 -
-从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
-
-从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
+你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
diff --git a/solution/0000-0099/0016.3Sum Closest/README.md b/solution/0000-0099/0016.3Sum Closest/README.md index 36a0f1a68f585..26a419cdec0e9 100644 --- a/solution/0000-0099/0016.3Sum Closest/README.md +++ b/solution/0000-0099/0016.3Sum Closest/README.md @@ -31,7 +31,7 @@ tags:输入:nums = [-1,2,1,-4], target = 1 输出:2 -解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。 +解释:与 target 最接近的和是 2 (-1 + 2 + 1 = 2)。
示例 2:
@@ -39,7 +39,7 @@ tags:输入:nums = [0,0,0], target = 1 输出:0 -+解释:与 target 最接近的和是 0(0 + 0 + 0 = 0)。
diff --git a/solution/0000-0099/0071.Simplify Path/README.md b/solution/0000-0099/0071.Simplify Path/README.md index 4ea9bfda09e25..6551d3fe9d4d2 100644 --- a/solution/0000-0099/0071.Simplify Path/README.md +++ b/solution/0000-0099/0071.Simplify Path/README.md @@ -17,9 +17,9 @@ tags: -
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,'//')都被视为单个斜杠 '/' 。 对于此问题,任何其他格式的点(例如,'...')均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
@@ -32,44 +32,74 @@ tags:返回简化后得到的 规范路径 。
-+
-
示例 1:
+示例 1:
--输入:path = "/home/" -输出:"/home" -解释:注意,最后一个目录名后面没有斜杠。+
输入:path = "/home/"
-示例 2:
+输出:"/home"
--输入:path = "/../" -输出:"/" -解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。 -+
解释:
-示例 3:
+应删除尾部斜杠。
+-输入:path = "/home//foo/" -输出:"/home/foo" -解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。 -+
示例 2:
-示例 4:
+输入:path = "/home//foo/"
--输入:path = "/a/./b/../../c/" -输出:"/c" -+
输出:"/home/foo"
-+
解释:
+ +多个连续的斜杠被单个斜杠替换。
+示例 3:
+ +输入:path = "/home/user/Documents/../Pictures"
+ +输出:"/home/user/Pictures"
+ +解释:
+ +两个点 ".." 表示上一级目录。
示例 4:
+ +输入:path = "/../"
+ +输出:"/"
+ +解释:
+ +不可能从根目录上升级一级。
+示例 5:
+ +输入:path = "/.../a/../b/c/../d/./"
+ +输出:"/.../b/d"
+ +解释:
+ +"..." 是此问题中目录的有效名称。
提示:
1 <= path.length <= 30001 <= path.length <= 3000path 由英文字母,数字,'.','/' 或 '_' 组成。path 是一个有效的 Unix 风格绝对路径。-
示例 1:
- +示例 1:
+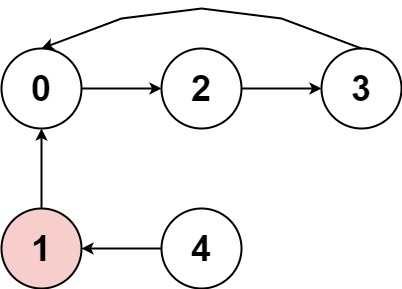
输入:nums = [2,-1,1,2,2] 输出:true -解释:存在循环,按下标 0 -> 2 -> 3 -> 0 。循环长度为 3 。 +解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。 +我们可以看到存在循环,按下标 0 -> 2 -> 3 -> 0 --> ...,并且其中的所有节点都是白色(以相同方向跳跃)。-
示例 2:
- +示例 2:
+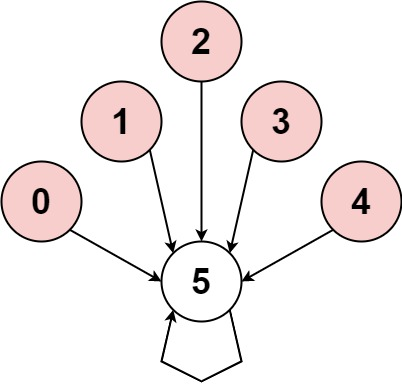
-输入:nums = [-1,2] +输入:nums = [-1,-2,-3,-4,-5,6] 输出:false -解释:按下标 1 -> 1 -> 1 ... 的运动无法构成循环,因为循环的长度为 1 。根据定义,循环的长度必须大于 1 。 +解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。 +唯一的循环长度为 1,所以返回 false。-
示例 3:
- +示例 3:
+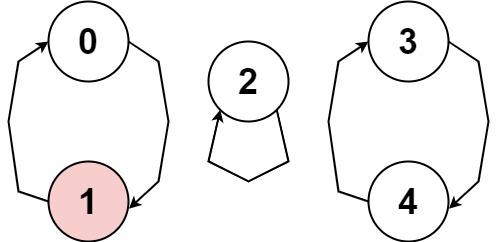
