Git和其他版本控制系统(包括Subversion及其他相似的工具)的主要差别在于Git对待数据的方法。概念上来区分,其它大部分系统以文件变更列表的方式存储信息。
这类系统(CVS、Subversion、Perforce、Bazaar等等)将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。存储每个文件与初始版本的差异。
Git不按照以上方式对待或保存数据。反之,Git更像是把数据看作是对小型文件系统的一组快照。每次你提交更新,或在Git中保存项目状态时,
它主要对当时的全部文件制作一个快照并保存这个快照的索引。为了高效,如果文件没有修改,Git不再重新存储该文件,而是只保留一个链接指向之前存储的文件。Git对待数据更像是一个快照流。
Git是分布式版本控制系统,集中式和分布式版本控制有什么区别呢?
-
集中式版本控制系统
版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
-
分布式版本控制系统
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个 人 的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
什么是版本库呢?版本库又名仓库,英文名repository,你可以简单理解成一个目录,这个目录里面的所有文件都可以被Git管理起来,每个文件的修改、删除,Git都能跟踪,
以便任何时刻都可以追踪历史,或者在将来某个时刻可以“还原”。
所以,创建一个版本库非常简单:
- 创建一个空目录
- 通过
git init命令把这个目录变成Git可以管理的仓库: 瞬间Git就把仓库建好了,而且告诉你是一个空的仓库(empty Git repository),细心的读者可以发现当前目录下多了一个.git的目录, 这个目录是Git来跟踪管理版本库的,没事千万不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。 - 使用命令
git add <file>,注意,可反复多次使用,添加多个文件; - 使用命令
git commit,完成。
Git有五种状态,你的文件可能处于其中之一:
- 未修改
(origin) - 已修改
(modified) - 已暂存
(staged) - 已提交
(committed) - 已推送
(pushed)
已提交表示数据已经安全的保存在本地数据库中。 已修改表示修改了文件,但还没保存到数据库中。 已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
Git仓库目录是Git用来保存项目的元数据和对象数据库的地方。这是Git中最重要的部分,从其它计算机克隆仓库时,拷贝的就是这里的数据。
工作目录是对项目的某个版本独立提取出来的内容。这些从Git仓库的压缩数据库中提取出来的文件,放在磁盘上供你使用或修改。
暂存区域是一个文件,保存了下次将提交的文件列表信息,一般在Git仓库目录中。 有时候也被称作‘索引’,不过一般说法还是叫暂存区域。
基本的Git工作流程如下:
- 在工作目录中修改文件。
- 暂存文件,将文件的快照放入暂存区域。
- 提交更新,找到暂存区域的文件,将快照永久性存储到
Git仓库目录。
Git主要分为四个区:
- 工作区
(Working Area) - 暂存区
(Stage或Index Area) - 本地仓库
(Local Repository) - 远程仓库
(Remote Repository)
上面说了git add和git commit的惭怍,总体分为了三个部分,其实更加详细的来分析,还需要一个git push的过程,也就是把更改push到远程仓库中。

正常情况下,我们的工作流程就是三个步骤,分别对应上图中的三个箭头线:
git add . // 把所有文件放入暂存区
git commit -m "comment" // 把所有文件从暂存区提交进本地仓库
git push // 把所有文件从本地仓库推送进远程仓库先上一张图
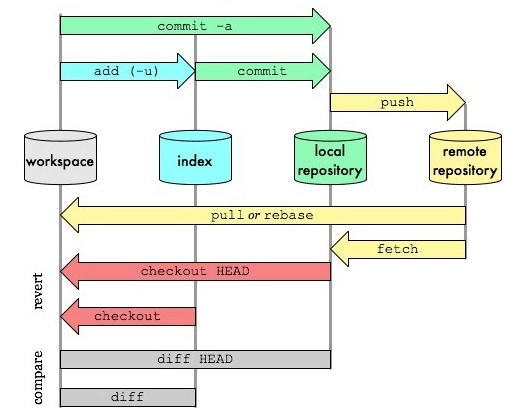
图中的index部分就是暂存区
Git 作为一个系统,是以它的一般操作来管理并操纵这三棵树的:
| 树 | 用途 |
|---|---|
| HEAD | 上一次提交的快照,下一次提交的父结点 |
| Index | 预期的下一次提交的快照 |
| Working Directory | 沙盒 |
HEAD 是当前分支引用的指针,它总是指向该分支上的最后一次提交。 这表示 HEAD 将是下一次提交的父结点。 通常,理解 HEAD 的最简方式,就是将它看做 该分支上的最后一次提交 的快照。
索引是你的 预期的下一次提交。 我们也会将这个概念引用为 Git 的“暂存区”,这就是当你运行 git commit 时 Git 看起来的样子。
最后,你就有了自己的 工作目录(通常也叫 工作区)。 另外两棵树以一种高效但并不直观的方式,将它们的内容存储在 .git 文件夹中。 工作目录会将它们解包为实际的文件以便编辑。 你可以把工作目录当做 沙盒。在你将修改提交到暂存区并记录到历史之前,可以随意更改。
-
安装好git后我们要先配置一下。以便
git跟踪。git config --global user.name "xxx" git config --global user.email "xxx@xxx.com"上面修改后可以使用
cat ~/.gitconfig查看
如果指向修改仓库中的用户名时可以不加--global,这样可以用cat .git/config来查看
git config --list来查看所有的配置。
如果需要查看当前的user.name和user.email的值可以通过。git config user.name -
新建仓库
mkdir gitDemo cd gitDemo git init这样就创建完了。
-
clone仓库
在某一目录下执行.
git clone [git path]
只是后Git会自动把当地仓库的master分支和远程仓库的master分支对应起来,远程仓库默认的名称是origin。 -
git add提交文件更改(修改和新增),把当前的修改添加到暂存区
git add xxx.txt添加某一个文件
git add .添加当前目录所有的文件 -
git commit提交,把修改由暂存区提交到仓库中
git commit提交,然后在出来的提示框内查看当前提交的内容以及输入注释。
或者也可以用git commit -m "xxx"提交到本地仓库并且注释是xxxgit commit是很小的一件事情,但是往往小的事情往往引不起大家的关注,不妨打开公司的任一个repo,查看commit log,满篇的update和fix, 完全不知道这些commit是要做啥。在提交commit的时候尽量保证这个commit只做一件事情,比如实现某个功能或者修改了配置文件。注意是保证每个commit只做一件事,而不是让你做了一件事commit后就push,那样就有点过分了。 -
git cherry-pick
git cherry-pick可以选择某一个分支中的一个或几个commit(s)来进行操作。例如,假设我们有个稳定版本的分支,叫v2.0,另外还有个开发版本的分支v3.0,我们不能直接把两个分支合并,这样会导致稳定版本混乱,但是又想增加一个v3.0中的功能到v2.0中,这里就可以使用cherry-pick了。
就是对已经存在的commit进行 再次提交;
简单用法:
git cherry-pick <commit id> -
git status查看当前仓库的状态和信息,会提示哪些内容做了改变已经当前所在的分支。 -
git diff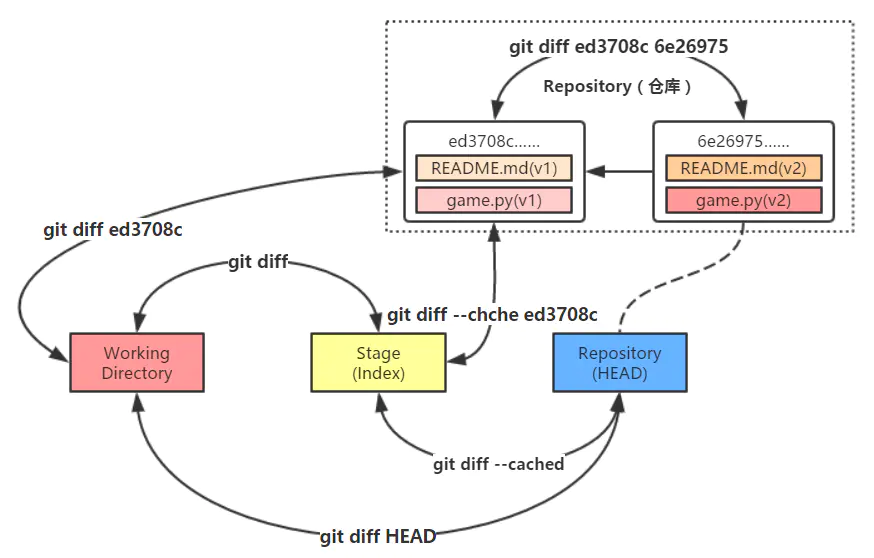
git diff直接查看当前修改未add(暂存staged)的差别git diff --staged查看已add(到暂存区)的差别
git diff HEAD -- xx.txt查看工作区与版本库最新版的差别。- 首先如果我们只是本地修改了一个文件,但是还没有执行
git add .之前,该如何查看有那些修改。这种情况下直接执行git diff就可以了。 - 那如果我们执行了
git add .操作,然后你再执行git diff这时就会发现没有任何结果,这时因为git diff这个命令只是检查工作区和暂存区之间的差异。
如果我们要查看暂存区和本地仓库之间的差异就需要加一个参数使用--staged参数或者--cached,git diff --cached。这样再执行就可以看到暂存区和本地仓库之间的差异。 - 现在如果我们把修改使用
git commit从暂存区提交到本地仓库,再看一下差异。这时候再执行git diff --cached就会发现没有任何差异。 如果我们行查看本地仓库和远程仓库的差异,就要换另一个参数,执行git diff master origin/master这样就可以看到差异了。 这里面master是本地的仓库,而origin/master是 远程仓库,因为默认都是在主分支上工作,所以两边都是master而origin代表远程。
- 首先如果我们只是本地修改了一个文件,但是还没有执行
-
git push提交到远程仓库
可以直接调用git push推送到当前分支
或者git push origin master推送到远程master分支
git push origin devBranch推送到远程devBranch分支 -
git log查看当前分支下的提交记录
用git log可以查看提交历史,以便确定要回退到哪个版本。 如果已经使用git log查出版本commit id后reset到某一次提交后,又要重返回来, 用git reflog查看命令历史,以便确定要回到未来的哪个版本。git log -p -2 // -p 是仅显示最近的x次提交 git log --stat // stat简略的显示每次提交的内容梗概,如哪些文件变更,多少删除,多少添加 git log --oneline --graph下面是常用的参数:
–-author=“Alex Kras”——只显示某个用户的提交任务–-name-only——只显示变更文件的名称–-oneline——将提交信息压缩到一行显示–-graph——显示所有提交的依赖树–-reverse——按照逆序显示提交记录(最先提交的在最前面)–-after——显示某个日期之后发生的提交–-before——显示发生某个日期之前的提交--grep——过滤内容
-
git reflog
可以查看所有操作记录包括commit和reset操作以及删除的commit记录 -
git reset
git reset命令用于将当前HEAD复位到指定状态。一般用于撤消之前的一些操作(如:git add,git commit等)。
在git的一般使用中,如果发现错误的将不想暂存的文件被git add进入索引之后,想回退取消,则可以使用命令:git reset HEAD <file>, 同时git add完毕之后,git也会做相应的提示,比如:# Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # # new file: test.py
git reset [--hard|soft|mixed|merge|keep] [<commit>或HEAD]:将当前的分支重设(reset)到指定的<commit>或者HEAD(默认,如果不显示指定<commit>,默认是HEAD,即最新的一次提交),并且根据[mode]有可能更新索引和工作目录。mode的取值可以是hard、soft、mixed、merged、keep。下面来详细说明每种模式的意义和效果:--hard:彻底回退到某一个版本,本地的源码也会变为上一个版本的内容。重删除工作空间改动代码,撤销commit,撤销git add .。所有变更集都会被丢弃。--mixed:默认方式,它回退到某个版本,只保留源码,不删除工作空间改动代码,撤销commit,并且撤销git add . 。所有变更集都放在工作区。--soft: 回退到某个版本,不删除工作空间改动代码,撤销commit,不撤销git add . ,所有变更集都放在暂存区,如果还要提交直接重新commit即可。
下面是具体一个例子,假设有三个
commit,执行git status结果如下:commit3: add test3.c commit2: add test2.c commit1: add test1.c执行
git reset --hard HEAD~1命令后, 显示:HEAD is now at commit2,运行git log,如下所示:commit2: add test2.c commit1: add test1.c- 回滚最近一次提交
$ git commit -a -m "这是提交的备注信息" $ git reset --soft HEAD^ #(1) $ edit code #(2) 编辑代码操作 $ git commit -a -c ORIG_HEAD #(3)Git中用HEAD表示当前版本,上一版本就是HEAD^,上上一版本就是HEAD^^.如果往前一千个版本呢? 那就是HEAD~1000.
