 -[Gitpod.io](https://www.gitpod.io) 是一个免费的在线开发环境,你也可以使用它参与本项目。
-
-
-[Gitpod.io](https://www.gitpod.io) 是一个免费的在线开发环境,你也可以使用它参与本项目。
-
- +[](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=149001365&machine=basicLinux32gb&location=SoutheastAsia)
## Stars 趋势
diff --git a/README_EN.md b/README_EN.md
index 52e116dc70a55..a1b12f59c58c1 100644
--- a/README_EN.md
+++ b/README_EN.md
@@ -191,9 +191,7 @@ I'm looking for long-term contributors/partners to this repo! Send me [PRs](http
-You can also contribute to [doocs/leetcode](https://github.com/doocs/leetcode) using [Gitpod.io](https://www.gitpod.io), a free online dev environment with a single click.
-
-
+[](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=149001365&machine=basicLinux32gb&location=EastUs)
## Stargazers over time
diff --git a/basic/searching/BinarySearch/README.md b/basic/searching/BinarySearch/README.md
index 22daa83a7b447..0ac8b9019f901 100644
--- a/basic/searching/BinarySearch/README.md
+++ b/basic/searching/BinarySearch/README.md
@@ -42,16 +42,16 @@ int search(int left, int right) {
}
```
-我们做二分题目时,可以按照以下步骤:
+做二分题目时,可以按照以下套路:
-1. 写出循环条件:`while (left < right)`,注意是 `left < right`,而非 `left <= right`;
-1. 循环体内,先无脑写出 `mid = (left + right) >> 1`;
-1. 根据具体题目,实现 `check()` 函数(有时很简单的逻辑,可以不定义 `check`),想一下究竟要用 `right = mid`(模板 1) 还是 `left = mid`(模板 2);
- - 如果 `right = mid`,那么无脑写出 else 语句 `left = mid + 1`,并且不需要更改 mid 的计算,即保持 `mid = (left + right) >> 1`;
- - 如果 `left = mid`,那么无脑写出 else 语句 `right = mid - 1`,并且在 mid 计算时补充 +1,即 `mid = (left + right + 1) >> 1`。
-1. 循环结束时,left 与 right 相等。
+1. 写出循环条件 $left < right$;
+1. 循环体内,不妨先写 $mid = \lfloor \frac{left + right}{2} \rfloor$;
+1. 根据具体题目,实现 $check()$ 函数(有时很简单的逻辑,可以不定义 $check$),想一下究竟要用 $right = mid$(模板 $1$) 还是 $left = mid$(模板 $2$);
+ - 如果 $right = mid$,那么写出 else 语句 $left = mid + 1$,并且不需要更改 mid 的计算,即保持 $mid = \lfloor \frac{left + right}{2} \rfloor$;
+ - 如果 $left = mid$,那么写出 else 语句 $right = mid - 1$,并且在 $mid$ 计算时补充 +1,即 $mid = \lfloor \frac{left + right + 1}{2} \rfloor$;
+1. 循环结束时,$left$ 与 $right$ 相等。
-注意,这两个模板的优点是始终保持答案位于二分区间内,二分结束条件对应的值恰好在答案所处的位置。 对于可能无解的情况,只要判断二分结束后的 left 或者 right 是否满足题意即可。
+注意,这两个模板的优点是始终保持答案位于二分区间内,二分结束条件对应的值恰好在答案所处的位置。 对于可能无解的情况,只要判断二分结束后的 $left$ 或者 $right$ 是否满足题意即可。
## 例题
diff --git a/basic/searching/BinarySearch/README_EN.md b/basic/searching/BinarySearch/README_EN.md
index b62d6130309bc..75541d4883db9 100644
--- a/basic/searching/BinarySearch/README_EN.md
+++ b/basic/searching/BinarySearch/README_EN.md
@@ -2,6 +2,8 @@
## Algorithm Templates
+The essence of binary search is not "monotonicity", but "boundary". As long as a certain property is found that divides the entire interval into two, the boundary point can be found using binary search.
+
### Template 1
```java
@@ -40,6 +42,17 @@ int search(int left, int right) {
}
```
+When doing binary search problems, you can follow the following routine:
+
+1. Write out the loop condition $left < right$;
+2. Inside the loop, you might as well write $mid = \lfloor \frac{left + right}{2} \rfloor$ first;
+3. According to the specific problem, implement the $check()$ function (sometimes the logic is very simple, you can not define $check$), think about whether to use $right = mid$ (Template $1$) or $left = mid$ (Template $2$);
+ - If $right = mid$, then write the else statement $left = mid + 1$, and there is no need to change the calculation of $mid$, that is, keep $mid = \lfloor \frac{left + right}{2} \rfloor$;
+ - If $left = mid$, then write the else statement $right = mid - 1$, and add +1 when calculating $mid$, that is, $mid = \lfloor \frac{left + right + 1}{2} \rfloor$;
+4. When the loop ends, $left$ equals $right$.
+
+Note that the advantage of these two templates is that they always keep the answer within the binary search interval, and the value corresponding to the end condition of the binary search is exactly at the position of the answer. For the case that may have no solution, just check whether the $left$ or $right$ after the binary search ends satisfies the problem.
