diff --git a/.github/CODEOWNERS b/.github/CODEOWNERS
index a0facaf..e170423 100644
--- a/.github/CODEOWNERS
+++ b/.github/CODEOWNERS
@@ -1 +1 @@
-* @dojinyou
+* @5uhwann @doxxx93 @rachel5004 @ujin2021 @lsj8367 @youngjijang @jivebreaddev
diff --git a/.github/workflows/pr_auto_merge.yaml b/.github/workflows/pr_auto_merge.yaml
index 8707d35..b2911df 100644
--- a/.github/workflows/pr_auto_merge.yaml
+++ b/.github/workflows/pr_auto_merge.yaml
@@ -1,7 +1,7 @@
name: PR auto merge
on:
schedule:
- - cron: '0 0 * * 1' # 매주 월요일 0시(UTC) -> 매주 월요일 오전 9시(KST) 9시간 시차존재
+ - cron: '0 0 * * 2' # 매주 월요일 0시(UTC) -> 매주 월요일 오전 9시(KST) 9시간 시차존재
jobs:
automerge:
runs-on: ubuntu-latest
diff --git a/README.md b/README.md
index 400b8ea..d4aa0c4 100644
--- a/README.md
+++ b/README.md
@@ -2,37 +2,36 @@
- 기간: 2024.01.08 ~ 03.25
- 시간 및 장소: 매주 월요일 오후 22시 (온라인 - 디스코드)
-- 스터디원: 6명
-
+- 스터디원: 7명
## 핵심 스터디 결과물
- [핵심 결과물 링크를 추가해주세요](https://github.com/Learning-Is-Vital-In-Development)
-
- | Week | Chapter | 발표자 | 발표자료 |
- |------|:-----------------------------------|-----|------|
- | 1 | Ch2. JVM 이야기
Ch3. 하드웨어와 운영체제 | | |
- | 2 | Ch4. 성능 테스트 패턴 및 안티패턴 | | |
- | 3 | Ch5. 마이크로벤치마킹과 통계 | | |
- | 4 | Ch6. 가비지 수집 기초
Ch7. 가비지 수집 고급 | | |
- | 5 | Ch8. GC 로깅, 모니터링, 튜닝, 툴 | | |
- | 6 | Ch9. JVM의 코드 실행 | | |
- | 7 | Ch10. JIT 컴파일의 세계로 | | |
- | 8 | Ch11. 자바 언어의 성능 향상 기법 | | |
- | 9 | Ch12. 동시 성능 기법 | | |
- | 10 | Ch13. 프로파일링 | | |
- | 11 | Ch14. 고성능 로깅 및 메시징 | | |
+
+ | Week | Chapter | 발표자 | 발표자료 |
+ |------|:-----------------------------------|-----|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+ | 1 | Ch2. JVM 이야기
Ch3. 하드웨어와 운영체제 | 이유진 | [Ch2. JVM 이야기](https://github.com/Learning-Is-Vital-In-Development/24-optimizing-java-2/blob/main/ch02/youjin.md)
[Ch3. 하드웨어와 운영체제](https://github.com/Learning-Is-Vital-In-Development/24-optimizing-java-2/blob/main/ch03/youjin.md) |
+ | 2 | Ch4. 성능 테스트 패턴 및 안티패턴 | 박수환 | [Ch4. 성능패턴 및 안티패턴](https://github.com/Learning-Is-Vital-In-Development/24-optimizing-java-2/blob/main/ch04/5uhwann.md) |
+ | 3 | Ch5. 마이크로벤치마킹과 통계 | | |
+ | 4 | Ch6. 가비지 수집 기초
Ch7. 가비지 수집 고급 | | |
+ | 5 | Ch8. GC 로깅, 모니터링, 튜닝, 툴 | | |
+ | 6 | Ch9. JVM의 코드 실행 | | |
+ | 7 | Ch10. JIT 컴파일의 세계로 | | |
+ | 8 | Ch11. 자바 언어의 성능 향상 기법 | | |
+ | 9 | Ch12. 동시 성능 기법 | | |
+ | 10 | Ch13. 프로파일링 | | |
+ | 11 | Ch14. 고성능 로깅 및 메시징 | | |
## 진행방식
- 주차별 챕터의 분량을 읽고 정리하여 pr을 작성한다.
-- 스터디인원 중 1인은 해당 주차에 학습한 내용을 발표한다.
- - 발표 내용에 대한 질의 응답 및 발표 내용에 대해 자유롭게 의논한다.
+- 스터디인원 중 1인은 해당 주차에 학습한 내용을 발표한다.
+ - 발표 내용에 대한 질의 응답 및 발표 내용에 대해 자유롭게 의논한다.
## 스터디 규칙
- 학습 내용에 대한 pr은 스터디원 전체가 작성한다.
- - pr은 작성은 스터디 진행일 1일 전 00시까지 작성 완료한다.
+ - pr은 작성은 스터디 진행일 1일 전 00시까지 작성 완료한다.
- **사전에 고지되지 않은** 스터디원들에게 피해가 가는 행동은 벌금이 존재한다.
- - **지각(5분) 및 pr 지각 제출**: 3,000원
- - **결석 및 pr 미제출** : 5,000원
+ - **지각(5분) 및 pr 지각 제출**: 3,000원
+ - **결석 및 pr 미제출** : 5,000원
diff --git a/ch02/5uhwann.md b/ch02/5uhwann.md
new file mode 100644
index 0000000..117b555
--- /dev/null
+++ b/ch02/5uhwann.md
@@ -0,0 +1,45 @@
+# Ch2. JVM 이야기
+
+## 인터프리팅과 클래스로딩
+- JVM은 스택 기반 해석 머신
+ - 인터프리터의 기본 로직은 마지막에 실행된 명령어를 순서대로 처리하는 **while 루프 안의 switch문**
+- 자바 어플리케이션의 진입점인 `main()` 메서드에 프로그램의 제어권을 넘기기 위해서는 클래스 로딩이 필요하다.
+ - **자바 클래스 로딩 매커니즘**
+ 1. 부트스트랩 클래스가 자바 런타임 코어 클래스 로드(java.lang, java.util, java.io ...)
+ 2. 확장 클래스 로더 생성
+ 3. 어플리케이션 클래스 로더 생성
+ - 한 시스템에서 클래스는 풀 클래스명(패키지명 포함)과 자신을 로드한 클래스로더, 두 가지 정보로 식별됨
+
+## 바이트 코드 실행
+- javac(자바 컴파일러)의 자바 소스 코드 컴파일. 소스코드 -> .class 파일
+ - **클래스 파일 구조**
+ 1. Magic Number
+ 2. Version
+ 3. Constant Pool
+ 4. Access Plug
+ 5. this Class
+ 6. SuperClass
+ 7. Interface
+ 8. field
+ 9. method
+ 10. attribute
+
+## 핫스팟 입문
+### JIT 컴파일
+- 자바 프로그램이 성능을 최대로 내기 위해 바이트 코드를 네이티브 코드로 컴파일 기법
+- 어플리케이션을 모니터링 하면서 가장 자주 실행되는 코드 파트를 발견해 JIT 컴파일 수행
+- 컴파일러가 해석 단계에서 수집한 추적 정보를 바탕으로 최적화를 결정
+- 자바 소스코드와 실제로 JIT컴파일 후 실행되는 코드는 원본 코드와 전혀 다른 모습
+
+## JVM 메모리 관리
+- Garbage Collection을 이용해 힙 메모리를 자동관리
+- **자바 성능 최적화의 중심 주제**
+
+## JVM 모니터링과 툴링
+- JMX
+ - JVM 기반 어플리케이션 제어, 모니터링 툴
+- 자바 에이전트
+ - 자바 언어로 작성된 툴 컴포넌트
+ - java.lang.instrument 인터페이스를 통해 메서드 바이트코드 조작
+- VisualVM
+ - 자바 어플리케이션 시각화 툴
diff --git a/ch02/doxxx.md b/ch02/doxxx.md
new file mode 100644
index 0000000..dd1ab75
--- /dev/null
+++ b/ch02/doxxx.md
@@ -0,0 +1,106 @@
+# Ch2. JVM 이야기
+
+JVM이 자바 코드를 실행하는 방법
+
+## 2.1 인터프리팅과 클래스로딩
+
+1. JVM 실행 과정
+
+ - 명령어 실행: java HelloWorld 명령으로 자바 애플리케이션 실행 시작.
+ - OS 구동: OS는 자바 가상 머신 프로세스(자바 바이너리)를 구동.
+ - 가상 환경 초기화: JVM 구성 및 스택 머신 초기화.
+
+2. 자바 클래스로딩 메커니즘
+
+ - 부트스트랩 클래스로더: 부트스트랩 클래스로더가 자바 런타임 코어 클래스 로드. 필수 클래스만 로드.
+ - 확장 클래스로더: 확장 클래스로더 생성, 부트스트랩 클래스로더를 부모로 설정. 특정 OS나 플랫폼에 네이티브 코드를 제공하고 환경을 오버라이드 가능.
+ - 애플리케이션 클래스로더: 애플리케이션 클래스로더 생성, 지정된 클래스패스에서 유저 클래스 로드.
+
+3. 클래스로딩 순서 및 특이사항
+
+ - 디펜던시 로드: 프로그램 실행 중 처음 보는 새 클래스는 디펜던시에 로드. 클래스로더는 찾지 못한 클래스를 부모에게 룩업을 요청.
+ - 클래스 식별: 클래스는 풀 클래스명과 로드한 클래스로더로 식별.
+
+4. 메인 메서드 실행
+
+ - 진입점 지정: 애플리케이션 클래스로더가 메인 메서드를 찾아 제어권을 해당 클래스로 넘김.
+ - main() 메서드 실행: 실제 유저가 작성한 HelloWorld 클래스의 main() 메서드 실행.
+5. 주의사항
+
+ - ClassNotFoundException 처리: 클래스를 찾지 못한 클래스로더는 부모 클래스로더에게 룩업을 요청하고, 부트스트랩까지 찾지 못하면 ClassNotFoundException 예외 발생.
+ - 중복 클래스로딩 주의: 동일한 클래스를 상이한 클래스로더가 두 번 로드할 수 있으므로 주의 필요.
+ - 클래스 식별: 클래스는 풀 클래스명과 로드한 클래스로더로 식별되므로 빌드 프로세스에서 운영 환경과 동일한 클래스패스로 컴파일하는 것이 좋음.
+
+## 2.2 바이트코드 실행
+
+- 컴파일 단계: 자바 소스 코드를 javac 컴파일러를 사용하여`.class` 파일로 변환. 최적화는 거의 하지
+ 않아 `javap`와 같은 역 어셈블리툴로 해독 가능한 바이트코드 생성.
+ - 바이트코드 특징:
+ - 바이트코드는 특정 컴퓨터 아키텍처에 종속되지 않은 중간 표현형(IR)이며, JVM이 이를 실행.
+ - 컴파일된 소프트웨어는 JVM 지원 플랫폼 어디서든 실행 가능하며 자바 언어에 대해 추상화 되어 있음.
+- 클래스 파일 구조:
+ - 클래스 파일은 0XCAFEBABE 매직 넘버로 시작.
+ - 메이저/마이너 버전 숫자로 JVM 호환성 확인, `UnsupportedClassVersionError` 예외 발생.
+ - 상수 풀에는 상숫값 등이 포함되며, 코드 실행 시 참조됨.
+ - 액세스 플래그는 클래스의 수정자 결정. 예: Public, final, 인터페이스, 추상 클래스 등.
+ - this 클래스, 슈퍼클래스, 인터페이스 엔트리는 타입 계층을 나타내는 인덱스로 표시.
+ - 필드와 메서드는 시그니처와 수정자를 포함하는 구조로 정의.
+ - 속성 세트는 메서드의 바이트코드 등을 나타내는데 사용.
+- 런타임 검사 및 실행:
+ - JVM은 클래스를 로드할 때 VM 명세서에 정의된 구조를 검사하여 올바른 형식인지 확인.
+ - 런타임에는 상수 풀 등을 참조하며, 실행 중에 메모리에 배치되는 것이 아니라 상수 풀 테이블을
+ 참조하여 필요한 값을 얻음.
+
+```Bash
+javap -c HelloWorld
+Compiled from "HelloWorld.java"
+public class HelloWorld {
+ public HelloWorld();
+ Code:
+ 0: aload_0
+ 1: invokespecial #1 // Method java/lang/Object."":()V
+ 4: return
+
+ public static void main(java.lang.String[]);
+ Code:
+ 0: iconst_0
+ 1: istore_1
+ 2: iload_1
+ 3: bipush 10
+ 5: if_icmpge 22
+ 8: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
+ 11: ldc #13 // String Hello, World!
+ 13: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
+ 16: iinc 1, 1
+ 19: goto 2
+ 22: return
+}
+```
+
+위 명렁을 해석해보면 다음과 같다.
+
+1. 기본 생성자
+
+ - `aload_0`: `this` 의 레퍼런스를 stack에 로드한다
+ - `invokespecial`: super 생성자를 호출하고 객체를 생성하는 method 를 실행한다.
+ - default constructor를 override 하지 않았으므로 `java/lang/Object` 의 default constructor 매치
+
+2. main method
+
+ - `iconst_0`: 정수형 상수 0을 스택에 푸쉬한다
+ - `istore_1`: 스택의 값을 로컬 변수 1에 저장합니다.
+ - 0 부터 시작한다
+ - instance method 에서 0번째 entry 는 this 이다
+ - `iload_1`: 은 로컬 변수 1의 값을 스택에 로드합니다.
+ - `if_icmpge`: 스택에 있는 값이 10보다 크거나 같으면 목표 지점(22번째 줄)으로 이동합니다.
+ - `getstatic`: `System.out`의 정적 필드를 스택에 넣습니다.
+ - `ldc`: 상수 풀에서 문자열 "Hello World"를 스택에 넣습니다.
+ - `invokevirtual`: `PrintStream.println` 메서드를 호출하여 화면에 "Hello World"를 출력합니다.
+ - `iinc(1, 1)`: 로컬 변수를 증가시킵니다.
+ - `goto`: 주어진 목표 지점으로 이동합니다.
+ - `if_icmpge` 가 성공할 때 까지 반복하다가 마지막 22번 `return` 을 실행하고 제어권이 넘어간다
+
+## 마무리
+
+이후 내용은 뒤의 장들에서 다뤄질 예정
+
diff --git a/ch02/lsj8367.md b/ch02/lsj8367.md
new file mode 100644
index 0000000..1f70209
--- /dev/null
+++ b/ch02/lsj8367.md
@@ -0,0 +1,216 @@
+# 2장. JVM 이야기
+
+JVM이 자바 코드를 실행하는 방법
+
+## 2.1 인터프리팅과 클래스로딩
+
+JVM은 스택기반의 해석 머신이다.
+
+그래서 일부 결과들을 실행 스택에 보관하며, 이 스택의 맨위부터 쌓인 값들을 가져와 계산하게 된다.
+
+JVM 인터프리터의 기본 로직은 while루프 안의 switch문이라고 생각하면 쉽다.
+
+자바 파일을 실행하게 되면 OS는 가상 머신 프로세스인 자바 바이너리를 구동한다.
+
+자바 가상 환경이 구성되고 스택 머신이 초기화된 이후 클래스 파일이 실행되는 구조로 되어있다.
+
+항상 애플리케이션의 진입점은 `main()` 메소드다.
+
+제어권을 구현한 클래스로 넘기고 싶다면 가상 머신이 실행되기 이전에 이 클래스를 로드시켜야 한다.
+
+→ 이 때, 자바 클래스로딩이 실행된다.
+
+자바 프로세스가 새로 초기화 되면 클래스 로더가 차례대로 동작한다.
+
+### 1. 부트스트랩 클래스
+
+가장 먼저 동작하며 자바 런타임 코어 클래스를 로드한다.
+
+자바8이전까지는 `rt.jar` 에서 가져왔지만 자바9 버전부터는 런타임이 모듈화되고 클래스로딩 개념 자체가 달라졌다.
+
+최소한의 `java.lang.Object` , Class, ClassLoader 만 로드한다.
+
+### 2. 확장 클래스 로더
+
+부트스트랩 클래스로더를 자기 부모로 설정 후 필요한 작업이 있는 경우 클래스 로딩작업을 부트스트랩한테 넘긴다.
+
+특정 OS나 플랫폼에 native code를 제공 및 기본 환경 재정의가 가능하다.
+
+### 3. 애플리케이션 클래스 로더
+
+지정된 classpath에 위치한 유저 클래스를 로드한다.
+
+프로그램 실행 중 처음보는 클래스는 자신의 부모 클래스로더에게 위임하고, 찾아보는 기능을 넘긴다.
+
+이 때도 찾지 못하면 계속해서 위의 부모로 올라가게 된다.
+
+이 상태에서 부트스트랩까지 찾지 못한다면 `ClassNotFoundException` 이 실행된다.
+
+보통환경에서 자바는 클래스를 로드할 때 런타임 환경에서 Class객체를 만드는데, 같은 클래스를 여러번 다른 클래스로더가 n회 로드할 수 있다.
+
+한 시스템에서 클래스는 풀 클래스명과 자신을 로드한 클래스로더 이 두가지 정보로 식별한다.
+
+## 2.2 바이트코드 실행
+
+### 1. javac
+
+javac을 이용해 컴파일을 수행한다.
+
+javac이 하는 일은 자바 소스코드를 바이트코드 `.class` 파일로 변환해주는 것
+
+javac은 컴파일 하는동안 최적화를 많이 하지 않기 때문에 쉽게 해독이 가능하다.
+
+바이트코드는 특정 컴퓨터 아키텍처에 특정되지 않은 중간 표현형이다.
+
+JVM이 설치되어 있는 소프트웨어라면 이식성이 좋아서 어디서든 실행이 가능하다.
+
+모든 클래스파일은 `0xCAFEBEBE` 라는 매직넘버로 이 파일이 클래스파일임을 나타내는 4바이트 16진수로 시작한다.
+
+그 다음 4바이트는 컴파일 시 메이저/마이너 버전의 숫자이다
+
+클래스 로더의 호환성 보장을 위해 검사하고 호환되지 않는다면 `UnsupportedClassVersionError` 가 난다.
+
+> 상수 풀
+>
+
+클래스명, 인터페이스명, 필드명 등등의 상수값이 존재한다.
+
+JVM은 코드를 실행할 때 런타임에 배치된 메모리 대신, 상수 테이블을 찾아보고 필요한 값을 참조한다.
+
+> 액세스 플래그
+>
+
+클래스에 적용한 수정자 결정.
+
+첫 부분은 일반 프로퍼티며, public 클래스인지 final 클래스인지 나타냄.
+
+클래스 유형도 이 플래그로 표시한다.
+
+플래그 끝에는 클래스 파일이 합성 클래스인지 다른 타입인지 나타냄.
+
+this, 슈퍼, 인터페이스 엔트리는 클래스에 포함된 타입계층을 나타냄.
+
+상수풀을 가리키는 인덱스로 표시한다.
+
+
+
+
+## 2.3 핫스팟 입문
+
+썬 마이크로시스템즈가 성능 관점에서 자바에 가장 큰 변화를 가져왔다.
+
+여기서 핫스팟 가상머신이 나온다.
+
+
+
+
+제로-오버헤드를 위해 C언어 같은 언어들은 소스코드를 빌드하면 플랫폼에 특정한 기계어로 컴파일된다. → AOT(Ahead Of Time) 컴파일이라고 한다.
+
+핫스팟 VM은 개발자가 억지로 VM에 맞게 프로그램을 욱여넣는대신 자바 코드를 자연스레 작성하고 바람직한 설계원리를 따르도록 하는 것이다.
+
+## JIT 컴파일이란?
+
+자바 프로그램은 바이트코드 인터프리터가 가상화한 스택 머신에서 명령어를 실행하며 시작된다.
+
+CPU를 추상화했기에 다른 플랫폼에서도 클래스 파일을 문제없이 실행할 수 있지만, 성능을 최대치로 내기 위해서는 네이티브 기능을 활용해 CPU에서 직접 프로그램을 실행시켜주어야 한다.
+
+핫스팟이 여기서 프로그램 단위를 인터프리터 바이트코드에서 네이티브 코드로 컴파일하는데, 이를 JIT(Just In Time) 컴파일이라고 한다.
+
+인터프리티드 모드로 실행하는 동안 애플리케이션에 대한 모니터링을 수행하며 가장 자주 실행되는 코드 부분을 JIT 컴파일 수행한다.
+
+자바처럼 프로필 기반 최적화를 하는 환경에선 동적 인라이닝 또는 가상 호출로 성능을 개선할 수 있다.
+
+핫스팟VM은 시동 시 CPU 타입을 정확히 감지하여 특정 프로세서의 기능에 맞게 최적화를 적용할 수 있다.
+
+## JVM 메모리 관리
+
+자바는 가비지 수집이라는 프로세스를 이용해 힙 메모리를 자동 관리하는 방식으로 해결한다.
+
+## 스레딩과 자바 메모리 모델
+
+자바는 1.0 버전부터 멀티스레드 프로그래밍을 기본적으로 지원했다.
+
+자바 애플리케이션 스레드는 하나의 전용 OS 스레드에 대응된다.
+
+공유 스레드 풀을 이용해서 전체 자바 애플리케이션 스레드를 실행하는 그린스레드도 있지만, 만족할 성능은 나오지 않았다.
+
+### 자바의 멀티스레드 방식
+
+- 자바 프로세스의 모든 스레드는 가비지가 수집되는 하나의 공용 힙을 가진다.
+- 한 스레드가 생성한 객체는 그 객체를 참조하는 다른 스레드가 액세스 할 수 있다.
+- 기본적으로 객체는 변경 가능하다. 즉, 객체 필드에 할당된 값은 프로그래머가 애써 final 키워드로 불변표시하지 않는 한 바뀔 수 있다.
+
+## JVM 구현체 종류
+
+### OpenJDK
+
+자바 기준 구현체를 제공하는 오픈소스.
+
+오라클이 직업 프로젝트 주관하며 자바 릴리즈 기준을 발표한다.
+
+### OracleJDK
+
+가장 널리 알려진 구현체, OpenJDK 기반이지만 오라클 상용 라이선스로 재 라이선스를 받음.
+
+### Zulu
+
+Azul 시스템이 제작한 무료 OpenJDK 구현체
+
+### IcedTea
+
+레드햇의 작품. 풀 인증 받음.
+
+### Zing
+
+Azul 시스템이 제작한 고성능 상용 JVM
+
+64bit Linux에서만 작동한다. 대용량 힙메모리와 멀티 CPU서버급 시스템을 위해 설계된 제품이다.
+
+### ETC
+
+J9, Avian, Android 등이 있다.
+
+## JVM 모니터링과 툴링
+
+### JMX
+
+JVM과 그 위에서 동작하는 애플리케이션을 제어하고 모니터링하는 툴
+
+클라이언트 애플리케이션처럼 메소드를 호출하고 매개변수를 바꿀 수 있다.
+
+### Javaagent
+
+자바 언어로 작성된 툴 컴포넌트, `java.lang.instrument` 인터페이스로 메소드 바이트코드를 조작한다.
+
+`-javaagent:<에이전트 JAR파일 경로>=<옵션>`
+
+manifest.mf 파일은 에이전트 JAR파일에서 필수이다.
+
+`PremainClass` 속성에 클래스명을 반드시 지정해야함.
+
+### SA
+
+자바 객체, 핫스팟 자료구조 모두 표출 가능한 API와 툴을 모아놓은 것.
+
+### VisualVM
+
+JVM 어태치 메커니즘을 통해 실행 프로세스를 실시간 모니터링한다.
+
+> 개요
+>
+
+자바 프로세스에 관한 요약 정보를 표시.
+
+프로세스에 전달한 전체 플래그와 시스템 프로퍼티, 실행중인 자바 버전 표기
+
+> 모니터
+>
+
+CPU, Heap 사용량 등 JVM 을 고수준에서 원격 측정한 값들이 표시된다.
+
+> 스레드
+>
+
+실행중인 애플리케이션 각 스레드가 시간대별로 표시된다.