-输入:nums = [-2,1,-1,-2,-2] -输出:false -解释:按下标 1 -> 2 -> 1 -> ... 的运动无法构成循环,因为 nums[1] 是正数,而 nums[2] 是负数。 -所有 nums[seq[j]] 应当不是全正就是全负。+输入:nums = [1,-1,5,1,4] +输出:true +解释:图片展示了节点间如何连接。白色节点向前跳跃,而红色节点向后跳跃。 +我们可以看到存在循环,按下标 0 --> 1 --> 0 --> ...,当它的大小大于 1 时,它有一个向前跳的节点和一个向后跳的节点,所以 它不是一个循环。 +我们可以看到存在循环,按下标 3 --> 4 --> 3 --> ...,并且其中的所有节点都是白色(以相同方向跳跃)。 +
diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png new file mode 100644 index 0000000000000..e7dae87d55ec7 Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688159-qYjpWT-image.png differ diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png new file mode 100644 index 0000000000000..fb641081dd4fc Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688183-lRSkjp-image.png differ diff --git a/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png b/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png new file mode 100644 index 0000000000000..36c4e5416f848 Binary files /dev/null and b/solution/0400-0499/0457.Circular Array Loop/images/1723688199-nhaMuF-image.png differ diff --git a/solution/0600-0699/0638.Shopping Offers/README.md b/solution/0600-0699/0638.Shopping Offers/README.md index eb75179881823..26c28a6dc0958 100644 --- a/solution/0600-0699/0638.Shopping Offers/README.md +++ b/solution/0600-0699/0638.Shopping Offers/README.md @@ -29,7 +29,7 @@ tags:
返回 确切 满足购物清单所需花费的最低价格,你可以充分利用大礼包的优惠活动。你不能购买超出购物清单指定数量的物品,即使那样会降低整体价格。任意大礼包可无限次购买。
-+
示例 1:
@@ -51,19 +51,18 @@ tags: 需要买 1A ,2B 和 1C ,所以付 ¥4 买 1A 和 1B(大礼包 1),以及 ¥3 购买 1B , ¥4 购买 1C 。 不可以购买超出待购清单的物品,尽管购买大礼包 2 更加便宜。 -+
提示:
n == price.lengthn == needs.length1 <= n <= 60 <= price[i] <= 100 <= needs[i] <= 101 <= special.length <= 100n == price.length == needs.length1 <= n <= 60 <= price[i], needs[i] <= 101 <= special.length <= 100special[i].length == n + 10 <= special[i][j] <= 500 <= special[i][j] <= 500 <= j <= n - 1 至少有一个 special[i][j] 非零。1 <= special.length <= 100special[i].length == n + 10 <= special[i][j] <= 50special[i][j] is non-zero for 0 <= j <= n - 1.In a string composed of 'L', 'R', and 'X' characters, like "RXXLRXRXL", a move consists of either replacing one occurrence of "XL" with "LX", or replacing one occurrence of "RX" with "XR". Given the starting string start and the ending string end, return True if and only if there exists a sequence of moves to transform one string to the other.
In a string composed of 'L', 'R', and 'X' characters, like "RXXLRXRXL", a move consists of either replacing one occurrence of "XL" with "LX", or replacing one occurrence of "RX" with "XR". Given the starting string start and the ending string end, return True if and only if there exists a sequence of moves to transform start to end.
