next ,目标方格的编号符合范围 [curr + 1, min(curr + 6, n2)] 。
+ next ,目标方格的编号在范围 [curr + 1, min(curr + 6, n2)] 。
- 该选择模拟了掷 六面体骰子 的情景,无论棋盘大小如何,玩家最多只能有 6 个目的地。 @@ -36,12 +34,12 @@ tags:
r 行 c 列的棋盘,按前述方法编号,棋盘格中可能存在 “蛇” 或 “梯子”;如果 board[r][c] != -1,那个蛇或梯子的目的地将会是 board[r][c]。编号为 1 和 n2 的方格不是任何蛇或梯子的起点。
如果 board[r][c] != -1 ,位于 r 行 c 列的棋盘格中可能存在 “蛇” 或 “梯子”。那个蛇或梯子的目的地将会是 board[r][c]。编号为 1 和 n2 的方格不是任何蛇或梯子的起点。
注意,玩家在每回合的前进过程中最多只能爬过蛇或梯子一次:就算目的地是另一条蛇或梯子的起点,玩家也 不能 继续移动。
-
-
- 举个例子,假设棋盘是
[[-1,4],[-1,3]],第一次移动,玩家的目标方格是2。那么这个玩家将会顺着梯子到达方格3,但 不能 顺着方格3上的梯子前往方格4。
+ - 举个例子,假设棋盘是
[[-1,4],[-1,3]],第一次移动,玩家的目标方格是2。那么这个玩家将会顺着梯子到达方格3,但 不能 顺着方格3上的梯子前往方格4。(简单来说,类似飞行棋,玩家掷出骰子点数后移动对应格数,遇到单向的路径(即梯子或蛇)可以直接跳到路径的终点,但如果多个路径首尾相连,也不能连续跳多个路径)
返回达到编号为 n2 的方格所需的最少移动次数,如果不可能,则返回 -1。
在一个长度 无限 的数轴上,第 i 颗石子的位置为 stones[i]。如果一颗石子的位置最小/最大,那么该石子被称作 端点石子 。
在 X 轴上有一些不同位置的石子。给定一个整数数组 stones 表示石子的位置。
每个回合,你可以将一颗端点石子拿起并移动到一个未占用的位置,使得该石子不再是一颗端点石子。
+如果一个石子在最小或最大的位置,称其为 端点石子。每个回合,你可以将一颗 端点石子 拿起并移动到一个未占用的位置,使得该石子不再是一颗 端点石子。
-值得注意的是,如果石子像 stones = [1,2,5] 这样,你将 无法 移动位于位置 5 的端点石子,因为无论将它移动到任何位置(例如 0 或 3),该石子都仍然会是端点石子。
-
+
- 值得注意的是,如果石子像
stones = [1,2,5]这样,你将 无法 移动位于位置5的端点石子,因为无论将它移动到任何位置(例如0或3),该石子都仍然会是端点石子。
+
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
-要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves] 。
以长度为 2 的数组形式返回答案,其中:
+ +-
+
answer[0]是你可以移动的最小次数
+ answer[1]是你可以移动的最大次数。
+
+
示例 1:
@@ -39,38 +46,32 @@ tags: 输入:[7,4,9] 输出:[1,2] 解释: -我们可以移动一次,4 -> 8,游戏结束。 -或者,我们可以移动两次 9 -> 5,4 -> 6,游戏结束。 +我们可以移动一次,4 -> 8,游戏结束。 +或者,我们可以移动两次 9 -> 5,4 -> 6,游戏结束。 -示例 2:
+示例 2:
输入:[6,5,4,3,10] 输出:[2,3] 解释: -我们可以移动 3 -> 8,接着是 10 -> 7,游戏结束。 -或者,我们可以移动 3 -> 7, 4 -> 8, 5 -> 9,游戏结束。 -注意,我们无法进行 10 -> 2 这样的移动来结束游戏,因为这是不合要求的移动。 +我们可以移动 3 -> 8,接着是 10 -> 7,游戏结束。 +或者,我们可以移动 3 -> 7, 4 -> 8, 5 -> 9,游戏结束。 +注意,我们无法进行 10 -> 2 这样的移动来结束游戏,因为这是不合要求的移动。-
示例 3:
- --输入:[100,101,104,102,103] -输出:[0,0]- -
+
提示:
-
-
3 <= stones.length <= 10^4
- 1 <= stones[i] <= 10^9
- stones[i]的值各不相同。
+ 3 <= stones.length <= 104
+ 1 <= stones[i] <= 109
+ stones的值各不相同。
+
diff --git a/solution/1000-1099/1052.Grumpy Bookstore Owner/README.md b/solution/1000-1099/1052.Grumpy Bookstore Owner/README.md index a2858cd1439ff..fb35423d8191a 100644 --- a/solution/1000-1099/1052.Grumpy Bookstore Owner/README.md +++ b/solution/1000-1099/1052.Grumpy Bookstore Owner/README.md @@ -21,7 +21,7 @@ tags:
有一个书店老板,他的书店开了 n 分钟。每分钟都有一些顾客进入这家商店。给定一个长度为 n 的整数数组 customers ,其中 customers[i] 是在第 i 分钟开始时进入商店的顾客数量,所有这些顾客在第 i 分钟结束后离开。