+
+스레드별 상태와 변화들을 보며 스레드덤프를 뜰 수 있다.
diff --git a/ch02/yoojeong.md b/ch02/yoojeong.md
new file mode 100644
index 0000000..3fd9f82
--- /dev/null
+++ b/ch02/yoojeong.md
@@ -0,0 +1,161 @@
+JVM이 자바 코드를 실행하는 방법을 소개한다.
+
+### 인터프리팅과 클래스로딩 (Interpreting and Classloading)
+
+JVM은 스택 기반의 해석 머신이다. register 는 없지만 일부 결과를 실행 스택에 보관하며, 이 스택의 가장 위에 쌓인 값을 가져와 계산한다.
+JVM interpreter 는 while문 안에 switch 문 으로 이해할 수 있다.
+
+
+java HelloWorld 라는 명령을 실행하면
+```
+1. OS는 가상 머신 프로세스(java binary)를 구동한다.
+2. 자바 가상 환경이 구성된다.
+3. stack 머신이 초기화 된다.
+4. HelloWorld 클래스가 실행된다.
+ - 여기서 application 의 진입은 HelloWorld.class 의 main() method 이다.
+```
+
+제어권을 이 클래스로 넘기기 위해 가상 머신(이하 VM) 이 실행되기 전에 이 클래스를 load 해야한다.
+
+#### classloading 매커니즘
+
+1. Bootstrap ClassLoader
+- 최소한의 필수 클래스(java.lang.Object, Class, ClassLoader..)만 로드
+- Java 8 이전 : `${JAVA_HOME}/jre/lib/rt.jar` 및 기타 핵심 라이브러리와 같은 JDK의 내부 클래스를 로드한다.
+- Java 9 이후 : `/re.jar`이 존재하지 않으며, `/lib` 내에 모듈화되어 포함됐다. 이제는 정확하게 ClassLoader 내 최상위 클래스들만 로드한다.
+
+2. Extension ClassLoader(Platform ClassLoader)
+- 부트스트랩 클래스 로더를 부모로 갖는 클래스 로더로서, 확장 자바 클래스들을 로드한다.
+- Java 8 이전 : `java.ext.dirs` 환경 변수에 설정된 디렉토리의 클래스 파일을 로드하고, 이 값이 설정되어 있지 않은 경우 `${JAVA_HOME}/jre/lib/ext` 에 있는 클래스 파일을 로드한다.
+- OS나 플랫폼에 native code 를 제공하고 기본 환경을 overriding 하는데 사용된다.
+
+3. Application ClassLoader(System ClassLoader)
+- 실행 시 지정한 Classpath에 있는 클래스 파일 혹은 jar에 속한 클래스들을 로드한다. (== 사용자가 생성한 .class 확장자 파일을 로드한다.)
+
+ClassLoader는 모두 상속 관계이다.
+
+`bootstrap (최상단 부모) → extension classload → application classloader (최하단 자식)`
+
+새 클래스를 발견하여 찾지 못하면 한 단계씩 상위로 올려 lookup 을 하고, 끝까지 찾지 못한다면 ClassNotFoundException 을 일으킨다.
+`클래스 = 패키지명을 포함한 full class name + 자신을 로드한 classloader` 두가지 정보로 식별하여 이중 로딩 방지한다.
+
+[Understanding the Java Class Loader Starting from Java 9](https://sergiomartinrubio.com/articles/understanding-the-java-class-loader-starting-from-java-9/)
+[New Class Loader Implementations](https://docs.oracle.com/javase/9/migrate/toc.htm#JSMIG-GUID-A868D0B9-026F-4D46-B979-901834343F9E)
+
+
+
+### 바이트코드 실행 (Executing Bytecode)
+
+
+bytecode 는 컴퓨터의 아키텍쳐에 특정되지 않는 중간 표현형(Intermediate Representation, IR) 으로 JVM 이 지원되는 플랫폼 어디서든 실행할 수 있다.
+컴파일러가 생성한 클래스파일은 아래 형식을 준수한다.
+
+|Component|Description|
+|:--:|:--|
+|Magic Number|0xCAFEBABE|
+|클래스 파일 format version|class 파일의 major / minor 버젼|
+|상수 풀(constant pool)|class 파일의 상수가 모여있는 위치|
+|access flag|public,static,final 등 modifiers와 interface, annotation, enum 등 클래스 종류 |
+|this class|현재 클래스의 이름|
+|super class|부모 클래스의 이름|
+|interface|현재 클래스가 implements 한 모든 interface|
+|field|클래스에 들어가 있는 모든 필드|
+|method|클래스에 들어가 있는 모든 methods|
+|attribute|클래스의 속성(소스 파일 이름 등)|
+
+```java
+// HelloWorld.java
+class HelloWorld {
+ public static void main(String[] args) {
+ System.out.println("Hello World!");
+
+ }
+}
+
+// HelloWorld.class (bytecode)
+public class HelloWorld {
+ public HelloWorld();
+ Code:
+ 0: aload_0
+ 1: invokespecial #1 // Method java/lang/Object."":()V
+ 4: return
+
+ public static void main(java.lang.String[]);
+ Code:
+ 0: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
+ 3: ldc #13 // String Hello World
+ 5: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
+ 8: return
+}
+
+```
+
+### 핫스팟 JVM
+zero cost(비용이 들지 않는) 추상화 사상에 근거하는 C++ 과 같은 언어는 AOP(Ahead-of-time: 사전 컴파일)를 하기 때문에 Platfotm(OS)에 최적화 되어 실행된다.
+
+Java 는 이러한 zero-overhead 추상화 원칙을 동조하지 않는다.
+hotspot은 runtime 에 동작을 분석하고, 성능에 가장 유리한 방향으로 그때그때 최적화를 적용하는 가상머신이다.
+
+### JIT 컴파일이란?(Just-in-Time)
+
+자바 프로그램은 bytecoe interpreter 가 가상화한 stack 머신에서 실행하며 시작된다.
+CPU 를 추상화 한 구조이기 때문에 다른 platform 에서 class 파일을 문제 없이 실행할 수 있지만, 성능을 최대로 내려면 native 기능을 활용해 CPU 에서 직접 실행시켜야 한다.
+hotspot 은 자주 실행되는 코드 파트를 찾아내 JIT 컴파일을 수행한다.(interpreted bytecode -> native code)
+
+`SourceCode(.java) → Compiler(javac) → ByteCode(.class) → JVM → Interpreter → NativeCode`
+
+> **JVM의 실행 엔진의 인터프리터**
+> 바로 기계어로 변환하는 컴파일러의 경우는 프로그램이 작성된 기계상에서 매우 효율적으로 실행된다. 그러나 이와 동시에 기계에 종속된다는 말이기도 하다.
+> 만약 JVM 내에서 컴파일러를 사용하여 바이트코드의 목적 파일을 생성한다면 이는 기계에 종속되는 파일이다.
+> 때문에 자바 인터프리터는 자바 컴파일러를 통해 생성된 바이트코드를 한 줄씩 읽어 기계어로 번역하고 실행한다.
+> 하지만 인터프리터는 컴파일러보다 실행 속도가 느리기 때문에 이를 해결하고자 JVM은 부분적으로 JIT 컴파일러를 사용하여 바이트코드를 컴파일하여 사용한다.
+
+> JIT 컴파일러는 실행 시점에서는 인터프리터와 같이 기계어 코드를 생성하면서 해당 코드가 컴파일 대상이 되면 컴파일하고 그 코드를 캐싱한다.
+> JIT 컴파일은 코드가 실행되는 과정에 실시간으로 일어나며(Just-In-Time), 전체 코드의 필요한 부분만 변환한다.
+> 기계어로 변환된 코드는 캐시에 저장되기 때문에 재사용 시 컴파일을 다시 할 필요가 없다.
+
+[[Java] JIT 컴파일러란?](https://hyeinisfree.tistory.com/26)
+
+
+
+
+### JVM 메모리 관리 (JVM Memory Management)
+
+GC는 JVM이 더 많은 메모리를 할당해야 할 때 불필요한 메모리를 회수하거나 재사용하는 불확정적 프로세스이다.
+GC가 실행되는 동안 다른 애플리케이션은 모두 멈춰야 하는데 이것은 애플리케이션의 부하가 늘어날 수록 무시할 수 없는 시간이 된다.
+
+### Threading 과 자바 메모리 모델(JMM)
+```java
+Thread t = new Thread(() -> { System.out.println("Hello World"); });
+```
+
+java 환경 자체가 JVM 처럼 multi-thread 기반이기 때문에 java 프로그램이 작동하는 방식은 더 복잡하고 성능 분석도 어렵다.
+JVM 구현체에서 java application thread 는 각각 하나의 전용 OS thread 에 대응한다.
+
+자바 멀티스레드 설계 원칙
+- java process의 모든 thread는 GC되는 하나의 공용 heap 을 갖는다
+- 한 thread 가 생성한 객체는 그 객체를 참조하는 다른 thread 가 access 할 수 있다.
+- 기본적으로 객체는 변경이 가능하다.(final 이 붙은 클래스가 아니라면)
+- exclusive lock은 코드가 동시 실행되는 중 객체가 손상되는 현상을 막을 수 있다
+
+### JVM 구현체 종류
+
+- openJDK
+ - 자바 기준 구현체를 제공하는 특별한 open source 이다.
+ - 오라클이 직접 주관/지원하며 java release 기준을 발표한다
+- oracle Java
+ - 가장 널리 알려진 구현체로 OpenJDK 기반이지만, 오라클의 상용 라이센스이다.
+
+### JVM 모니터링과 툴링
+
+- JMX(Java management Extension)
+- Java agent
+
+### VisualVM
+
+Attach machanism을 이용해 실행 프로세스를 실시간으로 모니터링 한다.
+
+- 개요(java process 요약)
+- 모니터: CPU, heap 사용량 등 JVM 을 고수준에서 원격 측정한 값 제공
+- thread: 애플리케이션의 각 thread 를 시간대별로 표시 (thread dump 가능)
+- sampler and profiler
diff --git a/ch02/youjin.md b/ch02/youjin.md
new file mode 100644
index 0000000..ae8f5d4
--- /dev/null
+++ b/ch02/youjin.md
@@ -0,0 +1,78 @@
+# Chapter2 - JVM 이야기
+< JVM이 Java 코드를 실행하는 방법 >
+
+* JVM은 Stack 기반의 해석 머신
+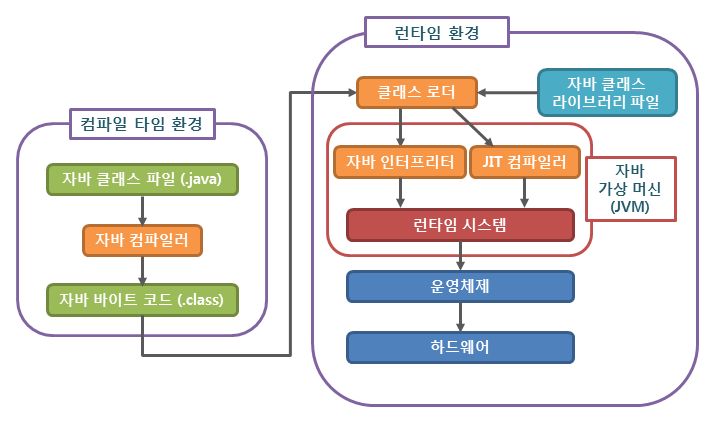
+
+(출처: https://tcpschool.com/java/java_intro_programming)
+
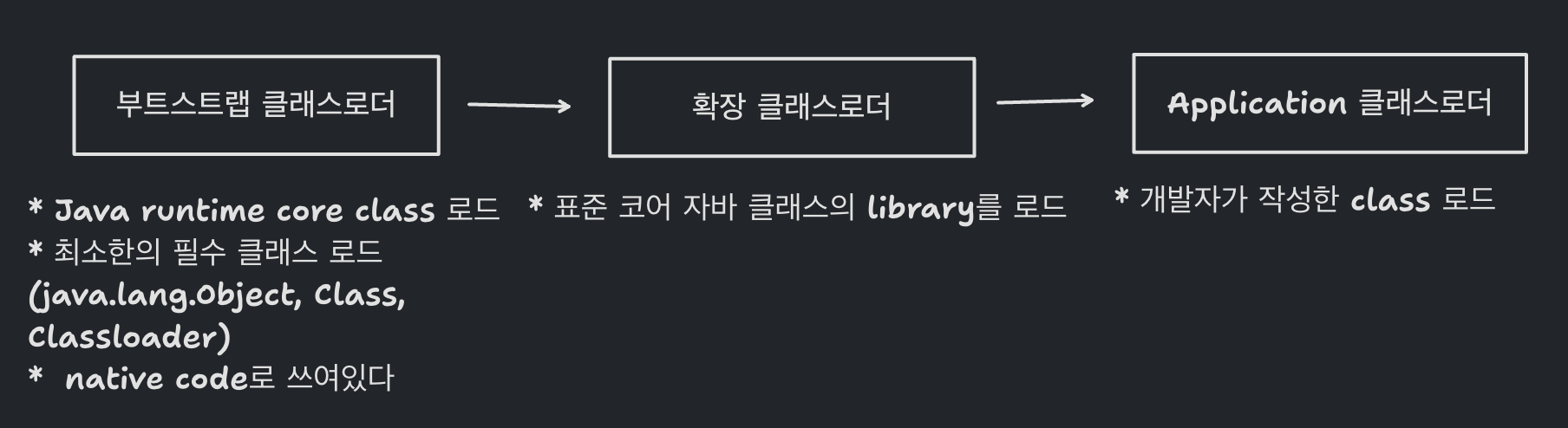
+## Java Classloading
+Java Compiler(javac)를 통해 .class 파일로 변환한다.
+변환된 class 파일을 JVM 메모리에 탑재 해야한다 ➡️ 이 과정은 컴파일 타임이 아니라 런타임에 일어난다 (Java의 동적 클래스 로딩 기능이라고 함)
+이것을 Class load라고 하고, classloader가 해당 작업을 수행한다.
+
+
+* 참고
+ * https://www.baeldung.com/java-classloaders
+ * https://tecoble.techcourse.co.kr/post/2021-07-15-jvm-classloader/
+
+
+* JVM이 Class를 요청하면, classloader가 class를 찾는다
+* 하위에서 못찾으면 상위에 요청한다
+* 만약 가장 상위(부트스트랩)에서도 찾지 못하면 `ClassNotFoundException`이 발생한다.
+
+## Bytecode
+* javac(java compiler)는 Java파일(`.java`)을 bytecode(`.class`)로 변환한다
+* Java bytecode는 JVM이 알아들을 수 있는 코드이다
+* bytecode는 특정 아키테처에 특정하지 않은 중간표현형(IR)이다
+ * JVM만 있다면 어떤 OS에서도 실행될 수 있다 (이식성이 좋다)
+
+**.class file**
+
+(출처: https://blog.hexabrain.net/397)
+
+**javap (역어셈블러)**
+``` shell
+$javap -c [Class명]
+```
+
+``` java
+public class com.company.Foo {
+ int data;
+
+ public com.company.Foo(); // 클래스 Foo의 디폴트 생성자
+ Code:
+ // 여기서는 this를 피연산자 스택에 푸시한다.
+ 0: aload_0
+ // 부모 클래스인 Object의 디폴트 생성자를 호출한다. (super())
+ 1: invokespecial #1 // Method java/lang/Object."":()V
+ 4: return
+
+ public void doSomething();
+ Code:
+ 0: return
+}
+```
+
+## 핫스팟
+* 프로그램의 런타임 동작을 분석하고, **성능에 가장 유리한 방향으로 최적화를 적용하는 가상머신**
+
+프로그램이 성능을 최대로 내려면?
+➡️ native 기능을 활용해 CPU에서 직접 프로그램을 실행시켜야 한다
+(native code는 CPU가 이해할 수 있는 code)
+
+> 따라서 핫스팟은 가장 자주 실행되는 bytecode를 native code로 컴파일 한다. (핫스팟의 기능1)
+> ➡️ JIT(Just-In-Time, 적시, 그때그때 하는) 컴파일
+
+핫스팟은 동적 인라이닝도 수행한다 (핫스팟의 기능2)
+
+## JVM 메모리
+* Java는 Garbage Collection 프로세스로 Heap 메모리를 자동 관리한다
+* Garbage Collection(GC): 불필요한 메모리 회수 or 재사용
+* GC가 실행되는 동안 다른 application은 중단된다
+
+## JVM 모니터링, 툴링
+* JMX
+* Java agent
+* JVMTI
+* SA
diff --git a/ch02/youngji.md b/ch02/youngji.md
new file mode 100644
index 0000000..0305726
--- /dev/null
+++ b/ch02/youngji.md
@@ -0,0 +1,167 @@
+> 자바 개발자가 플랫폼을 저수준에서 다 알필요 없도록 설계되어 있지만, 성능에 관심이 있다면 기본적인 JVM을 이해해야 한다.
+>
+
+> JVM 기술 스택의 구조와 JVM이 자바 코드를 실행하는 법을 학습한다.
+>
+
+---
+
+## 1. 인터프리팅과 클래스로딩
+
+JVM은 스택 기반의 해석 머신이다.
+
+물리적인 하드웨어인 레지스터는 없지만 일부 결과를 실행 스택에 보관하며, 스택의 맨위에 쌓인 값들을 가져와 계산한다.
+
+JVM **인터프리터(해석기)**의 기본 로직은, 평가 스택을 이용해 중산값들을 담아두고 가장 마지막에 실행된 명령어와 독립적으로 프로그램을 구성하는 옵코드를 하나씩 순서대로 처리하는 ‘while 루프 안의 switch문’이다. (실제품급 자바 인터프리터는 이보다 훨씬 복잡하지만, 지금은 while 루프 문안에 switch문 정도의 이미지를 떠올리면 이해하기 쉽다.)
+
+```bash
+java HelloWorld
+```
+
+명령어를 입력하여 자바 어플리케이션을 실행해보자
+
+1. OS는 가상 머신 프로세스(자바 바이너리)를 구동한다.
+2. 자바 가상 환경이 구성되고 스택 머신이 초기화된 다음, 사용자가 작성한 HelloWorld 클래스 파일이 실행된다.
+
+애플리케이션의 진입점은 HelloWorld.class에 있는 main() 메소드이다.
+
+제어권을 이 클래스로 넘기려면 가상 머신이 실행되기 전에 이 클래스를 로드해야한다. 이때 자바 **클래스로딩 메커니즘**이 관여한다.
+
+자바 프로세스가 새로 초기화되면 사슬처럼 줄지어 연결된 클래스 로더가 차례로 동작하게 된다.
+
+1. 제일 먼저 **부트스트랩 클래스**가 동작하며 자바 런타임 코어 클래스를 로드한다.
+
+ 부트스트랩 클래스로더의 주임무는 다른 클래스로더가 나머지 시스템에 필요한 클래스를 로드할 수 있게 최소한의 필수 클래스(Object, Class, Classloader 등..)만 로드하는 것이다.
+
+ → 런타임 코어 클래스는 자바8 이전까지는 rt.jar 파일에서 가져오지만, 자바9 이후부터는 런타임이 모듈화되고 클래스로딩 개념 자체가 많이 달라졌다.
+
+ → 자바에서 Classloader는 런타임과 타입체계 내부에 있는 하나의 객체에 불과하다. 따라서 클래스 초기 세트가 존재하게 할 방법이 없다. (그걸 해주는 것이 부크스트랩 클래스) 그렇지 않으면 클래스로더를 정의하는 과정에서 순환오류 문제가 발생할 것이다.
+
+2. 그 다음, **확장 클래스로더**가 생긴다.
+
+ 확장 클래스로더는 부트스트랩 클래스로더를 자기 부모로 설정하고 필요할때 클래스로딩 작업을 부모에게 넘긴다.
+
+3. 끝으로 확장 클래스로더의 자식인 **애플리케이션 클래스로더**가 생성되고 지정된 클래스패스에 위치한 **유저 클래스**를 로드한다.
+
+자바는 프로그램 실행 중 처음 보는 새 클래스를 **티펜던시(의존체)**에 로드한다. 클래스를 찾지 못한 클래스로더는 기본적으로 자신의 부모 클래스로더에게 대신 룩업을 넘긴다. 부모로 거슬러 올라가 결국 부트스트랩도 룩업을 하지 못하면 ClassNotFoundException 예외가 발생한다.
+
+때문에 빌더 프로세스 수립 시 운영 환경과 동일한 클래스패스로 컴파일하는 것이 좋다.
+
+한 시스템에서 클래스는 패키지명을 포함한 풀 클래스명과 자신을 로드한 클래스로더, 두가지 정보로 식별된다. (똑같은 클래스를 상이한 클래스로더가 두 번 로드할 가능성이 있으니 주의한다.)
+
+---
+
+## 2. 바이트코드 실행
+
+자바 소스 코드가 실행되는 첫 단계는 자바 컴파일러 javac를 이용해 컴파일하는 것으로, 자바 소스 코드를 바이트코드로 가득 찬 .class 파일로 바꾸는 것이다.
+
+(native code는 OS상에서 직접 컴파일하여 바로 기계로 실행 가능한 반면 인터프리터가 반드시 있어야 실행되는 코드를 managed code라고 한다.)
+
+javac는 컴파일하는 동안 최적화는 거의 하지 않기 때문에 그 결과로 생성된 바이트코드는 쉽게 해독할 수 있다.
+
+(javap 같은 표준 역어셈블리 툴로 열어보면 원래 자바 코드도 어렵지 않게 알아볼 수 있다.)
+
+→ 바이트코드는 특정 컴퓨터 아키텍쳐에 특정하지 않은, 중간 표현형이다. 컴퓨터 아키텍쳐에 종속적이지 않아 이식성이 좋아 개발을 마친(컴파일된) 소프트웨어는 JVM 지원 플랫폼 어디든 실행이 가능하다.
+
+컴파일러가 생성한 클래스파일은 아주 명확하게 잘 정의된 구조를 갖춘다.
+
+| entry | 설명 |
+| --- | --- |
+| 매직넘버 | 0XCAFEBABE : 해당 파일이 클래스 파일임을 나타내는 4바이트 16진수로 시작한다. |
+| 클래스 파일 포맷 버전 | 그 다음 4바이트는 클래스 파일을 컴파일할때 필요한 메이저/마이너 버전 숫자이다. 대상 JVM 버전이 컴파일한 JVM 버전보다 낮을 경우 호환되지 않아 런타임에 UnsupportedClassVersionError 예외가 발생한다. |
+| 상수 풀 | 상수값. 클래스명, 인터페이스명, 필드명 등등
+JVM은 코드를 실행할 때 런타임에 배치된 메모리 대신, 해당 상수 풀 테이블을 찾아보고 필요한 값을 참조한다. |
+| 액세스 플래그 | 클래스에 적용한 수정자를 결정한다.
+ACC_PUBLIC(0x0001), ACC_FiNAL(0x0010), ACC_SUPER(0x0020), ACC_INTERFACE(0x0200), ACC_ABSTRACT(0x0400), ACC_SYNTHETIC(0x1000), ACC_ANNOTATION(0x2000), ACC_ ENUM(0x4000) |
+| this 클래스 | |
+| 슈퍼클래스 | |
+| 인터페이스 | 위 세가지 엔트리는 클래스에 포함된 타입 계층을 나타내며, 각각 상수 풀을 가르키는 인덱스로 표시된다. |
+| 필드 | |
+| 메소드 | 필드와 메소드는 시그니처 비슷한 구조를 정의하고 수정자도 포함한다. |
+| 속상 | 더 복잡하고 크기가 고정되어 있지 않은 구조를 나타내는 데 쓰인다. |
+
+---
+
+## 3. 핫스팟 입문
+
+성능 관점에서 자바에 가장 큰 변화를 가져왔던것은 핫스팟 가상 머신이다.
+
+핫스팟을 처음 선보인 이후로 C/C++ 같은 언어에 필적할 만한 성능을 자랑하며 진화를 거듭했다.
+
+언어 및 플랫폼 설계 과정은 ‘기계어에 가까운 언어’와 개발자의 생산성에 무개를 둔 ‘일을 대행하는 언어’ 사이에서의 갈등을 겪게 된다.
+
+제로-오버헤드 원칙은 이론적으로는 그럴싸하지만 아래와 같은 문제가 있다.
