配置文件和 SQL 语句就能完成数据库操作,从而大大简化了开发过程。
+2. 提高了 SQL 的可维护性:使用 JDBC 进行数据库操作,SQL 语句通常会散布在代码中的各个位置,当 SQL 语句需要修改时,需要找到所有使用该语句的地方进行修改,这非常不方便,也容易出错。而使用 MyBatis,SQL 语句都可以集中在配置文件中,可以更加方便地修改和维护,同时也提高了 SQL 语句的可读性。
+3. 支持动态 SQL:MyBatis 提供了强大的动态 SQL 功能,可以根据不同的条件生成不同的 SQL 语句,这对于复杂的查询操作非常有用。
+4. 易于集成:MyBatis 可以与 Spring 等流行的框架集成使用,可以通过 XML 或注解配置进行灵活的配置,同时 MyBatis 也提供了非常全面的文档和示例代码,学习和使用 MyBatis 非常方便。
+
+综上所述,使用 MyBatis 可以大大简化数据库操作的代码,提高 SQL 语句的可维护性和可读性,同时还提供了强大的动态 SQL 功能,易于集成使用。因此,相比于直接使用 JDBC,使用 MyBatis 更为便捷、高效和方便。
+
## **ORM是什么**
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
@@ -107,7 +118,7 @@ Mybatis仅可以编写针对 `ParameterHandler`、`ResultSetHandler`、`Statemen
编写插件:实现 Mybatis 的 Interceptor 接口并复写 intercept()方法,然后再给插件编写注解,指定要拦截哪一个接口的哪些方法即可,最后在配置文件中配置你编写的插件。
-## .Mybatis 是否支持延迟加载?
+## Mybatis 是否支持延迟加载?
Mybatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 Mybatis 配置文件中,可以配置是否启用延迟加载`lazyLoadingEnabled=true|false`。
diff --git a/docs/framework/spring.md b/docs/framework/spring.md
index 410e4e3..4ea008b 100644
--- a/docs/framework/spring.md
+++ b/docs/framework/spring.md
@@ -102,6 +102,18 @@ AOP有两种实现方式:静态代理和动态代理。
动态代理:代理类在程序运行时创建,AOP框架不会去修改字节码,而是在内存中临时生成一个代理对象,在运行期间对业务方法进行增强,不会生成新类。
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## Spring AOP的实现原理
`Spring`的`AOP`实现原理其实很简单,就是通过**动态代理**实现的。如果我们为`Spring`的某个`bean`配置了切面,那么`Spring`在创建这个`bean`的时候,实际上创建的是这个`bean`的一个代理对象,我们后续对`bean`中方法的调用,实际上调用的是代理类重写的代理方法。而`Spring`的`AOP`使用了两种动态代理,分别是**JDK的动态代理**,以及**CGLib的动态代理**。
@@ -977,4 +989,14 @@ Spring常用的注入方式有:属性注入, 构造方法注入, set 方法注
+> 最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+>
+> 
+>
+> 
+>
+> **200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+>
+> 备用链接:https://pan.quark.cn/s/3f1321952a16
+

diff --git a/docs/framework/springboot.md b/docs/framework/springboot.md
index 496473c..a0b52ad 100644
--- a/docs/framework/springboot.md
+++ b/docs/framework/springboot.md
@@ -60,12 +60,78 @@ starter提供了一个自动化配置类,一般命名为 XXXAutoConfiguration
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
+- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
+- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
+- @ComponentScan:Spring组件扫描。
+
+## 有哪些常用的SpringBoot注解?
+
+- @SpringBootApplication。这个注解是Spring Boot最核心的注解,用在 Spring Boot的主类上,标识这是一个 Spring Boot 应用,用来开启 Spring Boot 的各项能力
+
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
+- @Repository:用于标注数据访问组件,即DAO组件。
+
+- @Service:一般用于修饰service层的组件
+
+- **@RestController**。用于标注控制层组件(如struts中的action),表示这是个控制器bean,并且是将函数的返回值直 接填入HTTP响应体中,是REST风格的控制器;它是@Controller和@ResponseBody的合集。
+
+- **@ResponseBody**。表示该方法的返回结果直接写入HTTP response body中
+
+- **@Component**。泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
+
+- **@Bean**,相当于XML中的``,放在方法的上面,而不是类,意思是产生一个bean,并交给spring管理。
+
+- **@AutoWired**,byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。
+
+- **@Qualifier**。当有多个同一类型的Bean时,可以用@Qualifier("name")来指定。与@Autowired配合使用
+
+- **@Resource(name="name",type="type")**。没有括号内内容的话,默认byName。与@Autowired干类似的事。
+
+- **@RequestMapping**
+
+ RequestMapping是一个用来处理请求地址映射的注解;提供路由信息,负责URL到Controller中的具体函数的映射,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
+
+- **@RequestParam**
+
+ 用在方法的参数前面。
+
+- ### @Scope
+
+ 用于声明一个Spring`Bean`实例的作用域
+
+- ### @Primary
+
+ 当同一个对象有多个实例时,优先选择该实例。
+
+- ### @PostConstruct
+
+ 用于修饰方法,当对象实例被创建并且依赖注入完成后执行,可用于对象实例的初始化操作。
+
+- ### @PreDestroy
+
+ 用于修饰方法,当对象实例将被Spring容器移除时执行,可用于对象实例持有资源的释放。
+
+- ### @EnableTransactionManagement
+
+ 启用Spring基于注解的事务管理功能,需要和`@Configuration`注解一起使用。
+
+- ### @Transactional
+
+ 表示方法和类需要开启事务,当作用与类上时,类中所有方法均会开启事务,当作用于方法上时,方法开启事务,方法上的注解无法被子类所继承。
+
+- ### @ControllerAdvice
+
+ 常与`@ExceptionHandler`注解一起使用,用于捕获全局异常,能作用于所有controller中。
+
+- ### @ExceptionHandler
+
+ 修饰方法时,表示该方法为处理全局异常的方法。
+
## 自动配置原理
SpringBoot实现自动配置原理图解:
diff --git a/docs/framework/springboot/springboot-cross-domain.md b/docs/framework/springboot/springboot-cross-domain.md
index fa7dac3..b93a909 100644
--- a/docs/framework/springboot/springboot-cross-domain.md
+++ b/docs/framework/springboot/springboot-cross-domain.md
@@ -90,4 +90,4 @@ public class AccountController {
6、打卡学习,**大学自习室的氛围**,一起蜕变成长
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/framework/springcloud-interview.md b/docs/framework/springcloud-interview.md
index 619e950..f95f36b 100644
--- a/docs/framework/springcloud-interview.md
+++ b/docs/framework/springcloud-interview.md
@@ -24,17 +24,66 @@ head:
:::
+## 更新记录
+
+- 2024.5.15,完善[Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?](##Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?)
## 1、什么是Spring Cloud ?
Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
-## spring、 springboot、 springcloud 的区别是什么?
+
+
+Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
+
+## Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?
+
+### Spring
+
+Spring是一个生态体系(也可以说是技术体系),是集大成者,它包含了Spring Framework、Spring Boot、Spring Cloud等。**它是一个轻量级控制反转(IOC)和面向切面(AOP)的容器框架**,为开发者提供了一个简易的开发方式。
+
+Spring的核心特性思想之一IOC,它实现了容器对Bean对象的管理、降低组件耦合,使各层服务解耦。
+
+Spring的另一个核心特性就是AOP,面向切面编程。面向切面编程需要将程序逻辑分解为称为所谓关注点的不同部分。跨越应用程序多个点的功能称为跨领域问题,这些跨领域问题在概念上与应用程序的业务逻辑分离。有许多常见的例子,如日志记录,声明式事务,安全性,缓存等。
+
+**如果说IOC依赖注入可以帮助我们将应用程序对象相互分离,那么AOP可以帮助我们将交叉问题与它们所影响的对象分离。二者目的都是使服务解耦,使开发简易。**
+
+当然,除了Spring 的两大核心功能,还有如下这些,如:
+
+- Spring JDBC
+- Spring MVC
+- Spring ORM
+- Spring Test
-Spring是一个生态体系(也可以说是技术体系),是集大成者,它包含了Spring Framework、Spring Boot、Spring Cloud等。
+### SpringMVC
+
+Spring与MVC可以更好地解释什么是SpringMVC,MVC为现代web项目开发的一种很常见的模式,简言之C(控制器)将V(视图、用户客户端)与M(模块,业务)分开构成了MVC ,业内常见的MVC模式的开发框架有Struts。
+
+Spring MVC是Spring的一部分,主要用于开发WEB应用和网络接口,它是Spring的一个模块,通过DispatcherServlet, ModelAndView 和View Resolver,让应用开发变得很容易。
+
+### SpringBoot
+
+SpringBoot是一套整合了框架的框架。
+
+它的初衷:解决Spring框架配置文件的繁琐、搭建服务的复杂性。
+
+它的设计理念:**约定优于配置**(convention over configuration)。
+
+基于此理念实现了**自动配置**,且降低项目搭建的复杂度。
+
+搭建一个接口服务,通过SpringBoot几行代码即可实现。基于Spring Boot,不是说原来的配置没有了,而是Spring Boot有一套默认配置,我们可以把它看做比较通用的约定,而Spring Boot遵循的是**约定优于配置**原则,同时,如果你需要使用到Spring以往提供的各种复杂但功能强大的配置功能,Spring Boot一样支持。
+
+在Spring Boot中,你会发现引入的所有包都是starter形式,如:
+
+- spring-boot-starter-web-services,针对SOAP Web Services
+- spring-boot-starter-web,针对Web应用与网络接口
+- spring-boot-starter-jdbc,针对JDBC
+- spring-boot-starter-cache,针对缓存支持
Spring Boot是基于 Spring 框架开发的用于开发 Web 应用程序的框架,它帮助开发人员快速搭建和配置一个独立的、可执行的、基于 Spring 的应用程序,从而减少了繁琐和重复的配置工作。
+### Spring Cloud
+
Spring Cloud事实上是一整套基于Spring Boot的微服务解决方案。它为开发者提供了很多工具,用于快速构建分布式系统的一些通用模式,例如:配置管理、注册中心、服务发现、限流、网关、链路追踪等。Spring Boot是build anything,而Spring Cloud是coordinate anything,Spring Cloud的每一个微服务解决方案都是基于Spring Boot构建的。
## 2、什么是微服务?
diff --git a/docs/framework/springmvc.md b/docs/framework/springmvc.md
index e6a39b6..6bf2369 100644
--- a/docs/framework/springmvc.md
+++ b/docs/framework/springmvc.md
@@ -13,194 +13,38 @@ head:
content: 高质量的Spring MVC常见知识点和面试题总结,让天下没有难背的八股文!
---
-::: tip 这是一则或许对你有帮助的信息
-- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
-- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
-:::
+**Spring MVC高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
-## 说说你对 SpringMVC 的理解
+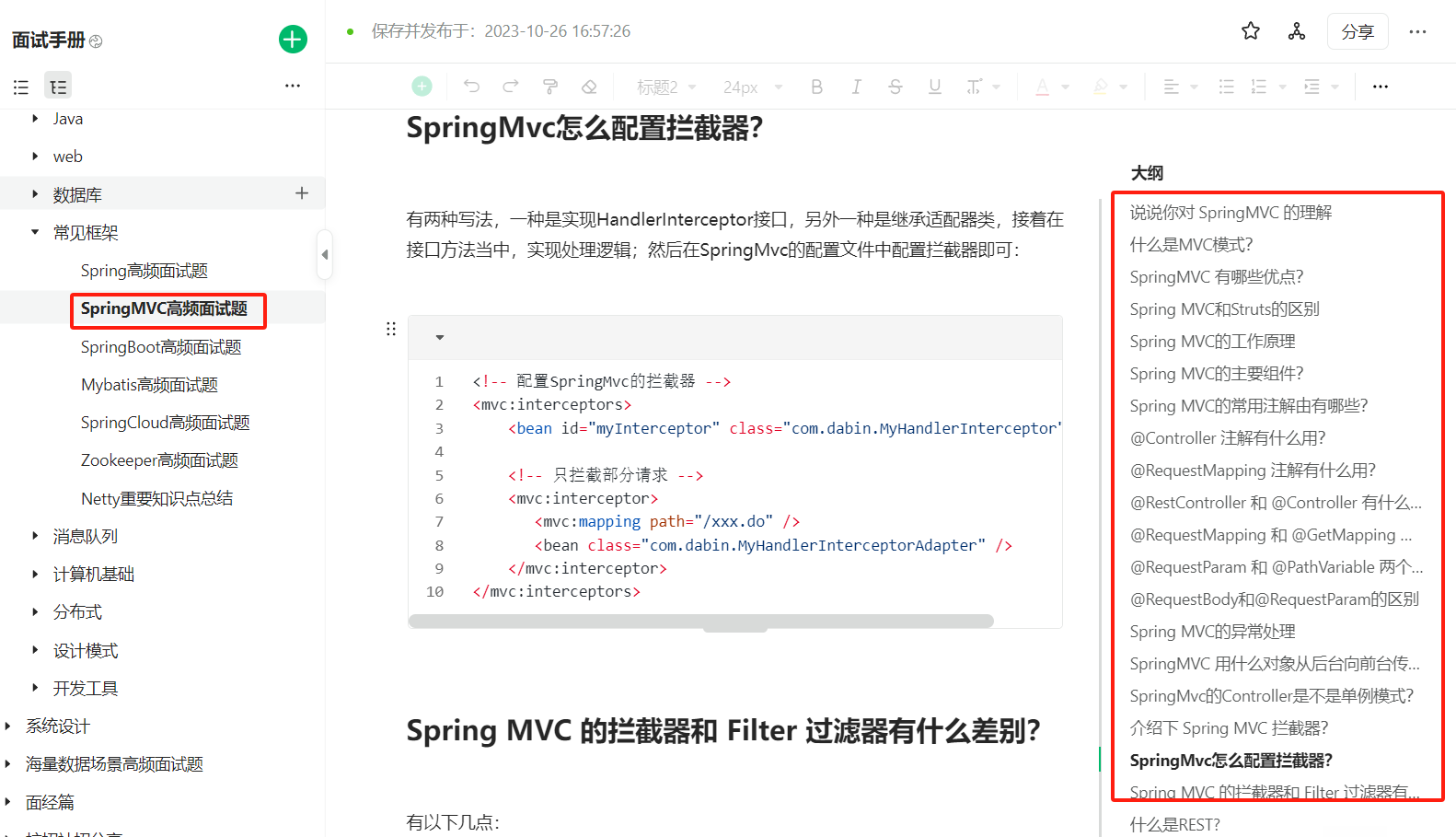
-SpringMVC是一种基于 Java 的实现MVC设计模型的请求驱动类型的轻量级Web框架,属于Spring框架的一个模块。
+如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
-它通过一套注解,让一个简单的Java类成为处理请求的控制器,而无须实现任何接口。同时它还支持RESTful编程风格的请求。
+
-## 什么是MVC模式?
+
-MVC的全名是`Model View Controller`,是模型(model)-视图(view)-控制器(controller)的缩写,是一种软件设计典范。它是用一种业务逻辑、数据与界面显示分离的方法来组织代码,将众多的业务逻辑聚集到一个部件里面,在需要改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑,达到减少编码的时间。
+另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
-View,视图是指用户看到并与之交互的界面。比如由html元素组成的网页界面,或者软件的客户端界面。MVC的好处之一在于它能为应用程序处理很多不同的视图。在视图中其实没有真正的处理发生,它只是作为一种输出数据并允许用户操纵的方式。
+
-model,模型是指模型表示业务规则。在MVC的三个部件中,模型拥有最多的处理任务。被模型返回的数据是中立的,模型与数据格式无关,这样一个模型能为多个视图提供数据,由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性。
+
-controller,控制器是指控制器接受用户的输入并调用模型和视图去完成用户的需求,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示返回的数据。
+
-## SpringMVC 有哪些优点?
+星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
-1. 与 Spring 集成使用非常方便,生态好。
-2. 配置简单,快速上手。
-3. 支持 RESTful 风格。
-4. 支持各种视图技术,支持各种请求资源映射策略。
+
-## Spring MVC和Struts的区别
+
-1. Spring MVC是基于方法开发,Struts2是基于类开发的。
- - Spring MVC会将用户请求的URL路径信息与Controller的某个方法进行映射,所有请求参数会注入到对应方法的形参上,生成Handler对象,对象中只有一个方法;
- - Struts每处理一次请求都会实例一个Action,Action类的所有方法使用的请求参数都是Action类中的成员变量,随着方法增多,整个Action也会变得混乱。
-2. Spring MVC支持单例开发模式,Struts只能使用多例
+
- - Struts由于只能通过类的成员变量接收参数,故只能使用多例。
-3. Struts2 的核心是基于一个Filter即StrutsPreparedAndExcuteFilter,Spring MVC的核心是基于一个Servlet即DispatcherServlet(前端控制器)。
-4. Struts处理速度稍微比Spring MVC慢,Struts使用了Struts标签,加载数据较慢。
+怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-## Spring MVC的工作原理
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-Spring MVC的工作原理如下:
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
-1. DispatcherServlet 接收用户的请求
-2. 找到用于处理request的 handler 和 Interceptors,构造成 HandlerExecutionChain 执行链
-3. 找到 handler 相对应的 HandlerAdapter
-4. 执行所有注册拦截器的preHandler方法
-5. 调用 HandlerAdapter 的 handle() 方法处理请求,返回 ModelAndView
-6. 倒序执行所有注册拦截器的postHandler方法
-7. 请求视图解析和视图渲染
-
-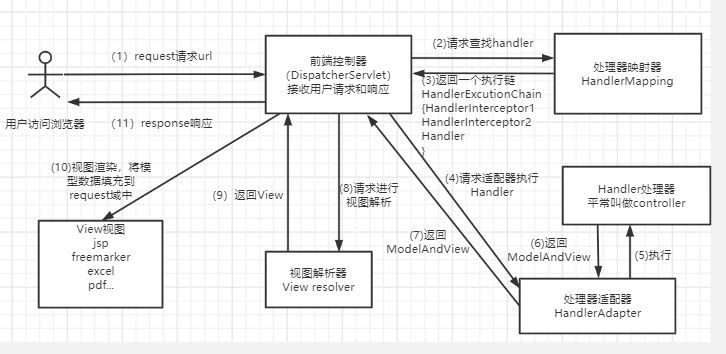
-
-## Spring MVC的主要组件?
-
-- 前端控制器(DispatcherServlet):接收用户请求,给用户返回结果。
-- 处理器映射器(HandlerMapping):根据请求的url路径,通过注解或者xml配置,寻找匹配的Handler。
-- 处理器适配器(HandlerAdapter):Handler 的适配器,调用 handler 的方法处理请求。
-- 处理器(Handler):执行相关的请求处理逻辑,并返回相应的数据和视图信息,将其封装到ModelAndView对象中。
-- 视图解析器(ViewResolver):将逻辑视图名解析成真正的视图View。
-- 视图(View):接口类,实现类可支持不同的View类型(JSP、FreeMarker、Excel等)。
-
-## Spring MVC的常用注解由有哪些?
-- @Controller:用于标识此类的实例是一个控制器。
-- @RequestMapping:映射Web请求(访问路径和参数)。
-- @ResponseBody:注解返回数据而不是返回页面
-- @RequestBody:注解实现接收 http 请求的 json 数据,将 json 数据转换为 java 对象。
-- @PathVariable:获得URL中路径变量中的值
-- @RestController:@Controller+@ResponseBody
-- @ExceptionHandler标识一个方法为全局异常处理的方法。
-
-## @Controller 注解有什么用?
-
-`@Controller` 注解标记一个类为 Spring Web MVC 控制器。Spring MVC 会将扫描到该注解的类,然后扫描这个类下面带有 `@RequestMapping` 注解的方法,根据注解信息,为这个方法生成一个对应的处理器对象,在上面的 HandlerMapping 和 HandlerAdapter组件中讲到过。
-
-当然,除了添加 `@Controller` 注解这种方式以外,你还可以实现 Spring MVC 提供的 `Controller` 或者 `HttpRequestHandler` 接口,对应的实现类也会被作为一个处理器对象
-
-## @RequestMapping 注解有什么用?
-
-`@RequestMapping` 注解,用于配置处理器的 HTTP 请求方法,URI等信息,这样才能将请求和方法进行映射。这个注解可以作用于类上面,也可以作用于方法上面,在类上面一般是配置这个控制器的 URI 前缀。
-
-## @RestController 和 @Controller 有什么区别?
-
-`@RestController` 注解,在 `@Controller` 基础上,增加了 `@ResponseBody` 注解,更加适合目前前后端分离的架构下,提供 Restful API ,返回 JSON 数据格式。
-
-## @RequestMapping 和 @GetMapping 注解有什么不同?
-
-1. `@RequestMapping`:可注解在类和方法上;`@GetMapping` 仅可注册在方法上
-2. `@RequestMapping`:可进行 GET、POST、PUT、DELETE 等请求方法;`@GetMapping` 是 `@RequestMapping` 的 GET 请求方法的特例。
-
-## @RequestParam 和 @PathVariable 两个注解的区别
-
-两个注解都用于方法参数,获取参数值的方式不同,`@RequestParam` 注解的参数从请求携带的参数中获取,而 `@PathVariable` 注解从请求的 URI 中获取
-
-## @RequestBody和@RequestParam的区别
-
-@RequestBody一般处理的是在ajax请求中声明contentType: "application/json; charset=utf-8"时候。也就是json数据或者xml数据。
-
-@RequestParam一般就是在ajax里面没有声明contentType的时候,为默认的`x-www-form-urlencoded`格式时。
-
-## Spring MVC的异常处理
-
-可以将异常抛给Spring框架,由Spring框架来处理;我们只需要配置简单的异常处理器,在异常处理器中添视图页面即可。
-
-- 使用系统定义好的异常处理器 SimpleMappingExceptionResolver
-- 使用自定义异常处理器
-- 使用异常处理注解
-
-## SpringMVC 用什么对象从后台向前台传递数据的?
-
-1. 将数据绑定到 request;
-2. 返回 ModelAndView;
-3. 通过ModelMap对象,可以在这个对象里面调用put方法,把对象加到里面,前端就可以通过el表达式拿到;
-4. 绑定数据到 Session中。
-
-## SpringMvc的Controller是不是单例模式?
-
-单例模式。在多线程访问的时候有线程安全问题,解决方案是在控制器里面不要写可变状态量,如果需要使用这些可变状态,可以使用ThreadLocal,为每个线程单独生成一份变量副本,独立操作,互不影响。
-
-## 介绍下 Spring MVC 拦截器?
-
-Spring MVC 拦截器对应HandlerInterceor接口,该接口位于org.springframework.web.servlet的包中,定义了三个方法,若要实现该接口,就要实现其三个方法:
-
-1. **前置处理(preHandle()方法)**:该方法在执行控制器方法之前执行。返回值为Boolean类型,如果返回false,表示拦截请求,不再向下执行,如果返回true,表示放行,程序继续向下执行(如果后面没有其他Interceptor,就会执行controller方法)。所以此方法可对请求进行判断,决定程序是否继续执行,或者进行一些初始化操作及对请求进行预处理。
-2. **后置处理(postHandle()方法)**:该方法在执行控制器方法调用之后,且在返回ModelAndView之前执行。由于该方法会在DispatcherServlet进行返回视图渲染之前被调用,所以此方法多被用于处理返回的视图,可通过此方法对请求域中的模型和视图做进一步的修改。
-3. **已完成处理(afterCompletion()方法)**:该方法在执行完控制器之后执行,由于是在Controller方法执行完毕后执行该方法,所以该方法适合进行一些资源清理,记录日志信息等处理操作。
-
-可以通过拦截器进行权限检验,参数校验,记录日志等操作
-
-## SpringMvc怎么配置拦截器?
-
-有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器类,接着在接口方法当中,实现处理逻辑;然后在SpringMvc的配置文件中配置拦截器即可:
-
-```java
-
-
-
-
-
-
-
-
-
-
-```
-
-## Spring MVC 的拦截器和 Filter 过滤器有什么差别?
-
-有以下几点:
-
-- **功能相同**:拦截器和 Filter 都能实现相应的功能
-- **容器不同**:拦截器构建在 Spring MVC 体系中;Filter 构建在 Servlet 容器之上
-- **使用便利性不同**:拦截器提供了三个方法,分别在不同的时机执行;过滤器仅提供一个方法
-
-## 什么是REST?
-
-REST,英文全称,Resource Representational State Transfer,对资源的访问状态的变化通过url的变化表述出来。
-
-Resource:**资源**。资源是REST架构或者说整个网络处理的核心。
-
-Representational:**某种表现形式**,比如用JSON,XML,JPEG等。
-
-State Transfer:**状态变化**。通过HTTP method实现。
-
-REST描述的是在网络中client和server的一种交互形式。用大白话来说,就是**通过URL就知道要什么资源,通过HTTP method就知道要干什么,通过HTTP status code就知道结果如何**。
-
-举个例子:
-
-```java
-GET /tasks 获取所有任务
-POST /tasks 创建新任务
-GET /tasks/{id} 通过任务id获取任务
-PUT /tasks/{id} 更新任务
-DELETE /tasks/{id} 删除任务
-```
-
-GET代表获取一个资源,POST代表添加一个资源,PUT代表修改一个资源,DELETE代表删除一个资源。
-
-server提供的RESTful API中,URL中只使用名词来指定资源,原则上不使用动词。用`HTTP Status Code`传递server的状态信息。比如最常用的 200 表示成功,500 表示Server内部错误等。
-
-## 使用REST有什么优势呢?
-
-第一,**风格统一**了,不会出现`delUser/deleteUser/removeUser`各种命名的代码了。
-
-第二,**面向资源**,一目了然,具有自解释性。
-
-第三,**充分利用 HTTP 协议本身语义**。
-
-
+
\ No newline at end of file
diff --git a/docs/java/java-basic.md b/docs/java/java-basic.md
index 5a4b19a..ad1b6a4 100644
--- a/docs/java/java-basic.md
+++ b/docs/java/java-basic.md
@@ -95,6 +95,19 @@ JRE是Java的运行环境,并不是一个开发环境,所以没有包含任
+
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## Java程序是编译执行还是解释执行?
先看看什么是编译型语言和解释型语言。
@@ -274,6 +287,8 @@ Integer x = 1; // 装箱 调⽤ Integer.valueOf(1)
int y = x; // 拆箱 调⽤了 X.intValue()
```
+## 两个Integer 用== 比较不相等的原因
+
下面看一道常见的面试题:
```java
@@ -293,7 +308,7 @@ true
false
```
-为什么第三个输出是false?看看 Integer 类的源码就知道啦。
+为什么第二个输出是false?看看 Integer 类的源码就知道啦。
```java
public static Integer valueOf(int i) {
@@ -303,7 +318,7 @@ public static Integer valueOf(int i) {
}
```
-`Integer c = 200;` 会调用 调⽤`Integer.valueOf(200)`。而从Integer的valueOf()源码可以看到,这里的实现并不是简单的new Integer,而是用IntegerCache做一个cache。
+`Integer c = 200;` 会调用`Integer.valueOf(200)`。而从Integer的valueOf()源码可以看到,这里的实现并不是简单的new Integer,而是用IntegerCache做一个cache。
```java
private static class IntegerCache {
@@ -1509,21 +1524,19 @@ server {
过滤器和拦截器底层实现不同。过滤器是基于函数回调的,拦截器是基于Java的反射机制(动态代理)实现的。一般自定义的过滤器中都会实现一个doFilter()方法,这个方法有一个FilterChain参数,而实际上它是一个回调接口。
-2、**使用范围不同**。
-
-过滤器实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。而拦截器是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。拦截器不仅能应用在web程序中,也可以用于Application、Swing等程序中。
+2、**触发时机不同**。
-3、**使用的场景不同**。
+过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
-因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
+拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
-4、**触发时机不同**。
+
-过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
+3、**使用的场景不同**。
-拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
+因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
-5、**拦截的请求范围不同**。
+4、**拦截的请求范围不同**。
请求的执行顺序是:请求进入容器 -> 进入过滤器 -> 进入 Servlet -> 进入拦截器 -> 执行控制器。可以看到过滤器和拦截器的执行时机也是不同的,过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
@@ -1628,5 +1641,17 @@ server {
> 参考:https://juejin.cn/post/7167153109158854687
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
+
+
+

diff --git a/docs/java/java-collection.md b/docs/java/java-collection.md
index 76f73f0..df13bad 100644
--- a/docs/java/java-collection.md
+++ b/docs/java/java-collection.md
@@ -152,7 +152,7 @@ HashMap有扩容机制,就是当达到扩容条件时会进行扩容。扩容
如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容。而HashMap每次扩容都需要重建hash表,非常影响性能。所以建议开发者在创建HashMap的时候指定初始化容量。
-### 扩容过程?
+### HashMap扩容过程是怎样的?
1.8扩容机制:当元素个数大于`threshold`时,会进行扩容,使用2倍容量的数组代替原有数组。采用尾插入的方式将原数组元素拷贝到新数组。1.8扩容之后链表元素相对位置没有变化,而1.7扩容之后链表元素会倒置。
@@ -160,7 +160,7 @@ HashMap有扩容机制,就是当达到扩容条件时会进行扩容。扩容
原数组的元素在重新计算hash之后,因为数组容量n变为2倍,那么n-1的mask范围在高位多1bit。在元素拷贝过程不需要重新计算元素在数组中的位置,只需要看看原来的hash值新增的那个bit是1还是0,是0的话索引没变,是1的话索引变成“原索引+oldCap”(根据`e.hash & oldCap == 0`判断) 。这样可以省去重新计算hash值的时间,而且由于新增的1bit是0还是1可以认为是随机的,因此resize的过程会均匀的把之前的冲突的节点分散到新的bucket。
-### put方法流程?
+### 说说HashMapput方法的流程?
1. 如果table没有初始化就先进行初始化过程
2. 使用hash算法计算key的索引
diff --git a/docs/java/java-concurrent.md b/docs/java/java-concurrent.md
index bb62dcc..09c408f 100644
--- a/docs/java/java-concurrent.md
+++ b/docs/java/java-concurrent.md
@@ -22,7 +22,9 @@ head:
## 线程池
-线程池:一个管理线程的池子。
+### 什么是线程池,如何使用?为什么要使用线程池?
+
+线程池就是事先将多个线程对象放到一个容器中,使用的时候就不用new线程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高了代码执行效率。
### 为什么平时都是使用线程池创建线程,直接new一个线程不好吗?
@@ -35,7 +37,7 @@ head:
系统资源有限,每个人针对不同业务都可以手动创建线程,并且创建线程没有统一标准,比如创建的线程有没有名字等。当系统运行起来,所有线程都在抢占资源,毫无规则,混乱场面可想而知,不好管控。
-**频繁手动创建线程为什么开销会大?跟new Object() 有什么差别?**
+### 频繁手动创建线程为什么开销会大?跟new Object() 有什么差别?
虽然Java中万物皆对象,但是new Thread() 创建一个线程和 new Object()还是有区别的。
@@ -231,6 +233,14 @@ executor提供一个原生函数isTerminated()来判断线程池中的任务是
- 调用new Thread()创建的线程缺乏管理,可以无限制的创建,线程之间的相互竞争会导致过多占用系统资源而导致系统瘫痪
- 直接使用new Thread()启动的线程不利于扩展,比如定时执行、定期执行、定时定期执行、线程中断等都不好实现
+## execute和submit的区别
+
+execute只能提交Runnable类型的任务,无返回值。submit既可以提交Runnable类型的任务,也可以提交Callable类型的任务,会有一个类型为Future的返回值,但当任务类型为Runnable时,返回值为null。
+
+execute在执行任务时,如果遇到异常会直接抛出,而submit不会直接抛出,只有在使用Future的get方法获取返回值时,才会抛出异常
+
+execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
+
## 进程线程
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间。
@@ -725,9 +735,23 @@ class SeasonThreadTask implements Runnable{
## ThreadLocal
+### ThreadLocal是什么
+
线程本地变量。当使用`ThreadLocal`维护变量时,`ThreadLocal`为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程。
-### ThreadLocal原理
+### 为什么要使用ThreadLocal?
+
+并发场景下,会存在多个线程同时修改一个共享变量的场景。这就可能会出现**线性安全问题**。
+
+为了解决线性安全问题,可以用加锁的方式,比如使用`synchronized` 或者`Lock`。但是加锁的方式,可能会导致系统变慢。
+
+还有另外一种方案,就是使用空间换时间的方式,即使用`ThreadLocal`。使用`ThreadLocal`类访问共享变量时,会在每个线程的本地,都保存一份共享变量的拷贝副本。多线程对共享变量修改时,实际上操作的是这个变量副本,从而保证线性安全。
+
+### Thread和ThreadLocal有什么联系呢?
+
+Thread和ThreadLocal是绑定的, ThreadLocal依赖于Thread去执行, Thread将需要隔离的数据存放到ThreadLocal(准确的讲是ThreadLocalMap)中,来实现多线程处理。
+
+### 说说ThreadLocal的原理?
每个线程都有一个`ThreadLocalMap`(`ThreadLocal`内部类),Map中元素的键为`ThreadLocal`,而值对应线程的变量副本。
@@ -1238,4 +1262,115 @@ epoll的时间复杂度O(1)。epoll可以理解为event poll,不同于忙轮
> 参考链接:https://blog.csdn.net/u014209205/article/details/80598209
+## ReadWriteLock 和 StampedLock 的区别
+
+在多线程编程中,对于共享资源的访问控制是一个非常重要的问题。在并发环境下,多个线程同时访问共享资源可能会导致数据不一致的问题,因此需要一种机制来保证数据的一致性和并发性。
+
+Java提供了多种机制来实现并发控制,其中 ReadWriteLock 和 StampedLock 是两个常用的锁类。本文将分别介绍这两个类的特性、使用场景以及示例代码。
+
+**ReadWriteLock**
+
+ReadWriteLock 是Java提供的一个接口,全类名:`java.util.concurrent.locks.ReentrantLock`。它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种机制可以提高读取操作的并发性,但写入操作需要独占资源。
+
+**特性**
+
+- 多个线程可以同时获取读锁,但只有一个线程可以获取写锁。
+- 当一个线程持有写锁时,其他线程无法获取读锁和写锁,读写互斥。
+- 当一个线程持有读锁时,其他线程可以同时获取读锁,读读共享。
+
+**使用场景**
+
+**ReadWriteLock** 适用于读多写少的场景,例如缓存系统、数据库连接池等。在这些场景中,读取操作占据大部分时间,而写入操作较少。
+
+**示例代码**
+
+下面是一个使用 ReadWriteLock 的示例,实现了一个简单的缓存系统:
+
+```java
+public class Cache {
+ private Map data = new HashMap<>();
+ private ReadWriteLock lock = new ReentrantReadWriteLock();
+
+ public Object get(String key) {
+ lock.readLock().lock();
+ try {
+ return data.get(key);
+ } finally {
+ lock.readLock().unlock();
+ }
+ }
+
+ public void put(String key, Object value) {
+ lock.writeLock().lock();
+ try {
+ data.put(key, value);
+ } finally {
+ lock.writeLock().unlock();
+ }
+ }
+}
+```
+
+在上述示例中,Cache 类使用 ReadWriteLock 来实现对 data 的并发访问控制。get 方法获取读锁并读取数据,put 方法获取写锁并写入数据。
+
+**StampedLock**
+
+StampedLock 是Java 8 中引入的一种新的锁机制,全类名:`java.util.concurrent.locks.StampedLock`,它提供了一种乐观读的机制,可以进一步提升读取操作的并发性能。
+
+**特性**
+
+- 与 ReadWriteLock 类似,StampedLock 也支持多个线程同时获取读锁,但只允许一个线程获取写锁。
+- 与 ReadWriteLock 不同的是,StampedLock 还提供了一个乐观读锁(Optimistic Read Lock),即不阻塞其他线程的写操作,但在读取完成后需要验证数据的一致性。
+
+**使用场景**
+
+StampedLock 适用于读远远大于写的场景,并且对数据的一致性要求不高,例如统计数据、监控系统等。
+
+**示例代码**
+
+下面是一个使用 StampedLock 的示例,实现了一个计数器:
+
+```java
+public class Counter {
+ private int count = 0;
+ private StampedLock lock = new StampedLock();
+
+ public int getCount() {
+ long stamp = lock.tryOptimisticRead();
+ int value = count;
+ if (!lock.validate(stamp)) {
+ stamp = lock.readLock();
+ try {
+ value = count;
+ } finally {
+ lock.unlockRead(stamp);
+ }
+ }
+ return value;
+ }
+
+ public void increment() {
+ long stamp = lock.writeLock();
+ try {
+ count++;
+ } finally {
+ lock.unlockWrite(stamp);
+ }
+ }
+}
+```
+
+在上述示例中,Counter 类使用 StampedLock 来实现对计数器的并发访问控制。getCount 方法首先尝试获取乐观读锁,并读取计数器的值,然后通过 validate 方法验证数据的一致性。如果验证失败,则获取悲观读锁,并重新读取计数器的值。increment 方法获取写锁,并对计数器进行递增操作。
+
+**总结**
+
+**ReadWriteLock** 和 **StampedLock** 都是Java中用于并发控制的重要机制。
+
+- **ReadWriteLock** 适用于读多写少的场景;
+- **StampedLock** 则适用于读远远大于写的场景,并且对数据的一致性要求不高;
+
+在实际应用中,我们需要根据具体场景来选择合适的锁机制。通过合理使用这些锁机制,我们可以提高并发程序的性能和可靠性。
+
+
+

diff --git a/docs/java/jvm.md b/docs/java/jvm.md
index 8690bfc..5400aac 100644
--- a/docs/java/jvm.md
+++ b/docs/java/jvm.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
\ No newline at end of file
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
\ No newline at end of file
diff --git a/docs/learn/ghelper.md b/docs/learn/ghelper.md
index a640f63..f5de885 100644
--- a/docs/learn/ghelper.md
+++ b/docs/learn/ghelper.md
@@ -1,4 +1,17 @@
-# 科学上网教程
+---
+sidebar: heading
+title: 科学上网教程
+category: 工具
+tag:
+ - 工具
+head:
+ - - meta
+ - name: keywords
+ content: ghelper
+ - - meta
+ - name: description
+ content: 提高工作效率的工具
+---
@@ -64,10 +77,16 @@ Ghelper可以在google play商店进行下载,需要访问google商店,无
-> 最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、架构、分布式、微服务、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-
-
+最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-**Github地址**:https://github.com/Tyson0314/java-books
\ No newline at end of file
+
+
+
+
+[**Github地址**](https://github.com/Tyson0314/java-books)
+
+如果访问不了Github,可以访问码云地址。
+
+[码云地址](https://gitee.com/tysondai/java-books)
\ No newline at end of file
diff --git a/docs/note/README.md b/docs/note/README.md
new file mode 100644
index 0000000..3a19bc2
--- /dev/null
+++ b/docs/note/README.md
@@ -0,0 +1,6 @@
+- [一小时彻底吃透Redis](https://topjavaer.cn/note/redis-note.html)
+- [21个写SQL的好习惯](https://topjavaer.cn/note/write-sql.html)
+- [Docker详解与部署微服务实战](https://topjavaer.cn/note/docker-note.html)
+- [计算机专业的同学都看看这几点建议](https://topjavaer.cn/note/computor-advice.html)
+- [建议计算机专业同学都看看这门课](https://topjavaer.cn/note/computor-advice.html)
+
diff --git a/docs/note/docker-note.md b/docs/note/docker-note.md
new file mode 100644
index 0000000..68a8f62
--- /dev/null
+++ b/docs/note/docker-note.md
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+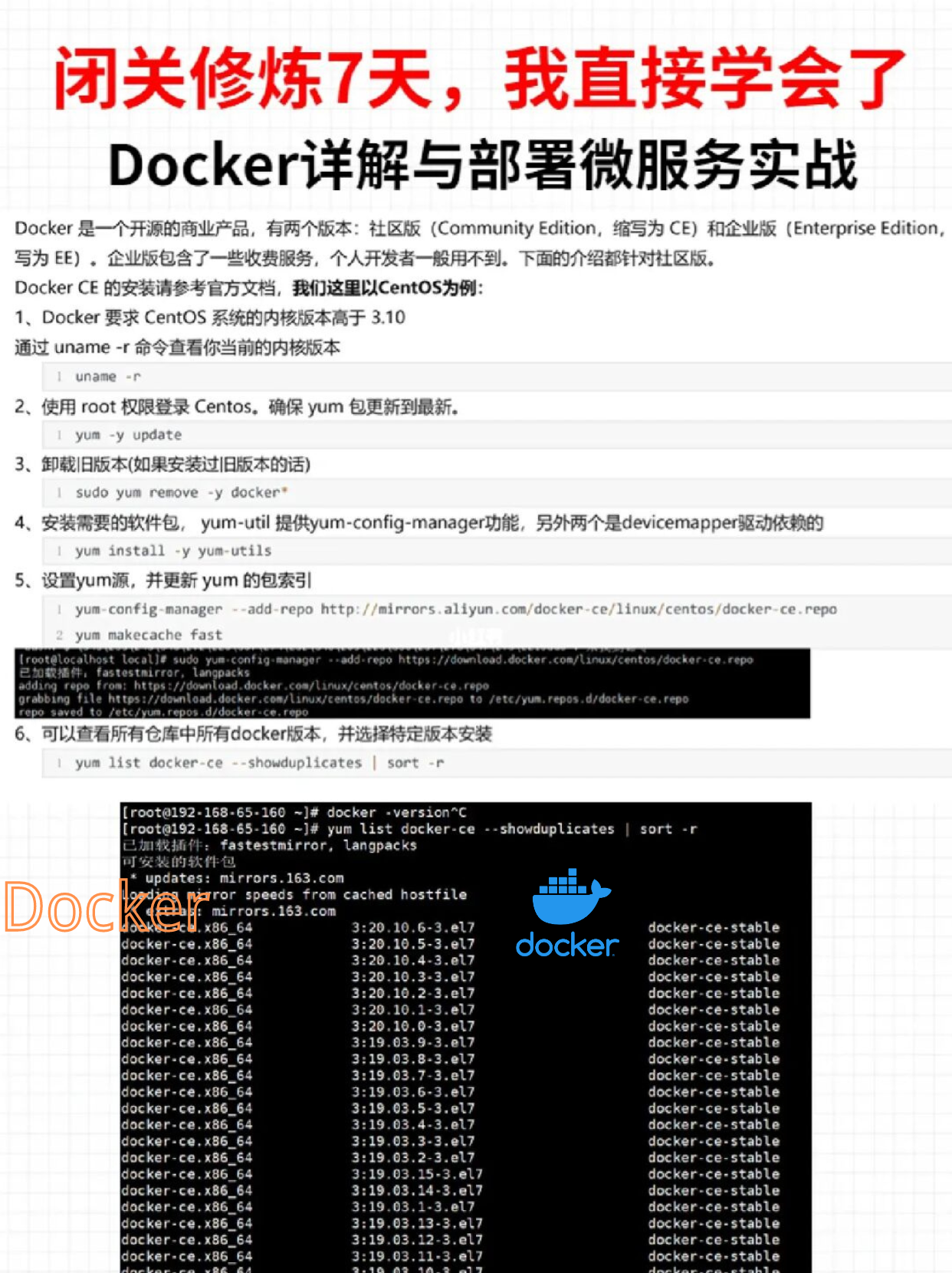
+
+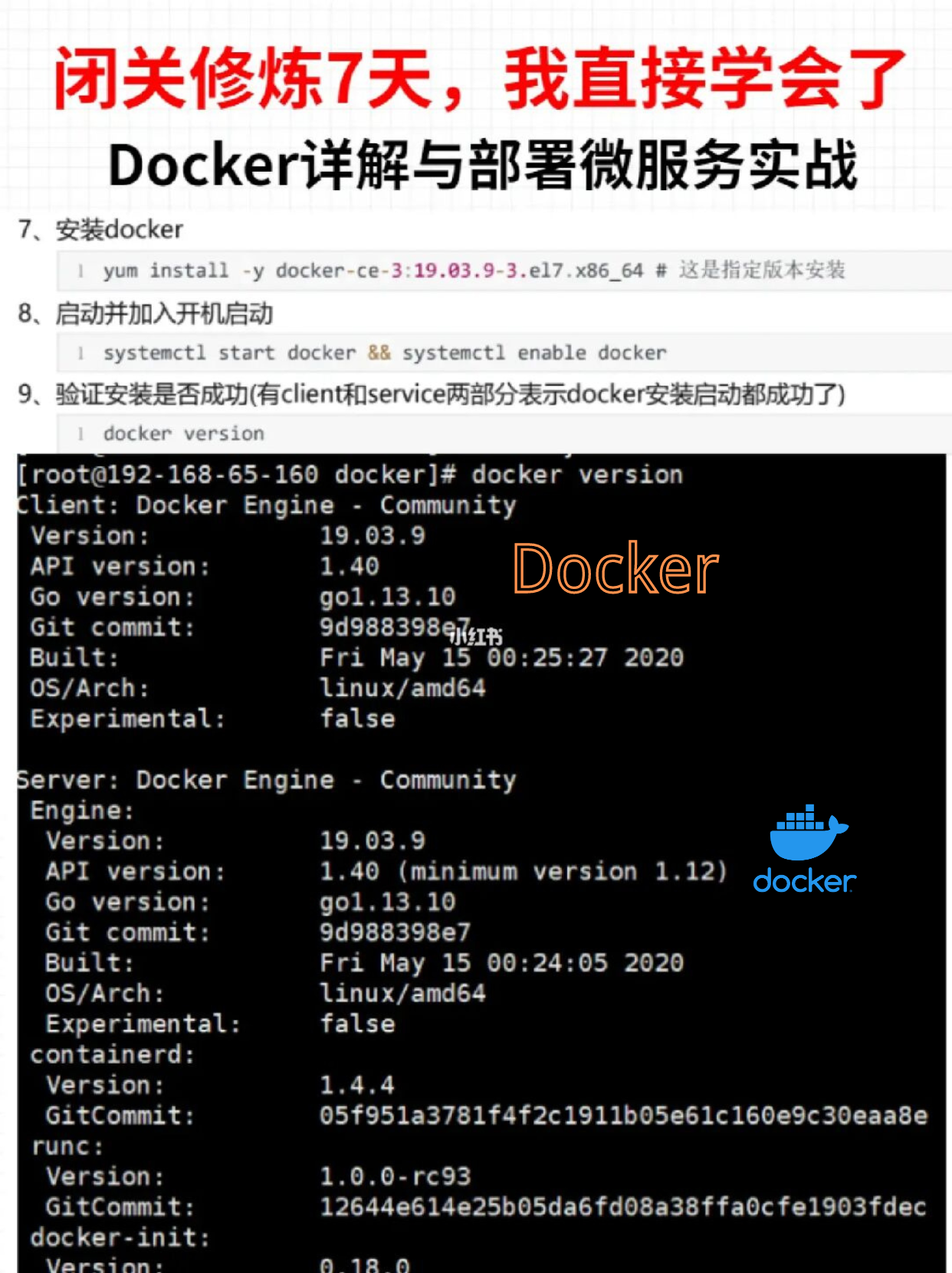
+
+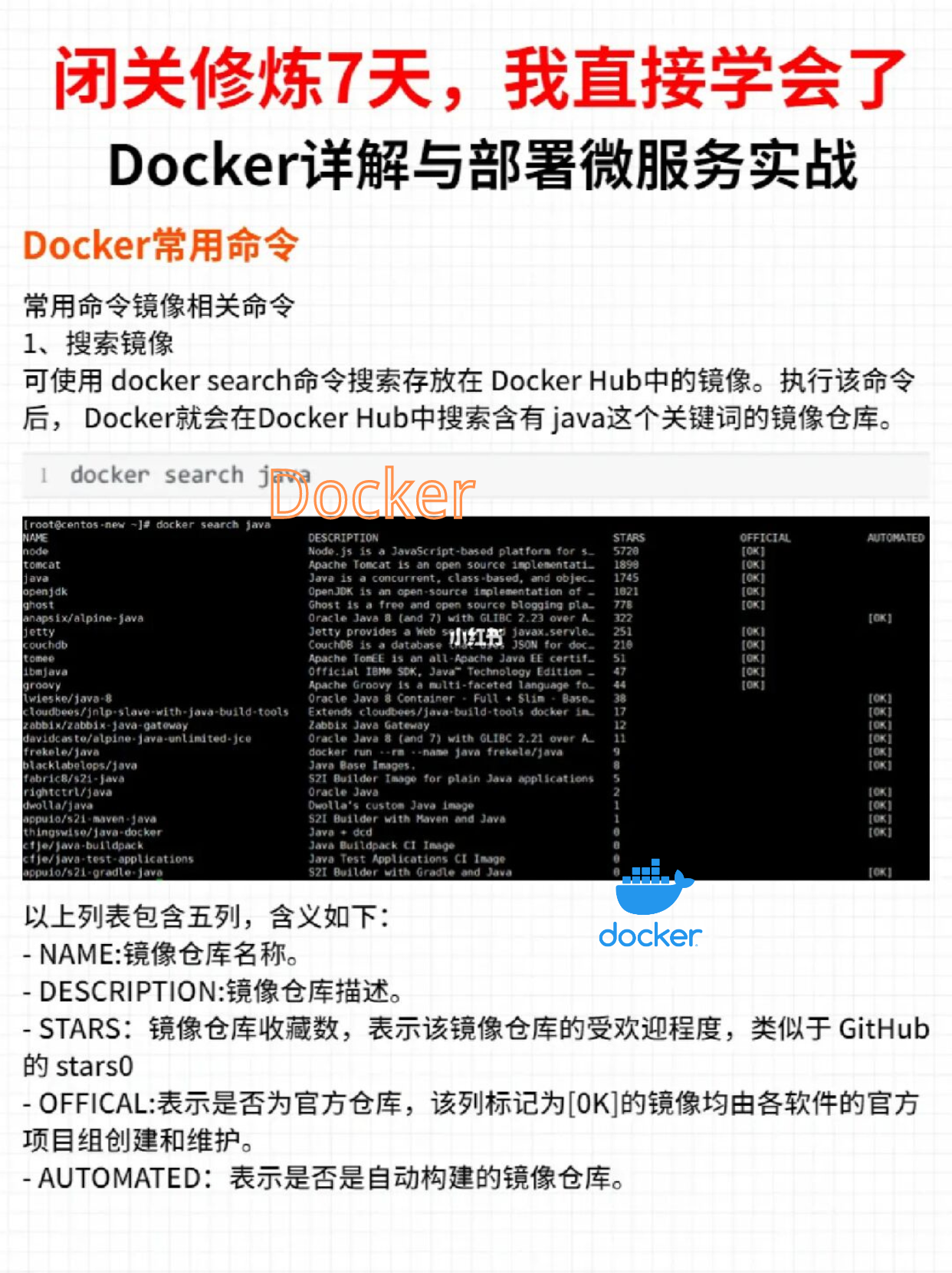
+
+
+
+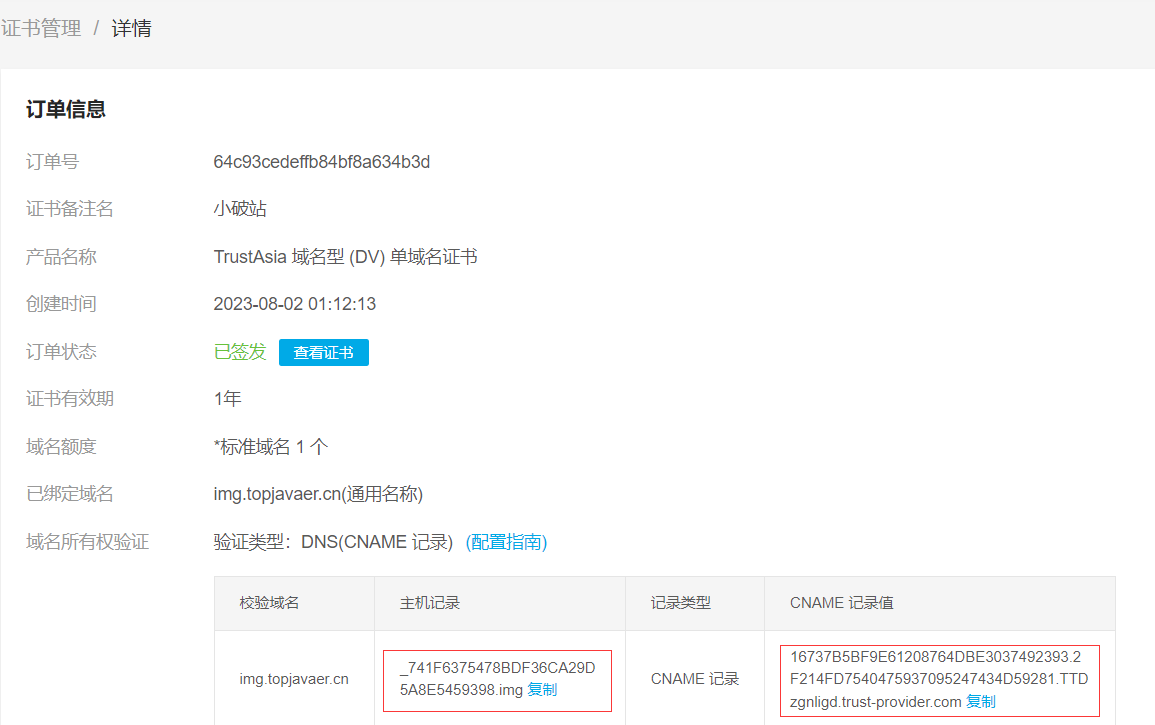
\ No newline at end of file
diff --git a/docs/note/redis-note.md b/docs/note/redis-note.md
new file mode 100644
index 0000000..02e5569
--- /dev/null
+++ b/docs/note/redis-note.md
@@ -0,0 +1,28 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 一小时彻底吃透Redis
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+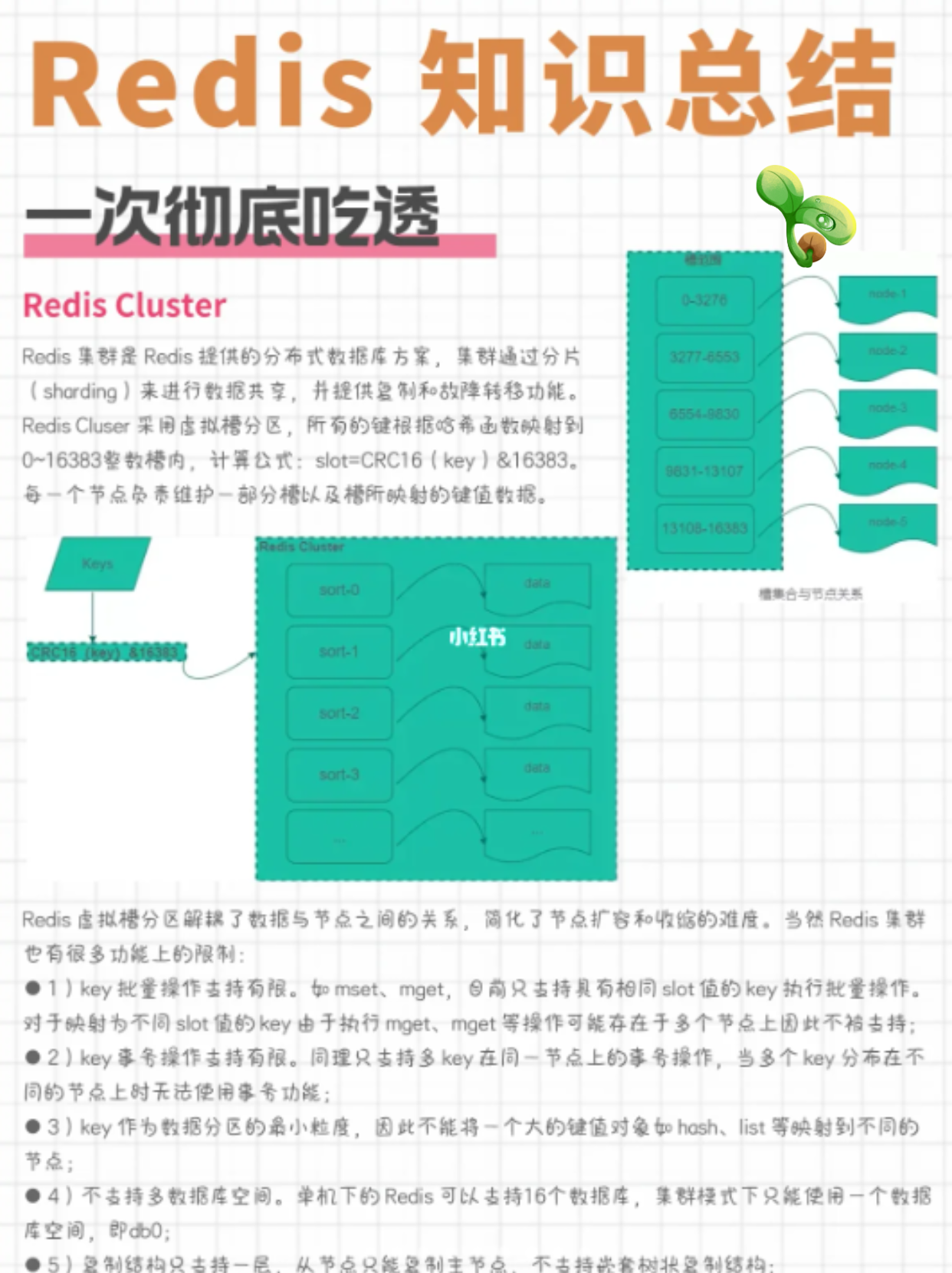
+
+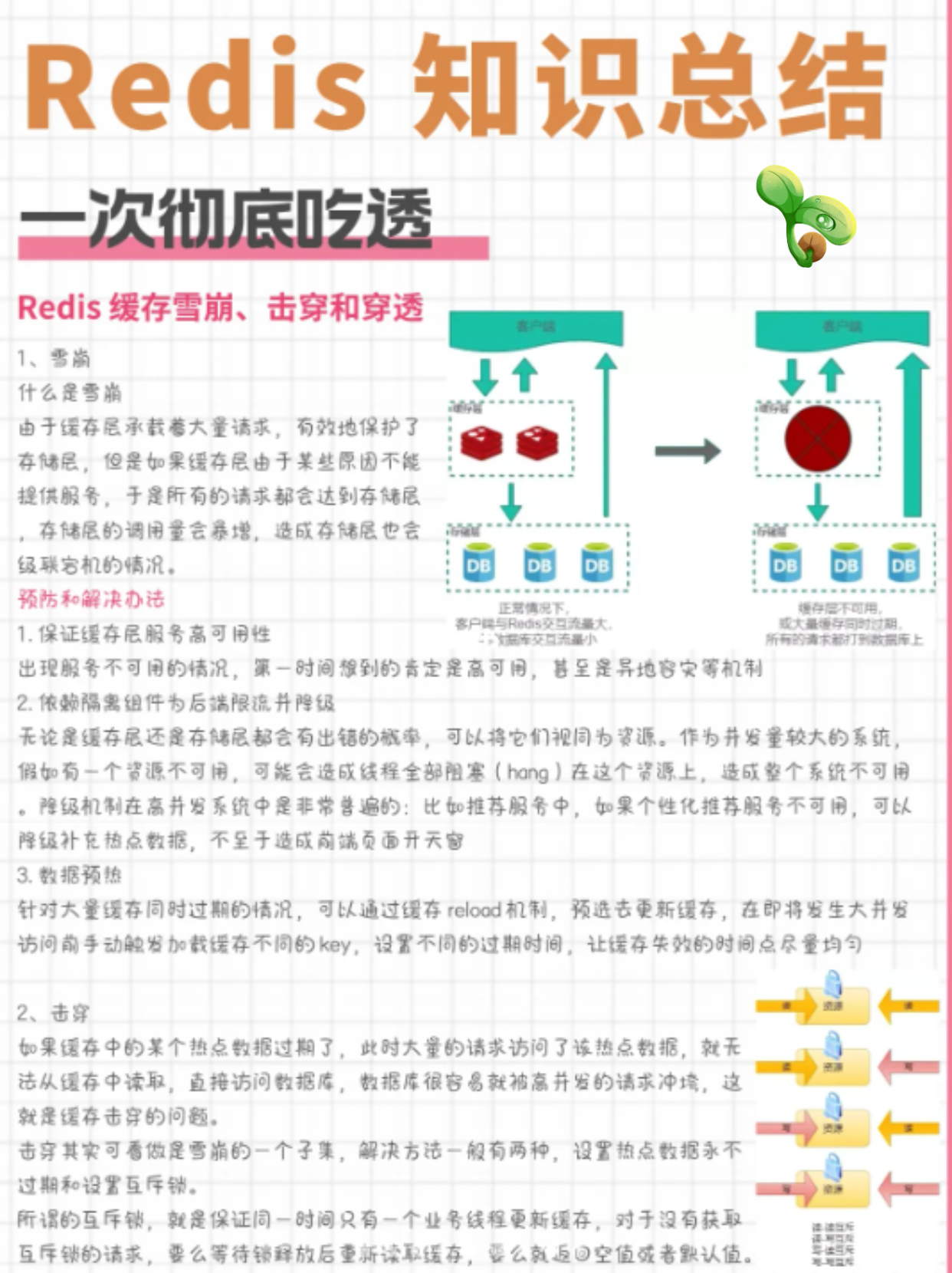
+
+
\ No newline at end of file
diff --git a/docs/note/write-sql.md b/docs/note/write-sql.md
new file mode 100644
index 0000000..14faa3a
--- /dev/null
+++ b/docs/note/write-sql.md
@@ -0,0 +1,93 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 21个写SQL的好习惯
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## MySQL面试题
+
+下面分享MySQL常考的**面试题目**。
+
+- [事务的四大特性?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E7%9A%84%E5%9B%9B%E5%A4%A7%E7%89%B9%E6%80%A7)
+- [数据库的三大范式](https://topjavaer.cn/database/mysql.html#%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E4%B8%89%E5%A4%A7%E8%8C%83%E5%BC%8F)
+- [事务隔离级别有哪些?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [生产环境数据库一般用的什么隔离级别呢?](https://topjavaer.cn/database/mysql.html#%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%80%E8%88%AC%E7%94%A8%E7%9A%84%E4%BB%80%E4%B9%88%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E5%91%A2)
+- [编码和字符集的关系](https://topjavaer.cn/database/mysql.html#%E7%BC%96%E7%A0%81%E5%92%8C%E5%AD%97%E7%AC%A6%E9%9B%86%E7%9A%84%E5%85%B3%E7%B3%BB)
+- [utf8和utf8mb4的区别](https://topjavaer.cn/database/mysql.html#utf8%E5%92%8Cutf8mb4%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [什么是索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95)
+- [索引的优缺点?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9)
+- [索引的作用?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BD%9C%E7%94%A8)
+- [什么情况下需要建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E9%9C%80%E8%A6%81%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [什么情况下不建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E4%B8%8D%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [索引的数据结构](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
+- [Hash索引和B+树索引的区别?](https://topjavaer.cn/database/mysql.html#hash%E7%B4%A2%E5%BC%95%E5%92%8Cb%E6%A0%91%E7%B4%A2%E5%BC%95%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [为什么B+树比B树更适合实现数据库索引?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88b%E6%A0%91%E6%AF%94b%E6%A0%91%E6%9B%B4%E9%80%82%E5%90%88%E5%AE%9E%E7%8E%B0%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95)
+- [索引有什么分类?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E6%9C%89%E4%BB%80%E4%B9%88%E5%88%86%E7%B1%BB)
+- [什么是最左匹配原则?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E6%9C%80%E5%B7%A6%E5%8C%B9%E9%85%8D%E5%8E%9F%E5%88%99)
+- [什么是聚集索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%81%9A%E9%9B%86%E7%B4%A2%E5%BC%95)
+- [什么是覆盖索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%A6%86%E7%9B%96%E7%B4%A2%E5%BC%95)
+- [索引的设计原则?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99)
+- [索引什么时候会失效?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%BB%80%E4%B9%88%E6%97%B6%E5%80%99%E4%BC%9A%E5%A4%B1%E6%95%88)
+- [什么是前缀索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%89%8D%E7%BC%80%E7%B4%A2%E5%BC%95)
+- [索引下推](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%B8%8B%E6%8E%A8)
+- [常见的存储引擎有哪些?](https://topjavaer.cn/database/mysql.html#%E5%B8%B8%E8%A7%81%E7%9A%84%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [MyISAM和InnoDB的区别?](https://topjavaer.cn/database/mysql.html#myisam%E5%92%8Cinnodb%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL有哪些锁?](https://topjavaer.cn/database/mysql.html#mysql%E6%9C%89%E5%93%AA%E4%BA%9B%E9%94%81)
+- [MVCC 实现原理?](https://topjavaer.cn/database/mysql.html#mvcc-%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86)
+- [快照读和当前读](https://topjavaer.cn/database/mysql.html#%E5%BF%AB%E7%85%A7%E8%AF%BB%E5%92%8C%E5%BD%93%E5%89%8D%E8%AF%BB)
+- [共享锁和排他锁](https://topjavaer.cn/database/mysql.html#%E5%85%B1%E4%BA%AB%E9%94%81%E5%92%8C%E6%8E%92%E4%BB%96%E9%94%81)
+- [bin log/redo log/undo log](https://topjavaer.cn/database/mysql.html#bin-logredo-logundo-log)
+- [bin log和redo log有什么区别?](https://topjavaer.cn/database/mysql.html#bin-log%E5%92%8Credo-log%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [讲一下MySQL架构?](https://topjavaer.cn/database/mysql.html#%E8%AE%B2%E4%B8%80%E4%B8%8Bmysql%E6%9E%B6%E6%9E%84)
+- [分库分表](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [什么是分区表?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%88%86%E5%8C%BA%E8%A1%A8)
+- [分区表类型](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E8%A1%A8%E7%B1%BB%E5%9E%8B)
+- [分区的问题?](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E7%9A%84%E9%97%AE%E9%A2%98)
+- [查询语句执行流程?](https://topjavaer.cn/database/mysql.html#%E6%9F%A5%E8%AF%A2%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B)
+- [更新语句执行过程?](https://topjavaer.cn/database/mysql.html#%E6%9B%B4%E6%96%B0%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E8%BF%87%E7%A8%8B)
+- [exist和in的区别?](https://topjavaer.cn/database/mysql.html#exist%E5%92%8Cin%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中int()和char()的区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADint10%E5%92%8Cchar10%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [truncate、delete与drop区别?](https://topjavaer.cn/database/mysql.html#truncatedelete%E4%B8%8Edrop%E5%8C%BA%E5%88%AB)
+- [having和where区别?](https://topjavaer.cn/database/mysql.html#having%E5%92%8Cwhere%E5%8C%BA%E5%88%AB)
+- [什么是MySQL主从同步?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AFmysql%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [为什么要做主从同步?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E5%81%9A%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [乐观锁和悲观锁是什么?](https://topjavaer.cn/database/mysql.html#%E4%B9%90%E8%A7%82%E9%94%81%E5%92%8C%E6%82%B2%E8%A7%82%E9%94%81%E6%98%AF%E4%BB%80%E4%B9%88)
+- [用过processlist吗?](https://topjavaer.cn/database/mysql.html#%E7%94%A8%E8%BF%87processlist%E5%90%97)
+- [MySQL查询 limit 1000,10 和limit 10 速度一样快吗?](https://topjavaer.cn/database/mysql.html#mysql%E6%9F%A5%E8%AF%A2-limit-100010-%E5%92%8Climit-10-%E9%80%9F%E5%BA%A6%E4%B8%80%E6%A0%B7%E5%BF%AB%E5%90%97)
+- [深分页怎么优化?](https://topjavaer.cn/database/mysql.html#%E6%B7%B1%E5%88%86%E9%A1%B5%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [高度为3的B+树,可以存放多少数据?](https://topjavaer.cn/database/mysql.html#%E9%AB%98%E5%BA%A6%E4%B8%BA3%E7%9A%84b%E6%A0%91%E5%8F%AF%E4%BB%A5%E5%AD%98%E6%94%BE%E5%A4%9A%E5%B0%91%E6%95%B0%E6%8D%AE)
+- [MySQL单表多大进行分库分表?](https://topjavaer.cn/database/mysql.html#mysql%E5%8D%95%E8%A1%A8%E5%A4%9A%E5%A4%A7%E8%BF%9B%E8%A1%8C%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [大表查询慢怎么优化?](https://topjavaer.cn/database/mysql.html#%E5%A4%A7%E8%A1%A8%E6%9F%A5%E8%AF%A2%E6%85%A2%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [说说count()、count()和count()的区别](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4count1count%E5%92%8Ccount%E5%AD%97%E6%AE%B5%E5%90%8D%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中DATETIME 和 TIMESTAMP有什么区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADdatetime-%E5%92%8C-timestamp%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [说说为什么不建议用外键?](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E5%BB%BA%E8%AE%AE%E7%94%A8%E5%A4%96%E9%94%AE)
+- [使用自增主键有什么好处?](https://topjavaer.cn/database/mysql.html#%E4%BD%BF%E7%94%A8%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E6%9C%89%E4%BB%80%E4%B9%88%E5%A5%BD%E5%A4%84)
+- [自增主键保存在什么地方?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%BF%9D%E5%AD%98%E5%9C%A8%E4%BB%80%E4%B9%88%E5%9C%B0%E6%96%B9)
+- [自增主键一定是连续的吗?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%B8%80%E5%AE%9A%E6%98%AF%E8%BF%9E%E7%BB%AD%E7%9A%84%E5%90%97)
+- [InnoDB的自增值为什么不能回收利用?](https://topjavaer.cn/database/mysql.html#innodb%E7%9A%84%E8%87%AA%E5%A2%9E%E5%80%BC%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E8%83%BD%E5%9B%9E%E6%94%B6%E5%88%A9%E7%94%A8)
+- [MySQL数据如何同步到Redis缓存?](https://topjavaer.cn/database/mysql.html#mysql%E6%95%B0%E6%8D%AE%E5%A6%82%E4%BD%95%E5%90%8C%E6%AD%A5%E5%88%B0redis%E7%BC%93%E5%AD%98)
\ No newline at end of file
diff --git a/docs/other/site-diary.md b/docs/other/site-diary.md
index d9b9ac9..477801a 100644
--- a/docs/other/site-diary.md
+++ b/docs/other/site-diary.md
@@ -8,7 +8,22 @@ sidebar: heading
## 更新记录
+- 2024.06.11,更新-Redis大key怎么处理?
+
+- 2024.06.11,新增-聊聊如何用Redis 实现分布式锁?
+
+- 2024.06.07,更新-为什么Redis单线程还这么快?
+
+- 2024.05.21,新增一条SQL是怎么执行的
+
+- 2023.12.28,[增加源码解析模块,包含Sprign/SpringMVC/MyBatis(更新中)](/source/mybatis/1-overview.html)。
+
+- 2023.12.28,[遭受黑客攻击,植入木马程序](/zsxq/article/site-hack.html)。
+
+- 2023.08.10,分布式锁实现-[RedLock](http://topjavaer.cn/advance/distributed/2-distributed-lock.html)补充图片
+
- 2023.05.04,导航栏增加图标。
+
- 2023.05.01,新增[Tomcat基础知识总结](/web/tomcat.html)
- 2023.03.25,新增[TCP面试题](/computer-basic/tcp.html)、[MongoDB面试题](/database/mongodb.html)、[ZooKeeper面试题](/zookeeper/zk.html)
diff --git a/docs/redis/redis.md b/docs/redis/redis.md
index 8a6d471..0890449 100644
--- a/docs/redis/redis.md
+++ b/docs/redis/redis.md
@@ -20,6 +20,11 @@ head:
:::
+## 更新记录
+
+- 2024.1.7,新增[Redis存在线程安全问题吗?](##Redis存在线程安全问题吗?)
+- 2024.5.9,补充[Redis应用场景有哪些?](##Redis应用场景有哪些?)
+
## Redis是什么?
Redis(`Remote Dictionary Server`)是一个使用 C 语言编写的,高性能非关系型的键值对数据库。与传统数据库不同的是,Redis 的数据是存在内存中的,所以读写速度非常快,被广泛应用于缓存方向。Redis可以将数据写入磁盘中,保证了数据的安全不丢失,而且Redis的操作是原子性的。
@@ -72,12 +77,18 @@ Redis基于Reactor模式开发了网络事件处理器,这个处理器被称
## Redis应用场景有哪些?
-1. **缓存热点数据**,缓解数据库的压力。
-2. 利用 Redis 原子性的自增操作,可以实现**计数器**的功能,比如统计用户点赞数、用户访问数等。
-3. **分布式锁**。在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
-4. **简单的消息队列**,可以使用Redis自身的发布/订阅模式或者List来实现简单的消息队列,实现异步操作。
-5. **限速器**,可用于限制某个用户访问某个接口的频率,比如秒杀场景用于防止用户快速点击带来不必要的压力。
-6. **好友关系**,利用集合的一些命令,比如交集、并集、差集等,实现共同好友、共同爱好之类的功能。
+Redis作为一种优秀的基于key/value的缓存,有非常不错的性能和稳定性,无论是在工作中,还是面试中,都经常会出现。
+
+下面来聊聊Redis的常见的8种应用场景。
+
+1. **缓存热点数据**,缓解数据库的压力。例如:热点数据缓存(例如报表、明星出轨),对象缓存、全页缓存、可以提升热点数据的访问数据。
+2. **计数器**。利用 Redis 原子性的自增操作,可以实现**计数器**的功能,内存操作,性能非常好,非常适用于这些计数场景,比如统计用户点赞数、用户访问数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。
+3. **分布式会话**。集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
+4. **分布式锁**。在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX(SET if Not eXists) 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
+5. **简单的消息队列**,消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。可以使用Redis自身的发布/订阅模式或者List来实现简单的消息队列,实现异步操作。
+6. **限速器**,可用于限制某个用户访问某个接口的频率,比如秒杀场景用于防止用户快速点击带来不必要的压力。
+7. **社交网络**,点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。
+8. **排行榜**。很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
## Memcached和Redis的区别?
@@ -140,6 +151,22 @@ Redis基于Reactor模式开发了网络事件处理器,这个处理器被称
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
+## Redis存在线程安全问题吗?
+
+首先,从Redis 服务端层面分析。
+
+Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Server上执行的指令,不需要任何同步机制,不会存在线程安全问题。
+
+虽然Redis 6.0里面,增加了多线程的模型,但是增加的多线程只是用来处理网络IO事件,对于指令的执行过程,仍然是由主线程来处理,所以不会存在多个线程通知执行操作指令的情况。
+
+第二个,从Redis客户端层面分析。
+
+虽然Redis Server中的指令执行是原子的,但是如果有多个Redis客户端同时执行多个指令的时候,就无法保证原子性。
+
+假设两个redis client同时获取Redis Server上的key1, 同时进行修改和写入,因为多线程环境下的原子性无法被保障,以及多进程情况下的共享资源访问的竞争问题,使得数据的安全性无法得到保障。
+
+当然,对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
+
## keys命令存在的问题?
redis的单线程的。keys指令会导致线程阻塞一段时间,直到执行完毕,服务才能恢复。scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是`O(1)`,但是要真正实现keys的功能,需要执行多次scan。
@@ -787,4 +814,105 @@ Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Se
对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
+
+
+## Redis遇到哈希冲突怎么办?
+
+当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。
+
+Redis 的哈希表使用链地址法(separate chaining)来解决键冲突: 每个哈希表节点都有一个 `next` 指针, 多个哈希表节点可以用 `next` 指针构成一个单向链表, 被分配到同一个索引上的多个节点可以用这个单向链表连接起来, 这就解决了键冲突的问题。
+
+原理跟 Java 的 HashMap 类似,都是数组+链表的结构。当发生 hash 碰撞时将会把元素追加到链表上。
+
+## Redis实现分布式锁有哪些方案?
+
+在这里分享六种Redis分布式锁的正确使用方式,由易到难。
+
+方案一:SETNX+EXPIRE
+
+方案二:SETNX+value值(系统时间+过期时间)
+
+方案三:使用Lua脚本(包含SETNX+EXPIRE两条指令)
+
+方案四::ET的扩展命令(SETEXPXNX)
+
+方案五:开源框架~Redisson
+
+方案六:多机实现的分布式锁Redlock
+
+**首先什么是分布式锁**?
+
+分布式锁是一种机制,用于确保在分布式系统中,多个节点在同一时刻只能有一个节点对共享资源进行操作。它是解决分布式环境下并发控制和数据一致性问题的关键技术之一。
+
+分布式锁的特征:
+
+1、「互斥性」:任意时刻,只有一个客户端能持有锁。
+
+2、「锁超时释放」:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁。
+
+3、「可重入性」“一个线程如果获取了锁之后,可以再次对其请求加锁。
+
+4、「安全性」:锁只能被持有的客户端删除,不能被其他客户端删除
+
+5、「高性能和高可用」:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效。
+
+
+
+**Redis分布式锁方案一:SETNX+EXPIRE**
+
+提到Redis的分布式锁,很多朋友可能就会想到setnx+expire命令。即先用setnx来抢锁,如果抢到之后,再用expire给锁设置一个过期时间,防止锁忘记了释放。SETNX是SETIF NOT EXISTS的简写。日常命令格式是SETNXkey value,如果 key不存在,则SETNX成功返回1,如果这个key已经存在了,则返回0。假设某电商网站的某商品做秒杀活动,key可以设置为key_resource_id,value设置任意值,伪代码如下:
+
+
+
+缺陷:加锁与设置过期时间是非原子操作,如果加锁后未来得及设置过期时间系统异常等,会导致其他线程永远获取不到锁。
+
+**Redis分布式锁方案二**:SETNX+value值(系统时间+过期时间)
+
+为了解决方案一,「发生异常锁得不到释放的场景」,有小伙伴认为,可以把过期时间放到setnx的value值里面。如果加锁失败,再拿出value值校验一下即可。
+
+这个方案的优点是,避免了expire 单独设置过期时间的操作,把「过期时间放到setnx的value值」里面来。解决了方案一发生异常,锁得不到释放的问题。
+
+但是这个方案有别的缺点:过期时间是客户端自己生成的(System.currentTimeMillis()是当前系统的时间),必须要求分布式环境下,每个客户端的时间必须同步。如果锁过期的时候,并发多个客户端同时请求过来,都执行jedis.get()和set(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。该锁没有保存持有者的唯一标识,可能坡别的客户端释放/解锁
+
+**分布式锁方案三:使用Lua脚本(包含SETNX+EXPIRE两条指令)**
+
+实际上,我们还可以使用Lua脚本来保证原子性(包含setnx和expire两条指令),lua脚本如下:
+
+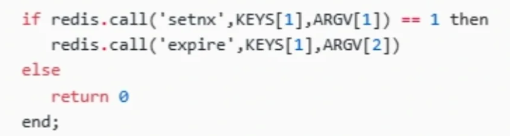
+
+加锁代码如下:
+
+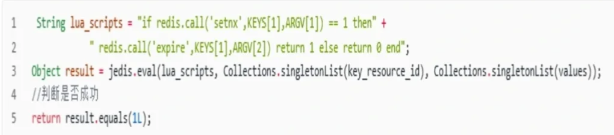
+
+**Redis分布式锁方案四:SET的扩展命令(SET EX PX NX)**
+
+除了使用,使用Lua脚本,保证SETNX+EXPIRE两条指令的原子性,我们还可以巧用Redis的SET指令扩展参数。(`SET key value[EX seconds]`PX milliseconds][NX|XX]`),它也是原子性的
+
+`SET key value[EX seconds][PX milliseconds][NX|XX]`
+
+1. NX:表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁, 才能获取。
+2. EXseconds:设定key的过期时间,时间单位是秒。
+3. PX milliseconds:设定key的过期时间,单位为毫秒。
+4. XX:仅当key存在时设置值。
+
+伪代码如下:
+
+
+
+**Redis分布式锁方案五:Redisson框架**
+
+方案四还是可能存在「锁过期释放,业务没执行完」的问题。设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。当前开源框架Redisson解决了这个问题。一起来看下Redisson底层原理图:
+
+
+
+只要线程一加锁成功,就会启动一个watchdog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了「锁过期释放,业务没执行完」问题。
+
+**分布式锁方案六:多机实现的分布式锁Redlock+Redisson**
+
+前面五种方案都是基于单机版的讨论,那么集群部署该怎么处理?
+
+答案是多机实现的分布式锁Redlock+Redisson
+
+
+

diff --git "a/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md" "b/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md"
new file mode 100644
index 0000000..b691b56
--- /dev/null
+++ "b/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md"
@@ -0,0 +1,266 @@
+# MyBatis 源码分析(七):接口层
+
+## sql 会话创建工厂
+
+`SqlSessionFactoryBuilder` 经过复杂的解析逻辑之后,会根据全局配置创建 `DefaultSqlSessionFactory`,该类是 `sql` 会话创建工厂抽象接口 `SqlSessionFactory` 的默认实现,其提供了若干 `openSession` 方法用于打开一个会话,在会话中进行相关数据库操作。这些 `openSession` 方法最终都会调用 `openSessionFromDataSource` 或 `openSessionFromConnection` 创建会话,即基于数据源配置创建还是基于已有连接对象创建。
+
+### 基于数据源配置创建会话
+
+要使用数据源打开一个会话需要先从全局配置中获取当前生效的数据源环境配置,如果没有生效配置或没用设置可用的事务工厂,就会创建一个 `ManagedTransactionFactory` 实例作为默认事务工厂实现,其与 `MyBatis` 提供的另一个事务工厂实现 `JdbcTransactionFactory` 的区别在于其生成的事务实现 `ManagedTransaction` 的提交和回滚方法是空实现,即希望将事务管理交由外部容器管理。
+
+```java
+ private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
+ Transaction tx = null;
+ try {
+ final Environment environment = configuration.getEnvironment();
+ // 获取事务工厂
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ // 创建事务配置
+ tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
+ // 创建执行器
+ final Executor executor = configuration.newExecutor(tx, execType);
+ // 创建 sql 会话
+ return new DefaultSqlSession(configuration, executor, autoCommit);
+ } catch (Exception e) {
+ closeTransaction(tx); // may have fetched a connection so lets call close()
+ throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 获取生效数据源环境配置的事务工厂
+ */
+ private TransactionFactory getTransactionFactoryFromEnvironment(Environment environment) {
+ if (environment == null || environment.getTransactionFactory() == null) {
+ // 未配置数据源环境或事务工厂,默认使用 ManagedTransactionFactory
+ return new ManagedTransactionFactory();
+ }
+ return environment.getTransactionFactory();
+ }
+```
+
+随后会根据入参传入的 `execType` 选择对应的执行器 `Executor`,`execType` 的取值来源于 `ExecutorType`,这是一个枚举类。在下一章将会详细分析各类 `Executor` 的作用及其实现。
+
+获取到事务工厂配置和执行器对象后会结合传入的数据源自动提交属性创建 `DefaultSqlSession`,即 `sql` 会话对象。
+
+### 基于数据库连接创建会话
+
+基于连接创建会话的流程大致与基于数据源配置创建相同,区别在于自动提交属性 `autoCommit` 是从连接对象本身获取的。
+
+```java
+ private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {
+ try {
+ // 获取自动提交配置
+ boolean autoCommit;
+ try {
+ autoCommit = connection.getAutoCommit();
+ } catch (SQLException e) {
+ // Failover to true, as most poor drivers
+ // or databases won't support transactions
+ autoCommit = true;
+ }
+ final Environment environment = configuration.getEnvironment();
+ // 获取事务工厂
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ // 创建事务配置
+ final Transaction tx = transactionFactory.newTransaction(connection);
+ // 创建执行器
+ final Executor executor = configuration.newExecutor(tx, execType);
+ // 创建 sql 会话
+ return new DefaultSqlSession(configuration, executor, autoCommit);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+```
+
+## sql 会话
+
+`SqlSession` 是 `MyBatis` 面向用户编程的接口,其提供了一系列方法用于执行相关数据库操作,默认实现为 `DefaultSqlSession`,在该类中,增删查改对应的操作最终会调用 `selectList`、`select` 和 `update` 方法,其分别用于普通查询、执行存储过程和修改数据库记录。
+
+```java
+ /**
+ * 查询结果集
+ */
+ @Override
+ public List selectList(String statement, Object parameter, RowBounds rowBounds) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 调用存储过程
+ */
+ @Override
+ public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ executor.query(ms, wrapCollection(parameter), rowBounds, handler);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 修改
+ */
+ @Override
+ public int update(String statement, Object parameter) {
+ try {
+ dirty = true;
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.update(ms, wrapCollection(parameter));
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+```
+
+以上操作均是根据传入的 `statement` 名称到全局配置中查找对应的 `MappedStatement` 对象,并将操作委托给执行器对象 `executor` 完成。`select`、`selectMap` 等方法则是对 `selectList` 方法返回的结果集做处理来实现的。
+
+此外,提交和回滚方法也是基于 `executor` 实现的。
+
+```java
+ /**
+ * 提交事务
+ */
+ @Override
+ public void commit(boolean force) {
+ try {
+ executor.commit(isCommitOrRollbackRequired(force));
+ dirty = false;
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 回滚事务
+ */
+ @Override
+ public void rollback(boolean force) {
+ try {
+ executor.rollback(isCommitOrRollbackRequired(force));
+ dirty = false;
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error rolling back transaction. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 非自动提交且事务未提交 || 强制提交或回滚 时返回 true
+ */
+ private boolean isCommitOrRollbackRequired(boolean force) {
+ return (!autoCommit && dirty) || force;
+ }
+```
+
+在执行 `update` 方法时,会设置 `dirty` 属性为 `true` ,意为事务还未提交,当事务提交或回滚后才会将 `dirty` 属性修改为 `false`。如果当前会话不是自动提交且 `dirty` 熟悉为 `true`,或者设置了强制提交或回滚的标志,则会将强制标志提交给 `executor` 处理。
+
+## Sql 会话管理器
+
+`SqlSessionManager` 同时实现了 `SqlSessionFactory` 和 `SqlSession` 接口,使得其既能够创建 `sql` 会话,又能够执行 `sql` 会话的相关数据库操作。
+
+```java
+ /**
+ * sql 会话创建工厂
+ */
+ private final SqlSessionFactory sqlSessionFactory;
+
+ /**
+ * sql 会话代理对象
+ */
+ private final SqlSession sqlSessionProxy;
+
+ /**
+ * 保存线程对应 sql 会话
+ */
+ private final ThreadLocal localSqlSession = new ThreadLocal<>();
+
+ private SqlSessionManager(SqlSessionFactory sqlSessionFactory) {
+ this.sqlSessionFactory = sqlSessionFactory;
+ this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
+ SqlSessionFactory.class.getClassLoader(),
+ new Class[]{SqlSession.class},
+ new SqlSessionInterceptor());
+ }
+
+ @Override
+ public SqlSession openSession() {
+ return sqlSessionFactory.openSession();
+ }
+
+ /**
+ * 设置当前线程对应的 sql 会话
+ */
+ public void startManagedSession() {
+ this.localSqlSession.set(openSession());
+ }
+
+ /**
+ * sql 会话代理逻辑
+ */
+ private class SqlSessionInterceptor implements InvocationHandler {
+
+ public SqlSessionInterceptor() {
+ // Prevent Synthetic Access
+ }
+
+ @Override
+ public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
+ // 获取当前线程对应的 sql 会话对象并执行对应方法
+ final SqlSession sqlSession = SqlSessionManager.this.localSqlSession.get();
+ if (sqlSession != null) {
+ try {
+ return method.invoke(sqlSession, args);
+ } catch (Throwable t) {
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ } else {
+ // 如果当前线程没有对应的 sql 会话,默认创建不自动提交的 sql 会话
+ try (SqlSession autoSqlSession = openSession()) {
+ try {
+ final Object result = method.invoke(autoSqlSession, args);
+ autoSqlSession.commit();
+ return result;
+ } catch (Throwable t) {
+ autoSqlSession.rollback();
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ }
+ }
+ }
+ }
+```
+
+`SqlSessionManager` 的构造方法要求 `SqlSessionFactory` 对象作为入参传入,其各个创建会话的方法实际是由该传入对象完成的。执行 `sql` 会话的操作由 `sqlSessionProxy` 对象完成,这是一个由 `JDK` 动态代理创建的对象,当执行方法时会去 `ThreadLocal` 对象中查找当前线程有没有对应的 `sql` 会话对象,如果有则使用已有的会话对象执行,否则创建新的会话对象执行,而线程对应的会话对象需要使用 `startManagedSession` 方法来维护。
+
+之所以 `SqlSessionManager` 需要为每个线程维护会话对象,是因为 `DefaultSqlSession` 是非线程安全的,多线程操作会导致执行错误。如上文中提到的 `dirty` 属性,其修改是没有经过任何同步操作的。
+
+## 小结
+
+`SqlSession` 是 `MyBatis` 提供的面向开发者编程的接口,其提供了一系列数据库相关操作,并屏蔽了底层细节。使用 `MyBatis` 的正确方式应该是像 `SqlSessionManager` 那样为每个线程创建 `sql` 会话对象,避免造成线程安全问题。
+
+- `org.apache.ibatis.session.SqlSessionFactory`:`sql` 会话创建工厂。
+- `org.apache.ibatis.session.defaults.DefaultSqlSessionFactory`: `sql` 会话创建工厂默认实现。
+- `org.apache.ibatis.session.SqlSession`:`sql` 会话。
+- `org.apache.ibatis.session.defaults.DefaultSqlSession`:`sql` 会话默认实现。
+- `org.apache.ibatis.session.SqlSessionManager`:`sql` 会话管理器
\ No newline at end of file
diff --git a/docs/source/mybatis/1-overview.md b/docs/source/mybatis/1-overview.md
new file mode 100644
index 0000000..550a96a
--- /dev/null
+++ b/docs/source/mybatis/1-overview.md
@@ -0,0 +1,43 @@
+---
+sidebar: heading
+title: MyBatis源码分析
+category: 源码分析
+tag:
+ - MyBatis
+head:
+ - - meta
+ - name: keywords
+ content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
+ - - meta
+ - name: description
+ content: 高质量的MyBatis源码分析总结
+---
+
+`MyBatis` 是一款旨在帮助开发人员屏蔽底层重复性原生 `JDBC` 代码的持久化框架,其支持通过映射文件配置或注解将 `ResultSet` 映射为 `Java` 对象。相对于其它 `ORM` 框架,`MyBatis` 更为轻量级,支持定制化 `SQL` 和动态 `SQL`,方便优化查询性能,同时包含了良好的缓存机制。
+
+## MyBatis 整体架构
+
+
+
+### 基础支持层
+
+- 反射模块:提供封装的反射 `API`,方便上层调用。
+- 类型转换:为简化配置文件提供了别名机制,并且实现了 `Java` 类型和 `JDBC` 类型的互转。
+- 日志模块:能够集成多种第三方日志框架。
+- 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
+- 数据源模块:提供数据源实现并能够集成第三方数据源模块。
+- 事务管理:可以和 `Spring` 集成开发,对事务进行管理。
+- 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
+- `Binding` 模块:在调用 `SqlSession` 相应方法执行数据库操作时,需要指定映射文件中的 `SQL` 节点,`MyBatis` 通过 `Binding` 模块将自定义 `Mapper` 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
+
+### 核心处理层
+
+- 配置解析:`MyBatis` 初始化时会加载配置文件、映射文件和 `Mapper` 接口的注解信息,解析后会以对象的形式保存到 `Configuration` 对象中。
+- `SQL` 解析与 `scripting` 模块:`MyBatis` 支持通过配置实现动态 `SQL`,即根据不同入参生成 `SQL`。
+- `SQL` 执行与结果解析:`Executor` 负责维护缓存和事务管理,并将数据库相关操作委托给 `StatementHandler`,`ParmeterHadler` 负责完成 `SQL` 语句的实参绑定并通过 `Statement` 对象执行 `SQL`,通过 `ResultSet` 返回结果,交由 `ResultSetHandler` 处理。
+
+- 插件:支持开发者通过插件接口对 `MyBatis` 进行扩展。
+
+### 接口层
+
+`SqlSession` 接口定义了暴露给应用程序调用的 `API`,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
\ No newline at end of file
diff --git a/docs/source/mybatis/2-reflect.md b/docs/source/mybatis/2-reflect.md
new file mode 100644
index 0000000..06e4ea7
--- /dev/null
+++ b/docs/source/mybatis/2-reflect.md
@@ -0,0 +1,634 @@
+---
+sidebar: heading
+title: MyBatis源码分析
+category: 源码分析
+tag:
+ - MyBatis
+head:
+ - - meta
+ - name: keywords
+ content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis反射,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
+ - - meta
+ - name: description
+ content: 高质量的MyBatis源码分析总结
+---
+
+大家好,我是大彬。今天分享Mybatis源码的反射模块。
+
+`MyBatis` 在进行参数处理、结果映射时等操作时,会涉及大量的反射操作。为了简化这些反射相关操作,`MyBatis` 在 `org.apache.ibatis.reflection` 包下提供了专门的反射模块,对反射操作做了近一步封装,提供了更为简洁的 `API`。
+
+## 缓存类的元信息
+
+`MyBatis` 提供 `Reflector` 类来缓存类的字段名和 `getter/setter` 方法的元信息,使得反射时有更好的性能。使用方式是将原始类对象传入其构造方法,生成 `Reflector` 对象。
+
+```java
+ public Reflector(Class clazz) {
+ type = clazz;
+ // 如果存在,记录无参构造方法
+ addDefaultConstructor(clazz);
+ // 记录字段名与get方法、get方法返回值的映射关系
+ addGetMethods(clazz);
+ // 记录字段名与set方法、set方法参数的映射关系
+ addSetMethods(clazz);
+ // 针对没有getter/setter方法的字段,通过Filed对象的反射来设置和读取字段值
+ addFields(clazz);
+ // 可读的字段名
+ readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);
+ // 可写的字段名
+ writablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);
+ // 保存一份所有字段名大写与原始字段名的隐射
+ for (String propName : readablePropertyNames) {
+ caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
+ }
+ for (String propName : writablePropertyNames) {
+ caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
+ }
+ }
+```
+
+`addGetMethods` 和 `addSetMethods` 分别获取类的所有方法,从符合 `getter/setter` 规范的方法中解析出字段名,并记录方法的参数类型、返回值类型等信息:
+
+```java
+ private void addGetMethods(Class cls) {
+ // 字段名-get方法
+ Map> conflictingGetters = new HashMap<>();
+ // 获取类的所有方法,及其实现接口的方法,并根据方法签名去重
+ Method[] methods = getClassMethods(cls);
+ for (Method method : methods) {
+ if (method.getParameterTypes().length > 0) {
+ // 过滤有参方法
+ continue;
+ }
+ String name = method.getName();
+ if ((name.startsWith("get") && name.length() > 3)
+ || (name.startsWith("is") && name.length() > 2)) {
+ // 由get属性获取对应的字段名(去除前缀,首字母转小写)
+ name = PropertyNamer.methodToProperty(name);
+ addMethodConflict(conflictingGetters, name, method);
+ }
+ }
+ // 保证每个字段只对应一个get方法
+ resolveGetterConflicts(conflictingGetters);
+ }
+```
+
+对 `getter/setter` 方法进行去重是通过类似 `java.lang.String#getSignature:java.lang.reflect.Method` 的方法签名来实现的,如果子类在实现过程中,参数、返回值使用了不同的类型(使用原类型的子类),则会导致方法签名不一致,同一字段就会对应不同的 `getter/setter` 方法,因此需要进行去重。
+
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
+```java
+ private void resolveGetterConflicts(Map> conflictingGetters) {
+ for (Entry> entry : conflictingGetters.entrySet()) {
+ Method winner = null;
+ // 属性名
+ String propName = entry.getKey();
+ for (Method candidate : entry.getValue()) {
+ if (winner == null) {
+ winner = candidate;
+ continue;
+ }
+ // 字段对应了多个get方法
+ Class winnerType = winner.getReturnType();
+ Class candidateType = candidate.getReturnType();
+ if (candidateType.equals(winnerType)) {
+ // 返回值类型相同
+ if (!boolean.class.equals(candidateType)) {
+ throw new ReflectionException(
+ "Illegal overloaded getter method with ambiguous type for property "
+ + propName + " in class " + winner.getDeclaringClass()
+ + ". This breaks the JavaBeans specification and can cause unpredictable results.");
+ } else if (candidate.getName().startsWith("is")) {
+ // 返回值为boolean的get方法可能有多个,如getIsSave和isSave,优先取is开头的
+ winner = candidate;
+ }
+ } else if (candidateType.isAssignableFrom(winnerType)) {
+ // OK getter type is descendant
+ // 可能会出现接口中的方法返回值是List,子类实现方法返回值是ArrayList,使用子类返回值方法
+ } else if (winnerType.isAssignableFrom(candidateType)) {
+ winner = candidate;
+ } else {
+ throw new ReflectionException(
+ "Illegal overloaded getter method with ambiguous type for property "
+ + propName + " in class " + winner.getDeclaringClass()
+ + ". This breaks the JavaBeans specification and can cause unpredictable results.");
+ }
+ }
+ // 记录字段名对应的get方法对象和返回值类型
+ addGetMethod(propName, winner);
+ }
+ }
+```
+
+去重的方式是使用更规范的方法以及使用子类的方法。在确认字段名对应的唯一 `getter/setter` 方法后,记录方法名对应的方法、参数、返回值等信息。`MethodInvoker` 可用于调用 `Method` 类的 `invoke` 方法来执行 `getter/setter` 方法(`addSetMethods` 记录映射关系的方式与 `addGetMethods` 大致相同)。
+
+```java
+private void addGetMethod(String name, Method method) {
+ // 过滤$开头、serialVersionUID的get方法和getClass()方法
+ if (isValidPropertyName(name)) {
+ // 字段名-对应get方法的MethodInvoker对象
+ getMethods.put(name, new MethodInvoker(method));
+ Type returnType = TypeParameterResolver.resolveReturnType(method, type);
+ // 字段名-运行时方法的真正返回类型
+ getTypes.put(name, typeToClass(returnType));
+ }
+}
+```
+
+接下来会执行 `addFields` 方法,此方法针对没有 `getter/setter` 方法的字段,通过包装为 `SetFieldInvoker` 在需要时通过 `Field` 对象的反射来设置和读取字段值。
+
+```java
+private void addFields(Class clazz) {
+ Field[] fields = clazz.getDeclaredFields();
+ for (Field field : fields) {
+ if (!setMethods.containsKey(field.getName())) {
+ // issue #379 - removed the check for final because JDK 1.5 allows
+ // modification of final fields through reflection (JSR-133). (JGB)
+ // pr #16 - final static can only be set by the classloader
+ int modifiers = field.getModifiers();
+ if (!(Modifier.isFinal(modifiers) && Modifier.isStatic(modifiers))) {
+ // 非final的static变量,没有set方法,可以通过File对象做赋值操作
+ addSetField(field);
+ }
+ }
+ if (!getMethods.containsKey(field.getName())) {
+ addGetField(field);
+ }
+ }
+ if (clazz.getSuperclass() != null) {
+ // 递归查找父类
+ addFields(clazz.getSuperclass());
+ }
+}
+```
+
+## 抽象字段赋值与读取
+
+`Invoker` 接口用于抽象设置和读取字段值的操作。对于有 `getter/setter` 方法的字段,通过 `MethodInvoker` 反射执行;对应其它字段,通过 `GetFieldInvoker` 和 `SetFieldInvoker` 操作 `Field` 对象的 `getter/setter` 方法反射执行。
+
+```java
+/**
+ * 用于抽象设置和读取字段值的操作
+ *
+ * {@link MethodInvoker} 反射执行getter/setter方法
+ * {@link GetFieldInvoker} {@link SetFieldInvoker} 反射执行Field对象的get/set方法
+ *
+ * @author Clinton Begin
+ */
+public interface Invoker {
+
+ /**
+ * 通过反射设置或读取字段值
+ *
+ * @param target
+ * @param args
+ * @return
+ * @throws IllegalAccessException
+ * @throws InvocationTargetException
+ */
+ Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
+
+ /**
+ * 字段类型
+ *
+ * @return
+ */
+ Class getType();
+}
+```
+
+## 解析参数类型
+
+针对 `Java-Type` 体系的多种实现,`TypeParameterResolver` 提供一系列方法来解析指定类中的字段、方法返回值或方法参数的类型。
+
+`Type` 接口包含 4 个子接口和 1 个实现类:
+
+
+
+- `Class`:原始类型
+- `ParameterizedType`:泛型类型,如:`List`
+- `TypeVariable`:泛型类型变量,如: `List` 中的 `T`
+- `GenericArrayType`:组成元素是 `ParameterizedType` 或 `TypeVariable` 的数组类型,如:`List[]`、`T[]`
+- `WildcardType`:通配符泛型类型变量,如:`List` 中的 `?`
+
+`TypeParameterResolver` 分别提供 `resolveFieldType`、`resolveReturnType`、`resolveParamTypes` 方法用于解析字段类型、方法返回值类型和方法入参类型,这些方法均调用 `resolveType` 来获取类型信息:
+
+```java
+/**
+ * 获取类型信息
+ *
+ * @param type 根据是否有泛型信息签名选择传入泛型类型或简单类型
+ * @param srcType 引用字段/方法的类(可能是子类,字段和方法在父类声明)
+ * @param declaringClass 字段/方法声明的类
+ * @return
+ */
+private static Type resolveType(Type type, Type srcType, Class declaringClass) {
+ if (type instanceof TypeVariable) {
+ // 泛型类型变量,如:List 中的 T
+ return resolveTypeVar((TypeVariable) type, srcType, declaringClass);
+ } else if (type instanceof ParameterizedType) {
+ // 泛型类型,如:List
+ return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
+ } else if (type instanceof GenericArrayType) {
+ // TypeVariable/ParameterizedType 数组类型
+ return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
+ } else {
+ // 原始类型,直接返回
+ return type;
+ }
+}
+```
+
+`resolveTypeVar` 用于解析泛型类型变量参数类型,如果字段或方法在当前类中声明,则返回泛型类型的上界或 `Object` 类型;如果在父类中声明,则递归解析父类;父类也无法解析,则递归解析实现的接口。
+
+```java
+private static Type resolveTypeVar(TypeVariable typeVar, Type srcType, Class declaringClass) {
+ Type result;
+ Class clazz;
+ if (srcType instanceof Class) {
+ // 原始类型
+ clazz = (Class) srcType;
+ } else if (srcType instanceof ParameterizedType) {
+ // 泛型类型,如 TestObj
+ ParameterizedType parameterizedType = (ParameterizedType) srcType;
+ // 取原始类型TestObj
+ clazz = (Class) parameterizedType.getRawType();
+ } else {
+ throw new IllegalArgumentException("The 2nd arg must be Class or ParameterizedType, but was: " + srcType.getClass());
+ }
+
+ if (clazz == declaringClass) {
+ // 字段就是在当前引用类中声明的
+ Type[] bounds = typeVar.getBounds();
+ if (bounds.length > 0) {
+ // 返回泛型类型变量上界,如:T extends String,则返回String
+ return bounds[0];
+ }
+ // 没有上界返回Object
+ return Object.class;
+ }
+
+ // 字段/方法在父类中声明,递归查找父类泛型
+ Type superclass = clazz.getGenericSuperclass();
+ result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superclass);
+ if (result != null) {
+ return result;
+ }
+
+ // 递归泛型接口
+ Type[] superInterfaces = clazz.getGenericInterfaces();
+ for (Type superInterface : superInterfaces) {
+ result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superInterface);
+ if (result != null) {
+ return result;
+ }
+ }
+ return Object.class;
+}
+```
+
+通过调用 `scanSuperTypes` 实现递归解析:
+
+```java
+private static Type scanSuperTypes(TypeVariable typeVar, Type srcType, Class declaringClass, Class clazz, Type superclass) {
+ if (superclass instanceof ParameterizedType) {
+ // 父类是泛型类型
+ ParameterizedType parentAsType = (ParameterizedType) superclass;
+ Class parentAsClass = (Class) parentAsType.getRawType();
+ // 父类中的泛型类型变量集合
+ TypeVariable[] parentTypeVars = parentAsClass.getTypeParameters();
+ if (srcType instanceof ParameterizedType) {
+ // 子类可能对父类泛型变量做过替换,使用替换后的类型
+ parentAsType = translateParentTypeVars((ParameterizedType) srcType, clazz, parentAsType);
+ }
+ if (declaringClass == parentAsClass) {
+ // 字段/方法在当前父类中声明
+ for (int i = 0; i < parentTypeVars.length; i++) {
+ if (typeVar == parentTypeVars[i]) {
+ // 使用变量对应位置的真正类型(可能已经被替换),如父类 A,子类 B extends A,则返回String
+ return parentAsType.getActualTypeArguments()[i];
+ }
+ }
+ }
+ // 字段/方法声明的类是当前父类的父类,继续递归
+ if (declaringClass.isAssignableFrom(parentAsClass)) {
+ return resolveTypeVar(typeVar, parentAsType, declaringClass);
+ }
+ } else if (superclass instanceof Class && declaringClass.isAssignableFrom((Class) superclass)) {
+ // 父类是原始类型,继续递归父类
+ return resolveTypeVar(typeVar, superclass, declaringClass);
+ }
+ return null;
+}
+```
+
+解析方法返回值和方法参数的逻辑大致与解析字段类型相同,`MyBatis` 源码的`TypeParameterResolverTest` 类提供了相关的测试用例。
+
+## 元信息工厂
+
+`MyBatis` 还提供 `ReflectorFactory` 接口用于实现 `Reflector` 容器,其默认实现为 `DefaultReflectorFactory`,其中可以使用 `classCacheEnabled` 属性来配置是否使用缓存。
+
+```java
+public class DefaultReflectorFactory implements ReflectorFactory {
+
+ /**
+ * 是否缓存Reflector类信息
+ */
+ private boolean classCacheEnabled = true;
+
+ /**
+ * Reflector缓存容器
+ */
+ private final ConcurrentMap, Reflector> reflectorMap = new ConcurrentHashMap<>();
+
+ public DefaultReflectorFactory() {
+ }
+
+ @Override
+ public boolean isClassCacheEnabled() {
+ return classCacheEnabled;
+ }
+
+ @Override
+ public void setClassCacheEnabled(boolean classCacheEnabled) {
+ this.classCacheEnabled = classCacheEnabled;
+ }
+
+ /**
+ * 获取类的Reflector信息
+ *
+ * @param type
+ * @return
+ */
+ @Override
+ public Reflector findForClass(Class type) {
+ if (classCacheEnabled) {
+ // synchronized (type) removed see issue #461
+ // 如果缓存Reflector信息,放入缓存容器
+ return reflectorMap.computeIfAbsent(type, Reflector::new);
+ } else {
+ return new Reflector(type);
+ }
+ }
+
+}
+```
+
+## 对象创建工厂
+
+`ObjectFactory` 接口是 `MyBatis` 对象创建工厂,其默认实现 `DefaultObjectFactory` 通过构造器反射创建对象,支持使用无参构造器和有参构造器。
+
+## 属性工具集
+
+`MyBatis` 在映射文件定义 `resultMap` 支持如下形式:
+
+```xml
+
+
+
+ ...
+
+```
+
+`orders[0].items[0].name` 这样的表达式是由 `PropertyTokenizer` 解析的,其构造方法能够对表达式进行解析;同时还实现了 `Iterator` 接口,能够迭代解析表达式。
+
+```java
+public PropertyTokenizer(String fullname) {
+ // orders[0].items[0].name
+ int delim = fullname.indexOf('.');
+ if (delim > -1) {
+ // name = orders[0]
+ name = fullname.substring(0, delim);
+ // children = items[0].name
+ children = fullname.substring(delim + 1);
+ } else {
+ name = fullname;
+ children = null;
+ }
+ // orders[0]
+ indexedName = name;
+ delim = name.indexOf('[');
+ if (delim > -1) {
+ // 0
+ index = name.substring(delim + 1, name.length() - 1);
+ // order
+ name = name.substring(0, delim);
+ }
+}
+
+ /**
+ * 是否有children表达式继续迭代
+ *
+ * @return
+ */
+ @Override
+ public boolean hasNext() {
+ return children != null;
+ }
+
+ /**
+ * 分解出的 . 分隔符的 children 表达式可以继续迭代
+ * @return
+ */
+ @Override
+ public PropertyTokenizer next() {
+ return new PropertyTokenizer(children);
+ }
+```
+
+`PropertyNamer` 可以根据 `getter/setter` 规范解析字段名称;`PropertyCopier` 则支持对有相同父类的对象,通过反射拷贝字段值。
+
+## 封装类信息
+
+`MetaClass` 类依赖 `PropertyTokenizer` 和 `Reflector` 查找表达式是否可以匹配 `Java` 对象中的字段,以及对应字段是否有 `getter/setter` 方法。
+
+```java
+/**
+ * 验证传入的表达式,是否存在指定的字段
+ *
+ * @param name
+ * @param builder
+ * @return
+ */
+private StringBuilder buildProperty(String name, StringBuilder builder) {
+ // 映射文件表达式迭代器
+ PropertyTokenizer prop = new PropertyTokenizer(name);
+ if (prop.hasNext()) {
+ // 复杂表达式,如name = items[0].name,则prop.getName() = items
+ String propertyName = reflector.findPropertyName(prop.getName());
+ if (propertyName != null) {
+ builder.append(propertyName);
+ // items.
+ builder.append(".");
+ // 加载内嵌字段类型对应的MetaClass
+ MetaClass metaProp = metaClassForProperty(propertyName);
+ // 迭代子字段
+ metaProp.buildProperty(prop.getChildren(), builder);
+ }
+ } else {
+ // 非复杂表达式,获取字段名,如:userid->userId
+ String propertyName = reflector.findPropertyName(name);
+ if (propertyName != null) {
+ builder.append(propertyName);
+ }
+ }
+ return builder;
+}
+```
+
+## 包装字段对象
+
+相对于 `MetaClass` 关注类信息,`MetalObject` 关注的是对象的信息,除了保存传入的对象本身,还会为对象指定一个 `ObjectWrapper` 将对象包装起来。`ObejctWrapper` 体系如下:
+
+
+
+`ObjectWrapper` 的默认实现包括了对 `Map`、`Collection` 和普通 `JavaBean` 的包装。`MyBatis` 还支持通过 `ObjectWrapperFactory` 接口对 `ObejctWrapper` 进行扩展,生成自定义的包装类。`MetaObject` 对对象的具体操作,就委托给真正的 `ObjectWrapper` 处理。
+
+```java
+private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
+ this.originalObject = object;
+ this.objectFactory = objectFactory;
+ this.objectWrapperFactory = objectWrapperFactory;
+ this.reflectorFactory = reflectorFactory;
+
+ // 根据传入object类型不同,指定不同的wrapper
+ if (object instanceof ObjectWrapper) {
+ this.objectWrapper = (ObjectWrapper) object;
+ } else if (objectWrapperFactory.hasWrapperFor(object)) {
+ this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
+ } else if (object instanceof Map) {
+ this.objectWrapper = new MapWrapper(this, (Map) object);
+ } else if (object instanceof Collection) {
+ this.objectWrapper = new CollectionWrapper(this, (Collection) object);
+ } else {
+ this.objectWrapper = new BeanWrapper(this, object);
+ }
+}
+```
+
+例如赋值操作,`BeanWrapper` 的实现如下:
+
+```java
+ @Override
+ public void set(PropertyTokenizer prop, Object value) {
+ if (prop.getIndex() != null) {
+ // 当前表达式是集合,如:items[0],就需要获取items集合对象
+ Object collection = resolveCollection(prop, object);
+ // 在集合的指定索引上赋值
+ setCollectionValue(prop, collection, value);
+ } else {
+ // 解析完成,通过Invoker接口做赋值操作
+ setBeanProperty(prop, object, value);
+ }
+ }
+
+ protected Object resolveCollection(PropertyTokenizer prop, Object object) {
+ if ("".equals(prop.getName())) {
+ return object;
+ } else {
+ // 在对象信息中查到此字段对应的集合对象
+ return metaObject.getValue(prop.getName());
+ }
+ }
+```
+
+根据 `PropertyTokenizer` 对象解析出的当前字段是否存在 `index` 索引来判断字段是否为集合。如果当前字段对应集合,则需要在对象信息中查到此字段对应的集合对象:
+
+```javascript
+public Object getValue(String name) {
+ PropertyTokenizer prop = new PropertyTokenizer(name);
+ if (prop.hasNext()) {
+ // 如果表达式仍可迭代,递归寻找字段对应的对象
+ MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
+ if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
+ return null;
+ } else {
+ return metaValue.getValue(prop.getChildren());
+ }
+ } else {
+ // 字段解析完成
+ return objectWrapper.get(prop);
+ }
+}
+```
+
+如果字段是简单类型,`BeanWrapper` 获取字段对应的对象逻辑如下:
+
+```java
+@Override
+public Object get(PropertyTokenizer prop) {
+ if (prop.getIndex() != null) {
+ // 集合类型,递归获取
+ Object collection = resolveCollection(prop, object);
+ return getCollectionValue(prop, collection);
+ } else {
+ // 解析完成,反射读取
+ return getBeanProperty(prop, object);
+ }
+}
+```
+
+可以看到,仍然是会判断表达式是否迭代完成,如果未解析完字段会不断递归,直至找到对应的类型。前面说到 `Reflector` 创建过程中将对字段的读取和赋值操作通过 `Invoke` 接口抽象出来,针对最终获取的字段,此时就会调用 `Invoke` 接口对字段反射读取对象值:
+
+```java
+/**
+ * 通过Invoker接口反射执行读取操作
+ *
+ * @param prop
+ * @param object
+ */
+private Object getBeanProperty(PropertyTokenizer prop, Object object) {
+ try {
+ Invoker method = metaClass.getGetInvoker(prop.getName());
+ try {
+ return method.invoke(object, NO_ARGUMENTS);
+ } catch (Throwable t) {
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ } catch (RuntimeException e) {
+ throw e;
+ } catch (Throwable t) {
+ throw new ReflectionException("Could not get property '" + prop.getName() + "' from " + object.getClass() + ". Cause: " + t.toString(), t);
+ }
+}
+```
+
+对象读取完毕再通过 `setCollectionValue` 方法对集合指定索引进行赋值或通过 `setBeanProperty` 方法对简单类型反射赋值。`MapWrapper` 的操作与 `BeanWrapper` 大致相同,`CollectionWrapper` 相对更会简单,只支持对原始集合对象进行添加操作。
+
+## 小结
+
+`MyBatis` 根据自身需求,对反射 `API` 做了近一步封装。其目的是简化反射操作,为对象字段的读取和赋值提供更好的性能。
+
+- `org.apache.ibatis.reflection.Reflector`:缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。
+- `org.apache.ibatis.reflection.invoker.Invoker:`:用于抽象设置和读取字段值的操作。
+- `org.apache.ibatis.reflection.TypeParameterResolver`:针对 Java-Type 体系的多种实现,解析指定类中的字段、方法返回值或方法参数的类型。
+- `org.apache.ibatis.reflection.ReflectorFactory`:反射信息创建工厂抽象接口。
+- `org.apache.ibatis.reflection.DefaultReflectorFactory`:默认的反射信息创建工厂。
+- `org.apache.ibatis.reflection.factory.ObjectFactory`:MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象。
+- `org.apache.ibatis.reflection.property`:property 工具包,针对映射文件表达式进行解析和 Java 对象的反射赋值。
+- `org.apache.ibatis.reflection.MetaClass`:依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
+- `org.apache.ibatis.reflection.MetaObject`:对原始对象进行封装,将对象操作委托给 ObjectWrapper 处理。
+- `org.apache.ibatis.reflection.wrapper.ObjectWrapper`:对象包装类,封装对象的读取和赋值等操作。
+
+
+
+
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git "a/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md" "b/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md"
new file mode 100644
index 0000000..234ffcf
--- /dev/null
+++ "b/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md"
@@ -0,0 +1,1563 @@
+## 类型转换
+
+`JDBC` 规范定义的数据类型与 `Java` 数据类型并不是完全对应的,所以在 `PrepareStatement` 为 `SQL` 语句绑定参数时,需要从 `Java` 类型转为 `JDBC` 类型;而从结果集中获取数据时,则需要将 `JDBC` 类型转为 `Java` 类型。
+
+### 类型转换操作
+
+`MyBatis` 中的所有类型转换器都继承自 `BaseTypeHandler` 抽象类,此类实现了 `TypeHandler` 接口。接口中定义了 1 个向 `PreparedStatement` 对象中设置参数的方法和 3 个从结果集中取值的方法:
+
+```java
+ public interface TypeHandler {
+
+ /**
+ * 为PreparedStatement对象设置参数
+ *
+ * @param ps SQL 预编译对象
+ * @param i 参数索引
+ * @param parameter 参数值
+ * @param jdbcType 参数 JDBC类型
+ * @throws SQLException
+ */
+ void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
+
+ /**
+ * 根据列名从结果集中取值
+ *
+ * @param rs 结果集
+ * @param columnName 列名
+ * @return
+ * @throws SQLException
+ */
+ T getResult(ResultSet rs, String columnName) throws SQLException;
+
+ /**
+ * 根据索引从结果集中取值
+ * @param rs 结果集
+ * @param columnIndex 索引
+ * @return
+ * @throws SQLException
+ */
+ T getResult(ResultSet rs, int columnIndex) throws SQLException;
+
+ /**
+ * 根据索引从存储过程函数中取值
+ *
+ * @param cs 存储过程对象
+ * @param columnIndex 索引
+ * @return
+ * @throws SQLException
+ */
+ T getResult(CallableStatement cs, int columnIndex) throws SQLException;
+
+ }
+```
+
+### BaseTypeHandler 及其实现
+
+`BaseTypeHandler` 实现了 `TypeHandler` 接口,针对 `null` 和异常处理做了封装,但是具体逻辑封装成 4 个抽象方法仍交由相应的类型转换器子类实现,以 `IntegerTypeHandler` 为例,其实现如下:
+
+```java
+ public class IntegerTypeHandler extends BaseTypeHandler {
+
+ @Override
+ public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
+ throws SQLException {
+ ps.setInt(i, parameter);
+ }
+
+ @Override
+ public Integer getNullableResult(ResultSet rs, String columnName)
+ throws SQLException {
+ int result = rs.getInt(columnName);
+ // 如果列值为空值返回控制否则返回原值
+ return result == 0 && rs.wasNull() ? null : result;
+ }
+
+ @Override
+ public Integer getNullableResult(ResultSet rs, int columnIndex)
+ throws SQLException {
+ int result = rs.getInt(columnIndex);
+ return result == 0 && rs.wasNull() ? null : result;
+ }
+
+ @Override
+ public Integer getNullableResult(CallableStatement cs, int columnIndex)
+ throws SQLException {
+ int result = cs.getInt(columnIndex);
+ return result == 0 && cs.wasNull() ? null : result;
+ }
+ }
+```
+
+其实现主要是调用 `JDBC API` 设置查询参数或取值,并对 `null` 等特定情况做特殊处理。
+
+### 类型转换器注册
+
+`TypeHandlerRegistry` 是 `TypeHandler` 的注册类,在其无参构造方法中维护了 `JavaType`、`JdbcType` 和 `TypeHandler` 的关系。其主要使用的容器如下:
+
+```java
+ /**
+ * JdbcType - TypeHandler对象
+ * 用于将Jdbc类型转为Java类型
+ */
+ private final Map> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class);
+
+ /**
+ * JavaType - JdbcType - TypeHandler对象
+ * 用于将Java类型转为指定的Jdbc类型
+ */
+ private final Map>> typeHandlerMap = new ConcurrentHashMap<>();
+
+ /**
+ * TypeHandler类型 - TypeHandler对象
+ * 注册所有的TypeHandler类型
+ */
+ private final Map, TypeHandler> allTypeHandlersMap = new HashMap<>();
+```
+
+## 别名注册
+
+### 别名转换器注册
+
+`TypeAliasRegistry` 提供了多种方式用于为 `Java` 类型注册别名。包括直接指定别名、注解指定别名、为指定包下类型注册别名:
+
+```java
+ /**
+ * 注册指定包下所有类型别名
+ *
+ * @param packageName
+ */
+ public void registerAliases(String packageName) {
+ registerAliases(packageName, Object.class);
+ }
+
+ /**
+ * 注册指定包下指定类型的别名
+ *
+ * @param packageName
+ * @param superType
+ */
+ public void registerAliases(String packageName, Class superType) {
+ ResolverUtil> resolverUtil = new ResolverUtil<>();
+ // 找出该包下superType所有的子类
+ resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
+ Set>> typeSet = resolverUtil.getClasses();
+ for (Class type : typeSet) {
+ // Ignore inner classes and interfaces (including package-info.java)
+ // Skip also inner classes. See issue #6
+ if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
+ registerAlias(type);
+ }
+ }
+ }
+
+ /**
+ * 注册类型别名,默认为简单类名,优先从Alias注解获取
+ *
+ * @param type
+ */
+ public void registerAlias(Class type) {
+ String alias = type.getSimpleName();
+ // 从Alias注解读取别名
+ Alias aliasAnnotation = type.getAnnotation(Alias.class);
+ if (aliasAnnotation != null) {
+ alias = aliasAnnotation.value();
+ }
+ registerAlias(alias, type);
+ }
+
+ /**
+ * 注册类型别名
+ *
+ * @param alias 别名
+ * @param value 类型
+ */
+ public void registerAlias(String alias, Class value) {
+ if (alias == null) {
+ throw new TypeException("The parameter alias cannot be null");
+ }
+ // issue #748
+ String key = alias.toLowerCase(Locale.ENGLISH);
+ if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
+ throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
+ }
+ typeAliases.put(key, value);
+ }
+
+ /**
+ * 注册类型别名
+ * @param alias 别名
+ * @param value 指定类型全名
+ */
+ public void registerAlias(String alias, String value) {
+ try {
+ registerAlias(alias, Resources.classForName(value));
+ } catch (ClassNotFoundException e) {
+ throw new TypeException("Error registering type alias " + alias + " for " + value + ". Cause: " + e, e);
+ }
+ }
+```
+
+所有别名均注册到名为 `typeAliases` 的容器中。`TypeAliasRegistry` 的无参构造方法默认为一些常用类型注册了别名,如 `Integer`、`String`、`byte[]` 等。
+
+## 日志配置
+
+`MyBatis` 支持与多种日志工具集成,包括 `Slf4j`、`log4j`、`log4j2`、`commons-logging` 等。这些第三方工具类对应日志的实现各有不同,`MyBatis` 通过适配器模式抽象了这些第三方工具的集成过程,按照一定的优先级选择具体的日志工具,并将真正的日志实现委托给选择的日志工具。
+
+### 日志适配接口
+
+`Log` 接口是 `MyBatis` 的日志适配接口,支持 `trace`、`debug`、`warn`、`error` 四种级别。
+
+### 日志工厂
+
+`LogFactory` 负责对第三方日志工具进行适配,在类加载时会通过静态代码块按顺序选择合适的日志实现。
+
+```java
+ static {
+ // 按顺序加载日志实现,如果有某个第三方日志实现可以成功加载,则不继续加载其它实现
+ tryImplementation(LogFactory::useSlf4jLogging);
+ tryImplementation(LogFactory::useCommonsLogging);
+ tryImplementation(LogFactory::useLog4J2Logging);
+ tryImplementation(LogFactory::useLog4JLogging);
+ tryImplementation(LogFactory::useJdkLogging);
+ tryImplementation(LogFactory::useNoLogging);
+ }
+
+ /**
+ * 初始化 logConstructor
+ *
+ * @param runnable
+ */
+ private static void tryImplementation(Runnable runnable) {
+ if (logConstructor == null) {
+ try {
+ // 同步执行
+ runnable.run();
+ } catch (Throwable t) {
+ // ignore
+ }
+ }
+ }
+
+ /**
+ * 配置第三方日志实现适配器
+ *
+ * @param implClass
+ */
+ private static void setImplementation(Class implClass) {
+ try {
+ Constructor candidate = implClass.getConstructor(String.class);
+ Log log = candidate.newInstance(LogFactory.class.getName());
+ if (log.isDebugEnabled()) {
+ log.debug("Logging initialized using '" + implClass + "' adapter.");
+ }
+ logConstructor = candidate;
+ } catch (Throwable t) {
+ throw new LogException("Error setting Log implementation. Cause: " + t, t);
+ }
+ }
+```
+
+`tryImplementation` 按顺序加载第三方日志工具的适配实现,如 `Slf4j` 的适配器 `Slf4jImpl`:
+
+```java
+public Slf4jImpl(String clazz) {
+ Logger logger = LoggerFactory.getLogger(clazz);
+
+ if (logger instanceof LocationAwareLogger) {
+ try {
+ // check for slf4j >= 1.6 method signature
+ logger.getClass().getMethod("log", Marker.class, String.class, int.class, String.class, Object[].class, Throwable.class);
+ log = new Slf4jLocationAwareLoggerImpl((LocationAwareLogger) logger);
+ return;
+ } catch (SecurityException | NoSuchMethodException e) {
+ // fail-back to Slf4jLoggerImpl
+ }
+ }
+
+ // Logger is not LocationAwareLogger or slf4j version < 1.6
+ log = new Slf4jLoggerImpl(logger);
+}
+```
+
+如果 `Slf4jImpl` 能成功执行构造方法,则 `LogFactory` 的 `logConstructor` 被成功赋值,`MyBatis` 就找到了合适的日志实现,可以通过 `getLog` 方法获取 `Log` 对象。
+
+### JDBC 日志代理
+
+`org.apache.ibatis.logging.jdbc` 包提供了 `Connection`、`PrepareStatement`、`Statement`、`ResultSet` 类中的相关方法执行的日志记录代理。`BaseJdbcLogger` 在创建时整理了 `PreparedStatement` 执行的相关方法名,并提供容器保存列值:
+
+```java
+ /**
+ * PreparedStatement 接口中的 set* 方法名称集合
+ */
+ protected static final Set SET_METHODS;
+
+ /**
+ * PreparedStatement 接口中的 部分执行方法
+ */
+ protected static final Set EXECUTE_METHODS = new HashSet<>();
+
+ /**
+ * 列名-列值
+ */
+ private final Map columnMap = new HashMap<>();
+
+ /**
+ * 列名集合
+ */
+ private final List
](https://github.com/Tyson0314/java-books)
-## 秋招提前批信息汇总
-
-[秋招提前批及正式批信息汇总(含内推)](https://docs.qq.com/sheet/DYW9ObnpobXNRTXpq?tab=BB08J2)
-
## 面试手册电子版
本网站所有内容已经汇总成**PDF电子版**,**PDF电子版**在我的[**学习圈**](zsxq/introduce.md)可以获取~
diff --git a/docs/advance/distributed/2-distributed-lock.md b/docs/advance/distributed/2-distributed-lock.md
index a269865..1016022 100644
--- a/docs/advance/distributed/2-distributed-lock.md
+++ b/docs/advance/distributed/2-distributed-lock.md
@@ -181,6 +181,8 @@ public class RedisTest {
前面的方案是基于**Redis单机版**的分布式锁讨论,还不是很完美。因为Redis一般都是集群部署的。
+
+
如果线程一在`Redis`的`master`节点上拿到了锁,但是加锁的`key`还没同步到`slave`节点。恰好这时,`master`节点发生故障,一个`slave`节点就会升级为`master`节点。线程二就可以顺理成章获取同个`key`的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者antirez提出一种高级的分布式锁算法:**Redlock**。它的核心思想是这样的:
@@ -189,6 +191,8 @@ public class RedisTest {
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
+
+
RedLock的实现步骤:
1. 获取当前时间,以毫秒为单位。
@@ -204,6 +208,8 @@ RedLock的实现步骤:
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
+Redisson 实现了 redLock 版本的锁,有兴趣的小伙伴,可以去了解一下。
+
### 基于ZooKeeper的实现方式
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。基于ZooKeeper实现分布式锁的步骤如下:
diff --git a/docs/advance/distributed/4-micro-service.md b/docs/advance/distributed/4-micro-service.md
index 286e61b..aec218d 100644
--- a/docs/advance/distributed/4-micro-service.md
+++ b/docs/advance/distributed/4-micro-service.md
@@ -47,9 +47,15 @@ head:
## 分布式和微服务的区别
-从概念理解,分布式服务架构强调的是服务化以及服务的**分散化**,微服务则更强调服务的**专业化和精细分工**;
+微服务解决的是系统复杂度问题,一般来说是业务问题,即在一个系统中承担职责太多了,需要打散,便于理解和维护,进而提升系统的开发效率和运行效率,微服务一般来说是针对应用层面的。
-从实践的角度来看,**微服务架构通常是分布式服务架构**,反之则未必成立。
+分布式解决的是系统性能问题,即解决系统部署上单点的问题,尽量让组成系统的子系统分散在不同的机器上进而提高系统的吞吐能力。
+
+两者概念层面也是不一样的,微服务是设计层面的东西,一般考虑如何将系统从逻辑上进行拆分,也就是垂直拆分;
+
+而分布式是部署层面的东西,即强调物理层面的组成,即系统的各子系统部署在不同计算机上。
+
+微服务可以是分布式的,即可以将不同服务部署在不同计算机上,当然如果量小也可以部署在单机上。
一句话概括:分布式:分散部署;微服务:分散能力。
diff --git a/docs/advance/excellent-article/10-file-upload.md b/docs/advance/excellent-article/10-file-upload.md
index f483d02..0064765 100644
--- a/docs/advance/excellent-article/10-file-upload.md
+++ b/docs/advance/excellent-article/10-file-upload.md
@@ -345,9 +345,7 @@ public abstract class SliceUploadTemplate implements SliceUploadStrategy {
本示例代码在电脑配置为4核内存8G情况下,上传24G大小的文件,上传时间需要30多分钟,主要时间耗费在前端的**md5**值计算,后端写入的速度还是比较快。
-如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器,其介绍可以查看官网:
-
-> https://help.aliyun.com/product/31815.html
+如果项目组觉得自建文件服务器太花费时间,且项目的需求仅仅只是上传下载,那么推荐使用阿里的oss服务器。
阿里的oss它本质是一个对象存储服务器,而非文件服务器,因此如果有涉及到大量删除或者修改文件的需求,oss可能就不是一个好的选择。
diff --git a/docs/advance/excellent-article/29-idempotent-design.md b/docs/advance/excellent-article/29-idempotent-design.md
index 3ab7b34..6cf7d5b 100644
--- a/docs/advance/excellent-article/29-idempotent-design.md
+++ b/docs/advance/excellent-article/29-idempotent-design.md
@@ -12,6 +12,7 @@ head:
- name: description
content: 努力打造最优质的Java学习网站
---
+
## 接口的幂等性如何设计?
分布式系统中的某个接口,该如何保证幂等性?
diff --git a/docs/advance/excellent-article/30-yi-di-duo-huo.md b/docs/advance/excellent-article/30-yi-di-duo-huo.md
new file mode 100644
index 0000000..75657f1
--- /dev/null
+++ b/docs/advance/excellent-article/30-yi-di-duo-huo.md
@@ -0,0 +1,563 @@
+---
+sidebar: heading
+title: 异地多活
+category: 优质文章
+tag:
+ - 架构
+head:
+ - - meta
+ - name: keywords
+ content: 异地多活,同城灾备,同城双活,两地三中心,异地双活,异地多活
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+在软件开发领域,「异地多活」是分布式系统架构设计的一座高峰,很多人经常听过它,但很少人理解其中的原理。
+
+**异地多活到底是什么?为什么需要异地多活?它到底解决了什么问题?究竟是怎么解决的?**
+
+这些疑问,想必是每个程序看到异地多活这个名词时,都想要搞明白的问题。
+
+有幸,我曾经深度参与过一个中等互联网公司,建设异地多活系统的设计与实施过程。所以今天,我就来和你聊一聊异地多活背后的的实现原理。
+
+认真读完这篇文章,我相信你会对异地多活架构,有更加深刻的理解。
+
+**这篇文章干货很多,希望你可以耐心读完。**
+
+
+
+
+
+# 01 系统可用性
+
+要想理解异地多活,我们需要从架构设计的原则说起。
+
+现如今,我们开发一个软件系统,对其要求越来越高,如果你了解一些「架构设计」的要求,就知道一个好的软件架构应该遵循以下 3 个原则:
+
+1. 高性能
+2. 高可用
+3. 易扩展
+
+其中,高性能意味着系统拥有更大流量的处理能力,更低的响应延迟。例如 1 秒可处理 10W 并发请求,接口响应时间 5 ms 等等。
+
+易扩展表示系统在迭代新功能时,能以最小的代价去扩展,系统遇到流量压力时,可以在不改动代码的前提下,去扩容系统。
+
+而「高可用」这个概念,看起来很抽象,怎么理解它呢?通常用 2 个指标来衡量:
+
+- **平均故障间隔 MTBF**(Mean Time Between Failure):表示两次故障的间隔时间,也就是系统「正常运行」的平均时间,这个时间越长,说明系统稳定性越高
+- **故障恢复时间 MTTR**(Mean Time To Repair):表示系统发生故障后「恢复的时间」,这个值越小,故障对用户的影响越小
+
+可用性与这两者的关系:
+
+> 可用性(Availability)= MTBF / (MTBF + MTTR) * 100%
+
+这个公式得出的结果是一个「比例」,通常我们会用「N 个 9」来描述一个系统的可用性。
+
+
+
+从这张图你可以看到,要想达到 4 个 9 以上的可用性,平均每天故障时间必须控制在 10 秒以内。
+
+也就是说,只有故障的时间「越短」,整个系统的可用性才会越高,每提升 1 个 9,都会对系统提出更高的要求。
+
+我们都知道,系统发生故障其实是不可避免的,尤其是规模越大的系统,发生问题的概率也越大。这些故障一般体现在 3 个方面:
+
+1. **硬件故障**:CPU、内存、磁盘、网卡、交换机、路由器
+2. **软件问题**:代码 Bug、版本迭代
+3. **不可抗力**:地震、水灾、火灾、战争
+
+这些风险随时都有可能发生。所以,在面对故障时,我们的系统能否以「最快」的速度恢复,就成为了可用性的关键。
+
+可如何做到快速恢复呢?
+
+这篇文章要讲的「异地多活」架构,就是为了解决这个问题,而提出的高效解决方案。
+
+下面,我会从一个最简单的系统出发,带你一步步演化出一个支持「异地多活」的系统架构。
+
+在这个过程中,你会看到一个系统会遇到哪些可用性问题,以及为什么架构要这样演进,从而理解异地多活架构的意义。
+
+# 02 单机架构
+
+我们从最简单的开始讲起。
+
+假设你的业务处于起步阶段,体量非常小,那你的架构是这样的:
+
+
+
+这个架构模型非常简单,客户端请求进来,业务应用读写数据库,返回结果,非常好理解。
+
+但需要注意的是,这里的数据库是「单机」部署的,所以它有一个致命的缺点:一旦遭遇意外,例如磁盘损坏、操作系统异常、误删数据,那这意味着所有数据就全部「丢失」了,这个损失是巨大的。
+
+如何避免这个问题呢?我们很容易想到一个方案:**备份**。
+
+
+
+你可以对数据做备份,把数据库文件「定期」cp 到另一台机器上,这样,即使原机器丢失数据,你依旧可以通过备份把数据「恢复」回来,以此保证数据安全。
+
+这个方案实施起来虽然比较简单,但存在 2 个问题:
+
+1. **恢复需要时间**:业务需先停机,再恢复数据,停机时间取决于恢复的速度,恢复期间服务「不可用」
+2. **数据不完整**:因为是定期备份,数据肯定不是「最新」的,数据完整程度取决于备份的周期
+
+很明显,你的数据库越大,意味故障恢复时间越久。那按照前面我们提到的「高可用」标准,这个方案可能连 1 个 9 都达不到,远远无法满足我们对可用性的要求。
+
+那有什么更好的方案,既可以快速恢复业务?还能尽可能保证数据完整性呢?
+
+这时你可以采用这个方案:**主从副本**。
+
+# 03 主从副本
+
+你可以在另一台机器上,再部署一个数据库实例,让这个新实例成为原实例的「副本」,让两者保持「实时同步」,就像这样:
+
+
+
+我们一般把原实例叫作主库(master),新实例叫作从库(slave)。这个方案的优点在于:
+
+- **数据完整性高**:主从副本实时同步,数据「差异」很小
+- **抗故障能力提升**:主库有任何异常,从库可随时「切换」为主库,继续提供服务
+- **读性能提升**:业务应用可直接读从库,分担主库「压力」读压力
+
+这个方案不错,不仅大大提高了数据库的可用性,还提升了系统的读性能。
+
+同样的思路,你的「业务应用」也可以在其它机器部署一份,避免单点。因为业务应用通常是「无状态」的(不像数据库那样存储数据),所以直接部署即可,非常简单。
+
+
+
+因为业务应用部署了多个,所以你现在还需要部署一个「接入层」,来做请求的「负载均衡」(一般会使用 nginx 或 LVS),这样当一台机器宕机后,另一台机器也可以「接管」所有流量,持续提供服务。
+
+
+
+从这个方案你可以看出,提升可用性的关键思路就是:**冗余**。
+
+没错,担心一个实例故障,那就部署多个实例,担心一个机器宕机,那就部署多台机器。
+
+到这里,你的架构基本已演变成主流方案了,之后开发新的业务应用,都可以按照这种模式去部署。
+
+
+
+但这种方案还有什么风险吗?
+
+# 04 风险不可控
+
+现在让我们把视角下放,把焦点放到具体的「部署细节」上来。
+
+按照前面的分析,为了避免单点故障,你的应用虽然部署了多台机器,但这些机器的分布情况,我们并没有去深究。
+
+而一个机房有很多服务器,这些服务器通常会分布在一个个「机柜」上,如果你使用的这些机器,刚好在一个机柜,还是存在风险。
+
+如果恰好连接这个机柜的交换机 / 路由器发生故障,那么你的应用依旧有「不可用」的风险。
+
+> 虽然交换机 / 路由器也做了路线冗余,但不能保证一定不出问题。
+
+部署在一个机柜有风险,那把这些机器打散,分散到不同机柜上,是不是就没问题了?
+
+这样确实会大大降低出问题的概率。但我们依旧不能掉以轻心,因为无论怎么分散,它们总归还是在一个相同的环境下:**机房**。
+
+那继续追问,机房会不会发生故障呢?
+
+一般来讲,建设一个机房的要求其实是很高的,地理位置、温湿度控制、备用电源等等,机房厂商会在各方面做好防护。但即使这样,我们每隔一段时间还会看到这样的新闻:
+
+- 2015 年 5 月 27 日,杭州市某地光纤被挖断,近 3 亿用户长达 5 小时无法访问支付宝
+- 2021 年 7 月 13 日,B 站部分服务器机房发生故障,造成整站持续 3 个小时无法访问
+- 2021 年 10 月 9 日,富途证券服务器机房发生电力闪断故障,造成用户 2 个小时无法登陆、交易
+- …
+
+可见,即使机房级别的防护已经做得足够好,但只要有「概率」出问题,那现实情况就有可能发生。虽然概率很小,但一旦真的发生,影响之大可见一斑。
+
+看到这里你可能会想,机房出现问题的概率也太小了吧,工作了这么多年,也没让我碰上一次,有必要考虑得这么复杂吗?
+
+但你有没有思考这样一个问题:**不同体量的系统,它们各自关注的重点是什么?**
+
+体量很小的系统,它会重点关注「用户」规模、增长,这个阶段获取用户是一切。等用户体量上来了,这个阶段会重点关注「性能」,优化接口响应时间、页面打开速度等等,这个阶段更多是关注用户体验。
+
+等体量再大到一定规模后你会发现,「可用性」就变得尤为重要。像微信、支付宝这种全民级的应用,如果机房发生一次故障,那整个影响范围可以说是非常巨大的。
+
+所以,再小概率的风险,我们在提高系统可用性时,也不能忽视。
+
+分析了风险,再说回我们的架构。那到底该怎么应对机房级别的故障呢?
+
+没错,还是**冗余**。
+
+# 05 同城灾备
+
+想要抵御「机房」级别的风险,那应对方案就不能局限在一个机房内了。
+
+现在,你需要做机房级别的冗余方案,也就是说,你需要再搭建一个机房,来部署你的服务。
+
+简单起见,你可以在「同一个城市」再搭建一个机房,原机房我们叫作 A 机房,新机房叫 B 机房,这两个机房的网络用一条「专线」连通。
+
+
+
+有了新机房,怎么把它用起来呢?这里还是要优先考虑「数据」风险。
+
+为了避免 A 机房故障导致数据丢失,所以我们需要把数据在 B 机房也存一份。最简单的方案还是和前面提到的一样:**备份**。
+
+A 机房的数据,定时在 B 机房做备份(拷贝数据文件),这样即使整个 A 机房遭到严重的损坏,B 机房的数据不会丢,通过备份可以把数据「恢复」回来,重启服务。
+
+
+
+这种方案,我们称之为「**冷备**」。为什么叫冷备呢?因为 B 机房只做备份,不提供实时服务,它是冷的,只会在 A 机房故障时才会启用。
+
+但备份的问题依旧和之前描述的一样:数据不完整、恢复数据期间业务不可用,整个系统的可用性还是无法得到保证。
+
+所以,我们还是需要用「主从副本」的方式,在 B 机房部署 A 机房的数据副本,架构就变成了这样:
+
+
+
+这样,就算整个 A 机房挂掉,我们在 B 机房也有比较「完整」的数据。
+
+数据是保住了,但这时你需要考虑另外一个问题:**如果 A 机房真挂掉了,要想保证服务不中断,你还需要在 B 机房「紧急」做这些事情**:
+
+1. B 机房所有从库提升为主库
+2. 在 B 机房部署应用,启动服务
+3. 部署接入层,配置转发规则
+4. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+看到了么?A 机房故障后,B 机房需要做这么多工作,你的业务才能完全「恢复」过来。
+
+你看,整个过程需要人为介入,且需花费大量时间来操作,恢复之前整个服务还是不可用的,这个方案还是不太爽,如果能做到故障后立即「切换」,那就好了。
+
+因此,要想缩短业务恢复的时间,你必须把这些工作在 B 机房「提前」做好,也就是说,你需要在 B 机房提前部署好接入层、业务应用,等待随时切换。架构就变成了这样:
+
+
+
+这样的话,A 机房整个挂掉,我们只需要做 2 件事即可:
+
+1. B 机房所有从库提升为主库
+2. DNS 指向 B 机房接入层,接入流量,业务恢复
+
+这样一来,恢复速度快了很多。
+
+到这里你会发现,B 机房从最开始的「空空如也」,演变到现在,几乎是「镜像」了一份 A 机房的所有东西,从最上层的接入层,到中间的业务应用,到最下层的存储。两个机房唯一的区别是,**A 机房的存储都是主库,而 B 机房都是从库**。
+
+这种方案,我们把它叫做「**热备**」。
+
+热的意思是指,B 机房处于「待命」状态,A 故障后 B 可以随时「接管」流量,继续提供服务。热备相比于冷备最大的优点是:**随时可切换**。
+
+无论是冷备还是热备,因为它们都处于「备用」状态,所以我们把这两个方案统称为:**同城灾备**。
+
+同城灾备的最大优势在于,我们再也不用担心「机房」级别的故障了,一个机房发生风险,我们只需把流量切换到另一个机房即可,可用性再次提高,是不是很爽?(后面还有更爽的)
+
+# 06 同城双活
+
+我们继续来看这个架构。
+
+虽然我们有了应对机房故障的解决方案,但这里有个问题是我们不能忽视的:**A 机房挂掉,全部流量切到 B 机房,B 机房能否真的如我们所愿,正常提供服务?**
+
+这是个值得思考的问题。
+
+这就好比有两支军队 A 和 B,A 军队历经沙场,作战经验丰富,而 B 军队只是后备军,除了有军人的基本素养之外,并没有实战经验,战斗经验基本为 0。
+
+如果 A 军队丧失战斗能力,需要 B 军队立即顶上时,作为指挥官的你,肯定也会担心 B 军队能否真的担此重任吧?
+
+我们的架构也是如此,此时的 B 机房虽然是随时「待命」状态,但 A 机房真的发生故障,我们要把全部流量切到 B 机房,其实是不敢百分百保证它可以「如期」工作的。
+
+你想,我们在一个机房内部署服务,还总是发生各种各样的问题,例如:发布应用的版本不一致、系统资源不足、操作系统参数不一样等等。现在多部署一个机房,这些问题只会增多,不会减少。
+
+另外,从「成本」的角度来看,我们新部署一个机房,需要购买服务器、内存、硬盘、带宽资源,花费成本也是非常高昂的,只让它当一个后备军,未免也太「大材小用」了!
+
+因此,我们需要让 B 机房也接入流量,实时提供服务,这样做的好处,**一是可以实时训练这支后备军,让它达到与 A 机房相同的作战水平,随时可切换,二是 B 机房接入流量后,可以分担 A 机房的流量压力**。这才是把 B 机房资源优势,发挥最大化的最好方案!
+
+那怎么让 B 机房也接入流量呢?很简单,就是把 B 机房的接入层 IP 地址,加入到 DNS 中,这样,B 机房从上层就可以有流量进来了。
+
+
+
+但这里有一个问题:别忘了,B 机房的存储,现在可都是 A 机房的「从库」,从库默认可都是「不可写」的,B 机房的写请求打到本机房存储上,肯定会报错,这还是不符合我们预期。怎么办?
+
+这时,你就需要在「业务应用」层做改造了。
+
+你的业务应用在操作数据库时,需要区分「读写分离」(一般用中间件实现),即两个机房的「读」流量,可以读任意机房的存储,但「写」流量,只允许写 A 机房,因为主库在 A 机房。
+
+
+
+这会涉及到你用的所有存储,例如项目中用到了 MySQL、Redis、MongoDB 等等,操作这些数据库,都需要区分读写请求,所以这块需要一定的业务「改造」成本。
+
+因为 A 机房的存储都是主库,所以我们把 A 机房叫做「主机房」,B 机房叫「从机房」。
+
+两个机房部署在「同城」,物理距离比较近,而且两个机房用「专线」网络连接,虽然跨机房访问的延迟,比单个机房内要大一些,但整体的延迟还是可以接受的。
+
+业务改造完成后,B 机房可以慢慢接入流量,从 10%、30%、50% 逐渐覆盖到 100%,你可以持续观察 B 机房的业务是否存在问题,有问题及时修复,逐渐让 B 机房的工作能力,达到和 A 机房相同水平。
+
+现在,因为 B 机房实时接入了流量,此时如果 A 机房挂了,那我们就可以「大胆」地把 A 的流量,全部切换到 B 机房,完成快速切换!
+
+到这里你可以看到,我们部署的 B 机房,在物理上虽然与 A 有一定距离,但整个系统从「逻辑」上来看,我们是把这两个机房看做一个「整体」来规划的,也就是说,相当于把 2 个机房当作 1 个机房来用。
+
+这种架构方案,比前面的同城灾备更「进了一步」,B 机房实时接入了流量,还能应对随时的故障切换,这种方案我们把它叫做「**同城双活**」。
+
+因为两个机房都能处理业务请求,这对我们系统的内部维护、改造、升级提供了更多的可实施空间(流量随时切换),现在,整个系统的弹性也变大了,是不是更爽了?
+
+那这种架构有什么问题呢?
+
+# 07 两地三中心
+
+还是回到风险上来说。
+
+虽然我们把 2 个机房当做一个整体来规划,但这 2 个机房在物理层面上,还是处于「一个城市」内,如果是整个城市发生自然灾害,例如地震、水灾(河南水灾刚过去不久),那 2 个机房依旧存在「全局覆没」的风险。
+
+真是防不胜防啊?怎么办?没办法,继续冗余。
+
+但这次冗余机房,就不能部署在同一个城市了,你需要把它放到距离更远的地方,部署在「异地」。
+
+> 通常建议两个机房的距离要在 1000 公里以上,这样才能应对城市级别的灾难。
+
+假设之前的 A、B 机房在北京,那这次新部署的 C 机房可以放在上海。
+
+按照前面的思路,把 C 机房用起来,最简单粗暴的方案还就是做「冷备」,即定时把 A、B 机房的数据,在 C 机房做备份,防止数据丢失。
+
+
+
+这种方案,就是我们经常听到的「**两地三中心**」。
+
+**两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市,并且同时提供服务,第 3 个机房部署在异地,只做数据灾备。**
+
+这种架构方案,通常用在银行、金融、政企相关的项目中。它的问题还是前面所说的,启用灾备机房需要时间,而且启用后的服务,不确定能否如期工作。
+
+所以,要想真正的抵御城市级别的故障,越来越多的互联网公司,开始实施「**异地双活**」。
+
+# 08 伪异地双活
+
+这里,我们还是分析 2 个机房的架构情况。我们不再把 A、B 机房部署在同一个城市,而是分开部署,例如 A 机房放在北京,B 机房放在上海。
+
+前面我们讲了同城双活,那异地双活是不是直接「照搬」同城双活的模式去部署就可以了呢?
+
+事情没你想的那么简单。
+
+如果还是按照同城双活的架构来部署,那异地双活的架构就是这样的:
+
+
+
+注意看,两个机房的网络是通过「跨城专线」连通的。
+
+此时两个机房都接入流量,那上海机房的请求,可能要去读写北京机房的存储,这里存在一个很大的问题:**网络延迟**。
+
+因为两个机房距离较远,受到物理距离的限制,现在,两地之间的网络延迟就变成了「**不可忽视**」的因素了。
+
+北京到上海的距离大约 1300 公里,即使架设一条高速的「网络专线」,光纤以光速传输,一个来回也需要近 10ms 的延迟。
+
+况且,网络线路之间还会经历各种路由器、交换机等网络设备,实际延迟可能会达到 30ms ~ 100ms,如果网络发生抖动,延迟甚至会达到 1 秒。
+
+> 不止是延迟,远距离的网络专线质量,是远远达不到机房内网络质量的,专线网络经常会发生延迟、丢包、甚至中断的情况。总之,不能过度信任和依赖「跨城专线」。
+
+你可能会问,这点延迟对业务影响很大吗?影响非常大!
+
+试想,一个客户端请求打到上海机房,上海机房要去读写北京机房的存储,一次跨机房访问延迟就达到了 30ms,这大致是机房内网网络(0.5 ms)访问速度的 60 倍(30ms / 0.5ms),一次请求慢 60 倍,来回往返就要慢 100 倍以上。
+
+而我们在 App 打开一个页面,可能会访问后端几十个 API,每次都跨机房访问,整个页面的响应延迟有可能就达到了**秒级**,这个性能简直惨不忍睹,难以接受。
+
+看到了么,虽然我们只是简单的把机房部署在了「异地」,但「同城双活」的架构模型,在这里就不适用了,还是按照这种方式部署,这是「伪异地双活」!
+
+那如何做到真正的异地双活呢?
+
+# 09 真正的异地双活
+
+既然「跨机房」调用延迟是不容忽视的因素,那我们只能尽量避免跨机房「调用」,规避这个延迟问题。
+
+也就是说,上海机房的应用,不能再「跨机房」去读写北京机房的存储,只允许读写上海本地的存储,实现「就近访问」,这样才能避免延迟问题。
+
+还是之前提到的问题:上海机房存储都是从库,不允许写入啊,除非我们只允许上海机房接入「读流量」,不接收「写流量」,否则无法满足不再跨机房的要求。
+
+很显然,只让上海机房接收读流量的方案不现实,因为很少有项目是只有读流量,没有写流量的。所以这种方案还是不行,这怎么办?
+
+此时,你就必须在「**存储层**」做改造了。
+
+要想上海机房读写本机房的存储,那上海机房的存储不能再是北京机房的从库,而是也要变为「主库」。
+
+你没看错,两个机房的存储必须都是「**主库**」,而且两个机房的数据还要「**互相同步**」数据,即客户端无论写哪一个机房,都能把这条数据同步到另一个机房。
+
+因为只有两个机房都拥有「全量数据」,才能支持任意切换机房,持续提供服务。
+
+怎么实现这种「双主」架构呢?它们之间如何互相同步数据?
+
+如果你对 MySQL 有所了解,MySQL 本身就提供了双主架构,它支持双向复制数据,但平时用的并不多。而且 Redis、MongoDB 等数据库并没有提供这个功能,所以,你必须开发对应的「数据同步中间件」来实现双向同步的功能。
+
+此外,除了数据库这种有状态的软件之外,你的项目通常还会使用到消息队列,例如 RabbitMQ、Kafka,这些也是有状态的服务,所以它们也需要开发双向同步的中间件,支持任意机房写入数据,同步至另一个机房。
+
+看到了么,这一下子复杂度就上来了,单单针对每个数据库、队列开发同步中间件,就需要投入很大精力了。
+
+> 业界也开源出了很多数据同步中间件,例如阿里的 Canal、RedisShake、MongoShake,可分别在两个机房同步 MySQL、Redis、MongoDB 数据。
+>
+> 很多有能力的公司,也会采用自研同步中间件的方式来做,例如饿了么、携程、美团都开发了自己的同步中间件。
+>
+> 我也有幸参与设计开发了 MySQL、Redis/Codis、MongoDB 的同步中间件,有时间写一篇文章详细聊聊实现细节,欢迎持续关注。:)
+
+现在,整个架构就变成了这样:
+
+
+
+注意看,两个机房的存储层都互相同步数据的。有了数据同步中间件,就可以达到这样的效果:
+
+- 北京机房写入 X = 1
+- 上海机房写入 Y = 2
+- 数据通过中间件双向同步
+- 北京、上海机房都有 X = 1、Y = 2 的数据
+
+这里我们用中间件双向同步数据,就不用再担心专线问题,专线出问题,我们的中间件可以自动重试,直到成功,达到数据最终一致。
+
+但这里还会遇到一个问题,两个机房都可以写,操作的不是同一条数据那还好,如果修改的是同一条的数据,发生冲突怎么办?
+
+- 用户短时间内发了 2 个修改请求,都是修改同一条数据
+- 一个请求落在北京机房,修改 X = 1(还未同步到上海机房)
+- 另一个请求落在上海机房,修改 X = 2(还未同步到北京机房)
+- 两个机房以哪个为准?
+
+也就是说,在很短的时间内,同一个用户修改同一条数据,两个机房无法确认谁先谁后,数据发生「冲突」。
+
+这是一个很严重的问题,系统发生故障并不可怕,可怕的是数据发生「错误」,因为修正数据的成本太高了。我们一定要避免这种情况的发生。解决这个问题,有 2 个方案。
+
+**第一个方案**,数据同步中间件要有自动「合并」数据、解决「冲突」的能力。
+
+这个方案实现起来比较复杂,要想合并数据,就必须要区分出「先后」顺序。我们很容易想到的方案,就是以「时间」为标尺,以「后到达」的请求为准。
+
+但这种方案需要两个机房的「时钟」严格保持一致才行,否则很容易出现问题。例如:
+
+- 第 1 个请求落到北京机房,北京机房时钟是 10:01,修改 X = 1
+- 第 2 个请求落到上海机房,上海机房时钟是 10:00,修改 X = 2
+
+因为北京机房的时间「更晚」,那最终结果就会是 X = 1。但这里其实应该以第 2 个请求为准,X = 2 才对。
+
+可见,完全「依赖」时钟的冲突解决方案,不太严谨。
+
+所以,通常会采用第二种方案,从「源头」就避免数据冲突的发生。
+
+# 10 如何实施异地双活
+
+既然自动合并数据的方案实现成本高,那我们就要想,能否从源头就「避免」数据冲突呢?
+
+这个思路非常棒!
+
+从源头避免数据冲突的思路是:**在最上层接入流量时,就不要让冲突的情况发生**。
+
+具体来讲就是,要在最上层就把用户「区分」开,部分用户请求固定打到北京机房,其它用户请求固定打到上海 机房,进入某个机房的用户请求,之后的所有业务操作,都在这一个机房内完成,从根源上避免「跨机房」。
+
+所以这时,你需要在接入层之上,再部署一个「路由层」(通常部署在云服务器上),自己可以配置路由规则,把用户「分流」到不同的机房内。
+
+
+
+但这个路由规则,具体怎么定呢?有很多种实现方式,最常见的我总结了 3 类:
+
+1. 按业务类型分片
+2. 直接哈希分片
+3. 按地理位置分片
+
+**1、按业务类型分片**
+
+这种方案是指,按应用的「业务类型」来划分。
+
+举例:假设我们一共有 4 个应用,北京和上海机房都部署这些应用。但应用 1、2 只在北京机房接入流量,在上海机房只是热备。应用 3、4 只在上海机房接入流量,在北京机房是热备。
+
+这样一来,应用 1、2 的所有业务请求,只读写北京机房存储,应用 3、4 的所有请求,只会读写上海机房存储。
+
+
+
+这样按业务类型分片,也可以避免同一个用户修改同一条数据。
+
+> 这里按业务类型在不同机房接入流量,还需要考虑多个应用之间的依赖关系,要尽可能的把完成「相关」业务的应用部署在同一个机房,避免跨机房调用。
+>
+> 例如,订单、支付服务有依赖关系,会产生互相调用,那这 2 个服务在 A 机房接入流量。社区、发帖服务有依赖关系,那这 2 个服务在 B 机房接入流量。
+
+**2、直接哈希分片**
+
+这种方案就是,最上层的路由层,会根据用户 ID 计算「哈希」取模,然后从路由表中找到对应的机房,之后把请求转发到指定机房内。
+
+举例:一共 200 个用户,根据用户 ID 计算哈希值,然后根据路由规则,把用户 1 - 100 路由到北京机房,101 - 200 用户路由到上海机房,这样,就避免了同一个用户修改同一条数据的情况发生。
+
+
+
+**3、按地理位置分片**
+
+这种方案,非常适合与地理位置密切相关的业务,例如打车、外卖服务就非常适合这种方案。
+
+拿外卖服务举例,你要点外卖肯定是「就近」点餐,整个业务范围相关的有商家、用户、骑手,它们都是在相同的地理位置内的。
+
+针对这种特征,就可以在最上层,按用户的「地理位置」来做分片,分散到不同的机房。
+
+举例:北京、河北地区的用户点餐,请求只会打到北京机房,而上海、浙江地区的用户,请求则只会打到上海机房。这样的分片规则,也能避免数据冲突。
+
+
+
+> 提醒:这 3 种常见的分片规则,第一次看不太好理解,建议配合图多理解几遍。搞懂这 3 个分片规则,你才能真正明白怎么做异地多活。
+
+总之,分片的核心思路在于,**让同一个用户的相关请求,只在一个机房内完成所有业务「闭环」,不再出现「跨机房」访问**。
+
+阿里在实施这种方案时,给它起了个名字,叫做「**单元化**」。
+
+> 当然,最上层的路由层把用户分片后,理论来说同一个用户只会落在同一个机房内,但不排除程序 Bug 导致用户会在两个机房「漂移」。
+>
+> 安全起见,每个机房在写存储时,还需要有一套机制,能够检测「数据归属」,应用层操作存储时,需要通过中间件来做「兜底」,避免不该写本机房的情况发生。(篇幅限制,这里不展开讲,理解思路即可)
+
+现在,两个机房就可以都接收「读写」流量(做好分片的请求),底层存储保持「双向」同步,两个机房都拥有全量数据,当任意机房故障时,另一个机房就可以「接管」全部流量,实现快速切换,简直不要太爽。
+
+不仅如此,因为机房部署在异地,我们还可以更细化地「优化」路由规则,让用户访问就近的机房,这样整个系统的性能也会大大提升。
+
+> 这里还有一种情况,是无法做数据分片的:**全局数据**。例如系统配置、商品库存这类需要强一致的数据,这类服务依旧只能采用写主机房,读从机房的方案,不做双活。
+>
+> 双活的重点,是要优先保证「核心」业务先实现双活,并不是「全部」业务实现双活。
+
+至此,我们才算实现了真正的「**异地双活**」!
+
+> 到这里你可以看出,完成这样一套架构,需要投入的成本是巨大的。
+>
+> 路由规则、路由转发、数据同步中间件、数据校验兜底策略,不仅需要开发强大的中间件,同时还要业务配合改造(业务边界划分、依赖拆分)等一些列工作,没有足够的人力物力,这套架构很难实施。
+
+# 11 异地多活
+
+理解了异地双活,那「异地多活」顾名思义,就是在异地双活的基础上,部署多个机房即可。架构变成了这样:
+
+
+
+这些服务按照「单元化」的部署方式,可以让每个机房部署在任意地区,随时扩展新机房,你只需要在最上层定义好分片规则就好了。
+
+但这里还有一个小问题,随着扩展的机房越来越多,当一个机房写入数据后,需要同步的机房也越来越多,这个实现复杂度会比较高。
+
+所以业界又把这一架构又做了进一步优化,把「网状」架构升级为「星状」:
+
+
+
+这种方案必须设立一个「中心机房」,任意机房写入数据后,都只同步到中心机房,再由中心机房同步至其它机房。
+
+这样做的好处是,一个机房写入数据,只需要同步数据到中心机房即可,不需要再关心一共部署了多少个机房,实现复杂度大大「简化」。
+
+但与此同时,这个中心机房的「稳定性」要求会比较高。不过也还好,即使中心机房发生故障,我们也可以把任意一个机房,提升为中心机房,继续按照之前的架构提供服务。
+
+至此,我们的系统彻底实现了「**异地多活**」!
+
+多活的优势在于,**可以任意扩展机房「就近」部署。任意机房发生故障,可以完成快速「切换」**,大大提高了系统的可用性。
+
+同时,我们也再也不用担心系统规模的增长,因为这套架构具有极强的「**扩展能力**」。
+
+怎么样?我们从一个最简单的应用,一路优化下来,到最终的架构方案,有没有帮你彻底理解异地多活呢?
+
+# 总结
+
+好了,总结一下这篇文章的重点。
+
+1、一个好的软件架构,应该遵循高性能、高可用、易扩展 3 大原则,其中「高可用」在系统规模变得越来越大时,变得尤为重要
+
+2、系统发生故障并不可怕,能以「最快」的速度恢复,才是高可用追求的目标,异地多活是实现高可用的有效手段
+
+3、提升高可用的核心是「冗余」,备份、主从副本、同城灾备、同城双活、两地三中心、异地双活,异地多活都是在做冗余
+
+4、同城灾备分为「冷备」和「热备」,冷备只备份数据,不提供服务,热备实时同步数据,并做好随时切换的准备
+
+5、同城双活比灾备的优势在于,两个机房都可以接入「读写」流量,提高可用性的同时,还提升了系统性能。虽然物理上是两个机房,但「逻辑」上还是当做一个机房来用
+
+6、两地三中心是在同城双活的基础上,额外部署一个异地机房做「灾备」,用来抵御「城市」级别的灾害,但启用灾备机房需要时间
+
+7、异地双活才是抵御「城市」级别灾害的更好方案,两个机房同时提供服务,故障随时可切换,可用性高。但实现也最复杂,理解了异地双活,才能彻底理解异地多活
+
+8、异地多活是在异地双活的基础上,任意扩展多个机房,不仅又提高了可用性,还能应对更大规模的流量的压力,扩展性最强,是实现高可用的最终方案
+
+# 后记
+
+这篇文章我从「宏观」层面,向你介绍了异地多活架构的「核心」思路,整篇文章的信息量还是很大的,如果不太好理解,我建议你多读几遍。
+
+因为篇幅限制,很多细节我并没有展开来讲。这篇文章更像是讲异地多活的架构之「道」,而真正实施的「术」,要考虑的点其实也非常繁多,因为它需要开发强大的「基础设施」才可以完成实施。
+
+不仅如此,要想真正实现异地多活,还需要遵循一些原则,例如业务梳理、业务分级、数据分类、数据最终一致性保障、机房切换一致性保障、异常处理等等。同时,相关的运维设施、监控体系也要能跟得上才行。
+
+宏观上需要考虑业务(微服务部署、依赖、拆分、SDK、Web 框架)、基础设施(服务发现、流量调度、持续集成、同步中间件、自研存储),微观上要开发各种中间件,还要关注中间件的高性能、高可用、容错能力,其复杂度之高,只有亲身参与过之后才知道。
+
+我曾经有幸参与过,存储层同步中间件的设计与开发,实现过「跨机房」同步 MySQL、Redis、MongoDB 的中间件,踩过的坑也非常多。当然,这些中间件的设计思路也非常有意思,有时间单独分享一下这些中间件的设计思路。
+
+值得提醒你的是,只有真正理解了「异地双活」,才能彻底理解「异地多活」。在我看来,从同城双活演变为异地双活的过程,是最为复杂的,最核心的东西包括,**业务单元化划分、存储层数据双向同步、最上层的分片逻辑**,这些是实现异地多活的重中之重。
+
diff --git a/docs/advance/excellent-article/31-mysql-data-sync-es.md b/docs/advance/excellent-article/31-mysql-data-sync-es.md
new file mode 100644
index 0000000..8d43d94
--- /dev/null
+++ b/docs/advance/excellent-article/31-mysql-data-sync-es.md
@@ -0,0 +1,503 @@
+---
+sidebar: heading
+title: MySQL数据如何实时同步到ES
+category: 优质文章
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL,ES,elasticsearch,数据同步
+ - - meta
+ - name: description
+ content: 努力打造最优质的Java学习网站
+---
+
+
+## 前言
+
+我们一般会使用MySQL用来存储数据,用Es来做全文检索和特殊查询,那么如何将数据优雅的从MySQL同步到Es呢?我们一般有以下几种方式:
+
+1.**双写**。在代码中先向MySQL中写入数据,然后紧接着向Es中写入数据。这个方法的缺点是代码严重耦合,需要手动维护MySQL和Es数据关系,非常不便于维护。
+
+2.**发MQ,异步执行**。在执行完向Mysql中写入数据的逻辑后,发送MQ,告诉消费端这个数据需要写入Es,消费端收到消息后执行向Es写入数据的逻辑。这个方式的优点是Mysql和Es数据维护分离,开发Mysql和Es的人员只需要关心各自的业务。缺点是依然需要维护发送、接收MQ的逻辑,并且引入了MQ组件,增加了系统的复杂度。
+
+3.**使用Datax进行全量数据同步**。这个方式优点是可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。缺点是Datax是一种全量同步数据的方式,不使用实时同步。如果系统对数据时效性不强,可以考虑此方式。
+
+4.**使用Canal进行实时数据同步**。这个方式具有跟Datax一样的优点,可以完全不用写维护数据关系的代码,各自只需要关心自己的业务,对代码侵入性几乎为零。与Datax不同的是Canal是一种实时同步数据的方式,对数据时效性较强的系统,我们会采用Canal来进行实时数据同步。
+
+那么就让我们来看看Canal是如何使用的。
+
+## 官网
+
+https://github.com/alibaba/canal
+
+## 1.Canal简介
+
+
+
+**canal [kə'næl]** ,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
+
+早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
+
+基于日志增量订阅和消费的业务包括
+
+- 数据库镜像
+- 数据库实时备份
+- 索引构建和实时维护(拆分异构索引、倒排索引等)
+- 业务 cache 刷新
+- 带业务逻辑的增量数据处理
+
+当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
+
+### **MySQL主备复制原理**
+
+
+
+- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
+- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
+- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
+
+### **canal工作原理**
+
+- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
+- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
+- canal 解析 binary log 对象(原始为 byte 流)
+
+## 2.开启MySQL Binlog
+
+- 对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
+
+```ini
+[mysqld]
+log-bin=mysql-bin # 开启 binlog
+binlog-format=ROW # 选择 ROW 模式
+server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
+lua
+## 复制代码注意:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
+```
+
+- 授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
+
+```sql
+CREATE USER canal IDENTIFIED BY 'canal';
+GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
+-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
+FLUSH PRIVILEGES;
+```
+
+注意:Mysql版本为8.x时启动canal可能会出现“caching_sha2_password Auth failed”错误,这是因为8.x创建用户时默认的密码加密方式为**caching_sha2_password**,与canal的方式不一致,所以需要将canal用户的密码加密方式修改为**mysql_native_password**
+
+```sql
+ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY 'canal'; #更新一下用户密码
+FLUSH PRIVILEGES; #刷新权限
+```
+
+## 3.安装Canal
+
+### 3.1 下载Canal
+
+**点击下载地址,选择版本后点击canal.deployer文件下载**
+
+
+
+### 3.2 修改配置文件
+
+打开目录下conf/example/instance.properties文件,主要修改以下内容
+
+```ini
+## mysql serverId,不要和 mysql 的 server_id 重复
+canal.instance.mysql.slaveId = 10
+#position info,需要改成自己的数据库信息
+canal.instance.master.address = 127.0.0.1:3306
+#username/password,需要改成自己的数据库信息,与刚才添加的用户保持一致
+canal.instance.dbUsername = canal
+canal.instance.dbPassword = canal
+```
+
+### 3.3 启动和关闭
+
+```bash
+#进入文件目录下的bin文件夹
+#启动
+sh startup.sh
+#关闭
+sh stop.sh
+```
+
+## 4.Springboot集成Canal
+
+### 4.1 Canal数据结构
+
+
+
+### 4.2 引入依赖
+
+```xml
+
+
+ com.alibaba.otter
+ canal.client
+ 1.1.6
+
+
+
+
+
+ com.alibaba.otter
+ canal.protocol
+ 1.1.6
+
+
+
+
+ co.elastic.clients
+ elasticsearch-java
+ 8.4.3
+
+
+
+
+ jakarta.json
+ jakarta.json-api
+ 2.0.1
+
+```
+
+### 4.3 application.yaml
+
+```yaml
+custom:
+ elasticsearch:
+ host: localhost #主机
+ port: 9200 #端口
+ username: elastic #用户名
+ password: 3bf24a76 #密码
+```
+
+### 4.4 EsClient
+
+```java
+@Setter
+@ConfigurationProperties(prefix = "custom.elasticsearch")
+@Configuration
+public class EsClient {
+
+ /**
+ * 主机
+ */
+ private String host;
+
+ /**
+ * 端口
+ */
+ private Integer port;
+
+ /**
+ * 用户名
+ */
+ private String username;
+
+ /**
+ * 密码
+ */
+ private String password;
+
+
+ @Bean
+ public ElasticsearchClient elasticsearchClient() {
+ CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
+ credentialsProvider.setCredentials(
+ AuthScope.ANY, new UsernamePasswordCredentials(username, password));
+
+ // Create the low-level client
+ RestClient restClient = RestClient.builder(new HttpHost(host, port))
+ .setHttpClientConfigCallback(httpAsyncClientBuilder ->
+ httpAsyncClientBuilder.setDefaultCredentialsProvider(credentialsProvider))
+ .build();
+ // Create the transport with a Jackson mapper
+ RestClientTransport transport = new RestClientTransport(
+ restClient, new JacksonJsonpMapper());
+ // Create the transport with a Jackson mapper
+ return new ElasticsearchClient(transport);
+ }
+}
+```
+
+### 4.5 Music实体类
+
+```java
+@Data
+@Builder
+@NoArgsConstructor
+@AllArgsConstructor
+public class Music {
+
+ /**
+ * id
+ */
+ private String id;
+
+ /**
+ * 歌名
+ */
+ private String name;
+
+ /**
+ * 歌手名
+ */
+ private String singer;
+
+ /**
+ * 封面图地址
+ */
+ private String imageUrl;
+
+ /**
+ * 歌曲地址
+ */
+ private String musicUrl;
+
+ /**
+ * 歌词地址
+ */
+ private String lrcUrl;
+
+ /**
+ * 歌曲类型id
+ */
+ private String typeId;
+
+ /**
+ * 是否被逻辑删除,1 是,0 否
+ */
+ private Integer isDeleted;
+
+ /**
+ * 创建时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date createTime;
+
+ /**
+ * 更新时间
+ */
+ @JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+8")
+ private Date updateTime;
+
+}
+```
+
+### 4.6 CanalClient
+
+```java
+@Slf4j
+@Component
+public class CanalClient {
+
+ @Resource
+ private ElasticsearchClient client;
+
+
+ /**
+ * 实时数据同步程序
+ *
+ * @throws InterruptedException
+ * @throws InvalidProtocolBufferException
+ */
+ public void run() throws InterruptedException, IOException {
+ CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(
+ "localhost", 11111), "example", "", "");
+
+ while (true) {
+ //连接
+ connector.connect();
+ //订阅数据库
+ connector.subscribe("cloudmusic_music.music");
+ //获取数据
+ Message message = connector.get(100);
+
+ List entryList = message.getEntries();
+ if (CollectionUtils.isEmpty(entryList)) {
+ //没有数据,休息一会
+ TimeUnit.SECONDS.sleep(2);
+ } else {
+ for (CanalEntry.Entry entry : entryList) {
+ //获取类型
+ CanalEntry.EntryType entryType = entry.getEntryType();
+
+ //判断类型是否为ROWDATA
+ if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
+ //获取序列化后的数据
+ ByteString storeValue = entry.getStoreValue();
+ //反序列化数据
+ CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
+ //获取当前事件操作类型
+ CanalEntry.EventType eventType = rowChange.getEventType();
+ //获取数据集
+ List rowDataList = rowChange.getRowDatasList();
+
+ if (eventType == CanalEntry.EventType.INSERT) {
+ log.info("------新增操作------");
+
+ List musicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ musicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量新增文档
+ index(musicList);
+ //打印新增集合
+ log.info(Arrays.toString(musicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.UPDATE) {
+ log.info("------更新操作------");
+
+ List beforeMusicList = new ArrayList<>();
+ List afterMusicList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ //更新前
+ beforeMusicList.add(createMusic(rowData.getBeforeColumnsList()));
+ //更新后
+ afterMusicList.add(createMusic(rowData.getAfterColumnsList()));
+ }
+ //es批量更新文档
+ index(afterMusicList);
+ //打印更新前集合
+ log.info("更新前:{}", Arrays.toString(beforeMusicList.toArray()));
+ //打印更新后集合
+ log.info("更新后:{}", Arrays.toString(afterMusicList.toArray()));
+ } else if (eventType == CanalEntry.EventType.DELETE) {
+ //删除操作
+ log.info("------删除操作------");
+
+ List idList = new ArrayList<>();
+ for (CanalEntry.RowData rowData : rowDataList) {
+ for (CanalEntry.Column column : rowData.getBeforeColumnsList()) {
+ if("id".equals(column.getName())) {
+ idList.add(column.getValue());
+ break;
+ }
+ }
+ }
+ //es批量删除文档
+ delete(idList);
+ //打印删除id集合
+ log.info(Arrays.toString(idList.toArray()));
+ }
+ }
+ }
+ }
+ }
+ }
+
+ /**
+ * 根据canal获取的数据创建Music对象
+ *
+ * @param columnList
+ * @return
+ */
+ private Music createMusic(List columnList) {
+ Music music = new Music();
+ DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
+
+ for (CanalEntry.Column column : columnList) {
+ switch (column.getName()) {
+ case "id" -> music.setId(column.getValue());
+ case "name" -> music.setName(column.getValue());
+ case "singer" -> music.setSinger(column.getValue());
+ case "image_url" -> music.setImageUrl(column.getValue());
+ case "music_url" -> music.setMusicUrl(column.getValue());
+ case "lrc_url" -> music.setLrcUrl(column.getValue());
+ case "type_id" -> music.setTypeId(column.getValue());
+ case "is_deleted" -> music.setIsDeleted(Integer.valueOf(column.getValue()));
+ case "create_time" ->
+ music.setCreateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ case "update_time" ->
+ music.setUpdateTime(Date.from(LocalDateTime.parse(column.getValue(), formatter).atZone(ZoneId.systemDefault()).toInstant()));
+ default -> {
+ }
+ }
+ }
+
+ return music;
+ }
+
+ /**
+ * es批量新增、更新文档(不存在:新增, 存在:更新)
+ *
+ * @param musicList 音乐集合
+ * @throws IOException
+ */
+ private void index(List musicList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ musicList.forEach(music -> br
+ .operations(op -> op
+ .index(idx -> idx
+ .index("music")
+ .id(music.getId())
+ .document(music))));
+
+ client.bulk(br.build());
+ }
+
+ /**
+ * es批量删除文档
+ *
+ * @param idList 音乐id集合
+ * @throws IOException
+ */
+ private void delete(List idList) throws IOException {
+ BulkRequest.Builder br = new BulkRequest.Builder();
+
+ idList.forEach(id -> br
+ .operations(op -> op
+ .delete(idx -> idx
+ .index("music")
+ .id(id))));
+
+ client.bulk(br.build());
+ }
+
+}
+```
+
+### 4.7 ApplicationContextAware
+
+```java
+@Component
+public class ApplicationContextUtil implements ApplicationContextAware {
+
+ private static ApplicationContext applicationContext;
+
+ @Override
+ public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
+ ApplicationContextUtil.applicationContext = applicationContext;
+ }
+
+ public static T getBean (Class classType) {
+ return applicationContext.getBean(classType);
+ }
+
+}
+```
+
+### 4.8 main
+
+```java
+@Slf4j
+@SpringBootApplication
+public class CanalApplication {
+ public static void main(String[] args) throws InterruptedException, IOException {
+ SpringApplication.run(CanalApplication.class, args);
+ log.info("数据同步程序启动");
+
+ CanalClient client = ApplicationContextUtil.getBean(CanalClient.class);
+ client.run();
+ }
+}
+```
+
+## 5.总结
+
+那么以上就是Canal组件的介绍啦,希望大家都能有所收获~
+
diff --git "a/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md" "b/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md"
new file mode 100644
index 0000000..9a2241a
--- /dev/null
+++ "b/docs/advance/excellent-article/MySQL\344\270\255N\344\270\252\345\206\231SQL\347\232\204\345\245\275\344\271\240\346\203\257.md"
@@ -0,0 +1,91 @@
+MySQL中编写SQL时,遵循良好的习惯能够提高查询性能、保障数据一致性、提升代码可读性和维护性。以下列举了多个编写SQL的好习惯
+
+#### 1.使用EXPLAIN分析查询计划
+
+在编写或优化复杂查询时,先使用EXPLAIN命令查看查询执行计划,理解MySQL如何执行查询、访问哪些表、使用哪种类型的联接以及索引的使用情况。
+
+好处:有助于识别潜在的性能瓶颈,如全表扫描、错误的索引选择、过多的临时表或文件排序等,从而针对性地优化查询或调整索引结构。
+
+#### 2.避免全表扫描
+
+2. 习惯:尽可能利用索引来避免全表扫描,尤其是在处理大表时。确保在WHERE、JOIN条件和ORDER BY、GROUP BY子句中使用的列有适当的索引。
+
+好处:极大地减少数据访问量,提高查询性能,减轻I/O压力。
+
+#### 3. 为表和字段添加注释
+
+3. 习惯:在创建表时,为表和每个字段添加有意义的注释,描述其用途、数据格式、业务规则等信息。
+
+好处:提高代码可读性和可维护性,帮助其他开发人员快速理解表结构和字段含义,减少沟通成本和误解。
+
+#### 4. 明确指定INSERT语句的列名
+
+习惯:在INSERT语句中显式列出要插入数据的列名,即使插入所有列也应如此。
+
+好处:避免因表结构变化导致的插入错误,增强代码的健壮性,同时也提高了语句的清晰度。
+
+#### 5. 格式化SQL语句
+
+习惯:保持SQL语句的格式整洁,使用一致的大小写(如关键词大写、表名和列名小写),合理缩进,避免过长的单行语句。
+
+好处:提高代码可读性,便于审查、调试和团队协作。
+
+#### 6. 使用LIMIT限制结果集大小
+
+习惯:在执行SELECT、DELETE或UPDATE操作时,若不需要处理全部数据,务必使用LIMIT子句限制结果集大小,特别是在生产环境中。
+
+好处:防止因误操作导致大量数据被修改或删除,降低风险,同时也能提高查询性能。
+
+#### 7.使用JOIN语句代替子查询
+
+习惯:在可能的情况下,优先使用JOIN操作代替嵌套的子查询,特别是在处理多表关联查询时。
+
+好处:许多情况下JOIN的执行效率高于子查询,而且JOIN语句通常更易于理解和优化。
+
+#### 8.避免在WHERE子句中对NULL进行比较
+
+习惯:使用IS NULL和IS NOT NULL来检查字段是否为NULL,而不是直接与NULL进行等值或不等值比较。
+
+好处:正确处理NULL值,避免逻辑错误和未预期的结果。
+
+#### 9.避免在查询中使用SELECT
+
+习惯:明确列出需要的列名,而不是使用SELECT *从表中获取所有列。
+
+好处:减少网络传输的数据量,降低I/O开销,提高查询性能,同时也有利于代码的清晰性和可维护性。
+
+#### 10. 数据库对象命名规范
+
+习惯:遵循一致且有意义的命名约定,如使用小写字母、下划线分隔单词,避免使用MySQL保留字,保持表名、列名、索引名等的简洁性和一致性。
+
+好处:提高代码可读性,减少命名冲突,便于团队协作和维护。
+
+#### 11. 事务管理
+
+习惯:对一系列需要保持原子性的操作使用事务管理,确保数据的一致性。
+
+好处:在发生异常时能够回滚未完成的操作,避免数据处于不一致状态。
+
+#### 12.适时使用索引覆盖
+
+习惯:对于只查询索引列且不需要访问数据行的查询(如计数、统计),创建覆盖索引以避免回表操作。
+
+好处:极大提升查询性能,减少I/O开销。
+
+#### 13.遵循第三范式或适当反范式
+
+习惯:根据业务需求和查询模式,合理设计表结构,遵循第三范式以减少数据冗余和更新异常,或适当反范式以优化查询性能。
+
+好处:保持数据一致性,减少数据维护成本,或提高查询效率。
+
+#### 14.使用预编译语句(PreparedStatement)
+
+习惯:在应用程序中使用预编译语句(如Java中的PreparedStatement)执行SQL,特别是对于动态拼接SQL语句的情况。
+
+好处:避免SQL注入攻击,提高查询性能,减少数据库服务器的解析开销。
+
+#### 15.定期分析与优化表和索引
+
+习惯:定期运行ANALYZE TABLE收集统计信息,以便MySQL优化器做出更准确的查询计划决策。根据查询性能监控结果,适时调整索引或重构表结构。
+
+好处:确保数据库持续高效运行,适应不断变化的业务需求和数据分布。
\ No newline at end of file
diff --git "a/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md" "b/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md"
new file mode 100644
index 0000000..92ca41f
--- /dev/null
+++ "b/docs/advance/excellent-article/\345\256\236\347\216\260\345\274\202\346\255\245\347\274\226\347\250\213\357\274\214\346\210\221\346\234\211\345\205\253\347\247\215\346\226\271\345\274\217\357\274\201.md"
@@ -0,0 +1,430 @@
+# 实现异步编程,我有八种方式!
+
+## **一、前言**
+
+> 异步执行对于开发者来说并不陌生,在实际的开发过程中,很多场景多会使用到异步,相比同步执行,异步可以大大缩短请求链路耗时时间,比如:**发送短信、邮件、异步更新等**,这些都是典型的可以通过异步实现的场景。
+
+## **二、异步的八种实现方式**
+
+1. 线程Thread
+2. Future
+3. 异步框架`CompletableFuture`
+4. Spring注解@Async
+5. Spring `ApplicationEvent`事件
+6. 消息队列
+7. 第三方异步框架,比如Hutool的`ThreadUtil`
+8. Guava异步
+
+## **三、什么是异步?**
+
+首先我们先看一个常见的用户下单的场景:
+
+
+
+在同步操作中,我们执行到 **发送短信** 的时候,我们必须等待这个方法彻底执行完才能执行 **赠送积分** 这个操作,如果 **赠送积分** 这个动作执行时间较长,发送短信需要等待,这就是典型的同步场景。
+
+实际上,发送短信和赠送积分没有任何的依赖关系,通过异步,我们可以实现`赠送积分`和`发送短信`这两个操作能够同时进行,比如:
+
+
+
+这就是所谓的异步,是不是非常简单,下面就说说异步的几种实现方式吧。
+
+## **四、异步编程**
+
+#### **4.1 线程异步**
+
+```java
+public class AsyncThread extends Thread {
+
+ @Override
+ public void run() {
+ System.out.println("Current thread name:" + Thread.currentThread().getName() + " Send email success!");
+ }
+
+ public static void main(String[] args) {
+ AsyncThread asyncThread = new AsyncThread();
+ asyncThread.run();
+ }
+}
+```
+
+当然如果每次都创建一个`Thread`线程,频繁的创建、销毁,浪费系统资源,我们可以采用线程池:
+
+```java
+private ExecutorService executorService = Executors.newCachedThreadPool();
+
+public void fun() {
+ executorService.submit(new Runnable() {
+ @Override
+ public void run() {
+ log.info("执行业务逻辑...");
+ }
+ });
+}
+```
+
+可以将业务逻辑封装到`Runnable`或`Callable`中,交由线程池来执行。
+
+#### **4.2 Future异步**
+
+```java
+@Slf4j
+public class FutureManager {
+
+ public String execute() throws Exception {
+
+ ExecutorService executor = Executors.newFixedThreadPool(1);
+ Future future = executor.submit(new Callable() {
+ @Override
+ public String call() throws Exception {
+
+ System.out.println(" --- task start --- ");
+ Thread.sleep(3000);
+ System.out.println(" --- task finish ---");
+ return "this is future execute final result!!!";
+ }
+ });
+
+ //这里需要返回值时会阻塞主线程
+ String result = future.get();
+ log.info("Future get result: {}", result);
+ return result;
+ }
+
+ @SneakyThrows
+ public static void main(String[] args) {
+ FutureManager manager = new FutureManager();
+ manager.execute();
+ }
+}
+```
+
+输出结果:
+
+```
+ --- task start ---
+ --- task finish ---
+ Future get result: this is future execute final result!!!
+```
+
+##### **4.2.1 Future的不足之处**
+
+Future的不足之处的包括以下几点:
+
+1️⃣ 无法被动接收异步任务的计算结果:虽然我们可以主动将异步任务提交给线程池中的线程来执行,但是待异步任务执行结束之后,主线程无法得到任务完成与否的通知,它需要通过get方法主动获取任务执行的结果。
+
+2️⃣ Future件彼此孤立:有时某一个耗时很长的异步任务执行结束之后,你想利用它返回的结果再做进一步的运算,该运算也会是一个异步任务,两者之间的关系需要程序开发人员手动进行绑定赋予,Future并不能将其形成一个任务流(pipeline),每一个Future都是彼此之间都是孤立的,所以才有了后面的`CompletableFuture`,`CompletableFuture`就可以将多个Future串联起来形成任务流。
+
+3️⃣ Futrue没有很好的错误处理机制:截止目前,如果某个异步任务在执行发的过程中发生了异常,调用者无法被动感知,必须通过捕获get方法的异常才知晓异步任务执行是否出现了错误,从而在做进一步的判断处理。
+
+#### **4.3 CompletableFuture实现异步**
+
+```java
+public class CompletableFutureCompose {
+
+ /**
+ * thenAccept子任务和父任务公用同一个线程
+ */
+ @SneakyThrows
+ public static void thenRunAsync() {
+ CompletableFuture cf1 = CompletableFuture.supplyAsync(() -> {
+ System.out.println(Thread.currentThread() + " cf1 do something....");
+ return 1;
+ });
+ CompletableFuture cf2 = cf1.thenRunAsync(() -> {
+ System.out.println(Thread.currentThread() + " cf2 do something...");
+ });
+ //等待任务1执行完成
+ System.out.println("cf1结果->" + cf1.get());
+ //等待任务2执行完成
+ System.out.println("cf2结果->" + cf2.get());
+ }
+
+ public static void main(String[] args) {
+ thenRunAsync();
+ }
+}
+```
+
+我们不需要显式使用`ExecutorService,CompletableFuture `内部使用了`ForkJoinPool`来处理异步任务,如果在某些业务场景我们想自定义自己的异步线程池也是可以的。
+
+#### **4.4 Spring的@Async异步**
+
+##### **4.4.1 自定义异步线程池**
+
+```
+/**
+ * 线程池参数配置,多个线程池实现线程池隔离,@Async注解,默认使用系统自定义线程池,可在项目中设置多个线程池,在异步调用的时候,指明需要调用的线程池名称,比如:@Async("taskName")
+ *
+ * @author: jacklin
+ * @since: 2021/5/18 11:44
+ **/
+@EnableAsync
+@Configuration
+public class TaskPoolConfig {
+
+ /**
+ * 自定义线程池
+ *
+ * @author: jacklin
+ * @since: 2021/11/16 17:41
+ **/
+ @Bean("taskExecutor")
+ public Executor taskExecutor() {
+ //返回可用处理器的Java虚拟机的数量 12
+ int i = Runtime.getRuntime().availableProcessors();
+ System.out.println("系统最大线程数 : " + i);
+ ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
+ //核心线程池大小
+ executor.setCorePoolSize(16);
+ //最大线程数
+ executor.setMaxPoolSize(20);
+ //配置队列容量,默认值为Integer.MAX_VALUE
+ executor.setQueueCapacity(99999);
+ //活跃时间
+ executor.setKeepAliveSeconds(60);
+ //线程名字前缀
+ executor.setThreadNamePrefix("asyncServiceExecutor -");
+ //设置此执行程序应该在关闭时阻止的最大秒数,以便在容器的其余部分继续关闭之前等待剩余的任务完成他们的执行
+ executor.setAwaitTerminationSeconds(60);
+ //等待所有的任务结束后再关闭线程池
+ executor.setWaitForTasksToCompleteOnShutdown(true);
+ return executor;
+ }
+}
+```
+
+##### **4.4.2 AsyncService**
+
+```java
+public interface AsyncService {
+
+ MessageResult sendSms(String callPrefix, String mobile, String actionType, String content);
+
+ MessageResult sendEmail(String email, String subject, String content);
+}
+
+@Slf4j
+@Service
+public class AsyncServiceImpl implements AsyncService {
+
+ @Autowired
+ private IMessageHandler mesageHandler;
+
+ @Override
+ @Async("taskExecutor")
+ public MessageResult sendSms(String callPrefix, String mobile, String actionType, String content) {
+ try {
+
+ Thread.sleep(1000);
+ mesageHandler.sendSms(callPrefix, mobile, actionType, content);
+
+ } catch (Exception e) {
+ log.error("发送短信异常 -> ", e)
+ }
+ }
+
+
+ @Override
+ @Async("taskExecutor")
+ public sendEmail(String email, String subject, String content) {
+ try {
+
+ Thread.sleep(1000);
+ mesageHandler.sendsendEmail(email, subject, content);
+
+ } catch (Exception e) {
+ log.error("发送email异常 -> ", e)
+ }
+ }
+}
+```
+
+在实际项目中, 使用`@Async`调用线程池,推荐等方式是是使用自定义线程池的模式,不推荐直接使用@Async直接实现异步。
+
+#### **4.5 Spring ApplicationEvent事件实现异步**
+
+##### **4.5.1 定义事件**
+
+```java
+public class AsyncSendEmailEvent extends ApplicationEvent {
+
+ /**
+ * 邮箱
+ **/
+ private String email;
+
+ /**
+ * 主题
+ **/
+ private String subject;
+
+ /**
+ * 内容
+ **/
+ private String content;
+
+ /**
+ * 接收者
+ **/
+ private String targetUserId;
+
+}
+```
+
+##### **4.5.2 定义事件处理器**
+
+```java
+@Slf4j
+@Component
+public class AsyncSendEmailEventHandler implements ApplicationListener {
+
+ @Autowired
+ private IMessageHandler mesageHandler;
+
+ @Async("taskExecutor")
+ @Override
+ public void onApplicationEvent(AsyncSendEmailEvent event) {
+ if (event == null) {
+ return;
+ }
+
+ String email = event.getEmail();
+ String subject = event.getSubject();
+ String content = event.getContent();
+ String targetUserId = event.getTargetUserId();
+ mesageHandler.sendsendEmailSms(email, subject, content, targerUserId);
+ }
+}
+```
+
+另外,可能有些时候采用ApplicationEvent实现异步的使用,当程序出现异常错误的时候,需要考虑补偿机制,那么这时候可以结合Spring Retry重试来帮助我们避免这种异常造成数据不一致问题。
+
+#### **4.6 消息队列**
+
+##### **4.6.1 回调事件消息生产者**
+
+```
+@Slf4j
+@Component
+public class CallbackProducer {
+
+ @Autowired
+ AmqpTemplate amqpTemplate;
+
+ public void sendCallbackMessage(CallbackDTO allbackDTO, final long delayTimes) {
+
+ log.info("生产者发送消息,callbackDTO,{}", callbackDTO);
+
+ amqpTemplate.convertAndSend(CallbackQueueEnum.QUEUE_GENSEE_CALLBACK.getExchange(), CallbackQueueEnum.QUEUE_GENSEE_CALLBACK.getRoutingKey(), JsonMapper.getInstance().toJson(genseeCallbackDTO), new MessagePostProcessor() {
+ @Override
+ public Message postProcessMessage(Message message) throws AmqpException {
+ //给消息设置延迟毫秒值,通过给消息设置x-delay头来设置消息从交换机发送到队列的延迟时间
+ message.getMessageProperties().setHeader("x-delay", delayTimes);
+ message.getMessageProperties().setCorrelationId(callbackDTO.getSdkId());
+ return message;
+ }
+ });
+ }
+}
+```
+
+##### **4.6.2 回调事件消息消费者**
+
+```
+@Slf4j
+@Component
+@RabbitListener(queues = "message.callback", containerFactory = "rabbitListenerContainerFactory")
+public class CallbackConsumer {
+
+ @Autowired
+ private IGlobalUserService globalUserService;
+
+ @RabbitHandler
+ public void handle(String json, Channel channel, @Headers Map map) throws Exception {
+
+ if (map.get("error") != null) {
+ //否认消息
+ channel.basicNack((Long) map.get(AmqpHeaders.DELIVERY_TAG), false, true);
+ return;
+ }
+
+ try {
+
+ CallbackDTO callbackDTO = JsonMapper.getInstance().fromJson(json, CallbackDTO.class);
+ //执行业务逻辑
+ globalUserService.execute(callbackDTO);
+ //消息消息成功手动确认,对应消息确认模式acknowledge-mode: manual
+ channel.basicAck((Long) map.get(AmqpHeaders.DELIVERY_TAG), false);
+
+ } catch (Exception e) {
+ log.error("回调失败 -> {}", e);
+ }
+ }
+}
+```
+
+#### **4.7 ThreadUtil异步工具类**
+
+```java
+@Slf4j
+public class ThreadUtils {
+
+ public static void main(String[] args) {
+ for (int i = 0; i < 3; i++) {
+ ThreadUtil.execAsync(() -> {
+ ThreadLocalRandom threadLocalRandom = ThreadLocalRandom.current();
+ int number = threadLocalRandom.nextInt(20) + 1;
+ System.out.println(number);
+ });
+ log.info("当前第:" + i + "个线程");
+ }
+
+ log.info("task finish!");
+ }
+}
+```
+
+#### **4.8 Guava异步**
+
+`Guava`的`ListenableFuture`顾名思义就是可以监听的`Future`,是对java原生Future的扩展增强。我们知道Future表示一个异步计算任务,当任务完成时可以得到计算结果。
+
+如果我们希望一旦计算完成就拿到结果展示给用户或者做另外的计算,就必须使用另一个线程不断的查询计算状态。这样做,代码复杂,而且效率低下。
+
+使用**Guava ListenableFuture**可以帮我们检测Future是否完成了,不需要再通过get()方法苦苦等待异步的计算结果,如果完成就自动调用回调函数,这样可以减少并发程序的复杂度。
+
+`ListenableFuture`是一个接口,它从`jdk`的`Future`接口继承,添加了`void addListener(Runnable listener, Executor executor)`方法。
+
+我们看下如何使用`ListenableFuture`。首先需要定义`ListenableFuture`的实例:
+
+```java
+ListeningExecutorService executorService = MoreExecutors.listeningDecorator(Executors.newCachedThreadPool());
+ final ListenableFuture listenableFuture = executorService.submit(new Callable() {
+ @Override
+ public Integer call() throws Exception {
+ log.info("callable execute...")
+ TimeUnit.SECONDS.sleep(1);
+ return 1;
+ }
+ });
+```
+
+首先通过`MoreExecutors`类的静态方法`listeningDecorator`方法初始化一个`ListeningExecutorService`的方法,然后使用此实例的`submit`方法即可初始化`ListenableFuture`对象。
+
+`ListenableFuture`要做的工作,在Callable接口的实现类中定义,这里只是休眠了1秒钟然后返回一个数字1,有了`ListenableFuture`实例,可以执行此Future并执行Future完成之后的回调函数。
+
+```java
+ Futures.addCallback(listenableFuture, new FutureCallback() {
+ @Override
+ public void onSuccess(Integer result) {
+ //成功执行...
+ System.out.println("Get listenable future's result with callback " + result);
+ }
+
+ @Override
+ public void onFailure(Throwable t) {
+ //异常情况处理...
+ t.printStackTrace();
+ }
+});
+```
\ No newline at end of file
diff --git a/docs/advance/system-design/2-order-timeout-auto-cancel.md b/docs/advance/system-design/2-order-timeout-auto-cancel.md
index 5ffaf4e..b100f91 100644
--- a/docs/advance/system-design/2-order-timeout-auto-cancel.md
+++ b/docs/advance/system-design/2-order-timeout-auto-cancel.md
@@ -42,11 +42,11 @@ head:
对上述的任务,我们给一个专业的名字来形容,那就是延时任务。那么这里就会产生一个问题,这个延时任务和定时任务的区别究竟在哪里呢?一共有如下几点区别
-定时任务有明确的触发时间,延时任务没有
+1、定时任务有明确的触发时间,延时任务没有
-定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
+2、定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
-定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
+3、定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
下面,我们以判断订单是否超时为例,进行方案分析
@@ -340,13 +340,13 @@ public class HashedWheelTimerTest {
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
-## 方案 4:redis 缓存
+## 方案 4:Redis 缓存
### 思路一
利用 redis 的 zset,zset 是一个有序集合,每一个元素(member)都关联了一个 score,通过 score 排序来取集合中的值
-添加元素:ZADD key score member [[score member][score member] …]
+添加元素:ZADD key score member [score member …]
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
@@ -619,11 +619,11 @@ ps:redis 的 pub/sub 机制存在一个硬伤,官网内容如下
### 思路
-我们可以采用 rabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
+我们可以采用 RabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
RabbitMQ 可以针对 Queue 和 Message 设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为 dead letter
-lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。
+lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能。
### 优点
diff --git a/docs/advance/system-design/README.md b/docs/advance/system-design/README.md
index 79b8eb1..15ef840 100644
--- a/docs/advance/system-design/README.md
+++ b/docs/advance/system-design/README.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
\ No newline at end of file
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/3-baidu.md b/docs/campus-recruit/interview/3-baidu.md
index d5918e5..3cd2f26 100644
--- a/docs/campus-recruit/interview/3-baidu.md
+++ b/docs/campus-recruit/interview/3-baidu.md
@@ -36,6 +36,18 @@
- 刷脏页的流程
- 算法题:平方根
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经3
- 自我介绍
@@ -104,6 +116,12 @@
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/4-ali.md b/docs/campus-recruit/interview/4-ali.md
index 2c99b2e..00b2a7a 100644
--- a/docs/campus-recruit/interview/4-ali.md
+++ b/docs/campus-recruit/interview/4-ali.md
@@ -48,6 +48,18 @@
24. 操作系统的内存管理的页面淘汰 算法 ,介绍下LRU(最近最少使用算法 )
25. B+树的特点与优势
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经3
- 自我介绍,说简历里没有的东西
@@ -74,6 +86,14 @@
- 服务注册的时候发现没有注册成功会是什么原因。
- 讲讲你认为的rpc和service mesh之间的关系。
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/5-kuaishou.md b/docs/campus-recruit/interview/5-kuaishou.md
index 1b24e6d..539a84a 100644
--- a/docs/campus-recruit/interview/5-kuaishou.md
+++ b/docs/campus-recruit/interview/5-kuaishou.md
@@ -67,6 +67,18 @@
1. 对于部门的业务、技术栈
2. 对我的建议、和整个面试的感觉
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## 面经1-二面
> **Java基础**
@@ -307,6 +319,14 @@ while (true) {
-**最后给大家分享一份精心整理的大厂高频面试题PDF,需要的小伙伴可以自行下载:**
-[大厂面试手册](http://mp.weixin.qq.com/s?__biz=Mzg2OTY1NzY0MQ==&mid=2247485445&idx=1&sn=1c6e224b9bb3da457f5ee03894493dbc&chksm=ce98f543f9ef7c55325e3bf336607a370935a6c78dbb68cf86e59f5d68f4c51d175365a189f8#rd)
\ No newline at end of file
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/interview/6-meituan.md b/docs/campus-recruit/interview/6-meituan.md
index 43a1b71..32cb5bf 100644
--- a/docs/campus-recruit/interview/6-meituan.md
+++ b/docs/campus-recruit/interview/6-meituan.md
@@ -68,3 +68,12 @@
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git a/docs/campus-recruit/share/2-years-tech-upgrade.md b/docs/campus-recruit/share/2-years-tech-upgrade.md
index b2aa471..5322d98 100644
--- a/docs/campus-recruit/share/2-years-tech-upgrade.md
+++ b/docs/campus-recruit/share/2-years-tech-upgrade.md
@@ -58,4 +58,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券即可加入~
-
+
diff --git a/docs/career-plan/3-years-reflect.md b/docs/career-plan/3-years-reflect.md
index 8c4c12c..21e4cfc 100644
--- a/docs/career-plan/3-years-reflect.md
+++ b/docs/career-plan/3-years-reflect.md
@@ -95,5 +95,5 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/career-plan/how-to-prepare-job-hopping.md b/docs/career-plan/how-to-prepare-job-hopping.md
index 0dea290..59aee75 100644
--- a/docs/career-plan/how-to-prepare-job-hopping.md
+++ b/docs/career-plan/how-to-prepare-job-hopping.md
@@ -85,4 +85,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/career-plan/java-or-bigdata.md b/docs/career-plan/java-or-bigdata.md
index d3bbf32..cf98ec1 100644
--- a/docs/career-plan/java-or-bigdata.md
+++ b/docs/career-plan/java-or-bigdata.md
@@ -59,4 +59,4 @@ head:
**加入方式**:**扫描二维码**领取优惠券加入(**即将恢复原价**)~
-
+
diff --git a/docs/computer-basic/network.md b/docs/computer-basic/network.md
index 465d1bc..831488a 100644
--- a/docs/computer-basic/network.md
+++ b/docs/computer-basic/network.md
@@ -41,6 +41,8 @@ head:
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
diff --git a/docs/database/mysql.md b/docs/database/mysql.md
index 9559ede..c8b0032 100644
--- a/docs/database/mysql.md
+++ b/docs/database/mysql.md
@@ -20,6 +20,12 @@ head:
:::
+## 更新记录
+
+- 2024.06.05,更新[MySQL查询 limit 1000,10 和limit 10 速度一样快吗?](###MySQL查询 limit 1000,10 和limit 10 速度一样快吗?)
+
+- 2024.5.15,新增[B树和B+树的区别?](###B树和B+树的区别?)
+
## 什么是MySQL
MySQL是一个关系型数据库,它采用表的形式来存储数据。你可以理解成是Excel表格,既然是表的形式存储数据,就有表结构(行和列)。行代表每一行数据,列代表该行中的每个值。列上的值是有数据类型的,比如:整数、字符串、日期等等。
@@ -262,6 +268,18 @@ Index_comment:
- 哈希索引**不支持模糊查询**及多列索引的最左前缀匹配。
- 因为哈希表中会**存在哈希冲突**,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。
+### B树和B+树的区别?
+
+
+
+
+
+1. **数据存储方式**:在B树中,每个节点都包含键和对应的值,叶子节点存储了实际的数据记录;而B+树中,仅仅只有叶子节点存储了实际的数据记录,非叶子节点只包含键信息和指向子节点的指针。
+2. **数据检索方式**:在B树中,由于非叶子节点也存储了数据,所以查询时可以直接在非叶子节点找到对应的数据,具有更短的查询路径;
+ 而B+树的所有数据都存储在叶子节点上,只有通过子节点才能获取到完整的数据。
+3. **范围查询效率**:由于B+树的所有数据都存储在叶子节点上,并且叶子节点之间使用链表连接,所以范围查询的效率比较高。而在B树中,范围查询需要通过遍历多个层级的节点,效率相对较低。
+4. **适用场景**:B树适合进行随机读写操作,因为每个节点都包含了数据。而B+树适合进行范围查询和顺序访问,因为数据都存储在叶子节点上,并且叶子节点之间使用链表连接,便于进行顺序遍历。
+
### 为什么B+树比B树更适合实现数据库索引?
- 由于B+树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以通常B+树用于数据库索引。
@@ -1180,4 +1198,38 @@ COUNT(`*`)是SQL92定义的标准统计行数的语法,效率高,MySQL对它
所以,建议使用COUNT(\*)查询表的行数!
+## 存储MD5值应该用VARCHAR还是用CHAR?
+
+首先说说CHAR和VARCHAR的区别:
+
+1、存储长度:
+
+CHAR类型的长度是固定的
+
+当我们当定义CHAR(10),输入的值是"abc",但是它占用的空间一样是10个字节,会包含7个空字节。当输入的字符长度超过指定的数时,CHAR会截取超出的字符。而且,当存储为CHAR的时候,MySQL会自动删除输入字符串末尾的空格。
+
+VARCHAR的长度是可变的
+
+比如VARCHAR(10),然后输入abc三个字符,那么实际存储大小为3个字节。
+
+除此之外,VARCHAR还会保留1个或2个额外的字节来记录字符串的实际长度。如果定义的最大长度小于等于255个字节,那么,就会预留1个字节;如果定义的最大长度大于255个字节,那么就会预留2个字节。
+
+2、存储效率
+
+CHAR类型每次修改后的数据长度不变,效率更高。
+
+VARCHAR每次修改的数据要更新数据长度,效率更低。
+
+3、存储空间
+
+CHAR存储空间是初始的预计长度字符串再加上一个记录字符串长度的字节,可能会存在多余的空间。
+
+VARCHAR存储空间的时候是实际字符串再加上一个记录字符串长度的字节,占用空间较小。
+
+
+
+根据以上的分析,由于MD5是一个定长的值,所以MD5值适合使用CHAR存储。对于固定长度的非常短的列,CHAR比VARCHAR效率也更高。
+
+
+

diff --git "a/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md" "b/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md"
new file mode 100644
index 0000000..94d82b5
--- /dev/null
+++ "b/docs/database/\344\270\200\346\235\241 SQL \346\237\245\350\257\242\350\257\255\345\217\245\345\246\202\344\275\225\346\211\247\350\241\214\347\232\204.md"
@@ -0,0 +1,67 @@
+一条 SQL 查询语句如何执行的
+
+在平常的开发中,可能很多人都是 CRUD,对 SQL 语句的语法很熟练,但是说起一条 SQL 语句在 MySQL 中是怎么执行的却浑然不知,今天大彬就由浅入深,带大家一点点剖析一条 SQL 语句在 MySQL 中是怎么执行的。
+
+比如你执行下面这个 SQL 语句时,我们看到的只是输入一条语句,返回一个结果,却不知道 MySQL 内部的执行过程:
+
+```mysql
+mysql> select * from T where ID=10;
+```
+
+在剖析这个语句怎么执行之前,我们先看一下 MySQL 的基本架构示意图,能更清楚的看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。
+
+
+
+整体来说,MySQL 可以分为 Server 层和存储引擎两部分。
+
+Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
+
+### 连接器
+
+如果要操作 MySQL 数据库,我们必须使用 MySQL 客户端来连接 MySQL 服务器,这时候就是服务器中的连接器来负责根客户端建立连接、获取权限、维持和管理连接。
+
+在和服务端完成 TCP 连接后,连接器就要认证身份,需要用到用户名和密码,确保用户有足够的权限执行该SQL语句。
+
+### 查询缓存
+
+建立完连接后,就可以执行查询语句了,来到第二步:查询缓存。
+
+MySQL 拿到第一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中,如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
+
+如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
+
+### 分析器
+
+如果没有命中缓存,就要开始真正执行语句了,MySQL 首先会对 SQL 语句做解析。
+
+分析器会先做 “词法分析”,MySQL 需要识别出 SQL 里面的字符串分别是什么,代表什么。
+
+做完之后就要做“语法分析”,根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。若果语句不对,就会收到错误提醒。
+
+### 优化器
+
+经过了分析器,MySQL 就知道要做什么了,但是在开始执行之前,要先经过优化器的处理。
+
+比如:优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
+
+MySQL 会帮我去使用他自己认为的最好的方式去优化这条 SQL 语句,并生成一条条的执行计划,比如你创建了多个索引,MySQL 会依据**成本最小原则**来选择使用对应的索引,这里的成本主要包括两个方面, IO 成本和 CPU 成本。
+
+### 执行器
+
+执行优化之后的执行计划,在开始执行之前,先判断一下用户对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误;如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
+
+### 存储引擎
+
+执行器将查询请求发送给存储引擎组件。
+
+存储引擎组件负责具体的数据存储、检索和修改操作。
+
+存储引擎根据执行器的请求,从磁盘或内存中读取或写入相关数据。
+
+### 返回结果
+
+存储引擎将查询结果返回给执行器。
+
+执行器将结果返回给连接器。
+
+最后,连接器将结果发送回客户端,完成整个执行过程。
\ No newline at end of file
diff --git a/docs/framework/mybatis.md b/docs/framework/mybatis.md
index 0337815..b21cb9d 100644
--- a/docs/framework/mybatis.md
+++ b/docs/framework/mybatis.md
@@ -27,6 +27,17 @@ head:
- MyBatis作为持久层框架,其主要思想是将程序中的大量SQL语句剥离出来,配置在配置文件当中,实现SQL的灵活配置。
- 这样做的好处是将SQL与程序代码分离,可以在不修改代码的情况下,直接在配置文件当中修改SQL。
+## 为什么使用Mybatis代替JDBC?
+
+MyBatis 是一种优秀的 ORM(Object-Relational Mapping)框架,与 JDBC 相比,有以下几点优势:
+
+1. 简化了 JDBC 的繁琐操作:使用 JDBC 进行数据库操作需要编写大量的样板代码,如获取连接、创建 Statement/PreparedStatement,设置参数,处理结果集等。而使用 MyBatis 可以将这些操作封装起来,通过简单的配置文件和 SQL 语句就能完成数据库操作,从而大大简化了开发过程。
+2. 提高了 SQL 的可维护性:使用 JDBC 进行数据库操作,SQL 语句通常会散布在代码中的各个位置,当 SQL 语句需要修改时,需要找到所有使用该语句的地方进行修改,这非常不方便,也容易出错。而使用 MyBatis,SQL 语句都可以集中在配置文件中,可以更加方便地修改和维护,同时也提高了 SQL 语句的可读性。
+3. 支持动态 SQL:MyBatis 提供了强大的动态 SQL 功能,可以根据不同的条件生成不同的 SQL 语句,这对于复杂的查询操作非常有用。
+4. 易于集成:MyBatis 可以与 Spring 等流行的框架集成使用,可以通过 XML 或注解配置进行灵活的配置,同时 MyBatis 也提供了非常全面的文档和示例代码,学习和使用 MyBatis 非常方便。
+
+综上所述,使用 MyBatis 可以大大简化数据库操作的代码,提高 SQL 语句的可维护性和可读性,同时还提供了强大的动态 SQL 功能,易于集成使用。因此,相比于直接使用 JDBC,使用 MyBatis 更为便捷、高效和方便。
+
## **ORM是什么**
ORM(Object Relational Mapping),对象关系映射,是一种为了解决关系型数据库数据与简单Java对象(POJO)的映射关系的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系型数据库中。
@@ -107,7 +118,7 @@ Mybatis仅可以编写针对 `ParameterHandler`、`ResultSetHandler`、`Statemen
编写插件:实现 Mybatis 的 Interceptor 接口并复写 intercept()方法,然后再给插件编写注解,指定要拦截哪一个接口的哪些方法即可,最后在配置文件中配置你编写的插件。
-## .Mybatis 是否支持延迟加载?
+## Mybatis 是否支持延迟加载?
Mybatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 Mybatis 配置文件中,可以配置是否启用延迟加载`lazyLoadingEnabled=true|false`。
diff --git a/docs/framework/spring.md b/docs/framework/spring.md
index 410e4e3..4ea008b 100644
--- a/docs/framework/spring.md
+++ b/docs/framework/spring.md
@@ -102,6 +102,18 @@ AOP有两种实现方式:静态代理和动态代理。
动态代理:代理类在程序运行时创建,AOP框架不会去修改字节码,而是在内存中临时生成一个代理对象,在运行期间对业务方法进行增强,不会生成新类。
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## Spring AOP的实现原理
`Spring`的`AOP`实现原理其实很简单,就是通过**动态代理**实现的。如果我们为`Spring`的某个`bean`配置了切面,那么`Spring`在创建这个`bean`的时候,实际上创建的是这个`bean`的一个代理对象,我们后续对`bean`中方法的调用,实际上调用的是代理类重写的代理方法。而`Spring`的`AOP`使用了两种动态代理,分别是**JDK的动态代理**,以及**CGLib的动态代理**。
@@ -977,4 +989,14 @@ Spring常用的注入方式有:属性注入, 构造方法注入, set 方法注
+> 最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+>
+> 
+>
+> 
+>
+> **200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+>
+> 备用链接:https://pan.quark.cn/s/3f1321952a16
+

diff --git a/docs/framework/springboot.md b/docs/framework/springboot.md
index 496473c..a0b52ad 100644
--- a/docs/framework/springboot.md
+++ b/docs/framework/springboot.md
@@ -60,12 +60,78 @@ starter提供了一个自动化配置类,一般命名为 XXXAutoConfiguration
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
+- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
+- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
+- @ComponentScan:Spring组件扫描。
+
+## 有哪些常用的SpringBoot注解?
+
+- @SpringBootApplication。这个注解是Spring Boot最核心的注解,用在 Spring Boot的主类上,标识这是一个 Spring Boot 应用,用来开启 Spring Boot 的各项能力
+
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
+- @Repository:用于标注数据访问组件,即DAO组件。
+
+- @Service:一般用于修饰service层的组件
+
+- **@RestController**。用于标注控制层组件(如struts中的action),表示这是个控制器bean,并且是将函数的返回值直 接填入HTTP响应体中,是REST风格的控制器;它是@Controller和@ResponseBody的合集。
+
+- **@ResponseBody**。表示该方法的返回结果直接写入HTTP response body中
+
+- **@Component**。泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。
+
+- **@Bean**,相当于XML中的``,放在方法的上面,而不是类,意思是产生一个bean,并交给spring管理。
+
+- **@AutoWired**,byType方式。把配置好的Bean拿来用,完成属性、方法的组装,它可以对类成员变量、方法及构造函数进行标注,完成自动装配的工作。
+
+- **@Qualifier**。当有多个同一类型的Bean时,可以用@Qualifier("name")来指定。与@Autowired配合使用
+
+- **@Resource(name="name",type="type")**。没有括号内内容的话,默认byName。与@Autowired干类似的事。
+
+- **@RequestMapping**
+
+ RequestMapping是一个用来处理请求地址映射的注解;提供路由信息,负责URL到Controller中的具体函数的映射,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
+
+- **@RequestParam**
+
+ 用在方法的参数前面。
+
+- ### @Scope
+
+ 用于声明一个Spring`Bean`实例的作用域
+
+- ### @Primary
+
+ 当同一个对象有多个实例时,优先选择该实例。
+
+- ### @PostConstruct
+
+ 用于修饰方法,当对象实例被创建并且依赖注入完成后执行,可用于对象实例的初始化操作。
+
+- ### @PreDestroy
+
+ 用于修饰方法,当对象实例将被Spring容器移除时执行,可用于对象实例持有资源的释放。
+
+- ### @EnableTransactionManagement
+
+ 启用Spring基于注解的事务管理功能,需要和`@Configuration`注解一起使用。
+
+- ### @Transactional
+
+ 表示方法和类需要开启事务,当作用与类上时,类中所有方法均会开启事务,当作用于方法上时,方法开启事务,方法上的注解无法被子类所继承。
+
+- ### @ControllerAdvice
+
+ 常与`@ExceptionHandler`注解一起使用,用于捕获全局异常,能作用于所有controller中。
+
+- ### @ExceptionHandler
+
+ 修饰方法时,表示该方法为处理全局异常的方法。
+
## 自动配置原理
SpringBoot实现自动配置原理图解:
diff --git a/docs/framework/springboot/springboot-cross-domain.md b/docs/framework/springboot/springboot-cross-domain.md
index fa7dac3..b93a909 100644
--- a/docs/framework/springboot/springboot-cross-domain.md
+++ b/docs/framework/springboot/springboot-cross-domain.md
@@ -90,4 +90,4 @@ public class AccountController {
6、打卡学习,**大学自习室的氛围**,一起蜕变成长
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/framework/springcloud-interview.md b/docs/framework/springcloud-interview.md
index 619e950..f95f36b 100644
--- a/docs/framework/springcloud-interview.md
+++ b/docs/framework/springcloud-interview.md
@@ -24,17 +24,66 @@ head:
:::
+## 更新记录
+
+- 2024.5.15,完善[Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?](##Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?)
## 1、什么是Spring Cloud ?
Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
-## spring、 springboot、 springcloud 的区别是什么?
+
+
+Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微服务框架,用于快速构建执行有限数据处理的应用程序。
+
+## Spring、SpringMVC、Springboot、 Springcloud 的区别是什么?
+
+### Spring
+
+Spring是一个生态体系(也可以说是技术体系),是集大成者,它包含了Spring Framework、Spring Boot、Spring Cloud等。**它是一个轻量级控制反转(IOC)和面向切面(AOP)的容器框架**,为开发者提供了一个简易的开发方式。
+
+Spring的核心特性思想之一IOC,它实现了容器对Bean对象的管理、降低组件耦合,使各层服务解耦。
+
+Spring的另一个核心特性就是AOP,面向切面编程。面向切面编程需要将程序逻辑分解为称为所谓关注点的不同部分。跨越应用程序多个点的功能称为跨领域问题,这些跨领域问题在概念上与应用程序的业务逻辑分离。有许多常见的例子,如日志记录,声明式事务,安全性,缓存等。
+
+**如果说IOC依赖注入可以帮助我们将应用程序对象相互分离,那么AOP可以帮助我们将交叉问题与它们所影响的对象分离。二者目的都是使服务解耦,使开发简易。**
+
+当然,除了Spring 的两大核心功能,还有如下这些,如:
+
+- Spring JDBC
+- Spring MVC
+- Spring ORM
+- Spring Test
-Spring是一个生态体系(也可以说是技术体系),是集大成者,它包含了Spring Framework、Spring Boot、Spring Cloud等。
+### SpringMVC
+
+Spring与MVC可以更好地解释什么是SpringMVC,MVC为现代web项目开发的一种很常见的模式,简言之C(控制器)将V(视图、用户客户端)与M(模块,业务)分开构成了MVC ,业内常见的MVC模式的开发框架有Struts。
+
+Spring MVC是Spring的一部分,主要用于开发WEB应用和网络接口,它是Spring的一个模块,通过DispatcherServlet, ModelAndView 和View Resolver,让应用开发变得很容易。
+
+### SpringBoot
+
+SpringBoot是一套整合了框架的框架。
+
+它的初衷:解决Spring框架配置文件的繁琐、搭建服务的复杂性。
+
+它的设计理念:**约定优于配置**(convention over configuration)。
+
+基于此理念实现了**自动配置**,且降低项目搭建的复杂度。
+
+搭建一个接口服务,通过SpringBoot几行代码即可实现。基于Spring Boot,不是说原来的配置没有了,而是Spring Boot有一套默认配置,我们可以把它看做比较通用的约定,而Spring Boot遵循的是**约定优于配置**原则,同时,如果你需要使用到Spring以往提供的各种复杂但功能强大的配置功能,Spring Boot一样支持。
+
+在Spring Boot中,你会发现引入的所有包都是starter形式,如:
+
+- spring-boot-starter-web-services,针对SOAP Web Services
+- spring-boot-starter-web,针对Web应用与网络接口
+- spring-boot-starter-jdbc,针对JDBC
+- spring-boot-starter-cache,针对缓存支持
Spring Boot是基于 Spring 框架开发的用于开发 Web 应用程序的框架,它帮助开发人员快速搭建和配置一个独立的、可执行的、基于 Spring 的应用程序,从而减少了繁琐和重复的配置工作。
+### Spring Cloud
+
Spring Cloud事实上是一整套基于Spring Boot的微服务解决方案。它为开发者提供了很多工具,用于快速构建分布式系统的一些通用模式,例如:配置管理、注册中心、服务发现、限流、网关、链路追踪等。Spring Boot是build anything,而Spring Cloud是coordinate anything,Spring Cloud的每一个微服务解决方案都是基于Spring Boot构建的。
## 2、什么是微服务?
diff --git a/docs/framework/springmvc.md b/docs/framework/springmvc.md
index e6a39b6..6bf2369 100644
--- a/docs/framework/springmvc.md
+++ b/docs/framework/springmvc.md
@@ -13,194 +13,38 @@ head:
content: 高质量的Spring MVC常见知识点和面试题总结,让天下没有难背的八股文!
---
-::: tip 这是一则或许对你有帮助的信息
-- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
-- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
-:::
+**Spring MVC高频面试题**是我的[知识星球](https://topjavaer.cn/zsxq/introduce.html)**内部专属资料**,已经整理到**Java面试手册完整版**。
-## 说说你对 SpringMVC 的理解
+
-SpringMVC是一种基于 Java 的实现MVC设计模型的请求驱动类型的轻量级Web框架,属于Spring框架的一个模块。
+如果你正在打算准备跳槽、面试,星球还提供**简历指导、修改服务**,大彬已经帮**120**+个小伙伴修改了简历,相对还是比较有经验的。
-它通过一套注解,让一个简单的Java类成为处理请求的控制器,而无须实现任何接口。同时它还支持RESTful编程风格的请求。
+
-## 什么是MVC模式?
+
-MVC的全名是`Model View Controller`,是模型(model)-视图(view)-控制器(controller)的缩写,是一种软件设计典范。它是用一种业务逻辑、数据与界面显示分离的方法来组织代码,将众多的业务逻辑聚集到一个部件里面,在需要改进和个性化定制界面及用户交互的同时,不需要重新编写业务逻辑,达到减少编码的时间。
+另外星球也提供**专属一对一的提问答疑**,帮你解答各种疑难问题,包括自学Java路线、职业规划、面试问题等等。大彬会**优先解答**球友的问题。
-View,视图是指用户看到并与之交互的界面。比如由html元素组成的网页界面,或者软件的客户端界面。MVC的好处之一在于它能为应用程序处理很多不同的视图。在视图中其实没有真正的处理发生,它只是作为一种输出数据并允许用户操纵的方式。
+
-model,模型是指模型表示业务规则。在MVC的三个部件中,模型拥有最多的处理任务。被模型返回的数据是中立的,模型与数据格式无关,这样一个模型能为多个视图提供数据,由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性。
+
-controller,控制器是指控制器接受用户的输入并调用模型和视图去完成用户的需求,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示返回的数据。
+
-## SpringMVC 有哪些优点?
+星球还有很多其他**优质资料**,比如包括Java项目、进阶知识、实战经验总结、优质书籍、笔试面试资源等等。
-1. 与 Spring 集成使用非常方便,生态好。
-2. 配置简单,快速上手。
-3. 支持 RESTful 风格。
-4. 支持各种视图技术,支持各种请求资源映射策略。
+
-## Spring MVC和Struts的区别
+
-1. Spring MVC是基于方法开发,Struts2是基于类开发的。
- - Spring MVC会将用户请求的URL路径信息与Controller的某个方法进行映射,所有请求参数会注入到对应方法的形参上,生成Handler对象,对象中只有一个方法;
- - Struts每处理一次请求都会实例一个Action,Action类的所有方法使用的请求参数都是Action类中的成员变量,随着方法增多,整个Action也会变得混乱。
-2. Spring MVC支持单例开发模式,Struts只能使用多例
+
- - Struts由于只能通过类的成员变量接收参数,故只能使用多例。
-3. Struts2 的核心是基于一个Filter即StrutsPreparedAndExcuteFilter,Spring MVC的核心是基于一个Servlet即DispatcherServlet(前端控制器)。
-4. Struts处理速度稍微比Spring MVC慢,Struts使用了Struts标签,加载数据较慢。
+怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-## Spring MVC的工作原理
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-Spring MVC的工作原理如下:
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
-1. DispatcherServlet 接收用户的请求
-2. 找到用于处理request的 handler 和 Interceptors,构造成 HandlerExecutionChain 执行链
-3. 找到 handler 相对应的 HandlerAdapter
-4. 执行所有注册拦截器的preHandler方法
-5. 调用 HandlerAdapter 的 handle() 方法处理请求,返回 ModelAndView
-6. 倒序执行所有注册拦截器的postHandler方法
-7. 请求视图解析和视图渲染
-
-
-
-## Spring MVC的主要组件?
-
-- 前端控制器(DispatcherServlet):接收用户请求,给用户返回结果。
-- 处理器映射器(HandlerMapping):根据请求的url路径,通过注解或者xml配置,寻找匹配的Handler。
-- 处理器适配器(HandlerAdapter):Handler 的适配器,调用 handler 的方法处理请求。
-- 处理器(Handler):执行相关的请求处理逻辑,并返回相应的数据和视图信息,将其封装到ModelAndView对象中。
-- 视图解析器(ViewResolver):将逻辑视图名解析成真正的视图View。
-- 视图(View):接口类,实现类可支持不同的View类型(JSP、FreeMarker、Excel等)。
-
-## Spring MVC的常用注解由有哪些?
-- @Controller:用于标识此类的实例是一个控制器。
-- @RequestMapping:映射Web请求(访问路径和参数)。
-- @ResponseBody:注解返回数据而不是返回页面
-- @RequestBody:注解实现接收 http 请求的 json 数据,将 json 数据转换为 java 对象。
-- @PathVariable:获得URL中路径变量中的值
-- @RestController:@Controller+@ResponseBody
-- @ExceptionHandler标识一个方法为全局异常处理的方法。
-
-## @Controller 注解有什么用?
-
-`@Controller` 注解标记一个类为 Spring Web MVC 控制器。Spring MVC 会将扫描到该注解的类,然后扫描这个类下面带有 `@RequestMapping` 注解的方法,根据注解信息,为这个方法生成一个对应的处理器对象,在上面的 HandlerMapping 和 HandlerAdapter组件中讲到过。
-
-当然,除了添加 `@Controller` 注解这种方式以外,你还可以实现 Spring MVC 提供的 `Controller` 或者 `HttpRequestHandler` 接口,对应的实现类也会被作为一个处理器对象
-
-## @RequestMapping 注解有什么用?
-
-`@RequestMapping` 注解,用于配置处理器的 HTTP 请求方法,URI等信息,这样才能将请求和方法进行映射。这个注解可以作用于类上面,也可以作用于方法上面,在类上面一般是配置这个控制器的 URI 前缀。
-
-## @RestController 和 @Controller 有什么区别?
-
-`@RestController` 注解,在 `@Controller` 基础上,增加了 `@ResponseBody` 注解,更加适合目前前后端分离的架构下,提供 Restful API ,返回 JSON 数据格式。
-
-## @RequestMapping 和 @GetMapping 注解有什么不同?
-
-1. `@RequestMapping`:可注解在类和方法上;`@GetMapping` 仅可注册在方法上
-2. `@RequestMapping`:可进行 GET、POST、PUT、DELETE 等请求方法;`@GetMapping` 是 `@RequestMapping` 的 GET 请求方法的特例。
-
-## @RequestParam 和 @PathVariable 两个注解的区别
-
-两个注解都用于方法参数,获取参数值的方式不同,`@RequestParam` 注解的参数从请求携带的参数中获取,而 `@PathVariable` 注解从请求的 URI 中获取
-
-## @RequestBody和@RequestParam的区别
-
-@RequestBody一般处理的是在ajax请求中声明contentType: "application/json; charset=utf-8"时候。也就是json数据或者xml数据。
-
-@RequestParam一般就是在ajax里面没有声明contentType的时候,为默认的`x-www-form-urlencoded`格式时。
-
-## Spring MVC的异常处理
-
-可以将异常抛给Spring框架,由Spring框架来处理;我们只需要配置简单的异常处理器,在异常处理器中添视图页面即可。
-
-- 使用系统定义好的异常处理器 SimpleMappingExceptionResolver
-- 使用自定义异常处理器
-- 使用异常处理注解
-
-## SpringMVC 用什么对象从后台向前台传递数据的?
-
-1. 将数据绑定到 request;
-2. 返回 ModelAndView;
-3. 通过ModelMap对象,可以在这个对象里面调用put方法,把对象加到里面,前端就可以通过el表达式拿到;
-4. 绑定数据到 Session中。
-
-## SpringMvc的Controller是不是单例模式?
-
-单例模式。在多线程访问的时候有线程安全问题,解决方案是在控制器里面不要写可变状态量,如果需要使用这些可变状态,可以使用ThreadLocal,为每个线程单独生成一份变量副本,独立操作,互不影响。
-
-## 介绍下 Spring MVC 拦截器?
-
-Spring MVC 拦截器对应HandlerInterceor接口,该接口位于org.springframework.web.servlet的包中,定义了三个方法,若要实现该接口,就要实现其三个方法:
-
-1. **前置处理(preHandle()方法)**:该方法在执行控制器方法之前执行。返回值为Boolean类型,如果返回false,表示拦截请求,不再向下执行,如果返回true,表示放行,程序继续向下执行(如果后面没有其他Interceptor,就会执行controller方法)。所以此方法可对请求进行判断,决定程序是否继续执行,或者进行一些初始化操作及对请求进行预处理。
-2. **后置处理(postHandle()方法)**:该方法在执行控制器方法调用之后,且在返回ModelAndView之前执行。由于该方法会在DispatcherServlet进行返回视图渲染之前被调用,所以此方法多被用于处理返回的视图,可通过此方法对请求域中的模型和视图做进一步的修改。
-3. **已完成处理(afterCompletion()方法)**:该方法在执行完控制器之后执行,由于是在Controller方法执行完毕后执行该方法,所以该方法适合进行一些资源清理,记录日志信息等处理操作。
-
-可以通过拦截器进行权限检验,参数校验,记录日志等操作
-
-## SpringMvc怎么配置拦截器?
-
-有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器类,接着在接口方法当中,实现处理逻辑;然后在SpringMvc的配置文件中配置拦截器即可:
-
-```java
-
-
-
-
-
-
-
-
-
-
-```
-
-## Spring MVC 的拦截器和 Filter 过滤器有什么差别?
-
-有以下几点:
-
-- **功能相同**:拦截器和 Filter 都能实现相应的功能
-- **容器不同**:拦截器构建在 Spring MVC 体系中;Filter 构建在 Servlet 容器之上
-- **使用便利性不同**:拦截器提供了三个方法,分别在不同的时机执行;过滤器仅提供一个方法
-
-## 什么是REST?
-
-REST,英文全称,Resource Representational State Transfer,对资源的访问状态的变化通过url的变化表述出来。
-
-Resource:**资源**。资源是REST架构或者说整个网络处理的核心。
-
-Representational:**某种表现形式**,比如用JSON,XML,JPEG等。
-
-State Transfer:**状态变化**。通过HTTP method实现。
-
-REST描述的是在网络中client和server的一种交互形式。用大白话来说,就是**通过URL就知道要什么资源,通过HTTP method就知道要干什么,通过HTTP status code就知道结果如何**。
-
-举个例子:
-
-```java
-GET /tasks 获取所有任务
-POST /tasks 创建新任务
-GET /tasks/{id} 通过任务id获取任务
-PUT /tasks/{id} 更新任务
-DELETE /tasks/{id} 删除任务
-```
-
-GET代表获取一个资源,POST代表添加一个资源,PUT代表修改一个资源,DELETE代表删除一个资源。
-
-server提供的RESTful API中,URL中只使用名词来指定资源,原则上不使用动词。用`HTTP Status Code`传递server的状态信息。比如最常用的 200 表示成功,500 表示Server内部错误等。
-
-## 使用REST有什么优势呢?
-
-第一,**风格统一**了,不会出现`delUser/deleteUser/removeUser`各种命名的代码了。
-
-第二,**面向资源**,一目了然,具有自解释性。
-
-第三,**充分利用 HTTP 协议本身语义**。
-
-
+
\ No newline at end of file
diff --git a/docs/java/java-basic.md b/docs/java/java-basic.md
index 5a4b19a..ad1b6a4 100644
--- a/docs/java/java-basic.md
+++ b/docs/java/java-basic.md
@@ -95,6 +95,19 @@ JRE是Java的运行环境,并不是一个开发环境,所以没有包含任

+
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
## Java程序是编译执行还是解释执行?
先看看什么是编译型语言和解释型语言。
@@ -274,6 +287,8 @@ Integer x = 1; // 装箱 调⽤ Integer.valueOf(1)
int y = x; // 拆箱 调⽤了 X.intValue()
```
+## 两个Integer 用== 比较不相等的原因
+
下面看一道常见的面试题:
```java
@@ -293,7 +308,7 @@ true
false
```
-为什么第三个输出是false?看看 Integer 类的源码就知道啦。
+为什么第二个输出是false?看看 Integer 类的源码就知道啦。
```java
public static Integer valueOf(int i) {
@@ -303,7 +318,7 @@ public static Integer valueOf(int i) {
}
```
-`Integer c = 200;` 会调用 调⽤`Integer.valueOf(200)`。而从Integer的valueOf()源码可以看到,这里的实现并不是简单的new Integer,而是用IntegerCache做一个cache。
+`Integer c = 200;` 会调用`Integer.valueOf(200)`。而从Integer的valueOf()源码可以看到,这里的实现并不是简单的new Integer,而是用IntegerCache做一个cache。
```java
private static class IntegerCache {
@@ -1509,21 +1524,19 @@ server {
过滤器和拦截器底层实现不同。过滤器是基于函数回调的,拦截器是基于Java的反射机制(动态代理)实现的。一般自定义的过滤器中都会实现一个doFilter()方法,这个方法有一个FilterChain参数,而实际上它是一个回调接口。
-2、**使用范围不同**。
-
-过滤器实现的是 javax.servlet.Filter 接口,而这个接口是在Servlet规范中定义的,也就是说过滤器Filter的使用要依赖于Tomcat等容器,导致它只能在web程序中使用。而拦截器是一个Spring组件,并由Spring容器管理,并不依赖Tomcat等容器,是可以单独使用的。拦截器不仅能应用在web程序中,也可以用于Application、Swing等程序中。
+2、**触发时机不同**。
-3、**使用的场景不同**。
+过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
-因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
+拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
-4、**触发时机不同**。
+
-过滤器Filter是在请求进入容器后,但在进入servlet之前进行预处理,请求结束是在servlet处理完以后。
+3、**使用的场景不同**。
-拦截器 Interceptor 是在请求进入servlet后,在进入Controller之前进行预处理的,Controller 中渲染了对应的视图之后请求结束。
+因为拦截器更接近业务系统,所以拦截器主要用来实现项目中的业务判断的,比如:日志记录、权限判断等业务。而过滤器通常是用来实现通用功能过滤的,比如:敏感词过滤、响应数据压缩等功能。
-5、**拦截的请求范围不同**。
+4、**拦截的请求范围不同**。
请求的执行顺序是:请求进入容器 -> 进入过滤器 -> 进入 Servlet -> 进入拦截器 -> 执行控制器。可以看到过滤器和拦截器的执行时机也是不同的,过滤器会先执行,然后才会执行拦截器,最后才会进入真正的要调用的方法。
@@ -1628,5 +1641,17 @@ server {
> 参考:https://juejin.cn/post/7167153109158854687
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
+
+
+

diff --git a/docs/java/java-collection.md b/docs/java/java-collection.md
index 76f73f0..df13bad 100644
--- a/docs/java/java-collection.md
+++ b/docs/java/java-collection.md
@@ -152,7 +152,7 @@ HashMap有扩容机制,就是当达到扩容条件时会进行扩容。扩容
如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容。而HashMap每次扩容都需要重建hash表,非常影响性能。所以建议开发者在创建HashMap的时候指定初始化容量。
-### 扩容过程?
+### HashMap扩容过程是怎样的?
1.8扩容机制:当元素个数大于`threshold`时,会进行扩容,使用2倍容量的数组代替原有数组。采用尾插入的方式将原数组元素拷贝到新数组。1.8扩容之后链表元素相对位置没有变化,而1.7扩容之后链表元素会倒置。
@@ -160,7 +160,7 @@ HashMap有扩容机制,就是当达到扩容条件时会进行扩容。扩容
原数组的元素在重新计算hash之后,因为数组容量n变为2倍,那么n-1的mask范围在高位多1bit。在元素拷贝过程不需要重新计算元素在数组中的位置,只需要看看原来的hash值新增的那个bit是1还是0,是0的话索引没变,是1的话索引变成“原索引+oldCap”(根据`e.hash & oldCap == 0`判断) 。这样可以省去重新计算hash值的时间,而且由于新增的1bit是0还是1可以认为是随机的,因此resize的过程会均匀的把之前的冲突的节点分散到新的bucket。
-### put方法流程?
+### 说说HashMapput方法的流程?
1. 如果table没有初始化就先进行初始化过程
2. 使用hash算法计算key的索引
diff --git a/docs/java/java-concurrent.md b/docs/java/java-concurrent.md
index bb62dcc..09c408f 100644
--- a/docs/java/java-concurrent.md
+++ b/docs/java/java-concurrent.md
@@ -22,7 +22,9 @@ head:
## 线程池
-线程池:一个管理线程的池子。
+### 什么是线程池,如何使用?为什么要使用线程池?
+
+线程池就是事先将多个线程对象放到一个容器中,使用的时候就不用new线程而是直接去池中拿线程即可,节省了开辟子线程的时间,提高了代码执行效率。
### 为什么平时都是使用线程池创建线程,直接new一个线程不好吗?
@@ -35,7 +37,7 @@ head:
系统资源有限,每个人针对不同业务都可以手动创建线程,并且创建线程没有统一标准,比如创建的线程有没有名字等。当系统运行起来,所有线程都在抢占资源,毫无规则,混乱场面可想而知,不好管控。
-**频繁手动创建线程为什么开销会大?跟new Object() 有什么差别?**
+### 频繁手动创建线程为什么开销会大?跟new Object() 有什么差别?
虽然Java中万物皆对象,但是new Thread() 创建一个线程和 new Object()还是有区别的。
@@ -231,6 +233,14 @@ executor提供一个原生函数isTerminated()来判断线程池中的任务是
- 调用new Thread()创建的线程缺乏管理,可以无限制的创建,线程之间的相互竞争会导致过多占用系统资源而导致系统瘫痪
- 直接使用new Thread()启动的线程不利于扩展,比如定时执行、定期执行、定时定期执行、线程中断等都不好实现
+## execute和submit的区别
+
+execute只能提交Runnable类型的任务,无返回值。submit既可以提交Runnable类型的任务,也可以提交Callable类型的任务,会有一个类型为Future的返回值,但当任务类型为Runnable时,返回值为null。
+
+execute在执行任务时,如果遇到异常会直接抛出,而submit不会直接抛出,只有在使用Future的get方法获取返回值时,才会抛出异常
+
+execute所属顶层接口是Executor,submit所属顶层接口是ExecutorService,实现类ThreadPoolExecutor重写了execute方法,抽象类AbstractExecutorService重写了submit方法。
+
## 进程线程
进程是指一个内存中运行的应用程序,每个进程都有自己独立的一块内存空间。
@@ -725,9 +735,23 @@ class SeasonThreadTask implements Runnable{
## ThreadLocal
+### ThreadLocal是什么
+
线程本地变量。当使用`ThreadLocal`维护变量时,`ThreadLocal`为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程。
-### ThreadLocal原理
+### 为什么要使用ThreadLocal?
+
+并发场景下,会存在多个线程同时修改一个共享变量的场景。这就可能会出现**线性安全问题**。
+
+为了解决线性安全问题,可以用加锁的方式,比如使用`synchronized` 或者`Lock`。但是加锁的方式,可能会导致系统变慢。
+
+还有另外一种方案,就是使用空间换时间的方式,即使用`ThreadLocal`。使用`ThreadLocal`类访问共享变量时,会在每个线程的本地,都保存一份共享变量的拷贝副本。多线程对共享变量修改时,实际上操作的是这个变量副本,从而保证线性安全。
+
+### Thread和ThreadLocal有什么联系呢?
+
+Thread和ThreadLocal是绑定的, ThreadLocal依赖于Thread去执行, Thread将需要隔离的数据存放到ThreadLocal(准确的讲是ThreadLocalMap)中,来实现多线程处理。
+
+### 说说ThreadLocal的原理?
每个线程都有一个`ThreadLocalMap`(`ThreadLocal`内部类),Map中元素的键为`ThreadLocal`,而值对应线程的变量副本。
@@ -1238,4 +1262,115 @@ epoll的时间复杂度O(1)。epoll可以理解为event poll,不同于忙轮
> 参考链接:https://blog.csdn.net/u014209205/article/details/80598209
+## ReadWriteLock 和 StampedLock 的区别
+
+在多线程编程中,对于共享资源的访问控制是一个非常重要的问题。在并发环境下,多个线程同时访问共享资源可能会导致数据不一致的问题,因此需要一种机制来保证数据的一致性和并发性。
+
+Java提供了多种机制来实现并发控制,其中 ReadWriteLock 和 StampedLock 是两个常用的锁类。本文将分别介绍这两个类的特性、使用场景以及示例代码。
+
+**ReadWriteLock**
+
+ReadWriteLock 是Java提供的一个接口,全类名:`java.util.concurrent.locks.ReentrantLock`。它允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种机制可以提高读取操作的并发性,但写入操作需要独占资源。
+
+**特性**
+
+- 多个线程可以同时获取读锁,但只有一个线程可以获取写锁。
+- 当一个线程持有写锁时,其他线程无法获取读锁和写锁,读写互斥。
+- 当一个线程持有读锁时,其他线程可以同时获取读锁,读读共享。
+
+**使用场景**
+
+**ReadWriteLock** 适用于读多写少的场景,例如缓存系统、数据库连接池等。在这些场景中,读取操作占据大部分时间,而写入操作较少。
+
+**示例代码**
+
+下面是一个使用 ReadWriteLock 的示例,实现了一个简单的缓存系统:
+
+```java
+public class Cache {
+ private Map data = new HashMap<>();
+ private ReadWriteLock lock = new ReentrantReadWriteLock();
+
+ public Object get(String key) {
+ lock.readLock().lock();
+ try {
+ return data.get(key);
+ } finally {
+ lock.readLock().unlock();
+ }
+ }
+
+ public void put(String key, Object value) {
+ lock.writeLock().lock();
+ try {
+ data.put(key, value);
+ } finally {
+ lock.writeLock().unlock();
+ }
+ }
+}
+```
+
+在上述示例中,Cache 类使用 ReadWriteLock 来实现对 data 的并发访问控制。get 方法获取读锁并读取数据,put 方法获取写锁并写入数据。
+
+**StampedLock**
+
+StampedLock 是Java 8 中引入的一种新的锁机制,全类名:`java.util.concurrent.locks.StampedLock`,它提供了一种乐观读的机制,可以进一步提升读取操作的并发性能。
+
+**特性**
+
+- 与 ReadWriteLock 类似,StampedLock 也支持多个线程同时获取读锁,但只允许一个线程获取写锁。
+- 与 ReadWriteLock 不同的是,StampedLock 还提供了一个乐观读锁(Optimistic Read Lock),即不阻塞其他线程的写操作,但在读取完成后需要验证数据的一致性。
+
+**使用场景**
+
+StampedLock 适用于读远远大于写的场景,并且对数据的一致性要求不高,例如统计数据、监控系统等。
+
+**示例代码**
+
+下面是一个使用 StampedLock 的示例,实现了一个计数器:
+
+```java
+public class Counter {
+ private int count = 0;
+ private StampedLock lock = new StampedLock();
+
+ public int getCount() {
+ long stamp = lock.tryOptimisticRead();
+ int value = count;
+ if (!lock.validate(stamp)) {
+ stamp = lock.readLock();
+ try {
+ value = count;
+ } finally {
+ lock.unlockRead(stamp);
+ }
+ }
+ return value;
+ }
+
+ public void increment() {
+ long stamp = lock.writeLock();
+ try {
+ count++;
+ } finally {
+ lock.unlockWrite(stamp);
+ }
+ }
+}
+```
+
+在上述示例中,Counter 类使用 StampedLock 来实现对计数器的并发访问控制。getCount 方法首先尝试获取乐观读锁,并读取计数器的值,然后通过 validate 方法验证数据的一致性。如果验证失败,则获取悲观读锁,并重新读取计数器的值。increment 方法获取写锁,并对计数器进行递增操作。
+
+**总结**
+
+**ReadWriteLock** 和 **StampedLock** 都是Java中用于并发控制的重要机制。
+
+- **ReadWriteLock** 适用于读多写少的场景;
+- **StampedLock** 则适用于读远远大于写的场景,并且对数据的一致性要求不高;
+
+在实际应用中,我们需要根据具体场景来选择合适的锁机制。通过合理使用这些锁机制,我们可以提高并发程序的性能和可靠性。
+
+
+

diff --git a/docs/java/jvm.md b/docs/java/jvm.md
index 8690bfc..5400aac 100644
--- a/docs/java/jvm.md
+++ b/docs/java/jvm.md
@@ -26,6 +26,8 @@
怎么加入[知识星球](https://topjavaer.cn/zsxq/introduce.html)?
-**扫描以下二维码**领取50元的优惠券即可加入。星球定价**158**元,减去**50**元的优惠券,等于说只需要**108**元的价格就可以加入,服务期一年,**每天不到三毛钱**(0.29元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
+**扫描以下二维码**领取50元的优惠券即可加入。星球定价**188**元,减去**50**元的优惠券,等于说只需要**138**元的价格就可以加入,服务期一年,**每天只要4毛钱**(0.37元),相比培训班几万块的学费,非常值了,星球提供的服务可以说**远超**门票价格了。
-
\ No newline at end of file
+随着星球内容不断积累,星球定价也会不断**上涨**(最初原价**68**元,现在涨到**188**元了,后面还会持续**上涨**),所以,想提升自己的小伙伴要趁早加入,**早就是优势**(优惠券只有50个名额,用完就恢复**原价**了)。
+
+
\ No newline at end of file
diff --git a/docs/learn/ghelper.md b/docs/learn/ghelper.md
index a640f63..f5de885 100644
--- a/docs/learn/ghelper.md
+++ b/docs/learn/ghelper.md
@@ -1,4 +1,17 @@
-# 科学上网教程
+---
+sidebar: heading
+title: 科学上网教程
+category: 工具
+tag:
+ - 工具
+head:
+ - - meta
+ - name: keywords
+ content: ghelper
+ - - meta
+ - name: description
+ content: 提高工作效率的工具
+---
@@ -64,10 +77,16 @@ Ghelper可以在google play商店进行下载,需要访问google商店,无
-> 最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、架构、分布式、微服务、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-
-
+最后给大家分享一个Github仓库,上面有大彬整理的**300多本经典的计算机书籍PDF**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~
-**Github地址**:https://github.com/Tyson0314/java-books
\ No newline at end of file
+
+
+
+
+[**Github地址**](https://github.com/Tyson0314/java-books)
+
+如果访问不了Github,可以访问码云地址。
+
+[码云地址](https://gitee.com/tysondai/java-books)
\ No newline at end of file
diff --git a/docs/note/README.md b/docs/note/README.md
new file mode 100644
index 0000000..3a19bc2
--- /dev/null
+++ b/docs/note/README.md
@@ -0,0 +1,6 @@
+- [一小时彻底吃透Redis](https://topjavaer.cn/note/redis-note.html)
+- [21个写SQL的好习惯](https://topjavaer.cn/note/write-sql.html)
+- [Docker详解与部署微服务实战](https://topjavaer.cn/note/docker-note.html)
+- [计算机专业的同学都看看这几点建议](https://topjavaer.cn/note/computor-advice.html)
+- [建议计算机专业同学都看看这门课](https://topjavaer.cn/note/computor-advice.html)
+
diff --git a/docs/note/docker-note.md b/docs/note/docker-note.md
new file mode 100644
index 0000000..68a8f62
--- /dev/null
+++ b/docs/note/docker-note.md
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/note/redis-note.md b/docs/note/redis-note.md
new file mode 100644
index 0000000..02e5569
--- /dev/null
+++ b/docs/note/redis-note.md
@@ -0,0 +1,28 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 一小时彻底吃透Redis
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs/note/write-sql.md b/docs/note/write-sql.md
new file mode 100644
index 0000000..14faa3a
--- /dev/null
+++ b/docs/note/write-sql.md
@@ -0,0 +1,93 @@
+::: tip 这是一则或许对你有帮助的信息
+
+- **面试手册**:这是一份大彬精心整理的[**大厂面试手册**](https://topjavaer.cn/zsxq/mianshishouce.html)最新版,目前已经更新迭代了**19**个版本,质量很高(专为面试打造)
+- **知识星球**:**专属面试手册/一对一交流/简历修改/超棒的学习氛围/学习路线规划**,欢迎加入[大彬的知识星球](https://topjavaer.cn/zsxq/introduce.html)(点击链接查看星球的详细介绍)
+
+:::
+
+## 21个写SQL的好习惯
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## MySQL面试题
+
+下面分享MySQL常考的**面试题目**。
+
+- [事务的四大特性?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E7%9A%84%E5%9B%9B%E5%A4%A7%E7%89%B9%E6%80%A7)
+- [数据库的三大范式](https://topjavaer.cn/database/mysql.html#%E6%95%B0%E6%8D%AE%E5%BA%93%E7%9A%84%E4%B8%89%E5%A4%A7%E8%8C%83%E5%BC%8F)
+- [事务隔离级别有哪些?](https://topjavaer.cn/database/mysql.html#%E4%BA%8B%E5%8A%A1%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [生产环境数据库一般用的什么隔离级别呢?](https://topjavaer.cn/database/mysql.html#%E7%94%9F%E4%BA%A7%E7%8E%AF%E5%A2%83%E6%95%B0%E6%8D%AE%E5%BA%93%E4%B8%80%E8%88%AC%E7%94%A8%E7%9A%84%E4%BB%80%E4%B9%88%E9%9A%94%E7%A6%BB%E7%BA%A7%E5%88%AB%E5%91%A2)
+- [编码和字符集的关系](https://topjavaer.cn/database/mysql.html#%E7%BC%96%E7%A0%81%E5%92%8C%E5%AD%97%E7%AC%A6%E9%9B%86%E7%9A%84%E5%85%B3%E7%B3%BB)
+- [utf8和utf8mb4的区别](https://topjavaer.cn/database/mysql.html#utf8%E5%92%8Cutf8mb4%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [什么是索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E7%B4%A2%E5%BC%95)
+- [索引的优缺点?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BC%98%E7%BC%BA%E7%82%B9)
+- [索引的作用?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E4%BD%9C%E7%94%A8)
+- [什么情况下需要建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E9%9C%80%E8%A6%81%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [什么情况下不建索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%83%85%E5%86%B5%E4%B8%8B%E4%B8%8D%E5%BB%BA%E7%B4%A2%E5%BC%95)
+- [索引的数据结构](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
+- [Hash索引和B+树索引的区别?](https://topjavaer.cn/database/mysql.html#hash%E7%B4%A2%E5%BC%95%E5%92%8Cb%E6%A0%91%E7%B4%A2%E5%BC%95%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [为什么B+树比B树更适合实现数据库索引?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88b%E6%A0%91%E6%AF%94b%E6%A0%91%E6%9B%B4%E9%80%82%E5%90%88%E5%AE%9E%E7%8E%B0%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B4%A2%E5%BC%95)
+- [索引有什么分类?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E6%9C%89%E4%BB%80%E4%B9%88%E5%88%86%E7%B1%BB)
+- [什么是最左匹配原则?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E6%9C%80%E5%B7%A6%E5%8C%B9%E9%85%8D%E5%8E%9F%E5%88%99)
+- [什么是聚集索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%81%9A%E9%9B%86%E7%B4%A2%E5%BC%95)
+- [什么是覆盖索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E8%A6%86%E7%9B%96%E7%B4%A2%E5%BC%95)
+- [索引的设计原则?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E7%9A%84%E8%AE%BE%E8%AE%A1%E5%8E%9F%E5%88%99)
+- [索引什么时候会失效?](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%BB%80%E4%B9%88%E6%97%B6%E5%80%99%E4%BC%9A%E5%A4%B1%E6%95%88)
+- [什么是前缀索引?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%89%8D%E7%BC%80%E7%B4%A2%E5%BC%95)
+- [索引下推](https://topjavaer.cn/database/mysql.html#%E7%B4%A2%E5%BC%95%E4%B8%8B%E6%8E%A8)
+- [常见的存储引擎有哪些?](https://topjavaer.cn/database/mysql.html#%E5%B8%B8%E8%A7%81%E7%9A%84%E5%AD%98%E5%82%A8%E5%BC%95%E6%93%8E%E6%9C%89%E5%93%AA%E4%BA%9B)
+- [MyISAM和InnoDB的区别?](https://topjavaer.cn/database/mysql.html#myisam%E5%92%8Cinnodb%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL有哪些锁?](https://topjavaer.cn/database/mysql.html#mysql%E6%9C%89%E5%93%AA%E4%BA%9B%E9%94%81)
+- [MVCC 实现原理?](https://topjavaer.cn/database/mysql.html#mvcc-%E5%AE%9E%E7%8E%B0%E5%8E%9F%E7%90%86)
+- [快照读和当前读](https://topjavaer.cn/database/mysql.html#%E5%BF%AB%E7%85%A7%E8%AF%BB%E5%92%8C%E5%BD%93%E5%89%8D%E8%AF%BB)
+- [共享锁和排他锁](https://topjavaer.cn/database/mysql.html#%E5%85%B1%E4%BA%AB%E9%94%81%E5%92%8C%E6%8E%92%E4%BB%96%E9%94%81)
+- [bin log/redo log/undo log](https://topjavaer.cn/database/mysql.html#bin-logredo-logundo-log)
+- [bin log和redo log有什么区别?](https://topjavaer.cn/database/mysql.html#bin-log%E5%92%8Credo-log%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [讲一下MySQL架构?](https://topjavaer.cn/database/mysql.html#%E8%AE%B2%E4%B8%80%E4%B8%8Bmysql%E6%9E%B6%E6%9E%84)
+- [分库分表](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [什么是分区表?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AF%E5%88%86%E5%8C%BA%E8%A1%A8)
+- [分区表类型](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E8%A1%A8%E7%B1%BB%E5%9E%8B)
+- [分区的问题?](https://topjavaer.cn/database/mysql.html#%E5%88%86%E5%8C%BA%E7%9A%84%E9%97%AE%E9%A2%98)
+- [查询语句执行流程?](https://topjavaer.cn/database/mysql.html#%E6%9F%A5%E8%AF%A2%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B)
+- [更新语句执行过程?](https://topjavaer.cn/database/mysql.html#%E6%9B%B4%E6%96%B0%E8%AF%AD%E5%8F%A5%E6%89%A7%E8%A1%8C%E8%BF%87%E7%A8%8B)
+- [exist和in的区别?](https://topjavaer.cn/database/mysql.html#exist%E5%92%8Cin%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中int()和char()的区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADint10%E5%92%8Cchar10%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [truncate、delete与drop区别?](https://topjavaer.cn/database/mysql.html#truncatedelete%E4%B8%8Edrop%E5%8C%BA%E5%88%AB)
+- [having和where区别?](https://topjavaer.cn/database/mysql.html#having%E5%92%8Cwhere%E5%8C%BA%E5%88%AB)
+- [什么是MySQL主从同步?](https://topjavaer.cn/database/mysql.html#%E4%BB%80%E4%B9%88%E6%98%AFmysql%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [为什么要做主从同步?](https://topjavaer.cn/database/mysql.html#%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E5%81%9A%E4%B8%BB%E4%BB%8E%E5%90%8C%E6%AD%A5)
+- [乐观锁和悲观锁是什么?](https://topjavaer.cn/database/mysql.html#%E4%B9%90%E8%A7%82%E9%94%81%E5%92%8C%E6%82%B2%E8%A7%82%E9%94%81%E6%98%AF%E4%BB%80%E4%B9%88)
+- [用过processlist吗?](https://topjavaer.cn/database/mysql.html#%E7%94%A8%E8%BF%87processlist%E5%90%97)
+- [MySQL查询 limit 1000,10 和limit 10 速度一样快吗?](https://topjavaer.cn/database/mysql.html#mysql%E6%9F%A5%E8%AF%A2-limit-100010-%E5%92%8Climit-10-%E9%80%9F%E5%BA%A6%E4%B8%80%E6%A0%B7%E5%BF%AB%E5%90%97)
+- [深分页怎么优化?](https://topjavaer.cn/database/mysql.html#%E6%B7%B1%E5%88%86%E9%A1%B5%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [高度为3的B+树,可以存放多少数据?](https://topjavaer.cn/database/mysql.html#%E9%AB%98%E5%BA%A6%E4%B8%BA3%E7%9A%84b%E6%A0%91%E5%8F%AF%E4%BB%A5%E5%AD%98%E6%94%BE%E5%A4%9A%E5%B0%91%E6%95%B0%E6%8D%AE)
+- [MySQL单表多大进行分库分表?](https://topjavaer.cn/database/mysql.html#mysql%E5%8D%95%E8%A1%A8%E5%A4%9A%E5%A4%A7%E8%BF%9B%E8%A1%8C%E5%88%86%E5%BA%93%E5%88%86%E8%A1%A8)
+- [大表查询慢怎么优化?](https://topjavaer.cn/database/mysql.html#%E5%A4%A7%E8%A1%A8%E6%9F%A5%E8%AF%A2%E6%85%A2%E6%80%8E%E4%B9%88%E4%BC%98%E5%8C%96)
+- [说说count()、count()和count()的区别](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4count1count%E5%92%8Ccount%E5%AD%97%E6%AE%B5%E5%90%8D%E7%9A%84%E5%8C%BA%E5%88%AB)
+- [MySQL中DATETIME 和 TIMESTAMP有什么区别?](https://topjavaer.cn/database/mysql.html#mysql%E4%B8%ADdatetime-%E5%92%8C-timestamp%E6%9C%89%E4%BB%80%E4%B9%88%E5%8C%BA%E5%88%AB)
+- [说说为什么不建议用外键?](https://topjavaer.cn/database/mysql.html#%E8%AF%B4%E8%AF%B4%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E5%BB%BA%E8%AE%AE%E7%94%A8%E5%A4%96%E9%94%AE)
+- [使用自增主键有什么好处?](https://topjavaer.cn/database/mysql.html#%E4%BD%BF%E7%94%A8%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E6%9C%89%E4%BB%80%E4%B9%88%E5%A5%BD%E5%A4%84)
+- [自增主键保存在什么地方?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%BF%9D%E5%AD%98%E5%9C%A8%E4%BB%80%E4%B9%88%E5%9C%B0%E6%96%B9)
+- [自增主键一定是连续的吗?](https://topjavaer.cn/database/mysql.html#%E8%87%AA%E5%A2%9E%E4%B8%BB%E9%94%AE%E4%B8%80%E5%AE%9A%E6%98%AF%E8%BF%9E%E7%BB%AD%E7%9A%84%E5%90%97)
+- [InnoDB的自增值为什么不能回收利用?](https://topjavaer.cn/database/mysql.html#innodb%E7%9A%84%E8%87%AA%E5%A2%9E%E5%80%BC%E4%B8%BA%E4%BB%80%E4%B9%88%E4%B8%8D%E8%83%BD%E5%9B%9E%E6%94%B6%E5%88%A9%E7%94%A8)
+- [MySQL数据如何同步到Redis缓存?](https://topjavaer.cn/database/mysql.html#mysql%E6%95%B0%E6%8D%AE%E5%A6%82%E4%BD%95%E5%90%8C%E6%AD%A5%E5%88%B0redis%E7%BC%93%E5%AD%98)
\ No newline at end of file
diff --git a/docs/other/site-diary.md b/docs/other/site-diary.md
index d9b9ac9..477801a 100644
--- a/docs/other/site-diary.md
+++ b/docs/other/site-diary.md
@@ -8,7 +8,22 @@ sidebar: heading
## 更新记录
+- 2024.06.11,更新-Redis大key怎么处理?
+
+- 2024.06.11,新增-聊聊如何用Redis 实现分布式锁?
+
+- 2024.06.07,更新-为什么Redis单线程还这么快?
+
+- 2024.05.21,新增一条SQL是怎么执行的
+
+- 2023.12.28,[增加源码解析模块,包含Sprign/SpringMVC/MyBatis(更新中)](/source/mybatis/1-overview.html)。
+
+- 2023.12.28,[遭受黑客攻击,植入木马程序](/zsxq/article/site-hack.html)。
+
+- 2023.08.10,分布式锁实现-[RedLock](http://topjavaer.cn/advance/distributed/2-distributed-lock.html)补充图片
+
- 2023.05.04,导航栏增加图标。
+
- 2023.05.01,新增[Tomcat基础知识总结](/web/tomcat.html)
- 2023.03.25,新增[TCP面试题](/computer-basic/tcp.html)、[MongoDB面试题](/database/mongodb.html)、[ZooKeeper面试题](/zookeeper/zk.html)
diff --git a/docs/redis/redis.md b/docs/redis/redis.md
index 8a6d471..0890449 100644
--- a/docs/redis/redis.md
+++ b/docs/redis/redis.md
@@ -20,6 +20,11 @@ head:
:::
+## 更新记录
+
+- 2024.1.7,新增[Redis存在线程安全问题吗?](##Redis存在线程安全问题吗?)
+- 2024.5.9,补充[Redis应用场景有哪些?](##Redis应用场景有哪些?)
+
## Redis是什么?
Redis(`Remote Dictionary Server`)是一个使用 C 语言编写的,高性能非关系型的键值对数据库。与传统数据库不同的是,Redis 的数据是存在内存中的,所以读写速度非常快,被广泛应用于缓存方向。Redis可以将数据写入磁盘中,保证了数据的安全不丢失,而且Redis的操作是原子性的。
@@ -72,12 +77,18 @@ Redis基于Reactor模式开发了网络事件处理器,这个处理器被称
## Redis应用场景有哪些?
-1. **缓存热点数据**,缓解数据库的压力。
-2. 利用 Redis 原子性的自增操作,可以实现**计数器**的功能,比如统计用户点赞数、用户访问数等。
-3. **分布式锁**。在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
-4. **简单的消息队列**,可以使用Redis自身的发布/订阅模式或者List来实现简单的消息队列,实现异步操作。
-5. **限速器**,可用于限制某个用户访问某个接口的频率,比如秒杀场景用于防止用户快速点击带来不必要的压力。
-6. **好友关系**,利用集合的一些命令,比如交集、并集、差集等,实现共同好友、共同爱好之类的功能。
+Redis作为一种优秀的基于key/value的缓存,有非常不错的性能和稳定性,无论是在工作中,还是面试中,都经常会出现。
+
+下面来聊聊Redis的常见的8种应用场景。
+
+1. **缓存热点数据**,缓解数据库的压力。例如:热点数据缓存(例如报表、明星出轨),对象缓存、全页缓存、可以提升热点数据的访问数据。
+2. **计数器**。利用 Redis 原子性的自增操作,可以实现**计数器**的功能,内存操作,性能非常好,非常适用于这些计数场景,比如统计用户点赞数、用户访问数等。为了保证数据实时效,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力。
+3. **分布式会话**。集群模式下,在应用不多的情况下一般使用容器自带的session复制功能就能满足,当应用增多相对复杂的系统中,一般都会搭建以Redis等内存数据库为中心的session服务,session不再由容器管理,而是由session服务及内存数据库管理。
+4. **分布式锁**。在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX(SET if Not eXists) 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
+5. **简单的消息队列**,消息队列是大型网站必用中间件,如ActiveMQ、RabbitMQ、Kafka等流行的消息队列中间件,主要用于业务解耦、流量削峰及异步处理实时性低的业务。可以使用Redis自身的发布/订阅模式或者List来实现简单的消息队列,实现异步操作。
+6. **限速器**,可用于限制某个用户访问某个接口的频率,比如秒杀场景用于防止用户快速点击带来不必要的压力。
+7. **社交网络**,点赞、踩、关注/被关注、共同好友等是社交网站的基本功能,社交网站的访问量通常来说比较大,而且传统的关系数据库类型不适合存储这种类型的数据,Redis提供的哈希、集合等数据结构能很方便的的实现这些功能。
+8. **排行榜**。很多网站都有排行榜应用的,如京东的月度销量榜单、商品按时间的上新排行榜等。Redis提供的有序集合数据类构能实现各种复杂的排行榜应用。
## Memcached和Redis的区别?
@@ -140,6 +151,22 @@ Redis基于Reactor模式开发了网络事件处理器,这个处理器被称
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
+## Redis存在线程安全问题吗?
+
+首先,从Redis 服务端层面分析。
+
+Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Server上执行的指令,不需要任何同步机制,不会存在线程安全问题。
+
+虽然Redis 6.0里面,增加了多线程的模型,但是增加的多线程只是用来处理网络IO事件,对于指令的执行过程,仍然是由主线程来处理,所以不会存在多个线程通知执行操作指令的情况。
+
+第二个,从Redis客户端层面分析。
+
+虽然Redis Server中的指令执行是原子的,但是如果有多个Redis客户端同时执行多个指令的时候,就无法保证原子性。
+
+假设两个redis client同时获取Redis Server上的key1, 同时进行修改和写入,因为多线程环境下的原子性无法被保障,以及多进程情况下的共享资源访问的竞争问题,使得数据的安全性无法得到保障。
+
+当然,对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
+
## keys命令存在的问题?
redis的单线程的。keys指令会导致线程阻塞一段时间,直到执行完毕,服务才能恢复。scan采用渐进式遍历的方式来解决keys命令可能带来的阻塞问题,每次scan命令的时间复杂度是`O(1)`,但是要真正实现keys的功能,需要执行多次scan。
@@ -787,4 +814,105 @@ Redis Server本身是一个线程安全的K-V数据库,也就是说在Redis Se
对于客户端层面的线程安全性问题,解决方法有很多,比如尽可能的使用Redis里面的原子指令,或者对多个客户端的资源访问加锁,或者通过Lua脚本来实现多个指令的操作等等。
+
+
+## Redis遇到哈希冲突怎么办?
+
+当有两个或以上数量的键被分配到了哈希表数组的同一个索引上面时, 我们称这些键发生了冲突(collision)。
+
+Redis 的哈希表使用链地址法(separate chaining)来解决键冲突: 每个哈希表节点都有一个 `next` 指针, 多个哈希表节点可以用 `next` 指针构成一个单向链表, 被分配到同一个索引上的多个节点可以用这个单向链表连接起来, 这就解决了键冲突的问题。
+
+原理跟 Java 的 HashMap 类似,都是数组+链表的结构。当发生 hash 碰撞时将会把元素追加到链表上。
+
+## Redis实现分布式锁有哪些方案?
+
+在这里分享六种Redis分布式锁的正确使用方式,由易到难。
+
+方案一:SETNX+EXPIRE
+
+方案二:SETNX+value值(系统时间+过期时间)
+
+方案三:使用Lua脚本(包含SETNX+EXPIRE两条指令)
+
+方案四::ET的扩展命令(SETEXPXNX)
+
+方案五:开源框架~Redisson
+
+方案六:多机实现的分布式锁Redlock
+
+**首先什么是分布式锁**?
+
+分布式锁是一种机制,用于确保在分布式系统中,多个节点在同一时刻只能有一个节点对共享资源进行操作。它是解决分布式环境下并发控制和数据一致性问题的关键技术之一。
+
+分布式锁的特征:
+
+1、「互斥性」:任意时刻,只有一个客户端能持有锁。
+
+2、「锁超时释放」:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁。
+
+3、「可重入性」“一个线程如果获取了锁之后,可以再次对其请求加锁。
+
+4、「安全性」:锁只能被持有的客户端删除,不能被其他客户端删除
+
+5、「高性能和高可用」:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效。
+
+
+
+**Redis分布式锁方案一:SETNX+EXPIRE**
+
+提到Redis的分布式锁,很多朋友可能就会想到setnx+expire命令。即先用setnx来抢锁,如果抢到之后,再用expire给锁设置一个过期时间,防止锁忘记了释放。SETNX是SETIF NOT EXISTS的简写。日常命令格式是SETNXkey value,如果 key不存在,则SETNX成功返回1,如果这个key已经存在了,则返回0。假设某电商网站的某商品做秒杀活动,key可以设置为key_resource_id,value设置任意值,伪代码如下:
+
+
+
+缺陷:加锁与设置过期时间是非原子操作,如果加锁后未来得及设置过期时间系统异常等,会导致其他线程永远获取不到锁。
+
+**Redis分布式锁方案二**:SETNX+value值(系统时间+过期时间)
+
+为了解决方案一,「发生异常锁得不到释放的场景」,有小伙伴认为,可以把过期时间放到setnx的value值里面。如果加锁失败,再拿出value值校验一下即可。
+
+这个方案的优点是,避免了expire 单独设置过期时间的操作,把「过期时间放到setnx的value值」里面来。解决了方案一发生异常,锁得不到释放的问题。
+
+但是这个方案有别的缺点:过期时间是客户端自己生成的(System.currentTimeMillis()是当前系统的时间),必须要求分布式环境下,每个客户端的时间必须同步。如果锁过期的时候,并发多个客户端同时请求过来,都执行jedis.get()和set(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。该锁没有保存持有者的唯一标识,可能坡别的客户端释放/解锁
+
+**分布式锁方案三:使用Lua脚本(包含SETNX+EXPIRE两条指令)**
+
+实际上,我们还可以使用Lua脚本来保证原子性(包含setnx和expire两条指令),lua脚本如下:
+
+
+
+加锁代码如下:
+
+
+
+**Redis分布式锁方案四:SET的扩展命令(SET EX PX NX)**
+
+除了使用,使用Lua脚本,保证SETNX+EXPIRE两条指令的原子性,我们还可以巧用Redis的SET指令扩展参数。(`SET key value[EX seconds]`PX milliseconds][NX|XX]`),它也是原子性的
+
+`SET key value[EX seconds][PX milliseconds][NX|XX]`
+
+1. NX:表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁, 才能获取。
+2. EXseconds:设定key的过期时间,时间单位是秒。
+3. PX milliseconds:设定key的过期时间,单位为毫秒。
+4. XX:仅当key存在时设置值。
+
+伪代码如下:
+
+
+
+**Redis分布式锁方案五:Redisson框架**
+
+方案四还是可能存在「锁过期释放,业务没执行完」的问题。设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。当前开源框架Redisson解决了这个问题。一起来看下Redisson底层原理图:
+
+
+
+只要线程一加锁成功,就会启动一个watchdog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了「锁过期释放,业务没执行完」问题。
+
+**分布式锁方案六:多机实现的分布式锁Redlock+Redisson**
+
+前面五种方案都是基于单机版的讨论,那么集群部署该怎么处理?
+
+答案是多机实现的分布式锁Redlock+Redisson
+
+
+

diff --git "a/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md" "b/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md"
new file mode 100644
index 0000000..b691b56
--- /dev/null
+++ "b/docs/source/mybatis/# MyBatis \346\272\220\347\240\201\345\210\206\346\236\220\357\274\210\344\270\203\357\274\211\357\274\232\346\216\245\345\217\243\345\261\202.md"
@@ -0,0 +1,266 @@
+# MyBatis 源码分析(七):接口层
+
+## sql 会话创建工厂
+
+`SqlSessionFactoryBuilder` 经过复杂的解析逻辑之后,会根据全局配置创建 `DefaultSqlSessionFactory`,该类是 `sql` 会话创建工厂抽象接口 `SqlSessionFactory` 的默认实现,其提供了若干 `openSession` 方法用于打开一个会话,在会话中进行相关数据库操作。这些 `openSession` 方法最终都会调用 `openSessionFromDataSource` 或 `openSessionFromConnection` 创建会话,即基于数据源配置创建还是基于已有连接对象创建。
+
+### 基于数据源配置创建会话
+
+要使用数据源打开一个会话需要先从全局配置中获取当前生效的数据源环境配置,如果没有生效配置或没用设置可用的事务工厂,就会创建一个 `ManagedTransactionFactory` 实例作为默认事务工厂实现,其与 `MyBatis` 提供的另一个事务工厂实现 `JdbcTransactionFactory` 的区别在于其生成的事务实现 `ManagedTransaction` 的提交和回滚方法是空实现,即希望将事务管理交由外部容器管理。
+
+```java
+ private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
+ Transaction tx = null;
+ try {
+ final Environment environment = configuration.getEnvironment();
+ // 获取事务工厂
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ // 创建事务配置
+ tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
+ // 创建执行器
+ final Executor executor = configuration.newExecutor(tx, execType);
+ // 创建 sql 会话
+ return new DefaultSqlSession(configuration, executor, autoCommit);
+ } catch (Exception e) {
+ closeTransaction(tx); // may have fetched a connection so lets call close()
+ throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 获取生效数据源环境配置的事务工厂
+ */
+ private TransactionFactory getTransactionFactoryFromEnvironment(Environment environment) {
+ if (environment == null || environment.getTransactionFactory() == null) {
+ // 未配置数据源环境或事务工厂,默认使用 ManagedTransactionFactory
+ return new ManagedTransactionFactory();
+ }
+ return environment.getTransactionFactory();
+ }
+```
+
+随后会根据入参传入的 `execType` 选择对应的执行器 `Executor`,`execType` 的取值来源于 `ExecutorType`,这是一个枚举类。在下一章将会详细分析各类 `Executor` 的作用及其实现。
+
+获取到事务工厂配置和执行器对象后会结合传入的数据源自动提交属性创建 `DefaultSqlSession`,即 `sql` 会话对象。
+
+### 基于数据库连接创建会话
+
+基于连接创建会话的流程大致与基于数据源配置创建相同,区别在于自动提交属性 `autoCommit` 是从连接对象本身获取的。
+
+```java
+ private SqlSession openSessionFromConnection(ExecutorType execType, Connection connection) {
+ try {
+ // 获取自动提交配置
+ boolean autoCommit;
+ try {
+ autoCommit = connection.getAutoCommit();
+ } catch (SQLException e) {
+ // Failover to true, as most poor drivers
+ // or databases won't support transactions
+ autoCommit = true;
+ }
+ final Environment environment = configuration.getEnvironment();
+ // 获取事务工厂
+ final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
+ // 创建事务配置
+ final Transaction tx = transactionFactory.newTransaction(connection);
+ // 创建执行器
+ final Executor executor = configuration.newExecutor(tx, execType);
+ // 创建 sql 会话
+ return new DefaultSqlSession(configuration, executor, autoCommit);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+```
+
+## sql 会话
+
+`SqlSession` 是 `MyBatis` 面向用户编程的接口,其提供了一系列方法用于执行相关数据库操作,默认实现为 `DefaultSqlSession`,在该类中,增删查改对应的操作最终会调用 `selectList`、`select` 和 `update` 方法,其分别用于普通查询、执行存储过程和修改数据库记录。
+
+```java
+ /**
+ * 查询结果集
+ */
+ @Override
+ public List selectList(String statement, Object parameter, RowBounds rowBounds) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 调用存储过程
+ */
+ @Override
+ public void select(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
+ try {
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ executor.query(ms, wrapCollection(parameter), rowBounds, handler);
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 修改
+ */
+ @Override
+ public int update(String statement, Object parameter) {
+ try {
+ dirty = true;
+ MappedStatement ms = configuration.getMappedStatement(statement);
+ return executor.update(ms, wrapCollection(parameter));
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error updating database. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+```
+
+以上操作均是根据传入的 `statement` 名称到全局配置中查找对应的 `MappedStatement` 对象,并将操作委托给执行器对象 `executor` 完成。`select`、`selectMap` 等方法则是对 `selectList` 方法返回的结果集做处理来实现的。
+
+此外,提交和回滚方法也是基于 `executor` 实现的。
+
+```java
+ /**
+ * 提交事务
+ */
+ @Override
+ public void commit(boolean force) {
+ try {
+ executor.commit(isCommitOrRollbackRequired(force));
+ dirty = false;
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 回滚事务
+ */
+ @Override
+ public void rollback(boolean force) {
+ try {
+ executor.rollback(isCommitOrRollbackRequired(force));
+ dirty = false;
+ } catch (Exception e) {
+ throw ExceptionFactory.wrapException("Error rolling back transaction. Cause: " + e, e);
+ } finally {
+ ErrorContext.instance().reset();
+ }
+ }
+
+ /**
+ * 非自动提交且事务未提交 || 强制提交或回滚 时返回 true
+ */
+ private boolean isCommitOrRollbackRequired(boolean force) {
+ return (!autoCommit && dirty) || force;
+ }
+```
+
+在执行 `update` 方法时,会设置 `dirty` 属性为 `true` ,意为事务还未提交,当事务提交或回滚后才会将 `dirty` 属性修改为 `false`。如果当前会话不是自动提交且 `dirty` 熟悉为 `true`,或者设置了强制提交或回滚的标志,则会将强制标志提交给 `executor` 处理。
+
+## Sql 会话管理器
+
+`SqlSessionManager` 同时实现了 `SqlSessionFactory` 和 `SqlSession` 接口,使得其既能够创建 `sql` 会话,又能够执行 `sql` 会话的相关数据库操作。
+
+```java
+ /**
+ * sql 会话创建工厂
+ */
+ private final SqlSessionFactory sqlSessionFactory;
+
+ /**
+ * sql 会话代理对象
+ */
+ private final SqlSession sqlSessionProxy;
+
+ /**
+ * 保存线程对应 sql 会话
+ */
+ private final ThreadLocal localSqlSession = new ThreadLocal<>();
+
+ private SqlSessionManager(SqlSessionFactory sqlSessionFactory) {
+ this.sqlSessionFactory = sqlSessionFactory;
+ this.sqlSessionProxy = (SqlSession) Proxy.newProxyInstance(
+ SqlSessionFactory.class.getClassLoader(),
+ new Class[]{SqlSession.class},
+ new SqlSessionInterceptor());
+ }
+
+ @Override
+ public SqlSession openSession() {
+ return sqlSessionFactory.openSession();
+ }
+
+ /**
+ * 设置当前线程对应的 sql 会话
+ */
+ public void startManagedSession() {
+ this.localSqlSession.set(openSession());
+ }
+
+ /**
+ * sql 会话代理逻辑
+ */
+ private class SqlSessionInterceptor implements InvocationHandler {
+
+ public SqlSessionInterceptor() {
+ // Prevent Synthetic Access
+ }
+
+ @Override
+ public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
+ // 获取当前线程对应的 sql 会话对象并执行对应方法
+ final SqlSession sqlSession = SqlSessionManager.this.localSqlSession.get();
+ if (sqlSession != null) {
+ try {
+ return method.invoke(sqlSession, args);
+ } catch (Throwable t) {
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ } else {
+ // 如果当前线程没有对应的 sql 会话,默认创建不自动提交的 sql 会话
+ try (SqlSession autoSqlSession = openSession()) {
+ try {
+ final Object result = method.invoke(autoSqlSession, args);
+ autoSqlSession.commit();
+ return result;
+ } catch (Throwable t) {
+ autoSqlSession.rollback();
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ }
+ }
+ }
+ }
+```
+
+`SqlSessionManager` 的构造方法要求 `SqlSessionFactory` 对象作为入参传入,其各个创建会话的方法实际是由该传入对象完成的。执行 `sql` 会话的操作由 `sqlSessionProxy` 对象完成,这是一个由 `JDK` 动态代理创建的对象,当执行方法时会去 `ThreadLocal` 对象中查找当前线程有没有对应的 `sql` 会话对象,如果有则使用已有的会话对象执行,否则创建新的会话对象执行,而线程对应的会话对象需要使用 `startManagedSession` 方法来维护。
+
+之所以 `SqlSessionManager` 需要为每个线程维护会话对象,是因为 `DefaultSqlSession` 是非线程安全的,多线程操作会导致执行错误。如上文中提到的 `dirty` 属性,其修改是没有经过任何同步操作的。
+
+## 小结
+
+`SqlSession` 是 `MyBatis` 提供的面向开发者编程的接口,其提供了一系列数据库相关操作,并屏蔽了底层细节。使用 `MyBatis` 的正确方式应该是像 `SqlSessionManager` 那样为每个线程创建 `sql` 会话对象,避免造成线程安全问题。
+
+- `org.apache.ibatis.session.SqlSessionFactory`:`sql` 会话创建工厂。
+- `org.apache.ibatis.session.defaults.DefaultSqlSessionFactory`: `sql` 会话创建工厂默认实现。
+- `org.apache.ibatis.session.SqlSession`:`sql` 会话。
+- `org.apache.ibatis.session.defaults.DefaultSqlSession`:`sql` 会话默认实现。
+- `org.apache.ibatis.session.SqlSessionManager`:`sql` 会话管理器
\ No newline at end of file
diff --git a/docs/source/mybatis/1-overview.md b/docs/source/mybatis/1-overview.md
new file mode 100644
index 0000000..550a96a
--- /dev/null
+++ b/docs/source/mybatis/1-overview.md
@@ -0,0 +1,43 @@
+---
+sidebar: heading
+title: MyBatis源码分析
+category: 源码分析
+tag:
+ - MyBatis
+head:
+ - - meta
+ - name: keywords
+ content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
+ - - meta
+ - name: description
+ content: 高质量的MyBatis源码分析总结
+---
+
+`MyBatis` 是一款旨在帮助开发人员屏蔽底层重复性原生 `JDBC` 代码的持久化框架,其支持通过映射文件配置或注解将 `ResultSet` 映射为 `Java` 对象。相对于其它 `ORM` 框架,`MyBatis` 更为轻量级,支持定制化 `SQL` 和动态 `SQL`,方便优化查询性能,同时包含了良好的缓存机制。
+
+## MyBatis 整体架构
+
+
+
+### 基础支持层
+
+- 反射模块:提供封装的反射 `API`,方便上层调用。
+- 类型转换:为简化配置文件提供了别名机制,并且实现了 `Java` 类型和 `JDBC` 类型的互转。
+- 日志模块:能够集成多种第三方日志框架。
+- 资源加载模块:对类加载器进行封装,提供加载类文件和其它资源文件的功能。
+- 数据源模块:提供数据源实现并能够集成第三方数据源模块。
+- 事务管理:可以和 `Spring` 集成开发,对事务进行管理。
+- 缓存模块:提供一级缓存和二级缓存,将部分请求拦截在缓存层。
+- `Binding` 模块:在调用 `SqlSession` 相应方法执行数据库操作时,需要指定映射文件中的 `SQL` 节点,`MyBatis` 通过 `Binding` 模块将自定义 `Mapper` 接口与映射文件关联,避免拼写等错误导致在运行时才发现相应异常。
+
+### 核心处理层
+
+- 配置解析:`MyBatis` 初始化时会加载配置文件、映射文件和 `Mapper` 接口的注解信息,解析后会以对象的形式保存到 `Configuration` 对象中。
+- `SQL` 解析与 `scripting` 模块:`MyBatis` 支持通过配置实现动态 `SQL`,即根据不同入参生成 `SQL`。
+- `SQL` 执行与结果解析:`Executor` 负责维护缓存和事务管理,并将数据库相关操作委托给 `StatementHandler`,`ParmeterHadler` 负责完成 `SQL` 语句的实参绑定并通过 `Statement` 对象执行 `SQL`,通过 `ResultSet` 返回结果,交由 `ResultSetHandler` 处理。
+
+- 插件:支持开发者通过插件接口对 `MyBatis` 进行扩展。
+
+### 接口层
+
+`SqlSession` 接口定义了暴露给应用程序调用的 `API`,接口层在收到请求时会调用核心处理层的相应模块完成具体的数据库操作。
\ No newline at end of file
diff --git a/docs/source/mybatis/2-reflect.md b/docs/source/mybatis/2-reflect.md
new file mode 100644
index 0000000..06e4ea7
--- /dev/null
+++ b/docs/source/mybatis/2-reflect.md
@@ -0,0 +1,634 @@
+---
+sidebar: heading
+title: MyBatis源码分析
+category: 源码分析
+tag:
+ - MyBatis
+head:
+ - - meta
+ - name: keywords
+ content: MyBatis面试题,MyBatis源码分析,MyBatis整体架构,MyBatis反射,MyBatis源码,Hibernate,Executor,MyBatis分页,MyBatis插件运行原理,MyBatis延迟加载,MyBatis预编译,一级缓存和二级缓存
+ - - meta
+ - name: description
+ content: 高质量的MyBatis源码分析总结
+---
+
+大家好,我是大彬。今天分享Mybatis源码的反射模块。
+
+`MyBatis` 在进行参数处理、结果映射时等操作时,会涉及大量的反射操作。为了简化这些反射相关操作,`MyBatis` 在 `org.apache.ibatis.reflection` 包下提供了专门的反射模块,对反射操作做了近一步封装,提供了更为简洁的 `API`。
+
+## 缓存类的元信息
+
+`MyBatis` 提供 `Reflector` 类来缓存类的字段名和 `getter/setter` 方法的元信息,使得反射时有更好的性能。使用方式是将原始类对象传入其构造方法,生成 `Reflector` 对象。
+
+```java
+ public Reflector(Class clazz) {
+ type = clazz;
+ // 如果存在,记录无参构造方法
+ addDefaultConstructor(clazz);
+ // 记录字段名与get方法、get方法返回值的映射关系
+ addGetMethods(clazz);
+ // 记录字段名与set方法、set方法参数的映射关系
+ addSetMethods(clazz);
+ // 针对没有getter/setter方法的字段,通过Filed对象的反射来设置和读取字段值
+ addFields(clazz);
+ // 可读的字段名
+ readablePropertyNames = getMethods.keySet().toArray(new String[getMethods.keySet().size()]);
+ // 可写的字段名
+ writablePropertyNames = setMethods.keySet().toArray(new String[setMethods.keySet().size()]);
+ // 保存一份所有字段名大写与原始字段名的隐射
+ for (String propName : readablePropertyNames) {
+ caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
+ }
+ for (String propName : writablePropertyNames) {
+ caseInsensitivePropertyMap.put(propName.toUpperCase(Locale.ENGLISH), propName);
+ }
+ }
+```
+
+`addGetMethods` 和 `addSetMethods` 分别获取类的所有方法,从符合 `getter/setter` 规范的方法中解析出字段名,并记录方法的参数类型、返回值类型等信息:
+
+```java
+ private void addGetMethods(Class cls) {
+ // 字段名-get方法
+ Map> conflictingGetters = new HashMap<>();
+ // 获取类的所有方法,及其实现接口的方法,并根据方法签名去重
+ Method[] methods = getClassMethods(cls);
+ for (Method method : methods) {
+ if (method.getParameterTypes().length > 0) {
+ // 过滤有参方法
+ continue;
+ }
+ String name = method.getName();
+ if ((name.startsWith("get") && name.length() > 3)
+ || (name.startsWith("is") && name.length() > 2)) {
+ // 由get属性获取对应的字段名(去除前缀,首字母转小写)
+ name = PropertyNamer.methodToProperty(name);
+ addMethodConflict(conflictingGetters, name, method);
+ }
+ }
+ // 保证每个字段只对应一个get方法
+ resolveGetterConflicts(conflictingGetters);
+ }
+```
+
+对 `getter/setter` 方法进行去重是通过类似 `java.lang.String#getSignature:java.lang.reflect.Method` 的方法签名来实现的,如果子类在实现过程中,参数、返回值使用了不同的类型(使用原类型的子类),则会导致方法签名不一致,同一字段就会对应不同的 `getter/setter` 方法,因此需要进行去重。
+
+> 分享一份大彬精心整理的大厂面试手册,包含计**算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享**等高频面试题,非常实用,有小伙伴靠着这份手册拿过字节offer~
+>
+> 
+>
+> 
+>
+> 需要的小伙伴可以自行**下载**:
+>
+> 链接:https://pan.xunlei.com/s/VNgU60NQQNSDaEy9z955oufbA1?pwd=y9fy#
+>
+> 备用链接:https://pan.quark.cn/s/cbbb681e7c19
+
+```java
+ private void resolveGetterConflicts(Map> conflictingGetters) {
+ for (Entry> entry : conflictingGetters.entrySet()) {
+ Method winner = null;
+ // 属性名
+ String propName = entry.getKey();
+ for (Method candidate : entry.getValue()) {
+ if (winner == null) {
+ winner = candidate;
+ continue;
+ }
+ // 字段对应了多个get方法
+ Class winnerType = winner.getReturnType();
+ Class candidateType = candidate.getReturnType();
+ if (candidateType.equals(winnerType)) {
+ // 返回值类型相同
+ if (!boolean.class.equals(candidateType)) {
+ throw new ReflectionException(
+ "Illegal overloaded getter method with ambiguous type for property "
+ + propName + " in class " + winner.getDeclaringClass()
+ + ". This breaks the JavaBeans specification and can cause unpredictable results.");
+ } else if (candidate.getName().startsWith("is")) {
+ // 返回值为boolean的get方法可能有多个,如getIsSave和isSave,优先取is开头的
+ winner = candidate;
+ }
+ } else if (candidateType.isAssignableFrom(winnerType)) {
+ // OK getter type is descendant
+ // 可能会出现接口中的方法返回值是List,子类实现方法返回值是ArrayList,使用子类返回值方法
+ } else if (winnerType.isAssignableFrom(candidateType)) {
+ winner = candidate;
+ } else {
+ throw new ReflectionException(
+ "Illegal overloaded getter method with ambiguous type for property "
+ + propName + " in class " + winner.getDeclaringClass()
+ + ". This breaks the JavaBeans specification and can cause unpredictable results.");
+ }
+ }
+ // 记录字段名对应的get方法对象和返回值类型
+ addGetMethod(propName, winner);
+ }
+ }
+```
+
+去重的方式是使用更规范的方法以及使用子类的方法。在确认字段名对应的唯一 `getter/setter` 方法后,记录方法名对应的方法、参数、返回值等信息。`MethodInvoker` 可用于调用 `Method` 类的 `invoke` 方法来执行 `getter/setter` 方法(`addSetMethods` 记录映射关系的方式与 `addGetMethods` 大致相同)。
+
+```java
+private void addGetMethod(String name, Method method) {
+ // 过滤$开头、serialVersionUID的get方法和getClass()方法
+ if (isValidPropertyName(name)) {
+ // 字段名-对应get方法的MethodInvoker对象
+ getMethods.put(name, new MethodInvoker(method));
+ Type returnType = TypeParameterResolver.resolveReturnType(method, type);
+ // 字段名-运行时方法的真正返回类型
+ getTypes.put(name, typeToClass(returnType));
+ }
+}
+```
+
+接下来会执行 `addFields` 方法,此方法针对没有 `getter/setter` 方法的字段,通过包装为 `SetFieldInvoker` 在需要时通过 `Field` 对象的反射来设置和读取字段值。
+
+```java
+private void addFields(Class clazz) {
+ Field[] fields = clazz.getDeclaredFields();
+ for (Field field : fields) {
+ if (!setMethods.containsKey(field.getName())) {
+ // issue #379 - removed the check for final because JDK 1.5 allows
+ // modification of final fields through reflection (JSR-133). (JGB)
+ // pr #16 - final static can only be set by the classloader
+ int modifiers = field.getModifiers();
+ if (!(Modifier.isFinal(modifiers) && Modifier.isStatic(modifiers))) {
+ // 非final的static变量,没有set方法,可以通过File对象做赋值操作
+ addSetField(field);
+ }
+ }
+ if (!getMethods.containsKey(field.getName())) {
+ addGetField(field);
+ }
+ }
+ if (clazz.getSuperclass() != null) {
+ // 递归查找父类
+ addFields(clazz.getSuperclass());
+ }
+}
+```
+
+## 抽象字段赋值与读取
+
+`Invoker` 接口用于抽象设置和读取字段值的操作。对于有 `getter/setter` 方法的字段,通过 `MethodInvoker` 反射执行;对应其它字段,通过 `GetFieldInvoker` 和 `SetFieldInvoker` 操作 `Field` 对象的 `getter/setter` 方法反射执行。
+
+```java
+/**
+ * 用于抽象设置和读取字段值的操作
+ *
+ * {@link MethodInvoker} 反射执行getter/setter方法
+ * {@link GetFieldInvoker} {@link SetFieldInvoker} 反射执行Field对象的get/set方法
+ *
+ * @author Clinton Begin
+ */
+public interface Invoker {
+
+ /**
+ * 通过反射设置或读取字段值
+ *
+ * @param target
+ * @param args
+ * @return
+ * @throws IllegalAccessException
+ * @throws InvocationTargetException
+ */
+ Object invoke(Object target, Object[] args) throws IllegalAccessException, InvocationTargetException;
+
+ /**
+ * 字段类型
+ *
+ * @return
+ */
+ Class getType();
+}
+```
+
+## 解析参数类型
+
+针对 `Java-Type` 体系的多种实现,`TypeParameterResolver` 提供一系列方法来解析指定类中的字段、方法返回值或方法参数的类型。
+
+`Type` 接口包含 4 个子接口和 1 个实现类:
+
+
+
+- `Class`:原始类型
+- `ParameterizedType`:泛型类型,如:`List`
+- `TypeVariable`:泛型类型变量,如: `List` 中的 `T`
+- `GenericArrayType`:组成元素是 `ParameterizedType` 或 `TypeVariable` 的数组类型,如:`List[]`、`T[]`
+- `WildcardType`:通配符泛型类型变量,如:`List` 中的 `?`
+
+`TypeParameterResolver` 分别提供 `resolveFieldType`、`resolveReturnType`、`resolveParamTypes` 方法用于解析字段类型、方法返回值类型和方法入参类型,这些方法均调用 `resolveType` 来获取类型信息:
+
+```java
+/**
+ * 获取类型信息
+ *
+ * @param type 根据是否有泛型信息签名选择传入泛型类型或简单类型
+ * @param srcType 引用字段/方法的类(可能是子类,字段和方法在父类声明)
+ * @param declaringClass 字段/方法声明的类
+ * @return
+ */
+private static Type resolveType(Type type, Type srcType, Class declaringClass) {
+ if (type instanceof TypeVariable) {
+ // 泛型类型变量,如:List 中的 T
+ return resolveTypeVar((TypeVariable) type, srcType, declaringClass);
+ } else if (type instanceof ParameterizedType) {
+ // 泛型类型,如:List
+ return resolveParameterizedType((ParameterizedType) type, srcType, declaringClass);
+ } else if (type instanceof GenericArrayType) {
+ // TypeVariable/ParameterizedType 数组类型
+ return resolveGenericArrayType((GenericArrayType) type, srcType, declaringClass);
+ } else {
+ // 原始类型,直接返回
+ return type;
+ }
+}
+```
+
+`resolveTypeVar` 用于解析泛型类型变量参数类型,如果字段或方法在当前类中声明,则返回泛型类型的上界或 `Object` 类型;如果在父类中声明,则递归解析父类;父类也无法解析,则递归解析实现的接口。
+
+```java
+private static Type resolveTypeVar(TypeVariable typeVar, Type srcType, Class declaringClass) {
+ Type result;
+ Class clazz;
+ if (srcType instanceof Class) {
+ // 原始类型
+ clazz = (Class) srcType;
+ } else if (srcType instanceof ParameterizedType) {
+ // 泛型类型,如 TestObj
+ ParameterizedType parameterizedType = (ParameterizedType) srcType;
+ // 取原始类型TestObj
+ clazz = (Class) parameterizedType.getRawType();
+ } else {
+ throw new IllegalArgumentException("The 2nd arg must be Class or ParameterizedType, but was: " + srcType.getClass());
+ }
+
+ if (clazz == declaringClass) {
+ // 字段就是在当前引用类中声明的
+ Type[] bounds = typeVar.getBounds();
+ if (bounds.length > 0) {
+ // 返回泛型类型变量上界,如:T extends String,则返回String
+ return bounds[0];
+ }
+ // 没有上界返回Object
+ return Object.class;
+ }
+
+ // 字段/方法在父类中声明,递归查找父类泛型
+ Type superclass = clazz.getGenericSuperclass();
+ result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superclass);
+ if (result != null) {
+ return result;
+ }
+
+ // 递归泛型接口
+ Type[] superInterfaces = clazz.getGenericInterfaces();
+ for (Type superInterface : superInterfaces) {
+ result = scanSuperTypes(typeVar, srcType, declaringClass, clazz, superInterface);
+ if (result != null) {
+ return result;
+ }
+ }
+ return Object.class;
+}
+```
+
+通过调用 `scanSuperTypes` 实现递归解析:
+
+```java
+private static Type scanSuperTypes(TypeVariable typeVar, Type srcType, Class declaringClass, Class clazz, Type superclass) {
+ if (superclass instanceof ParameterizedType) {
+ // 父类是泛型类型
+ ParameterizedType parentAsType = (ParameterizedType) superclass;
+ Class parentAsClass = (Class) parentAsType.getRawType();
+ // 父类中的泛型类型变量集合
+ TypeVariable[] parentTypeVars = parentAsClass.getTypeParameters();
+ if (srcType instanceof ParameterizedType) {
+ // 子类可能对父类泛型变量做过替换,使用替换后的类型
+ parentAsType = translateParentTypeVars((ParameterizedType) srcType, clazz, parentAsType);
+ }
+ if (declaringClass == parentAsClass) {
+ // 字段/方法在当前父类中声明
+ for (int i = 0; i < parentTypeVars.length; i++) {
+ if (typeVar == parentTypeVars[i]) {
+ // 使用变量对应位置的真正类型(可能已经被替换),如父类 A,子类 B extends A,则返回String
+ return parentAsType.getActualTypeArguments()[i];
+ }
+ }
+ }
+ // 字段/方法声明的类是当前父类的父类,继续递归
+ if (declaringClass.isAssignableFrom(parentAsClass)) {
+ return resolveTypeVar(typeVar, parentAsType, declaringClass);
+ }
+ } else if (superclass instanceof Class && declaringClass.isAssignableFrom((Class) superclass)) {
+ // 父类是原始类型,继续递归父类
+ return resolveTypeVar(typeVar, superclass, declaringClass);
+ }
+ return null;
+}
+```
+
+解析方法返回值和方法参数的逻辑大致与解析字段类型相同,`MyBatis` 源码的`TypeParameterResolverTest` 类提供了相关的测试用例。
+
+## 元信息工厂
+
+`MyBatis` 还提供 `ReflectorFactory` 接口用于实现 `Reflector` 容器,其默认实现为 `DefaultReflectorFactory`,其中可以使用 `classCacheEnabled` 属性来配置是否使用缓存。
+
+```java
+public class DefaultReflectorFactory implements ReflectorFactory {
+
+ /**
+ * 是否缓存Reflector类信息
+ */
+ private boolean classCacheEnabled = true;
+
+ /**
+ * Reflector缓存容器
+ */
+ private final ConcurrentMap, Reflector> reflectorMap = new ConcurrentHashMap<>();
+
+ public DefaultReflectorFactory() {
+ }
+
+ @Override
+ public boolean isClassCacheEnabled() {
+ return classCacheEnabled;
+ }
+
+ @Override
+ public void setClassCacheEnabled(boolean classCacheEnabled) {
+ this.classCacheEnabled = classCacheEnabled;
+ }
+
+ /**
+ * 获取类的Reflector信息
+ *
+ * @param type
+ * @return
+ */
+ @Override
+ public Reflector findForClass(Class type) {
+ if (classCacheEnabled) {
+ // synchronized (type) removed see issue #461
+ // 如果缓存Reflector信息,放入缓存容器
+ return reflectorMap.computeIfAbsent(type, Reflector::new);
+ } else {
+ return new Reflector(type);
+ }
+ }
+
+}
+```
+
+## 对象创建工厂
+
+`ObjectFactory` 接口是 `MyBatis` 对象创建工厂,其默认实现 `DefaultObjectFactory` 通过构造器反射创建对象,支持使用无参构造器和有参构造器。
+
+## 属性工具集
+
+`MyBatis` 在映射文件定义 `resultMap` 支持如下形式:
+
+```xml
+
+
+
+ ...
+
+```
+
+`orders[0].items[0].name` 这样的表达式是由 `PropertyTokenizer` 解析的,其构造方法能够对表达式进行解析;同时还实现了 `Iterator` 接口,能够迭代解析表达式。
+
+```java
+public PropertyTokenizer(String fullname) {
+ // orders[0].items[0].name
+ int delim = fullname.indexOf('.');
+ if (delim > -1) {
+ // name = orders[0]
+ name = fullname.substring(0, delim);
+ // children = items[0].name
+ children = fullname.substring(delim + 1);
+ } else {
+ name = fullname;
+ children = null;
+ }
+ // orders[0]
+ indexedName = name;
+ delim = name.indexOf('[');
+ if (delim > -1) {
+ // 0
+ index = name.substring(delim + 1, name.length() - 1);
+ // order
+ name = name.substring(0, delim);
+ }
+}
+
+ /**
+ * 是否有children表达式继续迭代
+ *
+ * @return
+ */
+ @Override
+ public boolean hasNext() {
+ return children != null;
+ }
+
+ /**
+ * 分解出的 . 分隔符的 children 表达式可以继续迭代
+ * @return
+ */
+ @Override
+ public PropertyTokenizer next() {
+ return new PropertyTokenizer(children);
+ }
+```
+
+`PropertyNamer` 可以根据 `getter/setter` 规范解析字段名称;`PropertyCopier` 则支持对有相同父类的对象,通过反射拷贝字段值。
+
+## 封装类信息
+
+`MetaClass` 类依赖 `PropertyTokenizer` 和 `Reflector` 查找表达式是否可以匹配 `Java` 对象中的字段,以及对应字段是否有 `getter/setter` 方法。
+
+```java
+/**
+ * 验证传入的表达式,是否存在指定的字段
+ *
+ * @param name
+ * @param builder
+ * @return
+ */
+private StringBuilder buildProperty(String name, StringBuilder builder) {
+ // 映射文件表达式迭代器
+ PropertyTokenizer prop = new PropertyTokenizer(name);
+ if (prop.hasNext()) {
+ // 复杂表达式,如name = items[0].name,则prop.getName() = items
+ String propertyName = reflector.findPropertyName(prop.getName());
+ if (propertyName != null) {
+ builder.append(propertyName);
+ // items.
+ builder.append(".");
+ // 加载内嵌字段类型对应的MetaClass
+ MetaClass metaProp = metaClassForProperty(propertyName);
+ // 迭代子字段
+ metaProp.buildProperty(prop.getChildren(), builder);
+ }
+ } else {
+ // 非复杂表达式,获取字段名,如:userid->userId
+ String propertyName = reflector.findPropertyName(name);
+ if (propertyName != null) {
+ builder.append(propertyName);
+ }
+ }
+ return builder;
+}
+```
+
+## 包装字段对象
+
+相对于 `MetaClass` 关注类信息,`MetalObject` 关注的是对象的信息,除了保存传入的对象本身,还会为对象指定一个 `ObjectWrapper` 将对象包装起来。`ObejctWrapper` 体系如下:
+
+
+
+`ObjectWrapper` 的默认实现包括了对 `Map`、`Collection` 和普通 `JavaBean` 的包装。`MyBatis` 还支持通过 `ObjectWrapperFactory` 接口对 `ObejctWrapper` 进行扩展,生成自定义的包装类。`MetaObject` 对对象的具体操作,就委托给真正的 `ObjectWrapper` 处理。
+
+```java
+private MetaObject(Object object, ObjectFactory objectFactory, ObjectWrapperFactory objectWrapperFactory, ReflectorFactory reflectorFactory) {
+ this.originalObject = object;
+ this.objectFactory = objectFactory;
+ this.objectWrapperFactory = objectWrapperFactory;
+ this.reflectorFactory = reflectorFactory;
+
+ // 根据传入object类型不同,指定不同的wrapper
+ if (object instanceof ObjectWrapper) {
+ this.objectWrapper = (ObjectWrapper) object;
+ } else if (objectWrapperFactory.hasWrapperFor(object)) {
+ this.objectWrapper = objectWrapperFactory.getWrapperFor(this, object);
+ } else if (object instanceof Map) {
+ this.objectWrapper = new MapWrapper(this, (Map) object);
+ } else if (object instanceof Collection) {
+ this.objectWrapper = new CollectionWrapper(this, (Collection) object);
+ } else {
+ this.objectWrapper = new BeanWrapper(this, object);
+ }
+}
+```
+
+例如赋值操作,`BeanWrapper` 的实现如下:
+
+```java
+ @Override
+ public void set(PropertyTokenizer prop, Object value) {
+ if (prop.getIndex() != null) {
+ // 当前表达式是集合,如:items[0],就需要获取items集合对象
+ Object collection = resolveCollection(prop, object);
+ // 在集合的指定索引上赋值
+ setCollectionValue(prop, collection, value);
+ } else {
+ // 解析完成,通过Invoker接口做赋值操作
+ setBeanProperty(prop, object, value);
+ }
+ }
+
+ protected Object resolveCollection(PropertyTokenizer prop, Object object) {
+ if ("".equals(prop.getName())) {
+ return object;
+ } else {
+ // 在对象信息中查到此字段对应的集合对象
+ return metaObject.getValue(prop.getName());
+ }
+ }
+```
+
+根据 `PropertyTokenizer` 对象解析出的当前字段是否存在 `index` 索引来判断字段是否为集合。如果当前字段对应集合,则需要在对象信息中查到此字段对应的集合对象:
+
+```javascript
+public Object getValue(String name) {
+ PropertyTokenizer prop = new PropertyTokenizer(name);
+ if (prop.hasNext()) {
+ // 如果表达式仍可迭代,递归寻找字段对应的对象
+ MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
+ if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
+ return null;
+ } else {
+ return metaValue.getValue(prop.getChildren());
+ }
+ } else {
+ // 字段解析完成
+ return objectWrapper.get(prop);
+ }
+}
+```
+
+如果字段是简单类型,`BeanWrapper` 获取字段对应的对象逻辑如下:
+
+```java
+@Override
+public Object get(PropertyTokenizer prop) {
+ if (prop.getIndex() != null) {
+ // 集合类型,递归获取
+ Object collection = resolveCollection(prop, object);
+ return getCollectionValue(prop, collection);
+ } else {
+ // 解析完成,反射读取
+ return getBeanProperty(prop, object);
+ }
+}
+```
+
+可以看到,仍然是会判断表达式是否迭代完成,如果未解析完字段会不断递归,直至找到对应的类型。前面说到 `Reflector` 创建过程中将对字段的读取和赋值操作通过 `Invoke` 接口抽象出来,针对最终获取的字段,此时就会调用 `Invoke` 接口对字段反射读取对象值:
+
+```java
+/**
+ * 通过Invoker接口反射执行读取操作
+ *
+ * @param prop
+ * @param object
+ */
+private Object getBeanProperty(PropertyTokenizer prop, Object object) {
+ try {
+ Invoker method = metaClass.getGetInvoker(prop.getName());
+ try {
+ return method.invoke(object, NO_ARGUMENTS);
+ } catch (Throwable t) {
+ throw ExceptionUtil.unwrapThrowable(t);
+ }
+ } catch (RuntimeException e) {
+ throw e;
+ } catch (Throwable t) {
+ throw new ReflectionException("Could not get property '" + prop.getName() + "' from " + object.getClass() + ". Cause: " + t.toString(), t);
+ }
+}
+```
+
+对象读取完毕再通过 `setCollectionValue` 方法对集合指定索引进行赋值或通过 `setBeanProperty` 方法对简单类型反射赋值。`MapWrapper` 的操作与 `BeanWrapper` 大致相同,`CollectionWrapper` 相对更会简单,只支持对原始集合对象进行添加操作。
+
+## 小结
+
+`MyBatis` 根据自身需求,对反射 `API` 做了近一步封装。其目的是简化反射操作,为对象字段的读取和赋值提供更好的性能。
+
+- `org.apache.ibatis.reflection.Reflector`:缓存类的字段名和 getter/setter 方法的元信息,使得反射时有更好的性能。
+- `org.apache.ibatis.reflection.invoker.Invoker:`:用于抽象设置和读取字段值的操作。
+- `org.apache.ibatis.reflection.TypeParameterResolver`:针对 Java-Type 体系的多种实现,解析指定类中的字段、方法返回值或方法参数的类型。
+- `org.apache.ibatis.reflection.ReflectorFactory`:反射信息创建工厂抽象接口。
+- `org.apache.ibatis.reflection.DefaultReflectorFactory`:默认的反射信息创建工厂。
+- `org.apache.ibatis.reflection.factory.ObjectFactory`:MyBatis 对象创建工厂,其默认实现 DefaultObjectFactory 通过构造器反射创建对象。
+- `org.apache.ibatis.reflection.property`:property 工具包,针对映射文件表达式进行解析和 Java 对象的反射赋值。
+- `org.apache.ibatis.reflection.MetaClass`:依赖 PropertyTokenizer 和 Reflector 查找表达式是否可以匹配 Java 对象中的字段,以及对应字段是否有 getter/setter 方法。
+- `org.apache.ibatis.reflection.MetaObject`:对原始对象进行封装,将对象操作委托给 ObjectWrapper 处理。
+- `org.apache.ibatis.reflection.wrapper.ObjectWrapper`:对象包装类,封装对象的读取和赋值等操作。
+
+
+
+
+
+最后给大家分享**200多本计算机经典书籍PDF电子书**,包括**C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生**等,感兴趣的小伙伴可以自取:
+
+
+
+
+
+**200多本计算机经典书籍PDF电子书**:https://pan.xunlei.com/s/VNlmlh9jBl42w0QH2l4AJaWGA1?pwd=j8eq#
+
+备用链接:https://pan.quark.cn/s/3f1321952a16
\ No newline at end of file
diff --git "a/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md" "b/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md"
new file mode 100644
index 0000000..234ffcf
--- /dev/null
+++ "b/docs/source/mybatis/MyBatis \346\272\220\347\240\201\345\210\206\346\236\2203--\345\237\272\347\241\200\346\224\257\346\214\201\346\250\241\345\235\227.md"
@@ -0,0 +1,1563 @@
+## 类型转换
+
+`JDBC` 规范定义的数据类型与 `Java` 数据类型并不是完全对应的,所以在 `PrepareStatement` 为 `SQL` 语句绑定参数时,需要从 `Java` 类型转为 `JDBC` 类型;而从结果集中获取数据时,则需要将 `JDBC` 类型转为 `Java` 类型。
+
+### 类型转换操作
+
+`MyBatis` 中的所有类型转换器都继承自 `BaseTypeHandler` 抽象类,此类实现了 `TypeHandler` 接口。接口中定义了 1 个向 `PreparedStatement` 对象中设置参数的方法和 3 个从结果集中取值的方法:
+
+```java
+ public interface TypeHandler {
+
+ /**
+ * 为PreparedStatement对象设置参数
+ *
+ * @param ps SQL 预编译对象
+ * @param i 参数索引
+ * @param parameter 参数值
+ * @param jdbcType 参数 JDBC类型
+ * @throws SQLException
+ */
+ void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException;
+
+ /**
+ * 根据列名从结果集中取值
+ *
+ * @param rs 结果集
+ * @param columnName 列名
+ * @return
+ * @throws SQLException
+ */
+ T getResult(ResultSet rs, String columnName) throws SQLException;
+
+ /**
+ * 根据索引从结果集中取值
+ * @param rs 结果集
+ * @param columnIndex 索引
+ * @return
+ * @throws SQLException
+ */
+ T getResult(ResultSet rs, int columnIndex) throws SQLException;
+
+ /**
+ * 根据索引从存储过程函数中取值
+ *
+ * @param cs 存储过程对象
+ * @param columnIndex 索引
+ * @return
+ * @throws SQLException
+ */
+ T getResult(CallableStatement cs, int columnIndex) throws SQLException;
+
+ }
+```
+
+### BaseTypeHandler 及其实现
+
+`BaseTypeHandler` 实现了 `TypeHandler` 接口,针对 `null` 和异常处理做了封装,但是具体逻辑封装成 4 个抽象方法仍交由相应的类型转换器子类实现,以 `IntegerTypeHandler` 为例,其实现如下:
+
+```java
+ public class IntegerTypeHandler extends BaseTypeHandler {
+
+ @Override
+ public void setNonNullParameter(PreparedStatement ps, int i, Integer parameter, JdbcType jdbcType)
+ throws SQLException {
+ ps.setInt(i, parameter);
+ }
+
+ @Override
+ public Integer getNullableResult(ResultSet rs, String columnName)
+ throws SQLException {
+ int result = rs.getInt(columnName);
+ // 如果列值为空值返回控制否则返回原值
+ return result == 0 && rs.wasNull() ? null : result;
+ }
+
+ @Override
+ public Integer getNullableResult(ResultSet rs, int columnIndex)
+ throws SQLException {
+ int result = rs.getInt(columnIndex);
+ return result == 0 && rs.wasNull() ? null : result;
+ }
+
+ @Override
+ public Integer getNullableResult(CallableStatement cs, int columnIndex)
+ throws SQLException {
+ int result = cs.getInt(columnIndex);
+ return result == 0 && cs.wasNull() ? null : result;
+ }
+ }
+```
+
+其实现主要是调用 `JDBC API` 设置查询参数或取值,并对 `null` 等特定情况做特殊处理。
+
+### 类型转换器注册
+
+`TypeHandlerRegistry` 是 `TypeHandler` 的注册类,在其无参构造方法中维护了 `JavaType`、`JdbcType` 和 `TypeHandler` 的关系。其主要使用的容器如下:
+
+```java
+ /**
+ * JdbcType - TypeHandler对象
+ * 用于将Jdbc类型转为Java类型
+ */
+ private final Map> jdbcTypeHandlerMap = new EnumMap<>(JdbcType.class);
+
+ /**
+ * JavaType - JdbcType - TypeHandler对象
+ * 用于将Java类型转为指定的Jdbc类型
+ */
+ private final Map>> typeHandlerMap = new ConcurrentHashMap<>();
+
+ /**
+ * TypeHandler类型 - TypeHandler对象
+ * 注册所有的TypeHandler类型
+ */
+ private final Map, TypeHandler> allTypeHandlersMap = new HashMap<>();
+```
+
+## 别名注册
+
+### 别名转换器注册
+
+`TypeAliasRegistry` 提供了多种方式用于为 `Java` 类型注册别名。包括直接指定别名、注解指定别名、为指定包下类型注册别名:
+
+```java
+ /**
+ * 注册指定包下所有类型别名
+ *
+ * @param packageName
+ */
+ public void registerAliases(String packageName) {
+ registerAliases(packageName, Object.class);
+ }
+
+ /**
+ * 注册指定包下指定类型的别名
+ *
+ * @param packageName
+ * @param superType
+ */
+ public void registerAliases(String packageName, Class superType) {
+ ResolverUtil> resolverUtil = new ResolverUtil<>();
+ // 找出该包下superType所有的子类
+ resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
+ Set>> typeSet = resolverUtil.getClasses();
+ for (Class type : typeSet) {
+ // Ignore inner classes and interfaces (including package-info.java)
+ // Skip also inner classes. See issue #6
+ if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
+ registerAlias(type);
+ }
+ }
+ }
+
+ /**
+ * 注册类型别名,默认为简单类名,优先从Alias注解获取
+ *
+ * @param type
+ */
+ public void registerAlias(Class type) {
+ String alias = type.getSimpleName();
+ // 从Alias注解读取别名
+ Alias aliasAnnotation = type.getAnnotation(Alias.class);
+ if (aliasAnnotation != null) {
+ alias = aliasAnnotation.value();
+ }
+ registerAlias(alias, type);
+ }
+
+ /**
+ * 注册类型别名
+ *
+ * @param alias 别名
+ * @param value 类型
+ */
+ public void registerAlias(String alias, Class value) {
+ if (alias == null) {
+ throw new TypeException("The parameter alias cannot be null");
+ }
+ // issue #748
+ String key = alias.toLowerCase(Locale.ENGLISH);
+ if (typeAliases.containsKey(key) && typeAliases.get(key) != null && !typeAliases.get(key).equals(value)) {
+ throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + typeAliases.get(key).getName() + "'.");
+ }
+ typeAliases.put(key, value);
+ }
+
+ /**
+ * 注册类型别名
+ * @param alias 别名
+ * @param value 指定类型全名
+ */
+ public void registerAlias(String alias, String value) {
+ try {
+ registerAlias(alias, Resources.classForName(value));
+ } catch (ClassNotFoundException e) {
+ throw new TypeException("Error registering type alias " + alias + " for " + value + ". Cause: " + e, e);
+ }
+ }
+```
+
+所有别名均注册到名为 `typeAliases` 的容器中。`TypeAliasRegistry` 的无参构造方法默认为一些常用类型注册了别名,如 `Integer`、`String`、`byte[]` 等。
+
+## 日志配置
+
+`MyBatis` 支持与多种日志工具集成,包括 `Slf4j`、`log4j`、`log4j2`、`commons-logging` 等。这些第三方工具类对应日志的实现各有不同,`MyBatis` 通过适配器模式抽象了这些第三方工具的集成过程,按照一定的优先级选择具体的日志工具,并将真正的日志实现委托给选择的日志工具。
+
+### 日志适配接口
+
+`Log` 接口是 `MyBatis` 的日志适配接口,支持 `trace`、`debug`、`warn`、`error` 四种级别。
+
+### 日志工厂
+
+`LogFactory` 负责对第三方日志工具进行适配,在类加载时会通过静态代码块按顺序选择合适的日志实现。
+
+```java
+ static {
+ // 按顺序加载日志实现,如果有某个第三方日志实现可以成功加载,则不继续加载其它实现
+ tryImplementation(LogFactory::useSlf4jLogging);
+ tryImplementation(LogFactory::useCommonsLogging);
+ tryImplementation(LogFactory::useLog4J2Logging);
+ tryImplementation(LogFactory::useLog4JLogging);
+ tryImplementation(LogFactory::useJdkLogging);
+ tryImplementation(LogFactory::useNoLogging);
+ }
+
+ /**
+ * 初始化 logConstructor
+ *
+ * @param runnable
+ */
+ private static void tryImplementation(Runnable runnable) {
+ if (logConstructor == null) {
+ try {
+ // 同步执行
+ runnable.run();
+ } catch (Throwable t) {
+ // ignore
+ }
+ }
+ }
+
+ /**
+ * 配置第三方日志实现适配器
+ *
+ * @param implClass
+ */
+ private static void setImplementation(Class implClass) {
+ try {
+ Constructor candidate = implClass.getConstructor(String.class);
+ Log log = candidate.newInstance(LogFactory.class.getName());
+ if (log.isDebugEnabled()) {
+ log.debug("Logging initialized using '" + implClass + "' adapter.");
+ }
+ logConstructor = candidate;
+ } catch (Throwable t) {
+ throw new LogException("Error setting Log implementation. Cause: " + t, t);
+ }
+ }
+```
+
+`tryImplementation` 按顺序加载第三方日志工具的适配实现,如 `Slf4j` 的适配器 `Slf4jImpl`:
+
+```java
+public Slf4jImpl(String clazz) {
+ Logger logger = LoggerFactory.getLogger(clazz);
+
+ if (logger instanceof LocationAwareLogger) {
+ try {
+ // check for slf4j >= 1.6 method signature
+ logger.getClass().getMethod("log", Marker.class, String.class, int.class, String.class, Object[].class, Throwable.class);
+ log = new Slf4jLocationAwareLoggerImpl((LocationAwareLogger) logger);
+ return;
+ } catch (SecurityException | NoSuchMethodException e) {
+ // fail-back to Slf4jLoggerImpl
+ }
+ }
+
+ // Logger is not LocationAwareLogger or slf4j version < 1.6
+ log = new Slf4jLoggerImpl(logger);
+}
+```
+
+如果 `Slf4jImpl` 能成功执行构造方法,则 `LogFactory` 的 `logConstructor` 被成功赋值,`MyBatis` 就找到了合适的日志实现,可以通过 `getLog` 方法获取 `Log` 对象。
+
+### JDBC 日志代理
+
+`org.apache.ibatis.logging.jdbc` 包提供了 `Connection`、`PrepareStatement`、`Statement`、`ResultSet` 类中的相关方法执行的日志记录代理。`BaseJdbcLogger` 在创建时整理了 `PreparedStatement` 执行的相关方法名,并提供容器保存列值:
+
+```java
+ /**
+ * PreparedStatement 接口中的 set* 方法名称集合
+ */
+ protected static final Set SET_METHODS;
+
+ /**
+ * PreparedStatement 接口中的 部分执行方法
+ */
+ protected static final Set EXECUTE_METHODS = new HashSet<>();
+
+ /**
+ * 列名-列值
+ */
+ private final Map columnMap = new HashMap<>();
+
+ /**
+ * 列名集合
+ */
+ private final List