在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。
在某些分钟内,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。
当书店老板生气时,那一分钟的顾客就会不满意,若老板不生气则顾客是满意的。
diff --git a/solution/1100-1199/1140.Stone Game II/README.md b/solution/1100-1199/1140.Stone Game II/README.md index 84d60a634f76b..a0fc0b8726004 100644 --- a/solution/1100-1199/1140.Stone Game II/README.md +++ b/solution/1100-1199/1140.Stone Game II/README.md @@ -22,15 +22,15 @@ tags: -爱丽丝和鲍勃继续他们的石子游戏。许多堆石子 排成一行,每堆都有正整数颗石子 piles[i]。游戏以谁手中的石子最多来决出胜负。
Alice 和 Bob 继续他们的石子游戏。许多堆石子 排成一行,每堆都有正整数颗石子 piles[i]。游戏以谁手中的石子最多来决出胜负。
爱丽丝和鲍勃轮流进行,爱丽丝先开始。最初,M = 1。
Alice 和 Bob 轮流进行,Alice 先开始。最初,M = 1。
在每个玩家的回合中,该玩家可以拿走剩下的 前 X 堆的所有石子,其中 1 <= X <= 2M。然后,令 M = max(M, X)。
游戏一直持续到所有石子都被拿走。
-假设爱丽丝和鲍勃都发挥出最佳水平,返回爱丽丝可以得到的最大数量的石头。
+假设 Alice 和 Bob 都发挥出最佳水平,返回 Alice 可以得到的最大数量的石头。
@@ -39,7 +39,8 @@ tags:
输入:piles = [2,7,9,4,4] 输出:10 -解释:如果一开始Alice取了一堆,Bob取了两堆,然后Alice再取两堆。爱丽丝可以得到2 + 4 + 4 = 10堆。如果Alice一开始拿走了两堆,那么Bob可以拿走剩下的三堆。在这种情况下,Alice得到2 + 7 = 9堆。返回10,因为它更大。 +解释:如果一开始 Alice 取了一堆,Bob 取了两堆,然后 Alice 再取两堆。Alice 可以得到 2 + 4 + 4 = 10 堆。 +如果 Alice 一开始拿走了两堆,那么 Bob 可以拿走剩下的三堆。在这种情况下,Alice 得到 2 + 7 = 9 堆。返回 10,因为它更大。
示例 2:
diff --git a/solution/1100-1199/1140.Stone Game II/README_EN.md b/solution/1100-1199/1140.Stone Game II/README_EN.md index 4a3a5d416d9db..c7719ada5b0cc 100644 --- a/solution/1100-1199/1140.Stone Game II/README_EN.md +++ b/solution/1100-1199/1140.Stone Game II/README_EN.md @@ -22,31 +22,41 @@ tags: -Alice and Bob continue their games with piles of stones. There are a number of piles arranged in a row, and each pile has a positive integer number of stones piles[i]. The objective of the game is to end with the most stones.
Alice and Bob continue their games with piles of stones. There are a number of piles arranged in a row, and each pile has a positive integer number of stones piles[i]. The objective of the game is to end with the most stones.
Alice and Bob take turns, with Alice starting first. Initially, M = 1.
Alice and Bob take turns, with Alice starting first.
-On each player's turn, that player can take all the stones in the first X remaining piles, where 1 <= X <= 2M. Then, we set M = max(M, X).
On each player's turn, that player can take all the stones in the first X remaining piles, where 1 <= X <= 2M. Then, we set M = max(M, X). Initially, M = 1.
The game continues until all the stones have been taken.
