Given an array of n integers nums and a target, find the number of index triplets i, j, k with 0 <= i < j < k < n that satisfy the condition nums[i] + nums[j] + nums[k] < target.
Example:
+ +
+Input: nums = [-2,0,1,3], and target = 2
+Output: 2
+Explanation: Because there are two triplets which sums are less than 2:
+ [-2,0,1]
+ [-2,0,3]
+
+
+Follow up: Could you solve it in O(n2) runtime?
### Related Topics [[Array](https://github.com/openset/leetcode/tree/master/tag/array/README.md)] diff --git a/problems/android-unlock-patterns/README.md b/problems/android-unlock-patterns/README.md index 5c4affecb..78c379a38 100644 --- a/problems/android-unlock-patterns/README.md +++ b/problems/android-unlock-patterns/README.md @@ -11,7 +11,54 @@ ## [351. Android Unlock Patterns (Medium)](https://leetcode.com/problems/android-unlock-patterns "安卓系统手势解锁") +Given an Android 3x3 key lock screen and two integers m and n, where 1 ≤ m ≤ n ≤ 9, count the total number of unlock patterns of the Android lock screen, which consist of minimum of m keys and maximum n keys.
++ +
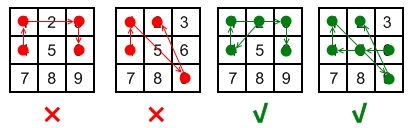
Rules for a valid pattern:
+ ++ +
++ +
+ +
Explanation:
+ ++| 1 | 2 | 3 | +| 4 | 5 | 6 | +| 7 | 8 | 9 |+ +
Invalid move: 4 - 1 - 3 - 6
+Line 1 - 3 passes through key 2 which had not been selected in the pattern.
Invalid move: 4 - 1 - 9 - 2
+Line 1 - 9 passes through key 5 which had not been selected in the pattern.
Valid move: 2 - 4 - 1 - 3 - 6
+Line 1 - 3 is valid because it passes through key 2, which had been selected in the pattern
Valid move: 6 - 5 - 4 - 1 - 9 - 2
+Line 1 - 9 is valid because it passes through key 5, which had been selected in the pattern.
+ +
Example:
+ ++Input: m = 1, n = 1 +Output: 9 +### Related Topics [[Dynamic Programming](https://github.com/openset/leetcode/tree/master/tag/dynamic-programming/README.md)] diff --git a/problems/best-meeting-point/README.md b/problems/best-meeting-point/README.md index c7a56d049..8f39648d6 100644 --- a/problems/best-meeting-point/README.md +++ b/problems/best-meeting-point/README.md @@ -11,7 +11,24 @@ ## [296. Best Meeting Point (Hard)](https://leetcode.com/problems/best-meeting-point "最佳的碰头地点") +
A group of two or more people wants to meet and minimize the total travel distance. You are given a 2D grid of values 0 or 1, where each 1 marks the home of someone in the group. The distance is calculated using Manhattan Distance, where distance(p1, p2) = |p2.x - p1.x| + |p2.y - p1.y|.
Example:
+ ++Input: + +1 - 0 - 0 - 0 - 1 +| | | | | +0 - 0 - 0 - 0 - 0 +| | | | | +0 - 0 - 1 - 0 - 0 + +Output: 6 + +Explanation: Given three people living at### Related Topics [[Sort](https://github.com/openset/leetcode/tree/master/tag/sort/README.md)] diff --git a/problems/binary-tree-longest-consecutive-sequence-ii/README.md b/problems/binary-tree-longest-consecutive-sequence-ii/README.md index ecc6a11ed..e923e4aa6 100644 --- a/problems/binary-tree-longest-consecutive-sequence-ii/README.md +++ b/problems/binary-tree-longest-consecutive-sequence-ii/README.md @@ -11,7 +11,37 @@ ## [549. Binary Tree Longest Consecutive Sequence II (Medium)](https://leetcode.com/problems/binary-tree-longest-consecutive-sequence-ii "二叉树中最长的连续序列") +(0,0),(0,4), and(2,2): + The point(0,2)is an ideal meeting point, as the total travel distance + of 2+2+2=6 is minimal. So return 6.
Given a binary tree, you need to find the length of Longest Consecutive Path in Binary Tree.
+Especially, this path can be either increasing or decreasing. For example, [1,2,3,4] and [4,3,2,1] are both considered valid, but the path [1,2,4,3] is not valid. On the other hand, the path can be in the child-Parent-child order, where not necessarily be parent-child order.
+ +Example 1:
+ ++Input: + 1 + / \ + 2 3 +Output: 2 +Explanation: The longest consecutive path is [1, 2] or [2, 1]. ++ +
+ +
Example 2:
+ ++Input: + 2 + / \ + 1 3 +Output: 3 +Explanation: The longest consecutive path is [1, 2, 3] or [3, 2, 1]. ++ +
+ +
Note: All the values of tree nodes are in the range of [-1e7, 1e7].
### Related Topics [[Tree](https://github.com/openset/leetcode/tree/master/tag/tree/README.md)] diff --git a/problems/binary-tree-longest-consecutive-sequence/README.md b/problems/binary-tree-longest-consecutive-sequence/README.md index 11bac2bda..ce05cfd2a 100644 --- a/problems/binary-tree-longest-consecutive-sequence/README.md +++ b/problems/binary-tree-longest-consecutive-sequence/README.md @@ -11,7 +11,43 @@ ## [298. Binary Tree Longest Consecutive Sequence (Medium)](https://leetcode.com/problems/binary-tree-longest-consecutive-sequence "二叉树最长连续序列") +Given a binary tree, find the length of the longest consecutive sequence path.
+The path refers to any sequence of nodes from some starting node to any node in the tree along the parent-child connections. The longest consecutive path need to be from parent to child (cannot be the reverse).
+ +Example 1:
+ ++Input: + + 1 + \ + 3 + / \ + 2 4 + \ + 5 + +Output:+ +3+ +Explanation: Longest consecutive sequence path is3-4-5, so return3.
Example 2:
+ ++Input: + + 2 + \ + 3 + / + 2 + / + 1 + +Output: 2 + +Explanation: Longest consecutive sequence path is### Related Topics [[Tree](https://github.com/openset/leetcode/tree/master/tag/tree/README.md)] diff --git a/problems/bold-words-in-string/README.md b/problems/bold-words-in-string/README.md index b04ce2690..5c0eb70fe 100644 --- a/problems/bold-words-in-string/README.md +++ b/problems/bold-words-in-string/README.md @@ -11,7 +11,21 @@ ## [758. Bold Words in String (Easy)](https://leetcode.com/problems/bold-words-in-string "字符串中的加粗单词") +2-3, not3-2-1, so return2.
+Given a set of keywords words and a string S, make all appearances of all keywords in S bold. Any letters between <b> and </b> tags become bold.
+
+The returned string should use the least number of tags possible, and of course the tags should form a valid combination. +
+
+For example, given that words = ["ab", "bc"] and S = "aabcd", we should return "a<b>abc</b>d". Note that returning "a<b>a<b>b</b>c</b>d" would use more tags, so it is incorrect.
+
Note:
words has length in range [0, 50].words[i] has length in range [1, 10].S has length in range [0, 500].words[i] and S are lowercase letters.Given a binary tree, return the values of its boundary in anti-clockwise direction starting from root. Boundary includes left boundary, leaves, and right boundary in order without duplicate nodes. (The values of the nodes may still be duplicates.)
+Left boundary is defined as the path from root to the left-most node. Right boundary is defined as the path from root to the right-most node. If the root doesn't have left subtree or right subtree, then the root itself is left boundary or right boundary. Note this definition only applies to the input binary tree, and not applies to any subtrees.
+ +The left-most node is defined as a leaf node you could reach when you always firstly travel to the left subtree if exists. If not, travel to the right subtree. Repeat until you reach a leaf node.
+ +The right-most node is also defined by the same way with left and right exchanged.
+ +Example 1
+ ++Input: + 1 + \ + 2 + / \ + 3 4 + +Ouput: +[1, 3, 4, 2] + +Explanation: +The root doesn't have left subtree, so the root itself is left boundary. +The leaves are node 3 and 4. +The right boundary are node 1,2,4. Note the anti-clockwise direction means you should output reversed right boundary. +So order them in anti-clockwise without duplicates and we have [1,3,4,2]. ++ +
+ +
Example 2
+ ++Input: + ____1_____ + / \ + 2 3 + / \ / +4 5 6 + / \ / \ + 7 8 9 10 + +Ouput: +[1,2,4,7,8,9,10,6,3] + +Explanation: +The left boundary are node 1,2,4. (4 is the left-most node according to definition) +The leaves are node 4,7,8,9,10. +The right boundary are node 1,3,6,10. (10 is the right-most node). +So order them in anti-clockwise without duplicate nodes we have [1,2,4,7,8,9,10,6,3]. ++ +
### Related Topics [[Tree](https://github.com/openset/leetcode/tree/master/tag/tree/README.md)] diff --git a/problems/candy-crush/README.md b/problems/candy-crush/README.md index 17b54d074..ab4ed5f32 100644 --- a/problems/candy-crush/README.md +++ b/problems/candy-crush/README.md @@ -11,7 +11,44 @@ ## [723. Candy Crush (Medium)](https://leetcode.com/problems/candy-crush "粉碎糖果") +
This question is about implementing a basic elimination algorithm for Candy Crush.
+Given a 2D integer array board representing the grid of candy, different positive integers board[i][j] represent different types of candies. A value of board[i][j] = 0 represents that the cell at position (i, j) is empty. The given board represents the state of the game following the player's move. Now, you need to restore the board to a stable state by crushing candies according to the following rules:
You need to perform the above rules until the board becomes stable, then return the current board.
+ ++ +
Example:
+ ++Input: +board = +[[110,5,112,113,114],[210,211,5,213,214],[310,311,3,313,314],[410,411,412,5,414],[5,1,512,3,3],[610,4,1,613,614],[710,1,2,713,714],[810,1,2,1,1],[1,1,2,2,2],[4,1,4,4,1014]] + +Output: +[[0,0,0,0,0],[0,0,0,0,0],[0,0,0,0,0],[110,0,0,0,114],[210,0,0,0,214],[310,0,0,113,314],[410,0,0,213,414],[610,211,112,313,614],[710,311,412,613,714],[810,411,512,713,1014]] + +Explanation: ++ ++
+ +
Note:
+ +board will be in the range [3, 50].board[i] will be in the range [3, 50].board[i][j] will initially start as an integer in the range [1, 2000].Given an array A (index starts at 1) consisting of N integers: A1, A2, ..., AN and an integer B. The integer B denotes that from any place (suppose the index is i) in the array A, you can jump to any one of the place in the array A indexed i+1, i+2, …, i+B if this place can be jumped to. Also, if you step on the index i, you have to pay Ai coins. If Ai is -1, it means you can’t jump to the place indexed i in the array.
Now, you start from the place indexed 1 in the array A, and your aim is to reach the place indexed N using the minimum coins. You need to return the path of indexes (starting from 1 to N) in the array you should take to get to the place indexed N using minimum coins.
If there are multiple paths with the same cost, return the lexicographically smallest such path.
+ +If it's not possible to reach the place indexed N then you need to return an empty array.
+ +Example 1:
+ ++Input: [1,2,4,-1,2], 2 +Output: [1,3,5] ++ +
+ +
Example 2:
+ ++Input: [1,2,4,-1,2], 1 +Output: [] ++ +
+ +
Note:
+ +i where Pai and Pbi differ, Pai < Pbi; when no such i exists, then n < m.### Related Topics [[Dynamic Programming](https://github.com/openset/leetcode/tree/master/tag/dynamic-programming/README.md)] diff --git a/problems/design-excel-sum-formula/README.md b/problems/design-excel-sum-formula/README.md index 6fec113cb..0a8d8d7ab 100644 --- a/problems/design-excel-sum-formula/README.md +++ b/problems/design-excel-sum-formula/README.md @@ -11,7 +11,63 @@ ## [631. Design Excel Sum Formula (Hard)](https://leetcode.com/problems/design-excel-sum-formula "设计 Excel 求和公式") +
Your task is to design the basic function of Excel and implement the function of sum formula. Specifically, you need to implement the following functions:
+ +Excel(int H, char W): This is the constructor. The inputs represents the height and width of the Excel form. H is a positive integer, range from 1 to 26. It represents the height. W is a character range from 'A' to 'Z'. It represents that the width is the number of characters from 'A' to W. The Excel form content is represented by a height * width 2D integer array C, it should be initialized to zero. You should assume that the first row of C starts from 1, and the first column of C starts from 'A'.
void Set(int row, char column, int val): Change the value at C(row, column) to be val.
int Get(int row, char column): Return the value at C(row, column).
int Sum(int row, char column, List of Strings : numbers): This function calculate and set the value at C(row, column), where the value should be the sum of cells represented by numbers. This function return the sum result at C(row, column). This sum formula should exist until this cell is overlapped by another value or another sum formula.
numbers is a list of strings that each string represent a cell or a range of cells. If the string represent a single cell, then it has the following format : ColRow. For example, "F7" represents the cell at (7, F).
If the string represent a range of cells, then it has the following format : ColRow1:ColRow2. The range will always be a rectangle, and ColRow1 represent the position of the top-left cell, and ColRow2 represents the position of the bottom-right cell.
Example 1:
+
+Excel(3,"C"); +// construct a 3*3 2D array with all zero. +// A B C +// 1 0 0 0 +// 2 0 0 0 +// 3 0 0 0 + +Set(1, "A", 2); +// set C(1,"A") to be 2. +// A B C +// 1 2 0 0 +// 2 0 0 0 +// 3 0 0 0 + +Sum(3, "C", ["A1", "A1:B2"]); +// set C(3,"C") to be the sum of value at C(1,"A") and the values sum of the rectangle range whose top-left cell is C(1,"A") and bottom-right cell is C(2,"B"). Return 4. +// A B C +// 1 2 0 0 +// 2 0 0 0 +// 3 0 0 4 + +Set(2, "B", 2); +// set C(2,"B") to be 2. Note C(3, "C") should also be changed. +// A B C +// 1 2 0 0 +// 2 0 2 0 +// 3 0 0 6 ++ + +
Note:
+
Design a search autocomplete system for a search engine. Users may input a sentence (at least one word and end with a special character '#'). For each character they type except '#', you need to return the top 3 historical hot sentences that have prefix the same as the part of sentence already typed. Here are the specific rules:
Your job is to implement the following functions:
+ +The constructor function:
+ +AutocompleteSystem(String[] sentences, int[] times): This is the constructor. The input is historical data. Sentences is a string array consists of previously typed sentences. Times is the corresponding times a sentence has been typed. Your system should record these historical data.
Now, the user wants to input a new sentence. The following function will provide the next character the user types:
+ +List<String> input(char c): The input c is the next character typed by the user. The character will only be lower-case letters ('a' to 'z'), blank space (' ') or a special character ('#'). Also, the previously typed sentence should be recorded in your system. The output will be the top 3 historical hot sentences that have prefix the same as the part of sentence already typed.
Example:
+Operation: AutocompleteSystem(["i love you", "island","ironman", "i love leetcode"], [5,3,2,2])
+The system have already tracked down the following sentences and their corresponding times:
+"i love you" : 5 times
+"island" : 3 times
+"ironman" : 2 times
+"i love leetcode" : 2 times
+Now, the user begins another search:
+
+Operation: input('i')
+Output: ["i love you", "island","i love leetcode"]
+Explanation:
+There are four sentences that have prefix "i". Among them, "ironman" and "i love leetcode" have same hot degree. Since ' ' has ASCII code 32 and 'r' has ASCII code 114, "i love leetcode" should be in front of "ironman". Also we only need to output top 3 hot sentences, so "ironman" will be ignored.
+
+Operation: input(' ')
+Output: ["i love you","i love leetcode"]
+Explanation:
+There are only two sentences that have prefix "i ".
+
+Operation: input('a')
+Output: []
+Explanation:
+There are no sentences that have prefix "i a".
+
+Operation: input('#')
+Output: []
+Explanation:
+The user finished the input, the sentence "i a" should be saved as a historical sentence in system. And the following input will be counted as a new search.
Note:
+ +### Related Topics [[Design](https://github.com/openset/leetcode/tree/master/tag/design/README.md)] diff --git a/problems/employee-free-time/README.md b/problems/employee-free-time/README.md index e221df32c..58aefdc02 100644 --- a/problems/employee-free-time/README.md +++ b/problems/employee-free-time/README.md @@ -11,7 +11,48 @@ ## [759. Employee Free Time (Hard)](https://leetcode.com/problems/employee-free-time "员工空闲时间") +
We are given a list schedule of employees, which represents the working time for each employee.
Each employee has a list of non-overlapping Intervals, and these intervals are in sorted order.
Return the list of finite intervals representing common, positive-length free time for all employees, also in sorted order.
+ +Example 1:
+ ++Input: schedule = [[[1,2],[5,6]],[[1,3]],[[4,10]]] +Output: [[3,4]] +Explanation: +There are a total of three employees, and all common +free time intervals would be [-inf, 1], [3, 4], [10, inf]. +We discard any intervals that contain inf as they aren't finite. ++ +
+ +
Example 2:
+ ++Input: schedule = [[[1,3],[6,7]],[[2,4]],[[2,5],[9,12]]] +Output: [[5,6],[7,9]] ++ +
+ +
(Even though we are representing Intervals in the form [x, y], the objects inside are Intervals, not lists or arrays. For example, schedule[0][0].start = 1, schedule[0][0].end = 2, and schedule[0][0][0] is not defined.)
Also, we wouldn't include intervals like [5, 5] in our answer, as they have zero length.
+ +Note:
+ +schedule and schedule[i] are lists with lengths in range [1, 50].0 <= schedule[i].start < schedule[i].end <= 10^8.NOTE: input types have been changed on June 17, 2019. Please reset to default code definition to get new method signature.
+ +### Related Topics [[Heap](https://github.com/openset/leetcode/tree/master/tag/heap/README.md)] diff --git a/problems/find-anagram-mappings/README.md b/problems/find-anagram-mappings/README.md index 6fe0b3d78..cf9da2489 100644 --- a/problems/find-anagram-mappings/README.md +++ b/problems/find-anagram-mappings/README.md @@ -11,7 +11,34 @@ ## [760. Find Anagram Mappings (Easy)](https://leetcode.com/problems/find-anagram-mappings "找出变位映射") +
+Given two lists Aand B, and B is an anagram of A. B is an anagram of A means B is made by randomizing the order of the elements in A.
+
+We want to find an index mapping P, from A to B. A mapping P[i] = j means the ith element in A appears in B at index j.
+
+These lists A and B may contain duplicates. If there are multiple answers, output any of them.
+
+For example, given +
+A = [12, 28, 46, 32, 50] +B = [50, 12, 32, 46, 28] ++ +We should return +
+[1, 4, 3, 2, 0] ++as
P[0] = 1 because the 0th element of A appears at B[1],
+and P[1] = 4 because the 1st element of A appears at B[4],
+and so on.
+
+
+Note:
A, B have equal lengths in range [1, 100].A[i], B[i] are integers in range [0, 10^5].Given a matrix mat where every row is sorted in increasing order, return the smallest common element in all rows.
If there is no common element, return -1.
+
Example 1:
+Input: mat = [[1,2,3,4,5],[2,4,5,8,10],[3,5,7,9,11],[1,3,5,7,9]] +Output: 5 ++
+
Constraints:
+ +1 <= mat.length, mat[i].length <= 5001 <= mat[i][j] <= 10^4mat[i] is sorted in increasing order.Write a function to generate the generalized abbreviations of a word.
+Note: The order of the output does not matter.
+ +Example:
+ +
+Input: "word"
+Output:
+["word", "1ord", "w1rd", "wo1d", "wor1", "2rd", "w2d", "wo2", "1o1d", "1or1", "w1r1", "1o2", "2r1", "3d", "w3", "4"]
+
+
+### Related Topics [[Bit Manipulation](https://github.com/openset/leetcode/tree/master/tag/bit-manipulation/README.md)] diff --git a/problems/insert-into-a-sorted-circular-linked-list/README.md b/problems/insert-into-a-sorted-circular-linked-list/README.md index 41d236dbe..532e92ac7 100644 --- a/problems/insert-into-a-sorted-circular-linked-list/README.md +++ b/problems/insert-into-a-sorted-circular-linked-list/README.md @@ -11,7 +11,25 @@ ## [708. Insert into a Sorted Circular Linked List (Medium)](https://leetcode.com/problems/insert-into-a-sorted-circular-linked-list "循环有序列表的插入") +
Given a node from a cyclic linked list which is sorted in ascending order, write a function to insert a value into the list such that it remains a cyclic sorted list. The given node can be a reference to any single node in the list, and may not be necessarily the smallest value in the cyclic list.
+If there are multiple suitable places for insertion, you may choose any place to insert the new value. After the insertion, the cyclic list should remain sorted.
+ +If the list is empty (i.e., given node is null), you should create a new single cyclic list and return the reference to that single node. Otherwise, you should return the original given node.
The following example may help you understand the problem better:
+ ++ +
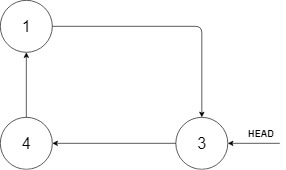
+
+In the figure above, there is a cyclic sorted list of three elements. You are given a reference to the node with value 3, and we need to insert 2 into the list.
+ +
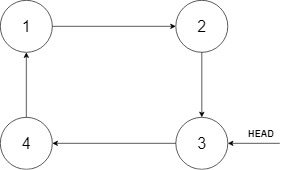
+
+The new node should insert between node 1 and node 3. After the insertion, the list should look like this, and we should still return node 3.
+Given a start IP address ip and a number of ips we need to cover n, return a representation of the range as a list (of smallest possible length) of CIDR blocks.
+
+A CIDR block is a string consisting of an IP, followed by a slash, and then the prefix length. For example: "123.45.67.89/20". That prefix length "20" represents the number of common prefix bits in the specified range. +
+Example 1:
+
+Input: ip = "255.0.0.7", n = 10 +Output: ["255.0.0.7/32","255.0.0.8/29","255.0.0.16/32"] +Explanation: +The initial ip address, when converted to binary, looks like this (spaces added for clarity): +255.0.0.7 -> 11111111 00000000 00000000 00000111 +The address "255.0.0.7/32" specifies all addresses with a common prefix of 32 bits to the given address, +ie. just this one address. + +The address "255.0.0.8/29" specifies all addresses with a common prefix of 29 bits to the given address: +255.0.0.8 -> 11111111 00000000 00000000 00001000 +Addresses with common prefix of 29 bits are: +11111111 00000000 00000000 00001000 +11111111 00000000 00000000 00001001 +11111111 00000000 00000000 00001010 +11111111 00000000 00000000 00001011 +11111111 00000000 00000000 00001100 +11111111 00000000 00000000 00001101 +11111111 00000000 00000000 00001110 +11111111 00000000 00000000 00001111 + +The address "255.0.0.16/32" specifies all addresses with a common prefix of 32 bits to the given address, +ie. just 11111111 00000000 00000000 00010000. + +In total, the answer specifies the range of 10 ips starting with the address 255.0.0.7 . + +There were other representations, such as: +["255.0.0.7/32","255.0.0.8/30", "255.0.0.12/30", "255.0.0.16/32"], +but our answer was the shortest possible. + +Also note that a representation beginning with say, "255.0.0.7/30" would be incorrect, +because it includes addresses like 255.0.0.4 = 11111111 00000000 00000000 00000100 +that are outside the specified range. ++ + +
Note:
+
ip will be a valid IPv4 address.ip + x (for x < n) will be a valid IPv4 address.n will be an integer in the range [1, 1000].You have N bulbs in a row numbered from 1 to N. Initially, all the bulbs are turned off. We turn on exactly one bulb everyday until all bulbs are on after N days.
You are given an array bulbs of length N where bulbs[i] = x means that on the (i+1)th day, we will turn on the bulb at position x where i is 0-indexed and x is 1-indexed.
Given an integer K, find out the minimum day number such that there exists two turned on bulbs that have exactly K bulbs between them that are all turned off.
If there isn't such day, return -1.
+ +
Example 1:
+ ++Input: +bulbs: [1,3,2] +K: 1 +Output: 2 +Explanation: +On the first day: bulbs[0] = 1, first bulb is turned on: [1,0,0] +On the second day: bulbs[1] = 3, third bulb is turned on: [1,0,1] +On the third day: bulbs[2] = 2, second bulb is turned on: [1,1,1] +We return 2 because on the second day, there were two on bulbs with one off bulb between them. ++ +
Example 2:
+ ++Input: +bulbs: [1,2,3] +K: 1 +Output: -1 ++ +
+ +
Note:
+ +1 <= N <= 200001 <= bulbs[i] <= Nbulbs is a permutation of numbers from 1 to N.0 <= K <= 20000
+Given an array consisting of n integers, find the contiguous subarray whose length is greater than or equal to k that has the maximum average value. And you need to output the maximum average value.
+
Example 1:
+
+Input: [1,12,-5,-6,50,3], k = 4 +Output: 12.75 +Explanation: +when length is 5, maximum average value is 10.8, +when length is 6, maximum average value is 9.16667. +Thus return 12.75. ++ + + +
Note:
+
k <= n <= 10,000.+LeetCode wants to give one of its best employees the option to travel among N cities to collect algorithm problems. But all work and no play makes Jack a dull boy, you could take vacations in some particular cities and weeks. Your job is to schedule the traveling to maximize the number of vacation days you could take, but there are certain rules and restrictions you need to follow. +
+Rules and restrictions:
+
You're given the flights matrix and days matrix, and you need to output the maximum vacation days you could take during K weeks.
+ +Example 1:
+
+Input:flights = [[0,1,1],[1,0,1],[1,1,0]], days = [[1,3,1],[6,0,3],[3,3,3]] +Output: 12 +Explanation:+ + +
Ans = 6 + 3 + 3 = 12.
+One of the best strategies is: +1st week : fly from city 0 to city 1 on Monday, and play 6 days and work 1 day.
(Although you start at city 0, we could also fly to and start at other cities since it is Monday.) +2nd week : fly from city 1 to city 2 on Monday, and play 3 days and work 4 days. +3rd week : stay at city 2, and play 3 days and work 4 days. +
Example 2:
+
+Input:flights = [[0,0,0],[0,0,0],[0,0,0]], days = [[1,1,1],[7,7,7],[7,7,7]] +Output: 3 +Explanation:+ + +
Ans = 1 + 1 + 1 = 3.
+Since there is no flights enable you to move to another city, you have to stay at city 0 for the whole 3 weeks.
For each week, you only have one day to play and six days to work.
So the maximum number of vacation days is 3. +
Example 3:
+
+Input:flights = [[0,1,1],[1,0,1],[1,1,0]], days = [[7,0,0],[0,7,0],[0,0,7]] +Output: 21 +Explanation:+ + + +
Ans = 7 + 7 + 7 = 21
+One of the best strategies is: +1st week : stay at city 0, and play 7 days. +2nd week : fly from city 0 to city 1 on Monday, and play 7 days. +3rd week : fly from city 1 to city 2 on Monday, and play 7 days. +
Note:
+
Given an array of meeting time intervals consisting of start and end times [[s1,e1],[s2,e2],...] (si < ei), find the minimum number of conference rooms required.
Example 1:
+ +
+Input: [[0, 30],[5, 10],[15, 20]]
+Output: 2
+
+Example 2:
+ ++Input: [[7,10],[2,4]] +Output: 1+ +
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
### Related Topics [[Heap](https://github.com/openset/leetcode/tree/master/tag/heap/README.md)] diff --git a/problems/meeting-rooms/README.md b/problems/meeting-rooms/README.md index 08c69b683..dea7c3edd 100644 --- a/problems/meeting-rooms/README.md +++ b/problems/meeting-rooms/README.md @@ -11,7 +11,23 @@ ## [252. Meeting Rooms (Easy)](https://leetcode.com/problems/meeting-rooms "会议室") +Given an array of meeting time intervals consisting of start and end times [[s1,e1],[s2,e2],...] (si < ei), determine if a person could attend all meetings.
Example 1:
+ +
+Input: [[0,30],[5,10],[15,20]]
+Output: false
+
+
+Example 2:
+ ++Input: [[7,10],[2,4]] +Output: true ++ +
NOTE: input types have been changed on April 15, 2019. Please reset to default code definition to get new method signature.
### Related Topics [[Sort](https://github.com/openset/leetcode/tree/master/tag/sort/README.md)] diff --git a/problems/minimize-max-distance-to-gas-station/README.md b/problems/minimize-max-distance-to-gas-station/README.md index 56d53b82e..57d09d745 100644 --- a/problems/minimize-max-distance-to-gas-station/README.md +++ b/problems/minimize-max-distance-to-gas-station/README.md @@ -11,7 +11,27 @@ ## [774. Minimize Max Distance to Gas Station (Hard)](https://leetcode.com/problems/minimize-max-distance-to-gas-station "最小化去加油站的最大距离") +On a horizontal number line, we have gas stations at positions stations[0], stations[1], ..., stations[N-1], where N = stations.length.
Now, we add K more gas stations so that D, the maximum distance between adjacent gas stations, is minimized.
Return the smallest possible value of D.
+ +Example:
+ ++Input: stations = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], K = 9 +Output: 0.500000 ++ +
Note:
+ +stations.length will be an integer in range [10, 2000].stations[i] will be an integer in range [0, 10^8].K will be an integer in range [1, 10^6].10^-6 of the true value will be accepted as correct.Given strings S and T, find the minimum (contiguous) substring W of S, so that T is a subsequence of W.
If there is no such window in S that covers all characters in T, return the empty string "". If there are multiple such minimum-length windows, return the one with the left-most starting index.
Example 1:
+ ++Input: +S = "abcdebdde", T = "bde" +Output: "bcde" +Explanation: +"bcde" is the answer because it occurs before "bdde" which has the same length. +"deb" is not a smaller window because the elements of T in the window must occur in order. ++ +
+ +
Note:
+ +S will be in the range [1, 20000].T will be in the range [1, 100].### Related Topics [[Dynamic Programming](https://github.com/openset/leetcode/tree/master/tag/dynamic-programming/README.md)] diff --git a/problems/nested-list-weight-sum/README.md b/problems/nested-list-weight-sum/README.md index 6dc0e4116..c78b48f3a 100644 --- a/problems/nested-list-weight-sum/README.md +++ b/problems/nested-list-weight-sum/README.md @@ -11,7 +11,25 @@ ## [339. Nested List Weight Sum (Easy)](https://leetcode.com/problems/nested-list-weight-sum "嵌套列表权重和") +
Given a nested list of integers, return the sum of all integers in the list weighted by their depth.
+Each element is either an integer, or a list -- whose elements may also be integers or other lists.
+ +Example 1:
+ ++Input: [[1,1],2,[1,1]] +Output: 10 +Explanation: Four 1's at depth 2, one 2 at depth 1.+ +
Example 2:
+ ++Input: [1,[4,[6]]] +Output: 27 +Explanation: One 1 at depth 1, one 4 at depth 2, and one 6 at depth 3; 1 + 4*2 + 6*3 = 27.### Related Topics [[Depth-first Search](https://github.com/openset/leetcode/tree/master/tag/depth-first-search/README.md)] diff --git a/problems/next-closest-time/README.md b/problems/next-closest-time/README.md index 483f5f326..76439bcea 100644 --- a/problems/next-closest-time/README.md +++ b/problems/next-closest-time/README.md @@ -11,7 +11,25 @@ ## [681. Next Closest Time (Medium)](https://leetcode.com/problems/next-closest-time "最近时刻") +
Given a time represented in the format "HH:MM", form the next closest time by reusing the current digits. There is no limit on how many times a digit can be reused.
+You may assume the given input string is always valid. For example, "01:34", "12:09" are all valid. "1:34", "12:9" are all invalid.
+ +Example 1: +
+Input: "19:34" +Output: "19:39" +Explanation: The next closest time choosing from digits 1, 9, 3, 4, is 19:39, which occurs 5 minutes later. It is not 19:33, because this occurs 23 hours and 59 minutes later. ++ + +
Example 2: +
+Input: "23:59" +Output: "22:22" +Explanation: The next closest time choosing from digits 2, 3, 5, 9, is 22:22. It may be assumed that the returned time is next day's time since it is smaller than the input time numerically. ++ ### Related Topics [[String](https://github.com/openset/leetcode/tree/master/tag/string/README.md)] diff --git a/problems/number-of-comments-per-post/README.md b/problems/number-of-comments-per-post/README.md index 34defe75d..b2acd2df8 100644 --- a/problems/number-of-comments-per-post/README.md +++ b/problems/number-of-comments-per-post/README.md @@ -11,4 +11,60 @@ ## [1241. Number of Comments per Post (Easy)](https://leetcode.com/problems/number-of-comments-per-post "每个帖子的评论数") +
Table: Submissions
+---------------+----------+
+| Column Name | Type |
++---------------+----------+
+| sub_id | int |
+| parent_id | int |
++---------------+----------+
+There is no primary key for this table, it may have duplicate rows.
+Each row can be a post or comment on the post.
+parent_id is null for posts.
+parent_id for comments is sub_id for another post in the table.
+
+
++ +
Write an SQL query to find number of comments per each post.
+ +Result table should contain post_id and its corresponding number_of_comments, and must be sorted by post_id in ascending order.
Submissions may contain duplicate comments. You should count the number of unique comments per post.
Submissions may contain duplicate posts. You should treat them as one post.
The query result format is in the following example:
+ +Submissions table: ++---------+------------+ +| sub_id | parent_id | ++---------+------------+ +| 1 | Null | +| 2 | Null | +| 1 | Null | +| 12 | Null | +| 3 | 1 | +| 5 | 2 | +| 3 | 1 | +| 4 | 1 | +| 9 | 1 | +| 10 | 2 | +| 6 | 7 | ++---------+------------+ + +Result table: ++---------+--------------------+ +| post_id | number_of_comments | ++---------+--------------------+ +| 1 | 3 | +| 2 | 2 | +| 12 | 0 | ++---------+--------------------+ + +The post with id 1 has three comments in the table with id 3, 4 and 9. The comment with id 3 is repeated in the table, we counted it only once. +The post with id 2 has two comments in the table with id 5 and 10. +The post with id 12 has no comments in the table. +The comment with id 6 is a comment on a deleted post with id 7 so we ignored it. +diff --git a/problems/number-of-corner-rectangles/README.md b/problems/number-of-corner-rectangles/README.md index 32e0b4078..a0a672c3f 100644 --- a/problems/number-of-corner-rectangles/README.md +++ b/problems/number-of-corner-rectangles/README.md @@ -11,7 +11,59 @@ ## [750. Number Of Corner Rectangles (Medium)](https://leetcode.com/problems/number-of-corner-rectangles "角矩形的数量") +
Given a grid where each entry is only 0 or 1, find the number of corner rectangles.
+A corner rectangle is 4 distinct 1s on the grid that form an axis-aligned rectangle. Note that only the corners need to have the value 1. Also, all four 1s used must be distinct.
+ ++ +
Example 1:
+ ++Input: grid = +[[1, 0, 0, 1, 0], + [0, 0, 1, 0, 1], + [0, 0, 0, 1, 0], + [1, 0, 1, 0, 1]] +Output: 1 +Explanation: There is only one corner rectangle, with corners grid[1][2], grid[1][4], grid[3][2], grid[3][4]. ++ +
+ +
Example 2:
+ ++Input: grid = +[[1, 1, 1], + [1, 1, 1], + [1, 1, 1]] +Output: 9 +Explanation: There are four 2x2 rectangles, four 2x3 and 3x2 rectangles, and one 3x3 rectangle. ++ +
+ +
Example 3:
+ ++Input: grid = +[[1, 1, 1, 1]] +Output: 0 +Explanation: Rectangles must have four distinct corners. ++ +
+ +
Note:
+ +grid will each be in the range [1, 200].grid[i][j] will be either 0 or 1.1s in the grid will be at most 6000.### Related Topics [[Dynamic Programming](https://github.com/openset/leetcode/tree/master/tag/dynamic-programming/README.md)] diff --git a/problems/number-of-distinct-islands-ii/README.md b/problems/number-of-distinct-islands-ii/README.md index 7ac5111bc..d414a18eb 100644 --- a/problems/number-of-distinct-islands-ii/README.md +++ b/problems/number-of-distinct-islands-ii/README.md @@ -11,7 +11,67 @@ ## [711. Number of Distinct Islands II (Hard)](https://leetcode.com/problems/number-of-distinct-islands-ii "不同岛屿的数量 II") +
Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
Count the number of distinct islands. An island is considered to be the same as another if they have the same shape, or have the same shape after rotation (90, 180, or 270 degrees only) or reflection (left/right direction or up/down direction).
+ +Example 1:
+
+11000 +10000 +00001 +00011 ++Given the above grid map, return
1.
++11 +1 ++and +
+ 1 +11 ++are considered same island shapes. Because if we make a 180 degrees clockwise rotation on the first island, then two islands will have the same shapes. + + +
Example 2:
+
+11100 +10001 +01001 +01110+Given the above grid map, return
2.+111 +1 ++and +
+1 +1 ++
+111 +1 ++and +
+1 +111 ++are considered same island shapes. Because if we flip the first array in the up/down direction, then they have the same shapes. + + +
Note:
+The length of each dimension in the given grid does not exceed 50.
+
Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.
Count the number of distinct islands. An island is considered to be the same as another if and only if one island can be translated (and not rotated or reflected) to equal the other.
+ +Example 1:
+
+11000 +11000 +00011 +00011 ++Given the above grid map, return
1.
+
+
+Example 2:
+
11011 +10000 +00001 +11011+Given the above grid map, return
3.+11 +1 ++and +
+ 1 +11 ++are considered different island shapes, because we do not consider reflection / rotation. + + +
Note:
+The length of each dimension in the given grid does not exceed 50.
+
A 2d grid map of m rows and n columns is initially filled with water. We may perform an addLand operation which turns the water at position (row, col) into a land. Given a list of positions to operate, count the number of islands after each addLand operation. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.
Example:
+ ++Input: m = 3, n = 3, positions = [[0,0], [0,1], [1,2], [2,1]] +Output: [1,1,2,3] ++ +
Explanation:
+ +Initially, the 2d grid grid is filled with water. (Assume 0 represents water and 1 represents land).
+0 0 0 +0 0 0 +0 0 0 ++ +
Operation #1: addLand(0, 0) turns the water at grid[0][0] into a land.
+ ++1 0 0 +0 0 0 Number of islands = 1 +0 0 0 ++ +
Operation #2: addLand(0, 1) turns the water at grid[0][1] into a land.
+ ++1 1 0 +0 0 0 Number of islands = 1 +0 0 0 ++ +
Operation #3: addLand(1, 2) turns the water at grid[1][2] into a land.
+ ++1 1 0 +0 0 1 Number of islands = 2 +0 0 0 ++ +
Operation #4: addLand(2, 1) turns the water at grid[2][1] into a land.
+ ++1 1 0 +0 0 1 Number of islands = 3 +0 1 0 ++ +
Follow up:
+ +Can you do it in time complexity O(k log mn), where k is the length of the positions?
+We are given an elevation map, heights[i] representing the height of the terrain at that index. The width at each index is 1. After V units of water fall at index K, how much water is at each index?
+
+Water first drops at index K and rests on top of the highest terrain or water at that index. Then, it flows according to the following rules:
+
+We can assume there's infinitely high terrain on the two sides out of bounds of the array. Also, there could not be partial water being spread out evenly on more than 1 grid block - each unit of water has to be in exactly one block. +
+
Example 1:
+
+Input: heights = [2,1,1,2,1,2,2], V = 4, K = 3 +Output: [2,2,2,3,2,2,2] +Explanation: +# # +# # +## # ### +######### + 0123456 <- index + +The first drop of water lands at index K = 3: + +# # +# w # +## # ### +######### + 0123456 + +When moving left or right, the water can only move to the same level or a lower level. +(By level, we mean the total height of the terrain plus any water in that column.) +Since moving left will eventually make it fall, it moves left. +(A droplet "made to fall" means go to a lower height than it was at previously.) + +# # +# # +## w# ### +######### + 0123456 + +Since moving left will not make it fall, it stays in place. The next droplet falls: + +# # +# w # +## w# ### +######### + 0123456 + +Since the new droplet moving left will eventually make it fall, it moves left. +Notice that the droplet still preferred to move left, +even though it could move right (and moving right makes it fall quicker.) + +# # +# w # +## w# ### +######### + 0123456 + +# # +# # +##ww# ### +######### + 0123456 + +After those steps, the third droplet falls. +Since moving left would not eventually make it fall, it tries to move right. +Since moving right would eventually make it fall, it moves right. + +# # +# w # +##ww# ### +######### + 0123456 + +# # +# # +##ww#w### +######### + 0123456 + +Finally, the fourth droplet falls. +Since moving left would not eventually make it fall, it tries to move right. +Since moving right would not eventually make it fall, it stays in place: + +# # +# w # +##ww#w### +######### + 0123456 + +The final answer is [2,2,2,3,2,2,2]: + + # + ####### + ####### + 0123456 ++ + +
Example 2:
+
+Input: heights = [1,2,3,4], V = 2, K = 2 +Output: [2,3,3,4] +Explanation: +The last droplet settles at index 1, since moving further left would not cause it to eventually fall to a lower height. ++ + +
Example 3:
+
+Input: heights = [3,1,3], V = 5, K = 1 +Output: [4,4,4] ++ + +
Note:
heights will have length in [1, 100] and contain integers in [0, 99].V will be in range [0, 2000].K will be in range [0, heights.length - 1].Assume you have an array of length n initialized with all 0's and are given k update operations.
+Each operation is represented as a triplet: [startIndex, endIndex, inc] which increments each element of subarray A[startIndex ... endIndex] (startIndex and endIndex inclusive) with inc.
+ +Return the modified array after all k operations were executed.
+ +Example:
+ ++Input: length = 5, updates = [[1,3,2],[2,4,3],[0,2,-2]] +Output: [-2,0,3,5,3] ++ +
Explanation:
+ ++Initial state: +[0,0,0,0,0] + +After applying operation [1,3,2]: +[0,2,2,2,0] + +After applying operation [2,4,3]: +[0,2,5,5,3] + +After applying operation [0,2,-2]: +[-2,0,3,5,3] +### Related Topics [[Array](https://github.com/openset/leetcode/tree/master/tag/array/README.md)] diff --git a/problems/sentence-similarity-ii/README.md b/problems/sentence-similarity-ii/README.md index 718056141..402d0a3c5 100644 --- a/problems/sentence-similarity-ii/README.md +++ b/problems/sentence-similarity-ii/README.md @@ -11,7 +11,28 @@ ## [737. Sentence Similarity II (Medium)](https://leetcode.com/problems/sentence-similarity-ii "句子相似性 II") +
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar.
For example, words1 = ["great", "acting", "skills"] and words2 = ["fine", "drama", "talent"] are similar, if the similar word pairs are pairs = [["great", "good"], ["fine", "good"], ["acting","drama"], ["skills","talent"]].
Note that the similarity relation is transitive. For example, if "great" and "good" are similar, and "fine" and "good" are similar, then "great" and "fine" are similar.
+ +Similarity is also symmetric. For example, "great" and "fine" being similar is the same as "fine" and "great" being similar.
+ +Also, a word is always similar with itself. For example, the sentences words1 = ["great"], words2 = ["great"], pairs = [] are similar, even though there are no specified similar word pairs.
Finally, sentences can only be similar if they have the same number of words. So a sentence like words1 = ["great"] can never be similar to words2 = ["doubleplus","good"].
Note:
+ +words1 and words2 will not exceed 1000.pairs will not exceed 2000.pairs[i] will be 2.words[i] and pairs[i][j] will be in the range [1, 20].### Related Topics [[Depth-first Search](https://github.com/openset/leetcode/tree/master/tag/depth-first-search/README.md)] diff --git a/problems/sentence-similarity/README.md b/problems/sentence-similarity/README.md index c37210a1f..63a6d8373 100644 --- a/problems/sentence-similarity/README.md +++ b/problems/sentence-similarity/README.md @@ -11,7 +11,28 @@ ## [734. Sentence Similarity (Easy)](https://leetcode.com/problems/sentence-similarity "句子相似性") +
Given two sentences words1, words2 (each represented as an array of strings), and a list of similar word pairs pairs, determine if two sentences are similar.
For example, "great acting skills" and "fine drama talent" are similar, if the similar word pairs are pairs = [["great", "fine"], ["acting","drama"], ["skills","talent"]].
Note that the similarity relation is not transitive. For example, if "great" and "fine" are similar, and "fine" and "good" are similar, "great" and "good" are not necessarily similar.
+ +However, similarity is symmetric. For example, "great" and "fine" being similar is the same as "fine" and "great" being similar.
+ +Also, a word is always similar with itself. For example, the sentences words1 = ["great"], words2 = ["great"], pairs = [] are similar, even though there are no specified similar word pairs.
Finally, sentences can only be similar if they have the same number of words. So a sentence like words1 = ["great"] can never be similar to words2 = ["doubleplus","good"].
Note:
+ +words1 and words2 will not exceed 1000.pairs will not exceed 2000.pairs[i] will be 2.words[i] and pairs[i][j] will be in the range [1, 20].### Related Topics [[Hash Table](https://github.com/openset/leetcode/tree/master/tag/hash-table/README.md)] diff --git a/problems/shortest-word-distance/README.md b/problems/shortest-word-distance/README.md index f41e86b44..a66b4ee8e 100644 --- a/problems/shortest-word-distance/README.md +++ b/problems/shortest-word-distance/README.md @@ -11,7 +11,23 @@ ## [243. Shortest Word Distance (Easy)](https://leetcode.com/problems/shortest-word-distance "最短单词距离") +
Given a list of words and two words word1 and word2, return the shortest distance between these two words in the list.
+Example:
+Assume that words = ["practice", "makes", "perfect", "coding", "makes"].
+Input: word1 =+ +“coding”, word2 =“practice”+Output: 3 +
+Input: word1 =+ +"makes", word2 ="coding"+Output: 1 +
Note:
+You may assume that word1 does not equal to word2, and word1 and word2 are both in the list.
In the following, every capital letter represents some hexadecimal digit from 0 to f.
The red-green-blue color "#AABBCC" can be written as "#ABC" in shorthand. For example, "#15c" is shorthand for the color "#1155cc".
Now, say the similarity between two colors "#ABCDEF" and "#UVWXYZ" is -(AB - UV)^2 - (CD - WX)^2 - (EF - YZ)^2.
Given the color "#ABCDEF", return a 7 character color that is most similar to #ABCDEF, and has a shorthand (that is, it can be represented as some "#XYZ"
+Example 1: +Input: color = "#09f166" +Output: "#11ee66" +Explanation: +The similarity is -(0x09 - 0x11)^2 -(0xf1 - 0xee)^2 - (0x66 - 0x66)^2 = -64 -9 -0 = -73. +This is the highest among any shorthand color. ++ +
Note:
+ +color is a string of length 7.color is a valid RGB color: for i > 0, color[i] is a hexadecimal digit from 0 to fAn image is represented by a binary matrix with 0 as a white pixel and 1 as a black pixel. The black pixels are connected, i.e., there is only one black region. Pixels are connected horizontally and vertically. Given the location (x, y) of one of the black pixels, return the area of the smallest (axis-aligned) rectangle that encloses all black pixels.
Example:
+ ++Input: +[ + "0010", + "0110", + "0100" +] +and### Related Topics [[Binary Search](https://github.com/openset/leetcode/tree/master/tag/binary-search/README.md)] diff --git a/problems/split-array-with-equal-sum/README.md b/problems/split-array-with-equal-sum/README.md index ab71d2a75..8c4afadbd 100644 --- a/problems/split-array-with-equal-sum/README.md +++ b/problems/split-array-with-equal-sum/README.md @@ -11,7 +11,33 @@ ## [548. Split Array with Equal Sum (Medium)](https://leetcode.com/problems/split-array-with-equal-sum "将数组分割成和相等的子数组") +x = 0,y = 2+ +Output: 6 +
+Given an array with n integers, you need to find if there are triplets (i, j, k) which satisfies following conditions: +
Example:
+
+Input: [1,2,1,2,1,2,1] +Output: True +Explanation: +i = 1, j = 3, k = 5. +sum(0, i - 1) = sum(0, 0) = 1 +sum(i + 1, j - 1) = sum(2, 2) = 1 +sum(j + 1, k - 1) = sum(4, 4) = 1 +sum(k + 1, n - 1) = sum(6, 6) = 1 ++ + +Note: +
Given a Binary Search Tree (BST) with root node root, and a target value V, split the tree into two subtrees where one subtree has nodes that are all smaller or equal to the target value, while the other subtree has all nodes that are greater than the target value. It's not necessarily the case that the tree contains a node with value V.
Additionally, most of the structure of the original tree should remain. Formally, for any child C with parent P in the original tree, if they are both in the same subtree after the split, then node C should still have the parent P.
+ +You should output the root TreeNode of both subtrees after splitting, in any order.
+ +Example 1:
+ ++Input: root = [4,2,6,1,3,5,7], V = 2 +Output: [[2,1],[4,3,6,null,null,5,7]] +Explanation: +Note that root, output[0], and output[1] are TreeNode objects, not arrays. + +The given tree [4,2,6,1,3,5,7] is represented by the following diagram: + + 4 + / \ + 2 6 + / \ / \ + 1 3 5 7 + +while the diagrams for the outputs are: + + 4 + / \ + 3 6 and 2 + / \ / + 5 7 1 ++ +
Note:
+ +50.An abbreviation of a word follows the form <first letter><number><last letter>. Below are some examples of word abbreviations:
++a) it --> it (no abbreviation) + + 1 + ↓ +b) d|o|g --> d1g + + 1 1 1 + 1---5----0----5--8 + ↓ ↓ ↓ ↓ ↓ +c) i|nternationalizatio|n --> i18n + + 1 + 1---5----0 + ↓ ↓ ↓ +d) l|ocalizatio|n --> l10n ++ +
Assume you have a dictionary and given a word, find whether its abbreviation is unique in the dictionary. A word's abbreviation is unique if no other word from the dictionary has the same abbreviation.
+ +Example:
+ +
+Given dictionary = [ "deer", "door", "cake", "card" ]
+
+isUnique("dear") -> false
+isUnique("cart") -> true
+isUnique("cane") -> false
+isUnique("make") -> true
+
### Related Topics
[[Design](https://github.com/openset/leetcode/tree/master/tag/design/README.md)]
diff --git a/problems/walls-and-gates/README.md b/problems/walls-and-gates/README.md
index 3706dfe93..643d71ae1 100644
--- a/problems/walls-and-gates/README.md
+++ b/problems/walls-and-gates/README.md
@@ -11,7 +11,35 @@
## [286. Walls and Gates (Medium)](https://leetcode.com/problems/walls-and-gates "墙与门")
+You are given a m x n 2D grid initialized with these three possible values.
+-1 - A wall or an obstacle.0 - A gate.INF - Infinity means an empty room. We use the value 231 - 1 = 2147483647 to represent INF as you may assume that the distance to a gate is less than 2147483647.Fill each empty room with the distance to its nearest gate. If it is impossible to reach a gate, it should be filled with INF.
Example:
+ +Given the 2D grid:
+ ++INF -1 0 INF +INF INF INF -1 +INF -1 INF -1 + 0 -1 INF INF ++ +
After running your function, the 2D grid should be:
+ ++ 3 -1 0 1 + 2 2 1 -1 + 1 -1 2 -1 + 0 -1 3 4 +### Related Topics [[Breadth-first Search](https://github.com/openset/leetcode/tree/master/tag/breadth-first-search/README.md)] diff --git a/problems/wiggle-sort/README.md b/problems/wiggle-sort/README.md index 153e8ccbd..0d842d02e 100644 --- a/problems/wiggle-sort/README.md +++ b/problems/wiggle-sort/README.md @@ -11,7 +11,13 @@ ## [280. Wiggle Sort (Medium)](https://leetcode.com/problems/wiggle-sort "摆动排序") +
Given an unsorted array nums, reorder it in-place such that nums[0] <= nums[1] >= nums[2] <= nums[3]....
Example:
+ +
+Input: nums = [3,5,2,1,6,4]
+Output: One possible answer is [3,5,1,6,2,4]
### Related Topics
[[Sort](https://github.com/openset/leetcode/tree/master/tag/sort/README.md)]
diff --git a/problems/word-abbreviation/README.md b/problems/word-abbreviation/README.md
index 84b774991..af9f1356a 100644
--- a/problems/word-abbreviation/README.md
+++ b/problems/word-abbreviation/README.md
@@ -11,7 +11,29 @@
## [527. Word Abbreviation (Hard)](https://leetcode.com/problems/word-abbreviation "单词缩写")
+Given an array of n distinct non-empty strings, you need to generate minimal possible abbreviations for every word following rules below.
+Example:
+
+Input: ["like", "god", "internal", "me", "internet", "interval", "intension", "face", "intrusion"] +Output: ["l2e","god","internal","me","i6t","interval","inte4n","f2e","intr4n"] ++ + + +Note: +
Given a set of words (without duplicates), find all word squares you can build from them.
+A sequence of words forms a valid word square if the kth row and column read the exact same string, where 0 ≤ k < max(numRows, numColumns).
+ +For example, the word sequence ["ball","area","lead","lady"] forms a word square because each word reads the same both horizontally and vertically.
+b a l l +a r e a +l e a d +l a d y ++ +
Note:
+
a-z.Example 1: +
+Input: +["area","lead","wall","lady","ball"] + +Output: +[ + [ "wall", + "area", + "lead", + "lady" + ], + [ "ball", + "area", + "lead", + "lady" + ] +] + +Explanation: +The output consists of two word squares. The order of output does not matter (just the order of words in each word square matters). ++ + +
Example 2: +
+Input: +["abat","baba","atan","atal"] + +Output: +[ + [ "baba", + "abat", + "baba", + "atan" + ], + [ "baba", + "abat", + "baba", + "atal" + ] +] + +Explanation: +The output consists of two word squares. The order of output does not matter (just the order of words in each word square matters). ++ ### Related Topics [[Trie](https://github.com/openset/leetcode/tree/master/tag/trie/README.md)]