-
A company wants to hire new employees. The budget of the company for the salaries is 70000. The company's criteria for hiring are:
A company wants to hire new employees. The budget of the company for the salaries is $70000. The company's criteria for hiring are:
- Keep hiring the senior with the smallest salary until you cannot hire any more seniors. diff --git a/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README.md b/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README.md index 1f207a0196f21..cfc2d25194e37 100644 --- a/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README.md +++ b/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README.md @@ -11,12 +11,14 @@
- 例如,如果
buildings = [[1,5,2],[3,10,4]],street = [[1,3,2],[3,5,3],[5,10,4]]可以表示街道,因为: +- 从 1 到 3 ,只有第一栋建筑的平均高度为
2 / 1 = 2。 - 从 3 到 5 ,第一和第二栋建筑的平均高度均为
(2+4) / 2 = 3。 - 从 5 到 10 ,只有第二栋建筑的平均高度为
4 / 1 = 4。
+
- 从 1 到 3 ,只有第一栋建筑的平均高度为
- For example, if
buildings = [[1,5,2],[3,10,4]],the street could be represented bystreet = [[1,3,2],[3,5,3],[5,10,4]]because: +- From 1 to 3, there is only the first building with an average height of
2 / 1 = 2. - From 3 to 5, both the first and the second building are there with an average height of
(2+4) / 2 = 3. - From 5 to 10, there is only the second building with an average height of
4 / 1 = 4.
+
- From 1 to 3, there is only the first building with an average height of
- 比方说,
arr = [4, 1, 5, 2, 6, 2]对于k = 2是 K 递增的,因为: +arr[0] <= arr[2] (4 <= 5)arr[1] <= arr[3] (1 <= 2)
@@ -20,6 +21,7 @@
- 但是,相同的数组
arr对于k = 1不是 K 递增的(因为arr[0] > arr[1]),对于k = 3也不是 K 递增的(因为arr[0] > arr[3])。
+
- For example,
arr = [4, 1, 5, 2, 6, 2]is K-increasing fork = 2because: +arr[0] <= arr[2] (4 <= 5)arr[1] <= arr[3] (1 <= 2)
@@ -18,6 +19,7 @@
- However, the same
arris not K-increasing fork = 1(becausearr[0] > arr[1]) ork = 3(becausearr[0] > arr[3]).
+
- 统计乘积中 后缀 0 的数目,并 移除 这些 0 ,将这个数目记为
C。 +- 比方说,
1000中有3个后缀 0 ,546中没有后缀 0 。
- 比方说,
- 比方说,
12345678987600000被表示为"12345...89876e5"。
+
- Count all trailing zeros in the product and remove them. Let us denote this count as
C. +- For example, there are
3trailing zeros in1000, and there are0trailing zeros in546.
- For example, there are
- For example,
12345678987600000will be represented as"12345...89876e5".
+
- 比方说,给你
questions = [[3, 2], [4, 3], [4, 4], [2, 5]]: +- 如果问题
0被解决了, 那么你可以获得3分,但你不能解决问题1和2。 - 如果你跳过问题
0,且解决问题1,你将获得4分但是不能解决问题2和3。
diff --git a/solution/2100-2199/2140.Solving Questions With Brainpower/README_EN.md b/solution/2100-2199/2140.Solving Questions With Brainpower/README_EN.md
index 7d5e99c8670e2..b6743e7bf74fe 100644
--- a/solution/2100-2199/2140.Solving Questions With Brainpower/README_EN.md
+++ b/solution/2100-2199/2140.Solving Questions With Brainpower/README_EN.md
@@ -10,6 +10,7 @@
- For example, given
questions = [[3, 2], [4, 3], [4, 4], [2, 5]]: +- If question
0is solved, you will earn3points but you will be unable to solve questions1and2. - If instead, question
0is skipped and question1is solved, you will earn4points but you will be unable to solve questions2and3.
diff --git a/solution/2100-2199/2145.Count the Hidden Sequences/README.md b/solution/2100-2199/2145.Count the Hidden Sequences/README.md
index 97f0970c09022..2a3f108b6c37c 100644
--- a/solution/2100-2199/2145.Count the Hidden Sequences/README.md
+++ b/solution/2100-2199/2145.Count the Hidden Sequences/README.md
@@ -12,12 +12,14 @@
- 比方说,
differences = [1, -3, 4],lower = 1,upper = 6,那么隐藏数组是一个长度为4且所有值都在1和6(包含两者)之间的数组。 +[3, 4, 1, 5]和[4, 5, 2, 6]都是符合要求的隐藏数组。[5, 6, 3, 7]不符合要求,因为它包含大于6的元素。[1, 2, 3, 4]不符合要求,因为相邻元素的差值不符合给定数据。
+
- For example, given
differences = [1, -3, 4],lower = 1,upper = 6, the hidden sequence is a sequence of length4whose elements are in between1and6(inclusive). +[3, 4, 1, 5]and[4, 5, 2, 6]are possible hidden sequences.[5, 6, 3, 7]is not possible since it contains an element greater than6.[1, 2, 3, 4]is not possible since the differences are not correct.
+
- 按 非递增 顺序排列
nums奇数下标 上的所有值。 +- 举个例子,如果排序前
nums = [4,1,2,3],对奇数下标的值排序后变为[4,3,2,1]。奇数下标1和3的值按照非递增顺序重排。
- 举个例子,如果排序前
- 举个例子,如果排序前
nums = [4,1,2,3],对偶数下标的值排序后变为[2,1,4,3]。偶数下标0和2的值按照非递减顺序重排。
请你返回 符合 要求的隐藏数组的数目。如果没有符合要求的隐藏数组,请返回
diff --git a/solution/2100-2199/2145.Count the Hidden Sequences/README_EN.md b/solution/2100-2199/2145.Count the Hidden Sequences/README_EN.md index 2ee7e828293bd..bceedc19614a0 100644 --- a/solution/2100-2199/2145.Count the Hidden Sequences/README_EN.md +++ b/solution/2100-2199/2145.Count the Hidden Sequences/README_EN.md @@ -10,12 +10,14 @@0。Return the number of possible hidden sequences there are. If there are no possible sequences, return
diff --git a/solution/2100-2199/2164.Sort Even and Odd Indices Independently/README.md b/solution/2100-2199/2164.Sort Even and Odd Indices Independently/README.md index ddea2621ad964..cfbaf6ef627a1 100644 --- a/solution/2100-2199/2164.Sort Even and Odd Indices Independently/README.md +++ b/solution/2100-2199/2164.Sort Even and Odd Indices Independently/README.md @@ -10,6 +10,7 @@0.
+
- If question
- 如果问题
给定 buildings ,返回如上所述的二维整数矩阵 street ( 不包括 街道上没有建筑物的任何区域)。您可以按 任何顺序 返回数组。
diff --git a/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README_EN.md b/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README_EN.md
index 98f2494642974..077abda823b06 100644
--- a/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README_EN.md
+++ b/solution/2000-2099/2015.Average Height of Buildings in Each Segment/README_EN.md
@@ -10,12 +10,14 @@
Given buildings, return the 2D integer array street as described above (excluding any areas of the street where there are no buldings). You may return the array in any order.
每一次 操作 中,你可以选择一个下标 i 并将 arr[i] 改成任意 正整数。
In one operation, you can choose an index i and change arr[i] into any positive integer.
请你返回一个字符串,表示 闭区间 [left, right] 中所有整数 乘积 的 缩写 。
Return a string denoting the abbreviated product of all integers in the inclusive range [left, right].
返回重排 nums 的值之后形成的数组。
- Sort the values at odd indices of
numsin non-increasing order. +- For example, if
nums = [4,1,2,3]before this step, it becomes[4,3,2,1]after. The values at odd indices1and3are sorted in non-increasing order.
- For example, if
- For example, if
nums = [4,1,2,3]before this step, it becomes[2,1,4,3]after. The values at even indices0and2are sorted in non-decreasing order.
+
Return the array formed after rearranging the values of nums.
示例 1:
-输入:mapping = [8,9,4,0,2,1,3,5,7,6], nums = [991,338,38] ++输入:mapping = [8,9,4,0,2,1,3,5,7,6], nums = [991,338,38] 输出:[338,38,991] 解释: 将数字 991 按照如下规则映射: 1. mapping[9] = 6 ,所有数位 9 都会变成 6 。 -2. mapping[1] = 9 ,所有数位 1 都会变成 8 。 +2. mapping[1] = 9 ,所有数位 1 都会变成 9 。 所以,991 映射的值为 669 。 338 映射为 007 ,去掉前导 0 后得到 7 。 38 映射为 07 ,去掉前导 0 后得到 7 。 @@ -38,7 +39,8 @@示例 2:
-输入:mapping = [0,1,2,3,4,5,6,7,8,9], nums = [789,456,123] ++输入:mapping = [0,1,2,3,4,5,6,7,8,9], nums = [789,456,123] 输出:[123,456,789] 解释:789 映射为 789 ,456 映射为 456 ,123 映射为 123 。所以排序后数组为 [123,456,789] 。diff --git a/solution/2200-2299/2241.Design an ATM Machine/README.md b/solution/2200-2299/2241.Design an ATM Machine/README.md index 2d81b292a497a..372435a5c9d05 100644 --- a/solution/2200-2299/2241.Design an ATM Machine/README.md +++ b/solution/2200-2299/2241.Design an ATM Machine/README.md @@ -11,16 +11,16 @@取款时,机器会优先取 较大 数额的钱。
-
-
- 比方说,你想取
300,并且机器里有2张50的钞票,1张100的钞票和1张200的钞票,那么机器会取出100和200的钞票。
- - 但是,如果你想取
600,机器里有3张200的钞票和1张500的钞票,那么取款请求会被拒绝,因为机器会先取出500的钞票,然后无法取出剩余的100。注意,因为有500钞票的存在,机器 不能 取200的钞票。
+ - 比方说,你想取
$300,并且机器里有2张$50的钞票,1张$100的钞票和1张$200的钞票,那么机器会取出$100和$200的钞票。
+ - 但是,如果你想取
$600,机器里有3张$200的钞票和1张$500的钞票,那么取款请求会被拒绝,因为机器会先取出$500的钞票,然后无法取出剩余的$100。注意,因为有$500钞票的存在,机器 不能 取$200的钞票。
请你实现 ATM 类:
ATM()初始化 ATM 对象。
- void deposit(int[] banknotesCount)分别存入20,50,100,200和500钞票的数目。
- int[] withdraw(int amount)返回一个长度为5的数组,分别表示20,50,100,200和500钞票的数目,并且更新 ATM 机里取款后钞票的剩余数量。如果无法取出指定数额的钱,请返回[-1](这种情况下 不 取出任何钞票)。
+ void deposit(int[] banknotesCount)分别存入$20,$50,$100,$200和$500钞票的数目。
+ int[] withdraw(int amount)返回一个长度为5的数组,分别表示$20,$50,$100,$200和$500钞票的数目,并且更新 ATM 机里取款后钞票的剩余数量。如果无法取出指定数额的钱,请返回[-1](这种情况下 不 取出任何钞票)。
@@ -36,13 +36,13 @@ 解释: ATM atm = new ATM(); -atm.deposit([0,0,1,2,1]); // 存入 1 张 100 ,2 张 200 和 1 张 500 的钞票。 -atm.withdraw(600); // 返回 [0,0,1,0,1] 。机器返回 1 张 100 和 1 张 500 的钞票。机器里剩余钞票的数量为 [0,0,0,2,0] 。 -atm.deposit([0,1,0,1,1]); // 存入 1 张 50 ,1 张 200 和 1 张 500 的钞票。 +atm.deposit([0,0,1,2,1]); // 存入 1 张 $100 ,2 张 $200 和 1 张 $500 的钞票。 +atm.withdraw(600); // 返回 [0,0,1,0,1] 。机器返回 1 张 $100 和 1 张 $500 的钞票。机器里剩余钞票的数量为 [0,0,0,2,0] 。 +atm.deposit([0,1,0,1,1]); // 存入 1 张 $50 ,1 张 $200 和 1 张 $500 的钞票。 // 机器中剩余钞票数量为 [0,1,0,3,1] 。 -atm.withdraw(600); // 返回 [-1] 。机器会尝试取出 500 的钞票,然后无法得到剩余的 100 ,所以取款请求会被拒绝。 +atm.withdraw(600); // 返回 [-1] 。机器会尝试取出 $500 的钞票,然后无法得到剩余的 $100 ,所以取款请求会被拒绝。 // 由于请求被拒绝,机器中钞票的数量不会发生改变。 -atm.withdraw(550); // 返回 [0,1,0,0,1] ,机器会返回 1 张 50 的钞票和 1 张 500 的钞票。 +atm.withdraw(550); // 返回 [0,1,0,0,1] ,机器会返回 1 张 $50 的钞票和 1 张 $500 的钞票。
diff --git a/solution/2200-2299/2241.Design an ATM Machine/README_EN.md b/solution/2200-2299/2241.Design an ATM Machine/README_EN.md index 1cda656acb3e2..ebcd74de5312e 100644 --- a/solution/2200-2299/2241.Design an ATM Machine/README_EN.md +++ b/solution/2200-2299/2241.Design an ATM Machine/README_EN.md @@ -9,16 +9,16 @@
When withdrawing, the machine prioritizes using banknotes of larger values.
-
-
- For example, if you want to withdraw
300and there are250banknotes,1100banknote, and1200banknote, then the machine will use the100and200banknotes.
- - However, if you try to withdraw
600and there are3200banknotes and1500banknote, then the withdraw request will be rejected because the machine will first try to use the500banknote and then be unable to use banknotes to complete the remaining100. Note that the machine is not allowed to use the200banknotes instead of the500banknote.
+ - For example, if you want to withdraw
$300and there are2$50banknotes,1$100banknote, and1$200banknote, then the machine will use the$100and$200banknotes.
+ - However, if you try to withdraw
$600and there are3$200banknotes and1$500banknote, then the withdraw request will be rejected because the machine will first try to use the$500banknote and then be unable to use banknotes to complete the remaining$100. Note that the machine is not allowed to use the$200banknotes instead of the$500banknote.
Implement the ATM class:
ATM()Initializes the ATM object.
- void deposit(int[] banknotesCount)Deposits new banknotes in the order20,50,100,200, and500.
- int[] withdraw(int amount)Returns an array of length5of the number of banknotes that will be handed to the user in the order20,50,100,200, and500, and update the number of banknotes in the ATM after withdrawing. Returns[-1]if it is not possible (do not withdraw any banknotes in this case).
+ void deposit(int[] banknotesCount)Deposits new banknotes in the order$20,$50,$100,$200, and$500.
+ int[] withdraw(int amount)Returns an array of length5of the number of banknotes that will be handed to the user in the order$20,$50,$100,$200, and$500, and update the number of banknotes in the ATM after withdrawing. Returns[-1]if it is not possible (do not withdraw any banknotes in this case).
@@ -33,20 +33,20 @@ Explanation ATM atm = new ATM(); -atm.deposit([0,0,1,2,1]); // Deposits 1 100 banknote, 2 200 banknotes, - // and 1 500 banknote. -atm.withdraw(600); // Returns [0,0,1,0,1]. The machine uses 1 100 banknote - // and 1 500 banknote. The banknotes left over in the +atm.deposit([0,0,1,2,1]); // Deposits 1 $100 banknote, 2 $200 banknotes, + // and 1 $500 banknote. +atm.withdraw(600); // Returns [0,0,1,0,1]. The machine uses 1 $100 banknote + // and 1 $500 banknote. The banknotes left over in the // machine are [0,0,0,2,0]. -atm.deposit([0,1,0,1,1]); // Deposits 1 50, 200, and 500 banknote. +atm.deposit([0,1,0,1,1]); // Deposits 1 $50, $200, and $500 banknote. // The banknotes in the machine are now [0,1,0,3,1]. -atm.withdraw(600); // Returns [-1]. The machine will try to use a 500 banknote - // and then be unable to complete the remaining 100, +atm.withdraw(600); // Returns [-1]. The machine will try to use a $500 banknote + // and then be unable to complete the remaining $100, // so the withdraw request will be rejected. // Since the request is rejected, the number of banknotes // in the machine is not modified. -atm.withdraw(550); // Returns [0,1,0,0,1]. The machine uses 1 50 banknote - // and 1 500 banknote. +atm.withdraw(550); // Returns [0,1,0,0,1]. The machine uses 1 $50 banknote + // and 1 $500 banknote.
Constraints:
@@ -57,6 +57,7 @@ atm.withdraw(550); // Returns [0,1,0,0,1]. The machine uses 1 50 banknote1 <= amount <= 1095000 calls in total will be made to withdraw and deposit.withdraw and deposit.banknotesCount[i] in all deposits doesn't exceed 109句子 是由若干个单词组成的字符串,单词之间用单个空格分隔,其中每个单词可以包含数字、小写字母、和美元符号 '' 。如果单词的形式为美元符号后跟着一个非负实数,那么这个单词就表示一个 价格 。
句子 是由若干个单词组成的字符串,单词之间用单个空格分隔,其中每个单词可以包含数字、小写字母、和美元符号 '$' 。如果单词的形式为美元符号后跟着一个非负实数,那么这个单词就表示一个 价格 。
-
-
- 例如
"100"、"23"和"6"表示价格,而"100"、""和"1e5不是。
+ - 例如
"$100"、"$23"和"$6"表示价格,而"100"、"$"和"$1e5不是。
给你一个字符串 sentence 表示一个句子和一个整数 discount 。对于每个表示价格的单词,都在价格的基础上减免 discount% ,并 更新 该单词到句子中。所有更新后的价格应该表示为一个 恰好保留小数点后两位 的数字。
示例 1:
-输入:sentence = "there are 1 2 and 5 candies in the shop", discount = 50 -输出:"there are 0.50 1.00 and 5 candies in the shop" +输入:sentence = "there are $1 $2 and 5$ candies in the shop", discount = 50 +输出:"there are $0.50 $1.00 and 5$ candies in the shop" 解释: -表示价格的单词是 "1" 和 "2" 。 -- "1" 减免 50% 为 "0.50" ,所以 "1" 替换为 "0.50" 。 -- "2" 减免 50% 为 "1" ,所以 "1" 替换为 "1.00" 。+表示价格的单词是 "$1" 和 "$2" 。 +- "$1" 减免 50% 为 "$0.50" ,所以 "$1" 替换为 "$0.50" 。 +- "$2" 减免 50% 为 "$1" ,所以 "$1" 替换为 "$1.00" 。
示例 2:
-输入:sentence = "1 2 3 4 5 6 7 8 9 10", discount = 100 -输出:"1 2 0.00 4 0.00 0.00 7 8 0.00 10" +输入:sentence = "1 2 $3 4 $5 $6 7 8$ $9 $10$", discount = 100 +输出:"1 2 $0.00 4 $0.00 $0.00 7 8$ $0.00 $10$" 解释: 任何价格减免 100% 都会得到 0 。 -表示价格的单词分别是 "3"、"5"、"6" 和 "9"。 -每个单词都替换为 "0.00"。 +表示价格的单词分别是 "$3"、"$5"、"$6" 和 "$9"。 +每个单词都替换为 "$0.00"。
@@ -47,7 +47,7 @@
1 <= sentence.length <= 105
- sentence由小写英文字母、数字、' '和''组成
+ sentence由小写英文字母、数字、' '和'$'组成sentence不含前导和尾随空格sentence的所有单词都用单个空格分隔- 所有价格都是 正 整数且不含前导零 diff --git a/solution/2200-2299/2288.Apply Discount to Prices/README_EN.md b/solution/2200-2299/2288.Apply Discount to Prices/README_EN.md index 39fe26bc3c188..ecf60e66ee51e 100644 --- a/solution/2200-2299/2288.Apply Discount to Prices/README_EN.md +++ b/solution/2200-2299/2288.Apply Discount to Prices/README_EN.md @@ -4,10 +4,10 @@ ## Description -
- For example,
"100","23", and"6"represent prices while"100","", and"1e5"do not.
+ - For example,
"$100","$23", and"$6"represent prices while"100","$", and"$1e5"do not.
A sentence is a string of single-space separated words where each word can contain digits, lowercase letters, and the dollar sign ''. A word represents a price if it is a sequence of digits preceded by a dollar sign.
A sentence is a string of single-space separated words where each word can contain digits, lowercase letters, and the dollar sign '$'. A word represents a price if it is a sequence of digits preceded by a dollar sign.
-
-
You are given a string sentence representing a sentence and an integer discount. For each word representing a price, apply a discount of discount% on the price and update the word in the sentence. All updated prices should be represented with exactly two decimal places.
Example 1:
-Input: sentence = "there are 1 2 and 5 candies in the shop", discount = 50 -Output: "there are 0.50 1.00 and 5 candies in the shop" +Input: sentence = "there are $1 $2 and 5$ candies in the shop", discount = 50 +Output: "there are $0.50 $1.00 and 5$ candies in the shop" Explanation: -The words which represent prices are "1" and "2". -- A 50% discount on "1" yields "0.50", so "1" is replaced by "0.50". -- A 50% discount on "2" yields "1". Since we need to have exactly 2 decimal places after a price, we replace "2" with "1.00". +The words which represent prices are "$1" and "$2". +- A 50% discount on "$1" yields "$0.50", so "$1" is replaced by "$0.50". +- A 50% discount on "$2" yields "$1". Since we need to have exactly 2 decimal places after a price, we replace "$2" with "$1.00".
Example 2:
-Input: sentence = "1 2 3 4 5 6 7 8 9 10", discount = 100 -Output: "1 2 0.00 4 0.00 0.00 7 8 0.00 10" +Input: sentence = "1 2 $3 4 $5 $6 7 8$ $9 $10$", discount = 100 +Output: "1 2 $0.00 4 $0.00 $0.00 7 8$ $0.00 $10$" Explanation: Applying a 100% discount on any price will result in 0. -The words representing prices are "3", "5", "6", and "9". -Each of them is replaced by "0.00". +The words representing prices are "$3", "$5", "$6", and "$9". +Each of them is replaced by "$0.00".
@@ -44,7 +44,7 @@ Each of them is replaced by "0.00".
1 <= sentence.length <= 105
- sentenceconsists of lowercase English letters, digits,' ', and''.
+ sentenceconsists of lowercase English letters, digits,' ', and'$'.sentencedoes not have leading or trailing spaces.- All words in
sentenceare separated by a single space. - All prices will be positive numbers without leading zeros. diff --git a/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README.md b/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README.md index c68c60e04c26f..60aea6bc22e73 100644 --- a/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README.md +++ b/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README.md @@ -26,10 +26,10 @@
输入:brackets = [[3,50],[7,10],[12,25]], income = 10 输出:2.65000 解释: -前 3 的税率为 50% 。需要支付税款 3 * 50% = 1.50 。 -接下来 7 - 3 = 4 的税率为 10% 。需要支付税款 4 * 10% = 0.40 。 -最后 10 - 7 = 3 的税率为 25% 。需要支付税款 3 * 25% = 0.75 。 -需要支付的税款总计 1.50 + 0.40 + 0.75 = 2.65 。 +前 $3 的税率为 50% 。需要支付税款 $3 * 50% = $1.50 。 +接下来 $7 - $3 = $4 的税率为 10% 。需要支付税款 $4 * 10% = $0.40 。 +最后 $10 - $7 = $3 的税率为 25% 。需要支付税款 $3 * 25% = $0.75 。 +需要支付的税款总计 $1.50 + $0.40 + $0.75 = $2.65 。
示例 2:
@@ -37,9 +37,9 @@输入:brackets = [[1,0],[4,25],[5,50]], income = 2 输出:0.25000 解释: -前 1 的税率为 0% 。需要支付税款 1 * 0% = 0 。 -剩下 1 的税率为 25% 。需要支付税款 1 * 25% = 0.25 。 -需要支付的税款总计 0 + 0.25 = 0.25 。 +前 $1 的税率为 0% 。需要支付税款 $1 * 0% = $0 。 +剩下 $1 的税率为 25% 。需要支付税款 $1 * 25% = $0.25 。 +需要支付的税款总计 $0 + $0.25 = $0.25 。
示例 3:
@@ -47,7 +47,7 @@输入:brackets = [[2,50]], income = 0 输出:0.00000 解释: -没有收入,无需纳税,需要支付的税款总计 0 。 +没有收入,无需纳税,需要支付的税款总计 $0 。
diff --git a/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README_EN.md b/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README_EN.md index cbd6ad7e8f294..a149c7cb97e5c 100644 --- a/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README_EN.md +++ b/solution/2300-2399/2303.Calculate Amount Paid in Taxes/README_EN.md @@ -26,7 +26,7 @@ Explanation: Based on your income, you have 3 dollars in the 1st tax bracket, 4 dollars in the 2nd tax bracket, and 3 dollars in the 3rd tax bracket. The tax rate for the three tax brackets is 50%, 10%, and 25%, respectively. -In total, you pay 3 * 50% + 4 * 10% + 3 * 25% = 2.65 in taxes. +In total, you pay $3 * 50% + $4 * 10% + $3 * 25% = $2.65 in taxes.
Example 2:
@@ -37,7 +37,7 @@ In total, you pay 3 * 50% + 4 * 10% + 3 * 25% = 2.65 in taxes. Explanation: Based on your income, you have 1 dollar in the 1st tax bracket and 1 dollar in the 2nd tax bracket. The tax rate for the two tax brackets is 0% and 25%, respectively. -In total, you pay 1 * 0% + 1 * 25% = 0.25 in taxes. +In total, you pay $1 * 0% + $1 * 25% = $0.25 in taxes.Example 3:
@@ -46,7 +46,7 @@ In total, you pay 1 * 0% + 1 * 25% = 0.25 in taxes. Input: brackets = [[2,50]], income = 0 Output: 0.00000 Explanation: -You have no income to tax, so you have to pay a total of 0 in taxes. +You have no income to tax, so you have to pay a total of $0 in taxes.diff --git a/solution/2300-2399/2353.Design a Food Rating System/README.md b/solution/2300-2399/2353.Design a Food Rating System/README.md index 6071a92fc0010..a1816e2181489 100644 --- a/solution/2300-2399/2353.Design a Food Rating System/README.md +++ b/solution/2300-2399/2353.Design a Food Rating System/README.md @@ -17,6 +17,7 @@
FoodRatings(String[] foods, String[] cuisines, int[] ratings)初始化系统。食物由foods、cuisines和ratings描述,长度均为n。 +foods[i]是第i种食物的名字。cuisines[i]是第i种食物的烹饪方式。
@@ -25,6 +26,7 @@
void changeRating(String food, int newRating)修改名字为food的食物的评分。String highestRated(String cuisine)返回指定烹饪方式cuisine下评分最高的食物的名字。如果存在并列,返回 字典序较小 的名字。
+
注意,字符串 x 的字典序比字符串 y 更小的前提是:x 在字典中出现的位置在 y 之前,也就是说,要么 x 是 y 的前缀,或者在满足 x[i] != y[i] 的第一个位置 i 处,x[i] 在字母表中出现的位置在 y[i] 之前。
FoodRatings(String[] foods, String[] cuisines, int[] ratings)Initializes the system. The food items are described byfoods,cuisinesandratings, all of which have a length ofn. +foods[i]is the name of theithfood,cuisines[i]is the type of cuisine of theithfood, and
@@ -23,6 +24,7 @@
void changeRating(String food, int newRating)Changes the rating of the food item with the namefood.String highestRated(String cuisine)Returns the name of the food item that has the highest rating for the given type ofcuisine. If there is a tie, return the item with the lexicographically smaller name.
+
Note that a string x is lexicographically smaller than string y if x comes before y in dictionary order, that is, either x is a prefix of y, or if i is the first position such that x[i] != y[i], then x[i] comes before y[i] in alphabetic order.
-
编写一个 SQL 查询来显示价格最高的发票的详细信息。如果两个或多个发票具有相同的价格,则返回 invoice_id 最小的发票的详细信息。
编写解决方案,展示价格最高的发票的详细信息。如果两个或多个发票具有相同的价格,则返回 invoice_id 最小的发票的详细信息。
以 任意顺序 返回结果表。
-查询结果格式示例如下。
+结果格式示例如下。
@@ -74,10 +74,10 @@ Purchases 表: | 1 | 4 | 400 | +------------+----------+-------+ 解释: -发票 1: price = (2 * 100) = 200 -发票 2: price = (4 * 100) + (3 * 200) = 1000 -发票 3: price = (1 * 200) = 200 -发票 4: price = (10 * 100) = 1000 +发票 1: price = (2 * 100) = $200 +发票 2: price = (4 * 100) + (3 * 200) = $1000 +发票 3: price = (1 * 200) = $200 +发票 4: price = (10 * 100) = $1000 最高价格是 1000 美元,最高价格的发票是 2 和 4。我们返回 ID 最小的发票 2 的详细信息。 diff --git a/solution/2300-2399/2362.Generate the Invoice/README_EN.md b/solution/2300-2399/2362.Generate the Invoice/README_EN.md index e75a073e7d11a..e1613a0c9a52e 100644 --- a/solution/2300-2399/2362.Generate the Invoice/README_EN.md +++ b/solution/2300-2399/2362.Generate the Invoice/README_EN.md @@ -13,7 +13,7 @@ | product_id | int | | price | int | +-------------+------+ -product_id is the primary key for this table. +product_id contains unique values. Each row in this table shows the ID of a product and the price of one unit. @@ -29,17 +29,17 @@ Each row in this table shows the ID of a product and the price of one unit. | product_id | int | | quantity | int | +-------------+------+ -(invoice_id, product_id) is the primary key for this table. +(invoice_id, product_id) is the primary key (combination of columns with unique values) for this table. Each row in this table shows the quantity ordered from one product in an invoice.
-
Write an SQL query to show the details of the invoice with the highest price. If two or more invoices have the same price, return the details of the one with the smallest invoice_id.
Write a solution to show the details of the invoice with the highest price. If two or more invoices have the same price, return the details of the one with the smallest invoice_id.
Return the result table in any order.
-The query result format is shown in the following example.
+The result format is shown in the following example.
Example 1:
@@ -71,12 +71,12 @@ Purchases table: | 1 | 4 | 400 | +------------+----------+-------+ Explanation: -Invoice 1: price = (2 * 100) = 200 -Invoice 2: price = (4 * 100) + (3 * 200) = 1000 -Invoice 3: price = (1 * 200) = 200 -Invoice 4: price = (10 * 100) = 1000 +Invoice 1: price = (2 * 100) = $200 +Invoice 2: price = (4 * 100) + (3 * 200) = $1000 +Invoice 3: price = (1 * 200) = $200 +Invoice 4: price = (10 * 100) = $1000 -The highest price is 1000, and the invoices with the highest prices are 2 and 4. We return the details of the one with the smallest ID, which is invoice 2. +The highest price is $1000, and the invoices with the highest prices are 2 and 4. We return the details of the one with the smallest ID, which is invoice 2. ## Solutions diff --git a/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README.md b/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README.md index 283347ee7f457..9f85f4d9764de 100644 --- a/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README.md +++ b/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README.md @@ -12,10 +12,12 @@- 选择任意两个 相邻 的元素并用它们的 和 替换 它们。
+
- 例如,如果
nums = [1,2,3,1],则可以应用一个操作使其变为[1,5,1]。
+
- 例如,如果
返回将数组转换为 回文序列 所需的 最小 操作数。
diff --git a/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README_EN.md b/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README_EN.md index e98de481f0294..250bf4376d531 100644 --- a/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README_EN.md +++ b/solution/2400-2499/2422.Merge Operations to Turn Array Into a Palindrome/README_EN.md @@ -10,10 +10,12 @@- Choose any two adjacent elements and replace them with their sum.
+
- For example, if
nums = [1,2,3,1], you can apply one operation to make it[1,5,1].
+
- For example, if
Return the minimum number of operations needed to turn the array into a palindrome.
diff --git a/solution/2400-2499/2488.Count Subarrays With Median K/README.md b/solution/2400-2499/2488.Count Subarrays With Median K/README.md index e77be1d758ca2..78e78e9d200b9 100644 --- a/solution/2400-2499/2488.Count Subarrays With Median K/README.md +++ b/solution/2400-2499/2488.Count Subarrays With Median K/README.md @@ -14,11 +14,13 @@- 数组的中位数是按 递增 顺序排列后位于 中间 的那个元素,如果数组长度为偶数,则中位数是位于中间靠 左 的那个元素。
+
- 例如,
[2,3,1,4]的中位数是2,[8,4,3,5,1]的中位数是4。
- 例如,
- 子数组是数组中的一个连续部分。 +
diff --git a/solution/2400-2499/2488.Count Subarrays With Median K/README_EN.md b/solution/2400-2499/2488.Count Subarrays With Median K/README_EN.md index 7d18e2e92c7cc..0f9062f74a035 100644 --- a/solution/2400-2499/2488.Count Subarrays With Median K/README_EN.md +++ b/solution/2400-2499/2488.Count Subarrays With Median K/README_EN.md @@ -12,11 +12,13 @@
- The median of an array is the middle element after sorting the array in ascending order. If the array is of even length, the median is the left middle element.
+
- For example, the median of
[2,3,1,4]is2, and the median of[8,4,3,5,1]is4.
- For example, the median of
- A subarray is a contiguous part of an array. +
diff --git a/solution/2500-2599/2525.Categorize Box According to Criteria/README.md b/solution/2500-2599/2525.Categorize Box According to Criteria/README.md index 531e8a820c343..db0597d66ed63 100644 --- a/solution/2500-2599/2525.Categorize Box According to Criteria/README.md +++ b/solution/2500-2599/2525.Categorize Box According to Criteria/README.md @@ -10,6 +10,7 @@
- 如果满足以下条件,那么箱子是
"Bulky"的: +- 箱子 至少有一个 维度大于等于
104。 - 或者箱子的 体积 大于等于
109。
@@ -20,6 +21,7 @@
- 如果箱子既不是
"Bulky",也不是"Heavy",那么返回类别为"Neither"。 - 如果箱子是
"Bulky"但不是"Heavy",那么返回类别为"Bulky"。 - 如果箱子是
"Heavy"但不是"Bulky",那么返回类别为"Heavy"。
+
注意,箱子的体积等于箱子的长度、宽度和高度的乘积。
diff --git a/solution/2500-2599/2525.Categorize Box According to Criteria/README_EN.md b/solution/2500-2599/2525.Categorize Box According to Criteria/README_EN.md index 55af69ca88525..425662af4cf2c 100644 --- a/solution/2500-2599/2525.Categorize Box According to Criteria/README_EN.md +++ b/solution/2500-2599/2525.Categorize Box According to Criteria/README_EN.md @@ -8,6 +8,7 @@- The box is
"Bulky"if: +- Any of the dimensions of the box is greater or equal to
104. - Or, the volume of the box is greater or equal to
109.
@@ -18,6 +19,7 @@
- If the box is neither
"Bulky"nor"Heavy", then its category is"Neither". - If the box is
"Bulky"but not"Heavy", then its category is"Bulky". - If the box is
"Heavy"but not"Bulky", then its category is"Heavy".
+
Note that the volume of the box is the product of its length, width and height.
diff --git a/solution/2500-2599/2578.Split With Minimum Sum/README.md b/solution/2500-2599/2578.Split With Minimum Sum/README.md index ff9b8e68a911e..02706b19feeca 100644 --- a/solution/2500-2599/2578.Split With Minimum Sum/README.md +++ b/solution/2500-2599/2578.Split With Minimum Sum/README.md @@ -10,11 +10,13 @@num1和num2直接连起来,得到num各数位的一个排列。 +- 换句话说,
num1和num2中所有数字出现的次数之和等于num中所有数字出现的次数。
- 换句话说,
num1和num2可以包含前导 0 。
+
请你返回
@@ -33,7 +35,7 @@num1和num2可以得到的和的 最小 值。输入:num = 4325 输出:59 -解释:我们可以将 4325 分割成
num1= 24 和 num2=35 ,和为 59 ,59 是最小和。 +解释:我们可以将 4325 分割成num1= 24 和num2= 35 ,和为 59 ,59 是最小和。示例 2:
diff --git a/solution/2500-2599/2578.Split With Minimum Sum/README_EN.md b/solution/2500-2599/2578.Split With Minimum Sum/README_EN.md index f884c082edb21..0364bfbfc5107 100644 --- a/solution/2500-2599/2578.Split With Minimum Sum/README_EN.md +++ b/solution/2500-2599/2578.Split With Minimum Sum/README_EN.md @@ -8,11 +8,13 @@- The concatenation of
num1andnum2is a permutation ofnum. +- In other words, the sum of the number of occurrences of each digit in
num1andnum2is equal to the number of occurrences of that digit innum.
- In other words, the sum of the number of occurrences of each digit in
num1andnum2can contain leading zeros.
+
Return the minimum possible sum of
diff --git a/solution/2600-2699/2606.Find the Substring With Maximum Cost/README.md b/solution/2600-2699/2606.Find the Substring With Maximum Cost/README.md index c725aeadcd028..6d226f1407e4b 100644 --- a/solution/2600-2699/2606.Find the Substring With Maximum Cost/README.md +++ b/solution/2600-2699/2606.Find the Substring With Maximum Cost/README.md @@ -14,11 +14,13 @@num1andnum2.- 如果字符不在字符串
chars中,那么它的价值是它在字母表中的位置(下标从 1 开始)。 +- 比方说,
'a'的价值为1,'b'的价值为2,以此类推,'z'的价值为26。
- 比方说,
- 否则,如果这个字符在
chars中的位置为i,那么它的价值就是vals[i]。
+
请你返回字符串
diff --git a/solution/2600-2699/2606.Find the Substring With Maximum Cost/README_EN.md b/solution/2600-2699/2606.Find the Substring With Maximum Cost/README_EN.md index 1a12d72408e20..4eae3b06b78d1 100644 --- a/solution/2600-2699/2606.Find the Substring With Maximum Cost/README_EN.md +++ b/solution/2600-2699/2606.Find the Substring With Maximum Cost/README_EN.md @@ -12,11 +12,13 @@s的所有子字符串中的最大开销。- If the character is not in the string
chars, then its value is its corresponding position (1-indexed) in the alphabet. +- For example, the value of
'a'is1, the value of'b'is2, and so on. The value of'z'is26.
- For example, the value of
- Otherwise, assuming
iis the index where the character occurs in the stringchars, then its value isvals[i].
+
Return the maximum cost among all substrings of the string
diff --git a/solution/2700-2799/2725.Interval Cancellation/README.md b/solution/2700-2799/2725.Interval Cancellation/README.md index 6e1f48cd142a8..8692ce03da8b3 100644 --- a/solution/2700-2799/2725.Interval Cancellation/README.md +++ b/solution/2700-2799/2725.Interval Cancellation/README.md @@ -8,7 +8,13 @@s.现给定一个函数
-fn,一个参数数组args和一个时间间隔t,返回一个取消函数cancelFn。函数
+fn应该立即使用args调用,并且在每个t毫秒内再次调用,直到调用cancelFn。在经过
+ +cancelTimeMs毫秒的延迟后,将调用返回的取消函数cancelFn。+setTimeout(cancelFn, cancelTimeMs) +
+ +函数
fn应立即使用参数args调用,然后每隔t毫秒调用一次,直到在cancelTimeMs毫秒时调用cancelFn。
@@ -26,23 +32,9 @@ {"time": 175, "returned": 8} ] 解释: -const result = [] -const fn = (x) => x * 2 -const args = [4], t = 35, cancelT = 190 - -const start = performance.now() - -const log = (...argsArr) => { - const diff = Math.floor(performance.now() - start) - result.push({"time": diff, "returned": fn(...argsArr)}) -} - -const cancel = cancellable(log, [4], 35); -setTimeout(cancel, 190); - -setTimeout(() => { - console.log(result) // Output - }, cancelT + t + 15) +const cancelTimeMs = 190; +const cancelFn = cancellable((x) => x * 2, [4], 35); +setTimeout(cancelFn, cancelTimeMs); 每隔 35ms,调用 fn(4)。直到 t=190ms,然后取消。 第一次调用 fn 是在 0ms。fn(4) 返回 8。 @@ -68,8 +60,9 @@ setTimeout(() => { {"time": 150, "returned": 10} ] 解释: -const cancel = cancellable((x1, x2) => (x1 * x2), [2, 5], 30); -setTimeout(cancel, 165); +const cancelTimeMs = 165; +const cancelFn = cancellable((x1, x2) => (x1 * x2), [2, 5], 30) +setTimeout(cancelFn, cancelTimeMs) 每隔 30ms,调用 fn(2, 5)。直到 t=165ms,然后取消。 第一次调用 fn 是在 0ms @@ -93,8 +86,9 @@ setTimeout(cancel, 165); {"time": 150, "returned": 9} ] 解释: -const cancel = cancellable((x1, x2, x3) => (x1 + x2 + x3), [5, 1, 3], 50); -setTimeout(cancel, cancelT); +const cancelTimeMs = 180; +const cancelFn = cancellable((x1, x2, x3) => (x1 + x2 + x3), [5, 1, 3], 50) +setTimeout(cancelFn, cancelTimeMs) 每隔 50ms,调用 fn(5, 1, 3)。直到 t=180ms,然后取消。 第一次调用 fn 是在 0ms diff --git a/solution/2700-2799/2725.Interval Cancellation/README_EN.md b/solution/2700-2799/2725.Interval Cancellation/README_EN.md index 119857a75e142..0d10ef9d634ee 100644 --- a/solution/2700-2799/2725.Interval Cancellation/README_EN.md +++ b/solution/2700-2799/2725.Interval Cancellation/README_EN.md @@ -6,8 +6,16 @@Given a function
+fn, an array of argumentsargs, and an interval timet, return a cancel functioncancelFn.After a delay of
+ +cancelTimeMs, the returned cancel functioncancelFnwill be invoked.+setTimeout(cancelFn, cancelTimeMs) +
+The function
+fnshould be called withargsimmediately and then called again everytmilliseconds untilcancelFnis called atcancelTimeMsms.
+Example 1:
diff --git a/solution/2700-2799/2731.Movement of Robots/README.md b/solution/2700-2799/2731.Movement of Robots/README.md index 94c5ed9e43988..4bf8343fd54f7 100644 --- a/solution/2700-2799/2731.Movement of Robots/README.md +++ b/solution/2700-2799/2731.Movement of Robots/README.md @@ -18,9 +18,10 @@- 对于坐标在
i和j的两个机器人,(i,j)和(j,i)视为相同的坐标对。也就是说,机器人视为无差别的。
- - 当机器人相撞时,它们 立即改变 它们的前进时间,这个过程不消耗任何时间。 +
- 当机器人相撞时,它们 立即改变 它们的前进方向,这个过程不消耗任何时间。
-
当两个机器人在同一时刻占据相同的位置时,就会相撞。
+-
例如,如果一个机器人位于位置 0 并往右移动,另一个机器人位于位置 2 并往左移动,下一秒,它们都将占据位置 1,并改变方向。再下一秒钟后,第一个机器人位于位置 0 并往左移动,而另一个机器人位于位置 2 并往右移动。
@@ -30,6 +31,7 @@
+
-
diff --git a/solution/2700-2799/2738.Count Occurrences in Text/README.md b/solution/2700-2799/2738.Count Occurrences in Text/README.md index 02bdfab074eee..62ff8c7789928 100644 --- a/solution/2700-2799/2738.Count Occurrences in Text/README.md +++ b/solution/2700-2799/2738.Count Occurrences in Text/README.md @@ -21,9 +21,9 @@ file_name 为该表的主键(具有唯一值的列)。
-编写解决方案,找出单词 'bull' 和 'bear' 作为 独立词 出现的次数,不考虑任何它出现在两侧没有空格的情况(例如,'bullet', 'bears', 'bull.',或者 'bear' 在句首或句尾 不会 被考虑)。
+编写解决方案,找出单词 'bull' 和 'bear' 作为 独立词 有出现的文件数量,不考虑任何它出现在两侧没有空格的情况(例如,'bullet', 'bears', 'bull.',或者 'bear' 在句首或句尾 不会 被考虑)。
-返回单词 'bull' 和 'bear' 以及它们对应的出现次数,顺序没有限制 。
+返回单词 'bull' 和 'bear' 以及它们对应的出现文件数量,顺序没有限制 。
结果的格式如下所示:
@@ -54,8 +54,8 @@ Files 表: | bear | 2 | +------+-------+ 解释: -- 单词 "bull" 在 "draft1.txt" 中出现1次,在 "draft2.txt" 中出现 1 次,在 "draft3.txt" 中出现 1 次。因此,单词 "bull" 的总出现次数为 3 次。 -- 单词 "bear" 在 "draft2.txt" 中出现1次,在 "draft3.txt" 中出现 1 次。因此,单词 "bear" 的总出现次数为 2 次。 +- 单词 "bull" 在 "draft1.txt" 中出现1次,在 "draft2.txt" 中出现 1 次,在 "draft3.txt" 中出现 1 次。因此,单词 "bull" 出现在 3 个文件中。 +- 单词 "bear" 在 "draft2.txt" 中出现1次,在 "draft3.txt" 中出现 1 次。因此,单词 "bear" 出现在 2 个文件中。 ## 解法 diff --git a/solution/2700-2799/2765.Longest Alternating Subarray/README.md b/solution/2700-2799/2765.Longest Alternating Subarray/README.md index 0be4ed8dddba2..685ad999fc9ed 100644 --- a/solution/2700-2799/2765.Longest Alternating Subarray/README.md +++ b/solution/2700-2799/2765.Longest Alternating Subarray/README.md @@ -1,4 +1,4 @@ -# [2765. 最长交替子序列](https://leetcode.cn/problems/longest-alternating-subarray) +# [2765. 最长交替子数组](https://leetcode.cn/problems/longest-alternating-subarray) [English Version](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README_EN.md) @@ -6,7 +6,7 @@ -给你一个下标从 0 开始的整数数组
+nums。如果nums中长度为m的子数组s满足以下条件,我们称它是一个 交替子序列 :给你一个下标从 0 开始的整数数组
nums。如果nums中长度为m的子数组s满足以下条件,我们称它是一个 交替子数组 :m大于1。
diff --git a/solution/2700-2799/2788.Split Strings by Separator/README.md b/solution/2700-2799/2788.Split Strings by Separator/README.md
index 8c2c8a603b708..db7f141792c21 100644
--- a/solution/2700-2799/2788.Split Strings by Separator/README.md
+++ b/solution/2700-2799/2788.Split Strings by Separator/README.md
@@ -36,12 +36,12 @@
示例 2:
-输入:words = ["$easy$","$problem$"], separator = "$" +输入:words = ["$easy$","$problem$"], separator = "$" 输出:["easy","problem"] 解释:在本示例中,我们进行下述拆分: -"$easy$" 拆分为 "easy"(不包括空字符串) -"$problem$" 拆分为 "problem"(不包括空字符串) +"$easy$" 拆分为 "easy"(不包括空字符串) +"$problem$" 拆分为 "problem"(不包括空字符串) 因此,结果数组为 ["easy","problem"] 。
@@ -60,8 +60,8 @@1 <= words.length <= 1001 <= words[i].length <= 20
- words[i]中的字符要么是小写英文字母,要么就是字符串".,|$#@"中的字符(不包括引号)
- separator是字符串".,|$#@"中的某个字符(不包括引号)
+ words[i]中的字符要么是小写英文字母,要么就是字符串".,|$#@"中的字符(不包括引号)
+ separator是字符串".,|$#@"中的某个字符(不包括引号)
Example 2:
-Input: words = ["$easy$","$problem$"], separator = "$" +Input: words = ["$easy$","$problem$"], separator = "$" Output: ["easy","problem"] Explanation: In this example we split as follows: -"$easy$" splits into "easy" (excluding empty strings) -"$problem$" splits into "problem" (excluding empty strings) +"$easy$" splits into "easy" (excluding empty strings) +"$problem$" splits into "problem" (excluding empty strings) Hence, the resulting array is ["easy","problem"].
@@ -56,8 +56,8 @@ Hence, the resulting array is ["easy","problem"].1 <= words.length <= 1001 <= words[i].length <= 20
- - characters in
words[i]are either lowercase English letters or characters from the string".,|$#@"(excluding the quotes)
- separatoris a character from the string".,|$#@"(excluding the quotes)
+ - characters in
words[i]are either lowercase English letters or characters from the string".,|$#@"(excluding the quotes)
+ separatoris a character from the string".,|$#@"(excluding the quotes)
给定
+id。id是从函数customInterval返回的值。customClearInterval应该停止在间隔中执行提供的函数fn。注意:在 Node.js 中,
+setTimeout和setInterval函数返回一个对象,而不是一个数字。示例 1:
diff --git a/solution/2800-2899/2805.Custom Interval/README_EN.md b/solution/2800-2899/2805.Custom Interval/README_EN.md index 3062c06b2f517..25052afe6b271 100644 --- a/solution/2800-2899/2805.Custom Interval/README_EN.md +++ b/solution/2800-2899/2805.Custom Interval/README_EN.md @@ -12,6 +12,8 @@Given the
+id.idis the returned value from the functioncustomInterval.customClearIntervalshould stop executing provided functionfnat intervals.Note: The
+setTimeoutandsetIntervalfunctions in Node.js return an object, not a number.Example 1:
diff --git a/solution/2900-2999/2955.Number of Same-End Substrings/README.md b/solution/2900-2999/2955.Number of Same-End Substrings/README.md index bdf7cb40c94ac..dd467fba2ca1a 100644 --- a/solution/2900-2999/2955.Number of Same-End Substrings/README.md +++ b/solution/2900-2999/2955.Number of Same-End Substrings/README.md @@ -1,4 +1,4 @@ -# [2955. Number of Same-End Substrings](https://leetcode.cn/problems/number-of-same-end-substrings) +# [2955. 同端子串的数量](https://leetcode.cn/problems/number-of-same-end-substrings) [English Version](/solution/2900-2999/2955.Number%20of%20Same-End%20Substrings/README_EN.md) @@ -6,41 +6,42 @@ -You are given a 0-indexed string
+s, and a 2D array of integersqueries, wherequeries[i] = [li, ri]indicates a substring ofsstarting from the indexliand ending at the indexri(both inclusive), i.e.s[li..ri].给定一个 下标从0开始 的字符串
-s,以及一个二维整数数组queries,其中queries[i] = [li, ri]表示s中从索引li开始到索引ri结束的子串(包括两端),即s[li..ri]。Return an array
+answhereans[i]is the number of same-end substrings ofqueries[i].返回一个数组
-ans,其中ans[i]是queries[i]的 同端 子串的数量。A 0-indexed string
+tof lengthnis called same-end if it has the same character at both of its ends, i.e.,t[0] == t[n - 1].如果一个 下标从0开始 且长度为
-n的字符串t两端的字符相同,即t[0] == t[n - 1],则该字符串被称为 同端。A substring is a contiguous non-empty sequence of characters within a string.
+子串 是一个字符串中连续的非空字符序列。
-Example 1:
+ +示例 1:
-Input: s = "abcaab", queries = [[0,0],[1,4],[2,5],[0,5]] -Output: [1,5,5,10] -Explanation: Here is the same-end substrings of each query: -1st query: s[0..0] is "a" which has 1 same-end substring: "a". -2nd query: s[1..4] is "bcaa" which has 5 same-end substrings: "bcaa", "bcaa", "bcaa", "bcaa", "bcaa". -3rd query: s[2..5] is "caab" which has 5 same-end substrings: "caab", "caab", "caab", "caab", "caab". -4th query: s[0..5] is "abcaab" which has 10 same-end substrings: "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab". -
+输入:s = "abcaab", queries = [[0,0],[1,4],[2,5],[0,5]] +输出:[1,5,5,10] +解释:每个查询的同端子串如下: +第一个查询:s[0..0] 是 "a",有 1 个同端子串:"a"。 +第二个查询:s[1..4] 是 "bcaa",有 5 个同端子串:"bcaa", "bcaa", "bcaa", "bcaa", "bcaa"。 +第三个查询:s[2..5] 是 "caab",有 5 个同端子串:"caab", "caab", "caab", "caab", "caab"。 +第四个查询:s[0..5] 是 "abcaab",有 10 个同端子串:"abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab", "abcaab"。 -Example 2:
+示例 2:
-Input: s = "abcd", queries = [[0,3]] -Output: [4] -Explanation: The only query is s[0..3] which is "abcd". It has 4 same-end substrings: "abcd", "abcd", "abcd", "abcd". +输入:s = "abcd", queries = [[0,3]] +输出:[4] +解释:唯一的查询是 s[0..3],它有 4 个同端子串:"abcd", "abcd", "abcd", "abcd"。
-Constraints:
+ +提示:
2 <= s.length <= 3 * 104
- sconsists only of lowercase English letters.
+ s仅包含小写英文字母。1 <= queries.length <= 3 * 104queries[i] = [li, ri]0 <= li <= ri < s.length
diff --git a/solution/2900-2999/2960.Count Tested Devices After Test Operations/README.md b/solution/2900-2999/2960.Count Tested Devices After Test Operations/README.md
index a3f04cd7fd2ac..dfda392f7d948 100644
--- a/solution/2900-2999/2960.Count Tested Devices After Test Operations/README.md
+++ b/solution/2900-2999/2960.Count Tested Devices After Test Operations/README.md
@@ -12,6 +12,7 @@
- 如果
batteryPercentages[i]大于0: +- 增加 已测试设备的计数。
- 将下标在
[i + 1, n - 1]的所有设备的电池百分比减少1,确保它们的电池百分比 不会低于0,即batteryPercentages[j] = max(0, batteryPercentages[j] - 1)。
@@ -19,6 +20,7 @@
- 否则,移动到下一个设备而不执行任何测试。 +
- If
batteryPercentages[i]is greater than0: +- Increment the count of tested devices.
- Decrease the battery percentage of all devices with indices
jin the range[i + 1, n - 1]by1, ensuring their battery percentage never goes below0, i.e,batteryPercentages[j] = max(0, batteryPercentages[j] - 1).
@@ -17,6 +18,7 @@
- Otherwise, move to the next device without performing any test. +
返回一个整数,表示按顺序执行测试操作后 已测试设备 的数量。
diff --git a/solution/2900-2999/2960.Count Tested Devices After Test Operations/README_EN.md b/solution/2900-2999/2960.Count Tested Devices After Test Operations/README_EN.md index 201ca04c69547..d2daa080298d4 100644 --- a/solution/2900-2999/2960.Count Tested Devices After Test Operations/README_EN.md +++ b/solution/2900-2999/2960.Count Tested Devices After Test Operations/README_EN.md @@ -10,6 +10,7 @@Return an integer denoting the number of devices that will be tested after performing the test operations in order.
diff --git a/solution/2900-2999/2978.Symmetric Coordinates/README.md b/solution/2900-2999/2978.Symmetric Coordinates/README.md index 61f8774596645..14fda796fbffa 100644 --- a/solution/2900-2999/2978.Symmetric Coordinates/README.md +++ b/solution/2900-2999/2978.Symmetric Coordinates/README.md @@ -1,4 +1,4 @@ -# [2978. Symmetric Coordinates](https://leetcode.cn/problems/symmetric-coordinates) +# [2978. 对称坐标](https://leetcode.cn/problems/symmetric-coordinates) [English Version](/solution/2900-2999/2978.Symmetric%20Coordinates/README_EN.md) @@ -6,7 +6,7 @@ -Table:
+Coordinates表:
Coordinates+-------------+------+ @@ -15,22 +15,23 @@ | X | int | | Y | int | +-------------+------+ -Each row includes X and Y, where both are integers. Table may contain duplicate values. +每一行包括 X 和 Y,都是整数。表格可能包含重复值。
-Two coordindates
+(X1, Y1)and(X2, Y2)are said to be symmetric coordintes ifX1 == Y2andX2 == Y1.如果两个坐标
-(X1, Y1)和(X2, Y2)满足条件X1 == Y2和X2 == Y1,则它们被称为 对称 坐标。Write a solution that outputs, among all these symmetric coordintes, only those unique coordinates that satisfy the condition
+X1 <= Y1.编写一个解决方案,找出在所有这些对称坐标中,满足条件
-X1 <= Y1的唯一坐标。Return the result table ordered by
+XandY(respectively) in ascending order.按照
-X和Y分别 升序 排列结果表。The result format is in the following example.
+结果格式如下示例所示。
-Example 1:
+ +示例 1:
-Input: +输入: Coordinates table: +----+----+ | X | Y | @@ -42,7 +43,7 @@ Coordinates table: | 22 | 23 | | 21 | 20 | +----+----+ -Output: +输出: +----+----+ | x | y | +----+----+ @@ -50,11 +51,11 @@ Coordinates table: | 20 | 21 | | 22 | 23 | +----+----+ -Explanation: -- (20, 20) and (20, 20) are symmetric coordinates because, X1 == Y2 and X2 == Y1. This results in displaying (20, 20) as a distinctive coordinates. -- (20, 21) and (21, 20) are symmetric coordinates because, X1 == Y2 and X2 == Y1. However, only (20, 21) will be displayed because X1 <= Y1. -- (23, 22) and (22, 23) are symmetric coordinates because, X1 == Y2 and X2 == Y1. However, only (22, 23) will be displayed because X1 <= Y1. -The output table is sorted by X and Y in ascending order. +解释: +- (20, 20) 和 (20, 20) 是对称坐标,因为 X1 == Y2 和 X2 == Y1。所以 (20, 20) 被显示为独特的坐标。 +- (20, 21) 和 (21, 20) 是对称坐标,因为 X1 == Y2 和 X2 == Y1。然而,只有 (20, 21) 会被显示,因为 X1 <= Y1。 +- (23, 22) 和 (22, 23) 是对称坐标,因为 X1 == Y2 和 X2 == Y1。然而,只有 (22, 23) 会被显示,因为 X1 <= Y1。 +输出表按照 X 和 Y 升序排列。
## 解法 diff --git a/solution/2900-2999/2984.Find Peak Calling Hours for Each City/README.md b/solution/2900-2999/2984.Find Peak Calling Hours for Each City/README.md index 5c594a581a41b..18e974f5c1ee7 100644 --- a/solution/2900-2999/2984.Find Peak Calling Hours for Each City/README.md +++ b/solution/2900-2999/2984.Find Peak Calling Hours for Each City/README.md @@ -23,7 +23,7 @@编写一个查询,找到每个
-city的 高峰 通话 时间。如果 多个时间 有 相同 数量的通话,则所有这些时间都将被视为该特定城市的 高峰时间。按照 高峰通话时间 和
+city按 降序 排序返回结果表。按照 高峰时间 和
city按 降序 排序返回结果表。结果格式如下例所示。
@@ -56,8 +56,8 @@ Calls table: 对于 Houston: - 高峰时间是 22:00,总共记录了 3 次通话。 对于 New York: - - 3:00 和 14:00 都有相同数量的通话,因此这两个时间都被视为高峰小时。 -输出表按照高峰通话小时和城市按降序排序。 + - 3:00 和 14:00 都有相同数量的通话,因此这两个时间都被视为高峰时间。 +输出表按照高峰时间和城市按降序排序。 ## 解法 diff --git a/solution/2900-2999/2986.Find Third Transaction/README.md b/solution/2900-2999/2986.Find Third Transaction/README.md index 9ae8a13ba8c4d..0ff4cb29199b4 100644 --- a/solution/2900-2999/2986.Find Third Transaction/README.md +++ b/solution/2900-2999/2986.Find Third Transaction/README.md @@ -20,7 +20,7 @@ 该表包含 user_id, spend,和 transaction_date。 -编写一个查询,找到每个用户的 第三笔交易 (如果他们有至少三笔交易),其中 前两笔交易 的花费 低于 第三笔交易的花费。
+编写一个查询,找到符合要求的用户的 第三笔交易 (如果他们有至少三笔交易),并且满足 前两笔交易 的花费 低于 第三笔交易的花费。
返回 按 升序
diff --git a/solution/2900-2999/2989.Class Performance/README.md b/solution/2900-2999/2989.Class Performance/README.md index 2d98fa9c46d39..10590f3595625 100644 --- a/solution/2900-2999/2989.Class Performance/README.md +++ b/solution/2900-2999/2989.Class Performance/README.md @@ -22,7 +22,7 @@ student_id 是这张表具有唯一值的列。 该表包含 student_id, student_name, assignment1, assignment2,和 assignment3。 -user_id排序的结果表。编写一个查询,计算学生获得的 最高分 和 最低分 之间的 总分差(
+3次作业的总和)。编写一个查询,计算学生获得的 最高总分 和 最低总分 之间的 差(
3次作业的总和)。以 任意 顺序返回结果表。
@@ -58,7 +58,7 @@ Scores 表: - student_id 423 的总分为 60 + 44 + 47 = 151。 - student_id 896 的总分为 32 + 37 + 50 = 119。 - student_id 235 的总分为 31 + 53 + 69 = 153。 -student_id 321 的最高分为 230,而 student_id 896 的最低分为 119。因此,它们之间的差异为 111。 +student_id 321 拥有最高分为 230,而 student_id 896 拥有最低分为 119。因此,它们之间的差异为 111。 ## 解法 diff --git a/solution/2900-2999/2990.Loan Types/README.md b/solution/2900-2999/2990.Loan Types/README.md index f9c80c85f8808..331f8e4d518fe 100644 --- a/solution/2900-2999/2990.Loan Types/README.md +++ b/solution/2900-2999/2990.Loan Types/README.md @@ -20,7 +20,7 @@ loan_id 是这张表具有唯一值的列。 该表包含 loan_id, user_id,和 loan_type。 -编写一个查询,找到所有至少有一种 Refinance 贷款类型和至少有一种 Mortgage 贷款类型的 不同
+user_id。编写一个解决方案,找出所有具有至少一种 再融资 贷款类型和至少一种 抵押 贷款类型的 不同的
user_id。按 升序 返回结果表中的
diff --git a/solution/2900-2999/2991.Top Three Wineries/README.md b/solution/2900-2999/2991.Top Three Wineries/README.md index 46bf7d32dddda..bbb41804247fb 100644 --- a/solution/2900-2999/2991.Top Three Wineries/README.md +++ b/solution/2900-2999/2991.Top Three Wineries/README.md @@ -21,7 +21,7 @@ id 是这张表具有唯一值的列。 这张表包含 id, country, points,和 winery。 -user_id。编写一个查询来找到 每个国家前三家 基于它们的 总分数 的 酒庄。如果 多个酒庄 具有 相同 的总分数,则按 升序 排列它们的
+winery名称。如果 没有第二家酒庄,则输出 'No Second Winery',如果 没有第三家酒庄,则输出 'No Third Winery'。编写一个解决方案,根据每家酒庄的 总分 找出 每个国家 的 前三名酒庄。如果有 多个酒庄 的总分 相同,则按
winery名称升序排列。如果没有 分数排在第二的酒庄,则输出 'No Second Winery',如果没有 分数排在第三的酒庄,则输出 'No Third Winery'。返回结果表按
diff --git a/solution/2900-2999/2992.Number of Self-Divisible Permutations/README.md b/solution/2900-2999/2992.Number of Self-Divisible Permutations/README.md index 307797b0e7249..6c09acebca442 100644 --- a/solution/2900-2999/2992.Number of Self-Divisible Permutations/README.md +++ b/solution/2900-2999/2992.Number of Self-Divisible Permutations/README.md @@ -6,16 +6,11 @@ -country升序 排列。给定一个整数
+n,返回 下标从 1 开始 的数组nums = [1, 2, ..., n]的 排列数,使其满足 自整除 条件。给定一个整数
-n,返回 下标从 1 开始 的数组nums = [1, 2, ..., n]的 可能的排列组合数量,使其满足 自整除 条件。如果对于每个
+1 <= i <= n,至少 满足以下条件之一,数组nums就是 自整除 的:如果对于每个
-1 <= i <= n,满足gcd(a[i], i) == 1,数组nums就是 自整除 的。-
-
nums[i] % i == 0
- i % nums[i] == 0
-
数组的 排列 是对数组元素的重新排列的数量,例如,下面是数组
+[1, 2, 3]的所有排列:数组的 排列 是对数组元素的重新排列组合,例如,下面是数组
[1, 2, 3]的所有排列组合:[1, 2, 3]
@@ -40,10 +35,10 @@
输入:n = 2 -输出:2 -解释:数组 [1,2] 有 2 个排列,都是自整除的: -nums = [1,2]:这是自整除的,因为 nums[1] % 1 == 0 和 nums[2] % 2 == 0。 -nums = [2,1]:这是自整除的,因为 nums[1] % 1 == 0 和 2 % nums[2] == 0。 +输出:1 +解释:数组 [1,2] 有 2 个排列,但只有其中一个是自整除的: +nums = [1,2]:这不是自整除的,因为 gcd(nums[2], 2) != 1。 +nums = [2,1]:这是自整除的,因为 gcd(nums[1], 1) == 1 并且 gcd(nums[2], 2) == 1。
示例 3:
@@ -60,7 +55,7 @@ nums = [2,1]:这是自整除的,因为 nums[1] % 1 == 0 和 2 % nums[2] == 0提示:
-
-
1 <= n <= 15
+ 1 <= n <= 12
Table:
+Purchases表:
Purchases+---------------+------+ @@ -16,22 +16,23 @@ | purchase_date | date | | amount_spend | int | +---------------+------+ -(user_id, purchase_date, amount_spend) is the primary key (combination of columns with unique values) for this table. -purchase_date will range from November 1, 2023, to November 30, 2023, inclusive of both dates. -Each row contains user id, purchase date, and amount spend. +(user_id, purchase_date, amount_spend) 是该表的主键(具有唯一值的列)。 +purchase_date 的范围从 2023 年 11 月 1 日到 2023 年 11 月 30 日,并包括这两个日期。 +每一行包含 user id, purchase date,和 amount spend。
-Write a solution to calculate the total spending by users on each Friday of every week in November 2023. Output only weeks that include at least one purchase on a Friday.
+编写一个解决方案,计算用户在 2023 年 11 月 的 每个星期五 的 总花费。输出所有在 周五 有购买记录的周。
-Return the result table ordered by week of month in ascending order.
+按照每月的周次序 升序 排列结果表。
-The result format is in the following example.
+结果格式如下示例所示。
-Example 1:
+ +示例 1:
-Input: +输入: Purchases table: +---------+---------------+--------------+ | user_id | purchase_date | amount_spend | @@ -45,19 +46,19 @@ Purchases table: | 10 | 2023-11-12 | 8266 | | 13 | 2023-11-24 | 12000 | +---------+---------------+--------------+ -Output: +输出: +---------------+---------------+--------------+ | week_of_month | purchase_date | total_amount | +---------------+---------------+--------------+ | 1 | 2023-11-03 | 5117 | | 4 | 2023-11-24 | 21692 | +---------------+---------------+--------------+ -Explanation: -- During the first week of November 2023, transactions amounting to $5,117 occurred on Friday, 2023-11-03. -- For the second week of November 2023, there were no transactions on Friday, 2023-11-10. -- Similarly, during the third week of November 2023, there were no transactions on Friday, 2023-11-17. -- In the fourth week of November 2023, two transactions took place on Friday, 2023-11-24, amounting to $12,000 and $9,692 respectively, summing up to a total of $21,692. -Output table is ordered by week_of_month in ascending order.
+解释: +- 在 2023 年 11 月的第一周,于 2023-11-03 星期五发生了总额为 $5,117 的交易。 +- 对于 2023 年 11 月的第二周,于 2023-11-10 星期五没有交易。 +- 同样,在 2023 年 11 月的第三周,于 2023-11-17 星期五没有交易。 +- 在 2023 年 11 月的第四周,于 2023-11-24 星期五发生了两笔交易,分别为 $12,000 和 $9,692,总计为 $21,692。 +输出表按照 week_of_month 升序排列。 ## 解法 diff --git a/solution/2900-2999/2994.Friday Purchases II/README.md b/solution/2900-2999/2994.Friday Purchases II/README.md index b2418f0de26bc..774f8f1f36632 100644 --- a/solution/2900-2999/2994.Friday Purchases II/README.md +++ b/solution/2900-2999/2994.Friday Purchases II/README.md @@ -1,4 +1,4 @@ -# [2994. Friday Purchases II](https://leetcode.cn/problems/friday-purchases-ii) +# [2994. 发生在周五的交易 II](https://leetcode.cn/problems/friday-purchases-ii) [English Version](/solution/2900-2999/2994.Friday%20Purchases%20II/README_EN.md) @@ -6,7 +6,7 @@ -Table:
+Purchases表:
Purchases+---------------+------+ @@ -16,22 +16,24 @@ | purchase_date | date | | amount_spend | int | +---------------+------+ -(user_id, purchase_date, amount_spend) is the primary key (combination of columns with unique values) for this table. -purchase_date will range from November 1, 2023, to November 30, 2023, inclusive of both dates. -Each row contains user id, purchase date, and amount spend. -
+(user_id, purchase_date, amount_spend) 是该表的主键(具有唯一值的列)。 +purchase_date 的范围从 2023 年 11 月 1 日到 2023 年 11 月 30 日,并包括这两个日期。 +每一行包含 user id, purchase date,和 amount spend。 -Write a solution to calculate the total spending by users on each Friday of every week in November 2023. If there are no purchases on a particular Friday of a week, it will be considered as
+0.编写一个解决方案,计算用户在 2023 年 11 月的 每个星期五 的 总花费。如果在 某个星期的星期五 没有 购买记录,则将其视为花费金额为
-0。Return the result table ordered by week of month in ascending order.
+ -The result format is in the following example.
+按照每月的周次序 升序 排列结果表。
+ +结果格式如下示例所示。
-Example 1:
+ +示例 1:
-Input: +输入: Purchases table: +---------+---------------+--------------+ | user_id | purchase_date | amount_spend | @@ -45,7 +47,7 @@ Purchases table: | 10 | 2023-11-12 | 8266 | | 13 | 2023-11-24 | 12000 | +---------+---------------+--------------+ -Output: +输出: +---------------+---------------+--------------+ | week_of_month | purchase_date | total_amount | +---------------+---------------+--------------+ @@ -54,12 +56,12 @@ Purchases table: | 3 | 2023-11-17 | 0 | | 4 | 2023-11-24 | 21692 | +---------------+---------------+--------------+ -Explanation: -- During the first week of November 2023, transactions amounting to $5,117 occurred on Friday, 2023-11-03. -- For the second week of November 2023, there were no transactions on Friday, 2023-11-10, resulting in a value of 0 in the output table for that day. -- Similarly, during the third week of November 2023, there were no transactions on Friday, 2023-11-17, reflected as 0 in the output table for that specific day. -- In the fourth week of November 2023, two transactions took place on Friday, 2023-11-24, amounting to $12,000 and $9,692 respectively, summing up to a total of $21,692. -Output table is ordered by week_of_month in ascending order.
+解释: +- 在 2023 年 11 月的第一周的周五(即 2023-11-03),共发生了总计 $5,117 的交易。 +- 在 2023 年 11 月的第二周的周五(即 2023-11-10),当天没有交易,因此在输出表中该天的值为 0。 +- 类似地,在 2023 年 11 月的第三周的周五(即 2023-11-17),当天没有交易,因此在输出表中该天的值为 0。 +- 在 2023 年 11 月的第四周的周五(即 2023-11-24),当天发生了两笔交易,分别为 $12,000 和 $9,692,总计 $21,692。 +输出表按照 week_of_month 按升序排序。 ## 解法 diff --git a/solution/2900-2999/2995.Viewers Turned Streamers/README.md b/solution/2900-2999/2995.Viewers Turned Streamers/README.md index 0ac0d892329e7..e13b43dbfa36e 100644 --- a/solution/2900-2999/2995.Viewers Turned Streamers/README.md +++ b/solution/2900-2999/2995.Viewers Turned Streamers/README.md @@ -23,7 +23,7 @@ session_type 是一个 ENUM (枚举) 类型,包含(Viewer, Streamer)两个类 这张表包含 user id, session start, session end, session id 和 session type。 -编写一个解决方案,找到 首次会话 为 观众 的用户的 会话 数量。
+编写一个解决方案,找到 首次会话 为 观众身份 的用户,其 主播会话 数量。
按照会话数量和
diff --git a/solution/3000-3099/3001.Minimum Moves to Capture The Queen/README.md b/solution/3000-3099/3001.Minimum Moves to Capture The Queen/README.md index 5db16efcfc553..f7a88a1e1babc 100644 --- a/solution/3000-3099/3001.Minimum Moves to Capture The Queen/README.md +++ b/solution/3000-3099/3001.Minimum Moves to Capture The Queen/README.md @@ -6,7 +6,7 @@ -user_id降序 排序返回结果表。现有一个下标从 0 开始的
+8 x 8棋盘,上面有3枚棋子。现有一个下标从 1 开始的
8 x 8棋盘,上面有3枚棋子。给你
diff --git a/solution/3000-3099/3004.Maximum Subtree of the Same Color/README.md b/solution/3000-3099/3004.Maximum Subtree of the Same Color/README.md index 9aa0773530f4d..2c450c404cbfc 100644 --- a/solution/3000-3099/3004.Maximum Subtree of the Same Color/README.md +++ b/solution/3000-3099/3004.Maximum Subtree of the Same Color/README.md @@ -1,4 +1,4 @@ -# [3004. Maximum Subtree of the Same Color](https://leetcode.cn/problems/maximum-subtree-of-the-same-color) +# [3004. 相同颜色的最大子树](https://leetcode.cn/problems/maximum-subtree-of-the-same-color) [English Version](/solution/3000-3099/3004.Maximum%20Subtree%20of%20the%20Same%20Color/README_EN.md) @@ -6,45 +6,47 @@ -6个整数a、b、c、d、e和f,其中:You are given a 2D integer array
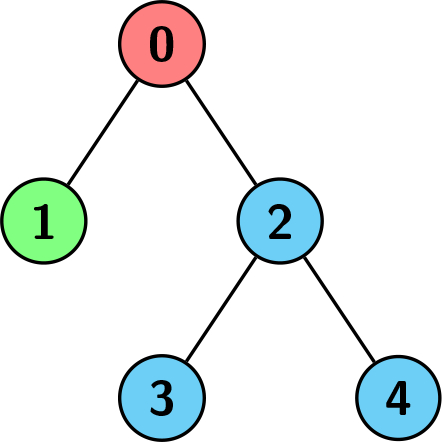
+edgesrepresenting a tree withnnodes, numbered from0ton - 1, rooted at node0, whereedges[i] = [ui, vi]means there is an edge between the nodesviandui.给定一个二维整数数组
-edges,表示一个有n个节点的树,节点编号从0到n - 1,以节点0为根,其中edges[i] = [ui, vi]表示节点vi和ui之间存在一条边。You are also given a 0-indexed integer array
+colorsof sizen, wherecolors[i]is the color assigned to nodei.还给定一个 下标从 0 开始,大小为
-n的整数数组colors,其中colors[i]表示节点i分配的颜色。We want to find a node
+vsuch that every node in the subtree ofvhas the same color.我们希望找到一个节点
-v,使得v的子树中的每个节点具有 相同 的颜色。Return the size of such subtree with the maximum number of nodes possible.
+返回 具有 尽可能多 节点 且 符合上述要求的子树大小。
+
-
Example 1:
+示例 1:
-Input: edges = [[0,1],[0,2],[0,3]], colors = [1,1,2,3] -Output: 1 -Explanation: Each color is represented as: 1 -> Red, 2 -> Green, 3 -> Blue. We can see that the subtree rooted at node 0 has children with different colors. Any other subtree is of the same color and has a size of 1. Hence, we return 1. +输入:edges = [[0,1],[0,2],[0,3]], colors = [1,1,2,3] +输出:1 +解释:每种颜色分别对应为:1 -> 红色,2 -> 绿色,3 -> 蓝色。我们可以看到以节点 0 为根的子树具有不同颜色的子节点。任何其他子树都是相同颜色的,并且大小为 1。因此,我们返回 1。
-Example 2:
+示例 2:
-Input: edges = [[0,1],[0,2],[0,3]], colors = [1,1,1,1] -Output: 4 -Explanation: The whole tree has the same color, and the subtree rooted at node 0 has the most number of nodes which is 4. Hence, we return 4. +输入:edges = [[0,1],[0,2],[0,3]], colors = [1,1,1,1] +输出:4 +解释:整个树具有相同的颜色,以节点 0 为根的子树具有节点数最多,为 4。因此,我们返回 4。
-
Example 3:
+示例 3:
-Input: edges = [[0,1],[0,2],[2,3],[2,4]], colors = [1,2,3,3,3] -Output: 3 -Explanation: Each color is represented as: 1 -> Red, 2 -> Green, 3 -> Blue. We can see that the subtree rooted at node 0 has children with different colors. Any other subtree is of the same color, but the subtree rooted at node 2 has a size of 3 which is the maximum. Hence, we return 3. +输入:edges = [[0,1],[0,2],[2,3],[2,4]], colors = [1,2,3,3,3] +输出:3 +解释:每种颜色分别对应为:1 -> 红色,2 -> 绿色,3 -> 蓝色。我们可以看到以节点 0 为根的子树有不同颜色的子节点。其他任何子树都是相同颜色的,但以节点 2 为根的子树的大小为 3,这是最大的。因此,我们返回 3。
-Constraints:
+ +提示:
n == edges.length + 1
@@ -53,7 +55,7 @@
0 <= ui, vi < ncolors.length == n1 <= colors[i] <= 105
- - The input is generated such that the graph represented by
edgesis a tree.
+ - 输入被生成,使得由
edges表示的图是一棵树。
- Any of the dimensions of the box is greater or equal to
- 箱子 至少有一个 维度大于等于