git reset —-hard HEAD^
git reset —-hard commit_idgit reset HEAD fileName可以把用git add之后但是还没有commit之前暂存区中的修改撤销。
说到这里就说一个问题,如果你reset到某一个版本之后,发现弄错了,还想返回去,这时候用git log已经找不到之前的commit id了。那怎么办?这时候可以使用下面的命令来找。
先执行git log命令,将此时的Git仓库可视化
三棵树的情况:
注:快照即提交的版本,每个版本我们称之为一个快照。
现在我们利用 reset 命令回滚快照,并看看 Git 仓库和三棵树分别发生了什么。
执行 git reset HEAD~ 命令:
注:HEAD 表示最新提交的快照,而 HEAD~ 表示 HEAD 的上一个快照,HEAD~~表示上上个快照,如果表示上10个快照,则可以用HEAD ~10
此时我们的快找回滚到了第二棵数(暂存区域)
第一次执行reset后Git仓库
第一次执行reset后三棵树
git reset HEAD~ 命令其实是 git reset --mixed HEAD~ 的缩写, --mixed 选项是默认的。
默认 git reset HEAD~ 命令其实影响了两棵树:首先是移动 HEAD 的指向,将其指向上一个快照(HEAD~);然后再将该位置的快照回滚到暂存区域。 --soft选项 git reset --soft HEAD~ 命令就相当于只移动 HEAD 的指向,但并不会将快照回滚到暂存区域。相当于撤消了上一次的提交(commit)。一不小心提交了,后悔了,那么你就执行 git reset --soft HEAD~ 命令即可(此时执行 git log 命令,也不会再看到已经撤消了的那个提交)。 --hard选项 reset 不仅移动 HEAD 的指向,将快照回滚动到暂存区域,它还将暂存区域的文件还原到工作目录。
-
git checkout撤销修改或者切换分支
git checkout -- xx.txt意思就是将xx.txt文件在工作区的修改全部撤销。可能会有两种情况:- 修改后还没有调用
git add添加到暂存区,现在撤销后就会和版本库一样的状态。 - 修改后已经调用
git add添加到暂存区后又做了修改,这时候撤销就会回到暂存区的状态。
总的来说
git checkout就是让这个文件回到最近一次git commit或者git add的状态。 这里还有一个问题就是我胡乱修改了某个文件内容然后调用了git add添加到缓存区中,这时候想丢弃修改该怎么办?也是要分两步:- 使用