+
+→ 개발자가 아주 세세한 저수준까지 알아야하는 학습 부담이 있다.
+
+→ 특정 플랫폼에서만 사용가능한 기계어로 컴파일 된다. (`**사진(AOT) 컴파일**`)
+
+자바는 이러한 제로-오버헤드 추상화 철학에 한번도 동조한 적이 없으며, 오히려 핫스팟은 프로그램의 런타임 동작을 분석하고 성능에 유리한 방향으로 최적화를 적용하는 가상 머신이다.
+
+핫스팟 VM의 목표는 개발자가 억지로 VM 틀에 맞게 프로그램을 욱여넣는 대신, 자연스럽게 자바 코드를 작성하고 바람직하게 설계원리를 따르도록 한다.
+
+- JIT 컴파일
+
+ 프로그램이 성능을 최대로 내려면 네이티브 기능을 활용하여 CPU에서 직접 프로그램을 실행시켜야한다. 이를 위해 핫스팟은 프로그램을 인터프리티 바이트코드에서 네이티브 코드로 컴파일한다.
+
+ → `**적시(JIT) 컴파일**`
+
+ JIT 컴파일을 수행하는 과정에서 컴파일러가 해석단계에서 미리 정보를 수집하여 추적 정보를 근거로 최적화를 결정한다는 것이 가장 큰 장점이다.
+
+
+---
+
+## 4. JVM 메모리 관리
+
+개발자가 직접 메모리를 관리하면 좀 더 확정적인 성능을 낼 수 있고 리소스 수명을 관리할 수 있다는 장점이 있지만, 그만큼 반드시 개발자가 메모리를 정확하게 계산해야 한다는 막중한 책임이 수반된다.
+
+자바는 **가비지수집**을 이용해 힙 메모리를 자동 관리하는 방식으로 이러한 문제를 해결한다.
+
+가비지 수집이란 JVM이 더 많은 메모리를 할당해야 할때 불필요한 메모리를 회수하거나 재사용하는 불확정적 프로세스이다.
+
+CG의 작업은 결코 간단하지 않고 자바 역사를 통틀어 온갖 알고리즘이 개발/응용되었다. 일단 CG가 실행되면 그동안 다른 애플리케이션은 모두 중단되고 하던일을 멈춰야한다. 이 중단 대기 시간은 대개 아주 짧지만, 부화가 늘수록 이 시간도 무시할 수는 없다. ****
+
+---
+
+## 5. 스레딩과 자바 메모리 모델(JMM)
+
+자바는 1.0부터 멀티스레드 프로그래밍을 기본 지원했다.
+
+주류 JVM 구현체에서 자바 어플리케이션 스레드는 각각 하나의 전용 OS 스레드에 대응된다.
+
+공유 스레드 풀을 이용해 전체 자바 어플리케이션 스레드를 실행하는 방안(그린 스레드)도 있지만, 복잡하고 만족할 만한 수준의 성능이 나오지 않아 보통 주류를 따른다.
+
+자바의 멀티스레드 방식 기본 설계 원칙
+
+1. 자바 프로세스의 모든 스레드는 가비지가 수집되는 하나의 공동 힙을가진다.
+2. 한스레드가 생성한 객체는 그 객체를 참조하는 다른 스레드가 액세스 할 수 있다.
+3. 기본적으로 객체는 변경 가능하다. (명시적 final 키워드를 표시하지 않는 이상)
+
+JMM은 서로 다른 실행 스레드가 객체 안에 변경되는 값을 어떻게 바라보는지 기술한 공식 메모리 모델이다.
+
+두개의 스레드가 하나의 객체를 참조할때 하나의 스레드가 해당 값을 바꾸면 어떻게 될까? → 상호 배타적 락은 코드가 동시에 실행되는 도중 객체가 손상는 현상을 막을 수 있지만, 실제 어플리케이션에 사용하려면 상당히 복잡해질 수 있다.
+
+---
+
+## 6. JVM 구현체 종류
+
+오라클이 제작한 핫스팟 이외에도 여러 자바 구현체가 있다.
+
+OpenJDK, Oracle, Zulu,..
+
+---
+
+## 7. JVM 모니터링 툴링
+
+JVM은 실행 중인 어플리케이션을 인스트루먼데이션, 모니터링, 관측하는 다양한 기술을 제공한다.
+
+- 자바 관리 확장 (JMX)
+- 자바 에이전트
+- JVM 툴 인터페이스 (JVMTI)
+- 서비서빌리티 에이전트 (SA)
+
+javac, java 등 잘 알려진 바이너리뿐 아니라 JDK에는 유용한 가외 툴이 많다.
+
+- VisualVM
+
+ : 넷빈즈 플랫폼 기반의 시각화 툴
diff --git a/ch03/5uhwann.md b/ch03/5uhwann.md
new file mode 100644
index 0000000..0299755
--- /dev/null
+++ b/ch03/5uhwann.md
@@ -0,0 +1,41 @@
+# Ch3. 하드웨어와 운영체제
+
+## 메모리
+### CPU 캐시
+- CPU에 있는 메모리 영역
+- 레지스터보다는 느리지만 메인 메모리보다는 빠름
+- 자주 엑세스하는 메모리 위치는 CPU가 메인 메모리를 재참조 하지 않게 사본을 CPU 캐시에 보관
+- 각 코어별 L1, L2 캐시, 모든 코어가 공유하는 클로벌 L3 캐시를 두어 최적화
+
+## 운영체제
+- 여러 실행 프로세스가 공유하는 리소스 엑세스를 관장(주로 메모리, CPU)
+
+### 스케줄러
+- 프로세스 스케줄러는 CPU 엑세스를 통제, 실행 큐 이용
+- OS는 특성상 CPU에서 코드가 실행되지 않는 시간을 유발, 따라서 실제 관측한 프로세스에서 나온 통계치는 다른 프로세스의 동작에도 영향을 받음 -> 측정 결과에 노이즈 생성
+- 스케줄러의 움직임을 확인하는 가장 쉬운 방법은 OS 스케줄링 과정에서 발생시킨 오버헤드를 관측하는 것
+
+### 시간 문제
+- OS는 저마다 타이밍이 다르게 작동한다.
+
+### 컨텍스트 교환
+- OS 스케줄러가 현재 실행 중인 스레드/태스크를 없애고 대기 중인 다른 스레드/태스크로 대체하는 프로세스
+- 스레드 실행 명령과 스택 상태를 교체하는 모든일에 연관
+- 유저 모드에서 커널 모드로의 교환 시 모든 OS의 모든 캐시가 무효화 되어 시스템 콜에 대한 비용이 가려짐
+ - 리눅스는 가상 동적 공유 객체(vDSO)를 통해 시스템 콜의 속도를 높여 커널 모드로 컨텍스트 교환을 하지 않음
+
+## 기본 감지 전략
+### CPU 사용률
+- CPU 사용률은 어플리케이션 성능을 나타내는 핵심 지표
+- CPU 효율성 상승은 성능 향상의 지름길
+- 어플리케이션 성능 분석 시에는 시스템에 충분한 부하를 가해 사용률을 간능한 한 100%에 가까워야 한다.
+- `vmstat`
+ - proc: 실행 가능(r) 블로킹된(b) 프로세스 개수 나타냄
+ - memory: 스왑 메모리(swpd), 미사용 메모리(free), 버퍼 사용 메모리(buff), 캐시 메모리(cache)
+ - cpu: 유저 시간(us), 커널 시간(sy), 유휴 시간(id), 대기 시간(wa), 도둑맞은 시간(st 가상 머신에 할애)에 대한 사용율 표기
+ - swap, io,, system
+- 성능 측정 결과 CPU 사용률이 100%에 근접하지 않았다면 그 원인을 따져봐야 한다.
+
+## 가비지 수집
+- GC는 유저 공간의 CPU 사이클을 소비하되 커널 공간의 사용률에는 영향을 미치지 않기 때문에, JVM 프로세스가 유저 공간에서 CPU를 100%에 가깝게 사용한다면, GC를 의심해야 한다.
+- GC 로깅은 데이터의 원천으로서의 가치가 높기 때문에 JVM 프로세스는 예외없이 GC로그를 남겨야 한다.
diff --git a/ch03/doxxx.md b/ch03/doxxx.md
new file mode 100644
index 0000000..22d2ce5
--- /dev/null
+++ b/ch03/doxxx.md
@@ -0,0 +1,110 @@
+# Ch3. 하드웨어와 운영체제
+
+## 3.1 최신 하드웨어 소개
+
+최신 컴퓨터 시스템은 다단계 캐시, 정교한 파이프라인, 상호 연결 및 기타 명확하지 않은 성능 특성으로 인해 매우 복잡합니다.
+
+알고리즘에 대한 O(n) 표기법과 같은 성능에 대한 고전적인 정신 모델은 이 복잡한 세상을 제대로 다루기에는 지나치게 단순한 경우가 많습니다.
+
+반면에 멘탈 모델은 그 자체로는 존재할 수 없으며 성능 카운터의 데이터와 같은 성능 측정값과 추적 정보에 의해 정보를 얻고 보정되어야 합니다. 최신 시스템에는 데이터를 수집하는 다양한 방법이 있으므로 구조화된
+방법론을 사용하여 중요한 정보에 집중하는 것이 중요합니다.
+
+[A Mental Model of CPU Performance](https://www.youtube.com/watch?v=qin-Eps3U_E)
+
+[Mental models for modern program tuning](https://www.youtube.com/watch?v=-Ynm2eHGAOU)
+
+## 3.2 메모리
+
+프로세서 코어의 데이터 수요를 메인 메모리의 데이터 공급이 충족시키지 못해 CPU는 대기해야 하는 상황이 발생했습니다.
+
+### 3.2.1 메모리 캐시
+
+레지스터보다는 느리지만 메인 메모리보다는 빠른 메모리 캐시가 도입되었습니다.
+
+덕분에 프로세서 처리율은 개선할 수 있었지만 메모리에 있는 데이터를 어떻게 캐시로 가져오고 캐시한 데이터를 어떻게 메모리에 다시 써야 하는가에 대한 고민이 생겼습니다.
+
+캐시 일관성 프로토콜을 통하여 이를 해결할 수 있었습니다.
+
+```java
+public class Caching {
+ private final int ARR_SIZE = 2 * 1024 * 1024;
+ private final int[] testData = new int[ARR_SIZE];
+
+ private void run() {
+ System.err.println("Start: " + System.currentTimeMillis());
+ for (int i = 0; i < 15_000; i++) {
+ touchEveryLine();
+ touchEveryItem();
+ }
+ System.err.println("Warmup Finished: " + System.currentTimeMillis());
+ System.err.println("Item Line");
+ for (int i = 0; i < 100; i++) {
+ long t0 = System.nanoTime();
+ touchEveryLine();
+ long t1 = System.nanoTime();
+ touchEveryItem();
+ long t2 = System.nanoTime();
+ long elItem = t2 - t1;
+ long elLine = t1 - t0;
+ double diff = elItem - elLine;
+ System.err.println(elItem + " " + elLine + " " + (100 * diff / elLine));
+ }
+ }
+
+ private void touchEveryItem() {
+ for (int i = 0; i < testData.length; i++) {
+ testData[i]++;
+ }
+ }
+
+ private void touchEveryLine() {
+ for (int i = 0; i < testData.length; i += 16) {
+ testData[i]++;
+ }
+ }
+
+ public static void main(String[] args) {
+ Caching c = new Caching();
+ c.run();
+ }
+}
+```
+
+CPU 캐시 효율성과 관련되어있는 것 같습니다.
+
+CPU 캐시라인은 대개 64바이트이고, 64바이트는 16개의 int를 담을 수 있습니다.
+
+즉, touchEveryLine() 메서드, touchEveryItem() 메서드 모두 캐시라인을 CPU 캐시에 로드하게 됩니다.
+
+따라서 성능 차이가 거의 없습니다.
+
+## 3.3 최신 프로세서의 특성
+
+### 3.3.1 변환 색인 버퍼(TLB)
+
+### 3.3.2 분기 예측과 추측 실행
+
+### 3.3.3 하드웨어 메모리 모델
+
+Java Memory Model은 weak model입니다.
+
+## 3.4 운영체제
+
+### 3.4.1 스케줄러
+
+green thread vs native thread
+
+geeksforgeeks의 글
+[Green vs Native Threads and Deprecated Methods in Java](https://www.geeksforgeeks.org/green-vs-native-threads-and-deprecated-methods-in-java/)
+
+
+
+
+
+### 3.4.2 시간 문제
+
+OS마다 시간을 측정하는 방법이 다릅니다.
+
+### 3.4.3 컨텍스트 교환
+
+vDSO와 같은 기술을 사용하여 컨텍스트 교환을 최적화할 수 있습니다.
diff --git a/ch03/img.png b/ch03/img.png
new file mode 100644
index 0000000..36fd163
Binary files /dev/null and b/ch03/img.png differ
diff --git a/ch03/img_1.png b/ch03/img_1.png
new file mode 100644
index 0000000..89cead9
Binary files /dev/null and b/ch03/img_1.png differ
diff --git a/ch03/lsj8367.md b/ch03/lsj8367.md
new file mode 100644
index 0000000..68ec10b
--- /dev/null
+++ b/ch03/lsj8367.md
@@ -0,0 +1,139 @@
+# 3장. 하드웨어와 운영체제
+
+# 메모리
+
+CPU 프로세서 코어 클럭 속도가 증가하니 메인 메모리를 맞추기 어려웠다.
+
+## 메모리 캐시
+
+CPU 캐시가 고안됐고, CPU 캐시는 CPU 내에 있는 메모리 영역이다.
+
+액세스 빈도가 높은 캐시일수록 프로세서 코어와 더 가까이 위치하게 여러 캐시계층이 존재한다.
+
+- L1 캐시
+ - CPU와 가장 가까운 캐시
+- L2 캐시
+- …
+
+각 실행코어에 L1, L2 전용 프라이빗 캐시를 두고, 일부나 전체가 공유하는 L3 캐시를 둔다.
+
+캐시라는 아키텍처를 추가하여 프로세서 처리율은 개선했지만. 메모리 데이터를 캐시로 어떻게 가져오고, 갱신은 어떻게 하는지를 결정해야 했다.
+
+이 문제는 `캐시 일관성 프로토콜` 이라는 방법으로 해결한다.
+
+> MESI프로토콜
+>
+- Modified(수정)
+ - 데이터가 수정된 상태
+- Exclusive(배타)
+ - 이 캐시에만 존재하고 메인 메모리 내용과 동일한 상태
+- Shared(공유)
+ - 둘 이상의 캐시에 데이터가 들어있고 메모리 내용과 동일한 상태
+- Invalid(무효)
+ - 다른 프로세스가 데이터를 수정하여 무효한 상태
+
+캐시기술덕에 데이터를 메모리에서 쓰고 읽을 수 있게 됐다.
+
+이론상 가능한 최대 전송률은 아래 인자들에 따라 달라진다.
+
+- 메모리 클록 주파수
+- 메모리 버스 폭(보통 64비트)
+- 인터페이스 개수(대부분 2개)
+
+## 최신 프로세스의 특성
+
+### 변환 색인 버퍼(Translation Lookaside Buffer)
+
+캐시에서 아주 요긴하게 쓰이는 장치
+
+가상 메모리 주소를 물리 메모리 주소로 매핑하는 페이지 테이블의 캐시 역할
+
+### 분기 예측과 추측 실행
+
+분기 예측은 고급 기법중 1개로 프로세서가 조건 분기하는 기준값을 평가하느라 대기하는 현상을 방지한다.
+
+# 운영체제
+
+여러 실행 프로세스가 공유하는 리소스 액세스를 관장하는 일
+
+메모리 관리 유닛을 통한 가상 주소방식과 페이지 테이블은 메모리 액세스 제어의 핵심이며, 한 프로세스가 소유한 영역을 다른 프로세스가 함부로 훼손하지 못하게한다.
+
+## 스케줄러
+
+프로세스 스케줄러는 CPU 액세스를 통제한다. 실행 큐라는 큐를 이용한다.
+
+스케줄러는 인터럽트에 응답하며 CPU 코어 액세스를 관리한다.
+
+자바 명세서에는 이론적으로 자바 스레드가 굳이 OS스레드와 일치할 필요 없는 스레딩 모델을 허용한다고 하지만, 실제론 이런 방식이 유용하지 않다는 사실이 밝혀져 배제되었다.
+
+## 시간문제
+
+POSIX 같은 업계 표준이 있어도 OS는 다르게 동작한다.
+
+호스트 OS가 제공하는 기능이라 네이티브 메소드로 구현된다.
+
+## 컨텍스트 스위칭
+
+OS 스케줄러가 현재 실행중인 스레드를 없애고 대기중인 다른 스레드로 대체하는 프로세스
+
+유저 스레드 사이에서든, 유저 ↔ 커널에서든 컨텍스트 스위칭은 비ㅛㅇ이 비싸다.
+
+유저 커널간 모드 변경이 더 비싸다.
+
+커널모드로 컨텍스트가 변경되면 이전의 TLB 및 다른 캐시도 무효화된다.
+
+# 기본 감지 전략
+
+애플리케이션이 잘 작동하고 있다는 것은, CPU, 메모리, 네트워크, I/O 대역폭 등 시스템 리소스를 효율적으로 잘 이용하고 있다는 뜻이다.
+
+## CPU 사용률
+
+CPU 사용률은 애플리케이션 성능을 나타내는 핵심지표이다.
+
+CPU 사이클은 애플리케이션이 가장 갈증을 잘 느끼는 리소스이기에 CPU의 효율적인 사용은 성능 향상의 지름길이다.
+
+부하가 집중된다면 사용률이 100%에 가까워야 한다.
+
+## 가비지 수집
+
+어떤 JVM 프로세스가 유저 공간에서 CPU를 100%에 가깝게 사용중이라면 GC를 의심해야 한다.
+
+JVM에서 GC 로깅은 공짜나 다름없고, 분석용 데이터로 가치가 높기에 운영환경에서는 꼭 GC로그를 남겨야한다.
+
+## 입출력
+
+자바 프로그램은 단순한 I/O만 처리하며 I/O 서브시스템을 심하게 가동하는 애플리케이션 클래스도 비교적 적은편이다.
+
+그러면서 동시에 CPU, 메모리 어느 한쪽과 I/O를 동시에 고갈시키는 애플리케이션은 거의 없다.
+
+### 커널 바이패스 I/O
+
+커널을 이용해 데이터를 복사하여 유저 공간에 넣는 고성능 애플리케이션
+
+커널 대신 네트워크 카드에서 유저가 접근가능한 영역으로 데이터를 매핑하는 전용 하드/소프트웨어를 사용함.
+
+이는 자바가 구현한게 없어서 네이티브 라이브러리를 사용하여야 한다.
+
+## 기계 공감
+
+JVM이 하드웨어를 추상화했고 JVM이 무엇인지, 상호작용은 어떻게 하는지들을 이해해야 한다.
+
+어느 것이 발생할 수 있는지를 염두에 둬야 해결 방법을 빠르게 찾아볼 수 있다.
+
+# 가상화
+
+가상화의 특징
+
+- 가상화OS에서 실행하는 프로그램은 베어메탈에서 실행할 때와 동일하게 작동해야 한다.
+- 하이퍼바이저는 모든 하드웨어 리소스 액세스를 조정해야 한다.
+- 가상화 오버헤드는 가급적 작아야 하며 실행 시간의 상당 부분을 차지해선 안된다.
+
+# JVM과 운영체제
+
+JVM은 자바 코드에 공용 인터페이스를 제공하여 OS에 독립적인 실행환경을 제공한다.
+
+스레드 스케줄링같은 기본적인 것도 OS에 반드시 액세스해야한다.
+
+native 메소드는 C언어로 작성되지만, 자바 메소드처럼 액세스가 가능하다.
+
+이러한 공통 인터페이스를 `자바 네이티브 인터페이스(JNI)` 라고 한다.
diff --git a/ch03/yoojeong.md b/ch03/yoojeong.md
new file mode 100644
index 0000000..f820a30
--- /dev/null
+++ b/ch03/yoojeong.md
@@ -0,0 +1,7 @@
+
+### 메모리
+- 무어의 법칙에 따라 개수가 급증한 트랜지스터는 clock speed 를 높이는데 쓰였다.
+- 하지만 프로세서 코어의 데이터 수요를 main memory 가 맞추기 어려워졌다.
+- 결국 연산 속도(clock 수)가 올라가도 데이터가 오길 기다려야 하니 CPU는 놀게 되었다.
+
+#### 메모리 캐시
diff --git a/ch03/youjin.md b/ch03/youjin.md
new file mode 100644
index 0000000..d9a50fb
--- /dev/null
+++ b/ch03/youjin.md
@@ -0,0 +1,93 @@
+# Chapter3 - 하드웨어와 운영체제
+< 최적화 이해에 필요한 HW와 OS 지식 기본 >
+* 성능을 고민하는 개발자에겐 가용 리소스를 최대한 활용할 수 있도록 자바 플랫폼의 근간 원리와 기술을 알고 있어야 한다
+
+## Memory
+
+
+
+(출처: 에브리타임)
+
+트랜지스터 개수 증가
+➡️ 클록 속도 향상(초당 더 많은 명령어 처리 가능)
+➡️ 클록속도 만큼 데이터도 빨리 움직여야 하는데 메모리가 이 속도를 맞추기 어렵다💥
+➡️ 데이터 도착 전 까지 CPU는 노는중 🤸🏻
+
+### Memory Cache
+* CPU Cache이다 (CPU에 있는 메모리 영역)
+* 자주 access하는 데이터는 CPU cache에 보관한다
+➡️ access 빈도가 높을수록 processor core(cpu)에 더 가까이 위치시킨다
+
+**따라서 CPU에 가장 가까운 cache가 L1 cache, 그 다음은 L2 cache**
+
+
+(출처: https://it.donga.com/215/)
+
+### Cache 일관성 프로토콜
+Memory Data ↔️ Cache Data 어떻게 맞추지?
+원래는 `write-through` (동시기록) 방법을 사용했다
+> write-through란, 매번 cache 연산 결과를 memory에 기록하는 것
+➡️ 메모리 대역폭을 너무 많이 소요. 현재 거의 안씀
+
+현재는 `write-back` 방법을 사용한다
+> write-back이란, 매번 dirty cache 블록만 memory에 기록
+➡️ 메인 메모리 traffic이 확 줄어든다
+
+## Processor (CPU)
+### TLB
+* 가상 메모리 주소를 물리 메모리 주소로 매핑하는 속도를 높이기 위해 사용되는 cache
+
+> 가상 메모리는 실제 물리적 메모리(RAM)의 한 부분을 사용하는 것이 아니라, 컴퓨터의 하드 드라이브나 SSD와 같은 보조 저장 장치의 일부를 실제 메모리처럼 사용하는 기술
+
+CPU가 가상 주소를 가지고 메모리에 접근하려고 할 때 우선은 TLB에 접근하여 가상 주소에 해당되는 물리 주소를 찾는다
+
+* 참고
+ * https://ahnanne.tistory.com/15
+ * https://about-myeong.tistory.com/35
+
+### 분기 예측과 추측 실행
+
+(출처: https://rmagur1203.tistory.com/17)
+
+### 하드웨어 메모리 모델
+서로 다른 여러 CPU(멀티코어)가 일관되게 동일한 메모리 주소를 access 할 수 있는 방법?
+➡️ JIT compiler인 javac, CPU는 일반적으로 코드 실행 순서를 바꿀 수 있다
+
+
+(메모리 일관성과 코드 실행 순서 바꾸는 것이 어떤 관련이 있는지 아직 잘 이해가 안됨... ➡️ 책 뒷부분에서 다시 한번 설명을 한다고 하니 그때 이해해보려고 함)
+
+## OS
+OS의 주 임무는 여러 실행 process가 공유하는 리소스 access를 관장하는 일.
+➡️ 한정된 리소스를 process에게 골고루 나눠주기
+
+### MMU
+가상주소를 물리주소로 변환한다
+위에서 설명한 TLB 캐시가 들어있다
+
+### Process Scheduler
+CPU access를 통제한다
+실행 Queue에 실행대상인 process/thread가 대기하고 있다.
+실행 중인 process가 있는데 인터럽트 발생 시(혹은 I/O 요청 등으로 인해 Block 상태가 되면), 실행 Queue에 있는 process/thread를 실행시킨다.
+
+### Context Switch
+Context Switch는 OS의 Process Scheduler가 현재 실행 중인 process를 중지하고 다른 process를 실행시킬 때 발생
+➡️ 비싼 작업이다 (오버헤드가 크다)
+
+Context Switch 교환 시, TLB를 비롯한 다른 Cache들이 무효화 된다.
+
+## 성능 핵심 지표 찾기
+### CPU 사용률
+``` shell
+$vmstat 1 # 1초마다 한번씩 상태 결과 표시
+```
+* 결과보는 법(참고): https://chloro.tistory.com/108
+
+## JVM과 OS
+JVM에서 OS에 반드시 access해야 하는 경우가 있다(시스템 클록에서 시간 정보를 얻는 작업, thread scheduling 등)
+➡️ `native` 키워드를 붙인 native 메서드로 구현
+➡️ native 메서드는 C언어로 구현하지만, 여느 Java 메서드 처럼 액세스 가능
+➡️ 어떻게? `JNI(Java Native Interface)`가 처리
+
+
+
+(출처: https://velog.io/@vrooming13/JNI-JAVA-Native-Interface)
diff --git a/ch03/youngji.md b/ch03/youngji.md
new file mode 100644
index 0000000..2af26e7
--- /dev/null
+++ b/ch03/youngji.md
@@ -0,0 +1,148 @@
+# 3장 - 하드웨어와 운영체제
+
+> 오랬동안 컴퓨터업계는 무어의 법칙대로 흘러갔다.
+그 결과, 소프트웨어는 강력한 파워를 자유자재로 구사할 정도로 발전했음에도, 성능 향상을 꾀하려면 복잡한 기반 기술에 의지 할 수 밖에 없게 되었다.
+이번 장에서 최신 하드웨어와 OS에 관해 빠르게 훑어보자.
+>
+
+---
+
+## 1. 최신 하드웨어 소개
+
+아직도 많은 수업에서 CPU에 실제로 일어나는 일을 시키는 C프로그래밍이야 말로 진리의 원천인양 강조하는 편이지만 요즘은 이러한 생각은 맞지 않다.
+
+1990년대 이후, 대부분 하드웨어는 인텔 x86/x64 아키텍처 위주로 돌아갔다.
+
+이제 프로세서 작동 원리를 단순화한 멘탈 모델(정신 모형)은 전혀 맞지 않고 그런 모델을 토대로 직관적인 추론을 하면 완전히 생뚱맞은 결론을 내리기 쉽습니다
+
+---
+
+## 2. 메모리
+
+요즘 자바 개발자에게 가장 중요한 메모리를 살펴보자.
+
+무어의 법칙에 따라 급증한 트랜지스터는 클록 속도를 높이는데 쓰였다. 클록 속도의 증가로 초당 더 많은 명령어를 처리할 수 있게 되었지만 시간이 갈수록 프로세서 코어의 데이터 수요를 메모리가 따라가 어려워 졌다.
+
+*4.77MHz(최초의 IBM PC칩) → 2GHz*
+
+클록 속도가 올라가도 데이터가 도착할 때까지 CPU는 놀면서 기다려야 하니 아무 소용 없게 됐다.
+
+- 메모리 캐시
+
+ CPU 캐시는 CPU에 있는 메모리 영역이다. 레지스터보다는 느리지만 메인 메모리 보다 훨씬 빠르다.
+
+ 액세스 빈도가 높은 캐시일수록 프로세서 코어와 더 가까이 위치하는 식으로 여러 캐시 계층이 있다.
+
+ 클록 속도와 액세스 시간 차이를 줄이기 위해 최신 CPU는 캐시에많은 예산을 투자한다.
+
+ 메모리에 있는 데이터를 어떻게 처리하고 어떻게 메모리에 다시 써야할지 결정하기위해 **캐시 일관성 프로토콜**이라는 방법을 사용한다.
+
+
+---
+
+## 3. 최신 프로세서의 특성
+
+메모리 캐시는 증가하는 트랜지스터를 확실하게 활용하는 주요 부분이지만, 수년간 여러 다른 기술도 등장했다.
+
+- 변환 색인 버퍼 (TLB)
+
+ 가상 메모리 주소를 물리 메모리 주소로 매핑하는 페이지 테이블의 캐시 역할을 수행한다. 덕분에 가상 주소를 참조해 물리 주소에 액세스하는 빈번한 작업 속도가 매우 빨라진다.
+
+ TLB가 없으면 캐시에 페이지 테이블이 있어도 가상 주소 룩업에 16사이클이나 걸리기 때문에 성능이 재대로 나오지 않는다.
+
+- 분기 예측과 추측 실행
+
+ 분기 예측은 프로세서가 조건 분기하는 기준값을 평가하느라 대기하는 현상을 방지한다. 최신 프로세서는 다단계 명령 파이프 라인을 사용하는데, 이런 모델은 선행되는 조건문을 다 평가하기 전까지 다음 명령을 알 수 없다. 그 결과 분기 뒤에 나오는 다단계 파이프라인을 비우는 동안 프로세서는 여러 사이클 동안 멎게 된다.
+
+ 이런일이 없도록 프로세스는 트랜지스터를 다양하게 활용해 가장 발생 가능성이 큰 브랜치를 미리 결정하는 휴리스틱을 형성한다. 추측이 맞아 떨어지면 좋지만, 예측이 틀릴경우 부분적으로 실행한 명령을 모두 폐기한 후 파이프라인을 비우는 대가를 치룬다.
+
+- 하드웨어 메모리 모델
+
+ 멀티코어 시스템에서 서로 다른 여러 CPU가 일관되게 동일한 메모리 주소를 액세스 할 수 있을까.
+
+ JMM은 프로세서 타입별로 상이한 메모리 액세스 일관성을 고려하여 명시적으로 *약한 모델*로 설계되었다. 따라서 멀티스레드 코드가 제대로 작동하게 하려면 락과 volatile(휘발성)을 적확히 알고 사용해야한다.
+
+
+---
+
+## 4. 운영체제
+
+OS의 주 임무는 여러 실행 프로세스가 공유하는 리소스 액세스를 관장한다. 한정된 리소스 가운데서도 메모리와 CPU 시간을 가장 중요한 리소스라고 할 수 있다.
+
+- 스케줄러
+
+ 프로세스 스케줄러는 CPU 엑세스를 통제한다. 이때 실행 큐를 이용하여 실행 대상을 관리하며 인터럽트에 응답하고 CPU 코어 엑세스를 관리한다.
+
+ 자바 명세서에 이론적으로 자바 스레드가 굳이 OS 스레드와 일치할 필요 없는 스레딩 모델(그린 스레드)을 허용하지만, 실제로 이런 방식은 유용하지 않아 주류에서 배재되었다.
+
+ OS 특성상 CPU에 코드가 실행되지 않는 시간을 유발한다. 코드가 정작 실행되는 시간 보다 기다리는 시간이 더 많다는 뜻이다. 때문에 실제로 관측한 프로세스는 지터(불안전한 신호)와 스케줄링 오버헤드로 인해 노이즈가 발생한다.
+
+ 아래 코드로 스케줄링 오버헤드가 얼마나 될지 짐작할 수 있다.
+
+ ```java
+ long start = System.currentTimeMillis();
+ for (int i = 0; i < 1_000; i++) {
+ Thread.sleep(1);
+ }
+ long end = System.currentTimeMillis();
+ System.out.println("Millis elapsed: " + (end - start) / 4000.0);
+ ```
+
+
+- 컨텍스트 교환
+
+ 컨텍스트 교환은 OS 스케줄러가 현재 실행 중인 스레드/태스크를 없애고 대기 중인 다른 작업을 대체하는 프로세스이다.
+
+ 유저 스레드 사이에 발생하든, 유저와 커널모드 사이에 발생하든 컨텍스트 교환은 비싼 작업이다. 특히 후자의 경우 유저의 공간과 커널 코드가 공유하는 부분이 거의 없기때문에 모드가 바뀌면 명령어와 TLB를 비롯한 다른 캐시를 모두 비워야한다.
+
+
+---
+
+## 5. 단순 시스템 모델
+
+유닉스 계열 OS에서 작동하는 애플리케이션의 단순 개념 모델
+
+- 애플리케이션이 실행되는 하드웨어와 OS
+- 애플리케이션이 실행되는 JVM/컨테이너
+- 애플리케이션 코드 자체
+- 애플리케이션을 호출하는 외부 시스템
+- 애플리케이션으로 유입되는 트래픽
+
+이 중 누구라도 성능 문제를 일으킬 수 있다.
+
+---
+
+## 6. 기본 감지 전략
+
+애플리케이션이 잘 돌아간다는 것은 CPU 사용량, 메모리, 네트워크, IO 대역폭 등 시스템 리소스를 효율적으로 잘 이용하고 있다는 뜻이다.
+
+성능 진단에 앞서 부족한 리소스가 뭔지 파악해악하고 튜닝 해야하지만 OS 자체가 시스템을 지치게 하는 원흉이 되어서도 안된다.
+
+- CPU 사용률
+
+ 애플리케이션 성능을 나타내는 핵심 지표. 부하가 집중되는 도중에는 사용률이 가능한 100%에 가까워야한다.
+
+ 유닉스 계열 OS에 `vmstat`, `iostat`와 같은 기본 툴을 사용하면 현재 가상 메모리 및 IO 서브시스템 상태 관리 데이터를 제공한다.
+
+- 가비자 수집
+
+ 핫스팟 JVM은 시작 시 메모리를 유저 공간에 할당/관리한다. 그래서 운영 도중 메모리를 할당하는 시스템 콜을 할 필요가 없다. 즉, 가비지 수집을 위해 커널을 교환하는 일은 거의 없다.
+
+ 때문에 어떤 JVM 프로세스가 유저 공간에서 CPU를 100% 가까이 사용하고있다면 GC를 의심해봐야한다.
+
+- 입출력
+
+ 파일 IO는 예로부터 전체 시스템 성능에 암적인 존재이다. 물리적 하드웨어와 밀접한 연관이 있기도 하지만 다른 OS 파트처럼 분명하게 추상화되어 있지 않다.
+
+ - 커널 바이패스 I/O
+
+ 커널을 이용해 데이터를 복사해 유저 공간에 넣는 작업으로 상당히 비싼 고성능 애플리케이션이 있다. 그래서 커널 대신 직접 네트워크 카드에서 유저가 접근 가능한 영역으로 데이터를 매핑하는 전용 하드웨어/소프트웨어를 쓴다.
+
+
+---
+
+## 7. 가상화
+
+이미 실행 중인 다른 OS 위에 OS 사본을 하나의 프로세스로 실행시키는 모양새.
+
+가상화 시스템에서는 게스트 OS가 하드웨어를 직접 액세스할수 없어 대게 명령어를 언프리빌리지드(비특권) 명령어로 고쳐쓴다. 커널의 자료구조를 섀도하여 컨텍스트 교환이 발생할때 지나친 캐시 플러시가 일어나지 않지만, 가상 환경 내에서 프로그램을 실행한다는 것 자체가 성능 분석 및 튜닝을 한층 복잡하게 만든다.
diff --git a/ch04/5uhwann.md b/ch04/5uhwann.md
new file mode 100644
index 0000000..bb02157
--- /dev/null
+++ b/ch04/5uhwann.md
@@ -0,0 +1,61 @@
+# 성능 테스트 패턴 및 안티패턴
+
+**성능 테스트 기획 Tip**
+- 테스트로 확인하고 싶은 정략적 질문 리스트와 그 테스트가 대상 어플리케이션 입장에서 중요한 이유를 작성해보기
+
+## **성능 테스트 종류**
+- 지연테스트(Latency Test) - 종단 트랜잭션에 걸리는 시간은?
+ - 가장 일반적인 성능 테스트
+ - 유저 경험을 직접적으로 개선하기 위해 지연 튜닝 시행
+ - 단순 측정 평균값은 어플리케이션의 요청 응답성을 측정하는 지표로는 효용서이 없음
+
+- 처리율 테스트(Throughput test) - 현재 시스템이 처리 가능한 동시 트랜잭션 개수는?
+ - 지연 테스트 수행 시 진행 중인 동시 트랜잭션을 반드시 명시, 제어 헤야 한다.
+ - 지연을 모니터링 하면서 테스트
+ - 지연 분포가 갑자기 변하는 변곡점이 시스템의 '최대 처리율'
+ - 시스템 성능이 급락하기 직전, 최대 처리율 수치를 측정하는 것이 목표
+
+- 부하 테스트(Load test) - 특정 부하를 시스템이 감당할 수 있는가?
+ - 시스템이 특정 부하를 견딜 수 있는지 yes or no를 확인하는 테스트
+ - 예상되는 트래픽을 대비하기 위해 테스트 수행
+
+- 스트레스 테스트(Stress test) - 이 시스템의 한계점(breaking point)은 어디까지인가?
+ - 시스템의 여력이 어느 정도인지 확인하는 수단
+ - 일정 수준의 트랜잭션(최대 처리율)을 시스템에 계속 부여, 시스템 성능이 저하되는 시점 바로 직전을 최대 처리율로 확인
+
+- 내구성 테스트(Endurance test) - 시스템을 장시간 실행할 경우 성능 이상 증상이 나타나는가?
+ - 메모리 누수, 캐시 오염, 메모리 단편화 등 시간이 지나고 나서야 드러나는 문제를 감지하기 위한 테스트
+ - 평균 사용률로 시스템에 일정 부하를 주어 모니터링하여 갑자기 리소스가 고갈되거나 시스템이 깨지는 지점 확인
+ - 빠른 응답을 요구하는(지연이 낮은) 시스템에서 주로 사용
+
+- 용량 계획 테스트(Capacity planning test) - 리소스를 추가한 만큼 시스템이 확장되는가?
+ - 업그레이드한 시스템이 어느 정도 부하를 감당할 수 있을지 미리 확인
+ - 특정 이벤트나 위협 요소에 대응하는 것이 아닌, 예정된 계획의 일부로 시행
+
+- 저하 테스트(Degradation) - 시스템이 부분적으로 실패할 경우 어떤 일이 벌어지는가?
+ - 부분 실패 테스트라고도 한다.
+ - 트랜잭션 지연 분포와 처리율을 눈여겨 보아야 함
+ - 카오스 멍키: 복원성 있는 아키텍처는 어느 한 컴포넌트에 문제가 생기더라도 다른 컴포넌트까지 연쇄적으로 문제를 전파해 시스템에 부정적 영향을 끼쳐서는 안된다.
+ - 운영 환경에 떠있는 라이브 프로세스를 하나씩 랜덤하게 죽이면서 검증
+ - 조직 차원에서 시스템 위성, 서비스 설계, 운영 탁월성을 최고 수준으로 확보해야 함
+
+## 성능 테스트 기본 베스트 프랙티스
+성능 튜닝 시 지켜야 할 3가지 원칙
+1. 나의 관심사가 무엇인지 식별하고 그 측정 방법을 고민
+2. 최적화하기 용이한 부분이 아니라, 중요한 부분을 최적화
+3. 중요한 관심사를 먼저 다룬다.
+
+### 하향식 성능(전체 어플리케이션 성능 부터 확인)
+- 자바 어플리케이션은 대규모 벤치마킹이 작은 코드 섹션 별 수치 확인보다 쉬움
+- 테스트 환경을 구축하여 무엇을 측정하고 무엇을 최적화 할지, 전체 소프트웨어 개발 주기에 어떻게 병행할지 명확히 이해해야 함
+
+### 테스트 환경 구축
+- 가급적 모든 면에서 운영환경과 똑같이 복제
+ - 어플리케이션 서버 뿐만 아니라 웹 서버, DB, 로드 밸랜서, 네트워크 방어벽 등
+
+### 성능 요건 식별
+- 성능을 평가하는 지표는 코드 관점에선 생각하는 것이 아니라 시스템을 전체적으로 바라보고 고객과 경영진에게 중요한 측정값을 제공해야 한다.
+- 이해관계자들의 논의가 필요
+
+## 성능 안티패턴
+성능 튜닝은 항상 초기 기획 단계부터 구체적으로 목표를 정해놓고 시작해야 한다.
diff --git a/ch04/doxxx.md b/ch04/doxxx.md
new file mode 100644
index 0000000..9c9e1d2
--- /dev/null
+++ b/ch04/doxxx.md
@@ -0,0 +1,57 @@
+# Ch.04성능 테스트 패턴 및 안티패턴
+
+## 성능 테스트 유형
+
+좋은 성능 테스트는 정량적입니다.
+
+### 지연 테스트(Latency Test)
+
+> 종단 트랜잭션에 걸리는 시간을 측정하는 테스트
+
+고객이 트랜잭션 (또는 페이지 로딩)을 얼마나 오래 기다려야 하는지를 측정합니다.
+
+유저 경험과 관련되어 있습니다.
+
+### 처리율 테스트(Throughput Test)
+
+> 현재 시스템이 처리 가능한 동시 트랜잭션의 수를 측정하는 테스트
+
+지연 테스트를 진행할 때는 동시에 어느 정도 수준의 처리율을 유지했는지를 기술합니다.
+
+레이턴시를 모니터링하면서 처리율을 측정합니다. 레이턴시의 분포가 변화하는 한계점을 '최대 처리율'이라고 합니다.
+
+### 부하 테스트(Load Test)
+
+> 특정 부하를 시스템이 감당할 수 있는지를 측정하는 테스트
+
+부하 테스트는 시스템이 어느 정도의 부하를 감당할 수 있는지를 측정합니다.
+
+신규 고객 유입이나 특정 이벤트가 발생했을 때 시스템이 어떻게 반응하는지를 측정합니다.
+
+### 스트레스 테스트(Stress Test)
+
+> 시스템의 한계를 측정하는 테스트입니다.
+
+일정한 수준의 트랜잭션, 특정 처리율을 시스템에 계속 걸어줍니다.
+
+시간이 갈수록 동시 트랜잭션이 증가하고 시스템 성능이 저하되는 최대 처리율 지점을 찾습니다.
+
+### 내구 테스트(Endurance Test)
+
+> 시스템을 장기간 실행할 경우 어떻게 반응하는지를 측정하는 테스트입니다.
+
+평균(이상)의 사용률로 시스템에 일정 부하를 주며 모니터링합니다.
+
+리소스가 고갈되거나 시스템이 깨지는 지점을 찾습니다.
+
+### 용량 계획 테스트(Capacity Planning Test)
+
+> 리소스를 추가한 만큼 시스템이 확장되는지를 측정하는 테스트입니다.
+
+업그레이드한 시스템이 기존 시스템보다 얼마나 더 많은 트랜잭션을 처리할 수 있는지를 측정합니다.
+
+### 저하 테스트(Degradation Test)
+
+> 시스템이 부분적으로 실패할 경우 어떻게 반응하는지를 측정하는 테스트입니다.
+
+# 안되면 조상 탓하자
\ No newline at end of file
diff --git a/ch04/seungjae.md b/ch04/seungjae.md
new file mode 100644
index 0000000..cf6e3e6
--- /dev/null
+++ b/ch04/seungjae.md
@@ -0,0 +1,233 @@
+# 4장. 성능 테스트 패턴 및 안티패턴
+
+# 4.1 성능 테스트 유형
+
+테스트를 할 때에는 해당 도메인을 생각해야한다.
+
+## 4.1.1 지연테스트
+
+가장 일반적인 성능 테스트
+
+고객이 트랜잭션 처리를 얼마나 기다려야 하는지를 테스트하는 기법.
+
+## 4.1.2 처리율 테스트
+
+지연테스트 다음으로 일반적인 테스트
+
+상황에 따라 처리율은 지연과 동등한 개념을 가질 수 있다.
+
+지연 분포가 갑자기 변하는 시점(한계점 or 변곡점)이 `최대 처리율` 이다.
+
+## 4.1.3 부하 테스트
+
+처리율 테스트와는 조금 다르고
+
+이정도의 부하를 견딜 수 있을까? 를 테스트하는 기법이다.
+
+서비스로 생각하면 어떤 선착순 이벤트 같은 것들을 처리할 때 테스트해볼 수 있을 것 같다.
+
+## 4.1.4 스트레스 테스트
+
+시스템 여력이 어느정도인지 알기위한 테스트
+
+어떤 고정된양의 트래픽을 정해두고 지속적으로 요청을 했을 때 동시 트랜잭션이 증가하고, 시스템 성능이 저하되는 시점을 추적한다.
+
+→ 이 부분이 최대처리율
+
+## 4.1.5 내구 테스트
+
+메모리 누수, 캐시 오염, 메모리 단편화(CMF Concurrent Mode Failure) 등
+
+시간이 한참 지나고 나서 드러나는 문제점들을 이 테스트로 감지한다.
+
+평균적으로 사용하는 부하를 계속해서 주고, 리소스가 고갈되거나 깨지는 지점을 찾는다.
+
+빠른 응답을 요구하는 시스템에서 많이 사용하는 기법이다.
+
+## 4.1.6 용량 계획 테스트
+
+스트레스 테스트와 여러모로 비슷하지만, 차이점이 있다.
+
+> 차이점
+>
+- 스트레스테스트
+ - 현재 시스템이 어느정도 부하를 버틸 수 있는지 테스트
+- 용량 계획 테스트
+ - 업그레이드한 시스템이 어느정도 부하를 감당할 수 있을까? 를 측정하는 테스트
+
+이벤트처럼 단발성 기능에 대한 테스트가 아니다.
+
+## 4.1.7 저하 테스트
+
+부분 실패 테스트라고도 한다.
+
+failover 대책이 잘 잡혀있는 환경에서 수행해볼 수 있는 테스트이다.
+
+책에서는 복원테스트를 생각하면 된다.
+
+→ 시스템이 기능을 잘 수행하다가, 갑자기 능력치가 떨어지는 시점에 생기는 일들을 확인한다.
+
+### 눈여겨 봐야할 점
+
+- 트랜잭션 지연 분포
+- 처리율
+
+> 카오스 멍키
+>
+
+부분 실패 테스트 중 하위 유형
+
+복원성이 강한 아키텍처에서는 한 컴포넌트가 잘못되어도 다른 컴포넌트까지 장애전파를 하는일이 없어야하는 것을 말한다. → MSA 장애전파
+
+카오스 멍키는 실제 운영환경에 있는 라이브 프로세스를 하나씩 죽이면서 검증한다.
+
+# 4.2 기본 베스트 프랙티스
+
+성능 튜닝시 3가지 기본 원칙에 따라 결정한다.
+
+1. 나의 관심사 식별 및 측정 방법을 고민
+2. 최적화하기 용이한 부분이 아니라, 중요한 부분을 최적화한다.
+3. 중요한 관심사를 먼저 다룬다.
+
+## 4.2.1 하향식 성능
+
+자바 애플리케이션을 대규모 벤치마킹하는 일이 코드 섹션별로 정확하게 수칠르 얻는것보다 쉽다.
+
+하향식 성능 접근 방식으로 성과를 극대화하기 위해서는 테스트팀이 테스트 환경을 구축
+
+성능 활동을 전체 소프트웨어 개발 주기에서 어떻게 병행해야 하는지
+
+전체 팀원이 명확하게 이해
+
+## 4.2.2 테스트 환경 구축
+
+성능 테스트팀이 가장 먼저 할 일
+
+가급적 모든 면에서 운영환경과 똑같이 복제해야 한다.
+
+(서버, DB, 로드밸런서, 방화벽 등)
+
+→ 운영환경에 존재하는 개인정보나 옮길 수 없는 공인인증서 같은 데이터는 어떻게 처리해야할까?
+
+클라우드 환경으로 변화했어도 테스트 환경을 구축하는 프로세스는 무조건적으로 수립해야 할 것이다.
+
+## 4.2.3 성능 요건 식별
+
+전체 시스템 성능은 OS, 하드웨어까지 고려가 되어야 한다.
+
+코드 관점에서만 성능을 평가해서도 안되고, 전체적으로 바라보면서 측정값을 고려해주어야 한다.
+
+이렇게 최적화하는 지표를 성능 비기능 요건이라고 한다.
+
+## 4.2.4 자바의 특정이슈
+
+JIT 컴파일은 중요한 부분.
+
+최신의 JVM은 어떤 메소드를 JIT 컴파일해서 최적화한 기계어로 변환할지 분석한다.
+
+JIT 컴파일을 안하기로 결정된 메소드종류
+
+- JIT 컴파일 할정도로 자주 실행되는 메소드가 아니다.
+- 메소드가 너무 크고 복잡해서 컴파일 분석을 할 수 없다.
+
+## 4.2.5 SDLC 일부로 성능 테스트 수행하기
+
+SDLC(Software Development LifeCycle)의 일부로 성능테스트를 수행
+
+특히 성능 회귀 테스트를 상시 수행하는 편이다.
+
+어느 시점에 어떤 버전코드로 성능 테스트 환경에 배포할지를 개발팀과 인프라팀이 협의해서 결정한다.
+
+→ 이는 너무 최상의 프랙티스이다.
+
+# 4.3 성능 안티패턴 개요
+
+성능 튜닝은 초기 기획단계부터 구체적으로 목표를 정해놓고 시작하는 목표지향 프로세스로 접근해야 한다.
+
+그리고 팀이 심한 일정 압박을 받고있거나 상식적으로 일 처리가 되지 않는 환경이라면 중도 실패할 가능성이 크다.
+
+새로운 기능을 오픈할 때 예측하지 못한 사고가 있을 수 있는데, 이를 인수테스트 도중 발견했다면 다행이지만, 배포 이후에 사고가 터지는 경우를 많이 경험했다.
+
+→ 이렇게 되는 것은 성능 테스트를 1회도 수행하지 않았거나 팀 일원중 하나가 온갖 추측만하고 도망간 경우들이 이 케이스에 해당할 수 있다.
+
+팀원간에 활발한 의사소통이 일어나지 않는다면 해당 케이스에 말려들 가능성이 높다.
+
+아래부터는 개발자가 잘못된 기술 선택을 하는 경우에 대한 케이스들이다.
+
+## 4.3.1 지루함
+
+개발자 대부분이 자기 역할에 지루함을 느끼고 새롭게 도전적인 일들을 찾아 같은 회사 또는 다른 곳으로 떠나려고 하는 사람들이 있다.
+
+개발자의 지루함이 단순한 유틸 메소드 한줄이면 될 것을 요상한 알고리즘을 통해 구현하여 필요 이상으로 코딩하는 개발자가 있다. 뿐만 아니라 알려지지 않은 기술로 컴포넌트 제작 및 맞지도 않는 유즈케이스를 도입하여 기술을 욱여넣는 것들도 포함된다.
+
+## 4.3.2 이력서 부풀리기
+
+이력서를 과대 포장할 구실을 찾는 개발자
+
+내 연봉과 몸값을 어떻게 높일 수 있을까? 를 시작으로 불필요한 기술을 붙인경우는 이 사람이 이직한 이후 오랫동안 시스템에 녹아들게 될 것이다.
+
+## 4.3.3 또래 압박
+
+기술을 결정할 때 관심사 밝히기와 논의가 충분하지 않은경우 결과가 좋지 못할 수 있다.
+
+실수를 안하려는 주니어가 잘 모른다는 사실을 두려워하는 것도 있다.
+
+이 때 경쟁심 때문에 분위기 속에서 개발 진행만 엄청나게 되어야 하는 경우에 섣부른 판단으로 중요한 결정을 막 내린경우 문제가 된다.
+
+## 4.3.4 이해 부족
+
+지금 사용하는 기술이나 툴도 어리숙하게 사용하는데, 추가적으로 어떤 툴로 문제 해결을 하려는 경우가 문제될 수 있다.
+
+가장 들기 쉬운예가 JPA일 수 있다.
+
+개인적인 의견으로 객체지향에 대한 공부가 빈약할 때 JPA를 쓰면 Mybatis를 쓰는것만 못한정도로 JPA를 쓰면서 항상 Lock이 잡히거나 하는 문제들을 많이 봤다.
+
+## 4.3.5 오해와 있지도 않은 문제
+
+문제가 뭔지 모르는채로 기술만을 이용해서 해결하려고 하는 개발자
+
+이게 제일 문제라고 생각하는건 어떻게 해결된건지도 모르는데 해결됐고 성능 수치를 정확하게 측정해볼 수도 없을 것이다.
+
+# 4.4 성능 안티패턴 카탈로그
+
+증상과 현실들의 예시여서 스킵
+
+# 4.5 인지 편향과 성능 테스트
+
+안티패턴은 확증편향과 최신편향 두가지가 조합된 것이다.
+
+각 편향들은 이중적이거나 상보적이다.
+
+## 4.5.1 환원주의
+
+시스템을 아주 작은 조각으로 나누어 그 구성 파트를 이해하면 전체 시스템도 다 이해할 수 있다는 분석주의적 사고방식이다.
+
+파트를 이해하지 못하면 올바른 가정을 내릴 가능성도 작아진다는 편향적인 사고
+
+→ 복잡한 시스템은 시스템 전체를 바라봐야 문제 원인을 찾을 수 있다.
+
+## 4.5.2 확증 편향
+
+성능면에서 중대한 문제를 초래하거나, 애플리케이션을 주관적으로 바라보게 한다.
+
+테스트 셋을 부실하게 선택하거나, 테스트 결과를 통계적으로 건전하게 분석하지 않으면 확증 편향의 포로가 되기 쉽다.
+
+이 현상은 강력한 동기부여되거나 감정 요소가 개입되기 때문에 거스르기가 어렵다.
+
+## 4.5.3 행동 편향
+
+시스템이 예상대로 작동하지 않는 상황 또는 아예 중단된 시간중에 발현되는 편향이다.
+
+- 영향도를 분석하지 않고 공지 없이 인프라를 변경한 경우
+- 시스템이 의존하는 라이브러리를 변경
+- 연중 가장 업무가 빠듯한 날에 처음보는 버그나 경합조건이 발생
+
+평소에 로깅과 모니터링을 꾸준히 하여 잘 가꾸어온 애플리케이션은 오류가 발생하면 명확하게 에러 메시지가 생성되기에 금새 원인을 찾아낼 수 있다.
+
+## 4.5.4 위험 편향
+
+개인적인 견해로는 레거시 애플리케이션을 만질 때 이 부분의 편향이 도드라질 것 같다.
+
+이 편향은 애플리케이션 문제가 생겼을 때 제대로 학습하고 적절한 조치를 하지 못한 까닭에 더 고착화된다.
+
+## 4.5.5 엘스버그 역설
\ No newline at end of file
diff --git a/ch04/yoojeong.md b/ch04/yoojeong.md
new file mode 100644
index 0000000..6d71d81
--- /dev/null
+++ b/ch04/yoojeong.md
@@ -0,0 +1,64 @@
+
+> 성능 테스트는 소프트웨어와 인프라의 속도를 테스트한다. 메모리 사용량, 네트워크 대역폭 및 처리량, 응답 시간, CPU 사용률 등의 기준을 두고 측정할 수 있다. 시스템 내에 통신 과정의 병목을 찾아내기 위해서 진행 한다.
+
+### 성능 테스트 유형
+
+
+
+
+|TEST|DESCRIPTION|방법|
+|:--:|:--|:--|
+|지연 테스트(Latency Test)| 종단 트랜잭션에 걸리는 시간 측정. 평균값은 사실 큰 의미가 없고 가장 느린 응답을 확인해야함 ||
+|처리율 테스트(Throughput Test)|지연 분포가 갑자기 변하는 시점(한계점,변곡점)이 사실상 최대 처리율||
+|부하 테스트(Load Test)| 일정 시간 동안 부하를 가해 서버가 처리할 수 있는 최대 TPS와 응답시간을 측정 |순차적으로 증가하는 부하를 제한 시간동안 부여. 한시간 이내|
+|내구 테스트(Endurance Test)|메모리릭, 캐시오염, 메모리단편화 등 시간이 지나고 드러나는 문제점 파악|특정한 부하를 오랜 시간동안 부여. 5시간 이상|
+|스트레스 테스트(Stress Test)| 시스템의 한계점 파악|임계값 이상의 부하를 제한 시간동안 부여|
+|스파이크 테스트(Spike Test)| 순간적으로 사용자 수가 증가했다 감소할 때 동작 테스트(AutoScale의 정상처리 등..)|일반적인 트래픽을 크게 초과하는 부하를 급격하게 부여, 감소|
+
+
+
+
+
+- 용량계획 테스트(Capacity Planning Test) : 리소스를 업그레이드하면 어느정도 성능이 늘어나는가?
+- 저하 테스트(Degradation Test) : 시스템이 부분적으로 실패할 경우 어떤 일이 벌어지나?(잘 복원되나?)
+
+
+#### 주요 측정 항목
+
+`응답`
+- Average ResponseTime
+- Max ResponseTime
+- Error rate
+
+`처리량`
+- Concurrent users: 일반적으로 테스트의 virtual user
+- Throughput: 주로 TPS 를 사용하고, 대상 리소스별로 지칭하는 용어가 별도 존재한다.
+ - CPU : MIPS, MFLOPS
+ - Network : BPS, pps
+ - Server : tpmC
+ - C/S, TP-Monitor, Mainframe : TPS
+ - Storage : IOPS
+
+
+### 기본 베스트 프랙티스
+
+- 테스트 환경은 운영 환경과 비슷하게 구축되어야 한다. (인프라 스펙, 데이터셋 등)
+- 성능 비기능 요건(최적화하려는 핵심 지표)을 구성원들과 잘 협의해야 한다.
+- 소프트웨어개발주기(SDLC) 의 일부에 포함 시켜 상시로 성능 회귀 테스트를 진행한다.
+- 자바에서 특정해 발생하는 이슈에 주의한다.
+
+#### Java의 특정 이슈
+
+메모리 영역 동적 튜닝 등 JVM 특유의 다이나믹한 자기관리 때문에 복잡도가 올라갈 수 있다.
+(ex. JIT 컴파일의 대상이 되는 메서드)
+
+- JIT 컴파일 할정도로 자주 실행되는 메서드가 아니거나
+- 메서드가 너무 크고 복잡해서 도저히 컴파일 분석을 할 수 없는 경우
+
+JIT 컴파일 대상이 되지 않을 수 있는데, JVM 이 어플리케이션의 중요 메서드를 JIT 컴파일 타깃으로 만드는 것이 중요
+
+9장에서 상세하게 나옴
+
+### 결론
+
+직접 테스트 해보고 병목 지점을 파악해라
diff --git a/ch04/youjin.md b/ch04/youjin.md
new file mode 100644
index 0000000..0b2115f
--- /dev/null
+++ b/ch04/youjin.md
@@ -0,0 +1,186 @@
+# 성능 테스트
+좋은 성능테스트는 정랑적이다. 어떤 질문을 던져도 실험결과를 토대로 수치화한 답변을 내놓을 수 있어야 한다.
+
+## 성능 테스트 종류
+
+### 지연테스트
+고객이 트랜잭션을 얼마나 오래 참고 기다려야 하는지 측정하는 것
+
+* 단순 평균값은 지연을 측정하는 지표로 소용이 없다
+➡️ 개선해야 할 것은 오래 걸리는 트랜잭션이므로 p95, p99 값을 확인한다
+
+> p95, p99: 백분위 값(각각 95%, 99%)
+> 시스템의 일반적인 성능뿐만 아니라 극단적인 경우(예: 높은 부하 또는 이상 상태)에서의 성능을 이해하는 데 중요하다
+
+### 처리율 테스트
+시스템이 **단위 시간당** 처리할 수 있는 최대 처리율을 결정하는 것
+
+* 특정 부하에서 지연분포가 갑자기 변한다면(한계점, 변곡점) 이것이 최대 처리율 이다
+
+### 부하 테스트
+시스템이 이정도 부하를 견딜수 있는지/없는지
+
+* 어떤 부하 수준에서 성능 저하나 오류가 발생하는지를 확인
+* 임계치가 초과 하는 그 시점까지 진행한다
+
+### 스트레스 테스트
+일정한 수준의 트랜잭션(특정 처리율)을 시스템에 계속 걸어두고 언제 성능이 저하되는지 확인
+
+* 내구성 테스트이다
+* 임계치가 초과 되었을 때 복구되는지 테스트한다
+* 내구테스트(Soak 테스트, spike 테스트를 포함한다)
+
+### 내구 테스트
+평균 또는 그 이상의 사용률로 시스템에 일정 부하를 계속 주며 리소스가 고갈되거나 시스템이 깨지는 지점을 찾는다
+
+* 빠른 응답을 요구하는 시스템에서 많이 테스트 한다
+
+### 용량 계획 테스트
+업그레이드한 시스템이 어느 정도 부하를 감당할 수 있는지 테스트
+
+* 예정된 계획의 일부분으로 실행
+
+### 저하 테스트
+복원테스트. 운영환경과 동등한 수준의 부하를 시스템에 가하고, 갑자기 시스템이 능력을 상실하는 시점에 벌어지는 일들을 확인한다
+
+* 트랜잭션 지연 분포와 처리율을 측정해야한다
+* 부분 실패 테스트 중에는 카오스멍키가 있다(넷플릭스 인프라 검증 프로젝트)
+ * 하나의 컴포넌트가 죽어도 잘 돌아가는지 확인하는 테스트
+ * 랜덤으로 프로세스를 하나씩 죽이면서 검증한다
+
+* 참고: [성능테스트, 부하테스트, 스트레스 테스트..무엇이 다를까?](https://seongwon.dev/ETC/20220919-%EC%84%B1%EB%8A%A5%ED%85%8C%EC%8A%A4%ED%8A%B8-%EB%B6%80%ED%95%98%ED%85%8C%EC%8A%A4%ED%8A%B8-%EC%8A%A4%ED%8A%B8%EB%A0%88%EC%8A%A4%ED%85%8C%EC%8A%A4%ED%8A%B8%EB%9E%80/)
+
+## 베스트 프랙티스
+쉽게 측정한 것 위주로 보고서를 작성하지 말고, 중요한 관심사에 대해 측정하자
+
+### 하향식 성능
+전체 Application의 성능 양상부터 먼저 알아보는 접근방식
+
+* 테스트팀이 테스트 환경을 구축한 다음, 무엇을 측정하고 무엇을 최적화 하는지 팀원이 명확하게 이해해야 한다
+
+### 테스트 환경 구축
+테스트 환경은 가급적 **운영환경과 동일하게 구성**해야 한다
+* application server, cpu수, os, java runtime version, Web Server, DB, 로드 밸런서, 네트워크 방화벽 등
+* 실제 운영 환경에서 어떤일들이 일어날지 예측할 수 있어야 하므로 환경을 맞춰야 함
+* 돈아까워서 미리 환경 안맞춰 놓고 나중에 운영환경에서 시스템 중단하지 말고, 테스트를 잘하자
+
+### 성능 요건 식별
+성능을 평가하는 지표는 코드 관점이 아니라, 시스템을 전체적으로 바라봐야 한다
+
+* 최적화 하려는 핵심 지표를 성능 비기능 요건(NFR)이라 한다
+
+ex) p95 트랜잭션 시간을 1--밀리초 줄인다, 평균 응답시간을 30%줄인다
+
+### 자바의 특정 이슈
+JVM은 성능 엔지니어가 잘 이해하고 주의깊게 살펴야 할 부분이 있다.
+JIT 컴파일은 중요한 부분이어서 유심히 잘 살펴야 한다.
+➡️ 어떤 메서드가 컴파일 중인지 로그를 남겨 살펴야 하고, 중요 메서드가 잘 컴파일 되고 있는지 확인해야 한다.
+
+> **JIT 컴파일 하지 않는 메소드**
+> * JIT 컴파일 할 정도로 자주 실행되는 메서드가 아닐 경우
+> * 메서드가 너무 크고 복잡하여 컴파일 분석을 할 수 없는 경우
+
+### SDLC(소프트웨어 개발 수명주기) 일부로서 성능 테스트 수행하기
+성능 회귀 테스트를 상시 수행하기
+
+> **회귀 테스트**
+> 기존 테스트를 반복하는 것
+> 결함 수정 이후 새롭게 발견되는 버그가 있는지 확인하는 테스트
+
+# 안티패턴
+프로젝트 또는 팀의 좋지 않은 패턴. 왜 이런 패턴이 생길가?
+➡️ 의외로 의사소통 같은 인적 요소가 원이이 될 때가 많다
+
+## 지루함
+지루한 프로젝트에서 간단히 구현할 수 있는 것을 필요 이상으로 복잡하게 구현한다
+알려지지 않은 기술로 컴포넌트를 제작한다거나, 맞지도 않는 유스케이스에 억지로 기술을 욱여넣거나.
+
+## 이력서 부풀리기
+자신의 몸값을 높이기 위해 불필요한 기술을 덧대게 된다
+
+## 또래 압박
+경쟁심이 불타오르는 팀 분위기 개발이 광속으로 진행되는 듯 보이고자 제대로 따지지 않고 섣불리 중요한 결정을 내리는 것
+
+## 이해 부족
+시금 사용하는 툴의 기능도 온전히 알지 못하는데 무턱대로 새로운 울로 문제를 해결하려는 것
+
+## 오해와 있지도 않은 문제
+문제 자체를 이해하지 못하고 오로지 기술로 해결하려는 것
+
+😅 읽다보니 너무도 공감되는...
+
+
+> **안티패턴을 예방하려면?**
+팀원 모두 참여하여 기술 이슈를 활발히 공유하는 분위기를 적극 장려해야 한다.
+불분명한 것에 대해선 사실에 근거한 증거를 수집해야 한다
+
+# 성능 안티패턴 카탈로그
+성능이 안나오네..? 뭐가 문제일까? 어떻게 고쳐야 할까?
+
+
+🙅🏻♀️ 최신의 멋진 기술을 튜닝 타겟으로 정한다
+🙅🏻♀️ 최신의 뜨고있는 기술을 숭배한다
+
+🙆🏻♀️ 측정을 해보고 진짜 성능 병목점을 찾자
+🙆🏻♀️ 팀원의 베스트 프랙티스 수준을 정하자
+
+---
+
+🙅🏻♀️ 객관적인 아픈부위를 들추려 하지 않고, 무작정 시스템에서 **제일 간단한 부분만 파고든다**
+🙅🏻♀️ 처음 개발한 사람에게 성능을 봐달라고 한다
+
+🙆🏻♀️ 측정을 해보고 진짜 성능 병목점을 찾자
+🙆🏻♀️ 짝 프로그래밍을 하자
+
+---
+
+🙅🏻♀️ 성능 전문가를 채용했는데, 특정 이슈를 해결한 방법을 자기만 알고있고 절대 공유하지 않는다
+
+🙆🏻♀️ 측정을 해보고 진짜 성능 병목점을 찾자
+🙆🏻♀️ 새로 채용한 팀내 전문가가 팀내에 지식을 공유할 수 있도록 한다
+
+---
+
+🙅🏻♀️ 웹사이트에서 "마법"의 설정 매개변수를 발견하고 운영서버에 곧장 적용한다... 하지만 그 팁이 어떤 영향을 미칠지 모른다
+
+🙆🏻♀️ 충분히 검증된 것들만 적용한다
+🙆🏻♀️ 매개변수를 UAT(인수테스트)에 적용해본다
+🙆🏻♀️ 데브옵스팀과 함께 설정 문제를 리뷰하고 토의한다
+
+---
+
+🙅🏻♀️ 정작 이슈와 관련없는 특정 컴포넌트를 문제삼는다
+
+🙆🏻♀️ 정상적으로 분석한다
+
+---
+
+🙅🏻♀️ 변경 영향도를 파악하지 않고 일단 JVM 스위치를 변경해본다
+
+🙆🏻♀️ 다음 절차를 따른다
+
+> 1. 운영계 성능 지표 측정
+> 2. UAT에서 한번에 스위치 하나씩 변경
+> 3. 스트레스를 받는 지점이 UAT와 운영계가 동일한지 확인
+> 4. 운영계에서 일반적인 부하를 나타내는 TC 확보
+> 5. UAT에서 스위치 바꾸면서 테스트
+> 6. UAT에서 다시 테스트
+> 7. 추론한 내용 팀원에게 리뷰받기
+> 8. 내가 내린 결론을 다른사람과 공유하기
+
+---
+
+🙅🏻♀️ UAT 환경을 운영환경과 동일하게 설정하려면 돈이 많이든다...
+
+🙆🏻♀️ 서비스 중단 비용과 고객 이탈로 인한 기회비용을 잘 따져본다
+🙆🏻♀️ UAT 환경은 운영환경과 동일하게!
+
+---
+
+🙅🏻♀️ UAT환경에서 운영환경과 맞게 데이터를 만드는건 정말 삽질이야
+
+🙆🏻♀️ 운영데이터를 UAT로 이전하는 프로세스에 시간과 노력을 투자하자
+
+
+# 성능 테스트시 주의할 점
+**주관적인 사고에 빠지지 않도록 조심하자!**
diff --git a/ch04/youngji.md b/ch04/youngji.md
new file mode 100644
index 0000000..f77d74a
--- /dev/null
+++ b/ch04/youngji.md
@@ -0,0 +1,74 @@
+## 1. 성능 테스트 유형
+
+---
+
+테스트로 확인하고 싶은 정량적 질문 리스트와 그 테스트가 대상 애플리케이션 입장에서 중요한 이유를 간단하게 적고 시작한다.
+
+- 지연 테스트
+
+ 종단 트랜잭션이 걸리는 시간?
+
+- 처리율 테스트
+
+ 현재 시스템이 처리 가능한 동시 트랜잭션 개수
+
+- 부화 테스트
+
+ 특정 부하를 시스템이 감당할 수 있는가?
+
+- 스트레스 테스트
+
+ 시스템의 한계점은 어디까지인가?
+
+- 내구성 테스트
+
+ 시스템을 장시간 실행할 경우 성능 이상 증상이 나타나는가
+
+- 용량 계획 테스트
+
+ 리소스를 추가한 만큼 시스템이 확정되었는가
+
+- 저하 테스트
+
+ 시스템이 부분적으로 실패할 경우 어떤 일이 벌어지는가
+
+
+## 2. 기본 베스트 프랙티스(모범 사례)
+
+---
+
+> 하향식 성능
+>
+
+> 테스트 환경 구축
+>
+
+> 성능 요건 식별
+>
+
+> 자바에 특정한 이슈
+>
+
+> SDLC 일부로 성능 테스트 수행하기
+>
+
+## 3. 성능 안티패턴 개요
+
+---
+
+## 4. 성능 안티패턴 카탈로그
+
+---
+
+- 화려함에 사로잡혀 최신의 멋진 기술을 튜닝 타겟으로 정한다.
+- 단순함에 사로잡혀 실제 아픈 부위인 ‘전문적’인 부분이 아닌 시스템의 간단한 부분만 파고든다.
+- 직접 성능을 측정하고 문제를 조사하지 않고 성능 튜닝 도사는 따로 있다고 생각한다.
+- 인터넷에서 본 민간 튜닝을 맹신한다. 전후 맥락이나 기초를 파악하지 못해 그 팁이 어떤 영향을 미칠지 알지 못한다.
+- 안되면 조상 탓. 정작 이슈와 상관없는 특정 컴포넌트를 문제 삼는다.
+- 숲을 못보고 나무만 본다. 전체적인 영향도를 파악하지 않고 일단 일부면 변경해본다.
+- 내 데스크트톱을 UAT환경이라 생각한다.
+- 운영 데이터는 만들기 어렵다. 시스템에 나타나는 버스트 양상과 웜업 현상을 포착할 수 없다.
+
+## 5. 인지 편향과 성능 테스트
+
+---
diff --git a/ch05/5uhwann.md b/ch05/5uhwann.md
new file mode 100644
index 0000000..60bc782
--- /dev/null
+++ b/ch05/5uhwann.md
@@ -0,0 +1,20 @@
+# Ch5. 마이크로벤치마킹과 통계
+
+## 자바 성능 측정 기초
+- **시스템 전체를 벤치마크하여 저수준 수치는 수집하지 않거나 그냥 무시**. -> 수많은 개별 작용의 전체 결과는 평균을 내어 더 큰 규모에서 유의미한 결과를 얻음
+- 연관된 저수준의 결과를 의미있게 비교하게 위해 저수준 결과 수집 시 생길 많을 문제를 공통 프레임워크를 이용하여 처리(**JMH**)
+
+## JVM 성능 통계
+
+### 오차 유형
+- **램덤 오차**: 측정 오차 또는 무관계 요인이 어떤 상관관계 없이 결과에 영향을 미치는 오차
+- **계통 오차**: 원인을 알 수 없는 요인이 산관관계 있는 형태로 측정에 영향을 미치는 오차
+
+- JVM 성능 통계에선 일반적인 측정값을 보다 유의미한 하위 구성 요소들로 분해하는 개념이 아주 유용하다.
+- 결괏값을 보고 결론을 도출하기 전에 먼저 본인이 데이터 및 도메인을 충분히 이해해야 합니다.
+
+## 마이크로 벤치마킹 체크
+- 유스케이스를 확실히 알고 마이크로벤치마킹을 사용하라.
+- 마이크로벤치마킹 사용 시 JMH를 사용하라.
+- 마이크로벤치마킹을 통해 얻은 결과를 가능한 한 많은 사람과 공유하고 동료들과 함께 의논하라.
+- 항상 잘못될 가능ㅅ헝을 염두에 두고 생각을 지속적으로 검증하라.
diff --git a/ch05/lsj8367.md b/ch05/lsj8367.md
new file mode 100644
index 0000000..30e5fb3
--- /dev/null
+++ b/ch05/lsj8367.md
@@ -0,0 +1,124 @@
+# 5. 마이크로벤치마킹과 통계
+
+자바 성능 수치를 직접 측정하는 내용을 다룬다.
+
+## 5.1 자바 성능 측정 기초
+
+벤치마크를 하나의 과학실험처럼 바라보면 좋은 벤치마크를 작성하는데 도움이 된다.
+
+벤치마크는, 입출력을 지닌 일종의 블랙 박스와도 같다.
+
+어떤 결과를 추측/추론 하는데 필요한 데이터를 수집하려 하지만, 데이터를 모으는 것으로 충분하지 않고 그 데이터에 현혹되지 않도록 주의해야 한다.
+
+자바 플랫폼을 벤치마크 할 때에는 자바 런타임의 정교함이 가장 문제이다.
+
+최적화가 미치는 영향을 완전히 이해하고 설명하기는 불가능하다.
+
+자바 코드 실행은 JIT 컴파일러, 메모리 관리, 그 밖의 자바 런타임이 제공하는 서브 시스템들과 완전히 떼어놓고 생각할 수 없다.
+
+> 작업당 소요시간을 측정하는 벤치마크
+
+이것의 문제점은 JVM의 웜업을 전혀 고려하지 않은 채로, 코드를 테스트했다.
+
+이런방식으로 실행하게되면 몇시간, 며칠씩 걸릴 수 있지만, JIT 컴파일러가 JVM에 내장된 덕분에 바이트코드는 고도로 최적화한 기계어로 변환된다.
+
+이 테스트만으로 운영계에서 어떻게 작동할지 모른다.
+
+- Xms, Xmx
+ - 힙 크기 조절 옵션
+- PrintCompilation
+ - 메소드를 컴파일할 때마다 로깅
+
+JIT 컴파일러는 코드를 조금이라도 더 효율적으로 동작할 수 있게 호출 계층을 최적화한다.
+
+벤치마크 성능은 캡처 타이밍에 따라 달라진다. 그렇기 때문에 JVM이 가동준비 마칠 수 있게 웜업단계를 거치는게 좋다.
+
+### 가비지 컬렉션
+
+GC가 일어나는 타이밍에 캡처하지 않는 것이 그나마 최선의 선택.
+
+타이밍뿐 아니라 이터레이션 횟수도 정해야 하는데, 이 값을 찾기 어려울 때가 있다.
+
+이 때 `--verbose.gc` 를 실행옵션으로 넣어주면 gc 동작을 볼 수 있다.
+
+한번 측정한 결과로는 벤치마크가 어찌 수행됐는지 전체 사정을 속속들이 알 수 없다.
+
+이 때, 허용오차를 구해 신뢰도를 파악하는게 좋다.
+
+## 벤치마크 결과를 제대로 받아보기위한 2가지 해결 방안
+
+### 시스템 전체를 벤치마크한다.
+
+저수준의 수치는 무시하거나 수집하지 않는다.
+
+수 많은 개별 작용의 전체 결과는 평균을 내어 더 큰 규모에서 유의미한 결과를 얻는다.
+
+### 공통 프레임워크를 이용한다.
+
+새로운 최적화 및 다른 외부 제어 변수가 잘 관리되도록 OpenJDK의 개발 흐름을 잘 따라가야 한다.
+
+# 5.2 JMH 소개
+
+## 5.2.1 될 수 있으면 마이크로 벤치마크하지 말자
+
+## 5.2.2 휴리스틱: 마이크로벤치마킹은 언제 하나?
+
+### 저수준 분석, 마이크로벤치마킹의 주요 유즈케이스
+
+- 사용 범위가 넓은 범용 라이브러리 코드 개발
+ - 사용되는 컨텍스트의 정보가 제한적
+ - 아주 폭넓은 유즈케이스에 걸쳐 쓸만한 더 나은 성능을 보여야함.
+- OpenJDK 또는 다른 자바 플랫폼 구현체 개발
+- 지연에 극도로 민감한 코드를 개발
+
+일반적으로 마이크로벤치마크는 가장 극단적 애플리케이션에 한해 사용하는게 좋다.
+
+- 총 코드 경로 실행 시간 적어도 1밀리초, 실제 100마이크로초 보다 짧아야 한다.
+- 메모리 할당률을 측정하는데, 그 값이 1MB/s 미만, 0에 가까운 값이어야 한다.
+- 100% 가까운 CPU사용량을 가지고, 이용률은 10% 밑으로 유지한다.
+- 실행 프로파일러로 CPU를 소비하는 메소드들의 분포를 이해해야 한다.
+
+## 5.2.3 JMH 프레임워크
+
+JMH는 자바를 비롯한 JVM 타깃하는 언어로 작성된 벤치마크를 제작, 실행, 분석하는 자바 도구
+
+JVM을 빌드한 사람들이 직접 만든 프레임워크이기에 JMH 제작자는 JVM 버전별로 숨겨진 함정과 베어트랩을 어떻게 피하는지 잘 안다.
+
+JMH는 벤치마크 툴에 관한 몇가지 핵심적인 설계 이슈를 고려했다.
+
+벤치마크 프레임워크는 컴파일 타임에 벤치마크 내용을 알 수 없으므로 동적이어야 한다.
+
+## 5.2.4 벤치마크 실행
+
+[JMH 공식 깃허브](https://github.com/melix/jmh-gradle-plugin)
+
+`@BenchMark` 를 메소드에 붙여 사용한다. JMH프레임워크는 상태를 제어하는 기능까지 제공한다.
+
+# 5.3 JVM 성능 통계
+
+모든 측정은 어느정도의 오차를 수반한다.
+
+## 5.3.1 오차 유형
+
+### 랜덤오차
+
+측정 오차 또는 무관계 요인이 어떤 상관관계 없이 결과에 영향을 미침.
+
+대부분 정규분포를 따른다.
+
+### 계통오차
+
+원인을 알 수 없는 요인이 상관관계 있는 형태로 측정에 영향을 미침.
+
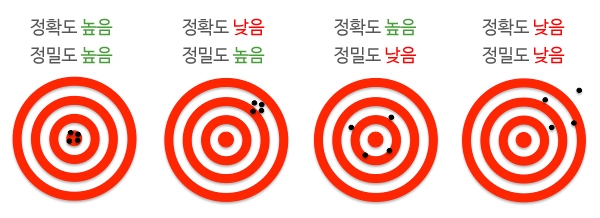
+`정확도`는 계통 오차의 수준을 나타내는 용어, 정확도가 높으면 계통 오차가 낮은 것이다.
+
+`정밀도`는 랜덤 오차를 나타내는 용어로서, 정밀도가 높으면 랜덤오차가 낮은 것이다.
+
+# 정리
+
+마이크로벤치마킹은 뭔가 대단하지만 실상은 꼭 그렇지 않다.
+
+- 유즈케이스를 모르는 상태에서 하지말자.
+- 그래도 벤치마킹을 해야한다면 JMH
+- 우리가 얻은 결과를 많은 사람과 공유하고 논의하자
+- 항상 잘못될 가능성을 염두에 두고 지속적으로 검증하자.
diff --git a/ch05/youjin.md b/ch05/youjin.md
new file mode 100644
index 0000000..06cb7c5
--- /dev/null
+++ b/ch05/youjin.md
@@ -0,0 +1,137 @@
+# 마이크로벤치마킹
+## 🤨 마이크로벤치마킹이란?
+* 컴퓨터 프로그램의 매우 작고 특정한 부분의 성능을 측정하는 것이다
+* 특정한 함수, 알고리즘, 또는 작업 처리 방식의 성능을 측정하는 데 초점을 맞춘다
+
+# 마이크로벤치마킹의 어려움
+성능 측정 시, 공정하게 테스트를 해야한다.
+
+* 시스템의 어느 한 곳 만 변경하고, 나머지 부분은 통제할 수 있어야 한다
+* 시스템의 가변적인 부분은 테스트 간에 불변성을 유지해야 한다
+
+➡️ 이것을 지키는 것은 매우 어렵다
+
+## 원인. Java Runtime의 정교함
+> **JVM과 Java Runtime**
+* JVM은 자바 바이트코드를 실행하는 데 중점을 두는 가상 머신
+* 자바 런타임은 JVM 뿐만 아니라 자바 애플리케이션을 실행하는 데 필요한 라이브러리와 기타 파일을 포함한 더 넓은 개념
+
+➡️ 간단히 말해, JVM은 자바 런타임의 핵심 구성요소 중 하나이며, 자바 런타임은 JVM을 포함하여 자바 프로그램을 실행하는 데 필요한 모든 것을 제공한다
+
+JVM은 개발자가 작성한 코드를 **자동 최적화** 한다.
+최적화가 미치는 영향을 구체적으로 완전히 이해하고 설명하는 것은 어렵다
+
+🤯 Java 코드는 JIT 컴파일러, 메모리 관리, 그밖의 Java Runtime이 제공하는 서브 시스템을 떼놓고 생각할 수 없다
+🤯 테스트 실행시의 OS, HW, Runtime 조건의 작용또한 무시할 수 없다
+
+### 고려해야 할 요인1. JVM Warm up
+벤치마크 중, JVM이 메서드 호출을 최적화할 수 있다
+➡️ 성능 캡처 전 JVM이 가동 준비를 마칠 수 있게 warm up 기간을 준다
+💁🏻♀️ 벤치마크 대상 코드를 여러번 반복 실행한다
+
+> 💡 힙 크기 조정하는 법 법: **-Xms, -Xmx** option
+``` shell
+java -Xms2048m -Xmx2048m -XX:+PrintCompilation [벤치마크 대상]
+```
+
+### 고려해야 할 요인2. Garbage Collection
+GC가 일어날 가능성이 큰 시기에 캡쳐하지 않는다
+(하지만 GC 수집은 불확정적이어서 어쩔 도리가 없다...)
+
+> 💡 GC Log 보는 법: **-verbose:gc** option
+``` shell
+java -Xms2048m -Xmx2048m -verbose:gc [벤치마크 대상]
+```
+
+### 고려해야 할 요인3. 죽은 코드
+테스트하려는 코드에서 생성된 결과를 실제로 사용하지 않는다
+
+``` java
+public class ClassicSort {
+ private static final List testData = new ArrayList<>();
+
+ public static void main(String[] args) {
+ // testData List 생성
+
+ double startTime = System.nanoTime();
+
+ for (int i = 0; i < I; i++) {
+ List copy = new ArrayList<>(testData);
+ Collections.sort(copy)
+ }
+
+ double endTime = System.nanoTime();
+
+ // 벤치마킹 코드 실행시간 출력
+ }
+}
+```
+
+위 코드에서 copy List를 만들고, sort했지만 그뒤에 sort를 가져다 쓰는 곳이 없기 때문에 **JIT 컴파일러가 이것을 죽은 코드 경로로 식별하고 벤치마킹 대상을 최적화 할 수 있다**
+
+
+위에서 설명한 것 처럼 마이크로벤치마킹 시 신경써야 할 것이 많았다.
+하지만 멀티스레드 코드라면? 더 어려워진다.
+
+## 마이크로벤치마킹 해결법
+1. 시스템 전체를 벤치마크 하자
+* 저수준 수치는 수집하지 않거나 무시한다
+* 수많은 개별 작용의 전체 결과는 더 큰 규모에서 유의미한 결과를 얻는다
+
+2. 공통 프레임워크를 사용하자
+* 위에서 말한 여러 고려사항들을 공통 프레임워크를 통해 해결한다
+➡️ JMH
+
+# Java 마이크로벤치마킹 Tool(JMH Framework)
+위에서 설명한 것 처럼, 마이크로벤치마킹은 어렵지만 해야만 하는 상황이 있다면 마이크로벤치마킹 툴의 **업계 표준**인 JMH(Java Microbenchmark Harness)를 사용하자!
+
+## 🤨 꼭 마이크로벤치마킹을 해야하는 상황은?
+* 사용 범위가 넒은 범용 라이브러리 코드 개발 시
+* OpenJDK 또는 다른 자바 플랫폼 구현체 개발 시
+* 지연에 극도로 민감한 코드 개발 시
+
+## JMH
+> JMH는 Java를 비롯해 JVM을 타깃으로 하는 언어로 작성된 나노/마이크로/밀리/매크로 벤치마크를 제작, 실행, 분석하는 Java 도구이다
+
+벤치마크 프레임워크는 어떤걸 벤치마킹 할 지 알 수 없으므로 동적이어야 한다
+➡️ 리플렉션 사용시, 벤치마크 실행 경로에 복잡한 JVM 서브시스템이 끼어들게 된다
+➡️ JMH는 벤치마크 코드에 annotation을 붙여 Java 소스를 추가 생성한다
+
+### JHM의 기능
+* 런타임에 죽은 코드를 제거하는 최적화를 못 하게 한다
+* 반복되는 계산을 상수폴딩(컴파일 타임에 계산 가능한 표현식을 상수로 바꾸어 처리하는 최적화 과정) 하지 않는다
+* 값을 읽거나 쓰는 행위가 현재 캐시 라인에 영향을 끼치는 잘못된 공유 현상을 방지한다
+* 쓰기 장벽(병목 지점)으로 부터 보호한다
+
+### JHM 사용 방법
+https://github.com/openjdk/jmh
+* 참고: https://ysjee141.github.io/blog/quality/java-benchmark/
+
+# JVM 성능 통계
+모든 측정은 어느 정도의 오차를 수반한다
+
+## 오차 유형
+### 랜덤 오차
+* 측정 오차 또는 무관계 요인이 어떤 **상관관계 없이** 결과에 영향을 미친다
+* 정밀도와 랜덤 오차는 반비례 관계
+* 보통 정규 분포를 따른다
+
+### 계통 오차
+* 원인을 알 수 없는 요인이 **상관관계 있는** 형태로 측정에 영향을 미친다
+* 정확도와 계통 오차는 반비례 관계
+
+
+(출처: https://www.dailyvet.co.kr/news/practice/companion-animal/88473)
+
+## 통계치 해석
+"웹 애플리케이션 응답" 그래프이다
+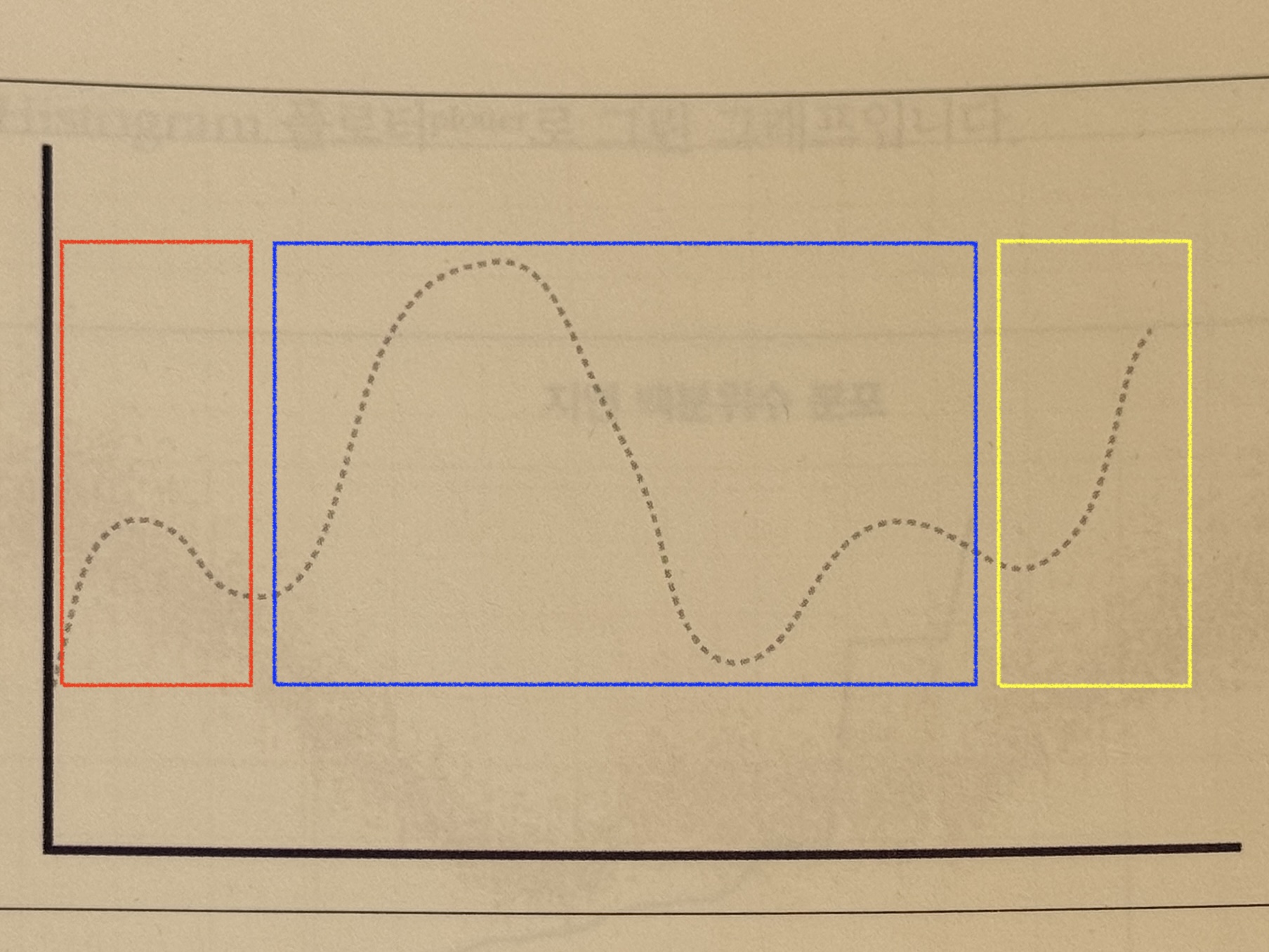
+
+빨간색 구간의 경우, 404 Error(Client Error)일 것이다
+➡️ 매핑되지 않은 URL 요청 시, 곧장 404를 반환하기 때문이다
+
+파란색 구간의 경우, 서버 Error일 것이다(장시간 부하 및 타임아웃)
+
+노란색 구간의 경우, 성공한 요청일 것이다
+
+> 유의미한 하위 구성요소들로 분해하는 개념은 유용하다
diff --git a/ch05/youngji.md b/ch05/youngji.md
new file mode 100644
index 0000000..bbc03e0
--- /dev/null
+++ b/ch05/youngji.md
@@ -0,0 +1,154 @@
+# 5장 - 마이크로벤치마킹과 통계
+
+JVM은 자유분방한 특성 탓에 성능 수치를 다루기가 만만치 않다. 특히, 작은 자바 코드 한 조각의 성능을 정확히 측정하기란 매우 미묘하고 어렵다.
+
+- **마이크로벤치마킹**
+
+마이크로벤치마킹은 작은 코드 단위의 성능을 측정하는 방법입니다. 이는 특정 기능이나 작업 응답 시간을 측정하고 분석하여 성능 최적화를 위한 데이터를 제공합니다.
+
+- **베어** **트랩**
+
+"베어 트랩"은 프로그램이나 시스템의 성능 측정 시 흔히 발생하는 오해나 함정을 지칭하는 용어입니다. 이를 이해하고 피하는 것은 정확한 성능 측정과 최적화를 위해 중요합니다.
+
+# 자바 성능 층정 기초
+
+벤치마크란, 입출력을 지닌 일종의 ‘블랙 박스’와 같다. 가급적 시스템의 어느 한 곳만 변경하고 다른 외부 요인은 벤치마크 안에 두고 통제하면 좋다. 이상적으로는 시스템에서 가변적인 부분은 테스트간에 불변성을 유지해야 하지만 실제로 그렇게 운 좋은 경우는 드문 편이다.
+
+**자바 플랫폼을 벤치마크할 때에 자바 런타임의 정교함이 가장 문제인다.** JVM이 개발자가 작성한 코드에 적용하는 자동 최적화의 맥락에서 벤치마크를 과학적인 테스트로 바라보면 우리가 가진 선택지는 한정적이다. 애플리케이션 코드가 정말 정확히 투영된 성능 모델은 생성 하기도 어렵고 적용 범위가 한정된다.
+
+즉, 자바 코드 실행은 JIT 컴파일러, 메모리 관리, 그 밖의 자바 런타임이 제공하는 시스템과 완전히 떼어놓고 생각할 수 없다. 테스트 당시의 OS, 하드웨어, 런타임 조건등의 작용 또한 무시할 수 없다.
+
+이와 같은 여러 작용은 보다 **큰 단위로 처리하여 상쇄시킬 수 있으나 작은 규모로 마이크로벤치마크를 할때는 확실하게 떼어놓기 어렵다. 이것이 마이크로벤치마킹이 어려운 근본적인 이유이다.**
+
+---
+
+**벤치마킹의 문제점 몇가지**
+
+- JVM 웜업
+
+ JVM 웜업(warm-up)은 자바 가상 머신(JVM)이 프로그램을 최적화하기 위해 초기 실행 시간 동안 일어나는 현상을 가리킵니다. JVM은 프로그램을 실행할 때 몇 가지 최적화 기법을 사용하여 성능을 향상시키는데, 이러한 최적화는 일반적으로 프로그램을 처음 실행할 때 수행됩니다.
+
+ 로딩, 링크, 초기화는 프로그램이 처음 실행될 때 발생하며, 이 과정은 JVM이 프로그램을 실행하는 동안 발생하는 초기 오버헤드입니다. 이후에는 JIT 컴파일러가 코드를 최적화하여 실행 속도를 향상시키지만, 초기 실행 시간 동안에는 이러한 최적화가 이루어지지 않을 수 있습니다.
+
+ 타이밍을 캡쳐(로깅)하기 전에 JVM이 가동 준비를 마칠 수 있게 웜엄 기간을 두는 것이 좋다. 타이밍 세부를 캡쳐하지 않은 상태로 벤치마크 대상 코드를 여러 번 반복 실행하는 식으로 JVM을 예열시킨다.
+
+- GC
+
+ 타이밍 캡처 도중에 GC가 안 일어나게 설정한 다음 가동시키면 좋지만 가비지 수집은 원래 불확정적이어서 개발자가 어쩔 도리가 없다. GC가 일어날 가능성이 큰 시기에는 캡쳐하지 않는 게 그나마 최선이다.
+
+- 테스트 하려는 코드에서 생성된 결과를 실제로 사용하지 않는다.
+
+ 사실상 죽은 코드이므로 JIT 컴파일러가 이를 죽은 코드 경로로 식별하고 정작 우리가 벤치마크하려던 것을 최적화해버릴 가능성이 있다.
+
+
+---
+
+벤치마크 코드를 바로 잡는 일은 복잡하다. 자신이 프로파일링하려는 코드 외에 위에 설명한 모든 이슈들을 진지하게 고민하지 않으면 엉뚱한 벤치마크 결과를 얻게 될 것이다.
+
+해결방안은 두가지 이다.
+
+1. 시스템 전체를 벤치마크한다. : 저수준 수치는 수집하지 않거나 무시한다. 전체 결과를 평균 내어 더 큰 규모의 유의미한 결과를 얻는다.
+2. 연관된 저수준의 결과를 의미있게 비교하기 위해 앞서 언급한 많은 문제들을 공통 프레임워크를 이용하여 처리한다. → JMH가 그러한 툴이다.
+
+# JMH 소개
+
+- **마이크로 벤치마킹 대상으로 적합한 유스케이스를 분별하는 휴리스틱**
+
+ 벤치마킹하는 것은 몹시 어려울 뿐 아니라 베어트랩에 빠질 위험이 있다.
+
+ 자바 플랫폼은 천성이 동적이며 가비지 수집 및 공격적인 JIT 최적화 특성으로 성능을 가늠하기 어렵고 런타임 환경마다 성능 수치도 제각각이다.
+
+ 하지만 어쩔 수 없이 코드 조각 하나를 직접 성능 분석해야 할 때가 있다. 일반적으로 저수준 분석이나 마이크로벤치마킹을 하는 유스케이스는 다음 세가지 이다.
+
+ 1. 사용 번위가 넓은 범용 라이브러리 코드를 개발한다.
+ 2. OpenJDK 또는 다른 자바 플랫폼 구현체를 개발한다.
+ 3. 지연에 극도로 민감함 코드를 개발한다.
+
+### **JMH 프레임워크**
+
+JMH는 자바를 비롯한 JVM을 타깃으로 하는 언어로 작성된 나노/마이크로/밀리/매크로 벤치마크를 제작, 실행, 분석하는 자바 도구이다.
+
+JMH는 JVM을 빌드한 사람들이 직접 만든 프레임워크라서, JVM 버전별로 숨겨진 함정과 베어트랩을 피하는 방법을 누구보다 잘 알고 있으며 새로운 최적화 및 다른 외부 제어 변수들이 잘 관리되도록 OpenJDK의 개발 흐름을 잘 따라가는 프레임워크다.
+
+벤치마크 프레임워크는 컴파일 타임에 벤치마크 내용울을 알 수 없으므로 동적이여야 한다. JMH는 벤치마크 코드에 어노테이션을 붙여서 자바 소스를 추가 생성하는 식으로 작동한다.
+
+또한 유저 코드를 반복 호출할 경우, 루프 최적화를 수행할 수 있기때문에 추프 최적화에 걸리지 않을 정도로 조심스레 반복횟수를 설정한 루프 안에 감싸 넣는다.
+
+
+
+- **벤치마크 실행**
+
+ : 필요한 아티팩트를 모두 내려받으면 벤치마크 메서드에 `@Benchmark` 를 붙인다.
+
+ ```java
+ public class MyBenchmark{
+
+ @Benchmark
+ public void testMethod(){
+ // 코드 스텁
+ }
+ }
+ ```
+
+ : 벤츠 마크 실행을 설정하는 매개변수는 명령줄에 넣거나, mian() 메소드에 세팅한다.
+
+ : 벤치마크 할 때 보통 데이터셋 생성 또는 성능 비교용 대조군에 필요한 조건을 세팅 등 몇가지 설정 작업이 필요하다.
+
+ : JMH는 타겟 메소드의 결과가 사용되지 않아 삭제 대상으로 여겨지는 것을 방지하기 위해 벤치마크 메소드가 반환한 단일 결과값을 암묵적으로 (무시해도 좋을 정도의 성능 오버헤드를 갖는)*블랙홀*에 할당한다.
+
+ 블랙홀은 네가지 장치를 이용해 테스트에 영향을 줄 수 있는 최적화로 부터 보호한다.
+
+ - 런타임에 죽은 코드를 제거하는 최적화를 못하게 한다.
+ - 반복되는 계산을 상수 폴딩하지 않게 만든다.
+ - 값을 읽거나 쓰는 행위가 현재 캐시 라인에 영향을 미치는 공유현상 방지
+ - 쓰기 장벽으로 부터의 보호
+
+ 스코프가 한정된 탓에 벤치마크가 과최적화되지 않게 만드는 장치들이다.
+
+
+# JVM 성능 통계
+
+모든 측정에는 어느 정도 오차를 수반한다. 성능 분석시 흔히 맞닥뜨리는 두가지 주요 오차가 있다.
+
+- **랜덤 오차**
+
+ 상관관계 없이 결과에 영향을 미친다.
+
+ 원인을 알 수 없는 예기치 못한 환경상의 변화에서 일어나며 랜덤 오차의 근원은 오직 운영환경이다.
+
+ 대부분 정규분포(가우시안 분포)에 따른다.
+
+- **계통 오차**
+
+ 원인을 알 수 없는 요인이 상관관계 있는 형태로 측정에 영향을 미친다. **정밀도**는 높으나, **정확도**가 늦은 경우를 말한다.
+
+ 선형적으로 응답시간이 느려지는 패턴 (메모리 누수 혹은 리소스 점유 등으로 한정된 서버 리소스가 조금씩 소모되고 있는 경우 주로 나타나는 패턴), 일괄적으로 모든 케이스에 지연이 나타나는 패턴(테스트 설정의 오류로 발생한 전반적인 이슈)등의 예시가 있다.
+
+- 허위 상관
+
+ 두 변수가 비슷하게 움직인다고 이들 사이에 연결고리가 있다고 볼 수는 없다.
+
+
+---
+
+**비정규 통계학**
+
+비정규 통계학은 다양한 비정규 분포를 다루며, 그 중에서도 특히 꼬리가 두터운(tailed) 분포, 우상향(skewed) 분포, 이산(discrete) 분포 등을 다룹니다.
+
+# 통계치 해석
+
+일반적으로 측정값을 보다 유의미한 하위 구성 요소들로 분해하는 개념이 아주 유용하다. 분석자는 결과값을 보고 결론을 도출하기 전에 먼저 본인이 데이터 및 도메인을 충분히 이해해야한다.
+
+통계학 및 분석 기법을 활용한 사례를 볼 수 있는 페이팔 기술팀 블로그를 추천한다.
+
+- https://www.paypal-engineering.com/
+
+---
+
+# 마치며
+
+- 유스케이스를 확실히 모르는 상태에서 마이크로벤치마킹을 하지 마라
+- 그래도 마이크로벤치마킹을 해야한다면 JMH를 이용해라
+- 얻을 결과를 가능한 많은 사람들과 공유하고 팀원들과 의논해라
+- 항상 잘못될 가능성을 염두해두고 내 생각을 지속적으로 검증해라.
+- 마이크로밴치마킹의 장점은 저수준 서브시스템이 유발한 고도로 동적인 움직임과 비정규 분포 양상을 명확하게 드러낸다.
diff --git a/ch06/5uhwann.md b/ch06/5uhwann.md
new file mode 100644
index 0000000..26aa661
--- /dev/null
+++ b/ch06/5uhwann.md
@@ -0,0 +1,68 @@
+# Ch6. 가비지 수집 기초
+
+## 마크 앤 스위프
+1. 할당 리스트를 순회하면서 마크비트를 제거
+2. GC 루트부터 살아 있는 객체 탐색
+3. 찾은 객체에 대한 마크 비트 세팅
+4. 할당 리스트를 순회하면서 마크 비트가 세팅되지 않은 객체 탐색
+ - 힙에서 메모리 회수 후 프리 리스트(메모리에 할당되지 않은 영역을 링크드 리스트로 연결)에 되돌린다.
+ - 할당 리스트에서 객체를 삭제
+
+### GC 용어
+- **STW(Stop The World)**
+ - GC가 가비지 수집을 진행하는 동안 모든 어플리케이션 스레드가 중단
+
+- **동시**
+ - GC 스레드는 어플리케이션 스레드와 동시(병행) 실행될 수 있다.
+ - 사실 상 100% 동시 실행을 보장하는 GC 알고리즘은 존재X
+
+- **병렬**
+ - 여러 스레드를 동원하여 가비지 수집 진행
+
+- **정확**
+ - 정확한 가비지 수집을 한번에 진행할 수 있게 힙 상태에 대한 충분한 타입 정보를 가지고 있음
+
+- **보수**
+ - 보수적인 스킴은 정확한 스킴의 정보가 없어 리소스를 낭비하는 일이 잦고 근본적을 타입 체계를 무시하기 때문에 비효율적
+
+- **이동**
+ - 이동 수집기에서 객체는 메모리를 여기저기 오갈 수 있다. -> 객체 주소 고정X
+
+- **압착**
+ - 할당된 메모리(살아남은 객체들)은 GC 사이클 마지막에 연속된 단일 영역으로 배열됨
+
+- **방출**
+ - 수집 사이클 마지막에 할당된 여역을 완전히 비우고 살아남은 객체는 모두다른 메모리 영역으로 이동
+
+## 핫스팟 런타임 개요
+
+### GC 루트 및 아레나
+- GC 루트는 메모리 고정점으로 메모리 풀 외부에서 내부를 가리키는 포인터.
+- 핫스팟 GC는 **아레나**라는 메모리 영역에서 작동
+- **핫스팟은 자바 힙을 관리할 때 시스템 콜을 하지 않는다.**
+
+## 할당과 수명
+- 자바 어플리케이션에서 가비지 수집이 일어나는 주된 원인
+ 1. 할당률
+ 2. 객체 수명
+
+- 할당률
+ - 일정 기간 새로 생성된 객체가 사용한 메모리량
+ - JVM이 할당률을 직접 기록하진 않지만, 비교적 쉽게 측정 가능(툴 이용 - 센섬)
+- 객체 수명
+ - 대부분 측정하기 어려움
+ - 할당률보다 더 핵심적인 요인
+
+### 약한 세대별 가설
+- 약한 세대별 가설: JVM 및 유사 소프트웨어 시스템에선 거의 대부분의 객체는 아주 짧은 시간만 살아 있지만, 나머지 객체는 기대 수명이 훨씬 길다.
+ -> 가비지를 수집하는 힙은, 단명 객체는 쉽고 빠르게 수집해야 하며 장수 객체와 단명 객체를 완전히 떼어놓는 게 좋다.
+- 핫스팟 메커니즘
+ - 객체마다 세대 카운트(객체가 가비지 수집에서 살아남은 횟수)
+ - 큰 객체를 제외한 나머지 객체는 에덴 공간에 생성. 여기서 살아남은 객체는 다른 곳으로 이동
+ - 충분히 오래 살아남은 객체들은 별도의 메모리 영역(올드 or 테뉴어드 generation)에 보관
+- **자바17까지도 G1GC가 default이기 때문에 G1GC에 대한 추가 학습 필요**
+
+## 할당의 역할
+- GC 사이클은 하나 이상의 힙 메모리 공간이 가득 차 더 이상 객체를 생성할 공간이 없을 때 일어난다. -> GC는 불확정적으로, 불규칙하게 발생하는 것이 가장 중요한 특징
+- 가비지 수집 로그는 기존의 시계열 해석 방법으로는 처리하기 어렵다.
+- 할당률이 높을수록 GC는 더욱 자주 발생하고, 할당률이 지나치게 높을 경우 객체는 어쩔 수 없이 테뉴어드로 바로 승격된다. 이러한 현상을 조기 승격이라한다. -> **가비지 수집에서 가장 중요한 간접 효과이자 튜닝 활동의 출발점**
diff --git a/ch06/lsj8367.md b/ch06/lsj8367.md
new file mode 100644
index 0000000..f83d332
--- /dev/null
+++ b/ch06/lsj8367.md
@@ -0,0 +1,186 @@
+# 6장. 가비지 수집 기초
+
+GC(Garbage Collector)는 자바 환경을 상징하는 여러 특성 가운데 돋보이지만, 자바 플랫폼이 처음 출시됐을 때 상당한 반감을 샀다.
+
+모든 가바지 컬렉터는 기본원칙을 준수해야 한다.
+
+- 알고리즘은 반드시 모든 가비지를 수집해야 한다.
+- 살아있는 객체는 절대로 수집해선 안된다. (해당 내용이 더 중요)
+
+## 마크 앤 스위프
+
+1. 할당 리스트를 순회하며 마크 비트를 지운다.
+2. GC 루트부터 살아있는 객체를 찾는다.
+3. 이렇게 찾은 객체마다 마크 비트를 세팅한다.
+4. 할당 리스트를 순회하며 마크 비트가 세팅되지 않은 객체를 찾는다
+ 1. 힙에서 메모리를 회수해 프리 리스트에 되돌린다.
+ 2. 할당 리스트에서 객체를 삭제한다.
+
+살아있는 객체는 dfs 방식으로 찾아낸다.
+
+이 객체 그래프를 라이브 객체 그래프 or 접근 가능한 객체의 전이 폐쇄라고 한다.
+
+## 가비지 수집 용어
+
+### STW (Stop The World)
+
+gc 사이클이 발생하여 가비지 수집하는 동안 모든 애플리케이션의 스레드가 중단된다.
+
+애플리케이션 코드는 gc 스레드가 바라보는 힙 상태를 무효화 할 수 없다.
+
+### 동시
+
+gc 스레드는 애플리케이션 스레드와 동시 실행될 수 있다.
+
+### 병렬
+
+여러 스레드를 동원해서 가비지 수집
+
+### 정확
+
+정확한 gc 스킴은 가비지를 한방에 수집할 수 있게 힙 상태에 관한 충분한 타입 정보를 지니고 있다.
+
+int와 포인터의 차이점을 언제나 분간할 수 있는 속성을 지닌 스킴이 정확한 것.
+
+### 보수
+
+보수적인 스킴은 정확한 스킴의 정보가 없다.
+
+리소스 낭비하는 일이 잦고 근본적으로 타입 체계를 무시하기에 비효율적이다.
+
+### 이동
+
+이동 수집기에서 객체는 메모리를 여기저기 오갈 수 있다.
+
+객체 주소가 고정된 것이 아니다
+
+### 압착
+
+할당된 메모리는 gc 사이클 마지막에 연속된 단일 영역으로 배열된다.
+
+객체 쓰기가 가능한 여백의 시작점을 가리키는 포인터가 있다.’
+
+압착 수집기는 메모리 단편화를 방지한다.
+
+### 방출
+
+수집 사이클 마지막에 할당된 영역을 완전히 비우고 살아남은 객체는 모두 다른 메모리 영역으로 이동한다.
+
+# 핫스팟 런타임 개요
+
+자바언어에서는 다음 두가지 값만 사용한다.
+
+- 기본형
+- 객체 레퍼런스
+
+## 객체를 런타임에 표현하는 방법
+
+핫스팟은 런타임에 oop라는 구조체로 자바 객체를 나타낸다.
+
+oop는 평펌한 객체 포인터의 줄임말
+
+oop는 참조형 지역변수 안에 위치하고, 여기서 자바 메소드의 스택 프레임으로부터 자바 힙을 구성하는 메모리 영역 내부를 가리킴
+
+oop를 구성하는 자료구조 중 instanceoops는 자바 클래스의 인스턴스를 나타낸다
+
+instanceoops의 메모리 레이아웃은 모든 객체에 대해 기계어 워드 2개로 구성된 헤더로 시작한다
+
+인스턴스 관련 메타데이터를 가리키는 Mark 워드와 클래스 메타데이터를 가리키는 Klass 워드가 나온다.
+
+자바 7까지는 Klass 워드가 힙의 일부인 PermGen영역을 가리켰다.
+
+자바 8부터는 Klass가 자바 힙의 주 영역 밖으로 빠지게 됐고, Klass 워드가 힙밖을 가리키므로 객체 헤더가 필요없다.
+
+oop는 대부분 기계어라서 비트 구조로는 메모리가 크게 낭비될 우려가 있기 때문에 메모리를 절약할 수 있게 압축 oop라는 기법을 제공한다.
+
+`-XX:UserCompressedOops` 라는 옵션을 주면 힙에있는 oop가 압축된다.
+
+- 힙에 있는 모든 객체의 Klass 워드
+- 참조형 인스턴스 필드
+- 객체 배열의 각 원소
+
+> 핫스팟 객체 헤더
+>
+- Mark 워드 (32비트 환경은 4바이트, 64비트 환경은 8바이트)
+- Klass 워드 (압축됐을 수도 있음)
+- 객체가 배열이면 length 워드 (항상 32비트임)
+- 32비트 여백(정렬 규칙 때문에 필요할 경우)
+
+자바에서 배열은 객체다. 그래서 JVM 배열도 oop로 표시되고, 배열은 Mark워드, Klass 워드 다음에 배열 길이를 나타내는 length 워드가 붙는다.
+
+자바 배열 인덱스가 32비트 값으로 제한되는건 이 때문이다.
+
+JVM 환경에서 자바 레퍼런스는 instanceOop 또는 null 을 제외한 어떤 것도 가리킬 수 없다.
+
+- 자바 값은 기본형 또는 instanceOop 주소에 대응되는 비트 패턴이다
+- 모든 자바 레퍼런스는 자바 힙의 주 영역에 있는 주소를 가리키는 포인터라고 볼 수 있다
+- 자바 레퍼런스가 가리키는 주소에는 Mark 워드 + Klass 워드가 들어있다
+- klassOop와 Class 인스턴스는 다르며, klassOop를 자바 변수 안에 넣을 수 없다
+
+> oop의 전체 상속 구조
+>
+
+```jsx
+oop(추상베이스)
+ instanceOop(인스턴스 객체)
+ methodOop(메소드 표현형)
+ arrayOop(배열 추상 베이스)
+ symbolOop(내부 심볼 / 스트링 클래스)
+ klassOop(Klass 헤더) 자바 7이전만 해당
+ markOop
+```
+
+## GC 루트 및 아레나
+
+GC루트는 핫스팟에 관한 블로그 글이나 기사에서 자주 나오는 말
+
+GC루트는 메모리의 고정점으로 메모리 풀 외부에서 내부를 가리키는 포인터이다.
+
+내부 포인터 - 메모리 풀 내부에서 메모리풀 내부 다른 메모리 위치를 가리키는 포인터
+
+외부 포인터 - 메모리 풀 외부에서 메모리풀 외부 다른 메모리 위치를 가리키는 포인터
+
+### GC 루트
+
+- 스택프레임
+- JNI (Java Native Interface)
+- 레지스터
+- 코드 루트
+- 전역 객체
+- 로드된 클래스의 메타데이터
+
+핫스팟 GC는 아레나 라는 메모리 영역에서 작동함.
+
+**핫스팟은 힙 관리 시 시스템 콜을 하지 않는다.**
+
+## 할당과 수명
+
+가비지 수집이 일어나는 주된 원인
+
+- 할당률
+ - 일정 기간 새로 생성된 객체가 사용한 메모리량
+- 객체 수명
+
+객체 수명은 대부분 측정하기 어려움.
+
+## 약한 세대별 가설
+
+소프트웨어 시스템의 런타임 작용을 관찰한 결과 알게된 경험지식으로 JVM 메모리 관리의 이론적 근간을 형성한다
+
+## 핫스팟의 가비지 수집
+
+자바는 C언어의 환경과 달리 OS를 이용하여 동적으로 메모리 관리를 하지 않는다.
+
+프로세스 시작 시 JVM 메모리를 할당하고 유저 공간에서 연속된 단일 메모리 풀을 관리한다
+
+## 스레드 로컬 할당
+
+JVM은 성능을 강화하여 에덴 영역을 관리한다.
+
+에덴은 대부분의 객체가 탄생하는 장소이고 단명 객체는 다른 곳에 위치할 수 없기에 관리를 잘 해주어야 하는 영역이다
+
+JVM은 에덴을 여러 버퍼로 나누어 각 애플리케이션 스레드가 새 객체를 할당하는 구역으로 활용하도록 배포한다.
+
+이렇게 구성하면 다른 스레드가 자신의 버퍼에 객체를 할당하는 경우를 고려할 필요가 없어진다.
+
+이를 스레드 로컬 할당 버퍼라고 칭한다
\ No newline at end of file
diff --git a/ch06/youjin.md b/ch06/youjin.md
new file mode 100644
index 0000000..b4a103d
--- /dev/null
+++ b/ch06/youjin.md
@@ -0,0 +1,140 @@
+# GC(Garbage Collection)
+* 메모리 관리는 컴파일러나 런타임의 영역
+* 런타임이 대신 객체를 추적하여 쓸모없는 객체를 알아서 제거해준다
+* 자동 회수한 메모리는 깨끗이 비우고 재활용 할 수 있다
+
+## GC의 기본원칙
+* 알고리즘은 반드시 모든 가비지를 수집해야한다
+* 살아있는 객체는 절대로 수집하면 안된다 (중요🌟)
+
+# Mark and Sweep 알고리즘
+* GC의 기초 알고리즘이다
+* 할당됐지만, 아직 회수되지 않은 객체를 가리키는 포인터를 포함한 할당 리스트를 사용한다
+
+> 1. 할당 리스트를 순회하며 마크비트를 지운다
+> 2. GC 루트부터 살아있는 객체를 찾는다
+> 3. 찾은 객체마다 마크비트를 세팅한다
+> 4. 마크비트가 세팅되지 않은 객체를 찾는다
+> 4-1. 힙에서 메모리를 회수해 프리 리스트에 되돌린다
+> 4-2. 할당 리스트에서 객체를 삭제한다
+
+* 살아있는 객체는 대부분 DFS로 찾는다
+
+# GC 용어
+### STW(Stop the world)
+* GC중에는 모든 application thread가 중단된다
+
+### 동시
+* GC thread는 application thread와 동시 실행될 수 있다
+* 비싼 작업인데다, 실상 100% 동시 실행을 보장하는 알고리즘은 없음
+
+### 병렬
+* 여러 thread를 동원하여 GC를 수행한다
+
+### 정확
+* GC 스킴(계획, 전략)은 전체 가비지를 한방에 수집할 수 있도록 힙 상태에 관한 충분한 타입 정보를 지니고 있다
+
+### 보수
+* 보수적인 스킴은 정보가 없다
+* 리소스를 낭비하는 일이 잦기 때문에 훨씬 비효율적이다
+
+### 이동
+* 이동 수집기에서 객체는 메모리를 여기저기 오갈 수 있다 (객체 주소가 고정된게 아니다)
+
+### 압착
+* 객체 쓰기가 가능한 여백의 시작점을 가리키는 포인터가 있다
+
+### 방출
+* 수집 사이클 마지막에 살아남은 객체는 모두 다른 메모리 영역으로 이동한다
+
+# 핫스팟 런타임
+## 객체를 런타임에 표현하기
+* 핫스팟은 런타임에 `oop` 라는 구조체로 자바 객체를 나타낸다
+* `oop`는 ordinary object pointer의 줄임말
+* 객체의 위치 정보나 메타정보를 담고있는 단위이다
+* instance가 생성될 때 마다, instance 정보가 담긴 `oop`가 생성된다
+
+### instanceOop
+* instanceOop는 자바 클래스의 인스턴스를 나타낸다
+
+### instanceOop의 메모리 레이아웃
+* **객체에 대한 메타정보를 저장한다**
+* header + 실제데이터로 구성되어 있다
+* header는 Mark 워드 + Klass 워드 로 구성된다(둘다 기계어 워드)
+
+### klassOop
+* **Class에 대한 메타정보를 저장한다**
+
+## instanceOop와 klassOop
+
+
+(출처: [Java 객체는 어떻게 이루어져 있을까?](�https://velog.io/@dev_dong07/Java-%EA%B0%9D%EC%B2%B4%EB%8A%94-%EC%96%B4%EB%96%BB%EA%B2%8C-%EC%9D%B4%EB%A3%A8%EC%96%B4%EC%A0%B8-%EC%9E%88%EC%9D%84%EA%B9%8C))
+
+* 왼쪽은 객체의 정보를 담은 instance oop, 오른쪽은 class 정보를 담은 klass oop이다
+* instance oop는 객체 정보(Klass word) + Mark word + 데이터 로 구성되어있다
+* klass oop는 실제 클래스가 가지고 있는 메서드 등의 정보가 담겨있다
+
+## GC 루트 및 아레나
+* GC루트는 메모리의 고정점(앵커포인트)로, 메모리 풀 외부에서 내부를 가리키는 포인터이다 (외부포인터)
+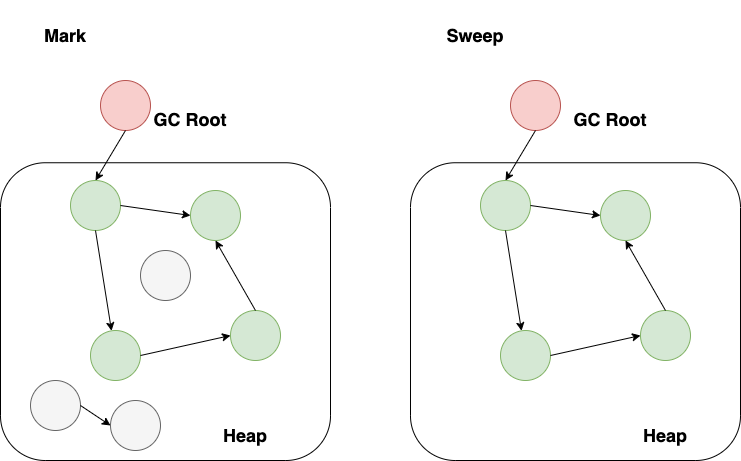
+(출처: [[JVM GC] GC 종류와 동작 방식과 G1GC 튜닝 포인트](https://syhwang.tistory.com/89))
+
+> **GC 루트의 종류**
+스택 프레임, JNI, 레지스터, 코드 루트, 전역 객체, 로드된 클래스의 메타데이터
+
+* heap에 있는 객체를 가리키는 참조형 지역변수도 말하자면 가장 단순한 형태의 GC루트이다
+
+* 핫스팟 GC는 아레나(무대)라는 메모리 영역에서 작동한다
+* 핫스팟은 java heap을 관리할 때 시스템 콜을 하지 않는다 (중요 🌟)
+ * Java heap을 영역에 대한 메모리를 할당하고 관리할 때, 운영체제 수준의 시스템 콜을 최소화한다는 의미
+ * 핫스팟 JVM은 **초기에** heap을 영역에 대한 **큰 덩어리의 메모리를 운영체제로부터 할당**받는다. 이후 Java 프로그램이 실행되면서 객체를 생성할 때, 핫스팟 JVM은 이미 할당받은 heap을 메모리 내에서 필요한 공간을 할당하고 관리한다. 이 방식으로, JVM은 Java 애플리케이션 실행 중에 객체를 생성하고 삭제하는 과정에서 발생하는 메모리 할당 요청을 처리할 때 매번 시스템 콜을 수행하지 않고, **미리 할당받은 메모리 영역 내에서 작업을 처리할 수 있다**. (by. chatgpt)
+
+➡️ 핫스팟은 유저 공간 코드에서 heap을 크기를 관리하므로 단순 측정값을 이용해 GC 서브시스템이 어떤 성능 문제를 일으키고 있는지 파악할 수 있다
+
+## 할당과 수명
+**GC가 일어나는 주된 원인?**
+➡️ 할당률, 객체수명
+
+> GC는 "메모리를 회수해 재사용"하는 일이다. 객체는 대부분 단명하므로 GC의 핵심 전제는 동일한 물리 메모리 조각을 몇번이고 계속 다시 쓸 수 있는가 하는 점이다
+
+### 할당률
+* 일정기간 새로 생성된 객체가 사용한 메모리량
+* JVM이 직접 기록하진 않지만, 비교적 쉽게 측정가능한 값이다 (센섬같은 툴을 쓰면 된다)
+
+### 객체수명
+측정하기 어렵다 ➡️ 핵심요인이다🌟
+
+## 가설
+객체의 수명과 가비지 컬렉션(Garbage Collection, GC)의 효율성에 관한 가설
+
+### 약한 세대별 가설
+* 시스템의 런타임 작용을 관찰
+* 거의 대부분의 객체는 아주 짧은 시간만 살아있지만, 나머지 객체는 기대수명이 훨씬 길다
+➡️ 단명 객체를 쉽고 빠르게 수집할 수 있게 설계해야 하고, **장수 객체와 단명 객체를 완전히 떼어놓는게 가장 좋다**
+
+🌟**객체를 세대에 따라 분류하고, 각 세대별로 다른 방식으로 메모리를 관리한다**🌟
+
+
+
+1. 객체마다 세대 카운트를 센다
+* 세대 카운트란, 객체가 지금까지 무사 통과한 GC 횟수이다
+2. 큰 객체를 제외한 나머지만 **에덴** 공간에 생성한다. 여기서 살아남은 객체는 다른 곳으로 옮긴다
+* 젊은 세대(Young Generation)의 일부
+* GC 발생 시, 에덴 공간에서 살아남은 객체들은 "**서바이버(Survivor)** 공간"으로 옮겨진다
+3. 장수했다고 할 정도로 오래 살아남은 객체들은 별도의 메모리영역(**올드 or 테뉴어드**)에 보관한다
+* 장수 했다는 것은, 여러번의 GC 수행에도 살아남은 것이다
+* 이곳에 옮겨진 객체들은 GC가 덜 자주 발생한다. 이는 메모리 관리의 효율성을 높이기 위한 조치이다
+
+#### 에덴 공간
+* 에덴은 대부분의 객체가 탄생하는 장소이고, 단명객체는 다른 곳에 위치할 수 없으므로 특별히 관리를 잘해야 한다
+
+## 할당
+GC 프로세스는 메모리가 부족할 때(heap 메모리 공간이 꽉 채워져 더이상 객체를 생성할 공간이 없을 때) 그때그때 필요에 의해 발생한다
+➡️ 예측 가능하지 않다. 불확정적이다. 규칙성이 없다
+
+
+* 할당률(일정기간 새로 생성된 객체가 사용한 메모리량)이 높으면 GC는 더 자주 발생한다
+ * 할당률이 높다는 것은 이 영역에 많은 객체가 할당되어 있어 사용 가능한 메모리 공간이 적다는 것을 의미한다
+ * 메모리가 가득 차게 되면, 새로운 객체를 위한 공간을 만들기 위해, JVM은 사용되지 않는 객체들을 제거해야 하므로 GC가 자주 발생한다
+* 할당률이 너무 높으면 객체는 테뉴어드로 곧장 승격된다 ➡️ "조기승격" 이라고 한다
+ * 할당률이 높으면 에덴 공간과 서바이버 공간에 더 이상 새 객체를 저장할 공간이 없거나 부족하기 때문이다
diff --git a/ch07/5uhwann.md b/ch07/5uhwann.md
new file mode 100644
index 0000000..4f9ae5a
--- /dev/null
+++ b/ch07/5uhwann.md
@@ -0,0 +1,54 @@
+# Ch7. 가비지 수집 고급
+
+## 동시 GC 이론
+
+### JVM 세이브포인트
+- 어플리케이션은 스레드마다 세이프포인트라는 특별한 실행 지점을 둔다.
+- 세이브포인트는 스레드의 내부 자료 구조가 훤히보이는 지점으로, 이 지점에서 어떤 작업을 하기 위해 스레드는 잠시 중단될 수 있다.
+- JVM 세이브 포인트 처리 규칙
+ - JVM은 강제로 스레드를 세이브포인트 상태로 바꿀 수 없다.
+ - JVM은 스레드가 세이브포인트 상태에서 벗어나지 못하게 할 수 없다.
+
+### 삼색 마킹
+- GC 루트를 흰색 표시
+- 다른 객체는 모두 흰색 표시
+- 마킹 스레드가 회색 노드로 랜덤하게 이동
+- 이동한 노드를 검은색 표시하고 이 노드가 가리키는 모든 흰색 노드를 회색 표시
+- 회색 노드가 하나도 남지 않을 때까지 위 과정을 반복
+- 검은색 객체는 모두 접근 가능한 것이므로 살아남느다.
+- 흰색 노드는 더 이상 접근 불가능한객체이므로 수집 대상이 된다.
+
+## CMS
+CMS 수집기는 중단 시간을 아주 짧게 하려고 설계된, 테뉴어드 공간 전용 수집기이다.
+- 수행 단계
+ 1. 초기 마킹 (STW)
+ 2. 동시 마킹
+ 3. 동시 사전 정리
+ 4. 재마킹 (STW)
+ 5. 동시 스위프
+ 6. 동시 리셋
+ - 한 차례 긴 STW 중단을 일반적으로 매우 짧은 두 차례 STW 중단으로 대체
+
+- CMS 특징
+ - 어플리케이션 스레드가 오랫동안 멈추지 않는다.
+ - 단일 풀 GC 사이클 시간이 더 길다.
+ - CMS GC 사이클 실행 시간 동안 어플리케이션 처리율은 감소한다
+ - GC가 객체를 추적해야 하므로 메모리를 더 많이 쓴다.
+ - GC 수행에 훨씬 더 많은 CPU 시간이 소모된다.
+ - CMS는 힘을 압착하지 않으므로 테뉴어드 영역을 단편화될 수 있다.
+
+## G1
+중단 시간이 짧은 새로운 수집기로 설계되었다.
+- G1 특징
+ - CMS보다 훨씬 튜닝하기 쉽다.
+ - 조기 승격에 덜 취약
+ - 대용량 힙에서 확장성(중단 시간)이 우수하다.
+ - 풀 STW 수집을 없앨 수 있다.
+- G1 힙은 리전(가상의 메모리 분할 공간)으로 구성된다.
+- 리전을 이용할 경우 세대를 불연속적으로 배치할 수 있고, 수집기가 매번 실행될 때마다 전체 가비지 수집을 진행할 필요가 없다.
+- G1 단계
+ 1. 초기 마킹(STW)
+ 2. 동시 루트 탐색
+ 3. 동시 마킹
+ 4. 재마킹(STW)
+ 5. 정리(STW)
diff --git a/ch07/lsj8367.md b/ch07/lsj8367.md
new file mode 100644
index 0000000..72d3314
--- /dev/null
+++ b/ch07/lsj8367.md
@@ -0,0 +1,139 @@
+# 7장. 가비지 수집 고급
+
+gc의 종류
+
+1. Serial Garbage Collector
+2. Parallel Garbage Collector (also known as Throughput Collector)
+3. Parallel Old Garbage Collector
+4. Concurrent Mark-Sweep (CMS) Garbage Collector
+5. Garbage-First (G1) Garbage Collector
+6. Z Garbage Collector (ZGC)
+7. Shenandoah Garbage Collector
+
+GC 선정시 고민해야하는 것들
+
+- 중단 시간
+- 처리율
+- 중단 빈도
+- 회수 효율
+- 중단 일관성
+
+## JVM Savepoint
+
+os는 언제든지 선제 개입이 가능하다.
+
+이런 것 처럼 JVM도 뭔가 조정작업이 필요할 수 있는데, 이 때 애플리케이션 스레드마다 세이브포인트라는 특별 실행 지점을 둔다.
+
+세이브포인트는 스레드 내부 자료구조가 훤히 보이는 지점이고 어떤 작업을 하기 위해 스레드는 잠시 중단될 수 있다.
+
+세이브포인트 시간 플래그를 세팅하면 모든 애플리케이션 스레드는 반드시 멈춰야한다.
+
+일찍 멈춘 스레드는 느리게 멈춘 스레드들을 기다려야 한다.
+
+> 자동 세이브포인트 상태가 되는 경우
+>
+- 모니터에서 차단
+- JNI 코드 실행
+
+> 세이브포인트가 되지 않을 수 있는 경우
+>
+- 바이트코드 실행 도중
+- OS의 인터럽트
+
+### 삼색마킹(Tri-Color-Marking)
+
+1. GC 루트 회색표시
+2. 다른 객체 모두 흰색표시
+3. 마킹 스레드가 임의 회색 노드로 이동
+4. 흰색 표시된 자식 노드가 있는 노드를 만나면 그 자식 노드들을 회색표시 후 해당 노드를 검은색 표시
+5. 회색 노드가 남지 않을 때까지 계속 되풀이
+6. 검은색 객체는 모두 접근 가능이므로 생존
+7. 흰색 노드는 더 이상 접근 불가한 객체이므로 수집 대상
+
+동시 마킹 도중에는 절대로 검은색 객체 노드가 흰색 객체 노드를 가리킬 수 없다
+
+## CMS
+
+중단 시간을 아주 짧게 하려고 설계된 컬렉터이다
+
+마킹은 삼색 마킹 알고리즘에 따라 수행하므로 힙을 탐색하는 도중에도 객체 그래프가 변경될 수 있다.
+
+### 순서
+
+1. 초기마킹 stw
+2. 동시 마킹
+3. 동시 사전 정리
+4. 재마킹
+5. 동시 스윕
+6. 동시 리셋
+
+### 장단점
+
+- 애플리케이션 스레드가 오랫동안 멈추지 않는다.
+- 단일 풀 GC 사이클 시간이 더 길다
+- CMS GC 사이클이 수행되는 동안, 애플리케이션 처리율은 감소한다
+- GC가 객체를 추적해야 하므로 메모리를 더 많이 쓴다
+- GC 수행에 훨씬 더 많은 CPU 시간이 필요
+- CMS는 힙을 압착하지 않으므로 테뉴어드 영역은 단편화 될 수 있다
+
+### 작동원리
+
+CMS는 애플리케이션 스레드와 동시에 작동
+
+가용 스레드 절반을 동원하여 GC 동시 단계를 수행하고, 나머지 절반은 애플리케이션 스레드가 자바 코드를 실행하는데 사용된다.
+
+> 에덴 공간이 꽉찬 경우?
+>
+
+실행이 중단되고 CMS 도중 영 GC 수행
+
+→ 영 GC는 코어 절반만 사용하기에 병렬 수집기 영 GC보다 더 오래 걸린다
+
+### 동시 모드 실패
+
+평상시에는 영 수집 이후 일부 객체만 테뉴어드 영역으로 승격되고 CMS 올드 수집을 진행하면 테뉴어드 공간이 정리된다.
+
+할당률이 급증하면 영 수집 시 조기 승격이 일어나는데 이 때 객체가 너무 많으면 테뉴어드도 부족한 상황이 생길 수 있다.
+
+이 상황이 동시모드 실패 이다
+
+JVM은 이 때 풀 STW를 유발하는 ParallelOld GC로 돌아간다
+
+`-XX:+UseConcMarkSweepGC` 플래그로 작동한다.
+
+# G1
+
+CMS와는 전혀 다른 수집기
+
+## 특징
+
+- CMS보다 훨씬 튜닝하기 쉽다
+- 조기 승격에 덜 취약
+- 대용량 힙에서 확장성이 우수하다
+- 풀 STW 수집을 없앨 수 있다
+
+## 레이아웃 및 영역
+
+힙은 영역단위로 구성된다.
+
+영역을 사용하니 불연속적으로 배치하거나 수집기가 매번 실행될 때 전체를 수집할 필요가 없다
+
+> 단계
+>
+1. 초기 마킹
+2. 동시 루트 탐색
+3. 동시 마킹
+4. 재마킹
+5. 정리
+
+`-XX:+UseG1GC` 플래그로 작동시킬 수 있다
+
+# 레거시 핫스팟 수집기
+
+## Serial 및 Serial Old
+
+이 GC들은 Parallel GC들과 작동원리는 같지만 CPU 하나의 코어만 사용하여 수행한다
+
+동시 수집이 불가능하고 풀 STW를 일으킨다.
+
+**멀티코어에선 이 구닥다리 GC는 절대 사용하지말자**
\ No newline at end of file
diff --git a/ch07/youjin.md b/ch07/youjin.md
new file mode 100644
index 0000000..9182e6d
--- /dev/null
+++ b/ch07/youjin.md
@@ -0,0 +1,111 @@
+**GC엔 여러 종류가 있다.**
+* CMS (거의 동시 수집기)
+* G1 (최신 범용 수집기)
+* 셰난도아
+* C4
+* 밸런스드
+* 레거시 핫스팟 수집기
+
+**모든 java구현체에 GC가 있는건 아니다**
+➡️ GC는 탈착형 서브시스템으로 취급된다
+
+**GC 선정 시 고려해야 할 것!**
+* 중단시간 (최고의 관심사🌟)
+* 처리율
+ * application 런타임 대비 GC 시간 %
+* 중단 빈도
+ * GC 때문에 얼마나 자주 멈추는지
+* 회수 효율
+ * GC 사이클 당 얼마나 많은 가비지가 수집되는지
+* 중단 일관성
+
+**관심사와 trade off를 고려해여 수집기를 선택해야 한다**
+
+# 동시 GC 이론
+동시 수집기를 써서 application thread 실행 도중 수집에 필요한 작업 일부를 수행해서 중단 시간을 줄이는 것도 방법이다
+
+## JVM Savepoint
+STW GC를 실행하려면 application thread를 모두 중단시켜야 한다.
+JVM이 이런 작업을 어떻게 수행하는걸까?
+➡️ application thread 마다 savepoint라는 특별한 실행 지점을 둔다
+➡️ GC가 수행되기 전과 같은 중요한 작업을 실행하기 전에, 모든 애플리케이션 스레드를 일시 정지시키는 지점을 말한다
+
+### 풀 STW GC의 경우
+* 전체 application thread를 중단시켜야 한다
+* GC thread가 OS에게 무조건 application thread를 강제 중단시켜달라고 요청할 수는 없다
+➡️ GC thread와 application thread는 반드시 공조 해야 한다
+* savepoint 요청을 받았을 때 thread가 제어권을 반납하게 만드는 코드가 VM 인터프리터 구현체 어딘가에 있어야 한다
+
+### Savepoint로 바뀌는 경우
+1. JVM이 전역 savepoint time flag를 세팅한다
+2. 각 application thread는 polling하면서 이 flag가 세팅되었는지 확인한다
+3. application thread는 일단 멈췄다가 다시 깨어날 때 까지 대기한다
+
+➡️ savepoint time flag를 세팅하면 모든 application thread는 반드시 멈추야 한다
+
+
+## 삼색마킹(Tri-color marking)
+savepoint는 GC 수행을 위해 모든 application thread를 중지 시키는 지점이다.
+모두 중지시키고 난 후, 삼색마킹 알고리즘을 실행한다
+
+> 삼색마킹 알고리즘에 사용되는 color
+> * White: 아직 접근되지 않은, 즉 가비지 컬렉터가 아직 방문하지 않은 객체들을 나타냄. 이 객체들은 잠재적으로 가비지일 수 있다
+> * Gray: 가비지 컬렉터가 방문했지만, 그 객체가 참조하는 다른 객체들을 아직 모두 검사하지 않은 상태. 즉, 이 객체는 살아있지만, 그 참조가 가리키는 객체들이 아직 검사 대기 상태
+> * Black: 해당 객체와 그 객체가 참조하는 모든 객체들이 가비지 컬렉터에 의해 검사된 상태. 이는 더 이상 검사할 필요가 없는, 살아 있는 객체를 의미
+
+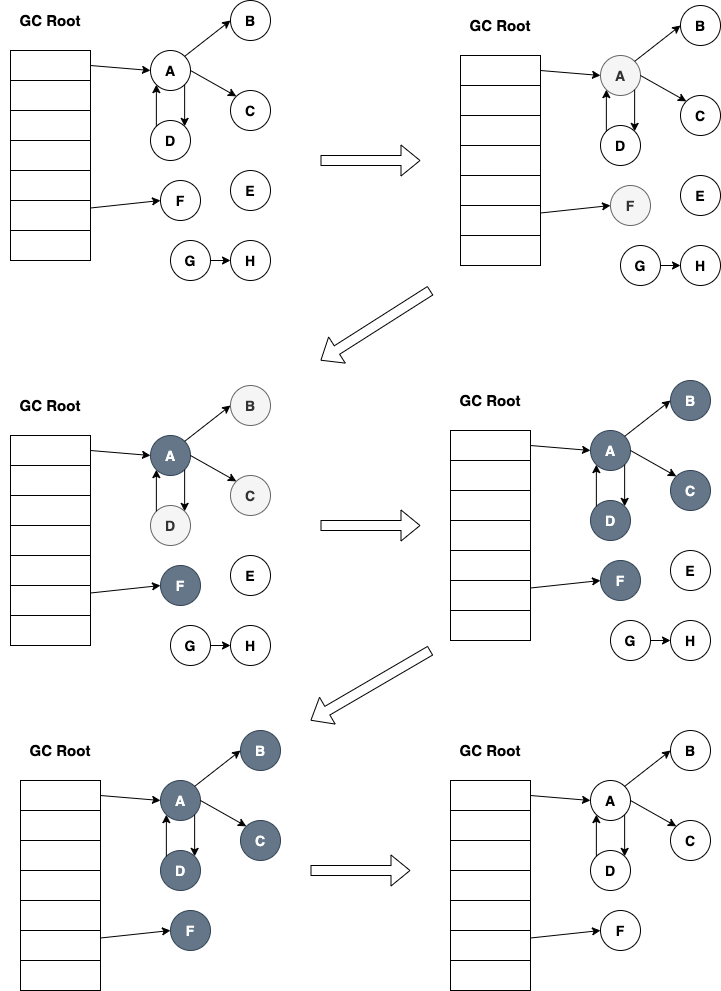
+(출처: [JVM Garbage Collection(GC)](https://velog.io/@zaccoding/JVM-Garbage-CollectionGC))
+
+1. GC 루트를 Gray 표시 한다 (A)
+2. 다른 객체는 모두 White 표시한다 (A 제외)
+3. 마킹 thread가 임의의 Gray 노드로 이동한다 (A)
+4. 마킹 thread가 White 표시된 자식노드를 만나면, 그 자식노드를 모두 Gray 표시한 후(B, C, D), 해당 노드를 Black 표시한다(A)
+5. Gray노드가 하나도 남지 않을 때 까지 위 과정을 되풀이한다
+6. Black 객체는 모두 접근가능하므로 살아남는다
+7. White 노드는 더 이상 접근 불가능한 객체이므로 수집 대상이 된다
+
+동시 수집을 하기 때문에, 변경자 thread(application thread)가 삼색마킹 알고리즘을 수행하는 동안 새 객체를 생성할 수 있다
+
+# CMS
+중단 시간을 아주 짧게 하려고 설계된 테뉴어드 공간 전용 수집기 이다.
+마킹은 삼색 마킹 알고리즘을 따른다
+➡️ 수집기가 heap을 탐색하는 도중 객체 그래프가 변경될 수 있다
+➡️ 초기 수행 단계가 복잡하다
+
+> 1. 초기 마킹(STW): GC 출발점을 얻는 것
+> 2. 동시 마킹: 삼색마킹 알고리즘 적용
+> 3. 동시 사전 정리
+> 4. 재마킹
+> 5. 동시 스위프
+> 6. 동시 리셋
+
+## 장점과 단점
+* application thread가 오랫동안 멈추지 않는다
+* CMS의 GC 처리 동안 application 처리율은 감소한다
+* GC가 객체를 추적해야 하므로 메모리를 더 많이 쓴다
+* GC 수행에 더 많은 CPU 시간이 필요한다
+
+## 작동 원리
+CMS는 application thread와 동시에 작동한다
+
+**CMS 실행 도중 에덴 공간이 다 차버리면?**
+➡️ application thread가 더 이상 진행할 수 없으니 실행이 중단되고, CMS 도중 영 GC가 일어난다
+* 영 GC: Java 힙의 젊은 세대(Young Generation)에서 사용되지 않는 객체를 정리하는 과정
+
+영 GC 이후, 일부 객체는 테뉴어드로 승격된다
+CMS 실행동안에도 승격된 객체는 테뉴어드로 이동해야 한다
+➡️ 두 수집기 간 긴밀한 조정이 필요하다
+
+할당률이 급증하면 영 GC 수행 시, 조기 승격이 일어난다
+➡️ 테뉴어드 공간이 부족해진다
+➡️ **동시 모드 실패(CMF)** 라고 부른다
+
+**동시 모드 실패가 일어나는 원인**
+
+
+## 기본 JVM Flag
+``` shell
+$ -XX:+UseConcMarkSweepGC
+```
+
+플래그로 작동한다