-Assuming Alice and Bob play optimally, return the maximum number of stones Alice can get.
+Assuming Alice and Bob play optimally, return the maximum number of stones Alice can get.
Example 1:
--Input: piles = [2,7,9,4,4] -Output: 10 -Explanation: If Alice takes one pile at the beginning, Bob takes two piles, then Alice takes 2 piles again. Alice can get 2 + 4 + 4 = 10 piles in total. If Alice takes two piles at the beginning, then Bob can take all three piles left. In this case, Alice get 2 + 7 = 9 piles in total. So we return 10 since it's larger. -+
Input: piles = [2,7,9,4,4]
+ +Output: 10
+ +Explanation:
+ +-
+
- If Alice takes one pile at the beginning, Bob takes two piles, then Alice takes 2 piles again. Alice can get
2 + 4 + 4 = 10stones in total.
+ - If Alice takes two piles at the beginning, then Bob can take all three piles left. In this case, Alice get
2 + 7 = 9stones in total.
+
So we return 10 since it's larger.
+Example 2:
--Input: piles = [1,2,3,4,5,100] -Output: 104 -+
Input: piles = [1,2,3,4,5,100]
+ +Output: 104
+
Constraints:
diff --git a/solution/1100-1199/1152.Analyze User Website Visit Pattern/README.md b/solution/1100-1199/1152.Analyze User Website Visit Pattern/README.md index fb70dbd269d87..5b959a1bb55b8 100644 --- a/solution/1100-1199/1152.Analyze User Website Visit Pattern/README.md +++ b/solution/1100-1199/1152.Analyze User Website Visit Pattern/README.md @@ -38,23 +38,25 @@ tags:返回 得分 最大的 访问模式 。如果有多个访问模式具有相同的最大分数,则返回字典序最小的。
+请注意,模式中的网站不需要连续访问,只需按照模式中出现的顺序访问即可。
+-
示例 1:
+示例 1:
输入:username = ["joe","joe","joe","james","james","james","james","mary","mary","mary"], timestamp = [1,2,3,4,5,6,7,8,9,10], website = ["home","about","career","home","cart","maps","home","home","about","career"]
输出:["home","about","career"]
解释:本例中的元组是:
-["joe","home",1],["joe","about",2],["joe","career",3],["james","home",4],["james","cart",5],["james","maps",6],["james","home",7],["mary","home",8],["mary","about",9], and ["mary","career",10].
-模式("home", "about", "career") has score 2 (joe and mary).
-模式("home", "cart", "maps") 的得分为 1 (james).
+["joe","home",1],["joe","about",2],["joe","career",3],["james","home",4],["james","cart",5],["james","maps",6],["james","home",7],["mary","home",8],["mary","about",9] 和 ["mary","career",10]。
+模式 ("home", "about", "career") 的得分为 2(joe 和 mary)。
+模式 ("home", "cart", "maps") 的得分为 1 (james).
模式 ("home", "cart", "home") 的得分为 1 (james).
模式 ("home", "maps", "home") 的得分为 1 (james).
模式 ("cart", "maps", "home") 的得分为 1 (james).