git reset HEAD file命令,将暂存区中的内容回退,这样修改的内容会从暂存区回到工作区。 - 使用
git checkout --file直接丢弃工作区的修改。
git checkout把当前目录所有修改的文件从HEAD都撤销修改。
为什么分支的地方也是用git checkout这里撤销还是用它呢?他们的区别在于--,如果没有--那就是检出分支了。git checkout origin/developer// 切换到orgin/developer分支 - 修改后还没有调用
上面介绍了两个回退操作git reset和git checkout,这里就总结一下如何来对修改进行撤销操作:
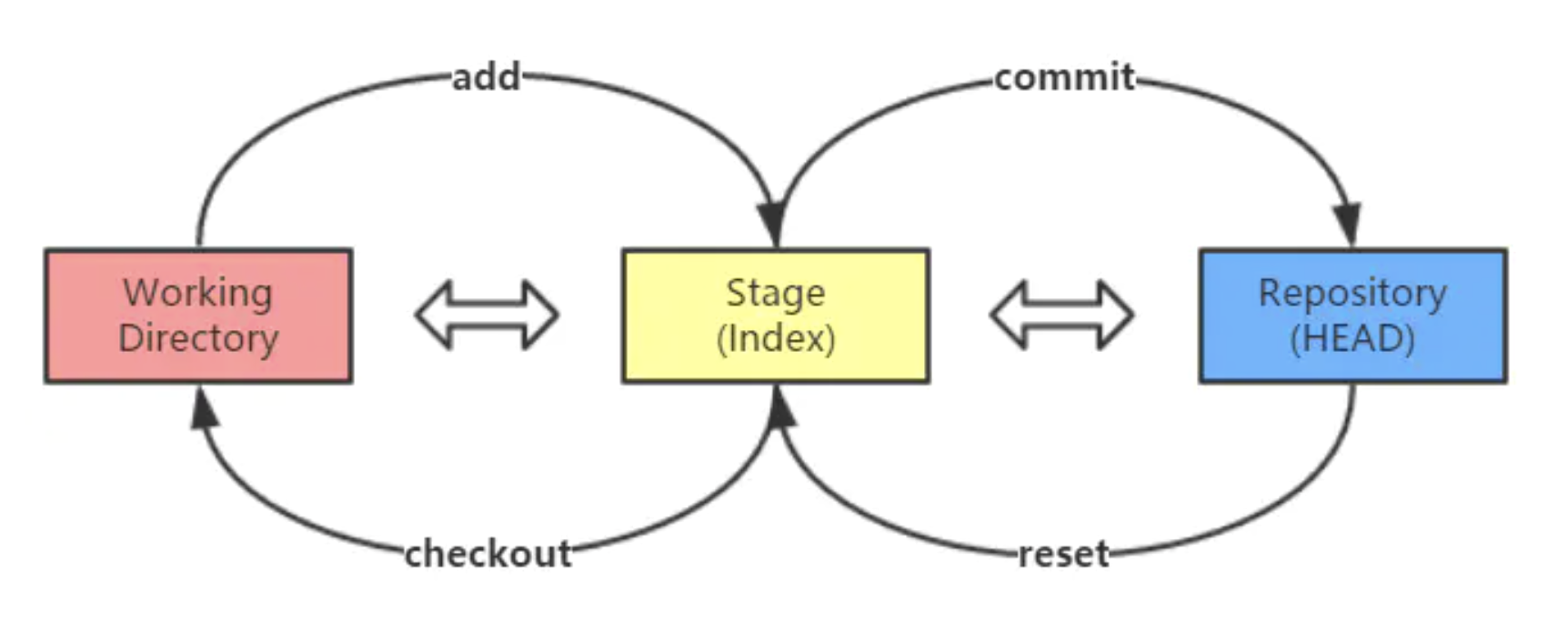
-
已经修改,但是并未执行
git add .进行暂存
如果只是修改了本地文件,但是还没有执行git add .这时候我们的修改还是再工作区,并未进入暂存区,我们可以使用:git checkouot .或者git reset --hard来进行 撤销操作。git add .的反义词是git checkout .做完修改后,如果想要向前一步,让修改进入暂存区执行git add .如果想退后一步,撤销修改就执行git checkout .。 -
已暂存,未提交
如果已经执行了git add .但是还没有执行git commit -m "comment"这时候你意识到了错误,想要撤销,可以执行:git reset // git reset 只是把修改退回到了git add .之前的状态,也就是让文件还处于已修改未暂存的状态 git checkout . // 上面让文件处于已修改未暂存的状态,还要执行git checkout .来撤销工作区的状态或
git reset --hard上面两个例子中都使用了
git reset --hard这个命令也可以完成,这个命令可以一步到位的把你的修改完全恢复到本地仓库的未修改的状态。 -
已提交,未推送
如果执行了git add .又执行了git commit -m "comment"提交了代码,这时候代码已经进入到了本地仓库,然而你发现问题了,想要撤销,怎么办?
执行git reset --hard origin/master还是git reset --hard命令,只不过这次多了一个参数origin/master,这代表远程仓库,既然本地仓库已经有了 你提交的脏代码,那么就从远程仓库中把代码恢复把。但是上面这样会导致你之前修改的代码都没有了,如果我只是想撤回提交,还想要我之前修改的东西重新回到本地仓库呢?
git reset --soft HEAD^,这样就成功的撤销了你的commit。注意,仅仅是撤回commit操作,您写的代码仍然保留。 -
已推送到远程仓库
如果你执行git add .后又commit又执行了git push操作了,这时候你的代码已经进入到了远程仓库中,如果你发现你提交的代码又问题想恢复的话,那你只能先把本地仓库的 代码恢复,然后再强制执行git push仓做,push到远程仓库就可以了。git reset --hard HEAD^ // HEAD^代表最新提交的前一次 git push -f // 强制推送 -
git revert撤销提交
git revert在撤销一个提交的同时会创建一个新的提交,这是一个安全的方法,因为它不会重写提交历史。git revert是生成一个新的提交来撤销某次提交,此次提交之前的commit都会被保留git reset是回到某次提交,提交及之前的commit都会被保留,但是此次之后的修改都会被退回到暂存区
相比
git reset它不会改变现在得提交历史。git reset是直接删除制定的commit并把HEAD向后移动了一下。而git revert是一次新的特殊的commit,HEAD继续前进,本质和普通add commit一样,仅仅是commit内容很特殊。内容是与前面普通commit变化的反操作。 比如前面普通commit是增加一行a,那么revert内容就是删除一行a。 -
git rm删除文件
该文件就不再纳入版本管理了。如果删除之前修改过并且已经放到暂存区域的话,则必须要用强制删除选项 -f(译注:即 force 的首字母),以防误删除文件后丢失修改的内容。 另外一种情况是,我们想把文件从 Git 仓库中删除(亦即从暂存区域移除),但仍然希望保留在当前工作目录中。换句话说,仅是从跟踪清单中删除。比如一些大型日志文件或者一堆 .a 编译文件,不小心纳入仓库后,要移除跟踪但不删除文件,以便稍后在 .gitignore 文件中补上,用 --cached 选项即可:git rm --cached readme.txt -
分支
git分支的创建和合并都是非常快的,因为增加一个分支其实就是增加一个指针,合并其实就是让某个分支的指针指向某一个位置。
-
创建分支
git branch devBranch创建名为devBranch的分支。
git checkout devBranch切换到devBranch分支。
git checkout -b devBranch创建+切换到分支devBranch。git branch查看当前仓库中的分支。
git branch -r查看远程仓库的分支。git branch -d devBranch删除devBranch分支。origin/HEAD -> origin/master origin/developer origin/developer_sg origin/master origin/master_sg origin/offlinegit branch -d devBranch删除devBranch分支。
当时如果在新建了一个分支后进行修改但是还没有合并到其他分支的时候就去使用git branch -d xxx删除的时候系统会手提示说这个分支没有被合并,删除失败。 这时如果你要强行删除的话可以使用命令git branch -D xxx. 如何删除远程分支呢?git branch -r -d origin/developer git push origin :developer如何本地创建分支并推送给远程仓库?
// 本地创建分支 git checkout master //进入master分支 git checkout -b frommaster //以master为源创建分支frommaster // 推送到远程仓库 git push origin frommaster// 推送到远程仓库所要使用的名字如何切到到远程仓库分支进行开发呢?
git checkout -b frommaster origin/frommaster// 本地新建frommaster分支并且与远程仓库的frommaster分支想关联 提交更改的话就用git push origin frommaster// 重命名分支
git branch -m new_branch wchar_support// 查看每一个分支的最后一次提交git branch -v -
git merge合并指定分支到当前分支
git merge devBranch将devBranch分支合并到master。 -
打