+
## Examples
- [Find First and Last Position of Element in Sorted Array](/solution/0000-0099/0034.Find%20First%20and%20Last%20Position%20of%20Element%20in%20Sorted%20Array/README_EN.md)
diff --git a/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md b/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
index 45b0058f47232..f4085cc6b610b 100644
--- a/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
+++ b/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
@@ -4,7 +4,7 @@
## Description
-
+[](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=149001365&machine=basicLinux32gb&location=SoutheastAsia)
## Stars 趋势
diff --git a/README_EN.md b/README_EN.md
index 52e116dc70a55..a1b12f59c58c1 100644
--- a/README_EN.md
+++ b/README_EN.md
@@ -191,9 +191,7 @@ I'm looking for long-term contributors/partners to this repo! Send me [PRs](http
-You can also contribute to [doocs/leetcode](https://github.com/doocs/leetcode) using [Gitpod.io](https://www.gitpod.io), a free online dev environment with a single click.
-
-
+[](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=149001365&machine=basicLinux32gb&location=EastUs)
## Stargazers over time
diff --git a/basic/searching/BinarySearch/README.md b/basic/searching/BinarySearch/README.md
index 22daa83a7b447..0ac8b9019f901 100644
--- a/basic/searching/BinarySearch/README.md
+++ b/basic/searching/BinarySearch/README.md
@@ -42,16 +42,16 @@ int search(int left, int right) {
}
```
-我们做二分题目时,可以按照以下步骤:
+做二分题目时,可以按照以下套路:
-1. 写出循环条件:`while (left < right)`,注意是 `left < right`,而非 `left <= right`;
-1. 循环体内,先无脑写出 `mid = (left + right) >> 1`;
-1. 根据具体题目,实现 `check()` 函数(有时很简单的逻辑,可以不定义 `check`),想一下究竟要用 `right = mid`(模板 1) 还是 `left = mid`(模板 2);
- - 如果 `right = mid`,那么无脑写出 else 语句 `left = mid + 1`,并且不需要更改 mid 的计算,即保持 `mid = (left + right) >> 1`;
- - 如果 `left = mid`,那么无脑写出 else 语句 `right = mid - 1`,并且在 mid 计算时补充 +1,即 `mid = (left + right + 1) >> 1`。
-1. 循环结束时,left 与 right 相等。
+1. 写出循环条件 $left < right$;
+1. 循环体内,不妨先写 $mid = \lfloor \frac{left + right}{2} \rfloor$;
+1. 根据具体题目,实现 $check()$ 函数(有时很简单的逻辑,可以不定义 $check$),想一下究竟要用 $right = mid$(模板 $1$) 还是 $left = mid$(模板 $2$);
+ - 如果 $right = mid$,那么写出 else 语句 $left = mid + 1$,并且不需要更改 mid 的计算,即保持 $mid = \lfloor \frac{left + right}{2} \rfloor$;
+ - 如果 $left = mid$,那么写出 else 语句 $right = mid - 1$,并且在 $mid$ 计算时补充 +1,即 $mid = \lfloor \frac{left + right + 1}{2} \rfloor$;
+1. 循环结束时,$left$ 与 $right$ 相等。
-注意,这两个模板的优点是始终保持答案位于二分区间内,二分结束条件对应的值恰好在答案所处的位置。 对于可能无解的情况,只要判断二分结束后的 left 或者 right 是否满足题意即可。
+注意,这两个模板的优点是始终保持答案位于二分区间内,二分结束条件对应的值恰好在答案所处的位置。 对于可能无解的情况,只要判断二分结束后的 $left$ 或者 $right$ 是否满足题意即可。
## 例题
diff --git a/basic/searching/BinarySearch/README_EN.md b/basic/searching/BinarySearch/README_EN.md
index b62d6130309bc..75541d4883db9 100644
--- a/basic/searching/BinarySearch/README_EN.md
+++ b/basic/searching/BinarySearch/README_EN.md
@@ -2,6 +2,8 @@
## Algorithm Templates
+The essence of binary search is not "monotonicity", but "boundary". As long as a certain property is found that divides the entire interval into two, the boundary point can be found using binary search.
+
### Template 1
```java
@@ -40,6 +42,17 @@ int search(int left, int right) {
}
```
+When doing binary search problems, you can follow the following routine:
+
+1. Write out the loop condition $left < right$;
+2. Inside the loop, you might as well write $mid = \lfloor \frac{left + right}{2} \rfloor$ first;
+3. According to the specific problem, implement the $check()$ function (sometimes the logic is very simple, you can not define $check$), think about whether to use $right = mid$ (Template $1$) or $left = mid$ (Template $2$);
+ - If $right = mid$, then write the else statement $left = mid + 1$, and there is no need to change the calculation of $mid$, that is, keep $mid = \lfloor \frac{left + right}{2} \rfloor$;
+ - If $left = mid$, then write the else statement $right = mid - 1$, and add +1 when calculating $mid$, that is, $mid = \lfloor \frac{left + right + 1}{2} \rfloor$;
+4. When the loop ends, $left$ equals $right$.
+
+Note that the advantage of these two templates is that they always keep the answer within the binary search interval, and the value corresponding to the end condition of the binary search is exactly at the position of the answer. For the case that may have no solution, just check whether the $left$ or $right$ after the binary search ends satisfies the problem.
+
## Examples
- [Find First and Last Position of Element in Sorted Array](/solution/0000-0099/0034.Find%20First%20and%20Last%20Position%20of%20Element%20in%20Sorted%20Array/README_EN.md)
diff --git a/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md b/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
index 45b0058f47232..f4085cc6b610b 100644
--- a/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
+++ b/solution/0100-0199/0167.Two Sum II - Input Array Is Sorted/README_EN.md
@@ -4,7 +4,7 @@
## Description
-Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 < numbers.length.
Given a 1-indexed array of integers numbers that is already sorted in non-decreasing order, find two numbers such that they add up to a specific target number. Let these two numbers be numbers[index1] and numbers[index2] where 1 <= index1 < index2 <= numbers.length.