-模式 ("home", "home", "home") 的得分为 0(没有用户访问过home 3次)。
+模式 ("home", "home", "home") 的得分为 0(没有用户访问过 home 3次)。
-示例 2:
+示例 2:
输入: username = ["ua","ua","ua","ub","ub","ub"], timestamp = [1,2,3,4,5,6], website = ["a","b","a","a","b","c"] diff --git a/solution/1200-1299/1207.Unique Number of Occurrences/README.md b/solution/1200-1299/1207.Unique Number of Occurrences/README.md index 726c5c2fcc85c..955323c79d6b1 100644 --- a/solution/1200-1299/1207.Unique Number of Occurrences/README.md +++ b/solution/1200-1299/1207.Unique Number of Occurrences/README.md @@ -19,27 +19,28 @@ tags: -给你一个整数数组
- -arr,请你帮忙统计数组中每个数的出现次数。如果每个数的出现次数都是独一无二的,就返回
+true;否则返回false。给你一个整数数组
arr,如果每个数的出现次数都是独一无二的,就返回true;否则返回false。
示例 1:
-输入:arr = [1,2,2,1,1,3] ++输入:arr = [1,2,2,1,1,3] 输出:true 解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。示例 2:
-输入:arr = [1,2] ++输入:arr = [1,2] 输出:false示例 3:
-输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] ++输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] 输出:truediff --git a/solution/1300-1399/1330.Reverse Subarray To Maximize Array Value/README.md b/solution/1300-1399/1330.Reverse Subarray To Maximize Array Value/README.md index c7b95f909d7d2..969f32e7d746a 100644 --- a/solution/1300-1399/1330.Reverse Subarray To Maximize Array Value/README.md +++ b/solution/1300-1399/1330.Reverse Subarray To Maximize Array Value/README.md @@ -30,14 +30,16 @@ tags:示例 1:
-输入:nums = [2,3,1,5,4] ++输入:nums = [2,3,1,5,4] 输出:10 解释:通过翻转子数组 [3,1,5] ,数组变成 [2,5,1,3,4] ,数组值为 10 。示例 2:
-输入:nums = [2,4,9,24,2,1,10] ++输入:nums = [2,4,9,24,2,1,10] 输出:68@@ -46,8 +48,9 @@ tags:提示:
-
-
1 <= nums.length <= 3*10^4
- -10^5 <= nums[i] <= 10^5
+ 2 <= nums.length <= 3*104
+ -105 <= nums[i] <= 105
+ - 答案保证在 32 位整数范围内。
表:MovieRating
You are given a string s. Reorder the string using the following algorithm:
-
-
- Pick the smallest character from
sand append it to the result.
- - Pick the smallest character from
swhich is greater than the last appended character to the result and append it.
- - Repeat step 2 until you cannot pick more characters. -
- Pick the largest character from
sand append it to the result.
- - Pick the largest character from
swhich is smaller than the last appended character to the result and append it.
- - Repeat step 5 until you cannot pick more characters. -
- Repeat the steps from 1 to 6 until you pick all characters from
s.
+ - Remove the smallest character from
sand append it to the result.
+ - Remove the smallest character from
sthat is greater than the last appended character, and append it to the result.
+ - Repeat step 2 until no more characters can be removed. +
- Remove the largest character from
sand append it to the result.
+ - Remove the largest character from
sthat is smaller than the last appended character, and append it to the result.
+ - Repeat step 5 until no more characters can be removed. +
- Repeat steps 1 through 6 until all characters from
shave been removed.
In each step, If the smallest or the largest character appears more than once you can choose any occurrence and append it to the result.
+If the smallest or largest character appears more than once, you may choose any occurrence to append to the result.
-Return the result string after sorting s with this algorithm.
Return the resulting string after reordering s using this algorithm.
Example 1:
diff --git a/solution/1400-1499/1432.Max Difference You Can Get From Changing an Integer/README_EN.md b/solution/1400-1499/1432.Max Difference You Can Get From Changing an Integer/README_EN.md index 5b5b3188c27dd..8b054be5c0d7b 100644 --- a/solution/1400-1499/1432.Max Difference You Can Get From Changing an Integer/README_EN.md +++ b/solution/1400-1499/1432.Max Difference You Can Get From Changing an Integer/README_EN.md @@ -57,7 +57,7 @@ We have now a = 9 and b = 1 and max difference = 8Constraints:
-
-
1 <= num <= 108
+ 1 <= num <= 108
-
示例 1:
+示例 1:

输入:numCourses = 2, prerequisites = [[1,0]], queries = [[0,1],[1,0]] 输出:[false,true] -解释:课程 0 不是课程 1 的先修课程,但课程 1 是课程 0 的先修课程。 +解释:[1, 0] 数对表示在你上课程 0 之前必须先上课程 1。 +课程 0 不是课程 1 的先修课程,但课程 1 是课程 0 的先修课程。-
示例 2:
+示例 2:
输入:numCourses = 2, prerequisites = [], queries = [[1,0],[0,1]] @@ -53,7 +54,7 @@ tags: 解释:没有先修课程对,所以每门课程之间是独立的。-
示例 3:
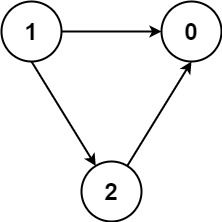
+示例 3:
2 <= numCourses <= 1000 <= prerequisites.length <= (numCourses * (numCourses - 1) / 2)prerequisites[i].length == 20 <= ai, bi <= n - 10 <= ai, bi <= numCourses - 1ai != bi[ai, bi] 都 不同1 <= queries.length <= 1040 <= ui, vi <= n - 10 <= ui, vi <= numCourses - 1ui != vi