diff --git a/index.html b/index.html
index 52a72b4a9ec5c..cffd328dde586 100644
--- a/index.html
+++ b/index.html
@@ -28,6 +28,11 @@
const isEn = () => location.hash.includes('README_EN');
const isRoot = () => ['', '#/', '#/README', '#/README_EN'].includes(location.hash);
const sidebar = () => isRoot() ? false : (isEn() ? 'summary_en.md' : 'summary.md');
+ const cleanedHtml = (html) => {
+ return html.replace(/([\s\S]*?)<\/pre>/g, function (match, group) {
+ return "" + group.replace(/([\s\S]*?)<\/code>/g, "$1") + "
";
+ });
+ };
window.addEventListener('hashchange', () => {
window.$docsify.loadSidebar = sidebar();
@@ -111,6 +116,7 @@
const github = `[GitHub](${url})`
const gitee = `[Gitee](${url.replace("github", "gitee")})`
+ html = cleanedHtml(html);
const editHtml = isEn() ? `:memo: Edit on ${github} / ${gitee}\n` : `:memo: 在 ${github} / ${gitee} 编辑\n`
return editHtml + html
})
diff --git a/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md b/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md
index 00f6d615bdd36..f965b75e497c2 100644
--- a/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md
+++ b/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md
@@ -15,7 +15,7 @@
输入: s = "abcabcbb"
输出: 3
-解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
+解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
@@ -23,7 +23,7 @@
输入: s = "bbbbb"
输出: 1
-解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
+解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
@@ -31,8 +31,8 @@
输入: s = "pwwkew"
输出: 3
-解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
-请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
+解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
+ 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
diff --git a/solution/0000-0099/0030.Substring with Concatenation of All Words/README.md b/solution/0000-0099/0030.Substring with Concatenation of All Words/README.md
index 57b9e9b7d5808..7a9497043b08a 100644
--- a/solution/0000-0099/0030.Substring with Concatenation of All Words/README.md
+++ b/solution/0000-0099/0030.Substring with Concatenation of All Words/README.md
@@ -14,7 +14,7 @@
例如,如果 words = ["ab","cd","ef"], 那么 "abcdef", "abefcd","cdabef", "cdefab","efabcd", 和 "efcdab" 都是串联子串。 "acdbef" 不是串联子串,因为他不是任何 words 排列的连接。
-返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
+返回所有串联子串在 s 中的开始索引。你可以以 任意顺序 返回答案。
@@ -22,7 +22,7 @@
输入:s = "barfoothefoobarman", words = ["foo","bar"]
-输出:[0,9]
+输出:[0,9]
解释:因为 words.length == 2 同时 words[i].length == 3,连接的子字符串的长度必须为 6。
子串 "barfoo" 开始位置是 0。它是 words 中以 ["bar","foo"] 顺序排列的连接。
子串 "foobar" 开始位置是 9。它是 words 中以 ["foo","bar"] 顺序排列的连接。
@@ -33,7 +33,7 @@
输入:s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
-输出:[]
+输出:[]
解释:因为 words.length == 4 并且 words[i].length == 4,所以串联子串的长度必须为 16。
s 中没有子串长度为 16 并且等于 words 的任何顺序排列的连接。
所以我们返回一个空数组。
diff --git a/solution/0000-0099/0030.Substring with Concatenation of All Words/README_EN.md b/solution/0000-0099/0030.Substring with Concatenation of All Words/README_EN.md
index 58014044c6d5f..09c528ae0066d 100644
--- a/solution/0000-0099/0030.Substring with Concatenation of All Words/README_EN.md
+++ b/solution/0000-0099/0030.Substring with Concatenation of All Words/README_EN.md
@@ -32,7 +32,7 @@ The output order does not matter. Returning [9,0] is fine too.
Input: s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
Output: []
Explanation: Since words.length == 4 and words[i].length == 4, the concatenated substring has to be of length 16.
-There is no substring of length 16 is s that is equal to the concatenation of any permutation of words.
+There is no substring of length 16 in s that is equal to the concatenation of any permutation of words.
We return an empty array.
diff --git a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
index 177b710b7ed04..5763f2f1203bb 100644
--- a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
+++ b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md
@@ -19,14 +19,14 @@
示例 1:
-输入:nums = [4,5,6,7,0,1,2], target = 0
+输入:nums = [4,5,6,7,0,1,2], target = 0
输出:4
示例 2:
-输入:nums = [4,5,6,7,0,1,2], target = 3
+输入:nums = [4,5,6,7,0,1,2], target = 3
输出:-1
示例 3:
diff --git a/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md b/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
index f895f2f563056..fa7e753e22710 100644
--- a/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
+++ b/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
@@ -17,13 +17,13 @@
示例 1:
-输入:nums = [5,7,7,8,8,10], target = 8
+输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
示例 2:
-输入:nums = [5,7,7,8,8,10], target = 6
+输入:nums = [5,7,7,8,8,10], target = 6
输出:[-1,-1]
示例 3:
diff --git a/solution/0000-0099/0038.Count and Say/README.md b/solution/0000-0099/0038.Count and Say/README.md
index c582bd152011b..a4e96b3a88f8f 100644
--- a/solution/0000-0099/0038.Count and Say/README.md
+++ b/solution/0000-0099/0038.Count and Say/README.md
@@ -26,10 +26,10 @@
4. 1211
5. 111221
第一项是数字 1
-描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 "11"
-描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 "21"
-描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 "1211"
-描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 "111221"
+描述前一项,这个数是 1 即 “ 一 个 1 ”,记作 "11"
+描述前一项,这个数是 11 即 “ 二 个 1 ” ,记作 "21"
+描述前一项,这个数是 21 即 “ 一 个 2 + 一 个 1 ” ,记作 "1211"
+描述前一项,这个数是 1211 即 “ 一 个 1 + 一 个 2 + 二 个 1 ” ,记作 "111221"
要 描述 一个数字字符串,首先要将字符串分割为 最小 数量的组,每个组都由连续的最多 相同字符 组成。然后对于每个组,先描述字符的数量,然后描述字符,形成一个描述组。要将描述转换为数字字符串,先将每组中的字符数量用数字替换,再将所有描述组连接起来。
diff --git a/solution/0000-0099/0039.Combination Sum/README.md b/solution/0000-0099/0039.Combination Sum/README.md
index b67e16b689bd1..4fb390624681e 100644
--- a/solution/0000-0099/0039.Combination Sum/README.md
+++ b/solution/0000-0099/0039.Combination Sum/README.md
@@ -17,7 +17,7 @@
示例 1:
-输入:candidates = [2,3,6,7], target = 7
+输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
@@ -27,13 +27,13 @@
示例 2:
-输入: candidates = [2,3,5], target = 8
+输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]]
示例 3:
-输入: candidates = [2], target = 1
+输入: candidates = [2], target = 1
输出: []
diff --git a/solution/0000-0099/0040.Combination Sum II/README.md b/solution/0000-0099/0040.Combination Sum II/README.md
index 0ee5d0d3fd8d9..3118c3e24e0b9 100644
--- a/solution/0000-0099/0040.Combination Sum II/README.md
+++ b/solution/0000-0099/0040.Combination Sum II/README.md
@@ -17,7 +17,7 @@
示例 1:
-输入: candidates = [10,1,2,7,6,1,5], target = 8,
+输入: candidates = [10,1,2,7,6,1,5], target = 8,
输出:
[
[1,1,6],
diff --git a/solution/0000-0099/0057.Insert Interval/README.md b/solution/0000-0099/0057.Insert Interval/README.md
index a0f89850c1b46..b29b88252ca24 100644
--- a/solution/0000-0099/0057.Insert Interval/README.md
+++ b/solution/0000-0099/0057.Insert Interval/README.md
@@ -24,7 +24,7 @@
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
-解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
+解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
示例 3:
diff --git a/solution/0100-0199/0115.Distinct Subsequences/README.md b/solution/0100-0199/0115.Distinct Subsequences/README.md
index c251d38269ce0..51743f4f0fe97 100644
--- a/solution/0100-0199/0115.Distinct Subsequences/README.md
+++ b/solution/0100-0199/0115.Distinct Subsequences/README.md
@@ -15,26 +15,26 @@
示例 1:
-输入:s = "rabbbit", t = "rabbit"
-输出:3
-解释:
-如下所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
-rabbbit
-rabbbit
-rabbbit
+输入:s = "rabbbit", t = "rabbit"
+输出:3
+解释:
+如下所示, 有 3 种可以从 s 中得到 "rabbit" 的方案。
+rabbbit
+rabbbit
+rabbbit
示例 2:
输入:s = "babgbag", t = "bag"
-输出:5
-解释:
-如下所示, 有 5 种可以从 s 中得到 "bag" 的方案。
-babgbag
-babgbag
-babgbag
-babgbag
-babgbag
+输出:5
+解释:
+如下所示, 有 5 种可以从 s 中得到 "bag" 的方案。
+babgbag
+babgbag
+babgbag
+babgbag
+babgbag
diff --git a/solution/0100-0199/0128.Longest Consecutive Sequence/README.md b/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
index b9cc3c2030a07..4ac617f4a11b4 100644
--- a/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
+++ b/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
@@ -17,7 +17,7 @@
输入:nums = [100,4,200,1,3,2]
输出:4
-解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
+解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
diff --git a/solution/0200-0299/0235.Lowest Common Ancestor of a Binary Search Tree/README.md b/solution/0200-0299/0235.Lowest Common Ancestor of a Binary Search Tree/README.md
index 3245523adc009..485dd5979181c 100644
--- a/solution/0200-0299/0235.Lowest Common Ancestor of a Binary Search Tree/README.md
+++ b/solution/0200-0299/0235.Lowest Common Ancestor of a Binary Search Tree/README.md
@@ -20,14 +20,14 @@
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
-解释: 节点 2 和节点 8 的最近公共祖先是 6。
+解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
-解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
+解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
diff --git a/solution/0200-0299/0236.Lowest Common Ancestor of a Binary Tree/README.md b/solution/0200-0299/0236.Lowest Common Ancestor of a Binary Tree/README.md
index e327309d65fb8..9fcebe16b53fb 100644
--- a/solution/0200-0299/0236.Lowest Common Ancestor of a Binary Tree/README.md
+++ b/solution/0200-0299/0236.Lowest Common Ancestor of a Binary Tree/README.md
@@ -17,7 +17,7 @@
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
输出:3
-解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
+解释:节点 5 和节点 1 的最近公共祖先是节点 3 。
示例 2:
@@ -25,7 +25,7 @@
输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4
输出:5
-解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
+解释:节点 5 和节点 4 的最近公共祖先是节点 5 。因为根据定义最近公共祖先节点可以为节点本身。
示例 3:
diff --git a/solution/0200-0299/0238.Product of Array Except Self/README.md b/solution/0200-0299/0238.Product of Array Except Self/README.md
index 908992ade3d1a..f7e6d083694b0 100644
--- a/solution/0200-0299/0238.Product of Array Except Self/README.md
+++ b/solution/0200-0299/0238.Product of Array Except Self/README.md
@@ -17,8 +17,8 @@
示例 1:
-输入: nums = [1,2,3,4]
-输出: [24,12,8,6]
+输入: nums = [1,2,3,4]
+输出: [24,12,8,6]
示例 2:
diff --git a/solution/0200-0299/0258.Add Digits/README.md b/solution/0200-0299/0258.Add Digits/README.md
index 4cc11f901ef2b..664158d557925 100644
--- a/solution/0200-0299/0258.Add Digits/README.md
+++ b/solution/0200-0299/0258.Add Digits/README.md
@@ -13,12 +13,12 @@
示例 1:
-输入: num = 38
+输入: num = 38
输出: 2
解释: 各位相加的过程为:
38 --> 3 + 8 --> 11
11 --> 1 + 1 --> 2
-由于 2 是一位数,所以返回 2。
+由于 2 是一位数,所以返回 2。
示例 2:
diff --git a/solution/0200-0299/0259.3Sum Smaller/README.md b/solution/0200-0299/0259.3Sum Smaller/README.md
index 7181dff585b86..9aae8fcdfc9e2 100644
--- a/solution/0200-0299/0259.3Sum Smaller/README.md
+++ b/solution/0200-0299/0259.3Sum Smaller/README.md
@@ -13,7 +13,7 @@
示例 1:
-输入: nums = [-2,0,1,3], target = 2
+输入: nums = [-2,0,1,3], target = 2
输出: 2
解释: 因为一共有两个三元组满足累加和小于 2:
[-2,0,1]
@@ -23,13 +23,13 @@
示例 2:
-输入: nums = [], target = 0
+输入: nums = [], target = 0
输出: 0
示例 3:
-输入: nums = [0], target = 0
+输入: nums = [0], target = 0
输出: 0
diff --git a/solution/0200-0299/0261.Graph Valid Tree/README.md b/solution/0200-0299/0261.Graph Valid Tree/README.md
index c196bc0724285..f8422b5ad548f 100644
--- a/solution/0200-0299/0261.Graph Valid Tree/README.md
+++ b/solution/0200-0299/0261.Graph Valid Tree/README.md
@@ -17,7 +17,7 @@
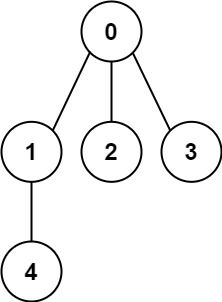
-输入: n = 5, edges = [[0,1],[0,2],[0,3],[1,4]]
+输入: n = 5, edges = [[0,1],[0,2],[0,3],[1,4]]
输出: true
示例 2:
@@ -25,7 +25,7 @@
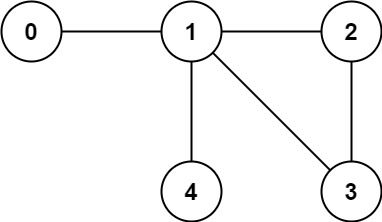
-输入: n = 5, edges = [[0,1],[1,2],[2,3],[1,3],[1,4]]
+输入: n = 5, edges = [[0,1],[1,2],[2,3],[1,3],[1,4]]
输出: false
diff --git a/solution/0200-0299/0263.Ugly Number/README.md b/solution/0200-0299/0263.Ugly Number/README.md
index b2ca680a79842..3a909e557750c 100644
--- a/solution/0200-0299/0263.Ugly Number/README.md
+++ b/solution/0200-0299/0263.Ugly Number/README.md
@@ -31,7 +31,7 @@
输入:n = 14
输出:false
-解释:14 不是丑数,因为它包含了另外一个质因数 7 。
+解释:14 不是丑数,因为它包含了另外一个质因数 7 。
diff --git a/solution/0200-0299/0266.Palindrome Permutation/README.md b/solution/0200-0299/0266.Palindrome Permutation/README.md
index 84fc1dbc52f5b..a4be9414ffc0e 100644
--- a/solution/0200-0299/0266.Palindrome Permutation/README.md
+++ b/solution/0200-0299/0266.Palindrome Permutation/README.md
@@ -10,17 +10,17 @@
示例 1:
-输入: "code"
+输入: "code"
输出: false
示例 2:
-输入: "aab"
+输入: "aab"
输出: true
示例 3:
-输入: "carerac"
+输入: "carerac"
输出: true
## 解法
diff --git a/solution/0200-0299/0267.Palindrome Permutation II/README.md b/solution/0200-0299/0267.Palindrome Permutation II/README.md
index e05d1c07d8302..7e887b7617ed1 100644
--- a/solution/0200-0299/0267.Palindrome Permutation II/README.md
+++ b/solution/0200-0299/0267.Palindrome Permutation II/README.md
@@ -15,14 +15,14 @@
示例 1:
-输入: s = "aabb"
-输出: ["abba", "baab"]>
+输入: s = "aabb"
+输出: ["abba", "baab"]
示例 2:
-输入: s = "abc"
-输出: []
+输入: s = "abc"
+输出: []
diff --git a/solution/0200-0299/0269.Alien Dictionary/README.md b/solution/0200-0299/0269.Alien Dictionary/README.md
index c327687f3f1e1..f7dc0ea0ce5a8 100644
--- a/solution/0200-0299/0269.Alien Dictionary/README.md
+++ b/solution/0200-0299/0269.Alien Dictionary/README.md
@@ -35,7 +35,7 @@
输入:words = ["z","x","z"]
输出:""
-解释:不存在合法字母顺序,因此返回 "" 。
+解释:不存在合法字母顺序,因此返回 "" 。
diff --git a/solution/0200-0299/0269.Alien Dictionary/README_EN.md b/solution/0200-0299/0269.Alien Dictionary/README_EN.md
index 9e4d158c85d74..55ad46e6fb3ef 100644
--- a/solution/0200-0299/0269.Alien Dictionary/README_EN.md
+++ b/solution/0200-0299/0269.Alien Dictionary/README_EN.md
@@ -32,7 +32,7 @@
Input: words = ["z","x","z"]
Output: ""
-Explanation: The order is invalid, so return "".
+Explanation: The order is invalid, so return "".
diff --git a/solution/0200-0299/0274.H-Index/README.md b/solution/0200-0299/0274.H-Index/README.md
index b2e38026847eb..bedd90e831c00 100644
--- a/solution/0200-0299/0274.H-Index/README.md
+++ b/solution/0200-0299/0274.H-Index/README.md
@@ -15,10 +15,10 @@
示例 1:
-输入:citations = [3,0,6,1,5]
+输入:citations = [3,0,6,1,5]
输出:3
-解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
- 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
+解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
+ 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
示例 2:
diff --git a/solution/0200-0299/0275.H-Index II/README.md b/solution/0200-0299/0275.H-Index II/README.md
index 00b4e0471acb5..3543d8d226294 100644
--- a/solution/0200-0299/0275.H-Index II/README.md
+++ b/solution/0200-0299/0275.H-Index II/README.md
@@ -17,10 +17,10 @@
示例 1:
-输入:citations = [0,1,3,5,6]
+输入:citations = [0,1,3,5,6]
输出:3
-解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。
- 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3 。
+解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6 次。
+ 由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3 。
示例 2:
diff --git a/solution/0200-0299/0279.Perfect Squares/README.md b/solution/0200-0299/0279.Perfect Squares/README.md
index cc83c6abee105..a183b1f926018 100644
--- a/solution/0200-0299/0279.Perfect Squares/README.md
+++ b/solution/0200-0299/0279.Perfect Squares/README.md
@@ -15,16 +15,16 @@
示例 1:
-输入:n = 12
+输入:n = 12
输出:3
-解释:12 = 4 + 4 + 4
+解释:12 = 4 + 4 + 4
示例 2:
-输入:n = 13
+输入:n = 13
输出:2
-解释:13 = 4 + 9
+解释:13 = 4 + 9
diff --git a/solution/0200-0299/0280.Wiggle Sort/README.md b/solution/0200-0299/0280.Wiggle Sort/README.md
index 47c3818462cd8..6fd102cb91753 100644
--- a/solution/0200-0299/0280.Wiggle Sort/README.md
+++ b/solution/0200-0299/0280.Wiggle Sort/README.md
@@ -15,7 +15,7 @@
示例 1:
-输入:nums = [3,5,2,1,6,4]
+输入:nums = [3,5,2,1,6,4]
输出:[3,5,1,6,2,4]
解释:[1,6,2,5,3,4]也是有效的答案
diff --git a/solution/0200-0299/0281.Zigzag Iterator/README.md b/solution/0200-0299/0281.Zigzag Iterator/README.md
index ba89c7c0663aa..1df4efb530813 100644
--- a/solution/0200-0299/0281.Zigzag Iterator/README.md
+++ b/solution/0200-0299/0281.Zigzag Iterator/README.md
@@ -14,10 +14,10 @@
v1 = [1,2]
v2 = [3,4,5,6]
-输出: [1,3,2,4,5,6]
+输出: [1,3,2,4,5,6]
-解析: 通过连续调用 next 函数直到 hasNext 函数返回 false,
- next 函数返回值的次序应依次为: [1,3,2,4,5,6]。
+解析: 通过连续调用 next 函数直到 hasNext 函数返回 false,
+ next 函数返回值的次序应依次为: [1,3,2,4,5,6]。
拓展:假如给你 k 个一维向量呢?你的代码在这种情况下的扩展性又会如何呢?
@@ -29,7 +29,7 @@ v2 = [3,4,5,6]
[4,5,6,7]
[8,9]
-输出: [1,4,8,2,5,9,3,6,7].
+输出: [1,4,8,2,5,9,3,6,7].
## 解法
diff --git a/solution/0200-0299/0282.Expression Add Operators/README.md b/solution/0200-0299/0282.Expression Add Operators/README.md
index aa78f5466f356..9a895f3e1d7d9 100644
--- a/solution/0200-0299/0282.Expression Add Operators/README.md
+++ b/solution/0200-0299/0282.Expression Add Operators/README.md
@@ -15,7 +15,7 @@
示例 1:
-输入: num = "123", target = 6
+输入: num = "123", target = 6
输出: ["1+2+3", "1*2*3"]
解释: “1*2*3” 和 “1+2+3” 的值都是6。
@@ -23,7 +23,7 @@
示例 2:
-输入: num = "232", target = 8
+输入: num = "232", target = 8
输出: ["2*3+2", "2+3*2"]
解释: “2*3+2” 和 “2+3*2” 的值都是8。
@@ -31,7 +31,7 @@
示例 3:
-输入: num = "3456237490", target = 9191
+输入: num = "3456237490", target = 9191
输出: []
解释: 表达式 “3456237490” 无法得到 9191 。
diff --git a/solution/0200-0299/0283.Move Zeroes/README.md b/solution/0200-0299/0283.Move Zeroes/README.md
index 216e27c27adbe..8f1e1ce423e48 100644
--- a/solution/0200-0299/0283.Move Zeroes/README.md
+++ b/solution/0200-0299/0283.Move Zeroes/README.md
@@ -15,15 +15,15 @@
示例 1:
-输入: nums = [0,1,0,3,12]
-输出: [1,3,12,0,0]
+输入: nums = [0,1,0,3,12]
+输出: [1,3,12,0,0]
示例 2:
-输入: nums = [0]
-输出: [0]
+输入: nums = [0]
+输出: [0]
diff --git a/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md b/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md
index 8ec9a51579b6d..62f49dc055039 100644
--- a/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md
+++ b/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md
@@ -16,7 +16,7 @@
输入:root = [1,null,3,2,4,null,null,null,5]
输出:3
-解释:当中,最长连续序列是 3-4-5 ,所以返回结果为 3 。
+解释:当中,最长连续序列是 3-4-5 ,所以返回结果为 3 。
示例 2:
@@ -24,7 +24,7 @@
输入:root = [2,null,3,2,null,1]
输出:2
-解释:当中,最长连续序列是 2-3 。注意,不是 3-2-1,所以返回 2 。
+解释:当中,最长连续序列是 2-3 。注意,不是 3-2-1,所以返回 2 。
diff --git a/solution/0300-0399/0322.Coin Change/README.md b/solution/0300-0399/0322.Coin Change/README.md
index 482a09e84f4f6..c50583d9da18c 100644
--- a/solution/0300-0399/0322.Coin Change/README.md
+++ b/solution/0300-0399/0322.Coin Change/README.md
@@ -17,14 +17,14 @@
示例 1:
-输入:coins = [1, 2, 5], amount = 11
-输出:3
+输入:coins = [1, 2, 5], amount = 11
+输出:3
解释:11 = 5 + 5 + 1
示例 2:
-输入:coins = [2], amount = 3
+输入:coins = [2], amount = 3
输出:-1
示例 3:
diff --git a/solution/0300-0399/0323.Number of Connected Components in an Undirected Graph/README.md b/solution/0300-0399/0323.Number of Connected Components in an Undirected Graph/README.md
index 21dc41b62a089..46a4c943aea00 100644
--- a/solution/0300-0399/0323.Number of Connected Components in an Undirected Graph/README.md
+++ b/solution/0300-0399/0323.Number of Connected Components in an Undirected Graph/README.md
@@ -17,7 +17,7 @@
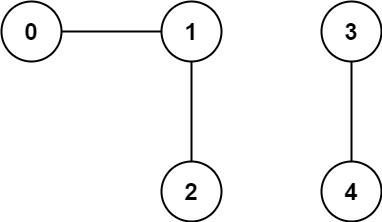
-输入: n = 5, edges = [[0, 1], [1, 2], [3, 4]]
+输入: n = 5, edges = [[0, 1], [1, 2], [3, 4]]
输出: 2
@@ -26,7 +26,7 @@
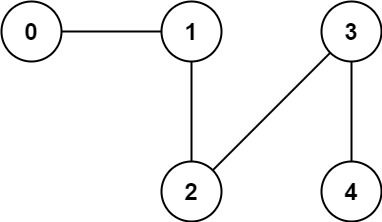
-输入: n = 5, edges = [[0,1], [1,2], [2,3], [3,4]]
+输入: n = 5, edges = [[0,1], [1,2], [2,3], [3,4]]
输出: 1
diff --git a/solution/0300-0399/0336.Palindrome Pairs/README.md b/solution/0300-0399/0336.Palindrome Pairs/README.md
index aa94663d50551..8ddfe421a3a8b 100644
--- a/solution/0300-0399/0336.Palindrome Pairs/README.md
+++ b/solution/0300-0399/0336.Palindrome Pairs/README.md
@@ -6,9 +6,21 @@
-给定一组 互不相同 的单词, 找出所有 不同 的索引对 (i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
+给定一个由唯一字符串构成的 0 索引 数组 words 。
-
+回文对 是一对整数 (i, j) ,满足以下条件:
+
+
+ 0 <= i, j < words.length,i != j ,并且words[i] + words[j](两个字符串的连接)是一个回文。
+
+返回一个数组,它包含 words 中所有满足 回文对 条件的字符串。
+
+你必须设计一个时间复杂度为 O(sum of words[i].length) 的算法。
+
+
示例 1:
@@ -32,11 +44,13 @@
输出:[[0,1],[1,0]]
+
+
提示:
- 1 <= words.length <= 50000 <= words[i].length <= 3001 <= words.length <= 50000 <= words[i].length <= 300words[i] 由小写英文字母组成
diff --git a/solution/0300-0399/0336.Palindrome Pairs/README_EN.md b/solution/0300-0399/0336.Palindrome Pairs/README_EN.md
index a061784c7f900..387a4946e1ed5 100644
--- a/solution/0300-0399/0336.Palindrome Pairs/README_EN.md
+++ b/solution/0300-0399/0336.Palindrome Pairs/README_EN.md
@@ -16,6 +16,8 @@
Return an array of all the palindrome pairs of words.
+You must write an algorithm with O(sum of words[i].length) runtime complexity.
+
Example 1:
diff --git a/solution/0600-0699/0695.Max Area of Island/README.md b/solution/0600-0699/0695.Max Area of Island/README.md
index 0e8d81009f313..335e54deec683 100644
--- a/solution/0600-0699/0695.Max Area of Island/README.md
+++ b/solution/0600-0699/0695.Max Area of Island/README.md
@@ -21,7 +21,7 @@
输入:grid = [[0,0,1,0,0,0,0,1,0,0,0,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,1,1,0,1,0,0,0,0,0,0,0,0],[0,1,0,0,1,1,0,0,1,0,1,0,0],[0,1,0,0,1,1,0,0,1,1,1,0,0],[0,0,0,0,0,0,0,0,0,0,1,0,0],[0,0,0,0,0,0,0,1,1,1,0,0,0],[0,0,0,0,0,0,0,1,1,0,0,0,0]]
输出:6
-解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
+解释:答案不应该是 11 ,因为岛屿只能包含水平或垂直这四个方向上的 1 。
示例 2:
diff --git a/solution/0800-0899/0822.Card Flipping Game/README.md b/solution/0800-0899/0822.Card Flipping Game/README.md
index c297a9d26f116..e59fc3e73e31f 100644
--- a/solution/0800-0899/0822.Card Flipping Game/README.md
+++ b/solution/0800-0899/0822.Card Flipping Game/README.md
@@ -6,35 +6,46 @@
-在桌子上有 N 张卡片,每张卡片的正面和背面都写着一个正数(正面与背面上的数有可能不一样)。
+在桌子上有 n 张卡片,每张卡片的正面和背面都写着一个正数(正面与背面上的数有可能不一样)。
我们可以先翻转任意张卡片,然后选择其中一张卡片。
-如果选中的那张卡片背面的数字 X 与任意一张卡片的正面的数字都不同,那么这个数字是我们想要的数字。
+如果选中的那张卡片背面的数字 x 与任意一张卡片的正面的数字都不同,那么这个数字是我们想要的数字。
-哪个数是这些想要的数字中最小的数(找到这些数中的最小值)呢?如果没有一个数字符合要求的,输出 0。
+哪个数是这些想要的数字中最小的数(找到这些数中的最小值)呢?如果没有一个数字符合要求的,输出 0 。
其中, fronts[i] 和 backs[i] 分别代表第 i 张卡片的正面和背面的数字。
如果我们通过翻转卡片来交换正面与背面上的数,那么当初在正面的数就变成背面的数,背面的数就变成正面的数。
-示例:
+
+
+示例 1:
输入:fronts = [1,2,4,4,7], backs = [1,3,4,1,3]
-输出:2
-解释:假设我们翻转第二张卡片,那么在正面的数变成了 [1,3,4,4,7] , 背面的数变成了 [1,2,4,1,3]。
+输出:2
+解释:假设我们翻转第二张卡片,那么在正面的数变成了 [1,3,4,4,7] , 背面的数变成了 [1,2,4,1,3]。
接着我们选择第二张卡片,因为现在该卡片的背面的数是 2,2 与任意卡片上正面的数都不同,所以 2 就是我们想要的数字。
+示例 2:
+
+
+输入:fronts = [1], backs = [1]
+输出:0
+解释:
+无论如何翻转都无法得到想要的数字,所以返回 0 。
+
+
提示:
-
- 1 <= fronts.length == backs.length <= 10001 <= fronts[i] <= 20001 <= backs[i] <= 2000
+
+ n == fronts.length == backs.length1 <= n <= 10001 <= fronts[i], backs[i] <= 2000
## 解法
diff --git a/solution/0800-0899/0823.Binary Trees With Factors/README.md b/solution/0800-0899/0823.Binary Trees With Factors/README.md
index 9e1406d1ad61c..bf957c7cc0212 100644
--- a/solution/0800-0899/0823.Binary Trees With Factors/README.md
+++ b/solution/0800-0899/0823.Binary Trees With Factors/README.md
@@ -17,16 +17,16 @@
示例 1:
-输入: arr = [2, 4]
+输入: arr = [2, 4]
输出: 3
-解释: 可以得到这些二叉树: [2], [4], [4, 2, 2]
+解释: 可以得到这些二叉树: [2], [4], [4, 2, 2]
示例 2:
-输入: arr = [2, 4, 5, 10]
-输出: 7
-解释: 可以得到这些二叉树: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
+输入: arr = [2, 4, 5, 10]
+输出: 7
+解释: 可以得到这些二叉树: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
diff --git a/solution/0800-0899/0823.Binary Trees With Factors/README_EN.md b/solution/0800-0899/0823.Binary Trees With Factors/README_EN.md
index a1d3e01ef5b54..5a93c927da94c 100644
--- a/solution/0800-0899/0823.Binary Trees With Factors/README_EN.md
+++ b/solution/0800-0899/0823.Binary Trees With Factors/README_EN.md
@@ -16,14 +16,14 @@
Input: arr = [2,4]
Output: 3
-Explanation: We can make these trees: [2], [4], [4, 2, 2]
+Explanation: We can make these trees: [2], [4], [4, 2, 2]
Example 2:
Input: arr = [2,4,5,10]
Output: 7
-Explanation: We can make these trees: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
+Explanation: We can make these trees: [2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
Constraints:
diff --git a/solution/0900-0999/0966.Vowel Spellchecker/README.md b/solution/0900-0999/0966.Vowel Spellchecker/README.md
index a453803701588..8b8c218f27b2e 100644
--- a/solution/0900-0999/0966.Vowel Spellchecker/README.md
+++ b/solution/0900-0999/0966.Vowel Spellchecker/README.md
@@ -12,6 +12,7 @@
- 大小写:如果查询匹配单词列表中的某个单词(不区分大小写),则返回的正确单词与单词列表中的大小写相同。
+
- 例如:
wordlist = ["yellow"], query = "YellOw": correct = "yellow"
- 例如:
wordlist = ["Yellow"], query = "yellow": correct = "Yellow"
@@ -25,6 +26,7 @@
- 例如:
wordlist = ["YellOw"], query = "yllw": correct = "" (无匹配项)
+
此外,拼写检查器还按照以下优先级规则操作:
diff --git a/solution/0900-0999/0972.Equal Rational Numbers/README.md b/solution/0900-0999/0972.Equal Rational Numbers/README.md
index 213ac5debbf56..13ed717827e14 100644
--- a/solution/0900-0999/0972.Equal Rational Numbers/README.md
+++ b/solution/0900-0999/0972.Equal Rational Numbers/README.md
@@ -12,6 +12,7 @@
<IntegerPart>
+
@@ -26,6 +27,7 @@
- 例:
0.1(6) , 1.(9), 123.00(1212)
+
十进制展开的重复部分通常在一对圆括号内表示。例如:
diff --git a/solution/0900-0999/0972.Equal Rational Numbers/README_EN.md b/solution/0900-0999/0972.Equal Rational Numbers/README_EN.md
index 403da27d509ef..550b3d04c5d85 100644
--- a/solution/0900-0999/0972.Equal Rational Numbers/README_EN.md
+++ b/solution/0900-0999/0972.Equal Rational Numbers/README_EN.md
@@ -10,6 +10,7 @@
<IntegerPart>
+
- For example,
12, 0, and 123.
@@ -24,6 +25,7 @@
- For example,
0.1(6), 1.(9), 123.00(1212).
+
The repeating portion of a decimal expansion is conventionally denoted within a pair of round brackets. For example:
diff --git a/solution/1100-1199/1187.Make Array Strictly Increasing/README.md b/solution/1100-1199/1187.Make Array Strictly Increasing/README.md
index dd8e6331dbad2..f373369d02ed2 100644
--- a/solution/1100-1199/1187.Make Array Strictly Increasing/README.md
+++ b/solution/1100-1199/1187.Make Array Strictly Increasing/README.md
@@ -19,7 +19,7 @@
输入:arr1 = [1,5,3,6,7], arr2 = [1,3,2,4]
输出:1
-解释:用 2 来替换 5,之后 arr1 = [1, 2, 3, 6, 7]。
+解释:用 2 来替换 5,之后 arr1 = [1, 2, 3, 6, 7]。
示例 2:
@@ -27,7 +27,7 @@
输入:arr1 = [1,5,3,6,7], arr2 = [4,3,1]
输出:2
-解释:用 3 来替换 5,然后用 4 来替换 3,得到 arr1 = [1, 3, 4, 6, 7]。
+解释:用 3 来替换 5,然后用 4 来替换 3,得到 arr1 = [1, 3, 4, 6, 7]。
示例 3:
@@ -35,7 +35,7 @@
输入:arr1 = [1,5,3,6,7], arr2 = [1,6,3,3]
输出:-1
-解释:无法使 arr1 严格递增。
+解释:无法使 arr1 严格递增。
diff --git a/solution/1100-1199/1187.Make Array Strictly Increasing/README_EN.md b/solution/1100-1199/1187.Make Array Strictly Increasing/README_EN.md
index 21dd7b41204ed..464dd2684bb1e 100644
--- a/solution/1100-1199/1187.Make Array Strictly Increasing/README_EN.md
+++ b/solution/1100-1199/1187.Make Array Strictly Increasing/README_EN.md
@@ -16,7 +16,7 @@
Input: arr1 = [1,5,3,6,7], arr2 = [1,3,2,4]
Output: 1
-Explanation: Replace 5 with 2, then arr1 = [1, 2, 3, 6, 7].
+Explanation: Replace 5 with 2, then arr1 = [1, 2, 3, 6, 7].
Example 2:
@@ -24,7 +24,7 @@
Input: arr1 = [1,5,3,6,7], arr2 = [4,3,1]
Output: 2
-Explanation: Replace 5 with 3 and then replace 3 with 4. arr1 = [1, 3, 4, 6, 7].
+Explanation: Replace 5 with 3 and then replace 3 with 4. arr1 = [1, 3, 4, 6, 7].
Example 3:
@@ -32,7 +32,7 @@
Input: arr1 = [1,5,3,6,7], arr2 = [1,6,3,3]
Output: -1
-Explanation: You can't make arr1 strictly increasing.
+Explanation: You can't make arr1 strictly increasing.
Constraints:
diff --git a/solution/1500-1599/1555.Bank Account Summary/README.md b/solution/1500-1599/1555.Bank Account Summary/README.md
index 0a9b8260925ed..b6e9dc8c06b24 100644
--- a/solution/1500-1599/1555.Bank Account Summary/README.md
+++ b/solution/1500-1599/1555.Bank Account Summary/README.md
@@ -16,7 +16,7 @@
| user_name | varchar |
| credit | int |
+--------------+---------+
-user_id 是这个表的主键。
+user_id 是这个表的主键(具有唯一值的列)。
表中的每一列包含每一个用户当前的额度信息。
@@ -33,7 +33,7 @@ user_id 是这个表的主键。
| amount | int |
| transacted_on | date |
+---------------+---------+
-trans_id 是这个表的主键。
+trans_id 是这个表的主键(具有唯一值的列)。
表中的每一列包含银行的交易信息。
ID 为 paid_by 的用户给 ID 为 paid_to 的用户转账。
@@ -42,7 +42,7 @@ ID 为 paid_by 的用户给 ID 为 paid_to 的用户转账。
力扣银行 (LCB) 帮助程序员们完成虚拟支付。我们的银行在表 Transaction 中记录每条交易信息,我们要查询每个用户的当前余额,并检查他们是否已透支(当前额度小于 0)。
-写一条 SQL 语句,查询:
+编写解决方案报告:
user_id 用户 ID以任意顺序返回结果表。
-查询格式见如下所示。
+结果格式见如下所示。
diff --git a/solution/1500-1599/1555.Bank Account Summary/README_EN.md b/solution/1500-1599/1555.Bank Account Summary/README_EN.md
index 8bae09bbfb82b..d0d422cc8bcbd 100644
--- a/solution/1500-1599/1555.Bank Account Summary/README_EN.md
+++ b/solution/1500-1599/1555.Bank Account Summary/README_EN.md
@@ -14,7 +14,7 @@
| user_name | varchar |
| credit | int |
+--------------+---------+
-user_id is the primary key for this table.
+user_id is the primary key (column with unique values) for this table.
Each row of this table contains the current credit information for each user.
@@ -32,7 +32,7 @@ Each row of this table contains the current credit information for each user.
| amount | int |
| transacted_on | date |
+---------------+---------+
-trans_id is the primary key for this table.
+trans_id is the primary key (column with unique values) for this table.
Each row of this table contains information about the transaction in the bank.
User with id (paid_by) transfer money to user with id (paid_to).
@@ -41,7 +41,7 @@ User with id (paid_by) transfer money to user with id (paid_to).
Leetcode Bank (LCB) helps its coders in making virtual payments. Our bank records all transactions in the table Transaction, we want to find out the current balance of all users and check whether they have breached their credit limit (If their current credit is less than 0).
-Write an SQL query to report.
+Write a solution to report.
user_id,Return the result table in any order.
-The query result format is in the following example.
+The result format is in the following example.
Example 1:
diff --git a/solution/1500-1599/1565.Unique Orders and Customers Per Month/README.md b/solution/1500-1599/1565.Unique Orders and Customers Per Month/README.md
index ec9512d8c74a1..de566d54cf2b9 100644
--- a/solution/1500-1599/1565.Unique Orders and Customers Per Month/README.md
+++ b/solution/1500-1599/1565.Unique Orders and Customers Per Month/README.md
@@ -23,7 +23,7 @@ order_id 是 Orders 表的主键。
-写一个查询语句来 按月 统计金额(invoice)大于 20 的唯一 订单数 和唯一 顾客数 。
+写一个查询语句来 按月 统计金额(invoice)大于 $20 的唯一 订单数 和唯一 顾客数 。
查询结果无排序要求。
diff --git a/solution/1500-1599/1565.Unique Orders and Customers Per Month/README_EN.md b/solution/1500-1599/1565.Unique Orders and Customers Per Month/README_EN.md
index 8452ba2eadf86..1d2c5514cc5eb 100644
--- a/solution/1500-1599/1565.Unique Orders and Customers Per Month/README_EN.md
+++ b/solution/1500-1599/1565.Unique Orders and Customers Per Month/README_EN.md
@@ -21,7 +21,7 @@ This table contains information about the orders made by customer_id.
-Write an SQL query to find the number of unique orders and the number of unique customers with invoices > 20 for each different month.
+Write an SQL query to find the number of unique orders and the number of unique customers with invoices > $20 for each different month.
Return the result table sorted in any order.
diff --git a/solution/1500-1599/1587.Bank Account Summary II/README.md b/solution/1500-1599/1587.Bank Account Summary II/README.md
index 48488f8cf1f85..b582520dc6d95 100644
--- a/solution/1500-1599/1587.Bank Account Summary II/README.md
+++ b/solution/1500-1599/1587.Bank Account Summary II/README.md
@@ -76,7 +76,7 @@ Users table:
+------------+------------+------------+---------------+
输出:
+------------+------------+
-| name | balance |
+| name | balance |
+------------+------------+
| Alice | 11000 |
+------------+------------+
diff --git a/solution/1700-1799/1797.Design Authentication Manager/README.md b/solution/1700-1799/1797.Design Authentication Manager/README.md
index da1057b68c772..00d37d86c630f 100644
--- a/solution/1700-1799/1797.Design Authentication Manager/README.md
+++ b/solution/1700-1799/1797.Design Authentication Manager/README.md
@@ -25,7 +25,7 @@
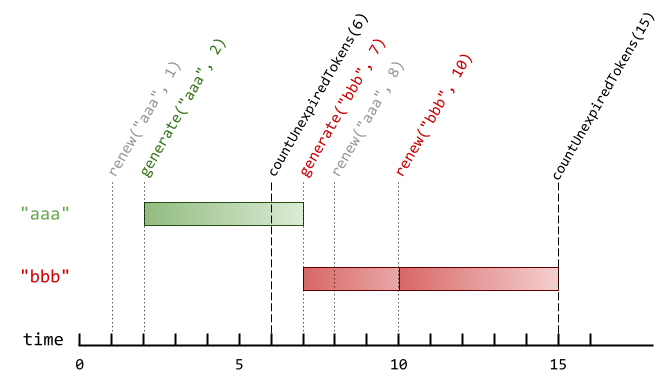
输入:
-["AuthenticationManager", "renew", "generate", "countUnexpiredTokens", "generate", "renew", "renew", "countUnexpiredTokens"]
+["AuthenticationManager", "renew", "generate", "countUnexpiredTokens", "generate", "renew", "renew", "countUnexpiredTokens"]
[[5], ["aaa", 1], ["aaa", 2], [6], ["bbb", 7], ["aaa", 8], ["bbb", 10], [15]]
输出:
[null, null, null, 1, null, null, null, 0]
@@ -42,6 +42,8 @@ authenticationManager.countUnexpiredTokens(15); // tokenId 为 "bbb
+
+
提示:
diff --git a/solution/1700-1799/1797.Design Authentication Manager/README_EN.md b/solution/1700-1799/1797.Design Authentication Manager/README_EN.md
index 9d50df9fab12f..714ffb0ae4646 100644
--- a/solution/1700-1799/1797.Design Authentication Manager/README_EN.md
+++ b/solution/1700-1799/1797.Design Authentication Manager/README_EN.md
@@ -22,20 +22,20 @@
Input
-["AuthenticationManager", "renew", "generate", "countUnexpiredTokens", "generate", "renew", "renew", "countUnexpiredTokens"]
-[[5], ["aaa", 1], ["aaa", 2], [6], ["bbb", 7], ["aaa", 8], ["bbb", 10], [15]]
+["AuthenticationManager", "renew", "generate", "countUnexpiredTokens", "generate", "renew", "renew", "countUnexpiredTokens"]
+[[5], ["aaa", 1], ["aaa", 2], [6], ["bbb", 7], ["aaa", 8], ["bbb", 10], [15]]
Output
[null, null, null, 1, null, null, null, 0]
Explanation
AuthenticationManager authenticationManager = new AuthenticationManager(5); // Constructs the AuthenticationManager with timeToLive = 5 seconds.
-authenticationManager.renew("aaa", 1); // No token exists with tokenId "aaa" at time 1, so nothing happens.
-authenticationManager.generate("aaa", 2); // Generates a new token with tokenId "aaa" at time 2.
-authenticationManager.countUnexpiredTokens(6); // The token with tokenId "aaa" is the only unexpired one at time 6, so return 1.
-authenticationManager.generate("bbb", 7); // Generates a new token with tokenId "bbb" at time 7.
-authenticationManager.renew("aaa", 8); // The token with tokenId "aaa" expired at time 7, and 8 >= 7, so at time 8 the renew request is ignored, and nothing happens.
-authenticationManager.renew("bbb", 10); // The token with tokenId "bbb" is unexpired at time 10, so the renew request is fulfilled and now the token will expire at time 15.
-authenticationManager.countUnexpiredTokens(15); // The token with tokenId "bbb" expires at time 15, and the token with tokenId "aaa" expired at time 7, so currently no token is unexpired, so return 0.
+authenticationManager.renew("aaa", 1); // No token exists with tokenId "aaa" at time 1, so nothing happens.
+authenticationManager.generate("aaa", 2); // Generates a new token with tokenId "aaa" at time 2.
+authenticationManager.countUnexpiredTokens(6); // The token with tokenId "aaa" is the only unexpired one at time 6, so return 1.
+authenticationManager.generate("bbb", 7); // Generates a new token with tokenId "bbb" at time 7.
+authenticationManager.renew("aaa", 8); // The token with tokenId "aaa" expired at time 7, and 8 >= 7, so at time 8 the renew request is ignored, and nothing happens.
+authenticationManager.renew("bbb", 10); // The token with tokenId "bbb" is unexpired at time 10, so the renew request is fulfilled and now the token will expire at time 15.
+authenticationManager.countUnexpiredTokens(15); // The token with tokenId "bbb" expires at time 15, and the token with tokenId "aaa" expired at time 7, so currently no token is unexpired, so return 0.
diff --git a/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README.md b/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README.md
index 151c3a1eaa446..36526424b4b94 100644
--- a/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README.md
+++ b/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README.md
@@ -30,7 +30,7 @@
输入:arr = [2,2,1,2,1]
输出:2
解释:
-我们可以重新排列 arr 得到 [1,2,2,2,1] ,该数组满足所有条件。
+我们可以重新排列 arr 得到 [1,2,2,2,1] ,该数组满足所有条件。
arr 中最大元素为 2 。
@@ -41,10 +41,10 @@ arr 中最大元素为 2 。
输出:3
解释:
一个可行的方案如下:
-1. 重新排列 arr< 得到 [1,100,1000] 。
+1. 重新排列 arr 得到 [1,100,1000] 。
2. 将第二个元素减小为 2 。
3. 将第三个元素减小为 3 。
-现在 arr = [1,2,3] ,满足所有条件。
+现在 arr = [1,2,3] ,满足所有条件。
arr 中最大元素为 3 。
diff --git a/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README_EN.md b/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README_EN.md
index f3526bf645de7..95265c5991198 100644
--- a/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README_EN.md
+++ b/solution/1800-1899/1846.Maximum Element After Decreasing and Rearranging/README_EN.md
@@ -27,8 +27,8 @@
Input: arr = [2,2,1,2,1]
Output: 2
Explanation:
-We can satisfy the conditions by rearranging arr so it becomes [1,2,2,2,1].
-The largest element in arr is 2.
+We can satisfy the conditions by rearranging arr so it becomes [1,2,2,2,1].
+The largest element in arr is 2.
Example 2:
@@ -38,11 +38,11 @@ The largest element in arr is 2.
Output: 3
Explanation:
One possible way to satisfy the conditions is by doing the following:
-1. Rearrange arr so it becomes [1,100,1000].
+1. Rearrange arr so it becomes [1,100,1000].
2. Decrease the value of the second element to 2.
3. Decrease the value of the third element to 3.
-Now arr = [1,2,3], which satisfies the conditions.
-The largest element in arr is 3.
+Now arr = [1,2,3], which satisfies the conditions.
+The largest element in arr is 3.
Example 3:
diff --git a/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README.md b/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README.md
index 4444f99e8f694..af304ea6aea4c 100644
--- a/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README.md
+++ b/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README.md
@@ -16,14 +16,14 @@
| experience | enum |
| salary | int |
+-------------+------+
-employee_id是此表的主键列。
+employee_id 是该表中具有唯一值的列。
经验是一个枚举,其中包含一个值(“高级”、“初级”)。
此表的每一行都显示候选人的id、月薪和经验。
每个候选人的工资保证是 唯一 的。
-一家公司想雇佣新员工。公司的工资预算是 7 万美元。公司的招聘标准是:
+一家公司想雇佣新员工。公司的工资预算是 70000 。公司的招聘标准是:
- 继续雇佣薪水最低的高级职员,直到你不能再雇佣更多的高级职员。
@@ -31,9 +31,9 @@ employee_id是此表的主键列。
- 继续以最低的工资雇佣初级职员,直到你不能再雇佣更多的初级职员。
-编写一个SQL查询,查找根据上述条件雇用职员的 ID。
+
编写一个解决方案,查找根据上述条件雇用职员的 ID。
按 任意顺序 返回结果表。
-查询结果格式如下例所示。
+返回结果格式如下例所示。
diff --git a/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README_EN.md b/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README_EN.md
index db641737abdd0..a3a1bd0b57162 100644
--- a/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README_EN.md
+++ b/solution/2000-2099/2010.The Number of Seniors and Juniors to Join the Company II/README_EN.md
@@ -14,8 +14,8 @@
| experience | enum |
| salary | int |
+-------------+------+
-employee_id is the primary key column for this table.
-experience is an enum with one of the values ('Senior', 'Junior').
+employee_id is the column with unique values for this table.
+experience is an ENUM (category) of types ('Senior', 'Junior').
Each row of this table indicates the id of a candidate, their monthly salary, and their experience.
The salary of each candidate is guaranteed to be unique.
@@ -29,11 +29,11 @@ The salary of each candidate is guaranteed to be unique.
Keep hiring the junior with the smallest salary until you cannot hire any more juniors.
-Write an SQL query to find the ids of seniors and juniors hired under the mentioned criteria.
+Write a solution to find the ids of seniors and juniors hired under the mentioned criteria.
Return the result table in any order.
-The query result format is in the following example.
+The result format is in the following example.
Example 1:
@@ -61,8 +61,8 @@ Candidates table:
| 9 |
+-------------+
Explanation:
-We can hire 2 seniors with IDs (11, 2). Since the budget is 70000 and the sum of their salaries is 36000, we still have 34000 but they are not enough to hire the senior candidate with ID 13.
-We can hire 2 juniors with IDs (1, 9). Since the remaining budget is 34000 and the sum of their salaries is 25000, we still have 9000 but they are not enough to hire the junior candidate with ID 4.
+We can hire 2 seniors with IDs (11, 2). Since the budget is $70000 and the sum of their salaries is $36000, we still have $34000 but they are not enough to hire the senior candidate with ID 13.
+We can hire 2 juniors with IDs (1, 9). Since the remaining budget is $34000 and the sum of their salaries is $25000, we still have $9000 but they are not enough to hire the junior candidate with ID 4.
Example 2:
@@ -89,7 +89,7 @@ Candidates table:
| 4 |
+-------------+
Explanation:
-We cannot hire any seniors with the current budget as we need at least 80000 to hire one senior.
+We cannot hire any seniors with the current budget as we need at least $80000 to hire one senior.
We can hire all three juniors with the remaining budget.
diff --git a/solution/2100-2199/2178.Maximum Split of Positive Even Integers/README.md b/solution/2100-2199/2178.Maximum Split of Positive Even Integers/README.md
index bb73b33b4da30..4b1ec3bfeac1d 100644
--- a/solution/2100-2199/2178.Maximum Split of Positive Even Integers/README.md
+++ b/solution/2100-2199/2178.Maximum Split of Positive Even Integers/README.md
@@ -21,7 +21,7 @@
输入:finalSum = 12
输出:[2,4,6]
-解释:以下是一些符合要求的拆分:(2 + 10),(2 + 4 + 6) 和 (4 + 8) 。
+解释:以下是一些符合要求的拆分:(2 + 10),(2 + 4 + 6) 和 (4 + 8) 。
(2 + 4 + 6) 为最多数目的整数,数目为 3 ,所以我们返回 [2,4,6] 。
[2,6,4] ,[6,2,4] 等等也都是可行的解。
@@ -40,8 +40,8 @@
输入:finalSum = 28
输出:[6,8,2,12]
-解释:以下是一些符合要求的拆分:(2 + 26),(6 + 8 + 2 + 12) 和 (4 + 24) 。
-(6 + 8 + 2 + 12) 有最多数目的整数,数目为 4 ,所以我们返回 [6,8,2,12] 。
+解释:以下是一些符合要求的拆分:(2 + 26),(6 + 8 + 2 + 12) 和 (4 + 24) 。
+(6 + 8 + 2 + 12) 有最多数目的整数,数目为 4 ,所以我们返回 [6,8,2,12] 。
[10,2,4,12] ,[6,2,4,16] 等等也都是可行的解。
diff --git a/solution/2600-2699/2677.Chunk Array/README.md b/solution/2600-2699/2677.Chunk Array/README.md
index ef00fbea37cf9..62c9fd09e8005 100644
--- a/solution/2600-2699/2677.Chunk Array/README.md
+++ b/solution/2600-2699/2677.Chunk Array/README.md
@@ -19,7 +19,7 @@
输入:arr = [1,2,3,4,5], size = 1
输出:[[1],[2],[3],[4],[5]]
-解释:数组 arr 被分割成了每个只有一个元素的子数组。
+解释:数组 arr 被分割成了每个只有一个元素的子数组。
示例 2:
@@ -27,7 +27,7 @@
输入:arr = [1,9,6,3,2], size = 3
输出:[[1,9,6],[3,2]]
-解释:数组 arr 被分割成了每个有三个元素的子数组。然而,第二个子数组只有两个元素。
+解释:数组 arr 被分割成了每个有三个元素的子数组。然而,第二个子数组只有两个元素。
示例 3:
@@ -35,7 +35,7 @@
输入:arr = [8,5,3,2,6], size = 6
输出:[[8,5,3,2,6]]
-解释:size 大于 arr.length ,因此所有元素都在第一个子数组中。
+解释:size 大于 arr.length ,因此所有元素都在第一个子数组中。
示例 4:
diff --git a/solution/2600-2699/2682.Find the Losers of the Circular Game/README.md b/solution/2600-2699/2682.Find the Losers of the Circular Game/README.md
index deeb1c5ac70cd..8f870e888ae7a 100644
--- a/solution/2600-2699/2682.Find the Losers of the Circular Game/README.md
+++ b/solution/2600-2699/2682.Find the Losers of the Circular Game/README.md
@@ -34,7 +34,7 @@
输入:n = 5, k = 2
输出:[4,5]
解释:以下为游戏进行情况:
-1)第 1 个朋友接球,第 1 个朋友将球传给距离他顺时针方向 2 步的玩家 —— 第 3 个朋友。
+1)第 1 个朋友接球,第 1 个朋友将球传给距离他顺时针方向 2 步的玩家 —— 第 3 个朋友。
2)第 3 个朋友将球传给距离他顺时针方向 4 步的玩家 —— 第 2 个朋友。
3)第 2 个朋友将球传给距离他顺时针方向 6 步的玩家 —— 第 3 个朋友。
4)第 3 个朋友接到两次球,游戏结束。
@@ -46,7 +46,7 @@
输入:n = 4, k = 4
输出:[2,3,4]
解释:以下为游戏进行情况:
-1)第 1 个朋友接球,第 1 个朋友将球传给距离他顺时针方向 4 步的玩家 —— 第 1 个朋友。
+1)第 1 个朋友接球,第 1 个朋友将球传给距离他顺时针方向 4 步的玩家 —— 第 1 个朋友。
2)第 1 个朋友接到两次球,游戏结束。
diff --git a/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README.md b/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README.md
index cac08444b157c..8d662b4e67b40 100644
--- a/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README.md
+++ b/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README.md
@@ -22,7 +22,7 @@
示例 1:
-输入:usageLimits = [1,2,5]
+输入:usageLimits = [1,2,5]
输出:3
解释:在这个示例中,我们可以使用 0 至多一次,使用 1 至多 2 次,使用 2 至多 5 次。
一种既能满足所有条件,又能创建最多组的方式是:
@@ -35,7 +35,7 @@
示例 2:
-输入:usageLimits = [2,1,2]
+输入:usageLimits = [2,1,2]
输出:2
解释:在这个示例中,我们可以使用 0 至多 2 次,使用 1 至多 1 次,使用 2 至多 2 次。
一种既能满足所有条件,又能创建最多组的方式是:
@@ -48,7 +48,7 @@
示例 3:
-输入:usageLimits = [1,1]
+输入:usageLimits = [1,1]
输出:1
解释:在这个示例中,我们可以使用 0 和 1 至多 1 次。
一种既能满足所有条件,又能创建最多组的方式是:
diff --git a/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README_EN.md b/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README_EN.md
index a19ff04239cca..c1f0cd451a915 100644
--- a/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README_EN.md
+++ b/solution/2700-2799/2790.Maximum Number of Groups With Increasing Length/README_EN.md
@@ -19,7 +19,7 @@
Example 1:
-Input: usageLimits = [1,2,5]
+Input: usageLimits = [1,2,5]
Output: 3
Explanation: In this example, we can use 0 at most once, 1 at most twice, and 2 at most five times.
One way of creating the maximum number of groups while satisfying the conditions is:
@@ -32,7 +32,7 @@ So, the output is 3.
Example 2:
-Input: usageLimits = [2,1,2]
+Input: usageLimits = [2,1,2]
Output: 2
Explanation: In this example, we can use 0 at most twice, 1 at most once, and 2 at most twice.
One way of creating the maximum number of groups while satisfying the conditions is:
@@ -45,7 +45,7 @@ So, the output is 2.
Example 3:
-Input: usageLimits = [1,1]
+Input: usageLimits = [1,1]
Output: 1
Explanation: In this example, we can use both 0 and 1 at most once.
One way of creating the maximum number of groups while satisfying the conditions is:
diff --git a/solution/2800-2899/2800.Shortest String That Contains Three Strings/README.md b/solution/2800-2899/2800.Shortest String That Contains Three Strings/README.md
index d562f0bf42dd3..75bfffb6fc65f 100644
--- a/solution/2800-2899/2800.Shortest String That Contains Three Strings/README.md
+++ b/solution/2800-2899/2800.Shortest String That Contains Three Strings/README.md
@@ -23,13 +23,13 @@
示例 1:
-输入:a = "abc", b = "bca", c = "aaa"
+输入:a = "abc", b = "bca", c = "aaa"
输出:"aaabca"
解释:字符串 "aaabca" 包含所有三个字符串:a = ans[2...4] ,b = ans[3..5] ,c = ans[0..2] 。结果字符串的长度至少为 6 ,且"aaabca" 是字典序最小的一个。
示例 2:
-输入:a = "ab", b = "ba", c = "aba"
+输入:a = "ab", b = "ba", c = "aba"
输出:"aba"
解释:字符串 "aba" 包含所有三个字符串:a = ans[0..1] ,b = ans[1..2] ,c = ans[0..2] 。由于 c 的长度为 3 ,结果字符串的长度至少为 3 。"aba" 是字典序最小的一个。
diff --git a/solution/README.md b/solution/README.md
index 92936d073acc9..3ecbe665051c1 100644
--- a/solution/README.md
+++ b/solution/README.md
@@ -2725,6 +2725,7 @@
| 2712 | [使所有字符相等的最小成本](/solution/2700-2799/2712.Minimum%20Cost%20to%20Make%20All%20Characters%20Equal/README.md) | `贪心`,`字符串`,`动态规划` | 中等 | 第 347 场周赛 |
| 2713 | [矩阵中严格递增的单元格数](/solution/2700-2799/2713.Maximum%20Strictly%20Increasing%20Cells%20in%20a%20Matrix/README.md) | `记忆化搜索`,`数组`,`二分查找`,`动态规划`,`矩阵`,`排序` | 困难 | 第 347 场周赛 |
| 2714 | [找到最短路径的 K 次跨越](/solution/2700-2799/2714.Find%20Shortest%20Path%20with%20K%20Hops/README.md) | `图`,`最短路`,`堆(优先队列)` | 困难 | 🔒 |
+| 2715 | [执行可取消的延迟函数](/solution/2700-2799/2715.Timeout%20Cancellation/README.md) | | 简单 | |
| 2716 | [最小化字符串长度](/solution/2700-2799/2716.Minimize%20String%20Length/README.md) | `哈希表`,`字符串` | 简单 | 第 348 场周赛 |
| 2717 | [半有序排列](/solution/2700-2799/2717.Semi-Ordered%20Permutation/README.md) | `数组`,`模拟` | 简单 | 第 348 场周赛 |
| 2718 | [查询后矩阵的和](/solution/2700-2799/2718.Sum%20of%20Matrix%20After%20Queries/README.md) | `数组`,`哈希表` | 中等 | 第 348 场周赛 |
diff --git a/solution/README_EN.md b/solution/README_EN.md
index 8cb43e45edbfd..d8528a9eb00cd 100644
--- a/solution/README_EN.md
+++ b/solution/README_EN.md
@@ -2723,6 +2723,7 @@ Press Control+F(or Command+F on the
| 2712 | [Minimum Cost to Make All Characters Equal](/solution/2700-2799/2712.Minimum%20Cost%20to%20Make%20All%20Characters%20Equal/README_EN.md) | `Greedy`,`String`,`Dynamic Programming` | Medium | Weekly Contest 347 |
| 2713 | [Maximum Strictly Increasing Cells in a Matrix](/solution/2700-2799/2713.Maximum%20Strictly%20Increasing%20Cells%20in%20a%20Matrix/README_EN.md) | `Memoization`,`Array`,`Binary Search`,`Dynamic Programming`,`Matrix`,`Sorting` | Hard | Weekly Contest 347 |
| 2714 | [Find Shortest Path with K Hops](/solution/2700-2799/2714.Find%20Shortest%20Path%20with%20K%20Hops/README_EN.md) | `Graph`,`Shortest Path`,`Heap (Priority Queue)` | Hard | 🔒 |
+| 2715 | [Timeout Cancellation](/solution/2700-2799/2715.Timeout%20Cancellation/README_EN.md) | | Easy | |
| 2716 | [Minimize String Length](/solution/2700-2799/2716.Minimize%20String%20Length/README_EN.md) | `Hash Table`,`String` | Easy | Weekly Contest 348 |
| 2717 | [Semi-Ordered Permutation](/solution/2700-2799/2717.Semi-Ordered%20Permutation/README_EN.md) | `Array`,`Simulation` | Easy | Weekly Contest 348 |
| 2718 | [Sum of Matrix After Queries](/solution/2700-2799/2718.Sum%20of%20Matrix%20After%20Queries/README_EN.md) | `Array`,`Hash Table` | Medium | Weekly Contest 348 |
diff --git a/solution/config.py b/solution/config.py
index 73f262c3536fa..aa86e05780677 100644
--- a/solution/config.py
+++ b/solution/config.py
@@ -1,50 +1,14 @@
# ignore problems that are unnecessary to refresh
skip_lc_problems = [
- 3,
- 30,
- 33,
- 34,
- 38,
- 39,
- 40,
- 57,
- 115,
- 128,
- 235,
- 236,
- 238,
- 258,
- 259,
- 261,
- 263,
- 266,
- 267,
- 269,
- 274,
- 275,
- 279,
- 280,
- 281,
- 282,
- 283,
- 298,
320,
- 322,
- 323,
- 336,
375,
465,
- 554,
638,
679,
682,
- 695,
753,
818,
- 822,
- 823,
824,
- 830,
860,
909,
936,
@@ -53,7 +17,6 @@
978,
983,
1096,
- 1187,
1244,
1266,
1396,
@@ -61,7 +24,6 @@
1538,
1555,
1565,
- 1587,
1599,
1620,
1657,
@@ -70,8 +32,6 @@
1717,
1754,
1760,
- 1797,
- 1846,
1850,
1891,
1899,
@@ -85,7 +45,6 @@
2140,
2145,
2164,
- 2178,
2241,
2288,
2303,
@@ -95,11 +54,6 @@
2525,
2578,
2606,
- 2643,
- 2677,
- 2682,
2731,
2788,
- 2790,
- 2800,
]
diff --git a/solution/summary.md b/solution/summary.md
index e4f8e82615ec9..7edc9f7efca95 100644
--- a/solution/summary.md
+++ b/solution/summary.md
@@ -2768,7 +2768,7 @@
- [2712.使所有字符相等的最小成本](/solution/2700-2799/2712.Minimum%20Cost%20to%20Make%20All%20Characters%20Equal/README.md)
- [2713.矩阵中严格递增的单元格数](/solution/2700-2799/2713.Maximum%20Strictly%20Increasing%20Cells%20in%20a%20Matrix/README.md)
- [2714.找到最短路径的 K 次跨越](/solution/2700-2799/2714.Find%20Shortest%20Path%20with%20K%20Hops/README.md)
- - [2715.Timeout Cancellation](/solution/2700-2799/2715.Timeout%20Cancellation/README.md)
+ - [2715.执行可取消的延迟函数](/solution/2700-2799/2715.Timeout%20Cancellation/README.md)
- [2716.最小化字符串长度](/solution/2700-2799/2716.Minimize%20String%20Length/README.md)
- [2717.半有序排列](/solution/2700-2799/2717.Semi-Ordered%20Permutation/README.md)
- [2718.查询后矩阵的和](/solution/2700-2799/2718.Sum%20of%20Matrix%20After%20Queries/README.md)