Return the indices of the two numbers, index1 and index2, added by one as an integer array [index1, index2] of length 2.
You are given an array of strings words and a string chars.
A string is good if it can be formed by characters from chars (each character can only be used once).
+A string is good if it can be formed by characters from chars (each character can only be used once).
Return the sum of lengths of all good strings in words.
diff --git a/solution/1600-1699/1671.Minimum Number of Removals to Make Mountain Array/README.md b/solution/1600-1699/1671.Minimum Number of Removals to Make Mountain Array/README.md index 92208ac79f890..2591c48e172a2 100644 --- a/solution/1600-1699/1671.Minimum Number of Removals to Make Mountain Array/README.md +++ b/solution/1600-1699/1671.Minimum Number of Removals to Make Mountain Array/README.md @@ -60,7 +60,7 @@ 那么最终答案就是 $n - \max(left[i] + right[i] - 1)$,其中 $1 \leq i \leq n$,并且 $left[i] \gt 1$ 且 $right[i] \gt 1$。 -时间复杂度 $O(n^2)$,空间复杂度 $O(n)$。其中 $n$ 为数组 `nums` 的长度。 +时间复杂度 $O(n^2)$,空间复杂度 $O(n)$。其中 $n$ 为数组 $nums$ 的长度。 @@ -193,8 +193,8 @@ func minimumMountainRemovals(nums []int) int { ```ts function minimumMountainRemovals(nums: number[]): number { const n = nums.length; - const left = new Array(n).fill(1); - const right = new Array(n).fill(1); + const left = Array(n).fill(1); + const right = Array(n).fill(1); for (let i = 1; i < n; ++i) { for (let j = 0; j < i; ++j) { if (nums[i] > nums[j]) { @@ -219,6 +219,41 @@ function minimumMountainRemovals(nums: number[]): number { } ``` +### **TypeScript** + +```ts +impl Solution { + pub fn minimum_mountain_removals(nums: Vec输入:nums = [1,7,9,2,5], lower = 11, upper = 11 输出:1 -解释:只有单个公平数对:(2,3) 。 +解释:只有单个公平数对:(2,9) 。
diff --git a/solution/2600-2699/2693.Call Function with Custom Context/README_EN.md b/solution/2600-2699/2693.Call Function with Custom Context/README_EN.md index 5b7890dec324a..97c0eebb69fce 100644 --- a/solution/2600-2699/2693.Call Function with Custom Context/README_EN.md +++ b/solution/2600-2699/2693.Call Function with Custom Context/README_EN.md @@ -51,7 +51,7 @@ args = [{"item": "burger"}, 10, 1.1]
Constraints:
-typeof args[0] == 'object' and args[0] != null1 <= args.length <= 1002 <= JSON.stringify(args[0]).length <= 105Write a function that accepts two deeply nested objects or arrays obj1 and obj2 and returns a new object representing their differences.
The function should compare the properties of the two objects and identify any changes. The returned object should only contains keys where the value is different from obj1 to obj2. For each changed key, the value should be represented as an array [obj1 value, obj2 value]. Keys that exist in one object but not in the other should not be included in the returned object. When comparing two arrays, the indices of the arrays are considered to be their keys. The end result should be a deeply nested object where each leaf value is a difference array.