Example 1:
diff --git a/solution/0700-0799/0787.Cheapest Flights Within K Stops/README.md b/solution/0700-0799/0787.Cheapest Flights Within K Stops/README.md index d2247c9c47319..3a85807862aee 100644 --- a/solution/0700-0799/0787.Cheapest Flights Within K Stops/README.md +++ b/solution/0700-0799/0787.Cheapest Flights Within K Stops/README.md @@ -28,32 +28,36 @@ tags:
示例 1:
- +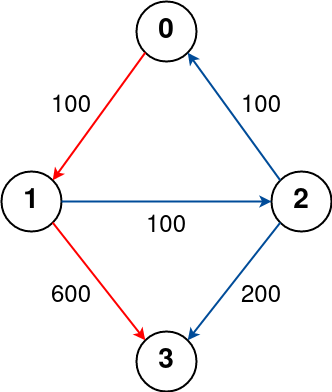
输入: -n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] -src = 0, dst = 2, k = 1 -输出: 200 -解释: -城市航班图如下 -+n = 4, flights = [[0,1,100],[1,2,100],[2,0,100],[1,3,600],[2,3,200]], src = 0, dst = 3, k = 1 +输出: 700 +解释: 城市航班图如上 +从城市 0 到城市 3 经过最多 1 站的最佳路径用红色标记,费用为 100 + 600 = 700。 +请注意,通过城市 [0, 1, 2, 3] 的路径更便宜,但无效,因为它经过了 2 站。 +
示例 2:
- +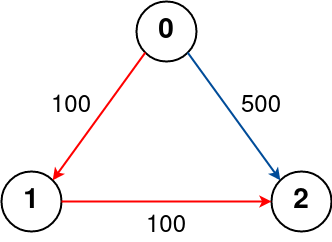
输入: -n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] -src = 0, dst = 2, k = 0 -输出: 500 +n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 1 +输出: 200 解释: -城市航班图如下 -+城市航班图如上 +从城市 0 到城市 2 经过最多 1 站的最佳路径标记为红色,费用为 100 + 100 = 200。 + -
+
示例 3:
+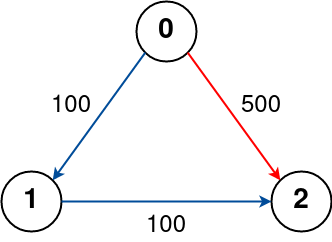 +
++输入:n = 3, flights = [[0,1,100],[1,2,100],[0,2,500]], src = 0, dst = 2, k = 0 +输出:500 +解释: +城市航班图如上 +从城市 0 到城市 2 不经过站点的最佳路径标记为红色,费用为 500。 +
提示:
diff --git a/solution/0700-0799/0787.Cheapest Flights Within K Stops/images/995.png b/solution/0700-0799/0787.Cheapest Flights Within K Stops/images/995.png deleted file mode 100644 index af24316fba883..0000000000000 Binary files a/solution/0700-0799/0787.Cheapest Flights Within K Stops/images/995.png and /dev/null differ diff --git a/solution/0800-0899/0841.Keys and Rooms/README.md b/solution/0800-0899/0841.Keys and Rooms/README.md index 8091541458754..6230cebdffa90 100644 --- a/solution/0800-0899/0841.Keys and Rooms/README.md +++ b/solution/0800-0899/0841.Keys and Rooms/README.md @@ -20,7 +20,7 @@ tags:有 n 个房间,房间按从 0 到 n - 1 编号。最初,除 0 号房间外的其余所有房间都被锁住。你的目标是进入所有的房间。然而,你不能在没有获得钥匙的时候进入锁住的房间。
当你进入一个房间,你可能会在里面找到一套不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
+当你进入一个房间,你可能会在里面找到一套 不同的钥匙,每把钥匙上都有对应的房间号,即表示钥匙可以打开的房间。你可以拿上所有钥匙去解锁其他房间。
给你一个数组 rooms 其中 rooms[i] 是你进入 i 号房间可以获得的钥匙集合。如果能进入 所有 房间返回 true,否则返回 false。
完全二叉树 是每一层(除最后一层外)都是完全填充(即,节点数达到最大)的,并且所有的节点都尽可能地集中在左侧。
-设计一种算法,将一个新节点插入到一个完整的二叉树中,并在插入后保持其完整。
+设计一种算法,将一个新节点插入到一棵完全二叉树中,并在插入后保持其完整。
实现 CBTInserter 类:
给定字符串 S,找出最长重复子串的长度。如果不存在重复子串就返回 0。
给定字符串 s,找出最长重复子串的长度。如果不存在重复子串就返回 0。
示例 1:
-输入:"abcd" ++输入:"abcd" 输出:0 解释:没有重复子串。示例 2:
-输入:"abbaba" ++输入:"abbaba" 输出:2 -解释:最长的重复子串为 "ab" 和 "ba",每个出现 2 次。 +解释:最长的重复子串为 "ab" 和 "ba",每个出现 2 次。示例 3:
-输入:"aabcaabdaab" ++输入:"aabcaabdaab" 输出:3 -解释:最长的重复子串为 "aab",出现 3 次。 +解释:最长的重复子串为 "aab",出现 3 次。-示例 4:
- -输入:"aaaaa" -输出:4 -解释:最长的重复子串为 "aaaa",出现 2 次。-
提示:
--
+- 字符串
-S仅包含从'a'到'z'的小写英文字母。- -
1 <= S.length <= 1500
1 <= s.length <= 2000s 仅包含从 'a' 到 'z' 的小写英文字母。示例 4:
- --输入:s = "a(bcdefghijkl(mno)p)q" -输出:"apmnolkjihgfedcbq" --
提示:
