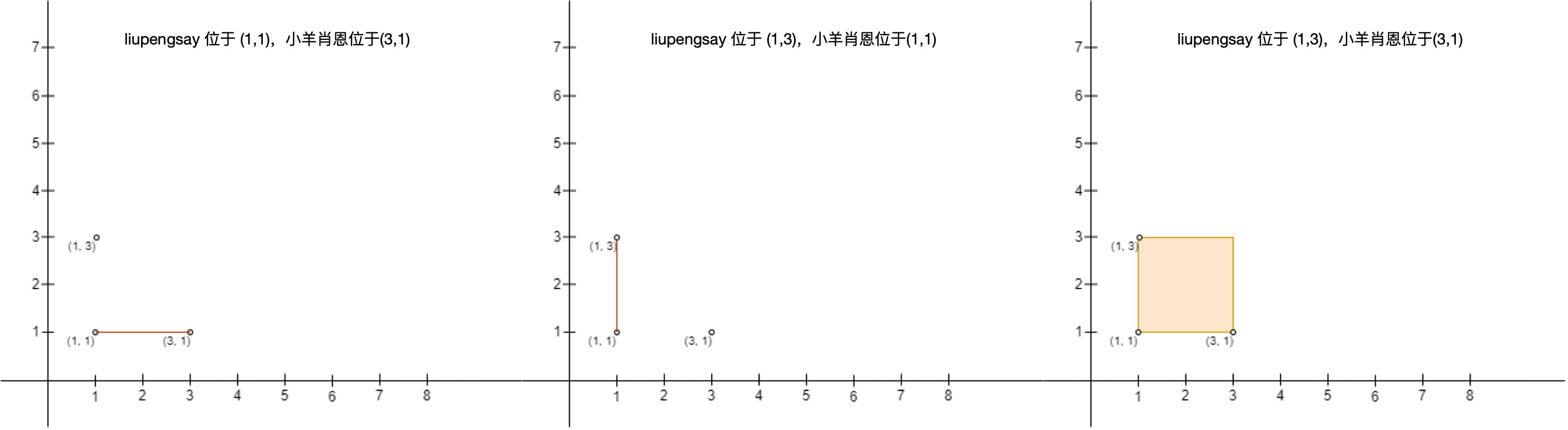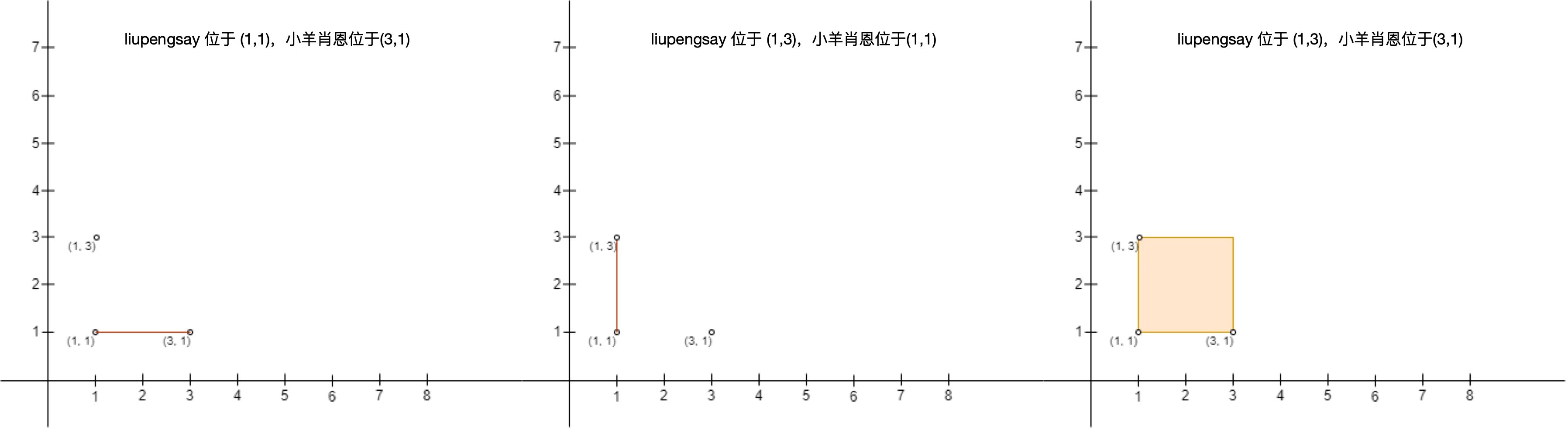
示例 2:
-
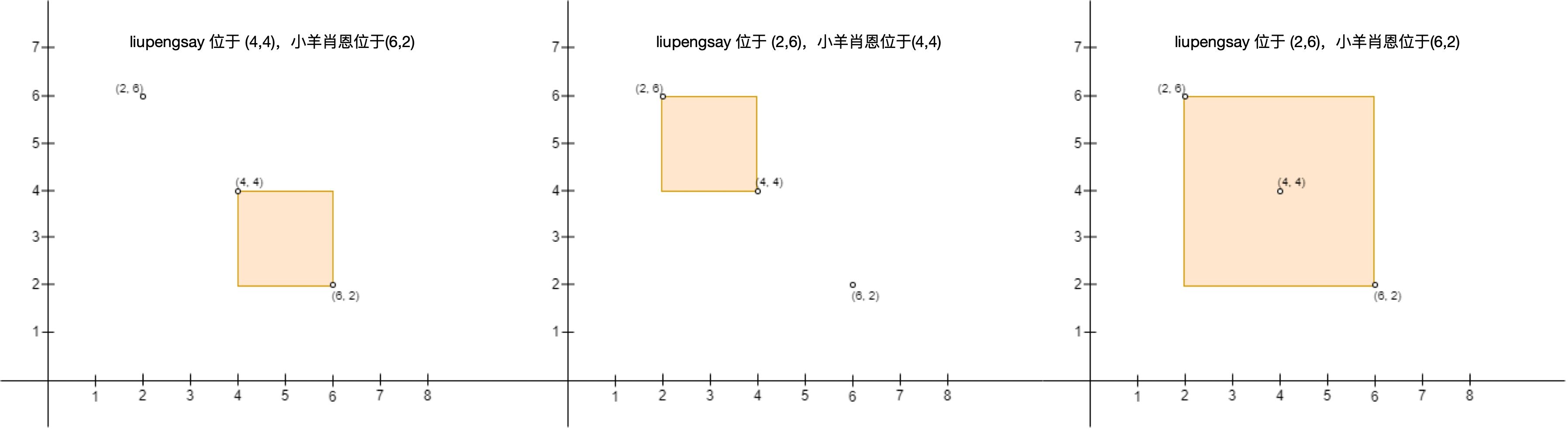
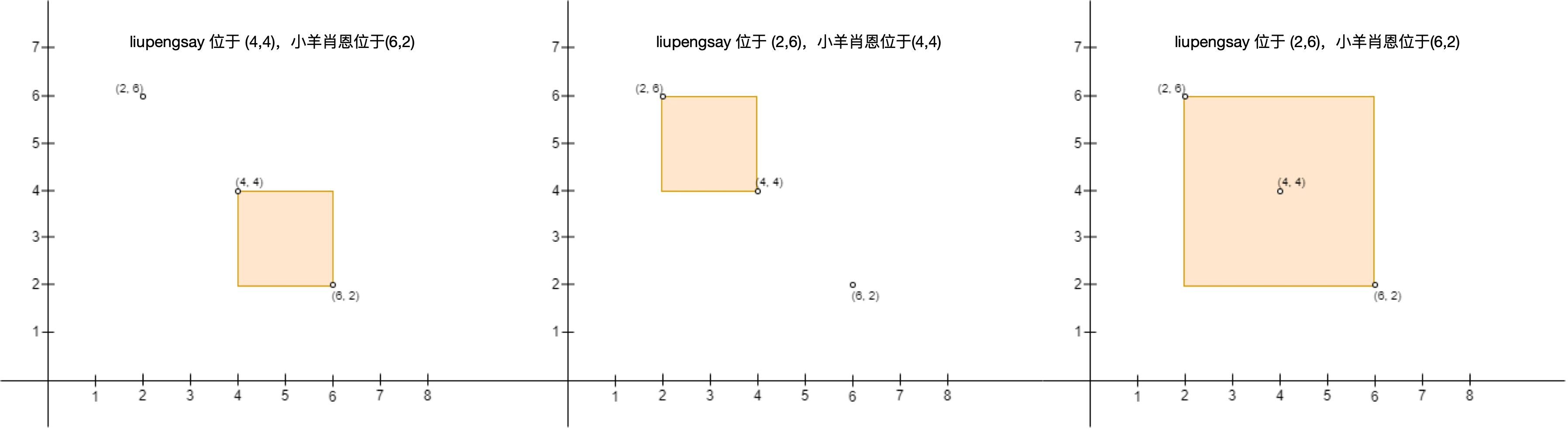
输入:points = [[6,2],[4,4],[2,6]] @@ -48,7 +48,7 @@示例 3:
-+
输入:points = [[3,1],[1,3],[1,1]] diff --git a/solution/3000-3099/3028.Ant on the Boundary/README.md b/solution/3000-3099/3028.Ant on the Boundary/README.md new file mode 100644 index 0000000000000..b46cec05f43d5 --- /dev/null +++ b/solution/3000-3099/3028.Ant on the Boundary/README.md @@ -0,0 +1,86 @@ +# [3028. 边界上的蚂蚁](https://leetcode.cn/problems/ant-on-the-boundary) + +[English Version](/solution/3000-3099/3028.Ant%20on%20the%20Boundary/README_EN.md) + +## 题目描述 + + + +边界上有一只蚂蚁,它有时向 左 走,有时向 右 走。
+ +给你一个 非零 整数数组
+ +nums。蚂蚁会按顺序读取nums中的元素,从第一个元素开始直到结束。每一步,蚂蚁会根据当前元素的值移动:
nums[i] < 0 ,向 左 移动 -nums[i]单位。nums[i] > 0 ,向 右 移动 nums[i]单位。返回蚂蚁 返回 到边界上的次数。
+ +注意:
+ +|nums[i]| 单位后才检查它是否位于边界上。换句话说,如果蚂蚁只是在移动过程中穿过了边界,则不会计算在内。+ +
示例 1:
+ ++输入:nums = [2,3,-5] +输出:1 +解释:第 1 步后,蚂蚁距边界右侧 2 单位远。 +第 2 步后,蚂蚁距边界右侧 5 单位远。 +第 3 步后,蚂蚁位于边界上。 +所以答案是 1 。 ++ +
示例 2:
+ ++输入:nums = [3,2,-3,-4] +输出:0 +解释:第 1 步后,蚂蚁距边界右侧 3 单位远。 +第 2 步后,蚂蚁距边界右侧 5 单位远。 +第 3 步后,蚂蚁距边界右侧 2 单位远。 +第 4 步后,蚂蚁距边界左侧 2 单位远。 +蚂蚁从未返回到边界上,所以答案是 0 。 ++ +
+ +
提示:
+ +1 <= nums.length <= 100-10 <= nums[i] <= 10nums[i] != 0An ant is on a boundary. It sometimes goes left and sometimes right.
+ +You are given an array of non-zero integers nums. The ant starts reading nums from the first element of it to its end. At each step, it moves according to the value of the current element:
nums[i] < 0, it moves left by -nums[i] units.nums[i] > 0, it moves right by nums[i] units.Return the number of times the ant returns to the boundary.
+ +Notes:
+ +|nums[i]| units. In other words, if the ant crosses the boundary during its movement, it does not count.+
Example 1:
+ ++Input: nums = [2,3,-5] +Output: 1 +Explanation: After the first step, the ant is 2 steps to the right of the boundary. +After the second step, the ant is 5 steps to the right of the boundary. +After the third step, the ant is on the boundary. +So the answer is 1. ++ +
Example 2:
+ ++Input: nums = [3,2,-3,-4] +Output: 0 +Explanation: After the first step, the ant is 3 steps to the right of the boundary. +After the second step, the ant is 5 steps to the right of the boundary. +After the third step, the ant is 2 steps to the right of the boundary. +After the fourth step, the ant is 2 steps to the left of the boundary. +The ant never returned to the boundary, so the answer is 0. ++ +
+
Constraints:
+ +1 <= nums.length <= 100-10 <= nums[i] <= 10nums[i] != 0给你一个下标从 0 开始的字符串 word 和一个整数 k 。
在每一秒,你必须执行以下操作:
+ +word 的前 k 个字符。word 的末尾添加 k 个任意字符。注意 添加的字符不必和移除的字符相同。但是,必须在每一秒钟都执行 两种 操作。
+ +返回将 word 恢复到其 初始 状态所需的 最短 时间(该时间必须大于零)。
+ +
示例 1:
+ ++输入:word = "abacaba", k = 3 +输出:2 +解释: +第 1 秒,移除 word 的前缀 "aba",并在末尾添加 "bac" 。因此,word 变为 "cababac"。 +第 2 秒,移除 word 的前缀 "cab",并在末尾添加 "aba" 。因此,word 变为 "abacaba" 并恢复到始状态。 +可以证明,2 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
示例 2:
+ ++输入:word = "abacaba", k = 4 +输出:1 +解释: +第 1 秒,移除 word 的前缀 "abac",并在末尾添加 "caba" 。因此,word 变为 "abacaba" 并恢复到初始状态。 +可以证明,1 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
示例 3:
+ ++输入:word = "abcbabcd", k = 2 +输出:4 +解释: +每一秒,我们都移除 word 的前 2 个字符,并在 word 末尾添加相同的字符。 +4 秒后,word 变为 "abcbabcd" 并恢复到初始状态。 +可以证明,4 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
+ +
提示:
+ +1 <= word.length <= 501 <= k <= word.lengthword仅由小写英文字母组成。You are given a 0-indexed string word and an integer k.
At every second, you must perform the following operations:
+ +k characters of word.k characters to the end of word.Note that you do not necessarily need to add the same characters that you removed. However, you must perform both operations at every second.
+ +Return the minimum time greater than zero required for word to revert to its initial state.
+
Example 1:
+ ++Input: word = "abacaba", k = 3 +Output: 2 +Explanation: At the 1st second, we remove characters "aba" from the prefix of word, and add characters "bac" to the end of word. Thus, word becomes equal to "cababac". +At the 2nd second, we remove characters "cab" from the prefix of word, and add "aba" to the end of word. Thus, word becomes equal to "abacaba" and reverts to its initial state. +It can be shown that 2 seconds is the minimum time greater than zero required for word to revert to its initial state. ++ +
Example 2:
+ ++Input: word = "abacaba", k = 4 +Output: 1 +Explanation: At the 1st second, we remove characters "abac" from the prefix of word, and add characters "caba" to the end of word. Thus, word becomes equal to "abacaba" and reverts to its initial state. +It can be shown that 1 second is the minimum time greater than zero required for word to revert to its initial state. ++ +
Example 3:
+ ++Input: word = "abcbabcd", k = 2 +Output: 4 +Explanation: At every second, we will remove the first 2 characters of word, and add the same characters to the end of word. +After 4 seconds, word becomes equal to "abcbabcd" and reverts to its initial state. +It can be shown that 4 seconds is the minimum time greater than zero required for word to revert to its initial state. ++ +
+
Constraints:
+ +1 <= word.length <= 50 1 <= k <= word.lengthword consists only of lowercase English letters.给你一个下标从 0 开始、大小为 m x n 的网格 image ,表示一个灰度图像,其中 image[i][j] 表示在范围 [0..255] 内的某个像素强度。另给你一个 非负 整数 threshold 。
如果 image[a][b] 和 image[c][d] 满足 |a - c| + |b - d| == 1 ,则称这两个像素是 相邻像素 。
区域 是一个 3 x 3 的子网格,且满足区域中任意两个 相邻 像素之间,像素强度的 绝对差 小于或等于 threshold 。
区域 内的所有像素都认为属于该区域,而一个像素 可以 属于 多个 区域。
+ +你需要计算一个下标从 0 开始、大小为 m x n 的网格 result ,其中 result[i][j] 是 image[i][j] 所属区域的 平均 强度,向下取整 到最接近的整数。如果 image[i][j] 属于多个区域,result[i][j] 是这些区域的 “取整后的平均强度” 的 平均值,也 向下取整 到最接近的整数。如果 image[i][j] 不属于任何区域,则 result[i][j] 等于 image[i][j] 。
返回网格 result 。
+ +
示例 1:
+ +
++输入:image = [[5,6,7,10],[8,9,10,10],[11,12,13,10]], threshold = 3 +输出:[[9,9,9,9],[9,9,9,9],[9,9,9,9]] +解释:图像中存在两个区域,如图片中的阴影区域所示。第一个区域的平均强度为 9 ,而第二个区域的平均强度为 9.67 ,向下取整为 9 。两个区域的平均强度为 (9 + 9) / 2 = 9 。由于所有像素都属于区域 1 、区域 2 或两者,因此 result 中每个像素的强度都为 9 。 +注意,在计算多个区域的平均值时使用了向下取整的值,因此使用区域 2 的平均强度 9 来进行计算,而不是 9.67 。 ++ +
示例 2:
+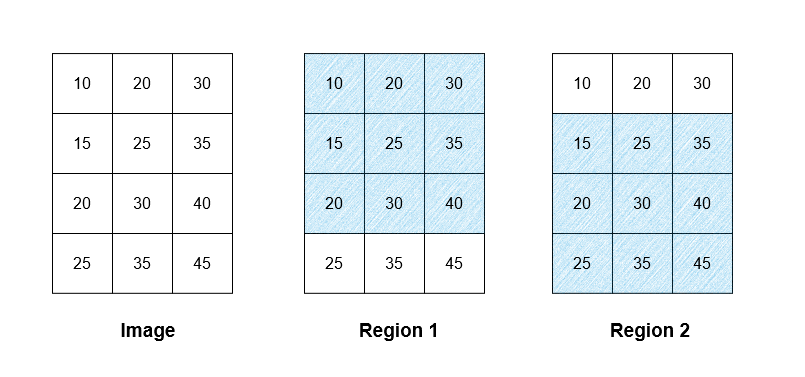 +
++输入:image = [[10,20,30],[15,25,35],[20,30,40],[25,35,45]], threshold = 12 +输出:[[25,25,25],[27,27,27],[27,27,27],[30,30,30]] +解释:图像中存在两个区域,如图片中的阴影区域所示。第一个区域的平均强度为 25 ,而第二个区域的平均强度为 30 。两个区域的平均强度为 (25 + 30) / 2 = 27.5 ,向下取整为 27 。图像中第 0 行的所有像素属于区域 1 ,因此 result 中第 0 行的所有像素为 25 。同理,result 中第 3 行的所有像素为 30 。图像中第 1 行和第 2 行的像素属于区域 1 和区域 2 ,因此它们在 result 中的值为 27 。 ++ +
示例 3:
+ ++输入:image = [[5,6,7],[8,9,10],[11,12,13]], threshold = 1 +输出:[[5,6,7],[8,9,10],[11,12,13]] +解释:图像中不存在任何区域,因此对于所有像素,result[i][j] == image[i][j] 。 ++ +
+ +
提示:
+ +3 <= n, m <= 5000 <= image[i][j] <= 2550 <= threshold <= 255You are given a 0-indexed m x n grid image which represents a grayscale image, where image[i][j] represents a pixel with intensity in the range[0..255]. You are also given a non-negative integer threshold.
Two pixels image[a][b] and image[c][d] are said to be adjacent if |a - c| + |b - d| == 1.
A region is a 3 x 3 subgrid where the absolute difference in intensity between any two adjacent pixels is less than or equal to threshold.
All pixels in a region belong to that region, note that a pixel can belong to multiple regions.
+ +You need to calculate a 0-indexed m x n grid result, where result[i][j] is the average intensity of the region to which image[i][j] belongs, rounded down to the nearest integer. If image[i][j] belongs to multiple regions, result[i][j] is the average of the rounded down average intensities of these regions, rounded down to the nearest integer. If image[i][j] does not belong to any region, result[i][j] is equal to image[i][j].
Return the grid result.
+
Example 1:
+
++Input: image = [[5,6,7,10],[8,9,10,10],[11,12,13,10]], threshold = 3 +Output: [[9,9,9,9],[9,9,9,9],[9,9,9,9]] +Explanation: There exist two regions in the image, which are shown as the shaded areas in the picture. The average intensity of the first region is 9, while the average intensity of the second region is 9.67 which is rounded down to 9. The average intensity of both of the regions is (9 + 9) / 2 = 9. As all the pixels belong to either region 1, region 2, or both of them, the intensity of every pixel in the result is 9. +Please note that the rounded-down values are used when calculating the average of multiple regions, hence the calculation is done using 9 as the average intensity of region 2, not 9.67. ++ +
Example 2:
+
++Input: image = [[10,20,30],[15,25,35],[20,30,40],[25,35,45]], threshold = 12 +Output: [[25,25,25],[27,27,27],[27,27,27],[30,30,30]] +Explanation: There exist two regions in the image, which are shown as the shaded areas in the picture. The average intensity of the first region is 25, while the average intensity of the second region is 30. The average intensity of both of the regions is (25 + 30) / 2 = 27.5 which is rounded down to 27. All the pixels in row 0 of the image belong to region 1, hence all the pixels in row 0 in the result are 25. Similarly, all the pixels in row 3 in the result are 30. The pixels in rows 1 and 2 of the image belong to region 1 and region 2, hence their assigned value is 27 in the result. ++ +
Example 3:
+ ++Input: image = [[5,6,7],[8,9,10],[11,12,13]], threshold = 1 +Output: [[5,6,7],[8,9,10],[11,12,13]] +Explanation: There does not exist any region in image, hence result[i][j] == image[i][j] for all the pixels. ++ +
+
Constraints:
+ +3 <= n, m <= 5000 <= image[i][j] <= 2550 <= threshold <= 255给你一个下标从 0 开始的字符串 word 和一个整数 k 。
在每一秒,你必须执行以下操作:
+ +word 的前 k 个字符。word 的末尾添加 k 个任意字符。注意 添加的字符不必和移除的字符相同。但是,必须在每一秒钟都执行 两种 操作。
+ +返回将 word 恢复到其 初始 状态所需的 最短 时间(该时间必须大于零)。
+ +
示例 1:
+ ++输入:word = "abacaba", k = 3 +输出:2 +解释: +第 1 秒,移除 word 的前缀 "aba",并在末尾添加 "bac" 。因此,word 变为 "cababac"。 +第 2 秒,移除 word 的前缀 "cab",并在末尾添加 "aba" 。因此,word 变为 "abacaba" 并恢复到始状态。 +可以证明,2 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
示例 2:
+ ++输入:word = "abacaba", k = 4 +输出:1 +解释: +第 1 秒,移除 word 的前缀 "abac",并在末尾添加 "caba" 。因此,word 变为 "abacaba" 并恢复到初始状态。 +可以证明,1 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
示例 3:
+ ++输入:word = "abcbabcd", k = 2 +输出:4 +解释: +每一秒,我们都移除 word 的前 2 个字符,并在 word 末尾添加相同的字符。 +4 秒后,word 变为 "abcbabcd" 并恢复到初始状态。 +可以证明,4 秒是 word 恢复到其初始状态所需的最短时间。 ++ +
+ +
提示:
+ +1 <= word.length <= 105 1 <= k <= word.lengthword仅由小写英文字母组成。You are given a 0-indexed string word and an integer k.
At every second, you must perform the following operations:
+ +k characters of word.k characters to the end of word.Note that you do not necessarily need to add the same characters that you removed. However, you must perform both operations at every second.
+ +Return the minimum time greater than zero required for word to revert to its initial state.
+
Example 1:
+ ++Input: word = "abacaba", k = 3 +Output: 2 +Explanation: At the 1st second, we remove characters "aba" from the prefix of word, and add characters "bac" to the end of word. Thus, word becomes equal to "cababac". +At the 2nd second, we remove characters "cab" from the prefix of word, and add "aba" to the end of word. Thus, word becomes equal to "abacaba" and reverts to its initial state. +It can be shown that 2 seconds is the minimum time greater than zero required for word to revert to its initial state. ++ +
Example 2:
+ ++Input: word = "abacaba", k = 4 +Output: 1 +Explanation: At the 1st second, we remove characters "abac" from the prefix of word, and add characters "caba" to the end of word. Thus, word becomes equal to "abacaba" and reverts to its initial state. +It can be shown that 1 second is the minimum time greater than zero required for word to revert to its initial state. ++ +
Example 3:
+ ++Input: word = "abcbabcd", k = 2 +Output: 4 +Explanation: At every second, we will remove the first 2 characters of word, and add the same characters to the end of word. +After 4 seconds, word becomes equal to "abcbabcd" and reverts to its initial state. +It can be shown that 4 seconds is the minimum time greater than zero required for word to revert to its initial state. ++ +
+
Constraints:
+ +1 <= word.length <= 105 1 <= k <= word.lengthword consists only of lowercase English letters.