tag
git tag v1.0来进行打tag,默认为HEAD
git tag查看所有tag
如果我想在之前提交的某次commit上打tag,git tag v1.0 commitID
当然也可以在打tag时带上参数git tag v1.0 -m "version 1.0 released" commitIDgit tag -d xxx删除xxxgit show tagName来查看某tag的详细信息。 -
打完
tag后怎么推送到远程仓库
git push origin tagName -
删除
tag
git tag -d tagName -
删除完
tag后怎么推送到远程仓库,这个写法有点复杂
git push origin:refs/tags/tagName -
忽略文件
在git根目录下创建一个特殊的.gitignore文件,把想要忽略的文件名填进去就可以了,匹配模式最后跟斜杠(/)说明要忽略的是目录,#是注释 。 其实不用一个个的去写,具体可以根据项目参考https://github.com/github/gitignore 当然不要忘了把该文件提交上去
在用linux的时候会自动生成一些以~结尾的备份文件,如果ignore掉呢?https://github.com/github/gitignore/blob/master/Global/Linux.gitignore -
撤销最后一次提交 有时候我们提交完了才发现漏掉了几个文件没有加或者提交信息写错了,想要撤销刚才的的提交操作。可以修改后重新git add 然后使用
--amend选项重新提交:git commit --amend,然后再执行git push操作。 -
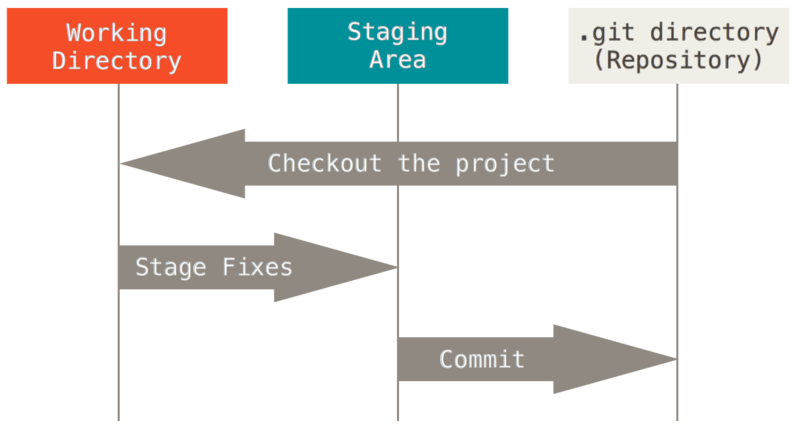
查看远程仓库克隆地址
git remote -v
关于git的工作区、缓存区可以看下图index标记部分的区域就是暂存区
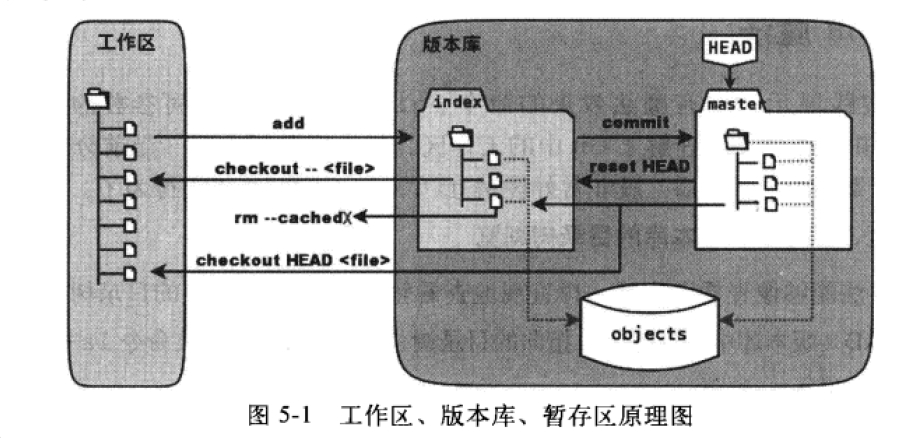
从这个图中能看到缓存区的存在,这就是为什么我们新加或者修改之后都要调用git add方法后再调用git commit。
其实我一直有点分不开reset和checkout的区别,从这个图里能明显看出来了:
-
取消暂存 当执行
git reset HEAD命令时,暂存区的目录树会被重写,会被master分支指向的目录树所替换,但是工作区不受影响。所以如果我们修改了一个问题,执行了add之后,还没有commit这时候想要取消add,可以执行git reset HEAD XXX -
撤销对文件的修改,将它还原成上次提交时的样子或者刚克隆完的样 当执行
git checkout .或git checkout -- file命令是,会用暂存区全部的文件或指定的文件替换工作区的文件。这个操作很危险,会清除工作区中未添加到暂存区的改动。 命令时,会用HEAD指向的master分支中的全部或部分文件替换暂存区和工作区中的文件。这个命令也是极度危险的。因为不但会清楚工作区中未提交的改动,也会清楚暂存区中未提交的改动。 -
git reset HEAD <file>是在添加到暂存区后,撤出暂存区使用,他只会把文件撤出暂存区,但是你的修改还在,仍然在工作区。当然如果使用git reset --hard HEAD这样就完了,工作区所有的内容都会被远程仓库最新代码覆盖。 -
git checkout -- xxx.txt是用于修改后未添加到暂存区时使用(如果修改后添加到暂存区后就没效果了,必须要先reset撤销暂存区后再使用checkout),这时候会把之前的修改覆盖掉。所以是危险的。 你对那个文件在本地的任何修改都会消失——Git 会用最近提交的版本覆盖掉它。 除非你确实清楚不想要对那个文件的本地修改了,否则请不要使用这个命令 -
隐藏操作
假设您正在为产品新的功能编写/实现代码,当正在编写代码时,突i然出现软件客户端升级。这时,您必须将新编写的功能代码保留几个小时然后去处理升级的问题。在这段时间内不能提交代码,也不能丢弃您的代码更改。 所以需要一些临时等待一段时间,您可以存储部分更改,然后再提交它。
在
Git中,隐藏操作将使您能够修改跟踪文件,阶段更改,并将其保存在一系列未完成的更改中,并可以随时重新应用。假设你现在在