The function should compare the properties of the two objects and identify any changes. The returned object should only contains keys where the value is different from obj1 to obj2.
For each changed key, the value should be represented as an array [obj1 value, obj2 value]. Keys that exist in one object but not in the other should not be included in the returned object. When comparing two arrays, the indices of the arrays are considered to be their keys. The end result should be a deeply nested object where each leaf value is a difference array.
You may assume that both objects are the output of JSON.parse.
Constraints:
arr is a valid JSON arrayfn is a function that returns a numberarr is a valid JSON arrayfn is a function that returns a number1 <= arr.length <= 5 * 105Constraints:
obj is a non-null objectobj is a non-null object0 <= inputs.length <= 100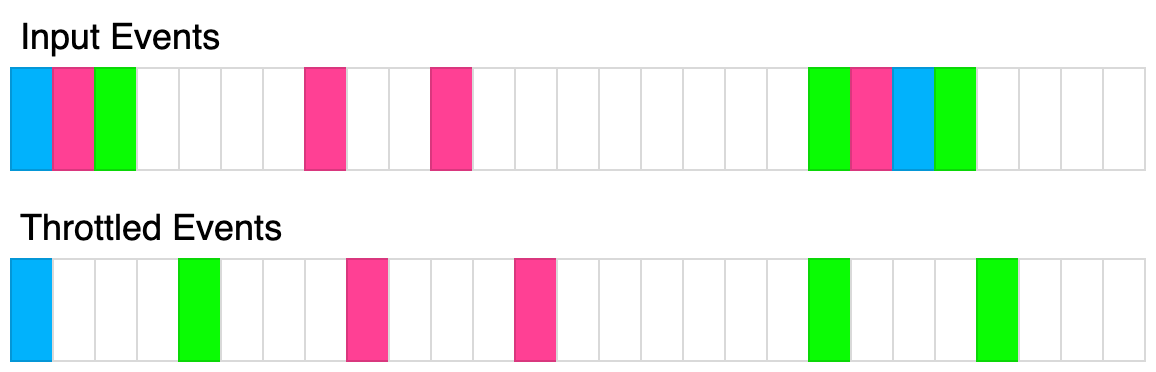
-
Example 1:
@@ -119,7 +117,7 @@ queryMultiple(['f']) is called at t=350ms, it is resolved at 450ms0 <= t <= 10000 <= calls.length <= 101 <= key.length <= 100all keys are unique
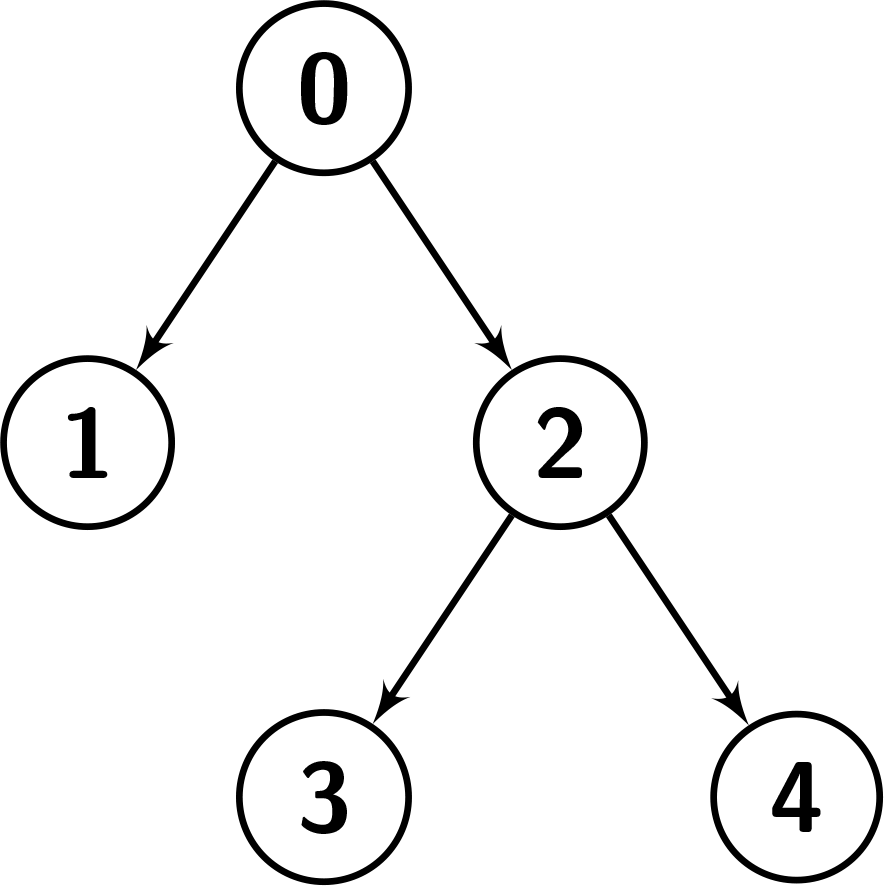
示例 2:
@@ -36,7 +36,7 @@ 对于前序遍历,首先访问节点 0,然后对左子节点进行前序遍历,即 [1,3,4],但是我们可以看到在给定的顺序中,2 位于 1 和 3 之间,因此它不是树的前序遍历。 -
diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" similarity index 93% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" index 09610786d812e..f6bc683163e36 100644 --- "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" +++ "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/README_EN.md" @@ -1,14 +1,14 @@ -# [2764. is Array a Preorder of Some Binary Tree](https://leetcode.com/problems/is-array-a-preorder-of-some-binary-tree) +# [2764. Is Array a Preorder of Some Binary Tree](https://leetcode.com/problems/is-array-a-preorder-of-some-binary-tree) -[中文文档](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) +[中文文档](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) ## Description
Given a 0-indexed integer 2D array nodes, your task is to determine if the given array represents the preorder traversal of some binary tree.
For each index i, nodes[i] = [id, parentId], where id is the id of the node at the index i and parentId is the id of its parent in the tree (if the node has no parent, then parentId = -1).
For each index i, nodes[i] = [id, parentId], where id is the id of the node at the index i and parentId is the id of its parent in the tree (if the node has no parent, then parentId == -1).
Return true if the given array represents the preorder traversal of some tree, and false otherwise.
Return true if the given array represents the preorder traversal of some tree, and false otherwise.
Note: the preorder traversal of a tree is a recursive way to traverse a tree in which we first visit the current node, then we do the preorder traversal for the left child, and finally, we do it for the right child.
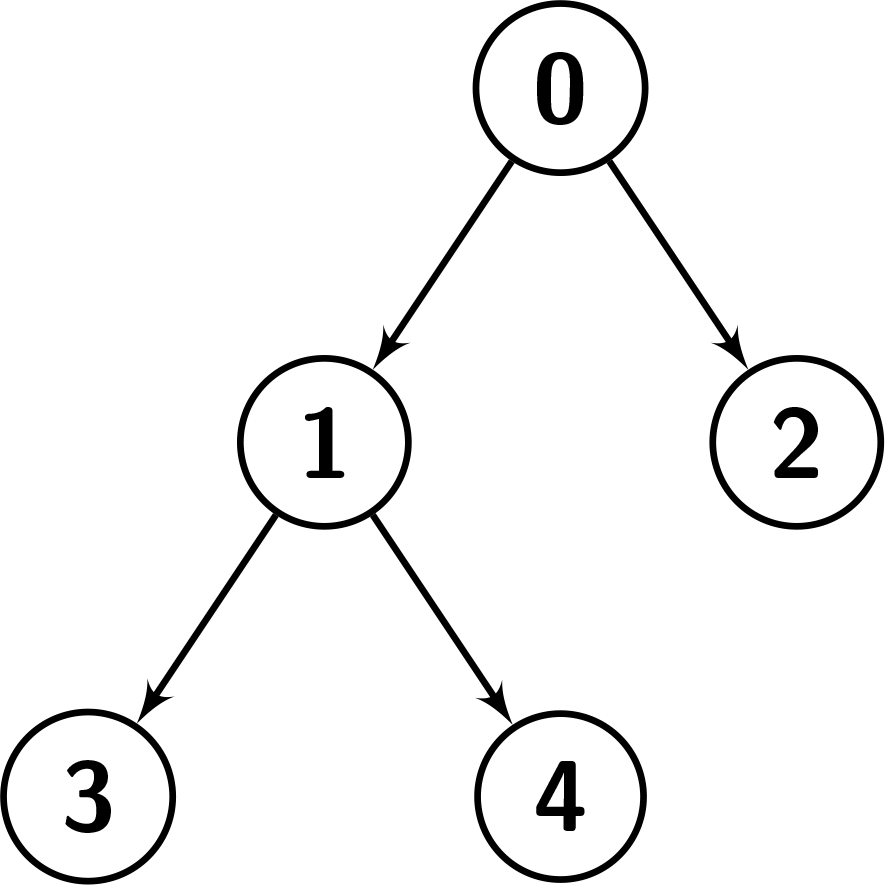
@@ -22,7 +22,7 @@ We can show that this is the preorder traversal of the tree, first we visit node 0, then we do the preorder traversal of the right child which is [1], then we do the preorder traversal of the left child which is [2,3,4]. -
Example 2:
@@ -33,7 +33,7 @@ We can show that this is the preorder traversal of the tree, first we visit node For the preorder traversal, first we visit node 0, then we do the preorder traversal of the right child which is [1,3,4], but we can see that in the given order, 2 comes between 1 and 3, so, it's not the preorder traversal of the tree. -
Constraints:
diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.cpp" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.cpp" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.cpp" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.cpp" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.go" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.go" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.go" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.go" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.java" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.java" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.java" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.java" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.py" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.py" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.py" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.py" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.ts" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.ts" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/Solution.ts" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/Solution.ts" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/images/1.png" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/images/1.png" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/images/1.png" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/images/1.png" diff --git "a/solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/images/2.png" "b/solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/images/2.png" similarity index 100% rename from "solution/2700-2799/2764.is Array a Preorder of Some \342\200\214Binary Tree/images/2.png" rename to "solution/2700-2799/2764.Is Array a Preorder of Some \342\200\214Binary Tree/images/2.png" diff --git a/solution/2700-2799/2774.Array Upper Bound/README_EN.md b/solution/2700-2799/2774.Array Upper Bound/README_EN.md index 8e06c07a1108f..6d6d17e5247f8 100644 --- a/solution/2700-2799/2774.Array Upper Bound/README_EN.md +++ b/solution/2700-2799/2774.Array Upper Bound/README_EN.md @@ -39,6 +39,9 @@nums is sorted in ascending order.+Follow up: Can you write an algorithm with O(log n) runtime complexity? + ## Solutions diff --git a/solution/2700-2799/2776.Convert Callback Based Function to Promise Based Function/README_EN.md b/solution/2700-2799/2776.Convert Callback Based Function to Promise Based Function/README_EN.md index fe35ce8c098ee..269e80ba8a88c 100644 --- a/solution/2700-2799/2776.Convert Callback Based Function to Promise Based Function/README_EN.md +++ b/solution/2700-2799/2776.Convert Callback Based Function to Promise Based Function/README_EN.md @@ -6,7 +6,9 @@
Write a function that accepts another function fn and converts the callback-based function into a promise-based function.
The promisify function takes in a function fn that accepts a callback as its first argument and also any additional arguments. It returns a new function that returns a promise instead. The returned promise should resolve with the result of the original function when the callback is called with a successful response, and reject with the error when the callback is called with an error. The returned promise-based function should accept the additional arguments as inputs.
The function fn takes a callback as its first argument, along with any additional arguments args passed as separate inputs.
The promisify function returns a new function that should return a promise. The promise should resolve with the argument passed as the first parameter of the callback when the callback is invoked without error, and reject with the error when the callback is called with an error as the second argument.
The following is an example of a function that could be passed into promisify.
Constraints:
1 <= str.length <= 10001 <= times <= 10001 <= str.length, times <= 105 |
+| ------------------------------------------------------------------------------------------------------------------------------ |
+
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
diff --git a/solution/DATABASE_README_EN.md b/solution/DATABASE_README_EN.md
index aad41ef999334..07fb8ec7a3df1 100644
--- a/solution/DATABASE_README_EN.md
+++ b/solution/DATABASE_README_EN.md
@@ -248,4 +248,15 @@ Press Control + F(or Command + F on
## Copyright
-[@Doocs](https://github.com/doocs)
+The copyright of this project belongs to [Doocs](https://github.com/doocs) community. For commercial reprints, please contact [@yanglbme](mailto:contact@yanglibin.info) for authorization. For non-commercial reprints, please indicate the source.
+
+## Contact Us
+
+We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), with the note "leetcode". In the future, we will create algorithm and technology related discussion groups, where we can learn and share experiences together, and make progress together.
+
+|
|
+| ------------------------------------------------------------------------------------------------------------------------------ |
+
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
diff --git a/solution/DATABASE_README_EN.md b/solution/DATABASE_README_EN.md
index aad41ef999334..07fb8ec7a3df1 100644
--- a/solution/DATABASE_README_EN.md
+++ b/solution/DATABASE_README_EN.md
@@ -248,4 +248,15 @@ Press Control + F(or Command + F on
## Copyright
-[@Doocs](https://github.com/doocs)
+The copyright of this project belongs to [Doocs](https://github.com/doocs) community. For commercial reprints, please contact [@yanglbme](mailto:contact@yanglibin.info) for authorization. For non-commercial reprints, please indicate the source.
+
+## Contact Us
+
+We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), with the note "leetcode". In the future, we will create algorithm and technology related discussion groups, where we can learn and share experiences together, and make progress together.
+
+|  |
+| --------------------------------------------------------------------------------------------------------------------------------- |
+
+## License
+
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/solution/JAVASCRIPT_README.md b/solution/JAVASCRIPT_README.md
index e24d9b431fc61..c95287c9c0c86 100644
--- a/solution/JAVASCRIPT_README.md
+++ b/solution/JAVASCRIPT_README.md
@@ -80,4 +80,15 @@
## 版权
-著作权归 [GitHub 开源社区 Doocs](https://github.com/doocs) 所有,商业转载请联系 [@yanglbme](mailto:contact@yanglibin.info) 获得授权,非商业转载请注明出处。
+本项目著作权归 [GitHub 开源社区 Doocs](https://github.com/doocs) 所有,商业转载请联系 @yanglbme 获得授权,非商业转载请注明出处。
+
+## 联系我们
+
+欢迎各位小伙伴们添加 @yanglbme 的个人微信(微信号:YLB0109),备注 「**leetcode**」。后续我们会创建算法、技术相关的交流群,大家一起交流学习,分享经验,共同进步。
+
+| |
+| ------------------------------------------------------------------------------------------------------------------------------ |
+
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
diff --git a/solution/JAVASCRIPT_README_EN.md b/solution/JAVASCRIPT_README_EN.md
index 6d0c0dbc0b136..e6781d310ba50 100644
--- a/solution/JAVASCRIPT_README_EN.md
+++ b/solution/JAVASCRIPT_README_EN.md
@@ -78,4 +78,15 @@ Press Control + F(or Command + F on
## Copyright
-[@Doocs](https://github.com/doocs)
+The copyright of this project belongs to [Doocs](https://github.com/doocs) community. For commercial reprints, please contact [@yanglbme](mailto:contact@yanglibin.info) for authorization. For non-commercial reprints, please indicate the source.
+
+## Contact Us
+
+We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), with the note "leetcode". In the future, we will create algorithm and technology related discussion groups, where we can learn and share experiences together, and make progress together.
+
+| |
+| --------------------------------------------------------------------------------------------------------------------------------- |
+
+## License
+
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/solution/README.md b/solution/README.md
index b2fd88bdf9cdb..aea51e28c1ce8 100644
--- a/solution/README.md
+++ b/solution/README.md
@@ -2774,7 +2774,7 @@
| 2761 | [和等于目标值的质数对](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README.md) | `数组`,`数学`,`枚举`,`数论` | 中等 | 第 352 场周赛 |
| 2762 | [不间断子数组](/solution/2700-2799/2762.Continuous%20Subarrays/README.md) | `队列`,`数组`,`有序集合`,`滑动窗口`,`单调队列`,`堆(优先队列)` | 中等 | 第 352 场周赛 |
| 2763 | [所有子数组中不平衡数字之和](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README.md) | `数组`,`哈希表`,`有序集合` | 困难 | 第 352 场周赛 |
-| 2764 | [数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) | `栈`,`树`,`深度优先搜索`,`二叉树` | 中等 | 🔒 |
+| 2764 | [数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) | `栈`,`树`,`深度优先搜索`,`二叉树` | 中等 | 🔒 |
| 2765 | [最长交替子序列](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README.md) | `数组`,`枚举` | 简单 | 第 108 场双周赛 |
| 2766 | [重新放置石块](/solution/2700-2799/2766.Relocate%20Marbles/README.md) | `数组`,`哈希表`,`排序`,`模拟` | 中等 | 第 108 场双周赛 |
| 2767 | [将字符串分割为最少的美丽子字符串](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README.md) | `哈希表`,`字符串`,`动态规划`,`回溯` | 中等 | 第 108 场双周赛 |
@@ -2989,8 +2989,4 @@
欢迎各位小伙伴们添加 @yanglbme 的个人微信(微信号:YLB0109),备注 「**leetcode**」。后续我们会创建算法、技术相关的交流群,大家一起交流学习,分享经验,共同进步。
| |
-| ------------------------------------------------------------------------------------------------------------------------------ |
-
-## 许可证
-
-知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
\ No newline at end of file
+| ------------------------------------------------------------------------------------------------------------------------------ |
\ No newline at end of file
diff --git a/solution/README_EN.md b/solution/README_EN.md
index 840750846244b..fbaba2fd8a2cf 100644
--- a/solution/README_EN.md
+++ b/solution/README_EN.md
@@ -2772,7 +2772,7 @@ Press Control + F(or Command + F on
| 2761 | [Prime Pairs With Target Sum](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README_EN.md) | `Array`,`Math`,`Enumeration`,`Number Theory` | Medium | Weekly Contest 352 |
| 2762 | [Continuous Subarrays](/solution/2700-2799/2762.Continuous%20Subarrays/README_EN.md) | `Queue`,`Array`,`Ordered Set`,`Sliding Window`,`Monotonic Queue`,`Heap (Priority Queue)` | Medium | Weekly Contest 352 |
| 2763 | [Sum of Imbalance Numbers of All Subarrays](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README_EN.md) | `Array`,`Hash Table`,`Ordered Set` | Hard | Weekly Contest 352 |
-| 2764 | [is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md) | `Stack`,`Tree`,`Depth-First Search`,`Binary Tree` | Medium | 🔒 |
+| 2764 | [Is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md) | `Stack`,`Tree`,`Depth-First Search`,`Binary Tree` | Medium | 🔒 |
| 2765 | [Longest Alternating Subarray](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README_EN.md) | `Array`,`Enumeration` | Easy | Biweekly Contest 108 |
| 2766 | [Relocate Marbles](/solution/2700-2799/2766.Relocate%20Marbles/README_EN.md) | `Array`,`Hash Table`,`Sorting`,`Simulation` | Medium | Biweekly Contest 108 |
| 2767 | [Partition String Into Minimum Beautiful Substrings](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README_EN.md) | `Hash Table`,`String`,`Dynamic Programming`,`Backtracking` | Medium | Biweekly Contest 108 |
@@ -2991,4 +2991,4 @@ We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), wit
## License
-This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
\ No newline at end of file
diff --git a/solution/summary.md b/solution/summary.md
index c0c71264c584e..78016bbc0885b 100644
--- a/solution/summary.md
+++ b/solution/summary.md
@@ -2817,7 +2817,7 @@
- [2761.和等于目标值的质数对](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README.md)
- [2762.不间断子数组](/solution/2700-2799/2762.Continuous%20Subarrays/README.md)
- [2763.所有子数组中不平衡数字之和](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README.md)
- - [2764.数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md)
+ - [2764.数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md)
- [2765.最长交替子序列](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README.md)
- [2766.重新放置石块](/solution/2700-2799/2766.Relocate%20Marbles/README.md)
- [2767.将字符串分割为最少的美丽子字符串](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README.md)
diff --git a/solution/summary_en.md b/solution/summary_en.md
index 8ca362264e6c1..4a4cb39a6461a 100644
--- a/solution/summary_en.md
+++ b/solution/summary_en.md
@@ -2817,7 +2817,7 @@
- [2761.Prime Pairs With Target Sum](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README_EN.md)
- [2762.Continuous Subarrays](/solution/2700-2799/2762.Continuous%20Subarrays/README_EN.md)
- [2763.Sum of Imbalance Numbers of All Subarrays](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README_EN.md)
- - [2764.is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md)
+ - [2764.Is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md)
- [2765.Longest Alternating Subarray](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README_EN.md)
- [2766.Relocate Marbles](/solution/2700-2799/2766.Relocate%20Marbles/README_EN.md)
- [2767.Partition String Into Minimum Beautiful Substrings](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README_EN.md)
diff --git a/solution/template.md b/solution/template.md
index b139c1832a136..4a83ccc7df5a8 100644
--- a/solution/template.md
+++ b/solution/template.md
@@ -23,6 +23,10 @@
| |
| ------------------------------------------------------------------------------------------------------------------------------ |
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
+
---
|
+| --------------------------------------------------------------------------------------------------------------------------------- |
+
+## License
+
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/solution/JAVASCRIPT_README.md b/solution/JAVASCRIPT_README.md
index e24d9b431fc61..c95287c9c0c86 100644
--- a/solution/JAVASCRIPT_README.md
+++ b/solution/JAVASCRIPT_README.md
@@ -80,4 +80,15 @@
## 版权
-著作权归 [GitHub 开源社区 Doocs](https://github.com/doocs) 所有,商业转载请联系 [@yanglbme](mailto:contact@yanglibin.info) 获得授权,非商业转载请注明出处。
+本项目著作权归 [GitHub 开源社区 Doocs](https://github.com/doocs) 所有,商业转载请联系 @yanglbme 获得授权,非商业转载请注明出处。
+
+## 联系我们
+
+欢迎各位小伙伴们添加 @yanglbme 的个人微信(微信号:YLB0109),备注 「**leetcode**」。后续我们会创建算法、技术相关的交流群,大家一起交流学习,分享经验,共同进步。
+
+| |
+| ------------------------------------------------------------------------------------------------------------------------------ |
+
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
diff --git a/solution/JAVASCRIPT_README_EN.md b/solution/JAVASCRIPT_README_EN.md
index 6d0c0dbc0b136..e6781d310ba50 100644
--- a/solution/JAVASCRIPT_README_EN.md
+++ b/solution/JAVASCRIPT_README_EN.md
@@ -78,4 +78,15 @@ Press Control + F(or Command + F on
## Copyright
-[@Doocs](https://github.com/doocs)
+The copyright of this project belongs to [Doocs](https://github.com/doocs) community. For commercial reprints, please contact [@yanglbme](mailto:contact@yanglibin.info) for authorization. For non-commercial reprints, please indicate the source.
+
+## Contact Us
+
+We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), with the note "leetcode". In the future, we will create algorithm and technology related discussion groups, where we can learn and share experiences together, and make progress together.
+
+| |
+| --------------------------------------------------------------------------------------------------------------------------------- |
+
+## License
+
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
diff --git a/solution/README.md b/solution/README.md
index b2fd88bdf9cdb..aea51e28c1ce8 100644
--- a/solution/README.md
+++ b/solution/README.md
@@ -2774,7 +2774,7 @@
| 2761 | [和等于目标值的质数对](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README.md) | `数组`,`数学`,`枚举`,`数论` | 中等 | 第 352 场周赛 |
| 2762 | [不间断子数组](/solution/2700-2799/2762.Continuous%20Subarrays/README.md) | `队列`,`数组`,`有序集合`,`滑动窗口`,`单调队列`,`堆(优先队列)` | 中等 | 第 352 场周赛 |
| 2763 | [所有子数组中不平衡数字之和](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README.md) | `数组`,`哈希表`,`有序集合` | 困难 | 第 352 场周赛 |
-| 2764 | [数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) | `栈`,`树`,`深度优先搜索`,`二叉树` | 中等 | 🔒 |
+| 2764 | [数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md) | `栈`,`树`,`深度优先搜索`,`二叉树` | 中等 | 🔒 |
| 2765 | [最长交替子序列](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README.md) | `数组`,`枚举` | 简单 | 第 108 场双周赛 |
| 2766 | [重新放置石块](/solution/2700-2799/2766.Relocate%20Marbles/README.md) | `数组`,`哈希表`,`排序`,`模拟` | 中等 | 第 108 场双周赛 |
| 2767 | [将字符串分割为最少的美丽子字符串](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README.md) | `哈希表`,`字符串`,`动态规划`,`回溯` | 中等 | 第 108 场双周赛 |
@@ -2989,8 +2989,4 @@
欢迎各位小伙伴们添加 @yanglbme 的个人微信(微信号:YLB0109),备注 「**leetcode**」。后续我们会创建算法、技术相关的交流群,大家一起交流学习,分享经验,共同进步。
| |
-| ------------------------------------------------------------------------------------------------------------------------------ |
-
-## 许可证
-
-知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
\ No newline at end of file
+| ------------------------------------------------------------------------------------------------------------------------------ |
\ No newline at end of file
diff --git a/solution/README_EN.md b/solution/README_EN.md
index 840750846244b..fbaba2fd8a2cf 100644
--- a/solution/README_EN.md
+++ b/solution/README_EN.md
@@ -2772,7 +2772,7 @@ Press Control + F(or Command + F on
| 2761 | [Prime Pairs With Target Sum](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README_EN.md) | `Array`,`Math`,`Enumeration`,`Number Theory` | Medium | Weekly Contest 352 |
| 2762 | [Continuous Subarrays](/solution/2700-2799/2762.Continuous%20Subarrays/README_EN.md) | `Queue`,`Array`,`Ordered Set`,`Sliding Window`,`Monotonic Queue`,`Heap (Priority Queue)` | Medium | Weekly Contest 352 |
| 2763 | [Sum of Imbalance Numbers of All Subarrays](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README_EN.md) | `Array`,`Hash Table`,`Ordered Set` | Hard | Weekly Contest 352 |
-| 2764 | [is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md) | `Stack`,`Tree`,`Depth-First Search`,`Binary Tree` | Medium | 🔒 |
+| 2764 | [Is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md) | `Stack`,`Tree`,`Depth-First Search`,`Binary Tree` | Medium | 🔒 |
| 2765 | [Longest Alternating Subarray](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README_EN.md) | `Array`,`Enumeration` | Easy | Biweekly Contest 108 |
| 2766 | [Relocate Marbles](/solution/2700-2799/2766.Relocate%20Marbles/README_EN.md) | `Array`,`Hash Table`,`Sorting`,`Simulation` | Medium | Biweekly Contest 108 |
| 2767 | [Partition String Into Minimum Beautiful Substrings](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README_EN.md) | `Hash Table`,`String`,`Dynamic Programming`,`Backtracking` | Medium | Biweekly Contest 108 |
@@ -2991,4 +2991,4 @@ We welcome everyone to add @yanglbme's personal WeChat (WeChat ID: YLB0109), wit
## License
-This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
+This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
\ No newline at end of file
diff --git a/solution/summary.md b/solution/summary.md
index c0c71264c584e..78016bbc0885b 100644
--- a/solution/summary.md
+++ b/solution/summary.md
@@ -2817,7 +2817,7 @@
- [2761.和等于目标值的质数对](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README.md)
- [2762.不间断子数组](/solution/2700-2799/2762.Continuous%20Subarrays/README.md)
- [2763.所有子数组中不平衡数字之和](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README.md)
- - [2764.数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md)
+ - [2764.数组是否表示某二叉树的前序遍历](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README.md)
- [2765.最长交替子序列](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README.md)
- [2766.重新放置石块](/solution/2700-2799/2766.Relocate%20Marbles/README.md)
- [2767.将字符串分割为最少的美丽子字符串](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README.md)
diff --git a/solution/summary_en.md b/solution/summary_en.md
index 8ca362264e6c1..4a4cb39a6461a 100644
--- a/solution/summary_en.md
+++ b/solution/summary_en.md
@@ -2817,7 +2817,7 @@
- [2761.Prime Pairs With Target Sum](/solution/2700-2799/2761.Prime%20Pairs%20With%20Target%20Sum/README_EN.md)
- [2762.Continuous Subarrays](/solution/2700-2799/2762.Continuous%20Subarrays/README_EN.md)
- [2763.Sum of Imbalance Numbers of All Subarrays](/solution/2700-2799/2763.Sum%20of%20Imbalance%20Numbers%20of%20All%20Subarrays/README_EN.md)
- - [2764.is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md)
+ - [2764.Is Array a Preorder of Some Binary Tree](/solution/2700-2799/2764.Is%20Array%20a%20Preorder%20of%20Some%20%E2%80%8CBinary%20Tree/README_EN.md)
- [2765.Longest Alternating Subarray](/solution/2700-2799/2765.Longest%20Alternating%20Subarray/README_EN.md)
- [2766.Relocate Marbles](/solution/2700-2799/2766.Relocate%20Marbles/README_EN.md)
- [2767.Partition String Into Minimum Beautiful Substrings](/solution/2700-2799/2767.Partition%20String%20Into%20Minimum%20Beautiful%20Substrings/README_EN.md)
diff --git a/solution/template.md b/solution/template.md
index b139c1832a136..4a83ccc7df5a8 100644
--- a/solution/template.md
+++ b/solution/template.md
@@ -23,6 +23,10 @@
| |
| ------------------------------------------------------------------------------------------------------------------------------ |
+## 许可证
+
+知识共享 版权归属-相同方式共享 4.0 国际 公共许可证
+
---