第 75 题:数组里面有10万个数据,取第一个元素和第10万个元素的时间相差多少 #124
Comments
|
数组可以直接根据索引取的对应的元素,所以不管取哪个位置的元素的时间复杂度都是 O(1) 得出结论:消耗时间几乎一致,差异可以忽略不计 |
|
JavaScript 没有真正意义上的数组,所有的数组其实是对象,其“索引”看起来是数字,其实会被转换成字符串,作为属性名(对象的 key)来使用。所以无论是取第 1 个还是取第 10 万个元素,都是用 key 精确查找哈希表的过程,其消耗时间大致相同。 |
Chrome 浏览器JS引擎 V8中,数组有两种存储模式,一种是类似C语言中的线性结构存储(索引值连续,且都是正整数的情况下),一种是采用Hash结构存储(索引值为负数,数组稀疏,间隔比较大);结论:以上说明对这个问题都没啥影响,同一个数组,在索引取值的时候,取第一个和最后一个效率没什么差别 |
|
正常来说取数组元素应该没差才对,都是按下标取的,也不是像链表那样要逐个查找。
|

|
js 中数组元素的存储方式并不是连续的,而是哈希映射关系。哈希映射关系,可以通过键名 key,直接计算出值存储的位置,所以查找起来很快。推荐一下这篇文章:深究 JavaScript 数组 |
大佬推荐的这篇文章里,链式哈希查找元素要从第一个去追溯,那index的不同应该是有差距的呀,是我对这篇文章的什么地方理解错了么 |
|
用下标是瞬间,链表也瞬间 |
|
没多大区别,都是比较短的 var arr = new Array(100000).fill(null)
console.time('first')
arr[0]
console.timeEnd('first')
console.time('end')
arr[99999]
console.timeEnd('end')
first: 0.010009765625ms
end: 0.003662109375ms |
|
如果是传统数组的方式,应该是没区别的。 |
|
我竟然去真的去做了实验: var arr=new Array(100000).fill(100);
console.time('index_0')
arr[0];
console.timeEnd('index_0')
console.time('index_100000')
arr[100000-1];
console.timeEnd('index_100000')index_0: 0.01708984375ms index_0: 0.01611328125ms index_0: 0.011962890625ms index_0: 0.012939453125ms index_0: 0.01171875ms index_0: 0.011962890625ms index_0: 0.0126953125ms |
|
06-js中的数组前言数组、链表、栈、队列都是线性表,它表示的结构都是一段线性的结构,与之对应的就是非线性表,例如树、图、堆等,它表示的结构都非线性。 思考
什么 是数组
以上是js数组在内存中大致位置 ,或者
为什么这么说,因为在 // The JSArray describes JavaScript Arrays
// Such an array can be in one of two modes:
// - fast, backing storage is a FixedArray and length <= elements.length();
// 存储结构是 FixedArray ,并且数组长度 <= elements.length() ,push 或 pop 时可能会伴随着动态扩容或减容
// Please note: push and pop can be used to grow and shrink the array.
// - slow, backing storage is a HashTable with numbers as keys
// 存储结构是 HashTable(哈希表),并且数组下标作为 key
class JSArray: public JSObject {
public:
// [length]: The length property.
DECL_ACCESSORS(length, Object)
// ...
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
};意思是说,我们可以看到 数组的优点
根据下标随机访问的时间复杂度为 O(1) 数组特性
我们已经知道数组是一段连续储存的内存,当我们要将新元素插入到数组k的位置时呢?这个时候需要将k索引处之后的所有元素往后挪一位,并将k索引的位置插入新元素.
删除操作其实与插入很类似,同样我要删除数组之内的k索引位置的元素,我们就需要将其删除后,为了保持内存的连续性,需要将k之后的元素通通向前移动一位,这个情况的时间复杂度也是O(n).
比如我们要查找一个数组中是否存在一个为2的元素,那么计算机需要如何操作呢? 如果是人的话,在少量数据的情况下我们自然可以一眼找到是否有2的元素,而计算机不是,计算机需要从索引0开始往下匹配,直到匹配到2的元素为止
我们已经强调过数组的特点是拥有相同的数据类型和一块连续的线性内存,那么正是基于以上的特点,数组的读取性能非常的卓越,时间复杂度为O(1),相比于链表、二叉树等数据结构,它的优势非常明显. 那么数组是如何做到这么低的时间复杂度呢? 假设我们的数组内存起始地址为 arr[i]_address = start + size * i比如我们要读取 总结JavaScript 中, let res = new Array(100000).fill(10)
console.log(res)
var arr=new Array(100000).fill(100);
console.time('timer')
arr[0];
console.timeEnd('timer')
console.time('timer')
arr[100000-1];
console.timeEnd('timer')参考 |
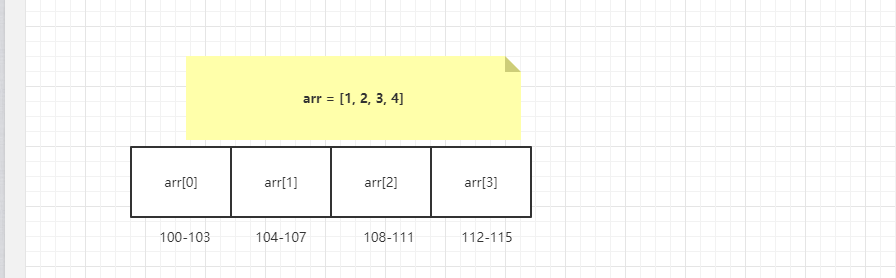
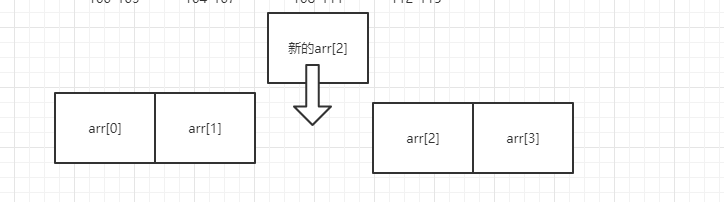
数组里面有10万个数据,取第一个元素和第10万个元素的时间相差多少?
|
|
js 的数组实现是基于对象 实现的 即 hash 的 key-value 形式,所以对于获取 任何一个 索引 的 时间复杂度都是 O(1) |
|
Version 107.0.5300.0 (Official Build) dev (x86_64) const arr = (new Uint32Array(100000)).map((item, i) => i + 1);
function testPerformance(arr, i) {
let startTime = performance.now();
console.log(`arr[i], i =`, arr[i], i);
let endTime = performance.now();
console.log(`🚀performance time is \`${endTime - startTime}\` ms`);
}
function testTime(arr, i) {
console.time('array test');
console.log(`arr[i], i =`, arr[i], i);
console.timeEnd('array test');
}
testPerformance(arr, 0);
testPerformance(arr, 99999);
console.log('\n');
testTime(arr, 0);
testTime(arr, 99999);
|

|
const array = new Array(100000).fill(0).map((_, index) => index); // 记录访问第一个元素的时间 // 记录访问第10万个元素的时间 测试结果,后面的快 |
测试结果:https://jsperf.com/getelemperformance/1
The text was updated successfully, but these errors were encountered: