diff --git a/.DS_Store b/.DS_Store
new file mode 100644
index 0000000000..5008ddfcf5
Binary files /dev/null and b/.DS_Store differ
diff --git a/.gitignore b/.gitignore
index 815e8cc827..c6fcbf307e 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,15 +1,7 @@
node_modules
.cache
.temp
+dist
package-lock.json
-.DS_Store
-dump.rdb
-docs/.vuepress/.cache/
-docs/.vuepress/.temp/
-docs/dist/
-dist.zip
-images
-*.log
-.yarn
-*-vip.md
-/.vscode
+yarn.lock
+package.json
diff --git a/README.md b/README.md
index efb70212e3..7d80dc033b 100644
--- a/README.md
+++ b/README.md
@@ -1,23 +1,27 @@
+👉 沉默王二-《Java 程序员进阶之路》官方知识星球来啦!!!
+
+如果你需要专属Java学习/面试小册/一对一交流/简历修改/专属求职指南/学习打卡,不妨花 3 分钟左右看看星球的详细介绍:沉默王二-《Java 程序员进阶之路》详细介绍 (一定要确定自己真的需要再加入,一定要看完详细介绍之后再加我)。
-
-  +
+
+
+ 
-  -
-  -
-  -
-  -
- 
- Github |
- Gitee
+  +
+  +
+  +
+
+
+  +
+
+
# 为什么会有这个开源知识库
-> 知识库取名 **toBeBetterJavaer**,即 **To Be Better Javaer**,意为「成为一名更好的 Java 程序员」,是我自学 Java 以来所有原创文章和学习资料的大聚合。内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发、Java 面试等核心知识点。据说每一个优秀的 Java 程序员都喜欢她,风趣幽默、通俗易懂。学 Java,就认准 二哥的Java进阶之路😄。
+> [!NOTE]
+> 知识库取名 **toBeBetterJavaer**,即 **To Be Better Javaer**,意为「成为一名更好的 Java 程序员」,是自学 Java 以来所有原创文章和学习资料的大聚合。内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发、Java 面试等核心知识点。据说每一个优秀的 Java 程序员都喜欢她,风趣幽默、通俗易懂。学 Java,就认准 Java 程序员进阶之路😄。
>
> 知识库旨在为学习 Java 的小伙伴提供一系列:
> - **优质的原创 Java 教程**
@@ -28,578 +32,435 @@
>
> 赠人玫瑰手有余香。知识库会持续保持**更新**,欢迎收藏品鉴!
>
-> **转载须知** :以下所有文章如非文首说明为转载皆为我(沉默王二)的原创,且不允许转载,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
+> **转载须知** :以下所有文章如非文首说明为转载皆为我(沉默王二)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
>
> 推荐你通过在线阅读网站进行阅读,体验更好,速度更快!
>
-> - [**二哥的Java进阶之路在线网站(新域名:javabetter.cn 好记,推荐👍)**](https://javabetter.cn)
-> - [老版 Java 程序员进阶之路在线网址(老域名 tobebetterjavaer.com 难记)](https://tobebetterjavaer.com)
-> - [技术派之二哥的Java进阶之路专栏](https://paicoding.com/column/5/1)
->
-> 如果你更喜欢离线的 PDF 版本,戳这个链接获取[👍二哥的 Java 进阶之路.pdf](docs/src/overview/readme.md)
+> - [Java 程序员进阶之路在线阅读网站(VuePress 版)](https://tobebetterjavaer.com/)
+> - [Java 程序员进阶之路在线阅读网站(docsify 版)](https://docsify.tobebetterjavaer.com/)
+>
+> 建议给本仓库点个 star,满足一下我的虚荣心,内容质量也绝对值得你一个 star。我还在继续创作,给我一点继续更新的动力,笔芯。
+
# 知识库地图
+> [!NOTE]
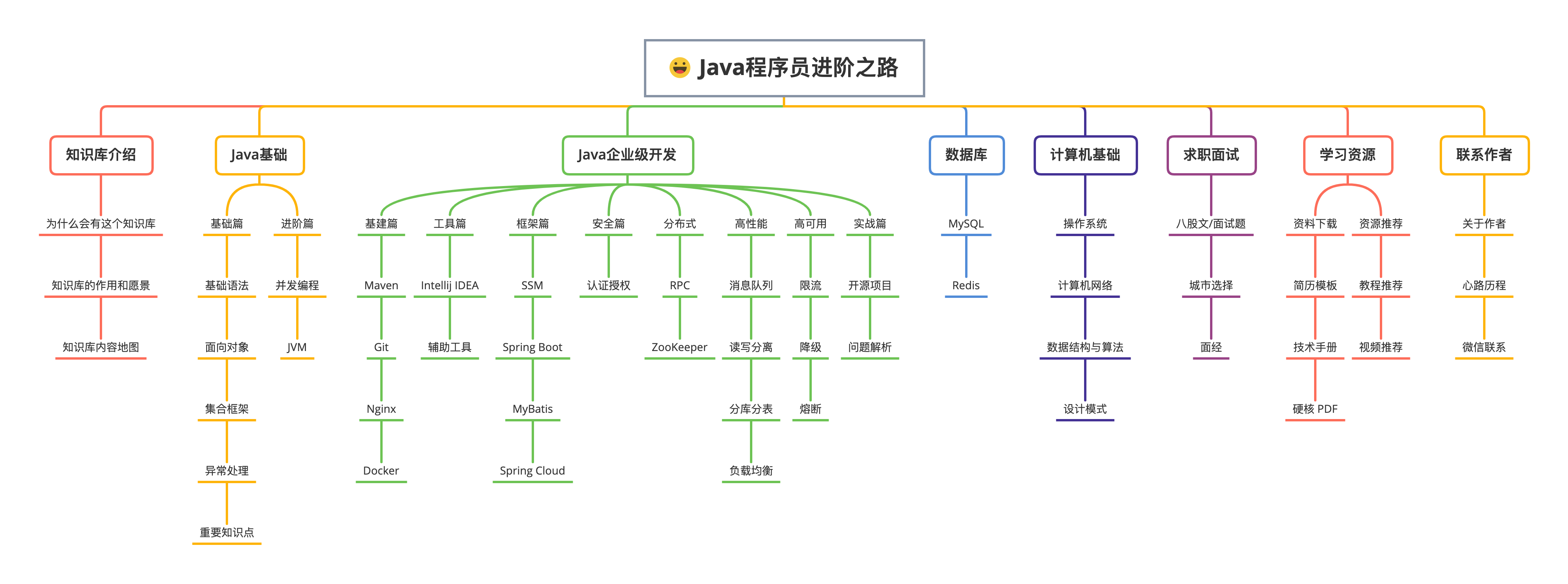
> 知识库收录的核心内容就全在这里面了,大类分为 Java 核心、Java 企业级开发、数据库、计算机基础、求职面试、学习资源、程序人生,几乎你需要的这里都有。
-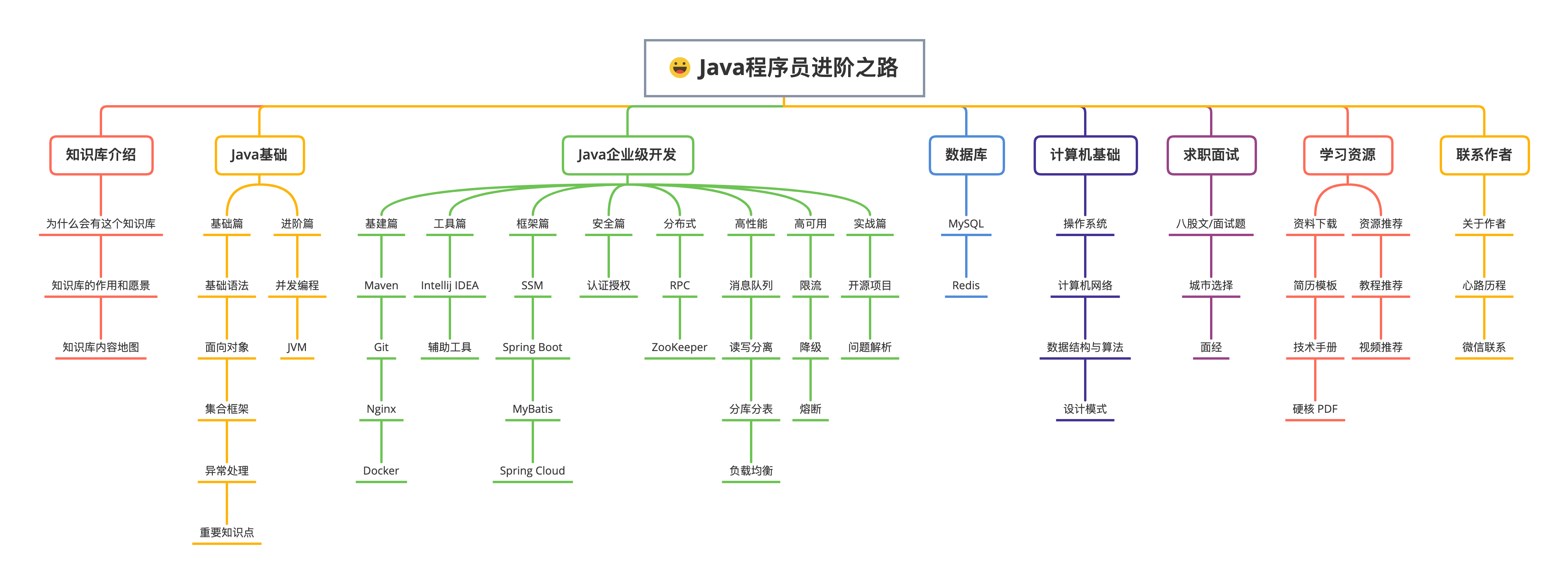
+
-一个人可以走得很快,但一群人才能走得更远。[二哥的编程星球](https://javabetter.cn/zhishixingqiu/)已经有 **10000 多名** 球友加入了(马上涨价到 169 元,抓紧时间趁没涨价前加入吧),如果你也需要一个优质的学习环境,扫描下方的优惠券加入我们吧。
-
-
-
-  -
-
-
-
-
-
+# 学习路线
-新人可免费体验 3 天,不满意可全额退款(只能帮你到这里了😄)。
+>[!NOTE]
+> 除了 Java 学习路线,还有 C语言、C++、Python、Go 语言、操作系统、前端、蓝桥杯等硬核学习路线,欢迎收藏品鉴!
+
+ * [Java学习路线一条龙版(建议收藏:+1:)](docs/xuexiluxian/java/yitiaolong.md)
+ * [Java并发编程学习路线(建议收藏:+1:)](docs/xuexiluxian/java/thread.md)
+ * [Java虚拟机学习路线(建议收藏:+1:)](docs/xuexiluxian/java/jvm.md)
+ * [C语言学习路线(建议收藏:+1:)](docs/xuexiluxian/c.md)
+ * [C++学习路线(建议收藏:+1:)](docs/xuexiluxian/ccc.md)
+ * [Python学习路线(建议收藏:+1:)](docs/xuexiluxian/python.md)
+ * [Go语言学习路线(建议收藏:+1:)](docs/xuexiluxian/go.md)
+ * [操作系统学习路线(建议收藏:+1:)](docs/xuexiluxian/os.md)
+ * [前端学习路线(建议收藏:+1:)](docs/xuexiluxian/qianduan.md)
+ * [蓝桥杯学习路线(建议收藏:+1:)](docs/xuexiluxian/lanqiaobei.md)
+ * [算法和数据结构学习路线(建议收藏:+1:)](docs/xuexiluxian/algorithm.md)
-这是一个 **简历精修 + 编程项目实战 + Java 面试指南 + LeetCode 刷题**的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的内容,**相信能帮助你走的更快、更稳、更远**。
+# 面渣逆袭
-- [二哥精修简历服务,让你投了就有笔试&面试✌️](https://javabetter.cn/zhishixingqiu/jianli.html)
-- [二哥的RAG知识库项目派聪明上线了,AI时代你必须拥有的实战项目✌️](https://javabetter.cn/zhishixingqiu/paismart.html)
-- [Go 版本的派聪明RAG知识库项目上线了,学习 Go 语言的小伙伴有福了✌️](https://javabetter.cn/zhishixingqiu/paismart-go.html)
-- [二哥的技术派实战项目更新了,秋招&暑期/日常实习大杀器✌️](https://javabetter.cn/zhishixingqiu/paicoding.html)
-- [二哥的PmHub微服务实战项目上线了,校招和社招均可用✌️](https://javabetter.cn/zhishixingqiu/paicoding.html)
-- [二哥的Java面试指南专栏更新了,求职面试必备✌️](https://javabetter.cn/zhishixingqiu/mianshi.html)
+> [!NOTE]
+> **面试前必读系列**!包括 Java 基础、Java 集合框架、Java 并发编程、Java 虚拟机、Spring、Redis 等等。
+- [面渣逆袭(Java 基础篇)必看:+1:](docs/sidebar/sanfene/javase.md)
+- [面渣逆袭(Java 集合框架篇)必看:+1:](docs/sidebar/sanfene/collection.md)
+- [面渣逆袭(Java 并发编程篇)必看:+1:](docs/sidebar/sanfene/javathread.md)
+- [面渣逆袭(Java 虚拟机篇)必看:+1:](docs/sidebar/sanfene/jvm.md)
+- [面渣逆袭(Spring)必看:+1:](docs/sidebar/sanfene/spring.md)
+- [面渣逆袭(Redis)必看:+1:](docs/sidebar/sanfene/redis.md)
-# 学习路线
+# 学习建议
-> 除了 Java 学习路线,还有 MySQL、Redis、C语言、C++、Python、Go 语言、操作系统、前端、数据结构与算法、蓝桥杯、大数据、Android、.NET等硬核学习路线,欢迎收藏品鉴!
-
- * [Java学习路线一条龙版(建议收藏🔥)](docs/src/xuexiluxian/java/yitiaolong.md)
- * [Java并发编程学习路线(建议收藏🔥)](docs/src/xuexiluxian/java/thread.md)
- * [Java虚拟机学习路线(建议收藏🔥)](docs/src/xuexiluxian/java/jvm.md)
- * [MySQL 学习路线(建议收藏🔥)](docs/src/xuexiluxian/mysql.md)
- * [Redis 学习路线(建议收藏🔥)](docs/src/xuexiluxian/redis.md)
- * [C语言学习路线(建议收藏🔥)](docs/src/xuexiluxian/c.md)
- * [C++学习路线(建议收藏🔥)](docs/src/xuexiluxian/ccc.md)
- * [Python学习路线(建议收藏🔥)](docs/src/xuexiluxian/python.md)
- * [Go语言学习路线(建议收藏🔥)](docs/src/xuexiluxian/go.md)
- * [操作系统学习路线(建议收藏🔥)](docs/src/xuexiluxian/os.md)
- * [前端学习路线(建议收藏🔥)](docs/src/xuexiluxian/qianduan.md)
- * [算法和数据结构学习路线(建议收藏🔥)](docs/src/xuexiluxian/algorithm.md)
- * [蓝桥杯学习路线(建议收藏🔥)](docs/src/xuexiluxian/lanqiaobei.md)
- * [大数据学习路线(建议收藏🔥)](docs/src/xuexiluxian/bigdata.md)
- * [Android 安卓学习路线(建议收藏🔥)](docs/src/xuexiluxian/android.md)
- * [.NET 学习路线(建议收藏🔥)](docs/src/xuexiluxian/donet.md)
- * [Linux 学习路线(建议收藏🔥)](docs/src/xuexiluxian/linux.md)
-
+> [!NOTE]
+> **收集了我所有的知乎高赞帖子**!全方位迷茫解惑。
-# 面渣逆袭
+- [如何阅读《深入理解计算机系统》这本书?](docs/xuexijianyi/read-csapp.md)
+- [电子信息工程最好的出路的是什么?](docs/xuexijianyi/electron-information-engineering.md)
-> **面试前必读系列**!包括 Java 基础、Java 集合框架、Java 并发编程、Java 虚拟机、Spring、Redis、MyBatis、MySQL、操作系统、计算机网络、RocketMQ、分布式、微服务、设计模式、Linux 等等。
-- [面渣逆袭(MySQL八股文面试题)必看👍](docs/src/sidebar/sanfene/mysql.md)
-- [面渣逆袭(Redis八股文面试题)必看👍](docs/src/sidebar/sanfene/redis.md)
-- [面渣逆袭(Spring八股文面试题)必看👍](docs/src/sidebar/sanfene/spring.md)
-- [面渣逆袭(Java 基础篇八股文面试题)必看👍](docs/src/sidebar/sanfene/javase.md)
-- [面渣逆袭(Java 集合框架篇八股文面试题)必看👍](docs/src/sidebar/sanfene/collection.md)
-- [面渣逆袭(Java 并发编程篇八股文面试题)必看👍](docs/src/sidebar/sanfene/javathread.md)
-- [面渣逆袭(Java 虚拟机篇八股文面试题)必看👍](docs/src/sidebar/sanfene/jvm.md)
-- [面渣逆袭(MyBatis八股文面试题)必看👍](docs/src/sidebar/sanfene/mybatis.md)
-- [面渣逆袭(操作系统八股文面试题)必看👍](docs/src/sidebar/sanfene/os.md)
-- [面渣逆袭(计算机网络八股文面试题)必看👍](docs/src/sidebar/sanfene/network.md)
-- [面渣逆袭(RocketMQ八股文面试题)必看👍](docs/src/sidebar/sanfene/rocketmq.md)
-- [面渣逆袭(分布式面试题八股文)必看👍](docs/src/sidebar/sanfene/fenbushi.md)
-- [面渣逆袭(微服务面试题八股文)必看👍](docs/src/sidebar/sanfene/weifuwu.md)
-- [面渣逆袭(设计模式面试题八股文)必看👍](docs/src/sidebar/sanfene/shejimoshi.md)
-- [面渣逆袭(Linux面试题八股文)必看👍](docs/src/sidebar/sanfene/linux.md)
+# Java核心
-# Java基础
+> [!NOTE]
+> **Java核心非常重要**!我将其分成了Java 基础篇(包括基础语法、面向对象、集合框架、异常处理、Java IO 等)、Java 并发篇和 Java 虚拟机篇。
-> **Java基础非常重要**!包括基础语法、面向对象、集合框架、异常处理、Java IO、网络编程、NIO、并发编程和 JVM。
+## Java概述
-## Java概述及环境配置
+- [什么是Java?Java发展简史,Java的优势](docs/overview/what-is-java.md)
+- [第一个Java程序:Hello World](docs/overview/hello-world.md)
-- [《二哥的Java进阶之路》小册简介](docs/src/overview/readme.md)
-- [Java简史、特性、前景](docs/src/overview/what-is-java.md)
-- [Windows和macOS下安装JDK教程](docs/src/overview/jdk-install-config.md)
-- [在macOS和Windows上安装Intellij IDEA](docs/src/overview/IDEA-install-config.md)
-- [编写第一个程序Hello World](docs/src/overview/hello-world.md)
## Java基础语法
-- [48个关键字及2个保留字全解析](docs/src/basic-extra-meal/48-keywords.md)
-- [了解Java注释](docs/src/basic-grammar/javadoc.md)
-- [基本数据类型与引用数据类型](docs/src/basic-grammar/basic-data-type.md)
-- [自动类型转换与强制类型转换](docs/src/basic-grammar/type-cast.md)
-- [Java基本数据类型缓存池剖析(IntegerCache)](docs/src/basic-extra-meal/int-cache.md)
-- [Java运算符详解](docs/src/basic-grammar/operator.md)
-- [Java流程控制语句详解](docs/src/basic-grammar/flow-control.md)
-- [Java 语法基础练习题](docs/src/basic-grammar/basic-exercise.md)
-
-## 数组&字符串
-
-- [掌握Java数组](docs/src/array/array.md)
-- [掌握 Java二维数组](docs/src/array/double-array.md)
-- [如何优雅地打印Java数组?](docs/src/array/print.md)
-- [深入解读String类源码](docs/src/string/string-source.md)
-- [为什么Java字符串是不可变的?](docs/src/string/immutable.md)
-- [深入理解Java字符串常量池](docs/src/string/constant-pool.md)
-- [详解 String.intern() 方法](docs/src/string/intern.md)
-- [String、StringBuilder、StringBuffer](docs/src/string/builder-buffer.md)
-- [Java中equals()与==的区别](docs/src/string/equals.md)
-- [最优雅的Java字符串拼接是哪种方式?](docs/src/string/join.md)
-- [如何在Java中拆分字符串?](docs/src/string/split.md)
+- [Java支持的8种基本数据类型](docs/basic-grammar/basic-data-type.md)
+- [Java流程控制语句](docs/basic-grammar/flow-control.md)
+- [Java运算符](docs/basic-grammar/operator.md)
+- [Java注释:单行、多行和文档注释](docs/basic-grammar/javadoc.md)
+- [Java中常用的48个关键字](docs/basic-extra-meal/48-keywords.md)
+- [Java命名规范(非常全面,可以收藏)](docs/basic-extra-meal/java-naming.md)
## Java面向对象编程
-- [类和对象](docs/src/oo/object-class.md)
-- [Java中的包](docs/src/oo/package.md)
-- [Java变量](docs/src/oo/var.md)
-- [Java方法](docs/src/oo/method.md)
-- [Java可变参数详解](docs/src/basic-extra-meal/varables.md)
-- [手把手教你用 C语言实现 Java native 本地方法](docs/src/oo/native-method.md)
-- [Java构造方法](docs/src/oo/construct.md)
-- [Java访问权限修饰符](docs/src/oo/access-control.md)
-- [Java代码初始化块](docs/src/oo/code-init.md)
-- [Java抽象类](docs/src/oo/abstract.md)
-- [Java接口](docs/src/oo/interface.md)
-- [Java内部类](docs/src/oo/inner-class.md)
-- [深入理解Java三大特性:封装、继承和多态](docs/src/oo/encapsulation-inheritance-polymorphism.md)
-- [详解Java this与super关键字](docs/src/oo/this-super.md)
-- [详解Java static 关键字](docs/src/oo/static.md)
-- [详解Java final 关键字](docs/src/oo/final.md)
-- [掌握Java instanceof关键字](docs/src/basic-extra-meal/instanceof.md)
-- [聊聊Java中的不可变对象](docs/src/basic-extra-meal/immutable.md)
-- [方法重写 Override 和方法重载 Overload 有什么区别?](docs/src/basic-extra-meal/override-overload.md)
-- [深入理解Java中的注解](docs/src/basic-extra-meal/annotation.md)
-- [Java枚举:小小enum,优雅而干净](docs/src/basic-extra-meal/enum.md)
+- [怎么理解Java中类和对象的概念?](docs/oo/object-class.md)
+- [Java变量的作用域:局部变量、成员变量、静态变量、常量](docs/oo/var.md)
+- [Java方法](docs/oo/method.md)
+- [Java构造方法](docs/oo/construct.md)
+- [Java代码初始化块](docs/oo/code-init.md)
+- [Java抽象类](docs/oo/abstract.md)
+- [Java接口](docs/oo/interface.md)
+- [Java中的static关键字解析](docs/oo/static.md)
+- [Java中this和super的用法总结](docs/oo/this-super.md)
+- [浅析Java中的final关键字](docs/oo/final.md)
+- [Java instanceof关键字用法](docs/oo/instanceof.md)
+- [深入理解Java中的不可变对象](docs/basic-extra-meal/immutable.md)
+- [Java中可变参数的使用](docs/basic-extra-meal/varables.md)
+- [深入理解Java泛型](docs/basic-extra-meal/generic.md)
+- [深入理解Java注解](docs/basic-extra-meal/annotation.md)
+- [Java枚举(enum)](docs/basic-extra-meal/enum.md)
+- [大白话说Java反射:入门、使用、原理](docs/basic-extra-meal/fanshe.md)
+
+## 字符串&数组
+
+- [为什么String是不可变的?](docs/string/immutable.md)
+- [深入了解Java字符串常量池](docs/string/constant-pool.md)
+- [深入解析 String#intern](docs/string/intern.md)
+- [Java判断两个字符串是否相等?](docs/string/equals.md)
+- [Java字符串拼接的几种方式](docs/string/join.md)
+- [如何在Java中优雅地分割String字符串?](docs/string/split.md)
+- [深入理解Java数组](docs/array/array.md)
+- [如何优雅地打印Java数组?](docs/array/print.md)
## 集合框架(容器)
-- [Java集合框架概览,包括List、Set、Map、队列](docs/src/collection/gailan.md)
-- [深入探讨 Java ArrayList](docs/src/collection/arraylist.md)
-- [深入探讨 Java LinkedList](docs/src/collection/linkedlist.md)
-- [Java Stack详解](docs/src/collection/stack.md)
-- [Java HashMap详解](docs/src/collection/hashmap.md)
-- [Java LinkedHashMap详解](docs/src/collection/linkedhashmap.md)
-- [Java TreeMap详解](docs/src/collection/treemap.md)
-- [Java 双端队列 ArrayDeque详解](docs/src/collection/arraydeque.md)
-- [Java 优先级队列PriorityQueue详解](docs/src/collection/PriorityQueue.md)
-- [Java Comparable和Comparator的区别](docs/src/collection/comparable-omparator.md)
-- [时间复杂度,评估ArrayList和LinkedList的执行效率](docs/src/collection/time-complexity.md)
-- [ArrayList和LinkedList的区别](docs/src/collection/list-war-2.md)
-- [Java 泛型深入解析](docs/src/basic-extra-meal/generic.md)
-- [Java迭代器Iterator和Iterable有什么区别?](docs/src/collection/iterator-iterable.md)
-- [为什么禁止在foreach里执行元素的删除操作?](docs/src/collection/fail-fast.md)
-
-## Java IO
-
-- [深入了解 Java IO](docs/src/io/shangtou.md)
-- [Java File:IO 流的起点与终点](docs/src/io/file-path.md)
-- [Java 字节流:Java IO 的基石](docs/src/io/stream.md)
-- [Java 字符流:Reader和Writer的故事](docs/src/io/reader-writer.md)
-- [Java 缓冲流:Java IO 的读写效率有了质的飞升](docs/src/io/buffer.md)
-- [Java 转换流:Java 字节流和字符流的桥梁](docs/src/io/char-byte.md)
-- [Java 打印流:PrintStream & PrintWriter](docs/src/io/print.md)
-- [Java 序列流:Java 对象的序列化和反序列化](docs/src/io/serialize.md)
-- [Java Serializable 接口:明明就一个空的接口嘛](docs/src/io/Serializbale.md)
-- [深入探讨 Java transient 关键字](docs/src/io/transient.md)
+- [Java集合框架](docs/collection/gailan.md)
+- [Java集合ArrayList详解](docs/collection/arraylist.md)
+- [Java集合LinkedList详解](docs/collection/linkedlist.md)
+- [Java中ArrayList和LinkedList的区别](docs/collection/list-war-2.md)
+- [Java中的Iterator和Iterable区别](docs/collection/iterator-iterable.md)
+- [为什么阿里巴巴强制不要在foreach里执行删除操作](docs/collection/fail-fast.md)
+- [Java8系列之重新认识HashMap](docs/collection/hashmap.md)
-## 异常处理
-
-- [一文彻底搞懂Java异常处理,YYDS](docs/src/exception/gailan.md)
-- [深入理解 Java 中的 try-with-resources](docs/src/exception/try-with-resources.md)
-- [Java异常处理的20个最佳实践](docs/src/exception/shijian.md)
-- [空指针NullPointerException的传说](docs/src/exception/npe.md)
-- [try-catch 捕获异常真的会影响性能吗?](docs/src/exception/try-catch-xingneng.md)
+## Java输入输出
-## 常用工具类
+- [Java IO学习整理](docs/io/shangtou.md)
+- [如何给女朋友解释什么是 BIO、NIO 和 AIO?](docs/io/BIONIOAIO.md)
-- [Java Scanner:扫描控制台输入的工具类](docs/src/common-tool/scanner.md)
-- [Java Arrays:专为数组而生的工具类](docs/src/common-tool/arrays.md)
-- [Apache StringUtils:专为Java字符串而生的工具类](docs/src/common-tool/StringUtils.md)
-- [Objects:专为操作Java对象而生的工具类](docs/src/common-tool/Objects.md)
-- [Java Collections:专为集合而生的工具类](docs/src/common-tool/collections.md)
-- [Hutool:国产良心工具包,让你的Java变得更甜](docs/src/common-tool/hutool.md)
-- [Guava:Google开源的Java工具库,太强大了](docs/src/common-tool/guava.md)
-- [其他常用Java工具类:IpUtil、MDC、ClassUtils、BeanUtils、ReflectionUtils](docs/src/common-tool/utils.md)
-## Java新特性
-
-- [Java 8 Stream流:掌握流式编程的精髓](docs/src/java8/stream.md)
-- [Java 8 Optional最佳指南:解决空指针问题的优雅之选](docs/src/java8/optional.md)
-- [深入浅出Java 8 Lambda表达式:探索函数式编程的魅力](docs/src/java8/Lambda.md)
-- [Java 14 开箱,新特性Record、instanceof、switch香香香香](docs/src/java8/java14.md)
+## 异常处理
-## Java网络编程
+- [一文读懂Java异常处理](docs/exception/gailan.md)
+- [详解Java7新增的try-with-resouces语法](docs/exception/try-with-resouces.md)
+- [Java异常处理的20个最佳实践](docs/exception/shijian.md)
+- [Java空指针NullPointerException的传说](docs/exception/npe.md)
-- [Java网络编程的基础:计算机网络](docs/src/socket/network-base.md)
-- [Java Socket:飞鸽传书的网络套接字](docs/src/socket/socket.md)
-- [牛逼,用Java Socket手撸了一个HTTP服务器](docs/src/socket/http.md)
+## 常用工具类
-## Java NIO
+- [Java Arrays工具类10大常用方法](docs/common-tool/arrays.md)
+- [Java集合框架:Collections工具类](docs/common-tool/collections.md)
+- [Hutool:国产良心工具包,让你的Java变得更甜](docs/common-tool/hutool.md)
+- [Google开源的Guava工具库,太强大了~](docs/common-tool/guava.md)
-- [Java NIO 比传统 IO 强在哪里?](docs/src/nio/nio-better-io.md)
-- [一文彻底解释清楚Java 中的NIO、BIO和AIO](docs/src/nio/BIONIOAIO.md)
-- [详解Java NIO的Buffer缓冲区和Channel通道](docs/src/nio/buffer-channel.md)
-- [聊聊 Java NIO中的Paths、Files](docs/src/nio/paths-files.md)
-- [Java NIO 网络编程实践:从入门到精通](docs/src/nio/network-connect.md)
-- [一文彻底理解Java IO模型](docs/src/nio/moxing.md)
+## Java新特性
-## 重要知识点
+- [Java 8 Stream流详细用法](docs/java8/stream.md)
+- [Java 8 Optional最佳指南](docs/java8/optional.md)
+- [深入浅出Java 8 Lambda表达式](docs/java8/Lambda.md)
+
+## Java重要知识点
+
+- [彻底弄懂Java中的Unicode和UTF-8编码](docs/basic-extra-meal/java-unicode.md)
+- [Java中int、Integer、new Integer之间的区别](docs/basic-extra-meal/int-cache.md)
+- [深入剖析Java中的拆箱和装箱](docs/basic-extra-meal/box.md)
+- [彻底讲明白的Java浅拷贝与深拷贝](docs/basic-extra-meal/deep-copy.md)
+- [深入理解Java中的hashCode方法](docs/basic-extra-meal/hashcode.md)
+- [一次性搞清楚equals和hashCode](docs/basic-extra-meal/equals-hashcode.md)
+- [Java重写(Override)与重载(Overload)](docs/basic-extra-meal/override-overload.md)
+- [Java重写(Overriding)时应当遵守的11条规则](docs/basic-extra-meal/Overriding.md)
+- [Java到底是值传递还是引用传递?](docs/basic-extra-meal/pass-by-value.md)
+- [Java不能实现真正泛型的原因是什么?](docs/basic-extra-meal/true-generic.md)
+- [详解Java中Comparable和Comparator的区别](docs/basic-extra-meal/comparable-omparator.md)
+- [jdk9为何要将String的底层实现由char[]改成了byte[]?](docs/basic-extra-meal/jdk9-char-byte-string.md)
+- [为什么JDK源码中,无限循环大多使用for(;;)而不是while(true)?](docs/basic-extra-meal/jdk-while-for-wuxian-xunhuan.md)
+- [先有Class还是先有Object?](docs/basic-extra-meal/class-object.md)
+- [instanceof关键字是如何实现的?](docs/basic-extra-meal/instanceof-jvm.md)
-- [Java命名规范:编写可读性强的代码](docs/src/basic-extra-meal/java-naming.md)
-- [解决中文乱码:字符编码全攻略 - ASCII、Unicode、UTF-8、GB2312详解](docs/src/basic-extra-meal/java-unicode.md)
-- [深入浅出Java拆箱与装箱](docs/src/basic-extra-meal/box.md)
-- [深入理解Java浅拷贝与深拷贝](docs/src/basic-extra-meal/deep-copy.md)
-- [Java hashCode方法解析](docs/src/basic-extra-meal/hashcode.md)
-- [Java到底是值传递还是引用传递?](docs/src/basic-extra-meal/pass-by-value.md)
-- [为什么无法实现真正的泛型?](docs/src/basic-extra-meal/true-generic.md)
-- [Java 反射详解](docs/src/basic-extra-meal/fanshe.md)
## Java并发编程
-- [并发编程小册简介](docs/src/thread/readme.md)
-- [Java多线程入门](docs/src/thread/wangzhe-thread.md)
-- [获取线程的执行结果](docs/src/thread/callable-future-futuretask.md)
-- [Java线程的6种状态及切换](docs/src/thread/thread-state-and-method.md)
-- [线程组和线程优先级](docs/src/thread/thread-group-and-thread-priority.md)
-- [进程与线程的区别](docs/src/thread/why-need-thread.md)
-- [多线程带来了哪些问题?](docs/src/thread/thread-bring-some-problem.md)
-- [Java的内存模型(JMM)](docs/src/thread/jmm.md)
-- [volatile关键字解析](docs/src/thread/volatile.md)
-- [synchronized关键字解析](docs/src/thread/synchronized-1.md)
-- [synchronized的四种锁状态](docs/src/thread/synchronized.md)
-- [深入浅出偏向锁](docs/src/thread/pianxiangsuo.md)
-- [CAS详解](docs/src/thread/cas.md)
-- [AQS详解](docs/src/thread/aqs.md)
-- [锁分类和 JUC](docs/src/thread/lock.md)
-- [重入锁ReentrantLock](docs/src/thread/reentrantLock.md)
-- [读写锁ReentrantReadWriteLock](docs/src/thread/ReentrantReadWriteLock.md)
-- [等待通知条件Condition](docs/src/thread/condition.md)
-- [线程阻塞唤醒类LockSupport](docs/src/thread/LockSupport.md)
-- [Java的并发容器](docs/src/thread/map.md)
-- [并发容器ConcurrentHashMap](docs/src/thread/ConcurrentHashMap.md)
-- [非阻塞队列ConcurrentLinkedQueue](docs/src/thread/ConcurrentLinkedQueue.md)
-- [阻塞队列BlockingQueue](docs/src/thread/BlockingQueue.md)
-- [并发容器CopyOnWriteArrayList](docs/src/thread/CopyOnWriteArrayList.md)
-- [本地变量ThreadLocal](docs/src/thread/ThreadLocal.md)
-- [线程池](docs/src/thread/pool.md)
-- [定时任务ScheduledThreadPoolExecutor](docs/src/thread/ScheduledThreadPoolExecutor.md)
-- [原子操作类Atomic](docs/src/thread/atomic.md)
-- [魔法类 Unsafe](docs/src/thread/Unsafe.md)
-- [通信工具类](docs/src/thread/CountDownLatch.md)
-- [Fork/Join](docs/src/thread/fork-join.md)
-- [生产者-消费者模式](docs/src/thread/shengchanzhe-xiaofeizhe.md)
+- [室友打了一把王者就学会了创建Java线程的3种方式](docs/thread/wangzhe-thread.md)
+- [Java线程的6种状态及切换(透彻讲解)](docs/thread/thread-state-and-method.md)
+- [线程组是什么?线程优先级如何设置?](docs/thread/thread-group-and-thread-priority.md)
+- [进程与线程的区别是什么?](docs/thread/why-need-thread.md)
+- [并发编程带来了哪些问题?](docs/thread/thread-bring-some-problem.md)
+- [全面理解Java的内存模型(JMM)](docs/thread/jmm.md)
+- [Java并发编程volatile关键字解析](docs/thread/volatile.md)
+- [Java中的synchronized关键字锁的到底是什么?](docs/thread/synchronized.md)
+- [Java实现CAS的原理](docs/thread/cas.md)
+- [Java并发AQS详解](docs/thread/aqs.md)
+- [大致了解下Java的锁接口和锁](docs/thread/lock.md)
+- [深入理解Java并发重入锁ReentrantLock](docs/thread/reentrantLock.md)
+- [深入理解Java并发读写锁ReentrantReadWriteLock](docs/thread/ReentrantReadWriteLock.md)
+- [深入理解Java并发线程协作类Condition](docs/thread/condition.md)
+- [深入理解Java并发线程线程阻塞唤醒类LockSupport](docs/thread/LockSupport.md)
+- [简单聊聊Java的并发集合容器](docs/thread/map.md)
+- [吊打Java并发面试官之ConcurrentHashMap](docs/thread/ConcurrentHashMap.md)
+- [吊打Java并发面试官之ConcurrentLinkedQueue](docs/thread/ConcurrentLinkedQueue.md)
+- [吊打Java并发面试官之CopyOnWriteArrayList](docs/thread/CopyOnWriteArrayList.md)
+- [吊打Java并发面试官之ThreadLocal](docs/thread/ThreadLocal.md)
+- [吊打Java并发面试官之BlockingQueue](docs/thread/BlockingQueue.md)
+- [面试必备:Java线程池解析](docs/thread/pool.md)
+- [为什么阿里巴巴要禁用Executors创建线程池?](docs/thread/ali-executors.md)
+- [深入剖析Java计划任务ScheduledThreadPoolExecutor](docs/thread/ScheduledThreadPoolExecutor.md)
+- [Java atomic包中的原子操作类总结](docs/thread/atomic.md)
+- [Java并发编程通信工具类CountDownLatch等一网打尽](docs/thread/CountDownLatch.md)
+- [深入理解Java并发编程之Fork/Join框架](docs/thread/fork-join.md)
+- [从根上理解生产者-消费者模式](docs/thread/shengchanzhe-xiaofeizhe.md)
## Java虚拟机
-- [JVM小册简介](docs/src/jvm/readme.md)
-- [大白话带你认识JVM](docs/src/jvm/what-is-jvm.md)
-- [JVM是如何运行Java代码的?](docs/src/jvm/how-run-java-code.md)
-- [Java的类加载机制(付费)](docs/src/jvm/class-load.md)
-- [Java的类文件结构](docs/src/jvm/class-file-jiegou.md)
-- [从javap的角度轻松看懂字节码](docs/src/jvm/bytecode.md)
-- [栈虚拟机与寄存器虚拟机](docs/src/jvm/vm-stack-register.md)
-- [字节码指令详解](docs/src/jvm/zijiema-zhiling.md)
-- [深入理解JVM的栈帧结构](docs/src/jvm/stack-frame.md)
-- [深入理解JVM的运行时数据区](docs/src/jvm/neicun-jiegou.md)
-- [深入理解JVM的垃圾回收机制](docs/src/jvm/gc.md)
-- [深入理解 JVM 的垃圾收集器:CMS、G1、ZGC](docs/src/jvm/gc-collector.md)
-- [Java 创建的对象到底放在哪?](docs/src/jvm/whereis-the-object.md)
-- [深入理解JIT(即时编译)](docs/src/jvm/jit.md)
-- [JVM 性能监控之命令行篇](docs/src/jvm/console-tools.md)
-- [JVM 性能监控之可视化篇](docs/src/jvm/view-tools.md)
-- [阿里开源的 Java 诊断神器 Arthas](docs/src/jvm/arthas.md)
-- [内存溢出排查优化实战](docs/src/jvm/oom.md)
-- [CPU 100% 排查优化实践](docs/src/jvm/cpu-percent-100.md)
-- [JVM 核心知识点总结](docs/src/jvm/zongjie.md)
-
-
-# Java进阶
-
-> - **到底能不能成为一名合格的 Java 程序员,从理论走向实战?Java进阶这部分内容就是一个分水岭**!
+- [JVM到底是什么?](docs/jvm/what-is-jvm.md)
+- [JVM到底是如何运行Java代码的?](docs/jvm/how-run-java-code.md)
+- [我竟然不再抗拒Java的类加载机制了](docs/jvm/class-load.md)
+- [详解Java的类文件(class文件)结构](docs/jvm/class-file-jiegou.md)
+- [从javap的角度轻松看懂字节码](docs/jvm/bytecode.md)
+- [JVM字节码指令详解](docs/jvm/zijiema-zhiling.md)
+- [虚拟机是如何执行字节码指令的?](docs/jvm/how-jvm-run-zijiema-zhiling.md)
+- [HSDB(Hotspot Debugger)从入门到实战](docs/jvm/hsdb.md)
+- [史上最通俗易懂的ASM教程](docs/jvm/asm.md)
+- [自己编译JDK](docs/jvm/compile-jdk.md)
+- [深入理解JVM的内存结构](docs/jvm/neicun-jiegou.md)
+- [Java 创建的对象到底放在哪?](docs/jvm/whereis-the-object.md)
+- [咱们从头到尾说一次Java垃圾回收](docs/jvm/gc.md)
+- [图解Java的垃圾回收机制](docs/jvm/tujie-gc.md)
+- [Java问题诊断和排查工具(查看JVM参数、内存使用情况及分析)](docs/jvm/problem-tools.md)
+- [Java即时编译(JIT)器原理解析及实践](docs/jvm/jit.md)
+- [一次内存溢出排查优化实战](docs/jvm/oom.md)
+- [一次生产CPU 100% 排查优化实践](docs/jvm/cpu-percent-100.md)
+- [JVM 核心知识点总结](docs/jvm/zongjie.md)
+
+
+# Java企业级开发
+
+> [!NOTE]
+> - **到底能不能成为一名合格的 Java 程序员,从理论走向实战?Java 企业级开发这部分内容就是一个分水岭**!
> - 纸上得来终觉浅,须知此事要躬行。
-## 开发/构建工具
-
-> 工欲善其事必先利其器,这句话大家都耳熟能详了,熟练使用开发/构建工具可以让我们极大提升开发效率,解放生产力。
-
-- [5分钟带你深入浅出搞懂Nginx](docs/src/nginx/nginx.md)
-
-### IDEA
-
-> 集成开发环境,Java 党主要就是 Intellij IDEA 了,号称史上最强大的 Java 开发工具,没有之一。
-
-- [分享 4 个阅读源码必备的 IDEA 调试技巧](docs/src/ide/4-debug-skill.md)
-- [分享 1 个可以在 IDEA 里下五子棋的插件](docs/src/ide/xechat.md)
-- [分享 10 个可以一站式开发的 IDEA 神级插件](docs/src/ide/shenji-chajian-10.md)
+## 开发工具
-### Maven
+- [终于把项目构建神器Maven捋清楚了~](docs/maven/maven.md)
+- [我在工作中是如何使用Git的](docs/git/git-qiyuan.md)
+- [5分钟带你深入浅出搞懂Nginx](docs/nginx/nginx.md)
-> Maven 是目前比较流行的一个项目构建工具,基于 pom 坐标来帮助我们管理第三方依赖,以及项目打包。
+## IDE/编辑器
-- [终于把项目构建神器Maven捋清楚了~](docs/src/maven/maven.md)
-
-### Git
-
-> Git 是一个分布式版本控制系统,缔造者是大名鼎鼎的林纳斯·托瓦茲 (Linus Torvalds),Git 最初的目的是为了能更好的管理 Linux 内核源码。如今,Git 已经成为全球软件开发者的标配。如果说 Linux 项目促成了开源软件的成功并改写了软件行业的格局,那么 Git 则是改变了全世界开发者的工作方式和写作方式。
-
-- [1小时彻底掌握Git](docs/src/git/git-qiyuan.md)
-- [GitHub 远程仓库端口切换](docs/src/git/port-22-to-443.md)
+- [4个高级的IntelliJ IDEA调试技巧](docs/ide/4-debug-skill.md)
## Spring
-- [Spring AOP扫盲](docs/src/springboot/aop-log.md)
-- [Spring IoC扫盲](docs/src/springboot/ioc.md)
+- [Spring AOP扫盲](docs/springboot/aop-log.md)
+- [Spring IoC扫盲](docs/springboot/ioc.md)
## SpringBoot
-- [一分钟快速搭建Spring Boot项目](docs/src/springboot/initializr.md)
-- [Spring Boot 整合 lombok](docs/src/springboot/lombok.md)
-- [Spring Boot 整合 MySQL 和 Druid](docs/src/springboot/mysql-druid.md)
-- [Spring Boot 整合 JPA](docs/src/springboot/jpa.md)
-- [Spring Boot 整合 Thymeleaf 模板引擎](docs/src/springboot/thymeleaf.md)
-- [Spring Boot 如何开启事务支持?](docs/src/springboot/transaction.md)
-- [Spring Boot 中使用过滤器、拦截器、监听器](docs/src/springboot/Filter-Interceptor-Listener.md)
-- [Spring Boot 整合 Redis 实现缓存](docs/src/redis/redis-springboot.md)
-- [Spring Boot 整合 Logback 定制日志框架](docs/src/springboot/logback.md)
-- [Spring Boot 整合 Swagger-UI 实现在线API文档](docs/src/springboot/swagger.md)
-- [Spring Boot 整合 Knife4j,美化强化丑陋的Swagger](docs/src/gongju/knife4j.md)
-- [Spring Boot 整合 Spring Task 实现定时任务](docs/src/springboot/springtask.md)
-- [Spring Boot 整合 MyBatis-Plus AutoGenerator 生成编程喵项目骨架代码](docs/src/kaiyuan/auto-generator.md)
-- [Spring Boot 整合Quartz实现编程喵定时发布文章](docs/src/springboot/quartz.md)
-- [Spring Boot 整合 MyBatis](docs/src/springboot/mybatis.md)
-- [一键部署 Spring Boot 到远程 Docker 容器](docs/src/springboot/docker.md)
-- [如何在本地(macOS环境)跑起来编程喵(Spring Boot+Vue)项目源码?](docs/src/springboot/macos-codingmore-run.md)
-- [如何在本地(Windows环境)跑起来编程喵(Spring Boot+Vue)项目源码?](docs/src/springboot/windows-codingmore-run.md)
-- [编程喵🐱实战项目如何在云服务器上跑起来?](docs/src/springboot/linux-codingmore-run.md)
-- [SpringBoot中处理校验逻辑的两种方式:Hibernate Validator+全局异常处理](docs/src/springboot/validator.md)
-
-
-## Netty
-
-- [超详细Netty入门,看这篇就够了!](docs/src/netty/rumen.md)
-
-
-## 辅助工具
-
-- [Chocolatey:一款GitHub星标8.2k+的Windows命令行软件管理器,好用到爆!](docs/src/gongju/choco.md)
-- [Homebrew,GitHub 星标 32.5k+的 macOS 命令行软件管理神器,功能真心强大!](docs/src/gongju/brew.md)
-- [Tabby:一款逼格更高的开源终端工具,GitHub 星标 21.4k](docs/src/gongju/tabby.md)
-- [Warp:号称下一代终端神器,GitHub星标2.8k+,用完爱不释手](docs/src/gongju/warp.md)
-- [WindTerm:新一代开源免费的终端工具,GitHub星标6.6k+,太酷了!](docs/src/gongju/windterm.md)
-- [chiner:干掉 PowerDesigner,国人开源的数据库设计工具,界面漂亮,功能强大](docs/src/gongju/chiner.md)
-- [DBeaver:干掉付费的 Navicat,操作所有数据库就靠它了!](docs/src/gongju/DBeaver.md)
-
-## 开源轮子
-
-- [Forest:一款极简的声明式HTTP调用API框架](docs/src/gongju/forest.md)
-- [Junit:一个开源的Java单元测试框架](docs/src/gongju/junit.md)
-- [fastjson:阿里巴巴开源的JSON解析库](docs/src/gongju/fastjson.md)
-- [Gson:Google开源的JSON解析库](docs/src/gongju/gson.md)
-- [Jackson:GitHub上star数最多的JSON解析库](docs/src/gongju/jackson.md)
-- [Log4j:Java日志框架的鼻祖](docs/src/gongju/log4j.md)
-- [Log4j 2:Apache维护的一款高性能日志记录工具](docs/src/gongju/log4j2.md)
-- [Logback:Spring Boot内置的日志处理框架](docs/src/gongju/logback.md)
-- [SLF4J:阿里巴巴强制使用的日志门面担当](docs/src/gongju/slf4j.md)
-
+- [一分钟快速搭建Spring Boot项目](docs/springboot/initializr.md)
+- [Spring Boot 整合 MySQL 和 Druid](docs/springboot/mysql-druid.md)
+- [Spring Boot 整合 JPA](docs/springboot/jpa.md)
+- [Spring Boot 整合 Thymeleaf 模板引擎](docs/springboot/thymeleaf.md)
+- [Spring Boot 如何开启事务支持?](docs/springboot/transaction.md)
+- [Spring Boot 中使用过滤器、拦截器、监听器](docs/springboot/Filter-Interceptor-Listener.md)
+- [Spring Boot 整合 Redis 实现缓存](docs/redis/redis-springboot.md)
+- [Spring Boot 整合 Logback 定制日志框架](docs/springboot/logback.md)
+- [Spring Boot 整合 Swagger-UI 实现在线API文档](docs/springboot/swagger.md)
+- [Spring Boot 整合 Knife4j,美化强化丑陋的Swagger](docs/gongju/knife4j.md)
+- [Spring Boot 整合 Spring Task 实现定时任务](docs/springboot/springtask.md)
+- [Spring Boot 整合 MyBatis-Plus AutoGenerator 生成编程喵项目骨架代码](docs/kaiyuan/auto-generator.md)
+
+
+## 辅助工具/轮子
+
+- [Tabby:一款逼格更高的开源终端工具](docs/gongju/tabby.md)
+- [Warp:一款21世纪人用的终端工具](docs/gongju/warp.md)
+- [Chocolatey:一款GitHub星标8.2k+的Windows命令行软件管理器](docs/gongju/choco.md)
+- [chiner:一款开源的数据库设计神器](docs/gongju/chiner.md)
+- [DBeaver:一款免费的数据库操作工具](docs/gongju/DBeaver.md)
+- [Forest:一款极简的声明式HTTP调用API框架](docs/gongju/forest.md)
+- [Junit:一个开源的Java单元测试框架](docs/gongju/junit.md)
+- [fastjson:阿里巴巴开源的JSON解析库](docs/gongju/fastjson.md)
+- [Gson:Google开源的JSON解析库](docs/gongju/gson.md)
+- [Jackson:GitHub上star数最多的JSON解析库](docs/gongju/jackson.md)
+- [Log4j:Java日志框架的鼻祖](docs/gongju/log4j.md)
+- [Log4j 2:Apache维护的一款高性能日志记录工具](docs/gongju/log4j2.md)
+- [Logback:Spring Boot内置的日志处理框架](docs/gongju/logback.md)
+- [SLF4J:阿里巴巴强制使用的日志门面担当](docs/gongju/slf4j.md)
+
+
+## 安全篇
## 分布式
-- [全文搜索引擎Elasticsearch入门教程](docs/src/elasticsearch/rumen.md)
-- [可能是把ZooKeeper概念讲的最清楚的一篇文章](docs/src/zookeeper/jibenjieshao.md)
-- [微服务网关:从对比到选型,由理论到实践](docs/src/microservice/api-wangguan.md)
+- [全文搜索引擎Elasticsearch入门教程](docs/elasticsearch/rumen.md)
+- [可能是把ZooKeeper概念讲的最清楚的一篇文章](docs/zookeeper/jibenjieshao.md)
+- [微服务网关:从对比到选型,由理论到实践](docs/microservice/api-wangguan.md)
-## 消息队列
+## 高性能
-- [RabbitMQ入门教程(概念、应用场景、安装、使用)](docs/src/mq/rabbitmq-rumen.md)
-- [怎么确保消息100%不丢失?](docs/src/mq/100-budiushi.md)
-- [Kafka核心知识点大梳理](docs/src/mq/kafka.md)
+### 消息队列
+
+- [RabbitMQ入门教程(概念、应用场景、安装、使用)](docs/mq/rabbitmq-rumen.md)
+- [怎么确保消息100%不丢失?](docs/mq/100-budiushi.md)
+
+## 高可用
# 数据库
+> [!NOTE]
> - **简而言之,就是按照数据结构来组织、存储和管理数据的仓库**。几乎所有的 Java 后端开发都要学习数据库这块的知识,包括关系型数据库 MySQL,缓存中间件 Redis,非关系型数据库 MongoDB 等。
## MySQL
-- [MySQL 的安装和连接,结合技术派实战项目来讲](docs/src/mysql/install.md)
-- [MySQL 的数据库操作,利用 Spring Boot 实现数据库的自动创建](docs/src/mysql/database.md)
-- [MySQL 表的基本操作,结合技术派的表自动初始化来讲](docs/src/mysql/table.md)
-- [MySQL 的数据类型,4000 字 20 张手绘图,彻底掌握](docs/src/mysql/data-type.md)
-- [MySQL 的字符集和比较规则,从跟上掌握](docs/src/mysql/charset.md)
-- [MySQL bin目录下的那些可执行文件,包括备份数据库、导入 CSV 等](docs/src/mysql/bin.md)
-- [MySQL 的字段属性,默认值、是否为空、主键、自增、ZEROLFILL等一网打尽](docs/src/mysql/column.md)
-- [MySQL 的简单查询,开始踏上 SELECT 之旅](docs/src/mysql/select-simple.md)
-- [MySQL 的 WEHRE 条件查询,重点搞懂 % 通配符](docs/src/mysql/select-where.md)
-- [如何保障MySQL和Redis的数据一致性?](docs/src/mysql/redis-shuju-yizhixing.md)
-- [从根上理解 MySQL 的事务](docs/src/mysql/lijie-shiwu.md)
-- [浅入深出 MySQL 中事务的实现](docs/src/mysql/shiwu-shixian.md)
+- [如何保障MySQL和Redis的数据一致性?](docs/mysql/redis-shuju-yizhixing.md)
## Redis
-- [Redis入门(适合新手)](docs/src/redis/rumen.md)
-- [聊聊缓存雪崩、穿透、击穿](docs/src/redis/xuebeng-chuantou-jichuan.md)
+- [Redis入门(适合新手)](docs/redis/rumen.md)
+- [聊聊缓存雪崩、穿透、击穿](docs/redis/xuebeng-chuantou-jichuan.md)
## MongoDB
-- [MongoDB最基础入门教程](docs/src/mongodb/rumen.md)
+- [MongoDB最基础入门教程](docs/mongodb/rumen.md)
# 计算机基础
+> [!NOTE]
> - **计算机基础包括操作系统、计算机网络、计算机组成原理、数据结构与算法等**。对于任何一名想要走得更远的 Java 后端开发来说,都是必须要花时间和精力去夯实的。
> - 万丈高露平地起,勿在浮沙筑高台。
-- [操作系统核心知识点大梳理](docs/src/cs/os.md)
-- [计算机网络核心知识点大梳理](docs/src/cs/wangluo.md)
+- [计算机操作系统知识点大梳理](docs/cs/os.md)
+- [计算机网络核心知识点大梳理](docs/cs/wangluo.md)
# 求职面试
+> [!NOTE]
> - **学习了那么多 Java 知识,耗费了无数的脑细胞,熬掉了无数根秀发,为的是什么?当然是谋取一份心仪的 offer 了**。那八股文、面试题、城市选择、优质面经又怎能少得了呢?
> - 千淘万漉虽辛苦,吹尽狂沙始到金。
-## 面试题&八股文
+## 面试题集合
-- [34 道 Java 精选面试题👍](docs/src/interview/java-34.md)
-- [13 道 Java HashMap 精选面试题👍](docs/src/interview/java-hashmap-13.md)
-- [60 道 MySQL 精选面试题👍](docs/src/interview/mysql-60.md)
-- [15 道 MySQL 索引精选面试题👍](docs/src/interview/mysql-suoyin-15.md)
-- [12 道 Redis 精选面试题👍](docs/src/interview/redis-12.md)
-- [40 道 Nginx 精选面试题👍](docs/src/interview/nginx-40.md)
-- [17 道 Dubbo 精选面试题👍](docs/src/interview/dubbo-17.md)
-- [40 道 Kafka 精选面试题👍](docs/src/interview/kafka-40.md)
-- [Java 基础背诵版八股文必看🍉](docs/src/interview/java-basic-baguwen.md)
-- [Java 并发编程背诵版八股文必看🍉](docs/src/interview/java-thread-baguwen.md)
-- [Java 虚拟机背诵版八股文必看🍉](docs/src/interview/java-jvm-baguwen.md)
-- [携程面试官👤:大文件上传时如何做到秒传?](docs/src/interview/mianshiguan-bigfile-miaochuan.md)
-- [阿里面试官👤:为什么要分库分表?](docs/src/interview/mianshiguan-fenkufenbiao.md)
-- [淘宝面试官👤:优惠券系统该如何设计?](docs/src/interview/mianshiguan-youhuiquan.md)
+- [Java:34道精选高频面试题](docs/baguwen/java-basic-34.md)
+- [Java:13道HashMap精选面试题](docs/collection/hashmap-interview.md)
+- [Redis:12道精选高频面试题)](docs/mianjing/redis12question.md)
+- [Nginx:40道精选面试题](docs/nginx/40-interview.md)
-## 优质面经
+## 背诵版八股文
-- [硕士读者春招斩获深圳腾讯PCG和杭州阿里云 offer✌️](docs/src/mianjing/shanganaliyun.md)
-- [本科读者小公司一年工作经验社招拿下阿里美团头条京东滴滴等 offer✌️](docs/src/mianjing/shezynmjfxhelmtttjddd.md)
-- [非科班读者,用一年时间社招拿下阿里 Offer✌️](docs/src/mianjing/xuelybdzheloffer.md)
-- [二本读者社招两年半10家公司28轮面试面经✌️](docs/src/mianjing/huanxgzl.md)
-- [双非一本秋招收获腾讯ieg、百度、字节等6家大厂offer✌️](docs/src/mianjing/quzjlsspdx.md)
-- [双非学弟收割阿里、字节、B站校招 offer,附大学四年硬核经验总结✌️](docs/src/mianjing/zheisnylzldhzd.md)
-- [深漂 6 年了,回西安的一波面经总结✌️](docs/src/mianjing/chengxyspnhxagzl.md)
+- [Java 基础八股文(背诵版)必看:+1:](docs/baguwen/java-basic.md)
+- [Java 并发编程八股文(背诵版)必看:+1:](docs/baguwen/java-thread.md)
+- [Java 虚拟机八股文(背诵版)必看:+1:](docs/baguwen/jvm.md)
+- [MySQL 八股文(背诵版)必看:+1:](docs/sidebar/herongwei/mysql.md)
+## 优质面经
+
+- [春招斩获深圳腾讯PCG和杭州阿里云](docs/mianjing/shanganaliyun.md)
+- [社招拿下阿里美团头条京东滴滴)](https://mp.weixin.qq.com/s/h2tV6v5Rh6jHdO9x0p63-g)
+- [字节小姐姐的一份秋招攻略](https://mp.weixin.qq.com/s/0hCJy0m8nHm08HfyXKQT1A)
+- [面试常见词汇扫盲+常见大厂面试特点分享](https://mp.weixin.qq.com/s/6TYEDM73N68vKXpmLRKhHA)
+- [双非学历的社畜,历经 6 轮面试,最终拿下阿里Offer](https://mp.weixin.qq.com/s/vnMZY9Gsy3o1FwMi4f1GlA)
+
## 面试准备
-- [面试常见词汇扫盲+大厂面试特点分享💪](docs/src/nice-article/weixin/miansmtgl.md)
-- [有无实习/暑期实习 offer 如何准备秋招?💪](docs/src/nice-article/weixin/zijxjjdyfqzgl.md)
-- [简历如何优化,简历如何投递,面试如何准备?💪](docs/src/nice-article/weixin/luoczbmsddyb.md)
-- [校招时间节点、简历编写、笔试、HR面、实习等注意事项💪](docs/src/nice-article/weixin/youdxzhhmjzlycfx.md)
+- [简历如何优化,简历如何投递,面试如何准备?](https://mp.weixin.qq.com/s/qurUqeD_VyiJRtB38vOuSw)
+- [校招时间节点、简历编写、笔试、、HR面、实习等注意事项](https://mp.weixin.qq.com/s/rO7cU4NX74CoWADo_O4IUw)
## 城市选择
-- [武汉都有哪些值得加入的IT互联网公司?](docs/src/cityselect/wuhan.md)
-- [北京都有哪些值得加入的IT互联网公司?](docs/src/cityselect/beijing.md)
-- [广州都有哪些值得加入的IT互联网公司?](docs/src/cityselect/guangzhou.md)
-- [深圳都有哪些值得加入的IT互联网公司?](docs/src/cityselect/shenzhen.md)
-- [西安都有哪些值得加入的IT互联网公司?](docs/src/cityselect/xian.md)
-- [青岛都有哪些值得加入的IT互联网公司?](docs/src/cityselect/qingdao.md)
-- [郑州都有哪些值得加入的IT互联网公司?](docs/src/cityselect/zhengzhou.md)
-- [苏州都有哪些值得加入的IT互联网公司?](docs/src/cityselect/suzhou.md)
-- [南京都有哪些值得加入的IT互联网公司?](docs/src/cityselect/nanjing.md)
-- [杭州都有哪些值得加入的IT互联网公司?](docs/src/cityselect/hangzhou.md)
-- [成都都有哪些值得加入的IT互联网公司?](docs/src/cityselect/chengdu.md)
-- [济南都有哪些值得加入的IT互联网公司?](docs/src/cityselect/jinan.md)
+- [北京都有哪些牛逼的互联网公司?](docs/cityselect/beijing.md)
+- [想去广州了!](docs/cityselect/guangzhou.md)
+- [深圳有哪些牛批的互联网公司?](docs/cityselect/shenzhen.md)
+- [西安有哪些不错的互联网公司?](docs/cityselect/xian.md)
+- [青岛有牛逼的互联网公司吗?](docs/cityselect/qingdao.md)
+- [郑州有哪些不错的互联网公司?](docs/cityselect/zhengzhou.md)
+- [想搬去苏州生活了。](docs/cityselect/suzhou.md)
+- [南京有哪些靠谱的互联网公司?](docs/cityselect/nanjing.md)
+- [杭州有哪些顶级的互联网公司?](docs/cityselect/hangzhou.md)
+- [成都有哪些牛批的互联网公司?](docs/cityselect/chengdu.md)
+
+## 工作体会
+
# 学习资源
+> [!NOTE]
> - **不知道学什么?不知道该怎么学?找不到优质的学习资源**?这些问题在这里统统都可以找到答案。
> - 我会把自己十多年的编程经验和学习资源毫不保留的分享出来。
## PDF下载
-- [👏下载→30天速通 Java.pdf](docs/src/pdf/java30day.md)
-- [👏下载→Linux速查备忘手册.pdf](docs/src/pdf/linux.md)
-- [👏下载→超1000本计算机经典书籍分享](docs/src/pdf/java.md)
-- [👏下载→2022年全网最全关于程序员学习和找工作的PDF资源](docs/src/pdf/programmer-111.md)
-- [👏下载→深入浅出Java多线程PDF](docs/src/pdf/java-concurrent.md)
-- [👏下载→GitHub星标115k+的Java教程](docs/src/pdf/github-java-jiaocheng-115-star.md)
-- [👏下载→重学Java设计模式PDF](docs/src/pdf/shejimoshi.md)
-- [👏下载→Java版LeetCode刷题笔记](docs/src/pdf/java-leetcode.md)
-- [👏下载→阿里巴巴Java开发手册](docs/src/pdf/ali-java-shouce.md)
-- [👏下载→阮一峰C语言入门教程](docs/src/pdf/yuanyifeng-c-language.md)
-- [👏下载→BAT大佬的刷题笔记](docs/src/pdf/bat-shuati.md)
-- [👏下载→给操作系统捋条线PDF](docs/src/pdf/os.md)
-- [👏下载→豆瓣9.1分的Pro Git中文版](docs/src/pdf/progit.md)
-- [👏下载→简历模板](docs/src/pdf/jianli.md)
-
-## 学习建议
+- [👏下载→Java程序员常读书单](docs/download/java.md)
+- [👏下载→最全最硬核的Java面试 “备战” 资料](https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw)
+- [👏下载→深入浅出Java多线程](https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w)
+- [👏下载→GitHub星标115k+的Java教程](https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw)
+- [👏下载→重学Java设计模式](https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw)
+- [👏下载→Java版LeetCode刷题笔记](https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ)
+- [👏下载→阮一峰C语言入门教程](docs/download/yuanyifeng-c-language.md)
+- [👏下载→BAT大佬的刷题笔记](docs/download/bat-shuati.md)
+- [👏下载→给操作系统捋条线](https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA)
+- [👏下载→豆瓣9.1分,Pro Git中文版](docs/download/progit.md)
+- [👏下载→简历模板](docs/download/jianli.md)
-- [计算机专业该如何自学编程,看哪些书籍哪些视频哪些教程?](docs/src/xuexijianyi/LearnCS-ByYourself.md)
-- [如何阅读《深入理解计算机系统》这本书?](docs/src/xuexijianyi/read-csapp.md)
-- [电子信息工程最好的出路的是什么?](docs/src/xuexijianyi/electron-information-engineering.md)
-- [如何填报计算机大类高考填志愿,计科、人工智能、软工、大数据、物联网、网络工程该怎么选?](docs/src/xuexijianyi/gaokao-zhiyuan-cs.md)
-- [测试开发工程师必读经典书籍有哪些?](docs/src/xuexijianyi/test-programmer-read-books.md)
-- [校招 Java 后端开发应该掌握到什么程度?](docs/src/xuexijianyi/xiaozhao-java-should-master.md)
-- [大裁员下,程序员如何做“副业”?](docs/src/xuexijianyi/chengxuyuan-fuye.md)
-- [如何在繁重的工作中持续成长?](docs/src/xuexijianyi/ruhzfzdgzzcxcz.md)
-- [如何获得高并发的经验?](docs/src/xuexijianyi/gaobingfa-jingyan-hsmcomputer.md)
-- [怎么跟 HR 谈薪资?](docs/src/xuexijianyi/hr-xinzi.md)
-- [程序员 35 岁危机,如何破局?](docs/src/xuexijianyi/35-weiji.md)
-- [不到 20 人的 IT 公司该去吗?](docs/src/xuexijianyi/20ren-it-quma.md)
-- [本科生如何才能进入腾讯、阿里等一流的互联网公司?](docs/src/xuexijianyi/benkesheng-ali-tengxun.md)
-- [计算机考研 408 统考该如何准备?](docs/src/xuexijianyi/408.md)
-# 知识库搭建
+# 知识库搭建历程
-> 从购买阿里云服务器+域名购买+域名备案+HTTP 升级到 HTTPS,全方面记录《二哥的Java进阶之路》知识库的诞生和改进过程,涉及到 docsify、Git、Linux 命令、GitHub 仓库等实用知识点。
+> [!NOTE]
+> 从购买阿里云服务器+域名购买+域名备案+HTTP 升级到 HTTPS,全方面记录《Java 程序员进阶之路》知识库的诞生和改进过程,涉及到 docsify、Git、Linux 命令、GitHub 仓库等实用知识点。
-- [购买云服务器](docs/src/szjy/buy-cloud-server.md)
-- [安装宝塔面板](docs/src/szjy/install-baota-mianban.md)
-- [购买域名&域名解析](docs/src/szjy/buy-domain.md)
-- [备案域名](docs/src/szjy/record-domain.md)
-- [给域名配置HTTPS证书](docs/src/szjy/https-domain.md)
-- [使用docsify+Git+GitHub+码云+阿里云服务器搭建知识库网站](docs/src/szjy/tobebetterjavaer-wangzhan-shangxian.md)
+- [阿里云服务器购买+宝塔面板安装+域名购买+域名备案+升级HTTPS](docs/szjy/tobebetterjavaer-beian.md)
+- [使用docsify+Git+GitHub+码云+阿里云服务器搭建知识库网站](docs/szjy/tobebetterjavaer-wangzhan-shangxian.md)
-本知识库使用 VuePress 搭建,并基于[VuePress Theme Hope](https://theme-hope.vuejs.press/zh/)主题,你可以把[仓库](https://github.com/itwanger/toBeBetterJavaer)拉到本地后直接通过 `pnpm docs:clean-dev` 跑起来。
-
->前提是你已经安装好 node.js 和 pnpm 环境。
-
-
-
-点击链接就可以在本地看到运行后的效果了。
-
-
-
-如果想部署服务器,可以执行 `pnpm docs:build` 打包生成 dist 目录,里面就是静态资源文件了。
-
-执行 `zip -r dist.zip dist` 压缩为 dist.zip 包,然后上传到服务器的 Nginx 对应的静态资源目录下。再执行 `unzip dist.zip` 解压即可。
# 联系作者
+> [!NOTE]
>- 作者是一名普通普通普通普通三连的 Java 后端开发者,热爱学习,热爱分享
>- 参加工作以后越来越理解交流和分享的重要性,在不停地汲取营养的同时,也希望帮助到更多的小伙伴们
->- 二哥的Java进阶之路,不仅是作者自学 Java 以来所有的原创文章和学习资料的大聚合,更是作者向这个世界传播知识的一个窗口。
+>- Java 程序员进阶之路,不仅是作者自学 Java 以来所有的原创文章和学习资料的大聚合,更是作者向这个世界传播知识的一个窗口。
## 心路历程
-- [走近作者:个人介绍 Q&A](docs/src/about-the-author/readme.md)
-- [我的第一个,10 万(B站视频播放)](docs/src/about-the-author/bzhan-10wan.md)
-- [我的第一个,一千万!知乎阅读](docs/src/about-the-author/zhihu-1000wan.md)
-- [我的第二个,一千万!CSDN阅读](docs/src/about-the-author/csdn-1000wan.md)
+- [走近作者:个人介绍 Q&A](docs/about-the-author/readme.md)
+- [我的第一个,10 万(B站视频播放)](docs/about-the-author/bzhan-10wan.md)
+- [我的第一个,一千万!知乎阅读](docs/about-the-author/zhihu-1000wan.md)
+- [我的第二个,一千万!CSDN阅读](docs/about-the-author/csdn-1000wan.md)
## 联系方式
### 原创公众号
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
+本号的slogan:技术文通俗易懂,吹水文风趣幽默。
目前已有 10 万+读者关注,微信搜索「**沉默王二**」(也可以扫描下方的二维码)就可以关注作者了。
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
+
+

+
-

+

+
+
+
+
+
+
+
+
+
+
+ 👁️本页总访问次数:
+
+
+ | 🧑总访客数:
+
+
+[联系作者](https://mp.weixin.qq.com/s/1_lOGt4Fl6Yy8iVdxWeI5g)
+开始阅读
+
+
+
diff --git a/_navbar.md b/_navbar.md
new file mode 100644
index 0000000000..779f04e6c5
--- /dev/null
+++ b/_navbar.md
@@ -0,0 +1,16 @@
+* [计算机经典书籍下载](https://tobebetterjavaer.com/download/java.html)
+* [B站视频](https://space.bilibili.com/513340480)
+* [尝试新版](https://tobebetterjavaer.com/)
+* 学习路线
+ * [Java学习路线一条龙版](https://tobebetterjavaer.com/xuexiluxian/java/yitiaolong.html)
+ * [Java并发学习路线](https://tobebetterjavaer.com/xuexiluxian/java-thread.html)
+ * [Java虚拟机学习路线](https://tobebetterjavaer.com/xuexiluxian/java/jvm.html)
+ * [C语言学习路线](https://tobebetterjavaer.com/xuexiluxian/c.html)
+ * [C++学习路线](https://tobebetterjavaer.com/xuexiluxian/ccc.html)
+ * [Python学习路线](https://tobebetterjavaer.com/xuexiluxian/python.html)
+ * [Go语言学习路线](https://tobebetterjavaer.com/xuexiluxian/go.html)
+ * [操作系统学习路线](https://tobebetterjavaer.com/xuexiluxian/os.html)
+ * [前端学习路线](https://tobebetterjavaer.com/xuexiluxian/qianduan.html)
+ * [蓝桥杯学习路线](https://tobebetterjavaer.com/xuexiluxian/lanqiaobei.html)
+ * [算法和数据结构学习路线](https://tobebetterjavaer.com/xuexiluxian/algorithm.html)
+
diff --git a/_sidebar.md b/_sidebar.md
new file mode 100644
index 0000000000..360c465abf
--- /dev/null
+++ b/_sidebar.md
@@ -0,0 +1,49 @@
+* [为什么会有这个开源知识库](README.md?id=为什么会有这个开源知识库)
+* [知识库地图](README.md?id=知识库地图)
+* [学习路线](README.md?id=学习路线)
+* [Java核心](README.md?id=java核心)
+ * [Java面渣逆袭](README.md?id=Java面渣逆袭)
+ * [Java概述](README.md?id=java概述)
+ * [Java基础语法](README.md?id=java基础语法)
+ * [Java面向对象编程](README.md?id=Java面向对象编程)
+ * [字符串&数组](README.md?id=字符串&数组)
+ * [集合框架(容器)](README.md?id=集合框架(容器))
+ * [Java输入输出](README.md?id=Java输入输出)
+ * [异常处理](README.md?id=异常处理)
+ * [常用工具类](README.md?id=常用工具类)
+ * [Java新特性](README.md?id=Java新特性)
+ * [Java重要知识点](README.md?id=java重要知识点)
+ * [Java并发编程](README.md?id=Java并发编程)
+ * [Java虚拟机](README.md?id=Java虚拟机)
+* [Java企业级开发](README.md?id=Java企业级开发)
+ * [开发工具](README.md?id=开发工具)
+ * [IDE/编辑器](README.md?id=IDE/编辑器)
+ * [Spring](README.md?id=Spring)
+ * [SpringBoot](README.md?id=SpringBoot)
+ * [辅助工具/轮子](README.md?id=辅助工具)
+ * [安全篇](README.md?id=安全篇)
+ * [分布式](README.md?id=分布式)
+ * [高性能](README.md?id=高性能)
+ * [高可用](README.md?id=高可用)
+* [数据库](README.md?id=数据库)
+ * [MySQL](README.md?id=MySQL)
+ * [Redis](README.md?id=Redis)
+ * [MongoDB](README.md?id=MongoDB)
+* [计算机基础](README.md?id=计算机基础)
+* [求职面试](README.md?id=求职面试)
+ * [面试题集合](README.md?id=面试题集合)
+ * [背诵版八股文](README.md?id=背诵版八股文)
+ * [优质面经](README.md?id=优质面经)
+ * [面试准备](README.md?id=面试准备)
+ * [城市选择](README.md?id=城市选择)
+* [学习资源](README.md?id=学习资源)
+ * [PDF下载](README.md?id=PDF下载)
+ * [图文教程](README.md?id=图文教程)
+ * [视频教程](README.md?id=视频教程)
+ * [优质书单](README.md?id=优质书单)
+ * [学习建议](README.md?id=学习建议)
+* [知识库建设](README.md?id=知识库建设)
+* [联系作者](README.md?id=联系作者)
+ * [心路历程](README.md?id=心路历程)
+ * [联系方式](README.md?id=联系方式)
+
diff --git a/docs/.vuepress/config.ts b/docs/.vuepress/config.ts
new file mode 100644
index 0000000000..c65e200a06
--- /dev/null
+++ b/docs/.vuepress/config.ts
@@ -0,0 +1,40 @@
+import { defineHopeConfig } from "vuepress-theme-hope";
+import themeConfig from "./themeConfig";
+
+export default defineHopeConfig({
+ base: "/",
+
+ dest: "./dist",
+
+ head: [
+ [
+ "script",{},
+ `
+ var _hmt = _hmt || [];
+ (function() {
+ var hm = document.createElement("script");
+ hm.src = "https://hm.baidu.com/hm.js?5230ac143650bf5eb3c14f3fb9b1d3ec";
+ var s = document.getElementsByTagName("script")[0];
+ s.parentNode.insertBefore(hm, s);
+ })();
+ `
+ ],
+ [
+ "link",
+ {
+ rel: "stylesheet",
+ href: "//at.alicdn.com/t/font_3180624_7cy10l7jqqh.css",
+ },
+ ],
+ ],
+
+ locales: {
+ "/": {
+ lang: "zh-CN",
+ title: "Java 程序员进阶之路",
+ description: "一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java企业级开发、Java面试等核心知识点。学Java,就认准Java程序员进阶之路",
+ },
+ },
+
+ themeConfig,
+});
diff --git a/docs/.vuepress/navbar.ts b/docs/.vuepress/navbar.ts
new file mode 100644
index 0000000000..7a02dd1fae
--- /dev/null
+++ b/docs/.vuepress/navbar.ts
@@ -0,0 +1,67 @@
+import { defineNavbarConfig } from "vuepress-theme-hope";
+
+export default defineNavbarConfig([
+
+ {
+ text: "进阶之路",
+ icon: "lujing",
+ link: "/home.md"
+ },
+ {
+ text: "星球专栏",
+ icon: "Artboard",
+ link: "/zhishixingqiu/java-mianshi-zhinan.md"
+ },
+ {
+ text: "学习路线",
+ icon: "luxian",
+ link: "/xuexiluxian/"
+ },
+ {
+ text: "B站视频",
+ icon: "bzhan",
+ link: "https://space.bilibili.com/513340480"
+ },
+ {
+ text: "珍藏资源",
+ icon: "youzhi",
+ children: [
+ {
+ text: "Java电子书下载",
+ icon: "java",
+ link: "/download/java.md"
+ },
+ {
+ text: "PDF干货笔记下载",
+ icon: "pdf",
+ link: "/download/pdf.md"
+ },
+ {
+ text: "学习建议",
+ icon: "xuexijianyi",
+ link: "/download/learn-jianyi.md"
+ },
+ {
+ text: "面渣逆袭",
+ icon: "zhunbei",
+ link: "/sidebar/sanfene/nixi.md"
+ },
+ {
+ text: "优质文章",
+ icon: "youzhi",
+ link: "/download/nicearticle.md"
+ },
+ {
+ text: "网络日志",
+ icon: "rizhi",
+ link: "/download/history.md"
+ },
+ {
+ text: "回到过去",
+ icon: "fanhuijiuban",
+ link: "https://docsify.tobebetterjavaer.com/"
+ },
+ ],
+ },
+
+]);
diff --git a/docs/src/.vuepress/public/assets/icon/apple-icon-152.png b/docs/.vuepress/public/assets/icon/apple-icon-152.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/apple-icon-152.png
rename to docs/.vuepress/public/assets/icon/apple-icon-152.png
diff --git a/docs/src/.vuepress/public/assets/icon/chrome-192.png b/docs/.vuepress/public/assets/icon/chrome-192.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/chrome-192.png
rename to docs/.vuepress/public/assets/icon/chrome-192.png
diff --git a/docs/src/.vuepress/public/assets/icon/chrome-512.png b/docs/.vuepress/public/assets/icon/chrome-512.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/chrome-512.png
rename to docs/.vuepress/public/assets/icon/chrome-512.png
diff --git a/docs/src/.vuepress/public/assets/icon/chrome-mask-192.png b/docs/.vuepress/public/assets/icon/chrome-mask-192.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/chrome-mask-192.png
rename to docs/.vuepress/public/assets/icon/chrome-mask-192.png
diff --git a/docs/src/.vuepress/public/assets/icon/chrome-mask-512.png b/docs/.vuepress/public/assets/icon/chrome-mask-512.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/chrome-mask-512.png
rename to docs/.vuepress/public/assets/icon/chrome-mask-512.png
diff --git a/docs/src/.vuepress/public/assets/icon/itwanger-282.png b/docs/.vuepress/public/assets/icon/itwanger-282.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/itwanger-282.png
rename to docs/.vuepress/public/assets/icon/itwanger-282.png
diff --git a/docs/src/.vuepress/public/assets/icon/itwanger-maskable.png b/docs/.vuepress/public/assets/icon/itwanger-maskable.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/itwanger-maskable.png
rename to docs/.vuepress/public/assets/icon/itwanger-maskable.png
diff --git a/docs/src/.vuepress/public/assets/icon/itwanger-monochrome.png b/docs/.vuepress/public/assets/icon/itwanger-monochrome.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/itwanger-monochrome.png
rename to docs/.vuepress/public/assets/icon/itwanger-monochrome.png
diff --git a/docs/src/.vuepress/public/assets/icon/ms-icon-144.png b/docs/.vuepress/public/assets/icon/ms-icon-144.png
similarity index 100%
rename from docs/src/.vuepress/public/assets/icon/ms-icon-144.png
rename to docs/.vuepress/public/assets/icon/ms-icon-144.png
diff --git a/docs/src/.vuepress/public/favicon.ico b/docs/.vuepress/public/favicon.ico
similarity index 100%
rename from docs/src/.vuepress/public/favicon.ico
rename to docs/.vuepress/public/favicon.ico
diff --git a/docs/src/.vuepress/public/logo.png b/docs/.vuepress/public/logo.png
similarity index 100%
rename from docs/src/.vuepress/public/logo.png
rename to docs/.vuepress/public/logo.png
diff --git a/docs/src/.vuepress/public/logo.svg b/docs/.vuepress/public/logo.svg
similarity index 100%
rename from docs/src/.vuepress/public/logo.svg
rename to docs/.vuepress/public/logo.svg
diff --git a/docs/.vuepress/sidebar.ts b/docs/.vuepress/sidebar.ts
new file mode 100644
index 0000000000..ae21d0880d
--- /dev/null
+++ b/docs/.vuepress/sidebar.ts
@@ -0,0 +1,1019 @@
+import { defineSidebarConfig } from "vuepress-theme-hope";
+export const sidebarConfig = defineSidebarConfig({
+ "/zhishixingqiu/": ["java-mianshi-zhinan","readme.md"],
+ "/download/": ["java","pdf","learn-jianyi","nicearticle", "history"],
+ "/xuexiluxian/": [
+ {
+ text: "Java",
+ icon: "java",
+ prefix: "java/",
+ collapsable: true,
+ children: [
+ {
+ text: "一条龙版",
+ link: "yitiaolong.md",
+ },
+ {
+ text: "并发编程",
+ link: "thread.md",
+ },
+ {
+ text: "JVM",
+ link: "jvm.md",
+ },
+ ],
+ },
+ {
+ text: "C语言",
+ link: "c.md",
+ },
+ {
+ text: "C++",
+ link: "ccc.md",
+ },
+ {
+ text: "Python",
+ link: "python.md",
+ },
+ {
+ text: "Go语言",
+ link: "go.md",
+ },
+ {
+ text: "操作系统",
+ link: "os.md",
+ },
+ {
+ text: "前端",
+ link: "qianduan.md",
+ },
+ {
+ text: "蓝桥杯",
+ link: "lanqiaobei.md",
+ },
+ {
+ text: "算法和数据结构",
+ link: "algorithm.md",
+ },
+ ],
+ "/sidebar/sanfene/": [
+ {
+ text: "Java 基础",
+ link: "javase.md",
+ },
+ {
+ text: "Java 集合框架",
+ link: "collection.md",
+ },
+ {
+ text: "Java 并发编程",
+ link: "javathread.md",
+ },
+ {
+ text: "Java 虚拟机",
+ link: "jvm.md",
+ },
+ {
+ text: "Spring",
+ link: "spring.md",
+ },
+ {
+ text: "Redis",
+ link: "redis.md",
+ },
+ ],
+ // 必须放在最后面
+ "/": [
+ {
+ text: "一、前言",
+ link: "home.md",
+ },
+ {
+ text: "二、Java核心",
+ collapsable: true,
+ children: [
+ {
+ prefix: "overview/",
+ text: "2.1 Java概述",
+ collapsable: true,
+ children: [
+ "what-is-java",
+ {
+ text: "编写第一个 Java 程序",
+ link: "hello-world",
+ },
+ ],
+ },
+ {
+ text: "2.2 Java基础语法",
+ collapsable: true,
+ children: [
+ {
+ text: "基本数据类型",
+ link: "basic-grammar/basic-data-type",
+ },
+ {
+ text: "流程控制语句",
+ link: "basic-grammar/flow-control",
+ },
+ {
+ text: "运算符",
+ link: "basic-grammar/operator",
+ },
+ {
+ text: "注释",
+ link: "basic-grammar/javadoc",
+ },
+ {
+ text: "关键字",
+ link: "basic-extra-meal/48-keywords",
+ },
+ {
+ text: "命名规范",
+ link: "basic-extra-meal/java-naming",
+ },
+ ],
+ },
+ {
+ text: "2.3 面向对象编程",
+ collapsable: true,
+ children: [
+ {
+ text: "对象和类",
+ link: "oo/object-class",
+ },
+ {
+ text: "变量",
+ link: "oo/var",
+ },
+ {
+ text: "方法",
+ link: "oo/method",
+ },
+ {
+ text: "构造方法",
+ link: "oo/construct",
+ },
+ {
+ text: "代码初始化块",
+ link: "oo/code-init",
+ },
+ {
+ text: "抽象类",
+ link: "oo/abstract",
+ },
+ {
+ text: "接口",
+ link: "oo/interface",
+ },
+ {
+ text: "内部类",
+ link: "oo/inner-class",
+ },
+ {
+ text: "static",
+ link: "oo/static",
+ },
+ {
+ text: "this 和 super",
+ link: "oo/this-super",
+ },
+ {
+ text: "final",
+ link: "oo/final",
+ },
+ {
+ text: "instanceof",
+ link: "oo/instanceof",
+ },
+ {
+ text: "不可变对象",
+ link: "basic-extra-meal/immutable",
+ },
+ {
+ text: "可变参数",
+ link: "basic-extra-meal/varables",
+ },
+ {
+ text: "泛型",
+ link: "basic-extra-meal/generic",
+ },
+ {
+ text: "注解",
+ link: "basic-extra-meal/annotation",
+ },
+ {
+ text: "枚举",
+ link: "basic-extra-meal/enum",
+ },
+ {
+ text: "反射",
+ link: "basic-extra-meal/fanshe",
+ },
+
+ ],
+ },
+ {
+ text: "2.4 字符串&数组",
+ collapsable: true,
+ children: [
+
+ {
+ text: "字符串为什么是不可变的",
+ link: "string/immutable",
+ },
+ {
+ text: "字符串常量池",
+ link: "string/constant-pool",
+ },
+ {
+ text: " String#intern",
+ link: "string/intern",
+ },
+ {
+ text: "字符串比较",
+ link: "string/equals",
+ },
+ {
+ text: "字符串拼接",
+ link: "string/join",
+ },
+ {
+ text: "字符串分割",
+ link: "string/split",
+ },
+ {
+ text: "数组",
+ link: "array/array",
+ },
+ {
+ text: "打印数组",
+ link: "array/print",
+ },
+
+ ],
+ },
+ {
+ text: "2.5 集合框架(容器)",
+ collapsable: true,
+ children: [
+
+ {
+ text: "概述",
+ link: "collection/gailan",
+ },
+ {
+ text: "ArrayList",
+ link: "collection/arraylist",
+ },
+ {
+ text: "LinkedList",
+ link: "collection/linkedlist",
+ },
+ {
+ text: "ArrayList和LinkedList的区别",
+ link: "collection/list-war-2",
+ },
+ {
+ text: "Iterator和Iterable",
+ link: "collection/iterator-iterable",
+ },
+ {
+ text: "fail-fast",
+ link: "collection/fail-fast",
+ },
+ {
+ text: "HashMap",
+ link: "collection/hashmap",
+ },
+
+ ],
+ },
+ {
+ text: "2.6 IO",
+ collapsable: true,
+ prefix:"io/",
+ children: [
+ {
+ text: "概览",
+ link: "shangtou",
+ },
+ {
+ text: "BIO、NIO和AIO",
+ link: "BIONIOAIO",
+ },
+ ],
+ },
+ {
+ text: "2.7 异常处理",
+ collapsable: true,
+ prefix:"exception/",
+ children: [
+ {
+ text: "概览",
+ link: "gailan",
+ },
+ {
+ text: "try-with-resouces",
+ link: "try-with-resouces",
+ },
+ {
+ text: "最佳实践",
+ link: "shijian",
+ },
+ {
+ text: "NullPointerException",
+ link: "npe",
+ },
+ ],
+ },
+ {
+ text: "2.8 常用工具类",
+ collapsable: true,
+ prefix:"common-tool/",
+ children: [
+ {
+ text: "Arrays",
+ link: "arrays",
+ },
+ {
+ text: "Collections",
+ link: "collections",
+ },
+ {
+ text: "Hutool",
+ link: "hutool",
+ },
+ {
+ text: "Guava",
+ link: "guava",
+ },
+ ],
+ },
+ {
+ text: "2.9 Java新特性",
+ prefix: "java8/",
+ collapsable: true,
+ children: [
+ {
+ text: "Stream",
+ link: "stream",
+ },
+ {
+ text: "Optional",
+ link: "optional",
+ },
+ {
+ text: "Lambda",
+ link: "Lambda",
+ },
+ ],
+ },
+ {
+ text: "2.10 Java重要知识点",
+ prefix:"basic-extra-meal/",
+ collapsable: true,
+ children: [
+ {
+ text: "Unicode和UTF-8编码",
+ link: "java-unicode",
+ },
+ {
+ text: "new Integer和Integer.valueOf区别",
+ link: "int-cache",
+ },
+ {
+ text: "拆箱和装箱",
+ link: "box",
+ },
+ {
+ text: "浅拷贝与深拷贝",
+ link: "deep-copy",
+ },
+ {
+ text: "深入理解Java中的hashCode方法",
+ link: "hashcode",
+ },
+ {
+ text: "重写equals时为什么要重写hashCode",
+ link: "equals-hashcode",
+ },
+ {
+ text: "重写和重载的区别",
+ link: "override-overload",
+ },
+ {
+ text: "重写时应当遵守的11条规则",
+ link: "Overriding",
+ },
+ {
+ text: "Java到底是值传递还是引用传递",
+ link: "pass-by-value",
+ },
+ {
+ text: "Java为什么不能实现真正的泛型",
+ link: "true-generic",
+ },
+ {
+ text: "Comparable和Comparator的区别",
+ link: "comparable-omparator",
+ },
+ {
+ text: "JDK9中String为什么由char[]改成byte[]",
+ link: "jdk9-char-byte-string",
+ },
+ {
+ text: "JDK源码无限循环用for(;;)还是while(true)",
+ link: "jdk-while-for-wuxian-xunhuan",
+ },
+ {
+ text: "先有Class还是先有Object",
+ link: "class-object",
+ },
+ {
+ text: "instanceof关键字是如何实现的",
+ link: "instanceof-jvm",
+ },
+ ],
+ },
+ {
+ text: "2.11 并发编程",
+ collapsable: true,
+ prefix: "thread/",
+ children: [
+ {
+ text: "创建Java线程的3种方式",
+ link: "wangzhe-thread",
+ },
+ {
+ text: "线程的6种状态及切换",
+ link: "thread-state-and-method",
+ },
+ {
+ text: "线程组和线程优先级",
+ link: "thread-group-and-thread-priority",
+ },
+ {
+ text: "进程与线程的区别",
+ link: "why-need-thread",
+ },
+ {
+ text: "并发编程带来了哪些问题",
+ link: "thread-bring-some-problem",
+ },
+ {
+ text: "Java内存模型",
+ link: "jmm",
+ },
+ {
+ text: "volatile",
+ link: "volatile",
+ },
+ {
+ text: "synchronized",
+ link: "synchronized",
+ },
+ {
+ text: "CAS的原理",
+ link: "cas",
+ },
+ {
+ text: "AQS详解",
+ link: "aqs",
+ },
+ {
+ text: "锁",
+ link: "lock",
+ },
+ {
+ text: "重入锁ReentrantLock",
+ link: "reentrantLock",
+ },
+ {
+ text: "读写锁ReentrantReadWriteLock",
+ link: "ReentrantReadWriteLock",
+ },
+ {
+ text: "线程协作类Condition",
+ link: "condition",
+ },
+ {
+ text: "线程阻塞唤醒类LockSupport",
+ link: "LockSupport",
+ },
+ {
+ text: "并发集合容器",
+ link: "map",
+ },
+ {
+ text: "ConcurrentHashMap",
+ link: "ConcurrentHashMap",
+ },
+ {
+ text: "ConcurrentLinkedQueue",
+ link: "ConcurrentLinkedQueue",
+ },
+ {
+ text: "CopyOnWriteArrayList",
+ link: "CopyOnWriteArrayList",
+ },
+ {
+ text: "ThreadLocal",
+ link: "ThreadLocal",
+ },
+ {
+ text: "BlockingQueue",
+ link: "BlockingQueue",
+ },
+ {
+ text: "线程池",
+ link: "pool",
+ },
+ {
+ text: "计划任务",
+ link: "ScheduledThreadPoolExecutor",
+ },
+ {
+ text: "原子操作类",
+ link: "atomic",
+ },
+ {
+ text: "通信工具类CountDownLatch",
+ link: "CountDownLatch",
+ },
+ {
+ text: "Fork/Join框架",
+ link: "fork-join",
+ },
+ {
+ text: "生产者-消费者模式",
+ link: "shengchanzhe-xiaofeizhe",
+ },
+
+ ],
+ },
+ {
+ text: "2.12 JVM",
+ prefix: "jvm/",
+ collapsable: true,
+ children: [
+ {
+ text: "JVM到底是什么?",
+ link: "what-is-jvm",
+ },
+ {
+ text: "JVM到底是如何运行Java代码的",
+ link: "how-run-java-code",
+ },
+ {
+ text: "类加载机制",
+ link: "class-load",
+ },
+ {
+ text: "详解Java的类文件结构",
+ link: "class-file-jiegou",
+ },
+ {
+ text: "从javap的角度轻松看懂字节码",
+ link: "bytecode",
+ },
+ {
+ text: "字节码指令详解",
+ link: "zijiema-zhiling",
+ },
+ {
+ text: "虚拟机是如何执行字节码指令的",
+ link: "how-jvm-run-zijiema-zhiling",
+ },
+ {
+ text: "HSDB(Hotspot Debugger)",
+ link: "hsdb",
+ },
+ {
+ text: "史上最通俗易懂的ASM教程",
+ link: "asm",
+ },
+ {
+ text: "自己编译JDK",
+ link: "compile-jdk",
+ },
+ {
+ text: "深入理解JVM的内存结构",
+ link: "neicun-jiegou",
+ },
+ {
+ text: "Java 创建的对象到底放在哪",
+ link: "whereis-the-object",
+ },
+ {
+ text: "从头到尾说一次Java垃圾回收",
+ link: "gc",
+ },
+ {
+ text: "图解Java的垃圾回收机制",
+ link: "tujie-gc",
+ },
+ {
+ text: "Java问题诊断和排查工具",
+ link: "problem-tools",
+ },
+ {
+ text: "JIT原理解析及实践",
+ link: "jit",
+ },
+ {
+ text: "内存溢出排查优化实战",
+ link: "oom",
+ },
+ {
+ text: "CPU 100% 排查优化实践",
+ link: "cpu-percent-100",
+ },
+ {
+ text: "JVM 核心知识点总结",
+ link: "zongjie",
+ },
+
+ ],
+ },
+ ],
+ },
+ {
+ text: "三、Java企业级开发",
+ collapsable: true,
+ children: [
+ {
+ text: "3.1 开发工具",
+ collapsable: true,
+ children: [
+ "maven/maven.md",
+ "git/git-qiyuan.md",
+ "nginx/nginx.md",
+ ],
+ },
+ {
+ text: "3.2 IDE/编辑器",
+ collapsable: true,
+ children: [
+ "ide/4-debug-skill.md",
+ ],
+ },
+ {
+ text: "3.3 Spring",
+ collapsable: true,
+ children: [
+ {
+ text: "Spring AOP扫盲",
+ link: "springboot/aop-log",
+ },
+ {
+ text: "Spring IoC扫盲",
+ link: "springboot/ioc",
+ },
+ ],
+ },
+ {
+ text: "3.4 SpringBoot",
+ collapsable: true,
+ children: [
+ {
+ text: "搭建第一个Spring Boot项目",
+ link: "springboot/initializr",
+ },
+ {
+ text: "整合MySQL和Druid",
+ link: "springboot/mysql-druid",
+ },
+ {
+ text: "整合JPA",
+ link: "springboot/jpa",
+ },
+ {
+ text: "整合Thymeleaf",
+ link: "springboot/thymeleaf",
+ },
+ {
+ text: "开启事务支持",
+ link: "springboot/transaction",
+ },
+ {
+ text: "过滤器、拦截器、监听器",
+ link: "springboot/Filter-Interceptor-Listener",
+ },
+ {
+ text: "整合Redis实现缓存",
+ link: "redis/redis-springboot",
+ },
+ {
+ text: "整合Logback",
+ link: "springboot/logback"
+ },
+ {
+ text: "整合Swagger-UI",
+ link: "springboot/swagger"
+ },
+ {
+ text: "整合Knife4j",
+ link: "gongju/knife4j"
+ },
+ {
+ text: "整合SpringTask",
+ link: "springboot/springtask"
+ },
+ {
+ text: "整合MyBatis-Plus AutoGenerator",
+ link: "kaiyuan/auto-generator",
+ },
+
+ ],
+ },
+ {
+ text: "3.5 辅助工具/轮子",
+ collapsable: true,
+ children: [
+ {
+ text: "Tabby",
+ link: "gongju/tabby",
+ },
+ {
+ text: "Warp",
+ link: "gongju/warp",
+ },
+ {
+ text: "Chocolatey",
+ link: "gongju/choco",
+ },
+ {
+ text: "chiner",
+ link: "gongju/chiner",
+ },
+ {
+ text: "DBeaver",
+ link: "gongju/DBeaver",
+ },
+ {
+ text: "Forest",
+ link: "gongju/forest",
+ },
+ {
+ text: "Junit",
+ link: "gongju/junit",
+ },
+ {
+ text: "fastjson",
+ link: "gongju/fastjson",
+ },
+ {
+ text: "Gson",
+ link: "gongju/gson",
+ },
+ {
+ text: "Jackson",
+ link: "gongju/jackson",
+ },
+ {
+ text: "Log4j",
+ link: "gongju/log4j",
+ },
+ {
+ text: "Log4j2",
+ link: "gongju/log4j2",
+ },
+ {
+ text: "Logback",
+ link: "gongju/logback",
+ },
+ {
+ text: "SLF4J",
+ link: "gongju/slf4j",
+ },
+
+ ],
+ },
+ {
+ text: "3.6 分布式",
+ collapsable: true,
+ children: [
+ {
+ text: "Elasticsearch入门",
+ link: "elasticsearch/rumen"
+ },
+ {
+ text: "聊聊ZooKeeper",
+ link: "zookeeper/jibenjieshao"
+ },
+ {
+ text: "聊聊微服务网关",
+ link: "microservice/api-wangguan"
+ },
+ ],
+ },
+ {
+ text: "3.7 消息队列",
+ collapsable: true,
+ children: [
+ {
+ text: "RabbitMQ入门",
+ link: "mq/rabbitmq-rumen"
+ },
+ {
+ text: "如何保障消息不丢失",
+ link: "mq/100-budiushi"
+ },
+ ],
+ },
+ ],
+ },
+ {
+ text: "四、数据库",
+ collapsable: true,
+ children: [
+ {
+ text: "MySQL",
+ collapsable: true,
+ children: [
+ {
+ text: "MySQL和Redis数据一致性",
+ link: "mysql/redis-shuju-yizhixing"
+ },
+ ],
+ },
+ {
+ text: "Redis",
+ collapsable: true,
+ children: [
+ {
+ text: "Redis入门",
+ link: "redis/rumen"
+ },
+ {
+ text: "缓存雪崩、穿透、击穿",
+ link: "redis/xuebeng-chuantou-jichuan"
+ },
+ ],
+ },
+ {
+ text: "MongoDB",
+ collapsable: true,
+ children: [
+ "mongodb/rumen",
+ ],
+ },
+ ],
+ },
+ {
+ text: "五、计算机基础",
+ collapsable: true,
+ prefix: "cs/",
+ children: [
+ {
+ text: "计算机操作系统",
+ link: "os",
+ },
+ {
+ text: "计算机网络",
+ link: "wangluo",
+ },
+ ],
+ },
+ {
+ text: "六、求职面试",
+ collapsable: true,
+ children: [
+ {
+ text: "面试题集合",
+ collapsable: true,
+ children: [
+ "baguwen/java-basic-34",
+ "collection/hashmap-interview",
+ "mianjing/redis12question",
+ "nginx/40-interview"
+ ],
+ },
+ {
+ text: "背诵版八股文",
+ collapsable: true,
+ children: [
+ "baguwen/java-basic",
+ "baguwen/java-thread",
+ "baguwen/jvm",
+ "sidebar/herongwei/mysql",
+ ],
+ },
+ {
+ text: "城市选择",
+ prefix: "cityselect/",
+ collapsable: true,
+ children: [
+ "beijing",
+ "chengdu",
+ "guangzhou",
+ "hangzhou",
+ "nanjing",
+ "qingdao",
+ "shenzhen",
+ "suzhou",
+ "xian",
+ "zhengzhou",
+ ],
+ },
+ ],
+ },
+ {
+ text: "七、学习资源",
+ collapsable: true,
+ children: [
+ {
+ text: "PDF下载",
+ collapsable: true,
+ children: [
+ {
+ text: "Java程序员常读书单",
+ icon: "xiazai",
+ link: "download/java.md",
+ },
+ {
+ text: "最全最硬核的Java面试 “备战” 资料",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw",
+ },
+ {
+ text: "深入浅出Java多线程",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w",
+ },
+ {
+ text: "GitHub星标115k+的Java教程",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw",
+ },
+ {
+ text: "重学Java设计模式",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw",
+ },
+ {
+ text: "Java版LeetCode刷题笔记",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ",
+ },
+ {
+ text: "阮一峰C语言入门教程",
+ icon: "xiazai",
+ link: "download/yuanyifeng-c-language.md",
+ },
+ {
+ text: "BAT大佬的刷题笔记",
+ icon: "xiazai",
+ link: "download/bat-shuati.md",
+ },
+ {
+ text: "给操作系统捋条线",
+ icon: "xiazai",
+ link: "https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA",
+ },
+ {
+ text: "豆瓣9.1分,Pro Git中文版",
+ icon: "xiazai",
+ link: "download/progit.md",
+ },
+ {
+ text: "简历模板",
+ icon: "xiazai",
+ link: "download/jianli.md",
+ },
+ ],
+ },
+ {
+ text: "学习建议",
+ collapsable: true,
+ prefix: "xuexijianyi/",
+ children: [
+ "read-csapp",
+ "electron-information-engineering",
+ ],
+ },
+ ],
+ },
+ {
+ text: "八、联系作者",
+ collapsable: true,
+ children: [
+ {
+ text: "心路历程",
+ prefix: "about-the-author/",
+ collapsable: true,
+ children: [
+ "bzhan-10wan",
+ "zhihu-1000wan",
+ "csdn-1000wan",
+ "readme.md",
+ ],
+ },
+ ],
+ },
+ ],
+});
+
+
+
diff --git a/docs/.vuepress/styles/config.scss b/docs/.vuepress/styles/config.scss
new file mode 100644
index 0000000000..3726b05ce8
--- /dev/null
+++ b/docs/.vuepress/styles/config.scss
@@ -0,0 +1,2 @@
+$codeLightTheme: "one-light";
+$codeDarkTheme: "one-dark"
\ No newline at end of file
diff --git a/docs/.vuepress/styles/index.scss b/docs/.vuepress/styles/index.scss
new file mode 100644
index 0000000000..e69de29bb2
diff --git a/docs/.vuepress/styles/palette.scss b/docs/.vuepress/styles/palette.scss
new file mode 100644
index 0000000000..efbb0e7f61
--- /dev/null
+++ b/docs/.vuepress/styles/palette.scss
@@ -0,0 +1,4 @@
+// colors
+$themeColor: #5b86ff;
+$sidebarMobileWidth: 16rem;
+$sidebarWidth: 20rem;
\ No newline at end of file
diff --git a/docs/.vuepress/themeConfig.ts b/docs/.vuepress/themeConfig.ts
new file mode 100644
index 0000000000..08a2f13caf
--- /dev/null
+++ b/docs/.vuepress/themeConfig.ts
@@ -0,0 +1,177 @@
+import { defineThemeConfig } from "vuepress-theme-hope";
+import navbar from "./navbar";
+import { sidebarConfig } from "./sidebar";
+
+export default defineThemeConfig({
+ hostname: "https://tobebetterjavaer.com",
+
+ author: {
+ name: "沉默王二",
+ url: "https://tobebetterjavaer.com",
+ },
+
+ iconPrefix: "iconfont icon-",
+
+ logo: "http://cdn.tobebetterjavaer.com/tobebetterjavaer/images/logo-02.png",
+
+ repo: "https://github.com/itwanger/toBeBetterJavaer",
+
+ docsDir: "docs",
+
+ // 以前的默认仓库分支
+ docsBranch: "master",
+
+ // 纯净模式
+ // pure: true,
+
+ darkmode: "switch",
+
+ // navbar
+ navbar: navbar,
+
+ // sidebar
+ sidebar: sidebarConfig,
+
+ footer: '豫ICP备2021038026号-1'
+ +' '
+ +''
+ +'豫公网安备 41030502000411号'
+ +'',
+
+ displayFooter: true,
+
+ pageInfo: ["Author", "Original", "Date", "Category", "Tag", "ReadingTime"],
+
+ blog: {
+ intro: "/about-the-author/",
+ sidebarDisplay: "mobile",
+ autoExcerpt: true,
+ avatar: "/assets/icon/itwanger-282.png",
+ description:"没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。",
+ medias: {
+ Zhihu: "https://www.zhihu.com/people/cmower",
+ Github: "https://github.com/itwanger",
+ Gitee: "https://gitee.com/itwanger",
+ },
+ },
+
+ plugins: {
+ // 评论区
+ comment: {
+ type: "giscus",
+ repo :"itwanger/tobebetterjavaer-giscus",
+ repoId:"R_kgDOHBJssg",
+ category:"Announcements",
+ categoryId:"DIC_kwDOHBJsss4COJOx",
+ mapping:"pathname",
+ inputPositio:"bottom"
+ },
+ docsearch: {
+ appId: "O566AMFNJH",
+ apiKey: "d9aebea8bd1a4f1e01201464bbab255f",
+ indexName: "tobebetterjavaer",
+ locales: {
+ "/": {
+ placeholder: "搜索文档",
+ translations: {
+ button: {
+ buttonText: "搜索文档",
+ buttonAriaLabel: "搜索文档",
+ },
+ modal: {
+ searchBox: {
+ resetButtonTitle: "清除查询条件",
+ resetButtonAriaLabel: "清除查询条件",
+ cancelButtonText: "取消",
+ cancelButtonAriaLabel: "取消",
+ },
+ startScreen: {
+ recentSearchesTitle: "搜索历史",
+ noRecentSearchesText: "没有搜索历史",
+ saveRecentSearchButtonTitle: "保存至搜索历史",
+ removeRecentSearchButtonTitle: "从搜索历史中移除",
+ favoriteSearchesTitle: "收藏",
+ removeFavoriteSearchButtonTitle: "从收藏中移除",
+ },
+ errorScreen: {
+ titleText: "无法获取结果",
+ helpText: "你可能需要检查你的网络连接",
+ },
+ footer: {
+ selectText: "选择",
+ navigateText: "切换",
+ closeText: "关闭",
+ searchByText: "搜索提供者",
+ },
+ noResultsScreen: {
+ noResultsText: "无法找到相关结果",
+ suggestedQueryText: "你可以尝试查询",
+ openIssueText: "你认为该查询应该有结果?",
+ openIssueLinkText: "点击反馈",
+ },
+ },
+ },
+ },
+ },
+ },
+
+
+ blog: {
+ // 生成摘要
+ autoExcerpt: true,
+ },
+
+ activeHeaderLinks: true,
+
+ mdEnhance: {
+ // 仅将此选项用于体验或测试。
+ align: true,
+ presentation: {
+ plugins: ["highlight", "math", "search", "notes", "zoom"],
+ },
+ },
+
+ // Progressive Web app,即渐进式网络应用程序,
+ // 允许网站通过支持该特性的浏览器将网站作为 App 安装在对应平台上。
+ pwa: {
+ // favicon.ico一般用于作为缩略的网站标志,它显示位于浏览器的地址栏或者在标签上,用于显示网站的logo,
+ favicon: "/favicon.ico",
+ // 如果你的站点体积不大,且配图大多为关键性说明,希望可以在离线模式下显示,建议将此项设置为 true
+ cachePic: true,
+ apple: {
+ icon: "/assets/icon/apple-icon-152.png",
+ statusBarColor: "black",
+ },
+ msTile: {
+ image: "/assets/icon/ms-icon-144.png",
+ color: "#ffffff",
+ },
+ manifest: {
+ icons: [
+ {
+ src: "/assets/icon/chrome-mask-512.png",
+ sizes: "512x512",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-mask-192.png",
+ sizes: "192x192",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-512.png",
+ sizes: "512x512",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-192.png",
+ sizes: "192x192",
+ type: "image/png",
+ },
+ ],
+ },
+ },
+ },
+});
diff --git a/docs/README.md b/docs/README.md
new file mode 100644
index 0000000000..dbace82ba7
--- /dev/null
+++ b/docs/README.md
@@ -0,0 +1,99 @@
+---
+home: true
+icon: home
+title: 主页
+heroImage: http://cdn.tobebetterjavaer.com/tobebetterjavaer/images/logo.png
+heroText: Java程序员进阶之路
+tagline: 沉默王二BB:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java企业级开发、Java面试等核心知识点。学Java,就认准Java程序员进阶之路😄
+actions:
+ - text: 立马上路→
+ link: /home/
+ type: primary
+ - text: 知识星球
+ link: /zhishixingqiu/
+ type: default
+---
+
+## 优质专栏
+
+- **[《Java 面试指南》](/zhishixingqiu/java-mianshi-zhinan.md)** : 内容上与《Java 程序员进阶之路》形成互补,助力你快速成长成为 Offer 收割机!
+- **[《亿点点小请求》](https://github.com/itwanger/toBeBetterJavaer)** : 建议戳链接给知识库点个 star,满足一下我的虚荣心,内容质量也绝对值得你一个 star。我还在继续创作,给我一点继续更新的动力,笔芯。
+
+
+## 推荐阅读
+
+- [CS 学习指南👉](/xuexiluxian/) : 一份涵盖 Java、C 语言、C++、Python、Go、前端、操作系统、蓝桥杯、算法和数据结构的全方位 CS 学习路线!清晰且有效!
+- [Java程序员常读书单📚,附下载地址](https://gitee.com/itwanger/JavaBooks) : 助力Java 程序员构建最强知识体系,涵盖Java、设计模式、数据库、数据结构与算法、大数据、架构等等,再也不用辛苦去找下载地址了。
+- [编程喵喵🐱实战项目学习教程](https://github.com/itwanger/codingmore-learning) :codingmore(Spring Boot+Vue 的前后端分离项目,一款值得一试的开源知识库学习网站)的学习教程,需要项目经验的 Java 开发者必备!
+- [面渣逆袭📗](sidebar/sanfene/nixi.md) :面试前必刷,硬核理解版八股文,包括 Java 基础、Java 集合框架、Java 并发编程、Java 虚拟机、Spring、Redis 等等,助你拿到心仪 offer!
+
+
+## PDF
+
+- [👏下载→Java程序员常读书单](download/java.md)
+- [👏下载→最全最硬核的Java面试 “备战” 资料](https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw)
+- [👏下载→深入浅出Java多线程](https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w)
+- [👏下载→GitHub星标115k+的Java教程](https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw)
+- [👏下载→重学Java设计模式](https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw)
+- [👏下载→Java版LeetCode刷题笔记](https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ)
+- [👏下载→阮一峰C语言入门教程](download/yuanyifeng-c-language.md)
+- [👏下载→BAT大佬的刷题笔记](download/bat-shuati.md)
+- [👏下载→给操作系统捋条线](https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA)
+- [👏下载→豆瓣9.1分,Pro Git中文版](download/progit.md)
+- [👏下载→简历模板](download/jianli.md)
+
+## 公众号
+
+强烈推荐大家关注一波作者的原创公众号,专注于分享硬核的 Java 后端技术文章,但又能保证你在阅读的时候轻松惬意。
+
+
+
+
+## star趋势图
+
+[](https://star-history.com/#itwanger/toBeBetterJavaer&Date)
+
+
+## 友情链接
+
+- [Hippo4J](https://github.com/acmenlt/dynamic-threadpool),🔥 强大的动态线程池,附带监控报警功能(没有依赖中间件),完全遵循阿里巴巴编码规范。
+- [JavaGuide](https://github.com/Snailclimb/JavaGuide),「Java学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!
+
+## 捐赠鼓励
+
+开源不易,如果《Java 程序员进阶之路》对你有些帮助,可以请作者喝杯咖啡,算是对开源做出的一点点鼓励吧!
+
+
'
+ +''
+ +'豫公网安备 41030502000411号'
+ +'',
+
+ displayFooter: true,
+
+ pageInfo: ["Author", "Original", "Date", "Category", "Tag", "ReadingTime"],
+
+ blog: {
+ intro: "/about-the-author/",
+ sidebarDisplay: "mobile",
+ autoExcerpt: true,
+ avatar: "/assets/icon/itwanger-282.png",
+ description:"没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。",
+ medias: {
+ Zhihu: "https://www.zhihu.com/people/cmower",
+ Github: "https://github.com/itwanger",
+ Gitee: "https://gitee.com/itwanger",
+ },
+ },
+
+ plugins: {
+ // 评论区
+ comment: {
+ type: "giscus",
+ repo :"itwanger/tobebetterjavaer-giscus",
+ repoId:"R_kgDOHBJssg",
+ category:"Announcements",
+ categoryId:"DIC_kwDOHBJsss4COJOx",
+ mapping:"pathname",
+ inputPositio:"bottom"
+ },
+ docsearch: {
+ appId: "O566AMFNJH",
+ apiKey: "d9aebea8bd1a4f1e01201464bbab255f",
+ indexName: "tobebetterjavaer",
+ locales: {
+ "/": {
+ placeholder: "搜索文档",
+ translations: {
+ button: {
+ buttonText: "搜索文档",
+ buttonAriaLabel: "搜索文档",
+ },
+ modal: {
+ searchBox: {
+ resetButtonTitle: "清除查询条件",
+ resetButtonAriaLabel: "清除查询条件",
+ cancelButtonText: "取消",
+ cancelButtonAriaLabel: "取消",
+ },
+ startScreen: {
+ recentSearchesTitle: "搜索历史",
+ noRecentSearchesText: "没有搜索历史",
+ saveRecentSearchButtonTitle: "保存至搜索历史",
+ removeRecentSearchButtonTitle: "从搜索历史中移除",
+ favoriteSearchesTitle: "收藏",
+ removeFavoriteSearchButtonTitle: "从收藏中移除",
+ },
+ errorScreen: {
+ titleText: "无法获取结果",
+ helpText: "你可能需要检查你的网络连接",
+ },
+ footer: {
+ selectText: "选择",
+ navigateText: "切换",
+ closeText: "关闭",
+ searchByText: "搜索提供者",
+ },
+ noResultsScreen: {
+ noResultsText: "无法找到相关结果",
+ suggestedQueryText: "你可以尝试查询",
+ openIssueText: "你认为该查询应该有结果?",
+ openIssueLinkText: "点击反馈",
+ },
+ },
+ },
+ },
+ },
+ },
+
+
+ blog: {
+ // 生成摘要
+ autoExcerpt: true,
+ },
+
+ activeHeaderLinks: true,
+
+ mdEnhance: {
+ // 仅将此选项用于体验或测试。
+ align: true,
+ presentation: {
+ plugins: ["highlight", "math", "search", "notes", "zoom"],
+ },
+ },
+
+ // Progressive Web app,即渐进式网络应用程序,
+ // 允许网站通过支持该特性的浏览器将网站作为 App 安装在对应平台上。
+ pwa: {
+ // favicon.ico一般用于作为缩略的网站标志,它显示位于浏览器的地址栏或者在标签上,用于显示网站的logo,
+ favicon: "/favicon.ico",
+ // 如果你的站点体积不大,且配图大多为关键性说明,希望可以在离线模式下显示,建议将此项设置为 true
+ cachePic: true,
+ apple: {
+ icon: "/assets/icon/apple-icon-152.png",
+ statusBarColor: "black",
+ },
+ msTile: {
+ image: "/assets/icon/ms-icon-144.png",
+ color: "#ffffff",
+ },
+ manifest: {
+ icons: [
+ {
+ src: "/assets/icon/chrome-mask-512.png",
+ sizes: "512x512",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-mask-192.png",
+ sizes: "192x192",
+ purpose: "maskable",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-512.png",
+ sizes: "512x512",
+ type: "image/png",
+ },
+ {
+ src: "/assets/icon/chrome-192.png",
+ sizes: "192x192",
+ type: "image/png",
+ },
+ ],
+ },
+ },
+ },
+});
diff --git a/docs/README.md b/docs/README.md
new file mode 100644
index 0000000000..dbace82ba7
--- /dev/null
+++ b/docs/README.md
@@ -0,0 +1,99 @@
+---
+home: true
+icon: home
+title: 主页
+heroImage: http://cdn.tobebetterjavaer.com/tobebetterjavaer/images/logo.png
+heroText: Java程序员进阶之路
+tagline: 沉默王二BB:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java企业级开发、Java面试等核心知识点。学Java,就认准Java程序员进阶之路😄
+actions:
+ - text: 立马上路→
+ link: /home/
+ type: primary
+ - text: 知识星球
+ link: /zhishixingqiu/
+ type: default
+---
+
+## 优质专栏
+
+- **[《Java 面试指南》](/zhishixingqiu/java-mianshi-zhinan.md)** : 内容上与《Java 程序员进阶之路》形成互补,助力你快速成长成为 Offer 收割机!
+- **[《亿点点小请求》](https://github.com/itwanger/toBeBetterJavaer)** : 建议戳链接给知识库点个 star,满足一下我的虚荣心,内容质量也绝对值得你一个 star。我还在继续创作,给我一点继续更新的动力,笔芯。
+
+
+## 推荐阅读
+
+- [CS 学习指南👉](/xuexiluxian/) : 一份涵盖 Java、C 语言、C++、Python、Go、前端、操作系统、蓝桥杯、算法和数据结构的全方位 CS 学习路线!清晰且有效!
+- [Java程序员常读书单📚,附下载地址](https://gitee.com/itwanger/JavaBooks) : 助力Java 程序员构建最强知识体系,涵盖Java、设计模式、数据库、数据结构与算法、大数据、架构等等,再也不用辛苦去找下载地址了。
+- [编程喵喵🐱实战项目学习教程](https://github.com/itwanger/codingmore-learning) :codingmore(Spring Boot+Vue 的前后端分离项目,一款值得一试的开源知识库学习网站)的学习教程,需要项目经验的 Java 开发者必备!
+- [面渣逆袭📗](sidebar/sanfene/nixi.md) :面试前必刷,硬核理解版八股文,包括 Java 基础、Java 集合框架、Java 并发编程、Java 虚拟机、Spring、Redis 等等,助你拿到心仪 offer!
+
+
+## PDF
+
+- [👏下载→Java程序员常读书单](download/java.md)
+- [👏下载→最全最硬核的Java面试 “备战” 资料](https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw)
+- [👏下载→深入浅出Java多线程](https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w)
+- [👏下载→GitHub星标115k+的Java教程](https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw)
+- [👏下载→重学Java设计模式](https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw)
+- [👏下载→Java版LeetCode刷题笔记](https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ)
+- [👏下载→阮一峰C语言入门教程](download/yuanyifeng-c-language.md)
+- [👏下载→BAT大佬的刷题笔记](download/bat-shuati.md)
+- [👏下载→给操作系统捋条线](https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA)
+- [👏下载→豆瓣9.1分,Pro Git中文版](download/progit.md)
+- [👏下载→简历模板](download/jianli.md)
+
+## 公众号
+
+强烈推荐大家关注一波作者的原创公众号,专注于分享硬核的 Java 后端技术文章,但又能保证你在阅读的时候轻松惬意。
+
+
+
+
+## star趋势图
+
+[](https://star-history.com/#itwanger/toBeBetterJavaer&Date)
+
+
+## 友情链接
+
+- [Hippo4J](https://github.com/acmenlt/dynamic-threadpool),🔥 强大的动态线程池,附带监控报警功能(没有依赖中间件),完全遵循阿里巴巴编码规范。
+- [JavaGuide](https://github.com/Snailclimb/JavaGuide),「Java学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!
+
+## 捐赠鼓励
+
+开源不易,如果《Java 程序员进阶之路》对你有些帮助,可以请作者喝杯咖啡,算是对开源做出的一点点鼓励吧!
+
+
+
+
+> 2.**类内部的结构可以自由修改**。
+> 3.可以对成员变量进行更**精确的控制**。
+> 4.**隐藏信息**实现细节。
+
+
+- 2.**继承**
+ - 继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
+
+**优点**:
+
+> 1.提高类代码的**复用性**
+> 2.提高了代码的**维护性**
+
+- 3.**多态**
+ - 多态是同一个行为具有多个不同表现形式或形态的能力。Java语言中含有方法重载与对象多态两种形式的多态:
+ - 1.**方法重载**:在一个类中,允许多个方法使用同一个名字,但方法的参数不同,完成的功能也不同。
+ - 2.**对象多态**:子类对象可以与父类对象进行转换,而且根据其使用的子类不同完成的功能也不同(重写父类的方法)。
+
+ **优点**
+
+> 1. **消除类型之间的耦合关系**
+> 2. **可替换性**
+> 3. **可扩充性**
+> 4. **接口性**
+> 5. **灵活性**
+> 6. **简化性**
+
+## 2.java 有哪些数据类型?
+
+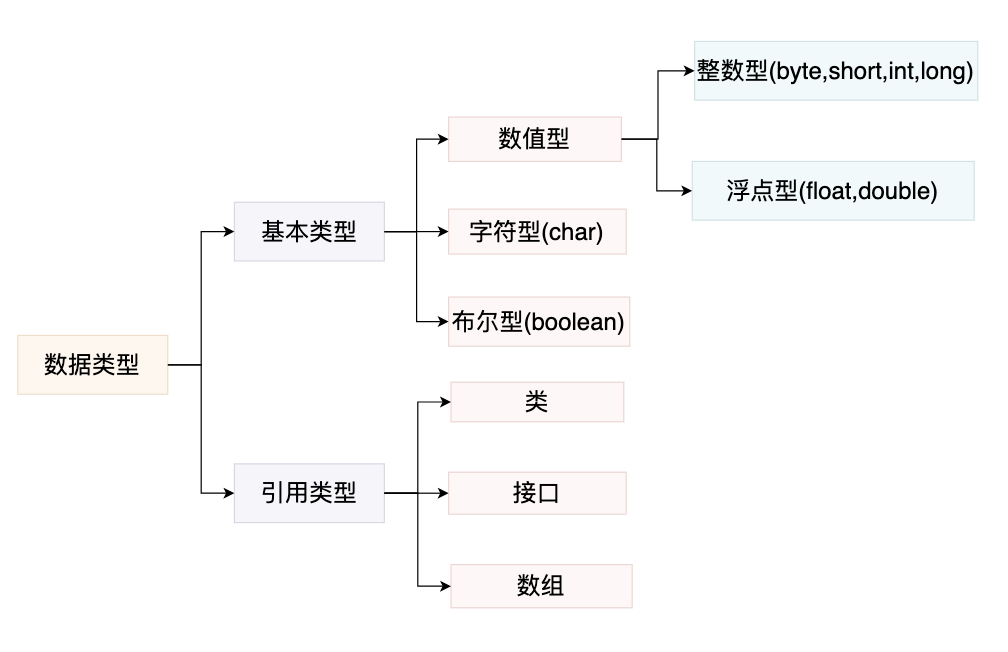
+
+java 主要有两种数据类型
+
+ - 1.**基本数据类型**
+ - 基本数据有**八个**,
+ - byte,short,int,long属于数值型中的整数型
+ - float,double属于数值型中的浮点型
+ - char属于字符型
+ - boolean属于布尔型
+ - 2.**引用数据类型**
+ - 引用数据类型有**三个**,分别是类,接口和数组
+
+## 3.接口和抽象类有什么区别?
+
+- 1.接口是抽象类的变体,**接口中所有的方法都是抽象的**。而抽象类是声明方法的存在而不去实现它的类。
+- 2.接口可以多继承,抽象类不行。
+- 3.接口定义方法,不能实现,默认是 **public abstract**,而抽象类可以实现部分方法。
+- 4.接口中基本数据类型为 **public static final** 并且需要给出初始值,而抽类象不是的。
+
+## 4.重载和重写什么区别?
+
+重写:
+
+- 1.参数列表必须**完全与被重写的方法**相同,否则不能称其为重写而是重载.
+- 2.**返回的类型必须一直与被重写的方法的返回类型相同**,否则不能称其为重写而是重载。
+- 3.访问**修饰符的限制一定要大于被重写方法的访问修饰符**
+- 4.重写方法一定**不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常**。
+
+重载:
+
+- 1.必须具有**不同的参数列表**;
+- 2.可以有不同的返回类型,只要参数列表不同就可以了;
+- 3.可以有**不同的访问修饰符**;
+- 4.可以抛出**不同的异常**;
+
+## 5.常见的异常有哪些?
+
+- NullPointerException 空指针异常
+- ArrayIndexOutOfBoundsException 索引越界异常
+- InputFormatException 输入类型不匹配
+- SQLException SQL异常
+- IllegalArgumentException 非法参数
+- NumberFormatException 类型转换异常
+ 等等....
+
+## 6.异常要怎么解决?
+
+Java标准库内建了一些通用的异常,这些类以Throwable为顶层父类。
+
+Throwable又派生出**Error类和Exception类**。
+
+错误:Error类以及他的子类的实例,代表了JVM本身的错误。错误不能被程序员通过代码处理,Error很少出现。因此,程序员应该关注Exception为父类的分支下的各种异常类。
+
+异常:Exception以及他的子类,代表程序运行时发送的各种不期望发生的事件。可以被Java异常处理机制使用,是异常处理的核心。
+
+处理方法:
+
+- 1.**try()catch(){}**
+
+```
+try{
+// 程序代码
+}catch(ExceptionName e1){
+//Catch 块
+}
+```
+
+- 2.**throw**
+ - throw 关键字作用是抛出一个异常,抛出的时候是抛出的是一个异常类的实例化对象,在异常处理中,try 语句要捕获的是一个异常对象,那么此异常对象也可以自己抛出
+- 3.**throws**
+ - 定义一个方法的时候可以使用 throws 关键字声明。使用 throws 关键字声明的方法表示此方法不处理异常,而交给方法调用处进行处理。
+
+## 7.arrayList 和 linkedList 的区别?
+
+
+
+
+- 1.ArrayList 是实现了基于**数组**的,存储空间是连续的。LinkedList 基于**链表**的,存储空间是不连续的。(LinkedList 是双向链表)
+
+- 2.对于**随机访问** get 和 set ,ArrayList 觉得优于 LinkedList,因为 LinkedList 要移动指针。
+
+- 3.对于**新增和删除**操作 add 和 remove ,LinedList 比较占优势,因为 ArrayList 要移动数据。
+
+- 4.同样的数据量 LinkedList 所占用空间可能会更小,因为 ArrayList 需要**预留空间**便于后续数据增加,而 LinkedList 增加数据只需要**增加一个节点**
+
+## 8.hashMap 1.7 和 hashMap 1.8 的区别?
+
+只记录**重点**
+
+| 不同点 | hashMap 1.7 | hashMap 1.8 |
+| :-------------- | :----------------------------: | -----------------------------: |
+| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
+| 插入数据的方式 | 头插法 | 尾插法 |
+| hash 值计算方式 | 9次扰动处理(4次位运算+5次异或) | 2次扰动处理(1次位运算+1次异或) |
+| 扩容策略 | 插入前扩容 | 插入后扩容 |
+
+## 9.hashMap 线程不安全体现在哪里?
+
+在 **hashMap1.7 中扩容**的时候,因为采用的是头插法,所以会可能会有循环链表产生,导致数据有问题,在 1.8 版本已修复,改为了尾插法
+
+在任意版本的 hashMap 中,如果在**插入数据时多个线程命中了同一个槽**,可能会有数据覆盖的情况发生,导致线程不安全。
+
+## 10.那么 hashMap 线程不安全怎么解决?
+
+
+
+- 一.给 hashMap **直接加锁**,来保证线程安全
+- 二.使用 **hashTable**,比方法一效率高,其实就是在其方法上加了 synchronized 锁
+- 三.使用 **concurrentHashMap** , 不管是其 1.7 还是 1.8 版本,本质都是**减小了锁的粒度,减少线程竞争**来保证高效.
+
+## 11.concurrentHashMap 1.7 和 1.8 有什么区别
+
+只记录**重点**
+
+| 不同点 | concurrentHashMap 1.7 | concurrentHashMap 1.8 |
+| :------- | :--------------------------: | ---------------------------------: |
+| 锁粒度 | 基于segment | 基于entry节点 |
+| 锁 | reentrantLock | synchronized |
+| 底层结构 | Segment + HashEntry + Unsafe | Synchronized + CAS + Node + Unsafe |
+
+## 12.介绍一下 hashset 吧
+
+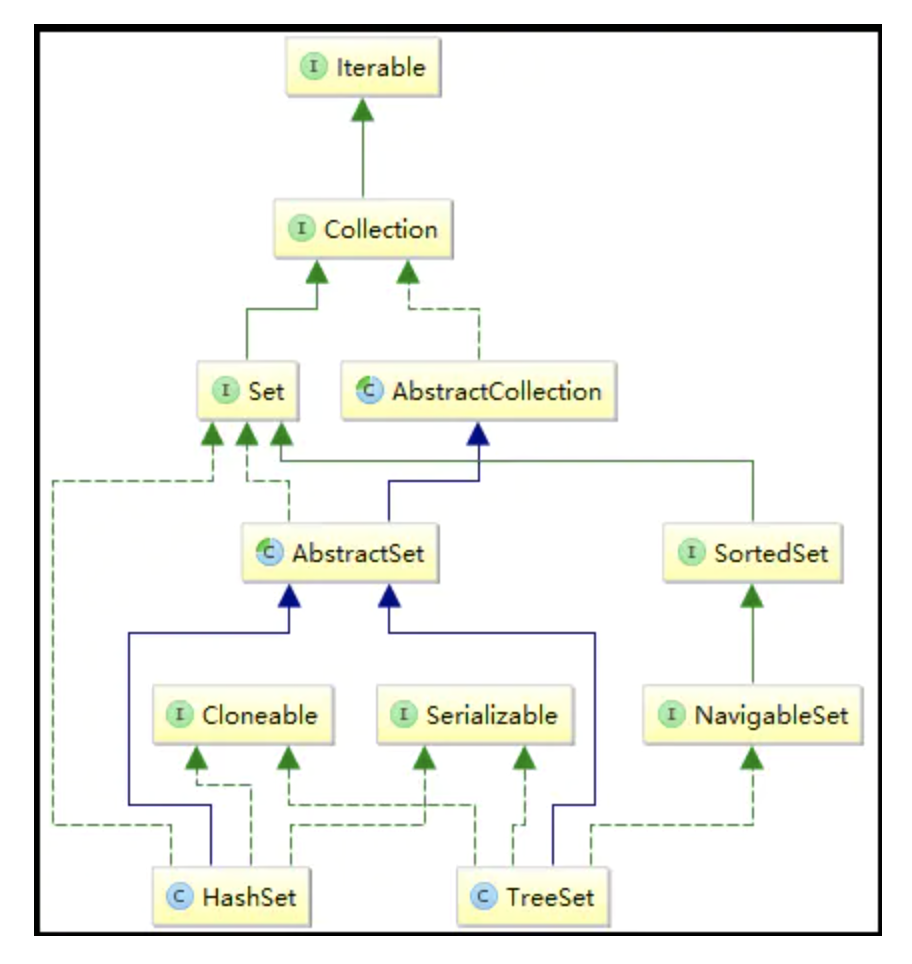
+
+上图是 set 家族整体的结构,
+
+set 继承于 Collection 接口,是一个**不允许出现重复元素,并且无序的集合**.
+
+HashSet 是**基于 HashMap 实现**的,底层**采用 HashMap 来保存元素**
+
+元素的哈希值是通过元素的 hashcode 方法 来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较 equals 方法 如果 equls 结果为 true ,HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。
+
+## 13.什么是泛型?
+
+泛型:**把类型明确的工作推迟到创建对象或调用方法的时候才去明确的特殊的类型**
+
+## 14.泛型擦除是什么?
+
+因为泛型其实只是在编译器中实现的而虚拟机并不认识泛型类项,所以要在虚拟机中将泛型类型进行擦除。也就是说,**在编译阶段使用泛型,运行阶段取消泛型,即擦除**。 擦除是将泛型类型以其父类代替,如String 变成了Object等。其实在使用的时候还是进行带强制类型的转化,只不过这是比较安全的转换,因为在编译阶段已经确保了数据的一致性。
+
+## 15.说说进程和线程的区别?
+
+**进程是系统资源分配和调度的基本单位**,它能并发执行较高系统资源的利用率.
+
+**线程**是**比进程更小**的能独立运行的基本单位,创建、销毁、切换成本要小于进程,可以减少程序并发执行时的时间和空间开销,使得操作系统具有更好的并发性。
+
+## 16.volatile 有什么作用?
+
+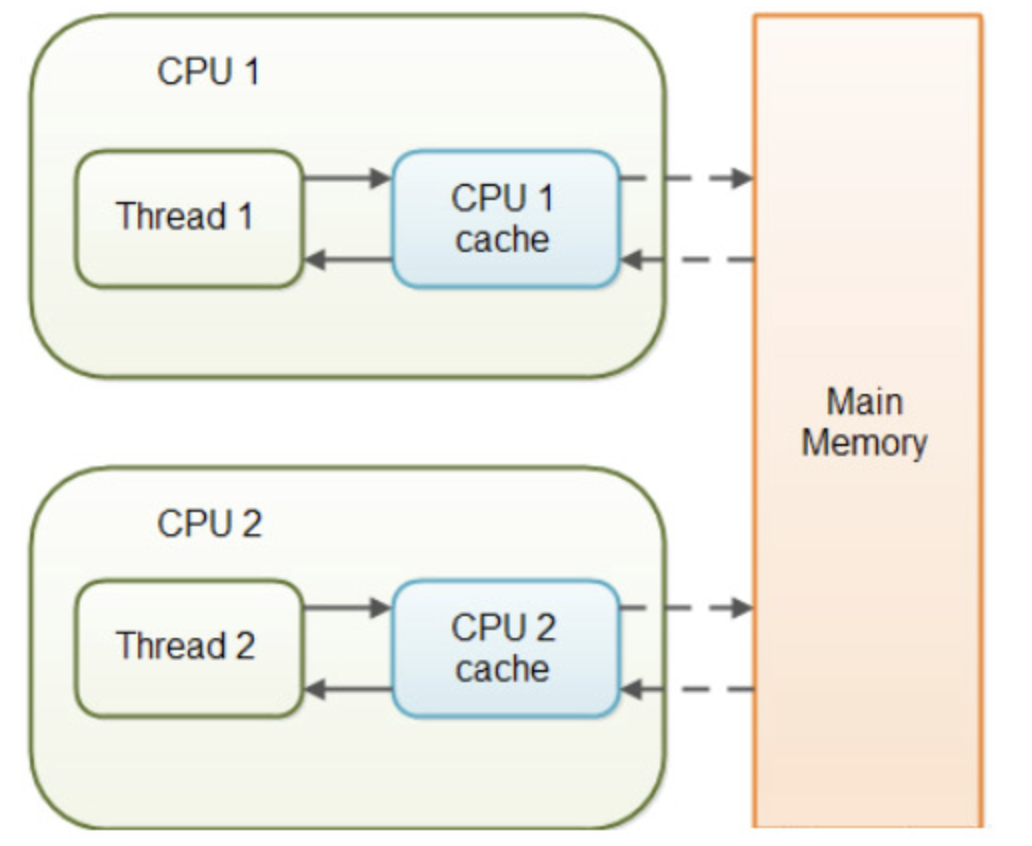
+
+- **1.保证内存可见性**
+ - 可见性是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果,另一个线程马上就能看到。
+- **2.禁止指令重排序**
+ - cpu 是和缓存做交互的,但是由于 cpu 运行效率太高,所以会不等待当前命令返回结果从而继续执行下一个命令,就会有乱序执行的情况发生
+
+## 17.什么是包装类?为什么需要包装类?
+
+**Java 中有 8 个基本类型,分别对应的 8 个包装类**
+
+- byte -- Byte
+- boolean -- Boolean
+- short -- Short
+- char -- Character
+- int -- Integer
+- long -- Long
+- float -- Float
+- double -- Double
+
+**为什么需要包装类**:
+
+- 基本数据类型方便、简单、高效,但泛型不支持、集合元素不支持
+- 不符合面向对象思维
+- 包装类提供很多方法,方便使用,如 Integer 类 toHexString(int i)、parseInt(String s) 方法等等
+
+## 18.Integer a = 1000,Integer b = 1000,a==b 的结果是什么?那如果 a,b 都为1,结果又是什么?
+
+Integer a = 1000,Integer b = 1000,a==b 结果为**false**
+
+Integer a = 1,Integer b = 1,a==b 结果为**true**
+
+这道题主要考察 Integer 包装类缓存的范围,**在-128~127之间会缓存起来**,比较的是直接缓存的数据,在此之外比较的是对象
+
+## 19.JMM 是什么?
+
+
+
+JMM 就是 **Java内存模型**(java memory model)。因为在不同的硬件生产商和不同的操作系统下,内存的访问有一定的差异,所以会造成相同的代码运行在不同的系统上会出现各种问题。所以java内存模型(JMM)**屏蔽掉各种硬件和操作系统的内存访问差异,以实现让java程序在各种平台下都能达到一致的并发效果**。
+
+Java内存模型规定所有的变量都存储在主内存中,包括实例变量,静态变量,但是不包括局部变量和方法参数。每个线程都有自己的工作内存,线程的工作内存保存了该线程用到的变量和主内存的副本拷贝,线程对变量的操作都在工作内存中进行。**线程不能直接读写主内存中的变量**。
+
+每个线程的工作内存都是独立的,**线程操作数据只能在工作内存中进行,然后刷回到主存**。这是 Java 内存模型定义的线程基本工作方式。
+
+
+## 20.创建对象有哪些方式
+
+有**五种创建对象的方式**
+
+- 1、new关键字
+
+```
+Person p1 = new Person();
+```
+
+- 2.Class.newInstance
+
+```
+Person p1 = Person.class.newInstance();
+```
+
+- 3.Constructor.newInstance
+
+```
+Constructor constructor = Person.class.getConstructor();
+Person p1 = constructor.newInstance();
+```
+
+- 4.clone
+
+```
+Person p1 = new Person();
+Person p2 = p1.clone();
+```
+
+- 5.反序列化
+
+```
+Person p1 = new Person();
+byte[] bytes = SerializationUtils.serialize(p1);
+Person p2 = (Person)SerializationUtils.deserialize(bytes);
+```
+
+## 21.讲讲单例模式懒汉式吧
+
+直接贴代码
+
+```
+// 懒汉式
+public class Singleton {
+// 延迟加载保证多线程安全
+ Private volatile static Singleton singleton;
+ private Singleton(){}
+ public static Singleton getInstance(){
+ if(singleton == null){
+ synchronized(Singleton.class){
+ if(singleton == null){
+ singleton = new Singleton();
+ }
+ }
+ }
+ return singleton;
+ }
+}
+```
+
+- 使用 volatile 是**防止指令重排序,保证对象可见**,防止读到半初始化状态的对象
+- 第一层if(singleton == null) 是为了防止有多个线程同时创建
+- synchronized 是加锁防止多个线程同时进入该方法创建对象
+- 第二层if(singleton == null) 是防止有多个线程同时等待锁,一个执行完了后面一个又继续执行的情况
+
+[关于双检锁可以参考](https://blog.csdn.net/fly910905/article/details/79286680)
+
+## 22.volatile 有什么作用
+
+
+
+- 1.**保证内存可见性**
+ - 当一个被volatile关键字修饰的变量被一个线程修改的时候,其他线程可以立刻得到修改之后的结果。当一个线程向被volatile关键字修饰的变量**写入数据**的时候,虚拟机会**强制它被值刷新到主内存中**。当一个线程**读取**被volatile关键字修饰的值的时候,虚拟机会**强制要求它从主内存中读取**。
+- 2.**禁止指令重排序**
+ - 指令重排序是编译器和处理器为了高效对程序进行优化的手段,cpu 是与内存交互的,而 cpu 的效率想比内存高很多,所以 cpu 会在不影响最终结果的情况下,不等待返回结果直接进行后续的指令操作,而 volatile 就是给相应代码加了**内存屏障**,在屏障内的代码禁止指令重排序。
+
+## 23.怎么保证线程安全?
+
+- 1.synchronized关键字
+ - 可以用于代码块,方法(静态方法,同步锁是当前字节码对象;实例方法,同步锁是实例对象)
+- 2.lock锁机制
+
+```
+Lock lock = new ReentrantLock();
+lock. lock();
+try {
+ System. out. println("获得锁");
+} catch (Exception e) {
+
+} finally {
+ System. out. println("释放锁");
+ lock. unlock();
+}
+```
+
+## 24.synchronized 锁升级的过程
+
+在 Java1.6 之前的版本中,synchronized 属于重量级锁,效率低下,**锁是** cpu 一个**总量级的资源**,每次获取锁都要和 cpu 申请,非常消耗性能。
+
+在 **jdk1.6 之后** Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了,Jdk1.6 之后,为了减少获得锁和释放锁所带来的性能消耗,引入了偏向锁和轻量级锁,**增加了锁升级的过程**,由无锁->偏向锁->自旋锁->重量级锁
+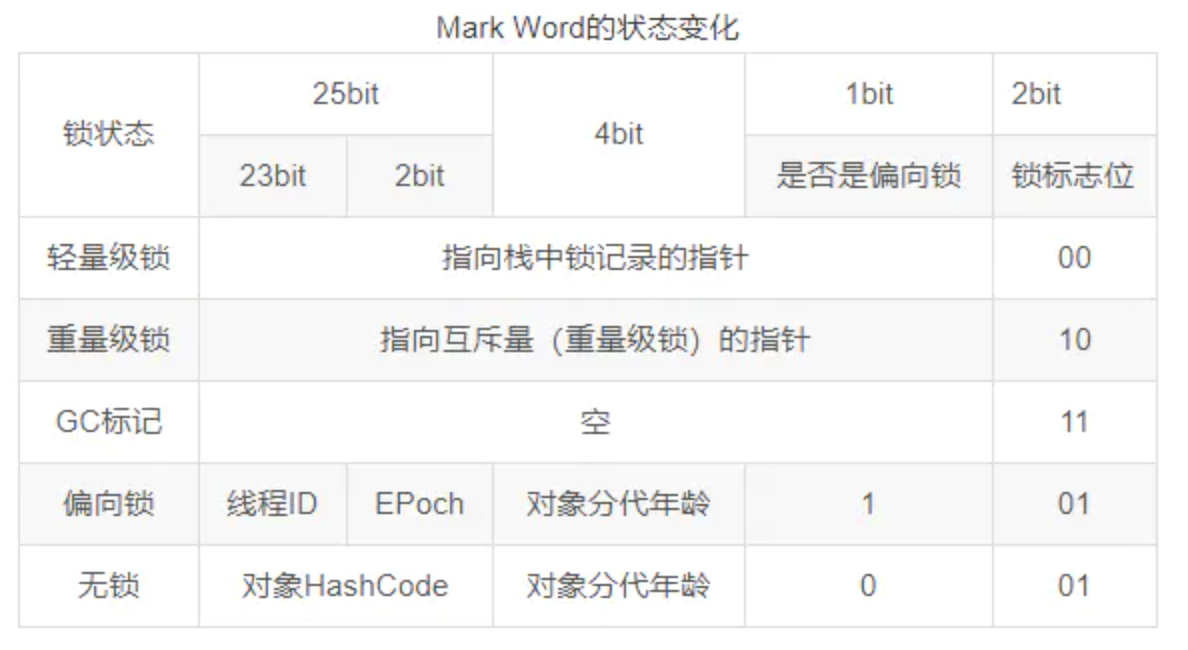
+
+增加锁升级的过程主要是**减少用户态到核心态的切换,提高锁的效率,从 jvm 层面优化锁**
+
+## 25.cas 是什么?
+
+cas 叫做 CompareAndSwap,**比较并交换**,很多地方使用到了它,比如锁升级中自旋锁就有用到,主要是**通过处理器的指令来保证操作的原子性**,它主要包含三个变量:
+
+- **1.变量内存地址**
+- **2.旧的预期值 A**
+- **3.准备设置的新值 B**
+
+当一个线程需要修改一个共享变量的值,完成这个操作需要先取出共享变量的值,赋给 A,基于 A 进行计算,得到新值 B,在用预期原值 A 和内存中的共享变量值进行比较,**如果相同就认为其他线程没有进行修改**,而将新值写入内存
+
+
+
+**CAS的缺点**
+
+- **CPU开销比较大**:在并发量比较高的情况下,如果许多线程反复尝试更新某一个变量,却又一直更新不成功,又因为自旋的时候会一直占用CPU,如果CAS一直更新不成功就会一直占用,造成CPU的浪费。
+
+- **ABA 问题**:比如线程 A 去修改 1 这个值,修改成功了,但是中间 线程 B 也修改了这个值,但是修改后的结果还是 1,所以不影响 A 的操作,这就会有问题。可以用**版本号**来解决这个问题。
+
+- **只能保证一个共享变量的原子性**
+
+## 26.聊聊 ReentrantLock 吧
+
+ReentrantLock 意为**可重入锁**,说起 ReentrantLock 就不得不说 AQS ,因为其底层就是**使用 AQS 去实现**的。
+
+ReentrantLock有两种模式,一种是公平锁,一种是非公平锁。
+
+- 公平模式下等待线程入队列后会严格按照队列顺序去执行
+- 非公平模式下等待线程入队列后有可能会出现插队情况
+
+**公平锁**
+
+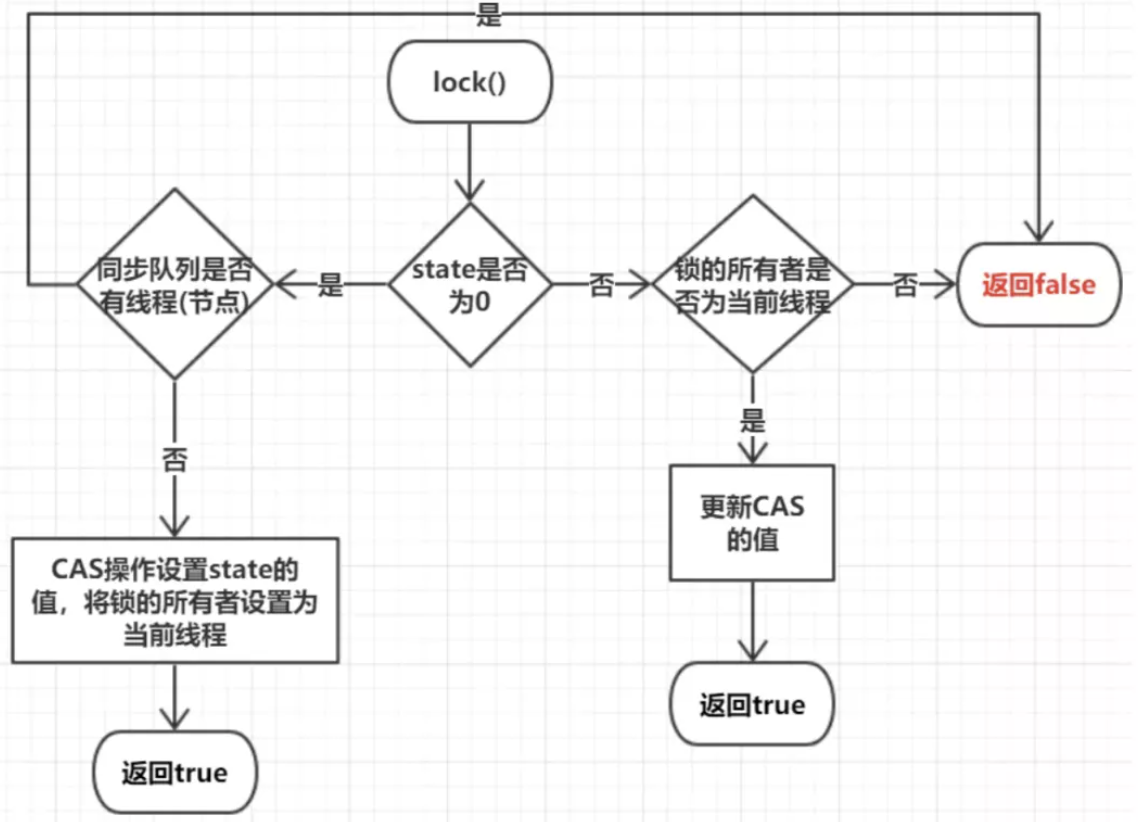
+
+- 第一步:**获取状态的 state 的值**
+ - 如果 state=0 即代表锁没有被其它线程占用,执行第二步。
+ - 如果 state!=0 则代表锁正在被其它线程占用,执行第三步。
+- 第二步:**判断队列中是否有线程在排队等待**
+ - 如果不存在则直接将锁的所有者设置成当前线程,且更新状态 state 。
+ - 如果存在就入队。
+- 第三步:**判断锁的所有者是不是当前线程**
+ - 如果是则更新状态 state 的值。
+ - 如果不是,线程进入队列排队等待。
+
+**非公平锁**
+
+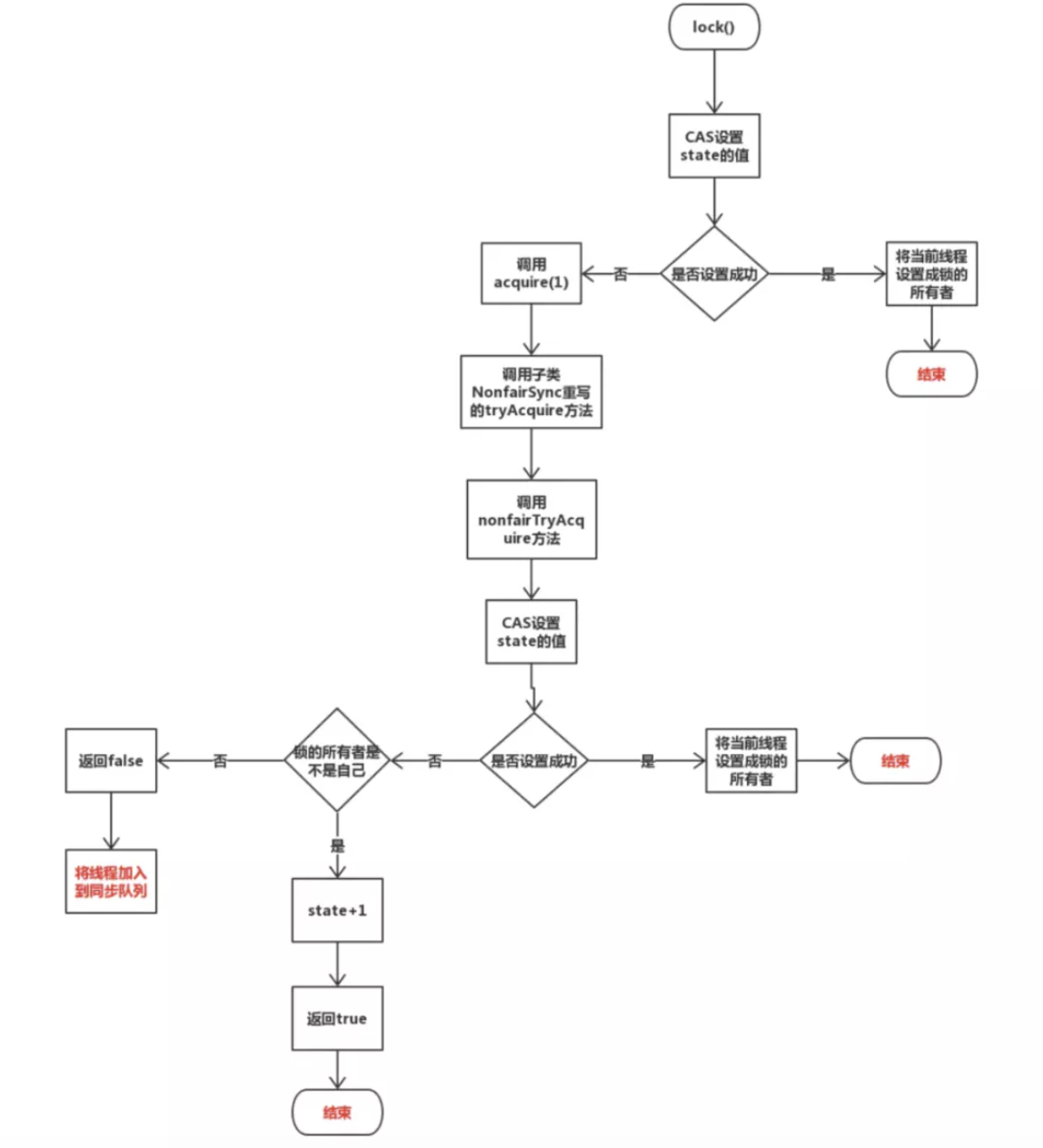
+
+- 获取状态的 state 的值
+ - 如果 state=0 即代表锁没有被其它线程占用,则设置当前锁的持有者为当前线程,该操作用 CAS 完成。
+ - 如果不为0或者设置失败,代表锁被占用进行下一步。
+- 此时**获取 state 的值**
+ - 如果是,则给state+1,获取锁
+ - 如果不是,则进入队列等待
+ - 如果是0,代表刚好线程释放了锁,此时将锁的持有者设为自己
+ - 如果不是0,则查看线程持有者是不是自己
+
+## 27.多线程的创建方式有哪些?
+
+- 1、**继承Thread类**,重写run()方法
+
+```
+public class Demo extends Thread{
+ //重写父类Thread的run()
+ public void run() {
+ }
+ public static void main(String[] args) {
+ Demo d1 = new Demo();
+ Demo d2 = new Demo();
+ d1.start();
+ d2.start();
+ }
+}
+```
+
+- 2.**实现Runnable接口**,重写run()
+
+```
+public class Demo2 implements Runnable{
+
+ //重写Runnable接口的run()
+ public void run() {
+ }
+
+ public static void main(String[] args) {
+ Thread t1 = new Thread(new Demo2());
+ Thread t2 = new Thread(new Demo2());
+ t1.start();
+ t2.start();
+ }
+
+}
+```
+
+- 3.**实现 Callable 接口**
+
+```
+public class Demo implements Callable{
+
+ public String call() throws Exception {
+ System.out.println("正在执行新建线程任务");
+ Thread.sleep(2000);
+ return "结果";
+ }
+
+ public static void main(String[] args) throws InterruptedException, ExecutionException {
+ Demo d = new Demo();
+ FutureTask task = new FutureTask<>(d);
+ Thread t = new Thread(task);
+ t.start();
+ //获取任务执行后返回的结果
+ String result = task.get();
+ }
+
+}
+```
+
+- 4.**使用线程池创建**
+
+```
+public class Demo {
+ public static void main(String[] args) {
+ Executor threadPool = Executors.newFixedThreadPool(5);
+ for(int i = 0 ;i < 10 ; i++) {
+ threadPool.execute(new Runnable() {
+ public void run() {
+ //todo
+ }
+ });
+ }
+
+ }
+}
+```
+
+## 28.线程池有哪些参数?
+
+- **1.corePoolSize**:**核心线程数**,线程池中始终存活的线程数。
+- **2.maximumPoolSize**: **最大线程数**,线程池中允许的最大线程数。
+- **3.keepAliveTime**: **存活时间**,线程没有任务执行时最多保持多久时间会终止。
+
+- **4.unit**: **单位**,参数keepAliveTime的时间单位,7种可选。
+- **5.workQueue**: 一个**阻塞队列**,用来存储等待执行的任务,均为线程安全,7种可选。
+- **6.threadFactory**: **线程工厂**,主要用来创建线程,默及正常优先级、非守护线程。
+
+- **7.handler**:**拒绝策略**,拒绝处理任务时的策略,4种可选,默认为AbortPolicy。
+
+## 29.线程池的执行流程?
+
+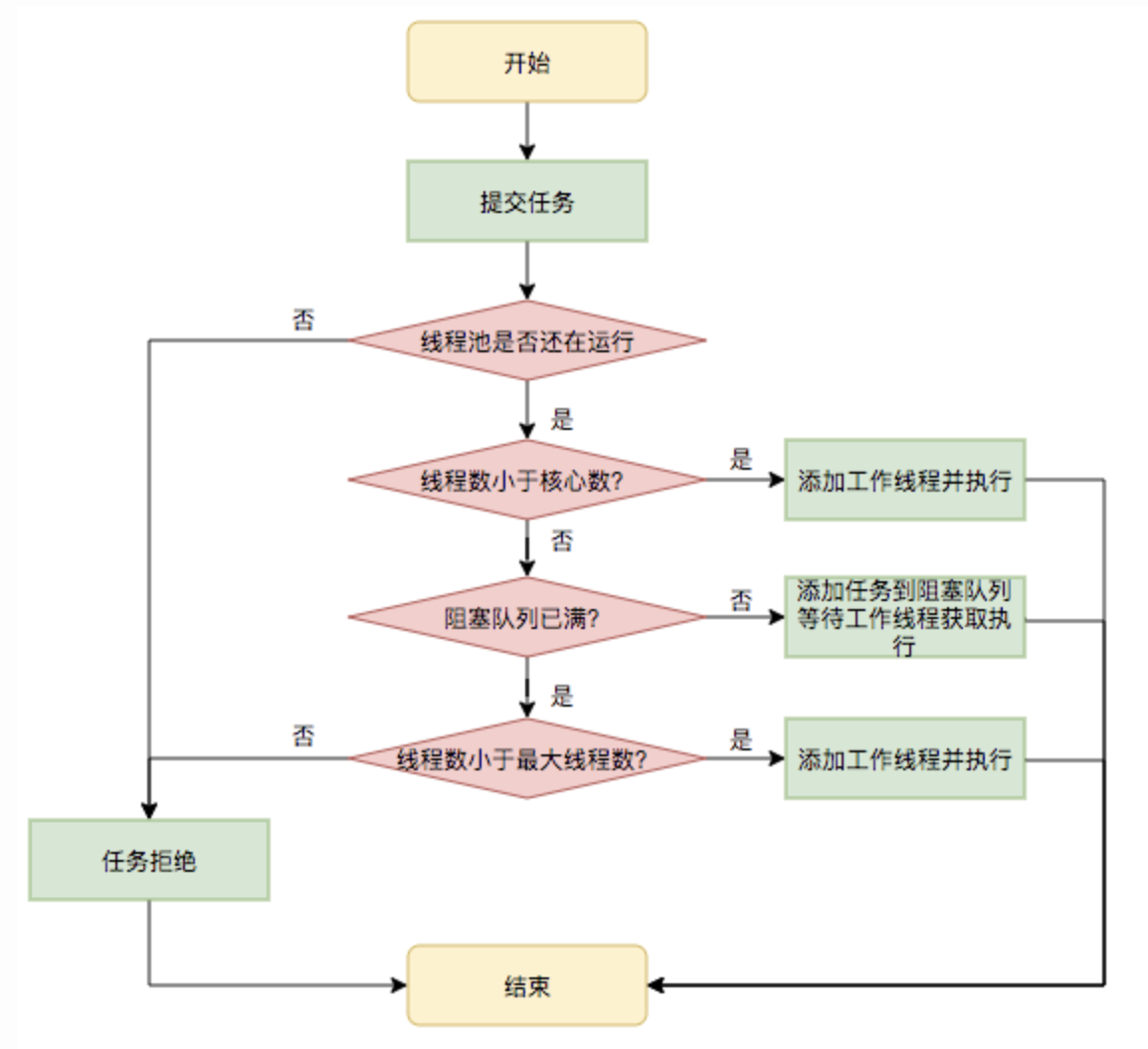
+
+- 判断线程池中的线程数**是否大于设置的核心线程数**
+ - 如果**小于**,就**创建**一个核心线程来执行任务
+ - 如果**大于**,就会**判断缓冲队列是否满了**
+ - 如果**没有满**,则**放入队列**,等待线程空闲时执行任务
+ - 如果队列已经**满了**,则判断**是否达到了线程池设置的最大线程数**
+ - 如果**没有达到**,就**创建新线程**来执行任务
+ - 如果已经**达到了**最大线程数,则**执行指定的拒绝策略**
+
+## 30.线程池的拒绝策略有哪些?
+
+- **AbortPolicy**:直接丢弃任务,抛出异常,这是默认策略
+- **CallerRunsPolicy**:只用调用者所在的线程来处理任务
+- **DiscardOldestPolicy**:丢弃等待队列中最旧的任务,并执行当前任务
+- **DiscardPolicy**:直接丢弃任务,也不抛出异常
+
+## 31.介绍一下四种引用类型?
+
+- **强引用 StrongReference**
+
+```
+Object obj = new Object();
+//只要obj还指向Object对象,Object对象就不会被回收
+```
+
+垃圾回收器不会回收被引用的对象,哪怕内存不足时,JVM 也会直接抛出 OutOfMemoryError,除非赋值为 null。
+
+- **软引用 SoftReference**
+
+软引用是用来描述一些非必需但仍有用的对象。在内存足够的时候,软引用对象不会被回收,只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。
+
+- **弱引用 WeakReference**
+
+弱引用的引用强度比软引用要更弱一些,无论内存是否足够,只要 JVM 开始进行垃圾回收,那些被弱引用关联的对象都会被回收。
+
+- **虚引用 PhantomReference**
+
+虚引用是最弱的一种引用关系,如果一个对象仅持有虚引用,那么它就和没有任何引用一样,它随时可能会被回收,在 JDK1.2 之后,用 PhantomReference 类来表示,通过查看这个类的源码,发现它只有一个构造函数和一个 get() 方法,而且它的 get() 方法仅仅是返回一个null,也就是说将永远无法通过虚引用来获取对象,虚引用必须要和 ReferenceQueue 引用队列一起使用,NIO 的堆外内存就是靠其管理。
+
+## 32.深拷贝、浅拷贝是什么?
+
+- 浅拷贝并不是真的拷贝,只是**复制指向某个对象的指针**,而不复制对象本身,新旧对象还是共享同一块内存。
+- 深拷贝会另外**创造一个一模一样的对象**,新对象跟原对象不共享内存,修改新对象不会改到原对象。
+
+## 33.聊聊 ThreadLocal 吧
+
+- ThreadLocal其实就是**线程本地变量**,他会在每个线程都创建一个副本,那么在线程之间访问内部副本变量就行了,做到了线程之间互相隔离。
+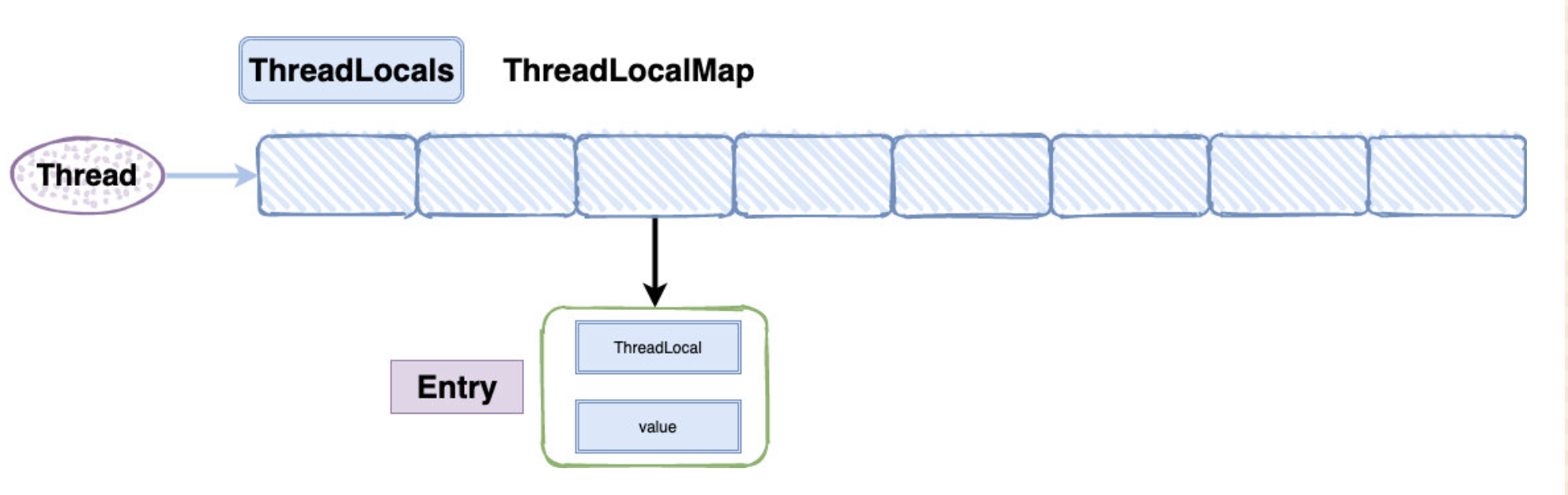
+- ThreadLocal 有一个**静态内部类 ThreadLocalMap**,ThreadLocalMap 又包含了一个 Entry 数组,**Entry 本身是一个弱引用**,他的 key 是指向 ThreadLocal 的弱引用,**弱引用的目的是为了防止内存泄露**,如果是强引用那么除非线程结束,否则无法终止,可能会有内存泄漏的风险。
+- 但是这样还是会存在内存泄露的问题,假如 key 和 ThreadLocal 对象被回收之后,entry 中就存在 key 为 null ,但是 value 有值的 entry 对象,但是永远没办法被访问到,同样除非线程结束运行。**解决方法就是调用 remove 方法删除 entry 对象**。
+
+## 34.一个对象的内存布局是怎么样的?
+
+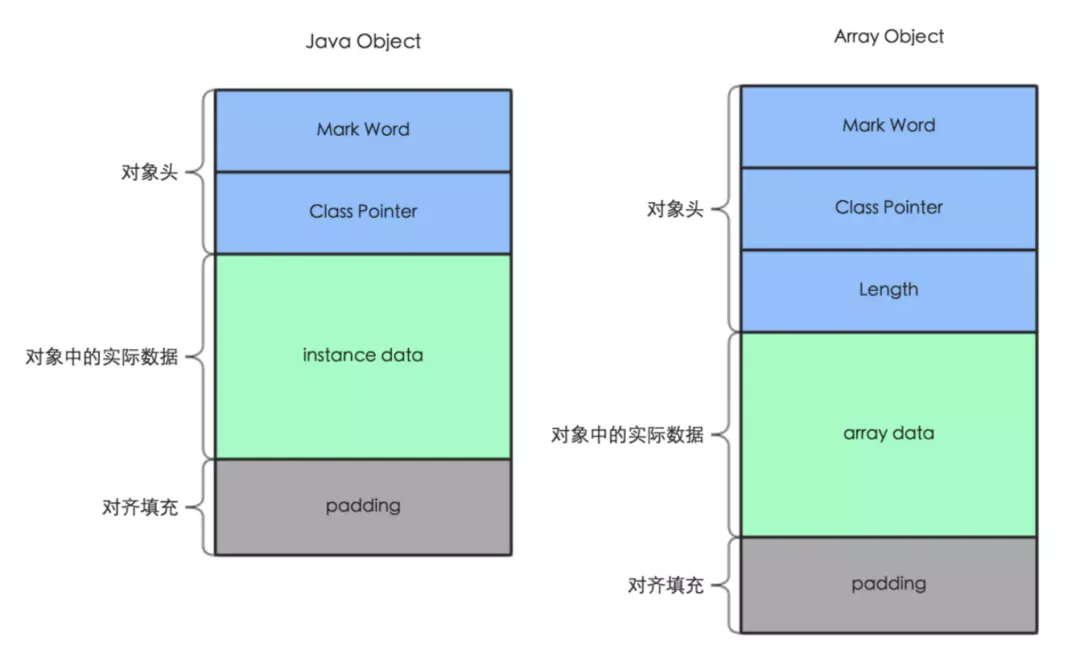
+
+- **1.对象头**:
+ 对象头又分为 **MarkWord** 和 **Class Pointer** 两部分。
+ - **MarkWord**:包含一系列的标记位,比如轻量级锁的标记位,偏向锁标记位,gc记录信息等等。
+ - **ClassPointer**:用来指向对象对应的 Class 对象(其对应的元数据对象)的内存地址。在 32 位系统占 4 字节,在 64 位系统中占 8 字节。
+- **2.Length**:只在数组对象中存在,用来记录数组的长度,占用 4 字节
+- **3.Instance data**:
+ 对象实际数据,对象实际数据包括了对象的所有成员变量,其大小由各个成员变量的大小决定。(这里不包括静态成员变量,因为其是在方法区维护的)
+- **4.Padding**:Java 对象占用空间是 8 字节对齐的,即所有 Java 对象占用 bytes 数必须是 8 的倍数,是因为当我们从磁盘中取一个数据时,不会说我想取一个字节就是一个字节,都是按照一块儿一块儿来取的,这一块大小是 8 个字节,所以为了完整,padding 的作用就是补充字节,**保证对象是 8 字节的整数倍**。
+
+---
+
+>作者:moon聊技术,转载链接:[https://mp.weixin.qq.com/s/aTWtqPyMQ-6P_c8iuMVrkg](https://mp.weixin.qq.com/s/aTWtqPyMQ-6P_c8iuMVrkg)
+
+
diff --git a/docs/baguwen/java-basic.md b/docs/baguwen/java-basic.md
new file mode 100644
index 0000000000..0407bbc3e7
--- /dev/null
+++ b/docs/baguwen/java-basic.md
@@ -0,0 +1,403 @@
+---
+category:
+ - 求职面试
+tag:
+ - 背诵版八股文
+---
+
+# Java 基础八股文(背诵版)必看:+1:
+
+### Java 语言具有哪些特点?
+
+- Java 为纯面向对象的语言。它能够直接反应现实生活中的对象。
+- 具有平台无关性。Java 利用 Java 虚拟机运行字节码,无论是在 Windows、Linux 还是 MacOS 等其它平台对 Java 程序进行编译,编译后的程序可在其它平台运行。
+- Java 为解释型语言,编译器把 Java 代码编译成平台无关的中间代码,然后在 JVM 上解释运行,具有很好的可移植性。
+- Java 提供了很多内置类库。如对多线程支持,对网络通信支持,最重要的一点是提供了垃圾回收器。
+- Java 具有较好的安全性和健壮性。Java 提供了异常处理和垃圾回收机制,去除了 C++中难以理解的指针特性。
+
+### JDK 与 JRE 有什么区别?
+
+- JDK:Java 开发工具包(Java Development Kit),提供了 Java 的开发环境和运行环境。
+- JRE:Java 运行环境(Java Runtime Environment),提供了 Java 运行所需的环境。
+- JDK 包含了 JRE。如果只运行 Java 程序,安装 JRE 即可。要编写 Java 程序需安装 JDK.
+
+### 简述 Java 基本数据类型
+
+- byte: 占用 1 个字节,取值范围-128 ~ 127
+- short: 占用 2 个字节,取值范围-2^15^ ~ 2^15^-1
+- int:占用 4 个字节,取值范围-2^31^ ~ 2^31^-1
+- long:占用 8 个字节
+- float:占用 4 个字节
+- double:占用 8 个字节
+- char: 占用 2 个字节
+- boolean:占用大小根据实现虚拟机不同有所差异
+
+
+
+### 简述自动装箱拆箱
+
+对于 Java 基本数据类型,均对应一个包装类。
+
+装箱就是自动将基本数据类型转换为包装器类型,如 int->Integer
+
+拆箱就是自动将包装器类型转换为基本数据类型,如 Integer->int
+
+
+
+
+
+### 简述 Java 访问修饰符
+
+- default: 默认访问修饰符,在同一包内可见
+- private: 在同一类内可见,不能修饰类
+- protected : 对同一包内的类和所有子类可见,不能修饰类
+- public: 对所有类可见
+
+### 构造方法、成员变量初始化以及静态成员变量三者的初始化顺序?
+
+先后顺序:静态成员变量、成员变量、构造方法。
+
+详细的先后顺序:父类静态变量、父类静态代码块、子类静态变量、子类静态代码块、父类非静态变量、父类非静态代码块、父类构造函数、子类非静态变量、子类非静态代码块、子类构造函数。
+
+### Java 代码块执行顺序
+
+- 父类静态代码块(只执行一次)
+- 子类静态代码块(只执行一次)
+- 父类构造代码块
+- 父类构造函数
+- 子类构造代码块
+- 子类构造函数
+- 普通代码块
+
+
+
+### 面向对象的三大特性?
+
+继承:对象的一个新类可以从现有的类中派生,派生类可以从它的基类那继承方法和实例变量,且派生类可以修改或新增新的方法使之更适合特殊的需求。
+
+封装:将客观事物抽象成类,每个类可以把自身数据和方法只让可信的类或对象操作,对不可信的进行信息隐藏。
+
+多态:允许不同类的对象对同一消息作出响应。不同对象调用相同方法即使参数也相同,最终表现行为是不一样的。
+
+### 为什么 Java 语言不支持多重继承?
+
+为了程序的结构能够更加清晰从而便于维护。假设 Java 语言支持多重继承,类 C 继承自类 A 和类 B,如果类 A 和 B 都有自定义的成员方法 `f()`,那么当代码中调用类 C 的 `f()` 会产生二义性。
+
+Java 语言通过实现多个接口间接支持多重继承,接口由于只包含方法定义,不能有方法的实现,类 C 继承接口 A 与接口 B 时即使它们都有方法`f()`,也不能直接调用方法,需实现具体的`f()`方法才能调用,不会产生二义性。
+
+多重继承会使类型转换、构造方法的调用顺序变得复杂,会影响到性能。
+
+### 简述 Java 的多态
+
+Java 多态可以分为编译时多态和运行时多态。
+
+编译时多态主要指方法的重载,即通过参数列表的不同来区分不同的方法。
+
+运行时多态主要指继承父类和实现接口时,可使用父类引用指向子类对象。
+
+运行时多态的实现:主要依靠方法表,方法表中最先存放的是 Object 类的方法,接下来是该类的父类的方法,最后是该类本身的方法。如果子类改写了父类的方法,那么子类和父类的那些同名方法共享一个方法表项,都被认作是父类的方法。因此可以实现运行时多态。
+
+### Java 提供的多态机制?
+
+Java 提供了两种用于多态的机制,分别是重载与覆盖。
+
+重载:重载是指同一个类中有多个同名的方法,但这些方法有不同的参数,在编译期间就可以确定调用哪个方法。
+
+覆盖:覆盖是指派生类重写基类的方法,使用基类指向其子类的实例对象,或接口的引用变量指向其实现类的实例对象,在程序调用的运行期根据引用变量所指的具体实例对象调用正在运行的那个对象的方法,即需要到运行期才能确定调用哪个方法。
+
+### 重载与覆盖的区别?
+
+- 覆盖是父类与子类之间的关系,是垂直关系;重载是同一类中方法之间的关系,是水平关系。
+- 覆盖只能由一个方法或一对方法产生关系;重载是多个方法之间的关系。
+- 覆盖要求参数列表相同;重载要求参数列表不同。
+- 覆盖中,调用方法体是根据对象的类型来决定的,而重载是根据调用时实参表与形参表来对应选择方法体。
+- 重载方法可以改变返回值的类型,覆盖方法不能改变返回值的类型。
+
+### 接口和抽象类的相同点和不同点?
+
+相同点:
+
+- 都不能被实例化。
+- 接口的实现类或抽象类的子类需实现接口或抽象类中相应的方法才能被实例化。
+
+不同点:
+
+- 接口只能有方法定义,不能有方法的实现,而抽象类可以有方法的定义与实现。
+
+- 实现接口的关键字为 implements,继承抽象类的关键字为 extends。一个类可以实现多个接口,只能继承一个抽象类。
+
+- 当子类和父类之间存在逻辑上的层次结构,推荐使用抽象类,有利于功能的累积。当功能不需要,希望支持差别较大的两个或更多对象间的特定交互行为,推荐使用接口。使用接口能降低软件系统的耦合度,便于日后维护或添加删除方法。
+
+### 简述抽象类与接口的区别
+
+抽象类:体现的是 is-a 的关系,如对于 man is a person,就可以将 person 定义为抽象类。
+
+接口:体现的是 can 的关系。是作为模板实现的。如设置接口 fly,plane 类和 bird 类均可实现该接口。
+
+一个类只能继承一个抽象类,但可以实现多个接口。
+
+### 简述内部类及其作用
+
+- 成员内部类:作为成员对象的内部类。可以访问 private 及以上外部类的属性和方法。外部类想要访问内部类属性或方法时,必须要创建一个内部类对象,然后通过该对象访问内部类的属性或方法。外部类也可访问 private 修饰的内部类属性。
+- 局部内部类:存在于方法中的内部类。访问权限类似局部变量,只能访问外部类的 final 变量。
+- 匿名内部类:只能使用一次,没有类名,只能访问外部类的 final 变量。
+- 静态内部类:类似类的静态成员变量。
+
+
+
+
+### Java 语言中关键字 static 的作用是什么?
+ static 的主要作用有两个:
+
+- 为某种特定数据类型或对象分配与创建对象个数无关的单一的存储空间。
+- 使得某个方法或属性与类而不是对象关联在一起,即在不创建对象的情况下可通过类直接调用方法或使用类的属性。
+
+具体而言 static 又可分为 4 种使用方式:
+
+- 修饰成员变量。用 static 关键字修饰的静态变量在内存中只有一个副本。只要静态变量所在的类被加载,这个静态变量就会被分配空间,可以使用“类.静态变量”和“对象.静态变量”的方法使用。
+- 修饰成员方法。static 修饰的方法无需创建对象就可以被调用。static 方法中不能使用 this 和 super 关键字,不能调用非 static 方法,只能访问所属类的静态成员变量和静态成员方法。
+- 修饰代码块。JVM 在加载类的时候会执行 static 代码块。static 代码块常用于初始化静态变量。static 代码块只会被执行一次。
+- 修饰内部类。static 内部类可以不依赖外部类实例对象而被实例化。静态内部类不能与外部类有相同的名字,不能访问普通成员变量,只能访问外部类中的静态成员和静态成员方法。
+
+
+
+
+
+### 为什么要把 String 设计为不可变?
+
+- 节省空间:字符串常量存储在 JVM 的字符串池中可以被用户共享。
+- 提高效率:String 可以被不同线程共享,是线程安全的。在涉及多线程操作中不需要同步操作。
+- 安全:String 常被用于用户名、密码、文件名等使用,由于其不可变,可避免黑客行为对其恶意修改。
+
+### 简述 String/StringBuffer 与 StringBuilder
+
+String 类采用利用 final 修饰的字符数组进行字符串保存,因此不可变。如果对 String 类型对象修改,需要新建对象,将老字符和新增加的字符一并存进去。
+
+StringBuilder,采用无 final 修饰的字符数组进行保存,因此可变。但线程不安全。
+
+StringBuffer,采用无 final 修饰的字符数组进行保存,可理解为实现线程安全的 StringBuilder。
+
+### 判等运算符==与 equals 的区别?
+
+== 比较的是引用,equals 比较的是内容。
+
+如果变量是基础数据类型,== 用于比较其对应值是否相等。如果变量指向的是对象,== 用于比较两个对象是否指向同一块存储空间。
+
+equals 是 Object 类提供的方法之一,每个 Java 类都继承自 Object 类,所以每个对象都具有 equals 这个方法。Object 类中定义的 equals 方法内部是直接调用 == 比较对象的。但通过覆盖的方法可以让它不是比较引用而是比较数据内容。
+
+### 简述 Object 类常用方法
+
+- hashCode:通过对象计算出的散列码。用于 map 型或 equals 方法。需要保证同一个对象多次调用该方法,总返回相同的整型值。
+- equals:判断两个对象是否一致。需保证 equals 方法相同对应的对象 hashCode 也相同。
+- toString: 用字符串表示该对象
+- clone:深拷贝一个对象
+
+### Java 中一维数组和二维数组的声明方式?
+
+一维数组的声明方式:
+
+```java
+type arrayName[]
+type[] arrayName
+```
+
+二维数组的声明方式:
+
+```java
+type arrayName[][]
+type[][] arrayName
+type[] arrayName[]
+```
+
+其中 type 为基本数据类型或类,arrayName 为数组名字
+
+### 简述 Java 异常的分类
+
+Java 异常分为 Error(程序无法处理的错误),和 Exception(程序本身可以处理的异常)。这两个类均继承 Throwable。
+
+Error 常见的有 StackOverFlowError、OutOfMemoryError 等等。
+
+Exception 可分为运行时异常和非运行时异常。对于运行时异常,可以利用 try catch 的方式进行处理,也可以不处理。对于非运行时异常,必须处理,不处理的话程序无法通过编译。
+
+### 简述 throw 与 throws 的区别
+
+throw 一般是用在方法体的内部,由开发者定义当程序语句出现问题后主动抛出一个异常。
+
+throws 一般用于方法声明上,代表该方法可能会抛出的异常列表。
+
+### 出现在 Java 程序中的 finally 代码块是否一定会执行?
+
+当遇到下面情况不会执行。
+
+- 当程序在进入 try 语句块之前就出现异常时会直接结束。
+- 当程序在 try 块中强制退出时,如使用 System.exit(0),也不会执行 finally 块中的代码。
+
+其它情况下,在 try/catch/finally 语句执行的时候,try 块先执行,当有异常发生,catch 和 finally 进行处理后程序就结束了,当没有异常发生,在执行完 finally 中的代码后,后面代码会继续执行。值得注意的是,当 try/catch 语句块中有 return 时,finally 语句块中的代码会在 return 之前执行。如果 try/catch/finally 块中都有 return 语句,finally 块中的 return 语句会覆盖 try/catch 模块中的 return 语句。
+
+### final、finally 和 finalize 的区别是什么?
+
+- final 用于声明属性、方法和类,分别表示属性不可变、方法不可覆盖、类不可继承。
+- finally 作为异常处理的一部分,只能在 try/catch 语句中使用,finally 附带一个语句块用来表示这个语句最终一定被执行,经常被用在需要释放资源的情况下。
+- finalize 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的 finalize()方法。当垃圾回收器准备好释放对象占用空间时,首先会调用 finalize()方法,并在下一次垃圾回收动作发生时真正回收对象占用的内存。
+
+### 简述泛型
+
+泛型,即“参数化类型”,解决不确定对象具体类型的问题。在编译阶段有效。在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型在类中称为泛型类、接口中称为泛型接口和方法中称为泛型方法。
+
+### 简述泛型擦除
+
+Java 编译器生成的字节码是不包涵泛型信息的,泛型类型信息将在编译处理是被擦除,这个过程被称为泛型擦除。
+
+### 简述注解
+
+Java 注解用于为 Java 代码提供元数据。作为元数据,注解不直接影响你的代码执行,但也有一些类型的注解实际上可以用于这一目的。
+
+其可以用于提供信息给编译器,在编译阶段时给软件提供信息进行相关的处理,在运行时处理写相应代码,做对应操作。
+
+### 简述元注解
+
+元注解可以理解为注解的注解,即在注解中使用,实现想要的功能。其具体分为:
+
+- @Retention: 表示注解存在阶段是保留在源码,还是在字节码(类加载)或者运行期(JVM 中运行)。
+- @Target:表示注解作用的范围。
+- @Documented:将注解中的元素包含到 Javadoc 中去。
+- @Inherited:一个被@Inherited 注解了的注解修饰了一个父类,如果他的子类没有被其他注解修饰,则它的子类也继承了父类的注解。
+- @Repeatable:被这个元注解修饰的注解可以同时作用一个对象多次,但是每次作用注解又可以代表不同的含义。
+
+
+
+
+### 简述 Java 中 Class 对象
+
+java 中对象可以分为实例对象和 Class 对象,每一个类都有一个 Class 对象,其包含了与该类有关的信息。
+
+获取 Class 对象的方法:
+
+```java
+Class.forName(“类的全限定名”)
+实例对象.getClass()
+类名.class
+```
+
+### Java 反射机制是什么?
+
+Java 反射机制是指在程序的运行过程中可以构造任意一个类的对象、获取任意一个类的成员变量和成员方法、获取任意一个对象所属的类信息、调用任意一个对象的属性和方法。反射机制使得 Java 具有动态获取程序信息和动态调用对象方法的能力。可以通过以下类调用反射 API。
+
+- Class 类:可获得类属性方法
+- Field 类:获得类的成员变量
+- Method 类:获取类的方法信息
+- Construct 类:获取类的构造方法等信息
+
+
+
+
+
+
+
+
+
+
+### 序列化是什么?
+
+序列化是一种将对象转换成字节序列的过程,用于解决在对对象流进行读写操作时所引发的问题。序列化可以将对象的状态写在流里进行网络传输,或者保存到文件、数据库等系统里,并在需要的时候把该流读取出来重新构造成一个相同的对象。
+
+
+### 简述 Java 序列化与反序列化的实现
+
+序列化:将 java 对象转化为字节序列,由此可以通过网络对象进行传输。
+
+反序列化:将字节序列转化为 java 对象。
+
+具体实现:实现 Serializable 接口,或实现 Externalizable 接口中的 writeExternal()与 readExternal()方法。
+
+### 简述 Java 的 List
+
+List 是一个有序队列,在 Java 中有两种实现方式:
+
+ArrayList 使用数组实现,是容量可变的非线程安全列表,随机访问快,集合扩容时会创建更大的数组,把原有数组复制到新数组。
+
+LinkedList 本质是双向链表,与 ArrayList 相比插入和删除速度更快,但随机访问元素很慢。
+
+### Java 中线程安全的基本数据结构有哪些
+
+- HashTable: 哈希表的线程安全版,效率低
+- ConcurrentHashMap:哈希表的线程安全版,效率高,用于替代 HashTable
+- Vector:线程安全版 Arraylist
+- Stack:线程安全版栈
+- BlockingQueue 及其子类:线程安全版队列
+
+### 简述 Java 的 Set
+
+Set 即集合,该数据结构不允许元素重复且无序。Java 对 Set 有三种实现方式:
+
+HashSet 通过 HashMap 实现,HashMap 的 Key 即 HashSet 存储的元素,Value 系统自定义一个名为 PRESENT 的 Object 类型常量。判断元素是否相同时,先比较 hashCode,相同后再利用 equals 比较,查询 O(1)
+
+LinkedHashSet 继承自 HashSet,通过 LinkedHashMap 实现,使用双向链表维护元素插入顺序。
+
+TreeSet 通过 TreeMap 实现的,底层数据结构是红黑树,添加元素到集合时按照比较规则将其插入合适的位置,保证插入后的集合仍然有序。查询 O(logn)
+
+### 简述 Java 的 HashMap
+
+JDK8 之前底层实现是数组 + 链表,JDK8 改为数组 + 链表/红黑树。主要成员变量包括存储数据的 table 数组、元素数量 size、加载因子 loadFactor。HashMap 中数据以键值对的形式存在,键对应的 hash 值用来计算数组下标,如果两个元素 key 的 hash 值一样,就会发生哈希冲突,被放到同一个链表上。
+
+table 数组记录 HashMap 的数据,每个下标对应一条链表,所有哈希冲突的数据都会被存放到同一条链表,Node/Entry 节点包含四个成员变量:key、value、next 指针和 hash 值。在 JDK8 后链表超过 8 会转化为红黑树。
+
+若当前数据/总数据容量>负载因子,Hashmap 将执行扩容操作。默认初始化容量为 16,扩容容量必须是 2 的幂次方、最大容量为 1<< 30 、默认加载因子为 0.75。
+
+### 为何 HashMap 线程不安全
+
+在 JDK1.7 中,HashMap 采用头插法插入元素,因此并发情况下会导致环形链表,产生死循环。
+
+虽然 JDK1.8 采用了尾插法解决了这个问题,但是并发下的 put 操作也会使前一个 key 被后一个 key 覆盖。
+
+由于 HashMap 有扩容机制存在,也存在 A 线程进行扩容后,B 线程执行 get 方法出现失误的情况。
+
+### 简述 Java 的 TreeMap
+
+TreeMap 是底层利用红黑树实现的 Map 结构,底层实现是一棵平衡的排序二叉树,由于红黑树的插入、删除、遍历时间复杂度都为 O(logN),所以性能上低于哈希表。但是哈希表无法提供键值对的有序输出,红黑树可以按照键的值的大小有序输出。
+
+
+
+### ArrayList、Vector 和 LinkedList 有什么共同点与区别?
+
+- ArrayList、Vector 和 LinkedList 都是可伸缩的数组,即可以动态改变长度的数组。
+- ArrayList 和 Vector 都是基于存储元素的 Object[] array 来实现的,它们会在内存中开辟一块连续的空间来存储,支持下标、索引访问。但在涉及插入元素时可能需要移动容器中的元素,插入效率较低。当存储元素超过容器的初始化容量大小,ArrayList 与 Vector 均会进行扩容。
+- Vector 是线程安全的,其大部分方法是直接或间接同步的。ArrayList 不是线程安全的,其方法不具有同步性质。LinkedList 也不是线程安全的。
+- LinkedList 采用双向列表实现,对数据索引需要从头开始遍历,因此随机访问效率较低,但在插入元素的时候不需要对数据进行移动,插入效率较高。
+
+### HashMap 和 Hashtable 有什么区别?
+
+- HashMap 是 Hashtable 的轻量级实现,HashMap 允许 key 和 value 为 null,但最多允许一条记录的 key 为 null.而 HashTable 不允许。
+- HashTable 中的方法是线程安全的,而 HashMap 不是。在多线程访问 HashMap 需要提供额外的同步机制。
+- Hashtable 使用 Enumeration 进行遍历,HashMap 使用 Iterator 进行遍历。
+
+### 如何决定使用 HashMap 还是 TreeMap?
+
+如果对 Map 进行插入、删除或定位一个元素的操作更频繁,HashMap 是更好的选择。如果需要对 key 集合进行有序的遍历,TreeMap 是更好的选择。
+
+
+
+### HashSet 中,equals 与 hashCode 之间的关系?
+
+equals 和 hashCode 这两个方法都是从 object 类中继承过来的,equals 主要用于判断对象的内存地址引用是否是同一个地址;hashCode 根据定义的哈希规则将对象的内存地址转换为一个哈希码。HashSet 中存储的元素是不能重复的,主要通过 hashCode 与 equals 两个方法来判断存储的对象是否相同:
+
+- 如果两个对象的 hashCode 值不同,说明两个对象不相同。
+- 如果两个对象的 hashCode 值相同,接着会调用对象的 equals 方法,如果 equlas 方法的返回结果为 true,那么说明两个对象相同,否则不相同。
+
+### fail-fast 和 fail-safe 迭代器的区别是什么?
+
+- fail-fast 直接在容器上进行,在遍历过程中,一旦发现容器中的数据被修改,就会立刻抛出 ConcurrentModificationException 异常从而导致遍历失败。常见的使用 fail-fast 方式的容器有 HashMap 和 ArrayList 等。
+- fail-safe 这种遍历基于容器的一个克隆。因此对容器中的内容修改不影响遍历。常见的使用 fail-safe 方式遍历的容器有 ConcurrentHashMap 和 CopyOnWriteArrayList。
+
+### Collection 和 Collections 有什么区别?
+
+- Collection 是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
+- Collections 是一个包装类,包含了很多静态方法、不能被实例化,而是作为工具类使用,比如提供的排序方法:Collections.sort(list);提供的反转方法:Collections.reverse(list)。
+
+---
+
+投稿作者:后端技术小牛说
+转载链接:[https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w](https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w)
+
+
+
diff --git a/docs/baguwen/java-thread.md b/docs/baguwen/java-thread.md
new file mode 100644
index 0000000000..b8ab81a267
--- /dev/null
+++ b/docs/baguwen/java-thread.md
@@ -0,0 +1,305 @@
+---
+category:
+ - 求职面试
+tag:
+ - 背诵版八股文
+---
+
+# Java 并发编程八股文(背诵版)必看:+1:
+
+### 简述Java内存模型(JMM)
+Java内存模型定义了程序中各种变量的访问规则:
+
+- 所有变量都存储在主存,每个线程都有自己的工作内存。
+- 工作内存中保存了被该线程使用的变量的主存副本,线程对变量的所有操作都必须在工作空间进行,不能直接读写主内存数据。
+- 操作完成后,线程的工作内存通过缓存一致性协议将操作完的数据刷回主存。
+
+### 简述as-if-serial
+编译器会对原始的程序进行指令重排序和优化。但不管怎么重排序,其结果都必须和用户原始程序输出的预定结果保持一致。
+
+### 简述happens-before八大规则
+- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
+- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
+- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
+- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
+- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
+- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
+- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
+- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
+
+### as-if-serial 和 happens-before 的区别
+as-if-serial 保证单线程程序的执行结果不变,happens-before 保证正确同步的多线程程序的执行结果不变。
+
+### 简述原子性操作
+一个操作或者多个操作,要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行,这就是原子性操作。
+
+### 简述线程的可见性
+可见性指当一个线程修改了共享变量时,其他线程能够立即得知修改。volatile、synchronized、final 关键字都能保证可见性。
+
+### 简述有序性
+虽然多线程存在并发和指令优化等操作,但在本线程内观察该线程的所有执行操作是有序的。
+
+### 简述Java中volatile关键字作用
+- 保证变量对所有线程的可见性。当一个线程修改了变量值,新值对于其他线程来说是立即可以得知的。
+- 禁止指令重排。使用 volatile 变量进行写操作,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器进行重排序。
+
+### Java线程的实现方式
+- 实现Runnable接口
+- 继承Thread类
+- 实现Callable接口
+### 简述Java线程的状态
+线程状态有 NEW、RUNNABLE、BLOCK、WAITING、TIMED_WAITING、THERMINATED
+
+- NEW:新建状态,线程被创建且未启动,此时还未调用 start 方法。
+- RUNNABLE:运行状态。表示线程正在JVM中执行,但是这个执行,不一定真的在跑,也可能在排队等CPU。
+- BLOCKED:阻塞状态。线程等待获取锁,锁还没获得。
+- WAITING:等待状态。线程内run方法执行完Object.wait()/Thread.join()进入该状态。
+- TIMED_WAITING:限期等待。在一定时间之后跳出状态。调用Thread.sleep(long) Object.wait(long) Thread.join(long)进入状态。其中这些参数代表等待的时间。
+- TERMINATED:结束状态。线程调用完run方法进入该状态。
+
+### 简述线程通信的方式
+- volatile 关键词修饰变量,保证所有线程对变量访问的可见性。
+- synchronized关键词。确保多个线程在同一时刻只能有一个处于方法或同步块中。
+- wait/notify方法
+- IO通信
+### 简述线程池
+没有线程池的情况下,多次创建,销毁线程开销比较大。如果在开辟的线程执行完当前任务后复用已创建的线程,可以降低开销、控制最大并发数。
+
+线程池创建线程时,会将线程封装成工作线程 Worker,Worker 在执行完任务后还会循环获取工作队列中的任务来执行。
+
+将任务派发给线程池时,会出现以下几种情况
+
+- 核心线程池未满,创建一个新的线程执行任务。
+- 如果核心线程池已满,工作队列未满,将线程存储在工作队列。
+- 如果工作队列已满,线程数小于最大线程数就创建一个新线程处理任务。
+- 如果超过大小线程数,按照拒绝策略来处理任务。
+
+线程池参数:
+
+- corePoolSize:常驻核心线程数。超过该值后如果线程空闲会被销毁。
+- maximumPoolSize:线程池能够容纳同时执行的线程最大数。
+- keepAliveTime:线程空闲时间,线程空闲时间达到该值后会被销毁,直到只剩下 corePoolSize 个线程为止,避免浪费内存资源。
+- workQueue:工作队列。
+- threadFactory:线程工厂,用来生产一组相同任务的线程。
+- handler:拒绝策略。
+
+拒绝策略有以下几种:
+
+- AbortPolicy:丢弃任务并抛出异常
+- CallerRunsPolicy:重新尝试提交该任务
+- DiscardOldestPolicy 抛弃队列里等待最久的任务并把当前任务加入队列
+- DiscardPolicy 表示直接抛弃当前任务但不抛出异常。
+
+
+### 简述Executor框架
+Executor框架目的是将任务提交和任务如何运行分离开来的机制。用户不再需要从代码层考虑设计任务的提交运行,只需要调用Executor框架实现类的Execute方法就可以提交任务。
+
+### 简述Executor的继承关系
+- Executor:一个接口,其定义了一个接收Runnable对象的方法executor,该方法接收一个Runable实例执行这个任务。
+- ExecutorService:Executor的子类接口,其定义了一个接收Callable对象的方法,返回 Future 对象,同时提供execute方法。
+- ScheduledExecutorService:ExecutorService的子类接口,支持定期执行任务。
+- AbstractExecutorService:抽象类,提供 ExecutorService 执行方法的默认实现。
+- Executors:实现ExecutorService接口的静态工厂类,提供了一系列工厂方法用于创建线程池。
+- ThreadPoolExecutor:继承AbstractExecutorService,用于创建线程池。
+- ForkJoinPool: 继承AbstractExecutorService,Fork 将大任务分叉为多个小任务,然后让小任务执行,Join 是获得小任务的结果,类似于map reduce。
+- ThreadPoolExecutor:继承ThreadPoolExecutor,实现ScheduledExecutorService,用于创建带定时任务的线程池。
+### 简述线程池的状态
+- Running:能接受新提交的任务,也可以处理阻塞队列的任务。
+- Shutdown:不再接受新提交的任务,但可以处理存量任务,线程池处于running时调用shutdown方法,会进入该状态。
+- Stop:不接受新任务,不处理存量任务,调用shutdownnow进入该状态。
+- Tidying:所有任务已经终止了,worker_count(有效线程数)为0。
+- Terminated:线程池彻底终止。在tidying模式下调用terminated方法会进入该状态。
+
+### 简述线程池类型
+- newCachedThreadPool 可缓存线程池,可设置最小线程数和最大线程数,线程空闲1分钟后自动销毁。
+- newFixedThreadPool 指定工作线程数量线程池。
+- newSingleThreadExecutor 单线程Executor。
+- newScheduleThreadPool 支持定时任务的指定工作线程数量线程池。
+- newSingleThreadScheduledExecutor 支持定时任务的单线程Executor。
+
+### 简述阻塞队列
+阻塞队列是生产者消费者的实现具体组件之一。当阻塞队列为空时,从队列中获取元素的操作将会被阻塞,当阻塞队列满了,往队列添加元素的操作将会被阻塞。具体实现有:
+
+- ArrayBlockingQueue:底层是由数组组成的有界阻塞队列。
+- LinkedBlockingQueue:底层是由链表组成的有界阻塞队列。
+- PriorityBlockingQueue:阻塞优先队列。
+- DelayQueue:创建元素时可以指定多久才能从队列中获取当前元素
+- SynchronousQueue:不存储元素的阻塞队列,每一个存储必须等待一个取出操作
+- LinkedTransferQueue:与LinkedBlockingQueue相比多一个transfer方法,即如果当前有消费者正等待接收元素,可以把生产者传入的元素立刻传输给消费者。
+- LinkedBlockingDeque:双向阻塞队列。
+### 谈一谈ThreadLocal
+ThreadLocal 是线程共享变量。ThreadLoacl 有一个静态内部类 ThreadLocalMap,其 Key 是 ThreadLocal 对象,值是 Entry 对象,ThreadLocalMap是每个线程私有的。
+
+- set 给ThreadLocalMap设置值。
+- get 获取ThreadLocalMap。
+- remove 删除ThreadLocalMap类型的对象。
+
+存在的问题:对于线程池,由于线程池会重用 Thread 对象,因此与 Thread 绑定的 ThreadLocal 也会被重用,造成一系列问题。
+
+比如说内存泄漏。由于 ThreadLocal 是弱引用,但 Entry 的 value 是强引用,因此当 ThreadLocal 被垃圾回收后,value 依旧不会被释放,产生内存泄漏。
+
+### 聊聊你对Java并发包下unsafe类的理解
+对于 Java 语言,没有直接的指针组件,一般也不能使用偏移量对某块内存进行操作。这些操作相对来讲是安全(safe)的。
+
+Java 有个类叫 Unsafe 类,这个类使 Java 拥有了像 C 语言的指针一样操作内存空间的能力,同时也带来了指针的问题。这个类可以说是 Java 并发开发的基础。
+
+### Java中的乐观锁与CAS算法
+乐观锁认为数据发送时发生并发冲突的概率不大,所以读操作前不上锁。
+
+到了写操作时才会进行判断,数据在此期间是否被其他线程修改。如果发生修改,那就返回写入失败;如果没有被修改,那就执行修改操作,返回修改成功。
+
+乐观锁一般都采用 Compare And Swap(CAS)算法进行实现。顾名思义,该算法涉及到了两个操作,比较(Compare)和交换(Swap)。
+
+CAS 算法的思路如下:
+
+- 该算法认为不同线程对变量的操作时产生竞争的情况比较少。
+- 该算法的核心是对当前读取变量值 E 和内存中的变量旧值 V 进行比较。
+- 如果相等,就代表其他线程没有对该变量进行修改,就将变量值更新为新值 N。
+- 如果不等,就认为在读取值 E 到比较阶段,有其他线程对变量进行过修改,不进行任何操作。
+
+### ABA问题及解决方法简述
+CAS 算法是基于值来做比较的,如果当前有两个线程,一个线程将变量值从 A 改为 B ,再由 B 改回为 A ,当前线程开始执行 CAS 算法时,就很容易认为值没有变化,误认为读取数据到执行 CAS 算法的期间,没有线程修改过数据。
+
+juc 包提供了一个 AtomicStampedReference,即在原始的版本下加入版本号戳,解决 ABA 问题。
+
+### 简述常见的Atomic类
+在很多时候,我们需要的仅仅是一个简单的、高效的、线程安全的++或者--方案,使用synchronized关键字和lock固然可以实现,但代价比较大,此时用原子类更加方便。基本数据类型的原子类有:
+
+- AtomicInteger 原子更新整型
+- AtomicLong 原子更新长整型
+- AtomicBoolean 原子更新布尔类型
+
+Atomic数组类型有:
+
+- AtomicIntegerArray 原子更新整型数组里的元素
+- AtomicLongArray 原子更新长整型数组里的元素
+- AtomicReferenceArray 原子更新引用类型数组里的元素。
+
+Atomic引用类型有:
+
+- AtomicReference 原子更新引用类型
+- AtomicMarkableReference 原子更新带有标记位的引用类型,可以绑定一个 boolean 标记
+- AtomicStampedReference 原子更新带有版本号的引用类型
+
+FieldUpdater类型:
+
+- AtomicIntegerFieldUpdater 原子更新整型字段的更新器
+- AtomicLongFieldUpdater 原子更新长整型字段的更新器
+- AtomicReferenceFieldUpdater 原子更新引用类型字段的更新器
+### 简述Atomic类基本实现原理
+以AtomicIntger 为例。
+
+方法getAndIncrement,以原子方式将当前的值加1,具体实现为:
+
+- 在 for 死循环中取得 AtomicInteger 里存储的数值
+- 对 AtomicInteger 当前的值加 1
+- 调用 compareAndSet 方法进行原子更新
+- 先检查当前数值是否等于 expect
+- 如果等于则说明当前值没有被其他线程修改,则将值更新为 next,
+- 如果不是会更新失败返回 false,程序会进入 for 循环重新进行 compareAndSet 操作。
+### 简述CountDownLatch
+CountDownLatch这个类使一个线程等待其他线程各自执行完毕后再执行。是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,调用countDown方法,计数器的值就减1,当计数器的值为0时,表示所有线程都执行完毕,然后在等待的线程就可以恢复工作了。只能一次性使用,不能reset。
+
+### 简述CyclicBarrier
+CyclicBarrier 主要功能和CountDownLatch类似,也是通过一个计数器,使一个线程等待其他线程各自执行完毕后再执行。但是其可以重复使用(reset)。
+
+### 简述Semaphore
+Semaphore即信号量。Semaphore 的构造方法参数接收一个 int 值,设置一个计数器,表示可用的许可数量即最大并发数。使用 acquire 方法获得一个许可证,计数器减一,使用 release 方法归还许可,计数器加一。如果此时计数器值为0,线程进入休眠。
+
+### 简述Exchanger
+Exchanger类可用于两个线程之间交换信息。可简单地将Exchanger对象理解为一个包含两个格子的容器,通过exchanger方法可以向两个格子中填充信息。线程通过exchange 方法交换数据,第一个线程执行 exchange 方法后会阻塞等待第二个线程执行该方法。当两个线程都到达同步点时这两个线程就可以交换数据当两个格子中的均被填充时,该对象会自动将两个格子的信息交换,然后返回给线程,从而实现两个线程的信息交换。
+
+### 简述ConcurrentHashMap
+JDK7采用锁分段技术。首先将数据分成 Segment 数据段,然后给每一个数据段配一把锁,当一个线程占用锁访问其中一个段的数据时,其他段的数据也能被其他线程访问。
+
+get 除读到空值不需要加锁。该方法先经过一次再散列,再用这个散列值通过散列运算定位到 Segment,最后通过散列算法定位到元素。put 须加锁,首先定位到 Segment,然后进行插入操作,第一步判断是否需要对 Segment 里的 HashEntry 数组进行扩容,第二步定位添加元素的位置,然后将其放入数组。
+
+JDK8的改进
+
+- 取消分段锁机制,采用CAS算法进行值的设置,如果CAS失败再使用 synchronized 加锁添加元素
+- 引入红黑树结构,当某个槽内的元素个数超过8且 Node数组 容量大于 64 时,链表转为红黑树。
+- 使用了更加优化的方式统计集合内的元素数量。
+### synchronized底层实现原理
+Java 对象底层都会关联一个 monitor,使用 synchronized 时 JVM 会根据使用环境找到对象的 monitor,根据 monitor 的状态进行加解锁的判断。如果成功加锁就成为该 monitor 的唯一持有者,monitor 在被释放前不能再被其他线程获取。
+
+synchronized在JVM编译后会产生monitorenter 和 monitorexit 这两个字节码指令,获取和释放 monitor。这两个字节码指令都需要一个引用类型的参数指明要锁定和解锁的对象,对于同步普通方法,锁是当前实例对象;对于静态同步方法,锁是当前类的 Class 对象;对于同步方法块,锁是 synchronized 括号里的对象。
+
+执行 monitorenter 指令时,首先尝试获取对象锁。如果这个对象没有被锁定,或当前线程已经持有锁,就把锁的计数器加 1,执行 monitorexit 指令时会将锁计数器减 1。一旦计数器为 0 锁随即就被释放。
+
+### synchronized关键词使用方法
+- 直接修饰某个实例方法
+- 直接修饰某个静态方法
+- 修饰代码块
+### 简述Java偏向锁
+JDK 1.6 中提出了偏向锁的概念。该锁提出的原因是,开发者发现多数情况下锁并不存在竞争,一把锁往往是由同一个线程获得的。偏向锁并不会主动释放,这样每次偏向锁进入的时候都会判断该资源是否是偏向自己的,如果是偏向自己的则不需要进行额外的操作,直接可以进入同步操作。
+
+其申请流程为:
+
+- 首先需要判断对象的 Mark Word 是否属于偏向模式,如果不属于,那就进入轻量级锁判断逻辑。否则继续下一步判断;
+- 判断目前请求锁的线程 ID 是否和偏向锁本身记录的线程 ID 一致。如果一致,继续下一步的判断,如果不一致,跳转到步骤4;
+- 判断是否需要重偏向。如果不用的话,直接获得偏向锁;
+- 利用 CAS 算法将对象的 Mark Word 进行更改,使线程 ID 部分换成本线程 ID。如果更换成功,则重偏向完成,获得偏向锁。如果失败,则说明有多线程竞争,升级为轻量级锁。
+### 简述轻量级锁
+轻量级锁是为了在没有竞争的前提下减少重量级锁出现并导致的性能消耗。
+
+其申请流程为:
+
+- 如果同步对象没有被锁定,虚拟机将在当前线程的栈帧中建立一个锁记录空间,存储锁对象目前 Mark Word 的拷贝。
+- 虚拟机使用 CAS 尝试把对象的 Mark Word 更新为指向锁记录的指针
+- 如果更新成功即代表该线程拥有了锁,锁标志位将转变为 00,表示处于轻量级锁定状态。
+- 如果更新失败就意味着至少存在一条线程与当前线程竞争。虚拟机检查对象的 Mark Word 是否指向当前线程的栈帧
+- 如果指向当前线程的栈帧,说明当前线程已经拥有了锁,直接进入同步块继续执行
+- 如果不是则说明锁对象已经被其他线程抢占。
+- 如果出现两条以上线程争用同一个锁,轻量级锁就不再有效,将膨胀为重量级锁,锁标志状态变为 10,此时Mark Word 存储的就是指向重量级锁的指针,后面等待锁的线程也必须阻塞。
+### 简述锁优化策略
+即自适应自旋、锁消除、锁粗化、锁升级等策略偏。
+
+### 简述Java的自旋锁
+线程获取锁失败后,可以采用这样的策略,可以不放弃 CPU ,不停的重试内重试,这种操作也称为自旋锁。
+
+### 简述自适应自旋锁
+自适应自旋锁自旋次数不再人为设定,通常由前一次在同一个锁上的自旋时间及锁的拥有者的状态决定。
+
+### 简述锁粗化
+锁粗化的思想就是扩大加锁范围,避免反复的加锁和解锁。
+
+### 简述锁消除
+锁消除是一种更为彻底的优化,在编译时,Java编译器对运行上下文进行扫描,去除不可能存在共享资源竞争的锁。
+
+### 简述Lock与ReentrantLock
+Lock接口是 Java并发包的顶层接口。
+
+可重入锁 ReentrantLock 是 Lock 最常见的实现,与 synchronized 一样可重入。ReentrantLock 在默认情况下是非公平的,可以通过构造方法指定公平锁。一旦使用了公平锁,性能会下降。
+
+### 简述AQS
+
+AQS(AbstractQuenedSynchronizer)抽象的队列式同步器。AQS是将每一条请求共享资源的线程封装成一个锁队列的一个结点(Node),来实现锁的分配。AQS是用来构建锁或其他同步组件的基础框架,它使用一个 volatile int state 变量作为共享资源,如果线程获取资源失败,则进入同步队列等待;如果获取成功就执行临界区代码,释放资源时会通知同步队列中的等待线程。
+
+子类通过继承同步器并实现它的抽象方法getState、setState 和 compareAndSetState对同步状态进行更改。
+
+AQS获取独占锁/释放独占锁原理:
+
+获取:(acquire)
+
+- 调用 tryAcquire 方法安全地获取线程同步状态,获取失败的线程会被构造同步节点并通过 addWaiter 方法加入到同步队列的尾部,在队列中自旋。
+- 调用 acquireQueued 方法使得该节点以死循环的方式获取同步状态,如果获取不到则阻塞。
+
+释放:(release)
+
+- 调用 tryRelease 方法释放同步状态
+- 调用 unparkSuccessor 方法唤醒头节点的后继节点,使后继节点重新尝试获取同步状态。
+
+AQS获取共享锁/释放共享锁原理
+
+获取锁(acquireShared)
+
+- 调用 tryAcquireShared 方法尝试获取同步状态,返回值不小于 0 表示能获取同步状态。
+- 释放(releaseShared),并唤醒后续处于等待状态的节点。
+
+----
+
+
+投稿作者:后端技术小牛说
+转载链接:[https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w](https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w)
+
+
diff --git a/docs/baguwen/jvm.md b/docs/baguwen/jvm.md
new file mode 100644
index 0000000000..94643ace85
--- /dev/null
+++ b/docs/baguwen/jvm.md
@@ -0,0 +1,207 @@
+---
+category:
+ - 求职面试
+tag:
+ - 背诵版八股文
+---
+
+# Java 虚拟机八股文(背诵版)必看:+1:
+
+### 简述JVM内存模型
+线程私有的运行时数据区: 程序计数器、Java 虚拟机栈、本地方法栈。
+
+线程共享的运行时数据区:Java 堆、方法区。
+
+### 简述程序计数器
+程序计数器表示当前线程所执行的字节码的行号指示器。
+
+程序计数器不会产生StackOverflowError和OutOfMemoryError。
+
+### 简述虚拟机栈
+Java 虚拟机栈用来描述 Java 方法执行的内存模型。线程创建时就会分配一个栈空间,线程结束后栈空间被回收。
+
+栈中元素用于支持虚拟机进行方法调用,每个方法在执行时都会创建一个栈帧存储方法的局部变量表、操作栈、动态链接和返回地址等信息。
+
+虚拟机栈会产生两类异常:
+
+- StackOverflowError:线程请求的栈深度大于虚拟机允许的深度抛出。
+- OutOfMemoryError:如果 JVM 栈容量可以动态扩展,虚拟机栈占用内存超出抛出。
+
+### 简述本地方法栈
+本地方法栈与虚拟机栈作用相似,不同的是虚拟机栈为虚拟机执行 Java 方法服务,本地方法栈为本地方法服务。可以将虚拟机栈看作普通的java函数对应的内存模型,本地方法栈看作由native关键词修饰的函数对应的内存模型。
+
+本地方法栈会产生两类异常:
+
+- StackOverflowError:线程请求的栈深度大于虚拟机允许的深度抛出。
+- OutOfMemoryError:如果 JVM 栈容量可以动态扩展,虚拟机栈占用内存超出抛出。
+
+### 简述JVM中的堆
+堆主要作用是存放对象实例,Java 里几乎所有对象实例都在堆上分配内存,堆也是内存管理中最大的一块。Java的垃圾回收主要就是针对堆这一区域进行。 可通过 -Xms 和 -Xmx 设置堆的最小和最大容量。
+
+堆会抛出 OutOfMemoryError异常。
+
+### 简述方法区
+方法区用于存储被虚拟机加载的类信息、常量、静态变量等数据。
+
+JDK6之前使用永久代实现方法区,容易内存溢出。JDK7 把放在永久代的字符串常量池、静态变量等移出,JDK8 中抛弃永久代,改用在本地内存中实现的元空间来实现方法区,把 JDK 7 中永久代内容移到元空间。
+
+方法区会抛出 OutOfMemoryError异常。
+
+### 简述运行时常量池
+运行时常量池存放常量池表,用于存放编译器生成的各种字面量与符号引用。一般除了保存 Class 文件中描述的符号引用外,还会把符号引用翻译的直接引用也存储在运行时常量池。除此之外,也会存放字符串基本类型。
+
+JDK8之前,放在方法区,大小受限于方法区。JDK8将运行时常量池存放堆中。
+
+### 简述直接内存
+直接内存也称为堆外内存,就是把内存对象分配在JVM堆外的内存区域。这部分内存不是虚拟机管理,而是由操作系统来管理。 Java通过DriectByteBuffer对其进行操作,避免了在 Java 堆和 Native堆来回复制数据。
+
+### 简述Java创建对象的过程
+- 检查该指令的参数能否在常量池中定位到一个类的符号引用,并检查引用代表的类是否已被加载、解析和初始化,如果没有就先执行类加载。
+- 通过检查通过后虚拟机将为新生对象分配内存。
+- 完成内存分配后虚拟机将成员变量设为零值
+- 设置对象头,包括哈希码、GC 信息、锁信息、对象所属类的类元信息等。
+- 执行 init 方法,初始化成员变量,执行实例化代码块,调用类的构造方法,并把堆内对象的首地址赋值给引用变量。
+### 简述JVM给对象分配内存的策略
+- 指针碰撞:这种方式在内存中放一个指针作为分界指示器将使用过的内存放在一边,空闲的放在另一边,通过指针挪动完成分配。
+- 空闲列表:对于 Java 堆内存不规整的情况,虚拟机必须维护一个列表记录哪些内存可用,在分配时从列表中找到一块足够大的空间划分给对象并更新列表记录。
+### Java对象内存分配是如何保证线程安全的
+第一种方法,采用CAS机制,配合失败重试的方式保证更新操作的原子性。该方式效率低。
+
+第二种方法,每个线程在Java堆中预先分配一小块内存,然后再给对象分配内存的时候,直接在自己这块"私有"内存中分配。一般采用这种策略。
+
+### 简述对象的内存布局
+对象在堆内存的存储布局可分为对象头、实例数据和对齐填充。
+
+1)对象头主要包含两部分数据: MarkWord、类型指针。
+
+MarkWord 用于存储哈希码(HashCode)、GC分代年龄、锁状态标志位、线程持有的锁、偏向线程ID等信息。
+
+类型指针即对象指向他的类元数据指针,如果对象是一个 Java 数组,会有一块用于记录数组长度的数据。
+
+2)实例数据存储代码中所定义的各种类型的字段信息。
+
+3)对齐填充起占位作用。HotSpot 虚拟机要求对象的起始地址必须是8的整数倍,因此需要对齐填充。
+
+### 如何判断对象是否是垃圾
+1)引用计数法:
+
+设置引用计数器,对象被引用计数器加 1,引用失效时计数器减 1,如果计数器为 0 则被标记为垃圾。会存在对象间循环引用的问题,一般不使用这种方法。
+
+2)可达性分析:
+
+通过 GC Roots 的根对象作为起始节点,从这些节点开始,根据引用关系向下搜索,如果某个对象没有被搜到,则会被标记为垃圾。可作为 GC Roots 的对象包括虚拟机栈和本地方法栈中引用的对象、类静态属性引用的对象、常量引用的对象。
+
+### 简述java的引用类型
+- 强引用: 被强引用关联的对象不会被回收。一般采用 new 方法创建强引用。
+- 软引用:被软引用关联的对象只有在内存不够的情况下才会被回收。一般采用 SoftReference 类来创建软引用。
+- 弱引用:垃圾收集器碰到即回收,也就是说它只能存活到下一次垃圾回收发生之前。一般采用 WeakReference 类来创建弱引用。
+- 虚引用: 无法通过该引用获取对象。唯一目的就是为了能在对象被回收时收到一个系统通知。虚引用必须与引用队列联合使用。
+
+### 简述标记清除算法、标记整理算法和标记复制算法
+- 标记清除算法:先标记需清除的对象,之后统一回收。这种方法效率不高,会产生大量不连续的碎片。
+- 标记整理算法:先标记存活对象,然后让所有存活对象向一端移动,之后清理端边界以外的内存
+- 标记复制算法:将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当使用的这块空间用完了,就将存活对象复制到另一块,再把已使用过的内存空间一次清理掉。
+
+### 简述分代收集算法
+根据对象存活周期将内存划分为几块,不同块采用适当的收集算法。
+
+一般将堆分为新生代和老年代,对这两块采用不同的算法。
+
+新生代使用:标记复制算法
+
+老年代使用:标记清除或者标记整理算法
+
+### 简述Serial垃圾收集器
+Serial垃圾收集器是单线程串行收集器。垃圾回收的时候,必须暂停其他所有线程。新生代使用标记复制算法,老年代使用标记整理算法。简单高效。
+
+### 简述ParNew垃圾收集器
+ParNew垃圾收集器可以看作Serial垃圾收集器的多线程版本,新生代使用标记复制算法,老年代使用标记整理算法。
+
+### 简述Parallel Scavenge垃圾收集器
+注重吞吐量,即 CPU运行代码时间/CPU耗时总时间(CPU运行代码时间+ 垃圾回收时间)。新生代使用标记复制算法,老年代使用标记整理算法。
+
+### 简述CMS垃圾收集器
+CMS垃圾收集器注重最短时间停顿。CMS垃圾收集器为最早提出的并发收集器,垃圾收集线程与用户线程同时工作。采用标记清除算法。该收集器分为初始标记、并发标记、并发预清理、并发清除、并发重置这么几个步骤。
+
+- 初始标记:暂停其他线程(stop the world),标记与GC roots直接关联的对象。
+- 并发标记:可达性分析过程(程序不会停顿)。
+- 并发预清理:查找执行并发标记阶段从年轻代晋升到老年代的对象,重新标记,暂停虚拟机(stop the world)扫描CMS堆中剩余对象。
+- 并发清除:清理垃圾对象,(程序不会停顿)。
+- 并发重置,重置CMS收集器的数据结构。
+
+### 简述G1垃圾收集器
+和Serial、Parallel Scavenge、CMS不同,G1垃圾收集器把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。
+
+- 初始标记:标记与GC roots直接关联的对象。
+- 并发标记:可达性分析。
+- 最终标记:对并发标记过程中,用户线程修改的对象再次标记一下。
+- 筛选回收:对各个Region的回收价值和成本进行排序,然后根据用户所期望的GC停顿时间制定回收计划并回收。
+
+### 简述Minor GC
+Minor GC指发生在新生代的垃圾收集,因为 Java 对象大多存活时间短,所以 Minor GC 非常频繁,一般回收速度也比较快。
+
+### 简述Full GC
+Full GC 是清理整个堆空间—包括年轻代和永久代。调用System.gc(),老年代空间不足,空间分配担保失败,永生代空间不足会产生full gc。
+
+### 常见内存分配策略
+大多数情况下对象在新生代 Eden 区分配,当 Eden 没有足够空间时将发起一次 Minor GC。
+
+大对象需要大量连续内存空间,直接进入老年代区分配。
+
+如果经历过第一次 Minor GC 仍然存活且能被 Survivor 容纳,该对象就会被移动到 Survivor 中并将年龄设置为 1,并且每熬过一次 Minor GC 年龄就加 1 ,当增加到一定程度(默认15)就会被晋升到老年代。
+
+如果在 Survivor 中相同年龄所有对象大小的总和大于 Survivor 的一半,年龄不小于该年龄的对象就可以直接进入老年代。
+
+MinorGC 前,虚拟机必须检查老年代最大可用连续空间是否大于新生代对象总空间,如果满足则说明这次 Minor GC 确定安全。如果不,JVM会查看HandlePromotionFailure 参数是否允许担保失败,如果允许会继续检查老年代最大可用连续空间是否大于历次晋升老年代对象的平均大小,如果满足将Minor GC,否则改成一次 FullGC。
+
+### 简述JVM类加载过程
+1)加载:
+
+- 通过全类名获取类的二进制字节流。
+- 将类的静态存储结构转化为方法区的运行时数据结构。
+- 在内存中生成类的Class对象,作为方法区数据的入口。
+
+2)验证:对文件格式,元数据,字节码,符号引用等验证正确性。
+
+3)准备:在方法区内为类变量分配内存并设置为0值。
+
+4)解析:将符号引用转化为直接引用。
+
+5)初始化:执行类构造器clinit方法,真正初始化。
+
+### 简述JVM中的类加载器
+- BootstrapClassLoader启动类加载器:加载/lib下的jar包和类。 由C++编写。
+- ExtensionClassLoader扩展类加载器: /lib/ext目录下的jar包和类。由Java编写。
+- AppClassLoader应用类加载器,加载当前classPath下的jar包和类。由Java编写。
+
+### 简述双亲委派机制
+一个类加载器收到类加载请求之后,首先判断当前类是否被加载过。已经被加载的类会直接返回,如果没有被加载,首先将类加载请求转发给父类加载器,一直转发到启动类加载器,只有当父类加载器无法完成时才尝试自己加载。
+
+加载类顺序:BootstrapClassLoader->ExtensionClassLoader->AppClassLoader->CustomClassLoader 检查类是否加载顺序: CustomClassLoader->AppClassLoader->ExtensionClassLoader->BootstrapClassLoader
+
+### 双亲委派机制的优点
+- 避免类的重复加载。相同的类被不同的类加载器加载会产生不同的类,双亲委派保证了Java程序的稳定运行。
+- 保证核心API不被修改。
+- 如何破坏双亲委派机制
+- 重载loadClass()方法,即自定义类加载器。
+
+### 如何构建自定义类加载器
+新建自定义类继承自java.lang.ClassLoader,重写findClass、loadClass、defineClass方法
+
+### JVM常见调优参数
+
+- -Xms 初始堆大小
+- -Xmx 最大堆大小
+- -XX:NewSize 年轻代大小
+- -XX:MaxNewSize 年轻代最大值
+- -XX:PermSize 永生代初始值
+- -XX:MaxPermSize 永生代最大值
+- -XX:NewRatio 新生代与老年代的比例
+
+----
+
+
+投稿作者:后端技术小牛说
+转载链接:[https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w](https://mp.weixin.qq.com/s/PmeH38qWVxyIhBpsAsjG7w)
+
+
diff --git a/docs/basic-extra-meal/48-keywords.md b/docs/basic-extra-meal/48-keywords.md
new file mode 100644
index 0000000000..430ff4f65d
--- /dev/null
+++ b/docs/basic-extra-meal/48-keywords.md
@@ -0,0 +1,118 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java中常用的48个关键字
+
+“二哥,就我之前学过的这些 Java 代码中,有 public、static、void、main 等等,它们应该都是关键字吧?”三妹的脸上泛着甜甜的笑容,我想她在学习 Java 方面已经变得越来越自信了。
+
+“是的,三妹。Java 中的关键字可不少呢!你一下子可能记不了那么多,不过,先保留个印象吧,对以后的学习会很有帮助。”
+
+PS:按照首字母的自然顺序排列。
+
+1. **abstract:** 用于声明抽象类,以及抽象方法。
+
+2. **boolean:** 用于将变量声明为布尔值类型,只有 true 和 false 两个值。
+
+3. **break:** 用于中断循环或 switch 语句。
+
+4. **byte:** 用于声明一个可以容纳 8 个比特的变量。
+
+5. **case:** 用于在 switch 语句中标记条件的值。
+
+6. **catch:** 用于捕获 try 语句中的异常。
+
+7. **char:** 用于声明一个可以容纳无符号 16 位比特的 [Unicode 字符](https://mp.weixin.qq.com/s/pNQjlXOivIgO3pbYc0GnpA)的变量。
+
+8. **class:** 用于声明一个类。
+
+9. **continue:** 用于继续下一个循环,可以在指定条件下跳过其余代码。
+
+10. **default:** 用于指定 switch 语句中除去 case 条件之外的默认代码块。
+
+11. **do:** 通常和 while 关键字配合使用,do 后紧跟循环体。
+
+12. **double:** 用于声明一个可以容纳 64 位浮点数的变量。
+
+13. **else:** 用于指示 if 语句中的备用分支。
+
+14. **enum:** 用于定义一组固定的常量(枚举)。
+
+15. **extends:** 用于指示一个类是从另一个类或接口继承的。
+
+16. **final:** 用于指示该变量是不可更改的。
+
+17. **finally:** 和 `try-catch` 配合使用,表示无论是否处理异常,总是执行 finally 块中的代码。
+
+18. **float:** 用于声明一个可以容纳 32 位浮点数的变量。
+
+19. **for:** 用于声明一个 for 循环,如果循环次数是固定的,建议使用 for 循环。
+
+20. **if:** 用于指定条件,如果条件为真,则执行对应代码。
+
+21. **implements:** 用于实现接口。
+
+22. **import:** 用于导入对应的类或者接口。
+
+23. **instanceof:** 用于判断对象是否属于某个类型(class)。
+
+24. **int:** 用于声明一个可以容纳 32 位带符号的整数变量。
+
+25. **interface:** 用于声明接口。
+
+26. **long:** 用于声明一个可以容纳 64 位整数的变量。
+
+27. **native:** 用于指定一个方法是通过调用本机接口(非 Java)实现的。
+
+28. **new:** 用于创建一个新的对象。
+
+29. **null:** 如果一个变量是空的(什么引用也没有指向),就可以将它赋值为 null,和空指针异常息息相关。
+
+30. **package:** 用于声明类所在的包。
+
+31. **private:** 一个访问权限修饰符,表示方法或变量只对当前类可见。
+
+32. **protected:** 一个访问权限修饰符,表示方法或变量对同一包内的类和所有子类可见。
+
+33. **public:** 一个访问权限修饰符,除了可以声明方法和变量(所有类可见),还可以声明类。`main()` 方法必须声明为 public。
+
+34. **return:** 用于在代码执行完成后返回(一个值)。
+
+35. **short:** 用于声明一个可以容纳 16 位整数的变量。
+
+36. **static:** 表示该变量或方法是静态变量或静态方法。
+
+37. **strictfp:** 并不常见,通常用于修饰一个方法,确保方法体内的浮点数运算在每个平台上执行的结果相同。
+
+38. **super:** 可用于调用父类的方法或者字段。
+
+39. **switch:** 通常用于三个(以上)的条件判断。
+
+40. **synchronized:** 用于指定多线程代码中的同步方法、变量或者代码块。
+
+41. **this:** 可用于在方法或构造函数中引用当前对象。
+
+42. **throw:** 主动抛出异常。
+
+43. **throws:** 用于声明异常。
+
+44. **transient:** 修饰的字段不会被序列化。
+
+45. **try:** 于包裹要捕获异常的代码块。
+
+46. **void:** 用于指定方法没有返回值。
+
+47. **volatile:** 保证不同线程对它修饰的变量进行操作时的可见性,即一个线程修改了某个变量的值,新值对其他线程来说是立即可见的。
+
+48. **while:** 如果循环次数不固定,建议使用 while 循环。
+
+
+“好了,三妹,关于 Java 中的关键字就先说这 48 个吧,这只是一个大概的介绍,后面还会对一些特殊的关键字单独拎出来详细地讲,比如说重要的 static、final 等。”转动了一下僵硬的脖子后,我对三妹说。
+
+“二哥,你辛苦了,足足 48 个啊,容我好好消化一下。”
+
+
+
diff --git a/docs/basic-extra-meal/Overriding.md b/docs/basic-extra-meal/Overriding.md
new file mode 100644
index 0000000000..884a79c90d
--- /dev/null
+++ b/docs/basic-extra-meal/Overriding.md
@@ -0,0 +1,321 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java重写(Overriding)时应当遵守的11条规则
+
+重写(Overriding)算是 Java 中一个非常重要的概念,理解重写到底是什么对每个 Java 程序员来说都至关重要,这篇文章就来给大家说说重写过程中应当遵守的 12 条规则。
+
+### 01、什么是重写?
+
+重写带来了一种非常重要的能力,可以让子类重新实现从超类那继承过来的方法。在下面这幅图中,Animal 是父类,Dog 是子类,Dog 重新实现了 `move()` 方法用来和父类进行区分,毕竟狗狗跑起来还是比较有特色的。
+
+
+
+重写的方法和被重写的方法,不仅方法名相同,参数也相同,只不过,方法体有所不同。
+
+### 02、哪些方法可以被重写?
+
+**规则一:只能重写继承过来的方法**。
+
+因为重写是在子类重新实现从父类继承过来的方法时发生的,所以只能重写继承过来的方法,这很好理解。这就意味着,只能重写那些被 public、protected 或者 default 修饰的方法,private 修饰的方法无法被重写。
+
+Animal 类有 `move()`、`eat()` 和 `sleep()` 三个方法:
+
+```java
+public class Animal {
+ public void move() { }
+
+ protected void eat() { }
+
+ void sleep(){ }
+}
+```
+
+Dog 类来重写这三个方法:
+
+```java
+public class Dog extends Animal {
+ public void move() { }
+
+ protected void eat() { }
+
+ void sleep(){ }
+}
+```
+
+ OK,完全没有问题。但如果父类中的方法是 private 的,就行不通了。
+
+```java
+public class Animal {
+ private void move() { }
+}
+```
+
+此时,Dog 类中的 `move()` 方法就不再是一个重写方法了,因为父类的 `move()` 方法是 private 的,对子类并不可见。
+
+```java
+public class Dog extends Animal {
+ public void move() { }
+}
+```
+
+### 03、哪些方法不能被重写?
+
+**规则二:final、static 的方法不能被重写**。
+
+一个方法是 final 的就意味着它无法被子类继承到,所以就没办法重写。
+
+```java
+public class Animal {
+ final void move() { }
+}
+```
+
+由于父类 Animal 中的 `move()` 是 final 的,所以子类在尝试重写该方法的时候就出现编译错误了!
+
+
+
+同样的,如果一个方法是 static 的,也不允许重写,因为静态方法可用于父类以及子类的所有实例。
+
+```java
+public class Animal {
+ final void move() { }
+}
+```
+
+重写的目的在于根据对象的类型不同而表现出多态,而静态方法不需要创建对象就可以使用。没有了对象,重写所需要的“对象的类型”也就没有存在的意义了。
+
+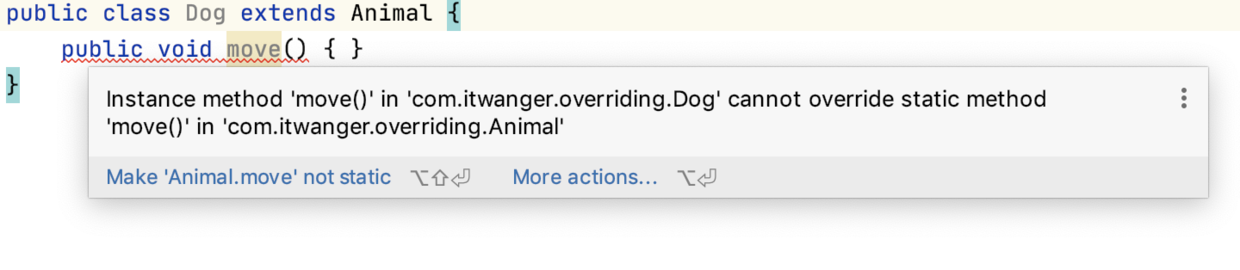
+
+### 04、重写方法的要求
+
+**规则三:重写的方法必须有相同的参数列表**。
+
+```java
+public class Animal {
+ void eat(String food) { }
+}
+```
+
+Dog 类中的 `eat()` 方法保持了父类方法 `eat()` 的同一个调调,都有一个参数——String 类型的 food。
+
+```java
+public class Dog extends Animal {
+ public void eat(String food) { }
+}
+```
+
+一旦子类没有按照这个规则来,比如说增加了一个参数:
+
+```java
+public class Dog extends Animal {
+ public void eat(String food, int amount) { }
+}
+```
+
+这就不再是重写的范畴了,当然也不是重载的范畴,因为重载考虑的是同一个类。
+
+**规则四:重写的方法必须返回相同的类型**。
+
+父类没有返回类型:
+
+```java
+public class Animal {
+ void eat(String food) { }
+}
+```
+
+子类尝试返回 String:
+
+```java
+public class Dog extends Animal {
+ public String eat(String food) {
+ return null;
+ }
+}
+```
+
+于是就编译出错了(返回类型不兼容)。
+
+
+
+**规则五:重写的方法不能使用限制等级更严格的权限修饰符**。
+
+可以这样来理解:
+
+- 如果被重写的方法是 default,那么重写的方法可以是 default、protected 或者 public。
+- 如果被重写的方法是 protected,那么重写的方法只能是 protected 或者 public。
+- 如果被重写的方法是 public, 那么重写的方法就只能是 public。
+
+举个例子,父类中的方法是 protected:
+
+```java
+public class Animal {
+ protected void eat() { }
+}
+```
+
+子类中的方法可以是 public:
+
+```java
+public class Dog extends Animal {
+ public void eat() { }
+}
+```
+
+如果子类中的方法用了更严格的权限修饰符,编译器就报错了。
+
+
+
+**规则六:重写后的方法不能抛出比父类中更高级别的异常**。
+
+举例来说,如果父类中的方法抛出的是 IOException,那么子类中重写的方法不能抛出 Exception,可以是 IOException 的子类或者不抛出任何异常。这条规则只适用于可检查的异常。
+
+可检查(checked)异常必须在源代码中显式地进行捕获处理,不检查(unchecked)异常就是所谓的运行时异常,比如说 NullPointerException、ArrayIndexOutOfBoundsException 之类的,不会在编译器强制要求。
+
+父类抛出 IOException:
+
+```java
+public class Animal {
+ protected void eat() throws IOException { }
+}
+```
+
+子类抛出 FileNotFoundException 是可以满足重写的规则的,因为 FileNotFoundException 是 IOException 的子类。
+
+```java
+public class Dog extends Animal {
+ public void eat() throws FileNotFoundException { }
+}
+```
+
+如果子类抛出了一个新的异常,并且是一个 checked 异常:
+
+```java
+public class Dog extends Animal {
+ public void eat() throws FileNotFoundException, InterruptedException { }
+}
+```
+
+那编译器就会提示错误:
+
+```
+Error:(9, 16) java: com.itwanger.overriding.Dog中的eat()无法覆盖com.itwanger.overriding.Animal中的eat()
+ 被覆盖的方法未抛出java.lang.InterruptedException
+```
+
+但如果子类抛出的是一个 unchecked 异常,那就没有冲突:
+
+```java
+public class Dog extends Animal {
+ public void eat() throws FileNotFoundException, IllegalArgumentException { }
+}
+```
+
+如果子类抛出的是一个更高级别的异常:
+
+```java
+public class Dog extends Animal {
+ public void eat() throws Exception { }
+}
+```
+
+编译器同样会提示错误,因为 Exception 是 IOException 的父类。
+
+```
+Error:(9, 16) java: com.itwanger.overriding.Dog中的eat()无法覆盖com.itwanger.overriding.Animal中的eat()
+ 被覆盖的方法未抛出java.lang.Exception
+```
+
+### 05、如何调用被重写的方法?
+
+**规则七:可以在子类中通过 super 关键字来调用父类中被重写的方法**。
+
+子类继承父类的方法而不是重新实现是很常见的一种做法,在这种情况下,可以按照下面的形式调用父类的方法:
+
+```java
+super.overriddenMethodName();
+```
+
+来看例子。
+
+```java
+public class Animal {
+ protected void eat() { }
+}
+```
+
+子类重写了 `eat()` 方法,然后在子类的 `eat()` 方法中,可以在方法体的第一行通过 `super.eat()` 调用父类的方法,然后再增加属于自己的代码。
+
+```java
+public class Dog extends Animal {
+ public void eat() {
+ super.eat();
+ // Dog-eat
+ }
+}
+```
+
+### 06、重写和构造方法
+
+**规则八:构造方法不能被重写**。
+
+因为构造方法很特殊,而且子类的构造方法不能和父类的构造方法同名(类名不同),所以构造方法和重写之间没有任何关系。
+
+### 07、重写和抽象方法
+
+**规则九:如果一个类继承了抽象类,抽象类中的抽象方法必须在子类中被重写**。
+
+先来看这样一个接口类:
+
+```java
+public interface Animal {
+ void move();
+}
+```
+
+接口中的方法默认都是抽象方法,通过反编译是可以看得到的:
+
+```java
+public interface Animal
+{
+ public abstract void move();
+}
+```
+
+如果一个抽象类实现了 Animal 接口,`move()` 方法不是必须被重写的:
+
+```java
+public abstract class AbstractDog implements Animal {
+ protected abstract void bark();
+}
+```
+
+但如果一个类继承了抽象类 AbstractDog,那么 Animal 接口中的 `move()` 方法和抽象类 AbstractDog 中的抽象方法 `bark()` 都必须被重写:
+
+```java
+public class BullDog extends AbstractDog {
+
+ public void move() {}
+
+ protected void bark() {}
+}
+```
+
+### 08、重写和 synchronized 方法
+
+**规则十:synchronized 关键字对重写规则没有任何影响**。
+
+synchronized 关键字用于在多线程环境中获取和释放监听对象,因此它对重写规则没有任何影响,这就意味着 synchronized 方法可以去重写一个非同步方法。
+
+### 09、重写和 strictfp 方法
+
+**规则十一:strictfp 关键字对重写规则没有任何影响**。
+
+如果你想让浮点运算更加精确,而且不会因为硬件平台的不同导致执行的结果不一致的话,可以在方法上添加 strictfp 关键字。因此 strictfp 关键和重写规则无关。
+
+
diff --git a/docs/src/basic-extra-meal/annotation.md b/docs/basic-extra-meal/annotation.md
similarity index 84%
rename from docs/src/basic-extra-meal/annotation.md
rename to docs/basic-extra-meal/annotation.md
index 829a06f6d1..e096ee8cd1 100644
--- a/docs/src/basic-extra-meal/annotation.md
+++ b/docs/basic-extra-meal/annotation.md
@@ -1,24 +1,19 @@
---
-title: Java注解,请别小看我。
-shortTitle: Java注解
category:
- Java核心
tag:
- - Java重要知识点
-description: 本文深入探讨了Java注解的概念、分类及其在实际项目中的应用。通过详细的示例和解释,帮助读者更好地理解和掌握Java注解技术,学会如何自定义注解以及在实际开发中灵活运用,提升代码的可读性和可维护性。
-head:
- - - meta
- - name: keywords
- content: Java,注解,annotation,java 注解,java annotation
+ - Java
---
+# 深入理解Java注解
+
“二哥,这节讲注解吗?”三妹问。
-“是的。”我说,“注解是 Java 中非常重要的一部分,但经常被忽视也是真的。之所以这么说是因为我们更倾向成为一名注解的使用者而不是创建者。`@Override` 注解用过吧?[方法重写](https://javabetter.cn/basic-extra-meal/override-overload.html)的时候用到过。但你知道怎么自定义一个注解吗?”
+“是的。”我说,“注解是 Java 中非常重要的一部分,但经常被忽视也是真的。之所以这么说是因为我们更倾向成为一名注解的使用者而不是创建者。`@Override` 注解用过吧?但你知道怎么自定义一个注解吗?”
三妹毫不犹豫地摇摇头,摆摆手,不好意思地承认自己的确没有自定义过。
-
+
“好吧,哥来告诉你吧。”
@@ -37,7 +32,7 @@ public class AutowiredTest {
}
```
-注意到 `@Autowired` 这个注解了吧?它本来是为 Spring(后面会讲)容器注入 Bean 的,现在被我无情地扔在了字段 name 的身上,但这段代码所在的项目中并没有启用 Spring,意味着 `@Autowired` 注解此时只是一个摆设。
+注意到 `@Autowired` 这个注解了吧?它本来是为 Spring 容器注入 Bean 的,现在被我无情地扔在了字段 name 的身上,但这段代码所在的项目中并没有启用 Spring,意味着 `@Autowired` 注解此时只是一个摆设。
“既然只是个摆设,那你这个地方为什么还要用 `@Autowired` 呢?”三妹好奇地问。
@@ -229,12 +224,4 @@ public class JsonFieldTest {
“嗯,你好好复习下,我看会《编译原理》。”说完我拿起桌子边上的一本书就走了。
-
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/basic-extra-meal/box.md b/docs/basic-extra-meal/box.md
new file mode 100644
index 0000000000..70ff3b278f
--- /dev/null
+++ b/docs/basic-extra-meal/box.md
@@ -0,0 +1,261 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 深入剖析Java中的拆箱和装箱
+
+“哥,听说 Java 的每个基本类型都对应了一个包装类型,比如说 int 的包装类型为 Integer,double 的包装类型为 Double,是这样吗?”从三妹这句话当中,能听得出来,她已经提前预习这块内容了。
+
+“是的,三妹。基本类型和包装类型的区别主要有以下 4 点,我来带你学习一下。”我回答说。我们家的斜对面刚好是一所小学,所以时不时还能听到朗朗的读书声,让人心情非常愉快。
+
+“三妹,你准备好了吗?我们开始吧。”
+
+“第一,**包装类型可以为 null,而基本类型不可以**。别小看这一点区别,它使得包装类型可以应用于 POJO 中,而基本类型则不行。”
+
+“POJO 是什么呢?”遇到不会的就问,三妹在这一点上还是非常兢兢业业的。
+
+“POJO 的英文全称是 Plain Ordinary Java Object,翻译一下就是,简单无规则的 Java 对象,只有字段以及对应的 setter 和 getter 方法。”
+
+```java
+class Writer {
+ private Integer age;
+ private String name;
+
+ public Integer getAge() {
+ return age;
+ }
+
+ public void setAge(Integer age) {
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+```
+
+和 POJO 类似的,还有数据传输对象 DTO(Data Transfer Object,泛指用于展示层与服务层之间的数据传输对象)、视图对象 VO(View Object,把某个页面的数据封装起来)、持久化对象 PO(Persistant Object,可以看成是与数据库中的表映射的 Java 对象)。
+
+“那为什么 POJO 的字段必须要用包装类型呢?”三妹问。
+
+“《阿里巴巴 Java 开发手册》上有详细的说明,你看。”我打开 PDF,并翻到了对应的内容,指着屏幕念道。
+
+>数据库的查询结果可能是 null,如果使用基本类型的话,因为要自动拆箱,就会抛出 NullPointerException 的异常。
+
+“什么是自动拆箱呢?”
+
+“自动拆箱指的是,将包装类型转为基本类型,比如说把 Integer 对象转换成 int 值;对应的,把基本类型转为包装类型,则称为自动装箱。”
+
+“哦。”
+
+“那接下来,我们来看第二点不同。**包装类型可用于泛型,而基本类型不可以**,否则就会出现编译错误。”一边说着,我一边在 Intellij IDEA 中噼里啪啦地敲了起来。
+
+“三妹,你瞧,编译器提示错误了。”
+
+```java
+List list = new ArrayList<>(); // 提示 Syntax error, insert "Dimensions" to complete ReferenceType
+List list = new ArrayList<>();
+```
+
+“为什么呢?”三妹及时地问道。
+
+“因为泛型在编译时会进行类型擦除,最后只保留原始类型,而原始类型只能是 Object 类及其子类——基本类型是个例外。”
+
+“那,接下来,我们来说第三点,**基本类型比包装类型更高效**。”我喝了一口茶继续说道。
+
+“作为局部变量时,基本类型在栈中直接存储的具体数值,而包装类型则存储的是堆中的引用。”我一边说着,一边打开 `draw.io` 画起了图。
+
+
+
+很显然,相比较于基本类型而言,包装类型需要占用更多的内存空间,不仅要存储对象,还要存储引用。假如没有基本类型的话,对于数值这类经常使用到的数据来说,每次都要通过 new 一个包装类型就显得非常笨重。
+
+“三妹,你想知道程序运行时,数据都存储在什么地方吗?”
+
+“嗯嗯,哥,你说说呗。”
+
+“通常来说,有 4 个地方可以用来存储数据。”
+
+1)寄存器。这是最快的存储区,因为它位于 CPU 内部,用来暂时存放参与运算的数据和运算结果。
+
+2)栈。位于 RAM(Random Access Memory,也叫主存,与 CPU 直接交换数据的内部存储器)中,速度仅次于寄存器。但是,在分配内存的时候,存放在栈中的数据大小与生存周期必须在编译时是确定的,缺乏灵活性。基本数据类型的值和对象的引用通常存储在这块区域。
+
+3)堆。也位于 RAM 区,可以动态分配内存大小,编译器不必知道要从堆里分配多少存储空间,生存周期也不必事先告诉编译器,Java 的垃圾收集器会自动收走不再使用的数据,因此可以得到更大的灵活性。但是,运行时动态分配内存和销毁对象都需要占用时间,所以效率比栈低一些。new 创建的对象都会存储在这块区域。
+
+4)磁盘。如果数据完全存储在程序之外,就可以不受程序的限制,在程序没有运行时也可以存在。像文件、数据库,就是通过持久化的方式,让对象存放在磁盘上。当需要的时候,再反序列化成程序可以识别的对象。
+
+“能明白吗?三妹?”
+
+“这节讲完后,我再好好消化一下。”
+
+“那好,我们来说第四点,**两个包装类型的值可以相同,但却不相等**。”
+
+```java
+Integer chenmo = new Integer(10);
+Integer wanger = new Integer(10);
+
+System.out.println(chenmo == wanger); // false
+System.out.println(chenmo.equals(wanger )); // true
+```
+
+“两个包装类型在使用“==”进行判断的时候,判断的是其指向的地址是否相等,由于是两个对象,所以地址是不同的。”
+
+“而 chenmo.equals(wanger) 的输出结果为 true,是因为 equals() 方法内部比较的是两个 int 值是否相等。”
+
+```java
+private final int value;
+
+public int intValue() {
+ return value;
+}
+public boolean equals(Object obj) {
+ if (obj instanceof Integer) {
+ return value == ((Integer)obj).intValue();
+ }
+ return false;
+}
+```
+
+虽然 chenmo 和 wanger 的值都是 10,但他们并不相等。换句话说就是:将“==”操作符应用于包装类型比较的时候,其结果很可能会和预期的不符。
+
+“三妹,瞧,`((Integer)obj).intValue()` 这段代码就是用来自动拆箱的。下面,我们来详细地说一说自动装箱和自动拆箱。”
+
+既然有基本类型和包装类型,肯定有些时候要在它们之间进行转换。把基本类型转换成包装类型的过程叫做装箱(boxing)。反之,把包装类型转换成基本类型的过程叫做拆箱(unboxing)。
+
+在 Java 1.5 之前,开发人员要手动进行装拆箱,比如说:
+
+```java
+Integer chenmo = new Integer(10); // 手动装箱
+int wanger = chenmo.intValue(); // 手动拆箱
+```
+
+Java 1.5 为了减少开发人员的工作,提供了自动装箱与自动拆箱的功能。这下就方便了。
+
+```jav
+Integer chenmo = 10; // 自动装箱
+int wanger = chenmo; // 自动拆箱
+```
+
+来看一下反编译后的代码。
+
+```java
+Integer chenmo = Integer.valueOf(10);
+int wanger = chenmo.intValue();
+```
+
+也就是说,自动装箱是通过 `Integer.valueOf()` 完成的;自动拆箱是通过 `Integer.intValue()` 完成的。
+
+“嗯,三妹,给你出一道面试题吧。”
+
+```java
+// 1)基本类型和包装类型
+int a = 100;
+Integer b = 100;
+System.out.println(a == b);
+
+// 2)两个包装类型
+Integer c = 100;
+Integer d = 100;
+System.out.println(c == d);
+
+// 3)
+c = 200;
+d = 200;
+System.out.println(c == d);
+```
+
+“给你 3 分钟时间,你先思考下,我去抽根华子,等我回来,然后再来分析一下为什么。”
+
+。。。。。。
+
+“嗯,哥,你过来吧,我说一说我的想法。”
+
+第一段代码,基本类型和包装类型进行 == 比较,这时候 b 会自动拆箱,直接和 a 比较值,所以结果为 true。
+
+第二段代码,两个包装类型都被赋值为了 100,这时候会进行自动装箱,按照你之前说的,将“==”操作符应用于包装类型比较的时候,其结果很可能会和预期的不符,我想结果可能为 false。
+
+第三段代码,两个包装类型重新被赋值为了 200,这时候仍然会进行自动装箱,我想结果仍然为 false。
+
+“嗯嗯,三妹,你分析的很有逻辑,但第二段代码的结果为 true,是不是感到很奇怪?”
+
+“为什么会这样呀?”三妹急切地问。
+
+“你说的没错,自动装箱是通过 Integer.valueOf() 完成的,我们来看看这个方法的源码就明白为什么了。”
+
+```java
+public static Integer valueOf(int i) {
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+}
+```
+
+是不是看到了一个之前从来没见过的类——IntegerCache?
+
+“难道说是 Integer 的缓存类?”三妹做出了自己的判断。
+
+“是的,来看一下 IntegerCache 的源码吧。”
+
+```java
+private static class IntegerCache {
+ static final int low = -128;
+ static final int high;
+ static final Integer cache[];
+
+ static {
+ // high value may be configured by property
+ int h = 127;
+ int i = parseInt(integerCacheHighPropValue);
+ i = Math.max(i, 127);
+ h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
+ high = h;
+
+ cache = new Integer[(high - low) + 1];
+ int j = low;
+ for(int k = 0; k < cache.length; k++)
+ cache[k] = new Integer(j++);
+
+ // range [-128, 127] must be interned (JLS7 5.1.7)
+ assert IntegerCache.high >= 127;
+ }
+}
+```
+
+大致瞟一下这段代码你就全明白了。-128 到 127 之间的数会从 IntegerCache 中取,然后比较,所以第二段代码(100 在这个范围之内)的结果是 true,而第三段代码(200 不在这个范围之内,所以 new 出来了两个 Integer 对象)的结果是 false。
+
+“三妹,看完上面的分析之后,我希望你记住一点:**当需要进行自动装箱时,如果数字在 -128 至 127 之间时,会直接使用缓存中的对象,而不是重新创建一个对象**。”
+
+“自动装拆箱是一个很好的功能,大大节省了我们开发人员的精力,但也会引发一些麻烦,比如下面这段代码,性能就很差。”
+
+```java
+long t1 = System.currentTimeMillis();
+Long sum = 0L;
+for (int i = 0; i < Integer.MAX_VALUE;i++) {
+ sum += i;
+}
+long t2 = System.currentTimeMillis();
+System.out.println(t2-t1);
+```
+
+“知道为什么吗?三妹。”
+
+“难道是因为 sum 被声明成了包装类型 Long 而不是基本类型 long。”三妹若有所思。
+
+“是滴,由于 sum 是个 Long 型,而 i 为 int 类型,`sum += i` 在执行的时候,会先把 i 强转为 long 型,然后再把 sum 拆箱为 long 型进行相加操作,之后再自动装箱为 Long 型赋值给 sum。”
+
+“三妹,你可以试一下,把 sum 换成 long 型比较一下它们运行的时间。”
+
+。。。。。。
+
+“哇,sum 为 Long 型的时候,足足运行了 5825 毫秒;sum 为 long 型的时候,只需要 679 毫秒。”
+
+“好了,三妹,今天的主题就先讲到这吧。我再去来根华子。”
+
+
\ No newline at end of file
diff --git a/docs/src/basic-extra-meal/class-object.md b/docs/basic-extra-meal/class-object.md
similarity index 79%
rename from docs/src/basic-extra-meal/class-object.md
rename to docs/basic-extra-meal/class-object.md
index b49fcb7627..b48749b326 100644
--- a/docs/src/basic-extra-meal/class-object.md
+++ b/docs/basic-extra-meal/class-object.md
@@ -1,18 +1,11 @@
---
-title: Java 中,先有Class还是先有Object?
-shortTitle: 先有Class还是先有Object?
category:
- Java核心
tag:
- - Java重要知识点
-description: 二哥的Java进阶之路,小白的零基础Java教程,从入门到进阶,Java 中,先有Class还是先有Object?
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Java入门,教程,java,class,object
+ - Java
---
-
+# 先有Class还是先有Object?
Java 对象模型中:
@@ -21,11 +14,11 @@ Java 对象模型中:
那到底是先有Class还是先有Object? JVM 是怎么处理这个“鸡·蛋”问题呢?
-
+
针对这个问题,我在知乎上看到了 R 大的一个回答,正好解答了我心中的疑惑,就分享出来给各位小伙伴一个参考和启发~
->作者:RednaxelaFX,整理:沉默王二,参考链接:[https://www.zhihu.com/question/30301819/answer/47539163](https://www.zhihu.com/question/30301819/answer/47539163)
+>作者:RednaxelaFX,整理:沉默王二,参考链接:https://www.zhihu.com/question/30301819/answer/47539163
-----
@@ -91,15 +84,8 @@ http://hg.openjdk.java.net/jdk8u/jdk8u/hotspot/file/ade5be2b1758/src/share/vm/cl
分享的最后,二哥要简单说两句,每次看 R 大的内容,总是感觉膝盖忍不住要跪一下,只能说写过 JVM 的男人就是不一样。喜欢研究 CPP 源码的话小伙伴可以再深入学习下,一定会有所收获。
-----
-
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
+
diff --git a/docs/basic-extra-meal/comparable-omparator.md b/docs/basic-extra-meal/comparable-omparator.md
new file mode 100644
index 0000000000..a122e6f100
--- /dev/null
+++ b/docs/basic-extra-meal/comparable-omparator.md
@@ -0,0 +1,174 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 详解Java中Comparable和Comparator的区别
+
+那天,小二去马蜂窝面试,面试官老王一上来就甩给了他一道面试题:请问Comparable和Comparator有什么区别?小二差点笑出声,因为三年前,也就是 2021 年,他在《Java 程序员进阶之路》专栏上看到过这题😆。
+
+Comparable 和 Comparator 是 Java 的两个接口,从名字上我们就能够读出来它们俩的相似性:以某种方式来比较两个对象。但它们之间到底有什么区别呢?请随我来,打怪进阶喽!
+
+### 01、Comparable
+
+Comparable 接口的定义非常简单,源码如下所示。
+
+```java
+public interface Comparable {
+ int compareTo(T t);
+}
+```
+
+如果一个类实现了 Comparable 接口(只需要干一件事,重写 `compareTo()` 方法),就可以按照自己制定的规则将由它创建的对象进行比较。下面给出一个例子。
+
+```java
+public class Cmower implements Comparable {
+ private int age;
+ private String name;
+
+ public Cmower(int age, String name) {
+ this.age = age;
+ this.name = name;
+ }
+
+ @Override
+ public int compareTo(Cmower o) {
+ return this.getAge() - o.getAge();
+ }
+
+ public static void main(String[] args) {
+ Cmower wanger = new Cmower(19,"沉默王二");
+ Cmower wangsan = new Cmower(16,"沉默王三");
+
+ if (wanger.compareTo(wangsan) < 0) {
+ System.out.println(wanger.getName() + "比较年轻有为");
+ } else {
+ System.out.println(wangsan.getName() + "比较年轻有为");
+ }
+ }
+}
+```
+
+在上面的示例中,我创建了一个 Cmower 类,它有两个字段:age 和 name。Cmower 类实现了 Comparable 接口,并重写了 `compareTo()` 方法。
+
+
+程序输出的结果是“沉默王三比较年轻有为”,因为他比沉默王二小三岁。这个结果有什么凭证吗?
+
+凭证就在于 `compareTo()` 方法,该方法的返回值可能为负数,零或者正数,代表的意思是该对象按照排序的规则小于、等于或者大于要比较的对象。如果指定对象的类型与此对象不能进行比较,则引发 `ClassCastException` 异常(自从有了泛型,这种情况就少有发生了)。
+
+### 02、Comparator
+
+Comparator 接口的定义相比较于 Comparable 就复杂的多了,不过,核心的方法只有两个,来看一下源码。
+
+```java
+public interface Comparator {
+ int compare(T o1, T o2);
+ boolean equals(Object obj);
+}
+```
+
+第一个方法 `compare(T o1, T o2)` 的返回值可能为负数,零或者正数,代表的意思是第一个对象小于、等于或者大于第二个对象。
+
+第二个方法 `equals(Object obj)` 需要传入一个 Object 作为参数,并判断该 Object 是否和 Comparator 保持一致。
+
+有时候,我们想让类保持它的原貌,不想主动实现 Comparable 接口,但我们又需要它们之间进行比较,该怎么办呢?
+
+Comparator 就派上用场了,来看一下示例。
+
+1)原封不动的 Cmower 类。
+
+```java
+public class Cmower {
+ private int age;
+ private String name;
+
+ public Cmower(int age, String name) {
+ this.age = age;
+ this.name = name;
+ }
+}
+```
+
+(说好原封不动,getter/setter 吃了啊)
+
+Cmower 类有两个字段:age 和 name,意味着该类可以按照 age 或者 name 进行排序。
+
+2)再来看 Comparator 接口的实现类。
+
+```java
+public class CmowerComparator implements Comparator {
+ @Override
+ public int compare(Cmower o1, Cmower o2) {
+ return o1.getAge() - o2.getAge();
+ }
+}
+```
+
+按照 age 进行比较。当然也可以再实现一个比较器,按照 name 进行自然排序,示例如下。
+
+```java
+public class CmowerNameComparator implements Comparator {
+ @Override
+ public int compare(Cmower o1, Cmower o2) {
+ if (o1.getName().hashCode() < o2.getName().hashCode()) {
+ return -1;
+ } else if (o1.getName().hashCode() == o2.getName().hashCode()) {
+ return 0;
+ }
+ return 1;
+ }
+}
+```
+
+3)再来看测试类。
+
+```java
+Cmower wanger = new Cmower(19,"沉默王二");
+Cmower wangsan = new Cmower(16,"沉默王三");
+Cmower wangyi = new Cmower(28,"沉默王一");
+
+List list = new ArrayList<>();
+list.add(wanger);
+list.add(wangsan);
+list.add(wangyi);
+
+list.sort(new CmowerComparator());
+
+for (Cmower c : list) {
+ System.out.println(c.getName());
+}
+```
+
+创建了三个对象,age 不同,name 不同,并把它们加入到了 List 当中。然后使用 List 的 `sort()` 方法进行排序,来看一下输出的结果。
+
+```
+沉默王三
+沉默王二
+沉默王一
+```
+
+这意味着沉默王三的年纪比沉默王二小,排在第一位;沉默王一的年纪比沉默王二大,排在第三位。和我们的预期完全符合。
+
+### 03、到底该用哪一个呢?
+
+通过上面的两个例子可以比较出 Comparable 和 Comparator 两者之间的区别:
+
+- 一个类实现了 Comparable 接口,意味着该类的对象可以直接进行比较(排序),但比较(排序)的方式只有一种,很单一。
+- 一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现 Comparator 接口)。
+- Comparable 接口在 `java.lang` 包下,而 `Comparator` 接口在 `java.util` 包下,算不上是亲兄弟,但可以称得上是表(堂)兄弟。
+
+举个不恰当的例子。我想从洛阳出发去北京看长城,体验一下好汉的感觉,要么坐飞机,要么坐高铁;但如果是孙悟空的话,翻个筋斗就到了。我和孙悟空之间有什么区别呢?孙悟空自己实现了 Comparable 接口(他那年代也没有飞机和高铁,没得选),而我可以借助 Comparator 接口(现代化的交通工具)。
+
+
+
+
+
+------
+
+
+好了,关于 Comparable 和 Comparator 我们就先聊这么多。总而言之,如果对象的排序需要基于自然顺序,请选择 `Comparable`,如果需要按照对象的不同属性进行排序,请选择 `Comparator`。
+
+
+
\ No newline at end of file
diff --git a/docs/src/basic-extra-meal/deep-copy.md b/docs/basic-extra-meal/deep-copy.md
similarity index 83%
rename from docs/src/basic-extra-meal/deep-copy.md
rename to docs/basic-extra-meal/deep-copy.md
index f5e662fa53..fb7d19dc55 100644
--- a/docs/src/basic-extra-meal/deep-copy.md
+++ b/docs/basic-extra-meal/deep-copy.md
@@ -1,31 +1,24 @@
---
-title: 深入理解Java浅拷贝与深拷贝
-shortTitle: 深入理解Java浅拷贝与深拷贝
category:
- Java核心
tag:
- - Java重要知识点
-description: 本文详细讨论了Java中的浅拷贝和深拷贝概念,解析了它们如何在实际编程中应用。文章通过实例演示了如何实现浅拷贝与深拷贝,以帮助读者更好地理解这两种拷贝方式在Java编程中的作用与应用场景。
-author: 沉默王二
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Java入门,教程,java,深拷贝,浅拷贝
+ - Java
---
+# 彻底讲明白的Java浅拷贝与深拷贝
+
“哥,听说浅拷贝和深拷贝是 Java 面试中经常会被问到的一个问题,是这样吗?”
-“还真的是,而且了解浅拷贝和深拷贝的原理,对 [Java 是值传递还是引用传递](https://javabetter.cn/basic-extra-meal/pass-by-value.html)也会有更深的理解。”我肯定地回答。
+“还真的是,而且了解浅拷贝和深拷贝的原理,对 Java 是值传递还是引用传递也会有更深的理解。”我肯定地回答。
“不管是浅拷贝还是深拷贝,都可以通过调用 Object 类的 `clone()` 方法来完成。”我一边说,一边打开 Intellij IDEA,并找到了 `clone()` 方法的源码。
```java
+@HotSpotIntrinsicCandidate
protected native Object clone() throws CloneNotSupportedException;
```
-需要注意的是,`clone()` 方法同时是一个本地(`native`)方法,它的具体实现会交给 HotSpot 虚拟机,那就意味着虚拟机在运行该方法的时候,会将其替换为更高效的 C/C++ 代码,进而调用操作系统去完成对象的克隆工作。
-
->Java 9 后,该方法会被标注 `@HotSpotIntrinsicCandidate` 注解,被该注解标注的方法,在 HotSpot 虚拟机中会有一套高效的实现。
+其中 `@HotSpotIntrinsicCandidate` 是 Java 9 引入的一个注解,被它标注的方法,在 HotSpot 虚拟机中会有一套高效的实现。需要注意的是,`clone()` 方法同时是一个本地(`native`)方法,它的具体实现会交给 HotSpot 虚拟机,那就意味着虚拟机在运行该方法的时候,会将其替换为更高效的 C/C++ 代码,进而调用操作系统去完成对象的克隆工作。
“哥,那你就先说浅拷贝吧!”
@@ -45,12 +38,21 @@ class Writer implements Cloneable{
", name='" + name + '\'' +
'}';
}
+
+ @Override
+ protected Object clone() throws CloneNotSupportedException {
+ return super.clone();
+ }
}
```
-Writer 类有两个字段,分别是 int 类型的 age,和 String 类型的 name。然后重写了 `toString()` 方法,方便打印对象的具体信息。
+Writer 类有两个字段,分别是 int 类型的 age,和 String 类型的 name。然后重写了 `toString()` 方法,方便打印对象的具体信息。并且重写了 `clone()` 方法,方法体里面也很简单,直接调用 Object 类的 `clone()` 方法。
-“为什么要实现 Cloneable 接口呢?”三妹开启了十万个为什么的模式。
+“既然 Writer 类的 `clone()` 方法体里只有一行代码,调用的还是超类 Object 的 `clone()` 方法?为什么还要重写呢?不是多此一举吗?”三妹着急地问。
+
+“嗯,是这样的,三妹。Object 类中的 `clone()` 方法是 protected 的,如果 Writer 类不去重写的话,Writer 类的对象是无法调用 `clone()` 方法的,因为 protected 修饰的方法对子类并不可见。”
+
+“哦哦,那为什么要实现 Cloneable 接口呢?”三妹开启了十万个为什么的模式。
Cloneable 接口是一个标记接口,它肚子里面是空的:
@@ -109,7 +111,7 @@ writer2:Writer@b97c004{age=18, name='三妹'}
可以看得出,浅拷贝后,writer1 和 writer2 引用了不同的对象,但值是相同的,说明拷贝成功。之后,修改了 writer2 的 name 字段,直接上图就明白了。
-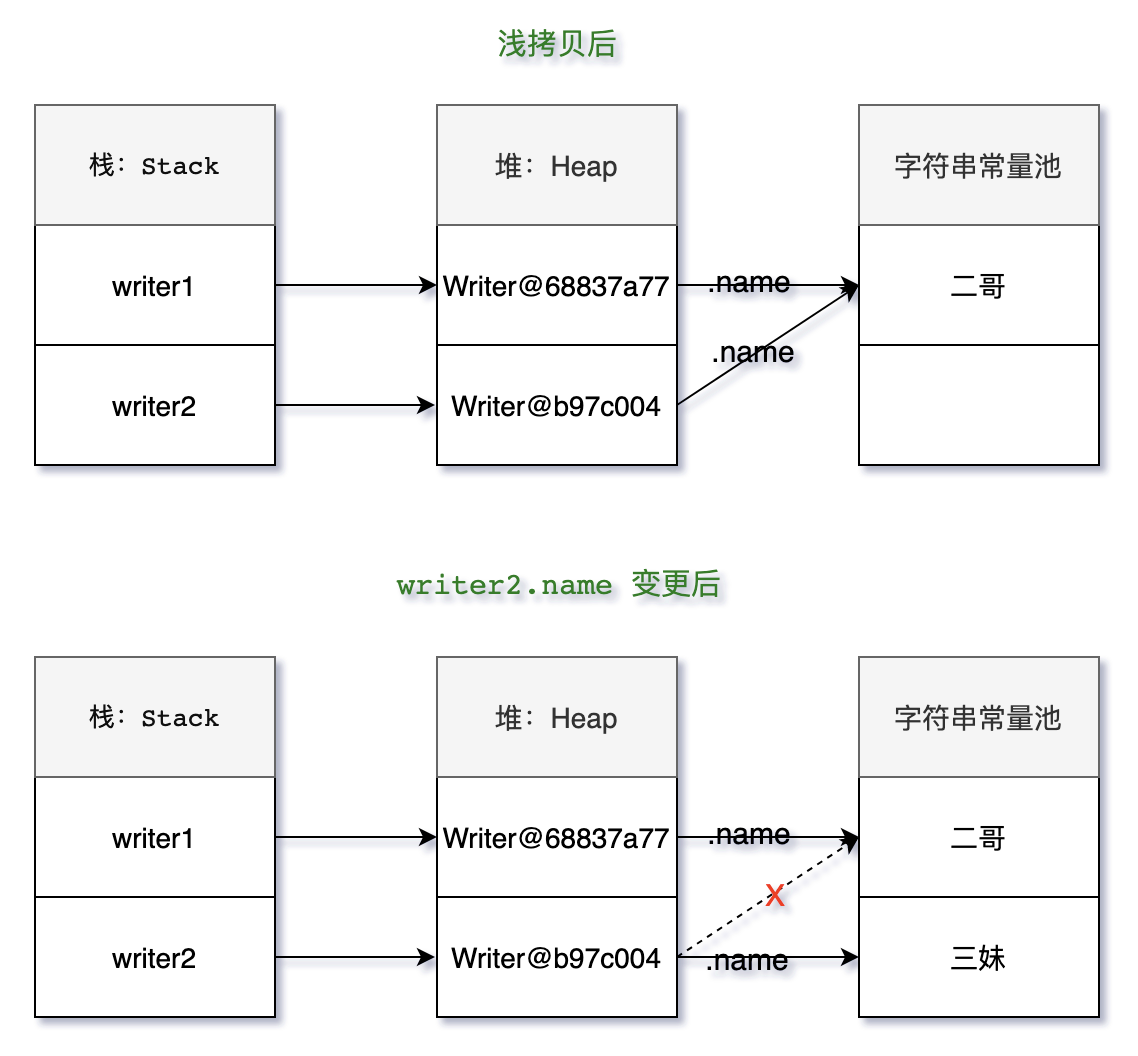
+
之前的例子中,Writer 类只有两个字段,没有引用类型字段。那么,我们再来看另外一个例子,为 Writer 类增加一个自定义的引用类型字段 Book,先来看 Book 的定义。
@@ -208,7 +210,7 @@ writer2:Writer@36d4b5c age=18, name='二哥', book=Book@32e6e9c3 bookName='永
与之前例子不同的是,writer2.book 变更后,writer1.book 也发生了改变。这是因为字符串 String 是不可变对象,一个新的值必须在字符串常量池中开辟一段新的内存空间,而自定义对象的内存地址并没有发生改变,只是对应的字段值发生了改变,见下图。
-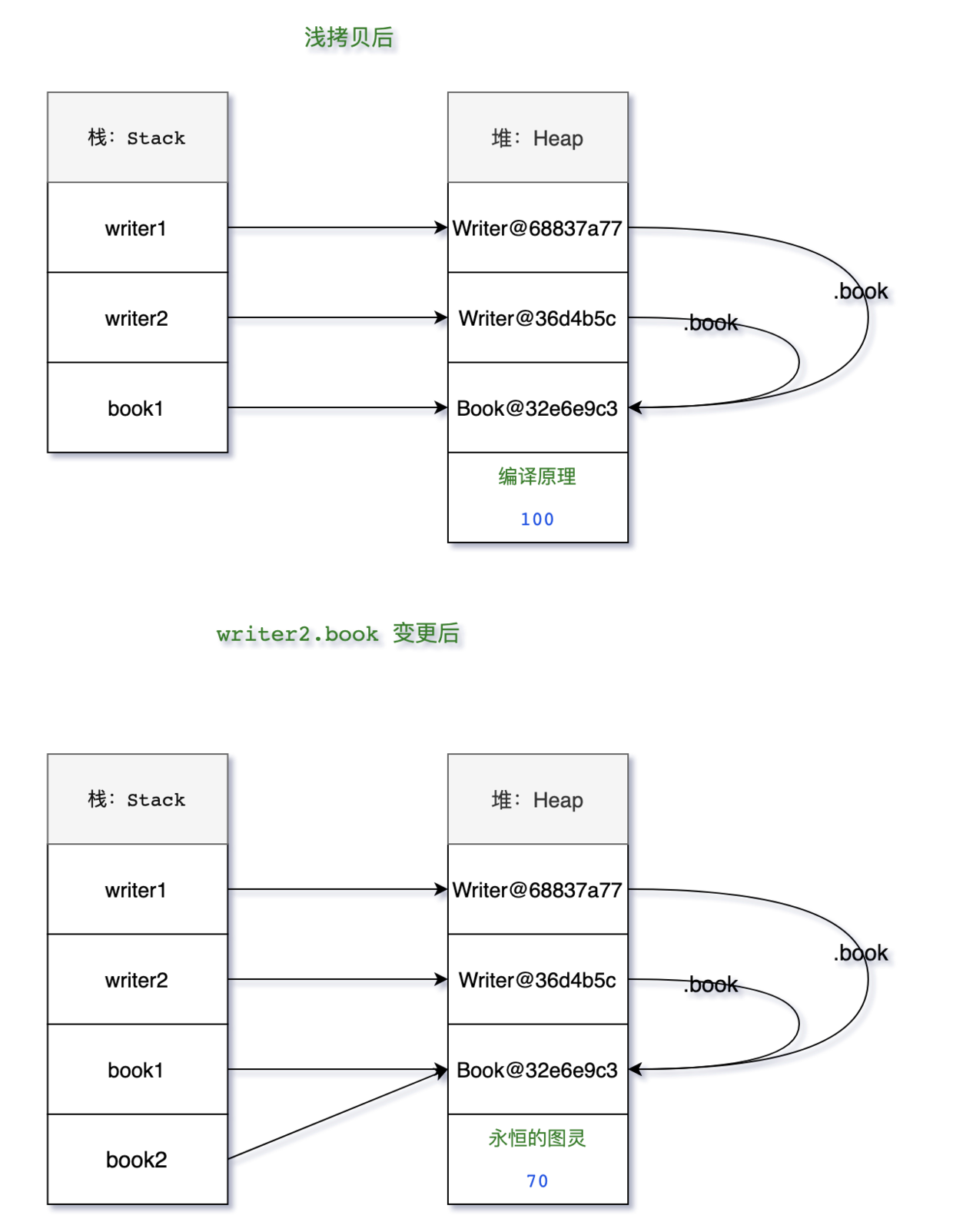
+
“哇,哥,果真一图胜千言,我明白了。”三妹似乎对我画的图很感兴趣呢,“那你继续说深拷贝吧!”
@@ -309,15 +311,15 @@ writer2:Writer@6d00a15d age=18, name='二哥', book=Book@51efea79 bookName='
不只是 writer1 和 writer2 是不同的对象,它们中的 book 也是不同的对象。所以,改变了 writer2 中的 book 并不会影响到 writer1。
-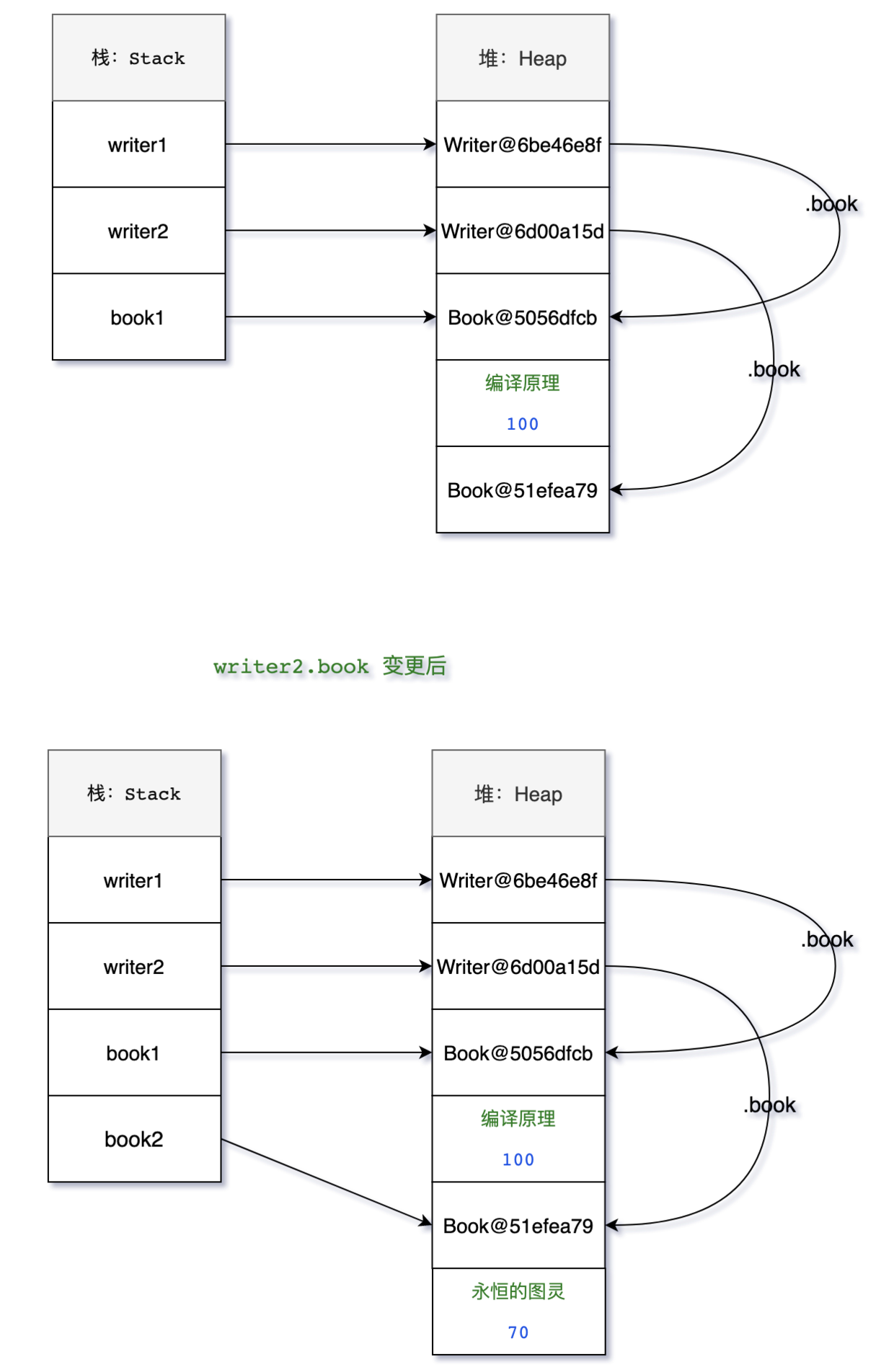
+
不过,通过 `clone()` 方法实现的深拷贝比较笨重,因为要将所有的引用类型都重写 `clone()` 方法,当嵌套的对象比较多的时候,就废了!
“那有没有好的办法呢?”三妹急切的问。
-“当然有了,利用[序列化](https://javabetter.cn/io/serialize.html)。”我胸有成竹的回答,“序列化是将对象写到流中便于传输,而反序列化则是将对象从流中读取出来。”
+“当然有了,利用序列化。”我胸有成竹的回答,“序列化是将对象写到流中便于传输,而反序列化则是将对象从流中读取出来。”
-“写入流中的对象就是对原始对象的拷贝。需要注意的是,每个要序列化的类都要实现 [Serializable 接口](https://javabetter.cn/io/Serializbale.html),该接口和 Cloneable 接口类似,都是标记型接口。”
+“写入流中的对象就是对原始对象的拷贝。需要注意的是,每个要序列化的类都要实现 Serializable 接口,该接口和 Cloneable 接口类似,都是标记型接口。”
来看例子。
@@ -421,12 +423,4 @@ writer2:Writer@544fe44c age=18, name='二哥', book=Book@31610302 bookName='
“嗯嗯。”
-
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/basic-extra-meal/enum.md b/docs/basic-extra-meal/enum.md
new file mode 100644
index 0000000000..7016485f5a
--- /dev/null
+++ b/docs/basic-extra-meal/enum.md
@@ -0,0 +1,292 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java枚举(enum)
+
+“今天我们来学习枚举吧,三妹!”我说,“同学让你去她家玩了两天,感觉怎么样呀?”
+
+“心情放松了不少。”三妹说,“可以开始学 Java 了,二哥。”
+
+“OK。”
+
+“枚举(enum),是 Java 1.5 时引入的关键字,它表示一种特殊类型的类,继承自 java.lang.Enum。”
+
+“我们来新建一个枚举 PlayerType。”
+
+```java
+public enum PlayerType {
+ TENNIS,
+ FOOTBALL,
+ BASKETBALL
+}
+```
+
+“二哥,我没看到有继承关系呀!”
+
+“别着急,看一下反编译后的字节码,你就明白了。”
+
+```java
+public final class PlayerType extends Enum
+{
+
+ public static PlayerType[] values()
+ {
+ return (PlayerType[])$VALUES.clone();
+ }
+
+ public static PlayerType valueOf(String name)
+ {
+ return (PlayerType)Enum.valueOf(com/cmower/baeldung/enum1/PlayerType, name);
+ }
+
+ private PlayerType(String s, int i)
+ {
+ super(s, i);
+ }
+
+ public static final PlayerType TENNIS;
+ public static final PlayerType FOOTBALL;
+ public static final PlayerType BASKETBALL;
+ private static final PlayerType $VALUES[];
+
+ static
+ {
+ TENNIS = new PlayerType("TENNIS", 0);
+ FOOTBALL = new PlayerType("FOOTBALL", 1);
+ BASKETBALL = new PlayerType("BASKETBALL", 2);
+ $VALUES = (new PlayerType[] {
+ TENNIS, FOOTBALL, BASKETBALL
+ });
+ }
+}
+```
+
+“看到没?Java 编译器帮我们做了很多隐式的工作,不然手写一个枚举就没那么省心省事了。”
+
+- 要继承 Enum 类;
+- 要写构造方法;
+- 要声明静态变量和数组;
+- 要用 static 块来初始化静态变量和数组;
+- 要提供静态方法,比如说 `values()` 和 `valueOf(String name)`。
+
+“确实,作为开发者,我们的代码量减少了,枚举看起来简洁明了。”三妹说。
+
+“既然枚举是一种特殊的类,那它其实是可以定义在一个类的内部的,这样它的作用域就可以限定于这个外部类中使用。”我说。
+
+```java
+public class Player {
+ private PlayerType type;
+ public enum PlayerType {
+ TENNIS,
+ FOOTBALL,
+ BASKETBALL
+ }
+
+ public boolean isBasketballPlayer() {
+ return getType() == PlayerType.BASKETBALL;
+ }
+
+ public PlayerType getType() {
+ return type;
+ }
+
+ public void setType(PlayerType type) {
+ this.type = type;
+ }
+}
+```
+
+PlayerType 就相当于 Player 的内部类。
+
+由于枚举是 final 的,所以可以确保在 Java 虚拟机中仅有一个常量对象,基于这个原因,我们可以使用“==”运算符来比较两个枚举是否相等,参照 `isBasketballPlayer()` 方法。
+
+“那为什么不使用 `equals()` 方法判断呢?”三妹问。
+
+```java
+if(player.getType().equals(Player.PlayerType.BASKETBALL)){};
+```
+
+“我来给你解释下。”
+
+“==”运算符比较的时候,如果两个对象都为 null,并不会发生 `NullPointerException`,而 `equals()` 方法则会。
+
+另外, “==”运算符会在编译时进行检查,如果两侧的类型不匹配,会提示错误,而 `equals()` 方法则不会。
+
+
+
+“枚举还可用于 switch 语句,和基本数据类型的用法一致。”我说。
+
+```java
+switch (playerType) {
+ case TENNIS:
+ return "网球运动员费德勒";
+ case FOOTBALL:
+ return "足球运动员C罗";
+ case BASKETBALL:
+ return "篮球运动员詹姆斯";
+ case UNKNOWN:
+ throw new IllegalArgumentException("未知");
+ default:
+ throw new IllegalArgumentException(
+ "运动员类型: " + playerType);
+
+ }
+```
+
+“如果枚举中需要包含更多信息的话,可以为其添加一些字段,比如下面示例中的 name,此时需要为枚举添加一个带参的构造方法,这样就可以在定义枚举时添加对应的名称了。”我继续说。
+
+```java
+public enum PlayerType {
+ TENNIS("网球"),
+ FOOTBALL("足球"),
+ BASKETBALL("篮球");
+
+ private String name;
+
+ PlayerType(String name) {
+ this.name = name;
+ }
+}
+```
+
+“get 了吧,三妹?”
+
+“嗯,比较好理解。”
+
+“那接下来,我就来说点不一样的。”
+
+“来吧,我准备好了。”
+
+“EnumSet 是一个专门针对枚举类型的 Set 接口(后面会讲)的实现类,它是处理枚举类型数据的一把利器,非常高效。”我说,“从名字上就可以看得出,EnumSet 不仅和 Set 有关系,和枚举也有关系。”
+
+“因为 EnumSet 是一个抽象类,所以创建 EnumSet 时不能使用 new 关键字。不过,EnumSet 提供了很多有用的静态工厂方法。”
+
+
+
+
+“来看下面这个例子,我们使用 `noneOf()` 静态工厂方法创建了一个空的 PlayerType 类型的 EnumSet;使用 `allOf()` 静态工厂方法创建了一个包含所有 PlayerType 类型的 EnumSet。”
+
+```java
+public class EnumSetTest {
+ public enum PlayerType {
+ TENNIS,
+ FOOTBALL,
+ BASKETBALL
+ }
+
+ public static void main(String[] args) {
+ EnumSet enumSetNone = EnumSet.noneOf(PlayerType.class);
+ System.out.println(enumSetNone);
+
+ EnumSet enumSetAll = EnumSet.allOf(PlayerType.class);
+ System.out.println(enumSetAll);
+ }
+}
+```
+
+“来看一下输出结果。”
+
+```java
+[]
+[TENNIS, FOOTBALL, BASKETBALL]
+```
+
+有了 EnumSet 后,就可以使用 Set 的一些方法了,见下图。
+
+
+
+“除了 EnumSet,还有 EnumMap,是一个专门针对枚举类型的 Map 接口的实现类,它可以将枚举常量作为键来使用。EnumMap 的效率比 HashMap 还要高,可以直接通过数组下标(枚举的 ordinal 值)访问到元素。”
+
+“和 EnumSet 不同,EnumMap 不是一个抽象类,所以创建 EnumMap 时可以使用 new 关键字。”
+
+```java
+EnumMap enumMap = new EnumMap<>(PlayerType.class);
+```
+
+有了 EnumMap 对象后就可以使用 Map 的一些方法了,见下图。
+
+
+
+和 HashMap(后面会讲)的使用方法大致相同,来看下面的例子。
+
+```java
+EnumMap enumMap = new EnumMap<>(PlayerType.class);
+enumMap.put(PlayerType.BASKETBALL,"篮球运动员");
+enumMap.put(PlayerType.FOOTBALL,"足球运动员");
+enumMap.put(PlayerType.TENNIS,"网球运动员");
+System.out.println(enumMap);
+
+System.out.println(enumMap.get(PlayerType.BASKETBALL));
+System.out.println(enumMap.containsKey(PlayerType.BASKETBALL));
+System.out.println(enumMap.remove(PlayerType.BASKETBALL));
+```
+
+“来看一下输出结果。”
+
+```
+{TENNIS=网球运动员, FOOTBALL=足球运动员, BASKETBALL=篮球运动员}
+篮球运动员
+true
+篮球运动员
+```
+
+“除了以上这些,《Effective Java》这本书里还提到了一点,如果要实现单例的话,最好使用枚举的方式。”我说。
+
+“等等二哥,单例是什么?”三妹没等我往下说,就连忙问道。
+
+“单例(Singleton)用来保证一个类仅有一个对象,并提供一个访问它的全局访问点,在一个进程中。因为这个类只有一个对象,所以就不能再使用 `new` 关键字来创建新的对象了。”
+
+“Java 标准库有一些类就是单例,比如说 Runtime 这个类。”
+
+```java
+Runtime runtime = Runtime.getRuntime();
+```
+
+“Runtime 类可以用来获取 Java 程序运行时的环境。”
+
+“关于单例,懂了些吧?”我问三妹。
+
+“噢噢噢噢。”三妹点了点头。
+
+“通常情况下,实现单例并非易事,来看下面这种写法。”
+
+```java
+public class Singleton {
+ private volatile static Singleton singleton;
+ private Singleton (){}
+ public static Singleton getSingleton() {
+ if (singleton == null) {
+ synchronized (Singleton.class) {
+ if (singleton == null) {
+ singleton = new Singleton();
+ }
+ }
+ }
+ return singleton;
+ }
+}
+```
+
+“要用到 volatile、synchronized 关键字等等,但枚举的出现,让代码量减少到极致。”
+
+```java
+public enum EasySingleton{
+ INSTANCE;
+}
+```
+
+“就这?”三妹睁大了眼睛。
+
+“对啊,枚举默认实现了 Serializable 接口,因此 Java 虚拟机可以保证该类为单例,这与传统的实现方式不大相同。传统方式中,我们必须确保单例在反序列化期间不能创建任何新实例。”我说。
+
+“好了,关于枚举就讲这么多吧,三妹,你把这些代码都手敲一遍吧!”
+
+“好勒,这就安排。二哥,你去休息吧。”
+
+“嗯嗯。”讲了这么多,必须跑去抽烟机那里安排一根华子了。
+
+
diff --git a/docs/basic-extra-meal/equals-hashcode.md b/docs/basic-extra-meal/equals-hashcode.md
new file mode 100644
index 0000000000..ad6f1b236e
--- /dev/null
+++ b/docs/basic-extra-meal/equals-hashcode.md
@@ -0,0 +1,233 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 一次性搞清楚equals和hashCode
+
+“二哥,我在读《Effective Java》 的时候,第 11 条规约说重写 equals 的时候必须要重写 hashCode 方法,这是为什么呀?”三妹单刀直入地问。
+
+“三妹啊,这个问题问得非常好,因为它也是面试中经常考的一个知识点。今天哥就带你来梳理一下。”我说。
+
+Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,而 Object 的中文意思就是“对象”。
+
+Object 类中有这么两个方法:
+
+```java
+public native int hashCode();
+
+public boolean equals(Object obj) {
+ return (this == obj);
+}
+```
+1)hashCode 方法
+
+这是一个本地方法,用来返回对象的哈希值(一个整数)。在 Java 程序执行期间,对同一个对象多次调用该方法必须返回相同的哈希值。
+
+2)equals 方法
+
+对于任何非空引用 x 和 y,当且仅当 x 和 y 引用的是同一个对象时,equals 方法才返回 true。
+
+“二哥,看起来两个方法之间没有任何关联啊?”三妹质疑道。
+
+“单从这两段解释上来看,的确是这样的。”我解释道,“但两个方法的 doc 文档中还有这样两条信息。”
+
+第一,如果两个对象调用 equals 方法返回的结果为 true,那么两个对象调用 hashCode 方法返回的结果也必然相同——来自 hashCode 方法的 doc 文档。
+
+第二,每当重写 equals 方法时,hashCode 方法也需要重写,以便维护上一条规约。
+
+“哦,这样讲的话,两个方法确实关联上了,但究竟是为什么呢?”三妹抛出了终极一问。
+
+“hashCode 方法的作用是用来获取哈希值,而该哈希值的作用是用来确定对象在哈希表中的索引位置。”我说。
+
+哈希表的典型代表就是 HashMap,它存储的是键值对,能根据键快速地检索出对应的值。
+
+```java
+public V get(Object key) {
+ HashMap.Node e;
+ return (e = getNode(hash(key), key)) == null ? null : e.value;
+}
+```
+
+这是 HashMap 的 get 方法,通过键来获取值的方法。它会调用 getNode 方法:
+
+```java
+final HashMap.Node getNode(int hash, Object key) {
+ HashMap.Node[] tab; HashMap.Node first, e; int n; K k;
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (first = tab[(n - 1) & hash]) != null) {
+ if (first.hash == hash && // always check first node
+ ((k = first.key) == key || (key != null && key.equals(k))))
+ return first;
+ if ((e = first.next) != null) {
+ if (first instanceof HashMap.TreeNode)
+ return ((HashMap.TreeNode)first).getTreeNode(hash, key);
+ do {
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ return e;
+ } while ((e = e.next) != null);
+ }
+ }
+ return null;
+}
+```
+
+通常情况(没有发生哈希冲突)下,`first = tab[(n - 1) & hash]` 就是键对应的值。**按照时间复杂度来说的话,可表示为 O(1)**。
+
+如果发生哈希冲突,也就是 `if ((e = first.next) != null) {}` 子句中,可以看到如果节点不是红黑树的时候,会通过 do-while 循环语句判断键是否 equals 返回对应值的。**按照时间复杂度来说的话,可表示为 O(n)**。
+
+HashMap 是通过拉链法来解决哈希冲突的,也就是如果发生哈希冲突,同一个键的坑位会放好多个值,超过 8 个值后改为红黑树,为了提高查询的效率。
+
+显然,从时间复杂度上来看的话 O(n) 比 O(1) 的性能要差,这也正是哈希表的价值所在。
+
+“O(n) 和 O(1) 是什么呀?”三妹有些不解。
+
+“这是时间复杂度的一种表示方法,随后二哥专门给你讲一下。简单说一下 n 和 1 的意思,很显然,n 和 1 都代表的是代码执行的次数,假如数据规模为 n,n 就代表需要执行 n 次,1 就代表只需要执行一次。”我解释道。
+
+“三妹,你想一下,如果没有哈希表,但又需要这样一个数据结构,它里面存放的数据是不允许重复的,该怎么办呢?”我问。
+
+“要不使用 equals 方法进行逐个比较?”三妹有些不太确定。
+
+“这种方法当然是可行的,就像 `if ((e = first.next) != null) {}` 子句中那样,但如果数据量特别特别大,性能就会很差,最好的解决方案还是 HashMap。”
+
+HashMap 本质上是通过数组实现的,当我们要从 HashMap 中获取某个值时,实际上是要获取数组中某个位置的元素,而位置是通过键来确定的。
+
+```java
+public V put(K key, V value) {
+ return putVal(hash(key), key, value, false, true);
+}
+```
+
+这是 HashMap 的 put 方法,会将键值对放入到数组当中。它会调用 putVal 方法:
+
+```java
+final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ HashMap.Node[] tab; HashMap.Node p; int n, i;
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ // 拉链
+ }
+ return null;
+}
+```
+
+通常情况下,`p = tab[i = (n - 1) & hash])` 就是键对应的值。而数组的索引 `(n - 1) & hash` 正是基于 hashCode 方法计算得到的。
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+“那二哥,你好像还是没有说为什么重写 equals 方法的时候要重写 hashCode 方法呀?”三妹忍不住了。
+
+“来看下面这段代码。”我说。
+
+```java
+public class Test {
+ public static void main(String[] args) {
+ Student s1 = new Student(18, "张三");
+ Map scores = new HashMap<>();
+ scores.put(s1, 98);
+
+ Student s2 = new Student(18, "张三");
+ System.out.println(scores.get(s2));
+ }
+}
+ class Student {
+ private int age;
+ private String name;
+
+ public Student(int age, String name) {
+ this.age = age;
+ this.name = name;
+ }
+
+ @Override
+ public boolean equals(Object o) {
+ Student student = (Student) o;
+ return age == student.age &&
+ Objects.equals(name, student.name);
+ }
+ }
+```
+
+我们重写了 Student 类的 equals 方法,如果两个学生的年纪和姓名相同,我们就认为是同一个学生,虽然很离谱,但我们就是这么草率。
+
+在 main 方法中,18 岁的张三考试得了 98 分,很不错的成绩,我们把张三和他的成绩放到 HashMap 中,然后准备取出:
+
+```
+null
+```
+
+“二哥,怎么输出了 null,而不是预期当中的 98 呢?”三妹感到很不可思议。
+
+“原因就在于重写 equals 方法的时候没有重写 hashCode 方法。”我回答道,“equals 方法虽然认定名字和年纪相同就是同一个学生,但它们本质上是两个对象,hashCode 并不相同。”
+
+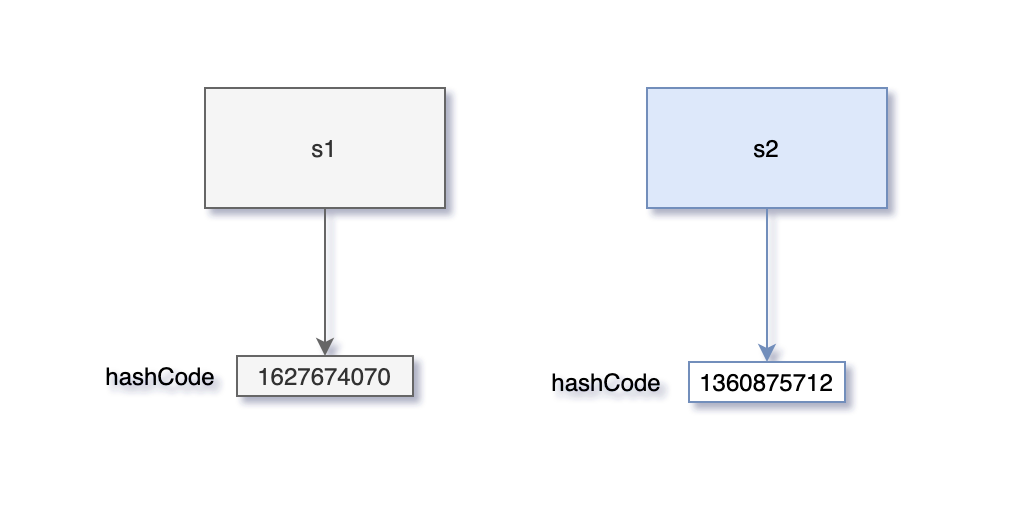
+
+“那怎么重写 hashCode 方法呢?”三妹问。
+
+“可以直接调用 Objects 类的 hash 方法。”我回答。
+
+```java
+ @Override
+ public int hashCode() {
+ return Objects.hash(age, name);
+ }
+```
+
+Objects 类的 hash 方法可以针对不同数量的参数生成新的哈希值,hash 方法调用的是 Arrays 类的 hashCode 方法,该方法源码如下:
+
+```java
+public static int hashCode(Object a[]) {
+ if (a == null)
+ return 0;
+
+ int result = 1;
+
+ for (Object element : a)
+ result = 31 * result + (element == null ? 0 : element.hashCode());
+
+ return result;
+}
+```
+
+第一次循环:
+
+```
+result = 31*1 + Integer(18).hashCode();
+```
+
+第二次循环:
+
+```
+result = (31*1 + Integer(18).hashCode()) * 31 + String("张三").hashCode();
+```
+
+针对姓名年纪不同的对象,这样计算后的哈希值很难很难很难重复的;针对姓名年纪相同的对象,哈希值保持一致。
+
+再次执行 main 方法,结果如下所示:
+
+```
+98
+```
+
+因为此时 s1 和 s2 对象的哈希值都为 776408。
+
+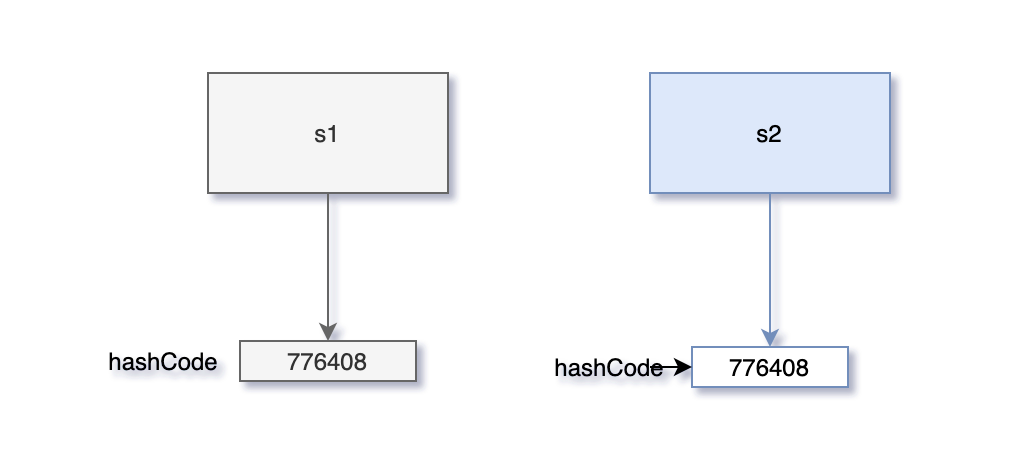
+
+
+“每当重写 equals 方法时,hashCode 方法也需要重写,原因就是为了保证:如果两个对象调用 equals 方法返回的结果为 true,那么两个对象调用 hashCode 方法返回的结果也必然相同。”我点题了。
+
+“OK,get 了。”三妹开心地点了点头,看得出来,今天学到了不少。
+
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/fanshe.md b/docs/basic-extra-meal/fanshe.md
new file mode 100644
index 0000000000..c28b1ee32c
--- /dev/null
+++ b/docs/basic-extra-meal/fanshe.md
@@ -0,0 +1,323 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 大白话说Java反射:入门、使用、原理
+
+“二哥,什么是反射呀?”三妹开门见山地问。
+
+“要想知道什么是反射,就需要先来了解什么是‘正射’。”我笑着对三妹说,“一般情况下,我们在使用某个类之前已经确定它到底是个什么类了,拿到手就直接可以使用 `new` 关键字来调用构造方法进行初始化,之后使用这个类的对象来进行操作。”
+
+```java
+Writer writer = new Writer();
+writer.setName("沉默王二");
+```
+
+像上面这个例子,就可以理解为“正射”。而反射就意味着一开始我们不知道要初始化的类到底是什么,也就没法直接使用 `new` 关键字创建对象了。
+
+我们只知道这个类的一些基本信息,就好像我们看电影的时候,为了抓住一个犯罪嫌疑人,警察就会问一些目击证人,根据这些证人提供的信息,找专家把犯罪嫌疑人的样貌给画出来——这个过程,就可以称之为**反射**。
+
+```java
+Class clazz = Class.forName("com.itwanger.s39.Writer");
+Method method = clazz.getMethod("setName", String.class);
+Constructor constructor = clazz.getConstructor();
+Object object = constructor.newInstance();
+method.invoke(object,"沉默王二");
+```
+
+像上面这个例子,就可以理解为“反射”。
+
+“反射的写法比正射复杂得多啊!”三妹感慨地说。
+
+“是的,反射的成本是要比正射的高得多。”我说,“反射的缺点主要有两个。”
+
+- **破坏封装**:由于反射允许访问私有字段和私有方法,所以可能会破坏封装而导致安全问题。
+- **性能开销**:由于反射涉及到动态解析,因此无法执行 Java 虚拟机优化,再加上反射的写法的确要复杂得多,所以性能要比“正射”差很多,在一些性能敏感的程序中应该避免使用反射。
+
+“那反射有哪些好处呢?”三妹问。
+
+反射的主要应用场景有:
+
+- **开发通用框架**:像 Spring,为了保持通用性,通过配置文件来加载不同的对象,调用不同的方法。
+- **动态代理**:在面向切面编程中,需要拦截特定的方法,就会选择动态代理的方式,而动态代理的底层技术就是反射。
+- **注解**:注解本身只是起到一个标记符的作用,它需要利用发射机制,根据标记符去执行特定的行为。
+
+“好了,来看一下完整的例子吧。”我对三妹说。
+
+Writer 类,有两个字段,然后还有对应的 getter/setter。
+
+```java
+public class Writer {
+ private int age;
+ private String name;
+
+ public int getAge() {
+ return age;
+ }
+
+ public void setAge(int age) {
+ this.age = age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+```
+
+测试类:
+
+```java
+public class ReflectionDemo1 {
+ public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
+ Writer writer = new Writer();
+ writer.setName("沉默王二");
+ System.out.println(writer.getName());
+
+ Class clazz = Class.forName("com.itwanger.s39.Writer");
+ Constructor constructor = clazz.getConstructor();
+ Object object = constructor.newInstance();
+
+ Method setNameMethod = clazz.getMethod("setName", String.class);
+ setNameMethod.invoke(object, "沉默王二");
+ Method getNameMethod = clazz.getMethod("getName");
+ System.out.println(getNameMethod.invoke(object));
+ }
+}
+```
+
+来看一下输出结果:
+
+```
+沉默王二
+沉默王二
+```
+
+只不过,反射的过程略显曲折了一些。
+
+第一步,获取反射类的 Class 对象:
+
+```java
+Class clazz = Class.forName("com.itwanger.s39.Writer");
+```
+
+第二步,通过 Class 对象获取构造方法 Constructor 对象:
+
+```java
+Constructor constructor = clazz.getConstructor();
+```
+
+第三步,通过 Constructor 对象初始化反射类对象:
+
+```java
+Object object = constructor.newInstance();
+```
+
+第四步,获取要调用的方法的 Method 对象:
+
+```java
+Method setNameMethod = clazz.getMethod("setName", String.class);
+Method getNameMethod = clazz.getMethod("getName");
+```
+
+第五步,通过 `invoke()` 方法执行:
+
+```java
+setNameMethod.invoke(object, "沉默王二");
+getNameMethod.invoke(object)
+```
+
+“三妹,你看,经过这五个步骤,基本上就掌握了反射的使用方法。”我说。
+
+“好像反射也没什么复杂的啊!”三妹说。
+
+我先对三妹点点头,然后说:“是的,掌握反射的基本使用方法确实不难,但要理解整个反射机制还是需要花一点时间去了解一下 Java 虚拟机的类加载机制的。”
+
+要想使用反射,首先需要获得反射类的 Class 对象,每一个类,不管它最终生成了多少个对象,这些对象只会对应一个 Class 对象,这个 Class 对象是由 Java 虚拟机生成的,由它来获悉整个类的结构信息。
+
+也就是说,`java.lang.Class` 是所有反射 API 的入口。
+
+而方法的反射调用,最终是由 Method 对象的 `invoke()` 方法完成的,来看一下源码(JDK 8 环境下)。
+
+```java
+@CallerSensitive
+public Object invoke(Object obj, Object... args)
+ throws IllegalAccessException, IllegalArgumentException,
+ InvocationTargetException
+{
+ if (!override) {
+ if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
+ Class caller = Reflection.getCallerClass();
+ checkAccess(caller, clazz, obj, modifiers);
+ }
+ }
+ MethodAccessor ma = methodAccessor; // read volatile
+ if (ma == null) {
+ ma = acquireMethodAccessor();
+ }
+ return ma.invoke(obj, args);
+}
+```
+
+两个嵌套的 if 语句是用来进行权限检查的。
+
+`invoke()` 方法实际上是委派给 MethodAccessor 接口来完成的。
+
+
+
+MethodAccessor 接口有三个实现类,其中的 MethodAccessorImpl 是一个抽象类,另外两个具体的实现类继承了这个抽象类。
+
+
+
+- NativeMethodAccessorImpl:通过本地方法来实现反射调用;
+- DelegatingMethodAccessorImpl:通过委派模式来实现反射调用;
+
+通过 debug 的方式进入 `invoke()` 方法后,可以看到第一次反射调用会生成一个委派实现 DelegatingMethodAccessorImpl,它在生成的时候会传递一个本地实现 NativeMethodAccessorImpl。
+
+
+
+也就是说,`invoke()` 方法在执行的时候,会先调用 DelegatingMethodAccessorImpl,然后调用 NativeMethodAccessorImpl,最后再调用实际的方法。
+
+“为什么不直接调用本地实现呢?”三妹问。
+
+“之所以采用委派实现,是为了能够在本地实现和动态实现之间切换。动态实现是另外一种反射调用机制,它是通过生成字节码的形式来实现的。如果反射调用的次数比较多,动态实现的效率就会更高,因为本地实现需要经过 Java 到 C/C++ 再到 Java 之间的切换过程,而动态实现不需要;但如果反射调用的次数比较少,反而本地实现更快一些。”我说。
+
+“那临界点是多少呢?”三妹问。
+
+“默认是 15 次。”我说,“可以通过 `-Dsun.reflect.inflationThreshold` 参数类调整。”
+
+来看下面这个例子。
+
+```java
+Method setAgeMethod = clazz.getMethod("setAge", int.class);
+for (int i = 0;i < 20; i++) {
+ setAgeMethod.invoke(object, 18);
+}
+```
+
+在 `invoke()` 方法处加断点进入 debug 模式,当 i = 15 的时候,也就是第 16 次执行的时候,会进入到 if 条件分支中,改变 DelegatingMethodAccessorImpl 的委派模式 delegate 为 `(MethodAccessorImpl)(new MethodAccessorGenerator()).generateMethod()`,而之前的委派模式 delegate 为 NativeMethodAccessorImpl。
+
+
+
+“这下明白了吧?三妹。”我说,“接下来,我们再来熟悉一下反射当中常用的 API。”
+
+**1)获取反射类的 Class 对象**
+
+`Class.forName()`,参数为反射类的完全限定名。
+
+```java
+Class c1 = Class.forName("com.itwanger.s39.ReflectionDemo3");
+System.out.println(c1.getCanonicalName());
+
+Class c2 = Class.forName("[D");
+System.out.println(c2.getCanonicalName());
+
+Class c3 = Class.forName("[[Ljava.lang.String;");
+System.out.println(c3.getCanonicalName());
+```
+
+来看一下输出结果:
+
+```
+com.itwanger.s39.ReflectionDemo3
+double[]
+java.lang.String[][]
+```
+
+类名 + `.class`,只适合在编译前就知道操作的 Class。。
+
+```java
+Class c1 = ReflectionDemo3.class;
+System.out.println(c1.getCanonicalName());
+
+Class c2 = String.class;
+System.out.println(c2.getCanonicalName());
+
+Class c3 = int[][][].class;
+System.out.println(c3.getCanonicalName());
+```
+
+来看一下输出结果:
+
+```java
+com.itwanger.s39.ReflectionDemo3
+java.lang.String
+int[][][]
+```
+
+**2)创建反射类的对象**
+
+通过反射来创建对象的方式有两种:
+
+- 用 Class 对象的 `newInstance()` 方法。
+- 用 Constructor 对象的 `newInstance()` 方法。
+
+```java
+Class c1 = Writer.class;
+Writer writer = (Writer) c1.newInstance();
+
+Class c2 = Class.forName("com.itwanger.s39.Writer");
+Constructor constructor = c2.getConstructor();
+Object object = constructor.newInstance();
+```
+
+**3)获取构造方法**
+
+Class 对象提供了以下方法来获取构造方法 Constructor 对象:
+
+- `getConstructor()`:返回反射类的特定 public 构造方法,可以传递参数,参数为构造方法参数对应 Class 对象;缺省的时候返回默认构造方法。
+- `getDeclaredConstructor()`:返回反射类的特定构造方法,不限定于 public 的。
+- `getConstructors()`:返回类的所有 public 构造方法。
+- `getDeclaredConstructors()`:返回类的所有构造方法,不限定于 public 的。
+
+```java
+Class c2 = Class.forName("com.itwanger.s39.Writer");
+Constructor constructor = c2.getConstructor();
+
+Constructor[] constructors1 = String.class.getDeclaredConstructors();
+for (Constructor c : constructors1) {
+ System.out.println(c);
+}
+```
+
+**4)获取字段**
+
+大体上和获取构造方法类似,把关键字 Constructor 换成 Field 即可。
+
+```java
+Method setNameMethod = clazz.getMethod("setName", String.class);
+Method getNameMethod = clazz.getMethod("getName");
+```
+
+**5)获取方法**
+
+大体上和获取构造方法类似,把关键字 Constructor 换成 Method 即可。
+
+```java
+Method[] methods1 = System.class.getDeclaredMethods();
+Method[] methods2 = System.class.getMethods();
+```
+
+“注意,三妹,如果你想反射访问私有字段和(构造)方法的话,需要使用 `Constructor/Field/Method.setAccessible(true)` 来绕开 Java 语言的访问限制。”我说。
+
+“好的,二哥。还有资料可以参考吗?”三妹问。
+
+“有的,有两篇文章写得非常不错,你在学习反射的时候可以作为参考。”我说。
+
+第一篇:深入理解 Java 反射和动态代理
+
+>链接:https://dunwu.github.io/javacore/basics/java-reflection.html#_1-%E5%8F%8D%E5%B0%84%E7%AE%80%E4%BB%8B
+
+第二篇:大白话说Java反射:入门、使用、原理:
+
+>链接:https://www.cnblogs.com/chanshuyi/p/head_first_of_reflection.html
+
+
+
diff --git a/docs/basic-extra-meal/generic.md b/docs/basic-extra-meal/generic.md
new file mode 100644
index 0000000000..a92ba6ac24
--- /dev/null
+++ b/docs/basic-extra-meal/generic.md
@@ -0,0 +1,468 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 深入理解Java泛型
+
+“二哥,为什么要设计泛型啊?”三妹开门见山地问。
+
+“三妹啊,听哥慢慢给你讲啊。”我说。
+
+Java 在 1.5 时增加了泛型机制,据说专家们为此花费了 5 年左右的时间(听起来很不容易)。有了泛型之后,尤其是对集合类的使用,就变得更规范了。
+
+看下面这段简单的代码。
+
+```java
+ArrayList list = new ArrayList();
+list.add("沉默王二");
+String str = list.get(0);
+```
+
+“三妹,你能想象到在没有泛型之前该怎么办吗?”
+
+“嗯,想不到,还是二哥你说吧。”
+
+嗯,我们可以使用 Object 数组来设计 `Arraylist` 类。
+
+```java
+class Arraylist {
+ private Object[] objs;
+ private int i = 0;
+ public void add(Object obj) {
+ objs[i++] = obj;
+ }
+
+ public Object get(int i) {
+ return objs[i];
+ }
+}
+```
+
+然后,我们向 `Arraylist` 中存取数据。
+
+```java
+Arraylist list = new Arraylist();
+list.add("沉默王二");
+list.add(new Date());
+String str = (String)list.get(0);
+```
+
+“三妹,你有没有发现这两个问题?”
+
+- Arraylist 可以存放任何类型的数据(既可以存字符串,也可以混入日期),因为所有类都继承自 Object 类。
+- 从 Arraylist 取出数据的时候需要强制类型转换,因为编译器并不能确定你取的是字符串还是日期。
+
+“嗯嗯,是的呢。”三妹说。
+
+对比一下,你就能明显地感受到泛型的优秀之处:使用**类型参数**解决了元素的不确定性——参数类型为 String 的集合中是不允许存放其他类型元素的,取出数据的时候也不需要强制类型转换了。
+
+“二哥,那怎么才能设计一个泛型呢?”
+
+“三妹啊,你一个小白只要会用泛型就行了,还想设计泛型啊?!不过,既然你想了解,那么哥义不容辞。”
+
+
+
+首先,我们来按照泛型的标准重新设计一下 `Arraylist` 类。
+
+```java
+class Arraylist {
+ private Object[] elementData;
+ private int size = 0;
+
+ public Arraylist(int initialCapacity) {
+ this.elementData = new Object[initialCapacity];
+ }
+
+ public boolean add(E e) {
+ elementData[size++] = e;
+ return true;
+ }
+
+ E elementData(int index) {
+ return (E) elementData[index];
+ }
+}
+```
+
+一个泛型类就是具有一个或多个类型变量的类。Arraylist 类引入的类型变量为 E(Element,元素的首字母),使用尖括号 `<>` 括起来,放在类名的后面。
+
+然后,我们可以用具体的类型(比如字符串)替换类型变量来实例化泛型类。
+
+```java
+Arraylist list = new Arraylist();
+list.add("沉默王三");
+String str = list.get(0);
+```
+
+Date 类型也可以的。
+
+```java
+Arraylist list = new Arraylist();
+list.add(new Date());
+Date date = list.get(0);
+```
+
+其次,我们还可以在一个非泛型的类(或者泛型类)中定义泛型方法。
+
+```java
+class Arraylist {
+ public T[] toArray(T[] a) {
+ return (T[]) Arrays.copyOf(elementData, size, a.getClass());
+ }
+}
+```
+
+不过,说实话,泛型方法的定义看起来略显晦涩。来一副图吧(注意:方法返回类型和方法参数类型至少需要一个)。
+
+
+
+现在,我们来调用一下泛型方法。
+
+```java
+Arraylist list = new Arraylist<>(4);
+list.add("沉");
+list.add("默");
+list.add("王");
+list.add("二");
+
+String [] strs = new String [4];
+strs = list.toArray(strs);
+
+for (String str : strs) {
+ System.out.println(str);
+}
+```
+
+然后,我们再来说说泛型变量的限定符 `extends`。
+
+在解释这个限定符之前,我们假设有三个类,它们之间的定义是这样的。
+
+```java
+class Wanglaoer {
+ public String toString() {
+ return "王老二";
+ }
+}
+
+class Wanger extends Wanglaoer{
+ public String toString() {
+ return "王二";
+ }
+}
+
+class Wangxiaoer extends Wanger{
+ public String toString() {
+ return "王小二";
+ }
+}
+```
+
+我们使用限定符 `extends` 来重新设计一下 `Arraylist` 类。
+
+```java
+class Arraylist {
+}
+```
+
+当我们向 `Arraylist` 中添加 `Wanglaoer` 元素的时候,编译器会提示错误:`Arraylist` 只允许添加 `Wanger` 及其子类 `Wangxiaoer` 对象,不允许添加其父类 `Wanglaoer`。
+
+```java
+Arraylist list = new Arraylist<>(3);
+list.add(new Wanger());
+list.add(new Wanglaoer());
+// The method add(Wanger) in the type Arraylist is not applicable for the arguments
+// (Wanglaoer)
+list.add(new Wangxiaoer());
+```
+
+也就是说,限定符 `extends` 可以缩小泛型的类型范围。
+
+“哦,明白了。”三妹若有所思的点点头,“二哥,听说虚拟机没有泛型?”
+
+“三妹,你功课做得可以啊。哥可以肯定地回答你,虚拟机是没有泛型的。”
+
+“怎么确定虚拟机有没有泛型呢?”三妹问。
+
+“只要我们把泛型类的字节码进行反编译就看到了!”用反编译工具将 class 文件反编译后,我说,“三妹,你看。”
+
+```java
+// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
+// Jad home page: http://www.kpdus.com/jad.html
+// Decompiler options: packimports(3)
+// Source File Name: Arraylist.java
+
+package com.cmower.java_demo.fanxing;
+
+import java.util.Arrays;
+
+class Arraylist
+{
+
+ public Arraylist(int initialCapacity)
+ {
+ size = 0;
+ elementData = new Object[initialCapacity];
+ }
+
+ public boolean add(Object e)
+ {
+ elementData[size++] = e;
+ return true;
+ }
+
+ Object elementData(int index)
+ {
+ return elementData[index];
+ }
+
+ private Object elementData[];
+ private int size;
+}
+```
+
+类型变量 `` 消失了,取而代之的是 Object !
+
+“既然如此,那如果泛型类使用了限定符 `extends`,结果会怎么样呢?”三妹这个问题问的很巧妙。
+
+来看这段代码。
+
+```java
+class Arraylist2 {
+ private Object[] elementData;
+ private int size = 0;
+
+ public Arraylist2(int initialCapacity) {
+ this.elementData = new Object[initialCapacity];
+ }
+
+ public boolean add(E e) {
+ elementData[size++] = e;
+ return true;
+ }
+
+ E elementData(int index) {
+ return (E) elementData[index];
+ }
+}
+```
+
+反编译后的结果如下。
+
+```java
+// Decompiled by Jad v1.5.8g. Copyright 2001 Pavel Kouznetsov.
+// Jad home page: http://www.kpdus.com/jad.html
+// Decompiler options: packimports(3)
+// Source File Name: Arraylist2.java
+
+package com.cmower.java_demo.fanxing;
+
+
+// Referenced classes of package com.cmower.java_demo.fanxing:
+// Wanger
+
+class Arraylist2
+{
+
+ public Arraylist2(int initialCapacity)
+ {
+ size = 0;
+ elementData = new Object[initialCapacity];
+ }
+
+ public boolean add(Wanger e)
+ {
+ elementData[size++] = e;
+ return true;
+ }
+
+ Wanger elementData(int index)
+ {
+ return (Wanger)elementData[index];
+ }
+
+ private Object elementData[];
+ private int size;
+}
+```
+
+“你看,类型变量 `` 不见了,E 被替换成了 `Wanger`”,我说,“通过以上两个例子说明,Java 虚拟机会将泛型的类型变量擦除,并替换为限定类型(没有限定的话,就用 `Object`)”
+
+“二哥,类型擦除会有什么问题吗?”三妹又问了一个很有水平的问题。
+
+“三妹啊,你还别说,类型擦除真的会有一些问题。”我说,“来看一下这段代码。”
+
+```java
+public class Cmower {
+
+ public static void method(Arraylist list) {
+ System.out.println("Arraylist list");
+ }
+
+ public static void method(Arraylist list) {
+ System.out.println("Arraylist list");
+ }
+
+}
+```
+
+在浅层的意识上,我们会想当然地认为 `Arraylist list` 和 `Arraylist list` 是两种不同的类型,因为 String 和 Date 是不同的类。
+
+但由于类型擦除的原因,以上代码是不会通过编译的——编译器会提示一个错误(这正是类型擦除引发的那些“问题”):
+
+```
+>Erasure of method method(Arraylist) is the same as another method in type
+ Cmower
+>
+>Erasure of method method(Arraylist) is the same as another method in type
+ Cmower
+```
+
+
+大致的意思就是,这两个方法的参数类型在擦除后是相同的。
+
+也就是说,`method(Arraylist list)` 和 `method(Arraylist list)` 是同一种参数类型的方法,不能同时存在。类型变量 `String` 和 `Date` 在擦除后会自动消失,method 方法的实际参数是 `Arraylist list`。
+
+有句俗话叫做:“百闻不如一见”,但即使见到了也未必为真——泛型的擦除问题就可以很好地佐证这个观点。
+
+“哦,明白了。二哥,听说泛型还有通配符?”
+
+“三妹啊,哥突然觉得你很适合作一枚可爱的程序媛啊!你这预习的功课做得可真到家啊,连通配符都知道!”
+
+通配符使用英文的问号(?)来表示。在我们创建一个泛型对象时,可以使用关键字 `extends` 限定子类,也可以使用关键字 `super` 限定父类。
+
+我们来看下面这段代码。
+
+```java
+class Arraylist {
+ private Object[] elementData;
+ private int size = 0;
+
+ public Arraylist(int initialCapacity) {
+ this.elementData = new Object[initialCapacity];
+ }
+
+ public boolean add(E e) {
+ elementData[size++] = e;
+ return true;
+ }
+
+ public E get(int index) {
+ return (E) elementData[index];
+ }
+
+ public int indexOf(Object o) {
+ if (o == null) {
+ for (int i = 0; i < size; i++)
+ if (elementData[i]==null)
+ return i;
+ } else {
+ for (int i = 0; i < size; i++)
+ if (o.equals(elementData[i]))
+ return i;
+ }
+ return -1;
+ }
+
+ public boolean contains(Object o) {
+ return indexOf(o) >= 0;
+ }
+
+ public String toString() {
+ StringBuilder sb = new StringBuilder();
+
+ for (Object o : elementData) {
+ if (o != null) {
+ E e = (E)o;
+ sb.append(e.toString());
+ sb.append(',').append(' ');
+ }
+ }
+ return sb.toString();
+ }
+
+ public int size() {
+ return size;
+ }
+
+ public E set(int index, E element) {
+ E oldValue = (E) elementData[index];
+ elementData[index] = element;
+ return oldValue;
+ }
+}
+```
+
+1)新增 `indexOf(Object o)` 方法,判断元素在 `Arraylist` 中的位置。注意参数为 `Object` 而不是泛型 `E`。
+
+2)新增 `contains(Object o)` 方法,判断元素是否在 `Arraylist` 中。注意参数为 `Object` 而不是泛型 `E`。
+
+3)新增 `toString()` 方法,方便对 `Arraylist` 进行打印。
+
+4)新增 `set(int index, E element)` 方法,方便对 `Arraylist` 元素的更改。
+
+因为泛型擦除的原因,`Arraylist list = new Arraylist();` 这样的语句是无法通过编译的,尽管 Wangxiaoer 是 Wanger 的子类。但如果我们确实需要这种 “向上转型” 的关系,该怎么办呢?这时候就需要通配符来发挥作用了。
+
+利用 `` 形式的通配符,可以实现泛型的向上转型,来看例子。
+
+```java
+Arraylist list2 = new Arraylist<>(4);
+list2.add(null);
+// list2.add(new Wanger());
+// list2.add(new Wangxiaoer());
+
+Wanger w2 = list2.get(0);
+// Wangxiaoer w3 = list2.get(1);
+```
+
+list2 的类型是 `Arraylist`,翻译一下就是,list2 是一个 `Arraylist`,其类型是 `Wanger` 及其子类。
+
+注意,“关键”来了!list2 并不允许通过 `add(E e)` 方法向其添加 `Wanger` 或者 `Wangxiaoer` 的对象,唯一例外的是 `null`。
+
+“那就奇了怪了,既然不让存放元素,那要 `Arraylist` 这样的 list2 有什么用呢?”三妹好奇地问。
+
+虽然不能通过 `add(E e)` 方法往 list2 中添加元素,但可以给它赋值。
+
+```java
+Arraylist list = new Arraylist<>(4);
+
+Wanger wanger = new Wanger();
+list.add(wanger);
+
+Wangxiaoer wangxiaoer = new Wangxiaoer();
+list.add(wangxiaoer);
+
+Arraylist list2 = list;
+
+Wanger w2 = list2.get(1);
+System.out.println(w2);
+
+System.out.println(list2.indexOf(wanger));
+System.out.println(list2.contains(new Wangxiaoer()));
+```
+
+`Arraylist list2 = list;` 语句把 list 的值赋予了 list2,此时 `list2 == list`。由于 list2 不允许往其添加其他元素,所以此时它是安全的——我们可以从容地对 list2 进行 `get()`、`indexOf()` 和 `contains()`。想一想,如果可以向 list2 添加元素的话,这 3 个方法反而变得不太安全,它们的值可能就会变。
+
+利用 `` 形式的通配符,可以向 Arraylist 中存入父类是 `Wanger` 的元素,来看例子。
+
+```java
+Arraylist list3 = new Arraylist<>(4);
+list3.add(new Wanger());
+list3.add(new Wangxiaoer());
+
+// Wanger w3 = list3.get(0);
+```
+
+需要注意的是,无法从 `Arraylist` 这样类型的 list3 中取出数据。
+
+“三妹,关于泛型,这里还有一篇很不错的文章,你等会去看一下。”我说。
+
+>https://www.pdai.tech/md/java/basic/java-basic-x-generic.html
+
+“对泛型机制讲的也很透彻,你结合二哥给你讲的这些,再深入的学习一下。”
+
+“好的,二哥。”
+
+
diff --git a/docs/basic-extra-meal/hashcode.md b/docs/basic-extra-meal/hashcode.md
new file mode 100644
index 0000000000..d481896064
--- /dev/null
+++ b/docs/basic-extra-meal/hashcode.md
@@ -0,0 +1,234 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 深入理解Java中的hashCode方法
+
+假期结束了,需要快速切换到工作的状态投入到新的一天当中。放假的时候痛快地玩耍,上班的时候积极的工作,这应该是我们大多数“现代人”该有的生活状态。
+
+我之所以费尽心思铺垫了前面这段话,就是想告诉大家,技术文虽迟但到,来吧,学起来~
+
+今天我们来谈谈 Java 中的 `hashCode()` 方法。众所周知,Java 是一门面向对象的编程语言,所有的类都会默认继承自 Object 类,而 Object 的中文意思就是“对象”。
+
+Object 类中就包含了 `hashCode()` 方法:
+
+```java
+@HotSpotIntrinsicCandidate
+public native int hashCode();
+```
+
+意味着所有的类都会有一个 `hashCode()` 方法,该方法会返回一个 int 类型的值。由于 `hashCode()` 方法是一个本地方法(`native` 关键字修饰的方法,用 `C/C++` 语言实现,由 Java 调用),意味着 Object 类中并没有给出具体的实现。
+
+具体的实现可以参考 `jdk/src/hotspot/share/runtime/synchronizer.cpp`(源码可以到 GitHub 上 OpenJDK 的仓库中下载)。`get_next_hash()` 方法会根据 hashCode 的取值来决定采用哪一种哈希值的生成策略。
+
+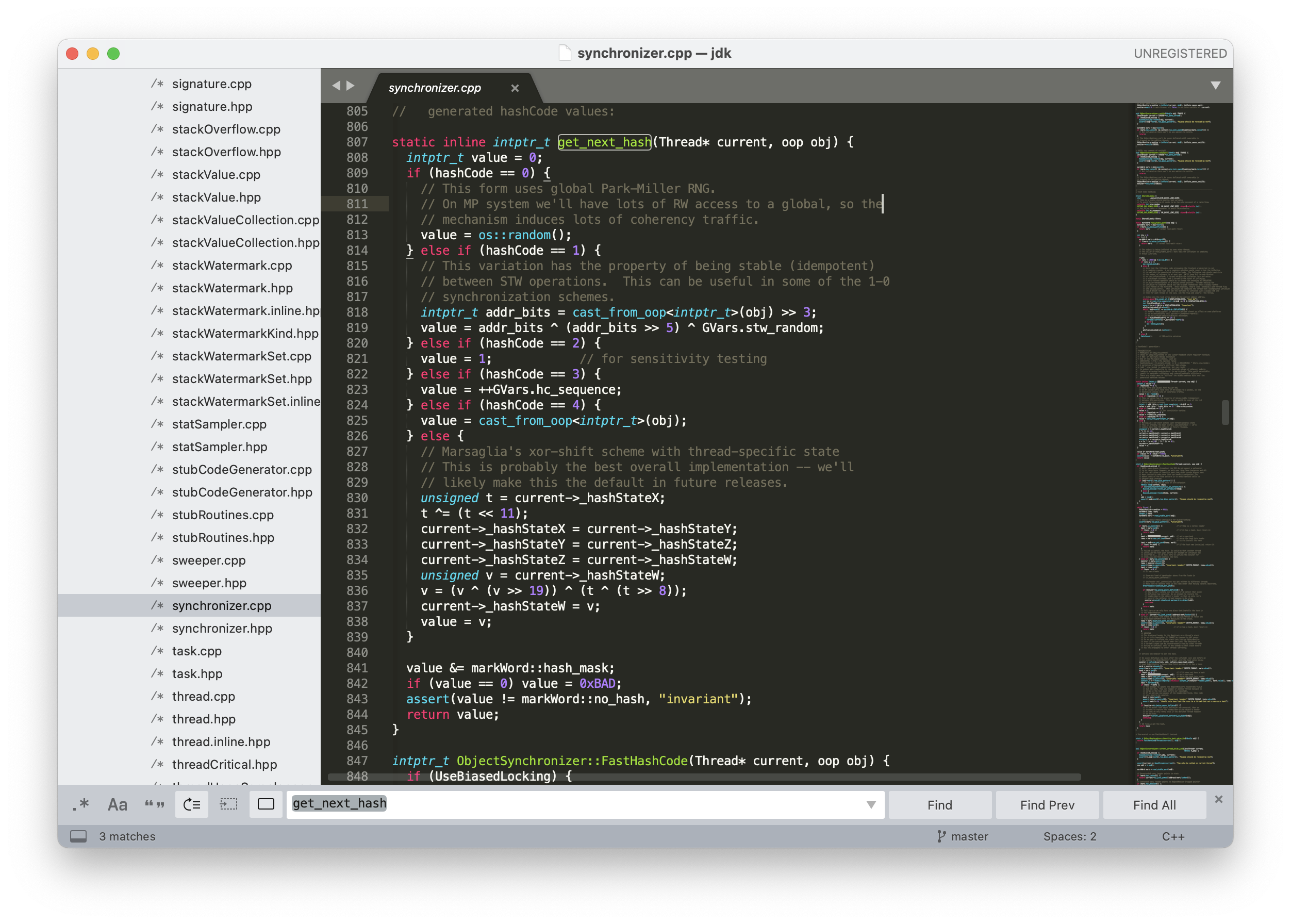
+
+并且 `hashCode()` 方法被 `@HotSpotIntrinsicCandidate` 注解修饰,说明它在 HotSpot 虚拟机中有一套高效的实现,基于 CPU 指令。
+
+那大家有没有想过这样一个问题:为什么 Object 类需要一个 `hashCode()` 方法呢?
+
+在 Java 中,`hashCode()` 方法的主要作用就是为了配合哈希表使用的。
+
+哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。其中用到的算法叫做哈希,就是把任意长度的输入,变换成固定长度的输出,该输出就是哈希值。像 MD5、SHA1 都用的是哈希算法。
+
+像 Java 中的 HashSet、Hashtable(注意是小写的 t)、HashMap 都是基于哈希表的具体实现。其中的 HashMap 就是最典型的代表,不仅面试官经常问,工作中的使用频率也非常的高。
+
+大家想一下,如果没有哈希表,但又需要这样一个数据结构,它里面存放的数据是不允许重复的,该怎么办呢?
+
+要不使用 `equals()` 方法进行逐个比较?这种方案当然是可行的。但如果数据量特别特别大,采用 `equals()` 方法进行逐个对比的效率肯定很低很低,最好的解决方案就是哈希表。
+
+拿 HashMap 来说吧。当我们要在它里面添加对象时,先调用这个对象的 `hashCode()` 方法,得到对应的哈希值,然后将哈希值和对象一起放到 HashMap 中。当我们要再添加一个新的对象时:
+
+- 获取对象的哈希值;
+- 和之前已经存在的哈希值进行比较,如果不相等,直接存进去;
+- 如果有相等的,再调用 `equals()` 方法进行对象之间的比较,如果相等,不存了;
+- 如果不等,说明哈希冲突了,增加一个链表,存放新的对象;
+- 如果链表的长度大于 8,转为红黑树来处理。
+
+就这么一套下来,调用 `equals()` 方法的频率就大大降低了。也就是说,只要哈希算法足够的高效,把发生哈希冲突的频率降到最低,哈希表的效率就特别的高。
+
+来看一下 HashMap 的哈希算法:
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+先调用对象的 `hashCode()` 方法,然后对该值进行右移运算,然后再进行异或运算。
+
+通常来说,String 会用来作为 HashMap 的键进行哈希运算,因此我们再来看一下 String 的 `hashCode()` 方法:
+
+```java
+public int hashCode() {
+ int h = hash;
+ if (h == 0 && value.length > 0) {
+ hash = h = isLatin1() ? StringLatin1.hashCode(value)
+ : StringUTF16.hashCode(value);
+ }
+ return h;
+}
+public static int hashCode(byte[] value) {
+ int h = 0;
+ int length = value.length >> 1;
+ for (int i = 0; i < length; i++) {
+ h = 31 * h + getChar(value, i);
+ }
+ return h;
+}
+```
+
+可想而知,经过这么一系列复杂的运算,再加上 JDK 作者这种大师级别的设计,哈希冲突的概率我相信已经降到了最低。
+
+当然了,从理论上来说,对于两个不同对象,它们通过 `hashCode()` 方法计算后的值可能相同。因此,不能使用 `hashCode()` 方法来判断两个对象是否相等,必须得通过 `equals()` 方法。
+
+也就是说:
+
+- 如果两个对象调用 `equals()` 方法得到的结果为 true,调用 `hashCode()` 方法得到的结果必定相等;
+- 如果两个对象调用 `hashCode()` 方法得到的结果不相等,调用 `equals()` 方法得到的结果必定为 false;
+
+反之:
+
+- 如果两个对象调用 `equals()` 方法得到的结果为 false,调用 `hashCode()` 方法得到的结果不一定不相等;
+- 如果两个对象调用 `hashCode()` 方法得到的结果相等,调用 `equals()` 方法得到的结果不一定为 true;
+
+来看下面这段代码。
+
+```java
+public class Test {
+ public static void main(String[] args) {
+ Student s1 = new Student(18, "张三");
+ Map scores = new HashMap<>();
+ scores.put(s1, 98);
+ System.out.println(scores.get(new Student(18, "张三")));
+ }
+}
+ class Student {
+ private int age;
+ private String name;
+
+ public Student(int age, String name) {
+ this.age = age;
+ this.name = name;
+ }
+
+ @Override
+ public boolean equals(Object o) {
+ Student student = (Student) o;
+ return age == student.age &&
+ Objects.equals(name, student.name);
+ }
+ }
+```
+
+我们重写了 Student 类的 `equals()` 方法,如果两个学生的年纪和姓名相同,我们就认为是同一个学生,虽然很离谱,但我们就是这么草率。
+
+在 `main()` 方法中,18 岁的张三考试得了 98 分,很不错的成绩,我们把张三和成绩放到了 HashMap 中,然后准备输出张三的成绩:
+
+```
+null
+```
+
+很不巧,结果为 null,而不是预期当中的 98。这是为什么呢?
+
+原因就在于重写 `equals()` 方法的时候没有重写 `hashCode()` 方法。默认情况下,`hashCode()` 方法是一个本地方法,会返回对象的存储地址,显然 `put()` 中的 s1 和 `get()` 中的 `new Student(18, "张三")` 是两个对象,它们的存储地址肯定是不同的。
+
+HashMap 的 `get()` 方法会调用 `hash(key.hashCode())` 计算对象的哈希值,虽然两个不同的 `hashCode()` 结果经过 `hash()` 方法计算后有可能得到相同的结果,但这种概率微乎其微,所以就导致 `scores.get(new Student(18, "张三"))` 无法得到预期的值 18。
+
+怎么解决这个问题呢?很简单,重写 `hashCode()` 方法。
+
+```java
+ @Override
+ public int hashCode() {
+ return Objects.hash(age, name);
+ }
+```
+
+Objects 类的 `hash()` 方法可以针对不同数量的参数生成新的 `hashCode()` 值。
+
+```java
+public static int hashCode(Object a[]) {
+ if (a == null)
+ return 0;
+
+ int result = 1;
+
+ for (Object element : a)
+ result = 31 * result + (element == null ? 0 : element.hashCode());
+
+ return result;
+}
+```
+
+代码似乎很简单,归纳出的数学公式如下所示(n 为字符串长度)。
+
+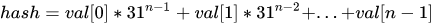
+
+注意:31 是个奇质数,不大不小,一般质数都非常适合哈希计算,偶数相当于移位运算,容易溢出,造成数据信息丢失。
+
+这就意味着年纪和姓名相同的情况下,会得到相同的哈希值。`scores.get(new Student(18, "张三"))` 就会返回 98 的预期值了。
+
+《Java 编程思想》这本圣经中有一段话,对 `hashCode()` 方法进行了一段描述。
+
+>设计 `hashCode()` 时最重要的因素就是:无论何时,对同一个对象调用 `hashCode()` 都应该生成同样的值。如果在将一个对象用 `put()` 方法添加进 HashMap 时产生一个 `hashCode()` 值,而用 `get()` 方法取出时却产生了另外一个 `hashCode()` 值,那么就无法重新取得该对象了。所以,如果你的 `hashCode()` 方法依赖于对象中易变的数据,用户就要当心了,因为此数据发生变化时,`hashCode()` 就会生成一个不同的哈希值,相当于产生了一个不同的键。
+
+也就是说,如果在重写 `hashCode()` 和 `equals()` 方法时,对象中某个字段容易发生改变,那么最好舍弃这些字段,以免产生不可预期的结果。
+
+好。有了上面这些内容作为基础后,我们回头再来看看本地方法 `hashCode()` 的 C++ 源码。
+
+```java
+static inline intptr_t get_next_hash(Thread* current, oop obj) {
+ intptr_t value = 0;
+ if (hashCode == 0) {
+ // This form uses global Park-Miller RNG.
+ // On MP system we'll have lots of RW access to a global, so the
+ // mechanism induces lots of coherency traffic.
+ value = os::random();
+ } else if (hashCode == 1) {
+ // This variation has the property of being stable (idempotent)
+ // between STW operations. This can be useful in some of the 1-0
+ // synchronization schemes.
+ intptr_t addr_bits = cast_from_oop(obj) >> 3;
+ value = addr_bits ^ (addr_bits >> 5) ^ GVars.stw_random;
+ } else if (hashCode == 2) {
+ value = 1; // for sensitivity testing
+ } else if (hashCode == 3) {
+ value = ++GVars.hc_sequence;
+ } else if (hashCode == 4) {
+ value = cast_from_oop(obj);
+ } else {
+ // Marsaglia's xor-shift scheme with thread-specific state
+ // This is probably the best overall implementation -- we'll
+ // likely make this the default in future releases.
+ unsigned t = current->_hashStateX;
+ t ^= (t << 11);
+ current->_hashStateX = current->_hashStateY;
+ current->_hashStateY = current->_hashStateZ;
+ current->_hashStateZ = current->_hashStateW;
+ unsigned v = current->_hashStateW;
+ v = (v ^ (v >> 19)) ^ (t ^ (t >> 8));
+ current->_hashStateW = v;
+ value = v;
+ }
+
+ value &= markWord::hash_mask;
+ if (value == 0) value = 0xBAD;
+ assert(value != markWord::no_hash, "invariant");
+ return value;
+}
+```
+
+如果没有 C++ 基础的话,不用细致去看每一行代码,我们只通过表面去了解一下 `get_next_hash()` 这个方法就行。其中的 `hashCode` 变量是 JVM 启动时的一个全局参数,可以通过它来切换哈希值的生成策略。
+
+- `hashCode==0`,调用操作系统 OS 的 `random()` 方法返回随机数。
+- `hashCode == 1`,在 STW(stop-the-world)操作中,这种策略通常用于同步方案中。利用对象地址进行计算,使用不经常更新的随机数(`GVars.stw_random`)参与其中。
+- `hashCode == 2`,使用返回 1,用于某些情况下的测试。
+- `hashCode == 3`,从 0 开始计算哈希值,不是线程安全的,多个线程可能会得到相同的哈希值。
+- `hashCode == 4`,与创建对象的内存位置有关,原样输出。
+- `hashCode == 5`,默认值,支持多线程,使用了 Marsaglia 的 xor-shift 算法产生伪随机数。所谓的 xor-shift 算法,简单来说,看起来就是一个移位寄存器,每次移入的位由寄存器中若干位取异或生成。所谓的伪随机数,不是完全随机的,但是真随机生成比较困难,所以只要能通过一定的随机数统计检测,就可以当作真随机数来使用。
+
+
diff --git a/docs/basic-extra-meal/immutable.md b/docs/basic-extra-meal/immutable.md
new file mode 100644
index 0000000000..3be63eae23
--- /dev/null
+++ b/docs/basic-extra-meal/immutable.md
@@ -0,0 +1,204 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 深入理解Java中的不可变对象
+
+>二哥,你能给我说说为什么 String 是 immutable 类(不可变对象)吗?我想研究它,想知道为什么它就不可变了,这种强烈的愿望就像想研究浩瀚的星空一样。但无奈自身功力有限,始终觉得雾里看花终隔一层。二哥你的文章总是充满趣味性,我想一定能够说明白,我也一定能够看明白,能在接下来写一写吗?
+
+收到读者小 R 的私信后,我就总感觉自己有一种义不容辞的责任,非要把 immutable 类说明白不可!
+
+
+### 01、什么是不可变类
+
+一个类的对象在通过构造方法创建后如果状态不会再被改变,那么它就是一个不可变(immutable)类。它的所有成员变量的赋值仅在构造方法中完成,不会提供任何 setter 方法供外部类去修改。
+
+还记得《神雕侠侣》中小龙女的古墓吗?随着那一声巨响,仅有的通道就被无情地关闭了。别较真那个密道,我这么说只是为了打开你的想象力,让你对不可变类有一个更直观的印象。
+
+自从有了多线程,生产力就被无限地放大了,所有的程序员都爱它,因为强大的硬件能力被充分地利用了。但与此同时,所有的程序员都对它心生忌惮,因为一不小心,多线程就会把对象的状态变得混乱不堪。
+
+为了保护状态的原子性、可见性、有序性,我们程序员可以说是竭尽所能。其中,synchronized(同步)关键字是最简单最入门的一种解决方案。
+
+假如说类是不可变的,那么对象的状态就也是不可变的。这样的话,每次修改对象的状态,就会产生一个新的对象供不同的线程使用,我们程序员就不必再担心并发问题了。
+
+### 02、常见的不可变类
+
+提到不可变类,几乎所有的程序员第一个想到的,就是 String 类。那为什么 String 类要被设计成不可变的呢?
+
+1)常量池的需要
+
+字符串常量池是 Java 堆内存中一个特殊的存储区域,当创建一个 String 对象时,假如此字符串在常量池中不存在,那么就创建一个;假如已经存,就不会再创建了,而是直接引用已经存在的对象。这样做能够减少 JVM 的内存开销,提高效率。
+
+2)hashCode 的需要
+
+因为字符串是不可变的,所以在它创建的时候,其 hashCode 就被缓存了,因此非常适合作为哈希值(比如说作为 HashMap 的键),多次调用只返回同一个值,来提高效率。
+
+3)线程安全
+
+就像之前说的那样,如果对象的状态是可变的,那么在多线程环境下,就很容易造成不可预期的结果。而 String 是不可变的,就可以在多个线程之间共享,不需要同步处理。
+
+因此,当我们调用 String 类的任何方法(比如说 `trim()`、`substring()`、`toLowerCase()`)时,总会返回一个新的对象,而不影响之前的值。
+
+```java
+String cmower = "沉默王二,一枚有趣的程序员";
+cmower.substring(0,4);
+System.out.println(cmower);// 沉默王二,一枚有趣的程序员
+```
+
+虽然调用 `substring()` 方法对 cmower 进行了截取,但 cmower 的值没有改变。
+
+除了 String 类,包装器类 Integer、Long 等也是不可变类。
+
+### 03、手撸不可变类
+
+看懂一个不可变类也许容易,但要创建一个自定义的不可变类恐怕就有点难了。但知难而进是我们作为一名优秀的程序员不可或缺的品质,正因为不容易,我们才能真正地掌握它。
+
+接下来,就请和我一起,来自定义一个不可变类吧。一个不可变诶,必须要满足以下 4 个条件:
+
+1)确保类是 final 的,不允许被其他类继承。
+
+2)确保所有的成员变量(字段)是 final 的,这样的话,它们就只能在构造方法中初始化值,并且不会在随后被修改。
+
+3)不要提供任何 setter 方法。
+
+4)如果要修改类的状态,必须返回一个新的对象。
+
+按照以上条件,我们来自定义一个简单的不可变类 Writer。
+
+```java
+public final class Writer {
+ private final String name;
+ private final int age;
+
+ public Writer(String name, int age) {
+ this.name = name;
+ this.age = age;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public String getName() {
+ return name;
+ }
+}
+```
+
+Writer 类是 final 的,name 和 age 也是 final 的,没有 setter 方法。
+
+OK,据说这个作者分享了很多博客,广受读者的喜爱,因此某某出版社找他写了一本书(Book)。Book 类是这样定义的:
+
+```java
+public class Book {
+ private String name;
+ private int price;
+
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getPrice() {
+ return price;
+ }
+
+ public void setPrice(int price) {
+ this.price = price;
+ }
+
+ @Override
+ public String toString() {
+ return "Book{" +
+ "name='" + name + '\'' +
+ ", price=" + price +
+ '}';
+ }
+}
+```
+
+2 个字段,分别是 name 和 price,以及 getter 和 setter,重写后的 `toString()` 方法。然后,在 Writer 类中追加一个可变对象字段 book。
+
+```java
+public final class Writer {
+ private final String name;
+ private final int age;
+ private final Book book;
+
+ public Writer(String name, int age, Book book) {
+ this.name = name;
+ this.age = age;
+ this.book = book;
+ }
+
+ public int getAge() {
+ return age;
+ }
+
+ public String getName() {
+ return name;
+ }
+
+ public Book getBook() {
+ return book;
+ }
+}
+```
+
+并在构造方法中追加了 Book 参数,以及 Book 的 getter 方法。
+
+完成以上工作后,我们来新建一个测试类,看看 Writer 类的状态是否真的不可变。
+
+```java
+public class WriterDemo {
+ public static void main(String[] args) {
+ Book book = new Book();
+ book.setName("Web全栈开发进阶之路");
+ book.setPrice(79);
+
+ Writer writer = new Writer("沉默王二",18, book);
+ System.out.println("定价:" + writer.getBook());
+ writer.getBook().setPrice(59);
+ System.out.println("促销价:" + writer.getBook());
+ }
+}
+```
+
+程序输出的结果如下所示:
+
+```java
+定价:Book{name='Web全栈开发进阶之路', price=79}
+促销价:Book{name='Web全栈开发进阶之路', price=59}
+```
+
+糟糕,Writer 类的不可变性被破坏了,价格发生了变化。为了解决这个问题,我们需要为不可变类的定义规则追加一条内容:
+
+如果一个不可变类中包含了可变类的对象,那么就需要确保返回的是可变对象的副本。也就是说,Writer 类中的 `getBook()` 方法应该修改为:
+
+```java
+public Book getBook() {
+ Book clone = new Book();
+ clone.setPrice(this.book.getPrice());
+ clone.setName(this.book.getName());
+ return clone;
+}
+```
+
+这样的话,构造方法初始化后的 Book 对象就不会再被修改了。此时,运行 WriterDemo,就会发现价格不再发生变化了。
+
+```
+定价:Book{name='Web全栈开发进阶之路', price=79}
+促销价:Book{name='Web全栈开发进阶之路', price=79}
+```
+
+### 04、总结
+
+不可变类有很多优点,就像之前提到的 String 类那样,尤其是在多线程环境下,它非常的安全。尽管每次修改都会创建一个新的对象,增加了内存的消耗,但这个缺点相比它带来的优点,显然是微不足道的——无非就是捡了西瓜,丢了芝麻。
+
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/instanceof-jvm.md b/docs/basic-extra-meal/instanceof-jvm.md
new file mode 100644
index 0000000000..a3f4241b8a
--- /dev/null
+++ b/docs/basic-extra-meal/instanceof-jvm.md
@@ -0,0 +1,110 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# instanceof关键字是如何实现的?
+
+小二那天去面试,碰到了这个问题:“**instanceof 关键字是如何实现的**?”面试官希望他能从底层来分析一下,结果小二没答上来,就来问我。
+
+我唯唯诺诺,强装镇定,只好把 R 大的一篇回答甩给了他,并且叮嘱他:“认认真真看,玩完后要是还不明白,再来问我。。。”
+
+>作者:RednaxelaFX,整理:沉默王二,链接:https://www.zhihu.com/question/21574535/answer/18998914
+
+
+
+--------
+
+### 场景一:月薪 3000 元一下的码农职位
+
+用 Java 伪代码来表现instanceof关键字在Java语言规范所描述的运行时语义,是这样的:
+
+```java
+// obj instanceof T
+boolean result;
+if (obj == null) {
+ result = false;
+} else {
+ try {
+ T temp = (T) obj; // checkcast
+ result = true;
+ } catch (ClassCastException e) {
+ result = false;
+ }
+}
+```
+
+用中文说就是:如果有表达式 `obj instanceof T`,那么如果 obj 不为 null 并且 (T) obj 不抛 ClassCastException 异常则该表达式值为 true ,否则值为 false 。
+
+如果面试官说“这不是废话嘛”,进入场景二。
+
+### 场景二:月薪6000-8000的Java研发职位
+
+JVM有一条名为 instanceof 的指令,而Java源码编译到Class文件时会把Java语言中的 instanceof 运算符映射到JVM的 instanceof 指令上。
+
+javac是这样做的:
+
+- instanceof 是javac能识别的一个关键字,对应到Token.INSTANCEOF的token类型。做词法分析的时候扫描到"instanceof"关键字就映射到了一个Token.INSTANCEOF token。
+- 该编译器的抽象语法树节点有一个JCTree.JCInstanceOf类用于表示instanceof运算。做语法分析的时候解析到[instanceof运算符](https://tobebetterjavaer.com/oo/instanceof.html)就会生成这个JCTree.JCInstanceof类型的节点。
+- 中途还得根据Java语言规范对instanceof运算符的编译时检查的规定把有问题的情况找出来。
+- 到最后生成字节码的时候为JCTree.JCInstanceof节点生成instanceof字节码指令。
+
+回答到这层面就已经能解决好些实际问题了,如果面试官还说,“这不还是废话嘛”,进入场景三。
+
+### 场景三:月薪10000的Java高级研发职位
+
+先简单介绍一下instanceof的字节码:
+
+- 操作:确定对象是否为给定的类型
+- 指令格式:instanceof|indexbyte1|indexbyte2
+- 指令执行前后的栈顶状态:
+ - ……,objectref=>
+ - ……,result
+
+再简单描述下:indexbyte1和indexbyte2用于构造对当前类的常量池的索引,objectref为reference类型,可以是某个类,数组的实例或者是接口。
+
+基本的实现过程:对indexbyte1和indexbyte2构造的常量池索引进行解析,然后根据java规范判断解析的类是不是objectref的一个实例,最后在栈顶写入结果。
+
+基本上就是根据规范来 YY 下实现,就能八九不离十蒙混过关了。
+
+如果面试官还不满意,进入场景四。
+
+### 场景四:月薪10000以上的Java资深研发职位
+
+这个岗位注重性能调优什么的,R 大说可以上论文了:
+
+>https://dl.acm.org/doi/10.1145/583810.583821
+
+论文我也看不懂,所以这里就不 BB 了。(逃
+
+篇论文描述了HotSpot VM做子类型判断的算法,这里简单补充一下JDK6至今的HotSpot VM实际采用的算法:
+
+```java
+S.is_subtype_of(T) := {
+ int off = T.offset;
+ if (S == T) return true;
+ if (T == S[off]) return true;
+ if (off != &cache) return false;
+ if ( S.scan_secondary_subtype_array(T) ) {
+ S.cache = T;
+ return true;
+ }
+ return false;
+}
+```
+
+HotSpot VM的两个编译器,Client Compiler (C1) 与 Server Compiler (C2) 各自对子类型判断的实现有更进一步的优化。实际上在JVM里,instanceof的功能就实现了4份,VM runtime、解释器、C1、C2各一份。
+
+VM runtime的:
+
+>http://hg.openjdk.java.net/jdk7u/jdk7u/hotspot/file/tip/src/share/vm/oops/oop.inline.hpp
+
+分享的最后,二哥简单来说一下。
+
+这个问题涉及语法细节,涉及jvm实现,涉及编译器,还涉及一点点数据结构设计,比较考验一个 Java 程序员的内功,如果要回答到论文的程度,那真的是,面试官也得提前备好知识点,不然应聘者的回答啥也听不懂就挺尴尬的。
+
+反正 R 大回答里的很多细节我都是第一次听,逃了逃了。。。。。。
+
+
diff --git a/docs/basic-extra-meal/int-cache.md b/docs/basic-extra-meal/int-cache.md
new file mode 100644
index 0000000000..e453bed329
--- /dev/null
+++ b/docs/basic-extra-meal/int-cache.md
@@ -0,0 +1,171 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java中int、Integer、new Integer之间的区别
+
+“三妹,今天我们来补一个小的知识点:Java 数据类型缓存池。”我喝了一口枸杞泡的茶后对三妹说,“考你一个问题哈:`new Integer(18) 与 Integer.valueOf(18) ` 的区别是什么?”
+
+“难道不一样吗?”三妹有点诧异。
+
+“不一样的。”我笑着说。
+
+- `new Integer(18)` 每次都会新建一个对象;
+- `Integer.valueOf(18)` 会使⽤用缓存池中的对象,多次调用只会取同⼀一个对象的引用。
+
+来看下面这段代码:
+
+```java
+Integer x = new Integer(18);
+Integer y = new Integer(18);
+System.out.println(x == y);
+
+Integer z = Integer.valueOf(18);
+Integer k = Integer.valueOf(18);
+System.out.println(z == k);
+
+Integer m = Integer.valueOf(300);
+Integer p = Integer.valueOf(300);
+System.out.println(m == p);
+```
+
+来看一下输出结果吧:
+
+```
+false
+true
+false
+```
+
+“第一个 false,我知道原因,因为 new 出来的是不同的对象,地址不同。”三妹解释道,“第二个和第三个我认为都应该是 true 啊,为什么第三个会输出 false 呢?这个我理解不了。”
+
+“其实原因也很简单。”我胸有成竹地说。
+
+基本数据类型的包装类除了 Float 和 Double 之外,其他六个包装器类(Byte、Short、Integer、Long、Character、Boolean)都有常量缓存池。
+
+- Byte:-128~127,也就是所有的 byte 值
+- Short:-128~127
+- Long:-128~127
+- Character:\u0000 - \u007F
+- Boolean:true 和 false
+
+拿 Integer 来举例子,Integer 类内部中内置了 256 个 Integer 类型的缓存数据,当使用的数据范围在 -128~127 之间时,会直接返回常量池中数据的引用,而不是创建对象,超过这个范围时会创建新的对象。
+
+ 18 在 -128~127 之间,300 不在。
+
+来看一下 valueOf 方法的源码吧。
+
+```java
+public static Integer valueOf(int i) {
+ if (i >=IntegerCache.low && i <=IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+}
+```
+
+“哦,原来是因为 Integer.IntegerCache 这个内部类的原因啊!”三妹好像发现了新大陆。
+
+“是滴。来看一下 IntegerCache 这个静态内部类的源码吧。”
+
+```java
+private static class IntegerCache {
+ static final int low = -128;
+ static final int high;
+ static final Integer cache[];
+
+ static {
+ // high value may be configured by property
+ int h = 127;
+ String integerCacheHighPropValue =
+ sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
+ if (integerCacheHighPropValue != null) {
+ try {
+ int i = parseInt(integerCacheHighPropValue);
+ i = Math.max(i, 127);
+ // Maximum array size is Integer.MAX_VALUE
+ h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
+ } catch( NumberFormatException nfe) {
+ // If the property cannot be parsed into an int, ignore it.
+ }
+ }
+ high = h;
+
+ cache = new Integer[(high - low) + 1];
+ int j = low;
+ for(int k = 0; k < cache.length; k++)
+ cache[k] = new Integer(j++);
+
+ // range [-128, 127] must be interned (JLS7 5.1.7)
+ assert Integer.IntegerCache.high >= 127;
+ }
+
+ private IntegerCache() {}
+}
+```
+
+
+
+之前我们在[学习 static 关键字](https://github.com/itwanger/toBeBetterJavaer/blob/master/docs/keywords/java-static.md)的时候,提到过静态代码块,还记得吧?三妹。静态代码块通常用来初始化一些静态变量,它会优先于 main() 方法执行。
+
+在静态代码块中,low 为 -128,也就是缓存池的最小值;high 默认为 127,也就是缓存池的最大值,共计 256 个。
+
+*可以在 JVM 启动的时候,通过 `-XX:AutoBoxCacheMax=NNN` 来设置缓存池的大小,当然了,不能无限大,最大到 `Integer.MAX_VALUE -129`*
+
+之后,初始化 cache 数组的大小,然后遍历填充,下标从 0 开始。
+
+“明白了吧?三妹。”我喝了一口水后,扭头看了看旁边的三妹。
+
+“这段代码不难理解,难理解的是 `assert Integer.IntegerCache.high >= 127;`,这行代码是干嘛的呀?”三妹很是不解。
+
+“哦哦,你挺细心的呀!”三妹真不错,求知欲望越来越强烈了。
+
+assert 是 Java 中的一个关键字,寓意是断言,为了方便调试程序,并不是发布程序的组成部分。
+
+默认情况下,断言是关闭的,可以在命令行运行 Java 程序的时候加上 `-ea` 参数打开断言。
+
+来看这段代码。
+
+```java
+public class AssertTest {
+ public static void main(String[] args) {
+ int high = 126;
+ assert high >= 127;
+ }
+}
+```
+
+假设手动设置的缓存池大小为 126,显然不太符合缓存池的预期值 127,结果会输出什么呢?
+
+直接在 Intellij IDEA 中打开命令行终端,进入 classes 文件,执行:
+
+```
+ /usr/libexec/java_home -v 1.8 --exec java -ea com.itwanger.s51.AssertTest
+```
+
+*我用的 macOS 环境,装了好多个版本的 JDK,该命令可以切换到 JDK 8*
+
+也可以不指定 Java 版本直接执行(加上 `-ea` 参数):
+
+```
+java -ea com.itwanger.s51.AssertTest
+```
+
+“呀,报错了呀。”三妹喊道。
+
+```
+Exception in thread "main" java.lang.AssertionError
+ at com.itwanger.s51.AssertTest.main(AssertTest.java:9)
+```
+
+“是滴,因为 126 小于 127。”我回答道。
+
+“原来 assert 是这样用的啊,我明白了。”三妹表示学会了。
+
+“那,缓存池之所以存在的原因也是因为这样做可以提高程序的整体性能,因为相对来说,比如说 Integer,-128~127 这个范围内的 256 个数字使用的频率会高一点。”我总结道。
+
+“get 了!二哥你真棒,又学到了。”三妹很开心~
+
+
\ No newline at end of file
diff --git a/docs/src/basic-extra-meal/java-naming.md b/docs/basic-extra-meal/java-naming.md
similarity index 82%
rename from docs/src/basic-extra-meal/java-naming.md
rename to docs/basic-extra-meal/java-naming.md
index 10e6e3663a..4dd1cc07aa 100644
--- a/docs/src/basic-extra-meal/java-naming.md
+++ b/docs/basic-extra-meal/java-naming.md
@@ -1,18 +1,12 @@
---
-title: 5 分钟编码,1 小时命名,笑
-shortTitle: Java命名规范
category:
- Java核心
tag:
- - Java语法基础
-description: 本文介绍了Java编程中的命名规范,以帮助程序员编写可读性强、易于维护的代码。我们将从变量、方法、类和接口命名等方面讲解最佳实践,以便在项目中保持一致的代码风格。学习并实践这些命名规范,将使你成为更出色的Java程序员。
-author: 沉默王二
-head:
- - - meta
- - name: keywords
- content: Java,Java命名规范, 变量命名, 方法命名, 类命名, 接口命名, 代码风格, 代码质量
+ - Java
---
+# Java命名规范(非常全面,可以收藏)
+
“二哥,Java 中的命名约定都有哪些呢?”三妹的脸上泛着甜甜的笑容,她开始对接下来要学习的内容充满期待了,这正是我感到欣慰的地方。
“对于我们中国人来说,名字也是有讲究的,比如说我叫沉默王二,你就叫沉默王三,哈哈。”我笑着对三妹说。
@@ -25,27 +19,32 @@ head:
拿我这个笔名“沉默王二”来举例吧,读起来我就觉得朗朗上口,读者看到这个笔名就知道我是一个什么样的人——对不熟的人保持沉默,对熟的人妙语连珠,哈哈。
->当然了,如果你暂时记不住也没关系,后面再回头来记一下就好了。
-
### 01、包(package)
包的命名应该遵守以下规则:
- 应该全部是小写字母
+
- 点分隔符之间有且仅有一个自然语义的英语单词
+
- 包名统一使用单数形式,比如说 `com.itwanger.util` 不能是 `com.itwanger.utils`
+
- 在最新的 Java 编程规范中,要求开发人员在自己定义的包名前加上唯一的前缀。由于互联网上的域名是不会重复的,所以多数开发人员采用自己公司(或者个人博客)在互联网上的域名称作为包的唯一前缀。比如我文章中出现的代码示例的包名就是 `package com.itwanger`。
+
### 02、类(class)
类的命名应该遵守以下规则:
- 必须以大写字母开头
+
- 最好是一个名词,比如说 System
+
- 类名使用 UpperCamelCase(驼峰式命名)风格
-- 尽量不要省略成单词的首字母,但以下情形例外:DO/BO/DTO/VO/AO/PO/UID 等
-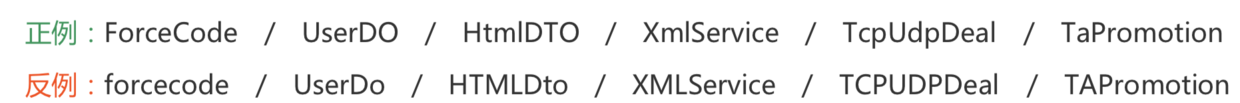
+- 尽量不要省略成单词的首字母,但以下情形例外:DO/BO/DTO/VO/AO/ PO / UID 等
+
+
另外,如果是抽象类的话,使用 Abstract 或 Base 开头;如果是异常类的话,使用 Exception 结尾;如果是测试类的话,使用 Test 结尾。
@@ -54,7 +53,9 @@ head:
接口的命名应该遵守以下规则:
- 必须以大写字母开头
+
- 最好是一个形容词,比如说 Runnable
+
- 尽量不要省略成单词的首字母
来看个例子:
@@ -66,6 +67,7 @@ interface Printable {}
接口和实现类之间也有一些规则:
- 实现类用 Impl 的后缀与接口区别,比如说 CacheServiceImpl 实现 CacheService 接口
+
- 或者,AbstractTranslator 实现 Translatable 接口
### 04、字段(field)和变量(variable)
@@ -73,10 +75,15 @@ interface Printable {}
字段和变量的命名应该遵守以下规则:
- 必须以小写字母开头
+
- 可以包含多个单词,第一个单词的首字母小写,其他的单词首字母大写,比如说 `firstName`
+
- 最好不要使用单个字符,比如说 `int a`,除非是局部变量
+
- 类型与中括号紧挨相连来表示数组,比如说 `int[] arrayDemo`,main 方法中字符串数组参数不应该写成 `String args[]`
+
- POJO 类中的任何布尔类型的变量,都不要加 is 前缀,否则部分框架解析会引起序列化错误,我自己知道的有 fastjson
+
- 避免在子类和父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名,使可理解性降低。子类、父类成员变量名相同,即使是 public 类型的变量也能够通过编译,另外,局部变量在同一方法内的不同代码块中同名也是合法的,这些情况都要避免。
反例:
@@ -108,7 +115,9 @@ class Son extends ConfusingName {
常量的命名应该遵守以下规则:
- 应该全部是大写字母
+
- 可以包含多个单词,单词之间使用“_”连接,比如说 `MAX_PRIORITY`,力求语义表达完整清楚,不要嫌名字长
+
- 可以包含数字,但不能以数字开头
来看个例子:
@@ -117,12 +126,15 @@ class Son extends ConfusingName {
static final int MIN_AGE = 18;
```
+
### 06、方法(method)
方法的命名应该遵守以下规则:
- 必须以小写字母开头
+
- 最好是一个动词,比如说 `print()`
+
- 可以包含多个单词,第一个单词的首字母小写,其他的单词首字母大写,比如说 `actionPerformed()`
来看个例子:
@@ -134,10 +146,15 @@ void writeBook(){}
Service/DAO 层的方法命名规约:
- 获取单个对象的方法用 get 做前缀
+
- 获取多个对象的方法用 list 做前缀,复数结尾,如:listObjects
+
- 获取统计值的方法用 count 做前缀
+
- 插入的方法用 save/insert 做前缀
+
- 删除的方法用 remove/delete 做前缀
+
- 修改的方法用 update 做前缀
@@ -157,9 +174,4 @@ Service/DAO 层的方法命名规约:
-----
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/java-unicode.md b/docs/basic-extra-meal/java-unicode.md
new file mode 100644
index 0000000000..35ca351e2d
--- /dev/null
+++ b/docs/basic-extra-meal/java-unicode.md
@@ -0,0 +1,175 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 彻底弄懂Java中的Unicode和UTF-8编码
+
+“二哥,[上一篇](https://mp.weixin.qq.com/s/twim3w_dp5ctCigjLGIbFw)文章中提到了 Unicode,说 Java 中的
+ char 类型之所以占 2 个字节,是因为 Java 使用的是 Unicode 字符集而不是 ASCII 字符集,我有点迷,想了解一下,能细致给我说说吗?”
+
+“当然没问题啊,三妹。”
+
+**1)ASCII**
+
+对于计算机来说,只认 0 和 1,所有的信息最终都是一个二进制数。一个二进制数要么是 0,要么是 1,所以 8 个二进制数放在一起(一个字节),就会组合出 256 种状态,也就是 2 的 8 次方(`2^8`),从 00000000 到 11111111。
+
+ASCII 码由电报码发展而来,第一版标准发布于 1963 年,最后一次更新则是在1986 年,至今为止共定义了 128 个字符。其中 33 个字符无法显示在一般的设备上,需要用特殊的设备才能显示。
+
+ASCII 码的局限在于只能显示 26 个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语,对于其他一些语言则无能无力,比如在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
+
+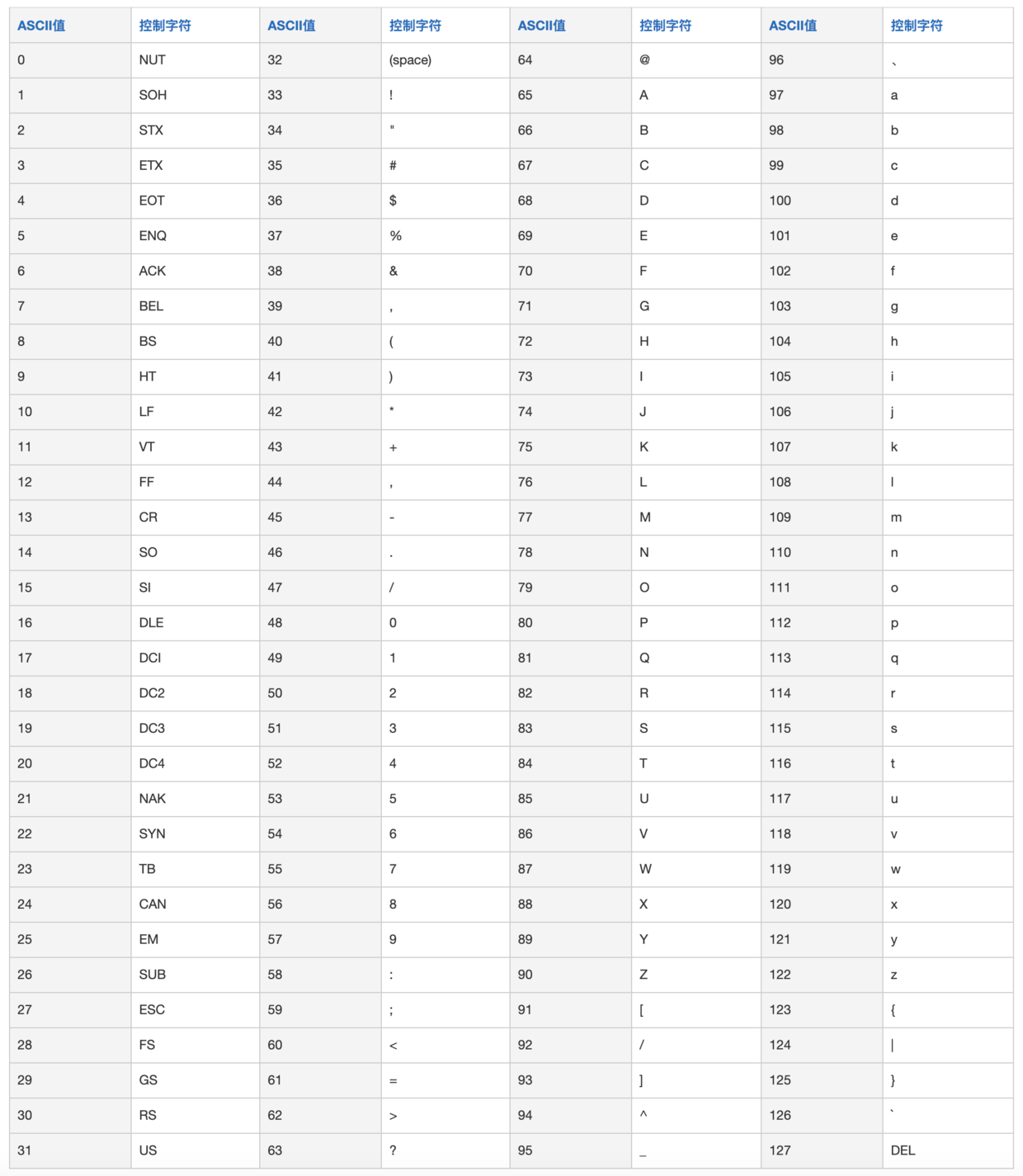
+
+PS:拉丁字母(也称为罗马字母)是多数欧洲语言采用的字母系统,是世界上最通行的字母文字系统,是罗马文明的成果之一。
+
+虽然名称上叫作拉丁字母,但拉丁文中并没有用 J、U 和 W 这三个字母。
+
+在我们的印象中,可能说拉丁字母多少有些陌生,说英语字母可能就有直观的印象了。
+
+
+
+PPS:阿拉伯数字,我们都很熟悉了。
+
+
+
+但是,阿拉伯数字并非起源于阿拉伯,而是起源于古印度。学过历史的我们应该有一些印象,阿拉伯分布于西亚和北非,以阿拉伯语为主要语言,以伊斯兰教为主要信仰。
+
+
+
+处在这样的地理位置,做起东亚和欧洲的一些生意就很有优势,于是阿拉伯数字就由阿拉伯人传到了欧洲,因此得名。
+
+PPPS:英式标点符号,也叫英文标点符号,和中文标点符号很相近。标点符号是辅助文字记录语言的符号,是书面语的组成部分,用来表示停顿、加强语气等。
+
+英文标点符号在 16 世纪时,分为朗诵学派和句法学派,主要由古典时期的希腊文和拉丁文演变而来,在 17 世纪后进入稳定阶段。俄文的标点符号依据希腊文而来,到了 18 世纪后也采用了英文标点符号。
+
+在很多人的印象中,古文是没有标点符号的,但管锡华博士研究指出,中国早在先秦时代就有标点符号了,后来融合了一些英文标点符号后,逐渐形成了现在的中文标点符号。
+
+
+
+
+**2)Unicode**
+
+这个世界上,除了英语,还有法语、葡萄牙语、西班牙语、德语、俄语、阿拉伯语、韩语、日语等等等等。ASCII 码用来表示英语是绰绰有余的,但其他这些语言就没办法了。
+
+像我们的母语,博大精深,汉字的数量很多很多,东汉的《说文解字》收字 9353 个,清朝《康熙字典》收字 47035 个,当代的《汉语大字典》收字 60370 个。1994 年中华书局、中国友谊出版公司出版的《中华字海》收字 85568 个。
+
+PS:常用字大概 2500 个,次常用字 1000 个。
+
+一个字节只能表示 256 种符号,所以如果拿 ASCII 码来表示汉字的话,是远远不够用的,那就必须要用更多的字节。简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,理论上最多可以表示 256 x 256 = 65536 个符号。
+
+要知道,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
+
+
+
+PPS:这“锟斤拷”价格挺公道的啊!!!(逃
+
+如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会彻底消失。
+
+这个艰巨的任务有谁来完成呢?**Unicode**,中文译作万国码、国际码、统一码、单一码,就像它的名字都表示的,这是一种所有符号的编码。
+
+Unicode 至今仍在不断增修,每个新版本都会加入更多新的字符。目前最新的版本为 2020 年 3 月公布的 13.0,收录了 13 万个字符。
+
+
+
+Unicode 是一个很大的集合,现在的规模可以容纳 100 多万个符号。每个符号的编码都不一样,比如,`U+0639`表示阿拉伯字母 `Ain`,`U+0041` 表示英语的大写字母 `A`,`U+4E25` 表示汉字`严`。
+
+具体的符号对应表,可以查询 [unicode.org](http://www.unicode.org/),或者专门的[汉字对应表](http://www.chi2ko.com/tool/CJK.htm)。
+
+曾有人这样说:
+
+>Unicode 支持的字符上限是 65536 个,Unicode 字符必须占两个字节。
+
+但这是一种误解,记住,Unicode 只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节,所以它可以无穷大。
+
+Unicode 虽然统一了全世界字符的编码,但没有规定如何存储。如果统一规定的话,每个符号就要用 3 个或 4 个字节表示,因为 2 个字节只能表示 65536 个,根本表示不全。
+
+那怎么办呢?
+
+UTF(Unicode Transformation Formats,Unicode 的编码方式)来了!最常见的就是 UTF-8 和 UTF-16。
+
+在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
+
+如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
+
+具体的表现形式为:
+
+0xxxxxxx:一个字节;
+110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
+1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
+11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
+
+也就是说,UTF-8 是一种可变长度的编码方式——这是它的优势也是劣势。
+
+怎么讲呢?优势就是它包罗万象,劣势就是浪费空间。举例来说吧,UTF-8 采用了 3 个字节(256*256*256=16777216)来编码常用的汉字,但常用的汉字没有这么多,这对于计算机来说,就是一种严重的资源浪费。
+
+基于这样的考虑,中国国家标准总局于 1980 年发布了 GB 2312 编码,即中华人民共和国国家标准简体中文字符集。GB 2312 标准共收录 6763 个汉字(2 个字节就够用了),其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
+
+GB 2312 的出现,基本满足了汉字的计算机处理需求。对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312 不能处理,就有了 GBK(K 为“扩展”的汉语拼音(kuòzhǎn)第一个声母)。
+
+来看一段代码:
+
+```java
+public class Demo {
+ public static void main(String[] args) {
+ String wanger = "沉默王二";
+ byte[] bytes = wanger.getBytes(Charset.forName("GBK"));
+ String result = new String(bytes, Charset.forName("UTF-8"));
+ System.out.println(result);
+ }
+}
+```
+
+先用 GBK 编码,再用 UTF-8 解码,程序会输出什么呢?
+
+```
+��Ĭ����
+```
+
+嘿嘿,乱码来了!在 Unicode 中,� 是一个特殊的符号,它用来表示无法显示,它的十六进制是 `0xEF 0xBF 0xBD`。那么两个 �� 就是 `0xEF 0xBF 0xBD 0xEF 0xBF 0xBD`,如果用 GBK 进行解码的话,就是大名鼎鼎的“**锟斤拷**”。
+
+可以通过代码来验证一下:
+
+```java
+// 输出 efbfbdefbfbd
+System.out.println(HexUtil.encodeHex("��", Charset.forName("UTF-8")));
+// 借助 hutool 转成二进制
+byte[] testBytes = HexUtil.decodeHex("efbfbdefbfbd");
+// 使用 GBK 解码
+String testResult = new String(testBytes, Charset.forName("GBK"));
+// 输出锟斤拷
+System.out.println(testResult);
+```
+
+PPPS:hutool 的使用方法可以参照我的另外一篇[文章](https://mp.weixin.qq.com/s/hso-Hm5NuFStMu3m0iz_0w)。
+
+所以,以后再见到**锟斤拷**,第一时间想到 UTF-8 和 GBK 的转换问题准没错。
+
+UTF-16 使用 2 个或者 4 个字节来存储字符。
+
+- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
+
+- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
+
+**3)char**
+
+搞清楚了 Unicode 之后,再回头来看 char 为什么是两个字节的问题,就很容易搞明白了。
+
+在 Unicode 的设计之初,人们认为两个字节足以对世界上各种语言的所有字符进行编码,在 1991 年发布的 Unicode 1.0 中,仅用了 65536 个代码值中不到一半的部分。
+
+所以,Java 决定采用 16 位的 Unicode 字符集([诞生于 90 年代](https://mp.weixin.qq.com/s/Ctouw652iC0qtrmjen9aEw))。也就是说,当时的 char 类型可以表示任意一个 Unicode 字符。
+
+但是,不可避免的事情发生了,Unicode 收录的字符越来越多,超过了 65536 个(2 个字节的最大表示范围)。超过的部分怎么办呢?只能用两个 char 来表示了。
+
+这个 `𐐷` 字符很特殊,Unicode 编码是 `U+10437`,它就无法使用一个 char 来表示,当你尝试用 char 来表示时,它会被 IDEA 转成 UTF-16 十六进制字符代码 `\uD801\uDC37`(与此同时,编译器会提醒你最好把它声明成 String 类型)。
+
+
+
+也就是说,在 Java 中,char 会占用两个字节,超出 char 的承受范围('\u0000'(0)和 '\uffff'(65,535))的字符,都将无法表示。
+
+
+
+“好了,三妹,关于 Unicode 就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
+
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/jdk-while-for-wuxian-xunhuan.md b/docs/basic-extra-meal/jdk-while-for-wuxian-xunhuan.md
new file mode 100644
index 0000000000..4c0c9fee8a
--- /dev/null
+++ b/docs/basic-extra-meal/jdk-while-for-wuxian-xunhuan.md
@@ -0,0 +1,103 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 为什么JDK源码中,无限循环大多使用for(;;)而不是while(true)?
+
+在知乎上看到 R 大的这篇回答,着实感觉需要分享给在座的各位 javaer 们,真心透彻。
+
+>https://www.zhihu.com/question/52311366/answer/130090347
+
+-----
+
+首先是先问是不是再问为什么系列。
+
+在JDK8u的jdk项目下做个很粗略的搜索:
+
+```
+mymbp:/Users/me/workspace/jdk8u/jdk/src
+$ egrep -nr "for \\(\\s?;\\s?;" . | wc -l
+ 369
+mymbp:/Users/me/workspace/jdk8u/jdk/src
+$ egrep -nr "while \\(true" . | wc -l
+ 323
+```
+
+并没有差多少。
+
+其次,for (;;) 在Java中的来源。个人看法是喜欢用这种写法的人,追根溯源是受到C语言里的写法的影响。这些人不一定是自己以前写C习惯了这样写,而可能是间接受以前写C的老师、前辈的影响而习惯这样写的。
+
+在C语言里,如果不include某些头文件或者自己声明的话,是没有内建的_Bool / bool类型,也没有TRUE / FALSE / true / false这些_Bool / bool类型值的字面量的。
+
+所以,假定没有include那些头文件或者自己define出上述字面量,一个不把循环条件写在while (...)括号里的while语句,最常见的是这样:
+```
+while (1) {
+ /* ... */
+ }
+```
+
+ …但不是所有人都喜欢看到那个魔数“1”的。
+
+ 而用for (;;)来表达不写循环条件(也就是循环体内不用break或goto就会是无限循环)则非常直观——这就是for语句本身的功能,而且不需要写任何魔数。所以这个写法就流传下来了。
+
+顺带一提,在Java里我是倾向于写while (true)的,不过我也不介意别人在他们自己的项目里写for (;;)。
+
+=====================================
+
+至于Java里while (true)与for (;;)哪个“效率更高”。这种规范没有规定的问题,答案都是“看实现”,毕竟实现只要保证语义符合规范就行了,而效率并不在规范管得着的范畴内。
+
+以Oracle/Sun JDK8u / OpenJDK8u的实现来看,首先看javac对下面俩语句的编译结果:
+
+```java
+public void foo() {
+ int i = 0;
+ while (true) { i++; }
+ }
+
+/*
+ public void foo();
+ Code:
+ stack=1, locals=2, args_size=1
+ 0: iconst_0
+ 1: istore_1
+ 2: iinc 1, 1
+ 5: goto 2
+*/
+```
+
+
+与
+
+```java
+public void bar() {
+ int i = 0;
+ for (;;) { i++; }
+ }```
+
+/*
+ public void bar();
+ Code:
+ stack=1, locals=2, args_size=1
+ 0: iconst_0
+ 1: istore_1
+ 2: iinc 1, 1
+ 5: goto 2
+*/
+```
+
+连javac这种几乎什么优化都不做(只做了Java语言规范规定一定要做的常量折叠,和非常少量别的优化)的编译器,对上面俩版本的代码都生成了一样的字节码。后面到解释执行、JIT编译之类的就不用说了,输入都一样,输出也不会不同。
+
+-----
+
+分享的最后,二哥简单说几句。
+
+可能在我们普通人眼中,这种问题完全没有求真的必要性,但 R大认真去研究了,并且得出了非常令人信服的答案。
+
+所以,牛逼之人必有三连之处啊。
+
+以后就可以放心大胆在代码里写 `for(;;) while(true)` 这样的死循环了。
+
+
diff --git a/docs/basic-extra-meal/jdk9-char-byte-string.md b/docs/basic-extra-meal/jdk9-char-byte-string.md
new file mode 100644
index 0000000000..8d7c9d6df5
--- /dev/null
+++ b/docs/basic-extra-meal/jdk9-char-byte-string.md
@@ -0,0 +1,111 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# jdk9为何要将String的底层实现由char[]改成了byte[]?
+
+大家好,我是二哥呀!如果你不是 Java8 的钉子户,你应该早就发现了:String 类的源码已经由 `char[]` 优化为了 `byte[]` 来存储字符串内容,为什么要这样做呢?
+
+开门见山地说,从 `char[]` 到 `byte[]`,最主要的目的是**为了节省字符串占用的内存**。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。
+
+### 一、为什么要优化 String 节省内存空间
+
+我们使用 `jmap -histo:live pid | head -n 10` 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
+
+以我正在运行着的编程喵喵项目实例(基于 Java 8)来说,结果是这样的。
+
+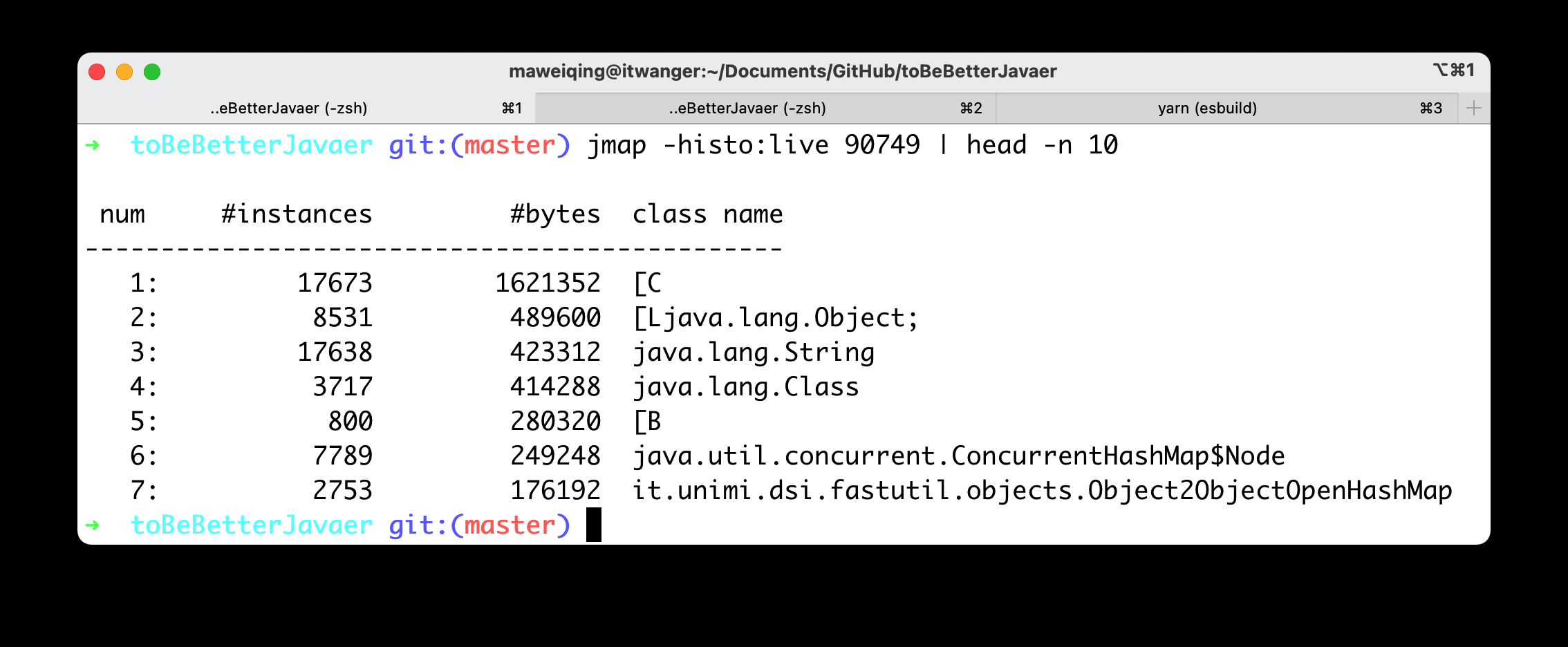
+
+其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
+
+由于 Java 8 的 String 内部实现仍然是 `char[]`,所以我们可以看到内存占用排在第 1 位的就是 char 数组。
+
+`char[]` 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
+
+那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类库,就显得非常的鸡肋。
+
+### 二、`byte[]` 为什么就能节省内存空间呢?
+
+众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 编码,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
+
+
+
+也就是说,使用 `char[]` 来表示 String 就导致了即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
+
+而实际开发中,单字节的字符使用频率仍然要高于双字节的。
+
+当然了,仅仅将 `char[]` 优化为 `byte[]` 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
+
+换句话说,对于:
+
+```java
+String name = "jack";
+```
+
+这样的,使用 Latin-1 编码,占用 4 个字节就够了。
+
+但对于:
+
+```java
+String name = "小二";
+```
+
+这种,木的办法,只能使用 UTF16 来编码。
+
+针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
+
+```java
+/**
+ * The identifier of the encoding used to encode the bytes in
+ * {@code value}. The supported values in this implementation are
+ *
+ * LATIN1
+ * UTF16
+ *
+ * @implNote This field is trusted by the VM, and is a subject to
+ * constant folding if String instance is constant. Overwriting this
+ * field after construction will cause problems.
+ */
+private final byte coder;
+```
+
+Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
+
+也就是说,从 `char[]` 到 `byte[]`,**中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,应为也是两个字节**。
+
+### 三、为什么用UTF-16而不用UTF-8呢?
+
+在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
+
+- 如果只有一个字节,那么最高的比特位为 0;
+- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
+
+具体的表现形式为:
+
+- 0xxxxxxx:一个字节;
+- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1); - 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
+- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
+
+关于字符编码,我在《Java 程序员进阶之路》里曾讲到过,想要深入了解的小伙伴查看下面的链接🔗:
+
+>https://tobebetterjavaer.com/basic-extra-meal/java-unicode.html
+
+也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
+
+那有小伙伴可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
+
+的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
+
+- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
+- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
+
+但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
+
+所以UTF-16在Java的世界里,就可以视为一个定长的编码。
+
+>参考链接:https://www.zhihu.com/question/447224628
+
+
diff --git a/docs/basic-extra-meal/override-overload.md b/docs/basic-extra-meal/override-overload.md
new file mode 100644
index 0000000000..65d351ac58
--- /dev/null
+++ b/docs/basic-extra-meal/override-overload.md
@@ -0,0 +1,314 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java重写(Override)与重载(Overload)
+
+### 01、开篇
+
+入冬的夜,总是来得特别的早。我静静地站在阳台,目光所及之处,不过是若隐若现的钢筋混凝土,还有那毫无情调的灯光。
+
+“哥,别站在那发呆了。今天学啥啊,七点半我就要回学校了,留给你的时间不多了,你要抓紧哦。”三妹傲娇的声音一下子把我从游离的状态拉回到了现实。
+
+“今天要学习 Java 中的方法重载与方法重写。”我迅速地走到电脑前面,打开一份 Excel 文档,看了一下《教妹学 Java》的进度,然后对三妹说。
+
+“如果一个类有多个名字相同但参数个数不同的方法,我们通常称这些方法为方法重载。 ”我面带着朴实无华的微笑继续说,“如果方法的功能是一样的,但参数不同,使用相同的名字可以提高程序的可读性。”
+
+“如果子类具有和父类一样的方法(参数相同、返回类型相同、方法名相同,但方法体可能不同),我们称之为方法重写。 方法重写用于提供父类已经声明的方法的特殊实现,是实现多态的基础条件。”
+
+“只不过,方法重载与方法重写在名字上很相似,就像是兄弟俩,导致初学者经常把它们俩搞混。”
+
+“方法重载的英文名叫 Overloading,方法重写的英文名叫 Overriding,因此,不仅中文名很相近,英文名之间也很相近,这就更容易让初学者搞混了。”
+
+“但两者其实是完全不同的!通过下面这张图,你就能看得一清二楚。”
+
+话音刚落,我就在 IDEA 中噼里啪啦地敲了起来。两段代码,分别是方法重写和方法重载。然后,把这两段代码截图到 draw.io(一个很漂亮的在线画图网站)上,加了一些文字说明。最后,打开 Photoscape X,把两张图片合并到了一起。
+
+
+
+### 02、方法重载
+
+“三妹,你仔细听哦。”我缓了一口气后继续说道。
+
+“在 Java 中,有两种方式可以达到方法重载的目的。”
+
+“第一,改变参数的数目。来看下面这段代码。”
+
+```java
+public class OverloadingByParamNum {
+ public static void main(String[] args) {
+ System.out.println(Adder.add(10, 19));
+ System.out.println(Adder.add(10, 19, 20));
+ }
+}
+
+class Adder {
+ static int add(int a, int b) {
+ return a + b;
+ }
+
+ static int add(int a, int b, int c) {
+ return a + b + c;
+ }
+}
+```
+
+“Adder 类有两个方法,第一个 `add()` 方法有两个参数,在调用的时候可以传递两个参数;第二个 `add()` 方法有三个参数,在调用的时候可以传递三个参数。”
+
+“二哥,这样的代码不会显得啰嗦吗?如果有四个参数的时候就再追加一个方法?”三妹突然提了一个很尖锐的问题。
+
+“那倒是,这个例子只是为了说明方法重载的一种类型。如果参数类型相同的话,Java 提供了可变参数的方式,就像下面这样。”
+
+```java
+static int add(int ... args) {
+ int sum = 0;
+ for ( int a: args) {
+ sum += a;
+ }
+ return sum;
+}
+```
+
+“第二,通过改变参数类型,也可以达到方法重载的目的。来看下面这段代码。”
+
+```java
+public class OverloadingByParamType {
+ public static void main(String[] args) {
+ System.out.println(Adder.add(10, 19));
+ System.out.println(Adder.add(10.1, 19.2));
+ }
+}
+
+class Adder {
+ static int add(int a, int b) {
+ return a + b;
+ }
+
+ static double add(double a, double b) {
+ return a + b;
+ }
+}
+```
+
+“Adder 类有两个方法,第一个 `add()` 方法的参数类型为 int,第二个 `add()` 方法的参数类型为 double。”
+
+“二哥,改变参数的数目和类型都可以实现方法重载,为什么改变方法的返回值类型就不可以呢?”三妹很能抓住问题的重点嘛。
+
+“因为仅仅改变返回值类型的话,会把编译器搞懵逼的。”我略带调皮的口吻回答她。
+
+“编译时报错优于运行时报错,所以当两个方法的名字相同,参数个数和类型也相同的时候,虽然返回值类型不同,但依然会提示方法已经被定义的错误。”
+
+
+
+“你想啊,三妹。我们在调用一个方法的时候,可以指定返回值类型,也可以不指定。当不指定的时候,直接指定 `add(1, 2)` 的时候,编译器就不知道该调用返回 int 的 `add()` 方法还是返回 double 的 `add()` 方法,产生了歧义。”
+
+“方法的返回值只是作为方法运行后的一个状态,它是保持方法的调用者和被调用者进行通信的一个纽带,但并不能作为某个方法的‘标识’。”
+
+“二哥,我想到了一个点,`main()` 方法可以重载吗?”
+
+“三妹,这是个好问题啊!答案是肯定的,毕竟 `main()` 方法也是个方法,只不过,Java 虚拟机在运行的时候只会调用带有 String 数组的那个 `main()` 方法。”
+
+```java
+public class OverloadingMain {
+ public static void main(String[] args) {
+ System.out.println("String[] args");
+ }
+
+ public static void main(String args) {
+ System.out.println("String args");
+ }
+
+ public static void main() {
+ System.out.println("无参");
+ }
+}
+```
+
+“第一个 `main()` 方法的参数形式为 `String[] args`,是最标准的写法;第二个 `main()` 方法的参数形式为 `String args`,少了中括号;第三个 `main()` 方法没有参数。”
+
+“来看一下程序的输出结果。”
+
+```
+String[] args
+```
+
+“从结果中,我们可以看得出,尽管 `main()` 方法可以重载,但程序只认标准写法。”
+
+“由于可以通过改变参数类型的方式实现方法重载,那么当传递的参数没有找到匹配的方法时,就会发生隐式的类型转换。”
+
+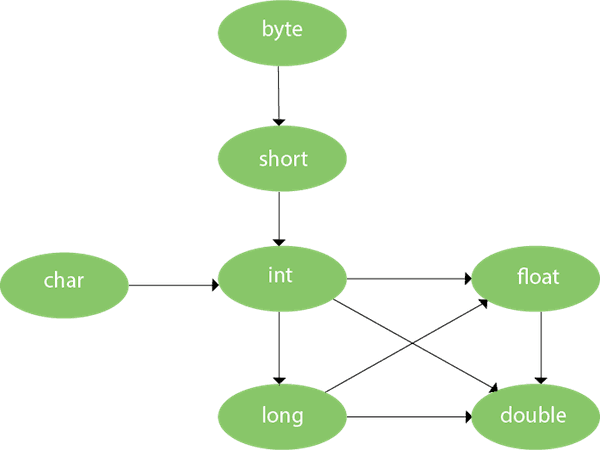
+
+“如上图所示,byte 可以向上转换为 short、int、long、float 和 double,short 可以向上转换为 int、long、float 和 double,char 可以向上转换为 int、long、float 和 double,依次类推。”
+
+“三妹,来看下面这个示例。”
+
+```java
+public class OverloadingTypePromotion {
+ void sum(int a, long b) {
+ System.out.println(a + b);
+ }
+
+ void sum(int a, int b, int c) {
+ System.out.println(a + b + c);
+ }
+
+ public static void main(String args[]) {
+ OverloadingTypePromotion obj = new OverloadingTypePromotion();
+ obj.sum(20, 20);
+ obj.sum(20, 20, 20);
+ }
+}
+```
+
+“执行 `obj.sum(20, 20)` 的时候,发现没有 `sum(int a, int b)` 的方法,所以此时第二个 20 向上转型为 long,所以调用的是 `sum(int a, long b)` 的方法。”
+
+“再来看一个示例。”
+
+```java
+public class OverloadingTypePromotion1 {
+ void sum(int a, int b) {
+ System.out.println("int");
+ }
+
+ void sum(long a, long b) {
+ System.out.println("long");
+ }
+
+ public static void main(String args[]) {
+ OverloadingTypePromotion1 obj = new OverloadingTypePromotion1();
+ obj.sum(20, 20);
+ }
+}
+```
+
+“执行 `obj.sum(20, 20)` 的时候,发现有 `sum(int a, int b)` 的方法,所以就不会向上转型为 long,调用 `sum(long a, long b)`。”
+
+“来看一下程序的输出结果。”
+
+```
+int
+```
+
+“继续来看示例。”
+
+```java
+public class OverloadingTypePromotion2 {
+ void sum(long a, int b) {
+ System.out.println("long int");
+ }
+
+ void sum(int a, long b) {
+ System.out.println("int long");
+ }
+
+ public static void main(String args[]) {
+ OverloadingTypePromotion2 obj = new OverloadingTypePromotion2();
+ obj.sum(20, 20);
+ }
+}
+```
+
+“二哥,我又想到一个问题。当有两个方法 `sum(long a, int b)` 和 `sum(int a, long b)`,参数个数相同,参数类型相同,只不过位置不同的时候,会发生什么呢?”
+
+“当通过 `obj.sum(20, 20)` 来调用 sum 方法的时候,编译器会提示错误。”
+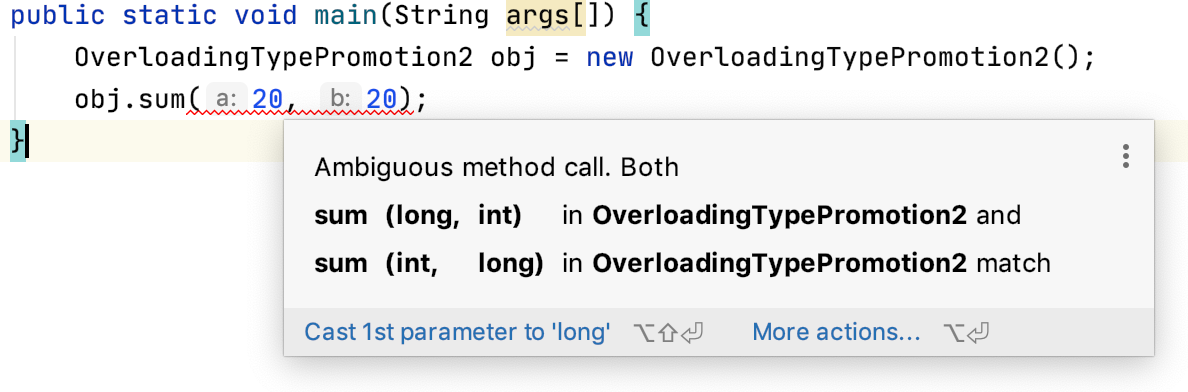
+
+“不明确,编译器会很为难,究竟是把第一个 20 从 int 转成 long 呢,还是把第二个 20 从 int 转成 long,智障了!所以,不能写这样让编译器左右为难的代码。”
+
+### 03、方法重写
+
+“三妹,累吗?我们稍微休息一下吧。”我把眼镜摘下来,放到桌子上,闭上了眼睛,开始胡思乱想起来。
+
+2000 年,周杰伦横空出世,让青黄不接的唱片行业为之一振,由此开启了新一代天王争霸的黄金时代。2020 年,杰伦胖了,也贪玩了,一年出一张单曲都变得可遇不可求。
+
+20 年前,程序员很稀有;20 年后,程序员内卷了。时间永远不会停下脚步,明年会不会好起来呢?
+
+“哥,醒醒,你就说休息一会,没说睡着啊。赶紧,我还有半个小时就要走了。”
+
+我戴上眼镜,对三妹继续说道:“在 Java 中,方法重写需要满足以下三个规则。”
+
+- 重写的方法必须和父类中的方法有着相同的名字;
+- 重写的方法必须和父类中的方法有着相同的参数;
+- 必须是 is-a 的关系(继承关系)。
+
+“来看下面这段代码。”
+
+```java
+public class Bike extends Vehicle {
+ public static void main(String[] args) {
+ Bike bike = new Bike();
+ bike.run();
+ }
+}
+
+class Vehicle {
+ void run() {
+ System.out.println("车辆在跑");
+ }
+}
+```
+
+“来看一下程序的输出结果。”
+
+```
+车辆在跑
+```
+
+“Bike is-a Vehicle,自行车是一种车,没错。Vehicle 类有一个 `run()` 的方法,也就是说车辆可以跑,Bike 继承了 Vehicle,也可以跑。但如果 Bike 没有重写 `run()` 方法的话,自行车就只能是‘车辆在跑’,而不是‘自行车在跑’,对吧?”
+
+“如果有了方法重写,一切就好办了。”
+
+```java
+public class Bike extends Vehicle {
+ @Override
+ void run() {
+ System.out.println("自行车在跑");
+ }
+
+ public static void main(String[] args) {
+ Bike bike = new Bike();
+ bike.run();
+ }
+}
+
+class Vehicle {
+ void run() {
+ System.out.println("车辆在跑");
+ }
+}
+```
+
+我把鼠标移动到 Bike 类的 `run()` 方法,对三妹说:“你看,在方法重写的时候,IDEA 会建议使用 `@Override` 注解,显式的表示这是一个重写后的方法,尽管可以缺省。”
+
+“来看一下程序的输出结果。”
+
+```
+自行车在跑
+```
+
+“Bike 重写了 `run()` 方法,也就意味着,Bike 可以跑出自己的风格。”
+
+### 04、总结
+
+“好了,三妹,我来简单做个总结。”我瞥了一眼电脑右上角的时钟,离三妹离开的时间不到 10 分钟了。
+
+“首先来说一下方法重载时的注意事项,‘两同一不同’。”
+
+“‘两同’:在同一个类,方法名相同。”
+
+“‘一不同’:参数不同。”
+
+“再来说一下方法重写时的注意事项,‘两同一小一大’。”
+
+“‘两同’:方法名相同,参数相同。”
+
+“‘一小’:子类方法声明的异常类型要比父类小一些或者相等。”
+
+“‘一大’:子类方法的访问权限应该比父类的更大或者相等。”
+
+“记住了吧?三妹。带上口罩,拿好手机,咱准备出门吧。”今天限号,没法开车送三妹去学校了。
+
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/pass-by-value.md b/docs/basic-extra-meal/pass-by-value.md
new file mode 100644
index 0000000000..a422174eff
--- /dev/null
+++ b/docs/basic-extra-meal/pass-by-value.md
@@ -0,0 +1,142 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java到底是值传递还是引用传递?
+
+“哥,说说 Java 到底是值传递还是引用传递吧?”三妹一脸的困惑,看得出来她被这个问题折磨得不轻。
+
+“说实在的,我在一开始学 Java 的时候也被这个问题折磨得够呛,总以为基本数据类型在传参的时候是值传递,而引用类型是引用传递。”我对三妹袒露了心声,为的就是让她不再那么焦虑,她哥当年也是这么过来的。
+
+ C 语言是很多编程语言的母胎,包括 Java,那么对于 C 语言来说,所有的方法参数都是“通过值”传递的,也就是说,传递给被调用方法的参数值存放在临时变量中,而不是存放在原来的变量中。这就意味着,被调用的方法不能修改调用方法中变量的值,而只能修改其私有变量的临时副本的值。
+
+Java 继承了 C 语言这一特性,因此 Java 是按照值来传递的。
+
+接下来,我们必须得搞清楚,到底什么是值传递(pass by value),什么是引用传递(pass by reference),否则,讨论 Java 到底是值传递还是引用传递就显得毫无意义。
+
+当一个参数按照值的方式在两个方法之间传递时,调用者和被调用者其实是用的两个不同的变量——被调用者中的变量(原始值)是调用者中变量的一份拷贝,对它们当中的任何一个变量修改都不会影响到另外一个变量,据说 Fortran 语言是通过引用传递的。
+
+“Fortran 语言?”三妹睁大了双眼,似乎听见了什么新的名词。
+
+“是的,Fortran 语言,1957 年由 IBM 公司开发,是世界上第一个被正式采用并流传至今的高级编程语言。”
+
+当一个参数按照引用传递的方式在两个方法之间传递时,调用者和被调用者其实用的是同一个变量,当该变量被修改时,双方都是可见的。
+
+“我们之所以容易搞不清楚 Java 到底是值传递还是引用传递,主要是因为 Java 中的两类数据类型的叫法容易引发误会,比如说 int 是基本类型,说它是值传递的,我们就很容易理解;但对于引用类型,比如说 String,说它也是值传递的时候,我们就容易弄不明白。”
+
+我们来看看基本数据类型和引用数据类型之间的差别。
+
+```java
+int age = 18;
+String name = "二哥";
+```
+
+age 是基本类型,值就保存在变量中,而 name 是引用类型,变量中保存的是对象的地址。一般称这种变量为对象的引用,引用存放在栈中,而对象存放在堆中。
+
+这里说的栈和堆,是指内存中的一块区域,和数据结构中的栈和堆不一样。栈是由编译器自动分配释放的,所以适合存放编译期就确定生命周期的数据;而堆中存放的数据,编译器是不需要知道生命周期的,创建后的回收工作由垃圾收集器来完成。
+
+“画幅图。”
+
+
+
+当用 = 赋值运算符改变 age 和 name 的值时。
+
+```java
+age = 16;
+name = "三妹";
+```
+
+对于基本类型 age,赋值运算符会直接改变变量的值,原来的值被覆盖。
+
+对于引用类型 name,赋值运算符会改变对象引用中保存的地址,原来的地址被覆盖,但原来的对象不会被覆盖。
+
+
+
+“三妹,注意听,接下来,我们来说说基本数据类型的参数传递。”
+
+Java 有 8 种基本数据类型,分别是 int、long、byte、short、float、double 、char 和 boolean,就拿 int 类型来举例吧。
+
+```java
+class PrimitiveTypeDemo {
+ public static void main(String[] args) {
+ int age = 18;
+ modify(age);
+ System.out.println(age);
+ }
+
+ private static void modify(int age1) {
+ age1 = 30;
+ }
+}
+```
+
+1)`main()` 方法中的 age 为基本类型,所以它的值 18 直接存储在变量中。
+
+2)调用 `modify()` 方法的时候,将会把 age 的值 18 复制给形参 age1。
+
+3)`modify()` 方法中,对 age1 做出了修改。
+
+4)回到 `main()` 方法中,age 的值仍然为 18,并没有发生改变。
+
+如果我们想让 age 的值发生改变,就需要这样做。
+
+```java
+class PrimitiveTypeDemo1 {
+ public static void main(String[] args) {
+ int age = 18;
+ age = modify(age);
+ System.out.println(age);
+ }
+
+ private static int modify(int age1) {
+ age1 = 30;
+ return age1;
+ }
+}
+```
+
+第一,让 `modify()` 方法有返回值;
+
+第二,使用赋值运算符重新对 age 进行赋值。
+
+“好了,再来说说引用类型的参数传递。”
+
+就以 String 为例吧。
+
+```java
+class ReferenceTypeDemo {
+ public static void main(String[] args) {
+ String name = "二哥";
+ modify(name);
+ System.out.println(name);
+ }
+
+ private static void modify(String name1) {
+ name1 = "三妹";
+ }
+}
+```
+
+在调用 `modify()` 方法的时候,形参 name1 复制了 name 的地址,指向的是堆中“二哥”的位置。
+
+
+
+当 `modify()` 方法调用结束后,改变了形参 name1 的地址,但 `main()` 方法中 name 并没有发生改变。
+
+
+
+总结:
+
+- Java 中的参数传递是按值传递的。
+- 如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
+- 如果参数是引用类型,传递的是引用的对象在堆中地址的拷贝。
+
+“好了,三妹,今天的学习就到这吧。”
+
+
+
+
+
diff --git a/docs/src/basic-extra-meal/true-generic.md b/docs/basic-extra-meal/true-generic.md
similarity index 78%
rename from docs/src/basic-extra-meal/true-generic.md
rename to docs/basic-extra-meal/true-generic.md
index 0b3356dd3a..50a877ba0f 100644
--- a/docs/src/basic-extra-meal/true-generic.md
+++ b/docs/basic-extra-meal/true-generic.md
@@ -1,22 +1,15 @@
---
-title: Java 为什么无法实现真正的泛型?
-shortTitle: Java为什么无法实现真正的泛型
category:
- Java核心
tag:
- - Java重要知识点
-description: Java 无法实现真正泛型的原因在于类型擦除,这种设计是为了兼容早期 Java 版本。本文详细探讨 Java 泛型的实现机制、类型擦除背后的原理,以及 Java 泛型在编程中的局限性。
-author: 沉默王二
-head:
- - - meta
- - name: keywords
- content: Java, 泛型, 类型擦除
+ - Java
---
+# Java不能实现真正泛型的原因是什么?
-“二哥,为啥 Java 不能实现真正的泛型啊?”三妹开门见山地问。
+“二哥,为啥 Java 不能实现真正泛型啊?”三妹开门见山地问。
-简单来回顾一下[类型擦除](https://javabetter.cn/basic-extra-meal/generic.html),看下面这段代码。
+简单来回顾一下类型擦除,看下面这段代码。
```java
public class Cmower {
@@ -58,7 +51,8 @@ public class Cmower {
“保持耐心,好不好?”我安慰道。
-**第一,兼容性**
+
+第一,兼容性
Java 在 2004 年已经积累了较为丰富的生态,如果把现有的类修改为泛型类,需要让所有的用户重新修改源代码并且编译,这就会导致 Java 1.4 之前打下的江山可能会完全覆灭。
@@ -68,9 +62,9 @@ Java 在 2004 年已经积累了较为丰富的生态,如果把现有的类修
老用户不受影响,新用户可以自由地选择使用泛型,可谓一举两得。
-**第二,不是“实现不了”**。Pizza,1996 年的实验语言,在 Java 的基础上扩展了泛型。
+第二,不是“实现不了”。Pizza,1996 年的实验语言,在 Java 的基础上扩展了泛型。
->Pizza 教程地址:[http://pizzacompiler.sourceforge.net/doc/tutorial.html](http://pizzacompiler.sourceforge.net/doc/tutorial.html)
+>Pizza 教程地址:http://pizzacompiler.sourceforge.net/doc/tutorial.html
“1996 年?”三妹表示很吃惊。
@@ -120,7 +114,7 @@ String s = a.get();
对吧?这就是我们想要的“真正意义上的泛型”,A 不仅仅可以是引用类型 String,还可以是基本数据类型。要知道,Java 的泛型不允许是基本数据类型,只能是包装器类型。
-
+
除此之外,Pizza 的泛型还可以直接使用 `new` 关键字进行声明,并且 Pizza 编译器会从构造方法的参数上推断出具体的对象类型,究竟是 String 还是 int。要知道,Java 的泛型因为类型擦除的原因,程序员是无法知道一个 ArrayList 究竟是 `ArrayList` 还是 `ArrayList` 的。
@@ -187,11 +181,11 @@ Java 语言和其他编程语言不一样,有着沉重的历史包袱,1.5
Java 一直以来都强调兼容性,我认为这也是 Java 之所以能被广泛使用的主要原因之一,开发者不必担心 Java 版本升级的问题,一个在 JDK 1.4 上可以跑的代码,放在 JDK 1.5 上仍然可以跑。
-这里必须得说明一点,J2SE1.5 的发布,是 Java 语言发展史上的重要里程碑,为了表示该版本的重要性,J2SE1.5 也正式更名为 Java SE 5.0,往后去就是 Java SE 6.0,Java SE 7.0。。。。
+*这里必须得说明一点,J2SE1.5 的发布,是 Java 语言发展史上的重要里程碑,为了表示该版本的重要性,J2SE1.5 也正式更名为 Java SE 5.0,往后去就是 Java SE 6.0,Java SE 7.0。。。。*
但 Java 并不支持高版本 JDK 编译生成的字节码文件在低版本的 JRE(Java 运行时环境)上跑。
-
+
针对泛型,兼容性具体表现在什么地方呢?来看下面这段代码。
@@ -220,12 +214,12 @@ Java 神奇就神奇在这,表面上万物皆对象,但为了性能上的考
一个好消息是 Valhalla 项目正在努力解决这些因为泛型擦除带来的历史遗留问题。
-
+
Project Valhalla:正在进行当中的 OpenJDK 项目,计划给未来的 Java 添加改进的泛型支持。
->源码地址:[http://openjdk.java.net/projects/valhalla/](http://openjdk.java.net/projects/valhalla/)
+>源码地址:http://openjdk.java.net/projects/valhalla/
让我们拭目以待吧!
@@ -233,11 +227,4 @@ Project Valhalla:正在进行当中的 OpenJDK 项目,计划给未来的 Jav
“嗯嗯。二哥,你讲得可真棒👍”三妹夸奖得我有点小开心,嘿嘿。
----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/basic-extra-meal/varables.md b/docs/basic-extra-meal/varables.md
new file mode 100644
index 0000000000..ea9b0a8ec7
--- /dev/null
+++ b/docs/basic-extra-meal/varables.md
@@ -0,0 +1,144 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java中可变参数的使用
+
+为了让铁粉们能白票到阿里云的服务器,老王当了整整两天的客服,真正体验到了什么叫做“为人民群众谋福利”的不易和辛酸。正在他眼睛红肿打算要休息之际,小二跑过来问他:“Java 的可变参数究竟是怎么一回事?”老王一下子又清醒了,他爱 Java,他爱传道解惑,他爱这群尊敬他的读者。
+
+可变参数是 Java 1.5 的时候引入的功能,它允许方法使用任意多个、类型相同(`is-a`)的值作为参数。就像下面这样。
+
+```java
+public static void main(String[] args) {
+ print("沉");
+ print("沉", "默");
+ print("沉", "默", "王");
+ print("沉", "默", "王", "二");
+}
+
+public static void print(String... strs) {
+ for (String s : strs)
+ System.out.print(s);
+ System.out.println();
+}
+```
+
+静态方法 `print()` 就使用了可变参数,所以 `print("沉")` 可以,`print("沉", "默")` 也可以,甚至 3 个、 4 个或者更多个字符串都可以作为参数传递给 `print()` 方法。
+
+说到可变参数,我想起来阿里巴巴开发手册上有这样一条规约。
+
+
+
+意思就是尽量不要使用可变参数,如果要用的话,可变参数必须要在参数列表的最后一位。既然坑位有限,只能在最后,那么可变参数就只能有一个(悠着点,悠着点)。如果可变参数不在最后一位,IDE 就会提示对应的错误,如下图所示。
+
+
+
+
+
+
+可变参数看起来就像是个语法糖,它背后究竟隐藏了什么呢?老王想要一探究竟,它在追求真理这条路上一直很执着。
+
+其实也很简单。**当使用可变参数的时候,实际上是先创建了一个数组,该数组的大小就是可变参数的个数,然后将参数放入数组当中,再将数组传递给被调用的方法**。
+
+这就是为什么可以使用数组作为参数来调用带有可变参数的方法的根本原因。代码如下所示。
+
+```java
+public static void main(String[] args) {
+ print(new String[]{"沉"});
+ print(new String[]{"沉", "默"});
+ print(new String[]{"沉", "默", "王"});
+ print(new String[]{"沉", "默", "王", "二"});
+}
+
+public static void print(String... strs) {
+ for (String s : strs)
+ System.out.print(s);
+ System.out.println();
+}
+```
+
+那如果方法的参数是一个数组,然后像使用可变参数那样去调用方法的时候,能行得通吗?
+
+*留个思考题,大家也可以去试一试*
+
+
+
+那一般什么时候使用可变参数呢?
+
+可变参数,可变参数,顾名思义,当一个方法需要处理任意多个相同类型的对象时,就可以定义可变参数。Java 中有一个很好的例子,就是 String 类的 `format()` 方法,就像下面这样。
+
+```java
+System.out.println(String.format("年纪是: %d", 18));
+System.out.println(String.format("年纪是: %d 名字是: %s", 18, "沉默王二"));
+```
+
+`%d` 表示将整数格式化为 10 进制整数,`%s` 表示输出字符串。
+
+如果不使用可变参数,那需要格式化的参数就必须使用“+”号操作符拼接起来了。麻烦也就惹上身了。
+
+在实际的项目代码中,开源包 slf4j.jar 的日志输出就经常要用到可变参数(log4j 就没法使用可变参数,日志中需要记录多个参数时就痛苦不堪了)。就像下面这样。
+
+```java
+protected Logger logger = LoggerFactory.getLogger(getClass());
+logger.debug("名字是{}", mem.getName());
+logger.debug("名字是{},年纪是{}", mem.getName(), mem.getAge());
+```
+
+查看源码就可以发现,`debug()` 方法使用了可变参数。
+
+```java
+public void debug(String format, Object... arguments);
+```
+
+那在使用可变参数的时候有什么注意事项吗?
+
+有的。我们要避免重载带有可变参数的方法——这样很容易让编译器陷入自我怀疑中。
+
+```java
+public static void main(String[] args) {
+ print(null);
+}
+
+public static void print(String... strs) {
+ for (String a : strs)
+ System.out.print(a);
+ System.out.println();
+}
+
+public static void print(Integer... ints) {
+ for (Integer i : ints)
+ System.out.print(i);
+ System.out.println();
+}
+```
+
+这时候,编译器完全不知道该调用哪个 `print()` 方法,`print(String... strs)` 还是 `print(Integer... ints)`,傻傻分不清。
+
+
+
+
+假如真的需要重载带有可变参数的方法,就必须在调用方法的时候给出明确的指示,不要让编译器去猜。
+
+```java
+public static void main(String[] args) {
+ String [] strs = null;
+ print(strs);
+
+ Integer [] ints = null;
+ print(ints);
+}
+
+public static void print(String... strs) {
+}
+
+public static void print(Integer... ints) {
+}
+```
+
+上面这段代码是可以编译通过的。因为编译器知道参数是 String 类型还是 Integer 类型,只不过为了运行时不抛出 `NullPointerException`,两个 `print()` 方法的内部要做好判空操作。
+
+
+
\ No newline at end of file
diff --git a/docs/basic-grammar/basic-data-type.md b/docs/basic-grammar/basic-data-type.md
new file mode 100644
index 0000000000..74d41d15e6
--- /dev/null
+++ b/docs/basic-grammar/basic-data-type.md
@@ -0,0 +1,330 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java 支持的 8 种基本数据类型
+
+“二哥,[上一节](https://mp.weixin.qq.com/s/IgBpLGn0L1HZymgI4hWGVA)提到了 Java 变量的数据类型,是不是指定了类型就限定了变量的取值范围啊?”三妹吸了一口麦香可可奶茶后对我说。
+
+“三妹,你不得了啊,长进很大嘛,都学会推理判断了。Java 是一种静态类型的编程语言,这意味着所有变量必须在使用之前声明好,也就是必须得先指定变量的类型和名称。”
+
+Java 中的数据类型可分为 2 种:
+
+1)**基本数据类型**。
+
+基本数据类型是 Java 语言操作数据的基础,包括 boolean、char、byte、short、int、long、float 和 double,共 8 种。
+
+2)**引用数据类型**。
+
+除了基本数据类型以外的类型,都是所谓的引用类型。常见的有数组(对,没错,数组是引用类型)、class(也就是类),以及接口(指向的是实现接口的类的对象)。
+
+来个思维导图,感受下。
+
+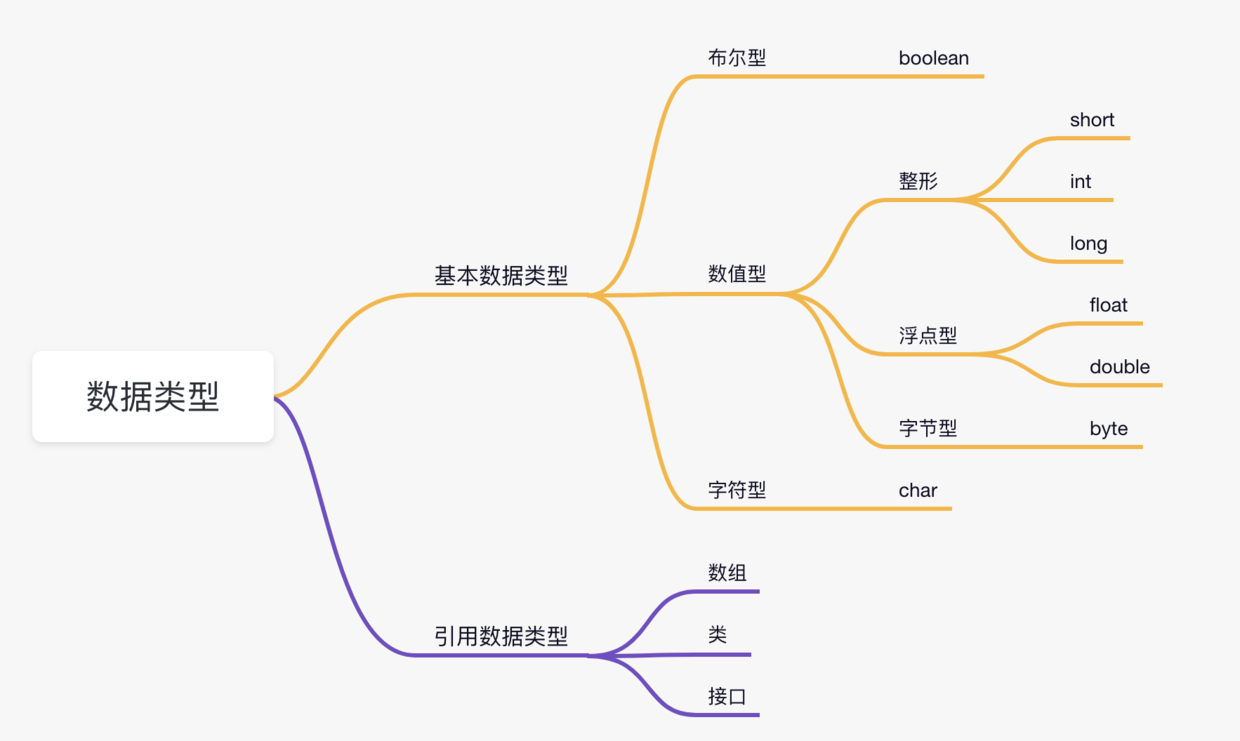
+
+通过[上一节](https://mp.weixin.qq.com/s/IgBpLGn0L1HZymgI4hWGVA)的学习,我们知道变量可以分为局部变量、成员变量、静态变量。
+
+当变量是局部变量的时候,必须得先初始化,否则编译器不允许你使用它。拿 int 来举例吧,看下图。
+
+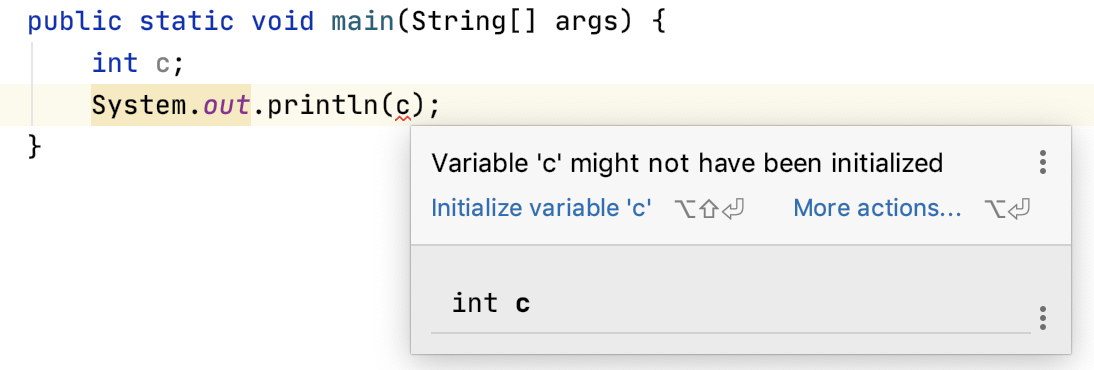
+
+当变量是成员变量或者静态变量时,可以不进行初始化,它们会有一个默认值,仍然以 int 为例,来看代码:
+
+```java
+/**
+ * @author 微信搜「沉默王二」,回复关键字 PDF
+ */
+public class LocalVar {
+ private int a;
+ static int b;
+
+ public static void main(String[] args) {
+ LocalVar lv = new LocalVar();
+ System.out.println(lv.a);
+ System.out.println(b);
+ }
+}
+```
+
+来看输出结果:
+
+```
+0
+0
+```
+
+瞧见没,int 作为成员变量时或者静态变量时的默认值是 0。那不同的基本数据类型,是有不同的默认值和大小的,来个表格感受下。
+
+| 数据类型 | 默认值 | 大小 |
+| -------- | -------- | ----- |
+| boolean | false | 1比特 |
+| char | '\u0000' | 2字节 |
+| byte | 0 | 1字节 |
+| short | 0 | 2字节 |
+| int | 0 | 4字节 |
+| long | 0L | 8字节 |
+| float | 0.0f | 4字节 |
+| double | 0.0 | 8字节 |
+
+那三妹可能要问,“比特和字节是什么鬼?”
+
+比特币听说过吧?字节跳动听说过吧?这些名字当然不是乱起的,确实和比特、字节有关系。
+
+**1)bit(比特)**
+
+比特作为信息技术的最基本存储单位,非常小,但大名鼎鼎的比特币就是以此命名的,它的简写为小写字母“b”。
+
+大家都知道,计算机是以二进制存储数据的,二进制的一位,就是 1 比特,也就是说,比特要么为 0 要么为 1。
+
+**2)Byte(字节)**
+
+通常来说,一个英文字符是一个字节,一个中文字符是两个字节。字节与比特的换算关系是:1 字节 = 8 比特。
+
+在往上的单位就是 KB,并不是 1000 字节,因为计算机只认识二进制,因此是 2 的 10 次方,也就是 1024 个字节。
+
+(终于知道 1024 和程序员的关系了吧?狗头保命)
+
+
+
+接下来,我们再来详细地了解一下 8 种基本数据类型。
+
+### 01、布尔
+
+布尔(boolean)仅用于存储两个值:true 和 false,也就是真和假,通常用于条件的判断。代码示例:
+
+```java
+boolean flag = true;
+```
+
+
+### 02、byte
+
+byte 的取值范围在 -128 和 127 之间,包含 127。最小值为 -128,最大值为 127,默认值为 0。
+
+在网络传输的过程中,为了节省空间,常用字节来作为数据的传输方式。代码示例:
+
+
+```java
+byte a = 10;
+byte b = -10;
+```
+
+
+
+
+### 03、short
+
+short 的取值范围在 -32,768 和 32,767 之间,包含 32,767。最小值为 -32,768,最大值为 32,767,默认值为 0。代码示例:
+
+```java
+short s = 10000;
+short r = -5000;
+```
+
+
+
+### 04、int
+
+int 的取值范围在 -2,147,483,648(-2 ^ 31)和 2,147,483,647(2 ^ 31 -1)(含)之间,默认值为 0。如果没有特殊需求,整型数据就用 int。代码示例:
+
+```java
+int a = 100000;
+int b = -200000;
+```
+
+### 05、long
+
+long 的取值范围在 -9,223,372,036,854,775,808(-2^63) 和 9,223,372,036,854,775,807(2^63 -1)(含)之间,默认值为 0。如果 int 存储不下,就用 long,整型数据就用 int。代码示例:
+
+```java
+long a = 100000L;
+long b = -200000L;
+```
+
+为了和 int 作区分,long 型变量在声明的时候,末尾要带上大写的“L”。不用小写的“l”,是因为小写的“l”容易和数字“1”混淆。
+
+### 06、float
+
+float 是单精度的浮点数,遵循 IEEE 754(二进制浮点数算术标准),取值范围是无限的,默认值为 0.0f。float 不适合用于精确的数值,比如说货币。代码示例:
+
+```java
+float f1 = 234.5f;
+```
+
+为了和 double 作区分,float 型变量在声明的时候,末尾要带上小写的“f”。不需要使用大写的“F”,是因为小写的“f”很容易辨别。
+
+
+### 07、double
+
+double 是双精度的浮点数,遵循 IEEE 754(二进制浮点数算术标准),取值范围也是无限的,默认值为 0.0。double 同样不适合用于精确的数值,比如说货币。代码示例:
+
+```java
+double d1 = 12.3
+```
+
+那精确的数值用什么表示呢?最好使用 BigDecimal,它可以表示一个任意大小且精度完全准确的浮点数。针对货币类型的数值,也可以先乘以 100 转成整型进行处理。
+
+Tips:单精度是这样的格式,1 位符号,8 位指数,23 位小数,有效位数为 7 位。
+
+
+
+双精度是这样的格式,1 位符号,11 位指数,52 为小数,有效位数为 16 位。
+
+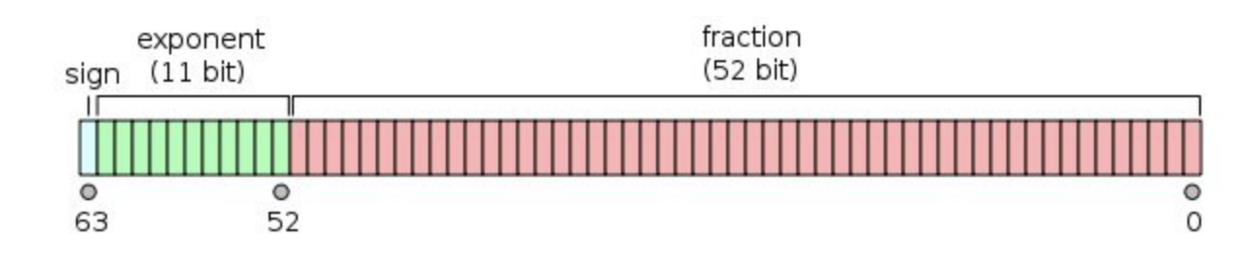
+
+取值范围取决于指数位,计算精度取决于小数位(尾数)。小数位越多,则能表示的数越大,那么计算精度则越高。
+
+>一个数由若干位数字组成,其中影响测量精度的数字称作有效数字,也称有效数位。有效数字指科学计算中用以表示一个浮点数精度的那些数字。一般地,指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字。如 1.24 和 0.00124 的有效数字都有 3 位。
+
+### 08、char
+
+char 可以表示一个 16 位的 Unicode 字符,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。代码示例:
+
+```java
+char letterA = 'A'; // 用英文的单引号包裹住。
+```
+
+那三妹可能要问,“char 既然只有一个字符,为什么占 2 个字节呢?”
+
+“主要是因为 Java 使用的是 Unicode 字符集而不是 ASCII 字符集。”
+
+这又是为什么呢?我们留到下一节再讲。
+
+基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有的。
+
+String 是最典型的引用数据类型,所以我们就拿 String 类举例,看下面这段代码:
+
+```java
+/**
+ * @author 微信搜「沉默王二」,回复关键字 PDF
+ */
+public class LocalRef {
+ private String a;
+ static String b;
+
+ public static void main(String[] args) {
+ LocalRef lv = new LocalRef();
+ System.out.println(lv.a);
+ System.out.println(b);
+ }
+}
+```
+
+输出结果如下所示:
+
+```
+null
+null
+```
+
+null 在 Java 中是一个很神奇的存在,在你以后的程序生涯中,见它的次数不会少,尤其是伴随着令人烦恼的“[空指针异常](https://mp.weixin.qq.com/s/PBqR_uj6dd4xKEX8SUWIYQ)”,也就是所谓的 `NullPointerException`。
+
+也就是说,引用数据类型的默认值为 null,包括数组和接口。
+
+那三妹是不是很好奇,为什么数组和接口也是引用数据类型啊?
+
+先来看数组:
+
+```java
+/**
+ * @author 微信搜「沉默王二」,回复关键字 java
+ */
+public class ArrayDemo {
+ public static void main(String[] args) {
+ int [] arrays = {1,2,3};
+ System.out.println(arrays);
+ }
+}
+```
+
+arrays 是一个 int 类型的数组,对吧?打印结果如下所示:
+
+```
+[I@2d209079
+```
+
+`[I` 表示数组是 int 类型的,@ 后面是十六进制的 hashCode——这样的打印结果太“人性化”了,一般人表示看不懂!为什么会这样显示呢?查看一下 `java.lang.Object` 类的 `toString()` 方法就明白了。
+
+
+
+数组虽然没有显式定义成一个类,但它的确是一个对象,继承了祖先类 Object 的所有方法。那为什么数组不单独定义一个类来表示呢?就像字符串 String 类那样呢?
+
+一个合理的解释是 Java 将其隐藏了。假如真的存在一个 Array.java,我们也可以假想它真实的样子,它必须要定义一个容器来存放数组的元素,就像 String 类那样。
+
+```java
+public final class String
+ implements java.io.Serializable, Comparable, CharSequence {
+ /** The value is used for character storage. */
+ private final char value[];
+}
+```
+
+数组内部定义数组?没必要的!
+
+再来看接口:
+
+```java
+/**
+ * @author 微信搜「沉默王二」,回复关键字 Java
+ */
+public class IntefaceDemo {
+ public static void main(String[] args) {
+ List list = new ArrayList<>();
+ System.out.println(list);
+ }
+}
+```
+
+List 是一个非常典型的接口:
+
+```java
+public interface List extends Collection {}
+```
+
+而 ArrayList 是 List 接口的一个实现:
+
+```java
+public class ArrayList extends AbstractList
+ implements List, RandomAccess, Cloneable, java.io.Serializable
+{}
+```
+
+对于接口类型的引用变量来说,你没法直接 new 一个:
+
+
+
+
+只能 new 一个实现它的类的对象——那自然接口也是引用数据类型了。
+
+来看一下基本数据类型和引用数据类型之间最大的差别。
+
+基本数据类型:
+
+- 1、变量名指向具体的数值。
+- 2、基本数据类型存储在栈上。
+
+引用数据类型:
+
+- 1、变量名指向的是存储对象的内存地址,在栈上。
+- 2、内存地址指向的对象存储在堆上。
+
+看到这,三妹是不是又要问,“堆是什么,栈又是什么?”
+
+堆是堆(heap),栈是栈(stack),如果看到“堆栈”的话,请不要怀疑自己,那是翻译的错,堆栈也是栈,反正我很不喜欢“堆栈”这种叫法,容易让新人掉坑里。
+
+堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java 中的对象就放在这里,这样做的好处就是:
+
+>当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
+
+栈,能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快。既然访问速度快,要好好利用啊!Java 就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
+
+不是的,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
+
+这么说就理解了吧?
+
+“好了,三妹,关于 Java 中的数据类型就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
+
+
\ No newline at end of file
diff --git a/docs/basic-grammar/flow-control.md b/docs/basic-grammar/flow-control.md
new file mode 100644
index 0000000000..2a9a10f486
--- /dev/null
+++ b/docs/basic-grammar/flow-control.md
@@ -0,0 +1,909 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java流程控制语句
+
+“二哥,流程控制语句都有哪些呢?”三妹的脸上泛着甜甜的笑容,她开始对接下来要学习的内容充满期待了,这正是我感到欣慰的地方。
+
+“比如说 if-else、switch、for、while、do-while、return、break、continue 等等,接下来,我们一个个来了解下。”
+
+### 01、if-else 相关
+
+
+
+
+**1)if 语句**
+
+if 语句的格式如下:
+
+```java
+if(布尔表达式){
+// 如果条件为 true,则执行这块代码
+}
+```
+
+画个流程图表示一下:
+
+
+
+
+来写个示例:
+
+```java
+public class IfExample {
+ public static void main(String[] args) {
+ int age = 20;
+ if (age < 30) {
+ System.out.println("青春年华");
+ }
+ }
+}
+```
+
+输出:
+
+```
+青春年华
+```
+
+**2)if-else 语句**
+
+if-else 语句的格式如下:
+
+```java
+if(布尔表达式){
+// 条件为 true 时执行的代码块
+}else{
+// 条件为 false 时执行的代码块
+}
+```
+
+画个流程图表示一下:
+
+
+
+
+来写个示例:
+
+```java
+public class IfElseExample {
+ public static void main(String[] args) {
+ int age = 31;
+ if (age < 30) {
+ System.out.println("青春年华");
+ } else {
+ System.out.println("而立之年");
+ }
+ }
+}
+```
+
+输出:
+
+```
+而立之年
+```
+
+除了这个例子之外,还有一个判断闰年(被 4 整除但不能被 100 整除或者被 400 整除)的例子:
+
+```java
+public class LeapYear {
+ public static void main(String[] args) {
+ int year = 2020;
+ if (((year % 4 == 0) && (year % 100 != 0)) || (year % 400 == 0)) {
+ System.out.println("闰年");
+ } else {
+ System.out.println("普通年份");
+ }
+ }
+}
+```
+
+输出:
+
+```
+闰年
+```
+
+如果执行语句比较简单的话,可以使用三元运算符来代替 if-else 语句,如果条件为 true,返回 ? 后面 : 前面的值;如果条件为 false,返回 : 后面的值。
+
+```java
+public class IfElseTernaryExample {
+ public static void main(String[] args) {
+ int num = 13;
+ String result = (num % 2 == 0) ? "偶数" : "奇数";
+ System.out.println(result);
+ }
+}
+```
+
+输出:
+
+```
+奇数
+```
+
+**3)if-else-if 语句**
+
+if-else-if 语句的格式如下:
+
+```java
+if(条件1){
+// 条件1 为 true 时执行的代码
+}else if(条件2){
+// 条件2 为 true 时执行的代码
+}
+else if(条件3){
+// 条件3 为 true 时执行的代码
+}
+...
+else{
+// 以上条件均为 false 时执行的代码
+}
+```
+
+画个流程图表示一下:
+
+
+
+
+来写个示例:
+
+```java
+public class IfElseIfExample {
+ public static void main(String[] args) {
+ int age = 31;
+ if (age < 30) {
+ System.out.println("青春年华");
+ } else if (age >= 30 && age < 40 ) {
+ System.out.println("而立之年");
+ } else if (age >= 40 && age < 50 ) {
+ System.out.println("不惑之年");
+ } else {
+ System.out.println("知天命");
+ }
+ }
+}
+```
+
+输出:
+
+```
+而立之年
+```
+
+**4)if 嵌套语句**
+
+if 嵌套语句的格式如下:
+
+```java
+if(外侧条件){
+ // 外侧条件为 true 时执行的代码
+ if(内侧条件){
+ // 内侧条件为 true 时执行的代码
+ }
+}
+```
+
+画个流程图表示一下:
+
+
+
+
+来写个示例:
+
+```java
+public class NestedIfExample {
+ public static void main(String[] args) {
+ int age = 20;
+ boolean isGirl = true;
+ if (age >= 20) {
+ if (isGirl) {
+ System.out.println("女生法定结婚年龄");
+ }
+ }
+ }
+}
+```
+
+输出:
+
+```
+女生法定结婚年龄
+```
+
+### 02、switch 语句
+
+switch 语句用来判断变量与多个值之间的相等性。变量的类型可以是 byte、short、int、long,或者对应的包装器类型 Byte、Short、Integer、Long,以及字符串和枚举。
+
+来看一下 switch 语句的格式:
+
+```java
+switch(变量) {
+case 可选值1:
+ // 可选值1匹配后执行的代码;
+ break; // 该关键字是可选项
+case 可选值2:
+ // 可选值2匹配后执行的代码;
+ break; // 该关键字是可选项
+......
+
+default: // 该关键字是可选项
+ // 所有可选值都不匹配后执行的代码
+}
+```
+
+- 变量可以有 1 个或者 N 个值。
+
+- 值类型必须和变量类型是一致的,并且值是确定的。
+
+- 值必须是唯一的,不能重复,否则编译会出错。
+
+- break 关键字是可选的,如果没有,则执行下一个 case,如果有,则跳出 switch 语句。
+
+- default 关键字也是可选的。
+
+
+
+画个流程图:
+
+
+
+
+
+来个示例:
+
+```java
+public class Switch1 {
+ public static void main(String[] args) {
+ int age = 20;
+ switch (age) {
+ case 20 :
+ System.out.println("上学");
+ break;
+ case 24 :
+ System.out.println("苏州工作");
+ break;
+ case 30 :
+ System.out.println("洛阳工作");
+ break;
+ default:
+ System.out.println("未知");
+ break; // 可省略
+ }
+ }
+}
+```
+
+输出:
+
+```
+上学
+```
+
+当两个值要执行的代码相同时,可以把要执行的代码写在下一个 case 语句中,而上一个 case 语句中什么也没有,来看一下示例:
+
+```java
+public class Switch2 {
+ public static void main(String[] args) {
+ String name = "沉默王二";
+ switch (name) {
+ case "詹姆斯":
+ System.out.println("篮球运动员");
+ break;
+ case "穆里尼奥":
+ System.out.println("足球教练");
+ break;
+ case "沉默王二":
+ case "沉默王三":
+ System.out.println("乒乓球爱好者");
+ break;
+ default:
+ throw new IllegalArgumentException(
+ "名字没有匹配项");
+
+ }
+ }
+}
+```
+
+输出:
+
+```
+乒乓球爱好者
+```
+
+枚举作为 switch 语句的变量也很常见,来看例子:
+
+```java
+public class SwitchEnumDemo {
+ public enum PlayerTypes {
+ TENNIS,
+ FOOTBALL,
+ BASKETBALL,
+ UNKNOWN
+ }
+
+ public static void main(String[] args) {
+ System.out.println(createPlayer(PlayerTypes.BASKETBALL));
+ }
+
+ private static String createPlayer(PlayerTypes playerType) {
+ switch (playerType) {
+ case TENNIS:
+ return "网球运动员费德勒";
+ case FOOTBALL:
+ return "足球运动员C罗";
+ case BASKETBALL:
+ return "篮球运动员詹姆斯";
+ case UNKNOWN:
+ throw new IllegalArgumentException("未知");
+ default:
+ throw new IllegalArgumentException(
+ "运动员类型: " + playerType);
+
+ }
+ }
+}
+```
+
+输出:
+
+```
+篮球运动员詹姆斯
+```
+
+### 03、for 循环
+
+
+
+**1)普通 for 循环**
+
+普通的 for 循环可以分为 4 个部分:
+
+1)初始变量:循环开始执行时的初始条件。
+
+2)条件:循环每次执行时要判断的条件,如果为 true,就执行循环体;如果为 false,就跳出循环。当然了,条件是可选的,如果没有条件,则会一直循环。
+
+3)循环体:循环每次要执行的代码块,直到条件变为 false。
+
+4)自增/自减:初识变量变化的方式。
+
+
+
+来看一下普通 for 循环的格式:
+
+
+
+```java
+for(初识变量;条件;自增/自减){
+// 循环体
+}
+```
+
+
+
+画个流程图:
+
+
+
+
+
+
+来个示例:
+
+```java
+public class ForExample {
+ public static void main(String[] args) {
+ for (int i = 0; i < 5; i++) {
+ System.out.println("沉默王三好美啊");
+ }
+ }
+}
+```
+
+输出:
+
+```
+沉默王三好美啊
+沉默王三好美啊
+沉默王三好美啊
+沉默王三好美啊
+沉默王三好美啊
+```
+
+“哎呀,二哥,你真的是变着法夸我啊。”
+
+“非也非也,三妹,你看不出我其实在夸我自己吗?循环语句还可以嵌套呢,这样就可以打印出更好玩的呢,你要不要看看?”
+
+“好呀好呀!”
+
+“看好了啊。”
+
+```java
+public class PyramidForExample {
+ public static void main(String[] args) {
+ for (int i = 0; i < 5; i++) {
+ for (int j = 0;j<= i;j++) {
+ System.out.print("❤");
+ }
+ System.out.println();
+ }
+ }
+}
+```
+
+打印出什么玩意呢?
+
+```
+❤
+❤❤
+❤❤❤
+❤❤❤❤
+❤❤❤❤❤
+```
+
+“哇,太不可思议了,二哥。”
+
+“嘿嘿。”
+
+**2)for-each**
+
+for-each 循环通常用于遍历数组和集合,它的使用规则比普通的 for 循环还要简单,不需要初始变量,不需要条件,不需要下标来自增或者自减。来看一下语法:
+
+```java
+for(元素类型 元素 : 数组或集合){
+// 要执行的代码
+}
+```
+
+
+来看一下示例:
+
+```java
+public class ForEachExample {
+ public static void main(String[] args) {
+ String[] strs = {"沉默王二", "一枚有趣的程序员"};
+
+ for (String str : strs) {
+ System.out.println(str);
+ }
+ }
+}
+```
+
+输出:
+
+```
+沉默王二
+一枚有趣的程序员
+```
+
+“呀,二哥,你开始王哥卖瓜了啊。”
+
+“嘿嘿,三妹,你这样说哥会脸红的。”
+
+**3)无限 for 循环**
+
+“三妹,你想不想体验一下无限 for 循环的威力,也就是死循环。”
+
+“二哥,那会有什么样的后果啊?”
+
+“来,看看就知道了。”
+
+```java
+public class InfinitiveForExample {
+ public static void main(String[] args) {
+ for(;;){
+ System.out.println("停不下来。。。。");
+ }
+ }
+}
+```
+
+输出:
+
+```
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+```
+
+一旦运行起来,就停不下来了,除非强制停止。
+
+### 04、while 循环
+
+来看一下 while 循环的格式:
+
+
+
+```java
+while(条件){
+//循环体
+}
+```
+
+
+
+画个流程图:
+
+
+
+
+
+
+
+来个示例:
+
+```java
+public class WhileExample {
+ public static void main(String[] args) {
+ int i = 0;
+ while (true) {
+ System.out.println("沉默王三");
+ i++;
+ if (i == 5) {
+ break;
+ }
+ }
+ }
+}
+```
+
+“三妹,你猜猜会输出几次?”
+
+“五次吗?”
+
+“对了,你可真聪明。”
+
+```
+沉默王三
+沉默王三
+沉默王三
+沉默王三
+沉默王三
+```
+
+
+
+“三妹,你想不想体验一下无限 while 循环的威力,也就是死循环。”
+
+“二哥,那会有什么样的后果啊?”
+
+“来,看看就知道了。”
+
+```java
+public class InfinitiveWhileExample {
+ public static void main(String[] args) {
+ while (true) {
+ System.out.println("停不下来。。。。");
+ }
+ }
+}
+```
+
+输出:
+
+```
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+```
+
+把 while 的条件设置为 true,并且循环体中没有 break 关键字的话,程序一旦运行起来,就根本停不下来了,除非强制停止。
+
+### 05、do-while 循环
+
+来看一下 do-while 循环的格式:
+
+
+
+```java
+do{
+// 循环体
+}while(提交);
+```
+
+
+
+画个流程图:
+
+
+
+
+
+
+
+
+来个示例:
+
+```java
+public class DoWhileExample {
+ public static void main(String[] args) {
+ int i = 0;
+ do {
+ System.out.println("沉默王三");
+ i++;
+ if (i == 5) {
+ break;
+ }
+ } while (true);
+ }
+}
+```
+
+“三妹,你猜猜会输出几次?”
+
+“五次吗?”
+
+“对了,你可真聪明。”
+
+```
+沉默王三
+沉默王三
+沉默王三
+沉默王三
+沉默王三
+```
+
+
+
+“三妹,你想不想体验一下无限 do-while 循环的威力......”
+
+“二哥,又来啊,我都腻了。”
+
+“来吧,例行公事,就假装看看嘛。”
+
+```java
+public class InfinitiveDoWhileExample {
+ public static void main(String[] args) {
+ do {
+ System.out.println("停不下来。。。。");
+ } while (true);
+ }
+}
+```
+
+输出:
+
+```
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+停不下来。。。。
+```
+
+把 do-while 的条件设置为 true,并且循环体中没有 break 关键字的话,程序一旦运行起来,就根本停不下来了,除非强制停止。
+
+
+
+### 06、break
+
+break 关键字通常用于中断循环或 switch 语句,它在指定条件下中断程序的当前流程。如果是内部循环,则仅中断内部循环。
+
+可以将 break 关键字用于所有类型循环语句中,比如说 for 循环、while 循环,以及 do-while 循环。
+
+来画个流程图感受一下:
+
+
+
+
+
+用在 for 循环中的示例:
+
+```java
+for (int i = 1; i <= 10; i++) {
+ if (i == 5) {
+ break;
+ }
+ System.out.println(i);
+}
+```
+
+用在嵌套 for 循环中的示例:
+
+```java
+for (int i = 1; i <= 3; i++) {
+ for (int j = 1; j <= 3; j++) {
+ if (i == 2 && j == 2) {
+ break;
+ }
+ System.out.println(i + " " + j);
+ }
+}
+```
+
+用在 while 循环中的示例:
+
+```java
+int i = 1;
+while (i <= 10) {
+ if (i == 5) {
+ i++;
+ break;
+ }
+ System.out.println(i);
+ i++;
+}
+```
+
+用在 do-while 循环中的示例:
+
+```java
+int j = 1;
+do {
+ if (j == 5) {
+ j++;
+ break;
+ }
+ System.out.println(j);
+ j++;
+} while (j <= 10);
+```
+
+用在 switch 语句中的示例:
+
+```java
+switch (age) {
+ case 20 :
+ System.out.println("上学");
+ break;
+ case 24 :
+ System.out.println("苏州工作");
+ break;
+ case 30 :
+ System.out.println("洛阳工作");
+ break;
+ default:
+ System.out.println("未知");
+ break; // 可省略
+}
+```
+
+### 07、continue
+
+当我们需要在 for 循环或者 (do)while 循环中立即跳转到下一个循环时,就可以使用 continue 关键字,通常用于跳过指定条件下的循环体,如果循环是嵌套的,仅跳过当前循环。
+
+来个示例:
+
+```java
+public class ContinueDemo {
+ public static void main(String[] args) {
+ for (int i = 1; i <= 10; i++) {
+ if (i == 5) {
+ // 使用 continue 关键字
+ continue;// 5 将会被跳过
+ }
+ System.out.println(i);
+ }
+ }
+}
+```
+
+输出:
+
+```
+1
+2
+3
+4
+6
+7
+8
+9
+10
+```
+
+“二哥,5 真的被跳过了呀。”
+
+“那必须滴。不然就是 bug。”
+
+再来个循环嵌套的例子。
+
+```java
+public class ContinueInnerDemo {
+ public static void main(String[] args) {
+ for (int i = 1; i <= 3; i++) {
+ for (int j = 1; j <= 3; j++) {
+ if (i == 2 && j == 2) {
+ // 当i=2,j=2时跳过
+ continue;
+ }
+ System.out.println(i + " " + j);
+ }
+ }
+ }
+}
+```
+
+打印出什么玩意呢?
+
+```
+1 1
+1 2
+1 3
+2 1
+2 3
+3 1
+3 2
+3 3
+```
+
+“2 2” 没有输出,被跳过了。
+
+再来看一下 while 循环时 continue 的使用示例:
+
+```java
+public class ContinueWhileDemo {
+ public static void main(String[] args) {
+ int i = 1;
+ while (i <= 10) {
+ if (i == 5) {
+ i++;
+ continue;
+ }
+ System.out.println(i);
+ i++;
+ }
+ }
+}
+```
+
+输出:
+
+```
+1
+2
+3
+4
+6
+7
+8
+9
+10
+```
+
+注意:如果把 if 条件中的“i++”省略掉的话,程序就会进入死循环,一直在 continue。
+
+最后,再来看一下 do-while 循环时 continue 的使用示例:
+
+```java
+public class ContinueDoWhileDemo {
+ public static void main(String[] args) {
+ int i=1;
+ do{
+ if(i==5){
+ i++;
+ continue;
+ }
+ System.out.println(i);
+ i++;
+ }while(i<=10);
+ }
+}
+
+```
+
+输出:
+
+```
+1
+2
+3
+4
+6
+7
+8
+9
+10
+```
+
+注意:同样的,如果把 if 条件中的“i++”省略掉的话,程序就会进入死循环,一直在 continue。
+
+
\ No newline at end of file
diff --git a/docs/basic-grammar/javadoc.md b/docs/basic-grammar/javadoc.md
new file mode 100644
index 0000000000..f6107e34a5
--- /dev/null
+++ b/docs/basic-grammar/javadoc.md
@@ -0,0 +1,179 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java注释:单行、多行和文档注释
+
+“二哥,Java 中的注释好像真没什么可讲的,我已经提前预习了,不过是单行注释,多行注释,还有文档注释。”三妹的脸上泛着甜甜的笑容,她竟然提前预习了接下来要学习的知识,有一种“士别三日,当刮目相看”的感觉。
+
+“注释的种类确实不多,但还是挺有意思的,且听哥来给你说道说道。”
+
+
+
+
+
+
+### 01、单行注释
+
+单行注释通常用于解释方法内某单行代码的作用。
+
+```java
+public void method() {
+ int age = 18; // age 用于表示年龄
+}
+```
+
+**但如果写在行尾的话,其实是不符合阿里巴巴的开发规约的**。
+
+
+
+正确的单行注释如上图中所说,在被注释语句上方另起一行,使用 `//` 注释。
+
+```java
+public void method() {
+ // age 用于表示年龄
+ int age = 18;
+}
+```
+
+
+### 02、多行注释
+
+多行注释使用的频率其实并不高,通常用于解释一段代码的作用。
+
+```java
+/*
+age 用于表示年纪
+name 用于表示姓名
+*/
+int age = 18;
+String name = "沉默王二";
+```
+
+以 `/*` 开始,以 `*/` 结束,但不如用多个 `//` 来得痛快,因为 `*` 和 `/` 不在一起,敲起来麻烦。
+
+```java
+// age 用于表示年纪
+// name 用于表示姓名
+int age = 18;
+String name = "沉默王二";
+```
+
+### 03、文档注释
+
+文档注释可用在三个地方,类、字段和方法,用来解释它们是干嘛的。
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class Demo {
+ /**
+ * 姓名
+ */
+ private int age;
+
+ /**
+ * main 方法作为程序的入口
+ *
+ * @param args 参数
+ */
+ public static void main(String[] args) {
+
+ }
+}
+```
+
+PS:在 Intellij IDEA 中,按下 `/**` 后敲下回车键就可以自动添加文档注释的格式,`*/` 是自动补全的。
+
+接下来,我们来看看如何通过 javadoc 命令生成代码文档。
+
+**第一步**,在该类文件上右键,找到「Open in Terminal」 可以打开命令行窗口。
+
+
+
+
+**第二步**,执行 javadoc 命令 `javadoc Demo.java -encoding utf-8`。`-encoding utf-8` 可以保证中文不发生乱码。
+
+
+
+**第三步,**执行 `ls -l` 命令就可以看到生成代码文档时产生的文件,主要是一些可以组成网页的 html、js 和 css 文件。
+
+
+
+**第四步**,执行 `open index.html` 命令可以通过默认的浏览器打开文档注释。
+
+
+
+点击「Demo」,可以查看到该类更具体的注释文档。
+
+
+
+### 04、文档注释的注意事项
+
+1)`javadoc` 命令只能为 public 和 protected 修饰的字段、方法和类生成文档。
+
+default 和 private 修饰的字段和方法的注释将会被忽略掉。因为我们本来就不希望这些字段和方法暴露给调用者。
+
+如果类不是 public 的话,javadoc 会执行失败。
+
+
+
+2)文档注释中可以嵌入一些 HTML 标记,比如说段落标记 ``,超链接标记 `` 等等,但不要使用标题标记,比如说 `
`,因为 javadoc 会插入自己的标题,容易发生冲突。
+
+3)文档注释中可以插入一些 `@` 注解,比如说 `@see` 引用其他类,`@version` 版本号,`@param` 参数标识符,`@author` 作者标识符,`@deprecated` 已废弃标识符,等等。
+
+### 05、注释规约
+
+1)类、字段、方法必须使用文档注释,不能使用单行注释和多行注释。因为注释文档在 IDE 编辑窗口中可以悬浮提示,提高编码效率。
+
+比如说,在使用 String 类的时候,鼠标悬停在 String 上时可以得到以下提示。
+
+
+
+2)所有的抽象方法(包括接口中的方法)必须要用Javadoc注释、除了返回值、参数、 异常说明外,还必须指出该方法做什么事情,实现什么功能。
+
+3)所有的类都必须添加创建者和创建日期。
+
+Intellij IDEA 中可以在「File and Code Templates」中设置。
+
+
+
+语法如下所示:
+
+```
+/**
+* 微信搜索「沉默王二」,回复 Java
+* @author 沉默王二
+* @date ${DATE}
+*/
+```
+
+设置好后,在新建一个类的时候就可以自动生成了。
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ *
+ * @author 沉默王二
+ * @date 2020/11/16
+ */
+public class Test {
+}
+```
+
+4)所有的枚举类型字段必须要有注释,说明每个数据项的用途。
+
+5)代码修改的同时,注释也要进行相应的修改。
+
+
+“好了,三妹,关于 Java 中的注释就先说这么多吧。”转动了一下僵硬的脖子后,我对三妹说。“记住一点,注释是程序固有的一部分。”
+
+>第一、注释要能够准确反映设计思想和代码逻辑;第二、注释要能够描述业务含 义,使别的程序员能够迅速了解到代码背后的信息。完全没有注释的大段代码对于阅读者形同 天书,注释是给自己看的,即使隔很长时间,也能清晰理解当时的思路;注释也是给继任者看 的,使其能够快速接替自己的工作。
+
+-----
+
+
\ No newline at end of file
diff --git a/docs/basic-grammar/operator.md b/docs/basic-grammar/operator.md
new file mode 100644
index 0000000000..e38544faf7
--- /dev/null
+++ b/docs/basic-grammar/operator.md
@@ -0,0 +1,379 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java运算符
+
+“二哥,让我盲猜一下哈,运算符是不是指的就是加减乘除啊?”三妹的脸上泛着甜甜的笑容,我想她一定对提出的问题很有自信。
+
+“是的,三妹。运算符在 Java 中占据着重要的位置,对程序的执行有着很大的帮助。除了常见的加减乘除,还有许多其他类型的运算符,来看下面这张思维导图。”
+
+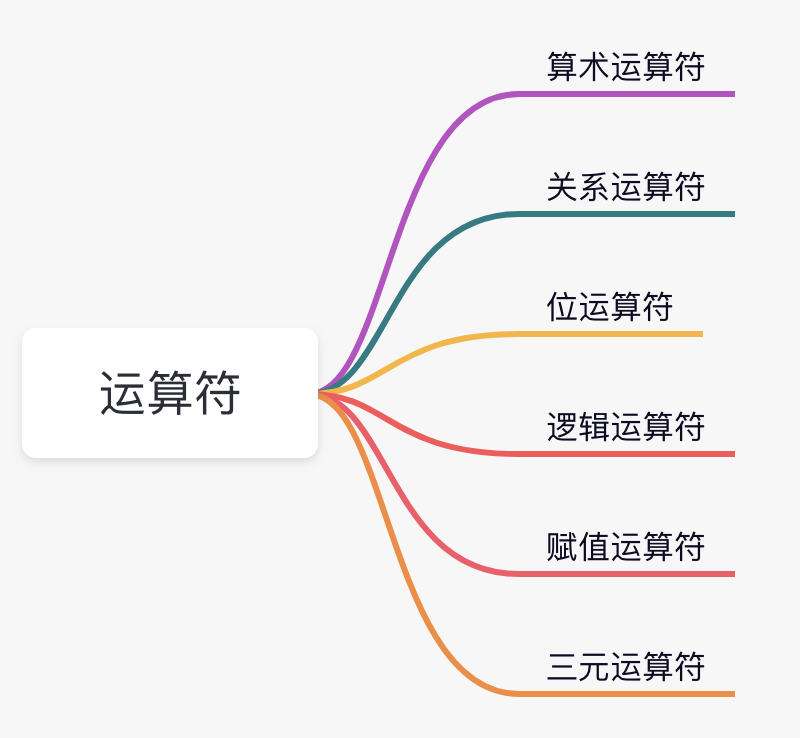
+
+
+### 01、算数运算符
+
+算术运算符除了最常见的加减乘除,还有一个取余的运算符,用于得到除法运算后的余数,来串代码感受下。
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class ArithmeticOperator {
+ public static void main(String[] args) {
+ int a = 10;
+ int b = 5;
+
+ System.out.println(a + b);//15
+ System.out.println(a - b);//5
+ System.out.println(a * b);//50
+ System.out.println(a / b);//2
+ System.out.println(a % b);//0
+
+ b = 3;
+ System.out.println(a + b);//13
+ System.out.println(a - b);//7
+ System.out.println(a * b);//30
+ System.out.println(a / b);//3
+ System.out.println(a % b);//1
+ }
+}
+```
+
+对于初学者来说,加法(+)、减法(-)、乘法(*)很好理解,但除法(/)和取余(%)会有一点点疑惑。在以往的认知里,10/3 是除不尽的,结果应该是 3.333333...,而不应该是 3。相应的,余数也不应该是 1。这是为什么呢?
+
+因为数字在程序中可以分为两种,一种是整型,一种是浮点型(不清楚的同学可以回头看看[数据类型那篇](https://mp.weixin.qq.com/s/twim3w_dp5ctCigjLGIbFw)),整型和整型的运算结果就是整型,不会出现浮点型。否则,就会出现浮点型。
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class ArithmeticOperator {
+ public static void main(String[] args) {
+ int a = 10;
+ float c = 3.0f;
+ double d = 3.0;
+ System.out.println(a / c); // 3.3333333
+ System.out.println(a / d); // 3.3333333333333335
+ System.out.println(a % c); // 1.0
+ System.out.println(a % d); // 1.0
+ }
+}
+```
+
+需要注意的是,当浮点数除以 0 的时候,结果为 Infinity 或者 NaN。
+
+```
+System.out.println(10.0 / 0.0); // Infinity
+System.out.println(0.0 / 0.0); // NaN
+```
+
+Infinity 的中文意思是无穷大,NaN 的中文意思是这不是一个数字(Not a Number)。
+
+
+当整数除以 0 的时候(`10 / 0`),会抛出异常:
+
+```
+Exception in thread "main" java.lang.ArithmeticException: / by zero
+ at com.itwanger.eleven.ArithmeticOperator.main(ArithmeticOperator.java:32)
+```
+
+所以整数在进行除法运算时,需要先判断除数是否为 0,以免程序抛出异常。
+
+算术运算符中还有两种特殊的运算符,自增运算符(++)和自减运算符(--),它们也叫做一元运算符,只有一个操作数。
+
+```java
+public class UnaryOperator1 {
+ public static void main(String[] args) {
+ int x = 10;
+ System.out.println(x++);//10 (11)
+ System.out.println(++x);//12
+ System.out.println(x--);//12 (11)
+ System.out.println(--x);//10
+ }
+}
+```
+
+一元运算符可以放在数字的前面或者后面,放在前面叫前自增(前自减),放在后面叫后自增(后自减)。
+
+前自增和后自增是有区别的,拿 `int y = ++x` 这个表达式来说(x = 10),它可以拆分为 `x = x+1 = 11; y = x = 11`,所以表达式的结果为 `x = 11, y = 11`。拿 `int y = x++` 这个表达式来说(x = 10),它可以拆分为 `y = x = 10; x = x+1 = 11`,所以表达式的结果为 `x = 11, y = 10`。
+
+```java
+int x = 10;
+int y = ++x;
+System.out.println(y + " " + x);// 11 11
+
+x = 10;
+y = x++;
+System.out.println(y + " " + x);// 10 11
+```
+
+对于前自减和后自减来说,同学们可以自己试一把。
+
+
+### 02、关系运算符
+
+关系运算符用来比较两个操作数,返回结果为 true 或者 false。
+
+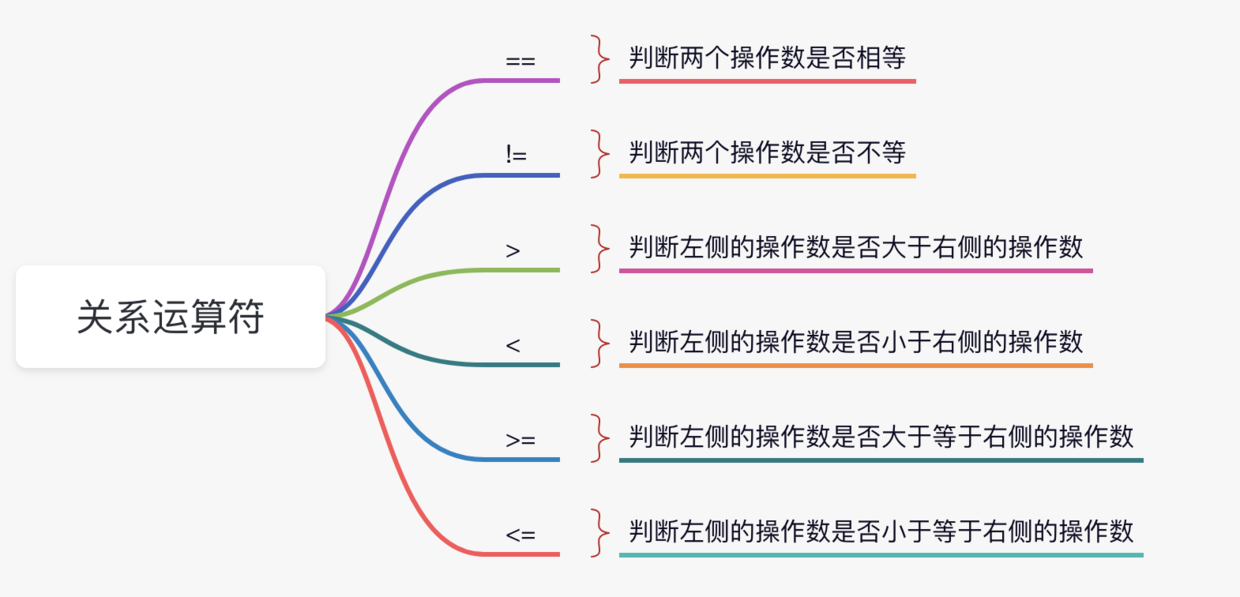
+
+来看示例:
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class RelationOperator {
+ public static void main(String[] args) {
+ int a = 10, b = 20;
+ System.out.println(a == b); // false
+ System.out.println(a != b); // true
+ System.out.println(a > b); // false
+ System.out.println(a < b); // true
+ System.out.println(a >= b); // false
+ System.out.println(a <= b); // true
+ }
+}
+```
+
+### 03、位运算符
+
+在学习位运算符之前,需要先学习一下二进制,因为位运算符操作的不是整型数值(int、long、short、char、byte)本身,而是整型数值对应的二进制。
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class BitOperator {
+ public static void main(String[] args) {
+ System.out.println(Integer.toBinaryString(60)); // 111100
+ System.out.println(Integer.toBinaryString(13)); // 1101
+ }
+}
+```
+
+ 从程序的输出结果可以看得出来,60 的二进制是 0011 1100(用 0 补到 8 位),13 的二进制是 0000 1101。
+
+PS:现代的二进制记数系统由戈特弗里德·威廉·莱布尼茨于 1679 年设计。莱布尼茨是德意志哲学家、数学家,历史上少见的通才。
+
+
+
+来看示例:
+
+```java
+/**
+ * 微信搜索「沉默王二」,回复 Java
+ */
+public class BitOperator {
+ public static void main(String[] args) {
+ int a = 60, b = 13;
+ System.out.println("a 的二进制:" + Integer.toBinaryString(a)); // 111100
+ System.out.println("b 的二进制:" + Integer.toBinaryString(b)); // 1101
+
+ int c = a & b;
+ System.out.println("a & b:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = a | b;
+ System.out.println("a | b:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = a ^ b;
+ System.out.println("a ^ b:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = ~a;
+ System.out.println("~a:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = a << 2;
+ System.out.println("a << 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = a >> 2;
+ System.out.println("a >> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
+
+ c = a >>> 2;
+ System.out.println("a >>> 2:" + c + ",二进制是:" + Integer.toBinaryString(c));
+ }
+}
+```
+
+对于初学者来说,位运算符无法从直观上去计算出结果,不像加减乘除那样。因为我们日常接触的都是十进制,位运算的时候需要先转成二进制,然后再计算出结果。
+
+鉴于此,初学者在写代码的时候其实很少会用到位运算。对于编程高手来说,为了提高程序的性能,会在一些地方使用位运算。比如说,HashMap 在计算哈希值的时候:
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+如果对位运算一点都不懂的话,遇到这样的源码就很吃力。所以说,虽然位运算用的少,但还是要懂。
+
+1)按位左移运算符:
+
+```java
+public class LeftShiftOperator {
+ public static void main(String[] args) {
+ System.out.println(10<<2);//10*2^2=10*4=40
+ System.out.println(10<<3);//10*2^3=10*8=80
+ System.out.println(20<<2);//20*2^2=20*4=80
+ System.out.println(15<<4);//15*2^4=15*16=240
+ }
+}
+```
+
+`10<<2` 等于 10 乘以 2 的 2 次方;`10<<3` 等于 10 乘以 2 的 3 次方。
+
+2)按位右移运算符:
+
+```java
+public class RightShiftOperator {
+ public static void main(String[] args) {
+ System.out.println(10>>2);//10/2^2=10/4=2
+ System.out.println(20>>2);//20/2^2=20/4=5
+ System.out.println(20>>3);//20/2^3=20/8=2
+ }
+}
+```
+
+`10>>2` 等于 10 除以 2 的 2 次方;`20>>2` 等于 20 除以 2 的 2 次方。
+
+### 04、逻辑运算符
+
+逻辑与运算符(&&):多个条件中只要有一个为 false 结果就为 false。
+
+逻辑或运算符(||):多个条件只要有一个为 true 结果就为 true。
+
+```java
+public class LogicalOperator {
+ public static void main(String[] args) {
+ int a=10;
+ int b=5;
+ int c=20;
+ System.out.println(ab||ab|a作者:朱晋君,转载链接:[https://mp.weixin.qq.com/s/xlPZfpd89rDq6L-Me80wnw](https://mp.weixin.qq.com/s/xlPZfpd89rDq6L-Me80wnw)
-
+
diff --git a/docs/src/cityselect/chengdu.md b/docs/cityselect/chengdu.md
similarity index 98%
rename from docs/src/cityselect/chengdu.md
rename to docs/cityselect/chengdu.md
index e1bfef642a..f97c53fa8f 100644
--- a/docs/src/cityselect/chengdu.md
+++ b/docs/cityselect/chengdu.md
@@ -1,12 +1,11 @@
---
-shortTitle: 成都
category:
- 求职面试
tag:
- 城市选择
---
-# 成都都有哪些值得加入的IT互联网公司?
+# 成都有哪些牛批的互联网公司?
今天应小伙伴们的要求,再来聊一聊美丽的**四川省成都市**有哪些酷酷的IT/技术类公司(不仅仅局限于纯互联网)。
@@ -484,4 +483,4 @@ tag:
>链接:[https://mp.weixin.qq.com/s/eaX9QhLwy_VsGIH0apA4qw](https://mp.weixin.qq.com/s/eaX9QhLwy_VsGIH0apA4qw)
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/src/cityselect/guangzhou.md b/docs/cityselect/guangzhou.md
similarity index 77%
rename from docs/src/cityselect/guangzhou.md
rename to docs/cityselect/guangzhou.md
index bbaedaa35a..f97c4e00e1 100644
--- a/docs/src/cityselect/guangzhou.md
+++ b/docs/cityselect/guangzhou.md
@@ -1,12 +1,11 @@
---
-shortTitle: 广州
category:
- 求职面试
tag:
- 城市选择
---
-# 广州都有哪些值得加入的IT互联网公司?
+# 想去广州了!
@@ -16,7 +15,7 @@ tag:
广州的繁华以及它的魅力不用我多说,无论从人文还是从经济来说都是不虚其它城市的。不过我在面试时发现,广州除了几个头部大厂是统一薪资标准外,相较于其它一线城市,广州的互联网行业给我的感觉是整体薪资水平偏低。
-
+
大家注意呀,其实学计算机相关专业的想在广州挣钱,不止可以通过互联网公司,也可以通过当公务员,教师等方式去挣钱呀。应届生考进体制内当公务员,年薪也20多万呢,并且各方面福利待遇绝对到位,相当不错了。下面我们还是分互联网公司以及国企央企研究所介绍吧。
@@ -28,61 +27,61 @@ tag:
**网易**
-
+
网易在广州主要是游戏部门。算是网易的核心业务了。注意,网易面试时候是散装的,网易互娱、网易雷火和网易互联网是分开招聘的,我当时投简历都是分开给他们投的,同样的简历我在网站上填了三次,累死。不过好处就是你有三次机会能进网易 ~ 注意,互娱、雷火、互联网的薪资方案也是不一样的。网易的薪资方案很复杂,这里面水太深,我感觉我有点把握不住~ 我知道有人拿到sp大概就是 25k * 16吧,还会有股票。网易食堂的伙食是真的好,大部分人去了工作一段时间都胖了。
**微信**
-
+
广州主要是腾讯的 wxg 事业群,也就是微信。wxg 事业群的效益非常好,能进 wxg 还是很棒的,不过面试难度也挺大的。腾讯去年校招的薪资分 17k,18.5k,20k,21.5k,23k 几个档次,hr说是应届生第一年保证18薪,不过第二年就不保证了哈。注意,腾讯开出的薪资是可以argue的,如果他给你的薪资不满意,你可以用其它offer跟腾讯的 hr argue 更高档次的薪资,有成功的。另外校招生还有签字费以及股票以及租房补贴。腾讯时不时送点小礼物,工作的舒适度还是不错的。
**字节跳动**
-
+
广州的字节整体上不如其它地方的字节加班严重,不过也要看部门,有的部门听说挺累的。字节之前一直是大小周,前不久刚刚宣布要取消大小周,有双休还是挺幸福的,就是要少挣不少钱了,看你是不是奋斗逼了。我看到21届字节校招的薪资主要是每月20k,22k,24k,26k,28k,30k不等。不过我看校招拿到广州这边offer的大部分是22k和24k的月薪,
**欢聚时代**
-
+
大家看到欢聚时代这个名称可能有点陌生,其实 YY 和 虎牙 都是欢聚时代的。欢聚时代的薪资水平我不清楚,我问了朋友也不清楚,我就去查校招薪水上的薪资爆料。有点迷呀,去年校招,开发方向的月薪14k、16k、18k 的都有,但是这算法薪资的爆料咋还直接就 27k 呢?这也差的太多了吧。有靠谱消息的老铁欢迎来补充。
**唯品会**
-
+
唯品会算是广州本地的一霸了吧,唯品会的福利挺给力的,包三餐,双休,租房补贴。本科生开发的月薪主要集中在14k-16k。
**SHEIN**
-
+
这家公司我熟,我就给你们展开讲讲。这家公司最近势头很猛,做跨境电商的,主要卖女装。我在去年秋招初期还面试过这家公司,面试难度比较友好。首先是 hr 给我发了个笔试链接,让我几天内找个时间做了。通过笔试后,第一轮面试,面试了大概有 30 多分钟,主要问了项目以及面试八股文,没有让写代码,然后面试就通过了。第二轮面试,面试官随便问了两个八股文问题就开始聊理想了。第三轮面试好像是他们的 cto,问我高考数学考多少分 ~ 问我上学期间大概写了多少行代码~ 然后又聊了几句就跟我结束面试了。就给我 offer了。后续hr跟我谈薪的时候说他们加班少,工资是 16k * 14,我觉得工资有点少,就没接offer。
**三七互娱**
-
+
我了解到三七互娱后端岗位大部分是 PHP,本科生校招进来薪资大概是12k 左右吧,每年发 15个月的工资。在知乎上对三七互娱的讨论比较多,有黑点,每个部门的情况也不太一样,大家可以再去了解下呀。
**小鹏汽车**
-
+
小鹏汽车最近风头正盛,应届生校招进来的工资基本在 16k 左右,每年15薪。小鹏汽车目前是大小周呀,工作强度还是比较大的。
**酷狗音乐**
-
+
酷狗音乐是腾讯的这应该大家都知道,不过内部的薪资职级不是完全对齐的哈。酷狗的不同部门工作强度差别很大,有的闲的要死,有的忙的要死。选择部门时要注意。
**4399**
-
+
4399大家应该都不陌生,好多小游戏都是从小开始玩的,工资也在16k左右。
@@ -96,19 +95,19 @@ tag:
**移动**
-
+
移动每月的工资很低,可能到手就五六千块钱,然后年底会一下再发五六万的年终奖,有时候会更多一些。据说 18 年效益好年底一下发了 8 万,19 年就拉跨了。
**联通**
-
+
转正后每月到手八九千,绩效好能到手一万左右。
**电信**
-
+
我看到 offershow 上有做网络运维的爆料,入职第一年每月到手8.5k,年终发了3.5万。
@@ -128,13 +127,13 @@ tag:
### 房价
-
+
大家直接看图,相比于其它一线城市房价算是便宜了。但是按照广州互联网的工资水平想在广州差不多的区域和地段买房,压力是很大的。
### 教育
-
+
广州的985大学有两所,分别是中山大学和华南理工,211也有两所是暨南大学以及华南师范大学,另外广州大学、广东工业大学等等也都不错。广州的高中也很给力,华南师范大学附属中学、广东实验中学、广东广雅中学、广州市执信中学、广州二中、六中等等学校都很不错。
@@ -142,17 +141,17 @@ tag:
一线城市的医疗资源肯定是没问题的,我粗略数了一下,广州有不下40所三甲医院。我了解到顶级医疗资源主要有中山系、南方系、广中医系等等。
-
+
### 风景&美食
-
+
广州的美景自然不用多说,另外空气质量也很好,说起空气质量,我这个北方人已经习惯冬天经常见不到太阳了。广州的美食也很多,白切鸡、煲仔饭和肠粉等等,还有很多我就不报菜名了,我在西安上学时食堂有个卖肠粉的窗口,我很爱吃,不过这个肠粉明显是本地化了。话说南北差异还是挺大的,我一个同学去广州上学,去洗澡带着搓澡巾,他的广州舍友都十分的好奇~ 当然广州的同学看我拍雪景也很好奇 ~ 还有一次实验室和厦门大学一起合作做项目,我和一个厦门大学的博士都要了一份豆腐脑,我加韭菜花,他加糖,我两面对面坐着都觉得对方的不能吃。
-
+
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/uZQ8p0ytsQFXzt5ppzx6fA](https://mp.weixin.qq.com/s/uZQ8p0ytsQFXzt5ppzx6fA)
-
+
diff --git a/docs/src/cityselect/hangzhou.md b/docs/cityselect/hangzhou.md
similarity index 89%
rename from docs/src/cityselect/hangzhou.md
rename to docs/cityselect/hangzhou.md
index 7a0589b3eb..cc158e4680 100644
--- a/docs/src/cityselect/hangzhou.md
+++ b/docs/cityselect/hangzhou.md
@@ -1,20 +1,19 @@
---
-shortTitle: 杭州
category:
- 求职面试
tag:
- 城市选择
---
-# 杭州都有哪些值得加入的IT互联网公司?
+# 杭州有哪些顶级的互联网公司?
大家好,我是二哥呀!上期发了南京的互联网公司后,杭州的呼声非常高。
-
+
-有小伙伴在公众号后台私信催,还有小伙伴在二哥的《二哥的Java进阶之路》的开源专栏提交了 issue,那今天必须得来整一波了。
+有小伙伴在公众号后台私信催,还有小伙伴在二哥的《Java 程序员进阶之路》的开源专栏提交了 issue,那今天必须得来整一波了。
-
+
杭州的互联网公司比较多,我先列举一些大家瞅瞅(部分数据来源于好朋友 Carl 的统计)。
@@ -78,7 +77,7 @@ tag:
### 字节跳动
-
+
- 「基本情况」 :字节总部在北京,在上海、深圳、杭州、广州、成都等地都有办公室。去年 6 月,抖音电商落户杭州。
- 「业务方向」 :抖音电商、抖音餐饮、字节跳动广告业务、字节跳动本地生活
@@ -89,7 +88,7 @@ tag:
### 阿里系
-
+
- 「基本情况」 :阿里系占据了杭州互联网的一片天,相关联的企业是在是太多了。
- 「业务方向」 :达摩院、淘宝、菜鸟、钉钉、飞猪、盒马、支付宝、夸克、UC、书旗小说......
@@ -101,7 +100,7 @@ tag:
### 京东
-
+
- 「基本情况」 :京东在杭州也有招聘,不过,招聘的岗位比较少。
- 「业务方向」 :京东金融、京东云
@@ -112,7 +111,7 @@ tag:
### 网易
-
+
- 「基本情况」 :网易在杭州有一个研究院,成立于 2006 年 6 月。
- 「业务方向」 :⽹易杭州研究院,简称“杭研”。杭研是⽹易内部的基础技术研发中⼼和前沿技术研究中⼼,在云计算、⼤数据、安全、⼈⼯智能等⽅⾯进⾏前沿技术研究、关键技术攻关和基础技术平台研发,服务⽹易系游戏、邮箱、⾳乐、电商、新闻、在线教育等产品,触达近 10 亿⽤户。
@@ -123,7 +122,7 @@ tag:
### 华为
-
+
- 「基本情况」 :华为在杭州有一个研究所。
- 「业务方向」 :智能摄像机、云服务
@@ -135,7 +134,7 @@ tag:
### 中移杭研
-
+
- 「基本情况」 :中国移动的一个全资子公司,2014 年在杭州成立。
- 「业务方向」 :统一认证、融合通信、魔固云
@@ -146,7 +145,7 @@ tag:
### 之江实验室
-
+
- 「基本情况」 :之江实验室是浙江省委、省政府贯彻落实科技创新思想,深入实施创新驱动发展战略的重大科技创新平台。
- 「业务方向」 :智能感知、智能计算、智能网络、智能系统
@@ -157,7 +156,7 @@ tag:
### 同花顺
-
+
- 「基本情况」 :同花顺成立于 2001 年,总部位于杭州未来科技城,是国内第一家互联网金融信息服务业上市公司。同花顺作为一家互联网金融信息提供商,致力于为各类机构提供软件产品和系统维护服务、金融数据服务和智能推广服务,为个人投资者提供金融资讯和投资理财分析工具。
- 「业务方向」 :旗下有多款热门投资理财类 APP。
@@ -168,7 +167,7 @@ tag:
### 51 信用卡
-
+
- 「基本情况」 :51 信用卡(母公司为杭州恩牛网络技术有限公司),公司创立于 2012 年,是一家服务于中国亿万信用卡用户的互联网金融公司。
- 「业务方向」 :旗下有“51 信用卡管家”、“51 人品”、“51 人品贷”等 APP
@@ -180,7 +179,7 @@ tag:
### 蘑菇街
-
+
- 「基本情况」 :2011 年,蘑菇街正式上线,2016 年 1 月与美丽说战略融合,公司旗下包括:蘑菇街、美丽说、uni 等产品与服务。
- 「业务方向」 :电商
@@ -192,7 +191,7 @@ tag:
### 有赞
-
+
- 「基本情况」 :有赞,原名口袋通,2012 年 11 月 27 日在杭州贝塔咖啡馆孵化成立,是一家主要从事零售科技 SaaS 服务的企业,帮助商家进行网上开店、社交营销、提高留存复购,拓展全渠道新零售业务。2014 年 11 月 27 日,口袋通正式更名为有赞。2018 年 4 月 18 日,有赞完成在港上市。2019 年 4 月,腾讯领投有赞 10 亿港元融资。
- 「业务方向」 :SaaS 服务(帮助商家网上开店、社交营销......)、PaaS 云服务。
@@ -204,7 +203,7 @@ tag:
### Zoom
-
+
- 「基本情况」 :Zoom 是一位美国华人企业家创办的公司,主营业务就是提供视频会议服务。总部位于硅谷,国内的话,杭州、苏州、合肥均有研发中心。
- 「业务方向」 :视频会议
@@ -216,7 +215,7 @@ tag:
### Cisco(思科)
-
+
- 「基本情况」 :思科系统公司(Cisco Systems, Inc.),简称思科公司或思科,1984 年 12 月正式成立,是互联网解决方案的领先提供者,其设备和软件产品主要用于连接计算机网络系统,总部位于美国加利福尼亚州圣何塞。
- 「业务方向」 :路由器、交换机等网络基础设施
@@ -234,13 +233,13 @@ tag:
顺带再聊聊杭州的房价、教育吧。杭州的房价不忍直视啊!!!涨的实在是太厉害了!
-
+
杭州只有一所 985,也就是浙江大学。除了浙江大学之外,浙江省没有 211 院校。不过,杭州电子科技大学虽然不是 211,但是实力很强,外界也很认可。
-
+
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/hrL2tqXHT5AjOqrQlRhR-w](https://mp.weixin.qq.com/s/hrL2tqXHT5AjOqrQlRhR-w)
-
+
diff --git a/docs/src/cityselect/nanjing.md b/docs/cityselect/nanjing.md
similarity index 82%
rename from docs/src/cityselect/nanjing.md
rename to docs/cityselect/nanjing.md
index 0e5134dcfc..8325e6be1c 100644
--- a/docs/src/cityselect/nanjing.md
+++ b/docs/cityselect/nanjing.md
@@ -1,12 +1,11 @@
---
-shortTitle: 南京
category:
- 求职面试
tag:
- 城市选择
---
-# 南京都有哪些值得加入的IT互联网公司?
+# 南京有哪些靠谱的互联网公司?
@@ -14,7 +13,7 @@ tag:
有句话说的很对,“安徽不能没有南京,就像东北不能没有三亚”。不过调研中也发现,对于程序员来说,想要在南京留下也不是件很容易的事情,因为南京程序员的工作机会只能算一般,薪资水平这两年许多大公司选择在南京设立分部后才带起来一些,但是南京的房价已经很高了。
-
+
提一下哈,在这个系列里说的校招薪资都是常规招聘计划的薪资,说的常规招聘计划给出的 offer 包含普通 offer,sp (special offer) 和 ssp。不包含那些比如华为天才少年、美团北斗之类的。那种神仙 offer 怎么样我这种凡人还真不了解。这些招聘的薪资也都是针对本科生和研究生的。如果你是博士,薪资方面和公司都好商量。
@@ -24,7 +23,7 @@ tag:
### 阿里巴巴
-
+
校招薪资:招的人不多,具体薪资情况不太清楚。据说和总部薪资水平差不多。阿里的薪资水平可以参考下[链接](https://mp.weixin.qq.com/s/3c-a7GpkTzAU2DFWSwN4lw)。
@@ -32,7 +31,7 @@ tag:
### 字节跳动
-
+
校招薪资:字节在南京的薪资是字节在北京上海深圳薪资的 0.9。感觉薪资水平挺不错了。今年字节校招薪资也可以点这个[链接](https://mp.weixin.qq.com/s/3c-a7GpkTzAU2DFWSwN4lw)查看。
@@ -40,7 +39,7 @@ tag:
### 荣耀
-
+
校招薪资:月薪 17k - 27k(对应13-15级),每年 14-16 薪。
@@ -50,7 +49,7 @@ tag:
### 华为
-
+
校招薪资:13级月薪 20-21k,14 级 23-25k,15级月薪 26-27k。每年 14-16 薪。16级我就不清楚了。
@@ -58,7 +57,7 @@ tag:
### 小米
-
+
校招薪资:小米的薪资是挺抠,不过放在南京来看也还行。看校招薪水上南京的薪资爆料今年有 11k,14k,16k,18k,19k,21k,23k 几个档。11k,14k基本都是本科生,硕士做开发岗的大部分是16k,18k,19k这几个档。20k 以上的基本都是做算法的。
@@ -66,7 +65,7 @@ tag:
### Vivo
-
+
校招薪资:南京这边目前看到给应届生的价钱分为月薪17k,20k,24k三个档,,每年15薪。额外每个月有 1500 的租房补贴。住房公积金5%。
@@ -74,7 +73,7 @@ tag:
### OPPO
-
+
校招薪资:具体薪资不太清楚,大致应届生月薪在 20k 上下,每年 14 -15 个月薪资。
@@ -82,7 +81,7 @@ tag:
### 中兴
-
+
校招薪资:中兴常规计划(指的是普通 offer)的月薪基本都在20k 以内,蓝剑计划年薪会在 40w 以上。
@@ -90,7 +89,7 @@ tag:
### 360
-
+
校招薪资:没调查清楚,年薪差不多 23w 左右。
@@ -98,7 +97,7 @@ tag:
### 深信服
-
+
校招薪资:开发岗有3个档,月薪分布在15.6 - 22.8k 这个区间,算法岗也是三个档,月薪分布在19 - 25.2k 这个区间。每年13 - 15 薪
@@ -106,7 +105,7 @@ tag:
### 趋势科技
-
+
校招薪资:看到校招薪资爆料有三个档,分别是年薪 20w,23.5w 和 25w。
@@ -114,7 +113,7 @@ tag:
### 亚信安全
-
+
校招薪资:基本上月薪在15-18.5k 这个区间,每年 13- 15薪。
@@ -122,7 +121,7 @@ tag:
### SHEIN
-
+
校招薪资:目前看校招薪资爆料月薪基本集中在16-23k,有个说自己 27k 的不知道真的假的(如果是真的,感觉 SHEIN 大部分老员工要RUN了)。每年14薪。
@@ -130,7 +129,7 @@ tag:
### 满帮集团
-
+
校招薪资:校招薪水上的爆料开发月薪基本都在 20-30k 这个区间,算法基本都在 27-36k 这个区间。大部分人每年 14 薪。
@@ -140,25 +139,25 @@ tag:
### 中电系列
-
+
南京有中电 28 所、中电 14 所、中电 841 所。有一些读者跟我说想去研究所,想法是去研究所可以工作生活平衡。但是现在有很多的研究所其实很忙的,工作生活平衡的研究所尤其不包括南京这几个。841 所还不是特别清楚。大部分互联网公司和中电 28 所以及 14 所 比起来还真是弟弟,不过根据南京的薪资的水平来说,这两个所得福利待遇算是顶级了。刚毕业的应届生进去工资大概每月到手是一万出头吧,有食堂有宿舍,出差会有出差补贴,差不多一天三四百,这几个所出差会非常的多。
### 南瑞集团(国网电科院)
-
+
南瑞集团是国家电网直属的科研企业单位,主要做电力系统自动化相关设备,所以会招很多程序员。年薪 14 万左右。南瑞要给各个省公司做电力软件,所以出差的情况会非常多。面试上南瑞以后你还没有国家电网编制,想要编制还要去参加电网的考试。感觉性价比一般,不如去省公司,听说省公司工资还挺高的。
### 运营商
-
+
几个运营商里只有联通在南京有研究院专门做软件相关,除此之外想去运营商就只有省公司了。一些运营商的子公司我就不多介绍了,我是感觉国企的子公司性价比一般,既没有国企的稳定也没互联网的高薪。
### 烽火
-
+
简单说下烽火,下面有烽火星空还有烽火通信。是国企,不过感觉一直处于一个乙方的位置。项目很多是涉密项目,但是我劝大家尽量少碰涉密类型的项目。如果手头没大公司可以去烽火锻炼下,如果有其它大公司的 offer,我感觉还是优先其它大公司了。
@@ -170,18 +169,18 @@ tag:
南京的房价还是比较高的,比较好的区域的房价直逼一线城市了,对于刚毕业的学生来说压力很大了,感觉这个房价应该逼走不少人。 另外南京物价也不低噢。下面这张图是网上找的,不一定准,可以当作参考。
-
+
### 教育
-
+
南京高校资源方面很强。南京大学、东南大学、南航、河海大学、南理工等等都是很不错的学校。另外南邮、南京工业大学这些双非学校的计算机也很强。感觉近几年各个大厂陆续在南京设分布也是看中了南京有大量的计算机相关专业的毕业生。
江苏高考题的难是出了名的,当然江苏省的中小学教育资源也很优质,所以在教育这方面选择南京还是不错的。
### 交通&风景&气候&美食
-
+
南京拥堵程度是上过全国前十榜单的,我租房是喜欢宁愿住的小一点差一点也尽可能离上班地方近一点,我比较抗拒通勤。宏观上来说,南京的地理位置特别好,离苏州、杭州、上海都很近,另外离安徽也很近,这也是安徽人喜欢往南京跑的原因。
@@ -194,4 +193,4 @@ tag:
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/CfZ1CEmtPOP4TAwAs8Ocrw](https://mp.weixin.qq.com/s/CfZ1CEmtPOP4TAwAs8Ocrw)
-
+
diff --git a/docs/src/cityselect/qingdao.md b/docs/cityselect/qingdao.md
similarity index 77%
rename from docs/src/cityselect/qingdao.md
rename to docs/cityselect/qingdao.md
index f100d03eda..ca5138be3d 100644
--- a/docs/src/cityselect/qingdao.md
+++ b/docs/cityselect/qingdao.md
@@ -1,12 +1,11 @@
---
-shortTitle: 青岛
category:
- 求职面试
tag:
- 城市选择
---
-# 青岛都有哪些值得加入的IT互联网公司?
+# 青岛有牛逼的互联网公司吗?
@@ -14,7 +13,7 @@ tag:
当时我妹还在沙滩上留了一张“沉默王二在青岛”的印迹。
-
+
按照我妹的说法,“青岛真是一座网红城市,美女是真多!”
@@ -26,13 +25,13 @@ tag:
### 海尔
-
+
海尔在青岛多年了,曾经有段辉煌期的。我舍友带着我在山东哈酒时,一个老大哥在酒桌上就跟我们聊起来,说他当初在海尔买家都是要请他们吃饭才卖给产品的。不过近些年海尔就不太行了,但依然在青岛是个工作上的好选择。海尔 Java 岗位给应届 985 硕士的报价是年薪 14 万。本科生相对少一点,年薪大概在 8万 到 12万 左右。我路过海尔时感觉海尔的园区还修的挺漂亮的。另外说一句,感觉海尔卡奥斯还行,在工业互联网领域做的还可以。
### 海信
-
+
我之前总觉得海信和海尔有某种联系,不过我查了下并没有,路过海信的园区时觉得海信也修的挺漂亮的。一个 211 硕士爆料的薪资是每月 10k,然后一年 13 个月工资。福利待遇方面感觉还可以,前两年有免费宿舍,交通补贴每月 200,住房补贴 800 每月,可以领三年。试用期 6 个月,试用期间 90% 薪资,免费班车,公积金 10%,社保全额。工作早9晚6,中午休息一小时。
@@ -40,43 +39,43 @@ tag:
### 光大银行青岛研发中心
-
+
待遇听说还不错,以前是归分行管,现在归总行管。青岛这边主要开发云缴费业务。据说是有末尾淘汰机制。近几年好多员工都跑到青岛银行了。
### 青岛银行
-
+
青岛银行总行的技术岗。薪资不算高,有薪资爆料是年薪12w,不过算是摸鱼的天堂了,活大部分是外包干。
### 青岛凯亚
-
+
在青岛软件企业能算中上游了,不过全靠同行衬托。加上各种补贴,一年的工资差不多是是十二三万吧。试用期工资打五六折。技术还可以,不过有人爆料说他加班还挺多的。
### 青岛鼎信
-
+
主要做通信的公司,一个应届硕士的爆料是税前13k,每年13个月的工资,有食堂,每个月600的饭补。
### Yeelight
-
+
Yeelight 算是在青岛为数不多的小而美的公司了,目前团队330人,研发人员超过一半,主要做智能照明,有小米的投资。听说团队氛围还不错,比较重视技术。我在网上没找到校招待遇的介绍,社招的话 BOSS 招聘 3-5年 Java 经验的报价是 12k-24k。
### 中车四方
-
+
中车四方是国有控股公司,薪资待遇在青岛算中上。也招程序员。应届毕业生是6个月试用期,转正以后每年工资税前差不多15w左右。不过他这个工资构成和别人不一样呀。每月税前一万左右的工资好像其中六千左右是绩效,然后每年年中会发一个业绩奖金,不同部门的奖金差别很大。
### 中电41所
-
+
说实话,我一直对中电系列的研究所印象不是很好,不过听说中电28所的薪资后对中电系列的印象有所改观(这里是闲扯一句哈,中电28所在南京,和青岛没啥关系)。注意41所得总部是在安徽,青岛只是一个分部,我了解到是加班会比较严重。
@@ -88,7 +87,7 @@ Yeelight 算是在青岛为数不多的小而美的公司了,目前团队330
青岛房均价两万多了吧。崂山和市南比较贵,其它地相对好一些。下面这张图有各区的房价,不是太准,不过可以参考下呀。感觉程序员在北京干几年,攒个首付,然后回青岛找个相对稳定的公司上班,买房压力还不是很大(除了买崂山和市南啊)。
-
+
### 教育
@@ -96,7 +95,7 @@ Yeelight 算是在青岛为数不多的小而美的公司了,目前团队330
大学方面,山东大学在青岛是有校区的,虽然离市区是真的远,但是人家有地铁呀。我记得坐那趟地铁去山东大学青岛校区找我舍友时穿越崂山,窗外的风景是真的漂亮。中国海洋大学也是一所985,校区是真的漂亮。中国石油大学是一所211,也挺不错的。另外像青岛大学、青岛理工大学、山东科技大学这些院校也是不错的。这几年各个高校也在青岛修建了研究院,感觉还是挺有发展前景的。
-
+
高中方面,青岛二中、青岛一中、青岛五十八中、青岛九中、即墨一中等都非常好。不过山东高考的压力是真的大,感觉我大学和读研时身边的山东同学,当年高考都是英雄般的人物。
@@ -104,11 +103,11 @@ Yeelight 算是在青岛为数不多的小而美的公司了,目前团队330
青岛是真的挺美的,感觉在青岛既能感觉到现代化大都市的感觉、又能体验到民国风情还能体验到欧式风情。另外我同学带我在青岛转时,经常走着走着就见到了大海,这让我这个多年身居内陆,没见过海的少年来说还是挺欣喜的。感觉青岛比西安冷很多,今年4月西安已经很热了,花都开了,但是去了青岛以后发现柳树才刚有一点点绿,还挺凉快的。
-
+
青岛的海鲜是挺丰富了,让我这个很少吃海鲜的少年一次吃了个够,还买了些海鲜给家里面寄了点。果然内陆的海鲜吃起来和沿海城市的海鲜差好多,另外山东菜是真的能倒酱油。
-
+
### 交通
@@ -117,4 +116,4 @@ Yeelight 算是在青岛为数不多的小而美的公司了,目前团队330
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/8QQvOrkG3Vdjj3GxP1zxBQ](https://mp.weixin.qq.com/s/8QQvOrkG3Vdjj3GxP1zxBQ)
-
+
diff --git a/docs/src/cityselect/shenzhen.md b/docs/cityselect/shenzhen.md
similarity index 95%
rename from docs/src/cityselect/shenzhen.md
rename to docs/cityselect/shenzhen.md
index ec27cf797a..8ff60726c4 100644
--- a/docs/src/cityselect/shenzhen.md
+++ b/docs/cityselect/shenzhen.md
@@ -1,12 +1,11 @@
---
-shortTitle: 深圳
category:
- 求职面试
tag:
- 城市选择
---
-# 深圳都有哪些值得加入的IT互联网公司?
+# 深圳有哪些牛批的互联网公司?
@@ -83,5 +82,5 @@ AI独角兽公司
>作者:代码随想录,转载链接:[https://mp.weixin.qq.com/s/hBU-eEUq8aN5PWwdZFmC4g](https://mp.weixin.qq.com/s/hBU-eEUq8aN5PWwdZFmC4g)
-
+
diff --git a/docs/src/cityselect/suzhou.md b/docs/cityselect/suzhou.md
similarity index 83%
rename from docs/src/cityselect/suzhou.md
rename to docs/cityselect/suzhou.md
index cbaa3f299e..4750d0a770 100644
--- a/docs/src/cityselect/suzhou.md
+++ b/docs/cityselect/suzhou.md
@@ -1,12 +1,11 @@
---
-shortTitle: 苏州
category:
- 求职面试
tag:
- 城市选择
---
-# 苏州都有哪些值得加入的IT互联网公司?
+# 想搬去苏州生活了。。
@@ -22,7 +21,7 @@ tag:
有句话叫做上有天堂,下有苏杭,不过有一说一,互联网环境方面苏州和杭州感觉还是有点差距。但是个人觉得还是不错的,而且从 18 年左右开始,苏州的互联网环境开始有了明显的改善。生活方面无论是苏州的地理位置,还是人文环境,都是十分适合居住生活的。
-
+
老规矩,下面我们还是按照程序员的工作机会和生活环境来介绍苏州。
@@ -32,7 +31,7 @@ tag:
### 微软
-
+
微软可以说是程序员在苏州最好的工作机会了。微软近些年也一直扩大在苏州的投资力度,目前微软苏州研究院的研发团队已经有 2000 人左右了,并且还在近一步扩建。2022 年微软将启动微软苏州三期新大楼的建设,建成后预计微软在苏州的研发团队会达到5000人。所以,目前想拿微软苏州的 offer 的难度,相比于拿北京上海等其它几个工作地 offer 的难度会低一些,大家抓紧呀。
@@ -44,55 +43,55 @@ tag:
### ZOOM
-
+
在苏州,Zoom是除微软外的另一个好选择。Zoom 曾经被评为全球最佳雇主。根据 zoom 员工的说法,zoom的技术水平大概和国内二三线厂的水平差不多。薪资方面,比国内互联网也要低一些,看到一个校招薪资的爆料,一个做前端的硕士在苏州zoom的薪资是17k * 14。额外有 7 万美元的股票,分 4 年发完。虽然 base 薪资方面相对低一些,但是 zoom 工作是真的爽呀,没有 996,没有 kpi,办公环境好,无限零食和水果供应,这还要啥自行车。
### 华为
-
+
华为在苏州的研究院设立时间不长。华为的苏研院的加班在各地所有的研发中心中是排的上号的。华为各地研发中心的忙碌程度差不多是成都 》= 西安 》= 苏州 > 武汉 > 东莞 > 杭州 > 南京 > 深圳 > 北京 > 上海(整体感觉是这样,每个研发中心各部门的加班情况也不同)。不过华为有一个好处就是你挣的钱能和你的付出成正比,所以想快速挣钱的还是建议去。
### 360
-
+
360 来苏州时间不长,2018年才逐渐开始在苏州设立开发部门。目前 360 苏州包含了未来安全研究、360政企、安全等部门。目前 360苏州的薪资水平是北京上海薪资水平的 8 折,看到 21 年毕业的一个应届硕士爆料月薪是 16k,工资有点少,不过感觉在苏州也不错呀。
### Momenta
-
+
一开始我对 Momenta 还真没什么了解,直到我有一天突然在校招薪水上搜了下 Momenta,然后我不由得直呼卧槽,这特么是给应届生的薪资?认真的?
-
+
然后我详细的了解了下这家公司,这是一家做自动驾驶的公司,创立时间也不长,2016年创立的。不过据说这家公司加班特别猛,有的组 10 10 5,有的组 996,有的组比 996 还要累。Momenta 现在能给的起这么高的工资,实力还是有的,不过对于发展的前景来说,领域这么垂直的公司风险性是比较大的。
### 企查查
-
+
跟上面的公司相比,企查查算是一个小而美的公司。企查查是苏州的本地企业,目前来说口碑还是很不错的。目前企查查的业务很赚钱,自己的大楼也差不多修好了。没有强制加班,全额社保和公积金。我没有查到企查查的校招薪资,看 boss 上的社招薪资水平不算太高,只能算还可以了。
-
+
### 收钱吧
-
+
这个公司大家应该都听说过,每次你用支付宝或者微信给商家付钱时都能听到“收钱吧到账xx元”。收钱吧的技术不错,加班也比较少,收钱吧的风评不错。不过就是工资相对给的少点,月薪 17k 左右(在苏州也还行了),每年14 个月的月薪。
### 中国移动苏州研究院
-
+
中国移动苏州研究院又叫苏小研,其实犹豫了很久要不要把他放在推荐里。苏小妍在知乎上的争议很大,有说待遇福利很好的,也有狂喷的。苏小研肯定有国企的通病,这个我确认,但具体怎么样就靠大家自己判断了,贴两张知乎上对苏小研的评价,好坏要大家自己去具体确认了。这两张图评价完全是两个极端呀。
-
+
-
+
上面是我认为苏州的比较不错的程序员就业机会,其它的一些苏州比较成规模的提供程序员就业机会的公司就列在下面,并且快速的简单介绍一下。
@@ -120,7 +119,7 @@ tag:
### 教育
-
+
高等教育方面。其实就苏州本身而言,高校并不多,只有苏州大学一所 211(苏大的自然语言处理挺强的)。但是前些年许多地理位置偏北的高校为了打造自己在南方的影响力,提高生源质量,都会选择在南方办学。其中一部分选择了深圳,另一部分选择了苏州。西交大、中科大、中国人民大学、东南大学、西工大等院校都在苏州设有校区。所以虽然苏州本地院校不多,但是苏州计算机软件相关的高校毕业生并不少。不过这种现象随着西工大太仓校区刚修好,异地办学就被叫停了,我瓜实惨~
@@ -130,11 +129,11 @@ tag:
相比于苏州的工资水平,其实苏州的房价也不低了,看网站上的新房均价大约两万五一平。但是和旁边的城市一比,那苏州的房价就比较香了。在苏州咬咬牙还是能考虑买房的。
-
+
### 娱乐&交通&美食
-
+
娱乐方面苏州好玩的地方很多,传统的苏州园林风格和苏州现代风格都让人十分留恋。周末在苏州园林逛一逛真的很惬意。
@@ -147,4 +146,4 @@ tag:
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/cnYsZLudFOwv5EKYMsMh0Q](https://mp.weixin.qq.com/s/cnYsZLudFOwv5EKYMsMh0Q)
-
+
diff --git a/docs/src/cityselect/xian.md b/docs/cityselect/xian.md
similarity index 87%
rename from docs/src/cityselect/xian.md
rename to docs/cityselect/xian.md
index 23ef78967a..5b720f2f70 100644
--- a/docs/src/cityselect/xian.md
+++ b/docs/cityselect/xian.md
@@ -1,12 +1,11 @@
---
-shortTitle: 西安
category:
- 求职面试
tag:
- 城市选择
---
-# 西安都有哪些值得加入的IT互联网公司?
+# 西安有哪些不错的互联网公司?
2019 年国庆节的时候去了一趟西安,和朋友一起,开车去的,大概 4 个多小时的车程,从洛阳到西安,不算太远。
@@ -31,7 +30,7 @@ tag:
**华为**
-
+
如果想在西安快速挣钱的话,华为几乎是最好的选择了,按照华为的工资水平在西安买房根本没有压力。华为在西安的建制很齐全,消费者、CloudBu、云核心等事业群以及`华为海思`,2012 实验室都有。但是因为去年美国对华为的打压,消费者、华为海思以及 2012 实验室这些之前很香的事业群目前日子都不太好过。
@@ -45,13 +44,13 @@ tag:
**阿里巴巴**
-
+
阿里巴巴还没大范围的在西安招人,情况目前还不太清楚。我问过阿里巴巴的员工,只知道目前在西安设点的部门是阿里云,需要半年在杭州上班,半年在西安上班,工资水平和杭州一致。不过目前招的量比较小,基本都是招高p,主要是做售前的业务架构设计,只有很少的校招名额。
**京东**
-
+
京东把京东物流的团队设在了西安航天城,目测团队规模在几百人,工资水平大约是京东在北京工资的 80%。大家可以参考一下,京东去年在北京的部门,校招普通 offer 是年包 28 万,sp 是年包 32.9 万。
@@ -59,7 +58,7 @@ tag:
**腾讯云**
-
+
腾讯云是腾讯的全资子公司,目前对这里褒贬不一。校招薪资水平本科和硕士生大概是月薪 13-16k,每年 16 薪,大家可以参考一下,腾讯 21 届校招的薪资是 17-21.5k ,每年 18 薪。社招我看一个本科毕业四年经验的老哥拿到的年包是 33 万。腾讯云的职级和腾讯不是对齐的,并且业务比较边缘,这也是网上被喷的一个主要原因。目前西安腾讯云创立时间不久,加班强度是比较大的。
@@ -69,7 +68,7 @@ tag:
**广联达**
-
+
广联达西安的部门在针对 21 届毕业生的校招中开出的薪资是很有诚意的。给应届硕士的 sp 是 19k x 15,普通 offer 是 17k x 15,本科生每月基本都在 13-17k 之间。广联达工作制度基本是 965 或者 975,每个月还有一天的带薪病假。这还要啥自行车?不过广联达曾经也有过黑料,大家自行上网了解。
@@ -79,7 +78,7 @@ tag:
**360**
-
+
360 在西安只有一个几十人的团队。没听说过这里有校招,社招的话 3 年以上经验的差不多能每月给到 20k 。有说在这里待的舒服的,也有喷的。
@@ -89,7 +88,7 @@ tag:
**科大讯飞**
-
+
科大讯飞西安丝路总部主要是算法岗,不过我看网上喷的比较多。据说是活多钱少。
@@ -103,7 +102,7 @@ tag:
**绿盟**
-
+
绿盟算是中型企业里比较香的,绿盟在安全领域还是比较强的。工资比较低,硕士校招才能给到 14k x 14,但是这家公司几乎不加班,员工的离职率也一直很低,我同学有违约中兴三方去绿盟的。
@@ -119,7 +118,7 @@ tag:
**寒武纪**
-
+
寒武纪是做智能芯片的公司,背后站着中科院计算所。2019 年落户的西咸新区,相关信息比较少。我知道的是加班比较多,不过薪资也高。
@@ -133,7 +132,7 @@ tag:
感觉西安几家国企的性价比略低,工资不高,且大部分加班严重。校招应届硕士工资税前年薪基本都在 15w-20w 之间,本科生的年薪比硕士少 3w 左右。国企相较于私企涨薪会慢很多,不过相对稳定一些。
-
+
**中兴**
@@ -145,7 +144,7 @@ tag:
**联通**
-
+
西安联通软件研究院,应届硕士的总包和移动差不多,大约 16-19 万。不过联通比较清闲,大部分部门都能下午六点就下班。目前在网上的评价相对好一些。
@@ -163,7 +162,7 @@ tag:
**荣耀**
-
+
荣耀目前的招人需求是很大的,工作强度未知,薪资水平目前是完全对标华为的。
@@ -181,7 +180,7 @@ tag:
**农行软开**
-
+
农行软开目前是在西安工作的最好的几个选择之一,硕士每月到手 12k,本科生少几百块钱,年终奖 2-4 个月。大部分部门都能晚上 7 点以前下班,并且周末双休。目前农行软开有子公司化软件开发中心的计划,听消息说可以选择去子公司,也可以留在软开。目前西安的农行软开也越来越卷,大部分的 offer 都给了西电、西交、西工大这三个学校了,另外这三个学校的学生现在也不是想去农行就能去了。农行软开有个硬性规定是必须通过六级才能报。
@@ -207,7 +206,7 @@ tag:
**邮政银行**
-
+
邮储银行软件开发中心在西安刚成立,还不太确定。目前宣传是年包 28 万以上,工作强度目测比较大。
@@ -221,7 +220,7 @@ tag:
**三星**
-
+
大部分应届生都是(11-14)k \*13.5k。965 工作制。几乎都是芯片、运维相关岗位。
@@ -237,7 +236,7 @@ SAP 是一家做企业软件的德企,技术十分强大。硕士年薪 20 万
**Thougtworks**
-
+
在 Thoughtworks 工作是很舒服的,开放式办公、扁平化管理、技术氛围浓厚。工资本硕都是 13k x 14。
@@ -253,7 +252,7 @@ ThougtWorks 的新人培养机制还是很赞的!对于应届生入职 ThougtW
### 研究所
-
+
西安航空航天类的研究所特别多,我知道的招计算机方面的研究所有航天 504 所、771 所,航空 631 所、618 所、603 所,中电 20 所、39 所,兵器工业 203 所、204 所、205 所。
@@ -265,7 +264,7 @@ ThougtWorks 的新人培养机制还是很赞的!对于应届生入职 ThougtW
## 生活
-
+
陕西的资源基本都集中在西安,从人口上也能看出西安的资源有多集中。整个陕西三千多万人,在西安就有一千多万。并且这些年中央对西安的扶植力度越来越大。
@@ -273,23 +272,25 @@ ThougtWorks 的新人培养机制还是很赞的!对于应届生入职 ThougtW
西安的房价从 18 年到现在翻了一倍,但就目前的房价相较于其它同类型城市算是比较友好的。现在西安的房价最贵的在曲江、第二贵是高新区。其它地方的房价差不多一万六左右吧,不过今年的全运会过后可能会长一波。按照程序员的工资来说,在西安买房的问题不算很大,这也是程序员待在西安比较舒服的地方。对于程序员来说,租房的压力相对较小,我同学有在农行软开工作的,在附近租了一个一居室的开间四十平左右,一个月一千五,上班步行用不了十分钟。高新那边租房贵一些,你愿意合租的话压力也不大。
-
+
西安住建前段时间出了二手房交易参考价格,我贴在下面大家可以参考下,不过这个价格感觉低于市场价了。我感觉这直接打了个八折~西安住建发布二手房交易参考价格的链接在这里 https://mp.weixin.qq.com/s/Gis7kIJklWygTseztydDaw
+
+
### 教育资源
西安的教育资源很好。高中教育资源方面,西安的名校众多。西工大附中、西安铁一中、高新一中、交大附中、陕师大附中这些学校在全国都是很有名的,另外还有一批在陕西省很有名的高中也很不错。大学教育资源方面,整个陕西有三所 985,西工大和西安交大都在西安,西北农林科技大学就在离西安不远的杨凌。
-
+
另外,还有像西安电子科技大学、西北大学、陕西师范大学、长安大学、第四军医大学这些不错的 211,还有像西安邮电、西安理工、西安科技大学、西安工业大学等等这些不错的双非院校。西安每年产出的人才的数量是很庞大的。这是很值得西安自豪的一点,但是这也造成了一个问题,西安就业十分的内卷。有一个现象是陕西人都愿意在西安,不愿意出来,计算去外面上学的陕西人毕业也大部分都回到了西安,另外在西安上过学的也大部分留在了西安。西安的几个效益比较好的研究所、银行软开的应聘难度比在北京的同级别单位都难很多。内卷不仅表现在计算机,计算机算好的,我了解到目前好多西安的小学老师都敢只要 211 以上毕业的硕士生。
### 医疗资源
-
+
医疗资源方面西安也很给力,交大一附院、交大二附院、唐都医院、西京医院、红会医院都是放在全国都很强的,另外其他一批省内比较有名的医院也很不错。
@@ -297,7 +298,7 @@ ThougtWorks 的新人培养机制还是很赞的!对于应届生入职 ThougtW
西安的交通方面不敢恭维,堵车那是一绝,我的感觉是西安比北京都要堵。西安的地铁 21 年初新开了 3 条线路,目前共有 8 条线路才勉强够的上需求。每逢法定节假日,旅游的人都会把西安挤炸。说到旅游,近年来西安对游客的吸引力是越来越大,一方面西安在弘扬大唐文化,另一方面西安的美食也叫一个美滴很。
-
+
另外,大唐不夜城这里的人是真的多,尤其是夏天,晚上的时候基本打不到车!
@@ -311,8 +312,7 @@ ThougtWorks 的新人培养机制还是很赞的!对于应届生入职 ThougtW
综上所述,西安目前正处在高速上升的阶段,互联网行业相对北上广深杭还有一定的差距,相比与成都也还稍差一点。但是西安绝对是有潜力的,并且目前西安的房价还是比较友好的。大家如果能选择在西安发展,生活幸福感会比较高。
-更多西安的信息,可以戳这个链接:[西安互联网](https://github.com/madawei2699/xian-IT)
>作者:大白,转载链接:[https://mp.weixin.qq.com/s/s0Ub1CHC9eEi0YrqPrnRog](https://mp.weixin.qq.com/s/s0Ub1CHC9eEi0YrqPrnRog)
-
+
diff --git a/docs/cityselect/zhengzhou.md b/docs/cityselect/zhengzhou.md
new file mode 100644
index 0000000000..646540fced
--- /dev/null
+++ b/docs/cityselect/zhengzhou.md
@@ -0,0 +1,278 @@
+---
+category:
+ - 求职面试
+tag:
+ - 城市选择
+---
+
+# 郑州有哪些不错的互联网公司?
+
+
+首先我们来看工作机会!
+
+一位读者的评论我觉得特别的好,我贴到这里给大家看下:
+
+网名"咔嚓":作为在郑州工作的前端,表示遇见好厂的话,生活节奏还是很爽的,房租不贵,直接住公司旁边,通勤5分钟,不加班的话,每天晚上6点下班,双休。确实郑州互联网不强,但是,我们也不应该忘了生活本该有的样子啊。
+
+## 工作机会
+
+郑州的互联网资源还是比较匮乏的,究其原因,我觉得和教育资源的匮乏有非常大的关系。
+
+教育资源极度匮乏导致好的企业不来,好的企业不来又导致人才外流,恶性循环。
+
+
+
+
+
+### 数字郑州
+
+
+
+这个是阿里和郑州的政府合作的,目前评价大家对数字郑州的评价很不错呀,薪资也挺给力的,大家可以看下 Boss 上数字郑州的招聘岗位以及薪资报价呀。
+
+
+
+### 中原银行
+
+
+
+中原银行的工资比较高,在郑州生活的话去中原银行是很不错的选择,不过想进中原银行的话,不是校招想进去有点难。薪资水平可以看下 Boss 上的招聘薪资水平。
+
+
+
+
+
+### 浪潮
+
+浪潮在郑州的研发中心法定节假日加班是有加班费的,但平时加班就没有加班费了,每月要求加够50个小时的班。薪资水平大家也可以参考下 Boss 上放出的招聘薪资水平。
+
+
+
+### 新华三
+
+新华三大部分情况下能双休,周末加班也有加班费,不过涨薪很缓慢。在网上看到一个帖子,有人问 offer 选西安中兴还算郑州新华三,中兴和华三的职工都在互相劝退,说这是一个送命题。薪资水平大家还是参考下Boss上的招聘薪资水平吧。
+
+
+
+
+
+### UU 跑腿
+
+
+
+UU 跑腿主要提供同城送件服务,是郑州本土最大的互联网公司,隶属于郑州时空隧道信息技术有限公司,地址位于郑州市金水区。
+
+UU 跑腿的工作环境以及各种福利都还算不错!
+
+面试的话,总体体验还不错,技术面试一般问的还比较全面。拿 Java 后端开发来说,像 SQL 优化、分布式、缓存这些一般都会问到。
+
+薪资的话,看准网上的平均薪资是 10k 附近,其中后端开发的薪资在 14k 附近,前端开发的薪资在 10k 附近,软件测试的薪资在 10k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入)。
+
+
+
+### 中原消费金融
+
+
+
+河南中原消费金融股份有限公司是一家全国性非银行金融机构,地址位于郑州市郑东新区。
+
+中原消费金融的办公环境非常不错,薪资福利相对也还不错。
+
+整体面试体验不错,效率也非常高,像技术面试的话一般是三轮或者四轮。不过,中原消费金融比较看重学历,985/211 上岸的几率比较大。
+
+薪资的话,看准网上的平均薪资是 16k 附近,其中后端开发的薪资在 17k 附近,前端开发的薪资在 16k 附近,软件测试的薪资在 14k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入,应该到不了这么高)。
+
+注意:大家注意一个情况,中原消费的软件研发岗位大部分都搬迁到上海了,目前在郑州的大部分是行政岗位,只有少部分研发岗位。
+
+
+
+### 刀锋互娱
+
+
+
+刀锋互娱是一家专注游戏服务市场的互联网公司,2019 年完成 A+轮融资,平台注册用户量突破千万。
+
+旗下比较出名的产品有租号玩、一派陪玩,都是和游戏领域相关的产品。相信比较喜欢玩游戏的小伙伴应该对这个两个产品有了解。
+
+
+
+整体面试不是很难,薪资相对来说也还可以。
+
+薪资的话,看准网上的平均薪资是 16k 附近,其中后端开发(C++)的薪资在 20k 附近,前端开发的薪资在 8.5k 附近,软件测试的薪资在 9.5k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入)。
+
+
+
+### 新开普
+
+
+
+新开普也是郑州的一家本土互联网公司,成立于郑州高新技术产业开发区,主要做 NFC 近场移动支付、金融 IC 卡等业务。
+
+新开普是目前国内一卡通行业唯一一家上市公司,已经为全国千所高校,千万名大学生提供服务。
+
+技术面试的话,一般第一面是笔试,笔试之后会再问你一些相关的技术问题。
+
+薪资的话,看准网上的平均薪资是 7.6k 附近,其中后端开发(Java)的薪资在 9k 附近,前端开发的薪资在 9k 附近,软件测试的薪资在 5.5k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入)。
+
+
+
+### 中移在线
+
+中国移动旗下的一家“互联网”公司,实际不像是“互联网”公司。
+
+对于技术开发来说,去中移在线一是对技术没有提升或者挑战,二是工资是真的低(看准网上的 Java 开发薪资在 8k 附近)。
+
+真心不太建议去,除非你没有其他更好的选择。
+
+我能想到唯一的优势可能是公司相对来说能提供给你的一个相对稳定的工作。
+
+### 爱云校
+
+爱云校常见于 2014 年,主要做的是在校教育这块,致力于通过 AI 建一所云上的学校。
+
+单看公司所做的业务方向来说,发展相对来说还是不错的。不过,据说公司的管理真的是渣到了一定程度。
+
+另外,根据大部分面试求职者的反馈来看,这家公司的整体面试体验比较差。
+
+薪资的话,看准网上的平均薪资是 12k 附近,其中后端开发(Java)的薪资在 14k 附近,前端开发的薪资在 8k 附近,软件测试的薪资在 10k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入)。
+
+
+
+### 妙优车
+
+
+
+妙优车主要做的是汽车方面的业务,涵盖整车销售、汽车金融、汽车保险、汽车用品、汽车美容等方面。
+
+公司发展一般,网上也有一些黑历史(可以自己查一下)。
+
+不过,根据大部分面试求职者的反馈来看,这家公司的整体面试体验还是可以的。
+
+薪资这块的一般偏上,看准网上的平均薪资是 11k 附近,其中后端开发(Java)的薪资在 12k 附近,前端开发的薪资在 10k 附近(薪资水平仅供参考,实际情况因人和岗位或许会有一些出入)。
+
+
+
+### 腾河
+
+腾讯是河南腾河网络科技有限公司的最大股东,第二大股东是河南日报。
+
+主要做的业务方向是河南城市生活第一网。
+
+工资比较低,另外,后端这块好像只招 PHP。
+
+### 真二网
+
+不得不说,这个名字有点东西!
+
+真二网创立于 2014 年,也是郑州本土的一家互联网公司,主要做 C2C 模式的 0 中介费真实二手房交易平台。
+
+工资比较低,另外,后端这块好像只招 PHP。
+
+### 硕诺科技
+
+硕诺科技创立于 2014 年,总部位于上海,主要做物流软件系统高端定制的软件开发。
+
+网上可以查到的消息比较少,感兴趣的小伙伴可以自己去查一下相关信息啊!
+
+另外,如果有小伙伴对这家公司比较了解,也可以在评论区说一下啊!
+
+### 科大讯飞
+
+科大讯飞在郑州金水区有一个小分部,大部分招聘的都是和技术无关的岗位,不过也有一个 Java 开发岗。
+
+
+
+### 字节跳动
+
+郑州也有字节跳动分部,不过都是和市场拓展与运营相关的岗位,像技术开发岗是没有的。
+
+
+
+类似的还有美团、华为、阿里巴巴等大厂,这些公司在郑州招聘的基本也都是非技术岗位。
+
+### 其他
+
+其他还有像郑州点读电子科技有限公司(旗下产品有咿啦看书)、羲和网络(河南唯一一家游戏上市企业)、米宅(中国知名的楼市自媒体,新三板上市企业)等互联网公司,感兴趣的小伙伴可以自行查阅相关信息呀!
+
+读者补充:海康威视、APUS、云鸟、亚信科技、牧原食品、小鱼易联、神州信息、云智慧都在郑州招开发工程师。
+
+## 生活环境&生活成本
+
+我们再来看看生活环境和生活成本。
+
+### 房价
+
+郑州的房价对于其发展来说还是比较贵的。当然了,相比于一线城市肯定还是要便宜很多的!
+
+以下房价数据来源于安居客,可以作为参考。
+
+
+
+### 教育
+
+郑州的教育资源极度匮乏!据统计郑州一共有 65 所高校,其中,本科 26 所,专科 39 所。
+
+不过,211 院校仅有一所——郑州大学。
+
+
+
+是的!作为偌大的河南省的省会,国家历史文化名城,也就只有一所 211!
+
+我们来对比一下湖北省省会武汉,武汉 7 所 985/211 高校,分别是武汉大学、华中科技大学、中国地质大学、武汉理工大学、华中师范大学、华中农业大学、中南财经政法大学。
+
+再来对比一下湖南省省会长沙,长沙有 4 所 985/211 高校,分别是国防科大、中南大学、湖南大学、湖南师范大学。
+
+### 医疗
+
+郑州的每万人床位数排名比较靠前。
+
+另外,郑州市的优质医疗资源,在金水区、中原区、管城区比较集中;
+
+
+
+### 本地居民
+
+网上有很多“河南黑”,让很多人对河南的影响不好!
+
+实际情况可能并不是这样的!郑州本地居民不排外,绝大部分都特别老实,本本分分。
+
+我去过很多城市,郑州人的友善程度我觉得是可以排在 Top 级别的!
+
+另外,郑州这边的居民还是比较恋家的。有很多在北上广混的还不错的人,最后也还是选择回来!
+
+### 交通
+
+作为一个北方内陆城市,郑州可以说是一个“交通枢纽”。从郑州出发坐高铁,你去国内大部分地方都非常方便。
+
+下图中的部分高铁线路正在修建,比如郑万高铁全线大概是 2021 年中旬通车。
+
+
+
+郑州的地铁规划情况如下图所示。
+
+
+
+目前的话,郑州地铁有 1 号线、2 号线、3 号线、4 号线、城郊线、5 号线、14 号线一期 7 条地铁线。
+
+
+
+### 美食
+
+郑州的各种商业设施还是比较齐全的,有很多大型的商场,商场里面基本是样样俱全。
+
+郑州好吃的还挺多的!去了郑州之后,一定要去喝胡辣汤,真的不要太好喝!
+
+
+
+本地的美食还有烩面、焖饼、烧鸡等等都非常不错。
+
+巩义那边有一家花雕醉鸡真心不错,价格便宜,2 个人不到 100 元就能吃的很好!最关键的是味道真的好!!!
+
+像浙菜、豫菜、火锅串串这边都能找到比较好吃的店子,可以满足绝大部分小伙伴的味蕾。
+
+
+
+>作者:大白,转载链接:[https://mp.weixin.qq.com/s/SU9drg2xJKcheIwJ6OSSBQ](https://mp.weixin.qq.com/s/SU9drg2xJKcheIwJ6OSSBQ)
+
+
+
diff --git a/docs/collection/arraylist.md b/docs/collection/arraylist.md
new file mode 100644
index 0000000000..2461d6b90d
--- /dev/null
+++ b/docs/collection/arraylist.md
@@ -0,0 +1,396 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java集合ArrayList详解
+
+
+“二哥,听说今天我们开讲 ArrayList 了?好期待哦!”三妹明知故问,这个托配合得依然天衣无缝。
+
+“是的呀,三妹。”我肯定地点了点头,继续说道,“ArrayList 可以称得上是集合框架方面最常用的类了,可以和 HashMap 一较高下。”
+
+从名字就可以看得出来,ArrayList 实现了 List 接口,并且是基于数组实现的。
+
+数组的大小是固定的,一旦创建的时候指定了大小,就不能再调整了。也就是说,如果数组满了,就不能再添加任何元素了。ArrayList 在数组的基础上实现了自动扩容,并且提供了比数组更丰富的预定义方法(各种增删改查),非常灵活。
+
+Java 这门编程语言和 C语言的不同之处就在这里,如果是 C语言的话,就必须动手实现自己的 ArrayList,原生的库函数里面是没有的。
+
+“二哥,**如何创建一个 ArrayList 啊**?”三妹问。
+
+```java
+ArrayList alist = new ArrayList();
+```
+
+可以通过上面的语句来创建一个字符串类型的 ArrayList(通过尖括号来限定 ArrayList 中元素的类型,如果尝试添加其他类型的元素,将会产生编译错误),更简化的写法如下:
+
+```java
+List alist = new ArrayList<>();
+```
+
+由于 ArrayList 实现了 List 接口,所以 alist 变量的类型可以是 List 类型;new 关键字声明后的尖括号中可以不再指定元素的类型,因为编译器可以通过前面尖括号中的类型进行智能推断。
+
+如果非常确定 ArrayList 中元素的个数,在创建的时候还可以指定初始大小。
+
+```java
+List alist = new ArrayList<>(20);
+```
+
+这样做的好处是,可以有效地避免在添加新的元素时进行不必要的扩容。但通常情况下,我们很难确定 ArrayList 中元素的个数,因此一般不指定初始大小。
+
+“二哥,**那怎么向 ArrayList 中添加一个元素呢**?”三妹继续问。
+
+可以通过 `add()` 方法向 ArrayList 中添加一个元素,如果不指定下标的话,就默认添加在末尾。
+
+```java
+alist.add("沉默王二");
+```
+
+“三妹,你可以研究一下 `add()` 方法的源码(基于 JDK 8 会好一点),它在添加元素的时候会判断需不需要进行扩容,如果需要的话,会执行 `grow()` 方法进行扩容,这个也是面试官特别喜欢考察的一个重点。”我叮嘱道。
+
+下面是 `add(E e)` 方法的源码:
+
+```java
+public boolean add(E e) {
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ elementData[size++] = e;
+ return true;
+}
+```
+
+调用了私有的 `ensureCapacityInternal` 方法:
+
+```java
+private void ensureCapacityInternal(int minCapacity) {
+ if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
+ minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
+ }
+
+ ensureExplicitCapacity(minCapacity);
+}
+```
+
+假如一开始创建 ArrayList 的时候没有指定大小,elementData 就会被初始化成一个空的数组,也就是 DEFAULTCAPACITY_EMPTY_ELEMENTDATA。
+
+进入到 if 分支后,minCapacity 的值就会等于 DEFAULT_CAPACITY,可以看一下 DEFAULT_CAPACITY 的初始值:
+
+```java
+private static final int DEFAULT_CAPACITY = 10;
+```
+也就是说,如果 ArrayList 在创建的时候没有指定大小,默认可以容纳 10 个元素。
+
+接下来会进入 `ensureExplicitCapacity` 方法:
+
+```java
+private void ensureExplicitCapacity(int minCapacity) {
+ modCount++;
+
+ // overflow-conscious code
+ if (minCapacity - elementData.length > 0)
+ grow(minCapacity);
+}
+```
+
+接着进入 `grow(int minCapacity)` 方法:
+
+```java
+private void grow(int minCapacity) {
+ // overflow-conscious code
+ int oldCapacity = elementData.length;
+ int newCapacity = oldCapacity + (oldCapacity >> 1);
+ if (newCapacity - minCapacity < 0)
+ newCapacity = minCapacity;
+ if (newCapacity - MAX_ARRAY_SIZE > 0)
+ newCapacity = hugeCapacity(minCapacity);
+ // minCapacity is usually close to size, so this is a win:
+ elementData = Arrays.copyOf(elementData, newCapacity);
+}
+```
+
+然后对数组进行第一次扩容 `Arrays.copyOf(elementData, newCapacity)`,由原来的 DEFAULTCAPACITY_EMPTY_ELEMENTDATA 扩容为容量为 10 的数组。
+
+“那假如向 ArrayList 添加第 11 个元素呢?”三妹看到了问题的关键。
+
+此时,minCapacity 等于 11,elementData.length 为 10,`ensureExplicitCapacity()` 方法中 if 条件分支就起效了:
+
+```java
+private void ensureExplicitCapacity(int minCapacity) {
+ modCount++;
+
+ // overflow-conscious code
+ if (minCapacity - elementData.length > 0)
+ grow(minCapacity);
+}
+```
+
+会再次进入到 `grow()` 方法:
+
+```java
+private void grow(int minCapacity) {
+ // overflow-conscious code
+ int oldCapacity = elementData.length;
+ int newCapacity = oldCapacity + (oldCapacity >> 1);
+ if (newCapacity - minCapacity < 0)
+ newCapacity = minCapacity;
+ if (newCapacity - MAX_ARRAY_SIZE > 0)
+ newCapacity = hugeCapacity(minCapacity);
+ // minCapacity is usually close to size, so this is a win:
+ elementData = Arrays.copyOf(elementData, newCapacity);
+}
+```
+
+“oldCapacity 等于 10,`oldCapacity >> 1` 这个表达式等于多少呢?三妹你知道吗?”我问三妹。
+
+“不知道啊,`>>` 是什么意思呢?”三妹很疑惑。
+
+“`>>` 是右移运算符,`oldCapacity >> 1` 相当于 oldCapacity 除以 2。”我给三妹解释道,“在计算机内部,都是按照二进制存储的,10 的二进制就是 1010,也就是 `0*2^0 + 1*2^1 + 0*2^2 + 1*2^3`=0+2+0+8=10 。。。。。。”
+
+还没等我解释完,三妹就打断了我,“二哥,能再详细解释一下到底为什么吗?”
+
+“当然可以啊。”我拍着胸脯对三妹说。
+
+先从位全的含义说起吧。
+
+平常我们使用的是十进制数,比如说 39,并不是简单的 3 和 9,3 表示的是 `3*10 = 30`,9 表示的是 `9*1 = 9`,和 3 相乘的 10,和 9 相乘的 1,就是**位权**。位数不同,位权就不同,第 1 位是 10 的 0 次方(也就是 `10^0=1`),第 2 位是 10 的 1 次方(`10^1=10`),第 3 位是 10 的 2 次方(`10^2=100`),最右边的是第一位,依次类推。
+
+位权这个概念同样适用于二进制,第 1 位是 2 的 0 次方(也就是 `2^0=1`),第 2 位是 2 的 1 次方(`2^1=2`),第 3 位是 2 的 2 次方(`2^2=4`),第 34 位是 2 的 3 次方(`2^3=8`)。
+
+十进制的情况下,10 是基数,二进制的情况下,2 是基数。
+
+10 在十进制的表示法是 `0*10^0+1*10^1`=0+10=10。
+
+10 的二进制数是 1010,也就是 `0*2^0 + 1*2^1 + 0*2^2 + 1*2^3`=0+2+0+8=10。
+
+然后是**移位运算**,移位分为左移和右移,在 Java 中,左移的运算符是 `<<`,右移的运算符 `>>`。
+
+拿 `oldCapacity >> 1` 来说吧,`>>` 左边的是被移位的值,此时是 10,也就是二进制 `1010`;`>>` 右边的是要移位的位数,此时是 1。
+
+1010 向右移一位就是 101,空出来的最高位此时要补 0,也就是 0101。
+
+“那为什么不补 1 呢?”三妹这个问题很尖锐。
+
+“因为是算术右移,并且是正数,所以最高位补 0;如果表示的是负数,就需要补 1。”我慢吞吞地回答道,“0101 的十进制就刚好是 `1*2^0 + 0*2^1 + 1*2^2 + 0*2^3`=1+0+4+0=5,如果多移几个数来找规律的话,就会发现,右移 1 位是原来的 1/2,右移 2 位是原来的 1/4,诸如此类。”
+
+也就是说,ArrayList 的大小会扩容为原来的大小+原来大小/2,也就是差不多 1.5 倍。
+
+除了 `add(E e)` 方法,还可以通过 `add(int index, E element)` 方法把元素添加到指定的位置:
+
+```java
+alist.add(0, "沉默王三");
+```
+
+ `add(int index, E element)` 方法的源码如下:
+
+```java
+public void add(int index, E element) {
+ rangeCheckForAdd(index);
+
+ ensureCapacityInternal(size + 1); // Increments modCount!!
+ System.arraycopy(elementData, index, elementData, index + 1,
+ size - index);
+ elementData[index] = element;
+ size++;
+}
+```
+
+该方法会调用到一个非常重要的本地方法 `System.arraycopy()`,它会对数组进行复制(要插入位置上的元素往后复制)。
+
+“三妹,注意看,我画幅图来表示下。”我认真地做起了图。
+
+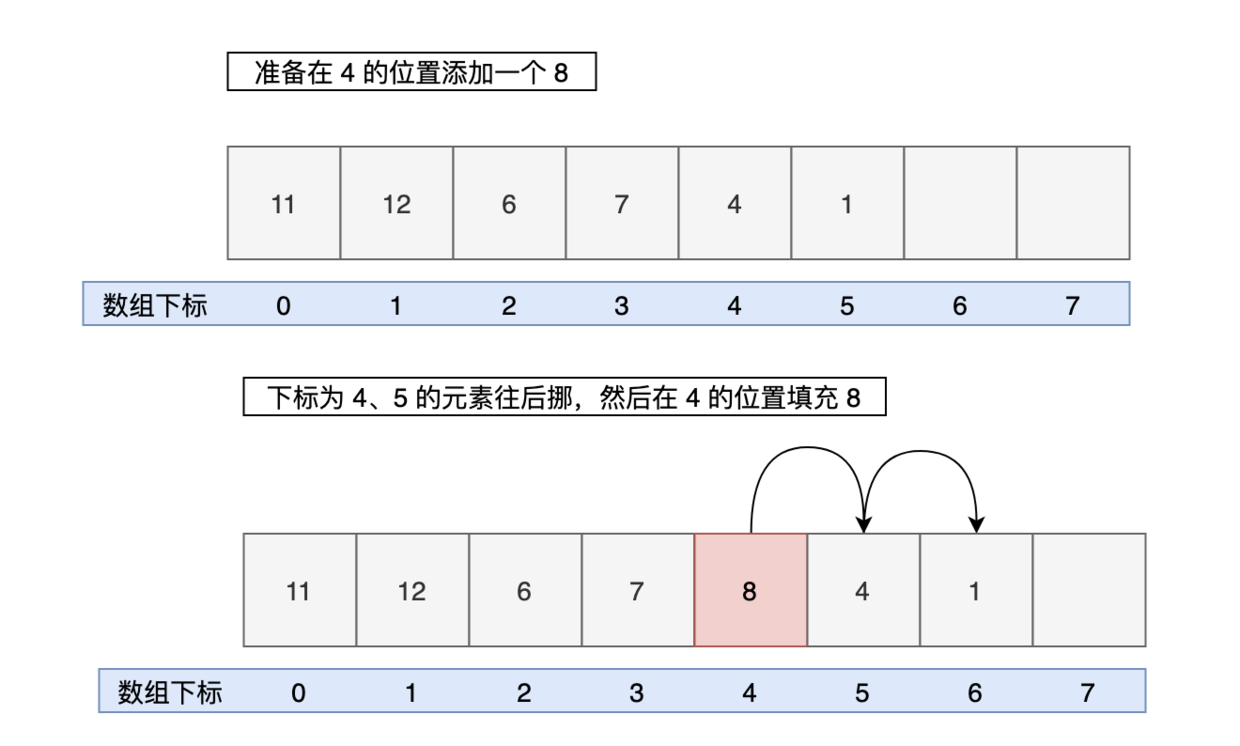
+
+
+“二哥,那怎么**更新 ArrayList 中的元素**呢?”三妹继续问。
+
+可以使用 `set()` 方法来更改 ArrayList 中的元素,需要提供下标和新元素。
+
+```java
+alist.set(0, "沉默王四");
+```
+
+假设原来 0 位置上的元素为“沉默王三”,现在可以将其更新为“沉默王四”。
+
+来看一下 `set()` 方法的源码:
+
+```java
+public E set(int index, E element) {
+ rangeCheck(index);
+
+ E oldValue = elementData(index);
+ elementData[index] = element;
+ return oldValue;
+}
+```
+
+该方法会先对指定的下标进行检查,看是否越界,然后替换新值并返回旧值。
+
+“二哥,那怎么**删除 ArrayList 中的元素**呢?”三妹继续问。
+
+`remove(int index)` 方法用于删除指定下标位置上的元素,`remove(Object o)` 方法用于删除指定值的元素。
+
+```java
+alist.remove(1);
+alist.remove("沉默王四");
+```
+
+先来看 `remove(int index)` 方法的源码:
+
+```java
+public E remove(int index) {
+ rangeCheck(index);
+
+ modCount++;
+ E oldValue = elementData(index);
+
+ int numMoved = size - index - 1;
+ if (numMoved > 0)
+ System.arraycopy(elementData, index+1, elementData, index,
+ numMoved);
+ elementData[--size] = null; // clear to let GC do its work
+
+ return oldValue;
+}
+```
+
+该方法会调用 ` System.arraycopy()` 对数组进行复制移动,然后把要删除的元素位置清空 `elementData[--size] = null`。
+
+再来看 `remove(Object o)` 方法的源码:
+
+```java
+public boolean remove(Object o) {
+ if (o == null) {
+ for (int index = 0; index < size; index++)
+ if (elementData[index] == null) {
+ fastRemove(index);
+ return true;
+ }
+ } else {
+ for (int index = 0; index < size; index++)
+ if (o.equals(elementData[index])) {
+ fastRemove(index);
+ return true;
+ }
+ }
+ return false;
+}
+```
+
+该方法通过遍历的方式找到要删除的元素,null 的时候使用 == 操作符判断,非 null 的时候使用 `equals()` 方法,然后调用 `fastRemove()` 方法;有相同元素时,只会删除第一个。
+
+既然都调用了 `fastRemove()` 方法,那就继续来跟踪一下源码:
+
+```java
+private void fastRemove(int index) {
+ modCount++;
+ int numMoved = size - index - 1;
+ if (numMoved > 0)
+ System.arraycopy(elementData, index+1, elementData, index,
+ numMoved);
+ elementData[--size] = null; // clear to let GC do its work
+}
+```
+
+同样是调用 `System.arraycopy()` 方法对数组进行复制和移动。
+
+“三妹,注意看,我画幅图来表示下。”我认真地做起了图。
+
+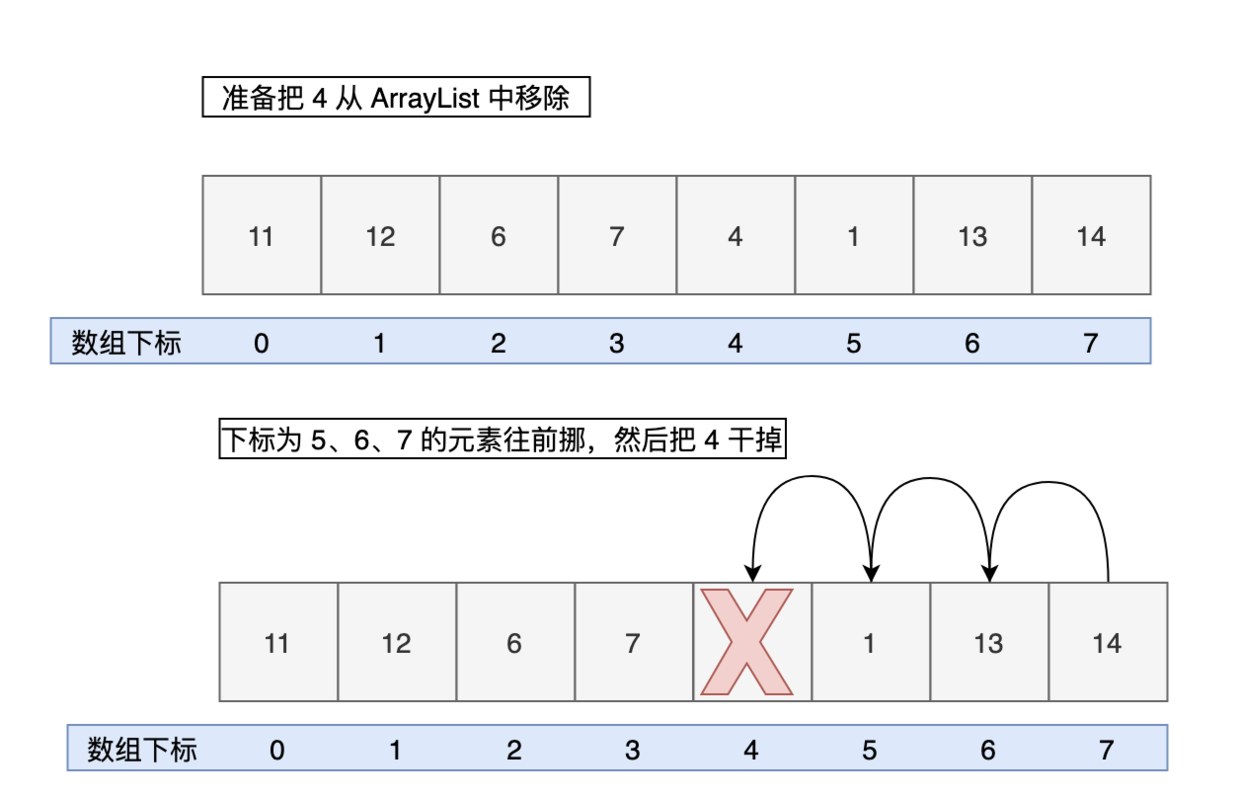
+
+
+
+“二哥,那怎么**查找 ArrayList 中的元素**呢?”三妹继续问。
+
+如果要正序查找一个元素,可以使用 `indexOf()` 方法;如果要倒序查找一个元素,可以使用 `lastIndexOf()` 方法。
+
+```java
+alist.indexOf("沉默王二");
+alist.lastIndexOf("沉默王二");
+```
+
+来看一下 `indexOf()` 方法的源码:
+
+```java
+public int indexOf(Object o) {
+ if (o == null) {
+ for (int i = 0; i < size; i++)
+ if (elementData[i]==null)
+ return i;
+ } else {
+ for (int i = 0; i < size; i++)
+ if (o.equals(elementData[i]))
+ return i;
+ }
+ return -1;
+}
+```
+
+如果元素为 null 的时候使用“==”操作符,否则使用 `equals()` 方法。
+
+`lastIndexOf()` 方法和 `indexOf()` 方法类似,不过遍历的时候从最后开始。
+
+`contains()` 方法可以判断 ArrayList 中是否包含某个元素,其内部调用了 `indexOf()` 方法:
+
+```java
+public boolean contains(Object o) {
+ return indexOf(o) >= 0;
+}
+```
+
+如果 ArrayList 中的元素是经过排序的,就可以使用二分查找法,效率更快。
+
+`Collections` 类的 `sort()` 方法可以对 ArrayList 进行排序,该方法会按照字母顺序对 String 类型的列表进行排序。如果是自定义类型的列表,还可以指定 Comparator 进行排序。
+
+```java
+List copy = new ArrayList<>(alist);
+copy.add("a");
+copy.add("c");
+copy.add("b");
+copy.add("d");
+
+Collections.sort(copy);
+System.out.println(copy);
+```
+
+输出结果如下所示:
+
+```
+[a, b, c, d]
+```
+
+排序后就可以使用二分查找法了:
+
+```java
+int index = Collections.binarySearch(copy, "b");
+```
+
+“最后,三妹,我来简单总结一下 ArrayList 的时间复杂度吧,方便后面学习 LinkedList 时对比。”我喝了一口水后补充道。
+
+1)通过下标(也就是 `get(int index)`)访问一个元素的时间复杂度为 O(1),因为是直达的,无论数据增大多少倍,耗时都不变。
+
+```java
+public E get(int index) {
+ rangeCheck(index);
+
+ return elementData(index);
+}
+```
+
+2)默认添加一个元素(调用 `add()` 方法时)的时间复杂度为 O(1),因为是直接添加到数组末尾的,但需要考虑到数组扩容时消耗的时间。
+
+3)删除一个元素(调用 `remove(Object)` 方法时)的时间复杂度为 O(n),因为要遍历列表,数据量增大几倍,耗时也增大几倍;如果是通过下标删除元素时,要考虑到数组的移动和复制所消耗的时间。
+
+4)查找一个未排序的列表时间复杂度为 O(n)(调用 `indexOf()` 或者 `lastIndexOf()` 方法时),因为要遍历列表;查找排序过的列表时间复杂度为 O(log n),因为可以使用二分查找法,当数据增大 n 倍时,耗时增大 logn 倍(这里的 log 是以 2 为底的,每找一次排除一半的可能)。
+
+-------
+
+ArrayList,如果有个中文名的话,应该叫动态数组,也就是可增长的数组,可调整大小的数组。动态数组克服了静态数组的限制,静态数组的容量是固定的,只能在首次创建的时候指定。而动态数组会随着元素的增加自动调整大小,更符合实际的开发需求。
+
+学习集合框架,ArrayList 是第一课,也是新手进阶的重要一课。要想完全掌握 ArrayList,扩容这个机制是必须得掌握,也是面试中经常考察的一个点。
+
+要想掌握扩容机制,就必须得读源码,也就肯定会遇到 `oldCapacity >> 1`,有些初学者会选择跳过,虽然不影响整体上的学习,但也错过了一个精进的机会。
+
+计算机内部是如何表示十进制数的,右移时又发生了什么,静下心来去研究一下,你就会发现,哦,原来这么有趣呢?
+
+
\ No newline at end of file
diff --git a/docs/collection/fail-fast.md b/docs/collection/fail-fast.md
new file mode 100644
index 0000000000..d79a5d99af
--- /dev/null
+++ b/docs/collection/fail-fast.md
@@ -0,0 +1,248 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 为什么阿里巴巴强制不要在foreach里执行删除操作
+
+
+那天,小二去阿里面试,面试官老王一上来就甩给了他一道面试题:为什么阿里的 Java 开发手册里会强制不要在 foreach 里进行元素的删除操作?
+
+-----
+
+为了镇楼,先搬一段英文来解释一下 fail-fast。
+
+>In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process. Such designs often check the system's state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
+
+这段话的大致意思就是,fail-fast 是一种通用的系统设计思想,一旦检测到可能会发生错误,就立马抛出异常,程序将不再往下执行。
+
+```java
+public void test(Wanger wanger) {
+ if (wanger == null) {
+ throw new RuntimeException("wanger 不能为空");
+ }
+
+ System.out.println(wanger.toString());
+}
+```
+
+一旦检测到 wanger 为 null,就立马抛出异常,让调用者来决定这种情况下该怎么处理,下一步 `wanger.toString()` 就不会执行了——避免更严重的错误出现。
+
+很多时候,我们会把 fail-fast 归类为 Java 集合框架的一种错误检测机制,但其实 fail-fast 并不是 Java 集合框架特有的机制。
+
+之所以我们把 fail-fast 放在集合框架篇里介绍,是因为问题比较容易再现。
+
+```java
+List list = new ArrayList<>();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("一个文章真特么有趣的程序员");
+
+for (String str : list) {
+ if ("沉默王二".equals(str)) {
+ list.remove(str);
+ }
+}
+
+System.out.println(list);
+```
+
+这段代码看起来没有任何问题,但运行起来就报错了。
+
+
+
+
+根据错误的堆栈信息,我们可以定位到 ArrayList 的第 901 行代码。
+
+```java
+final void checkForComodification() {
+ if (modCount != expectedModCount)
+ throw new ConcurrentModificationException();
+}
+```
+
+也就是说,remove 的时候触发执行了 `checkForComodification` 方法,该方法对 modCount 和 expectedModCount 进行了比较,发现两者不等,就抛出了 `ConcurrentModificationException` 异常。
+
+为什么会执行 `checkForComodification` 方法呢?
+
+是因为 for-each 本质上是个语法糖,底层是通过[迭代器 Iterator](戳链接🔗,详细了解下) 配合 while 循环实现的,来看一下反编译后的字节码。
+
+```java
+List list = new ArrayList();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("一个文章真特么有趣的程序员");
+Iterator var2 = list.iterator();
+
+while(var2.hasNext()) {
+ String str = (String)var2.next();
+ if ("沉默王二".equals(str)) {
+ list.remove(str);
+ }
+}
+
+System.out.println(list);
+```
+
+来看一下 ArrayList 的 iterator 方法吧:
+
+```java
+public Iterator iterator() {
+ return new Itr();
+}
+```
+
+内部类 Itr 实现了 Iterator 接口。
+
+```java
+private class Itr implements Iterator {
+ int cursor; // index of next element to return
+ int lastRet = -1; // index of last element returned; -1 if no such
+ int expectedModCount = modCount;
+
+ Itr() {}
+
+ public boolean hasNext() {
+ return cursor != size;
+ }
+
+ @SuppressWarnings("unchecked")
+ public E next() {
+ checkForComodification();
+ int i = cursor;
+ Object[] elementData = ArrayList.this.elementData;
+ if (i >= elementData.length)
+ throw new ConcurrentModificationException();
+ cursor = i + 1;
+ return (E) elementData[lastRet = i];
+ }
+}
+```
+
+也就是说 `new Itr()` 的时候 expectedModCount 被赋值为 modCount,而 modCount 是 List 的一个成员变量,表示集合被修改的次数。由于 list 此前执行了 3 次 add 方法。
+
+- add 方法调用 ensureCapacityInternal 方法
+- ensureCapacityInternal 方法调用 ensureExplicitCapacity 方法
+- ensureExplicitCapacity 方法中会执行 `modCount++`
+
+所以 modCount 的值在经过三次 add 后为 3,于是 `new Itr()` 后 expectedModCount 的值也为 3。
+
+执行第一次循环时,发现“沉默王二”等于 str,于是执行 `list.remove(str)`。
+
+- remove 方法调用 fastRemove 方法
+- fastRemove 方法中会执行 `modCount++`
+
+
+```java
+private void fastRemove(int index) {
+ modCount++;
+ int numMoved = size - index - 1;
+ if (numMoved > 0)
+ System.arraycopy(elementData, index+1, elementData, index,
+ numMoved);
+ elementData[--size] = null; // clear to let GC do its work
+}
+```
+
+modCount 的值变成了 4。
+
+执行第二次循环时,会执行 Itr 的 next 方法(`String str = (String) var3.next();`),next 方法就会调用 `checkForComodification` 方法,此时 expectedModCount 为 3,modCount 为 4,就只好抛出 ConcurrentModificationException 异常了。
+
+那其实在阿里巴巴的 Java 开发手册里也提到了,不要在 for-each 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator 方式。
+
+
+
+那原因其实就是我们上面分析的这些,出于 fail-fast 保护机制。
+
+**那该如何正确地删除元素呢**?
+
+**1)remove 后 break**
+
+```java
+List list = new ArrayList<>();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("一个文章真特么有趣的程序员");
+
+for (String str : list) {
+ if ("沉默王二".equals(str)) {
+ list.remove(str);
+ break;
+ }
+}
+```
+
+break 后循环就不再遍历了,意味着 Iterator 的 next 方法不再执行了,也就意味着 `checkForComodification` 方法不再执行了,所以异常也就不会抛出了。
+
+但是呢,当 List 中有重复元素要删除的时候,break 就不合适了。
+
+
+**2)for 循环**
+
+```java
+List list = new ArrayList<>();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("一个文章真特么有趣的程序员");
+for (int i = 0, n = list.size(); i < n; i++) {
+ String str = list.get(i);
+ if ("沉默王二".equals(str)) {
+ list.remove(str);
+ }
+}
+```
+
+for 循环虽然可以避开 fail-fast 保护机制,也就说 remove 元素后不再抛出异常;但是呢,这段程序在原则上是有问题的。为什么呢?
+
+第一次循环的时候,i 为 0,`list.size()` 为 3,当执行完 remove 方法后,i 为 1,`list.size()` 却变成了 2,因为 list 的大小在 remove 后发生了变化,也就意味着“沉默王三”这个元素被跳过了。能明白吗?
+
+remove 之前 `list.get(1)` 为“沉默王三”;但 remove 之后 `list.get(1)` 变成了“一个文章真特么有趣的程序员”,而 `list.get(0)` 变成了“沉默王三”。
+
+**3)使用 Iterator**
+
+```java
+List list = new ArrayList<>();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("一个文章真特么有趣的程序员");
+
+Iterator itr = list.iterator();
+
+while (itr.hasNext()) {
+ String str = itr.next();
+ if ("沉默王二".equals(str)) {
+ itr.remove();
+ }
+}
+```
+
+为什么使用 Iterator 的 remove 方法就可以避开 fail-fast 保护机制呢?看一下 remove 的源码就明白了。
+
+```java
+public void remove() {
+ if (lastRet < 0)
+ throw new IllegalStateException();
+ checkForComodification();
+
+ try {
+ ArrayList.this.remove(lastRet);
+ cursor = lastRet;
+ lastRet = -1;
+ expectedModCount = modCount;
+ } catch (IndexOutOfBoundsException ex) {
+ throw new ConcurrentModificationException();
+ }
+}
+```
+
+删除完会执行 `expectedModCount = modCount`,保证了 expectedModCount 与 modCount 的同步。
+
+-----
+
+简单地总结一下,fail-fast 是一种保护机制,可以通过 for-each 循环删除集合的元素的方式验证这种保护机制。
+
+那也就是说,for-each 本质上是一种语法糖,遍历集合时很方面,但并不适合拿来操作集合中的元素(增删)。
+
+
\ No newline at end of file
diff --git a/docs/collection/gailan.md b/docs/collection/gailan.md
new file mode 100644
index 0000000000..3d87535199
--- /dev/null
+++ b/docs/collection/gailan.md
@@ -0,0 +1,296 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java集合框架
+
+
+眼瞅着三妹的王者荣耀杀得正嗨,我趁机喊到:“别打了,三妹,我们来一起学习 Java 的集合框架吧。”
+
+“才不要呢,等我打完这一局啊。”三妹倔强地说。
+
+“好吧。”我只好摊摊手地说,“那我先画张集合框架的结构图等着你。”
+
+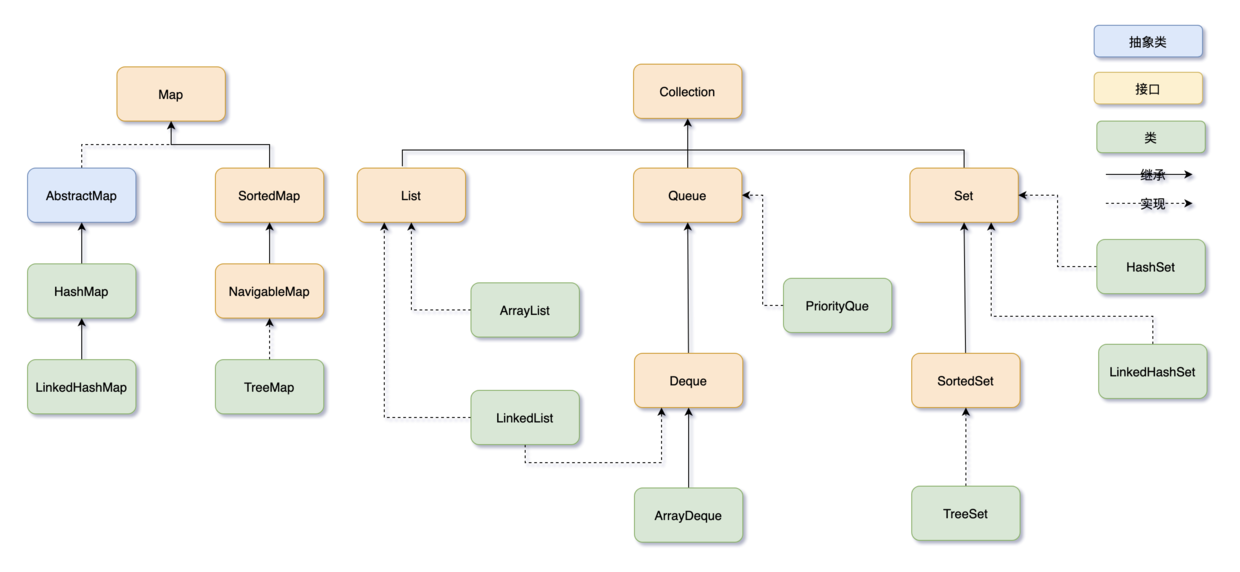
+
+
+“完了没?三妹。”
+
+“完了好一会儿了,二哥,你图画得真慢,让我瞧瞧怎么样?”
+
+“害,图要画得清晰明了,不容易的。三妹,你瞧,不错吧。”
+
+Java 集合框架可以分为两条大的支线:
+
+- Collection,主要由 List、Set、Queue 组成,List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQue。
+- Map,代表键值对的集合,典型代表就是 HashMap。
+
+“接下来,我们再来过一遍。”
+
+### 01、List
+
+>List 的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作
+
+**1)ArrayList**
+
+- ArrayList 是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素;
+- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动;
+- 如果内部数组的容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低。
+
+**2)LinkedList**
+
+- LinkedList 是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回;
+- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可,不像 ArrayList 那样需要复制和移动数组元素;
+- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些。
+
+**3)Vector 和 Stack**
+
+List 的实现类还有一个 Vector,是一个元老级的类,比 ArrayList 出现得更早。ArrayList 和 Vector 非常相似,只不过 Vector 是线程安全的,像 get、set、add 这些方法都加了 `synchronized` 关键字,就导致执行执行效率会比较低,所以现在已经很少用了。
+
+更好的选择是并发包下的 CopyOnWriteArrayList。
+
+Stack 是 Vector 的一个子类,本质上也是由动态数组实现的,只不过还实现了先进后出的功能(在 get、set、add 方法的基础上追加了 pop、peek 等方法),所以叫栈。
+
+不过,由于 Stack 执行效率比较低(方法上同样加了 synchronized 关键字),就被双端队列 ArrayDeque 取代了。
+
+### 02、Set
+
+> Set 的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作,和 List 有很多不同
+
+**1)HashSet**
+
+HashSet 其实是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。
+
+```java
+public class HashSet
+ extends AbstractSet
+ implements Set, Cloneable, java.io.Serializable
+{
+ private transient HashMap map;
+
+ // Dummy value to associate with an Object in the backing Map
+ private static final Object PRESENT = new Object();
+
+ public HashSet() {
+ map = new HashMap<>();
+ }
+
+ public boolean add(E e) {
+ return map.put(e, PRESENT)==null;
+ }
+
+ public boolean remove(Object o) {
+ return map.remove(o)==PRESENT;
+ }
+}
+```
+
+**2)LinkedHashSet**
+
+LinkedHashSet 继承自 HashSet,其实是由 LinkedHashMap 实现的,LinkedHashSet 的构造方法调用了 HashSet 的一个特殊的构造方法:
+
+```java
+HashSet(int initialCapacity, float loadFactor, boolean dummy) {
+ map = new LinkedHashMap<>(initialCapacity, loadFactor);
+}
+```
+
+**3)TreeSet**
+
+“二哥,不用你讲了,我能猜到,TreeSet 是由 TreeMap 实现的,只不过同样操作的键位,值由一个固定的 Object 对象填充。”
+
+哇,三妹都学会了推理。
+
+“是的,总体上来说,Set 集合不是关注的重点,因为底层都是由 Map 实现的,为什么要用 Map 实现呢?三妹你能猜到原因吗?”
+
+“让我想想。”
+
+“嗯?难道是因为 Map 的键不允许重复、无序吗?”
+
+老天,竟然被三妹猜到了。
+
+“是的,你这水平长进了呀,三妹。”
+
+### 03、Queue
+
+> Queue,也就是队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部。
+
+**1)ArrayDeque**
+
+从名字上可以看得出,ArrayDeque 是一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点。
+
+这是一个包含了 4 个元素的双端队列,和一个包含了 5 个元素的双端队列。
+
+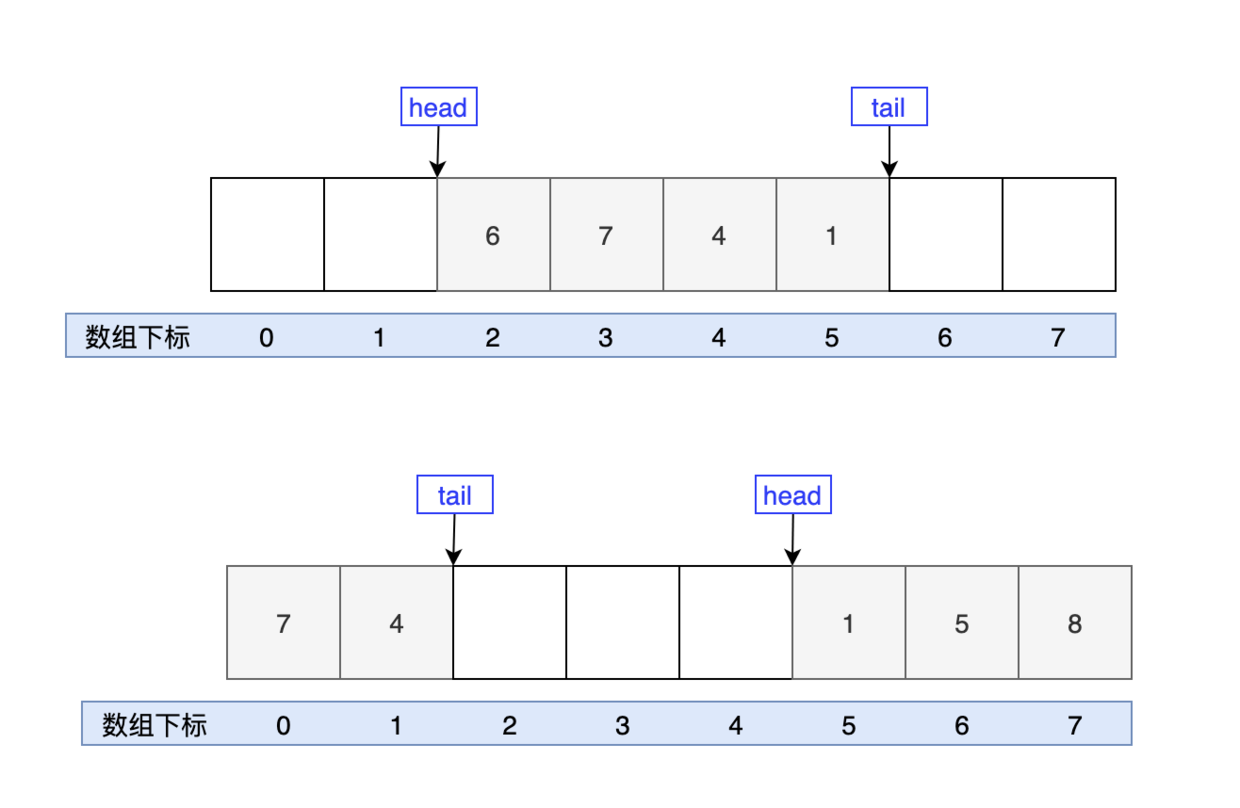
+
+head 指向队首的第一个有效的元素,tail 指向队尾第一个可以插入元素的空位,因为是循环数组,所以 head 不一定从是从 0 开始,tail 也不一定总是比 head 大。
+
+**2)LinkedList**
+
+LinkedList 一般都归在 List 下,只不过,它也实现了 Deque 接口,可以作为队列来使用。等于说,LinkedList 同时实现了 Stack、Queue、PriorityQueue 的所有功能。
+
+**3)PriorityQueue**
+
+PriorityQueue 是一种优先级队列,它的出队顺序与元素的优先级有关,执行 remove 或者 poll 方法,返回的总是优先级最高的元素。
+
+要想有优先级,元素就需要实现 Comparable 接口或者 Comparator 接口。
+
+### 04、Map
+
+> Map 保存的是键值对,键要求保持唯一性,值可以重复。
+
+**1)HashMap**
+
+HashMap 实现了 Map 接口,根据键的 HashCode 值来存储数据,具有很快的访问速度,最多允许一个 null 键。
+
+HashMap 不论是在学习还是工作当中,使用频率都是相当高的。随着 JDK 版本的不断更新,HashMap 的底层也优化了很多次,JDK 8 的时候引入了红黑树。
+
+```java
+final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ HashMap.Node[] tab; HashMap.Node p; int n, i;
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ HashMap.Node e; K k;
+ if (p.hash == hash &&
+ ((k = p.key) == key || (key != null && key.equals(k))))
+ e = p;
+ else if (p instanceof HashMap.TreeNode)
+ e = ((HashMap.TreeNode)p).putTreeVal(this, tab, hash, key, value);
+ else {
+ for (int binCount = 0; ; ++binCount) {
+ if ((e = p.next) == null) {
+ p.next = newNode(hash, key, value, null);
+ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+ break;
+ }
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ break;
+ p = e;
+ }
+ }
+ return null;
+}
+```
+
+一旦 HashMap 发生哈希冲突,就把相同键位的地方改成链表,如果链表的长度超过 8,就该用红黑树。
+
+**2)LinkedHashMap**
+
+大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
+
+大多数情况下,只要不涉及到线程安全的问题,有需要键值对的时候就会使用 HashMap,但 HashMap 有一个问题,就是 HashMap 是无序的。在某些场景下,我们需要一个有序的 Map。
+
+于是 LinkedHashMap 就闪亮登场了。LinkedHashMap 是 HashMap 的子类,内部使用链表来记录插入/访问元素的顺序。
+
+LinkedHashMap 可以看作是 HashMap + LinkedList 的合体,它使用了 哈希表来存储数据,又用了双向链表来维持顺序。
+
+**3)TreeMap**
+
+HashMap 是无序的,所以遍历的时候元素的顺序也是不可测的。TreeMap 是有序的,它在内部会对键进行排序,所以遍历的时候就可以得到预期的顺序。
+
+为了保证顺序,TreeMap 的键必须要实现 Comparable 接口或者 Comparator 接口。
+
+### 05、时间复杂度
+
+“二哥,为什么要讲时间复杂度呀?”三妹问。
+
+“因为接下来要用到啊。后面我们学习 ArrayList、LinkedList 的时候,会比较两者在增删改查时的执行效率,而时间复杂度是衡量执行效率的一个重要标准。”我说。
+
+“到时候跑一下代码,统计一下前后的时间差不更准确吗?”三妹反问道。
+
+“实际上,你说的是另外一种评估方法,这种评估方法可以得出非常准确的数值,但也有很大的局限性。”我不急不慢地说。
+
+第一,测试结果会受到测试环境的影响。你比如说,同样的代码,在我这台 iMac 上跑出来的时间和在你那台华为的 MacBook 上抛出的时间可能就差别很大。
+
+第二,测试结果会受到测试数据的影响。你比如说,一个排序后的数组和一个没有排序后的数组,调用了同一个查询方法,得出来的结果可能会差别特别大。
+
+“因此,我们需要这种不依赖于具体测试环境和测试数据就能粗略地估算出执行效率的方法,时间复杂度就是其中的一种,还有一种是空间复杂度。”我继续补充道。
+
+来看下面这段代码:
+
+```java
+public static int sum(int n) {
+ int sum = 0; // 第 1 行
+ for (int i=0;i T(n) = O(f(n))
+
+f(n) 表示代码总的执行次数,大写 O 表示代码的执行时间 T(n) 和 f(n) 成正比。
+
+这也就是大 O 表示法,它不关心代码具体的执行时间是多少,它关心的是代码执行时间的变化趋势,这也就是时间复杂度这个概念的由来。
+
+对于上面那段代码 `sum()` 来说,影响时间复杂度的主要是第 2 行代码,其余的,像系数 2、常数 2 都是可以忽略不计的,我们只关心影响最大的那个,所以时间复杂度就表示为 `O(n)`。
+
+常见的时间复杂度有这么 3 个:
+
+1)`O(1)`
+
+代码的执行时间,和数据规模 n 没有多大关系。
+
+括号中的 1 可以是 3,可以是 5,可以 100,我们习惯用 1 来表示,表示这段代码的执行时间是一个常数级别。比如说下面这段代码:
+
+```java
+int i = 0;
+int j = 0;
+int k = i + j;
+```
+
+实际上执行了 3 次,但我们也认为这段代码的时间复杂度为 `O(1)`。
+
+2)`O(n)`
+
+时间复杂度和数据规模 n 是线性关系。换句话说,数据规模增大 K 倍,代码执行的时间就大致增加 K 倍。
+
+3)`O(logn)`
+
+时间复杂度和数据规模 n 是对数关系。换句话说,数据规模大幅增加时,代码执行的时间只有少量增加。
+
+来看一下代码示例,
+
+```java
+public static void logn(int n) {
+ int i = 1;
+ while (i < n) {
+ i *= 2;
+ }
+}
+```
+
+换句话说,当数据量 n 从 2 增加到 2^64 时,代码执行的时间只增加 64 倍。
+
+```
+遍历次数 | i
+----------+-------
+ 0 | i
+ 1 | i*2
+ 2 | i*4
+ ... | ...
+ ... | ...
+ k | i*2^k
+```
+
+“好了,三妹,这节就讲到这吧,理解了上面 3 个时间复杂度,后面我们学习 ArrayList、LinkedList 的时候,两者在增删改查时的执行效率就很容易对比清楚了。”我伸了个懒腰后对三妹说,“整体上,集合框架就这么多东西了,随后我们会一一展开来讲,比如说 ArrayList、LinkedList、HashMap 等。”。
+
+“好的,二哥。”三妹重新回答沙发上,一盘王者荣耀即将开始。
+
+
\ No newline at end of file
diff --git a/docs/collection/hashmap-interview.md b/docs/collection/hashmap-interview.md
new file mode 100644
index 0000000000..8a68bc6ba9
--- /dev/null
+++ b/docs/collection/hashmap-interview.md
@@ -0,0 +1,201 @@
+---
+category:
+ - 求职面试
+tag:
+ - 面试题集合
+---
+
+# Java HashMap精选面试题
+
+
+对于 Java 求职者来说,HashMap 可谓是重中之重,是面试的必考点。然而 HashMap 的知识点非常多,复习起来花费精力很大。
+
+
+
+### 01、HashMap的底层数据结构是什么?
+
+JDK 7 中,HashMap 由“数组+链表”组成,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的。
+
+在 JDK 8 中,HashMap 由“数组+链表+红黑树”组成。链表过长,会严重影响 HashMap 的性能,而红黑树搜索的时间复杂度是 O(logn),而链表是糟糕的 O(n)。因此,JDK 8 对数据结构做了进一步的优化,引入了红黑树,链表和红黑树在达到一定条件会进行转换:
+
+- 当链表超过 8 且数据总量超过 64 时会转红黑树。
+- 将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树,以减少搜索时间。
+
+链表长度超过 8 体现在 putVal 方法中的这段代码:
+
+```java
+//链表长度大于8转换为红黑树进行处理
+if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+```
+
+ table 长度为 64 体现在 treeifyBin 方法中的这段代码::
+
+```java
+final void treeifyBin(Node[] tab, int hash) {
+ int n, index; Node e;
+ if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
+ resize();
+}
+```
+
+MIN_TREEIFY_CAPACITY 的值正好为 64。
+
+```java
+static final int MIN_TREEIFY_CAPACITY = 64;
+```
+
+JDK 8 中 HashMap 的结构示意图:
+
+
+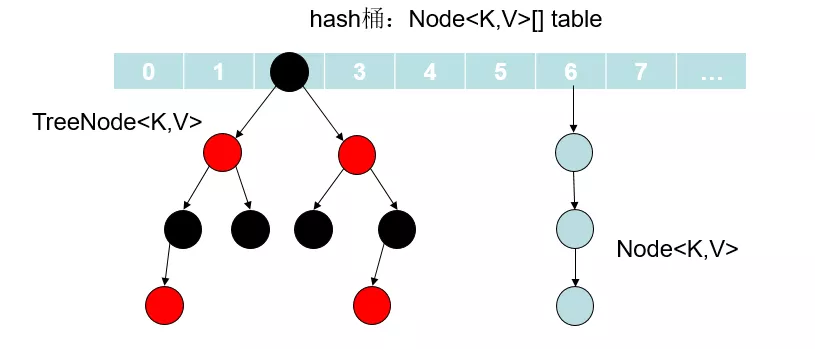
+
+### 02、为什么链表改为红黑树的阈值是 8?
+
+因为泊松分布,我们来看作者在源码中的注释:
+
+>Because TreeNodes are about twice the size of regular nodes, we
+ use them only when bins contain enough nodes to warrant use
+ (see TREEIFY_THRESHOLD). And when they become too small (due to
+ removal or resizing) they are converted back to plain bins. In
+ usages with well-distributed user hashCodes, tree bins are
+ rarely used. Ideally, under random hashCodes, the frequency of
+ nodes in bins follows a Poisson distribution
+ (http://en.wikipedia.org/wiki/Poisson_distribution) with a
+ parameter of about 0.5 on average for the default resizing
+ threshold of 0.75, although with a large variance because of
+ resizing granularity. Ignoring variance, the expected
+ occurrences of list size k are (exp(-0.5) pow(0.5, k) /
+ factorial(k)). The first values are:
+ 0: 0.60653066
+ 1: 0.30326533
+ 2: 0.07581633
+ 3: 0.01263606
+ 4: 0.00157952
+ 5: 0.00015795
+ 6: 0.00001316
+ 7: 0.00000094
+ 8: 0.00000006
+ more: less than 1 in ten million
+
+翻译过来大概的意思是:理想情况下使用随机的哈希码,容器中节点分布在 hash 桶中的频率遵循泊松分布,按照泊松分布的计算公式计算出了桶中元素个数和概率的对照表,可以看到链表中元素个数为 8 时的概率已经非常小,再多的就更少了,所以原作者在选择链表元素个数时选择了 8,是根据概率统计而选择的。
+
+### 03、解决hash冲突的办法有哪些?HashMap用的哪种?
+
+解决Hash冲突方法有:
+
+- 开放定址法:也称为再散列法,基本思想就是,如果p=H(key)出现冲突时,则以p为基础,再次hash,p1=H(p),如果p1再次出现冲突,则以p1为基础,以此类推,直到找到一个不冲突的哈希地址pi。因此开放定址法所需要的hash表的长度要大于等于所需要存放的元素,而且因为存在再次hash,所以只能在删除的节点上做标记,而不能真正删除节点。
+- 再哈希法:双重散列,多重散列,提供多个不同的hash函数,当R1=H1(key1)发生冲突时,再计算R2=H2(key1),直到没有冲突为止。这样做虽然不易产生堆集,但增加了计算的时间。
+- 链地址法:拉链法,将哈希值相同的元素构成一个同义词的单链表,并将单链表的头指针存放在哈希表的第i个单元中,查找、插入和删除主要在同义词链表中进行。链表法适用于经常进行插入和删除的情况。
+- 建立公共溢出区:将哈希表分为公共表和溢出表,当溢出发生时,将所有溢出数据统一放到溢出区。
+
+HashMap中采用的是链地址法 。
+
+### 04、为什么在解决 hash 冲突的时候,不直接用红黑树?而选择先用链表,再转红黑树?
+
+因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。
+
+当元素小于 8 个的时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于 8 个的时候, 红黑树搜索时间复杂度是 O(logn),而链表是 O(n),此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
+
+因此,如果一开始就用红黑树结构,元素太少,新增效率又比较慢,无疑这是浪费性能的。
+
+### 05、HashMap默认加载因子是多少?为什么是 0.75,不是 0.6 或者 0.8 ?
+
+作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。
+
+[详情参照这篇](https://mp.weixin.qq.com/s/a3qfatEWizKK1CpYaxVBbA)
+
+### 06、HashMap 中 key 的存储索引是怎么计算的?
+
+首先根据key的值计算出hashcode的值,然后根据hashcode计算出hash值,最后通过hash&(length-1)计算得到存储的位置。
+
+
+[详情参照这篇](https://mp.weixin.qq.com/s/aS2dg4Dj1Efwujmv-6YTBg)
+
+### 07、JDK 8 为什么要 hashcode 异或其右移十六位的值?
+
+因为在JDK 7 中扰动了 4 次,计算 hash 值的性能会稍差一点点。
+
+从速度、功效、质量来考虑,JDK 8 优化了高位运算的算法,通过hashCode()的高16位异或低16位实现:`(h = k.hashCode()) ^ (h >>> 16)`。
+
+这么做可以在数组 table 的 length 比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中,同时不会有太大的开销。
+
+### 08、为什么 hash 值要与length-1相与?
+
+- 把 hash 值对数组长度取模运算,模运算的消耗很大,没有位运算快。
+- 当 length 总是 2 的n次方时,`h& (length-1) `运算等价于对length取模,也就是 h%length,但是 & 比 % 具有更高的效率。
+
+### 09、HashMap数组的长度为什么是 2 的幂次方?
+
+2 的 N 次幂有助于减少碰撞的几率。如果 length 为2的幂次方,则 length-1 转化为二进制必定是11111……的形式,在与h的二进制与操作效率会非常的快,而且空间不浪费。我们来举个例子,看下图:
+
+
+
+
+当 length =15时,6 和 7 的结果一样,这样表示他们在 table 存储的位置是相同的,也就是产生了碰撞,6、7就会在一个位置形成链表,4和5的结果也是一样,这样就会导致查询速度降低。
+
+如果我们进一步分析,还会发现空间浪费非常大,以 length=15 为例,在 1、3、5、7、9、11、13、15 这八处没有存放数据。因为hash值在与14(即 1110)进行&运算时,得到的结果最后一位永远都是0,即 0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的。
+
+**再补充数组容量计算的小奥秘。**
+
+HashMap 构造函数允许用户传入的容量不是 2 的 n 次方,因为它可以自动地将传入的容量转换为 2 的 n 次方。会取大于或等于这个数的 且最近的2次幂作为 table 数组的初始容量,使用tableSizeFor(int)方法,如 tableSizeFor(10) = 16(2 的 4 次幂),tableSizeFor(20) = 32(2 的 5 次幂),也就是说 table 数组的长度总是 2 的次幂。JDK 8 源码如下:
+
+```java
+static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+```
+
+让cap-1再赋值给n的目的是另找到的目标值大于或等于原值。例如二进制1000,十进制数值为8。如果不对它减1而直接操作,将得到答案10000,即16。显然不是结果。减1后二进制为111,再进行操作则会得到原来的数值1000,即8。
+
+### 10、HashMap 的put方法流程?
+
+以JDK 8为例,简要流程如下:
+
+1、首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
+
+2、如果数组是空的,则调用 resize 进行初始化;
+
+3、如果没有哈希冲突直接放在对应的数组下标里;
+
+4、如果冲突了,且 key 已经存在,就覆盖掉 value;
+
+5、如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
+
+6、如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
+
+
+
+### 11、HashMap 的扩容方式?
+
+HashMap 在容量超过负载因子所定义的容量之后,就会扩容。
+
+[详情参照这篇](https://mp.weixin.qq.com/s/0KSpdBJMfXSVH63XadVdmw)
+
+### 12、一般用什么作为HashMap的key?
+
+一般用Integer、String 这种不可变类当作 HashMap 的 key,String 最为常见。
+
+- 因为字符串是不可变的,所以在它创建的时候 hashcode 就被缓存了,不需要重新计算。
+- 因为获取对象的时候要用到 equals() 和 hashCode() 方法,那么键对象正确的重写这两个方法是非常重要的。Integer、String 这些类已经很规范的重写了 hashCode() 以及 equals() 方法。
+
+### 13、HashMap为什么线程不安全?
+
+- JDK 7 时多线程下扩容会造成死循环。
+- 多线程的put可能导致元素的丢失。
+- put和get并发时,可能导致get为null。
+
+[详情参照这篇](https://mp.weixin.qq.com/s/qk_neCdzM3aB6pVWVTHhNw)
+
+
+
+>参考链接:https://zhuanlan.zhihu.com/p/362214327
+
+
+
diff --git a/docs/collection/hashmap.md b/docs/collection/hashmap.md
new file mode 100644
index 0000000000..78426ecf76
--- /dev/null
+++ b/docs/collection/hashmap.md
@@ -0,0 +1,800 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java8系列之重新认识HashMap
+
+## 一、hash 方法的原理
+
+来看一下 hash 方法的源码(JDK 8 中的 HashMap):
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+这段代码究竟是用来干嘛的呢?
+
+我们都知道,`key.hashCode()` 是用来获取键位的哈希值的,理论上,哈希值是一个 int 类型,范围从-2147483648 到 2147483648。前后加起来大概 40 亿的映射空间,只要哈希值映射得比较均匀松散,一般是不会出现哈希碰撞的。
+
+但问题是一个 40 亿长度的数组,内存是放不下的。HashMap 扩容之前的数组初始大小只有 16,所以这个哈希值是不能直接拿来用的,用之前要和数组的长度做取模运算,用得到的余数来访问数组下标才行。
+
+取模运算有两处。
+
+> 取模运算(“Modulo Operation”)和取余运算(“Remainder Operation ”)两个概念有重叠的部分但又不完全一致。主要的区别在于对负整数进行除法运算时操作不同。取模主要是用于计算机术语中,取余则更多是数学概念。
+
+一处是往 HashMap 中 put 的时候(`putVal` 方法中):
+
+```java
+final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
+ HashMap.Node[] tab; HashMap.Node p; int n, i;
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+}
+```
+
+一处是从 HashMap 中 get 的时候(`getNode` 方法中):
+
+```java
+final Node getNode(int hash, Object key) {
+ Node[] tab; Node first, e; int n; K k;
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (first = tab[(n - 1) & hash]) != null) {}
+}
+```
+
+其中的 `(n - 1) & hash` 正是取模运算,就是把哈希值和(数组长度-1)做了一个“与”运算。
+
+可能大家在疑惑:**取模运算难道不该用 `%` 吗?为什么要用 `&` 呢**?
+
+这是因为 `&` 运算比 `%` 更加高效,并且当 b 为 2 的 n 次方时,存在下面这样一个公式。
+
+> a % b = a & (b-1)
+
+用 $2^n$ 替换下 b 就是:
+
+>a % $2^n$ = a & ($2^n$-1)
+
+我们来验证一下,假如 a = 14,b = 8,也就是 $2^3$,n=3。
+
+14%8,14 的二进制为 1110,8 的二进制 1000,8-1 = 7 的二进制为 0111,1110&0111=0110,也就是 0`*`$2^0$+1`*`$2^1$+1`*`$2^2$+0`*`$2^3$=0+2+4+0=6,14%8 刚好也等于 6。
+
+这也正好解释了为什么 HashMap 的数组长度要取 2 的整次方。
+
+因为(数组长度-1)正好相当于一个“低位掩码”——这个掩码的低位最好全是 1,这样 & 操作才有意义,否则结果就肯定是 0,那么 & 操作就没有意义了。
+
+> a&b 操作的结果是:a、b 中对应位同时为 1,则对应结果位为 1,否则为 0
+
+2 的整次幂刚好是偶数,偶数-1 是奇数,奇数的二进制最后一位是 1,保证了 hash &(length-1) 的最后一位可能为 0,也可能为 1(这取决于 h 的值),即 & 运算后的结果可能为偶数,也可能为奇数,这样便可以保证哈希值的均匀性。
+
+& 操作的结果就是将哈希值的高位全部归零,只保留低位值,用来做数组下标访问。
+
+假设某哈希值为 `10100101 11000100 00100101`,用它来做取模运算,我们来看一下结果。HashMap 的初始长度为 16(内部是数组),16-1=15,二进制是 `00000000 00000000 00001111`(高位用 0 来补齐):
+
+```
+ 10100101 11000100 00100101
+& 00000000 00000000 00001111
+----------------------------------
+ 00000000 00000000 00000101
+```
+
+因为 15 的高位全部是 0,所以 & 运算后的高位结果肯定是 0,只剩下 4 个低位 `0101`,也就是十进制的 5,也就是将哈希值为 `10100101 11000100 00100101` 的键放在数组的第 5 位。
+
+明白了取模运算后,我们再来看 put 方法的源码:
+
+```java
+public V put(K key, V value) {
+ return putVal(hash(key), key, value, false, true);
+}
+```
+
+以及 get 方法的源码:
+
+```java
+public V get(Object key) {
+ HashMap.Node e;
+ return (e = getNode(hash(key), key)) == null ? null : e.value;
+}
+```
+
+它们在调用 putVal 和 getNode 之前,都会先调用 hash 方法:
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+那为什么取模运算之前要调用 hash 方法呢?
+
+看下面这个图。
+
+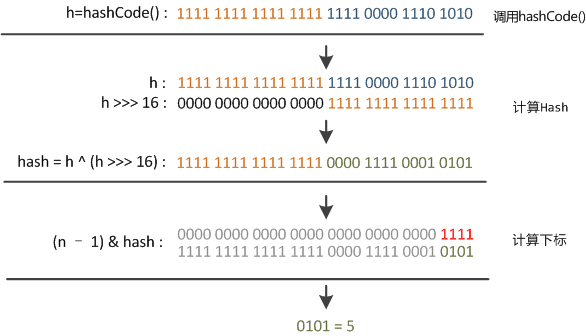
+
+某哈希值为 `11111111 11111111 11110000 1110 1010`,将它右移 16 位(h >>> 16),刚好是 `00000000 00000000 11111111 11111111`,再进行异或操作(h ^ (h >>> 16)),结果是 `11111111 11111111 00001111 00010101`
+
+> 异或(`^`)运算是基于二进制的位运算,采用符号 XOR 或者`^`来表示,运算规则是:如果是同值取 0、异值取 1
+
+由于混合了原来哈希值的高位和低位,所以低位的随机性加大了(掺杂了部分高位的特征,高位的信息也得到了保留)。
+
+结果再与数组长度-1(`00000000 00000000 00000000 00001111`)做取模运算,得到的下标就是 `00000000 00000000 00000000 00000101`,也就是 5。
+
+还记得之前我们假设的某哈希值 `10100101 11000100 00100101` 吗?在没有调用 hash 方法之前,与 15 做取模运算后的结果也是 5,我们不妨来看看调用 hash 之后的取模运算结果是多少。
+
+某哈希值 `00000000 10100101 11000100 00100101`(补齐 32 位),将它右移 16 位(h >>> 16),刚好是 `00000000 00000000 00000000 10100101`,再进行异或操作(h ^ (h >>> 16)),结果是 `00000000 10100101 00111011 10000000`
+
+结果再与数组长度-1(`00000000 00000000 00000000 00001111`)做取模运算,得到的下标就是 `00000000 00000000 00000000 00000000`,也就是 0。
+
+综上所述,hash 方法是用来做哈希值优化的,把哈希值右移 16 位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。
+
+说白了,**hash 方法就是为了增加随机性,让数据元素更加均衡的分布,减少碰撞**。
+
+## 二、扩容机制
+
+大家都知道,数组一旦初始化后大小就无法改变了,所以就有了 [ArrayList](https://mp.weixin.qq.com/s/7puyi1PSbkFEIAz5zbNKxA)这种“动态数组”,可以自动扩容。
+
+HashMap 的底层用的也是数组。向 HashMap 里不停地添加元素,当数组无法装载更多元素时,就需要对数组进行扩容,以便装入更多的元素。
+
+当然了,数组是无法自动扩容的,所以如果要扩容的话,就需要新建一个大的数组,然后把小数组的元素复制过去。
+
+HashMap 的扩容是通过 resize 方法来实现的,JDK 8 中融入了红黑树,比较复杂,为了便于理解,就还使用 JDK 7 的源码,搞清楚了 JDK 7 的,我们后面再详细说明 JDK 8 和 JDK 7 之间的区别。
+
+resize 方法的源码:
+
+```java
+// newCapacity为新的容量
+void resize(int newCapacity) {
+ // 小数组,临时过度下
+ Entry[] oldTable = table;
+ // 扩容前的容量
+ int oldCapacity = oldTable.length;
+ // MAXIMUM_CAPACITY 为最大容量,2 的 30 次方 = 1<<30
+ if (oldCapacity == MAXIMUM_CAPACITY) {
+ // 容量调整为 Integer 的最大值 0x7fffffff(十六进制)=2 的 31 次方-1
+ threshold = Integer.MAX_VALUE;
+ return;
+ }
+
+ // 初始化一个新的数组(大容量)
+ Entry[] newTable = new Entry[newCapacity];
+ // 把小数组的元素转移到大数组中
+ transfer(newTable, initHashSeedAsNeeded(newCapacity));
+ // 引用新的大数组
+ table = newTable;
+ // 重新计算阈值
+ threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
+}
+```
+
+代码注释里出现了左移(`<<`),这里简单介绍一下:
+
+```
+a=39
+b = a << 2
+```
+
+十进制 39 用 8 位的二进制来表示,就是 00100111,左移两位后是 10011100(低位用 0 补上),再转成十进制数就是 156。
+
+移位运算通常可以用来代替乘法运算和除法运算。例如,将 0010011(39)左移两位就是 10011100(156),刚好变成了原来的 4 倍。
+
+实际上呢,二进制数左移后会变成原来的 2 倍、4 倍、8 倍。
+
+transfer 方法用来转移,将小数组的元素拷贝到新的数组中。
+
+```java
+void transfer(Entry[] newTable, boolean rehash) {
+ // 新的容量
+ int newCapacity = newTable.length;
+ // 遍历小数组
+ for (Entry e : table) {
+ while(null != e) {
+ // 拉链法,相同 key 上的不同值
+ Entry next = e.next;
+ // 是否需要重新计算 hash
+ if (rehash) {
+ e.hash = null == e.key ? 0 : hash(e.key);
+ }
+ // 根据大数组的容量,和键的 hash 计算元素在数组中的下标
+ int i = indexFor(e.hash, newCapacity);
+
+ // 同一位置上的新元素被放在链表的头部
+ e.next = newTable[i];
+
+ // 放在新的数组上
+ newTable[i] = e;
+
+ // 链表上的下一个元素
+ e = next;
+ }
+ }
+}
+```
+
+`e.next = newTable[i]`,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置;这样先放在一个索引上的元素终会被放到链表的尾部(如果发生了hash冲突的话),这一点和 JDK 8 有区别。
+
+**在旧数组中同一个链表上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上**(仔细看下面的内容,会解释清楚这一点)。
+
+假设 hash 算法([之前的章节有讲到](https://mp.weixin.qq.com/s/aS2dg4Dj1Efwujmv-6YTBg),点击链接再温故一下)就是简单的用键的哈希值(一个 int 值)和数组大小取模(也就是 hashCode % table.length)。
+
+继续假设:
+
+- 数组 table 的长度为 2
+- 键的哈希值为 3、7、5
+
+取模运算后,哈希冲突都到 table[1] 上了,因为余数为 1。那么扩容前的样子如下图所示。
+
+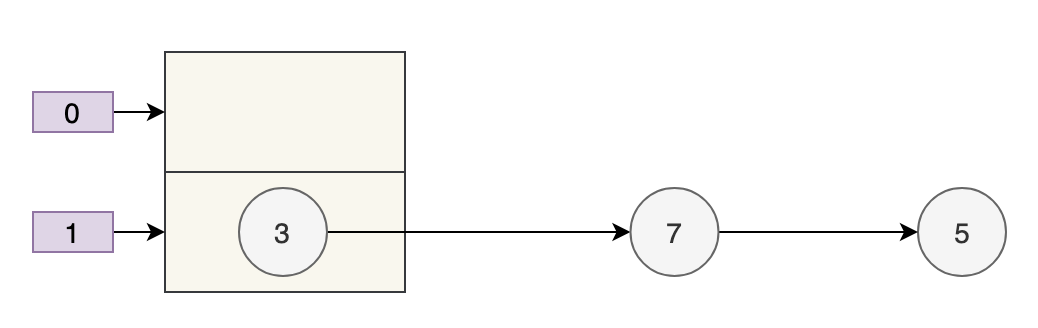
+
+小数组的容量为 2, key 3、7、5 都在 table[1] 的链表上。
+
+假设负载因子 loadFactor 为 1,也就是当元素的实际大小大于 table 的实际大小时进行扩容。
+
+扩容后的大数组的容量为 4。
+
+- key 3 取模(3%4)后是 3,放在 table[3] 上。
+- key 7 取模(7%4)后是 3,放在 table[3] 上的链表头部。
+- key 5 取模(5%4)后是 1,放在 table[1] 上。
+
+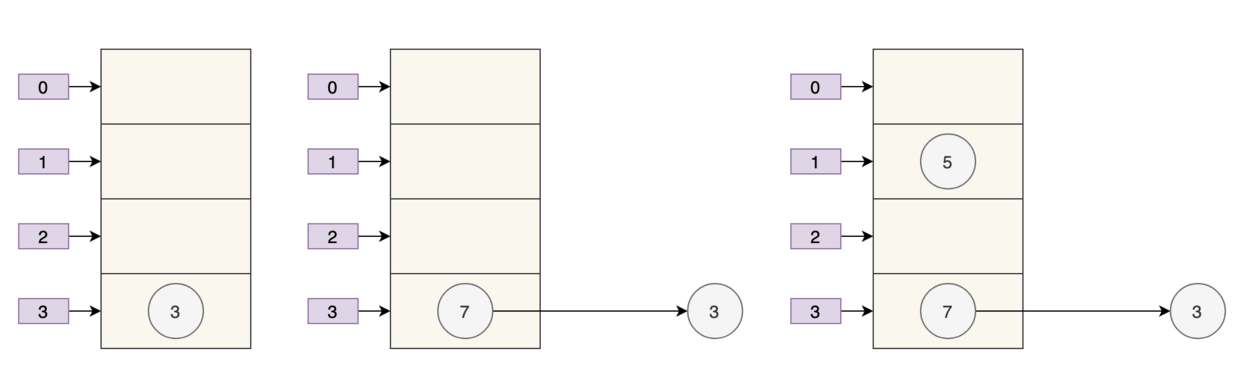
+
+按照我们的预期,扩容后的 7 仍然应该在 3 这条链表的后面,但实际上呢? 7 跑到 3 这条链表的头部了。针对 JDK 7 中的这个情况,JDK 8 做了哪些优化呢?
+
+看下面这张图。
+
+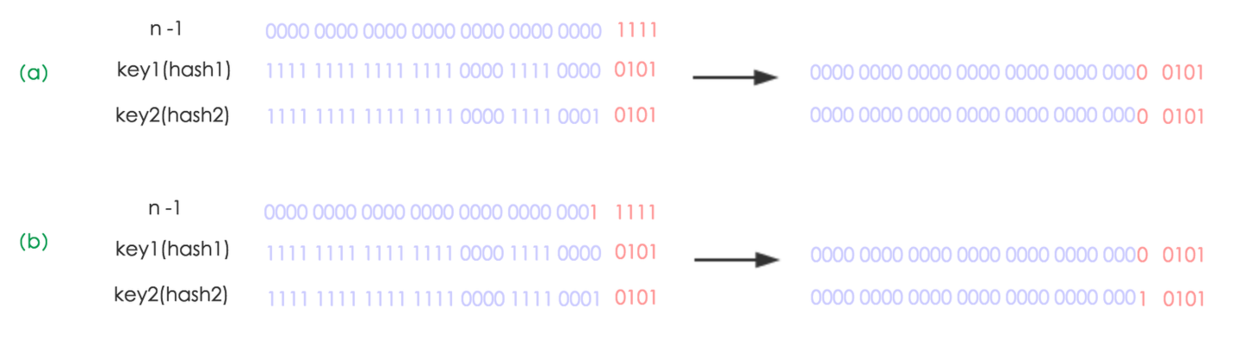
+
+n 为 table 的长度,默认值为 16。
+
+- n-1 也就是二进制的 0000 1111(1X$2^0$+1X$2^1$+1X$2^2$+1X$2^3$=1+2+4+8=15);
+- key1 哈希值的最后 8 位为 0000 0101
+- key2 哈希值的最后 8 位为 0001 0101(和 key1 不同)
+- 做与运算后发生了哈希冲突,索引都在(0000 0101)上。
+
+扩容后为 32。
+
+- n-1 也就是二进制的 0001 1111(1X$2^0$+1X$2^1$+1X$2^2$+1X$2^3$+1X$2^4$=1+2+4+8+16=31),扩容前是 0000 1111。
+- key1 哈希值的低位为 0000 0101
+- key2 哈希值的低位为 0001 0101(和 key1 不同)
+- key1 做与运算后,索引为 0000 0101。
+- key2 做与运算后,索引为 0001 0101。
+
+新的索引就会发生这样的变化:
+
+- 原来的索引是 5(*0* 0101)
+- 原来的容量是 16
+- 扩容后的容量是 32
+- 扩容后的索引是 21(*1* 0101),也就是 5+16,也就是原来的索引+原来的容量
+
+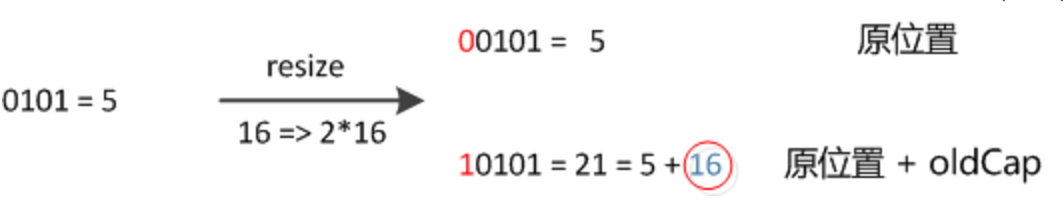
+
+
+也就是说,JDK 8 不需要像 JDK 7 那样重新计算 hash,只需要看原来的hash值新增的那个bit是1还是0就好了,是0的话就表示索引没变,是1的话,索引就变成了“原索引+原来的容量”。
+
+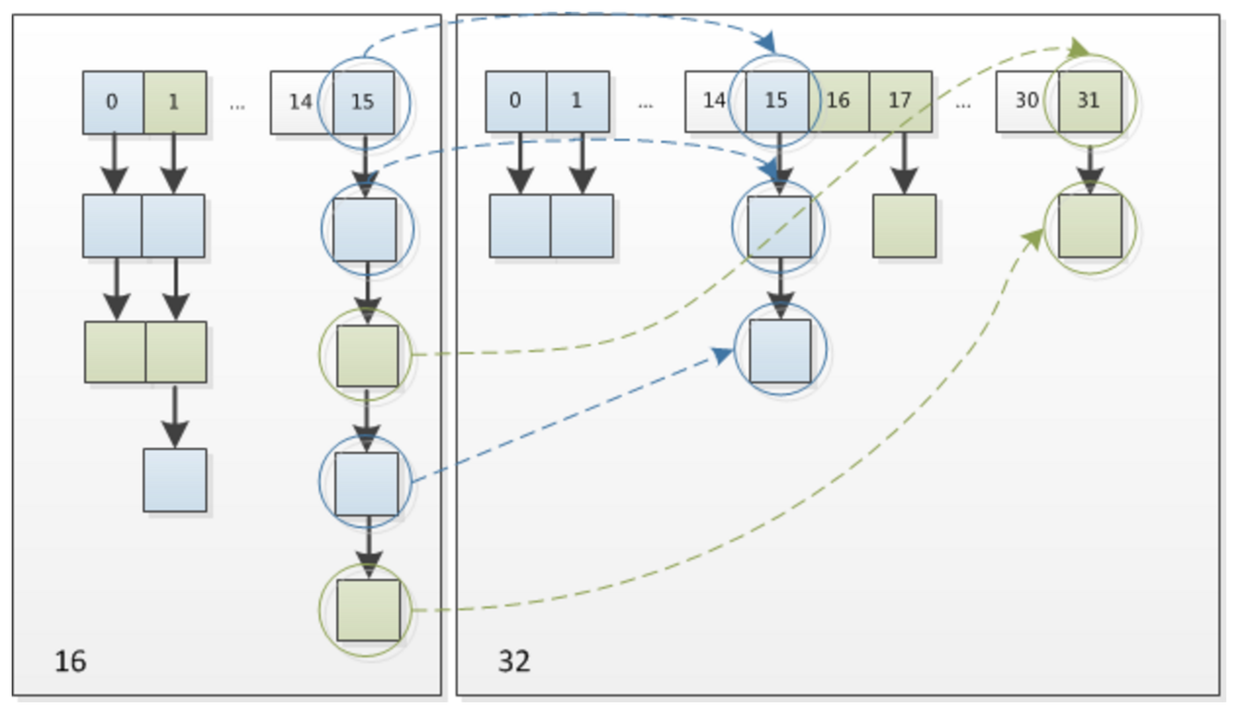
+
+JDK 8 的这个设计非常巧妙,既省去了重新计算hash的时间,同时,由于新增的1 bit是0还是1是随机的,因此扩容的过程,可以均匀地把之前的节点分散到新的位置上。
+
+ woc,只能说 HashMap 的作者 Doug Lea、Josh Bloch、Arthur van Hoff、Neal Gafter 真的强——的一笔。
+
+JDK 8 扩容的源代码:
+
+```java
+final Node[] resize() {
+ Node[] oldTab = table;
+ int oldCap = (oldTab == null) ? 0 : oldTab.length;
+ int oldThr = threshold;
+ int newCap, newThr = 0;
+ if (oldCap > 0) {
+ // 超过最大值就不再扩充了,就只好随你碰撞去吧
+ if (oldCap >= MAXIMUM_CAPACITY) {
+ threshold = Integer.MAX_VALUE;
+ return oldTab;
+ }
+ // 没超过最大值,就扩充为原来的2倍
+ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
+ oldCap >= DEFAULT_INITIAL_CAPACITY)
+ newThr = oldThr << 1; // double threshold
+ }
+ else if (oldThr > 0) // initial capacity was placed in threshold
+ newCap = oldThr;
+ else { // zero initial threshold signifies using defaults
+ newCap = DEFAULT_INITIAL_CAPACITY;
+ newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
+ }
+ // 计算新的resize上限
+ if (newThr == 0) {
+ float ft = (float)newCap * loadFactor;
+ newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
+ (int)ft : Integer.MAX_VALUE);
+ }
+ threshold = newThr;
+ @SuppressWarnings({"rawtypes","unchecked"})
+ Node[] newTab = (Node[])new Node[newCap];
+ table = newTab;
+ if (oldTab != null) {
+ // 小数组复制到大数组
+ for (int j = 0; j < oldCap; ++j) {
+ Node e;
+ if ((e = oldTab[j]) != null) {
+ oldTab[j] = null;
+ if (e.next == null)
+ newTab[e.hash & (newCap - 1)] = e;
+ else if (e instanceof TreeNode)
+ ((TreeNode)e).split(this, newTab, j, oldCap);
+ else { // preserve order
+ // 链表优化重 hash 的代码块
+ Node loHead = null, loTail = null;
+ Node hiHead = null, hiTail = null;
+ Node next;
+ do {
+ next = e.next;
+ if ((e.hash & oldCap) == 0) {
+ if (loTail == null)
+ loHead = e;
+ else
+ loTail.next = e;
+ loTail = e;
+ }
+ else {
+ if (hiTail == null)
+ hiHead = e;
+ else
+ hiTail.next = e;
+ hiTail = e;
+ }
+ } while ((e = next) != null);
+ // 原来的索引
+ if (loTail != null) {
+ loTail.next = null;
+ newTab[j] = loHead;
+ }
+ // 索引+原来的容量
+ if (hiTail != null) {
+ hiTail.next = null;
+ newTab[j + oldCap] = hiHead;
+ }
+ }
+ }
+ }
+ }
+ return newTab;
+}
+```
+
+## 三、加载因子为什么是0.75
+
+JDK 8 中的 HashMap 是用数组+链表+红黑树实现的,我们要想往 HashMap 中放数据或者取数据,就需要确定数据在数组中的下标。
+
+先把数据的键进行一次 hash:
+
+```java
+static final int hash(Object key) {
+ int h;
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+}
+```
+
+再做一次取模运算确定下标:
+
+```
+i = (n - 1) & hash
+```
+
+哈希表这样的数据结构容易产生两个问题:
+
+- 数组的容量过小,经过哈希计算后的下标,容易出现冲突;
+- 数组的容量过大,导致空间利用率不高。
+
+加载因子是用来表示 HashMap 中数据的填满程度:
+
+>加载因子 = 填入哈希表中的数据个数 / 哈希表的长度
+
+这就意味着:
+
+- 加载因子越小,填满的数据就越少,哈希冲突的几率就减少了,但浪费了空间,而且还会提高扩容的触发几率;
+- 加载因子越大,填满的数据就越多,空间利用率就高,但哈希冲突的几率就变大了。
+
+好难!!!!
+
+这就必须在“**哈希冲突**”与“**空间利用率**”两者之间有所取舍,尽量保持平衡,谁也不碍着谁。
+
+我们知道,HashMap 是通过拉链法来解决哈希冲突的。
+
+为了减少哈希冲突发生的概率,当 HashMap 的数组长度达到一个**临界值**的时候,就会触发扩容(可以点击[链接](https://mp.weixin.qq.com/s/0KSpdBJMfXSVH63XadVdmw)查看 HashMap 的扩容机制),扩容后会将之前小数组中的元素转移到大数组中,这是一个相当耗时的操作。
+
+这个临界值由什么来确定呢?
+
+>临界值 = 初始容量 * 加载因子
+
+一开始,HashMap 的容量是 16:
+
+```java
+static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
+```
+
+加载因子是 0.75:
+
+```java
+static final float DEFAULT_LOAD_FACTOR = 0.75f;
+```
+
+也就是说,当 16*0.75=12 时,会触发扩容机制。
+
+为什么加载因子会选择 0.75 呢?为什么不是0.8、0.6呢?
+
+这跟统计学里的一个很重要的原理——泊松分布有关。
+
+是时候上维基百科了:
+
+>泊松分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松在1838年时提出。它会对随机事件的发生次数进行建模,适用于涉及计算在给定的时间段、距离、面积等范围内发生随机事件的次数的应用情形。
+
+阮一峰老师曾在一篇博文中详细的介绍了泊松分布和指数分布,大家可以去看一下。
+
+>链接:https://www.ruanyifeng.com/blog/2015/06/poisson-distribution.html
+
+具体是用这么一个公式来表示的。
+
+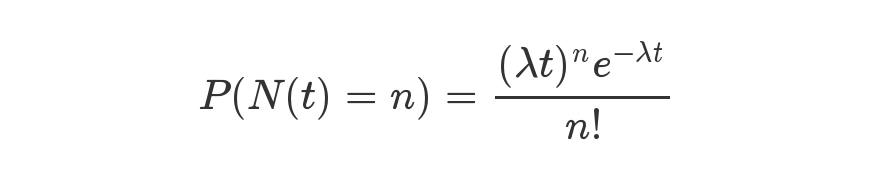
+
+等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量。
+
+在 HashMap 的 doc 文档里,曾有这么一段描述:
+
+```
+Because TreeNodes are about twice the size of regular nodes, we
+use them only when bins contain enough nodes to warrant use
+(see TREEIFY_THRESHOLD). And when they become too small (due to
+removal or resizing) they are converted back to plain bins. In
+usages with well-distributed user hashCodes, tree bins are
+rarely used. Ideally, under random hashCodes, the frequency of
+nodes in bins follows a Poisson distribution
+(http://en.wikipedia.org/wiki/Poisson_distribution) with a
+parameter of about 0.5 on average for the default resizing
+threshold of 0.75, although with a large variance because of
+resizing granularity. Ignoring variance, the expected
+occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
+factorial(k)). The first values are:
+0: 0.60653066
+1: 0.30326533
+2: 0.07581633
+3: 0.01263606
+4: 0.00157952
+5: 0.00015795
+6: 0.00001316
+7: 0.00000094
+8: 0.00000006
+more: less than 1 in ten million
+```
+
+大致的意思就是:
+
+因为 TreeNode(红黑树)的大小约为链表节点的两倍,所以我们只有在一个拉链已经拉了足够节点的时候才会转为tree(参考TREEIFY_THRESHOLD)。并且,当这个hash桶的节点因为移除或者扩容后resize数量变小的时候,我们会将树再转为拉链。如果一个用户的数据的hashcode值分布得很均匀的话,就会很少使用到红黑树。
+
+理想情况下,我们使用随机的hashcode值,加载因子为0.75情况,尽管由于粒度调整会产生较大的方差,节点的分布频率仍然会服从参数为0.5的泊松分布。链表的长度为 8 发生的概率仅有 0.00000006。
+
+虽然这段话的本意更多的是表示 jdk 8中为什么拉链长度超过8的时候进行了红黑树转换,但提到了 0.75 这个加载因子——但这并不是为什么加载因子是 0.75 的答案。
+
+为了搞清楚到底为什么,我看到了这篇文章:
+
+>参考链接:https://segmentfault.com/a/1190000023308658
+
+里面提到了一个概念:**二项分布**(二哥概率论没学好,只能简单说一说)。
+
+在做一件事情的时候,其结果的概率只有2种情况,和抛硬币一样,不是正面就是反面。
+
+为此,我们做了 N 次实验,那么在每次试验中只有两种可能的结果,并且每次实验是独立的,不同实验之间互不影响,每次实验成功的概率都是一样的。
+
+以此理论为基础,我们来做这样的实验:我们往哈希表中扔数据,如果发生哈希冲突就为失败,否则为成功。
+
+我们可以设想,实验的hash值是随机的,并且经过hash运算的键都会映射到hash表的地址空间上,那么这个结果也是随机的。所以,每次put的时候就相当于我们在扔一个16面(我们先假设默认长度为16)的骰子,扔骰子实验那肯定是相互独立的。碰撞发生即扔了n次有出现重复数字。
+
+然后,我们的目的是啥呢?
+
+就是掷了k次骰子,没有一次是相同的概率,需要尽可能的大些,一般意义上我们肯定要大于0.5(这个数是个理想数,但是我是能接受的)。
+
+于是,n次事件里面,碰撞为0的概率,由上面公式得:
+
+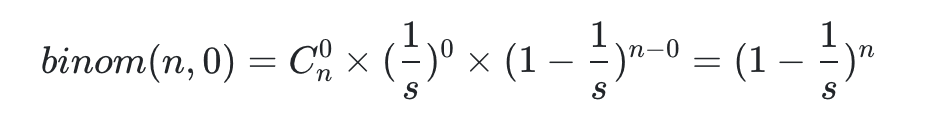
+
+这个概率值需要大于0.5,我们认为这样的hashmap可以提供很低的碰撞率。所以:
+
+
+
+这时候,我们对于该公式其实最想求的时候长度s的时候,n为多少次就应该进行扩容了?而负载因子则是$n/s$的值。所以推导如下:
+
+
+
+所以可以得到
+
+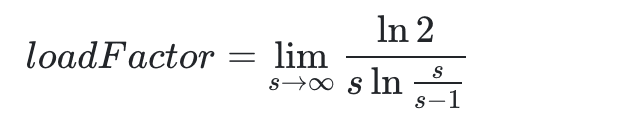
+
+其中
+
+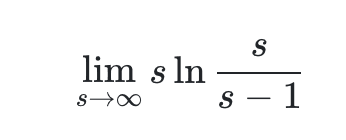
+
+这就是一个求 `∞⋅0`函数极限问题,这里我们先令$s = m+1(m \to \infty)$则转化为
+
+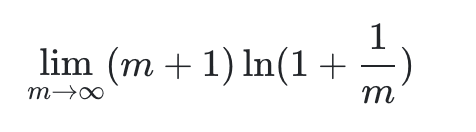
+
+我们再令 $x = \frac{1}{m} (x \to 0)$ 则有,
+
+
+
+所以,
+
+
+
+
+考虑到 HashMap的容量有一个要求:它必须是2的n 次幂(这个[之前的文章](https://mp.weixin.qq.com/s/aS2dg4Dj1Efwujmv-6YTBg)讲过了,点击链接回去可以再温故一下)。当加载因子选择了0.75就可以保证它与容量的乘积为整数。
+
+```
+16*0.75=12
+32*0.75=24
+```
+
+除了 0.75,0.5~1 之间还有 0.625(5/8)、0.875(7/8)可选,从中位数的角度,挑 0.75 比较完美。另外,维基百科上说,拉链法(解决哈希冲突的一种)的加载因子最好限制在 0.7-0.8以下,超过0.8,查表时的CPU缓存不命中(cache missing)会按照指数曲线上升。
+
+综上,0.75 是个比较完美的选择。
+
+## 四、线程不安全
+
+三方面原因:多线程下扩容会死循环、多线程下 put 会导致元素丢失、put 和 get 并发时会导致 get 到 null,我们来一一分析。
+
+### 01、多线程下扩容会死循环
+
+众所周知,HashMap 是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来。
+
+JDK 7 时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面(同一位置上的新元素被放在链表的头部)。扩容的时候就有可能导致出现环形链表,造成死循环。
+
+resize 方法的源码:
+
+```java
+// newCapacity为新的容量
+void resize(int newCapacity) {
+ // 小数组,临时过度下
+ Entry[] oldTable = table;
+ // 扩容前的容量
+ int oldCapacity = oldTable.length;
+ // MAXIMUM_CAPACITY 为最大容量,2 的 30 次方 = 1<<30
+ if (oldCapacity == MAXIMUM_CAPACITY) {
+ // 容量调整为 Integer 的最大值 0x7fffffff(十六进制)=2 的 31 次方-1
+ threshold = Integer.MAX_VALUE;
+ return;
+ }
+
+ // 初始化一个新的数组(大容量)
+ Entry[] newTable = new Entry[newCapacity];
+ // 把小数组的元素转移到大数组中
+ transfer(newTable, initHashSeedAsNeeded(newCapacity));
+ // 引用新的大数组
+ table = newTable;
+ // 重新计算阈值
+ threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
+}
+```
+
+transfer 方法用来转移,将小数组的元素拷贝到新的数组中。
+
+```java
+void transfer(Entry[] newTable, boolean rehash) {
+ // 新的容量
+ int newCapacity = newTable.length;
+ // 遍历小数组
+ for (Entry e : table) {
+ while(null != e) {
+ // 拉链法,相同 key 上的不同值
+ Entry next = e.next;
+ // 是否需要重新计算 hash
+ if (rehash) {
+ e.hash = null == e.key ? 0 : hash(e.key);
+ }
+ // 根据大数组的容量,和键的 hash 计算元素在数组中的下标
+ int i = indexFor(e.hash, newCapacity);
+
+ // 同一位置上的新元素被放在链表的头部
+ e.next = newTable[i];
+
+ // 放在新的数组上
+ newTable[i] = e;
+
+ // 链表上的下一个元素
+ e = next;
+ }
+ }
+}
+```
+
+注意 `e.next = newTable[i]` 和 `newTable[i] = e` 这两行代码,就会将同一位置上的新元素被放在链表的头部。
+
+扩容前的样子假如是下面这样子。
+
+
+
+那么正常扩容后就是下面这样子。
+
+
+
+假设现在有两个线程同时进行扩容,线程 A 在执行到 `newTable[i] = e;` 被挂起,此时线程 A 中:e=3、next=7、e.next=null
+
+
+
+
+线程 B 开始执行,并且完成了数据转移。
+
+
+
+
+此时,7 的 next 为 3,3 的 next 为 null。
+
+随后线程A获得CPU时间片继续执行 `newTable[i] = e`,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
+
+
+
+执行下一轮循环,此时 e=7,原本线程 A 中 7 的 next 为 5,但由于 table 是线程 A 和线程 B 共享的,而线程 B 顺利执行完后,7 的 next 变成了 3,那么此时线程 A 中,7 的 next 也为 3 了。
+
+采用头部插入的方式,变成了下面这样子:
+
+
+
+好像也没什么问题,此时 next = 3,e = 3。
+
+进行下一轮循环,但此时,由于线程 B 将 3 的 next 变为了 null,所以此轮循环应该是最后一轮了。
+
+接下来当执行完 `e.next=newTable[i]` 即 3.next=7 后,3 和 7 之间就相互链接了,执行完 `newTable[i]=e` 后,3 被头插法重新插入到链表中,执行结果如下图所示:
+
+
+
+套娃开始,元素 5 也就成了弃婴,惨~~~
+
+不过,JDK 8 时已经修复了这个问题,扩容时会保持链表原来的顺序,参照[HashMap 扩容机制](https://mp.weixin.qq.com/s/0KSpdBJMfXSVH63XadVdmw)的这一篇。
+
+### 02、多线程下 put 会导致元素丢失
+
+正常情况下,当发生哈希冲突时,HashMap 是这样的:
+
+
+
+但多线程同时执行 put 操作时,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。
+
+put 的源码:
+
+```java
+final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
+ boolean evict) {
+ Node[] tab; Node p; int n, i;
+
+ // 步骤①:tab为空则创建
+ if ((tab = table) == null || (n = tab.length) == 0)
+ n = (tab = resize()).length;
+
+ // 步骤②:计算index,并对null做处理
+ if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+ else {
+ Node e; K k;
+
+ // 步骤③:节点key存在,直接覆盖value
+ if (p.hash == hash &&
+ ((k = p.key) == key || (key != null && key.equals(k))))
+ e = p;
+
+ // 步骤④:判断该链为红黑树
+ else if (p instanceof TreeNode)
+ e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
+
+ // 步骤⑤:该链为链表
+ else {
+ for (int binCount = 0; ; ++binCount) {
+ if ((e = p.next) == null) {
+ p.next = newNode(hash, key, value, null);
+
+ //链表长度大于8转换为红黑树进行处理
+ if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
+ treeifyBin(tab, hash);
+ break;
+ }
+
+ // key已经存在直接覆盖value
+ if (e.hash == hash &&
+ ((k = e.key) == key || (key != null && key.equals(k))))
+ break;
+ p = e;
+ }
+ }
+
+ // 步骤⑥、直接覆盖
+ if (e != null) { // existing mapping for key
+ V oldValue = e.value;
+ if (!onlyIfAbsent || oldValue == null)
+ e.value = value;
+ afterNodeAccess(e);
+ return oldValue;
+ }
+ }
+ ++modCount;
+
+ // 步骤⑦:超过最大容量 就扩容
+ if (++size > threshold)
+ resize();
+ afterNodeInsertion(evict);
+ return null;
+}
+```
+
+问题发生在步骤 ② 这里:
+
+```java
+if ((p = tab[i = (n - 1) & hash]) == null)
+ tab[i] = newNode(hash, key, value, null);
+```
+
+两个线程都执行了 if 语句,假设线程 A 先执行了 ` tab[i] = newNode(hash, key, value, null)`,那 table 是这样的:
+
+
+
+接着,线程 B 执行了 ` tab[i] = newNode(hash, key, value, null)`,那 table 是这样的:
+
+
+
+3 被干掉了。
+
+### 03、put 和 get 并发时会导致 get 到 null
+
+线程 A 执行put时,因为元素个数超出阈值而出现扩容,线程B 此时执行get,有可能导致这个问题。
+
+注意来看 resize 源码:
+
+```java
+final Node[] resize() {
+ Node[] oldTab = table;
+ int oldCap = (oldTab == null) ? 0 : oldTab.length;
+ int oldThr = threshold;
+ int newCap, newThr = 0;
+ if (oldCap > 0) {
+ // 超过最大值就不再扩充了,就只好随你碰撞去吧
+ if (oldCap >= MAXIMUM_CAPACITY) {
+ threshold = Integer.MAX_VALUE;
+ return oldTab;
+ }
+ // 没超过最大值,就扩充为原来的2倍
+ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
+ oldCap >= DEFAULT_INITIAL_CAPACITY)
+ newThr = oldThr << 1; // double threshold
+ }
+ else if (oldThr > 0) // initial capacity was placed in threshold
+ newCap = oldThr;
+ else { // zero initial threshold signifies using defaults
+ newCap = DEFAULT_INITIAL_CAPACITY;
+ newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
+ }
+ // 计算新的resize上限
+ if (newThr == 0) {
+ float ft = (float)newCap * loadFactor;
+ newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
+ (int)ft : Integer.MAX_VALUE);
+ }
+ threshold = newThr;
+ @SuppressWarnings({"rawtypes","unchecked"})
+ Node[] newTab = (Node[])new Node[newCap];
+ table = newTab;
+}
+```
+
+线程 A 执行完 `table = newTab` 之后,线程 B 中的 table 此时也发生了变化,此时去 get 的时候当然会 get 到 null 了,因为元素还没有转移。
+
+参考链接:
+
+> - https://blog.csdn.net/lonyw/article/details/80519652
+> - https://zhuanlan.zhihu.com/p/91636401
+> - https://www.zhihu.com/question/20733617
+> - https://zhuanlan.zhihu.com/p/21673805
+
+
\ No newline at end of file
diff --git a/docs/collection/iterator-iterable.md b/docs/collection/iterator-iterable.md
new file mode 100644
index 0000000000..9bdcf7f410
--- /dev/null
+++ b/docs/collection/iterator-iterable.md
@@ -0,0 +1,247 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java中的Iterator和Iterable区别
+
+
+那天,小二去海康威视面试,面试官老王一上来就甩给了他一道面试题:请问 Iterator与Iterable有什么区别?
+
+-----
+
+在 Java 中,我们对 List 进行遍历的时候,主要有这么三种方式。
+
+第一种:for 循环。
+
+```java
+for (int i = 0; i < list.size(); i++) {
+ System.out.print(list.get(i) + ",");
+}
+```
+
+第二种:迭代器。
+
+```java
+Iterator it = list.iterator();
+while (it.hasNext()) {
+ System.out.print(it.next() + ",");
+}
+```
+
+第三种:for-each。
+
+```java
+for (String str : list) {
+ System.out.print(str + ",");
+}
+```
+
+第一种我们略过,第二种用的是 Iterator,第三种看起来是 for-each,其实背后也是 Iterator,看一下反编译后的代码就明白了。
+
+```java
+Iterator var3 = list.iterator();
+
+while(var3.hasNext()) {
+ String str = (String)var3.next();
+ System.out.print(str + ",");
+}
+```
+
+for-each 只不过是个语法糖,让我们在遍历 List 的时候代码更简洁明了。
+
+Iterator 是个接口,JDK 1.2 的时候就有了,用来改进 Enumeration:
+
+- 允许删除元素(增加了 remove 方法)
+- 优化了方法名(Enumeration 中是 hasMoreElements 和 nextElement,不简洁)
+
+来看一下 Iterator 的源码:
+
+```java
+public interface Iterator {
+ // 判断集合中是否存在下一个对象
+ boolean hasNext();
+ // 返回集合中的下一个对象,并将访问指针移动一位
+ E next();
+ // 删除集合中调用next()方法返回的对象
+ default void remove() {
+ throw new UnsupportedOperationException("remove");
+ }
+}
+```
+
+JDK 1.8 时,Iterable 接口中新增了 forEach 方法:
+
+```java
+default void forEach(Consumer action) {
+ Objects.requireNonNull(action);
+ for (T t : this) {
+ action.accept(t);
+ }
+}
+```
+
+它对 Iterable 的每个元素执行给定操作,具体指定的操作需要自己写Consumer接口通过accept方法回调出来。
+
+```java
+List list = new ArrayList<>(Arrays.asList(1, 2, 3));
+list.forEach(integer -> System.out.println(integer));
+```
+
+写得更浅显易懂点,就是:
+
+```java
+List list = new ArrayList<>(Arrays.asList(1, 2, 3));
+list.forEach(new Consumer() {
+ @Override
+ public void accept(Integer integer) {
+ System.out.println(integer);
+ }
+});
+```
+
+如果我们仔细观察ArrayList 或者 LinkedList 的“户口本”就会发现,并没有直接找到 Iterator 的影子。
+
+
+
+反而找到了 Iterable!
+
+```java
+public interface Iterable {
+ Iterator iterator();
+}
+```
+
+也就是说,List 的关系图谱中并没有直接使用 Iterator,而是使用 Iterable 做了过渡。
+
+回头再来看一下第二种遍历 List 的方式。
+
+```java
+Iterator it = list.iterator();
+while (it.hasNext()) {
+}
+```
+
+发现刚好呼应上了。拿 ArrayList 来说吧,它重写了 Iterable 接口的 iterator 方法:
+
+```java
+public Iterator iterator() {
+ return new Itr();
+}
+```
+
+返回的对象 Itr 是个内部类,实现了 Iterator 接口,并且按照自己的方式重写了 hasNext、next、remove 等方法。
+
+```java
+private class Itr implements Iterator {
+
+ public boolean hasNext() {
+ return cursor != size;
+ }
+
+ @SuppressWarnings("unchecked")
+ public E next() {
+ Object[] elementData = ArrayList.this.elementData;
+ cursor = i + 1;
+ return (E) elementData[lastRet = i];
+ }
+
+ public void remove() {
+ try {
+ ArrayList.this.remove(lastRet);
+ cursor = lastRet;
+ lastRet = -1;
+ expectedModCount = modCount;
+ } catch (IndexOutOfBoundsException ex) {
+ throw new ConcurrentModificationException();
+ }
+ }
+
+}
+```
+
+那可能有些小伙伴会问:为什么不直接将 Iterator 中的核心方法 hasNext、next 放到 Iterable 接口中呢?直接像下面这样使用不是更方便?
+
+```java
+Iterable it = list.iterator();
+while (it.hasNext()) {
+}
+```
+
+从英文单词的后缀语法上来看,(Iterable)able 表示这个 List 是支持迭代的,而 (Iterator)tor 表示这个 List 是如何迭代的。
+
+支持迭代与具体怎么迭代显然不能混在一起,否则就乱的一笔。还是各司其职的好。
+
+想一下,如果把 Iterator 和 Iterable 合并,for-each 这种遍历 List 的方式是不是就不好办了?
+
+原则上,只要一个 List 实现了 Iterable 接口,那么它就可以使用 for-each 这种方式来遍历,那具体该怎么遍历,还是要看它自己是怎么实现 Iterator 接口的。
+
+Map 就没办法直接使用 for-each,因为 Map 没有实现 Iterable 接口,只有通过 `map.entrySet()`、`map.keySet()`、`map.values()` 这种返回一个 Collection 的方式才能 使用 for-each。
+
+如果我们仔细研究 LinkedList 的源码就会发现,LinkedList 并没有直接重写 Iterable 接口的 iterator 方法,而是由它的父类 AbstractSequentialList 来完成。
+
+```java
+public Iterator iterator() {
+ return listIterator();
+}
+```
+
+LinkedList 重写了 listIterator 方法:
+
+```java
+public ListIterator listIterator(int index) {
+ checkPositionIndex(index);
+ return new ListItr(index);
+}
+```
+
+这里我们发现了一个新的迭代器 ListIterator,它继承了 Iterator 接口,在遍历List 时可以从任意下标开始遍历,而且支持双向遍历。
+
+```java
+public interface ListIterator extends Iterator {
+ boolean hasNext();
+ E next();
+ boolean hasPrevious();
+ E previous();
+}
+```
+
+我们知道,集合(Collection)不仅有 List,还有 Map 和 Set,那 Iterator 不仅支持 List,还支持 Set,但 ListIterator 就只支持 List。
+
+那可能有些小伙伴会问:为什么不直接让 List 实现 Iterator 接口,而是要用内部类来实现呢?
+
+这是因为有些 List 可能会有多种遍历方式,比如说 LinkedList,除了支持正序的遍历方式,还支持逆序的遍历方式——DescendingIterator:
+
+```java
+private class DescendingIterator implements Iterator {
+ private final ListItr itr = new ListItr(size());
+ public boolean hasNext() {
+ return itr.hasPrevious();
+ }
+ public E next() {
+ return itr.previous();
+ }
+ public void remove() {
+ itr.remove();
+ }
+}
+```
+
+可以看得到,DescendingIterator 刚好利用了 ListIterator 向前遍历的方式。可以通过以下的方式来使用:
+
+```java
+Iterator it = list.descendingIterator();
+while (it.hasNext()) {
+}
+```
+-----
+
+好了,关于Iterator与Iterable我们就先聊这么多,总结两点:
+
+- 学会深入思考,一点点抽丝剥茧,多想想为什么这样实现,很多问题没有自己想象中的那么复杂。
+- 遇到疑惑不放弃,这是提升自己最好的机会,遇到某个疑难的点,解决的过程中会挖掘出很多相关的东西。
+
+
+
\ No newline at end of file
diff --git a/docs/collection/linkedlist.md b/docs/collection/linkedlist.md
new file mode 100644
index 0000000000..5375b09fad
--- /dev/null
+++ b/docs/collection/linkedlist.md
@@ -0,0 +1,387 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java集合LinkedList详解
+
+
+### 一、LinkedList 的剖白
+
+大家好,我是 LinkedList,和 ArrayList 是同门师兄弟,但我俩练的内功却完全不同。师兄练的是动态数组,我练的是链表。
+
+问大家一个问题,知道我为什么要练链表这门内功吗?
+
+举个例子来讲吧,假如你们手头要管理一推票据,可能有一张,也可能有一亿张。
+
+该怎么办呢?
+
+申请一个 10G 的大数组等着?那万一票据只有 100 张呢?
+
+申请一个默认大小的数组,随着数据量的增大扩容?要知道扩容是需要重新复制数组的,很耗时间。
+
+关键是,数组还有一个弊端就是,假如现在有 500 万张票据,现在要从中间删除一个票据,就需要把 250 万张票据往前移动一格。
+
+遇到这种情况的时候,我师兄几乎情绪崩溃,难受的要命。师父不忍心看到师兄这样痛苦,于是打我进入师门那一天,就强迫我练链表这门内功,一开始我很不理解,害怕师父偏心,不把师门最厉害的内功教我。
+
+直到有一天,我亲眼目睹师兄差点因为移动数据而走火入魔,我才明白师父的良苦用心。从此以后,我苦练“链表”这门内功,取得了显著的进步,师父和师兄都夸我有天赋。
+
+链表这门内功大致分为三个层次:
+
+- 第一层叫做“单向链表”,我只有一个后指针,指向下一个数据;
+- 第二层叫做“双向链表”,我有两个指针,后指针指向下一个数据,前指针指向上一个数据。
+- 第三层叫做“二叉树”,把后指针去掉,换成左右指针。
+
+但我现在的功力还达不到第三层,不过师父说我有这个潜力,练成神功是早晚的事。
+
+### 二、LinkedList 的内功心法
+
+好了,经过我这么样的一个剖白后,大家对我应该已经不陌生了。那么接下来,我给大家展示一下我的内功心法。
+
+我的内功心法主要是一个私有的静态内部类,叫 Node,也就是节点。
+
+```java
+private static class Node {
+ E item;
+ Node next;
+ Node prev;
+
+ Node(Node prev, E element, Node next) {
+ this.item = element;
+ this.next = next;
+ this.prev = prev;
+ }
+}
+```
+
+它由三部分组成:
+
+- 节点上的元素
+- 下一个节点
+- 上一个节点
+
+我画幅图给你们展示下吧。
+
+
+
+- 对于第一个节点来说,prev 为 null;
+- 对于最后一个节点来说,next 为 null;
+- 其余的节点呢,prev 指向前一个,next 指向后一个。
+
+我的内功心法就这么简单,其实我早已经牢记在心了。但师父叮嘱我,每天早上醒来的时候,每天晚上睡觉的时候,一定要默默地背诵一遍。虽然我有些厌烦,但我对师父的教诲从来都是言听计从。
+
+### 03、LinkedList 的招式
+
+和师兄 ArrayList 一样,我的招式也无外乎“增删改查”这 4 种。在此之前,我们都必须得初始化。
+
+```java
+LinkedList list = new LinkedList();
+```
+
+师兄在初始化的时候,默认大小为 10,也可以指定大小,依据要存储的元素数量来。我就不需要。
+
+**1)招式一:增**
+
+可以调用 add 方法添加元素:
+
+```java
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("沉默王四");
+```
+
+add 方法内部其实调用的是 linkLast 方法:
+
+```java
+public boolean add(E e) {
+ linkLast(e);
+ return true;
+}
+```
+
+linkLast,顾名思义,就是在链表的尾部链接:
+
+```java
+void linkLast(E e) {
+ final Node l = last;
+ final Node newNode = new Node<>(l, e, null);
+ last = newNode;
+ if (l == null)
+ first = newNode;
+ else
+ l.next = newNode;
+ size++;
+ modCount++;
+}
+```
+
+- 添加第一个元素的时候,first 和 last 都为 null。
+- 然后新建一个节点 newNode,它的 prev 和 next 也为 null。
+- 然后把 last 和 first 都赋值为 newNode。
+
+此时还不能称之为链表,因为前后节点都是断裂的。
+
+
+
+- 添加第二个元素的时候,first 和 last 都指向的是第一个节点。
+- 然后新建一个节点 newNode,它的 prev 指向的是第一个节点,next 为 null。
+- 然后把第一个节点的 next 赋值为 newNode。
+
+此时的链表还不完整。
+
+
+
+- 添加第三个元素的时候,first 指向的是第一个节点,last 指向的是最后一个节点。
+- 然后新建一个节点 newNode,它的 prev 指向的是第二个节点,next 为 null。
+- 然后把第二个节点的 next 赋值为 newNode。
+
+此时的链表已经完整了。
+
+
+
+我这个增的招式,还可以演化成另外两个:
+
+- `addFirst()` 方法将元素添加到第一位;
+- `addLast()` 方法将元素添加到末尾。
+
+addFirst 内部其实调用的是 linkFirst:
+
+```java
+public void addFirst(E e) {
+ linkFirst(e);
+}
+```
+
+linkFirst 负责把新的节点设为 first,并将新的 first 的 next 更新为之前的 first。
+
+```java
+private void linkFirst(E e) {
+ final Node f = first;
+ final Node newNode = new Node<>(null, e, f);
+ first = newNode;
+ if (f == null)
+ last = newNode;
+ else
+ f.prev = newNode;
+ size++;
+ modCount++;
+}
+```
+
+addLast 的内核其实和 addFirst 差不多,就交给大家自行理解了。
+
+
+**2)招式二:删**
+
+我这个删的招式还挺多的:
+
+- `remove()`:删除第一个节点
+- `remove(int)`:删除指定位置的节点
+- `remove(Object)`:删除指定元素的节点
+- `removeFirst()`:删除第一个节点
+- `removeLast()`:删除最后一个节点
+
+remove 内部调用的是 removeFirst,所以这两个招式的功效一样。
+
+`remove(int)` 内部其实调用的是 unlink 方法。
+
+```java
+public E remove(int index) {
+ checkElementIndex(index);
+ return unlink(node(index));
+}
+```
+
+unlink 方法其实很好理解,就是更新当前节点的 next 和 prev,然后把当前节点上的元素设为 null。
+
+```java
+E unlink(Node x) {
+ // assert x != null;
+ final E element = x.item;
+ final Node next = x.next;
+ final Node prev = x.prev;
+
+ if (prev == null) {
+ first = next;
+ } else {
+ prev.next = next;
+ x.prev = null;
+ }
+
+ if (next == null) {
+ last = prev;
+ } else {
+ next.prev = prev;
+ x.next = null;
+ }
+
+ x.item = null;
+ size--;
+ modCount++;
+ return element;
+}
+```
+
+remove(Object) 内部也调用了 unlink 方法,只不过在此之前要先找到元素所在的节点:
+
+```java
+public boolean remove(Object o) {
+ if (o == null) {
+ for (Node x = first; x != null; x = x.next) {
+ if (x.item == null) {
+ unlink(x);
+ return true;
+ }
+ }
+ } else {
+ for (Node x = first; x != null; x = x.next) {
+ if (o.equals(x.item)) {
+ unlink(x);
+ return true;
+ }
+ }
+ }
+ return false;
+}
+```
+
+这内部就分为两种,一种是元素为 null 的时候,必须使用 == 来判断;一种是元素为非 null 的时候,要使用 equals 来判断。equals 是不能用来判 null 的,会抛出 NPE 错误。
+
+removeFirst 内部调用的是 unlinkFirst 方法:
+
+```java
+public E removeFirst() {
+ final Node f = first;
+ if (f == null)
+ throw new NoSuchElementException();
+ return unlinkFirst(f);
+}
+```
+
+unlinkFirst 负责的就是把第一个节点毁尸灭迹,并且捎带把后一个节点的 prev 设为 null。
+
+```java
+private E unlinkFirst(Node f) {
+ // assert f == first && f != null;
+ final E element = f.item;
+ final Node next = f.next;
+ f.item = null;
+ f.next = null; // help GC
+ first = next;
+ if (next == null)
+ last = null;
+ else
+ next.prev = null;
+ size--;
+ modCount++;
+ return element;
+}
+```
+
+**3)招式三:改**
+
+可以调用 `set()` 方法来更新元素:
+
+```java
+list.set(0, "沉默王五");
+```
+
+来看一下 `set()` 方法:
+
+```java
+public E set(int index, E element) {
+ checkElementIndex(index);
+ Node x = node(index);
+ E oldVal = x.item;
+ x.item = element;
+ return oldVal;
+}
+```
+
+首先对指定的下标进行检查,看是否越界;然后根据下标查找原有的节点:
+
+```java
+Node node(int index) {
+ // assert isElementIndex(index);
+
+ if (index < (size >> 1)) {
+ Node x = first;
+ for (int i = 0; i < index; i++)
+ x = x.next;
+ return x;
+ } else {
+ Node x = last;
+ for (int i = size - 1; i > index; i--)
+ x = x.prev;
+ return x;
+ }
+}
+```
+
+`size >> 1`:也就是右移一位,相当于除以 2。对于计算机来说,移位比除法运算效率更高,因为数据在计算机内部都是二进制存储的。
+
+换句话说,node 方法会对下标进行一个初步判断,如果靠近前半截,就从下标 0 开始遍历;如果靠近后半截,就从末尾开始遍历。
+
+找到指定下标的节点就简单了,直接把原有节点的元素替换成新的节点就 OK 了,prev 和 next 都不用改动。
+
+**4)招式四:查**
+
+我这个查的招式可以分为两种:
+
+- indexOf(Object):查找某个元素所在的位置
+- get(int):查找某个位置上的元素
+
+indexOf 的内部分为两种,一种是元素为 null 的时候,必须使用 == 来判断;一种是元素为非 null 的时候,要使用 equals 来判断。因为 equals 是不能用来判 null 的,会抛出 NPE 错误。
+
+```java
+public int indexOf(Object o) {
+ int index = 0;
+ if (o == null) {
+ for (Node x = first; x != null; x = x.next) {
+ if (x.item == null)
+ return index;
+ index++;
+ }
+ } else {
+ for (Node x = first; x != null; x = x.next) {
+ if (o.equals(x.item))
+ return index;
+ index++;
+ }
+ }
+ return -1;
+}
+```
+
+get 方法的内核其实还是 node 方法,这个之前已经说明过了,这里略过。
+
+```java
+public E get(int index) {
+ checkElementIndex(index);
+ return node(index).item;
+}
+```
+
+其实,查这个招式还可以演化为其他的一些,比如说:
+
+- `getFirst()` 方法用于获取第一个元素;
+- `getLast()` 方法用于获取最后一个元素;
+- `poll()` 和 `pollFirst()` 方法用于删除并返回第一个元素(两个方法尽管名字不同,但方法体是完全相同的);
+- `pollLast()` 方法用于删除并返回最后一个元素;
+- `peekFirst()` 方法用于返回但不删除第一个元素。
+
+### 四、LinkedList 的挑战
+
+说句实在话,我不是很喜欢和师兄 ArrayList 拿来比较,因为我们各自修炼的内功不同,没有孰高孰低。
+
+虽然师兄经常喊我一声师弟,但我们之间其实挺和谐的。但我知道,在外人眼里,同门师兄弟,总要一较高下的。
+
+比如说,我们俩在增删改查时候的时间复杂度。
+
+也许这就是命运吧,从我进入师门的那天起,这种争论就一直没有停息过。
+
+无论外人怎么看待我们,在我眼里,师兄永远都是一哥,我敬重他,他也愿意保护我。
+
+
\ No newline at end of file
diff --git a/docs/collection/list-war-2.md b/docs/collection/list-war-2.md
new file mode 100644
index 0000000000..9f97795431
--- /dev/null
+++ b/docs/collection/list-war-2.md
@@ -0,0 +1,844 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java中ArrayList和LinkedList的区别
+
+
+### 01、ArrayList 是如何实现的?
+
+ArrayList 实现了 List 接口,继承了 AbstractList 抽象类。
+
+
+
+底层是基于数组实现的,并且实现了动态扩容
+
+
+```java
+public class ArrayList extends AbstractList
+ implements List, RandomAccess, Cloneable, java.io.Serializable
+{
+ private static final int DEFAULT_CAPACITY = 10;
+ transient Object[] elementData;
+ private int size;
+}
+```
+
+ArrayList 还实现了 RandomAccess 接口,这是一个标记接口:
+
+```java
+public interface RandomAccess {
+}
+```
+
+内部是空的,标记“实现了这个接口的类支持快速(通常是固定时间)随机访问”。快速随机访问是什么意思呢?就是说不需要遍历,就可以通过下标(索引)直接访问到内存地址。
+
+```java
+public E get(int index) {
+ Objects.checkIndex(index, size);
+ return elementData(index);
+}
+E elementData(int index) {
+ return (E) elementData[index];
+}
+```
+
+ArrayList 还实现了 Cloneable 接口,这表明 ArrayList 是支持拷贝的。ArrayList 内部的确也重写了 Object 类的 `clone()` 方法。
+
+```java
+public Object clone() {
+ try {
+ ArrayList v = (ArrayList) super.clone();
+ v.elementData = Arrays.copyOf(elementData, size);
+ v.modCount = 0;
+ return v;
+ } catch (CloneNotSupportedException e) {
+ // this shouldn't happen, since we are Cloneable
+ throw new InternalError(e);
+ }
+}
+```
+
+ArrayList 还实现了 Serializable 接口,同样是一个标记接口:
+
+```java
+public interface Serializable {
+}
+```
+
+内部也是空的,标记“实现了这个接口的类支持序列化”。序列化是什么意思呢?Java 的序列化是指,将对象转换成以字节序列的形式来表示,这些字节序中包含了对象的字段和方法。序列化后的对象可以被写到数据库、写到文件,也可用于网络传输。
+
+眼睛雪亮的小伙伴可能会注意到,ArrayList 中的关键字段 elementData 使用了 transient 关键字修饰,这个关键字的作用是,让它修饰的字段不被序列化。
+
+这不前后矛盾吗?一个类既然实现了 Serilizable 接口,肯定是想要被序列化的,对吧?那为什么保存关键数据的 elementData 又不想被序列化呢?
+
+这还得从 “ArrayList 是基于数组实现的”开始说起。大家都知道,数组是定长的,就是说,数组一旦声明了,长度(容量)就是固定的,不能像某些东西一样伸缩自如。这就很麻烦,数组一旦装满了,就不能添加新的元素进来了。
+
+ArrayList 不想像数组这样活着,它想能屈能伸,所以它实现了动态扩容。一旦在添加元素的时候,发现容量用满了 `s == elementData.length`,就按照原来数组的 1.5 倍(`oldCapacity >> 1`)进行扩容。扩容之后,再将原有的数组复制到新分配的内存地址上 `Arrays.copyOf(elementData, newCapacity)`。
+
+```java
+private void add(E e, Object[] elementData, int s) {
+ if (s == elementData.length)
+ elementData = grow();
+ elementData[s] = e;
+ size = s + 1;
+}
+
+private Object[] grow() {
+ return grow(size + 1);
+}
+
+private Object[] grow(int minCapacity) {
+ int oldCapacity = elementData.length;
+ if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
+ int newCapacity = ArraysSupport.newLength(oldCapacity,
+ minCapacity - oldCapacity, /* minimum growth */
+ oldCapacity >> 1 /* preferred growth */);
+ return elementData = Arrays.copyOf(elementData, newCapacity);
+ } else {
+ return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
+ }
+}
+```
+
+动态扩容意味着什么?大家伙想一下。嗯,还是我来告诉大家答案吧,有点迫不及待。
+
+意味着数组的实际大小可能永远无法被填满的,总有多余出来空置的内存空间。
+
+比如说,默认的数组大小是 10,当添加第 11 个元素的时候,数组的长度扩容了 1.5 倍,也就是 15,意味着还有 4 个内存空间是闲置的,对吧?
+
+序列化的时候,如果把整个数组都序列化的话,是不是就多序列化了 4 个内存空间。当存储的元素数量非常非常多的时候,闲置的空间就非常非常大,序列化耗费的时间就会非常非常多。
+
+于是,ArrayList 做了一个愉快而又聪明的决定,内部提供了两个私有方法 writeObject 和 readObject 来完成序列化和反序列化。
+
+```java
+private void writeObject(java.io.ObjectOutputStream s)
+ throws java.io.IOException {
+ // Write out element count, and any hidden stuff
+ int expectedModCount = modCount;
+ s.defaultWriteObject();
+
+ // Write out size as capacity for behavioral compatibility with clone()
+ s.writeInt(size);
+
+ // Write out all elements in the proper order.
+ for (int i=0; i
+ extends AbstractSequentialList
+ implements List, Deque, Cloneable, java.io.Serializable
+{
+ transient int size = 0;
+ transient Node first;
+ transient Node last;
+}
+```
+
+ LinkedList 内部定义了一个 Node 节点,它包含 3 个部分:元素内容 item,前引用 prev 和后引用 next。代码如下所示:
+
+```java
+private static class Node {
+ E item;
+ LinkedList.Node next;
+ LinkedList.Node prev;
+
+ Node(LinkedList.Node prev, E element, LinkedList.Node next) {
+ this.item = element;
+ this.next = next;
+ this.prev = prev;
+ }
+}
+```
+
+LinkedList 还实现了 Cloneable 接口,这表明 LinkedList 是支持拷贝的。
+
+LinkedList 还实现了 Serializable 接口,这表明 LinkedList 是支持序列化的。眼睛雪亮的小伙伴可能又注意到了,LinkedList 中的关键字段 size、first、last 都使用了 transient 关键字修饰,这不又矛盾了吗?到底是想序列化还是不想序列化?
+
+答案是 LinkedList 想按照自己的方式序列化,来看它自己实现的 `writeObject()` 方法:
+
+```java
+private void writeObject(java.io.ObjectOutputStream s)
+ throws java.io.IOException {
+ // Write out any hidden serialization magic
+ s.defaultWriteObject();
+
+ // Write out size
+ s.writeInt(size);
+
+ // Write out all elements in the proper order.
+ for (LinkedList.Node x = first; x != null; x = x.next)
+ s.writeObject(x.item);
+}
+```
+
+发现没?LinkedList 在序列化的时候只保留了元素的内容 item,并没有保留元素的前后引用。这样就节省了不少内存空间,对吧?
+
+那有些小伙伴可能就疑惑了,只保留元素内容,不保留前后引用,那反序列化的时候怎么办?
+
+```java
+private void readObject(java.io.ObjectInputStream s)
+ throws java.io.IOException, ClassNotFoundException {
+ // Read in any hidden serialization magic
+ s.defaultReadObject();
+
+ // Read in size
+ int size = s.readInt();
+
+ // Read in all elements in the proper order.
+ for (int i = 0; i < size; i++)
+ linkLast((E)s.readObject());
+}
+
+void linkLast(E e) {
+ final LinkedList.Node l = last;
+ final LinkedList.Node newNode = new LinkedList.Node<>(l, e, null);
+ last = newNode;
+ if (l == null)
+ first = newNode;
+ else
+ l.next = newNode;
+ size++;
+ modCount++;
+}
+```
+
+注意 for 循环中的 `linkLast()` 方法,它可以把链表重新链接起来,这样就恢复了链表序列化之前的顺序。很妙,对吧?
+
+和 ArrayList 相比,LinkedList 没有实现 RandomAccess 接口,这是因为 LinkedList 存储数据的内存地址是不连续的,所以不支持随机访问。
+
+### 03、ArrayList 和 LinkedList 新增元素时究竟谁快?
+
+前面我们已经从多个维度了解了 ArrayList 和 LinkedList 的实现原理和各自的特点。那接下来,我们就来聊聊 ArrayList 和 LinkedList 在新增元素时究竟谁快?
+
+**1)ArrayList**
+
+ArrayList 新增元素有两种情况,一种是直接将元素添加到数组末尾,一种是将元素插入到指定位置。
+
+添加到数组末尾的源码:
+
+```java
+public boolean add(E e) {
+ modCount++;
+ add(e, elementData, size);
+ return true;
+}
+
+private void add(E e, Object[] elementData, int s) {
+ if (s == elementData.length)
+ elementData = grow();
+ elementData[s] = e;
+ size = s + 1;
+}
+```
+
+很简单,先判断是否需要扩容,然后直接通过索引将元素添加到末尾。
+
+插入到指定位置的源码:
+
+```java
+public void add(int index, E element) {
+ rangeCheckForAdd(index);
+ modCount++;
+ final int s;
+ Object[] elementData;
+ if ((s = size) == (elementData = this.elementData).length)
+ elementData = grow();
+ System.arraycopy(elementData, index,
+ elementData, index + 1,
+ s - index);
+ elementData[index] = element;
+ size = s + 1;
+}
+```
+
+先检查插入的位置是否在合理的范围之内,然后判断是否需要扩容,再把该位置以后的元素复制到新添加元素的位置之后,最后通过索引将元素添加到指定的位置。这种情况是非常伤的,性能会比较差。
+
+**2)LinkedList**
+
+LinkedList 新增元素也有两种情况,一种是直接将元素添加到队尾,一种是将元素插入到指定位置。
+
+添加到队尾的源码:
+
+```java
+public boolean add(E e) {
+ linkLast(e);
+ return true;
+}
+void linkLast(E e) {
+ final LinkedList.Node l = last;
+ final LinkedList.Node newNode = new LinkedList.Node<>(l, e, null);
+ last = newNode;
+ if (l == null)
+ first = newNode;
+ else
+ l.next = newNode;
+ size++;
+ modCount++;
+}
+```
+
+先将队尾的节点 last 存放到临时变量 l 中(不是说不建议使用 I 作为变量名吗?Java 的作者们明知故犯啊),然后生成新的 Node 节点,并赋给 last,如果 l 为 null,说明是第一次添加,所以 first 为新的节点;否则将新的节点赋给之前 last 的 next。
+
+插入到指定位置的源码:
+
+```java
+public void add(int index, E element) {
+ checkPositionIndex(index);
+
+ if (index == size)
+ linkLast(element);
+ else
+ linkBefore(element, node(index));
+}
+LinkedList.Node node(int index) {
+ // assert isElementIndex(index);
+
+ if (index < (size >> 1)) {
+ LinkedList.Node x = first;
+ for (int i = 0; i < index; i++)
+ x = x.next;
+ return x;
+ } else {
+ LinkedList.Node x = last;
+ for (int i = size - 1; i > index; i--)
+ x = x.prev;
+ return x;
+ }
+}
+void linkBefore(E e, LinkedList.Node succ) {
+ // assert succ != null;
+ final LinkedList.Node pred = succ.prev;
+ final LinkedList.Node newNode = new LinkedList.Node<>(pred, e, succ);
+ succ.prev = newNode;
+ if (pred == null)
+ first = newNode;
+ else
+ pred.next = newNode;
+ size++;
+ modCount++;
+}
+```
+
+先检查插入的位置是否在合理的范围之内,然后判断插入的位置是否是队尾,如果是,添加到队尾;否则执行 `linkBefore()` 方法。
+
+在执行 `linkBefore()` 方法之前,会调用 `node()` 方法查找指定位置上的元素,这一步是需要遍历 LinkedList 的。如果插入的位置靠前前半段,就从队头开始往后找;否则从队尾往前找。也就是说,如果插入的位置越靠近 LinkedList 的中间位置,遍历所花费的时间就越多。
+
+找到指定位置上的元素(succ)之后,就开始执行 `linkBefore()` 方法了,先将 succ 的前一个节点(prev)存放到临时变量 pred 中,然后生成新的 Node 节点(newNode),并将 succ 的前一个节点变更为 newNode,如果 pred 为 null,说明插入的是队头,所以 first 为新节点;否则将 pred 的后一个节点变更为 newNode。
+
+
+
+经过源码分析以后,小伙伴们是不是在想:“好像 ArrayList 在新增元素的时候效率并不一定比 LinkedList 低啊!”
+
+当两者的起始长度是一样的情况下:
+
+- 如果是从集合的头部新增元素,ArrayList 花费的时间应该比 LinkedList 多,因为需要对头部以后的元素进行复制。
+
+```java
+public class ArrayListTest {
+ public static void addFromHeaderTest(int num) {
+ ArrayList list = new ArrayList(num);
+ int i = 0;
+
+ long timeStart = System.currentTimeMillis();
+
+ while (i < num) {
+ list.add(0, i + "沉默王二");
+ i++;
+ }
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("ArrayList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+
+/**
+ * @author 微信搜「沉默王二」,回复关键字 PDF
+ */
+public class LinkedListTest {
+ public static void addFromHeaderTest(int num) {
+ LinkedList list = new LinkedList();
+ int i = 0;
+ long timeStart = System.currentTimeMillis();
+ while (i < num) {
+ list.addFirst(i + "沉默王二");
+ i++;
+ }
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("LinkedList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+```
+
+num 为 10000,代码实测后的时间如下所示:
+
+```
+ArrayList从集合头部位置新增元素花费的时间595
+LinkedList从集合头部位置新增元素花费的时间15
+```
+
+ArrayList 花费的时间比 LinkedList 要多很多。
+
+- 如果是从集合的中间位置新增元素,ArrayList 花费的时间搞不好要比 LinkedList 少,因为 LinkedList 需要遍历。
+
+```java
+public class ArrayListTest {
+ public static void addFromMidTest(int num) {
+ ArrayList list = new ArrayList(num);
+ int i = 0;
+
+ long timeStart = System.currentTimeMillis();
+ while (i < num) {
+ int temp = list.size();
+ list.add(temp / 2 + "沉默王二");
+ i++;
+ }
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("ArrayList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+
+public class LinkedListTest {
+ public static void addFromMidTest(int num) {
+ LinkedList list = new LinkedList();
+ int i = 0;
+ long timeStart = System.currentTimeMillis();
+ while (i < num) {
+ int temp = list.size();
+ list.add(temp / 2, i + "沉默王二");
+ i++;
+ }
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("LinkedList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+```
+
+num 为 10000,代码实测后的时间如下所示:
+
+```
+ArrayList从集合中间位置新增元素花费的时间1
+LinkedList从集合中间位置新增元素花费的时间101
+```
+
+ArrayList 花费的时间比 LinkedList 要少很多很多。
+
+- 如果是从集合的尾部新增元素,ArrayList 花费的时间应该比 LinkedList 少,因为数组是一段连续的内存空间,也不需要复制数组;而链表需要创建新的对象,前后引用也要重新排列。
+
+```java
+public class ArrayListTest {
+ public static void addFromTailTest(int num) {
+ ArrayList list = new ArrayList(num);
+ int i = 0;
+
+ long timeStart = System.currentTimeMillis();
+
+ while (i < num) {
+ list.add(i + "沉默王二");
+ i++;
+ }
+
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("ArrayList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+
+public class LinkedListTest {
+ public static void addFromTailTest(int num) {
+ LinkedList list = new LinkedList();
+ int i = 0;
+ long timeStart = System.currentTimeMillis();
+ while (i < num) {
+ list.add(i + "沉默王二");
+ i++;
+ }
+ long timeEnd = System.currentTimeMillis();
+
+ System.out.println("LinkedList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
+ }
+}
+```
+
+num 为 10000,代码实测后的时间如下所示:
+
+```
+ArrayList从集合尾部位置新增元素花费的时间69
+LinkedList从集合尾部位置新增元素花费的时间193
+```
+
+ArrayList 花费的时间比 LinkedList 要少一些。
+
+这样的结论和预期的是不是不太相符?ArrayList 在添加元素的时候如果不涉及到扩容,性能在两种情况下(中间位置新增元素、尾部新增元素)比 LinkedList 好很多,只有头部新增元素的时候比 LinkedList 差,因为数组复制的原因。
+
+当然了,如果涉及到数组扩容的话,ArrayList 的性能就没那么可观了,因为扩容的时候也要复制数组。
+
+### 04、ArrayList 和 LinkedList 删除元素时究竟谁快?
+
+**1)ArrayList**
+
+ArrayList 删除元素的时候,有两种方式,一种是直接删除元素(`remove(Object)`),需要直先遍历数组,找到元素对应的索引;一种是按照索引删除元素(`remove(int)`)。
+
+```java
+public boolean remove(Object o) {
+ final Object[] es = elementData;
+ final int size = this.size;
+ int i = 0;
+ found: {
+ if (o == null) {
+ for (; i < size; i++)
+ if (es[i] == null)
+ break found;
+ } else {
+ for (; i < size; i++)
+ if (o.equals(es[i]))
+ break found;
+ }
+ return false;
+ }
+ fastRemove(es, i);
+ return true;
+}
+public E remove(int index) {
+ Objects.checkIndex(index, size);
+ final Object[] es = elementData;
+
+ @SuppressWarnings("unchecked") E oldValue = (E) es[index];
+ fastRemove(es, index);
+
+ return oldValue;
+}
+```
+
+但从本质上讲,都是一样的,因为它们最后调用的都是 `fastRemove(Object, int)` 方法。
+
+```java
+private void fastRemove(Object[] es, int i) {
+ modCount++;
+ final int newSize;
+ if ((newSize = size - 1) > i)
+ System.arraycopy(es, i + 1, es, i, newSize - i);
+ es[size = newSize] = null;
+}
+```
+
+从源码可以看得出,只要删除的不是最后一个元素,都需要数组重组。删除的元素位置越靠前,代价就越大。
+
+
+**2)LinkedList**
+
+LinkedList 删除元素的时候,有四种常用的方式:
+
+- `remove(int)`,删除指定位置上的元素
+
+```java
+public E remove(int index) {
+ checkElementIndex(index);
+ return unlink(node(index));
+}
+```
+
+先检查索引,再调用 `node(int)` 方法( 前后半段遍历,和新增元素操作一样)找到节点 Node,然后调用 `unlink(Node)` 解除节点的前后引用,同时更新前节点的后引用和后节点的前引用:
+
+```java
+ E unlink(Node x) {
+ // assert x != null;
+ final E element = x.item;
+ final Node next = x.next;
+ final Node prev = x.prev;
+
+ if (prev == null) {
+ first = next;
+ } else {
+ prev.next = next;
+ x.prev = null;
+ }
+
+ if (next == null) {
+ last = prev;
+ } else {
+ next.prev = prev;
+ x.next = null;
+ }
+
+ x.item = null;
+ size--;
+ modCount++;
+ return element;
+ }
+```
+
+- `remove(Object)`,直接删除元素
+
+```java
+public boolean remove(Object o) {
+ if (o == null) {
+ for (LinkedList.Node x = first; x != null; x = x.next) {
+ if (x.item == null) {
+ unlink(x);
+ return true;
+ }
+ }
+ } else {
+ for (LinkedList.Node x = first; x != null; x = x.next) {
+ if (o.equals(x.item)) {
+ unlink(x);
+ return true;
+ }
+ }
+ }
+ return false;
+}
+```
+
+也是先前后半段遍历,找到要删除的元素后调用 `unlink(Node)`。
+
+- `removeFirst()`,删除第一个节点
+
+```java
+public E removeFirst() {
+ final LinkedList.Node f = first;
+ if (f == null)
+ throw new NoSuchElementException();
+ return unlinkFirst(f);
+}
+private E unlinkFirst(LinkedList.Node f) {
+ // assert f == first && f != null;
+ final E element = f.item;
+ final LinkedList.Node next = f.next;
+ f.item = null;
+ f.next = null; // help GC
+ first = next;
+ if (next == null)
+ last = null;
+ else
+ next.prev = null;
+ size--;
+ modCount++;
+ return element;
+}
+```
+
+删除第一个节点就不需要遍历了,只需要把第二个节点更新为第一个节点即可。
+
+- `removeLast()`,删除最后一个节点
+
+删除最后一个节点和删除第一个节点类似,只需要把倒数第二个节点更新为最后一个节点即可。
+
+可以看得出,LinkedList 在删除比较靠前和比较靠后的元素时,非常高效,但如果删除的是中间位置的元素,效率就比较低了。
+
+这里就不再做代码测试了,感兴趣的小伙伴可以自己试试,结果和新增元素保持一致:
+
+- 从集合头部删除元素时,ArrayList 花费的时间比 LinkedList 多很多;
+
+- 从集合中间位置删除元素时,ArrayList 花费的时间比 LinkedList 少很多;
+
+- 从集合尾部删除元素时,ArrayList 花费的时间比 LinkedList 少一点。
+
+我本地的统计结果如下所示,小伙伴们可以作为参考:
+
+```
+ArrayList从集合头部位置删除元素花费的时间380
+LinkedList从集合头部位置删除元素花费的时间4
+ArrayList从集合中间位置删除元素花费的时间381
+LinkedList从集合中间位置删除元素花费的时间5922
+ArrayList从集合尾部位置删除元素花费的时间8
+LinkedList从集合尾部位置删除元素花费的时间12
+```
+
+### 05、ArrayList 和 LinkedList 遍历元素时究竟谁快?
+
+**1)ArrayList**
+
+遍历 ArrayList 找到某个元素的话,通常有两种形式:
+
+- `get(int)`,根据索引找元素
+
+```java
+public E get(int index) {
+ Objects.checkIndex(index, size);
+ return elementData(index);
+}
+```
+
+由于 ArrayList 是由数组实现的,所以根据索引找元素非常的快,一步到位。
+
+- `indexOf(Object)`,根据元素找索引
+
+```java
+public int indexOf(Object o) {
+ return indexOfRange(o, 0, size);
+}
+
+int indexOfRange(Object o, int start, int end) {
+ Object[] es = elementData;
+ if (o == null) {
+ for (int i = start; i < end; i++) {
+ if (es[i] == null) {
+ return i;
+ }
+ }
+ } else {
+ for (int i = start; i < end; i++) {
+ if (o.equals(es[i])) {
+ return i;
+ }
+ }
+ }
+ return -1;
+}
+```
+
+根据元素找索引的话,就需要遍历整个数组了,从头到尾依次找。
+
+
+**2)LinkedList**
+
+遍历 LinkedList 找到某个元素的话,通常也有两种形式:
+
+- `get(int)`,找指定位置上的元素
+
+```java
+public E get(int index) {
+ checkElementIndex(index);
+ return node(index).item;
+}
+```
+
+既然需要调用 `node(int)` 方法,就意味着需要前后半段遍历了。
+
+- `indexOf(Object)`,找元素所在的位置
+
+```java
+public int indexOf(Object o) {
+ int index = 0;
+ if (o == null) {
+ for (LinkedList.Node x = first; x != null; x = x.next) {
+ if (x.item == null)
+ return index;
+ index++;
+ }
+ } else {
+ for (LinkedList.Node x = first; x != null; x = x.next) {
+ if (o.equals(x.item))
+ return index;
+ index++;
+ }
+ }
+ return -1;
+}
+```
+
+需要遍历整个链表,和 ArrayList 的 `indexOf()` 类似。
+
+那在我们对集合遍历的时候,通常有两种做法,一种是使用 for 循环,一种是使用迭代器(Iterator)。
+
+如果使用的是 for 循环,可想而知 LinkedList 在 get 的时候性能会非常差,因为每一次外层的 for 循环,都要执行一次 `node(int)` 方法进行前后半段的遍历。
+
+```java
+LinkedList.Node node(int index) {
+ // assert isElementIndex(index);
+
+ if (index < (size >> 1)) {
+ LinkedList.Node x = first;
+ for (int i = 0; i < index; i++)
+ x = x.next;
+ return x;
+ } else {
+ LinkedList.Node x = last;
+ for (int i = size - 1; i > index; i--)
+ x = x.prev;
+ return x;
+ }
+}
+```
+
+
+
+那如果使用的是迭代器呢?
+
+```java
+LinkedList list = new LinkedList();
+for (Iterator it = list.iterator(); it.hasNext();) {
+ it.next();
+}
+```
+
+迭代器只会调用一次 `node(int)` 方法,在执行 `list.iterator()` 的时候:先调用 AbstractSequentialList 类的 `iterator()` 方法,再调用 AbstractList 类的 `listIterator()` 方法,再调用 LinkedList 类的 `listIterator(int)` 方法,如下图所示。
+
+
+
+最后返回的是 LinkedList 类的内部私有类 ListItr 对象:
+
+```java
+public ListIterator listIterator(int index) {
+ checkPositionIndex(index);
+ return new LinkedList.ListItr(index);
+}
+
+private class ListItr implements ListIterator {
+ private LinkedList.Node lastReturned;
+ private LinkedList.Node next;
+ private int nextIndex;
+ private int expectedModCount = modCount;
+
+ ListItr(int index) {
+ // assert isPositionIndex(index);
+ next = (index == size) ? null : node(index);
+ nextIndex = index;
+ }
+
+ public boolean hasNext() {
+ return nextIndex < size;
+ }
+
+ public E next() {
+ checkForComodification();
+ if (!hasNext())
+ throw new NoSuchElementException();
+
+ lastReturned = next;
+ next = next.next;
+ nextIndex++;
+ return lastReturned.item;
+ }
+}
+```
+
+执行 ListItr 的构造方法时调用了一次 `node(int)` 方法,返回第一个节点。在此之后,迭代器就执行 `hasNext()` 判断有没有下一个,执行 `next()` 方法下一个节点。
+
+由此,可以得出这样的结论:**遍历 LinkedList 的时候,千万不要使用 for 循环,要使用迭代器。**
+
+也就是说,for 循环遍历的时候,ArrayList 花费的时间远小于 LinkedList;迭代器遍历的时候,两者性能差不多。
+
+### 06、总结
+
+花了两天时间,终于肝完了!相信看完这篇文章后,再有面试官问你 ArrayList 和 LinkedList 有什么区别的话,你一定会胸有成竹地和他扯上半小时了。
+
+
diff --git a/docs/src/common-tool/arrays.md b/docs/common-tool/arrays.md
similarity index 82%
rename from docs/src/common-tool/arrays.md
rename to docs/common-tool/arrays.md
index 09bdb0c19e..55893c4073 100644
--- a/docs/src/common-tool/arrays.md
+++ b/docs/common-tool/arrays.md
@@ -1,19 +1,14 @@
---
-title: Java Arrays:专为数组而生的工具类
-shortTitle: Arrays工具类
category:
- Java核心
tag:
- - 常用工具类
-description: 本文详细介绍了Java中的Arrays工具类,阐述了它在数组操作中的实际应用和优势。通过具体的代码示例,展示了如何使用Arrays类处理数组排序、查找、转换等常见问题。学习Arrays工具类的技巧,让您在Java编程中轻松应对各种数组操作,提高开发效率。
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Java入门,教程,java,Arrays,数组,java arrays,java 数组
+ - Java
---
+# Java Arrays工具类10大常用方法
-“哥,数组专用工具类是专门用来操作[数组](https://javabetter.cn/array/array.html)的吗?比如说创建数组、数组排序、数组检索等等。”三妹的提问其实已经把答案说了出来。
+
+“哥,数组专用工具类是专门用来操作数组的吗?比如说创建数组、数组排序、数组检索等等。”三妹的提问其实已经把答案说了出来。
“是滴,这里说的数组专用工具类指的是 `java.util.Arrays` 类,基本上常见的数组操作,这个类都提供了静态方法可供直接调用。毕竟数组本身想完成这些操作还是挺麻烦的,有了这层封装,就方便多了。”在回答三妹的同时,我打开 Intellij IDEA,找到了 Arrays 类的源码。
@@ -50,9 +45,7 @@ public class Arrays {}
- copyOfRange,复制指定范围内的数组到一个新的数组
- fill,对数组进行填充
-#### 1)copyOf
-
-直接来看例子:
+1)copyOf,直接来看例子:
```java
String[] intro = new String[] { "沉", "默", "王", "二" };
@@ -80,9 +73,7 @@ private Object[] grow(int minCapacity) {
}
```
-#### 2)copyOfRange
-
-直接来看例子:
+2)copyOfRange,直接来看例子:
```java
String[] intro = new String[] { "沉", "默", "王", "二" };
@@ -115,9 +106,8 @@ System.out.println(Arrays.toString(abridgementExpanded));
“嗯,我想是 Arrays 的设计者考虑到了数组越界的问题,不然每次调用 Arrays 类就要先判断很多次长度,很麻烦。”稍作思考后,我给出了这样一个回答。
-#### 3)fill
-直接来看例子:
+3)fill,直接来看例子:
```java
String[] stutter = new String[4];
@@ -176,7 +166,7 @@ public static boolean equals(Object[] a, Object[] a2) {
}
```
-因为数组是一个对象,所以先使用“==”操作符进行判断,如果不相等,再判断是否为 null,其中一个为 null,返回 false;紧接着判断 length,不等的话,返回 false;否则的话,依次调用 `Objects.equals()` 比较相同位置上的元素是否相等。
+因为数组是一个对象,所以先使用“==”操作符进行判断,如果不相等,再判断是否为 null,两个都为 null,返回 false;紧接着判断 length,不等的话,返回 false;否则的话,依次调用 `Objects.equals()` 比较相同位置上的元素是否相等。
“这段代码还是非常严谨的,对吧?三妹,这也就是我们学习源码的意义,欣赏的同时,可以学习源码作者清晰的编码思路。”我语重心长地给三妹讲。
@@ -268,7 +258,7 @@ System.out.println(caseInsensitive);
“流是什么呀?”三妹好奇的问。
-“流的英文单词是 Stream,它可以极大提高 Java 程序员的生产力,让程序员写出高效、干净、简洁的代码。 这种风格将要处理的集合看作是一种流,想象一下水流在管道中流过的样子,我们可以在管道中对流进行处理,比如筛选、排序等等。[Stream 具体怎么使用](https://javabetter.cn/java8/stream.html),我们留到后面再详细地讲,这里你先有一个大致的印象就可以了。”我回答到。
+“流的英文单词是 Stream,它可以极大提高 Java 程序员的生产力,让程序员写出高效、干净、简洁的代码。 这种风格将要处理的集合看作是一种流,想象一下水流在管道中流过的样子,我们可以在管道中对流进行处理,比如筛选、排序等等。Stream 具体怎么使用,我们留到后面再详细地讲,这里你先有一个大致的印象就可以了。”我回答到。
Arrays 类的 `stream()` 方法可以将数组转换成流:
@@ -299,7 +289,7 @@ Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: origin(2) >
[Ljava.lang.String;@3d075dc0
```
-[最优雅的打印方式](https://javabetter.cn/array/print.html),是使用 `Arrays.toString()`,其实前面讲过。来看一下该方法的源码:
+最优雅的打印方式,是使用 `Arrays.toString()`,来看一下该方法的源码:
```java
public static String toString(Object[] a) {
@@ -337,7 +327,7 @@ public static String toString(Object[] a) {
### 07、数组转 List
-尽管数组非常强大,但它自身可以操作的工具方法很少,比如说判断数组中是否包含某个值。如果能转成 List 的话,就简便多了,因为 Java 的[集合框架 List](https://javabetter.cn/collection/gailan.html) 中封装了很多常用的方法。
+尽管数组非常强大,但它自身可以操作的工具方法很少,比如说判断数组中是否包含某个值。如果能转成 List 的话,就简便多了,因为 Java 的集合框架 List 中封装了很多常用的方法。
```java
String[] intro = new String[] { "沉", "默", "王", "二" };
@@ -345,7 +335,7 @@ List rets = Arrays.asList(intro);
System.out.println(rets.contains("二"));
```
-不过需要注意的是,`Arrays.asList()` 返回的是 `java.util.Arrays.ArrayList`,并不是 [`java.util.ArrayList`](https://javabetter.cn/collection/arraylist.html),它的长度是固定的,无法进行元素的删除或者添加。
+不过需要注意的是,`Arrays.asList()` 返回的是 `java.util.Arrays.ArrayList`,并不是 `java.util.ArrayList`,它的长度是固定的,无法进行元素的删除或者添加。
```java
rets.add("三");
@@ -370,7 +360,7 @@ rets1.remove("二");
### 08、setAll
-Java 8 新增了 `setAll()` 方法,它提供了一个[函数式编程](https://javabetter.cn/java8/Lambda.html)的入口,可以对数组的元素进行填充:
+Java 8 新增了 `setAll()` 方法,它提供了一个函数式编程的入口,可以对数组的元素进行填充:
```java
int[] array = new int[10];
@@ -433,11 +423,4 @@ System.out.println(Arrays.toString(arr));
我来到客厅,坐到沙发上,捧起黄永玉先生的《无愁河上的浪荡汉子·八年卷 1》看了起来,津津有味。。。。。。
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
\ No newline at end of file
+
\ No newline at end of file
diff --git a/docs/common-tool/collections.md b/docs/common-tool/collections.md
new file mode 100644
index 0000000000..b8121a3eb1
--- /dev/null
+++ b/docs/common-tool/collections.md
@@ -0,0 +1,256 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java集合框架:Collections工具类
+
+
+Collections 是 JDK 提供的一个工具类,位于 java.util 包下,提供了一系列的静态方法,方便我们对集合进行各种骚操作,算是集合框架的一个大管家。
+
+还记得我们前面讲过的 [Arrays 工具类](https://mp.weixin.qq.com/s/9dYmKXEErZbyPJ_GxwWYug)吗?可以回去温习下。
+
+Collections 的用法很简单,在 Intellij IDEA 中敲完 `Collections.` 之后就可以看到它提供的方法了,大致看一下方法名和参数就能知道这个方法是干嘛的。
+
+
+
+
+为了节省大家的学习时间,我将这些方法做了一些分类,并列举了一些简单的例子。
+
+### 01、排序操作
+
+- `reverse(List list)`:反转顺序
+- `shuffle(List list)`:洗牌,将顺序打乱
+- `sort(List list)`:自然升序
+- `sort(List list, Comparator c)`:按照自定义的比较器排序
+- `swap(List list, int i, int j)`:将 i 和 j 位置的元素交换位置
+
+来看例子:
+
+```java
+List list = new ArrayList<>();
+list.add("沉默王二");
+list.add("沉默王三");
+list.add("沉默王四");
+list.add("沉默王五");
+list.add("沉默王六");
+
+System.out.println("原始顺序:" + list);
+
+// 反转
+Collections.reverse(list);
+System.out.println("反转后:" + list);
+
+// 洗牌
+Collections.shuffle(list);
+System.out.println("洗牌后:" + list);
+
+// 自然升序
+Collections.sort(list);
+System.out.println("自然升序后:" + list);
+
+// 交换
+Collections.swap(list, 2,4);
+System.out.println("交换后:" + list);
+```
+
+输出后:
+
+```
+原始顺序:[沉默王二, 沉默王三, 沉默王四, 沉默王五, 沉默王六]
+反转后:[沉默王六, 沉默王五, 沉默王四, 沉默王三, 沉默王二]
+洗牌后:[沉默王五, 沉默王二, 沉默王六, 沉默王三, 沉默王四]
+自然升序后:[沉默王三, 沉默王二, 沉默王五, 沉默王六, 沉默王四]
+交换后:[沉默王三, 沉默王二, 沉默王四, 沉默王六, 沉默王五]
+```
+
+### 02、查找操作
+
+- `binarySearch(List list, Object key)`:二分查找法,前提是 List 已经排序过了
+- `max(Collection coll)`:返回最大元素
+- `max(Collection coll, Comparator comp)`:根据自定义比较器,返回最大元素
+- `min(Collection coll)`:返回最小元素
+- `min(Collection coll, Comparator comp)`:根据自定义比较器,返回最小元素
+- `fill(List list, Object obj)`:使用指定对象填充
+- `frequency(Collection c, Object o)`:返回指定对象出现的次数
+
+来看例子:
+
+```java
+System.out.println("最大元素:" + Collections.max(list));
+System.out.println("最小元素:" + Collections.min(list));
+System.out.println("出现的次数:" + Collections.frequency(list, "沉默王二"));
+
+// 没有排序直接调用二分查找,结果是不确定的
+System.out.println("排序前的二分查找结果:" + Collections.binarySearch(list, "沉默王二"));
+Collections.sort(list);
+// 排序后,查找结果和预期一致
+System.out.println("排序后的二分查找结果:" + Collections.binarySearch(list, "沉默王二"));
+
+Collections.fill(list, "沉默王八");
+System.out.println("填充后的结果:" + list);
+```
+
+输出后:
+
+```
+原始顺序:[沉默王二, 沉默王三, 沉默王四, 沉默王五, 沉默王六]
+最大元素:沉默王四
+最小元素:沉默王三
+出现的次数:1
+排序前的二分查找结果:0
+排序后的二分查找结果:1
+填充后的结果:[沉默王八, 沉默王八, 沉默王八, 沉默王八, 沉默王八]
+```
+
+### 03、同步控制
+
+[HashMap 是线程不安全](https://mp.weixin.qq.com/s/qk_neCdzM3aB6pVWVTHhNw)的,这个我们前面讲到了。那其实 ArrayList 也是线程不安全的,没法在多线程环境下使用,那 Collections 工具类中提供了多个 synchronizedXxx 方法,这些方法会返回一个同步的对象,从而解决多线程中访问集合时的安全问题。
+
+
+
+使用起来也非常的简单:
+
+```java
+SynchronizedList synchronizedList = Collections.synchronizedList(list);
+```
+
+看一眼 SynchronizedList 的源码就明白了,不过是在方法里面使用 synchronized 关键字加了一层锁而已。
+
+```java
+static class SynchronizedList
+ extends SynchronizedCollection
+ implements List {
+ private static final long serialVersionUID = -7754090372962971524L;
+
+ final List list;
+
+ SynchronizedList(List list) {
+ super(list);
+ this.list = list;
+ }
+
+ public E get(int index) {
+ synchronized (mutex) {return list.get(index);}
+ }
+
+ public void add(int index, E element) {
+ synchronized (mutex) {list.add(index, element);}
+ }
+ public E remove(int index) {
+ synchronized (mutex) {return list.remove(index);}
+ }
+}
+```
+
+那这样的话,其实效率和那些直接在方法上加 synchronized 关键字的 Vector、Hashtable 差不多(JDK 1.0 时期就有了),而这些集合类基本上已经废弃了,几乎不怎么用。
+
+```java
+public class Vector
+ extends AbstractList
+ implements List, RandomAccess, Cloneable, java.io.Serializable
+{
+
+ public synchronized E get(int index) {
+ if (index >= elementCount)
+ throw new ArrayIndexOutOfBoundsException(index);
+
+ return elementData(index);
+ }
+
+ public synchronized E remove(int index) {
+ modCount++;
+ if (index >= elementCount)
+ throw new ArrayIndexOutOfBoundsException(index);
+ E oldValue = elementData(index);
+
+ int numMoved = elementCount - index - 1;
+ if (numMoved > 0)
+ System.arraycopy(elementData, index+1, elementData, index,
+ numMoved);
+ elementData[--elementCount] = null; // Let gc do its work
+
+ return oldValue;
+ }
+}
+```
+
+正确的做法是使用并发包下的 CopyOnWriteArrayList、ConcurrentHashMap。这些我们放到并发编程时再讲。
+
+### 04、不可变集合
+
+- `emptyXxx()`:制造一个空的不可变集合
+- `singletonXxx()`:制造一个只有一个元素的不可变集合
+- `unmodifiableXxx()`:为指定集合制作一个不可变集合
+
+举个例子:
+
+```java
+List emptyList = Collections.emptyList();
+emptyList.add("非空");
+System.out.println(emptyList);
+```
+
+这段代码在执行的时候就抛出错误了。
+
+```
+Exception in thread "main" java.lang.UnsupportedOperationException
+ at java.util.AbstractList.add(AbstractList.java:148)
+ at java.util.AbstractList.add(AbstractList.java:108)
+ at com.itwanger.s64.Demo.main(Demo.java:61)
+```
+
+这是因为 `Collections.emptyList()` 会返回一个 Collections 的内部类 EmptyList,而 EmptyList 并没有重写父类 AbstractList 的 `add(int index, E element)` 方法,所以执行的时候就抛出了不支持该操作的 UnsupportedOperationException 了。
+
+这是从分析 add 方法源码得出的原因。除此之外,emptyList 方法是 final 的,返回的 EMPTY_LIST 也是 final 的,种种迹象表明 emptyList 返回的就是不可变对象,没法进行增伤改查。
+
+```java
+public static final List emptyList() {
+ return (List) EMPTY_LIST;
+}
+
+public static final List EMPTY_LIST = new EmptyList<>();
+```
+
+### 05、其他
+
+还有两个方法比较常用:
+
+- `addAll(Collection c, T... elements)`,往集合中添加元素
+- `disjoint(Collection c1, Collection c2)`,判断两个集合是否没有交集
+
+举个例子:
+
+```java
+List allList = new ArrayList<>();
+Collections.addAll(allList, "沉默王九","沉默王十","沉默王二");
+System.out.println("addAll 后:" + allList);
+
+System.out.println("是否没有交集:" + (Collections.disjoint(list, allList) ? "是" : "否"));
+```
+
+输出后:
+
+```
+原始顺序:[沉默王二, 沉默王三, 沉默王四, 沉默王五, 沉默王六]
+addAll 后:[沉默王九, 沉默王十, 沉默王二]
+是否没有交集:否
+```
+
+整体上,Collections 工具类作为集合框架的大管家,提供了一些非常便利的方法供我们调用,也非常容易掌握,没什么难点,看看方法的注释就能大致明白干嘛的。
+
+不过,工具就放在那里,用是一回事,为什么要这么用就是另外一回事了。能不能提高自己的编码水平,很大程度上取决于你到底有没有去钻一钻源码,看这些设计 JDK 的大师们是如何写代码的,学会一招半式,在工作当中还是能很快脱颖而出的。
+
+恐怕 JDK 的设计者是这个世界上最好的老师了,文档写得不能再详细了,代码写得不能再优雅了,基本上都达到了性能上的极致。
+
+可能有人会说,工具类没什么鸟用,不过是调用下方法而已,但这就大错特错了:如果要你来写,你能写出来 Collections 这样一个工具类吗?
+
+这才是高手要思考的一个问题。
+
+
+
+
+
+
diff --git a/docs/common-tool/guava.md b/docs/common-tool/guava.md
new file mode 100644
index 0000000000..b8fd331748
--- /dev/null
+++ b/docs/common-tool/guava.md
@@ -0,0 +1,256 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Google开源的Guava工具库,太强大了
+
+
+### 01、前世今生
+
+你好呀,我是 Guava。
+
+我由 Google 公司开源,目前在 GitHub 上已经有 39.9k 的铁粉了,由此可以证明我的受欢迎程度。
+
+
+
+
+我的身体里主要包含有这些常用的模块:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等。新版的 JDK 中已经直接把我引入了,可想而知我有多优秀,忍不住骄傲了。
+
+这么说吧,学好如何使用我,能让你在编程中变得更快乐,写出更优雅的代码!
+
+*PS:star 这种事,只能求,不求没效果😭😭😭。二哥开源的《Java 程序员进阶之路》专栏在 GitHub 上已经收获了 595 枚星标,铁粉们赶紧去点点啦,帮二哥冲 600 star,笔芯*!
+
+>https://github.com/itwanger/toBeBetterJavaer
+
+### 02、引入 Guava
+
+如果你要在 Maven 项目使用我的话,需要先在 pom.xml 文件中引入我的依赖。
+
+```
+
+ com.google.guava
+ guava
+ 30.1-jre
+
+```
+
+一点要求,JDK 版本需要在 8 以上。
+
+### 03、基本工具
+
+Doug Lea,java.util.concurrent 包的作者,曾说过一句话:“null 真糟糕”。Tony Hoare,图灵奖得主、快速排序算法的作者,当然也是 null 的创建者,也曾说过类似的话:“null 的使用,让我损失了十亿美元。”鉴于此,我用 Optional 来表示可能为 null 的对象。
+
+
+
+
+代码示例如下所示。
+
+```java
+Optional possible = Optional.of(5);
+possible.isPresent(); // returns true
+possible.get(); // returns 5
+```
+
+我大哥 Java 在 JDK 8 中新增了 [Optional 类](https://mp.weixin.qq.com/s/PqK0KNVHyoEtZDtp5odocA),显然是从我这借鉴过去的,不过他的和我的有些不同。
+
+- 我的 Optional 是 abstract 的,意味着我可以有子类对象;我大哥的是 final 的,意味着没有子类对象。
+
+- 我的 Optional 实现了 Serializable 接口,可以序列化;我大哥的没有。
+
+- 我的一些方法和我大哥的也不尽相同。
+
+使用 Optional 除了赋予 null 语义,增加了可读性,最大的优点在于它是一种傻瓜式的防护。Optional 迫使你积极思考引用缺失的情况,因为你必须显式地从 Optional 获取引用。
+
+除了 Optional 之外,我还提供了:
+
+- 参数校验
+- 常见的 Object 方法,比如说 Objects.equals、Objects.hashCode,JDK 7 引入的 Objects 类提供同样的方法,当然也是从我这借鉴的灵感。
+- 更强大的比较器
+
+### 04、集合
+
+首先我来说一下,为什么需要不可变集合。
+
+- 保证线程安全。在并发程序中,使用不可变集合既保证线程的安全性,也大大地增强了并发时的效率(跟并发锁方式相比)。
+
+- 如果一个对象不需要支持修改操作,不可变的集合将会节省空间和时间的开销。
+
+- 可以当作一个常量来对待,并且集合中的对象在以后也不会被改变。
+
+与 JDK 中提供的不可变集合相比,我提供的 Immutable 才是真正的不可变,我为什么这么说呢?来看下面这个示例。
+
+下面的代码利用 JDK 的 `Collections.unmodifiableList(list)` 得到一个不可修改的集合 unmodifiableList。
+
+```java
+List list = new ArrayList();
+list.add("雷军");
+list.add("乔布斯");
+
+List unmodifiableList = Collections.unmodifiableList(list);
+unmodifiableList.add("马云");
+```
+
+运行代码将会出现以下异常:
+
+```
+Exception in thread "main" java.lang.UnsupportedOperationException
+ at java.base/java.util.Collections$UnmodifiableCollection.add(Collections.java:1060)
+ at com.itwanger.guava.NullTest.main(NullTest.java:29)
+```
+
+很好,执行 `unmodifiableList.add()` 的时候抛出了 UnsupportedOperationException 异常,说明 `Collections.unmodifiableList()` 返回了一个不可变集合。但真的是这样吗?
+
+你可以把 `unmodifiableList.add()` 换成 `list.add()`。
+
+```java
+List list = new ArrayList();
+list.add("雷军");
+list.add("乔布斯");
+
+List unmodifiableList = Collections.unmodifiableList(list);
+list.add("马云");
+```
+
+再次执行的话,程序并没有报错,并且你会发现 unmodifiableList 中真的多了一个元素。说明什么呢?
+
+`Collections.unmodifiableList(…)` 实现的不是真正的不可变集合,当原始集合被修改后,不可变集合里面的元素也是跟着发生变化。
+
+我就不会犯这种错,来看下面的代码。
+
+```java
+List stringArrayList = Lists.newArrayList("雷军","乔布斯");
+ImmutableList immutableList = ImmutableList.copyOf(stringArrayList);
+immutableList.add("马云");
+```
+
+尝试 `immutableList.add()` 的时候会抛出 `UnsupportedOperationException`。我在源码中已经把 `add()` 方法废弃了。
+
+```java
+ /**
+ * Guaranteed to throw an exception and leave the collection unmodified.
+ *
+ * @throws UnsupportedOperationException always
+ * @deprecated Unsupported operation.
+ */
+ @CanIgnoreReturnValue
+ @Deprecated
+ @Override
+ public final boolean add(E e) {
+ throw new UnsupportedOperationException();
+ }
+```
+
+尝试 `stringArrayList.add()` 修改原集合的时候 immutableList 并不会因此而发生改变。
+
+除了不可变集合以外,我还提供了新的集合类型,比如说:
+
+- Multiset,可以多次添加相等的元素。当把 Multiset 看成普通的 Collection 时,它表现得就像无序的 ArrayList;当把 Multiset 看作 `Map` 时,它也提供了符合性能期望的查询操作。
+
+- Multimap,可以很容易地把一个键映射到多个值。
+
+- BiMap,一种特殊的 Map,可以用 `inverse()` 反转
+ `BiMap` 的键值映射;保证值是唯一的,因此 `values()` 返回 Set 而不是普通的 Collection。
+
+
+
+### 05、字符串处理
+
+字符串表示字符的不可变序列,创建后就不能更改。在我们日常的工作中,字符串的使用非常频繁,熟练的对其操作可以极大的提升我们的工作效率。
+
+我提供了连接器——Joiner,可以用分隔符把字符串序列连接起来。下面的代码将会返回“雷军; 乔布斯”,你可以使用 `useForNull(String)` 方法用某个字符串来替换 null,而不像 `skipNulls()` 方法那样直接忽略 null。
+
+```java
+Joiner joiner = Joiner.on("; ").skipNulls();
+return joiner.join("雷军", null, "乔布斯");
+```
+
+我还提供了拆分器—— Splitter,可以按照指定的分隔符把字符串序列进行拆分。
+
+```java
+Splitter.on(',')
+ .trimResults()
+ .omitEmptyStrings()
+ .split("雷军,乔布斯,, 沉默王二");
+```
+
+### 06、缓存
+
+缓存在很多场景下都是相当有用的。你应该知道,检索一个值的代价很高,尤其是需要不止一次获取值的时候,就应当考虑使用缓存。
+
+我提供的 Cache 和 ConcurrentMap 很相似,但也不完全一样。最基本的区别是 ConcurrentMap 会一直保存所有添加的元素,直到显式地移除。相对地,我提供的 Cache 为了限制内存占用,通常都设定为自动回收元素。
+
+如果你愿意消耗一些内存空间来提升速度,你能预料到某些键会被查询一次以上,缓存中存放的数据总量不会超出内存容量,就可以使用 Cache。
+
+来个示例你感受下吧。
+
+```java
+@Test
+public void testCache() throws ExecutionException, InterruptedException {
+
+ CacheLoader cacheLoader = new CacheLoader() {
+ // 如果找不到元素,会调用这里
+ @Override
+ public Animal load(String s) {
+ return null;
+ }
+ };
+ LoadingCache loadingCache = CacheBuilder.newBuilder()
+ .maximumSize(1000) // 容量
+ .expireAfterWrite(3, TimeUnit.SECONDS) // 过期时间
+ .removalListener(new MyRemovalListener()) // 失效监听器
+ .build(cacheLoader); //
+ loadingCache.put("狗", new Animal("旺财", 1));
+ loadingCache.put("猫", new Animal("汤姆", 3));
+ loadingCache.put("狼", new Animal("灰太狼", 4));
+
+ loadingCache.invalidate("猫"); // 手动失效
+
+ Animal animal = loadingCache.get("狼");
+ System.out.println(animal);
+ Thread.sleep(4 * 1000);
+ // 狼已经自动过去,获取为 null 值报错
+ System.out.println(loadingCache.get("狼"));
+}
+
+/**
+ * 缓存移除监听器
+ */
+class MyRemovalListener implements RemovalListener {
+
+ @Override
+ public void onRemoval(RemovalNotification notification) {
+ String reason = String.format("key=%s,value=%s,reason=%s", notification.getKey(), notification.getValue(), notification.getCause());
+ System.out.println(reason);
+ }
+}
+
+class Animal {
+ private String name;
+ private Integer age;
+
+ public Animal(String name, Integer age) {
+ this.name = name;
+ this.age = age;
+ }
+}
+```
+
+CacheLoader 中重写了 load 方法,这个方法会在查询缓存没有命中时被调用,我这里直接返回了 null,其实这样会在没有命中时抛出 CacheLoader returned null for key 异常信息。
+
+MyRemovalListener 作为缓存元素失效时的监听类,在有元素缓存失效时会自动调用 onRemoval 方法,这里需要注意的是这个方法是同步方法,如果这里耗时较长,会阻塞直到处理完成。
+
+LoadingCache 就是缓存的主要操作对象了,常用的就是其中的 put 和 get 方法了。
+
+### 07、尾声
+
+上面介绍了我认为最常用的功能,作为 Google 公司开源的 Java 开发核心库,个人觉得实用性还是很高的(不然呢?嘿嘿嘿)。引入到你的项目后不仅能快速的实现一些开发中常用的功能,而且还可以让代码更加的优雅简洁。
+
+我觉得适用于每一个 Java 项目,至于其他的一些功能,比如说散列、事件总线、数学运算、反射,就等待你去发掘了。
+
+
+
+
+
diff --git a/docs/src/common-tool/hutool.md b/docs/common-tool/hutool.md
similarity index 84%
rename from docs/src/common-tool/hutool.md
rename to docs/common-tool/hutool.md
index d231603426..13e954d405 100644
--- a/docs/src/common-tool/hutool.md
+++ b/docs/common-tool/hutool.md
@@ -1,25 +1,21 @@
---
-title: Hutool:国产良心工具包,让你的Java变得更甜
-shortTitle: Hutool工具类库
category:
- Java核心
tag:
- - 常用工具类
-description: 本文详细介绍了国产Java工具包Hutool,阐述了它在简化Java编程中的实际应用和优势。通过具体的代码示例,展示了如何使用Hutool解决字符串处理、集合操作、日期时间处理等常见问题。学习Hutool的技巧,让您在Java编程中更加轻松、高效,享受编程的乐趣。
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Java入门,教程,java,Hutool,java hutool
+ - Java
---
+# Hutool:国产良心工具包,让你的Java变得更甜
+
读者群里有个小伙伴感慨说,“Hutool 这款开源类库太厉害了,基本上该有该的工具类,它里面都有。”讲真的,我平常工作中也经常用 Hutool,它确实可以帮助我们简化每一行代码,使 Java 拥有函数式语言般的优雅,让 Java 语言变得“甜甜的”。
-Hutool 的作者在[官网](https://hutool.cn/)上说,Hutool 是 Hu+tool 的自造词(好像不用说,我们也能猜得到),“Hu”用来致敬他的“前任”公司,“tool”就是工具的意思,谐音就有意思了,“糊涂”,寓意追求“万事都作糊涂观,无所谓失,无所谓得”(一个开源类库,上升到了哲学的高度,作者厉害了)。
+Hutool 的作者在官网上说,Hutool 是 Hu+tool 的自造词(好像不用说,我们也能猜得到),“Hu”用来致敬他的“前任”公司,“tool”就是工具的意思,谐音就有意思了,“糊涂”,寓意追求“万事都作糊涂观,无所谓失,无所谓得”(一个开源类库,上升到了哲学的高度,作者厉害了)。
看了一下开发团队的一个成员介绍,一个 Java 后端工具的作者竟然爱前端、爱数码,爱美女,嗯嗯嗯,确实“难得糊涂”(手动狗头)。
-
+
+
废话就说到这,来吧,实操走起!
@@ -40,11 +36,11 @@ Hutool 的设计思想是尽量减少重复的定义,让项目中的 util 包
就像作者在官网上说的那样:
- 以前,我们打开搜索引擎 -> 搜“Java MD5 加密” -> 打开某篇博客 -> 复制粘贴 -> 改改,变得好用些
-- 有了 Hutool 以后呢,引入 Hutool -> 直接 `SecureUtil.md5()`
+>有了 Hutool 以后呢,引入 Hutool -> 直接 `SecureUtil.md5()`
Hutool 对不仅对 JDK 底层的文件、流、加密解密、转码、正则、线程、XML等做了封装,还提供了以下这些组件:
-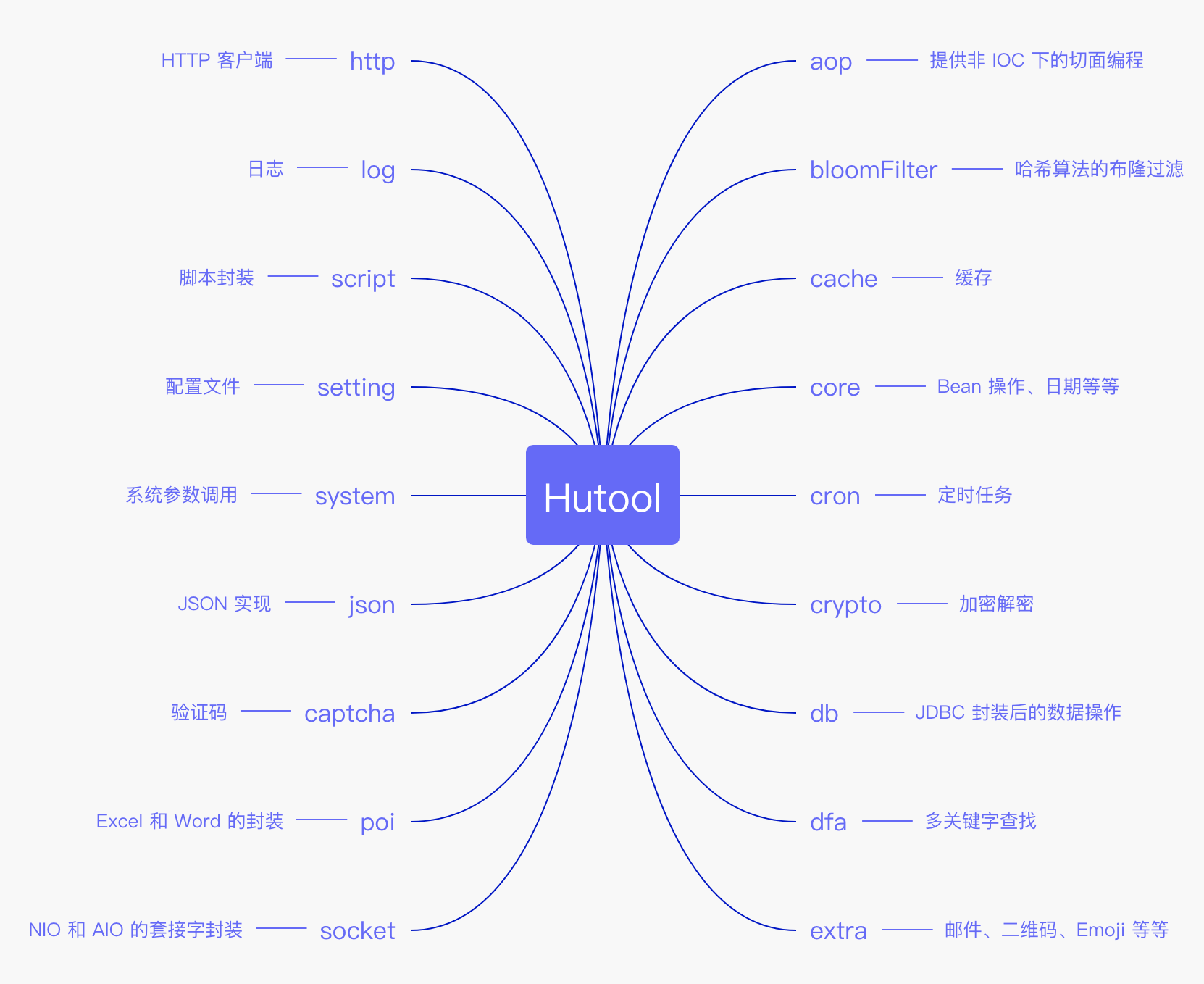
+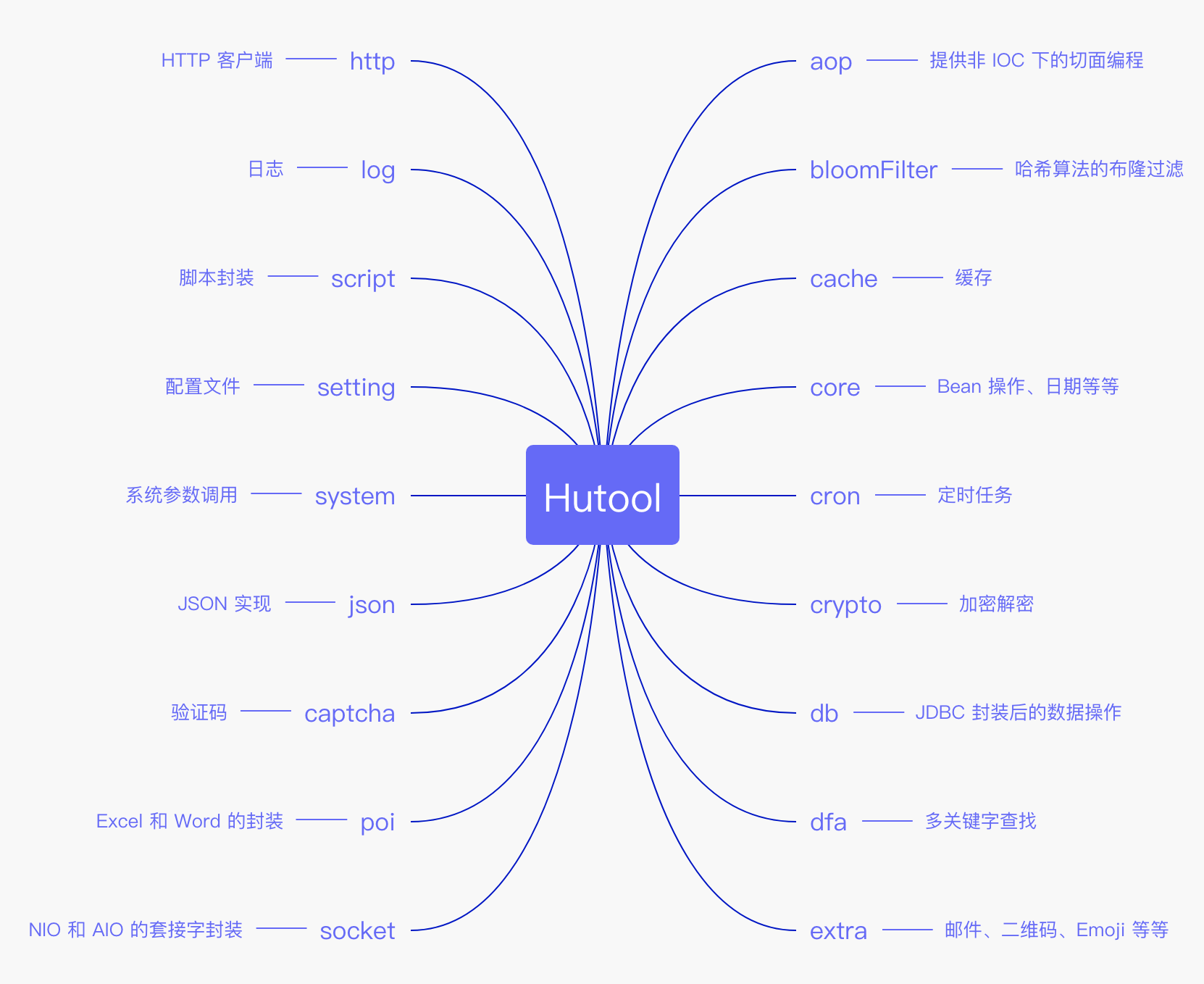
非常多,非常全面,鉴于此,我只挑选一些我喜欢的来介绍下(偷偷地告诉你,我就是想偷懒)。
@@ -137,7 +133,7 @@ String chineseZodiac = DateUtil.getChineseZodiac(1989);
### 04、IO 流相关
-[IO 操作包括读和写](https://javabetter.cn/io/shangtou.html),应用的场景主要包括网络操作和文件操作,原生的 Java 类库区分[字符流](https://javabetter.cn/io/reader-writer.html)和[字节流](https://javabetter.cn/io/stream.html),字节流 InputStream 和 OutputStream 就有很多很多种,使用起来让人头皮发麻。
+IO 操作包括读和写,应用的场景主要包括网络操作和文件操作,原生的 Java 类库区分字符流和字节流,字节流 InputStream 和 OutputStream 就有很多很多种,使用起来让人头皮发麻。
Hutool 封装了流操作工具类 IoUtil、文件读写操作工具类 FileUtil、文件类型判断工具类 FileTypeUtil 等等。
@@ -160,11 +156,11 @@ long copySize = IoUtil.copy(in, out, IoUtil.DEFAULT_BUFFER_SIZE);
在实际编码当中,我们通常需要从某些文件里面读取一些数据,比如配置文件、文本文件、图片等等,那这些文件通常放在什么位置呢?
-
+
放在项目结构图中的 resources 目录下,当项目编译后,会出现在 classes 目录下。对应磁盘上的目录如下图所示:
-
+
当我们要读取文件的时候,我是不建议使用绝对路径的,因为操作系统不一样的话,文件的路径标识符也是不一样的。最好使用相对路径。
@@ -317,7 +313,7 @@ public class ConsoleDemo {
- 是不是电话号码
- 等等
-
+
```java
Validator.isEmail("沉默王二");
@@ -326,7 +322,7 @@ Validator.isMobile("itwanger.com");
### 12、双向查找 Map
-[Guava](https://javabetter.cn/common-tool/guava.html) 中提供了一种特殊的 Map 结构,叫做 BiMap,实现了一种双向查找的功能,可以根据 key 查找 value,也可以根据 value 查找 key,Hutool 也提供这种 Map 结构。
+Guava 中提供了一种特殊的 Map 结构,叫做 BiMap,实现了一种双向查找的功能,可以根据 key 查找 value,也可以根据 value 查找 key,Hutool 也提供这种 Map 结构。
```java
BiMap biMap = new BiMap<>(new HashMap<>());
@@ -344,7 +340,7 @@ biMap.getKey("沉默王三");
在实际的开发工作中,其实我更倾向于使用 Guava 的 BiMap,而不是 Hutool 的。这里提一下,主要是我发现了 Hutool 在线文档上的一处错误,提了个 issue(从中可以看出我一颗一丝不苟的心和一双清澈明亮的大眼睛啊)。
-
+
### 13、图片工具
@@ -386,7 +382,7 @@ ImgUtil.pressText(//
趁机让大家欣赏一下二哥帅气的真容。
-
+
### 14、配置文件
@@ -554,13 +550,5 @@ Hutool 中的类库还有很多,尤其是一些对第三方类库的进一步
项目源码地址:[https://github.com/looly/hutool](https://github.com/looly/hutool)
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
-
+ diff --git a/docs/cs/os.md b/docs/cs/os.md
new file mode 100644
index 0000000000..dc0177e843
--- /dev/null
+++ b/docs/cs/os.md
@@ -0,0 +1,1340 @@
+---
+category:
+ - 计算机基础
+tag:
+ - 操作系统
+---
+
+# 计算机操作系统知识点大梳理
+
+>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ](https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ)
+
+
+
+## 计算机结构
+
+现代计算机模型是基于-**冯诺依曼计算机模型**
+
+计算机在运行时,先从内存中取出第一条指令,通过控制器的译码,按指令的要求,从存储器中取出数据进行指定的运算和逻辑操作等加工,然后再按地址把结果送到内存中去,接下来,再取出第二条指令,在控制器的指挥下完成规定操作,依此进行下去。直至遇到停止指令
+
+程序与数据一样存贮,按程序编排的顺序,一步一步地取出指令,自动地完成指令规定的操作是计算机最基本的工作模型
+
+**计算机五大核心组成部分**
+
+控制器:是整个计算机的中枢神经,其功能是对程序规定的控制信息进行解释,根据其要求进行控制,调度程序、数据、地址,协调计算机各部分工作及内存与外设的访问等。
+
+运算器:运算器的功能是对数据进行各种算术运算和逻辑运算,即对数据进行加工处理。
+
+存储器:存储器的功能是存储程序、数据和各种信号、命令等信息,并在需要时提供这些信息。
+
+输入:输入设备是计算机的重要组成部分,输入设备与输出设备合你为外部设备,简称外设,输入设备的作用是将程序、原始数据、文字、字符、控制命令或现场采集的数据等信息输入到计算机。
+
+> 常见的输入设备有键盘、鼠标器、光电输入机、磁带机、磁盘机、光盘机等。
+
+输出:输出设备与输入设备同样是计算机的重要组成部分,它把外算机的中间结果或最后结果、机内的各种数据符号及文字或各种控制信号等信息输出出来,微机常用的输出设备有显示终端CRT、打印机、激光印字机、绘图仪及磁带、光盘机等。
+
+**计算机结构分成以下 5 个部分:**
+
+输入设备;输出设备;内存;中央处理器;总线。
+
+
+
+### 内存
+
+在冯诺依曼模型中,程序和数据被存储在一个被称作内存的线性排列存储区域。
+
+存储的数据单位是一个二进制位,英文是 bit,最小的存储单位叫作字节,也就是 8 位,英文是 byte,每一个字节都对应一个内存地址。
+
+内存地址由 0 开始编号,比如第 1 个地址是 0,第 2 个地址是 1, 然后自增排列,最后一个地址是内存中的字节数减 1。
+
+我们通常说的内存都是随机存取器,也就是读取任何一个地址数据的速度是一样的,写入任何一个地址数据的速度也是一样的。
+
+### CPU
+
+冯诺依曼模型中 CPU 负责控制和计算,为了方便计算较大的数值,CPU 每次可以计算多个字节的数据。
+
+* 如果 CPU 每次可以计算 4 个 byte,那么我们称作 32 位 CPU;
+
+* 如果 CPU 每次可以计算 8 个 byte,那么我们称作 64 位 CPU。
+
+这里的 32 和 64,称作 CPU 的位宽。
+
+**为什么 CPU 要这样设计呢?**
+
+因为一个 byte 最大的表示范围就是 0~255。
+
+比如要计算 `20000*50`,就超出了byte 最大的表示范围了。
+
+因此,CPU 需要支持多个 byte 一起计算,当然,CPU 位数越大,可以计算的数值就越大,但是在现实生活中不一定需要计算这么大的数值,比如说 32 位 CPU 能计算的最大整数是 4294967295,这已经非常大了。
+
+**控制单元和逻辑运算单元**
+
+CPU 中有一个控制单元专门负责控制 CPU 工作;还有逻辑运算单元专门负责计算。
+
+**寄存器**
+
+CPU 要进行计算,比如最简单的加和两个数字时,因为 CPU 离内存太远,所以需要一种离自己近的存储来存储将要被计算的数字。
+
+这种存储就是寄存器,寄存器就在 CPU 里,控制单元和逻辑运算单元非常近,因此速度很快。
+
+常见的寄存器种类:
+
+- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
+- 程序计数器,用来存储 CPU 要执行下一条指令所在的内存地址,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令的地址。
+- 指令寄存器,用来存放程序计数器指向的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
+
+#### 多级缓存
+
+现代CPU为了提升执行效率,减少CPU与内存的交互(交互影响CPU效率),一般在CPU上集成了多级缓存架构
+
+**CPU缓存**即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器
+
+由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,减少CPU的等待时间,提高了系统的效率,具体包括以下几种:
+
+**L1-Cache**
+
+L1- 缓存在 CPU 中,相比寄存器,虽然它的位置距离 CPU 核心更远,但造价更低,通常 L1-Cache 大小在几十 Kb 到几百 Kb 不等,读写速度在 2~4 个 CPU 时钟周期。
+
+**L2-Cache**
+
+L2- 缓存也在 CPU 中,位置比 L1- 缓存距离 CPU 核心更远,它的大小比 L1-Cache 更大,具体大小要看 CPU 型号,有 2M 的,也有更小或者更大的,速度在 10~20 个 CPU 周期。
+
+**L3-Cache**
+
+L3- 缓存同样在 CPU 中,位置比 L2- 缓存距离 CPU 核心更远,大小通常比 L2-Cache 更大,读写速度在 20~60 个 CPU 周期。
+
+L3 缓存大小也是看型号的,比如 i9 CPU 有 512KB L1 Cache;有 2MB L2 Cache; 有16MB L3 Cache。
+
+
+
+当 CPU 需要内存中某个数据的时候,如果寄存器中有这个数据,我们可以直接使用;如果寄存器中没有这个数据,我们就要先查询 L1 缓存;L1 中没有,再查询 L2 缓存;L2 中没有再查询 L3 缓存;L3 中没有,再去内存中拿。
+
+
+
+
+
+**总结:**
+
+存储器存储空间大小:内存>L3>L2>L1>寄存器;
+
+存储器速度快慢排序:寄存器>L1>L2>L3>内存;
+
+#### 安全等级
+
+**CPU运行安全等级**
+
+CPU有4个运行级别,分别为:
+
+- ring0,ring1,ring2,ring3
+
+ring0只给操作系统用,ring3谁都能用。
+
+ring0是指CPU的运行级别,是最高级别,ring1次之,ring2更次之……
+
+系统(内核)的代码运行在最高运行级别ring0上,可以使用特权指令,控制中断、修改页表、访问设备等等。
+
+应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。
+
+如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。
+
+这个过程也称作用户态和内核态的切换。
+
+#### 局部性原理
+
+在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理
+
+**时间局部性(Temporal Locality):**
+
+如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
+
+比如循环、递归、方法的反复调用等。
+
+**空间局部性(Spatial Locality):**
+
+如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
+
+比如顺序执行的代码、连续创建的两个对象、数组等。
+
+#### 程序的执行过程
+
+程序实际上是一条一条指令,所以程序的运行过程就是把每一条指令一步一步的执行起来,负责执行指令的就是 CPU 了。
+
+**那 CPU 执行程序的过程如下:**
+
+- 第一步,CPU 读取程序计数器的值,这个值是指令的内存地址,然后 CPU 的控制单元操作地址总线指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过数据总线将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到指令寄存器。
+- 第二步,CPU 分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给逻辑运算单元运算;如果是存储类型的指令,则交由控制单元执行;
+- 第三步,CPU 执行完指令后,程序计数器的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此程序计数器的值会自增 4;
+
+简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
+
+CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 **CPU 的指令周期**。
+
+
+
+### 总线
+
+CPU 和内存以及其他设备之间,也需要通信,因此我们用一种特殊的设备进行控制,就是总线。
+
+- 地址总线,用于指定 CPU 将要操作的内存地址;
+- 数据总线,用于读写内存的数据;
+- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
+
+当 CPU 要读写内存数据的时候,一般需要通过两个总线:
+
+- 首先要通过地址总线来指定内存的地址;
+- 再通过数据总线来传输数据;
+
+### 输入、输出设备
+
+输入设备向计算机输入数据,计算机经过计算,将结果通过输出设备向外界传达。
+
+如果输入设备、输出设备想要和 CPU 进行交互,比如说用户按键需要 CPU 响应,这时候就需要用到控制总线。
+
+
+
+## 基础知识
+
+### 中断
+
+**中断的类型**
+
+* 按照中断的触发方分成同步中断和异步中断;
+
+* 根据中断是否强制触发分成可屏蔽中断和不可屏蔽中断。
+
+中断可以由 CPU 指令直接触发,这种主动触发的中断,叫作同步中断。
+
+> 同步中断有几种情况。
+
+* 比如系统调用,需要从用户态切换内核态,这种情况需要程序触发一个中断,叫作陷阱(Trap),中断触发后需要继续执行系统调用。
+
+* 还有一种同步中断情况是错误(Fault),通常是因为检测到某种错误,需要触发一个中断,中断响应结束后,会重新执行触发错误的地方,比如后面我们要学习的缺页中断。
+
+* 最后还有一种情况是程序的异常,这种情况和 Trap 类似,用于实现程序抛出的异常。
+
+另一部分中断不是由 CPU 直接触发,是因为需要响应外部的通知,比如响应键盘、鼠标等设备而触发的中断,这种中断我们称为异步中断。
+
+CPU 通常都支持设置一个中断屏蔽位(一个寄存器),设置为 1 之后 CPU 暂时就不再响应中断。
+
+对于键盘鼠标输入,比如陷阱、错误、异常等情况,会被临时屏蔽。
+
+但是对于一些特别重要的中断,比如 CPU 故障导致的掉电中断,还是会正常触发。
+
+**可以被屏蔽的中断我们称为可屏蔽中断,多数中断都是可屏蔽中断。**
+
+### 内核态和用户态
+
+**什么是用户态和内核态**
+
+Kernel 运行在超级权限模式下,所以拥有很高的权限。
+
+按照权限管理的原则,多数应用程序应该运行在最小权限下。
+
+因此,很多操作系统,将内存分成了两个区域:
+
+* 内核空间(Kernal Space),这个空间只有内核程序可以访问;
+
+* 用户空间(User Space),这部分内存专门给应用程序使用。
+
+用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态 执行。
+
+内核空间中的代码可以访问所有内存,我们称这些程序在内核态 执行。
+
+> 按照级别分:
+
+当程序运行在0级特权级上时,就可以称之为运行在内核态
+
+当程序运行在3级特权级上时,就可以称之为运行在用户态
+
+运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。
+
+当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态(比如操作硬件)
+
+**这两种状态的主要差别**
+
+处于用户态执行时,进程所能访问的内存空间和对象受到限制,其所处于占有的处理器是可被抢占的
+
+处于内核态执行时,则能访问所有的内存空间和对象,且所占有的处理器是不允许被抢占的。
+
+**为什么要有用户态和内核态**
+
+由于需要限制不同的程序之间的访问能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,并发送到网络
+
+**用户态与内核态的切换**
+
+所有用户程序都是运行在用户态的,但是有时候程序确实需要做一些内核态的事情, 例如从硬盘读取数据,或者从键盘获取输入等,而唯一可以做这些事情的就是操作系统,所以此时程序就需要先操作系统请求以程序的名义来执行这些操作
+
+**用户态和内核态的转换**
+
+> 系统调用
+
+用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如fork()实际上就是执行了一个创建新进程的系统调用
+
+而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断
+
+**举例:**
+
+
+
+如上图所示:内核程序执行在内核态(Kernal Mode),用户程序执行在用户态(User Mode)。
+
+当发生系统调用时,用户态的程序发起系统调用,因为系统调用中牵扯特权指令,用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
+
+发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序,内核程序开始执行,也就是开始处理系统调用。
+
+内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。
+
+> 异常
+
+当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常
+
+> 外围设备的中断
+
+当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换
+
+比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等
+
+
+
+## 线程
+
+线程:系统分配处理器时间资源的基本单元,是程序执行的最小单位
+
+线程可以看做轻量级的进程,共享内存空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
+
+在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
+
+进程可以通过 API 创建用户态的线程,也可以通过系统调用创建内核态的线程。
+
+### 用户态线程
+
+用户态线程也称作用户级线程,操作系统内核并不知道它的存在,它完全是在用户空间中创建。
+
+用户级线程有很多优势,比如:
+
+* 管理开销小:创建、销毁不需要系统调用。
+
+* 切换成本低:用户空间程序可以自己维护,不需要走操作系统调度。
+
+但是这种线程也有很多的缺点:
+
+* 与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行 I/O 的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
+
+* 线程间协作成本高:设想两个线程需要通信,通信需要 I/O,I/O 需要系统调用,因此用户态线程需要额外的系统调用成本。
+
+* 无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
+
+操作系统无法针对线程调度进行优化:当一个进程的一个用户态线程阻塞(Block)了,操作系统无法及时发现和处理阻塞问题,它不会更换执行其他线程,从而造成资源浪费。
+
+### 内核态线程
+
+内核态线程也称作内核级线程(Kernel Level Thread),这种线程执行在内核态,可以通过系统调用创造一个内核级线程。
+
+内核级线程有很多优势:
+
+* 可以利用多核 CPU 优势:内核拥有较高权限,因此可以在多个 CPU 核心上执行内核线程。
+
+* 操作系统级优化:内核中的线程操作 I/O 不需要进行系统调用;一个内核线程阻塞了,可以立即让另一个执行。
+
+当然内核线程也有一些缺点:
+
+* 创建成本高:创建的时候需要系统调用,也就是切换到内核态。
+
+* 扩展性差:由一个内核程序管理,不可能数量太多。
+
+* 切换成本较高:切换的时候,也同样存在需要内核操作,需要切换内核态。
+
+**用户态线程和内核态线程之间的映射关系**
+
+如果有一个用户态的进程,它下面有多个线程,如果这个进程想要执行下面的某一个线程,应该如何做呢?
+
+> 这时,比较常见的一种方式,就是将需要执行的程序,让一个内核线程去执行。
+
+毕竟,内核线程是真正的线程,因为它会分配到 CPU 的执行资源。
+
+如果一个进程所有的线程都要自己调度,相当于在进程的主线程中实现分时算法调度每一个线程,也就是所有线程都用操作系统分配给主线程的时间片段执行。
+
+> 这种做法,相当于操作系统调度进程的主线程;进程的主线程进行二级调度,调度自己内部的线程。
+
+这样操作劣势非常明显,比如无法利用多核优势,每个线程调度分配到的时间较少,而且这种线程在阻塞场景下会直接交出整个进程的执行权限。
+
+由此可见,用户态线程创建成本低,问题明显,不可以利用多核。
+
+内核态线程,创建成本高,可以利用多核,切换速度慢。
+
+因此通常我们会在内核中预先创建一些线程,并反复利用这些线程。
+
+### 协程
+
+
+
+协程,是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
+
+这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
+
+**子程序**
+
+或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
+
+所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
+
+子程序调用总是一个入口,一次返回,调用顺序是明确的。
+
+**协程的特点在于是一个线程执行,那和多线程比,协程有何优势?**
+
+* 极高的执行效率:因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显;
+* 不需要多线程的锁机制:因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
+
+### 线程安全
+
+如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。
+
+如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
+
+
+
+## 进程
+
+在系统中正在运行的一个应用程序;程序一旦运行就是进程;是资源分配的最小单位。
+
+在操作系统中能同时运行多个进程;
+
+开机的时候,磁盘的内核镜像被导入内存作为一个执行副本,成为内核进程。
+
+进程可以分成**用户态进程和内核态进程**两类,用户态进程通常是应用程序的副本,内核态进程就是内核本身的进程。
+
+如果用户态进程需要申请资源,比如内存,可以通过系统调用向内核申请。
+
+每个进程都有独立的内存空间,存放代码和数据段等,程序之间的切换会有较大的开销;
+
+**分时和调度**
+
+每个进程在执行时都会获得操作系统分配的一个时间片段,如果超出这个时间,就会轮到下一个进程(线程)执行。
+
+> 注意,现代操作系统都是直接调度线程,不会调度进程。
+
+**分配时间片段**
+
+如下图所示,进程 1 需要 2 个时间片段,进程 2 只有 1 个时间片段,进程 3 需要 3 个时间片段。
+
+因此当进程 1 执行到一半时,会先挂起,然后进程 2 开始执行;进程 2 一次可以执行完,然后进程 3 开始执行,不过进程 3 一次执行不完,在执行了 1 个时间片段后,进程 1 开始执行;就这样如此周而复始,这个就是分时技术。
+
+
+
+### 创建进程
+
+用户想要创建一个进程,最直接的方法就是从命令行执行一个程序,或者双击打开一个应用,但对于程序员而言,显然需要更好的设计。
+
+首先,应该有 API 打开应用,比如可以通过函数打开某个应用;
+
+另一方面,如果程序员希望执行完一段代价昂贵的初始化过程后,将当前程序的状态复制好几份,变成一个个单独执行的进程,那么操作系统提供了 fork 指令。
+
+
+
+也就是说,每次 fork 会多创造一个克隆的进程,这个克隆的进程,所有状态都和原来的进程一样,但是会有自己的地址空间。
+
+如果要创造 2 个克隆进程,就要 fork 两次。
+
+> 那如果我就是想启动一个新的程序呢?
+
+操作系统提供了启动新程序的 API。
+
+如果我就是想用一个新进程执行一小段程序,比如说每次服务端收到客户端的请求时,我都想用一个进程去处理这个请求。
+
+如果是这种情况,建议你不要单独启动进程,而是使用线程。
+
+因为进程的创建成本实在太高了,因此不建议用来做这样的事情:要创建条目、要分配内存,特别是还要在内存中形成一个个段,分成不同的区域。所以通常,我们更倾向于多创建线程。
+
+不同程序语言会自己提供创建线程的 API,比如 Java 有 Thread 类;go 有 go-routine(注意不是协程,是线程)。
+
+### 进程状态
+
+
+
+**创建状态**
+
+进程由创建而产生,创建进程是一个非常复杂的过程,一般需要通过多个步骤才能完成:如首先由进程申请一个空白的进程控制块(PCB),并向PCB中填写用于控制和管理进程的信息;然后为该进程分配运行时所必须的资源;最后,把该进程转入就绪状态并插入到就绪队列中
+
+**就绪状态**
+
+这是指进程已经准备好运行的状态,即进程已分配到除CPU以外所有的必要资源后,只要再获得CPU,便可立即执行,如果系统中有许多处于就绪状态的进程,通常将它们按照一定的策略排成一个队列,该队列称为就绪队列,有执行资格,没有执行权的进程
+
+**运行状态**
+
+这里指进程已经获取CPU,其进程处于正在执行的状态。对任何一个时刻而言,在单处理机的系统中,只有一个进程处于执行状态而在多处理机系统中,有多个进程处于执行状态,既有执行资格,又有执行权的进程
+
+**阻塞状态**
+
+这里是指正在执行的进程由于发生某事件(如I/O请求、申请缓冲区失败等)暂时无法继续执行的状态,即进程执行受到阻塞,此时引起进程调度,操作系统把处理机分配给另外一个就绪的进程,而让受阻的进程处于暂停的状态,一般将这个暂停状态称为阻塞状态
+
+**终止状态**
+
+### 进程间通信IPC
+
+每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信
+
+**管道/匿名管道**
+
+管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
+
+* 只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
+
+* 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
+
+* 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出,写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
+
+**有名管道(FIFO)**
+
+匿名管道,由于没有名字,只能用于亲缘关系的进程间通信。
+
+为了克服这个缺点,提出了有名管道(FIFO)。
+
+有名管道不同于匿名管道之处在于它提供了一个路径名与之关联,以有名管道的文件形式存在于文件系统中,这样,即使与有名管道的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过有名管道相互通信,因此,通过有名管道不相关的进程也能交换数据。
+
+**信号**
+
+信号是Linux系统中用于进程间互相通信或者操作的一种机制,信号可以在任何时候发给某一进程,而无需知道该进程的状态。
+
+如果该进程当前并未处于执行状态,则该信号就有内核保存起来,知道该进程回复执行并传递给它为止。
+
+如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消是才被传递给进程。
+
+**消息队列**
+
+消息队列是存放在内核中的消息链表,每个消息队列由消息队列标识符表示。
+
+与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即操作系统重启)或者显示地删除一个消息队列时,该消息队列才会被真正的删除。
+
+另外与管道不同的是,消息队列在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达
+
+**共享内存**
+
+使得多个进程可以直接读写同一块内存空间,是最快的可用IPC形式,是针对其他通信机制运行效率较低而设计的。
+
+为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间,进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率。
+
+由于多个进程共享一段内存,因此需要依靠某种同步机制(如信号量)来达到进程间的同步及互斥。
+
+共享内存示意图:
+
+
+
+一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。
+
+**信号量**
+
+信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。
+
+为了获得共享资源,进程需要执行下列操作:
+
+1. 创建一个信号量:这要求调用者指定初始值,对于二值信号量来说,它通常是1,也可是0。
+
+2. 等待一个信号量:该操作会测试这个信号量的值,如果小于0,就阻塞,也称为P操作。
+3. 挂出一个信号量:该操作将信号量的值加1,也称为V操作。
+
+**套接字(Socket)**
+
+套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。
+
+### 信号
+
+信号是进程间通信机制中唯一的异步通信机制,可以看作是异步通知,通知接收信号的进程有哪些事情发生了。
+
+也可以简单理解为信号是某种形式上的软中断
+
+可运行`kill -l`查看Linux支持的信号列表:
+
+```
+kill -l
+ 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
+ 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
+11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
+16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
+21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
+26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
+31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
+38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
+43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
+48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
+53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
+58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
+63) SIGRTMAX-1 64) SIGRTMAX
+```
+
+**几个常用的信号:**
+
+| 信号 | 描述 |
+| ------- | ------------------------------------------------------------ |
+| SIGHUP | 当用户退出终端时,由该终端开启的所有进程都会接收到这个信号,默认动作为终止进程。 |
+| SIGINT | 程序终止(interrupt)信号, 在用户键入INTR字符(通常是`Ctrl+C`)时发出,用于通知前台进程组终止进程。 |
+| SIGQUIT | 和`SIGINT`类似, 但由QUIT字符(通常是`Ctrl+\`)来控制,进程在因收到`SIGQUIT`退出时会产生`core`文件, 在这个意义上类似于一个程序错误信号。 |
+| SIGKILL | 用来立即结束程序的运行,本信号不能被阻塞、处理和忽略。 |
+| SIGTERM | 程序结束(terminate)信号, 与`SIGKILL`不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出。 |
+| SIGSTOP | 停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行,本信号不能被阻塞, 处理或忽略 |
+
+### 进程同步
+
+**临界区**
+
+通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问
+
+优点:保证在某一时刻只有一个线程能访问数据的简便办法
+
+缺点:虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程
+
+**互斥量**
+
+为协调共同对一个共享资源的单独访问而设计的
+
+互斥量跟临界区很相似,比临界区复杂,互斥对象只有一个,只有拥有互斥对象的线程才具有访问资源的权限
+
+优点:使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享
+
+**信号量**
+
+为控制一个具有有限数量用户资源而设计,它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目,互斥量是信号量的一种特殊情况,当信号量的最大资源数=1就是互斥量了
+
+信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作
+
+- **down** : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
+- **up** :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
+
+down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
+
+如果信号量的取值只能为 0 或者 1,那么就成为了 **互斥量(Mutex)** ,0 表示临界区已经加锁,1 表示临界区解锁。
+
+**事件**
+
+用来通知线程有一些事件已发生,从而启动后继任务的开始
+
+优点:事件对象通过通知操作的方式来保持线程的同步,并且可以实现不同进程中的线程同步操作
+
+**管程**
+
+管程有一个重要特性:在一个时刻只能有一个进程使用管程。
+
+进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
+
+管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。
+
+对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。
+
+signal() 操作用于唤醒被阻塞的进程。
+
+使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
+
+### 上下文切换
+
+对于单核单线程CPU而言,在某一时刻只能执行一条CPU指令。
+
+上下文切换(Context Switch)是一种将CPU资源从一个进程分配给另一个进程的机制。
+
+从用户角度看,计算机能够并行运行多个进程,这恰恰是操作系统通过快速上下文切换造成的结果。
+
+**在切换的过程中,操作系统需要先存储当前进程的状态(包括内存空间的指针,当前执行完的指令等等),再读入下一个进程的状态,然后执行此进程。**
+
+### 进程调度算法
+
+**先来先服务调度算法**
+
+该算法既可用于作业调度,也可用于进程调度,当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列
+
+**短作业优先调度算法**
+
+从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行
+
+**时间片轮转法**
+
+每次调度时,把CPU分配给队首进程,并令其执行一个时间片,时间片的大小从几ms到几百ms,当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾
+
+然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片,这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间
+
+**最短剩余时间优先**
+
+最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度,当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。
+
+如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
+
+**多级反馈队列调度算法**:
+
+前面介绍的几种进程调度的算法都有一定的局限性,如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程**,多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业迅速完成,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
+
+> 举例:
+
+多级队列,就是多个队列执行调度,先考虑最简单的两级模型
+
+
+
+上图中设计了两个优先级不同的队列,从下到上优先级上升,上层队列调度紧急任务,下层队列调度普通任务。
+
+只要上层队列有任务,下层队列就会让出执行权限。
+
+低优先级队列可以考虑抢占 + 优先级队列的方式实现,这样每次执行一个时间片段就可以判断一下高优先级的队列中是否有任务。
+
+高优先级队列可以考虑用非抢占(每个任务执行完才执行下一个)+ 优先级队列实现,这样紧急任务优先级有个区分,如果遇到十万火急的情况,就可以优先处理这个任务。
+
+上面这个模型虽然解决了任务间的优先级问题,但是还是没有解决短任务先行的问题,可以考虑再增加一些队列,让级别更多。
+
+> 比如下图这个模型:
+
+
+
+紧急任务仍然走高优队列,非抢占执行。
+
+普通任务先放到优先级仅次于高优任务的队列中,并且只分配很小的时间片;如果没有执行完成,说明任务不是很短,就将任务下调一层。
+
+下面一层,最低优先级的队列中时间片很大,长任务就有更大的时间片可以用。
+
+通过这种方式,短任务会在更高优先级的队列中执行完成,长任务优先级会下调,也就类似实现了最短作业优先的问题。
+
+实际操作中,可以有 n 层,一层层把大任务筛选出来,最长的任务,放到最闲的时间去执行,要知道,大部分时间 CPU 不是满负荷的。
+
+**优先级调度**
+
+为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推,具有相同优先级的进程以 FCFS 方式执行,可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
+
+### 守护进程
+
+守护进程是脱离于终端并且在后台运行的进程,脱离终端是为了避免在执行的过程中的信息在终端上显示,并且进程也不会被任何终端所产生的终端信息所打断。
+
+守护进程一般的生命周期是系统启动到系统停止运行。
+
+Linux系统中有很多的守护进程,最典型的就是我们经常看到的服务进程。
+
+当然,我们也经常会利用守护进程来完成很多的系统或者自动化任务。
+
+### 孤儿进程
+
+父进程早于子进程退出时候子进程还在运行,子进程会成为孤儿进程,Linux会对孤儿进程的处理,把孤儿进程的父进程设为进程号为1的进程,也就是由init进程来托管,init进程负责子进程退出后的善后清理工作
+
+### 僵尸进程
+
+子进程执行完毕时发现父进程未退出,会向父进程发送 SIGCHLD 信号,但父进程没有使用 wait/waitpid 或其他方式处理 SIGCHLD 信号来回收子进程,子进程变成为了对系统有害的僵尸进程
+
+子进程退出后留下的进程信息没有被收集,会导致占用的进程控制块PCB不被释放,形成僵尸进程,进程已经死去,但是进程资源没有被释放掉
+
+**问题及危害**
+
+如果系统中存在大量的僵尸进程,他们的进程号就会一直被占用,但是系统所能使用的进程号是有限的,系统将因为没有可用的进程号而导致系统不能产生新的进程
+
+任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理,这是每个子进程在结束时都要经过的阶段,如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是Z。
+
+如果父进程能及时处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态
+
+产生僵尸进程的元凶其实是他们的父进程,杀掉父进程,僵尸进程就变为了孤儿进程,便可以转交给 init 进程回收处理
+
+### 死锁
+
+**产生原因**
+
+系统资源的竞争:系统资源的竞争导致系统资源不足,以及资源分配不当,导致死锁。
+
+进程运行推进顺序不合适:进程在运行过程中,请求和释放资源的顺序不当,会导致死锁。
+
+**发生死锁的四个必要条件**
+
+互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某资源仅为一个进程所占有,此时若有其他进程请求该资源,则请求进程只能等待
+
+请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求时,该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放
+
+不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)
+
+循环等待条件: 若干进程间形成首尾相接循环等待资源的关系
+
+这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁
+
+**只要我们破坏其中一个,就可以成功避免死锁的发生**
+
+其中,互斥这个条件我们没有办法破坏,因为我们用锁为的就是互斥
+
+1. 对于占用且等待这个条件,我们可以一次性申请所有的资源,这样就不存在等待了。
+2. 对于不可抢占这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
+3. 对于循环等待这个条件,可以靠按序申请资源来预防,所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后自然就不存在循环了。
+
+**处理方法**
+
+主要有以下四种方法:
+
+- 鸵鸟策略
+- 死锁检测与死锁恢复
+- 死锁预防,破坏4个必要条件
+- 死锁避免,银行家算法
+
+**鸵鸟策略**
+
+把头埋在沙子里,假装根本没发生问题。
+
+因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
+
+当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
+
+**死锁检测**
+
+不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
+
+1. 每种类型一个资源的死锁检测
+
+2. 每种类型多个资源的死锁检测
+
+**死锁恢复**
+
+- 利用抢占恢复
+- 利用回滚恢复
+- 通过杀死进程恢复
+
+#### 哲学家进餐问题
+
+五个哲学家围着一张圆桌,每个哲学家面前放着食物。
+
+哲学家的生活有两种交替活动:吃饭以及思考。
+
+当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
+
+如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
+
+哲学家进餐问题可看作是并发进程并发执行时处理共享资源的一个有代表性的问题。
+
+**为了防止死锁的发生,可以设置两个条件:**
+
+- 必须同时拿起左右两根筷子;
+- 只有在两个邻居都没有进餐的情况下才允许进餐。
+
+#### 银行家算法
+
+银行家算法的命名是它可以用了银行系统,当不能满足所有客户的需求时,银行绝不会分配其资金。
+
+当新进程进入系统时,它必须说明其可能需要的每种类型资源实例的最大数量这一数量不可以超过系统资源的总和。
+
+当用户申请一组资源时,系统必须确定这些资源的分配是否处于安全状态,如何安全,则分配,如果不安全,那么进程必须等待指导某个其他进程释放足够资源为止。
+
+**安全状态**
+
+在避免死锁的方法中,允许进程动态地申请资源,但系统在进行资源分配之前,应先计算此次资源分配的安全性,若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,令进程等待
+
+因此,避免死锁的实质在于:系统在进行资源分配时,如何使系统不进入不安全状态
+
+### Fork函数
+
+`fork`函数用于创建一个与当前进程一样的子进程,所创建的子进程将复制父进程的代码段、数据段、BSS段、堆、栈等所有用户空间信息,在内核中操作系统会重新为其申请一个子进程执行的位置。
+
+`fork`系统调用会通过复制一个现有进程来创建一个全新的进程,新进程被存放在一个叫做任务队列的双向循环链表中,链表中的每一项都是类型为`task_struct`的进程控制块`PCB`的结构。
+
+
+
+每个进程都由独特换不相同的进程标识符(PID),通过`getpid()`函数可获取当前进程的进程标识符,通过`getppid()`函数可获得父进程的进程标识符。
+
+一个现有的进程可通过调用`fork`函数创建一个新进程,由`fork`创建的新进程称为子进程`child process`,`fork`函数被调用一次但返回两次,两次返回的唯一区别是子进程中返回0而父进程中返回子进程ID。
+
+**为什么`fork`会返回两次呢?**
+
+因为复制时会复制父进程的堆栈段,所以两个进程都停留在`fork`函数中等待返回,因此会返回两次,一个是在父进程中返回,一次是在子进程中返回,两次返回值是不一样的。
+
+- 在父进程中将返回新建子进程的进程ID
+- 在子进程中将返回0
+- 若出现错误则返回一个负数
+
+因此可以通过`fork`的返回值来判断当前进程是子进程还是父进程。
+
+**fork执行执行流程**
+
+当进程调用`fork`后控制转入内核,内核将会做4件事儿:
+
+1. 分配新的内存块和内核数据结构给子进程
+2. 将父进程部分数据结构内容(数据空间、堆栈等)拷贝到子进程
+3. 添加子进程到系统进程列表中
+4. `fork`返回开始调度器调度
+
+**为什么`pid`在父子进程中不同呢?**
+
+其实就相当于链表,进程形成了链表,父进程的`pid`指向子进程的进程ID,因此子进程没有子进程,所以PID为0,这里的`pid`相当于链表中的指针。
+
+## 设备管理
+
+### 磁盘调度算法
+
+读写一个磁盘块的时间的影响因素有:
+
+- 旋转时间
+- 寻道时间实际的数据传输时间
+
+其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
+
+> 先来先服务 FCFS, First Come First Served
+
+按照磁盘请求的顺序进行调度,优点是公平和简单,缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
+
+> 最短寻道时间优先,SSTF, Shortest Seek Time First
+
+优先调度与当前磁头所在磁道距离最近的磁道, 虽然平均寻道时间比较低,但是不够公平,如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的 磁道请求会一直等待下去,也就是出现饥饿现象,具体来说,两边的磁道请求更容易出现饥饿现象。
+
+> 电梯算法,SCAN
+
+电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向, 电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘 请求,然后改变方向,因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题
+
+
+
+## 内存管理
+
+**逻辑地址和物理地址**
+
+我们编程一般只有可能和逻辑地址打交道,比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的逻辑地址,逻辑地址由操作系统决定。
+
+物理地址指的是真实物理内存中地址,更具体一点来说就是内存地址寄存器中的地址,物理地址是内存单元真正的地址。
+
+编译时只需确定变量x存放的相对地址是100 ( 也就是说相对于进程在内存中的起始地址而言的地址)。
+
+CPU想要找到x在内存中的实际存放位置,只需要用进程的起始地址+100即可。
+
+相对地址又称逻辑地址,绝对地址又称物理地址。
+
+**内存管理有哪几种方式**
+
+1. **块式管理**:将内存分为几个固定大小的块,每个块中只包含一个进程,如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了,这些在每个块中未被利用的空间,我们称之为碎片。
+2. **页式管理**:把主存分为大小相等且固定的一页一页的形式,页较小,相对相比于块式管理的划分力度更大,提高了内存利用率,减少了碎片,页式管理通过页表对应逻辑地址和物理地址。
+
+
+
+1. **段式管理**: 页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义, 段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多 ,段式管理通过段表对应逻辑地址和物理地址。
+2. **段页式管理机制:**段页式管理机制结合了段式管理和页式管理的优点,简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说**段页式管理机制**中段与段之间以及段的内部的都是离散的。
+
+
+
+### 虚拟地址
+
+现代处理器使用的是一种称为**虚拟寻址(Virtual Addressing)**的寻址方式
+
+**使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。**
+
+实际上完成虚拟地址转换为物理地址转换的硬件是 CPU 中含有一个被称为**内存管理单元(Memory Management Unit, MMU)**的硬件
+
+
+
+**为什么要有虚拟地址空间**
+
+没有虚拟地址空间的时候,**程序都是直接访问和操作的都是物理内存**。
+
+但是这样有什么问题?
+
+1. 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易破坏操作系统,造成操作系统崩溃。
+2. 想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行,为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
+
+**通过虚拟地址访问内存有以下优势:**
+
+- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
+- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。
+- 不同进程使用的虚拟地址彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+
+**MMU如何把虚拟地址翻译成物理地址的**
+
+对于每个程序,内存管理单元MMU都为其保存一个页表,该页表中存放的是虚拟页面到物理页面的映射。
+
+每当为一个虚拟页面寻找到一个物理页面之后,就在页表里增加一条记录来保留该映射关系,当然,随着虚拟页面进出物理内存,页表的内容也会不断更新变化。
+
+
+
+### 虚拟内存
+
+很多时候我们使用点开了很多占内存的软件,这些软件占用的内存可能已经远远超出了我们电脑本身具有的物理内存
+
+通过 **虚拟内存** 可以让程序可以拥有超过系统物理内存大小的可用内存空间。
+
+另外,虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间),这样会更加有效地管理内存并减少出错。
+
+**虚拟内存**是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存
+
+**虚拟内存的重要意义是它定义了一个连续的虚拟地址空间**,并且 **把内存扩展到硬盘空间**
+
+**虚拟内存的实现有以下三种方式:**
+
+1. **请求分页存储管理** :请求分页是目前最常用的一种实现虚拟存储器的方法,请求分页存储管理系统中,在作业开始运行之前,仅装入当前要执行的部分段即可运行,假如在作业运行的过程中发现要访问的页面不在内存,则由处理器通知操作系统按照对应的页面置换算法将相应的页面调入到主存,同时操作系统也可以将暂时不用的页面置换到外存中。
+2. **请求分段存储管理** :请求分段储存管理方式就如同请求分页储存管理方式一样,在作业开始运行之前,仅装入当前要执行的部分段即可运行;在执行过程中,可使用请求调入中断动态装入要访问但又不在内存的程序段;当内存空间已满,而又需要装入新的段时,根据置换功能适当调出某个段,以便腾出空间而装入新的段。
+3. **请求段页式存储管理**
+
+不管是上面那种实现方式,我们一般都需要:
+
+> 一定容量的内存和外存:在载入程序的时候,只需要将程序的一部分装入内存,而将其他部分留在外存,然后程序就可以执行了;
+
+
+
+
+
+### 缺页中断
+
+如果**需执行的指令或访问的数据尚未在内存**(称为缺页或缺段),则由处理器通知操作系统将相应的页面或段**调入到内存**,然后继续执行程序;
+
+在分页系统中,一个虚拟页面既有可能在物理内存,也有可能保存在磁盘上。
+
+如果CPU发出的虚拟地址对应的页面不在物理内存,就将产生一个缺页中断,而缺页中断服务程序负责将需要的虚拟页面找到并加载到内存。
+
+缺页中断的处理步骤如下,省略了中间很多的步骤,只保留最核心的几个步骤:
+
+
+
+### 页面置换算法
+
+当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。
+
+用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则
+
+- **OPT 页面置换算法(最佳页面置换算法)** :该置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率,但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,一般作为衡量其他置换算法的方法。
+- **FIFO(First In First Out) 页面置换算法(先进先出页面置换算法)** : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
+
+- **LRU (Least Currently Used)页面置换算法(最近最久未使用页面置换算法)** :LRU算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
+- **LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法)** : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
+
+### 局部性原理
+
+局部性原理是虚拟内存技术的基础,正是因为程序运行具有局部性原理,才可以只装入部分程序到内存就开始运行。
+
+局部性原理表现在以下两个方面:
+
+1. **时间局部性** :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问,产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
+2. **空间局部性** :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
+
+时间局部性是通过将近来使用的指令和数据保存到**高速缓存存储器**中,并使用高速缓存的层次结构实现。
+
+空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。
+
+### 页表
+
+操作系统将虚拟内存分块,每个小块称为一个页(Page);真实内存也需要分块,每个小块我们称为一个 Frame。
+
+Page 到 Frame 的映射,需要一种叫作页表的结构。
+
+
+
+上图展示了 Page、Frame 和页表 (PageTable)三者之间的关系。
+
+Page 大小和 Frame 大小通常相等,页表中记录的某个 Page 对应的 Frame 编号。
+
+页表也需要存储空间,比如虚拟内存大小为 10G, Page 大小是 4K,那么需要 10G/4K = 2621440 个条目。
+
+如果每个条目是 64bit,那么一共需要 20480K = 20M 页表,操作系统在内存中划分出小块区域给页表,并负责维护页表。
+
+**页表维护了虚拟地址到真实地址的映射。**
+
+每次程序使用内存时,需要把虚拟内存地址换算成物理内存地址,换算过程分为以下 3 个步骤:
+
+* 通过虚拟地址计算 Page 编号;
+
+* 查页表,根据 Page 编号,找到 Frame 编号;
+
+* 将虚拟地址换算成物理地址。
+
+#### 多级页表
+
+引入多级页表的主要目的是为了避免把全部页表一直放在内存中占用过多空间,特别是那些根本就不需要的页表就不需要保留在内存中
+
+**一级页表:**
+
+假如物理内存中一共有1048576个页,那么页表就需要总共就是`1048576 * 4B = 4M`。
+
+也就是说我需要4M连续的内存来存放这个页表,也就是一级页表。
+
+随着虚拟地址空间的增大,存放页表所需要的连续空间也会增大,在操作系统内存紧张或者内存碎片较多时,这无疑会带来额外的开销。
+
+页表寻址是用寄存器来确定一级页表地址的,所以一级页表的地址必须指向确定的物理页,否则就会出现错误,所以如果用一级页表的话,就必须把全部的页表都加载进去。
+
+**二级页表:**
+
+而使用二级页表的话,只需要加载一个页目录表(一级页表),大小为4K,可以管理1024个二级页表。
+
+可能你会有疑问,这1024个二级页表也是需要内存空间的,这下反而需要4MB+4KB的内存,反而更多了。
+
+其实二级页表并不是一定要存在内存中的,内存中只需要一个一级页表地址存在存器即可,二级页表可以使用缺页中断从外存移入内存。
+
+**多级页表属于时间换空间的典型场景**
+
+### 快表
+
+为了解决虚拟地址到物理地址的转换速度,操作系统在**页表方案**基础之上引入了**快表**来加速虚拟地址到物理地址的转换
+
+我们可以把快表理解为一种特殊的**高速缓冲存储器(Cache)**,其中的内容是页表的一部分或者全部内容,作为页表的 Cache,它的作用与页表相似,但是提高了访问速率,由于采用页表做地址转换,读写内存数据时 CPU 要访问两次主存,有了快表,有时只要访问一次高速缓冲存储器,一次主存,这样可加速查找并提高指令执行速度。
+
+**使用快表之后的地址转换流程是这样的:**
+
+1. 根据虚拟地址中的页号查快表;
+2. 如果该页在快表中,直接从快表中读取相应的物理地址;
+3. 如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中;
+4. 当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
+
+
+
+### 内存管理单元
+
+在 CPU 中一个小型的设备——内存管理单元(MMU)
+
+
+
+当 CPU 需要执行一条指令时,如果指令中涉及内存读写操作,CPU 会把虚拟地址给 MMU,MMU 自动完成虚拟地址到真实地址的计算;然后,MMU 连接了地址总线,帮助 CPU 操作真实地址。
+
+在不同 CPU 的 MMU 可能是不同的,因此这里会遇到很多跨平台的问题。
+
+解决跨平台问题不但有繁重的工作量,更需要高超的编程技巧。
+
+### 动态分区分配算法
+
+内存分配算法,大体来说分为:**连续式分配 与 非连续式分配**
+
+连续式分配就是把所以要执行的程序 **完整的,有序的** 存入内存,连续式分配又可以分为**固定分区分配 和 动态分区分配**
+
+非连续式分配就是把要执行的程序按照一定规则进行拆分,显然这样更有效率,现在的操作系统通常也都是采用这种方式分配内存
+
+所谓动态分区分配,就是指**内存在初始时不会划分区域,而是会在进程装入时,根据所要装入的进程大小动态地对内存空间进行划分,以提高内存空间利用率,降低碎片的大小**
+
+动态分区分配算法有以下四种:
+
+> 首次适应算法(First Fit)
+
+空闲分区以地址递增的次序链接,分配内存时顺序查找,找到大小满足要求的第一个空闲分区就进行分配
+
+
+
+又称循环首次适应法,由首次适应法演变而成,不同之处是分配内存时从上一次查找结束的位置开始继续查找
+
+
+
+> 最佳适应算法(Best Fit)
+
+空闲分区按容量递增形成分区链,找到第一个能满足要求的空闲分区就进行分配
+
+
+
+又称最大适应算法,空闲分区以容量递减的次序链接,找到第一个能满足要求的空闲分区(也就是最大的分区)就进行分配
+
+
+
+**总结**
+
+首次适应不仅最简单,通常也是最好最快,不过首次适应算法会使得内存低地址部分出现很多小的空闲分区,而每次查找都要经过这些分区,因此也增加了查找的开销。
+
+邻近算法试图解决这个问题,但实际上,它常常会导致在内存的末尾分配空间分裂成小的碎片,它通常比首次适应算法结果要差。
+
+最佳适应算法导致大量碎片,最坏适应算法导致没有大的空间。
+
+### 内存覆盖
+
+覆盖与交换技术是在程序用来扩充内存的两种方法。
+
+早期的计算机系统中,主存容量很小,虽然主存中仅存放一道用户程序,但是存储空间放不下用户进程的现象也经常发生,这一矛盾可以用覆盖技术来解决。
+
+**覆盖的基本思想是:**
+
+由于程序运行时并非任何时候都要访问程序及数据的各个部分(尤其是大程序),因此可以把用户空间分成一个固定区和若干个覆盖区。
+
+将经常活跃的部分放在固定区,其余部分按调用关系分段。
+
+首先将那些即将要访问的段放入覆盖区,其他段放在外存中,在需要调用前,系统再将其调入覆盖区,替换覆盖区中原有的段。
+
+覆盖技术的特点是打破了必须将一个进程的全部信息装入主存后才能运行的限制,但当同时运行程序的代码量大于主存时仍不能运行。
+
+### 内存交换
+
+**交换的基本思想**
+
+把处于等待状态(或在CPU调度原则下被剥夺运行权利)的程序从内存移到辅存,把内存空间腾出来,这一过程又叫换出;
+
+把准备好竞争CPU运行的程序从辅存移到内存,这一过程又称为换入。
+
+> 例如,有一个CPU釆用时间片轮转调度算法的多道程序环境。
+
+时间片到,内存管理器将刚刚执行过的进程换出,将另一进程换入到刚刚释放的内存空间中。
+
+同时,CPU调度器可以将时间片分配给其他已在内存中的进程。
+
+每个进程用完时间片都与另一进程交换。
+
+理想情况下,内存管理器的交换过程速度足够快,总有进程在内存中可以执行。
+
+> 交换技术主要是在不同进程(或作业)之间进行,而覆盖则用于同一个程序或进程中。
+
+由于覆盖技术要求给出程序段之间的覆盖结构,使得其对用户和程序员不透明,所以对于主存无法存放用户程序的矛盾
+
+现代操作系统是通过虚拟内存技术来解决的,覆盖技术则已成为历史;而交换技术在现代操作系统中仍具有较强的生命力。
+
+
+
+## 常见面试题
+
+**进程、线程的区别**
+
+操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
+
+
+
+调度:线程作为CPU调度和分配的基本单位,进程作为拥有资源的基本单位;
+
+并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
+
+> 拥有资源:
+
+进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
+
+进程所维护的是程序所包含的资源(静态资源), 如:地址空间,打开的文件句柄集,文件系统状态,信号处理handler等;
+
+线程所维护的运行相关的资源(动态资源),如:运行栈,调度相关的控制信息,待处理的信号集等;
+
+> 系统开销:
+
+在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
+
+但是进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。
+
+线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个进程死掉就等于所有的线程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
+
+**一个进程可以创建多少线程**
+
+理论上,一个进程可用虚拟空间是2G,默认情况下,线程的栈的大小是1MB,所以理论上最多只能创建2048个线程。
+
+如果要创建多于2048的话,必须修改编译器的设置。
+
+在一般情况下,你不需要那么多的线程,过多的线程将会导致大量的时间浪费在线程切换上,给程序运行效率带来负面影响。
+
+**外中断和异常有什么区别**
+
+外中断是指由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求,此外还有时钟中断、控制台中断等。
+
+而异常时由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
+
+**解决Hash冲突四种方法**
+
+开放定址法
+
+- 开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
+
+链地址法
+
+- 将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
+
+再哈希法
+
+- 当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
+
+建立公共溢出区
+
+- 将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
+
+**分页机制和分段机制有哪些共同点和区别**
+
+共同点
+
+- 分页机制和分段机制都是为了提高内存利用率,较少内存碎片。
+- 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
+
+区别
+
+- 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
+- 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
+- 分页是一维地址空间,分段是二维的。
+
+**介绍一下几种典型的锁**
+
+> 读写锁
+
+- 可以同时进行多个读
+- 写者必须互斥(只允许一个写者写,也不能读者写者同时进行)
+- 写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
+
+> 互斥锁
+
+一次只能一个线程拥有互斥锁,其他线程只有等待
+
+互斥锁是在抢锁失败的情况下主动放弃CPU进入睡眠状态直到锁的状态改变时再唤醒,而操作系统负责线程调度,为了实现锁的状态发生改变时唤醒阻塞的线程或者进程,需要把锁交给操作系统管理,所以互斥锁在加锁操作时涉及上下文的切换。
+
+互斥锁实际的效率还是可以让人接受的,加锁的时间大概100ns左右,而实际上互斥锁的一种可能的实现是先自旋一段时间,当自旋的时间超过阀值之后再将线程投入睡眠中,因此在并发运算中使用互斥锁(每次占用锁的时间很短)的效果可能不亚于使用自旋锁
+
+> 条件变量
+
+互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。
+
+而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。
+
+当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。
+
+一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。
+
+总的来说**互斥锁是线程间互斥的机制,条件变量则是同步机制。**
+
+> 自旋锁
+
+如果进线程无法取得锁,进线程不会立刻放弃CPU时间片,而是一直循环尝试获取锁,直到获取为止。
+
+如果别的线程长时期占有锁,那么自旋就是在浪费CPU做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。
+
+虽然它的效率比互斥锁高,但是它也有些不足之处:
+
+- 自旋锁一直占用CPU,在未获得锁的情况下,一直进行自旋,所以占用着CPU,如果不能在很短的时间内获得锁,无疑会使CPU效率降低。
+- 在用自旋锁时有可能造成死锁,当递归调用时有可能造成死锁。
+
+**如何让进程后台运行**
+
+1.命令后面加上&即可,实际上,这样是将命令放入到一个作业队列中了
+
+2.ctrl + z 挂起进程,使用jobs查看序号,在使用bg %序号后台运行进程
+
+3.nohup + &,将标准输出和标准错误缺省会被重定向到 `nohup.out` 文件中,忽略所有挂断(SIGHUP)信号
+
+```
+nohup ping www.ibm.com &
+```
+
+4.运行指令前面 + setsid,使其父进程变成init进程,不受SIGHUP信号的影响
+
+```
+[root@pvcent107 ~]## setsid ping www.ibm.com
+[root@pvcent107 ~]## ps -ef |grep www.ibm.com
+root 31094 1 0 07:28 ? 00:00:00 ping www.ibm.com
+root 31102 29217 0 07:29 pts/4 00:00:00 grep www.ibm.com
+```
+
+上例中我们的进程 ID(PID)为31094,而它的父 ID(PPID)为1(即为 init 进程 ID),并不是当前终端的进程 ID。
+
+> 5.将命令+ &放在()括号中,也可以是进程不受HUP信号的影响
+
+```
+[root@pvcent107 ~]## (ping www.ibm.com &)
+```
+
+**异常和中断的区别**
+
+> 中断
+
+当我们在敲击键盘的同时就会产生中断,当硬盘读写完数据之后也会产生中断,所以,我们需要知道,中断是由硬件设备产生的,而它们从物理上说就是电信号,之后,它们通过中断控制器发送给CPU,接着CPU判断收到的中断来自于哪个硬件设备(这定义在内核中),最后,由CPU发送给内核,有内核处理中断。
+
+下面这张图显示了中断处理的流程:
+
+
+
+> 相同点
+
+- 最后都是由CPU发送给内核,由内核去处理
+- 处理程序的流程设计上是相似的
+
+> 不同点
+
+- 产生源不相同,异常是由CPU产生的,而中断是由硬件设备产生的
+- 内核需要根据是异常还是中断调用不同的处理程序
+- 中断不是时钟同步的,这意味着中断可能随时到来;异常由于是CPU产生的,所以它是时钟同步的
+- 当处理中断时,处于中断上下文中;处理异常时,处于进程上下文中
+
+---
+
+>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ](https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ)
+
+
diff --git a/docs/src/cs/wangluo.md b/docs/cs/wangluo.md
similarity index 95%
rename from docs/src/cs/wangluo.md
rename to docs/cs/wangluo.md
index 5482d155e5..36e001d342 100644
--- a/docs/src/cs/wangluo.md
+++ b/docs/cs/wangluo.md
@@ -5,12 +5,12 @@ tag:
- 计算机网络
---
-# 计算机网络核心知识点
+# 计算机网络核心知识点大梳理
>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw](https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw)
-
+
## OSI七层模型
@@ -94,7 +94,7 @@ Linux给WIndows发包,不同系统语法不一致,如exe不能在`Linux`下
一层物理层时数据被称为**比特流**(Bits)。
-
+
## TCP和IP模型
@@ -107,7 +107,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
- 第三层:网络层,主要是IP协议。主要负责寻址(找到目标设备的位置)
- 第四层:数据链路层,主要是负责转换数字信号和物理二进制信号。
-
+
**四层网络协议的作用**
@@ -127,7 +127,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
在数据链路层,对应的协议也会在IP数据包前端加上以太网的部首。
-
+
源设备和目标设备通过网线连接,就可以通过物理层的二进制传输数据。
@@ -135,7 +135,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
数据链路层>网络层>传输层>应用层,一层层的解码,最后就可以在浏览器中得到目标设备传送过来的**index.html**。
-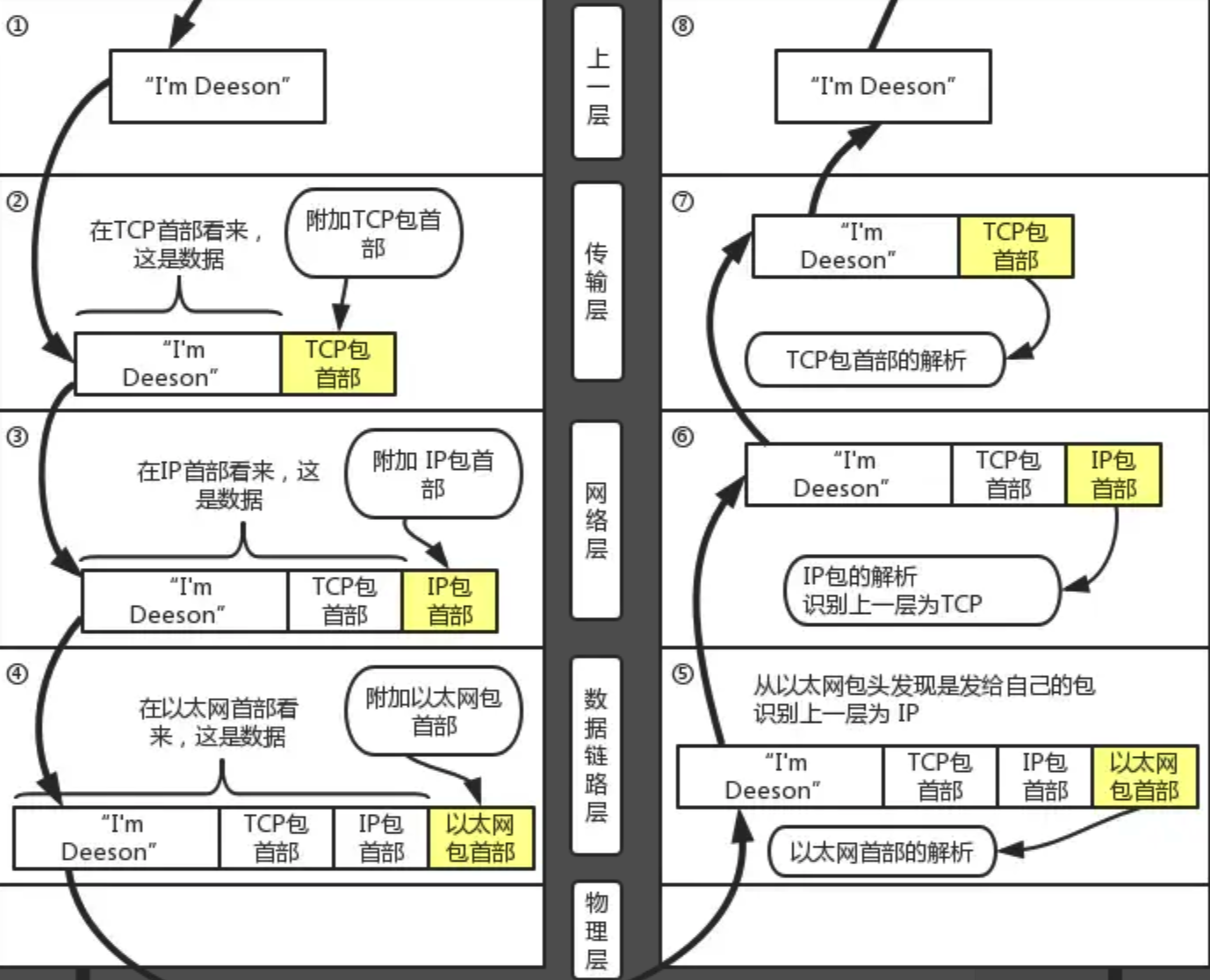
+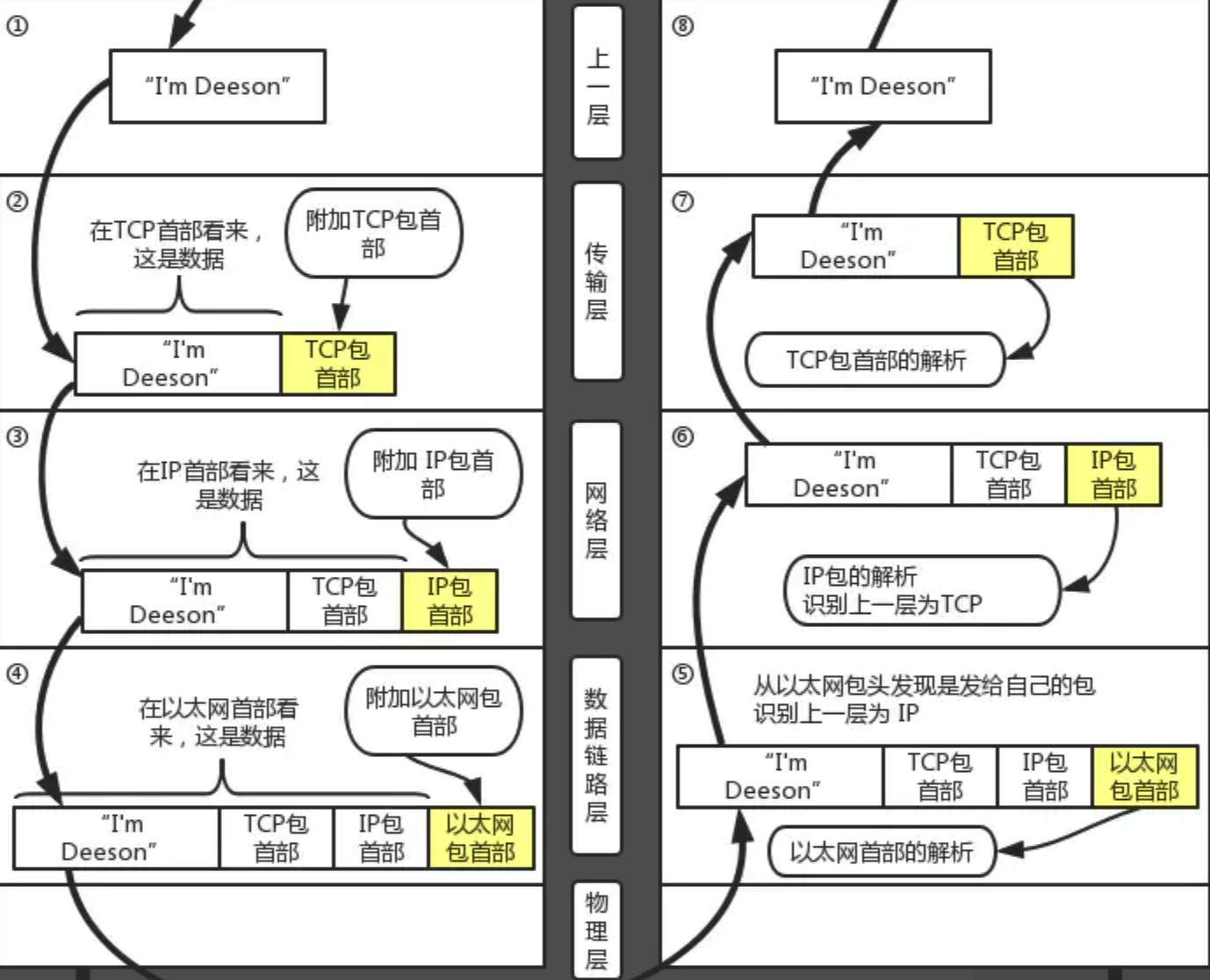
**TCP/IP协议族**
@@ -145,7 +145,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
具体来说,在网络层是IP/ICMP协议、在传输层是TCP/UDP协议、在应用层是SMTP、FTP、以及 HTTP 等。他们都属于 TCP/IP 协议。
-
+
## 网络设备
@@ -179,7 +179,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
它通过识别目的 IP 地址的**网络号**,再根据**路由表**进行数据转发
-
+
## HTTP
@@ -374,7 +374,7 @@ HTTPS 协议会对传输的数据进行加密,而加密过程是使用了非
HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过程如下:
-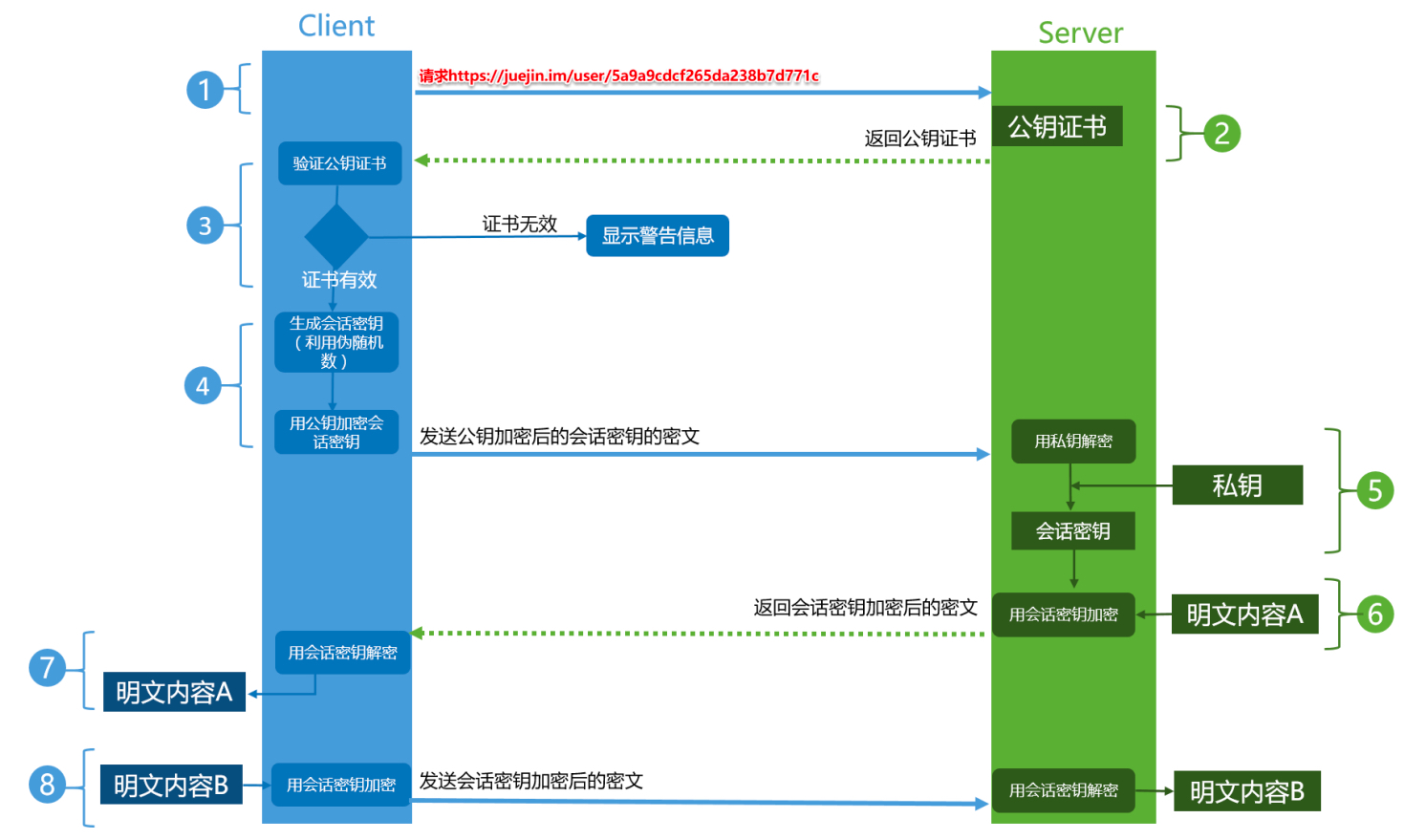
+
* Client发起一个HTTPS的请求
* Server把事先配置好的公钥证书返回给客户端。
@@ -395,7 +395,7 @@ HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过
通过数字证书的方式保证服务器公钥的身份,解决冒充的风险。
-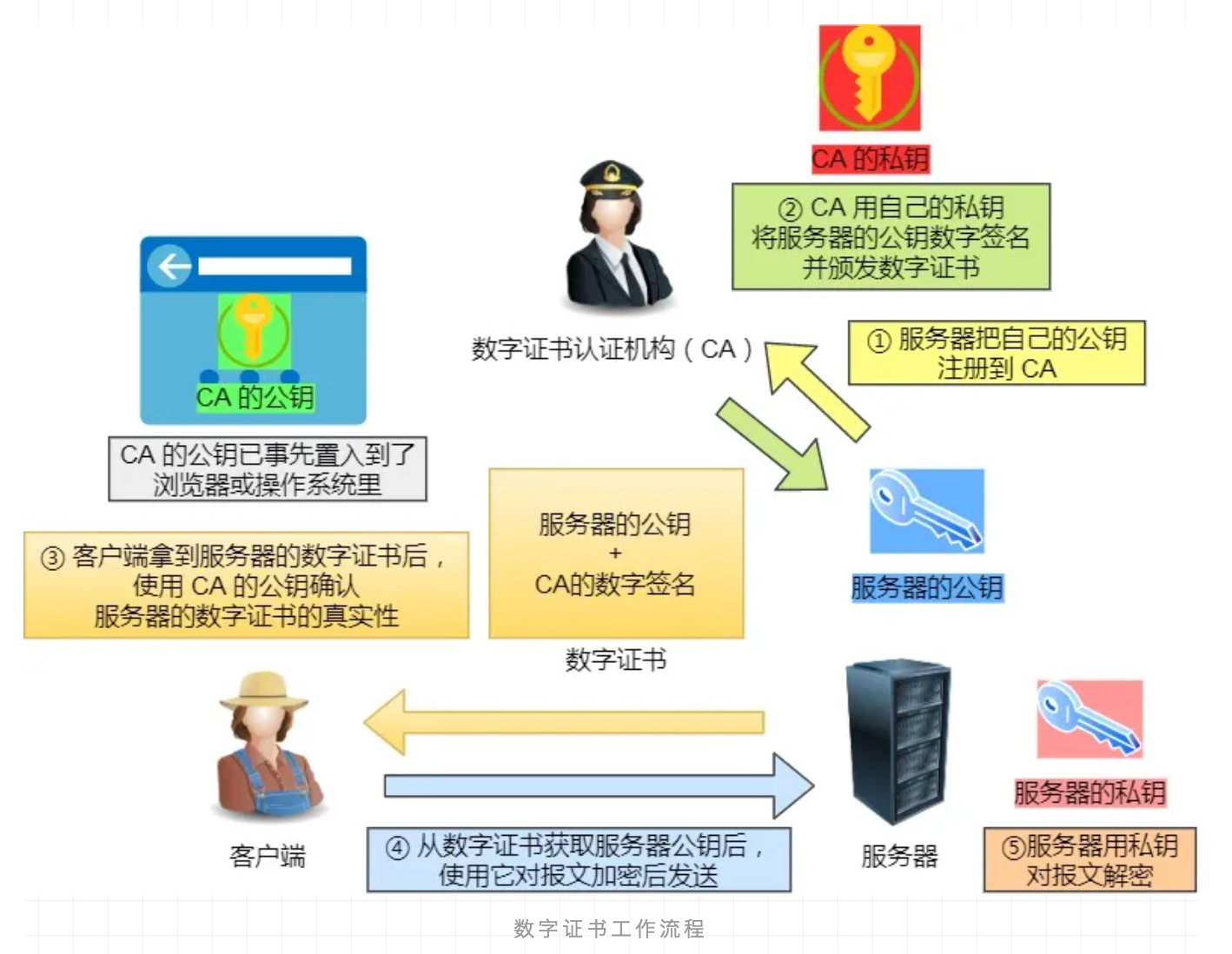
+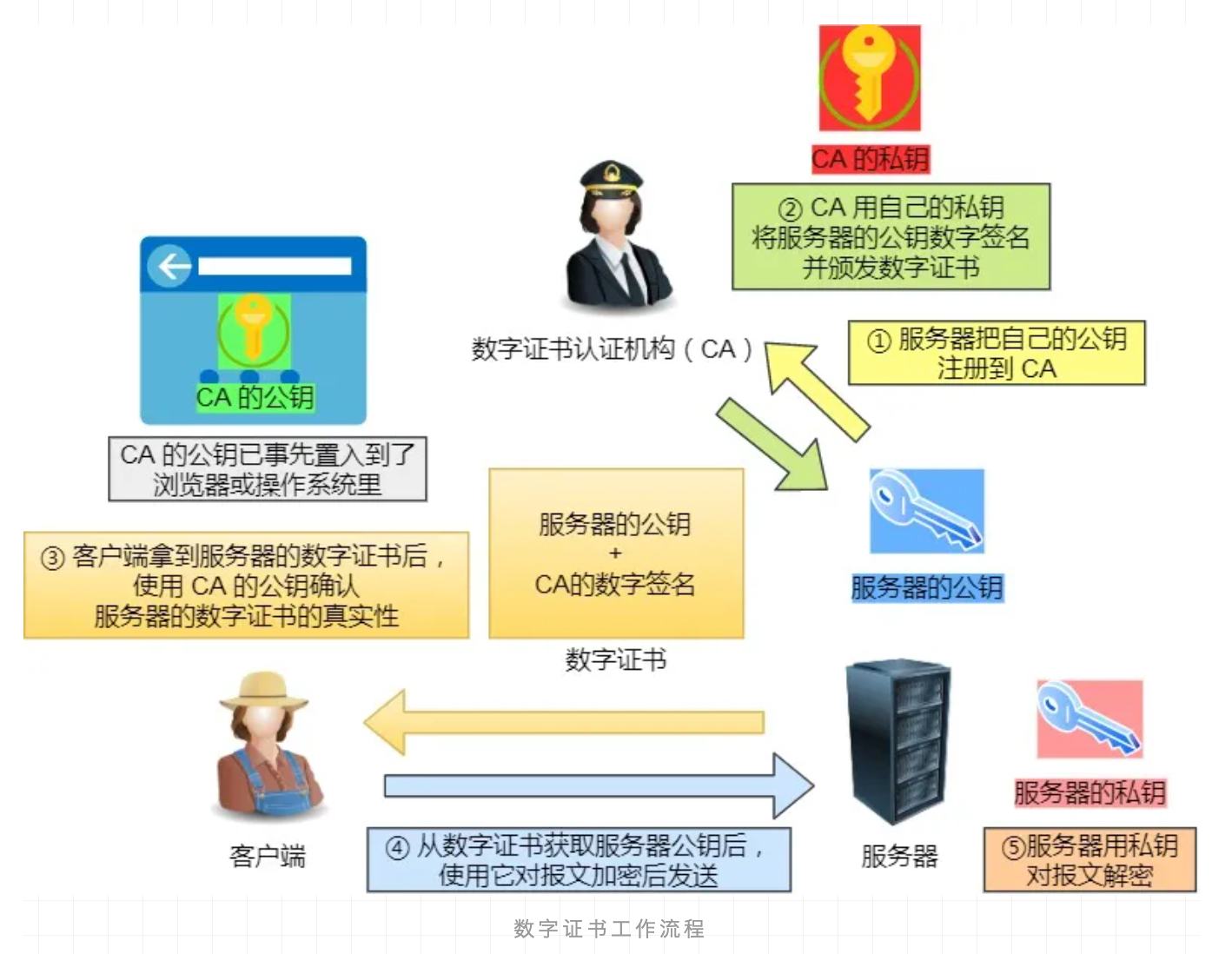
### 请求报文
@@ -403,7 +403,7 @@ HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过
HTTP 请求报文由3部分组成(请求行+请求头+请求体)
-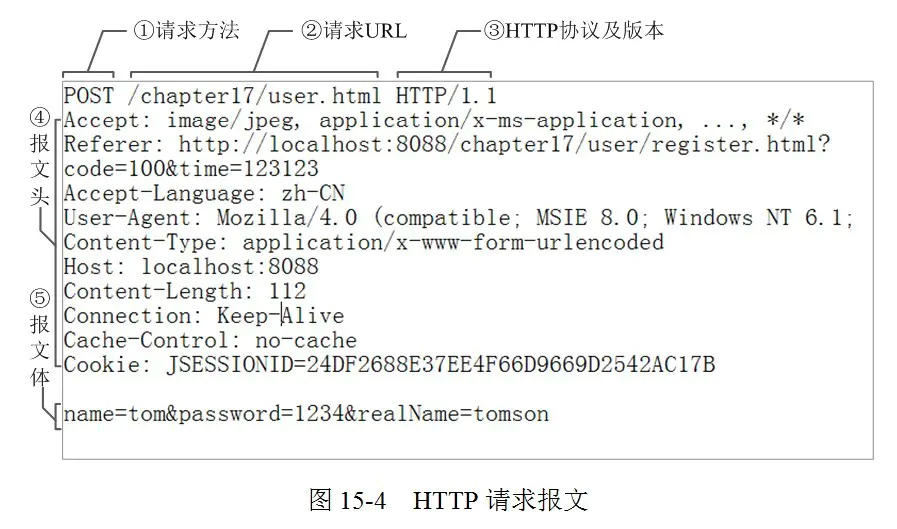
+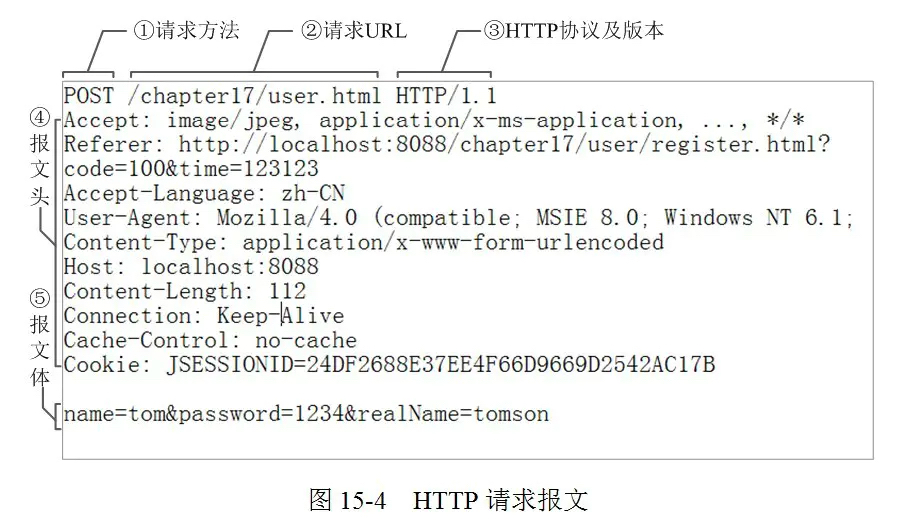
**常见的HTTP报文头属性**
@@ -431,7 +431,7 @@ HTTP 请求报文由3部分组成(请求行+请求头+请求体)
响应报文与请求报文一样,由三个部分组成(响应行,响应头,响应体)
-
+
**HTTP响应报文属性**
@@ -445,7 +445,7 @@ HTTP 请求报文由3部分组成(请求行+请求头+请求体)
- 服务端可以设置客户端的cookie
-
+
## TCP
@@ -499,7 +499,7 @@ TCP的全部功能体现在它首部中各字段的作用
> 1. 首部前20个字符固定、后面有4n个字节是根据需而增加的选项
> 2. 故 TCP首部最小长度 = 20字节
-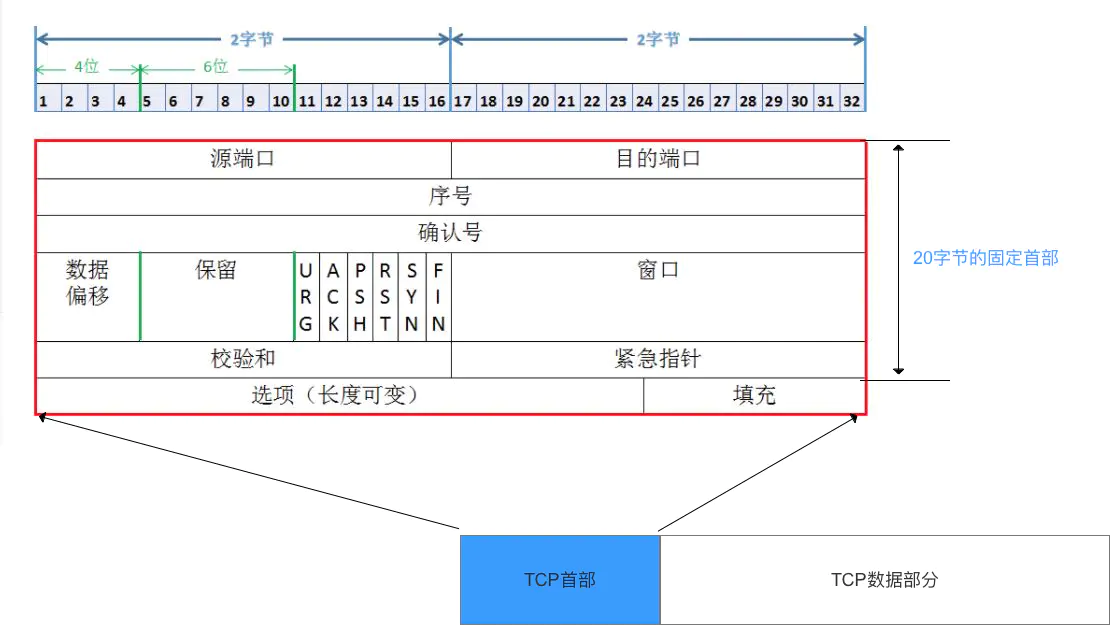
+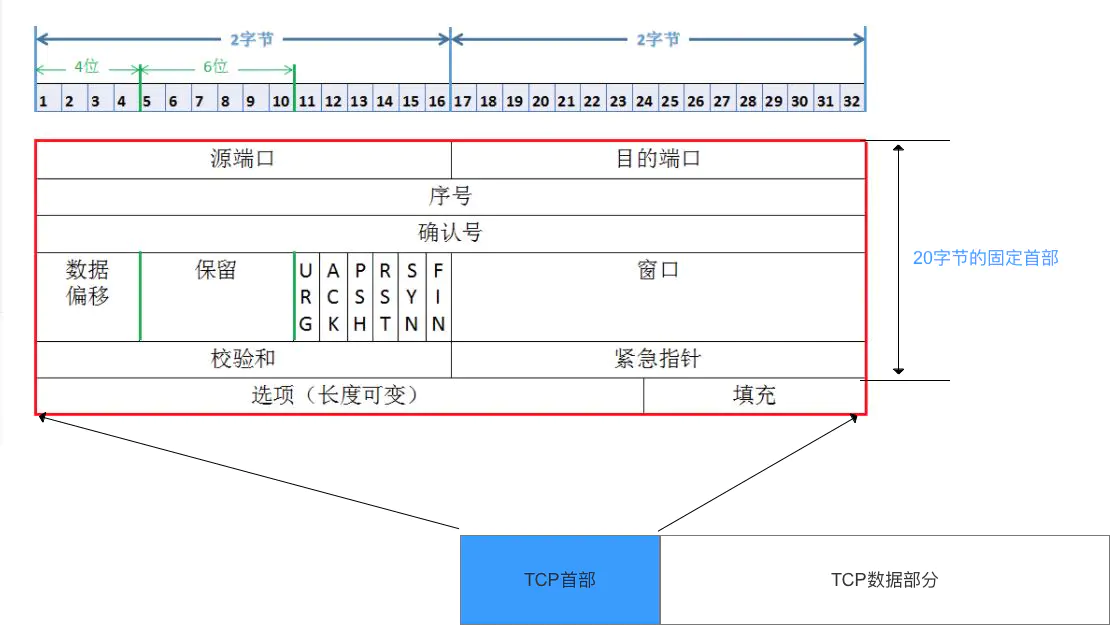
**端口**:
@@ -565,7 +565,7 @@ TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲
### 三次握手
-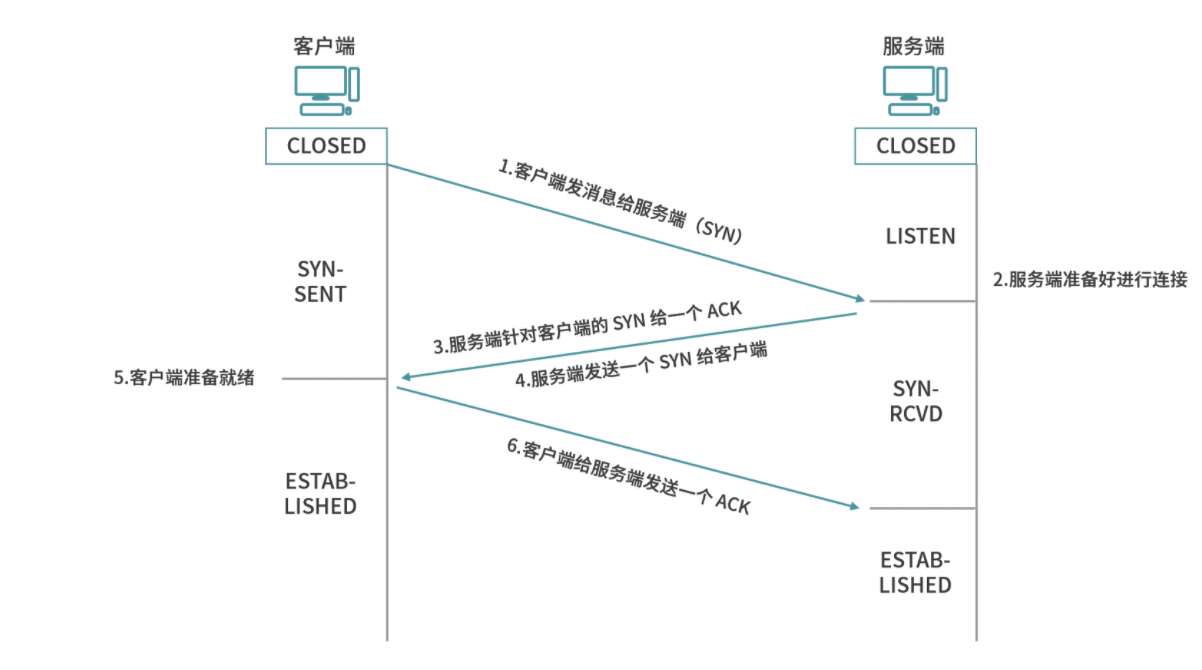
+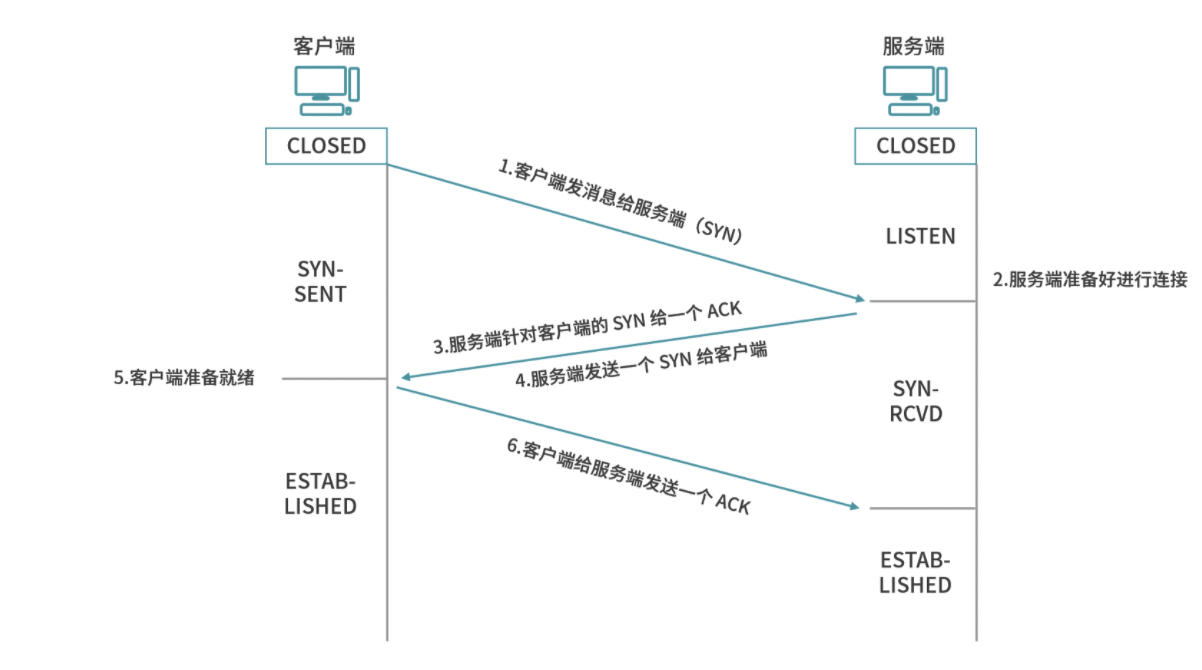
**第一次握手**:
@@ -625,7 +625,7 @@ TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲
### 四次挥手
-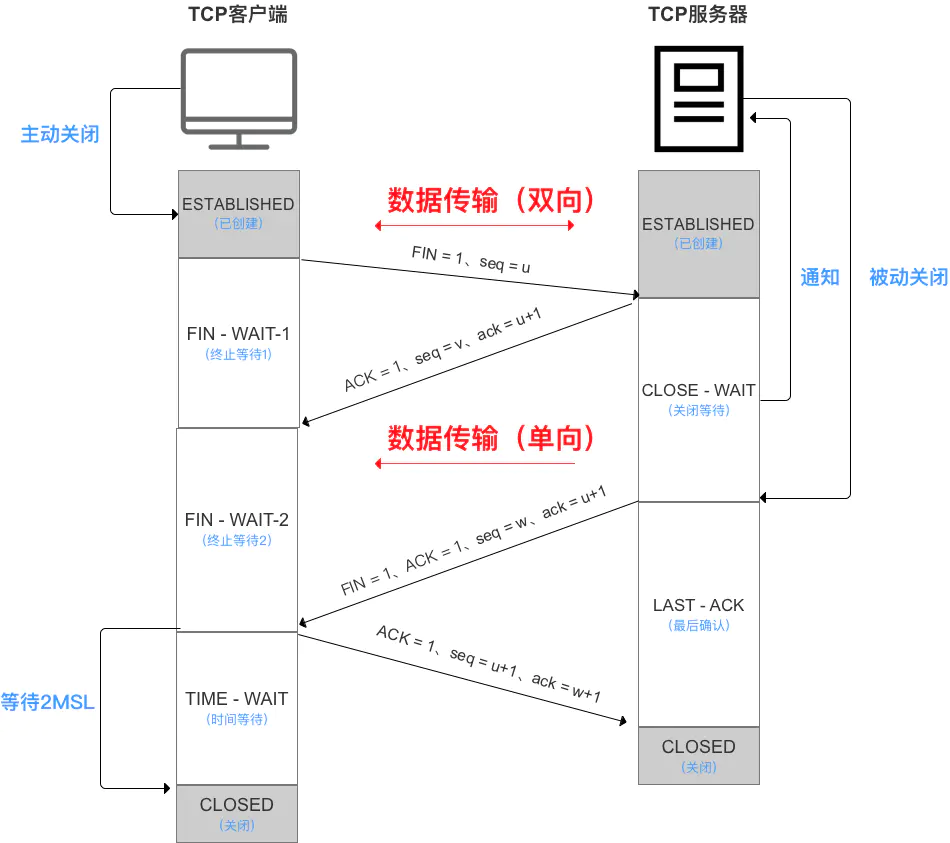
+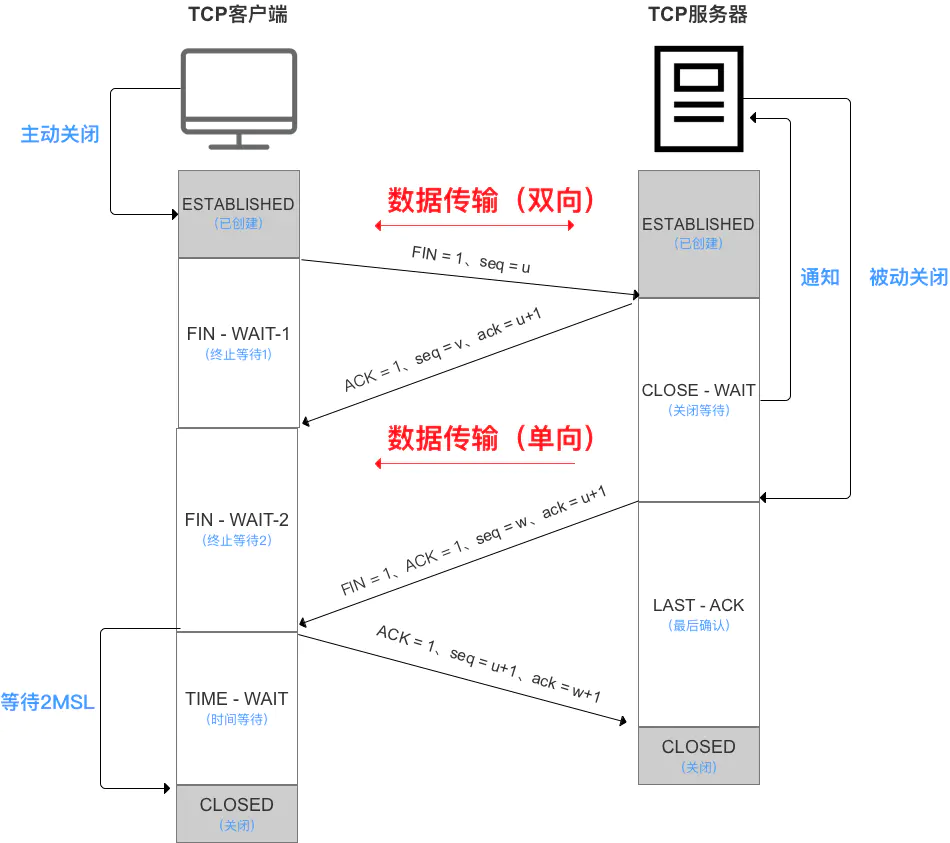
挥手请求可以是Client端,也可以是Server端发起的,我们假设是Client端发起:
@@ -688,7 +688,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧
-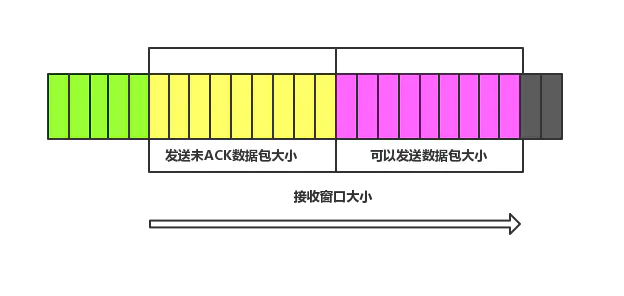
+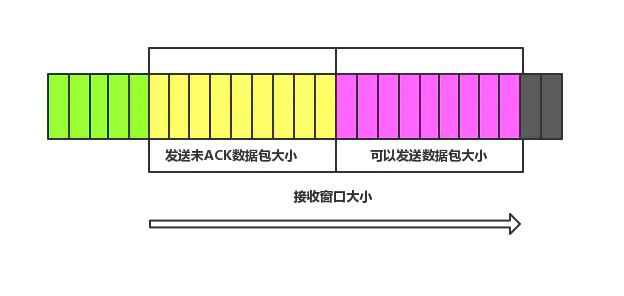
滑动窗口由四部分组成每个字节的数据都有唯一顺序的编码,随着时间发展,未确认部分与可以发送数据包编码部分向右移动,形式滑动窗口
@@ -717,7 +717,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
主要的方式就是接收方返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
-
+
**流量控制引发的死锁**
@@ -796,7 +796,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
注意:拥塞避免并非完全能够避免了阻塞,而是使网络比较不容易出现拥塞。
-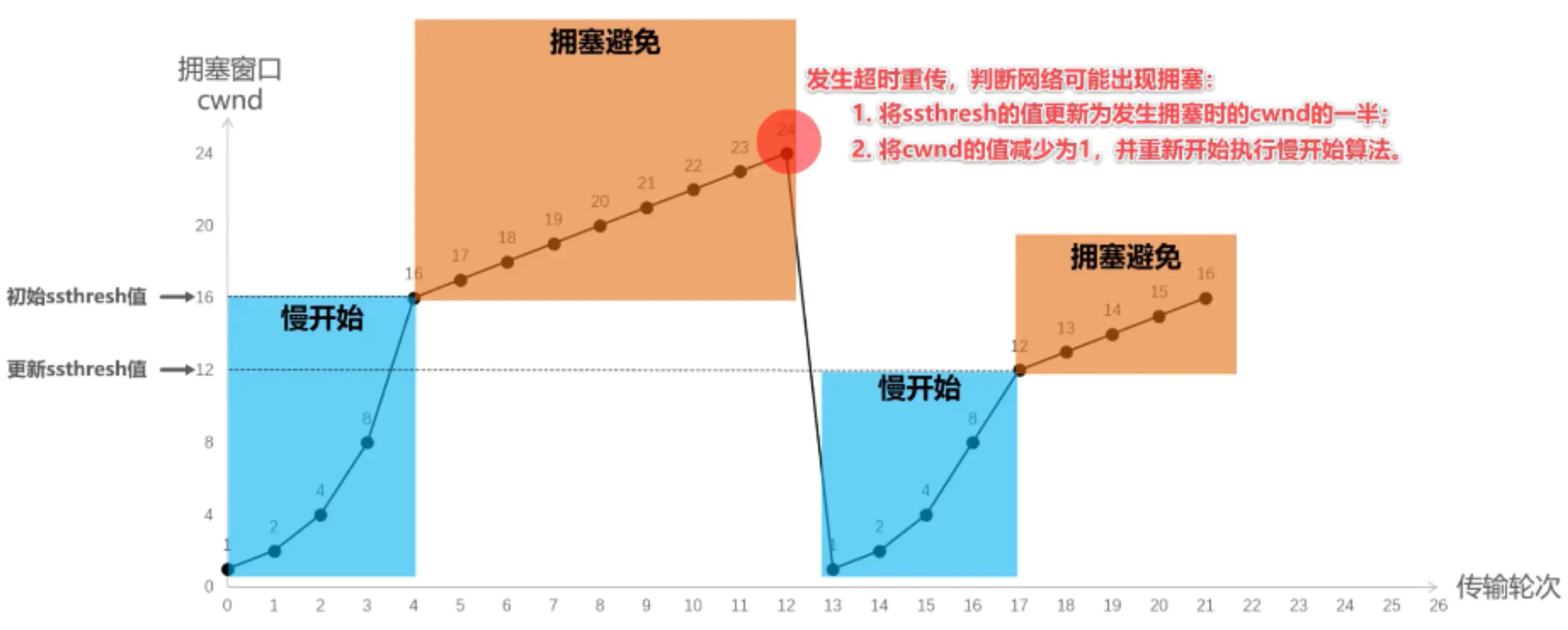
+
**快重传算法**
@@ -816,19 +816,19 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。
-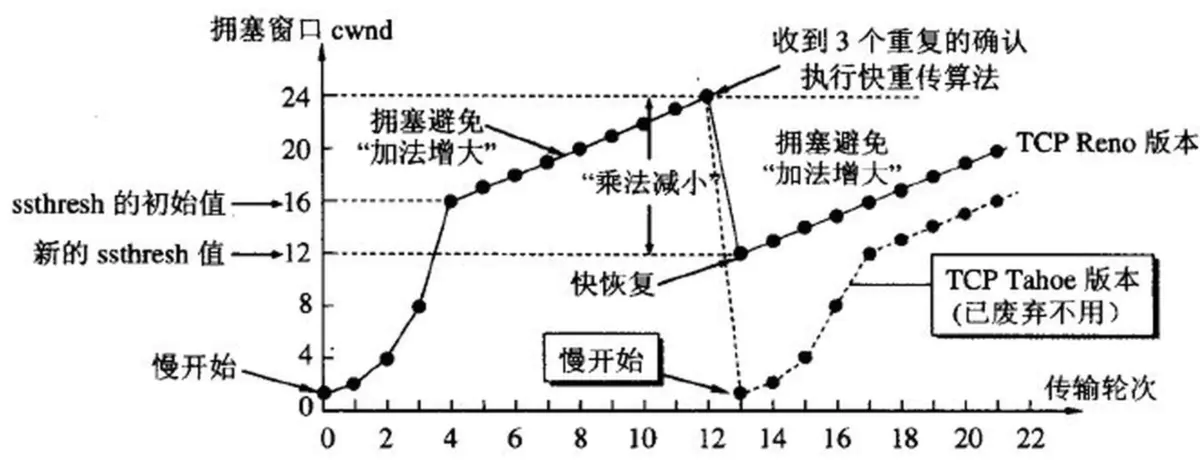
+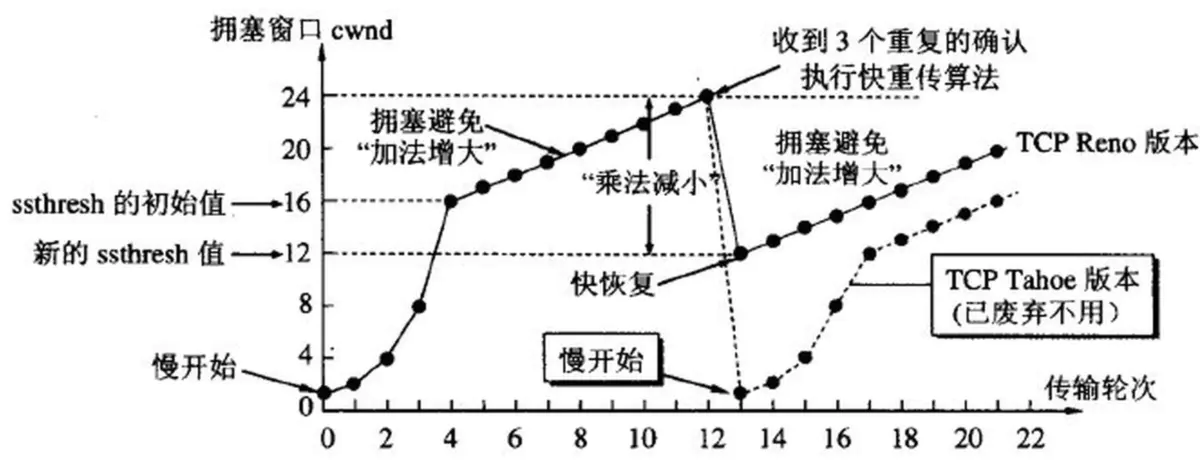
### Socket
即套接字,是应用层 与 `TCP/IP` 协议族通信的中间软件抽象层,表现为一个封装了 TCP / IP协议族 的编程接口(API)
-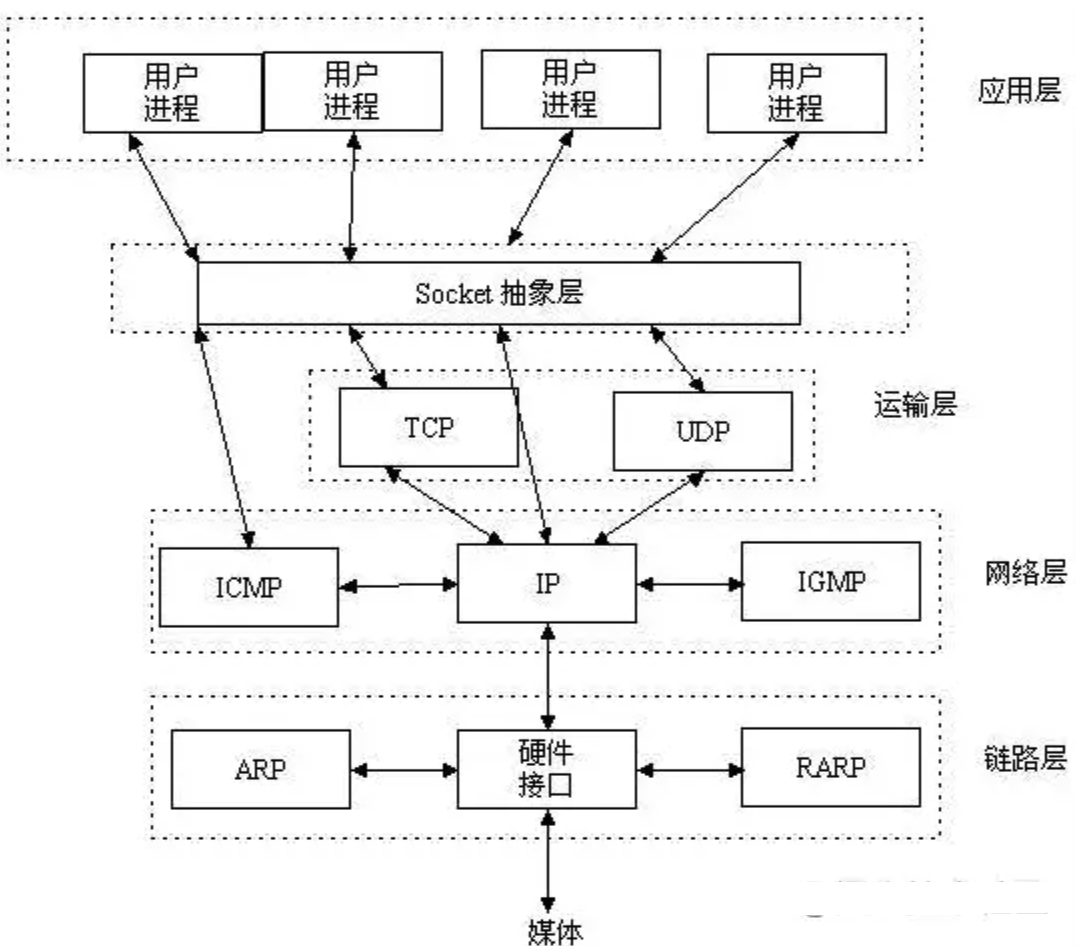
+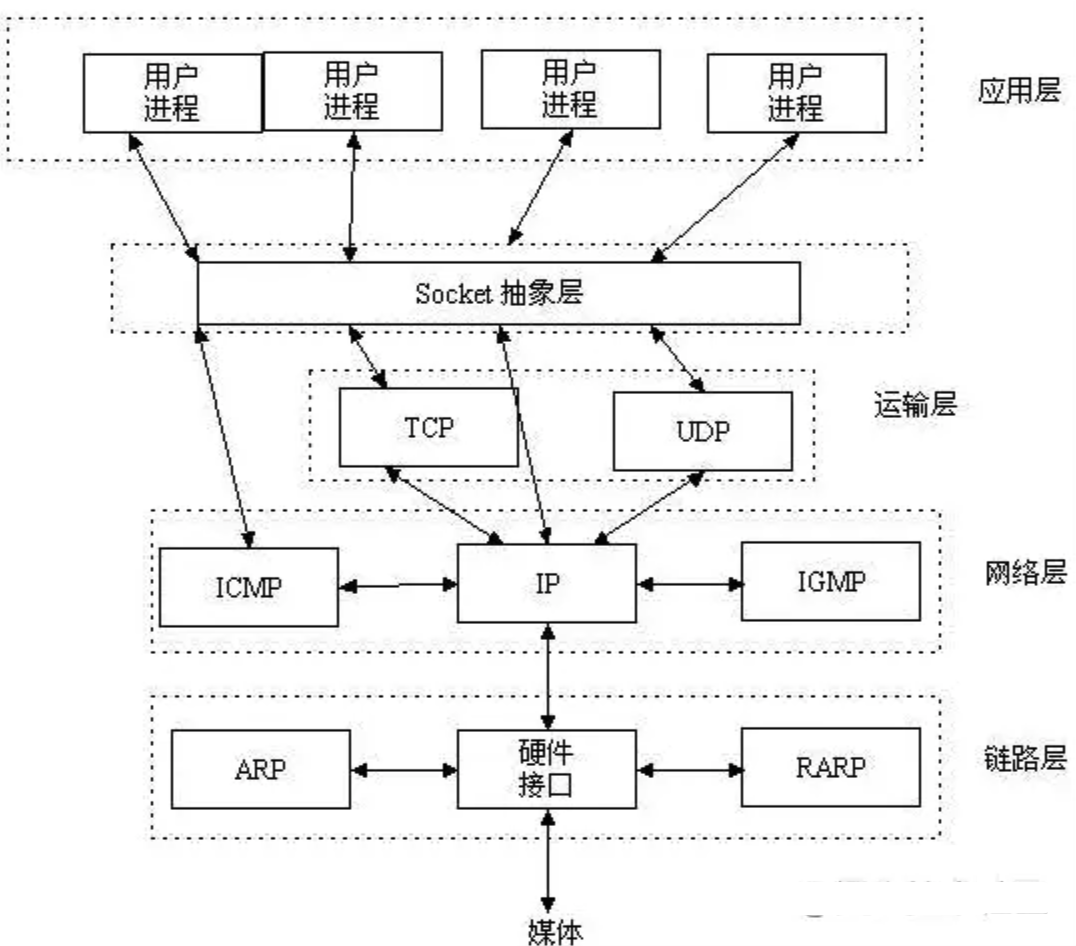
`Socket`不是一种协议,而是一个编程调用接口(`API`),属于传输层(主要解决数据如何在网络中传输)
对用户来说,只需调用Socket去组织数据,以符合指定的协议,即可通信
-
+
## UDP
@@ -874,7 +874,7 @@ TFTP、DNS、DHCP、TFTP、SNMP(简单网络管理协议)、RIP基于不可靠
UDP的报文段共有2个字段:数据字段 + 首部字段
-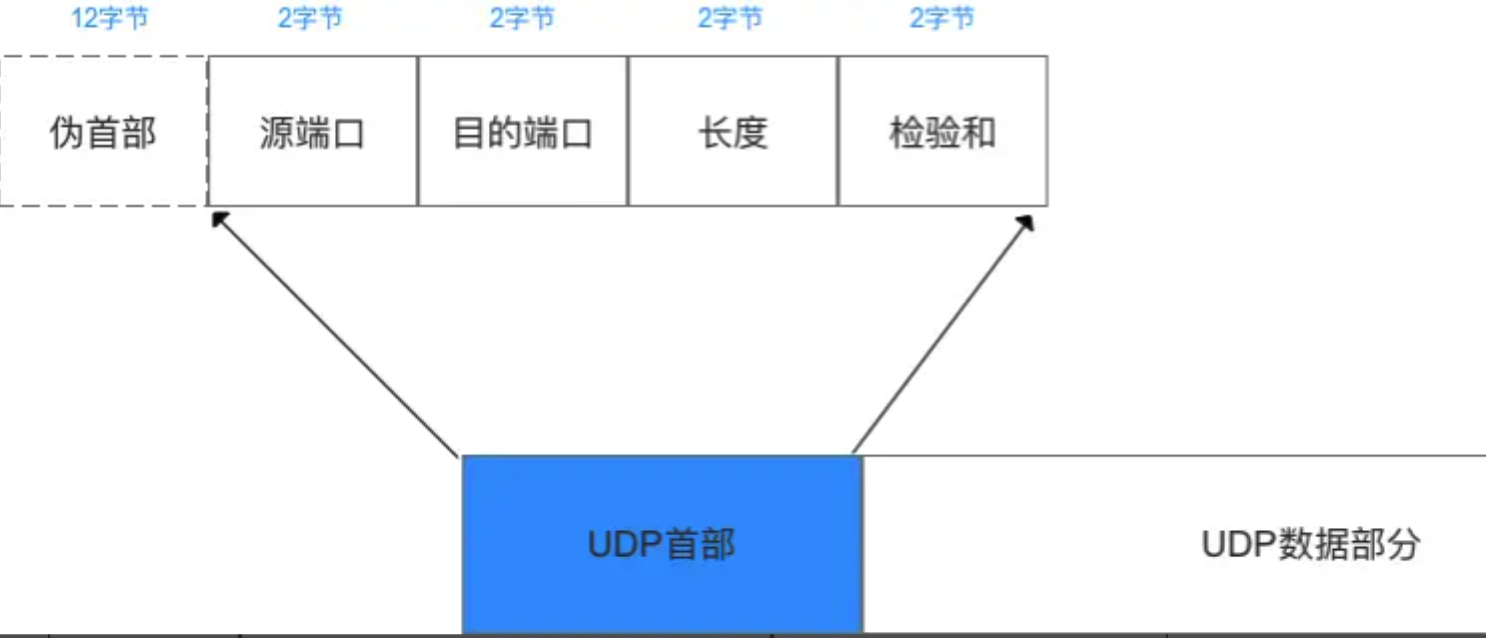
+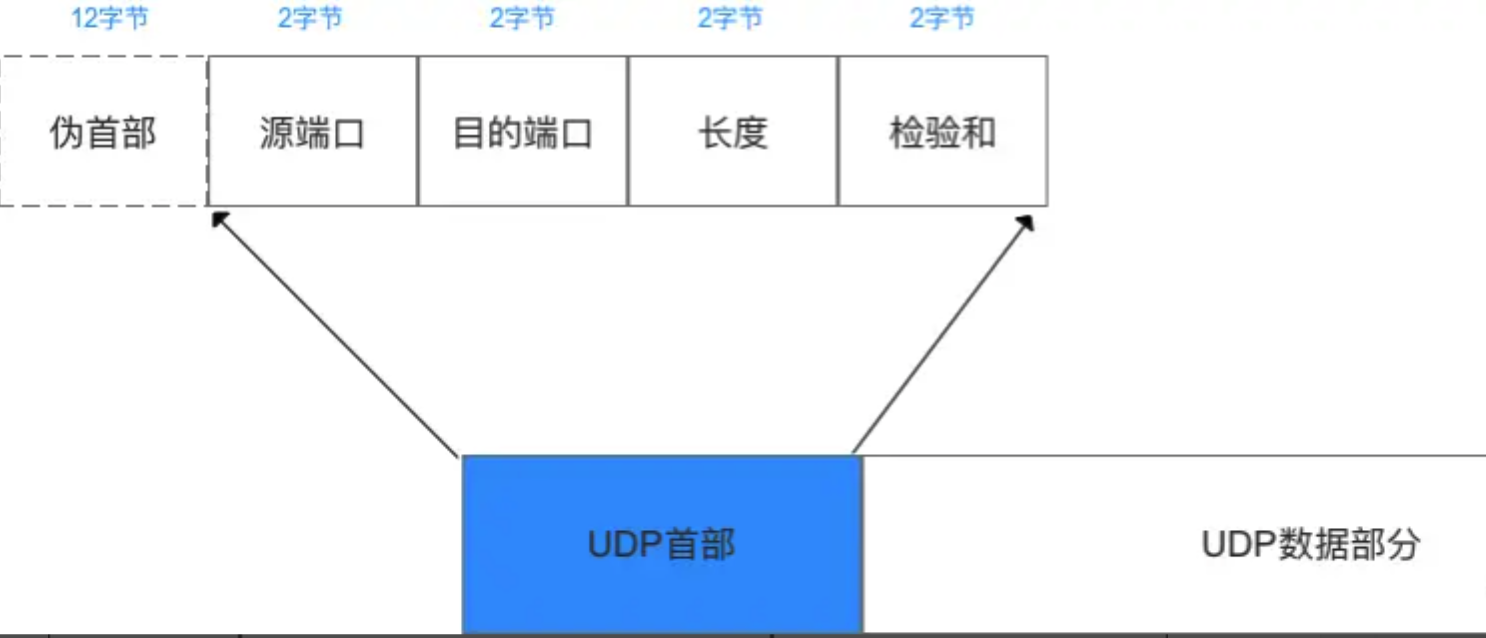
**UDP报文中每个字段的含义如下:**
@@ -927,7 +927,7 @@ IP地址表示为:`xxx.xxx.xxx.xxx`
IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的IP地址,D、E类为特殊地址。
-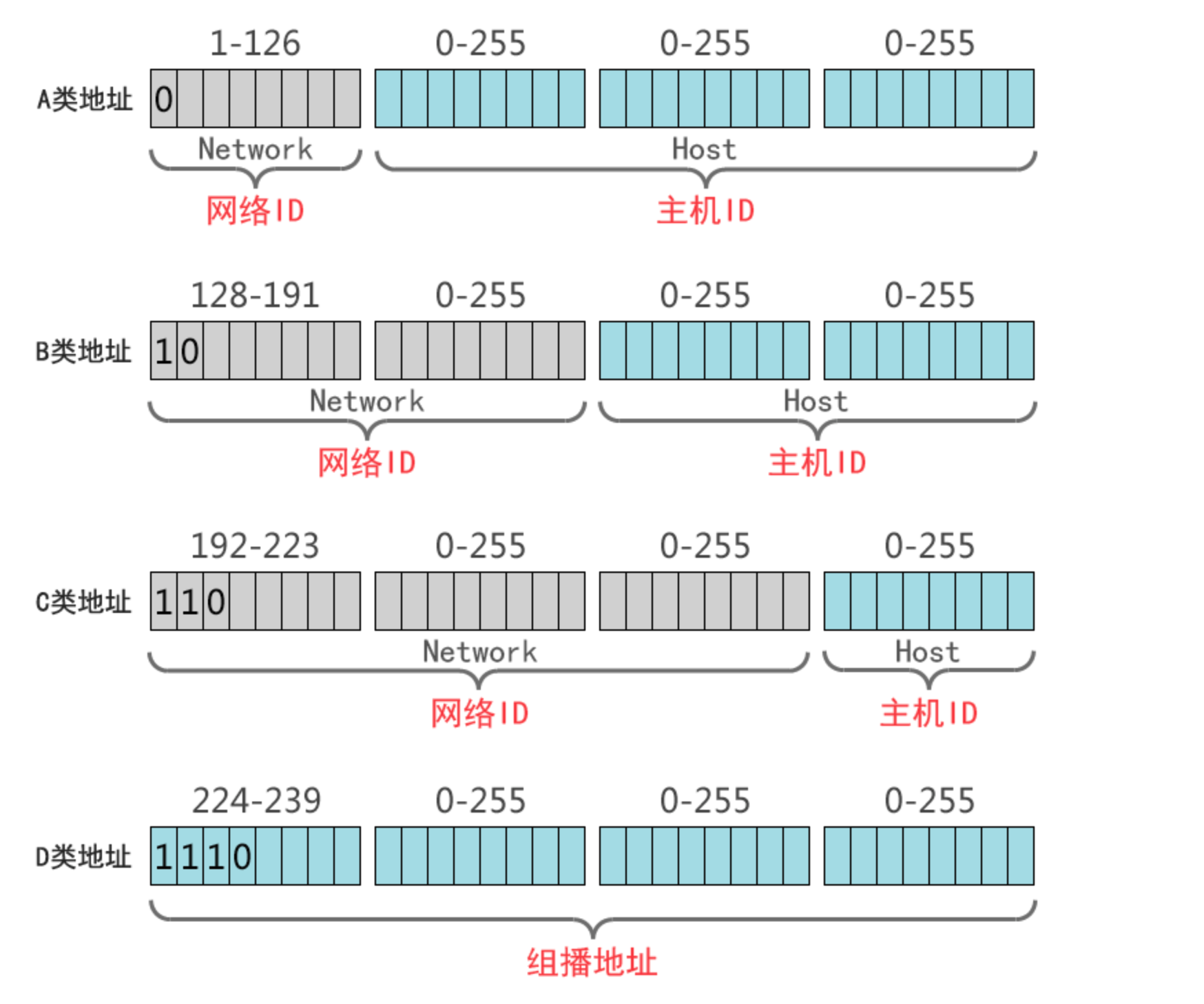
+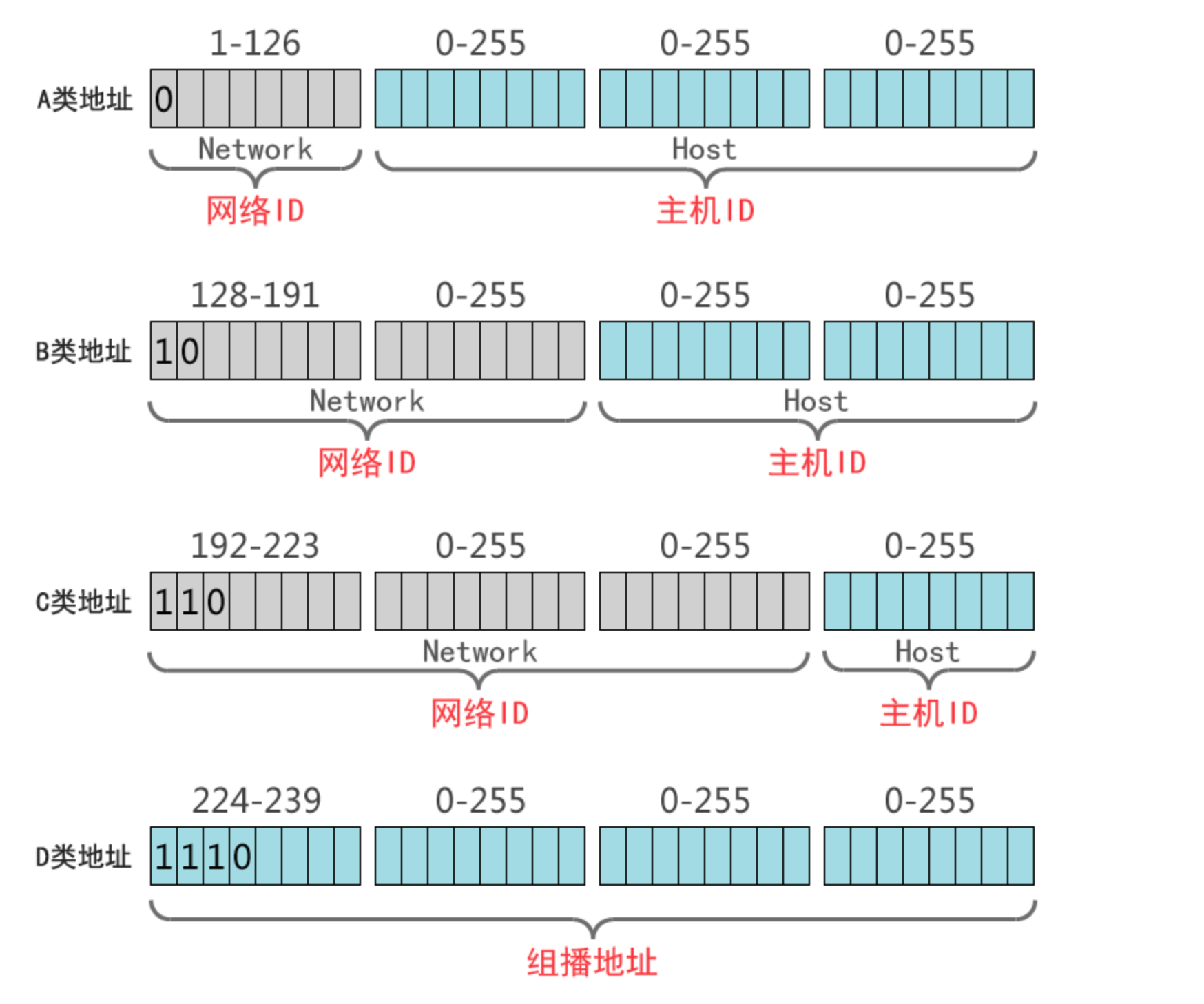
### 子网掩码
@@ -971,7 +971,7 @@ IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的I
但是A与C,A与D,B与C,B与D它们之间不属于同一网段,所以它们通信是要经过本地网关,然后路由器根据对方IP地址,在路由表中查找恰好有匹配到对方IP地址的直连路由,于是从另一边网关接口转发出去实现互连
-
+
**子网掩码和IP地址的关系**
@@ -987,7 +987,7 @@ IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的I
将得出的结果转化为十进制,便得到网络地址。
-
+
### 网关
@@ -1051,9 +1051,9 @@ DNS通过主机名,最终得到该主机名对应的IP地址的过程叫做域
将主机域名转换为ip地址,属于应用层协议,使用UDP传输。
-
+
-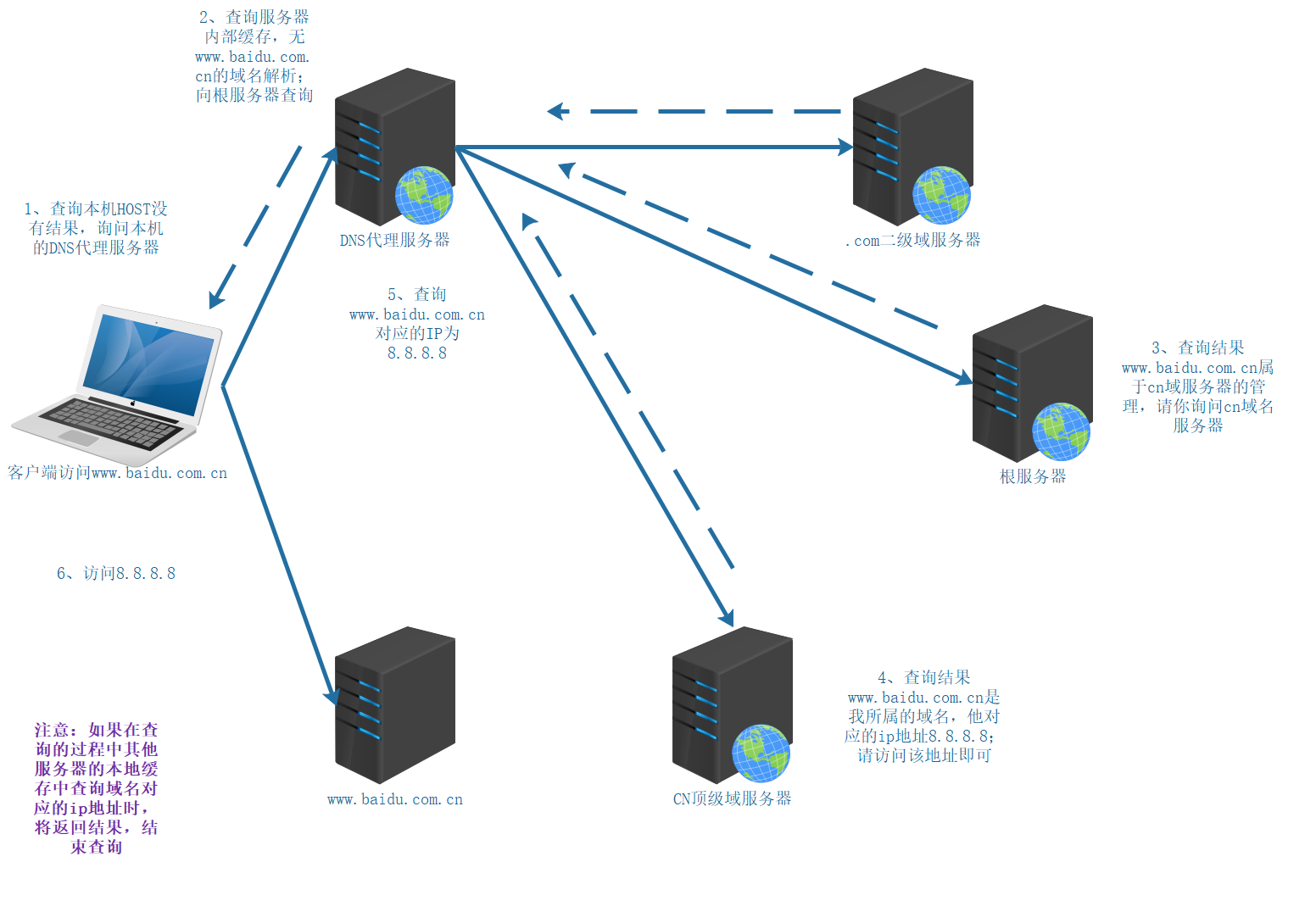
+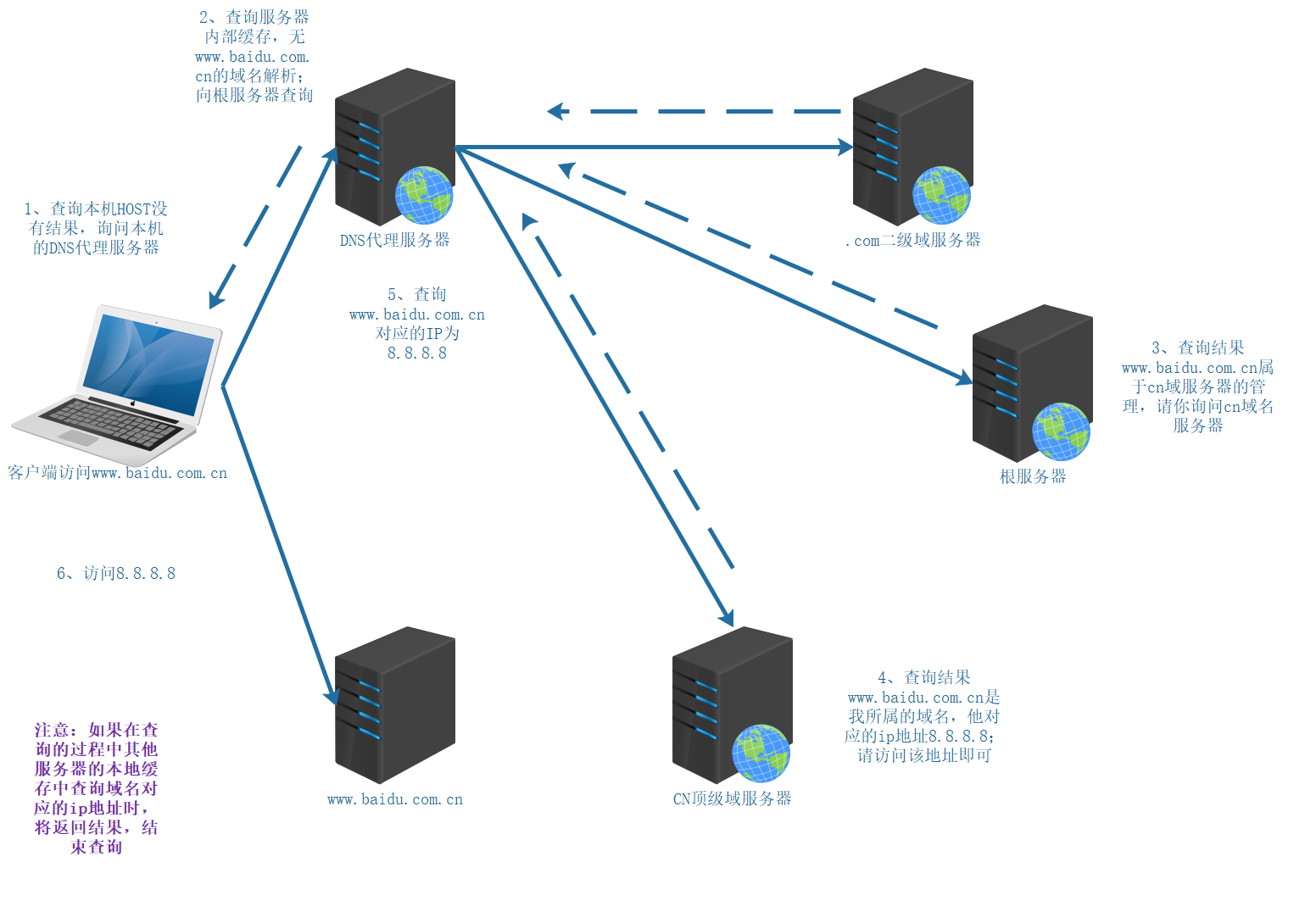
第一步,客户端向本地DNS服务器发送解析请求
@@ -1166,7 +1166,7 @@ ARP即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,
源主机收到ARP响应包后,将目的主机的IP和MAC地址写入ARP列表,并利用此信息发送数据,如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
-
+
## 数字签名
@@ -1259,7 +1259,7 @@ SELECT * FROM user_table WHERE username=’’or 1 = 1 –- and password=’’
**例子**:甲方生成 **一对密钥** 并将其中的一把作为 **公钥** 向其它人公开,得到该公钥的 **乙方** 使用该密钥对机密信息 **进行加密** 后再发送给甲方,甲方再使用自己保存的另一把 **专用密钥** (**私钥**),对 **加密** 后的信息 **进行解密**。
-
+
## 网络攻击
@@ -1390,7 +1390,7 @@ Session 的**认证过程**:
3. 有效期,Cookie 可以设置任意时间有效,而 Session 一般失效时间短
-
+
## 常见面试题
@@ -1418,4 +1418,4 @@ Session 的**认证过程**:
>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw](https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw)
-
+
diff --git a/docs/src/pdf/bat-shuati.md b/docs/download/bat-shuati.md
similarity index 76%
rename from docs/src/pdf/bat-shuati.md
rename to docs/download/bat-shuati.md
index 82d00171ce..b2f2d34764 100644
--- a/docs/src/pdf/bat-shuati.md
+++ b/docs/download/bat-shuati.md
@@ -1,28 +1,22 @@
---
-title: 👏下载→BAT大佬的刷题笔记
-shortTitle: 👏下载→BAT大佬的刷题笔记
+title: BAT大佬的刷题笔记
category:
- - PDF
+ - 学习资源
tag:
- PDF
-description: 下载BAT大佬的刷题笔记,下载 LeetCode 刷题笔记
-head:
- - - meta
- - name: keywords
- content: LeetCode 刷题笔记,力扣刷题笔记,leetcode Java刷题笔记,leetcode 刷题笔记github,leetcode pdf
---
**大家应该都知道,现在的互联网公司面试,只要是研发岗位,基本上都跑不了算法题的折磨,所以大家在准备校招和社招的时候,或者业余时间,还是要多刷刷 LeetCode,保持状态的**。
需要刷题笔记的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**100**」就可以拉取到下载链接了。
-
+
> 二哥,去年校招前准备算法时,我在 LeetCode 上刷了很多题,但总感觉题虽然刷了很多,解题能力却没怎么提高,怎么解决这种刷题效率低下的问题呢?
这是三个月前一个读者给我的私信,他的困惑让我心有戚戚焉!于是我赶紧问了身边的一些就职于大厂的朋友,他们不约而同地给我推荐了这份刷题笔记。
-
+
细致地研究了一周后,我感觉发现了宝藏!赶紧发给了这位读者。前天,他回复我了,说:“二哥,你太强了,**这刷题笔记好使啊**。我按照上面提供的方法认真地刷了两个月的时间,惊奇地发现算法能力提高了,刷 LeetCode 上中等难度的题目基本不会被卡住了!”
@@ -32,13 +26,13 @@ head:
不管你使用的编程语言是 Java、C++,还是 Go,都可以学习,适合刷题的同学反复学习。认真地揣摩其中的框架思维,你会发现,这是一本非常用心的刷题类书籍。笔记总共 1200 页,分编程技巧、线性表、字符串、栈队列、树、排序、查找、BFS、DFS、贪心、动态规划等。
-
+
每个章节都会先讲解框架思维,然后挑选非常典型的十几道 LeetCode 题进行实战讲解。这份笔记不仅排版十分精美,内容也异常充实,每一题都是细致的讲解,有时候还会配上图片,就怕你搞不懂,大大的良心啊!
-
+
-
+
以前呢,我也很讨厌刷题,觉得这就像古代的八股文一样,又臭又刻板,但互联网的公司都喜欢这么考,因为确实也找不到更好的替代方案,那如果你不准备不去刷 LeetCode 的话,面试必定挂啊!
@@ -51,7 +45,7 @@ head:
二哥已经把这份刷题笔记下载好了,需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**100**」就可以拉取到下载链接了(无套路,没加密)。
-
+
> 笔记版权归原作者(霜神)所有,出处:https://books.halfrost.com/leetcode/
diff --git a/docs/download/history.md b/docs/download/history.md
new file mode 100644
index 0000000000..92e77fcc3b
--- /dev/null
+++ b/docs/download/history.md
@@ -0,0 +1,62 @@
+# 网络日志
+
+### 2022年05月21日
+
+- 增加 Spring Boot 专栏
+- 增加 MySQL 文档
+- 增加微服务网关文档
+
+### 2022年05月09日
+
+- [增加面渣逆袭板块](/download/nixi)
+- [Spring Boot 整合 MySQL-Druid](/springboot/mysql-druid)
+
+### 2022年04月30日
+
+- 批量替换所有图片链接为阿里云的 CDN 链接
+
+### 2022年04月29日
+
+- [增加内部类](/oo/inner-class)
+
+### 2022年04月27日
+
+- 修改整形到整型,By Lettuce
+
+### 2022年04月21日
+
+- 重新定制左侧菜单
+
+### 2022年04月19日
+
+- [增加文档搜索功能](https://mp.weixin.qq.com/s/JVdQj-Fl9RPjt4P0y5Ws8g)
+
+### 2022年04月02日
+
+- [杨锅锅同学提出错误:浮点多了个long, 整数少了个int](/sidebar/sanfene/javase)
+- [增加数据结构与算法的学习路线](/xuexiluxian/algorithm)
+
+### 2022年03月31日
+
+- 增加学习建议板块
+
+### 2022年03月29日
+
+- [修改学习路线部分的404错误](/xuexiluxian/)
+- [增加Java整体学习路线](/xuexiluxian/java/yitiaolong)
+- [增加Java虚拟机学习路线](/xuexiluxian/java/jvm)
+
+### 2022年03月27日
+
+- [增加Java并发编程的内容](/home#java并发编程);
+- [增加Java虚拟机模块的内容](/home#java虚拟机);
+
+
+### 2022年03月19日
+
+[Docsify 升级到 VuePress](https://mp.weixin.qq.com/s/cNtUmtVJsF0d6lQ26UFFOw)
+
+
+### 2022年01月01日
+
+[二哥的小破站终于上线了](https://mp.weixin.qq.com/s/NtOD5q95xPEs4aQpu4lGcg)
\ No newline at end of file
diff --git a/docs/download/java.md b/docs/download/java.md
new file mode 100644
index 0000000000..ca183d8187
--- /dev/null
+++ b/docs/download/java.md
@@ -0,0 +1,125 @@
+---
+title: Java电子书下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+# Java程序员常读书单📚,附下载地址
+
+伟大的高尔基曾说过:“书籍是人类进步的阶梯”,读经典的书就好像是站在巨人的肩膀上,视野更开阔,思考问题的方式也会更全面。
+
+讲真,挺遗憾的,大学期间,我读了不少垃圾书,比如说《21 天学会 xxx》,《3 天教你学会 xxx》。
+
+直到工作后的第二年,遇到了一个非常 nice 的领导,他给我推荐了不少经典的书单,比如说《代码大全》、《编程珠玑》、《代码整洁之道》、《深入理解计算机系统》等等。
+
+哇,虽然一开始读得很痛苦,但就这么坚持了一年半的时间,唉,真的发现自己的编程能力在突飞猛进呢,关键是,对业务的理解啊、对架构的设计啊、对代码的编写啊,都有了显著的提升。
+
+这个书单非常的庞大,为了方便大家查找,我将它们又分门别类地上传到了 GitHub 和码云:
+
+- [GitHub备用地址](https://github.com/itwanger/JavaBooks)
+- [Gitee备用地址](https://gitee.com/itwanger/JavaBooks)
+
+上传到 GitHub 和码云上还有一个好处,就是方便大家提需求,如果上面没有你想要的书籍,可以直接提 issue,我看到后就会立马去搜集和整理。
+
+喜欢的话可以点个 star。
+
+这是我看过的一些书:
+
+
+
+那其实很多人在学习编程的时候,很容易陷入一个误区,就是没有计划、没有路线,就导致看似投入了很多精力,但最后的学习效果却有点对不住付出的时间和精力。
+
+为此,我花了将近一个月的时间,整理了这样一条学习路线,并且把我读过的电子书全部做了归类:**入门→工具→框架→数据库→并发编程→底层→性能优化→设计模式→操作系统→计算机网络→数据结构与算法→面试→架构→管理**
+
+
+
+就连颈椎康复指南都有了,这波良心吧?大家可以通过下面的方式获取,我想不管是科班还是非科班的,只要你喜欢计算机、喜欢编程,应该都会有很大的帮助。
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**pdf**」就可以拉取到下载链接了。
+
+
+
+
+## 一、编程语言
+### C语言
+- 《阮一峰老师的 C语言入门教程》
+- 《C程序设计语言》
+- 《C 和指针》
+- 《C 陷阱与缺陷》
+- 《C Primer Plus》
+### Java 语言
+- 《二哥的 Java 程序员进阶之路》,GitHub 上已经开源,持续更新
+- 《Java 编程思想》
+- 《深入浅出 Java 多线程》
+- 《深入理解 Java 虚拟机》
+
+学习任何一门编程语言,一定不要浅尝辄止,因为入门都很容易,进阶却很难。如果只是蜻蜓点水,到最后可能就是竹篮打水一场空,精华的永远也学不到。
+
+初学阶段,一定要多 coding,coding,coding,千万不要眼高手低。希望我的这份计算机书单能帮助到大家。
+
+### C++ 语言
+- 《C++ primer》
+- 《Effective C++》
+- 《STL源码解析》
+### Python 语言
+- 《流畅的 Python》
+- 《Python编程:从入门到实践》
+- 《零基础学 Python》
+- 《用Python进行自然语言处理》
+### JavaScript 语言
+- 《JavaScript 王者归来》
+- 《你不知道的 JavaScript》
+- 《JavaScript 高级程序设计》
+## 二、数据结构与算法
+- 《算法导论》
+- 《算法 4》
+- 《编程珠玑》
+- 《编程之美》
+- 《趣学数据结构》
+## 三、计算机基础
+### 操作系统
+- 《现代操作系统》
+- 《鸟哥的 Linux 私房菜》
+### 计算机组成原理
+- 《程序是如何跑起来的》
+- 《计算机是如何跑起来的》
+- 《编码:隐匿在计算机软硬件背后的语言》
+### 计算机网络
+- 《图解 HTTP》
+- 《图解 TCP/IP》
+- 《计算机网络自顶向下》
+- 《网络是怎样连接的》
+### 数据库
+- 《SQL必知必会》
+- 《高性能 MySQL》
+- 《MySQL技术内幕 InnoDB存储引擎》
+- 《Redis 深度历险:核心原理与应用实践》
+### 四、编程实战
+- 《代码整洁之道》
+- 《阿里巴巴 Java 开发手册》
+- 《重构:改善既有代码的设计》
+- 《Effective Java》
+### 五、代码人生
+- 《黑客与画家》
+- 《人月神话》
+- 《人件》
+- 《代码大全》
+- 《数学之美》
+- 《图灵的秘密》
+
+。。。。持续更新
+
+当然了,我个人是有局限性的,如果大家有什么好书也可以推荐给我,我更新上来,也为后来者提供一个更体系化的书单。
+
+讲真心话,随着时间的推移,我对整个计算机体系的认知也更加全面和深刻了,那这份书单真的希望能帮助到大家。
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**pdf**」就可以拉取到下载链接了。
+
+
+
+
+几年后,你将是一名善于解决实际问题的工程师,而不是一名普普通通的码农。
+
+>毋庸置疑,这是一条坎坷的路,但学弟学妹们就是来披荆斩棘的,对吧?
diff --git a/docs/download/jianli.md b/docs/download/jianli.md
new file mode 100644
index 0000000000..138a0cc3d5
--- /dev/null
+++ b/docs/download/jianli.md
@@ -0,0 +1,186 @@
+---
+title: 简历下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+大家好,我是二哥呀。
+
+随着校招季的到来,不少同学都准备找工作了,也陆陆续续有同学找我看简历以及修改简历。
+
+其实我以前就分享过自己的简历写法和迭代完善的过程,可能有同学没来得及看。今天客户从长沙远道而来,我要接待,所以没时间自己写了,就转一篇阿秀的文章给大家参照下。
+
+需要简历模板的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**简历**」就可以拉取到下载链接了。
+
+
+
+这位学弟说自己在秋招的时候没用心找工作,等毕业后才发现找的工作不满意,勉强干了半年就不想干了,然后走的社招,发现社招比校招要难一点。
+
+在正式分享简历修改案例前,二哥先简单总结一下校招和社招吧。
+
+**校招看基础、潜力,社招看能力、即战力**。
+
+**校招**,对于某些技术问题你可以不懂不会,没关系,看的是你的潜力,你的基本功。框架不会?没事,学就是了。
+
+**社招**,并不是的,社招看的是你的过往经历以及你解决问题的能力。人家招你过来是需要你来干活的,不是让你来带薪学习的,公司又不是慈善机构啊。
+
+所以希望还是在校的学弟学妹们好好学学计算机基本功,打打基础。
+
+程序员内功是很重要的,比如操作系统、计算机网络、数据库、计算机组成原理这些。
+
+好了,废话不多说,开始今天的主题吧。
+
+以下内容涉及到这位学弟的一些关键信息已脱敏,不影响大家阅读,我按照修改模块给大家分享。
+
+### 专业技能
+
+首先来看一下这位学弟的专业技能部分。
+
+
+
+其实,这部分他写的已经挺好的了,简单大方、条理清晰。
+
+也能从他的专业技能描述看出来这位学弟挺厉害的,可还是有些不足之处,我也想相应的给出了一些建议和意见。
+
+**修改意见**
+
+1、**编程语言**部分的第一句话我建议他改一下,因为原文说的有点冗余。我建议他改成“熟悉C++编程语言,基本功扎实,熟练掌握STL模板库”。
+
+后面的“阅读源码”我建议是不加的,因为STL下的思想确实比较精妙,如果别人抓住你的“阅读过部分源码”这几个字使劲问你,十有八九要吃不消,保险起见还是不要加上为好。你需要对你简历上的每一个字,或者说每一个标点符号负责。
+
+2、**数据结构**部分,其实他写的挺好的了,我建议他写得更精炼具体一点,**将原文**“ 熟悉常用算法(Leetcode 200道)、数据结构 (链表、栈、队列、哈希表、二叉树、B/B+树、红黑树等) ”**改为**“熟悉常见数据结构与算法,如链表、栈、哈希表、二叉树等,以74%正确率通过力扣网站 214 道算法题”。
+
+因为74%的正确率这种很精确的数字指标给面试官的直观感受更**具象**一些,并且这个正确率在力扣官网上也是可查的。
+
+3、**设计模式**部分,其实他写的有点多了。对于校招而言,在设计模式上考察的并不多,没必要。
+
+我建议他**改成**“了解常用设计模式如单例模式、工厂模式等”。这么写的目的也是为了方式一种情况的出现,那就是面试官很可能不问你单例、工厂,他会问你一句,你还会不会其他的设计模式,这个时候,你就可以回答“还会观察者、迭代器模式等”
+
+4、**数据库**部分,感觉这位小学弟有点目标过于明显了。
+
+他的**原文是**“ 熟悉 MySQL 关系型数据库、Redis 非关系型数据库,了解 MySQL 查询性能优化相关技术,Redis 五大数据类型,持久化机制以及主从复制技术 ”这就相当于直接让面试官问你Redis的五种数据结构是什么?持久化、主从复制又是什么了?
+
+面试官又不是傻子...
+
+我建议他改成“熟悉关系型数据库MySQL、内存型数据库Redis,了解常见查询优化技术。”这样稍微委婉一些。。。
+
+下面是我当时给他的修改意见。
+
+
+
+### 项目经历
+
+其实一份校招简历,最重要的就是项目经历、实习经历(有则加分,没有也行)、专业技能了。
+
+
+
+可以从这位学弟的描述中看出来,他毕业后的这四个月里确实做了不少的工作,但感觉没说出来自己所做工作的意义和难点所在。
+
+你可能觉得没什么,但那才是面试官在意的地方。
+
+设身处地的想,如果你是一个面试官,你也希望招来的新鲜血液能力越强越好。那能力强不强在面试初期就是通过你的实习经历或者项目经验体现的啊。
+
+**针对第一个项目,二哥给出了几点修改意见**:
+
+1、一个项目,你承担的角色是什么?主要负责人还是核心成员?包括项目的起始时间要注明。
+
+2、对于其中的数据库密码验证。我建议他去掉,因为有点水平较低,还不如不写。虽说后端都是增删改查,但你不能直接说你就是搞了个密码验证啊,你这也太耿直了吧。
+
+3、技术亮点部分描述不够清楚,虽然这位学弟做了很多工作,可从他的描述中是看不出来什么工作的,我给他换了一种说法。
+
+**技术亮点原文描述**:
+
+实现与 bash 几乎完全相同的 cd 功能;使用边缘触发优化 epoll 频繁响应,使用进程池与线程池减少 CPU 运转负载;超时断开,针对连接上的客户端,若超过 30 秒未发送任何请求,断开连接,并使用环形队列技术实现高并发 ;
+
+其实他写的挺好的了,但我还是觉得差点意思,就是说的太白话了一些,所以我用自己的语言帮他加工润色了一下,下面是我的修改版。
+
+**技术亮点修改版**:
+
+1、实现与 bash 几乎完全相同的 cd 功能,但反应时间更短
+
+2、使用epoll边缘触发进行频繁响应,并辅助以进程池和线程池技术来减少CPU运转负载,增加系统CPU利用率
+
+3、智能化断开设计:使用环形队列技术实现高并发,对于30秒内无任何网络包交互的连接进行强制断开处理,有效XXXX。
+
+**是不是感觉瞬间好一点了**。。。。我只能说,**中华语言,博大精深,不服不行**。
+
+以下是修改意见标注
+
+
+
+至此,帮他把第一个项目修改完毕了,**针对第二个项目的修改**,我就不多BB了,直接贴上来吧。
+
+**以下是我给出的修改意见**:
+
+这个项目名改成:汽车出行APP 缺少你的角色 和 项目起始时间 该APP主要业务是什么?最终的功能有哪些?然后写上自己在其中的工作。个人工作对于该APP的加成在哪里,需要具体的量化词。
+
+技术亮点中的删除相似网页,删除正确率有多少,针对该APP某某缺陷和不足,提出建立倒排索引技术,推送强相关的网页,最终提升点击率XX.XX%。
+
+最后写上个人收获:学到了哪些?对XXX有了更深的认识和了解
+
+**下面是当时给他做的标注**:
+
+
+
+其实对于该部分的修改,我是紧紧抓住一个要点,那就是尽可能使用具化的指标即明确的信息而不是概括性的描述。
+
+比如直接告诉别人提升了XX%,而不是说一句“有着较好的提升效果”;直接告诉别人“项目优化了XX秒,相较于上一版本速度加快了XX%”,而不是”经过XX技术,速度有了较大提高“。
+
+这一点,我在自己的简历修改迭代文章中也提到过,很重要,特别重要,具化的指标信息给人的第一感觉就是不一样的。
+
+### 工作经历、教育经历、奖项证书
+
+这里比较类似,我就一起放上来说了
+
+首先是原文。
+
+
+
+
+我给的修改意见批注。
+
+
+
+1、在工作经历这里,注意细节问题,比如你的岗位名称是什么?你在实习过程中,你的工作有哪些?在这过程中用到了哪些技能?
+
+不要直接就是一句话写出来,不明不白的,没什么愿意看的。人都是视觉动物,都希望看到整齐有序的内容。
+
+这里的整齐有序不仅要求你的排版整齐,你想要表达的意思也要有序。
+
+比如把你的工作或者实习分为团队工作、个人工作、个人收获,挨个展开。
+
+2、由于这位学弟已经毕业了,已经不能再以校招身份去面试找工作了,所以教育经历这里其实已经没必要写在校学习的课程了。
+
+一旦你踏入社会,失去了应届生身份你就不再是校招生了,这个时候看的就是你的能力了。
+
+3、对于一些细节问题记得做好,关键字该加粗加粗。比如有分量的国奖还是值得一个加粗显示的。
+
+4、如果你过了六级,那直接写**六级**,分数还可以的话就写上分数;分数比较低的话,比如430这种刚飘过,就写六级就行。
+
+如果六级没过,那就写上四级吧。
+
+### 简历模板下载方式
+
+我把这位小学弟和我自己以前的简历模板放在一起了,需要简历模板的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**简历**」就可以拉取到下载链接了。
+
+
+
+记住!简历并不是单纯意义上的自我介绍,比如说我是沉默王二,今年 18 岁,来自洛阳,毕业于某某学校。这样的简历太苍白了。
+
+简历就好像电梯广告的单页一样,它富有鲜活的生命力,它在呐喊,它不需要过多的润色,只需要铿锵有力、赤裸裸的“炫耀”。
+
+比如说我是沉默王二, 2019 年参与了 XXX 项目的开发。作为项目团队的核心 开发人员,我不仅能够提前完成自己的开发任务,还设计了一个高效的缓存中间件,大大提高了系统的性能。
+
+该中间件上线后,Web 前端性能从 10 QPS 提升到 120 QPS,服务器由 10 台缩减为 5 台。
+
+鉴于之前的良好表现,我在 2020 年升任项目的主要负责人,虽然小组成员只有 15 个,但硬生生地肩负起了每天超过 2000 万的 PV。
+
+看,这样的简历是不是让人耳目一新,证明自己价值的同时,没有过多的粉饰,让招聘方觉得你很靠谱,迫切地想要把你这个人才“抢”到手,免费被别的公司挖走了。
+
+简历上的内容不要太多,尽量不要超过一页,因为招聘方没有那么多时间去翻看你的简历。我是挺相信第一印象的,好的简历看一眼就会过目不忘,真的。
+
+我是二哥呀,人生最可怕的事莫过于在别人放弃你之前,你先放弃了自己,我们下期再见。
+
+>作者:阿秀,转载链接:[https://mp.weixin.qq.com/s/soVldFzBbqwm_vM35afFvg](https://mp.weixin.qq.com/s/soVldFzBbqwm_vM35afFvg)
diff --git a/docs/src/download/learn-jianyi.md b/docs/download/learn-jianyi.md
similarity index 100%
rename from docs/src/download/learn-jianyi.md
rename to docs/download/learn-jianyi.md
diff --git a/docs/src/download/nicearticle.md b/docs/download/nicearticle.md
similarity index 98%
rename from docs/src/download/nicearticle.md
rename to docs/download/nicearticle.md
index cdf95c925b..0c3ae181b8 100644
--- a/docs/src/download/nicearticle.md
+++ b/docs/download/nicearticle.md
@@ -5,7 +5,7 @@
### 图文教程
- [Java 正则表达式详解](https://segmentfault.com/a/1190000009162306)
-- [Java 正则从入门到精通](https://dunwu.github.io/javacore/pages/4c1dd4/)
+- [Java 正则从入门到精通](https://dunwu.github.io/javacore/advanced/java-regex.html)
- [GitHub 上优质的 Java 知识总结项](https://mp.weixin.qq.com/s/-lQ2PTEO4F2d92GDDxKVpw)
- [处于萌芽阶段的 Java 核心知识库](https://mp.weixin.qq.com/s/_Q7lopxM1sJtMA-NOE_v3A)
- [大数据入门指南 ](https://github.com/heibaiying/BigData-Notes)
@@ -91,6 +91,8 @@
- [降薪 45%,从互联网回到国企](https://mp.weixin.qq.com/s/qHGdIuA32X-zydbMTKDPuA)
- [学弟在微软的这六个月](https://mp.weixin.qq.com/s/08Ax1ArAjchemjUXih7zNw)
- [找个程序员做老公/男票有多爽???](https://mp.weixin.qq.com/s/mK0yaen1mhCoWZ6ZLC5vQg)
+- [研究所月入两万,是什么体验?](/manongshenghuo/yanjiusuo-20wan.md)
+- [裸辞全职做外包一个月的感受](/manongshenghuo/waibao-1geyue.md)
- [转眼就来字节六个月了,真的不一样](https://mp.weixin.qq.com/s/jG7DLrCFf_pYoMLFiVbaaA)
- [在监狱里编程是一种什么体验(上)?](https://mp.weixin.qq.com/s/ci5Meem_d3g2BphDmMP8VQ)
- [29 岁,非科班零基础,想兼职做外包。。](https://mp.weixin.qq.com/s/CTTlnXNXY9j3Bm3_4gmIbw)
@@ -204,8 +206,10 @@
> [!TIP]
> 开发过程中遇到的一些典型问题,该如何解决?
+- [Log4j2突发重大漏洞](/shigu/log4j2.md)
- [重现了一波 Log4j2 核弹级漏洞,同事的电脑沦为炮灰](https://mp.weixin.qq.com/s/zXzJVxRxMUnoyJs6_NojMQ)
- [生成订单30分钟未支付,则自动取消,该怎么实现?](https://mp.weixin.qq.com/s/J6jb_Dt3C49CIjYBTrN4gQ)
+- [两天两夜,1M图片优化到100kb!](/shigu/image-yasuo.md)
- [内部群炸了锅,隔壁同事真删库了啊。。](https://mp.weixin.qq.com/s/lvyoN1gHCWhcPqudcjcRgQ)
- [B 站崩了](https://mp.weixin.qq.com/s/PfJe5rXednkXTq8EKT0xpw)
- [因为一个低级错误,生产数据库崩溃了将近半个小时](https://mp.weixin.qq.com/s/ec6u8WsPt7zJ0eul8sPEhg)
@@ -223,6 +227,7 @@
## MySQL重要知识点
+- [从京东到家程序员删库被判 10 个月来聊聊 MySQL 数据备份的杀手锏](/mysql/deletedb-binlog-weiguanjishu.md)
- [深入浅出MySQL crash safe](https://tech.youzan.com/shen-ru-qian-chu-mysql-crash-safe/)
## 待收录文章
diff --git a/docs/download/pdf.md b/docs/download/pdf.md
new file mode 100644
index 0000000000..6b1e7e4d99
--- /dev/null
+++ b/docs/download/pdf.md
@@ -0,0 +1,24 @@
+---
+title: PDF干货笔记下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+# PDF干货笔记📚,附下载地址
+
+
+>- **找不到优质的学习资源**?这些问题在这里统统都可以找到答案。
+>- 我会把自己十多年的学习资源毫不保留的分享出来。
+
+- [👏下载→最全最硬核的Java面试 “备战” 资料](https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw)
+- [👏下载→深入浅出Java多线程](https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w)
+- [👏下载→GitHub星标115k+的Java教程](https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw)
+- [👏下载→重学Java设计模式](https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw)
+- [👏下载→Java版LeetCode刷题笔记](https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ)
+- [👏下载→阮一峰C语言入门教程](/download/yuanyifeng-c-language.md)
+- [👏下载→BAT大佬的刷题笔记](/download/bat-shuati.md)
+- [👏下载→给操作系统捋条线](https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA)
+- [👏下载→豆瓣9.1分,Pro Git中文版](/download/progit.md)
+- [👏下载→简历模板](/download/jianli.md)
\ No newline at end of file
diff --git a/docs/download/progit.md b/docs/download/progit.md
new file mode 100644
index 0000000000..781d7473cb
--- /dev/null
+++ b/docs/download/progit.md
@@ -0,0 +1,48 @@
+---
+title: 豆瓣9.1分,Pro Git中文版
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+今天给大家分享一本个人最近看过觉得非常不错的Git开源手册,可能有些小伙伴也看过了,我是最近在通勤路上用PAD看的。这本开源手册,它除了有**PDF版**,还有**epub电子书版**,非常适合电子阅读:
+
+
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**git**」就可以拉取到下载链接了。
+
+
+
+相信看完对于个人Git知识体系的梳理和掌握是非常有帮助的。
+
+这本手册在豆瓣上评价极高,之前9.3,现在也有9.1的高分,其作者是GitHub的员工,内容主要侧重于各种场合中的惯用法和底层原理的讲述,手册中还针对不同的使用场景,设计了几个合适的版本管理策略。简而言之,这本手册无论是对于初学者还是想进一步了解Git工作原理的开发者都非常合适。
+
+
+
+
+
+这个手册一共分为十章,详细内容如下:
+
+
+
+**手册中部分内容展示如下:**
+
+
+
+
+
+
+
+
+
+**需要该Git手册PDF+epub电子书的小伙伴:**
+
+
+
+可扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**git**」就可以拉取到下载链接了。
+
+
+
+
+好了,这次资源分享就到这里!后续如果遇到有用的工具或者资源,依然还会持续分享,也欢迎大家多多安利和交流,一起分享成长。
diff --git a/docs/src/pdf/yuanyifeng-c-language.md b/docs/download/yuanyifeng-c-language.md
similarity index 84%
rename from docs/src/pdf/yuanyifeng-c-language.md
rename to docs/download/yuanyifeng-c-language.md
index fccde50d59..b0f653a407 100644
--- a/docs/src/pdf/yuanyifeng-c-language.md
+++ b/docs/download/yuanyifeng-c-language.md
@@ -1,26 +1,20 @@
---
-title: 👏下载→阮一峰C语言入门教程
-shortTitle: 👏下载→阮一峰C语言入门教程
+title: 阮一峰-C语言入门教程
category:
- - PDF
+ - 学习资源
tag:
- PDF
-description: 给操作系统学习资料下载
-head:
- - - meta
- - name: keywords
- content: C语言教程,阮一峰,阮一峰 C语言,C语言入门教程
---
给大家报告下,阮一峰老师的《**C语言入门教程**》于 2021 年 9 月 7 日上线了!
对,和往常一样,这个教程是开源的,采用知识共享许可证,源码托管在 GitHub,大家可以自由使用。
->[https://github.com/wangdoc/clang-tutorial](https://github.com/wangdoc/clang-tutorial)
+>https://github.com/wangdoc/clang-tutorial
在线阅读地址也有:
->[https://wangdoc.com/clang/](https://wangdoc.com/clang/)
+>https://wangdoc.com/clang/
我第一时间就拜读了一遍,受益匪浅!可以说目前我见到的最好的 C语言入门教程了,没有之一!
@@ -35,7 +29,7 @@ head:
需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**08**」就可以拉取到下载链接了。
-
+
也可以微信搜「**沉默王二**」关注后回复关键字「**08**」。
@@ -45,7 +39,7 @@ head:
那配上阮一峰老师的这个在线文档教程,可以说是完美!
-
+
我对这份教程是非常满意的,该讲的地方都讲到了,示例也给了很多,对初学者来说,完全够用了。
@@ -77,9 +71,9 @@ C语言在武林界的地位就相当于少林的地位,天下武功皆出少
不过网上也有蛮多在线编译器的,可以直接在网页上模拟运行 C 代码,查看结果,非常方便。
-
+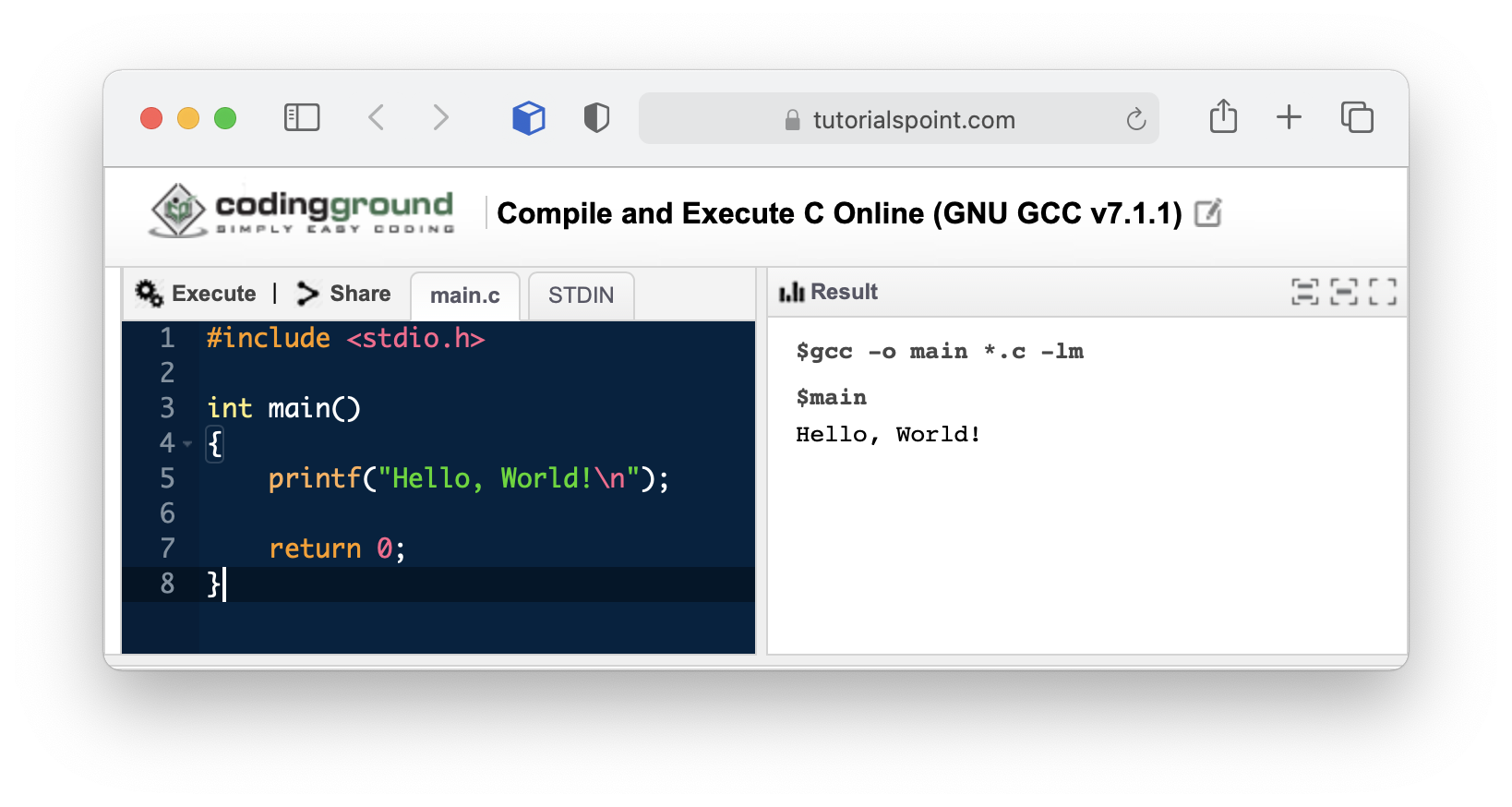
->CodingGround网址:[https://www.tutorialspoint.com/compile_c_online.php](https://www.tutorialspoint.com/compile_c_online.php)
+>CodingGround网址:https://www.tutorialspoint.com/compile_c_online.php
C 语言是一种编译型语言,源码是文本文件,本身是无法执行的,需要通过编译器,生成二进制的可执行文件。
@@ -99,7 +93,7 @@ C语言中,指针是令初学者头痛的一块内容,所以我这里简单
>需要阮一峰老师的这份《C语言入门教程》的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**08**」就可以拉取到下载链接了。
-
+
也可以微信搜「**沉默王二**」关注后回复关键字「**08**」。
diff --git a/docs/elasticsearch/rumen.md b/docs/elasticsearch/rumen.md
new file mode 100644
index 0000000000..8b5eaaef7e
--- /dev/null
+++ b/docs/elasticsearch/rumen.md
@@ -0,0 +1,189 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - Elasticsearch
+---
+
+# 全文搜索引擎Elasticsearch入门教程
+
+学习真的是一件令人开心的事情,上次分享了 [Redis 入门](https://mp.weixin.qq.com/s/NPJkMy5RppyFk9QhzHxhrw)的文章后,收到了很多小伙伴的鼓励,比如说:“哎呀,不错呀,二哥,通俗易懂,十分钟真的入门了”。瞅瞅,瞅瞅,我决定再接再厉,入门一下 Elasticsearch,因为我们公司的商城系统升级了,需要用 Elasticsearch 做商品的搜索。
+
+不过,我首先要声明一点,我对 Elasticsearch 并没有进行很深入的研究,仅仅是因为要用,就学一下。但作为一名负责任的技术博主,我是用心的,为此还特意在某某时间上买了一门视频课程,作者叫阮一鸣。说实话,他光秃秃的头顶让我对这门课程产生了浓厚的兴趣。
+
+经过三天三夜的学习,总算是入了 Elasticsearch 的门,我就决定把这些心得体会分享出来,感兴趣的小伙伴可以作为参考。遇到文章中有错误的地方,不要手下留情,过来捶我,只要不打脸就好。
+
+
+
+
+### 01、Elasticsearch 是什么
+
+>Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
+
+以上引用来自于官方,不得不说,解释得蛮文艺的。意料之中和意料之外,这两个词让我想起来了某一年的高考作文题(情理之中和意料之外)。
+
+Elastic Stack 又是什么呢?整个架构图如下图(来源于网络,侵删)所示。
+
+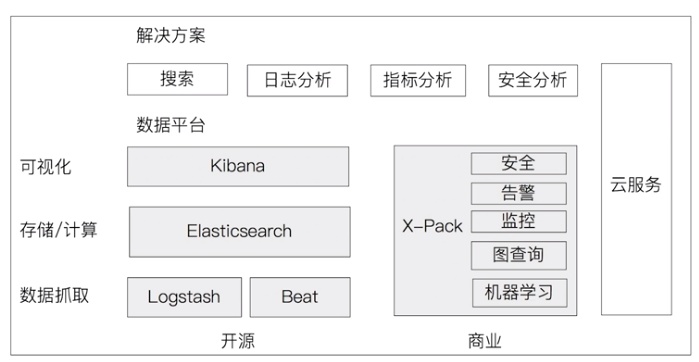
+
+信息量比较多,对吧?那就记住一句话吧,Elasticsearch 是 Elastic Stack 的核心。
+
+国内外的很多知名公司都在用 Elasticsearch,比如说滴滴、今日头条、谷歌、微软等等。Elasticsearch 有很多强大的功能,比如说全文搜索、购物推荐、附近定位推荐等等。
+
+理论方面的内容就不说太多了,我怕小伙伴们会感到枯燥。毕竟入门嘛,实战才重要。
+
+### 02、安装 Elasticsearch
+
+Elasticsearch 是由 Java 开发的,所以早期的版本需要先在电脑上安装 JDK 进行支持。后来的版本中内置了 Java 环境,所以直接下载就行了。Elasticsearch 针对不同的操作系统有不同的安装包,我们这篇入门的文章就以 Windows 为例吧。
+
+下载地址如下:
+
+[https://www.elastic.co/cn/downloads/elasticsearch](https://www.elastic.co/cn/downloads/elasticsearch)
+
+最新的版本是 7.6.2,280M 左右。但我硬生生花了 10 分钟的时间才下载完毕,不知道是不是连通的 200M 带宽不给力,还是官网本身下载的速度就慢,反正我去洗了 6 颗葡萄吃完后还没下载完。
+
+Elasticsearch 是免安装的,只需要把 zip 包解压就可以了。
+
+
+
+1)bin 目录下是一些脚本文件,包括 Elasticsearch 的启动执行文件。
+
+2)config 目录下是一些配置文件。
+
+3)jdk 目录下是内置的 Java 运行环境。
+
+4)lib 目录下是一些 Java 类库文件。
+
+5)logs 目录下会生成一些日志文件。
+
+6)modules 目录下是一些 Elasticsearch 的模块。
+
+7)plugins 目录下可以放一些 Elasticsearch 的插件。
+
+直接双击 bin 目录下的 elasticsearch.bat 文件就可以启动 Elasticsearch 服务了。
+
+
+
+输出的日志信息有点多,不用细看,注意看到有“started”的字样就表明启动成功了。为了进一步确认 Elasticsearch 有没有启动成功,可以在浏览器的地址栏里输入 `http://localhost:9200` 进行查看(9200 是 Elasticsearch 的默认端口号)。
+
+
+
+你看,为了 Search。
+
+那如何停止服务呢?可以直接按下 `Ctrl+C` 组合键——粗暴、壁咚。
+
+### 03、安装 Kibana
+
+通过 Kibana,我们可以对 Elasticsearch 服务进行可视化操作,就像在 Linux 操作系统下安装一个图形化界面一样。
+
+下载地址如下:
+
+[https://www.elastic.co/cn/downloads/kibana](https://www.elastic.co/cn/downloads/kibana)
+
+最新的版本是 7.6.2,284M 左右,体积和 Elasticsearch 差不多。选择下载 Windows 版,zip 格式的,完成后直接解压就行了。下载的过程中又去洗了 6 颗葡萄吃,狗头。
+
+
+
+包目录不再一一解释了,进入 bin 目录下,双击运行 kibana.bat 文件,启动 Kibana 服务。整个过程比 Elasticsearch 要慢一些,当看到 `[Kibana][http] http server running` 的信息后,说明服务启动成功了。
+
+
+
+在浏览器地址栏输入 `http://localhost:5601` 查看 Kibana 的图形化界面。
+
+
+
+由于当前的 Elasticsearch 服务端中还没有任何数据,所以我们可以选择「Try Our Sample Data」导入 Kibana 提供的模拟数据体验一下。下图是导入电商数据库的看板页面,是不是很丰富?
+
+
+
+打开 Dev Tools 面板,可以看到一个简单的 DSL 查询语句(一种完全基于 JSON 的特定于领域的语言),点击「运行」按钮后就可以看到 JSON 格式的数据了。
+
+
+
+### 04、Elasticsearch 的关键概念
+
+在进行下一步之前,需要先来理解 Elasticsearch 中的几个关键概念,比如说什么是索引,什么是类型,什么是文档等等。Elasticsearch 既然是一个数据引擎,它里面的一些概念就和 MySQL 有一定的关系。
+
+
+
+看完上面这幅图(来源于网络,侵删),是不是瞬间就清晰了。向 Elasticsearch 中存储数据,其实就是向 Elasticsearch 中的 index 下面的 type 中存储 JSON 类型的数据。
+
+
+### 05、在 Java 中使用 Elasticsearch
+
+有些小伙伴可能会问,“二哥,我是一名 Java 程序员,我该如何在 Java 中使用 Elasticsearch 呢?”这个问题问得好,这就来,这就来。
+
+Elasticsearch 既然内置了 Java 运行环境,自然就提供了一系列 API 供我们操作。
+
+第一步,在项目中添加 Elasticsearch 客户端依赖:
+
+```
+
+ org.elasticsearch.client
+ elasticsearch-rest-high-level-client
+ 7.6.2
+
+```
+
+第二步,新建测试类 ElasticsearchTest:
+
+```java
+public class ElasticsearchTest {
+ public static void main(String[] args) throws IOException {
+
+ RestHighLevelClient client = new RestHighLevelClient(
+ RestClient.builder(
+ new HttpHost("localhost", 9200, "http")));
+
+ IndexRequest indexRequest = new IndexRequest("writer")
+ .id("1")
+ .source("name", "沉默王二",
+ "age", 18,
+ "memo", "一枚有趣的程序员");
+ IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
+
+ GetRequest getRequest = new GetRequest("writer", "1");
+
+ GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
+ String sourceAsString = getResponse.getSourceAsString();
+
+ System.out.println(sourceAsString);
+ client.close();
+ }
+}
+```
+
+1)RestHighLevelClient 为 Elasticsearch 提供的 REST 客户端,可以通过 HTTP 的形式连接到 Elasticsearch 服务器,参数为主机名和端口号。
+
+有了 RestHighLevelClient 客户端,我们就可以向 Elasticsearch 服务器端发送请求并获取响应。
+
+2)IndexRequest 用于向 Elasticsearch 服务器端添加一个索引,参数为索引关键字,比如说“writer”,还可以指定 id。通过 source 的方式可以向当前索引中添加文档数据源(键值对的形式)。
+
+有了 IndexRequest 对象后,可以调用客户端的 `index()` 方法向 Elasticsearch 服务器添加索引。
+
+3)GetRequest 用于向 Elasticsearch 服务器端发送一个 get 请求,参数为索引关键字,以及 id。
+
+有了 GetRequest 对象后,可以调用客户端的 `get()` 方法向 Elasticsearch 服务器获取索引。`getSourceAsString()` 用于从响应中获取文档数据源(JSON 字符串的形式)。
+
+好了,来看一下程序的输出结果:
+
+```
+{"name":"沉默王二","age":18,"memo":"一枚有趣的程序员"}
+```
+
+完全符合我们的预期,perfect!
+
+也可以通过 Kibana 的 Dev Tools 面板查看“writer”索引,结果如下图所示。
+
+
+
+
+
+
+### 06、鸣谢
+
+好了,我亲爱的小伙伴们,以上就是本文的全部内容了,是不是看完后很想实操一把 Elasticsearch,赶快行动吧!如果你在学习的过程中遇到了问题,欢迎随时和我交流,虽然我也是个菜鸟,但我有热情啊。
+
+另外,如果你想写入门级别的文章,这篇就是最好的范例。
+
+
diff --git a/docs/exception/gailan.md b/docs/exception/gailan.md
new file mode 100644
index 0000000000..6143fd980f
--- /dev/null
+++ b/docs/exception/gailan.md
@@ -0,0 +1,464 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 一文读懂Java异常处理
+
+## 一、什么是异常
+
+“二哥,今天就要学习异常了吗?”三妹问。
+
+“是的。只有正确地处理好异常,才能保证程序的可靠性,所以异常的学习还是很有必要的。”我说。
+
+“那到底什么是异常呢?”三妹问。
+
+“异常是指中断程序正常执行的一个不确定的事件。当异常发生时,程序的正常执行流程就会被打断。一般情况下,程序都会有很多条语句,如果没有异常处理机制,前面的语句一旦出现了异常,后面的语句就没办法继续执行了。”
+
+“有了异常处理机制后,程序在发生异常的时候就不会中断,我们可以对异常进行捕获,然后改变程序执行的流程。”
+
+“除此之外,异常处理机制可以保证我们向用户提供友好的提示信息,而不是程序原生的异常信息——用户根本理解不了。”
+
+“不过,站在开发者的角度,我们更希望看到原生的异常信息,因为这有助于我们更快地找到 bug 的根源,反而被过度包装的异常信息会干扰我们的视线。”
+
+“Java 语言在一开始就提供了相对完善的异常处理机制,这种机制大大降低了编写可靠程序的门槛,这也是 Java 之所以能够流行的原因之一。”
+
+“那导致程序抛出异常的原因有哪些呢?”三妹问。
+
+比如说:
+
+- 程序在试图打开一个不存在的文件;
+- 程序遇到了网络连接问题;
+- 用户输入了糟糕的数据;
+- 程序在处理算术问题时没有考虑除数为 0 的情况;
+
+等等等等。
+
+挑个最简单的原因来说吧。
+
+```java
+public class Demo {
+ public static void main(String[] args) {
+ System.out.println(10/0);
+ }
+}
+```
+
+这段代码在运行的时候抛出的异常信息如下所示:
+
+```
+Exception in thread "main" java.lang.ArithmeticException: / by zero
+ at com.itwanger.s41.Demo.main(Demo.java:8)
+```
+
+“你看,三妹,这个原生的异常信息对用户来说,显然是不太容易理解的,但对于我们开发者来说,简直不要太直白了——很容易就能定位到异常发生的根源。”
+
+## 二、Exception和Error的区别
+
+“哦,我知道了。下一个问题,我经常看到一些文章里提到 Exception 和 Error,二哥你能帮我解释一下它们之间的区别吗?”三妹问。
+
+“这是一个好问题呀,三妹!”
+
+从单词的释义上来看,error 为错误,exception 为异常,错误的等级明显比异常要高一些。
+
+从程序的角度来看,也的确如此。
+
+Error 的出现,意味着程序出现了严重的问题,而这些问题不应该再交给 Java 的异常处理机制来处理,程序应该直接崩溃掉,比如说 OutOfMemoryError,内存溢出了,这就意味着程序在运行时申请的内存大于系统能够提供的内存,导致出现的错误,这种错误的出现,对于程序来说是致命的。
+
+Exception 的出现,意味着程序出现了一些在可控范围内的问题,我们应当采取措施进行挽救。
+
+比如说之前提到的 ArithmeticException,很明显是因为除数出现了 0 的情况,我们可以选择捕获异常,然后提示用户不应该进行除 0 操作,当然了,更好的做法是直接对除数进行判断,如果是 0 就不进行除法运算,而是告诉用户换一个非 0 的数进行运算。
+
+## 三、checked和unchecked异常
+
+“三妹,还能想到其他的问题吗?”
+
+“嗯,不用想,二哥,我已经提前做好预习工作了。”三妹自信地说,“异常又可以分为 checked 和 unchecked,它们之间又有什么区别呢?”
+
+“哇,三妹,果然又是一个好问题呢。”
+
+checked 异常(检查型异常)在源代码里必须显式地捕获或者抛出,否则编译器会提示你进行相应的操作;而 unchecked 异常(非检查型异常)就是所谓的运行时异常,通常是可以通过编码进行规避的,并不需要显式地捕获或者抛出。
+
+“我先画一幅思维导图给你感受一下。”
+
+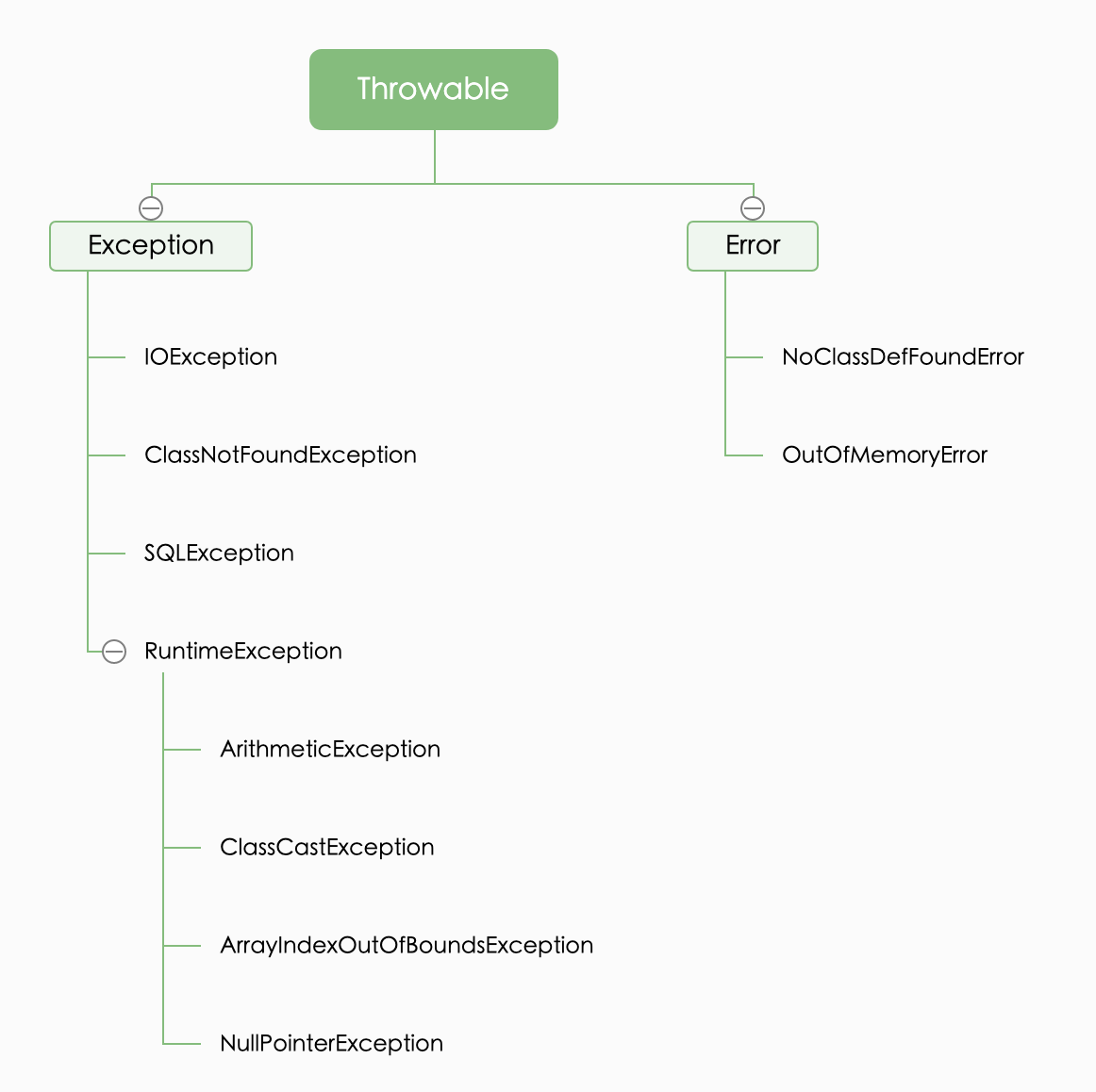
+
+首先,Exception 和 Error 都继承了 Throwable 类。换句话说,只有 Throwable 类(或者子类)的对象才能使用 throw 关键字抛出,或者作为 catch 的参数类型。
+
+面试中经常问到的一个问题是,NoClassDefFoundError 和 ClassNotFoundException 有什么区别?
+
+“三妹你知道吗?”
+
+“不知道,二哥,你解释下呗。”
+
+它们都是由于系统运行时找不到要加载的类导致的,但是触发的原因不一样。
+
+- NoClassDefFoundError:程序在编译时可以找到所依赖的类,但是在运行时找不到指定的类文件,导致抛出该错误;原因可能是 jar 包缺失或者调用了初始化失败的类。
+- ClassNotFoundException:当动态加载 Class 对象的时候找不到对应的类时抛出该异常;原因可能是要加载的类不存在或者类名写错了。
+
+
+其次,像 IOException、ClassNotFoundException、SQLException 都属于 checked 异常;像 RuntimeException 以及子类 ArithmeticException、ClassCastException、ArrayIndexOutOfBoundsException、NullPointerException,都属于 unchecked 异常。
+
+unchecked 异常可以不在程序中显示处理,就像之前提到的 ArithmeticException 就是的;但 checked 异常必须显式处理。
+
+比如说下面这行代码:
+
+```java
+Class clz = Class.forName("com.itwanger.s41.Demo1");
+```
+
+如果没做处理,比如说在 Intellij IDEA 环境下,就会提示你这行代码可能会抛出 `java.lang.ClassNotFoundException`。
+
+
+
+建议你要么使用 try-catch 进行捕获:
+
+```java
+try {
+ Class clz = Class.forName("com.itwanger.s41.Demo1");
+} catch (ClassNotFoundException e) {
+ e.printStackTrace();
+}
+```
+
+注意打印异常堆栈信息的 `printStackTrace()` 方法,该方法会将异常的堆栈信息打印到标准的控制台下,如果是测试环境,这样的写法还 OK,如果是生产环境,这样的写法是不可取的,必须使用日志框架把异常的堆栈信息输出到日志系统中,否则可能没办法跟踪。
+
+要么在方法签名上使用 throws 关键字抛出:
+
+```java
+public class Demo1 {
+ public static void main(String[] args) throws ClassNotFoundException {
+ Class clz = Class.forName("com.itwanger.s41.Demo1");
+ }
+}
+```
+
+这样做的好处是不需要对异常进行捕获处理,只需要交给 Java 虚拟机来处理即可;坏处就是没法针对这种情况做相应的处理。
+
+“二哥,针对 checked 异常,我在知乎上看到一个帖子,说 Java 中的 checked 很没有必要,这种异常在编译期要么 try-catch,要么 throws,但又不一定会出现异常,你觉得这样的设计有意义吗?”三妹提出了一个很尖锐的问题。
+
+“哇,这种问题问的好。”我不由得对三妹心生敬佩。
+
+“的确,checked 异常在业界是有争论的,它假设我们捕获了异常,并且针对这种情况作了相应的处理,但有些时候,根本就没法处理。”我说,“就拿上面提到的 ClassNotFoundException 异常来说,我们假设对其进行了 try-catch,可真的出现了 ClassNotFoundException 异常后,我们也没多少的可操作性,再 `Class.forName()` 一次?”
+
+另外,checked 异常也不兼容函数式编程,后面如果你写 Lambda/Stream 代码的时候,就会体验到这种苦涩。
+
+当然了,checked 异常并不是一无是处,尤其是在遇到 IO 或者网络异常的时候,比如说进行 Socket 链接,我大致写了一段:
+
+```java
+public class Demo2 {
+ private String mHost;
+ private int mPort;
+ private Socket mSocket;
+ private final Object mLock = new Object();
+
+ public void run() {
+ }
+
+ private void initSocket() {
+ while (true) {
+ try {
+ Socket socket = new Socket(mHost, mPort);
+ synchronized (mLock) {
+ mSocket = socket;
+ }
+ break;
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}
+```
+
+当发生 IOException 的时候,socket 就重新尝试连接,否则就 break 跳出循环。意味着如果 IOException 不是 checked 异常,这种写法就略显突兀,因为 IOException 没办法像 ArithmeticException 那样用一个 if 语句判断除数是否为 0 去规避。
+
+或者说,强制性的 checked 异常可以让我们在编程的时候去思考,遇到这种异常的时候该怎么更优雅的去处理。显然,Socket 编程中,肯定是会遇到 IOException 的,假如 IOException 是非检查型异常,就意味着开发者也可以不考虑,直接跳过,交给 Java 虚拟机来处理,但我觉得这样做肯定更不合适。
+
+## 四、关于 try-catch-finally
+
+“二哥,你能告诉我 throw 和 throws 两个关键字的区别吗?”三妹问。
+
+“throw 关键字,用于主动地抛出异常;正常情况下,当除数为 0 的时候,程序会主动抛出 ArithmeticException;但如果我们想要除数为 1 的时候也抛出 ArithmeticException,就可以使用 throw 关键字主动地抛出异常。”我说。
+
+```java
+throw new exception_class("error message");
+```
+
+语法也非常简单,throw 关键字后跟上 new 关键字,以及异常的类型还有参数即可。
+
+举个例子。
+
+```java
+public class ThrowDemo {
+ static void checkEligibilty(int stuage){
+ if(stuage<18) {
+ throw new ArithmeticException("年纪未满 18 岁,禁止观影");
+ } else {
+ System.out.println("请认真观影!!");
+ }
+ }
+
+ public static void main(String args[]){
+ checkEligibilty(10);
+ System.out.println("愉快地周末..");
+ }
+}
+```
+
+这段代码在运行的时候就会抛出以下错误:
+
+```
+Exception in thread "main" java.lang.ArithmeticException: 年纪未满 18 岁,禁止观影
+ at com.itwanger.s43.ThrowDemo.checkEligibilty(ThrowDemo.java:9)
+ at com.itwanger.s43.ThrowDemo.main(ThrowDemo.java:16)
+```
+
+“throws 关键字的作用就和 throw 完全不同。”我说,“[异常处理机制](https://mp.weixin.qq.com/s/fXRJ1xdz_jNSSVTv7ZrYGQ)这小节中讲了 checked exception 和 unchecked exception,也就是检查型异常和非检查型异常;对于检查型异常来说,如果你没有做处理,编译器就会提示你。”
+
+`Class.forName()` 方法在执行的时候可能会遇到 `java.lang.ClassNotFoundException` 异常,一个检查型异常,如果没有做处理,IDEA 就会提示你,要么在方法签名上声明,要么放在 try-catch 中。
+
+
+
+“那什么情况下使用 throws 而不是 try-catch 呢?”三妹问。
+
+“假设现在有这么一个方法 `myMethod()`,可能会出现 ArithmeticException 异常,也可能会出现 NullPointerException。这种情况下,可以使用 try-catch 来处理。”我回答。
+
+```java
+public void myMethod() {
+ try {
+ // 可能抛出异常
+ } catch (ArithmeticException e) {
+ // 算术异常
+ } catch (NullPointerException e) {
+ // 空指针异常
+ }
+}
+```
+
+“但假设有好几个类似 `myMethod()` 的方法,如果为每个方法都加上 try-catch,就会显得非常繁琐。代码就会变得又臭又长,可读性就差了。”我继续说。
+
+“一个解决办法就是,使用 throws 关键字,在方法签名上声明可能会抛出的异常,然后在调用该方法的地方使用 try-catch 进行处理。”
+
+```java
+public static void main(String args[]){
+ try {
+ myMethod1();
+ } catch (ArithmeticException e) {
+ // 算术异常
+ } catch (NullPointerException e) {
+ // 空指针异常
+ }
+}
+public static void myMethod1() throws ArithmeticException, NullPointerException{
+ // 方法签名上声明异常
+}
+```
+
+“好了,我来总结下 throw 和 throws 的区别,三妹,你记一下。”
+
+ 1)throws 关键字用于声明异常,它的作用和 try-catch 相似;而 throw 关键字用于显式的抛出异常。
+
+2)throws 关键字后面跟的是异常的名字;而 throw 关键字后面跟的是异常的对象。
+
+示例。
+
+```
+throws ArithmeticException;
+```
+
+```
+throw new ArithmeticException("算术异常");
+```
+
+ 3)throws 关键字出现在方法签名上,而 throw 关键字出现在方法体里。
+
+4)throws 关键字在声明异常的时候可以跟多个,用逗号隔开;而 throw 关键字每次只能抛出一个异常。
+
+## 五、关于 throw 和 throws
+
+“二哥,[上一节](https://mp.weixin.qq.com/s/fXRJ1xdz_jNSSVTv7ZrYGQ)你讲了异常处理机制,这一节讲什么呢?”三妹问。
+
+“该讲 try-catch-finally 了。”我说,“try 关键字后面会跟一个大括号 `{}`,我们把一些可能发生异常的代码放到大括号里;`try` 块后面一般会跟 `catch` 块,用来处理发生异常的情况;当然了,异常不一定会发生,为了保证发不发生异常都能执行一些代码,就会跟一个 `finally` 块。”
+
+“具体该怎么用呀,二哥?”三妹问。
+
+“别担心,三妹,我一一来说明下。”我说。
+
+`try` 块的语法很简单:
+
+```java
+try{
+// 可能发生异常的代码
+}
+```
+
+“注意啊,三妹,如果一些代码确定不会抛出异常,就尽量不要把它包裹在 `try` 块里,因为加了异常处理的代码执行起来要比没有加的花费更多的时间。”
+
+`catch` 块的语法也很简单:
+
+```java
+try{
+// 可能发生异常的代码
+}catch (exception(type) e(object)){
+// 异常处理代码
+}
+```
+
+一个 `try` 块后面可以跟多个 `catch` 块,用来捕获不同类型的异常并做相应的处理,当 try 块中的某一行代码发生异常时,之后的代码就不再执行,而是会跳转到异常对应的 catch 块中执行。
+
+如果一个 try 块后面跟了多个与之关联的 catch 块,那么应该把特定的异常放在前面,通用型的异常放在后面,不然编译器会提示错误。举例来说。
+
+```java
+static void test() {
+ int num1, num2;
+ try {
+ num1 = 0;
+ num2 = 62 / num1;
+ System.out.println(num2);
+ System.out.println("try 块的最后一句");
+ } catch (ArithmeticException e) {
+ // 算术运算发生时跳转到这里
+ System.out.println("除数不能为零");
+ } catch (Exception e) {
+ // 通用型的异常意味着可以捕获所有的异常,它应该放在最后面,
+ System.out.println("异常发生了");
+ }
+ System.out.println("try-catch 之外的代码.");
+}
+```
+
+“为什么 Exception 不能放到 ArithmeticException 前面呢?”三妹问。
+
+“因为 ArithmeticException 是 Exception 的子类,它更具体,我们看到就这个异常就知道是发生了算术错误,而 Exception 比较泛,它隐藏了具体的异常信息,我们看到后并不确定到底是发生了哪一种类型的异常,对错误的排查很不利。”我说,“再者,如果把通用型的异常放在前面,就意味着其他的 catch 块永远也不会执行,所以编译器就直接提示错误了。”
+
+“再给你举个例子,注意看,三妹。”
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[4]=30/0;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException e){
+ System.out.println("除数必须是 0");
+ } catch(ArrayIndexOutOfBoundsException e){
+ System.out.println("数组越界了");
+ } catch(Exception e){
+ System.out.println("一些其他的异常");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+这段代码在执行的时候,第一个 catch 块会执行,因为除数为零;我再来稍微改动下代码。
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[9]=30/1;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException e){
+ System.out.println("除数必须是 0");
+ } catch(ArrayIndexOutOfBoundsException e){
+ System.out.println("数组越界了");
+ } catch(Exception e){
+ System.out.println("一些其他的异常");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+“我知道,二哥,第二个 catch 块会执行,因为没有发生算术异常,但数组越界了。”三妹没等我把代码运行起来就说出了答案。
+
+“三妹,你说得很对,我再来改一下代码。”
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[9]=30/1;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException | ArrayIndexOutOfBoundsException e){
+ System.out.println("除数必须是 0");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+“当有多个 catch 的时候,也可以放在一起,用竖划线 `|` 隔开,就像上面这样。”我说。
+
+“这样不错呀,看起来更简洁了。”三妹说。
+
+`finally` 块的语法也不复杂。
+
+```java
+try {
+ // 可能发生异常的代码
+}catch {
+ // 异常处理
+}finally {
+ // 必须执行的代码
+}
+```
+
+在没有 `try-with-resources` 之前,finally 块常用来关闭一些连接资源,比如说 socket、数据库链接、IO 输入输出流等。
+
+```java
+OutputStream osf = new FileOutputStream( "filename" );
+OutputStream osb = new BufferedOutputStream(opf);
+ObjectOutput op = new ObjectOutputStream(osb);
+try{
+ output.writeObject(writableObject);
+} finally{
+ op.close();
+}
+```
+
+“三妹,注意,使用 finally 块的时候需要遵守这些规则。”
+
+- finally 块前面必须有 try 块,不要把 finally 块单独拉出来使用。编译器也不允许这样做。
+- finally 块不是必选项,有 try 块的时候不一定要有 finally 块。
+- 如果 finally 块中的代码可能会发生异常,也应该使用 try-catch 进行包裹。
+- 即便是 try 块中执行了 return、break、continue 这些跳转语句,finally 块也会被执行。
+
+“真的吗,二哥?”三妹对最后一个规则充满了疑惑。
+
+“来试一下就知道了。”我说。
+
+```java
+static int test2 () {
+ try {
+ return 112;
+ }
+ finally {
+ System.out.println("即使 try 块有 return,finally 块也会执行");
+ }
+}
+```
+
+来看一下输出结果:
+
+```
+即使 try 块有 return,finally 块也会执行
+```
+
+“那,会不会有不执行 finally 的情况呀?”三妹很好奇。
+
+“有的。”我斩钉截铁地回答。
+
+- 遇到了死循环。
+- 执行了 `System. exit()` 这行代码。
+
+`System.exit()` 和 `return` 语句不同,前者是用来退出程序的,后者只是回到了上一级方法调用。
+
+“三妹,来看一下源码的文档注释就全明白了!”
+
+
+
+至于参数 status 的值也很好理解,如果是异常退出,设置为非 0 即可,通常用 1 来表示;如果是想正常退出程序,用 0 表示即可。
+
+
\ No newline at end of file
diff --git a/docs/src/exception/npe.md b/docs/exception/npe.md
similarity index 89%
rename from docs/src/exception/npe.md
rename to docs/exception/npe.md
index 1f86928b00..c43debd280 100644
--- a/docs/src/exception/npe.md
+++ b/docs/exception/npe.md
@@ -1,17 +1,11 @@
---
-title: Java空指针NullPointerException的传说
-shortTitle: 空指针的传说
category:
- Java核心
tag:
- - 异常处理
-description: 本文详细解析了Java编程中的空指针异常(NullPointerException)现象,从产生原因、常见场景到预防方法,为您揭开NullPointerException的神秘面纱。文章还提供了实际代码示例,帮助您理解如何在实际开发中避免空指针异常,提高代码的健壮性和可靠性。
-head:
- - - meta
- - name: keywords
- content: java,npe,NullPointerException
+ - Java
---
+# Java空指针NullPointerException的传说
**空指针**,号称天下最强刺客。
@@ -21,13 +15,13 @@ head:
... ...
-我叫王二,我来到这个奇怪的世界已经一年了,我等了一年,穿越附赠的老爷爷、戒指、系统什么的我到现在都没发现。
+我叫铁柱,我来到这个奇怪的世界已经一年了,我等了一年,穿越附赠的老爷爷、戒指、系统什么的我到现在都没发现。
而且这个世界看起来也太奇怪了,这里好像叫什么 **Java** 大陆,我只知道这个世界的最强者叫做 **Object**,听说是什么道祖级的存在,我也不知道是什么意思,毕竟我现在好像还是个菜鸡,别的主角一年都应该要飞升仙界了吧,我还连个小火球都放不出来。
哦,对了,上面的那段话是我在茶馆喝茶的时候听说书的先生说的,总觉得空指针这个名字怪怪的,好像在什么地方听说过。
-我的头痛的毛病又犯了,我已经记不起来我为什么来到这里了,我只记得我的名字叫王二,其他的,我只感觉这个奇怪的世界有一种熟悉,但是我什么都记不起来了。
+我的头痛的毛病又犯了,我已经记不起来我为什么来到这里了,我只记得我的名字叫铁柱,其他的,我只感觉这个奇怪的世界有一种熟悉,但是我什么都记不起来了。
算了,得过且过吧。
@@ -177,7 +171,7 @@ Object听到这话,皱了皱眉,他沉默了一会儿,缓缓站起身子
我见他好像魔怔了,仿佛在思考什么,于是迈步走到他刚才站立的地方看着前面,原来,这是他们的族谱!这里是异常的祠堂!
-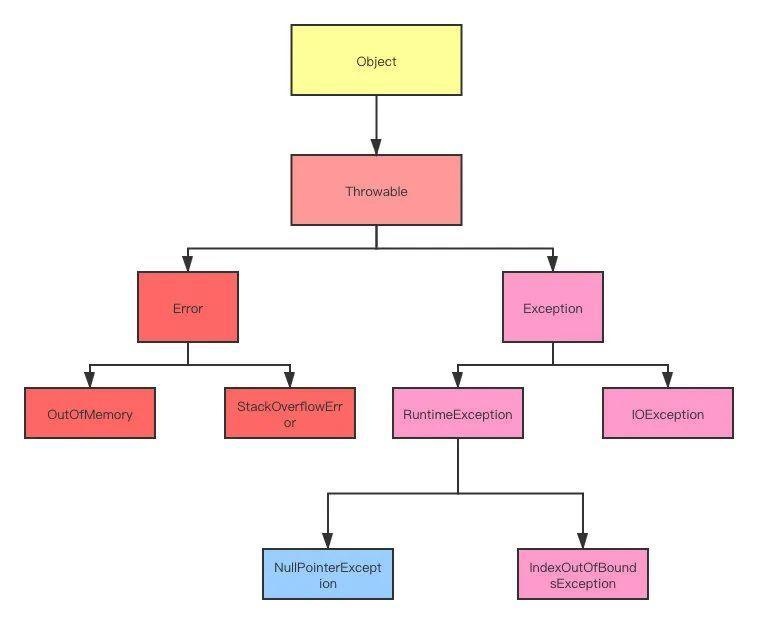
+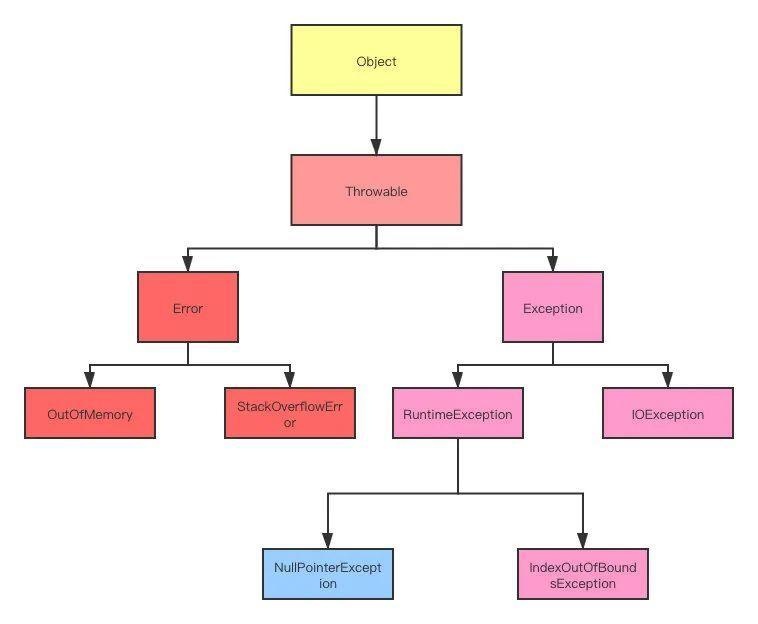
看完这张族谱,我恍然大悟,好像明白了什么。突然,我的脑袋里出现了一个冰冷的机器声音:“获取异常族谱,历练完成度+100。”
@@ -223,14 +217,7 @@ Object听到这话,皱了皱眉,他沉默了一会儿,缓缓站起身子
可是,他为什么要给我,看他刚才的样子都想打我了,又突然给了我这些?还有他一直在说的规则之力又是什么?这座城市为什么又这么诡异?
->转载链接:[https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg](https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg),作者:艾小仙
+>转载链接:https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/exception/shijian.md b/docs/exception/shijian.md
new file mode 100644
index 0000000000..9150539c70
--- /dev/null
+++ b/docs/exception/shijian.md
@@ -0,0 +1,219 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java异常处理的20个最佳实践
+
+“三妹啊,今天我来给你传授几个异常处理的最佳实践经验,以免你以后在开发中采坑。”我面带着微笑对三妹说。
+
+“好啊,二哥,我洗耳恭听。”三妹也微微一笑,欣然接受。
+
+“好,那哥就不废话了。开整。”
+
+--------
+
+**1)尽量不要捕获 RuntimeException**
+
+阿里出品的嵩山版 Java 开发手册上这样规定:
+
+>尽量不要 catch RuntimeException,比如 NullPointerException、IndexOutOfBoundsException 等等,应该用预检查的方式来规避。
+
+正例:
+
+```java
+if (obj != null) {
+ //...
+}
+```
+
+反例:
+
+```java
+try {
+ obj.method();
+} catch (NullPointerException e) {
+ //...
+}
+```
+
+“哦,那如果有些异常预检查不出来呢?”三妹问。
+
+“的确会存在这样的情况,比如说 NumberFormatException,虽然也属于 RuntimeException,但没办法预检查,所以还是应该用 catch 捕获处理。”我说。
+
+**2)尽量使用 try-with-resource 来关闭资源**
+
+当需要关闭资源时,尽量不要使用 try-catch-finally,禁止在 try 块中直接关闭资源。
+
+反例:
+
+```java
+public void doNotCloseResourceInTry() {
+ FileInputStream inputStream = null;
+ try {
+ File file = new File("./tmp.txt");
+ inputStream = new FileInputStream(file);
+ inputStream.close();
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } catch (IOException e) {
+ log.error(e);
+ }
+}
+```
+
+“为什么呢?”三妹问。
+
+“原因也很简单,因为一旦 `close()` 之前发生了异常,那么资源就无法关闭。直接使用 [try-with-resource](https://mp.weixin.qq.com/s/7yhHOG0SVCfoHdhtZHfeVg) 来处理是最佳方式。”我说。
+
+```java
+public void automaticallyCloseResource() {
+ File file = new File("./tmp.txt");
+ try (FileInputStream inputStream = new FileInputStream(file);) {
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } catch (IOException e) {
+ log.error(e);
+ }
+}
+```
+
+“除非资源没有实现 AutoCloseable 接口。”我补充道。
+
+“那这种情况下怎么办呢?”三妹问。
+
+“就在 finally 块关闭流。”我说。
+
+```java
+public void closeResourceInFinally() {
+ FileInputStream inputStream = null;
+ try {
+ File file = new File("./tmp.txt");
+ inputStream = new FileInputStream(file);
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } finally {
+ if (inputStream != null) {
+ try {
+ inputStream.close();
+ } catch (IOException e) {
+ log.error(e);
+ }
+ }
+ }
+}
+```
+
+**3)不要捕获 Throwable**
+
+Throwable 是 exception 和 error 的父类,如果在 catch 子句中捕获了 Throwable,很可能把超出程序处理能力之外的错误也捕获了。
+
+```java
+public void doNotCatchThrowable() {
+ try {
+ } catch (Throwable t) {
+ // 不要这样做
+ }
+}
+```
+
+“到底为什么啊?”三妹问。
+
+“因为有些 error 是不需要程序来处理,程序可能也处理不了,比如说 OutOfMemoryError 或者 StackOverflowError,前者是因为 Java 虚拟机无法申请到足够的内存空间时出现的非正常的错误,后者是因为线程申请的栈深度超过了允许的最大深度出现的非正常错误,如果捕获了,就掩盖了程序应该被发现的严重错误。”我说。
+
+“打个比方,一匹马只能拉一车厢的货物,拉两车厢可能就挂了,但一 catch,就发现不了问题了。”我补充道。
+
+**4)不要省略异常信息的记录**
+
+很多时候,由于疏忽大意,开发者很容易捕获了异常却没有记录异常信息,导致程序上线后真的出现了问题却没有记录可查。
+
+```java
+public void doNotIgnoreExceptions() {
+ try {
+ } catch (NumberFormatException e) {
+ // 没有记录异常
+ }
+}
+```
+
+应该把错误信息记录下来。
+
+```java
+public void logAnException() {
+ try {
+ } catch (NumberFormatException e) {
+ log.error("哦,错误竟然发生了: " + e);
+ }
+}
+```
+
+**5)不要记录了异常又抛出了异常**
+
+这纯属画蛇添足,并且容易造成错误信息的混乱。
+
+反例:
+
+```java
+try {
+} catch (NumberFormatException e) {
+ log.error(e);
+ throw e;
+}
+```
+
+要抛出就抛出,不要记录,记录了又抛出,等于多此一举。
+
+反例:
+
+```java
+public void wrapException(String input) throws MyBusinessException {
+ try {
+ } catch (NumberFormatException e) {
+ throw new MyBusinessException("错误信息描述:", e);
+ }
+}
+```
+
+这种也是一样的道理,既然已经捕获了,就不要在方法签名上抛出了。
+
+**6)不要在 finally 块中使用 return**
+
+阿里出品的嵩山版 Java 开发手册上这样规定:
+
+>try 块中的 return 语句执行成功后,并不会马上返回,而是继续执行 finally 块中的语句,如果 finally 块中也存在 return 语句,那么 try 块中的 return 就将被覆盖。
+
+反例:
+
+```java
+private int x = 0;
+public int checkReturn() {
+ try {
+ return ++x;
+ } finally {
+ return ++x;
+ }
+}
+```
+
+“哦,确实啊,try 块中 x 返回的值为 1,到了 finally 块中就返回 2 了。”三妹说。
+
+“是这样的。”我点点头。
+
+----------
+
+“好了,三妹,关于异常处理实践就先讲这 6 条吧,实际开发中你还会碰到其他的一些坑,自己踩一踩可能印象更深刻一些。”我说。
+
+“那万一到时候我工作后被领导骂了怎么办?”三妹委屈地说。
+
+“新人嘛,总要写几个 bug 才能对得起新人这个称号嘛。”我轻描淡写地说。
+
+“好吧。”三妹无奈地叹了口气。
+
+
+
+
+
+
+
diff --git a/docs/exception/try-with-resouces.md b/docs/exception/try-with-resouces.md
new file mode 100644
index 0000000000..51f5f26a68
--- /dev/null
+++ b/docs/exception/try-with-resouces.md
@@ -0,0 +1,301 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 详解Java7新增的try-with-resouces语法
+
+
+“二哥,终于等到你讲 try-with-resouces 了!”三妹夸张的表情让我有些吃惊。
+
+“三妹,不要激动呀!开讲之前,我们还是要来回顾一下 try–catch-finally,好做个铺垫。”我说,“来看看这段代码吧。”
+
+```java
+public class TrycatchfinallyDecoder {
+ public static void main(String[] args) {
+ BufferedReader br = null;
+ try {
+ String path = TrycatchfinallyDecoder.class.getResource("/牛逼.txt").getFile();
+ String decodePath = URLDecoder.decode(path,"utf-8");
+ br = new BufferedReader(new FileReader(decodePath));
+
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ System.out.println(str);
+ }
+ } catch (IOException e) {
+ e.printStackTrace();
+ } finally {
+ if (br != null) {
+ try {
+ br.close();
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+}
+```
+
+“我简单来解释下。”等三妹看完这段代码后,我继续说,“在 try 块中读取文件中的内容,并一行一行地打印到控制台。如果文件找不到或者出现 IO 读写错误,就在 catch 中捕获并打印错误的堆栈信息。最后,在 finally 中关闭缓冲字符读取器对象 BufferedReader,有效杜绝了资源未被关闭的情况下造成的严重性能后果。”
+
+“在 Java 7 之前,try–catch-finally 的确是确保资源会被及时关闭的最佳方法,无论程序是否会抛出异常。”
+
+三妹点了点头,表示同意。
+
+“不过,这段代码还是有些臃肿,尤其是 finally 中的代码。”我说,“况且,try–catch-finally 至始至终存在一个严重的隐患:try 中的 `br.readLine()` 有可能会抛出 `IOException`,finally 中的 `br.close()` 也有可能会抛出 `IOException`。假如两处都不幸地抛出了 IOException,那程序的调试任务就变得复杂了起来,到底是哪一处出了错误,就需要花一番功夫,这是我们不愿意看到的结果。”
+
+“我来给你演示下,三妹。”
+
+“首先,我们来定义这样一个类 MyfinallyReadLineThrow,它有两个方法,分别是 `readLine()` 和 `close()`,方法体都是主动抛出异常。”
+
+```java
+class MyfinallyReadLineThrow {
+ public void close() throws Exception {
+ throw new Exception("close");
+ }
+
+ public void readLine() throws Exception {
+ throw new Exception("readLine");
+ }
+}
+```
+
+“然后在 `main()` 方法中使用 try-catch-finally 的方式调用 MyfinallyReadLineThrow 的 `readLine()` 和 `close()` 方法。”
+
+```java
+public class TryfinallyCustomReadLineThrow {
+ public static void main(String[] args) throws Exception {
+ MyfinallyReadLineThrow myThrow = null;
+ try {
+ myThrow = new MyfinallyReadLineThrow();
+ myThrow.readLine();
+ } finally {
+ myThrow.close();
+ }
+ }
+}
+```
+
+运行上述代码后,错误堆栈如下所示:
+
+```
+Exception in thread "main" java.lang.Exception: close
+ at com.cmower.dzone.trycatchfinally.MyfinallyOutThrow.close(TryfinallyCustomOutThrow.java:17)
+ at com.cmower.dzone.trycatchfinally.TryfinallyCustomOutThrow.main(TryfinallyCustomOutThrow.java:10)
+```
+
+“看出来问题了吗,三妹?”
+
+“啊?`readLine()` 方法的异常信息竟然被 `close()` 方法的堆栈信息吃了!”
+
+“不错啊,三妹,火眼金睛,的确,这会让我们误以为要调查的目标是 `close()` 方法而不是 `readLine()` 方法——尽管它也是应该怀疑的对象。”
+
+“但有了 try-with-resources 后,这些问题就迎刃而解了。前提条件只有一个,就是需要释放的资源(比如 BufferedReader)实现了 AutoCloseable 接口。”
+
+```java
+try (BufferedReader br = new BufferedReader(new FileReader(decodePath));) {
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ System.out.println(str);
+ }
+} catch (IOException e) {
+ e.printStackTrace();
+}
+```
+
+“你瞧,三妹,finally 块消失了,取而代之的是把要释放的资源写在 try 后的 `()` 中。如果有多个资源(BufferedReader 和 PrintWriter)需要释放的话,可以直接在 `()` 中添加。”
+
+```java
+try (BufferedReader br = new BufferedReader(new FileReader(decodePath));
+ PrintWriter writer = new PrintWriter(new File(writePath))) {
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ writer.print(str);
+ }
+} catch (IOException e) {
+ e.printStackTrace();
+}
+```
+
+“如果想释放自定义资源的话,只要让它实现 AutoCloseable 接口,并提供 `close()` 方法即可。”
+
+```java
+public class TrywithresourcesCustom {
+ public static void main(String[] args) {
+ try (MyResource resource = new MyResource();) {
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+
+class MyResource implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+}
+```
+
+来看一下代码运行后的输出结果:
+
+```
+关闭自定义资源
+```
+
+“好神奇呀!”三妹欣喜若狂,“在 `try ()` 中只是 new 了一个 MyResource 的对象,其他什么也没干,`close()` 方法就执行了!”
+
+“想知道为什么吗?三妹。”
+
+“当然想啊。”
+
+“来看看反编译后的字节码吧。”
+
+```java
+class MyResource implements AutoCloseable {
+ MyResource() {
+ }
+
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+}
+
+public class TrywithresourcesCustom {
+ public TrywithresourcesCustom() {
+ }
+
+ public static void main(String[] args) {
+ try {
+ MyResource resource = new MyResource();
+ resource.close();
+ } catch (Exception var2) {
+ var2.printStackTrace();
+ }
+
+ }
+}
+```
+
+“啊,原来如此。编译器主动为 try-with-resources 进行了变身,在 try 中调用了 `close()` 方法。”
+
+“是这样的。接下来,我们在 `MyResourceOut` 类中再添加一个 `out()` 方法。”
+
+```java
+class MyResourceOut implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+
+ public void out() throws Exception{
+ System.out.println("沉默王二,一枚有趣的程序员");
+ }
+}
+```
+
+“这次,我们在 try 中调用一下 `out()` 方法。”
+
+```java
+public class TrywithresourcesCustomOut {
+ public static void main(String[] args) {
+ try (MyResourceOut resource = new MyResourceOut();) {
+ resource.out();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+“再来看一下反编译的字节码。”
+
+```
+public class TrywithresourcesCustomOut {
+ public TrywithresourcesCustomOut() {
+ }
+
+ public static void main(String[] args) {
+ try {
+ MyResourceOut resource = new MyResourceOut();
+
+ try {
+ resource.out();
+ } catch (Throwable var5) {
+ try {
+ resource.close();
+ } catch (Throwable var4) {
+ var5.addSuppressed(var4);
+ }
+
+ throw var5;
+ }
+
+ resource.close();
+ } catch (Exception var6) {
+ var6.printStackTrace();
+ }
+
+ }
+}
+```
+
+“这次,`catch` 块主动调用了 `resource.close()`,并且有一段很关键的代码 ` var5.addSuppressed(var4)`。”
+
+“这是为了什么呢?”三妹问。
+
+“当一个异常被抛出的时候,可能有其他异常因为该异常而被抑制住,从而无法正常抛出。这时可以通过 `addSuppressed()` 方法把这些被抑制的方法记录下来,然后被抑制的异常就会出现在抛出的异常的堆栈信息中,可以通过 `getSuppressed()` 方法来获取这些异常。这样做的好处是不会丢失任何异常,方便我们进行调试。”我说。
+
+“有没有想到之前的那个例子——在 try-catch-finally 中,`readLine()` 方法的异常信息竟然被 `close()` 方法的堆栈信息吃了。现在有了 try-with-resources,再来看看和 `readLine()` 方法一致的 `out()` 方法会不会被 `close()` 吃掉吧。”
+
+```java
+class MyResourceOutThrow implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ throw new Exception("close()");
+ }
+
+ public void out() throws Exception{
+ throw new Exception("out()");
+ }
+}
+```
+
+“调用这 2 个方法。”
+
+```java
+public class TrywithresourcesCustomOutThrow {
+ public static void main(String[] args) {
+ try (MyResourceOutThrow resource = new MyResourceOutThrow();) {
+ resource.out();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+“程序输出的结果如下所示。”
+
+```
+java.lang.Exception: out()
+ at com.cmower.dzone.trycatchfinally.MyResourceOutThrow.out(TrywithresourcesCustomOutThrow.java:20)
+ at com.cmower.dzone.trycatchfinally.TrywithresourcesCustomOutThrow.main(TrywithresourcesCustomOutThrow.java:6)
+ Suppressed: java.lang.Exception: close()
+ at com.cmower.dzone.trycatchfinally.MyResourceOutThrow.close(TrywithresourcesCustomOutThrow.java:16)
+ at com.cmower.dzone.trycatchfinally.TrywithresourcesCustomOutThrow.main(TrywithresourcesCustomOutThrow.java:5)
+```
+
+“瞧,这次不会了,`out()` 的异常堆栈信息打印出来了,并且 `close()` 方法的堆栈信息上加了一个关键字 `Suppressed`,一目了然。”
+
+“三妹,怎么样?是不是感觉 try-with-resouces 好用多了!我来简单总结下哈,在处理必须关闭的资源时,始终有限考虑使用 try-with-resources,而不是 try–catch-finally。前者产生的代码更加简洁、清晰,产生的异常信息也更靠谱。”
+
+“靠谱!”三妹说。
+
+
+
+
diff --git a/docs/src/git/git-qiyuan.md b/docs/git/git-qiyuan.md
similarity index 87%
rename from docs/src/git/git-qiyuan.md
rename to docs/git/git-qiyuan.md
index ed60af3df6..10f83e0103 100644
--- a/docs/src/git/git-qiyuan.md
+++ b/docs/git/git-qiyuan.md
@@ -1,24 +1,24 @@
---
-title: 1小时彻底掌握 Git,(可能是)史上最简单明了的 Git 教程
-shortTitle: 最简单明了的 Git 教程
category:
- - 开发/构建工具
+ - Java企业级开发
tag:
- Git
-description: 二哥的Java进阶之路,小白的零基础Java教程,从入门到进阶,1小时彻底掌握 Git,(可能是)史上最简单明了的 Git 教程
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Git入门,Git教程,git
---
+# 我在工作中是如何使用 Git 的
+
## 一、Git 起源
Git 是一个分布式版本控制系统,缔造者是大名鼎鼎的林纳斯·托瓦茲 (Linus Torvalds),Git 最初的目的是为了能更好的管理 Linux 内核源码。
-
+
+
+PS:**为了能够帮助更多的 Java 爱好者,已将《Java 程序员进阶之路》开源到了 GitHub(本篇已收录)。如果你也喜欢这个专栏,觉得有帮助的话,可以去点个 star,这样也方便以后进行更系统化的学习**:
+[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)
+
+*每天看着 star 数的上涨我心里非常的开心,希望越来越多的 Java 爱好者能因为这个开源项目而受益,而越来越多人的 star,也会激励我继续更新下去*~
大家都知道,Linux 内核是开源的,参与者众多,到目前为止,共有两万多名开发者给 Linux Kernel 提交过代码。
@@ -54,7 +54,7 @@ Junio Hamano 觉得 Linus 设计的这些命令对于普通用户不太友好,
如今,Git 已经成为全球软件开发者的标配。
-
+
原本的 Git 只适用于 Unix/Linux 平台,但随着 Cygwin、msysGit 环境的成熟,以及 TortoiseGit 这样易用的GUI工具,Git 在 Windows 平台下也逐渐成熟。
@@ -65,7 +65,7 @@ Junio Hamano 觉得 Linus 设计的这些命令对于普通用户不太友好,
Git 和传统的版本控制工具 CVS、SVN 有不小的区别,前者关心的是文件的整体性是否发生了改变,后两者更关心文件内容上的差异。
-
+
除此之外,Git 更像是一个文件系统,每个使用它的主机都可以作为版本库,并且不依赖于远程仓库而离线工作。开发者在本地就有历史版本的副本,因此就不用再被远程仓库的网络传输而束缚。
@@ -88,7 +88,7 @@ Git 中的绝大多数操作都只需要访问本地文件和资源,一般不
Git 的工作流程是这样的:
-
+
- 在工作目录中修改文件
@@ -102,11 +102,11 @@ Git 的工作流程是这样的:
>https://git-scm.com/downloads
-
+
我个人使用的 macOS 系统,可以直接使用 `brew install git` 命令安装,非常方便。
-
+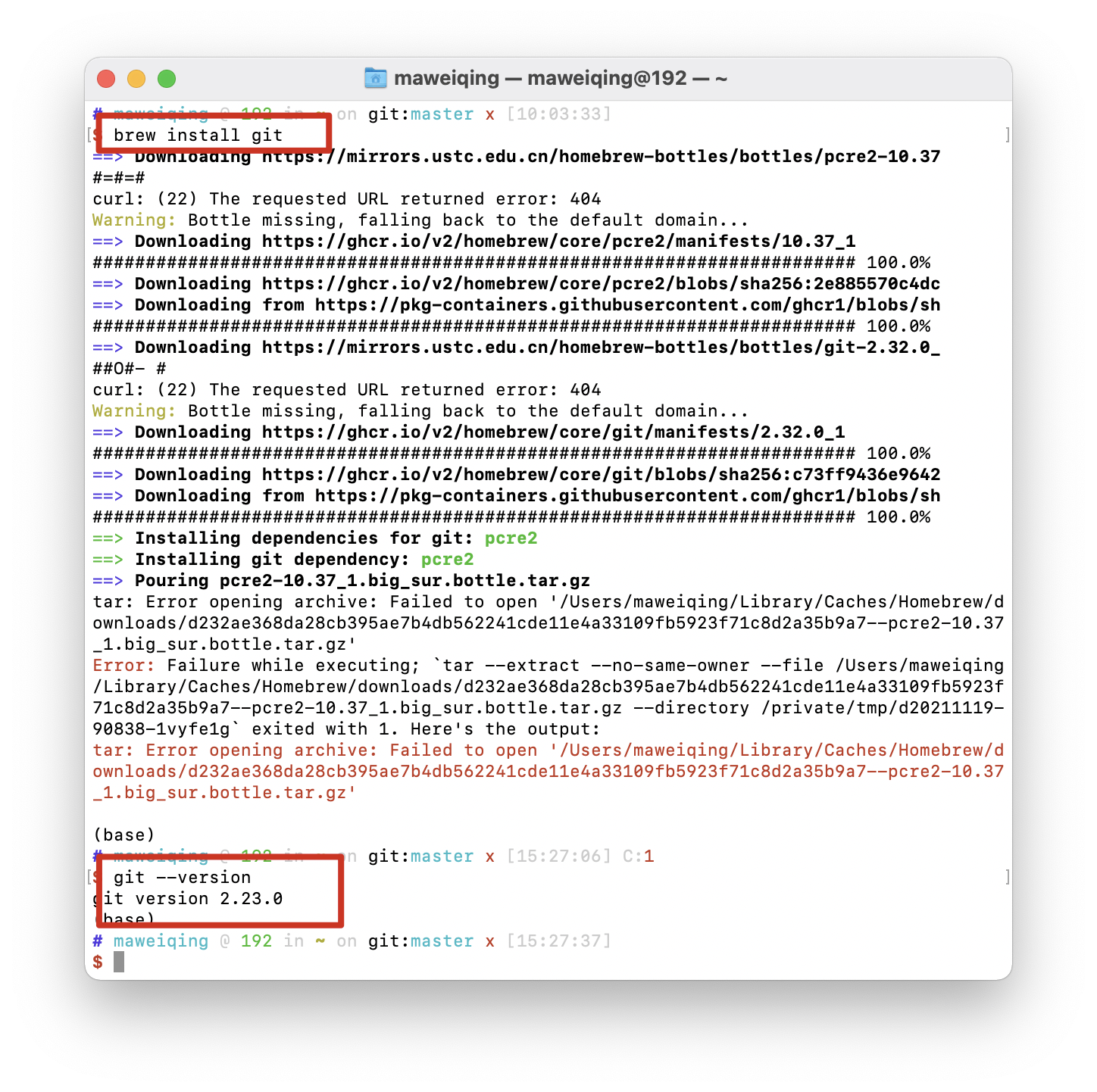
安装成功后,再使用 `git --version` 就可以查看版本号了,我本机上安装的是 2.23.0 版本。
@@ -287,7 +287,7 @@ TREE: 目录树对象。在 Linus 的设计里,TREE 对象就是一个时间
另外,由于 TREE 上记录文件名及属性信息,对于修改文件属性或修改文件名、移动目录而不修改文件内容的情况,可以复用 BLOB 对象,节省存储资源。而 Git 在后来的开发演进中又优化了 TREE 的设计,变成了某一时间点文件夹信息的抽象,TREE 包含其子目录的 TREE 的对象信息(SHA1)。这样,对于目录结构很复杂或层级较深的 Git 库 可以节约存储资源。历史信息被记录在第三种对象 CHANGESET 里。
-
+
CHANGESET:即 Commit 对象。一个 CHANGESET 对象中记录了该次提交的 TREE 对象信息(SHA1),以及提交者(committer)、提交备注(commit message)等信息。
@@ -304,7 +304,7 @@ Linus 解释了“当前目录缓存”的设计,该缓存就是一个二进
- 1. 能够快速的复原缓存的完整内容,即使不小心把当前工作区的文件删除了,也可以从缓存中恢复所有文件;
- 2. 能够快速找出缓存中和当前工作区内容不一致的文件。
-
+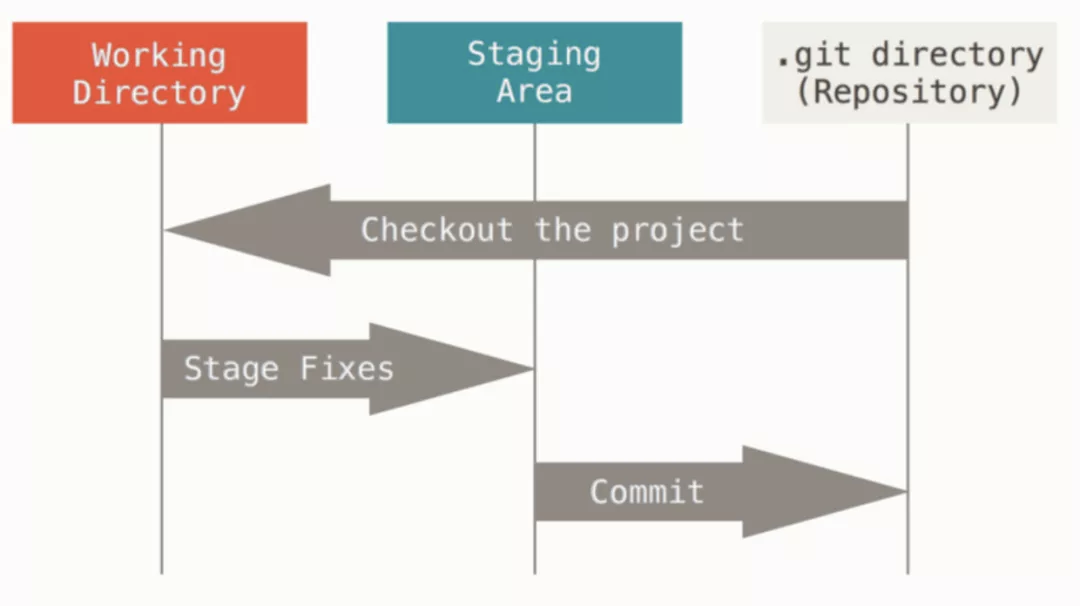
Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,并可以编译使用。代码极为简洁,加上 Makefile 一共只有 848 行。感兴趣的话可以通过上一段所述方法 checkout Git 最早的 commit 上手编译玩玩,只要有 Linux 环境即可。
@@ -332,7 +332,7 @@ Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,
一般来说,日常使用只要记住下图中这 6 个命令就可以了,但是熟练使用 Git,恐怕要记住60~100个命令~
-
+
@@ -347,7 +347,7 @@ Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,
下面是阮一峰老师整理的常用 Git 命令清单,有必要的话,可以打印一份出来,放在工作台~
->[http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html](http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html)
+>http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html
### 1、新建代码库
@@ -641,7 +641,7 @@ $ git archive
但是,太方便了也会产生副作用。如果你不加注意,很可能会留下一个枝节蔓生、四处开放的版本库,到处都是分支,完全看不出主干发展的脉络。
-
+
那有没有一个好的分支策略呢?答案当然是有的。
@@ -650,7 +650,7 @@ $ git archive
首先,代码库应该有一个、且仅有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。
-
+
Git主分支的名字,默认叫做Master。它是自动建立的,版本库初始化以后,默认就是在主分支在进行开发。
@@ -658,7 +658,7 @@ Git主分支的名字,默认叫做Master。它是自动建立的,版本库
主分支只用来发布重大版本,日常开发应该在另一条分支上完成。我们把开发用的分支,叫做Develop。
-
+
这个分支可以用来生成代码的最新隔夜版本(nightly)。如果想正式对外发布,就在Master分支上,对Develop分支进行"合并"(merge)。
@@ -680,11 +680,11 @@ Git创建Develop分支的命令:
这里稍微解释一下上一条命令的--no-ff参数是什么意思。默认情况下,Git执行"快进式合并"(fast-farward merge),会直接将Master分支指向Develop分支。
-
+
使用--no-ff参数后,会执行正常合并,在Master分支上生成一个新节点。为了保证版本演进的清晰,我们希望采用这种做法。
-
+
### 3、临时性分支
@@ -702,7 +702,7 @@ Git创建Develop分支的命令:
**第一种是功能分支**,它是为了开发某种特定功能,从Develop分支上面分出来的。开发完成后,要再并入Develop。
-
+
功能分支的名字,可以采用feature-*的形式命名。
@@ -755,7 +755,7 @@ Git创建Develop分支的命令:
修补bug分支是从Master分支上面分出来的。修补结束以后,再合并进Master和Develop分支。它的命名,可以采用fixbug-*的形式。
-
+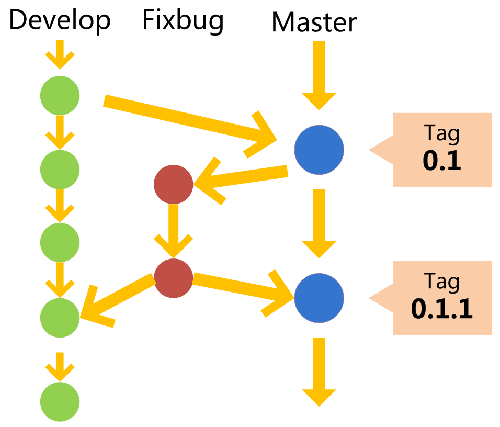
创建一个修补bug分支:
```
@@ -791,7 +791,7 @@ Git创建Develop分支的命令:
新建一个文件夹,比如说 testgit,然后使用 `git init` 命令就可以把这个文件夹初始化为 Git 仓库了。
-
+
初始化Git 仓库成功后,可以看到多了一个 .git 的目录,没事不要乱动,免得破坏了 Git 仓库的结构。
@@ -802,17 +802,17 @@ Git创建Develop分支的命令:
第二步,使用 `git commit` 命令告诉 Git,把文件提交到仓库。
-
+
可以使用 `git status` 来查看是否还有文件未提交。
也可以在文件中新增一行内容“传统美德不能丢,记得点赞哦~”,再使用 `git status` 来查看结果。
-
+
如果想查看文件到底哪里做了修改,可以使用 `git diff` 命令:
-
+
确认修改的内容后,可以使用 `git add` 和 `git commit` 再次提交。
@@ -822,11 +822,11 @@ Git创建Develop分支的命令:
现在我已经对 readme.txt 文件做了三次修改了。可以通过 `git log` 命令来查看历史记录:
-
+
也可以通过 `gitk` 这个命令来启动图形化界面来查看版本历史。
-
+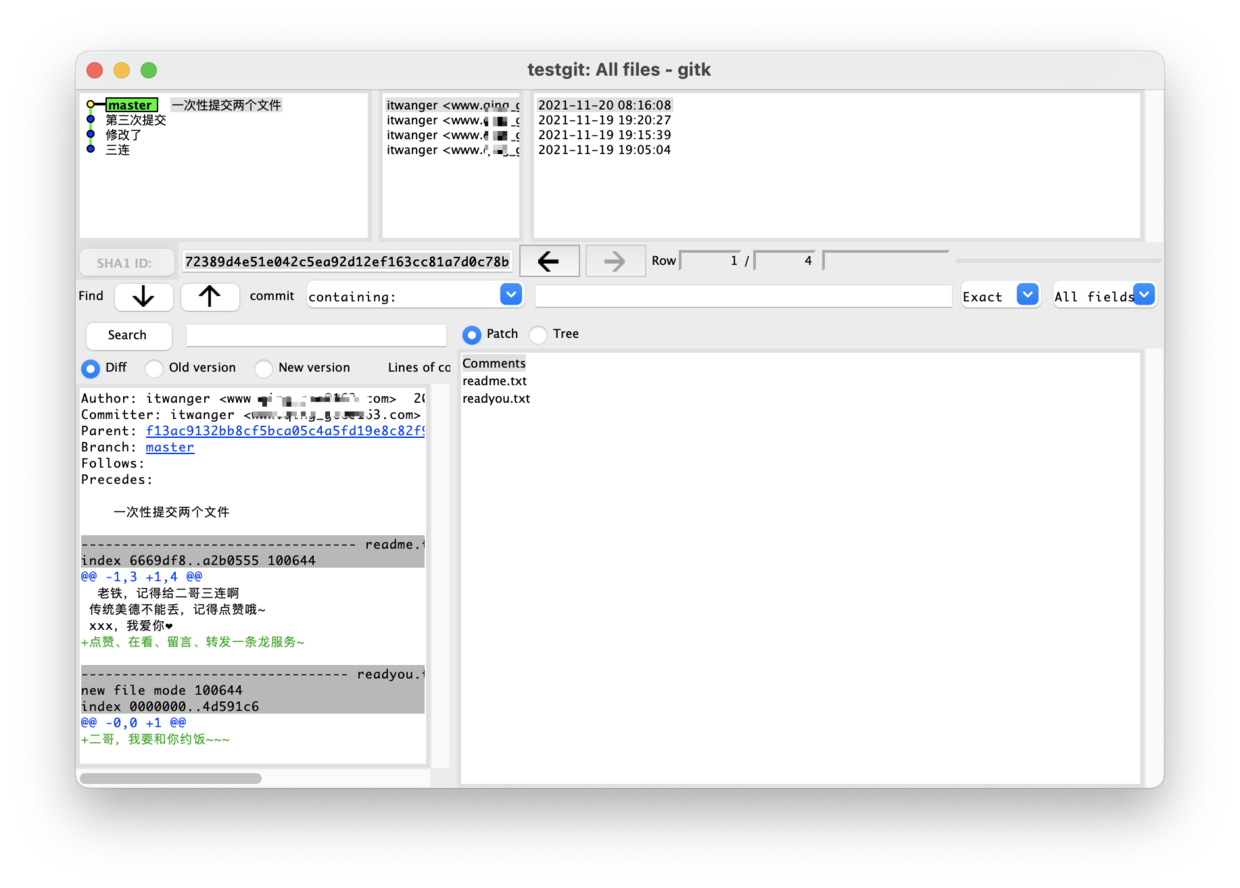
如果想回滚的话,比如说回滚到上一个版本,可以执行以下两种命令:
@@ -835,15 +835,15 @@ Git创建Develop分支的命令:
2)`git reset --hard HEAD~100`,如果回滚到前 100 个版本,用这个命令比上一个命令更方便。
-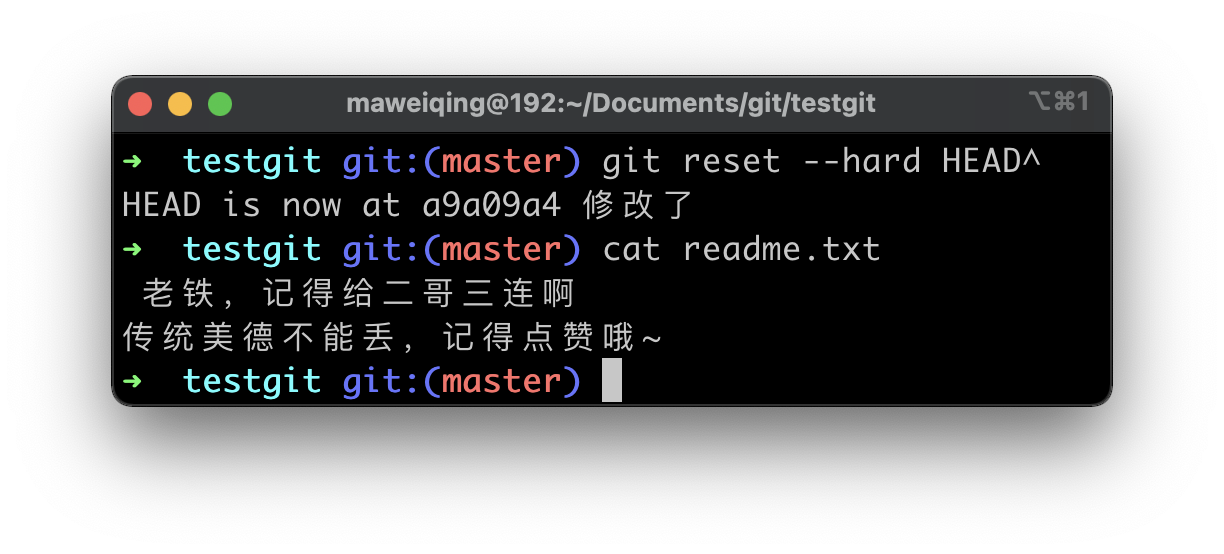
+
那假如回滚错了,想恢复,不记得版本号了,可以先执行 `git reflog` 命令查看版本号:
-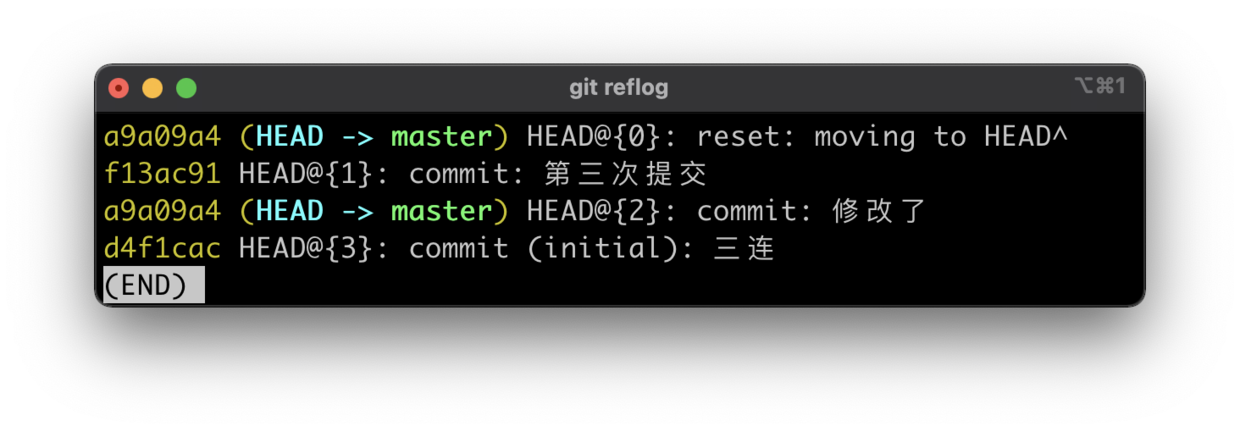
+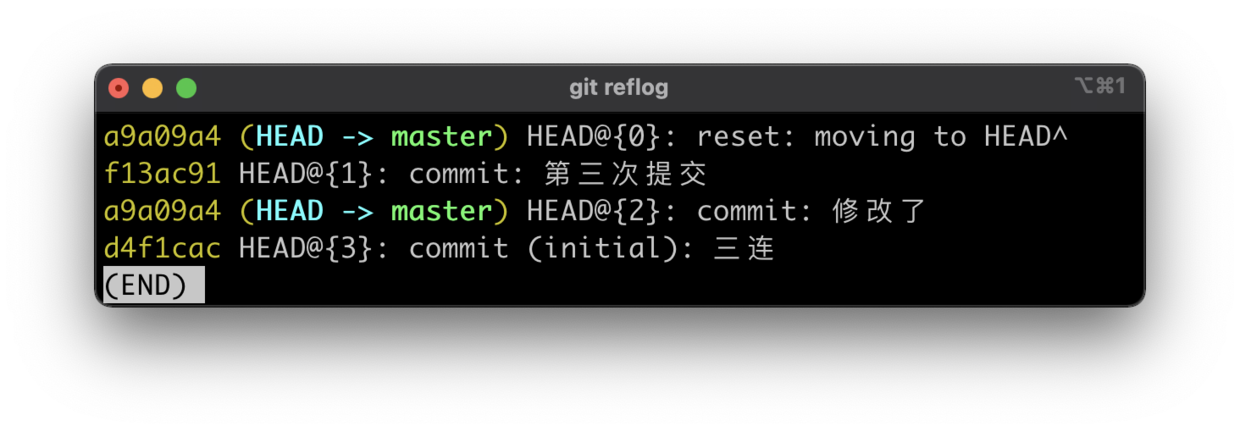
然后再通过 `git reset --hard` 命令来恢复:
-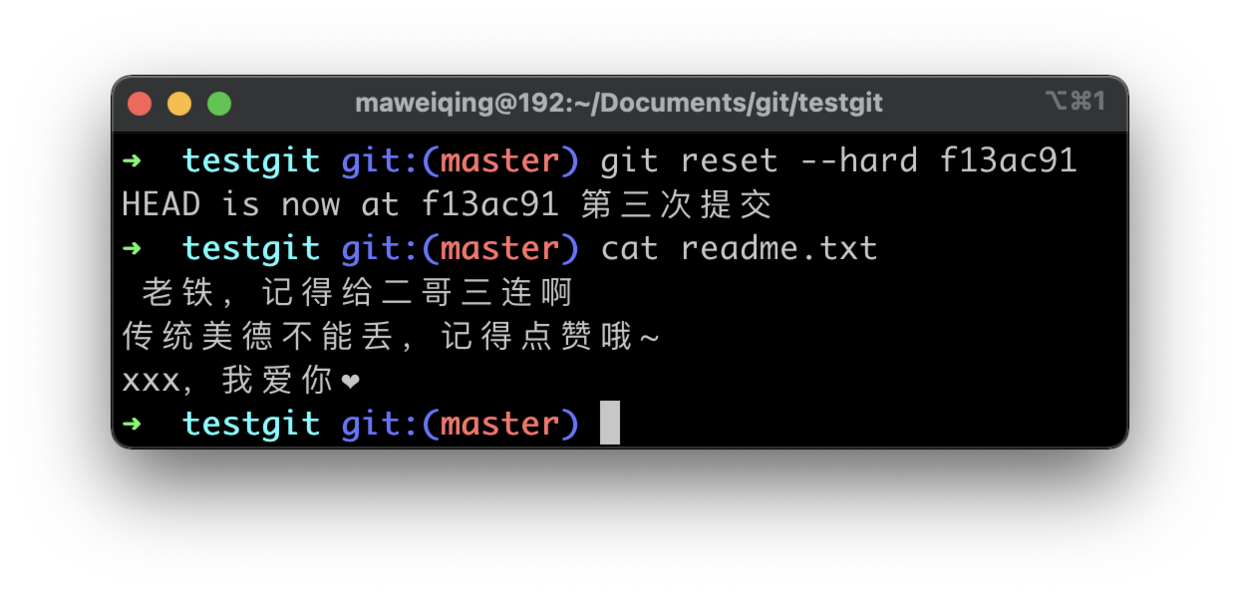
+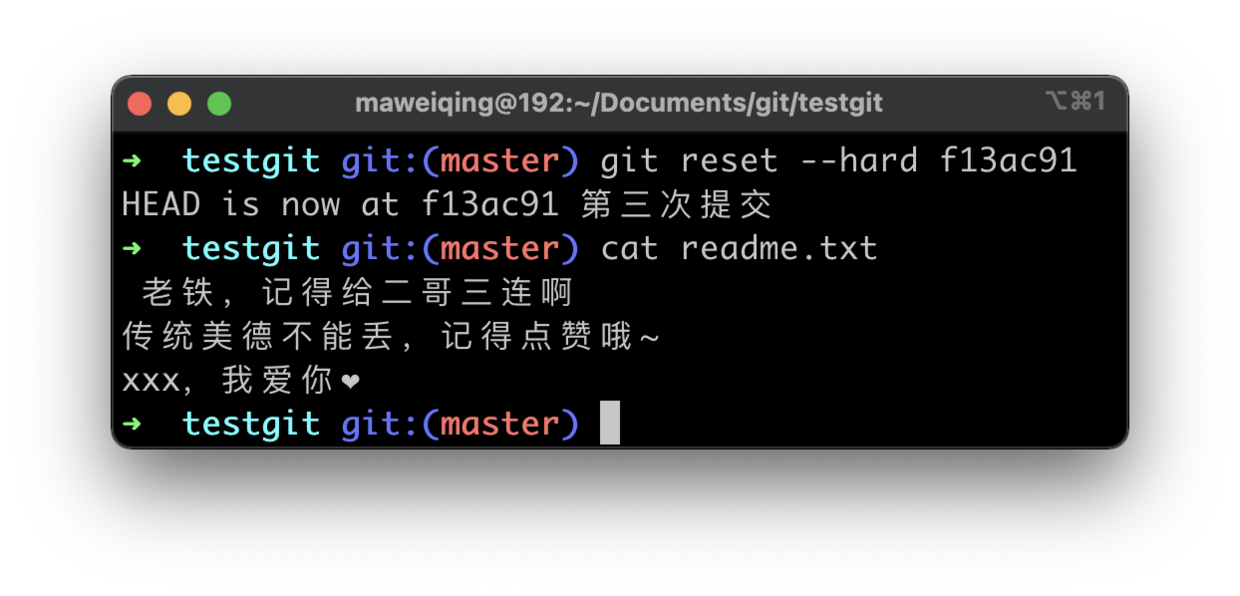
### 3、工作区和暂存区的区别
@@ -865,7 +865,7 @@ Git 在提交文件的时候分两步,第一步 `git add` 命令是把文件
原子性带来的好处是显而易见的,这使得我们可以把项目整体还原到某个时间点,就这一点,SVN 就完虐 CVS 这些代码版本管理系统了。
-
+
Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个优良特性的。但不同于 SVN 的是,Git 一开始搞的都是命令行,没有图形化界面,如果想要像 SVN 那样一次性选择多个文件或者不选某些文件(见上图),还真特喵的是个麻烦事。
@@ -881,7 +881,7 @@ Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个
我们先用 `git status` 命令查看一下状态,再用 `git add` 将文件添加到暂存区,最后再用 `git commit` 一次性提交到 Git 仓库。
-
+
### 4、撤销修改
@@ -895,17 +895,17 @@ Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个
答案当然是有了,其实在我们执行 `git status` 命令查看 Git 状态的时候,结果就提示我们可以使用 `git restore` 命令来撤销这次操作的。
-
+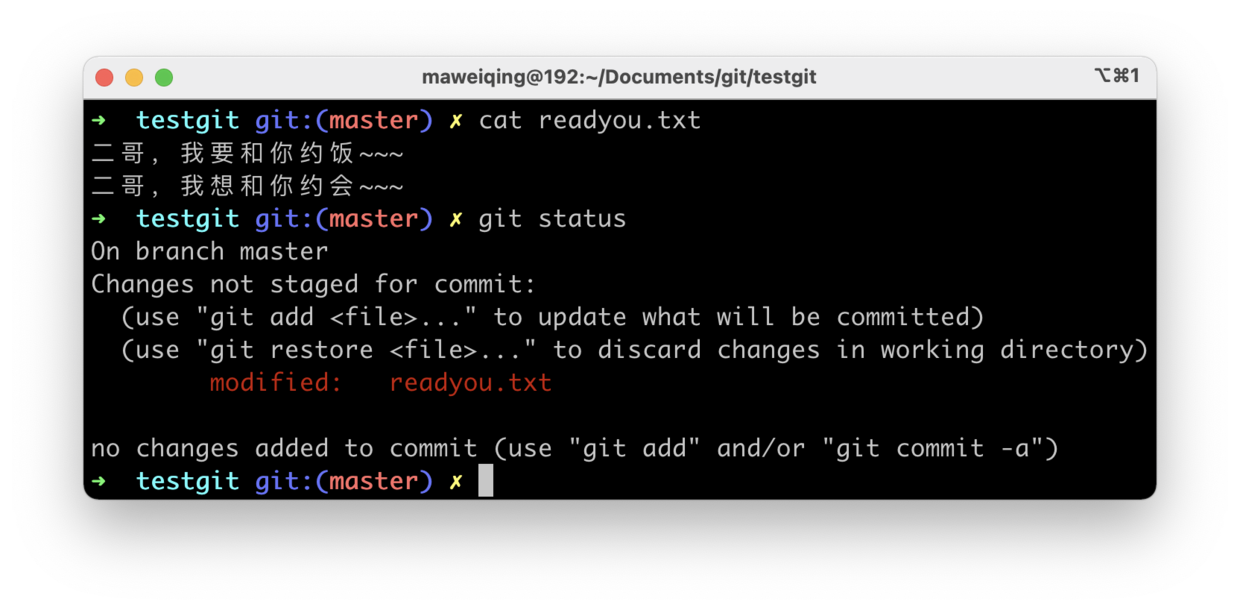
那其实在 git version 2.23.0 版本之前,是可以通过 `git checkout` 命令来完成撤销操作的。
-
+
checkout 可以创建分支、导出分支、切换分支、从暂存区删除文件等等,一个命令有太多功能就容易让人产生混淆。2.23.0 版本改变了这种混乱局面,git switch 和 git restore 两个新的命令应运而生。
switch 专注于分支的切换,restore 专注于撤销修改。
-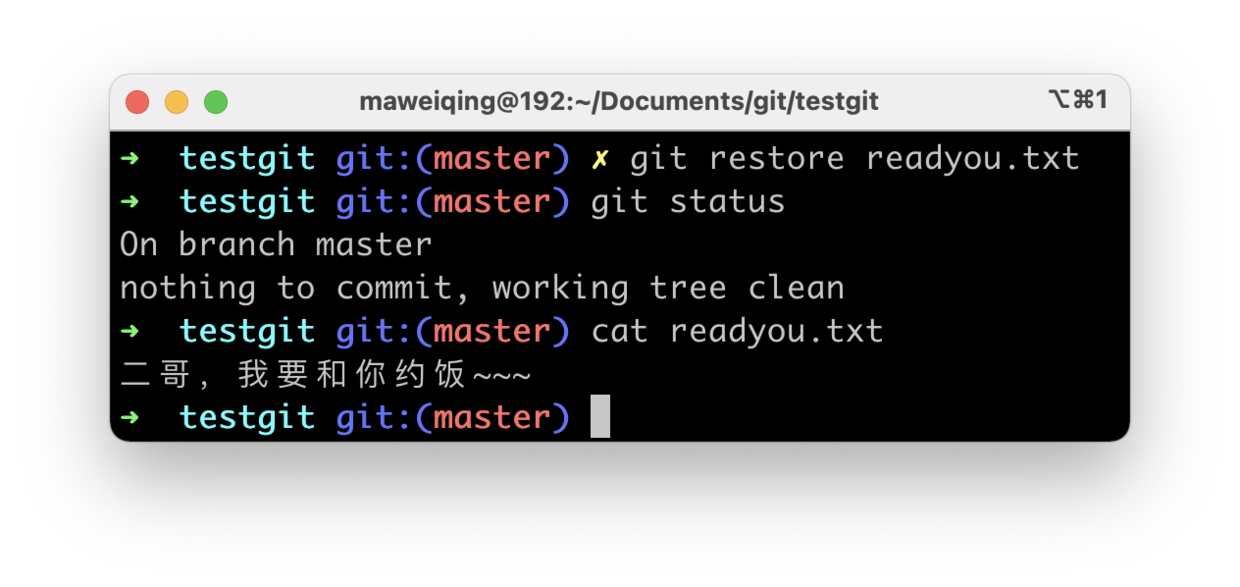
+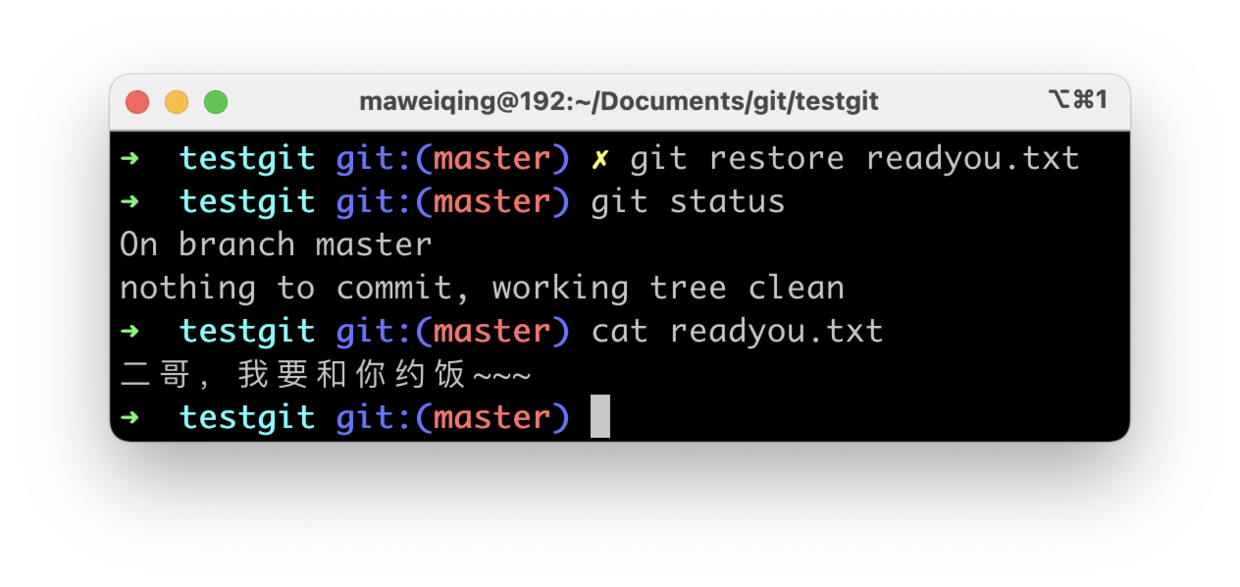
### 5、远程仓库
@@ -923,7 +923,7 @@ Git 是一款分布式版本控制系统,所以同一个 Git 仓库,可以
**第一步,通过 `ls -al ~/.ssh` 命令检查 SSH 密钥是否存在**
-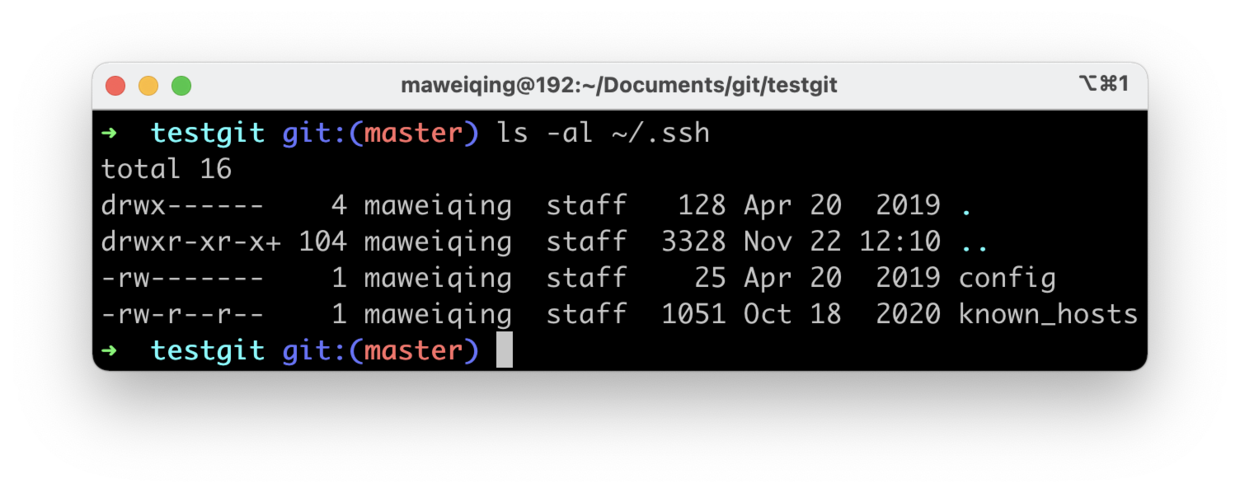
+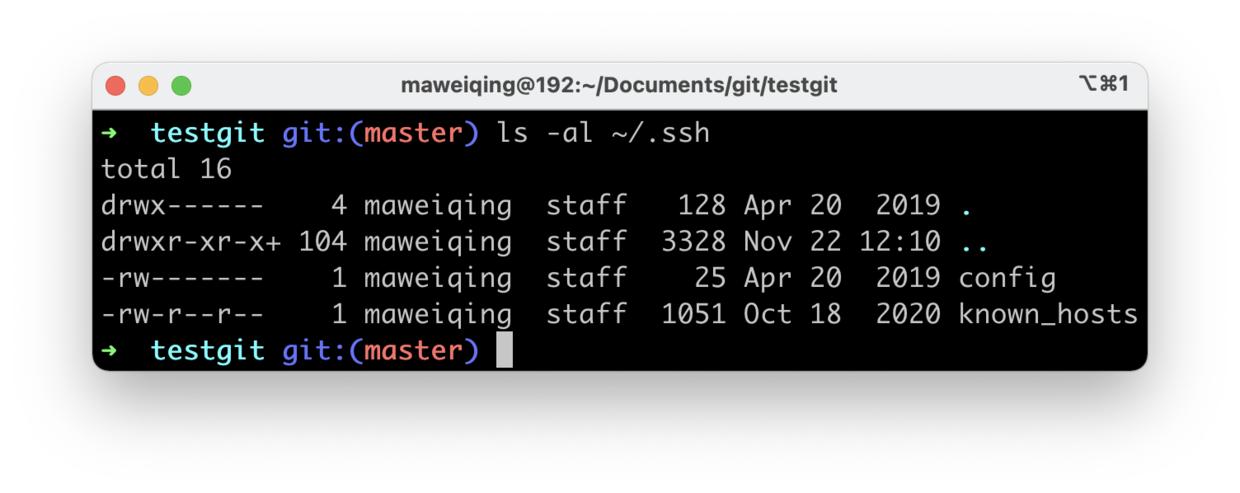
如果没有 id_rsa.pub、id_ecdsa.pub、id_ed25519.pub 这 3 个文件,表示密钥不存在。
@@ -932,26 +932,26 @@ Git 是一款分布式版本控制系统,所以同一个 Git 仓库,可以
执行以下命令,注意替换成你的邮箱:
```
-ssh-keygen -t ed25519 -C "your_email@example.com"
+ssh-keygen -t ed25519 -C "your_email@example.com
```
然后一路回车:
-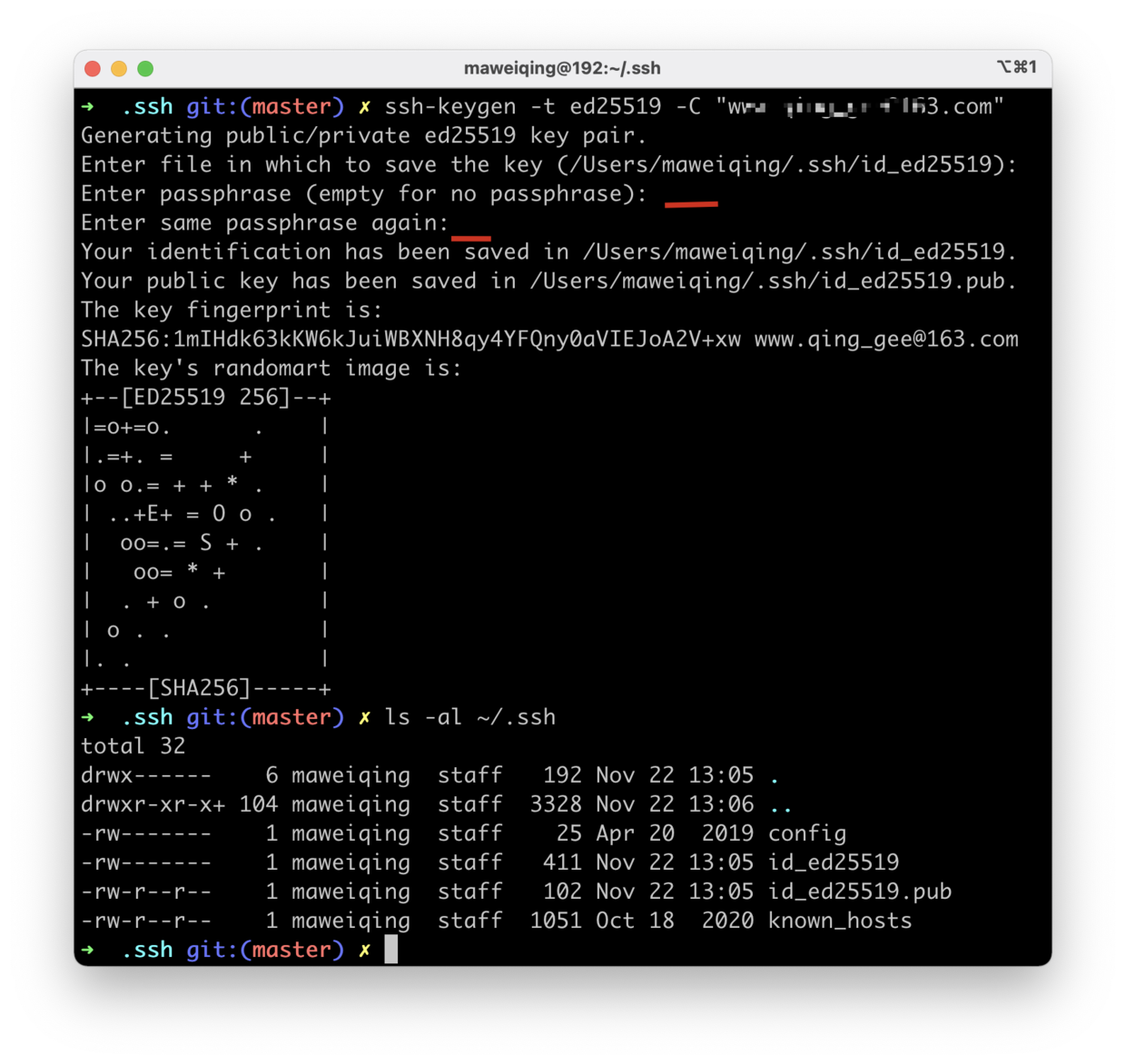
+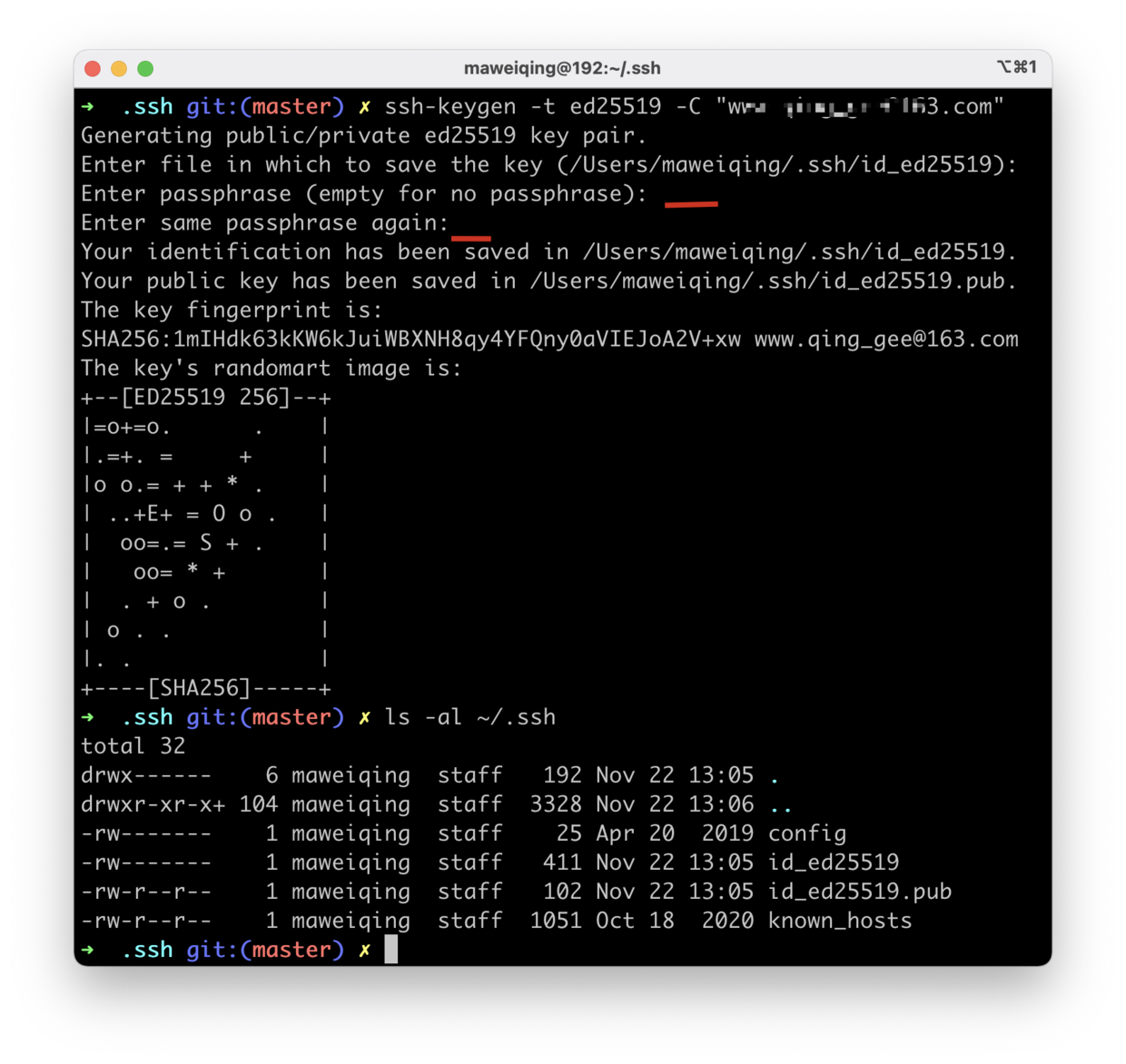
记得复制一下密钥,在 id_ed25519.pub 文件中:
-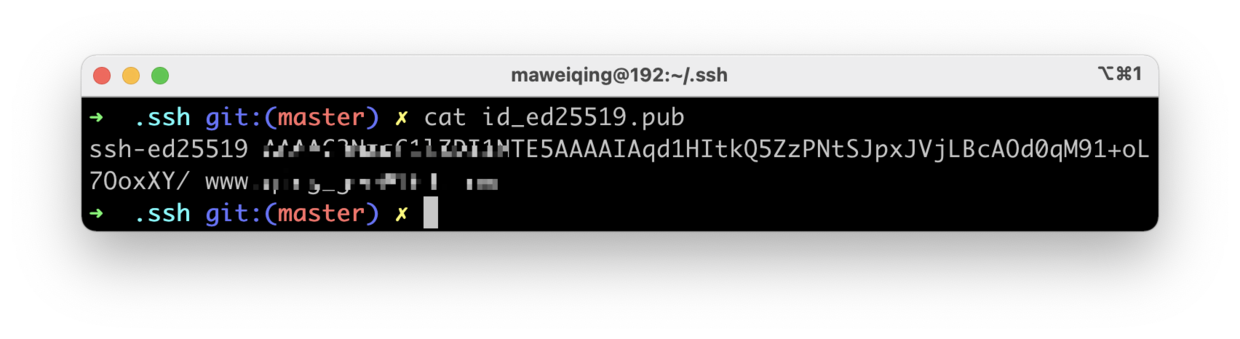
+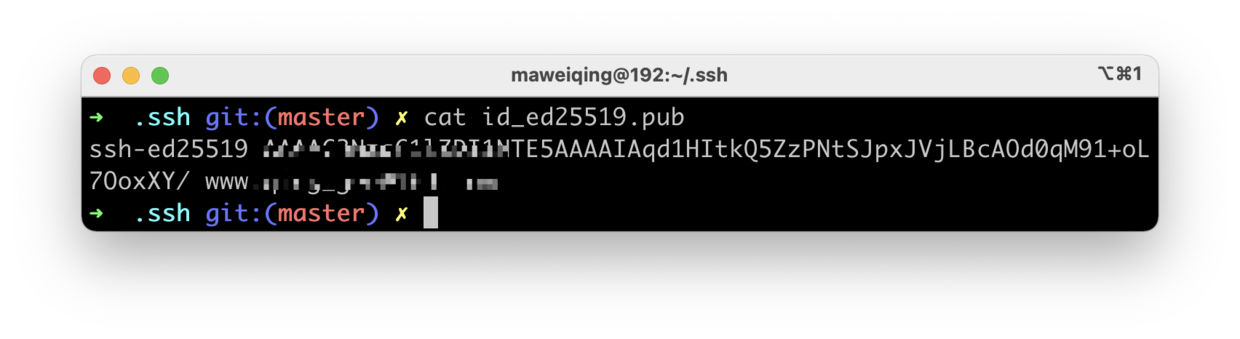
**第三步,添加 SSH 密钥到 GitHub 帐户**
在个人账户的 settings 菜单下找到 SSH and GPG keys,将刚刚复制的密钥添加到 key 这一栏中,点击「add SSH key」提交。
-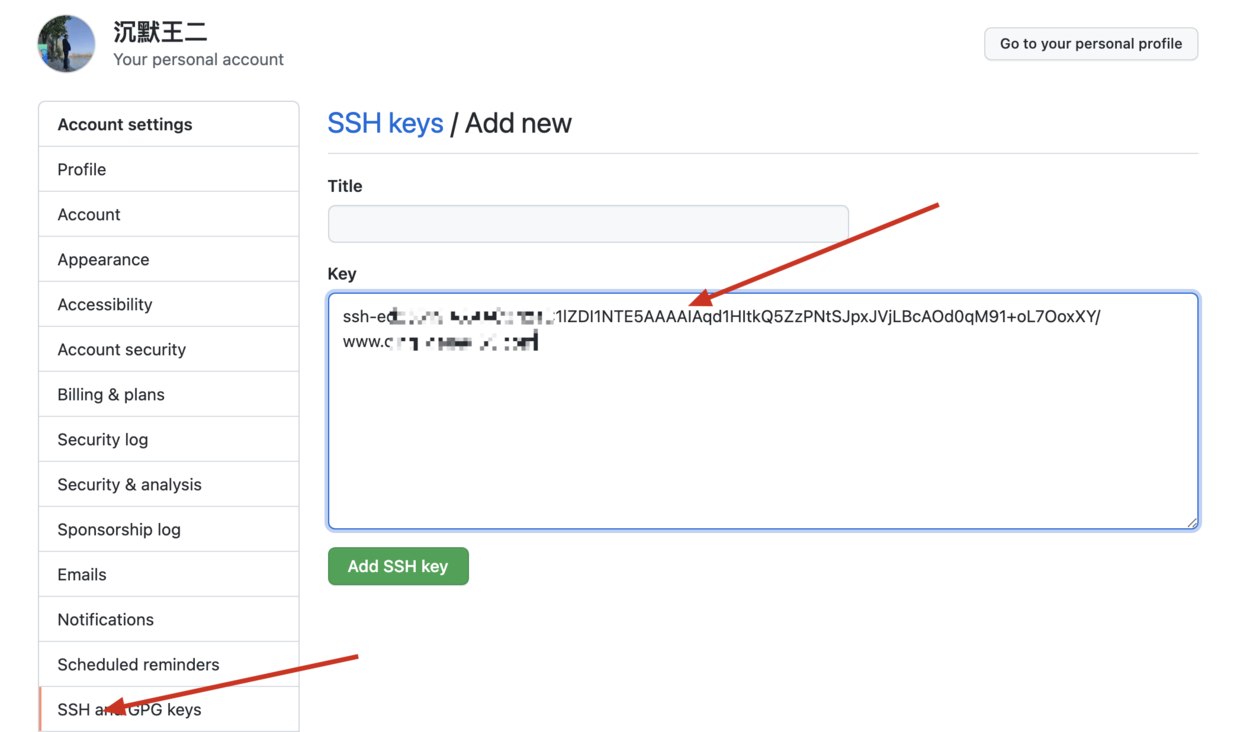
+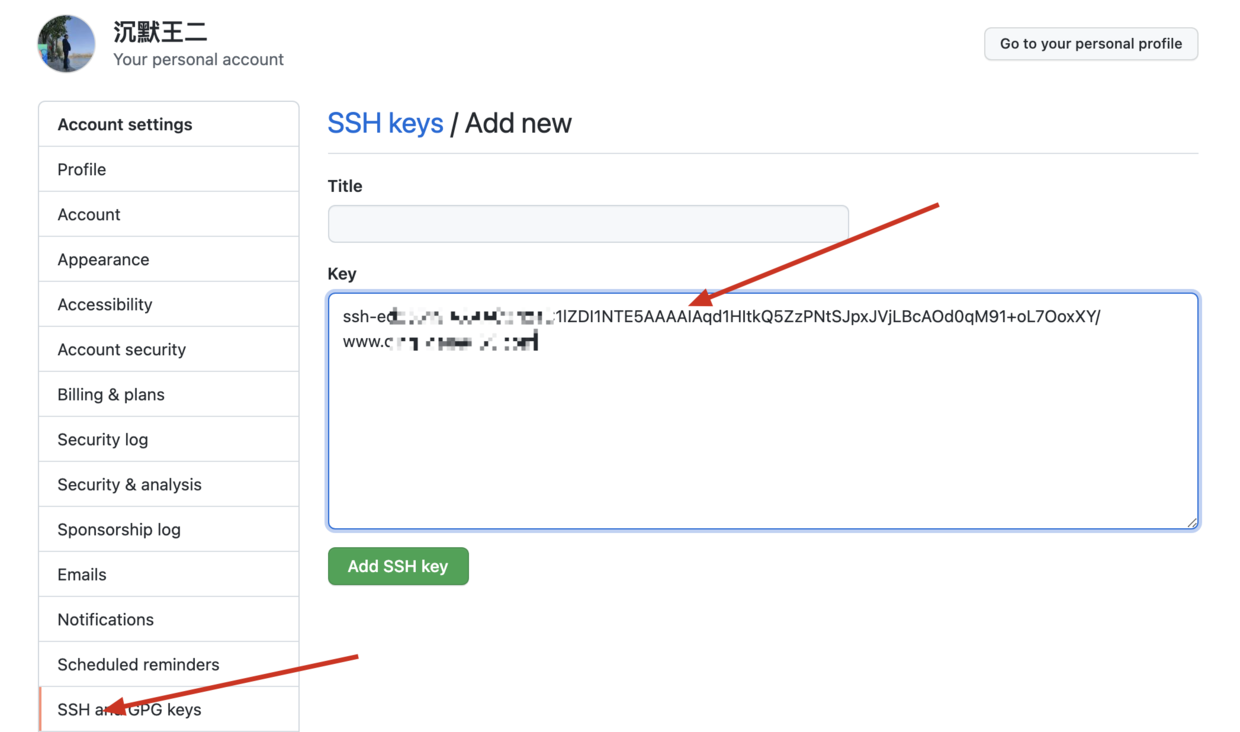
Title 可不填写,提交成功后会列出对应的密钥:
-
+
**为什么 GitHub 需要 SSH 密钥呢**?
@@ -961,17 +961,17 @@ Title 可不填写,提交成功后会列出对应的密钥:
点击新建仓库,填写仓库名称等信息:
-
+
**第五步,把本地仓库同步到 GitHub**
复制远程仓库的地址:
-
+
在本地仓库中执行 `git remote add` 命令将 GitHub 仓库添加到本地:
-
+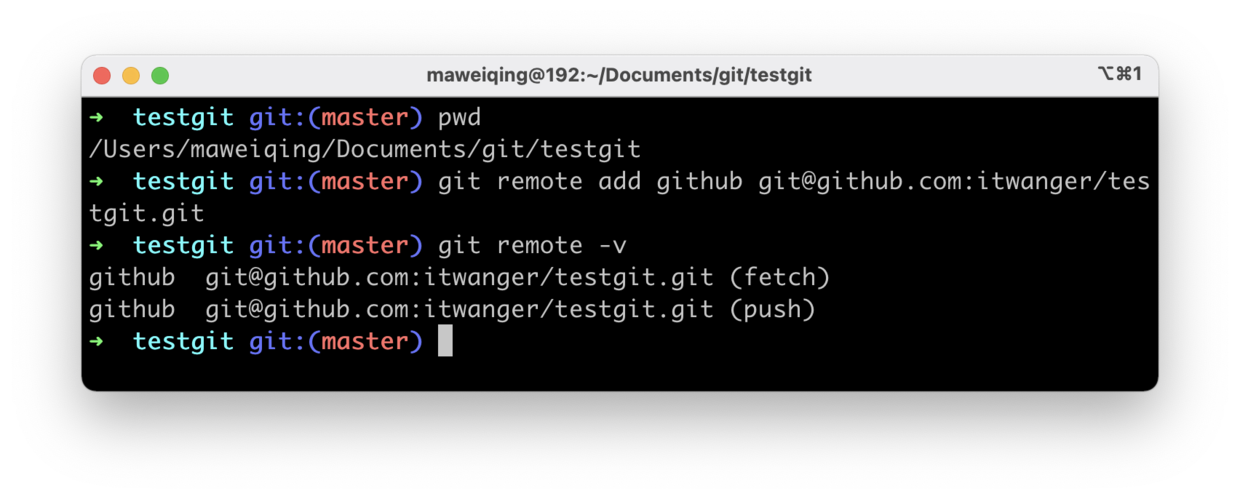
当我们第一次使用Git 的 push 命令连接 GitHub 时,会得到一个警告⚠️:
@@ -985,28 +985,28 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
接下来,我们使用 `git push` 命令将当前本地分支推送到 GitHub。加上了 -u 参数后,Git 不但会把本地的 master 分支推送的远程 master 分支上,还会把本地的 master 分支和远程的master 分支关联起来,在以后的推送或者拉取时就可以简化命令(比如说 `git push github master`)。
-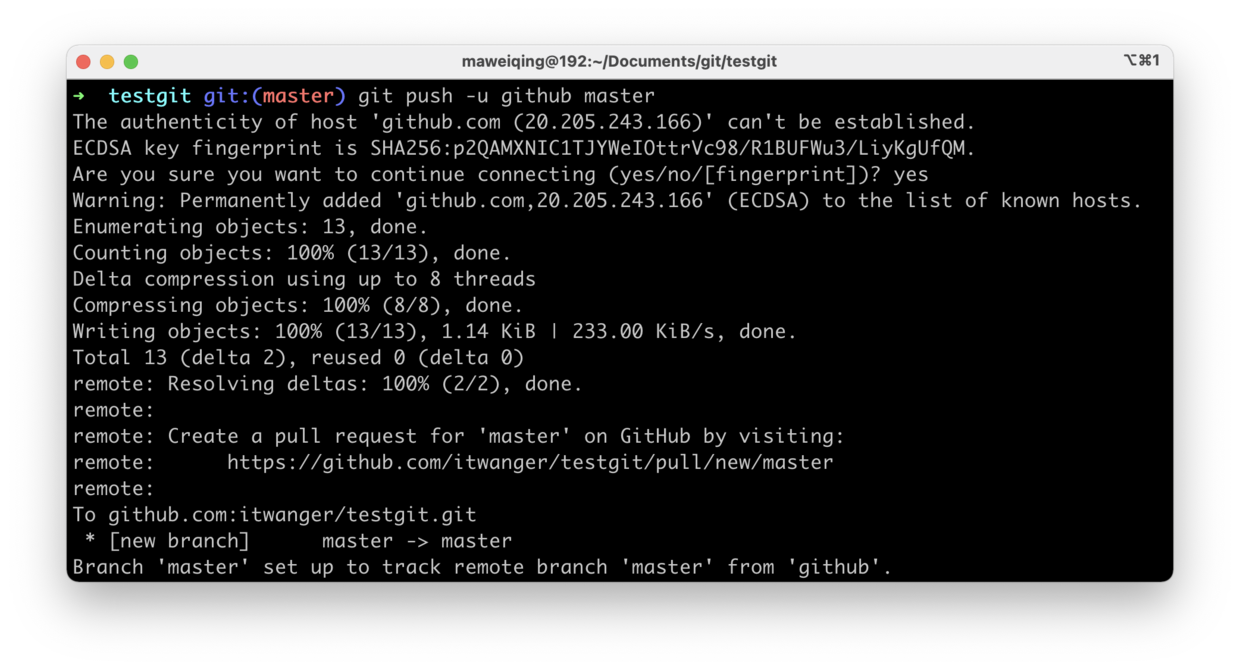
+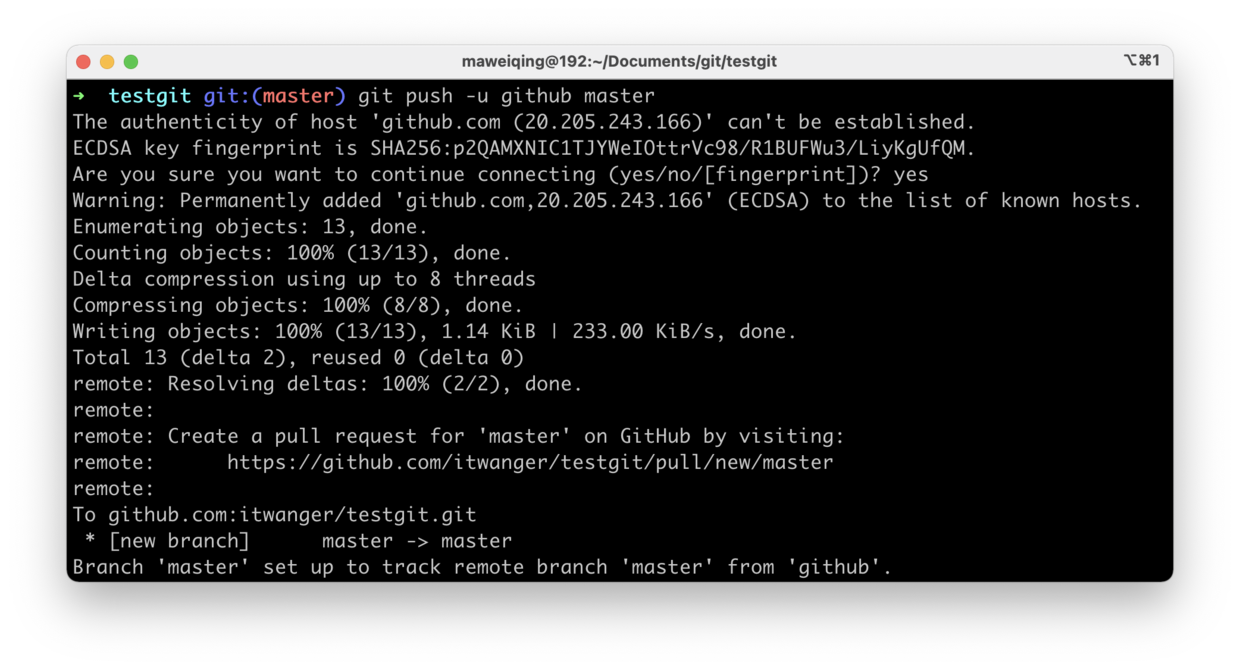
此时,我们刷一下 GitHub,可以看到多了一个 master 分支,并且本地的两个文件都推送成功了!
-
+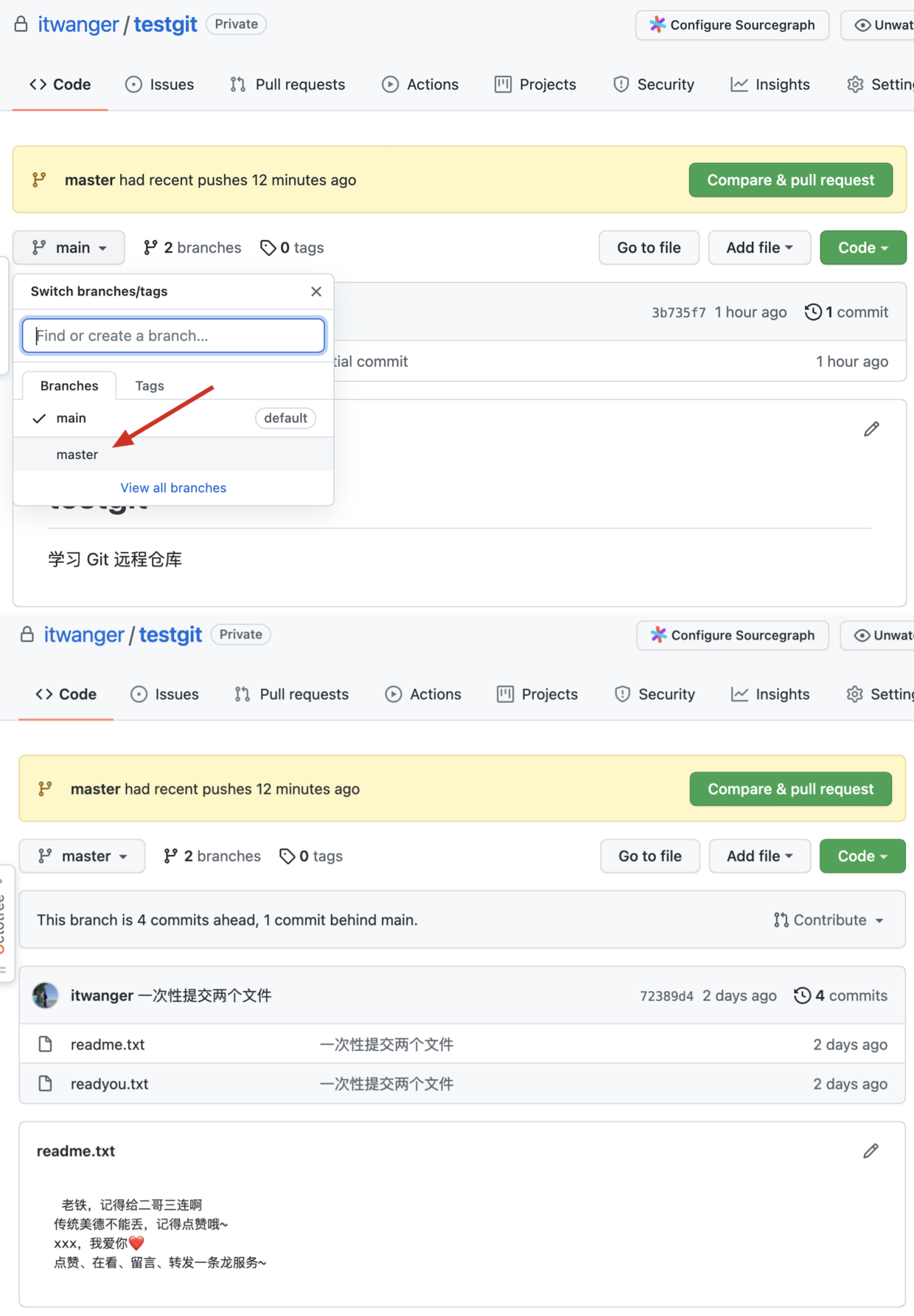
从现在开始,只要本地做了修改,就可以通过 `git push` 命令推送到 GitHub 远程仓库了。
还可以使用 `git clone` 命令将远程仓库拷贝到本地。比如说我现在有一个 3.4k star 的仓库 JavaBooks,
-
+
然后我使用 `git clone` 命令将其拷贝到本地。
-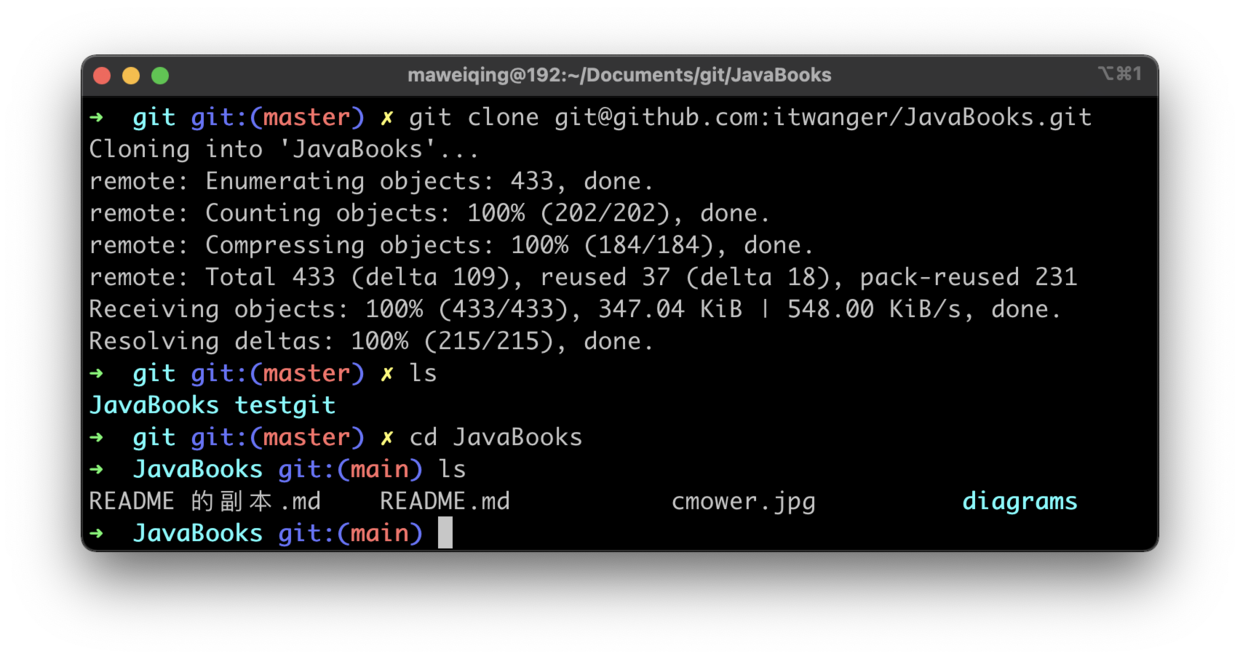
+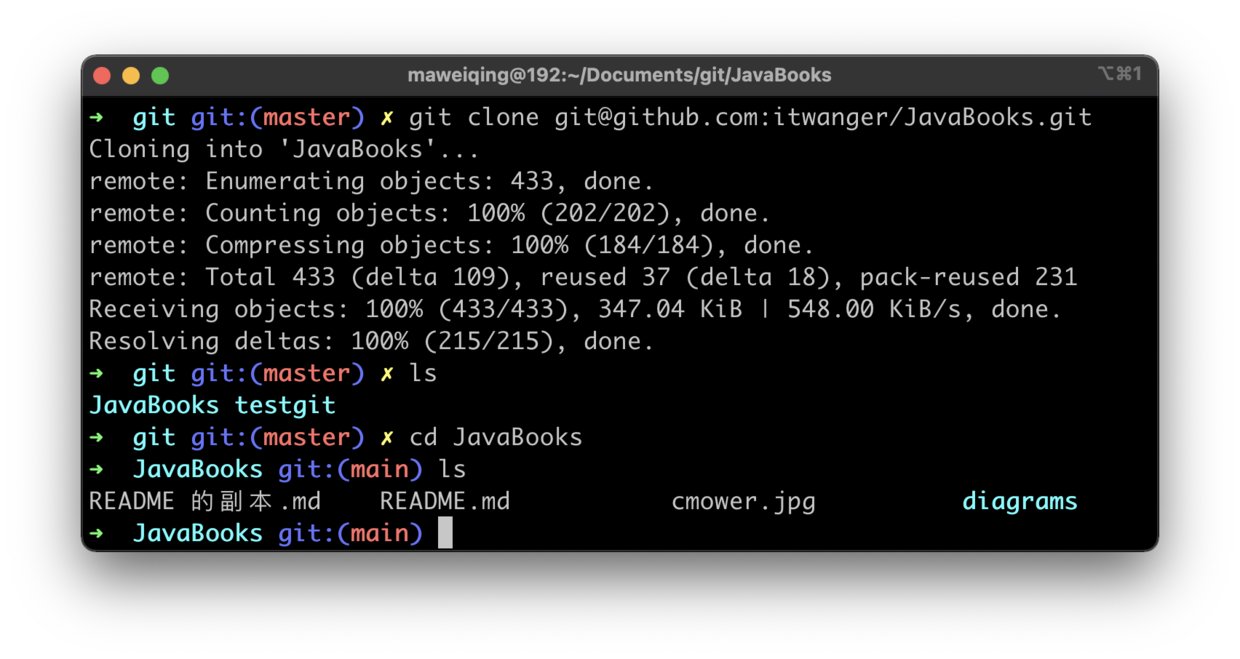
## 八、详解 sparse-checkout 命令
-前天不是搭建了一个《二哥的Java进阶之路》的网站嘛,其中用到了 Git 来作为云服务器和 GitHub 远程仓库之间的同步工具。
+前天不是搭建了一个《Java 程序员进阶之路》的网站嘛,其中用到了 Git 来作为云服务器和 GitHub 远程仓库之间的同步工具。
-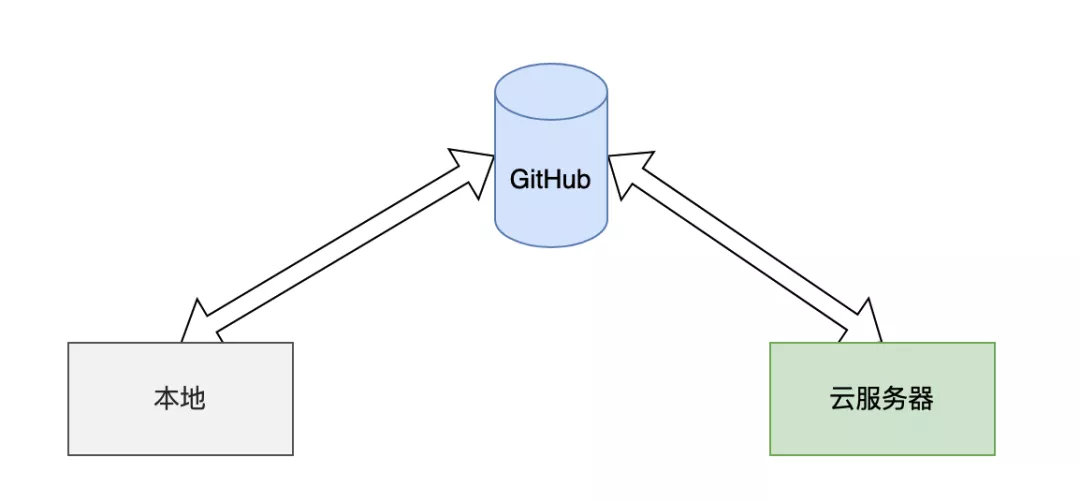
+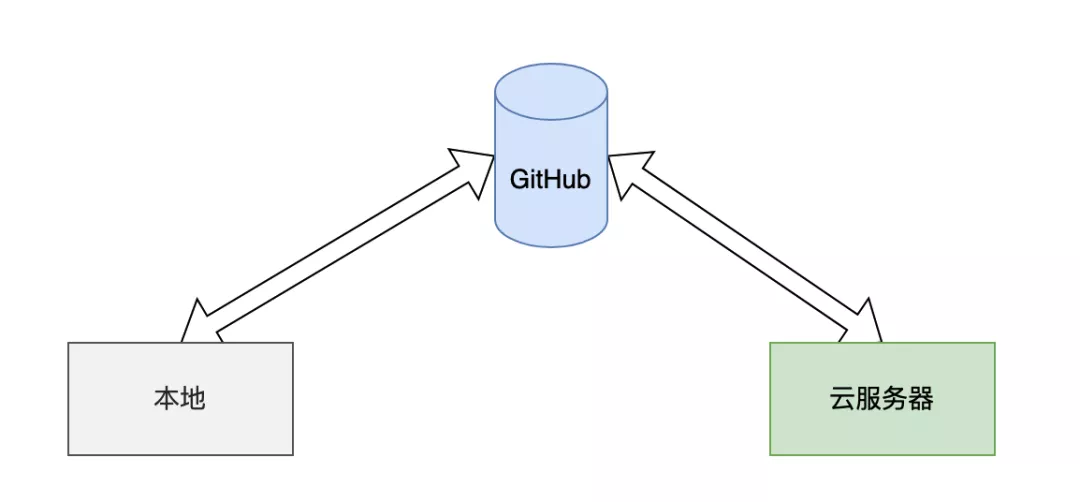
@@ -1017,9 +1017,9 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
### 1、使用 Git 中遇到的一个大麻烦
-首先给大家通报一下,一天前[上线的《二哥的Java进阶之路》网站](https://javabetter.cn),目前访问次数已经突破 1000 了。
+首先给大家通报一下,一天前[上线的《Java 程序员进阶之路》网站](https://tobebetterjavaer.com),目前访问次数已经突破 1000 了。
-
+
正所谓**不积跬步无以至千里,不积小流无以成江海**。
@@ -1034,7 +1034,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
大家可以先看一下我这个 GitHub 仓库的目录结构哈。
-
+
- docs 是文档目录,里面是 md 文件,所有的教程原稿都在这里。
- codes 是代码目录,里面是教程的配套源码。
@@ -1042,11 +1042,11 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
这样就可以利用 GitHub 来做免费的图床,并且还可以白票 jsDelivr CDN 的全球加速,简直不要太爽!
-
+
比如说 images 目录下有一张 logo 图 logo-01.png:
-
+
如果使用 GitHub 仓库的原始路径来访问的话,速度贼慢!
@@ -1054,7 +1054,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
使用 jsDelivr 加速后就不一样了,速度飞起!
->https://cdn.paicoding.com/tobebetterjavaer/images/logo-01.png
+>http://cdn.tobebetterjavaer.com/tobebetterjavaer/images/logo-01.png
简单总结下 GitHub 作为图床的正确用法,就两条:
@@ -1064,7 +1064,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
付费七牛云或者阿里云图床的小伙伴不妨试试这种方式,能白票咱绝不花一分冤枉钱。
-那也就是说,《二哥的Java进阶之路》网站上的图片都是通过 GitHub 图床加载的,不需要将图片从 GitHub 仓库拉取到云服务器上。要知道,一台云服务器的空间是极其昂贵的,能省的空间咱必须得省。
+那也就是说,《Java 程序员进阶之路》网站上的图片都是通过 GitHub 图床加载的,不需要将图片从 GitHub 仓库拉取到云服务器上。要知道,一台云服务器的空间是极其昂贵的,能省的空间咱必须得省。
### 2、学习 Git 中遇到的一个大惊喜
@@ -1074,16 +1074,16 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
最后还是浏览 Git 官方手册(也可以看[Pro Git](https://mp.weixin.qq.com/s/RpFzXOa2VlFNd7ylLmr9LQ))才找到了一个牛逼的命令:**git sparse-checkout,它可以帮助我们在拉取远程仓库的时候只同步那些我们想要的目录和文件**。
-
+
具体怎么用,可以看官方文档:
->[https://git-scm.com/docs/git-sparse-checkout](https://git-scm.com/docs/git-sparse-checkout)
+>https://git-scm.com/docs/git-sparse-checkout
但没必要,hhhh,我们直接实战。
第一步,通过 `git remote add -f orgin git@github.com:itwanger/toBeBetterJavaer.git` 命令从 GitHub 上拉取仓库。
-
+
第二步,启用 sparse-checkout,并初始化
@@ -1091,30 +1091,30 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
然后再执行 `git sparse-checkout init` 初始化。
-
+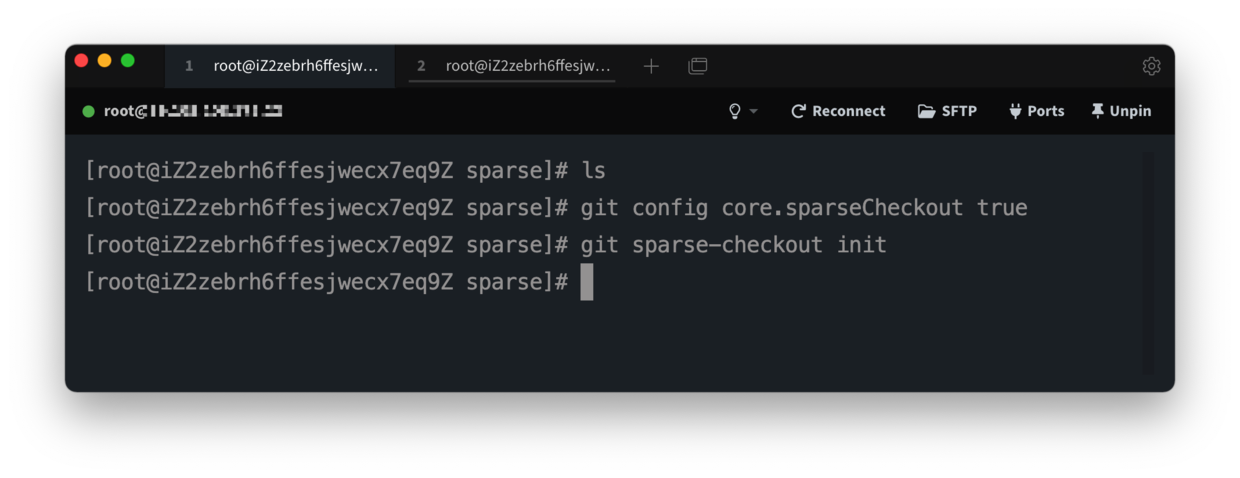
第三步,使用 sparse-checkout 来拉取我们想要的仓库目录
-
+
比如说,我们只想拉取 docs 目录,可以执行 `git sparse-checkout set docs` 命令。
-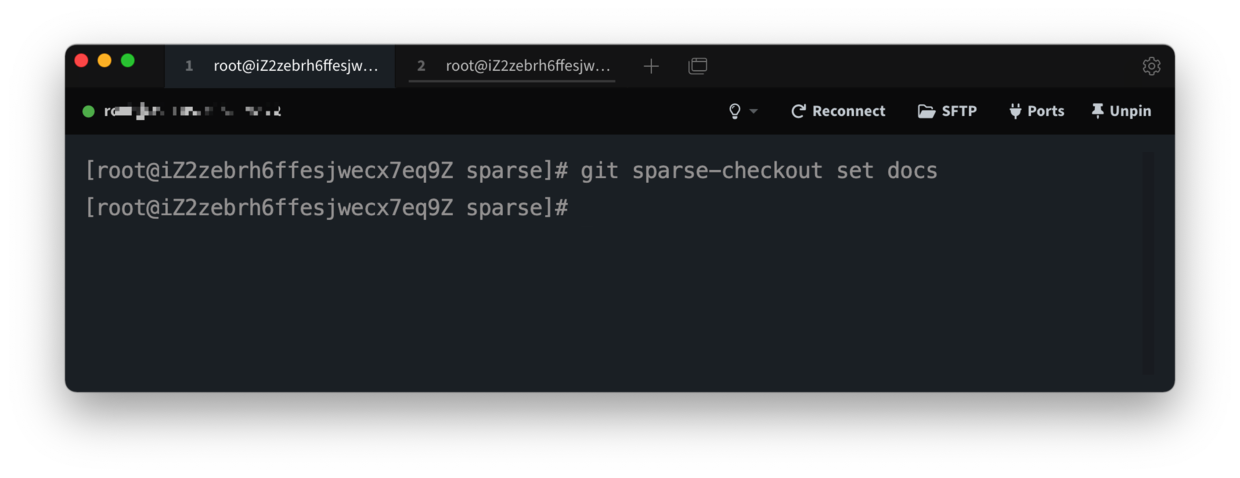
+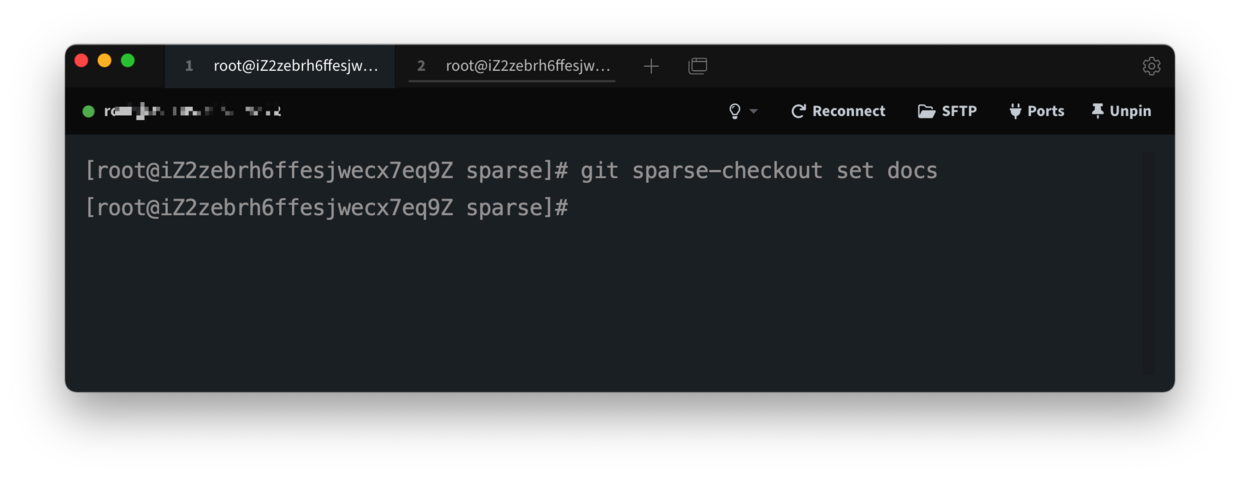
如果是第一次使用 sparse-checkout 的话,还需要执行一下 `git pull orgin master` 命令拉取一次。
-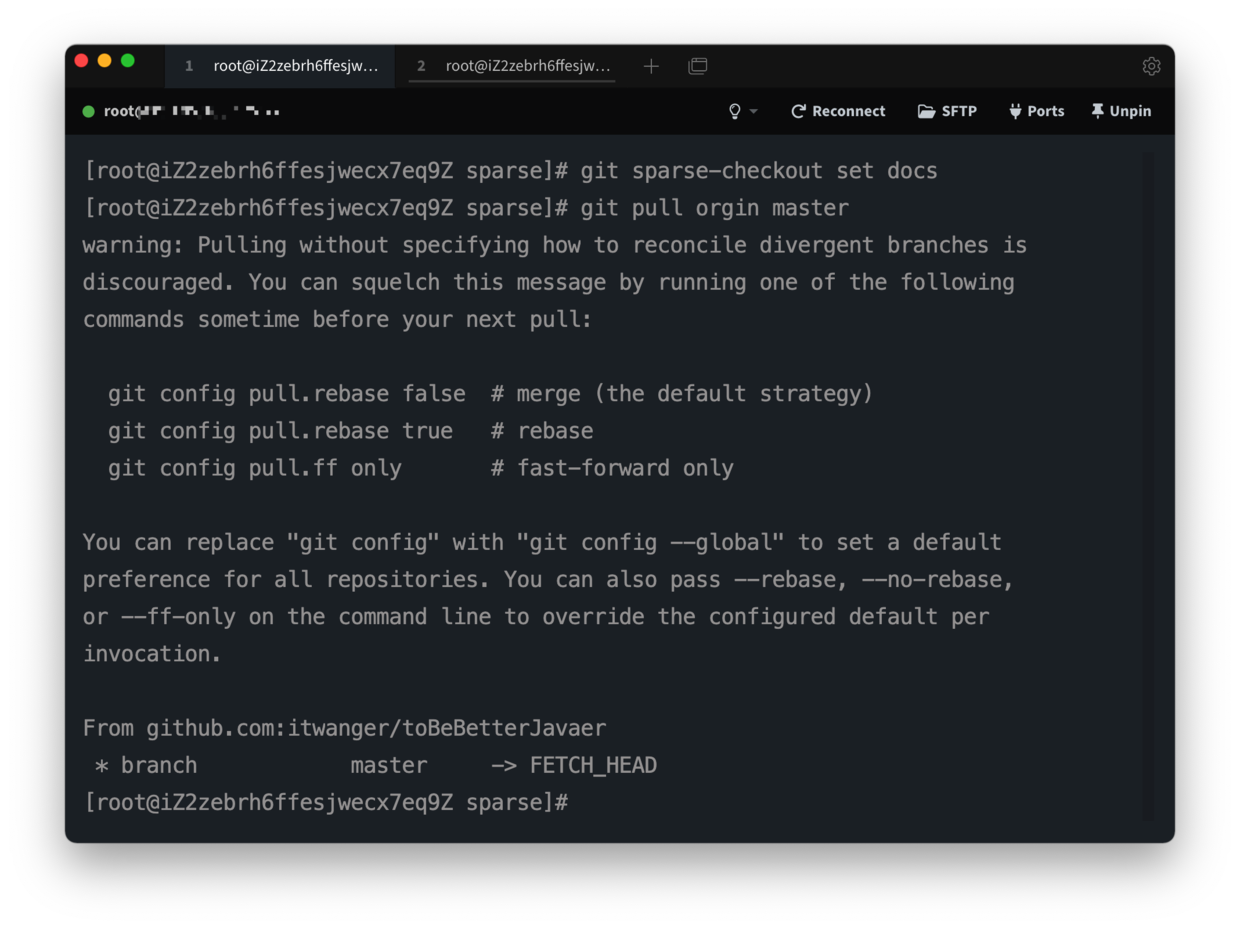
+
第四步,验证是否生效
可以执行 `ls -al` 命令来确认 sparse-checkout 是否生效。
-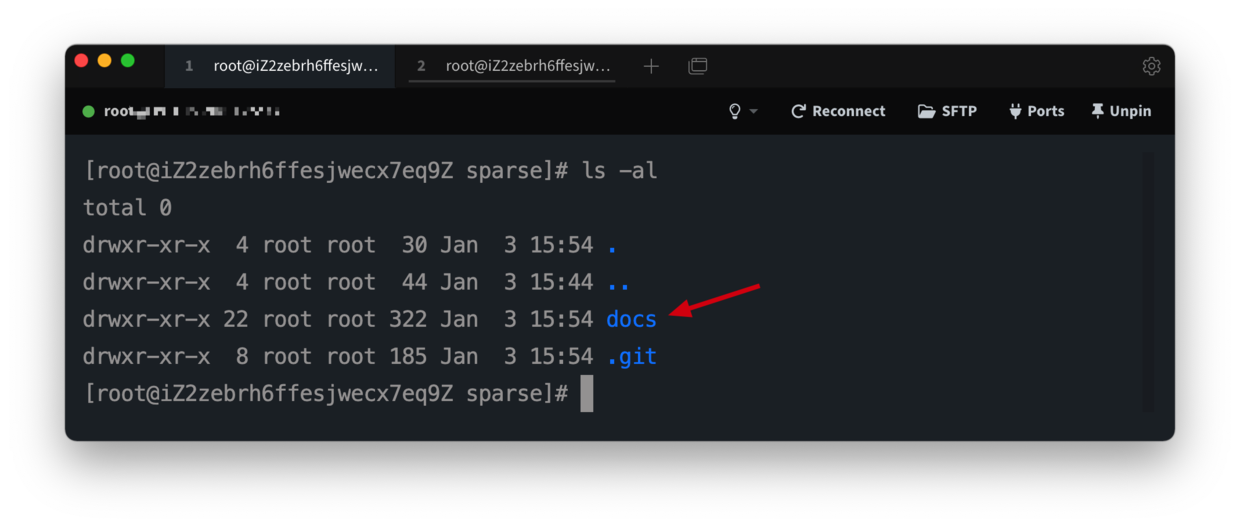
+
如图所示,确实只拉取到了 docs 目录。
假如还想要拉取其他文件或者目录的话,可以通过 `git sparse-checkout add` 命令来添加。
-
+
这就实现了,**远程仓库和云服务器仓库之间的定制化同步,需要什么目录和文件就同步什么目录和文件,不需要的可以统统不要**。
@@ -1122,13 +1122,13 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
我对比了一下,远程仓库大概 145 M,图片就占了 72 M,妥妥地省下了一半的存储空间。
-
+
如何禁用 git sparse-checkout 呢?
也简单,只需要执行一下 `git sparse-checkout disable` 命令就可以了。
-
+
可以看到,那些我们不想要的目录和文件统统都又回来了。
@@ -1136,7 +1136,7 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
也简单,只需要执行一下 `git sparse-checkout reapply` 命令就可以了。
-
+
简单总结下:如果你要把一个庞大到撑满你硬盘的远程仓库拉取到本地,而你只需要其中的一部分目录和文件,那就可以试一试
`git sparse-checkout` 了。
@@ -1147,7 +1147,7 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
不得不说,Git 实在是太强大了。就一行命令,解决了困扰我一天的烦恼,我的 80G 存储空间的云服务器又可以再战 3 年了,从此以后再也不用担心了。
-
+
Git 是真的牛逼,Linus 是真的牛逼,神不愧是神!
@@ -1161,16 +1161,9 @@ Git 是真的牛逼,Linus 是真的牛逼,神不愧是神!
参考资料:
->- 维基百科:[https://zh.wikipedia.org/wiki/Git](https://zh.wikipedia.org/wiki/Git)
+>- 维基百科:https://zh.wikipedia.org/wiki/Git
>- hutusi:[改变世界的一次代码提交](https://mp.weixin.qq.com/s/gM__sQPILkAKWsMejOO8cA)
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/git/progit.md b/docs/git/progit.md
new file mode 100644
index 0000000000..a7ac49e746
--- /dev/null
+++ b/docs/git/progit.md
@@ -0,0 +1,38 @@
+今天给大家分享一本个人最近看过觉得非常不错的Git开源手册,可能有些小伙伴也看过了,我是最近在通勤路上用PAD看的。这本开源手册,它除了有**PDF版**,还有**epub电子书版**,非常适合电子阅读,有需要的小伙伴可以在文末自行下载:
+
+
+
+相信看完对于个人Git知识体系的梳理和掌握是非常有帮助的。
+
+这本手册在豆瓣上评价极高,之前9.3,现在也有9.1的高分,其作者是GitHub的员工,内容主要侧重于各种场合中的惯用法和底层原理的讲述,手册中还针对不同的使用场景,设计了几个合适的版本管理策略。简而言之,这本手册无论是对于初学者还是想进一步了解Git工作原理的开发者都非常合适。
+
+
+
+
+
+这个手册一共分为十章,详细内容如下:
+
+
+
+**手册中部分内容展示如下:**
+
+
+
+
+
+
+
+
+
+**需要该Git手册PDF+epub电子书的小伙伴:**
+
+
+
+可直接长按扫码关注下方二维码,回复 「**git**」 即可下载:
+
+
+
+
+好了,这次资源分享就到这里!后续如果遇到有用的工具或者资源,依然还会持续分享,也欢迎大家多多安利和交流,一起分享成长。
+
+以上,我们下篇见。
diff --git a/docs/gongju/Chocolatey-Homebrew.md b/docs/gongju/Chocolatey-Homebrew.md
new file mode 100644
index 0000000000..6e94190936
--- /dev/null
+++ b/docs/gongju/Chocolatey-Homebrew.md
@@ -0,0 +1,231 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+title: Chocolatey Homebrew:两款惊艳的Shell软件管理器
+---
+
+小二是公司新来的实习生,之前面试的过程中对答如流,所以我非常看好他。第一天,我给他了一台新电脑,要他先在本地搭建个 Java 开发环境。
+
+二话不说,他就开始马不停蹄地行动了。真没想到,他竟然是通过命令行的方式安装的 JDK,这远远超出了我对他的预期。
+
+我以为,他会使用图形化的方式来安装 JDK 的,就像这样。
+
+
+
+还有这样。
+
+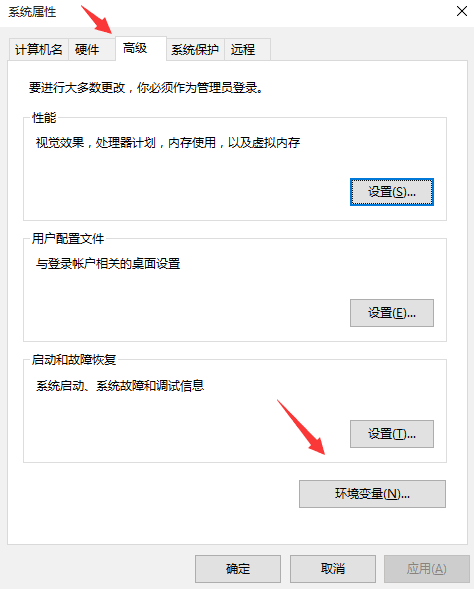
+
+结果他是这样的。
+
+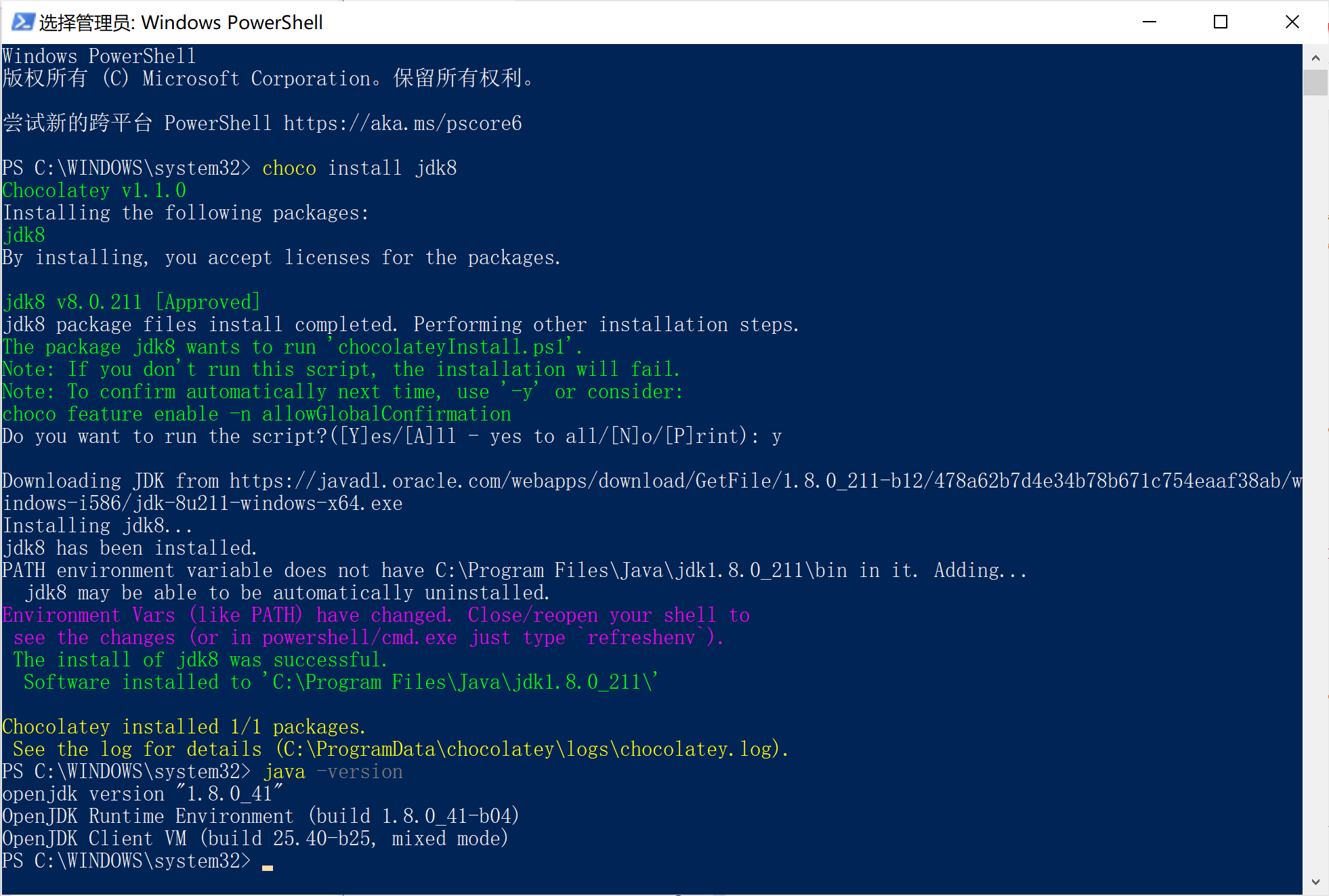
+
+卧槽!牛逼高大上啊!
+
+看着他熟练地在命令行里安装 JDK 的样子,我的嘴角开始微微上扬,真不错!这次总算招到了一个靠谱的。
+
+于是我就安排他做一个记录,打算发表在我的小破站《Java 程序员进阶之路》上。从他嘴里了解到,他用的命令行软件管理器叫 chocolatey,这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,我感觉非常酷炫。
+
+
+
+
+以下是他的记录,一起来欣赏下。
+
+### 关于shell
+
+对于一名 Java 后端程序员来说,初学阶段,你可以选择在 IDE 中直接编译运行 Java 代码,但有时候也需要在 Shell 下编译和运行 Java 代码。
+
+>Windows 下自带的 Shell 叫命令提示符,或者 cmd 或者 powershell,macOS 下叫终端 terminal。
+
+- [终端与 Shell 的区别](https://mp.weixin.qq.com/s?__biz=MzIxNzQwNjM3NA==&mid=2247491253&idx=1&sn=9a46879174f7240267fe5b5205d16d22&scene=21#wechat_redirect)
+- [初次体验 macOS 下的 Shell](https://mp.weixin.qq.com/s/oEo8N3nE0wR1zl7qD4nh3w)
+
+但当你需要在生产环境下部署 Java项目或者查看日志的话,就必然会用到 Shell,这个阶段,Shell 的使用频率高到可以用一个成语来形容——朝夕相伴。
+
+一些第三方软件会在原生的 Shell 基础上提供更强大的功能,常见的有 tabby、Warp、xhsell、FinalShell、MobaXterm、Aechoterm、WindTerm、termius、iterm2 等等,有些只能在 Windows 上使用,有些只能在 macOS 上使用,有些支持全平台。还有 ohmyzsh 这种超神的 Shell 美化工具。
+
+这里,我们列举一些 Shell 的基本操作命令(Windows 和 macOS/Linux 有些许差异):
+
+- 切换目录,可以使用 cd 命令切换目录,`cd ..` 返回上级目录。
+
+
+
+
+- 目录列表,macos/linux 下可以使用 ls 命令列出目录下所有的文件和子目录(Windows 下使用 dir 命令),使用通配符 `*` 对展示的内容进行过滤,比如 `ls *.java` 列出所有 `.java`后缀的文件,如果想更进一步的话,可以使用 `ls H*.java` 列出所有以 H 开头 `.java` 后缀的文件。
+- 新建目录,macOS/Linux 下可以使用 mkdir 命令新建一个目录(比如 `mkdir hello` 可以新建一个 hello 的目录),Windows 下可以使用 md 命令。
+- 删除文件,macOS/Linux 下可以使用 `rm` 命令删除文件(比如 `rm hello.java` 删除 hello.java 文件),Windows 下可以使用 del 命令。
+- 删除目录,macOS/Linux 下可以使用 `rm -r` 命令删除目录以及它所包含的所有文件(比如说 `rm -r hello` 删除 hello 目录)。Windows 下可以使用 deltree 命令。
+- 重复命令,macOS/Linux/Windows 下都可以使用上下箭头来选择以往执行过的命令。
+
+
+
+- 命令历史,macOS/Linux 下可以使用 `history` 命令查看所有使用过的命令。Windows 可以按下 F7 键。
+
+
+
+
+- 解压文件,后缀名为“.zip”的文件是一个包含了其他文件的压缩包,macOS/Linux 系统自身已经提供了用于解压的 unzip 命令, Windows 的话需要手动安装。
+
+### 安装JDK
+
+**1)Windows**
+
+推荐先安装 chocolatey。这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+>The biggest challenge is reducing duplication of effort, so users turn to Chocolatey for simplicity
+
+传统的安装方式要么非常耗时,要么非常低效,在命令行安装软件除了简单高效,还能自动帮我们配置环境变量。
+
+>- 官方地址:[https://chocolatey.org/](https://chocolatey.org/)
+>- 安装文档:[https://chocolatey.org/install#individual](https://chocolatey.org/install#individual)
+
+安装完成后如下图所示:
+
+
+
+如果不确定是否安装成功的话,可以通过键入 `choco` 命令来确认。
+
+
+
+这里推荐几个非常高效的操作命令:
+
+- choco search xxx,查找 xxx 安装包
+- choco info xxx,查看 xxx 安装包信息
+- choco install xxx,安装 xxx 软件
+- choco upgrade xxx,升级 xxx 软件
+- choco uninstall xxx, 卸载 xxx 软件
+
+如何知道 chocolatey 仓库中都有哪些安装包可用呢?
+
+可以通过上面提到的命令行的方式,也可以访问官方仓库进行筛选。
+
+>[https://community.chocolatey.org/packages](https://community.chocolatey.org/packages)
+
+比如说我们来查找 Java。
+
+
+
+好,现在可以直接在shell中键入 `choco install jdk8` 来安装 JDK8 了,并且会自动将Java加入到环境变量中,不用再去「我的电脑」「环境变量」中新建 JAVA_HOME 并复制 JDK 安装路径配置 PATH 变量了,是不是非常 nice?
+
+稍等片刻,键入 `java -version` 就可以确认Java是否安装成功了。
+
+
+
+
+不得不承认!非常nice!
+
+**2)macOS**
+
+首先推荐安装 homebrew,这是macOS下的命令行软件管理器,用来简化 macOS 上软件的安装过程。homebrew 是开源的,在 GitHub 已收获 32k star。
+
+
+
+homebrew 的安装也非常的简单,只需要一行命令即可。
+
+>官方网址:[https://brew.sh/index_zh-cn](https://brew.sh/index_zh-cn)
+
+
+
+
+- 使用 `brew install xxx` 可以安装 macOS 上没有预装的软件
+- 使用 `brew install --cask yyy` 可以安装 macOS 其他非开源软件。
+
+这里是 homebrew 常用命令的一个清单,可供参考。
+
+命令| 描述
+---|---
+brew update| 更新 Homebrew
+brew search package| 搜索软件包
+brew install package| 安装软件包
+brew uninstall package| 卸载软件包
+brew upgrade| 升级所有软件包
+brew upgrade package| 升级指定软件包
+brew list| 列出已安装的软件包列表
+brew services command package| 管理 brew 安装软件包
+brew services list| 列出 brew 管理运行的服务
+brew info package| 查看软件包信息
+brew deps package| 列出软件包的依赖关系
+brew help| 查看帮助
+brew cleanup| 清除过时软件包
+brew link package| 创建软件包符号链接
+brew unlink package| 取消软件包符号链接
+brew doctor| 检查系统是否存在问题
+
+安装完 homebrew 后,建议替换homebrew 的默认源为中科大的,原因就不用我多说了吧?替换方法如下所示:
+
+```
+替换brew.git:
+cd "$(brew --repo)"
+git remote set-url origin https://mirrors.ustc.edu.cn/brew.git
+
+替换homebrew-core.git:
+cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
+git remote set-url origin https://mirrors.ustc.edu.cn/homebrew-core.git
+```
+
+如何知道 homebrew 仓库中都有哪些安装包可用呢?
+
+第一种,通过 `brew search xxx` 命令搜索,比如说我们要搜索 jdk
+
+
+
+
+第二种,通过 homebrew 官网搜索,比如说我们要搜索 openjdk。
+
+
+>官方地址:[https://formulae.brew.sh](https://formulae.brew.sh)
+
+
+
+
+这里有一份不错的 homebrew 帮助文档,可供参考:
+
+
+>[https://sspai.com/post/56009](https://sspai.com/post/56009)
+
+
+
+OK,我们来安装JDK,只需要简单的一行命令就可以搞定。
+
+`brew install openjdk@8`
+
+对比下载安装包,通过图形化界面的方式安装 JDK,是不是感觉在 Shell 下安装 JDK 更炫酷一些?
+
+关键是还省去了环境变量的配置。
+
+记得还没有走出新手村的时候,就经常被环境变量配置烦不胜烦。那下载这种命令行的方式,要比手动在环境变量中配置要省事一百倍,也更不容易出错。
+
+### 关于编辑器
+
+安装完 Java 之后,你还需要一个编辑器,用来编写 Java 代码。
+
+编辑器多种多样,常见的有集成开发环境(IDE,比如 Intellij IDEA 和 vscode),和简单的文本编辑工具(比如 sublime text)。
+
+我建议这三个工具都要装,日常开发中,我会在这三个编辑器中来回切换。
+
+Intellij IDEA:主要用来编写Java代码,并且最好安装旗舰版,社区版用来学习JavaSE部分是绰绰有余的,但要想拥有更强大的生产力,旗舰版是必须的,因为功能更加强大。
+
+比如说 idea 旗舰版中可以直接通过 Initializr 来创建springboot项目,但社区版就没有此功能。
+
+
+
+
+
+vscode:更加轻量级的 IDE,在编写Java代码上可以和idea媲美,但要想调试Java代码的话,vscode 和idea的差距还是非常明显的。
+
+
+
+
+我会使用 Intellij IDEA 开发编程喵的后端代码,vscode 来开发编程喵的前端代码。
+
+
+sublime text:功能更强大的文本编辑器,比记事本这种强大一万倍,也更符合21世纪开发者的外观审美。如果只是简单的修改一下代码格式,或者注释,显然更加方便,因为idea还是比较吃内存的,出差旅行的时候,在笔记本上紧急修改一些代码时,更易用。
+
+
+
+
+我会配合 GitHub 桌面版来使用 sublime text,编辑 MD 文档的时候会比较舒服。
+
+
diff --git a/docs/gongju/DBeaver.md b/docs/gongju/DBeaver.md
new file mode 100644
index 0000000000..cf4193ff57
--- /dev/null
+++ b/docs/gongju/DBeaver.md
@@ -0,0 +1,165 @@
+---
+title: DBeaver:一款免费的数据库操作工具
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+---
+
+
+作为一名开发者,免不了要和数据库打交道,于是我们就需要一款顺手的数据库管理工具。很长一段时间里,Navicat 都是我的首选,但最近更换了一台新电脑,之前的绿色安装包找不到了。
+
+于是就琢磨着,找一款免费的,功能和 Navicat 有一拼的数据库管理工具来替代。好朋友 macrozheng 给我推荐了 DBeaver,试用完后体验真心不错,于是就来给大家安利一波。
+
+### 一、关于 DBeaver
+
+DBeaver 是一个跨平台的数据库管理工具,支持 Windows、Linux 和 macOS。它有两个版本,企业版和社区版,对于个人开发者来说,社区版的功能已经足够强大。
+
+DBeaver 是由 Java 编写的,默认使用 JDK 11 进行编译。社区版基于 [Apache-2.0 License](https://github.com/dbeaver/dbeaver/blob/devel/LICENSE.md) 在 GitHub 上开源,目前已获得 24k+ 的星标。
+
+>[https://github.com/dbeaver/dbeaver](https://github.com/dbeaver/dbeaver)
+
+
+
+DBeaver 支持几乎所有主流的数据库,包括关系型数据库和非关系数据库。
+
+
+
+### 二、安装 DBeaver
+
+可以通过 DBeaver 官方下载安装包,也可以通过 GitHub 下载 release 版本。
+
+>官方下载地址:[https://dbeaver.io/download/](https://dbeaver.io/download/)
+
+
+
+根据自己电脑的操作系统下载对应的安装包,完整安装后,第一步要做的是配置 Maven 镜像,否则在后续下载数据库驱动的时候会非常的慢。
+
+
+
+
+因为 DBeaver 是基于 [Maven 构建](https://github.com/itwanger/toBeBetterJavaer/blob/master/docs/maven/maven.md)的,数据库驱动也就是链接数据库的 JDBC 驱动是通过 Maven 仓库下载的。选择「首选项」→「Maven」,添加阿里云镜像地址:
+
+>[http://maven.aliyun.com/nexus/content/groups/public](http://maven.aliyun.com/nexus/content/groups/public)
+
+和配置 Maven 镜像一样,如下图所示。
+
+
+
+
+配置完成后,记得把阿里云镜像仓库置顶。
+
+
+
+
+### 三、管理数据源
+
+像使用 Navicat 一样,我们需要先建立连接,这里就以 MySQL 为例。点击「连接」小图标,选择数据库。
+
+
+
+点击下一步,这时候需要填写数据库连接信息。
+
+
+
+点击「测试链接」,如果使用默认的 Maven 仓库时,下载驱动会非常慢,如下图所示,还容易失败「踩过的坑就不要再踩了」。
+
+
+
+如果你前面按照我说的配置了阿里云的 Maven 镜像,程序就不一样了,点了「测试链接」,瞬间会弹出「连接已成功」的提示框。
+
+
+
+链接成功后,就可以看到数据库中的表啊、视图啊、索引啊等等。
+
+
+
+### 四、管理表
+
+数据库连接成功后,最重要的还是操作表。
+
+**01、查看表**
+
+选择一张表,双击后就可以看到表的属性了,可以查看表的列、约束(主键)、外键、索引等等信息。
+
+
+
+点击「DDL(Data Definition Language,数据定义语言)」可以看到详细的建表语句。
+
+
+
+点击「数据」可以查看表的数据,底部有「新增」、「修改」、「删除」等行操作按钮。
+
+
+
+可以在顶部的过滤框中填写筛选条件,然后直接查询结果。
+
+
+
+如果不想显示某一列的话,可以直接点击「自定义结果集」图表,将某个字段的状态设置为不可见即可。
+
+
+
+**02、新增表**
+
+在左侧选择「表」,然后右键选择「新建表」即可建表id。
+
+
+
+之后在右侧列的区域右键,选择「新建列」即可添加字段。
+
+
+
+比如说我们新建一个主键 ID,如下图所示。
+
+
+
+在 DBeaver 中,`[v]` 表示真,`[]` 表示否。紧接着在「约束」里选择 ID 将其设置为主键。
+
+
+
+最后点击保存,会弹出一个建表语句的预览框,点击「执行」即可完成表的创建。
+
+
+
+### 五、执行 SQL
+
+右键数据库表,选择右键菜单中的「SQL 编辑器」可以打开 SQL 编辑面板。
+
+
+
+然后编辑 SQL 语句,点击运行的小图标就可以查询数据了。这个过程会有语法提示,非常 nice。
+
+
+
+DBeaver 有一个很亮眼的操作就是,可以直接选中一条结果集,然后右键生成 SQL。
+
+
+
+比如说 insert 语句,这样再插入一条重复性内容的时候就非常方便了。
+
+
+
+### 六、外观配置
+
+可以在首选项里对外观进行设置,比如说把主题修改为暗黑色。
+
+
+
+然后界面就变成了暗黑系。
+
+
+
+还可以设置字体大小等。
+
+
+
+从整体的风格来看,DBeaver 和 Eclipse 有些类似,事实上也的确如此,DBeaver 是基于 Eclipse 平台构建的。
+
+
+
+### 七、总结
+
+总体来说,DBeaver是一款非常优秀的开源数据库管理工具了,功能很全面,日常的开发基本上是够用了。对比收费的 Navicat 和 DataGrip,可以说非常良心了。大家如果遇到收费版不能使用的时候,可以来体验一下社区版 DBeaver。
+
+
\ No newline at end of file
diff --git a/docs/gongju/chiner.md b/docs/gongju/chiner.md
new file mode 100644
index 0000000000..4b20320ef7
--- /dev/null
+++ b/docs/gongju/chiner.md
@@ -0,0 +1,162 @@
+---
+title: chiner:一款开源的数据库设计神器
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+
+---
+
+最近在造轮子,从 0 到 1 的那种,就差前台的界面了,大家可以耐心耐心耐心期待一下。其中需要设计一些数据库表,可以通过 Navicat 这种图形化管理工具直接开搞,也可以通过一些数据库设计工具来搞,比如说 PowerDesigner,更专业一点。
+
+ 今天我给大家推荐的这款国人开源的数据库设计工具 chiner,界面漂亮,功能强大,体验后给我的感觉是真香......
+
+
+
+
+### 一、关于 PowerDesigner
+
+PowerDesigner 是一款功能非常强大的建模工具,可以和 Rational Rose 媲美。Rose 专攻 UML 对象模型的建模,之后才拓展到数据库这块。而 PowerDesigner 是一开始就为数据库建模服务的,后来才发展为一款综合战斗力都还不错的建模工具。
+
+不过,说句实在话,PowerDesigner 的界面偏古典一些,下面是我用 PowerDesigner 设计 DB 的效果。
+
+
+
+### 二、关于 chiner
+
+chiner,发音:[kaɪˈnər],使用React+Electron+Java技术体系构建的一款元数建模平台。
+
+2018 年,作者和几个对开源有兴趣的社区好友开始打磨产品的原因,历经三代,直到 2021 年 7 月份,终于推出了船新的 3.0 版本。
+
+2019 年底,团队差点解散,幸好有几位好友关照,给了团队两个项目做,这才算是熬了过去。
+
+不得不说,做任何一件事情都不容易啊,光靠情怀也许可以撑过产品初期,但越往后去,遇到生存问题时,就会非常困难。
+
+在此,我们必须得为每一位开源作者奉上最真诚的掌声,希望他们的产品都能有一番天地。也希望,未来我的产品出现在大家的面前时,能给它多一点点包容和支持。
+
+
+
+### 三、安装 chiner
+
+chiner 支持 Windows、macOS 和 Linux,下载地址如下所示:
+
+>[https://gitee.com/robergroup/chiner/releases](https://gitee.com/robergroup/chiner/releases)
+
+码云做了外部链接的拦截,导致直接复制链接到地址栏才能完成下载。我这里以 macOS 为例。
+
+
+
+安装完成后首次打开的样子是这样的。
+
+
+
+chiner 提供了非常贴心的操作手册和参考模板,如果时间比较充分的话,可以先把操作手册过一遍,写得非常详细。
+
+
+
+### 四、上手 chiner
+
+**01、导入导出**
+
+因为我之前有一份 PowerDesigner 文件,所以可以直接导入到 chiner。
+
+第一步,新建一个项目 codingmore。
+
+第二步,选择导入 PowerDesigner 文件。
+
+
+
+第三步,选择要添加的数据表。
+
+
+
+第四步,导入完成后,就可以点开单表进行查看了。
+
+
+
+第五步,当完成重新设计后,就可以选择导出 DDL 到数据库表了。
+
+
+
+当然了,也可以直接配置数据库 DB,这样就可以直接连接导入导出了。
+
+
+
+导出的 SQL 文件可以直接通过宝塔面板上传到服务器端,然后再直接导入到数据库。
+
+
+
+如果需要用到数据库说明文档的话,也可以直接通过导出到 Word 文档来完成。
+
+
+
+**02、维护数据类型**
+
+chiner 自带了几种常见的数据类型,比如字串、小数、日期等,我们也可以根据自己的需要添加新的数据类型。
+
+比如说默认的字串类型关联到其他数据库的类型如下所示:
+
+
+
+数据域是在数据类型的基础上,基于当前项目定义的有一定业务含义的数据类型,比如说我这里维护了一个长度为 90 的名称数据域。
+
+
+
+当我需要把某个数据字段的数据域设置成「名称」的时候,长度就会自动填充为 90,不需要手动再去设置。
+
+
+
+**03、维护数据表**
+
+第一步,选中数据表,右键选择「新增数据表」
+
+
+
+第二步,填写数据表名
+
+
+
+点击「确定」后,chiner 会帮我们自动生成一些常见常用的字段,比如说创建人、创建时间、更新人、更新时间等,非常的智能化。通常来说,这些字段都是必须的。
+
+
+
+如果这些默认字段不满足需求的时候,还可以点击「设置」新增默认字段,比如说删除标记,一般来说为了安全起见,数据库都会采用非物理删除。
+
+
+
+一般来说,我们更习惯字段小写命名,因此可以直接选中一列,然后选择大小写转换。
+
+
+
+就变成小写了。
+
+
+
+**04、维护关系图**
+
+第一步,选择「关系图」,右键选择「新增关系图」
+
+第二步,把需要关联的表拖拽到右侧的面板当中,然后按照字段进行连线,非常的方便。比如说班级和学院表、班级和专业表的关系,就如下图所示。
+
+
+
+来看一下整体给出来的关系图,还是非常清爽的。
+
+
+
+### 五、尾声
+
+chiner 还有更多更强大的功能,大家觉得不错的话,可以去尝试一下。用的熟练的话,肯定能在很大程度上提高生产效率。
+
+就我个人的使用体验来说,chiner 比 PowerDesigner 更轻量级,也更符合日常的操作习惯,为国产开源点赞!
+
+项目地址:
+
+>[https://gitee.com/robergroup/chiner](https://gitee.com/robergroup/chiner)
+
+使用手册:
+
+>[https://www.yuque.com/chiner/docs/manual](https://www.yuque.com/chiner/docs/manual)
+
+
+
\ No newline at end of file
diff --git a/docs/gongju/choco.md b/docs/gongju/choco.md
new file mode 100644
index 0000000000..2e385b89a2
--- /dev/null
+++ b/docs/gongju/choco.md
@@ -0,0 +1,179 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+title: chocolatey:一款 GitHub 星标 8.2k+的Windows命令行软件管理器
+
+---
+
+小二是公司新来的实习生,之前面试的过程中对答如流,所以我非常看好他。第一天,我给他了一台新电脑,要他先在本地搭建个 Java 开发环境。
+
+二话不说,他就开始马不停蹄地行动了。**真没想到,他竟然是通过命令行的方式安装的 JDK,一行命令就搞定了!连环境变量都不用配置,这远远超出了我对他的预期**。
+
+我以为,他会傻乎乎地下一步下一步来安装 JDK,就像这样。
+
+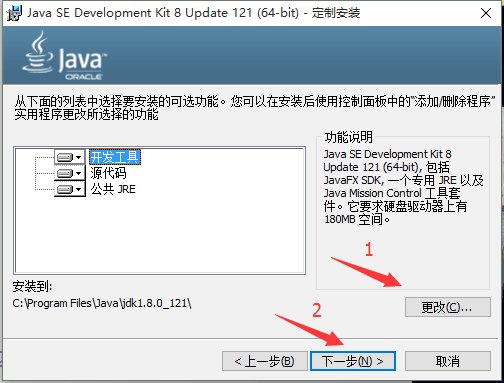
+
+然后这样配置环境变量。
+
+
+
+结果他是这样的,就一行命令,环境变量也不用配置!
+
+
+
+卧槽!牛逼高大上啊!
+
+看着他熟练地在命令行里安装 JDK 的样子,我的嘴角开始微微上扬,真不错!这次总算招到了一个靠谱的。
+
+于是我就安排他做一个记录,打算发表在我的小破站《Java 程序员进阶之路》上。从他嘴里了解到,他用的命令行软件管理器叫 chocolatey,这是一个Windows下的命令行软件管理器,在 GitHub 上已经收获 8.2k+的星标,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+
+
+
+
+以下是他的记录,一起来欣赏下。
+
+### 先来了解 shell
+
+对于一名 Java 后端程序员来说,初学阶段,你可以选择在 IDE 中直接编译运行 Java 代码,但有时候也需要在 Shell 下编译和运行 Java 代码。
+
+>Windows 下自带的 Shell 叫命令提示符,或者 cmd 或者 powershell,macOS 下叫终端 terminal。
+
+但当你需要在生产环境下部署 Java项目或者查看日志的话,就必然会用到 Shell,这个阶段,Shell 的使用频率高到可以用一个成语来形容——朝夕相伴。
+
+一些第三方软件会在原生的 Shell 基础上提供更强大的功能,常见的有 tabby、Warp、xhsell、FinalShell、MobaXterm、Aechoterm、WindTerm、termius、iterm2 等等,有些只能在 Windows 上使用,有些只能在 macOS 上使用,有些支持全平台。还有 ohmyzsh 这种超神的 Shell 美化工具。
+
+这里,我们列举一些 Shell 的基本操作命令(Windows 和 macOS/Linux 有些许差异):
+
+- 切换目录,可以使用 cd 命令切换目录,`cd ..` 返回上级目录。
+
+
+
+
+- 目录列表,macos/linux 下可以使用 ls 命令列出目录下所有的文件和子目录(Windows 下使用 dir 命令),使用通配符 `*` 对展示的内容进行过滤,比如 `ls *.java` 列出所有 `.java`后缀的文件,如果想更进一步的话,可以使用 `ls H*.java` 列出所有以 H 开头 `.java` 后缀的文件。
+- 新建目录,macOS/Linux 下可以使用 mkdir 命令新建一个目录(比如 `mkdir hello` 可以新建一个 hello 的目录),Windows 下可以使用 md 命令。
+- 删除文件,macOS/Linux 下可以使用 `rm` 命令删除文件(比如 `rm hello.java` 删除 hello.java 文件),Windows 下可以使用 del 命令。
+- 删除目录,macOS/Linux 下可以使用 `rm -r` 命令删除目录以及它所包含的所有文件(比如说 `rm -r hello` 删除 hello 目录)。Windows 下可以使用 deltree 命令。
+- 重复命令,macOS/Linux/Windows 下都可以使用上下箭头来选择以往执行过的命令。
+
+
+
+- 命令历史,macOS/Linux 下可以使用 `history` 命令查看所有使用过的命令。Windows 可以按下 F7 键。
+
+
+
+
+- 解压文件,后缀名为“.zip”的文件是一个包含了其他文件的压缩包,macOS/Linux 系统自身已经提供了用于解压的 unzip 命令, Windows 的话需要手动安装。
+
+### 再来了解chocolatey
+
+先安装 chocolatey。这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+>The biggest challenge is reducing duplication of effort, so users turn to Chocolatey for simplicity
+
+传统的安装方式要么非常耗时,要么非常低效,在命令行安装软件除了简单高效,还能自动帮我们配置环境变量。
+
+>- 官方地址:[https://chocolatey.org/](https://chocolatey.org/)
+>- 安装文档:[https://chocolatey.org/install#individual](https://chocolatey.org/install#individual)
+
+第一步,以管理员的身份打开 cmd 命令行。
+
+
+
+
+第二步,执行以下命令:
+
+```
+Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
+```
+
+稍等片刻,就完成安装了。
+
+安装完成后如下图所示:
+
+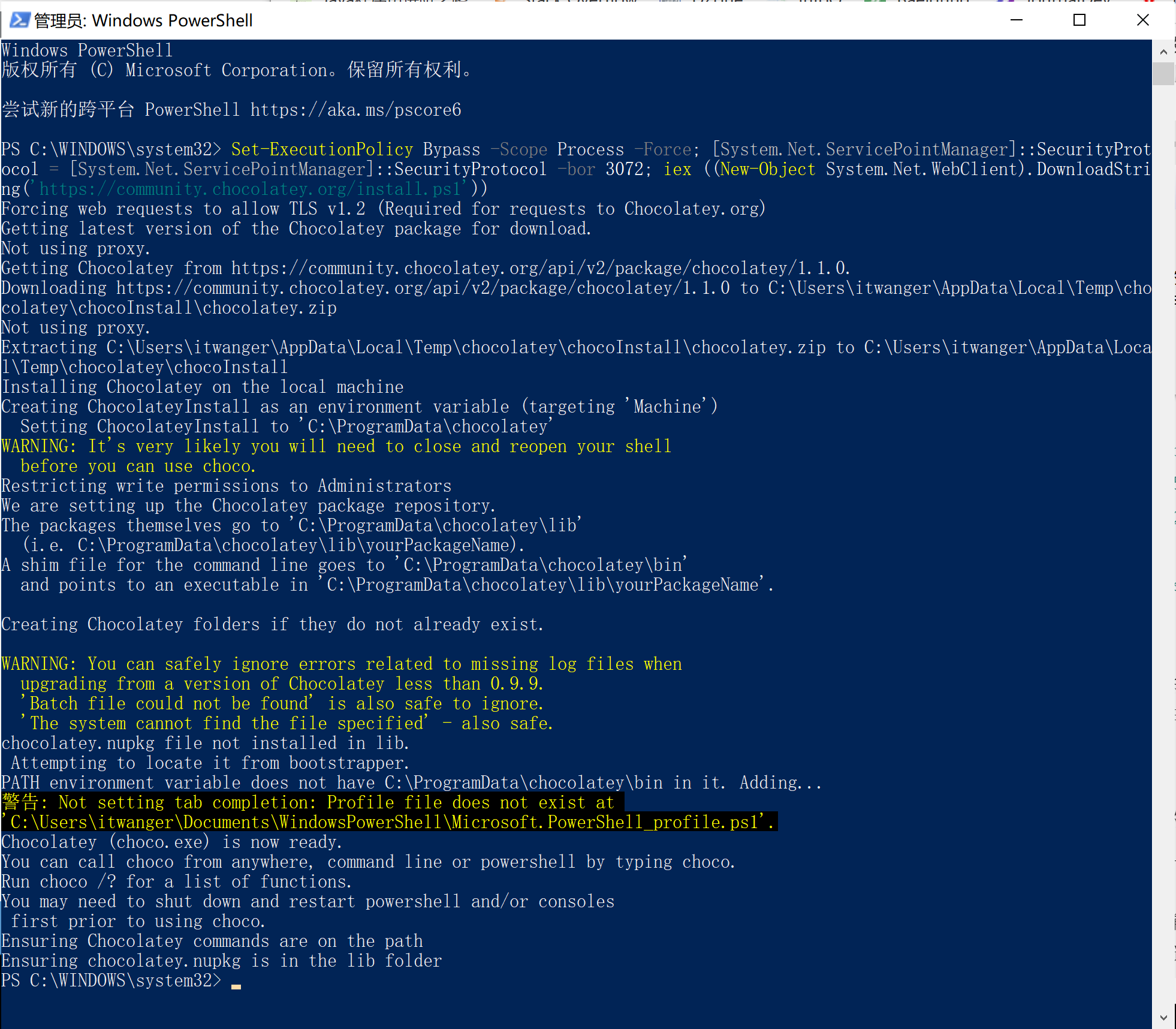
+
+如果不确定是否安装成功的话,可以通过键入 `choco` 命令来确认。
+
+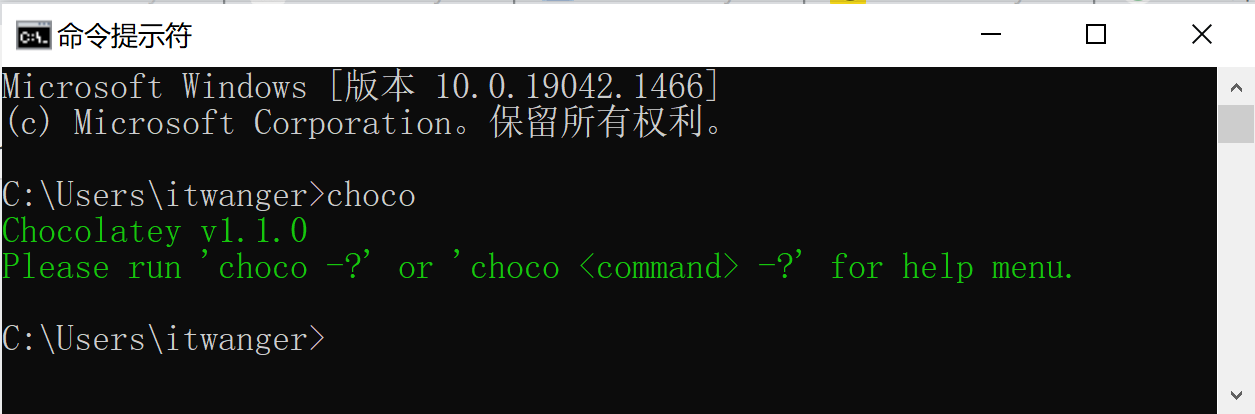
+
+这里推荐几个非常高效的操作命令:
+
+- choco search xxx,查找 xxx 安装包
+- choco info xxx,查看 xxx 安装包信息
+- choco install xxx,安装 xxx 软件
+- choco upgrade xxx,升级 xxx 软件
+- choco uninstall xxx, 卸载 xxx 软件
+
+如何知道 chocolatey 仓库中都有哪些安装包可用呢?
+
+可以通过上面提到的命令行的方式,也可以访问官方仓库进行筛选。
+
+>[https://community.chocolatey.org/packages](https://community.chocolatey.org/packages)
+
+比如说我们来查找 Java。
+
+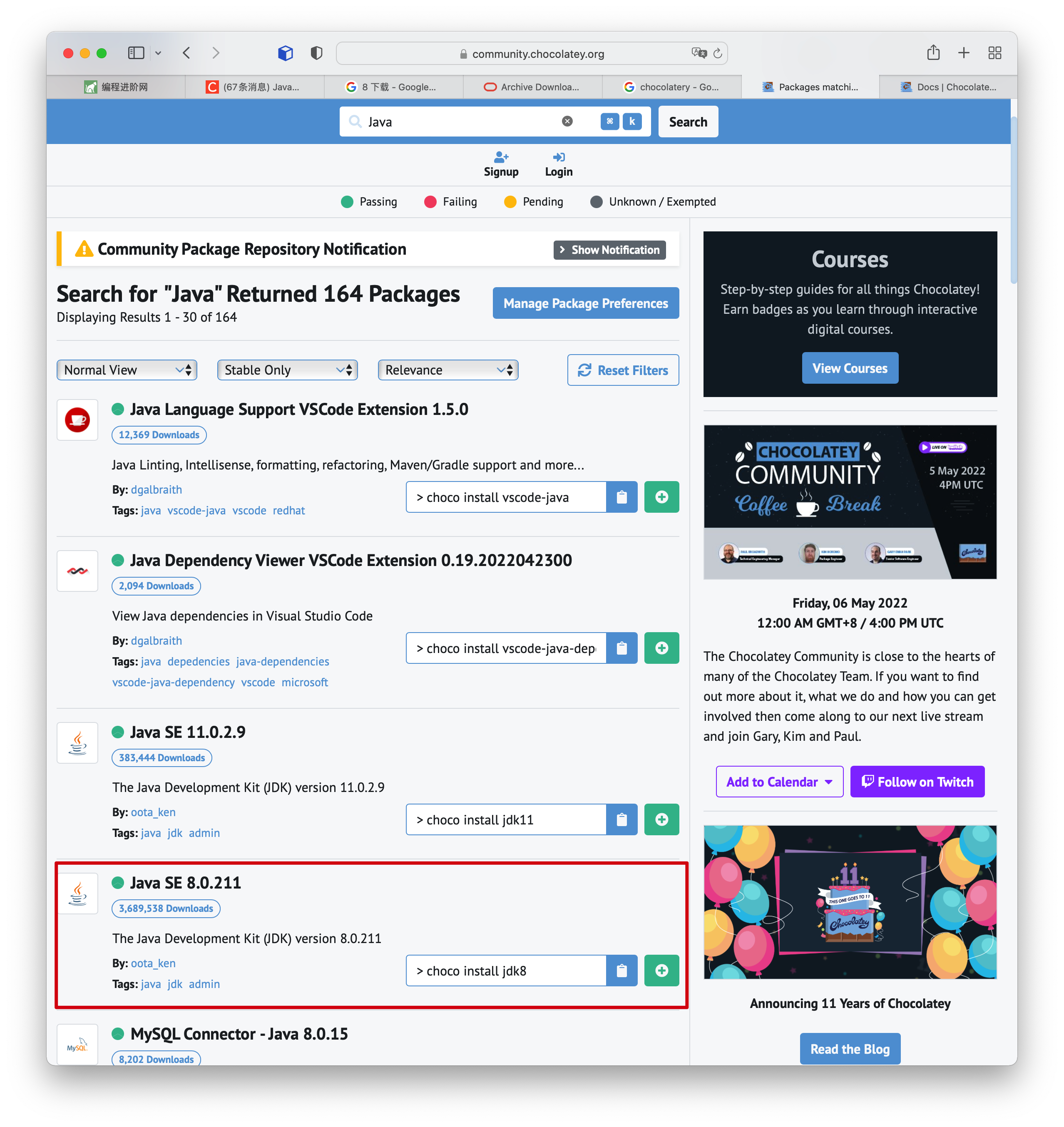
+
+好,现在可以直接在shell中键入 `choco install jdk8` 来安装 JDK8 了,并且会自动将Java加入到环境变量中,不用再去「我的电脑」「环境变量」中新建 JAVA_HOME 并复制 JDK 安装路径配置 PATH 变量了,是不是非常 nice?
+
+稍等片刻,键入 `java -version` 就可以确认Java是否安装成功了。
+
+
+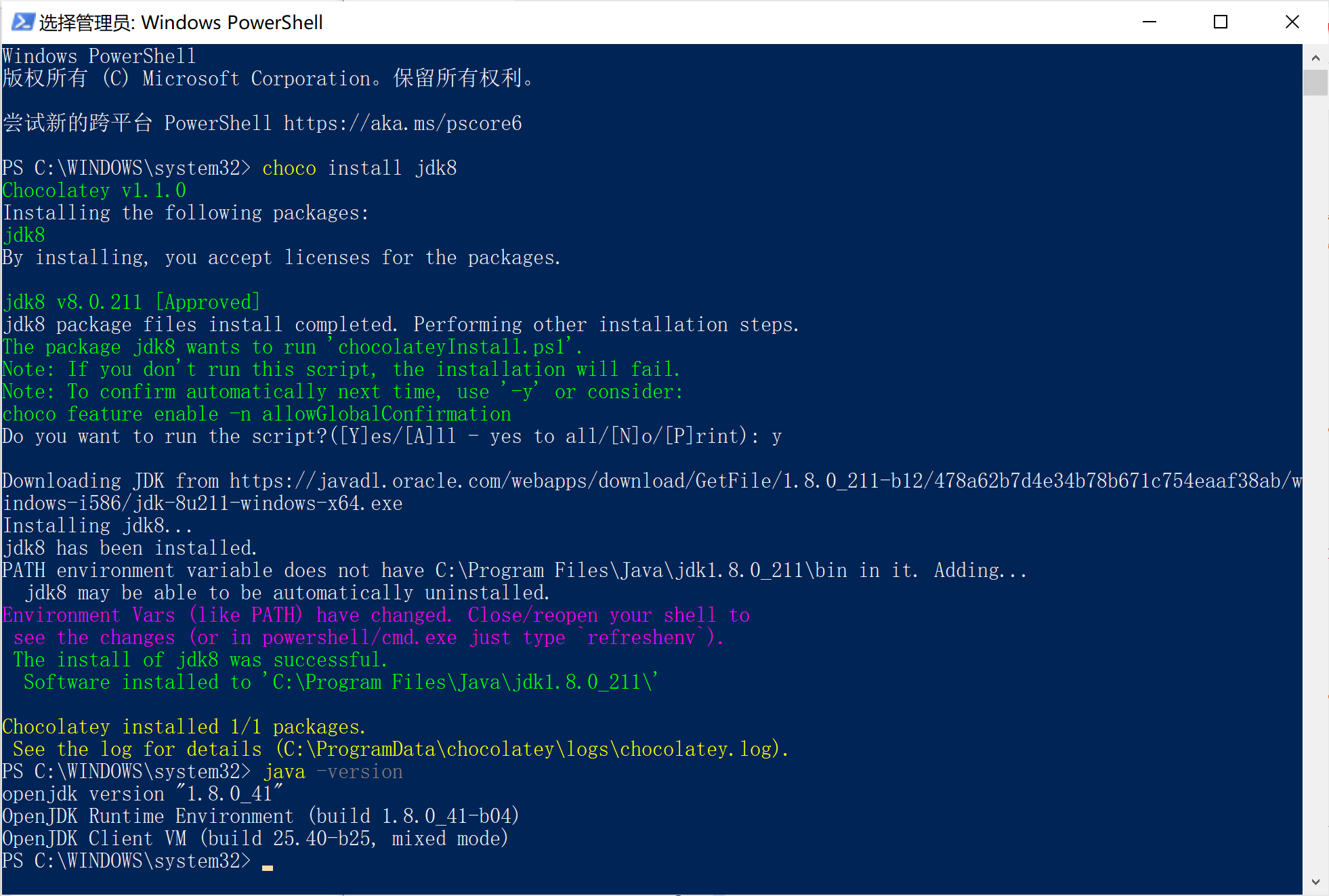
+
+不得不承认!非常nice!
+
+再比如说安装 Redis,只需要找到 Redis 的安装命令在 Choco 下执行一下就 OK 了。
+
+
+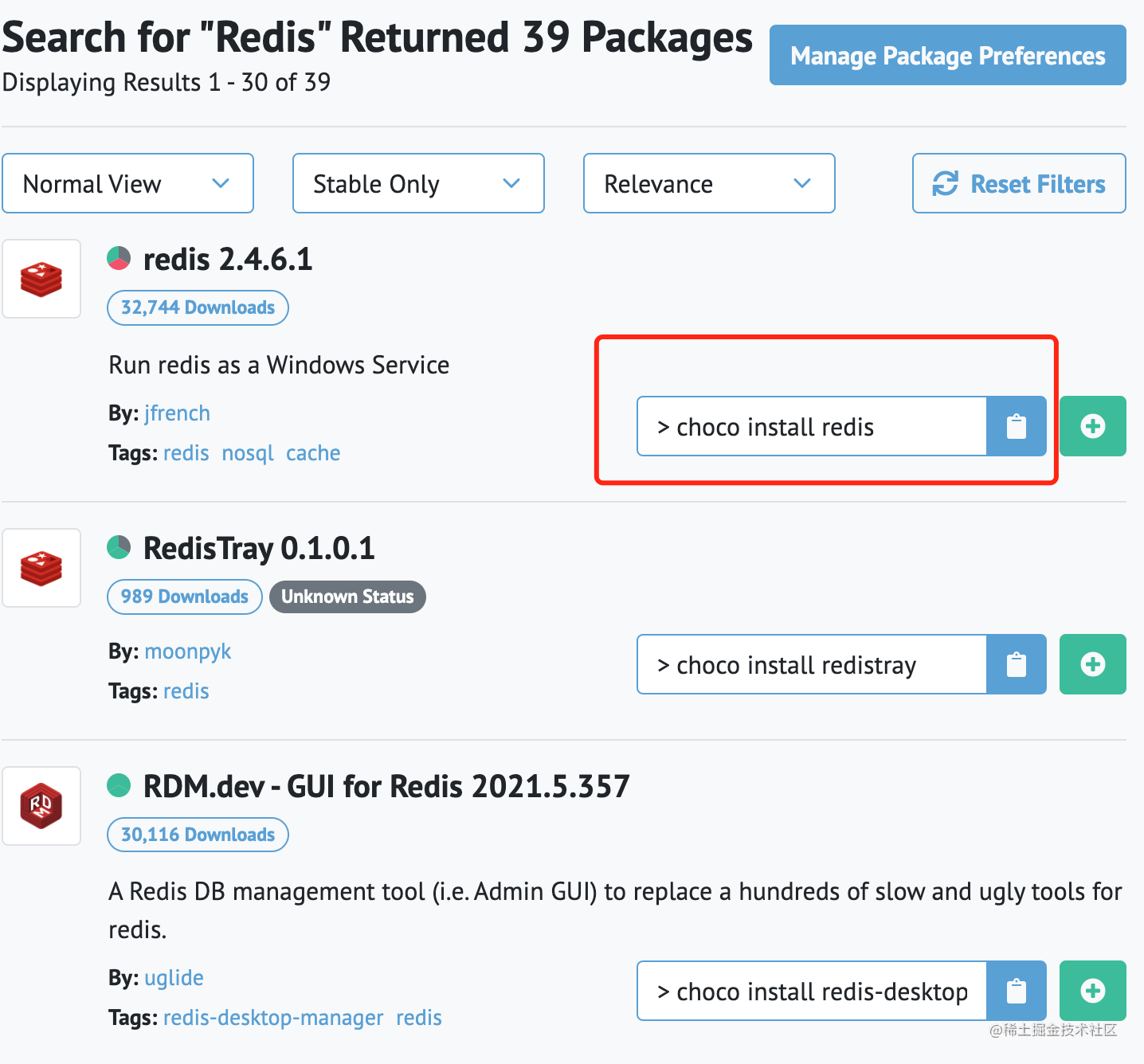
+
+安装 Git:
+
+```
+choco install git.install
+```
+
+安装 node.js
+
+```
+choco install nodejs.install
+```
+
+安装 7zip
+
+```
+choco install 7zip
+```
+
+安装 **Filezilla**
+
+```
+choco install filezilla
+```
+
+Choco 上的软件包也非常的多,基本上软件开发中常见的安装包都有。
+
+
+
+
+### 小结
+
+通过小二的实战笔记,我们可以了解到。
+
+对比下载安装包,通过图形化界面的方式安装 JDK,然后下一步,下一步是不是感觉在 Shell 下安装 JDK 更炫酷一些?
+
+关键是还省去了环境变量的配置。
+
+记得还没有走出新手村的时候,就经常被环境变量配置烦不胜烦。那下载这种命令行的方式,要比手动在环境变量中配置要省事一百倍,也更不容易出错。
+
+通过 Choco 可以集中安装、管理、更新各种各样的软件。特别适合管理一些轻量级的开源软件,一条命令搞定,升级的时候也方便,不用再重新去下载新的安装包,可以有效治愈更新强迫症患者的症状。
+
+如果不想特殊设置的话,Chocolatey 整体的操作与使用还是比较亲民的。就连刚接触软件开发的小白也可以直接使用,而且路人看着会觉得你特别厉害。
+
+
+
+
diff --git a/docs/src/gongju/fastjson.md b/docs/gongju/fastjson.md
similarity index 93%
rename from docs/src/gongju/fastjson.md
rename to docs/gongju/fastjson.md
index dcc69913bb..c5e36e795b 100644
--- a/docs/src/gongju/fastjson.md
+++ b/docs/gongju/fastjson.md
@@ -12,7 +12,7 @@ tag:
我是 fastjson,是个地地道道的杭州土著,但我始终怀揣着一颗走向全世界的雄心。这不,我在 GitHub 上的简介都换成了英文,国际范十足吧?
-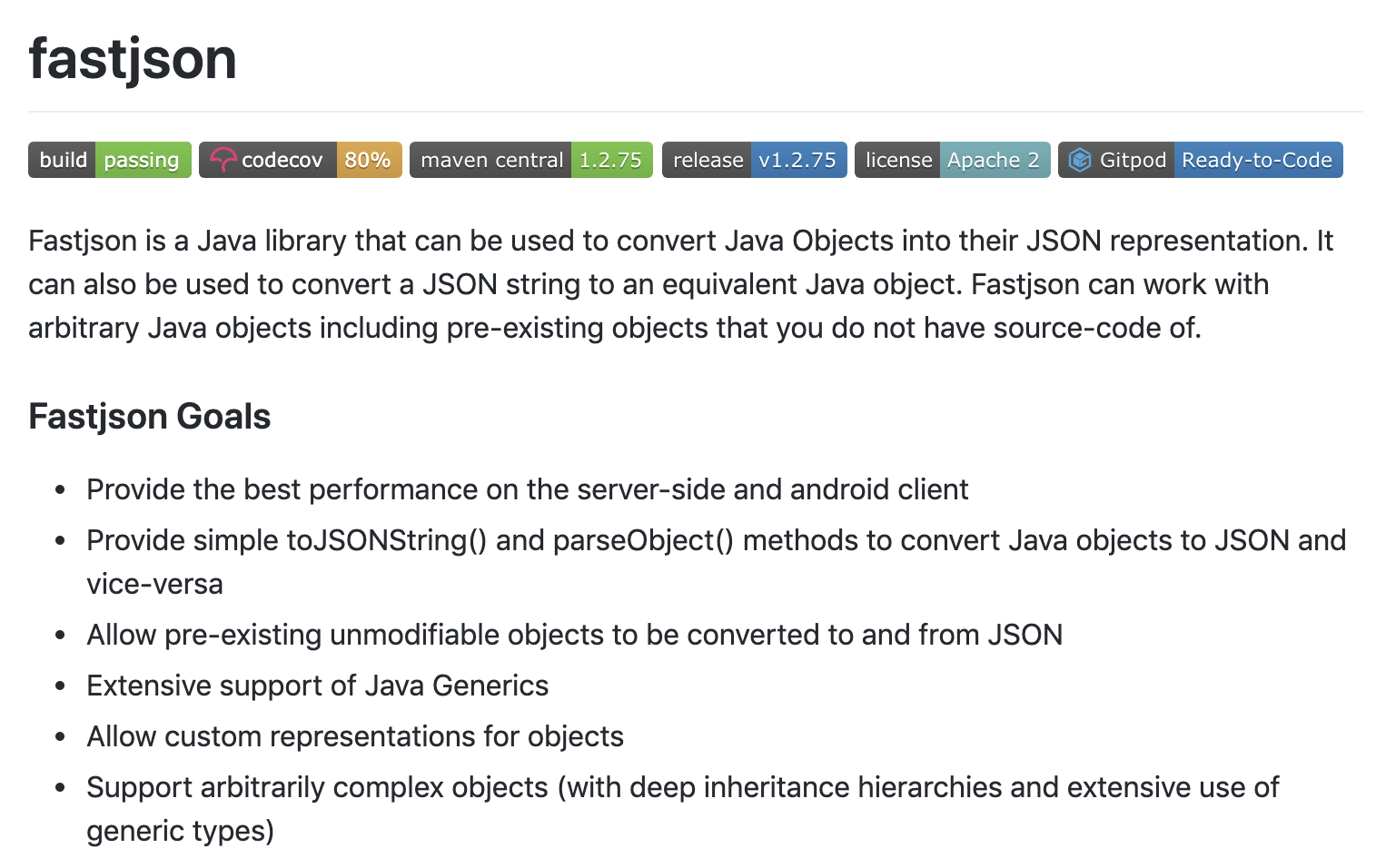
+
如果你的英语功底没有我家老板 666 的话,我可以简单地翻译下(说人话,不装逼)。
@@ -233,7 +233,7 @@ public class IdentityHashMap {
再比如说,使用 asm 技术来避免反射导致的开销。
-
+
我承认,快的同时,也带来了一些安全性的问题。尤其是 AutoType 的引入,让黑客有了可乘之机。
@@ -257,14 +257,14 @@ public class IdentityHashMap {
在于黑客的反复较量中,我虽然变得越来越稳重成熟了,但与此同时,让我的用户为此也付出了沉重的代价。
-
+
网络上也出现了很多不和谐的声音,他们声称我是最垃圾的国产开源软件之一,只不过凭借着一些投机取巧赢得了国内开发者的信赖。
但更多的是,对我的不离不弃。
-
+
最令我感到为之动容的一句话是:
@@ -274,7 +274,7 @@ public class IdentityHashMap {
为了彻底解决 AutoType 带来的问题,在 1.2.68 版本中,我引入了 safeMode 的安全模式,无论白名单和黑名单,都不支持 AutoType,这样就可以彻底地杜绝攻击。
-
+
安全模式下,`checkAutoType()` 方法会直接抛出异常。
@@ -285,4 +285,4 @@ public class IdentityHashMap {
2020 年的最后一篇文章!看到的就点个赞吧,2021 年顺顺利利。
-
+
diff --git a/docs/src/gongju/forest.md b/docs/gongju/forest.md
similarity index 97%
rename from docs/src/gongju/forest.md
rename to docs/gongju/forest.md
index f282f7c0b8..762db306ae 100644
--- a/docs/src/gongju/forest.md
+++ b/docs/gongju/forest.md
@@ -141,11 +141,11 @@ Forest 的字面意思是森林的意思,更内涵点的话,可以拆成For
**虽然 star 数还不是很多,但 star 趋势图正在趋于爬坡阶段,大家可以拿来作为一个练手项目,我觉得还是不错的选择**。
-
+
Forest 本身是处理前端过程的框架,是对后端 HTTP API 框架的进一步封装。
-
+
前端部分:
@@ -382,4 +382,4 @@ myClient.send("foo", (String resText, ForestRequest request, ForestResponse resp
这篇文章不仅介绍了 Forest 这个轻量级的 HTTP 客户端框架,还回顾了它的底层实现:HttpClient 和 OkHttp,希望能对大家有所帮助。
-
+
diff --git a/docs/src/gongju/gson.md b/docs/gongju/gson.md
similarity index 97%
rename from docs/src/gongju/gson.md
rename to docs/gongju/gson.md
index ce70a00711..67653fb6f9 100644
--- a/docs/src/gongju/gson.md
+++ b/docs/gongju/gson.md
@@ -243,7 +243,7 @@ class Bar{
假如你 debug 的时候,进入到 `toJson()` 方法的内部,就可以观察到。
-
+
foo 的实际类型为 `Foo`,但我女朋友在调用 `foo.getClass()` 的时候,只会得到 Foo,这就意味着她并不知道 foo 的实际类型。
@@ -283,11 +283,11 @@ Bar bar1 = foo1.get();
debug 进入 `toJson()` 方法内部查看的话,就可以看到 foo 的真实类型了。
-
+
`fromJson()` 在反序列化的时候,和此类似。
-
+
这样的话,bar1 就可以通过 `foo1.get()` 到了。
@@ -455,4 +455,4 @@ private int age = 18;
如果你觉得我有点用的话,不妨点个赞,留个言,see you。
-
+
diff --git a/docs/src/gongju/jackson.md b/docs/gongju/jackson.md
similarity index 98%
rename from docs/src/gongju/jackson.md
rename to docs/gongju/jackson.md
index c2ab9fef63..5bde839e17 100644
--- a/docs/src/gongju/jackson.md
+++ b/docs/gongju/jackson.md
@@ -19,7 +19,7 @@ Java 之所以牛逼,很大的功劳在于它的生态非常完备,JDK 没
当我们通过 starter 新建一个 Spring Boot 的 Web 项目后,就可以在 Maven 的依赖项中看到 Jackson 的身影。
-
+
Jackson 有很多优点:
@@ -47,7 +47,7 @@ Jackson 的核心模块由三部分组成:
jackson-databind 依赖于 jackson-core 和 jackson-annotations,所以添加完 jackson-databind 之后,Maven 会自动将 jackson-core 和 jackson-annotations 引入到项目当中。
-
+
Maven 之所以讨人喜欢的一点就在这,能偷偷摸摸地帮我们把该做的做了。
@@ -563,4 +563,4 @@ Woman{age=18, name='三妹'}
好了,通过这篇文章的系统化介绍,相信你已经完全摸透 Jackson 了,我们下篇文章见。
-
+
diff --git a/docs/src/gongju/junit.md b/docs/gongju/junit.md
similarity index 91%
rename from docs/src/gongju/junit.md
rename to docs/gongju/junit.md
index d472e52fbb..daeb3dfac5 100644
--- a/docs/src/gongju/junit.md
+++ b/docs/gongju/junit.md
@@ -16,7 +16,7 @@ tag:
微软公司之前有这样一个统计:bug 在单元测试阶段被发现的平均耗时是 3.25 小时,如果遗漏到系统测试则需要 11.5 个小时。
-
+
经我这么一说,你应该已经很清楚单元测试的重要性了。那在你最初编写测试代码的时候,是不是经常这么做?就像下面这样。
@@ -56,17 +56,17 @@ public class Factorial {
第一步,直接在当前的代码编辑器窗口中按下 `Command+N` 键(Mac 版),在弹出的菜单中选择「Test...」。
-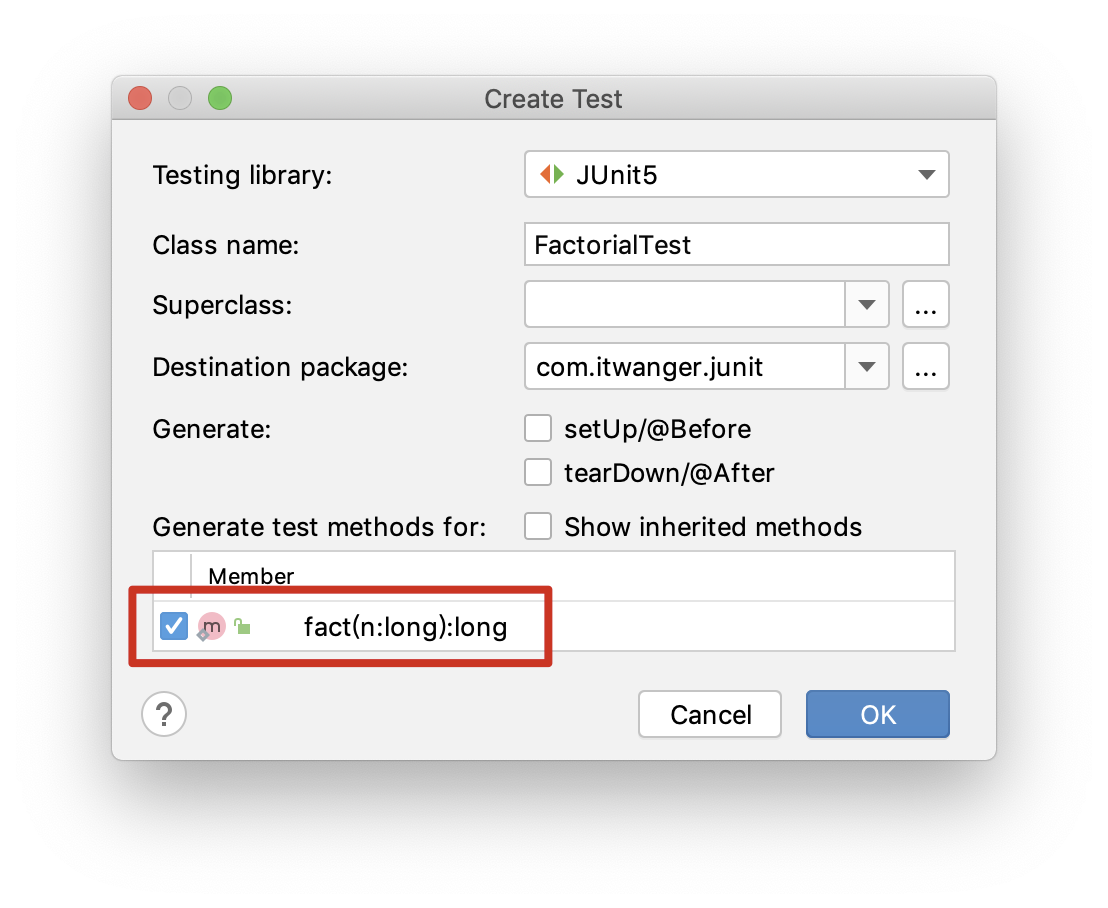
+
勾选上要编写测试用例的方法 `fact()`,然后点击「OK」。
此时,IDEA 会自动在当前类所在的包下生成一个类名带 Test(惯例)的测试类。如下图所示。
-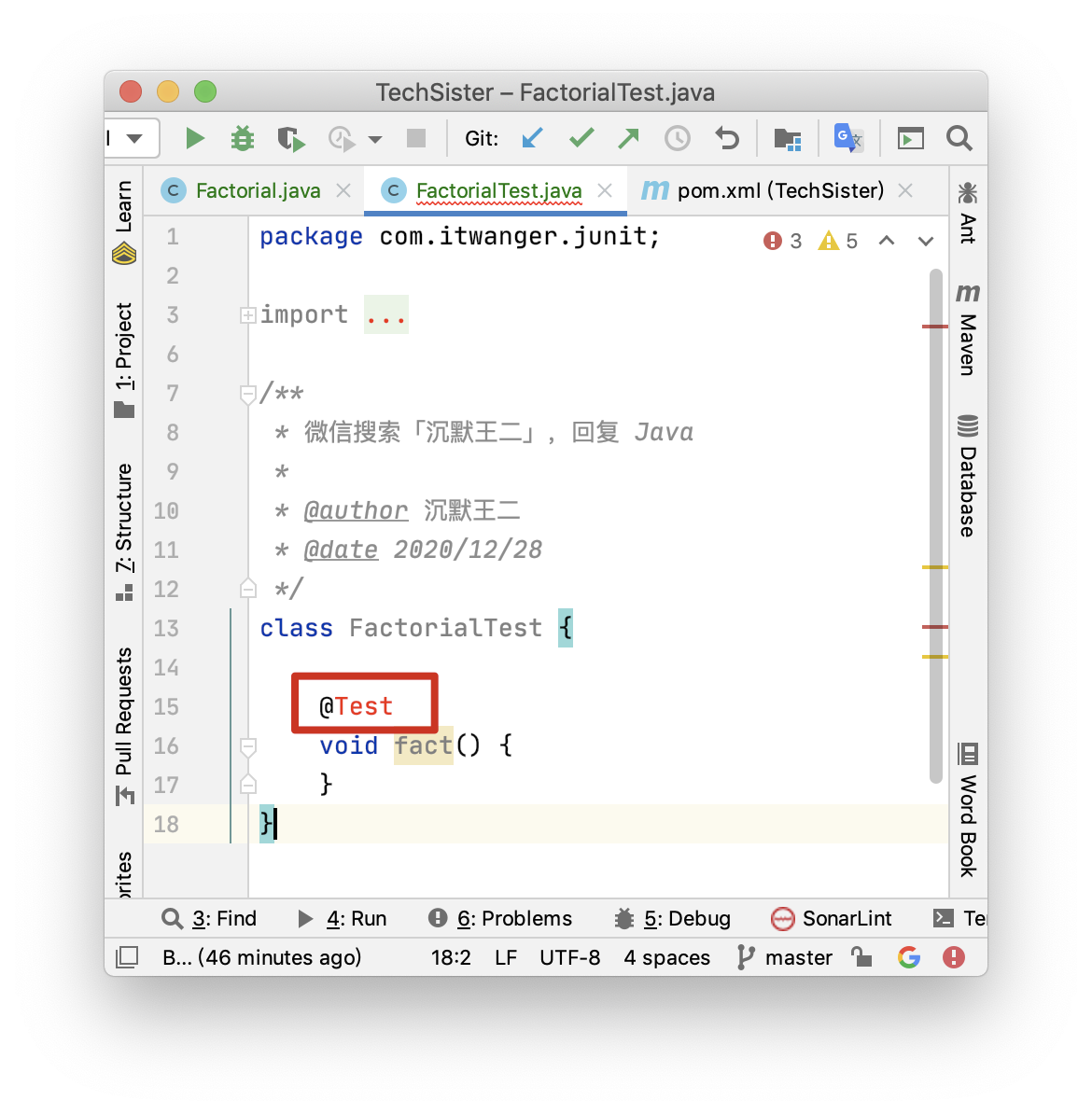
+
如果你是第一次使用我的话,IDEA 会提示你导入我的依赖包。建议你选择最新的 JUnit 5.4。
-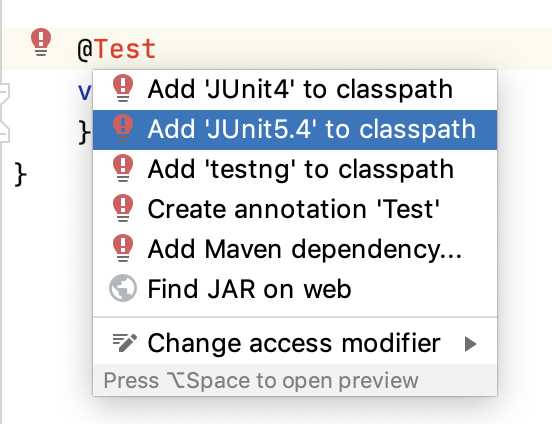
+
导入完毕后,你可以打开 pom.xml 文件确认一下,里面多了对我的依赖。
@@ -95,11 +95,11 @@ void fact() {
第三步,你可以在邮件菜单中选择「Run FactorialTest」来运行测试用例,结果如下所示。
-
+
测试失败了,因为第 20 行的预期结果和实际不符,预期是 100,实际是 120。此时,你要么修正实现代码,要么修正测试代码,直到测试通过为止。
-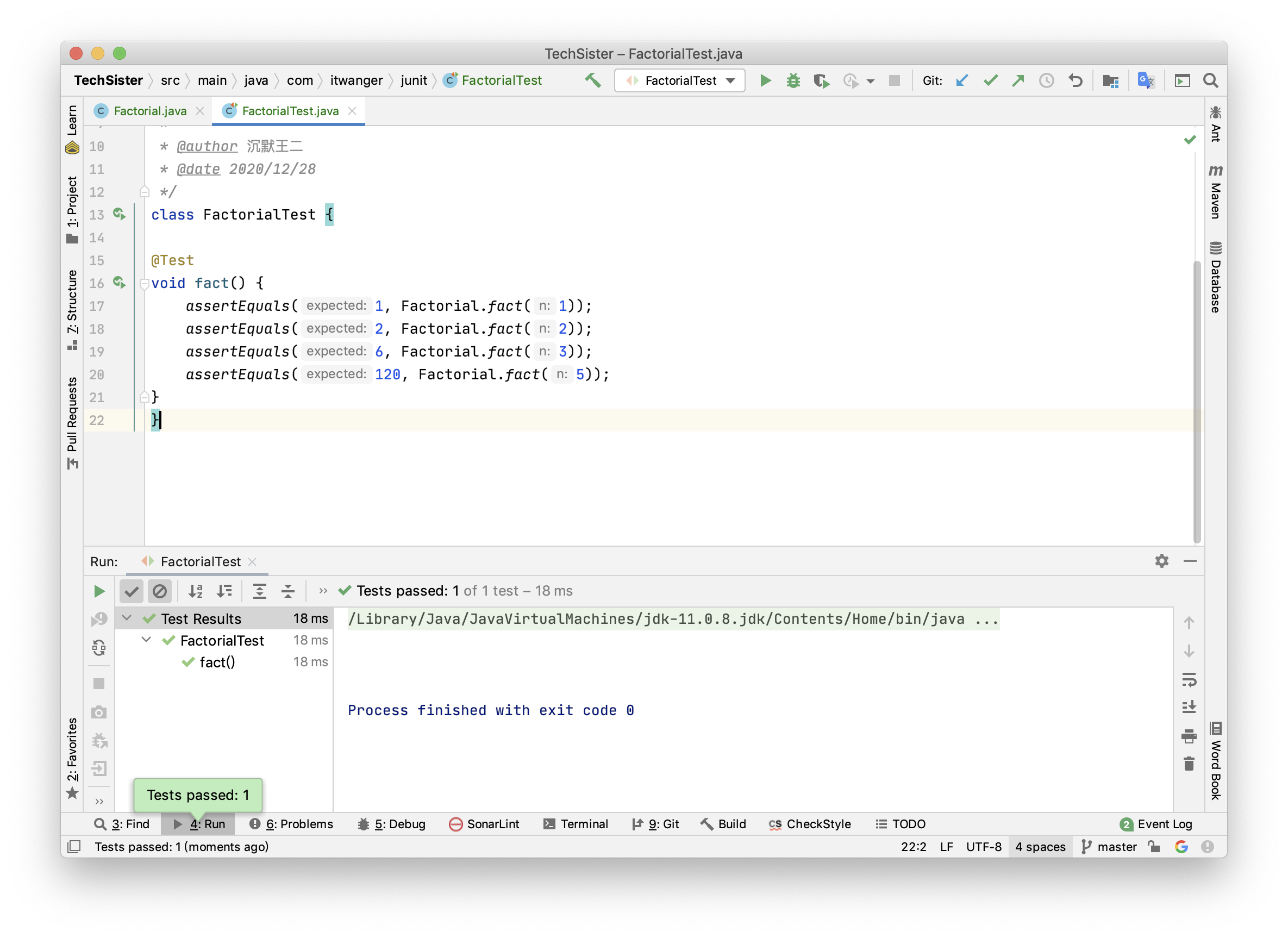
+
不难吧?单元测试可以确保单个方法按照正确的预期运行,如果你修改了某个方法的代码,只需确保其对应的单元测试通过,即可认为改动是没有问题的。
@@ -124,7 +124,7 @@ public class Calculator {
新建测试用例的时候记得勾选`setUp` 和 `tearDown`。
-
+
生成后的代码如下所示。
@@ -307,4 +307,4 @@ void fromJava9to11() {
希望我能尽早的替你发现代码中的 bug,毕竟越早的发现,造成的损失就会越小。see you!
-
+
diff --git a/docs/src/gongju/knife4j.md b/docs/gongju/knife4j.md
similarity index 76%
rename from docs/src/gongju/knife4j.md
rename to docs/gongju/knife4j.md
index 2ffa9d1599..58893b4562 100644
--- a/docs/src/gongju/knife4j.md
+++ b/docs/gongju/knife4j.md
@@ -7,27 +7,27 @@ tag:
---
-一般在使用 Spring Boot 开发前后端分离项目的时候,都会用到 [Swagger](https://javabetter.cn/springboot/swagger.html)(戳链接详细了解)。
+一般在使用 Spring Boot 开发前后端分离项目的时候,都会用到 [Swagger](https://tobebetterjavaer.com/springboot/swagger.html)(戳链接详细了解)。
但随着系统功能的不断增加,接口数量的爆炸式增长,Swagger 的使用体验就会变得越来越差,比如请求参数为 JSON 的时候没办法格式化,返回结果没办法折叠,还有就是没有提供搜索功能。
今天我们介绍的主角 Knife4j 弥补了这些不足,赋予了 Swagger 更强的生命力和表现力。
-## 关于 Knife4j
+### 关于 Knife4j
Knife4j 的前身是 swagger-bootstrap-ui,是 springfox-swagger-ui 的增强 UI 实现。swagger-bootstrap-ui 采用的是前端 UI 混合后端 Java 代码的打包方式,在微服务的场景下显得非常臃肿,改良后的 Knife4j 更加小巧、轻量,并且功能更加强大。
springfox-swagger-ui 的界面长这个样子,说实话,确实略显丑陋。
-
+
swagger-bootstrap-ui 增强后的样子长下面这样。单纯从直观体验上来看,确实增强了。
-
+
那改良后的 Knife4j 不仅在界面上更加优雅、炫酷,功能上也更加强大:后端 Java 代码和前端 UI 模块分离了出来,在微服务场景下更加灵活;还提供了专注于 Swagger 的增强解决方案。
-
+
官方文档:
@@ -41,7 +41,7 @@ swagger-bootstrap-ui 增强后的样子长下面这样。单纯从直观体验
>[https://gitee.com/xiaoym/swagger-bootstrap-ui-demo](https://gitee.com/xiaoym/swagger-bootstrap-ui-demo)
-## 整合 Knife4j
+### 整合 Knife4j
Knife4j 完全遵循了 Swagger 的使用方式,所以可以无缝切换。
@@ -102,7 +102,7 @@ public class Knife4jController {
}
```
-第四步,由于 springfox 3.0.x 版本 和 Spring Boot 2.6.x 版本有冲突,所以还需要先解决这个 bug,一共分两步(在[Swagger](https://javabetter.cn/springboot/swagger.html) 那篇已经解释过了,这里不再赘述,但防止有小伙伴在学习的时候再次跳坑,这里就重复一下步骤)。
+第四步,由于 springfox 3.0.x 版本 和 Spring Boot 2.6.x 版本有冲突,所以还需要先解决这个 bug,一共分两步(在[Swagger](https://tobebetterjavaer.com/springboot/swagger.html) 那篇已经解释过了,这里不再赘述,但防止有小伙伴在学习的时候再次跳坑,这里就重复一下步骤)。
先在 application.yml 文件中加入:
@@ -157,17 +157,17 @@ public static BeanPostProcessor springfoxHandlerProviderBeanPostProcessor() {
>访问地址(和 Swagger 不同):[http://localhost:8080/doc.html](http://localhost:8080/doc.html)
-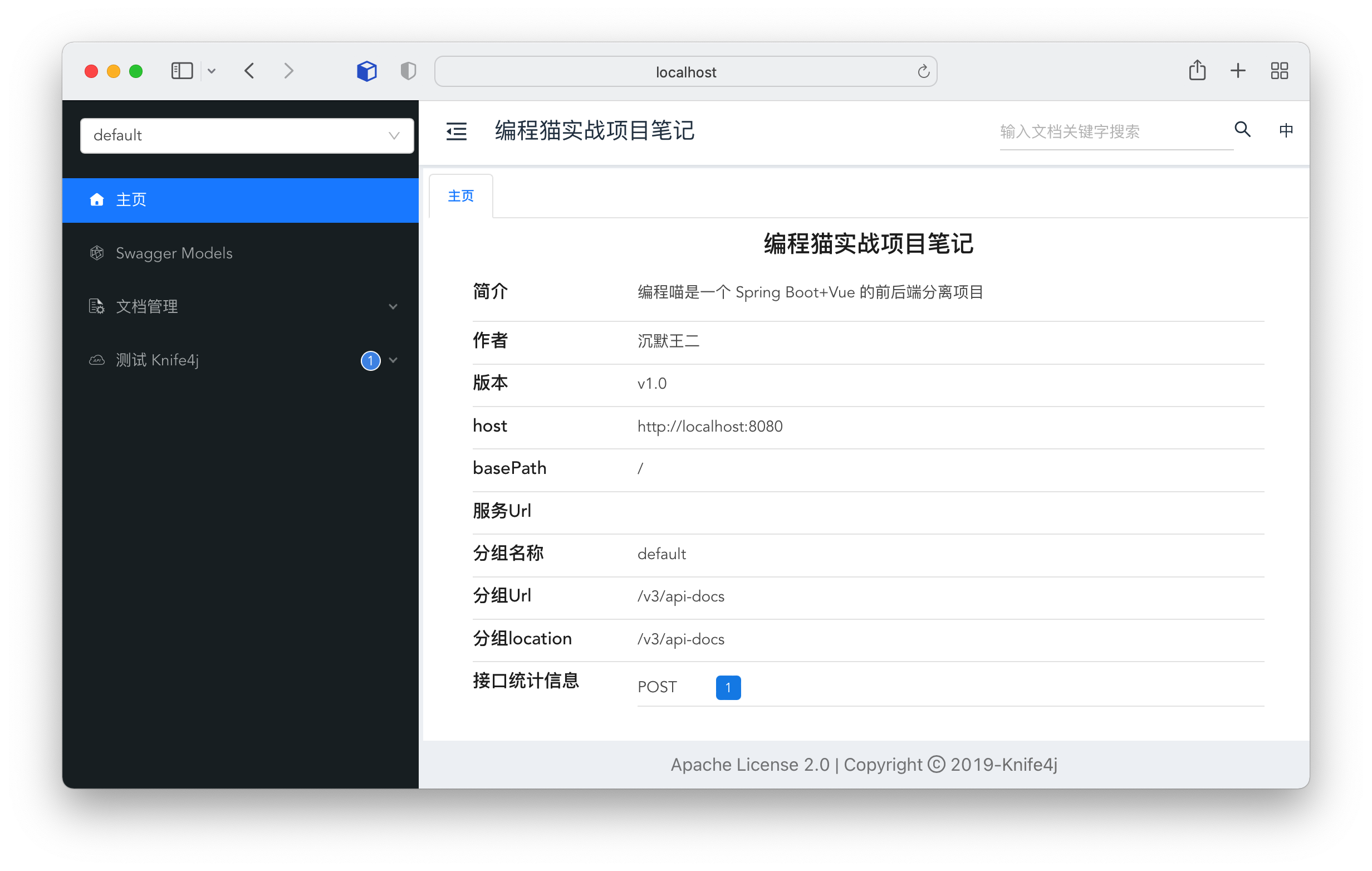
+
是不是比 Swagger 简洁大方多了?如果想测试接口的话,可以直接点击接口,然后点击「测试」,点击发送就可以看到返回结果了。
-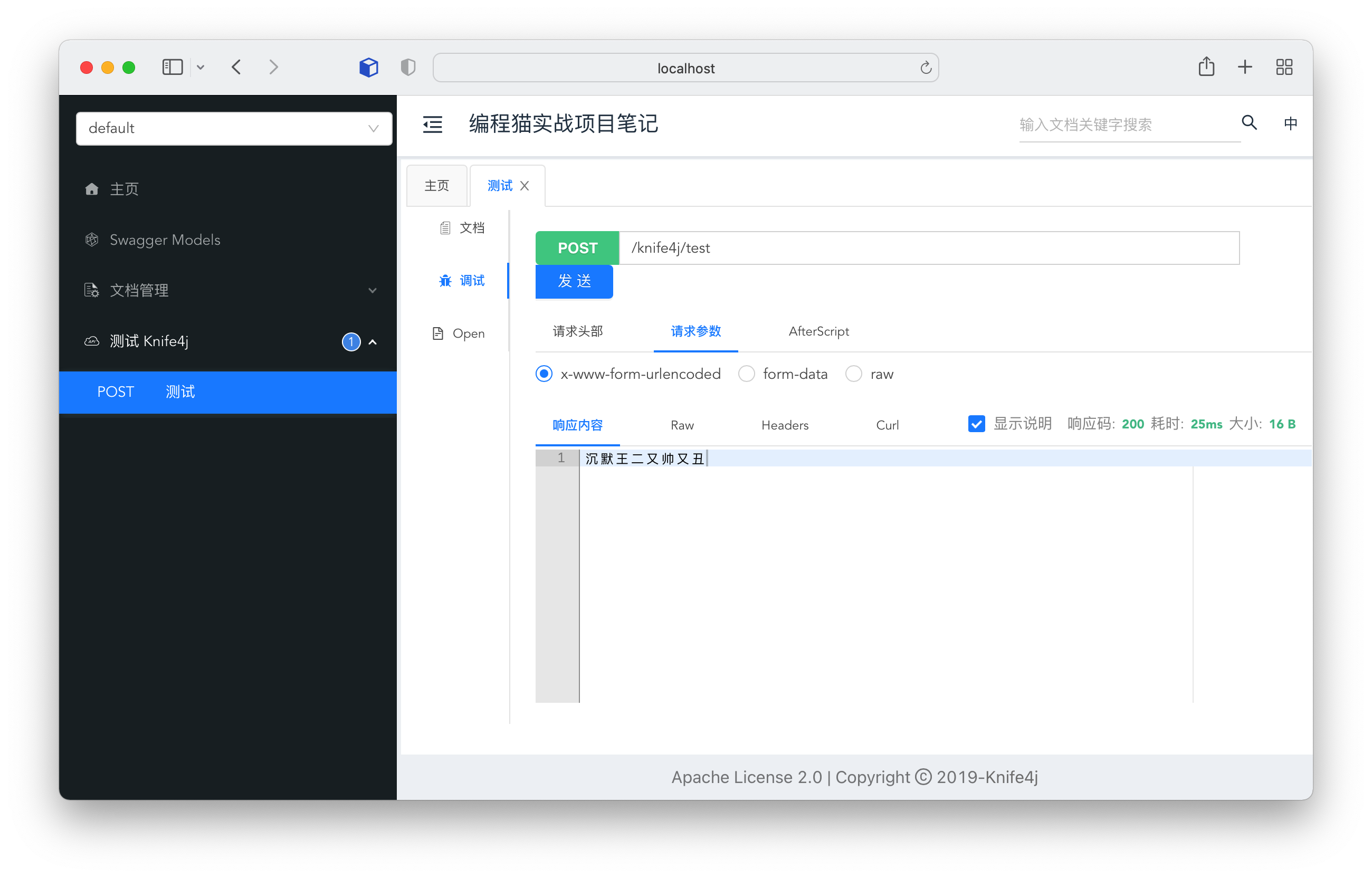
+
-## Knife4j 的功能特点
+### Knife4j 的功能特点
编程喵🐱实战项目中已经整合好了 Knife4j,在本地跑起来后,就可以查看所有 API 接口了。编程喵中的管理端(codingmore-admin)端口为 9002,启动服务后,在浏览器中输入 [http://localhost:9002/doc.html](http://localhost:9002/doc.html) 就可以访问到了。
-
+
简单来介绍下 Knife4j 的 功能特点:
@@ -176,68 +176,68 @@ public static BeanPostProcessor springfoxHandlerProviderBeanPostProcessor() {
Knife4j 和 Swagger 一样,也是支持头部登录认证的,点击「authorize」菜单,添加登录后的信息即可保持登录认证的 token。
-
+
如果某个 API 需要登录认证的话,就会把之前填写的信息带过来。
-
+
**2)支持 JSON 折叠**
Swagger 是不支持 JSON 折叠的,当返回的信息非常多的时候,界面就会显得非常的臃肿。Knife4j 则不同,可以对返回的 JSON 节点进行折叠。
-
+
**3)离线文档**
Knife4j 支持把 API 文档导出为离线文档(支持 markdown 格式、HTML 格式、Word 格式),
-
+
使用 Typora 打开后的样子如下,非常的大方美观。
-
+
**4)全局参数**
当某些请求需要全局参数时,这个功能就很实用了,Knife4j 支持 header 和 query 两种方式。
-
+
之后进行请求的时候,就会把这个全局参数带过去。
-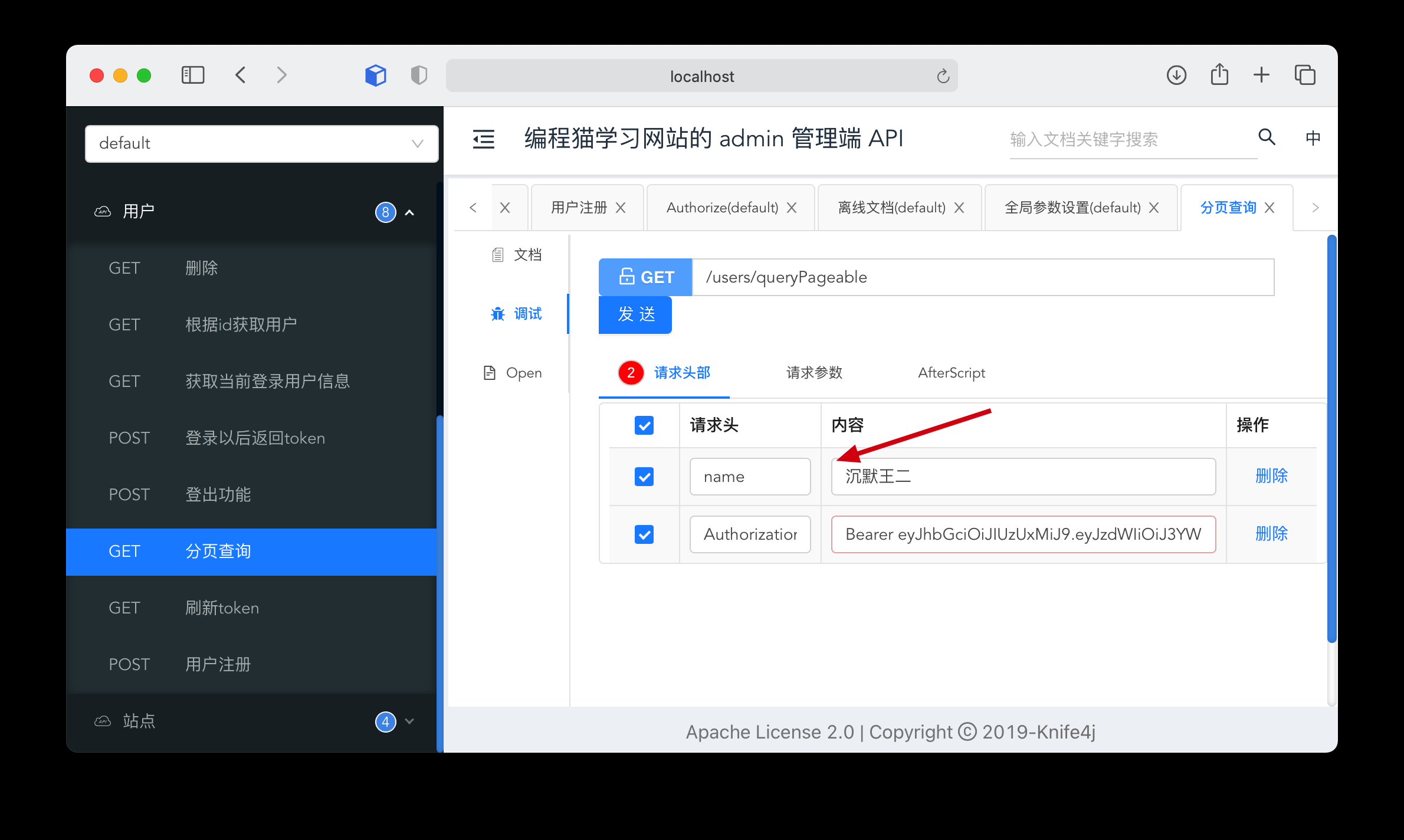
+
**5)搜索 API 接口**
Swagger 是没有搜索功能的,当要测试的接口有很多的时候,当需要去找某一个 API 的时候就傻眼了,只能一个个去拖动滚动条去找。
-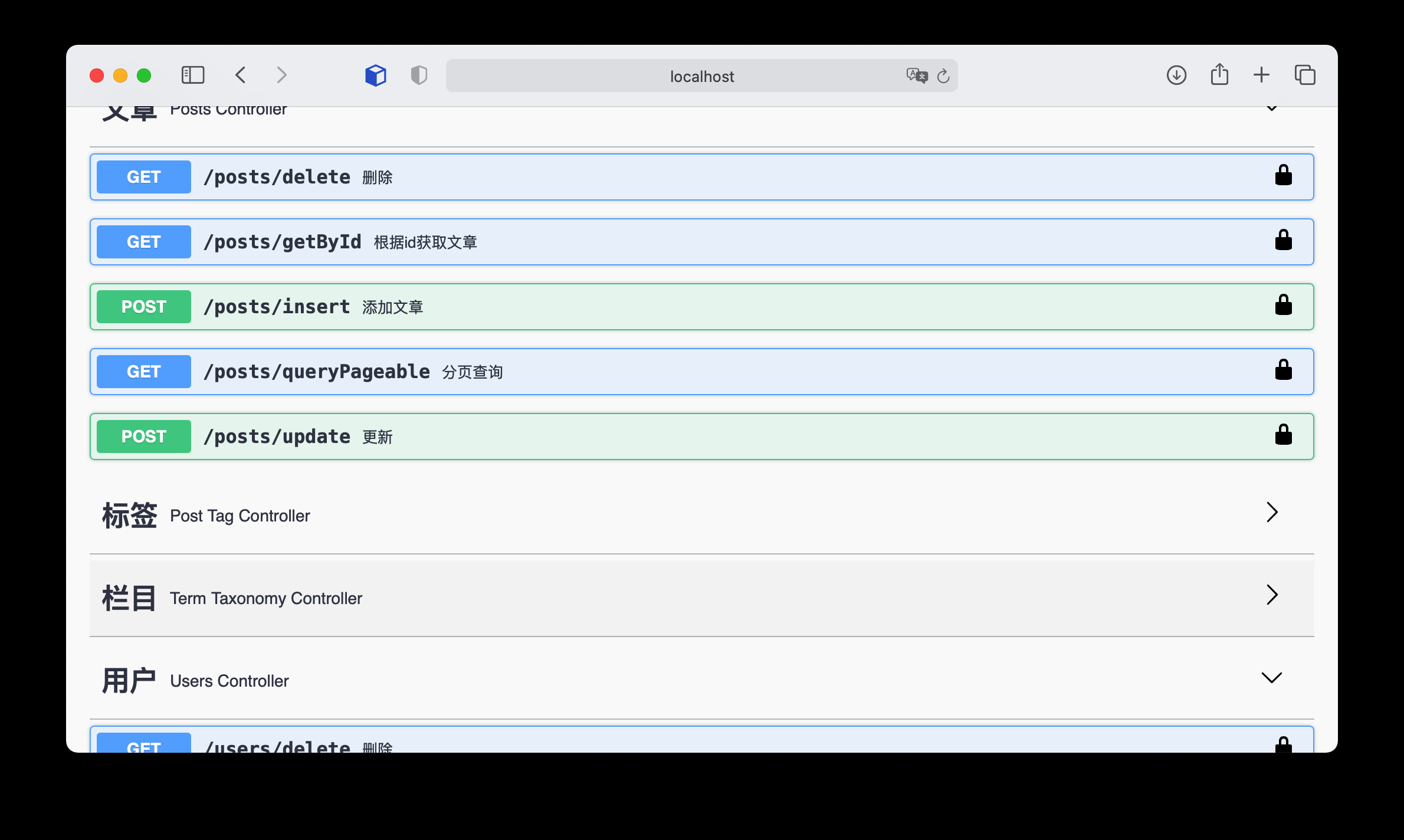
+
在文档的右上角,Knife4j 提供了文档搜索功能,输入要查询的关键字,就可以检索筛选了,是不是很方便?
-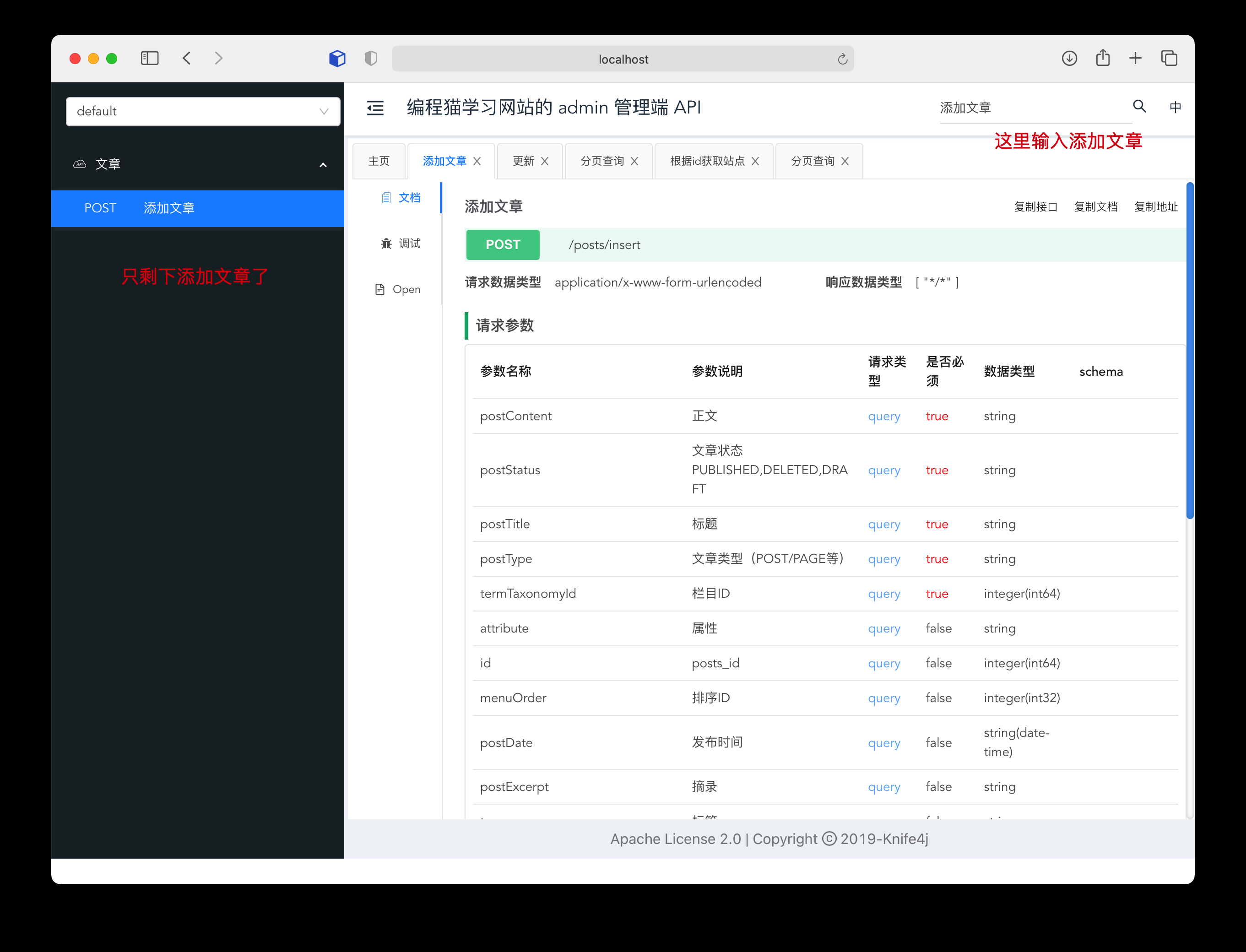
+
目前支持搜索接口的地址、名称和描述。
-## 尾声
+### 尾声
除了我上面提到的增强功能,Knife4j 还提供了很多实用的功能,大家可以通过官网的介绍一一尝试下,生产效率会提高不少。
>[https://doc.xiaominfo.com/knife4j/documentation/enhance.html](https://doc.xiaominfo.com/knife4j/documentation/enhance.html)
-
+
----
-更多内容,只针对《二哥的Java进阶之路》星球用户开放,需要的小伙伴可以[戳链接🔗](https://javabetter.cn/zhishixingqiu/)加入我们的星球,一起学习,一起卷。。**编程喵**🐱是一个 Spring Boot+Vue 的前后端分离项目,融合了市面上绝大多数流行的技术要点。通过学习实战项目,你可以将所学的知识通过实践进行检验、你可以拓宽自己的技术边界,你可以掌握一个真正的实战项目是如何从 0 到 1 的。
+更多内容,只针对《Java 程序员进阶之路》星球用户开放,需要的小伙伴可以[戳链接🔗](docs/zhishixingqiu/)加入我们的星球,一起学习,一起卷。。**编程喵**🐱是一个 Spring Boot+Vue 的前后端分离项目,融合了市面上绝大多数流行的技术要点。通过学习实战项目,你可以将所学的知识通过实践进行检验、你可以拓宽自己的技术边界,你可以掌握一个真正的实战项目是如何从 0 到 1 的。
----
-## 源码路径
+### 源码路径
> - 编程喵:[https://github.com/itwanger/coding-more](https://github.com/itwanger/coding-more)
> - codingmore-knife4j:[https://github.com/itwanger/codingmore-learning](https://github.com/itwanger/codingmore-learning/tree/main/codingmore-knife4j)
-
+
diff --git a/docs/src/gongju/log4j.md b/docs/gongju/log4j.md
similarity index 94%
rename from docs/src/gongju/log4j.md
rename to docs/gongju/log4j.md
index 308091e8b7..d7d046eb93 100644
--- a/docs/src/gongju/log4j.md
+++ b/docs/gongju/log4j.md
@@ -12,7 +12,7 @@ tag:
这不,我在战国时代读者群里发现了这么一串聊天记录:
-
+
竟然有小伙伴不知道“打日志”是什么意思,不知道该怎么学习,还有小伙伴回答说,只知道 Log4j!
@@ -22,7 +22,7 @@ tag:
(说好的不在乎,怎么在乎起来了呢?手动狗头)
-
+
管他呢,**我行我素**吧,保持初心不改就对了!这篇文章就来说说 Log4j,这个打印日志的鼻祖。Java 中的日志打印其实是个艺术活,我保证,这句话绝不是忽悠。
@@ -37,7 +37,7 @@ tag:
之所以这样打印日志,是因为很方便,上手难度很低,尤其是在 IDEA 的帮助下,只需在键盘上按下 `so` 两个字母就可以调出 `System.out.println()`。
-
+
在本地环境下,使用 `System.out.println()` 打印日志是没问题的,可以在控制台看到信息。但如果是在生产环境下的话,`System.out.println()` 就变得毫无用处了。
@@ -63,7 +63,7 @@ OFF,最高级别,意味着所有消息都不会输出了。
这个级别是基于 Log4j 的,和 java.util.logging 有所不同,后者提供了更多的日志级别,比如说 SEVERE、FINER、FINEST。
-
+
### 03、错误的日志记录方式是如何影响性能的
@@ -86,7 +86,7 @@ if(logger.isDebugEnabled()){
切记,在生产环境下,一定不要开启 DEBUG 级别的日志,否则程序在大量记录日志的时候会变很慢,还有可能在你不注意的情况下,悄悄地把磁盘空间撑爆。
-
+
### 04、为什么选择 Log4j 而不是 java.util.logging
@@ -123,7 +123,7 @@ public class JavaUtilLoggingDemo {
程序运行后会在 target 目录下生成一个名叫 javautillog.txt 的文件,内容如下所示:
-
+
再来看一下 Log4j 的使用方式。
@@ -349,11 +349,11 @@ if(logger.isDebugEnabled()) {
8)不要在日志文件中打印密码、银行账号等敏感信息。
-
+
### 06、 总结
打印日志真的是一种艺术活,搞不好会严重影响服务器的性能。最可怕的是,记录了日志,但最后发现屁用没有,那简直是苍了个天啊!尤其是在生产环境下,问题没有记录下来,但重现有一定的随机性,到那时候,真的是叫天天不应,叫地地不灵啊!
-
+
diff --git a/docs/gongju/log4j2.md b/docs/gongju/log4j2.md
new file mode 100644
index 0000000000..ac617061e7
--- /dev/null
+++ b/docs/gongju/log4j2.md
@@ -0,0 +1,312 @@
+---
+title: Log4j 2:Apache维护的一款高性能日志记录工具
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+---
+
+Log4j 2,顾名思义,它就是 Log4j 的升级版,就好像手机里面的 Pro 版。我作为一个写文章方面的工具人,或者叫打工人,怎么能不写完这最后一篇。
+
+Log4j、SLF4J、Logback 是一个爹——Ceki Gulcu,但 Log4j 2 却是例外,它是 Apache 基金会的产品。
+
+SLF4J 和 Logback 作为 Log4j 的替代品,在很多方面都做了必要的改进,那为什么还需要 Log4j 2 呢?我只能说 Apache 基金会的开发人员很闲,不,很拼,要不是他们这种精益求精的精神,这个编程的世界该有多枯燥,毕竟少了很多可以用“拿来就用”的轮子啊。
+
+上一篇也说了,老板下死命令要我把日志系统切换到 Logback,我顺利交差了,老板很开心,夸我这个打工人很敬业。为了表达对老板的这份感谢,我决定偷偷摸摸地试水一下 Log4j 2,尽管它还不是个成品,可能会会项目带来一定的隐患。但谁让咱是一个敬岗爱业的打工人呢。
+
+
+
+
+### 01、Log4j 2 强在哪
+
+1)在多线程场景下,Log4j 2 的吞吐量比 Logback 高出了 10 倍,延迟降低了几个数量级。这话听起来像吹牛,反正是 Log4j 2 官方自己吹的。
+
+Log4j 2 的异步 Logger 使用的是无锁数据结构,而 Logback 和 Log4j 的异步 Logger 使用的是 ArrayBlockingQueue。对于阻塞队列,多线程应用程序在尝试使日志事件入队时通常会遇到锁争用。
+
+下图说明了多线程方案中无锁数据结构对吞吐量的影响。 Log4j 2 随着线程数量的扩展而更好地扩展:具有更多线程的应用程序可以记录更多的日志。其他日志记录库由于存在锁竞争的关系,在记录更多线程时,总吞吐量保持恒定或下降。这意味着使用其他日志记录库,每个单独的线程将能够减少日志记录。
+
+
+
+性能方面是 Log4j 2 的最大亮点,至于其他方面的一些优势,比如说下面这些,可以忽略不计,文字有多短就代表它有多不重要。
+
+2)Log4j 2 可以减少垃圾收集器的压力。
+
+3)支持 Lambda 表达式。
+
+4)支持自动重载配置。
+
+### 02、Log4j 2 使用示例
+
+废话不多说,直接实操开干。理论知识有用,但不如上手实操一把,这也是我多年养成的一个“不那么良好”的编程习惯:在实操中发现问题,解决问题,寻找理论基础。
+
+**第一步**,在 pom.xml 文件中添加 Log4j 2 的依赖:
+
+```xml
+
+ org.apache.logging.log4j
+ log4j-api
+ 2.5
+
+
+ org.apache.logging.log4j
+ log4j-core
+ 2.5
+
+```
+
+(这个 artifactId 还是 log4j,没有体现出来 2,而在 version 中体现,多少叫人误以为是 log4j)
+
+**第二步**,来个最简单的测试用例:
+
+```java
+import org.apache.logging.log4j.LogManager;
+import org.apache.logging.log4j.Logger;
+
+public class Demo {
+ private static final Logger logger = LogManager.getLogger(Demo.class);
+ public static void main(String[] args) {
+ logger.debug("log4j2");
+ }
+}
+```
+
+运行 Demo 类,可以在控制台看到以下信息:
+
+```
+ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
+```
+
+Log4j 2 竟然没有在控制台打印“ log4j2”,还抱怨我们没有为它指定配置文件。在这一点上,我就觉得它没有 Logback 好,毕竟人家会输出。
+
+这对于新手来说,很不友好,因为新手在遇到这种情况的时候,往往不知所措。日志里面虽然体现了 ERROR,但代码并没有编译出错或者运行出错,凭什么你不输出?
+
+那作为编程老鸟来说,我得告诉你,这时候最好探究一下为什么。怎么做呢?
+
+我们可以复制一下日志信息中的关键字,比如说:“No log4j2 configuration file found”,然后在 Intellij IDEA 中搜一下,如果你下载了源码和文档的话,不除意外,你会在 ConfigurationFactory 类中搜到这段话。
+
+可以在方法中打个断点,然后 debug 一下,你就会看到下图中的内容。
+
+
+
+通过源码,你可以看得到,Log4j 2 会去寻找 4 种类型的配置文件,后缀分别是 properties、yaml、json 和 xml。前缀是 log4j2-test 或者 log4j2。
+
+得到这个提示后,就可以进行第三步了。
+
+**第三步,**在 resource 目录下增加 log4j2-test.xml 文件(方便和 Logback 做对比),内容如下所示:
+
+```xml
+
+
+
+
+
diff --git a/docs/cs/os.md b/docs/cs/os.md
new file mode 100644
index 0000000000..dc0177e843
--- /dev/null
+++ b/docs/cs/os.md
@@ -0,0 +1,1340 @@
+---
+category:
+ - 计算机基础
+tag:
+ - 操作系统
+---
+
+# 计算机操作系统知识点大梳理
+
+>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ](https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ)
+
+
+
+## 计算机结构
+
+现代计算机模型是基于-**冯诺依曼计算机模型**
+
+计算机在运行时,先从内存中取出第一条指令,通过控制器的译码,按指令的要求,从存储器中取出数据进行指定的运算和逻辑操作等加工,然后再按地址把结果送到内存中去,接下来,再取出第二条指令,在控制器的指挥下完成规定操作,依此进行下去。直至遇到停止指令
+
+程序与数据一样存贮,按程序编排的顺序,一步一步地取出指令,自动地完成指令规定的操作是计算机最基本的工作模型
+
+**计算机五大核心组成部分**
+
+控制器:是整个计算机的中枢神经,其功能是对程序规定的控制信息进行解释,根据其要求进行控制,调度程序、数据、地址,协调计算机各部分工作及内存与外设的访问等。
+
+运算器:运算器的功能是对数据进行各种算术运算和逻辑运算,即对数据进行加工处理。
+
+存储器:存储器的功能是存储程序、数据和各种信号、命令等信息,并在需要时提供这些信息。
+
+输入:输入设备是计算机的重要组成部分,输入设备与输出设备合你为外部设备,简称外设,输入设备的作用是将程序、原始数据、文字、字符、控制命令或现场采集的数据等信息输入到计算机。
+
+> 常见的输入设备有键盘、鼠标器、光电输入机、磁带机、磁盘机、光盘机等。
+
+输出:输出设备与输入设备同样是计算机的重要组成部分,它把外算机的中间结果或最后结果、机内的各种数据符号及文字或各种控制信号等信息输出出来,微机常用的输出设备有显示终端CRT、打印机、激光印字机、绘图仪及磁带、光盘机等。
+
+**计算机结构分成以下 5 个部分:**
+
+输入设备;输出设备;内存;中央处理器;总线。
+
+
+
+### 内存
+
+在冯诺依曼模型中,程序和数据被存储在一个被称作内存的线性排列存储区域。
+
+存储的数据单位是一个二进制位,英文是 bit,最小的存储单位叫作字节,也就是 8 位,英文是 byte,每一个字节都对应一个内存地址。
+
+内存地址由 0 开始编号,比如第 1 个地址是 0,第 2 个地址是 1, 然后自增排列,最后一个地址是内存中的字节数减 1。
+
+我们通常说的内存都是随机存取器,也就是读取任何一个地址数据的速度是一样的,写入任何一个地址数据的速度也是一样的。
+
+### CPU
+
+冯诺依曼模型中 CPU 负责控制和计算,为了方便计算较大的数值,CPU 每次可以计算多个字节的数据。
+
+* 如果 CPU 每次可以计算 4 个 byte,那么我们称作 32 位 CPU;
+
+* 如果 CPU 每次可以计算 8 个 byte,那么我们称作 64 位 CPU。
+
+这里的 32 和 64,称作 CPU 的位宽。
+
+**为什么 CPU 要这样设计呢?**
+
+因为一个 byte 最大的表示范围就是 0~255。
+
+比如要计算 `20000*50`,就超出了byte 最大的表示范围了。
+
+因此,CPU 需要支持多个 byte 一起计算,当然,CPU 位数越大,可以计算的数值就越大,但是在现实生活中不一定需要计算这么大的数值,比如说 32 位 CPU 能计算的最大整数是 4294967295,这已经非常大了。
+
+**控制单元和逻辑运算单元**
+
+CPU 中有一个控制单元专门负责控制 CPU 工作;还有逻辑运算单元专门负责计算。
+
+**寄存器**
+
+CPU 要进行计算,比如最简单的加和两个数字时,因为 CPU 离内存太远,所以需要一种离自己近的存储来存储将要被计算的数字。
+
+这种存储就是寄存器,寄存器就在 CPU 里,控制单元和逻辑运算单元非常近,因此速度很快。
+
+常见的寄存器种类:
+
+- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
+- 程序计数器,用来存储 CPU 要执行下一条指令所在的内存地址,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令的地址。
+- 指令寄存器,用来存放程序计数器指向的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
+
+#### 多级缓存
+
+现代CPU为了提升执行效率,减少CPU与内存的交互(交互影响CPU效率),一般在CPU上集成了多级缓存架构
+
+**CPU缓存**即高速缓冲存储器,是位于CPU与主内存间的一种容量较小但速度很高的存储器
+
+由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,减少CPU的等待时间,提高了系统的效率,具体包括以下几种:
+
+**L1-Cache**
+
+L1- 缓存在 CPU 中,相比寄存器,虽然它的位置距离 CPU 核心更远,但造价更低,通常 L1-Cache 大小在几十 Kb 到几百 Kb 不等,读写速度在 2~4 个 CPU 时钟周期。
+
+**L2-Cache**
+
+L2- 缓存也在 CPU 中,位置比 L1- 缓存距离 CPU 核心更远,它的大小比 L1-Cache 更大,具体大小要看 CPU 型号,有 2M 的,也有更小或者更大的,速度在 10~20 个 CPU 周期。
+
+**L3-Cache**
+
+L3- 缓存同样在 CPU 中,位置比 L2- 缓存距离 CPU 核心更远,大小通常比 L2-Cache 更大,读写速度在 20~60 个 CPU 周期。
+
+L3 缓存大小也是看型号的,比如 i9 CPU 有 512KB L1 Cache;有 2MB L2 Cache; 有16MB L3 Cache。
+
+
+
+当 CPU 需要内存中某个数据的时候,如果寄存器中有这个数据,我们可以直接使用;如果寄存器中没有这个数据,我们就要先查询 L1 缓存;L1 中没有,再查询 L2 缓存;L2 中没有再查询 L3 缓存;L3 中没有,再去内存中拿。
+
+
+
+
+
+**总结:**
+
+存储器存储空间大小:内存>L3>L2>L1>寄存器;
+
+存储器速度快慢排序:寄存器>L1>L2>L3>内存;
+
+#### 安全等级
+
+**CPU运行安全等级**
+
+CPU有4个运行级别,分别为:
+
+- ring0,ring1,ring2,ring3
+
+ring0只给操作系统用,ring3谁都能用。
+
+ring0是指CPU的运行级别,是最高级别,ring1次之,ring2更次之……
+
+系统(内核)的代码运行在最高运行级别ring0上,可以使用特权指令,控制中断、修改页表、访问设备等等。
+
+应用程序的代码运行在最低运行级别上ring3上,不能做受控操作。
+
+如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从ring3到ring0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从ring0返回ring3。
+
+这个过程也称作用户态和内核态的切换。
+
+#### 局部性原理
+
+在CPU访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理
+
+**时间局部性(Temporal Locality):**
+
+如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
+
+比如循环、递归、方法的反复调用等。
+
+**空间局部性(Spatial Locality):**
+
+如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。
+
+比如顺序执行的代码、连续创建的两个对象、数组等。
+
+#### 程序的执行过程
+
+程序实际上是一条一条指令,所以程序的运行过程就是把每一条指令一步一步的执行起来,负责执行指令的就是 CPU 了。
+
+**那 CPU 执行程序的过程如下:**
+
+- 第一步,CPU 读取程序计数器的值,这个值是指令的内存地址,然后 CPU 的控制单元操作地址总线指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过数据总线将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到指令寄存器。
+- 第二步,CPU 分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给逻辑运算单元运算;如果是存储类型的指令,则交由控制单元执行;
+- 第三步,CPU 执行完指令后,程序计数器的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此程序计数器的值会自增 4;
+
+简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
+
+CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 **CPU 的指令周期**。
+
+
+
+### 总线
+
+CPU 和内存以及其他设备之间,也需要通信,因此我们用一种特殊的设备进行控制,就是总线。
+
+- 地址总线,用于指定 CPU 将要操作的内存地址;
+- 数据总线,用于读写内存的数据;
+- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
+
+当 CPU 要读写内存数据的时候,一般需要通过两个总线:
+
+- 首先要通过地址总线来指定内存的地址;
+- 再通过数据总线来传输数据;
+
+### 输入、输出设备
+
+输入设备向计算机输入数据,计算机经过计算,将结果通过输出设备向外界传达。
+
+如果输入设备、输出设备想要和 CPU 进行交互,比如说用户按键需要 CPU 响应,这时候就需要用到控制总线。
+
+
+
+## 基础知识
+
+### 中断
+
+**中断的类型**
+
+* 按照中断的触发方分成同步中断和异步中断;
+
+* 根据中断是否强制触发分成可屏蔽中断和不可屏蔽中断。
+
+中断可以由 CPU 指令直接触发,这种主动触发的中断,叫作同步中断。
+
+> 同步中断有几种情况。
+
+* 比如系统调用,需要从用户态切换内核态,这种情况需要程序触发一个中断,叫作陷阱(Trap),中断触发后需要继续执行系统调用。
+
+* 还有一种同步中断情况是错误(Fault),通常是因为检测到某种错误,需要触发一个中断,中断响应结束后,会重新执行触发错误的地方,比如后面我们要学习的缺页中断。
+
+* 最后还有一种情况是程序的异常,这种情况和 Trap 类似,用于实现程序抛出的异常。
+
+另一部分中断不是由 CPU 直接触发,是因为需要响应外部的通知,比如响应键盘、鼠标等设备而触发的中断,这种中断我们称为异步中断。
+
+CPU 通常都支持设置一个中断屏蔽位(一个寄存器),设置为 1 之后 CPU 暂时就不再响应中断。
+
+对于键盘鼠标输入,比如陷阱、错误、异常等情况,会被临时屏蔽。
+
+但是对于一些特别重要的中断,比如 CPU 故障导致的掉电中断,还是会正常触发。
+
+**可以被屏蔽的中断我们称为可屏蔽中断,多数中断都是可屏蔽中断。**
+
+### 内核态和用户态
+
+**什么是用户态和内核态**
+
+Kernel 运行在超级权限模式下,所以拥有很高的权限。
+
+按照权限管理的原则,多数应用程序应该运行在最小权限下。
+
+因此,很多操作系统,将内存分成了两个区域:
+
+* 内核空间(Kernal Space),这个空间只有内核程序可以访问;
+
+* 用户空间(User Space),这部分内存专门给应用程序使用。
+
+用户空间中的代码被限制了只能使用一个局部的内存空间,我们说这些程序在用户态 执行。
+
+内核空间中的代码可以访问所有内存,我们称这些程序在内核态 执行。
+
+> 按照级别分:
+
+当程序运行在0级特权级上时,就可以称之为运行在内核态
+
+当程序运行在3级特权级上时,就可以称之为运行在用户态
+
+运行在用户态下的程序不能直接访问操作系统内核数据结构和程序。
+
+当我们在系统中执行一个程序时,大部分时间是运行在用户态下的,在其需要操作系统帮助完成某些它没有权力和能力完成的工作时就会切换到内核态(比如操作硬件)
+
+**这两种状态的主要差别**
+
+处于用户态执行时,进程所能访问的内存空间和对象受到限制,其所处于占有的处理器是可被抢占的
+
+处于内核态执行时,则能访问所有的内存空间和对象,且所占有的处理器是不允许被抢占的。
+
+**为什么要有用户态和内核态**
+
+由于需要限制不同的程序之间的访问能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,并发送到网络
+
+**用户态与内核态的切换**
+
+所有用户程序都是运行在用户态的,但是有时候程序确实需要做一些内核态的事情, 例如从硬盘读取数据,或者从键盘获取输入等,而唯一可以做这些事情的就是操作系统,所以此时程序就需要先操作系统请求以程序的名义来执行这些操作
+
+**用户态和内核态的转换**
+
+> 系统调用
+
+用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如fork()实际上就是执行了一个创建新进程的系统调用
+
+而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断
+
+**举例:**
+
+
+
+如上图所示:内核程序执行在内核态(Kernal Mode),用户程序执行在用户态(User Mode)。
+
+当发生系统调用时,用户态的程序发起系统调用,因为系统调用中牵扯特权指令,用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
+
+发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序,内核程序开始执行,也就是开始处理系统调用。
+
+内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。
+
+> 异常
+
+当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常
+
+> 外围设备的中断
+
+当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换
+
+比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等
+
+
+
+## 线程
+
+线程:系统分配处理器时间资源的基本单元,是程序执行的最小单位
+
+线程可以看做轻量级的进程,共享内存空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
+
+在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
+
+进程可以通过 API 创建用户态的线程,也可以通过系统调用创建内核态的线程。
+
+### 用户态线程
+
+用户态线程也称作用户级线程,操作系统内核并不知道它的存在,它完全是在用户空间中创建。
+
+用户级线程有很多优势,比如:
+
+* 管理开销小:创建、销毁不需要系统调用。
+
+* 切换成本低:用户空间程序可以自己维护,不需要走操作系统调度。
+
+但是这种线程也有很多的缺点:
+
+* 与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行 I/O 的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
+
+* 线程间协作成本高:设想两个线程需要通信,通信需要 I/O,I/O 需要系统调用,因此用户态线程需要额外的系统调用成本。
+
+* 无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
+
+操作系统无法针对线程调度进行优化:当一个进程的一个用户态线程阻塞(Block)了,操作系统无法及时发现和处理阻塞问题,它不会更换执行其他线程,从而造成资源浪费。
+
+### 内核态线程
+
+内核态线程也称作内核级线程(Kernel Level Thread),这种线程执行在内核态,可以通过系统调用创造一个内核级线程。
+
+内核级线程有很多优势:
+
+* 可以利用多核 CPU 优势:内核拥有较高权限,因此可以在多个 CPU 核心上执行内核线程。
+
+* 操作系统级优化:内核中的线程操作 I/O 不需要进行系统调用;一个内核线程阻塞了,可以立即让另一个执行。
+
+当然内核线程也有一些缺点:
+
+* 创建成本高:创建的时候需要系统调用,也就是切换到内核态。
+
+* 扩展性差:由一个内核程序管理,不可能数量太多。
+
+* 切换成本较高:切换的时候,也同样存在需要内核操作,需要切换内核态。
+
+**用户态线程和内核态线程之间的映射关系**
+
+如果有一个用户态的进程,它下面有多个线程,如果这个进程想要执行下面的某一个线程,应该如何做呢?
+
+> 这时,比较常见的一种方式,就是将需要执行的程序,让一个内核线程去执行。
+
+毕竟,内核线程是真正的线程,因为它会分配到 CPU 的执行资源。
+
+如果一个进程所有的线程都要自己调度,相当于在进程的主线程中实现分时算法调度每一个线程,也就是所有线程都用操作系统分配给主线程的时间片段执行。
+
+> 这种做法,相当于操作系统调度进程的主线程;进程的主线程进行二级调度,调度自己内部的线程。
+
+这样操作劣势非常明显,比如无法利用多核优势,每个线程调度分配到的时间较少,而且这种线程在阻塞场景下会直接交出整个进程的执行权限。
+
+由此可见,用户态线程创建成本低,问题明显,不可以利用多核。
+
+内核态线程,创建成本高,可以利用多核,切换速度慢。
+
+因此通常我们会在内核中预先创建一些线程,并反复利用这些线程。
+
+### 协程
+
+
+
+协程,是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
+
+这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
+
+**子程序**
+
+或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。
+
+所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。
+
+子程序调用总是一个入口,一次返回,调用顺序是明确的。
+
+**协程的特点在于是一个线程执行,那和多线程比,协程有何优势?**
+
+* 极高的执行效率:因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显;
+* 不需要多线程的锁机制:因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
+
+### 线程安全
+
+如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。
+
+如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
+
+
+
+## 进程
+
+在系统中正在运行的一个应用程序;程序一旦运行就是进程;是资源分配的最小单位。
+
+在操作系统中能同时运行多个进程;
+
+开机的时候,磁盘的内核镜像被导入内存作为一个执行副本,成为内核进程。
+
+进程可以分成**用户态进程和内核态进程**两类,用户态进程通常是应用程序的副本,内核态进程就是内核本身的进程。
+
+如果用户态进程需要申请资源,比如内存,可以通过系统调用向内核申请。
+
+每个进程都有独立的内存空间,存放代码和数据段等,程序之间的切换会有较大的开销;
+
+**分时和调度**
+
+每个进程在执行时都会获得操作系统分配的一个时间片段,如果超出这个时间,就会轮到下一个进程(线程)执行。
+
+> 注意,现代操作系统都是直接调度线程,不会调度进程。
+
+**分配时间片段**
+
+如下图所示,进程 1 需要 2 个时间片段,进程 2 只有 1 个时间片段,进程 3 需要 3 个时间片段。
+
+因此当进程 1 执行到一半时,会先挂起,然后进程 2 开始执行;进程 2 一次可以执行完,然后进程 3 开始执行,不过进程 3 一次执行不完,在执行了 1 个时间片段后,进程 1 开始执行;就这样如此周而复始,这个就是分时技术。
+
+
+
+### 创建进程
+
+用户想要创建一个进程,最直接的方法就是从命令行执行一个程序,或者双击打开一个应用,但对于程序员而言,显然需要更好的设计。
+
+首先,应该有 API 打开应用,比如可以通过函数打开某个应用;
+
+另一方面,如果程序员希望执行完一段代价昂贵的初始化过程后,将当前程序的状态复制好几份,变成一个个单独执行的进程,那么操作系统提供了 fork 指令。
+
+
+
+也就是说,每次 fork 会多创造一个克隆的进程,这个克隆的进程,所有状态都和原来的进程一样,但是会有自己的地址空间。
+
+如果要创造 2 个克隆进程,就要 fork 两次。
+
+> 那如果我就是想启动一个新的程序呢?
+
+操作系统提供了启动新程序的 API。
+
+如果我就是想用一个新进程执行一小段程序,比如说每次服务端收到客户端的请求时,我都想用一个进程去处理这个请求。
+
+如果是这种情况,建议你不要单独启动进程,而是使用线程。
+
+因为进程的创建成本实在太高了,因此不建议用来做这样的事情:要创建条目、要分配内存,特别是还要在内存中形成一个个段,分成不同的区域。所以通常,我们更倾向于多创建线程。
+
+不同程序语言会自己提供创建线程的 API,比如 Java 有 Thread 类;go 有 go-routine(注意不是协程,是线程)。
+
+### 进程状态
+
+
+
+**创建状态**
+
+进程由创建而产生,创建进程是一个非常复杂的过程,一般需要通过多个步骤才能完成:如首先由进程申请一个空白的进程控制块(PCB),并向PCB中填写用于控制和管理进程的信息;然后为该进程分配运行时所必须的资源;最后,把该进程转入就绪状态并插入到就绪队列中
+
+**就绪状态**
+
+这是指进程已经准备好运行的状态,即进程已分配到除CPU以外所有的必要资源后,只要再获得CPU,便可立即执行,如果系统中有许多处于就绪状态的进程,通常将它们按照一定的策略排成一个队列,该队列称为就绪队列,有执行资格,没有执行权的进程
+
+**运行状态**
+
+这里指进程已经获取CPU,其进程处于正在执行的状态。对任何一个时刻而言,在单处理机的系统中,只有一个进程处于执行状态而在多处理机系统中,有多个进程处于执行状态,既有执行资格,又有执行权的进程
+
+**阻塞状态**
+
+这里是指正在执行的进程由于发生某事件(如I/O请求、申请缓冲区失败等)暂时无法继续执行的状态,即进程执行受到阻塞,此时引起进程调度,操作系统把处理机分配给另外一个就绪的进程,而让受阻的进程处于暂停的状态,一般将这个暂停状态称为阻塞状态
+
+**终止状态**
+
+### 进程间通信IPC
+
+每个进程各自有不同的用户地址空间,任何一个进程的全局变量在另一个进程中都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,内核提供的这种机制称为进程间通信
+
+**管道/匿名管道**
+
+管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
+
+* 只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
+
+* 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
+
+* 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出,写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
+
+**有名管道(FIFO)**
+
+匿名管道,由于没有名字,只能用于亲缘关系的进程间通信。
+
+为了克服这个缺点,提出了有名管道(FIFO)。
+
+有名管道不同于匿名管道之处在于它提供了一个路径名与之关联,以有名管道的文件形式存在于文件系统中,这样,即使与有名管道的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过有名管道相互通信,因此,通过有名管道不相关的进程也能交换数据。
+
+**信号**
+
+信号是Linux系统中用于进程间互相通信或者操作的一种机制,信号可以在任何时候发给某一进程,而无需知道该进程的状态。
+
+如果该进程当前并未处于执行状态,则该信号就有内核保存起来,知道该进程回复执行并传递给它为止。
+
+如果一个信号被进程设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消是才被传递给进程。
+
+**消息队列**
+
+消息队列是存放在内核中的消息链表,每个消息队列由消息队列标识符表示。
+
+与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即操作系统重启)或者显示地删除一个消息队列时,该消息队列才会被真正的删除。
+
+另外与管道不同的是,消息队列在某个进程往一个队列写入消息之前,并不需要另外某个进程在该队列上等待消息的到达
+
+**共享内存**
+
+使得多个进程可以直接读写同一块内存空间,是最快的可用IPC形式,是针对其他通信机制运行效率较低而设计的。
+
+为了在多个进程间交换信息,内核专门留出了一块内存区,可以由需要访问的进程将其映射到自己的私有地址空间,进程就可以直接读写这一块内存而不需要进行数据的拷贝,从而大大提高效率。
+
+由于多个进程共享一段内存,因此需要依靠某种同步机制(如信号量)来达到进程间的同步及互斥。
+
+共享内存示意图:
+
+
+
+一旦这样的内存映射到共享它的进程的地址空间,这些进程间数据传递不再涉及到内核,换句话说是进程不再通过执行进入内核的系统调用来传递彼此的数据。
+
+**信号量**
+
+信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。
+
+为了获得共享资源,进程需要执行下列操作:
+
+1. 创建一个信号量:这要求调用者指定初始值,对于二值信号量来说,它通常是1,也可是0。
+
+2. 等待一个信号量:该操作会测试这个信号量的值,如果小于0,就阻塞,也称为P操作。
+3. 挂出一个信号量:该操作将信号量的值加1,也称为V操作。
+
+**套接字(Socket)**
+
+套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。
+
+### 信号
+
+信号是进程间通信机制中唯一的异步通信机制,可以看作是异步通知,通知接收信号的进程有哪些事情发生了。
+
+也可以简单理解为信号是某种形式上的软中断
+
+可运行`kill -l`查看Linux支持的信号列表:
+
+```
+kill -l
+ 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
+ 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
+11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
+16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
+21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
+26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
+31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
+38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
+43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
+48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
+53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
+58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
+63) SIGRTMAX-1 64) SIGRTMAX
+```
+
+**几个常用的信号:**
+
+| 信号 | 描述 |
+| ------- | ------------------------------------------------------------ |
+| SIGHUP | 当用户退出终端时,由该终端开启的所有进程都会接收到这个信号,默认动作为终止进程。 |
+| SIGINT | 程序终止(interrupt)信号, 在用户键入INTR字符(通常是`Ctrl+C`)时发出,用于通知前台进程组终止进程。 |
+| SIGQUIT | 和`SIGINT`类似, 但由QUIT字符(通常是`Ctrl+\`)来控制,进程在因收到`SIGQUIT`退出时会产生`core`文件, 在这个意义上类似于一个程序错误信号。 |
+| SIGKILL | 用来立即结束程序的运行,本信号不能被阻塞、处理和忽略。 |
+| SIGTERM | 程序结束(terminate)信号, 与`SIGKILL`不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出。 |
+| SIGSTOP | 停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行,本信号不能被阻塞, 处理或忽略 |
+
+### 进程同步
+
+**临界区**
+
+通过对多线程的串行化来访问公共资源或一段代码,速度快,适合控制数据访问
+
+优点:保证在某一时刻只有一个线程能访问数据的简便办法
+
+缺点:虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程
+
+**互斥量**
+
+为协调共同对一个共享资源的单独访问而设计的
+
+互斥量跟临界区很相似,比临界区复杂,互斥对象只有一个,只有拥有互斥对象的线程才具有访问资源的权限
+
+优点:使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对资源的安全共享
+
+**信号量**
+
+为控制一个具有有限数量用户资源而设计,它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目,互斥量是信号量的一种特殊情况,当信号量的最大资源数=1就是互斥量了
+
+信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作
+
+- **down** : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
+- **up** :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
+
+down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
+
+如果信号量的取值只能为 0 或者 1,那么就成为了 **互斥量(Mutex)** ,0 表示临界区已经加锁,1 表示临界区解锁。
+
+**事件**
+
+用来通知线程有一些事件已发生,从而启动后继任务的开始
+
+优点:事件对象通过通知操作的方式来保持线程的同步,并且可以实现不同进程中的线程同步操作
+
+**管程**
+
+管程有一个重要特性:在一个时刻只能有一个进程使用管程。
+
+进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
+
+管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。
+
+对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。
+
+signal() 操作用于唤醒被阻塞的进程。
+
+使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
+
+### 上下文切换
+
+对于单核单线程CPU而言,在某一时刻只能执行一条CPU指令。
+
+上下文切换(Context Switch)是一种将CPU资源从一个进程分配给另一个进程的机制。
+
+从用户角度看,计算机能够并行运行多个进程,这恰恰是操作系统通过快速上下文切换造成的结果。
+
+**在切换的过程中,操作系统需要先存储当前进程的状态(包括内存空间的指针,当前执行完的指令等等),再读入下一个进程的状态,然后执行此进程。**
+
+### 进程调度算法
+
+**先来先服务调度算法**
+
+该算法既可用于作业调度,也可用于进程调度,当在作业调度中采用该算法时,每次调度都是从后备作业队列中选择一个或多个最先进入该队列的作业,将它们调入内存,为它们分配资源、创建进程,然后放入就绪队列
+
+**短作业优先调度算法**
+
+从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行
+
+**时间片轮转法**
+
+每次调度时,把CPU分配给队首进程,并令其执行一个时间片,时间片的大小从几ms到几百ms,当执行的时间片用完时,由一个计时器发出时钟中断请求,调度程序便据此信号来停止该进程的执行,并将它送往就绪队列的末尾
+
+然后,再把处理机分配给就绪队列中新的队首进程,同时也让它执行一个时间片,这样就可以保证就绪队列中的所有进程在一给定的时间内均能获得一时间片的处理机执行时间
+
+**最短剩余时间优先**
+
+最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度,当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。
+
+如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
+
+**多级反馈队列调度算法**:
+
+前面介绍的几种进程调度的算法都有一定的局限性,如**短进程优先的调度算法,仅照顾了短进程而忽略了长进程**,多级反馈队列调度算法既能使高优先级的作业得到响应又能使短作业迅速完成,因而它是目前**被公认的一种较好的进程调度算法**,UNIX 操作系统采取的便是这种调度算法。
+
+> 举例:
+
+多级队列,就是多个队列执行调度,先考虑最简单的两级模型
+
+
+
+上图中设计了两个优先级不同的队列,从下到上优先级上升,上层队列调度紧急任务,下层队列调度普通任务。
+
+只要上层队列有任务,下层队列就会让出执行权限。
+
+低优先级队列可以考虑抢占 + 优先级队列的方式实现,这样每次执行一个时间片段就可以判断一下高优先级的队列中是否有任务。
+
+高优先级队列可以考虑用非抢占(每个任务执行完才执行下一个)+ 优先级队列实现,这样紧急任务优先级有个区分,如果遇到十万火急的情况,就可以优先处理这个任务。
+
+上面这个模型虽然解决了任务间的优先级问题,但是还是没有解决短任务先行的问题,可以考虑再增加一些队列,让级别更多。
+
+> 比如下图这个模型:
+
+
+
+紧急任务仍然走高优队列,非抢占执行。
+
+普通任务先放到优先级仅次于高优任务的队列中,并且只分配很小的时间片;如果没有执行完成,说明任务不是很短,就将任务下调一层。
+
+下面一层,最低优先级的队列中时间片很大,长任务就有更大的时间片可以用。
+
+通过这种方式,短任务会在更高优先级的队列中执行完成,长任务优先级会下调,也就类似实现了最短作业优先的问题。
+
+实际操作中,可以有 n 层,一层层把大任务筛选出来,最长的任务,放到最闲的时间去执行,要知道,大部分时间 CPU 不是满负荷的。
+
+**优先级调度**
+
+为每个流程分配优先级,首先执行具有最高优先级的进程,依此类推,具有相同优先级的进程以 FCFS 方式执行,可以根据内存要求,时间要求或任何其他资源要求来确定优先级。
+
+### 守护进程
+
+守护进程是脱离于终端并且在后台运行的进程,脱离终端是为了避免在执行的过程中的信息在终端上显示,并且进程也不会被任何终端所产生的终端信息所打断。
+
+守护进程一般的生命周期是系统启动到系统停止运行。
+
+Linux系统中有很多的守护进程,最典型的就是我们经常看到的服务进程。
+
+当然,我们也经常会利用守护进程来完成很多的系统或者自动化任务。
+
+### 孤儿进程
+
+父进程早于子进程退出时候子进程还在运行,子进程会成为孤儿进程,Linux会对孤儿进程的处理,把孤儿进程的父进程设为进程号为1的进程,也就是由init进程来托管,init进程负责子进程退出后的善后清理工作
+
+### 僵尸进程
+
+子进程执行完毕时发现父进程未退出,会向父进程发送 SIGCHLD 信号,但父进程没有使用 wait/waitpid 或其他方式处理 SIGCHLD 信号来回收子进程,子进程变成为了对系统有害的僵尸进程
+
+子进程退出后留下的进程信息没有被收集,会导致占用的进程控制块PCB不被释放,形成僵尸进程,进程已经死去,但是进程资源没有被释放掉
+
+**问题及危害**
+
+如果系统中存在大量的僵尸进程,他们的进程号就会一直被占用,但是系统所能使用的进程号是有限的,系统将因为没有可用的进程号而导致系统不能产生新的进程
+
+任何一个子进程(init除外)在exit()之后,并非马上就消失掉,而是留下一个称为僵尸进程(Zombie)的数据结构,等待父进程处理,这是每个子进程在结束时都要经过的阶段,如果子进程在exit()之后,父进程没有来得及处理,这时用ps命令就能看到子进程的状态是Z。
+
+如果父进程能及时处理,可能用ps命令就来不及看到子进程的僵尸状态,但这并不等于子进程不经过僵尸状态
+
+产生僵尸进程的元凶其实是他们的父进程,杀掉父进程,僵尸进程就变为了孤儿进程,便可以转交给 init 进程回收处理
+
+### 死锁
+
+**产生原因**
+
+系统资源的竞争:系统资源的竞争导致系统资源不足,以及资源分配不当,导致死锁。
+
+进程运行推进顺序不合适:进程在运行过程中,请求和释放资源的顺序不当,会导致死锁。
+
+**发生死锁的四个必要条件**
+
+互斥条件:一个资源每次只能被一个进程使用,即在一段时间内某资源仅为一个进程所占有,此时若有其他进程请求该资源,则请求进程只能等待
+
+请求与保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求时,该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放
+
+不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)
+
+循环等待条件: 若干进程间形成首尾相接循环等待资源的关系
+
+这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁
+
+**只要我们破坏其中一个,就可以成功避免死锁的发生**
+
+其中,互斥这个条件我们没有办法破坏,因为我们用锁为的就是互斥
+
+1. 对于占用且等待这个条件,我们可以一次性申请所有的资源,这样就不存在等待了。
+2. 对于不可抢占这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
+3. 对于循环等待这个条件,可以靠按序申请资源来预防,所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后自然就不存在循环了。
+
+**处理方法**
+
+主要有以下四种方法:
+
+- 鸵鸟策略
+- 死锁检测与死锁恢复
+- 死锁预防,破坏4个必要条件
+- 死锁避免,银行家算法
+
+**鸵鸟策略**
+
+把头埋在沙子里,假装根本没发生问题。
+
+因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
+
+当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
+
+**死锁检测**
+
+不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
+
+1. 每种类型一个资源的死锁检测
+
+2. 每种类型多个资源的死锁检测
+
+**死锁恢复**
+
+- 利用抢占恢复
+- 利用回滚恢复
+- 通过杀死进程恢复
+
+#### 哲学家进餐问题
+
+五个哲学家围着一张圆桌,每个哲学家面前放着食物。
+
+哲学家的生活有两种交替活动:吃饭以及思考。
+
+当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
+
+如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
+
+哲学家进餐问题可看作是并发进程并发执行时处理共享资源的一个有代表性的问题。
+
+**为了防止死锁的发生,可以设置两个条件:**
+
+- 必须同时拿起左右两根筷子;
+- 只有在两个邻居都没有进餐的情况下才允许进餐。
+
+#### 银行家算法
+
+银行家算法的命名是它可以用了银行系统,当不能满足所有客户的需求时,银行绝不会分配其资金。
+
+当新进程进入系统时,它必须说明其可能需要的每种类型资源实例的最大数量这一数量不可以超过系统资源的总和。
+
+当用户申请一组资源时,系统必须确定这些资源的分配是否处于安全状态,如何安全,则分配,如果不安全,那么进程必须等待指导某个其他进程释放足够资源为止。
+
+**安全状态**
+
+在避免死锁的方法中,允许进程动态地申请资源,但系统在进行资源分配之前,应先计算此次资源分配的安全性,若此次分配不会导致系统进入不安全状态,则将资源分配给进程;否则,令进程等待
+
+因此,避免死锁的实质在于:系统在进行资源分配时,如何使系统不进入不安全状态
+
+### Fork函数
+
+`fork`函数用于创建一个与当前进程一样的子进程,所创建的子进程将复制父进程的代码段、数据段、BSS段、堆、栈等所有用户空间信息,在内核中操作系统会重新为其申请一个子进程执行的位置。
+
+`fork`系统调用会通过复制一个现有进程来创建一个全新的进程,新进程被存放在一个叫做任务队列的双向循环链表中,链表中的每一项都是类型为`task_struct`的进程控制块`PCB`的结构。
+
+
+
+每个进程都由独特换不相同的进程标识符(PID),通过`getpid()`函数可获取当前进程的进程标识符,通过`getppid()`函数可获得父进程的进程标识符。
+
+一个现有的进程可通过调用`fork`函数创建一个新进程,由`fork`创建的新进程称为子进程`child process`,`fork`函数被调用一次但返回两次,两次返回的唯一区别是子进程中返回0而父进程中返回子进程ID。
+
+**为什么`fork`会返回两次呢?**
+
+因为复制时会复制父进程的堆栈段,所以两个进程都停留在`fork`函数中等待返回,因此会返回两次,一个是在父进程中返回,一次是在子进程中返回,两次返回值是不一样的。
+
+- 在父进程中将返回新建子进程的进程ID
+- 在子进程中将返回0
+- 若出现错误则返回一个负数
+
+因此可以通过`fork`的返回值来判断当前进程是子进程还是父进程。
+
+**fork执行执行流程**
+
+当进程调用`fork`后控制转入内核,内核将会做4件事儿:
+
+1. 分配新的内存块和内核数据结构给子进程
+2. 将父进程部分数据结构内容(数据空间、堆栈等)拷贝到子进程
+3. 添加子进程到系统进程列表中
+4. `fork`返回开始调度器调度
+
+**为什么`pid`在父子进程中不同呢?**
+
+其实就相当于链表,进程形成了链表,父进程的`pid`指向子进程的进程ID,因此子进程没有子进程,所以PID为0,这里的`pid`相当于链表中的指针。
+
+## 设备管理
+
+### 磁盘调度算法
+
+读写一个磁盘块的时间的影响因素有:
+
+- 旋转时间
+- 寻道时间实际的数据传输时间
+
+其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
+
+> 先来先服务 FCFS, First Come First Served
+
+按照磁盘请求的顺序进行调度,优点是公平和简单,缺点也很明显,因为未对寻道做任何优化,使平均寻道时间可能较长。
+
+> 最短寻道时间优先,SSTF, Shortest Seek Time First
+
+优先调度与当前磁头所在磁道距离最近的磁道, 虽然平均寻道时间比较低,但是不够公平,如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的 磁道请求会一直等待下去,也就是出现饥饿现象,具体来说,两边的磁道请求更容易出现饥饿现象。
+
+> 电梯算法,SCAN
+
+电梯总是保持一个方向运行,直到该方向没有请求为止,然后改变运行方向, 电梯算法(扫描算法)和电梯的运行过程类似,总是按一个方向来进行磁盘调度,直到该方向上没有未完成的磁盘 请求,然后改变方向,因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题
+
+
+
+## 内存管理
+
+**逻辑地址和物理地址**
+
+我们编程一般只有可能和逻辑地址打交道,比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的逻辑地址,逻辑地址由操作系统决定。
+
+物理地址指的是真实物理内存中地址,更具体一点来说就是内存地址寄存器中的地址,物理地址是内存单元真正的地址。
+
+编译时只需确定变量x存放的相对地址是100 ( 也就是说相对于进程在内存中的起始地址而言的地址)。
+
+CPU想要找到x在内存中的实际存放位置,只需要用进程的起始地址+100即可。
+
+相对地址又称逻辑地址,绝对地址又称物理地址。
+
+**内存管理有哪几种方式**
+
+1. **块式管理**:将内存分为几个固定大小的块,每个块中只包含一个进程,如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了,这些在每个块中未被利用的空间,我们称之为碎片。
+2. **页式管理**:把主存分为大小相等且固定的一页一页的形式,页较小,相对相比于块式管理的划分力度更大,提高了内存利用率,减少了碎片,页式管理通过页表对应逻辑地址和物理地址。
+
+
+
+1. **段式管理**: 页式管理虽然提高了内存利用率,但是页式管理其中的页实际并无任何实际意义, 段式管理把主存分为一段段的,每一段的空间又要比一页的空间小很多 ,段式管理通过段表对应逻辑地址和物理地址。
+2. **段页式管理机制:**段页式管理机制结合了段式管理和页式管理的优点,简单来说段页式管理机制就是把主存先分成若干段,每个段又分成若干页,也就是说**段页式管理机制**中段与段之间以及段的内部的都是离散的。
+
+
+
+### 虚拟地址
+
+现代处理器使用的是一种称为**虚拟寻址(Virtual Addressing)**的寻址方式
+
+**使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。**
+
+实际上完成虚拟地址转换为物理地址转换的硬件是 CPU 中含有一个被称为**内存管理单元(Memory Management Unit, MMU)**的硬件
+
+
+
+**为什么要有虚拟地址空间**
+
+没有虚拟地址空间的时候,**程序都是直接访问和操作的都是物理内存**。
+
+但是这样有什么问题?
+
+1. 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易破坏操作系统,造成操作系统崩溃。
+2. 想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行,为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
+
+**通过虚拟地址访问内存有以下优势:**
+
+- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
+- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。
+- 不同进程使用的虚拟地址彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+
+**MMU如何把虚拟地址翻译成物理地址的**
+
+对于每个程序,内存管理单元MMU都为其保存一个页表,该页表中存放的是虚拟页面到物理页面的映射。
+
+每当为一个虚拟页面寻找到一个物理页面之后,就在页表里增加一条记录来保留该映射关系,当然,随着虚拟页面进出物理内存,页表的内容也会不断更新变化。
+
+
+
+### 虚拟内存
+
+很多时候我们使用点开了很多占内存的软件,这些软件占用的内存可能已经远远超出了我们电脑本身具有的物理内存
+
+通过 **虚拟内存** 可以让程序可以拥有超过系统物理内存大小的可用内存空间。
+
+另外,虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间),这样会更加有效地管理内存并减少出错。
+
+**虚拟内存**是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存
+
+**虚拟内存的重要意义是它定义了一个连续的虚拟地址空间**,并且 **把内存扩展到硬盘空间**
+
+**虚拟内存的实现有以下三种方式:**
+
+1. **请求分页存储管理** :请求分页是目前最常用的一种实现虚拟存储器的方法,请求分页存储管理系统中,在作业开始运行之前,仅装入当前要执行的部分段即可运行,假如在作业运行的过程中发现要访问的页面不在内存,则由处理器通知操作系统按照对应的页面置换算法将相应的页面调入到主存,同时操作系统也可以将暂时不用的页面置换到外存中。
+2. **请求分段存储管理** :请求分段储存管理方式就如同请求分页储存管理方式一样,在作业开始运行之前,仅装入当前要执行的部分段即可运行;在执行过程中,可使用请求调入中断动态装入要访问但又不在内存的程序段;当内存空间已满,而又需要装入新的段时,根据置换功能适当调出某个段,以便腾出空间而装入新的段。
+3. **请求段页式存储管理**
+
+不管是上面那种实现方式,我们一般都需要:
+
+> 一定容量的内存和外存:在载入程序的时候,只需要将程序的一部分装入内存,而将其他部分留在外存,然后程序就可以执行了;
+
+
+
+
+
+### 缺页中断
+
+如果**需执行的指令或访问的数据尚未在内存**(称为缺页或缺段),则由处理器通知操作系统将相应的页面或段**调入到内存**,然后继续执行程序;
+
+在分页系统中,一个虚拟页面既有可能在物理内存,也有可能保存在磁盘上。
+
+如果CPU发出的虚拟地址对应的页面不在物理内存,就将产生一个缺页中断,而缺页中断服务程序负责将需要的虚拟页面找到并加载到内存。
+
+缺页中断的处理步骤如下,省略了中间很多的步骤,只保留最核心的几个步骤:
+
+
+
+### 页面置换算法
+
+当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。
+
+用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则
+
+- **OPT 页面置换算法(最佳页面置换算法)** :该置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率,但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,一般作为衡量其他置换算法的方法。
+- **FIFO(First In First Out) 页面置换算法(先进先出页面置换算法)** : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
+
+- **LRU (Least Currently Used)页面置换算法(最近最久未使用页面置换算法)** :LRU算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
+- **LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法)** : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
+
+### 局部性原理
+
+局部性原理是虚拟内存技术的基础,正是因为程序运行具有局部性原理,才可以只装入部分程序到内存就开始运行。
+
+局部性原理表现在以下两个方面:
+
+1. **时间局部性** :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问,产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
+2. **空间局部性** :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
+
+时间局部性是通过将近来使用的指令和数据保存到**高速缓存存储器**中,并使用高速缓存的层次结构实现。
+
+空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。
+
+### 页表
+
+操作系统将虚拟内存分块,每个小块称为一个页(Page);真实内存也需要分块,每个小块我们称为一个 Frame。
+
+Page 到 Frame 的映射,需要一种叫作页表的结构。
+
+
+
+上图展示了 Page、Frame 和页表 (PageTable)三者之间的关系。
+
+Page 大小和 Frame 大小通常相等,页表中记录的某个 Page 对应的 Frame 编号。
+
+页表也需要存储空间,比如虚拟内存大小为 10G, Page 大小是 4K,那么需要 10G/4K = 2621440 个条目。
+
+如果每个条目是 64bit,那么一共需要 20480K = 20M 页表,操作系统在内存中划分出小块区域给页表,并负责维护页表。
+
+**页表维护了虚拟地址到真实地址的映射。**
+
+每次程序使用内存时,需要把虚拟内存地址换算成物理内存地址,换算过程分为以下 3 个步骤:
+
+* 通过虚拟地址计算 Page 编号;
+
+* 查页表,根据 Page 编号,找到 Frame 编号;
+
+* 将虚拟地址换算成物理地址。
+
+#### 多级页表
+
+引入多级页表的主要目的是为了避免把全部页表一直放在内存中占用过多空间,特别是那些根本就不需要的页表就不需要保留在内存中
+
+**一级页表:**
+
+假如物理内存中一共有1048576个页,那么页表就需要总共就是`1048576 * 4B = 4M`。
+
+也就是说我需要4M连续的内存来存放这个页表,也就是一级页表。
+
+随着虚拟地址空间的增大,存放页表所需要的连续空间也会增大,在操作系统内存紧张或者内存碎片较多时,这无疑会带来额外的开销。
+
+页表寻址是用寄存器来确定一级页表地址的,所以一级页表的地址必须指向确定的物理页,否则就会出现错误,所以如果用一级页表的话,就必须把全部的页表都加载进去。
+
+**二级页表:**
+
+而使用二级页表的话,只需要加载一个页目录表(一级页表),大小为4K,可以管理1024个二级页表。
+
+可能你会有疑问,这1024个二级页表也是需要内存空间的,这下反而需要4MB+4KB的内存,反而更多了。
+
+其实二级页表并不是一定要存在内存中的,内存中只需要一个一级页表地址存在存器即可,二级页表可以使用缺页中断从外存移入内存。
+
+**多级页表属于时间换空间的典型场景**
+
+### 快表
+
+为了解决虚拟地址到物理地址的转换速度,操作系统在**页表方案**基础之上引入了**快表**来加速虚拟地址到物理地址的转换
+
+我们可以把快表理解为一种特殊的**高速缓冲存储器(Cache)**,其中的内容是页表的一部分或者全部内容,作为页表的 Cache,它的作用与页表相似,但是提高了访问速率,由于采用页表做地址转换,读写内存数据时 CPU 要访问两次主存,有了快表,有时只要访问一次高速缓冲存储器,一次主存,这样可加速查找并提高指令执行速度。
+
+**使用快表之后的地址转换流程是这样的:**
+
+1. 根据虚拟地址中的页号查快表;
+2. 如果该页在快表中,直接从快表中读取相应的物理地址;
+3. 如果该页不在快表中,就访问内存中的页表,再从页表中得到物理地址,同时将页表中的该映射表项添加到快表中;
+4. 当快表填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
+
+
+
+### 内存管理单元
+
+在 CPU 中一个小型的设备——内存管理单元(MMU)
+
+
+
+当 CPU 需要执行一条指令时,如果指令中涉及内存读写操作,CPU 会把虚拟地址给 MMU,MMU 自动完成虚拟地址到真实地址的计算;然后,MMU 连接了地址总线,帮助 CPU 操作真实地址。
+
+在不同 CPU 的 MMU 可能是不同的,因此这里会遇到很多跨平台的问题。
+
+解决跨平台问题不但有繁重的工作量,更需要高超的编程技巧。
+
+### 动态分区分配算法
+
+内存分配算法,大体来说分为:**连续式分配 与 非连续式分配**
+
+连续式分配就是把所以要执行的程序 **完整的,有序的** 存入内存,连续式分配又可以分为**固定分区分配 和 动态分区分配**
+
+非连续式分配就是把要执行的程序按照一定规则进行拆分,显然这样更有效率,现在的操作系统通常也都是采用这种方式分配内存
+
+所谓动态分区分配,就是指**内存在初始时不会划分区域,而是会在进程装入时,根据所要装入的进程大小动态地对内存空间进行划分,以提高内存空间利用率,降低碎片的大小**
+
+动态分区分配算法有以下四种:
+
+> 首次适应算法(First Fit)
+
+空闲分区以地址递增的次序链接,分配内存时顺序查找,找到大小满足要求的第一个空闲分区就进行分配
+
+
+
+又称循环首次适应法,由首次适应法演变而成,不同之处是分配内存时从上一次查找结束的位置开始继续查找
+
+
+
+> 最佳适应算法(Best Fit)
+
+空闲分区按容量递增形成分区链,找到第一个能满足要求的空闲分区就进行分配
+
+
+
+又称最大适应算法,空闲分区以容量递减的次序链接,找到第一个能满足要求的空闲分区(也就是最大的分区)就进行分配
+
+
+
+**总结**
+
+首次适应不仅最简单,通常也是最好最快,不过首次适应算法会使得内存低地址部分出现很多小的空闲分区,而每次查找都要经过这些分区,因此也增加了查找的开销。
+
+邻近算法试图解决这个问题,但实际上,它常常会导致在内存的末尾分配空间分裂成小的碎片,它通常比首次适应算法结果要差。
+
+最佳适应算法导致大量碎片,最坏适应算法导致没有大的空间。
+
+### 内存覆盖
+
+覆盖与交换技术是在程序用来扩充内存的两种方法。
+
+早期的计算机系统中,主存容量很小,虽然主存中仅存放一道用户程序,但是存储空间放不下用户进程的现象也经常发生,这一矛盾可以用覆盖技术来解决。
+
+**覆盖的基本思想是:**
+
+由于程序运行时并非任何时候都要访问程序及数据的各个部分(尤其是大程序),因此可以把用户空间分成一个固定区和若干个覆盖区。
+
+将经常活跃的部分放在固定区,其余部分按调用关系分段。
+
+首先将那些即将要访问的段放入覆盖区,其他段放在外存中,在需要调用前,系统再将其调入覆盖区,替换覆盖区中原有的段。
+
+覆盖技术的特点是打破了必须将一个进程的全部信息装入主存后才能运行的限制,但当同时运行程序的代码量大于主存时仍不能运行。
+
+### 内存交换
+
+**交换的基本思想**
+
+把处于等待状态(或在CPU调度原则下被剥夺运行权利)的程序从内存移到辅存,把内存空间腾出来,这一过程又叫换出;
+
+把准备好竞争CPU运行的程序从辅存移到内存,这一过程又称为换入。
+
+> 例如,有一个CPU釆用时间片轮转调度算法的多道程序环境。
+
+时间片到,内存管理器将刚刚执行过的进程换出,将另一进程换入到刚刚释放的内存空间中。
+
+同时,CPU调度器可以将时间片分配给其他已在内存中的进程。
+
+每个进程用完时间片都与另一进程交换。
+
+理想情况下,内存管理器的交换过程速度足够快,总有进程在内存中可以执行。
+
+> 交换技术主要是在不同进程(或作业)之间进行,而覆盖则用于同一个程序或进程中。
+
+由于覆盖技术要求给出程序段之间的覆盖结构,使得其对用户和程序员不透明,所以对于主存无法存放用户程序的矛盾
+
+现代操作系统是通过虚拟内存技术来解决的,覆盖技术则已成为历史;而交换技术在现代操作系统中仍具有较强的生命力。
+
+
+
+## 常见面试题
+
+**进程、线程的区别**
+
+操作系统会以进程为单位,分配系统资源(CPU时间片、内存等资源),进程是资源分配的最小单位。
+
+
+
+调度:线程作为CPU调度和分配的基本单位,进程作为拥有资源的基本单位;
+
+并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行;
+
+> 拥有资源:
+
+进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源。
+
+进程所维护的是程序所包含的资源(静态资源), 如:地址空间,打开的文件句柄集,文件系统状态,信号处理handler等;
+
+线程所维护的运行相关的资源(动态资源),如:运行栈,调度相关的控制信息,待处理的信号集等;
+
+> 系统开销:
+
+在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
+
+但是进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。
+
+线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个进程死掉就等于所有的线程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。
+
+**一个进程可以创建多少线程**
+
+理论上,一个进程可用虚拟空间是2G,默认情况下,线程的栈的大小是1MB,所以理论上最多只能创建2048个线程。
+
+如果要创建多于2048的话,必须修改编译器的设置。
+
+在一般情况下,你不需要那么多的线程,过多的线程将会导致大量的时间浪费在线程切换上,给程序运行效率带来负面影响。
+
+**外中断和异常有什么区别**
+
+外中断是指由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求,此外还有时钟中断、控制台中断等。
+
+而异常时由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
+
+**解决Hash冲突四种方法**
+
+开放定址法
+
+- 开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
+
+链地址法
+
+- 将哈希表的每个单元作为链表的头结点,所有哈希地址为i的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
+
+再哈希法
+
+- 当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
+
+建立公共溢出区
+
+- 将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
+
+**分页机制和分段机制有哪些共同点和区别**
+
+共同点
+
+- 分页机制和分段机制都是为了提高内存利用率,较少内存碎片。
+- 页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
+
+区别
+
+- 页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
+- 分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
+- 分页是一维地址空间,分段是二维的。
+
+**介绍一下几种典型的锁**
+
+> 读写锁
+
+- 可以同时进行多个读
+- 写者必须互斥(只允许一个写者写,也不能读者写者同时进行)
+- 写者优先于读者(一旦有写者,则后续读者必须等待,唤醒时优先考虑写者)
+
+> 互斥锁
+
+一次只能一个线程拥有互斥锁,其他线程只有等待
+
+互斥锁是在抢锁失败的情况下主动放弃CPU进入睡眠状态直到锁的状态改变时再唤醒,而操作系统负责线程调度,为了实现锁的状态发生改变时唤醒阻塞的线程或者进程,需要把锁交给操作系统管理,所以互斥锁在加锁操作时涉及上下文的切换。
+
+互斥锁实际的效率还是可以让人接受的,加锁的时间大概100ns左右,而实际上互斥锁的一种可能的实现是先自旋一段时间,当自旋的时间超过阀值之后再将线程投入睡眠中,因此在并发运算中使用互斥锁(每次占用锁的时间很短)的效果可能不亚于使用自旋锁
+
+> 条件变量
+
+互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。
+
+而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。
+
+当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。
+
+一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。
+
+总的来说**互斥锁是线程间互斥的机制,条件变量则是同步机制。**
+
+> 自旋锁
+
+如果进线程无法取得锁,进线程不会立刻放弃CPU时间片,而是一直循环尝试获取锁,直到获取为止。
+
+如果别的线程长时期占有锁,那么自旋就是在浪费CPU做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。
+
+虽然它的效率比互斥锁高,但是它也有些不足之处:
+
+- 自旋锁一直占用CPU,在未获得锁的情况下,一直进行自旋,所以占用着CPU,如果不能在很短的时间内获得锁,无疑会使CPU效率降低。
+- 在用自旋锁时有可能造成死锁,当递归调用时有可能造成死锁。
+
+**如何让进程后台运行**
+
+1.命令后面加上&即可,实际上,这样是将命令放入到一个作业队列中了
+
+2.ctrl + z 挂起进程,使用jobs查看序号,在使用bg %序号后台运行进程
+
+3.nohup + &,将标准输出和标准错误缺省会被重定向到 `nohup.out` 文件中,忽略所有挂断(SIGHUP)信号
+
+```
+nohup ping www.ibm.com &
+```
+
+4.运行指令前面 + setsid,使其父进程变成init进程,不受SIGHUP信号的影响
+
+```
+[root@pvcent107 ~]## setsid ping www.ibm.com
+[root@pvcent107 ~]## ps -ef |grep www.ibm.com
+root 31094 1 0 07:28 ? 00:00:00 ping www.ibm.com
+root 31102 29217 0 07:29 pts/4 00:00:00 grep www.ibm.com
+```
+
+上例中我们的进程 ID(PID)为31094,而它的父 ID(PPID)为1(即为 init 进程 ID),并不是当前终端的进程 ID。
+
+> 5.将命令+ &放在()括号中,也可以是进程不受HUP信号的影响
+
+```
+[root@pvcent107 ~]## (ping www.ibm.com &)
+```
+
+**异常和中断的区别**
+
+> 中断
+
+当我们在敲击键盘的同时就会产生中断,当硬盘读写完数据之后也会产生中断,所以,我们需要知道,中断是由硬件设备产生的,而它们从物理上说就是电信号,之后,它们通过中断控制器发送给CPU,接着CPU判断收到的中断来自于哪个硬件设备(这定义在内核中),最后,由CPU发送给内核,有内核处理中断。
+
+下面这张图显示了中断处理的流程:
+
+
+
+> 相同点
+
+- 最后都是由CPU发送给内核,由内核去处理
+- 处理程序的流程设计上是相似的
+
+> 不同点
+
+- 产生源不相同,异常是由CPU产生的,而中断是由硬件设备产生的
+- 内核需要根据是异常还是中断调用不同的处理程序
+- 中断不是时钟同步的,这意味着中断可能随时到来;异常由于是CPU产生的,所以它是时钟同步的
+- 当处理中断时,处于中断上下文中;处理异常时,处于进程上下文中
+
+---
+
+>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ](https://mp.weixin.qq.com/s/G9ZqwEMxjrG5LbgYwM5ACQ)
+
+
diff --git a/docs/src/cs/wangluo.md b/docs/cs/wangluo.md
similarity index 95%
rename from docs/src/cs/wangluo.md
rename to docs/cs/wangluo.md
index 5482d155e5..36e001d342 100644
--- a/docs/src/cs/wangluo.md
+++ b/docs/cs/wangluo.md
@@ -5,12 +5,12 @@ tag:
- 计算机网络
---
-# 计算机网络核心知识点
+# 计算机网络核心知识点大梳理
>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw](https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw)
-
+
## OSI七层模型
@@ -94,7 +94,7 @@ Linux给WIndows发包,不同系统语法不一致,如exe不能在`Linux`下
一层物理层时数据被称为**比特流**(Bits)。
-
+
## TCP和IP模型
@@ -107,7 +107,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
- 第三层:网络层,主要是IP协议。主要负责寻址(找到目标设备的位置)
- 第四层:数据链路层,主要是负责转换数字信号和物理二进制信号。
-
+
**四层网络协议的作用**
@@ -127,7 +127,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
在数据链路层,对应的协议也会在IP数据包前端加上以太网的部首。
-
+
源设备和目标设备通过网线连接,就可以通过物理层的二进制传输数据。
@@ -135,7 +135,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
数据链路层>网络层>传输层>应用层,一层层的解码,最后就可以在浏览器中得到目标设备传送过来的**index.html**。
-
+
**TCP/IP协议族**
@@ -145,7 +145,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
具体来说,在网络层是IP/ICMP协议、在传输层是TCP/UDP协议、在应用层是SMTP、FTP、以及 HTTP 等。他们都属于 TCP/IP 协议。
-
+
## 网络设备
@@ -179,7 +179,7 @@ OSI模型注重通信协议必要的功能;TCP/IP更强调在计算机上实
它通过识别目的 IP 地址的**网络号**,再根据**路由表**进行数据转发
-
+
## HTTP
@@ -374,7 +374,7 @@ HTTPS 协议会对传输的数据进行加密,而加密过程是使用了非
HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过程如下:
-
+
* Client发起一个HTTPS的请求
* Server把事先配置好的公钥证书返回给客户端。
@@ -395,7 +395,7 @@ HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过
通过数字证书的方式保证服务器公钥的身份,解决冒充的风险。
-
+
### 请求报文
@@ -403,7 +403,7 @@ HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过
HTTP 请求报文由3部分组成(请求行+请求头+请求体)
-
+
**常见的HTTP报文头属性**
@@ -431,7 +431,7 @@ HTTP 请求报文由3部分组成(请求行+请求头+请求体)
响应报文与请求报文一样,由三个部分组成(响应行,响应头,响应体)
-
+
**HTTP响应报文属性**
@@ -445,7 +445,7 @@ HTTP 请求报文由3部分组成(请求行+请求头+请求体)
- 服务端可以设置客户端的cookie
-
+
## TCP
@@ -499,7 +499,7 @@ TCP的全部功能体现在它首部中各字段的作用
> 1. 首部前20个字符固定、后面有4n个字节是根据需而增加的选项
> 2. 故 TCP首部最小长度 = 20字节
-
+
**端口**:
@@ -565,7 +565,7 @@ TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲
### 三次握手
-
+
**第一次握手**:
@@ -625,7 +625,7 @@ TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲
### 四次挥手
-
+
挥手请求可以是Client端,也可以是Server端发起的,我们假设是Client端发起:
@@ -688,7 +688,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧
-
+
滑动窗口由四部分组成每个字节的数据都有唯一顺序的编码,随着时间发展,未确认部分与可以发送数据包编码部分向右移动,形式滑动窗口
@@ -717,7 +717,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
主要的方式就是接收方返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
-
+
**流量控制引发的死锁**
@@ -796,7 +796,7 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
注意:拥塞避免并非完全能够避免了阻塞,而是使网络比较不容易出现拥塞。
-
+
**快重传算法**
@@ -816,19 +816,19 @@ TCP报文头有个字段叫Window,用于接收方通知发送方自己还有
所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。
-
+
### Socket
即套接字,是应用层 与 `TCP/IP` 协议族通信的中间软件抽象层,表现为一个封装了 TCP / IP协议族 的编程接口(API)
-
+
`Socket`不是一种协议,而是一个编程调用接口(`API`),属于传输层(主要解决数据如何在网络中传输)
对用户来说,只需调用Socket去组织数据,以符合指定的协议,即可通信
-
+
## UDP
@@ -874,7 +874,7 @@ TFTP、DNS、DHCP、TFTP、SNMP(简单网络管理协议)、RIP基于不可靠
UDP的报文段共有2个字段:数据字段 + 首部字段
-
+
**UDP报文中每个字段的含义如下:**
@@ -927,7 +927,7 @@ IP地址表示为:`xxx.xxx.xxx.xxx`
IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的IP地址,D、E类为特殊地址。
-
+
### 子网掩码
@@ -971,7 +971,7 @@ IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的I
但是A与C,A与D,B与C,B与D它们之间不属于同一网段,所以它们通信是要经过本地网关,然后路由器根据对方IP地址,在路由表中查找恰好有匹配到对方IP地址的直连路由,于是从另一边网关接口转发出去实现互连
-
+
**子网掩码和IP地址的关系**
@@ -987,7 +987,7 @@ IP地址分A、B、C、D、E五类,其中A、B、C这三类是比较常用的I
将得出的结果转化为十进制,便得到网络地址。
-
+
### 网关
@@ -1051,9 +1051,9 @@ DNS通过主机名,最终得到该主机名对应的IP地址的过程叫做域
将主机域名转换为ip地址,属于应用层协议,使用UDP传输。
-
+
-
+
第一步,客户端向本地DNS服务器发送解析请求
@@ -1166,7 +1166,7 @@ ARP即地址解析协议, 用于实现从 IP 地址到 MAC 地址的映射,
源主机收到ARP响应包后,将目的主机的IP和MAC地址写入ARP列表,并利用此信息发送数据,如果源主机一直没有收到ARP响应数据包,表示ARP查询失败。
-
+
## 数字签名
@@ -1259,7 +1259,7 @@ SELECT * FROM user_table WHERE username=’’or 1 = 1 –- and password=’’
**例子**:甲方生成 **一对密钥** 并将其中的一把作为 **公钥** 向其它人公开,得到该公钥的 **乙方** 使用该密钥对机密信息 **进行加密** 后再发送给甲方,甲方再使用自己保存的另一把 **专用密钥** (**私钥**),对 **加密** 后的信息 **进行解密**。
-
+
## 网络攻击
@@ -1390,7 +1390,7 @@ Session 的**认证过程**:
3. 有效期,Cookie 可以设置任意时间有效,而 Session 一般失效时间短
-
+
## 常见面试题
@@ -1418,4 +1418,4 @@ Session 的**认证过程**:
>作者:月伴飞鱼,转载链接:[https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw](https://mp.weixin.qq.com/s/7EddtzpwIRvYfw34QE4zvw)
-
+
diff --git a/docs/src/pdf/bat-shuati.md b/docs/download/bat-shuati.md
similarity index 76%
rename from docs/src/pdf/bat-shuati.md
rename to docs/download/bat-shuati.md
index 82d00171ce..b2f2d34764 100644
--- a/docs/src/pdf/bat-shuati.md
+++ b/docs/download/bat-shuati.md
@@ -1,28 +1,22 @@
---
-title: 👏下载→BAT大佬的刷题笔记
-shortTitle: 👏下载→BAT大佬的刷题笔记
+title: BAT大佬的刷题笔记
category:
- - PDF
+ - 学习资源
tag:
- PDF
-description: 下载BAT大佬的刷题笔记,下载 LeetCode 刷题笔记
-head:
- - - meta
- - name: keywords
- content: LeetCode 刷题笔记,力扣刷题笔记,leetcode Java刷题笔记,leetcode 刷题笔记github,leetcode pdf
---
**大家应该都知道,现在的互联网公司面试,只要是研发岗位,基本上都跑不了算法题的折磨,所以大家在准备校招和社招的时候,或者业余时间,还是要多刷刷 LeetCode,保持状态的**。
需要刷题笔记的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**100**」就可以拉取到下载链接了。
-
+
> 二哥,去年校招前准备算法时,我在 LeetCode 上刷了很多题,但总感觉题虽然刷了很多,解题能力却没怎么提高,怎么解决这种刷题效率低下的问题呢?
这是三个月前一个读者给我的私信,他的困惑让我心有戚戚焉!于是我赶紧问了身边的一些就职于大厂的朋友,他们不约而同地给我推荐了这份刷题笔记。
-
+
细致地研究了一周后,我感觉发现了宝藏!赶紧发给了这位读者。前天,他回复我了,说:“二哥,你太强了,**这刷题笔记好使啊**。我按照上面提供的方法认真地刷了两个月的时间,惊奇地发现算法能力提高了,刷 LeetCode 上中等难度的题目基本不会被卡住了!”
@@ -32,13 +26,13 @@ head:
不管你使用的编程语言是 Java、C++,还是 Go,都可以学习,适合刷题的同学反复学习。认真地揣摩其中的框架思维,你会发现,这是一本非常用心的刷题类书籍。笔记总共 1200 页,分编程技巧、线性表、字符串、栈队列、树、排序、查找、BFS、DFS、贪心、动态规划等。
-
+
每个章节都会先讲解框架思维,然后挑选非常典型的十几道 LeetCode 题进行实战讲解。这份笔记不仅排版十分精美,内容也异常充实,每一题都是细致的讲解,有时候还会配上图片,就怕你搞不懂,大大的良心啊!
-
+
-
+
以前呢,我也很讨厌刷题,觉得这就像古代的八股文一样,又臭又刻板,但互联网的公司都喜欢这么考,因为确实也找不到更好的替代方案,那如果你不准备不去刷 LeetCode 的话,面试必定挂啊!
@@ -51,7 +45,7 @@ head:
二哥已经把这份刷题笔记下载好了,需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**100**」就可以拉取到下载链接了(无套路,没加密)。
-
+
> 笔记版权归原作者(霜神)所有,出处:https://books.halfrost.com/leetcode/
diff --git a/docs/download/history.md b/docs/download/history.md
new file mode 100644
index 0000000000..92e77fcc3b
--- /dev/null
+++ b/docs/download/history.md
@@ -0,0 +1,62 @@
+# 网络日志
+
+### 2022年05月21日
+
+- 增加 Spring Boot 专栏
+- 增加 MySQL 文档
+- 增加微服务网关文档
+
+### 2022年05月09日
+
+- [增加面渣逆袭板块](/download/nixi)
+- [Spring Boot 整合 MySQL-Druid](/springboot/mysql-druid)
+
+### 2022年04月30日
+
+- 批量替换所有图片链接为阿里云的 CDN 链接
+
+### 2022年04月29日
+
+- [增加内部类](/oo/inner-class)
+
+### 2022年04月27日
+
+- 修改整形到整型,By Lettuce
+
+### 2022年04月21日
+
+- 重新定制左侧菜单
+
+### 2022年04月19日
+
+- [增加文档搜索功能](https://mp.weixin.qq.com/s/JVdQj-Fl9RPjt4P0y5Ws8g)
+
+### 2022年04月02日
+
+- [杨锅锅同学提出错误:浮点多了个long, 整数少了个int](/sidebar/sanfene/javase)
+- [增加数据结构与算法的学习路线](/xuexiluxian/algorithm)
+
+### 2022年03月31日
+
+- 增加学习建议板块
+
+### 2022年03月29日
+
+- [修改学习路线部分的404错误](/xuexiluxian/)
+- [增加Java整体学习路线](/xuexiluxian/java/yitiaolong)
+- [增加Java虚拟机学习路线](/xuexiluxian/java/jvm)
+
+### 2022年03月27日
+
+- [增加Java并发编程的内容](/home#java并发编程);
+- [增加Java虚拟机模块的内容](/home#java虚拟机);
+
+
+### 2022年03月19日
+
+[Docsify 升级到 VuePress](https://mp.weixin.qq.com/s/cNtUmtVJsF0d6lQ26UFFOw)
+
+
+### 2022年01月01日
+
+[二哥的小破站终于上线了](https://mp.weixin.qq.com/s/NtOD5q95xPEs4aQpu4lGcg)
\ No newline at end of file
diff --git a/docs/download/java.md b/docs/download/java.md
new file mode 100644
index 0000000000..ca183d8187
--- /dev/null
+++ b/docs/download/java.md
@@ -0,0 +1,125 @@
+---
+title: Java电子书下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+# Java程序员常读书单📚,附下载地址
+
+伟大的高尔基曾说过:“书籍是人类进步的阶梯”,读经典的书就好像是站在巨人的肩膀上,视野更开阔,思考问题的方式也会更全面。
+
+讲真,挺遗憾的,大学期间,我读了不少垃圾书,比如说《21 天学会 xxx》,《3 天教你学会 xxx》。
+
+直到工作后的第二年,遇到了一个非常 nice 的领导,他给我推荐了不少经典的书单,比如说《代码大全》、《编程珠玑》、《代码整洁之道》、《深入理解计算机系统》等等。
+
+哇,虽然一开始读得很痛苦,但就这么坚持了一年半的时间,唉,真的发现自己的编程能力在突飞猛进呢,关键是,对业务的理解啊、对架构的设计啊、对代码的编写啊,都有了显著的提升。
+
+这个书单非常的庞大,为了方便大家查找,我将它们又分门别类地上传到了 GitHub 和码云:
+
+- [GitHub备用地址](https://github.com/itwanger/JavaBooks)
+- [Gitee备用地址](https://gitee.com/itwanger/JavaBooks)
+
+上传到 GitHub 和码云上还有一个好处,就是方便大家提需求,如果上面没有你想要的书籍,可以直接提 issue,我看到后就会立马去搜集和整理。
+
+喜欢的话可以点个 star。
+
+这是我看过的一些书:
+
+
+
+那其实很多人在学习编程的时候,很容易陷入一个误区,就是没有计划、没有路线,就导致看似投入了很多精力,但最后的学习效果却有点对不住付出的时间和精力。
+
+为此,我花了将近一个月的时间,整理了这样一条学习路线,并且把我读过的电子书全部做了归类:**入门→工具→框架→数据库→并发编程→底层→性能优化→设计模式→操作系统→计算机网络→数据结构与算法→面试→架构→管理**
+
+
+
+就连颈椎康复指南都有了,这波良心吧?大家可以通过下面的方式获取,我想不管是科班还是非科班的,只要你喜欢计算机、喜欢编程,应该都会有很大的帮助。
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**pdf**」就可以拉取到下载链接了。
+
+
+
+
+## 一、编程语言
+### C语言
+- 《阮一峰老师的 C语言入门教程》
+- 《C程序设计语言》
+- 《C 和指针》
+- 《C 陷阱与缺陷》
+- 《C Primer Plus》
+### Java 语言
+- 《二哥的 Java 程序员进阶之路》,GitHub 上已经开源,持续更新
+- 《Java 编程思想》
+- 《深入浅出 Java 多线程》
+- 《深入理解 Java 虚拟机》
+
+学习任何一门编程语言,一定不要浅尝辄止,因为入门都很容易,进阶却很难。如果只是蜻蜓点水,到最后可能就是竹篮打水一场空,精华的永远也学不到。
+
+初学阶段,一定要多 coding,coding,coding,千万不要眼高手低。希望我的这份计算机书单能帮助到大家。
+
+### C++ 语言
+- 《C++ primer》
+- 《Effective C++》
+- 《STL源码解析》
+### Python 语言
+- 《流畅的 Python》
+- 《Python编程:从入门到实践》
+- 《零基础学 Python》
+- 《用Python进行自然语言处理》
+### JavaScript 语言
+- 《JavaScript 王者归来》
+- 《你不知道的 JavaScript》
+- 《JavaScript 高级程序设计》
+## 二、数据结构与算法
+- 《算法导论》
+- 《算法 4》
+- 《编程珠玑》
+- 《编程之美》
+- 《趣学数据结构》
+## 三、计算机基础
+### 操作系统
+- 《现代操作系统》
+- 《鸟哥的 Linux 私房菜》
+### 计算机组成原理
+- 《程序是如何跑起来的》
+- 《计算机是如何跑起来的》
+- 《编码:隐匿在计算机软硬件背后的语言》
+### 计算机网络
+- 《图解 HTTP》
+- 《图解 TCP/IP》
+- 《计算机网络自顶向下》
+- 《网络是怎样连接的》
+### 数据库
+- 《SQL必知必会》
+- 《高性能 MySQL》
+- 《MySQL技术内幕 InnoDB存储引擎》
+- 《Redis 深度历险:核心原理与应用实践》
+### 四、编程实战
+- 《代码整洁之道》
+- 《阿里巴巴 Java 开发手册》
+- 《重构:改善既有代码的设计》
+- 《Effective Java》
+### 五、代码人生
+- 《黑客与画家》
+- 《人月神话》
+- 《人件》
+- 《代码大全》
+- 《数学之美》
+- 《图灵的秘密》
+
+。。。。持续更新
+
+当然了,我个人是有局限性的,如果大家有什么好书也可以推荐给我,我更新上来,也为后来者提供一个更体系化的书单。
+
+讲真心话,随着时间的推移,我对整个计算机体系的认知也更加全面和深刻了,那这份书单真的希望能帮助到大家。
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**pdf**」就可以拉取到下载链接了。
+
+
+
+
+几年后,你将是一名善于解决实际问题的工程师,而不是一名普普通通的码农。
+
+>毋庸置疑,这是一条坎坷的路,但学弟学妹们就是来披荆斩棘的,对吧?
diff --git a/docs/download/jianli.md b/docs/download/jianli.md
new file mode 100644
index 0000000000..138a0cc3d5
--- /dev/null
+++ b/docs/download/jianli.md
@@ -0,0 +1,186 @@
+---
+title: 简历下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+大家好,我是二哥呀。
+
+随着校招季的到来,不少同学都准备找工作了,也陆陆续续有同学找我看简历以及修改简历。
+
+其实我以前就分享过自己的简历写法和迭代完善的过程,可能有同学没来得及看。今天客户从长沙远道而来,我要接待,所以没时间自己写了,就转一篇阿秀的文章给大家参照下。
+
+需要简历模板的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**简历**」就可以拉取到下载链接了。
+
+
+
+这位学弟说自己在秋招的时候没用心找工作,等毕业后才发现找的工作不满意,勉强干了半年就不想干了,然后走的社招,发现社招比校招要难一点。
+
+在正式分享简历修改案例前,二哥先简单总结一下校招和社招吧。
+
+**校招看基础、潜力,社招看能力、即战力**。
+
+**校招**,对于某些技术问题你可以不懂不会,没关系,看的是你的潜力,你的基本功。框架不会?没事,学就是了。
+
+**社招**,并不是的,社招看的是你的过往经历以及你解决问题的能力。人家招你过来是需要你来干活的,不是让你来带薪学习的,公司又不是慈善机构啊。
+
+所以希望还是在校的学弟学妹们好好学学计算机基本功,打打基础。
+
+程序员内功是很重要的,比如操作系统、计算机网络、数据库、计算机组成原理这些。
+
+好了,废话不多说,开始今天的主题吧。
+
+以下内容涉及到这位学弟的一些关键信息已脱敏,不影响大家阅读,我按照修改模块给大家分享。
+
+### 专业技能
+
+首先来看一下这位学弟的专业技能部分。
+
+
+
+其实,这部分他写的已经挺好的了,简单大方、条理清晰。
+
+也能从他的专业技能描述看出来这位学弟挺厉害的,可还是有些不足之处,我也想相应的给出了一些建议和意见。
+
+**修改意见**
+
+1、**编程语言**部分的第一句话我建议他改一下,因为原文说的有点冗余。我建议他改成“熟悉C++编程语言,基本功扎实,熟练掌握STL模板库”。
+
+后面的“阅读源码”我建议是不加的,因为STL下的思想确实比较精妙,如果别人抓住你的“阅读过部分源码”这几个字使劲问你,十有八九要吃不消,保险起见还是不要加上为好。你需要对你简历上的每一个字,或者说每一个标点符号负责。
+
+2、**数据结构**部分,其实他写的挺好的了,我建议他写得更精炼具体一点,**将原文**“ 熟悉常用算法(Leetcode 200道)、数据结构 (链表、栈、队列、哈希表、二叉树、B/B+树、红黑树等) ”**改为**“熟悉常见数据结构与算法,如链表、栈、哈希表、二叉树等,以74%正确率通过力扣网站 214 道算法题”。
+
+因为74%的正确率这种很精确的数字指标给面试官的直观感受更**具象**一些,并且这个正确率在力扣官网上也是可查的。
+
+3、**设计模式**部分,其实他写的有点多了。对于校招而言,在设计模式上考察的并不多,没必要。
+
+我建议他**改成**“了解常用设计模式如单例模式、工厂模式等”。这么写的目的也是为了方式一种情况的出现,那就是面试官很可能不问你单例、工厂,他会问你一句,你还会不会其他的设计模式,这个时候,你就可以回答“还会观察者、迭代器模式等”
+
+4、**数据库**部分,感觉这位小学弟有点目标过于明显了。
+
+他的**原文是**“ 熟悉 MySQL 关系型数据库、Redis 非关系型数据库,了解 MySQL 查询性能优化相关技术,Redis 五大数据类型,持久化机制以及主从复制技术 ”这就相当于直接让面试官问你Redis的五种数据结构是什么?持久化、主从复制又是什么了?
+
+面试官又不是傻子...
+
+我建议他改成“熟悉关系型数据库MySQL、内存型数据库Redis,了解常见查询优化技术。”这样稍微委婉一些。。。
+
+下面是我当时给他的修改意见。
+
+
+
+### 项目经历
+
+其实一份校招简历,最重要的就是项目经历、实习经历(有则加分,没有也行)、专业技能了。
+
+
+
+可以从这位学弟的描述中看出来,他毕业后的这四个月里确实做了不少的工作,但感觉没说出来自己所做工作的意义和难点所在。
+
+你可能觉得没什么,但那才是面试官在意的地方。
+
+设身处地的想,如果你是一个面试官,你也希望招来的新鲜血液能力越强越好。那能力强不强在面试初期就是通过你的实习经历或者项目经验体现的啊。
+
+**针对第一个项目,二哥给出了几点修改意见**:
+
+1、一个项目,你承担的角色是什么?主要负责人还是核心成员?包括项目的起始时间要注明。
+
+2、对于其中的数据库密码验证。我建议他去掉,因为有点水平较低,还不如不写。虽说后端都是增删改查,但你不能直接说你就是搞了个密码验证啊,你这也太耿直了吧。
+
+3、技术亮点部分描述不够清楚,虽然这位学弟做了很多工作,可从他的描述中是看不出来什么工作的,我给他换了一种说法。
+
+**技术亮点原文描述**:
+
+实现与 bash 几乎完全相同的 cd 功能;使用边缘触发优化 epoll 频繁响应,使用进程池与线程池减少 CPU 运转负载;超时断开,针对连接上的客户端,若超过 30 秒未发送任何请求,断开连接,并使用环形队列技术实现高并发 ;
+
+其实他写的挺好的了,但我还是觉得差点意思,就是说的太白话了一些,所以我用自己的语言帮他加工润色了一下,下面是我的修改版。
+
+**技术亮点修改版**:
+
+1、实现与 bash 几乎完全相同的 cd 功能,但反应时间更短
+
+2、使用epoll边缘触发进行频繁响应,并辅助以进程池和线程池技术来减少CPU运转负载,增加系统CPU利用率
+
+3、智能化断开设计:使用环形队列技术实现高并发,对于30秒内无任何网络包交互的连接进行强制断开处理,有效XXXX。
+
+**是不是感觉瞬间好一点了**。。。。我只能说,**中华语言,博大精深,不服不行**。
+
+以下是修改意见标注
+
+
+
+至此,帮他把第一个项目修改完毕了,**针对第二个项目的修改**,我就不多BB了,直接贴上来吧。
+
+**以下是我给出的修改意见**:
+
+这个项目名改成:汽车出行APP 缺少你的角色 和 项目起始时间 该APP主要业务是什么?最终的功能有哪些?然后写上自己在其中的工作。个人工作对于该APP的加成在哪里,需要具体的量化词。
+
+技术亮点中的删除相似网页,删除正确率有多少,针对该APP某某缺陷和不足,提出建立倒排索引技术,推送强相关的网页,最终提升点击率XX.XX%。
+
+最后写上个人收获:学到了哪些?对XXX有了更深的认识和了解
+
+**下面是当时给他做的标注**:
+
+
+
+其实对于该部分的修改,我是紧紧抓住一个要点,那就是尽可能使用具化的指标即明确的信息而不是概括性的描述。
+
+比如直接告诉别人提升了XX%,而不是说一句“有着较好的提升效果”;直接告诉别人“项目优化了XX秒,相较于上一版本速度加快了XX%”,而不是”经过XX技术,速度有了较大提高“。
+
+这一点,我在自己的简历修改迭代文章中也提到过,很重要,特别重要,具化的指标信息给人的第一感觉就是不一样的。
+
+### 工作经历、教育经历、奖项证书
+
+这里比较类似,我就一起放上来说了
+
+首先是原文。
+
+
+
+
+我给的修改意见批注。
+
+
+
+1、在工作经历这里,注意细节问题,比如你的岗位名称是什么?你在实习过程中,你的工作有哪些?在这过程中用到了哪些技能?
+
+不要直接就是一句话写出来,不明不白的,没什么愿意看的。人都是视觉动物,都希望看到整齐有序的内容。
+
+这里的整齐有序不仅要求你的排版整齐,你想要表达的意思也要有序。
+
+比如把你的工作或者实习分为团队工作、个人工作、个人收获,挨个展开。
+
+2、由于这位学弟已经毕业了,已经不能再以校招身份去面试找工作了,所以教育经历这里其实已经没必要写在校学习的课程了。
+
+一旦你踏入社会,失去了应届生身份你就不再是校招生了,这个时候看的就是你的能力了。
+
+3、对于一些细节问题记得做好,关键字该加粗加粗。比如有分量的国奖还是值得一个加粗显示的。
+
+4、如果你过了六级,那直接写**六级**,分数还可以的话就写上分数;分数比较低的话,比如430这种刚飘过,就写六级就行。
+
+如果六级没过,那就写上四级吧。
+
+### 简历模板下载方式
+
+我把这位小学弟和我自己以前的简历模板放在一起了,需要简历模板的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**简历**」就可以拉取到下载链接了。
+
+
+
+记住!简历并不是单纯意义上的自我介绍,比如说我是沉默王二,今年 18 岁,来自洛阳,毕业于某某学校。这样的简历太苍白了。
+
+简历就好像电梯广告的单页一样,它富有鲜活的生命力,它在呐喊,它不需要过多的润色,只需要铿锵有力、赤裸裸的“炫耀”。
+
+比如说我是沉默王二, 2019 年参与了 XXX 项目的开发。作为项目团队的核心 开发人员,我不仅能够提前完成自己的开发任务,还设计了一个高效的缓存中间件,大大提高了系统的性能。
+
+该中间件上线后,Web 前端性能从 10 QPS 提升到 120 QPS,服务器由 10 台缩减为 5 台。
+
+鉴于之前的良好表现,我在 2020 年升任项目的主要负责人,虽然小组成员只有 15 个,但硬生生地肩负起了每天超过 2000 万的 PV。
+
+看,这样的简历是不是让人耳目一新,证明自己价值的同时,没有过多的粉饰,让招聘方觉得你很靠谱,迫切地想要把你这个人才“抢”到手,免费被别的公司挖走了。
+
+简历上的内容不要太多,尽量不要超过一页,因为招聘方没有那么多时间去翻看你的简历。我是挺相信第一印象的,好的简历看一眼就会过目不忘,真的。
+
+我是二哥呀,人生最可怕的事莫过于在别人放弃你之前,你先放弃了自己,我们下期再见。
+
+>作者:阿秀,转载链接:[https://mp.weixin.qq.com/s/soVldFzBbqwm_vM35afFvg](https://mp.weixin.qq.com/s/soVldFzBbqwm_vM35afFvg)
diff --git a/docs/src/download/learn-jianyi.md b/docs/download/learn-jianyi.md
similarity index 100%
rename from docs/src/download/learn-jianyi.md
rename to docs/download/learn-jianyi.md
diff --git a/docs/src/download/nicearticle.md b/docs/download/nicearticle.md
similarity index 98%
rename from docs/src/download/nicearticle.md
rename to docs/download/nicearticle.md
index cdf95c925b..0c3ae181b8 100644
--- a/docs/src/download/nicearticle.md
+++ b/docs/download/nicearticle.md
@@ -5,7 +5,7 @@
### 图文教程
- [Java 正则表达式详解](https://segmentfault.com/a/1190000009162306)
-- [Java 正则从入门到精通](https://dunwu.github.io/javacore/pages/4c1dd4/)
+- [Java 正则从入门到精通](https://dunwu.github.io/javacore/advanced/java-regex.html)
- [GitHub 上优质的 Java 知识总结项](https://mp.weixin.qq.com/s/-lQ2PTEO4F2d92GDDxKVpw)
- [处于萌芽阶段的 Java 核心知识库](https://mp.weixin.qq.com/s/_Q7lopxM1sJtMA-NOE_v3A)
- [大数据入门指南 ](https://github.com/heibaiying/BigData-Notes)
@@ -91,6 +91,8 @@
- [降薪 45%,从互联网回到国企](https://mp.weixin.qq.com/s/qHGdIuA32X-zydbMTKDPuA)
- [学弟在微软的这六个月](https://mp.weixin.qq.com/s/08Ax1ArAjchemjUXih7zNw)
- [找个程序员做老公/男票有多爽???](https://mp.weixin.qq.com/s/mK0yaen1mhCoWZ6ZLC5vQg)
+- [研究所月入两万,是什么体验?](/manongshenghuo/yanjiusuo-20wan.md)
+- [裸辞全职做外包一个月的感受](/manongshenghuo/waibao-1geyue.md)
- [转眼就来字节六个月了,真的不一样](https://mp.weixin.qq.com/s/jG7DLrCFf_pYoMLFiVbaaA)
- [在监狱里编程是一种什么体验(上)?](https://mp.weixin.qq.com/s/ci5Meem_d3g2BphDmMP8VQ)
- [29 岁,非科班零基础,想兼职做外包。。](https://mp.weixin.qq.com/s/CTTlnXNXY9j3Bm3_4gmIbw)
@@ -204,8 +206,10 @@
> [!TIP]
> 开发过程中遇到的一些典型问题,该如何解决?
+- [Log4j2突发重大漏洞](/shigu/log4j2.md)
- [重现了一波 Log4j2 核弹级漏洞,同事的电脑沦为炮灰](https://mp.weixin.qq.com/s/zXzJVxRxMUnoyJs6_NojMQ)
- [生成订单30分钟未支付,则自动取消,该怎么实现?](https://mp.weixin.qq.com/s/J6jb_Dt3C49CIjYBTrN4gQ)
+- [两天两夜,1M图片优化到100kb!](/shigu/image-yasuo.md)
- [内部群炸了锅,隔壁同事真删库了啊。。](https://mp.weixin.qq.com/s/lvyoN1gHCWhcPqudcjcRgQ)
- [B 站崩了](https://mp.weixin.qq.com/s/PfJe5rXednkXTq8EKT0xpw)
- [因为一个低级错误,生产数据库崩溃了将近半个小时](https://mp.weixin.qq.com/s/ec6u8WsPt7zJ0eul8sPEhg)
@@ -223,6 +227,7 @@
## MySQL重要知识点
+- [从京东到家程序员删库被判 10 个月来聊聊 MySQL 数据备份的杀手锏](/mysql/deletedb-binlog-weiguanjishu.md)
- [深入浅出MySQL crash safe](https://tech.youzan.com/shen-ru-qian-chu-mysql-crash-safe/)
## 待收录文章
diff --git a/docs/download/pdf.md b/docs/download/pdf.md
new file mode 100644
index 0000000000..6b1e7e4d99
--- /dev/null
+++ b/docs/download/pdf.md
@@ -0,0 +1,24 @@
+---
+title: PDF干货笔记下载
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+# PDF干货笔记📚,附下载地址
+
+
+>- **找不到优质的学习资源**?这些问题在这里统统都可以找到答案。
+>- 我会把自己十多年的学习资源毫不保留的分享出来。
+
+- [👏下载→最全最硬核的Java面试 “备战” 资料](https://mp.weixin.qq.com/s/US5nTxbC2nYc1hWpn5Bozw)
+- [👏下载→深入浅出Java多线程](https://mp.weixin.qq.com/s/pxKrjw_5NTdZfHOKCkwn8w)
+- [👏下载→GitHub星标115k+的Java教程](https://mp.weixin.qq.com/s/d7Z0QoChNuP9bTwAGh2QCw)
+- [👏下载→重学Java设计模式](https://mp.weixin.qq.com/s/PH5AizUAnTz0CuvJclpAKw)
+- [👏下载→Java版LeetCode刷题笔记](https://mp.weixin.qq.com/s/FyoOPIMGcaeH0z5RMhxtaQ)
+- [👏下载→阮一峰C语言入门教程](/download/yuanyifeng-c-language.md)
+- [👏下载→BAT大佬的刷题笔记](/download/bat-shuati.md)
+- [👏下载→给操作系统捋条线](https://mp.weixin.qq.com/s/puTGbgU7xQnRcvz5hxGBHA)
+- [👏下载→豆瓣9.1分,Pro Git中文版](/download/progit.md)
+- [👏下载→简历模板](/download/jianli.md)
\ No newline at end of file
diff --git a/docs/download/progit.md b/docs/download/progit.md
new file mode 100644
index 0000000000..781d7473cb
--- /dev/null
+++ b/docs/download/progit.md
@@ -0,0 +1,48 @@
+---
+title: 豆瓣9.1分,Pro Git中文版
+category:
+ - 学习资源
+tag:
+ - PDF
+---
+
+今天给大家分享一本个人最近看过觉得非常不错的Git开源手册,可能有些小伙伴也看过了,我是最近在通勤路上用PAD看的。这本开源手册,它除了有**PDF版**,还有**epub电子书版**,非常适合电子阅读:
+
+
+
+需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**git**」就可以拉取到下载链接了。
+
+
+
+相信看完对于个人Git知识体系的梳理和掌握是非常有帮助的。
+
+这本手册在豆瓣上评价极高,之前9.3,现在也有9.1的高分,其作者是GitHub的员工,内容主要侧重于各种场合中的惯用法和底层原理的讲述,手册中还针对不同的使用场景,设计了几个合适的版本管理策略。简而言之,这本手册无论是对于初学者还是想进一步了解Git工作原理的开发者都非常合适。
+
+
+
+
+
+这个手册一共分为十章,详细内容如下:
+
+
+
+**手册中部分内容展示如下:**
+
+
+
+
+
+
+
+
+
+**需要该Git手册PDF+epub电子书的小伙伴:**
+
+
+
+可扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**git**」就可以拉取到下载链接了。
+
+
+
+
+好了,这次资源分享就到这里!后续如果遇到有用的工具或者资源,依然还会持续分享,也欢迎大家多多安利和交流,一起分享成长。
diff --git a/docs/src/pdf/yuanyifeng-c-language.md b/docs/download/yuanyifeng-c-language.md
similarity index 84%
rename from docs/src/pdf/yuanyifeng-c-language.md
rename to docs/download/yuanyifeng-c-language.md
index fccde50d59..b0f653a407 100644
--- a/docs/src/pdf/yuanyifeng-c-language.md
+++ b/docs/download/yuanyifeng-c-language.md
@@ -1,26 +1,20 @@
---
-title: 👏下载→阮一峰C语言入门教程
-shortTitle: 👏下载→阮一峰C语言入门教程
+title: 阮一峰-C语言入门教程
category:
- - PDF
+ - 学习资源
tag:
- PDF
-description: 给操作系统学习资料下载
-head:
- - - meta
- - name: keywords
- content: C语言教程,阮一峰,阮一峰 C语言,C语言入门教程
---
给大家报告下,阮一峰老师的《**C语言入门教程**》于 2021 年 9 月 7 日上线了!
对,和往常一样,这个教程是开源的,采用知识共享许可证,源码托管在 GitHub,大家可以自由使用。
->[https://github.com/wangdoc/clang-tutorial](https://github.com/wangdoc/clang-tutorial)
+>https://github.com/wangdoc/clang-tutorial
在线阅读地址也有:
->[https://wangdoc.com/clang/](https://wangdoc.com/clang/)
+>https://wangdoc.com/clang/
我第一时间就拜读了一遍,受益匪浅!可以说目前我见到的最好的 C语言入门教程了,没有之一!
@@ -35,7 +29,7 @@ head:
需要的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**08**」就可以拉取到下载链接了。
-
+
也可以微信搜「**沉默王二**」关注后回复关键字「**08**」。
@@ -45,7 +39,7 @@ head:
那配上阮一峰老师的这个在线文档教程,可以说是完美!
-
+
我对这份教程是非常满意的,该讲的地方都讲到了,示例也给了很多,对初学者来说,完全够用了。
@@ -77,9 +71,9 @@ C语言在武林界的地位就相当于少林的地位,天下武功皆出少
不过网上也有蛮多在线编译器的,可以直接在网页上模拟运行 C 代码,查看结果,非常方便。
-
+
->CodingGround网址:[https://www.tutorialspoint.com/compile_c_online.php](https://www.tutorialspoint.com/compile_c_online.php)
+>CodingGround网址:https://www.tutorialspoint.com/compile_c_online.php
C 语言是一种编译型语言,源码是文本文件,本身是无法执行的,需要通过编译器,生成二进制的可执行文件。
@@ -99,7 +93,7 @@ C语言中,指针是令初学者头痛的一块内容,所以我这里简单
>需要阮一峰老师的这份《C语言入门教程》的小伙伴请扫描下方的二维码关注作者的原创公众号「**沉默王二**」回复关键字「**08**」就可以拉取到下载链接了。
-
+
也可以微信搜「**沉默王二**」关注后回复关键字「**08**」。
diff --git a/docs/elasticsearch/rumen.md b/docs/elasticsearch/rumen.md
new file mode 100644
index 0000000000..8b5eaaef7e
--- /dev/null
+++ b/docs/elasticsearch/rumen.md
@@ -0,0 +1,189 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - Elasticsearch
+---
+
+# 全文搜索引擎Elasticsearch入门教程
+
+学习真的是一件令人开心的事情,上次分享了 [Redis 入门](https://mp.weixin.qq.com/s/NPJkMy5RppyFk9QhzHxhrw)的文章后,收到了很多小伙伴的鼓励,比如说:“哎呀,不错呀,二哥,通俗易懂,十分钟真的入门了”。瞅瞅,瞅瞅,我决定再接再厉,入门一下 Elasticsearch,因为我们公司的商城系统升级了,需要用 Elasticsearch 做商品的搜索。
+
+不过,我首先要声明一点,我对 Elasticsearch 并没有进行很深入的研究,仅仅是因为要用,就学一下。但作为一名负责任的技术博主,我是用心的,为此还特意在某某时间上买了一门视频课程,作者叫阮一鸣。说实话,他光秃秃的头顶让我对这门课程产生了浓厚的兴趣。
+
+经过三天三夜的学习,总算是入了 Elasticsearch 的门,我就决定把这些心得体会分享出来,感兴趣的小伙伴可以作为参考。遇到文章中有错误的地方,不要手下留情,过来捶我,只要不打脸就好。
+
+
+
+
+### 01、Elasticsearch 是什么
+
+>Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
+
+以上引用来自于官方,不得不说,解释得蛮文艺的。意料之中和意料之外,这两个词让我想起来了某一年的高考作文题(情理之中和意料之外)。
+
+Elastic Stack 又是什么呢?整个架构图如下图(来源于网络,侵删)所示。
+
+
+
+信息量比较多,对吧?那就记住一句话吧,Elasticsearch 是 Elastic Stack 的核心。
+
+国内外的很多知名公司都在用 Elasticsearch,比如说滴滴、今日头条、谷歌、微软等等。Elasticsearch 有很多强大的功能,比如说全文搜索、购物推荐、附近定位推荐等等。
+
+理论方面的内容就不说太多了,我怕小伙伴们会感到枯燥。毕竟入门嘛,实战才重要。
+
+### 02、安装 Elasticsearch
+
+Elasticsearch 是由 Java 开发的,所以早期的版本需要先在电脑上安装 JDK 进行支持。后来的版本中内置了 Java 环境,所以直接下载就行了。Elasticsearch 针对不同的操作系统有不同的安装包,我们这篇入门的文章就以 Windows 为例吧。
+
+下载地址如下:
+
+[https://www.elastic.co/cn/downloads/elasticsearch](https://www.elastic.co/cn/downloads/elasticsearch)
+
+最新的版本是 7.6.2,280M 左右。但我硬生生花了 10 分钟的时间才下载完毕,不知道是不是连通的 200M 带宽不给力,还是官网本身下载的速度就慢,反正我去洗了 6 颗葡萄吃完后还没下载完。
+
+Elasticsearch 是免安装的,只需要把 zip 包解压就可以了。
+
+
+
+1)bin 目录下是一些脚本文件,包括 Elasticsearch 的启动执行文件。
+
+2)config 目录下是一些配置文件。
+
+3)jdk 目录下是内置的 Java 运行环境。
+
+4)lib 目录下是一些 Java 类库文件。
+
+5)logs 目录下会生成一些日志文件。
+
+6)modules 目录下是一些 Elasticsearch 的模块。
+
+7)plugins 目录下可以放一些 Elasticsearch 的插件。
+
+直接双击 bin 目录下的 elasticsearch.bat 文件就可以启动 Elasticsearch 服务了。
+
+
+
+输出的日志信息有点多,不用细看,注意看到有“started”的字样就表明启动成功了。为了进一步确认 Elasticsearch 有没有启动成功,可以在浏览器的地址栏里输入 `http://localhost:9200` 进行查看(9200 是 Elasticsearch 的默认端口号)。
+
+
+
+你看,为了 Search。
+
+那如何停止服务呢?可以直接按下 `Ctrl+C` 组合键——粗暴、壁咚。
+
+### 03、安装 Kibana
+
+通过 Kibana,我们可以对 Elasticsearch 服务进行可视化操作,就像在 Linux 操作系统下安装一个图形化界面一样。
+
+下载地址如下:
+
+[https://www.elastic.co/cn/downloads/kibana](https://www.elastic.co/cn/downloads/kibana)
+
+最新的版本是 7.6.2,284M 左右,体积和 Elasticsearch 差不多。选择下载 Windows 版,zip 格式的,完成后直接解压就行了。下载的过程中又去洗了 6 颗葡萄吃,狗头。
+
+
+
+包目录不再一一解释了,进入 bin 目录下,双击运行 kibana.bat 文件,启动 Kibana 服务。整个过程比 Elasticsearch 要慢一些,当看到 `[Kibana][http] http server running` 的信息后,说明服务启动成功了。
+
+
+
+在浏览器地址栏输入 `http://localhost:5601` 查看 Kibana 的图形化界面。
+
+
+
+由于当前的 Elasticsearch 服务端中还没有任何数据,所以我们可以选择「Try Our Sample Data」导入 Kibana 提供的模拟数据体验一下。下图是导入电商数据库的看板页面,是不是很丰富?
+
+
+
+打开 Dev Tools 面板,可以看到一个简单的 DSL 查询语句(一种完全基于 JSON 的特定于领域的语言),点击「运行」按钮后就可以看到 JSON 格式的数据了。
+
+
+
+### 04、Elasticsearch 的关键概念
+
+在进行下一步之前,需要先来理解 Elasticsearch 中的几个关键概念,比如说什么是索引,什么是类型,什么是文档等等。Elasticsearch 既然是一个数据引擎,它里面的一些概念就和 MySQL 有一定的关系。
+
+
+
+看完上面这幅图(来源于网络,侵删),是不是瞬间就清晰了。向 Elasticsearch 中存储数据,其实就是向 Elasticsearch 中的 index 下面的 type 中存储 JSON 类型的数据。
+
+
+### 05、在 Java 中使用 Elasticsearch
+
+有些小伙伴可能会问,“二哥,我是一名 Java 程序员,我该如何在 Java 中使用 Elasticsearch 呢?”这个问题问得好,这就来,这就来。
+
+Elasticsearch 既然内置了 Java 运行环境,自然就提供了一系列 API 供我们操作。
+
+第一步,在项目中添加 Elasticsearch 客户端依赖:
+
+```
+
+ org.elasticsearch.client
+ elasticsearch-rest-high-level-client
+ 7.6.2
+
+```
+
+第二步,新建测试类 ElasticsearchTest:
+
+```java
+public class ElasticsearchTest {
+ public static void main(String[] args) throws IOException {
+
+ RestHighLevelClient client = new RestHighLevelClient(
+ RestClient.builder(
+ new HttpHost("localhost", 9200, "http")));
+
+ IndexRequest indexRequest = new IndexRequest("writer")
+ .id("1")
+ .source("name", "沉默王二",
+ "age", 18,
+ "memo", "一枚有趣的程序员");
+ IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
+
+ GetRequest getRequest = new GetRequest("writer", "1");
+
+ GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
+ String sourceAsString = getResponse.getSourceAsString();
+
+ System.out.println(sourceAsString);
+ client.close();
+ }
+}
+```
+
+1)RestHighLevelClient 为 Elasticsearch 提供的 REST 客户端,可以通过 HTTP 的形式连接到 Elasticsearch 服务器,参数为主机名和端口号。
+
+有了 RestHighLevelClient 客户端,我们就可以向 Elasticsearch 服务器端发送请求并获取响应。
+
+2)IndexRequest 用于向 Elasticsearch 服务器端添加一个索引,参数为索引关键字,比如说“writer”,还可以指定 id。通过 source 的方式可以向当前索引中添加文档数据源(键值对的形式)。
+
+有了 IndexRequest 对象后,可以调用客户端的 `index()` 方法向 Elasticsearch 服务器添加索引。
+
+3)GetRequest 用于向 Elasticsearch 服务器端发送一个 get 请求,参数为索引关键字,以及 id。
+
+有了 GetRequest 对象后,可以调用客户端的 `get()` 方法向 Elasticsearch 服务器获取索引。`getSourceAsString()` 用于从响应中获取文档数据源(JSON 字符串的形式)。
+
+好了,来看一下程序的输出结果:
+
+```
+{"name":"沉默王二","age":18,"memo":"一枚有趣的程序员"}
+```
+
+完全符合我们的预期,perfect!
+
+也可以通过 Kibana 的 Dev Tools 面板查看“writer”索引,结果如下图所示。
+
+
+
+
+
+
+### 06、鸣谢
+
+好了,我亲爱的小伙伴们,以上就是本文的全部内容了,是不是看完后很想实操一把 Elasticsearch,赶快行动吧!如果你在学习的过程中遇到了问题,欢迎随时和我交流,虽然我也是个菜鸟,但我有热情啊。
+
+另外,如果你想写入门级别的文章,这篇就是最好的范例。
+
+
diff --git a/docs/exception/gailan.md b/docs/exception/gailan.md
new file mode 100644
index 0000000000..6143fd980f
--- /dev/null
+++ b/docs/exception/gailan.md
@@ -0,0 +1,464 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 一文读懂Java异常处理
+
+## 一、什么是异常
+
+“二哥,今天就要学习异常了吗?”三妹问。
+
+“是的。只有正确地处理好异常,才能保证程序的可靠性,所以异常的学习还是很有必要的。”我说。
+
+“那到底什么是异常呢?”三妹问。
+
+“异常是指中断程序正常执行的一个不确定的事件。当异常发生时,程序的正常执行流程就会被打断。一般情况下,程序都会有很多条语句,如果没有异常处理机制,前面的语句一旦出现了异常,后面的语句就没办法继续执行了。”
+
+“有了异常处理机制后,程序在发生异常的时候就不会中断,我们可以对异常进行捕获,然后改变程序执行的流程。”
+
+“除此之外,异常处理机制可以保证我们向用户提供友好的提示信息,而不是程序原生的异常信息——用户根本理解不了。”
+
+“不过,站在开发者的角度,我们更希望看到原生的异常信息,因为这有助于我们更快地找到 bug 的根源,反而被过度包装的异常信息会干扰我们的视线。”
+
+“Java 语言在一开始就提供了相对完善的异常处理机制,这种机制大大降低了编写可靠程序的门槛,这也是 Java 之所以能够流行的原因之一。”
+
+“那导致程序抛出异常的原因有哪些呢?”三妹问。
+
+比如说:
+
+- 程序在试图打开一个不存在的文件;
+- 程序遇到了网络连接问题;
+- 用户输入了糟糕的数据;
+- 程序在处理算术问题时没有考虑除数为 0 的情况;
+
+等等等等。
+
+挑个最简单的原因来说吧。
+
+```java
+public class Demo {
+ public static void main(String[] args) {
+ System.out.println(10/0);
+ }
+}
+```
+
+这段代码在运行的时候抛出的异常信息如下所示:
+
+```
+Exception in thread "main" java.lang.ArithmeticException: / by zero
+ at com.itwanger.s41.Demo.main(Demo.java:8)
+```
+
+“你看,三妹,这个原生的异常信息对用户来说,显然是不太容易理解的,但对于我们开发者来说,简直不要太直白了——很容易就能定位到异常发生的根源。”
+
+## 二、Exception和Error的区别
+
+“哦,我知道了。下一个问题,我经常看到一些文章里提到 Exception 和 Error,二哥你能帮我解释一下它们之间的区别吗?”三妹问。
+
+“这是一个好问题呀,三妹!”
+
+从单词的释义上来看,error 为错误,exception 为异常,错误的等级明显比异常要高一些。
+
+从程序的角度来看,也的确如此。
+
+Error 的出现,意味着程序出现了严重的问题,而这些问题不应该再交给 Java 的异常处理机制来处理,程序应该直接崩溃掉,比如说 OutOfMemoryError,内存溢出了,这就意味着程序在运行时申请的内存大于系统能够提供的内存,导致出现的错误,这种错误的出现,对于程序来说是致命的。
+
+Exception 的出现,意味着程序出现了一些在可控范围内的问题,我们应当采取措施进行挽救。
+
+比如说之前提到的 ArithmeticException,很明显是因为除数出现了 0 的情况,我们可以选择捕获异常,然后提示用户不应该进行除 0 操作,当然了,更好的做法是直接对除数进行判断,如果是 0 就不进行除法运算,而是告诉用户换一个非 0 的数进行运算。
+
+## 三、checked和unchecked异常
+
+“三妹,还能想到其他的问题吗?”
+
+“嗯,不用想,二哥,我已经提前做好预习工作了。”三妹自信地说,“异常又可以分为 checked 和 unchecked,它们之间又有什么区别呢?”
+
+“哇,三妹,果然又是一个好问题呢。”
+
+checked 异常(检查型异常)在源代码里必须显式地捕获或者抛出,否则编译器会提示你进行相应的操作;而 unchecked 异常(非检查型异常)就是所谓的运行时异常,通常是可以通过编码进行规避的,并不需要显式地捕获或者抛出。
+
+“我先画一幅思维导图给你感受一下。”
+
+
+
+首先,Exception 和 Error 都继承了 Throwable 类。换句话说,只有 Throwable 类(或者子类)的对象才能使用 throw 关键字抛出,或者作为 catch 的参数类型。
+
+面试中经常问到的一个问题是,NoClassDefFoundError 和 ClassNotFoundException 有什么区别?
+
+“三妹你知道吗?”
+
+“不知道,二哥,你解释下呗。”
+
+它们都是由于系统运行时找不到要加载的类导致的,但是触发的原因不一样。
+
+- NoClassDefFoundError:程序在编译时可以找到所依赖的类,但是在运行时找不到指定的类文件,导致抛出该错误;原因可能是 jar 包缺失或者调用了初始化失败的类。
+- ClassNotFoundException:当动态加载 Class 对象的时候找不到对应的类时抛出该异常;原因可能是要加载的类不存在或者类名写错了。
+
+
+其次,像 IOException、ClassNotFoundException、SQLException 都属于 checked 异常;像 RuntimeException 以及子类 ArithmeticException、ClassCastException、ArrayIndexOutOfBoundsException、NullPointerException,都属于 unchecked 异常。
+
+unchecked 异常可以不在程序中显示处理,就像之前提到的 ArithmeticException 就是的;但 checked 异常必须显式处理。
+
+比如说下面这行代码:
+
+```java
+Class clz = Class.forName("com.itwanger.s41.Demo1");
+```
+
+如果没做处理,比如说在 Intellij IDEA 环境下,就会提示你这行代码可能会抛出 `java.lang.ClassNotFoundException`。
+
+
+
+建议你要么使用 try-catch 进行捕获:
+
+```java
+try {
+ Class clz = Class.forName("com.itwanger.s41.Demo1");
+} catch (ClassNotFoundException e) {
+ e.printStackTrace();
+}
+```
+
+注意打印异常堆栈信息的 `printStackTrace()` 方法,该方法会将异常的堆栈信息打印到标准的控制台下,如果是测试环境,这样的写法还 OK,如果是生产环境,这样的写法是不可取的,必须使用日志框架把异常的堆栈信息输出到日志系统中,否则可能没办法跟踪。
+
+要么在方法签名上使用 throws 关键字抛出:
+
+```java
+public class Demo1 {
+ public static void main(String[] args) throws ClassNotFoundException {
+ Class clz = Class.forName("com.itwanger.s41.Demo1");
+ }
+}
+```
+
+这样做的好处是不需要对异常进行捕获处理,只需要交给 Java 虚拟机来处理即可;坏处就是没法针对这种情况做相应的处理。
+
+“二哥,针对 checked 异常,我在知乎上看到一个帖子,说 Java 中的 checked 很没有必要,这种异常在编译期要么 try-catch,要么 throws,但又不一定会出现异常,你觉得这样的设计有意义吗?”三妹提出了一个很尖锐的问题。
+
+“哇,这种问题问的好。”我不由得对三妹心生敬佩。
+
+“的确,checked 异常在业界是有争论的,它假设我们捕获了异常,并且针对这种情况作了相应的处理,但有些时候,根本就没法处理。”我说,“就拿上面提到的 ClassNotFoundException 异常来说,我们假设对其进行了 try-catch,可真的出现了 ClassNotFoundException 异常后,我们也没多少的可操作性,再 `Class.forName()` 一次?”
+
+另外,checked 异常也不兼容函数式编程,后面如果你写 Lambda/Stream 代码的时候,就会体验到这种苦涩。
+
+当然了,checked 异常并不是一无是处,尤其是在遇到 IO 或者网络异常的时候,比如说进行 Socket 链接,我大致写了一段:
+
+```java
+public class Demo2 {
+ private String mHost;
+ private int mPort;
+ private Socket mSocket;
+ private final Object mLock = new Object();
+
+ public void run() {
+ }
+
+ private void initSocket() {
+ while (true) {
+ try {
+ Socket socket = new Socket(mHost, mPort);
+ synchronized (mLock) {
+ mSocket = socket;
+ }
+ break;
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+}
+```
+
+当发生 IOException 的时候,socket 就重新尝试连接,否则就 break 跳出循环。意味着如果 IOException 不是 checked 异常,这种写法就略显突兀,因为 IOException 没办法像 ArithmeticException 那样用一个 if 语句判断除数是否为 0 去规避。
+
+或者说,强制性的 checked 异常可以让我们在编程的时候去思考,遇到这种异常的时候该怎么更优雅的去处理。显然,Socket 编程中,肯定是会遇到 IOException 的,假如 IOException 是非检查型异常,就意味着开发者也可以不考虑,直接跳过,交给 Java 虚拟机来处理,但我觉得这样做肯定更不合适。
+
+## 四、关于 try-catch-finally
+
+“二哥,你能告诉我 throw 和 throws 两个关键字的区别吗?”三妹问。
+
+“throw 关键字,用于主动地抛出异常;正常情况下,当除数为 0 的时候,程序会主动抛出 ArithmeticException;但如果我们想要除数为 1 的时候也抛出 ArithmeticException,就可以使用 throw 关键字主动地抛出异常。”我说。
+
+```java
+throw new exception_class("error message");
+```
+
+语法也非常简单,throw 关键字后跟上 new 关键字,以及异常的类型还有参数即可。
+
+举个例子。
+
+```java
+public class ThrowDemo {
+ static void checkEligibilty(int stuage){
+ if(stuage<18) {
+ throw new ArithmeticException("年纪未满 18 岁,禁止观影");
+ } else {
+ System.out.println("请认真观影!!");
+ }
+ }
+
+ public static void main(String args[]){
+ checkEligibilty(10);
+ System.out.println("愉快地周末..");
+ }
+}
+```
+
+这段代码在运行的时候就会抛出以下错误:
+
+```
+Exception in thread "main" java.lang.ArithmeticException: 年纪未满 18 岁,禁止观影
+ at com.itwanger.s43.ThrowDemo.checkEligibilty(ThrowDemo.java:9)
+ at com.itwanger.s43.ThrowDemo.main(ThrowDemo.java:16)
+```
+
+“throws 关键字的作用就和 throw 完全不同。”我说,“[异常处理机制](https://mp.weixin.qq.com/s/fXRJ1xdz_jNSSVTv7ZrYGQ)这小节中讲了 checked exception 和 unchecked exception,也就是检查型异常和非检查型异常;对于检查型异常来说,如果你没有做处理,编译器就会提示你。”
+
+`Class.forName()` 方法在执行的时候可能会遇到 `java.lang.ClassNotFoundException` 异常,一个检查型异常,如果没有做处理,IDEA 就会提示你,要么在方法签名上声明,要么放在 try-catch 中。
+
+
+
+“那什么情况下使用 throws 而不是 try-catch 呢?”三妹问。
+
+“假设现在有这么一个方法 `myMethod()`,可能会出现 ArithmeticException 异常,也可能会出现 NullPointerException。这种情况下,可以使用 try-catch 来处理。”我回答。
+
+```java
+public void myMethod() {
+ try {
+ // 可能抛出异常
+ } catch (ArithmeticException e) {
+ // 算术异常
+ } catch (NullPointerException e) {
+ // 空指针异常
+ }
+}
+```
+
+“但假设有好几个类似 `myMethod()` 的方法,如果为每个方法都加上 try-catch,就会显得非常繁琐。代码就会变得又臭又长,可读性就差了。”我继续说。
+
+“一个解决办法就是,使用 throws 关键字,在方法签名上声明可能会抛出的异常,然后在调用该方法的地方使用 try-catch 进行处理。”
+
+```java
+public static void main(String args[]){
+ try {
+ myMethod1();
+ } catch (ArithmeticException e) {
+ // 算术异常
+ } catch (NullPointerException e) {
+ // 空指针异常
+ }
+}
+public static void myMethod1() throws ArithmeticException, NullPointerException{
+ // 方法签名上声明异常
+}
+```
+
+“好了,我来总结下 throw 和 throws 的区别,三妹,你记一下。”
+
+ 1)throws 关键字用于声明异常,它的作用和 try-catch 相似;而 throw 关键字用于显式的抛出异常。
+
+2)throws 关键字后面跟的是异常的名字;而 throw 关键字后面跟的是异常的对象。
+
+示例。
+
+```
+throws ArithmeticException;
+```
+
+```
+throw new ArithmeticException("算术异常");
+```
+
+ 3)throws 关键字出现在方法签名上,而 throw 关键字出现在方法体里。
+
+4)throws 关键字在声明异常的时候可以跟多个,用逗号隔开;而 throw 关键字每次只能抛出一个异常。
+
+## 五、关于 throw 和 throws
+
+“二哥,[上一节](https://mp.weixin.qq.com/s/fXRJ1xdz_jNSSVTv7ZrYGQ)你讲了异常处理机制,这一节讲什么呢?”三妹问。
+
+“该讲 try-catch-finally 了。”我说,“try 关键字后面会跟一个大括号 `{}`,我们把一些可能发生异常的代码放到大括号里;`try` 块后面一般会跟 `catch` 块,用来处理发生异常的情况;当然了,异常不一定会发生,为了保证发不发生异常都能执行一些代码,就会跟一个 `finally` 块。”
+
+“具体该怎么用呀,二哥?”三妹问。
+
+“别担心,三妹,我一一来说明下。”我说。
+
+`try` 块的语法很简单:
+
+```java
+try{
+// 可能发生异常的代码
+}
+```
+
+“注意啊,三妹,如果一些代码确定不会抛出异常,就尽量不要把它包裹在 `try` 块里,因为加了异常处理的代码执行起来要比没有加的花费更多的时间。”
+
+`catch` 块的语法也很简单:
+
+```java
+try{
+// 可能发生异常的代码
+}catch (exception(type) e(object)){
+// 异常处理代码
+}
+```
+
+一个 `try` 块后面可以跟多个 `catch` 块,用来捕获不同类型的异常并做相应的处理,当 try 块中的某一行代码发生异常时,之后的代码就不再执行,而是会跳转到异常对应的 catch 块中执行。
+
+如果一个 try 块后面跟了多个与之关联的 catch 块,那么应该把特定的异常放在前面,通用型的异常放在后面,不然编译器会提示错误。举例来说。
+
+```java
+static void test() {
+ int num1, num2;
+ try {
+ num1 = 0;
+ num2 = 62 / num1;
+ System.out.println(num2);
+ System.out.println("try 块的最后一句");
+ } catch (ArithmeticException e) {
+ // 算术运算发生时跳转到这里
+ System.out.println("除数不能为零");
+ } catch (Exception e) {
+ // 通用型的异常意味着可以捕获所有的异常,它应该放在最后面,
+ System.out.println("异常发生了");
+ }
+ System.out.println("try-catch 之外的代码.");
+}
+```
+
+“为什么 Exception 不能放到 ArithmeticException 前面呢?”三妹问。
+
+“因为 ArithmeticException 是 Exception 的子类,它更具体,我们看到就这个异常就知道是发生了算术错误,而 Exception 比较泛,它隐藏了具体的异常信息,我们看到后并不确定到底是发生了哪一种类型的异常,对错误的排查很不利。”我说,“再者,如果把通用型的异常放在前面,就意味着其他的 catch 块永远也不会执行,所以编译器就直接提示错误了。”
+
+“再给你举个例子,注意看,三妹。”
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[4]=30/0;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException e){
+ System.out.println("除数必须是 0");
+ } catch(ArrayIndexOutOfBoundsException e){
+ System.out.println("数组越界了");
+ } catch(Exception e){
+ System.out.println("一些其他的异常");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+这段代码在执行的时候,第一个 catch 块会执行,因为除数为零;我再来稍微改动下代码。
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[9]=30/1;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException e){
+ System.out.println("除数必须是 0");
+ } catch(ArrayIndexOutOfBoundsException e){
+ System.out.println("数组越界了");
+ } catch(Exception e){
+ System.out.println("一些其他的异常");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+“我知道,二哥,第二个 catch 块会执行,因为没有发生算术异常,但数组越界了。”三妹没等我把代码运行起来就说出了答案。
+
+“三妹,你说得很对,我再来改一下代码。”
+
+```java
+static void test1 () {
+ try{
+ int arr[]=new int[7];
+ arr[9]=30/1;
+ System.out.println("try 块的最后");
+ } catch(ArithmeticException | ArrayIndexOutOfBoundsException e){
+ System.out.println("除数必须是 0");
+ }
+ System.out.println("try-catch 之外");
+}
+```
+
+“当有多个 catch 的时候,也可以放在一起,用竖划线 `|` 隔开,就像上面这样。”我说。
+
+“这样不错呀,看起来更简洁了。”三妹说。
+
+`finally` 块的语法也不复杂。
+
+```java
+try {
+ // 可能发生异常的代码
+}catch {
+ // 异常处理
+}finally {
+ // 必须执行的代码
+}
+```
+
+在没有 `try-with-resources` 之前,finally 块常用来关闭一些连接资源,比如说 socket、数据库链接、IO 输入输出流等。
+
+```java
+OutputStream osf = new FileOutputStream( "filename" );
+OutputStream osb = new BufferedOutputStream(opf);
+ObjectOutput op = new ObjectOutputStream(osb);
+try{
+ output.writeObject(writableObject);
+} finally{
+ op.close();
+}
+```
+
+“三妹,注意,使用 finally 块的时候需要遵守这些规则。”
+
+- finally 块前面必须有 try 块,不要把 finally 块单独拉出来使用。编译器也不允许这样做。
+- finally 块不是必选项,有 try 块的时候不一定要有 finally 块。
+- 如果 finally 块中的代码可能会发生异常,也应该使用 try-catch 进行包裹。
+- 即便是 try 块中执行了 return、break、continue 这些跳转语句,finally 块也会被执行。
+
+“真的吗,二哥?”三妹对最后一个规则充满了疑惑。
+
+“来试一下就知道了。”我说。
+
+```java
+static int test2 () {
+ try {
+ return 112;
+ }
+ finally {
+ System.out.println("即使 try 块有 return,finally 块也会执行");
+ }
+}
+```
+
+来看一下输出结果:
+
+```
+即使 try 块有 return,finally 块也会执行
+```
+
+“那,会不会有不执行 finally 的情况呀?”三妹很好奇。
+
+“有的。”我斩钉截铁地回答。
+
+- 遇到了死循环。
+- 执行了 `System. exit()` 这行代码。
+
+`System.exit()` 和 `return` 语句不同,前者是用来退出程序的,后者只是回到了上一级方法调用。
+
+“三妹,来看一下源码的文档注释就全明白了!”
+
+
+
+至于参数 status 的值也很好理解,如果是异常退出,设置为非 0 即可,通常用 1 来表示;如果是想正常退出程序,用 0 表示即可。
+
+
\ No newline at end of file
diff --git a/docs/src/exception/npe.md b/docs/exception/npe.md
similarity index 89%
rename from docs/src/exception/npe.md
rename to docs/exception/npe.md
index 1f86928b00..c43debd280 100644
--- a/docs/src/exception/npe.md
+++ b/docs/exception/npe.md
@@ -1,17 +1,11 @@
---
-title: Java空指针NullPointerException的传说
-shortTitle: 空指针的传说
category:
- Java核心
tag:
- - 异常处理
-description: 本文详细解析了Java编程中的空指针异常(NullPointerException)现象,从产生原因、常见场景到预防方法,为您揭开NullPointerException的神秘面纱。文章还提供了实际代码示例,帮助您理解如何在实际开发中避免空指针异常,提高代码的健壮性和可靠性。
-head:
- - - meta
- - name: keywords
- content: java,npe,NullPointerException
+ - Java
---
+# Java空指针NullPointerException的传说
**空指针**,号称天下最强刺客。
@@ -21,13 +15,13 @@ head:
... ...
-我叫王二,我来到这个奇怪的世界已经一年了,我等了一年,穿越附赠的老爷爷、戒指、系统什么的我到现在都没发现。
+我叫铁柱,我来到这个奇怪的世界已经一年了,我等了一年,穿越附赠的老爷爷、戒指、系统什么的我到现在都没发现。
而且这个世界看起来也太奇怪了,这里好像叫什么 **Java** 大陆,我只知道这个世界的最强者叫做 **Object**,听说是什么道祖级的存在,我也不知道是什么意思,毕竟我现在好像还是个菜鸡,别的主角一年都应该要飞升仙界了吧,我还连个小火球都放不出来。
哦,对了,上面的那段话是我在茶馆喝茶的时候听说书的先生说的,总觉得空指针这个名字怪怪的,好像在什么地方听说过。
-我的头痛的毛病又犯了,我已经记不起来我为什么来到这里了,我只记得我的名字叫王二,其他的,我只感觉这个奇怪的世界有一种熟悉,但是我什么都记不起来了。
+我的头痛的毛病又犯了,我已经记不起来我为什么来到这里了,我只记得我的名字叫铁柱,其他的,我只感觉这个奇怪的世界有一种熟悉,但是我什么都记不起来了。
算了,得过且过吧。
@@ -177,7 +171,7 @@ Object听到这话,皱了皱眉,他沉默了一会儿,缓缓站起身子
我见他好像魔怔了,仿佛在思考什么,于是迈步走到他刚才站立的地方看着前面,原来,这是他们的族谱!这里是异常的祠堂!
-
+
看完这张族谱,我恍然大悟,好像明白了什么。突然,我的脑袋里出现了一个冰冷的机器声音:“获取异常族谱,历练完成度+100。”
@@ -223,14 +217,7 @@ Object听到这话,皱了皱眉,他沉默了一会儿,缓缓站起身子
可是,他为什么要给我,看他刚才的样子都想打我了,又突然给了我这些?还有他一直在说的规则之力又是什么?这座城市为什么又这么诡异?
->转载链接:[https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg](https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg),作者:艾小仙
+>转载链接:https://mp.weixin.qq.com/s/PDfd8HRtDZafXl47BCxyGg
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/exception/shijian.md b/docs/exception/shijian.md
new file mode 100644
index 0000000000..9150539c70
--- /dev/null
+++ b/docs/exception/shijian.md
@@ -0,0 +1,219 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# Java异常处理的20个最佳实践
+
+“三妹啊,今天我来给你传授几个异常处理的最佳实践经验,以免你以后在开发中采坑。”我面带着微笑对三妹说。
+
+“好啊,二哥,我洗耳恭听。”三妹也微微一笑,欣然接受。
+
+“好,那哥就不废话了。开整。”
+
+--------
+
+**1)尽量不要捕获 RuntimeException**
+
+阿里出品的嵩山版 Java 开发手册上这样规定:
+
+>尽量不要 catch RuntimeException,比如 NullPointerException、IndexOutOfBoundsException 等等,应该用预检查的方式来规避。
+
+正例:
+
+```java
+if (obj != null) {
+ //...
+}
+```
+
+反例:
+
+```java
+try {
+ obj.method();
+} catch (NullPointerException e) {
+ //...
+}
+```
+
+“哦,那如果有些异常预检查不出来呢?”三妹问。
+
+“的确会存在这样的情况,比如说 NumberFormatException,虽然也属于 RuntimeException,但没办法预检查,所以还是应该用 catch 捕获处理。”我说。
+
+**2)尽量使用 try-with-resource 来关闭资源**
+
+当需要关闭资源时,尽量不要使用 try-catch-finally,禁止在 try 块中直接关闭资源。
+
+反例:
+
+```java
+public void doNotCloseResourceInTry() {
+ FileInputStream inputStream = null;
+ try {
+ File file = new File("./tmp.txt");
+ inputStream = new FileInputStream(file);
+ inputStream.close();
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } catch (IOException e) {
+ log.error(e);
+ }
+}
+```
+
+“为什么呢?”三妹问。
+
+“原因也很简单,因为一旦 `close()` 之前发生了异常,那么资源就无法关闭。直接使用 [try-with-resource](https://mp.weixin.qq.com/s/7yhHOG0SVCfoHdhtZHfeVg) 来处理是最佳方式。”我说。
+
+```java
+public void automaticallyCloseResource() {
+ File file = new File("./tmp.txt");
+ try (FileInputStream inputStream = new FileInputStream(file);) {
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } catch (IOException e) {
+ log.error(e);
+ }
+}
+```
+
+“除非资源没有实现 AutoCloseable 接口。”我补充道。
+
+“那这种情况下怎么办呢?”三妹问。
+
+“就在 finally 块关闭流。”我说。
+
+```java
+public void closeResourceInFinally() {
+ FileInputStream inputStream = null;
+ try {
+ File file = new File("./tmp.txt");
+ inputStream = new FileInputStream(file);
+ } catch (FileNotFoundException e) {
+ log.error(e);
+ } finally {
+ if (inputStream != null) {
+ try {
+ inputStream.close();
+ } catch (IOException e) {
+ log.error(e);
+ }
+ }
+ }
+}
+```
+
+**3)不要捕获 Throwable**
+
+Throwable 是 exception 和 error 的父类,如果在 catch 子句中捕获了 Throwable,很可能把超出程序处理能力之外的错误也捕获了。
+
+```java
+public void doNotCatchThrowable() {
+ try {
+ } catch (Throwable t) {
+ // 不要这样做
+ }
+}
+```
+
+“到底为什么啊?”三妹问。
+
+“因为有些 error 是不需要程序来处理,程序可能也处理不了,比如说 OutOfMemoryError 或者 StackOverflowError,前者是因为 Java 虚拟机无法申请到足够的内存空间时出现的非正常的错误,后者是因为线程申请的栈深度超过了允许的最大深度出现的非正常错误,如果捕获了,就掩盖了程序应该被发现的严重错误。”我说。
+
+“打个比方,一匹马只能拉一车厢的货物,拉两车厢可能就挂了,但一 catch,就发现不了问题了。”我补充道。
+
+**4)不要省略异常信息的记录**
+
+很多时候,由于疏忽大意,开发者很容易捕获了异常却没有记录异常信息,导致程序上线后真的出现了问题却没有记录可查。
+
+```java
+public void doNotIgnoreExceptions() {
+ try {
+ } catch (NumberFormatException e) {
+ // 没有记录异常
+ }
+}
+```
+
+应该把错误信息记录下来。
+
+```java
+public void logAnException() {
+ try {
+ } catch (NumberFormatException e) {
+ log.error("哦,错误竟然发生了: " + e);
+ }
+}
+```
+
+**5)不要记录了异常又抛出了异常**
+
+这纯属画蛇添足,并且容易造成错误信息的混乱。
+
+反例:
+
+```java
+try {
+} catch (NumberFormatException e) {
+ log.error(e);
+ throw e;
+}
+```
+
+要抛出就抛出,不要记录,记录了又抛出,等于多此一举。
+
+反例:
+
+```java
+public void wrapException(String input) throws MyBusinessException {
+ try {
+ } catch (NumberFormatException e) {
+ throw new MyBusinessException("错误信息描述:", e);
+ }
+}
+```
+
+这种也是一样的道理,既然已经捕获了,就不要在方法签名上抛出了。
+
+**6)不要在 finally 块中使用 return**
+
+阿里出品的嵩山版 Java 开发手册上这样规定:
+
+>try 块中的 return 语句执行成功后,并不会马上返回,而是继续执行 finally 块中的语句,如果 finally 块中也存在 return 语句,那么 try 块中的 return 就将被覆盖。
+
+反例:
+
+```java
+private int x = 0;
+public int checkReturn() {
+ try {
+ return ++x;
+ } finally {
+ return ++x;
+ }
+}
+```
+
+“哦,确实啊,try 块中 x 返回的值为 1,到了 finally 块中就返回 2 了。”三妹说。
+
+“是这样的。”我点点头。
+
+----------
+
+“好了,三妹,关于异常处理实践就先讲这 6 条吧,实际开发中你还会碰到其他的一些坑,自己踩一踩可能印象更深刻一些。”我说。
+
+“那万一到时候我工作后被领导骂了怎么办?”三妹委屈地说。
+
+“新人嘛,总要写几个 bug 才能对得起新人这个称号嘛。”我轻描淡写地说。
+
+“好吧。”三妹无奈地叹了口气。
+
+
+
+
+
+
+
diff --git a/docs/exception/try-with-resouces.md b/docs/exception/try-with-resouces.md
new file mode 100644
index 0000000000..51f5f26a68
--- /dev/null
+++ b/docs/exception/try-with-resouces.md
@@ -0,0 +1,301 @@
+---
+category:
+ - Java核心
+tag:
+ - Java
+---
+
+# 详解Java7新增的try-with-resouces语法
+
+
+“二哥,终于等到你讲 try-with-resouces 了!”三妹夸张的表情让我有些吃惊。
+
+“三妹,不要激动呀!开讲之前,我们还是要来回顾一下 try–catch-finally,好做个铺垫。”我说,“来看看这段代码吧。”
+
+```java
+public class TrycatchfinallyDecoder {
+ public static void main(String[] args) {
+ BufferedReader br = null;
+ try {
+ String path = TrycatchfinallyDecoder.class.getResource("/牛逼.txt").getFile();
+ String decodePath = URLDecoder.decode(path,"utf-8");
+ br = new BufferedReader(new FileReader(decodePath));
+
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ System.out.println(str);
+ }
+ } catch (IOException e) {
+ e.printStackTrace();
+ } finally {
+ if (br != null) {
+ try {
+ br.close();
+ } catch (IOException e) {
+ e.printStackTrace();
+ }
+ }
+ }
+ }
+}
+```
+
+“我简单来解释下。”等三妹看完这段代码后,我继续说,“在 try 块中读取文件中的内容,并一行一行地打印到控制台。如果文件找不到或者出现 IO 读写错误,就在 catch 中捕获并打印错误的堆栈信息。最后,在 finally 中关闭缓冲字符读取器对象 BufferedReader,有效杜绝了资源未被关闭的情况下造成的严重性能后果。”
+
+“在 Java 7 之前,try–catch-finally 的确是确保资源会被及时关闭的最佳方法,无论程序是否会抛出异常。”
+
+三妹点了点头,表示同意。
+
+“不过,这段代码还是有些臃肿,尤其是 finally 中的代码。”我说,“况且,try–catch-finally 至始至终存在一个严重的隐患:try 中的 `br.readLine()` 有可能会抛出 `IOException`,finally 中的 `br.close()` 也有可能会抛出 `IOException`。假如两处都不幸地抛出了 IOException,那程序的调试任务就变得复杂了起来,到底是哪一处出了错误,就需要花一番功夫,这是我们不愿意看到的结果。”
+
+“我来给你演示下,三妹。”
+
+“首先,我们来定义这样一个类 MyfinallyReadLineThrow,它有两个方法,分别是 `readLine()` 和 `close()`,方法体都是主动抛出异常。”
+
+```java
+class MyfinallyReadLineThrow {
+ public void close() throws Exception {
+ throw new Exception("close");
+ }
+
+ public void readLine() throws Exception {
+ throw new Exception("readLine");
+ }
+}
+```
+
+“然后在 `main()` 方法中使用 try-catch-finally 的方式调用 MyfinallyReadLineThrow 的 `readLine()` 和 `close()` 方法。”
+
+```java
+public class TryfinallyCustomReadLineThrow {
+ public static void main(String[] args) throws Exception {
+ MyfinallyReadLineThrow myThrow = null;
+ try {
+ myThrow = new MyfinallyReadLineThrow();
+ myThrow.readLine();
+ } finally {
+ myThrow.close();
+ }
+ }
+}
+```
+
+运行上述代码后,错误堆栈如下所示:
+
+```
+Exception in thread "main" java.lang.Exception: close
+ at com.cmower.dzone.trycatchfinally.MyfinallyOutThrow.close(TryfinallyCustomOutThrow.java:17)
+ at com.cmower.dzone.trycatchfinally.TryfinallyCustomOutThrow.main(TryfinallyCustomOutThrow.java:10)
+```
+
+“看出来问题了吗,三妹?”
+
+“啊?`readLine()` 方法的异常信息竟然被 `close()` 方法的堆栈信息吃了!”
+
+“不错啊,三妹,火眼金睛,的确,这会让我们误以为要调查的目标是 `close()` 方法而不是 `readLine()` 方法——尽管它也是应该怀疑的对象。”
+
+“但有了 try-with-resources 后,这些问题就迎刃而解了。前提条件只有一个,就是需要释放的资源(比如 BufferedReader)实现了 AutoCloseable 接口。”
+
+```java
+try (BufferedReader br = new BufferedReader(new FileReader(decodePath));) {
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ System.out.println(str);
+ }
+} catch (IOException e) {
+ e.printStackTrace();
+}
+```
+
+“你瞧,三妹,finally 块消失了,取而代之的是把要释放的资源写在 try 后的 `()` 中。如果有多个资源(BufferedReader 和 PrintWriter)需要释放的话,可以直接在 `()` 中添加。”
+
+```java
+try (BufferedReader br = new BufferedReader(new FileReader(decodePath));
+ PrintWriter writer = new PrintWriter(new File(writePath))) {
+ String str = null;
+ while ((str =br.readLine()) != null) {
+ writer.print(str);
+ }
+} catch (IOException e) {
+ e.printStackTrace();
+}
+```
+
+“如果想释放自定义资源的话,只要让它实现 AutoCloseable 接口,并提供 `close()` 方法即可。”
+
+```java
+public class TrywithresourcesCustom {
+ public static void main(String[] args) {
+ try (MyResource resource = new MyResource();) {
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+
+class MyResource implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+}
+```
+
+来看一下代码运行后的输出结果:
+
+```
+关闭自定义资源
+```
+
+“好神奇呀!”三妹欣喜若狂,“在 `try ()` 中只是 new 了一个 MyResource 的对象,其他什么也没干,`close()` 方法就执行了!”
+
+“想知道为什么吗?三妹。”
+
+“当然想啊。”
+
+“来看看反编译后的字节码吧。”
+
+```java
+class MyResource implements AutoCloseable {
+ MyResource() {
+ }
+
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+}
+
+public class TrywithresourcesCustom {
+ public TrywithresourcesCustom() {
+ }
+
+ public static void main(String[] args) {
+ try {
+ MyResource resource = new MyResource();
+ resource.close();
+ } catch (Exception var2) {
+ var2.printStackTrace();
+ }
+
+ }
+}
+```
+
+“啊,原来如此。编译器主动为 try-with-resources 进行了变身,在 try 中调用了 `close()` 方法。”
+
+“是这样的。接下来,我们在 `MyResourceOut` 类中再添加一个 `out()` 方法。”
+
+```java
+class MyResourceOut implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ System.out.println("关闭自定义资源");
+ }
+
+ public void out() throws Exception{
+ System.out.println("沉默王二,一枚有趣的程序员");
+ }
+}
+```
+
+“这次,我们在 try 中调用一下 `out()` 方法。”
+
+```java
+public class TrywithresourcesCustomOut {
+ public static void main(String[] args) {
+ try (MyResourceOut resource = new MyResourceOut();) {
+ resource.out();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+“再来看一下反编译的字节码。”
+
+```
+public class TrywithresourcesCustomOut {
+ public TrywithresourcesCustomOut() {
+ }
+
+ public static void main(String[] args) {
+ try {
+ MyResourceOut resource = new MyResourceOut();
+
+ try {
+ resource.out();
+ } catch (Throwable var5) {
+ try {
+ resource.close();
+ } catch (Throwable var4) {
+ var5.addSuppressed(var4);
+ }
+
+ throw var5;
+ }
+
+ resource.close();
+ } catch (Exception var6) {
+ var6.printStackTrace();
+ }
+
+ }
+}
+```
+
+“这次,`catch` 块主动调用了 `resource.close()`,并且有一段很关键的代码 ` var5.addSuppressed(var4)`。”
+
+“这是为了什么呢?”三妹问。
+
+“当一个异常被抛出的时候,可能有其他异常因为该异常而被抑制住,从而无法正常抛出。这时可以通过 `addSuppressed()` 方法把这些被抑制的方法记录下来,然后被抑制的异常就会出现在抛出的异常的堆栈信息中,可以通过 `getSuppressed()` 方法来获取这些异常。这样做的好处是不会丢失任何异常,方便我们进行调试。”我说。
+
+“有没有想到之前的那个例子——在 try-catch-finally 中,`readLine()` 方法的异常信息竟然被 `close()` 方法的堆栈信息吃了。现在有了 try-with-resources,再来看看和 `readLine()` 方法一致的 `out()` 方法会不会被 `close()` 吃掉吧。”
+
+```java
+class MyResourceOutThrow implements AutoCloseable {
+ @Override
+ public void close() throws Exception {
+ throw new Exception("close()");
+ }
+
+ public void out() throws Exception{
+ throw new Exception("out()");
+ }
+}
+```
+
+“调用这 2 个方法。”
+
+```java
+public class TrywithresourcesCustomOutThrow {
+ public static void main(String[] args) {
+ try (MyResourceOutThrow resource = new MyResourceOutThrow();) {
+ resource.out();
+ } catch (Exception e) {
+ e.printStackTrace();
+ }
+ }
+}
+```
+
+“程序输出的结果如下所示。”
+
+```
+java.lang.Exception: out()
+ at com.cmower.dzone.trycatchfinally.MyResourceOutThrow.out(TrywithresourcesCustomOutThrow.java:20)
+ at com.cmower.dzone.trycatchfinally.TrywithresourcesCustomOutThrow.main(TrywithresourcesCustomOutThrow.java:6)
+ Suppressed: java.lang.Exception: close()
+ at com.cmower.dzone.trycatchfinally.MyResourceOutThrow.close(TrywithresourcesCustomOutThrow.java:16)
+ at com.cmower.dzone.trycatchfinally.TrywithresourcesCustomOutThrow.main(TrywithresourcesCustomOutThrow.java:5)
+```
+
+“瞧,这次不会了,`out()` 的异常堆栈信息打印出来了,并且 `close()` 方法的堆栈信息上加了一个关键字 `Suppressed`,一目了然。”
+
+“三妹,怎么样?是不是感觉 try-with-resouces 好用多了!我来简单总结下哈,在处理必须关闭的资源时,始终有限考虑使用 try-with-resources,而不是 try–catch-finally。前者产生的代码更加简洁、清晰,产生的异常信息也更靠谱。”
+
+“靠谱!”三妹说。
+
+
+
+
diff --git a/docs/src/git/git-qiyuan.md b/docs/git/git-qiyuan.md
similarity index 87%
rename from docs/src/git/git-qiyuan.md
rename to docs/git/git-qiyuan.md
index ed60af3df6..10f83e0103 100644
--- a/docs/src/git/git-qiyuan.md
+++ b/docs/git/git-qiyuan.md
@@ -1,24 +1,24 @@
---
-title: 1小时彻底掌握 Git,(可能是)史上最简单明了的 Git 教程
-shortTitle: 最简单明了的 Git 教程
category:
- - 开发/构建工具
+ - Java企业级开发
tag:
- Git
-description: 二哥的Java进阶之路,小白的零基础Java教程,从入门到进阶,1小时彻底掌握 Git,(可能是)史上最简单明了的 Git 教程
-head:
- - - meta
- - name: keywords
- content: Java,Java SE,Java基础,Java教程,二哥的Java进阶之路,Java进阶之路,Git入门,Git教程,git
---
+# 我在工作中是如何使用 Git 的
+
## 一、Git 起源
Git 是一个分布式版本控制系统,缔造者是大名鼎鼎的林纳斯·托瓦茲 (Linus Torvalds),Git 最初的目的是为了能更好的管理 Linux 内核源码。
-
+
+
+PS:**为了能够帮助更多的 Java 爱好者,已将《Java 程序员进阶之路》开源到了 GitHub(本篇已收录)。如果你也喜欢这个专栏,觉得有帮助的话,可以去点个 star,这样也方便以后进行更系统化的学习**:
+[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)
+
+*每天看着 star 数的上涨我心里非常的开心,希望越来越多的 Java 爱好者能因为这个开源项目而受益,而越来越多人的 star,也会激励我继续更新下去*~
大家都知道,Linux 内核是开源的,参与者众多,到目前为止,共有两万多名开发者给 Linux Kernel 提交过代码。
@@ -54,7 +54,7 @@ Junio Hamano 觉得 Linus 设计的这些命令对于普通用户不太友好,
如今,Git 已经成为全球软件开发者的标配。
-
+
原本的 Git 只适用于 Unix/Linux 平台,但随着 Cygwin、msysGit 环境的成熟,以及 TortoiseGit 这样易用的GUI工具,Git 在 Windows 平台下也逐渐成熟。
@@ -65,7 +65,7 @@ Junio Hamano 觉得 Linus 设计的这些命令对于普通用户不太友好,
Git 和传统的版本控制工具 CVS、SVN 有不小的区别,前者关心的是文件的整体性是否发生了改变,后两者更关心文件内容上的差异。
-
+
除此之外,Git 更像是一个文件系统,每个使用它的主机都可以作为版本库,并且不依赖于远程仓库而离线工作。开发者在本地就有历史版本的副本,因此就不用再被远程仓库的网络传输而束缚。
@@ -88,7 +88,7 @@ Git 中的绝大多数操作都只需要访问本地文件和资源,一般不
Git 的工作流程是这样的:
-
+
- 在工作目录中修改文件
@@ -102,11 +102,11 @@ Git 的工作流程是这样的:
>https://git-scm.com/downloads
-
+
我个人使用的 macOS 系统,可以直接使用 `brew install git` 命令安装,非常方便。
-
+
安装成功后,再使用 `git --version` 就可以查看版本号了,我本机上安装的是 2.23.0 版本。
@@ -287,7 +287,7 @@ TREE: 目录树对象。在 Linus 的设计里,TREE 对象就是一个时间
另外,由于 TREE 上记录文件名及属性信息,对于修改文件属性或修改文件名、移动目录而不修改文件内容的情况,可以复用 BLOB 对象,节省存储资源。而 Git 在后来的开发演进中又优化了 TREE 的设计,变成了某一时间点文件夹信息的抽象,TREE 包含其子目录的 TREE 的对象信息(SHA1)。这样,对于目录结构很复杂或层级较深的 Git 库 可以节约存储资源。历史信息被记录在第三种对象 CHANGESET 里。
-
+
CHANGESET:即 Commit 对象。一个 CHANGESET 对象中记录了该次提交的 TREE 对象信息(SHA1),以及提交者(committer)、提交备注(commit message)等信息。
@@ -304,7 +304,7 @@ Linus 解释了“当前目录缓存”的设计,该缓存就是一个二进
- 1. 能够快速的复原缓存的完整内容,即使不小心把当前工作区的文件删除了,也可以从缓存中恢复所有文件;
- 2. 能够快速找出缓存中和当前工作区内容不一致的文件。
-
+
Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,并可以编译使用。代码极为简洁,加上 Makefile 一共只有 848 行。感兴趣的话可以通过上一段所述方法 checkout Git 最早的 commit 上手编译玩玩,只要有 Linux 环境即可。
@@ -332,7 +332,7 @@ Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,
一般来说,日常使用只要记住下图中这 6 个命令就可以了,但是熟练使用 Git,恐怕要记住60~100个命令~
-
+
@@ -347,7 +347,7 @@ Linus 在 Git 的第一次代码提交里便完成了 Git 的最基础功能,
下面是阮一峰老师整理的常用 Git 命令清单,有必要的话,可以打印一份出来,放在工作台~
->[http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html](http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html)
+>http://www.ruanyifeng.com/blog/2015/12/git-cheat-sheet.html
### 1、新建代码库
@@ -641,7 +641,7 @@ $ git archive
但是,太方便了也会产生副作用。如果你不加注意,很可能会留下一个枝节蔓生、四处开放的版本库,到处都是分支,完全看不出主干发展的脉络。
-
+
那有没有一个好的分支策略呢?答案当然是有的。
@@ -650,7 +650,7 @@ $ git archive
首先,代码库应该有一个、且仅有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。
-
+
Git主分支的名字,默认叫做Master。它是自动建立的,版本库初始化以后,默认就是在主分支在进行开发。
@@ -658,7 +658,7 @@ Git主分支的名字,默认叫做Master。它是自动建立的,版本库
主分支只用来发布重大版本,日常开发应该在另一条分支上完成。我们把开发用的分支,叫做Develop。
-
+
这个分支可以用来生成代码的最新隔夜版本(nightly)。如果想正式对外发布,就在Master分支上,对Develop分支进行"合并"(merge)。
@@ -680,11 +680,11 @@ Git创建Develop分支的命令:
这里稍微解释一下上一条命令的--no-ff参数是什么意思。默认情况下,Git执行"快进式合并"(fast-farward merge),会直接将Master分支指向Develop分支。
-
+
使用--no-ff参数后,会执行正常合并,在Master分支上生成一个新节点。为了保证版本演进的清晰,我们希望采用这种做法。
-
+
### 3、临时性分支
@@ -702,7 +702,7 @@ Git创建Develop分支的命令:
**第一种是功能分支**,它是为了开发某种特定功能,从Develop分支上面分出来的。开发完成后,要再并入Develop。
-
+
功能分支的名字,可以采用feature-*的形式命名。
@@ -755,7 +755,7 @@ Git创建Develop分支的命令:
修补bug分支是从Master分支上面分出来的。修补结束以后,再合并进Master和Develop分支。它的命名,可以采用fixbug-*的形式。
-
+
创建一个修补bug分支:
```
@@ -791,7 +791,7 @@ Git创建Develop分支的命令:
新建一个文件夹,比如说 testgit,然后使用 `git init` 命令就可以把这个文件夹初始化为 Git 仓库了。
-
+
初始化Git 仓库成功后,可以看到多了一个 .git 的目录,没事不要乱动,免得破坏了 Git 仓库的结构。
@@ -802,17 +802,17 @@ Git创建Develop分支的命令:
第二步,使用 `git commit` 命令告诉 Git,把文件提交到仓库。
-
+
可以使用 `git status` 来查看是否还有文件未提交。
也可以在文件中新增一行内容“传统美德不能丢,记得点赞哦~”,再使用 `git status` 来查看结果。
-
+
如果想查看文件到底哪里做了修改,可以使用 `git diff` 命令:
-
+
确认修改的内容后,可以使用 `git add` 和 `git commit` 再次提交。
@@ -822,11 +822,11 @@ Git创建Develop分支的命令:
现在我已经对 readme.txt 文件做了三次修改了。可以通过 `git log` 命令来查看历史记录:
-
+
也可以通过 `gitk` 这个命令来启动图形化界面来查看版本历史。
-
+
如果想回滚的话,比如说回滚到上一个版本,可以执行以下两种命令:
@@ -835,15 +835,15 @@ Git创建Develop分支的命令:
2)`git reset --hard HEAD~100`,如果回滚到前 100 个版本,用这个命令比上一个命令更方便。
-
+
那假如回滚错了,想恢复,不记得版本号了,可以先执行 `git reflog` 命令查看版本号:
-
+
然后再通过 `git reset --hard` 命令来恢复:
-
+
### 3、工作区和暂存区的区别
@@ -865,7 +865,7 @@ Git 在提交文件的时候分两步,第一步 `git add` 命令是把文件
原子性带来的好处是显而易见的,这使得我们可以把项目整体还原到某个时间点,就这一点,SVN 就完虐 CVS 这些代码版本管理系统了。
-
+
Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个优良特性的。但不同于 SVN 的是,Git 一开始搞的都是命令行,没有图形化界面,如果想要像 SVN 那样一次性选择多个文件或者不选某些文件(见上图),还真特喵的是个麻烦事。
@@ -881,7 +881,7 @@ Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个
我们先用 `git status` 命令查看一下状态,再用 `git add` 将文件添加到暂存区,最后再用 `git commit` 一次性提交到 Git 仓库。
-
+
### 4、撤销修改
@@ -895,17 +895,17 @@ Git 作为逼格最高的代码版本管理系统,自然要借鉴 SVN 这个
答案当然是有了,其实在我们执行 `git status` 命令查看 Git 状态的时候,结果就提示我们可以使用 `git restore` 命令来撤销这次操作的。
-
+
那其实在 git version 2.23.0 版本之前,是可以通过 `git checkout` 命令来完成撤销操作的。
-
+
checkout 可以创建分支、导出分支、切换分支、从暂存区删除文件等等,一个命令有太多功能就容易让人产生混淆。2.23.0 版本改变了这种混乱局面,git switch 和 git restore 两个新的命令应运而生。
switch 专注于分支的切换,restore 专注于撤销修改。
-
+
### 5、远程仓库
@@ -923,7 +923,7 @@ Git 是一款分布式版本控制系统,所以同一个 Git 仓库,可以
**第一步,通过 `ls -al ~/.ssh` 命令检查 SSH 密钥是否存在**
-
+
如果没有 id_rsa.pub、id_ecdsa.pub、id_ed25519.pub 这 3 个文件,表示密钥不存在。
@@ -932,26 +932,26 @@ Git 是一款分布式版本控制系统,所以同一个 Git 仓库,可以
执行以下命令,注意替换成你的邮箱:
```
-ssh-keygen -t ed25519 -C "your_email@example.com"
+ssh-keygen -t ed25519 -C "your_email@example.com
```
然后一路回车:
-
+
记得复制一下密钥,在 id_ed25519.pub 文件中:
-
+
**第三步,添加 SSH 密钥到 GitHub 帐户**
在个人账户的 settings 菜单下找到 SSH and GPG keys,将刚刚复制的密钥添加到 key 这一栏中,点击「add SSH key」提交。
-
+
Title 可不填写,提交成功后会列出对应的密钥:
-
+
**为什么 GitHub 需要 SSH 密钥呢**?
@@ -961,17 +961,17 @@ Title 可不填写,提交成功后会列出对应的密钥:
点击新建仓库,填写仓库名称等信息:
-
+
**第五步,把本地仓库同步到 GitHub**
复制远程仓库的地址:
-
+
在本地仓库中执行 `git remote add` 命令将 GitHub 仓库添加到本地:
-
+
当我们第一次使用Git 的 push 命令连接 GitHub 时,会得到一个警告⚠️:
@@ -985,28 +985,28 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
接下来,我们使用 `git push` 命令将当前本地分支推送到 GitHub。加上了 -u 参数后,Git 不但会把本地的 master 分支推送的远程 master 分支上,还会把本地的 master 分支和远程的master 分支关联起来,在以后的推送或者拉取时就可以简化命令(比如说 `git push github master`)。
-
+
此时,我们刷一下 GitHub,可以看到多了一个 master 分支,并且本地的两个文件都推送成功了!
-
+
从现在开始,只要本地做了修改,就可以通过 `git push` 命令推送到 GitHub 远程仓库了。
还可以使用 `git clone` 命令将远程仓库拷贝到本地。比如说我现在有一个 3.4k star 的仓库 JavaBooks,
-
+
然后我使用 `git clone` 命令将其拷贝到本地。
-
+
## 八、详解 sparse-checkout 命令
-前天不是搭建了一个《二哥的Java进阶之路》的网站嘛,其中用到了 Git 来作为云服务器和 GitHub 远程仓库之间的同步工具。
+前天不是搭建了一个《Java 程序员进阶之路》的网站嘛,其中用到了 Git 来作为云服务器和 GitHub 远程仓库之间的同步工具。
-
+
@@ -1017,9 +1017,9 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
### 1、使用 Git 中遇到的一个大麻烦
-首先给大家通报一下,一天前[上线的《二哥的Java进阶之路》网站](https://javabetter.cn),目前访问次数已经突破 1000 了。
+首先给大家通报一下,一天前[上线的《Java 程序员进阶之路》网站](https://tobebetterjavaer.com),目前访问次数已经突破 1000 了。
-
+
正所谓**不积跬步无以至千里,不积小流无以成江海**。
@@ -1034,7 +1034,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
大家可以先看一下我这个 GitHub 仓库的目录结构哈。
-
+
- docs 是文档目录,里面是 md 文件,所有的教程原稿都在这里。
- codes 是代码目录,里面是教程的配套源码。
@@ -1042,11 +1042,11 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
这样就可以利用 GitHub 来做免费的图床,并且还可以白票 jsDelivr CDN 的全球加速,简直不要太爽!
-
+
比如说 images 目录下有一张 logo 图 logo-01.png:
-
+
如果使用 GitHub 仓库的原始路径来访问的话,速度贼慢!
@@ -1054,7 +1054,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
使用 jsDelivr 加速后就不一样了,速度飞起!
->https://cdn.paicoding.com/tobebetterjavaer/images/logo-01.png
+>http://cdn.tobebetterjavaer.com/tobebetterjavaer/images/logo-01.png
简单总结下 GitHub 作为图床的正确用法,就两条:
@@ -1064,7 +1064,7 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
付费七牛云或者阿里云图床的小伙伴不妨试试这种方式,能白票咱绝不花一分冤枉钱。
-那也就是说,《二哥的Java进阶之路》网站上的图片都是通过 GitHub 图床加载的,不需要将图片从 GitHub 仓库拉取到云服务器上。要知道,一台云服务器的空间是极其昂贵的,能省的空间咱必须得省。
+那也就是说,《Java 程序员进阶之路》网站上的图片都是通过 GitHub 图床加载的,不需要将图片从 GitHub 仓库拉取到云服务器上。要知道,一台云服务器的空间是极其昂贵的,能省的空间咱必须得省。
### 2、学习 Git 中遇到的一个大惊喜
@@ -1074,16 +1074,16 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
最后还是浏览 Git 官方手册(也可以看[Pro Git](https://mp.weixin.qq.com/s/RpFzXOa2VlFNd7ylLmr9LQ))才找到了一个牛逼的命令:**git sparse-checkout,它可以帮助我们在拉取远程仓库的时候只同步那些我们想要的目录和文件**。
-
+
具体怎么用,可以看官方文档:
->[https://git-scm.com/docs/git-sparse-checkout](https://git-scm.com/docs/git-sparse-checkout)
+>https://git-scm.com/docs/git-sparse-checkout
但没必要,hhhh,我们直接实战。
第一步,通过 `git remote add -f orgin git@github.com:itwanger/toBeBetterJavaer.git` 命令从 GitHub 上拉取仓库。
-
+
第二步,启用 sparse-checkout,并初始化
@@ -1091,30 +1091,30 @@ Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
然后再执行 `git sparse-checkout init` 初始化。
-
+
第三步,使用 sparse-checkout 来拉取我们想要的仓库目录
-
+
比如说,我们只想拉取 docs 目录,可以执行 `git sparse-checkout set docs` 命令。
-
+
如果是第一次使用 sparse-checkout 的话,还需要执行一下 `git pull orgin master` 命令拉取一次。
-
+
第四步,验证是否生效
可以执行 `ls -al` 命令来确认 sparse-checkout 是否生效。
-
+
如图所示,确实只拉取到了 docs 目录。
假如还想要拉取其他文件或者目录的话,可以通过 `git sparse-checkout add` 命令来添加。
-
+
这就实现了,**远程仓库和云服务器仓库之间的定制化同步,需要什么目录和文件就同步什么目录和文件,不需要的可以统统不要**。
@@ -1122,13 +1122,13 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
我对比了一下,远程仓库大概 145 M,图片就占了 72 M,妥妥地省下了一半的存储空间。
-
+
如何禁用 git sparse-checkout 呢?
也简单,只需要执行一下 `git sparse-checkout disable` 命令就可以了。
-
+
可以看到,那些我们不想要的目录和文件统统都又回来了。
@@ -1136,7 +1136,7 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
也简单,只需要执行一下 `git sparse-checkout reapply` 命令就可以了。
-
+
简单总结下:如果你要把一个庞大到撑满你硬盘的远程仓库拉取到本地,而你只需要其中的一部分目录和文件,那就可以试一试
`git sparse-checkout` 了。
@@ -1147,7 +1147,7 @@ GitHub 仓库可以免费用,空间也无限大,但云服务可是要抠抠
不得不说,Git 实在是太强大了。就一行命令,解决了困扰我一天的烦恼,我的 80G 存储空间的云服务器又可以再战 3 年了,从此以后再也不用担心了。
-
+
Git 是真的牛逼,Linus 是真的牛逼,神不愧是神!
@@ -1161,16 +1161,9 @@ Git 是真的牛逼,Linus 是真的牛逼,神不愧是神!
参考资料:
->- 维基百科:[https://zh.wikipedia.org/wiki/Git](https://zh.wikipedia.org/wiki/Git)
+>- 维基百科:https://zh.wikipedia.org/wiki/Git
>- hutusi:[改变世界的一次代码提交](https://mp.weixin.qq.com/s/gM__sQPILkAKWsMejOO8cA)
-----
-
-GitHub 上标星 10000+ 的开源知识库《[二哥的 Java 进阶之路](https://github.com/itwanger/toBeBetterJavaer)》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:[太赞了,GitHub 上标星 10000+ 的 Java 教程](https://javabetter.cn/overview/)
-
-
-微信搜 **沉默王二** 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 **222** 即可免费领取。
-
-
+
diff --git a/docs/git/progit.md b/docs/git/progit.md
new file mode 100644
index 0000000000..a7ac49e746
--- /dev/null
+++ b/docs/git/progit.md
@@ -0,0 +1,38 @@
+今天给大家分享一本个人最近看过觉得非常不错的Git开源手册,可能有些小伙伴也看过了,我是最近在通勤路上用PAD看的。这本开源手册,它除了有**PDF版**,还有**epub电子书版**,非常适合电子阅读,有需要的小伙伴可以在文末自行下载:
+
+
+
+相信看完对于个人Git知识体系的梳理和掌握是非常有帮助的。
+
+这本手册在豆瓣上评价极高,之前9.3,现在也有9.1的高分,其作者是GitHub的员工,内容主要侧重于各种场合中的惯用法和底层原理的讲述,手册中还针对不同的使用场景,设计了几个合适的版本管理策略。简而言之,这本手册无论是对于初学者还是想进一步了解Git工作原理的开发者都非常合适。
+
+
+
+
+
+这个手册一共分为十章,详细内容如下:
+
+
+
+**手册中部分内容展示如下:**
+
+
+
+
+
+
+
+
+
+**需要该Git手册PDF+epub电子书的小伙伴:**
+
+
+
+可直接长按扫码关注下方二维码,回复 「**git**」 即可下载:
+
+
+
+
+好了,这次资源分享就到这里!后续如果遇到有用的工具或者资源,依然还会持续分享,也欢迎大家多多安利和交流,一起分享成长。
+
+以上,我们下篇见。
diff --git a/docs/gongju/Chocolatey-Homebrew.md b/docs/gongju/Chocolatey-Homebrew.md
new file mode 100644
index 0000000000..6e94190936
--- /dev/null
+++ b/docs/gongju/Chocolatey-Homebrew.md
@@ -0,0 +1,231 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+title: Chocolatey Homebrew:两款惊艳的Shell软件管理器
+---
+
+小二是公司新来的实习生,之前面试的过程中对答如流,所以我非常看好他。第一天,我给他了一台新电脑,要他先在本地搭建个 Java 开发环境。
+
+二话不说,他就开始马不停蹄地行动了。真没想到,他竟然是通过命令行的方式安装的 JDK,这远远超出了我对他的预期。
+
+我以为,他会使用图形化的方式来安装 JDK 的,就像这样。
+
+
+
+还有这样。
+
+
+
+结果他是这样的。
+
+
+
+卧槽!牛逼高大上啊!
+
+看着他熟练地在命令行里安装 JDK 的样子,我的嘴角开始微微上扬,真不错!这次总算招到了一个靠谱的。
+
+于是我就安排他做一个记录,打算发表在我的小破站《Java 程序员进阶之路》上。从他嘴里了解到,他用的命令行软件管理器叫 chocolatey,这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,我感觉非常酷炫。
+
+
+
+
+以下是他的记录,一起来欣赏下。
+
+### 关于shell
+
+对于一名 Java 后端程序员来说,初学阶段,你可以选择在 IDE 中直接编译运行 Java 代码,但有时候也需要在 Shell 下编译和运行 Java 代码。
+
+>Windows 下自带的 Shell 叫命令提示符,或者 cmd 或者 powershell,macOS 下叫终端 terminal。
+
+- [终端与 Shell 的区别](https://mp.weixin.qq.com/s?__biz=MzIxNzQwNjM3NA==&mid=2247491253&idx=1&sn=9a46879174f7240267fe5b5205d16d22&scene=21#wechat_redirect)
+- [初次体验 macOS 下的 Shell](https://mp.weixin.qq.com/s/oEo8N3nE0wR1zl7qD4nh3w)
+
+但当你需要在生产环境下部署 Java项目或者查看日志的话,就必然会用到 Shell,这个阶段,Shell 的使用频率高到可以用一个成语来形容——朝夕相伴。
+
+一些第三方软件会在原生的 Shell 基础上提供更强大的功能,常见的有 tabby、Warp、xhsell、FinalShell、MobaXterm、Aechoterm、WindTerm、termius、iterm2 等等,有些只能在 Windows 上使用,有些只能在 macOS 上使用,有些支持全平台。还有 ohmyzsh 这种超神的 Shell 美化工具。
+
+这里,我们列举一些 Shell 的基本操作命令(Windows 和 macOS/Linux 有些许差异):
+
+- 切换目录,可以使用 cd 命令切换目录,`cd ..` 返回上级目录。
+
+
+
+
+- 目录列表,macos/linux 下可以使用 ls 命令列出目录下所有的文件和子目录(Windows 下使用 dir 命令),使用通配符 `*` 对展示的内容进行过滤,比如 `ls *.java` 列出所有 `.java`后缀的文件,如果想更进一步的话,可以使用 `ls H*.java` 列出所有以 H 开头 `.java` 后缀的文件。
+- 新建目录,macOS/Linux 下可以使用 mkdir 命令新建一个目录(比如 `mkdir hello` 可以新建一个 hello 的目录),Windows 下可以使用 md 命令。
+- 删除文件,macOS/Linux 下可以使用 `rm` 命令删除文件(比如 `rm hello.java` 删除 hello.java 文件),Windows 下可以使用 del 命令。
+- 删除目录,macOS/Linux 下可以使用 `rm -r` 命令删除目录以及它所包含的所有文件(比如说 `rm -r hello` 删除 hello 目录)。Windows 下可以使用 deltree 命令。
+- 重复命令,macOS/Linux/Windows 下都可以使用上下箭头来选择以往执行过的命令。
+
+
+
+- 命令历史,macOS/Linux 下可以使用 `history` 命令查看所有使用过的命令。Windows 可以按下 F7 键。
+
+
+
+
+- 解压文件,后缀名为“.zip”的文件是一个包含了其他文件的压缩包,macOS/Linux 系统自身已经提供了用于解压的 unzip 命令, Windows 的话需要手动安装。
+
+### 安装JDK
+
+**1)Windows**
+
+推荐先安装 chocolatey。这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+>The biggest challenge is reducing duplication of effort, so users turn to Chocolatey for simplicity
+
+传统的安装方式要么非常耗时,要么非常低效,在命令行安装软件除了简单高效,还能自动帮我们配置环境变量。
+
+>- 官方地址:[https://chocolatey.org/](https://chocolatey.org/)
+>- 安装文档:[https://chocolatey.org/install#individual](https://chocolatey.org/install#individual)
+
+安装完成后如下图所示:
+
+
+
+如果不确定是否安装成功的话,可以通过键入 `choco` 命令来确认。
+
+
+
+这里推荐几个非常高效的操作命令:
+
+- choco search xxx,查找 xxx 安装包
+- choco info xxx,查看 xxx 安装包信息
+- choco install xxx,安装 xxx 软件
+- choco upgrade xxx,升级 xxx 软件
+- choco uninstall xxx, 卸载 xxx 软件
+
+如何知道 chocolatey 仓库中都有哪些安装包可用呢?
+
+可以通过上面提到的命令行的方式,也可以访问官方仓库进行筛选。
+
+>[https://community.chocolatey.org/packages](https://community.chocolatey.org/packages)
+
+比如说我们来查找 Java。
+
+
+
+好,现在可以直接在shell中键入 `choco install jdk8` 来安装 JDK8 了,并且会自动将Java加入到环境变量中,不用再去「我的电脑」「环境变量」中新建 JAVA_HOME 并复制 JDK 安装路径配置 PATH 变量了,是不是非常 nice?
+
+稍等片刻,键入 `java -version` 就可以确认Java是否安装成功了。
+
+
+
+
+不得不承认!非常nice!
+
+**2)macOS**
+
+首先推荐安装 homebrew,这是macOS下的命令行软件管理器,用来简化 macOS 上软件的安装过程。homebrew 是开源的,在 GitHub 已收获 32k star。
+
+
+
+homebrew 的安装也非常的简单,只需要一行命令即可。
+
+>官方网址:[https://brew.sh/index_zh-cn](https://brew.sh/index_zh-cn)
+
+
+
+
+- 使用 `brew install xxx` 可以安装 macOS 上没有预装的软件
+- 使用 `brew install --cask yyy` 可以安装 macOS 其他非开源软件。
+
+这里是 homebrew 常用命令的一个清单,可供参考。
+
+命令| 描述
+---|---
+brew update| 更新 Homebrew
+brew search package| 搜索软件包
+brew install package| 安装软件包
+brew uninstall package| 卸载软件包
+brew upgrade| 升级所有软件包
+brew upgrade package| 升级指定软件包
+brew list| 列出已安装的软件包列表
+brew services command package| 管理 brew 安装软件包
+brew services list| 列出 brew 管理运行的服务
+brew info package| 查看软件包信息
+brew deps package| 列出软件包的依赖关系
+brew help| 查看帮助
+brew cleanup| 清除过时软件包
+brew link package| 创建软件包符号链接
+brew unlink package| 取消软件包符号链接
+brew doctor| 检查系统是否存在问题
+
+安装完 homebrew 后,建议替换homebrew 的默认源为中科大的,原因就不用我多说了吧?替换方法如下所示:
+
+```
+替换brew.git:
+cd "$(brew --repo)"
+git remote set-url origin https://mirrors.ustc.edu.cn/brew.git
+
+替换homebrew-core.git:
+cd "$(brew --repo)/Library/Taps/homebrew/homebrew-core"
+git remote set-url origin https://mirrors.ustc.edu.cn/homebrew-core.git
+```
+
+如何知道 homebrew 仓库中都有哪些安装包可用呢?
+
+第一种,通过 `brew search xxx` 命令搜索,比如说我们要搜索 jdk
+
+
+
+
+第二种,通过 homebrew 官网搜索,比如说我们要搜索 openjdk。
+
+
+>官方地址:[https://formulae.brew.sh](https://formulae.brew.sh)
+
+
+
+
+这里有一份不错的 homebrew 帮助文档,可供参考:
+
+
+>[https://sspai.com/post/56009](https://sspai.com/post/56009)
+
+
+
+OK,我们来安装JDK,只需要简单的一行命令就可以搞定。
+
+`brew install openjdk@8`
+
+对比下载安装包,通过图形化界面的方式安装 JDK,是不是感觉在 Shell 下安装 JDK 更炫酷一些?
+
+关键是还省去了环境变量的配置。
+
+记得还没有走出新手村的时候,就经常被环境变量配置烦不胜烦。那下载这种命令行的方式,要比手动在环境变量中配置要省事一百倍,也更不容易出错。
+
+### 关于编辑器
+
+安装完 Java 之后,你还需要一个编辑器,用来编写 Java 代码。
+
+编辑器多种多样,常见的有集成开发环境(IDE,比如 Intellij IDEA 和 vscode),和简单的文本编辑工具(比如 sublime text)。
+
+我建议这三个工具都要装,日常开发中,我会在这三个编辑器中来回切换。
+
+Intellij IDEA:主要用来编写Java代码,并且最好安装旗舰版,社区版用来学习JavaSE部分是绰绰有余的,但要想拥有更强大的生产力,旗舰版是必须的,因为功能更加强大。
+
+比如说 idea 旗舰版中可以直接通过 Initializr 来创建springboot项目,但社区版就没有此功能。
+
+
+
+
+
+vscode:更加轻量级的 IDE,在编写Java代码上可以和idea媲美,但要想调试Java代码的话,vscode 和idea的差距还是非常明显的。
+
+
+
+
+我会使用 Intellij IDEA 开发编程喵的后端代码,vscode 来开发编程喵的前端代码。
+
+
+sublime text:功能更强大的文本编辑器,比记事本这种强大一万倍,也更符合21世纪开发者的外观审美。如果只是简单的修改一下代码格式,或者注释,显然更加方便,因为idea还是比较吃内存的,出差旅行的时候,在笔记本上紧急修改一些代码时,更易用。
+
+
+
+
+我会配合 GitHub 桌面版来使用 sublime text,编辑 MD 文档的时候会比较舒服。
+
+
diff --git a/docs/gongju/DBeaver.md b/docs/gongju/DBeaver.md
new file mode 100644
index 0000000000..cf4193ff57
--- /dev/null
+++ b/docs/gongju/DBeaver.md
@@ -0,0 +1,165 @@
+---
+title: DBeaver:一款免费的数据库操作工具
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+---
+
+
+作为一名开发者,免不了要和数据库打交道,于是我们就需要一款顺手的数据库管理工具。很长一段时间里,Navicat 都是我的首选,但最近更换了一台新电脑,之前的绿色安装包找不到了。
+
+于是就琢磨着,找一款免费的,功能和 Navicat 有一拼的数据库管理工具来替代。好朋友 macrozheng 给我推荐了 DBeaver,试用完后体验真心不错,于是就来给大家安利一波。
+
+### 一、关于 DBeaver
+
+DBeaver 是一个跨平台的数据库管理工具,支持 Windows、Linux 和 macOS。它有两个版本,企业版和社区版,对于个人开发者来说,社区版的功能已经足够强大。
+
+DBeaver 是由 Java 编写的,默认使用 JDK 11 进行编译。社区版基于 [Apache-2.0 License](https://github.com/dbeaver/dbeaver/blob/devel/LICENSE.md) 在 GitHub 上开源,目前已获得 24k+ 的星标。
+
+>[https://github.com/dbeaver/dbeaver](https://github.com/dbeaver/dbeaver)
+
+
+
+DBeaver 支持几乎所有主流的数据库,包括关系型数据库和非关系数据库。
+
+
+
+### 二、安装 DBeaver
+
+可以通过 DBeaver 官方下载安装包,也可以通过 GitHub 下载 release 版本。
+
+>官方下载地址:[https://dbeaver.io/download/](https://dbeaver.io/download/)
+
+
+
+根据自己电脑的操作系统下载对应的安装包,完整安装后,第一步要做的是配置 Maven 镜像,否则在后续下载数据库驱动的时候会非常的慢。
+
+
+
+
+因为 DBeaver 是基于 [Maven 构建](https://github.com/itwanger/toBeBetterJavaer/blob/master/docs/maven/maven.md)的,数据库驱动也就是链接数据库的 JDBC 驱动是通过 Maven 仓库下载的。选择「首选项」→「Maven」,添加阿里云镜像地址:
+
+>[http://maven.aliyun.com/nexus/content/groups/public](http://maven.aliyun.com/nexus/content/groups/public)
+
+和配置 Maven 镜像一样,如下图所示。
+
+
+
+
+配置完成后,记得把阿里云镜像仓库置顶。
+
+
+
+
+### 三、管理数据源
+
+像使用 Navicat 一样,我们需要先建立连接,这里就以 MySQL 为例。点击「连接」小图标,选择数据库。
+
+
+
+点击下一步,这时候需要填写数据库连接信息。
+
+
+
+点击「测试链接」,如果使用默认的 Maven 仓库时,下载驱动会非常慢,如下图所示,还容易失败「踩过的坑就不要再踩了」。
+
+
+
+如果你前面按照我说的配置了阿里云的 Maven 镜像,程序就不一样了,点了「测试链接」,瞬间会弹出「连接已成功」的提示框。
+
+
+
+链接成功后,就可以看到数据库中的表啊、视图啊、索引啊等等。
+
+
+
+### 四、管理表
+
+数据库连接成功后,最重要的还是操作表。
+
+**01、查看表**
+
+选择一张表,双击后就可以看到表的属性了,可以查看表的列、约束(主键)、外键、索引等等信息。
+
+
+
+点击「DDL(Data Definition Language,数据定义语言)」可以看到详细的建表语句。
+
+
+
+点击「数据」可以查看表的数据,底部有「新增」、「修改」、「删除」等行操作按钮。
+
+
+
+可以在顶部的过滤框中填写筛选条件,然后直接查询结果。
+
+
+
+如果不想显示某一列的话,可以直接点击「自定义结果集」图表,将某个字段的状态设置为不可见即可。
+
+
+
+**02、新增表**
+
+在左侧选择「表」,然后右键选择「新建表」即可建表id。
+
+
+
+之后在右侧列的区域右键,选择「新建列」即可添加字段。
+
+
+
+比如说我们新建一个主键 ID,如下图所示。
+
+
+
+在 DBeaver 中,`[v]` 表示真,`[]` 表示否。紧接着在「约束」里选择 ID 将其设置为主键。
+
+
+
+最后点击保存,会弹出一个建表语句的预览框,点击「执行」即可完成表的创建。
+
+
+
+### 五、执行 SQL
+
+右键数据库表,选择右键菜单中的「SQL 编辑器」可以打开 SQL 编辑面板。
+
+
+
+然后编辑 SQL 语句,点击运行的小图标就可以查询数据了。这个过程会有语法提示,非常 nice。
+
+
+
+DBeaver 有一个很亮眼的操作就是,可以直接选中一条结果集,然后右键生成 SQL。
+
+
+
+比如说 insert 语句,这样再插入一条重复性内容的时候就非常方便了。
+
+
+
+### 六、外观配置
+
+可以在首选项里对外观进行设置,比如说把主题修改为暗黑色。
+
+
+
+然后界面就变成了暗黑系。
+
+
+
+还可以设置字体大小等。
+
+
+
+从整体的风格来看,DBeaver 和 Eclipse 有些类似,事实上也的确如此,DBeaver 是基于 Eclipse 平台构建的。
+
+
+
+### 七、总结
+
+总体来说,DBeaver是一款非常优秀的开源数据库管理工具了,功能很全面,日常的开发基本上是够用了。对比收费的 Navicat 和 DataGrip,可以说非常良心了。大家如果遇到收费版不能使用的时候,可以来体验一下社区版 DBeaver。
+
+
\ No newline at end of file
diff --git a/docs/gongju/chiner.md b/docs/gongju/chiner.md
new file mode 100644
index 0000000000..4b20320ef7
--- /dev/null
+++ b/docs/gongju/chiner.md
@@ -0,0 +1,162 @@
+---
+title: chiner:一款开源的数据库设计神器
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+
+---
+
+最近在造轮子,从 0 到 1 的那种,就差前台的界面了,大家可以耐心耐心耐心期待一下。其中需要设计一些数据库表,可以通过 Navicat 这种图形化管理工具直接开搞,也可以通过一些数据库设计工具来搞,比如说 PowerDesigner,更专业一点。
+
+ 今天我给大家推荐的这款国人开源的数据库设计工具 chiner,界面漂亮,功能强大,体验后给我的感觉是真香......
+
+
+
+
+### 一、关于 PowerDesigner
+
+PowerDesigner 是一款功能非常强大的建模工具,可以和 Rational Rose 媲美。Rose 专攻 UML 对象模型的建模,之后才拓展到数据库这块。而 PowerDesigner 是一开始就为数据库建模服务的,后来才发展为一款综合战斗力都还不错的建模工具。
+
+不过,说句实在话,PowerDesigner 的界面偏古典一些,下面是我用 PowerDesigner 设计 DB 的效果。
+
+
+
+### 二、关于 chiner
+
+chiner,发音:[kaɪˈnər],使用React+Electron+Java技术体系构建的一款元数建模平台。
+
+2018 年,作者和几个对开源有兴趣的社区好友开始打磨产品的原因,历经三代,直到 2021 年 7 月份,终于推出了船新的 3.0 版本。
+
+2019 年底,团队差点解散,幸好有几位好友关照,给了团队两个项目做,这才算是熬了过去。
+
+不得不说,做任何一件事情都不容易啊,光靠情怀也许可以撑过产品初期,但越往后去,遇到生存问题时,就会非常困难。
+
+在此,我们必须得为每一位开源作者奉上最真诚的掌声,希望他们的产品都能有一番天地。也希望,未来我的产品出现在大家的面前时,能给它多一点点包容和支持。
+
+
+
+### 三、安装 chiner
+
+chiner 支持 Windows、macOS 和 Linux,下载地址如下所示:
+
+>[https://gitee.com/robergroup/chiner/releases](https://gitee.com/robergroup/chiner/releases)
+
+码云做了外部链接的拦截,导致直接复制链接到地址栏才能完成下载。我这里以 macOS 为例。
+
+
+
+安装完成后首次打开的样子是这样的。
+
+
+
+chiner 提供了非常贴心的操作手册和参考模板,如果时间比较充分的话,可以先把操作手册过一遍,写得非常详细。
+
+
+
+### 四、上手 chiner
+
+**01、导入导出**
+
+因为我之前有一份 PowerDesigner 文件,所以可以直接导入到 chiner。
+
+第一步,新建一个项目 codingmore。
+
+第二步,选择导入 PowerDesigner 文件。
+
+
+
+第三步,选择要添加的数据表。
+
+
+
+第四步,导入完成后,就可以点开单表进行查看了。
+
+
+
+第五步,当完成重新设计后,就可以选择导出 DDL 到数据库表了。
+
+
+
+当然了,也可以直接配置数据库 DB,这样就可以直接连接导入导出了。
+
+
+
+导出的 SQL 文件可以直接通过宝塔面板上传到服务器端,然后再直接导入到数据库。
+
+
+
+如果需要用到数据库说明文档的话,也可以直接通过导出到 Word 文档来完成。
+
+
+
+**02、维护数据类型**
+
+chiner 自带了几种常见的数据类型,比如字串、小数、日期等,我们也可以根据自己的需要添加新的数据类型。
+
+比如说默认的字串类型关联到其他数据库的类型如下所示:
+
+
+
+数据域是在数据类型的基础上,基于当前项目定义的有一定业务含义的数据类型,比如说我这里维护了一个长度为 90 的名称数据域。
+
+
+
+当我需要把某个数据字段的数据域设置成「名称」的时候,长度就会自动填充为 90,不需要手动再去设置。
+
+
+
+**03、维护数据表**
+
+第一步,选中数据表,右键选择「新增数据表」
+
+
+
+第二步,填写数据表名
+
+
+
+点击「确定」后,chiner 会帮我们自动生成一些常见常用的字段,比如说创建人、创建时间、更新人、更新时间等,非常的智能化。通常来说,这些字段都是必须的。
+
+
+
+如果这些默认字段不满足需求的时候,还可以点击「设置」新增默认字段,比如说删除标记,一般来说为了安全起见,数据库都会采用非物理删除。
+
+
+
+一般来说,我们更习惯字段小写命名,因此可以直接选中一列,然后选择大小写转换。
+
+
+
+就变成小写了。
+
+
+
+**04、维护关系图**
+
+第一步,选择「关系图」,右键选择「新增关系图」
+
+第二步,把需要关联的表拖拽到右侧的面板当中,然后按照字段进行连线,非常的方便。比如说班级和学院表、班级和专业表的关系,就如下图所示。
+
+
+
+来看一下整体给出来的关系图,还是非常清爽的。
+
+
+
+### 五、尾声
+
+chiner 还有更多更强大的功能,大家觉得不错的话,可以去尝试一下。用的熟练的话,肯定能在很大程度上提高生产效率。
+
+就我个人的使用体验来说,chiner 比 PowerDesigner 更轻量级,也更符合日常的操作习惯,为国产开源点赞!
+
+项目地址:
+
+>[https://gitee.com/robergroup/chiner](https://gitee.com/robergroup/chiner)
+
+使用手册:
+
+>[https://www.yuque.com/chiner/docs/manual](https://www.yuque.com/chiner/docs/manual)
+
+
+
\ No newline at end of file
diff --git a/docs/gongju/choco.md b/docs/gongju/choco.md
new file mode 100644
index 0000000000..2e385b89a2
--- /dev/null
+++ b/docs/gongju/choco.md
@@ -0,0 +1,179 @@
+---
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+title: chocolatey:一款 GitHub 星标 8.2k+的Windows命令行软件管理器
+
+---
+
+小二是公司新来的实习生,之前面试的过程中对答如流,所以我非常看好他。第一天,我给他了一台新电脑,要他先在本地搭建个 Java 开发环境。
+
+二话不说,他就开始马不停蹄地行动了。**真没想到,他竟然是通过命令行的方式安装的 JDK,一行命令就搞定了!连环境变量都不用配置,这远远超出了我对他的预期**。
+
+我以为,他会傻乎乎地下一步下一步来安装 JDK,就像这样。
+
+
+
+然后这样配置环境变量。
+
+
+
+结果他是这样的,就一行命令,环境变量也不用配置!
+
+
+
+卧槽!牛逼高大上啊!
+
+看着他熟练地在命令行里安装 JDK 的样子,我的嘴角开始微微上扬,真不错!这次总算招到了一个靠谱的。
+
+于是我就安排他做一个记录,打算发表在我的小破站《Java 程序员进阶之路》上。从他嘴里了解到,他用的命令行软件管理器叫 chocolatey,这是一个Windows下的命令行软件管理器,在 GitHub 上已经收获 8.2k+的星标,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+
+
+
+
+以下是他的记录,一起来欣赏下。
+
+### 先来了解 shell
+
+对于一名 Java 后端程序员来说,初学阶段,你可以选择在 IDE 中直接编译运行 Java 代码,但有时候也需要在 Shell 下编译和运行 Java 代码。
+
+>Windows 下自带的 Shell 叫命令提示符,或者 cmd 或者 powershell,macOS 下叫终端 terminal。
+
+但当你需要在生产环境下部署 Java项目或者查看日志的话,就必然会用到 Shell,这个阶段,Shell 的使用频率高到可以用一个成语来形容——朝夕相伴。
+
+一些第三方软件会在原生的 Shell 基础上提供更强大的功能,常见的有 tabby、Warp、xhsell、FinalShell、MobaXterm、Aechoterm、WindTerm、termius、iterm2 等等,有些只能在 Windows 上使用,有些只能在 macOS 上使用,有些支持全平台。还有 ohmyzsh 这种超神的 Shell 美化工具。
+
+这里,我们列举一些 Shell 的基本操作命令(Windows 和 macOS/Linux 有些许差异):
+
+- 切换目录,可以使用 cd 命令切换目录,`cd ..` 返回上级目录。
+
+
+
+
+- 目录列表,macos/linux 下可以使用 ls 命令列出目录下所有的文件和子目录(Windows 下使用 dir 命令),使用通配符 `*` 对展示的内容进行过滤,比如 `ls *.java` 列出所有 `.java`后缀的文件,如果想更进一步的话,可以使用 `ls H*.java` 列出所有以 H 开头 `.java` 后缀的文件。
+- 新建目录,macOS/Linux 下可以使用 mkdir 命令新建一个目录(比如 `mkdir hello` 可以新建一个 hello 的目录),Windows 下可以使用 md 命令。
+- 删除文件,macOS/Linux 下可以使用 `rm` 命令删除文件(比如 `rm hello.java` 删除 hello.java 文件),Windows 下可以使用 del 命令。
+- 删除目录,macOS/Linux 下可以使用 `rm -r` 命令删除目录以及它所包含的所有文件(比如说 `rm -r hello` 删除 hello 目录)。Windows 下可以使用 deltree 命令。
+- 重复命令,macOS/Linux/Windows 下都可以使用上下箭头来选择以往执行过的命令。
+
+
+
+- 命令历史,macOS/Linux 下可以使用 `history` 命令查看所有使用过的命令。Windows 可以按下 F7 键。
+
+
+
+
+- 解压文件,后缀名为“.zip”的文件是一个包含了其他文件的压缩包,macOS/Linux 系统自身已经提供了用于解压的 unzip 命令, Windows 的话需要手动安装。
+
+### 再来了解chocolatey
+
+先安装 chocolatey。这是一个Windows下的命令行软件管理器,可以方便开发者像在Linux下使用yum命令来安装软件,或者像在macOS下使用brew 命令来安装软件,非常酷炫。
+
+>The biggest challenge is reducing duplication of effort, so users turn to Chocolatey for simplicity
+
+传统的安装方式要么非常耗时,要么非常低效,在命令行安装软件除了简单高效,还能自动帮我们配置环境变量。
+
+>- 官方地址:[https://chocolatey.org/](https://chocolatey.org/)
+>- 安装文档:[https://chocolatey.org/install#individual](https://chocolatey.org/install#individual)
+
+第一步,以管理员的身份打开 cmd 命令行。
+
+
+
+
+第二步,执行以下命令:
+
+```
+Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
+```
+
+稍等片刻,就完成安装了。
+
+安装完成后如下图所示:
+
+
+
+如果不确定是否安装成功的话,可以通过键入 `choco` 命令来确认。
+
+
+
+这里推荐几个非常高效的操作命令:
+
+- choco search xxx,查找 xxx 安装包
+- choco info xxx,查看 xxx 安装包信息
+- choco install xxx,安装 xxx 软件
+- choco upgrade xxx,升级 xxx 软件
+- choco uninstall xxx, 卸载 xxx 软件
+
+如何知道 chocolatey 仓库中都有哪些安装包可用呢?
+
+可以通过上面提到的命令行的方式,也可以访问官方仓库进行筛选。
+
+>[https://community.chocolatey.org/packages](https://community.chocolatey.org/packages)
+
+比如说我们来查找 Java。
+
+
+
+好,现在可以直接在shell中键入 `choco install jdk8` 来安装 JDK8 了,并且会自动将Java加入到环境变量中,不用再去「我的电脑」「环境变量」中新建 JAVA_HOME 并复制 JDK 安装路径配置 PATH 变量了,是不是非常 nice?
+
+稍等片刻,键入 `java -version` 就可以确认Java是否安装成功了。
+
+
+
+
+不得不承认!非常nice!
+
+再比如说安装 Redis,只需要找到 Redis 的安装命令在 Choco 下执行一下就 OK 了。
+
+
+
+
+安装 Git:
+
+```
+choco install git.install
+```
+
+安装 node.js
+
+```
+choco install nodejs.install
+```
+
+安装 7zip
+
+```
+choco install 7zip
+```
+
+安装 **Filezilla**
+
+```
+choco install filezilla
+```
+
+Choco 上的软件包也非常的多,基本上软件开发中常见的安装包都有。
+
+
+
+
+### 小结
+
+通过小二的实战笔记,我们可以了解到。
+
+对比下载安装包,通过图形化界面的方式安装 JDK,然后下一步,下一步是不是感觉在 Shell 下安装 JDK 更炫酷一些?
+
+关键是还省去了环境变量的配置。
+
+记得还没有走出新手村的时候,就经常被环境变量配置烦不胜烦。那下载这种命令行的方式,要比手动在环境变量中配置要省事一百倍,也更不容易出错。
+
+通过 Choco 可以集中安装、管理、更新各种各样的软件。特别适合管理一些轻量级的开源软件,一条命令搞定,升级的时候也方便,不用再重新去下载新的安装包,可以有效治愈更新强迫症患者的症状。
+
+如果不想特殊设置的话,Chocolatey 整体的操作与使用还是比较亲民的。就连刚接触软件开发的小白也可以直接使用,而且路人看着会觉得你特别厉害。
+
+
+
+
diff --git a/docs/src/gongju/fastjson.md b/docs/gongju/fastjson.md
similarity index 93%
rename from docs/src/gongju/fastjson.md
rename to docs/gongju/fastjson.md
index dcc69913bb..c5e36e795b 100644
--- a/docs/src/gongju/fastjson.md
+++ b/docs/gongju/fastjson.md
@@ -12,7 +12,7 @@ tag:
我是 fastjson,是个地地道道的杭州土著,但我始终怀揣着一颗走向全世界的雄心。这不,我在 GitHub 上的简介都换成了英文,国际范十足吧?
-
+
如果你的英语功底没有我家老板 666 的话,我可以简单地翻译下(说人话,不装逼)。
@@ -233,7 +233,7 @@ public class IdentityHashMap {
再比如说,使用 asm 技术来避免反射导致的开销。
-
+
我承认,快的同时,也带来了一些安全性的问题。尤其是 AutoType 的引入,让黑客有了可乘之机。
@@ -257,14 +257,14 @@ public class IdentityHashMap {
在于黑客的反复较量中,我虽然变得越来越稳重成熟了,但与此同时,让我的用户为此也付出了沉重的代价。
-
+
网络上也出现了很多不和谐的声音,他们声称我是最垃圾的国产开源软件之一,只不过凭借着一些投机取巧赢得了国内开发者的信赖。
但更多的是,对我的不离不弃。
-
+
最令我感到为之动容的一句话是:
@@ -274,7 +274,7 @@ public class IdentityHashMap {
为了彻底解决 AutoType 带来的问题,在 1.2.68 版本中,我引入了 safeMode 的安全模式,无论白名单和黑名单,都不支持 AutoType,这样就可以彻底地杜绝攻击。
-
+
安全模式下,`checkAutoType()` 方法会直接抛出异常。
@@ -285,4 +285,4 @@ public class IdentityHashMap {
2020 年的最后一篇文章!看到的就点个赞吧,2021 年顺顺利利。
-
+
diff --git a/docs/src/gongju/forest.md b/docs/gongju/forest.md
similarity index 97%
rename from docs/src/gongju/forest.md
rename to docs/gongju/forest.md
index f282f7c0b8..762db306ae 100644
--- a/docs/src/gongju/forest.md
+++ b/docs/gongju/forest.md
@@ -141,11 +141,11 @@ Forest 的字面意思是森林的意思,更内涵点的话,可以拆成For
**虽然 star 数还不是很多,但 star 趋势图正在趋于爬坡阶段,大家可以拿来作为一个练手项目,我觉得还是不错的选择**。
-
+
Forest 本身是处理前端过程的框架,是对后端 HTTP API 框架的进一步封装。
-
+
前端部分:
@@ -382,4 +382,4 @@ myClient.send("foo", (String resText, ForestRequest request, ForestResponse resp
这篇文章不仅介绍了 Forest 这个轻量级的 HTTP 客户端框架,还回顾了它的底层实现:HttpClient 和 OkHttp,希望能对大家有所帮助。
-
+
diff --git a/docs/src/gongju/gson.md b/docs/gongju/gson.md
similarity index 97%
rename from docs/src/gongju/gson.md
rename to docs/gongju/gson.md
index ce70a00711..67653fb6f9 100644
--- a/docs/src/gongju/gson.md
+++ b/docs/gongju/gson.md
@@ -243,7 +243,7 @@ class Bar{
假如你 debug 的时候,进入到 `toJson()` 方法的内部,就可以观察到。
-
+
foo 的实际类型为 `Foo`,但我女朋友在调用 `foo.getClass()` 的时候,只会得到 Foo,这就意味着她并不知道 foo 的实际类型。
@@ -283,11 +283,11 @@ Bar bar1 = foo1.get();
debug 进入 `toJson()` 方法内部查看的话,就可以看到 foo 的真实类型了。
-
+
`fromJson()` 在反序列化的时候,和此类似。
-
+
这样的话,bar1 就可以通过 `foo1.get()` 到了。
@@ -455,4 +455,4 @@ private int age = 18;
如果你觉得我有点用的话,不妨点个赞,留个言,see you。
-
+
diff --git a/docs/src/gongju/jackson.md b/docs/gongju/jackson.md
similarity index 98%
rename from docs/src/gongju/jackson.md
rename to docs/gongju/jackson.md
index c2ab9fef63..5bde839e17 100644
--- a/docs/src/gongju/jackson.md
+++ b/docs/gongju/jackson.md
@@ -19,7 +19,7 @@ Java 之所以牛逼,很大的功劳在于它的生态非常完备,JDK 没
当我们通过 starter 新建一个 Spring Boot 的 Web 项目后,就可以在 Maven 的依赖项中看到 Jackson 的身影。
-
+
Jackson 有很多优点:
@@ -47,7 +47,7 @@ Jackson 的核心模块由三部分组成:
jackson-databind 依赖于 jackson-core 和 jackson-annotations,所以添加完 jackson-databind 之后,Maven 会自动将 jackson-core 和 jackson-annotations 引入到项目当中。
-
+
Maven 之所以讨人喜欢的一点就在这,能偷偷摸摸地帮我们把该做的做了。
@@ -563,4 +563,4 @@ Woman{age=18, name='三妹'}
好了,通过这篇文章的系统化介绍,相信你已经完全摸透 Jackson 了,我们下篇文章见。
-
+
diff --git a/docs/src/gongju/junit.md b/docs/gongju/junit.md
similarity index 91%
rename from docs/src/gongju/junit.md
rename to docs/gongju/junit.md
index d472e52fbb..daeb3dfac5 100644
--- a/docs/src/gongju/junit.md
+++ b/docs/gongju/junit.md
@@ -16,7 +16,7 @@ tag:
微软公司之前有这样一个统计:bug 在单元测试阶段被发现的平均耗时是 3.25 小时,如果遗漏到系统测试则需要 11.5 个小时。
-
+
经我这么一说,你应该已经很清楚单元测试的重要性了。那在你最初编写测试代码的时候,是不是经常这么做?就像下面这样。
@@ -56,17 +56,17 @@ public class Factorial {
第一步,直接在当前的代码编辑器窗口中按下 `Command+N` 键(Mac 版),在弹出的菜单中选择「Test...」。
-
+
勾选上要编写测试用例的方法 `fact()`,然后点击「OK」。
此时,IDEA 会自动在当前类所在的包下生成一个类名带 Test(惯例)的测试类。如下图所示。
-
+
如果你是第一次使用我的话,IDEA 会提示你导入我的依赖包。建议你选择最新的 JUnit 5.4。
-
+
导入完毕后,你可以打开 pom.xml 文件确认一下,里面多了对我的依赖。
@@ -95,11 +95,11 @@ void fact() {
第三步,你可以在邮件菜单中选择「Run FactorialTest」来运行测试用例,结果如下所示。
-
+
测试失败了,因为第 20 行的预期结果和实际不符,预期是 100,实际是 120。此时,你要么修正实现代码,要么修正测试代码,直到测试通过为止。
-
+
不难吧?单元测试可以确保单个方法按照正确的预期运行,如果你修改了某个方法的代码,只需确保其对应的单元测试通过,即可认为改动是没有问题的。
@@ -124,7 +124,7 @@ public class Calculator {
新建测试用例的时候记得勾选`setUp` 和 `tearDown`。
-
+
生成后的代码如下所示。
@@ -307,4 +307,4 @@ void fromJava9to11() {
希望我能尽早的替你发现代码中的 bug,毕竟越早的发现,造成的损失就会越小。see you!
-
+
diff --git a/docs/src/gongju/knife4j.md b/docs/gongju/knife4j.md
similarity index 76%
rename from docs/src/gongju/knife4j.md
rename to docs/gongju/knife4j.md
index 2ffa9d1599..58893b4562 100644
--- a/docs/src/gongju/knife4j.md
+++ b/docs/gongju/knife4j.md
@@ -7,27 +7,27 @@ tag:
---
-一般在使用 Spring Boot 开发前后端分离项目的时候,都会用到 [Swagger](https://javabetter.cn/springboot/swagger.html)(戳链接详细了解)。
+一般在使用 Spring Boot 开发前后端分离项目的时候,都会用到 [Swagger](https://tobebetterjavaer.com/springboot/swagger.html)(戳链接详细了解)。
但随着系统功能的不断增加,接口数量的爆炸式增长,Swagger 的使用体验就会变得越来越差,比如请求参数为 JSON 的时候没办法格式化,返回结果没办法折叠,还有就是没有提供搜索功能。
今天我们介绍的主角 Knife4j 弥补了这些不足,赋予了 Swagger 更强的生命力和表现力。
-## 关于 Knife4j
+### 关于 Knife4j
Knife4j 的前身是 swagger-bootstrap-ui,是 springfox-swagger-ui 的增强 UI 实现。swagger-bootstrap-ui 采用的是前端 UI 混合后端 Java 代码的打包方式,在微服务的场景下显得非常臃肿,改良后的 Knife4j 更加小巧、轻量,并且功能更加强大。
springfox-swagger-ui 的界面长这个样子,说实话,确实略显丑陋。
-
+
swagger-bootstrap-ui 增强后的样子长下面这样。单纯从直观体验上来看,确实增强了。
-
+
那改良后的 Knife4j 不仅在界面上更加优雅、炫酷,功能上也更加强大:后端 Java 代码和前端 UI 模块分离了出来,在微服务场景下更加灵活;还提供了专注于 Swagger 的增强解决方案。
-
+
官方文档:
@@ -41,7 +41,7 @@ swagger-bootstrap-ui 增强后的样子长下面这样。单纯从直观体验
>[https://gitee.com/xiaoym/swagger-bootstrap-ui-demo](https://gitee.com/xiaoym/swagger-bootstrap-ui-demo)
-## 整合 Knife4j
+### 整合 Knife4j
Knife4j 完全遵循了 Swagger 的使用方式,所以可以无缝切换。
@@ -102,7 +102,7 @@ public class Knife4jController {
}
```
-第四步,由于 springfox 3.0.x 版本 和 Spring Boot 2.6.x 版本有冲突,所以还需要先解决这个 bug,一共分两步(在[Swagger](https://javabetter.cn/springboot/swagger.html) 那篇已经解释过了,这里不再赘述,但防止有小伙伴在学习的时候再次跳坑,这里就重复一下步骤)。
+第四步,由于 springfox 3.0.x 版本 和 Spring Boot 2.6.x 版本有冲突,所以还需要先解决这个 bug,一共分两步(在[Swagger](https://tobebetterjavaer.com/springboot/swagger.html) 那篇已经解释过了,这里不再赘述,但防止有小伙伴在学习的时候再次跳坑,这里就重复一下步骤)。
先在 application.yml 文件中加入:
@@ -157,17 +157,17 @@ public static BeanPostProcessor springfoxHandlerProviderBeanPostProcessor() {
>访问地址(和 Swagger 不同):[http://localhost:8080/doc.html](http://localhost:8080/doc.html)
-
+
是不是比 Swagger 简洁大方多了?如果想测试接口的话,可以直接点击接口,然后点击「测试」,点击发送就可以看到返回结果了。
-
+
-## Knife4j 的功能特点
+### Knife4j 的功能特点
编程喵🐱实战项目中已经整合好了 Knife4j,在本地跑起来后,就可以查看所有 API 接口了。编程喵中的管理端(codingmore-admin)端口为 9002,启动服务后,在浏览器中输入 [http://localhost:9002/doc.html](http://localhost:9002/doc.html) 就可以访问到了。
-
+
简单来介绍下 Knife4j 的 功能特点:
@@ -176,68 +176,68 @@ public static BeanPostProcessor springfoxHandlerProviderBeanPostProcessor() {
Knife4j 和 Swagger 一样,也是支持头部登录认证的,点击「authorize」菜单,添加登录后的信息即可保持登录认证的 token。
-
+
如果某个 API 需要登录认证的话,就会把之前填写的信息带过来。
-
+
**2)支持 JSON 折叠**
Swagger 是不支持 JSON 折叠的,当返回的信息非常多的时候,界面就会显得非常的臃肿。Knife4j 则不同,可以对返回的 JSON 节点进行折叠。
-
+
**3)离线文档**
Knife4j 支持把 API 文档导出为离线文档(支持 markdown 格式、HTML 格式、Word 格式),
-
+
使用 Typora 打开后的样子如下,非常的大方美观。
-
+
**4)全局参数**
当某些请求需要全局参数时,这个功能就很实用了,Knife4j 支持 header 和 query 两种方式。
-
+
之后进行请求的时候,就会把这个全局参数带过去。
-
+
**5)搜索 API 接口**
Swagger 是没有搜索功能的,当要测试的接口有很多的时候,当需要去找某一个 API 的时候就傻眼了,只能一个个去拖动滚动条去找。
-
+
在文档的右上角,Knife4j 提供了文档搜索功能,输入要查询的关键字,就可以检索筛选了,是不是很方便?
-
+
目前支持搜索接口的地址、名称和描述。
-## 尾声
+### 尾声
除了我上面提到的增强功能,Knife4j 还提供了很多实用的功能,大家可以通过官网的介绍一一尝试下,生产效率会提高不少。
>[https://doc.xiaominfo.com/knife4j/documentation/enhance.html](https://doc.xiaominfo.com/knife4j/documentation/enhance.html)
-
+
----
-更多内容,只针对《二哥的Java进阶之路》星球用户开放,需要的小伙伴可以[戳链接🔗](https://javabetter.cn/zhishixingqiu/)加入我们的星球,一起学习,一起卷。。**编程喵**🐱是一个 Spring Boot+Vue 的前后端分离项目,融合了市面上绝大多数流行的技术要点。通过学习实战项目,你可以将所学的知识通过实践进行检验、你可以拓宽自己的技术边界,你可以掌握一个真正的实战项目是如何从 0 到 1 的。
+更多内容,只针对《Java 程序员进阶之路》星球用户开放,需要的小伙伴可以[戳链接🔗](docs/zhishixingqiu/)加入我们的星球,一起学习,一起卷。。**编程喵**🐱是一个 Spring Boot+Vue 的前后端分离项目,融合了市面上绝大多数流行的技术要点。通过学习实战项目,你可以将所学的知识通过实践进行检验、你可以拓宽自己的技术边界,你可以掌握一个真正的实战项目是如何从 0 到 1 的。
----
-## 源码路径
+### 源码路径
> - 编程喵:[https://github.com/itwanger/coding-more](https://github.com/itwanger/coding-more)
> - codingmore-knife4j:[https://github.com/itwanger/codingmore-learning](https://github.com/itwanger/codingmore-learning/tree/main/codingmore-knife4j)
-
+
diff --git a/docs/src/gongju/log4j.md b/docs/gongju/log4j.md
similarity index 94%
rename from docs/src/gongju/log4j.md
rename to docs/gongju/log4j.md
index 308091e8b7..d7d046eb93 100644
--- a/docs/src/gongju/log4j.md
+++ b/docs/gongju/log4j.md
@@ -12,7 +12,7 @@ tag:
这不,我在战国时代读者群里发现了这么一串聊天记录:
-
+
竟然有小伙伴不知道“打日志”是什么意思,不知道该怎么学习,还有小伙伴回答说,只知道 Log4j!
@@ -22,7 +22,7 @@ tag:
(说好的不在乎,怎么在乎起来了呢?手动狗头)
-
+
管他呢,**我行我素**吧,保持初心不改就对了!这篇文章就来说说 Log4j,这个打印日志的鼻祖。Java 中的日志打印其实是个艺术活,我保证,这句话绝不是忽悠。
@@ -37,7 +37,7 @@ tag:
之所以这样打印日志,是因为很方便,上手难度很低,尤其是在 IDEA 的帮助下,只需在键盘上按下 `so` 两个字母就可以调出 `System.out.println()`。
-
+
在本地环境下,使用 `System.out.println()` 打印日志是没问题的,可以在控制台看到信息。但如果是在生产环境下的话,`System.out.println()` 就变得毫无用处了。
@@ -63,7 +63,7 @@ OFF,最高级别,意味着所有消息都不会输出了。
这个级别是基于 Log4j 的,和 java.util.logging 有所不同,后者提供了更多的日志级别,比如说 SEVERE、FINER、FINEST。
-
+
### 03、错误的日志记录方式是如何影响性能的
@@ -86,7 +86,7 @@ if(logger.isDebugEnabled()){
切记,在生产环境下,一定不要开启 DEBUG 级别的日志,否则程序在大量记录日志的时候会变很慢,还有可能在你不注意的情况下,悄悄地把磁盘空间撑爆。
-
+
### 04、为什么选择 Log4j 而不是 java.util.logging
@@ -123,7 +123,7 @@ public class JavaUtilLoggingDemo {
程序运行后会在 target 目录下生成一个名叫 javautillog.txt 的文件,内容如下所示:
-
+
再来看一下 Log4j 的使用方式。
@@ -349,11 +349,11 @@ if(logger.isDebugEnabled()) {
8)不要在日志文件中打印密码、银行账号等敏感信息。
-
+
### 06、 总结
打印日志真的是一种艺术活,搞不好会严重影响服务器的性能。最可怕的是,记录了日志,但最后发现屁用没有,那简直是苍了个天啊!尤其是在生产环境下,问题没有记录下来,但重现有一定的随机性,到那时候,真的是叫天天不应,叫地地不灵啊!
-
+
diff --git a/docs/gongju/log4j2.md b/docs/gongju/log4j2.md
new file mode 100644
index 0000000000..ac617061e7
--- /dev/null
+++ b/docs/gongju/log4j2.md
@@ -0,0 +1,312 @@
+---
+title: Log4j 2:Apache维护的一款高性能日志记录工具
+category:
+ - Java企业级开发
+tag:
+ - 辅助工具/轮子
+---
+
+Log4j 2,顾名思义,它就是 Log4j 的升级版,就好像手机里面的 Pro 版。我作为一个写文章方面的工具人,或者叫打工人,怎么能不写完这最后一篇。
+
+Log4j、SLF4J、Logback 是一个爹——Ceki Gulcu,但 Log4j 2 却是例外,它是 Apache 基金会的产品。
+
+SLF4J 和 Logback 作为 Log4j 的替代品,在很多方面都做了必要的改进,那为什么还需要 Log4j 2 呢?我只能说 Apache 基金会的开发人员很闲,不,很拼,要不是他们这种精益求精的精神,这个编程的世界该有多枯燥,毕竟少了很多可以用“拿来就用”的轮子啊。
+
+上一篇也说了,老板下死命令要我把日志系统切换到 Logback,我顺利交差了,老板很开心,夸我这个打工人很敬业。为了表达对老板的这份感谢,我决定偷偷摸摸地试水一下 Log4j 2,尽管它还不是个成品,可能会会项目带来一定的隐患。但谁让咱是一个敬岗爱业的打工人呢。
+
+
+
+
+### 01、Log4j 2 强在哪
+
+1)在多线程场景下,Log4j 2 的吞吐量比 Logback 高出了 10 倍,延迟降低了几个数量级。这话听起来像吹牛,反正是 Log4j 2 官方自己吹的。
+
+Log4j 2 的异步 Logger 使用的是无锁数据结构,而 Logback 和 Log4j 的异步 Logger 使用的是 ArrayBlockingQueue。对于阻塞队列,多线程应用程序在尝试使日志事件入队时通常会遇到锁争用。
+
+下图说明了多线程方案中无锁数据结构对吞吐量的影响。 Log4j 2 随着线程数量的扩展而更好地扩展:具有更多线程的应用程序可以记录更多的日志。其他日志记录库由于存在锁竞争的关系,在记录更多线程时,总吞吐量保持恒定或下降。这意味着使用其他日志记录库,每个单独的线程将能够减少日志记录。
+
+
+
+性能方面是 Log4j 2 的最大亮点,至于其他方面的一些优势,比如说下面这些,可以忽略不计,文字有多短就代表它有多不重要。
+
+2)Log4j 2 可以减少垃圾收集器的压力。
+
+3)支持 Lambda 表达式。
+
+4)支持自动重载配置。
+
+### 02、Log4j 2 使用示例
+
+废话不多说,直接实操开干。理论知识有用,但不如上手实操一把,这也是我多年养成的一个“不那么良好”的编程习惯:在实操中发现问题,解决问题,寻找理论基础。
+
+**第一步**,在 pom.xml 文件中添加 Log4j 2 的依赖:
+
+```xml
+
+ org.apache.logging.log4j
+ log4j-api
+ 2.5
+
+
+ org.apache.logging.log4j
+ log4j-core
+ 2.5
+
+```
+
+(这个 artifactId 还是 log4j,没有体现出来 2,而在 version 中体现,多少叫人误以为是 log4j)
+
+**第二步**,来个最简单的测试用例:
+
+```java
+import org.apache.logging.log4j.LogManager;
+import org.apache.logging.log4j.Logger;
+
+public class Demo {
+ private static final Logger logger = LogManager.getLogger(Demo.class);
+ public static void main(String[] args) {
+ logger.debug("log4j2");
+ }
+}
+```
+
+运行 Demo 类,可以在控制台看到以下信息:
+
+```
+ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
+```
+
+Log4j 2 竟然没有在控制台打印“ log4j2”,还抱怨我们没有为它指定配置文件。在这一点上,我就觉得它没有 Logback 好,毕竟人家会输出。
+
+这对于新手来说,很不友好,因为新手在遇到这种情况的时候,往往不知所措。日志里面虽然体现了 ERROR,但代码并没有编译出错或者运行出错,凭什么你不输出?
+
+那作为编程老鸟来说,我得告诉你,这时候最好探究一下为什么。怎么做呢?
+
+我们可以复制一下日志信息中的关键字,比如说:“No log4j2 configuration file found”,然后在 Intellij IDEA 中搜一下,如果你下载了源码和文档的话,不除意外,你会在 ConfigurationFactory 类中搜到这段话。
+
+可以在方法中打个断点,然后 debug 一下,你就会看到下图中的内容。
+
+
+
+通过源码,你可以看得到,Log4j 2 会去寻找 4 种类型的配置文件,后缀分别是 properties、yaml、json 和 xml。前缀是 log4j2-test 或者 log4j2。
+
+得到这个提示后,就可以进行第三步了。
+
+**第三步,**在 resource 目录下增加 log4j2-test.xml 文件(方便和 Logback 做对比),内容如下所示:
+
+```xml
+
+
+
+
+