a分支上开发新版本内容,已经开发了一部分,但是还没有达到可以提交的程度。你需要切换到b分支进行另一个升级的开发。那么可以 把当前工作的改变隐藏起来,要将一个新的存根推到堆栈上,运行git stash命令。$ git stash Saved working directory and index state WIP on master: ef07ab5 synchronized with the remote repository HEAD is now at ef07ab5 synchronized with the remote repository
现在,工作目录是干净的,所有更改都保存在堆栈中。 现在使用
git status命令来查看当前工作区状态:$ git status On branch master Your branch is up-to-date with 'origin/master'. nothing to commit, working directory clean现在,可以安全地切换分支并在其他地方工作。通过使用
git stash list命令来查看已存在更改的列表。$ git stash list stash@{0}: WIP on master: ef07ab5 synchronized with the remote repository假设您已经解决了客户升级问题,想要重新开始新的功能的代码编写,查找上次没有写完成的代码, 只需执行
git stash pop命令即可从堆栈中删除更改并将其放置在当前工作目录中。这样你之前隐藏的内容就会重新出现了,你可以继续开发了。
当要记录工作目录和索引的当前状态,但想要返回到干净的工作目录时,则使用
git stash。 该命令保存本地修改,并恢复工作目录以匹配HEAD提交。这个命令所储藏的修改可以使用
git stash list列出,使用git stash show进行检查,并使用git stash apply或git stash apply stash@{2}恢复(可能在不同的提交之上)。调用没有任何参数的git stash相当于git stash save -
Rebase操作
多人在同一个分支上协作时,很容易出现冲突,即使没有冲突,在
push代码之前也要先pull,在本地合并后再push,所以就经常会出现这样的分支:
$ git log --graph --pretty=oneline --abbrev-commit
* d1be385 (HEAD -> master, origin/master) init hello
* e5e69f1 Merge branch 'dev'
|\
| * 57c53ab (origin/dev, dev) fix env conflict
| |\
| | * 7a5e5dd add env
| * | 7bd91f1 add new env
| |/
* | 12a631b merged bug fix 101
|\ \
| * | 4c805e2 fix bug 101
|/ /
* | e1e9c68 merge with no-ff
|\ \
| |/
| * f52c633 add merge
|/
* cf810e4 conflict fixed
看上去会很乱,有些强迫症的人会问:为什么Git的提交历史不能是一条干净的直线?
rebase操作就是解决这个问题的,它可以把分叉的提交历史整理变成一条直线,看上去更直观。缺点是本地的分叉提交已经被修改过了。
也就是说gie merge和git rebase做的事情其实是一样的。它们都被设计来将一个分支的更改并入到另一个分支中。
-
git fetch与git pull的区别
git中fetch命令是将远程分支的最新内容拉到了本地,但是fecth后是看不到变化的,如果查看当前的分支,会发现此时本地多了一个FETCH_HEAD的指针,checkout到该指针后才可以查看远程分支的最新内容。而
git pull的作用相当于fetch和merge的组合,会自动合并:git fetch origin master git merge FETCH_HEAD -
git pull 与git pull --rebase的使用
使用下面的关系区别这两个操作:
git pull = git fetch + git merge git pull --rebase = git fetch + git rebasegit rebase的过程中,有时会有conflit这时Git会停止rebase并让用户去解决冲突,解决完冲突后,用git add命令去更新这些内容,然后不用执行git commit,直接执行git rebase --continue这样git会继续apply余下的补丁。
- 邮箱 :charon.chui@gmail.com
- Good Luck!