diff --git a/solution/1200-1299/1296.Divide Array in Sets of K Consecutive Numbers/README.md b/solution/1200-1299/1296.Divide Array in Sets of K Consecutive Numbers/README.md index 5fc673bb188c8..07db0477d9770 100644 --- a/solution/1200-1299/1296.Divide Array in Sets of K Consecutive Numbers/README.md +++ b/solution/1200-1299/1296.Divide Array in Sets of K Consecutive Numbers/README.md @@ -42,13 +42,6 @@ tags: 解释:数组可以分成 [1,2,3] , [2,3,4] , [3,4,5] 和 [9,10,11]。 -示例 3:
- --输入:nums = [3,3,2,2,1,1], k = 3 -输出:true --
示例 4:
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/README.md b/solution/1300-1399/1392.Longest Happy Prefix/README.md
index d0e4490cf2cdc..64ad42c7ae5f9 100644
--- a/solution/1300-1399/1392.Longest Happy Prefix/README.md
+++ b/solution/1300-1399/1392.Longest Happy Prefix/README.md
@@ -197,4 +197,134 @@ impl Solution {
+
+
+### 方法二:KMP 算法
+
+根据题目描述,我们需要找到一个字符串的最长快乐前缀,即找到一个字符串的最长前缀,使得这个前缀同时也是这个字符串的后缀。我们可以使用 KMP 算法来解决这个问题。
+
+时间复杂度 $O(n)$,空间复杂度 $O(n)$。其中 $n$ 为字符串的长度。
+
+
+
+#### Python3
+
+```python
+class Solution:
+ def longestPrefix(self, s: str) -> str:
+ s += "#"
+ n = len(s)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if s[i - 1] == s[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[: next[-1]]
+```
+
+#### Java
+
+```java
+class Solution {
+ public String longestPrefix(String s) {
+ s += "#";
+ int n = s.length();
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (s.charAt(i - 1) == s.charAt(j)) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substring(0, next[n - 1]);
+ }
+}
+```
+
+#### C++
+
+```cpp
+class Solution {
+public:
+ string longestPrefix(string s) {
+ s.push_back('#');
+ int n = s.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (s[i - 1] == s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substr(0, next[n - 1]);
+ }
+};
+```
+
+#### Go
+
+```go
+func longestPrefix(s string) string {
+ s += "#"
+ n := len(s)
+ next := make([]int, n)
+ next[0], next[1] = -1, 0
+ for i, j := 2, 0; i < n; {
+ if s[i-1] == s[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return s[:next[n-1]]
+}
+```
+
+#### TypeScript
+
+```ts
+function longestPrefix(s: string): string {
+ s += '#';
+ const n = s.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (s[i - 1] === s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.slice(0, next[n - 1]);
+}
+```
+
+
+
+
+
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/README_EN.md b/solution/1300-1399/1392.Longest Happy Prefix/README_EN.md
index 1cde8157af9b0..5217bb2fddf07 100644
--- a/solution/1300-1399/1392.Longest Happy Prefix/README_EN.md
+++ b/solution/1300-1399/1392.Longest Happy Prefix/README_EN.md
@@ -195,4 +195,134 @@ impl Solution {
+
+
+### Solution 2: KMP Algorithm
+
+According to the problem description, we need to find the longest happy prefix of a string, which is the longest prefix of the string that is also a suffix of the string. We can use the KMP algorithm to solve this problem.
+
+The time complexity is $O(n)$, and the space complexity is $O(n)$. Here, $n$ is the length of the string.
+
+
+
+#### Python3
+
+```python
+class Solution:
+ def longestPrefix(self, s: str) -> str:
+ s += "#"
+ n = len(s)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if s[i - 1] == s[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[: next[-1]]
+```
+
+#### Java
+
+```java
+class Solution {
+ public String longestPrefix(String s) {
+ s += "#";
+ int n = s.length();
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (s.charAt(i - 1) == s.charAt(j)) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substring(0, next[n - 1]);
+ }
+}
+```
+
+#### C++
+
+```cpp
+class Solution {
+public:
+ string longestPrefix(string s) {
+ s.push_back('#');
+ int n = s.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (s[i - 1] == s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substr(0, next[n - 1]);
+ }
+};
+```
+
+#### Go
+
+```go
+func longestPrefix(s string) string {
+ s += "#"
+ n := len(s)
+ next := make([]int, n)
+ next[0], next[1] = -1, 0
+ for i, j := 2, 0; i < n; {
+ if s[i-1] == s[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return s[:next[n-1]]
+}
+```
+
+#### TypeScript
+
+```ts
+function longestPrefix(s: string): string {
+ s += '#';
+ const n = s.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (s[i - 1] === s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.slice(0, next[n - 1]);
+}
+```
+
+
+
+
+
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/Solution2.cpp b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.cpp
new file mode 100644
index 0000000000000..0fc84e2455b42
--- /dev/null
+++ b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.cpp
@@ -0,0 +1,20 @@
+class Solution {
+public:
+ string longestPrefix(string s) {
+ s.push_back('#');
+ int n = s.size();
+ int next[n];
+ next[0] = -1;
+ next[1] = 0;
+ for (int i = 2, j = 0; i < n;) {
+ if (s[i - 1] == s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substr(0, next[n - 1]);
+ }
+};
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/Solution2.go b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.go
new file mode 100644
index 0000000000000..5acb4cf5c7e85
--- /dev/null
+++ b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.go
@@ -0,0 +1,19 @@
+func longestPrefix(s string) string {
+ s += "#"
+ n := len(s)
+ next := make([]int, n)
+ next[0], next[1] = -1, 0
+ for i, j := 2, 0; i < n; {
+ if s[i-1] == s[j] {
+ j++
+ next[i] = j
+ i++
+ } else if j > 0 {
+ j = next[j]
+ } else {
+ next[i] = 0
+ i++
+ }
+ }
+ return s[:next[n-1]]
+}
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/Solution2.java b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.java
new file mode 100644
index 0000000000000..22f0f898324c8
--- /dev/null
+++ b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.java
@@ -0,0 +1,18 @@
+class Solution {
+ public String longestPrefix(String s) {
+ s += "#";
+ int n = s.length();
+ int[] next = new int[n];
+ next[0] = -1;
+ for (int i = 2, j = 0; i < n;) {
+ if (s.charAt(i - 1) == s.charAt(j)) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.substring(0, next[n - 1]);
+ }
+}
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/Solution2.py b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.py
new file mode 100644
index 0000000000000..d3b9f63e8e3f0
--- /dev/null
+++ b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.py
@@ -0,0 +1,18 @@
+class Solution:
+ def longestPrefix(self, s: str) -> str:
+ s += "#"
+ n = len(s)
+ next = [0] * n
+ next[0] = -1
+ i, j = 2, 0
+ while i < n:
+ if s[i - 1] == s[j]:
+ j += 1
+ next[i] = j
+ i += 1
+ elif j:
+ j = next[j]
+ else:
+ next[i] = 0
+ i += 1
+ return s[: next[-1]]
diff --git a/solution/1300-1399/1392.Longest Happy Prefix/Solution2.ts b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.ts
new file mode 100644
index 0000000000000..56b46dd2cc752
--- /dev/null
+++ b/solution/1300-1399/1392.Longest Happy Prefix/Solution2.ts
@@ -0,0 +1,16 @@
+function longestPrefix(s: string): string {
+ s += '#';
+ const n = s.length;
+ const next: number[] = Array(n).fill(0);
+ next[0] = -1;
+ for (let i = 2, j = 0; i < n; ) {
+ if (s[i - 1] === s[j]) {
+ next[i++] = ++j;
+ } else if (j > 0) {
+ j = next[j];
+ } else {
+ next[i++] = 0;
+ }
+ }
+ return s.slice(0, next[n - 1]);
+}
diff --git a/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README.md b/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README.md
index 001e7409aaf5a..5ff2512acec48 100644
--- a/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README.md
+++ b/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README.md
@@ -3,9 +3,9 @@ comments: true
difficulty: 中等
edit_url: https://github.com/doocs/leetcode/edit/main/solution/1800-1899/1820.Maximum%20Number%20of%20Accepted%20Invitations/README.md
tags:
+ - 深度优先搜索
- 图
- 数组
- - 回溯
- 矩阵
---
diff --git a/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README_EN.md b/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README_EN.md
index c78b616789c4a..32891870d5391 100644
--- a/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README_EN.md
+++ b/solution/1800-1899/1820.Maximum Number of Accepted Invitations/README_EN.md
@@ -3,9 +3,9 @@ comments: true
difficulty: Medium
edit_url: https://github.com/doocs/leetcode/edit/main/solution/1800-1899/1820.Maximum%20Number%20of%20Accepted%20Invitations/README_EN.md
tags:
+ - Depth-First Search
- Graph
- Array
- - Backtracking
- Matrix
---
diff --git a/solution/1900-1999/1998.GCD Sort of an Array/README.md b/solution/1900-1999/1998.GCD Sort of an Array/README.md
index c4bcdff6afb10..1369b85664804 100644
--- a/solution/1900-1999/1998.GCD Sort of an Array/README.md
+++ b/solution/1900-1999/1998.GCD Sort of an Array/README.md
@@ -34,29 +34,32 @@ tags:
示例 1:
-输入:nums = [7,21,3]
+
+输入:nums = [7,21,3]
输出:true
解释:可以执行下述操作完成对 [7,21,3] 的排序:
-- 交换 7 和 21 因为 gcd(7,21) = 7 。nums = [21,7,3]
-- 交换 21 和 3 因为 gcd(21,3) = 3 。nums = [3,7,21]
+- 交换 7 和 21 因为 gcd(7,21) = 7 。nums = [21,7,3]
+- 交换 21 和 3 因为 gcd(21,3) = 3 。nums = [3,7,21]
示例 2:
-输入:nums = [5,2,6,2]
+
+输入:nums = [5,2,6,2]
输出:false
解释:无法完成排序,因为 5 不能与其他元素交换。
示例 3:
-输入:nums = [10,5,9,3,15]
+
+输入:nums = [10,5,9,3,15]
输出:true
解释:
可以执行下述操作完成对 [10,5,9,3,15] 的排序:
-- 交换 10 和 15 因为 gcd(10,15) = 5 。nums = [15,5,9,3,10]
-- 交换 15 和 3 因为 gcd(15,3) = 3 。nums = [3,5,9,15,10]
-- 交换 10 和 15 因为 gcd(10,15) = 5 。nums = [3,5,9,10,15]
+- 交换 10 和 15 因为 gcd(10,15) = 5 。nums = [15,5,9,3,10]
+- 交换 15 和 3 因为 gcd(15,3) = 3 。nums = [3,5,9,15,10]
+- 交换 10 和 15 因为 gcd(10,15) = 5 。nums = [3,5,9,10,15]
diff --git a/solution/2100-2199/2189.Number of Ways to Build House of Cards/README.md b/solution/2100-2199/2189.Number of Ways to Build House of Cards/README.md
index a0717156e998b..f7b856ad72188 100644
--- a/solution/2100-2199/2189.Number of Ways to Build House of Cards/README.md
+++ b/solution/2100-2199/2189.Number of Ways to Build House of Cards/README.md
@@ -21,13 +21,13 @@ tags:
返回使用所有 n 张卡片可以构建的不同纸牌屋的数量。如果存在一行两个纸牌屋包含不同数量的纸牌,那么两个纸牌屋被认为是不同的。
返回使用所有 n 张纸牌可以构建的不同纸牌屋的数量。如果存在一行两个纸牌屋包含不同数量的纸牌,那么两个纸牌屋被认为是不同的。
diff --git a/solution/2200-2299/2202.Maximize the Topmost Element After K Moves/README.md b/solution/2200-2299/2202.Maximize the Topmost Element After K Moves/README.md index 799703ce18a09..b7b94a2e49b4b 100644 --- a/solution/2200-2299/2202.Maximize the Topmost Element After K Moves/README.md +++ b/solution/2200-2299/2202.Maximize the Topmost Element After K Moves/README.md @@ -19,18 +19,18 @@ tags: -
给你一个下标从 0 开始的整数数组 nums ,它表示一个 栈 ,其中 nums[0] 是栈顶的元素。
给你一个下标从 0 开始的整数数组 nums ,它表示一个 堆 ,其中 nums[0] 是堆顶的元素。
每一次操作中,你可以执行以下操作 之一 :
同时给你一个整数 k ,它表示你总共需要执行操作的次数。
请你返回 恰好 执行 k 次操作以后,栈顶元素的 最大值 。如果执行完 k 次操作以后,栈一定为空,请你返回 -1 。
请你返回 恰好 执行 k 次操作以后,堆顶元素的 最大值 。如果执行完 k 次操作以后,堆一定为空,请你返回 -1 。
@@ -40,12 +40,12 @@ tags: 输入:nums = [5,2,2,4,0,6], k = 4 输出:5 解释: -4 次操作后,栈顶元素为 5 的方法之一为: -- 第 1 次操作:删除栈顶元素 5 ,栈变为 [2,2,4,0,6] 。 -- 第 2 次操作:删除栈顶元素 2 ,栈变为 [2,4,0,6] 。 -- 第 3 次操作:删除栈顶元素 2 ,栈变为 [4,0,6] 。 -- 第 4 次操作:将 5 添加回栈顶,栈变为 [5,4,0,6] 。 -注意,这不是最后栈顶元素为 5 的唯一方式。但可以证明,4 次操作以后 5 是能得到的最大栈顶元素。 +4 次操作后,堆顶元素为 5 的方法之一为: +- 第 1 次操作:删除堆顶元素 5 ,堆变为 [2,2,4,0,6] 。 +- 第 2 次操作:删除堆顶元素 2 ,堆变为 [2,4,0,6] 。 +- 第 3 次操作:删除堆顶元素 2 ,堆变为 [4,0,6] 。 +- 第 4 次操作:将 5 添加回堆顶,堆变为 [5,4,0,6] 。 +注意,这不是最后堆顶元素为 5 的唯一方式。但可以证明,4 次操作以后 5 是能得到的最大堆顶元素。
示例 2:
@@ -54,8 +54,8 @@ tags: 输入:nums = [2], k = 1 输出:-1 解释: -第 1 次操作中,我们唯一的选择是将栈顶元素弹出栈。 -由于 1 次操作后无法得到一个非空的栈,所以我们返回 -1 。 +第 1 次操作中,我们唯一的选择是将堆顶元素弹出堆。 +由于 1 次操作后无法得到一个非空的堆,所以我们返回 -1 。diff --git a/solution/3000-3099/3062.Winner of the Linked List Game/README.md b/solution/3000-3099/3062.Winner of the Linked List Game/README.md index 16659edbae76c..f8b8b75981e89 100644 --- a/solution/3000-3099/3062.Winner of the Linked List Game/README.md +++ b/solution/3000-3099/3062.Winner of the Linked List Game/README.md @@ -26,7 +26,7 @@ tags:
"Odd" 队得一分。"Even" 队得一分。返回分数更 高 的队名,如果分数相同,返回 "Tie"。
给你一个数组 arr ,数组中有 n 个 非空 字符串。
请你求出一个长度为 n 的字符串 answer ,满足:
请你求出一个长度为 n 的字符串数组 answer ,满足:
answer[i] 是 arr[i] 最短 的子字符串,且它不是 arr 中其他任何字符串的子字符串。如果有多个这样的子字符串存在,answer[i] 应该是它们中字典序最小的一个。如果不存在这样的子字符串,answer[i] 为空字符串。数组的 值 等于该数组的 最后一个 元素。
-你需要将 nums 划分为 m 个 不相交的连续 子数组,对于第 ith 个子数组 [li, ri],子数组元素的按位AND运算结果等于 andValues[i],换句话说,对所有的 1 <= i <= m,nums[li] & nums[li + 1] & ... & nums[ri] == andValues[i] ,其中 & 表示按位AND运算符。
你需要将 nums 划分为 m 个 不相交的连续 子数组,对于第 ith 个子数组 [li, ri],子数组元素的按位 AND 运算结果等于 andValues[i],换句话说,对所有的 1 <= i <= m,nums[li] & nums[li + 1] & ... & nums[ri] == andValues[i] ,其中 & 表示按位 AND 运算符。
返回将 nums 划分为 m 个子数组所能得到的可能的 最小 子数组 值 之和。如果无法完成这样的划分,则返回 -1 。
如果数组的每一对相邻元素都是两个奇偶性不同的数字,则该数组被认为是一个 特殊数组 。
-Aging 有一个整数数组 nums。如果 nums 是一个 特殊数组 ,返回 true,否则返回 false。
你有一个整数数组 nums。如果 nums 是一个 特殊数组 ,返回 true,否则返回 false。
diff --git a/solution/3100-3199/3152.Special Array II/README.md b/solution/3100-3199/3152.Special Array II/README.md index 7c4f7a32ca356..526fd8c912d5d 100644 --- a/solution/3100-3199/3152.Special Array II/README.md +++ b/solution/3100-3199/3152.Special Array II/README.md @@ -22,7 +22,7 @@ tags:
如果数组的每一对相邻元素都是两个奇偶性不同的数字,则该数组被认为是一个 特殊数组 。
-周洋哥有一个整数数组 nums 和一个二维整数矩阵 queries,对于 queries[i] = [fromi, toi],请你帮助周洋哥检查子数组 nums[fromi..toi] 是不是一个 特殊数组 。
你有一个整数数组 nums 和一个二维整数矩阵 queries,对于 queries[i] = [fromi, toi],请你帮助你检查 子数组 nums[fromi..toi] 是不是一个 特殊数组 。
返回布尔数组 answer,如果 nums[fromi..toi] 是特殊数组,则 answer[i] 为 true ,否则,answer[i] 为 false 。
车尔尼有一个数组 nums ,它只包含 正 整数,所有正整数的数位长度都 相同 。
你有一个数组 nums ,它只包含 正 整数,所有正整数的数位长度都 相同 。
两个整数的 数位不同 指的是两个整数 相同 位置上不同数字的数目。
-请车尔尼返回 nums 中 所有 整数对里,数位不同之和。
请你返回 nums 中 所有 整数对里,数位不同之和。
diff --git a/solution/3100-3199/3154.Find Number of Ways to Reach the K-th Stair/README.md b/solution/3100-3199/3154.Find Number of Ways to Reach the K-th Stair/README.md index 0f1a47832cb8d..2b2c5cc5bb5c0 100644 --- a/solution/3100-3199/3154.Find Number of Ways to Reach the K-th Stair/README.md +++ b/solution/3100-3199/3154.Find Number of Ways to Reach the K-th Stair/README.md @@ -24,16 +24,16 @@ tags:
给你有一个 非负 整数 k 。有一个无限长度的台阶,最低 一层编号为 0 。
虎老师有一个整数 jump ,一开始值为 0 。虎老师从台阶 1 开始,虎老师可以使用 任意 次操作,目标是到达第 k 级台阶。假设虎老师位于台阶 i ,一次 操作 中,虎老师可以:
Alice 有一个整数 jump ,一开始值为 0 。Alice 从台阶 1 开始,可以使用 任意 次操作,目标是到达第 k 级台阶。假设 Alice 位于台阶 i ,一次 操作 中,Alice 可以:
i - 1 ,但该操作 不能 连续使用,如果在台阶第 0 级也不能使用。i + 2jump 处,然后 jump 变为 jump + 1 。请你返回虎老师到达台阶 k 处的总方案数。
请你返回 Alice 到达台阶 k 处的总方案数。
注意 ,虎老师可能到达台阶 k 处后,通过一些操作重新回到台阶 k 处,这视为不同的方案。
注意,Alice 可能到达台阶 k 处后,通过一些操作重新回到台阶 k 处,这视为不同的方案。
@@ -49,12 +49,12 @@ tags:
2 种到达台阶 0 的方案为:
4 种到达台阶 1 的方案为: